Построение корпуса сравнимых документов на основе универсальной меры похожести
Область изобретения
[0001] Осуществление данного изобретения относится к области анализа естественного языка. В частности, осуществление относится к построению корпуса сравнимых документов на двух и более языках. Корпусом сравнимых документов называется корпус похожих документов на двух и более языках. Сравнимые документы используются при машинном переводе в качестве альтернативы параллельным корпусам. Это связано с тем, что создание параллельных корпусов - дорогостоящая процедура. Кроме того, параллельные корпуса - переводные, а переведенный текст всегда «привязан» к оригиналу, и из-за этого ограничения может оказаться не совсем показательным для языка, на котором он написан. Сравнимые же тексты представляют собой естественные образцы текстов на заданных языках. Сравнение документов может включать оценку, подсчет и визуализацию похожести (similarity) между любым количеством тестовых документов.
Уровень техники
[0002] Многие задачи, связанные с обработкой естественного языка, требуют сравнения документов для определения их сходства, а именно, оценки или вычисления меры «похожести» (similarity). Среди таких задач может быть, например, проверка текста на плагиат или удаление копий одного и того же документа в корпусе. Процесс определения похожести документов, обычно использует методы статистики, машинного обучения (например, классификацию, кластеризацию документов) и пр. Как правило, способы определения похожести основываются на лексических характеристиках текста, таких как ключевые слова, герои, имена собственные и пр. Для некоторых задач также используют методы, позволяющие оценить степень похожести документов. Однако, если необходимо найти дубликаты или проверить на плагиат документы, написанные на разных языках, методы, основанные только на лексических характеристиках текста, оказываются недостаточными.
[0003] Большинство систем обработки естественного языка, хорошо справляющихся с документами на одном языке, не могут выявить похожесть документов на разных языках.
[0004] Сравнимые документы используются при машинном переводе в качестве альтернативы параллельным корпусам. Преимуществом использования корпуса сравнимых документов является то, что параллельный текстовый корпус содержит исходный текст и его зависимый перевод, который не всегда является показательным для языка, на котором он написан. Сравнимые же тексты представляют собой оригинальные тексты на заданных языках. Примером такого корпуса является Wikipedia, где присутствуют страницы на разных языках, посвященные одной теме, причем эти страницы написаны с чистого листа, а не переведены с другого языка.
[0005] Известны методы построения корпуса сравнимых документов, основанные на поиске похожих текстов по совпадению тем и наличию одинаковых именованных сущностей. Однако совпадение тем не гарантирует схожести документов, а именованные сущности могут относиться к разным тематикам в силу омонимии. Метод данного изобретения помогает решить эти проблемы.
Раскрытие изобретения
[0006] Данное изобретение относится к способу и системе создания корпуса сравнимых документов, включающему создание исходного набора документов, содержащих тексты; построение не зависящих от языка семантических структур для текстов этих документов; определение универсальной меры похожести для групп документов, путем сравнения построенных не зависящих от языка семантических структур текстов этих документов; выявление схожих документов на основании определенных значений универсальной меры похожести групп документов; формирование корпуса сравнимых документов на основании выявленных схожих документов. Исходный набор документов может создаваться в результате поиска документов по теме. При этом в корпус сравнимых документов попадают только группы документов со значениями универсальной меры похожести, превышающими некоторое пороговое значение. Пороговое значение может подбираться на небольших наборах документов, путем попарного сравнения документов внутри наборов с разными пробными пороговыми значениями универсальной меры похожести и определения наилучших результатов сравнения среди всех наборов. Попарное сравнение документов проводится после предварительной обработки документов и перевода их в машиночитаемый формат, проведения анализа текстов, содержащихся в документах, включающего выделение логических структур и структурных блоков текстов, а также лексических, семантических и синтаксических характеристик текстов, построение наилучших синтаксических структур текстов и независящих от языка семантических структур текстов. Формирование корпуса сравнимых документов из групп документов со значениями универсальной меры похожести, превышающей выбранное пороговое значение, происходит после фильтрации дублей одного и того же документа.
[0007] Технический результат от внедрения изобретения состоит в повышении эффективности информационного поиска за счет получения возможности включать в поиск документы на разных языках, а также исключения похожих и дублирующих друг друга документов, оптимизации хранения и организации индекса.
Краткое описание чертежей
[0008] Указанные выше и другие признаки настоящего изобретения будут более понятными из приведенного ниже описания и прилагаемой формулы изобретения, которые рассматриваются совместно с прилагаемыми чертежами. Указанные чертежи иллюстрируют только отдельные варианты осуществления данного изобретения в соответствии с его раскрытием. Поэтому возможности раскрытия изобретения не ограничиваются вариантами, представленными в чертежах. Чертежи прилагаются для более подробного и точного описания
[0009] Фиг. 1 иллюстрирует блок - схему метода оценки похожести документов в соответствии с одним или несколькими вариантами осуществления данного изобретения.
[0010] Фиг. 1А иллюстрирует блок - схему метода в соответствии с одним или несколькими вариантами осуществления данного изобретения.
[0011] Фиг. 2 иллюстрирует подробная блок - схему метода в соответствии с одним или несколькими вариантами осуществления данного изобретения.
[0012] Фиг. 3 иллюстрирует синтаксическую структуру, полученную в качестве результата точного синтаксического анализа предложения.
[0013] Фиг. 4 иллюстрирует пример семантической структуры предложения.
[0014] Фиг. 5 иллюстрирует фрагмент семантической иерархии.
[0015]
[0016] Фиг. 6 иллюстрирует диаграмму языковых описаний в соответствии с одним или несколькими вариантами реализации изобретения.
[0017] Фиг. 7 иллюстрирует диаграмму морфологических описаний в соответствии с одним или несколькими вариантами реализации изобретения.
[0018] Фиг. 8 иллюстрирует диаграмму синтаксических описаний в соответствии с одним или несколькими вариантами реализации изобретения.
[0019] Фиг. 9 иллюстрирует диаграмму семантических описаний в соответствии с одним или несколькими вариантами реализации изобретения.
[0020] Фиг. 10 иллюстрирует диаграмму лексических описаний в соответствии с одним или несколькими вариантами реализации изобретения.
[0021] Фиг. 11 иллюстрирует пример визуализации результатов сравнения двух документов.
[0022] Фиг. 12 иллюстрирует метод нахождения схожих/различных документов внутри некоторого набора.
[0023] Фиг. 13 иллюстрирует метод подбора порогового значения универсальной меры похожести в соответствии с одним или несколькими вариантами реализации изобретения.
[0024] Фиг. 14 иллюстрирует пример схемы аппаратного обеспечения, необходимого для реализации изобретения.
[0025] На протяжении всего приведенного ниже подробного описания делаются ссылки на эти прилагаемые чертежи. На чертежах одинаковые символы обычно означают аналогичные компоненты, если контекст не требует иного. Иллюстрирующие варианты осуществления, приведенные в подробном описании, на чертежах и пунктах формулы изобретения, не являются единственно возможными. Возможны другие варианты осуществления изобретения, возможны и другие изменения, не затрагивающие его объект и сущность. Различные аспекты настоящего изобретения, приведенные в настоящем описании изобретения и проиллюстрированные чертежами, можно комбинировать, заменять, группировать и конструировать для получения широкого спектра различных вариантов применения, все они явно подразумеваются в настоящем описании изобретения и считаются его частью.
Подробное описание чертежей
[0026] Упоминание в настоящем описании «одного из вариантов реализации» или «варианта реализации» подразумевает, что определенный признак, структура или характеристика, описанная в связи с этим осуществлением, включен, по меньшей мере, в один из вариантов реализации. Выражение «в одном из вариантов реализации» в разных частях описания не обязательно относится к одному и тому же варианту реализации, а различные и альтернативные варианты реализации не являются взаимоисключающими и не исключают других вариантов реализации. Более того, различные описанные здесь признаки могут относиться к одним вариантам осуществления, но не относиться к другим вариантам осуществления. Подобным образом некоторые описанные здесь требования могут относиться к одним вариантам осуществления, но не относиться к другим вариантам осуществления.
[0027] Примеры некоторых вариантов осуществления описаны и проиллюстрированы на прилагаемых чертежах. Однако необходимо помнить, что эти варианты осуществления приводятся исключительно в иллюстративных целях, что они не ограничиваются описанными вариантами осуществления, а также то, что последние не привязаны конкретно к описанным модификациям и вариантам, и что специалисты могут создавать другие модификации на основе информации этого раскрытия изобретения. В столь быстро развивающейся технологической области многие улучшения сложно предусмотреть заранее. Поэтому описанные варианты осуществления могут видоизменяться по компоновке или деталями и облегчаться технологическими достижениями, что, однако, не будет означать отступления от сути настоящего изобретения.
[0028] В некоторых вариантах осуществления данного изобретения описаны способы сравнения нескольких документов, включающих, например, текстовую информацию на одном или нескольких языках. Сравнение может включать оценку, вычисление и визуализацию похожести между указанными документами. Способ включает инструменты работы с текстовой информацией, которая может сравниваться, в общем случае, на основе анализа с использованием исчерпывающих синтаксических и семантических описаний и построения не зависящих от языка семантических структур. Различные лексические, грамматические, синтаксические, семантические, прагматические и другие характеристики могут быть обнаружены в тексте и использованы для эффективного решения поставленной задачи. Варианты осуществления данного изобретения могут включать или не включать визуализацию похожести или различий.
[0029] В одном из вариантов осуществления данного изобретения вычисленная универсальная мера похожести может быть представлена своим значением. А также она может быть визуализирована с помощью различных инструментов, таких как, например, графических пользовательский интерфейс (GUI). Похожесть или различия в документах, содержащих текстовую информацию, может быть вычислено, например, как: sim(doc1,…, docn)=s(text(doc1),…, text(docn)), где n - это число документов, text() -функция выделения текстовой информации из документа, a s() - функция сравнения текстовой информации различных документов. В одном из вариантов осуществления данного изобретения, дополнительно, сравнение документов включает определение логической структуры (например, представленной в патенте US 8,260,049 "Model-based method of document logical structure recognition in OCR systems"("Основанный на моделях, способ выделения логической структуры текста в OCR системах") от 04.09.2012. Структурные блоки могут быть выявлены перед или после оптического распознавания текста. В этом случае дальнейшая оценка похожести может быть остановлена, если выявленные блоки различны. Сначала должны сравниваться наиболее важные блоки, такие как названия и заголовки. В одном из вариантов осуществления данного изобретения, структурные блоки документа сравниваются с некоторыми весами, т.е. заголовок в документе имеет больший вес и таким образом больше влияет на окончательное значение похожести, чем другие блоки. В одном из вариантов осуществления данного изобретения, если найденные логические и/или структурные блоки представлены в виде дерева. Сравнение может быть произведено пошагово сверху-вниз (от корня к листьям) и может быть остановлено, если необходимое число различий или достаточное их число обнаружено на каком-либо шаге.
[0030] В одном из вариантов осуществления данного изобретения, похожесть двух документов может вычисляться, как:

где doc(Texti) - части документов, содержащие текстовую информацию, а f -некоторая функция.
[0031] В одном из вариантов осуществления данного изобретения, указанная универсальная мера похожести может быть функцией от двух или более аргументов, принимающая, как правило, целочисленные, действительные значения.
[0032] В некоторых случаях документы выглядят похожими или даже идентичными, несмотря на присутствие различий в текстах. Есть ситуации, в которых отличия непросто отыскать, или может понадобиться много времени, чтобы доказать, что тексты не идентичны. Такими отличиями, могут быть, например, использование букв из другого алфавита, имеющих то же произношение, выделение цветом некоторых слов, чтобы их не было видно при распознавании, добавление пробелов, представление части текста в виде изображения и пр. В этом случае, осуществлением данного изобретения может быть определение универсальной меры похожести документов.
[0033] Простой способ сравнить два документа с информацией на разных языках -применить системы машинного перевода к одному или нескольким источникам, однако в виду несовершенства перевода могут возникать ошибки. В данном изобретении алгоритмы машинного перевода применяются не к источнику напрямую, так как текстовые части документа сначала переводятся в независимые от языка семантические структуры.
[0034] На Фиг. 1 изображена блок-схема метода оценки похожести текстов в соответствии с одним или несколькими вариантами осуществления данного изобретения. Сначала производится предварительная обработка текста 110. На шаге 110 определяется логические структуры и структурные блоки каждого документа, определяется вид каждого блока, текстовые блоки документа могут распознаваться методами оптической обработки текста. За первичной обработкой может следовать анализ 120, а именно, исчерпывающий семантический и синтаксический анализ текста, входящего в документ. Затем производится оценка универсальной меры похожести документов 130. Похожесть может быть представлена в виде функции от одного или более аргументов, имеющая действительные, целочисленные решения. Наконец, на этапе 140 может выполняться разного рода визуализация, иллюстрирующая похожесть документов. Визуализация может быть осуществлена посредством показа одного или нескольких документов с выделением, подчеркиванием или иным обозначением или индикацией схожих и различных частей.
[0035] Для каждого соответствующего текстового блока система может производить автоматически синтаксический и семантический анализ, чтобы выделить лексические, грамматические, синтаксические, прагматические, семантические и другие характеристики для дальнейшей обработки текста. Эти характеристики определяются в процессе исчерпывающего семантико-синтаксического анализа каждого предложения и построения не зависящих от языка семантических структур. Как правило, для одного предложения строится одна такая структура. Такой предварительный исчерпывающий анализ предшествует оценке похожести в одном из вариантов реализации данного изобретения. Система анализирует предложение, используя лингвистические описания естественного языка, чтобы отразить всю его сложность. Функционал системы основан на принципе полного и целенаправленного распознавания (integral and purpose- driven recognition), в котором гипотезы о синтаксических структурах частей предложения проверяются в рамках гипотезы о синтаксической структуре целого предложения. Такая процедура позволяет избежать анализа множества маловероятных вариантов разбора. Затем, выделяется синтаксическая и семантическая информация о каждом предложении, результаты подвергаются разбору, далее после разрешения неоднозначностей делают лексический выбор, включающий результаты. Информация и результаты могут индексироваться и сохраняться.
[0036] Фиг. 1А иллюстрирует блок-схему 100 метода исчерпывающих описаний в соответствии с одним или несколькими вариантами осуществления данного изобретения.
В соответствии с Фиг. 1А лингвистические описания могут включать, по крайней мере, лексические описания 101, морфологические описания 102, синтаксические описания 103, семантические описания 104. Метод применяется к исходному предложению 105. Исходное предложение 105 подвергается анализу 106 (описанному подробнее ниже). Затем идет построение не зависящей от языка семантической структуры 107 предложения. Данная структура формализует смысл высказывания, выраженного данным предложением. После, исходное предложение, синтаксическая структура и не зависящая от языка семантическая структура исходного предложения индексируются 108. В результате получают набор индексов 109.
[0037] Индекс можно представить как таблицу с указанием наименования каждой характеристики (слово, предложение, параметр и т.п.) в документе и списка чисел, представляющих адреса ее нахождения в документе. Например, для каждой характеристики (слова, символа, выражения, фразы) индекс может включать список предложений, где она была найдена и номер слова в предложении, ей соответствующего. Так, для слова «собака», найденного в тексте в первом предложении на четвертом месте, во втором предложении - на втором месте, в десятом - на четвертом, и в двадцать втором - на пятом, индекс будет иметь вид: «собака» - (1.4), (2.2), (10.4), (22.5). Номер предложения не является обязательным, можно просто нумеровать слова от начала текста.
[0038] Если индекс строится для корпуса текстов, то он может включать также номер текста в корпусе. Аналогично, индексы могут присваиваться и другим характеристикам текста, выявленным в результате анализа 106, а именно, семантическим классам, семантемам, граммемам, синтаксическим отношениям, семантическим отношениям и пр. В одном из вариантов осуществления данного изобретения индекс может присваиваться всем или по меньшем мере одной морфологической, синтаксической, лексической, семантической характеристике каждого предложения или другой значимой единицы текста. Индекс используется для ускорения обработки естественного языка.
[0039] В одном из вариантов реализации данного изобретения лингвистические описания включают множества лингвистических моделей и знаний о естественных языках. Эти данные могут быть размещены в базе данных и использоваться для анализа каждого текста или исходных предложений, как на шаге 106. Такое множество лингвистических описаний может включать, но не ограничиваться ими, морфологические модели, синтаксические модели, грамматические модели и лексико-семантические модели. В одном из вариантов осуществления данного изобретения, интегральные модели для описания синтаксиса и семантики языка используются для того, чтобы распознать значение исходного предложения, проанализировать сложные структуры языка, корректно передать информацию, закодированную в исходном предложении.
[0040] В соответствии с Фиг. 1А и Фиг. 2, при анализе 106 значения исходного предложения 105, определяется лексико-морфологическая структура 222. После этого производится синтаксический анализ, состоящий из двух этапов («грубого» и «точного» синтаксического анализа), с использованием лингвистических моделей и информации на разных уровнях, вычислением вероятностных оценок, чтобы сгенерировать наиболее возможную синтаксическую структуру предложения, а именно, лучшую синтаксическую структуру.
[0041] Соответственно, результатом грубого синтаксического анализа исходного предложения является граф обобщенных составляющих 232, который используется на следующем этапе синтаксического анализа. Для представлении всех возможных вариантов синтаксического разбора предложения делается попытка применить все возможные поверхностные синтаксические модели каждого элемента лексико-морфологической структуры, строятся все возможные составляющие и затем обобщаются. Ниже будет показано, какие структуры последовательно строятся на примере анализе русского предложения "Этот мальчик сообразительный, он преуспеет в жизни" в соответствии с одним из вариантов реализации данного изобретения.
[0042] За грубым синтаксическим анализом следует точный синтаксический анализ, который производится на графе обобщенных составляющих с тем, чтобы построить одно или более синтаксических деревьев 242 для исходного предложения. В одном из вариантов осуществления данного изобретения, процесс построения синтаксического дерева 242 включает выбор между лексическими альтернативами и выбор между связями в графе. Множество априорных и статистических оценок может быть использовано в процессе выбора между лексическими альтернативами и в процессе выбора между отношениями в графе. Априорные и статистические оценки могут также присваиваться частям дерева или всему дереву целиком. В одном из вариантов реализации изобретения деревья могут строиться и упорядочиваться в соответствии с присвоенными оценками. Таким образом, выбирается наилучшее синтаксическое дерево. Затем в синтаксическом дереве устанавливаются недревесные связи, поэтому дерево превращается в синтаксическую структуру. Если для первого построенного синтаксического дерева невозможно установить недревесные связи, то рассматривается второе синтаксическое дерево.
[0043] Многие лексические, грамматические, синтаксические, прагматические, семантические характеристики выявляются в ходе анализа. Например, система может выделять и хранить лексическую информацию и информацию о принадлежности лексических элементов семантическим классам, информацию о грамматических формах и линейном порядке, о синтаксических связях и поверхностных позициях, используя смысловые характеристики, такие как глубинные позиции, недревесные связи, семантемы и пр.
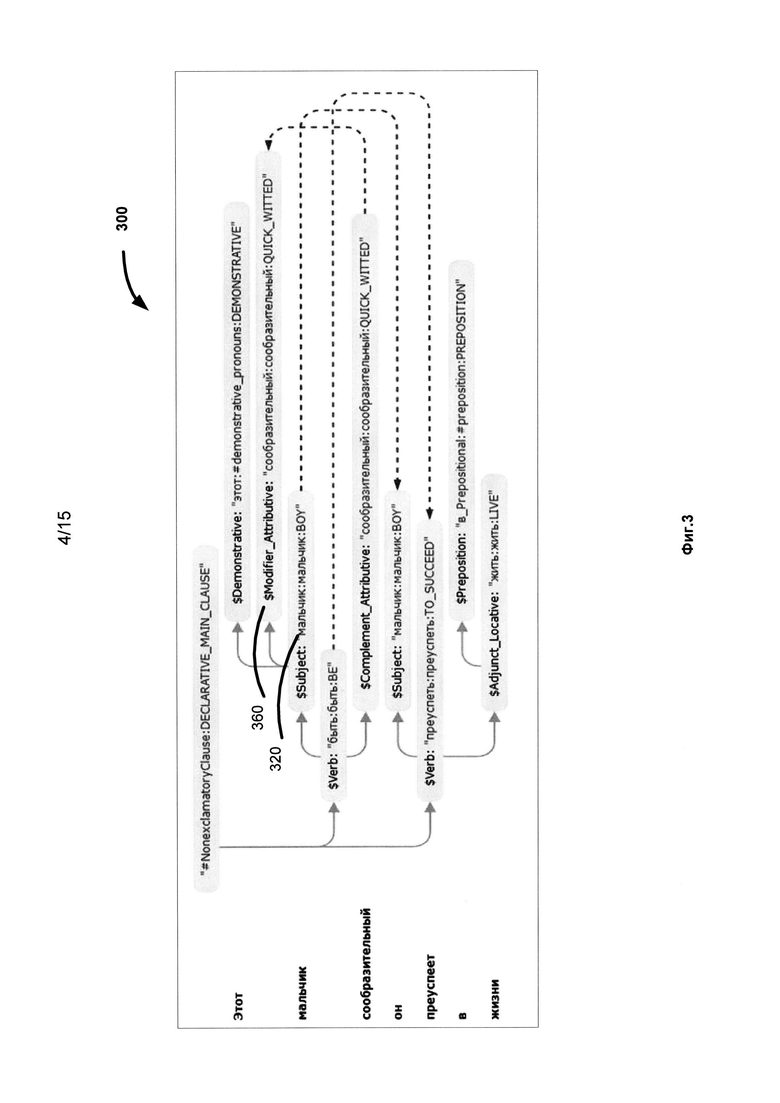
[0044] Фиг. 3 иллюстрирует пример синтаксической структуры 300, полученного в результате точного синтаксического анализа предложения "Этот мальчик сообразительный, он преуспеет в жизни". Это дерево содержит всю синтаксическую информацию о предложении, такую как лексические значения, части речи, грамматические значения, синтаксические отношения (позиции), синтаксические модели, типы недревесных связей и др. Например, $Demonstrative, $Modiffier_Atributive, $Subject, $Verb, $Complement_Attributive, $Preposition и $Adjunct_Locative - идентификаторы поверхностных позиций, a BE, BOY, LIVE, PREPOSITION, TO_SUCCEED, QUICK_WITTED - идентификаторы семантических классов. Например, "сообразительный" заполняет поверхностную позицию "$Modifier_Attributive" 360 управляющего слова "мальчик" (320) лексического класса "мальчик", принадлежащего семантическому классу BOY, что выражается в обозначении "мальчик:мальчик: BOY"(320).
[0045] В соответствии с Фиг. 2, двухэтапный анализ дает гарантию того, что значение исходного предложения представлено наилучшей синтаксической структурой 246, выбранной из одного или нескольких синтаксических деревьев. Преимущественно, двухэтапный анализ следует принципу полного и целенаправленного распознавания, а именно, гипотезы о структуре частей предложения проверяются в рамках гипотезы о структуре целого предложения. Такой подход позволяет избежать необходимости анализировать заведомо тупиковые варианты разбора.
[0046] В соответствии с Фиг. 1А, после того, как предложение проанализировано, на этапе 107 синтаксическая структура предложения интерпретируется семантически, и строится не зависимая от языка универсальная семантическая структура, передающая значение предложения. Не зависимая от языка семантическая структура - это обобщенная структура данных в не зависящей от языка форме или формате. Такая структура генерируется для каждого предложения и передает значение предложения в универсальных терминах, и аккумулирует все или практически все грамматические, лексические, синтаксические характеристики в не зависящих от языка терминах. Использование таких структур позволяет сравнивать высказывания друг с другом.
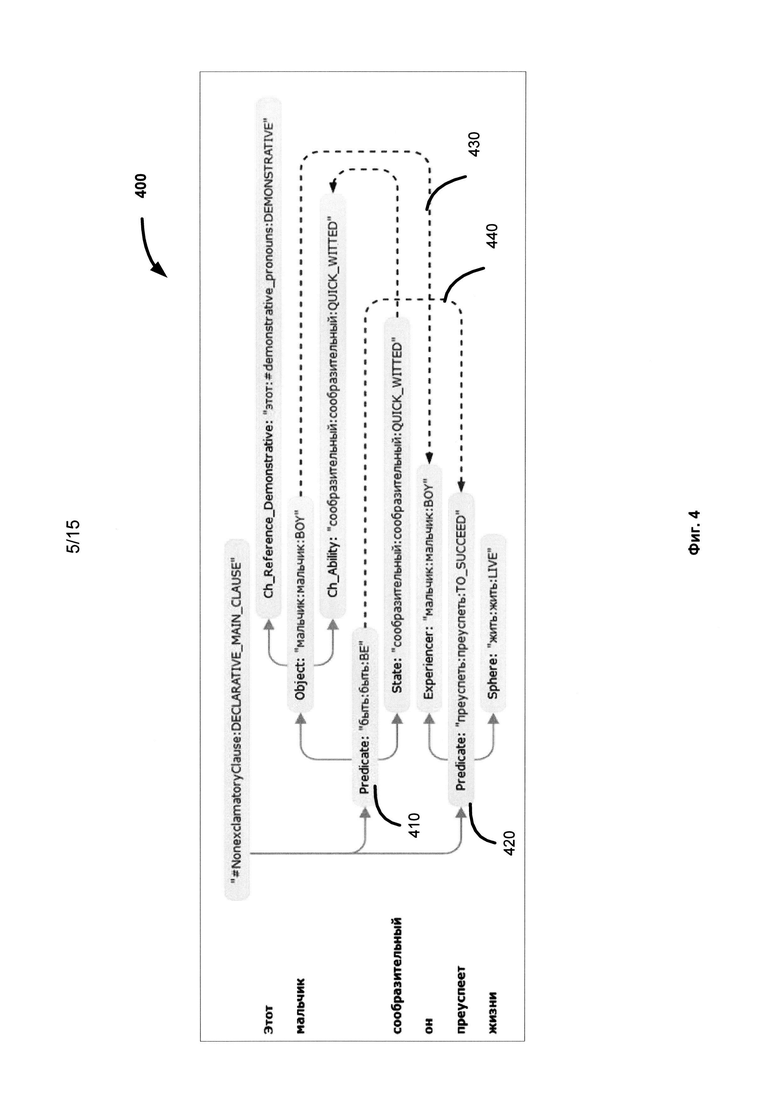
[0047] Фиг. 4 иллюстрирует пример семантической структуры 400, полученной для предложения "Этот мальчик сообразительный, он преуспеет в жизни". В соответствии с Фиг. 4, эта структура содержит всю синтаксическую и семантическую информацию, такую как семантический класс, семантемы (на рисунке не показаны), семантические отношения (глубинные позиции), недревесные связи и пр.
[0048] В соответствии с Фиг. 4 недревесная связь 440 соединяет две части - две составляющие 410 и 420 сложного предложения "Этот мальчик сообразительный, он преуспеет в жизни". Также, референциальная не древесная связь 430 отражает анафорическую связь между словами "мальчик" и "он", чтобы определить субъекты двух частей сложного предложения. Эта связь также изображается в синтаксическом дереве (Фиг. 3) после проведения анализа и установления недревесных связей.
[0049] В соответствии с Фиг. 2, описанный метод переводит исходное предложение 105 в не зависящую от языка семантическую структуру 252, используя различные структуры, в соответствие с вариантами осуществления изобретения, и различные лингвистические описания. В соответствии с Фиг. 2, для исходно предложения (для каждого предложения корпуса или текста) строится лексико-морфологическая структура 22. На ее основе строится граф обобщенных составляющих 232. Затем, строится одно или несколько синтаксических деревьев 246. Выбирается наилучшая или наиболее предпочтительная синтаксическая структура 246. Индексы для синтаксических структур формируются после того, как выбирается наилучшая структура 246. После того, как наилучшая структура 246 определена и выбрана, строится не зависящая от языка синтаксическая структура 252 и формируются индексы 262 для ее семантических и прочих (лексических, синтаксических, морфологических, прагматических) характеристик, которые были определены на всех этапах анализа.
[0050] Не зависящая от языка семантическая структура предложения представляется в виде ациклического графа (дерево, дополненное недревесными связями), в котором каждое слово определенного языка заменяется его универсальной (не зависящей от языка) семантической единицей или семантической сущностью, называемою здесь «семантическим классом». Семантический класс - это одна из наиболее важных семантических характеристик, которая может использоваться для задач классификации, кластеризации или фильтрации текстовых документов, написанных на одном или нескольких языках. Также для такого типа задач могут быть использованы, например, семантемы, отражающие не только семантические, но также синтаксические, грамматические и прочие конкретно языковые свойства в не зависящей от языка структуре.
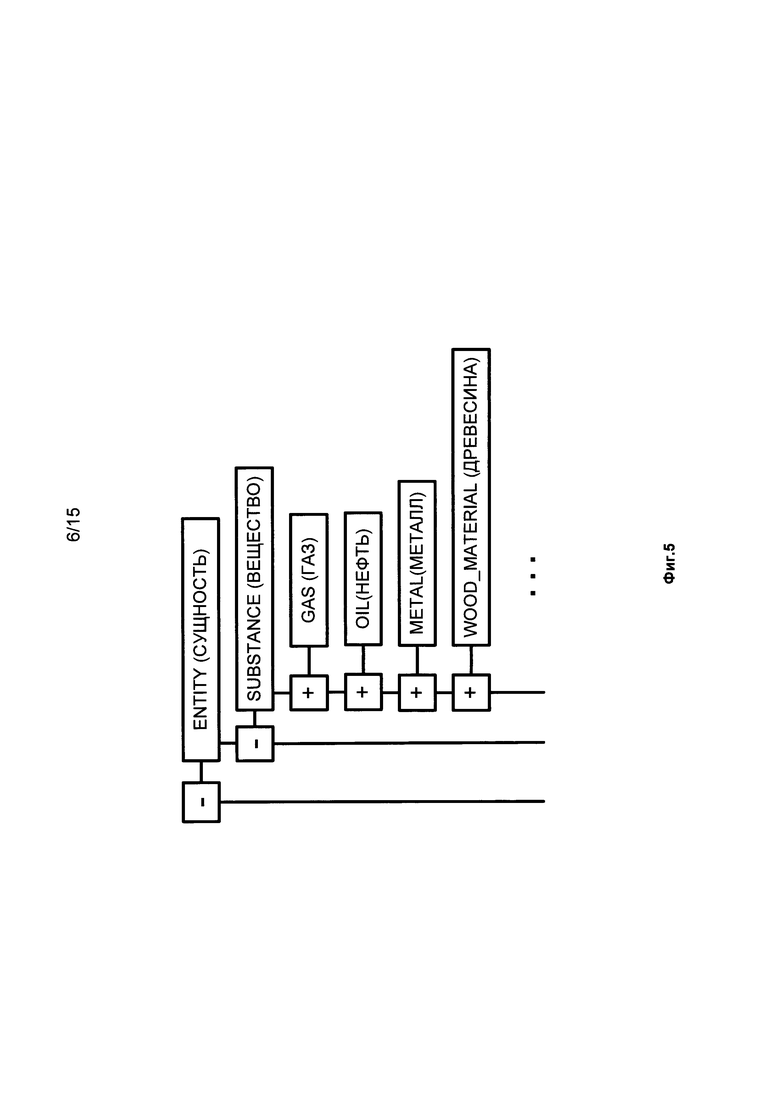
[0051] Семантические классы, как часть лингвистических описаний, образуют семантическую иерархию. В общем случае, все или практически все признаки класса-предка наследуются самим прямым потомком, а также всеми его потомками. Например, семантический класс SUBSTANCE является потомком семантического класса ENTITY и одновременно "родителем" для семантических классов GAS, LIQUID, METAL, WOODMATERIAL, и пр. Фиг. 5 иллюстрирует фрагмент описанной семантической иерархии.
[0052] Каждый семантический класс в семантической иерархии сопровождается глубинной моделью. Глубинная модель семантического класса представляет собой набор глубинных позиций. Глубинные позиции отражают семантические роли дочерних составляющих в различных предложениях с объектами данного семантического класса в качестве ядра родительской составляющей и возможными семантическими классами в качестве заполнителей глубинных позиций. Глубинные позиции отражают семантические отношения между составляющими, включая, например, «агент», «адресат», «инструмент», «количество», и пр. Дочерний семантический класс наследует и уточняет глубинную модель своего прямого родительского семантического класса.
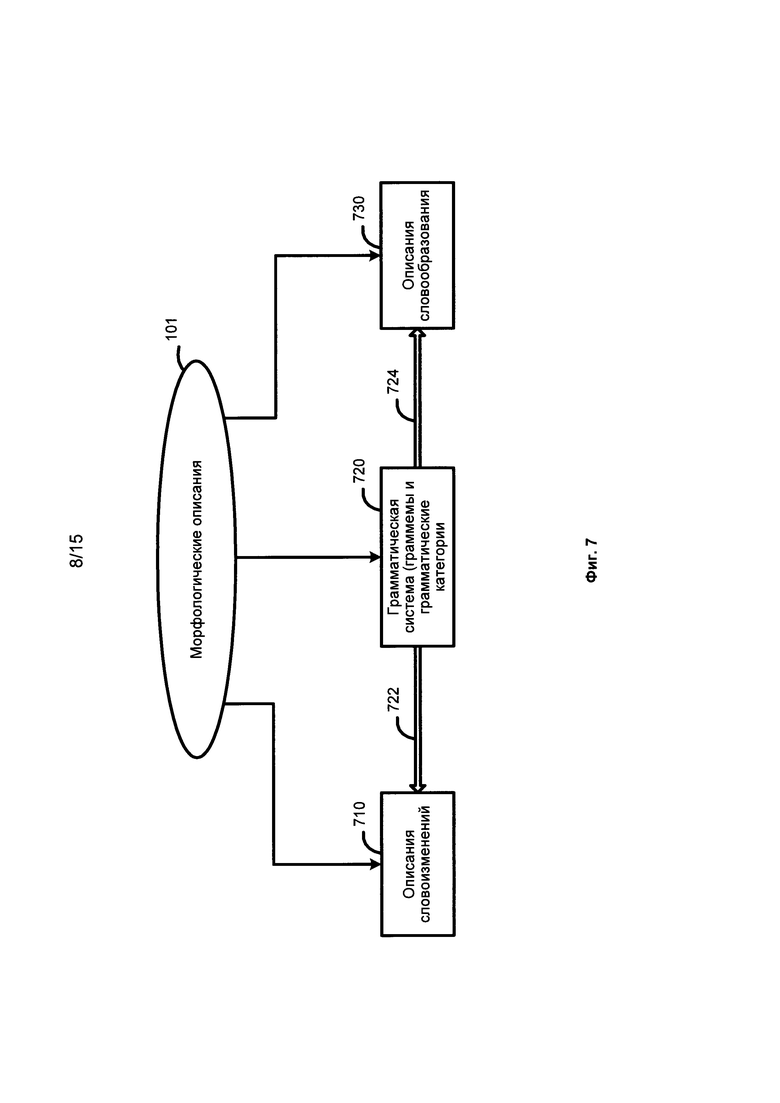
[0053] На Фиг. 6 изображена диаграмма, представляющая используемые языковые описания 610 в соответствии с одним из вариантов реализации изобретения. В соответствии с Фиг. 6 языковые описания 610 включают морфологические описания 101, синтаксические описания 102, лексические описания 103 и семантические описания 104. На Фиг. 7 изображена диаграмма, иллюстрирующая морфологические описания в соответствии с одним или несколькими вариантами реализации изобретения. На Фиг. 8 изображена диаграмма, иллюстрирующая синтаксические описания в соответствии с одним или несколькими вариантами реализации изобретения. На Фиг. 9 изображена диаграмма, иллюстрирующая семантические описания в соответствии с одним или несколькими вариантами реализации изобретения.
[0054] В соответствии с Фиг. 6 и Фиг. 9, будучи частью семантических описаний 104, семантическая иерархия 910 является ключевой частью языковых описаний 610, которая объединяет не зависящие от языка семантические описания 104 и конкретно-языковые лексические описания 103, что изображено двойной стрелкой 623, и морфологические описания 101 и синтаксические описания 102, что изображено двойной стрелкой 624. Семантическая иерархия может быть создана единовременно, а затем может быть заполнена для каждого определенного языка. Семантический класс в определенном языке включает лексические значения с соответствующими моделями. Семантические описания 104 не зависят от языка. Семантические описания 104 могут содержать описания глубинных составляющих и могут содержать семантическую иерархию, описания глубинных позиций, систему семантем и прагматических описаний.
[0055] В соответствии с Фиг. 6, морфологические описания 101, лексические описания 103, синтаксические описания 102 и семантические описания 104 связаны. Лексическое значение может иметь несколько поверхностных (синтаксических) моделей, сопровождаемых семантемами и прагматическими характеристиками. Синтаксические описания 102 и семантические описания 104 также связаны. Например, диатеза синтаксических описаний 102 может рассматриваться как "интерфейс" между зависимыми от языка поверхностными моделями и независимыми от языка глубинными моделями семантического описания 104.
[0056] Фиг. 7 иллюстрирует пример морфологических описаний 101. Как показано, составляющие морфологических описаний 101 включают, но не ограничиваются описаниями словоизменения 710, грамматической системой (граммемами) 720, и описаниями словообразования 730. В одной из возможных реализаций изобретения грамматическая система 720 включает набор грамматических категорий, таких как «Часть речи», «Падеж», «Род», «Число», «Лицо», «Возвратность», «Время», «Вид» и их значения, здесь и далее называемые граммемами. Например, граммемы, означающие части речи, могут включать прилагательное, существительное, глагол и т.д.; граммемы падежа могут включать «Именительный», «Родительный», «Дательный» и т.д.; граммемы рода могут включать «Мужской», «Женский», «Средний» и т.д.
[0057] Ссылаясь на Фиг. 7, описания словоизменения 710 описывают, как начальная форма слова может изменяться в зависимости от падежа, рода, числа, времени и т.д. и включают в широком смысле все возможные формы данного слова. Описания словообразования 730 описывают, какие новые слова могут быть построены с использованием данного слова. Граммемы - единицы грамматической системы 720 и, как показывает ссылка 722 и ссылка 724, граммемы могут быть использованы для построения описаний словоизменения 710 и описаний словообразования 730.
[0058] Фиг. 8 иллюстрирует синтаксические описания 102. Компоненты синтаксических описаний 102 могут содержать поверхностные модели 810, описания поверхностных позиций 820, описания референциального и структурного контроля 856, описания управления и согласования 840, недревесные описания 850 и правила анализа 860. Синтаксические описания 302 используются для построения возможных синтаксических структур предложения для данного исходного языка, учитывая порядок слов, недревесные синтаксические явления (например, согласование, эллипсис и т.д.), референциальный контроль (управление) и другие явления.
[0059] Фиг. 9 иллюстрирует семантические описания 104 согласно одной из возможных реализаций изобретения. В то время как поверхностные позиции 820 отражают синтаксические отношения и способы их реализации в конкретном языке, глубинные позиции 914 отражают семантические роли дочерних (зависимых) составляющих в глубинных моделях 912. Потому описания поверхностных позиций, и шире - поверхностные модели, могут быть специфичными для каждого конкретного языка. Описания глубинных моделей 920 содержат грамматические и семантические ограничения для заполнителей этих позиций. Свойства и ограничения глубинных позиций 914 и их заполнители в глубинных моделях 912 очень похожи и часто идентичны для различных языков.
[0060] Система семантем 930 представляет множество семантических категорий. Семантемы могут отражать лексические, грамматические свойства и атрибуты, а также дифференциальные свойства и стилистические, прагматические и коммуникативные характеристики. Для примера, семантическая категория "DegreeOfComparison" (степень сравнения) может быть использована для описания степеней сравнения, выраженных разными формами прилагательных, например, "easy", "easier" and "easiest". Так, семантическая категория "DegreeOfComparison" может включать семантемы, например "Positive", "ComparativeHigherDegree", "SuperlativeHighestDegree". В качестве другого примера, семантическая категория "RelationToReferencePoint" может быть использована для описания того, в каком линейном порядке - до или после объекта или события находится в предложении ссылка на него, и ее семантемами являются "Previous", "Subsequent". Еще один пример - семантическая категория "EvaluationObjective" может фиксировать наличие объективной оценки, такой как "Bad", "Good" и т.д. Лексические семантемы могут описывать специфические свойства объектов, например "быть плоским" ("being flat") или "быть жидким" ("being liquid") и используются в ограничениях на заполнители глубинных позиций. Классифицирующие дифференциальные семантемы используются для выражения дифференциальных свойств внутри одного семантического класса. Например, в английском языке "парикмахер" для мужчин переводится как "barber", и ему в семантическом классе "HAIRDRESSER" будет приписана семантема "RelatedToMen", в то время как в том же семантическом классе есть "hairdresser" и "hairstylist" и др.
[0061] Прагматические описания 940 служат для того, чтобы в процессе анализа текста фиксировать соответствующую тему, стиль или жанр текста, а также возможно приписать соответствующие характеристики объектам семантической иерархии. Например, "Economic Policy", "Foreign Policy", "Justice", "Legislation", "Trade", "Finance", etc.
[0062] Фиг. 10 является схемой, иллюстрирующей лексические описания 103, согласно одной или нескольким реализациям данного изобретения. Лексические описания 103 включают лексико-семантический словарь 1004, который включает в себя набор лексических значений 1012, образующих вместе со своими семантическими классами семантическую иерархию, где каждое лексическое значение может включать, но не ограничивается своей глубинной моделью 912, поверхностной моделью 810, грамматическим значением 1008 и семантическим значением 1010. Лексическое значение может объединять различные дериваты (например, слова, выражения, фразы), выражающие смысл с помощью различных частей речи, различных форм слова, однокоренных слов и пр. В свою очередь, семантический класс объединяет лексические значения близких по смыслу слов и выражений на разных языках.
[0063] Любой элемент языкового описания 610: лексические значения, семантические классы, граммемы, семантемы и многое другое, - может быть выделен в процессе описанного выше исчерпывающего семантико-синтаксического анализа текста, может быть проиндексирован (создан индекс характеристик). Индексы могут храниться и быть использованы для задач классификации, кластеризации и фильтрации текстовых документов, написанных на одном или более языках. В одном из вариантов реализации данного изобретения, индексация семантических классов является наиболее важной для решения названных задач. Синтаксические структуры и семантические структуры также могут индексироваться для использования в семантическом поиске, классификации, кластеризации и фильтрации.
[0064] Одним из простых способов сравнения текстовых документов, написанных на одном языке, является сравнение их индексов. Это могут быть индексы слов, либо индексы семантических классов, представленные в форме простых структур данных, например, последовательности чисел. Если индексы слов в текстах совпадают, то можно утверждать, что тексты идентичны или могут считаться идентичными для определенных целей. Если индексы семантических классов в двух текстах совпадают, то тексты идентичны, либо существенным образом схожи. Подход со сравнением индексов семантических классов может использоваться с некоторыми ограничениями и для текстов, написанных на различных языках. Линейный порядок слов в соответствующих предложениях может быть различным, потому, при вычислении универсальной меры похожести двух предложений, допускается игнорирование порядка слов и полного совпадения позиций слов в предложениях.
[0065] Другой проблемой является наличие часто употребляемых слов, таких как «the», «not» и др., которые обычно не индексируются. Потому предложения "The approval of the CEO is required" и "The approval of the CEO isn't required" будут иметь одинаковые индексы и рассмотрены как идентичные при сравнении. Методы настоящего изобретения идентифицируют эти предложения, как разные, поскольку они также принимают во внимание специфические лексические, синтаксические и семантические характеристики, выделенные на разных этапах анализа. Факт о том, что глагол "require" стоит в негативной форме, зафиксирован наличием соответствующей семантемы.
[0066] Но проблема возникает, например, в случае, если предложению на одном языке соответствует два и более предложения на другом языке. В таком случае, чтобы повысить точность настоящего метода, можно использовать методы предварительного выравнивания двух или более текстов, представленных, например, в заявке U.S. 13/464,447 "Methods and Systems for Alignment of Parallel Text Corpora" ("Метод и система выравнивания параллельного текстового корпуса") от 22.05.2012. Существует множество способов вычисления похожести двух текстов. Одним из наиболее простых способов является подсчет общих слов в них. Существует также несколько продвинутых модификаций такого подхода, включающих лемматизацию, морфологический поиск, взвешивание и др. Например, можно построить модель векторного пространства (G.Salton, 1975) и вычислить векторную меру похожести, такую как, например, косинусный коэффициент похожести.
[0067] В процессе обработки текста, описанном здесь, документы могут быть представлены с помощью не зависящих от языка семантических классов, которые в свою очередь могут рассматриваться как лексические характеристики. Таким образом, мера похожести, описанная выше, может существовать.
[0068] Недостатком описанных выше мер похожести является то, что они, по сути, не улавливают семантику. Например, два предложения «У Боба Кадиллак» и «Ричард имеет автомобиль» семантически похожи, но не имеют ни одного общего слова, а лишь общую тему. Это означает, что простая лексическая мера похожести не выявит схожесть данных предложений. Чтобы выявить этот тип схожести, можно использовать семантические меры, основанные на знаниях (knowledge-based). Для этого может быть использована семантическая иерархия. Похожесть двух слов обычно зависит от кратчайшего пути между двумя соответствующими понятиями в семантической иерархии. Например, «Кадиллак» из первого предложения в семантической иерархии является дочерним узлом (гипонимом) «автомобиля», и потому семантическая схожесть (semantic similarity) между понятиями будет велика. Универсальные меры похожести между словами (word - to - word) могут быть обобщены до универсальных мер похожести между текстами (text - to - text) комбинированием значений универсальных мер похожести для каждой пары слов. Семантическим классам соответствуют узлы в семантической иерархии. Таким образом, основанные на знаниях семантические меры похожести, описанные здесь и выше, могут быть использованы в процессе обработки документов.
[0069] Например, в соответствии с настоящим изобретением, текстовая информация может быть представлена в виде списка характеристик, включающих семантические классы{С1, С2,…, Cm}, семантические характеристики {M1, М2,…, Mn} и синтаксические характеристики {S1, S2,…, Sk}. Поскольку лексические значения могут быть выражены различными словами, а семантические классы могут объединять несколько близких лексических значений, то семантические классы могут реализовывать идею обобщения (синонимов и дериватов). Семантические классы также обобщают значения слов на разных языках, если мы работаем с текстами на различных языках. Семантические характеристики отражают семантическую структуру текста, которая содержит семантические роли элементов: агенс (одушевленный инициатор и контролер действия), экспериенцер (носитель чувств и восприятий) и пр. Синтаксические характеристики отражают синтаксическую структуру текста, построенную, например, грубым синтаксическим анализатором или точным синтаксическим анализатором.
[0070] В настоящем изобретении семантические классы объединены в семантическую иерархию, представленную в общем виде, графом. В одном из вариантов реализации, расстояние между двумя узлами графа является кратчайшим расстоянием между узлами. И похожесть между семантическими классами определяется как функция этого расстояния.
[0071] В другом варианте реализации настоящего изобретения, универсальная мера похожести двух или более документов может быть определена эвристически, на основе эксперимента. Например, у нас есть два текстовых документа - D1 и D2. После проведения семантического анализа мы получили 2 набора семантических классов C(D1)={С11, С12,…,C1n} и C(D2)={С21, С22,…, C2m}. У каждого класса может быть частотный коэффициент встречаемости в документе Fij. Наиболее часто встречающиеся в языке семантические, а также наиболее общие для разных языков классы (такие как ENTITY, ABSTRACT_SCIENTIFIC_OBJECT) могут быть отброшены. Далее универсальная мера похожести может быть вычислена как функция от расстояния между каждой парой семантических классов (C1, С2), где C1∈C(D1), a C2∈C(D2). В одном из вариантов реализации изобретения универсальная мера похожести или универсальная мера различия между семантическими классами может быть определена, как функция от расстояния между этими классами, а именно, sim(C1, С2)=f(path(C1, С2), dif(C1, С2)=g(path(C1, С2), функция идентичности. В другом варианте реализации изобретения, универсальная мера похожести или универсальная мера различия основана на идее нахождения ближайшего общего потомка классов: anc(C1, С2).
[0072] В одном из вариантов реализации изобретения, похожесть между текстами может быть определена следующим образом:
[0073] 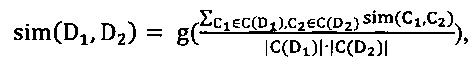
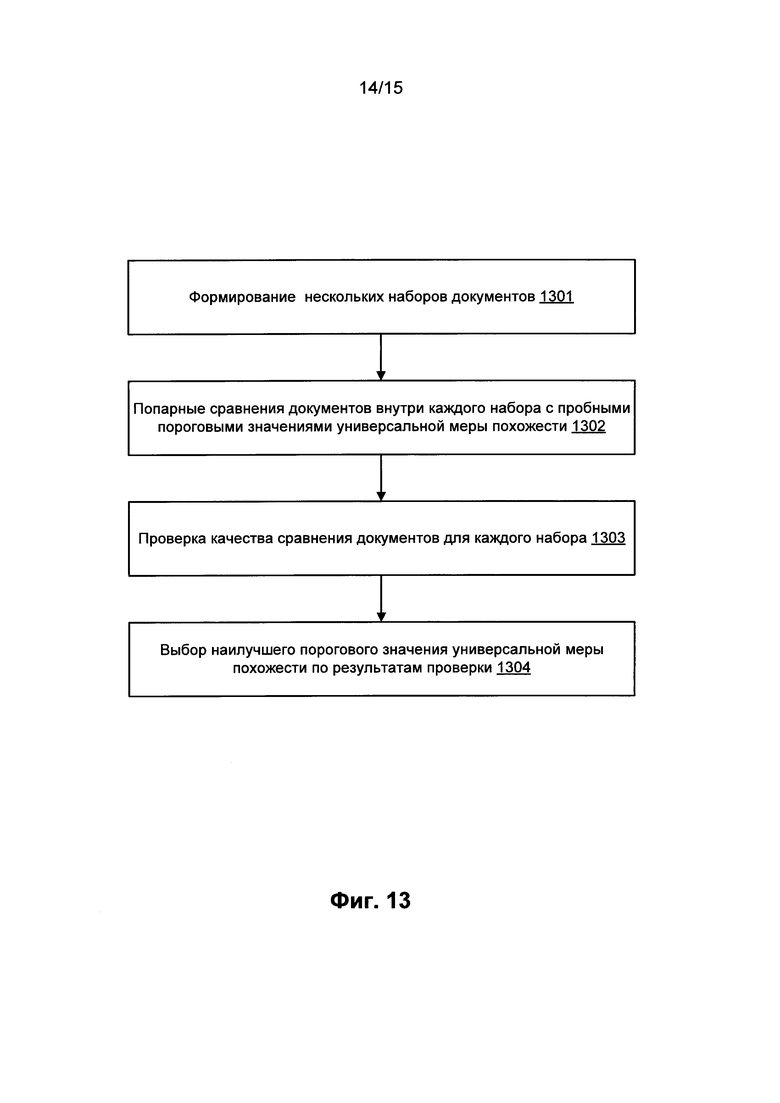
[0074] где |C(D)| означает количество семантических классов в C(D), a g - некоторая функция.
[0075] В одном из вариантов осуществления изобретения универсальная мера различия между документами вычисляется так:
[0076] 
[0077] Фиг. 11 иллюстрирует возможный пример визуализации определения похожести, в котором идентичные части документов 1101 выделены (указаны в рамках), а различные части 1102 не обозначены специальным образом. Другим примером визуализации может быть выделение цветом, изменение размера, шрифта и пр. слов, совпадающих, либо отличающихся в сравниваемых документах.
[0078] Фиг. 12 иллюстрирует блок - схему метода нахождения похожих документов в наборе документов и построения корпуса сравнимых документов в соответствии с одним из вариантов реализации изобретения. Описанная идея определения похожести документов может быть использована для поиска похожих документов внутри большого набора документов (например, результат поисковой выдачи), и составления корпуса сравнимых документов. В соответствии с Фиг. 12 для составления исходного набора документов 1201 можно провести поиск документов по теме 1200. После этого в исходном наборе 1201 производится поиск схожих документов 1202, который может включать: предварительную обработку документов 1203 (например, перевод документов в текстовый машиночитаемый формат), выделение логической структуры и структурных блоков текста 1204; проведение анализа текстов 1205, в ходе которого происходит выделение лексических, семантических, синтаксических и других характеристик текстов 1205; построение не зависящих от языка семантических структур текстов 1206; сравнение семантических структур текстов с помощью универсальной меры похожести 1207; определение похожести документов, содержащих соответствующие тексты. После того, как произведено сравнение текстов на основе универсальной меры похожести, мы получаем множество схожих документов 1208, причем в данное множество включаются пары (или большее число) документов, для которых значение универсальной меры похожести достигло заранее заданного порогового значения. Далее происходит фильтрация 1209 дубликатов одного и того же документа или близких документов, в терминах универсальной меры похожести. Например, если есть текст на русском языке R1 и два текста на английском - Е1 и Е2, для которых универсальная мера похожести между R1 и E1 sim(R1, E1)=а и универсальная мера похожести между R1 и Е2 sim(R1, Е2)=b, при этом а и b превосходят пороговое значение универсальной меры похожести, то в корпус войдет текст с наибольшим значением универсальной меры похожести. После фильтрации 1209 происходит формирование корпуса сравнимых документов 1210.
[0079] Этап построения не зависящей от языка семантической структуры текста 1206 может быть довольно длительным и ресурсозатратным, потому возможны методы ускорения данного процесса. Например, можно строить не зависящую от языка семантическую структуру не для целого текста, а для его значимых частей и сравнивать их.
[0080] Пороговое значение универсальной меры похожести, которое необходимо достигнуть, чтобы принять решения о внесении того или иного текста в корпус (в корпус вносятся семантически близкие тексты на разных языках, если в наборе присутствуют тексты - дубли или очень близкие тексты на одном языке, то в корпус попадает только один из них), можно выбирать эмпирически. Как именно, будет зависеть от конкретной задачи. Например, можно использовать метод «evaluation in vivo» (то есть не произвольно, а в рамках более широкой задачи). Поскольку корпус сравнимых документов, в общем случае, предназначен для обучения систем машинного перевода, то в одном из вариантов реализации изобретения можно брать наборы документов небольших размеров, и проводить их попарные сравнения с разными пробными значениями универсальной меры похожести (если пороговое значение универсальной меры похожести ограничено в пределах 0 и 1, то можно подбирать значения с шагом 0.1), а после ставить эксперименты на этих наборах. Затем пробное пороговое значение универсальной меры похожести, для которого результаты эксперимента наилучшие, используется для построения большегоий корпуса сравнимых документов с этим пороговым значением универсальной меры похожести. В другом варианте реализации можно подбирать пороговое значение универсальной меры похожести вручную, и после построения корпуса сравнимых документов смотреть, какой вариант подходит больше.
[0081] На Фиг. 13 изображены основные шаги метода подбора порогового значения универсальной меры похожести. Для начала можно сформировать несколько небольших наборов документов 1301. Затем для каждого набора провести попарные сравнения документов 1302 с пробными пороговыми значениями универсальной меры похожести, отличающимися на величину шага, как указано выше. После того как сравнения проведены и получено несколько наборов сравнимых документов, можно произвести проверку выполненных сравнений 1303. По результатам проверки можно выбрать наилучшее пробное пороговое значение универсальной меры похожести 1304, и уже с выбранным пороговым значением универсальной меры похожести приступать к построению большого корпуса сравнимых документов.
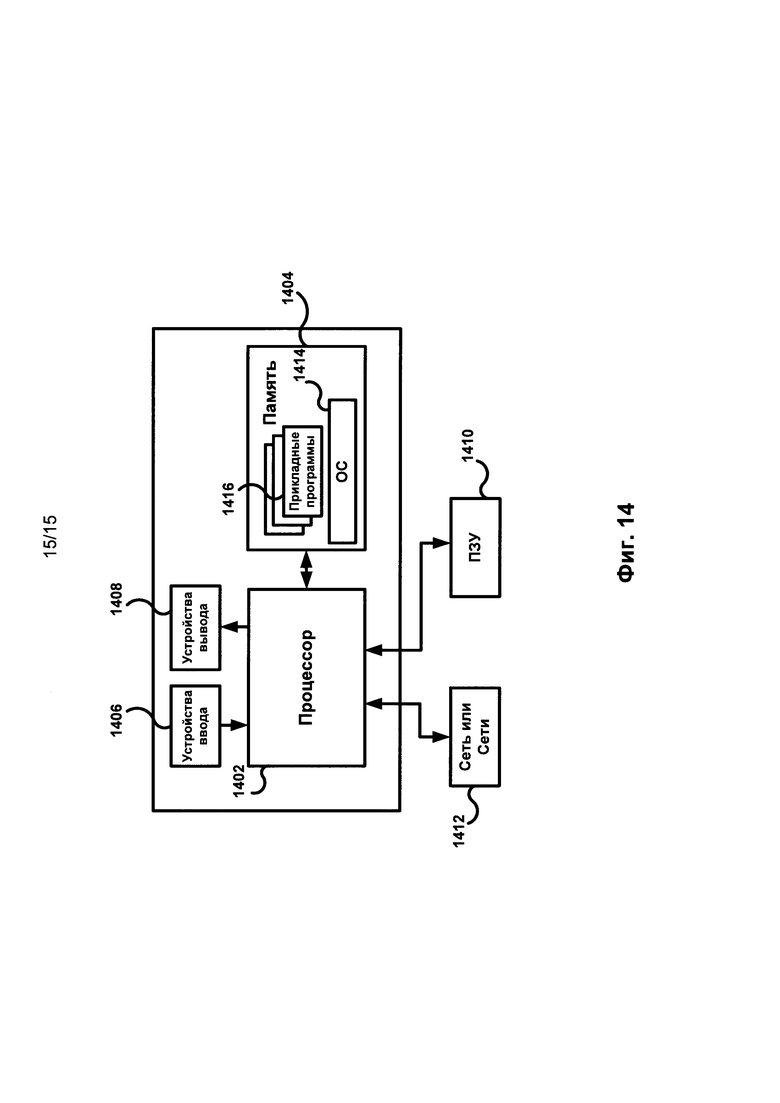
[0082] На Фиг. 14 приведен возможный пример вычислительного средства 1400, которое может быть использовано для внедрения настоящего изобретения, осуществленного так, как было описано выше. Вычислительное средство 1403 включает в себя, по крайней мере, один процессор 1402, соединенный с памятью 1404. Процессор 1402 может представлять собой один или более процессоров, может содержать одно, два или более вычислительных ядер или представлять собой чип или другое устройство, способное производить вычисления. Память 1404 может представлять собой оперативное запоминающее устройство (ОЗУ), а также содержать любые другие типы и виды памяти, в частности, устройства энергонезависимой памяти (например, флэш-накопители) и постоянные запоминающие устройства, например, жесткие диски и т.д. Кроме того, может считаться, что память 1404 включает в себя аппаратные средства хранения информации, физически размещенные где-либо еще в составе вычислительного средства 1400, например, кэш-память в процессоре 1402, память, используемую в качестве виртуальной и хранимую на внешнем либо внутреннем постоянном запоминающем устройстве 1410.
[0083] Вычислительное средство 1400 также обычно имеет некоторое количество входов и выходов для передачи информации вовне и получения информации извне. Для взаимодействия с пользователем вычислительное средство 1400 может содержать одно или более устройств ввода (например, клавиатура, мышь, сканер и т.д.) и устройство отображения 1408 (например, жидкокристаллический дисплей или сигнальные индикаторы). Вычислительное средство 1400 также может иметь одно или более постоянных запоминающих устройств 1410, например, привод оптических дисков (CD, DVD или другой), жесткий диск, ленточный накопитель. Кроме того, вычислительное средство 1400 может иметь интерфейс с одной или более сетями 1412, обеспечивающими соединение с другими сетями и вычислительными устройствами. В частности, это может быть локальная сеть (LAN), беспроводная сеть Wi-Fi, соединенные со всемирной сетью Интернет или нет. Подразумевается, что вычислительное средство 1400 включает подходящие аналоговые и/или цифровые интерфейсы между процессором 1402 и каждым из компонентов 1404, 1406, 1408, 1410 и 1412.
[0084] Вычислительное средство 1400 работает под управлением операционной системы 1414 и выполняет различные приложения, компоненты, программы, объекты, модули и т.д., указанные обобщенно цифрой 1416.
[0085] Программы, исполняемые для реализации способов, соответствующих данному изобретению, могут являться частью операционной системы или представлять собой обособленное приложение, компоненту, программу, динамическую библиотеку, модуль, скрипт, либо их комбинацию.
[0086] Настоящее описание излагает основной изобретательский замысел авторов, который не может быть ограничен теми аппаратными устройствами, которые упоминались ранее. Следует отметить, что аппаратные устройства, прежде всего, предназначены для решения узкой задачи. С течением времени и с развитием технического прогресса такая задача усложняется или эволюционирует. Появляются новые средства, которые способны выполнить новые требования. В этом смысле следует рассматривать данные аппаратные устройства с точки зрения класса решаемых ими технических задач, а не чисто технической реализации на некой элементной базе.
| название | год | авторы | номер документа |
|---|---|---|---|
| ИЗВЛЕЧЕНИЕ СУЩНОСТЕЙ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2626555C2 |
| СПОСОБ И СИСТЕМА ДЛЯ МАШИННОГО ИЗВЛЕЧЕНИЯ И ИНТЕРПРЕТАЦИИ ТЕКСТОВОЙ ИНФОРМАЦИИ | 2015 |
|
RU2592396C1 |
| ИСЧЕРПЫВАЮЩАЯ АВТОМАТИЧЕСКАЯ ОБРАБОТКА ТЕКСТОВОЙ ИНФОРМАЦИИ | 2014 |
|
RU2662699C2 |
| РАСШИРЕНИЕ ВОЗМОЖНОСТЕЙ ИНФОРМАЦИОННОГО ПОИСКА | 2015 |
|
RU2618375C2 |
| СИСТЕМА И МЕТОД СЕМАНТИЧЕСКОГО ПОИСКА | 2013 |
|
RU2563148C2 |
| СПОСОБ ИЗВЛЕЧЕНИЯ ФАКТОВ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2016 |
|
RU2637992C1 |
| СЕНТИМЕНТНЫЙ АНАЛИЗ НА УРОВНЕ АСПЕКТОВ С ИСПОЛЬЗОВАНИЕМ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2657173C2 |
| СЕНТИМЕНТНЫЙ АНАЛИЗ НА УРОВНЕ АСПЕКТОВ И СОЗДАНИЕ ОТЧЕТОВ С ИСПОЛЬЗОВАНИЕМ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2635257C1 |
| СИСТЕМА И МЕТОД АВТОМАТИЧЕСКОГО СОЗДАНИЯ ШАБЛОНОВ | 2018 |
|
RU2697647C1 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ ИЗ СМЫСЛОВЫХ БЛОКОВ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ МИКРОМОДЕЛЕЙ НА БАЗЕ ОНТОЛОГИИ | 2017 |
|
RU2662688C1 |








Изобретение относится к способу, машиночитаемому носителю данных и системе для создания корпуса сравнимых документов. Технический результат заключается в возможности автоматического формирования корпуса сравнимых документов. В способе выполняют получение вычислительным устройством исходного набора документов, содержащих тексты, проведение вычислительным устройством семантико-синтаксического анализа текстов для построения не зависящих от языка семантических структур предложений текстов этих документов, вычисление значений универсальной меры похожести для групп документов путем сравнения построенных, не зависящих от языка семантических структур для текстов этих документов, выявление вычислительным устройством групп схожих документов на основании вычисленных значений универсальной меры похожести групп документов, формирование вычислительным устройством корпуса сравнимых документов на основании выявленных схожих документов. 3 н. и 12 з.п. ф-лы, 15 ил.
1. Способ для компьютерной системы, предназначенный для создания корпуса сравнимых документов, используемого в задачах автоматической обработки естественного языка, информационного поиска, машинного обучения, включающий следующие этапы:
получение вычислительным устройством исходного набора документов, содержащих тексты;
проведение вычислительным устройством семантико-синтаксического анализа текстов для построения не зависящих от языка семантических структур предложений текстов этих документов;
вычисление значений универсальной меры похожести для групп документов путем сравнения построенных не зависящих от языка семантических структур для текстов этих документов;
выявление вычислительным устройством групп схожих документов на основании вычисленных значений универсальной меры похожести групп документов;
формирование вычислительным устройством корпуса сравнимых документов на основании выявленных схожих документов.
2. Способ по п. 1, в котором выявление групп схожих документов дополнительно содержит сравнение вычисленных значений универсальной меры похожести групп документов с пороговым значением универсальной меры похожести, где пороговое значение подбирается на небольших наборах документов, путем попарного сравнения документов внутри наборов с разными пробными пороговыми значениями универсальной меры похожести и определения наилучших результатов сравнения среди всех наборов.
3. Способ по п. 1, дополнительно содержащий этап создания исходного набора документов путем поиска документов по теме.
4. Способ по п. 1, дополнительно содержащий этапы
предварительной обработки исходных текстов и
выделения логической структуры и структурных блоков текстов.
5. Способ по п. 1, дополнительно содержащий этап фильтрации схожих документов, являющихся дубликатами.
6. Машиночитаемый носитель данных для компьютера, содержащий одну или несколько программ для компьютера, отличающийся тем, что одна или несколько программ для компьютера содержат команды, которые при выполнении устройством обработки данных, приводят к тому, что это устройство обработки данных выполняет операции, включающие:
получение вычислительным устройством исходного набора документов, содержащих тексты;
проведение вычислительным устройством семантико-синтаксического анализа текстов для построения не зависящих от языка семантических структур предложений текстов этих документов;
вычисление значений универсальной меры похожести для групп документов путем сравнения построенных не зависящих от языка семантических структур для текстов этих документов;
выявление вычислительным устройством групп схожих документов на основании вычисленных значений универсальной меры похожести групп документов;
формирование вычислительным устройством корпуса сравнимых документов на основании выявленных схожих документов.
7. Машиночитаемый носитель данных для компьютера по п. 6, отличающийся тем, что выявление групп схожих документов дополнительно содержит сравнение вычисленных значений универсальной меры похожести групп документов с пороговым значением универсальной меры похожести, где пороговое значение подбирается на небольших наборах документов, путем попарного сравнения документов внутри наборов с разными пробными пороговыми значениями универсальной меры похожести и определения наилучших результатов сравнения среди всех наборов.
8. Машиночитаемый носитель данных для компьютера по п. 6, отличающийся тем, что создание исходного набора документов дополнительно содержит этап поиска документов по теме.
9. Машиночитаемый носитель данных для компьютера по п. 6, отличающийся тем, что дополнительно проводится
предварительная обработки исходных текстов и
выделение логической структуры и структурных блоков текстов.
10. Машиночитаемый носитель данных для компьютера по п. 6, отличающийся тем, что дополнительно проводится этап фильтрации схожих документов, являющихся дубликатами.
11. Система для создания корпуса сравнимых документов, используемого в задачах автоматической обработки естественного языка, информационного поиска, машинного обучения, содержащая вычислительное устройство, и машиночитаемый носитель, соединенный с вычислительным устройством и имеющий хранящиеся в нем команды, которые при выполнении вычислительным устройством приводят к тому, что это вычислительное устройство выполняет операции, включающие:
получение вычислительным устройством исходного набора документов, содержащих тексты;
проведение вычислительным устройством семантико-синтаксического анализа текстов для построения не зависящих от языка семантических структур предложений текстов этих документов;
вычисление значений универсальной меры похожести для групп документов путем сравнения построенных не зависящих от языка семантических структур для текстов этих документов;
выявление вычислительным устройством групп схожих документов на основании вычисленных значений универсальной меры похожести групп документов;
формирование вычислительным устройством корпуса сравнимых документов на основании выявленных схожих документов.
12. Система по п. 11, отличающаяся тем, что выявление групп схожих документов дополнительно содержит сравнение вычисленных значений универсальной меры похожести групп документов с пороговым значением универсальной меры похожести, где пороговое значение подбирается на небольших наборах документов, путем попарного сравнения документов внутри наборов с разными пробными пороговыми значениями универсальной меры похожести и определения наилучших результатов сравнения среди всех наборов.
13. Система по п. 11, отличающаяся тем, что создание исходного набора документов дополнительно содержит этап поиска документов по теме.
14. Система по п. 11, отличающаяся тем, что дополнительно проводится
предварительная обработки исходных текстов и
выделение логической структуры и структурных блоков текстов.
15. Система по п. 11, отличающаяся тем, что дополнительно проводится этап фильтрации схожих документов, являющихся дубликатами.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| СПОСОБ АВТОМАТИЗИРОВАННОГО АНАЛИЗА ТЕКСТОВЫХ ДОКУМЕНТОВ | 2011 |
|
RU2474870C1 |
| МЕТОД ОТНЕСЕНИЯ РАНЕЕ НЕИЗВЕСТНОГО ФАЙЛА К КОЛЛЕКЦИИ ФАЙЛОВ В ЗАВИСИМОСТИ ОТ СТЕПЕНИ СХОЖЕСТИ | 2009 |
|
RU2420791C1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |

