Область техники, к которой относится изобретение
Изобретение относится к способу сортировки и системе обработки данных, содержащей множество соединенных между собой узлов обработки данных, для сортировки входных данных, распределенных по узлам обработки данных. Раскрываемое изобретение, кроме того, относится к компьютерным аппаратным средствам, характеризующимся асимметричной памятью, и способу параллельной сортировки для такой асимметричной памяти.
Уровень техники
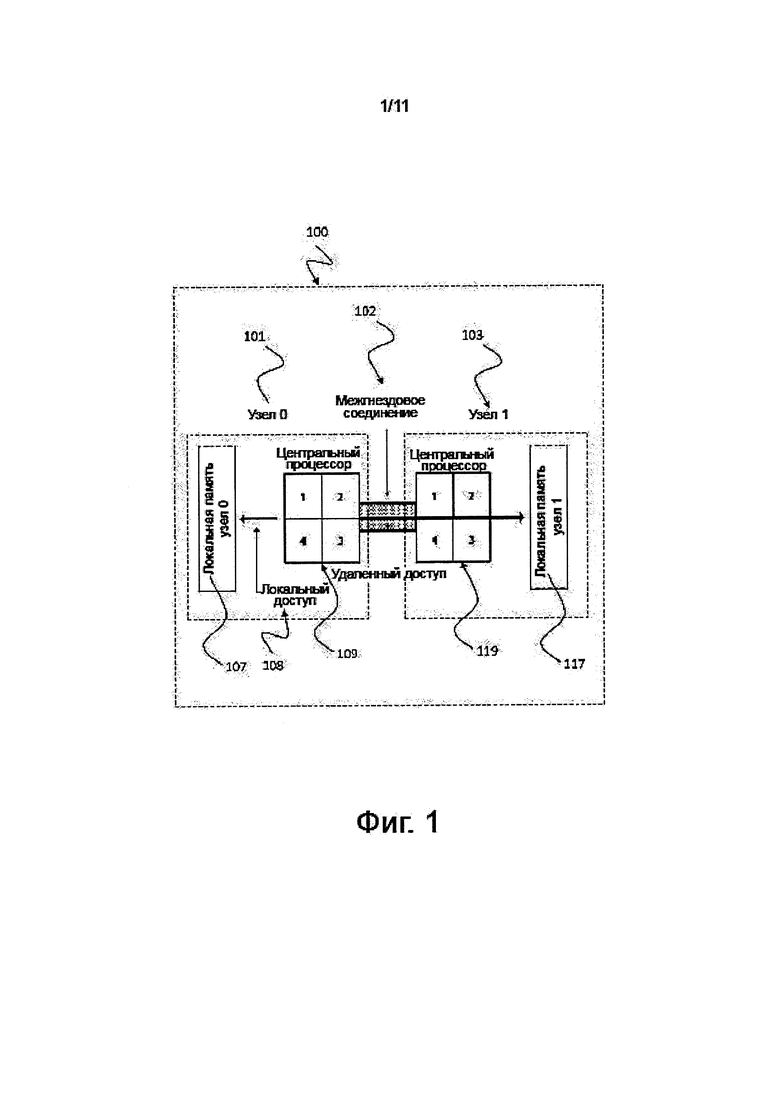
На современных компьютерных аппаратных средствах 100, характеризующихся асимметричной памятью для каждого исполнительного блока, например, процессора 101, 103 и ядра 109, 119, все места расположения памяти разделены на локальную 107 (по отношению к узлу 0 101) и удаленную 117 память, как это показано на фиг. 1. Доступ 108 к локальной памяти 107 является более быстрым, чем к удаленной памяти 117 вследствие различных длин физического пути 102 доступа, как это проиллюстрировано на фиг. 1. Проблема, создаваемая асимметричной памятью, заключается в том, что, в способах вычисления, не учитывающих асимметрию памяти, затраты на исполнение являются более высокими, чем те, которые могут быть достигнуты при оптимизированном использовании локальной и удаленной памяти.
Сортировка считается одной из основных операций, используемых во многих областях вычисления. Например, потребность в сортировке в асимметричной памяти является очевидной при сортировке результатов запроса, полученных способами параллельного запроса в системах баз данных. Такую сортировку требуют операторы SQL (Языка структурированных запросов) "ORDER BY" (''Упорядочить по'') и "GROUP BY" (''Сгруппировать по''). Некоторые способы соединения, как соединение "сортировка-слияние", также требуют сортировки. Существует много алгоритмов, которые используют множественные ядра системы для того, чтобы сделать сортировку параллельной и повысить производительность. Но ни один из этих алгоритмов не учитывает асимметрию архитектур памяти. В настоящее время, в алгоритмах сортировки, данные разделяются случайным образом, и работать с этими данными позволяется, случайным образом, различным потокам. Это приводит к чрезмерному использованию удаленного доступа и гнездовых межсоединений, и, соответственно, может сильно ограничивать пропускную способность системы.
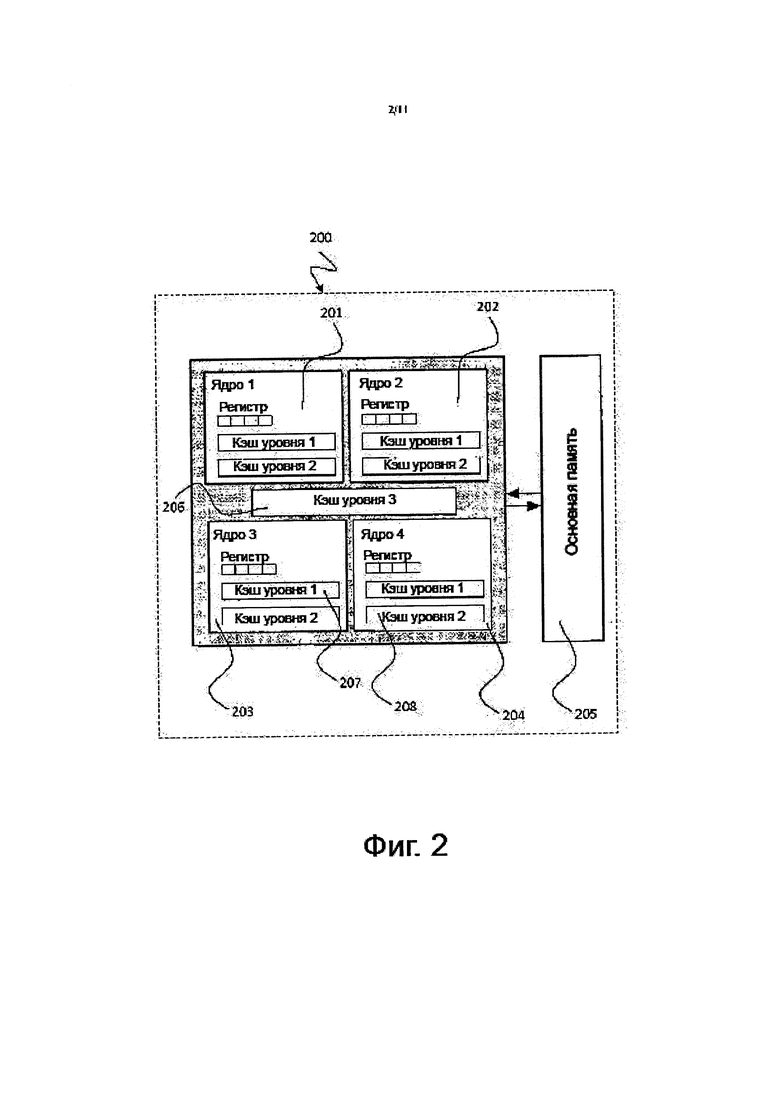
В современных процессорах 200 используются множественные ядра 201, 202, 203, 204, основная память 205 и несколько уровней кэшей 206, 207, 208 памяти, как это проиллюстрировано на фиг. 2. Имеющиеся на настоящее время алгоритмы сортировки, например, те, что описаны в US 8332595 В2, US 6427148 B1, US 5852826 А и US 7536432 В2 не обращаются к проблеме места расположения данных и осознанной работы с кэшем. Это приводит к частым неудачным обращениям в кэш и неэффективному исполнению. Процессоры оснащены аппаратным обеспечением с SIMD-архитектурой (архитектурой с одним потоком команд и множественными потоками данных), которое позволяет выполнять так называемую векторизованную обработку данных, то есть, исполнять одну и ту же операцию над последовательностью расположенных близко друг к другу данных. Существующие на настоящее время способы сортировки не оптимизированы для SIMD-архитектуры.
Раскрытие сущности изобретения
Цель изобретения заключается в том, чтобы предложить усовершенствованную технологию сортировки.
Эта цель достигается благодаря признакам, изложенным в независимых пунктах формулы изобретения. Дополнительные формы осуществления изобретения очевидны из зависимых пунктов формулы изобретения, описания и фигур.
Изобретение, как это описано ниже, основано на обнаружении того факта, что усовершенствованную технологию сортировки можно обеспечить воспользовавшись различиями в задержке доступа к асимметричной памяти для того, чтобы значительно уменьшить затраты на доступ к памяти в алгоритмах сортировки с высокоинтенсивным доступом к памяти.
Для подробного описывания изобретения будут использованы нижеследующие термины, сокращения и обозначения:
Системы управления базами данных (DBMS-системы) представляют собой специально разработанные приложения, которые взаимодействуют с пользователем, другими приложениями, и самой базой данных для того, чтобы собирать и анализировать данные. Универсальная система управления базами данных (DBMS-система) представляет собой систему программного обеспечения, разработанную таким образом, чтобы сделать возможным определение, создание, запрашивание, обновление и администрирование баз данных. Различный DBMS-системы могут взаимодействовать между собой с использованием стандартов, таких как SQL (Язык структурированных запросов) и ODBC (Открытый интерфейс доступа к базам данных) или JDBC (Интерфейс доступа Java-приложений к базам данных), позволяя одному приложению работать с более чем одной базой данных.
SQL (Язык структурированных запросов) представляет собой специализированный язык программирования, предназначенный для управления данными, хранящимися в системе управления реляционными базами данных (RDBMS-системе, СУРБД).
Изначально основанный на реляционной алгебре и реляционном исчислении кортежа, язык SQL состоит из языка определения данных и языка манипулирования данными. Область охвата языка SQL включает в себя внесение, запрос, обновление и удаление данных, создание и изменение схем и управление доступом к данным.
Архитектура с ''Одним потоком команд и множественными потоками данных'' (''SIMD'') представляет собой класс компьютеров параллельной обработки данных в классификации архитектур компьютеров. Она описывает компьютеры со множественными обрабатывающими элементами, которые одновременно выполняют одну и ту же операцию над множественными точками данных. Соответственно, такие машины используют параллелизм уровней данных, например, матричные процессоры или GPU-процессоры.
В соответствии с первым аспектом, изобретение относится к способу сортировки, предназначенному для сортировки входных данных, распределенных по сегментам локальной памяти множества соединенных между собой узлов обработки данных, причем способ сортировки содержит этапы, на которых: сортируют распределенные входные данные, локально по узлу обработки данных, посредством развертывания первых процессов на узлах обработки данных для того, чтобы создать множество сортированных списков в сегментах локальной памяти узлов обработки данных; создают последовательность диапазонных блоков в сегментах локальной памяти узлов обработки данных, при этом каждый диапазонный блок сконфигурирован таким образом, чтобы хранить значения данных, находящиеся в пределах его диапазона; копируют это множество сортированных списков в эту последовательность диапазонных блоков посредством развертывания вторых процессов на узлах обработки данных, при этом каждый диапазонный блок принимает те элементы сортированных списков, значения которых находятся в пределах его диапазона; сортируют элементы диапазонных блоков, локально по узлу обработки данных, используя вторые процессы для создания сортированных элементов в диапазонных блоках; и считывают сортированные элементы из последовательности диапазонных блоков последовательно в отношении их диапазона для того, чтобы получить сортированные входные данные.
Эффективность такого алгоритма сортировки повышена вследствие использования в большой степени локального доступа к данным, благодаря чему избегают неудобство удаленного доступа. Создание последовательности диапазонных блоков в сегментах локальной памяти узлов обработки данных позволяет использовать последовательный доступ к данным вместо произвольного доступа, что повышает локальность доступа и эффективность кэша. В частности, в случае удаленного доступа, использование последовательного доступа усиливает упреждающую выборку, которая уравновешивает неудобство удаленного доступа. Использование векторов, состоящих из соседних элементов данных, при вычислении позволяет использовать SIMD-архитектуру (архитектуру с одним потоком команд и множественными потоками данных).
В первой возможной форме осуществления способа сортировки, соответствующего первому аспекту изобретения, сегменты локальной памяти множества соединенных между собой узлов обработки данных структурированы как асимметричная память.
Использование вместо произвольного доступа последовательного доступа к данным повышает локальность доступа и эффективность кэша в асимметричной памяти.
Во второй возможной форме осуществления способа сортировки, соответствующего первому аспекту изобретения, как таковому, или соответствующего первой форме осуществления первого аспекта изобретения, количество первых процессов является равным количеству сегментов локальной памяти.
В случае, когда количество первых процессов является равным количеству сегментов локальной памяти, каждый сегмент локальной памяти может обрабатываться параллельно соответствующим первым процессом, что увеличивает скорость обработки данных.
В третьей возможной форме осуществления способа сортировки, соответствующего первому аспекту изобретения, как таковому, или соответствующего любой из вышеописанных форм осуществления первого аспекта изобретения, первые процессы создают непересекающиеся сортированные списки.
В случае, когда первые процессы создают непересекающиеся сортированные списки, локальная сортировка в одном списке может быть выполнена без осуществления доступа к другим спискам. Это повышает эффективность обработки данных.
В четвертой возможной форме осуществления способа сортировки, соответствующего первому аспекту изобретения, как таковому, или соответствующего любой из вышеописанных форм осуществления первого аспекта изобретения, сортировка распределенных входных данных, локальная по узлу обработки данных, основана на одной процедуре из числа: последовательной процедуры сортировки и параллельной процедуры сортировки.
Использование, на этапах сортировки, только локального доступа к памяти уменьшает накладные расходы межгнездовой связи и, таким образом, вычислительную сложность и повышает производительность способа сортировки.
В пятой возможной форме осуществления способа сортировки, соответствующего первому аспекту изобретения, как таковому, или соответствующего любой из вышеописанных форм осуществления первого аспекта изобретения, количество вторых процессов равно количеству диапазонных блоков.
В случае, когда количество вторых процессов равно количеству диапазонных блоков, каждый диапазонный блок может обрабатываться параллельно соответствующим вторым процессом, что увеличивает скорость обработки данных.
В шестой возможной форме осуществления способа сортировки, соответствующего первому аспекту изобретения, как таковому, или соответствующего любой из вышеописанных форм осуществления первого аспекта изобретения, каждый диапазонный блок имеет отличный от других диапазон.
В случае, когда каждый диапазонный блок имеет отличный от других диапазон, каждый сегмент памяти может работать с различными данными, что делает возможной параллельную обработку данных, которая повышает скорость обработки данных.
В седьмой возможной форме осуществления способа сортировки, соответствующего первому аспекту изобретения, как таковому, или соответствующего любой из вышеописанных форм осуществления первого аспекта изобретения, каждый диапазонный блок принимает множество сортированных списков, в частности, количество сортированных списков, соответствующее количеству первых процессов.
Данные в аналогичном диапазоне от различных узлов обработки данных могут, таким образом, быть сконцентрированы на одном узле обработки данных, что повышает вычислительную эффективность способа.
В восьмой возможной форме осуществления способа сортировки, соответствующего первому аспекту изобретения, как таковому, или соответствующего любой из вышеописанных форм осуществления первого аспекта изобретения, второй процесс из числа вторых процессов, исполняемых на одном узле обработки данных, копируя множество сортированных списков в последовательность диапазонных блоков, осуществляет чтение последовательно из локальной памяти этого одного узла обработки данных и из локальной памяти других узлов обработки данных.
Использование, на этапе копирования, последовательного удаленного доступа к памяти снижает неудобство удаленного доступа.
В девятой возможной форме осуществления способа сортировки, соответствующего восьмой форме осуществления первого аспекта изобретения, второй процесс, исполняемый на этом одном узле обработки данных, копируя множество сортированных списков в последовательность диапазонных блоков, осуществляет запись только в локальную память этого одного узла обработки данных.
Таким образом, второй процесс, осуществляя запись в память, не должен ожидать ответа по межгнездовому соединению.
В десятой возможной форме осуществления способа сортировки, соответствующего первому аспекту изобретения, как таковому, или соответствующего любой из вышеописанных форм осуществления первого аспекта изобретения, последовательное считывание сортированных элементов из последовательности диапазонных блоков выполняется с использованием аппаратной упреждающей выборки.
Использование аппаратной упреждающей выборки повышает скорость обработки данных.
В одиннадцатой возможной форме осуществления способа сортировки, соответствующего первому аспекту изобретения, как таковому, или соответствующего любой из вышеописанных форм осуществления первого аспекта изобретения, вторые процессы, для сравнения значений сортированных списков с диапазонами диапазонных блоков и для копирования множества сортированных списков в последовательность диапазонных блоков, используют векторизованную обработку данных, в частности, векторизованную обработку данных, исполняемую на аппаратных блоках архитектуры ''С одним потоком команд и множественными потоками данных''.
Использование векторизованной обработки данных, такой как SIMD (''С одним потоком команд и множественными потоками данных'') во время этапов сортировки повышает производительность сортировки. Использование векторизованной обработки данных, такой как SIMD, во время копирования позволяет использовать полную пропускную способность памяти.
В двенадцатой возможной форме осуществления способа сортировки, соответствующего первому аспекту изобретения, как таковому, или соответствующего любой из вышеописанных форм осуществления первого аспекта изобретения, множество узлов обработки данных соединены между собой посредством межгнездовых соединений, и локальная память одного узла обработки данных является, для другого узла обработки данных, удаленной памятью.
Способ может быть осуществлен на стандартных архитектурах аппаратных средств, использующих асимметричную память, соединенную посредством межгнездовых соединений. Способ может быть применен на мультиядерных и многоядерных процессорных платформах.
В соответствии со вторым аспектом, изобретение относится к системе обработки данных, содержащей: множество соединенных между собой узлов обработки данных, каждый из которых содержит локальную память и блок обработки данных, при этом входные данные распределены по локальной памяти узлов обработки данных, а блоки обработки данных выполнены с возможностью: сортировки распределенных входных данных, локально по узлу обработки данных, для создания множества сортированных списков в локальной памяти узлов обработки данных; создания последовательности диапазонных блоков в локальной памяти узлов обработки данных, причем каждый диапазонный блок выполнен с возможностью хранения значения данных, находящихся в пределах его диапазона; копирования указанного множества сортированных списков в указанную последовательность диапазонных блоков, причем каждый диапазонный блок принимает те элементы сортированных списков, значения которых находятся в пределах его диапазона; сортировки элементов диапазонных блоков, локально по узлу обработки данных, для создания сортированных элементов в диапазонных блоках; и считывания сортированных элементов из последовательности диапазонных блоков последовательно в отношении их диапазона для получения сортированных входных данных.
Такая новая система обработки данных, предназначенная для сортировки распределенных входных данных, способна сортировать большой набор случайным образом распределенных значений, максимизируя при этом эффективность использования аппаратных ресурсов.
В соответствии с третьим аспектом, изобретение относится к компьютерному программному продукту, содержащему машиночитаемый носитель информации, хранящий на себе программный код для использования компьютером, причем программный код, сортирующий входные данные, распределенные по сегментам локальной памяти множества соединенных между собой узлов обработки данных, причем программный код содержит: команды для сортировки распределенных входных данных, локальной по узлу обработки данных, с использованием первых процессов, исполняемых на узлах обработки данных для создания множества сортированных списков в сегментах локальной памяти узлов обработки данных; команды для создания последовательности диапазонных блоков в сегментах локальной памяти узлов обработки данных, при этом каждый диапазонный блок выполнен с возможностью хранения значения данных, находящиеся в пределах его диапазона; команды для копирования указанного множества сортированных списков в указанную последовательность диапазонных блоков с использованием вторых процессов, при этом каждый диапазонный блок принимает те элементы сортированных списков, значения которых находятся в пределах его диапазона; команды для сортировки элементов диапазонных блоков, локальной по узлу обработки данных, с использованием вторых процессов для создания сортированных элементов в диапазонных блоках; и команды для считывания сортированных элементов из последовательности диапазонных блоков, последовательного в отношении их диапазона, для получения сортированных входных данных.
Эта компьютерная программа может быть гибко спроектирована таким образом, чтобы было легко достигнуть обновления технических требований. Этот компьютерный программный продукт может исполняться в мультиядерной и многоядерной системе обработки данных.
В аспектах изобретения, таким образом, предлагается усовершенствованная технология сортировки, как это дополнительно описывается в нижеследующем.
Краткое описание чертежей
Дополнительные варианты воплощения изобретения будут описаны в отношении нижеследующих фигур, на которых:
на фиг. 1 показано схематическое изображение, на котором проиллюстрировано усовершенствованное компьютерное аппаратное обеспечение 100, соответствующее форме осуществления изобретения;
на фиг. 2 показано схематическое изображение, на котором проиллюстрирован усовершенствованный процессор 200, соответствующий форме осуществления изобретения;
на фиг. 3 показано схематическое изображение, на котором проиллюстрирован приводимый в качестве примера способ 300 сортировки, соответствующий некоторой форме осуществления изобретения;
на фиг. 4 показано схематическое изображение, на котором проиллюстрировано приводимое в качестве примера действие 301 разделения, относящееся к способу 300 сортировки, изображенному на фиг. 3, соответствующее некоторой форме осуществления изобретения;
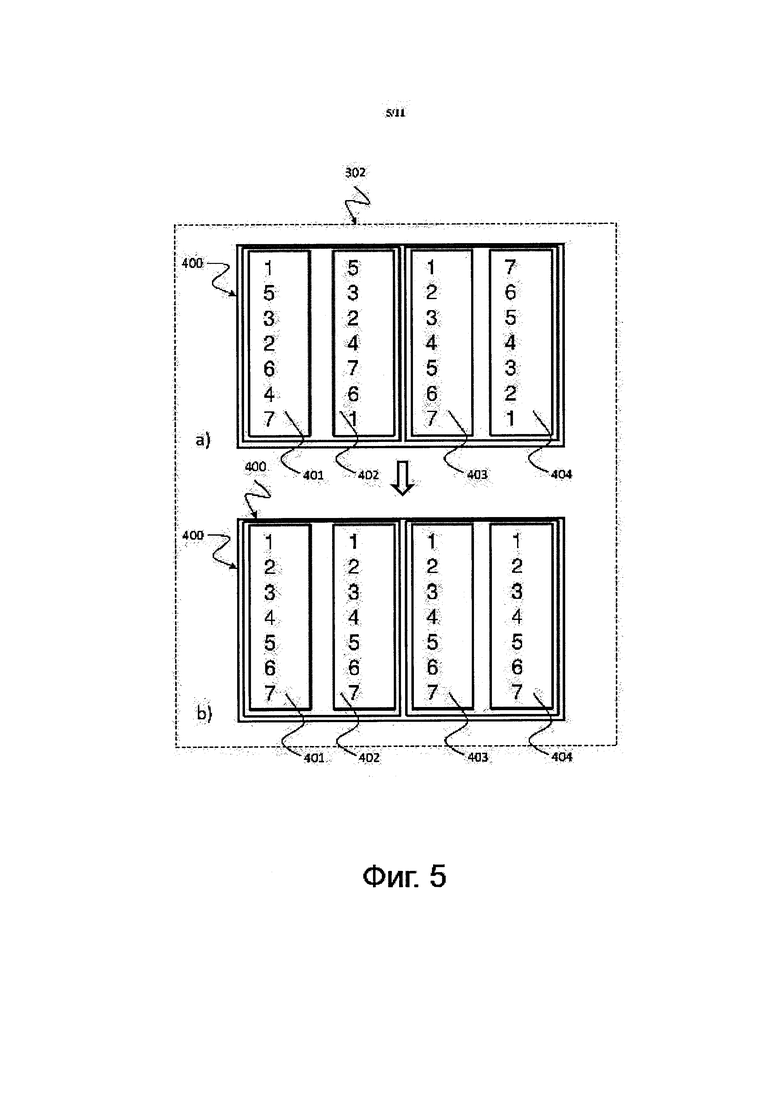
на фиг. 5 показано схематическое изображение, на котором проиллюстрировано приводимое в качестве примера действие 302 локальной сортировки сегмента, относящееся к способу 300 сортировки, изображенному на фиг. 3, соответствующее некоторой форме осуществления изобретения;
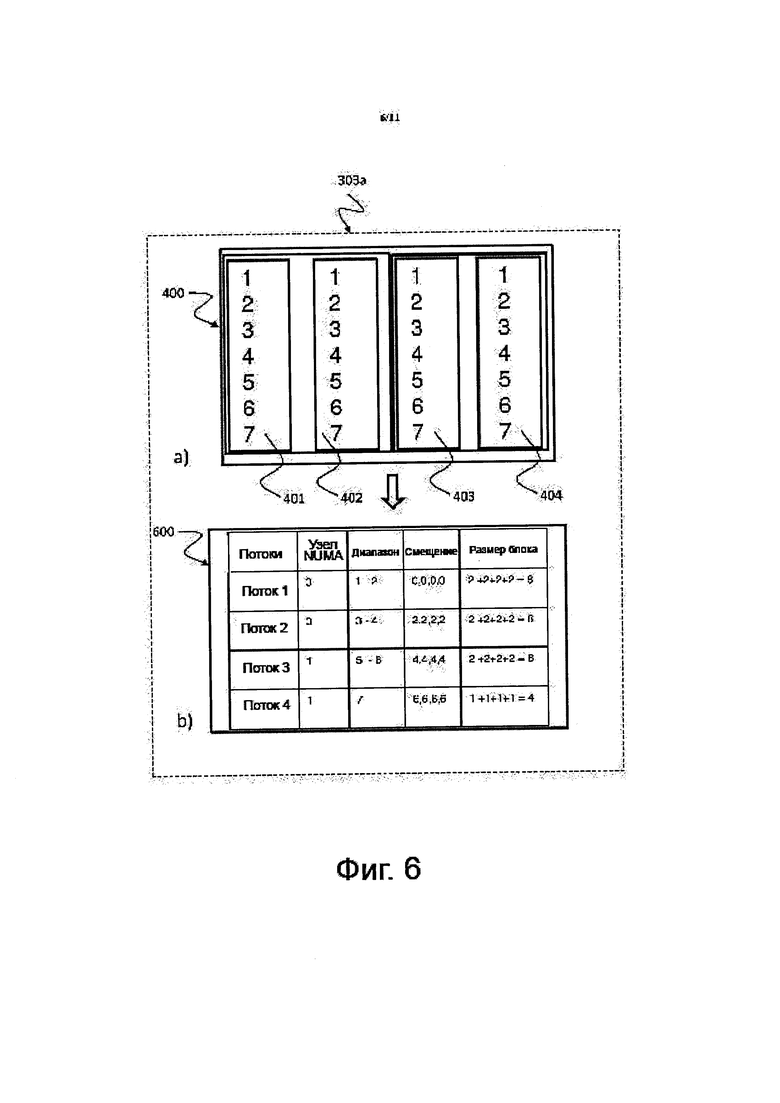
на фиг. 6 показано схематическое изображение, на котором проиллюстрировано приводимое в качестве примера действие 303а развертывания потоков в рамках действия 303 сортировки и извлечения, относящееся к способу 300 сортировки, изображенному на фиг. 3, соответствующее некоторой форме осуществления изобретения;
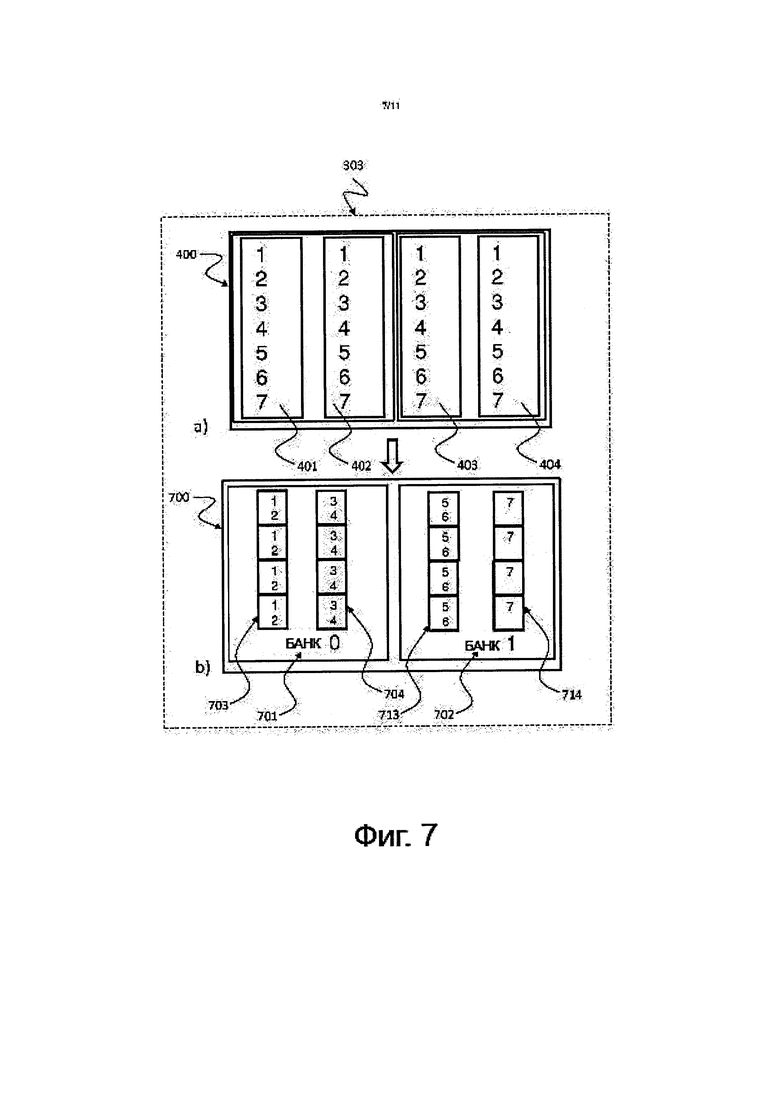
на фиг. 7 показано схематическое изображение, на котором проиллюстрировано приводимое в качестве примера действие 303 извлечения и сортировки, относящееся к способу 300 сортировки, изображенному на фиг. 3, соответствующее некоторой форме осуществления изобретения;
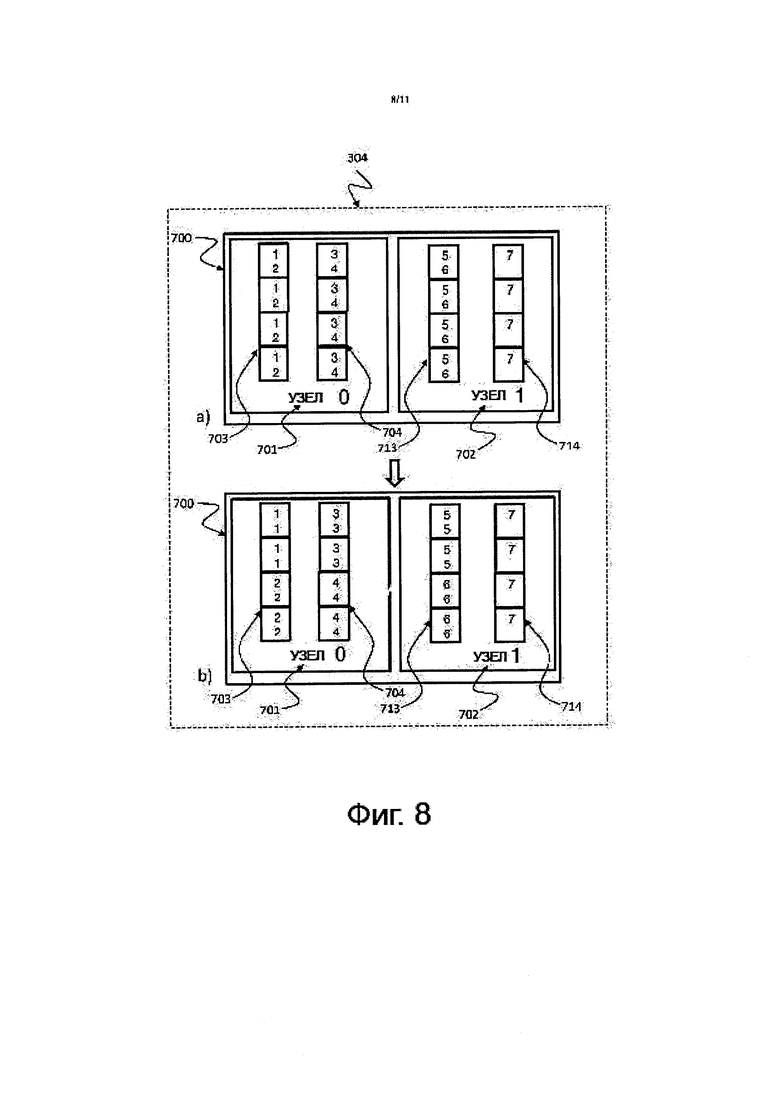
на фиг. 8 показано схематическое изображение, на котором проиллюстрировано приводимое в качестве примера действие 304 локальной сортировки диапазона, относящееся к способу 300 сортировки, изображенному на фиг. 3, соответствующее некоторой форме осуществления изобретения;
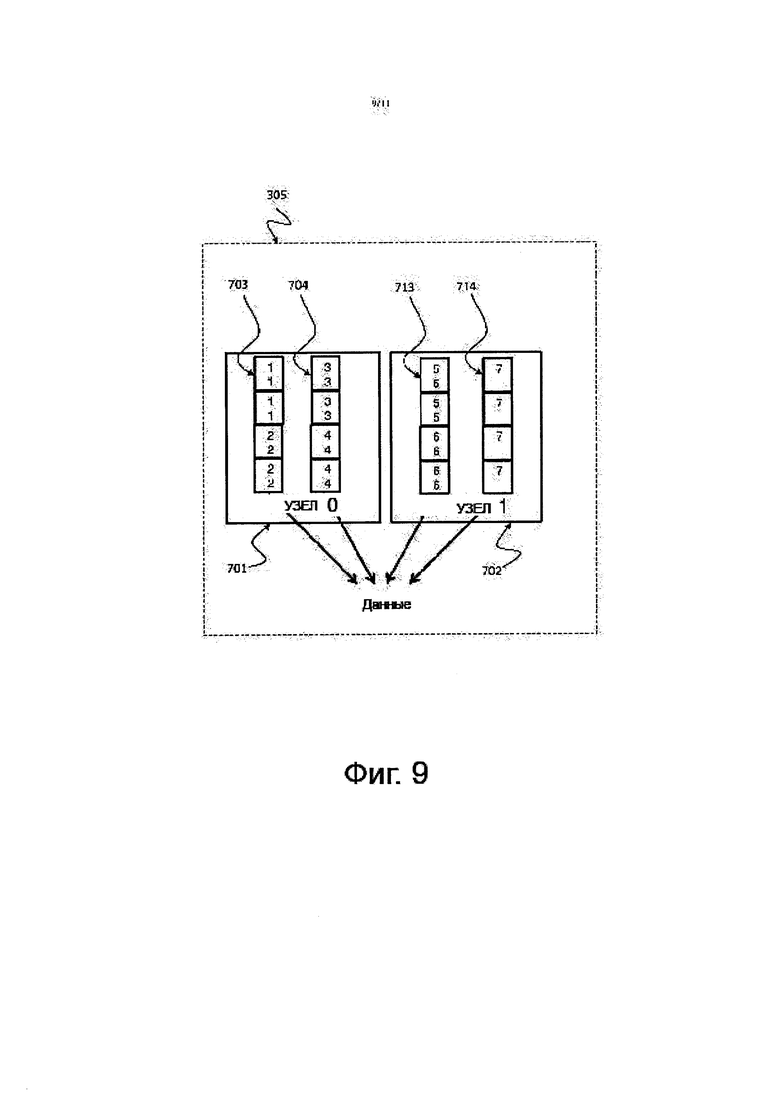
на фиг. 9 показано схематическое изображение, на котором проиллюстрировано приводимое в качестве примера действие 305 слияния, относящееся к способу 300 сортировки, изображенному на фиг. 3, соответствующее некоторой форме осуществления изобретения;
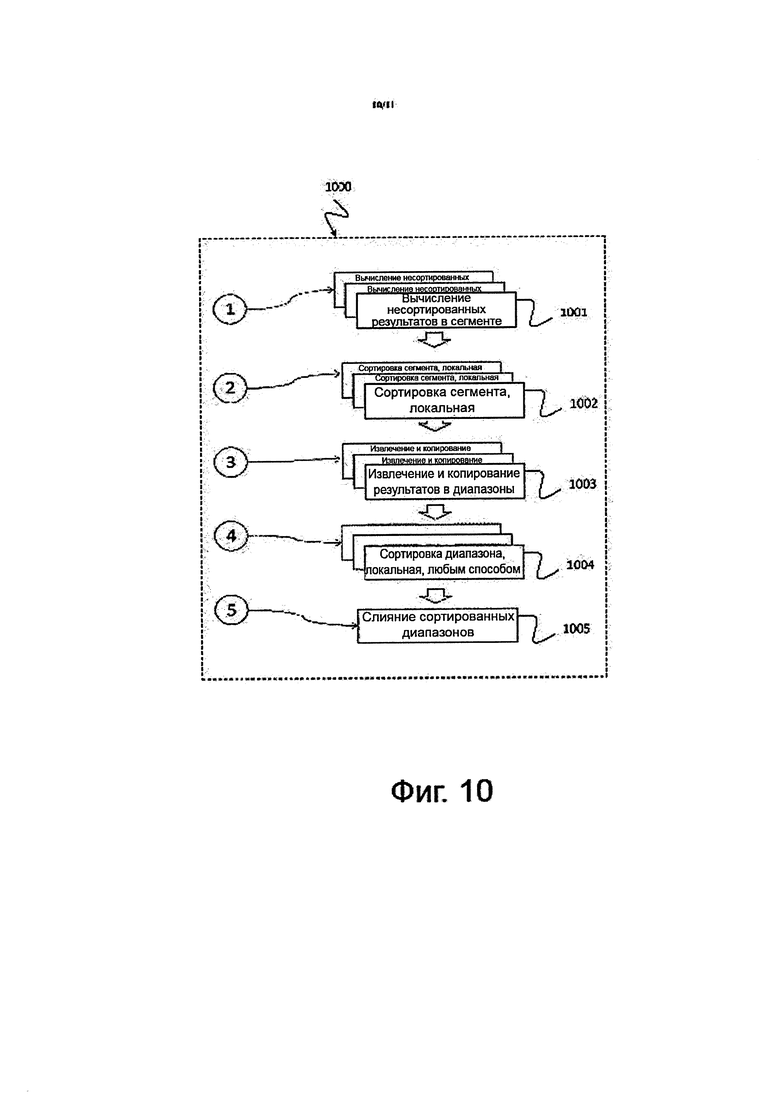
на фиг. 10 показано схематическое изображение, на котором проиллюстрирован приводимый в качестве примера способ 1000 сортировки результатов запроса в системе управления базами данных, использующий параллельную обработку запроса на разделенных данных;
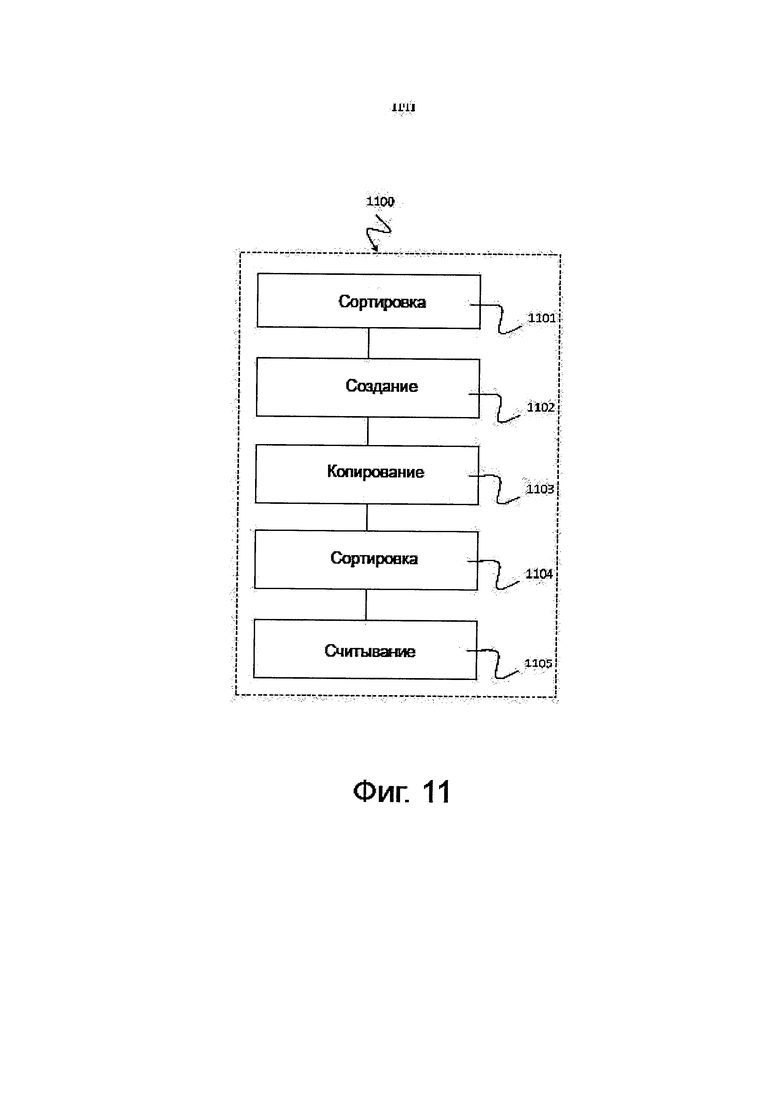
на фиг. 11 показано схематическое изображение, на котором проиллюстрирован приводимый в качестве примера способ 1100 сортировки, соответствующий некоторой форме варианта осуществления изобретения.
Осуществление изобретения
В нижеследующем детализированном описании дается ссылка на прилагаемые чертежи, которые являются его частью, и на которой в порядке иллюстрации показываются конкретные аспекты, в которых может быть практически осуществлено раскрываемое изобретение. Следует понимать, что можно использовать и другие аспекты, и можно произвести структурные или логические изменения, не выходя при этом за рамки объема настоящего раскрываемого изобретения. Следовательно, нижеследующее детализированное описание не должно восприниматься в ограничительном смысле, и объем настоящего раскрываемого изобретения определяется прилагаемой формулой изобретения.
Описываемые здесь устройства и способы, могут быть основанными на сортировке распределенных входных данных, сегментах локальной памяти и соединенных между собой узлах обработки данных. Подразумевается, что комментарии, сделанные в связи с описанным способом, могут также быть справедливыми и для соответствующего устройства или системы, сконфигурированных таким образом, чтобы выполнить этот способ, и наоборот. Например, если описан конкретный этап способа, то соответствующее устройство может включать в себя блок для выполнения описанного этапа способа, даже если такой блок явным образом не описан или не проиллюстрирован на фигурах. Кроме того, подразумевается, что признаки описанных здесь разнообразных приводимых в качестве примера аспектов, могут быть объединены друг с другом, если специально не оговаривается иное.
Описываемые здесь способы и устройства могут быть реализованы в аппаратных архитектурах, включающих в себя асимметричную память и системы управления базами данных, в частности систему управления базами данных, использующую язык SQL. Описанные устройства и системы могут включать в себя интегральные схемы и/или пассивные компоненты и могут быть изготовлены в соответствии с разнообразными технологиями. Например, схемы могут быть спроектированы как логические интегральные схемы, аналоговые интегральные схемы, комбинированные аналого-цифровые интегральные схемы, оптические схемы, запоминающие схемы и/или интегрированные пассивные компоненты.
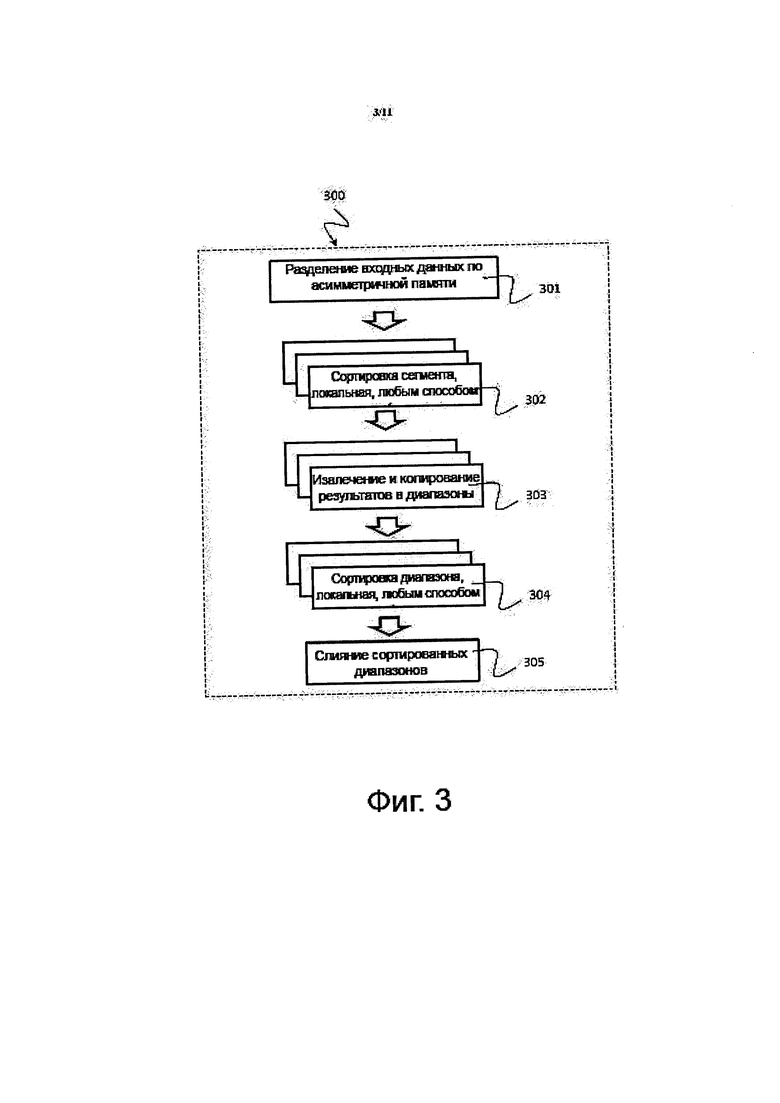
На фиг. 3 показано схематическое изображение, на котором проиллюстрирован приводимый в качестве примера способ 300 для сортировки входных данных, распределенных по сегментам 107, 117 локальной памяти во множестве соединенных между собой узлах 101, 103 обработки данных, например, в аппаратной системе 100, 200, описанной выше со ссылкой на фиг. 1 и фиг. 2, соответствующий некоторой форме осуществления изобретения.
Способ 300 сортировки может включать в себя разделение 301 распределенных входных данные по асимметричной памяти с получением множественных сегментов памяти. Способ 300 сортировки может включать в себя локальную сортировку 302 сегментов памяти, например, с использованием любого известного способа локальной сортировки. Действие 302 сортировки может быть выполнено для каждого сегмента памяти. Способ 300 сортировки может включать в себя извлечение и копирование 303 результатов локальной сортировки 302 в диапазоны, то есть участки памяти, сконфигурированные таким образом, чтобы хранить данные, находящиеся в пределах определенных диапазонов. Действие 303 извлечения и копирования могут быть выполнены для каждого сегмента памяти. Способ 300 сортировки может включать в себя локальную сортировку 304 каждого диапазона, например, с использованием любого известного способа локальной сортировки. Действие 304 сортировки может быть выполнено для каждого диапазона. Способ 300 сортировки может включать в себя слияние 305 сортированных диапазонов. Ниже, со ссылкой на фиг. 4-9, дополнительно описываются различные этапы или действия сортировки.
Способ 300, описываемый в этом раскрытии, может, в рамках пяти этапов, сортировать большой набор случайным образом распределенных значений и может, следовательно, быть способен максимизировать эффективность использования ресурсов аппаратного обеспечения. В этом способе 300 используются различия в задержке доступа к асимметричной памяти для того, чтобы значительно уменьшить затраты на доступ к памяти в алгоритмах сортировки с высокоинтенсивным доступом к памяти.
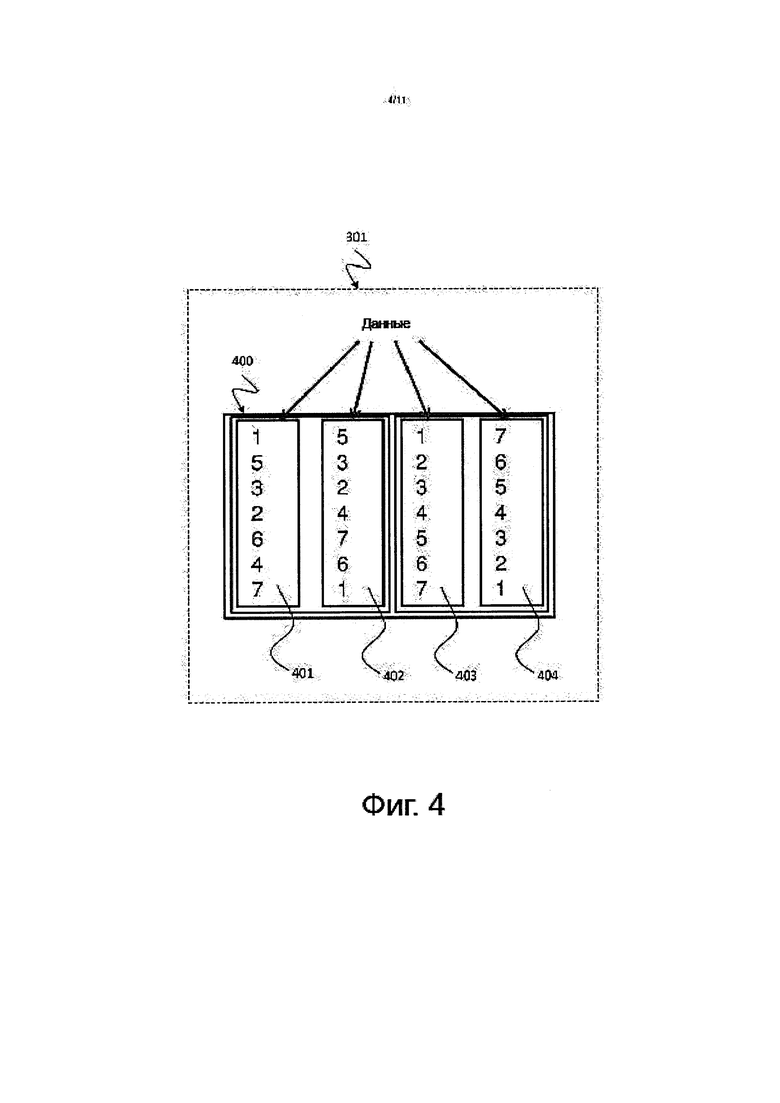
На фиг. 4 показано схематическое изображение, на котором проиллюстрировано приводимое в качестве примера действие 301 разделения, относящееся к способу 300 сортировки, изображенному на фиг. 3, соответствующее некоторой форме осуществления изобретения.
Входные данные разделяются по асимметричной памяти 400. Входные данные распределены по банкам (группам блоков) 401, 402, 403, 404 памяти, входящим в состав асимметричной памяти 400. Этот этап 301 разделения может быть необязательным, потому что большинство способов параллельной обработки данных, как способы параллельной обработки запросов, производят разделенные данные.
На фиг. 5 показано схематическое изображение, на котором проиллюстрировано приводимое в качестве примера действие 302 локальной сортировки сегмента, относящееся к способу 300 сортировки, изображенному на фиг. 3, соответствующее некоторой форме осуществления изобретения.
Для локальной сортировки данных развертываются потоки. Данные ''1, 5, 3, 2, 6, 4, 7'' в первом банке 401 памяти локально сортируются в первом банке 401 памяти, давая сортированные данные ''1, 2, 3, 4, 5, 6, 7''. Данные ''5, 3, 2, 4, 7, 6, 1'' во втором банке 402 памяти локально сортируются во втором банке 402 памяти, давая сортированные данные ''1, 2, 3, 4, 5, 6, 7''. Данные ''1, 2, 3, 4, 5, 6, 7'' в третьем банке 403 памяти локально сортируются в третьем банке 403 памяти, давая сортированные данные ''1, 2, 3, 4, 5, 6, 7''. Данные ''7, 6, 5, 4, 3, 2, 1'' в четвертом банке 404 памяти локально сортируются в четвертом банке 404 памяти, давая сортированные данные ''1, 2, 3, 4, 5, 6, 7''.
Количество потоков может быть равным количеству сегментов (на фиг. 5 показано четыре сегмента 401, 402, 403, 404, но возможно любое другое количество). Все потоки могут создавать непересекающиеся сортированные списки, которые могут быть слиты, как это описывается ниже, для того, чтобы получить окончательный сортированный результат. Для действия 302 сортировки может быть использован любой способ сортировки: последовательный или параллельны. Полностью используется локальный доступ.
На фиг. 6 показано схематическое изображение, на котором проиллюстрировано приводимое в качестве примера действие 303 а развертывания потоков в рамках действия 303 сортировки и извлечения, относящееся к способу 300 сортировки, изображенному на фиг. 3, соответствующее некоторой форме осуществления изобретения.
На основе выборке данных может быть создан набор 600 диапазонов, который может быть использован для распределения сортируемых данных между различными потоками. Диапазон может представлять собой подмножество входных данных, содержащих значения некоторого данного диапазона значений, например, в пределах от 1 до 7 в примере, показанном на фиг. 6. Диапазоны могут быть рассчитаны таким образом, чтобы иметь (приблизительно) один и тот же размер. Это может быть достигнуто при помощи гистограммы распределения значений, получаемой посредством выборки, выполняемой во время фазы сортировки. Диапазоны могут быть рассчитаны на основе данных из всех сегментов 401, 402, 403, 404. На фиг. 6 созданы четыре диапазона, причем первый диапазон включает в себя значения данных, составляющие 1 и 2, второй диапазон включает в себя значения данных, составляющие 3 и 4, третий диапазон включает в себя значения данных, составляющие 5 и 6, и четвертый диапазон включает в себя значение данных, составляющее 7.
Количество потоков, например, 4 в соответствии с фиг. 6, но возможно любое другое количество, может быть тем же самым, что и количество диапазонов. Первый поток "Поток 1" ассоциативно связан с первым диапазоном, второй поток "Поток 2" ассоциативно связан со вторым диапазоном, третий поток "Поток 3" ассоциативно связан с третьим диапазоном, и четвертый поток "Поток 4" ассоциативно связан с четвертым диапазоном.
На основе количества диапазонов в различных банках памяти может быть создано одно и то же количество диапазонных (предназначенных для диапазонов) блоков памяти. Количество диапазонных блоков в каждом банке памяти может быть одним и тем же для того, чтобы использовать все имеющиеся ядра.
На фиг. 7 показано схематическое изображение, на котором проиллюстрировано приводимое в качестве примера действие 303 извлечения и сортировки, относящееся к способу 300 сортировки, изображенному на фиг. 3, соответствующее некоторой форме осуществления изобретения.
Могут быть развернуты потоки для того, чтобы, основываясь на значении, копировать данные из сортированных списков 401, 402, 403, 404 во вновь созданные диапазонные блоки 703, 704, 713, 714. В результате этого, каждый диапазонный блок 703, 704, 713, 714 будет иметь множественные сортированные списки в пределах данного диапазона значений. В примере, показанном на фиг. 7, первый диапазонный блок 703 в банке 0, 701 памяти включает в себя значения данных, составляющие 1 и 2, второй диапазонный блок 704 в банке 0, 701 памяти включает в себя значения данных, составляющие 3 и 4, третий диапазонный блок 713 в банке 1, 702 памяти включает в себя значения данных, составляющие 4 и 5, и четвертый диапазонный блок 714 в банке 1, 702 памяти включает в себя значение данных, составляющее 7. Потоки могут записывать только в локальную память и могут осуществлять последовательное считывание как из локальной, так и из удаленной памяти. Выполняя сравнения значений, потоки могут использовать соседние следующие друг за другом данные. Может быть использовано преимущество SIMD-архитектуры.
На фиг. 8 показано схематическое изображение, на котором проиллюстрировано приводимое в качестве примера действие 304 локальной сортировки диапазона, относящееся к способу 300 сортировки, изображенному на фиг. 3, соответствующее некоторой форме осуществления изобретения.
Те же самые потоки (по одному на диапазонный блок) могут быть применены, как было описано выше в отношении фиг. 6 и 7, для выполнения осуществляемой на месте сортировки скопированных данных. Первый диапазонный блок 703 в банке 0 памяти, который может быть реализован на узле 0, 701, может пересортировать данные из "12121212" в "11112222", например, используя Поток 0. Второй диапазонный блок 704 в банке 0 памяти, который может быть реализован на узле 0, 701, может пересортировать данные из "34343434" в "33334444", например, используя Поток 1. Третий диапазонный блок 713 в банке 1 памяти, который может быть реализован на узле 1, 702, может пересортировать данные из "56565656" в "55556666", например, используя Поток 3. Четвертый диапазонный блок 714 в банке 1 памяти, который может быть реализован на узле 1, 702, может пересортировать данные из "7777" в "7777", например, используя Поток 3.
В результате этого, каждый блок 703, 704, 713, 714, может иметь сортированные данные в определенном диапазоне. Локальная сортировка может быть выполнена посредством любого известного способа сортировки, например, последовательного или параллельного. Можно в полной мере использовать локальность доступа к данным. Эта организация данных может помочь использовать SIMD-архитектуру для сравнения и копирования.
На фиг. 9 показано схематическое изображение, на котором проиллюстрировано приводимое в качестве примера действие 305 слияния, относящееся к способу 300 сортировки, изображенному на фиг. 3, соответствующее некоторой форме осуществления изобретения.
Для получения сортированных результатов может быть выполнена итерация над последовательностью диапазонных блоков 703, 704, 713, 714, и могут быть считаны данные. Данные могут считываться последовательно, как из локальных 701, так и из удаленных 702 мест расположения и, уменьшая, соответственно, влияние связи, осуществляемой ''от гнезда-к-гнезду'', с использованием аппаратной упреждающей выборки.
На фиг. 10 показано схематическое изображение, на котором проиллюстрирован приводимый в качестве примера способ 1000 сортировки результатов запроса в системе управления базами данных, использующий параллельную обработку запроса на разделенных данных.
На фиг. 10 описывается конкретный способ сортировки результатов запроса в системе управления базами данных, включающий в себя параллельную обработку запроса на разделенных данных. Приводимый в качестве примера запрос может быть выражен оператором SQL (Языка структурированных запросов), имеющим форму "SELECT А, … FROM table WHERE … ORDER BY А" ("ВЫБРАТЬ A, … ИЗ таблицы ГДЕ … УПОРЯДОЧИТЬ ПО А"). Способ (1000) может применяться к исполнению выражения ''УПОРЯДОЧИТЬ ПО''. Процессор запросов может произвести, в параллельных рабочих потоках, несортированные результаты, записанные в локальную память (сегмент) каждого потока. Это проиллюстрировано этапом 1 на фиг. 10.
На этапе 2, каждый несортированный сегмент может быть локально отсортирован посредством специально назначенного потока. На этапе 3, данные могут быть перераспределены таким образом, что (а) рассчитываются диапазоны значений данных, содержащие приблизительно равное количество данных, (b) в памяти, которая является локальной по отношению к рабочим потокам, размещают сегменты для диапазонов значений данных, и (с) эти диапазонные сегменты заполняют данными, соответствующими диапазону каждого рабочего процесса, посредством последовательного сканирования сортированных сегментов, созданных на этапе 2, и извлечения подходящих данных. На этапе 4, каждый диапазон может быть отсортирован локально, образуя надлежащим образом отсортированную часть результирующего набора (результирующий сегмент). На этапе 5, части результирующего набора могут быть слиты вместе, посредством связывания результирующих сегментов в надлежащем порядке и считывания результирующих сегментов последовательно в этом порядке.
В одном примере, способ 1000 может быть применен для выполнения сортировки в системе управления базами данных, в ходе процесса выполнения SQL-запроса, имеющего оператор JOIN (СОЕДИНИТЬ) или выраженного как неявное соединение. В этом случае, этапы: со 2 по 4, описанные выше, могут быть применены для сортировки таблиц в контексте способа слияния-соединения.
В другом примере, способ 1000 может быть применен для выполнения сортировки в системе управления базами данных, в ходе процесса исполнения SQL-запроса, имеющего оператор GROUP BY (СГРУППИРОВАТЬ ПО). В этом случае, этапы: со 2 по 4, описанные выше, могут быть применены для сортировки итоговых результатов вычисления (групп).
На фиг. 11 показано схематическое изображение, на котором проиллюстрирован приводимый в качестве примера способ 1100 сортировки, предназначенный для сортировки входных данных, распределенных по сегментам локальной памяти множества соединенных между собой узлов обработки данных, и соответствующий некоторой форме варианта осуществления изобретения.
Способ 1100 может включать в себя сортировку 1101 распределенных входных данных, локальную по узлу обработки данных, осуществляемую посредством развертывания первых процессов на узлах обработки данных для того, чтобы создать множество сортированных списков в сегментах локальной памяти узлов обработки данных. Способ 1100 может включать в себя создание 1102 последовательности диапазонных блоков в сегментах локальной памяти узлов обработки данных, при этом каждый диапазонный блок сконфигурирован таким образом, чтобы хранить значения данных, находящиеся в пределах его диапазона. Способ 1100 может включать в себя копирование 1103 этого множества сортированных списков в эту последовательность диапазонных блоков посредством развертывания вторых процессов на узлах обработки данных, при этом каждый диапазонный блок принимает те элементы сортированных списков, значения которых находятся в пределах его диапазона. Способ 1100 может включать в себя сортировку 1104 элементов диапазонных блоков, локальную по узлу обработки данных, с использованием вторых процессов для создания сортированных элементов в диапазонных блоках. Способ 1100 может включать в себя считывание 1105 сортированных элементов из последовательности диапазонных блоков, последовательное в отношении их диапазона, для того, чтобы получить сортированные входные данные.
Сортировка 1101 может соответствовать локальной сортировке 302 сегментов памяти, которая описана выше в отношении фиг. 3. Создание 1102 и копирование 1103 может соответствовать действию 303 извлечения и копирования, которое описано выше в отношении фиг. 3. Сортировка 1104 может соответствовать локальной сортировке 304 каждого диапазона, которая описана выше в отношении фиг. 3. Считывание 1105 может соответствовать слиянию 305 сортированных диапазонов, которое описано выше в отношении фиг. 3.
В одном примере, сегменты локальной памяти множества соединенных между собой узлов обработки данных могут быть структурированы как асимметричная память. В одном примере, количество первых процессов может быть равным количеству сегментов локальной памяти. В одном примере, первые процессы могут создавать непересекающиеся сортированные списки. В одном примере, сортировка распределенных входных данных, локальная по узлу обработки данных, может быть основанной на одной процедуре из числа: последовательной процедуры сортировки и параллельной процедуры сортировки. В одном примере, количество вторых процессов может быть равным количеству диапазонных блоков. В одном примере, каждый диапазонный блок может иметь отличный от других диапазон. В одном примере, каждый диапазонный блок может принимать множество сортированных списков, в частности, количество сортированных списков, соответствующее количеству первых процессов. В одном примере, второй процесс из числа вторых процессов, исполняемых на одном узле обработки данных, может, копируя множество сортированных списков в последовательность диапазонных блоков, осуществлять чтение последовательно из локальной памяти этого одного узла обработки данных и из локальной памяти других узлов обработки данных. В одном примере, второй процесс, исполняемый на этом одном узле обработки данных, может, копируя множество сортированных списков в последовательность диапазонных блоков, осуществлять запись только в локальную память этого одного узла обработки данных. В одном примере, последовательное считывание сортированных элементов из последовательности диапазонных блоков может быть выполнено с использованием аппаратной упреждающей выборки. В одном примере, вторые процессы, для сравнения значений сортированных списков с диапазонами диапазонных блоков и для копирования множества сортированных списков в последовательность диапазонных блоков, могут использовать векторизованную обработку данных, в частности, векторизованную обработку данных, исполняемую на аппаратных блоках архитектуры ''С одним потоком команд и множественными потоками данных''. В одном примере, множество узлов обработки данных могут быть соединены между собой посредством межгнездовых соединений, и локальная память одного узла обработки данных может для другого узла обработки данных являться удаленной памятью.
Изобретение включает в себя способ, использующий разность во времени доступа для другого банка памяти в системе. Это может быть достигнуто за счет минимального использования линии связи ''от гнезда-к-гнезду''. До сегодняшнего дня, не использовался никакой способ для сортировки случайным образом расположенных данных, который минимизирует произвольный доступ к данным через различные гнезда. Используя инструменты измерения, можно для сортировочной операции определить поток данных через гнезда и схемы доступа.
Описанные здесь способы, системы и устройства могут быть реализованы как программное обеспечение в Процессоре цифровой обработки сигналов (DSP-процессоре), в микроконтроллере или в любом другом побочном процессоре или как аппаратно реализованная схема в рамках специализированной интегральной схемы (ASIC).
Изобретение может быть осуществлено в цифровых электронных схемах, или в компьютерном аппаратном обеспечении, микропрограммном обеспечении, программном обеспечении, или в их сочетании, например, в имеющемся аппаратном обеспечении традиционных мобильных устройств или в новом аппаратном обеспечении, предназначенном для обработки описанных здесь способов.
Настоящее раскрытие также поддерживает компьютерный программный продукт, включающий в себя исполнимый компьютером код или исполнимые компьютером команды, который, при исполнении, заставляет, по меньшей мере, один компьютер исполнять описанных здесь этапы выполнения и вычисления, в частности, способы 300, которые были описаны выше в отношении фиг. 3-9, и способы 1000, 1100, описанные выше в отношении фиг. 10 и 11. Такого рода компьютерный программный продукт может включать в себя машиночитаемый носитель информации, хранящий на себе программный код для использования компьютером. Программный код может быть сконфигурирован таким образом, чтобы сортировать входные данные, распределенные по сегментам локальной памяти множества соединенных между собой узлов обработки данных. Программный код может включить в себя команды для сортировки распределенных входных данных, локальной по узлу обработки данных, с использованием первых процессов, исполняемых на узлах обработки данных для того, чтобы создать множество сортированных списков в сегментах локальной памяти узлов обработки данных; команды для создания последовательности диапазонных блоков в сегментах локальной памяти узлов обработки данных, при этом каждый диапазонный блок сконфигурирован таким образом, чтобы хранить значения данных, находящиеся в пределах его диапазона; команды для копирования этого множества сортированных списков в эту последовательность диапазонных блоков с использованием вторых процессов, при этом каждый диапазонный блок принимает те элементы сортированных списков, значения которых находятся в пределах его диапазона; команды для сортировки элементов диапазонных блоков, локальной по узлу обработки данных, с использованием вторых процессов для создания сортированных элементов в диапазонных блоках; и команды для считывания сортированных элементов из последовательности диапазонных блоков, последовательного в отношении их диапазона, для того, чтобы получить сортированные входные данные.
Хотя конкретный признак или аспект раскрываемого изобретения, возможно, были раскрыты в отношении только одного из нескольких вариантов осуществления изобретения, такой признак или аспект могут быть объединены с одним или более другими признаками или аспектами других вариантов осуществления изобретения, согласно тому, что может быть желательным или полезным для какого бы то ни было данного или частного варианта применения. Кроме того, в той мере, в которой термины ''включать в себя'', ''иметь'', ''с'', или другие их варианты используются либо в детализированном описании, либо в формуле изобретения, такие термины предназначены для того, чтобы быть инклюзивными аналогично термину ''содержать''. Кроме того, термины ''приводимый в качестве примера'', ''например'' и ''к примеру'' просто означают пример, а не наилучшее или оптимальное.
Хотя здесь были проиллюстрированы и описаны конкретные аспекты, специалисту обычного уровня квалификации в данной области техники будет понятно, что показанные и описанные конкретные аспекты можно заменить разнообразными альтернативными и/или эквивалентными вариантами осуществления изобретения, не выходя при этом за рамки объема настоящего раскрываемого изобретения. Эта заявка предназначена для того, чтобы охватывать любые адаптации или разновидности рассмотренных здесь конкретных аспектов.
Хотя элементы в нижеследующей формуле изобретения излагаются в некоторой конкретной последовательности с соответствующим маркированием, не обязательно, чтобы эти элементы подразумевались ограниченными осуществлением в этой конкретной последовательности, если только изложение пунктов формулы изобретения не подразумевает, в отличие от этого, конкретную последовательность для осуществления некоторых или всех этих элементов.
Специалистам в данной области техники в свете вышеприведенных идей будут очевидны много вариантов, модификаций и разновидностей. Конечно, специалисты в данной области техники с легко понимают, что имеются многочисленные варианты применения изобретения, помимо тех, что здесь описаны. Несмотря на то, что настоящие изобретения были описаны со ссылкой на один или более конкретных вариантов своего воплощения, специалисты в данной области техники понимают, в них можно внесены много изменений, не выходя при этом за рамки объема настоящего изобретения. Следует поэтому понимать, что в рамках объема прилагаемой формулы изобретения и ее эквивалентов, изобретение на практике может быть осуществлено иначе, чем то, как здесь конкретно описано.
Группа изобретений относится к вычислительной технике и может быть использована для сортировки данных в памяти. Техническим результатом является обеспечение сортировки для ассиметричной архитектуры памяти. Способ содержит этапы, на которых сортируют (1101) распределенные входные данные, локально по узлу (701, 702) обработки данных, посредством развертывания первых процессов на узлах (701, 702) обработки данных для создания множества сортированных списков в сегментах (401, 402, 403, 404) локальной памяти узлов (701, 702) обработки данных; создают (1102) последовательность диапазонных блоков (703, 704, 713, 714) в сегментах локальной памяти узлов (701, 702) обработки данных, копируют (1103) указанное множество сортированных списков в указанную последовательность диапазонных блоков (703, 704, 713, 714), сортируют (1104) элементы диапазонных блоков (703, 704, 713, 714), локально по узлу (701, 702) обработки данных, с использованием вторых процессов для создания сортированных элементов в диапазонных блоках (703, 704, 713, 714); и считывают (1105) сортированные элементы из последовательности диапазонных блоков (703, 704, 713, 714) последовательно в отношении их диапазона для получения сортированных входных данных, при этом сегменты (401, 402, 403, 404) локальной памяти множества соединенных между собой узлов (701, 702) обработки данных структурированы в качестве асимметричной памяти. 3 н. и 11 з.п. ф-лы, 11 ил.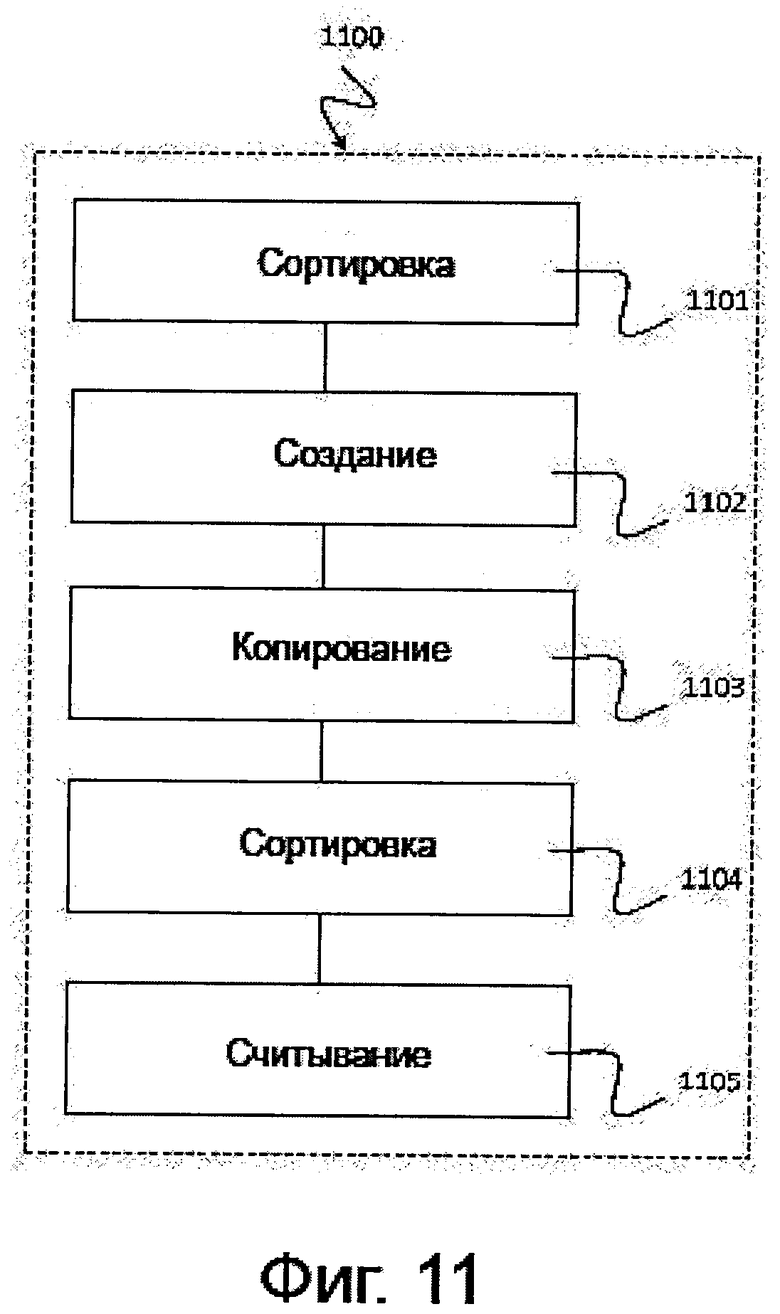
1. Способ (1100) сортировки для сортировки входных данных, распределенных по сегментам (401, 402, 403, 404) локальной памяти множества соединенных между собой узлов (701, 702) обработки данных, в архитектуре аппаратного обеспечения с асимметричной памятью, содержащий этапы, на которых:
сортируют (1101) распределенные входные данные, локально по узлу (701, 702) обработки данных, посредством развертывания первых процессов на узлах (701, 702) обработки данных для создания множества сортированных списков в сегментах (401, 402, 403, 404) локальной памяти узлов (701, 702) обработки данных;
создают (1102) последовательность диапазонных блоков (703, 704, 713, 714) в сегментах локальной памяти узлов (701, 702) обработки данных, при этом каждый диапазонный блок выполнен с возможностью хранения значений данных, находящихся в пределах его диапазона;
копируют (1103) указанное множество сортированных списков в указанную последовательность диапазонных блоков (703, 704, 713, 714) посредством развертывания вторых процессов на узлах (701, 702) обработки данных, при этом каждый диапазонный блок (703, 704, 713, 714) принимает те элементы сортированных списков, значения которых находятся в пределах его диапазона;
сортируют (1104) элементы диапазонных блоков (703, 704, 713, 714), локально по узлу (701, 702) обработки данных, с использованием вторых процессов для создания сортированных элементов в диапазонных блоках (703, 704, 713, 714); и
считывают (1105) сортированные элементы из последовательности диапазонных блоков (703, 704, 713, 714) последовательно в отношении их диапазона для получения сортированных входных данных, при этом
сегменты (401, 402, 403, 404) локальной памяти множества соединенных между собой узлов (701, 702) обработки данных структурированы в качестве асимметричной памяти.
2. Способ (1100) сортировки по п. 1, в котором количество первых процессов является равным количеству сегментов (401, 402, 403, 404) локальной памяти.
3. Способ (1100) сортировки по п. 1 или 2, в котором процессы выполнены с возможностью создания непересекающихся сортированных списков.
4. Способ (1100) сортировки по п. 1, в котором сортировка распределенных входных данных, локальная по узлу (701, 702) обработки данных, основана на одной процедуре из: последовательной процедуры сортировки и параллельной процедуры сортировки.
5. Способ (1100) сортировки по п. 1, в котором количество вторых процессов равно количеству диапазонных блоков (703, 704, 713, 714).
6. Способ (1100) сортировки по п. 1, в котором каждый диапазонный блок (703, 704, 713, 714) имеет отличный от других диапазон.
7. Способ (1100) сортировки по п. 1, в котором каждый диапазонный блок (703, 704, 713, 714) выполнен с возможностью приема множества сортированных списков, при этом количество сортированных списков в соответствии с количеством первых процессов.
8. Способ (1100) сортировки по п. 1, в котором второй процесс из числа вторых процессов, исполняемых на одном узле (701, 702) обработки данных, копируя множество сортированных списков в последовательность (703, 704, 713, 714) диапазонных блоков, осуществляет чтение последовательно из локальной памяти указанного одного узла (701) обработки данных и из локальной памяти других узлов (702) обработки данных.
9. Способ (1100) сортировки по п. 8, в котором второй процесс, исполняемый на указанном одном узле (701) обработки данных, посредством копирования множества сортированных списков в последовательность диапазонных блоков (703, 704, 713, 714), осуществляет запись только в локальную память указанного одного узла (701) обработки данных.
10. Способ (1100) сортировки по п. 1, в котором последовательное считывание сортированных элементов из последовательности диапазонных блоков (703, 704, 713, 714) выполняется с использованием аппаратной упреждающей выборки.
11. Способ (1100) сортировки по п. 1, в котором вторые процессы, для сравнения значений сортированных списков с диапазонами диапазонных блоков (703, 704, 713, 714) и для копирования множества сортированных списков в последовательность диапазонных блоков (703, 704, 713, 714), используют векторизованную обработку данных, в частности векторизованную обработку данных, исполняемую на аппаратных блоках архитектуры с одним потоком команд и множественными потоками данных.
12. Способ (1100) сортировки по п. 1, в котором множество узлов (701, 702) обработки данных соединены между собой посредством межгнездовых соединений; а
локальная память одного узла (701) обработки данных является, для другого узла (702) обработки данных, удаленной памятью.
13. Система (100) обработки данных в архитектуре аппаратного обеспечения с асимметричной памятью, содержащая:
множество соединенных между собой узлов (101, 103) обработки данных, каждый из которых содержит локальную память (107, 117) и блок (109, 119) обработки данных, при этом входные данные распределены по локальной памяти (107, 117) узлов (101, 103) обработки данных, а блоки (109, 119) обработки данных выполнены с возможностью:
сортировки (1001) распределенных входных данных, локально по узлу (701, 702) обработки данных, посредством развертывания первых процессов на узлах (701, 702) обработки данных для создания множества сортированных списков в сегментах (401, 402, 403, 404) локальной памяти узлов (701, 702) обработки данных;
создания (1102) последовательности диапазонных блоков (703, 704, 713, 714) в сегментах локальной памяти узлов (701, 702) обработки данных, при этом каждый диапазонный блок выполнен с возможностью хранения значения данных, находящихся в пределах его диапазона;
копирования (1103) указанного множества сортированных списков в указанную последовательность диапазонных блоков (703, 704, 713, 714) посредством развертывания вторых процессов на узлах (701, 702) обработки данных, при этом каждый диапазонный блок (703, 704, 713, 714) принимает те элементы сортированных списков, значения которых находятся в пределах его диапазона;
сортировки (1104) элементов диапазонных блоков (703, 704, 713, 714), локально по узлу обработки данных, с использованием вторых процессов для создания сортированных элементов в диапазонных блоках (703, 704, 713, 714); и
считывания (1105) сортированных элементов из последовательности диапазонных блоков (703, 704, 713, 714) последовательно в отношении их диапазона для получения сортированных входных данных, при этом
сегменты (401, 402, 403, 404) локальной памяти множества соединенных между собой узлов (701, 702) обработки данных структурированы в качестве асимметричной памяти.
14. Машиночитаемый носитель информации, хранящий программный код для использования компьютером, причем программный код выполнен с возможностью сортировки входных данных, распределенных по сегментам (401, 402, 403, 404) локальной памяти множества соединенных между собой узлов обработки данных, в архитектуре аппаратного обеспечения с асимметричной памятью и содержит:
команды для локальной сортировки (1101) распределенных входных данных по узлу (701, 702) обработки данных посредством развертывания первых процессов на узлах (701, 702) обработки данных для создания множества сортированных списков в сегментах (401, 402, 403, 404) локальной памяти узлов (701, 702) обработки данных;
команды для создания (1101) последовательности диапазонных блоков (703, 704, 713, 714) в сегментах локальной памяти узлов обработки данных, при этом каждый диапазонный блок выполнен с возможностью хранения значений данных, находящихся в пределах его диапазона;
команды для копирования (1103) этого множества сортированных списков в эту последовательность диапазонных блоков (703, 704, 713, 714) посредством развертывания вторых процессов на узлах (701, 702) обработки данных, при этом каждый диапазонный блок (703, 704, 713, 714) принимает те элементы сортированных списков, значения которых находятся в пределах его диапазона;
команды для локальной сортировки (1104) элементов диапазонных блоков (703, 704, 713, 714), по узлу (701, 702) обработки данных, с использованием вторых процессов для создания сортированных элементов в диапазонных блоках (703, 704, 713, 714); и
команды для считывания (1105) сортированных элементов из последовательности диапазонных блоков (703, 704, 713, 714), последовательного в отношении их диапазона, для получения сортированных входных данных, при этом
сегменты (401, 402, 403, 404) локальной памяти множества соединенных между собой узлов (701, 702) обработки данных структурированы в качестве асимметричной памяти.
| ЭЛЕКТРОМАГНИТНЫЙ СПОСОБ ОБНАРУЖЕНИЯ ЭЛЕКТРОПРОВОДЯЩИХ ТЕЛ | 0 |
|
SU377993A1 |
| US 6427148 B1, 30.07.2002 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| US 5671405 A, 23.09.1997 | |||
| СПОСОБ И УСТРОЙСТВО СОРТИРОВКИ НА ОСНОВЕ В-ДЕРЕВА ДЛЯ БОЛЬШИХ ОБЪЕМОВ СЕЙСМИЧЕСКИХ ДАННЫХ | 2002 |
|
RU2285276C2 |

