Область техники, к которой относится изобретение
Данное изобретение относится к сортировке больших объемов сейсмических данных, обеспечивающей экономию как времени, так и аппаратного обеспечения.
Область техники, к которой относится изобретение
При обработке сейсмических данных, в частности, в области нефтяной промышленности имеется огромное количество данных, подлежащих обработке, которое растет очень быстро. Например, для формирования трехмерного изображения число каналов уже достигло 3840 каналов на каждое положение вибросейса с получением набора данных порядка 1-2 терабайт (1012) или более. Наборы данных такого размера легко образуются с помощью 500 миллионов трассировок, а желаемый размер набора данных будет только расти.
Необходимой первоначальной стадией обработки для многих сейсмических алгоритмов является сортировка сейсмических данных в специальном порядке, таком как общая средняя точка или общие приемные собиратели. В целом, при использовании алгоритма для данных трассировки можно вычислить сложность (число операций), связанных с задачей, как NlnN, где N является числом трассировок. Например, для 500 миллионов трассировок необходимо 500·106·ln500·106=около 15,5 миллиардов операций.
На практике эта оценка вводит в заблуждение, поскольку она требует, чтобы все количество данных находилось в памяти в автономной компьютерной системе, а большинство систем не могут удерживать такое количество данных в памяти. Действительно, хотя хорошо известно, что развитие компьютерного аппаратного обеспечения продвигается огромными скачками в отношении скорости, объема и надежности, улучшения в аппаратном обеспечении являются недостаточными для удовлетворения потребностей текущей обработки сейсмических данных. Увеличение числа каналов и множественности трехмерных данных и необходимость использования усовершенствованных способов обработки, таких как предстековое время/миграции по глубине, требуют новых способов обработки данных. Быстрая сортировка является одним из ключевых факторов для эффективного выполнения усовершенствованных алгоритмов обработки.
В сейсмической области давно существует необходимость в способе сортировки, достаточно эффективном для обработки увеличивающихся больших объемов данных, однако до настоящего времени используемые способы не были адекватными.
Двумя основными способами сортировки сегодня являются основанная на памяти сортировка и основанная на диске сортировка. Основанная на памяти сортировка считывает и накапливает трассировки в памяти. После считывания всех трассировок, или выполнения определенного критерия, создаются выходные трассировки в желаемом порядке. Типичным критерием является заданный размер окна, который может быть минимальным числом трассировок, подлежащих удерживанию в памяти и/или на временных дисках. Этот способ не работает, когда объем данных или размер окна больше емкости памяти. Кроме того, этот способ неустойчив к ошибкам, поскольку трассировки могут быть потеряны, когда действительный размер окна в наборе входных данных больше заданного пользователем размера окна.
Основанная на диске сортировка, как второй обычный способ, сохраняет данные в ограниченной буферной памяти перед записью во временные файлы временных дисков. Трассировки в буфере можно частично сортировать перед записью на диск. После записи всех данных на жесткий диск (диски) их можно считывать в желаемом отсортированном порядке и выдавать в окончательные файлы диска. В этом способе необходим произвольный доступ к трассировкам во временном пространстве, что является относительно медленным. Кроме того, этот способ может нуждаться в большом объеме временных дисков в качестве полного набора входных данных. Это является недостатком или исключает возможность сортировки больших трехмерных сейсмических данных в указанной выше области терабайт.
Наряду с указанными выше двумя основными способами предложены гибридные способы, комбинирующие аспекты двух основных способов, которые уменьшают использование временных дисков и время обработки в центральном процессоре. Однако простое комбинирование двух основных способов не создает приемлемого способа, который хорошо работает для сортировки больших наборов входных данных, поскольку фундаментальные проблемы для каждого из двух способов остаются неразрешенными.
Таким образом, сортировка больших объемов сейсмических данных является серьезной задачей людских и компьютерных ресурсов. Большинство систем не могут удерживать все входные данные в памяти и обычные доступные способы занимают чрезмерное количество времени для обработки набора данных желаемого размера. Например, при использовании гибрида из двух основных способов необходимо 6-8 недель для сортировки данных объемом в 1,2 терабайт. В соответствии с этим требуется улучшенная схема сортировки.
Сущность изобретения
Поэтому задачей данного изобретения является создание способа и устройства для сортировки больших объемов сейсмических данных, который исключает указанные выше трудности уровня техники.
Другой задачей данного изобретения является создание способа и устройства, которые сортируют большие количества сейсмических данных в течение времени порядка не более дней, а не недель.
Указанные выше и другие задачи решены с помощью данного изобретения, которое согласно одному варианту выполнения относится к способу сортировки больших объемов сейсмических данных в заданном порядке. Способ содержит стадию приема одной или множества порций данных, где множество порций данных образует набор входных данных, при этом каждая порция данных содержит множество сейсмических данных и имеет связанный с ними индекс, отличающий соответствующую порцию данных от других порций данных в наборе входных данных. Способ дополнительно содержит стадию выделения принятой порции данных в один из множества листовых файлов структуры В-дерева, при этом структура В-дерева задает порядок листьев листовых файлов, первую стадию сохранения для сохранения выделенной порции данных в области временной памяти, соответствующей выделенному листовому файлу, и первую стадию повторения для повторения стадии приема, стадии выделения и первой стадии сохранения, пока следующий из листовых файлов в порядке листовых индексов не будет заполнен.
Способ дополнительно содержит еще стадию считывания заполненного файла из листовых файлов из области временной памяти, вторую стадию сохранения порций данных считанного листового файла в область памяти сортировки в соответствующем субпорядке, основанном на индексах порций данных в нем, и стадию выборочного повторения стадии считывания, второй стадии сохранения и стадии сортировки, пока все порции данных считанного листового файла не будут сортированы.
Наконец, способ содержит стадию выдачи сортированных порций данных считанного листового файла в их субпорядке в конечный поток выходных данных, и вторую стадию повторения по меньшей мере стадии считывания, второй стадии сохранения, стадии сортировки и стадии выдачи, пока все порции данных набора входных данных не будут выданы в соответствующих субпорядках для всех полных листовых файлов в листовом порядке в конечный поток выходных данных, где порции данных в их соответствующих субпорядках для всех заполненных листовых файлов в листовом порядке находятся в заданном общем порядке.
В предпочтительном варианте выполнения каждая порция данных является трассировкой сейсмических данных и каждая выделенная порция данных сохраняется в памяти временного диска.
Краткое описание чертежей
Эти и другие задачи, признаки и преимущества данного изобретения следуют из приведенного ниже подробного описания предпочтительных вариантов выполнения со ссылками на прилагаемые чертежи, на которых аналогичные элементы обозначены одинаковыми позициями и на которых:
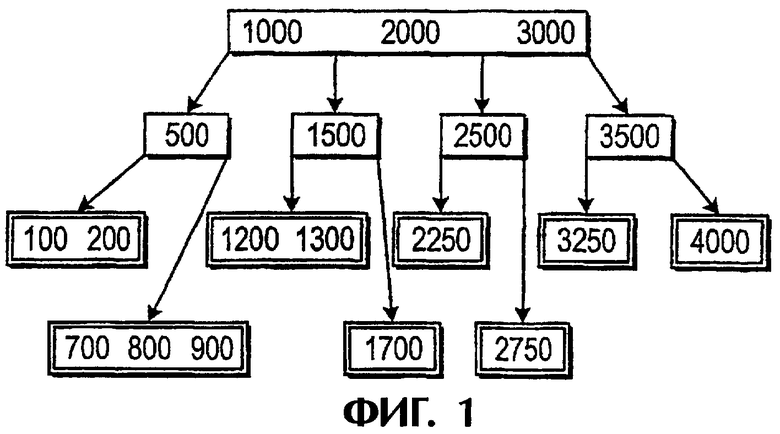
фиг.1 изображает схему сортировки для способа согласно уровню техники, используемого в системах управления базами данных;
фиг.2 - схему сортировки согласно одному варианту выполнения данного изобретения;
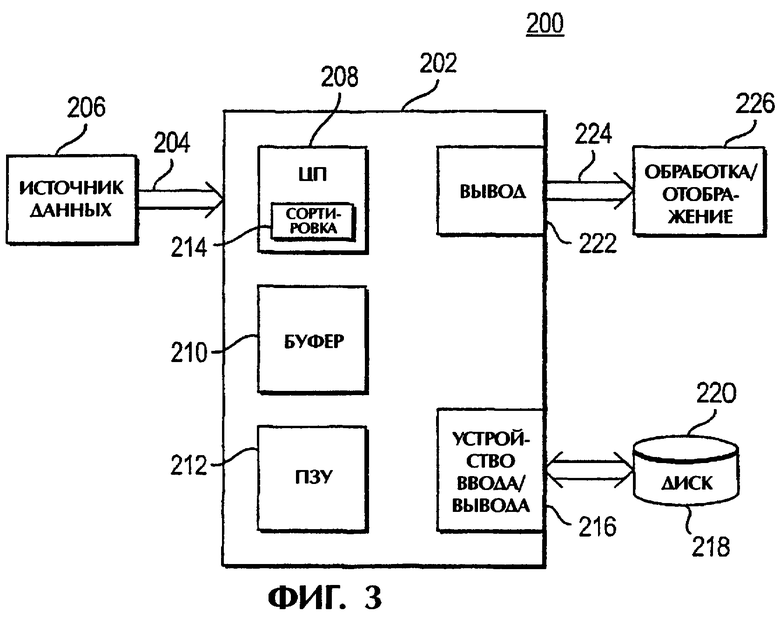
фиг.3 - блок-схему устройства согласно одному варианту выполнения данного изобретения;
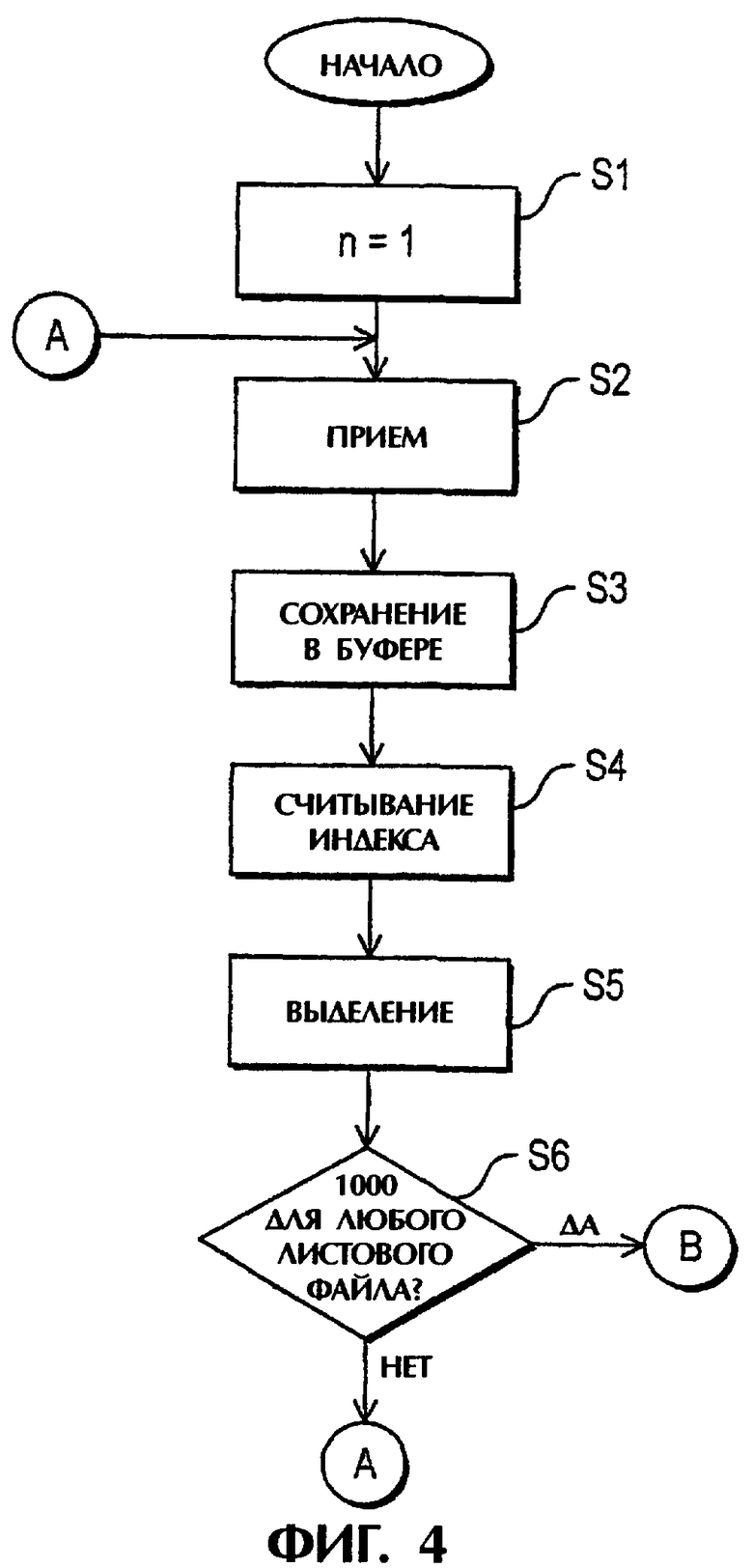
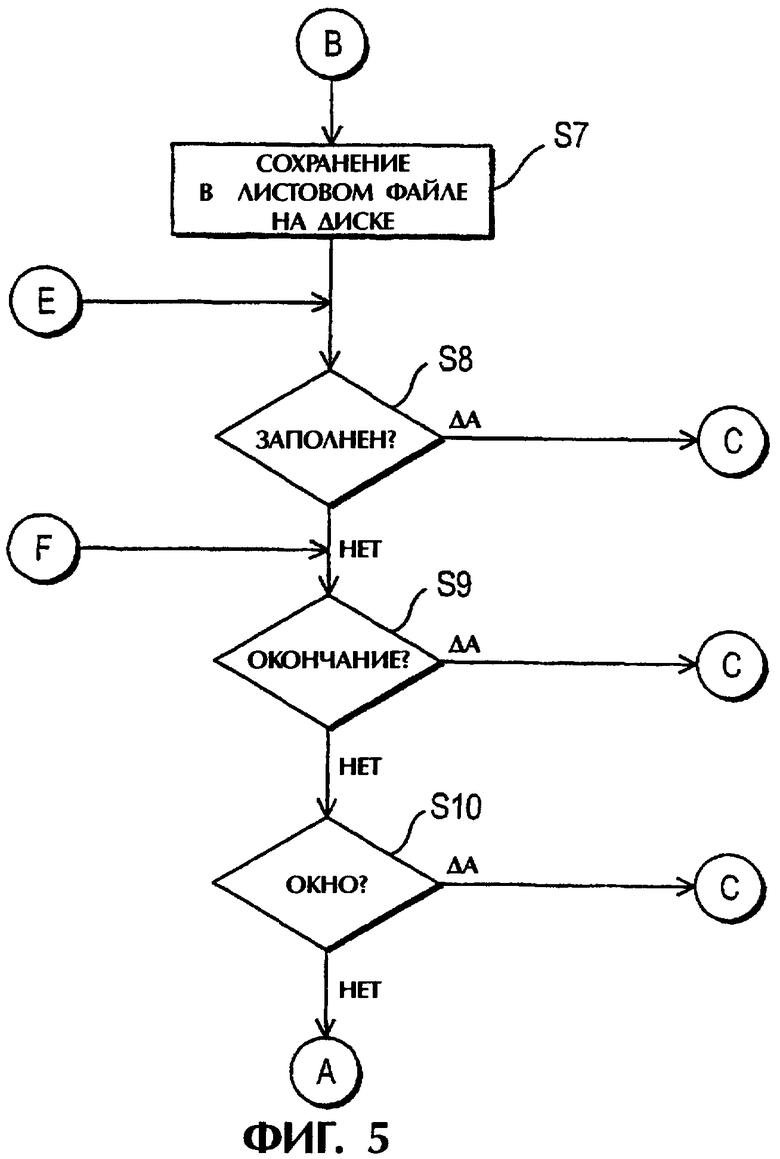
фиг.4 - 7 - графическую схему способа согласно одному варианту выполнения данного изобретения с использованием схемы сортировки согласно фиг.2;
фиг.8 - графическую схему программы одной стадии в графической схеме согласно фиг.4-7; и
фиг.9 - схему сортировки согласно другому варианту выполнения данного изобретения.
Подробное описание предпочтительных вариантов выполнения
Данное изобретение основывается на развитии обычного способа сортировки, известного как способ сбалансированного дерева Байера, называемого в последующем способом В-дерева. Способ описан в источниках, известных для специалистов в данной области техники, таких как Миллер. "Структуры файлов с использованием языка Pascal", Benjamin/Cummings, Menlow Park, Калифорния, США (1987); Корман и др. "Введение в алгоритм", MIT Press, Массачусетс, США (1992). Концепция В-дерева была разработана для сортировки и поиска больших наборов данных, хранящихся в дисках, для минимизации входа/выхода диска. Это достигается, когда данные организованы определенным образом для обеспечения быстрых операций. Обычно структура В-дерева встраивается в системы управления базами данных.
На фиг.1 показан простой случай структуры 10 В-дерева, представляющей данные, имеющие величины 1-4000. В данном случае главное дерево 12 имеет четыре узла 14, 16, 18, 20. Каждый узел имеет в свою очередь два листа, т.е. листовых файла. Таким образом, узел 14 имеет листья 22, 24, узел 16 - листья 26, 28, узел 18 - листья 30, 32 и узел 20 - листья 34, 36. В В-дереве любая заданная величина узла больше величины любого левого потомка/родственного узла и меньше величины любого правого потомка/родственного узла. Например, величина узла 16 равна 1500, указывая точку разделения. Величина 1500 больше величины левого родственного узла 14 (500) и левых потомственных листьев 22, 24, 26 (100-1300). Аналогичным образом, величина 1500 меньше величины правых родственных узлов 18, 20 (2500, 3500) и правых потомственных листьев 28-36 (1700-4000).
Таким образом, интерпретация В-дерева является простой и сортировка с помощью систематической интерпретации известна как относительно простая и относительно недорогая. В способе и устройстве согласно данному изобретению используются преимущества этой структуры для обеспечения эффективной сортировки, сейсмических данных, недоступной и неизвестной для уровня техники.
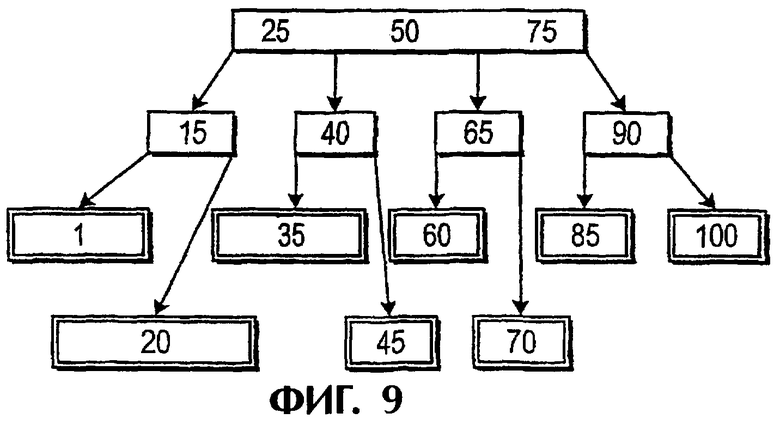
На фиг.2 показана предпочтительная структура 100 В-дерева, которая используется в способе согласно одному варианту выполнения изобретения. Для целей данного примера предполагается, что индексы СМР трассировок во входных данных находятся в диапазоне от 1 до 100. В-дерево 100 включает главный файл 102 и четыре листовых файла 104, 106, 108, 110. Желательно, чтобы листовой файл 104 удерживал трассировки с индексами СМР 1-25, листовой файл 106 - трассировки с индексами СМР 26-50, листовой файл 108 - трассировки с индексами СМР 51-75 и листовой файл 110 - трассировки с индексами СМР 76-100.
Таким образом, В-дерево 100 имеет листовые файлы в заданном листовом порядке. Согласно данному изобретению каждый листовой файл содержит порции данных (трассировки), которые представляют полный набор данных в желаемом порядке, когда порции данных упорядочены, листовые файлы рассматриваются в листовом порядке. В рассматриваемом варианте выполнения данного изобретения, где заданный общий порядок после сортировки желательно должен быть возрастающим порядком, данные в каждом листовом файле после сортировки находятся в возрастающем субпорядке. В соответствии с этим, когда данные рассортированы в заданном субпорядке внутри каждого листового файла и когда листовые файлы рассматриваются в листовом порядке, то данные всего набора входных данных находятся в заданном общем порядке.
На фиг.3 показана блок-схема одного варианта выполнения устройства для выполнения данного изобретения. Как показано на фигуре, устройство 200 содержит рабочую станцию 202, принимающую последовательно трассировки сейсмических данных 204 в виде трассировок (порций данных) в произвольном порядке СМР из источника 206 данных, например сейсмических детекторных микрофонов в пласте. Рабочая станция 202 содержит центральный процессор 208 для управления работой рабочей станции 202 по выполнению способа согласно данному изобретению, оперативную память (ОЗУ), действующую в качестве буферной памяти 210, и постоянное запоминающее устройство (ПЗУ) 212 для хранения программ управления и оперативных данных из центрального процессора 208. В частности, рабочая станция 202 хранит алгоритм 214 сортировки, например, в центральном процессоре 208 для сортировки данных трассировок согласно данному изобретению.
Рабочая станция 202 содержит также устройство 216 ввода/вывода для вывода данных 204 трассировок в дисковое устройство 218 файлов для ввода данных 204 трассировок обратно в рабочую станцию 202. Дисковое устройство 218 файлов содержит по меньшей мере один временный диск 220, на котором могут быть записаны листовые файлы 104-110. Как будет указано ниже, дисковое устройство 218 не должно записывать для считывания со случайным доступом. Наконец, рабочая станция 202 содержит устройство 222 вывода для выдачи сортированных данных трассировок в качестве выходного конечного потока 224 данных в другое устройство 226, где может происходить дальнейшая обработка или отображение данных.
При использовании структуры В-дерева 100 в устройстве согласно фиг.3 предпочтительный вариант выполнения способа обработки данных согласно данному изобретению содержит следующие стадии.
Предполагается, что входные данные 204 трассировок из входного устройства 206 принимаются рабочей станцией в произвольном порядке с индексами СРМ, находящимися в диапазоне от 1 до 100, и что желательно сортировать трассировки в соединения с нарастающим порядком индексов СМР. Когда центральный процессор 208, работающий в соответствии с алгоритмом 214 сортировки, получает входную трассировку с индексом СМР №Х во входных данных 204 трассировок, то он выделяет трассировку №Х в листовой файл, куда принадлежит входной индекс СМР, и записывает в нем выделенную трассировку. Например, входная трассировка с индексом СМР 24 записывается в листовой файл 104. В соответствии с этим центральный процессор 208 выделяет и записывает трассировку №24 через устройство 216 ввода/вывода на временный диск 220 в устройстве 218 файловых дисков в листовой файл 104. Аналогичным образом, если принимается входная трассировка с индексом СМР 55, то центральный процессор 208 выделяет и записывает эту трассировку №55 через устройство 216 ввода/вывода на временный диск 220 в устройстве 218 файловых дисков в листовой файл 108. Другие трассировки, имеющие другие индексы СМР, выделяются и записываются аналогичным образом на временный диск 220 или на другой временный диск в соответствующий листовой файл.
Предпочтительно временно сохранять несколько трассировок в буферной памяти 210 или в другой памяти рабочей станции 202 перед записью в виде пачки на временный диск 220 в соответствующий листовой файл. Например, если ожидается в целом 500 миллионов трассировок в полном наборе входных данных, то в буферной памяти 210 можно накапливать 1000 трассировок.
Когда листовой файл заполнен, то данные трассировок из него считываются обратно с временного диска 220 в буферную память 210 или другую память для сохранения в возрастающем порядке с помощью алгоритма 214 сортировки. После сортировки сохраненные трассировки можно снова сохранить в памяти, например в устройстве 220 файловых дисков, в рабочей станции 202 или в другом месте в качестве конечного выходного файла, пока не потребуется выполнять дальнейшую обработку данных.
В контексте данного изобретения листовой файл является заполненным, только когда выполняются одновременно два условия. Во-первых, нет больше входных трассировок, подлежащих внесению в этот листовой файл, например, при достижении конца входных данных или при превышении размера окна. Во-вторых, все листовые файлы слева от данного файла в В-дереве должны быть уже рассортированы и выданы в конечный поток данных/файлов. Например, если данный листовой файл является листовым файлом 106, то его можно рассматривать заполненным, только если листовой файл 104 уже был выдан, в то время как, если данный листовой файл является листовым файлом 108, то его можно рассматривать как заполненный, только если уже были выданы листовые файлы 104 и 105. Следует отметить, что листовой файл может быть заполненным, даже если листовые файлы более высокого порядка не являются заполненными. Например, если все трассировки с индексами СМР 1-25 приняты первыми, то листовой файл 104 может быть заполнен даже перед тем, как будут приняты все другие трассировки. В соответствии с этими условиями обеспечивается, что все трассировки в конечном потоке файлов/данных будут присутствовать в правильном возрастающем порядке.
Другое преимущество данного изобретения состоит в том, что если листовые файлы являются достаточно небольшими, то содержащиеся в нем трассировки не должны считываться с временного диска 220 в требуемом порядке выдачи, поскольку весь листовой файл можно считывать в буферную память 210 или в другую имеющуюся память. Меньший размер листового файла может быть обеспечен посредством увеличения числа листовых файлов. Считывание файлов по мере их записи на диски может исключить необходимость в произвольном доступе к данным. Это обеспечивает как увеличение скорости сортировки, так и уменьшение стоимости аппаратного обеспечения.
Действительно, даже если листовой файл больше размера памяти, то можно исключить необходимость произвольного доступа посредством считывания листового файла несколько раз. Например, если листовой файл в два раза больше размера буферной памяти 210, то во время первого последовательного считывания сохраняют в буферной памяти 210 только половину трассировок с более низкими номерами, а во время второго считывания сохраняют только половину трассировок с более высокими номерами. Это в свою очередь обеспечивает улучшение скорости и стоимости аппаратного обеспечения.
За счет минимизации потребности в произвольном доступе к сохраненным трассировкам на временном диске 220 код алгоритма 214 сортировки работает более эффективно. Каждый листовой файл может быть насыщен, когда превышается размер окна, и нет необходимости в сохранении всего набора входных данных на временном диске (дисках), что минимизирует использование дискового пространства. В частности, размер окна должен быть задан пользователем для минимизации использования диска. Если пространство временного диска не является проблемой, то размер окна можно предпочтительно установить равным или большим общего числа входных трассировок. Например, на практике пользователь может включить модуль анализа в поток перед сортировкой потока. Модуль анализа использует относительно немного времени центрального процессора и памяти, однако он может обеспечивать размер окна для алгоритма 214 сортировки.
Графические схемы описанных выше процессов сортировки показаны на фиг.4-8. Следует понимать, что эти графические схемы приведены лишь в качестве примеров и определенные стадии не должны выполняться точно в указанном порядке, а некоторые стадии можно опускать или добавлять в соответствии с частным вариантом выполнения.
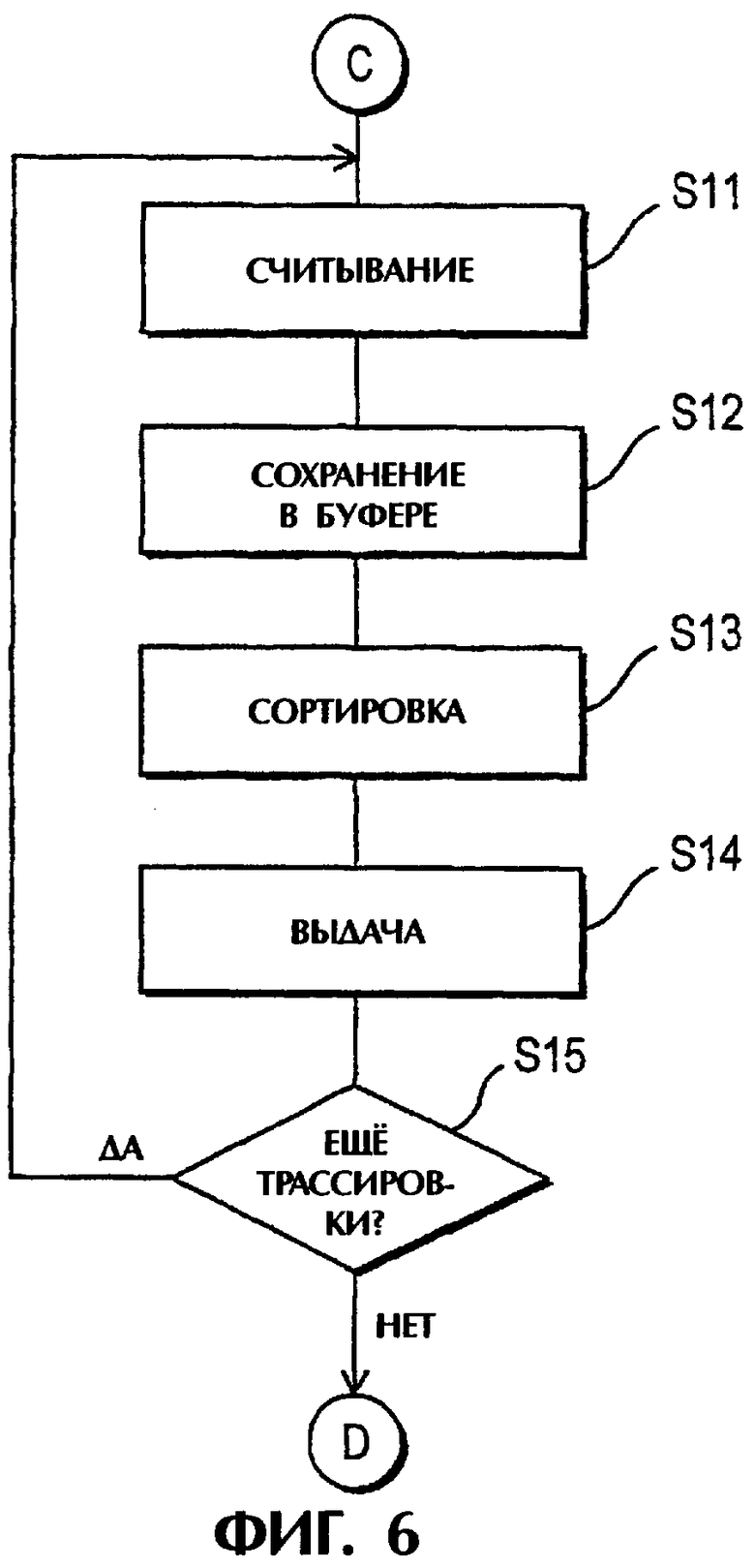
Как показано на фиг.4-7, на стадии S1 инициализируют номер n, представляющий порядок листового файла, который будет заполнен следующим, т.е. устанавливают n равным 1, представляющим самый левый листовой файл 104. На стадии S2 рабочая станция 202 принимает трассировку №Х из входного устройства 206. На стадии S3 трассировку №Х сохраняют в буферной памяти 210, на стадии S4 центральный процессор 208 считывает индекс СМР и на стадии S5 трассировка выделяется для соответствующего листового файла. На стадии S6 определяют, необходимо ли сохранять содержимое буферной памяти 210 на временном диске 220, например, сохранены ли 1000 трассировок для каждого листового файла в буферной памяти 210. Если нет, то процесс возвращается на стадию S2 для приема другой трассировки, в то время как, если да, то на стадии S7 трассировки в буферной памяти 210 сохраняют на временном диске в соответствующих выделенных листовых файлах.
Если таким образом сохранены все трассировки в буферной памяти 210, то на стадии S8 проверяют, является ли листовой файл n заполненным. Эта программа показана на фиг.8 и ее описание приводится ниже. Если на стадии S8 получают результат нет, то на стадии S9 проверяют, достигнут ли конец набора входных данных, а на стадии S10 проверяют, превышен ли размер окна. Если ответ в обеих стадиях S9 и S10 гласит нет, то процесс возвращается на стадию S2 для приема следующей трассировки. Однако, если ответ на любой из стадий S9 и S10 гласит да, то процесс переходит на стадию S11 для начала сортировки (изменения порядка) сохраненных трассировок.
На стадии S11 считывают трассировки листового файла n, предпочтительно без случайного доступа. На стадии S12 некоторые или все трассировки сохраняют обратно в буферной памяти 210 в зависимости от размера листового файла n по сравнению с размером буфера. Если только некоторые трассировки могут войти в буферную память 210, то при первом считывании сохраняют группу трассировок с самыми низкими номерами, в то время как в последующих считываниях сохраняют следующие группы. На стадии S13 трассировки сохраняют в буферной памяти 210 в желаемом порядке с помощью индексов СМР, а на стадии S22 упорядоченные трассировки выдают в виде выходного потока 224 данных для дальнейшей обработки.
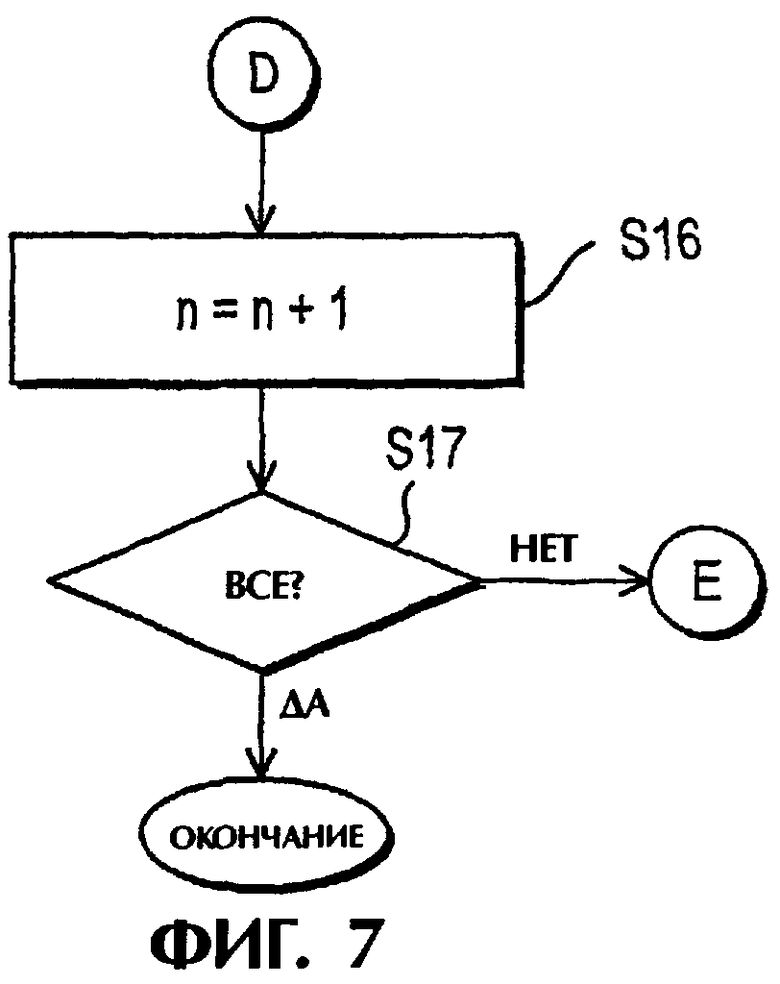
На стадии S 15 проверяют, имеет ли листовой файл n еще трассировки, подлежащие сохранению, и если да, то процесс возвращается на стадию S11. Если нет, то номер n листового файла увеличивают на шаг на стадии S16.
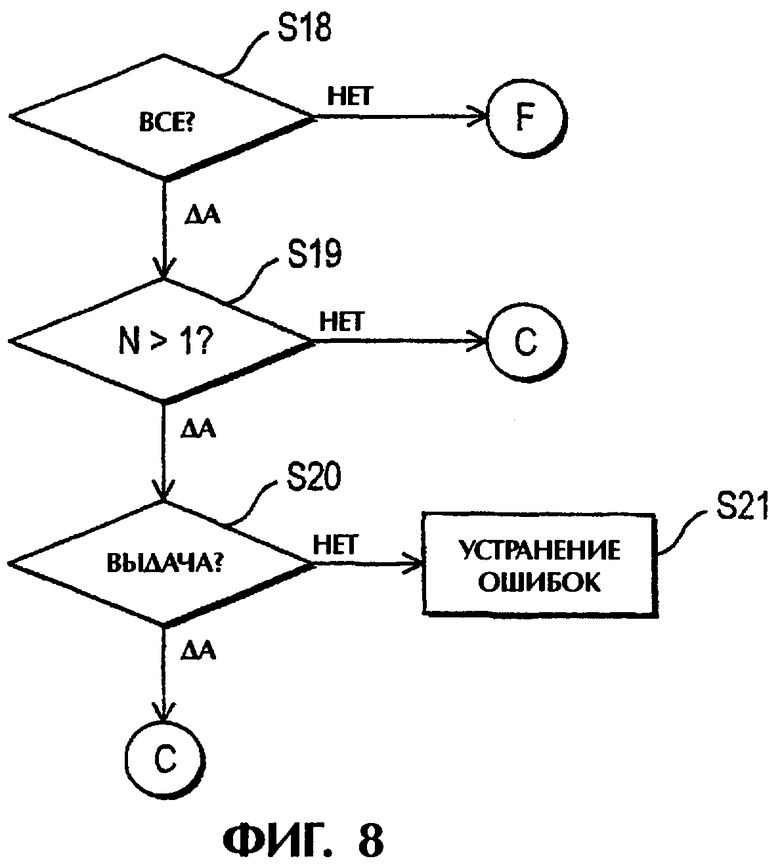
Затем на стадии S17 проверяют, все ли листовые файлы были сохранены и выданы. Если да, то процесс завершается. Если нет, то процесс возвращается на стадию S8 для проверки, готов ли другой заполненный листовой файл для сохранения. Если никакой другой листовой файл не заполнен и имеются еще данные, то процесс снова возвращается на стадию S2.
Ниже приводится описание подпрограммы стадии S8 для определения, является ли листовой файл заполненным. Подпрограмма начинается на стадии S18, на которой проверяют сначала, приняты ли все трассировки для текущего листового файла. Если нет, то подпрограмма возвращается в главную программу на стадии S9. Если да, то на стадии S19 подпрограмма проверяет, имеются ли слева от текущего листового файла какие-либо листовые файлы, т.е. является ли N больше 1. Если нет, то текущий листовой файл 1 является заполненным и подпрограмма возвращается в главную программу на стадии S 11. Если да, то на стадии S20 подпрограмма проверяет, чтобы все листовые файлы слева от текущего листового файла были рассортированы и выданы. Если нет, то была допущена ошибка, поскольку n не должно было быть увеличено на шаг, пока не будут выданы все находящиеся слева листовые файлы, и процесс переходит на стадию S21 обнаружения ошибки. Например, может быть снова инициализирован номер листового файла и снова считаны все трассировки, и наличие ошибки может быть отображено для вмешательства оператора. Однако, если ответ на стадии S20 гласит да, то текущий листовой файл n является заполненным и подпрограмма возвращается в главный процесс на стадии S11.
Обычно является предпочтительным, чтобы структура В-дерева была короткой по вертикали и широкой по горизонтали, поскольку это приводит к множеству небольших, обеспечивающих простой доступ листовых файлов, и поэтому В-дерево 100 создано без узлов. Однако при больших количествах данных или для разных задач используемая в других вариантах выполнения данного изобретения структура В-дерева может иметь любое необходимое число узлов и листьев. На фиг.5 показана альтернативная структура 300 В-дерева для сохранения данных 1-100 в соответствии со способом и устройством согласно данному изобретению.
Хотя процесс был описан с применением буферной памяти 210 для сохранения трассировок по мере их входа и снова при их сохранении, понятно, что для одной или обеих этих функций можно использовать другую память - либо внутри рабочей станции 202, либо вне ее. Кроме того, хотя процесс описан с использованием одной рабочей станции, понятно, что алгоритм 214 сортировки может выполняться параллельно в нескольких рабочих станциях посредством распределения нагрузки на разные процессы/узлы.
Дополнительно к этому, приведенный выше пример сортировки служит для сортировки трассировок в возрастающем порядке СМР, однако данное изобретение можно использовать для сортировки данных в любом заданном общем порядке. Согласно данному изобретению, когда данные рассортированы в заданном субпорядке внутри каждого заполненного листового файла и затем заполненные листовые файлы рассматриваются в порядке листьев, то данные всего набора входных данных находятся в заданном общем порядке.
Кроме того, хотя конечный поток выходных данных показан как поток 224 данных, понятно, что конечный поток выходных данных может проходить к другой памяти внутри или вне рабочей станции 202.
Хотя раскрываемые способ и устройство показаны и описаны, в частности, применительно к предпочтительным вариантам выполнения, для специалистов в данной области техники понятно, что возможны различные модификации по форме и в деталях без отхода от объема и идеи изобретения. В соответствии с этим модификации, такие как указанные выше, но не ограничивающиеся этим, необходимо рассматривать как входящие в объем изобретения, определяемого прилагаемой формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО И СПОСОБ ОБРАБОТКИ ИНФОРМАЦИИ | 1996 |
|
RU2182722C2 |
| СПОСОБ ЗАПИСИ ДАННЫХ НА НОСИТЕЛЬ ЗАПИСИ | 2003 |
|
RU2303822C2 |
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ УПРЕЖДАЮЩЕГО УПРАВЛЕНИЯ ПАМЯТЬЮ | 2003 |
|
RU2482535C2 |
| НОСИТЕЛЬ ЗАПИСИ И СПОСОБ ЗАПИСИ НА НОСИТЕЛЬ ЗАПИСИ | 2003 |
|
RU2305330C2 |
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ УПРЕЖДАЮЩЕГО УПРАВЛЕНИЯ ПАМЯТЬЮ | 2003 |
|
RU2348067C2 |
| ЗАПИСЬ ТРАССИРОВКИ НА ОСНОВЕ КЭША С ИСПОЛЬЗОВАНИЕМ ДАННЫХ ПРОТОКОЛА КОГЕРЕНТНОСТИ КЭША | 2018 |
|
RU2775818C2 |
| ЗАПИСЬ ТРАССИРОВКИ ПОСРЕДСТВОМ РЕГИСТРАЦИИ ВХОДЯЩИХ ПОТОКОВ В КЭШ НИЖНЕГО УРОВНЯ НА ОСНОВЕ ЭЛЕМЕНТОВ В КЭШЕ ВЕРХНЕГО УРОВНЯ | 2019 |
|
RU2773437C2 |
| СПОСОБ И СИСТЕМА РЕНДЕРИНГА 3D МОДЕЛЕЙ В БРАУЗЕРЕ С ИСПОЛЬЗОВАНИЕМ РАСПРЕДЕЛЕННЫХ РЕСУРСОВ | 2020 |
|
RU2736628C1 |
| КОМАНДА И ЛОГИЧЕСКАЯ СХЕМА ДЛЯ СОРТИРОВКИ И ВЫГРУЗКИ КОМАНД СОХРАНЕНИЯ | 2014 |
|
RU2663362C1 |
| СИСТЕМА ИДЕНТИФИКАЦИИ ИЗОБРАЖЕНИЙ | 2002 |
|
RU2302656C2 |
Изобретение относится к области геофизики и может быть использовано при обработке больших объемов сейсмических данных в нефтяной промышленности. Заявлены способ и устройство сортировки больших объемов порций сейсмических данных в заданном порядке, в котором порции данных выделяют в листовые файлы структуры В-дерева и сохраняют в соответствующей области временной памяти, соответствующей выделенному листовому файлу. Заполненный листовой файл считывают в область памяти сортировки, в которой их сортируют в соответствующем субпорядке. Все сортированные порции данных выдают в соответствующих субпорядках для всех заполненных листовых файлов в листовом порядке для создания конечного потока выходных данных, где порции данных в их соответствующих субпорядках для всех заполненных листовых файлов в листовом порядке находятся в заданном общем порядке. Технический результат: повышение эффективности сортировки больших объемов сейсмических данных. 3 н. и 19 з.п. ф-лы, 9 ил.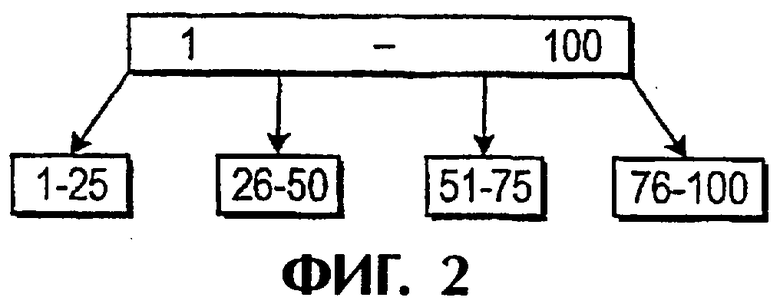
стадию приема одной или множества порций данных, где множество порций данных образуют набор входных данных, при этом каждая порция данных содержит множество сейсмических данных и имеет связанный с ними индекс, отличающий соответствующую порцию данных от других порций данных в наборе входных данных;
стадию выделения принятой порции данных в один из множества листовых файлов структуры В-дерева, при этом структура В-дерева задает порядок листьев листовых файлов;
первую стадию сохранения для сохранения выделенной порции данных в области временной памяти, соответствующей выделенному листовому файлу;
первую стадию повторения для повторения указанной стадии приема, указанной стадии выделения и указанной первой стадии сохранения, пока по меньшей мере один из листовых файлов не будет заполнен;
стадию считывания заполненного файла из временной области памяти;
вторую стадию сохранения порций данных считанного листового файла в области памяти сортировки;
стадию сортировки порций данных в области памяти сортировки в соответствующем субпорядке, основанном на индексах порций памяти в ней;
стадию выборочного повторения указанной стадии считывания, указанной второй стадии сохранения и указанной стадии сортировки, пока все порции данных считанного листового файла не будут сортированы;
стадию выдачи сортированных порций данных считанного листового файла в их субпорядке в конечный поток выходных данных;
и вторую стадию повторения по меньшей мере указанной стадии считывания, указанной второй стадии сохранения, указанной стадии сортировки и указанной стадии выдачи, пока все порции данных набора входных данных не будут выданы в соответствующих субпорядках для всех заполненных листовых файлов в листовом порядке в конечный поток выходных данных, где порции данных в их соответствующих субпорядках для всех заполненных листовых файлов в листовом порядке находятся в заданном общем порядке трассировок данных.
приемное средство для приема одной или множества порций данных, где множество порций данных образуют набор входных данных, при этом каждая порция данных содержит множество сейсмических данных и имеет связанный с ними индекс, отличающий соответствующую порцию данных от других порций данных в наборе входных данных;
средство выделения для выделения принятой порции данных в один из множества листовых файлов структуры В-дерева, при этом структура В-дерева задает порядок листьев листовых файлов;
первое средство сохранения для сохранения выделенной порции данных в области временной памяти, соответствующей выделенному листовому файлу;
средство управления для управления указанным приемным средством, указанным средством выделения и указанным первым средством сохранения для повторения их операций, пока по меньшей мере один из листовых файлов не будет заполнен;
средство считывания для считывания заполненного листового файла из области временной памяти;
второе средство сохранения для сохранения порций данных считанного листового файла в области памяти сортировки;
средство сортировки для сортировки порций данных в области памяти сортировки в соответствующем субпорядке в соответствии с индексами порций данных в ней;
при этом указанное средство управления управляет по меньшей мере указанным средством считывания, указанным вторым средством сохранения и указанным средством сортировки, пока все порции данных считанного листового файла не будут сортированы;
и средства выдачи для выдачи сортированных порций данных считанного листового файла в их субпорядке в конечный поток выходных данных;
при этом указанное средство управления дополнительно управляет по меньшей мере указанным считывающим средством, указанным вторым средством сохранения, указанным средством сортировки и указанным средством выдачи, пока все порции данных набора входных данных не будут выданы в соответствующих субпорядках для всех заполненных листовых файлов в листовом порядке в конечный поток выходных данных, где порции данных в их соответствующих субпорядках для всех заполненных листовых файлов в листовом порядке находятся в заданном общем порядке.
буферную память для последовательного приема множества порций данных, где множество порций данных образуют набор входных данных, при этом каждая порция данных содержит множество сейсмических данных и имеет связанный с ними индекс, отличающий соответствующую порцию данных от других порций данных в наборе входных данных;
процессор для выделения каждой порции данных в указанной буферной памяти в один из множества листовых файлов структуры В-дерева, при этом структура В-дерева задает порядок листьев листовых файлов;
устройство ввода/вывода для сохранения каждой выделенной порции данных в указанной буферной памяти в области временной памяти, соответствующей выделенному листовому файлу;
в котором в ответ на определение указанным процессором, что по меньшей мере один из указанных листовых файлов является заполненным, указанное устройство ввода/вывода считывает заполненный листовой файл из области временной памяти в указанную буферную память без обработки для случайного доступа, при этом указанный процессор сортирует порции данных заполненного листового файла в указанной буферной памяти в соответствующем субпорядке, основанном на индексах соответствующих порций данных, и указанная буферная память выдает сортированные порции данных в их соответствующем субпорядке, при этом указанный процессор повторяет этот процесс, пока не будут выданы все листовые файлы в листовом порядке в конечный поток данных, где порции данных в их соответствующих субпорядках для всех заполненных листовых файлов в листовом порядке находятся в заданном общем порядке трассировок данных.
| GB 1419458 А, 31.12.1975 | |||
| ГЕОФИЗИЧЕСКАЯ СИСТЕМА СБОРА И ОБРАБОТКИ ИНФОРМАЦИИ | 1994 |
|
RU2091820C1 |
| RU 2144683 С1, 20.01.2000 | |||
| Домовый номерной фонарь, служащий одновременно для указания названия улицы и номера дома и для освещения прилежащего участка улицы | 1917 |
|
SU93A1 |
| ОБУВНОЙ КРЕМ | 0 |
|
SU181216A1 |

