Изобретение относится к области цифровой связи, а именно, к обработке цифровых потоков канального уровня эталонной модели взаимодействия открытых систем и может быть использовано в широком классе средств обработки цифровых сигналов для распознавания новых протоколов низкоскоростного кодирования речи (НСКР), используемых при передаче речевых сообщений по цифровым каналам связи.
Заявленное техническое решение расширяет арсенал средств аналогичного назначения за счет возможности распознавания новых протоколов НСКР с меньшей вероятностью ложной тревоги.
Известен способ распознавания протоколов НСКР (см. Патент РФ № RU 2610285 С1, МПК G10L 19/008 (2013.01), Н03М 13/03 (2006.01). Способ распознавания протоколов низкоскоростного кодирования. Аладинский В.А., Кузьминский С.В., Смирнов П.Л., Чубатый Д.Н., опубл. 08.02.2017), в котором на основе сравнения эталонных описаний, представленных наборами усредненных значений коэффициента избыточности (КИ), и исследуемого образа, представленного набором значений КИ столбцов прямоугольной матрицы, сформированной из входного цифрового информационного потока, определяют величины отклонения между измеренным набором значений КИ и наборами усредненных значений КИ, в полученной совокупности значений отклонения выбирают минимальное, сравнивают его с пороговой величиной, по результатам сравнения принимают решение о том, что исследуемый цифровой поток сформирован на основе одного из известных протоколов НСКР, в противном случае полагают, что для формирования анализируемого цифрового потока был применен новый (неизвестный ранее) протокол НСКР. Недостатком способа является низкая помехоустойчивость распознавания, что приводит к появлению большого числа ложных решений о применении на линиях радиосвязи новых протоколов НСКР при вероятности битовой ошибки Рош>0,03.
Наиболее близким к заявленному является способ (прототип) распознавания протоколов низкоскоростного кодирования (см. Патент РФ № RU 2667462 С1, Способ распознавания протоколов низкоскоростного кодирования, МПК G10L 19/008 (2013.01), Н03М 13/03 (2006.01). Аладинский В.А., Вещунин Е.А., Кузьминский С.В., Смирнов П.Л. опубл. 19.09.2018), заключающийся в том, что принимают бинарный цифровой информационный поток у в течение интервала времени ΔT, формируют на основе у нормированную автокорреляционную функцию а, принимают решение о наличии блочной структуры в цифровом информационном потоке у по регулярным с равными интервалами Δτ экстремумам автокорреляционной функции а, делят цифровой информационный поток у на информационные блоки объемом Nб бит каждый с интервалами Δτ между экстремумами автокорреляционной функции а, последовательно присваивают информационным блокам порядковые номера k=1, 2, …, K, начиная с первого информационного блока, формируют прямоугольную информационную матрицу Y размеров K×L, L=Nб, строками которой являются последовательно размещенные друг под другом информационные блоки в соответствии с их порядковыми номерами k=1, 2, …, K, из матрицы Y выделяют столбцы yz, z=1, 2, …, L; вычисляют по каждому столбцу yz значение математического ожидания (МО) mz, на основе полученных значений mz формируют вектор значений МО m0=(m1, m2, …, mz, …, mL) путем последовательного их размещения в соответствии с порядковыми номерами z, на основе полученного вектора m0 формируют квадратную матрицу М значений МО размера L, строки ml, l=0, 1, 2, …, L-1, которой содержат значения вектора m0, последовательно циркулярно сдвинутые влево на величину l; формируют прямоугольные эталонные информационные матрицы на основе которых
вычисляют векторы эталонных значений МО mj эт, j=1, 2, …, J, и квадратные эталонные ковариационные матрицы {Cj эт}J, соответствующие J известным протоколам НСКР; вычисляют значения вероятности правильного распознавания Pjl j-то протокола НСКР, j=1, 2, …, J, по каждой l-й строке ml матрицы М, принимают решение в пользу того j-го протокола НСКР, для которого обеспечивается максимальное значение Pjl.
Способ-прототип обладает высокой точностью распознавания протоколов НСКР в условиях высокого уровня битовых ошибок в исследуемом цифровом информационном потоке у. Однако, недостатком прототипа является появление при вычислении вероятности правильного распознавания неопределенности вида Pjl=0/0 для всех j, l. Последняя возникает в случае подачи на вход цифровых информационных потоков, в том числе сформированных на основе новых протоколов НСКР, за исключением реализаций, для которых имеются эталонные описания. В результате имеет место увеличение вероятности ложной тревоги при распознавании новых протоколов НСКР в условиях уменьшения объема К входного цифрового информационного потока у, особенно при величине К<100. Следствием увеличения количества J эталонных описаний, формируемых за счет неправильно распознанных входных реализаций при обучении системы распознавания протоколов НСКР, является снижение вероятности правильного распознавания.
Целью заявленного технического решения является разработка способа, обеспечивающего снижение вероятности ложной тревоги и, как следствие, повышение достоверности распознавания (вероятности правильного распознавания) новых протоколов НСКР.
Поставленная цель достигается тем, что в известном способе распознавания протоколов НСКР, включающем прием бинарного цифрового информационного потока у в течение интервала времени ΔТ, формирование на основе у нормированной автокорреляционной функции а, принятие решения о наличии блочной структуры в информационном потоке у по регулярным с равными интервалами Δτ экстремумам автокорреляционной функции а, деление цифрового информационного потока у на информационные блоки объемом Nб бит каждый по интервалам между экстремумами автокорреляционной функции а, последовательное присвоение информационным блокам порядковых номеров k=1, 2, …, K, начиная с первого информационного блока, формирование прямоугольной информационной матрицы Y размеров K×L, L=Nб, строками которой являются последовательно размещенные друг под другом информационные блоки в соответствии с их порядковыми номерами k=1, 2, …, K, выделение из матрицы Y столбцов yz, z=1, 2, …, L, определение значений МО mz по каждому столбцу yz, формирование вектора значений МО m0=(m1, m2, …, mz, …, mL) последовательным размещением значений МО mz, формирование квадратной матрицы значений МО М размером L×L, строки ml, l=0, 1, 2, …, L-1, которой содержат значения вектора то, последовательно циркулярно сдвинутые влево на величину l, формирование прямоугольных эталонных информационных матриц {Yj эт}J, вычисление на основе эталонных информационных матриц {Yj эт}J векторов эталонных значений МО mj эт, у=1, 2,…, J и квадратных эталонных ковариационных матриц {Cj эт}J, вычисление значения вероятности правильного распознавания Pjl для каждого j-го протокола НСКР, j=1, 2, …, J, по каждой 1-й строке ml матрицы М, принятие решения в пользу j-го протокола НСКР, для которого обеспечивается максимальное значение Pjl, при получении результата вычисления вероятности правильного распознавания в виде неопределенности Pjl=0/0 для всех j, l, формируют совокупность прямоугольных матриц {Yl}L, столбцы которых сдвинуты циркулярно на l=0, 1, 2, …, L-1 относительно столбцов прямоугольной информационной матрицы Y. Для каждой матрицы Yl вычисляют соответствующую ей квадратную ковариационную матрицу Cl.
Определяют значение дивергенции vjl между образом входной реализации, представленной строками ml квадратной матрицы М значений МО и соответствующими ковариационными матрицами Cl, и каждым j-м эталонным образом, представленным вектором mj эт и соответствующей квадратной эталонной ковариационной матрицей Сj эт. на основе полученных значений vjl формируют вектор значений дивергенции vj=(vj0, vj1, …, vjl …, vj(L-1)) для каждого j-го эталонного образа. Составляют из J векторов vj матрицу значений дивергенции V размеров J×L.
Принимают решение о обнаружении нового ранее неизвестного протокола НСКР и присваивают условный номер J=J+1 новому эталонному описанию, которое включает вектор математического ожидания m(J+1)эт=m0 и квадратную эталонную ковариационную матрицу С(J+1)эт=С0, если для всех элементов vjl матрицы значений дивергенции V выполняется условие vjl>vпop=2000 при любых j, l, где vпop - пороговая величина, или только для одного элемента vjl<300, а все остальные vjl>vпор, принимают решение, что входная реализация у сформирована по j-му известному протоколу НСКР и в информационном потоке у отсутствуют начальные l бит в первом k=1 информационном блоке. В случае 300≤vjl≤2000 принимают решение о том, что входная реализация у не распознана.
Данному решению соответствует, например, ситуация, когда цифровой информационный поток у содержит менее 100 информационных блоков (т.е. K<100) или количество одиночных битовых ошибок составляет в нем более 10%.
Благодаря новой совокупности существенных признаков в заявленном способе достигается повышение достоверности распознавания (вероятности правильного распознавания) новых протоколов НСКР за счет более полного описания образа входной реализации, представленного строками ml квадратной матрицы М значений МО и соответствующими ковариационными матрицами Cl, а также определения дивергенции vjl между этим образом и эталонными образами, представленных векторами mj эт и соответствующими эталонными ковариационными матрицами Cj эт..
Заявленный способ поясняется чертежами, на которых показаны:
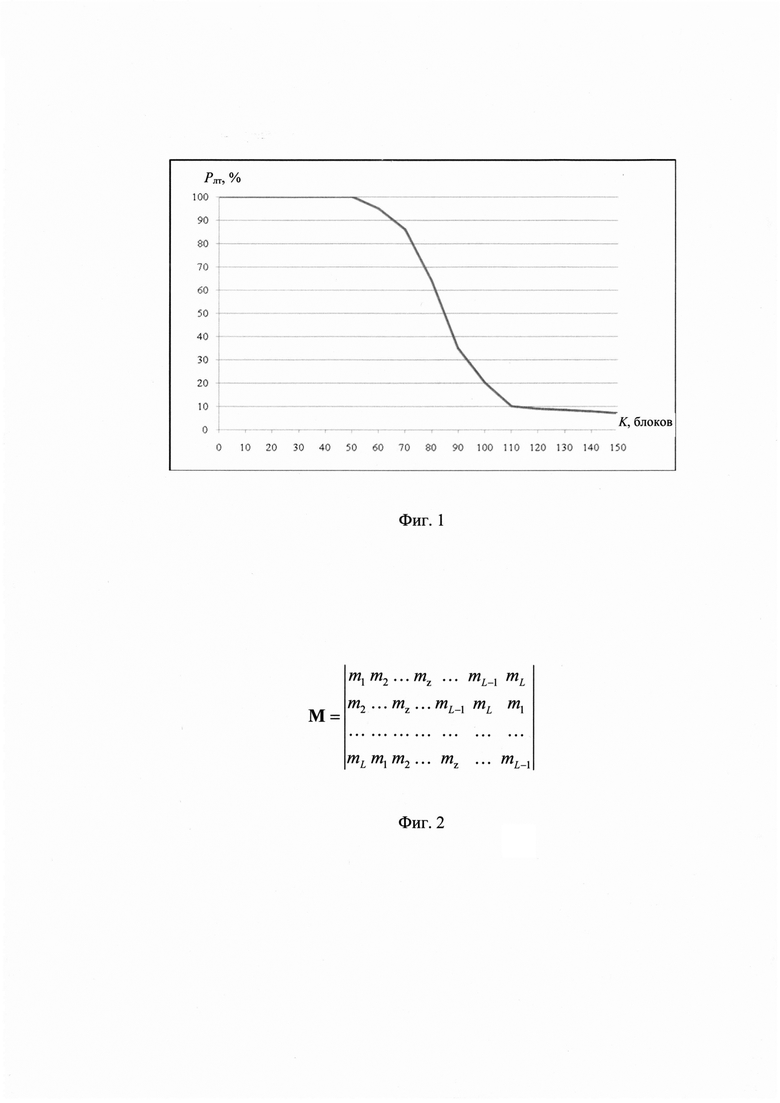
на фиг. 1 - зависимость вероятности ложной тревоги Рлт от количества блоков K, содержащихся в цифровом информационном потоке у, при распознавании протоколов НСКР;
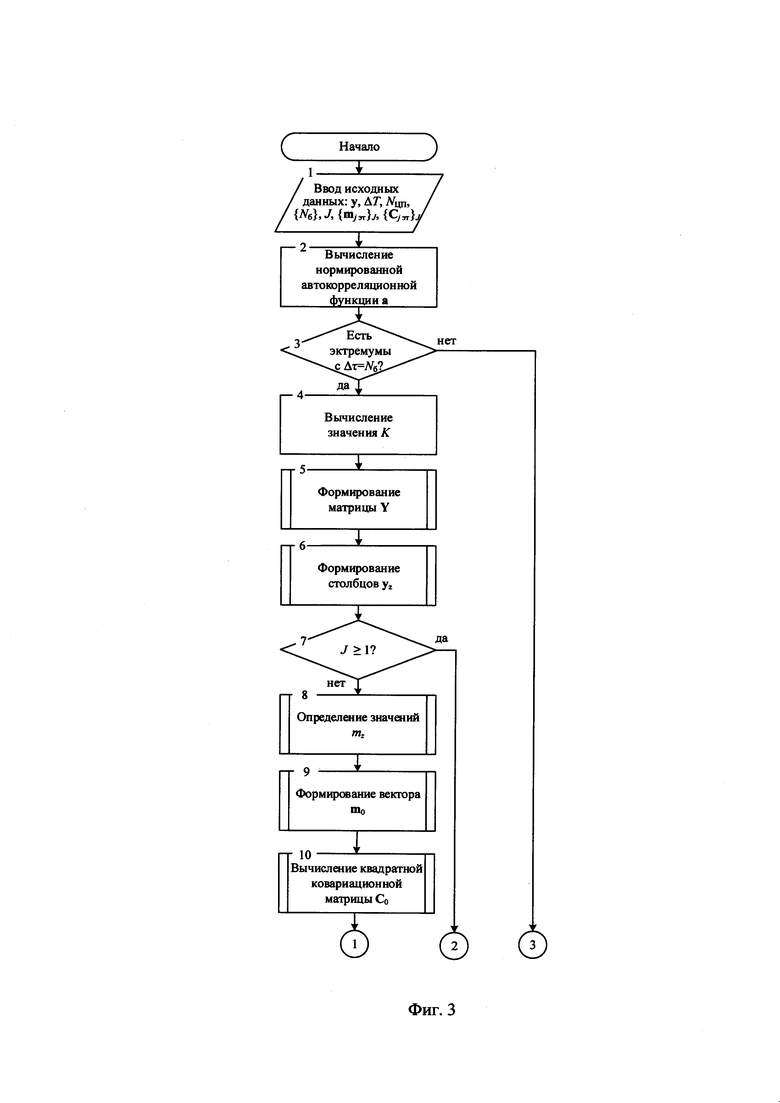
на фиг. 2 - порядок формирования квадратной матрицы значений МО М размеров Z=L;
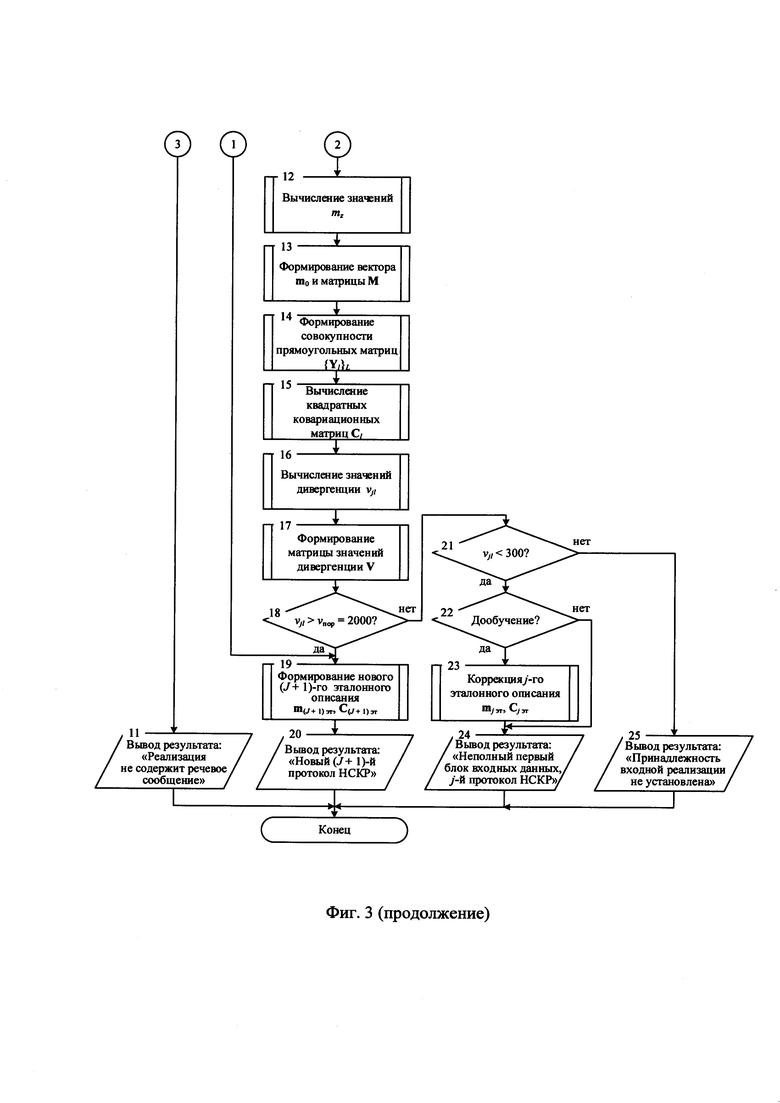
на фиг. 3 - алгоритм распознавания новых протоколов НСКР;
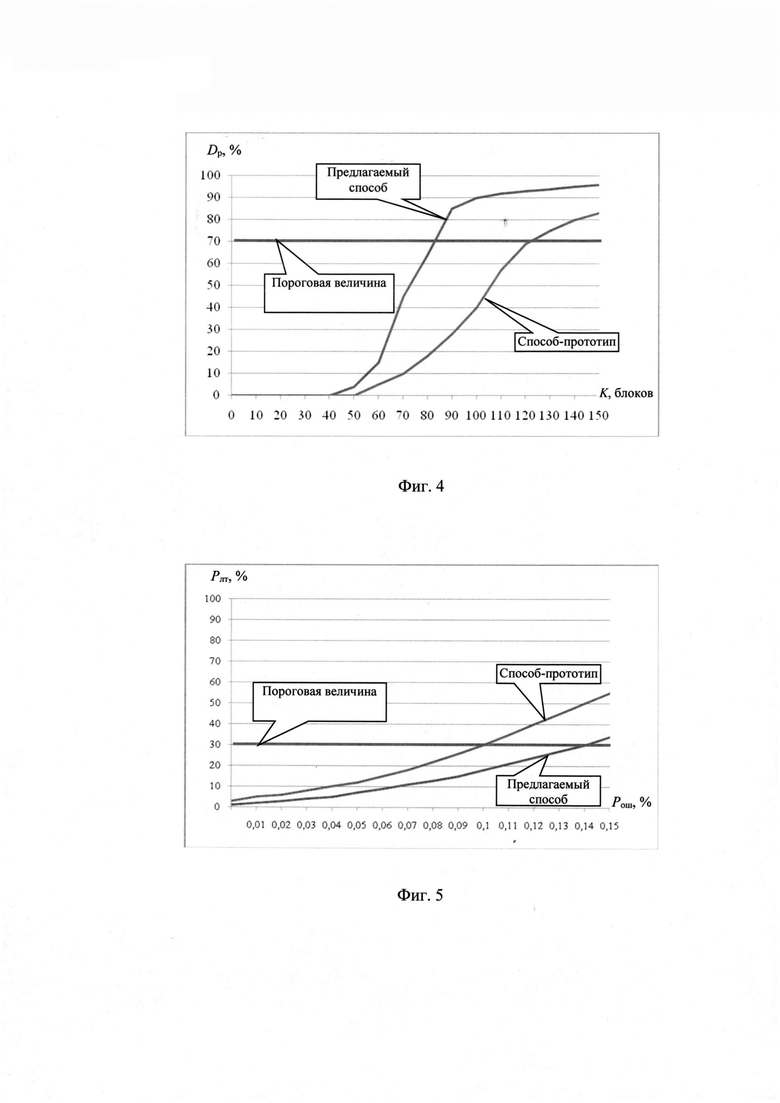
на фиг. 4 - зависимости достоверности Dp принимаемого решения от количества блоков K, содержащихся в цифровом информационном потоке у при распознавании протоколов НСКР;
на фиг. 5 - зависимость вероятности ложной тревоги Рлт от вероятности битовой ошибки Рош в цифровом информационном потоке у, при распознавании протоколов НСКР.
Развитие цифровой телефонной радиосвязи ведется по многим направлениям, одним из которых является разработка аппаратно-программных средств НСКР, называемых вокодерами. Например, для применения на линиях радиосвязи диапазона высоких частот (ВЧ) к настоящему моменту разработаны не менее 20-ти различных типов вокодеров и соответствующих им протоколов НСКР (см. Аладинский В.А, Кузьминский С.В. Анализ цифровых потоков на выходах вокодеров, принимаемых на зарубежных линиях радиосвязи диапазона высоких волн // Успехи современной радиоэлектроники. - М.: Радиотехника, №7, 2015 г. - С. 73-76). Известные протоколы НСКР могут быть открытыми или закрытыми. Информация о закрытых протоколах является конфиденциальной. В технике радиосвязи диапазона ВЧ применяются открытые протоколы LPC-10-2400 (STANAG 4198) и MELPe-2400 (STANAG 4591), опубликованные в соответствующих стандартах НАТО. В тоже время применяется закрытый протокол MELPe-600 (STANAG 4591). Новые (неизвестные, не применявшиеся ранее) протоколы НСКР являются закрытыми.
Появление новых протоколов НСКР на линиях радиосвязи обусловлено стремлением фирм-производителей аппаратуры радиосвязи к повышению занимаемой доли рынка, коммерческой прибыли и защите своих компетенций, с одной стороны, а также к повышению качества связи за счет внедрения новых технических решений, в том числе модификации ранее известных протоколов, с другой стороны. Реализация новых протоколов НСКР в существующих средствах радиосвязи может быть выполнена на программном уровне или подключением внешнего вокодера с помощью имеющихся интерфейсов. Таким образом, применение новых протоколов НСКР при передаче речевых сообщений с помощью средств радиосвязи не является исключительным событием, что определяет необходимость решения этой технической задачи методами распознавания образов.
Использование способа-прототипа распознавания протоколов НСКР в условиях большого количества ошибок (более 10% от общего числа бит) в исследуемых цифровых потоках, полученных при кодировании речевых сообщений с помощью известных протоколов НСКР, вызывает появление результатов вычисления вероятности правильного распознавания в виде неопределенности Pji=0/0 для всех j, l. Аналогичные результаты имеют место и при меньшем количестве битовых ошибок, если К<100. Это свидетельствует о недостаточной помехоустойчивости прототипа при распознавании новых протоколов НСКР и недостаточной информативности используемого набора признаков для описания образа входной реализации при малом объеме исследуемого информационного потока у, представленного только вектором МО m0.
Частным случаем является начало работы системы распознавания (начальный режим), при котором отмечается отсутствие эталонных описаний протоколов НСКР. Возникает необходимость в принятии решения о принадлежности входной реализации у к классу j=1 по результатам анализа параметров автокорреляционной функции а, формировании 1-го эталонного описания и дальнейшему сравнению с полученным эталонным описанием других входных реализаций.
В общем случае (включающем режим обучения) факт применения нового протокола НСКР необходимо установить при отсутствии его эталонного описания и произвести обучение системы распознавания на основе одной полученной реализации бинарного цифрового информационного потока у, что автоматически выполняется при решении в пользу нового протокола НСКР.
Положительный эффект в предлагаемом способе достигается за счет увеличения размерности данных для описания образа входной реализации, представляемых в виде квадратной матрицы М значений МО и соответствующих ковариационных матриц Сl, использованием более информативной меры различения, в качестве которой выступает дивергенция. Последняя позволяет сравнивать образ входной реализации увеличенной размерности с эталонными описаниями, в следствие чего обеспечивается повышение вероятности правильного распознавания новых протоколов НСКР. Кроме того, уменьшение влияния уровня битовых ошибок во входном цифровом информационном потоке у и значений его объема К на качество распознавания новых протоколов НСКР достигается введением дополнительной градации «Принадлежность реализации не установлена» в критерий принятия решения. В результате образы входных реализаций, имеющие по различным причинам существенные искажения, не признаются новыми, что существенно снижает вероятность ложной тревоги при распознавании новых протоколов НСКР.
Реализация заявленного способа может быть осуществлена следующим образом (см. Фиг. 3). На этапе ввода исходных данных целесообразно определить значения параметров ΔT, Nцп цифрового информационного потока у, длительность интервала анализа у и/или емкость анализируемого потока у соответственно, сформировать совокупность {Nб}, включающую все возможные значения этого параметра, в общем случае - ввести эталонные описания J известных протоколов НСКР, включающие совокупности {mj эт}J, {Cj эт}J, в частном случае - установить параметр J=0.
После этого вычисляют нормированную автокорреляционную функцию а, которая характеризует линейную зависимость исходной последовательности у от последовательности у(τ), сдвинутой циркулярно на τ=1, 2, …, Nцп - 1 бит по отношению к у. Нормированная автокорреляционная функция а цифрового потока, содержащего речевое сообщение, имеет явно выраженные локальные максимумы, расположенные с периодичностью Δτ. Наличие локальных максимумов автокорреляционной функции, расположенных с периодом Δτ, объясняется тем, что информационные символы, описывающие параметры цифрового потока с речевым сообщением, расположены внутри информационного блока строго в определенных местах, на интервалах Δτ, кратных длине информационного блока. Параметры речевого сигнала обладают значительной линейной зависимостью, поэтому значение АКФ в этих точках будет наибольшим. Искомой автокорреляционной функцией считают совокупность значений вида
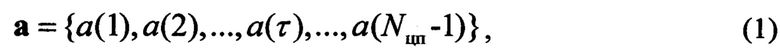
где а(τ)=c(τ)/d(y) - коэффициент корреляции; с(τ) - коэффициент ковариации; d(y) - дисперсия цифрового информационного потока у.
По регулярным с равными интервалами Δτ=Nб экстремумам нормированной автокорреляционной функции а принимают решение о наличии блочной структуры в информационном потоке у. Отсутствие экстремумов нормированной автокорреляционной функции а с равными интервалами Δτ свидетельствует о том, что цифровой информационный поток у не содержит речевое сообщение, а выполнение его анализа завершается выводом результата о том, что входная реализация у не содержит речевое сообщение, а выполнение его анализа завершается выводом результата о том, что входная реализация у не содержит речевое сообщение.
При наличии экстремумов нормированной автокорреляционной функции а с равными интервалами Δτ вычисляют количество информационных блоков, содержащихся в цифровом информационном потоке у следующим образом:

где 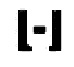 - оператор округления величины до меньшего целого значения.
- оператор округления величины до меньшего целого значения.
Делят информационный поток у на информационные блоки объемом Nб бит каждый. Последовательно присваивают информационным блокам порядковые номера k=1, 2, …, K, начиная с первого информационного блока. Формируют прямоугольную информационную матрицу Y, строками которой являются последовательно размещенные друг под другом информационные блоки в соответствии с их порядковыми номерами k=1, 2, …, K.
Из информационной матрицы Y выделяют столбцы yz. Проверяют условие J≥1 (т.е. наличие хотя бы одного эталонного описания), устанавливающее возможность введения режима обучения.
Если условие J≥1 не выполняется (это частный случай - начальный режим), то с помощью известных выражений (см. Аладинский В.А., Кузьминский С.В. Метод формирования признаков распознавания протоколов низкоскоростного кодирования речи / Наукоемкие технологии. - М.: Радиотехника. №12, 2015. - С. 20-25) определяют значения МО mz по столбцам yz. Из набора значений МО формируют вектор значений математического ожидания вида m0=(m1, m2, …, mz, …, mL) размера L. На основе прямоугольной информационной матрицы Y вычисляют квадратную ковариационную матрицу С0 (см. там же). Далее формируют эталонное описание, которому присваивают порядковый номер j=1, и в этом случае m0=m1 эт, С0=C1 эт.
При выполнении условия J≥1 также определяют значения МО mz, формируют вектор значений математического ожидания вида m0, квадратную матрицу М=(m0, m1, …, ml, …, mL-1) размеров L, содержащую строки ml, получаемые на основе циркулярного сдвига элементов вектора m0 (см. фиг. 2). Формируют совокупность прямоугольных матриц {Yl}L={Y0, Y1, …, Yl, …, YL-1}, у которых столбцы сдвинуты циркулярно на l=0, 1, 2, …, L-1 относительно столбцов прямоугольной информационной матрицы Y. По каждой матрице Yl из совокупности {Yl}z, вычисляют квадратные ковариационные матрицы Cl.
Определяют значения дивергенции vjl между образом входной реализации, представляемым соответствующими векторами ml и квадратными ковариационными матрицами Cl, и j-м эталонным описанием. Последний представляется вектором mj эт и соответствующей эталонной ковариационной матрицей Cj эт. В общем случае выявление нового протокола предполагает выполнение условий ml≠mj и Cl≠Cj, то дивергенция, характеризующая разделяющую поверхность образа и эталонного описания, вычисляется по формуле вида (см. Ту Дж., Гонсалес Р. Принципы распознавания образов / Пер. с англ. - М.: Мир, 1978. - 411 с.)

где 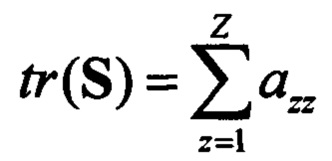 - след матрицы S размеров Z;
- след матрицы S размеров Z; 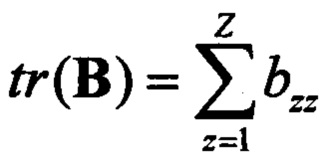 - след матрицы В размеров Z; azz, bzz - элементы диагоналей матриц S и В соответственно;
- след матрицы В размеров Z; azz, bzz - элементы диагоналей матриц S и В соответственно;
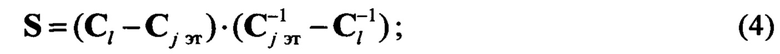
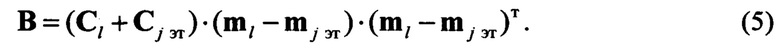
Из полученного набора значений vjl для удобства дальнейшего анализа формируют матрицу значений дивергенции V размеров J×L. Сравнивают значение каждого элемента vjl матрицы V с пороговым значением vпор=2000.
Если для всех элементов vjl матрицы V выполняется условие vjl>vпор, то принимают решение об обнаружении нового протокола НСКР и присваивают условный номер J-J+1 новому эталонному описанию, которое включает вектор математического ожидания m(j+1)эт=m0 и квадратную эталонную ковариационную матрицу С(J+1)эт=С0. Выводят сообщение «Новый J+1 протокол НСКР». При невыполнении данного условия и если выполняется условие vjl<300 только для одного элемента матрицы V, а остальные vjl>vпор=2000, то принимают решение, что входная реализация у сформирована по j-му известному протоколу НСКР и в информационном потоке у отсутствуют начальные l бит в первом k=1 информационном блоке. При необходимости проводят дообучение системы распознавания, осуществляют коррекцию j-го эталонного описания mj эт, Cj эт. Выводят сообщение «Неполный первый блок входных данных, j-й протокол НСКР».
В других случаях, когда справедливо 300≤vjl≤2000 для всех элементов матрицы V, считают, что входная реализация у не может быть отнесена к какому-либо j-му известному протоколу НСКР или новому протоколу НСКР, выводят сообщение «Принадлежность входной реализации не установлена».
Имитационное моделирование заявленного способа распознавания протоколов НСКР выполнено с использованием цифровых информационных потоков, сформированных на основе известных протоколов LPC-10-2400 (STANAG 4197), условный класс j=1, MELPe-2400 (STANAG 4591), j=2, применяемых на линиях радиосвязи диапазона высоких частот, и цифровых информационных потоков, сформированных программным способом вокодером вида MELP-240Q по протоколу НСКР с номером класса j=3, который рассматривается как новый, показало следующее. Принятое пороговое значение Dp=70% достигается на основе предлагаемого способа при значениях K=82, в то время как способ-прототип обеспечивает удовлетворение этого требования при K=124. Достоверность Dp распознавания предлагаемым способом при значениях K≥82 выше, чем при использовании прототипа на величину от (11 до 55)%, что подтверждает эффективность предлагаемых технических решений в условиях малого объема исследуемых цифровых информационных потоков.
Сравнение помехозащищенности предлагаемого способа и способа-прототипа также выполнено на основе имитационного моделирования при K≥100, битовые ошибки в цифровые информационные потоки вносились по случайному закону с равномерной вероятностью появления ошибки, что соответствует современным условиям формирования дискретных сигналов передачи речевых сообщений, когда используется помехоустойчивое кодирование, перемежение и скремблирование цифровых информационных потоков до передачи сигнала в канал радиосвязи. Принятое максимальное значение вероятности Рош_мах=15% соответствует значению, при котором еще возможно восстановление речевого сигнала. В результате установлено, что разработанный способ распознавания новых протоколов НСКР обеспечивает меньшую вероятность ложной тревоги Рош при равном значении вероятности битовой ошибки Рош в цифровом информационном потоке у (см. Фиг. 5) на величину от (2 до 25) %, чем при использовании способа-прототипа, условие Рлт≤30%, являющееся граничным, для прототипа выполняется при Рош≤10%, в то же время для предлагаемого способа - при Рош≤14%, что свидетельствует о его лучшей помехозащищенности по сравнению с прототипом.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ автоматической оценки качества речевых сигналов с низкоскоростным кодированием | 2021 |
|
RU2757860C1 |
| Способ распознавания протоколов низкоскоростного кодирования речи | 2017 |
|
RU2667462C1 |
| Способ распознавания протоколов низкоскоростного кодирования | 2016 |
|
RU2610285C1 |
| Способ селекции цифровых потоков | 2018 |
|
RU2701465C1 |
| СПОСОБ РАСПОЗНАВАНИЯ РАДИОСИГНАЛОВ | 2011 |
|
RU2466455C1 |
| СПОСОБ РАСПОЗНАВАНИЯ РАДИОСИГНАЛОВ | 2010 |
|
RU2430417C1 |
| Способ определения координат объектов и их распознавания | 2022 |
|
RU2787946C1 |
| СПОСОБ РАСПОЗНАВАНИЯ РАДИОСИГНАЛОВ | 2010 |
|
RU2423735C1 |
| СПОСОБ И УСТРОЙСТВО ОПРЕДЕЛЕНИЯ КООРДИНАТ ОБЪЕКТОВ | 2014 |
|
RU2550811C1 |
| СПОСОБ РАСПОЗНАВАНИЯ РАДИОСИГНАЛОВ | 2007 |
|
RU2356064C2 |
Изобретение относится к области информационных технологий, а именно к области цифровой связи. Технический результат заключается в снижении вероятности ложной тревоги и, как следствие, повышении достоверности распознавания (вероятности правильного распознавания) новых протоколов (НСКР). Предлагается способ распознавания (НСКР), реализуемых в вокодерах, принимают бинарный цифровой информационный поток у в течение интервала времени ΔT, формируют на основе у нормированную автокорреляционную функцию а, принимают решение о наличии блочной структуры в цифровом информационном потоке, используемых при описании образа входной реализации: в виде квадратной матрицы М значений математического ожидания и соответствующих ковариационных матриц С. На основе значений vjl формируют вектор дивергенции vj для каждого j-го эталонного образа. Из J векторов vj формируют матрицу значений дивергенции V размерности J×L, L - количество бит между экстремумами автокорреляционной функции. Принимают решение об обнаружении нового ранее неизвестного протокола НСКР и присваивают номер J+1 новому эталонному описанию. 5 ил.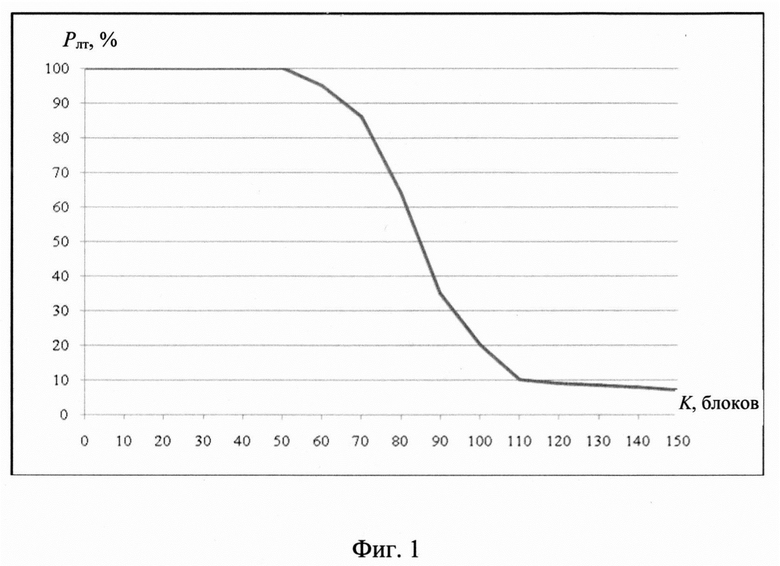
Способ распознавания новых протоколов низкоскоростного кодирования речи (НСКР), реализуемых в вокодерах, заключающийся в том, что принимают бинарный цифровой информационный поток у в течение интервала времени ΔT, формируют на основе у нормированную автокорреляционную функцию а, принимают решение о наличии блочной структуры в цифровом информационном потоке у по регулярным с равными интервалами Δτ экстремумам автокорреляционной функции а, делят цифровой информационный поток у на информационные блоки объемом Nб бит каждый по интервалам между экстремумами автокорреляционной функции а, последовательно присваивают информационным блокам порядковые номера k=1, 2, …, K, начиная с первого информационного блока, формируют прямоугольную информационную матрицу Y размером K×L, L=Nб, строками которой являются последовательно размещенные друг под другом информационные блоки в соответствии с их порядковыми номерами k=1, 2, …, K, выделяют из матрицы Y столбцы yz, z=1, 2, …, L; определяют по каждому столбцу yz значение его математического ожидания mz, формируют вектор значений математического ожидания m0=(m1, m2, …, mz, …, mL) размера L, на основе полученного вектора m0 формируют квадратную матрицу М значений математического ожидания размера L×L, строки ml, l=0, 1, 2, …, L-1, которой содержат значения вектора m0, последовательно циркулярно сдвинутые влево на величину l, по имеющимся обучающим выборкам {yj эт}J (j=1, 2, …, J), соответствующим J известным протоколам НСКР, формируют прямоугольные эталонные информационные матрицы {Yj эт}J, на основе которых вычисляют векторы эталонных значений математического ожидания mj эт, j=1, 2, …, J, и квадратные эталонные ковариационные матрицы {Cj эт}J, вычисляют значения вероятности правильного распознавания Pjl j-го протокола НСКР, j=1, 2, …, J, по каждой l-й строке ml матрицы М принимают решение в пользу j-го протокола НСКР, для которого обеспечивается максимальное значение Pjl, отличающийся тем, что для значения вероятности правильного распознавания Pjl=0/0 для всех j, l формируют совокупность прямоугольных матриц {Yl}L, столбцы которых сдвинуты циркулярно на l=0, 1, 2, …, L-1 относительно столбцов прямоугольной информационной матрицы Y, для каждой матрицы Yl вычисляют ее квадратную ковариационную матрицу Cl, определяют значения дивергенции vjl между образами входной реализации, представленными строками ml квадратной матрицы М значений математического ожидания и соответствующими ковариационными матрицами Cl, и каждым j-м эталонным образом, представленным вектором mj эт и соответствующей квадратной эталонной ковариационной матрицей Cj эт, на основе полученных значений vjl формируют вектор дивергенции vj=(vj0, vj1, …, vjl…, vj(L-1)) для каждого j-го эталонного образа, составляют из J векторов vj матрицу значений дивергенции V размером J×L, принимают решение об обнаружении нового ранее неизвестного протокола НСКР и присваивают условный номер J=J+1 новому эталонному описанию, которое включает вектор математического ожидания m(J+1)эт=m0 и квадратную эталонную ковариационную матрицу C(J+1)эт=С0, если для всех элементов vjl матрицы значений дивергенции V выполняется условие vjl>vпор=2000 при любых j, l, где vпор - пороговая величина, или только для одного элемента vjl<300, а остальные vjl>vпор, принимают решение, что входная реализация у сформирована по j-му известному протоколу НСКР и в информационном потоке у отсутствуют начальные l бит в первом k=1 информационном блоке, а в случае 300≤vjl≤2000 принимают решение о том, что входная реализация у не распознана.
| Способ распознавания протоколов низкоскоростного кодирования | 2016 |
|
RU2610285C1 |
| Способ распознавания протоколов низкоскоростного кодирования речи | 2017 |
|
RU2667462C1 |
| US 20040138888 A1, 15.07.2004 | |||
| US 8588073 B2, 19.11.2013 | |||
| US 20060262876 A1, 23.11.2006. | |||

