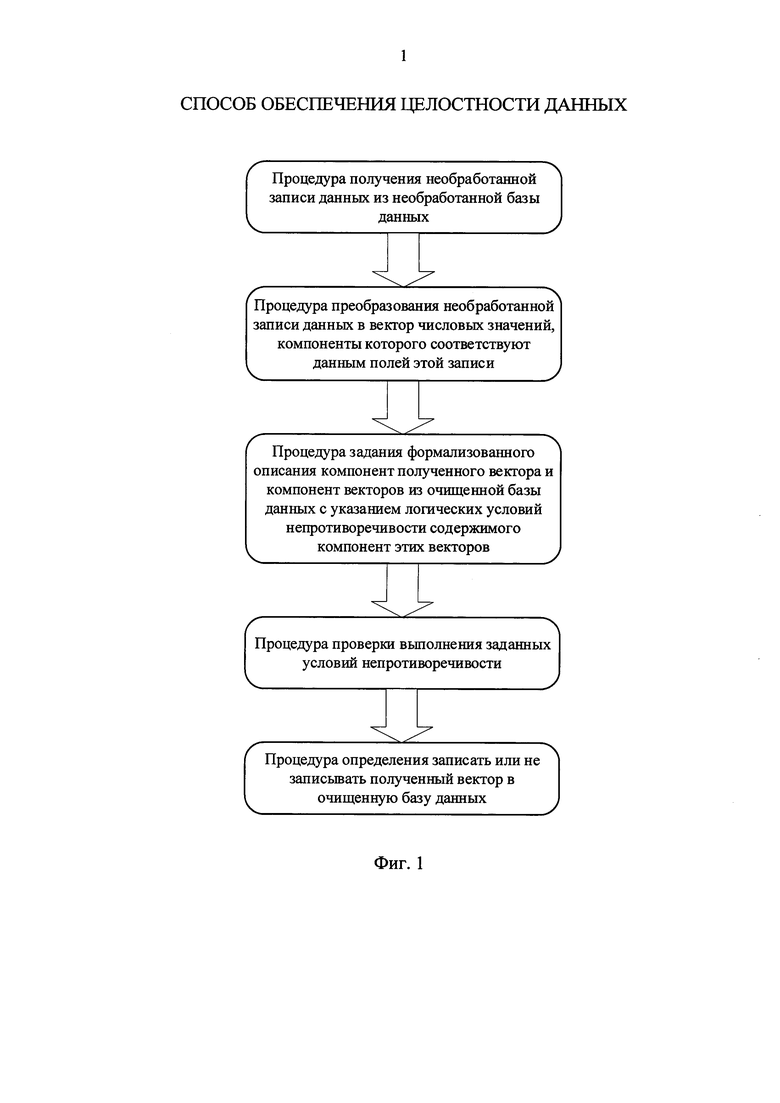
Изобретение относится к области информационных технологий, а именно к способам организации и/или нахождения данных в системах баз данных и может быть использовано в системах обработки данных.
Как отмечено в описании способа и системы организации данных (см. патент РФ №2268488, МПК G06F 17/30 опубл. 20.01.2006), в общем случае системы баз данных предназначены для организации, хранения и поиска данных таким образом, чтобы данные в базе данных были бы полезными. Например, данные или распределенные наборы данных могут быть найдены, отсортированы, организованы и/или объединены с другими данными. В большой степени полезность определенной системы баз данных зависит от целостности (т.е. точности и/или правильности) данных в системе баз данных. На целостность данных воздействует степень "беспорядка" в сохраненных данных. Беспорядок может появиться в форме ошибочных или неполных данных, таких как дублированные данные, фрагментированные данные, ложные данные и т.д. Во многих системах баз данных время от времени существующие данные могут редактироваться и обрабатываться, и в результате могут вноситься дополнительные ошибки. В некоторых системах баз данных могут вводиться новые данные. Дополнительно, поскольку системы баз данных модернизируются с помощью нового оборудования и/или программного обеспечения, может потребоваться преобразование данных, или могут стать необходимыми дополнительные поля. Кроме того, в некоторых прикладных задачах данные в базе данных могут просто устареть через какое-то время.
Целостность базы данных по ГОСТ 20886-85 - свойство базы данных, определяемое способностью системы управления базой данных защищать компоненты и связи базы данных от искажения в результате некорректных операций и сбоев технических средств. В соответствии с ГОСТ Р ИСО/МЭК 17799-2005, под целостностью понимается обеспечение достоверности и полноты информации и методов ее обработки. Следует добавить, что данные не могут быть достоверны, если они противоречивы.
Целостность БД - свойство базы данных, означающее, что в ней содержится полная, непротиворечивая и адекватно отражающая предметную область информация. Поддержание целостности БД включает проверку целостности и ее восстановление в случае обнаружения противоречий в базе данных. Целостное состояние БД описывается с помощью ограничений целостности в виде условий, которым должны удовлетворять хранимые в базе данные. (См. Беленченко В.М. Базы данных: конспект лекций - Шахты:ЮРГТУ, 2010. - 74 с.).
Следует добавить, в литературе, описывающей реляционные базы данных, отмечается, что "использование ненормализованных таблиц может привести к нарушению целостности данных (противоречивости информации)" (см. Юзбачков Ю.С., Петров В.Н., Васильев А.А., Телина И.С. Информационные системы: Учебник для вузов. 3-е изд. - СПб.: Питер, 2011. - 544 с.).
В данном пояснении к способу принято, что "данные" относятся к физическому цифровому представлению информации, а "содержимое" данных относится к значению (семантике) информации, включенной в эти данные или представленное этими данными (см. патент РФ №2268488, МПК G06F 17/30 опубл. 20.01.2006). Процедура задания формализованного описания позволяет в дальнейшем обрабатывать данные с учетом их содержимого или значения.
Существуют различные способы обеспечения целостности данных, которые несомненно увеличивают защищенность данных в случаях сбоя работы информационной системы, а также в случае намеренных противоправных действий злоумышленников. Известен способ обеспечения целостности набора записей данных (см. патент РФ №2351978, МПК G06F 11/08 опубл. 10.04.2009), заключающийся в том, что создают доступные общему просмотру базы данных с публично доступными контрольными суммами, которые могут использоваться для верификации целостности данных. Согласно изобретению контрольную сумму проверки целостности вычисляют криптографическим способом по хранимым данным, контрольной сумме предыдущей записи и ключу хранения. Ключ хранения известен только лицам, которые имеют право подписывать данные в базе данных. Лицо, имеющее право подписи, может и должно отличаться от администратора базы данных. Одно из решений состоит в том, что используют криптографию с открытым ключом, в которой подписывающее лицо вычисляет контрольную сумму проверки целостности с помощью своего секретного ключа, а лицо, желающее проверить целостность, может использовать свой открытый ключ для верификации. Вычисленная контрольная сумма присоединяется к записи данных. Первая запись может быть генерируемой начальной записью, либо может использовать предварительно согласованную предыдущую контрольную сумму, которая необходима, чтобы вычислить ее собственную контрольную сумму. При верификации контрольную сумму проверки целостности вычисляют аналогично и сравнивают с предварительно вычисленной контрольной суммой, присоединенной к определенной записи данных. Преимущество изобретения состоит в получении аутентичной базы данных с проверкой целостности. С помощью способа согласно изобретению база данных может быть подписана так, что содержимое базы данных могут изменять только уполномоченные лица, имеющие право подписи. Согласно изобретению записи данных, хранящиеся в базе данных, не могут быть удалены или изменены любым способом без нарушения цепочки вычисленных контрольных сумм проверки целостности.
Недостатком рассмотренного способа является отсутствие контроля целостности данных, вносимых пользователями, имеющими право подписи, в результате чего в информационную систему могут быть внесены данные, целостность которых была изначально нарушена.
Наиболее близким к изобретению аналогом (прототипом) является способ организации данных (см. патент РФ №2268488, МПК G06F 17/30 опубл. 20.01.2006), заключающийся в том, что преобразуют, по меньшей мере, одно из необработанных полей данных в необработанной записи данных в числовое значение, причем числовое значение генерируют путем представления каждого из множества элементов данных в необработанном поле данных как цифру в системе счисления, причем систему счисления выбирают на основе диапазона возможных значений для любого из множества элементов данных в поле данных, формируют вектор, включающий в себя, по меньшей мере, упомянутое числовое значение, причем указанный вектор является представлением упомянутой необработанной записи данных, и определяют, записать или не записывать упомянутое векторное представление необработанной записи данных в очищенную базу данных, путем сравнения упомянутого вектора с, по меньшей мере, одним другим вектором из очищенной базы данных.
Недостатком данного способа является то что он не позволяет обнаруживать противоречия в содержимом (семантике) данных, поэтому в очищенную базу данных могут быть внесены данные, противоречащие сами себе или содержащимся в ней данным, в результате чего целостность данных в очищенной базе данных будет нарушена.
Задачей изобретения является создание способа позволяющего повысить целостность данных, хранимых в системах баз данных. Повышение целостности (правильности, точности) обеспечивается выявлением и исключением искаженных или ошибочных данных, противоречащих самим себе или ранее внесенным данным.
Эта задача решается тем, что способ обеспечения целостности данных, заключающийся в том, что данные из необработанных полей данных в необработанной записи данных преобразуют в вектор из числовых значений в некоторой системе счисления, новый вектор сравнивают с одним или несколькими векторами из очищенной базы данных и определяют, записать или не записывать сформированный вектор в очищенную базу данных путем его сравнения с одним или несколькими векторами из очищенной базы данных, отличающийся тем, что дополнительно до процедуры сравнения векторов задают формализованное описание компонент сформированного вектора и компонент векторов из очищенной базы данных, при этом в формализованном описании указывают логические условия непротиворечивости, определяющие корректность содержимого компонент этих векторов, после чего проверяют выполнимость указанных логических условий, при выполнимости указанных логических условий сравнивают упомянутый вектор с остальными векторами из очищенной базы данных и при несовпадении дописывают упомянутое векторное представление необработанной записи данных в очищенную базу данных.
Перечисленная новая совокупность существенных признаков позволяет повысить целостность данных, хранимых в системах баз данных, за счет выявления и исключения ошибочных (искаженных, неточных) данных, а также данных, противоречащих самим себе или ранее внесенным данным.
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного технического решения, отсутствуют, что указывает на соответствие изобретения условию патентоспособности "новизна".
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного объекта, показали, что они не следуют явным образом из уровня техники. Из уровня техники также не выявлена известность влияния предусматриваемых существенными признаками заявленного изобретения преобразований на решение указанной задачи. Следовательно, заявленное изобретение соответствует условию патентоспособности "изобретательский уровень".
"Промышленная применимость" способа обусловлена наличием элементной базы, на основе которой могут быть выполнены устройства, реализующие данный способ с достижением указанного в изобретении назначения.
Заявляемый способ поясняется чертежами, на которых показаны:
фиг. 1 - последовательность процедур предложенного способа обеспечения целостности данных;
фиг. 2 - блок-схема алгоритма предложенного способа обеспечения целостности данных;
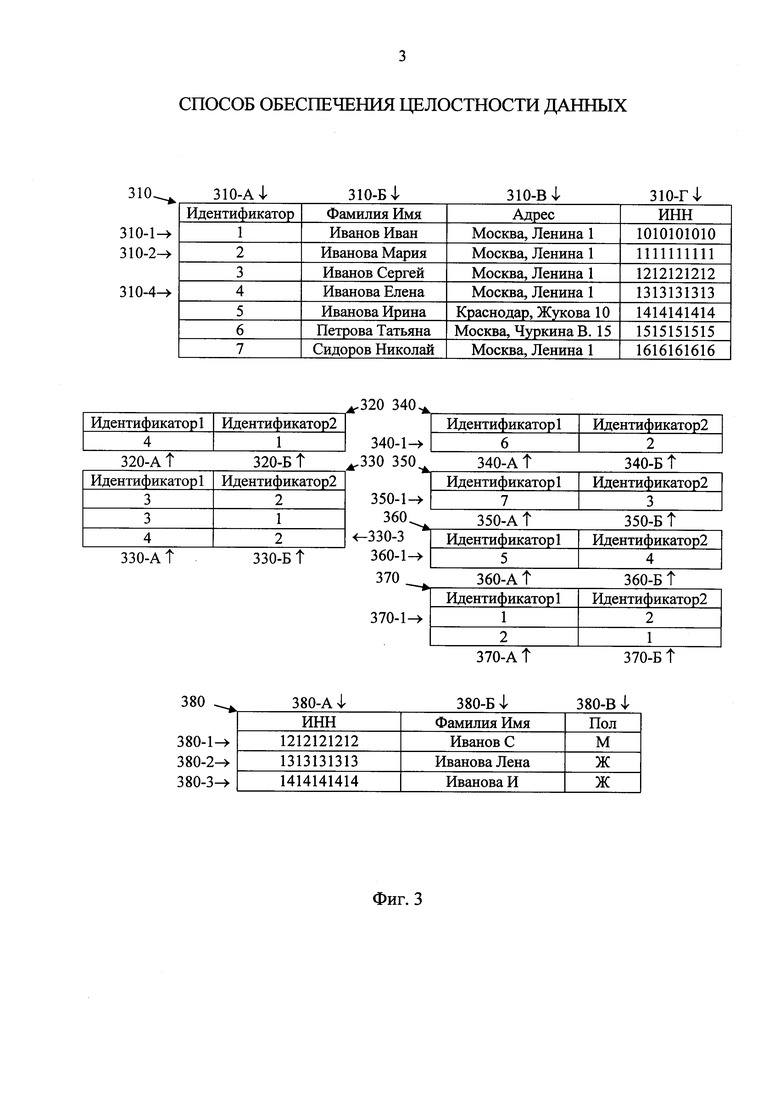
фиг. 3 - пример необработанных данных;
фиг. 4 - пример очищенной базы данных;
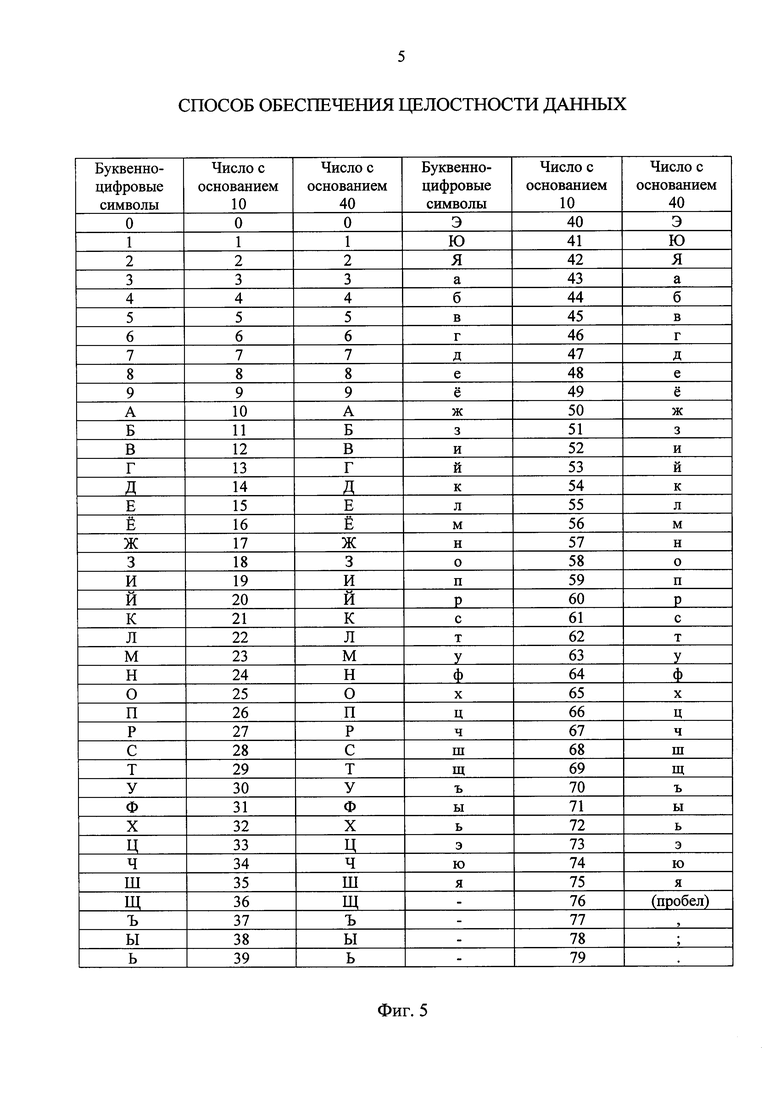
фиг. 5 - используемая в качестве примера система счисления с основанием 80;
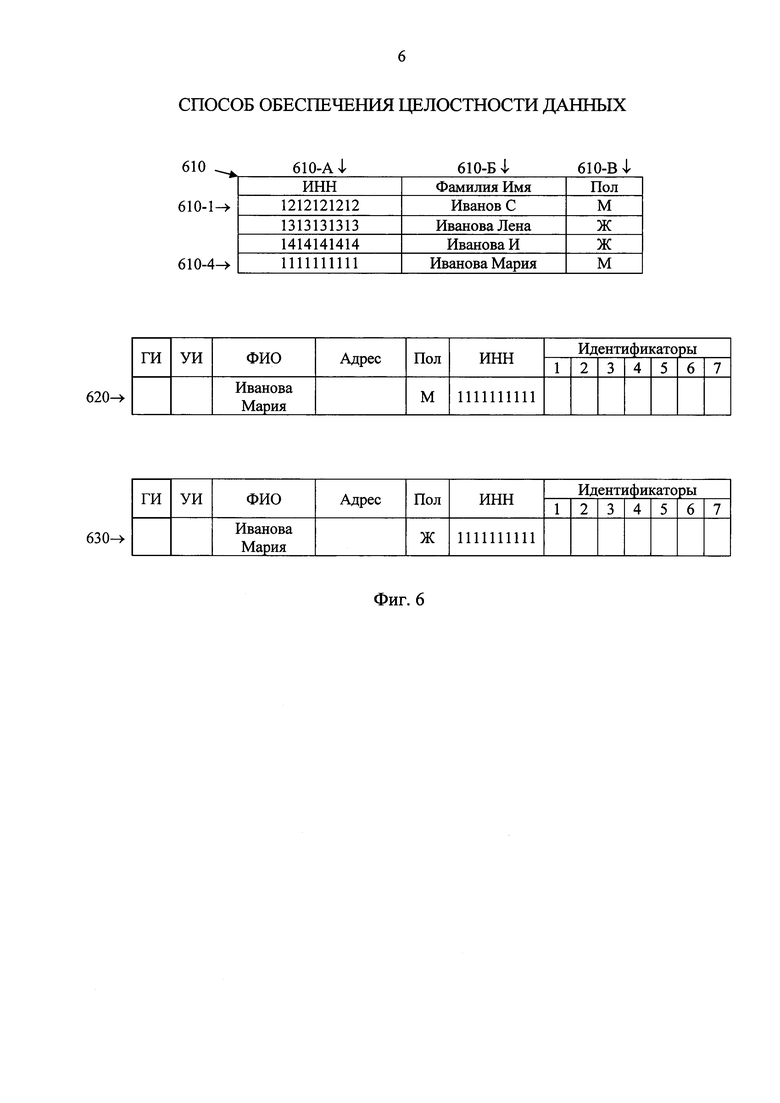
фиг. 6 - пример необработанных записей данных и векторов;
фиг. 7 - иерархия классов онтологии родственных отношений;
фиг. 8 - иерархия объектных отношений онтологии родственных отношений;
фиг. 9 - пример формализованного представления содержимого компонент векторов из очищенной базы данных в виде графа с использованием онтологии родственных отношений;
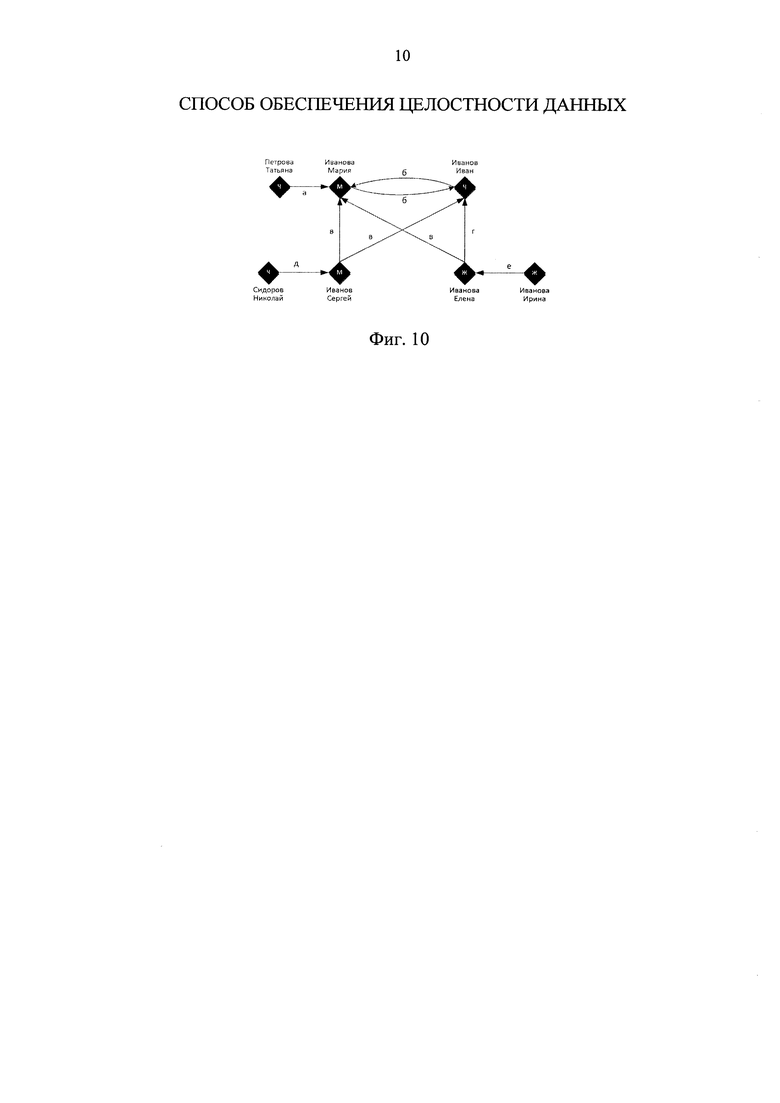
фиг. 10 - пример формализованного представления содержимого компонент преобразованной в вектор очередной необработанной записи данных и компонент векторов из очищенной базы данных в виде графа с использованием онтологии родственных отношений.
Последовательность процедур способа обеспечения целостности данных в системах баз данных, дополняющего известные способы, представлены на фигуре 1. Блок-схема алгоритма, соответствующая предложенному способу, представлена на фигуре 2.
Считается, что "необработанные данные" относятся к данным в том виде, в каком они принимаются из конкретного источника. Примеры необработанных данных представлены на фигуре 3. Таблицы 310-370 относятся к одной необработанной базе данных, а таблица 380 - к некоторой другой. При этом, необработанные записи таблиц 320-370 отражают следующие связи между необработанными записями в таблице 310: "иметь биологического отца", "иметь биологического родителя", "быть родной сестрой", "быть одноутробным братом", "иметь однородную сестру", "состоять в действующем браке с" соответственно. В частности, необработанная запись данных 330-3 в необработанной таблице данных 330 указывает на то, что объект, описываемый необработанной записью 310-4 ("Иванова Елена"), связан с объектом, описываемым необработанной записью 310-2 ("Иванова Мария"), отношением "иметь биологического родителя".
На фигуре 4 представлен пример очищенной базы данных (410), полученной из необработанных записей таблиц 310-380 с помощью процесса, называемого "диализом" данных (см. патент РФ №2268488, МПК G06F 17/30 опубл. 20.01.2006), и системы счисления с основанием 80, представленной на фигуре 5, выбранной таким образом, чтобы сохранить семантическое содержание преобразованных данных и обеспечить удобство их восприятия человеком. Очищенная база данных - это база данных, которая включает в себя уникальную информацию, найденную в необработанных данных (см. патент РФ №2268488, МПК G06F 17/30 опубл. 20.01.2006).
Очищенная база данных 410 содержит следующие поле: "ГИ" (410-А) - групповой идентификатор, который объединяет вектора, отнесенные к одной и той же группе связанных векторов; "УИ" (410-Б) - уникальный идентификатор, он однозначно определяет конкретный вектор в очищенной базе; "ФИО" (410-В) - представленное в выбранной системе счисления числовое значение, соответствующее полям 310-Б и 380-Б необработанных таблиц данных; "Адрес" (410-Г) - представленное в выбранной системе счисления числовое значение, соответствующее полю 310-В; "Пол" (410-Д) - представленное в выбранной системе счисления числовое значение, соответствующее полю 380-В; "ИНН" (410-Е) - представленное в выбранной системе счисления числовое значение, соответствующее полям необработанных таблиц 310-Г и 380-А; "Идентификаторы" (410-Ж) - представленное в выбранной системе счисления числовые значения, соответствующее полям необработанных таблиц - поле 410-Ж-1 соответствует полям 310-А-370-А, поле 410-Ж-2 соответствует полю 320-Б, поле 410-Ж-3 соответствует полю 330-Б, поле 410-Ж-4 соответствует полю 340-Б, поле 410-Ж-5 соответствует полю 350-Б, поле 410-Ж-6 соответствует полю 360-Б, поле 410-Ж-7 соответствует полю 370-Б. Например, вектору 410-1 в очищенной базе данных соответствует необработанная запись 310-1, а вектору 410-2 в очищенной базе - необработанная запись 370-1.
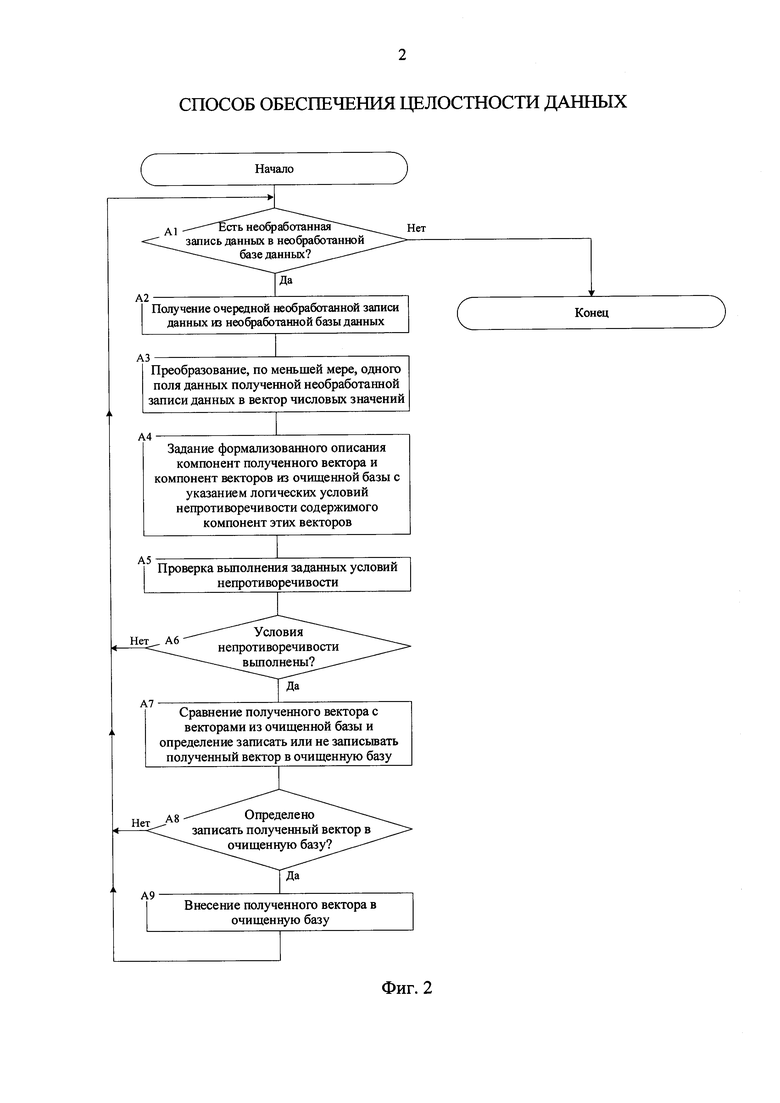
Как было отмечено выше, блок-схема алгоритма, реализующего предложенный способ, представлена на фигуре 2. Согласно этой схемы алгоритм включает в себя следующие шаги:
А1) На данном шаге проверяется, есть ли еще, по меньше мере, одна необработанная запись данных в, по меньшей мере, одной необработанной базе данных. Если да, то осуществляется переход к шагу А2, иначе алгоритм завершает свою работу.
А2) Из, по меньшей мере, одной необработанной базы данных извлекается, по меньшей мере, одна необработанная запись данных.
Например, этой записью может быть запись 610-4, представленная на фигуре 6 таблицы 610.
A3) Преобразование, по меньшей мере, одного поля необработанной записи данных в вектор числовых значений, компоненты которого соответствуют преобразованным полям данных этой записи (см. патент РФ №2268488, МПК G06F 17/30 опубл. 20.01.2006). В одном из вариантов осуществления, все поля необработанной записи 610-4 преобразуются с использованием системы счисления с основанием 80 (см. фигуру 5) в (новый) вектор 620 (для наглядности над вектором обозначены соответствующие поля очищенной базы данных).
А4) Задание формализованного описания компонент полученного (нового) вектора и компонент векторов из очищенной базы с указанием логических условий непротиворечивости содержимого компонент этих векторов. Как было отмечено ранее, задание формализованного описания позволяет в дальнейшем обрабатывать данные с учетом их содержимого или значения. Формализованное описание может быть задано с помощью логических формализмов - языков представления знаний.
В предпочтительном варианте осуществления формализованное описание может быть задано с помощью существующей или разработанной для этой цели онтологии, описанной с помощью базового языка представления знаний ALC, синтаксис которого включает:
- язык описания ALC-концептов (классов):
 имена концептов А0,А1, …;
имена концептов А0,А1, …;
 имена ролей r0, r1, …;
имена ролей r0, r1, …;
 концепт
концепт  (часто называют "вещь");
(часто называют "вещь");
 концепт
концепт 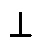 (пустой класс);
(пустой класс);
 логическая связка П (пересечение, конъюнкция, "и");
логическая связка П (пересечение, конъюнкция, "и");
 квантор
квантор  (существование);
(существование);
 квантор
квантор  (часто называют ограничение значения);
(часто называют ограничение значения);
 логическая связка
логическая связка 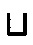 (объединение, дизъюнкция, "или");
(объединение, дизъюнкция, "или");
 логическая связка
логическая связка 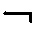 (дополнение, отрицание);
(дополнение, отрицание);
- ALC-концепты, определяемые индуктивно:
 все имена концептов,
все имена концептов, 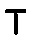 и
и  являются ALC-концептами;
являются ALC-концептами;
 если С является ALC-концептом, то и
если С является ALC-концептом, то и 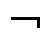 С является ALC-концептом;
С является ALC-концептом;
 если С и D являются ALC-концептами, а r - имя роли, то (С
если С и D являются ALC-концептами, а r - имя роли, то (С 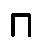 D), (С
D), (С 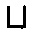 D),
D), 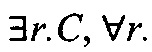 С являются ALC-концептами;
С являются ALC-концептами;
- ALC импликация концептов: С  D, где С и D являются ALC-концептами (ALC-TBox есть конечное множество импликаций ALC-концептов);
D, где С и D являются ALC-концептами (ALC-TBox есть конечное множество импликаций ALC-концептов);
- ALC отношения (аксиомы, определяющие ALC-ABox):
 отношение типа "экземпляр класса": а:С, где а - объект (индивидуум), а С - произвольный концепт (класс);
отношение типа "экземпляр класса": а:С, где а - объект (индивидуум), а С - произвольный концепт (класс);
 отношение типа "экземпляр свойства": (а, b):Р, где а и b обозначают два объекта (индивидуума), а Р - это произвольное свойство.
отношение типа "экземпляр свойства": (а, b):Р, где а и b обозначают два объекта (индивидуума), а Р - это произвольное свойство.
Семантика ALC задается интерпретацией, которая представляет собой структуру вида 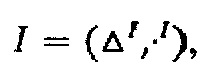 где ΔI - носитель (непустое множество),
где ΔI - носитель (непустое множество),
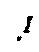 - интерпретирующая функция, отображающая имя концепта А в подмножество
- интерпретирующая функция, отображающая имя концепта А в подмножество 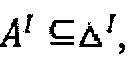 имя роли r - в бинарное отношение rI на ΔI
имя роли r - в бинарное отношение rI на ΔI 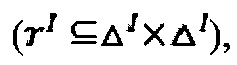 а имя объекта (индивидуума) а на элемент aI ∈ ΔI.
а имя объекта (индивидуума) а на элемент aI ∈ ΔI.
Интерпретация сложных концептов осуществляется по следующим правилам:
- 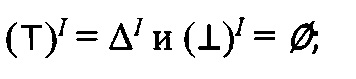
- 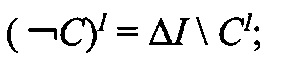
- 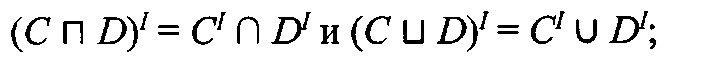
- 
- 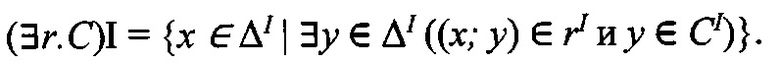
Для любой интерпретации I, любых концептов С, D и имени роли г справедливы следующие равенства:
- 
- 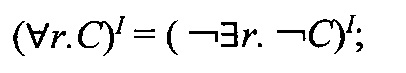
- 
- 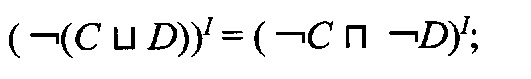
- 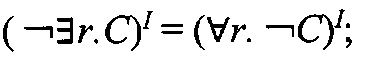
- 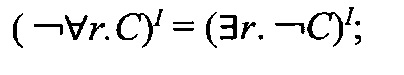
- 
- 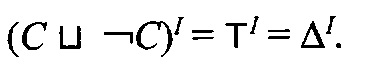
Подробная информация об онтологиях содержится в книге Лапшин В.А., Онтологии в компьютерных системах (М.: Научный мир, 2010. - 224 с.: ил.).
Важно отметить, что описание самой онтологии и ее интерпретации задается в виде данных, хранимых в ячейках памяти (например, могут быть использованы следующие распространенные форматы: OWL/XML, RDF/XML, Turtle, JSON-LD и др.).
В качестве примера, для формализации содержимого компонент векторного представления очередной необработанной записи данных (620) и компонент векторов из очищенной базы данных (410) использована онтология родственных отношений, иерархия классов и иерархия объектных отношений которой представлены на фигурах 7 и 8 соответственно. Логические условия непротиворечивости данной онтологии определены ее аксиомами (ограничениями, заданными формально), например такими, как:
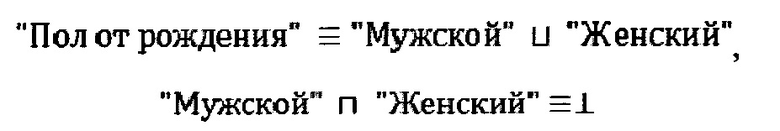
Приведенные аксиомы на языке дескрипционной логики означают, что класс "Пол от рождения" включает в себя объединение классов "Мужской" и "Женский", при этом классы "Мужской" и "Женский" не пересекаются (их пересечение эквивалентно пустому множеству).
Формализованное описание содержимого компонент векторов из очищенной базы данных (410) в виде графа с использованием онтологии родственных отношений представлено на фигуре 9. Данное представление включает совокупность индивидуумов (обозначены ромбами) с указанием классов их принадлежности (представлены буквами в ромбах), связей между ними (обозначены стрелками) и словесного описание, которое соответствует полю 410-В.
В приведенном примере индивидуумы, обозначенные буквой "Ч", относятся к классу "Человек", буквой "М" - к классу "Человек мужского пола", буквой "Ж" - к классу "Человек женского пола", буквой "Н" - к классу "Объект настоящего" (времени). Также заданы отношения: "а" - быть родной сестрой, "б" - "входить в брачный союз", "в" - "иметь биологического родителя", "г" - "иметь биологического отца", "д" - "быть одноутробным братом", "е" - "иметь однородную сестру".
Каждый индивидуум описывается содержимым компонентов векторов из очищенной базы данных, объединенных одним групповым идентификатором (поле 410-А). Например индивидуум "Иван Иванов" описывается содержимым компонентов векторов 410-1 и 410-2 из очищенной базы данных, поскольку они имеют общий групповой идентификатор равный "1". В этом примере поле 410-Е ("ИНН") использовано для определения факта различия индивидуумов. Для другого варианта осуществления это поле может быть использовано иначе. Класс принадлежности индивидуума определен полем 410-Д (поле "Пол", пустому полю ставится в соответствие значение "Ч"). Связи между индивидуумами определяются полем 410-Ж. Для того, чтобы не загромождать отображение графа, в приведенном примере не отображено поле410-Г.
Формализованное описание содержимого компонент векторного представления очередной необработанной записи данных (620) вместе с формализованным описанием содержимого компонент векторов из очищенной базы данных (410) в виде графа с использованием онтологии родственных отношений представлено на фигуре 10. Оно отличается от графа, представленного на фигуре 9 тем, что для индивидуума "Иванова Мария" конкретизирована принадлежность к классу - задано, что этот индивидуум относится к классу объектов "М" (класс объектов мужского пола) в соответствии с векторным представлением 620 необработанной записи 610-4.
Очевидно, что в виде графа формализованное описание представлено исключительно с целью пояснения. Реализация алгоритма на ЭВМ предполагает использование таких структур данных, как например, массивы, структуры, классы, указатели и т.п., позволяющих необходимым образом структурировать вносимые в ячейки памяти полученные вектора.
А5) Проверка выполнения заданных условий непротиворечивости.
Формализация содержимого компонент векторного представления необработанной записи данных и содержимого компонент векторов очищенной базы данных позволяет оценивать их целостность (или нарушение их целостности) в совокупности с учетом значений данных, заданных явно или определенных опосредовано. В предпочтительном варианте осуществления проверка выполнения заданных условий непротиворечивости осуществляется путем логического вывода, например, с помощью широко известного табло-алгоритма. Подробная информация о логическом выводе содержится книге F. Baader, D. Calvanese, D.L. McGuinness, D. Nardi P.F. Patel-Schneider, The Description Logic Handbook (Cambridge University Press, 2nd ed. 2010). Целесообразность применения логического вывода заключается в том, что с его помощью можно определять целостность (нарушение целостности) данных в случаях, когда необходимо оценить их значение (семантику). Например, применение в таких случаях диализа данных, подразумевающего использование функций корреляций, неэффективно.
Для приведенного примера логические условия непротиворечивости не будут выполнены, поскольку добавление вектора 620 в очищенную базу данных 410 приведет к противоречию: с одной стороны формализация содержимого компонент векторного представления 620 необработанной записи 610-4 явно указывает на то, что индивидуум "Иванова Мария" относится к классу "М" (объектов мужского пола), а с другой - на основе формализации содержимого компонент векторов очищенной базы данных 410 путем логического вывода следует, что индивидуум "Иванова Мария" относится к классу "Ж" (объектов женского пола); аксиомы используемой онтологии родственных отношений, как было показано выше, не допускают одновременной принадлежности одного индивидуума к классам "М" и "Ж". Вывод о принадлежности индивидуума "Иванова Мария" к классу "Ж" построен на том основании, что индивидуум "Иванов Сергей" связан отношением "иметь биологического родителя" с индивидуумом "Иванова Мария" и в то же врем связан отношением "иметь биологического отца" с индивидуумом "Иванов Иван", последний на основании области значений этой связи должен относится к классу "М" - объектов мужского пола. В онтологии родственных отношений указано, что каждый индивидуум имеет двух индивидуумов-биологических родителей, один из которых должен относиться к классу "М", а другой - к классу "Ж". Поскольку на основании связи "иметь биологического отца" определяется принадлежность индивидуума "Иванов Иван" к классу "М", то второй биологический родитель индивидуума "Иванов Сергей", т.е. индивидуум "Иванова Мария" должен относиться к классу "Ж".
В случае, если в качестве примера вместо вектора 620 рассмотреть вектор 630, то последний удовлетворяет логическим условиям непротиворечивости.
А6) На данном шаге проверяется, были ли выполнены заданные логические условия непротиворечивости, или нет. Если условия непротиворечивости были выполнены, то осуществляется переход к шагу А7, иначе - осуществляется переход к шагу А1.
А7) Сравнение полученного (нового) вектора с векторами из очищенно базы данных и определение записать или не записывать полученный вектор в очищенную базу данных. В предпочтительном варианте осуществления способа, решение записать полученный вектор принимается, если этот вектор содержит новые данные, ранее не содержавшиеся в очищенной базе данных. При этом, с помощью процедуры диализа данных определяется относится ли полученный вектор к некоторой группе связанных векторов из очищенной базы данных или нет.
Например, вектор 630 содержит новые данные для очищенной базы данных 410, т.к. в нем содержатся данные для поля 410-Д, поэтому на данном шаге было бы принято решение записать данный вектор в очищенную базу данных 410. При этом вектор 630 был бы отнесен к группе связанных векторов, каждый из которых имеет групповой идентификатор (значение поля ТИ" или 410-А) равное "2".
А6) На данном шаге проверяется, было ли определено записать полученное векторное представление очередной необработанной записи в очищенную базу данных или нет. Если было принято решение записать полученный вектор, то осуществляется переход к шагу А9, иначе - осуществляется переход к шагу А1.
А9) Внесение полученного вектора в очищенную базу. При этом, в предпочтительном варианте осуществления способа, полю "ПИ" полученного вектора присваивается произвольное уникальное числовое значение, а полю "ГИ" присваивается значение, определенное на шаге А7, если оно было определено, либо присваивается произвольное уникальное значение.
Для проверки эффективности заявляемого способа был проведен эксперимент, в ходе которого было сгенерировано и добавлено к исходным данным, представленным на фигуре 3, 30 необработанных записей, из них 10 содержали корректные данные, а 20 содержали данные, противоречащие содержимому данных других записей и/или содержимому данных компонент векторов очищенной базы данных (например, данные, указывающие на то, что индивидуум "Иванова Елена" связана отношением "иметь биологического родителя" с индивидуумом "Петрова Татьяна").
В результате применения предлагаемого способа в очищенную базу данных были перенесены только векторные представления 10 из 10 (100%) корректных записей и 0 из 20 (0%) ошибочных записей, содержащих данные, противоречащие содержимому данных других записей и/или содержимому данных компонент векторов очищенной базы данных (для них не были выполнены логические условия непротиворечивости).
Вместе с тем, применение известного способа (см. патент РФ №2268488, МПК G06F 17/30 опубл. 20.01.2006) привело к добавлению в очищенную базу 10 из 10 (100%) корректных записей и 20 из 20 (100%) ошибочных записей, содержащих данные, противоречащие содержимому данных других записей и/или содержимому данных компонент векторов очищенной базы данных. Т.е. вместе с корректными данными, с использованием известного способа, в очищенную базу данных были добавлены ошибочные (противоречивые) данные.
Таким образом, результаты эксперимента подтверждают, что разработанный способ позволяет повысить целостность данных, хранимых в системах баз данных, за счет выявления и исключения ошибочных (противоречивых) данных.




Изобретение относится к области информационных технологий, а именно к способам организации и/или нахождения данных в системах баз данных, и может быть использовано в системах обработки данных. Техническим результатом является повышение целостности данных, хранимых в системах баз данных, за счет выявления и исключения ошибочных, искаженных, неточных данных, а также данных, противоречащих самим себе или ранее внесенным данным. В способе обеспечения целостности данных данные из необработанных полей данных в необработанной записи данных преобразуют в вектор из числовых значений. Задают формализованное описание компонент сформированного вектора и компонент векторов из очищенной базы данных, при этом в формализованном описании указывают логические условия непротиворечивости, определяющие корректность содержимого компонент этих векторов. После чего проверяют выполнимость указанных логических условий, при выполнимости указанных логических условий сравнивают упомянутый вектор с остальными векторами из очищенной базы данных и при несовпадении дописывают упомянутое векторное представление необработанной записи данных в очищенную базу данных. 10 ил.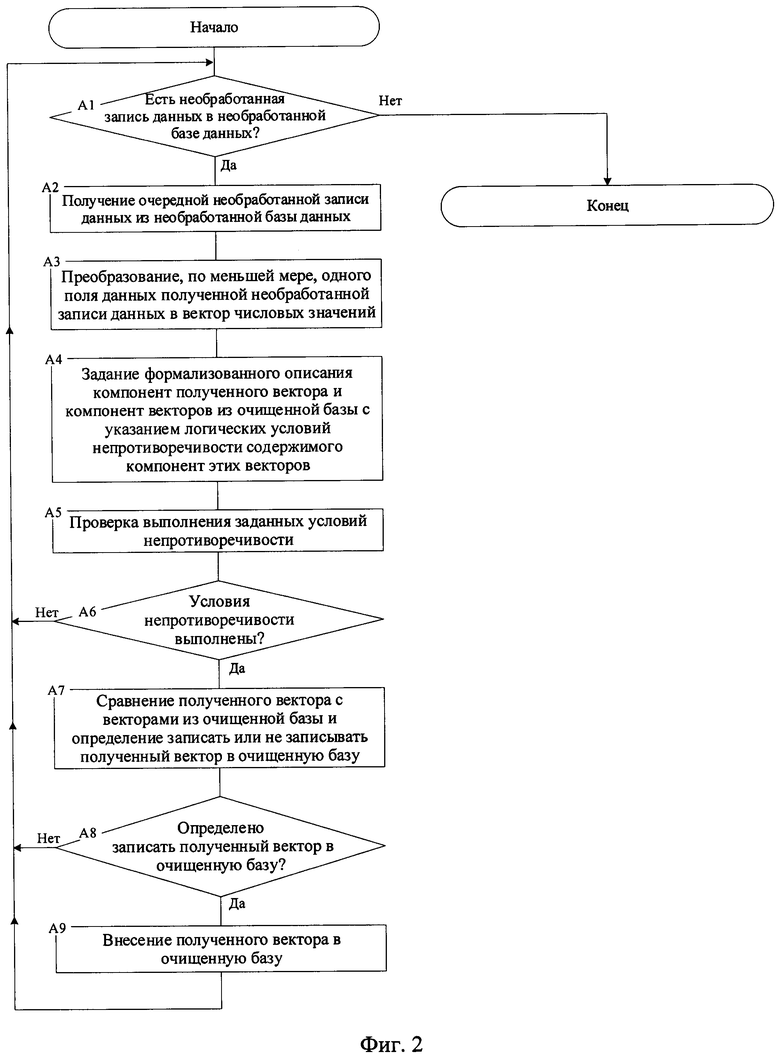
Способ обеспечения целостности данных, заключающийся в том, что данные из необработанных полей данных в необработанной записи данных преобразуют в вектор из числовых значений в некоторой системе счисления, новый вектор сравнивают с одним или несколькими векторами из очищенной базы данных и определяют, записать или не записывать сформированный вектор в очищенную базу данных путем его сравнения с одним или несколькими векторами из очищенной базы данных, отличающийся тем, что дополнительно до процедуры сравнения векторов задают формализованное описание компонент сформированного вектора и компонент векторов из очищенной базы данных, при этом в формализованном описании указывают логические условия непротиворечивости, определяющие корректность содержимого компонент этих векторов, после чего проверяют выполнимость указанных логических условий, при выполнимости указанных логических условий сравнивают упомянутый вектор с остальными векторами из очищенной базы данных и при несовпадении дописывают упомянутое векторное представление необработанной записи данных в очищенную базу данных.
| СПОСОБ И СИСТЕМА ДЛЯ ОРГАНИЗАЦИИ ДАННЫХ | 2000 |
|
RU2268488C2 |
| СПОСОБ ОБЕСПЕЧЕНИЯ ЦЕЛОСТНОСТИ НАБОРА ЗАПИСЕЙ ДАННЫХ | 2004 |
|
RU2351978C2 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ РЕАЛИЗАЦИИ ПРИБЛИЖЕННОГО СРАВНЕНИЯ СТРОК В БАЗЕ ДАННЫХ | 2008 |
|
RU2487394C2 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |

