Настоящее изобретение относится к системам баз данных, а более конкретно к системе и способу организации и/или нахождения данных в системе баз данных.
Компьютеризированные системы баз данных давно используются и их основные концепции хорошо известны. Подробная информация о системах баз данных содержится в книге C.J.Date, Introduction To Datebase Systems (Addison Wesley. 6th ed. 1994).
В общем случае системы баз данных предназначены для организации, хранения и поиска данных таким образом, чтобы данные в базе данных были бы полезными. Например, данные или распределенные наборы данных могут быть найдены, отсортированы, организованы и/или объединены с другими данными. В большой степени полезность определенной системы баз данных зависит от целостности (т.е. точности и/или правильности) данных в системе баз данных. На целостность данных воздействует степень "беспорядка" в сохраненных данных. Беспорядок может появиться в форме ошибочных или неполных данных, таких как дублированные данные, фрагментированные данные, ложные данные и т.д. Во многих системах баз данных время от времени существующие данные могут редактироваться и обрабатываться, и в результате могут вноситься дополнительные ошибки. В некоторых системах баз данных могут вводиться новые данные. Дополнительно, поскольку системы баз данных модернизируются с помощью нового оборудования и/или программного обеспечения, может потребоваться преобразование данных, или могут стать необходимыми дополнительные поля. Кроме того, в некоторых прикладных задачах данные в базе данных могут просто устареть через какое-то время.
Независимо от предпринимаемых профилактических шагов, некоторая степень беспорядка в конечном счете вводится в обычные системы баз данных. Эта степень беспорядка увеличивается по экспоненте во времени до тех пор, пока в конечном счете данные в обычной базе данных становятся полностью бесполезными. В результате, даже малая степень беспорядка в конечном счете воздействует на целостность системы баз данных.
К сожалению, определение и исправление беспорядка в данных часто является трудной, едва ли невыполнимой задачей, особенно в больших системах баз данных. Традиционно, такие задачи выполняются вручную, что требует большего времени, связано с высокими затратами и не исключает ошибки оператора. Кроме того, из-за характера этой задачи беспорядок в значительной степени может оказаться необнаруживаемым. Необходимы система и способ для организации данных в системе баз данных таким образом, чтобы преодолеть эти и другие связанные с ними проблемы.
Настоящее изобретение обеспечивает систему и способ для организации данных в системе баз данных. Настоящее изобретение получает высокоточную "очищенную" базу данных из необработанных данных, полученных из одного или множества источников необработанных данных. Необработанные данные преобразуются из первоначального формата (форматов) в цифровой формат.
Согласно одному из вариантов осуществления настоящего изобретения, необработанные данные представляются как вектор, имеющий цифровые элементы. После того, как необработанные данные представлены в цифровой форме, различные математические операции, такие как функции корреляции, способы распознавания образов или другие подобные численные методы могут быть выполнены с этими векторами, чтобы определить, каким образом содержимое определенного вектора соответствует другим векторам в "очищенной" или эталонной базе данных. Очищенная база данных формируется из наборов, состоящих из одного или большего количества связанных векторов, которые предполагаются однозначно определенными (например, ортогональными) относительно других наборов. Эти наборы представляют наилучшую информацию, доступную из необработанных данных. После того, как все необработанные данные включены в очищенную базу данных, база данных может быть экранирована от новых данных, чтобы гарантировать, что новые ошибки не будут введены в очищенную базу данных. Новые данные могут быть также оценены, чтобы определить, являются ли они уникальными или включают ли они в себя лучшую информацию, чем та, которая уже существует в очищенной базе данных. Новые данные добавляются в очищенную базу данных соответственно.
Согласно одному из вариантов осуществления настоящего изобретения, необработанные данные преобразуются в цифровой формат, основанный на системе счисления, имеющей соответствующее основание системы счисления. Соответствующее основание системы счисления определяется в соответствии с типом информации, включенной в необработанные данные. Например, для необработанных данных, в основном состоящих из буквенно-цифровых символов, соответствующее основание системы счисления может быть большим или равным количеству различных буквенно-цифровых символов, существующих в необработанных данных. Использование такой системы счисления позволяет представлять необработанные данные в цифровой форме, доступной для манипуляции посредством различных известных математических операций.
Согласно одному из вариантов осуществления настоящего изобретения, система счисления может быть выбрана так, чтобы сами числа сохраняли семантическое значение необработанных данных, которые они представляют. Другими словами, цифры в системе счисления выбираются так, чтобы они соответствовали необработанным данным. Например, в случае необработанных данных, составленных из буквенно-цифровых символов, цифры выбираются так, чтобы они охватывали все буквенно-цифровые символы, которые они представляют. Когда цифры в системе счисления впоследствии отображаются, они появляются как буквенно-цифровые символы, которые они представляют.
Согласно одному из вариантов осуществления настоящего изобретения, после того, как необработанные данные представлены как векторы в соответствующей системе счисления, представленными данными можно эффективно манипулировать в базе данных (например, сортировать и т.д.), используя различные известные методы. Кроме того, различные известные математические операции могут выполняться с векторами, чтобы проанализировать содержимое данных. Эти математические операции могут включать в себя корреляционную функцию, анализ собственных векторов, способы распознавания образов и другие методы, хорошо известные специалистам.
Согласно одному из вариантов осуществления настоящего изобретения, необработанные данные вводятся в очищенную базу данных. Очищенная база данных представляет наилучшую информацию, извлеченную из необработанных данных, без какого-либо беспорядка в данных.
Согласно одному из вариантов осуществления настоящего изобретения, новые данные могут сравниваться с очищенной базой данных, чтобы определить, включают ли новые данные на самом деле новую информацию или содержимое, не представленные в очищенной базе данных. Любая новая информация, которой еще нет в очищенной базе данных, добавляется в очищенную базу данных без добавления какого-либо беспорядка. Таким образом может поддерживаться целостность очищенной базы данных.
Согласно настоящему изобретению способ для обработки информации содержит этапы выбора соответствующей системы счисления, основанной на диапазоне возможных значений элемента данных, включенного в информацию, представления указанного элемента данных как цифры в данной системе счисления и использования указанного элемента данных, представленного в данной системе счисления, для обработки информации.
Согласно одному из вариантов осуществления настоящего изобретения, этап выбора соответствующей системы счисления содержит этап выбора системы счисления с основанием системы счисления, по меньшей мере равным и приблизительно тем же самым, что и порядок буквенно-цифровых символов от "0" до "9" и от "А" до "Z".
Согласно одному из вариантов осуществления настоящего изобретения, этап выбора соответствующей системы счисления содержит этап выбора системы счисления с основанием системы счисления большим, чем порядок буквенно-цифровых символов от "0" до "9" и от "А" до "Z".
Согласно одному из вариантов осуществления настоящего изобретения, этап выбора соответствующей системы счисления содержит этап выбора системы счисления с основанием, по меньшей мере равным порядку буквенно-цифровых символов от "0" до "9", от "А" до "Z" и от "а" до "z".
Согласно одному из вариантов осуществления настоящего изобретения, этап выбора соответствующей системы счисления содержит этап выбора системы счисления с основанием 40.
Согласно одному из вариантов осуществления настоящего изобретения, информация включает в себя финансовую информацию, научную информацию, промышленную информацию или химическую информацию.
Согласно одному из вариантов осуществления настоящего изобретения, этап назначения цифр дополнительно содержит назначение цифр от А до Z в системе счисления буквенно-цифровым символам от "а" до "z" соответственно.
Согласно одному из вариантов осуществления настоящего изобретения, этап сравнения вектора с очищенной матрицей содержит выполнение анализа собственных векторов, или выполнение анализа распознавания образов, или определение скалярного произведения между упомянутым вектором и вектором в очищенной матрице, или определение векторного произведения между упомянутым вектором и вектором в очищенной матрице, или определение разности между упомянутым вектором и вектором в очищенной матрице, или определение суммы упомянутого вектора и вектора в очищенной матрице, или определение определителя очищенной матрицы, или определение величины упомянутого вектора, или определение направления упомянутого вектора.
В общем случае изобретение характеризуется тем, что заявлено в независимых пунктах формулы изобретения, в то время как зависимые пункты формулы изобретения содержат предпочтительные варианты осуществления изобретения.
Предпочтительные варианты осуществления изобретения описываются со ссылками на чертежи. На чертежах одинаковыми ссылочными позициями обозначены идентичные или функционально подобные элементы. Кроме того, крайняя левая цифра (цифры) ссылочной позиции идентифицирует чертеж, на котором ссылочная позиция появилась первый раз.
Фиг.1 - пример системы обработки, в которой может быть осуществлено настоящее изобретение.
Фиг.2 - пример стадий обработки данных с помощью одного из вариантов осуществления настоящего изобретения.
Фиг.3 - последовательность операций программы для преобразования необработанных данных из первоначального формата в цифровой формат в соответствии с одним из вариантов осуществления настоящего изобретения.
Фиг.4 - пример записи данных, подходящей для использования в настоящем изобретении.
Фиг.5 - пример таблиц необработанных данных, подходящих для использования в настоящем изобретении.
Фиг.6 - пример таблиц эталонных данных, представляющих данные, отформатированные в соответствии с вариантом осуществления настоящего изобретения.
Фиг.7 - последовательность операций программы для анализа эталонных данных в соответствии с вариантом осуществления настоящего изобретения.
Фиг.8 - пример таблицы очищенных данных, представляющей связанные данные, коррелированные в соответствии с вариантом осуществления настоящего изобретения.
Фиг.9 - пример кластеризации данных в двумерном пространстве.
Фиг.10 - последовательность операций программы для идентификации дублированных данных среди пары векторов поля.
Фиг.11 - дополнительная детализация последовательности операций программы для идентификации дублированных данных среди пары векторов поля.
Фиг.12 - пример идентификации дублированных данных среди пары векторов поля.
Настоящее изобретение направлено на систему и способ для организации данных в системе баз данных. Настоящее изобретение описано ниже для различных типичных вариантов осуществления, в особенности для различных приложений баз данных. Однако очевидно, что различные особенности настоящего изобретения могут быть распространены на другие области. В общем случае настоящее изобретение может быть применено ко многим приложениям баз данных, в которых большой объем потенциально несвязанных данных должен накапливаться, храниться, подвергаться манипуляциям и/или анализироваться, чтобы определить различные связи, присутствующие в содержимом, представленном данными. Более конкретно, настоящее изобретение обеспечивает способ для достижения и поддержания целостности (т.е. точности и правильности) данных в системе баз данных, даже тогда, когда эти данные первоначально обладают высокой степенью беспорядка. Под беспорядком понимается наличие данных, которые являются дублированными, ошибочными, неполными, неточными, ложными или, иначе, неправильными или избыточными. Очевидно, что беспорядок может быть представлен в системе баз данных многими способами.
Один из вариантов осуществления настоящего изобретения используется для поддержания базы данных, связанной с ожидаемыми поступлениями (суммами, которые должны быть получены за поставленные товары). В этом варианте осуществления компания может собирать данные, относящиеся к различным людям, предпринимателям и/или счетам, из одного или большего количества источников. Эти источники могут включать в себя, например, компании, продающие товары по кредитным карточкам, финансовые учреждения, банки, предприятия розничной продажи и оптовых предпринимателей и другие подобные источники. В то время, как каждый из этих источников может передавать данные, относящиеся к различным счетам, каждый источник может передавать данные, представляющие различную информацию, основанную на его собственных потребностях. Кроме того, эти данные могут быть организованы совершенно различными способами. Например, оптовый продавец (дистрибьютор) может иметь данные, соответствующие ожидаемым поступлениям, которые соответствуют счетам предприятия. Такие данные могут быть организованы по номерам счета, причем каждая запись данных имеет поля данных, идентифицирующие номер счета, предприятие, связанное с этим номером счета, адрес этого предприятия и количество долга на этом счете. Розничная компания может иметь записи данных, представляющие подобную информацию, но основанные на счетах, соответствующих как отдельным лицам, так и предприятиям.
В других вариантах осуществления настоящего изобретения другие виды источников могут передавать данные различного типа. Например, научные учреждения могут передавать научные данные относительно различных областей исследования. Промышленные компании могут передавать промышленные данные относительно сырья, производства, продукции и/или поставок. Суды или другие виды юридических учреждений могут передавать юридические данные относительно юридического состояния, приговоров, банкротства и/или залога. Очевидно, что настоящее изобретение может использовать данные из самых различных источников.
В другом варианте осуществления настоящего изобретения база данных может поддерживаться для реализации интегрированной системы выставления счетов и управления заказами. В дополнение к информации выставления счетов из источников, подобных описанным выше, этот вариант осуществления может включать в себя записи данных, соответствующие товарам, записи данных, соответствующие поставщикам товара, и записи данных, соответствующих покупателям товара. Данные о товаре могут быть организованы по номерам деталей, причем каждая запись данных имеет поля данных, идентифицирующие внутренний номер детали, внешний номер детали (т.е. номер детали поставщика), количество на руках, ожидаемое количество для отправки, ожидаемое количество для получения, оптовую цену и розничную цену. Данные поставщика могут быть организованы с помощью номера поставщика; и данные заказчика могут быть организованы с помощью номера заказчика. Записи данных, соответствующие каждой из этих записей, могут включать в себя поля данных, идентифицирующие номер детали, цену детали, заказанное количество, данные поставки и другую подобную информацию.
Другой вариант осуществления настоящего изобретения может включать в себя систему хранения данных предприятия, которая объединяет общую информацию из множества различных источников и делает эту информацию доступной пользователям по ведомственной сети связи независимо от типа данных, типа компьютера, который генерировал данные, или типа компьютера, который запросил данные. Еще один вариант осуществления настоящего изобретения включает в себя интеллектуальную систему предприятия, которая хранит и реализует информацию и позволяет обрабатывать и анализировать эту информацию в оперативном режиме.
Настоящее изобретение дает возможность проанализировать и очистить необработанные данные, собранные из различных источников, для получения совокупности точных данных, организованных таким способом, который полезен для конкретного приложения. Используя вышеупомянутый пример интегрированной системы выставления счетов и управления заказами, разъясненный более полно ниже, настоящее изобретение может обеспечивать формирование очищенной базы данных, в которой связанные данные, такие как данные, относящиеся к конкретному поставщику или заказчику, также могут быть идентифицированы. В этом примере дублированные данные, соответствующие тому же самому поставщику или заказчику, могут быть идентифицированы и/или отвергнуты, а ошибочные данные, связанные с поставщиком или заказчиком, могут быть идентифицированы, проанализированы и, возможно, исправлены.
В общем случае, настоящее изобретение может быть реализовано с помощью аппаратных средств или программного обеспечения или их комбинации. Предпочтительно настоящее изобретение реализуется как программа, выполняемая в программируемой системе обработки, которая включает в себя процессор, систему хранения данных и устройства ввода и вывода. Пример такой системы 100 показан на фиг.1. Система 100 может включать в себя процессор 110, память 120, запоминающее устройство 130 и контроллер 140 ввода/вывода, соединенные друг с другом шиной 150 процессора. Контроллер 140 ввода/вывода также соединен через шину 160 ввода/вывода с различными устройствами ввода и вывода, такими как клавиатура 170, мышь 180 и дисплей 190. Очевидно, что и другие компоненты могут быть включены в систему 100.
На фиг.2 показаны различные формы данных, обрабатываемых в соответствии с настоящим изобретением. Необработанные данные 210, такие как необработанные данные 210А и необработанные данные 210В, могут собираться из одного или большего количества источников. Считается, что "необработанные данные" относятся к данным в том виде, в каком они принимаются из конкретного источника. Очевидно, что могут быть включены дополнительные источники необработанных данных 210. Как объяснено ниже, необработанные данные 230 из различных источников предпочтительно преобразуются в цифровой формат и сохраняются в эталонной базе данных 220. Используя процесс, названный "диализом данных", настоящее изобретение "очищает" необработанные данные 210 для того, чтобы сформировать эталонные данные в эталонной базе данных 220. Эталонная база данных 220 включает в себя всю информацию, найденную в необработанных данных 210, которая включает в себя дублированные, неполные, противоречивые и ошибочные данные.
Очищенные данные, сохраненные в очищенной базе данных 230, получают из эталонных данных эталонной базы данных 220. Очищенные данные представляют "точные" данные, доступные из необработанных данных 210. Очищенная база данных 230 включает в себя уникальную информацию, найденную в необработанных данных 210. Очищенные данные, таким образом, представляют наилучшую информацию, доступную из необработанных данных 210.
Как объяснено ниже, настоящее изобретение дополнительно обеспечивает использование очищенной базы данных 230 для анализа и проверки новых данных 240, которые также могут использоваться для обновления эталонной базы данных 220 и очищенной базы данных 230 соответственно.
Хотя настоящее изобретение имеет множество вариантов осуществления, оно поясняется с помощью предпочтительного варианта осуществления со ссылками на фиг.3-8 в контексте интегрированной системы выставления счетов и управления заказами. В этом варианте осуществления необработанные данные 210 - совокупность данных, собранных из различных источников, таких как обработка заказа, отгрузка, прием, оплачиваемые счета и получаемые счета и т.д. Эти необработанные данные 210 могут включать в себя записи данных, которые связаны, но имеют различные поля данных, дублирующие записи данных, записи данных, имеющие одно или большее количество ошибочных полей данных и т.д. Чтобы найти такие ошибки с помощью настоящего изобретения, преобразуют необработанные данные 210 из их первоначальных форматов и структур данных (которые могут изменяться в зависимости от источника) в цифровой формат и хранят эти эталонные данные в эталонной базе данных 220.
Согласно настоящему изобретению, эталонные данные затем сравнивают и анализируют, чтобы выявить наилучшую доступную информацию. В одном из вариантов осуществления настоящего изобретения эта наилучшая информация может быть сохранена как очищенные данные в очищенной базе данных 230. Ниже описан этот процесс.
Сбор необработанных данных
Фиг.3 иллюстрирует процесс, с помощью которого необработанные данные 210 преобразуются в эталонные данные в эталонной базе данных 220 согласно одному из вариантов осуществления настоящего изобретения. На этапе 310 осуществляется сбор необработанных данных 210 из источника необработанных данных. Как показано на фиг.2, необработанные данные 210 могут включать в себя данные из одного или большего количества источников, таких как необработанные данные 210А и 210В. В данном описании принято, что "данные" относятся к физическому цифровому представлению информации, а "содержимое" данных относится к значению информации, включенной в эти данные или представленной этими данными. Различные записи в необработанных данных 210 могут включать в себя подобные виды содержимого данных. Например, в контексте составления счетов все различные записи в необработанных данных 210 могут включать в себя содержимое данных, относящееся к определенному счету.
Необработанные данные 210 в типовом случае принимаются в форме записей данных 400, как показано на фиг.4. Каждая запись данных 400 в общем случае включает в себя связанную информацию, такую как информация об определенном лице, компании или счете. Каждая запись данных 400 хранит эту информацию в одном или большем количестве полей данных 410. Примеры возможных полей данных 410 включают в себя, например, номер счета, фамилию, имя, название компании, баланс счета и т.д. Каждое поле данных 410, в свою очередь, может включать в себя один или большее количество элементов данных 420 для представления информации для этой определенной записи и определенного поля. Очевидно, что элементы данных 420 могут существовать в различных форматах, таких как буквенно-цифровой, цифровой, американский стандартный код обмена информацией (ASCII) и расширенный двоичный код обмена информацией (EBCDIC), или в другом представлении. Необработанные данные 210, собранные из различных источников, могут быть отформатированы по-разному. Также очевидно, что записи данных 400 могут включать в себя различные поля данных 410, и информация, включенная в поля данных 410, может быть представлена с использованием элементов данных 420 в различных форматах.
Примеры необработанных данных 210 показаны в таблицах необработанных данных 510, 520 и 530 на фиг.5. Записи данных, такие как запись данных 510-1 и запись данных 510-2, показаны как строки необработанных таблиц данных 510, 520 и 530, принимая во внимание, что поля данных, такие как поля данных 510-А и поля данных 510-В, показаны как столбцы таблиц необработанных данных 510, 520 и 530. И поля данных, и записи данных можно считать обычными математическими векторами или тензорами и ими можно соответственно манипулировать. Таблицы, показанные на фиг.5, - примеры данных, которые могут быть найдены в различных вариантах осуществления настоящего изобретения. Очевидно, что в других вариантах осуществления данные могут поступать из многих источников и могут быть отформатированы как базы данных, имеющие намного большее число записей данных и/или полей данных.
Преобразование в цифровой формат
Согласно фиг.3, на этапе 320 в соответствии с настоящим изобретением преобразуют необработанные данные 210 из их первоначального представления (которое может быть буквенно-цифровым, цифровым, в американском стандартном коде обмена информацией ASCII, в расширенном двоичном коде обмена информацией (EBCDIC) или другом подобном формате) в цифровое представление. Это гарантирует, что эталонные данные представлены тем же самым способом. Таким образом, эталонные данные, которые включают в себя данные из различных источников, могут быть обработаны сходным образом.
Согласно настоящему изобретению, необработанные данные 210 преобразуются из их первоначального представления в соответствующее цифровое представление. Соответствующее цифровое представление использует систему счисления, в которой каждое возможное значение элемента данных 420 может быть представлено уникальной цифрой или значением в системе счисления. Другими словами, основание системы счисления выбирается таким, что оно по меньшей мере такое же большое, как число возможных значений для определенного элемента данных. Например, в приложении, относящемуся к биотехнологии, для обнаружения последовательности нуклеотидов Adenine (A), Guanine (G), Cytosine (С) и Thymine (Т) в нуклеиновых кислотах, каждый элемент данных может быть только одним из четырех значений: А, G, С и Т. В таком приложении основание системы счисления 4 для системы счисления может быть достаточным для того, чтобы представить каждый элемент данных как уникальную цифру. Такая система счисления может включать в себя цифры А, G, С и Т. В некоторых вариантах осуществления настоящего изобретения может быть желательно использовать основание системы счисления по меньшей мере на единицу большее, чем число различных возможных значений элемента данных 420, чтобы обеспечить символ, представляющий пустое поле. В этом случае система счисления может включать в себя символы А, G, С, Т и ^, где ^ - значение пустого поля.
Согласно предпочтительному варианту осуществления настоящего изобретения, элементы данных 420 в необработанных данных 210 составлены из символов, таких как буквенно-цифровые символы. В этом предпочтительном варианте осуществления выбрано основание системы счисления 40, чтобы представить буквенно-цифровые символы как показано в таблице, приведенной ниже. (Обратите внимание, что минимальное требуемое основание системы счисления - 36). Это основание системы счисления выбрано так, чтобы разместить десять цифр от "0" до "9" и двадцать шесть буквенных символов от "А" до "Z", а также чтобы предусмотреть несколько дополнительных символов. В этом варианте осуществления символы верхнего регистра и нижнего регистра не отличаются друг от друга.
Как показано в таблице 1, система счисления с основанием 40 включает в себя цифры от 0 до 9, за которыми следуют буквы от А до Z, за которыми далее следуют четыре дополнительных символа. Один из этих символов может использоваться для представления пустого поля. Этот символ используется, чтобы представить поле данных 410, который является пустым или не имеет никакого значения (в отличие от нулевого значения). Другие символы могут использоваться для того, например, чтобы представлять другие виды информации, такие как пробелы, или использоваться как информация управления.
Представление необработанных данных 210 в формате на основании системы счисления 40 имеет множество преимуществ. Одно преимущество состоит в том, что необработанные данные 210 могут быть представлены цифровым способом, облегчая прямые математические манипуляции. Другое преимущество состоит в том, что правильный выбор основания системы счисления и цифр в системе счисления позволяет представленному содержимому поддерживать семантическое значение, облегчая распознавание содержимого необработанных данных 210 при представлении в цифровом формате, например, слово "JOHN", представленное четырьмя алфавитно-цифровыми символами "J" "О" "Н" "N", может быть представлено в различных системах счисления. Одна из таких систем счисления - система счисления с основанием 40. Используя таблицу 1, представление алфавитно-цифровых символов "JOHN" как числа с основанием системы счисления 40 привело бы к значению (числа по основанию 40) "JOHN", которое эквивалентно десятичному значению 1255103 (19*403+24*402+17*401+23*400, где "J" по основанию 40 равняется десятичному числу 19 и т.д.). Обратите внимание, что число по основанию 10 теряет семантическое значение содержания необработанных данных 210, в то время как число по основанию 40 сохраняет семантическое значение, так как число "JOHN" распознается как содержимое "JOHN". Семантическое значение обеспечивает преимущества цифрового представления при поддержании способности передавать семантическое содержимое.
В некоторых вариантах осуществления настоящего изобретения выбор основания системы счисления и соответствующей ему системы счисления может зависеть от числа битов, используемых процессором 110. Число битов, используемых процессором 110, и основание системы счисления, выбранное для системы счисления, определяет символы числа, которые могут быть представлены информационным словом в процессоре 110. Эти отношения регулируются согласно следующему уравнению:
N = В*ln (2) /ln (R),
где N - число целых символов, представленных информационным словом процессора 110, В - число битов в информационном слове и R - выбранное основание системы счисления. Эти отношения ограничивают число элементов данных 420 необработанных данных 210, которые могут помещаться в информационном слове. Например, в 32-разрядной машине, максимальное число символов, которое может помещаться в информационном слове, используя систему счисления с основанием 40, - шесть (32 *ln (2) / ln (40) = 6013). Максимальное число символов, которое может помещаться в информационном слове, используя основание системы счисления 41, - только пять (32 *ln (2) / ln (41)=5973). Таким образом, в некоторых вариантах осуществления настоящего изобретения, в дополнение к наличию основания системы счисления, достаточно большого, чтобы поддерживать семантическое значение, основание системы счисления может также быть выбрано, чтобы максимизировать число символов, представленное одним информационным словом, и/или облегчить быстрые математические операции, основанные на преимуществах или определенных разработках различных процессоров. В варианте осуществления с необработанными данными, составленными из буквенно-цифровых символов, соответствующее основание системы счисления может располагаться в интервале от 36 до 40. Этот диапазон поддерживает семантическое значение при максимизации числа символов, представленных 32-разрядным информационным словом. Другие типы необработанных данных и другие размеры информационного слова могут диктовать другие соответствующие диапазоны основания системы счисления в других вариантах осуществления настоящего изобретения.
Вариант осуществления настоящего изобретения, описанный выше, не отличает символы верхнего регистра и нижнего регистра. Однако другие варианты осуществления настоящего изобретения могут отличать эти виды символов. Очевидно, что представление с основанием 64 ("0"-"9", "А"-"Z", "а"-"z" и два других значения) может обеспечивать различие этих символов.
Число элементов данных 420 в каждом поле данных 410 также определяет длину слова, которая требуется для представления числа в процессоре 110. Как описано выше, каждое поле данных 410 может иметь ширину только шесть символов или элементов данных 420 для операций с одной длиной слова в 32-разрядной машине. В некоторых вариантах осуществления настоящего изобретения этого может быть недостаточно. В этих вариантах осуществления двойная, тройная или даже четырехкратная длина слова может потребоваться, чтобы представить все поле 410 данных как одно значение. Числа двойной длины слова достаточны для полей 410 данных до двенадцати символов; числа тройной длины слова достаточны для данных до восемнадцати символов; и числа четырехкратной длины слова достаточны для данных до двадцати четырех символов.
Альтернативные варианты осуществления настоящего изобретения могут размещать большие поля данных с помощью разбиения большого поля данных на одно или большее количество меньших полей данных. Большие поля данных могут быть разбиты по естественным границам, таким как границы, определенные пробелами. Например, поле данных, представляющее адрес, такой как "123 West Main Street", может быть разбито на четыре меньших поля данных: "123", "West", "Main" и "Street". Большие поля данных также могут быть разбиты по границам информационного слова. В примере адреса, приведенном выше, меньшие поля данных могли бы быть: "123West", "st\Mai", "n\Stre" и "et", где символ \ используется, чтобы представить пробел. Очевидно, что в других вариантах осуществления настоящего изобретения большие поля данных могут размещаться другими способами.
Преобразование структуры данных
Как показано на фиг.3 на этапе 330 необработанные данные 210, представленные как число, сохраняются в предварительно определенной структуре данных. В одном варианте осуществления настоящего изобретения эта структура данных является таблицей с одним полем, как показано в таблицах 610-670 на фиг.6. Эта структура данных может изменяться. Например, в других вариантах осуществления настоящего изобретения структурой данных может быть таблица с множеством полей вместо таблицы с одним полем. В этих вариантах осуществления структуры данных могут быть осуществлены с помощью стандартных свойств, таких как заголовки и индексы таблицы, и как объяснено более подробно ниже, могут также включать в себя значения вероятности для каждой записи. Эти значения вероятности представляют вероятность того, что данные в этой записи являются полными. Более высокие значения вероятности могут указывать на более высокую вероятность полноты, а более низкие значения вероятности могут указывать на более низкую вероятность полноты. Это описано более подробно ниже. Первоначально значения вероятности устанавливаются в 0. Другие варианты осуществления могут также включать в себя ключевые числа или идентификационные номера, чтобы помочь в сортировке и в поддержании взаимосвязи среди записей данных.
В предпочтительном варианте осуществления настоящего изобретения необработанные данные 210, показанные на фиг.5, включают в себя три таблицы 510, 520 и 530. Таблица 510 может представлять необработанные данные 210 из, например, системы ожидаемых поступлений (сумм за поставленные товары) компании. Столбцы таблицы 510 представляют поля данных для номера счета, фамилии, первого инициала и дополнительные поля для записей, показывающих различные заказы, обрабатываемые для конкретного лица. Строки таблицы 510 (типа 510-1 и 510-2) представляют записи данных для различных лиц. Таблицы 520 и 530 могут представлять необработанные данные 210, которые поддерживаются компаниями, продающими товары по кредитным карточкам. Столбцы таблиц 520 и 530 представляют поля данных для номера счета, фамилии, имени и адреса. Строки таблиц 520 и 530 представляют записи данных для конкретных счетов.
В предпочтительном варианте осуществления на этапе 330 необработанные данные 210 преобразуются из формата, показанного на фиг.5, в формат, показанный на фиг.6. Фиг.6 показывает необработанные данные 210, объединенные из различных таблиц необработанных данных 510, 520, 530 на фиг.5, представленные как числа системы счисления с основанием 40 и отформатированные как новые таблицы (таблицы 610-670), которые вместе могут содержать эталонную базу данных 220.
Каждая таблица эталонной базы данных 610-670 соответствует отдельному полю таблиц необработанных данных 510, 520 и 530 на фиг.5. Более конкретно, записи данных таблиц эталонных данных 610-670 соответствуют записям данных таблицы необработанных данных 510, за которыми следуют записи данных таблицы необработанных данных 520, за которыми следуют записи данных таблицы необработанных данных 530. В одном варианте осуществления настоящего изобретения, когда запись данных таблицы необработанных данных не имеет информации в определенном поле данных 410, представленном в эталонной таблице 610-670, значение пустого поля вводится в это поле в эталонной таблице. Например, первая запись данных 510-1 из таблицы 510 не имеет информации об адресе, и таким образом значение пустого поля помещается в первую позицию таблицы 670.
Данные предпочтительно сохраняются в эталонной базе данных 220 таким образом, что все данные, соответствующие одиночной записи данных в таблице необработанных данных, легко идентифицируются. В варианте осуществления, представленном на фиг.5 и 6, например данные, соответствующие любой определенной записи данных таблиц необработанных данных (таблицы 530, 520, 530), предпочтительно представлены в эталонных таблицах 610-670 как "вектор" цифровых данных, сохраненных с индексом i в эталонных таблицах 610-670. Например, данные, соответствующие шестой записи 520-6 из таблицы необработанных данных 520 (показанной как номер счета "А60", принадлежащий "Jennifer Brown", постоянно проживающей по "51 Fourth Street") представлены в таблицах эталонной базы данных 610-670 как вектор, имеющий коэффициенты, сформированные из десятых записей 610-10, 620-10, 630-10, 640-10, 650-10, 660-10 и 670-10 таблиц 610-670.
Как показано на фиг.6, эталонная база данных 220 включает в себя новую таблицу 610, которая не соответствует ни одному полю данных 410 в необработанных данных 210, показанных на фиг.5. Эта таблица является "ключевой таблицей", которая идентифицирует соответствующие данные в этих векторах данных. Как описано ниже, эталонная база данных 220, которая содержит таблицы, показанные на фиг.6, может включать в себя дополнительные ключевые таблицы для полей данных. Они могут включать в себя персональный идентификационный номер ("ПИДН"), идентификационный номер счета ("ИДНС") или другие типы идентификационных номеров. Эти ключевые таблицы или идентификационные номера могут использоваться, чтобы идентифицировать наборы соответствующих векторов данных в эталонной базе данных 220.
В этом примере ключевая таблица 610 имеет одно поле "ПИДН", которое обозначает персональный идентификационный номер. Ключевая таблица 610 обеспечивает уникальный идентификатор таким образом, чтобы конкретный номер ПИДН никогда бы не относился более чем к одному лицу, представленному в необработанных данных 210. Другими словами, номер ПИДН отражает факт, что много множественных записей в необработанных данных 210 могут относиться к одному и тому же лицу.
Предпочтительно, чтобы каждая запись данных в ключевой таблице 610 первоначально соответствовала другой записи данных, представленной в таблицах необработанных данных 510, 520 и 530. Например, на фиг.6 запись данных 610-10 в ключевой таблице 610 реализована так, что она включает в себя идентификаторы (такие, как указатели или индексы) для соответствующих данных в эталонных таблицах 620-670, которые вместе соответствуют одной записи 520-6 в таблице необработанных данных 520.
Первоначально, в то время как один ПИДН не соответствует множеству лиц, одно лицо может соответствовать множеству ПИДН. Например, на фиг.6 вектор 4 (определенный с помощью ПИДН 4) и вектор 9 (определенный с помощью ПИДН 9) относятся к тому же самому лицу, но как показано, этому лицу первоначально присвоено два ПИДН номера - ПИДН 4 и ПИДН 9. Как описано ниже, настоящее изобретение дает возможность определить, относятся ли на самом деле ПИДН 4 и ПИДН 9 к тому же самому лицу, и если так, назначает один ПИДН этому лицу. Альтернативно, некоторые варианты осуществления могут присваивать новый номер ПИДН лицам, определенным таким образом, а ссылка на старый номер ПИДН может быть сохранена.
Как обсуждено выше, в этом варианте осуществления записи представлены в таблицах эталонной базы данных 610-670 как векторы, имеющие в качестве коэффициентов числа с основанием 40 по восьми таблицам с одним полем. Это цифровое представление позволяет проанализировать данные с использованием простых математических операций, которые могут использоваться, например, для выполнения корреляции, вычисления собственных векторов, выполнения различных координатных преобразований и использования различных процедур распознавания образов. Эти операции могут, в свою очередь, использоваться, чтобы выдавать или получать информацию относительно записей и их соотношения друг с другом. С использованием малых таблиц с одним полем эти операции могут быть выполнены быстро. Кроме того, как будет показано, представление необработанных данных 210, которые включают в себя буквенно-цифровые символы, числами с основанием 40, позволяет сохранять семантическое значение содержимого необработанных данных 210.
Диализ данных
Согласно фиг.2, как только эталонная база данных 220 создана, как показано на фиг.6, применяется процесс 700 диализа данных для получения наиболее точных данных для включения в очищенную базу данных 230. Диализ 700 описан ниже со ссылкой на фиг.7.
Разделение эталонных данных
На этапе 710 эталонная база данных 220 предпочтительно разделяется или сортируется на наборы, основываясь на некоторых критериях. Эти критерии сортировки могут изменяться. Например, как показано в таблице 810 на фиг.8, в этом варианте осуществления записи данных могут сортироваться на наборы, основываясь на фамилии, со значениями, упорядоченными по возрастанию чисел (содержимое необработанных данных теперь представлено как числа с основанием 40 в эталонной базе данных 220). Таблица 810 получена из таблицы эталонной базы данных 620, показанной на фиг.6, причем каждый элемент таблицы 810 определен уникальной фамилией и имеет соответствующий набор записей таблицы 620, соответствующих этой фамилии. В показанном представлении таблица 810 включает в себя поле для определения набора (в этом случае фамилия), а также идентификаторы для элементов набора (такие, как индексы, указатели или другие подходящие эталоны - в данном случае ПИДН).
В некоторых вариантах осуществления настоящего изобретения не все векторы в эталонной базе данных 220 будут иметь данные в том поле, на котором основаны наборы. Такие векторы могут обрабатываться различными способами. Например, все векторы в эталонной базе данных 220, которые не имеют данных в этом поле данных, могут быть расценены как элементы одного дополнительного набора. Альтернативно, каждый вектор в эталонной базе данных 220, который не имеет данных в этом поле данных, может быть расценен как единственный элемент своего собственного набора.
Идентификация дублированных данных
Согласно фиг.7, на этапе 720 отмечаются те записи данных в разделенных наборах, которые идентифицированы как дублированные. В некоторых вариантах осуществления настоящего изобретения дублированные данные могут быть не нужны и могут быть отброшены. В других вариантах осуществления вся информация остается в эталонной базе данных 220, т.к. вся информация, даже ошибочная, неполная или дублированная информация, может быть лучше, чем отсутствие информации, и может быть полезна для некоторых целей, таких как идентификация мошенничества или воровства.
В некоторых вариантах осуществления настоящего изобретения, сравнивая пару векторов, можно идентифицировать дубликаты. Очевидно, что могут использоваться различные операции. В простом примере может быть выполнено прямое векторное вычитание, чтобы измерить степень подобия между двумя записями. Могут использоваться другие методы для идентификации дублированных векторов, такие как использование таблиц "поиска", чтобы идентифицировать общие имена, прозвища, аббревиатуры и т.д.
Таблица 810 на фиг.8 показывает, что фамилия "Smith" соответствует ПИДН 2, 4, 8, 9 и 11, которые представляют векторы, сформированные из записей 2, 4, 8, 9 и 11 таблиц эталонной базы данных 610 - 670, показанных на фиг.6:
Для ПИДН 2: [SMITH, J, 98-002, А40, А60, ^]
Для ПИДН 4: [SMITH, 98-004, А50, В10, ^]
Для ПИДН 8: [SMITH, Jennifer, ^, А40, ^, 300 Pine St.]
Для ПИДН 9: [SMITH, John, ^, А50, ^, 37 Hunt Dr.]
Для ПИДН 11: [SMITH, John, ^, В10, ^, 85 Belmont Ave.]
Векторные (или матричные) операции, сравнивающие векторы и пороги для определения того, что две записи достаточно подобны, чтобы быть расцененными как дубликаты, могут быть определены, как подходящие для различных вариантов осуществления. В простом примере сумма абсолютных разностей между соответствующими коэффициентами пары векторов может указывать на подобие между соответствующей парой записей. Эта пара векторов может считаться дубликатами, если первый вектор не противоречит ни в одном поле второму вектору и не обеспечивает никаких дополнительных данных. В этом варианте осуществления также могут быть определены дополнительные правила, например, для сравнения элементов различных длин (например, выровненные вправо строки символов, соответствующие числам, и выровненные влево строки символов, соответствующие буквам) для распознавания обычной орфографической ошибки или слов с различным написанием и для распознавания переставленных букв в словах. Очевидно, что эта обработка может быть выполнена с помощью различных методов обработки. В примере таблицы 810 на фиг.8 ни одна из записей данных не является точным дубликатом, и таким образом на этапе 720 ничего не отмечается.
Корреляция данных
Согласно фиг.7, на этапе 730 в предпочтительном варианте осуществления настоящего изобретения определяется корреляция записей данных, остающихся в каждом наборе, и на этапе 740 записи данных подразделяются на независимые подмножества записей данных. В общем случае "корреляция" между двумя векторами является мерой того, как близко один соотносится с другим, и конкретные способы корреляции могут изменяться в зависимости от предполагаемого применения. Примеры корреляционных функций могут быть найдены в справочной литературе (см., например, NUMERICAL RECIPES IN С: THE ART OF SCIENTIFIC COMPUTING (Cambridge University Press, 2nd ed. 1992) by William H.Press, et al. THE ART OF COMPUTER PROGRAMMING (Addison-Wesley Pub., 1998) by Donald E.Knuth). Другие методы и примеры могут быть найдены в книге THE ART OF COMPUTER PROGRAMMING (Addison-Wesley Pub., 1998) by Donald E.Knuth.
Например, простое измерение корреляции между векторами представляет собой определение их скалярного произведения, которому может быть присвоен соответствующий коэффициент. В зависимости от приложения скалярное произведение может быть вычислено только на подмножестве векторных коэффициентов или определено путем сравнения не только соответствующих коэффициентов, но и других пар коэффициентов, которые определены как находящиеся в связанных полях (т.е. сравнивая коэффициент "имени" первого вектора с коэффициентом "второго имени" второго вектора). Как и в случае с операциями для идентификации дублированных данных, корреляционная функция может быть соответственно адаптирована для конкретного применения. Очевидно, например, что корреляционная функция может быть определена для соответственного сравнения элементов различной длины и различения существенных и несущественных различий.
В варианте осуществления, объясненном со ссылкой на таблицы, показанные на фиг.5, 6 и 8, приведен пример корреляционной функции, которая сравнивает векторы, соответствующие элементам набора, совместно использующим ту же самую фамилию для идентификации независимых подмножеств векторов. Точно так же это определение может быть основано на критериях, зависящих от приложения. В этом примере независимые векторы могут быть определены как векторы, представляющие различных лиц.
В результате применения корреляционной функции назначается параметр корреляции, отражающий степень независимости пары векторов. Например, высокое значение может быть назначено для указания высокой степени подобия, а низкое значение может быть назначено для указания ограниченной степени подобия. Значение корреляции затем сравнивается с предварительно определенным пороговым значением, которое может изменяться в различных приложениях, чтобы определить, являются ли независимыми две записи, соответствующие рассматриваемым векторам.
Основываясь на значениях корреляции, на этапе 740 в предпочтительном варианте осуществления изобретения записи данных разделяют на подмножества независимых записей данных в каждом наборе. В примерах по фиг.5, 6 и таблицах 810 на фиг.8 элементы независимого подмножества могут быть идентифицированы как элементы, имеющие ту же самую фамилию (учет орфографических ошибок и разновидностей написания); относительно подобные имена (учет орфографических ошибок, разновидностей написания, прозвищ и комбинаций первых и вторых имен и инициалов); один или большее количество совпадающих номеров счета; и имеющие не больше, чем три адреса (чтобы учесть рабочий и домашний адреса и одно изменение адреса).
Результаты применения такой функции показаны в таблице 820 на фиг.8. Идентифицированы следующие лица:
Jennifer Brown, ПИДН 10;
Howard Lee, ПИДН 3 и 6;
Carole Lee, ПИДН 7;
Jennifer Smith, ПИДН 2 и 8;
John Smith, ПИДН 4 и 11;
John Smith, ПИДН 9;
Ann Zane, ПИДН 1, 5 и 12; и
Molly Zane, ПИДН 13.
Для определения корреляции векторов доступны и другие операции. Они могут включать в себя вычисление скалярных произведений, векторных произведений, длин, векторов направления и множество других функций и алгоритмов, используемых для оценки согласно известным методам.
Фиг.9 иллюстрирует двумерный пример концепции, названной кластеризацией, которая используется концептуально для описания некоторых общих аспектов настоящего изобретения. На фиг.9 четыре кластера (группы) существуют как совокупность двумерных точек. Эти кластеры идентифицированы как (а, b), (с, d), (е, f), и (g, h). Как показано, каждый кластер сформирован из одной или большего количества точек в двумерном пространстве. Каждая точка соответствует записи данных, которая представляет (с большей или меньшей точностью) "истинное" значение кластера в пространстве. Как показано, кластеры (а, b,) и (с, d) довольно просто отличить друг от друга и от кластеров (е, f) и (g, h). Однако в этом простом примере кластеры (е, f) и (g, h) не легко отличить друг от друга. Расширение пространства (т.е. добавление дополнительных полей данных к векторам) может увеличивать степень различия между кластерами типа (е, f) и (g, h) так, чтобы они стали более сильно отличаться друг от друга. В свою очередь, расширение пространства может указывать, что (g, h) - точка, которая принадлежит кластеру (е, f) или даже кластеру (с, d). Если рассматривать абстрактно, пространство может расширяться бесконечно, что приведет к гильбертову пространству, которое имеет различные известные характеристики. Очевидно, что эти характеристики могут использоваться в настоящем изобретении для больших, хотя не бесконечных, векторов.
Кроме того, при добавлении дополнительных полей данных к векторам (т.е. расширяя пространство) можно отделить кластеры друг от друга, чтобы помочь в определении их корреляции, удаляя поля данных из векторов (т.е. сокращая пространство) можно также идентифицировать корреляцию. В некоторых вариантах осуществления настоящего изобретения, сокращая пространство, можно идентифицировать кластеры, которые фактически представляют то же самое лицо или другой уникальный объект. Например, одна запись в базе данных может иметь десять полей данных, в точности идентичных тем же самым десяти полям данных во второй записи в базе данных. Эти поля данных могут соответствовать по имени, дате рождения, адресу, девичьей фамилии матери и т.д. Однако эти две записи могут иметь два поля, которые являются различными. Эти два поля могут соответствовать фамилии и номеру социального обеспечения. В некоторых случаях эти записи могут соответствовать тому же самому человеку. Настоящее изобретение упрощает процесс идентификации этих типов записей, которые было бы трудно, если вообще возможно, обнаружить, используя обычные способы.
Таким образом, удаляя одно или большее количество определенных полей данных из вектора и сокращая соответствующее пространство, можно показать кластеры, которые иначе не были бы очевидны. Делая это для полей данных, традиционно используемых для целей идентификации (например, фамилия, номер социального обеспечения и т.д.), можно показать дублированные записи в базах данных. Это может быть особенно полезно для идентификации мошенничества. Удаляя поля данных в том случае, когда вектор включает в себя значение пустого поля данных, можно также показать кластеры, которые иначе не были бы очевидны.
Кроме того, как только кластеры идентифицированы, как представляющие одного и того же человека или объект, наилучшая информация для этого лица или объекта может быть извлечена из информации, обеспеченной каждой записью или "черной точкой".
Принципы настоящего изобретения могут быть расширены за пределы простых векторов и полей данных. Например, настоящее изобретение может быть расширено за счет тензоров, представляющих объекты в многомерном пространстве. Таким образом, настоящее изобретение может использоваться для представления параметров различных физических явлений, чтобы получить дополнительное представление об их работе и эффекте. Такое приложение может быть особенно полезно для декодирования гена человека и может помочь в программах исследований, таких как проект генома человека.
Обработка "переплетенных" данных
Согласно фиг.1, на этапе 750 в предпочтительном варианте осуществления настоящего изобретения оцениваются "переплетенные" записи данных. Переплетенные записи данных - это те записи из эталонной базы данных 220, которые не были распределены в какой-нибудь набор на этапе 730. В некоторых вариантах осуществления эталонная база данных 220 может включать в себя большое количество таблиц, соответствующих полям данных, и большое количество векторов, имеющих данные для различных комбинаций полей. Например, в варианте осуществления, имеющем эталонную базу данных 220, включающую в себя 20 таблиц для различных полей данных и 1000 векторов, определенных соответствующими записями данных для каждой таблицы, предположим, что только 800 из тех 1000 векторов имеют данные для поля "фамилия", по которым наборы создавались на этапе 710. На этапе 710 эти 200 векторов без данных "фамилия" могут не распределиться в какой-нибудь набор или каждый из этих 200 векторов может распределиться в собственный набор. В любом случае результатом является то, что эти 200 векторов не коррелируются с другими на этапах 720, 730 и 740. На этапе 750 эти векторы могут оцениваться.
Способы оценки могут изменяться. Например, в одном варианте осуществления каждый "переплетенный" элемент может коррелироваться с одним элементом каждого подмножества, идентифицированного на этапе 740. В зависимости от полученных в результате значений корреляции этот вектор может быть добавлен к подмножеству, с которым он наиболее сильно коррелируется, или может определить новое подмножество. Альтернативно, в некоторых вариантах осуществления может быть определено, что такая оценка требует слишком много времени и/или является дорогостоящей, и этап 750 может быть полностью пропущен.
Повторение процесса определения корреляции
Этапы 710-750 могут быть повторены, при необходимости, для определенных вариантов осуществления. Как отмечено выше, в некоторых вариантах осуществления будут иметься эталонные данные 220 с большим количеством полей и большим количеством записей, причем множество записей имеют данные только в подмножестве полей. В таком случае, выполняя этапы 710-750 с одним полем, вряд ли можно получить всю необходимую информацию. Даже в простом примере, объясненном со ссылкой на фиг.5, 6 и 8, коррелирование по одному полю "фамилия" может обеспечивать только частичную информацию относительно корреляции между этими элементами. Например, Jennifer Smith с соответствующим ПИДН 2 и 8 на фиг.6, может быть тем же самым человеком, что и Jennifer Brown с соответствующим ПИДН 10, потому что ПИДН 2 и 10 могут совместно использовать общий номер счета. Выполнение коррелирования по полю фамилии не может идентифицировать эти ПИДН, как соответствующие одному и тому же лицу, потому что это можно оценить только по другим ПИДН, совместно использующим ту же самую фамилию. Выполнение коррелирования по полю номера счета может обеспечивать дополнительную информацию о том, связаны ли эти ПИДН.
Таким образом, коррелирование по различным полям данных может быть необходимо для того, чтобы полностью оценить степень связанности данных в эталонной базе данных 220.
Использование результатов коррелирования для обновления эталонных данных
Как только этапы 710-760 закончены, эталонная база данных 220 очищена и в результате получена очищенная база данных 230, как показано на фиг.2. В некоторых вариантах осуществления настоящего изобретения эти две базы данных обрабатываются отдельно и сосуществуют друг с другом.
В других вариантах осуществления настоящего изобретения одна база данных существует с записями, отмеченными или иначе идентифицированными, как принадлежащими к эталонной базе данных 220 или к очищенной базе данных 230. Это может быть выполнено с помощью назначения различных диапазонов ПИДН, использующихся для записей в этих двух базах данных. Кроме того, отношения между записями в этих двух базах данных могут поддерживаться, добавляя постоянное значение к ПИДН для записи в эталонной базе данных 220, чтобы генерировать ПИДН для записи в очищенной базе данных 230. Например, запись с ПИДН 12345 в эталонной базе данных 220 может иметь ПИДН 9012345 в очищенной базе данных 230. Таким образом, эти две базы данных могут обрабатываться как разные части одной базы данных.
Использование очищенных данных
Как только процесс 700 диализа данных закончен, очищенная база данных 230 идентифицирует подмножество записей данных из эталонной базы данных 220 как связанные записи, и как отмечено выше, могут быть определены вероятности для полей в эталонной базе данных 220, чтобы обеспечить качественную меру их полноты. Это может быть выполнено с помощью назначения вероятности полноты каждому из отдельных полей данных и затем использования их для вычисления полной вероятности полноты для записи данных. Например, для поля данных, представляющего имя, значению "J" может быть назначена низкая вероятность (например 0 или 0,1), значению "JOHN" может быть назначена более высокая вероятность (например, 0,7 или 0,8) и значению "JONATHAN" может быть назначена самая высокая вероятность (например, 0,9 или 1,0). Эти значения могут быть назначены произвольно или согласно некоторой гипотезе структуры. Однако эти значения помогают идентифицировать, какие поля данных в наборе наиболее вероятно включают в себя наиболее полную информацию или, другими словами, наиболее вероятные данные.
Использование настоящего изобретения может определять значительное количество информации относительно записей и их соотношения друг с другом и может быть адаптировано для конкретных применений. Кроме того, используя стандартные операции базы данных, можно манипулировать очищенной базой данных 230 (которая создается из эталонных записей в эталонной базе данных 220) для того, чтобы, при необходимости, обеспечить отформатированные сообщения. Например, возможный вариант осуществления может быть приспособлен для генерирования сообщения, содержащего список подмножества связанных записей, при этом записи подмножества обеспечивают информацию относительно определенного лица или объекта. Записи в таком подмножестве могут обеспечивать информацию, например, о различных полях информации; псевдонимах и/или вариациях имен, адресах, номерах социального обеспечения и т.д., используемых одним лицом; и полях - таких как профессия, адрес и номера счетов, для которых у этого лица может иметься больше, чем один элемент.
С учетом того, что все данные представлены в цифровом формате с основанием 40, подмножества в сообщении можно упорядочивать в цифровой форме. Формат с основанием 40 обеспечивает дополнительное преимущество представления буквенно-цифровых символов как соответствующие им буквы (как показано в таблице преобразования выше). Таким образом, в то время как сообщение будет показывать элементы в цифровом представлении, это представление сохраняет семантическое значение данных, которые оно представляет, позволяя вручную читать и анализировать данные. Например, если сообщение показывает записи для лица, имеющего элементы для имен, которые включают в себя J SMITH, JOHN SMITH, JOHN G SMITH, G SMITH и GERALD SMITH, то человек, читающий это сообщение, поймет, что указанное лицо использует различные имена, которые включают в себя его имя или инициал, его второе имя или инициал или некоторую комбинацию из них.
Добавление новых данных
Как и в обычных прикладных задачах баз данных, время от времени могут добавляться новые данные. Как показано на фиг.2, настоящее изобретение учитывает добавление новых (или измененных) данных 240, которые будут оказывать влияние на эталонную базу данных 220 и очищенную базу данных 230.
В общем случае новые записи данных 240 могут быть отформатированы, как описано со ссылкой на фиг.3, и введены в существующую эталонную базу данных 220. Дополнительно, новые записи данных 240 могут сравниваться с очищенной базой данных 230, чтобы определить, доступна ли новая информация или содержимое в новой записи данных 240. Например, новая запись данных 240 может коррелироваться с записями данных в очищенной базе данных 230, чтобы определить, относится ли новая запись данных 240 к какой-нибудь записи данных, уже представленной в очищенной базе данных 230. Если это так, и новая запись данных 240 содержит информацию или содержимое, еще не находящиеся в очищенной базе данных 230, то новая запись данных 240 может использоваться для обновления очищенной базы данных 230. Например, если новая запись данных 240 включает информацию о человеке по имени John Smith, которая соответствует записям данных, уже представленным в очищенной базе данных 230, но которая обеспечивает дополнительную информацию о том, что второе имя г-на Smith -Greg, эта дополнительная информация может быть соответственно добавлена к очищенной базе данных 230.
Изменения в записях данных эталонной базы данных 220 и очищенной базы данных 230 могут быть осуществлены с помощью стандартных операций защиты базы данных, как описано в упомянутой выше справочной литературе (см. C.J.Date, Introduction To Datebase Systems (Addison Wesley. 6th ed. 1994), особенно часть IV). Например, в случае, когда изменения сделаны в эталонной базе данных 220 уполномоченным администратором базы данных, связанные записи данных в эталонной базе данных 220 обновляются, как определено стандартными реляционными определениями и где это целесообразно, в соответствии со связями, определенными в очищенной базе данных 230.
Идентификация дублированных данных в векторах полей
Одна из проблем, связанных с обычными базами данных, - трудность в объединении записей из первой базы данных, таких как необработанные данные 210А, с записями из второй базы данных, такими как необработанные данные 210В. Записи в этих базах данных, имеющие совместно использующиеся или дублированные данные, должны быть идентифицированы таким образом, чтобы содержимое, находящееся там, могло быть объединено в одну запись в базе данных, такой как эталонная база данных 220 или очищенная база данных 230. Например, обе базы данных 210 могут включать в себя один или большее количество элементов для John Smith. Если соответствующие записи в базах данных 210 представляют то же самое лицо -John Smith, то содержимое каждой из записей должно быть объединено в одну запись, например, в очищенной базе данных 230.
Обычные способы идентификации методом решения "в лоб" для таких дублированных данных в этих базах данных приводят к сравнению записей данных первой базы данных с каждой записью данных второй базы данных и повторению этого процесса для каждой записи первой базы данных. Этот процесс требует много времени и интенсивных вычислений и соответственно является дорогостоящим. Фактически, количество вычислений находится в геометрической прогрессии от количества записей в каждой из этих двух баз данных.
Возможный процесс для сокращения времени и объема вычислений, требуемых для идентификации дублированных данных в базах данных 210, описан ниже со ссылкой на фиг.10-12. В процессе, описанном ниже, выбирается определенное поле, общее или подобное для баз данных, например поле имени или поле адреса. Это поле располагается как таблица или массив для каждой из баз данных, которая включает в себя значение выбранного поля для каждой из записей. Например, как обсуждено выше, каждая таблица 610-670 представляет определенное поле каждой записи данных в базе данных. В целях настоящего обсуждения эти таблицы названы векторами полей.
Согласно настоящему изобретению, каждый из векторов полей сортируется по порядку чисел и в случае необходимости разбивается на наборы идентичных данных, как описано выше относительно фиг.7 и 8. Например, множество записей, связанных с John Smith, было бы выделено в общий набор в векторе поля. Предпочтительно, информация относительно расположения распределений между наборами сохраняется.
Как только векторы полей отсортированы и распределены, значение первого элемента первого вектора поля сравнивается с значением первого элемента второго вектора поля. По существу, если значение первого вектора поля больше, чем значение второго вектора поля, индекс второго вектора поля увеличивается или иначе настраивается на позицию в следующем распределенном наборе, чтобы получить следующее значение во втором векторе поля. Это следующее значение во втором векторе поля затем сравнивается со значением в первом векторе поля. Это продолжается до тех пор, пока значение в первом векторе поля больше, чем значение во втором векторе поля.
С другой стороны, если значение первого вектора поля меньше, чем значение второго вектора поля, индекс в первом векторе поля увеличивается или иначе настраивается на позицию в следующем распределенном наборе, чтобы получить следующее значение в первом векторе поля. Это следующее значение в первом векторе поля затем сравнивается со значением во втором векторе поля. Это продолжается до тех пор, пока значение в первом векторе поля меньше, чем значение во втором векторе поля.
Когда значение в первом векторе поля равняется значению во втором векторе поля, это значит, что процесс идентифицировал дублированные данные, которые затем предпочтительно сохраняются в векторе общих полей. После сохранения идентифицированных дублированных данных, индекс в первом векторе поля и индекс во втором векторе поля увеличиваются или иначе настраиваются на позиции в следующем распределенном наборе соответствующих векторов поля.
Описанный процесс может быть рассмотрен как метод управления с обратной связью, который настраивает индекс в каждом из массивов, основываясь на разнице между значениями в векторах поля. В варианте осуществления, описанном выше, положительная разность производит настройку индекса второго вектора поля, тогда как отрицательная разность производит настройку индекса первого вектора поля. Этот процесс приводит к линейному отношению между количеством значений в векторах поля и требуемым количеством вычислений (т.е. сравнений) в противоположность геометрическим отношениям, связанным с обычными способами.
Настоящее изобретение может быть распространено также на способы сортировки. В случаях, когда определенное значение должно быть помещено в вектор поля (т.е. запись должна быть помещена в базу данных), основываясь на упорядочении значений в векторе (например, в алфавитном порядке, в цифровом порядке и т.д.), вычисляется разность между определенным значением и значением одного из элементов в векторе. Эта разность "возвращается", чтобы настроить индекс в векторе для того, чтобы выбрать следующее значение из вектора. Используя известные способы теории управления, настройка индекса может быть интегрирована для определения надлежащего расположения значения, которое будет помещено. Очевидно, что в дополнение к интегратору может применяться пропорциональное усиление для разности, чтобы установить желаемую эффективность системы.
Настоящее изобретение описано ниже со ссылкой на фиг.10-12. Фиг.10 - последовательность операций программы для идентификации дублированных данных в паре векторов полей. Векторы полей могут быть из одного источника, такого как необработанные данные 210А (например, при сравнении поля адреса проживания с почтовым адресом в одной базе данных), или из многих источников, таких как необработанные данные 210А и необработанные данные 210В (например, при сравнении поля имени в двух базах данных).
Для настоящего описания пара векторов поля названа первым вектором поля ("FV1") и вторым вектором поля ("FV2") соответственно. Предпочтительно, данные в этих векторах поля являются числами с основанием 40, которые представляют буквенно-цифровые данные, как описано выше. Однако в некоторых вариантах осуществления настоящего изобретения данные также могут существовать в других формах.
На этапе 1010 первый вектор поля сортируется по порядку чисел. На этапе 1020 второй вектор поля также сортируется по порядку чисел. В одном варианте осуществления настоящего изобретения векторы сортируются по порядку увеличения чисел, хотя очевидно, что в других вариантах осуществления настоящего изобретения векторы могут сортироваться по порядку уменьшения чисел.
На этапе 1030 идентифицируются распределенные наборы в первом векторе поля, имеющие общие значения. Аналогично, на этапе 1040 также идентифицируются распределенные наборы во втором векторе поля, имеющие общие значения. Этапы 1010-1040 выполняют подобную функцию по отношению к этапу распределения эталонной базы данных 220, описанному выше со ссылкой на фиг.7 и 8. В некоторых вариантах осуществления настоящего изобретения векторы поля могут не включать в себя распределенные наборы, поскольку общие значения в каждом векторе поля, возможно, уже были удалены. Однако в предпочтительном варианте осуществления настоящего изобретения общие значения в определенном векторе поля существуют.
На этапе 1050 определяется вектор общих значений, который идентифицирует общие значения в первом и втором векторах поля, предпочтительно используя распределенные наборы. Этап 1050 описывается в дальнейшем подробно со ссылкой на фиг.11.
Фиг.11 - последовательность операций программы для идентификации общих значений в паре векторов поля. На этапе 1110 инициализируются три векторных индекса. Первый векторный индекс I является индексом первого вектора поля FVI; второй векторный индекс J является индексом второго вектора поля FV2; и третий векторный индекс К является индексом вектора общих значений ("CV"). Как сказано выше, вектор общих значений включает в себя значения, общие для первого и второго вектора поля, индексы I и J инициализируются для того, чтобы определить первую позицию в первом и втором векторах поля соответственно. Индекс К инициализируется для того, чтобы определить позицию для следующего общего значения, которое будет включено в вектор общих значений.
На этапе 1120 принятия решения в настоящем изобретении определяется, является ли значение в 1-ой позиции первого вектора поля большим или равным значению J-ой позиции второго вектора поля. Если это так, то обработка продолжается на этапе 1130 принятия решения; иначе, обработка продолжается на этапе 1170. Этап 1170 выполняется, когда значение в 1-ой позиции первого вектора поля меньше, чем значение J-ой позиции второго вектора поля. На этапе 1170 первый индекс I настраивается, чтобы определить начало следующего распределенного набора в первом векторе поля. После этапа 1170 обработка продолжается на этапе 1160 принятия решения.
На этапе 1130 принятия решения в настоящем изобретении определяется, является ли значение в 1-ой позиции первого вектора поля равным значению J-ой позиции второго вектора поля. Если это так, то обработка продолжается на этапе 1140 принятия решения; иначе обработка продолжается на этапе 1180. Этап 1180 выполняется, когда значение в 1-ой позиции первого вектора поля больше, чем значение J-ой позиции второго вектора поля. На этапе 1180 второй индекс J настраивается, чтобы определить начало следующего распределенного набора во втором векторе поля. После этапа 1180 обработка продолжается на этапе 1160 принятия решения.
Этап 1140 выполняется, когда значение в 1-ой позиции первого вектора поля равно значению J-ой позиции второго вектора поля. На этапе 1140 значение, включенное и в первый, и во второй векторы поля, помещается в вектор общих значений.
На этапе 1150 третий индекс К увеличивается, чтобы определить позицию следующего общего значения в векторе общих значений, которое будет идентифицироваться. Первый индекс I настраивается, чтобы определить начало следующего распределенного набора в первом векторе поля. Второй индекс J настраивается, чтобы определить начало следующего распределенного набора во втором векторе поля.
На этапе 1160 принятия решения в настоящем изобретении определяется, существуют ли дополнительные распределенные наборы в первом и во втором векторе поля. Если это так, то обработка продолжается на этапе 1120. Если распределенных наборов не остаются ни в первом векторе поля, ни во втором векторе поля, то обработка заканчивается. Когда обработка заканчивается, вектор общих значений включает в себя все идентифицированные дублированные данные в первом и втором векторах поля.
Фиг.12 показывает пример идентификации дублированных данных в векторах поля согласно настоящему изобретению. Этапы 1010 и 1030 сортируют и распределяют вектор поля 1 ("FV1"), а этапы 1020 и 1040 сортируют и распределяют вектор поля 2 ("FV2"). Операция этапа 1050 ниже описана со ссылками на этапы 1110-1180, где проход через этапы от 1120 к 1160 и обратно к этапу 1120 назван "циклом".
В первом цикле первый элемент (т.е. 0-ая позиция) FV1 сравнивается с первым элементом FV2. (Это показано на фиг.12 как линия между FV1 и FV2, имеющая стрелки на обоих концах и обозначенная как 1). В этом примере значение "8" FV1 сравнивается со значением "8" FV2. На этапах 1120 и 1130 принятия решения определяют, что эти значения равны, и на этапе 1140 значение "8" помещается в вектор общих значений. (Это показано на фиг.12 как линия между FV2 и вектором общих значений, имеющая стрелки на обоих концах и обозначенная как 1'.] Этап 1150 настраивает индексы обоих векторов поля для указания на следующий распределенный набор. На этапе 1160 принятия решения определяется, что распределенные наборы существуют в обоих векторах поля, и начинается второй цикл.
Во втором цикле следующий элемент FV1 сравнивается со следующим элементом FV2. В этом примере значение "9" FV1 сравнивается со значением "9" FV2. Снова определяется, что эти значения равны, и значение "9" помещается в вектор общих значений. Как прежде, этап 1150 настраивает оба индекса для указания на следующие распределенные наборы в соответствующих векторах поля. На этапе 1160 принятия решения определяется, что распределенные наборы существуют в обоих векторах поля, и начинается третий цикл.
В третьем цикле следующий элемент FV1 сравнивается со следующим элементом FV2. В этом примере значение "10" FV1 сравнивается со значением "12" FV2. На этапе 1120 принятия решения определяется, что значение в FV1 не больше или равно значению в FV2, и на этапе 1170 индекс FV1 настраивается для указания на следующий распределенный набор. На этапе 1160 принятия решения определяется, что распределенные наборы существуют в обоих векторах поля, и начинается четвертый цикл.
В четвертом цикле следующий элемент FV1 сравнивается с предыдущим значением FV2. В этом примере значение "12" FV1 сравнивается с предварительно сравненным значением "12" FV2. На этапах 1120 и 1130 принятия решения определяют, что значения равны, и на этапе 1140 значение "12" помещается в вектор общих значений. На этапе 1150 оба индекса настраиваются для указания на следующий распределенный набор в соответствующих векторах поля. На этапе 1160 принимается решение, что распределенные наборы существуют в обоих векторах поля, и начинается пятый цикл.
В пятом цикле следующий элемент FV1 сравнивается со следующим значением FV2. В этом примере значение "15" FV1 сравнивается со значением "18" FV2. На этапе 1120 принятия решения определяется, что значение в FV1 не большее или равно значению в FV2, и на этапе 1170 индекс к FV1 настраивается для указания на следующий распределенный набор. Поскольку распределенных наборов в FV1 более не существует, обработка заканчивается.
В этом примере требуется пять циклов с максимально двумя сравнениями за цикл для идентификации трех общих значений двух векторов поля. При обычном способе решения по методу "в лоб" требуется 132 сравнения (12*11).
Предварительное кодирование информации
В различных вариантах осуществления настоящего изобретения, до или одновременно с преобразованием данных из их первоначального формата в цифровой формат, данные предварительно кодируются в промежуточный кодовый формат. Это предварительное кодирование дополнительно уменьшает или сжимает информацию в первоначальном формате в кодовый формат. Находясь в кодовом формате, данные могут быть впоследствии представлены в соответствующем цифровом формате, как описано выше. Эти варианты осуществления настоящего изобретения описаны на примерах.
В одном варианте осуществления настоящего изобретения используются фонемы, чтобы представить данные в первоначальном формате как кодовый формат. В этом варианте осуществления фонемы могут использоваться, чтобы кодировать слова, части слов (например, слоги) или фразы из слов. Таким образом, идентичные или сходным образом звучащие слова или слоги представляются с использованием тех же самых фонем. Например, имена "John" или "Jon" были бы представлены с использованием тех же самых фонем. В некоторых вариантах осуществления имя "Joan" может также быть представлено с использованием тех же самых фонем, какие использовались для имен "John" и "Jon". Согласно настоящему изобретению, каждая фонема впоследствии представляется как цифра в соответствующей системе счисления, основанной частично на используемых фонемах.
Например, определенный язык может быть разбит на конечное число "звуков" или фонем и представлен как цифры в соответствующей системе счисления. Таким образом, текст может быть закодирован, основываясь на фонетике, а не на определенной орфографии, таким образом уменьшая влияние орфографических ошибок, например, при использовании поисковых серверов.
Эти варианты осуществления настоящего изобретения могут быть распространены на речь, распознавание речи и методы искусственного воспроизведения речи. В частности, слуховые речевые фонемы (в противоположность соответствующим текстовым фонемам) могут также быть представлены, как описано выше, в соответствующей системе счисления и могут использоваться, чтобы упростить распознавание речи и воспроизведение речи, как описано выше.
В других вариантах осуществления настоящего изобретения слова, фразы, идиомы, предложения и/или идеи могут быть предварительно закодированы и затем впоследствии представлены как цифры в соответствующей системе счисления, как описано выше. Такие варианты осуществления могут использоваться, например, для улучшения автоматических систем перевода с одного языка на другой. Эти варианты осуществления могут также использоваться, чтобы улучшить работу поисковых серверов. Большие части текста, которые относятся к одному или большему количеству идей или концепций, могут быть предварительно закодированы, основываясь на каждой из этих переданных идей или концепций. Эти варианты осуществления обеспечивают концептуальный поиск в противоположность идентификации и/или определению конкретных слов или фраз, которые могут или не могут появиться в процессе поиска.
В другом варианте осуществления настоящего изобретения необработанная информация адреса предварительно кодируется в координаты, выраженные, например, как долгота и широта, с последующим представлением в соответствующей системе счисления, например в системе счисления с основанием 60. Такая система может быть особенно полезна для картографических операций, навигационных систем или систем слежения.
В другом варианте осуществления настоящего изобретения необработанные данные отпечатков пальцев предварительно кодируются в различные параметры, совпадение точек или другие идентификационные индексы, подходящие для классификации отпечатков пальцев, каждый из которых затем представляется как соответствующая цифра в подходящей системе счисления. Каждый отпечаток пальца может таким образом быть представлен значением в поле, или альтернативно, каждый отпечаток пальца может быть представлен как вектор полей. Эти результирующие данные могут быть организованы и поддерживаться в базе данных такой информации, основанной на отпечатках пальцев, собранных у людей для различных целей (как криминальных, так и не криминальных). Они могут включать в себя отпечатки пальцев, собранные судебными специалистами, офицерами охраны, исследователями происхождения и т.д. Настоящее изобретение идеально подходит для чистки существующих баз данных отпечатков пальцев, объединения этих баз данных в эталонную базу данных, добавления новой информации об отпечатках пальцев, по мере того как она становится доступной, и сравнения информации отпечатков пальцев с информацией в эталонной базе данных.
Должно быть понятно, что в вариантах осуществления, использующих предварительное кодирование, во многих случаях основные исходные данные должны быть предварительно преобразованы в промежуточный формат. Таким образом, для использования настоящего изобретения в поисковом контексте искомая информация должна быть предварительно закодирована или "предварительно обработана". В некоторых случаях эта предварительная обработка может приводить к потере семантического значения, как описано выше для других вариантов осуществления настоящего изобретения.
Типичные варианты осуществления
Различные варианты осуществления настоящего изобретения могут использоваться для множества различных прикладных задач, ряд из которых был описан и/или на которые были приведены ссылки выше. Например, в описанном выше случае применения изобретение может использоваться для объединения информации составления счетов, собранной из множества источников, для получения очищенной базы данных, в которой связанные записи данных распознаны, а дублированные и ошибочные записи данных удалены. Это может быть особенно полезно, например, в случаях мошенничества. Как правило, лица, мошенническим путем использующие кредитную карточку или другие формы при розничной продаже, вносят незначительные изменения в некоторые части их персональной информации, сохраняя большую часть информации неизмененной. Например, часто, цифры в номере социального обеспечения могут быть перемещены, или может использоваться псевдоним. Часто, однако, другая информация, такая как адрес человека, дата рождения, девичья фамилия матери и т.д., используется без изменения. Эти типы мошенничества легко идентифицируются с помощью настоящего изобретения, при том, что их трудно определить с помощью анализа с участием человека.
Другие возможные применения включают в себя использование в телемаркетинге для составления перечня требуемых лиц или адресов; в каталогах заказа по почте для уменьшения количества каталогов, посланных одному и тому же лицу или семье; или для объединения записей в различных базах данных о продавцах, продающих подобные товары. Еще одной потенциальной областью применения являются медицинские исследования или диагностика, при которых могут быть идентифицированы последовательности нуклеотидов Adenine (A), Guanine (G), Cytosine (С) и Thymine (Т) в нуклеиновых кислотах. Изобретение может также применяться налоговыми органами, такими как Налоговое управление, государственные и местные органы власти и т.д. для организации и поддержания точных записей и основной налоговой информации.
В других вариантах осуществления настоящее изобретение может использоваться как "хранитель ввода" для конкретной базы данных с начала, чтобы поддерживать целостность базы данных с самого начала вместо того, чтобы достигать целостности базы данных позднее. В этих вариантах осуществления нет необработанных данных 210, а существуют только новые данные 240. Прежде чем новые данные 240 будут добавлены к базе данных, они сравниваются с очищенной базой данных 230, чтобы определить, включают ли в себя новые данные 240 дополнительную информацию или содержимое. Если это так, то только эта новая информация или содержимое добавляется к очищенной базе данных 230, обновляя существующую запись в очищенной базе данных 230, чтобы отразить новую информацию или содержимое.
В другом варианте осуществления настоящего изобретения почтовая служба, такая как почтовая служба США, или курьерская служба доставки, такая как воздушная курьерская служба, федеральная курьерская служба, объединенная служба посылок и т.д., использует настоящее изобретение, чтобы поддерживать перечень допустимых адресов доставки. Соответствующий адрес, куда предмет будет доставлен, проверяется в эталонной базе данных адресов, чтобы идентифицировать любые погрешности в адресе. Неточные адреса могут быть или исправлены (например, для переставленных чисел и т.д.) или можно войти в контакт с отправителем, чтобы проверить адрес. Новые адреса можно добавлять к эталонной базе данных, поскольку они станут доступными, например, когда предметы успешно доставлены. Кроме того, некоторые отправители могут быть идентифицированы как склонные к неправильной адресации предметов или выдаче неправильных адресов. В этом случае такие отправители могут соответственно уведомляться.
В дополнение к использованию настоящего изобретения для сравнения фрагментов последовательности ДНК, как обсуждено выше, генетические исследователи (например, компании, производящие лекарства, компании-селекционеры растений, селекционеры животных и т.д.) могут также использовать настоящее изобретение, чтобы представить явные, материальные и/или объективные характеристики отдельных особей в наборе и использовать эту информацию для идентификации отдельных генов или последовательности генов, ответственных за эти характеристики.
В другом варианте осуществления настоящее изобретение используется для переключения сигнала (пакета) и маршрутизации данных по сети, такой как Интернет. Входящие пакеты анализируются для определения адреса назначения и информации о последовательности и сортируются в соответствующую очередь вывода в надлежащем порядке. В этом варианте осуществления обеспечиваемая настоящим изобретением сортировка чисел позволяет получить значительное преимущество по сравнению с обычными системами. Данное преимущество вместе с расширенным пространством адресов из-за использования альтернативной системы счисления (в противоположность обычной традиционно используемой системе счисления) обеспечивает улучшенный способ адресации сети и протоколов связи.
В другом варианте осуществления настоящее изобретение используется для обработки и отображения объектов в трехмерной среде. Эти действия требуют огромного количества сортировок для определения того, какие объекты показывать на переднем плане, а какие объекты соответственно оказываются затененными на заднем плане, и для определения характеристик освещения для каждого из объектов (т.е. затенение и т.д.).
В то время как изобретение описано на примере конкретного предпочтительного варианта осуществления, другие варианты осуществления и видоизменения также включены в объем нижеследующей формулы изобретения. Например, в процессе 300 форматирования можно форматировать данные, используя различные основания системы счисления или другие наборы символов, и можно использовать различные структуры данных. Структуры данных могут представлять множество полей, и будут представлять разные поля в зависимости от конкретного применения. Например, в прикладной задаче кредита поля могут включать в себя состояние счета, номер счета и юридическое состояние, в дополнение к персональной информации относительно держателя счета. В прикладной задаче медицинской диагностики поля могут включать в себя различные аллели или другие генетические характеристики, обнаруженные в образцах ткани.
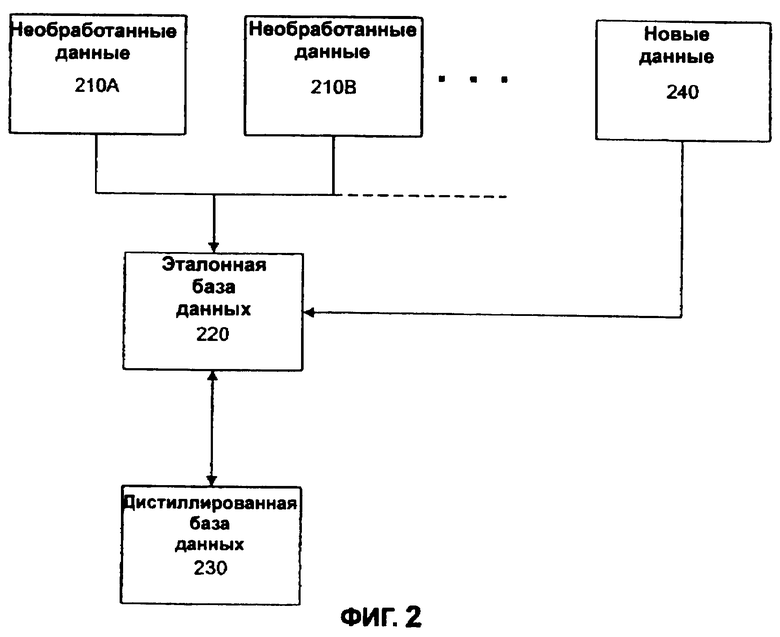
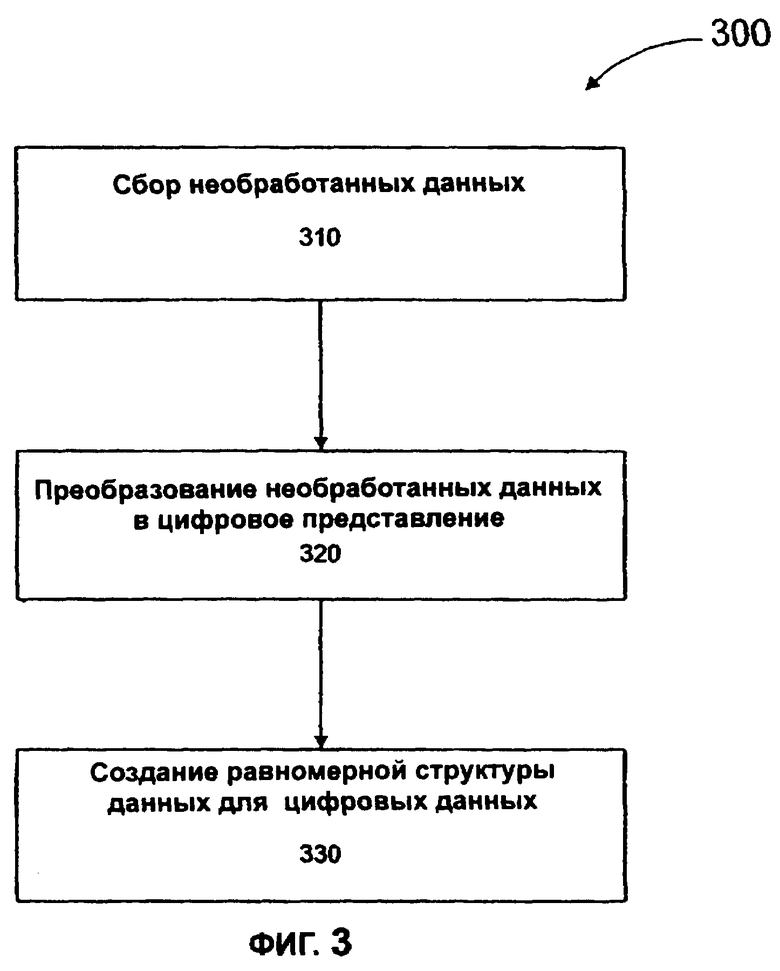
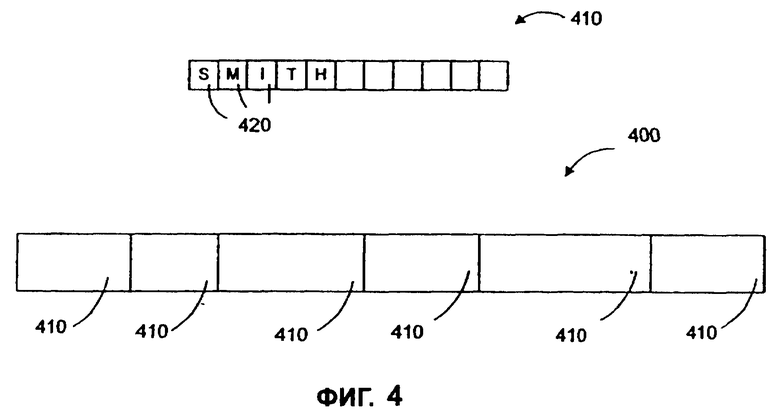
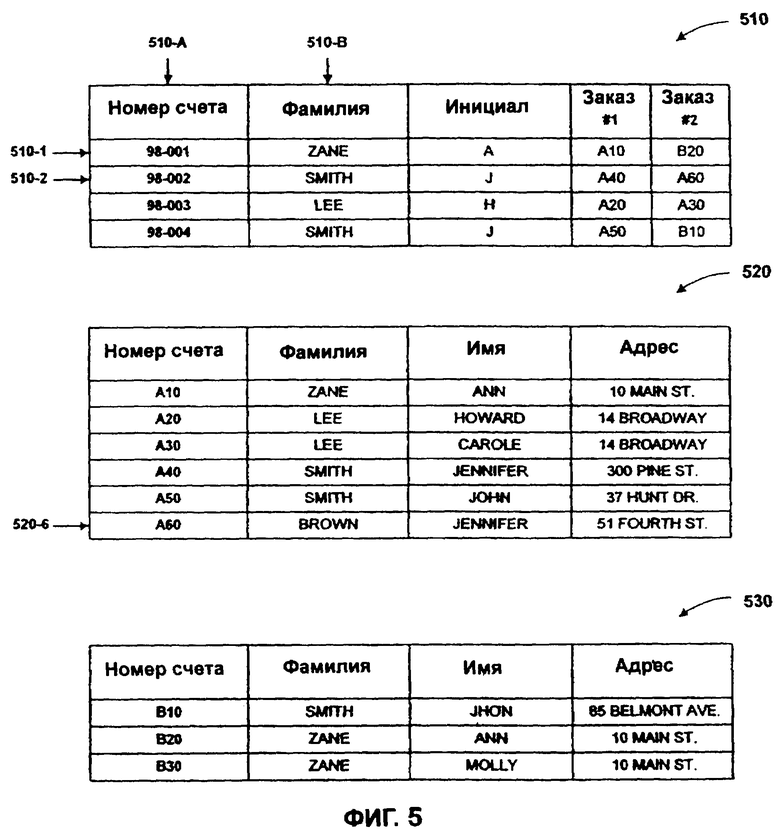
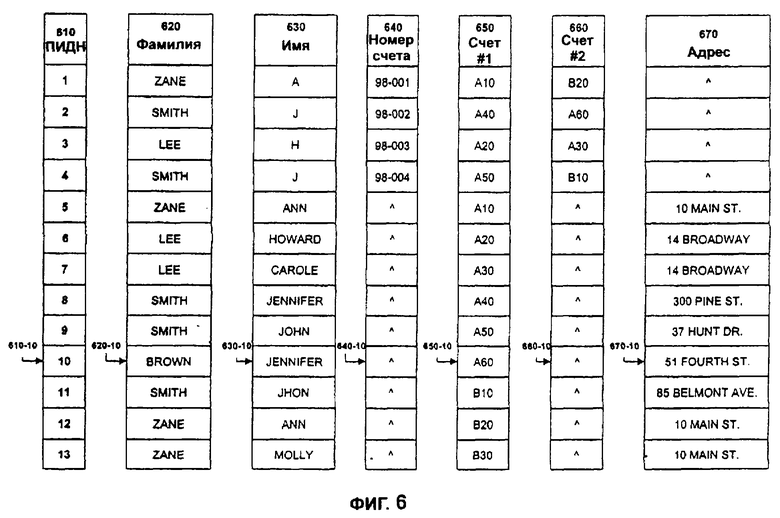
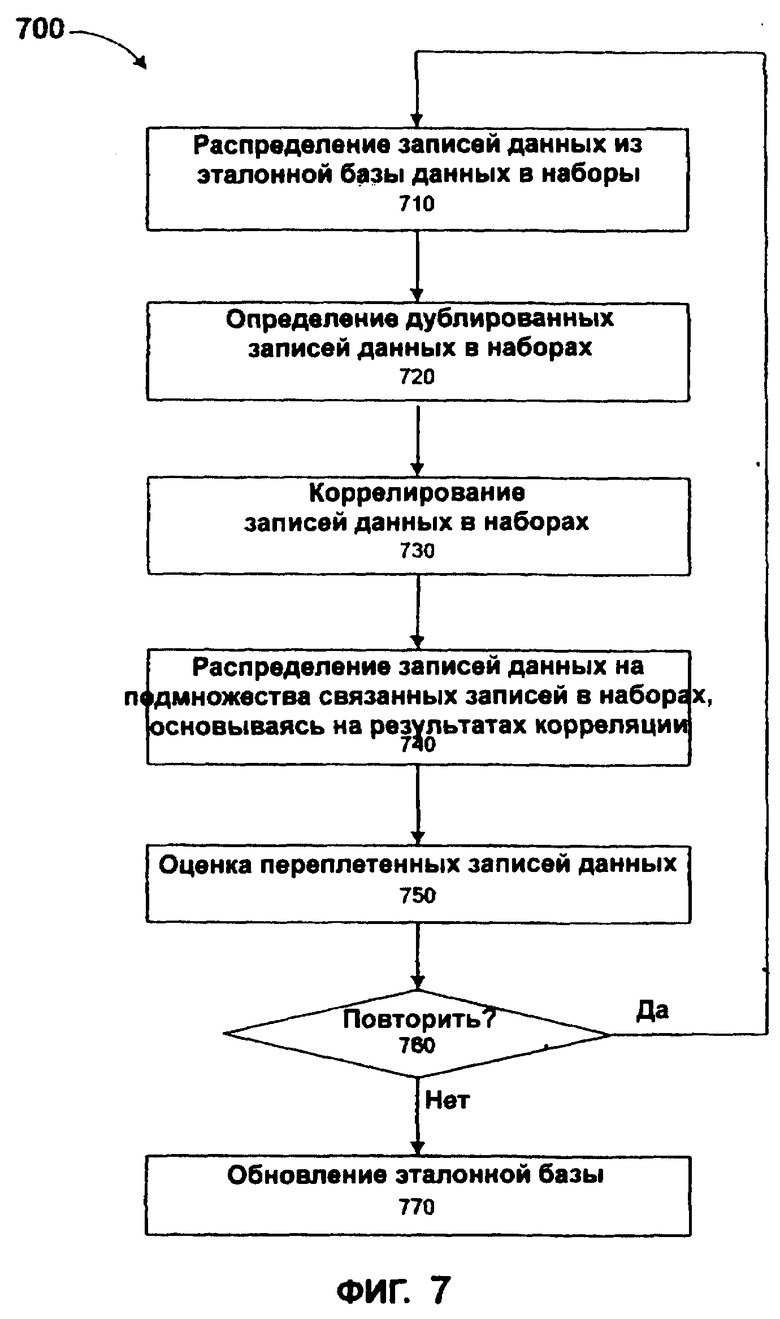

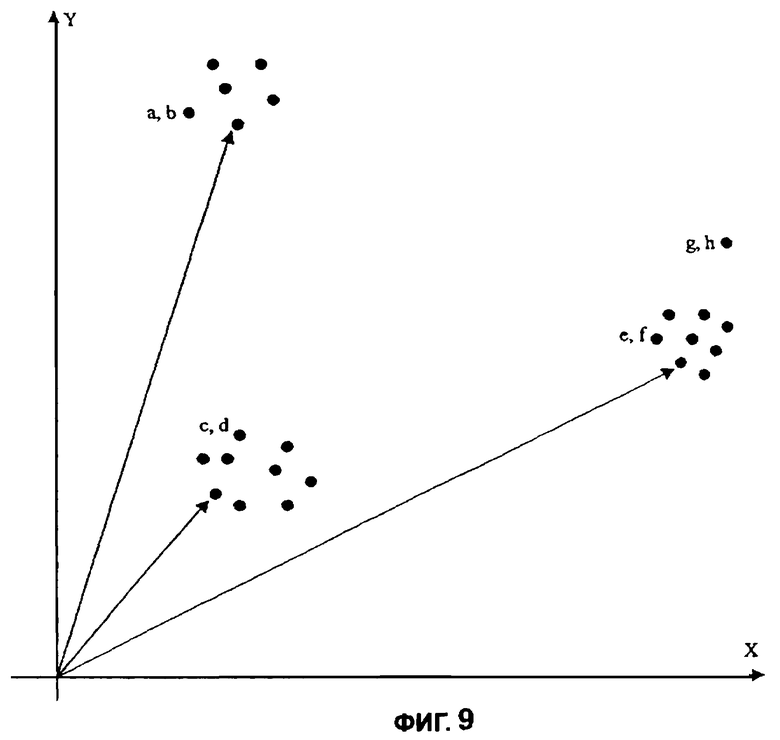
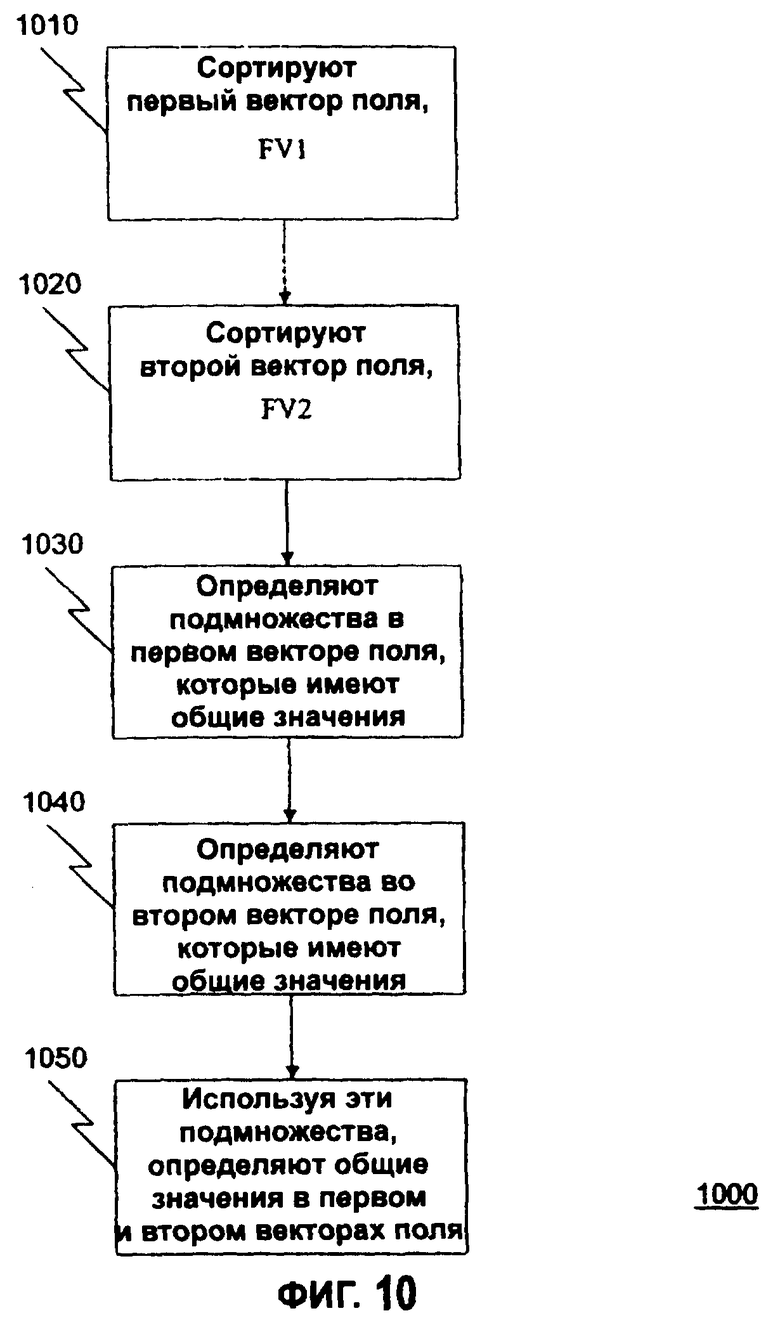
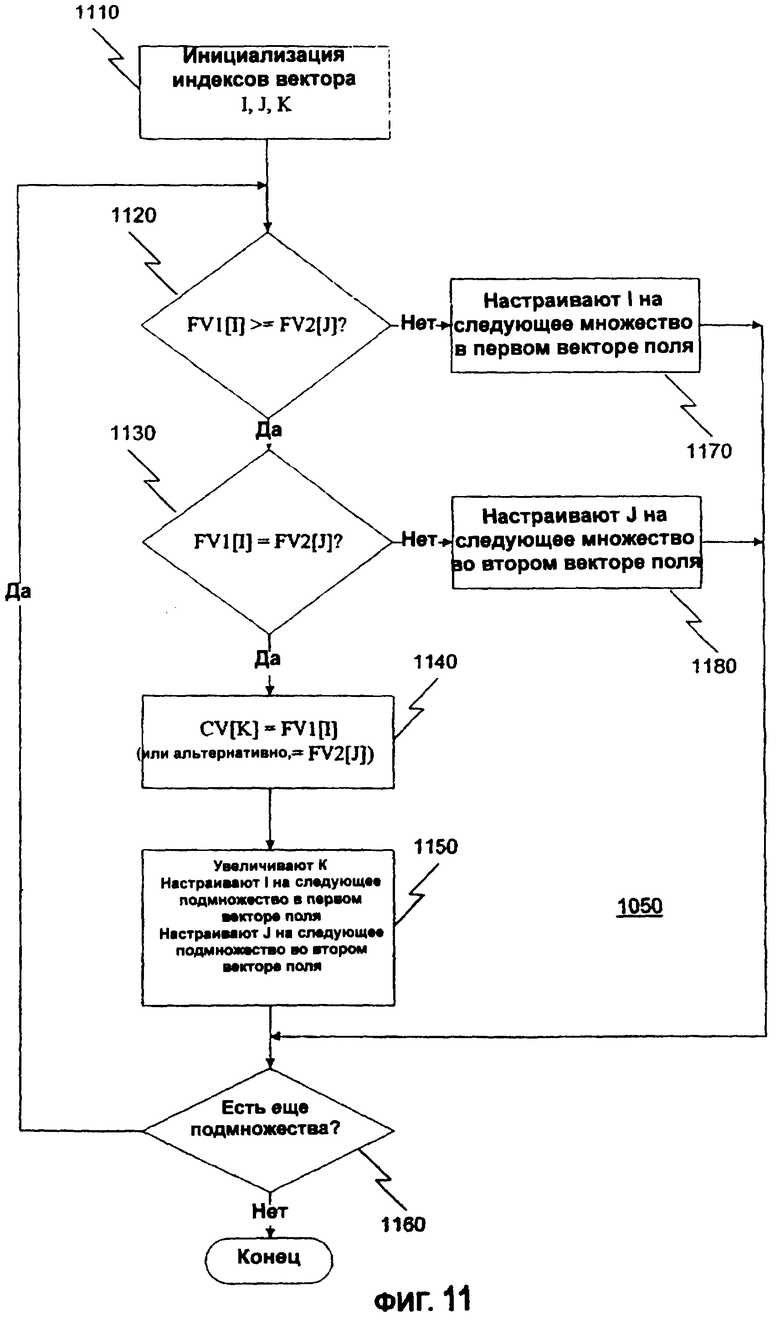

Изобретение относится к способу организации и/или нахождения данных в системах баз данных. Техническим результатом является повышение надежности организации и целостности баз данных. В способах преобразования информации по меньшей мере одной необработанной базы данных в очищенную базу данных, причем поля данных могут быть подобными полями в одной базе данных или подобными или идентичными полями в двух базах данных и организованными как массив или векторы поля. В способах преобразуют необработанные поля данных в необработанной записи данных в числовые значения, формируют из указанных числовых значений векторы, являющиеся представлением необработанной записи данных, и записывают векторы в очищенную базу данных. 4 н. и 12 з.п. ф-лы, 1 табл., 12 ил.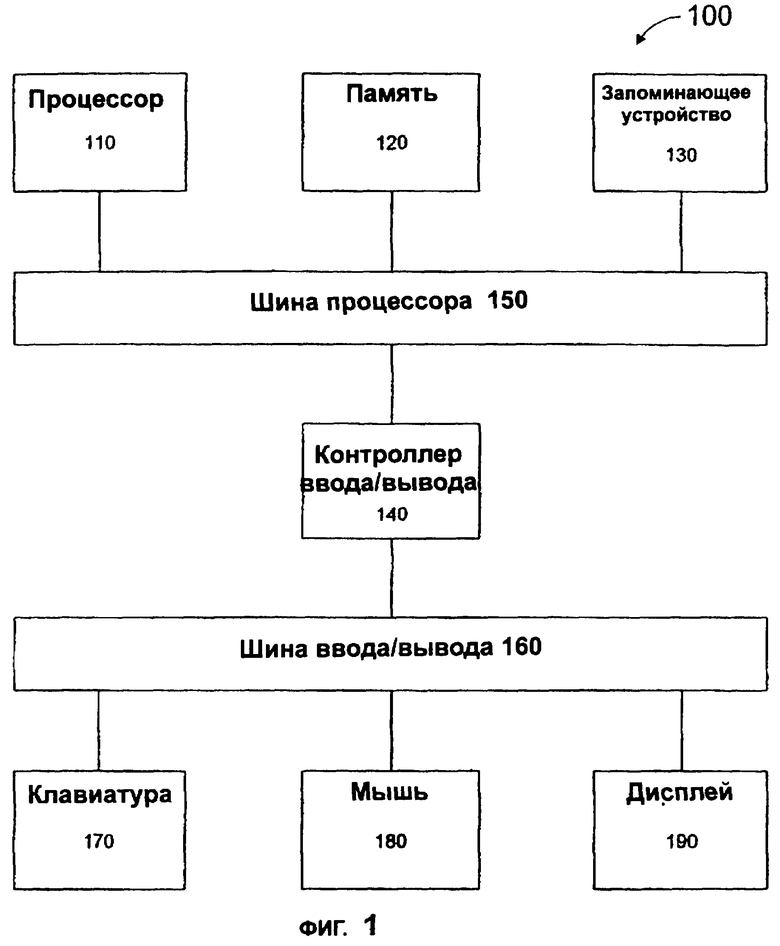
| УСТРОЙСТВО ДЛЯ ПАРАЛЛЕЛЬНОЙ ОБРАБОТКИ ДАННЫХ | 1991 |
|
RU2028664C1 |

