Настоящее изобретение относится к аудио кодированию/декодированию, в частности к пространственному аудио кодированию и пространственному аудио кодированию объекта и, более конкретно, к устройству и способу эффективного кодирования метаданных объекта.
Инструменты пространственного аудио кодирования хорошо известны из уровня техники и стандартизированы, например, в стандарте MPEG. Пространственное аудио кодирование начинается с исходных входных каналов, как, например, пять или семь каналов, которые идентифицируются их размещением в конфигурации воспроизведения, то есть, левый канал, центральный канал, правый канал, левый канал окружающего объемного звука, правый канал окружающего объемного звука и канал усиления низкой частоты. Устройство пространственного аудио кодирования, как правило, извлекает один или более каналов понижающего микширования из исходных каналов и, дополнительно, извлекает параметрические данные, относящиеся к пространственной опорной информации, как, например, межканальные разности уровней в величинах когерентности каналов, межканальные разности фаз, межканальные разности времени и так далее. Один или более каналов понижающего микширования передаются вместе с параметрической дополнительной информацией, указывающей пространственную опорную информацию устройству пространственного аудио декодирования, которое декодирует канал понижающего микширования и связанные параметрические данные, чтобы получить в итоге выходные каналы, которые являются приближенной версией исходных входных каналов. Размещение каналов в конфигурации вывода, как правило, фиксировано и является, например, форматом 5.1, форматом 7.1 и так далее.
Такие аудио форматы на основании канала широко используются для хранения или передачи многоканального аудио контента, где каждый канал относится к конкретному громкоговорителю в заданном положении. Качественное воспроизведение форматов такого типа требует такую конфигурацию громкоговорителя, в которой динамики размещены в тех же положениях, что и динамики, которые были использованы во время произведения аудио сигналов. Хотя увеличение числа громкоговорителей улучшает воспроизведение 3D аудио сцен с эффектом присутствия, становится все труднее выполнить это требование – особенно, в жилом помещении типа гостиной.
Потребность в конкретной конфигурации громкоговорителей можно удовлетворить путем объектно-ориентированного подхода, при котором сигналы громкоговорителя подготавливаются к воспроизведению конкретно для конфигурации воспроизведения.
Например, инструменты пространственного кодирования аудио объекта широко известны в текущем уровне техники и стандартизированы в стандарте MPEG SAOC (SAOC = пространственное кодирование аудио объекта). По сравнению с пространственным аудио кодированием, которое начинается с исходных каналов, пространственное кодирование аудио объекта начинается с аудио объектов, которые не закреплены автоматически за конкретной подготовкой к воспроизведению конфигурации воспроизведения. Напротив, расположение аудио объектов в сцене воспроизведения легко меняется и может быть определено пользователем с помощью ввода конкретной информации подготовки к воспроизведению в устройство декодирования пространственного кодирования аудио объекта. Альтернативно или дополнительно, информация подготовки к воспроизведению, то есть, информация о том, в каком положении в конфигурации воспроизведения необходимо расположить конкретный аудио объект обычно во времени, может быть передана в качестве дополнительной информации или метаданных. Чтобы получить конкретное сжатие данных, число аудио объектов кодируют с помощью устройства кодирования SAOC, которое вычисляет из входных объектов один или более транспортных каналов путем понижающего микширования объектов в соответствии с конкретной информацией понижающего микширования. Дополнительно, устройство кодирования SAOC вычисляет дополнительную параметрическую информацию, представляющую собой межобъектную опорную информацию, как, например, разности (OLD) уровня объектов, значения когерентности объектов и так далее. Так же, как и в SAC (SAC = Пространственное аудио кодирование), межобъектные параметрические данные вычисляют для отдельных временных/частотных элементов, то есть для конкретного кадра аудио сигнала, содержащего, например, 1024 или 2048 выборок, 24, 32 или 64 и так далее диапазонов частот, и рассматриваются так, чтобы, в конце концов, параметрические данные существовали для каждого кадра и каждого диапазона частот. В качестве примера, когда аудио отрезок имеет 20 кадров и когда каждый кадр подразделен на 32 диапазона частот, то число временных/частотных элементов равно 640.
При объектно-ориентированном подходе, звуковое поле описывают с помощью дискретных аудио объектов. Это требует метаданных объекта, которые описывают, среди прочего, переменное во времени положение каждого источника звука в 3D пространстве.
Первым принципом кодирования метаданных в уровне техники является формат (SpatDIF) взаимообмена пространственного описания звука, формат описания аудио сцены, который до сих находится в разработке [1]. Он предназначен в качестве формата взаимообмена для объектно-ориентированных звуковых сцен и не обеспечивает способ сжатия траекторий объекта. SpatDIF использует текстовый формат управления (OSC) открытым звуком для структурирования метаданных объекта [2]. Простое текстовое представление, однако, не является опцией для сжатой передачи траекторий объекта.
Другим принципом метаданных в уровне техники является формат (ASDF) описания аудио сцены [3], текстовое решение, которое имеет те же недостатки. Данные структурируют путем расширения языка (SMIL) интеграции синхронизированных мультимедийных данных, который является подмножеством расширяемого языка (XML) разметки [4,5].
Дополнительным принципом метаданных в уровне техники является двоичный аудио формат (AudioBIFS) для сцен, двоичный формат, который является частью спецификации MPEG-4 [6,7]. Он тесно связан с основанным на XML языком (VRML) моделирования виртуальной реальности, который был разработан для описания аудиовизуальных 3D сцен и интерактивных приложений виртуальной реальности [8]. Сложная спецификация AudioBIFS использует графы сцены для спецификации маршрутов движений объекта. Главным недостатком AudioBIFS является то, что он не предназначен для работы в реальном времени, где необходимым требованием являются ограниченная задержка системы и непрерывный доступ к потоку данных. Дополнительно, кодирование положений объекта не использует ограниченную локализацию воспроизведения слушателей. Для фиксированного положения слушателя внутри аудиовизуальной сцены, данные объекта могут быть квантованы со значительно более низким числом битов [9]. Следовательно, кодирование метаданных объекта, которое применяется в AudioBIFS, неэффективно по отношению к сжатию данных.
Следовательно, нужно принимать во внимание, что при улучшении указанных принципов, могут быть обеспечены принципы эффективного кодирования метаданных объекта.
Целью настоящего изобретения является обеспечение улучшенных принципов кодирования метаданных объекта. Цель настоящего изобретения достигается с помощью устройства по п.1, устройства по п.6, системы по п.12, способа по п.13, способа по п.14 и компьютерной программы по п.15.
Обеспечено устройство формирования одного или более аудио каналов. Устройство содержит устройство декодирования метаданных для формирования одного или более восстановленных сигналов (x1’,…,xN’) метаданных из одного или более обработанных сигналов (z1,…,zN) метаданных в зависимости от управляющего сигнала (b), причем каждый из одного или более восстановленных сигналов (x1’,…,xN’) метаданных указывает информацию, связанную с сигналом аудио объекта из одного или более сигналов аудио объекта, причем устройство декодирования метаданных выполнено с возможностью формировать один или более восстановленных сигналов (x1’,…,xN’) метаданных путем определения множества восстановленных выборок (x1’(n),…,xN’(n)) метаданных для каждого из одного или более восстановленных сигналов (x1’,…,xN’) метаданных. Более того, устройство содержит устройство формирования аудио канала для формирования одного или более аудио каналов в зависимости от одного или более сигналов аудио объекта и в зависимости от одного или более восстановленных сигналов (x1’,…,xN’) метаданных. Устройство декодирования метаданных выполнено с возможностью принимать множество обработанных выборок (z1(n),…,zN(n)) метаданных каждого из одного или более обработанных сигналов (z1,…,zN) метаданных. Более того, устройство декодирования метаданных выполнено с возможностью принимать управляющий сигнал (b). Дополнительно, устройство декодирования метаданных выполнено с возможностью определять каждую восстановленную выборку (xi’(n)) метаданных из множества восстановленных выборок (xi’(1),… xi’(n-1), xi’(n)) метаданных каждого восстановленного сигнала (xi’) метаданных одного или более восстановленных сигналов (x1’,…,xN’) метаданных, так, чтобы когда управляющий сигнал (b) указывает первое состояние (b(n)=0), то указанная восстановленная выборка (xi’(n)) метаданных является суммой одной из обработанных выборок (zi(n)) метаданных одного из одного или более обработанных сигналов (zi) метаданных и другой уже сформированной восстановленной выборки (xi’(n-1)) метаданных указанного восстановленного сигнала (xi’) метаданных, и так, чтобы когда управляющий сигнал указывает второе состояние (b(n)=1), отличное от первого состояния, то указанная восстановленная выборка (xi’(n)) метаданных является указанной одной (zi(n)) из обработанных выборок (zi(1),…,zi(n)) метаданных указанного одного (zi) из одного или более обработанных сигналов (z1,…,zN) метаданных.
Более того, обеспечено устройство формирования закодированной аудио информации, содержащее один или более закодированных аудио сигналов и один или более обработанных сигналов метаданных. Устройство содержит устройство кодирования метаданных для приема одного или более исходных сигналов метаданных и для определения одного или более обработанных сигналов метаданных, в котором каждый из одного или более исходных сигналов метаданных содержит множество исходных выборок метаданных, причем исходные выборки метаданных каждого из одного или более исходных сигналов метаданных указывают информацию, связанную с сигналом аудио объекта из одного или более сигналов аудио объекта.
Более того, устройство содержит устройство аудио кодирования для кодирования одного или более сигналов аудио объекта для получения одного или более закодированных аудио сигналов.
Устройство кодирования метаданных выполнено с возможностью определять каждую обработанную выборку (zi(n)) метаданных из множества обработанных выборок (zi(1),… zi(n-1), zi(n)) метаданных каждого обработанного сигнала (zi) метаданных одного или более обработанных сигналов (z1,…,zN) метаданных так, чтобы когда управляющий сигнал (b) указывает первое состояние (b(n)=0), то указанная восстановленная выборка (zi(n)) метаданных указывает разность или квантованную разность между одной из множества исходных выборок (xi(n)) метаданных одного из одного или более исходных сигналов (xi) метаданных и другой уже сформированной обработанной выборкой метаданных указанного обработанного сигнала (zi) метаданных, и так, чтобы когда управляющий сигнал указывает второе состояние (b(n)=1), отличное от первого состояния, то указанная восстановленная выборка (zi(n)) метаданных является указанной одной (xi(n)) из исходных выборок (xi(1),…,xi(n)) метаданных указанного одного из одного или более обработанных сигналов (xi) метаданных, или является квантованным представлением (qi(n)) указанной одной (xi(n)) из исходных выборок (xi(1),…,xi(n)) метаданных.
В соответствии с осуществлениями, обеспечены принципы сжатия данных для метаданных объекта, которые достигают эффективного механизма сжатия для каналов передачи с ограниченной скоростью передачи данных. Устройство кодирования и устройство декодирования не вносят никакой дополнительной задержки, соответственно. Более того, достигается хорошая скорость сжатия данных для чистых изменений по азимуту, например, вращений камеры. Дополнительно, обеспеченные принципы поддерживают прерывистые траектории, например, скачки в положении. Более того, достигается низкая сложность декодирования. Дополнительно, достигается непрерывный доступ с ограниченным временем повторной активации.
Более того, обеспечен способ формирования одного или более аудио каналов. Способ содержит:
- Формирование одного или более восстановленных сигналов (x1’,…,xN’) метаданных из одного или более обработанных сигналов (z1,…,zN) метаданных в зависимости от управляющего сигнала (b), причем каждый из одного или более восстановленных сигналов (x1’,…,xN’) метаданных указывает информацию, связанную с сигналом аудио объекта из одного или более сигналов аудио объекта, причем формирование одного или более восстановленных сигналов (x1’,…,xN’) метаданных выполняется путем определения множества восстановленных выборок (x1’(n),…,xN’(n)) метаданных для каждого из одного или более восстановленных сигналов (x1’,…,xN’) метаданных. И:
- Формирование одного или более аудио каналов в зависимости от одного или более сигналов аудио объекта и в зависимости от одного или более восстановленных сигналов (x1’,…,xN’) метаданных.
Формирование одного или более восстановленных сигналов (x1’,…,xN’) метаданных выполняется с помощью приема множества обработанных выборок (z1(n),…,zN(n)) метаданных каждого из одного или более обработанных сигналов (z1,…,zN) метаданных, с помощью приема управляющего сигнала (b), и с помощью определения каждой восстановленной выборки (xi’(n)) метаданных из множества восстановленных выборок (xi’(1),… xi’(n-1), xi’(n)) метаданных каждого восстановленного сигнала (xi’) метаданных одного или более восстановленных сигналов (x1’,…,xN’) метаданных, так, чтобы когда управляющий сигнал (b) указывает первое состояние (b(n)=0), то указанная восстановленная выборка (xi’(n)) метаданных является суммой одной из обработанных выборок (zi(n)) метаданных одного из одного или более обработанных сигналов (zi) метаданных и другой уже сформированной восстановленной выборки (xi’(n-1)) метаданных указанного восстановленного сигнала (xi’) метаданных, и так, чтобы когда управляющий сигнал указывает второе состояние (b(n)=1), отличное от первого состояния, то указанная восстановленная выборка (xi’(n)) метаданных является указанной одной (zi(n)) из обработанных выборок (zi(1),…,zi(n)) метаданных указанного одного (zi) из одного или более обработанных сигналов (z1,…,zN) метаданных.
Дополнительно, обеспечен способ формирования закодированной аудио информации, содержащей один или более закодированных аудио сигналов и один или более обработанных сигналов метаданных. Способ содержит:
- Прием одного или более исходных сигналов метаданных.
- Определение одного или более обработанных сигналов метаданных. И:
- Кодирование одного или более сигналов аудио объекта для получения одного или более закодированных аудио сигналов.
Каждый из одного или более исходных сигналов метаданных содержит множество исходных выборок метаданных, причем исходные выборки метаданных каждого из одного или более исходных сигналов метаданных указывают информацию, связанную с сигналом аудио объекта из одного или более сигналов аудио объекта. Определение одного или более обработанных сигналов метаданных содержит определение каждой обработанной выборки (zi(n)) метаданных из множества обработанных выборок (zi(1),… zi(n-1), zi(n)) метаданных каждого обработанного сигнала (zi) метаданных одного или более обработанных сигналов (z1,…,zN) метаданных так, чтобы когда управляющий сигнал (b) указывает первое состояние (b(n)=0), то указанная восстановленная выборка (zi(n)) метаданных указывает разность или квантованную разность между одной из множества исходных выборок (xi(n)) метаданных одного из одного или более исходных сигналов (xi) метаданных и другой уже сформированной обработанной выборкой метаданных указанного обработанного сигнала (zi) метаданных, и так, чтобы когда управляющий сигнал указывает второе состояние (b(n)=1), отличное от первого состояния, то указанная восстановленная выборка (zi(n)) метаданных является указанной одной (xi(n)) из исходных выборок (xi(1),…,xi(n)) метаданных указанного одного из одного или более обработанных сигналов (xi) метаданных, или является квантованным представлением (qi(n)) указанной одной (xi(n)) из исходных выборок (xi(1),…,xi(n)) метаданных.
Более того, обеспечена компьютерная программа для осуществления вышеописанного способа при выполнении на компьютере или устройстве обработки сигналов.
Далее подробно описаны осуществления настоящего изобретения со ссылкой на фигуры, на которых:
Фиг. 1 изображает устройство формирования одного или более аудио каналов в соответствии с осуществлением,
Фиг. 2 изображает устройство формирования закодированной аудио информации в соответствии с осуществлением,
Фиг. 3 изображает систему в соответствии с осуществлением,
Фиг. 4 изображает положение аудио объекта в трехмерном пространстве от нулевой точки, выраженное азимутом, углом наклона и радиусом,
Фиг. 5 изображает положения аудио объектов и конфигурацию громкоговорителя, предполагаемую устройством формирования аудио канала,
Фиг. 6 изображает устройство кодирования с дифференциальной импульсно-кодовой модуляцией,
Фиг. 7 изображает устройство декодирования с дифференциальной импульсно-кодовой модуляцией,
Фиг. 8a изображает устройство кодирования метаданных в соответствии с осуществлением,
Фиг. 8b изображает устройство кодирования метаданных в соответствии с другим осуществлением,
Фиг. 9a изображает устройство декодирования метаданных в соответствии с осуществлением,
Фиг. 9b изображает подблок устройства декодирования метаданных в соответствии с осуществлением,
Фиг. 10 изображает первое осуществление устройства 3D аудио кодирования,
Фиг. 11 изображает первое осуществление устройства 3D аудио декодирования,
Фиг. 12 изображает второе осуществление устройства 3D аудио кодирования,
Фиг. 13 изображает второе осуществление устройства 3D аудио декодирования,
Фиг. 14 изображает третье осуществление устройства 3D аудио кодирования, и
Фиг. 15 изображает третье осуществление устройства 3D аудио декодирования.
Фиг. 2 изображает устройство 250 формирования закодированной аудио информации, содержащей один или более закодированных аудио сигналов и один или более обработанных сигналов метаданных в соответствии с осуществлением.
Устройство 250 содержит устройство 210 кодирования метаданных для приема одного или более исходных сигналов метаданных и для определения одного или более обработанных сигналов метаданных, в котором каждый из одного или более исходных сигналов метаданных содержит множество исходных выборок метаданных, причем исходные выборки метаданных каждого из одного или более исходных сигналов метаданных указывают информацию, связанную с сигналом аудио объекта из одного или более сигналов аудио объекта.
Более того, устройство 250 содержит устройство 220 аудио кодирования для кодирования одного или более сигналов аудио объекта для получения одного или более закодированных аудио сигналов.
Устройство 210 кодирования метаданных выполнено с возможностью определять каждую обработанную выборку (zi(n)) метаданных множества обработанных выборок (zi(1),… zi(n-1), zi(n)) метаданных каждого обработанного сигнала (zi) метаданных одного или более обработанных сигналов (z1,…,zN) метаданных так, чтобы когда управляющий сигнал (b) указывает первое состояние (b(n)=0), то указанная восстановленная выборка (zi(n)) метаданных указывает разность или квантованную разность между одной из множества исходных выборок (xi(n)) метаданных одного из одного или более исходных сигналов (xi) метаданных и другой уже сформированной обработанной выборкой метаданных указанного обработанного сигнала (zi) метаданных, и так, чтобы когда управляющий сигнал указывает второе состояние (b(n)=1), отличное от первого состояния, то указанная восстановленная выборка (zi(n)) метаданных является указанной одной (xi(n)) из исходных выборок (xi(1),…,xi(n)) метаданных указанного одного из одного или более обработанных сигналов (xi) метаданных, или является квантованным представлением (qi(n)) указанной одной (xi(n)) из исходных выборок (xi(1),…,xi(n)) метаданных.
Фиг. 1 изображает устройство 100 формирования одного или более аудио каналов в соответствии с осуществлением.
Устройство 100 содержит устройство 110 декодирования метаданных для формирования одного или более восстановленных сигналов (x1’,…,xN’) метаданных из одного или более обработанных сигналов (z1,…,zN) метаданных в зависимости от управляющего сигнала (b), причем каждый из одного или более восстановленных сигналов (x1’,…,xN’) метаданных указывает информацию, связанную с сигналом аудио объекта из одного или более сигналов аудио объекта, причем устройство 110 декодирования метаданных выполнено с возможностью формировать один или более восстановленных сигналов (x1’,…,xN’) метаданных путем определения множества восстановленных выборок (x1’(n),…,xN’(n)) метаданных для каждого из одного или более восстановленных сигналов (x1’,…,xN’) метаданных.
Более того, устройство 100 содержит устройство 120 формирования аудио канала для формирования одного или более аудио каналов в зависимости от одного или более сигналов аудио объекта и в зависимости от одного или более восстановленных сигналов (x1’,…,xN’) метаданных.
Устройство декодирования 110 метаданных выполнено с возможностью принимать множество обработанных выборок (z1(n),…,zN(n)) метаданных каждого из одного или более обработанных сигналов (z1,…,zN) метаданных. Более того, устройство декодирования 110 метаданных выполнено с возможностью принимать управляющий сигнал (b).
Дополнительно, устройство декодирования 110 метаданных выполнено с возможностью определять каждую восстановленную выборку (xi’(n)) метаданных из множества восстановленных выборок (xi’(1),… xi’(n-1), xi’(n)) метаданных каждого восстановленного сигнала (xi’) метаданных одного или более восстановленных сигналов (x1’,…,xN’) метаданных, так, чтобы когда управляющий сигнал (b) указывает первое состояние (b(n)=0), то указанная восстановленная выборка (xi’(n)) метаданных является суммой одной из обработанных выборок (zi(n)) метаданных одного из одного или более обработанных сигналов (zi) метаданных и другой уже сформированной восстановленной выборки (xi’(n-1)) метаданных указанного восстановленного сигнала (xi’) метаданных, и так, чтобы когда управляющий сигнал указывает второе состояние (b(n)=1), отличное от первого состояния, то указанная восстановленная выборка (xi’(n)) метаданных является указанной одной (zi(n)) из обработанных выборок (zi(1),…,zi(n)) метаданных указанного одного (zi) из одного или более обработанных сигналов (z1,…,zN) метаданных.
При ссылке на выборки метаданных, необходимо отметить, что выборка метаданных характеризуется ее величиной выборки метаданных, а также моментом времени, к которому она относится. Например, такой момент времени может относиться к началу аудио последовательности или тому подобному. Например, индекс n или k может идентифицировать положение выборки метаданных в сигнале метаданных и с помощью него указывается (относительный) момент времени (относительный к начальному времени). Необходимо отметить, что, когда две выборки метаданных относятся к различным моментам времени, эти две выборки метаданных являются различными выборками метаданных, даже когда их значения выборки метаданных равны, что иногда случается.
Вышеуказанные осуществления основаны на том выводе, что информация о метаданных (содержащаяся в сигнале метаданных), которая связана с сигналом аудио объекта, зачастую изменяется медленно.
Например, сигнал метаданных может указывать информацию положения аудио объекта (например, угол азимута, угол наклона или радиус, определяющие положение аудио объекта). Можно предположить, что в большинстве случаев положение аудио объекта либо не меняется совсем или меняется медленно.
Или, сигнал метаданных может, например, указывать громкость (например, увеличение) аудио объекта, и также можно предположить, что в большинстве случаев громкость аудио объекта меняется медленно.
По этой причине, нет необходимости передавать (полную) информацию метаданных в каждый момент времени.
Напротив, (полная) информация метаданных может, например, в соответствии с некоторыми осуществлениями, передаваться только в конкретные моменты времени, например, периодически, например, в каждый N-ый момент времени, например, в момент времени 0, N, 2N, 3N и так далее.
Например, в осуществлениях, три сигнала метаданных задают положение аудио объекта в 3D пространстве. Первый из сигналов метаданных может, например, задавать угол азимута в положении аудио объекта. Второй из сигналов метаданных может, например, задавать угол наклона в положении аудио объекта. Третий из сигналов метаданных может, например, задавать радиус, относящийся к расстоянию аудио объекта.
Угол азимута, угол наклона и радиус однозначно определяют положение аудио объекта в 3D пространстве от нулевой точки. Это изображено со ссылкой на Фиг. 4.
Фиг. 4 изображает положение 410 аудио объекта в трехмерном (3D) пространстве от нулевой точки 400, выраженное азимутом, углом наклона и радиусом.
Угол наклона задает, например, угол между прямой линией от нулевой точки к положению объекта и нормальной проекцией этой прямой линии на плоскость xy (плоскость, определенную осью x и осью y). Угол азимута определяет, например, угол между осью x и указанной нормальной проекцией. Задавая угол азимута и угол наклона, можно определить прямую линию 415 через нулевую точку 400 и положение 410 аудио объекта. Дополнительно, задавая радиус, можно определить точное положение аудио объекта 410.
В осуществлении, угол азимута определен для диапазона: -180° < азимут ≤ 180°, угол наклона определен для диапазона: -90° ≤ угол наклона ≤ 90°, и радиус, например, может быть определен в метрах [м] (больше чем или равен 0м).
В другом осуществлении, где, например, можно предположить, что все x-величины положений аудио объекта в системе координат xyz больше чем или равны нулю, угол азимута может быть определен для диапазона: 90° ≤ азимут ≤ 90°, угол наклона может быть определен для диапазона: -90° ≤ угол наклона ≤ 90°, и радиус, например, может быть определен в метрах [м].
В дополнительном осуществлении, сигналы метаданных могут быть масштабированы так, что угол азимута определен для диапазона: -128° < азимут ≤ 128°, угол наклона может быть определен для диапазона: : -32° ≤ угол наклона ≤ 32°, и радиус, например, может быть определен в логарифмическом масштабе. В некоторых осуществлениях, исходные сигналы метаданных, обработанные сигналы метаданных и восстановленные сигналы метаданных, соответственно, могут содержать масштабированное представление информации положения и/или масштабированное представление громкости одного из одного или более сигналов аудио объектов.
Устройство 120 формирования аудио канала, например, может быть сконфигурировано для формирования одного или более аудио каналов в зависимости от одного или более сигналов аудио объектов и в зависимости от восстановленных сигналов метаданных, причем восстановленные сигналы метаданных, например, могут указывать положение аудио объектов.
Фиг. 5 изображает положения аудио объектов и конфигурации громкоговорителя, предположенной устройством формирования аудио канала. Изображена нулевая точка 500 системы координат xyz. Более того, изображено положение 510 первого аудио объекта и положение 520 второго аудио объекта. Дополнительно, Фиг. 5 изображает сценарий, при котором устройство 120 формирования аудио канала формирует четыре аудио канала для четырех громкоговорителей. Устройство 120 формирования аудио канала предполагает, что четыре громкоговорителя 511, 512, 513 и 514 расположены в положениях, изображенных на Фиг. 5.
На Фиг. 5, первый аудио объект расположен в положении 510, близком к предполагаемым положениям громкоговорителей 511 и 512, и расположен далеко от громкоговорителей 513 и 514. Следовательно, устройство 120 формирования аудио канала может формировать четыре аудио канала так, что первый аудио объект 510 воспроизводится громкоговорителями 511 и 512, но не громкоговорителями 513 и 514.
В других осуществлениях, устройство 120 формирования аудио канала может формировать четыре аудио канала так, что первый аудио объект 510 воспроизводится с высокой громкостью громкоговорителями 511 и 512 и с низкой громкостью громкоговорителями 513 и 514.
Более того, второй аудио объект расположен в положении 520, близком к предполагаемым положениям громкоговорителей 513 и 514, и расположен далеко от громкоговорителей 511 и 512. Следовательно, устройство 120 формирования аудио канала может формировать четыре аудио канала так, что второй аудио объект 520 воспроизводится громкоговорителями 513 и 514, но не громкоговорителями 511 и 512.
В других осуществлениях, устройство 120 формирования аудио канала может формировать четыре аудио канала так, что второй аудио объект 520 воспроизводится с высокой громкостью громкоговорителями 513 и 514 и с низкой громкостью громкоговорителями 511 и 512.
В альтернативных осуществлениях, только два сигнала метаданных используются для задания положения аудио объекта. Например, только азимут и радиус могут быть заданы, например, когда предполагается, что все аудио объекты расположены внутри одной плоскости.
В дополнительных других осуществлениях, для каждого аудио объекта, только один сигнал метаданных кодируют и передают в качестве информации положения. Например, только угол азимута может быть задан в качестве информации положения для аудио объекта (например, можно предположить, что все аудио объекты расположены в той же плоскости, имеющей одинаковое расстояние от центральной точки, и, таким образом, предполагают, что они имеют одинаковый радиус). Информации азимута, например, может быть достаточно для определения того, что аудио объект расположен близко к левому громкоговорителю и далеко от правого громкоговорителя. В таком случае, устройство 120 формирования аудио канала, например, может формировать один или более аудио каналов так, что аудио объект воспроизводится левым громкоговорителем, но не правым громкоговорителем.
Например, Векторное амплитудное панорамирование (VBAP) может быть использовано (см., например, [11]) для определения веса сигнала аудио объекта внутри каждого из аудио каналов громкоговорителей. Например, по отношению к VBAP, предполагают, что аудио объект относится к виртуальному источнику.
В осуществлениях, дополнительный сигнал метаданных может задавать громкость, например, увеличение (например, выраженное в децибелах [дБ]) для каждого аудио объекта.
Например, на Фиг. 5, первое значение увеличения может быть задано дополнительным сигналом метаданных для первого аудио объекта, расположенного в положении 510, которое больше, чем второе значение увеличения, заданного другим дополнительным сигналом метаданных для второго аудио объекта, расположенного в положении 520. В таком случае, громкоговорители 511 и 512 могут воспроизводить первый аудио объект с громкостью большей, чем громкость, с которой громкоговорители 513 и 514 воспроизводят второй аудио объект.
Осуществления также предполагают, что такие значения увеличения аудио объектов зачастую изменяются медленно. Следовательно, нет необходимости передавать такую информацию метаданных в каждый момент времени. Вместо этого информация метаданных передается только в конкретные моменты времени. В промежуточных моментах времени, информация метаданных, например, может быть аппроксимирована с помощью предшествующей выборки метаданных и последующей выборки метаданных, которые были переданы. Например, линейная интерполяция может быть использована для аппроксимации промежуточных величин. Например, увеличение, азимут, угол наклона и/или радиус каждого из аудио объектов могут быть приблизительно выражены для моментов времени, в которых такие метаданные не были переданы.
С помощью такого подхода, можно достигнуть значительных улучшений скорости передачи метаданных.
Фиг. 3 изображает систему в соответствии с осуществлением.
Система содержит устройство 250 формирования закодированной аудио информации, содержащей один или более закодированных аудио сигналов и один или более обработанных сигналов метаданных, как описано выше.
Более того, система содержит устройство 100 приема одного или более закодированных аудио сигналов и одного или более обработанных сигналов метаданных, и формирования одного или более аудио каналов в зависимости от одного или более закодированных аудио сигналов и в зависимости от одного или более обработанных сигналов метаданных, как описано выше.
Например, один или более закодированных аудио сигналов могут быть декодированы устройством 100 формирования одного или более аудио каналов с помощью использования устройства декодирования SAOC, в соответствии с состоянием текущего уровня техники, для получения одного или более сигналов аудио объекта, когда устройство 250 кодирования использовало устройство кодирования SAOC для кодирования одного или более аудио объектов.
Осуществления основаны на том выводе, что принципы Дифференциальной импульсно-кодовой модуляции могут быть расширены, и что такие расширенные принципы затем подходят для кодирования сигналов метаданных для аудио объектов.
Способ Дифференциальной импульсно-кодовой модуляции (DPCM) является устоявшимся способом для медленно изменяющихся во времени сигналов, который сокращает несоответствие посредством квантования, а избыточность – посредством дифференциальной передачи [10]. Устройство кодирования DCPM изображено на Фиг. 6.
В устройстве кодирования DCPM на Фиг. 6, актуальная входная выборка x(n) входного сигнала x подается в блок 610 вычитания. На другом входе блока вычитания, другое значение подается в блок вычитания. Можно предположить, что это другое значение является ранее принятой выборкой x(n-1), хотя ошибки квантования или другие ошибки могут привести к такому результату, когда значение на другом входе не является точно идентичным предыдущей выборке x(n-1). Из-за таких возможных отклонений от (x-1), другой входной сигнал устройства вычитания может быть обозначен как x*(n-1). Блок вычитания вычитает x*(n-1) из x(n) для получения значения d(n) разности.
d(n) затем квантуют в устройстве 620 квантования для получения другой выходной выборки y(n) выходного сигнала y. В общем, y(n) либо равен d(n), либо значению, близкому к d(n).
Более того, y(n) подается в сумматор 630. Дополнительно, x* (n-1) подается в сумматор 630. Так как d(n) получается из вычитания d(n) = x(n) – x* (n-1), и так как y(n) является величиной, равной или, по меньшей мере, близкой по значению, к d(n), выходной сигнал x* (n) сумматора 630 равен x(n) или, по меньшей мере, близок к x(n).
x* (n) находится в течение периода выборки в блоке 640, и затем обработка продолжается со следующей выборкой x(n+1).
Фиг. 7 изображает соответствующее устройство декодирования DPCM.
На Фиг. 7, выборка y(n) выходного сигнала y устройства кодирования DPCM подается в сумматор 710. y(n) представляет собой значение разности сигнала x(n), который подлежит восстановлению. На другом входе сумматора 710, ранее восстановленная выборка x’(n-1) подается в сумматор 710. Выходной сигнал x’(n) сумматора получается в результате сложения x’(n) = x’(n-1) + y(n). Как x’(n-1), в общем, равен или, по меньшей мере, близок к x(n-1), и как y(n), в общем, равен или близок к x(n) – x(n-1), так и выходной сигнал x’(n) сумматора 710, в общем, равен или близок к x(n).
x’(n) находится в течение периода выборки в блоке 740, и затем обработка продолжается со следующей выборкой y(n+1).
Хотя способ сжатия DPCM выполняет большинство из ранее указанных требуемых характеристик, он не позволяет непрерывный доступ.
Фиг. 8а изображает устройство 801 кодирования метаданных в соответствии с осуществлением.
Способ кодирования, используемый устройством 801 кодирования метаданных на Фиг. 8а, является расширением классического способа кодирования DPCM.
Устройство 801 кодирования метаданных на Фиг. 8а содержит одно или более устройств 811, …, 81N кодирования. Например, когда устройство 801 кодирования метаданных выполнено с возможностью принимать N исходных сигналов метаданных, устройство 801 кодирования метаданных, например, может содержать точно N устройств кодирования DPCM. В осуществлении, каждое из N устройств кодирования DPCM осуществлено, как описано по отношению к Фиг. 6.
В осуществлении, каждое из N устройств кодирования DPCM выполнено с возможностью принимать выборки xi(n) метаданных одного из N исходных сигналов x1, …, xN метаданных и формировать значение разности как разность выборки yi(n) сигнала yi разности метаданных для каждой из выборок xi(n) метаданных указанного исходного сигнала xi метаданных, который подается в указанное устройство кодирования DPCM. В осуществлении, формирование выборки yi(n) разности, например, может быть выполнено, как описано по отношению к Фиг. 6.
Устройство 801 кодирования метаданных на Фиг. 8а дополнительно содержит селектор 830 (“A”), который выполнен с возможностью принимать управляющий сигнал b(n).
Селектор 830, более того, выполнен с возможностью принимать N сигналов y1 … yN разности метаданных.
Дополнительно, в осуществлении на Фиг. 8а, устройство 801 кодирования метаданных содержит устройство 820 квантования, которое квантует N исходных сигналов x1, …, xN метаданных для получения N квантованных сигналов q1, …, qN метаданных. В таком осуществлении, устройство квантования может быть выполнено с возможностью подавать N квантованных сигналов метаданных в селектор 830.
Селектор 830 может быть выполнен с возможностью формировать обработанные сигналы zi метаданных из квантованных сигналов qi метаданных и из закодированных с помощью DPCM сигналов yi разности метаданных в зависимости от управляющего сигнала b(n).
Например, когда управляющий сигнал b находится в первом состоянии (например, b(n) = 0), то селектор 830 может быть выполнен с возможностью выводить выборки yi(n) разности сигналов yi разности метаданных в качестве выборок zi(n) метаданных обработанных сигналов zi метаданных.
Когда управляющий сигнал b находится во втором состоянии, отличном от первого состояния (например, b(n) = 1), то селектор 830 может быть выполнен с возможностью выводить выборки qi(n) метаданных квантованных сигналов qi метаданных в качестве выборок zi(n) метаданных обработанных сигналов zi метаданных.
Фиг. 8b изображает устройство 802 кодирования метаданных в соответствии с другим осуществлением.
В осуществлении на Фиг. 8b, устройство 802 кодирования метаданных не содержит устройство 820 квантования, и, вместо N квантованных сигналов q1, …, qN метаданных, N исходных сигналов x1, …, xN метаданных напрямую подаются в селектор 830.
В таком осуществлении, когда, например, управляющий сигнал b находится в первом состоянии (например, b(n) = 0), то селектор 830 может быть выполнен с возможностью выводить выборки yi(n) разности сигналов разности метаданных в качестве выборок zi(n) метаданных обработанных сигналов zi метаданных.
Когда управляющий сигнал b находится во втором состоянии, отличном от первого состояния (например, b(n) = 1), то селектор 830 может быть выполнен с возможностью выводить выборки xi(n) метаданных исходных сигналов xi метаданных в качестве выборок zi(n) метаданных обработанных сигналов zi метаданных.
Фиг. 9а изображает устройство 901 декодирования метаданных в соответствии с осуществлением. Устройство кодирования метаданных в соответствии с Фиг. 9а соответствует устройствам кодирования метаданных на Фиг. 8а и Фиг. 8b.
Устройство 901 декодирования метаданных на Фиг. 9а содержит один или более подблоков 911, …, 91N декодирования метаданных. Устройство 901 декодирования метаданных выполнено с возможностью принимать один или более обработанных сигналов z1, …, zN метаданных. Более того, устройство 901 декодирования метаданных выполнено с возможностью принимать управляющий сигнал b. Устройство декодирования метаданных выполнено с возможностью формировать один или более восстановленных сигналов x1’, … xN’ метаданных из одного или более обработанных сигналов z1, …, zN метаданных в зависимости от управляющего сигнала b.
В осуществлении, каждый из N обработанных сигналов z1, …, zN метаданных подается в отличный один из подблоков 911, …, 91N устройства декодирования метаданных. Более того, в соответствии с осуществлением, управляющий сигнал b подается в каждый из подблоков 911, …, 91N устройства декодирования метаданных. В соответствии с осуществлением, число подблоков 911, …, 91N устройства декодирования метаданных идентично числу обработанных сигналов z1, …, zN метаданных, которые приняты устройством 901 декодирования метаданных.
Фиг. 9b изображает подблок (91i) устройства декодирования метаданных подблоков 911, …, 91N устройства декодирования метаданных на Фиг. 9а, в соответствии с осуществлением. Подблок 91i устройства декодирования метаданных выполнен с возможностью выполнять декодирование одного обработанного сигнала zi метаданных. Подблок 91i устройства декодирования метаданных содержит селектор 930 (“B”) и сумматор 910.
Подблок 91i устройства декодирования метаданных выполнен с возможностью формировать восстановленный сигнал xi’ метаданных из принятого обработанного сигнала zi метаданных в зависимости от управляющего сигнала b(n).
Это, например, может быть реализовано следующим образом:
Последняя восстановленная выборка xi’(n-1) метаданных восстановленного сигнала xi’ метаданных подается в сумматор 910. Более того, актуальная выборка zi(n) метаданных обработанного сигнала zi метаданных также подается в сумматор 910. Сумматор выполнен с возможностью суммировать последнюю восстановленную выборку xi’(n-1) метаданных и актуальную выборку zi(n) метаданных для получения величины si(n) суммы, которая подается в селектор 930.
Более того, актуальная выборка zi(n) метаданных также подается в сумматор 930.
Селектор выполнен с возможностью выбирать либо величину si(n) суммы из сумматора 910, либо актуальную выборку zi(n) метаданных в качестве актуальной выборки xi’(n) метаданных восстановленного сигнала xi’(n) метаданных в зависимости от управляющего сигнала b.
Когда, например, управляющий сигнал b находится в первом состоянии (например, (b(n) = 0), то управляющий сигнал b указывает, что актуальная выборка zi(n) метаданных является величиной разности, и поэтому величина si(n) суммы является правильной актуальной выборкой xi’(n) метаданных восстановленного сигнала xi’ метаданных. Селектор 830 выполнен с возможностью выбирать величину si(n) суммы в качестве актуальной выборки xi’(n) метаданных восстановленного сигнала xi’ метаданных, когда управляющий сигнал находится в первом состоянии (когда b(n) = 0).
Когда управляющий сигнал b находится во втором состоянии, отличном от первого состояния (например, (b(n) = 1), то управляющий сигнал b указывает, что актуальная выборка zi(n) метаданных не является величиной разности, и поэтому актуальная выборка zi(n) метаданных является правильной актуальной выборкой xi’(n) метаданных восстановленного сигнала xi’ метаданных. Селектор 830 выполнен с возможностью выбирать актуальную выборку zi(n) метаданных в качестве актуальной выборки xi’(n) метаданных восстановленного сигнала xi’ метаданных, когда управляющий сигнал находится во втором состоянии (когда b(n) = 1).
В соответствии с осуществлениями, подблок 91i’ устройства декодирования метаданных дополнительно содержит блок 920. Блок 920 выполнен с возможностью хранить актуальную выборку xi’(n) метаданных восстановленного сигнала xi’ метаданных в течение периода выборки. В осуществлении, это обеспечивает то, что при формировании xi’(n) сформированный xi’(n) не отправляется обратно слишком рано, чтобы когда zi(n) является значением разности, то xi’(n) действительно формируется на основании xi’(n-1).
В осуществлении на Фиг. 9b, селектор 930 может формировать выборки xi'(n) метаданных из компонента zi(n) принятого сигнала и линейной комбинации компонента задержанного выходного сигнала (уже сформированной выборки метаданных восстановленного сигнала метаданных) и компонента zi(n) принятого сигнала в зависимости от управляющего сигнала b(n).
Далее, закодированные с помощью DPCM сигналы обозначаются как yi(n), а второй входной сигнал (сигнал суммы) В – как si(n). Для выходных компонентов, которые зависят только от соответствующих входных компонентов, выходной сигнал устройства кодирования и устройства декодирования описывается следующим образом:
zi(n) = A(xi(n), vi(n), b(n))
xi’(n) = B(zi(n), si(n), b(n))
Решение, в соответствии с осуществлением, для общего подхода, изображенного выше, заключается в использовании b(n) для переключения между закодированным с помощью DPCM сигналом и квантованным выходным сигналом. Опустим для простоты индекс n времени, тогда функциональные блоки А и В описываются следующим образом:
В устройствах 801, 802 кодирования метаданных, селектор 830 (А) выбирает:
A: zi(xi, yi, b) = yi, если b = 0 (zi указывает значение разности)
A: zi(xi, yi, b) = xi, если b = 1 (zi не указывает значение разности)
В устройствах 91i, 91i’ декодирования метаданных, селектор 830 (В) выбирает:
B: xi’(zi, si, b) = si, если b = 0 (zi указывает значение разности)
B: xi’(zi, si, b) = zi, если b = 1 (zi не указывает значение разности)
Это позволяет передавать квантованный входной сигнал, когда b(n) равен 1, и передавать сигнал DPCM, когда b(n) равен 0. В последнем случае, устройство декодирования становится устройством декодирования DPCM.
При применении для передачи метаданных объекта, этот механизм применяется для постоянной передачи несжатых положений объекта, которые могут быть использованы устройством декодирования для непрерывного доступа.
В предпочтительных осуществлениях, для кодирования значений разности используется меньшее число битов, чем число битов, используемое для кодирования выборок метаданных. Эти осуществления основаны на том выводе, что (например, N) последовательных выборок метаданных в большинстве случаев отличаются незначительно. Например, если закодирован только один тип метаданных выборок метаданных, например, с помощью 8 битов, то эти выборки метаданных могут принимать одно из 256 различных значений. В большинстве случаев, из-за незначительных изменений (например, N) последовательных значений метаданных, можно считать достаточным закодировать значения разности, например, только с помощью 5 битов. Таким образом, если передают значения разности, то можно сократить число переданных битов.
В осуществлении, устройство 210 кодирования метаданных выполнено с возможностью кодировать каждую из обработанных выборок (zi(1),…,zi(n)) метаданных одного zi () из одного или более обработанных сигналов (z1,…,zN) метаданных с помощью первого числа битов, когда управляющий сигнал указывает первое состояние (b(n) = 0), и с помощью второго числа битов, когда управляющий сигнал указывает второе состояние (b(n) = 1), причем первое число битов меньше, чем второе число битов.
В предпочтительном осуществлении, передают одно или более значений разности, причем каждое из одного или более значений разности кодируют с помощью меньшего числа битов, чем каждую из выборок метаданных, и каждое значение разности является целочисленным значением.
В соответствии с осуществлением, устройство 110 кодирования метаданных выполнено с возможностью кодировать одну или более выборок метаданных одного из одного или более обработанных сигналов метаданных с помощью первого числа битов, причем каждая из указанной одной или более выборок метаданных указанного одного из одного или более обработанных сигналов метаданных указывает целое число. Более того, устройство (110) кодирования метаданных выполнено с возможностью кодировать одно или более значений разности с помощью второго числа битов, причем каждое из указанных одного или более значений разности указывает целое число, причем второе число битов меньше, чем первое число битов.
Рассмотрим, например, что в осуществлении, выборки метаданных могут представлять собой азимут, кодируемый с помощью 8 битов. Например, азимут может быть целым числом между -90 ≤ азимут ≤ 90. Таким образом, азимут может принимать 181 различных значений. Если, однако, предположить, что (например, N) последовательных выборок азимута отличаются только не более чем, например,  15, то 5 битов (25 = 32) может быть достаточно для кодирования значений разности. Если значения разности представлены в качестве целых чисел, то определение значений разности автоматически преобразует дополнительные значения, подлежащие передаче, в подходящий диапазон значений.
15, то 5 битов (25 = 32) может быть достаточно для кодирования значений разности. Если значения разности представлены в качестве целых чисел, то определение значений разности автоматически преобразует дополнительные значения, подлежащие передаче, в подходящий диапазон значений.
Например, рассмотрим случай, когда первое значение азимута первого аудио объекта равно 60°, и его последовательные значения могут варьироваться от 45° до 75°. Более того, рассмотрим, что второе значение азимута второго аудио объекта равно 30°, и его последовательные значения могут варьироваться от -45° до -15°. При определении значений разности для последовательных значений первого аудио объекта и для последовательных значений второго аудио объекта, значения разности первого значения азимута и второго значения азимута находятся в диапазоне значений от -15° до +15°, так что 5 битов достаточно для кодирования каждого из значений разности и так что последовательность битов, которая кодирует значения разности, имеет одинаковый смысл для значений разности первого угла азимута и значений разности второго угла азимута.
Далее, описаны кадры метаданных объекта, в соответствии с осуществлениями, и символическое представление, в соответствии с осуществлениями.
Закодированные метаданные объекта передаются в кадрах. Эти кадры метаданных объекта могут содержать либо данные объекта с внутренним кодированием, либо динамические данные объекта, где последние содержат изменения со времени последнего переданного кадра.
Некоторые или все части последующего синтаксиса кадров метаданных объекта, например, могут быть использованы:

Далее, описаны данные объекта с внутренним кодированием, в соответствии с осуществлением.
Непрерывный доступ к закодированным метаданным объекта реализуется посредством данных объекта с внутренним кодированием (“I-кадры”), которые содержат квантованные значения, дискретизированные на регулярной матрице (например, каждые 32 кадра длины 1024). Эти I-кадры, например, могут иметь следующий синтаксис, где position_azimuth, position_elevation, position_radius, and gain_factor задают текущие квантованные значения:

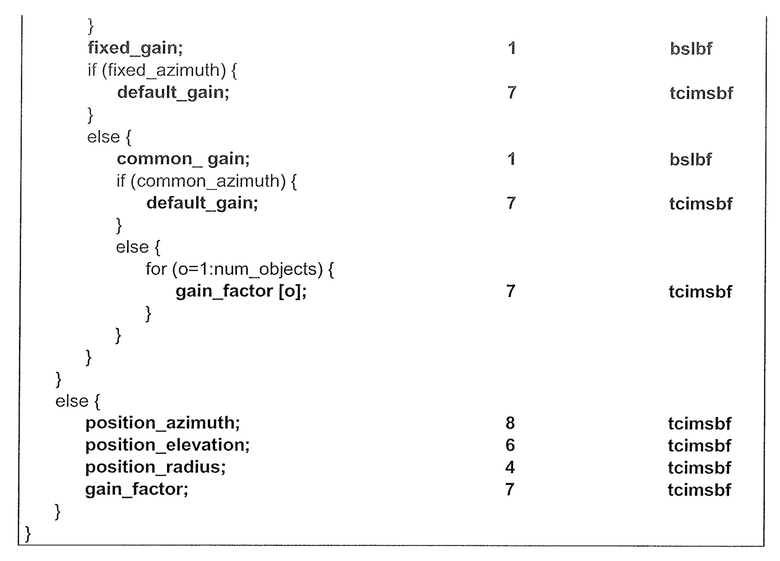
Далее, описаны динамические данные объекта, в соответствии с осуществлением.
Данные DPCM передаются в динамических кадрах объекта, которые, например, могут иметь следующий синтаксис:


Более конкретно, в осуществлении, вышеуказанный макрос, например, может иметь следующий смысл:
Определение полезной нагрузки object_data() в соответствии с осуществлением:
has_intracoded_object_metadata указывает, закодирован ли кадр с помощью внутреннего кодирования или дифференциального кодирования.
Определение полезной нагрузки intracoded_object_metadata() в соответствии с осуществлением:
fixed_azimuth флаг, указывающий, зафиксировано ли значение азимута для всех объектов и не передано ли в случае dynamic_object_metadata()
default_azimuth определяет значение фиксированного или общего угла азимута
common_azimuth указывает, используется ли общий угол азимута для всех объектов
position_azimuth если нет общего значения азимута, то передается значение для каждого объекта
fixed_elevation флаг, указывающий, зафиксировано ли значение наклона для всех объектов и не передано ли в случае dynamic_object_metadata()
default_elevation определяет значение фиксированного или общего угла наклона
common_elevation указывает, используется ли общий угол наклона для всех объектов
position_elevation если нет общего значения наклона, передается значение для каждого объекта
fixed_radius флаг, указывающий, зафиксирован ли радиус для всех объектов и не передан ли в случае dynamic_object_metadata()
default_radius определяет значение общего радиуса
common_radius указывает, используется ли значение общего радиуса для всех объектов
position_radius если нет общего значения радиуса, передается значение для каждого объекта
fixed_gain флаг, указывающий, зафиксирован ли коэффициент усиления для всех объектов и не передан ли в случае dynamic_object_metadata()
default_gain определяет значение фиксированного или общего коэффициента усиления
common_gain указывает, используется ли значение общего усиления для всех объектов
gain_factor если нет общего значения усиления, передается значение для каждого объекта
position_azimuth если есть только один объект, это его угол азимута
position_elevation если есть только один объект, это его угол наклона
position_radius если есть только один объект, это его радиус
gain_factor если есть только один объект, это его коэффициент усиления
Определение полезной нагрузки dynamic_object_metadata() в соответствии с осуществлением:
flag_absolute указывает, передаются ли значения компонентов дифференциально или в абсолютных значениях
has_object_metadata указывает, есть ли данные объекта в потоке двоичных данных или нет
Определение полезной нагрузки single_dynamic_object_metadata() в соответствии с осуществлением:
position_azimuth абсолютное значение угла азимута, если значение не фиксировано
position_elevation абсолютное значение угла наклона, если значение не фиксировано
position_radius абсолютное значение радиуса, если значение не фиксировано
gain_factor абсолютное значение коэффициента усиления, если значение не фиксировано
nbits сколько битов требуется для представления дифференциальных значений
flag_azimuth флаг на объект, указывающий, изменяется ли значение азимута
position_azimuth_difference разность между предыдущим и активным значением
flag_elevation флаг на объект, указывающий, изменяется ли значение наклона
position_elevation_difference значение разности между предыдущим и активным значением
flag_radius флаг на объект, указывающий, изменяется ли радиус
position_radius_difference разность между предыдущим и активным значением
flag_gain флаг на объект, указывающий, изменяется ли радиус усиления
gain_factor_difference разность между предыдущим и активным значением
В уровне техники не существует гибкой технологии, сочетающей, с одной стороны, кодирование канала и, с другой стороны, кодирование объекта, так чтобы достигнуть приемлемых аудио качеств при низкой скорости передачи данных в битах.
Это ограничение преодолевается с помощью Системы 3D Аудиокодека. Теперь будет описана Система 3D Аудиокодека.
Фиг. 10 изображает устройство 3D аудио кодирования в соответствии с осуществлением настоящего изобретения. Устройство 3D аудио кодирования выполнено с возможностью кодировать входные аудио данные 101 для получения выходных аудио данных 501. Устройство 3D аудио кодирования содержит интерфейс ввода для приема множества аудио каналов, указанных как CH, и множества аудио объектов, указанных как OBJ. Дополнительно, как изображено на Фиг. 10, интерфейс 1100 ввода дополнительно принимает метаданные, относящиеся к одному или более из множества аудио объектов OBJ. Дополнительно, устройство 3D аудио кодирования содержит микшер 200 для микширования множества объектов и множества каналов для получения множества предварительно микшированных каналов, причем каждый предварительно микшированный канал содержит аудио данные канала и аудио данные, по меньшей мере, одного объекта.
Дополнительно, устройство 3D аудио кодирования содержит базовое устройство 300 кодирования для базового кодирования входных данных базового устройства кодирования, устройство 400 сжатия метаданных для сжатия метаданных, относящихся к одному или более из множества аудио объектов.
Дополнительно, устройство 3D аудио кодирования может содержать устройство 600 управления режимом для управления микшером, базовое устройство кодирования и/или интерфейс 500 вывода в одном из нескольких операционных режимов, причем в первом режиме базовое устройство кодирования выполнено с возможностью кодировать множество аудио каналов и множество аудио объектов, принятых интерфейсом 1100 ввода без вмешательства микшера, то есть без микширования микшером 200. Во втором режиме, однако, в котором микшер 200 был активен, базовое устройство кодирования кодирует множество микшированных каналов, то есть выходной сигнал, сформированный блоком 200. В последнем случае, предпочтительно больше не кодировать никакие данные объекта. Напротив, метаданные, указывающие положения аудио объектов, уже используются микшером 200 для подготовки к воспроизведению объектов в каналы, как указано метаданными. Другими словами, микшер 200 использует метаданные, относящиеся ко множеству аудио объектов для предварительной подготовки к воспроизведению аудио объектов и затем предварительно подготовленные к воспроизведению аудио объекты микшируют с каналами для получения микшированных каналов на выходе микшера. В этом осуществлении, любые объекты не обязательно могут быть переданы, и это также применяется для сжатых метаданных в качестве выходного сигнала блока 400. Однако, если не все объекты, введенные в интерфейс 1100, микшированы, а только конкретная часть объектов микширована, то только оставшиеся не микшированные объекты и связанные метаданные, тем не менее, передаются в базовое устройство 300 кодирования или устройство 400 сжатия метаданных, соответственно.
На Фиг. 10, устройство 400 сжатия метаданных является устройством 210 кодирования метаданных устройства 250 для формирования закодированной аудио информации в соответствии с одним из вышеописанных осуществлений. Более того, на Фиг. 10, микшер 200 и базовое устройство 300 кодирования совместно образуют устройство 220 аудио кодирования устройства 250 для формирования закодированной аудио информации в соответствии с одним из вышеописанных осуществлений.
Фиг. 12 изображает дополнительное осуществление устройства 3D аудио кодирования, которое, дополнительно, содержит устройство 800 кодирования SAOC. Устройство 800 кодирования SAOC выполнено с возможностью формировать один или более транспортных каналов и параметрические данные из входных данных устройства пространственного кодирования аудио объекта. Как изображено на Фиг. 12, входные данные устройства пространственного кодирования аудио объекта являются объектами, которые не были обработаны устройством предварительной подготовки к воспроизведению/микшером. Альтернативно, с учетом того, что устройство предварительной подготовки к воспроизведению/микшер было пропущено, как в режиме один, где активно кодирование отдельного канала/объекта, все объекты, введенные в интерфейс 1100 ввода, закодированы устройством 800 кодирования SAOC.
Дополнительно, как изображено на Фиг. 12, базовое устройство 300 кодирования предпочтительно осуществлено в качестве устройства кодирования USAC, то есть, в качестве устройства кодирования, как определено и стандартизировано в стандарте MPEG-USAC (USAC = кодирование неопределенной речи и аудио кодирование). Вывод устройства 3D аудио кодирования, изображенный на Фиг. 12, является потоком данных MPEG 4, имеющим контейнерные структуры для отдельных типов данных. Дополнительно, метаданные указаны как данные “OAM”, и устройство 400 сжатия метаданных на Фиг. 10 соответствует устройству 400 кодирования OAM для получения сжатых данных OAM, которые вводятся в устройство 300 кодирования USAC, которое, как видно на Фиг. 12, дополнительно содержит интерфейс вывода для получения потока выходных данных MP4, имеющего не только закодированные данные канала/объекта, но также имеющего сжатые данные OAM.
На Фиг. 12, устройство 400 кодирования OAM является устройством 210 кодирования метаданных устройства 250 для формирования закодированной аудио информации в соответствии с одним из вышеописанных осуществлений. Более того, на Фиг. 12, устройство 800 кодирования SAOC и устройство 300 кодирования USAC совместно образуют устройство 220 аудио кодирования устройства 250 для формирования закодированной аудио информации в соответствии с одним из вышеописанных осуществлений.
Фиг. 14 изображает дополнительное осуществление устройства 3D аудио кодирования, где в противоположность Фиг. 12, устройство кодирования SAOC может быть выполнено с возможностью либо кодировать, с помощью алгоритма кодирования SAOC, каналы, обеспеченные в устройстве 200 предварительной подготовки к воспроизведению/микшере, не активные в данном режиме, либо, альтернативно, кодировать с помощью SAOC предварительно подготовленные к воспроизведению каналы плюс объекты. Таким образом, на Фиг. 14, устройство 800 кодирования SAOC может функционировать на трех различных видах входных данных, то есть, каналы без предварительно подготовленных к воспроизведению объектов, каналы и предварительно подготовленные к воспроизведению объекты или только объекты. Дополнительно, предпочтительно обеспечить дополнительное устройство 420 декодирования OAM на Фиг. 14, так чтобы устройство 800 кодирования SAOC использовало для своей обработки те же данные, что и сторона устройства декодирования, то есть данные, полученные сжатием с потерями, а не исходные данные OAM.
На Фиг. 14, устройство 3D аудио кодирования может функционировать в нескольких отдельных режимах.
Дополнительно к первому и второму режимам, как описано в контексте Фиг. 10, устройство 3D аудио кодирования на Фиг. 14 может дополнительно функционировать в третьем режиме, в котором базовое устройство кодирования формирует один или более транспортных каналов из отдельных объектов, когда устройство 200 предварительной подготовки к воспроизведению/микшер не был активен. Альтернативно или дополнительно, в этом третьем режиме устройство 800 кодирования SAOC может формировать один или более альтернативных или дополнительных транспортных каналов из исходных каналов, то есть заново, когда устройство 200 предварительной подготовки к воспроизведению/микшер, соответствующий микшеру 200 на Фиг. 10, не был активен.
Наконец, когда устройство 3D аудио кодирования функционирует в четвертом режиме, устройство 800 кодирования SAOC может кодировать каналы плюс предварительно подготовленные к воспроизведению объекты, сформированные устройством предварительной подготовки к воспроизведению/микшером. Таким образом, в четвертом режиме, приложения с самой низкой скоростью передачи данных в битах обеспечат хорошее качество благодаря тому факту, что каналы и объекты были полностью преобразованы в отдельные транспортные каналы SAOC и связанную дополнительную информацию, как указано на Фиг. 3 и 5 в качестве “SAOC-SI”, и, дополнительно, любые сжатые метаданные не надо передавать в четвертом режиме.
На Фиг. 14, устройство 400 кодирования OAM является устройством 210 кодирования метаданных устройства 250 для формирования закодированной аудио информации в соответствии с одним из вышеописанных осуществлений. Более того, на Фиг. 14, устройство 800 кодирования SAOC и устройство 300 кодирования USAC совместно образуют устройство 220 аудио кодирования устройства 250 для формирования закодированной аудио информации в соответствии с одним из вышеописанных осуществлений.
В соответствии с осуществлением, обеспечено устройство 101 кодирования входных аудио данных для получения выходных данных 501. Устройство 101 кодирования входных аудио данных содержит:
- интерфейс 1100 ввода для приема множества аудио каналов, множества аудио объектов и метаданных, относящихся к одному или более из множества аудио объектов,
- микшер 200 для микширования множества объектов и множества каналов для получения множества предварительно микшированных каналов, причем каждый из предварительно микшированных каналов содержит аудио данные канала и аудио данные, по меньшей мере, одного объекта, и
- устройство 250 для формирования закодированной аудио информации, которое содержит устройство кодирования метаданных, как описано выше.
Устройство 220 аудио кодирования устройства 250 для формирования закодированной аудио информации является базовым устройством (300) кодирования для базового кодирования входных данных базового устройства кодирования.
Устройство 210 кодирования метаданных устройства 250 для формирования закодированной аудио информации является устройством 400 сжатия метаданных для сжатия метаданных, относящихся к одному или более из множества аудио объектов.
Фиг. 11 изображает устройство 3D аудио декодирования в соответствии с осуществлением настоящего изобретения. Устройство 3D аудио декодирования принимает, в качестве входных данных, закодированные аудио данные, то есть данные 501 на Фиг. 10.
Устройство 3D аудио декодирования содержит устройство 1400 распаковки метаданных, базовое устройство 1300 декодирования, устройство 1200 обработки объекта, устройство 1600 управления режимом и устройство 1700 постобработки.
Более конкретно, устройство 3D аудио декодирования выполнено с возможностью декодирования закодированной аудио информации и интерфейс ввода для приема закодированной аудио информации, причем закодированные аудио данные содержат множество закодированных каналов и множество закодированных объектов и сжатые метаданные, относящиеся ко множеству объектов в конкретном режиме.
Дополнительно, базовое устройство 1300 декодирования выполнено с возможностью декодирования множества закодированных каналов и множества закодированных объектов, и, дополнительно, устройство распаковки метаданных выполнено с возможностью распаковки сжатых метаданных.
Дополнительно, устройство 1200 обработки объекта выполнено с возможностью обрабатывать множество декодированных объектов, сформированных базовым устройством 1300 декодирования, с использованием распакованных метаданных для получения предварительно определенного числа выходных каналов, содержащих данные объекта и декодированные каналы. Эти выходные каналы, как указано на 1205, затем вводятся в устройство 1700 постобработки. Устройство 1700 постобработки выполнено с возможностью преобразовывать число выходных каналов 1205 в конкретный формат вывода, который может быть стереофоническим форматом вывода или форматом вывода громкоговорителя, как, например, формат вывода 5.1, 7.1 и так далее.
Предпочтительно, устройство 3D аудио декодирования содержит устройство 1600 управления режимом, которое выполнено с возможностью анализа закодированных данных для обнаружения указания режима. Следовательно, устройство 1600 управления режимом соединено с интерфейсом 1100 ввода на Фиг. 11. Однако, альтернативно, устройство управления режимом необязательно должно присутствовать. Напротив, гибкое устройство аудио декодирования может быть предварительно настроено с помощью любого вида данных управления, как, например, ввод пользователя или любое другое управление. Устройство 3D аудио декодирования на Фиг. 11, предпочтительно, управляемое устройством 1600 управления режимом, выполнено с возможностью либо пропускать устройство обработки объекта и подавать множество декодированных каналов в устройство 1700 постобработки. Это функционирование в режиме 2, то есть, в котором принимают только предварительно подготовленные к воспроизведению каналы, то есть, когда режим 2 был применен в устройстве 3D аудио кодирования на Фиг. 10. Альтернативно, когда был применен режим 1 в устройстве 3D аудио кодирования, то есть, когда устройство 3D аудио кодирования выполнило кодирование отдельного канала/объекта, то устройство 1200 обработки объекта не пропускают, но множество декодированных каналов и множество декодированных объектов подают в устройство 1200 обработки объекта совместно с распакованными метаданными, сформированными устройством 1400 распаковки метаданных.
Предпочтительно, указание того, применен ли режим 1 или режим 2, включают в закодированные аудио данные, и затем устройство 1600 управления режимом анализирует закодированные данные для обнаружения указания режима. Режим 1 применяют, когда указание режима указывает, что закодированные аудио данные содержат закодированные каналы и закодированные объекты, и режим 2 применяют, когда индикатор режима указывает, что закодированные аудио данные не содержат никакие аудио объекты, то есть, содержат только предварительно подготовленные к воспроизведению каналы, полученные режимом 2 устройства 3D аудио кодирования на Фиг. 10.
На Фиг. 11, устройство 1400 распаковки метаданных является устройством 110 декодирования метаданных устройства 100 для формирования одного или более аудио каналов в соответствии с одним из вышеописанных осуществлений. Более того, на Фиг. 11, базовое устройство 1300 декодирования, устройство 1200 обработки объекта и устройство 1700 постобработки совместно образуют устройство 120 аудио декодирования устройства 100 для формирования одного или более аудио каналов в соответствии с одним из вышеописанных осуществлений.
Фиг. 13 изображает предпочтительное осуществление, по сравнению с Фиг. 11, устройства 3D аудио декодирования, и осуществление на Фиг. 13 соответствует устройству 3D аудио кодирования на Фиг. 12. Дополнительно к осуществлению устройства 3D аудио декодирования на Фиг. 11, устройство 3D аудио декодирования на Фиг. 13 содержит устройство 1800 декодирования SAOC. Дополнительно, устройство 1200 обработки объекта на Фиг. 11 осуществлено в качестве раздельных устройства 1210 подготовки к воспроизведению объекта и микшера 1220, хотя, в зависимости от режима, функциональность устройства 1210 подготовки к воспроизведению объекта также может быть осуществлена устройством 1800 декодирования SAOC.
Дополнительно, устройство 1700 постобработки может быть осуществлено в качестве устройства 1710 стереофонической подготовки к воспроизведению или преобразователя 1720 формата. Альтернативно, прямой вывод 1205 данных на Фиг. 11 также может быть осуществлен, как изображено с помощью 1730. Следовательно, предпочтительно выполнить обработку в устройстве декодирования с наибольшим числом каналов, как, например, 22.2 или 32, чтобы иметь гибкость и затем выполнить постобработку, если требуется меньший формат. Однако, когда с самого начала очевидно, что требуется только малый формат, как, например, формат 5.1, то предпочтительно, как указано на Фиг. 11 или 6 с помощью сокращения 1727, чтобы конкретное управление устройством декодирования SAOC и/или устройством декодирования USAC могло быть применено, чтобы избежать ненужных операций повышающего микширования и последующих операций понижающего микширования.
В предпочтительном осуществлении настоящего изобретения, устройство 1200 обработки объекта содержит устройство 1800 декодирования SAOC, и устройство декодирования SAOC выполнено с возможностью декодирования одного или более транспортных каналов, выведенных базовым устройством декодирования, и связанных параметрических данных и с возможностью использования распакованных метаданных для получения множества подготовленных к воспроизведению аудио объектов. С этой целью, выход OAM соединен с блоком 1800.
Дополнительно, устройство 1200 обработки объекта выполнено с возможностью готовить к воспроизведению декодированные объекты, выведенные базовым устройством декодирования, которые не закодированы в транспортные каналы SAOC, но которые отдельно закодированы в обычные единичные канальные элементы, как указано устройством 1210 подготовки к воспроизведению объекта. Дополнительно, устройство декодирования содержит интерфейс вывода, соответствующий выводу 1730, для вывода с микшера на громкоговорители.
В дополнительном осуществлении, устройство 1200 обработки объекта содержит устройство 1800 пространственного аудио декодирования объекта для декодирования одного или более транспортных каналов и связанной параметрической дополнительной информации, представляющей собой закодированные аудио сигналы или закодированные аудио каналы, причем устройство пространственного аудио декодирования объекта выполнено с возможностью перекодировать связанную параметрическую информацию и сжатые метаданные в перекодированную параметрическую дополнительную информацию, используемую для прямой подготовки к воспроизведению формата вывода, как, например, определено в более ранней версии SAOC. Устройство 1700 постобработки выполнено с возможностью вычисления аудио каналов формата вывода с использованием декодированных транспортных каналов и перекодированной параметрической дополнительной информации. Обработка, выполняемая устройством постобработки, может быть подобна обработке окружающего звука MPEG или может быть любой другой обработкой, как, например, обработкой BCC или тому подобное.
В дополнительном осуществлении, устройство 1200 обработки объекта содержит устройство 1800 пространственного аудио декодирования объекта, выполненное с возможностью напрямую выполнять повышающее микширование и готовить к воспроизведению сигналы каналов для формата вывода с использованием декодированных (базовым устройством декодирования) транспортных каналов и параметрической дополнительной информации.
Дополнительно и важно, устройство 1200 обработки объекта на Фиг. 11 дополнительно содержит микшер 1220, который принимает, в качестве входных данных, данные, выведенные устройством 1300 декодирования USAC напрямую, когда есть предварительно подготовленные к воспроизведению объекты, микшированные с каналами, то есть, когда микшер 200 на Фиг. 10, был активен. Дополнительно, микшер 1220 принимает данные от устройства подготовки к воспроизведению объекта, выполняющего подготовку к воспроизведению объекта без декодирования SAOC. Дополнительно, микшер принимает выходные данные устройства декодирования SAOC, то есть подготовленные к воспроизведению с помощью SAOC объекты.
Микшер 1220 соединен с интерфейсом 1730 вывода, устройством 1710 стереофонической подготовки к воспроизведению и преобразователем 1720 формата. Устройство 1710 стереофонической подготовки к воспроизведению выполнено с возможностью подготовки к воспроизведению выходных каналов в два стереофонических канала с использованием динамика, относящегося к функциям передачи или импульсным характеристикам (BRIR) стереофонического пространства. Преобразователь 1720 формата выполнен с возможностью преобразования выходных каналов в формат вывода, имеющий меньшее число каналов, чем выходные каналы 1205 микшера, и преобразователь 1720 формата требует информацию о схеме воспроизведения, как, например, громкоговорители 5.1 или тому подобное.
На Фиг. 13, устройство 1400 декодирования OAM является устройством 110 декодирования метаданных устройства 100 для формирования одного или более аудио каналов в соответствии с одним из вышеописанных осуществлений. Более того, на Фиг. 13, устройство 1210 подготовки к воспроизведению объекта, устройство 1300 декодирования USAC и микшер 1220 совместно образуют устройство 120 аудио декодирования устройства 100 для формирования одного или более аудио каналов в соответствии с одним из вышеописанных осуществлений.
Устройство 3D аудио декодирования на Фиг. 15 отличается от устройства 3D аудио декодирования на Фиг. 13 тем, что устройство декодирования SAOC не может формировать только подготовленные к воспроизведению объекты, но также подготовленные к воспроизведению каналы, и это и есть тот случай, когда используют устройство 3D аудио кодирования на Фиг. 14, и соединение 900 между каналами/предварительно подготовленными к воспроизведению объектами и интерфейсом ввода устройства 800 кодирования SAOC активно.
Дополнительно, выполнен каскад 1810 векторного амплитудного панорамирования (VBAP), который принимает от устройства декодирования SAOC информацию о схеме воспроизведения и который выводит матрицу подготовки к воспроизведению устройству декодирования SAOC так, что устройство декодирования SAOC может, в конце концов, обеспечивать подготовленные к воспроизведению каналы без дополнительной операции микшера в многоканальном формате 1205, то есть 32 громкоговорителя.
Блок VBAP предпочтительно принимает декодированные данные OAM для извлечения матриц подготовки к воспроизведению. В общем, это предпочтительно требует геометрическую информацию не только схемы воспроизведения, но также и положений, где входные сигналы должны быть подготовлены к воспроизведению на схеме воспроизведения. Геометрические входные данные могут быть данными OAM для объектов или информацией положения канала для каналов, которые были переданы с использованием SAOC.
Однако, если только требуется конкретный интерфейс вывода, то каскад 1810 VBAP может уже обеспечивать требуемую матрицу подготовки к воспроизведению, например, для вывода 5.1. Устройство 1800 декодирования SAOC затем выполняет прямую подготовку к воспроизведению транспортных каналов SAOC, связанных параметрических данных и распакованных метаданных, прямую подготовку к воспроизведению в требуемый формат вывода без вмешательства микшера 1220. Однако, когда применено конкретное микширование между режимами, то есть, где несколько каналов закодированы с помощью SAOC, но не все каналы закодированы с помощью SAOC, или где несколько объектов закодированы с помощью SAOC, но не все объекты закодированы с помощью SAOC, или когда только конкретное количество предварительно подготовленных к воспроизведению объектов с каналами декодированы с помощью SAOC и оставшиеся каналы не обработаны с помощью SAOC, то микшер выводит вместе данные от отдельных входных участков, то есть напрямую от базового устройства 1300 декодирования, от устройства 1210 подготовки к воспроизведению объекта и от устройства 1800 декодирования SAOC.
На Фиг. 15, устройство 1400 декодирования OAM является устройством 110 декодирования метаданных устройства 100 для формирования одного или более аудио каналов в соответствии с одним из вышеописанных осуществлений. Более того, на Фиг. 15, устройство 1210 подготовки к воспроизведению объекта, устройство 1300 декодирования USAC и микшер 1220 совместно образуют устройство 120 аудио декодирования устройства 100 для формирования одного или более аудио каналов в соответствии с одним из вышеописанных осуществлений.
Обеспечено устройство декодирования закодированных аудиоданных. Устройство декодирования закодированных аудиоданных содержит:
- интерфейс 1100 ввода для приема закодированных аудиоданных, причем закодированные аудиоданные содержат множество закодированных каналов или множество закодированных объектов или сжатые метаданные, относящиеся ко множеству объектов, и
- устройство 100, содержащее устройство 110 декодирования метаданных и устройство 120 формирования аудио канала для формирования одного или более аудио каналов, как описано выше.
Устройство 110 декодирования метаданных устройства 100 для формирования одного или более аудио каналов является устройством 400 распаковки метаданных для распаковки сжатых метаданных.
Устройство 120 формирования аудио канала устройства 100 для формирования одного или более аудио каналов содержит базовое устройство 1300 декодирования для декодирования множества закодированных каналов и множества закодированных объектов.
Более того, устройство 120 формирования аудио канала дополнительно содержит устройство 1200 обработки объекта для обработки множества декодированных объектов с использованием распакованных метаданных для получения числа выходных каналов 1205, содержащих аудио данные от объектов и декодированные каналы.
Дополнительно, устройство 120 формирования аудио канала дополнительно содержит устройство 1700 постобработки для преобразования числа выходных каналов 1205 в формат вывода.
Хотя некоторые аспекты описаны в контексте устройства, ясно, что эти аспекты также представляют собой описание соответствующего способа, где блок или устройство соответствуют этапу способа или характеристике этапа способа. Аналогичным образом, аспекты, описанные в контексте этапа способа, также представляют собой описание соответствующего блока, или элемента, или характеристики соответствующего устройства.
Изобретенный проанализированный сигнал можно хранить на цифровом носителе данных или можно передать по средству связи, как, например, беспроводное средство связи или проводное средство связи, как, например, интернет.
В зависимости от конкретных требований воплощения, осуществления настоящего изобретения могут быть воплощены в аппаратных средствах или программном обеспечении. Воплощение может быть выполнено с использованием цифрового носителя данных, например, гибкий диск, DVD, CD, ROM, PROM, EPROM, EEPROM или устройство флэш-памяти, имеющие электронно-считываемые сигналы управления, хранящиеся на них, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой так, чтобы выполнять соответствующий способ.
Некоторые осуществления в соответствии с изобретением содержат некратковременный носитель данных, имеющий электронно-считываемые сигналы управления, которые способны взаимодействовать с программируемой компьютерной системой так, чтобы выполнять один из способов, описанных в настоящей заявке.
В общем, осуществления настоящего изобретения могут быть воплощены в качестве компьютерного программного продукта с программным кодом, причем программный код функционирует для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код, например, может храниться на машиночитаемом носителе.
Другие осуществления содержат компьютерную программу для выполнения одного из способов, описанных в настоящей заявке, хранящуюся на машиночитаемом носителе.
Другими словами, осуществление способа согласно настоящему изобретению, следовательно, является компьютерной программой, имеющей программный код для выполнения одного из способов, описанных в настоящей заявке, когда компьютерная программа выполняется на компьютере.
Дополнительное осуществление способов согласно настоящему изобретению, следовательно, является носителем (или цифровым носителем данных, или машиночитаемым носителем) данных, содержащим записанную на нем компьютерную программу для выполнения одного из способов, описанных в настоящей заявке.
Дополнительное осуществление способа согласно настоящему изобретению, следовательно, является потоком данных или последовательностью сигналов, представляющей собой компьютерную программу для выполнения одного из способов, описанных в настоящей заявке. Поток данных или последовательность сигналов, например, могут быть выполнены с возможностью передаваться по соединению связи данных, например, по интернету.
Дополнительное осуществление содержит средство обработки, например, компьютер, или устройство с программируемой логикой, выполненное с возможностью или адаптированное к выполнению одного из способов, описанных в настоящей заявке.
Дополнительное осуществление содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в настоящей заявке.
В некоторых осуществлениях, устройство с программируемой логикой (например, программируемая пользователем вентильная матрица) может быть использовано для выполнения некоторых или всех функций способов, описанных в настоящей заявке. В некоторых осуществлениях, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы выполнить один из способов, описанных в настоящей заявке. В общем, способы предпочтительно выполняются любыми аппаратными средствами.
Вышеописанные осуществления приведены лишь для иллюстрации принципов настоящего изобретения. Понятно, что модификации и варианты расстановки, а также детали, описанные в настоящей заявке, будут очевидны специалистам в данной области техники. Следовательно, подразумевается ограничение только объемом предоставленной формулы изобретения, а не конкретных деталей, представленных для описания и объяснения осуществлений настоящего изобретения.
ССЫЛОЧНЫЕ МАТЕРИАЛЫ
[1] Peters, N., Lossius, T. and Schacher J. C., "SpatDIF: Principles, Specification, and Examples", 9th Sound and Music Computing Conference, Copenhagen, Denmark, Jul. 2012.
[2] Wright, M., Freed, A., "Open Sound Control: A New Protocol for Communicating with Sound Synthesizers", International Computer Music Conference, Thessaloniki, Greece, 1997.
[3] Matthias Geier, Jens Ahrens, and Sascha Spors. (2010), "Object-based audio reproduction and the audio scene description format", Org. Sound, Vol. 15, No. 3, pp. 219-227, December 2010.
[4] W3C, "Synchronized Multimedia Integration Language (SMIL 3.0)", Dec. 2008.
[5] W3C, "Extensible Markup Language (XML) 1.0 (Fifth Edition)", Nov. 2008.
[6] MPEG, "ISO/IEC International Standard 14496-3 - Coding of audio-visual objects, Part 3 Audio", 2009.
[7] Schmidt, J.; Schroeder, E. F. (2004), "New and Advanced Features for Audio Presentation in the MPEG-4 Standard", 116th AES Convention, Berlin, Germany, May 2004
[8] Web3D, "International Standard ISO/IEC 14772-1:1997 - The Virtual Reality Modeling Language (VRML), Part 1: Functional specification and UTF-8 encoding", 1997.
[9] Sporer, T. (2012), "Codierung räumlicher Audiosignale mit leichtgewichtigen Audio-Objekten", Proc. Annual Meeting of the German Audiological Society (DGA), Erlangen, Germany, Mar. 2012.
[10] Cutler, C. C. (1950), "Differential Quantization of Communication Signals", US Patent US2605361, Jul. 1952.
[11] Ville Pulkki, “Virtual Sound Source Positioning Using Vector Base Amplitude Panning”; J. Audio Eng. Soc., Volume 45, Issue 6, pp. 456-466, June 1997.
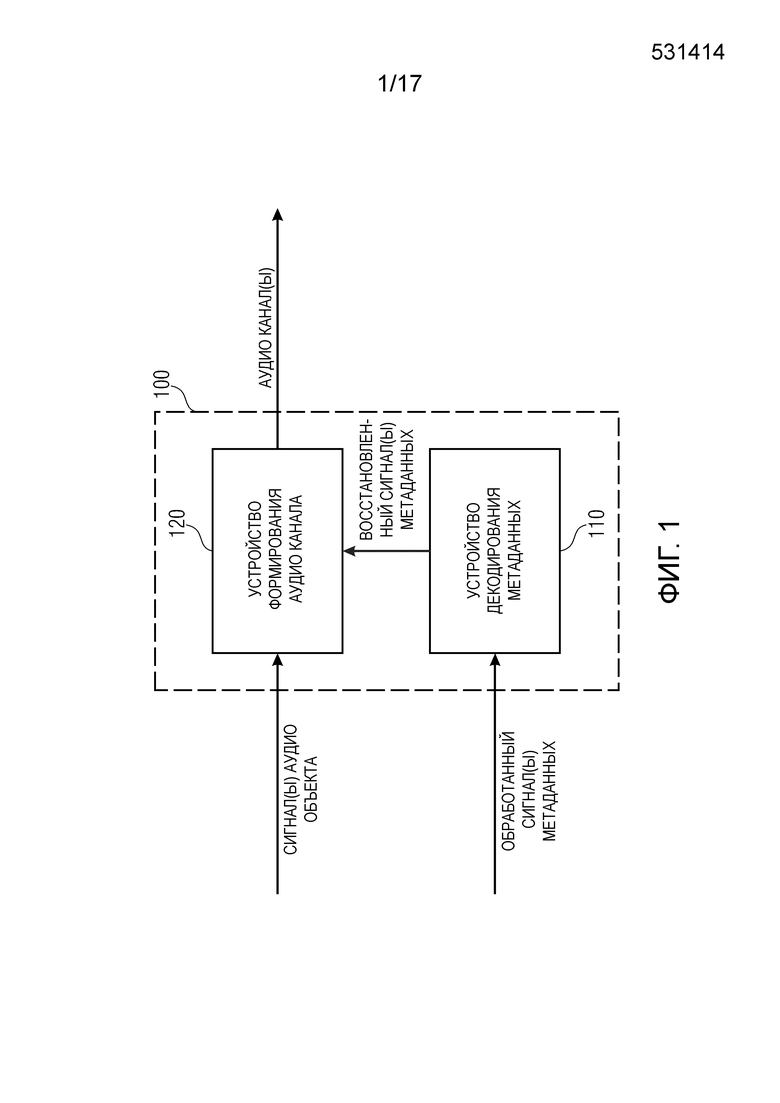
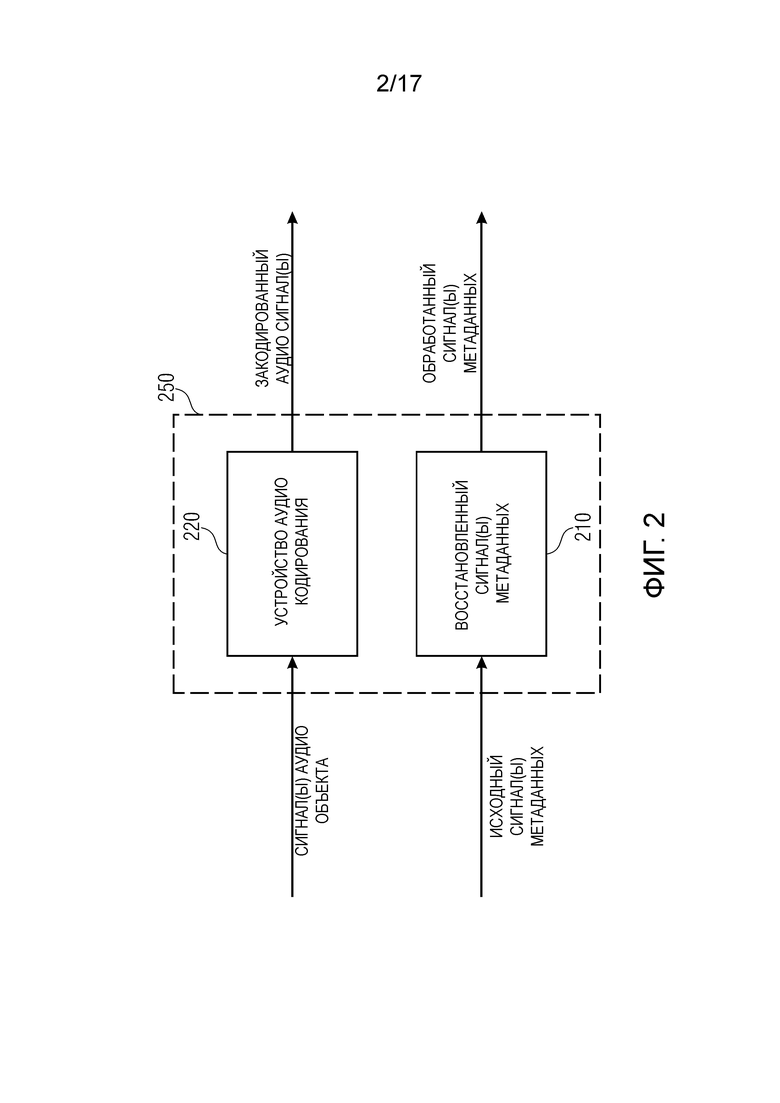
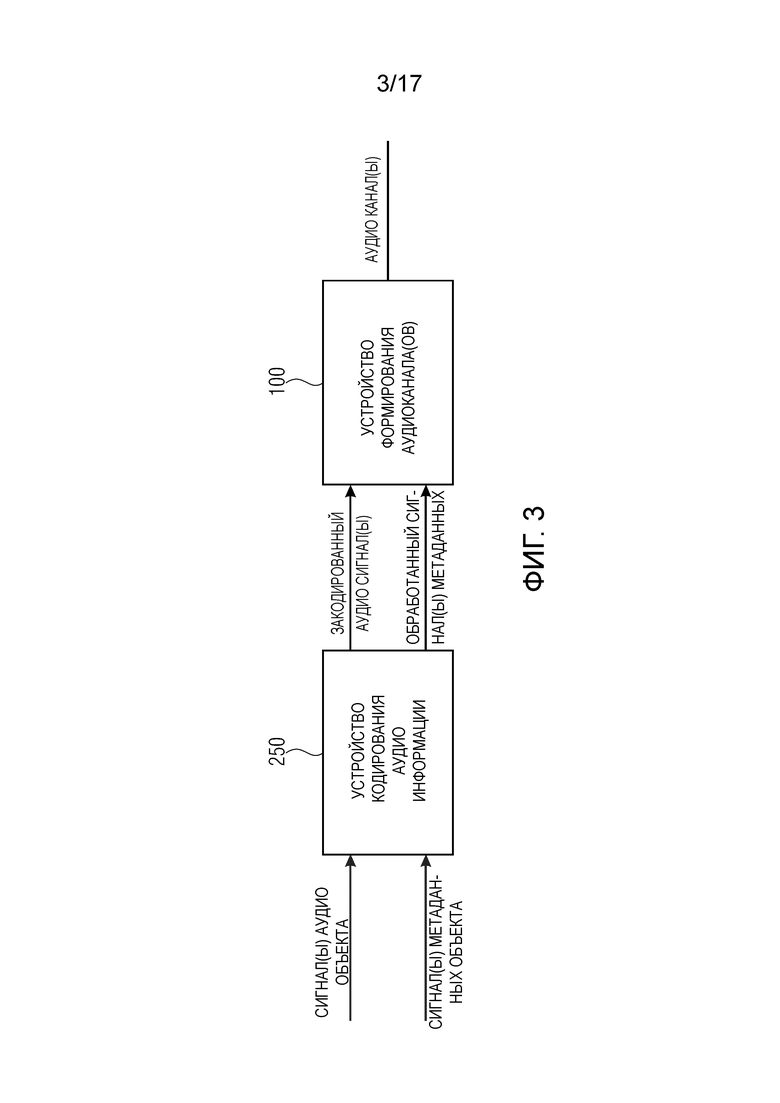
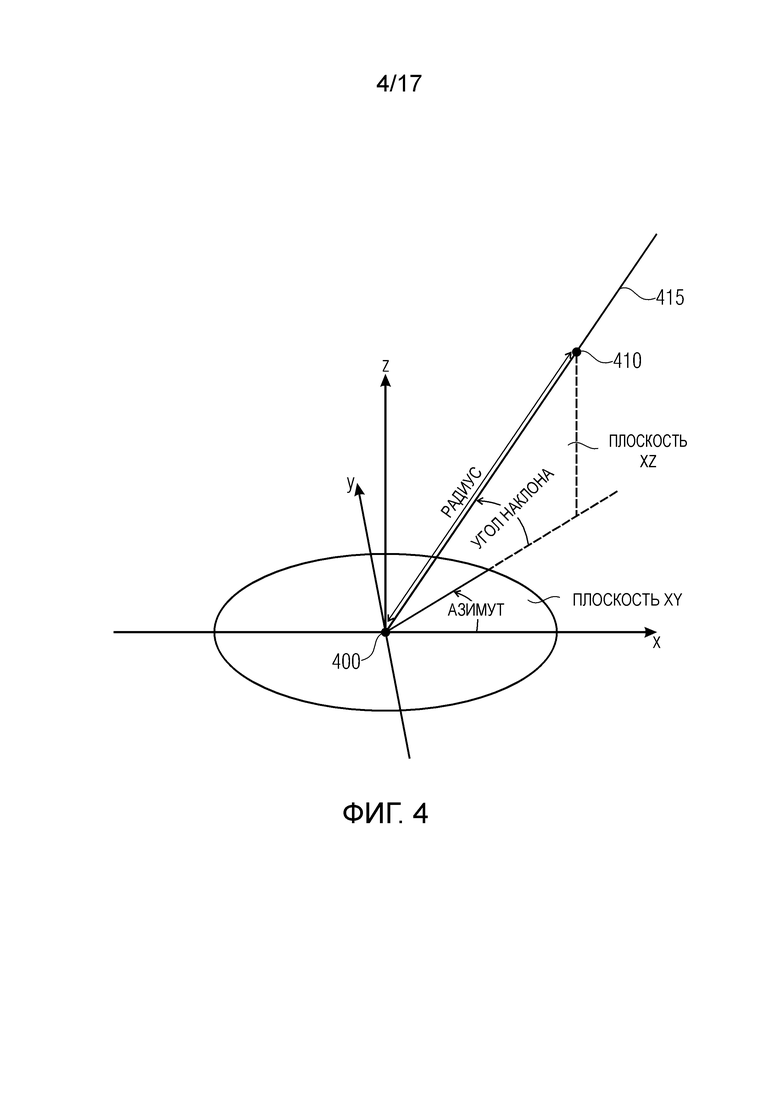
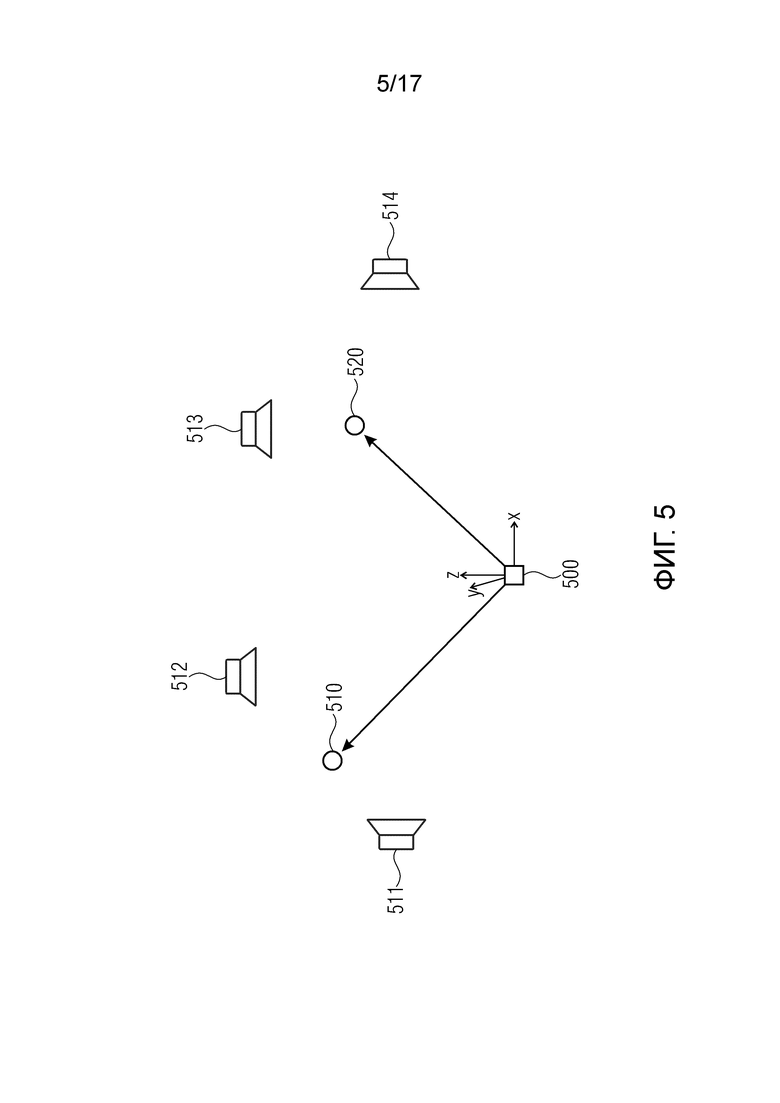
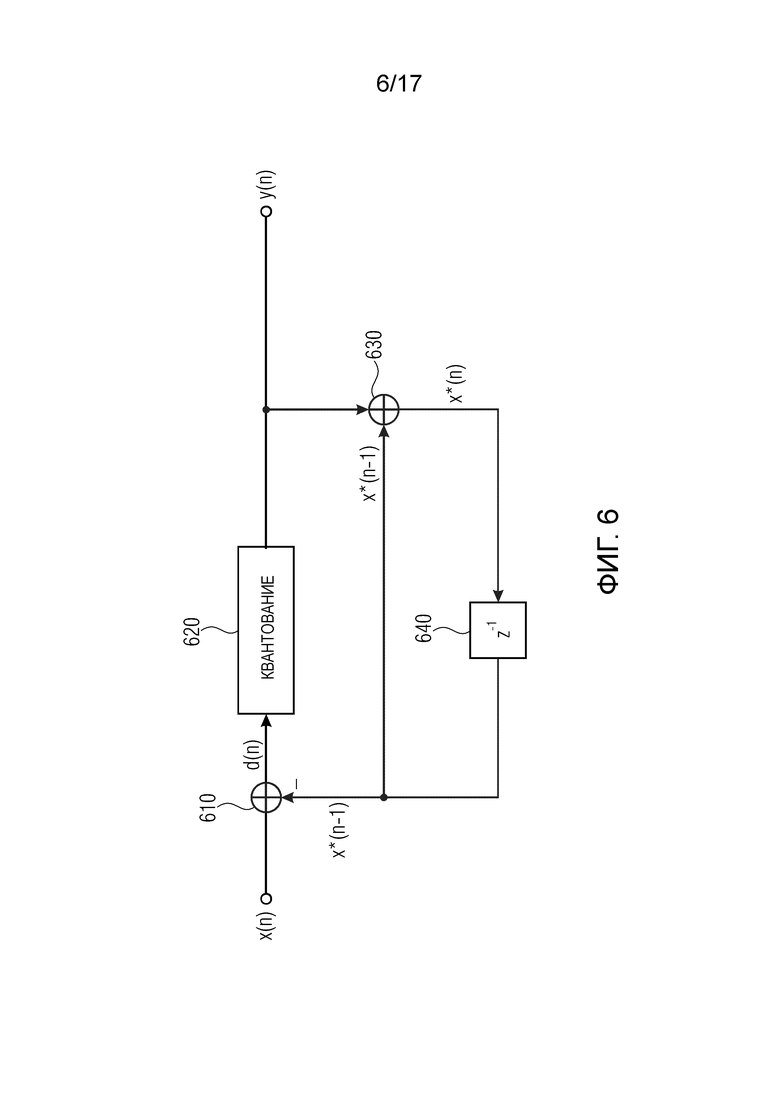
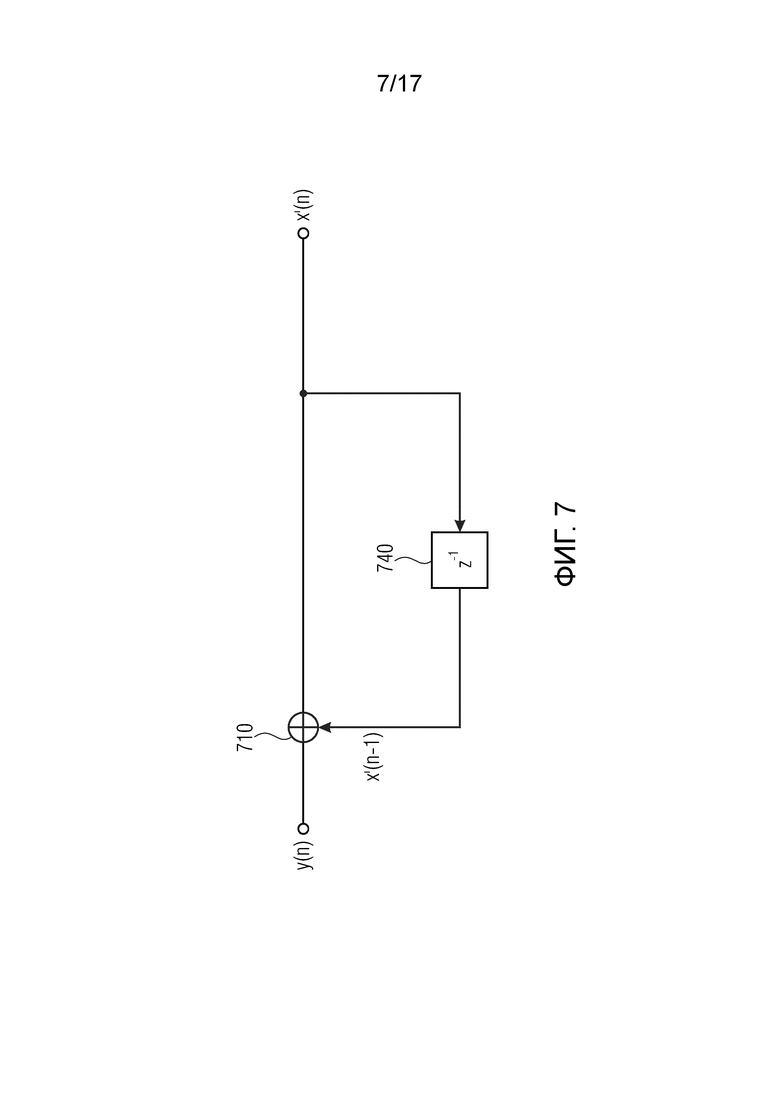

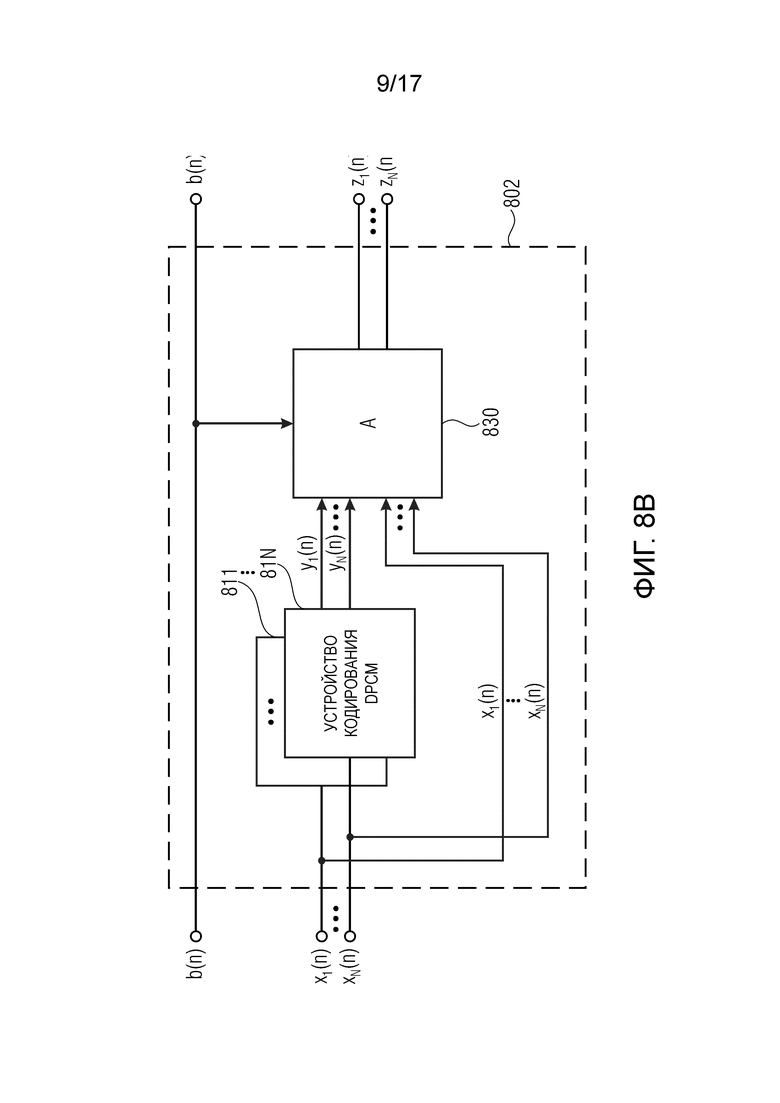
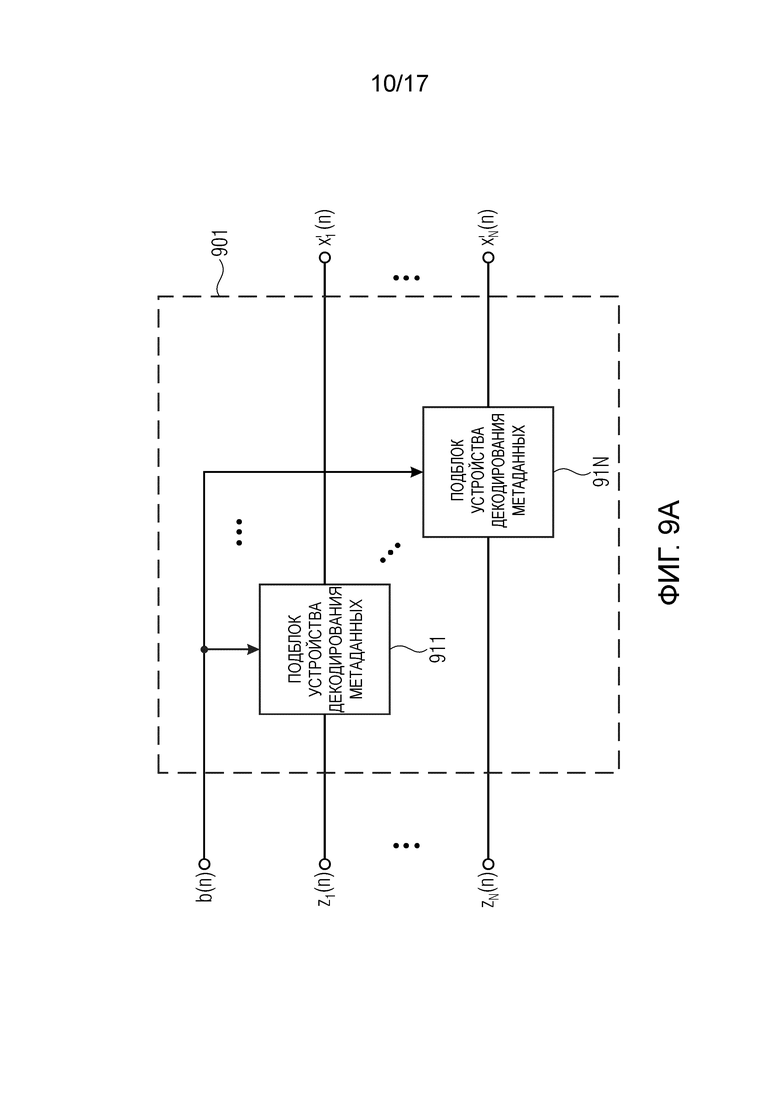
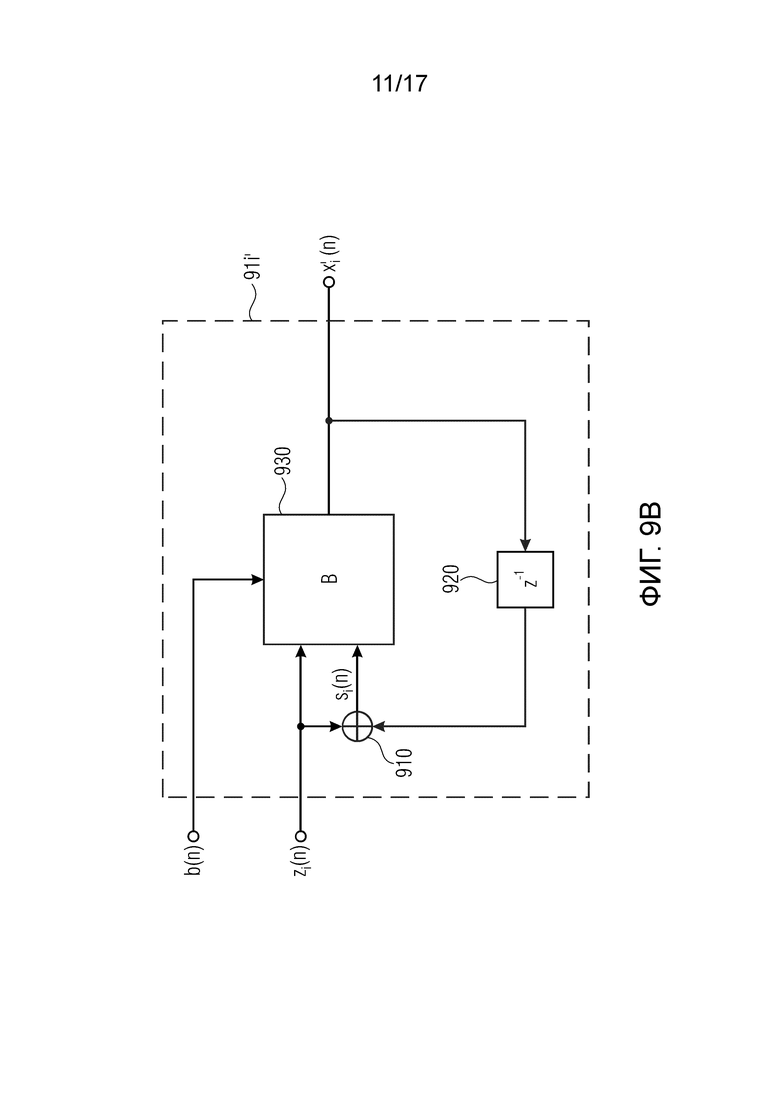
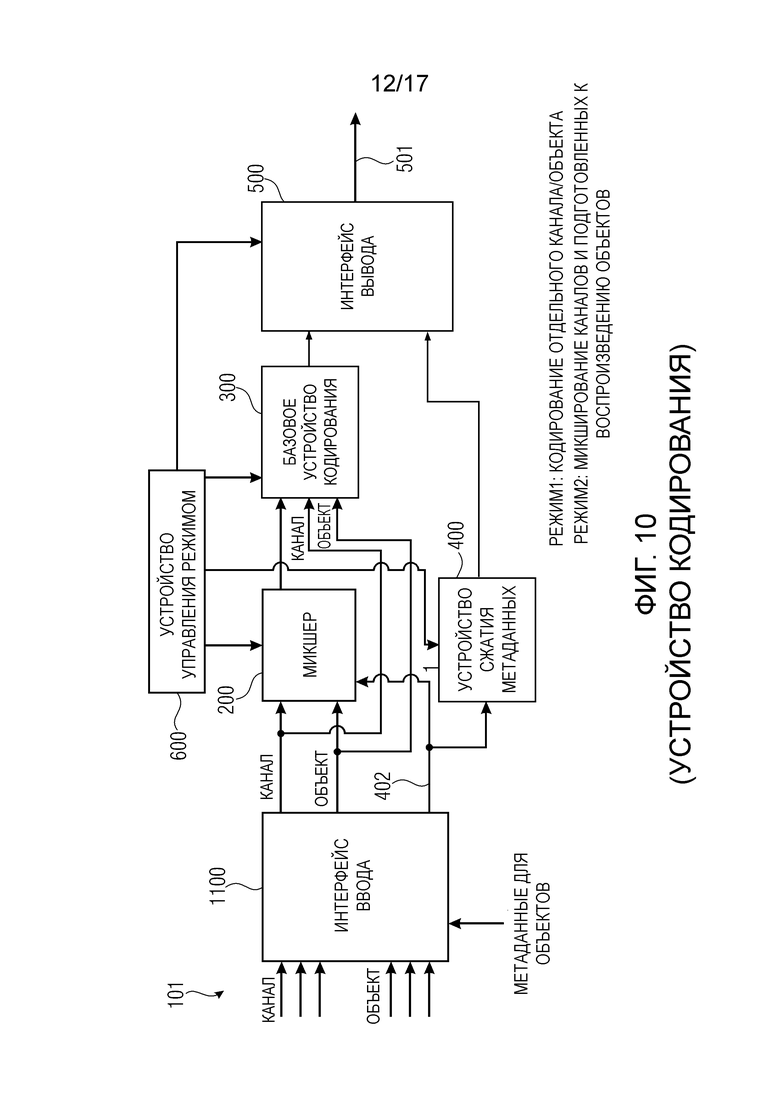
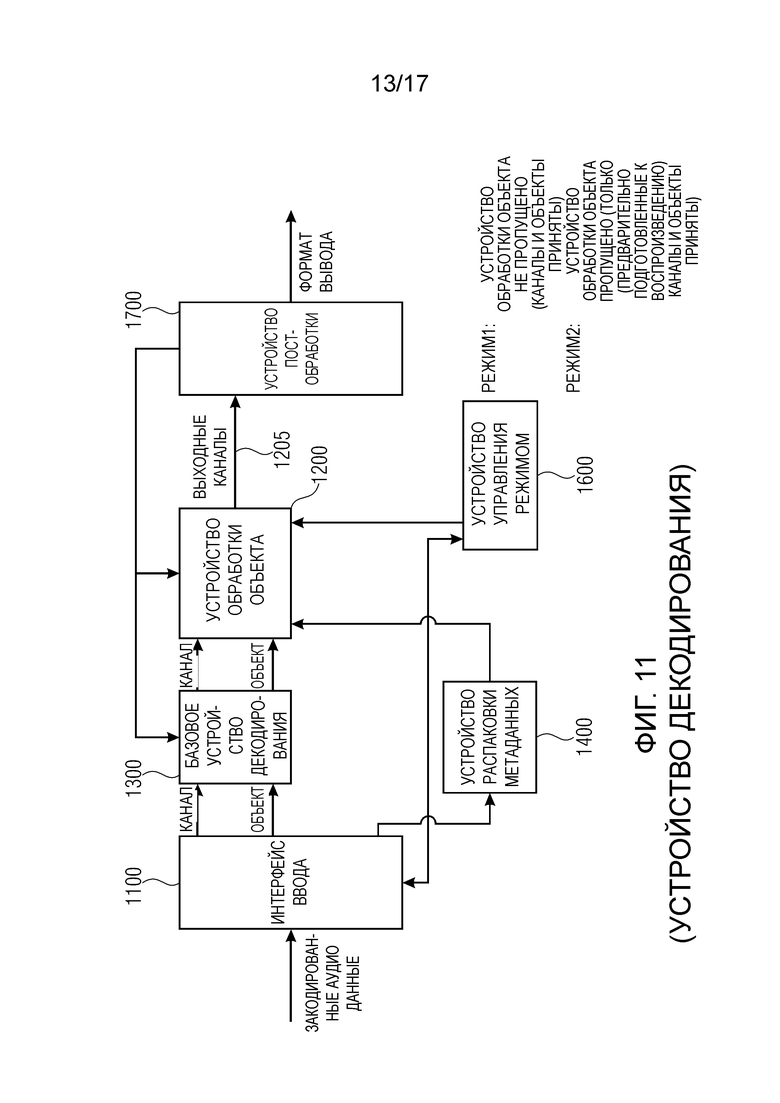

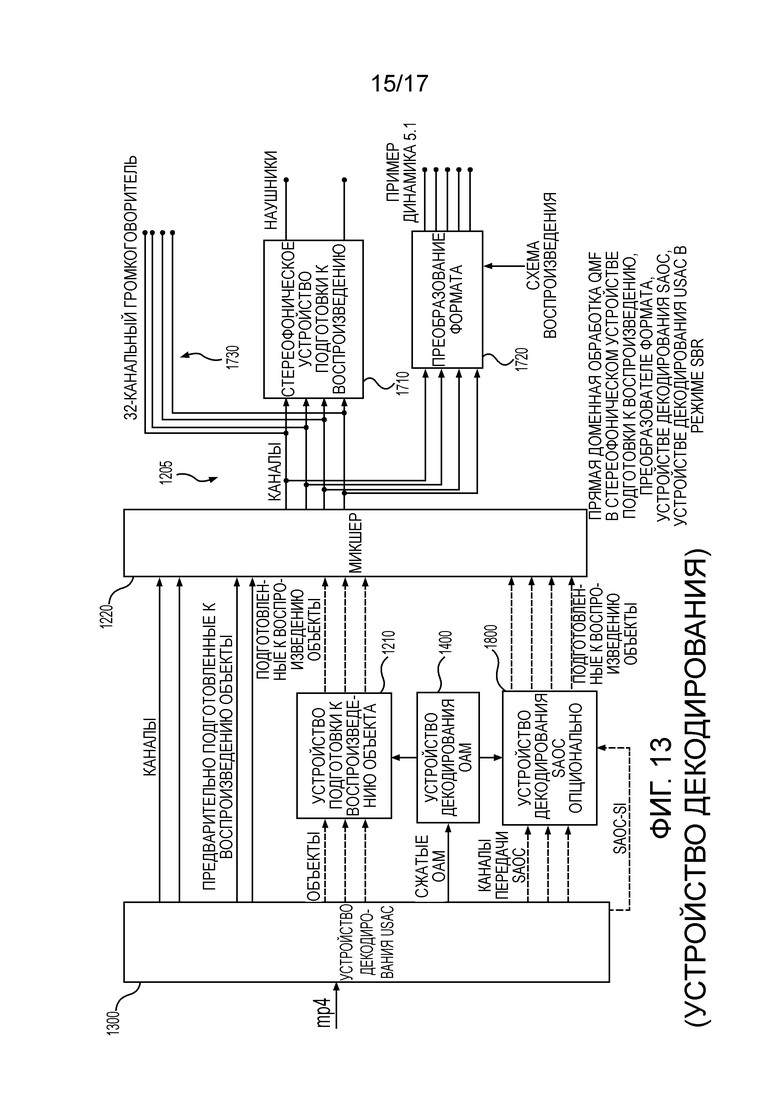
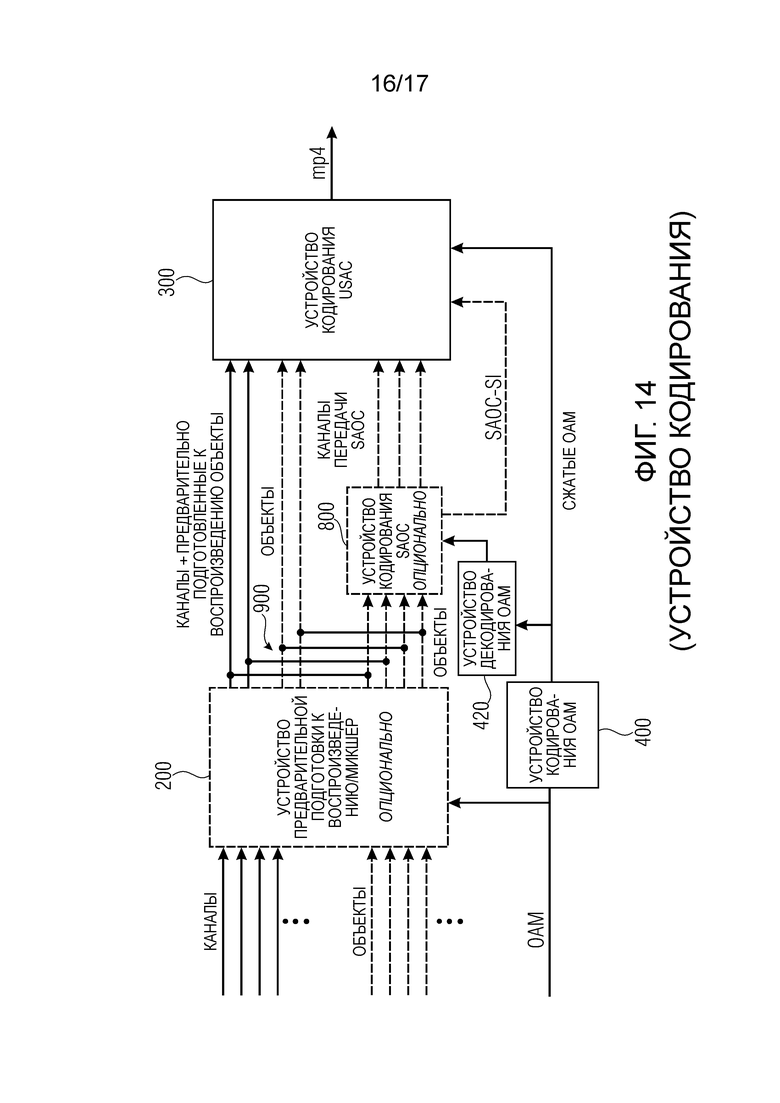
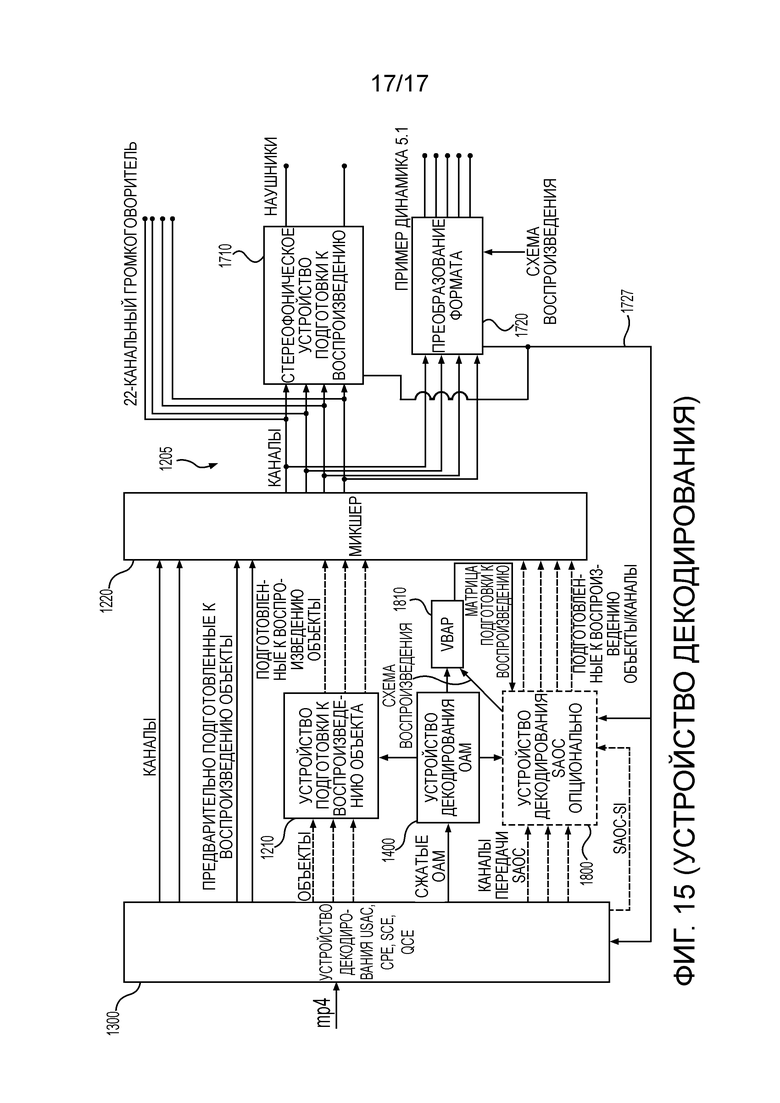
Изобретение относится к аудио кодированию и декодированию. Технический результат – обеспечение эффективного кодирования/декодирования метаданных объекта. Устройство для формирования одного или более аудио каналов содержит: устройство декодирования метаданных для формирования одного или более восстановленных сигналов метаданных из одного или более обработанных сигналов метаданных в зависимости от управляющего сигнала, причем каждый из одного или более восстановленных сигналов метаданных указывает информацию, связанную с сигналом аудио объекта из одного или более сигналов аудио объекта, причем устройство декодирования метаданных выполнено с возможностью формировать один или более восстановленных сигналов метаданных путем определения множества восстановленных выборок метаданных для каждого из одного или более восстановленных сигналов метаданных; и устройство формирования аудио канала для формирования одного или более аудио каналов в зависимости от одного или более сигналов аудио объекта и в зависимости от одного или более восстановленных сигналов метаданных. 9 н. и 7 з.п. ф-лы, 17 ил.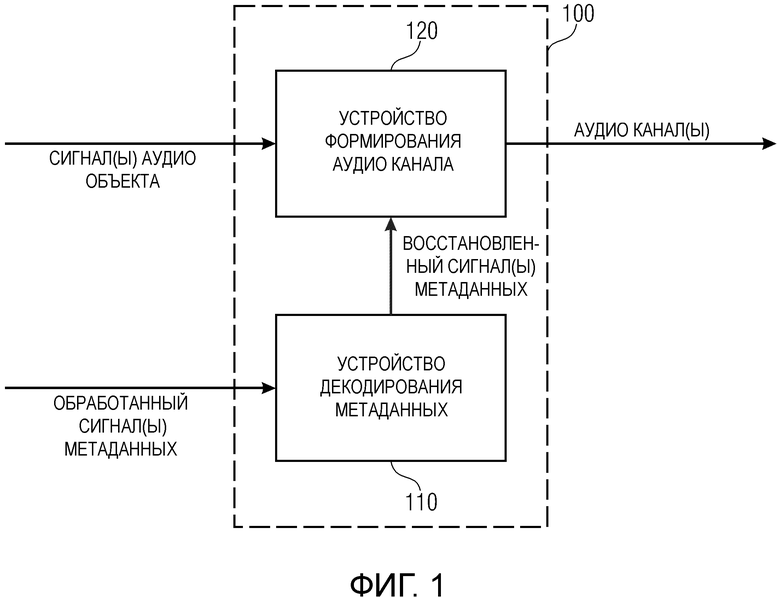
1. Устройство (100) для формирования одного или более аудио каналов, содержащее:
устройство (110; 901) декодирования метаданных для формирования одного или более восстановленных сигналов (x1’,…,xN’) метаданных из одного или более обработанных сигналов (z1,…,zN) метаданных в зависимости от управляющего сигнала (b), причем каждый из одного или более восстановленных сигналов (x1’,…,xN’) метаданных указывает информацию, связанную с сигналом аудио объекта из одного или более сигналов аудио объекта, причем устройство (110; 901) декодирования метаданных выполнено с возможностью формировать один или более восстановленных сигналов (x1’,…,xN’) метаданных путем определения множества восстановленных выборок (x1’(n),…,xN’(n)) метаданных для каждого из одного или более восстановленных сигналов (x1’,…,xN’) метаданных, и
устройство (120) формирования аудио канала для формирования одного или более аудио каналов в зависимости от одного или более сигналов аудио объекта и в зависимости от одного или более восстановленных сигналов (x1’,…,xN’) метаданных,
причем устройство (110; 901) декодирования метаданных выполнено с возможностью принимать множество обработанных выборок (z1(n),…,zN(n)) метаданных каждого из одного или более обработанных сигналов (z1,…,zN) метаданных,
причем устройство (110; 901) декодирования метаданных выполнено с возможностью принимать управляющий сигнал (b),
причем устройство (110; 901) декодирования метаданных выполнено с возможностью определять каждую восстановленную выборку (xi’(n)) метаданных из множества восстановленных выборок (xi’(1),… xi’(n-1), xi’(n)) метаданных каждого восстановленного сигнала (xi’) метаданных одного или более восстановленных сигналов (x1’,…,xN’) метаданных, так, чтобы, когда управляющий сигнал (b) указывает первое состояние (b(n)=0), то указанная восстановленная выборка (xi’(n)) метаданных является суммой одной из обработанных выборок (zi(n)) метаданных одного из одного или более обработанных сигналов (zi) метаданных и другой уже сформированной восстановленной выборки (xi’(n-1)) метаданных указанного восстановленного сигнала (xi’) метаданных, и так, чтобы, когда управляющий сигнал указывает второе состояние (b(n)=1), отличное от первого состояния, то указанная восстановленная выборка (xi’(n)) метаданных является указанной одной (zi(n)) из обработанных выборок (zi(1),…,zi(n)) метаданных указанного одного (zi) из одного или более обработанных сигналов (z1,…,zN) метаданных.
2. Устройство (100) по п.1,
в котором устройство (110; 901) декодирования метаданных выполнено с возможностью принимать два или более обработанных сигналов (z1,…,zN) метаданных и выполнено с возможностью формировать два или более восстановленных сигналов (x1’, …, xN’) метаданных,
в котором устройство (110; 901) декодирования метаданных содержит два или более подблоков (911; …, 91N) декодирования метаданных,
в котором каждый (91i; 91i’) из двух или более подблоков (911; …, 91N) декодирования метаданных выполнен с возможностью содержать сумматор (910) и селектор (930),
в котором каждый (91i; 91i’) из двух или более подблоков (911; …, 91N) декодирования метаданных выполнен с возможностью принимать множество обработанных выборок (zi(1),… zi(n-1), zi(n)) метаданных одного (zi) из двух или более обработанных сигналов (z1,…,zN) метаданных и выполнен с возможностью формировать один (xi’) из двух или более восстановленных сигналов (x1’, …, xN’) метаданных,
в котором сумматор (910) указанного (91i; 91i’) подблока (911; …, 91N) декодирования метаданных выполнен с возможностью суммировать одну (zi(n)) из обработанных выборок (zi(1),…zi(n)) метаданных указанного одного (zi) из двух или более обработанных сигналов (z1,…,zN) метаданных и другую уже сформированную восстановленную выборку (xi’(n-1)) метаданных указанного одного (xi’) из двух или более восстановленных сигналов (x1’, …, xN’) метаданных для получения значения (si(n)) суммы, и
в котором селектор (930) указанного подблока (91i; 91i’) декодирования метаданных выполнен с возможностью принимать указанную одну из обработанных выборок (zi(n)) метаданных, указанное значение (si(n)) суммы и управляющий сигнал, и в котором указанный селектор (930) выполнен с возможностью определять одну из множества выборок (xi’(1),… xi’(n-1), xi’(n)) метаданных указанного восстановленного сигнала (xi’) метаданных так, чтобы, когда управляющий сигнал (b) указывает первое состояние (b(n)=0), то указанная восстановленная выборка (xi’(n)) метаданных является значением (si(n)) суммы, и так, чтобы, когда управляющий сигнал указывает второе состояние (b(n)=1), то указанная восстановленная выборка (xi’(n)) метаданных является указанной одной (zi(n)) из обработанных выборок (zi(1),…,zi(n)) метаданных.
3. Устройство (100) по п.1,
в котором по меньшей мере один из одного или более восстановленных сигналов (x1’,…,xN’) метаданных указывает информацию положения одного из одного или более сигналов аудио объекта, и
в котором устройство (120) формирования аудио канала выполнено с возможностью формировать по меньшей мере один из одного или более аудио каналов в зависимости от указанного одного из одного или более сигналов аудио объекта и в зависимости от указанной информации положения.
4. Устройство (100) по п.1,
в котором по меньшей мере один из одного или более восстановленных сигналов (x1’,…,xN’) метаданных указывает громкость одного из одного или более сигналов аудио объекта, и
в котором устройство (120) формирования аудио канала выполнено с возможностью формировать по меньшей мере один из одного или более аудио каналов в зависимости от указанного одного из одного или более сигналов аудио объекта и в зависимости от указанной громкости.
5. Устройство для декодирования закодированных аудио данных, содержащее:
интерфейс (1100) ввода для приема закодированных аудио данных, причем закодированные аудио данные содержат множество закодированных каналов или множество закодированных объектов или сжатых метаданных, относящихся ко множеству объектов, и
устройство (100) по одному из пп.1-4,
причем устройство (110; 901) декодирования метаданных устройства (100) по одному из пп.1-4 является устройством (1400) распаковки метаданных для распаковки сжатых данных,
причем устройство (120) формирования аудио канала устройства (100) по любому из пп.1-4 содержит базовое устройство (1300) декодирования для декодирования множества закодированных каналов и множества закодированных объектов,
причем устройство (120) формирования аудио канала дополнительно содержит устройство (1200) обработки объектов для обработки множества декодированных объектов с использованием распакованных метаданных для получения числа выходных каналов (1205), содержащих аудио данные, из объектов и декодированных каналов, и
причем устройство (120) формирования аудио канала дополнительно содержит устройство (1700) постобработки для преобразования числа выходных каналов (1205) в формат вывода.
6. Устройство (250) для формирования закодированной аудио информации, содержащей один или более закодированных аудио сигналов и один или более обработанных сигналов метаданных, содержащее:
устройство (210; 801; 802) кодирования метаданных для приема одного или более исходных сигналов метаданных и для определения одного или более обработанных сигналов метаданных, причем каждый из одного или более исходных сигналов метаданных содержит множество исходных выборок метаданных, причем исходные выборки метаданных каждого из одного или более исходных сигналов метаданных указывают информацию, связанную с сигналом аудио объекта из одного или более сигналов аудио объекта, и
устройство (220) аудио кодирования для кодирования одного или более сигналов аудио объекта для получения одного или более закодированных аудио сигналов,
причем устройство (210; 801; 802) кодирования метаданных выполнено с возможностью определять каждую обработанную выборку (zi(n)) метаданных множества обработанных выборок (zi(1),… zi(n-1), zi(n)) метаданных каждого обработанного сигнала (zi) метаданных одного или более обработанных сигналов (z1,…,zN) метаданных так, чтобы, когда управляющий сигнал (b) указывает первое состояние (b(n)=0), то указанная обработанная выборка (zi(n)) метаданных указывает разность или квантованную разность между одной из множества исходных выборок (xi(n)) метаданных одного из одного или более исходных сигналов (xi) метаданных и другой уже сформированной обработанной выборкой метаданных указанного обработанного сигнала (zi) метаданных, и так, чтобы, когда управляющий сигнал указывает второе состояние (b(n)=1), отличное от первого состояния, то указанная обработанная выборка (zi(n)) метаданных является указанной одной (xi(n)) из исходных выборок (xi(1),…,xi(n)) метаданных указанного одного из одного или более исходных сигналов (xi) метаданных, или является квантованным представлением (qi(n)) указанной одной (xi(n)) из исходных выборок (xi(1),…,xi(n)) метаданных.
7. Устройство (250) по п.6,
в котором устройство (210; 801; 802) кодирования метаданных выполнено с возможностью принимать два или более исходных сигналов (x1,…,xN) метаданных и выполнено с возможностью формировать два или более обработанных сигналов (z1, …, zN) метаданных,
в котором устройство (210; 801; 802) кодирования метаданных содержит два или более устройств (811, …, 81N) кодирования с дифференциальной импульсно-кодовой модуляцией (DPCM),
в котором каждое из двух или более устройств (811, …, 81N) кодирования DPCM выполнено с возможностью определять разность или квантованную разность между одной (xi(n)) из исходных выборок (xi(1),…xi(n)) метаданных одного (xi) из двух или более исходных сигналов (x1,…,xN) метаданных и другой уже сформированной обработанной выборкой метаданных одного (zi) из двух или более обработанных сигналов (z1, …, zN) метаданных для получения разностной выборки (yi(n)), и
в котором устройство (210; 801; 802) кодирования метаданных дополнительно содержит селектор (830), выполненный с возможностью определять одну из множества обработанных выборок (zi(1),… zi(n-1), zi(n)) метаданных указанного обработанного сигнала (zi) метаданных так, чтобы, когда управляющий сигнал (b) указывает первое состояние (b(n)=0), то указанная обработанная выборка (zi(n)) метаданных является разностной выборкой (yi(n)), и так, чтобы, когда управляющий сигнал указывает второе состояние (b(n)=1), то указанная обработанная выборка (zi(n)) метаданных является указанной одной (xi(n)) из исходных выборок (xi(1),…,zi(n)) метаданных или квантованным представлением (qi(n)) указанной одной (xi(n)) из исходных выборок (xi(1),…, xi(n)) метаданных.
8. Устройство (250) по п.6,
в котором по меньшей мере один из одного или более исходных сигналов метаданных указывает информацию положения одного из одного или более сигналов аудио объекта, и
в котором устройство (210; 801; 802) кодирования метаданных выполнено с возможностью формировать по меньшей мере один из одного или более обработанных сигналов метаданных в зависимости от указанного по меньшей мере одного из одного или более исходных сигналов метаданных, который указывает указанную информацию положения.
9. Устройство (250) по п.6,
в котором по меньшей мере один из одного или более исходных сигналов метаданных указывает громкость одного из одного или более сигналов аудио объекта, и
в котором устройство (210; 801; 802) кодирования метаданных выполнено с возможностью формировать по меньшей мере один из одного или более обработанных сигналов метаданных в зависимости от указанного по меньшей мере одного из одного или более исходных сигналов метаданных, который указывает указанную громкость.
10. Устройство (250) по любому из пп.6-9, в котором устройство (210; 801; 802) кодирования метаданных выполнено с возможностью кодировать каждую из обработанных выборок (zi(1),…,zi(n)) метаданных одного (zi) из одного или более обработанных сигналов (z1,…,zN) метаданных с помощью первого числа битов, когда управляющий сигнал указывает первое состояние (b(n)=0), и с помощью второго числа битов, когда управляющий сигнал указывает второе состояние (b(n)=1), причем первое число битов меньше, чем второе число битов.
11. Устройство (101) для кодирования входных аудио данных для получения выходных аудио данных (501), содержащее:
интерфейс (1100) ввода для приема множества аудио каналов, множества аудио объектов и метаданных, относящихся к одному или более из множества аудио объектов,
устройство (200) микширования для микширования множества объектов и множества каналов для получения множества предварительно микшированных каналов, причем каждый предварительно микшированный канал содержит аудио данные канала и аудио данные по меньшей мере одного объекта, и
устройство (250) по любому из пп.6-10,
причем устройство (220) аудио кодирования устройства (250) по любому из пп.6-10 является базовым устройством (300) кодирования для базового кодирования входных данных базового устройства кодирования, и
причем устройство (210; 801; 802) кодирования метаданных устройства (250) по любому из пп.6-10 является устройством (400) сжатия метаданных для сжатия метаданных, относящихся к одному или более из множества аудио объектов.
12. Система для формирования закодированной аудио информации и одного или более аудио каналов, содержащая:
устройство (250) по любому из пп.6-10 для формирования закодированной аудио информации, содержащей один или более закодированных аудио сигналов и один или более обработанных сигналов метаданных, и
устройство (100) по любому из пп.1-4 для приема одного или более закодированных аудио сигналов и одного или более обработанных сигналов метаданных и для формирования одного или более аудио каналов в зависимости от одного или более закодированных аудио сигналов и в зависимости от одного или более обработанных сигналов метаданных.
13. Способ формирования одного или более аудио каналов, содержащий:
формирование одного или более восстановленных сигналов (x1’,…,xN’) метаданных из одного или более обработанных сигналов (z1,…,zN) метаданных в зависимости от управляющего сигнала (b), причем каждый из одного или более восстановленных сигналов (x1’,…,xN’) метаданных указывает информацию, связанную с сигналом аудио объекта из одного или более сигналов аудио объекта, причем формирование одного или более восстановленных сигналов (x1’,…,xN’) метаданных выполняется путем определения множества восстановленных выборок (x1’(n),…,xN’(n)) метаданных для каждого из одного или более восстановленных сигналов (x1’,…,xN’) метаданных, и
формирование одного или более аудио каналов в зависимости от одного или более сигналов аудио объекта и в зависимости от одного или более восстановленных сигналов (x1’,…,xN’) метаданных,
причем формирование одного или более восстановленных сигналов (x1’,…,xN’) метаданных выполняется с помощью приема множества обработанных выборок (z1(n),…,zN(n)) метаданных каждого из одного или более обработанных сигналов (z1,…,zN) метаданных, с помощью приема управляющего сигнала (b), и с помощью определения каждой восстановленной выборки (xi’(n)) метаданных из множества восстановленных выборок (xi’(1),… xi’(n-1), xi’(n)) метаданных каждого восстановленного сигнала (xi’) метаданных одного или более восстановленных сигналов (x1’,…,xN’) метаданных, так, чтобы, когда управляющий сигнал (b) указывает первое состояние (b(n)=0), то указанная восстановленная выборка (xi’(n)) метаданных является суммой одной из обработанных выборок (zi(n)) метаданных одного из одного или более обработанных сигналов (zi) метаданных и другой уже сформированной восстановленной выборкой (xi’(n-1)) метаданных указанного восстановленного сигнала (xi’) метаданных, и так, чтобы, когда управляющий сигнал указывает второе состояние (b(n)=1), отличное от первого состояния, то указанная восстановленная выборка (xi’(n)) метаданных является указанной одной (zi(n)) из обработанных выборок (zi(1),…,zi(n)) метаданных указанного одного (zi) из одного или более обработанных сигналов (z1,…,zN) метаданных.
14. Способ формирования закодированной аудио информации, содержащей один или более закодированных аудио сигналов и один или более обработанных сигналов метаданных, содержащий:
прием одного или более исходных сигналов метаданных,
определение одного или более обработанных сигналов метаданных, и
кодирование одного или более сигналов аудио объекта для получения одного или более закодированных аудио сигналов,
причем каждый из одного или более исходных сигналов метаданных содержит множество исходных выборок метаданных, причем исходные выборки метаданных каждого из одного или более исходных сигналов метаданных указывают информацию, связанную с сигналом аудио объекта из одного или более сигналов аудио объекта, и
причем определение одного или более обработанных сигналов метаданных содержит определение каждой обработанной выборки (zi(n)) метаданных из множества обработанных выборок (zi(1),… zi(n-1), zi(n)) метаданных каждого обработанного сигнала (zi) метаданных одного или более обработанных сигналов (z1,…,zN) метаданных так, чтобы, когда управляющий сигнал (b) указывает первое состояние (b(n)=0), то указанная обработанная выборка (zi(n)) метаданных указывает разность или квантованную разность между одной из множества исходных выборок (xi(n)) метаданных одного из одного или более исходных сигналов (xi) метаданных и другой уже сформированной обработанной выборкой метаданных указанного обработанного сигнала (zi) метаданных, и так, чтобы, когда управляющий сигнал указывает второе состояние (b(n)=1), отличное от первого состояния, то указанная обработанная выборка (zi(n)) метаданных является указанной одной (xi(n)) из исходных выборок (xi(1),…,xi(n)) метаданных указанного одного из одного или более исходных сигналов (xi) метаданных, или является квантованным представлением (qi(n)) указанной одной (xi(n)) из исходных выборок (xi(1),…,xi(n)) метаданных.
15. Машиночитаемый носитель данных, содержащий компьютерную программу для осуществления способа по п.13 при выполнении на компьютере или устройстве обработки сигналов.
16. Машиночитаемый носитель данных, содержащий компьютерную программу для осуществления способа по п.14 при выполнении на компьютере или устройстве обработки сигналов.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| NILS PETERS et al., "SpatDIF: Principles, Specification, and Examples", 6 c., 28.06.2013, [найдено 14.06.2017] | |||
| Найдено в Интернет по адресу: [https://web.archive.org/web/20130628031935/http://www.icsi.berkeley.edu/pubs/other/ICSI_SpatDif12.pdf] | |||
| US 8417531 B2, 09.04.2013 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| СПОСОБЫ И УСТРОЙСТВА КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ОСНОВЫВАЮЩИХСЯ НА ОБЪЕКТАХ ОРИЕНТИРОВАННЫХ АУДИОСИГНАЛОВ | 2008 |
|
RU2406166C2 |

