Настоящее изобретение имеет отношение к аудиокодированию/аудиодекодированию, в частности, к пространственному аудиокодированию и пространственному кодированию аудиообъектов, а конкретнее, к устройству и способу для осуществления понижающего микширования SAOC объемного (3D) аудиоконтента и к устройству и способу для эффективного декодирования понижающего микширования SAOC объемного аудиоконтента.
Инструменты пространственного аудиокодирования широко известны в данной области техники и стандартизованы, например, в стандарте MPEG-Surround. Пространственное аудиокодирование начинается с исходных входных каналов, например, пяти или семи входных каналов, которые идентифицируются по их размещению в настройке воспроизведения, то есть левый канал, центральный канал, правый канал, левый канал окружения, правый канал окружения и канал низкочастотного расширения. Пространственный аудиокодер, как правило, получает один или несколько каналов понижающего микширования из исходных каналов, а кроме того, получает параметрические данные, относящиеся к пространственным меткам, например межканальные разности уровней, межканальные разности фаз, межканальные разницы времени и т. п. Один или несколько каналов понижающего микширования передаются вместе с параметрической дополнительной информацией, указывающей пространственные метки, пространственному аудиодекодеру, который декодирует канал понижающего микширования и ассоциированные параметрические данные, чтобы получить в конечном счете выходные каналы, которые являются приблизительной версией исходных входных каналов. Размещение каналов в настройке вывода обычно неизменно и представляет собой, например, формат 5.1, формат 7.1 и т. п.
Такие аудиоформаты на основе каналов широко используются для хранения или передачи многоканального аудиоконтента, где каждый канал относится к определенному громкоговорителю в заданном положении. Точное воспроизведение этого вида форматов требует настройки громкоговорителей, где динамики размещаются в тех же положениях, что и динамики, которые использовались во время создания аудиосигналов. Хотя увеличивающееся количество громкоговорителей улучшает воспроизведение по-настоящему многонаправленных объемных аудиосцен, становится все сложнее выполнять это требование - особенно в домашней обстановке типа гостиной.
Необходимость специфической настройки громкоговорителей можно обойти с помощью объектно-ориентированного подхода, где проводят рендеринг сигналов громкоговорителя специально для настройки проигрывания.
Например, инструменты пространственного кодирования аудиообъектов широко известны в данной области техники и стандартизованы в стандарте SAOC MPEG (SAOC=пространственное кодирование аудиообъектов). В отличие от пространственного аудиокодирования, начинающего с исходных каналов, пространственное кодирование аудиообъектов начинает с аудиообъектов, которые не выделены автоматически для определенной настройки воспроизведения рендеринга. Вместо этого размещение аудиообъектов в сцене воспроизведения гибкое и может определяться пользователем путем ввода некоторой информации рендеринга в декодер пространственного кодирования аудиообъектов. В качестве альтернативы или дополнительно информация рендеринга, то есть информация о том, в какое положение в настройке воспроизведения нужно обычно помещать некоторый аудиообъект по прошествии времени, может передаваться в качестве дополнительной информации или метаданных. Чтобы добиться определенного сжатия данных, некоторое количество аудиообъектов кодируется кодером SAOC, который вычисляет из входных объектов один или несколько транспортных каналов путем понижающего микширования объектов в соответствии с некоторой информацией понижающего микширования. Кроме того, кодер SAOC вычисляет параметрическую дополнительную информацию, представляющую межобъектные метки, например разности уровней объектов (OLD), значения когерентности объектов и т. п. Межобъектные параметрические данные вычисляются для временных/частотных фрагментов параметра, то есть для некоторого кадра аудиосигнала, содержащего, например, 1024 или 2048 выборок, рассматриваются 28, 20, 14 или 10 и т. п. полос обработки, чтобы параметрические данные существовали в конечном счете для каждого кадра и каждой полосы обработки. В качестве примера, когда некая аудиочасть содержит 20 кадров, и когда каждый кадр подразделяется на 28 полос обработки, количество временных/частотных фрагментов равно 560.
В объектно-ориентированном подходе звуковое поле описывается дискретными аудиообъектами. Это требует метаданных объектов, которые, среди прочего, описывают изменяющееся во времени положение каждого источника звука в трехмерном (3D) пространстве.
Первой идеей кодирования метаданных на известном уровне техники является формат обмена описанием пространственного звука (SpatDIF), формат описания аудиосцены, который по-прежнему находится в разработке [M1]. Он задуман как формат обмена для объектно-ориентированных звуковых сцен и не предоставляет никакого способа сжатия для траекторий объектов. SpatDIF использует текстовый формат Открытого управления звуком (OSC) для структурирования метаданных объектов [M2]. Однако простое текстовое представление не является возможным вариантом для сжатой передачи траекторий объектов.
Другой идеей метаданных на известном уровне техники является Формат описания аудиосцен (ASDF) [M3], текстовое решение, которое обладает таким же недостатком. Данные структурируются с помощью расширения Языка синхронизированной мультимедийной интеграции (SMIL), который является подмножеством Расширяемого языка разметки (XML) [M4], [M5].
Дополнительной идеей метаданных на известном уровне техники является двоичный формат аудио для сцен (AudioBIFS), двоичный формат, который является частью спецификации MPEG-4 [M6], [M7]. Он тесно связан с основанным на XML языком моделирования виртуальной реальности (VRML), который был разработан для описания аудиовизуальных объемных (3D) сцен и интерактивных приложений виртуальной реальности [M8]. Сложная спецификация AudioBIFS использует графы сцен для задания маршрутов перемещений объектов. Основным недостатком AudioBIFS является то, что он не предназначен для работы в реальном масштабе времени, где требованием является ограниченная задержка системы и произвольный доступ к потоку данных. Кроме того, кодирование положений объектов не использует ограниченное выявление направленности у человека. Для неизменного положения слушателя в аудиовизуальной сцене данные объектов можно квантовать с гораздо меньшим количеством разрядов [M9]. Поэтому кодирование метаданных объектов, которое применяется в AudioBIFS, неэффективно в отношении сжатия данных.
US 2010/174548 A1 раскрывает устройство и способ для кодирования и декодирования многообъектного аудиосигнала. Устройство включает в себя средство понижающего микширования для понижающего микширования аудиосигналов в один микшированный аудиосигнал и извлечения дополнительной информации, включающей в себя информацию заголовка и информацию о пространственных метках для каждого из аудиосигналов, кодировщик для кодирования микшированного аудиосигнала и кодировщик дополнительной информации для формирования дополнительной информации в виде потока двоичных сигналов. Информация заголовка включает в себя идентификационную информацию для каждого из аудиосигналов и информацию о каналах для аудиосигналов.
Цель настоящего изобретения - предоставить усовершенствованные идеи для понижающего микширования аудиоконтента. Цель настоящего изобретения достигается с помощью устройства по п. 1, устройства по п. 9, системы по п. 12, способа по п. 13, способа по п. 14 и компьютерной программы по п. 15.
В соответствии с вариантами осуществления осуществляется эффективная транспортировка, и предоставляется средство для того, как декодировать понижающее микширование для объемного аудиоконтента.
Предоставляется устройство для формирования одного или более выходных аудиоканалов. Устройство содержит процессор параметров для вычисления информации микширования выходного канала и процессор понижающего микширования для формирования одного или более выходных аудиоканалов. Процессор понижающего микширования конфигурируется для приема транспортного аудиосигнала, содержащего один или несколько транспортных аудиоканалов, где два или более сигналов аудиообъектов микшируются в транспортный аудиосигнал, и где количество одного или более транспортных аудиоканалов меньше количества двух или более сигналов аудиообъектов. Транспортный аудиосигнал зависит от первого правила микширования и второго правила микширования. Первое правило микширования указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов. Кроме того, второе правило микширования указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала. Процессор параметров конфигурируется для приема информации о втором правиле микширования, где информация о втором правиле микширования указывает, как микшировать множество предварительно микшированных сигналов так, чтобы получился один или несколько транспортных аудиоканалов. Кроме того, процессор параметров конфигурируется для вычисления информации микширования выходного канала в зависимости от количества аудиообъектов, указывающего количество двух или более сигналов аудиообъектов, в зависимости от количества предварительно микшированных каналов, указывающего количество в множестве предварительно микшированных каналов, и в зависимости от информации о втором правиле микширования. Процессор понижающего микширования конфигурируется для формирования одного или более выходных аудиоканалов из транспортного аудиосигнала в зависимости от информации микширования выходного канала.
Кроме того, предоставляется устройство для формирования транспортного аудиосигнала, содержащего один или несколько транспортных аудиоканалов. Устройство содержит микшер объектов для формирования транспортного аудиосигнала, содержащего один или несколько транспортных аудиоканалов, из двух или более сигналов аудиообъектов, так что два или более сигналов аудиообъектов микшируются в транспортный аудиосигнал, и где количество одного или более транспортных аудиоканалов меньше количества двух или более сигналов аудиообъектов, и выходной интерфейс для вывода транспортного аудиосигнала. Микшер объектов конфигурируется для формирования одного или более транспортных аудиоканалов транспортного аудиосигнала в зависимости от первого правила микширования и в зависимости от второго правила микширования, где первое правило микширования указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов, и где второе правило микширования указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала. Первое правило микширования зависит от количества аудиообъектов, указывающего количество двух или более сигналов аудиообъектов, и зависит от количества предварительно микшированных каналов, указывающего количество в множестве предварительно микшированных каналов, и где второе правило микширования зависит от количества предварительно микшированных каналов. Выходной интерфейс конфигурируется для вывода информации о втором правиле микширования.
Кроме того, предоставляется система. Система содержит устройство для формирования транспортного аудиосигнала, как описано выше, и устройство для формирования одного или более выходных аудиоканалов, как описано выше. Устройство для формирования одного или более выходных аудиоканалов конфигурируется для приема транспортного аудиосигнала и информации о втором правиле микширования от устройства для формирования транспортного аудиосигнала. Кроме того, устройство для формирования одного или более выходных аудиоканалов конфигурируется для формирования одного или более выходных аудиоканалов из транспортного аудиосигнала в зависимости от информации о втором правиле микширования.
Кроме того, предоставляется способ для формирования одного или более выходных аудиоканалов. Способ содержит:
- Прием транспортного аудиосигнала, содержащего один или несколько транспортных аудиоканалов, где два или более сигналов аудиообъектов микшируются в транспортный аудиосигнал, и где количество одного или более транспортных аудиоканалов меньше количества двух или более сигналов аудиообъектов, где транспортный аудиосигнал зависит от первого правила микширования и второго правила микширования, где первое правило микширования указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов, и где второе правило микширования указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала.
- Прием информации о втором правиле микширования, где информация о втором правиле микширования указывает, как микшировать множество предварительно микшированных сигналов так, чтобы получился один или несколько транспортных аудиоканалов.
- Вычисление информации микширования выходного канала в зависимости от количества аудиообъектов, указывающего количество двух или более сигналов аудиообъектов, в зависимости от количества предварительно микшированных каналов, указывающего количество в множестве предварительно микшированных каналов, и в зависимости от информации о втором правиле микширования. И:
- Формирование одного или более выходных аудиоканалов из транспортного аудиосигнала в зависимости от информации микширования выходного канала.
Кроме того, предоставляется способ для формирования транспортного аудиосигнала, содержащего один или несколько транспортных аудиоканалов. Способ содержит:
- Формирование транспортного аудиосигнала, содержащего один или несколько транспортных аудиоканалов, из двух или более сигналов аудиообъектов.
- Вывод транспортного аудиосигнала. И:
- Вывод информации о втором правиле микширования.
Формирование транспортного аудиосигнала, содержащего один или несколько транспортных аудиоканалов, из двух или более сигналов аудиообъектов проводится так, что два или более сигналов аудиообъектов микшируются в транспортный аудиосигнал, где количество одного или более транспортных аудиоканалов меньше количества двух или более сигналов аудиообъектов. Формирование одного или более транспортных аудиоканалов транспортного аудиосигнала проводится в зависимости от первого правила микширования и в зависимости от второго правила микширования, где первое правило микширования указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов, и где второе правило микширования указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала. Первое правило микширования зависит от количества аудиообъектов, указывающего количество двух или более сигналов аудиообъектов, и зависит от количества предварительно микшированных каналов, указывающего количество в множестве предварительно микшированных каналов. Второе правило микширования зависит от количества предварительно микшированных каналов.
Кроме того, предоставляется компьютерная программа для реализации вышеописанного способа, когда исполняется на компьютере или процессоре сигналов.
Ниже подробнее описываются варианты осуществления настоящего изобретения со ссылкой на фигуры, на которых:
Фиг. 1 иллюстрирует устройство для формирования одного или более выходных аудиоканалов в соответствии с вариантом осуществления,
Фиг. 2 иллюстрирует устройство для формирования транспортного аудиосигнала, содержащего один или несколько транспортных аудиоканалов, в соответствии с вариантом осуществления,
Фиг. 3 иллюстрирует систему в соответствии с вариантом осуществления,
Фиг. 4 иллюстрирует первый вариант осуществления кодера объемного аудио,
Фиг. 5 иллюстрирует первый вариант осуществления декодера объемного аудио,
Фиг. 6 иллюстрирует второй вариант осуществления кодера объемного аудио,
Фиг. 7 иллюстрирует второй вариант осуществления декодера объемного аудио,
Фиг. 8 иллюстрирует третий вариант осуществления кодера объемного аудио,
Фиг. 9 иллюстрирует третий вариант осуществления декодера объемного аудио,
Фиг. 10 иллюстрирует положение аудиообъекта в трехмерном пространстве от начала координат, выраженное азимутом, возвышением и радиусом, и
Фиг. 11 иллюстрирует положения аудиообъектов и настройку громкоговорителей, предполагаемую генератором аудиоканалов.
Перед подробным описанием предпочтительных вариантов осуществления настоящего изобретения описывается новая система кодека объемного (3D) аудио.
На известном уровне техники не существует никакой гибкой технологии, объединяющей канальное кодирование с одной стороны и кодирование объектов с другой стороны, чтобы получить приемлемое качество аудио на низких скоростях передачи разрядов.
Это ограничение обходится новой системой кодека объемного аудио.
Перед подробным описанием предпочтительных вариантов осуществления описывается новая система кодека объемного аудио.
Фиг. 4 иллюстрирует кодер объемного аудио в соответствии с вариантом осуществления настоящего изобретения. Кодер объемного аудио конфигурируется для кодирования входных аудиоданных 101, чтобы получить выходные аудиоданные 501. Кодер объемного аудио содержит входной интерфейс для приема множества аудиоканалов, указанных с помощью CH, и множества аудиообъектов, указанных с помощью OBJ. Кроме того, как проиллюстрировано на фиг. 4, входной интерфейс 1100 дополнительно принимает метаданные, связанные с одним или более из множества аудиообъектов OBJ. Кроме того, кодер объемного аудио содержит микшер 200 для микширования множества объектов и множества каналов, чтобы получить множество предварительно микшированных каналов, в котором каждый предварительно микшированный канал содержит аудиоданные канала и аудиоданные по меньшей мере одного объекта.
Кроме того, кодер объемного аудио содержит базовый кодер 300 для базового кодирования входных данных базового кодера, компрессор 400 метаданных для сжатия метаданных, связанных с одним или более из множества аудиообъектов.
Кроме того, кодер объемного аудио может содержать контроллер 600 режимов для управления микшером, базовым кодером и/или выходным интерфейсом 500 в одном из нескольких режимов работы, где в первом режиме базовый кодер конфигурируется для кодирования множества аудиоканалов и множества аудиообъектов, принятых входным интерфейсом 1100, без какого-либо взаимодействия с микшером, то есть без какого-либо микширования с помощью микшера 200. Однако во втором режиме, в котором был активен микшер 200, базовый кодер кодирует множество микшированных каналов, то есть вывод, сформированный блоком 200. В этом последнем случае предпочтительно уже не кодировать никакие данные объектов. Вместо этого микшером 200 уже используются метаданные, указывающие положения аудиообъектов, для рендеринга объектов по каналам, как указано метаданными. Другими словами, микшер 200 использует метаданные, связанные с множеством аудиообъектов, чтобы предварительно провести рендеринг аудиообъектов, а затем аудиообъекты после предварительного рендеринга микшируются с каналами для получения микшированных каналов на выходе микшера. В этом варианте осуществления не обязательно могут передаваться любые объекты, и это также применяется к сжатым метаданным, которые выведены блоком 400. Однако, если микшируются не все введенные в интерфейс 1100 объекты, а микшируется только некоторое количество объектов, тогда только оставшиеся немикшированные объекты и ассоциированные метаданные все-таки передаются соответственно в базовый кодер 300 или компрессор 400 метаданных.
Фиг. 6 иллюстрирует дополнительный вариант осуществления кодера объемного аудио, который дополнительно содержит кодер 800 SAOC. Кодер 800 SAOC конфигурируется для формирования одного или более транспортных каналов и параметрических данных из входных данных в пространственный кодер аудиообъектов. Как проиллюстрировано на фиг. 6, входные данные в пространственный кодер аудиообъектов являются объектами, которые не обработаны устройством предварительного рендеринга/микшером. В качестве альтернативы при условии, что обходят устройство предварительного рендеринга/микшер, как в первом режиме, где активно кодирование отдельного канала/объекта, все введенные во входной интерфейс 1100 объекты кодируются кодером 800 SAOC.
Кроме того, как проиллюстрировано на фиг. 6, базовый кодер 300 предпочтительно реализуется в виде кодера USAC, то есть в виде кодера, который определен и стандартизован в стандарте MPEG-USAC (USAC=унифицированное кодирование речи и аудио). Выход всего кодера объемного аудио, проиллюстрированного на фиг. 6, является потоком данных MPEG 4, потоком данных MPEG H или потоком объемных аудиоданных, содержащим структуры типа контейнеров для отдельных типов данных. Кроме того, метаданные указываются как данные "OAM", и компрессор 400 метаданных на фиг. 4 соответствует кодеру 400 OAM для получения сжатых данных OAM, которые вводятся в кодер 300 USAC, который, как видно на фиг. 6, дополнительно содержит выходной интерфейс для получения выходного потока данных MP4, содержащего не только кодированные данные каналов/объектов, но также сжатые данные OAM.
Фиг. 8 иллюстрирует дополнительный вариант осуществления кодера объемного аудио, где в отличие от фиг. 6 кодер SAOC может быть сконфигурирован либо для кодирования с помощью алгоритма кодирования SAOC каналов, предоставленных в устройстве 200 предварительного рендеринга /микшере, не активном в этом режиме, либо, в качестве альтернативы, для SAOC-кодирования каналов плюс объектов после предварительного рендеринга. Таким образом, на фиг. 8 кодер 800 SAOC может воздействовать на три разных вида входных данных, то есть каналы без каких-либо объектов с предварительным рендерингом, каналы и объекты с предварительным рендерингом или только объекты. Кроме того, на фиг. 8 предпочтительно предоставить дополнительный декодер 420 OAM, чтобы кодер 800 SAOC использовал для своей обработки такие же данные, как и на стороне декодера, то есть данные, полученные путем сжатия с потерями, а не исходные данные OAM.
Кодер объемного аудио из фиг. 8 может работать в нескольких отдельных режимах.
В дополнение к первому и второму режимам, которые обсуждались применительно к фиг. 4, кодер объемного аудио из фиг. 8 дополнительно может работать в третьем режиме, в котором базовый кодер формирует один или несколько транспортных каналов из отдельных объектов, когда было не активно устройство 200 предварительного рендеринга /микшер. В качестве альтернативы или дополнительно в этом третьем режиме кодер 800 SAOC может формировать один или несколько альтернативных или дополнительных транспортных каналов из исходных каналов, то есть снова, когда было не активно устройство 200 предварительного рендеринга/микшер, соответствующее микшеру 200 из фиг. 4.
В конечном счете кодер 800 SAOC может кодировать, когда кодер объемного аудио конфигурируется в четвертом режиме, каналы плюс объекты с предварительным рендерингом, которые сформированы устройством предварительного рендеринга /микшером. Таким образом, в четвертом режиме приложения с наименьшей скоростью передачи разрядов обеспечат хорошее качество благодаря тому, что каналы и объекты полностью преобразованы в отдельные транспортные каналы SAOC и ассоциированную дополнительную информацию, которая указана на фиг. 3 и 5 как "SAOC-SI", а кроме того, никакие сжатые метаданные не нужно передавать в этом четвертом режиме.
Фиг. 5 иллюстрирует декодер объемного аудио в соответствии с вариантом осуществления настоящего изобретения. Декодер объемного аудио в качестве входа принимает кодированные аудиоданные, то есть данные 501 из фиг. 4.
Декодер объемного аудио содержит декомпрессор 1400 метаданных, базовый декодер 1300, процессор 1200 объектов, контроллер 1600 режимов и постпроцессор 1700.
В частности, декодер объемного аудио конфигурируется для декодирования кодированных аудиоданных, а входной интерфейс конфигурируется для приема кодированных аудиоданных, причем кодированные аудиоданные содержат множество кодированных каналов и множество кодированных объектов и сжатых метаданных, связанных с множеством объектов в некотором режиме.
Кроме того, базовый декодер 1300 конфигурируется для декодирования множества кодированных каналов и множества кодированных объектов, а кроме того, декомпрессор метаданных конфигурируется для распаковки сжатых метаданных.
Кроме того, процессор 1200 объектов конфигурируется для обработки множества декодированных объектов, которое сформировано базовым декодером 1300, используя распакованные метаданные, чтобы получить заранее установленное количество выходных каналов, содержащих данные объектов и декодированные каналы. Эти выходные каналы, которые указаны по ссылке 1205, затем вводятся в постпроцессор 1700. Постпроцессор 1700 конфигурируется для преобразования количества выходных каналов 1205 в некий выходной формат, который может быть бинауральным выходным форматом или выходным форматом громкоговорителей, например выходным форматом 5.1, 7.1 и т. п.
Предпочтительно, чтобы декодер объемного аудио содержал контроллер 1600 режимов, который конфигурируется для анализа кодированных данных, чтобы обнаружить указание режима. Поэтому контроллер 1600 режимов на фиг. 5 подключается к входному интерфейсу 1100. Однако в качестве альтернативы контроллер режимов не обязательно должен быть там. Вместо этого гибкий аудиодекодер может предварительно настраиваться с помощью любого другого вида управляющих данных, например пользовательского ввода или любого другого управления. Декодер объемного аудио на фиг. 5, предпочтительно управляемый контроллером 1600 режимов, конфигурируется для обхода процессора объектов и подачи множества декодированных каналов в постпроцессор 1700. Это работа в режиме 2, то есть в режиме, в котором принимаются только каналы с предварительным рендерингом, то есть когда в кодере объемного аудио фиг. 4 применен режим 2. В качестве альтернативы, когда в кодере объемного аудио применен режим 1, то есть когда кодер объемного аудио выполнил кодирование отдельного канала/объекта, тогда не обходят процессор 1200 объектов, а множество декодированных каналов и множество декодированных объектов подаются в процессор 1200 объектов вместе с распакованными метаданными, сформированными декомпрессором 1400 метаданных.
Предпочтительно, чтобы указание того, нужно ли применять режим 1 или режим 2, включалось в кодированные аудиоданные, и тогда контроллер 1600 режимов анализирует кодированные данные для обнаружения указания режима. Режим 1 используется, когда указание режима указывает, что кодированные аудиоданные содержат кодированные каналы и кодированные объекты, а режим 2 применяется, когда указание режима указывает, что кодированные аудиоданные не содержат никаких аудиообъектов, то есть содержат только каналы с предварительным рендерингом, полученные с помощью режима 2 в кодере объемного аудио из фиг. 4.
Фиг. 7 иллюстрирует предпочтительный вариант осуществления по сравнению с декодером объемного аудио из фиг. 5, и вариант осуществления из фиг. 7 соответствует кодеру объемного аудио из фиг. 6. В дополнение к реализации декодера объемного аудио из фиг. 5 декодер объемного аудио на фиг. 7 содержит декодер 1800 SAOC. Кроме того, процессор 1200 объектов из фиг. 5 реализуется как отдельное устройство 1210 рендеринга объектов и микшер 1220, хотя в зависимости от режима функциональные возможности устройства 1210 рендеринга объектов также можно реализовать с помощью декодера 1800 SAOC.
Кроме того, постпроцессор 1700 можно реализовать как устройство 1710 бинаурального рендеринга или преобразователь 1720 формата. В качестве альтернативы также можно реализовать прямой вывод данных 1205 из фиг. 5, как проиллюстрировано ссылкой 1730. Поэтому предпочтительно выполнять обработку в декодере над наибольшим количеством каналов, например 22.2 или 32, чтобы обладать гибкостью, а затем проводить постобработку, если понадобится меньший формат. Однако, когда с самого начала становится понятно, что необходим только другой формат с меньшим количеством каналов, например формат 5.1, то предпочтительно, как указано на фиг. 9 с помощью сокращенного пути 1727, чтобы могло применяться некоторое управление декодером SAOC и/или декодером USAC, чтобы избежать ненужных операций повышающего микширования и последующих операций понижающего микширования.
В предпочтительном варианте осуществления настоящего изобретения процессор 1200 объектов содержит декодер 1800 SAOC, и декодер SAOC конфигурируется для декодирования одного или более транспортных каналов, выведенных базовым декодером, и ассоциированных параметрических данных, и использования распакованных метаданных для получения множества подвергнутых рендерингу аудиообъектов. С этой целью выход OAM подключается к блоку 1800.
Кроме того, процессор 1200 объектов конфигурируется для рендеринга декодированных объектов, выведенных базовым декодером, которые не кодируются в транспортные каналы SAOC, а которые по отдельности кодируются обычно в одноканальные элементы, как указано устройством 1210 рендеринга объектов. Кроме того, декодер содержит выходной интерфейс, соответствующий выходу 1730, для вывода результата из микшера в громкоговорители.
В дополнительном варианте осуществления процессор 1200 объектов содержит декодер 1800 пространственного кодирования аудиообъектов для декодирования одного или более транспортных каналов и ассоциированной параметрической дополнительной информации, представляющей кодированные аудиосигналы или кодированные аудиоканалы, где декодер пространственного кодирования аудиообъектов конфигурируется для перекодирования ассоциированной параметрической информации и распакованных метаданных в перекодированную параметрическую дополнительную информацию, используемую для непосредственного рендеринга выходного формата, например, как задано в предыдущей версии SAOC. Постпроцессор 1700 конфигурируется для вычисления аудиоканалов выходного формата с использованием декодированных транспортных каналов и перекодированной параметрической дополнительной информации. Выполняемая постпроцессором обработка может быть аналогична обработке MPEG Surround либо может быть любой другой обработкой, например обработкой BCC или чем-то в этом роде.
В дополнительном варианте осуществления процессор 1200 объектов содержит декодер 1800 пространственного кодирования аудиообъектов, сконфигурированный для непосредственного повышающего микширования и рендеринга сигналов каналов для выходного формата, используя декодированные (базовым декодером) транспортные каналы и параметрическую дополнительную информацию.
Кроме того, и это важно, процессор 1200 объектов из фиг. 5 дополнительно содержит микшер 1220, который в качестве входа принимает данные, выведенные декодером 1300 USAC напрямую, когда существуют объекты с предварительным рендерингом, микшированные с каналами, то есть когда был активен микшер 200 из фиг. 4. Более того, микшер 1220 принимает данные от устройства рендеринга объектов, выполняющего рендеринг объектов без декодирования SAOC. Кроме того, микшер принимает выходные данные декодера SAOC, то есть объекты SAOC с рендерингом.
Микшер 1220 подключается к выходному интерфейсу 1730, устройству 1710 бинаурального рендеринга и преобразователю 1720 формата. Устройство 1710 бинаурального рендеринга конфигурируется для рендеринга выходных каналов в два бинауральных канала, используя функции моделирования восприятия звука человеком или бинауральные импульсные характеристики помещения (BRIR). Преобразователь 1720 формата конфигурируется для преобразования выходных каналов в выходной формат, имеющий меньшее количество каналов, чем выходные каналы 1205 микшера, и преобразователю 1720 формата необходима информация о компоновке воспроизведения, например динамики 5.1 или что-то в этом роде.
Декодер объемного аудио из фиг. 9 отличается от декодера объемного аудио из фиг. 7 в том, что декодер SAOC не может формировать только объекты с рендерингом, но также каналы с рендерингом, и это тот случай, когда использован кодер объемного аудио из фиг. 8, и активно соединение 900 между каналами/объектами с предварительным рендерингом и входным интерфейсом кодера 800 SAOC.
Кроме того, конфигурируется каскад 1810 векторного амплитудного панорамирования (VBAP), который принимает от декодера SAOC информацию о компоновке воспроизведения и который выводит матрицу рендеринга в декодер SAOC, чтобы декодер SAOC в конечном счете мог предоставить каналы с проведенным рендерингом без какой-либо дополнительной операции микшера в многоканальном формате 1205, то есть с 32 громкоговорителями.
Блок VBAP предпочтительно принимает декодированные данные OAM, чтобы получить матрицы рендеринга. В более общем смысле это предпочтительно требует геометрической информации не только о компоновке воспроизведения, но также о положениях, где следует провести рендеринг входных сигналов в компоновке воспроизведения. Эти геометрические входные данные могут быть данными OAM для объектов или информацией о положениях каналов для каналов, которые переданы с использованием SAOC.
Однако, если необходим только определенный выходной интерфейс, то каскад 1810 VBAP уже может предоставить необходимую матрицу рендеринга, например, для выхода 5.1. Декодер 1800 SAOC затем выполняет прямой рендеринг из транспортных каналов SAOC, ассоциированных параметрических данных и распакованных метаданных, прямой рендеринг в необходимый выходной формат без какого-либо взаимодействия с микшером 1220. Однако, когда применяется некоторое микширование между режимами, то есть, где несколько каналов кодируются по SAOC, но не все каналы кодируются по SAOC, или где несколько объектов кодируются по SAOC, но не все объекты кодируются по SAOC, или когда только некоторое количество объектов с предварительным рендерингом с каналами декодируется по SAOC, а оставшиеся каналы не обрабатываются по SAOC, тогда микшер соединит данные из отдельных входных частей, то есть напрямую из базового декодера 1300, из устройства 1210 рендеринга объектов и из декодера 1800 SAOC.
В объемном (3D) аудио азимутальный угол, угол возвышения и радиус используются для задания положения аудиообъекта. Кроме того, может передаваться усиление для аудиообъекта.
Азимутальный угол, угол возвышения и радиус однозначно задают положение аудиообъекта в трехмерном (3D) пространстве от начала координат. Это иллюстрируется со ссылкой на фиг. 10.
Фиг. 10 иллюстрирует положение 410 аудиообъекта в трехмерном (3D) пространстве от начала 400 координат, выраженное азимутом, возвышением и радиусом.
Азимутальный угол задает, например, угол в плоскости xy (плоскости, заданной осью x и осью y). Угол возвышения задает, например, угол в плоскости xz (плоскости, заданной осью x и осью z). С помощью задания азимутального угла и угла возвышения можно провести прямую линию 415 через начало 400 координат и положение 410 аудиообъекта. Кроме того, путем задания радиуса можно задать точное положение 410 аудиообъекта.
В варианте осуществления азимутальный угол задается для диапазона: -180° < азимут ≤ 180°, угол возвышения задается для диапазона: -90° < возвышение ≤ 90°, и радиус можно задать, например, в метрах [м] (больше либо равный 0 м). Сферу, описанную азимутом, возвышением и углом, можно разделить на две полусферы: левую полусферу (0° < азимут ≤ 180°) и правую полусферу (-180° < азимут ≤ 0°) либо верхнюю полусферу (0° < возвышение ≤ 90°) и нижнюю полусферу (-90° < возвышение ≤ 0°).
В другом варианте осуществления, где может предполагаться, например, что все значения x положений аудиообъекта в системе координат xyz больше либо равны нулю, азимутальный угол можно задать для диапазона: -90° ≤ азимут ≤ 90°, угол возвышения можно задать для диапазона: -90° < возвышение ≤ 90°, и радиус можно задать, например, в метрах [м].
Процессор 120 понижающего микширования может конфигурироваться, например, для формирования одного или более аудиоканалов в зависимости от одного или более сигналов аудиообъектов, зависящих от восстановленных значений из информации метаданных, где восстановленные значения из информации метаданных могут указывать, например, положение аудиообъектов.
В варианте осуществления значения из информации метаданных могут указывать, например, азимутальный угол, заданный для диапазона: -180° < азимут ≤ 180°, угол возвышения, заданный для диапазона: -90° < возвышение ≤ 90°, и радиус можно задать, например, в метрах [м] (больше либо равный 0 м).
Фиг. 11 иллюстрирует положения аудиообъектов и настройку громкоговорителей, предполагаемую генератором аудиоканалов. Иллюстрируется начало 500 координат у системы координат xyz. Кроме того, иллюстрируется положение 510 первого аудиообъекта и положение 520 второго аудиообъекта. Кроме того, фиг. 11 иллюстрирует сценарий, где генератор 120 аудиоканалов формирует четыре аудиоканала для четырех громкоговорителей. Генератор 120 аудиоканалов предполагает, что четыре громкоговорителя 511, 512, 513 и 514 располагаются в показанных на фиг. 11 положениях.
На фиг. 11 первый аудиообъект располагается в положении 510 близко к предполагаемым положениям громкоговорителей 511 и 512 и располагается далеко от громкоговорителей 513 и 514. Поэтому генератор 120 аудиоканалов может формировать четыре аудиоканала, так что первый аудиообъект 510 воспроизводится громкоговорителями 511 и 512, а не громкоговорителями 513 и 514.
В других вариантах осуществления генератор 120 аудиоканалов может формировать четыре аудиоканала, так что первый аудиообъект 510 воспроизводится с высоким уровнем громкоговорителями 511 и 512 и с низким уровнем громкоговорителями 513 и 514.
Кроме того, второй аудиообъект располагается в положении 520 близко к предполагаемым положениям громкоговорителей 513 и 514 и располагается далеко от громкоговорителей 511 и 512. Поэтому генератор 120 аудиоканалов может формировать четыре аудиоканала, так что второй аудиообъект 520 воспроизводится громкоговорителями 513 и 514, а не громкоговорителями 511 и 512.
В других вариантах осуществления процессор 120 понижающего микширования может формировать четыре аудиоканала, так что второй аудиообъект 520 воспроизводится с высоким уровнем громкоговорителями 513 и 514 и с низким уровнем громкоговорителями 511 и 512.
В альтернативных вариантах осуществления только два значения из информации метаданных используются для задания положения аудиообъекта. Например, можно задать только азимут и радиус, например, когда предполагается, что все аудиообъекты располагаются в одной плоскости.
В других дополнительных вариантах осуществления для каждого аудиообъекта только одно значение из информации метаданных в сигнале метаданных кодируется и передается в качестве информации о положении. Например, можно задать только азимутальный угол в качестве информации о положении для аудиообъекта (например, может предполагаться, что все аудиообъекты располагаются в одной и той же плоскости, имея одинаковое расстояние от центральной точки, и соответственно предполагаются имеющими одинаковый радиус). Информации об азимуте может быть достаточно, например, для определения, что аудиообъект располагается близко к левому громкоговорителю и далеко от правого громкоговорителя. В такой ситуации генератор 120 аудиоканалов может, например, сформировать один или несколько аудиоканалов, так что аудиообъект воспроизводится левым громкоговорителем, а не правым громкоговорителем.
Например, векторное амплитудное панорамирование может применяться для определения веса сигнала аудиообъекта в каждом из выходных аудиоканалов (см., например, [VBAP]). Относительно VBAP предполагается, что сигнал аудиообъекта назначается виртуальному источнику, и кроме того, предполагается, что выходной аудиоканал является каналом громкоговорителя.
В вариантах осуществления дополнительное значение из информации метаданных, например, из дополнительного сигнала метаданных, может задавать громкость, например, усиление (например, выраженное в децибелах [дБ]) для каждого аудиообъекта.
Например, на фиг. 11 первое значение усиления можно задать с помощью дополнительного значения из информации метаданных для первого аудиообъекта, расположенного в положении 510, которое больше второго значения усиления, задаваемого с помощью другого дополнительного значения из информации метаданных для второго аудиообъекта, расположенного в положении 520. В такой ситуации громкоговорители 511 и 512 могут воспроизводить первый аудиообъект с уровнем выше уровня, с которым громкоговорители 513 и 514 воспроизводят второй аудиообъект.
В соответствии с методикой SAOC кодер SAOC принимает множество сигналов X аудиообъектов и осуществляет их понижающее микширование путем применения матрицы D понижающего микширования, чтобы получить транспортный аудиосигнал Y, содержащий один или несколько транспортных аудиоканалов. Может применяться формула
Y=DX.
Кодер SAOC передает декодеру SAOC транспортный аудиосигнал Y и информацию о матрице D понижающего микширования (например, коэффициенты матрицы D понижающего микширования). Кроме того, кодер SAOC передает декодеру SAOC информацию о ковариационной матрице E (например, коэффициенты ковариационной матрицы E).
На стороне декодера можно восстановить сигналы X аудиообъектов для получения восстановленных аудиообъектов  путем применения формулы
путем применения формулы
=GY
где G - матрица параметрической оценки источника при G=E DH (D E DH)–1.
Тогда один или несколько выходных аудиоканалов Z можно сформировать путем применения матрицы R рендеринга к восстановленным аудиообъектам в соответствии с формулой:
Z=R .
Однако формирование одного или более выходных аудиоканалов Z из транспортного аудиосигнала также может проводиться в один этап путем применения матрицы U в соответствии с формулой:
Z=UY при U=RG.
Каждая строка матрицы R рендеринга ассоциируется с одним из выходных аудиоканалов, которые нужно сформировать. Каждый коэффициент в одной из строк матрицы R рендеринга определяет вес одного из восстановленных сигналов аудиообъектов в выходном аудиоканале, к которому относится упомянутая строка матрицы R рендеринга.
Например, матрица R рендеринга может зависеть от информации о положении для каждого из сигналов аудиообъектов, переданных декодеру SAOC в информации метаданных. Например, сигнал аудиообъекта, имеющий положение, которое находится близко к предполагаемому или реальному положению громкоговорителя, может, например, иметь больший вес в выходном аудиоканале упомянутого громкоговорителя, чем вес сигнала аудиообъекта, положение которого находится далеко от упомянутого громкоговорителя (см. фиг. 5). Например, векторное амплитудное панорамирование может применяться для определения веса сигнала аудиообъекта в каждом из выходных аудиоканалов (см., например, [VBAP]). Относительно VBAP предполагается, что сигнал аудиообъекта назначается виртуальному источнику, и кроме того, предполагается, что выходной аудиоканал является каналом громкоговорителя.
На фиг. 6 и 8 изображается кодер 800 SAOC. Кодер 800 SAOC используется для параметрического кодирования некоторого количества входных объектов/каналов путем их понижающего микширования в меньшее количество транспортных каналов и извлечения необходимой вспомогательной информации, которая внедряется в поток двоичных сигналов объемного аудио.
Понижающее микширование в меньшее количество транспортных каналов выполняется с использованием коэффициентов понижающего микширования для каждого входного сигнала и канала понижающего микширования (например, путем применения матрицы понижающего микширования).
Уровень техники при обработке сигналов аудиообъектов представляет система SAOC MPEG. Одним главным свойством такой системы является то, что промежуточные сигналы понижающего микширования (или транспортные каналы SAOC в соответствии с фиг. 6 и 8) можно прослушивать с помощью унаследованных устройств, неспособных декодировать информацию SAOC. Это накладывает ограничения на используемые коэффициенты понижающего микширования, которые обычно предоставляются создателем контента.
Система кодека объемного аудио имеет целью использование технологии SAOC для повышения эффективности для кодирования большого количества объектов или каналов. Понижающее микширование большого количества объектов в небольшое количество транспортных каналов экономит скорость передачи разрядов.
Фиг. 2 иллюстрирует устройство для формирования транспортного аудиосигнала, содержащего один или несколько транспортных аудиоканалов, в соответствии с вариантом осуществления.
Устройство содержит микшер 210 объектов для формирования транспортного аудиосигнала, содержащего один или несколько транспортных аудиоканалов, из двух или более сигналов аудиообъектов, так что два или более сигналов аудиообъектов микшируются в транспортный аудиосигнал, и где количество одного или более транспортных аудиоканалов меньше количества двух или более сигналов аудиообъектов.
Кроме того, устройство содержит выходной интерфейс 220 для вывода транспортного аудиосигнала.
Микшер 210 объектов конфигурируется для формирования одного или более транспортных аудиоканалов транспортного аудиосигнала в зависимости от первого правила микширования и в зависимости от второго правила микширования, где первое правило микширования указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов, и где второе правило микширования указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала. Первое правило микширования зависит от количества аудиообъектов, указывающего количество двух или более сигналов аудиообъектов, и зависит от количества предварительно микшированных каналов, указывающего количество в множестве предварительно микшированных каналов, и где второе правило микширования зависит от количества предварительно микшированных каналов. Выходной интерфейс 220 конфигурируется для вывода информации о втором правиле микширования.
Фиг. 1 иллюстрирует устройство для формирования одного или более выходных аудиоканалов в соответствии с вариантом осуществления.
Устройство содержит процессор 110 параметров для вычисления информации микширования выходного канала и процессор 120 понижающего микширования для формирования одного или более выходных аудиоканалов.
Процессор 120 понижающего микширования конфигурируется для приема транспортного аудиосигнала, содержащего один или несколько транспортных аудиоканалов, где два или более сигналов аудиообъектов микшируются в транспортный аудиосигнал, и где количество одного или более транспортных аудиоканалов меньше количества двух или более сигналов аудиообъектов. Транспортный аудиосигнал зависит от первого правила микширования и второго правила микширования. Первое правило микширования указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов. Кроме того, второе правило микширования указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала.
Процессор 110 параметров конфигурируется для приема информации о втором правиле микширования, где информация о втором правиле микширования указывает, как микшировать множество предварительно микшированных сигналов так, чтобы получился один или несколько транспортных аудиоканалов. Процессор 110 параметров конфигурируется для вычисления информации микширования выходного канала в зависимости от количества аудиообъектов, указывающего количество двух или более сигналов аудиообъектов, в зависимости от количества предварительно микшированных каналов, указывающего количество в множестве предварительно микшированных каналов, и в зависимости от информации о втором правиле микширования.
Процессор 120 понижающего микширования конфигурируется для формирования одного или более выходных аудиоканалов из транспортного аудиосигнала в зависимости от информации микширования выходного канала.
В соответствии с вариантом осуществления устройство может конфигурироваться, например, для приема по меньшей мере одного из количества аудиообъектов и количества предварительно микшированных каналов.
В другом варианте осуществления процессор 110 параметров может конфигурироваться, например, для определения, в зависимости от количества аудиообъектов и в зависимости от количества предварительно микшированных каналов, информации о первом правиле микширования, так что информация о первом правиле микширования указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов. В таком варианте осуществления процессор 110 параметров может конфигурироваться, например, для вычисления информации микширования выходного канала в зависимости от информации о первом правиле микширования и в зависимости от информации о втором правиле микширования.
В соответствии с вариантом осуществления процессор 110 параметров может конфигурироваться, например, для определения, в зависимости от количества аудиообъектов и в зависимости от количества предварительно микшированных каналов, множества коэффициентов первой матрицы P в качестве информации о первом правиле микширования, где первая матрица P указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала. В таком варианте осуществления процессор 110 параметров может конфигурироваться, например, для приема множества коэффициентов второй матрицы Q в качестве информации о втором правиле микширования, где вторая матрица Q указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала. Процессор 110 параметров в таком варианте осуществления может конфигурироваться, например, для вычисления информации микширования выходного канала в зависимости от первой матрицы P и в зависимости от второй матрицы Q.
Варианты осуществления основываются на заключении, что при понижающем микшировании двух или более сигналов X аудиообъектов для получения транспортного аудиосигнала Y на стороне кодера путем применения матрицы D понижающего микширования в соответствии с формулой
Y=DX,
матрицу D понижающего микширования можно разделить на две меньшие матрицы P и Q в соответствии с формулой
D=QP.
Здесь первая матрица P осуществляет микширование из сигналов X аудиообъектов в множество предварительно микшированных каналов Xpre в соответствии с формулой:
Xpre=PX.
Вторая матрица Q осуществляет микширование из множества предварительно микшированных каналов Xpre в один или несколько транспортных аудиоканалов транспортного аудиосигнала Y в соответствии с формулой:
Y=Q Xpre.
В соответствии с вариантами осуществления декодеру передается информация о втором правиле микширования, например, о коэффициентах второй матрицы Q микширования.
Коэффициенты первой матрицы P микширования не нужно передавать в декодер. Вместо этого декодер принимает информацию о количестве сигналов аудиообъектов и информацию о количестве предварительно микшированных каналов. Из этой информации декодер способен восстановить первую матрицу P микширования. Например, кодер и декодер определяют матрицу P микширования точно так же, как при микшировании первого количества Nobjects сигналов аудиообъектов во второе количество Npre предварительно микшированных каналов.
Фиг. 3 иллюстрирует систему в соответствии с вариантом осуществления. Система содержит устройство 310 для формирования транспортного аудиосигнала, которое описано выше со ссылкой на фиг. 2, и устройство 320 для формирования одного или более выходных аудиоканалов, которое описано выше со ссылкой на фиг. 1.
Устройство 320 для формирования одного или более выходных аудиоканалов конфигурируется для приема транспортного аудиосигнала и информации о втором правиле микширования от устройства 310 для формирования транспортного аудиосигнала. Кроме того, устройство 320 для формирования одного или более выходных аудиоканалов конфигурируется для формирования одного или более выходных аудиоканалов из транспортного аудиосигнала в зависимости от информации о втором правиле микширования.
Например, процессор 110 параметров может конфигурироваться для приема информации метаданных, содержащей информацию о положении для каждого из двух или более сигналов аудиообъектов, и определения информации о первом правиле понижающего микширования в зависимости от информации о положении каждого из двух или более сигналов аудиообъектов, например, путем применения векторного амплитудного панорамирования. Например, кодер также может иметь доступ к информации о положении каждого из двух или более сигналов аудиообъектов, а также может применять векторное амплитудное панорамирование для определения весов сигналов аудиообъектов в предварительно микшированных каналах, и с помощью этого кодер определяет коэффициенты первой матрицы P точно так же, как позже это выполняет декодер (например, кодер и декодер могут предполагать одинаковую расстановку предполагаемых громкоговорителей, назначенную Npre предварительно микшированным каналам).
С помощью приема коэффициентов второй матрицы Q и определения первой матрицы P декодер может определить матрицу D понижающего микширования в соответствии с D=QP.
В варианте осуществления процессор 110 параметров может конфигурироваться, например, для приема ковариационной информации, например, коэффициентов ковариационной матрицы E (например, от устройства для формирования транспортного аудиосигнала), указывающей разность уровней объектов для каждого из двух или более сигналов аудиообъектов и, по возможности, указывающей одну или более межобъектных корреляций между одним из сигналов аудиообъектов и другим из сигналов аудиообъектов.
В таком варианте осуществления процессор 110 параметров может конфигурироваться для вычисления информации микширования выходного канала в зависимости от количества аудиообъектов, в зависимости от количества предварительно микшированных каналов, в зависимости от информации о втором правиле микширования и в зависимости от ковариационной информации.
Например, используя ковариационную матрицу E, можно восстановить сигналы X аудиообъектов для получения восстановленных аудиообъектов путем применения формулы
=GY
где G - матрица параметрической оценки источника при G=E DH (D E DH)–1.
Тогда один или несколько выходных аудиоканалов Z можно сформировать путем применения матрицы R рендеринга к восстановленным аудиообъектам в соответствии с формулой:
Z=R .
Однако формирование одного или более выходных аудиоканалов Z из транспортного аудиосигнала также может проводиться в один этап путем применения матрицы U в соответствии с формулой:
Z=UY при S=UG.
Такая матрица S является примером для информации микширования выходного канала, определенной процессором 110 параметров.
Например, как уже объяснялось выше, каждая строка матрицы R рендеринга может ассоциироваться с одним из выходных аудиоканалов, которые нужно сформировать. Каждый коэффициент в одной из строк матрицы R рендеринга определяет вес одного из восстановленных сигналов аудиообъектов в выходном аудиоканале, к которому относится упомянутая строка матрицы R рендеринга.
В соответствии с вариантом осуществления процессор 110 параметров может конфигурироваться, например, для приема информации метаданных, содержащей информацию о положении для каждого из двух или более сигналов аудиообъектов, может конфигурироваться, например, для определения информации рендеринга, например, коэффициентов матрицы R рендеринга в зависимости от информации о положении каждого из двух или более сигналов аудиообъектов, и может конфигурироваться, например, для вычисления информации микширования выходного канала (например, вышеупомянутой матрицы S) в зависимости от количества аудиообъектов, в зависимости от количества предварительно микшированных каналов, в зависимости от информации о втором правиле микширования и в зависимости от информации рендеринга (например, матрицы R рендеринга).
Таким образом, матрица R рендеринга может зависеть, например, от информации о положении для каждого из сигналов аудиообъектов, переданных декодеру SAOC в информации метаданных. Например, сигнал аудиообъекта, имеющий положение, которое находится близко к предполагаемому или реальному положению громкоговорителя, может, например, иметь больший вес в выходном аудиоканале упомянутого громкоговорителя, чем вес сигнала аудиообъекта, положение которого находится далеко от упомянутого громкоговорителя (см. фиг. 5). Например, векторное амплитудное панорамирование может применяться для определения веса сигнала аудиообъекта в каждом из выходных аудиоканалов (см., например, [VBAP]). Относительно VBAP предполагается, что сигнал аудиообъекта назначается виртуальному источнику, и кроме того, предполагается, что выходной аудиоканал является каналом громкоговорителя. Тогда соответствующий коэффициент матрицы R рендеринга (коэффициент, который назначается рассматриваемому выходному аудиоканалу и рассматриваемому сигналу аудиообъекта) можно устанавливать в значение в зависимости от такого веса. Например, сам вес может быть значением упомянутого соответствующего коэффициента в матрице R рендеринга.
Ниже подробно объясняются варианты осуществления, реализующие пространственное понижающее микширование для объектно-ориентированных сигналов.
Приводится ссылка на следующие нотации и определения:
NObjects - количество сигналов входных аудиообъектов
NChannels - количество входных каналов
N – количество входных сигналов;
N может быть равно NObjects, NChannels или NObjects+NChannels.
NDmxCh - количество каналов понижающего микширования (обработанных)
Npre - количество предварительно микшированных каналов
NSamples - количество обработанных выборок данных
D - матрица понижающего микширования с размером NDmxCh x N
X - входной аудиосигнал, содержащий два или более входных аудиосигнала, с размером N x NSamples
Y - аудиосигнал понижающего микширования (транспортный аудиосигнал), с размером NDmxCh x NSamples, заданный как Y=DX
DMG - данные об усилении понижающего микширования для каждого входного сигнала, канала понижающего микширования и набора параметров
DDMG - трехмерная матрица, хранящая деквантованные и отображенные данные DMG для каждого входного сигнала, канала понижающего микширования и набора параметров
Чтобы улучшить удобочитаемость уравнений без потери общности, для всех введенных переменных опускаются индексы, обозначающие временную и частотную зависимость.
Если не задается никакое ограничение касательно входных сигналов (каналов или объектов), то коэффициенты понижающего микширования вычисляются точно так же для входных сигналов каналов и входных сигналов объектов. Используется нотация для количества N входных сигналов.
Некоторые варианты осуществления могут быть предназначены, например, для понижающего микширования сигналов объектов по-иному, нежели сигналов каналов, руководствуясь пространственной информацией, доступной в метаданных объектов.
Понижающее микширование можно разделить на два этапа:
- На первом этапе объекты предварительно подвергаются рендерингу на компоновку воспроизведения с наибольшим количеством Npre громкоговорителей (например, Npre=22, заданное конфигурацией 22.2). Например, может применяться первая матрица P.
- На втором этапе полученные Npre сигналы после предварительного рендеринга микшируются в количество доступных транспортных каналов (NDmxCh) (например, в соответствии с алгоритмом ортогонального распределения понижающего микширования). Например, может применяться вторая матрица Q.
Однако в некоторых вариантах осуществления понижающее микширование выполняется в один этап, например, путем применения матрицы D, заданной в соответствии с формулой: D=QP, и путем применения Y=DX при D=QP.
Среди прочего, дополнительным преимуществом предложенных идей является, например, то, что входные сигналы объектов, которые предполагаются прошедшими рендеринг в одном и том же пространственном положении в аудиосцене, микшируются вместе в одинаковые транспортные каналы. Следовательно, на стороне декодера получается лучшее разделение сигналов с предварительным рендерингом, избегая разделения аудиообъектов, которые будут снова микшироваться вместе в окончательной сцене воспроизведения.
В соответствии с конкретными предпочтительными вариантами осуществления понижающее микширование можно описать в виде матричного умножения:
Xpre=PX и Y=QXpre.
где P с размером (Npre x NObjects) и Q с размером (NDmxCh x Npre) вычисляют, как объясняется ниже.
Коэффициенты микширования в P создаются из метаданных сигналов объектов (радиус, усиление, азимут и угол возвышения), используя алгоритм панорамирования (например, векторное амплитудное панорамирование). Алгоритм панорамирования должен быть таким же, как используется на стороне декодера для создания выходных каналов.
Коэффициенты микширования в Q задаются на стороне кодера для Npre входных сигналов и NDmxCh доступных транспортных каналов.
Чтобы уменьшить вычислительную сложность, двухэтапное понижающее микширование можно упростить до одноэтапного путем вычисления окончательных усилений понижающего микширования в виде:
D=QP.
Тогда сигналы понижающего микширования задаются с помощью:
Y=DX.
Коэффициенты микширования в P не передаются в потоке двоичных сигналов. Вместо этого они восстанавливаются на стороне декодера, используя тот же алгоритм панорамирования. Поэтому скорость передачи разрядов уменьшается путем отправки только коэффициентов микширования в Q. В частности, так как коэффициенты микширования в P обычно изменяются во времени, и так как P не передается, можно добиться сильного снижения скорости передачи разрядов.
Ниже рассматривается синтаксис потока двоичных сигналов в соответствии с вариантом осуществления.
Для сигнализации используемого способа понижающего микширования и количества Npre каналов для предварительного рендеринга объектов на первом этапе синтаксис потока двоичных сигналов SAOC MPEG расширяется 4 разрядами:
bsNumPremixedChannels
В контексте SAOC MPEG этого можно достичь с помощью следующей модификации:
bsSaocDmxMethod: Указывает, как создается матрица понижающего микширования
Синтаксис SAOC3DSpecificConfig() - Сигнализация

Синтаксис Saoc3DFrame(): способ, которым DMG считываются для разных режимов

bsNumSaocDmxChannels Задает количество каналов понижающего микширования для канально-ориентированного контента. Если каналы отсутствуют в понижающем микшировании, то bsNumSaocDmxChannels устанавливается в ноль.
bsNumSaocChannels Задает количество входных каналов, для которых передаются параметры SAOC 3D. Если bsNumSaocChannels=0, то в понижающем микшировании каналы отсутствуют.
bsNumSaocDmxObjects Задает количество каналов понижающего микширования для объектно-ориентированного контента. Если объекты отсутствуют в понижающем микшировании, то bsNumSaocDmxObjects устанавливается в ноль.
bsNumPremixedChannels Задает количество каналов предварительного микширования для входных аудиообъектов. Если bsSaocDmxMethod равен 15, то фактическое количество предварительно микшированных каналов сигнализируется непосредственно значением bsNumPremixedChannels. Во всех остальных случаях bsNumPremixedChannels устанавливается в соответствии с предыдущей таблицей.
В соответствии с вариантом осуществления матрица D понижающего микширования, примененная к входным аудиосигналам S, определяет сигнал понижающего микширования в виде
X=DS.
Матрица D понижающего микширования с размером Ndmx×N получается в виде:
D=DdmxDpremix.
Матрица Ddmx и матрица Dpremix имеют разные размеры в зависимости от режима обработки.
Матрица Ddmx получается из параметров DMG в виде:

Здесь деквантованные параметры понижающего микширования получаются в виде:
 .
.
В случае прямого режима не используется никакое предварительное микширование. Матрица Dpremix обладает размером N×N и имеет вид: Dpremix=I. Матрица Ddmx обладает размером Ndmx×N и получается из параметров DMG.
В случае режима предварительного микширования матрица Dpremix обладает размером (Nch+Npremix)×N и имеет вид:
 ,
,
где матрица A предварительного микширования с размером Npremix×Nobj принимается от устройства рендеринга объектов в качестве входа в декодер SAOC 3D.
Матрица Ddmx обладает размером Ndmx×(Nch+Npremix) и получается из параметров DMG.
Хотя некоторые аспекты описаны применительно к устройству, понято, что эти аспекты также представляют собой описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. По аналогии аспекты, описанные применительно к этапу способа, также представляют собой описание соответствующего блока или элемента либо признака соответствующего устройства.
Патентоспособный разложенный сигнал может храниться на цифровом носителе информации или может передаваться по передающей среде, например беспроводной передающей среде или проводной передающей среде, такой как Интернет.
В зависимости от некоторых требований к реализации варианты осуществления изобретения можно реализовать в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя информации, например дискеты, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные на нем электронно считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой так, что выполняется соответствующий способ.
Некоторые варианты осуществления в соответствии с изобретением содержат постоянный носитель данных, имеющий электронно считываемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой так, что выполняется один из способов, описанных в этом документе.
Как правило, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, причем программный код действует для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может храниться, например, на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из описанных в этом документе способов, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления патентоспособного способа поэтому является компьютерной программой, имеющей программный код для выполнения одного из описанных в этом документе способов, когда компьютерная программа выполняется на компьютере.
Дополнительный вариант осуществления патентоспособных способов поэтому является носителем данных (или цифровым носителем информации, или машиночитаемым носителем), содержащим записанную на нем компьютерную программу для выполнения одного из способов, описанных в этом документе.
Дополнительный вариант осуществления патентоспособного способа поэтому является потоком данных или последовательностью сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в этом документе. Поток данных или последовательность сигналов могут конфигурироваться, например, для передачи по соединению передачи данных, например по Интернету.
Дополнительный вариант осуществления содержит средство обработки, например компьютер или программируемое логическое устройство, сконфигурированные или приспособленные для выполнения одного из способов, описанных в этом документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в этом документе.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторых или всех функциональных возможностей способов, описанных в этом документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы выполнить один из способов, описанных в этом документе. Как правило, способы предпочтительно выполняются любым аппаратным устройством.
Вышеописанные варианты осуществления являются всего лишь пояснительными для принципов настоящего изобретения. Подразумевается, что модификации и изменения компоновок и подробностей, описанных в этом документе, будут очевидны другим специалистам в данной области техники. Поэтому есть намерение ограничиться только объемом предстоящей формулы изобретения, а не определенными подробностями, представленными посредством описания и объяснения вариантов осуществления в этом документе.
Библиографический список
[SAOC1] J. Herre, S. Disch, J. Hilpert, O. Hellmuth: "From SAC To SAOC - Recent Developments in Parametric Coding of Spatial Audio", 22-ая региональная конференция AES UK, Кембридж, Соединенное Королевство, апрель 2007.
[SAOC2] J.  , B. Resch, C. Falch, O. Hellmuth, J. Hilpert, A.
, B. Resch, C. Falch, O. Hellmuth, J. Hilpert, A.  , L. Terentiev, J. Breebaart, J. Koppens, E. Schuijers и W. Oomen: "Spatial Audio Object Coding (SAOC) - The Upcoming MPEG Standard on Parametric Object Based Audio Coding", 124-ый съезд AES, Амстердам, 2008.
, L. Terentiev, J. Breebaart, J. Koppens, E. Schuijers и W. Oomen: "Spatial Audio Object Coding (SAOC) - The Upcoming MPEG Standard on Parametric Object Based Audio Coding", 124-ый съезд AES, Амстердам, 2008.
[SAOC] ISO/IEC, "MPEG audio technologies - Part 2: Spatial Audio Object Coding (SAOC)", Международный стандарт 23003-2 ISO/IEC JTC1/SC29/WG11 (MPEG).
[VBAP] Ville Pulkki, "Virtual Sound Source Positioning Using Vector Base Amplitude Panning"; J. Audio Eng. Soc., ступень 45, выпуск 6, стр. 456-466, июнь 1997.
[M1] Peters, N., Lossius, T. и Schacher J.C., "SpatDIF: Principles, Specification, and Examples", 9-ая Конференция по звуковому и музыкальному компьютингу, Копенгаген, Дания, июль 2012.
[M2] Wright, M., Freed, A., "Open Sound Control: A New Protocol for Communicating with Sound Synthesizers", Международная конференция по компьютерной музыке, Салоники, Греция, 1997.
[M3] Matthias Geier, Jens Ahrens и Sascha Spors. (2010), "Object-based audio reproduction and the audio scene description format", Org. Sound, том 15, № 3, стр. 219-227, декабрь 2010.
[M4] W3C, "Synchronized Multimedia Integration Language (SMIL 3.0)", декабрь 2008.
[M5] W3C, "Extensible Markup Language (XML) 1.0 (Fifth Edition)", ноябрь 2008.
[M6] MPEG, "ISO/IEC International Standard 14496-3 - Coding of audio-visual objects, Part 3 Audio", 2009.
[M7] Schmidt, J.; Schroeder, E.F. (2004), "New and Advanced Features for Audio Presentation in the MPEG-4 Standard", 116-ый съезд AES, Берлин, Германия, май 2004.
[M8] Web3D, "International Standard ISO/IEC 14772-1:1997 - The Virtual Reality Modeling Language (VRML), Part 1: Functional specification and UTF-8 encoding", 1997.
[M9] Sporer, T. (2012), "Codierung  Audiosignale mit leichtgewichtigen Audio-Objekten", материалы ежегодного собрания Немецкого общества аудиологии (DGA), Эрланген, Германия, март 2012.
Audiosignale mit leichtgewichtigen Audio-Objekten", материалы ежегодного собрания Немецкого общества аудиологии (DGA), Эрланген, Германия, март 2012.











Изобретение относится к средствам для осуществления понижающего микширования SAOC объемного аудиоконтента. Технический результат заключается в повышении эффективности понижающего микширования аудиоконтента. Принимают транспортный аудиосигнал, состоящий из двух или более микшированных сигналов аудиообъектов. Количество транспортных аудиоканалов меньше количества сигналов аудиообъектов. Транспортный аудиосигнал зависит от первого правила микширования и второго правила микширования. Первое правило микширования указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов. Второе правило микширования указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала. Принимают информацию о втором правиле микширования. Вычисляют информацию микширования выходного канала в зависимости от количества аудиообъектов, количества предварительно микшированных каналов и информации о втором правиле микширования. Формируют один или несколько выходных аудиоканалов из транспортного аудиосигнала в зависимости от информации микширования выходного канала. 7 н. и 9 з.п. ф-лы, 11 ил.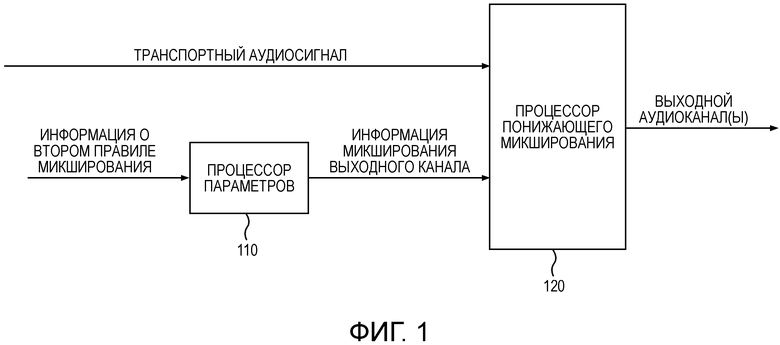
1. Устройство для формирования одного или более выходных аудиоканалов, содержащее:
процессор (110) параметров для вычисления информации микширования выходного канала и
процессор (120) понижающего микширования для формирования одного или более выходных аудиоканалов, причем процессор (120) понижающего микширования конфигурируется для приема транспортного аудиосигнала, содержащего один или несколько транспортных аудиоканалов, причем два или более сигналов аудиообъектов микшируются в транспортный аудиосигнал и причем количество одного или более транспортных аудиоканалов меньше количества двух или более сигналов аудиообъектов,
причем транспортный аудиосигнал зависит от первого правила микширования и второго правила микширования, причем первое правило микширования указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов, и причем второе правило микширования указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала,
причем процессор (110) параметров конфигурируется для приема информации о втором правиле микширования, причем информация о втором правиле микширования указывает, как микшировать множество предварительно микшированных сигналов так, чтобы получился один или несколько транспортных аудиоканалов,
причем процессор (110) параметров конфигурируется для вычисления информации микширования выходного канала в зависимости от количества аудиообъектов, указывающего количество двух или более сигналов аудиообъектов, в зависимости от количества предварительно микшированных каналов, указывающего количество в множестве предварительно микшированных каналов, и в зависимости от информации о втором правиле микширования, и
причем процессор (120) понижающего микширования конфигурируется для формирования одного или более выходных аудиоканалов из транспортного аудиосигнала в зависимости от информации микширования выходного канала.
2. Устройство по п. 1, причем устройство конфигурируется для приема по меньшей мере одного из количества аудиообъектов и количества предварительно микшированных каналов.
3. Устройство по п. 1,
в котором процессор (110) параметров конфигурируется для определения, в зависимости от количества аудиообъектов и в зависимости от количества предварительно микшированных каналов, информации о первом правиле микширования, так что информация о первом правиле микширования указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов, и
в котором процессор (110) параметров конфигурируется для вычисления информации микширования выходного канала в зависимости от информации о первом правиле микширования и в зависимости от информации о втором правиле микширования.
4. Устройство по п. 3,
в котором процессор (110) параметров конфигурируется для определения, в зависимости от количества аудиообъектов и в зависимости от количества предварительно микшированных каналов, множества коэффициентов первой матрицы (P) в качестве информации о первом правиле микширования, причем первая матрица (P) указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов,
в котором процессор (110) параметров конфигурируется для приема множества коэффициентов второй матрицы (Q) в качестве информации о втором правиле микширования, причем вторая матрица (Q) указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала, и
в котором процессор (110) параметров конфигурируется для вычисления информации микширования выходного канала в зависимости от первой матрицы (P) и в зависимости от второй матрицы (Q).
5. Устройство по п. 1,
в котором процессор (110) параметров конфигурируется для приема информации метаданных, содержащей информацию о положении для каждого из двух или более сигналов аудиообъектов,
в котором процессор (110) параметров конфигурируется для определения информации о первом правиле микширования в зависимости от информации о положении каждого из двух или более сигналов аудиообъектов.
6. Устройство по п. 3,
в котором процессор (110) параметров конфигурируется для приема информации метаданных, содержащей информацию о положении для каждого из двух или более сигналов аудиообъектов,
в котором процессор (110) параметров конфигурируется для определения информации о первом правиле микширования в зависимости от информации о положении каждого из двух или более сигналов аудиообъектов.
7. Устройство по п. 5,
в котором процессор (110) параметров конфигурируется для определения информации рендеринга в зависимости от информации о положении каждого из двух или более сигналов аудиообъектов и
в котором процессор (110) параметров конфигурируется для вычисления информации микширования выходного канала в зависимости от количества аудиообъектов, в зависимости от количества предварительно микшированных каналов, в зависимости от информации о втором правиле микширования и в зависимости от информации рендеринга.
8. Устройство по п. 1,
в котором процессор (110) параметров конфигурируется для приема ковариационной информации, указывающей разность уровней объектов для каждого из двух или более сигналов аудиообъектов, и
в котором процессор (110) параметров конфигурируется для вычисления информации микширования выходного канала в зависимости от количества аудиообъектов, в зависимости от количества предварительно микшированных каналов, в зависимости от информации о втором правиле микширования и в зависимости от ковариационной информации.
9. Устройство по п. 8,
в котором ковариационная информация дополнительно указывает по меньшей мере одну межобъектную корреляцию между одним из двух или более сигналов аудиообъектов и другим из двух или более сигналов аудиообъектов и
в котором процессор (110) параметров конфигурируется для вычисления информации микширования выходного канала в зависимости от количества аудиообъектов, в зависимости от количества предварительно микшированных каналов, в зависимости от информации о втором правиле микширования, в зависимости от разности уровней объектов каждого из двух или более сигналов аудиообъектов и в зависимости по меньшей мере от одной межобъектной корреляции между одним из двух или более сигналов аудиообъектов и другим из двух или более сигналов аудиообъектов.
10. Устройство для формирования транспортного аудиосигнала, содержащего один или несколько транспортных аудиоканалов, причем устройство содержит:
микшер (210) объектов для формирования транспортного аудиосигнала, содержащего один или несколько транспортных аудиоканалов, из двух или более сигналов аудиообъектов, так что два или более сигналов аудиообъектов микшируются в транспортный аудиосигнал, и причем количество одного или более транспортных аудиоканалов меньше количества двух или более сигналов аудиообъектов, и
выходной интерфейс (220) для вывода транспортного аудиосигнала, причем устройство конфигурируется для передачи транспортного аудиосигнала в декодер,
причем микшер (210) объектов конфигурируется для формирования одного или более транспортных аудиоканалов транспортного аудиосигнала в зависимости от первого правила микширования и в зависимости от второго правила микширования, причем первое правило микширования указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов, и причем второе правило микширования указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала,
причем первое правило микширования зависит от количества аудиообъектов, указывающего количество двух или более сигналов аудиообъектов, и зависит от количества предварительно микшированных каналов, указывающего количество в множестве предварительно микшированных каналов, и причем второе правило микширования зависит от количества предварительно микшированных каналов, и
причем микшер (210) объектов конфигурируется для формирования одного или более транспортных аудиоканалов транспортного аудиосигнала в зависимости от первой матрицы (P), причем первая матрица (P) указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов, и в зависимости от второй матрицы (Q), причем вторая матрица (Q) указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала,
причем первые коэффициенты первой матрицы (P) указывают информацию о первом правиле микширования и причем вторые коэффициенты второй матрицы (Q) указывают информацию о втором правиле микширования,
причем устройство конфигурируется для передачи вторых коэффициентов второй матрицы (Q) микширования в декодер и причем устройство конфигурируется не передавать первые коэффициенты первой матрицы (P) микширования в декодер.
11. Устройство по п. 10,
в котором микшер (210) объектов конфигурируется для приема информации о положении для каждого из двух или более сигналов аудиообъектов и
в котором микшер (210) объектов конфигурируется для определения первого правила микширования в зависимости от информации о положении каждого из двух или более сигналов аудиообъектов.
12. Система для формирования одного или более выходных аудиоканалов из транспортного аудиосигнала, содержащая:
устройство (310) по п. 10 для формирования транспортного аудиосигнала и
устройство (320) по п. 1 для формирования одного или более выходных аудиоканалов,
причем устройство (320) конфигурируется для приема транспортного аудиосигнала и информации о втором правиле микширования от устройства (310) и
причем устройство (320) конфигурируется для формирования одного или более выходных аудиоканалов из транспортного аудиосигнала в зависимости от информации о втором правиле микширования.
13. Способ для формирования одного или более выходных аудиоканалов, содержащий этапы, на которых:
принимают транспортный аудиосигнал, содержащий один или несколько транспортных аудиоканалов, причем два или более сигналов аудиообъектов микшируются в транспортный аудиосигнал и причем количество одного или более транспортных аудиоканалов меньше количества двух или более сигналов аудиообъектов, причем транспортный аудиосигнал зависит от первого правила микширования и второго правила микширования, причем первое правило микширования указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов, и причем второе правило микширования указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала,
принимают информацию о втором правиле микширования, причем информация о втором правиле микширования указывает, как микшировать множество предварительно микшированных сигналов так, чтобы получился один или несколько транспортных аудиоканалов,
вычисляют информацию микширования выходного канала в зависимости от количества аудиообъектов, указывающего количество двух или более сигналов аудиообъектов, в зависимости от количества предварительно микшированных каналов, указывающего количество в множестве предварительно микшированных каналов, и в зависимости от информации о втором правиле микширования и
формируют один или несколько выходных аудиоканалов из транспортного аудиосигнала в зависимости от информации микширования выходного канала.
14. Способ для формирования транспортного аудиосигнала, содержащего один или несколько транспортных аудиоканалов, причем способ содержит этапы, на которых:
формируют транспортный аудиосигнал, содержащий один или несколько транспортных аудиоканалов, из двух или более сигналов аудиообъектов,
выводят транспортный аудиосигнал и передают транспортный аудиосигнал декодеру и
передают вторые коэффициенты второй матрицы (Q) микширования в декодер и не передают первые коэффициенты первой матрицы (P) микширования в декодер,
причем этап, на котором формируют транспортный аудиосигнал, содержащий один или несколько транспортных аудиоканалов, из двух или более сигналов аудиообъектов, проводится так, что два или более сигналов аудиообъектов микшируются в транспортный аудиосигнал, причем количество одного или более транспортных аудиоканалов меньше количества двух или более сигналов аудиообъектов, и
причем этап, на котором формируют один или несколько транспортных аудиоканалов транспортного аудиосигнала, проводится в зависимости от первого правила микширования и в зависимости от второго правила микширования, причем первое правило микширования указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов, и причем второе правило микширования указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала, причем первое правило микширования зависит от количества аудиообъектов, указывающего количество двух или более сигналов аудиообъектов, и зависит от количества предварительно микшированных каналов, указывающего количество в множестве предварительно микшированных каналов, и причем второе правило микширования зависит от количества предварительно микшированных каналов,
причем этап, на котором формируют один или несколько транспортных аудиоканалов транспортного аудиосигнала, проводится в зависимости от первой матрицы (P), причем первая матрица (P) указывает, как микшировать два или более сигналов аудиообъектов, чтобы получить множество предварительно микшированных каналов, и в зависимости от второй матрицы (Q), причем вторая матрица (Q) указывает, как микшировать множество предварительно микшированных каналов, чтобы получить один или несколько транспортных аудиоканалов транспортного аудиосигнала,
причем первые коэффициенты первой матрицы (P) указывают информацию о первом правиле микширования и причем вторые коэффициенты второй матрицы (Q) указывают информацию о втором правиле микширования.
15. Машиночитаемый носитель, содержащий компьютерную программу для реализации способа по п. 13 при исполнении на компьютере или процессоре сигналов.
16. Машиночитаемый носитель, содержащий компьютерную программу для реализации способа по п. 14 при исполнении на компьютере или процессоре сигналов.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СПОСОБ АВТОМАТИЧЕСКОГО РЕГУЛИРОВАНИЯ СКОРОСТИ ВАЛА ТЕПЛОВОГО ДВИГАТЕЛЯ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2001 |
|
RU2209328C2 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБРАБОТКИ СИГНАЛА | 2008 |
|
RU2449387C2 |

