Изобретение относится к кодированию/декодированию аудио, в частности, к пространственному кодированию аудио и пространственному кодированию аудиообъектов, а более конкретно, к устройству и способу для эффективного кодирования метаданных объектов.
Инструментальные средства пространственного кодирования аудио известны в данной области техники и стандартизированы, например, в стандарте объемного звучания MPEG. Пространственное кодирование аудио начинается с исходных входных каналов, к примеру, с пяти или семи каналов, которые идентифицируются посредством их размещения в компоновке для воспроизведения, т.е. как левого канала, центрального канала, правого канала, левого канала объемного звучания, правого канала объемного звучания и канала улучшения низких частот. Пространственный аудиокодер типично извлекает один или более каналов понижающего микширования из исходных каналов и, дополнительно, извлекает параметрические данные, связанные с пространственными сигнальными метками, такие как межканальные разности уровней в значениях канальной когерентности, межканальные разности фаз, межканальные разности времен и т.д. Один или более каналов понижающего микширования передаются вместе с параметрической вспомогательной информацией, указывающей пространственные сигнальные метки, в пространственный аудиодекодер, который декодирует канал понижающего микширования и ассоциированные параметрические данные, чтобы в итоге получать выходные каналы, которые являются аппроксимированной версией исходных входных каналов. Размещение каналов в выходной компоновке типично является фиксированным и представляет собой, например, 5.1-формат, 7.1-формат и т.д.
Такие канальные аудиоформаты широко используются для сохранения или передачи многоканального аудиоконтента, в котором каждый канал связан с конкретным громкоговорителем в данной позиции. Высококачественное воспроизведение подобных форматов требует компоновки громкоговорителей, в которой динамики размещены в позициях, идентичных позициям динамиков, которые использованы во время формирования аудиосигналов. Хотя увеличение числа громкоговорителей улучшает воспроизведение истинно иммерсивных трехмерных аудиосцен, становится все более затруднительным удовлетворять это требование, особенно в такой внутренней среде, как гостиная.
Необходимость наличия конкретной компоновки громкоговорителей может преодолеваться посредством объектно-ориентированного подхода, в котором сигналы громкоговорителей подготавливаются посредством рендеринга, в частности, для компоновки для воспроизведения.
Например, инструментальные средства пространственного кодирования аудиообъектов известны в данной области техники и стандартизированы в MPEG SAOC-стандарте (SAOC - пространственное кодирование аудиообъектов). В отличие от пространственного кодирования аудио, начинающегося с исходных каналов, пространственное кодирование аудиообъектов начинается с аудиообъектов, которые автоматически не выделяются для определенной компоновки для воспроизведения при рендеринге. Вместо этого, размещение аудиообъектов в сцене для воспроизведения является гибким и может определяться пользователем посредством ввода определенной информации рендеринга в декодер по стандарту пространственного кодирования аудиообъектов. Альтернативно или дополнительно, информация рендеринга, т.е. информация в отношении того, в какой позиции в компоновке для воспроизведения типично должен размещаться определенный аудиообъект во времени, может передаваться в качестве дополнительной вспомогательной информации или метаданных. Чтобы получать определенное сжатие данных, определенное число аудиообъектов кодируются посредством SAOC-кодера, который вычисляет, из входных объектов, один или более транспортных каналов посредством понижающего микширования объектов в соответствии с определенной информацией понижающего микширования. Кроме того, SAOC-кодер вычисляет параметрическую вспомогательную информацию, представляющую межобъектные сигнальные метки, к примеру, разности уровней объектов (OLD), значения когерентности объектов и т.д. Аналогично SAC (SAC - пространственное кодирование аудио), межобъектные параметрические данные вычисляются для отдельных частотно-временных мозаичных фрагментов, т.е. для определенного кадра аудиосигнала, содержащего, например, 1024 или 2048 выборок, рассматриваются 24, 32 или 64 и т.д. полос частот, так что, в конечном счете, параметрические данные существуют для каждого кадра и каждой полосы частот. В качестве примера, когда аудиофрагмент имеет 20 кадров, и когда каждый кадр подразделяется на 32 полосы частот, в таком случае число частотно-временных мозаичных фрагментов равно 640.
В объектно-ориентированном подходе, звуковое поле описывается посредством дискретных аудиообъектов. Это требует метаданных объектов, которые описывают, в числе прочего, зависимую от времени позицию каждого источника звука в трехмерном пространстве.
Первый принцип кодирования метаданных в предшествующем уровне техники представляет собой формат обмена пространственными звуковыми описаниями (SpatDIF), формат описания аудиосцен, который по-прежнему разрабатывается [1]. Он спроектирован в качестве формата обмена для объектно-ориентированных звуковых сцен и не предоставляет способы сжатия для траекторий объектов. SpatDIF использует текстовый формат открытого звукового управления (OSC) для того, чтобы структурировать метаданные объектов [2]. Тем не менее, простое текстовое представление не представляет собой вариант для сжатой передачи траекторий объектов.
Другой принцип на основе метаданных в предшествующем уровне техники представляет собой формат описания аудиосцен (ASDF) [3], текстовое решение, которое имеет идентичный недостаток. Данные структурированы посредством расширения языка интеграции синхронных потоков мультимедиа (SMIL), который представляет собой поднабор расширяемого языка разметки (XML) [4,5].
Дополнительный принцип на основе метаданных в предшествующем уровне техники представляет собой двоичный аудиоформат для сцен (AudioBIFS), двоичный формат, который является частью MPEG-4-спецификации [6,7]. Он тесно связан с языком моделирования виртуальной реальности (VRML) на основе XML, который разработан для описания аудиовизуальных трехмерных сцен и интерактивных приложений в стиле виртуальной реальности [8]. Комплексная AudioBIFS-спецификация использует графы сцен, чтобы указывать маршруты перемещений объектов. Главный недостаток AudioBIFS заключается в том, что он не спроектирован для работы в режиме реального времени, в котором ограниченная задержка в системе и произвольный доступ к потоку данных являются обязательными. Кроме того, кодирование позиций объектов не использует ограниченную производительность локализации слушателей-людей. Для фиксированной позиции слушателя в аудиовизуальной сцене, данные объектов могут квантоваться с гораздо более низким числом битов [9]. Следовательно, кодирование метаданных объектов, которые применяются в AudioBIFS, не является эффективным относительно сжатия данных.
Следовательно, существует высокая потребность в том, чтобы предоставить улучшенные принципы эффективного кодирования метаданных объектов.
Цель настоящего изобретения заключается в том, чтобы предоставлять усовершенствованные принципы для эффективного кодирования метаданных объектов. Цель настоящего изобретения достигается посредством устройства по п. 1, посредством устройства по п. 8, посредством системы по п. 14, посредством способа по п. 15, посредством способа по п. 16 и посредством компьютерной программы по п. 17.
Предусмотрено устройство для формирования одного или более аудиоканалов. Устройство содержит декодер метаданных для приема одного или более сжатых сигналов метаданных. Каждый из одного или более сжатых сигналов метаданных содержит множество первых выборок метаданных. Первые выборки метаданных каждого из одного или более сжатых сигналов метаданных указывают информацию, ассоциированную с сигналом аудиообъекта для одного или более сигналов аудиообъектов. Декодер метаданных выполнен с возможностью формировать один или более восстановленных сигналов метаданных таким образом, что каждый из одного или более восстановленных сигналов метаданных содержит первые выборки метаданных одного из одного или более сжатых сигналов метаданных и дополнительно содержит множество вторых выборок метаданных. Кроме того, декодер метаданных выполнен с возможностью формировать каждую из вторых выборок метаданных каждого восстановленного сигнала метаданных из одного или более восстановленных сигналов метаданных в зависимости, по меньшей мере, от двух из первых выборок метаданных упомянутого восстановленного сигнала метаданных. Кроме того, устройство содержит формирователь аудиоканалов для формирования одного или более аудиоканалов в зависимости от одного или более сигналов аудиообъектов и в зависимости от одного или более восстановленных сигналов метаданных.
Кроме того, предусмотрено устройство для формирования кодированной аудиоинформации, содержащей один или более кодированных аудиосигналов и один или более сжатых сигналов метаданных. Устройство содержит кодер метаданных для приема одного или более исходных сигналов метаданных. Каждый из одного или более исходных сигналов метаданных содержит множество выборок метаданных. Выборки метаданных каждого из одного или более исходных сигналов метаданных указывают информацию, ассоциированную с сигналом аудиообъекта для одного или более сигналов аудиообъектов. Кодер метаданных выполнен с возможностью формировать один или более сжатых сигналов метаданных таким образом, что каждый сжатый сигнал метаданных из одного или более сжатых сигналов метаданных содержит первую группу из двух или более выборок метаданных одного из исходных сигналов метаданных, и таким образом, что упомянутый сжатый сигнал метаданных не содержит какой-либо выборки метаданных второй группы из других двух или более выборок метаданных упомянутого одного из исходных сигналов метаданных. Кроме того, устройство содержит аудиокодер для кодирования одного или более сигналов аудиообъектов, чтобы получать один или более кодированных аудиосигналов.
Кроме того, предусмотрена система. Система содержит устройство для формирования кодированной аудиоинформации, содержащей один или более кодированных аудиосигналов и один или более сжатых сигналов метаданных, как описано выше. Кроме того, система содержит устройство для приема одного или более кодированных аудиосигналов и одного или более сжатых сигналов метаданных и для формирования одного или более аудиоканалов в зависимости от одного или более кодированных аудиосигналов и в зависимости от одного или более сжатых сигналов метаданных, как описано выше.
Согласно вариантам осуществления, предусмотрены принципы сжатия данных для метаданных объектов, которые достигают эффективного механизма сжатия для каналов передачи с ограниченной скоростью передачи данных. Кроме того, достигается хороший коэффициент сжатия для чистых изменений азимута, например, вращений камеры. Кроме того, предоставляемые принципы поддерживают прерывистые траектории, например, позиционные переходы. Кроме того, реализована низкая сложность декодирования. Кроме того, достигается произвольный доступ с ограниченным временем повторной инициализации.
Кроме того, предусмотрен способ формирования одного или более аудиоканалов. Способ содержит:
- прием одного или более сжатых сигналов метаданных, при этом каждый из одного или более сжатых сигналов метаданных содержит множество первых выборок метаданных, при этом первые выборки метаданных каждого из одного или более сжатых сигналов метаданных указывают информацию, ассоциированную с сигналом аудиообъекта для одного или более сигналов аудиообъектов;
- формирование одного или более восстановленных сигналов метаданных таким образом, что каждый из одного или более восстановленных сигналов метаданных содержит первые выборки метаданных одного из одного или более сжатых сигналов метаданных и дополнительно содержит множество вторых выборок метаданных, при этом формирование одного или более восстановленных сигналов метаданных содержит этап формирования каждой из вторых выборок метаданных каждого восстановленного сигнала метаданных из одного или более восстановленных сигналов метаданных в зависимости, по меньшей мере, от двух из первых выборок метаданных упомянутого восстановленного сигнала метаданных; и
- формирование одного или более аудиоканалов в зависимости от одного или более сигналов аудиообъектов и в зависимости от одного или более восстановленных сигналов метаданных.
Кроме того, предусмотрен способ формирования кодированной аудиоинформации, содержащей один или более кодированных аудиосигналов и один или более сжатых сигналов метаданных. Способ содержит:
- прием одного или более исходных сигналов метаданных, при этом каждый из одного или более исходных сигналов метаданных содержит множество выборок метаданных, при этом выборки метаданных каждого из одного или более исходных сигналов метаданных указывают информацию, ассоциированную с сигналом аудиообъекта для одного или более сигналов аудиообъектов;
- формирование одного или более сжатых сигналов метаданных таким образом, что каждый сжатый сигнал метаданных из одного или более сжатых сигналов метаданных содержит первую группу из двух или более выборок метаданных одного из исходных сигналов метаданных, и таким образом, что упомянутый сжатый сигнал метаданных не содержит какой-либо выборки метаданных второй группы из других двух или более выборок метаданных упомянутого одного из исходных сигналов метаданных; и
- кодирование одного или более сигналов аудиообъектов, чтобы получать один или более кодированных аудиосигналов.
Кроме того, предусмотрена компьютерная программа для реализации вышеописанного способа при выполнении на компьютере или в процессоре сигналов.
Далее подробнее описываются варианты осуществления настоящего изобретения в отношении чертежей, на которых:
Фиг. 1 иллюстрирует устройство для формирования одного или более аудиоканалов согласно варианту осуществления.
Фиг. 2 иллюстрирует устройство для формирования кодированной аудиоинформации, содержащей один или более кодированных аудиосигналов и один или более сжатых сигналов метаданных согласно варианту осуществления.
Фиг. 3 иллюстрирует систему согласно варианту осуществления.
Фиг. 4 иллюстрирует позицию аудиообъекта в трехмерном пространстве относительно начала координат, выражаемую посредством азимута, подъема и радиуса.
Фиг. 5 иллюстрирует позиции аудиообъектов и компоновку громкоговорителей, предполагаемую посредством формирователя аудиоканалов.
Фиг. 6 иллюстрирует кодирование метаданных согласно варианту осуществления.
Фиг. 7 иллюстрирует декодирование метаданных согласно варианту осуществления.
Фиг. 8 иллюстрирует кодирование метаданных согласно другому варианту осуществления.
Фиг. 9 иллюстрирует декодирование метаданных согласно другому варианту осуществления.
Фиг. 10 иллюстрирует кодирование метаданных согласно дополнительному варианту осуществления.
Фиг. 11 иллюстрирует декодирование метаданных согласно дополнительному варианту осуществления.
Фиг. 12 иллюстрирует первый вариант осуществления трехмерного аудиокодера.
Фиг. 13 иллюстрирует первый вариант осуществления трехмерного аудиодекодера.
Фиг. 14 иллюстрирует второй вариант осуществления трехмерного аудиокодера.
Фиг. 15 иллюстрирует второй вариант осуществления трехмерного аудиодекодера.
Фиг. 16 иллюстрирует третий вариант осуществления трехмерного аудиокодера.
Фиг. 17 иллюстрирует третий вариант осуществления трехмерного аудиодекодера.
Фиг. 2 иллюстрирует устройство 250 для формирования кодированной аудиоинформации, содержащей один или более кодированных аудиосигналов и один или более сжатых сигналов метаданных согласно варианту осуществления.
Устройство 250 содержит кодер 210 метаданных для приема одного или более исходных сигналов метаданных. Каждый из одного или более исходных сигналов метаданных содержит множество выборок метаданных. Выборки метаданных каждого из одного или более исходных сигналов метаданных указывают информацию, ассоциированную с сигналом аудиообъекта для одного или более сигналов аудиообъектов. Кодер 210 метаданных выполнен с возможностью формировать один или более сжатых сигналов метаданных таким образом, что каждый сжатый сигнал метаданных из одного или более сжатых сигналов метаданных содержит первую группу из двух или более выборок метаданных одного из исходных сигналов метаданных, и таким образом, что упомянутый сжатый сигнал метаданных не содержит какой-либо выборки метаданных второй группы из других двух или более выборок метаданных упомянутого одного из исходных сигналов метаданных.
Кроме того, устройство 250 содержит аудиокодер 220 для кодирования одного или более сигналов аудиообъектов, чтобы получать один или более кодированных аудиосигналов. Например, формирователь аудиоканалов может содержать SAOC-кодер согласно предшествующему уровню техники, чтобы кодировать один или более сигналов аудиообъектов, чтобы получать один или более транспортных SAOC-каналов в качестве одного или более кодированных аудиосигналов. Различные другие технологии кодирования для того, чтобы кодировать один или более каналов аудиообъекта, альтернативно или дополнительно могут использоваться для того, чтобы кодировать один или более каналов аудиообъекта.
Фиг. 1 иллюстрирует устройство 100 для формирования одного или более аудиоканалов согласно варианту осуществления.
Устройство 100 содержит декодер 110 метаданных для приема одного или более сжатых сигналов метаданных. Каждый из одного или более сжатых сигналов метаданных содержит множество первых выборок метаданных. Первые выборки метаданных каждого из одного или более сжатых сигналов метаданных указывают информацию, ассоциированную с сигналом аудиообъекта для одного или более сигналов аудиообъектов. Декодер 110 метаданных выполнен с возможностью формировать один или более восстановленных сигналов метаданных таким образом, что каждый из одного или более восстановленных сигналов метаданных содержит первые выборки метаданных одного из одного или более сжатых сигналов метаданных и дополнительно содержит множество вторых выборок метаданных. Кроме того, декодер 110 метаданных выполнен с возможностью формировать каждую из вторых выборок метаданных каждого восстановленного сигнала метаданных из одного или более восстановленных сигналов метаданных в зависимости, по меньшей мере, от двух из первых выборок метаданных упомянутого восстановленного сигнала метаданных.
Кроме того, устройство 100 содержит формирователь 120 аудиоканалов для формирования одного или более аудиоканалов в зависимости от одного или более сигналов аудиообъектов и в зависимости от одного или более восстановленных сигналов метаданных.
При упоминании выборок метаданных, следует отметить, что выборка метаданных характеризуется посредством ее значения выборки метаданных, но также и посредством момента времени, к которому она относится. Например, такой момент времени может быть относительным для начала аудиопоследовательности и т.п. Например, индекс N или K может идентифицировать позицию выборки метаданных в сигнале метаданных, и посредством этого указывается (относительный) момент времени (относительно начального времени). Следует отметить, что когда две выборки метаданных связаны с различными моментами времени, эти две выборки метаданных представляют собой различные выборки метаданных, даже когда их значения выборок метаданных равны, что иногда может иметь место.
Вышеописанные варианты осуществления основаны на таких выявленных сведениях, что информация метаданных (состоящая из сигнала метаданных), которая ассоциирована с сигналом аудиообъекта, зачастую изменяется медленно.
Например, сигнал метаданных может указывать информацию позиции для аудиообъекта (например, азимутальный угол, угол подъема или радиус, задающий позицию аудиообъекта). Можно предполагать, что в большинстве случаев, позиция аудиообъекта либо не изменяется, либо только медленно изменяется.
Альтернативно, сигнал метаданных, например, может указывать громкость (например, усиление) аудиообъекта, и также можно предполагать, что в большинстве случаев, громкость аудиообъекта изменяется медленно.
По этой причине, необязательно передавать (полную) информацию метаданных в каждый момент времени. Вместо этого, (полная) информация метаданных передается только в определенные моменты времени, например, периодически, например, в каждый N-й момент времени, например, в момент времени 0, N, 2N, 3 Н и т.д. На стороне декодера, для промежуточных моментов времени (например, моментов 1, 2,..., N-1 времени), метаданные затем могут быть аппроксимированы на основе выборок метаданных для двух или более моментов времени. Например, выборки метаданных для моментов 1, 2,..., N-1 времени могут быть аппроксимированы на стороне декодера в зависимости от выборок метаданных для моментов 0 и N времени, например, посредством использования линейной интерполяции. Как указано выше, этот подход основан на таких выявленных сведениях, что информация метаданных относительно аудиообъектов, в общем, изменяется медленно.
Например, в вариантах осуществления, три сигнала метаданных указывают позицию аудиообъекта в трехмерном пространстве. Первый из сигналов метаданных, например, может указывать азимутальный угол позиции аудиообъекта. Второй из сигналов метаданных, например, может указывать угол подъема позиции аудиообъекта. Третий из сигналов метаданных, например, может указывать радиус, связанный с расстоянием аудиообъекта.
Азимутальный угол, угол подъема и радиус однозначно задают позицию аудиообъекта в трехмерном пространстве относительно начала координат. Это проиллюстрировано со ссылкой на фиг. 4.
Фиг. 4 иллюстрирует позицию 410 аудиообъекта в трехмерном пространстве относительно начала 400 координат, выражаемую посредством азимута, подъема и радиуса.
Угол подъема указывает, например, угол между прямой линией от начала координат до позиции объекта и нормальной проекцией этой прямой линии на плоскость XY (плоскость, заданную посредством оси X и оси Y). Азимутальный угол задает, например, угол между осью X и упомянутой нормальной проекцией. Посредством указания азимутального угла и угла подъема, может задаваться прямая линия 415 через начало 400 координат и позицию 410 аудиообъекта. Посредством дополнительного указания радиуса, может задаваться точная позиция 410 аудиообъекта.
В варианте осуществления, азимутальный угол задается для диапазона: -180°<азимут≤180°, угол подъема задается для диапазона: -90°≤подъем≤90°, и радиус, например, может задаваться в метрах (м) (больше или равен 0 м).
В другом варианте осуществления, в котором, например, можно предполагать, что все значения X позиций аудиообъектов в системе координат XYZ превышают или равны нулю, азимутальный угол может задаваться для диапазона: -90°≤азимут≤90°, угол подъема может задаваться для диапазона: -90°≤подъем≤90°, и радиус, например, может задаваться в метрах (м).
В дополнительном варианте осуществления, сигналы метаданных могут масштабироваться таким образом, что азимутальный угол задается для диапазона: -128°<азимут≤128°, угол подъема задается для диапазона: -32°≤подъем≤32°, и радиус, например, может задаваться на логарифмической шкале. В некоторых вариантах осуществления, исходные сигналы метаданных, сжатые сигналы метаданных и восстановленные сигналы метаданных, соответственно, могут содержать масштабированное представление информации позиции и/или масштабированное представление громкости одного из одного или более сигналов аудиообъектов.
Формирователь 120 аудиоканалов, например, может быть выполнен с возможностью формировать один или более аудиоканалов в зависимости от одного или более сигналов аудиообъектов и в зависимости от восстановленных сигналов метаданных, при этом восстановленные сигналы метаданных, например, могут указывать позицию аудиообъектов.
Фиг. 5 иллюстрирует позиции аудиообъектов и компоновку громкоговорителей, предполагаемую посредством формирователя аудиоканалов. Проиллюстрировано начало 500 координат системы координат XYZ. Кроме того, проиллюстрированы позиция 510 первого аудиообъекта и позиция 520 второго аудиообъекта. Кроме того, фиг. 5 иллюстрирует сценарий, в котором формирователь 120 аудиоканалов формирует четыре аудиоканала для четырех громкоговорителей. Формирователь 120 аудиоканалов предполагает то, что четыре громкоговорителя 511, 512, 513 и 514 расположены в позициях, показанных на фиг. 5.
На фиг. 5, первый аудиообъект расположен в позиции 510 близко к предполагаемым позициям громкоговорителей 511 и 512 и расположен на большом расстоянии от громкоговорителей 513 и 514. Следовательно, формирователь 120 аудиоканалов может формировать четыре аудиоканала таким образом, что первый аудиообъект 510 воспроизводится посредством громкоговорителей 511 и 512, а не посредством громкоговорителей 513 и 514.
В других вариантах осуществления, формирователь 120 аудиоканалов может формировать четыре аудиоканала таким образом, что первый аудиообъект 510 воспроизводится с высокой громкостью посредством громкоговорителей 511 и 512 и с низкой громкостью посредством громкоговорителей 513 и 514.
Кроме того, второй аудиообъект расположен в позиции 520 близко к предполагаемым позициям громкоговорителей 513 и 514 и расположен на большом расстоянии от громкоговорителей 511 и 512. Следовательно, формирователь 120 аудиоканалов может формировать четыре аудиоканала таким образом, что второй аудиообъект 520 воспроизводится посредством громкоговорителей 513 и 514, а не посредством громкоговорителей 511 и 512.
В других вариантах осуществления, формирователь 120 аудиоканалов может формировать четыре аудиоканала таким образом, что второй аудиообъект 520 воспроизводится с высокой громкостью посредством громкоговорителей 513 и 514 и с низкой громкостью посредством громкоговорителей 511 и 512.
В альтернативных вариантах осуществления, только два сигнала метаданных используются для того, чтобы указывать позицию аудиообъекта. Например, могут указываться только азимут и радиус, например, когда предполагается, что все аудиообъекты расположены в одной плоскости.
В дополнительно других вариантах осуществления, для каждого аудиообъекта, только один сигнал метаданных кодируется и передается в качестве информации позиции. Например, только азимутальный угол может указываться в качестве информации позиции для аудиообъекта (например, можно предполагать, что все аудиообъекты расположены в идентичной плоскости, имеющей идентичное расстояние от центральной точки, и в силу этого предположительно имеют идентичный радиус). Информация азимута, например, может быть достаточной для того, чтобы определять то, что аудиообъект расположен близко к левому громкоговорителю и на большом расстоянии от правого громкоговорителя. В таком случае, формирователь 120 аудиоканалов, например, может формировать один или более аудиоканалов таким образом, что аудиообъект воспроизводится посредством левого громкоговорителя, а не посредством правого громкоговорителя.
Например, векторное амплитудное панорамирование (VBAP) может использоваться (см., например, [12]) для того, чтобы определять весовой коэффициент сигнала аудиообъекта в каждом из аудиоканалов громкоговорителей. Например, относительно VBAP, предполагается, что аудиообъект связан с виртуальным источником.
В вариантах осуществления, дополнительный сигнал метаданных может указывать громкость, например, усиление (например, выражаемое в децибеле [дБ]) для каждого аудиообъекта.
Например, на фиг. 5, первое значение усиления может указываться посредством дополнительного сигнала метаданных для первого аудиообъекта, расположенного в позиции 510, которое выше второго значения усиления, указываемого посредством другого дополнительного сигнала метаданных для второго аудиообъекта, расположенного в позиции 520. В таком случае, громкоговорители 511 и 512 могут воспроизводить первый аудиообъект с громкостью, превышающей громкость, с которой громкоговорители 513 и 514 воспроизводят второй аудиообъект.
Варианты осуществления также предполагают, что такие значения усиления аудиообъектов зачастую изменяются медленно. Следовательно, необязательно передавать такую информацию метаданных в каждый момент времени. Вместо этого, информация метаданных передается только в определенные моменты со временем. В промежуточные моменты времени, информация метаданных, например, может быть аппроксимирована с использованием предшествующей выборки метаданных и последующей выборки метаданных, которые переданы. Например, линейная интерполяция может использоваться для аппроксимации промежуточных значений. Например, усиление, азимут, подъем и/или радиус каждого из аудиообъектов могут быть аппроксимированы для моментов времени, в которые такие метаданные не переданы.
Посредством такого подхода может достигаться значительная экономия по скорости передачи метаданных.
Фиг. 3 иллюстрирует систему согласно варианту осуществления.
Система содержит устройство 250 для формирования кодированной аудиоинформации, содержащей один или более кодированных аудиосигналов и один или более сжатых сигналов метаданных, как описано выше.
Кроме того, система содержит устройство 100 для приема одного или более кодированных аудиосигналов и одного или более сжатых сигналов метаданных и для формирования одного или более аудиоканалов в зависимости от одного или более кодированных аудиосигналов и в зависимости от одного или более сжатых сигналов метаданных, как описано выше.
Например, один или более кодированных аудиосигналов могут декодироваться посредством устройства 100 для формирования одного или более аудиоканалов посредством использования SAOC-декодера согласно предшествующему уровню техники, чтобы получать один или более сигналов аудиообъектов, когда устройство 250 для кодирования использует SAOC-кодер для кодирования одного или более аудиообъектов.
При рассмотрении позиций объектов только в качестве примера для метаданных, чтобы обеспечивать произвольный доступ с ограниченным временем повторной инициализации, варианты осуществления предоставляют полную повторную передачу всех позиций объектов на регулярной основе.
Согласно варианту осуществления, устройство 100 выполнено с возможностью принимать информацию произвольного доступа, при этом, для каждого сжатого сигнала метаданных из одного или более сжатых сигналов метаданных, информация произвольного доступа указывает часть сигнала, к которой осуществляется доступ, для упомянутого сжатого сигнала метаданных, при этом, по меньшей мере, еще одна часть сигнала для упомянутого сигнала метаданных не указывается посредством упомянутой информации произвольного доступа, и при этом декодер 110 метаданных выполнен с возможностью формировать один из одного или более восстановленных сигналов метаданных в зависимости от первых выборок метаданных упомянутой части сигнала, к которой осуществляется доступ, для упомянутого сжатого сигнала метаданных, но независимо от любых других первых выборок метаданных любой другой части сигнала для упомянутого сжатого сигнала метаданных. Другими словами, посредством указания информации произвольного доступа, может указываться часть каждого из сжатых сигналов метаданных, при этом другие части упомянутого сигнала метаданных не указываются. В этом случае, только указанная часть упомянутого сжатого сигнала метаданных восстановлена в качестве одного из восстановленных сигналов метаданных, но не другие части. Восстановление является возможным, поскольку передаваемые первые выборки метаданных упомянутого сжатого сигнала метаданных представляют полную информацию метаданных упомянутого сжатого сигнала метаданных для определенных моментов времени (тем не менее, для других моментов времени информация метаданных не передается).
Фиг. 6 иллюстрирует кодирование метаданных согласно варианту осуществления. Кодер 210 метаданных согласно вариантам осуществления может быть выполнен с возможностью реализовывать кодирование метаданных, проиллюстрированное посредством фиг. 6.
На фиг. 6 s(n) может представлять один из исходных сигналов метаданных. Например, s(n), к примеру, может представлять функцию азимутального угла одного из аудиообъектов, и n может указывать время (например, посредством указания позиций выборок в исходном сигнале метаданных).
Зависимый от времени компонент s(n) траектории, который дискретизируется на частоте дискретизации, которая значительно ниже (например, 1:1024 или ниже) частоты аудиодискретизации, квантуется (см. 611) и понижающе дискретизируется (см. 612) на коэффициент N. Это приводит к вышеуказанному регулярно передаваемому цифровому сигналу, который обозначается как z(k).
Z(k) представляет собой один из одного или более сжатых сигналов метаданных. Например, каждая N-я выборка ŝ(n) метаданных также представляет собой выборку метаданных сжатого сигнала z(k) метаданных, в то время как другие N-1 выборок ŝ(n) метаданных между каждой N-й выборкой метаданных не представляют собой выборки метаданных сжатого сигнала z(k) метаданных.
Например, предположим, что в s(n), n указывает время (например, посредством указания позиций выборок в исходном сигнале метаданных), где n является положительным целым числом или 0 (например, начальное время: n=0). N является коэффициентом понижающей дискретизации. Например, N=32 или любой другой подходящий коэффициент понижающей дискретизации.
Например, понижающая дискретизация на 612, чтобы получать сжатый сигнал z метаданных из исходного сигнала s метаданных, например, может быть реализована таким образом, что:
z(k)=ŝ(k*N), где k является положительным целым числом или 0 (k=0, 1, 2...)
Таким образом:
z(0)=ŝ(0); z(1)=ŝ(32); z(2)=ŝ(64); z(3)=ŝ(96).
Фиг. 7 иллюстрирует декодирование метаданных согласно варианту осуществления. Декодер 110 метаданных согласно вариантам осуществления может быть выполнен с возможностью реализовывать декодирование метаданных, проиллюстрированное посредством фиг. 7.
Согласно варианту осуществления, проиллюстрированному посредством фиг. 7, декодер 110 метаданных выполнен с возможностью формировать каждый восстановленный сигнал метаданных из одного или более восстановленных сигналов метаданных посредством повышающей дискретизации одного из одного или более сжатых сигналов метаданных, при этом декодер 110 метаданных выполнен с возможностью формировать каждую из вторых выборок метаданных каждого восстановленного сигнала метаданных из одного или более восстановленных сигналов метаданных посредством осуществления линейной интерполяции в зависимости, по меньшей мере, от двух из первых выборок метаданных упомянутого восстановленного сигнала метаданных.
Таким образом, каждый восстановленный сигнал метаданных содержит все выборки метаданных своего сжатого сигнала метаданных (эти выборки упоминаются в качестве "первых выборок метаданных" одного или более сжатых сигналов метаданных).
Посредством осуществления повышающей дискретизации, дополнительные ("вторые") выборки метаданных добавляются в восстановленный сигнал метаданных. Этап повышающей дискретизации определяет то, в каких позициях в восстановленном сигнале метаданных (например, в какие "относительные" моменты времени) дополнительные (вторые) выборки метаданных добавляются в сигнал метаданных.
Посредством осуществления линейной интерполяции определяются значения выборок метаданных для вторых выборок метаданных. Линейная интерполяция осуществляется на основе двух выборок метаданных сжатого сигнала метаданных (которые становятся первыми выборками метаданных восстановленного сигнала метаданных).
Согласно вариантам осуществления, повышающая дискретизация и формирование вторых выборок метаданных посредством осуществления линейной интерполяции, например, может осуществляться на одном этапе.
На фиг. 7, процесс обратной повышающей дискретизации (см. 721) в комбинации с линейной интерполяцией (см. 722) приводит к приблизительной аппроксимации исходного сигнала. Процесс обратной повышающей дискретизации (см. 721) и линейная интерполяция (см. 722), например, могут осуществляться на одном этапе.
Например, повышающая дискретизация (721) и линейная интерполяция (722) на стороне декодера, например, могут осуществляться таким образом, что:
s'(k*N)=z(k), где k является положительным целым числом или 0
s'(k*N+j)=z(k-1)+j/N [z(k)-z(k-1)], где j является целым числом, причем 1≤j≤N-1
Здесь, z(k) является фактически принимаемой выборкой метаданных сжатого сигнала z метаданных и z(k-1) является выборкой метаданных сжатого сигнала z метаданных, который принят непосредственно перед фактически принимаемой выборкой z(k) метаданных.
Фиг. 8 иллюстрирует кодирование метаданных согласно другому варианту осуществления. Кодер 210 метаданных согласно вариантам осуществления может быть выполнен с возможностью реализовывать кодирование метаданных, проиллюстрированное посредством фиг. 8.
В вариантах осуществления, например, как проиллюстрировано посредством фиг. 8, при кодировании метаданных, точная структура может указываться посредством кодированной разности между входным сигналом с компенсацией задержки и линейно интерполированной приблизительной аппроксимацией.
Согласно таким вариантам осуществления, процесс обратной повышающей дискретизации в комбинации с линейной интерполяцией также осуществляется в качестве части кодирования метаданных на стороне кодера (см. 621 и 622 на фиг. 6). С другой стороны, процесс обратной повышающей дискретизации (см. 621) и линейная интерполяция (см. 622), например, могут осуществляться на одном этапе.
Как уже описано выше, кодер 210 метаданных выполнен с возможностью формировать один или более сжатых сигналов метаданных таким образом, что каждый сжатый сигнал метаданных из одного или более сжатых сигналов метаданных содержит первую группу из двух или более выборок метаданных исходного сигнала метаданных из одного или более исходных сигналов метаданных. Упомянутый сжатый сигнал метаданных может рассматриваться как ассоциированный с упомянутым исходным сигналом метаданных.
Каждая из выборок метаданных, которая состоит из исходного сигнала метаданных из одного или более исходных сигналов метаданных и которая также состоит из сжатого сигнала метаданных, который ассоциирован с упомянутым исходным сигналом метаданных, может рассматриваться как одна из множества первых выборок метаданных.
Кроме того, каждая из выборок метаданных, которая состоит из исходного сигнала метаданных из одного или более исходных сигналов метаданных и которая не состоит из сжатого сигнала метаданных, который ассоциирован с упомянутым исходным сигналом метаданных, представляет собой одну из множества вторых выборок метаданных.
Согласно варианту осуществления по фиг. 8, кодер 210 метаданных выполнен с возможностью формировать аппроксимированную выборку метаданных для каждой из множества вторых выборок метаданных одного из исходных сигналов метаданных посредством осуществления линейной интерполяции в зависимости, по меньшей мере, от двух из первых выборок метаданных упомянутого одного из одного или более исходных сигналов метаданных.
Кроме того, в варианте осуществления по фиг. 8, кодер 210 метаданных выполнен с возможностью формировать разностное значение для каждой второй выборки метаданных из упомянутого множества вторых выборок метаданных упомянутого одного из одного или более исходных сигналов метаданных таким образом, что упомянутое разностное значение указывает разность между упомянутой второй выборкой метаданных и аппроксимированной выборкой метаданных для упомянутой второй выборки метаданных.
В предпочтительном варианте осуществления, который описывается ниже со ссылкой на фиг. 10, кодер 210 метаданных, например, может быть выполнен с возможностью определять, по меньшей мере, для одного из разностных значений упомянутого множества вторых выборок метаданных упомянутого одного из одного или более исходных сигналов метаданных то, превышает ли каждое, по меньшей мере, одно из упомянутых разностных значений пороговое значение.
В вариантах осуществления согласно фиг. 8, аппроксимированные выборки метаданных, например, могут определяться (например, в качестве выборок s''(n) сигнала s'') посредством осуществления повышающей дискретизации для сжатого сигнала z(k) метаданных и посредством осуществления линейной интерполяции. Повышающая дискретизация и линейная интерполяция, например, могут осуществляться в качестве части кодирования метаданных на стороне кодера (см. 621 и 622 на фиг. 6), например, аналогичным образом, как описано для декодирования метаданных в отношении 721 и 722:
s''(k*N)=z(k), где k является положительным целым числом или 0
s''(k*N+j)=z(k-1)+j/N [z(k)-z(k-1)], где j является целым числом, причем 1≤j≤N-1
Например, в варианте осуществления, проиллюстрированном посредством фиг. 8, при осуществлении кодирования метаданных, разностные значения могут определяться на 630 для разностей:
s(n)-s''(n), например, для всех n с (k-1)*N<n<k*N, или
например, для всех n с (k-1)*N<n≤k*N.
В вариантах осуществления, одно или более из этих разностных значений передаются в декодер метаданных.
Фиг. 9 иллюстрирует декодирование метаданных согласно другому варианту осуществления. Декодер 110 метаданных согласно вариантам осуществления может быть выполнен с возможностью реализовывать декодирование метаданных, проиллюстрированное посредством фиг. 9.
Как уже описано выше, каждый восстановленный сигнал метаданных из одного или более восстановленных сигналов метаданных содержит первые выборки метаданных сжатого сигнала метаданных из одного или более сжатых сигналов метаданных. Упомянутый восстановленный сигнал метаданных рассматривается как ассоциированный с упомянутым сжатым сигналом метаданных.
В вариантах осуществления, проиллюстрированных посредством фиг. 9, декодер 110 метаданных выполнен с возможностью формировать вторые выборки метаданных каждого из одного или более восстановленных сигналов метаданных посредством формирования множества аппроксимированных выборок метаданных для упомянутого восстановленного сигнала метаданных, при этом декодер 110 метаданных выполнен с возможностью формировать каждую из множества аппроксимированных выборок метаданных в зависимости по меньшей мере от двух из первых выборок метаданных упомянутого восстановленного сигнала метаданных. Например, эти аппроксимированные выборки метаданных могут формироваться посредством линейной интерполяции, как описано со ссылкой на фиг. 7.
Согласно варианту осуществления, проиллюстрированному посредством фиг. 9, декодер 110 метаданных выполнен с возможностью принимать множество разностных значений для сжатого сигнала метаданных из одного или более сжатых сигналов метаданных. Кроме того, декодер 110 метаданных выполнен с возможностью суммировать каждое из множества разностных значений с одной из аппроксимированных выборок метаданных восстановленного сигнала метаданных, ассоциированного с упомянутым сжатым сигналом метаданных, чтобы получать вторые выборки метаданных упомянутого восстановленного сигнала метаданных.
Для всех тех аппроксимированных выборок метаданных, для которых принято разностное значение, это разностное значение суммируется с аппроксимированной выборкой метаданных, чтобы получать вторые выборки метаданных.
Согласно варианту осуществления, аппроксимированная выборка метаданных, для которой не принято разностное значение, используется в качестве второй выборки метаданных восстановленного сигнала метаданных.
Тем не менее, согласно другому варианту осуществления, если разностное значение не принимается для аппроксимированной выборки метаданных, аппроксимированное разностное значение формируется для упомянутой аппроксимированной выборки метаданных в зависимости от одного или более принимаемых разностных значений, и упомянутая аппроксимированная выборка метаданных суммируется с упомянутой аппроксимированной выборкой метаданных, см. ниже.
Согласно варианту осуществления, проиллюстрированному посредством фиг. 9, принятые разностные значения суммируются (см. 730) с соответствующими выборками метаданных сигнала метаданных после повышающей дискретизации. Посредством этого, соответствующие интерполированные выборки метаданных, для которых разностные значения переданы, могут корректироваться, при необходимости, чтобы получать корректные выборки метаданных.
Если возвращаться к кодированию метаданных на фиг. 8, в предпочтительных вариантах осуществления, меньшее число битов используется для кодирования разностных значений, чем число битов, используемых для кодирования выборок метаданных. Эти варианты осуществления основаны на таких выявленных сведениях, что (например, N) последующих выборок метаданных в большинстве случаев варьируются только незначительно. Например, если один вид выборок метаданных кодируется, например, посредством 8 битов, эти выборки метаданных могут принимать одно из 256 различных значений. Вследствие, в общем, незначительных изменений (например, N) последующих значений метаданных, может считаться достаточным кодировать разностные значения только, например, посредством 5 битов. Таким образом, даже если передаются разностные значения, число передаваемых битов может уменьшаться.
В предпочтительном варианте осуществления, передаются одно или более разностных значений, каждое из одного или более разностных значений кодируется с меньшим числом битов, чем каждая из выборок метаданных, и каждое разностное значение являются целочисленным значением.
Согласно варианту осуществления, кодер 110 метаданных выполнен с возможностью кодировать одну или более выборок метаданных одного из одного или более сжатых сигналов метаданных с первым числом битов, при этом каждая из упомянутой одной или более выборок метаданных упомянутого одного из одного или более сжатых сигналов метаданных указывает целое число. Кроме того, кодер (110) метаданных выполнен с возможностью кодировать одно или более разностных значений со вторым числом битов, при этом каждое из упомянутого одного или более разностных значений указывает целое число, при этом второе число битов меньше первого числа битов.
Рассмотрим, например, что в варианте осуществления, выборки метаданных могут представлять азимут, кодированный посредством 8 битов. Например, азимут может быть целым числом между -90≤азимут≤90. Таким образом, азимут может принимать 181 различное значение. Тем не менее, если предположить, что (например, N) последующих выборок азимута отличаются только не более чем, например, на  15, то 5 битов (25=32) может быть достаточно для того, чтобы кодировать разностные значения. Если разностные значения представляются как целые числа, то определение разностных значений автоматически преобразует дополнительные значения, которые должны передаваться, в подходящий диапазон значений.
15, то 5 битов (25=32) может быть достаточно для того, чтобы кодировать разностные значения. Если разностные значения представляются как целые числа, то определение разностных значений автоматически преобразует дополнительные значения, которые должны передаваться, в подходящий диапазон значений.
Например, рассмотрим случай, в котором первое значение азимута первого аудиообъекта составляет 60°, и его последующие значения варьируются от 45° до 75°. Кроме того, рассмотрим, что второе значение азимута второго аудиообъекта составляет -30°, и его последующие значения варьируются от -45° до -15°. Посредством определения разностных значений как для последующих значений первого аудиообъекта, так и для последующих значений второго аудиообъекта, разностные значения первого значения азимута и второго значения азимута находятся в диапазоне значений от -15° до +15°, так что 5 битов достаточно для того, чтобы кодировать каждое из разностных значений, и так что битовая последовательность, которая кодирует разностные значения, имеет идентичный смысл для разностных значений первого азимутального угла и разностных значений второго значения азимута.
В варианте осуществления, каждое разностное значение, для которого выборки метаданных не существуют в сжатом сигнале метаданных, передается на сторону декодирования. Кроме того, согласно варианту осуществления, каждое разностное значение, для которого выборки метаданных не существуют в сжатом сигнале метаданных, принимается и обрабатывается посредством декодера метаданных. Тем не менее, некоторые предпочтительные варианты осуществления, проиллюстрированные посредством фиг. 10 и 11, реализуют другой принцип.
Фиг. 10 иллюстрирует кодирование метаданных согласно дополнительному варианту осуществления. Кодер 210 метаданных согласно вариантам осуществления может быть выполнен с возможностью реализовывать кодирование метаданных, проиллюстрированное посредством фиг. 10.
Аналогично некоторым вышеприведенным вариантах осуществления, на фиг. 10, разностные значения, например, определяются для каждой выборки метаданных исходного сигнала метаданных, которая не состоит из сжатого сигнала метаданных. Например, когда выборки метаданных в момент времени n=0 и момент времени n=N состоят из сжатого сигнала метаданных, но выборок метаданных в моменты времени от n=1 до n=N-1, в таком случае разностные значения определяются для моментов времени до n=1 до n=N-1.
Тем не менее, согласно варианту осуществления по фиг. 10, многоугольная аппроксимация затем осуществляется на 640. Кодер 210 метаданных выполнен с возможностью определять то, какие из разностных значений должны передаваться, и то, передаются ли разностные значения вообще.
Например, кодер 210 метаданных может быть выполнен с возможностью передавать только эти разностные значения, имеющие разностное значение, которое превышает пороговое значение.
В другом варианте осуществления, кодер 210 метаданных может быть выполнен с возможностью передавать только эти разностные значения, когда отношение того разностного значения в соответствующую выборку метаданных превышает пороговое значение.
В варианте осуществления, кодер 210 метаданных анализирует для самого большого абсолютного разностного значения то, превышает ли это абсолютное разностное значение пороговое значение. Если это абсолютное разностное значение превышает пороговое значение, это разностное значение передается, в противном случае разностное значение не передается, и анализ завершается. Анализ продолжается для второго наибольшего разностного значения, для третьего наибольшего значения и т.д. до тех пор, пока все разностные значения не станут меньше порогового значения.
Поскольку не все разностные значения обязательно передаются, согласно вариантам осуществления, кодер 210 метаданных не только кодирует (размер) непосредственно разностное значение (одно из значений y1[k],,..., yN-1[k] на фиг. 10), но также и передает информацию в отношении того, к какой выборке метаданных исходного сигнала метаданных относится разностное значение (одно из значений x1[k]... xN-1[k] на фиг. 10). Например, кодер 210 метаданных может кодировать момент времени, к которому относится разностное значение. Например, кодер 210 метаданных может кодировать значение между 1 и N-1, чтобы указывать то, к какой выборке метаданных между выборками 0 и N метаданных, которые уже переданы в сжатом сигнале метаданных, относится разностное значение. Перечень значений x1[k]... xN-1[k] y1[k]... yN-1[k] в выводе многоугольной аппроксимации не означает, что все эти значения обязательно передаются, а вместо этого означает, что ни одно, одно, некоторые или все эти пары значений передаются, в зависимости от разностных значений.
В варианте осуществления, кодер 210 метаданных может обрабатывать сегмент, например, N последовательных разностных значений и аппроксимирует каждый сегмент посредством многоугольного хода, который формируется посредством переменного числа квантованных точек [xi, yi] многоугольника.
Можно предполагать, что число точек многоугольника, которое требуется для того, чтобы аппроксимировать разностный сигнал с достаточной точностью, в среднем значительно меньше N. Кроме того, поскольку [xi, yi] являются небольшими целыми числами, они могут кодироваться с низким числом битов.
Фиг. 11 иллюстрирует декодирование метаданных согласно дополнительному варианту осуществления. Декодер 110 метаданных согласно вариантам осуществления может быть выполнен с возможностью реализовывать декодирование метаданных, проиллюстрированное посредством фиг. 11.
В вариантах осуществления, декодер 110 метаданных принимает некоторые разностные значения и суммирует эти разностные значения с соответствующими линейными интерполированными выборками метаданных на 730.
В некоторых вариантах осуществления, декодер 110 метаданных суммирует принятые разностные значения только с соответствующими линейными интерполированными выборками метаданных на 730 и оставляет другие линейные интерполированные выборки метаданных, для которых разностные значения не принимаются, неизмененными.
Тем не менее, ниже описываются варианты осуществления, которые реализуют другой принцип.
Согласно таким вариантам осуществления, декодер 110 метаданных выполнен с возможностью принимать множество разностных значений для сжатого сигнала метаданных из одного или более сжатых сигналов метаданных. Каждое из разностных значений может упоминаться в качестве "принимаемого разностного значения". Принимаемое разностное значение назначается одной из аппроксимированных выборок метаданных восстановленного сигнала метаданных, который ассоциирован (состоит из) с упомянутым сжатым сигналом метаданных, к которому относятся принятые разностные значения.
Как уже описано относительно фиг. 9, декодер 110 метаданных выполнен с возможностью суммировать принимаемое разностное значение из множества принимаемых разностных значений с аппроксимированной выборкой метаданных, ассоциированной с упомянутым принимаемым разностным значением. Посредством суммирования принимаемого разностного значения с аппроксимированной выборкой метаданных, получается одна из вторых выборок метаданных упомянутого восстановленного сигнала метаданных.
Тем не менее, для некоторых (или иногда, для большинства) аппроксимированных выборок метаданных, зачастую, разностные значения не принимаются.
В некоторых вариантах осуществления, декодер 110 метаданных, например, может быть выполнен с возможностью определять аппроксимированное разностное значение в зависимости от одного или более из множества принимаемых разностных значений для каждой аппроксимированной выборки метаданных из множества аппроксимированных выборок метаданных восстановленного сигнала метаданных, ассоциированного с упомянутым сжатым сигналом метаданных, когда ни одно из множества принимаемых разностных значений не ассоциировано с упомянутой аппроксимированной выборкой метаданных.
Другими словами, для всех тех аппроксимированных выборок метаданных, для которых не принимается разностное значение, аппроксимированное разностное значение формируется в зависимости от одного или более принимаемых разностных значений.
Декодер 110 метаданных выполнен с возможностью суммировать каждое аппроксимированное разностное значение из множества аппроксимированных разностных значений с аппроксимированной выборкой метаданных упомянутого аппроксимированного разностного значения, чтобы получать другую из вторых выборок метаданных упомянутого восстановленного сигнала метаданных.
Тем не менее, в других вариантах осуществления, декодер 110 метаданных аппроксимирует разностные значения для тех выборок метаданных, для которых разностные значения не приняты посредством осуществления линейной интерполяции в зависимости от этих разностных значений, которые приняты на этапе 740.
Например, если первое значение разности и второе значение разности принимаются, то разностные значения, расположенные между этими принимаемыми разностными значениями, могут быть аппроксимированы, например, с использованием линейной интерполяции.
Например, когда первое значение разности в момент времени n=15 имеет разностное значение d[15]=5; кроме того, когда второе значение разности в момент времени n=18 имеет разностное значение d[18]=2, в таком случае разностные значения для n=16 и d=17 могут быть линейно аппроксимированы в качестве d[16]=4 и d[17]=3.
В дополнительном варианте осуществления, когда выборки метаданных состоят из сжатого сигнала метаданных, разностные значения упомянутых выборок метаданных предположительно равны 0, и линейная интерполяция разностных значений, которые не принимаются, может осуществляться посредством декодера метаданных на основе упомянутых выборок метаданных, которые предположительно равны нулю.
Например, когда одно разностное значение d=8 передается для n=16 и когда для n=0 и n=32, выборка метаданных передается в сжатом сигнале метаданных, в таком случае непередаваемые разностные значения при n=0 и n=32 предположительно равны 0.
Пусть n обозначает время, и пусть d[n] является разностным значением в момент времени n. В таком случае:
d[16]=8 (принимаемое разностное значение)
d[0]=0 (предполагаемое разностное значение, поскольку выборка метаданных существует в z(k)),
d[32]=0 (предполагаемое разностное значение, поскольку выборка метаданных существует в z(k)),
аппроксимированные разностные значения:
d[1]=0,5; d[2]=1; d[3]=1,5; d[4]=2; d[5]=2,5; d[6]=3; d[7]=3,5; d[8]=4;
d[9]=4,5; d[10]=5; d[11]=5,5; d[12]=6; d[13]=6,5; d[14]=7; d[15]=7,5;
d[17]=7,5; d[18]=7; d[19]=6,5; d[20]=6; d[21]=5,5; d[22]=5; d[23]=4,5; d[24]=4;
d[25]=3,5; d[26]=3; d[27]=2,5; d[28]=2; d[29]=1,5; d[30]=1; d[31]=0,5.
В вариантах осуществления, принятые, а также аппроксимированные разностные значения суммируются с соответствующими линейными интерполированными выборками (на 730).
Далее описываются предпочтительные варианты осуществления.
Кодер метаданных (объектов), например, может объединенно кодировать последовательность регулярно (суб)-дискретизированных значений траектории с использованием упреждающего буфера данного размера N. После того, как этот буфер заполнен, весь блок данных кодируется и передается. Кодированные данные объектов могут состоять из 2 частей, внутренне кодированных данных объектов и необязательно дифференциальной части данных, которая содержит точную структуру каждого сегмента.
Внутренне кодированные данные объектов содержат квантованные значения z(k), которые дискретизируются на обычной сетке (например, каждые 32 аудиокадра длины в 1024). Булевы переменные могут использоваться для того, чтобы указывать то, что значения указываются по отдельности для каждого объекта, либо то, что далее следует значение, которое является общим для всех объектов.
Декодер может быть выполнен с возможностью извлекать приблизительную траекторию из внутренне кодированных данных объектов посредством линейной интерполяции. Точная структура траекторий задается посредством дифференциальной части данных, которая содержит кодированную разность между входной траекторией и линейной интерполяцией. Многоугольное представление в комбинации с различными шагами квантования для значений азимута, подъема, радиуса и усиления приводит к требуемому уменьшению нерелевантности.
Многоугольное представление может получаться из варианта алгоритма Рамера-Дугласа-Пекера [10, 11], который не использует рекурсию и который отличается от исходного подхода посредством дополнительного критерия прерывания, т.е. максимального числа точек многоугольника для всех объектов и всех компонентов объектов.
Результирующие точки многоугольника могут кодироваться в дифференциальной части данных с использованием переменной длины слова, которая указывается в потоке битов. Дополнительные булевы переменные указывают общее кодирование равных значений.
Далее описываются кадры метаданных объектов согласно вариантам осуществления и символьное представление согласно вариантам осуществления.
Для обеспечения эффективности, последовательность регулярно (суб)-дискретизированных значений траектории объединенно кодируется. Кодер может использовать упреждающий буфер данного размера, и как только этот буфер заполняется, весь блок данных кодируется и передается. Эти кодированные данные объектов (например, рабочие данные для метаданных объектов), например, могут содержать две части, внутренне кодированные данные объектов (первую часть) и, необязательно, дифференциальную часть данных (вторую часть).
Могут использоваться, например, некоторые или все части следующего синтаксиса:
Далее описываются внутренне кодированные данные объектов согласно варианту осуществления.
Чтобы поддерживать произвольный доступ для кодированных метаданных объектов, полная и автономная спецификация всех метаданных объектов должна регулярно передаваться. Это реализовано через внутренне кодированные данные объектов ("I-кадры"), которые содержат квантованные значения, дискретизированные на обычной сетке (например, каждые 32 кадра длины в 1024). Эти I-кадры имеют следующий синтаксис, в котором position_azimuth, position_elevation, position_radius и gain_factor указывают квантованные значения в iframe_period кадров после текущего I-кадра:
Далее описываются дифференциальные данные объектов согласно варианту осуществления.
Аппроксимация с большей точностью достигается посредством передачи многоугольных ходов на основе сокращенного числа точек дискретизации. Следовательно, может передаваться очень разреженная трехмерная матрица, в которой первая размерность может представлять собой индекс объекта, вторая размерность может формироваться посредством компонентов метаданных (азимута, подъема, радиуса и усиления), и третья размерность может представлять собой индекс кадра точек дискретизации на многоугольнике. Без дополнительных показателей, индикатор того, какие элементы матрицы содержат значения, уже требует num_objects*num_components*(iframe_period-1) битов. Первый этап для того, чтобы уменьшать это число битов, может заключаться в добавлении четырех флагов, которые указывают то, имеется ли, по меньшей мере, одно значение, которое принадлежит одному из четырех компонентов. Например, можно предполагать, что только в редких случаях предусмотрены дифференциальные значения радиуса или усиления. Третья размерность уменьшенной трехмерной матрицы содержит вектор с iframe_period-1 элементов. Если ожидается только небольшое число точек многоугольника, то может быть более эффективным параметризовать этот вектор посредством набора индексов кадров и числа элементов этого набора. Например, для iframe_period в Nperiod=32 кадра, максимального числа в 16 точек многоугольника, этот способ может быть предпочтительным для Npoints<(32-log2(16))/log2 (32)=5,6 точек многоугольника. Согласно вариантам осуществления, для такой схемы кодирования используется следующий синтаксис:
Макрос offset_data() кодирует позиции (кадровые смещения) точек многоугольника либо в качестве простого битового поля, либо с использованием принципов, описанных выше. Num_bits значений предоставляют возможность кодирования больших позиционных переходов, в то время как остальная часть дифференциальных данных кодируется с меньшим размером слова.
В частности, в варианте осуществления, вышеприведенные макросы, например, могут иметь следующий смысл:
Определение рабочих данных object_metadata() согласно варианту осуществления:
has_differential_metadata - указывает то, присутствуют ли дифференциальные метаданные объектов.
Определение рабочих данных intracoded_object_metadata() согласно варианту осуществления:
ifperiod - задает число кадров промежуточные независимые кадры.
common_azimuth - указывает то, используется ли общий азимутальный угол для всех объектов.
default_azimuth - задает значение общего азимутального угла.
position_azimuth - если отсутствует значение общего азимута, передается значение для каждого объекта.
common_elevation - указывает то, используется ли общий угол подъема для всех объектов.
default_elevation - задает значение общего угла подъема.
position_elevation - если отсутствует значение общего подъема, передается значение для каждого объекта.
common_radius - указывает то, используется ли значение общего радиуса для всех объектов.
default_radius - задает значение общего радиуса.
position_radius - если отсутствует значение общего радиуса, передается значение для каждого объекта.
common_gain - указывает то, используется ли значение общего усиления для всех объектов.
default_gain - задает значение общего коэффициента усиления.
gain_factor - если отсутствует значение общего усиления, передается значение для каждого объекта.
position_azimuth - если существует только один объект, он представляет собой азимутальный угол.
position_elevation - если существует только один объект, он представляет собой угол подъема.
position_radius - если существует только один объект, он представляет собой радиус.
gain_factor - если существует только один объект, он представляет собой коэффициент усиления.
Определение рабочих данных differential_object_metadata() согласно варианту осуществления:
bits_per_point - число битов, требуемое для того, чтобы представлять число точек многоугольника.
fixed_azimuth - флаг, указывающий то, является ли значение азимута фиксированным для всего объекта.
flag_azimuth - флаг в расчете на объект, указывающий то, изменяется ли значение азимута.
nbits_azimuth - сколько битов требуется для того, чтобы представлять дифференциальное значение.
differential_azimuth - значение разности между линейно интерполированным и фактическим значением.
fixed_elevation - флаг, указывающий то, является ли значение подъема фиксированным для всего объекта.
flag_elevation - флаг в расчете на объект, указывающий то, изменяется ли значение подъема.
nbits_elevation - сколько битов требуется для того, чтобы представлять дифференциальное значение.
differential_elevation - значение разности между линейно интерполированным и фактическим значением.
fixed_radius - флаг, указывающий то, является ли радиус фиксированным для всего объекта.
flag_radius - флаг в расчете на объект, указывающий то, изменяется ли радиус.
nbits_radius - сколько битов требуется для того, чтобы представлять дифференциальное значение.
differential_radius - значение разности между линейно интерполированным и фактическим значением.
fixed_gain - флаг, указывающий то, является ли коэффициент усиления фиксированным для всего объекта.
flag_gain - флаг в расчете на объект, указывающий то, изменяется ли радиус усиления.
nbits_gain - сколько битов требуется для того, чтобы представлять дифференциальное значение.
differential_gain - значение разности между линейно интерполированным и фактическим значением.
Определение рабочих данных offset_data() согласно варианту осуществления:
bitfield_syntax - флаг, указывающий то, присутствует ли вектор с индексами многоугольника в потоке битов.
offset_bitfield - булев массив, содержащий флаг для каждой точки iframe_period независимо от того, представляет она собой точку многоугольника или нет.
npoints - число точек многоугольника минус 1 (num_points=npoints+1).
foffset - индекс временного кванта точек многоугольника в iframe_period (frame_offset=foffset+1).
Согласно варианту осуществления, метаданные, например, могут быть переданы для каждого аудиообъекта, в качестве данных позиций (например, указываемых посредством азимута, подъема и радиуса) в заданных временных метках.
В предшествующем уровне техники, отсутствуют гибкие технологии для комбинирования кодирования каналов, с одной стороны, и кодирования объектов, с другой стороны, таким образом, что на низких скоростях передачи битов получаются приемлемые качества звука.
Это ограничение преодолевается посредством системы трехмерных аудиокодеков. Далее описывается система трехмерных аудиокодеков.
Фиг. 12 иллюстрирует трехмерный аудиокодер в соответствии с вариантом осуществления настоящего изобретения. Трехмерный аудиокодер выполнен с возможностью кодирования входных аудиоданных 101, чтобы получать выходные аудиоданные 501. Трехмерный аудиокодер содержит входной интерфейс для приема множества аудиоканалов, указываемых посредством CH, и множества аудиообъектов, указываемых посредством OBJ. Кроме того, как проиллюстрировано на фиг. 12, входной интерфейс 1100 дополнительно принимает метаданные, связанные с одним или более из множества аудиообъектов OBJ. Кроме того, трехмерный аудиокодер содержит микшер 200 для микширования множества объектов и множества каналов таким образом, чтобы получать множество предварительно микшированных каналов, при этом каждый предварительно микшированный канал содержит аудиоданные канала и аудиоданные, по меньшей мере, одного объекта.
Кроме того, трехмерный аудиокодер содержит базовый кодер 300 для базового кодирования входных данных базового кодера, модуль 400 сжатия метаданных для сжатия метаданных, связанных с одним или более из множества аудиообъектов.
Кроме того, трехмерный аудиокодер может содержать контроллер 600 режима для управления микшером, базовым кодером и/или выходным интерфейсом 500 в одном из нескольких рабочих режимов, при этом в первом режиме, базовый кодер выполнен с возможностью кодировать множество аудиоканалов и множество аудиообъектов, принимаемых посредством входного интерфейса 1100, без взаимодействия посредством микшера, т.е. без микширования посредством микшера 200. Тем не менее, во втором режиме, в котором микшер 200 является активным, базовый кодер кодирует множество микшированных каналов, т.е. вывод, сформированный посредством блока 200. В этом втором случае, предпочтительно более не кодировать данные объектов. Вместо этого, метаданные, указывающие позиции аудиообъектов, уже использованы посредством микшера 200 для того, чтобы подготавливать посредством рендеринга объекты для каналов, как указано посредством метаданных. Другими словами, микшер 200 использует метаданные, связанные с множеством аудиообъектов, для того чтобы предварительно подготавливать посредством рендеринга аудиообъекты, и затем предварительно подготовленные посредством рендеринга аудиообъекты микшируются с каналами для того, чтобы получать микшированные каналы в выводе микшера. В этом варианте осуществления, любые объекты не обязательно могут передаваться, и это также применимо для сжатых метаданных в качестве вывода посредством блока 400. Тем не менее, если микшируются не все объекты, вводимые в интерфейс 1100, а микшируется только определенное количество объектов, то несмотря на это, только оставшиеся немикшированные объекты и ассоциированные метаданные передаются в базовый кодер 300 или модуль 400 сжатия метаданных, соответственно.
На фиг. 12, модуль 400 сжатия метаданных представляет собой кодер 210 метаданных устройства 250 для формирования кодированной аудиоинформации согласно одному из вышеописанных вариантов осуществления. Кроме того, на фиг. 12, микшер 200 и базовый кодер 300 вместе формируют аудиокодер 220 устройства 250 для формирования кодированной аудиоинформации согласно одному из вышеописанных вариантов осуществления.
Фиг. 14 иллюстрирует дополнительный вариант осуществления трехмерного аудиокодера, который, дополнительно, содержит SAOC-кодер 800. SAOC-кодер 800 выполнен с возможностью формирования одного или более транспортных каналов и параметрических данных из входных данных кодера пространственных аудиообъектов. Как проиллюстрировано на фиг. 14, входные данные кодера пространственных аудиообъектов представляют собой объекты, которые не обработаны посредством модуля предварительного рендеринга/микшера. Альтернативно, при условии, что модуль предварительного рендеринга/микшер обходится, аналогично режиму один, в котором отдельное кодирование каналов/объектов является активным, все объекты, вводимые во входной интерфейс 1100, кодируются посредством SAOC-кодера 800.
Кроме того, как проиллюстрировано на фиг. 14, базовый кодер 300 предпочтительно реализован в качестве USAC-кодера, т.е. в качестве кодера, заданного и стандартизированного в MPEG USAC-стандарте (USAC - стандартизированное кодирование речи и аудио). Вывод всего трехмерного аудиокодера, проиллюстрированный на фиг. 14, представляет собой MPEG4-поток данных, имеющий структуры в форме контейнера для отдельных типов данных. Кроме того, метаданные указываются в качестве OAM-данных, и модуль 400 сжатия метаданных на фиг. 12 соответствует OAM-кодеру 400 для того, чтобы получать сжатые OAM-данные, которые вводятся в USAC-кодер 300 который, как можно видеть на фиг. 14, дополнительно содержит выходной интерфейс, чтобы получать выходной MP4-поток данных, имеющий не только кодированные данные каналов/объектов, но также и имеющий сжатые OAM-данные.
На фиг. 14, OAM-кодер 400 представляет собой кодер 210 метаданных устройства 250 для формирования кодированной аудиоинформации согласно одному из вышеописанных вариантов осуществления. Кроме того, на фиг. 14, SAOC-кодер 800 и USAC-кодер 300 вместе формируют аудиокодер 220 устройства 250 для формирования кодированной аудиоинформации согласно одному из вышеописанных вариантов осуществления.
Фиг. 16 иллюстрирует дополнительный вариант осуществления трехмерного аудиокодера, в котором в отличие от фиг. 14, SAOC-кодер может быть выполнен с возможностью либо кодировать, с помощью алгоритма SAOC-кодирования, каналы, предоставленные в модуле 200 предварительного рендеринга/микшере, не активные в этом режиме, либо, альтернативно, SAOC-кодировать предварительно подготовленные посредством рендеринга каналы плюс объекты. Таким образом, на фиг. 16, SAOC-кодер 800 может управлять тремя различными видами входных данных, т.е. каналами без предварительно подготовленных посредством рендеринга объектов, каналами и предварительно подготовленными посредством рендеринга объектами либо только объектами. Кроме того, предпочтительно предоставлять дополнительный OAM-декодер 420 на фиг. 16, так что SAOC-кодер 800 использует, для своей обработки, данные, идентичные данным на стороне декодера, т.е. данные, полученные посредством сжатия с потерями, а не исходные OAM-данные.
Трехмерный аудиокодер по фиг. 16 может работать в нескольких отдельных режимах.
В дополнение к первому и второму режимам, как пояснено в контексте фиг. 12, трехмерный аудиокодер по фиг. 16 дополнительно может работать в третьем режиме, в котором базовый кодер формирует один или более транспортных каналов из отдельных объектов, когда модуль 200 предварительного рендеринга/микшер не является активным. Альтернативно или дополнительно, в этом третьем режиме, SAOC-кодер 800 может формировать один или более альтернативных или дополнительных транспортных каналов из исходных каналов, т.е. так же тогда, когда модуль 200 предварительного рендеринга/микшер, соответствующий микшеру 200 по фиг. 12, не является активным.
В завершение, SAOC-кодер 800 может кодировать, когда трехмерный аудиокодер сконфигурирован в четвертом режиме, каналы плюс предварительно подготовленные посредством рендеринга объекты, сформированные посредством модуля предварительного рендеринга/микшера. Таким образом, в четвертом режиме, варианты применения с наименьшей скоростью передачи битов должны предоставлять хорошее качество вследствие того факта, что каналы и объекты полностью преобразованы в отдельные транспортные SAOC-каналы и ассоциированную вспомогательную информацию, как указано на фиг. 3 и 5 в качестве "SAOC-SI", и дополнительно, сжатые метаданные не должны обязательно передаваться в этом четвертом режиме.
На фиг. 16, OAM-кодер 400 представляет собой кодер 210 метаданных устройства 250 для формирования кодированной аудиоинформации согласно одному из вышеописанных вариантов осуществления. Кроме того, на фиг. 16, SAOC-кодер 800 и USAC-кодер 300 вместе формируют аудиокодер 220 устройства 250 для формирования кодированной аудиоинформации согласно одному из вышеописанных вариантов осуществления.
Согласно варианту осуществления, предусмотрено устройство для кодирования входных аудиоданных 101, чтобы получать выходные аудиоданные 501. Устройство для кодирования входных аудиоданных 101 содержит:
- входной интерфейс 1100 для приема множества аудиоканалов, множества аудиообъектов и метаданных, связанных с одним или более из множества аудиообъектов;
- микшер 200 для микширования множества объектов и множества каналов таким образом, чтобы получать множество предварительно микшированных каналов, причем каждый предварительно микшированный канал содержит аудиоданные канала и аудиоданные, по меньшей мере, одного объекта; и
- устройство 250 для формирования кодированной аудиоинформации, который содержит кодер метаданных и аудиокодер, как описано выше.
Аудиокодер 220 устройства 250 для формирования кодированной аудиоинформации представляет собой базовый кодер (300) для базового кодирования входных данных базового кодера.
Кодер 210 метаданных устройства 250 для формирования кодированной аудиоинформации представляет собой модуль 400 сжатия метаданных для сжатия метаданных, связанных с одним или более из множества аудиообъектов.
Фиг. 13 иллюстрирует трехмерный аудиодекодер в соответствии с вариантом осуществления настоящего изобретения. Трехмерный аудиодекодер принимает, в качестве ввода, кодированные аудиоданные, т.е. данные 501 по фиг. 12.
Трехмерный аудиодекодер содержит модуль 1400 распаковки метаданных, базовый декодер 1300, процессор 1200 объектов, контроллер 1600 режима и постпроцессор 1700.
В частности, трехмерный аудиодекодер выполнен с возможностью декодирования кодированных аудиоданных, и входной интерфейс выполнен с возможностью приема кодированных аудиоданных, причем кодированные аудиоданные содержат множество кодированных каналов и множество кодированных объектов, а также сжатые метаданные, связанные с множеством объектов в определенном режиме.
Кроме того, базовый декодер 1300 выполнен с возможностью декодирования множества кодированных каналов и множества кодированных объектов, и дополнительно, модуль распаковки метаданных выполнен с возможностью распаковки сжатых метаданных.
Кроме того, процессор 1200 объектов выполнен с возможностью обработки множества декодированных объектов, сформированных посредством базового декодера 1300 с использованием распакованных метаданных, чтобы получать предварительно определенное число выходных каналов, содержащих данные объектов и декодированные каналы. Эти выходные каналы, как указано на 1205, затем вводятся в постпроцессор 1700. Постпроцессор 1700 выполнен с возможностью преобразования определенного числа выходных каналов 1205 в определенный выходной формат, который может представлять собой бинауральный выходной формат или выходной формат громкоговорителей, такой как выходной 5.1-, 7.1- и т.д. формат.
Предпочтительно, трехмерный аудиодекодер содержит контроллер 1600 режима, который выполнен с возможностью анализа кодированных данных, чтобы обнаруживать индикатор режима. Следовательно, контроллер 1600 режима соединяется с входным интерфейсом 1100 на фиг. 13. Тем не менее, альтернативно, контроллер режима необязательно должен предоставляться здесь. Вместо этого, гибкий аудиодекодер может быть предварительно установлен посредством любого другого вида управляющих данных, таких как пользовательский ввод или любое другое управление. Трехмерный аудиодекодер на фиг. 13, предпочтительно управляемый посредством контроллера 1600 режима, выполнен с возможностью обходить процессор объектов и подавать множество декодированных каналов в постпроцессор 1700. Это представляет собой работу в режиме 2, т.е., в котором принимаются только предварительно подготовленные посредством рендеринга каналы, т.е. когда режим 2 применяется в трехмерном аудиокодере по фиг. 12. Альтернативно, когда режим 1 применяется в трехмерном аудиокодере, т.е. когда трехмерный аудиокодер выполняет отдельное кодирование каналов/объектов, в таком случае процессор 1200 объектов не обходится, но множество декодированных каналов и множество декодированных объектов подаются в процессор 1200 объектов вместе с распакованными метаданными, сформированными посредством модуля 1400 распаковки метаданных.
Предпочтительно, индикатор того, должен применяться режим 1 или режим 2, включен в кодированные аудиоданные, и затем контроллер 1600 режима анализирует кодированные данные, чтобы обнаруживать индикатор режима. Режим 1 используется, когда индикатор режима указывает то, что кодированные аудиоданные содержат кодированные каналы и кодированные объекты, и режим 2 применяется, когда индикатор режима указывает то, что кодированные аудиоданные не содержат аудиообъекты, т.е. содержат только предварительно подготовленные посредством рендеринга каналы, полученные посредством режима 2 трехмерного аудиокодера по фиг. 12.
На фиг. 13, модуль 1400 распаковки метаданных представляет собой декодер 110 метаданных устройства 100 для формирования одного или более аудиоканалов согласно одному из вышеописанных вариантов осуществления. Кроме того, на фиг. 13, базовый декодер 1300, процессор 1200 объектов и постпроцессор 1700 вместе формируют аудиодекодер 120 устройства 100 для формирования одного или более аудиоканалов согласно одному из вышеописанных вариантов осуществления.
Фиг. 15 иллюстрирует предпочтительный вариант осуществления по сравнению с трехмерным аудиодекодером по фиг. 13, и вариант осуществления по фиг. 15 соответствует трехмерному аудиокодеру по фиг. 14. В дополнение к реализации трехмерного аудиодекодера по фиг. 13, трехмерный аудиодекодер на фиг. 15 содержит SAOC-декодер 1800. Кроме того, процессор 1200 объектов по фиг. 13 реализуется как отдельный модуль 1210 рендеринга объектов и микшер 1220, в то время как, в зависимости от режима, функциональность модуля 1210 рендеринга объектов также может реализовываться посредством SAOC-декодера 1800.
Кроме того, постпроцессор 1700 может реализовываться как модуль 1710 бинаурального рендеринга или преобразователь 1720 форматов. Альтернативно, прямой вывод данных 1205 по фиг. 13 также может реализовываться так, как проиллюстрировано посредством 1730. Следовательно, предпочтительно выполнять обработку в декодере для наибольшего числа каналов, к примеру, 22.2 или 32, с тем чтобы получать гибкость, а затем постобрабатывать, если требуется меньший формат. Тем не менее, когда становится очевидным с самого начала, что требуется только небольшой формат, такой как 5.1-формат, то предпочтительно, как указано посредством фиг. 13 или 6 посредством срезки 1727, когда определенное управление SAOC-декодером и/или USAC-декодером может применяться во избежание необязательных операций повышающего микширования и последующих операций понижающего микширования.
В предпочтительном варианте осуществления настоящего изобретения, процессор 1200 объектов содержит SAOC-декодер 1800, и SAOC-декодер выполнен с возможностью декодирования одного или более транспортных каналов, выводимых посредством базового декодера, и ассоциированных параметрических данных и с использованием распакованных метаданных, чтобы получать множество подготовленных посредством рендеринга аудиообъектов. С этой целью, OAM-вывод соединяется с блоком 1800.
Кроме того, процессор 1200 объектов выполнен с возможностью подготавливать посредством рендеринга декодированные объекты, выводимые посредством базового декодера, которые не кодируются в транспортных SAOC-каналах, а которые по отдельности кодируются типично в одноканальных элементах, как указано посредством модуля 1210 рендеринга объектов. Кроме того, декодер содержит выходной интерфейс, соответствующий выходу 1730, для вывода содержимого вывода микшера в громкоговорители.
В дополнительном варианте осуществления, процессор 1200 объектов содержит декодер 1800 по стандарту пространственного кодирования аудиообъектов для декодирования одного или более транспортных каналов и ассоциированной параметрической вспомогательной информации, представляющей кодированные аудиосигналы или кодированные аудиоканалы, при этом декодер по стандарту пространственного кодирования аудиообъектов выполнен с возможностью транскодировать ассоциированную параметрическую информацию и распакованные метаданные в транскодированную параметрическую вспомогательную информацию, применимую для непосредственного рендеринга выходного формата, например, как задано в более ранней версии SAOC. Постпроцессор 1700 выполнен с возможностью вычисления аудиоканалов выходного формата с использованием декодированных транспортных каналов и транскодированной параметрической вспомогательной информации. Обработка, выполняемая посредством постпроцессора, может быть аналогичной обработке на основе стандарта объемного звучания MPEG или может представлять собой любую другую обработку, к примеру, BCC-обработку и т.п.
В дополнительном варианте осуществления, процессор 1200 объектов содержит декодер 1800 по стандарту пространственного кодирования аудиообъектов, выполненный с возможностью непосредственно микшировать с повышением и подготавливать посредством рендеринга сигналы каналов для выходного формата с использованием декодированных (посредством базового декодера) транспортных каналов и параметрической вспомогательной информации.
Кроме того, важно то, что процессор 1200 объектов по фиг. 13 дополнительно содержит микшер 1220, который принимает, в качестве ввода, непосредственно данные, выводимые посредством USAC-декодера 1300, когда существуют предварительно подготовленные посредством рендеринга объекты, микшированные с каналами, т.е. когда микшер 200 по фиг. 12 является активным. Дополнительно, микшер 1220 принимает данные из модуля рендеринга объектов, выполняющего рендеринг объектов без SAOC-декодирования. Кроме того, микшер принимает выходные данные SAOC-декодера, т.е. подготовленные посредством SAOC-рендеринга объекты.
Микшер 1220 соединяется с выходным интерфейсом 1730, модулем 1710 бинаурального рендеринга и преобразователем 1720 форматов. Модуль 1710 бинаурального рендеринга выполнен с возможностью рендеринга выходных каналов в два бинауральных канала с использованием передаточных функций восприятия звука человеком или бинауральных импульсных характеристик в помещении (BRIR). Преобразователь 1720 форматов выполнен с возможностью преобразования выходных каналов в выходной формат, имеющий меньшее число каналов относительно выходных каналов 1205 микшера, и преобразователь 1720 форматов запрашивает информацию по схеме размещения для воспроизведения, такую как 5.1-динамики и т.п.
На фиг. 15, OAM-декодер 1400 представляет собой декодер 110 метаданных устройства 100 для формирования одного или более аудиоканалов согласно одному из вышеописанных вариантов осуществления. Кроме того, на фиг. 15, модуль 1210 рендеринга объектов, USAC-декодер 1300 и микшер 1220 вместе формируют аудиодекодер 120 устройства 100 для формирования одного или более аудиоканалов согласно одному из вышеописанных вариантов осуществления.
Трехмерный аудиодекодер по фиг. 17 отличается от трехмерного аудиодекодера фиг. 15 тем, что SAOC-декодер может не только формировать подготовленные посредством рендеринга объекты, но также и подготовленные посредством рендеринга каналы, и это имеет место, когда использован трехмерный аудиокодер по фиг. 16, и соединение 900 между каналами/предварительно подготовленными посредством рендеринга объектами и входным интерфейсом SAOC-кодера 800 является активным.
Кроме того, сконфигурирован каскад 1810 векторного амплитудного панорамирования (VBAP), который принимает, из SAOC-декодера, информацию относительно схемы размещения для воспроизведения и который выводит матрицу рендеринга в SAOC-декодер таким образом, что SAOC-декодер может, в конечном счете, предоставлять подготовленные посредством рендеринга каналы без дальнейшей работы микшера в формате с большим числом каналов 1205, т.е. с 32 громкоговорителями.
VBAP-блок предпочтительно принимает декодированные OAM-данные, чтобы извлекать матрицы рендеринга. Обобщая, он предпочтительно запрашивает геометрическую информацию не только схемы размещения для воспроизведения, но также и позиций, в которых входные сигналы должны подготавливаться посредством рендеринга в схеме размещения для воспроизведения. Это геометрические входные данные могут быть OAM-данными для объектов или информацией позиций каналов для каналов, которые переданы с использованием SAOC.
Тем не менее, если требуется только конкретный выходной интерфейс, то VBAP-состояние 1810 уже может предоставлять требуемую матрицу рендеринга, например, для 5.1-вывода. SAOC-декодер 1800 затем выполняет прямой рендеринг из транспортных SAOC-каналов, ассоциированных параметрических данных и распакованных метаданных, прямой рендеринг в требуемый выходной формат без взаимодействия микшера 1220. Тем не менее, когда применяется определенное микширование между режимами, т.е. если SAOC-кодируются несколько каналов, а не все каналы SAOC-кодируются, либо если SAOC-кодируются несколько объектов, а не все объекты SAOC-кодируются, либо когда SAOC-декодируется только определенное количество предварительно подготовленных посредством рендеринга объектов с каналами, и оставшиеся каналы не SAOC-обрабатываются, то микшер объединяет данные из отдельных входных частей, т.е. непосредственно из базового декодера 1300, из модуля 1210 рендеринга объектов и из SAOC-декодера 1800.
На фиг. 17, OAM-декодер 1400 представляет собой декодер 110 метаданных устройства 100 для формирования одного или более аудиоканалов согласно одному из вышеописанных вариантов осуществления. Кроме того, на фиг. 17, модуль 1210 рендеринга объектов, USAC-декодер 1300 и микшер 1220 вместе формируют аудиодекодер 120 устройства 100 для формирования одного или более аудиоканалов согласно одному из вышеописанных вариантов осуществления.
Предусмотрено устройство для декодирования кодированных аудиоданных. Устройство для декодирования аудиоданных содержит:
- входной интерфейс 1100 для приема кодированных аудиоданных, причем кодированные аудиоданные содержат множество кодированных каналов или множество кодированных объектов либо сжатые метаданные, связанные с множеством объектов;
- устройство 100, содержащее декодер 110 метаданных и формирователь 120 аудиоканалов для формирования одного или более аудиоканалов, как описано выше.
Декодер 110 метаданных устройства 100 для формирования одного или более аудиоканалов представляет собой модуль 400 распаковки метаданных для распаковки сжатых метаданных.
Формирователь 120 аудиоканалов устройства 100 для формирования одного или более аудиоканалов содержит базовый декодер 1300 для декодирования множества кодированных каналов и множества кодированных объектов.
Кроме того, формирователь 120 аудиоканалов дополнительно содержит процессор 1200 объектов для обработки множества декодированных объектов с использованием распакованных метаданных, чтобы получать число выходных каналов 1205, содержащих аудиоданные из объектов и декодированных каналов.
Кроме того, формирователь 120 аудиоканалов дополнительно содержит постпроцессор 1700 для преобразования числа выходных каналов 1205 в выходной формат.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства.
Разложенный сигнал согласно настоящему изобретению может быть сохранен на цифровом запоминающем носителе или может быть передан по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, к примеру, Интернет.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового запоминающего носителя, например, гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронно-читаемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат некратковременный носитель данных, содержащий электронно-читаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, следовательно, вариант осуществления способа согласно настоящему изобретению представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления способов согласно настоящему изобретению представляет собой носитель данных (цифровой запоминающий носитель или компьютерно-читаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Следовательно, дополнительный вариант осуществления способа согласно настоящему изобретению представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого устройства.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
[1] Peters, N., Lossius, T. и Schacher J. C. "SpatDIF: Principles, Specification and Examples", 9th Sound and Music Computing Conference, Копенгаген, Дания, июль 2012 г.
[2] Wright, M., Freed, A. "Open Sound Control: A New Protocol for Communicating with Sound Synthesizers", International Computer Music Conference, Салоники, Греция, 1997 г.
[3] Matthias Geier, Jens Ahrens и Sascha Spors. (2010) "Object-based audio reproduction and the audio scene description format", Org. Sound, издание 15, номер 3, стр. 219-227, декабрь 2010 г.
[4] W3C "Synchronized Multimedia Integration Language (SMIL 3.0)", декабрь 2008 г.
[5] W3C "Extensible Markup Language (XML) 1.0 (Fifth Edition)", ноябрь 2008 г.
[6] MPEG, "ISO/IEC International Standard 14496-3 - Coding of audio-visual objects, Part 3 Audio", 2009 г.
[7] Schmidt, J.; Schroeder, E. F. (2004) "New and Advanced Features for Audio Presentation in the MPEG-4 Standard", 116th AES Convention, Берлин, Германия, май 2004 г.
[8] Web3D "International Standard ISO/IEC 14772-1:1997 - The Virtual Reality Modeling Language (VRML), Part 1: Functional specification and UTF-8 encoding", 1997 г.
[9] Sporer, T. (2012) "Codierung räumlicher Audiosignale mit leicht-gewichtigen Audio-Objekten", Proc. Annual Meeting of the German Audiological Society (DGA), Эрланген, Германия, март 2012 г.
[10] Ramer, U. (1972) "An iterative procedure for the polygonal approximation of plane curves", Computer Graphics and Image Processing, 1(3), 244-256.
[11] Douglas, D.; Peucker, T. (1973), "Algorithms for the reduction of the number of points required to represent the digitized line or its caricature", The Canadian Cartographer 10(2), 112-122.
[12] Ville Pulkki, "Virtual Sound Source Positioning Using Vector Base Amplitude Panning"; J. Audio Eng. Soc., издание 45, выпуск 6, стр. 456-466, июнь 1997 г.

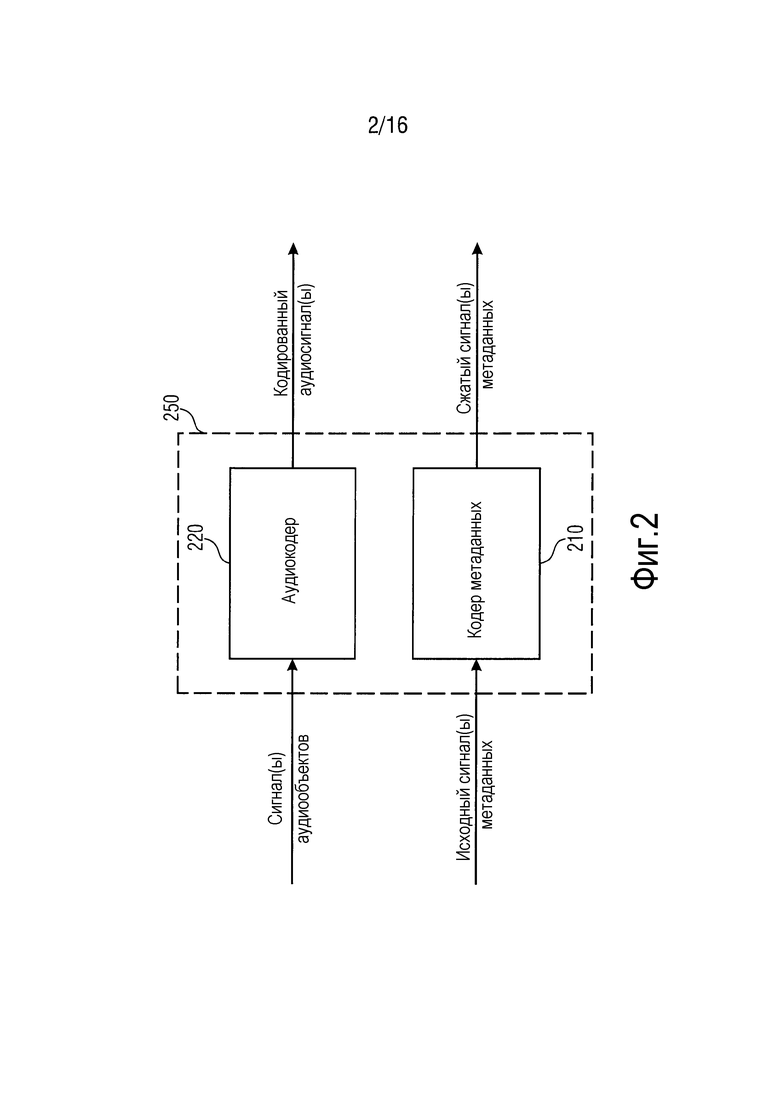
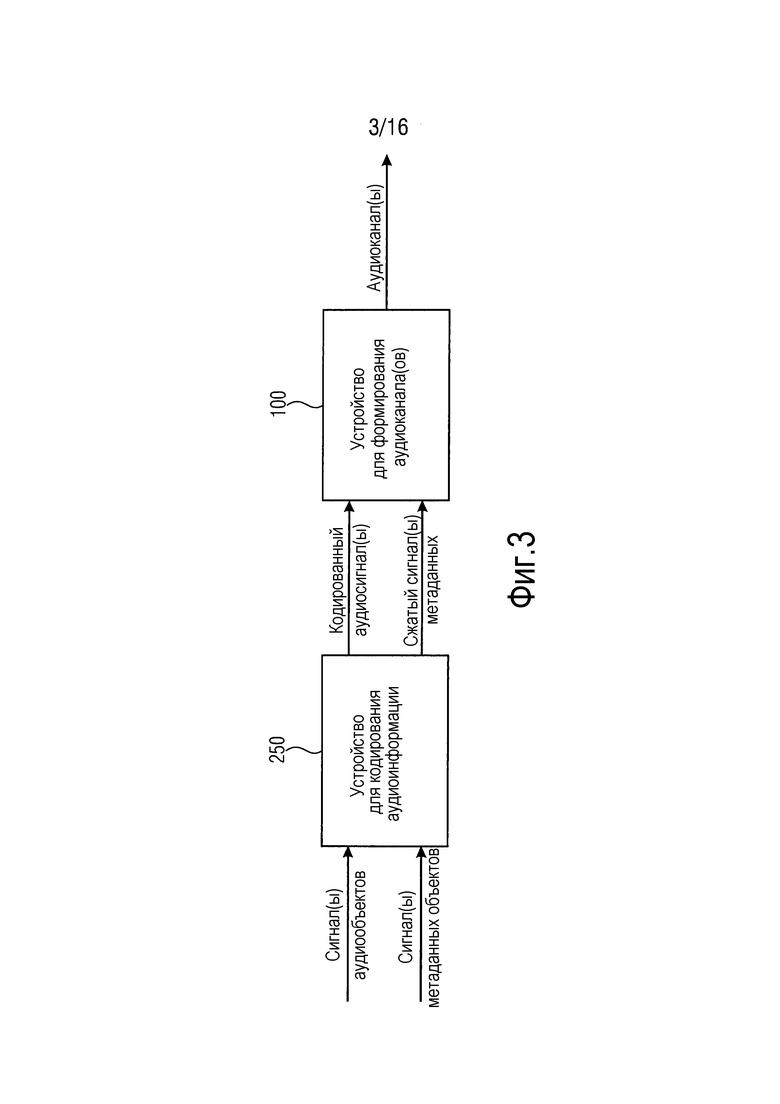
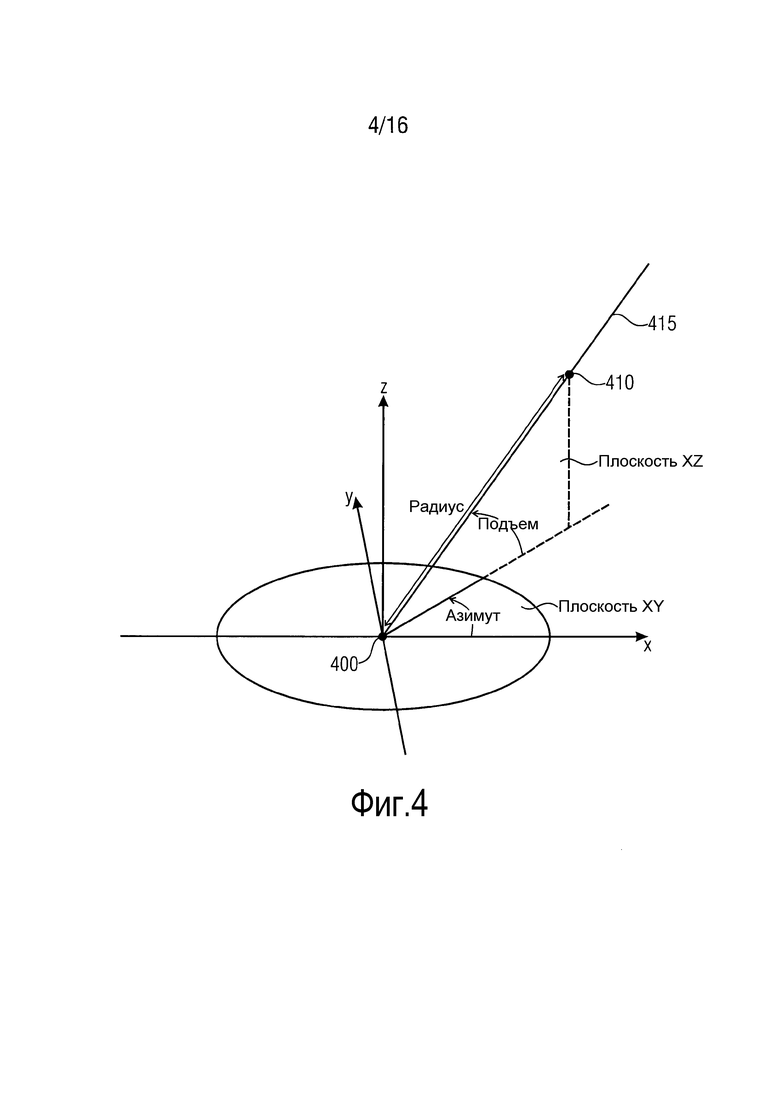
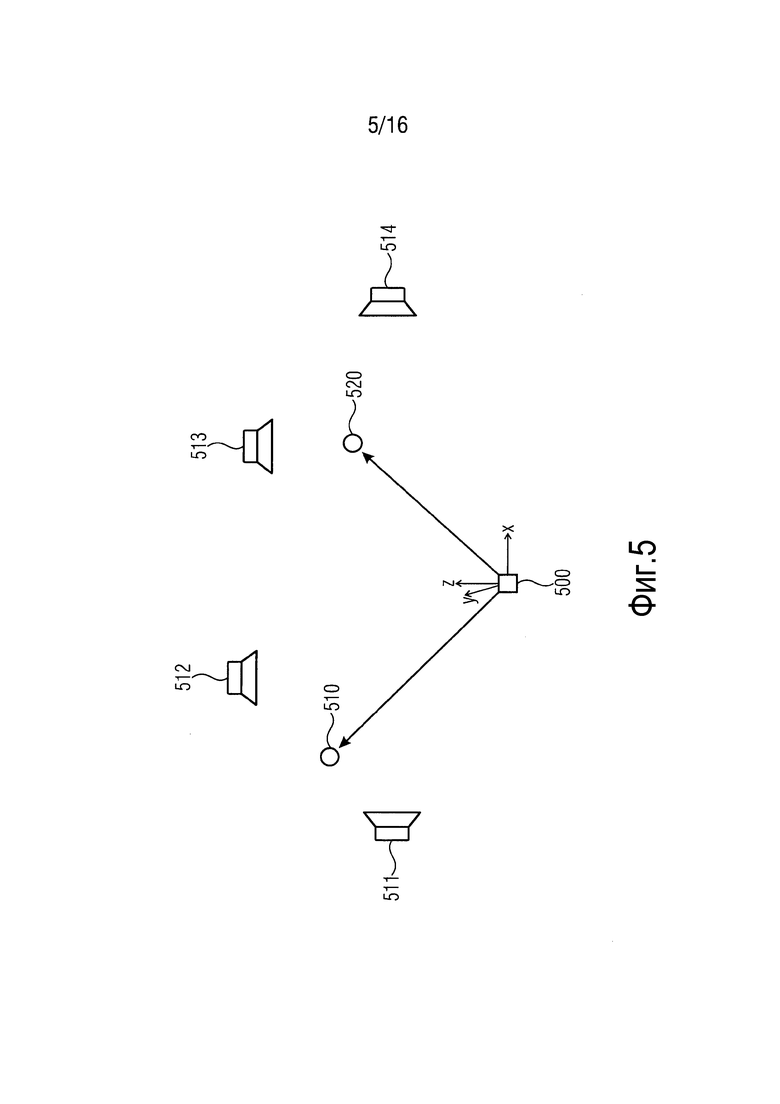

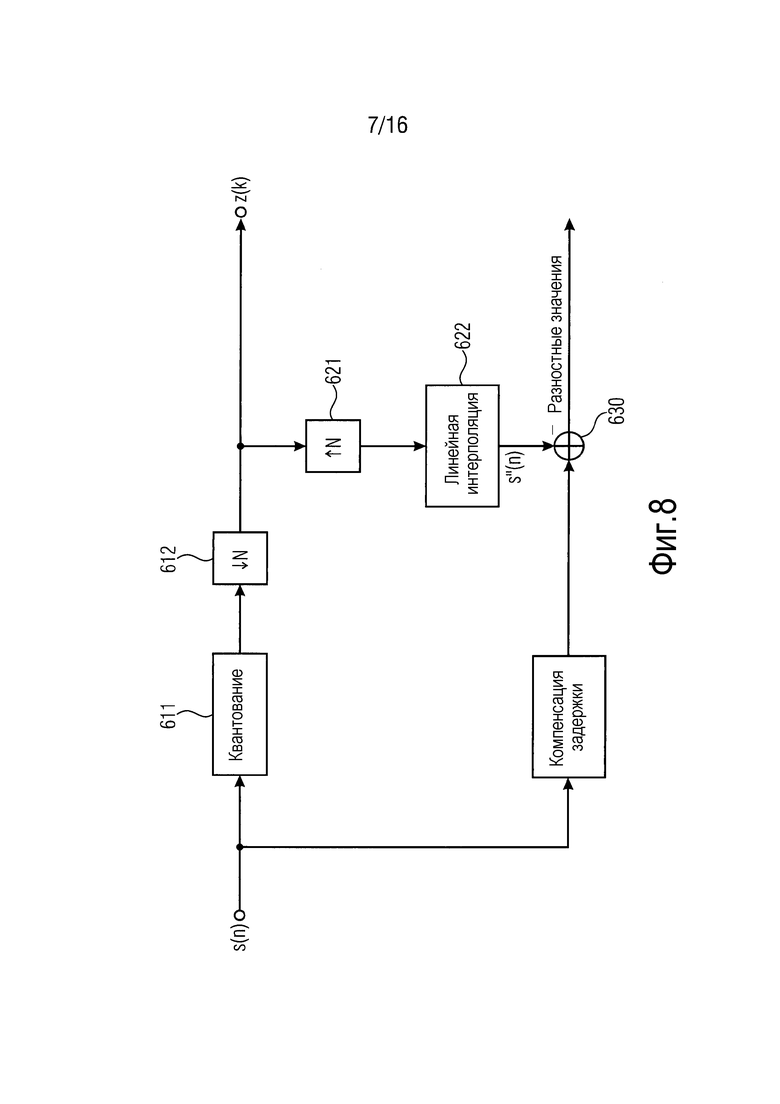
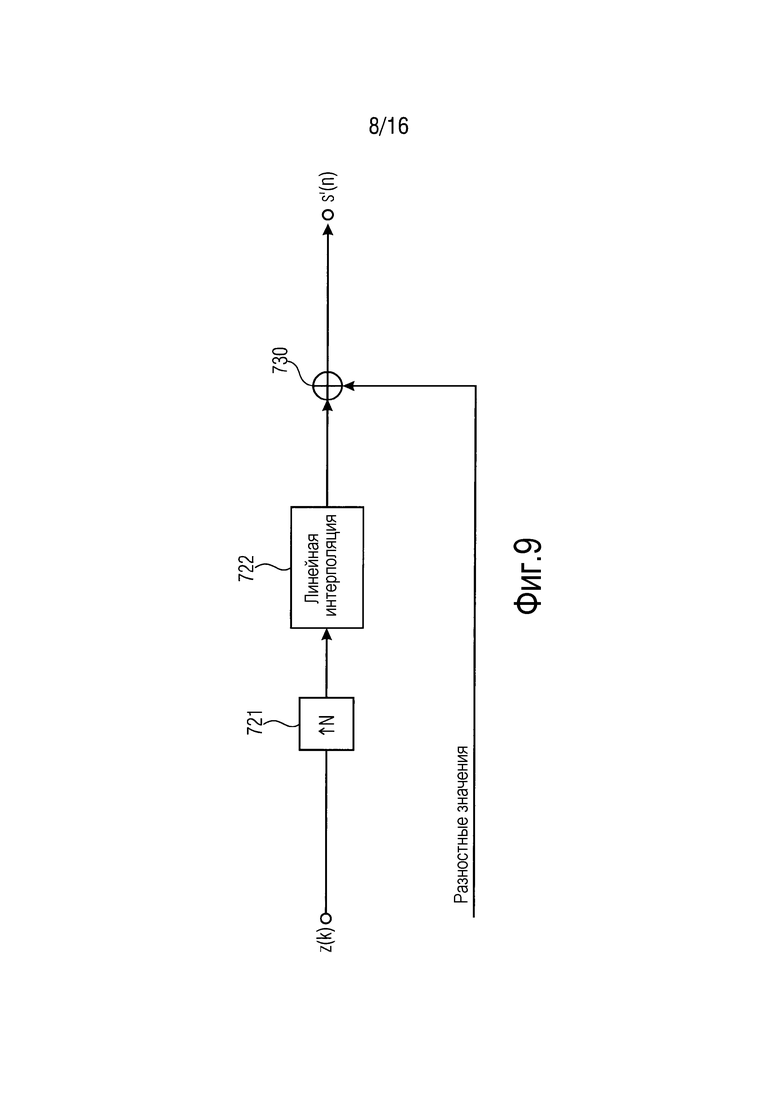
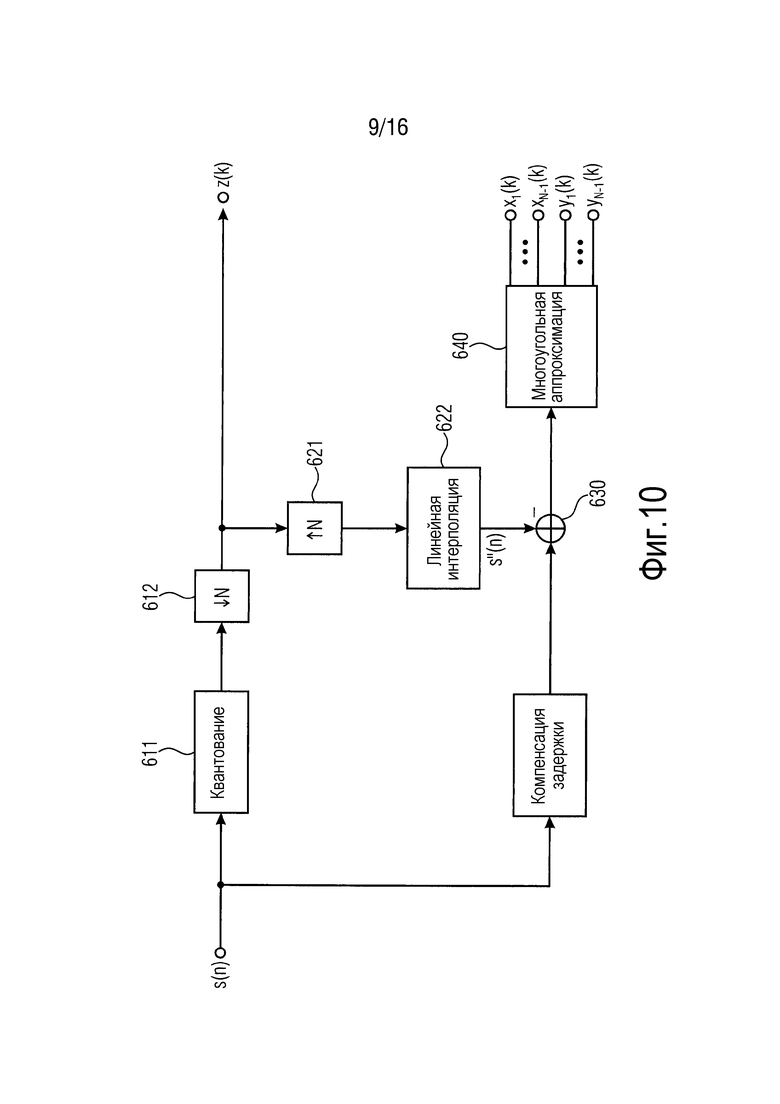
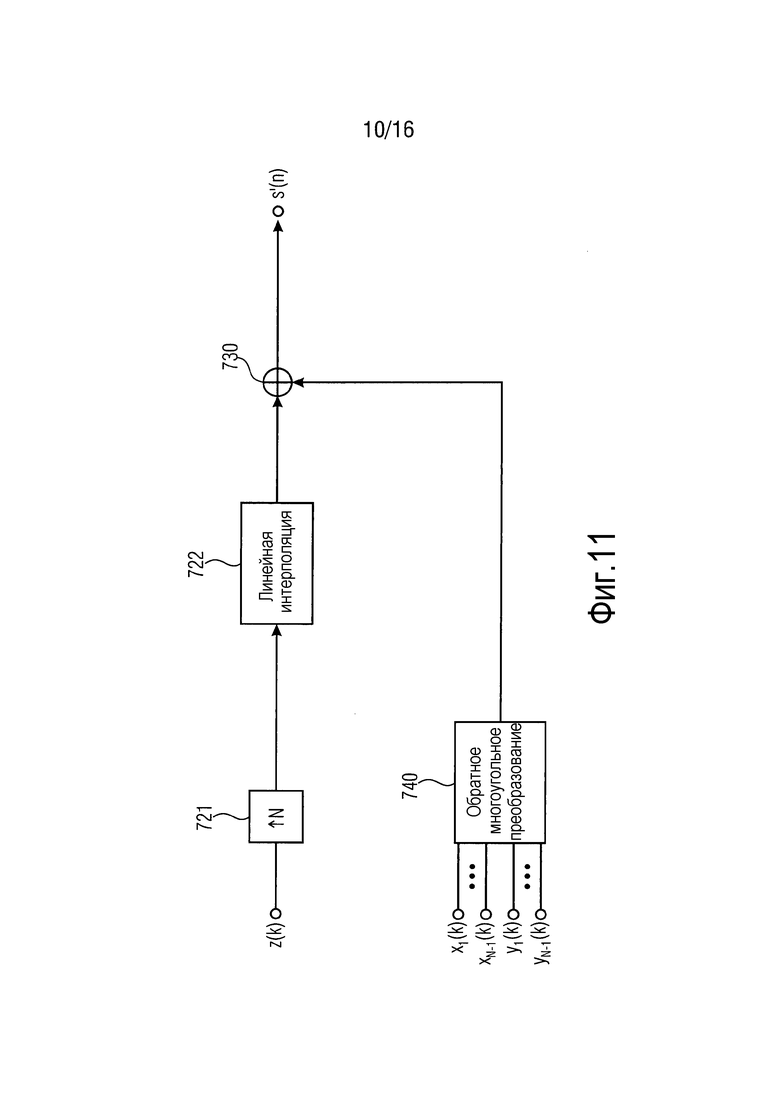
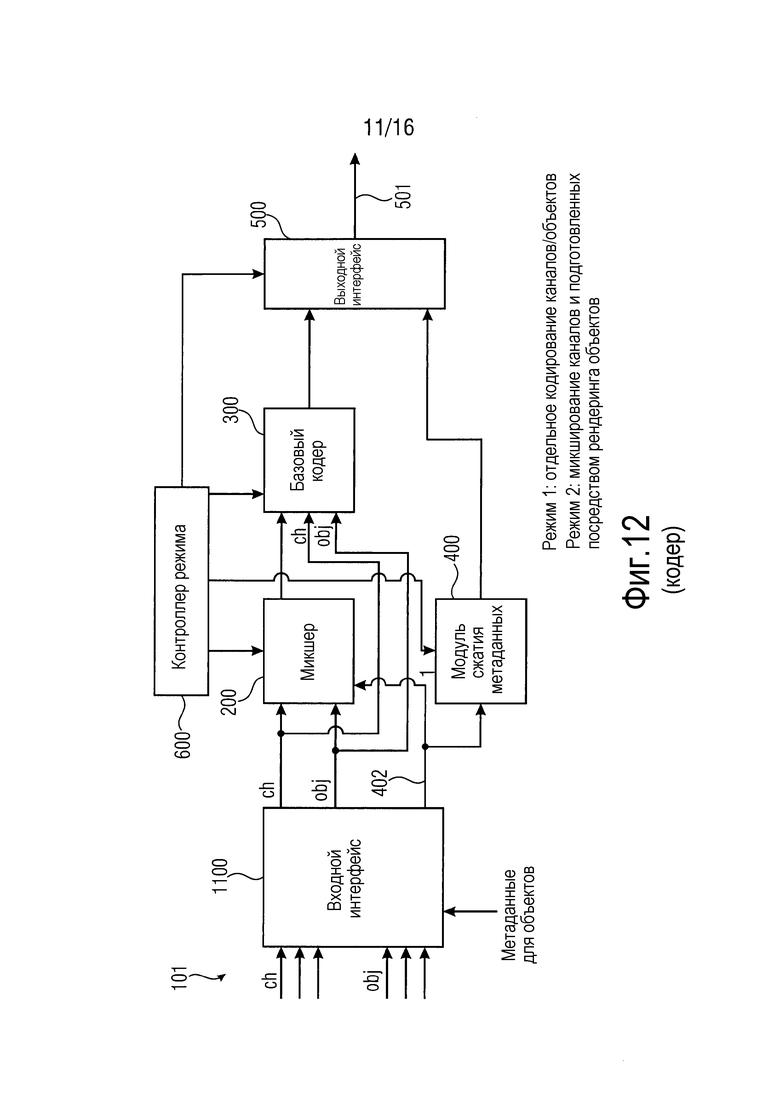
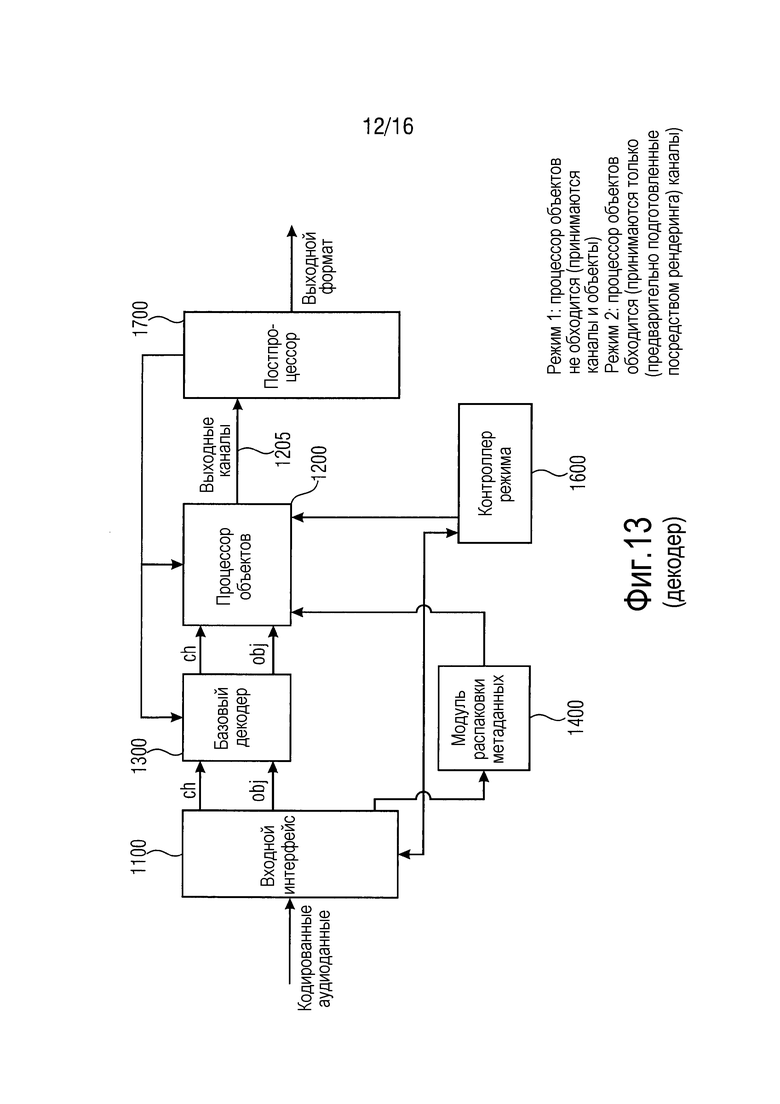
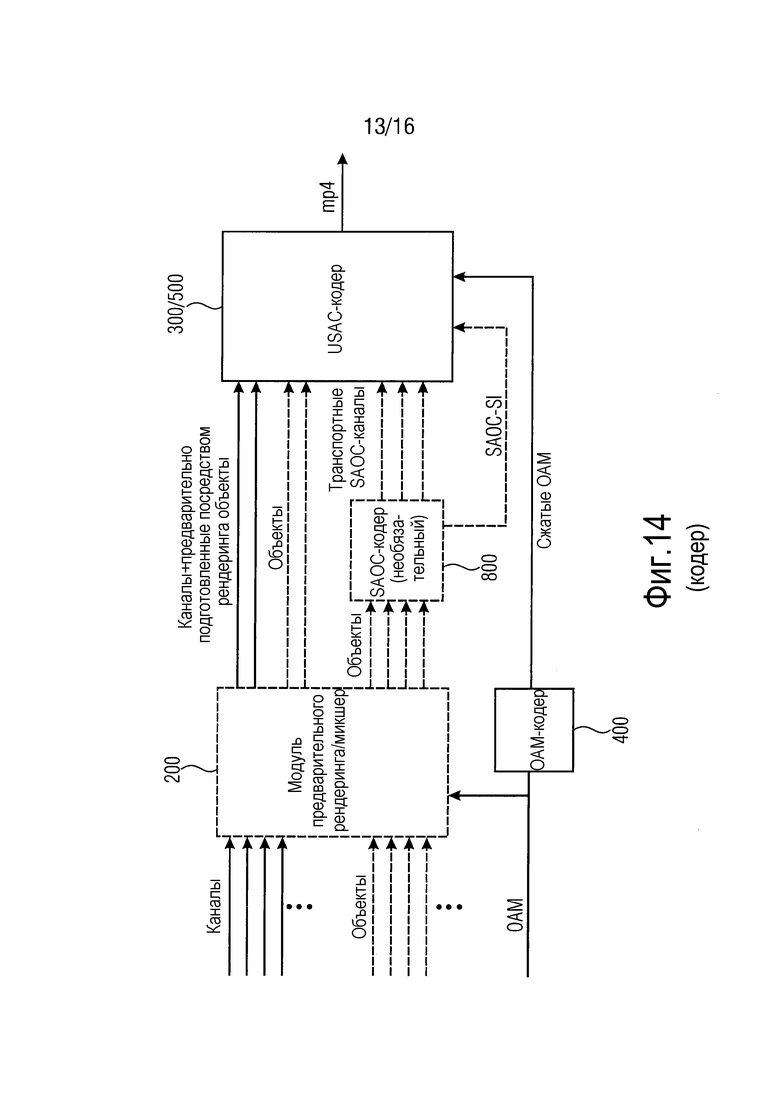
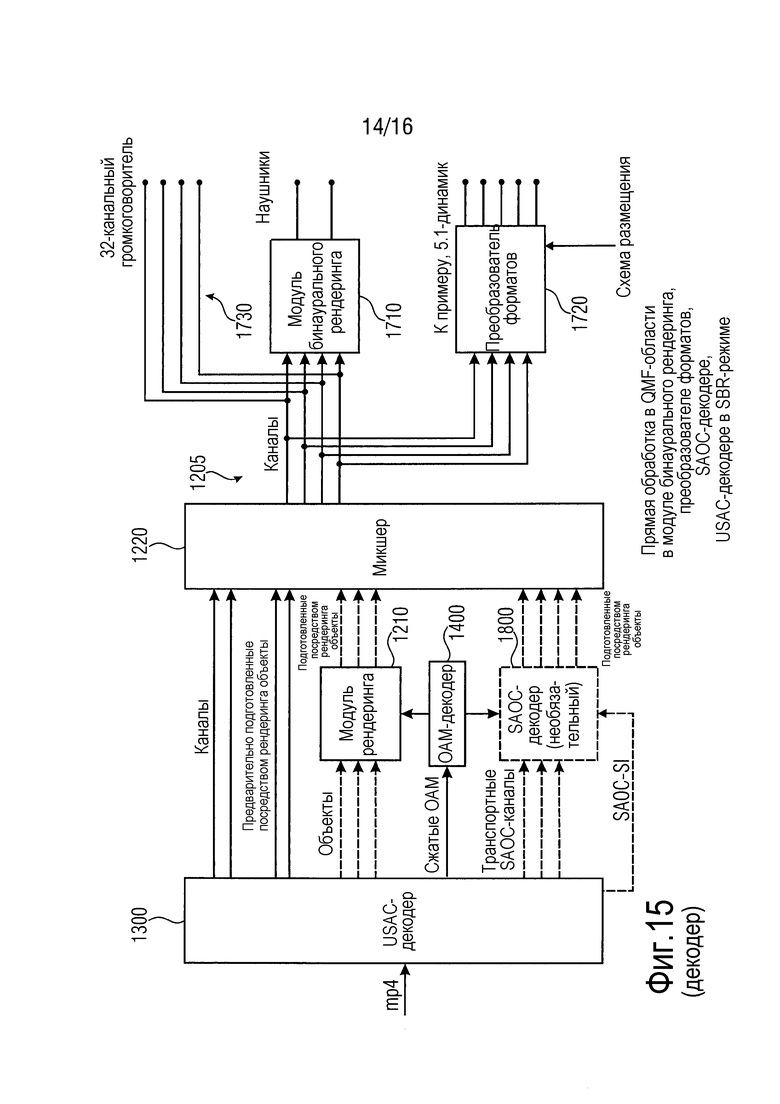
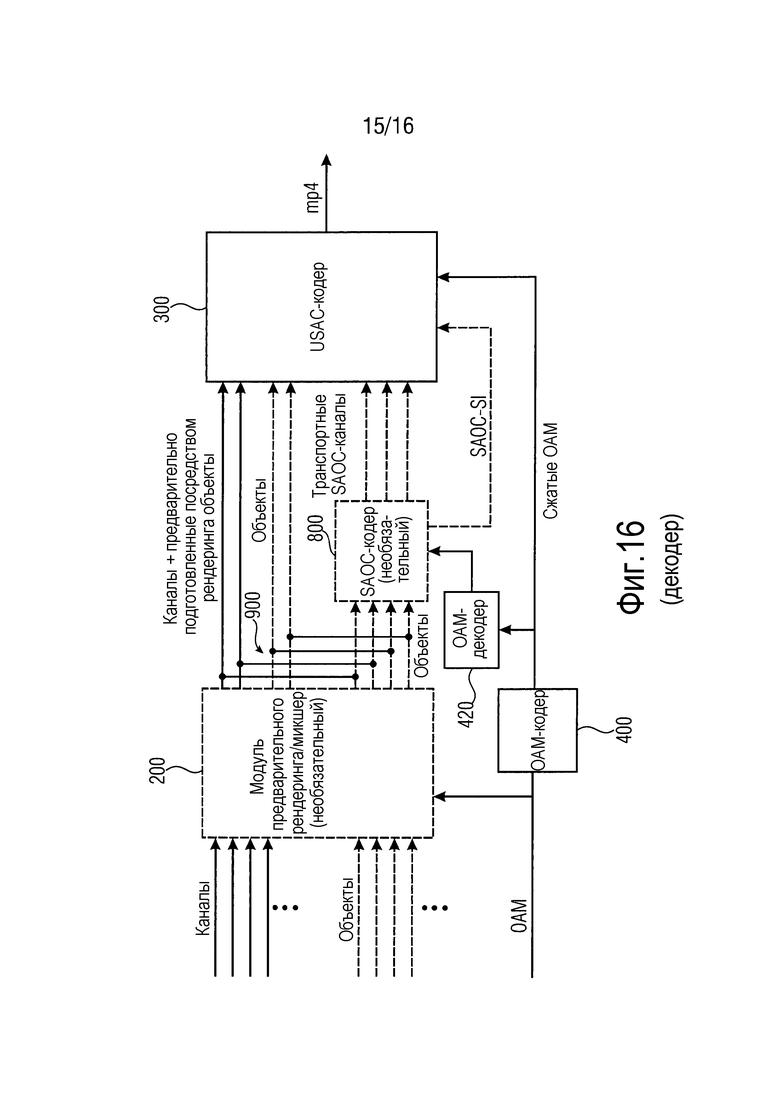
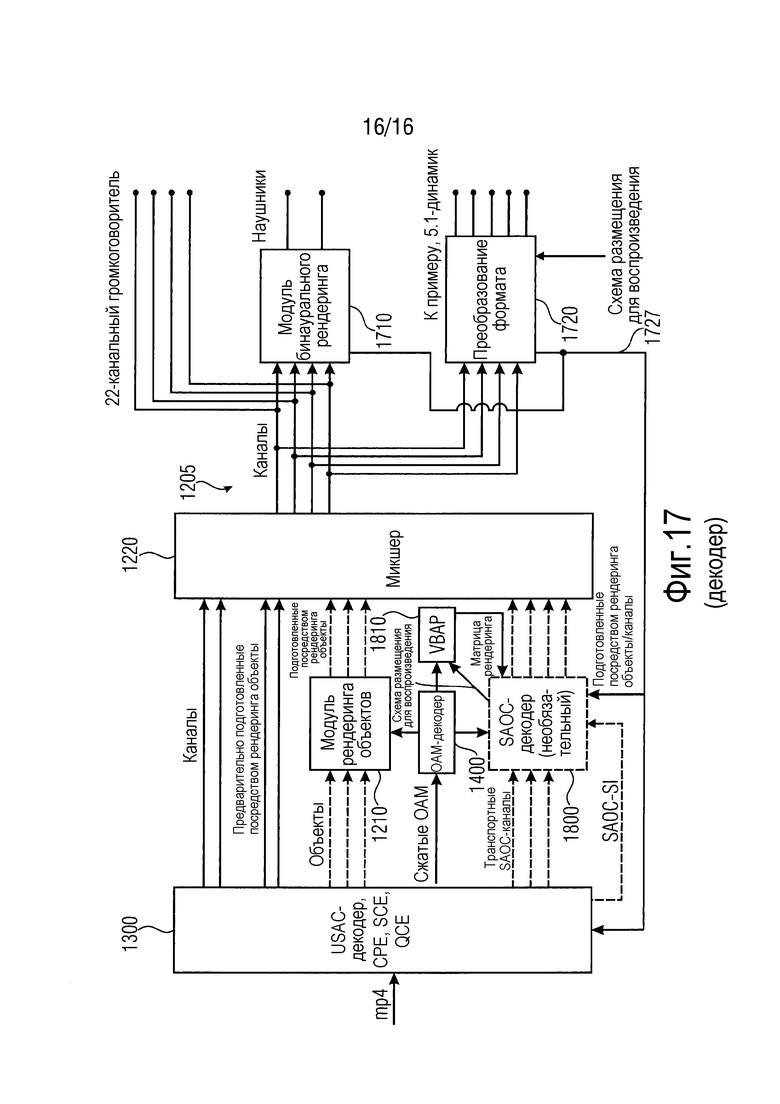
Изобретение относится к средствам для формирования одного или более аудиоканалов. Технический результат заключается в повышении эффективности кодирования метаданных. Принимают один или более сжатых сигналов метаданных. Каждый из сжатых сигналов метаданных содержит множество первых выборок метаданных. Первые выборки метаданных каждого из сжатых сигналов метаданных указывают информацию, ассоциированную с сигналом аудиообъекта для одного или более сигналов аудиообъектов. Формируют один или более восстановленных сигналов метаданных таким образом, что каждый восстановленный сигнал метаданных содержит первые выборки метаданных сжатого сигнала метаданных, причем упомянутый восстановленный сигнал метаданных ассоциирован с упомянутым сжатым сигналом метаданных и дополнительно содержит множество вторых выборок метаданных. Формирование восстановленных сигналов метаданных содержит этап, на котором формируют вторые выборки метаданных каждого из восстановленных сигналов метаданных посредством формирования множества аппроксимированных выборок метаданных для упомянутого восстановленного сигнала метаданных. 9 н. и 9 з.п. ф-лы, 17 ил.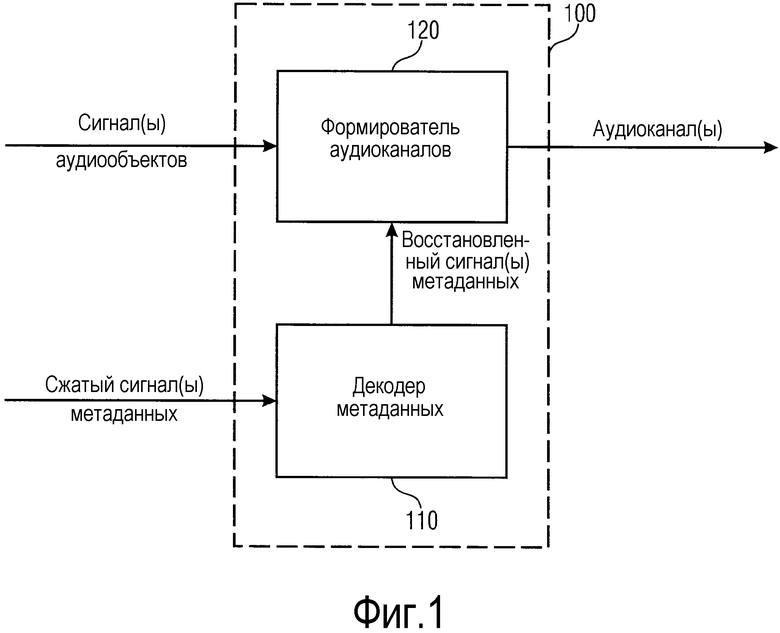
1. Устройство (100) для формирования одного или более аудиоканалов, при этом устройство содержит:
декодер (110) метаданных для приема одного или более сжатых сигналов метаданных, при этом каждый из одного или более сжатых сигналов метаданных содержит множество первых выборок метаданных, при этом первые выборки метаданных каждого из одного или более сжатых сигналов метаданных указывают информацию, ассоциированную с сигналом аудиообъекта для одного или более сигналов аудиообъектов, при этом декодер (110) метаданных выполнен с возможностью формировать один или более восстановленных сигналов метаданных таким образом, что каждый восстановленный сигнал метаданных из одного или более восстановленных сигналов метаданных содержит первые выборки метаданных сжатого сигнала метаданных из одного или более сжатых сигналов метаданных, причем упомянутый восстановленный сигнал метаданных ассоциирован с упомянутым сжатым сигналом метаданных и дополнительно содержит множество вторых выборок метаданных, при этом декодер (110) метаданных выполнен с возможностью формировать вторые выборки метаданных каждого из одного или более восстановленных сигналов метаданных посредством формирования множества аппроксимированных выборок метаданных для упомянутого восстановленного сигнала метаданных, при этом декодер (110) метаданных выполнен с возможностью формировать каждую из множества аппроксимированных выборок метаданных в зависимости от по меньшей мере двух из первых выборок метаданных упомянутого восстановленного сигнала метаданных, и
формирователь (120) аудиоканалов для формирования одного или более аудиоканалов в зависимости от одного или более сигналов аудиообъектов и в зависимости от одного или более восстановленных сигналов метаданных,
при этом декодер (110) метаданных выполнен с возможностью принимать множество разностных значений для сжатого сигнала метаданных из одного или более сжатых сигналов метаданных и выполнен с возможностью суммировать каждое из множества разностных значений с одной из аппроксимированных выборок метаданных восстановленного сигнала метаданных, ассоциированного с упомянутым сжатым сигналом метаданных, чтобы получать вторые выборки метаданных упомянутого восстановленного сигнала метаданных.
2. Устройство (100) по п. 1, в котором декодер (110) метаданных выполнен с возможностью формировать каждый восстановленный сигнал метаданных из одного или более восстановленных сигналов метаданных посредством повышающей дискретизации одного из одного или более сжатых сигналов метаданных, при этом декодер (110) метаданных выполнен с возможностью формировать каждую из вторых выборок метаданных каждого восстановленного сигнала метаданных из одного или более восстановленных сигналов метаданных посредством осуществления линейной интерполяции в зависимости от по меньшей мере двух из первых выборок метаданных упомянутого восстановленного сигнала метаданных.
3. Устройство (100) по п. 1,
при этом декодер (110) метаданных выполнен с возможностью принимать множество разностных значений для сжатого сигнала метаданных из одного или более сжатых сигналов метаданных, при этом каждое из разностных значений является принимаемым разностным значением, назначаемым одной из аппроксимированных выборок метаданных восстановленного сигнала метаданных, ассоциированного с упомянутым сжатым сигналом метаданных,
при этом декодер (110) метаданных выполнен с возможностью суммировать каждое принимаемое разностное значение из множества принимаемых разностных значений с аппроксимированной выборкой метаданных, ассоциированной с упомянутым принимаемым разностным значением, чтобы получать одну из вторых выборок метаданных упомянутого восстановленного сигнала метаданных,
при этом декодер (110) метаданных выполнен с возможностью определять аппроксимированное разностное значение в зависимости от одного или более из множества принимаемых разностных значений для каждой аппроксимированной выборки метаданных из множества аппроксимированных выборок метаданных восстановленного сигнала метаданных, ассоциированного с упомянутым сжатым сигналом метаданных, когда ни одно из множества принимаемых разностных значений не ассоциировано с упомянутой аппроксимированной выборкой метаданных,
при этом декодер (110) метаданных выполнен с возможностью суммировать каждое аппроксимированное разностное значение из множества аппроксимированных разностных значений с аппроксимированной выборкой метаданных упомянутого аппроксимированного разностного значения, чтобы получать другую из вторых выборок метаданных упомянутого восстановленного сигнала метаданных.
4. Устройство (100) по п. 1,
в котором по меньшей мере один из одного или более восстановленных сигналов метаданных содержит информацию позиции относительно одного из одного или более сигналов аудиообъектов или содержит масштабированное представление информации позиции по упомянутому одному из одного или более сигналов аудиообъектов, и
при этом формирователь (120) аудиоканалов выполнен с возможностью формировать по меньшей мере один из одного или более аудиоканалов в зависимости от упомянутого одного из одного или более сигналов аудиообъектов и в зависимости от упомянутой информации позиции.
5. Устройство (100) по п. 1,
в котором по меньшей мере один из одного или более восстановленных сигналов метаданных содержит громкость одного из одного или более сигналов аудиообъектов или содержит масштабированное представление громкости упомянутого одного из одного или более сигналов аудиообъектов, и
при этом формирователь (120) аудиоканалов выполнен с возможностью формировать по меньшей мере один из одного или более аудиоканалов в зависимости от упомянутого одного из одного или более сигналов аудиообъектов и в зависимости от упомянутой громкости.
6. Устройство (100) по п. 1, при этом устройство (100) выполнено с возможностью принимать информацию произвольного доступа, при этом для каждого сжатого сигнала метаданных из одного или более сжатых сигналов метаданных информация произвольного доступа указывает часть сигнала, к которой осуществляется доступ, для упомянутого сжатого сигнала метаданных, при этом по меньшей мере еще одна часть сигнала для упомянутого сигнала метаданных не указывается посредством упомянутой информации произвольного доступа, и при этом декодер (110) метаданных выполнен с возможностью формировать один из одного или более восстановленных сигналов метаданных в зависимости от первых выборок метаданных упомянутой части сигнала, к которой осуществляется доступ, для упомянутого сжатого сигнала метаданных, но независимо от любых других первых выборок метаданных любой другой части сигнала для упомянутого сжатого сигнала метаданных.
7. Устройство (250) для формирования кодированной аудиоинформации, содержащей один или более кодированных аудиосигналов и один или более сжатых сигналов метаданных, при этом устройство содержит:
кодер (210) метаданных для приема одного или более исходных сигналов метаданных, при этом каждый из одного или более исходных сигналов метаданных содержит множество выборок метаданных, при этом выборки метаданных каждого из одного или более исходных сигналов метаданных указывают информацию, ассоциированную с сигналом аудиообъекта для одного или более сигналов аудиообъектов, при этом кодер (210) метаданных выполнен с возможностью формировать один или более сжатых сигналов метаданных таким образом, что каждый сжатый сигнал метаданных из одного или более сжатых сигналов метаданных содержит первую группу из двух или более выборок метаданных исходного сигнала метаданных из одного или более исходных сигналов метаданных, причем упомянутый сжатый сигнал метаданных ассоциирован с упомянутым исходным сигналом метаданных, и таким образом, что упомянутый сжатый сигнал метаданных не содержит какой-либо выборки метаданных второй группы из других двух или более выборок метаданных упомянутого одного из исходных сигналов метаданных, и
аудиокодер (220) для кодирования одного или более сигналов аудиообъектов, чтобы получать один или более кодированных аудиосигналов,
при этом каждая из выборок метаданных, которая состоит из исходного сигнала метаданных из одного или более исходных сигналов метаданных и которая также состоит из сжатого сигнала метаданных, который ассоциирован с упомянутым исходным сигналом метаданных, представляет собой одну из множества первых выборок метаданных,
при этом каждая из выборок метаданных, которая состоит из исходного сигнала метаданных из одного или более исходных сигналов метаданных и которая не состоит из сжатого сигнала метаданных, который ассоциирован с упомянутым исходным сигналом метаданных, представляет собой одну из множества вторых выборок метаданных,
при этом кодер (210) метаданных выполнен с возможностью формировать аппроксимированную выборку метаданных для каждой из множества вторых выборок метаданных одного из исходных сигналов метаданных посредством осуществления линейной интерполяции в зависимости от по меньшей мере двух из первых выборок метаданных упомянутого одного из одного или более исходных сигналов метаданных, и
при этом кодер (210) метаданных выполнен с возможностью формировать разностное значение для каждой второй выборки метаданных из упомянутого множества вторых выборок метаданных упомянутого одного из одного или более исходных сигналов метаданных таким образом, что упомянутое разностное значение указывает разность между упомянутой второй выборкой метаданных и аппроксимированной выборкой метаданных для упомянутой второй выборки метаданных.
8. Устройство (250) по п. 7,
в котором кодер (210) метаданных выполнен с возможностью определять для по меньшей мере одного из разностных значений упомянутого множества вторых выборок метаданных упомянутого одного из одного или более исходных сигналов метаданных, превышает ли каждое по меньшей мере одно из упомянутых разностных значений пороговое значение.
9. Устройство (250) по п. 7,
в котором кодер (210) метаданных выполнен с возможностью кодировать одну или более выборок метаданных одного из одного или более сжатых сигналов метаданных с первым числом битов, при этом каждая из упомянутой одной или более выборок метаданных упомянутого одного из одного или более сжатых сигналов метаданных указывает целое число,
при этом кодер (210) метаданных выполнен с возможностью кодировать одно или более разностных значений упомянутого множества вторых выборок метаданных со вторым числом битов, при этом каждое из упомянутого одного или более разностных значений упомянутого множества вторых выборок метаданных указывает целое число, и
при этом второе число битов меньше первого числа битов.
10. Устройство (250) по п. 7,
в котором по меньшей мере один из одного или более исходных сигналов метаданных содержит информацию позиции относительно одного из одного или более сигналов аудиообъектов или содержит масштабированное представление информации позиции по упомянутому одному из одного или более сигналов аудиообъектов, и
при этом кодер (210) метаданных выполнен с возможностью формировать по меньшей мере один из одного или более сжатых сигналов метаданных в зависимости от упомянутого по меньшей мере одного из одного или более исходных сигналов метаданных.
11. Устройство (250) по п. 7,
в котором по меньшей мере один из одного или более исходных сигналов метаданных содержит громкость одного из одного или более сигналов аудиообъектов или содержит масштабированное представление громкости упомянутого одного из одного или более сигналов аудиообъектов, и
при этом кодер (210) метаданных выполнен с возможностью формировать по меньшей мере один из одного или более сжатых сигналов метаданных в зависимости от упомянутого по меньшей мере одного из одного или более исходных сигналов метаданных.
12. Система для формирования одного или более аудиоканалов из кодированной аудиоинформации, содержащая:
устройство (250) по одному из пп. 7-11 для формирования кодированной аудиоинформации, содержащей один или более кодированных аудиосигналов и один или более сжатых сигналов метаданных, и
устройство (100) по одному из пп. 1-6 для приема одного или более кодированных аудиосигналов и одного или более сжатых сигналов метаданных и для формирования одного или более аудиоканалов в зависимости от одного или более кодированных аудиосигналов и в зависимости от одного или более сжатых сигналов метаданных.
13. Способ формирования одного или более аудиоканалов, при этом способ содержит этапы, на которых:
принимают один или более сжатых сигналов метаданных, при этом каждый из одного или более сжатых сигналов метаданных содержит множество первых выборок метаданных, при этом первые выборки метаданных каждого из одного или более сжатых сигналов метаданных указывают информацию, ассоциированную с сигналом аудиообъекта для одного или более сигналов аудиообъектов,
формируют один или более восстановленных сигналов метаданных таким образом, что каждый восстановленный сигнал метаданных из одного или более восстановленных сигналов метаданных содержит первые выборки метаданных сжатого сигнала метаданных из одного или более сжатых сигналов метаданных, причем упомянутый восстановленный сигнал метаданных ассоциирован с упомянутым сжатым сигналом метаданных и дополнительно содержит множество вторых выборок метаданных, при этом формирование одного или более восстановленных сигналов метаданных содержит этап, на котором формируют вторые выборки метаданных каждого из одного или более восстановленных сигналов метаданных посредством формирования множества аппроксимированных выборок метаданных для упомянутого восстановленного сигнала метаданных, при этом формирование каждой из множества аппроксимированных выборок метаданных осуществляется в зависимости от по меньшей мере двух из первых выборок метаданных упомянутого восстановленного сигнала метаданных, и
формируют один или более аудиоканалов в зависимости от одного или более сигналов аудиообъектов и в зависимости от одного или более восстановленных сигналов метаданных,
при этом способ дополнительно содержит этап, на котором принимают множество разностных значений для сжатого сигнала метаданных из одного или более сжатых сигналов метаданных и суммируют каждое из множества разностных значений с одной из аппроксимированных выборок метаданных восстановленного сигнала метаданных, ассоциированного с упомянутым сжатым сигналом метаданных, чтобы получать вторые выборки метаданных упомянутого восстановленного сигнала метаданных.
14. Способ формирования кодированной аудиоинформации, содержащей один или более кодированных аудиосигналов и один или более сжатых сигналов метаданных, при этом способ содержит этапы, на которых:
принимают один или более исходных сигналов метаданных, при этом каждый из одного или более исходных сигналов метаданных содержит множество выборок метаданных, при этом выборки метаданных каждого из одного или более исходных сигналов метаданных указывают информацию, ассоциированную с сигналом аудиообъекта для одного или более сигналов аудиообъектов,
формируют один или более сжатых сигналов метаданных таким образом, что каждый сжатый сигнал метаданных из одного или более сжатых сигналов метаданных содержит первую группу из двух или более выборок метаданных исходного сигнала метаданных из одного или более исходных сигналов метаданных, причем упомянутый сжатый сигнал метаданных ассоциирован с упомянутым исходным сигналом метаданных, и таким образом, что упомянутый сжатый сигнал метаданных не содержит какой-либо выборки метаданных второй группы из других двух или более выборок метаданных упомянутого одного из исходных сигналов метаданных, и
кодируют один или более сигналов аудиообъектов, чтобы получать один или более кодированных аудиосигналов,
при этом каждая из выборок метаданных, которая состоит из исходного сигнала метаданных из одного или более исходных сигналов метаданных и которая также состоит из сжатого сигнала метаданных, который ассоциирован с упомянутым исходным сигналом метаданных, представляет собой одну из множества первых выборок метаданных,
при этом каждая из выборок метаданных, которая состоит из исходного сигнала метаданных из одного или более исходных сигналов метаданных и которая не состоит из сжатого сигнала метаданных, который ассоциирован с упомянутым исходным сигналом метаданных, представляет собой одну из множества вторых выборок метаданных,
при этом способ дополнительно содержит этап, на котором формируют аппроксимированную выборку метаданных для каждой из множества вторых выборок метаданных одного из исходных сигналов метаданных посредством осуществления линейной интерполяции в зависимости от по меньшей мере двух из первых выборок метаданных упомянутого одного из одного или более исходных сигналов метаданных, и
при этом способ дополнительно содержит этап, на котором формируют разностное значение для каждой второй выборки метаданных из упомянутого множества вторых выборок метаданных упомянутого одного из одного или более исходных сигналов метаданных таким образом, что упомянутое разностное значение указывает разность между упомянутой второй выборкой метаданных и аппроксимированной выборкой метаданных для упомянутой второй выборки метаданных.
15. Считываемый компьютером носитель, содержащий компьютерную программу для реализации способа по п. 13 при выполнении на компьютере или в процессоре сигналов.
16. Считываемый компьютером носитель, содержащий компьютерную программу для реализации способа по п. 14 при выполнении на компьютере или в процессоре сигналов.
17. Устройство для кодирования входных аудиоданных (101), чтобы получать выходные аудиоданные (501), содержащее:
входной интерфейс (1100) для приема множества аудиоканалов, множества аудиообъектов и метаданных, связанных с одним или более из множества аудиообъектов;
микшер (200) для микширования множества объектов и множества каналов таким образом, чтобы получать множество предварительно микшированных каналов, причем каждый предварительно микшированный канал содержит аудиоданные канала и аудиоданные по меньшей мере одного объекта;
устройство (250) по одному из пп. 7-11,
при этом аудиокодер (220) устройства (250) по одному из пп. 7-11 представляет собой базовый кодер (300) для базового кодирования входных данных базового кодера, и
при этом кодер (210) метаданных устройства (250) по одному из пп. 7-11 представляет собой модуль (400) сжатия метаданных для сжатия метаданных, связанных с одним или более из множества аудиообъектов.
18. Устройство для декодирования аудиоданных, содержащее:
входной интерфейс (1100) для приема кодированных аудиоданных, причем кодированные аудиоданные содержат множество кодированных каналов или множество кодированных объектов либо сжатые метаданные, связанные с множеством объектов; и
устройство (100) по одному из пп. 1-6,
при этом декодер (110) метаданных устройства (100) по одному из пп. 1-6 представляет собой модуль (400) распаковки метаданных для распаковки сжатых метаданных,
при этом формирователь (120) аудиоканалов устройства (100) по одному из пп. 1-6 содержит базовый декодер (1300) для декодирования множества кодированных каналов и множества кодированных объектов,
при этом формирователь (120) аудиоканалов дополнительно содержит процессор (1200) объектов для обработки множества декодированных объектов с использованием распакованных метаданных, чтобы получать число выходных каналов (1205), содержащих аудиоданные из объектов и декодированных каналов, и
при этом формирователь (120) аудиоканалов дополнительно содержит постпроцессор (1700) для преобразования числа выходных каналов (1205) в выходной формат.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| СХЕМА АУДИОКОДИРОВАНИЯ/ДЕКОДИРОВАНИЯ С ПЕРЕКЛЮЧЕНИЕМ БАЙПАС | 2009 |
|
RU2483364C2 |

