ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение относится к способу обработки информации и, в частности, относится к способу обработки естественного выражения, полученного от человека, способу обработки и ответа для естественного выражения и к устройству обработки информации и системе обработки информации, использующей способ обработки и ответа.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
[0002] Машинный перевод (MT) относится к области компьютерной лингвистики, которая использует компьютерные программы для перевода текстовых или речевых выражений с одного естественного языка на другой естественный язык. В некотором смысле, реализуются словарные замены между различными естественными языками. Кроме того, с использованием основанных на корпусах текстов методов, может выполняться более сложный автоматический перевод и, тем самым, достигаться лучшая обработка различных грамматических структур, распознавания по словарю, соответствие идиоматических выражений и т.д.
[0003] Современные средства машинного перевода могут, в принципе, позволять настройку на конкретную область или профессию (например, метеопрогноз), в целях сужения перевода по словарю до надлежащего имени существительного в конкретной области, чтобы улучшить результат перевода. Этот метод является, в частности, эффективным для некоторых областей, которые используют более формализованные или более стандартизованные способы представления. Например, правительственные документы или документы, относящиеся к области права, обычно являются более формализованными и более стандартизованными, чем другие документы, использующие обычные буквальные выражения, и, соответственно, результат машинного перевода для таких документов часто лучше, чем таковой для неформализованных документов, таких как диалоги в повседневной жизни.
[0004] Однако качество машинного перевода обычно зависит от различий между исходным языком и целевым языком с точки зрения словаря, грамматической структуры, лингвистики и даже культуры. Например, поскольку как английский, так и датский языки относятся к индогерманскому семейству, результат машинного перевода между этими двумя языками зачастую намного лучше, чем результат машинного перевода между английским и китайским языками.
[0005] Поэтому, чтобы улучшить результат машинного перевода, все еще остается важным ручное вмешательство. Например, в некоторых системах машинного перевода, за счет ручного определения или выбора более подходящих слов, точность и качество машинного перевода могут быть значительно улучшены.
[0006] Некоторые существующие средства перевода, такие как Alta Vista Babelfish, иногда могут получать понятные результаты перевода. Однако если желателен более осмысленный результат, то часто необходимо выполнять соответствующее редактирование при вводе предложения, чтобы облегчить анализ компьютерными программами.
[0007] В общем, целью использования машинного перевода людьми может быть только ознакомление с сущностью предложений или абзацев в исходном тексте, а не получение точного перевода. В общем, машинный перевод не достиг такого качественного уровня, при котором он мог бы предоставляться как профессиональный (ручной) перевод, и по-прежнему не может быть официальным переводом.
[0008] Обработка естественного языка (NLP) является под-дисциплиной в области искусственного интеллекта и лингвистики. В этой области обсуждается, как обрабатывать и применять естественный язык; и распознавание естественного языка относится к тому, что делает компьютер, чтобы “понять” реальный смысл, стоящий за человеческими языками.
[0009] Система генерации естественного языка преобразует компьютерные данные в естественный язык. Система понимания естественного языка преобразует естественный язык в некоторую форму, которая может быть более просто обработана компьютерными программами.
[0010] В теории, NLP является очень привлекательным путем человеко-машинного взаимодействия. Прежние системы обработки языка, такие как SHRDLU, при использовании ограниченного словарного запаса (лексикона) для выполнения сессий в пределах ограниченного “блочного мира” могут работать довольно хорошо. Это вызывает обоснованный оптимизм исследователей в отношении этой системы. Однако когда системы разрабатываются для помещения в среду, заполненную неоднозначностью и неопределенностью реального мира, они быстро теряют доверие. Поскольку понимание естественного языка требует обширного знания окружающего мира и возможности использовать и манипулировать знанием, распознавание естественного языка также рассматривается как AI-полная задача, т.е. задача, решаемая средствами искусственного интеллекта.
[0011] Основанная на статистике NLP использует вероятностные и статистические методы для решения проблем, существующих в NLP, основываясь на грамматических правилах. Особенно для длинных предложений, которым свойственна высокая степень неоднозначности, когда для анализа применяется практическая грамматика, могут быть сгенерированы тысячи возможностей. Методы устранения неоднозначностей, принятые для обработки этих высоко неоднозначных предложений, часто используют корпуса и марковские модели. Основанная на статистике технология NLP в основном разработана путем эволюции из суб-областей, а именно, машинного обучения и анализа данных, ассоциированных с поведением обучения в технологии искусственного интеллекта.
[0012] Однако, для основанного на статистике метода NLP, должен быть установлен корпус из парных корпусов языков, содержащих большой объем данных, для обучения и использования компьютера; и для корпуса большого объема данных, извлечение соответствующего результата машинного перевода (понимания) из корпуса и возврат результата назад также требуют для поддержки большого объема вычислительных ресурсов. Кроме того, даже если этот метод будет принят, все еще существуют большие трудности в манипулировании с разнообразием и неопределенностью практического естественного языка.
[0013] Технология NLP широко использовалась на практике. Например, она использовалась в интерактивной системе голосового ответа, Интернет-системе кол-центра и т.д..
[0014] Интерактивный голосовой ответ (IVR) является общим термином телефонных голосовых дополнительных (платных) услуг. Многие учреждения (такие как банки, центры кредитных карт, телекоммуникационные операторы и т.д.) обеспечивают клиентов широким спектром самообслуживания через интерактивную систему голосового ответа (IVRS), в которой клиент может набрать установленный телефонный номер, чтобы войти в систему, и вводить соответствующие опции или персональную информацию в соответствии с инструкцией системы, чтобы просушивать предварительно записанную информацию, или комбинировать данные в соответствии с предварительно установленной программой (Call Flow – поток вызова) через компьютерную систему и считывать конкретную информацию (такую как баланс счета, сумму к получению и т.д.) голосовым способом и может также вводить инструкцию транзакции через систему, чтобы выполнять предварительно установленную транзакцию (такую как перевод, изменение пароля, изменение контактного телефона и т.д.).
[0015] Несмотря на то, что система IVR была широко использована в последнее десятилетие, однако технически, система IVR была создана с критическим дефектом, который по-прежнему вызывает затруднения для всех учреждений: неприводимое дерево меню с многоуровневыми опциями. Большинству пользователей, при использовании системы IVR для выбора вариантов самообслуживания, не хватает терпения, чтобы потратить время на прохождение по дереву меню с многоуровневыми опциями, и они прямо обращаются к центру ручного обслуживания клиентов путем нажатия “0”, что приводит к непреодолимому разрыву между ожиданиями учреждений относительно возможности системы IVR “эффективно повышать степень использования самообслуживания клиентами и существенным образом заменять ручные операции” и реальностью.
[0016] Интернет-система кол-центра (ICCS) является новым типом системы кол-центра, получившим развитие в последние годы, которая принимает популярный Интернет-метод мгновенной передачи сообщений (IM), чтобы выполнять текстовую передачу в реальном времени учреждениями и их клиентами через Интернет, и применяется для обеспечиваемых учреждениями клиентских служб и дистанционных продаж. Агент ручной поддержки, использующий ICCS, может осуществлять связь одновременно с двумя или более клиентами.
[0017] Таким образом, можно сказать, что текстовая система ICC является вариантом голосовой системы IVR. Обе являются необходимыми инструментами (как для клиентских служб, так и для дистанционных продаж) для коммуникации между учреждениями и их клиентами, и обе требуют высокого уровня участия агента ручной поддержки. Поэтому, подобно IVR системе, для системы ICC также трудно удовлетворить такое требование учреждений, как “эффективное повышение степени использования самообслуживания клиентами и существенная замена ручных операций".
[0018] С другой стороны, традиционная технология голосовой идентификации, основываясь на результате голосовой идентификации с недостаточной точностью и стабильностью, использует технологию поиска по ключевым словам и использует “всесторонний поиск” для выполнения семантического анализа речи. Хотя многие компании, специализирующиеся в технологии голосовой идентификации, тратят большой объем трудовых усилий и денежных средств на два объекта работ, т.е. “транскрипцию” и “определение ключевых слов”, и постоянно обучают речевой робот в течение длительного времени, но реальные результаты часто весьма далеки от идеальных результатов.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0019] В соответствии с одним аспектом настоящего изобретения, предложен способ обработки естественного выражения, который включает в себя: идентификацию естественного выражения от пользователя, чтобы получать некоторую форму информации языка, которая может обрабатываться компьютером; и преобразование полученной информации языка в стандартное выражение в кодированной форме.
[0020] В способе обработки естественного выражения согласно вариантам осуществления настоящего изобретения, опционально, стандартное выражение включает в себя коды требований, воплощающие требования пользователя.
[0021] В способе обработки естественного выражения согласно вариантам осуществления настоящего изобретения, опционально, коды требований выражены цифровыми кодами.
[0022] В способе обработки естественного выражения согласно вариантам осуществления настоящего изобретения, опционально, стандартные выражения дополнительно включают в себя параметры требований, дополнительно воплощающие специфические для пользователя требования.
[0023] В способе обработки естественного выражения согласно вариантам осуществления настоящего изобретения, опционально, информация языка образована блоками информации языка, полученными посредством локализации и преобразования, выполненного над естественным выражением в форме речи, с использованием средства моделирования.
[0024] В способе обработки естественного выражения согласно вариантам осуществления настоящего изобретения, опционально, информация языка образована одним из фонемы, символа и фразы.
[0025] В способе обработки естественного выражения согласно вариантам осуществления настоящего изобретения, опционально, преобразование из информации языка в стандартное выражение реализовано на основе тренировочного набора данных MT (машинного перевода) между информацией языка и стандартным выражением.
[0026] В способе обработки естественного выражения согласно вариантам осуществления настоящего изобретения, опционально, информация, ассоциированная с естественным выражением, получается посредством идентификации естественного выражения, и упомянутая информация преобразуется в часть стандартного выражения.
[0027] В соответствии с другим аспектом настоящего изобретения, предложен способ для тренировки робота искусственного интеллекта, который включает в себя: установление тренировочного набора данных MT, где тренировочный набор данных МТ содержит: обрабатываемую компьютером информацию языка, получаемую путем преобразования естественного выражения, кодированного стандартного выражения и соответствующего соотношения между информацией языка и стандартным выражением; и выполнение, посредством робота искусственного интеллекта, итеративного сравнения между различными перестановками и комбинациями элементов информации языка, существующей в тренировочном наборе данных МТ, и различными перестановками и комбинациями элементов стандартного выражения, чтобы найти соответствующее соотношение между перестановками и комбинациями элементов информации языка и перестановками и комбинациями элементов стандартного выражения.
[0028] В способе тренировки робота искусственного интеллекта согласно вариантам осуществления настоящего изобретения, опционально, данные в тренировочном наборе данных МТ могут быть импортированы из внешней базы данных и могут также быть сгенерированы или добавлены на основе понимания с ручной поддержкой.
[0029] В соответствии с другим аспектом настоящего изобретения, предложен способ обработки естественного выражения, который включает в себя: ввод естественного выражения; идентификацию естественного выражения, чтобы получить некоторую форму информации языка, которая может обрабатываться компьютером; определение, может ли информация языка быть преобразована в кодированное стандартное выражение посредством машинного преобразования; если определено, что желательное стандартное выражение не может быть получено посредством машинного преобразования, выполнение обработки ручного преобразования; и вывод стандартных выражений из машинного преобразования или ручного преобразования.
[0030] В способе обработки естественного выражения согласно вариантам осуществления настоящего изобретения, опционально, определение относится к определению, является ли понимание робота зрелым, причем определение, является ли понимание робота зрелым, выполняется на основе оценки степени точности понимания робота в течение некоторого временного интервала.
[0031] В соответствии с еще одним аспектом настоящего изобретения, предложен способ обработки естественного выражения и ответа, который включает в себя: ввод естественного выражения; идентификацию естественного выражения, чтобы получить некоторую форму информации языка, которая может обрабатываться компьютером, и релевантную информацию типа выражения; определение, могут ли идентифицированное естественное выражение и информация типа выражения быть преобразованы в кодированное стандартное выражение посредством машинного преобразования; если определено, что желательное стандартное выражение не может быть получено посредством машинного преобразования, выполнение обработки ручного преобразования; извлечение или генерация стандартного ответа, согласующегося со стандартным выражением, полученным посредством машинного преобразования и ручного преобразования; и вывод сгенерированного стандартного ответа таким способом, который соответствует информации типа выражения.
[0032] В способе обработки естественного выражения и ответа согласно вариантам осуществления настоящего изобретения, опционально, стандартный ответ является фиксированными данными, предварительно сохраненными в базе данных, или стандартный ответ генерируется на основе базовых данных стандартных ответов, предварительно сохраненных в базе данных, и переменных параметров.
[0033] В соответствии с другим аспектом настоящего изобретения, предложено устройство обработки естественного выражения и ответа, которое включает в себя: диалоговый шлюз, центральный контроллер, MAU рабочую станцию, робот, базу данных выражений, базу данных ответов и генератор ответов, причем диалоговый шлюз принимает естественное выражение от пользователя, передает его в центральный контроллер для последующей обработки и передает ответ для естественного выражения к пользователю; центральный контроллер принимает естественное выражение от диалогового шлюза и взаимодействует с роботом и MAU рабочей станцией, чтобы преобразовать естественное выражение в кодированное стандартное выражение и инструктировать генератор ответов, чтобы генерировать стандартный ответ, соответствующий стандартному выражению, в соответствии со стандартным выражением; робот идентифицирует естественное выражение в соответствии с инструкцией центрального контроллера, чтобы получить некоторую форму информации языка, которая может обрабатываться компьютером, и преобразует информацию языка в стандартное выражение с использованием базы данных выражений; MAU рабочая станция представляет идентифицированное естественное выражение или естественное выражение от пользователя к внешнему MAU-агенту ручной поддержки, MAU-агент ручной поддержки вводит или выбирает стандартное выражение посредством MAU рабочей станции, и затем MAU рабочая станция передает стандартное выражение на центральный контроллер; и база данных выражений сконфигурирована для хранения относящихся к выражению данных, включая: данные информации языка, ассоциированные с естественным выражением, данные стандартного выражения, ассоциированные со стандартным выражением, и данные, ассоциированные с соотношением между информацией языка и стандартным выражением; база данных ответов хранит относящиеся к ответу данные, включая данные стандартного ответа для извлечения и/или данные для генерации ответа; и генератор ответов принимает инструкцию центрального контроллера и генерирует ответ для естественного выражения от пользователя путем извлечения и/или прогона данных в базе данных ответов.
[0034] В устройстве обработки естественного выражения и ответа, согласно вариантам осуществления настоящего изобретения, опционально, центральный контроллер обновляет базу данных выражений и/или базу данных ответов.
[0035] В устройстве обработки естественного выражения и ответа, согласно вариантам осуществления настоящего изобретения, опционально, устройство дополнительно включает в себя тренажер (обучающий модуль), сконфигурированный для тренировки робота преобразовывать естественное выражение в стандартное выражение.
[0036] В устройстве обработки естественного выражения и ответа, согласно вариантам осуществления настоящего изобретения, опционально, диалоговый шлюз дополнительно включает в себя аутентификатор идентификационных данных, сконфигурированный, чтобы идентифицировать и верифицировать идентификационные данные пользователя перед приемом информации естественного выражения, причем методы аутентификации идентификационных данных пользователя по меньшей мере включают в себя идентификацию фразы-пароля & “отпечатка голоса” (сонограммы).
[0037] В соответствии с еще одним аспектом настоящего изобретения, предложена система обработки естественного выражения и ответа, которая включает в себя: интеллектуальное устройство ответа и устройство вызова; причем пользователь осуществляет связь с интеллектуальным устройством ответа через устройство вызова, и MAU-агент ручной поддержки приводит в действие интеллектуальное устройство ответа, причем интеллектуальное устройство ответа включает в себя: диалоговый шлюз, центральный контроллер, MAU рабочую станцию, робот, базу данных выражений, базу данных ответов и генератор ответов, причем диалоговый шлюз принимает, от устройства вызова, естественное выражение от пользователя и передает его в центральный контроллер; центральный контроллер инструктирует робот идентифицировать некоторую форму информации языка, которая может обрабатываться компьютером, и связанную информацию выражения из естественного выражения, и затем инструктирует робот преобразовывать информацию языка и связанную информацию выражения в стандартное выражение; если понимание робота является недостаточно зрелым, чтобы выполнить преобразование в стандартное выражение, центральный контроллер инструктирует MAU рабочую станцию предложить MAU-агенту ручной поддержки выполнить ручное преобразование в стандартное выражение, MAU-агент ручной поддержки преобразует информацию языка и связанную информацию выражения, идентифицированную роботом, в стандартное выражение и вводит и передает его в центральный контроллер через MAU рабочую станцию; центральный контроллер инструктирует генератор ответов вызывать или прогонять данные в базе данных ответов на основе стандартного выражения, чтобы генерировать ответ для естественного выражения от пользователя; и диалоговый шлюз выводит обратно ответ к пользователю через устройство вызова.
[0038] В способе обработки естественного выражения согласно вариантам осуществления настоящего изобретения, естественное выражение может быть преобразовано в кодированное стандартное выражение; поскольку преобразование в стандартное выражение преобразует семантику естественного выражения в коды и параметры, и точный дословный перевод не требуется, требование по точности для машинного перевода может быть снижено, и при этом сложность базы данных для преобразования выражений (машинного перевода) снижается, увеличивая скорость запроса и обновления данных и, таким образом, повышая эффективность интеллектуальной обработки. Кроме того, относительно простое кодированное выражение уменьшает рабочую нагрузку вмешательств ручной поддержки, увеличивая эффективность выполнения вмешательств ручной поддержки.
[0039] В способе, устройстве и системе обработки естественного выражения и ответа, согласно вариантам осуществления настоящего изобретения, стандартное выражение может быть использовано, чтобы быстро указывать на ответ, так что клиенту больше не требуется тратить много времени на переход по сложному процедурному меню функций, чтобы найти желательный вариант самообслуживания. Кроме того, база данных стандартизованных естественных выражений - стандартных выражений - стандартных ответов может быть установлена путем автоматического обучения, тренировки и понимания робота с ручной поддержкой, чтобы поэтапно реализовать автоматическое понимание и ответ системы. Кроме того, база данных также может иметь преимущества, включая малую степень дисперсности, суженный объем знаний и высокую достоверность данных, чтобы снизить трудности обучения робота и сократить период развития интеллектуальности робота.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0040] Чтобы более ясно проиллюстрировать технические решения в вариантах осуществления настоящего изобретения, далее кратко описаны чертежи, используемые в вариантах осуществления. Соответственно, чертежи в последующем описании только иллюстрируют варианты осуществления настоящего изобретения и не предназначены для ограничения настоящего изобретения.
[0041] Фиг. 1 схематично показывает блок-схему последовательности действий способа обработки естественного выражения в соответствии с вариантом осуществления настоящего изобретения;
[0042] Фиг. 2 схематично показывает блок-схему последовательности действий способа обработки естественного выражения и ответа согласно варианту осуществления настоящего изобретения;
[0043] Фиг. 3 схематично показывает интеллектуальную систему ответа согласно вариантам осуществления настоящего изобретения;
[0044] Фиг. 4 дополнительно показывает часть интеллектуального устройства ответа в системе по фиг. 3;
[0045] Фиг. 5 схематично показывает пример операционного интерфейса, представляемого MAU рабочей станцией агенту ручной поддержки;
[0046] Фиг. 6 показывает пример идентификации по речевой информации;
[0047] Фиг. 7 показывает пример преобразования уловленной акустической волны на X элементах с использованием гауссовой модели смеси;
[0048] Фиг. 8 показывает пример преобразования из уловленной акустической волны (информации языка А) в информацию языка Y;
[0049] Фиг. 9 в общем показывает преобразование от уровня к уровню из уловленной акустической волны (информации языка А) в информацию языка Y; и
[0050] Фиг. 10 является схематичным видом принципа многоуровневого восприятия.
ДЕТАЛЬНОЕ ОПИСАНИЕ
[0051] Для пояснения целей, технических решений и преимуществ вариантов осуществления настоящего изобретения, технические решения вариантов осуществления настоящего изобретения детально описываются ниже со ссылками на приложенные чертежи вариантов осуществления настоящего изобретения. Очевидно, что описанные варианты осуществления являются только частью вариантов осуществления настоящего изобретения, а не всеми вариантами осуществления. Все другие варианты осуществления, полученные специалистами в данной области техники на основе описанных вариантов осуществления настоящего изобретения без приложения творческих усилий, должны включаться в объем защиты настоящего изобретения.
[0052] Если не определено иначе, технические термины или научные термины, использованные здесь, должны иметь общее значение, которое может быть понятно специалистам в области техники, к которой относится настоящее изобретение. Термины “первый” или “второй” и другие подобные термины, использованные в описании и формуле изобретения, не указывают какой-либо порядок, величину или важность, а просто используются для различения между различными компонентами. Аналогично, термины, указывающие на единственное число, не указывают какого-либо количественного ограничения, а просто указывают на наличие по меньшей мере одного.
[0053] Способ обработки естественного выражения согласно вариантам осуществления настоящего изобретения может быть применен в системе обслуживания клиентов, такой как вышеупомянутая интерактивного система голосового ответа (IVR) или Интернет-система кол-центра (ICCS) или другие системы дистанционного контакта с клиентами (такие как системы продаж по телефону, системы сетевых продаж и VTM интеллектуальный дистанционный терминал). Как указано выше, в таких приложениях, требование к машинному переводу заключается не в том, чтобы выполнить точный пословный перевод, а чтобы преобразовать естественное выражение клиента в информацию, которая может быть понята системой, тем самым обеспечивая ответ, соответствующий выражению клиента. Иными словами, машинный перевод здесь фокусируется на понимании реального смысла человеческого языка, чтобы выразить действительное намерение или требование клиента, “понятное” из естественного выражения, в форме, которая может быть более просто обработана компьютерными программами.
[0054] В способе обработки естественного выражения, согласно вариантам осуществления настоящего изобретения, естественное выражение от пользователя сначала идентифицируется или преобразуется, чтобы получить некоторую форму информации языка, которая может обрабатываться компьютером, и затем полученная информация языка преобразуется в стандартное выражение в некоторой форме.
[0055] Нерегулярная информация естественного выражения, представленная в физических данных от пользователя, такая как акустическая волна, может упоминаться как “информация языка на физическом уровне” и также упоминается ниже как “информация языка А” для краткости. Посредством некоторого инструмента моделирования выполняется базовая автоматическая идентификация или преобразование для получения информации языка (далее упоминаемого как “язык X”) на первом логическом уровне, представленном в форме перестановок и комбинаций различных базовых элементов (далее упоминаемых как “элемент X”). Стандартное выражение в некоторой форме, сгенерированное путем преобразования информации языка Х, полученной путем идентификации или преобразования информации языка А, далее упоминается как “информация языка Y”.
[0056] Имеются различные способы получения естественного выражения от человека. Например, естественное выражение от клиента, а именно “информация языка А”, может быть разделена на следующие четыре категории: текстовая информация, речевая информация, информация изображения и информация анимации.
[0057] Среди них, выражение текстовой информации может быть следующим: клиент выражает себя путем ввода текста через клавиатуру, например, клиент вводит: “Сколько денег на моем сберегательном счете?” на пользовательском интерфейсе кол-центра Интернет-канала одного банка; выражение информации изображения может быть следующим: клиент выражает себя через изображение, например, клиент выражает обнаруженную проблему посредством изображения, снятого для информации об ошибке во время использования некоторого программного обеспечения через средство съемки экрана рабочего стола компьютера; выражение речевой информации может быть следующим: клиент выражает себя через разговор, например, с персоналом клиентской службы по горячей линии службы (кол-центра телефонного канала) банка и спрашивает в разговоре по телефону: “Что конкретно вы думаете? Я не вполне уверен в этом”; и выражение информации анимации (также упоминаемой как “видео”) может быть следующим: клиент качает головой перед камерой, чтобы выразить свое несогласие.
[0058] Как отмечено выше, естественное выражение (информация языка А) клиента автоматически идентифицируется и преобразуется, чтобы получить информацию в форме некоторого языка. Если информация языка А является речевой информацией, информация акустической волны может, например, быть собрана с помощью инструмента моделирования и автоматически идентифицирована или преобразована в некоторый тип (соответствующий речевой информации) языка X посредством системы (интеллектуального робота); если информация языка является графической информацией, графическая пиксельная информация может, например, собираться с помощью инструмента моделирования и автоматически идентифицироваться или преобразовываться в язык X (соответственно информации изображения) посредством системы (интеллектуального робота); если информация языка А является информацией анимации, графическая пиксельная информация и информация скорости изменения изображения могут, например, собираться с помощью инструмента моделирования и автоматически идентифицироваться или преобразовываться в язык X (соответственно информации анимации) посредством системы (интеллектуального робота); и если информация языка А является текстовой информацией, не требуется выполнять никакого преобразования.
[0059] Затем, вышеупомянутая информация языка Х, полученная посредством автоматического преобразования из информации языка А или текстовой информации, для которой не требуется никакого преобразования, “переводится” в регуляризованное стандартное выражение (информацию языка Y), которое может “понимать” компьютер или другие устройства обработки. Информация языка Y может автоматически обрабатываться компьютерной системой решения коммерческих задач.
[0060] Согласно вариантам осуществления настоящего изобретения, регуляризованные коды могут быть использованы для реализации регуляризованного стандартного выражения (информации языка Y). Например, приняты следующие режимы кодирования, включая код отрасли, код деловых операций отрасли, код учреждения, код деловых операций учреждения и код информации выражения.
[0061] (1) Код отрасли
[0062] Основная отрасль (2 буквы, до 26×26=676 основных отраслей)
[0063] Подчиненная отрасль (3 буквы, до 26×26×26p=17576 подчиненных отраслей на основную отрасль)
[0064] (2) Код деловых операций отрасли
[0065] Категория деловых операций отрасли уровня-1 (1-разрядное число 0-9)
[0066] Категория деловых операций отрасли уровня-2 (1-разрядное число 0-9)
[0067] Категория деловых операций отрасли уровня-3 (1-разрядное число 0-9)
[0068] Категория деловых операций отрасли уровня-4 (1-разрядное число 0-9)
[0069] Категория деловых операций отрасли уровня-5 (1-разрядное число 0-9)
[0070] Категория деловых операций отрасли уровня-6 (1-разрядное число 0-9)
[0071] Категория деловых операций отрасли уровня-7 (1-разрядное число 0-9)
[0072] Категория деловых операций отрасли уровня-8 (1-разрядное число 0-9)
[0073] Категория деловых операций отрасли уровня-9 (1-разрядное число 0-9)
[0074] Категория деловых операций отрасли уровня-10 (1-разрядное число 0-9)
[0075] (3) Код учреждения (UID) (24-разрядное число=3-разрядный код страны+3-разрядный номер города+18-разрядный номер учреждения)
[0076] (4) Код деловых операций учреждения
[0077] Категория деловых операций учреждения уровня-1 (0-9)
[0078] Категория деловых операций учреждения уровня-2 (0-9)
[0079] Категория деловых операций учреждения уровня-3 (0-9)
[0080] Категория деловых операций учреждения уровня-4 (0-9)
[0081] Категория деловых операций учреждения уровня-5 (0-9)
[0082] (5) Код информации выражения
[0083] Код типа информации (2-разрядное число 1-99)
[0084] Код языка (использующий RFC3066 стандарт: http://tools.ietf.org/html/rfc3066, например, zh-CN представляет “Упрощенный китайский”)
[0085] Код диалекта (3-разрядное число 1-999)
[0086] Здесь код отрасли представляет отрасли, к которым принадлежит субъект, который обеспечивает услуги, как указано нерегулярным естественным выражением (информацией языка А) от клиента. Например, он может быть представлен посредством 2 букв, охватывая 676 отраслей, и опционально, может быть добавлен подчиненный код отрасли из 3 букв, охватывая дополнительные 17576 подчиненных отраслей на отрасль. Таким путем, код может в основном охватывать все общие отрасли; код деловых операций отрасли представляет потребность в услуге, как указано информацией языка А от клиента, и может также быть представлен арабским числом. Например, 10-разрядное число используется для кодирования крупных категорий деловых операций отрасли; код учреждения представляет объект, который обеспечивает услуги, как указано информацией языка А от клиента, и, например, может обозначать страну и город, где расположено учреждение. Код деловых операций учреждения представляет внутреннее персонализированное подразделение деловых операций субъекта, который предоставляет услуги, для облегчения персонализированного внутреннего управления учреждения. Код информации выражения представляет идентифицирующую информацию собственно информации языка А клиента, которая может включать в себя тип информации, тип языка и т.п., представленные числами и буквами.
[0087] Ниже показаны два примера регуляризованного стандартного выражения (информации языка Y) в соответствии с вышеуказанным способом кодирования:
[0088] Пример 1:
FSBNK27100000000860109558800000000000000000002zh-CN003
[0089] где
[0090] код отрасли представляет собой
[0091] FS=финансовую услугу (основная отрасль)
[0092] BNK=банк (подчиненная отрасль)
[0093] код деловых операций отрасли представляет собой
[0094] 2710000000=категория деловых операций отрасли уровня-1-2 (кредитная карта) Категория деловых операций отрасли уровня-2-7 (настройка кредитной линии) Категория деловых операций отрасли уровня-3-1 (повышение кредитной линии) 000000 (больше нет категорий подразделения)
[0095] Код учреждения представляет собой
[0096] 086010955880000000000000=Код страны 086 (Китай) 010 (Пекин) 955880000000000000 (Головной офис Промышленного и Коммерческого Банка Китая)
[0097] Код деловых операций учреждения представляет собой
[0098] 00000=нет категории деловых операций учреждения (в этой информации языка Y нет категории деловых операций учреждения, самоопределяемой учреждением “Головной офис Промышленного и Коммерческого Банка Китая”, что означает, что: информация языка Y принадлежит полностью категории деловых операций отрасли, которая является универсальной в банковской отрасли.)
[0099] Код информации выражения представляет собой
[00100] 02=речь (типом информации языка А, предоставленной клиентом, является “речь”)
[00101] zh-CN=материковый китайский
[00102] 003=кантонский диалект
[00103] В этом примере, информацией языка А, соответствующей информации языка Y, может быть, например: “Кредитная линия моей кредитной карты является слишком низкой”, “Я хочу повысить мою кредитную линию, “Я хочу понизить мою кредитную линию”, “Мне нужно настроить кредитную линию” и другая речевая информация.
[00104] В некоторых конкретных обстоятельствах применения, особенно в условиях, когда субъект, который предоставляет услугу, определен, вышеуказанные код отрасли, код учреждения и код деловых операций учреждения все могут быть предварительно установлены как значения по умолчанию системы. Иными словами, код деловых операций и код информации выражения получают из информации языка А, предоставленной только клиентом, и в этом случае информация языка Y может быть представлена как “271000000002zh-CN003”; альтернативно, если 3-разрядное число достаточно для представления кода деловых операций отрасли для конкретного приложения, информация языка Y может быть дополнительно представлена как “27102zh-CN003”; кроме того, если только для речевой услуги, она может быть представлена как “271zh-CN003”; если только выражение требований клиента принимается во внимание, а информация типа самого выражения не принимается во внимание, то информация языка Y может даже быть представлена всего лишь как “271”. Пример 2: TVTKT11200000000014047730305000000000001240003fr-CH000
[00105] TV=Служба путешествий (основная отрасль)
[00106] TKT=заказ билетов (подчиненная отрасль)
[00107] 1120000000=Категория деловых операций отрасли уровня-1-1 (авиабилет) Категория деловых операций отрасли уровня-2-1 (замена авиабилета) Категория деловых операций отрасли уровня-3-2 (задержка) 0000000 (больше нет категорий подразделения)
[00108] 001404773030500000000000=код страны 001 (США) 404 (Атланта, шт. Джорджия) 773030500000000000 (Delta Airlines, США)
[00109] 12400=Категория деловых операций учреждения уровня-1-1 (билет со скидкой) Категория деловых операций учреждения уровня-2-2 (несезонное время) Категория деловых операций учреждения уровня-4-4 (Азиатско-Тихоокеанские) 00 (больше нет категорий подразделения)
[00110] 03=изображение (типом информации языка А, предоставленной клиентом, является “изображение”, например, когда клиент выполняет операцию замены авиабилета на официальном веб-сайте Delta и обнаруживает отчет о системной ошибке, он делает снимок экрана в качестве естественного выражения для обращения за помощью в центр обслуживания клиентов Delta.)
[00111] fr-CH=швейцарский французский
[00112] 000=нет диалекта
[00113] В этом примере информацию языка А, соответствующую информации языка Y, получают путем идентификации изображения. Аналогично, при обстоятельствах, где субъект, который предоставляет услуги, определен, вышеуказанный код отрасли и код учреждения могут оба быть предварительно установлены как значения по умолчанию системы. В этом случае информация языка Y может быть представлена как “11200000001240003fr-CH000”; если только выражение требований клиента принимается во внимание, а информация о типе самого выражения не учитывается, то информация языка Y представляется только как “112000000012400”; и в случае, когда 3-разрядное число применяется специально для представления кода деловых операций отрасли, и 3-разрядное число применяется для представления кода деловых операций учреждения, информация языка Y представляется только как “112124”.
[00114] Выше приведены только примеры регуляризованного стандартного выражения (информации языка Y), согласно вариантам осуществления настоящего изобретения, могут использоваться другие разряды кодов и последовательности кодовых конфигураций, а также могут использоваться различные выражения кодов или способы кодирования.
[00115] Естественное выражение (информация языка А) от клиента всегда отражает конкретные требования клиента. Как указано выше, информация языка А клиента сначала автоматически преобразуется в информацию языка Х или информацию языка, для которой не требуется выполнять никакого преобразования (когда информация языка А является текстовой информацией), и затем информация языка Х или текстовая информация языка преобразуется в стандартное выражение в некоторой кодированной форме (информацию языка Y). В приведенных выше примерах, информация языка Y может включать в себя код отрасли, код деловых операций отрасли, код учреждения, код деловых операций учреждения и код информации выражения. Опционально, информация языка А может также включать в себя конкретные параметры категории, которая отражает требования клиента (которые могут упоминаться как “параметры требований”), например: “перевод 5000 юаней некоторому лицу” (Пример 1), “Я хочу посмотреть фильм, называемый “Китайские партнеры”” (Пример 2) и т.д. Конкретный набор кодов требований (например, включающий в себя один или более из вышеупомянутых кода отрасли, кода деловых операций отрасли, кода учреждения, кода деловых операций учреждения и кода информации выражения) соответствует конкретному набору параметров. Как в вышеуказанном Примере 2, если код требования “посмотреть фильм” представляет собой 123, соответствующий набор параметров может также включать в себя параметр: наименование фильма. Тогда информация языка Y, соответствующая информации языка А, представляет собой “123 <Китайские партнеры>”. Код 123 является кодом требования, и пять символов в <> являются параметрами требования. Имеется много способов для разделения кодов требований и параметров требований в информации языка Y, которые могут использовать символ, такой как “<>”, также может быть пробел или упорядочение в конкретном предложении и т.п. Вышеуказанный процесс преобразования информации языка А клиента в информацию в некоторой форме языка, которая может обрабатываться компьютером, может быть реализован посредством метода обработки речевого сигнала, метода идентификации речи, метода идентификации изображения и метода обработки видео, и эти методы могут быть существующими методами. Фактически, принцип кодированного стандартного выражения согласно вариантам осуществления настоящего изобретения может также применяться в обработке идентификации естественного выражения.
[00116] Далее, обработка речевой информации сначала принимается в качестве примера, чтобы ввести обработку идентификации естественного выражения и чтобы дополнительно проиллюстрировать применение технической концепции настоящего изобретения в обработке идентификации естественного выражения. Фиг. 6 иллюстративно показывает процесс обработки речевой информации. В ходе обработки, реализуется обработка от языка А к языку D. Следует отметить, что соответствующее соотношение между информацией “языка Х” и информацией “языка А” и соответствующее соотношение между информацией “языка Х” и информацией “языка В” на фиг. 6 иллюстрируются только для примера.
[00117] Язык А, а именно, акустическая волна, является данными на физическом уровне, собранными устройством улавливания акустической волны (например, микрофоном).
[00118] Язык Х является данными на первом логическом уровне, полученными после обработки речевого сигнала над данными языка А, которые упоминаются здесь как “язык Х”. Язык Х является языком, сформированным различными перестановками и комбинациями элементов Х. Элементы X являются различными столбчатыми элементами, имеющими разные высоты, сформированными автоматической локализацией акустической волны посредством некоторого инструмента моделирования, такого как гауссова модель смеси (GMM). Фиг. 7 показывает пример преобразования уловленной акустической волны (показанной гистограммой) в элементы X (показанные векторной гистограммой квантования) с использованием гауссовой модели смеси.
[00119] На основе различных инструментов моделирования, применяемых к различным наборам естественной речи, количество элементов X может управляться в некотором диапазоне (например, ниже 200). Согласно вариантам осуществления настоящего изобретения, комбинация 2-разрядных ASCII-символов определена как ID элементов X, как показано на фиг. 8. Иными словами, количество элементов X может быть максимум до 16384 (128×128=16384), что может удовлетворять требование для увеличения числа элементов X ввиду дальнейшего развития метода моделирования акустической волны в будущем. После локализации, единицы акустической волны находятся в соответствии один-к-одному по отношению к элементам X. Поскольку информация языка А может рассматриваться как комбинация единиц акустической волны, и информация языка Х является комбинацией элементов X, соотношение преобразования (или упоминаемое как “идентификация”) от языка А к языку Х на фиг. 6 является соотношением “многие-к-многим”. Фиг. 6 показывает пример элементов X, представленных ASCII-символами.
[00120] “Язык В” является языком, сформированным различными перестановками и комбинациями элементов B, и является данными на втором логическом уровне на фиг. 6. Все или часть перестановок и комбинаций элементов X образуют элементы B, так что это может также пониматься так, как то, что язык Х преобразуется в элементы B, и элементы B образуют язык B. Таким образом, соотношение преобразования из языка Х в язык B является соотношением “многих-к-многим”. Элементы B могут быть фонемами, а некоторые перестановки и комбинации элементов B образуют слоги. “Фонема” и “слог” здесь имеют тот же самый смысл, как в категории лингвистики. Фиг. 6 показывает примеры элементов В, и эти примеры являются фонемами китайского языка (мандаринский диалект).
[00121] “Язык С” является языком, сформированным посредством различных перестановок и комбинаций элементов C и является данными на третьем логическом уровне на фиг. 6. Все или часть перестановок и комбинаций элементов B формируют элементы C, так что это также может пониматься таким образом, что язык В преобразуется в элементы С, и элементы C образуют язык С. Таким образом, соотношение преобразования из языка B в язык C является соотношением “многих-к-многим”. Если далее используется лингвистическая система из фонем и слогов, элементы С соответствуют “символам” в естественном языке. Фиг. 6 показывает примеры элементов C, и эти примеры являются символами (иероглифами) в китайском языке.
[00122] “Язык D” является языком, сформированным посредством различных перестановок и комбинаций элементов D и является данными на четвертом логическом уровне на фиг. 6. Все или часть перестановок и комбинаций элементов C формируют элементы D, так что это также может пониматься таким образом, что язык C преобразуется в элементы D, и элементы D образуют язык D. Таким образом, соотношение преобразования из языка C в язык D является соотношением “многих-к-многим”. Если далее используется лингвистическая система из фонем и слогов, элементы D соответствуют “словам” или “фразам” в естественном языке. Фиг. 6 показывает примеры элементов D, и эти примеры являются словами в китайском языке.
[00123] Пример “языка С” и пример “языка D” на фиг. 6 представляются имеющими то же самое содержание, оба составлены из 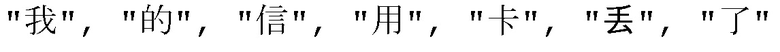 в последовательности, но знакомые с китайским языком могут знать, что понимание, обеспеченное только в соответствии с языком С, может создать высокую степень неоднозначности, а выражение, после преобразования в “язык D”, может иметь определенный смысл. Для других языков, преобразования символы→слова или фразы также весьма важны для понимания семантики, в частности, в случае, где идентификация речи реализуется интеллектуальной системой (речевым роботом). В соответствии с различными естественными языками, “символы” и “слова”, т.е., информация языка С и информация языка D могут также быть классифицированы как тот же самый уровень информации языка.
в последовательности, но знакомые с китайским языком могут знать, что понимание, обеспеченное только в соответствии с языком С, может создать высокую степень неоднозначности, а выражение, после преобразования в “язык D”, может иметь определенный смысл. Для других языков, преобразования символы→слова или фразы также весьма важны для понимания семантики, в частности, в случае, где идентификация речи реализуется интеллектуальной системой (речевым роботом). В соответствии с различными естественными языками, “символы” и “слова”, т.е., информация языка С и информация языка D могут также быть классифицированы как тот же самый уровень информации языка.
[00124] “Язык Y” является данными на четвертом логическом уровне (как показано на фиг. 8), который относится к информации языка, воплощающей “смысл” или “смыслы”, полученные после понимания информации А исходного естественного языка. “Стандартное выражение”, определенное выше в настоящем изобретении, является формой “языка Y”. Согласно вариантам осуществления настоящего изобретения, например, банковская отрасль может использовать код деловых операций “21”, чтобы представлять смысл “сообщения о потере кредитной карты”; использовать код деловых операций “252”, чтобы представлять смысл “частичного погашения кредитной карты”, и “252-5000” (код требования = 252, и параметр требования=5000), чтобы представлять смысл “погашения 5000 юаней для кредитной карты”; отрасль развлечений может использовать код “24”, чтобы представлять смысл “просмотра фильма”, и “24-Китайские партнеры” (код требования=24, и параметр требования=“Китайские партнеры”), чтобы представлять смысл “просмотра фильма, называемого “Китайские партнеры””. Таким образом, соотношение преобразования из языка D в язык Y также является соотношением “многих-к-многим”.
[00125] Фиг. 9 схематично показывает процесс преобразования из уловленной акустической волны (информации языка А) в информацию языка Y от уровня к уровню. Из фиг. 9 можно видеть, что пять раз выполняется преобразование (перевод) на шести типах информации языка, из “акустической волны” (информации языка А) в “элементы X” (информацию языка Х), затем в “фонемы” (информацию языка В), затем в “символы” (информацию языка С), затем в “слова” (информацию языка D) и, наконец, в “смысл” или “смыслы” (информацию языка Y). С точки зрения структуры данных базы данных, это начинается с “акустической волны” в качестве исходной информации языка A и выбирает части перестановок и комбинаций составных элементов пяти языков, чтобы отыскать или соответствовать шестому типу данных информации языка, а именно, информации целевого языка Y.
[00126] Поскольку необходимо выполнять вышеупомянутые пять раз преобразований информации языка, также требуется, чтобы робот имел способность осуществлять пять типов преобразования информации языка. В общем, пятиэтапное преобразование может быть разделено на три стадии. На трех стадиях, чтобы обучать речевой робот, всегда требуется идентификация с ручной поддержкой.
[00127] Первая стадия: из информации языка А (акустическая волна) в информацию языка С (символы). Двухэтапное преобразование из информации языка А (акустической волны) в информацию языка В (фонемы), с помощью алгоритмов извлечения и преобразования информации (таких как вышеупомянутая гауссова модель смеси) информации языка X, обычно может быть выполнено автоматически роботом более точно. Однако в преобразовании из информации языка В (фонемы) в информацию языка С (символы) может возникнуть более высокая частота ошибок. Например, в китайском языке, как показано в примере на фиг. 6, исходная информация языка, введенная клиентом, представляет собой  (ракетка для теннисного стола продана)”, но, вероятно, из-за произношения или акцента клиента,
(ракетка для теннисного стола продана)”, но, вероятно, из-за произношения или акцента клиента,  может быть идентифицировано как
может быть идентифицировано как  , и
, и  может быть идентифицировано как
может быть идентифицировано как 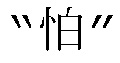 ; в результате акустическая волна будет преобразована в конечном счете в семь символов, а именно,
; в результате акустическая волна будет преобразована в конечном счете в семь символов, а именно,  . Чтобы улучшить точность идентификации робота, особенно по отношению к проблемам, таким как вышеупомянутые произношение или акцент, результат идентификации робота должен корректироваться, обычно с помощью идентификации с ручной поддержкой. Идентификация с ручной поддержкой на этой стадии упоминается как транскрипция. Так называемая транскрипция относится к тому, что транскрибирующий персонал, с использованием конкретных инструментов, выполняет точную локализацию на “акустической волне” (информации языка А) и преобразует диапазоны волны, полученные локализацией, в соответствующие “символы” (информацию языка С), тем самыми определяя соотношение преобразования/перевода между языком А (акустической волной) и языком С (символами) для робота. Точность локализации главным образом зависит от скрупулезности транскрибирующего персонала и знания инструментов транскрипции; и возможность точного преобразования в соответствующие “символы” зависит от точности понимания транскрибирующим персоналом языковой среды, в которой находится эта акустическая волна, и контекста (других акустических волн перед и после данной акустической волны). Особенно для китайских иероглифов, имеется много иероглифов, имеющих то же самое произношение, что увеличивает трудность в точной работе транскрибирующего персонала.
. Чтобы улучшить точность идентификации робота, особенно по отношению к проблемам, таким как вышеупомянутые произношение или акцент, результат идентификации робота должен корректироваться, обычно с помощью идентификации с ручной поддержкой. Идентификация с ручной поддержкой на этой стадии упоминается как транскрипция. Так называемая транскрипция относится к тому, что транскрибирующий персонал, с использованием конкретных инструментов, выполняет точную локализацию на “акустической волне” (информации языка А) и преобразует диапазоны волны, полученные локализацией, в соответствующие “символы” (информацию языка С), тем самыми определяя соотношение преобразования/перевода между языком А (акустической волной) и языком С (символами) для робота. Точность локализации главным образом зависит от скрупулезности транскрибирующего персонала и знания инструментов транскрипции; и возможность точного преобразования в соответствующие “символы” зависит от точности понимания транскрибирующим персоналом языковой среды, в которой находится эта акустическая волна, и контекста (других акустических волн перед и после данной акустической волны). Особенно для китайских иероглифов, имеется много иероглифов, имеющих то же самое произношение, что увеличивает трудность в точной работе транскрибирующего персонала.
[00128] Вторая стадия: из информации языка С (символы) в информацию языка D (слова, фразы). Преобразование от символов к словам также открыто для различных интерпретаций, как в предыдущем примере, даже если идентификация из акустической волны в символы является точной, и получен результат из отдельных символов  , упорядоченных в последовательность, по меньшей мере два результата преобразования могут быть сгенерированы, а именно,
, упорядоченных в последовательность, по меньшей мере два результата преобразования могут быть сгенерированы, а именно, 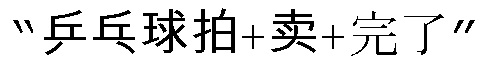 и
и 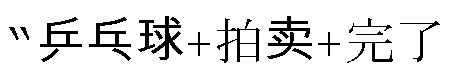 ”, которые могут иметь очевидно разные смыслы. Аналогичным образом, идентификация с ручной поддержкой может быть принята для выполнения уточнения. Идентификация с ручной поддержкой на этой стадии упоминается как локализация ключевых слов и может также называться “локализацией слов” для краткости; то есть, персонал по локализации слов комбинирует “символы” (информацию языка C), полученные через транскрипцию, чтобы формировать “слова (ключевые слова)” (информацию языка D), тем самым определяя соотношение преобразования/перевода между языком C (символами) и языком D (словами) для робота. То, является ли локализация точной, часто зависит от степени мастерства персонала по локализации слов в области знаний деловых операций. По отношению к различным областям, персонал, знакомый с содержанием деловых операций и терминологией в этой области, необходим для выполнения операции локализации слов, и ее стоимость тем выше, чем таковая для транскрипции.
”, которые могут иметь очевидно разные смыслы. Аналогичным образом, идентификация с ручной поддержкой может быть принята для выполнения уточнения. Идентификация с ручной поддержкой на этой стадии упоминается как локализация ключевых слов и может также называться “локализацией слов” для краткости; то есть, персонал по локализации слов комбинирует “символы” (информацию языка C), полученные через транскрипцию, чтобы формировать “слова (ключевые слова)” (информацию языка D), тем самым определяя соотношение преобразования/перевода между языком C (символами) и языком D (словами) для робота. То, является ли локализация точной, часто зависит от степени мастерства персонала по локализации слов в области знаний деловых операций. По отношению к различным областям, персонал, знакомый с содержанием деловых операций и терминологией в этой области, необходим для выполнения операции локализации слов, и ее стоимость тем выше, чем таковая для транскрипции.
[00129] Третья стадия: от информации языка D к информации языка Y, т.е. понимание смысла. Если просто получены несколько слов, упорядоченных в последовательности, истинный смысл, предполагаемый клиентом, часто все еще не может быть точно понят. Например, клиент говорит:  (Моя кредитная карта потеряна)”, робот не может идентифицировать смысл этого, и техник вводит
(Моя кредитная карта потеряна)”, робот не может идентифицировать смысл этого, и техник вводит  ,
,  и
и 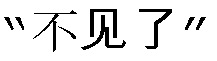 в синтаксическую таблицу базы данных в качестве новых ключевых слов; а другой клиент говорит:
в синтаксическую таблицу базы данных в качестве новых ключевых слов; а другой клиент говорит: 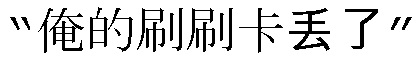 , робот вновь не может идентифицировать смысл этого, и техник вводит
, робот вновь не может идентифицировать смысл этого, и техник вводит  ,
,  (что означает
(что означает  ), и
), и  в синтаксическую таблицу базы данных в качестве новых ключевых слов. Таким путем, с помощью ручной поддержки, смысл или требования клиента поняты и введены в базу данных. Эта идентификация с ручной поддержкой называется скоплением ключевых слов или “скоплением слов” для краткости, а именно, перестановки и комбинации “слов” накапливаются и вводятся в базу данных в соответствии с их значениями. Рабочая нагрузка такой задачи огромна, и квалификация обучающего персонала также требуется, чтобы способствовать пониманию.
в синтаксическую таблицу базы данных в качестве новых ключевых слов. Таким путем, с помощью ручной поддержки, смысл или требования клиента поняты и введены в базу данных. Эта идентификация с ручной поддержкой называется скоплением ключевых слов или “скоплением слов” для краткости, а именно, перестановки и комбинации “слов” накапливаются и вводятся в базу данных в соответствии с их значениями. Рабочая нагрузка такой задачи огромна, и квалификация обучающего персонала также требуется, чтобы способствовать пониманию.
[00130] Как указано выше, в способе обработки естественного выражения согласно вариантам осуществления настоящего изобретения, естественное выражение клиента (информация языка А) сначала автоматически преобразуется, чтобы получить информацию языка Х, или никакое преобразование не требуется, чтобы непосредственно получить информацию языка С (если информация языка А является текстовой информацией); и затем информация языка Х или информация языка С преобразуется в информацию языка Y. Со ссылкой на предшествующий анализ, нерегулярное естественное выражение может быть одним из информации языка Х, информации языка В, информации языка С и информации языка D. Иными словами, процесс обработки естественного выражения может быть одним из: A→X→Y, A→B→Y, A→C→Y и A→D→Y.
[00131] Если, в соответствии с моделью преобразования информации языка, показанной на фиг. 9, необходимо выполнять многоуровневое преобразование соотношения “многие-к-многим” над вышеупомянутыми шестью типами языков A→X→B→C→D→Y, это теоретически называется многоуровневым осмыслением (MLP), как показано на фиг. 10. Недостаток многоуровневого преобразования соотношения “многие-к-многим” состоит в следующем: каждый раз преобразование будет вызывать искажение исходной информации в некоторой степени и будет добавлять больше нагрузки обработки в системе, что приводит в результате к дополнительной потере в эффективности. Большее количество раз преобразования вызывает более серьезное искажение исходной информации, так что скорость обработки системы снижается. Аналогичным образом, поскольку вмешательство с ручной поддержкой требуется в тренировке робота на всех трех вышеупомянутых стадиях, очень высокая рабочая нагрузка и затраты будут производиться, с одной стороны, а с другой стороны, многократное вмешательство человека будет также увеличивать вероятность ошибок. Поэтому, если может быть реализовано преобразование A→X→Y, а многоуровневое преобразование “многие-к-многим” X→B→C→D→Y опускается, точность и эффективность преобразования информации выражения может быть улучшена, и рабочая нагрузка и частота ошибок идентификации с ручной поддержкой могут также быть снижены.
[00132] В соответствии с методом настоящего изобретения, сначала, нерегулярная информация естественного выражения, такая как текст, речь, изображение или видео, преобразуется в информацию языка Х посредством инструмента моделирования; затем, с языком Х в качестве языка на левой стороне и языком Y в качестве языка на правой стороне, преобразование из информации языка Х в информацию языка Y реализуется с использованием метода машинного перевода (MT).
[00133] Более конкретно, например, при обработке нерегулярной информации естественного выражения, такой как речь, метод “обработки речевого сигнала” сначала используется, чтобы автоматически преобразовывать/переводить на язык Х (на основе современного метода “обработки речевого сигнала”, показатель точности преобразования A→X может в общем случае достигать 95%, и усовершенствованный метод “обработки речевого сигнала” работает лучше при снижении шумов и может увеличить показатель точности преобразования A→X до 99%); и затем метод машинного перевода может быть использован, чтобы реализовать автоматический машинный перевод X→Y, без необходимости многоуровневого преобразования X→B→C→D→Y.
[00134] Алгоритм машинного перевода, сходный со статистическим анализом над выборками класса, может быть использован для преобразования нерегулярного естественного выражения (информации языка Х), полученного через преобразование, в регуляризованное стандартное выражение (информацию языка Y). Этот алгоритм машинного перевода требует достаточного количества и достаточной точности соответствующих данных между языком Х и языком Y.
[00135] В способе согласно настоящему изобретению, с учетом того, что точное автоматическое машинное преобразование A→X может быть реализовано, чтобы накопить соответствующие данные между языком Х и языком Y, накапливаются соответствующие данные между языком А и языком Y. Таким образом, решение согласно настоящему изобретению обеспечивает новый рабочий режим агента ручной поддержки, а именно, понимание на основе ручной поддержки (MAU), который реализует накопление соответствующих данных между языком А и языком Y посредством понимания на основе ручной поддержки в комбинации с вводом кода. Как в предыдущем примере, код требования “271” может быть использован, чтобы выразить смысл настройки кредитной линии кредитной карты, и аналогично, “21” может также быть использован, чтобы выразить смысл сообщения о потере кредитной карты, и, таким образом, “21” может быть использован, чтобы соответствовать вышеупомянутой информации естественного выражения  или
или  . Такой простой способ ввода кода, традиционный “агенты с диалогом” превращается в “агенты без диалога”, так что работа агентов становится более комфортной, способность человеческого понимания наивысшей степени используется более полно при значительном повышении эффективности работы, и огромное количество соответствующих данных между языком A/Х и языком Y собирается быстро и точно; данные подаются на MT-процессор для циклической итерации, самообучения правила преобразования/перевода A/X→Y и формирования модели перевода A/X→Y.
. Такой простой способ ввода кода, традиционный “агенты с диалогом” превращается в “агенты без диалога”, так что работа агентов становится более комфортной, способность человеческого понимания наивысшей степени используется более полно при значительном повышении эффективности работы, и огромное количество соответствующих данных между языком A/Х и языком Y собирается быстро и точно; данные подаются на MT-процессор для циклической итерации, самообучения правила преобразования/перевода A/X→Y и формирования модели перевода A/X→Y.
[00136] Ниже введены принципы метода машинного перевода и метод тренировки робота машинного перевода в соответствии с настоящим изобретением.
[00137] Машинный перевод представляет собой метод искусственного интеллекта для автоматического перевода двух языков. “Язык”, упоминаемый здесь, не является узко определенным национальным языком (например: китайский, английский…), а является обобщенным режимом представления информации. Как упомянуто выше, в отношении режима представления, язык может быть разделен на четыре основные категории: текст, речь, изображение, анимация (также упоминается как “видео”).
[00138] Язык представляет собой информацию, образованную различными перестановками и комбинациями элементов в наборе элементов. Например: английский текст является языком, сформированным 128 ASCII-символами (элементами) в наборе ASCII-символов (наборе элементов) посредством различных одномерных (последовательных) перестановок и комбинаций; китайский язык сформирован бесконечными перестановками и комбинациями тысячи символов в комбинации с пунктуациями в международных кодах (базовые элементы, составляющие информацию на китайском языке); и, в качестве другого примера, RGB плоское изображение является еще одним языком, образованным тремя суб-пикселами, включающими красный, зеленый и синий, посредством различных двумерных (по длине и ширине) перестановок и комбинаций.
[00139] Если некоторое правило преобразования/перевода существует между любыми двумя языками, автоматическое правило преобразования/перевода между двумя языками может быть найдено посредством анализа соответствующего соотношения между перестановками и комбинациями двух элементов языка. Сначала требуется вручную собрать соответствующие данные (или “образцы перевода”) двух языков, затем найти автоматическое правило преобразования/перевода между двумя языками посредством циклической итерации перестановок и комбинаций двух элементов языка, чтобы сформировать модель перевода двух языков.
[00140] Два набора данных требуются для выполнения машинного перевода: “тренировочный набор данных” и “тестовый набор данных”.
[00141] Два набора данных имеют сходную структуру данных: сохранены пары данных, в которых левое значение является “левым языком” (или упоминается как “исходный язык”), и правое значение является “правым языком” (или упоминается как “целевой язык”). Можно привести образную аналогию: “тренировочный набор данных” является самоучителем, предоставляемым человеком MT-роботу, а “тестовый набор данных” является тестовым вопросом, задаваемым человеком MT-роботу, для оценивания результата самообучения робота.
[00142] Ниже приведен пример “тренировочного набора данных” и “тестового набора данных” для англо→китайского MT:
ТРЕНИРОВОЧНЫЙ НАБОР ДАННЫХ
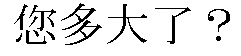




ТЕСТОВЫЙ НАБОР ДАННЫХ

[00143] MT-робот выполняет циклическую итерацию на перестановках и комбинациях, беря элементы, составляющие язык, в качестве единиц. Как в приведенном выше примере, посредством двух пар данных #3 и #4 в обучающем наборе данных найдено, что перестановки и комбинации 15 элементов ASCII-символов (3 английских буквы “May” (могу)+1 пробел+1 английская буква “I” (я)+1 пробел+4 английских буквы “have” (узнать)+1 пробел+4 английских буквы “your” (Ваш)) английской фразы “May I have your” соответствуют перестановкам и комбинациям трех китайских иероглифов  GB кодов; и посредством двух пар данных #2 и #5 в обучающем наборе данных найдено, что перестановки и комбинации 3 элементов ASCII-символов английского “age” соответствуют перестановкам и комбинациям 2 китайских иероглифов
GB кодов; и посредством двух пар данных #2 и #5 в обучающем наборе данных найдено, что перестановки и комбинации 3 элементов ASCII-символов английского “age” соответствуют перестановкам и комбинациям 2 китайских иероглифов  GB кодов.
GB кодов.
[00144] Поэтому, если робот может перевести английскую фразу “May I have your age?” в обучающем наборе данных на китайский язык  точно, это доказывает, что робот обучен этому англо-китайскому переводу данного предложения; а в противном случае, это доказывает, что робот не обучен этому. Затем роботу нужно перепроверить свой метод обучения (например, найти другой путь для повторного обучения), для которого обучающий набор данных снова систематизирован, и это является следующей итерацией; … если это “итеративное изменение” постоянно повторяется, степень точности перевода робота постоянно повышается. Когда степень точности перевода повысится до некоторой степени (например, степень точности перевода равна 70%), степень точности перевода робота может зависать около этого уровня, и является затруднительным повышать его далее; то есть, обнаруживается узкое место в “самообучении робота”, и затем, необходимо увеличить данные в тренировочном (обучающем) наборе данных МТ для робота. Данные в тренировочном наборе данных МТ могут быть импортированы из внешней базы данных и могут также генерироваться или добавляться через “понимание на основе ручной поддержки”.
точно, это доказывает, что робот обучен этому англо-китайскому переводу данного предложения; а в противном случае, это доказывает, что робот не обучен этому. Затем роботу нужно перепроверить свой метод обучения (например, найти другой путь для повторного обучения), для которого обучающий набор данных снова систематизирован, и это является следующей итерацией; … если это “итеративное изменение” постоянно повторяется, степень точности перевода робота постоянно повышается. Когда степень точности перевода повысится до некоторой степени (например, степень точности перевода равна 70%), степень точности перевода робота может зависать около этого уровня, и является затруднительным повышать его далее; то есть, обнаруживается узкое место в “самообучении робота”, и затем, необходимо увеличить данные в тренировочном (обучающем) наборе данных МТ для робота. Данные в тренировочном наборе данных МТ могут быть импортированы из внешней базы данных и могут также генерироваться или добавляться через “понимание на основе ручной поддержки”.
[00145] Например, в предыдущем примере деловых операций с кредитной картой, если предположить, что полученным нерегулярным естественным выражением является  (предел превышения кредита моей кредитной карты является слишком низким)”, и если понимание робота является недостаточно зрелым, то можно применить “понимание на основе ручной поддержки”, так что выражение может быть понято как
(предел превышения кредита моей кредитной карты является слишком низким)”, и если понимание робота является недостаточно зрелым, то можно применить “понимание на основе ручной поддержки”, так что выражение может быть понято как  (Я хочу повысить кредитную линию кредитной карты)” вручную, и соответствующая информация языка Y вводится. Опционально, во время обработки “понимания на основе ручной поддержки”, процесс понимания и результат понимания для естественного выражения не требуется записывать, и только соответствующее стандартное выражение (информация языка Y) записывается в качестве окончательного результата обработки. Таким способом, ручная операция упрощается, и ресурсы сберегаются. Например, оператору требуется только ввести “271” в качестве стандартного выражения, чтобы завершить обработку нерегулярного естественного выражения
(Я хочу повысить кредитную линию кредитной карты)” вручную, и соответствующая информация языка Y вводится. Опционально, во время обработки “понимания на основе ручной поддержки”, процесс понимания и результат понимания для естественного выражения не требуется записывать, и только соответствующее стандартное выражение (информация языка Y) записывается в качестве окончательного результата обработки. Таким способом, ручная операция упрощается, и ресурсы сберегаются. Например, оператору требуется только ввести “271” в качестве стандартного выражения, чтобы завершить обработку нерегулярного естественного выражения  (предел превышения кредита моей кредитной карты является слишком низким)”. Например, новый экземпляр естественного выражения, такого как вышеуказанное естественное выражение
(предел превышения кредита моей кредитной карты является слишком низким)”. Например, новый экземпляр естественного выражения, такого как вышеуказанное естественное выражение  (предел превышения кредита моей кредитной карты является слишком низким)” и соответствующее стандартное выражение “271” добавляются к существующему тренировочному набору данных МТ, тем самым увеличивая и обновляя данные в тренировочном наборе данных МТ. Таким образом, через “понимание на основе ручной поддержки”, может быть достигнуто, с одной стороны, точное и стабильное преобразование на целевом естественном выражении (преобразованном в стандартное выражение, а именно информацию языка Y), и может быть достигнуто, с другой стороны, эффективное добавление и обновление данных в тренировочном наборе данных МТ, так что данные в тренировочном наборе данных системы МТ становятся обогащенными и более точными, степень точности перевода (преобразования) робота может также быть эффективно улучшена.
(предел превышения кредита моей кредитной карты является слишком низким)” и соответствующее стандартное выражение “271” добавляются к существующему тренировочному набору данных МТ, тем самым увеличивая и обновляя данные в тренировочном наборе данных МТ. Таким образом, через “понимание на основе ручной поддержки”, может быть достигнуто, с одной стороны, точное и стабильное преобразование на целевом естественном выражении (преобразованном в стандартное выражение, а именно информацию языка Y), и может быть достигнуто, с другой стороны, эффективное добавление и обновление данных в тренировочном наборе данных МТ, так что данные в тренировочном наборе данных системы МТ становятся обогащенными и более точными, степень точности перевода (преобразования) робота может также быть эффективно улучшена.
[00146] Теоретически, робот MT должен исчерпывающим образом перечислить все перестановки и комбинации 20 элементов ASCII-символов левого значения #3 “May I have your time” (могу я узнать Ваш возраст), а также должен исчерпывающим образом перечислить все перестановки и комбинации 10 GB кода китайских иероглифов правого значения #3  . То есть, робот МТ должен исчерпывающим образом перечислить все перестановки и комбинации левой и правой групп элементов каждой пары данных в тренировочном наборе данных. Через перечисление исчерпывающим образом на уровне элементов, робот MT должен быть способен найти множество повторяющихся перестановок и комбинаций (таких как “your”, “May I have your”, “age”, “time”,
. То есть, робот МТ должен исчерпывающим образом перечислить все перестановки и комбинации левой и правой групп элементов каждой пары данных в тренировочном наборе данных. Через перечисление исчерпывающим образом на уровне элементов, робот MT должен быть способен найти множество повторяющихся перестановок и комбинаций (таких как “your”, “May I have your”, “age”, “time”,  ,
,  ,
, 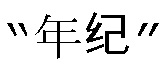 …), чтобы найти определенное соответствующее соотношение между перестановками и комбинациями левых элементов языка и перестановками и комбинациями правых элементов языка, которые представляются повторяющимися, т.е., модель перевода между двумя языками. Другими словами, большее количество пар данных левого и правого языка в тренировочном наборе данных дает большее количество перестановок и комбинаций элементов левого и правого языка, представляющихся повторяющимися, как найдено роботом МТ, большее количество соответствующих соотношений между перестановками и комбинациями левых и правых элементов, представляющихся повторяющимися, и, таким образом, большее количество правил преобразования/перевода левого и правого языка, освоенных роботом МТ, тем самым обеспечивая более зрелую модель перевода. Поэтому с “регуляризованным стандартным выражением” и “пониманием на основе ручной поддержки” в соответствии с техническим принципом настоящего изобретения, данные тренировочного набора данных МТ могут накапливаться более эффективно, таким образом, помогая достичь самообучения и автоматического машинного перевода робота.
…), чтобы найти определенное соответствующее соотношение между перестановками и комбинациями левых элементов языка и перестановками и комбинациями правых элементов языка, которые представляются повторяющимися, т.е., модель перевода между двумя языками. Другими словами, большее количество пар данных левого и правого языка в тренировочном наборе данных дает большее количество перестановок и комбинаций элементов левого и правого языка, представляющихся повторяющимися, как найдено роботом МТ, большее количество соответствующих соотношений между перестановками и комбинациями левых и правых элементов, представляющихся повторяющимися, и, таким образом, большее количество правил преобразования/перевода левого и правого языка, освоенных роботом МТ, тем самым обеспечивая более зрелую модель перевода. Поэтому с “регуляризованным стандартным выражением” и “пониманием на основе ручной поддержки” в соответствии с техническим принципом настоящего изобретения, данные тренировочного набора данных МТ могут накапливаться более эффективно, таким образом, помогая достичь самообучения и автоматического машинного перевода робота.
[00147] В настоящем изобретении, машинный перевод между языком Х→языком Y имеет тот же принцип, что и при машинном переводе между китайским языком и английским языком, за исключением того, что английский заменен на язык Х, а китайский язык – на язык Y, и соответственно наборы элементов левого и правого языков различны.
[00148] Как отмечено выше, метод машинного перевода может быть использован для автоматического перевода одного языка на другой язык. Технический принцип этого состоит в том, чтобы выполнять анализ на уровне базовых элементов на собранной информации образования пар для двух языков (языка А с левой стороны и языка с правой стороны), путем выполнения итеративного сравнения на различных перестановках и комбинациях на базовых элементах большого количества языковых пар, чтобы найти правила преобразования/перевода между двумя языками, тем самым формируя модель преобразования двух языков.
[00149] Настоящее изобретение распространяет объем применения метода машинного перевода от автоматического перевода между различными национальными языками на автоматическое преобразование от всей нерегулярной мультимедийной информации естественного выражения (текста, речи, изображения или видео, а именно, информации языка А) в регулярную стандартную информацию (информацию языка Y), так что она может быть обработана системами для решения коммерческих задач различных секторов, чтобы реализовать практическую обработку естественного языка (NLP) в истинном смысле.
[00150] Поскольку многоуровневый лингвистический анализ, необходимый для традиционного машинного перевода, не требуется, с анализом экземпляров на уровне базовых элементов точность и скорость перевода может быть повышена, и обновление и расширение могут также быть легко достигнуты путем добавления экземпляров естественного выражения и стандартного выражения.
[00151] В отношении обработки естественного выражения согласно вариантам осуществления настоящего изобретения, поскольку необходимо только преобразование от естественного выражения (информации языка A) в стандартное выражение (речевую информацию Y), иными словами, требуется только установить модель перевода A/X→Y, без необходимости обработки результата перевода языка текста, не требуется выполнять модификации обработки над результатом перевода.
[00152] В дополнение, обработка естественного выражения согласно вариантам осуществления настоящего изобретения может быть ограничена использованием в конкретных коммерческих задачах специфических секторов и учреждений, например, в вышеуказанных деловых операциях с кредитными картами, так что масштаб тренировочного набора данных МТ, требуемого системой обработки, может быть значительно уменьшен. Таким образом порог зрелости для понимания робота повышается, затраты на создание и поддержание тренировочного набора данных МТ сокращаются, и период достижения зрелости для модели перевода A/X→Y эффективно уменьшается.
[00153] Как отмечено выше, система обработки естественного выражения согласно вариантам осуществления настоящего изобретения реализует преобразование из естественного выражения в кодированное стандартное выражение. Преобразование основано на тренировочном наборе данных МТ, хранящем парные данные языка A/Х и информации языка Y, и модели перевода A/X→Y, полученной на основе тренировочного набора данных МТ. Поэтому требуется собрать некоторое количество точных данных языка A/Х и языка Y, чтобы генерировать тренировочный набор данных МТ, и сформировать модель перевода A/X→Y посредством самообучения (само-тренировки) робота (системы обработки информации). Формирование тренировочного набора данных МТ может проводиться через понимание с ручной поддержкой.
[00154] Фиг. 1 схематично показывает блок-схему последовательности действий способа обработки естественного выражения в соответствии с одним вариантом осуществления настоящего изобретения.
[00155] На этапе S11 система принимает информацию естественного выражения (информацию языка А) и, как изложено выше, информация естественного выражения может быть текстовой информацией, речевой информацией, информацией изображения, информацией видео и т.д.
[00156] На этапе S21 определяется, является ли понимание робота зрелым. Здесь, основой определения, является ли понимание робота зрелым, является то, что в течение определенного временного интервала (установленного в соответствии с конкретными требованиями приложения), результат Y1, полученный через преобразование, роботом, информации языка А в информацию языка Х, и затем преобразование информации языка Х в информацию языка Y, сравнивается с результатом Y2, полученным посредством прямого ручного преобразования информации языка А в информацию языка Y, и число раз, когда Y1 и Y2 являются одинаковыми друг с другом, делится на общее число раз, чтобы получить процент, который является степенью точности понимания робота. Степень точности понимания робота, устанавливаемая в соответствии с требованиями приложения, упоминается как “порог зрелости понимания робота”. Если степень точности понимания робота ниже, чем порог зрелости понимания робота, система считает, что понимание робота еще не зрелое, и далее принимается результат Y2 ручного преобразования вместо результата Y1 преобразования робота, чтобы гарантировать точность и стабильность понимания системой информации языка А. В то же время, система добавляет информацию языка Х (языка на левой стороне), полученную посредством автоматического машинного преобразования, выполненного над информацией языка А машиной, и результат Y2 ручного преобразования (языка на правой сторон) в тренировочный набор данных МТ для использования в само-тренировке MT робота.
[00157] Если понимание робота является зрелым, на этапе S22, робот автоматически преобразует естественное выражение A в стандартное выражение Y непосредственно; и если понимание робота не является зрелым, на этапе S23, робот пытается преобразовать естественное выражение A в стандартное выражение Y1, и в то же самое время, на этапе S24, MAU-агент преобразует естественное выражение A в стандартное выражение Y2.
[00158] На этапе S32, если на этапе S21 определено, что способность понимания робота уже стала зрелой, выводится результат Y автоматического преобразования робота; и в противном случае, выводится результат Y2 ручного преобразования MAU-агента.
[00159] Опционально, на этапе S31, выполняется последующая обработка над естественным выражением A, результатом Y1 попытки преобразования роботом и результатом Y2 ручного преобразования MAU-агентом путем помещения информации языка Х (языка на левой стороне), автоматически преобразованной из А, вместе с Y2 (языком на правой стороне), в тренировочный набор данных МТ в качестве пары для новых парных данных; и сравнение Y1 с Y2, чтобы служить в качестве статистических данных для “определения, является ли понимание робота зрелым”. Опционально, исходные данные A сохраняются, и если метод преобразования A→X дополнительно разрабатывается для обеспечения зрелости (достижения более высокой степени точности преобразования) в будущем, данные языка на левой стороне тренировочного набора данных МТ обновляются.
[00160] Фиг. 2 схематично показывает блок-схему последовательности действий способа обработки естественного выражения и ответа в соответствии с вариантом осуществления настоящего изобретения.
[00161] В обработке, показанной на фиг. 2, как на фиг. 1, естественное выражение A сначала принимается на этапе S12. Затем то, может ли естественное выражение A быть преобразовано в стандартное выражение Y посредством машинного преобразования, определяется на этапе S31. Этот этап эквивалентен этапу S21 на фиг. 1. Аналогично обработке на фиг. 1, если на этапе S31 определено, что желательное стандартное выражение не может быть получено посредством машинного преобразования, то обработка ручного преобразования выполняется на этапе S32.
[00162] В практических применениях, могут существовать случаи, в которых идентифицированное естественное выражение или требование, выраженное клиентом, не может быть понято даже посредством обработки человеком, и в этом случае ответ для предложения клиенту выполнить повторный ввод выполняется на этапе S33, и затем обработка возвращается к этапу S12, где принимается информация А естественного выражения, повторно введенная клиентом. “Ответ для предложения клиенту выполнить повторный ввод” может быть, например, речевыми подсказками: “пожалуйста, повторите то, что Вам требуется”, “не могли бы Вы говорить медленнее?”; текстовыми подсказками: “пожалуйста, напишите более конкретно”; или подсказками изображения.
[00163] На этапе S34 выводится стандартное выражение машинного преобразования или ручного преобразования. На этапе S35 запрашивается стандартный ответ, согласующийся со стандартным выражением. Стандартный ответ может быть фиксированными данными, предварительно сохраненными в базе данных; альтернативно, базовые данные стандартного ответа предварительно сохранены в базе данных, и затем системой базовые данные синтезируются с переменными параметрами индивидуального случая, чтобы генерировать стандартный ответ. В одном варианте осуществления, ID стандартного ответа установлен как основой ключ данных ответа, и соответствующая таблица соотношений между кодами требований стандартного выражения (информации языка Y) и ID стандартного ответа устанавливается в базе данных, так что коды требований стандартного выражения (информации языка Y) ассоциируются с данными ответа. Таблица 1 – Таблица 3 ниже схематично показывают примеры таблицы данных выражений, таблицы соотношений выражений-ответов и таблицы данных ответов, соответственно. Опционально, стандартное выражение и ID стандартного ответа находятся в соотношении многих-к-одному, как показано в Таблице 4. Кроме того, в других вариантах осуществления, так как коды требований стандартного выражения (информации языка Y) сами закодированы, коды требований стандартного выражения (информации языка Y) могут также непосредственно использоваться в качестве основного ключа данных ответа.
[00164] Как отмечено выше, стандартное выражение может включать в себя информацию, связанную с естественным выражением, например, тип выражения, тип языка, тип диалекта и т.д. Например, естественным выражением от клиента является “принятая” речь, стандартным ответом, полученным путем запроса преобразованного стандартного выражения, является речь: “ОК! Я знаю, спасибо!”. В качестве другого примера, естественным выражением от клиента является изображение “скриншот страницы сбоя перевода”; стандартным ответом, полученным путем запроса преобразованного стандартного выражения, является видео “простая инструкция о коррекции ошибки в переводе”.
[00165] Если стандартный ответ, согласующийся со стандартным выражением, не существует в базе данных, соответствующий ответ может быть согласован вручную на этапе S36. Ручное согласование может ассоциировать стандартное выражение с ID стандартного ответа путем ввода или выбора ID стандартного ответа, или ассоциирования стандартного выражения с данными ответа непосредственно, и может также устанавливать новые данные ответа. Причина того, почему стандартный ответ не найден, вероятно, состоит в том, что стандартное выражение вновь добавлено вручную, или, возможно, что тот же самый тип стандартного ответа не согласован. Затем, ответ машинного согласования или машинного согласования выводится на этапе S37. Содержание ответа извлекается или генерируется в соответствии с различными типами информации. Например, для речевого ответа, может быть выполнено воспроизведение живой записи, или выводится речь, для которой выполнен TTS (синтез речи как преобразование текста в речь); для цифровой операции пользователя, такой как последовательная комбинация кнопок телефона “2-5-1000”, операция “возврат 1000 юаней на кредитную карту” завершается выполнением программы.
[00166] Для текстовой информации, такой как “перевод 5000 юаней моей маме”, выполняется операция “Перевод 5000 юаней MS X” путем выполнения программы, но система не может знать информацию о счете “MS X” заранее, и поэтому, с одной стороны, информация о счете должна быть вручную добавлена для реализации преобразования в стандартное выражение, а с другой стороны, даже если преобразование в стандартное выражение реализовано, соответствующий стандартный ответ может не быть запрошен, и потребуется выполнять обработку ответа вручную. В этот момент, данные нового ответа (такие как рабочая процедура) будут генерироваться, новый ID стандартного ответа может также вручную или автоматически назначаться к данным ответа, и ID стандартного ответа ассоциируется с вышеуказанным преобразованным стандартным выражением. Таким образом, хотя ответ для естественного выражения клиента получен, может быть достигнуто понимание с ручной поддержкой и тренировкой, и база данных выражений-ответов обновляется.
[00167] В способе обработки естественного выражения и ответа согласно вариантам осуществления настоящего изобретения, стандартное выражение может быть использовано для быстрого указания на ответ, так что клиенту не требуется больше тратить много времени для прохождения по сложному процедурному меню функций, чтобы отыскивать желательный вариант самообслуживания.
[00168] С другой стороны, в отличие от обычного режима ответа, ручная операция главным образом ограничена фоновым “решением”, что включает в себя определение кодов требований стандартного выражения (информации языка Y) и выбор ответа (или ID ответа) или генерацию операции ответа, не требуя непосредственной приоритетной коммуникации с клиентом по телефону или через текстовый ввод (иной, чем ввод параметров требований стандартного выражения (информации языка Y)). Таким образом, большой объем человеческих усилий может быть сбережен, и эффективность работы может быть заметно повышена. Кроме того, по сравнению с традиционным ответом в свободном стиле, обеспечиваемым агентом ручной поддержки клиенту непосредственно, стандартизованный ответ, обеспечиваемый системой клиенту, не подвержен влиянию многих факторов, включая эмоции агента ручной поддержки, состояние гланд, акцент, профессиональную подготовку, тем самым дополнительно гарантируя стабильность опыта клиента.
[00169] Кроме того, база данных стандартизованных естественных выражений - стандартных выражений – стандартных ответов может быть установлена посредством автоматического обучения, тренировки и понимания с ручной поддержкой системы (робота), чтобы реализовать поэтапное автоматическое понимание и ответ системы. Кроме того, данные естественного выражения в базе данных могут также иметь преимущества, включая малую дисперсность, узкий объем коммерческих задач и высокую достоверность данных, чтобы уменьшить трудности тренировки робота и сократить период достижения зрелости интеллектуальности робота.
[00170] Фиг. 3 схематично показывает интеллектуальную систему ответа согласно вариантам осуществления настоящего изобретения. Как показано на фиг. 3, интеллектуальная система ответа включает в себя интеллектуальное устройство 1 ответа (эквивалентно серверной стороне) и устройство 2 вызова (эквивалентно клиентской стороне), клиент 8 осуществляет связь с интеллектуальным устройством 1 ответа через устройство 2 вызова, и MAU-агент 9 ручной поддержки (обслуживающий персонал системы) выполняет ручную операцию на интеллектуальном устройстве 1 ответа. Здесь, интеллектуальное устройство 1 ответа включает в себя диалоговый шлюз 11, центральный контроллер 12, MAU рабочую станцию 13 и робот 14. Опционально, интеллектуальное устройство 1 ответа дополнительно включает в себя тренажер 15.
[00171] Клиент 8 относится к объекту дистанционных продаж и дистанционной услуги учреждения. Дистанционные продажи обычно относятся к тому, что учреждение активно контактирует с клиентом в форме “исходящего вызова” через его специализированные телефонные или Интернет-каналы и пытается стимулировать продажи своих продуктов и услуг. Дистанционные услуги обычно относятся к тому, что клиент учреждения активно контактирует с учреждением в форме “входящего вызова” через специализированные телефонные или Интернет-каналы учреждения и запрашивает или использует продукты или услуги учреждения.
[00172] Устройство 2 вызова является специализированным телефонным или Интернет-каналом, установленным учреждением, для выполнения дистанционных продаж (услуги исходящего вызова) по клиенту 8 и обеспечения дистанционных услуг (услуги входящего вызова) к клиенту. Система вызова по телефонному каналу, например, система автоматического распределения вызова (ACD) (например, ACD от Avaya), является каналом преобразования для учреждения, чтобы взаимодействовать с клиентом 8 в форме речи через автоматическую систему коммерческих задач (например, традиционную IVR систему, основанную на методе телефонных кнопок, или новую систему голосового портала (VP), основанную на интеллектуальном речевом методе) и фоновый агент ручной поддержки.
[00173] Система вызова с Интернет-каналом, например, Интернет-система кол-центра (ICC), основанная на методе мгновенной передачи сообщений (IM), является диалоговым каналом для учреждения, чтобы взаимодействовать с клиентом 8 в форме текста, речи, изображения, видео или другого через клиентскую систему самообслуживания (например, систему обработки естественного языка (NLP)) и фонового агента ручной поддержки.
[00174] Интеллектуальное устройство 1 ответа позволяет учреждению управлять автоматической системой коммерческих задач и фоновым агентом ручной поддержки, а также диалогом с клиентом 8 в форме текста, речи, изображения, видео и других мультимедийных форм, тем самым реализуя стандартизованный и автоматизированный диалог между учреждением и клиентом.
[00175] Диалоговый шлюз 11 играет роль “предположенного портала” в интеллектуальном устройстве 1 ответа, и его основные функции включают в себя: прием нерегулярного естественного выражения (в форме текста, речи, изображения и видео) и регулярного не-естественного выражения (например, в форме кнопок телефонной клавиатуры) от клиента 8 через устройство 2 вызова, и передачу их в центральный контроллер 12 для последующей обработки; прием инструкций от центрального контроллера 12, тем самым реализуя ответ на выражение клиента 8 (в форме текста, речи, изображения, видео, программы или других форм).
[00176] Как показано на фиг. 4, диалоговый шлюз 11 включает в себя приемник 111 выражения, аутентификатор 112 идентификационных данных, базу данных 113 ответов и генератор 114 ответов.
[00177] Приемник 111 выражения принимает выражение от клиента 8 через устройство 2 вызова. Выражение может быть вышеупомянутыми различными нерегулярными естественными выражениями и регулярным не-естественным выражением.
[00178] Опционально, аутентификатор 112 идентификационных данных расположен перед приемником 111 выражения. Аутентификатор 112 идентификационных данных может идентифицировать и верифицировать идентификационные данные клиента на первой стадии диалога. Традиционный метод “ввода пароля” (такой как: пароль ввода телефонных кнопок, пароль регистрации веб-сайта для ввода с клавиатуры и т.д.) может быть принят; также может быть принят новый метод “фразы-пароля + идентификации по отпечатку голоса”; и два вышеуказанных метода могут объединяться для использования. Хотя традиционный метод аутентификации с помощью пароля не удобен, он уже давно широко принят и используется повсеместно на рынке, и он может быть принят в качестве основного средства идентификации и верификации идентификационных данных клиента на критически чувствительном диалоговом узле (например, банковского перевода); хотя последний намного более удобен, но он широко не принят и не используется повсеместно на рынке, и он может быть принят в качестве совершенно нового основного средства идентификации и верификации идентификационных данных клиента для заметного улучшения клиентского опыта на не-критически чувствительном диалоговом узле (например, запрашивающих торговых точек), а также может быть использован в качестве средства поддержки идентификации и верификации для повышения безопасности первого метода на критически чувствительном диалоговом узле.
[00179] Аутентификатор 112 идентификационных данных установлен, и средства идентификации и верификации идентификационных данных клиента на основе “фразы-пароля + идентификации по отпечатку голоса” принят, так что клиентский опыт улучшается, и клиенту больше не требуется дополнительно запоминать множество различных паролей; угроза для безопасности в связи с тем, что пароль может быть похищен в традиционном методе “ввода пароля” снижается; кроме того, метод “фразы-пароля + идентификации по отпечатку голоса” комбинируется с традиционным методом “ввода пароля” для использования, что может широко применяться на рынке и может дополнительно повысить безопасность идентификации и верификации идентификационных данных клиента.
[00180] База данных 113 ответов хранит данные ответов для ответа клиенту. Подобно перечисленному в приведенной выше таблице в качестве примеров, данные могут включать в себя многие из следующих типов:
[00181] Текст: предварительно программированный текст, например, текстовые ответы в онлайн-банке FAQ (часто задаваемых вопросов).
[00182] Речь: предварительно записанная живая запись или запись синтезированной TTS-речи без переменных, например: “Здравствуйте, это будущий банк. Я могу что-либо сделать для Вас?”
[00183] Изображение: предварительно сформированное изображение, например, изображение сети пекинского метро. Не-видео анимация также включена, например: GIF-файлы, FLASH-файлы и т.п., предоставленные банком для ознакомления клиента с тем, как выполнять операцию международного денежного перевода в онлайновой банковской системе.
[00184] Видео: предварительно сформированное видео, например, предоставленное поставщиком электрических утюгов для демонстрации клиенту, как использовать его новые продукты.
[00185] Программы: последовательность запрограммированных инструкций, например, когда клиент говорит, чтобы выразить требование: “Я хочу посмотреть фильм “Китайские партнеры””, iCloud-смарт-TV работает в соответствии с требованиями клиента, чтобы ответить клиенту: сначала включить TV, затем загрузить и кэшировать фильм “Китайские партнеры” автоматически для iCloud-серверной стороны и, наконец, начать воспроизведение.
[00186] Шаблон: шаблоны, заполняемые различным текстом, речью, изображением, программой.
[00187] Генератор 114 ответов принимает инструкции центрального контроллера 12 и генерирует ответ на выражение клиента 8 путем извлечения и/или прогона данных в базе данных 113 ответов. Более конкретно, в соответствии с ID стандартного ответа в инструкциях, данные ответа запрашиваются и извлекаются из базы данных 113 ответов, или текст и изображение отображаются, или речь и видео воспроизводятся, или программа выполняется; альтернативно, шаблон извлекается из базы данных 113 ответов в соответствии с инструкциями, и переменные параметры, переданные в инструкциях, заполняются, или синтезированная TTS-речь, генерируемая в реальном времени, воспроизводится (например, “Вы успешно возвратили 5000 юаней на кредитную карту”, где “5000” является переменной в инструкциях), или абзац текста отображается, или изображение или анимация, генерируемая в реальном времени, отображается, или сегмент программы исполняется.
[00188] Опционально, центральный контроллер 12 может поддерживать и обновлять данные в базе данных 113 ответов, включая данные ответа, ID стандартного ответа и т.д.
[00189] Центральный контроллер 12 принимает информацию выражения требования клиента от приемника 111 выражения (включая: нерегулярное естественное выражение и регулярное не-естественное выражение) и взаимодействует с роботом 14, а также с MAU-агентом 9 ручной поддержки через MAU рабочую станцию 13, чтобы преобразовать информацию нерегулярного естественного выражения клиента в соответствии с вышеописанным способом в стандартное выражение, определяет соответствующий ID стандартного ответа, соответствующий стандартному выражению, и затем передает ID стандартного ответа к генератору 114 ответов. Опционально, центральный контроллер 12 может обновлять данные в тренировочном наборе данных МТ.
[00190] Робот 14 является роботом приложения для реализации вышеописанного метода искусственного интеллекта. Робот 14 может реализовать преобразование на текстовой информации, речевой информации, информации изображения, информации видео и других естественных выражений (информации языка), чтобы получить стандартное выражение (информацию языка Y). Как отмечено выше, когда способность понимания робота 14 достигает определенного уровня, например, когда определено, что способность понимания является зрелой в пределах некоторой конкретной категории, преобразование A→X→Y может быть выполнено независимо без какой-либо помощи агента ручной поддержки. Тренировочный набор данных МТ может быть размещен в роботе 14 или может быть внешней базой данных, и коды требований данных стандартных выражений, сохраненных в ней (язык на правой стороне), могут быть ассоциированы с ID стандартного ответа. База данных может быть обновлена центральным контроллером 12. Кроме того, база данных для использования в переводе текстов, идентификации речи, идентификации изображения, обработке видео и т.д. может быть внешней базой данных и может также размещаться в роботе 14.
[00191] MAU рабочая станция 13 является интерфейсом между интеллектуальным устройством 1 ответа и MAU-агентом 9 ручной поддержки. MAU рабочая станция 13 представляет идентифицированное естественное выражение или исходное выражение клиента на MAU-агент 9 ручной поддержки. MAU-агент 9 ручной поддержки вводит или выбирает стандартное выражение посредством MAU рабочей станции 13, и MAU рабочая станция 13 передает стандартное выражение на центральный контроллер 12. Опционально, если ответ должен быть определен с ручной поддержкой, MAU-агент 9 ручной поддержки вводит или выбирает ответ (или ID стандартного ответа) посредством MAU рабочей станции 13.
[00192] Опционально, интеллектуальное устройство 1 ответа дополнительно включает в себя тренажер 15. Тренажер 15 сконфигурирован для тренировки способности робота 14 преобразовывать естественное выражение в стандартное выражение. Например, тренажер 15 тренирует робота 11 с использованием результата определения MAU-агента 9 ручной поддержки, при этом постоянно повышая степень точности понимания робота 11 в различных категориях (например, вышеупомянутой категории коммерческих задач и вторичной категории коммерческих задач и т.д.). Для каждой категории, в случае, когда степень точности понимания робота не может достичь “порога зрелости понимания робота”, тренажер 15 выполняет сравнение обработки между результатом преобразования стандартного выражения MAU-агента 9 ручной поддержки и результатом преобразования стандартного выражения для стандартного выражения робота 11, и если два результата одинаковы, “число раз точного определения робота” и “число раз определения робота” в данной категории соответственно повышаются на 1; в противном случае результат ручного преобразования добавляется в тренировочный набор данных МТ, в качестве новых тренировочных данных робота. Тренажер 15 может также инструктировать робота 14, чтобы выполнять вышеупомянутое “самообучение”.
[00193] Кроме того, тренажер 15 может также быть сконфигурирован, чтоб тренировать робота 14 в терминах перевода текста, перевода речи, идентификации изображения, обработки видео и других методов искусственного интеллекта. Тренажер 15 может также поддерживать или обновлять тренировочный набор данных МТ и базу данных для использования в переводе текста, переводе речи, идентификации изображения и обработке видео.
[00194] Опционально, тренажер 15 может также быть интегрирован в центральный контроллер 12.
[00195] Опционально, генератор 114 ответов и база данных 113 ответов могут быть независимыми от диалогового шлюза 11 и могут быть также интегрированы в центральный контроллер 12.
[00196] Интеллектуальное устройство 1 ответа может реализовывать вышеописанный способ обработки естественного выражения и ответа. Например, диалоговый шлюз 11 принимает, от устройства 2 вызова, информацию нерегулярного естественного выражения от клиента 8 через приемник 111 выражения и передает ее на центральный контроллер 12; центральный контроллер 12 инструктирует робот 11 идентифицировать информацию нерегулярного естественного выражения как некоторую форму информации языка, которая может обрабатываться компьютером, и связанную информацию выражения, и затем инструктирует робот 11 преобразовывать информацию языка и связанную информацию выражения в стандартное выражение; если понимание робота 11 является недостаточно зрелым или согласованность корпуса не настроена, что приводит к неудаче преобразования в стандартное выражение, то центральный контроллер 12 инструктирует MAU рабочую станцию 13 предложить MAU-агенту 9 ручной поддержки выполнить ручное преобразование в стандартное выражение; MAU-агент 9 ручной поддержки преобразует информацию языка и связанную информацию выражения, идентифицированную роботом 11, в стандартное выражение, которое вводится и передается в центральный контроллер 12 через MAU рабочую станцию 13. Опционально, MAU-агент 9 ручной поддержки может непосредственно преобразовывать не-идентифицированную нерегулярную информацию естественного выражения в стандартное выражение; центральный контроллер 12 запрашивает базу данных выражений-ответов, чтобы извлечь ID стандартного ответа, согласующееся со стандартным выражением, и если отсутствует согласующийся результат, дополнительно предлагает MAU-агенту 9 ручной поддержки через MAU рабочую станцию 13 выбрать стандартный ответ и ввести соответствующий ID стандартного ответа; опционально, MAU-агент 9 ручной поддержки может также непосредственно ассоциировать стандартное выражение с данными ответа, или установить новые данные ответа; центральный контроллер 12 инструктирует генератор 114 ответов извлечь и/или прогнать данные в базе данных 113 ответов, чтобы генерировать ответ на выражение клиента 8; затем диалоговый шлюз 11 посылает ответ клиенту 8 через устройство 2 вызова; опционально, центральный контроллер 12 соответственно поддерживает и обновляет тренировочный набор данных МТ или базу данных ответов в соответствии со стандартным выражением или стандартным ответом, определенным или добавленным MAU-агентом 9 ручной поддержки, и соответственно поддерживает и обновляет базу данных выражений-ответов.
[00197] Фиг. 5 схематично показывает пример операционного интерфейса, представленного MAU рабочей станцией MAU-агенту 9 ручной поддержки. Как показано на фиг. 5, операционные интерфейсы MAU рабочей станции 13 включают: область 131 отображения выражений клиента, область 132 отображения состояния диалога, область 133 навигации, область 134 выбора категории и область 135 быстрого вызова.
[00198] Область 131 отображения выражений клиента показывает естественное выражение клиента и, например, визуализируется как формы, такие как текст, преобразованный из текста, изображения или речи.
[00199] Область 132 отображения состояния диалога отображает информацию состояния реального времени диалога между клиентом 8 и MAU-агентом 9 ручной поддержки или роботом 14, такую как: число раз диалога в прямом и обратном направлении, полная длительность диалога, клиентская информация и т.д. Область отображения может также быть не упорядоченной.
[00200] Область 133 навигации показывает категорию, которую MAU-агент 9 ручной поддержки в текущий момент выбирает для использования. Левая сторона области отображает текстовую версию пути текущей категории (как показано на чертежах: банк→кредитная карта), правая сторона отображает код, соответствующий категории (как показано на чертежах: “12” и “1” соответствует категории “банк”, “2” соответствует следующему уровню категории “кредитная карта” в категории “банк”. В отличие от предыдущих примеров, в данном применении, “1” соответствует категории “банк”, а не “BNK”, что имеет ту же самую функцию идентификации).
[00201] Область 134 выбора категории обеспечена для MAU-агента 9 ручной поддержки, чтобы выбирать следующий уровень категории. Как показано на чертежах: MAU-агент 9 ручной поддержки ввел следующий уровень категории “кредитная карта” категории “банк”, и 7 подкатегорий управляются под этим уровнем категории “кредитная карта”: “активировать новую карту”, “применить для новой карты и запрашивать статус приложения”, “кредитная карта”, “возврат” и т.д. Если выражение клиента 8 представляет собой: “предел превышения кредита моей кредитной карты является слишком низким”, MAU-агент 9 ручной поддержки выбирает “7” в текущей категории “банк→кредитная карта”, область навигации обновляется для отображения “банк→кредитная карта→настройка кредитной линии …127” и затем вводит следующий уровень категории. MAU-агент 9 ручной поддержки может также непосредственно ввести “127” на клавиатуре после того, как увидит выражение клиента 8, чтобы достичь целевой категории “банк→кредитная карта→настройка кредитной линии”. Таким образом, пользователю 8 больше не требуется тратить много времени, чтобы проходить по сложному дереву функций меню, чтобы отыскать желательный вариант самообслуживания, а нужно просто высказать свое требование, так что MAU-агент 9 ручной поддержки может быстро помочь клиенту непосредственно начать обработку ”настройки кредитной линии кредитной карты”. Таким образом, пользовательский опыт становится проще и удобнее, и частота использования процесса самообслуживания существующей традиционной системы IVR будет значительно повышена.
[00202] Область 135 быстрого вызова обеспечивает обычно используемые клавиши быстрого вызова для MAU-агента 9 ручной поддержки, например, “-” для возврата на предшествующий уровень категории, “0” для перехода к агенту ручной поддержки и “+” для возврата на верхний уровень категории (которая представляет собой корневую категорию “банк” в данном случае). Область 135 быстрого вызова может также обеспечивать другие клавиши быстрого вызова для MAU-агента 9 ручной поддержки. Область 135 быстрого вызова может повысить скорость обработки MAU-агента 9 ручной поддержки. Область 135 быстрого вызова также является областью опционального расположения.
[00203] Здесь приведен только один пример операционного интерфейса MAU рабочей станции 13, которая используется для обработки преобразования MAU-агента 9 ручной поддержки на стандартном выражении. Подобные операционные интерфейсы могут также быть использованы для выполнения ручной обработки над ответом.
[00204] Интеллектуальное устройство ответа согласно вариантам осуществления настоящего изобретения может быть реализовано одним или более компьютерами, мобильным терминалом или другими устройствами обработки данных.
[00205] В способе, устройстве и системе обработки естественного выражения и ответа, согласно вариантам осуществления настоящего изобретения, стандартное выражение может быть использовано, чтобы быстро указывать на ответ, так что клиенту более не требуется тратить много времени, чтобы проходить по сложному процедурному меню функций для отыскания желательного варианта самообслуживания.
[00206] База данных информации стандартизованного выражения - стандартного выражения - стандартного ответа может быть установлена через автоматическое обучение, тренировку и понимание с ручной поддержкой робота, чтобы реализовать поэтапное автоматическое понимание и ответ системы. Кроме того, данные естественного выражения в базе данных могут также иметь преимущества, включая малую дисперсность, узкий объем коммерческих задач и высокую достоверность, чтобы снизить трудности тренировки робота и сократить период достижения зрелости интеллектуальности робота.
[00207] В отличие от традиционного режима ответа, ручная операция главным образом ограничена фоновым “решением”, что включает в себя определение кодов требований стандартного выражения (информации языка Y) и выбор ответа (или ID ответа) или генерирование операции ответа, без необходимости непосредственной приоритетной коммуникации с клиентом по телефону или посредством текстового ввода (иного, чем ввод параметров требований стандартного выражения (информации языка Y)). Таким образом, большой объем человеческих усилий может быть сэкономлен, и эффективность функционирования может быть повышена. Кроме того, по сравнению с традиционным ответом в свободном стиле, обеспечиваемым традиционным агентом ручной поддержки клиенту непосредственно, стандартизованный ответ, обеспечиваемый системой клиенту, не подвергается влиянию многих факторов, включая эмоции агента ручной поддержки, состояние гланд, акцент, профессиональную подготовку, тем самым дополнительно гарантируя стабильность опыта клиента.
[00208] Кроме того, самообучение, тренировка и оценивание степени зрелости могут быть реализованы в каждой индивидуальной специфической категории коммерческих задач (узле), чтобы достичь интеллектуальности всей системы от точки к точке. В практических применениях, механизм “понимание робота становится зрелым поэтапно” более вероятен для опробования и принятия учреждениями, так как риск является относительно низким, затраты на реконструкцию старой системы невысоки, и не будет создаваться никаких негативных влияний на повседневные операции.
[00209] Выше приведены только примерные варианты осуществления настоящего изобретения, которые не предназначены для ограничения объема защиты настоящего изобретения, который определяется только приложенной формулой изобретения.



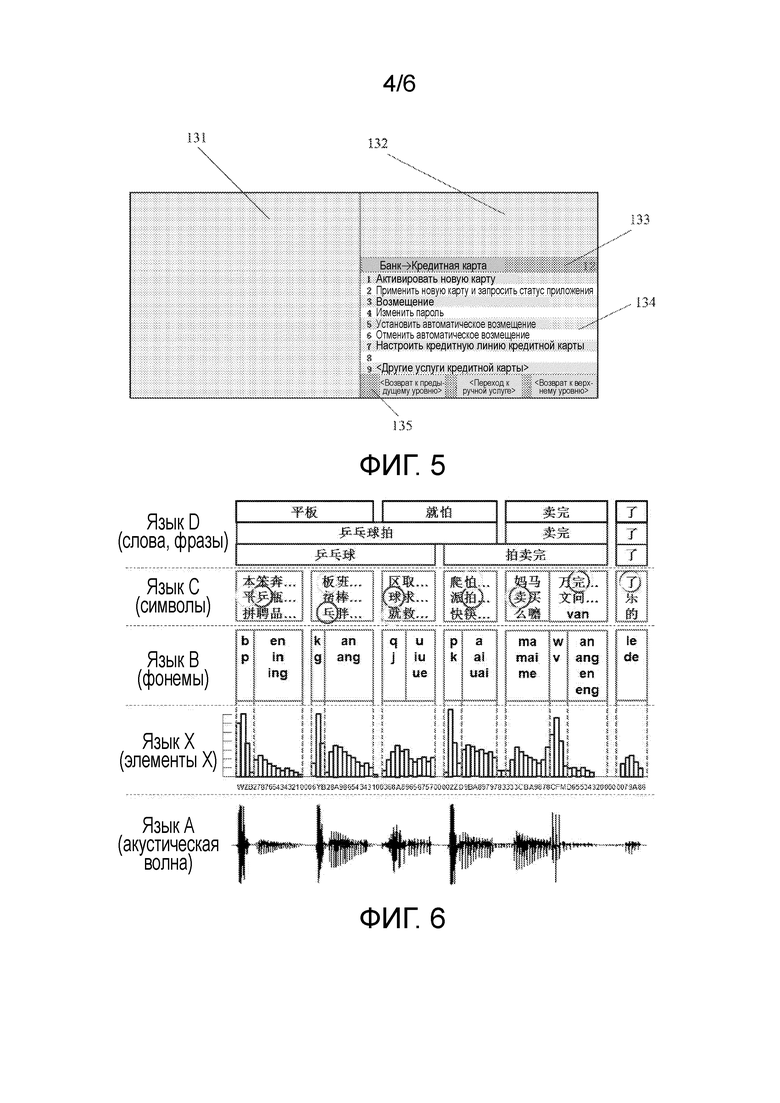
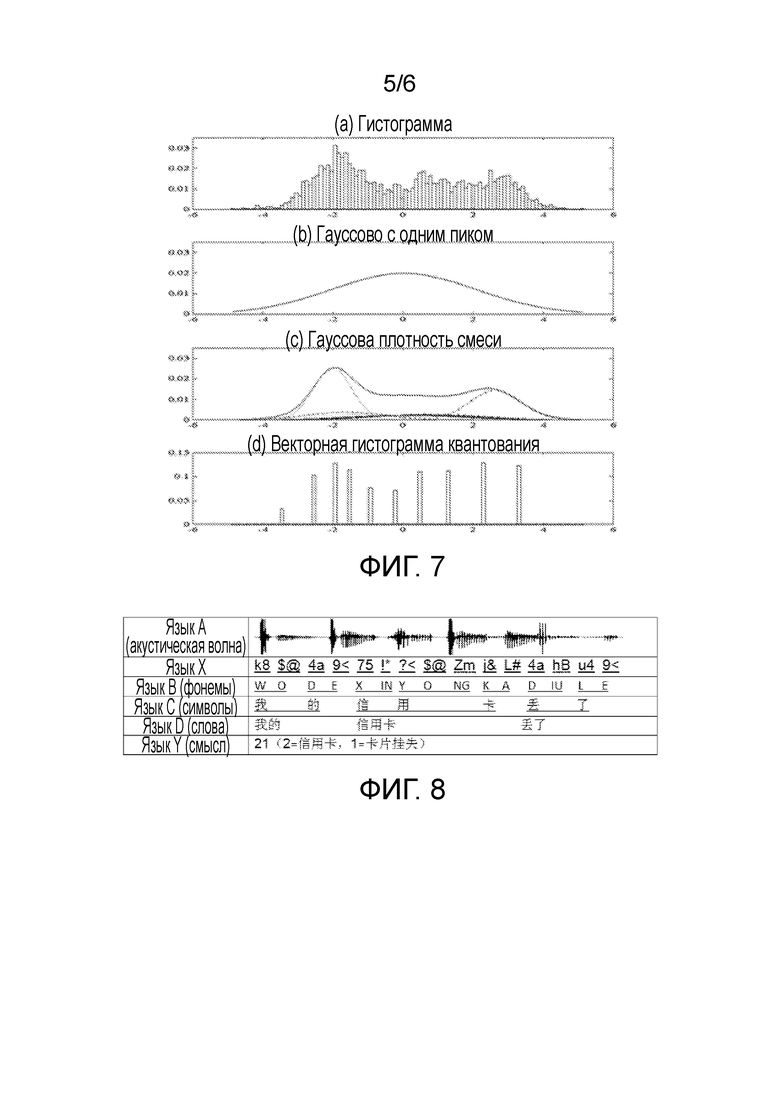
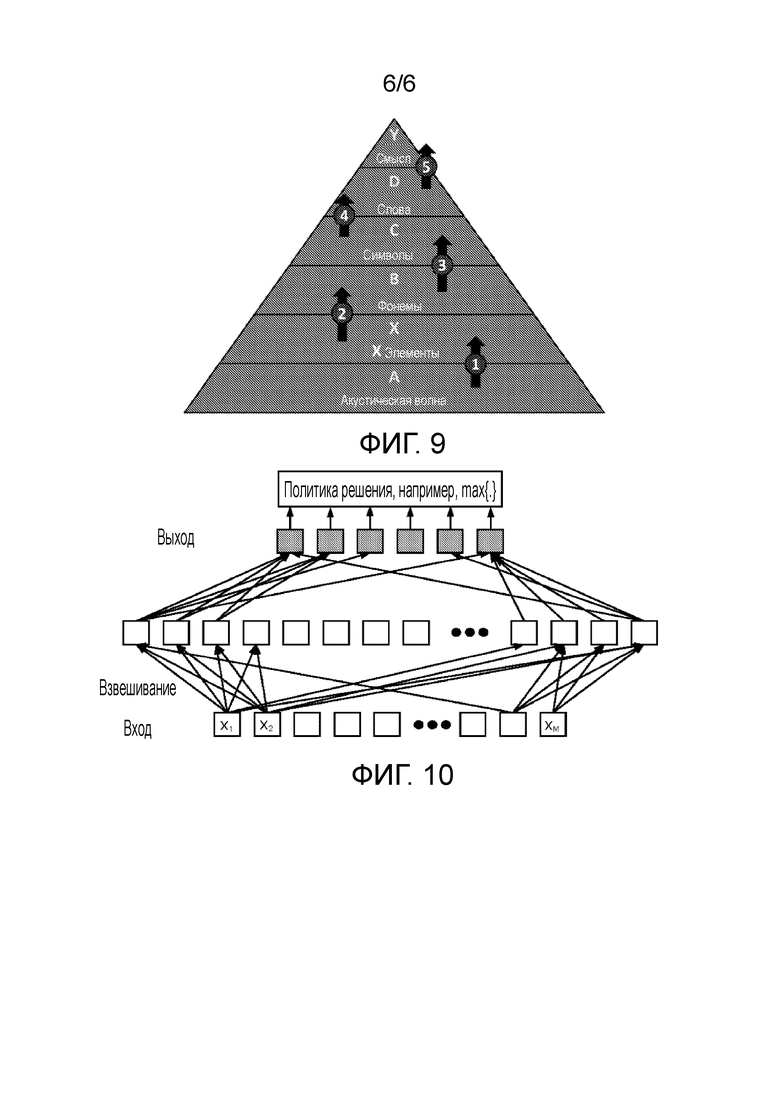
Изобретение относится к способу обработки информации. Техническим результатом является увеличение скорости запроса и обновления данных за счет снижения сложности базы данных для преобразования выражений. В способе обработки естественного выражения идентифицируют естественное выражение от пользователя и получают форму информации языка, которая может обрабатываться компьютером. Преобразуют, посредством вычислительного устройства робота или рабочей станции, реализующей режим понимания на основе ручной поддержки (MAU рабочей станции), идентифицированную и полученную информацию языка в стандартное выражение в кодированной форме. Преобразование в стандартное выражение является преобразованием семантики естественного выражения в коды и параметры. При этом выполняют или машинное преобразование для определения стандартного выражения, или ручное преобразование за счет осуществления координации с MAU рабочей станцией. 3 н. и 13 з.п. ф-лы, 10 ил., 4 табл.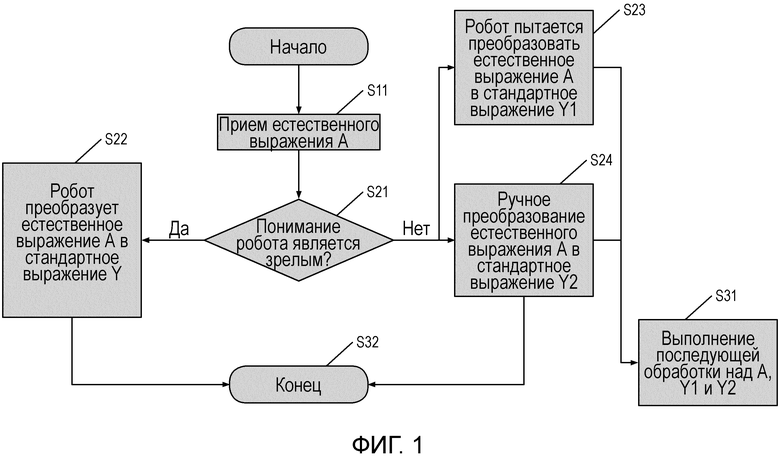
1. Компьютерно-реализуемый способ обработки естественного выражения, содержащий этапы, на которых:
принимают, посредством вычислительного устройства центрального контроллера, ввод естественного выражения, при этом ввод естественного выражения получают через интерфейс клиентского устройства и содержит первую форму информации языка;
идентифицируют, посредством вычислительного устройства робота, естественное выражение путем преобразования ввода естественного выражения во вторую форму информации языка, которая может обрабатываться компьютером; и
преобразовывают, посредством вычислительного устройства робота или рабочей станции, реализующей режим понимания на основе ручной поддержки (MAU рабочей станции), идентифицированное естественное выражение во второй форме информации языка в стандартное выражение в третьей, кодированной форме информации языка, каковое преобразование второй формы информации языка в стандартное выражение содержит этапы, на которых:
определяют, является ли понимание робота зрелым, на основе, по меньшей мере, отчасти оценки степени точности понимания роботом посредством сравнения, в течение некоторого временного интервала, первого результата преобразования роботом первой формы информации языка во вторую форму информации языка и второй формы информации языка в третью форму информации языка со вторым результатом ручного преобразования первой формы информации языка в третью форму информации языка, причем степень точности оценивается как процентная доля количества раз, когда первый результат совпадает со вторым результатом, от общего количества сравнений за упомянутый временной интервал,
когда определено, что понимание робота является зрелым, выполняют машинное преобразование для определения стандартного выражения,
когда определено, что понимание робота не является зрелым, осуществляют координацию с MAU рабочей станцией для выполнения обработки ручного преобразования, чтобы определить стандартное выражение, и
выдают стандартное выражение либо из машинного преобразования, либо из ручного преобразования.
2. Способ обработки естественного выражения по п. 1, в котором стандартное выражение включает в себя коды требований, воплощающие требования пользователя.
3. Способ обработки естественного выражения по п. 2, в котором коды требований выражены цифровыми кодами.
4. Способ обработки естественного выражения по п. 2, в котором стандартное выражение дополнительно включает в себя параметры требования, дополнительно воплощающие индивидуальное для пользователя требование.
5. Способ обработки естественного выражения по любому из пп. 1-4, в котором информация языка образована блоками информации языка, полученными посредством локализации и преобразования, выполняемыми над естественным выражением в форме речи с использованием инструмента моделирования.
6. Способ обработки естественного выражения по любому из пп. 1-4, в котором информация языка образована одними из фонем, символов и фраз.
7. Способ обработки естественного выражения по любому из пп. 1-4, в котором преобразование из второй формы информации языка в стандартное выражение реализуется на основе тренировочного набора данных машинного обучения (MT) между второй формой информации языка и стандартным выражением.
8. Способ обработки естественного выражения по любому из пп. 1-4, в котором во время идентификации естественного выражения получают информацию, ассоциированную с естественным выражением, и данную информацию преобразуют в часть стандартного выражения.
9. Способ обработки естественного выражения по п. 7, дополнительно содержащий тренировку вычислительного устройства робота, каковая тренировка содержит:
установление, посредством устройства тренажера, тренировочного набора данных машинного перевода (MT), где тренировочный набор данных МТ содержит: обрабатываемую компьютером информацию языка, получаемую путем преобразования естественного выражения, кодированного стандартного выражения и соответствующего соотношения между обрабатываемой компьютером информацией языка и стандартным выражением; и
выполнение, посредством вычислительного устройства робота, итеративного сравнения между различными перестановками и комбинациями элементов информации языка, имеющейся в тренировочном наборе данных МТ, и различными перестановками и комбинациями элементов стандартного выражения, чтобы найти соответствующее соотношение между перестановками и комбинациями элементов информации языка и перестановками и комбинациями элементов стандартного выражения.
10. Способ обработки естественного выражения по п. 9, в котором элементы информации языка являются блоками информации языка, полученными посредством локализации и преобразования, выполняемыми над естественным выражением в форме речи с использованием инструмента моделирования.
11. Способ обработки естественного выражения по п. 9 или 10, в котором данные в тренировочном наборе данных МТ импортируются из внешней базы данных или генерируются и добавляются на основе понимания с ручной поддержкой.
12. Компьютерная система для обработки естественного выражения и ответа, содержащая:
диалоговый шлюз, центральный контроллер, рабочую станцию, реализующую режим понимания на основе ручной поддержки (MAU рабочую станцию), робот, базу данных выражений, базу данных ответов и генератор ответов, при этом
диалоговый шлюз выполнен с возможностью принимать естественное выражение, передавать естественное выражение в центральный контроллер для последующей обработки и передавать ответ на естественное выражение;
центральный контроллер выполнен с возможностью принимать естественное выражение от диалогового шлюза, взаимодействовать с роботом и MAU рабочей станцией для преобразования естественного выражения в стандартное выражение и инструктировать генератор ответов в соответствии со стандартным выражением cгенерировать стандартный ответ, соответствующий стандартному выражению;
робот выполнен с возможностью преобразовывать естественное выражение в информацию языка, которая может обрабатываться компьютером, и преобразовывать информацию языка в стандартное выражение с использованием базы данных выражений;
MAU рабочая станция выполнена с возможностью представлять естественное выражение через интерфейс агента ручной поддержки, принимать стандартное выражение во входных данных, принимаемых через интерфейс агента ручной поддержки, и передавать стандартное выражение в центральный контроллер;
база данных выражений приспособлена для хранения относящихся к выражению данных, которые включают в себя: данные информации языка, ассоциированные с естественным выражением, данные стандартного выражения, ассоциированные со стандартным выражением, и данные, ассоциированные с соотношением между информацией языка и стандартным выражением;
база данных ответов хранит относящиеся к ответу данные, включая данные стандартного ответа для извлечения и/или данные для генерации ответа; и
генератор ответов выполнен с возможностью принимать инструкции центрального контроллера и генерировать ответ для естественного выражения с использованием данных в базе данных ответов.
13. Компьютерная система для обработки естественного выражения и ответа по п. 12, в которой центральный контроллер обновляет базу данных выражений и/или базу данных ответов.
14. Компьютерная система для обработки естественного выражения и ответа по п. 12 или 13, дополнительно включающая в себя тренажер, сконфигурированный для тренировки робота преобразовывать естественное выражение в стандартное выражение.
15. Компьютерная система для обработки естественного выражения и ответа по п. 12 или 13, в которой диалоговый шлюз дополнительно содержит аутентификатор идентификационных данных, сконфигурированный идентифицировать и верифицировать идентификационные данные перед приемом информации естественного выражения, причем методы аутентификации идентификационных данных, по меньшей мере, включают в себя идентификацию на основе фразы-пароля и отпечатка голоса.
16. Компьютерная система для обработки естественного выражения и ответа, содержащая: интеллектуальное устройство ответа, содержащее:
диалоговый шлюз, центральный контроллер, рабочую станцию, реализующую режим понимания на основе ручной поддержки (MAU рабочую станцию), робот, базу данных выражений, базу данных ответов и генератор ответов, при этом
диалоговый шлюз выполнен с возможностью принимать ввод естественного выражения, полученный через интерфейс клиентского устройства и содержащий первую форму информации языка, и передавать ввод естественного выражения в центральный контроллер;
центральный контроллер выполнен с возможностью инструктировать робот идентифицировать естественное выражение посредством преобразования ввода естественного выражения во вторую форму информации языка, которая может обрабатываться компьютером, и инструктировать робот преобразовывать идентифицированное естественное выражение во второй форме информации языка в стандартное выражение в третьей форме информации языка, при этом центральный контроллер дополнительно выполнен с возможностью:
определять, является ли понимание робота достаточно зрелым, на основе, по меньшей мере, отчасти оценки степени точности понимания роботом посредством сравнения, в течение некоторого временного интервала, первого результата преобразования роботом первой формы информации языка во вторую форму информации языка и второй формы информации языка в третью форму информации языка со вторым результатом ручного преобразования первой формы информации языка в третью форму информации языка, причем степень точности оценивается как процентная доля количества раз, когда первый результат совпадает со вторым результатом, от общего количества сравнений за упомянутый временной интервал,
когда определено, что понимание робота является достаточно зрелым, выполнять машинное преобразование для определения стандартного выражения,
когда определено, что понимание робота не является достаточно зрелым, осуществлять координацию с MAU рабочей станцией для выполнения обработки ручного преобразования идентифицированного естественного выражения в стандартное выражение, и
на основе стандартного выражения инструктировать генератор ответов сгенерировать ответ на ввод естественного выражения;
диалоговый шлюз выполнен с возможностью выдавать сгенерированный ответ в вызывающее устройство, ассоциированное с вводом естественного выражения.
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 4849898, 18.07.1989 | |||
| КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ ПОДГОТОВКИ ТЕКСТА НА ИСХОДНОМ ЯЗЫКЕ И ПЕРЕВОДА НА ИНОСТРАННЫЕ ЯЗЫКИ | 1993 |
|
RU2136038C1 |

