Настоящая заявка рассматривает аудиокодек, подходящий, например, для использования параллельно с кодированным видео.
При доставке аудио- и видеоконтента по каналу передачи с постоянной или переменной скоростью передачи битов одна из целей состоит в обеспечении синхронизации аудио и видео и поддержке продвинутых вариантов использования, например стыковки.
Синхронизация и выравнивание аудио и видео всегда были решающей частью при построении аудио- видео систем. Обычно аудио- и видеокодеки не используют одну и ту же длительность кадра. По этой причине современные аудиокодеки не выровнены по кадру. В качестве примера это также справедливо для широко используемого AAC-семейства. Пример основывается на стандарте DVB, где используется размер кадра 1024 и частота дискретизации 48 кГц. Это приводит к аудиокадрам с длительностью 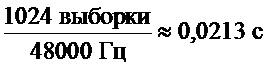 . В отличие от этого распространенной частотой обновления DVB для видео является 25 Гц или 50 Гц, что приводит к длительностям видеокадров 0,02 с или 0,04 с соответственно.
. В отличие от этого распространенной частотой обновления DVB для видео является 25 Гц или 50 Гц, что приводит к длительностям видеокадров 0,02 с или 0,04 с соответственно.
Необходимо, чтобы видео и аудио выравнивались снова, особенно при изменении конфигурации аудиопотока или переключении программы. Современные системы незначительно изменят конфигурацию аудио до или после соответствующего видео, потому что люди не способны распознавать небольшие разницы в синхронизации аудио и видео.
К сожалению, это увеличивает сложность стыковки, где реклама в масштабе страны заменяется местной рекламой, поскольку замененный видеопоток также должен начинаться с этого небольшого смещения. К тому же новые стандарты запрашивают более точную синхронизацию видео и аудио для улучшения общего взаимодействия с пользователем.
Поэтому последние аудиокодеки могут справляться с широким диапазоном возможных размеров кадров для подгонки размера видеокадра. Проблема здесь в том, что это - помимо решения проблемы выравнивания - обладает большим влиянием на эффективность и производительность кодирования.
Потоковая передача данных в широковещательных средах создает особые проблемы.
Недавние события показали, что "адаптивная" потоковая передача рассматривается как транспортный уровень даже для аналоговой трансляции. Для соответствия всем требованиям, которые немного отличаются для Интернет-применения и эфирного применения, адаптивная потоковая передача была оптимизирована. Здесь мы сфокусируемся на одной конкретной технологии адаптивной потоковой передачи, но все приведенные примеры также будут работать для других файловых технологий типа MMT.
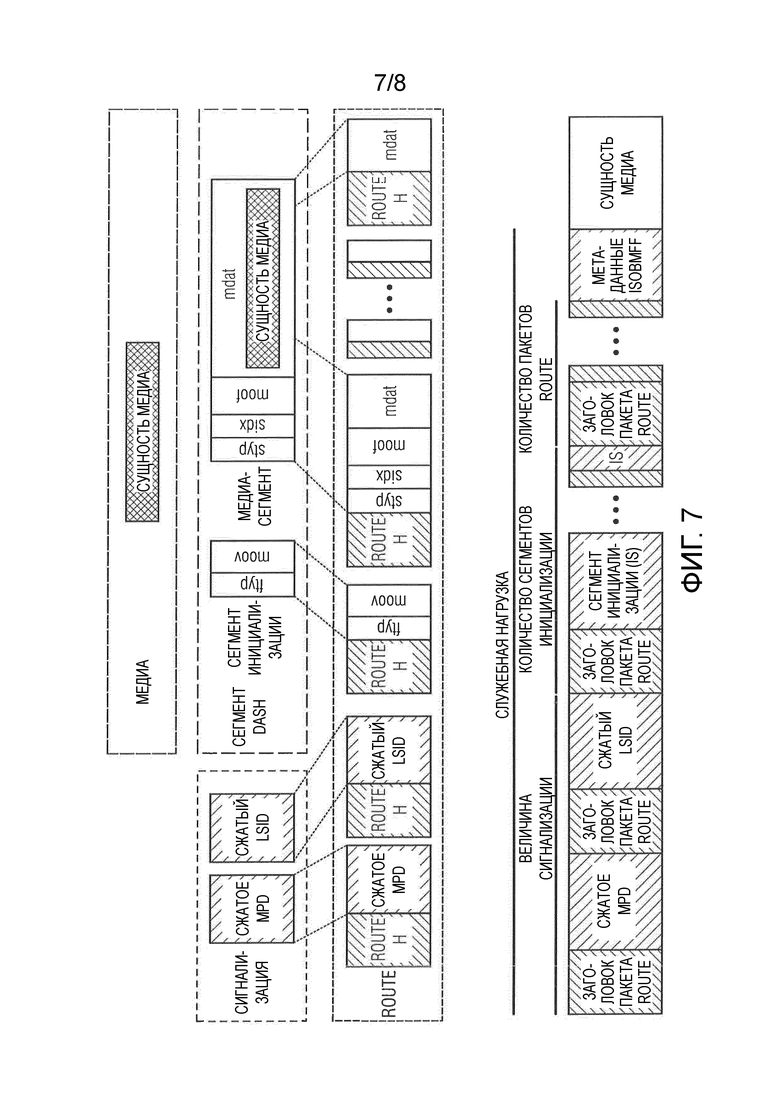
Фиг. 7 показывает предложение для стандарта ATSC 3.0, который разрабатывается в настоящее время. В этом предложении оптимизированная версия MPEG-DASH рассматривается для использования в канале вещания с постоянной скоростью. Поскольку DASH был предназначен для одноадресного канала переменной скорости типа LTE, 3G или широкополосного Интернета, были необходимы некоторые регулировки, которые охвачены предложением. Основное отличие от стандартного варианта использования DASH состоит в том, что приемник канала вещания не имеет обратного канала и принимает одноадресную передачу. Обычно клиент может извлечь местоположение сегмента инициализации после приема и синтаксического анализа MPD. После этого клиент способен декодировать один сегмент за другим или может переходить к заданной отметке времени. Как показано на вышеупомянутой фигуре, в широковещательной среде этот подход вообще не возможен. Вместо этого MPD и сегмент (сегменты) инициализации систематически повторяется/повторяются. Тогда приемник способен настроиться, как только он принимает MPD и все необходимые сегменты инициализации.
Это включает в себя компромисс между коротким временем настройки и небольшой служебной нагрузкой. Для обычной вещательной компании представляется осуществимой длина сегмента приблизительно в 1 секунду. Это означает, что между двумя MPD имеется один аудиосегмент и один видеосегмент (если программа содержит только аудио и видео), оба с длиной приблизительно в одну секунду.
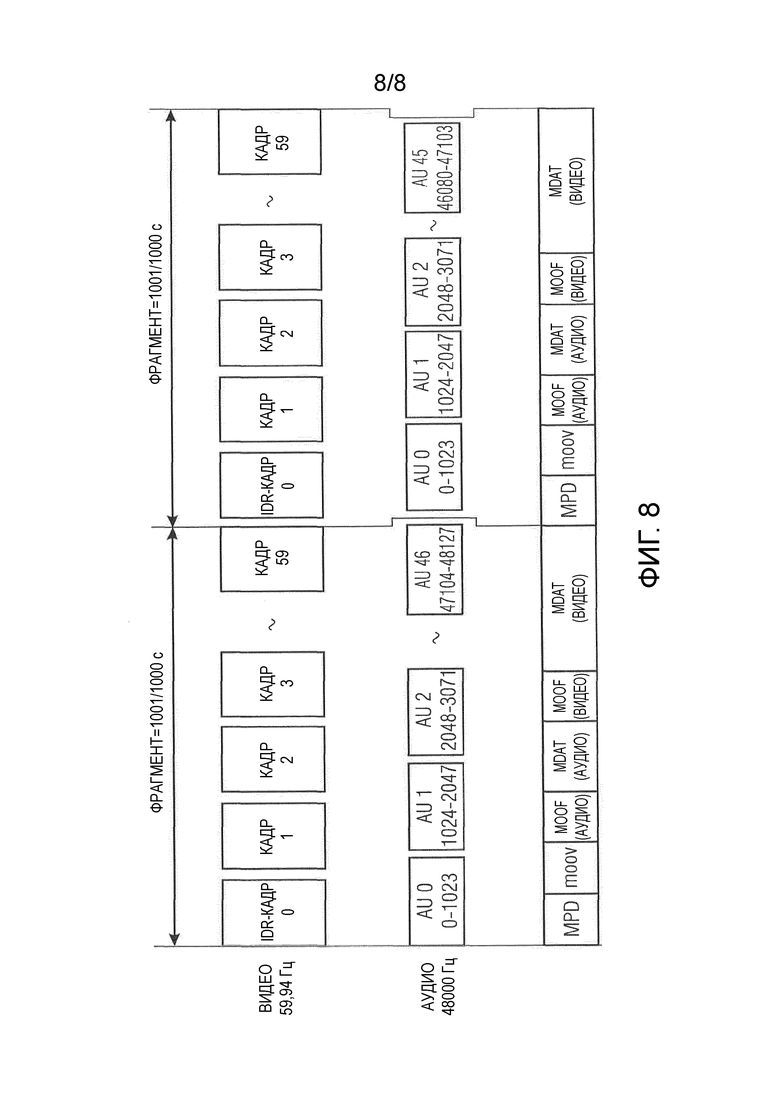
Для выравнивания аудио и видео первый упомянутый аспект также справедлив при использовании DASH. К тому же аудиосегменты должны быть немного длиннее или короче для сохранения выравнивания аудио и видео. Это показано на фиг. 8.
Если инициируется изменение конфигурации аудио или видео, то это изменение должно происходить на границе сегмента, поскольку нет другого способа передать обновленный сегмент инициализации. Для этого видео и аудио дополняются (либо черными кадрами, либо тишиной) для заполнения полного сегмента. Но это не решает проблему рассогласования видео и аудио. Для стыковки и переключения программы может быть небольшое несовпадение аудио и видео в зависимости от ухода длительности текущего сегмента.
Цель настоящего изобретения - предоставить аудиокодек, который эффективнее решает задачу, например, синхронизации и выравнивания аудио и видео, например, проще ее реализует на основе существующих методик сжатия аудио.
Эта цель достигается с помощью предмета изобретения из рассматриваемых независимых пунктов формулы изобретения.
Основополагающая идея, лежащая в основе настоящей заявки, состоит в том, что синхронизация и выравнивание аудио и видео либо выравнивание аудио с некоторым другим внешним генератором может проводиться эффективнее или проще, когда сетка фрагмента и сетка кадра рассматриваются как независимые значения, но тем не менее, когда для каждого фрагмента сетка кадра выравнивается с началом соответствующего фрагмента. Потерю эффективности сжатия можно поддерживать низкой при подходящем выборе размера фрагмента. С другой стороны, выравнивание сетки кадра относительно начал фрагментов предусматривает легкий и синхронизированный с фрагментом способ обработки фрагментов по отношению, например, к параллельной потоковой передаче аудио и видео, адаптивной по скорости потоковой передаче или т. п.
Полезные реализации являются предметом зависимых пунктов формулы изобретения. Ниже описываются предпочтительные варианты осуществления настоящей заявки по отношению к фигурам, среди которых
Фиг. 1 показывает схематическое представление временного фрагмента, содержащего видео и аудио, где видео- и аудиофрагменты выравниваются по времени в соответствии с вариантом осуществления настоящей заявки;
Фиг. 2 показывает полусхематическую блок-схему кодера, кодированный посредством него аудиоконтент и сформированный посредством него кодированный поток данных в соответствии вариантом осуществления;
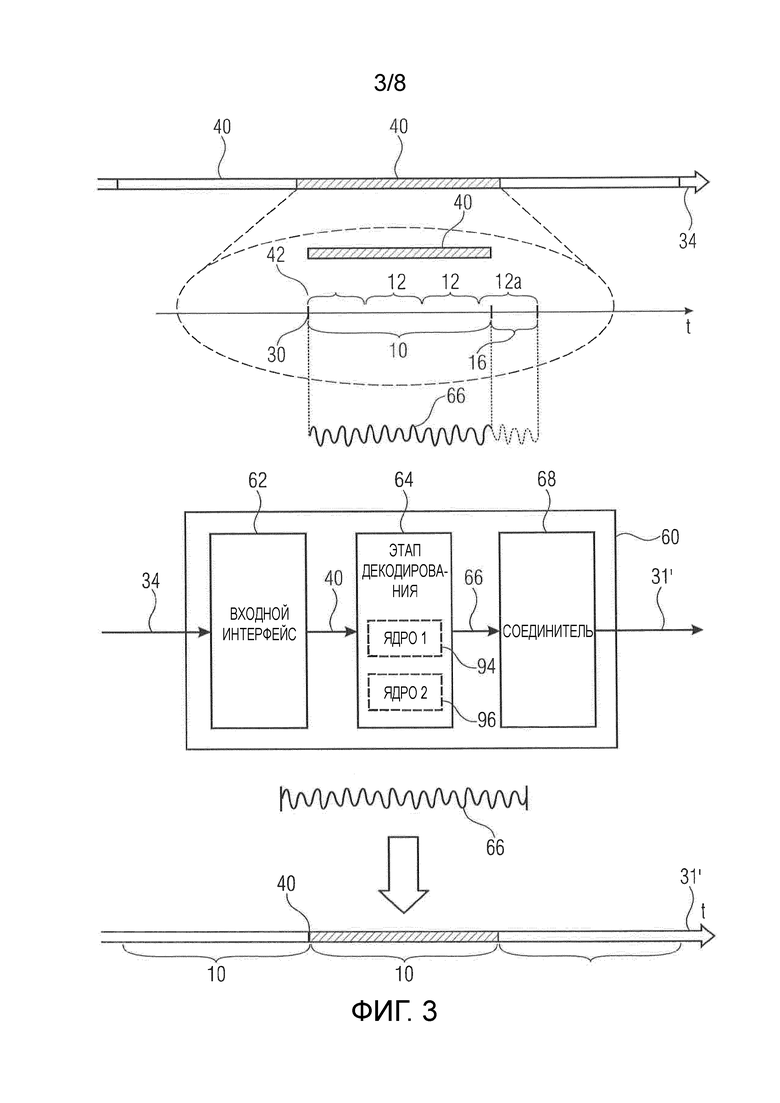
Фиг. 3 показывает полусхематическую блок-схему подгонки декодера к кодеру из фиг. 2 в соответствии вариантом осуществления;
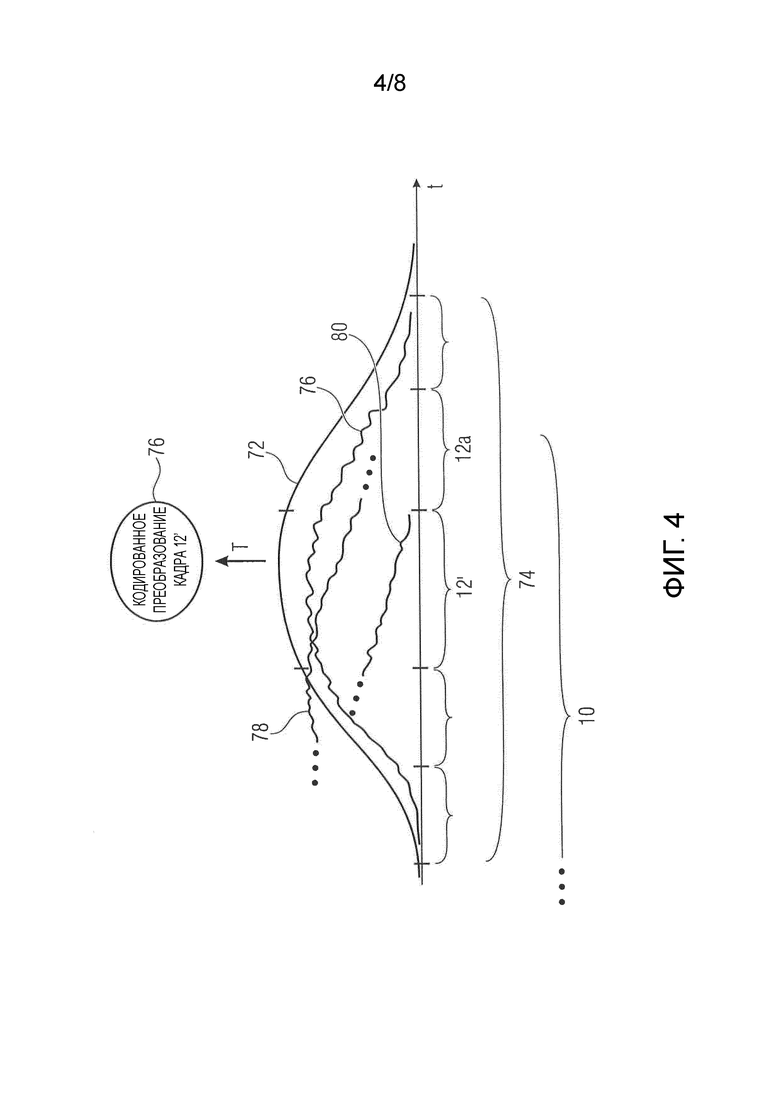
Фиг. 4 показывает схематическое представление окон, частей временной области, участвующих в процессе кодирования/декодирования в соответствии вариантом осуществления, в соответствии с которыми кодирование/декодирование на основе преобразования используется для кодирования/декодирования кадров, а именно путем применения перекрывающегося преобразования;
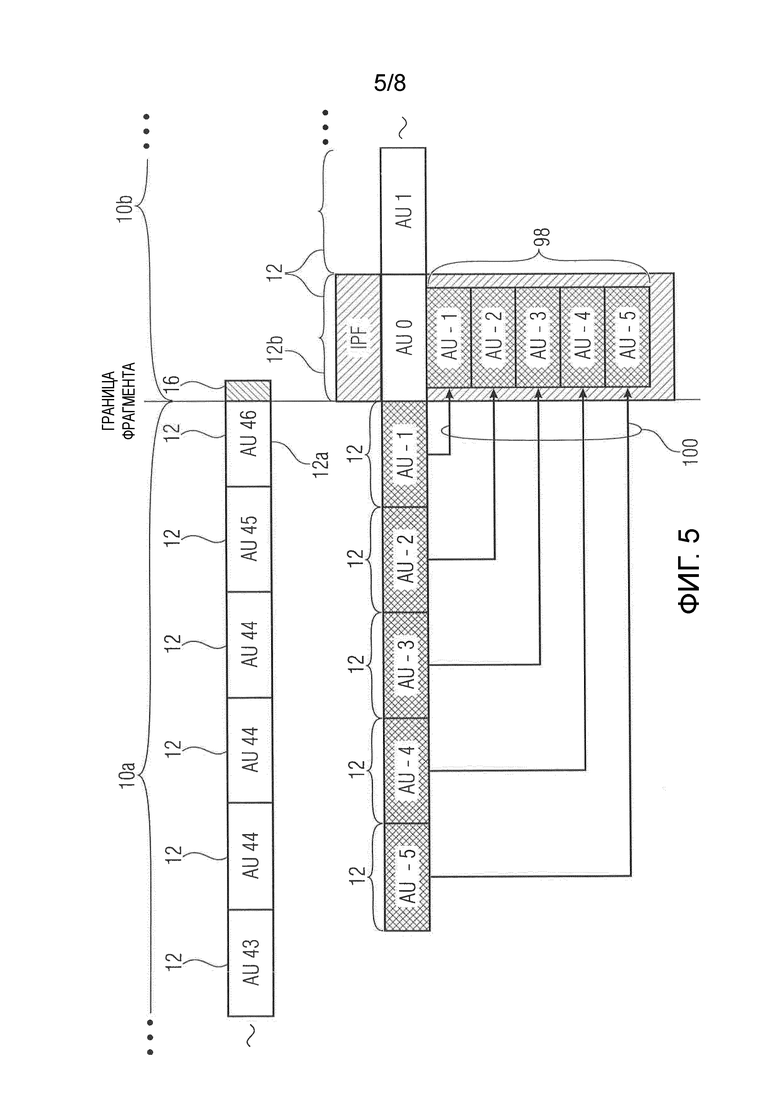
Фиг. 5 показывает схематическое представление, иллюстрирующее формирование информации немедленного воспроизведения в соответствии вариантом осуществления;
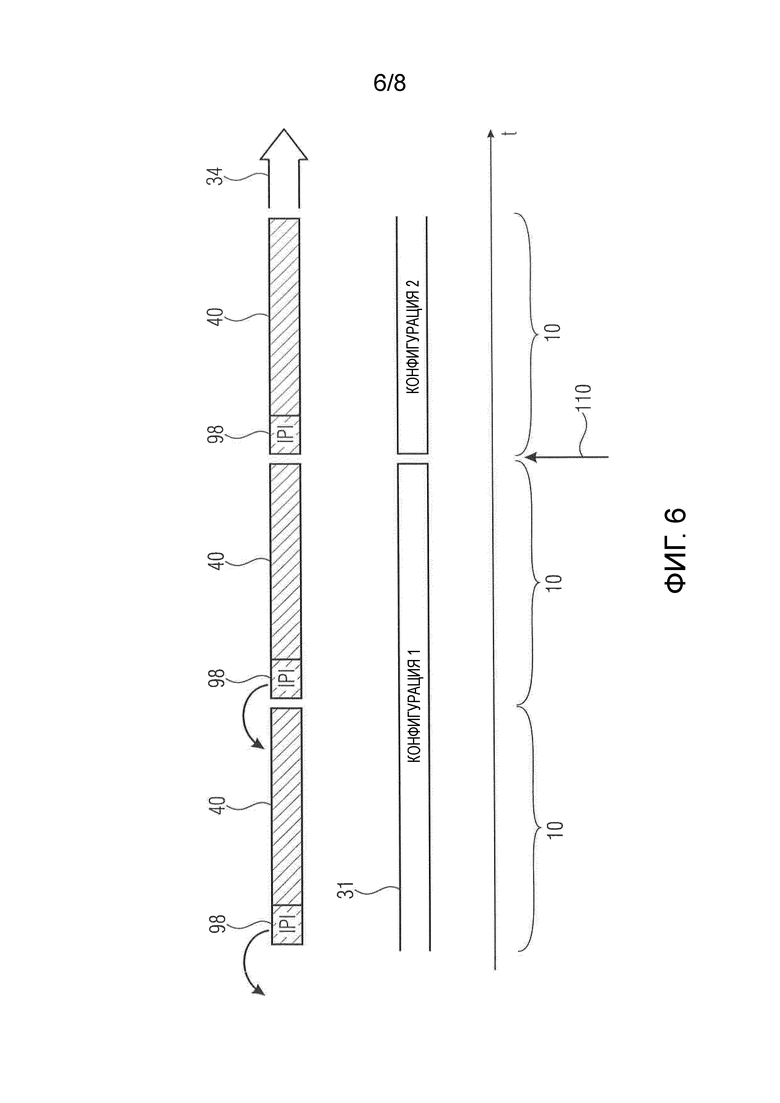
Фиг. 6 показывает схематическое представление, иллюстрирующее случай изменения конфигурации в аудиоконтенте в соответствии вариантом осуществления, показывающий, например, что информация немедленного воспроизведения может отсутствовать в случае изменения конфигурации в начале соответствующего временного фрагмента, или где информация немедленного воспроизведения у такого временного фрагмента кодирует вместо этого ноль выборок;
Фиг. 7 с целью сравнения показывает пакетированный сегмент DASH, доставляемый посредством ROUTE в соответствии с [1]; и
Фиг. 8 показывает два последовательных фрагмента, переносящих аудио и видео в соответствии с текущей идеей фрагментации, в соответствии с которой фрагментация аудио затрагивает разные фрагментированные длительности.
Перед описанием различных вариантов осуществления настоящей заявки сначала описываются преимущества, предоставленные этими вариантами осуществления, и лежащие в их основе мысли. В частности, представим, что нужно кодировать аудиоконтент, чтобы сопровождать видеокадр, состоящий из последовательности видеокадров. Проблема, которая указана выше во вступительной части настоящей заявки: в настоящее время аудиокодеки работают на основе выборки и кадра, что не является целой долей или целым кратным частоты видеокадра. Соответственно, описываемые в дальнейшем варианты осуществления используют этапы кодирования/декодирования, действующие в единицах "обычных" кадров, для которых они оптимизируются. С другой стороны, аудиоконтент подвергается действию аудиокодека, лежащего в основе этих этапов кодирования/декодирования, в единицах временных фрагментов, которые могут иметь длину в один или несколько, предпочтительно от одного до пяти, или даже больше, предпочтительно один или два видеокадра. Для каждого такого временного фрагмента сетка кадра выбирается выровненной с началом соответствующего временного фрагмента. Другими словами, идея, лежащая в основе описываемых впоследствии вариантов осуществления, состоит в создании аудиофрагментов, которые имеют точно такую же длину, как и соответствующий видеокадр, причем этот подход обладает двумя преимуществами:
1) Аудиокодер по-прежнему может работать с оптимизированной/собственной длительностью кадра и не должен оставлять сетку кадра на границах фрагмента.
2) Любую задержку аудио можно компенсировать путем использования информации немедленного воспроизведения для кодированных представлений временных фрагментов. Стыковка может происходить на каждой границе фрагмента. Это значительно уменьшает общую сложность вещательного оборудования.
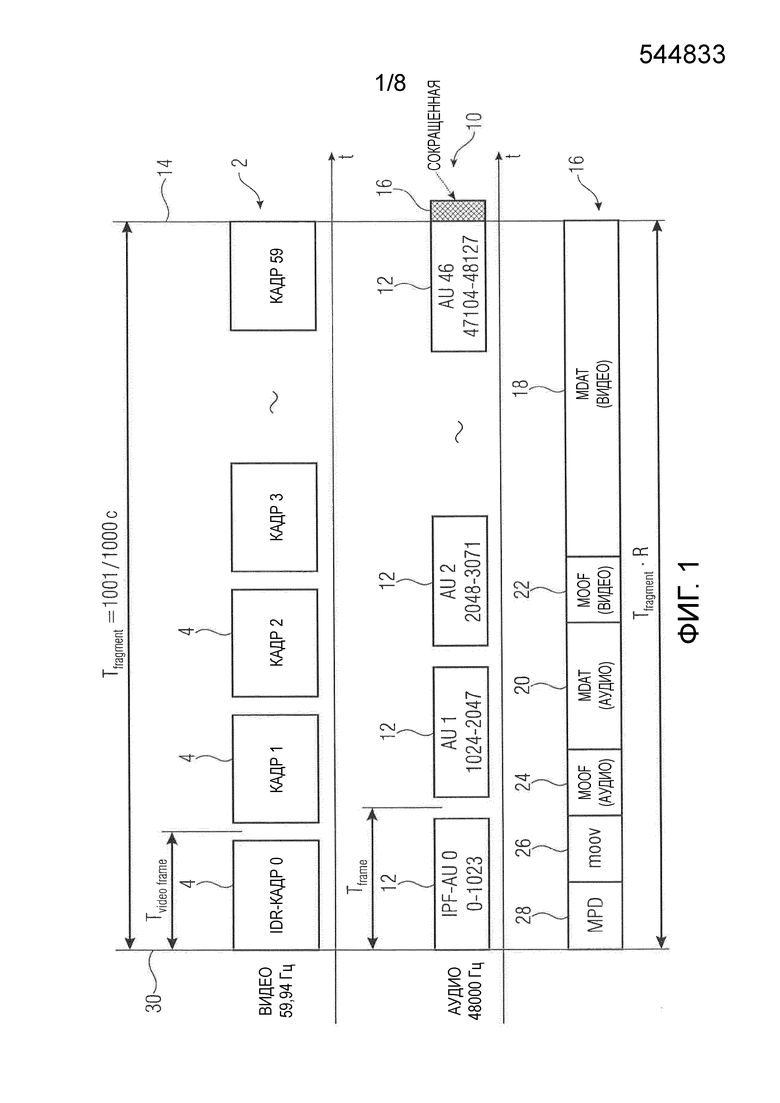
Фиг. 1 показывает пример для аудиофрагмента, сформированного в соответствии с приведенным ниже примером, и этот аудиофрагмент сопровождает соответствующий видеофрагмент. Аудиофрагмент и видеофрагмент иллюстрируются способом, соответствующим фиг. B. А именно фиг. 1 по ссылке 2, то есть верхняя строка фиг. 1, иллюстрирует видеофрагмент как состоящий из некоторого числа N кадров 4, то есть видеокадров, где кадры показаны в виде квадратов, последовательно расположенных построчно слева направо по их порядку воспроизведения во времени, как проиллюстрировано осью t времени. Левый край кадра 0 и правый край кадра 59 показаны как соответствующие началу и концу фрагмента, означая, что временная длина Tfragment фрагмента является целым кратным длины видеокадра, при этом целое кратное N здесь для примера равно 60. Выровненная по времени с видеофрагментом 2, фиг. 2 иллюстрирует ниже аудиофрагмент 10, содержащий кодированный в нем аудиоконтент, сопровождающий видеофрагмент 2, в единицах кадров или блоков 12 доступа, проиллюстрированных здесь в виде прямоугольников, вытянутых горизонтально, то есть во времени, с временным шагом, который должен иллюстрировать их длину кадра во времени, и эта длина аудиокадра, к сожалению, такова, что временная длина Tfragment аудиофрагмента 10 не является целым кратным этой длины Tframe кадра. Например, отношение между длиной Tframe кадра и соответствующей длиной кадра у видеокадров Tvideoframe может быть таким, что коэффициент между ними либо иррациональный, либо коэффициент между ними можно представить правильной дробью, полностью сокращенной, где при умножении числителя на знаменатель получается больше, например, 1000, чтобы длина фрагмента, которая была бы кратной длине Tvideo frame видеокадра и длине Tframe аудиокадра, была бы невыгодно большой.
Фиг. 1 иллюстрирует соответственно, что последний или замыкающий кадр, а именно блок 46 доступа, охватывает во времени временную часть аудиоконтента, которая выходит за задний конец 14 аудиофрагмента 10. Позднее будет показано, что часть 16, выходящую или следующую за задним концом 14, можно сокращать либо пренебрегать ею на стороне декодера при воспроизведении, или что весь замыкающий кадр фактически не кодируется декодером, всего лишь очищающим (сбрасывающим) внутренние состояния, чтобы заполнить "временную пустоту" части замыкающего кадра до самого перекрытия с временным фрагментом 10.
С целью иллюстрации фиг. 1 иллюстрирует на нижней половине, а именно по ссылке 16, что запас битов, доступный для временного фрагмента, состоящего из видео и аудио, а именно Tfragment ⋅ R, причем R - скорость передачи битов, мог бы использоваться для переноса видеоданных 18, в которые кодируются видеокадры 4 фрагмента 2, аудиоданных 20, в которые кодируется аудиоконтент аудиофрагмента 10, их данных 22 и 24 заголовка соответственно, конфигурационных данных 26, указывающих, например, пространственное разрешение, временное разрешение и так далее, при которых видеокадры 4 кодируются в данные 18, и конфигурации, например количества каналов, с которой аудиокадры 12 фрагмента 2 кодируются в данные 20, а также манифеста или описания представления медиапотока, здесь для иллюстрации включенных в данные для совмещенных фрагментов 2 и 10, чтобы указывать, например, версии, в которых доступны видео и аудио, при этом версии отличаются по скорости передачи битов. Следует понимать, что пример из фиг. 1 всего лишь пояснительный, и что описываемые в дальнейшем варианты осуществления не ограничиваются использованием применительно к адаптивной по скорости потоковой передаче и отправке манифеста клиенту, и так далее. Фиг. 1 должна всего лишь иллюстрировать общую идею объясняемых ниже вариантов осуществления, в соответствии с которыми фрагментация аудио выполняется полностью выровненной с фрагментацией видео путем выравнивания аудиокадров 12 с началом 30 фрагментов 10, которые, в свою очередь, выбираются, например, полностью выровненными с видеокадрами 4.
Фиг. 1 соответственно показывает аудио- и видеофрагмент, выравниваемые описанным способом. В примере из фиг. 1, видео- и аудиофрагмент выбирались имеющими постоянную временную длину Tfragment, равную 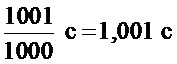 , что эквивалентно 60 видеокадрам при частоте кадров NTSC в 59,94 Гц.
, что эквивалентно 60 видеокадрам при частоте кадров NTSC в 59,94 Гц.
Последний аудиокадр каждого аудиофрагмента, здесь AU 46, например, сокращается для соответствия длительности фрагмента. В приведенном примере последний аудиокадр доходит от выборки 47104 до 48127, где выбрана нумерация от нуля, то есть первая аудиовыборка в этом фрагменте нумеруется нулем. Это приводит к размеру фрагмента в некоторое количество выборок, которое немного больше нужного, а именно 48128 вместо 48048. Поэтому последний кадр обрезается справа после 944ой выборки. Это может совершаться с использованием, например, монтажного листа, содержащегося, например, в данных 24 заголовка или в конфигурационных данных 26. Сокращенная часть 16 может кодироваться, например, с меньшим качеством. В качестве альтернативы была бы возможность не передавать все аудиокадры 12, а пропустить, например, кодирование последнего кадра, здесь для примера AU 46, поскольку декодер обычно можно очищать (сбрасывать) в зависимости от конфигурации аудио.
В описанных далее вариантах осуществления будет показано, что можно принять меры для нейтрализации проблемы, что декодер, который работает, например, на функции перекрывающихся окон, утратит свою предысторию и не сможет создать полный сигнал для первого кадра следующего фрагмента. По этой причине первый кадр, на фиг. 1 для примера AU 0, кодируется как кадр IPF, допускающий немедленное воспроизведение (IPF=кадр немедленного воспроизведения). Он размещается справа в начале соответствующего фрагмента и любого аудиофрагмента соответственно. Также первый видеокадр 4 может быть кадром IDR (IDR=мгновенное обновление декодирования).
Таблица 1: Служебная нагрузка от скорости передачи битов
Вышеприведенная таблица приводит пример для предполагаемой служебной нагрузки от скорости передачи битов, если бы не применялась никакая оптимизация. Видно, что служебная нагрузка сильно зависит от используемой длительности Tfragment фрагмента. В зависимости от требования вещательной компании реально выровнять только каждый второй или третий фрагмент соответственно, то есть выбирая аудиофрагменты подлиннее.
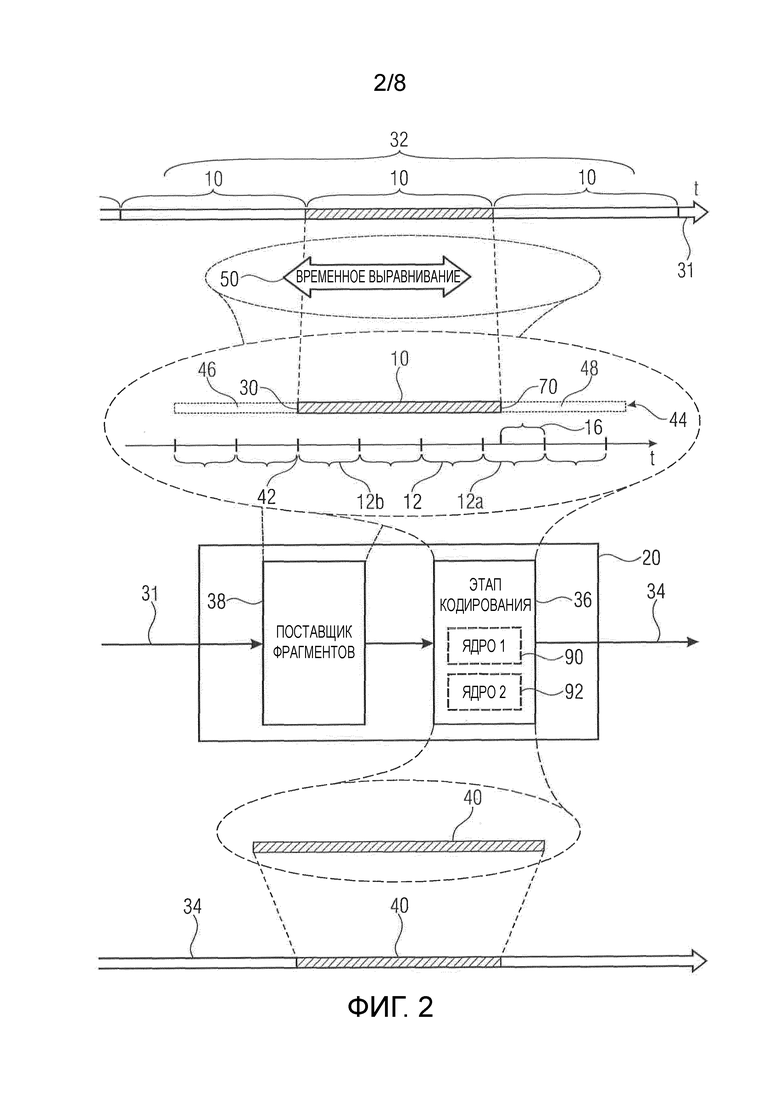
Фиг. 2 показывает кодер для кодирования аудиоконтента в единицах временных фрагментов 10 на сетке 32 фрагмента в кодированный поток 34 данных. Кодер указан в целом с использованием номера 20 ссылки и содержит этап 36 кодирования и поставщика 38 фрагментов. Этап 36 кодирования конфигурируется для кодирования аудиоконтента в единицах кадров 12 на сетке кадра, а поставщик 38 фрагментов конфигурируется для предоставления аудиоконтента 31 на этап 36 кодирования в единицах временных фрагментов 10, чтобы каждый временной фрагмент кодировался этапом 36 кодирования в кодированное представление 38 соответствующего временного фрагмента 10, где поставщик 38 фрагментов конфигурируется для предоставления аудиоконтента 31 на этап 36 кодирования в единицах временных фрагментов 10 так, что каждый временной фрагмент на соответствующей сетке кадра у кадров 12 выравнивается по времени с началом 30 соответствующего временного фрагмента 10, чтобы начало 30 совпадало с границей 42 кадра на соответствующей сетке кадра у кадров 12. То есть, как дополнительно описывается ниже, поставщик 38 фрагментов может предоставить этапу 36 кодирования временной фрагмент 10 с частью 44 аудиоконтента 31, которая включает в себя временной фрагмент 10, предоставляемый в настоящее время, и при необходимости частью 46 аудиоконтента 31, предшествующей во времени текущему временному фрагменту 10, и частью 48, следующей во времени за текущим временным фрагментом 10. При предоставлении этапу 36 кодирования текущей части 44 текущий временной фрагмент 10 выравнивается по времени 50 поставщиком 38 фрагментов так, что границы 42 кадра содержат одну границу кадра, которая совпадает с началом 30 текущего временного фрагмента 10. Как описано выше по отношению к фиг. 1, вследствие того, что временная длина временного фрагмента 10 является нецелым кратным временной длины кадров 12, замыкающий кадр 12a только частично охватывает или перекрывается во времени с временным фрагментом 10, при этом его часть 16 охватывает следующую часть 48 аудиоконтента.
Перед подробным описанием функциональных возможностей кодера из фиг. 2 сошлемся на фиг. 3, которая показывает соответствующий декодер в соответствии вариантом осуществления. Декодер из фиг. 3 указан в целом с использованием номера 60 ссылки и конфигурируется для декодирования аудиоконтента 31 в единицах временных фрагментов 10 из кодированного потока 34 данных. Декодер 60 содержит входной интерфейс 62, который принимает кодированные представления временных фрагментов. Как проиллюстрировано на фиг. 3 с использованием штриховки и как уже объяснялось по отношению к фиг. 2, для каждого временного фрагмента 10 в потоке 34 данных присутствует его кодированное представление 40. Каждое кодированное представление 40 содержит кодированный в нем ассоциированный временной фрагмент 10 в единицах вышеупомянутых кадров 12, выровненных во времени с началом 30 соответствующего временного фрагмента 10, чтобы начало 30 совпадало с границей 42 кадра на сетке кадра.
Декодер 60 дополнительно содержит этап 64 декодирования, сконфигурированный для декодирования восстановленных версий 66 временных фрагментов 10 из кодированных представлений 40. То есть этап 64 декодирования для каждого временного фрагмента 40 выводит восстановленную версию 66 аудиоконтента как охватываемую временным фрагментом 10, которому принадлежит соответствующее кодированное представление 40.
Декодер 60 дополнительно содержит соединитель 68, сконфигурированный для соединения восстановленных версий 66 временных фрагментов 10 для воспроизведения, по сути, вместе с выравниванием начал восстановленных версий 66 временных фрагментов, чтобы совпадали с границами фрагмента на сетке фрагмента, то есть в началах 30 сетки фрагмента, так как отдельные сетки кадров у фрагментов 10 соответствуют им.
Таким образом, кодер 20 и декодер 60 из фиг. 2 и 3 работают следующим образом. Кодер 20 кодирует каждый временной фрагмент 10 в соответствующее кодированное представление 40, так что сетка кадра у кадров 12 выравнивается с началом 30 соответствующего временного фрагмента 10 так, что первый или головной кадр 12b начинается сразу в начале 30, то есть начала у временного фрагмента 10 и первого кадра 12b совпадают. Проблему того, как этап 36 кодирования обрабатывает замыкающий кадр 12a, который только частично перекрывает временной фрагмент 10, можно решать по-разному, как изложено ниже. Кроме того, так как этап 36 кодирования перестраивает сетку кадра для каждого временного фрагмента 10, этап 36 кодирования кодирует временные фрагменты 10 в их соответствующее кодированное представление 40 полностью самостоятельно, то есть независимо от других временных фрагментов. Тем не менее, этап 36 кодирования кодирует временные фрагменты 10 в их соответствующие кодированные представления 40 так, что предоставляется возможность немедленного воспроизведения на стороне декодирования для каждого временного фрагмента. Возможные подробности реализации излагаются ниже. В свою очередь, декодер 60 восстанавливает из каждого кодированного представления 40 восстановленную версию 66 соответствующего временного фрагмента 10. Восстановленная версия 66 может иметь такую же длину, как и соответствующий временной фрагмент 10. С этой целью, как дополнительно описывается ниже, этап 64 декодирования может выполнять очистку (сброс), чтобы удлинить временную длину восстановленной версии 66 до временной длины временных фрагментов 10, либо этап 64 декодирования и соединитель 66 могут сотрудничать, как обсуждается ниже, чтобы сократить или игнорировать временные части восстановленной версии 66, которые в противном случае превысили бы временную длину временных фрагментов. Этап 64 декодирования при выполнении декодирования кодированных представлений 40 также использует сетку кадра, то есть выполняет декодирование в единицах кадров 12 и по существу выполняет инверсию процесса кодирования.
Далее обсуждается возможность, в соответствии с которой этап 36 кодирования также занимается кодированием замыкающего кадра 12a в соответствующее кодированное представление 40, а декодер занимается сокращением соответствующих выступающих частей восстановленной версии 66. В частности, в соответствии с этим примером этап 36 кодирования и поставщик 38 фрагментов могут сотрудничать так, что для текущего временного фрагмента 10 кодирование этого временного фрагмента 10 в кодированное представление 40 продолжается после заднего конца 70 текущего временного фрагмента 10, поскольку это касается замыкающего кадра 12a. То есть этап 36 кодирования также кодирует выступающую часть 16 аудиоконтента в кодированное представление 40. Однако при этом этап 36 кодирования может сдвинуть скорость передачи битов, затраченную для кодирования этого замыкающего кадра 12a в кодированное представление 40, из выступающей части 16 в оставшуюся часть замыкающего кадра 12a, то есть часть, перекрывающуюся во времени с текущим временным фрагментом 10. Например, этап 36 кодирования может понизить качество, с которым выступающая часть 16 кодируется в кодированное представление 40, по сравнению с качеством, с которым другая часть замыкающего кадра 12a кодируется в кодированное представление 40, а именно принадлежащая текущему временному фрагменту 10. В этом случае этап 64 декодирования соответственно декодировал бы из этого кодированного представления 40 восстановленную версию 66 соответствующего временного фрагмента 10, которая превышает во времени временную длину временного фрагмента 10, а именно в части, касающейся выступающей части 16 замыкающего кадра 12a. Соединитель 68 при выравнивании восстановленной версии 66 с сеткой фрагментации, то есть с началами 30 фрагментов, сократил бы восстановленную версию 66 в выступающей части 16. То есть соединитель 68 игнорировал бы эту часть 16 восстановленной версии 66 при воспроизведении. То, что эта часть 16 могла быть кодированной с меньшим качеством, как объяснялось выше, соответственно очевидно для слушателя восстановленного аудиоконтента 31', который является результатом соединения восстановленных версий 66 на выходном соединителе 68, так как эта часть заменяется при воспроизведении началом восстановленной версии следующего временного фрагмента 10.
В качестве альтернативы кодер 20 может функционировать для пропуска замыкающего кадра 12a при кодировании текущего временного фрагмента 10. Вместо этого декодер может заняться заполнением некодированной части временного фрагмента 10, а именно части, с которой частично перекрывается замыкающий кадр 12a, путем очистки внутреннего состояния, как описано ниже для примера. То есть этап 36 кодирования и поставщик 38 фрагментов могут сотрудничать так, что для текущего временного фрагмента 10 кодирование этого временного фрагмента в кодированное представление 40 прекращается в кадре 12, непосредственно предшествующем замыкающему кадру 12a. Этап кодирования может сигнализировать в кодированном представлении 40 сигнализацию очистки, указывающую декодеру заполнить оставшуюся, соответственно некодированную часть временного фрагмента 10, а именно часть, которая перекрывается с замыкающим кадром 12a, посредством очистки (сброса) внутренних состояний кодера в виде их объявления вплоть до кадра 12, непосредственно предшествующего замыкающему кадру 12a. На стороне декодера этап 64 кодирования может откликаться на эту сигнализацию очистки, чтобы при декодировании соответствующего кодированного представления 40 формировать восстановленную версию 66 временного фрагмента 10, соответствующую этому кодированному представлению 40, в части, в которой перекрываются временной фрагмент 10 и замыкающий кадр 12a, путем очистки внутренних состояний этапа 64 декодирования в виде их объявления вплоть до непосредственно предшествующего кадра 12 у замыкающего кадра 12a.
Чтобы подробнее проиллюстрировать процедуру очистки, сошлемся на фиг. 4, которая иллюстрирует случай формирования некодированной оставшейся части восстановленной версии 66 для примерного случая этапов кодирования и декодирования, функционирующих на основе преобразующего кодека. Например, для кодирования кадров может использоваться перекрывающееся преобразование. То есть этап 36 кодирования использует одно окно 72 из нескольких окон, чтобы взвесить соответствующий интервал(ы) 74 аудиоконтента со спектральным разложением результирующей поделенной на окна части путем использования преобразования с разложением на частотные составляющие, например MDCT или т. п. Поделенная на окна часть 74 охватывает и выходит по времени за границы текущего кадра 12'. Фиг. 4, например, иллюстрирует, что окно 72 или поделенная на окна часть 74 перекрывается во времени с двумя кадрами 12, предшествующими текущему кадру 12', в двух кадрах, следующих за текущим кадром 12'. Таким образом, кодированное представление 40 для текущего временного фрагмента 10 содержит кодирование преобразования поделенной на окна части 74, так как это кодирование 76 является кодированным представлением кадра 12'. Этап 64 декодирования выполняет обратный процесс, чтобы восстановить кадры 12 временных фрагментов 10: он декодирует преобразование 76 посредством, например, энтропийного декодирования, выполняет обратное преобразование, чтобы получить в результате поделенную на окна часть 74, которая охватывает текущий кадр 12', которому принадлежит преобразование 76, но этап 64 декодирования дополнительно выполняет процесс перекрытия с суммированием между последовательными, поделенными на окна частями 74, чтобы получить окончательное восстановление аудиоконтента 31'. Процесс перекрытия с суммированием может выполняться соединителем 68. Это означает следующее: Фиг. 4, например, предполагает, что текущий кадр 12' является предпоследним кадром, непосредственно предшествующим замыкающему кадру 12a текущего временного фрагмента 10. Этап 64 декодирования восстанавливает аудиоконтент, охватываемый этим предпоследним кадром 12', путем выполнения, как уже указано, обратного преобразования над преобразованием 76, чтобы получить часть 76 временной области в поделенной на окна части 74. Как объяснялось выше, эта часть 76 временной области перекрывается во времени с текущим кадром 12'. Другие части временной области, полученные обратным преобразованием кодированных преобразований соседних во времени кадров текущего кадра 12' перекрываются во времени, однако тоже с текущим кадром 12'.
На фиг. 4 это иллюстрируется для поделенных на окна частей, принадлежащих двум предшествующим кадрам текущего кадра 12', и указывается номерами 78 и 80 ссылки. Однако полное восстановление кадра 12' получается с помощью процесса перекрытия с суммированием, который суммирует части всех частей 76, 78 и 80 временной области, получающихся в результате обратных преобразований, примененных к кодированному преобразованию 76 кадра 12' и его соседних кадров, как перекрывающихся с текущим кадром 12' во времени. Для последнего или замыкающего кадра 12a это означает следующее. Даже если этап 36 кодирования не кодирует преобразование (преобразования) поделенной на окна части для этого замыкающего кадра 12a в кодированное представление 40, декодер способен получить оценку аудиоконтента в этом замыкающем кадре 12a путем суммирования всех частей временной области, перекрывающих во времени замыкающий кадр 12a, которые получены обратным преобразованием кодированных преобразований 76 одного или нескольких предыдущих кадров, то есть кадра 12' и, при необходимости, одного или нескольких кадров 12, предшествующих предпоследнему кадру 12', в зависимости от размера окна, который может меняться по сравнению с фиг. 4. Например, размер окна может быть таким, что перекрытие во времени с предшествующими во времени кадрами больше перекрытия во времени со следующими кадрами. Кроме того, перекрытие во времени может затрагивать только непосредственно предшествующий и/или непосредственно следующий кадр для кодируемого в настоящее время кадра.
Существуют разные возможности относительно способа, которым информируют декодер 60 о размере выступающей части 16. Например, декодер 60 может конфигурироваться для передачи информации о сокращении, связанной с этим размером, в потоке 34 данных в виде информации о сокращении, содержащей значение длины кадра и значение длины фрагмента. Значение длины кадра могло бы указывать Tframe, а значение длины фрагмента - Tfragment. Другой возможностью было значение длины сокращения, которое указывает временную длину самой выступающей части 16 или временную длину части, в которой временной фрагмент 10 и замыкающий кадр 12a перекрываются во времени. Чтобы сделать возможным немедленное воспроизведение восстановленной версии 66 каждого временного фрагмента 10, этап 36 кодирования и поставщик 38 фрагментов могут сотрудничать, чтобы для каждого временного фрагмента 10 кодированное представление 40 также снабжалось информацией немедленного воспроизведения, которая относится к части 46, предшествующей во времени соответствующему временному фрагменту 10. Например, представим, что перекрывающееся преобразование, упомянутое на фиг. 4, является перекрывающимся преобразованием, вносящим искажение, например MDCT. В этом случае без кодированной с преобразованием версии предшествующей части 46 декодер не смог бы восстановить без искажения текущий временной фрагмент 10 в его начале, например, в его первом одном или нескольких кадрах 12. Соответственно, чтобы выполнить подавление искажения временной области посредством процесса перекрытия с суммированием, информация немедленного воспроизведения, передаваемая в кодированном представлении 40, могла бы относиться к кодированной с преобразованием версии предшествующей части 46, при этом этапы кодирования и декодирования используют процесс кодирования с перекрывающимся преобразованием, который уже проиллюстрирован в отношении фиг. 4.
Хотя подробнее не обсуждалось выше, отметим, что этап 36 кодирования и/или этап 64 декодирования могли бы состоять из двух или даже более ядер. Например, фиг. 2 иллюстрирует, что этап кодирования мог бы содержать первое ядро 90 кодирования и второе ядро 92 кодирования, а также фиг. 3 дополнительно или в качестве альтернативы показывает, что этап 64 декодирования мог бы содержать первое ядро 94 декодирования и второе ядро 96 декодирования. Вместо последовательного кодирования/декодирования соответствующих временных фрагментов 10 и соответствующих кодированных представлений 40 процедура кодирования/декодирования, выполняемая относительно каждой из этих пар временных фрагментов 10 и кодированных представлений 40, могла бы выполняться конвейерным способом с поочередным привлечением ядер 94 и 96 (и 90 и 92) к декодированию/кодированию соответственно последовательности временных фрагментов 10 и кодированных представлений 40.
Таким образом, в соответствии с вариантом осуществления из фиг. 2 аудиокодер выравнивает первый аудиокадр 12b с началом 30 соответствующего временного фрагмента 10. Чтобы обеспечить сплошное или немедленное воспроизведение соответствующей созданной версии 66 того временного фрагмента 10 без слышимых артефактов на стороне декодирования, описанный выше кодер работает на двух разных сетках кадров на границах фрагмента. Также упоминалось, что для того, чтобы предусмотреть немедленное воспроизведение отдельных восстановленных версий 66 в начале 30 фрагмента в зависимости от аудиокодека, лежащего в основе этапов кодирования/декодирования, информация немедленного воспроизведения может передаваться в кодированных представлениях. Например, первый кадр 12b каждого временного фрагмента может кодироваться как кадр IPF немедленного воспроизведения. Такой IPF, помещаемый в начало каждого нового временного фрагмента может, например, охватывать всю задержку декодера. Чтобы снова проиллюстрировать это, сошлемся на фиг. 5, которая показывает часть аудиоконтента возле границы фрагмента между двумя временными фрагментами 10a и 10b. Также на фиг. 5 показаны кадры 12, в единицах которых кодируются/декодируются временные фрагменты 10a и 10b. В частности, фиг. 5 показывает, что замыкающий кадр 12a временного фрагмента 10a перекрывает во времени первый кадр 12b из кадров на сетке кадра, с использованием которого кодируется/декодируется временной фрагмент 10b. В частности, это часть 16, которая выходит за задний конец временного фрагмента 10a и начало 30 временного фрагмента 10b замыкающего кадра 12a, который перекрывается во времени с первым кадром 12b временного фрагмента 10b. При кодировании первого кадра 12b состояние кодирования дополнительно кодирует в кодированное представление 40 для временного фрагмента 10b информацию 98 немедленного воспроизведения, а именно здесь для примера кодирование 100 пяти опережающих кадров 12 на сетке кадра для кодирования/декодирования временного фрагмента 10b, предшествующего первому кадру 12b, при этом опережающие кадры указаны на фиг. 1 с помощью "AU -5" - "AU -1". Эти опережающие кадры соответственно охватывают вышеупомянутую предшествующую часть 46. Кодирование 100, как указано выше по отношению к фиг. 4, может относиться к версии кодирования с преобразованием аудиоконтента в опережающих кадрах, чтобы позволить стороне декодера выполнять подавление искажения временной области с использованием частей временной области, окружающих эти опережающие кадры, используя обратное преобразование и используя их части, заходящие во временной фрагмент 10b, чтобы выполнить подавление искажения временной области в процессе перекрытия с суммированием.
Кодер знает точную длительность фрагмента. Как объяснялось выше, в соответствии вариантом осуществления перекрывающаяся часть 16 аудио может кодироваться два раза с разными сетками кадров.
Дадим краткое изложение по отношению к "самостоятельности", с которой отдельные временные фрагменты 10 кодируются в их кодированные представления 40. Хотя этот самостоятельный способ также мог бы относиться к конфигурационным данным, например параметрам кодирования в отношении редко меняющихся данных, например количества кодированных аудиоканалов или т. п., чтобы каждое кодированное представление 40 могло содержать эти конфигурационные данные, в качестве альтернативы было бы возможно, что такие редко меняющиеся данные, то есть конфигурационные данные, вместо включения в каждое кодированное представление 40 передаются стороне декодирования вне полосы, не в каждом кодированном представлении 40. Если включены в кодированное представление, то конфигурационные данные могут передаваться на другом транспортном уровне. Например, конфигурация может передаваться в сегменте инициализации, и кадр 12b IPF каждого временного фрагмента можно было бы освободить от переноса информации конфигурационных данных.
Что касается стороны декодирования, вышеприведенное описание из фиг. 3 показало, что декодер конфигурируется для декодирования опережающих кадров, то есть кадров, предшествующих первому кадру 12b для каждого временного фрагмента. Декодер может заниматься этим декодированием независимо от того, меняется ли конфигурация от предыдущего временного фрагмента к текущему временному фрагменту. Это, конечно, влияет на общую производительность декодера, но преимущественно декодер может быть уже должен выполнять требование, в соответствии с которым декодер способен декодировать IPF на каждой границе фрагмента, например, в соответствии с наихудшим вариантом использования адаптивной потоковой передачи, чтобы никакое дополнительное требование не предъявлялось в таких случаях. Что касается вышеупомянутой информации о сокращении, следует отметить, что ее сигнализация может выполняться на уровне потока двоичных сигналов или на некотором другом транспортном уровне, например с помощью инструментов системного уровня.
В конечном счете фиг. 6 показывает случай, где кодируемый аудиоконтент 31 показывает изменение конфигурации, например, изменение количества аудиоканалов, в некоторый момент 110 времени, а именно на границе фрагмента между двумя временными фрагментами 10. Например, в непосредственно предшествующий момент 110 времени применяется первая конфигурация, например стерео, тогда как после момента 110 времени аудиоконтент 31 является, например, пятиканальной аудиосценой. Поток 34 аудиоданных содержит информацию конфигурационных данных. Таким образом, из потока 34 данных понятно, что кодированные представления временных фрагментов 10 потока данных, предшествующие моменту 110 времени, кодируются в соответствии с первой конфигурацией, и что вторая конфигурация используется для кодирования временных фрагментов 10, следующих за моментом 110 времени. Фиг. 6 также показывает информацию 98 немедленного воспроизведения кодированных представлений 40. В случае временного фрагмента 10, предшествующего моменту 110 времени, информацию 98 немедленного воспроизведения можно вывести, как описано выше, например, по отношению к фиг. 5. Однако ситуация отличается для временного фрагмента 10, начинающегося непосредственно в момент 110 времени. Здесь аудиоконтент 39 не предусматривает создание информации 98 немедленного воспроизведения для кодированного представления 40 временного фрагмента, начинающегося непосредственно в момент 110 времени, так как аудиоконтент 39 во второй конфигурации не выбирается перед моментом 110 времени. Вместо этого можно кодировать нулевой сигнал в качестве информации 98 немедленного воспроизведения по отношению к этому временному фрагменту 10, начинающемуся в момент 110 времени. То есть в случае изменения конфигурации кодер может кодировать ноль выборок, поскольку нет фактического аудиосигнала, доступного для прошедшего, например, при переключении с моно на 5.1 или т. п. Возможной оптимизацией было бы формирование этого нулевого кадра, то есть нулевого опережающего кадра, на стороне декодера и передача только кодирования первого кадра 12b первого временного фрагмента. То есть в таком случае информацию 98 немедленного воспроизведения можно было бы полностью исключить.
Таким образом, вышеприведенные варианты осуществления дают возможность доставки аудио- и видеоконтента по каналу передачи либо с постоянной, либо с переменной скоростью передачи битов и дают, в частности, возможность синхронизации аудио и видео и обеспечивают усовершенствованные варианты использования, например стыковку. Как упоминалось выше, кодированный поток данных, который кодирован выше, также может выполнять простую синхронизацию с другими генераторами, например генераторами, заданными другими медиа-сигналами. Описанные выше кодеры предусматривают адаптацию существующей длины аудиокадра. Длина временных фрагментов может задаваться в зависимости от потребностей приложения. Варианты осуществления кодера создают кодированный поток данных в частях кодированного представления временных фрагментов, который, например, но не исключительно, можно сделать предметом адаптивной потоковой передачи с использованием этих фрагментов в качестве фрагментов медиа-представления. То есть кодированный поток данных, состоящий из результирующих фрагментов, можно предложить клиенту с помощью сервера посредством протокола адаптивной потоковой передачи, и клиент посредством протокола может извлечь фрагменты потока данных с возможной вставленной туда добавкой и перенаправить их декодеру для декодирования. Но это не является обязательным. Точнее, стыковка преимущественно может подвергаться влиянию создания патентоспособного кодированного потока данных даже в других сценариях применения. Описанные выше варианты осуществления можно реализовать или использовать по отношению к аудиокодеку MPEG-H с аудиокадрами, являющимися аудиокадрами MPEG-H, но вышеприведенные варианты осуществления не ограничиваются использованием этого кодека, а могут быть приспособлены ко всем (современным) аудиокодекам.
Хотя некоторые аспекты описаны применительно к устройству, понято, что эти аспекты также представляют собой описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. По аналогии аспекты, описанные применительно к этапу способа, также представляют собой описание соответствующего блока или элемента либо признака соответствующего устройства. Некоторые или все этапы способа могут исполняться аппаратным устройством (или с его использованием), например микропроцессором, программируемым компьютером или электронной схемой. В некоторых вариантах осуществления какой-нибудь один или несколько самых важных этапов способа могут исполняться таким устройством.
Патентоспособные стыкованные или стыкуемые потоки аудиоданных могут храниться на цифровом носителе информации или могут передаваться по передающей среде, например беспроводной передающей среде или проводной передающей среде, такой как Интернет.
В зависимости от некоторых требований к реализации варианты осуществления изобретения можно реализовать в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя информации, например дискеты, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, содержащего сохраненные на нем электронно считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой так, что выполняется соответствующий способ. Поэтому цифровой носитель информации может быть машиночитаемым.
Некоторые варианты осуществления в соответствии с изобретением содержат носитель информации, содержащий электронно считываемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой так, что выполняется один из способов, описанных в этом документе.
Как правило, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, причем программный код действует для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может храниться, например, на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из описанных в этом документе способов, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления патентоспособного способа поэтому является компьютерной программой, содержащей программный код для выполнения одного из описанных в этом документе способов, когда компьютерная программа выполняется на компьютере.
Дополнительный вариант осуществления патентоспособных способов поэтому является носителем информации (или цифровым носителем информации, или машиночитаемым носителем), содержащим записанную на нем компьютерную программу для выполнения одного из способов, описанных в этом документе. Носитель информации, цифровой носитель информации или записанный носитель обычно являются материальными и/или неизменяемыми со временем.
Дополнительный вариант осуществления патентоспособного способа поэтому является потоком данных или последовательностью сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в этом документе. Поток данных или последовательность сигналов могут конфигурироваться, например, для передачи по соединению передачи данных, например по Интернету.
Дополнительный вариант осуществления содержит средство обработки, например компьютер или программируемое логическое устройство, сконфигурированные или приспособленные для выполнения одного из способов, описанных в этом документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в этом документе.
Дополнительный вариант осуществления в соответствии с изобретением содержит устройство или систему, сконфигурированные для передачи приемнику (например, электронно или оптически) компьютерной программы для выполнения одного из способов, описанных в этом документе. Приемник может быть, например, компьютером, мобильным устройством, запоминающим устройством или т. п. Устройство или система могут, например, содержать файл-сервер для передачи компьютерной программы приемнику.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторых или всех функциональных возможностей способов, описанных в этом документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы выполнить один из способов, описанных в этом документе. Как правило, способы предпочтительно выполняются любым аппаратным устройством.
Описанное в этом документе устройство можно реализовать с использованием аппаратного устройства или с использованием компьютера, или с использованием сочетания аппаратного устройства и компьютера.
Описанные в этом документе способы можно выполнять с использованием аппаратного устройства или с использованием компьютера, или с использованием сочетания аппаратного устройства и компьютера.
Вышеописанные варианты осуществления являются всего лишь пояснительными для принципов настоящего изобретения. Подразумевается, что модификации и изменения компоновок и подробностей, описанных в этом документе, будут очевидны другим специалистам в данной области техники. Поэтому есть намерение ограничиться только объемом предстоящей формулы изобретения, а не определенными подробностями, представленными посредством описания и объяснения вариантов осуществления в этом документе.
Определения и сокращения
AAC Усовершенствованное аудиокодирование
ATSC Комитет по перспективным телевизионным системам
AU Блок доступа к аудио
DASH Динамическая адаптивная потоковая передача по HTTP
DVB Цифровое видеовещание
IPF Кадр мгновенного воспроизведения
MPD Описание представления медиапотока
MPEG Экспертная группа по движущимся изображениям
MMT Медиа-транспорт MPEG
NTSC Национальный комитет по телевизионным стандартам
PAL Строка с переменной фазой
Ссылки
[1] "Delivery/Sync/FEC-Evaluation Criteria Report", ROUTE/DASH
[2] ISO/IEC 23008-3, "Information technology - High efficiency coding and media delivery in heterogeneous environments - Part 3: 3D audio"
[3] ISO/IEC 23009-1, "Information technology - Dynamic adaptive streaming over HTTP (DASH) - Part 1: Media presentation description and segment formats"
[4] ISO/IEC 23008-1, "Information technology - High efficiency coding and media delivery in heterogeneous environments - Part 1: MPEG media transport (MMT)".
Изобретение относится к аудиокодеку для использования параллельно с кодированным видео. Техническим результатом является обеспечение синхронизации и выравнивания аудио и видео. Указанный технический результат достигается тем, что в результате рассмотрения сетки фрагмента и сетки кадра как независимых значений, но тем не менее, для каждого фрагмента сетка кадра выравнивается с началом соответствующего фрагмента. Потерю эффективности сжатия можно поддерживать низкой при подходящем выборе размера фрагмента. С другой стороны, выравнивание сетки кадра относительно начал фрагментов предусматривает легкий и синхронизированный с фрагментом способ обработки фрагментов по отношению, например, к параллельной потоковой передаче аудио и видео, адаптивной по скорости потоковой передаче. 6 н.п. и 16 з.п. ф-лы, 1 табл., 8 ил. 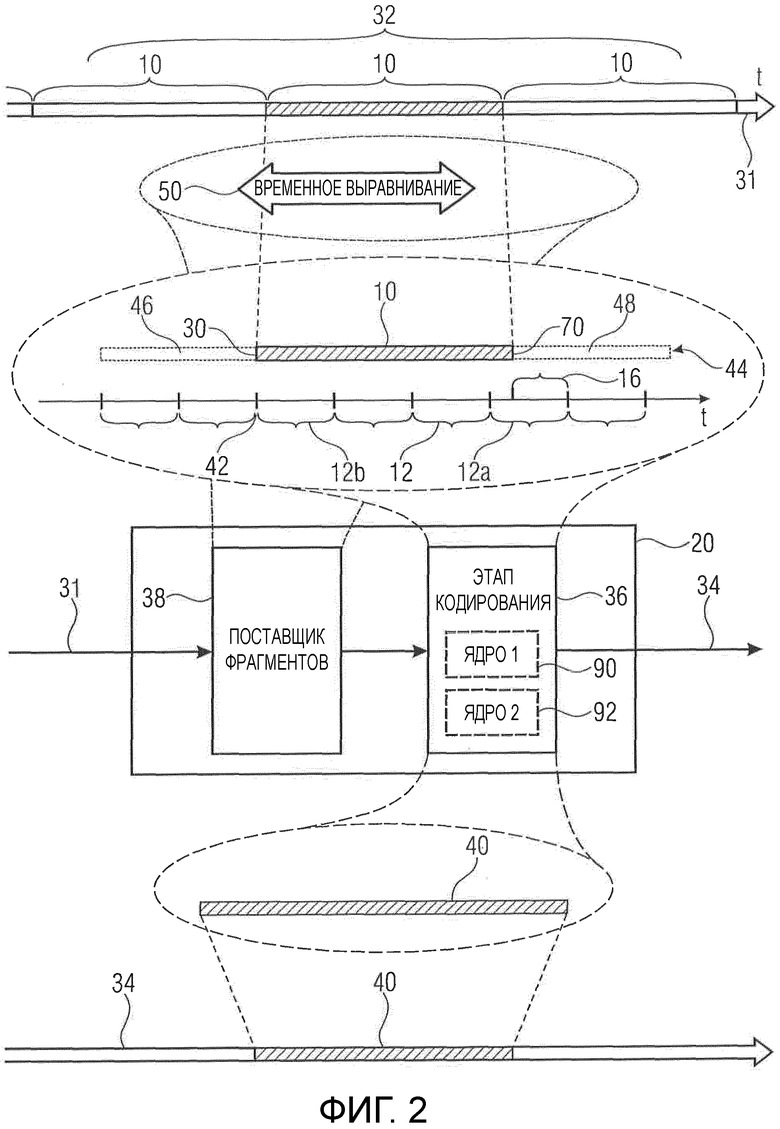
1. Кодер (20) для кодирования аудиоконтента в кодированный поток данных (34), содержащий:
этап кодирования (36), сконфигурированный для кодирования аудиоконтента в единицах аудиокадров (12); и
поставщика фрагментов (38), сконфигурированного для предоставления аудиоконтента (31) этапу кодирования (36) в единицах временных фрагментов (10) путем предоставления этапу кодирования (36) для предоставляемого в настоящее время временного фрагмента (10) части аудиоконтента (31), которая включает в себя предоставляемый в настоящее время временной фрагмент (10),
где кодер конфигурируется для кодирования каждого временного фрагмента (10) в кодированное представление (40) соответствующего временного фрагмента в единицах аудиокадров (12), а поставщик фрагментов конфигурируется для предоставления аудиоконтента (31) этапу кодирования (36) так, что аудиокадры (12) выравниваются с соответствующим временным фрагментом (10), так что для каждого временного фрагмента (10) начало первого аудиокадра и начало (30) соответствующего временного фрагмента совпадают, и
где кодированные представления временных фрагментов (10) состоят из кодированного потока данных, и временная длина временных фрагментов (10) является нецелым кратным временной длины аудиокадров,
где кодер конфигурируется для сигнализации информации о сокращении в кодированном потоке данных для идентификации части замыкающего аудиокадра в аудиокадрах, в единицах которых кодируются временные фрагменты, которая выходит за задний конец временных фрагментов и перекрывается во времени с непосредственно следующим временным фрагментом на сетке фрагмента, где информация о сокращении содержит
значение длины кадра, указывающее временную длину аудиокадров, и значение длины фрагмента, указывающее временную длину временных фрагментов, и/или
значение длины сокращения, указывающее временную длину части замыкающего аудиокадра в аудиокадрах, в единицах которых кодируются временные фрагменты, которая выходит за задний конец временных фрагментов и перекрывается во времени с непосредственно следующим временным фрагментом, или разность между временной длиной части замыкающего аудиокадра и временной длиной замыкающего аудиокадра.
2. Кодер (20) по п. 1, в котором этап кодирования (36) и поставщик фрагментов (38) сотрудничают так, что для заранее установленного временного фрагмента (10) кодирование заранее установленного временного фрагмента (10) в кодированное представление (40) соответствующего временного фрагмента прекращается в аудиокадре, непосредственно предшествующем замыкающему аудиокадру в аудиокадрах, в единицах которых кодируется заранее установленный временной фрагмент, который выходит за задний конец заранее установленного временного фрагмента и перекрывается во времени с непосредственно следующим временным фрагментом на сетке фрагмента.
3. Кодер (20) по п. 2, в котором этап кодирования (36) конфигурируется для сигнализации в кодированном представлении (40) заранее установленного временного фрагмента сигнализации очистки, указывающей декодеру заполнить часть заранее установленного временного фрагмента, охватываемую замыкающим аудиокадром, на основе очистки внутренних состояний декодера в виде их объявления вплоть до аудиокадра, непосредственно предшествующего замыкающему аудиокадру.
4. Кодер (20) по п. 1, в котором этап кодирования (36) и поставщик фрагментов (38) сотрудничают так, что для заранее установленного временного фрагмента (10) кодирование заранее установленного временного фрагмента в кодированное представление соответствующего временного фрагмента продолжается после заднего конца заранее установленного временного фрагмента в замыкающем аудиокадре в аудиокадрах (12), в единицах которых кодируется заранее установленный временной фрагмент, который выходит за задний конец заранее установленного временного фрагмента и перекрывается во времени с непосредственно следующим временным фрагментом на сетке фрагмента.
5. Кодер (20) по п. 4, в котором этап кодирования (36) конфигурируется для кодирования аудиоконтента (31) в части замыкающего аудиокадра, выходящей за задний конец заранее установленного временного фрагмента и перекрывающейся во времени с непосредственно следующим временным фрагментом, с меньшим качеством, чем в заранее установленном временном фрагменте.
6. Кодер (20) по п. 1, в котором этап кодирования (36) и поставщик фрагментов (38) сотрудничают так, что для заранее установленного временного фрагмента (10) кодирование заранее установленного временного фрагмента в кодированное представление соответствующего временного фрагмента включает в себя выведение информации немедленного воспроизведения (98) из одного или нескольких опережающих аудиокадров аудиоконтента, непосредственно предшествующих первому аудиокадру в аудиокадрах, в единицах которых заранее установленный временной фрагмент (10) кодируется в кодированное представление (40) соответствующего временного фрагмента, и кодирование информации немедленного воспроизведения в кодированное представление заранее установленного временного фрагмента.
7. Кодер (20) по п. 6, в котором этап кодирования (36) конфигурируется для выполнения кодирования с использованием кодирования с преобразованием на основе вносящего искажение перекрывающегося преобразования и для выведения информации немедленного воспроизведения путем применения кодирования с преобразованием на основе вносящего искажение перекрывающегося преобразования к аудиоконтенту в одном или нескольких опережающих аудиокадрах.
8. Кодер по п. 1, в котором этап кодирования (36) содержит
первое ядро кодирования (90) и второе ядро кодирования (92),
где поставщик фрагментов (38) конфигурируется для привлечения первого ядра кодирования (90) к кодированию первого временного фрагмента аудиоконтента, при этом первое ядро кодирования (90) конфигурируется для кодирования первого временного фрагмента аудиоконтента в единицах аудиокадров с выравниванием во времени аудиокадров с началом первого временного фрагмента, чтобы первый аудиокадр в аудиокадрах, в единицах которых кодируется первый временной фрагмент аудиоконтента, начинался сразу в начале первого временного фрагмента, чтобы вывести кодированное представление первого временного фрагмента, и где поставщик фрагментов (38) конфигурируется для привлечения второго ядра кодирования к кодированию второго временного фрагмента аудиоконтента, непосредственно следующего за первым временным фрагментом, при этом второе ядро кодирования (92) конфигурируется для кодирования второго временного фрагмента аудиоконтента в единицах аудиокадров с выравниванием во времени аудиокадров с началом второго временного фрагмента, чтобы первый аудиокадр в аудиокадрах, в единицах которых кодируется второй временной фрагмент аудиоконтента, начинался сразу в начале второго временного фрагмента, чтобы вывести кодированное представление второго временного фрагмента,
где поставщик конфигурируется для привлечения первого ядра кодирования (90) также к кодированию третьего временного фрагмента аудиоконтента.
9. Кодер (20) по п. 8, в котором поставщик фрагментов (38) конфигурируется для привлечения первого и второго ядер кодирования (90, 92) поочередно к кодированию временных фрагментов аудиоконтента.
10. Декодер (60) для декодирования аудиоконтента из кодированного потока данных, содержащий
входной интерфейс (62), сконфигурированный для приема кодированных представлений временных фрагментов аудиоконтента, каждое из которых содержит кодированный в нем соответствующий временной фрагмент в единицах аудиокадров, выровненных во времени с началом соответствующего временного фрагмента, чтобы начало соответствующего временного фрагмента совпадало с началом первого аудиокадра в аудиокадрах;
этап декодирования (64), сконфигурированный для декодирования восстановленных версий (66) временных фрагментов аудиоконтента из кодированных представлений временных фрагментов; и
соединитель (68), сконфигурированный для соединения восстановленных версий временных фрагментов аудиоконтента для воспроизведения,
где временная длина между границами фрагмента на сетке фрагмента является нецелым кратным временной длины аудиокадров,
где соединитель (68) конфигурируется для сокращения восстановленной версии (66) заранее установленного временного фрагмента в части замыкающего аудиокадра в аудиокадрах, в единицах которых заранее установленный временной фрагмент кодируется в кодированное представление заранее установленного временного фрагмента, которая превышает во времени задний конец заранее установленного временного фрагмента и перекрывается во времени с восстановленной версией непосредственно следующего временного фрагмента,
где декодер конфигурируется для определения части замыкающего аудиокадра на основе информации о сокращении в кодированном потоке данных, где информация о сокращении содержит
значение длины кадра, указывающее временную длину аудиокадров, в единицах которых заранее установленный временной фрагмент кодируется в кодированное представление заранее установленного временного фрагмента, и значение длины фрагмента, указывающее временную длину заранее установленного временного фрагмента от начала восстановленной версии заранее установленного фрагмента до границы фрагмента, с которой совпадает начало восстановленной версии следующего временного фрагмента, и/или
значение длины сокращения, указывающее временную длину части замыкающего аудиокадра или разность между временной длиной части замыкающего аудиокадра и временной длиной замыкающего аудиокадра.
11. Декодер (60) по п. 10, в котором этап декодирования (64) при декодировании заранее установленного временного фрагмента из кодированного представления заранее установленного временного фрагмента конфигурируется для формирования восстановленной версии заранее установленного временного фрагмента в части замыкающего аудиокадра в аудиокадрах, в единицах которых заранее установленный временной фрагмент кодируется в кодированное представление заранее установленного временного фрагмента, которая идет от переднего конца замыкающего аудиокадра до границы фрагмента восстановленной версии следующего временного фрагмента, путем очистки внутренних состояний этапа декодирования в виде их объявления вплоть до аудиокадра, непосредственно предшествующего замыкающему аудиокадру.
12. Декодер (60) по п. 10, в котором этап декодирования (64) конфигурируется для выведения информации немедленного воспроизведения из кодированных представлений заранее установленного временного фрагмента, при этом информация немедленного воспроизведения связана с аудиоконтентом в одном или нескольких опережающих аудиокадрах аудиоконтента, который (которые) предшествует (предшествуют) по времени началу заранее установленного временного фрагмента, и использования информации немедленного воспроизведения, чтобы восстановить аудиоконтент в одном или нескольких аудиокадрах заранее установленного временного фрагмента, непосредственно следующего за началом временного фрагмента.
13. Декодер (60) по п. 12, в котором этап декодирования (64) конфигурируется так, что информация немедленного воспроизведения является восстановлением аудиоконтента в одном или нескольких опережающих аудиокадрах.
14. Декодер (60) по п. 12, в котором этап декодирования (64) конфигурируется для использования информации немедленного воспроизведения при восстановлении аудиоконтента в одном или нескольких аудиокадрах заранее установленного временного фрагмента, непосредственно следующего за началом временного фрагмента, для подавления искажения временной области.
15. Декодер по п. 10, в котором этап декодирования (64) конфигурируется для декодирования аудиокадров по отдельности с использованием инверсии перекрывающегося преобразования, которое вызывает искажение и влечет за собой окна преобразования, выходящие за границы кадров.
16. Декодер по п. 10, в котором этап декодирования (64) содержит
первое ядро декодирования (94), сконфигурированное для декодирования восстановленной версии первого временного фрагмента аудиоконтента в единицах аудиокадров из кодированного представления первого временного фрагмента, чтобы восстановленная версия первого временного фрагмента начиналась в переднем конце первого аудиокадра в аудиокадрах первого временного фрагмента;
второе ядро декодирования (96), сконфигурированное для декодирования восстановленной версии второго временного фрагмента аудиоконтента, непосредственно следующего за первым временным фрагментом, в единицах аудиокадров из кодированного представления второго временного фрагмента, чтобы восстановленная версия второго временного фрагмента начиналась зарегистрированной в переднем конце первого аудиокадра в аудиокадрах второго временного фрагмента,
где соединитель (68) конфигурируется для соединения восстановленной версии (66) первого временного фрагмента и восстановленной версии второго временного фрагмента.
17. Декодер по п. 16, в котором первое ядро декодирования конфигурируется также для декодирования восстановленной версии третьего временного фрагмента аудиоконтента из кодированного потока данных.
18. Декодер по п. 16, в котором первое и второе ядра декодирования конфигурируются, чтобы поочередного заниматься декодированием восстановленных версий временных фрагментов аудиоконтента из кодированных представлений временных фрагментов.
19. Способ (20) для кодирования аудиоконтента в кодированный поток данных (34) с использованием этапа кодирования (36), сконфигурированного для кодирования аудиоконтента в единицах кадров (12), при этом способ содержит этапы, на которых
предоставляют аудиоконтент (31) этапу кодирования (36) в единицах временных фрагментов (10) путем предоставления этапу кодирования (36) для предоставляемого в настоящее время временного фрагмента (10) части аудиоконтента (31), которая включает в себя предоставляемый в настоящее время временной фрагмент (10),
кодируют с помощью этапа кодирования каждый временной фрагмент (10) в кодированное представление (40) соответствующего временного фрагмента в единицах аудиокадров (12), где аудиоконтент (31) предоставляется этапу кодирования (36) так, что аудиокадры (12) выравниваются с соответствующим временным фрагментом (10), так что для каждого временного фрагмента (10) начало первого аудиокадра в аудиокадрах, в единицах которых соответствующий временной фрагмент (10) кодируется в кодированное представление (40) соответствующего временного фрагмента, и начало (30) соответствующего временного фрагмента совпадают,
где кодированные представления временных фрагментов (10) состоят из кодированного потока данных, и временная длина временных фрагментов (10) является нецелым кратным временной длины кадров,
где способ содержит этап, на котором сигнализируют информацию о сокращении в кодированном потоке данных для идентификации части замыкающего аудиокадра в аудиокадрах, в единицах которых кодируются временные фрагменты, которая выходит за задний конец временных фрагментов и перекрывается во времени с непосредственно следующим временным фрагментом на сетке фрагмента, где информация о сокращении содержит
значение длины кадра, указывающее временную длину аудиокадров, и значение длины фрагмента, указывающее временную длину временных фрагментов, и/или
значение длины сокращения, указывающее временную длину части замыкающего аудиокадра в аудиокадрах, в единицах которых кодируются временные фрагменты, которая выходит за задний конец временных фрагментов и перекрывается во времени с непосредственно следующим временным фрагментом на сетке фрагмента, или разность между временной длиной части замыкающего аудиокадра и временной длиной замыкающего аудиокадра.
20. Способ (60) для декодирования аудиоконтента в единицах временных фрагментов на сетке фрагмента из кодированного потока данных, содержащий этапы, на которых
принимают кодированные представления временных фрагментов аудиоконтента, каждое из которых содержит кодированный в нем соответствующий временной фрагмент в единицах аудиокадров, выровненных во времени с началом соответствующего временного фрагмента, чтобы начало соответствующего временного фрагмента совпадало с началом первого аудиокадра в аудиокадрах;
декодируют восстановленные версии (66) временных фрагментов аудиоконтента из кодированных представлений временных фрагментов; и
соединяют восстановленные версии временных фрагментов аудиоконтента для воспроизведения,
где временная длина между границами фрагмента на сетке фрагмента является нецелым кратным временной длины аудиокадров,
где этап, на котором соединяют (68), содержит этап, на котором сокращают восстановленную версию (66) заранее установленного временного фрагмента в части замыкающего аудиокадра в аудиокадрах, в единицах которых заранее установленный временной фрагмент кодируется в кодированное представление заранее установленного временного фрагмента, которая превышает во времени задний конец заранее установленного временного фрагмента и перекрывается во времени с восстановленной версией непосредственно следующего временного фрагмента,
где способ дополнительно содержит этап, на котором определяют часть замыкающего аудиокадра на основе информации о сокращении в кодированном потоке данных,
где информация о сокращении содержит
значение длины кадра, указывающее временную длину аудиокадров, в единицах которых заранее установленный временной фрагмент кодируется в кодированное представление заранее установленного временного фрагмента, и значение длины фрагмента, указывающее временную длину заранее установленного временного фрагмента от начала восстановленной версии заранее установленного фрагмента до границы фрагмента, с которой совпадает начало восстановленной версии следующего временного фрагмента, и/или
значение длины сокращения, указывающее временную длину части замыкающего аудиокадра или разность между временной длиной части замыкающего аудиокадра и временной длиной замыкающего аудиокадра.
21. Машиночитаемый носитель, содержащий программный код для выполнения способа по п. 19 при выполнении на компьютере.
22. Машиночитаемый носитель, содержащий программный код для выполнения способа по п. 20 при выполнении на компьютере.
| OpenCable™ Specifications Adaptive Transport Stream Specification, OC-SP-ATS-I01-140214, Cable Television Laboratories, February 14, 2014 | |||
| Technical Note: AAC Implementation Guidelines for DASH, ISO/IEC JTC1/SC29 WG11, N15072, February 2015, Geneva, Switzerland | |||
| US 6124895 A, 2000-09-26 | |||
| WO 2012126893 A1, 2012-09-27 | |||
| RU 2012148132 A, 2014-05-20. |

