УРОВЕНЬ ТЕХНИКИ
[0001] Центр обработки и хранения данных представляет собой совокупность вычислительных устройств, которые взаимодействуют друг с другом по сети и работают совместно для предоставления вычислительных услуг и/или услуг хранения данных одному или более конечным пользователям, при этом конечным пользователем может являться человек, предприятие и т.п. Центр обработки и хранения данных, таким образом, включает в себя многочисленные вычислительные устройства, многочисленные устройства сетевой инфраструктуры, такие как маршрутизаторы, ремаршрутизаторы, коммутаторы, шлюзы, брандмауэры, виртуальные частные сети (VPN), мосты и т.д., каналы связи между вычислительными устройствами и устройствами сетевой инфраструктуры и каналы связи между устройствами сетевой инфраструктуры. При предоставлении упомянутых выше услуг данные передаются через сеть и между вычислительными устройствами в центре обработки и хранения данных. Устройства сетевой инфраструктуры выполнены с возможностью осуществлять прямой трафик через сеть.
[0002] В традиционных центрах обработки и хранения данных устройства сетевой инфраструктуры включают в себя высококачественные устройства, которые обычно бывают относительно дорогими. Однако в последнее время центры обработки и хранения данных стали рассчитаны на то, чтобы включать в себя многочисленные типовые (например, стандартные) устройства сетевой инфраструктуры, чтобы уменьшить капитальные затраты, связанные с центром обработки и хранения данных. Хотя типовые устройства дешевле, чем "высококачественные" устройства, типовые устройства обычно несколько менее надежны, чем высококачественные устройства, и это приводит к увеличенной нагрузке на операторов центра обработки и хранения данных, чтобы гарантировать непрерывный сервис. Однако устранение отказов сети может быть сложным и, таким образом, отнимающим много времени, поскольку устройства сетевой инфраструктуры в центре обработки и хранения данных могут быть произведены множеством различных изготовителей, поскольку на вычислительных и/или сетевых устройствах в центре обработки и хранения данных могут быть установлены разные операционные системы, поскольку изготовитель может производить разные модели устройства одного и того же типа и т.д. Таким образом, имеется существенное количество разнородности в традиционных центрах обработки и хранения данных.
[0003] В относительно крупных информационных центрах операционная команда работает над тем, чтобы гарантировать исполнение вычислительных услуг и услуг хранения, обещанных конечным пользователям (например, в соглашениях об уровне обслуживания). В соответствии с этим, когда сетевое устройство (например, вычислительное устройство или устройство сетевой инфраструктуры) формирует аварийный сигнал, аварийный сигнал направляется на пульт оператора, отслеживаемый оператором из операционной команды. Оператор рассматривает аварийный сигнал и на основе своих личных знаний и опыта (и, возможно, некоторых статических рекомендаций) выполняет выявление неисправностей и отладку, чтобы попытаться либо только смягчить последствия (а не диагностировать), либо зафиксировать отказ в работе (посредством диагностики первопричины проблемы), указанный аварийным сигналом. Хотя этот подход может быть пригодным для относительно небольших центров обработки и хранения данных, такой подход не масштабируем. Например, центры обработки и хранения данных масштабируются и включают в себя сотни тысяч вычислительных устройств и несколько тысяч устройств сетевой инфраструктуры. Когда происходят конкретные события, большое количество аварийных сигналов может быть сформировано устройствами в центре обработки и хранения данных в относительно короткий срок. Оператор должен проанализировать аварийные сигналы, чтобы назначить приоритеты, к каким аварийным сигналам следует обратиться в первую очередь, и затем обычно использует эмпирический подход (потенциально управляемый предопределенными сформированными человеком рекомендациями), чтобы обратиться к аварийным сигналам, имеющим высокий приоритет. Вследствие относительно высокой сложности потенциальных сетевых проблем оператору может потребоваться длительный период времени для устранения неисправности, и это может привести к простою сервиса.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0004] Далее следует краткий обзор сущности изобретения, которое описано более подробно в настоящем документе. Этот краткий обзор сущности не предназначен для ограничения объема формулы изобретения.
[0005] Здесь описаны различные технологии, имеющие отношение к идентификации потенциальных вариантов выявления неисправностей и этапов устранения, которые могут использоваться для устранения отказа сети в центре обработки и хранения данных. Варианты выявления неисправностей и этапы устранения предоставляются оператору, который может использовать варианты выявления неисправностей и этапы устранения для устранения отказа сети с использованием обеспеченных вариантов выявления неисправностей и этапов устранения. Здесь дополнительно описаны различные технологии, имеющие отношение к назначению приоритетов отказам сети на основе аварийных сигналов, сформированных устройствами в центре обработки и хранения данных, причем список с назначенными приоритетами может быть выдан оператору, чтобы облегчить сортировку аварийных сигналов.
[0006] Центр обработки и хранения данных включает в себя множество сетевых вычислительных устройств, причем данные могут передаваться между вычислительными устройствами по сетевым линиям связи посредством множества устройств сетевой инфраструктуры, таких как, среди прочих, маршрутизаторы, ремаршрутизаторы, коммутаторы, стабилизаторы нагрузки, брандмауэры, виртуальные частные сети (VPN). Вычислительные устройства и/или устройства сетевой инфраструктуры (совместно называемые "устройствами") могут быть выполнены с возможностью формировать аварийные сигналы, которые являются показателем отказов сети. Например, коммутатор может быть выполнен с возможностью формировать аварийный сигнал, когда переключатель обнаруживает, что линия связи между коммутатором и другим устройством отключена. Аварийный сигнал принимается, и выполняется определение относительно того, является ли аварийный сигнал показателем требующего действий сетевого события (например, отказом сети, который должен быть устранен). Когда определено, что аварийный сигнал является показателем устранимого отказа сети, для условий отказа и соответствующих данных телеметрии может быть установлено соответствие множеству наблюдавшихся симптомов, испытанных на: 1) отказавшем устройстве или линии связи; 2) платформе отказавшего устройства; 3) устройствах, соседних с отказавшим устройством в сетевой топографии; 4) устройствах, находящихся в той же собственности, как отказавшее устройство; и/или 5) устройствах в одном и том же центре обработки и хранения данных, как отказавшее устройство, среди других аспектов. В соответствии с этим по меньшей мере один симптом (например, "устройство отключено", "неустойчивая линии связи", "высокая загрузка центрального процессора", …) может быть идентифицирован для отказавшего устройства или линии связи.
[0007] В ответ на идентификацию симптома для отказавшего устройства или линии связи может быть идентифицировано множество рекомендуемых вариантов выявления неисправностей, которые потенциально могут устранить отказ сети. Варианты выявления неисправностей могут быть основаны на предыдущих вариантах выявления неисправностей, которые, как наблюдалось в прошлом, устранили отказ сети, имеющий отношение к отказавшему устройству или линии связи, типу отказавшего устройства, платформе отказавшего устройства и т.д. Варианты выявления неисправностей могут иметь присвоенные им соответствующие метки, причем метки являются показателем соответствующих вероятностей того, что варианты выявления неисправностей при их выборе оператором устранят отказ сети, указанный аварийным сигналом. Метки могут быть идентифицированы на основе прошлых успехов или неудач вариантов выявления неисправностей, когда они выбирались относительно отказавшего устройства или линии связи, типа отказавшего устройства, платформы отказавшего устройства и т.д. В соответствии с этим оператору может быть предоставлен список вариантов выявления неисправностей для устранения отказа сети, а также метки, соответственно присвоенные вариантам выявления неисправностей, которые являются показателем соответствующих вероятностей того, что варианты выявления неисправностей устранят отказ сети. Кроме того, оператор может использовать знания проблемной области (например, на основе опыта или знаний, обеспеченных экспертом в проблемной области) в сочетании с вероятностями варианта выявления неисправностей, чтобы определить последовательность выполнения действий ля устранения отказа.
[0008] Кроме того, для варианта выявления неисправностей в списке вариантов выявления неисправностей оператору может быть обеспечено множество этапов отладки, причем этапам отладки могут быть присвоены метки, которые являются соответственно показателем вероятностей того, что этапы отладки исправят отказ сети. В не ограничивающем примере устройство сетевой инфраструктуры может выдать аварийный сигнал, который указывает, что расположенное ниже устройство сетевой инфраструктуры не отвечает на контрольные запросы. Аварийный сигнал может быть принят, и для условий отказа в аварийном сигнале может быть установлено соответствие ранее наблюдавшемуся симптому "устройство отключено". Для такого симптома оператору могут быть представлены три варианта выявления неисправностей, ранжированные по их соответствующим вероятностям устранения отказа в работе: 1) "проверить кабель", 2) "проверить источник питания" и 3) "проверить сетевую плату". Метки, присвоенные вариантам выявления неисправностей, могут указать, что первый вариант выявления неисправностей наиболее вероятно устранит отказ сети, второй вариант выявления неисправностей является вторым по вероятности устранения отказа сети, и третий вариант выявления неисправностей является третьим по вероятности устранения отказа сети. Кроме того, для варианта выявления неисправностей в списке вариантов выявления неисправностей оператору может быть обеспечен по меньшей мере один этап отладки. Например, для варианта выявления неисправностей "проверить кабель" оператору могут быть представлены два потенциальных этапа отладки. Каждому этапу отладки может быть присвоена соответствующая метка, которая является показателем вероятности того, что этап отладки устранит отказ сети. Например, этапы отладки "зафиксировать кабель повторно" и "очистить кабель" могут быть представлены как этапы отладки, и первый этап отладки указан как более вероятный для исправления отказа сети, чем второй этап отладки. Показатель относительно вероятности может являться функцией вероятностей, вычисленных на основе наблюдавшихся этапов отладки, выбранных ранее операторами центра обработки и хранения данных для отказавшего устройства или линии связи или для устройства (устройств), относящегося к отказавшему устройству или линии связи.
[0009] Управляемый данными подход может использоваться для идентификации вариантов выявления неисправностей и этапов отладки и присвоения соответствующих меток вариантам выявления неисправностей и этапам отладки. Например, когда оператор устраняет отказ сети посредством варианта выявления неисправностей и соответствующего этапа отладки, оператор может обеспечить информацию обратной связи, которая указывает, был ли симптом правильно идентифицирован, может идентифицировать, какой вариант выявления неисправностей был выбран, и может идентифицировать, какие этапы отладки использовались для устранения отказа сети. В соответствии с этим, когда впоследствии принимается другой аварийный сигнал (имеющий отношение к отказавшему устройству или линии связи, типу отказавшего устройства, платформе отказавшего устройства и т.д.), для условий отказа может быть должным образом установлено соответствие симптому, и метки, присвоенные вариантам выявления неисправностей и этапам отладки, могут быть соответственно обновлены на основе этой информации обратной связи. Таким образом, в течение времени точность вариантов выявления неисправностей и этапов отладки может увеличиваться.
[0010] Кроме того, как будет описано здесь, аварийные сигналы могут быть сгруппированы, чтобы представлять единственный отказ сети, и отказам сети могут быть назначены приоритеты. Таким образом, вместо того, чтобы рассматривать сетевые аварийные сигналы низкого уровня изолированно, может быть установлена взаимосвязь между аварийными сигналами (они могут быть сгруппированы друг с другом), чтобы представлять единственный отказ сети. В соответствии с примером эта группировка может быть основана на трех критериях: 1) время; первый аварийный сигнал, сформированный первым устройством, может быть сгруппирован со вторым аварийным сигналом, сформированным недавно по времени первым устройством или вторым устройством на том же самом интерфейсе; 2) местоположение; первый аварийный сигнал может быть сгруппирован со вторым аварийным сигналом, сформированным вторым устройством, которое является соседом первого устройства в сети (например, через 1-2 транзитных участка в восходящем или нисходящем направлении в сетевой иерархической топографии); и 3) группа избыточности; первый аварийный сигнал может быть сгруппирован со вторым аварийным сигналом, сформированным вторым устройством в той же самой группе избыточности, как первое устройство (например, может указать на проблему с протоколом аварийного переключения). Группировка аварийных сигналов для представления отказов сети может использоваться, чтобы разбить на категории и ранжировать текущие отказы сети, в результате чего отказам сети, которые могут привести к большому влиянию на бизнес, могут быть назначены более высокие приоритеты, чем отказам сети, которые приводят к малому влиянию на бизнес.
[0011] Приведенное выше описание сущности изобретения представляет краткое изложение, чтобы обеспечить основное понимание некоторых аспектов описываемых здесь систем и/или способов. Это краткое изложение не является полным обзором описанных здесь систем и/или способов. Оно не предназначено для идентификации ключевых/критических элементов или определения объема таких систем и/или способов. Его единственная цель состоит в том, чтобы в упрощенной форме представить некоторые понятия в качестве вводной части к более подробному описанию, которое представлено позже.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0012] Фиг. 1 демонстрирует иллюстративную часть центра обработки и хранения данных.
[0013] Фиг. 2 демонстрирует иллюстративную архитектуру центра обработки и хранения данных.
[0014] Фиг. 3 - функциональная блок-схема иллюстративной системы устранения, которая принимает аварийные сигналы, сформированные сетевыми устройствами в центре обработки и хранения данных, и выдает варианты выявления неисправностей и этапы отладки в ответ на прием аварийных сигналов.
[0015] Фиг. 4 - функциональная блок-схема иллюстративного компонента идентификации устранения, включенного в систему устранения.
[0016] Фиг. 5 - иллюстративная хронологическая таблица отказов.
[0017] Фиг. 6 - иллюстративный графический пользовательский интерфейс, который изображает потенциальные варианты выявления неисправностей и этапы отладки для устранения отказа сети, указанного аварийным сигналом.
[0018] Фиг. 7 демонстрирует иллюстративный компонент назначения приоритетов аварийных сигналов, который факультативно включен в систему устранения.
[0019] Фиг. 8 - блок-схема последовательности операций, которая демонстрирует иллюстративную методологию для выдачи вариантов выявления неисправностей для устранения отказа сети, указанного аварийным сигналом, сформированным сетевым устройством.
[0020] Фиг. 9 - блок-схема последовательности операций, которая демонстрирует иллюстративную методологию для группировки взаимосвязанных аварийных сигналов и выдачи ранжированного списка отказов сети.
[0021] Фиг. 10 - блок-схема последовательности операций, которая демонстрирует иллюстративную методологию для обновления хронологических данных, имеющих отношение к центру обработки и хранения данных, на основе информации обратной связи оператора.
[0022] Фиг. 11 - иллюстративная вычислительная система.
ПОДРОБНОЕ ОПИСАНИЕ
[0023] Различные технологии, имеющие отношение к устранению отказов сети в центре обработки и хранения данных, теперь описываются со ссылкой на чертежи, на которых одинаковые номера для ссылок везде используются для ссылки на одинаковые элементы. В последующем описании в целях объяснения изложены многочисленные конкретные подробности, чтобы обеспечить всестороннее понимание одного или более аспектов. Однако, может быть очевидно, что такой аспект (аспекты) может быть осуществлен без этих конкретных подробностей. В других случаях известные структуры и устройства показаны в форме блок-схемы, чтобы облегчить описание одного или более аспектов. Кроме того, следует понимать, что функциональность, которая описана как выполняемая некоторыми системными компонентами, может быть выполнена несколькими компонентами. Аналогичным образом, например, компонент может быть сконфигурирован для выполнения функциональности, которая описана как выполняемая несколькими компонентами.
[0024] Кроме того, термин "или" предназначен для обозначения включающего "или", а не исключающего "или". Таким образом, если не определено иначе или не ясно из контекста, фраза "X использует A или B" предназначена для обозначения любой из естественных включающих перестановок. Таким образом, фразе "X использует A или B" удовлетворяет любой из следующих случаев: X использует A; X использует B; или X использует и A, и B. Кроме того, использование единственного числа в этой заявке и в приложенной формуле изобретения обычно должно истолковываться для обозначения "один или более", если не определено иначе или не ясно из контекста, что оно ориентировано на форму единственного числа.
[0025] Кроме того, предполагается, что используемые здесь термины "компонент" и "система" охватывают машиночитаемое хранилище данных, которое сконфигурировано с помощью исполняемых компьютером инструкций, которые при их исполнении процессором приводят к выполнению некоторой функциональности. Исполняемые компьютером инструкции могут включить в себя подпрограмму, функцию и т.п. Также следует понимать, что компонент или система могут быть локализованы на одном устройстве или распределены по нескольким устройствам. Кроме того, используемый здесь термин "иллюстративный" предназначен для обозначения "служащий в качестве иллюстрации или примера чего-либо" и не предназначен для указания предпочтения.
[0026] Теперь со ссылкой на фиг. 1 продемонстрирована часть иллюстративного центра 100 обработки и хранения данных (упоминаемого здесь как центр 100 обработки и хранения данных). Центр 100 обработки и хранения данных может быть выполнен с возможностью предоставлять услуги конечному пользователю 102, причем такими услугами могут являться вычислительные услуги и/или услуги хранения, и конечным пользователем 102 может являться человек, предприятие и т.п. В примере центр 100 обработки и хранения данных может представлять собой центр обработки и хранения данных предприятия, который принадлежит конкретному предприятию и предоставляет вычислительные услуги и услуги хранения для предприятия. В такой ситуации конечный пользователь 102 может являться человеком, который работает на предприятии, в подразделении предприятия и т.д. В другом примере центром 100 обработки и хранения данных может управлять первая компания, и конечным пользователем 102 может являться вторая компания (например, первая компания сдает в аренду ресурсы хранения данных и вычислительные ресурсы для второй компании). Еще в одном примере центром 100 обработки и хранения данных может управлять компания, и конечным пользователем 102 может являться человек. Иллюстративные вычислительные услуги и/или услуги хранения, которые могут быть предложены центром 100 обработки и хранения данных, включают в себя почтовые службы, поисковые службы, хранение, онлайновые службы и т.п. В примере конечный пользователь 102 может управлять вычислительным устройством 103 и может передавать данные и принимать данные из центра 100 обработки и хранения данных посредством вычислительного устройства 103, причем вычислительным устройством 103 может являться вычислительное устройство любого подходящего типа, в том числе, но без ограничения, настольное вычислительное устройство, мобильное вычислительное устройство (например, ноутбук, мобильный телефон, планшетное вычислительное устройство, носимое вычислительное устройство и т.д.), сервер и т.п.
[0027] Центр 100 обработки и хранения данных включает в себя множество вычислительных устройств 104-110, причем вычислительные устройства 104-110 могут включать в себя серверы, выделенные запоминающие устройства и т.д. Вычислительные устройства 104-110 выполнены с возможностью выполнять действия (например, хранить данные, обрабатывать данные и/или передавать данные) на основе запроса от вычислительного устройства 103 конечного пользователя 102. Например, конечный пользователь 102 может запросить исполнение поиска по информационному содержанию в хранилище первого вычислительного устройства 104, и первое вычислительное устройство 104 может быть выполнено с возможностью исполнять поиск и выдавать результаты поиска в ответ на прием запроса центром 100 обработки и хранения данных. В другом примере второе вычислительное устройство 106 может сохранить часть индекса поисковой системы и может быть выполнено с возможностью передавать часть индекса поисковой системы другому вычислительному устройству в центре 100 обработки и хранения данных (или к другому центру обработки и хранения данных) в ответ на прием запроса сделать это от вычислительного устройства 103.
[0028] Центр 100 обработки и хранения данных также содержит множество устройств 114-120 сетевой инфраструктуры. Устройства 114-120 сетевой инфраструктуры выполнены с возможностью облегчать передачу данных между вычислительными устройствами в вычислительных устройствах 104-110 в центре 100 обработки и хранения данных, облегчать передачу данных между центрами обработки и хранения данных, а также облегчать передачу данных между вычислительным устройством 103, управляемым конечным пользователем 102, и вычислительными устройствами 104-110. В иллюстративном центре 100 обработки и хранения данных, изображенном на фиг. 1, устройства 114-120 сетевой инфраструктуры включают в себя два коммутатора 114 и 116, маршрутизатор 118 и брандмауэр 120. Устройства в центре 100 обработки и хранения данных (где термин "устройства" в целом относится к вычислительным устройствам и устройствам сетевой инфраструктуры) соединены с возможностью взаимодействия друг с другом посредством сетевых линий связи. Таким образом, например, первое вычислительное устройство 104 соединено с возможностью взаимодействия с коммутатором 114 посредством первой сетевой линии связи, второе вычислительное устройство 106 соединено с возможностью взаимодействия с коммутатором 114 посредством второй сетевой линии связи, коммутатор 114 соединен с возможностью взаимодействия с маршрутизатором 118 посредством третьей сетевой линии связи и так далее. Следует понимать, что хотя показано, что центр 100 обработки и хранения данных включает в себя относительно небольшое количество устройств, центр обработки и хранения данных может включать в себя много тысяч вычислительных устройств и много тысяч устройств сетевой инфраструктуры. Кроме того, устройства 114-120 сетевой инфраструктуры могут включать в себя устройства на основе аппаратных средств и/или программного обеспечения. Например, маршрутизатор 118 может представлять собой маршрутизатор на основе программного обеспечения, которое исполняется вычислительным устройством. Аналогичным образом, брандмауэр 120 может представлять собой программный брандмауэр, который исполняется в аппаратном маршрутизаторе или вычислительном устройстве.
[0029] Вычислительные устройства 104-110 и/или устройства 114-120 сетевой инфраструктуры могут быть выполнены с возможностью выдавать аварийные сигналы, когда обнаружены некоторые соответствующие события. В примере маршрутизатор 118 может быть выполнен с возможностью выдавать аварийный сигнал, когда маршрутизатор 118 выдает контрольный запрос (например, запрос ответа на сообщение), направленный конкретному вычислительному устройству, и не принимает один или более ответов в пределах порогового времени с момента контрольной передачи. В другом примере множество распределенных процессов, работающих в центре 100 обработки и хранения данных (называемые "сторожевыми таймерами") или вне центра 100 обработки и хранения данных, могут периодически отправлять контрольный запрос службе, серверу или вычислительному устройству в дополнение к исполняющемуся множеству комбинированных микротранзакций, чтобы гарантировать, что служба, сервер или вычислительное устройство доступны с точки зрения конечного пользователя (например, отправлять маленькое тестовое почтовое сообщение, чтобы проверить, что почтовая служба работает должным образом). Аварийный сигнал может быть сформирован, когда ответ на контрольный запрос не принят. Соответственно, аварийный сигнал может являться показателем отказа сети: например, того, что вычислительное устройство отключено, или что сетевая линия связи между маршрутизатором 118 и конкретным вычислительным устройством отключена. В другом примере коммутатор 114 может быть выполнен с возможностью формировать аварийный сигнал, когда объем данных, направленных через коммутатор 114, достигает предопределенного порога.
[0030] Система 122 устранения принимает аварийные сигналы, сформированные вычислительными устройствами 104-110 и/или устройствами 114-120 сетевой инфраструктуры, и выдает данные станции 124 оператора, используемой сетевым оператором 126, чтобы помочь сетевому оператору 126 в устранении отказов сети, указанных по меньшей мере одним аварийным сигналом. Как будет описано здесь более подробно, система 122 устранения может идентифицировать отказ сети на основе по меньшей мере одного принятого аварийного сигнала и может идентифицировать множество потенциальных вариантов выявления неисправностей для устранения отказа сети. Вариант выявления неисправностей может быть воспринят как проверка высокого уровня, которая может быть выполнена оператором, например “проверить сетевую плату”, “проверить кабель” и т.п. Кроме того, система 122 устранения может присвоить соответствующие метки вариантам выявления неисправностей, причем метки являются соответствующими показателями вероятностей того, что варианты выявления неисправностей устранят отказ сети, когда они выбираются сетевым оператором 126. Как будет описано здесь более подробно, система 122 устранения может идентифицировать варианты выявления неисправностей и соответствующие метки на основе предыдущих вариантов выявления неисправностей, выбранных сетевым оператором 126 (или другими операторами в операционной команде для центра 100 обработки и хранения данных) для устранения подобных отказов сети (например, отказов работы в сети с подобными симптомами).
[0031] Таким образом, оператору 126 предоставлен список вариантов выявления неисправностей с назначенными приоритетами, по которому оператор 126 может пройти для устранения отказа сети. Кроме того, вариант выявления неисправностей может иметь один или более этапов отладки, присвоенных ему, причем этап отладки обеспечивает более детализированные инструкции (по сравнению с вариантом выявления неисправностей) оператору 126 для устранения отказа сети. В примере, когда оператор 126 выбирает конкретный вариант выявления неисправностей, список этапов отладки может быть представлен оператору 126. Кроме того, каждому этапу отладки может быть присвоена соответствующая метка, причем метка является показателем вероятности того, что этап отладки устранит идентифицированный отказ сети (в предположении, что вариант выявления неисправностей представляет собой правильный вариант). С точки зрения оператора 126 ему предоставлен список вариантов выявления неисправностей, из которого оператор 126 может выбрать конкретный вариант выявления неисправностей (например, вариант выявления неисправностей, связанный с самой высокой вероятностью устранения отказа сети), и затем может выполнить этапы отладки в порядке вероятности. Кроме того, оператору 126 дополнительно может быть представлены счетчики, указывающие, сколько раз этот вариант выявления неисправностей и/или этап отладки был выбран, и/или сколько раз этот вариант выявления неисправностей и/или этап отладки был успешен. Например, двум вариантам выявления неисправностей могут быть присвоены эквивалентные вероятности (например, 50%). Однако первая метка, присвоенная первому варианту выявления неисправностей, может указать, что вариант выявления неисправностей был выбран дважды и был успешен один раз, в то время как вторая метка, присвоенная второму варианту выявления неисправностей, может указать, что вариант выявления неисправностей был выбран одну тысячу раз и был успешен пятьсот раз. Когда оператор 126 устраняет отказ сети, оператор 126 может обеспечить информацию обратной связи системе 122 устранения относительно того, какой вариант выявления неисправностей (если таковой имеется) и какие этапы отладки (если таковые имеются) устранили отказ сети. Эта информация обратной связи может использоваться системой 122 устранения, когда принимаются последующие аварийные сигналы, причем варианты выявления неисправностей, этапы отладки и соответствующие метки могут быть основаны на информации обратной связи. Таким образом, система 122 устранения использует управляемый данными подход для предоставления операторам инструкций по устранению отказа сети.
[0032] Система 122 устранения дополнительно может быть выполнена с возможностью назначать приоритеты отказам сети для оператора 126, в результате чего отказы сети отсортированы. Как будет понятно специалисту в области техники, некоторые отказы сети оказывают большее влияние на прибыль, пропускную способность и т.п., чем другие отказы сети. Система 122 устранения может быть выполнена с возможностью принимать аварийный сигнал от вычислительных устройств 104-110 и/или устройств 114-120 сетевой инфраструктуры и группировать аварийный сигнал по меньшей мере с одним другим аварийным сигналом, чтобы представить один отказ сети. Таким образом, вместо того, чтобы оператор 126 анализировал независимые аварийные сигналы низкого уровня, оператор 126 может быть обеспечен представлением отказов сети более высокого уровня. Кроме того, система 122 устранения может назначать приоритеты отказам сети относительно друг друга, в результате чего оператор 126 нацеливается на выявление сначала неисправностей в работе сети, оказывающих самое большое влияние, и потом неисправностей в работе сети, оказывающих меньшее влияние.
[0033] Хотя система 122 устранения показана как включенная в центр 100 обработки и хранения данных, следует понимать, что система 122 устранения может исполняться на вычислительном устройстве, которое является внешним по отношению к центру 100 обработки и хранения данных. Например, центр 100 обработки и хранения данных может включать в себя вычислительное устройство, которое выполнено с возможностью передавать все собранные сетевые аварийные сигналы внешнему устройству, которое исполняет систему 122 устранения. Кроме того, следует понимать, что система 122 устранения может исполняться на вычислительном устройстве или распределена по нескольким вычислительным устройствам. Еще в одном примере система 122 устранения может исполняться на виртуальной машине (VM), причем виртуальная машина исполняется на вычислительном устройстве или распределена по нескольким вычислительным устройствам (внутренним или внешним по отношению к центру 100 обработки и хранения данных).
[0034] Теперь со ссылкой на фиг. 2 продемонстрирована иллюстративная (частичная) архитектура 200 центра обработки и хранения данных, причем центр 100 обработки и хранения данных может быть включен в архитектуру 200 центра обработки и хранения данных. Следует понимать, что архитектура 200 центра обработки и хранения данных является иллюстративной, и что другие модификации топологии, такие как топологии плоских сетей / Клоза, могут включать в себя центр 100 обработки и хранения данных, и подразумевается, что они охватываются приложенной формулой изобретения. Архитектура 200 центра обработки и хранения данных содержит множество стоечных коммутаторов 202-208 верхнего уровня (ToR). Соответствующее множество смонтированных на стойках серверов (не показаны) может быть соединено (или размещено двойным образом) с каждым коммутатором ToR среди коммутаторов 202-208 ToR.
[0035] Архитектура 200 также включает в себя первичный коммутатор 210 агрегирования (AggS) и резервный коммутатор 212 агрегирования, причем каждый коммутатор ToR среди коммутаторов 202-208 ToR соединен с первичным коммутатором 210 агрегирования и резервным коммутатором 212 агрегирования (для избыточности). На практике центр обработки и хранения данных включает в себя несколько пар первичных и резервных коммутаторов агрегирования, и каждая избыточная пара коммутаторов агрегирования агрегирует трафик от нескольких (например, десяти) коммутаторов ToR. Архитектура 200 может включать в себя первую избыточную пару стабилизаторов 214-216 нагрузки (LB), соединенных с первичным коммутатором 210 агрегирования, и вторую избыточную пару стабилизаторов 218 и 220 нагрузки, соединенных с резервным коммутатором 212 агрегирования. Стабилизаторы 214-220 нагрузки могут выполнять преобразование между статическими IP-адресами (например, показываемыми клиентам через систему DNS) и динамическими IP-адресами серверов, которые обрабатывают пользовательские запросы.
[0036] Архитектура 200 также включает в себя первичный маршрутизатор 222 доступа (AccR) и резервный маршрутизатор 224 доступа. Первичный коммутатор 210 агрегирования, резервный коммутатор 212 агрегирования, первичный маршрутизатор 222 доступа и резервный маршрутизатор 224 доступа могут сформировать группу избыточности. В центре обработки и хранения данных, имеющем архитектуру 200, избыточные группы устройств и линий связи могут использоваться для маскировки отказов сети. Коммутаторы 210-212 агрегирования направляют трафик (агрегированный от коммутаторов 202-208 ToR) на маршрутизаторы 222-224 доступа. Архитектура 200 также включает в себя первичный базовый маршрутизатор (CORE) 226 и резервный базовый маршрутизатор 228, каждый из которых соединен с обоими маршрутизаторами 222-224 доступа. Первичный маршрутизатор 222 доступа, резервный маршрутизатор 224 доступа, первичный базовый маршрутизатор 226 и резервный базовый маршрутизатор 228 формируют другую группу избыточности. Маршрутизаторы 222-224 доступа, например, маршрутизируют агрегированный трафик вплоть до нескольких тысяч серверов и маршрутизируют трафик к базовым маршрутизаторам 226-228. Базовые маршрутизаторы 226-228 соединяются с остальной частью сети центра обработки и хранения данных и Интернетом 230.
[0037] В иллюстративном варианте осуществления серверы в архитектуре (например, соединенные с коммутаторами 202-208 ToR) могут быть разделены на виртуальные локальные сети (VLAN) для ограничения накладных расходов и изолирования разных приложений, размещенных в сети. На каждом уровне топологии центра обработки и хранения данных (за возможным исключением подмножества коммутаторов ToR), избыточность (например, избыточность 1:1) может быть встроена в топологию сети для смягчения последствий отказов в работе. Кроме того, в дополнение к маршрутизаторам и коммутаторам архитектура 200 может включать в себя промежуточные устройства, такие как стабилизаторы нагрузки, брандмауэры и т.п. Из изложенного выше можно выявить, что вычислительные устройства 104-110 могут представлять собой серверные вычислительные устройства в архитектуре, коммутаторы 114-116 могут представлять собой коммутаторы агрегирования, маршрутизатор 118 может представлять собой маршрутизатор доступа или базовый маршрутизатор и т.д.
[0038] Теперь со ссылкой на фиг. 3 проиллюстрирована функциональная блок-схема системы 122 устранения. Как указано выше, система 122 устранения может принимать аварийные сигналы, сформированные несколькими устройствами в центре 100 обработки и хранения данных в разные моменты времени. Система 120 устранения включает в себя компонент 302 приема аварийного сигнала, который принимает аварийные сигналы, сформированные устройствами в центре 100 обработки и хранения данных. Компонент 304 идентификации устранения имеет связь с компонентом 302 приема аварийного сигнала и выполнен с возможностью выявлять, является ли аварийный сигнал, принятый компонентом 304 приема аварийного сигнала, показателем требующего принятия мер отказа сети (например, отказа сети, который оператор 126 может устранить через выявление неисправностей и отладку). В соответствии с примером аварийный сигнал, сформированный маршрутизатором 118, может указать, что маршрутизатор 118 не может связаться с коммутатором 116, что может в свою очередь (например), указывать на любое событие из следующих: 1) маршрутизатор работает со сбоями 2) коммутатор отключен; 3) потеряно кабельное соединение на сетевой линии связи между маршрутизатором 118 и коммутатором 116; и т.д. Это требующие принятия мер отказы сети, которые могут быть устранены оператором 126.
[0039] Система 122 устранения может включать в себя или иметь доступ к хранилищу 306 данных, которое содержит хронологические данные 308. Как будет более подробно описано ниже, хронологические данные 306 могут содержать "хронологические таблицы отказов” для устройств и линий связи в центре 100 обработки и хранения данных, причем хронологическая таблица отказов для устройства или линии связи может включать в себя информацию, которая является описательной для прошлых отказов устройства или линии связи, в том числе симптомы отказа, время последнего отказа, количество отказов за пороговый период времени, изменения конфигурации и т.п.
[0040] При работе компонент 302 приема аварийного сигнала принимает аварийный сигнал, который включает в себя условия отказа. Условия отказа могут включать в себя время формирования аварийного сигнала, идентификационную информацию устройства или линии связи, которые проявляют симптом отказа, идентификационную информацию устройства, которое сформировало аварийный сигнал, идентификацию интерфейса, который соответствует обнаруженному событию, идентификационную информацию центра обработки и хранения данных, который включает в себя устройство или линию связи, которые проявляют симптом отказа, и т.д. Компонент 304 идентификации устранения на основе аварийного сигнала (и факультативно других принятых аварийных сигналов) может определить, что аварийный сигнал является показателем требующего принятия мер отказа сети и может также идентифицировать отказавшее устройство или линию связи на основе содержания аварийного сигнала (например, в некоторых случаях устройство, которое формирует аварийный сигнал, не является отказавшим устройством). Компонент 304 идентификации устранения может установить соответствие условий отказа, указанных в аварийном сигнале, и соответствующих данных телеметрии множеству ранее наблюдавшихся симптомов отказа, включенных в хронологические данные 308. В примере отказавшее устройство или линия связи могли ранее проявлять симптомы отказа, устройство такого же типа, как отказавшее устройство, могло ранее проявлять симптомы отказа, устройство, совместно использующее платформу с отказавшим устройством, могло ранее проявлять симптомы отказа, соседнее устройство в сети (например, через 1-2 транзитных участка в восходящем или нисходящем направлении от отказавшего устройства) могло ранее проявлять симптомы отказа и т.д. В дальнейшем подразумевается, что в случаях, когда не может быть установлено соответствие условий отказа для аварийного сигнала симптому, тогда оператору 126 могут быть выданы статические рекомендации.
[0041] В ответ на наблюдаемый симптом (симптомы), идентифицированный через установление соответствия, компонент 304 идентификации устранения может выполнить статистический анализ по хронологическим данным 308, чтобы идентифицировать множество рекомендуемых вариантов выявления неисправностей, а также этапы отладки, которые соответствуют вариантам выявления неисправностей, для использования оператором 126 для устранения отказа сети. Кроме того, каждый из вариантов выявления неисправностей и соответствующих этапов отладки может быть ранжирован по достоверности, в результате чего варианты выявления неисправностей и этапы отладки с наибольшей достоверностью устранения проблемы сети представлены оператору 126 наиболее заметным образом.
[0042] Например, компонент 304 идентификации устранения может определить, что сетевой аварийный сигнал, сформированный коммутатором 116, указывает, что третье вычислительное устройство 108 в центре 100 обработки и хранения данных не отвечает на контрольные запросы, и может быть установлено соответствие этого, например, следующим ранее наблюдавшимися симптомам отказа для третьего вычислительного устройства 108 (или других устройств в центре 100 обработки и хранения данных или в другом центре обработки и хранения данных): 1) “неустойчивая линии связи”; и 2) “устройство отключено”. Для каждого из таких симптомов, идентифицированных компонентом 304 идентификации устранения, компонент 304 идентификации устранения может идентифицировать варианты выявления неисправностей и соответствующие этапы отладки в хронологических данных 308, указанных как ранее выполнявшиеся для устранения отказов сети, которые имеют такой симптом. Кроме того, компонент 304 идентификации устранения может присвоить метки вариантам выявления неисправностей и этапам отладки, которые соответственно являются показателями вероятностей того, что варианты выявления неисправностей и этапы отладки смягчат последствия отказа сети. Иллюстративная структура данных в хронологических данных 308, которая облегчает идентификацию симптомов, вариантов выявления неисправностей, этапов отладки и метки, более подробно описана ниже.
[0043] В иллюстративном варианте осуществления компонент 304 идентификации устранения затем может выдать симптомы, варианты выявления неисправностей, этапы отладки и соответствующие метки оператору 126. Фактически тогда оператору 126 предоставляется список вариантов выявления неисправностей и этапов устранения для каждого симптома с назначенными приоритетами, для которого установлено соответствие условиям отказа принятого аварийного сигнала (который является показателем требующего принятия мер отказа сети). Затем оператор 126 может пройти по вариантам выявления неисправностей и этапам отладки в порядке, основанном на метках, присвоенных вариантам выявления неисправностей и этапам отладки, что приводит к относительно эффективному устранению отказа сети.
[0044] В другом иллюстративном варианте осуществления компонент 304 идентификации устранения может идентифицировать по меньшей мере один вариант выявления неисправностей и по меньшей мере один этап отладки и может передать сигнал в устройство в центре 100 обработки и хранения данных, который заставляет выбрать по меньшей мере один вариант выявления неисправностей и выполнить по меньшей мере один этап отладки без вмешательства оператора 126. В не ограничивающем примере компонент 304 идентификации устранения может определить, что имеется относительно высокая вероятность, что перезагрузка коммутатора 116 смягчит последствия наблюдаемого симптома отказа сети. Компонент 304 идентификации устранения может передать сигнал коммутатору 116, который заставляет перезагрузить коммутатор 116 без выдачи аварийного сигнала оператору 126 или иного требования вмешательства оператора.
[0045] В примере компонент 304 идентификации устранения может попытаться автоматически устранить отказ сети до выдачи вариантов выявления неисправностей и этапов отладки оператору 126, когда 1) вычисленная вероятность варианта выявления неисправностей и этапа отладки для устранения отказа сети выше предопределенного порога вероятности (например, 0,9); 2) вычисленная вероятность варианта выявления неисправностей и этапа отладки для устранения отказа сети находится среди k наивысших вероятностей вариантов выявления неисправностей и этапов отладки для устранения отказа сети (например, среди трех вариантов выявления неисправностей и этапов отладки, которые являются наиболее вероятными для устранения отказа сети); 3) автоматический выбор варианта выявления неисправностей и выполнение этапа отладки не приводят к отказу в избыточности; 4) автоматический выбор варианта выявления неисправностей и выполнение этапа отладки не занимают более чем пороговое количество времени (например, одну минута); и/или 5) автоматический выбор варианта выявления неисправностей и выполнение этапа отладки не удаляют устройство, которое облегчает транспортировку относительно большого объема трафика через центр 100 обработки и хранения данных. Также предусматриваются другие факторы для определения, когда следует автоматически выбрать вариант отладки и выполнить этап отладки.
[0046] Компонент 304 идентификации устранения дополнительно может быть выполнен с возможностью выдавать оператору 126 дополнительные данные, имеющие отношение к отказам сети. Например, компонент 304 идентификации устранения может сделать запрос хронологических данных 308 для агрегирования данных отказа по множеству размерностей. В примере относительно конкретного отказавшего устройства или линии связи (например, идентифицированного как отказавшее устройство или иным образом идентифицированного оператором 126) компонент 304 идентификации устранения может выдать данные, который являются показателем количества раз, когда устройство или линия связи отказывали в работе (например, по порогу хронологического интервала времени), частоты, с которой устройство или линия связи отказывают в работе, относительно частоты, с которой другие устройства или линии связи в центре 100 обработки и хранения данных отказывают в работе, частоты, с которой устройство отказывает в работе, относительно частоты, с которой другие устройства такого же типа в центре 100 обработки и хранения данных отказывают в работе, и т.д.
[0047] В другом примере оператор 126 может сформулировать запрос информации, имеющий отношение к конкретному типу устройства, платформе или центру обработки и хранения данных, и компонент 304 идентификации устранения может агрегировать данные отказов по множеству параметров, чтобы выдать информацию об отказах оператору 126. В не ограничивающем примере в ответ на прием запроса от оператора 126 информации о платформе устройства компонент 304 идентификации устранения может выдать данные, которые идентифицируют наиболее часто отказывающие устройства на этой платформе, частоту отказов устройства на платформе относительно других платформ, частоту отказов устройств разных типов относительно друг друга и т.д.
[0048] Еще в одном примере оператор 126 может запросить выдачу информации о размерности/осях центра обработки и хранения данных, а не конкретного устройства или типа устройства. Например, оператор 126 может запросить идентификацию о наиболее часто отказывающих устройствах в центре 100 обработки и хранения данных, и компонент 304 идентификации устранения может возвратить список устройств в центре 100 обработки и хранения данных, которые отказывают в работе наиболее часто. Аналогичным образом, оператор 126 может запросить идентификацию наиболее стабильных устройств в центре 100 обработки и хранения данных, и компонент 304 идентификации устранения может возвратить список устройств в центре 100 обработки и хранения данных, которые отказывают в работе наименее часто. Структура хронологических данных 308 облегчает агрегацию информации о многочисленных размерностях/осях.
[0049] Система 122 устранения также может включать в себя компонент 312 обратной связи, который выполнен с возможностью принимать информацию обратной связи от оператора 126 относительно симптомов, наблюдаемых для отказавшего устройства, вариантов выявления неисправностей и/или этапов отладки, выбранных для исправления отказа сети, вызванного отказавшим устройством, среди другой информации. Тогда компонент 312 обратной связи в ответ на прием ввода от оператора 126 может быть выполнен с возможностью обновлять хронологические данные 308 (например, хронологическую таблицу отказов для отказавшего устройства). Таким образом, когда впоследствии системой 122 устранения принят аварийный сигнал, компонент 304 идентификации устранения может выдать обновленные симптомы отказа, варианты выявления неисправностей, этапы отладки и/или метки на основе недавних наблюдений оператора 126.
[0050] Система 122 устранения факультативно может включать в себя компонент 314 назначения приоритетов событий, который назначает приоритеты требующим принятия мер отказам сети для представления оператору 126. Например, во время конкретного интервала времени (например, вследствие развертывания исправления операционной системы) многочисленные устройства в центре 100 обработки и хранения данных могут формировать аварийные сигналы, обычным образом требуя, чтобы оператор 126 проанализировал большой объем аварийных сигналов и определил, какие аварийные сигналы представляют требующие принятия мер отказы сети, и затем назначил приоритеты отказам сети. Компонент 314 назначения приоритетов событий уменьшает нагрузку на оператора 126, устанавливая взаимосвязь нескольких аварийных сигналов, чтобы они представляли один отказ сети, и назначая приоритеты отказам сети (например, как функцию влияния отказа сети).
[0051] В связи с назначением приоритетов отказов сети хранилище данных 306 может включать в себя сетевой граф 310, который представляет иерархическую сетевую топографию центра 100 обработки и хранения данных, и компонент 314 назначения приоритетов событий может назначать приоритеты отказам сети на основе сетевого графа 310. Например, отказ сети, вызванный устройством, находящимся близко к вершине сетевой иерархии (как идентифицировано в сетевом графе 308), представляет высокий риск приостановки обслуживания и, таким образом, ему может быть назначен более высокий приоритет, чем отказам сети, вызванным устройствами, находящимися ниже в сетевой иерархии. В другом примере компонент 312 назначения приоритетов событий может назначать приоритеты отказам сети как функцию многих свойств, на которые могут повлиять соответствующие отказы сети (или даже одного свойства с риском большого влияния на бизнес-аналитику).
[0052] Теперь со ссылкой на фиг. 4 изображена функциональная блок-схема компонента 304 идентификации устранения. Компонент 304 идентификации устранения принимает аварийный сигнал 400, сформированный устройством в центре 100 обработки и хранения данных. Например, устройством может являться одно из вычислительных устройств 104-110 или одно из устройств 114-120 сетевой инфраструктуры. В примере, показанном на фиг. 4 аварийный сигнал 400 включает в себя множество условий отказа: 1) метку времени, которая указывает, когда аварийный сигнал был сформирован устройством; 2) идентификатор аварийного сигнала, который идентифицирует уникальный аварийный сигнал, сформированный от устройства; 3) идентификатор устройства, который идентифицирует устройство, которое сформировало аварийный сигнал; 4) интерфейсную линию связи, которая идентифицирует конкретный порт или сетевую линию связи, которые испытывают отказ в работе; и 5) и описание события, которое включает в себя генерируемый машиной текст, предоставляющий более подробную информацию об отказе, и выдается устройством, которое сформировало аварийный сигнал 400. Следует понимать, что информационное содержание аварийного сигнала 400 может отличаться от показанного на фиг. 4 и описанного здесь.
[0053] Компонент 304 идентификации устранения принимает аварийный сигнал 400 и, в иллюстративном варианте осуществления, может определить, является ли аварийный сигнал показателем требующего принятия мер отказа сети. Более конкретно, компонент 304 идентификации устранения включает в себя компонент 402 идентификации отказа, который анализирует аварийный сигнал 400 и может идентифицировать, что аварийный сигнал 400 представляет требующий принятия мер отказ сети, и затем может идентифицировать отказавшее устройство или линию связи (например, на основе идентификатора устройства и/или сетевого графа 310). Например, устройство, которое сформировало аварийный сигнал 400 (формирующее устройство) может работать должным образом; однако устройство сетевой инфраструктуры (отказавшее устройство), соединенное с устройством, которое сформировало аварийный сигнал (например, посредством интерфейсной линии связи, идентифицированной в аварийном сигнале 400), может отказывать в работе. В примере описание события в аварийном сигнале 400 может указывать, что устройство, идентифицированное посредством идентификатора устройства, не отвечает на контрольные запросы по конкретной сетевой линии связи.
[0054] Кроме, компонент 402 идентификации отказа может присвоить аварийному сигналу 400 метаданные, которые являются показателем серьезности отказа сети, указанного аварийным сигналом. В примере в ответ на идентификацию компонентом 402 идентификации отказа отказавшего устройства или линии связи, компонент 402 идентификации отказа может идентифицировать потерю трафика, которая вызвана отказом устройства или линии связи. Например, компонент 402 идентификации отказа может присвоить одно из множества предопределенных значений аварийному сигналу 400 на основе объема потери трафика, которая может быть вызвана событием, представленным аварийным сигналом 400. Таким образом, компонент 402 идентификации отказа может присвоить для аварийного сигнала 400 одно значение из "высокая", "средняя" или "низкая", чтобы представлять серьезность сетевого аварийного сигнала. В соответствии с примером, это значение может быть помещено в хронологическую таблицу отказов устройства и/или хронологическую таблицу отказов линии связи.
[0055] Кроме того, компонент 402 идентификации отказа может присвоить аварийному сигналу 400 значение, которое является показателем рисков, связанных с избыточностью в центре 100 обработки и хранения данных. Например, значение может указывать, вызывает ли отказ, представленный аварийным сигналом 400, потерю трафика в пределах группы избыточности. Для событий, в которых избыточность является эффективной и потеря трафика минимальна, вариант выявления неисправностей может быть выбран автоматически, и этап отладки может быть выполнен автоматически для автоматической сортировки события отказа, представленного аварийным сигналом 400. Иллюстративные значения могут включить в себя "успешная избыточность”, "отказ в избыточности" или "избыточность под угрозой", причем "избыточность под угрозой" может указывать, что отказавшее устройство или линия связи не защищены с помощью избыточности.
[0056] Компонент 304 идентификации устранения также включает в себя компонент 404 установления соответствия. В ответ на идентификацию отказавшего устройства или линии связи компонентом 402 идентификации отказа компонент 404 установления соответствия может осуществить доступ к хронологическим данным 308 и установить соответствие условий отказа (и соответствующих данные телеметрии), указанных в аварийном сигнале 400 (или в группе взаимосвязанных аварийных сигналов, которые представляют отказ сети), по меньшей мере одному ранее наблюдавшемуся симптому, представленному в хронологических данных 308.
[0057] Более конкретно в отношении иллюстративной структуры хронологических данных 308 хронологические данные 308 могут содержать множество хронологических таблиц 406-408 отказов устройства и множество хронологических таблиц 410-412 отказов линии связи, причем каждая хронологическая таблица отказов среди хронологических таблиц 406-408 отказов устройства предназначена для соответствующего устройства в центре 100 обработки и хранения данных, и каждая хронологическая таблица отказов среди хронологических таблиц 410-412 отказов линии связи предназначена для соответствующей линии связи в центре 100 обработки и хранения данных. Факультативно хронологические данные 308 могут включать в себя хронологические таблицы отказов для устройств/линий связи в других центрах обработки и хранения данных. Кроме того, хотя хронологические данные 308 показаны как централизованные, следует понимать, что хронологические таблицы 406-412 отказов могут быть распределены по нескольким запоминающим устройствам.
[0058] Первая хронологическая таблица 406 отказов устройства может включать в себя хронологическую информацию об отказах для первого устройства в центре 100 обработки и хранения данных. Эта информация об отказах может включать в себя, но без ограничения: 1) данные, которые являются описательными для первого устройства, в том числе идентификационная информация первого устройства, производитель первого устройства, тип первого устройства, модель первого устройства, платформа первого устройства и т.д.; 2) доступность первого устройства в течение времени (и количество времени, которое прошло с последнего отказа); 3) данные отслеживания сети, такие как трафик, проходящий через первое устройство, текущая загрузка центрального процессора и памяти первого устройства, загрузка центрального процесса первого устройства в течение времени, загрузка памяти первого устройства в течение времени, количество соединений первого устройства и т.д.; 4) данные, являющиеся показателем изменений конфигурации, внесенных в первое устройство; 5) наблюдавшиеся симптомы отказов для первого устройства, варианты выявления неисправностей, использованные ранее для смягчения последствий симптомов отказов, и этапы отладки, выбранные ранее для устранения симптомов отказов; 6) аппаратные и программные изменения, выполненные на первом устройстве; 7) идентификационная информация инженеров и операторов, которые ранее работали на устройстве; и 8) количество замен компонентов после окончания гарантийного срока, сделанных на первом устройстве. Хронологическая таблица 408 отказов n-го устройства может включать в себя аналогичную информацию. На фиг. 5 сокращенно проиллюстрировано информационное содержание иллюстративной хронологической таблицы 500.
[0059] Первая хронологическая таблица 410 отказов линии связи может включать в себя хронологические данные отказов для первой линии связи в центре обработки и хранения данных. Эта информация об отказах может включать в себя, но без ограничения: 1) данные, которые являются описательными для первой линии связи, в том числе идентификационная информация первой линии связи, устройства, соединенные через первую линию связи, производители таких устройств/линий связи, платформы таких устройств и т.д.; 2) доступность первой линии связи в течение времени (и количество времени, которое прошло с последнего отказа); 3) данные отслеживания сети, такие как текущий трафик, проходящий по линии связи, хронология трафика по линии связи и т.д.; 4) данные, являющиеся показателем изменений конфигурации устройств, соединенных через линию связи; 5) наблюдавшиеся симптомы отказов для линии связи, варианты выявления неисправностей, использованные ранее для смягчения последствий симптомов отказов, и этапы отладки, выбранные ранее для устранения симптомов отказов; 6) аппаратные и программные изменения, выполненные на устройствах, соединенных через линию связи, 7) тип линии связи, например, медная или оптическая, 8) возможности линии связи и т.д. Хронологическая таблица 412 отказов n-ой линии связи может включать в себя аналогичную информацию.
[0060] Таким образом, компонент 408 установления соответствия может принять аварийный сигнал 400 и установить соответствие условий отказа для аварийного сигнала 400 по меньшей мере одному наблюдавшемуся симптому для отказавшего устройства, идентифицированного по меньшей мере в одной из хронологических таблиц 406-408 отказов устройства или хронологических таблиц 410-412 отказов линии связи. Например, компонент 404 установления соответствия может первоначально осуществить доступ к хронологической таблице отказов отказавшего устройства и выявить, устанавливается ли соответствие условий отказа ранее наблюдавшимся симптомам отказов для отказавшего устройства. Затем компонент 404 установления соответствия может развернуть поиск к соседним устройствам в сети и/или устройствам такого же типа и/или модели, как отказавшее устройство, чтобы идентифицировать ранее наблюдавшиеся симптомы отказов, для которых устанавливается соответствие условиям отказа, указанным в аварийном сигнале 400. В не ограничивающем примере компонент 404 установления соответствия может установить соответствие условий отказа для аварийного сигнала 400 ранее наблюдавшимся симптомам: 1) "устройство отключено"; и 2) “неустойчивая линия связи" для отказавшего устройства, как идентифицировано в хронологической таблице отказов для отказавшего устройства.
[0061] Компонент 304 идентификации устранения также включает в себя компонент 414 присвоения метки, который идентифицирует варианты выявления неисправностей, идентифицированные в хронологических данных 308, как ранее выбранные для устранения симптома отказа сети, идентифицированного компонентом 404 установления соответствия. Затем компонент 414 присвоения метки присваивает метки соответствующим вариантам выявления неисправностей, причем метка является показателем вероятности того, что вариант выявления неисправностей смягчит последствия симптома отказа сети.
[0062] В иллюстративном варианте осуществления компонент 414 присвоения метки может первоначально осуществить поиск в хронологической таблице отказов устройства для отказавшего устройства (или в хронологической таблице отказов линии связи для отказавшей линии связи), чтобы выявить, были ли ранее выбраны какие-либо варианты выявления неисправностей и/или этапы отладки для наблюдавшихся симптомов и устройства. Когда отказавшее устройство и/или линия связи были подвергнуты относительно большому объему выявления неисправностей и отладки, компоненту 414 присвоения метки может не требоваться выполнять дальнейший поиск по хронологическим данным 308. Например, когда хронологическая таблица отказов для отказавшего устройства указывает, что вариант выявления неисправностей перезагрузки устройства ранее (и с высокой достоверностью) смягчил последствия симптома отказа, проявляемого отказавшим устройством, компонент 414 присвоения метки может выдать вариант выявления неисправностей, не анализируя информационное содержание других хронологических таблиц отказов других устройств. В качестве альтернативы, когда хронологическая таблица отказов для отказавшего устройства указывает, что отказавшее устройство ранее не проявляло симптом (или нечасто проявляло симптом), тогда компонент 414 присвоения метки осуществить поиск в хронологических таблицах отказов других устройств, например, соседних устройств в топологии сети, устройств того же самого производителя, устройства такого же типа и т.д. Посредством осуществления поиска по хронологическим таблицам 406-412 отказов в хронологических данных 308 компонент 414 присвоения метки может идентифицировать ранее успешные варианты выявления неисправностей и этапы отладки, а также соответствующие метки достоверности для устранения симптома отказа.
[0063] Компонент идентификации 304 устранения также может содержать компонент 416 вывода, который выдает варианты выявления неисправностей, этапы отладки и соответствующие метки. В примере компонент 416 вывода может выдать такие варианты выявления неисправностей, этапы отладки и метки на дисплей вычислительного устройства 124, используемого оператором 126. В другом примере компонент 416 вывода может передать варианты выявления неисправностей, этапы отладки и метки другому вычислительному устройству. Еще в одном примере компонент 416 вывода может заставить автоматически выбрать вариант выявления неисправностей и автоматически выполнить этап отладки без вмешательства оператора.
[0064] В дополнение к выдаче вариантов выявления неисправностей и этапов отладки компонент 416 вывода также может выдать (для отказавшего устройства или линии связи) сводную хронологическую таблицу отказов для представления оператору 126. Это может предоставить оператору 126 хронологический контекст, имеющий отношение к предыдущим отказам устройства или линии связи. Например, идентификатор устранения может поддерживать сводную хронологическую таблицу отказов для устройств и/или линий связи в центре 100 обработки и хранения данных, причем иллюстративная сводная хронологическая таблица отказов может включать в себя, но без ограничения: 1) название устройства или линии связи; 2) показатель частоты отказов устройства или линии связи относительно других устройств или линий связи (например, показатель относительно того, находится ли устройство или линия связи среди k самых проблематичных устройств); 3) недавние изменения, внесенные в устройство или линию связи (например, изменения аппаратных средств, программного обеспечения и/или конфигурации); 4) количество времени с прошлого отказа устройства или линии связи; и 5) последние выбранные варианты выявления неисправностей и/или операторы, которые выполнили выявление неисправностей.
[0065] На фиг. 6 продемонстрирован иллюстративный графический пользовательский интерфейс 600, который может быть представлен на дисплее вычислительного устройства 124, используемого оператором 126. Графический пользовательский интерфейс 600 может быть сформирован компонентом 304 идентификации устранения. Графический пользовательский интерфейс включает в себя поле 602, которое представляет оператору 126 следующую информацию, имеющую отношение либо к отказавшему устройству, идентифицированному компонентом 402 идентификации отказа, либо к устройству, иным образом представляющему интерес для оператора 126: 1) название отказавшего устройства; 2) модель отказавшего устройства; 3) идентификационная информация центра обработки и хранения данных, который включает в себя отказавшее устройство; 4) владелец отказавшего устройства; 5) тип отказавшего устройства; 6) недавние изменения аппаратной конфигурации и недавние изменения программного обеспечения; и 7) ссылки на карточки, которые описывают эти изменения более подробно.
[0066] Графический пользовательский интерфейс 600 дополнительно включает в себя поле 604, которое иллюстрирует ранее наблюдавшиеся симптомы, для которых устанавливается соответствие содержанию принятого аварийного сигнала (например, аварийного сигнала 400). Как показано на фиг. 6, иллюстративные симптомы могут включать в себя "линия связи неустойчива" и "устройство отключено”. Поле 604 также включает в себя для каждого наблюдаемого симптома множества потенциальных вариантов выявления неисправностей. Например, для симптома "устройство отключено" в поле 604 отображаются следующие варианты выявления неисправностей: 1) "проверить кабель"; 2) "проверить источник питания"; и 3) "проверить сетевую плату". Варианты выявления неисправностей имеют соответствующие присвоенные им метки, которые являются показателями вероятностей того, что соответствующие варианты выявления неисправностей смягчат последствия соответствующего симптома отказа. Например, варианту выявления неисправностей "проверить кабель" присвоена метка, которая указывает имеется вероятность 60% того, что выявление неисправности для симптома отказа "устройство отключено" посредством использования по меньшей мере одного этапа отладки, соответствующего такому варианту выявления неисправностей, смягчит последствия проблемы. Аналогичным образом, варианту выявления неисправностей "проверить источник питания" может быть присвоена метка, которая указывает, что имеется вероятность 25%, что выполнение этапа (этапов) отладки, соответствующего такому варианту выявления неисправностей, приведет к смягчению последствий симптома отказа.
[0067] Как установлено, каждый вариант выявления неисправностей имеет по меньшей мере один этап отладки, соответствующий ему. Например, вариант выявления неисправностей "проверить кабель" имеет два соответствующие ему этапа отладки (и проиллюстрированные в графическом пользовательском интерфейсе 600): 1) "зафиксировать кабель повторно"; и 2) "очистить кабель". Этим этапам отладки также присвоены метки, которые являются показателем соответствующих вероятностей того, что этапы устранения устранят симптом отказа (когда будет выбран родительский вариант выявления неисправностей).
[0068] Кроме того, некоторые этапы отладки могут иметь дополнительные присвоенные им инструкции, чтобы помочь оператору 126 в выполнении этапов отладки. Например, для этапа отладки "заменить сетевую плату" оператору 126 могут быть представлены дополнительные инструкции в ответ на выбор оператором графического значка 606 в графическом пользовательском интерфейсе 600, который помещен рядом с упомянутым выше этапом устранения. Это может привести к отображению всплывающего окна 607 (или отдельного окна), которое предоставляет оператору 126 дополнительную информацию о замене сетевой платы. В иллюстративном варианте осуществления дополнительной информации может быть присвоена гиперссылка, причем выбор гиперссылки оператором 126 может направить оператора к дополнительной информации.
[0069] Графический пользовательский интерфейс 600 также может включать в себя различные поля 608-612, которые могут включать в себя графические данные (например, графики), которые представляют различные операционные параметры отказавшего устройства. Например, поле 608 может изобразить график, который иллюстрирует объем трафика, проходящего через отказавшее устройство в конкретном интервале времени, поле 610 может изобразить график, который представляет доступность отказавшего устройства в интервале времени, и поле 612 может изображать график, который иллюстрирует моменты времени, когда наблюдался отказ отказавшего устройства.
[0070] Графический пользовательский интерфейс 600 также может включать в себя признаки, которые облегчают прием информации обратной связи от оператора 126. Например, в графический пользовательский интерфейс 600 может быть включена кнопка 614, которая при ее выборе заставляет представить оператору 126 окно 616, причем окно 126 включает в себя несколько полей, которые могут быть заполнены оператором 126. Это позволяет оператору 126 идентифицировать симптомы, наблюдавшиеся при выявлении неисправности отказавшего устройство, вариант выявления неисправностей, использованный оператором 126 при выявлении неисправности отказавшего устройства, и этапы отладки, выбранные оператором 126 при выявлении неисправности отказавшего устройства.
[0071] Графический пользовательский интерфейс 600 также может включать в себя графический объект 618, который представляет топологические изображение части центра 100 обработки и хранения данных, причем устройство, идентифицированное в поле 602, может быть представлено как центральный графический значок 620 в графическом объекте 618, и устройства, расположенные через один транзитный участок от устройства, идентифицированного в поле 602, могут быть представлены графическими значками 622-634, окружающими центральный графический значок 620 (например, с соединениями между графическими значками, представляющими линии связи между ними). Кроме того, на графические значки 620-634 может быть нанесена цветовая маркировка, чтобы указать типы соответствующих устройств, представленных графическими значками 620-634. В другом примере графические значки 620-634 в графическом объекте 618 могут иметь соответствующие формы, которые являются показателем типов устройств, представленных графическими значками. Например, графический значок в форме квадрата может представлять базовый маршрутизатор, графический объект в форме круга может представлять VPN и т.д. Графические значки 620-634 в графическом объекте 618 могут быть выбираемыми, причем выбор графического значка заставляет предоставить информацию об устройстве, представленном графическим значком, в поле 602 (и других полях в графическом пользовательском интерфейсе 600). Еще в одном примере форма графического значка может представлять тип устройства, представленного значком, и цвет графического значка может представлять производителя устройства. Также предусматриваются другие варианты.
[0072] Теперь ссылкой на фиг. 7 продемонстрировано иллюстративное описание компонента 312 назначения приоритетов событий. Компонент 312 назначения приоритетов событий может принимать аварийные сигналы, сформированные устройствами в центре 100 обработки и хранения данных. Компонент 312 назначения приоритетов событий включает в себя компонент 700 установления взаимосвязи аварийных сигналов, причем компонент 700 установления взаимосвязи аварийных сигналов устанавливает взаимосвязь между аварийными сигналами и объединяет их в соответствующие группы, причем группы представляют соответствующие отказы сети. В иллюстративном варианте осуществления компонент 700 установления взаимосвязи аварийных сигналов при приеме аварийного сигнала может выполнить поиск в хронологических данных 308, чтобы идентифицировать недавние аварийные сигналы, для которых может быть установлена взаимосвязь с принятым аварийным сигналом. Например, компонент 700 установления взаимосвязи аварийных сигналов может искать в хронологических данных 308 предыдущие аварийные сигналы, сформированные тем же самым устройством и/или для того же самого интерфейса (например, по некоторому пороговому хронологическому промежутку времени, например, последние 30 минут). В иллюстративном варианте осуществления компонент 700 установления взаимосвязи аварийных сигналов может сгруппировать принятый аварийный сигнал с другими аварийными сигналами, сформированными тем же самым устройством и/или для того же самого интерфейса в пределах порогового промежутка времени. В другом примере компонент 700 установления взаимосвязи аварийных сигналов может сгруппировать принятый аварийный сигнал по меньшей мере с одним аварийным сигналом, сформированным соседними устройствами в топологии сети (причем компонент 700 установления взаимосвязи аварийных сигналов идентифицирует соседние устройства посредством анализа сетевого графа 310). Например, компонент 700 установления взаимосвязи аварийных сигналов может сгруппировать аварийный сигнал с аварийными сигналами, cформированными на соседних устройствах, которые находятся через 1-2 транзитных участка в восходящем или нисходящем направлении от отказавшего устройства в иерархической сетевой топологии, и которые были сформированы в пределах порогового промежутка времени с момента, когда был сформирован принятый аварийный сигнал. Кроме того, компонент 700 установления взаимосвязи аварийных сигналов может сгруппировать принятый аварийный сигнал по меньшей мере с одним другим аварийным сигналом, сформированным одним или более устройствами в сетевой группе избыточности (с устройством, которое сформировало аварийный сигнал), для которого может быть установлена взаимосвязь (например, иллюстрируя проблему с протоколом аварийного переключения). Можно констатировать, что группа аварийных сигналов может представлять один отдельный отказ сети, и разные группы аварийных сигналов могут представлять разные отказы сети.
[0073] Более подробно относительно работы компонента 700 установления взаимосвязи аварийных сигналов, для каждого принятого аварийного сигнала компонент 700 установления взаимосвязи аварийных сигналов может попытаться сопоставить предупредительный сигнал с приоритетным событием или заявкой на устранение неисправности (если имеется). Например, компонент 700 установления взаимосвязи аварийных сигналов может выполнить сопоставление на множестве полей: 1) сетевое устройство и/или имя интерфейса. Имя устройства обычно кодируется как aa bb cc dd, где aa - центр обработки и хранения данных, bb - название платформы, cc - название размещенного на хосте сервиса или приложения, и dd - логическое число, относящееся к развертыванию устройства, которое сформировало предупредительный сигнал; 2) тип устройства, 3) сообщение об ошибке и 4) время уведомления о событии. Чтобы сравнить строковые поля (имя устройства и сообщение об ошибке), компонент 700 установления взаимосвязи аварийных сигналов может использовать множество алгоритмов сопоставления строк (например, редакционное расстояние, сопоставление образцов по алгоритму Ахо-Корасик, расстояние Левенштейна и т.д.). Это позволяет сопоставлять аварийный сигнал с возможными сопоставлениями в недавнем прошлом (на основе установки порога на время уведомления). Во-вторых, компонент 700 установления взаимосвязи аварийных сигналов может выполнить сопоставление на основе отказов, возникающих на соседних устройствах. Соседи определяются посредством анализа сетевого графа 310 на основе связи канального уровня. В-третьих, компонент 700 установления взаимосвязи аварийных сигналов может выполнить сопоставление на основе типа сетевого устройства - например, ошибка конфигурации по всем стабилизаторам нагрузки в одном и том же центре обработки и хранения данных или по нескольким центрам обработки и хранения данных, приводящая к большому взаимосвязанному отказу.
[0074] Компонент 312 назначения приоритетов событий также включает в себя компонент 702 ранжирования, который ранжирует группы аварийных сигналов (события отказа) для выявления неисправностей. Компонент 702 ранжирования может быть выполнен с возможностью назначать приоритеты событиям, чтобы минимизировать негативное воздействие на центр 100 обработки и хранения данных и/или потребителей центра 100 обработки и хранения данных. Например, компонент 702 ранжирования может назначать приоритеты событиям на основе того, что отказавшее устройство находится близко к вершине сетевой иерархии, поскольку такие устройства представляют относительно высокий риск приостановки обслуживания. В другом примере компонент 702 ранжирования может назначить приоритет события как функцию многих свойств, на которые можно повлиять вследствие отказа устройства. Кроме того, влияние единственного свойства может заставить компонент 702 ранжирования назначить событию относительно высокий приоритет. В другом примере компонент 702 ранжирования может назначить приоритеты событиям на основе величины трафика, который переносит отказавшее устройство. Еще в одном примере компонент 702 ранжирования может назначить приоритеты событиям на основе влияния на трафик через центр 100 обработки и хранения данных - например, отказ устройства может вызвать значительную потерю трафика. Еще в одном примере компонент 702 ранжирования может назначить приоритеты событиям на основе потенциального отказа в избыточности. Например, события отказа, не замаскированные избыточностью внутри устройства или между устройствами, могут быть относительно высоко ранжированы. Наконец, компонент 702 ранжирования может назначить приоритеты событиям отказа, вызванным устройством без защиты с помощью избыточности или влияющим на него. Например, если событие относится к успешной обработке отказа, но создает опасность вызвать отказ в избыточности, то оно может быть относительно высоко ранжировано. На выходе компонента 312 блока назначения приоритетов событий, таким образом, имеется список событий с назначенными приоритетами, в результате чего оператор 126 может расположить по приоритетам отказы сети, чтобы минимизировать их воздействие на размещенные приложения и службы.
[0075] Фиг. 8-10 демонстрируют иллюстративные методологии, относящиеся к устранению отказов сети. Хотя методологии показаны и описаны как последовательности действий, которые выполняются последовательно, следует понимать, что методологии не ограничены порядком последовательности. Например, некоторые действия могут произойти в другом порядке, а не в описанном здесь. Кроме того, действие может произойти одновременно с другим действием. Кроме того, в некоторых случаях не все действия могут потребоваться для реализации описанной здесь методологии.
[0076] Кроме того, описанные здесь действия могут представлять собой исполняемые компьютером инструкции, которые могут быть реализованы одним или более процессорами и/или храниться на машиночитаемом носителе или носителях. Исполняемые компьютером инструкции могут включать в себя подпрограмму, программу, поток исполнения и т.п. Кроме того, результаты действий методологий могут быть сохранены на машиночитаемом носителе, отображены на устройстве отображения и т.п.
[0077] Теперь со ссылкой на фиг. 8 продемонстрирована блок-схема последовательности операций, показывающая иллюстративную методологию 800 для выдачи множества вариантов выявления неисправностей для использования при выявлении неисправностей отказа сети. Методология 800 начинается на этапе 802, и на этапе 804 принимается аварийный сигнал, который является показателем отказа сети. Аварийный сигнал сформирован устройством в центре обработки и хранения данных, которое может представлять собой вычислительное устройство или устройство сетевой инфраструктуры. Среди других данных аварийный сигнал может идентифицировать устройство, которое считается отказавшим, устройство, которое сформировало аварийный сигнал, интерфейс на отказавшем устройстве, который затронут, метку времени, которая указывает, когда аварийный сигнал был сформирован.
[0078] На этапе 806 в ответ на прием аварийного сигнала идентифицируется отказавшее устройство и/или отказавшая линия связи. Отказавшим устройством может являться устройство, которое сформировало аварийный сигнал, или устройство, имеющее связь с устройством, которое сформировало аварийный сигнал. Следует понимать, что когда отказавшее устройство формирует аварийный сигнал, это не обязательно означает, что устройство полностью отключено. Вместо этого аварийный сигнал может указывать, что одна из линий связи устройства отключена, загрузка центрального процессора устройства превысила предварительно заданный порог, загрузка памяти превысила предварительно заданный порог и т.д. На этапе 808 в ответ на идентификацию отказавшего устройства для условий отказа, указанных в аварийном сигнале, устанавливается соответствие хронологически наблюдавшимся симптомам отказов, причем симптомы отказа могли ранее наблюдаться как проявлявшиеся отказавшим устройством, устройствами, относящимися к отказавшему устройству, и т.д. Как указано выше, для соответствующих сетевых устройств могут храниться хронологические таблицы отказов, которые облегчают установление соответствия между условиями отказа для аварийного сигнала и возможными симптомами отказа.
[0079] На этапе 810 для идентифицированного симптома отказа идентифицируется множество вариантов выявления неисправностей, причем варианты выявления неисправностей являются показателем потенциальных решений для исправления симптома отказа. Кроме того, варианты выявления неисправностей могут иметь присвоенные им соответствующие метки, которые являются показателем вероятностей того, что варианты выявления неисправностей исправляют симптом отказа. Метки могут представлять собой вероятности или более скрытыми метками (например, "высокая достоверность", "средняя достоверность", "низкая достоверность" и т.д.). На этапе 812 множество вариантов выявления неисправностей и их соответствующие метки выдаются для использования оператором, чтобы устранить отказ сети. Как отмечено выше, метки могут являться показателями достоверности того, что варианты выявления неисправностей при их выборе оператором соответствующим образом смягчат последствия отказа сети. Методология 800 завершается на этапе 814.
[0080] Теперь со ссылкой на фиг. 9 продемонстрирована иллюстративная методология 900, которая облегчает группировку аварийных сигналов для идентификации отказа сети и назначения приоритетов отказам сети. Методология 900 начинается на этапе 902, и на этапе 904 принимается аварийный сигнал, который является показателем отказа сети. На этапе 906 в ответ на прием аварийного сигнала выдается запрос к базе данных. Запрос основан на времени формирования аварийного сигнала, типе устройства, которое выдало аварийный сигнал, и местоположении устройства в сетевой иерархии. На этапе 908 в ответ на выдачу запроса принимаются результаты на основе запроса, результаты содержат второй аварийный сигнал. На этапе 910 аварийный сигнал группируется со вторым аварийным сигналом, и на этапе 912 выдается ранжированный список аварийных сигналов на основе группировки аварийного сигнала со вторым аварийным сигналом. Методология 900 завершается на этапе 914.
[0081] Теперь со ссылкой на фиг. 10 продемонстрирована иллюстративная методология 1000 для приема информации обратной связи относительно вариантов выявления неисправностей и/или этапов отладки и обновления вероятностей, соответствующих вариантам выявления неисправностей и/или этапам отладки, на основе информации обратной связи. Методология 1000 начинается на этапе 1002, и на этапе 1004 принимается информация обратной связи от оператора. Информация обратной связи может идентифицировать 1) сетевое устройство или линию связи, которые испытывают отказ (например, в том числе тип устройства, платформа устройства, местоположение устройства в сетевой топографии и т.д.); 2) симптом отказа; 3) идентификационная информация варианта выявления неисправностей, выбранного оператором для смягчения последствий отказа; 4) показатель относительно того, успешно ли смягчил последствия отказа вариант выявления неисправностей; 5) идентификационная информация этапа отладки, выполненного оператором для смягчения последствий отказа в работе; и 6) показатель относительно того, успешно ли смягчил последствия отказа этап отладки.
[0082] На этапе 1006 хронологические данные, которые являются описательными для отказов сети, обновляются на основе информации обратной связи. Более подробно, хронологическая таблица отказов устройства и/или хронологическая таблица отказов линии связи могут быть обновлены на основе принятой информации обратной связи. На этапе 1008 после того, как хронологические данные обновлены, принимается аварийный сигнал, и на этапе 1010 запрашиваются хронологические данные на основе аварийного сигнала. Например, хронологические данные могут быть запрошены по нескольким размерностям (например, идентификатор устройства, тип устройства, платформа устройства, идентификатор линии связи и т.д.). На этапе 1012 вычисляются вероятности для вариантов выявления неисправностей и/или этапов отладки, которые могут потенциально смягчить последствия отказа сети, указанного аварийным сигналом (например, в реальном времени или в режиме офлайн). Такие вероятности могут быть основаны на информации обратной связи от оператора, в результате чего вероятности уточняются в течение времени, поскольку принимается дополнительная информация обратной связи. Кроме того, если оператор должен был выбрать вариант выявления неисправностей, не использованный ранее в связи с устройством, хронологические данные и/или вероятности могут быть обновлены посредством этого нового варианта выявления неисправностей, который может быть выдан позже, когда будет сформирован подобный аварийный сигнал. Методология 1000 завершается на этапе 1014.
[0083] Теперь со ссылкой на фиг. 11 продемонстрирована иллюстрация высокого уровня иллюстративного вычислительного устройства 1100, которое может использоваться в соответствии с раскрытыми здесь системами и методологиями. Например, вычислительное устройство 1100 может использоваться в системе, которая поддерживает выдачу вариантов выявления неисправностей и этапов отладки для исправления симптомов отказа в центре обработки и хранения данных. Посредством другого примера вычислительное устройство 1100 может использоваться в системе, которая поддерживает назначение приоритетов отказов сети для оператора. Вычислительное устройство 1100 включает в себя по меньшей мере один процессор 1102, который исполняет инструкции, хранящиеся в памяти 1104. Инструкции могут представлять собой, например, инструкции для реализации функциональности, описанной как исполняемой одним или более описанными выше компонентами, или инструкции для реализации одного или более описанных выше способов. Процессор 1102 может осуществить доступ к памяти 1104 посредством системной шины 1106. В дополнение к хранению исполняемых инструкций память 1104 также может хранить хронологические таблицы отказов, сетевой граф, и т.д.
[0084] Вычислительное устройство 1100 дополнительно включает в себя хранилище 1108 данных, к которому может осуществлять доступ процессор 1102 посредством системной шины 1106. Хранилище 1108 данных может включать в себя исполняемые инструкции, хронологические таблицы отказов и т.д. Вычислительное устройство 1100 также включает в себя интерфейс 1110 ввода, который позволяет внешним устройствам взаимодействовать с вычислительным устройством 1100. Например, интерфейс 1110 ввода может использоваться для приема инструкций от внешнего вычислительного устройства, от пользователя и т.д. Вычислительное устройство 1100 также включает в себя интерфейс 1112 вывода, который соединяет с помощью интерфейса вычислительное устройство 1100 с одним или более внешними устройствами. Например, вычислительное устройство 1100 может отобразить текст, изображения и т.д. посредством интерфейса 1112 вывода.
[0085] Предполагается, что внешние устройства, которые взаимодействуют с вычислительным устройством 1100 через интерфейс 1110 ввода и интерфейс 1112 вывода, могут быть включены в вычислительную среду, которая обеспечивает пользовательский интерфейс в значительной степени любого типа, с которым может взаимодействовать пользователь. Примеры типов пользовательского интерфейса включают в себя графические пользовательские интерфейсы, естественные пользовательские интерфейсы и т.д. Например, графический пользовательский интерфейс может принять ввод от пользователя с использованием устройства (устройства) ввода, такого как клавиатура, мышь, пульт дистанционного управления и т.п., и обеспечить вывод на устройстве вывода, таком как дисплей. Кроме того, естественный пользовательский интерфейс может дать пользователю возможность взаимодействовать с вычислительным устройством 1100 методом, лишенным ограничений, налагаемых устройством ввода, таким как клавиатуры, мыши, пульты дистанционного управления и т.п. Вместо этого естественный пользовательский интерфейс может полагаться на распознавание речи, распознавание прикосновений и сенсорного пера, распознавание жестов как на экране, так и рядом с экраном, свободные жесты, отслеживание движения головы и глаз, голос и речь, зрение, прикосновение, жестикуляцию, искусственный интеллект и т.д.
[0086] Кроме того, хотя вычислительное устройство 1100 проиллюстрировано как единая система, следует понимать, что оно может представлять собой распределенную систему. Таким образом, например, несколько устройств могут иметь связь посредством сетевого соединения и могут совместно выполнять задачи, описанные как выполняемые вычислительным устройством 900.
[0087] Различные описанные здесь функции могут быть реализованы в аппаратных средствах, программном обеспечении или любой их комбинации. При реализации в программном обеспечении функции могут быть сохранены или переданы как одна или более инструкций или код на машиночитаемом носителе. Машиночитаемые носители включают в себя машиночитаемые запоминающие носители. Машиночитаемые запоминающие носители могут представлять собой любые доступные запоминающие носители, к которым может осуществить доступ компьютер. В качестве примера, но без ограничения, такие машиночитаемые носители могут содержать оперативное запоминающее устройство (ОЗУ; RAM), постоянное запоминающее устройство (ПЗУ; ROM), электрически стираемое программируемое постоянное запоминающее устройство (ЭСППЗУ; EEPROM), компакт-диск (CD-ROM) или другую память на оптическом диске, память на магнитном диске или другие магнитные устройства хранения, или любой другой носитель, который может использоваться для хранения желаемого программного кода в виде инструкций или структур данных, и к которому может получить доступ компьютер. Используемый здесь термин "диск" включает в себя компакт-диск (CD), лазерный диск, оптический диск, цифровой универсальный диск (DVD), гибкий диск и диск Blu-ray, причем диски обычно воспроизводят данные магнитным способом или оптическим способом с помощью лазера. Кроме того, распространяемый сигнал не включен в объем термина "машиночитаемые запоминающие носители". Машиночитаемые носители также включают в себя носители связи, включающие в себя любой носитель, который облегчает передачу компьютерной программы из одного места в другое. Соединение, например, может представлять собой носитель связи. Например, если программное обеспечение передано с веб-сайта, сервера или другого удаленного источника с использованием коаксиального кабеля, волоконно-оптического кабеля, витой пары, цифровой абонентской линии (DSL) или беспроводных технологий, таких как инфракрасное излучение, радиоволны и микроволны, то коаксиальный кабель, волоконно-оптический кабель, витая пара, DSL или беспроводные технологии, такие как инфракрасное излучение, радиоволны и микроволны, включены в определение носителя связи. Комбинации упомянутого выше также должны быть включены в объем термина "машиночитаемый носитель".
[0088] В качестве альтернативы или в дополнение, описанная здесь функциональность может быть выполнена, по меньшей мере частично, посредством одного или более аппаратных логических компонентов. Например, но без ограничения, иллюстративные типы аппаратных логических компонентов, которые могут быть использованы, включают в себя программируемые пользователем вентильные матрицы (FPGA), специализированные интегральные схемы (ASIC), ориентированные на приложение стандартные продукты (ASSP), системы на микросхеме (SOC), сложные программируемые логические интегральные схемы (CPLD) и т.д.
[0089] Приведенное выше описание содержит примеры одного или более вариантов воплощения. Безусловно, невозможно описать каждую мыслимую модификацию и изменение описанных выше устройств или методологий в целях описания упомянутых выше аспектов, но специалист в области техники может понять, что возможно выполнить много дополнительных комбинаций и изменений различных вариантов воплощения. В соответствии с этим подразумевается, что описанные варианты воплощения охватывают все такие изменения, модификации и разновидности, которые находятся в пределах сущности и объема приложенной формулы изобретения. Кроме того, в тех случаях, когда термин "включает в себя" используется либо в подробном описании, либо в формуле изобретения, такой термин подразумевает охватывающий смысл, подобно термину "содержащий", интерпретируемому как переходное слово в формуле изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ предсказания выхода из строя оборудования сенсорных и беспроводных сетей на основе онтологии с применением машинного обучения | 2021 |
|
RU2786934C1 |
| Сетевой помощник на основе искусственного интеллекта | 2017 |
|
RU2753962C2 |
| Способ, комплекс обработки информации об отказах устройств беспроводных сенсорных сетей передачи данных и связанных сетей | 2021 |
|
RU2801825C2 |
| СИСТЕМА И СПОСОБ ОБРАБОТКИ, СОХРАНЕНИЯ И ПЕРЕДАЧИ ДАННЫХ ОТ ПО МЕНЬШЕЙ МЕРЕ ОДНОГО ПОДВИЖНОГО ОБЪЕКТА | 2021 |
|
RU2839362C1 |
| СПОСОБ ОЦЕНКИ ПОТРЕБЛЕНИЯ МОЩНОСТИ | 2010 |
|
RU2636848C2 |
| МЕЖ-ОБЛАЧНОЕ УПРАВЛЕНИЕ И УСТРАНЕНИЕ НЕПОЛАДОК | 2012 |
|
RU2604519C2 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ И КЛАССИФИКАЦИИ ПРИЧИН ВОЗНИКНОВЕНИЯ ПРЕТЕНЗИЙ ПОЛЬЗОВАТЕЛЕЙ В УСТРОЙСТВАХ САМООБСЛУЖИВАНИЯ | 2017 |
|
RU2673001C1 |
| Интегрированная вычислительная система самолета МС-21 | 2017 |
|
RU2667040C1 |
| АНАЛИЗ ВРЕМЕННЫХ РЯДОВ ДЛЯ ОЦЕНКИ ИСПРАВНОСТИ РЕГУЛИРУЮЩЕГО КЛАПАНА | 2017 |
|
RU2745514C2 |
| ОПРЕДЕЛЕНИЕ НЕОБХОДИМОСТИ ТЕХНИЧЕСКОГО ОБСЛУЖИВАНИЯ КЛАПАНА С ПОМОЩЬЮ АНАЛИЗА ДАННЫХ | 2017 |
|
RU2745258C2 |
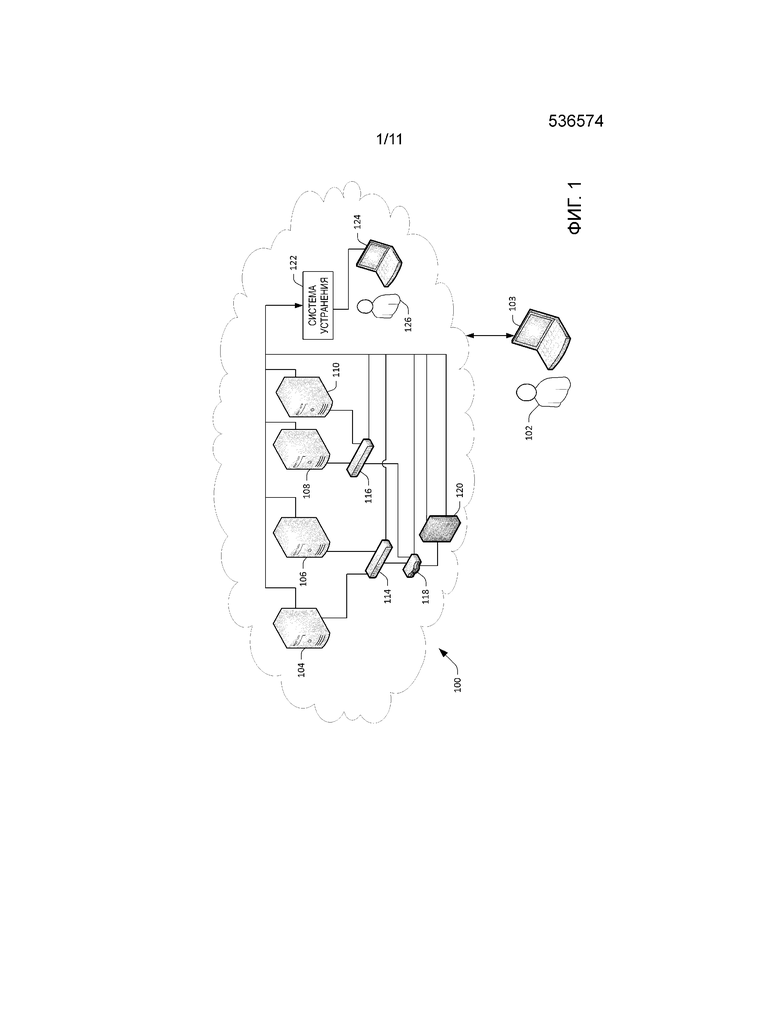
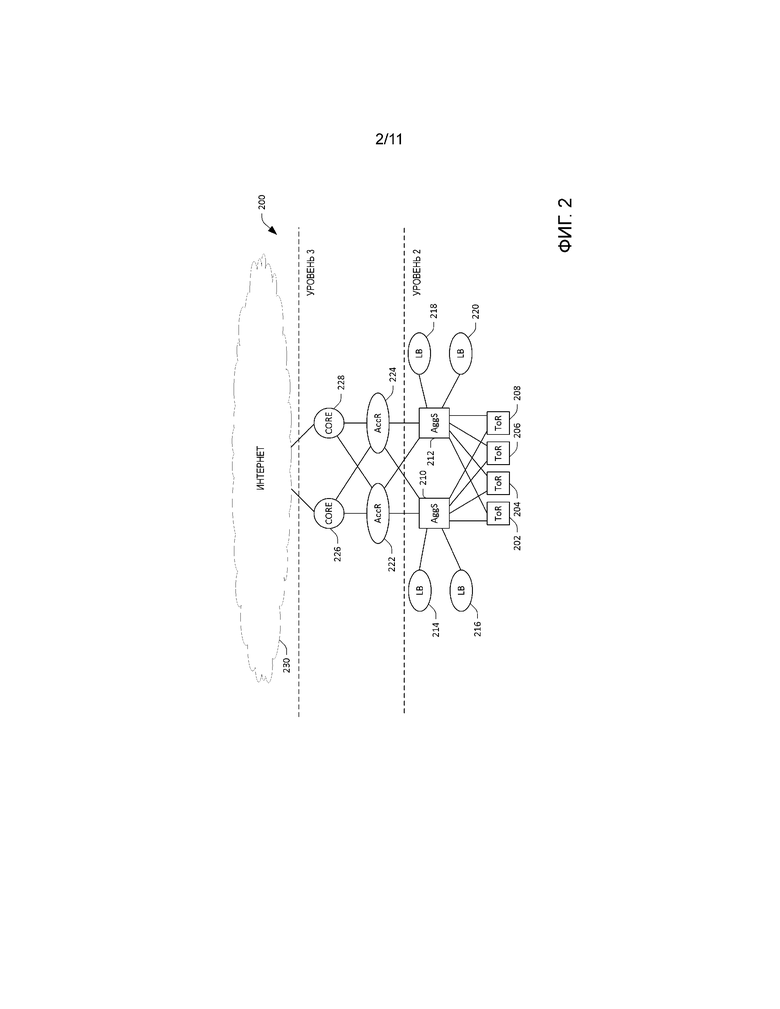
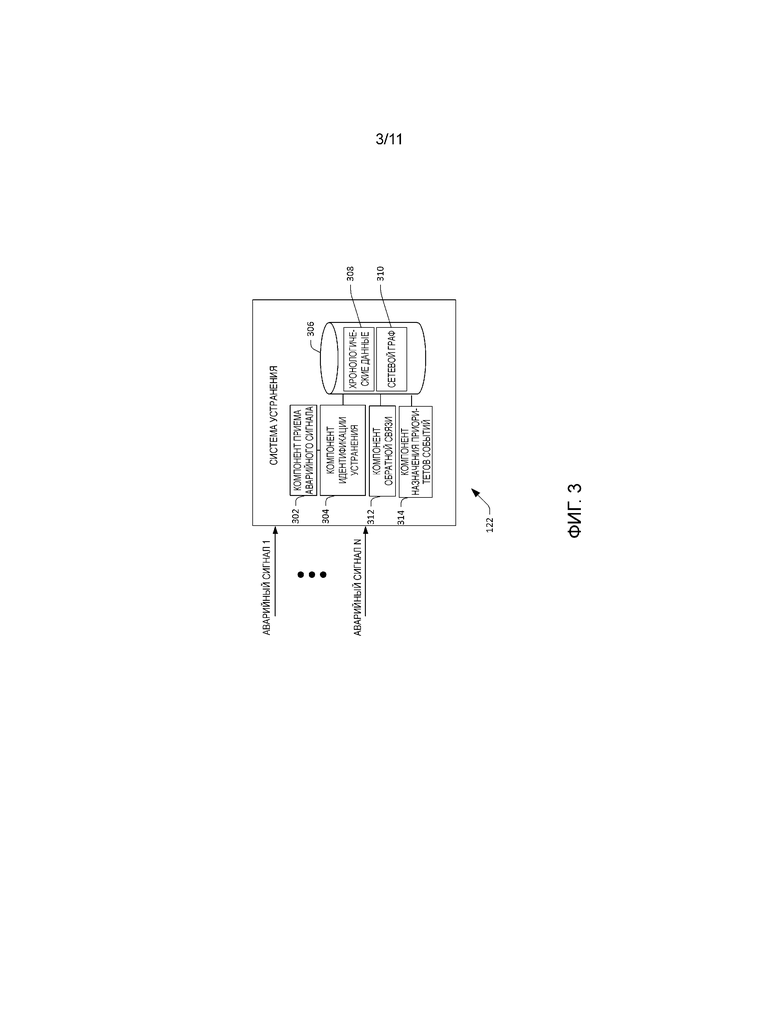
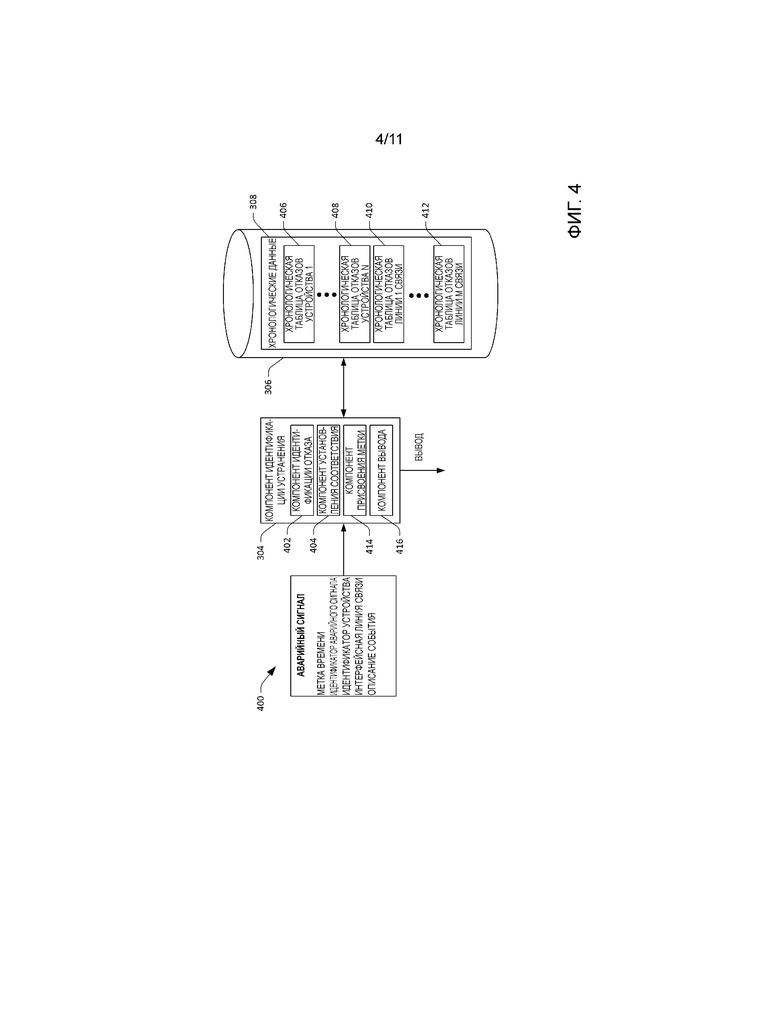

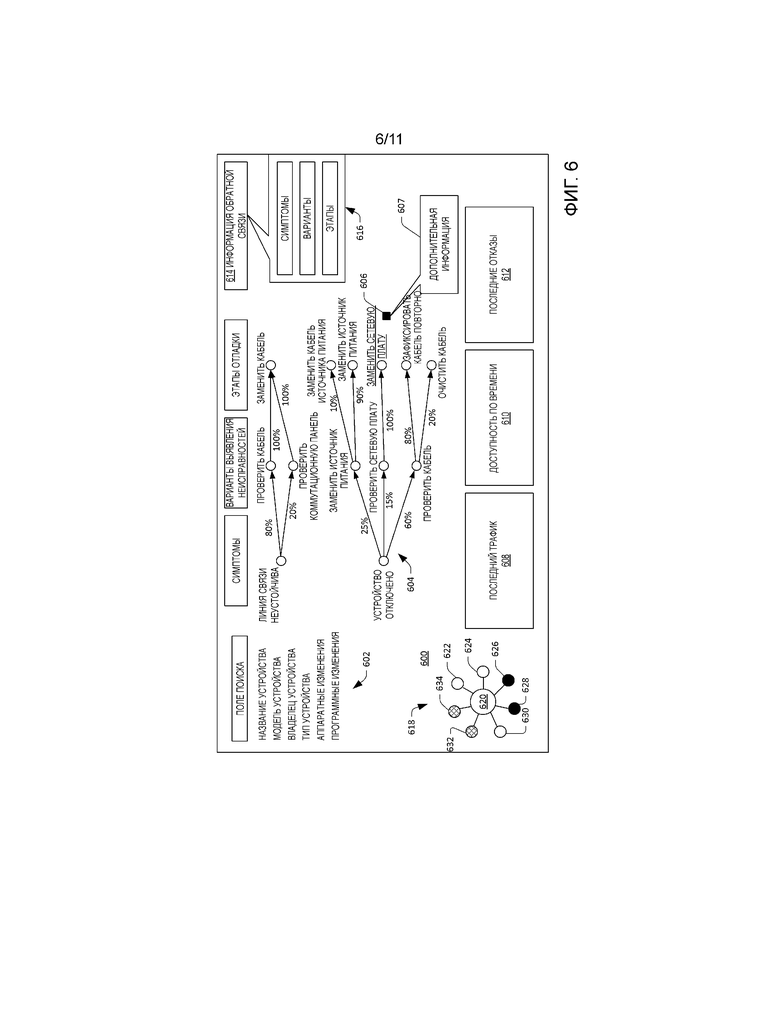
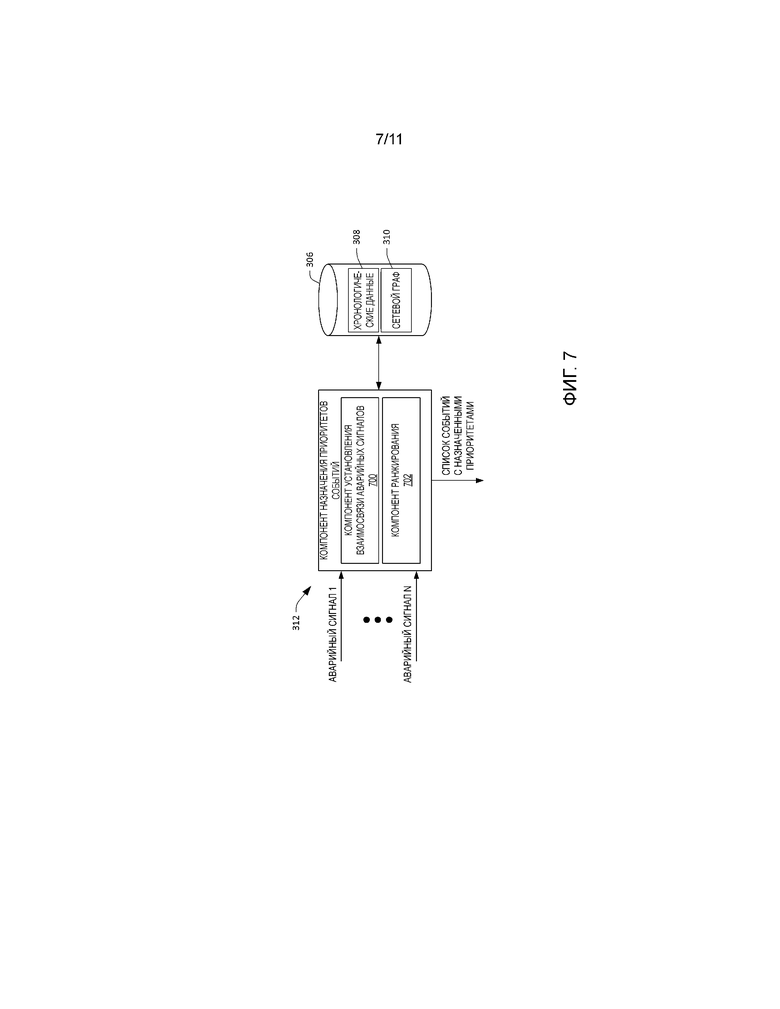
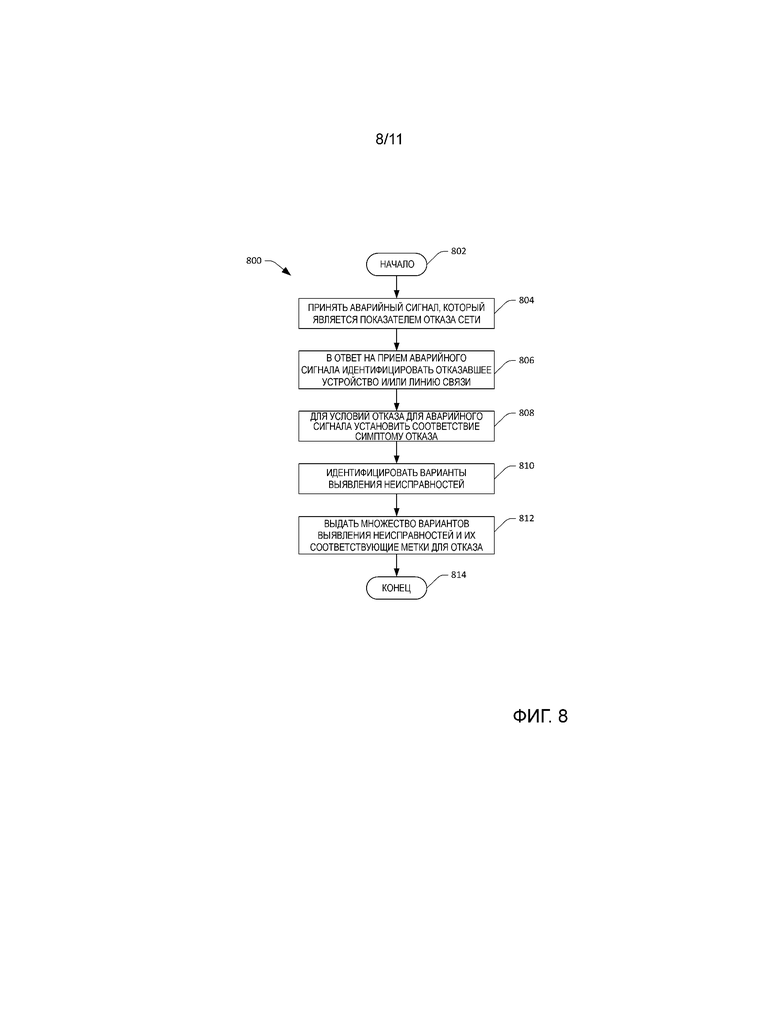
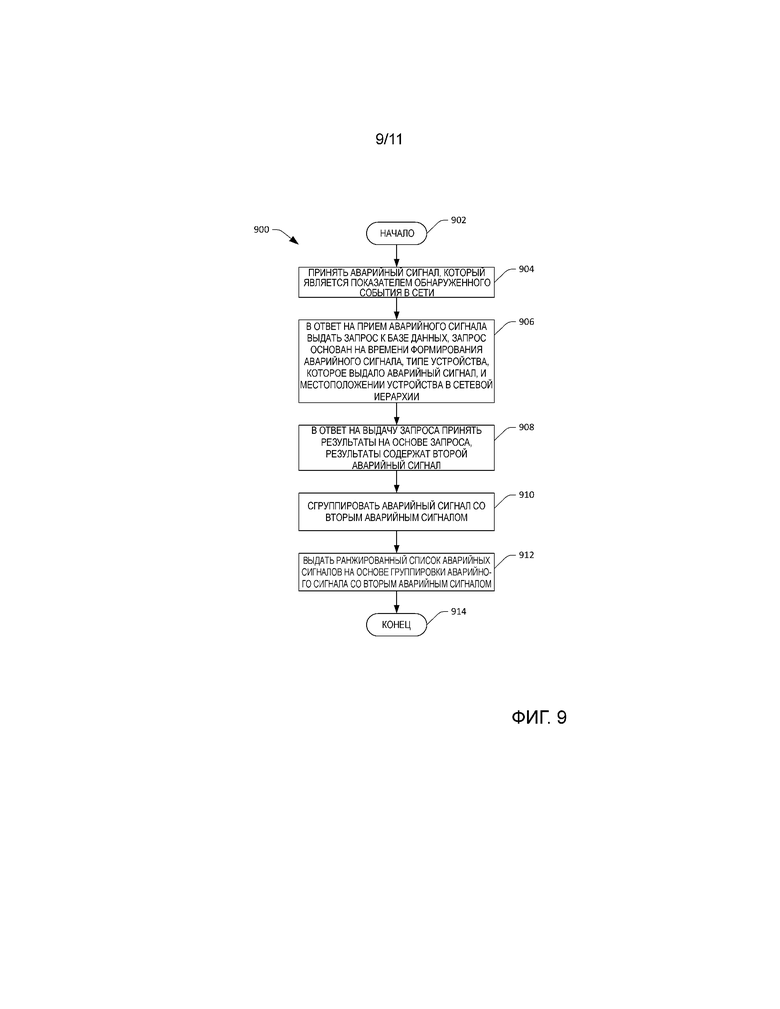
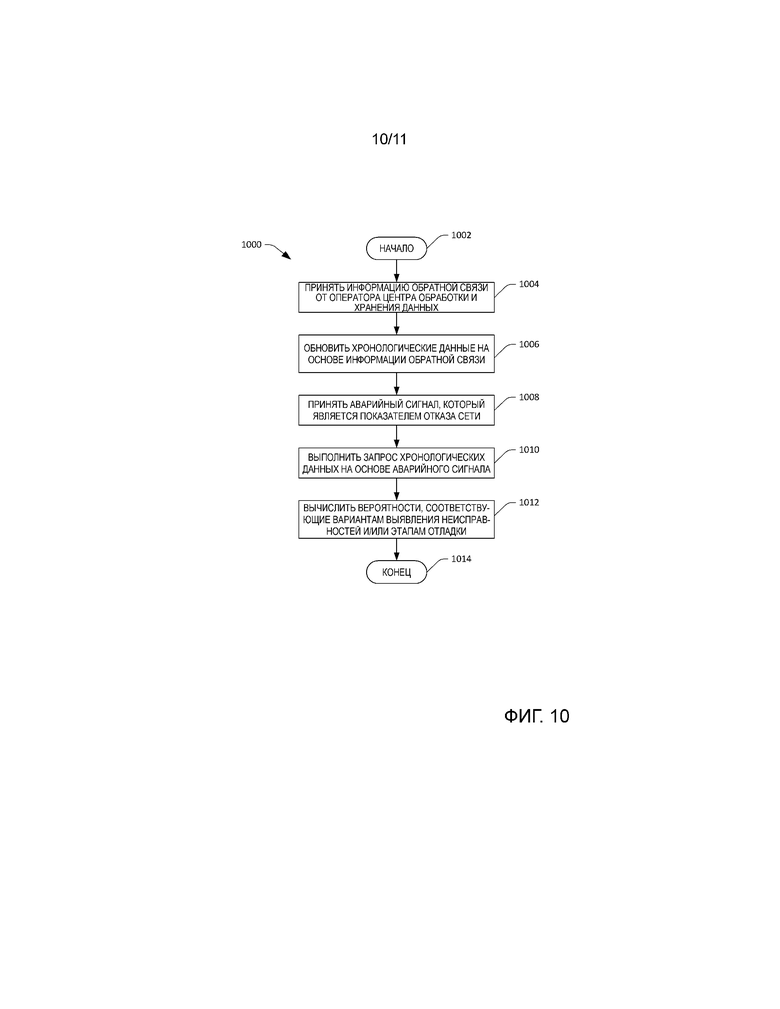
Изобретение относится к отрасли обработки и хранения данных. Технический результат – сокращение периода времени оператору для устранения неисправности сети. Для этого принимается аварийный сигнал, и на основе содержания аварийного сигнала идентифицируется отказавшее устройство. Для условий отказа для аварийного сигнала устанавливается соответствие симптому отказа, который мог проявляться отказавшим устройством, и варианты выявления неисправностей, использованные ранее для смягчения последствий симптома отказа, извлекаются из хронологических данных. Вариантам выявления неисправностей соответственно присвоены метки, причем метка является показателем вероятности того, что вариант выявления неисправностей, которому была присвоена метка, смягчит последствия симптома отказа. 3 н. и 17 з.п. ф-лы, 11 ил.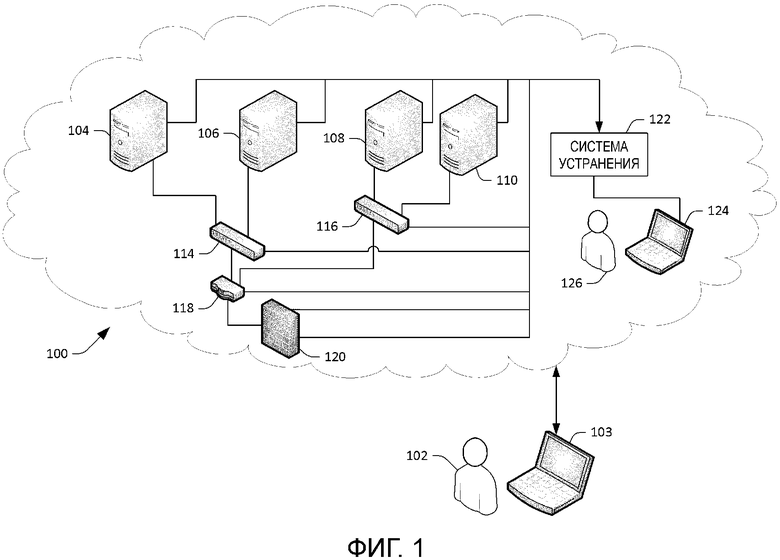
1. Способ устранения отказов сети в центре обработки и хранения данных, содержащий этапы, на которых:
принимают аварийный сигнал, сгенерированный устройством в центре обработки и хранения данных, причем аварийный сигнал содержит условие отказа, которое является показателем отказа сети в центре обработки и хранения данных;
в ответ на прием аварийного сигнала и на основе упомянутого аварийного сигнала идентифицируют отказавшее устройство, которое вызывает отказ сети;
в ответ на идентификацию отказавшего устройства и на основе хронологических данных, хранимых в репозитории данных, идентифицируют симптом отказа для отказа сети на основе условия отказа и отказавшего устройства, причем хронологические данные содержат:
по меньшей мере один симптом отказа;
варианты выявления неисправностей, ранее предпринятые в отношении отказавшего устройства в центре обработки и хранения данных для смягчения последствий отказа сети; и
хронологическую таблицу отказов, которая содержит хронологическую частоту отказов отказавшего устройства; выдают данные, указывающие хронологическую частоту отказов отказавшего устройства, в ответ на идентификацию отказавшего устройства;
в ответ на идентификацию отказавшего устройства идентифицируют варианты выявления неисправностей;
присваивают метки вариантам выявления неисправностей, причем метки являются указывающими вероятности того, что варианты выявления неисправностей, когда предприняты в отношении соответствующего отказавшего устройства, смягчат последствия симптома отказа;
выдают множество вариантов выявления неисправностей и их метки;
принимают информацию обратной связи от оператора о том, что последствия симптома отказа были смягчены и что вариант выявления неисправностей из вариантов выявления неисправностей был использован для смягчения последствий симптома отказа; и
обновляют хронологическую таблицу отказов на основе информации обратной связи.
2. Способ по п. 1, в котором хронологическая таблица отказов устройства дополнительно содержит:
симптомы отказа, ранее проявленные отказавшим устройством, причем симптом отказа включен в симптомы отказа, ранее проявленные отказавшим устройством; и
вторые варианты выявления неисправностей для симптомов отказа, ранее проявленных отказавшим устройством.
3. Способ по п. 1, в котором хронологические данные дополнительно содержат хронологическую таблицу отказов второго устройства для второго устройства, которое находится на той же платформе, что и отказавшее устройство, причем хронологическая таблица отказов второго устройства содержит симптомы отказа, ранее проявленные вторым устройством, и причем симптом отказа включен в симптомы отказа, ранее проявленные вторым устройством.
4. Способ по п. 1, в котором хронологические данные дополнительно содержат хронологическую таблицу отказов линии связи, которая содержит данные, касающиеся хронологических отказов линии связи в центре обработки и хранения данных, и при этом хронологическая таблица отказов линии связи содержит симптом отказа.
5. Способ по п. 1, дополнительно содержащий этапы, на которых:
принимают выбор варианта выявления неисправностей из вариантов выявления неисправностей; и
в ответ на прием выбора варианта выявления неисправностей отображают этап отладки, причем этап отладки содержит инструкцию для устранения отказа сети.
6. Способ по п. 1, дополнительно содержащий этап, на котором:
в ответ на выдачу множества вариантов выявления неисправностей и их соответствующих меток передают сигнал отказавшему устройству, причем сигнал вызывает выполнение варианта выявления неисправностей из вариантов выявления неисправностей без вмешательства оператора.
7. Способ по п. 1, дополнительно содержащий этап, на котором:
в ответ на прием аварийного сигнала устанавливают взаимосвязь аварийного сигнала со вторым аварийным сигналом для представления отказа сети, причем симптом отказа идентифицируется в хронологических данных на основе аварийного сигнала, для которого установлена взаимосвязь со вторым аварийным сигналом.
8. Способ по п. 7, в котором установление взаимосвязи аварийного сигнала со вторым аварийным сигналом основано на по меньшей мере одном из количества времени между тем, когда аварийный сигнал и второй аварийный сигнал были сгенерированы, устройств, которые соответственно сгенерировали аварийный сигнал и второй аварийный сигнал, типов устройств, которые соответственно сгенерировали аварийный сигнал и второй аварийный сигнал, или количества транзитных участков между устройствами, которые соответственно сгенерировали аварийный сигнал и второй аварийный сигнал.
9. Способ по п. 1, дополнительно содержащий этап, на котором вычисляют вероятности на основе количества раз, когда варианты выявления неисправностей были указаны как выбранные в хронологических данных, и количества раз, когда операции по выявлению неисправностей были указаны как успешно устранившие соответствующие отказы сети.
10. Способ по п. 1, в котором устройство является одним из коммутатора, маршрутизатора, ремаршрутизатора, шлюза, концентратора или моста.
11. Система устранения отказов сети в центре обработки и хранения данных, причем система устранения содержит:
по меньшей мере один процессор; и
память, которая хранит инструкции, которые когда исполняются упомянутым по меньшей мере одним процессором, вынуждают упомянутый по меньшей мере один процессор выполнять действия, содержащие:
прием аварийного сигнала, сгенерированного устройством в центре обработки и хранения данных, причем аварийный сигнал указывает отказ сети в центре обработки и хранения данных;
в ответ на прием аварийного сигнала идентификацию симптома отказа для отказа сети на основе условия отказа в принятом аварийном сигнале;
идентификацию отказавшего устройства, которое вызвало отказ сети, причем отказавшее устройство идентифицируется на основе аварийного сигнала;
вывод данных, указывающих хронлогическую частоту отказов отказавшего устройства относительно хронологических частот отказов других устройств в центре обработки и хранения данных, в ответ на идентификацию отказавшего устройства; и
вывод вариантов выявления неисправностей для устранения отказа сети на основе симптома отказа, причем варианты выявления неисправностей имеют присвоенные им метки, которые указывают показатели достоверности того, что варианты выявления неисправностей, при их выполнении оператором центра обработки и хранения данных, устранят отказ сети.
12. Система устранения по п. 11, в которой упомянутые действия дополнительно содержат определение меток на основе информации обратной связи оператора, касающейся вариантов выявления неисправностей, причем информация обратной связи оператора указывает, устранили или нет ранее варианты выявления неисправностей отказ сети.
13. Система устранения по п. 11, дополнительно содержащая хранилище данных, которое содержит хронологические данные, причем хронологические данные содержат хронлогическую таблицу отказов для отказавшего устройства, причем хронологическая таблица отказов содержит симптом отказа и дополнительно при этом для симптома отказа в хронологической таблице отказов устанавливается соответствие условию отказа аварийного сигнала.
14. Система устранения по п. 13, причем действия дополнительно содержат: прием информации обратной связи от оператора, причем информация обратной связи указывает, успешно ли оператор устранил отказ сети посредством использования варианта выявления неисправностей; и обновление хронологической таблицы отказов на основе информации обратной связи.
15. Система устранения по п. 11, причем устройство является одним из коммутатора, маршрутизатора, ремаршрутизатора, шлюза, концентратора или моста.
16. Система устранения по п. 13, причем действия дополнительно содержат: выдачу этапа отладки, который соответствует варианту выявления неисправностей в вариантах выявления неисправностей, причем этап отладки обеспечивает инструкции для оператора для устранения отказа сети.
17. Система устранения по п. 13, причем хронологическая таблица отказов содержит хронологическую частоту отказов отказавшего устройства.
18. Система устранения по п. 13, причем действия дополнительно содержат: в ответ на вывод вариантов выявления неисправностей, передачу сигнала отказавшему устройству, причем сигнал вызывает выполнение варианта выявления неисправностей в вариантах выявления неисправностей без вмешательства оператора.
19. Машиночитаемый носитель, содержащий инструкции, которые когда исполняются процессором, вынуждают процессор выполнять действия, содержащие:
прием аварийного сигнала, причем аварийный сигнал содержит условие отказа, которое указывает отказ сети в центре обработки и хранения данных;
в ответ на прием аварийного сигнала идентификацию отказавшего устройства, которое вызвало отказ сети, причем отказавшее устройство идентифицировано на основе условия отказа;
вывод данных, указывающих хронлогическую частоту отказов отказавшего устройства, в ответ на идентификацию отказавшего устройства;
в ответ на идентификацию отказавшего устройства идентификацию симптома отказа в хронологической таблице отказов на основе условия отказа, причем хронологическая таблица отказов указывает, что симптом отказа был ранее проявлен отказавшим устройством, и дополнительно при этом хронологическая таблица отказов содержит варианты выявления неисправностей, ранее использованные для смягчения последствий симптома отказа;
извлекают варианты выявления неисправностей в ответ на идентификацию симптома отказа; и выводят варианты выявления неисправностей и метки для вариантов выявления неисправностей, причем метки указывают показатели достоверности того, что варианты выявления неисправностей, при их выполнении оператором, смягчат последствия симптома отказа, причем метки определены на основе информации обратной связи оператора, касающейся вариантов выявления неисправностей, и дополнительно при этом информация обратной связи оператора указывает, устранили или нет ранее варианты выявления неисправностей отказ сети.
20. Машиночитаемый носитель по п. 19, причем действия дополнительно содержат:
прием информации обратной связи от оператора о том, что последствия симптома отказа смягчены и что вариант выявления неисправностей в вариантах выявления неисправностей был использован для смягчения последствий отказа; и
обновление хронологической таблицы отказов на основе информации обратной связи.
| СОСТАВ МУЛЬЧИРУЮЩЕГО ПОКРЫТИЯ (ВАРИАНТЫ) | 2012 |
|
RU2500740C1 |
| US 20130250779 A1, 26.09.2013 | |||
| МЕХАНИЗМЫ, ПРЕДНАЗНАЧЕННЫЕ ДЛЯ ОБНАРУЖЕНИЯ И УМЕНЬШЕНИЯ ОТКАЗОВ В УСТРОЙСТВЕ ШЛЮЗА | 2007 |
|
RU2463718C2 |
| СПОСОБ РЕАЛИЗАЦИИ ПЕРЕДАЧИ СОСТОЯНИЯ ЛИНИИ СВЯЗИ В СЕТИ | 2003 |
|
RU2304849C2 |
| СИСТЕМА ТРЕВОЖНОЙ СИГНАЛИЗАЦИИ | 1994 |
|
RU2103744C1 |

