Устройство, способ формирования характеристики звукового поля и машиночитаемый носитель информации
Описание
Настоящее изобретение относится к устройству, способу и к машиночитаемому носителю информации для формирования Характеристики Звукового Поля, а также к синтезу сигналов Амбисоник (Более высокого порядка) в частотно-временной области с использованием информации о направлении звука.
Настоящее изобретение относится к области записи пространственного звука и воспроизведения звука. Запись пространственного звука направлена на захват звукового поля посредством группы микрофонов таким образом, чтобы на стороне воспроизведения звука слушатель мог воспринимать звуковое изображение таким, каким оно было в месте записи. В стандартных подходах к записи пространственного звука обычно используются разнесенные всенаправленные микрофоны (например, в AB-стереофонии) или совмещенные направленные микрофоны (например, в интенсивной стереофонии). Записанные сигналы могут воспроизводиться из стандартного стереофонического громкоговорящего устройства для достижения стереофонического звукового изображения. Для воспроизведения объемного звука, например, с использованием громкоговорящего устройства 5.1, можно использовать аналогичные способы записи, например, пять кардиоидных микрофонов, которые направлены на местоположение громкоговорителей [ArrayDesign]. В последнее время появились системы воспроизведения 3D-звука, например, громкоговорящее устройство 7.1+4, где для воспроизведения звуков повышенной высоты используются 4 высотные колонки. Сигналы для такого громкоговорящего устройства могут быть записаны, например, с помощью очень специфических устройств с разнесенными 3D-микрофонами [MicSetup3D]. Общее у всех этих способов записи – то, что они предназначены для специфичного громкоговорящего устройства, которое ограничивает практическую применимость, например, когда необходимо воспроизвести записанный звук на громкоговорителях различной конфигурации.
Большая гибкость достигается, когда сигналы для специфичного громкоговорящего устройства не записываются напрямую, а вместо этого записываются сигналы промежуточного формата, из которого затем можно формировать сигналы независимого громкоговорящего устройства на стороне воспроизведения звука. Такой промежуточный формат, который хорошо известен на практике, представлен системой Амбисоник (более высокого порядка) [Ambisonics]. Из сигнала системы Амбисоник можно формировать сигналы любого желаемого громкоговорящего устройства, включая бинауральные сигналы для воспроизведения звука через наушники. Для этого требуется конкретный рендерер, который применяется к сигналу системы Амбисоник, например, классический рендерер системы Амбисоник [Ambisonics], Направленное Звуковое Кодирование (DirAC) [DirAC] или алгоритм обработки сигналов HARPEX [HARPEX].
Сигнал системы Амбисоник представляет собой многоканальный сигнал, где каждый канал (упоминаемый как компонент системы Амбисоник) эквивалентен коэффициенту так называемой пространственной базисной функции. Используя взвешенную сумму этих пространственных базисных функций (со значениями веса, соответствующими коэффициентам) можно воссоздать исходное звуковое поле в месте записи [FourierAcoust]. Поэтому коэффициенты пространственной базисной функции (то есть, компоненты системы Амбисоник) представляют собой компактную характеристику звукового поля в месте записи. Существуют различные типы пространственных базисных функций, например сферические гармоники (SHs) [FourierAcoust] или цилиндрические гармоники (CHs) [FourierAcoust]. CHs могут использоваться при задании характеристики звукового поля в 2D-пространстве (например, для воспроизведения 2D-звука), тогда как SHs могут использоваться для задания характеристики звукового поля в 2D- и 3D-пространстве (например, для воспроизведения 2D- и 3D-звука).
Пространственные базисные функции существуют для различных порядков  и мод
и мод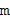 в случае 3D-пространственных базисных функций (например, SHs). В последнем случае, существуют
в случае 3D-пространственных базисных функций (например, SHs). В последнем случае, существуют 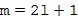 моды для каждого порядка , где и представляют собой целые числа в диапазоне
моды для каждого порядка , где и представляют собой целые числа в диапазоне 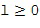 и
и 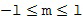 . Соответствующий пример пространственных базисных функций показан на Фигуре 1a, который показывает функции сферических гармоник для различных порядков и мод . Заметьте, что порядок иногда упоминается как уровни, и что моды также могут упоминаться как градусы. Как видно из Фигуры 1a, сферическая гармоника нулевого порядка (нулевого уровня)
. Соответствующий пример пространственных базисных функций показан на Фигуре 1a, который показывает функции сферических гармоник для различных порядков и мод . Заметьте, что порядок иногда упоминается как уровни, и что моды также могут упоминаться как градусы. Как видно из Фигуры 1a, сферическая гармоника нулевого порядка (нулевого уровня) 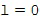 представляет собой всенаправленное звуковое давление в месте записи, тогда как сферические гармоники первого порядка (первого уровня)
представляет собой всенаправленное звуковое давление в месте записи, тогда как сферические гармоники первого порядка (первого уровня) 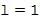 представляют собой дипольные компоненты по трем измерениям декартовой системы координат. Это означает, что пространственная базисная функция конкретного порядка (уровня) задает характеристику направленности микрофона порядка . Другими словами, коэффициент пространственной базисной функции соответствует сигналу микрофона порядка (уровня) и моды . Заметим, что пространственные базисные функции различных порядков и мод – взаимно ортогональны. Это означает, например, что в чисто диффузном звуковом поле коэффициенты всех пространственных базисных функций – взаимно некоррелированные.
представляют собой дипольные компоненты по трем измерениям декартовой системы координат. Это означает, что пространственная базисная функция конкретного порядка (уровня) задает характеристику направленности микрофона порядка . Другими словами, коэффициент пространственной базисной функции соответствует сигналу микрофона порядка (уровня) и моды . Заметим, что пространственные базисные функции различных порядков и мод – взаимно ортогональны. Это означает, например, что в чисто диффузном звуковом поле коэффициенты всех пространственных базисных функций – взаимно некоррелированные.
Как объяснялось выше, каждый компонент системы Амбисоник сигнала системы Амбисоник соответствует коэффициенту пространственной базисной функции конкретного уровня (и моды). Например, если звуковому полю задана характеристика до уровня с использованием SHs в качестве пространственной базисной функции, то тогда сигнал системы Амбисоник будет содержать четыре компонента системы Амбисоник (так как, мы имеем одну моду для порядка плюс три моды для порядка ). В дальнейшем сигналы системы Амбисоник высшего порядка упоминаются как система Амбисоник первого порядка (FOA), а сигналы системы Амбисоник высшего порядка 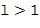 упоминаются как система Амбисоник более высокого порядка (HOA). При использовании более высоких порядков для задания характеристики звукового поля пространственное разрешение становится более высоким, то есть, можно задать характеристику или воссоздать звуковое поле с более высокой точностью. Поэтому можно задать характеристику звукового поля только с меньшим количеством порядков, что приведет к меньшей точности (но к меньшему количеству данных), или можно использовать более высокие порядки, что приведет к более высокой точности (и к большему количеству данных).
упоминаются как система Амбисоник более высокого порядка (HOA). При использовании более высоких порядков для задания характеристики звукового поля пространственное разрешение становится более высоким, то есть, можно задать характеристику или воссоздать звуковое поле с более высокой точностью. Поэтому можно задать характеристику звукового поля только с меньшим количеством порядков, что приведет к меньшей точности (но к меньшему количеству данных), или можно использовать более высокие порядки, что приведет к более высокой точности (и к большему количеству данных).
Существуют различные, но тесно связанные математические определения для различных пространственных базисных функций. Например, может вычислить комплекснозначные сферические гармоники, а также вещественнозначные сферические гармоники. Кроме того, сферические гармоники можно вычислять с помощью различных нормализационных терм, например, с помощью SN3D, N3D или N2D-нормализации. Различные определения можно найти, например, в [Ambix]. Некоторые конкретные примеры будут показаны позже, вместе с описанием настоящего изобретения и вариантами осуществления настоящего изобретения.
Желаемый сигнал системы Амбисоник можно определить из записей звуков посредством группы микрофонов. Прямым способом получения сигналов системы Амбисоник является прямое вычисление компонентов системы Амбисоник (коэффициентов пространственной базисной функции) из микрофонных сигналов. Такой подход требует измерения звукового давления в очень специфичных положениях, например, на круге или на поверхности сферы. Впоследствии коэффициенты пространственной базисной функции могут быть вычислены путем интегрирования по измеренным значениям звукового давления, как описано, например, в [FourierAcoust, p. 218]. Этот прямой подход требует специфичного микрофонного устройства, например, кольцевой решётки или сферической решётки всенаправленных микрофонов. Два типичных примера коммерчески доступных микрофонных устройств – это микрофон SoundField ST350 или EigenMike® [EigenMike]. К сожалению, требование конкретной формы микрофона сильно ограничивает практическую применимость, например, когда микрофоны необходимо интегрировать в небольшое устройство, или если микрофонную решетку необходимо объединить с видеокамерой. Кроме того, для определения пространственных коэффициентов более высоких порядков посредством этого прямого подхода требуется относительно большое количество микрофонов, чтобы обеспечить достаточную устойчивость к шуму. Таким образом, прямой подход получения сигнала системы Амбисоник зачастую является очень дорогим.
Целью настоящего изобретения является разработка усовершенствованной концепции для задания характеристики звукового поля, имеющего представление компонентов звукового поля.
Эта цель достигается с помощью устройства, в соответствии с пунктом 1, способа – в соответствии с пунктом 23 или машиночитаемого носителя информации – в соответствии с пунктом 24.
Настоящее изобретение относится к устройству или способу, или к машиночитаемому носителю информации для задания характеристики звукового поля, имеющего представление компонентов звукового поля. В определителе направления определяется, по меньшей мере, одно направление звука для каждой частотно-временной плитки из группы частотно-временных плиток из группы микрофонных сигналов. Оцениватель пространственной базисной функции оценивает, для каждой частотно-временной плитки из группы частотно-временных плиток, по меньшей мере, одну пространственную базисную функцию с использованием, по меньшей мере, одного направления звука. Кроме того, калькулятор компонента звукового поля рассчитывает, для каждой частотно-временной плитки из группы частотно-временных плиток, по меньшей мере, один компонент звукового поля, соответствующий, по меньшей мере, одной пространственной базисной функции, оцененной с использованием, по меньшей мере, одного направления звука, и с использованием опорного сигнала для соответствующей частотно-временной плитки, при этом опорный сигнал выводится из, по меньшей мере, одного микрофонного сигнала из группы микрофонных сигналов.
Настоящее изобретение основано на обнаружении того факта, что характеристика звукового поля, характеризующая независимое сложное звуковое поле, может быть эффективно получена из группы микрофонных сигналов в пределах частотно-временного представления, состоящего из частотно-временных плиток. Эти частотно-временные плитки, с одной стороны, относятся к множеству микрофонных сигналов а, с другой стороны, используются для определения направлений звука. Следовательно, определение направления звука происходит в пределах спектральной области с использованием частотно-временных плиток частотно-временного представления. Затем основная часть последующей обработки в предпочтительном варианте осуществления настоящего изобретения выполняется в пределах одного и того же частотно-временного представления. Поэтому оценка пространственных базисных функций выполняется с использованием определенного, по меньшей мере, одного направления звука для каждой частотно-временной плитки. Пространственные базисные функции зависят от направлений звука, но не зависят от частоты. Таким образом, применяется оценка пространственных базисных функций с сигналами в частотной области, то есть сигналами в частотно-временных плитках. В пределах одного и того же частотно-временного представления, по меньшей мере, один компонент звукового поля, соответствующий, по меньшей мере, одной пространственной базисной функции, которая была оценена с использованием, по меньшей мере, одного направления звука, рассчитывается вместе с опорным сигналом, также существующим в пределах одного и того же частотно-временного представления.
Этот, по меньшей мере, один компонент звукового поля для каждого блока и каждого элемента разрешения по частоте сигнала, то есть, для каждой частотно-временной плитки, может быть конечным результатом или, в альтернативном варианте осуществления настоящего изобретения, может быть выполнено преобразование обратно во временную область для того, чтобы получить, по меньшей мере, один компонент звукового поля во временной области, соответствующий, по меньшей мере, одной пространственной базисной функции. В зависимости от вариантов реализации настоящего изобретения, по меньшей мере, один компонент звукового поля может быть компонентом прямого звукового поля, определенным в пределах частотно-временного представления с использованием частотно-временных плиток, или он может быть компонентом диффузного звукового поля, который обычно определяется в дополнение к компоненту прямого звукового поля. Конечные компоненты звукового поля, имеющие прямую часть и диффузную часть, могут быть затем получены путем объединения компонентов прямого звукового поля и компонентов диффузного звукового поля, при этом это объединение может выполняться либо во временной области, либо в частотной области, в зависимости от фактического варианта реализации настоящего изобретения.
Некоторые процедуры могут быть выполнены для того, чтобы вывести опорный сигнал, по меньшей мере, из одного микрофонного сигнала. Такие процедуры могут содержать простой выбор определенного микрофонного сигнала из группы микрофонных сигналов или расширенный выбор, основанный на, по меньшей мере, одном направлении звука. При расширенном выборе опорного сигнала выбирают конкретный микрофонный сигнал из группы микрофонных сигналов, который получают из микрофона, расположенного ближе всего к направлению звука среди микрофонов, из которых были получены микрофонные сигналы. Другим альтернативным вариантом осуществления настоящего изобретения является применение многоканального фильтра, по меньшей мере, к двум микрофонным сигналам для того, чтобы совместно фильтровать эти микрофонные сигналы, чтобы получить общий опорный сигнал для всех частотных плиток временного блока. В альтернативном варианте осуществления настоящего изобретения могут быть выведены различные опорные сигналы для различных частотных плиток в пределах временного блока. Конечно, также могут быть сформированы и различные опорные сигналы для различных временных блоков, но для одних и тех же частот в пределах различных временных блоков. Следовательно, в зависимости от варианта реализации настоящего изобретения, опорный сигнал для частотно-временной плитки можно свободно выбрать или вывести из группы микрофонных сигналов.
В этом контексте следует подчеркнуть, что микрофоны могут быть расположены в произвольных местах. Микрофоны также могут иметь различные характеристики направленности. Кроме того, множественные микрофонные сигналы не обязательно должны быть сигналами, которые были записаны физически реальными микрофонами. Наоборот, микрофонные сигналы могут представлять собой микрофонные сигналы, которые были искусственно созданы из определенного звукового поля с использованием определенных операций обработки данных, которые имитируют физически реальные микрофоны.
В целях определения компонентов диффузного звукового поля возможно и рекомендуется проведение различных процедур для определенных вариантов реализации настоящего изобретения. Как правило, диффузную часть выводят из группы микрофонных сигналов в качестве опорного сигнала, и этот (диффузный) опорный сигнал затем обрабатывается вместе со средним откликом пространственной базисной функции определенного порядка (или уровня и/или моды) для того, чтобы получить компонент диффузного звука для этого порядка или уровня, или моды. Таким образом, компонент прямого звука рассчитывается с использованием оценки определенной пространственной базисной функции с определенным направлением поступления, а компонент диффузного звука, естественно, не рассчитывается с использованием определенного направления поступления, но он рассчитывается с использованием диффузного опорного сигнала и посредством объединения диффузного опорного сигнала и среднего отклика пространственной базисной функции определенного порядка или уровня, или моды, посредством определенной функции. Таким функциональным объединением может быть, например, умножение, которое также можно выполнять при расчете компонента прямого звука, или таким объединением может быть взвешенное умножение или сложение, или вычитание, например, когда расчет выполняется в логарифмической области. Другие объединения, отличные от умножения или сложения/вычитания, выполняются с использованием дополнительной нелинейной или линейной функции, при этом нелинейные функции являются предпочтительными. После формирования компонента прямого звукового поля и компонента диффузного звукового поля определенного порядка, может быть выполнено объединение посредством объединения компонента прямого звукового поля и компонента диффузного звукового поля в пределах спектральной области для каждой отдельной частотной/временной плитки. В альтернативном варианте осуществления настоящего изобретения компоненты диффузного звукового поля и компоненты прямого звукового поля для определенного порядка могут быть преобразованы из частотной области во временную область, и затем также может быть выполнено объединение во временной области прямого компонента временной области и диффузного компонента временной области определенного порядка.
В зависимости от ситуации, могут использоваться дополнительные декорреляторы для декоррелирования компонентов диффузного звукового поля. В альтернативном варианте осуществления настоящего изобретения декоррелированные компоненты диффузного звукового поля могут быть сформированы с использованием других микрофонных сигналов или других элементов разрешения по времени/частоте для других компонентов диффузного звукового поля других порядков, или с использованием другого микрофонного сигнала для расчета компонента прямого звукового поля и дополнительного другого микрофонного сигнала для расчета компонента диффузного звукового поля.
В предпочтительном варианте осуществления настоящего изобретения пространственные базисные функции представляют собой пространственные базисные функции, связанные с определенными уровнями (порядками) и модами хорошо известной характеристики звукового поля системы Амбисоник. Компонент звукового поля определенного порядка и определенной моды будет соответствовать компоненту звукового поля системы Амбисоник, связанному с определенным уровнем и определенной модой. Как правило, первым компонентом звукового поля будет компонент звукового поля, связанный со всенаправленной пространственной базисной функцией, как показано на Фигуре 1a для порядка l = 0 и моды m = 0.
Второй компонент звукового поля может быть связан, например, с пространственной базисной функцией, имеющей максимальную направленность в направлении х, соответствующем порядку l = 1 и моде m = -1, как показано на Фигуре 1a. Третьим компонентом звукового поля может быть, например, пространственная базисная функция, имеющая направленность в направлении y, соответствующем моде m = 0 и порядку l = 1, как показано на Фигуре 1a, а четвертым компонентом звукового поля может быть, например, пространственная базисная функция имеющая направленность в направлении z, соответствующем моде m = 1 и порядку l = 1, как показано на Фигуре 1a.
Однако другие характеристики звукового поля, помимо системы Амбисоник, конечно, хорошо известны специалистам в данной области техники, и такие другие компоненты звукового поля, основанные на различных пространственных базисных функциях из пространственных базисных функций системы Амбисоник, также могут быть эффективно рассчитаны в пределах частотно-временной области, как обсуждалось выше.
Варианты осуществления изобретения описывают практический способ получения сигналов системы Амбисоник. В отличие от вышеупомянутых подходов, используемых в существующем уровне техники, настоящий подход может быть применен к произвольным микрофонным устройствам, которые имеют, по меньшей мере, два микрофона. Кроме того, компоненты системы Амбисоник более высоких порядков могут быть рассчитаны с использованием только относительно небольшого количества микрофонов. Поэтому нынешний подход является сравнительно дешевым и практичным. В предлагаемом варианте осуществления настоящего изобретения компоненты системы Амбисоник не вычисляются напрямую из информации о звуковом давлении по конкретной поверхности, как в подходах, используемых в существующем уровне техники, которые описаны выше, но они синтезируются на основе параметрического подхода. Для этой цели предлагается использовать довольно простую модель звукового поля, аналогичную модели, которая используется, например, в DirAC [DirAC]. Точнее, предполагается, что звуковое поле в месте записи состоит, по меньшей мере, из одного прямого звука, поступающего из конкретных направлений звука, плюс диффузный звук, поступающий из всех направлений. На основании этой модели и используя параметрическую информацию о звуковом поле, например, звуковое направление прямых звуков, можно синтезировать компоненты системы Амбисоник или любые другие компоненты звукового поля на основании только некоторых измерений звукового давления. Настоящий подход подробно объясняется в нижеупомянутых разделах.
Объяснения предпочтительных вариантов осуществления настоящего изобретения приводятся ниже на сопроводительных чертежах, при этом:
На Фигуре 1a показаны функции сферических гармоник для различных порядков и мод;
На Фигуре 1b показан один пример того, как выбрать опорный микрофон на основании информации о направлении поступления;
На Фигуре 1c показан предпочтительный вариант осуществления устройства или способа задания характеристики звукового поля;
На Фигуре 1d показано частотно-временное преобразование примерного микрофонного сигнала, где конкретно выявлены конкретные частотно-временные плитки (10, 1) для элемента разрешения по частоте 10 и временного блока 1, с одной стороны, и конкретные частотно-временные плитки (5, 2) для элемента разрешения по частоте 5 и временного блока 2;
На Фигуре 1e показана оценка примерных четырех пространственных базисных функций, использующих направления звука для выявленных элементов разрешения по частоте (10, 1) и (5, 2);
На Фигуре 1f показан расчет компонентов звукового поля для двух элементов разрешения по частоте (10, 1) и (5, 2) и последующее частотно-временное преобразование и обработка методом плавного микширования/перекрытия с суммированием;
На Фигуре 1g показано представление во временной области примерных четырех компонентов звукового поля b1- b4, полученных путем обработки Фигуры 1f;
На Фигуре 2a показана общая блок-схема настоящего изобретения;
На Фигуре 2b показана общая блок-схема настоящего изобретения, в которой перед объединением применяется обратное частотно-временное преобразование;
На Фигуре 3а показан вариант осуществления настоящего изобретения, в котором компонент системы Амбисоник желаемого уровня и моды рассчитывается из опорного микрофонного сигнала и информации о направлении звука;
На Фигуре 3b показан вариант осуществления настоящего изобретения, в котором опорный микрофон выбран на основе информации о направлении поступления;
На Фигуре 4 показан вариант осуществления настоящего изобретения, в котором рассчитывается компонент прямого звука системы Амбисоник и компонент диффузного звука системы Амбисоник;
На Фигуре 5 показан вариант осуществления настоящего изобретения, в котором компонент диффузного звука системы Амбисоник – декоррелирован;
На Фигуре 6 показан вариант осуществления настоящего изобретения, в котором прямой звук и диффузный звук извлекаются из группы микрофонов и информации о направлении звука;
На Фигуре 7 показан вариант осуществления настоящего изобретения, в котором диффузный звук извлекается из нескольких микрофонов, и в котором компонент диффузного звука системы Амбисоник – декоррелирован; и
На Фигуре 8 показан вариант осуществления настоящего изобретения, в котором усиленное сглаживание применяется к отклику пространственной базисной функции.
Предпочтительный вариант осуществления настоящего изобретения показан на Фигуре 1с. Фигура 1с показывает вариант осуществления устройства или способа для задания характеристики звукового поля 130, имеющего представление компонентов звукового поля, например, представление во временной области компонентов звукового поля или представление в частотной области компонентов звукового поля, кодированное или декодированное представление или промежуточное представление.
Поэтому определитель направления 102 определяет, по меньшей мере, одно направление звука 131 для каждой частотно-временной плитки из группы частотно-временных плиток из группы микрофонных сигналов.
Таким образом, определитель направления принимает в состав своих входных данных 132, по меньшей мере, два различных микрофонных сигнала, и для каждого из этих двух различных микрофонных сигналов доступно частотно-временное представление, обычно состоящее из последовательных блоков спектральных элементов разрешения, при этом блок спектральных элементов разрешения уже связан с определенным временным индексом n, при этом частотный индекс равен k. Блок частотных элементов разрешения для временного индекса представляет собой спектр сигнала временной области для блока выборок временной области, сформированных определенной операцией обработки методом окна.
Направления звука 131 используются оценивателем пространственной базисной функции 103 для оценивания, для каждой частотно-временной плитки из группы частотно-временных плиток, по меньшей мере, одной пространственной базисной функции. Таким образом, результатом обработки в блоке 103 является, по меньшей мере, одна оцененная пространственная базисная функция для каждой частотно-временной плитки. В предпочтительном варианте осуществления настоящего изобретения используются две или даже более различные пространственные базисные функции, например, четыре пространственные базисные функции, как обсуждалось в отношении Фигур 1e и 1f. Таким образом, в составе выходных данных 133 блока 103 доступны оцененные пространственные базисные функции различных порядков и мод для различных частотно-временных плиток временного спектрального представления, и они вводятся в калькулятор компонентов звукового поля 201. Калькулятор компонентов звукового поля 201 дополнительно использует опорный сигнал 134, сформированный калькулятором опорного сигнала (не показан на Фигуре 1c). Опорный сигнал 134 выводится из, по меньшей мере, одного микрофонного сигнала из группы микрофонных сигналов, и он используется калькулятором компонентов звукового поля в пределах одного и того же представления времени/частоты.
Следовательно, калькулятор компонентов звукового поля 201 выполнен с возможностью расчета, для каждой частотно-временной плитки из группы частотно-временных плиток, по меньшей мере, одного компонента звукового поля, соответствующего, по меньшей мере, одной пространственной базисной функции, оцененной с использованием, по меньшей мере, одного направления звука с помощью, по меньшей мере, одного опорного сигнала для соответствующей частотно-временной плитки.
В зависимости от варианта реализации настоящего изобретения оцениватель пространственной базисной функции 103 выполнен с возможностью использования, для пространственной базисной функции, параметризованного представления, при этом параметром параметризованного представления является направление звука, при этом направление звука является одномерным в двухмерной ситуации, или двухмерным в трехмерной ситуации, и вставления параметра, соответствующего направлению звука, в параметризованное представление для того, чтобы получить результат оценки для каждой пространственной базисной функции.
В альтернативном варианте осуществления настоящего изобретения, оцениватель пространственной базисной функции выполнен с возможностью использования справочной таблицы для каждой пространственной базисной функции, имеющей, в качестве входных данных, идентификацию пространственной базисной функции и направление звука, и имеющей, в качестве выходных данных, результат оценки. В этой ситуации оцениватель пространственной базисной функции выполнен с возможностью определения для, по меньшей мере, одного направления звука, определяемого определителем направления 102, соответствующего направлению звука по входным данным справочной таблицы. Как правило, входные данные различных направлений квантуются таким образом, что, например, существует определенное количество входных табличных данных, например, десять различных направлений звука.
Оцениватель пространственной базисной функции 103 выполнен с возможностью определения соответствующих входных данных справочной таблицы для определенного конкретного направления звука, не совпадающего непосредственно со входными данными направления звука справочной таблицы. Например, это можно сделать, используя, для конкретного определенного направления звука, входные данные следующего более высокого или следующего более низкого направления звука из справочной таблицы. В альтернативном варианте осуществления настоящего изобретения, таблица используется таким образом, что рассчитывается среднее взвешенное между двумя соседними входными данными справочной таблицы. Таким образом, процедура будет заключаться в определении выходных данных таблицы для входных данных следующего направления с более низкими значениями. Кроме того, определяются выходные данные справочной таблицы для следующих входных данных с более высокими значениями, а затем вычисляется среднее значение между этими значениями.
Это среднее значение может быть простым средним значением, полученным путем добавления двух элементов выходных данных и деления результатов на два, или оно может быть средним взвешенным, в зависимости от положения определенного направления звука относительно выходных данных следующего более высокого и следующего более низкого значений таблицы. Таким образом, в качестве примера, весовой коэффициент будет зависеть от разности между определенным направлением звука и соответствующим следующим более высоким/следующим боле низким значением входных данных в справочной таблице. Например, когда измеренное направление – близко к следующему более низкому значению входных данных, то результат для следующего более низкого значения входных данных справочной таблицы умножается на более высокий весовой коэффициент, по сравнению с весовым коэффициентом, по которому определяется весовое значение выходных данных справочной таблицы для следующего более высокого значения входных данных. Таким образом, для небольшой разницы между определенным направлением и следующим более низким значением входных данных, весовое значение выходных данных справочной таблицы для следующего более низкого значения входных данных будет определяться с более высоким весовым коэффициентом, по сравнению с весовым коэффициентом, используемым для определения весового значения выходных данных справочной таблицы, соответствующим следующему более высокому значению входных данных справочной таблицы для направления звука.
Затем приводится обсуждение Фигур 1d-1g для более подробного описания примеров конкретного расчета различных блоков.
На верхнем рисунке Фигуры 1d показано схематическое изображение микрофонного сигнала. Однако фактическая амплитуда микрофонного сигнала не показана. Вместо этого показаны окна и, в частности, окна 151 и 152. Окно 151 определяет первый блок 1, а окно 152 идентифицирует и определяет второй блок 2. Таким образом, микрофонный сигнал обрабатывается в предпочтительном варианте осуществления настоящего изобретения посредством метода перекрытия блоков, где перекрытие равно 50%. Однако можно было бы использовать и более высокое или более низкое значение перекрытия, и даже возможно полное отсутствие перекрытия. Однако обработка посредством метода перекрытия выполняется для того, чтобы избежать блокировки артефактов.
Каждый блок выборочных значений микрофонного сигнала преобразуется в спектральное представление. Спектральное представление или спектр для блока с временным индексом n = 1, то есть, для блока 151, показано на среднем представлении на Фигуре 1d, а спектральное представление второго блока 2, соответствующего позиционному обозначению 152, показано на нижнем рисунке на Фигуре 1d. Кроме того, для примера показано, что каждый спектр имеет десять элементов разрешения по частоте, то есть, например, частотный индекс k находится в диапазоне от 1 до 10.
Таким образом, частотно-временная плитка (k, n) представляет собой частотно-временную плитку (10, 1) под номером 153, и еще один пример показывает другую частотно-временную плитку (5, 2) под номером 154. Дальнейшая обработка, выполняемая устройством для задания характеристики звукового поля, показана, в качестве примера, на Фигуре 1d, на которой, в качестве примера, показано использование этих частотно-временных плиток с позиционными обозначениями 153 и 154.
Кроме того, предполагается, что определитель направления 102 определяет направление звука или «DOA» (направление поступления), в качестве примера обозначенное вектором с единичной нормой n. Альтернативные указатели направления содержат азимутальный угол, угол возвышения или оба угла вместе. Поэтому все микрофонные сигналы из группы микрофонных сигналов, где каждый микрофонный сигнал представлен последовательными блоками элементов разрешения по частоте, как показано на Фигуре 1d, используются определителем направления 102, и определитель направления 102 Фигуры 1c затем определяет направление звука или DOA, например. Таким образом, в качестве примера, частотно-временная плитка (10, 1) имеет направление звука n(10, 1), а частотно-временная плитка (5, 2) имеет направление звука n(5, 2), как показано в верхней части Фигуры 1е. В трехмерном случае направление звука представляет собой трехмерный вектор, имеющий компонент x, y или z. Конечно, могут использоваться и другие системы координат, такие как сферические координаты, которые основываются на двух углах и радиусе. В альтернативном варианте осуществления настоящего изобретения углами могут быть, например, азимут и возвышение. Тогда радиус не требуется. Аналогичным образом, существуют два компонента направления звука в двухмерном случае, например, декартовы координаты, то есть, направление х и y, но, в альтернативном варианте осуществления настоящего изобретения также могут быть использованы циклические координаты, имеющие радиус и угол, или азимут и углы возвышения.
Эта процедура выполняется не только для частотно-временных плиток (10, 1) и (5, 2), но и для всех частотно-временных плиток, посредством которых представлены микрофонные сигналы.
Затем определяется требуемая, по меньшей мере, одна пространственная базисная функция. В частности, определяется, какое количество компонентов звукового поля или, как правило, представление компонентов звукового поля должно быть сформировано. Количество пространственных базисных функций, которые в настоящее время используются оценивателем пространственной базисной функции 103 Фигуры 1с, окончательно определяет количество компонентов звукового поля для каждой частотно-временной плитки в спектральном представлении или количество компонентов звукового поля во временной области.
В следующем варианте осуществления настоящего изобретения предполагается, что необходимо определить количество четырех компонентов звукового поля, где, в качестве примера, этими четырьмя компонентами звукового поля могут быть: компонент всенаправленного звукового поля (соответствующего порядку, равному 0) и три направленных компонента звукового поля, которые имеют направленность в соответствующих координатных направлениях декартовой системы координат.
Нижний рисунок на Фигуре 1е показывает оцененные пространственные базисные функции Gi для различных временных плит. Таким образом, становится понятно, что в этом примере определяются четыре оцененные пространственные базисные функции для каждой частотно-временной плитки. Когда, в качестве примера, предполагается, что каждый блок имеет десять элементов разрешения на частоте, тогда для каждого блока, например, для блока n = 1 и для блока n = 2, определяется количество из 40 оцененных пространственных базисных функций Gi, как показано на Фигуре 1е. Таким образом, суммируя сказанное, можно утверждать, что когда рассматриваются только два блока, и каждый блок имеет десять элементов разрешения по частоте, тогда в результате процедуры получают 80 оцененных пространственных базисных функций, поскольку в двух блоках имеется двадцать частотно-временных плиток, и каждая частотно-временная плитка имеет четыре оцененные пространственные базисные функции.
На Фигуре 1f показаны предпочтительные варианты реализации калькулятора компонентов звукового поля 201 Фигуры 1c. На Фигуре 1f на двух верхних рисунках показаны два блока элементов разрешения по частоте для определенных входных данных опорного сигнала в блоке 201 на Фигуре 1 c посредством линии 134. В частности, опорный сигнал, который может быть конкретным микрофонным сигналом или объединением различных микрофонных сигналов, обрабатывается таким же образом, как обсуждалось в отношении Фигуры 1d. Таким образом, в качестве примера, опорный сигнал представлен посредством справочного спектра для блока n = 1 и спектра опорного сигнала для блока n = 2. Таким образом, опорный сигнал раскладывается на тот же частотно-временной шаблон, который использовался для расчета оцененных пространственных базисных функций для выходных данных частотно-временных плит посредством линии 133 от блока 103 к блоку 201.
Затем фактический расчет компонентов звукового поля производится посредством функционального объединения между соответствующей частотно-временной плиткой для опорного сигнала P и соответствующей оцененной пространственной базисной функцией G, как указано под номером 155. В предпочтительном варианте осуществления настоящего изобретения функциональная комбинация, представленная f(...), представляет собой умножение, показанное под номером 115 на приведенных ниже Фигурах 3a, 3b. Однако также можно использовать другие функциональные объединения, как обсуждалось выше. С помощью функционального объединения в блоке 155, по меньшей мере, один компонент звукового поля Bi рассчитывается для каждой частотно-временной плитки, чтобы получить представление частотной области (спектральное) компонентов звукового поля Bi, как показано под номером 156 для блока n = 1 и под номером 157 для блока n = 2.
Таким образом, в качестве примера, представление в частотной области компонентов звукового поля Bi показано для частотно-временной плитки (10, 1), с одной стороны, а также для частотно-временной плитки (5, 2) для второго блока, с другой стороны. Однако в очередной раз становится ясно, что количество компонентов звукового поля Bi, показанных на Фигуре 1f под номерами 156 и 157 – такое же, как и количество оцененных пространственных базисных функций, показанных в нижней части Фигуры 1e.
Когда требуются только компоненты звукового поля частотной области, расчет завершается выходными данными блоков 156 и 157. Однако в других вариантах осуществления настоящего изобретения требуется представление во временной области компонентов звукового поля, чтобы получить представление во временной области для первого компонента звукового поля B1, следующее представление во временной области для второго компонента звукового поля B2 и так далее.
Поэтому компоненты звукового поля B1 из диапазона элементов разрешения по частоте 1 - 10 в первом блоке 156 вставляются в блок частотно-временной передачи 159, чтобы получить представление во временной области для первого блока и первого компонента.
Аналогичным образом, для того чтобы определить и рассчитать первый компонент во временной области, то есть, b1 (t), спектральные компоненты звукового поля B1 для второго блока, находящиеся в диапазоне элементов разрешения по частоте 1 - 10, преобразуются в представление во временной области посредством дополнительного частотно-временного преобразования 160.
Из-за того, что перекрывающиеся окна были использованы, как показано в верхней части Фигуры 1d, операция методом плавного микширования/перекрытия с суммированием 161, показанная внизу на Фигуре 1f, может быть использована для того, чтобы рассчитать выходные данные выборок временной области первого спектрального представления b1 (d) в диапазоне перекрытия между блоком 1 и блоком 2, как показано под номером 162 на Фигуре 1g.
Такая же процедура выполняется для того, чтобы рассчитать второй компонент звукового поля во временной области b2 (t) в пределах диапазона перекрытия 163 между первым блоком и вторым блоком. Кроме того, для того чтобы рассчитать третий компонент звукового поля b3 (t) во временной области и, в частности, для того, чтобы рассчитать выборки в диапазоне перекрытия 164, компоненты D3 из первого блока и компоненты D3 из второго блока преобразуются, соответственно, в представление во временной области посредством процедур 159, 160, и полученные значения затем обрабатываются методом плавного микширования/перекрытия с суммированием в блоке 161.
Наконец, такая же процедура выполняется для четвертых компонентов B4 для первого блока и B4 для второго блока для того, чтобы получить окончательные выборки четвертого компонента представления звукового поля во временной области b4(t) в диапазоне перекрытия 165, как показано на Фигуре 1g.
Следует отметить, что не требуется какое-либо плавное микширование/перекрытие с суммированием, как показано в блоке 161, когда обработка для получения частотно-временных плит не выполняется с перекрывающимися блоками, а выполняется с неперекрывающимися блоками.
Кроме того, в случае более высокого перекрытия, когда более двух блоков перекрывают друг друга, требуется, соответственно, большее количество блоков 159, 160, и плавное микширование/перекрытие с суммированием блока 161 рассчитывается не только с двумя входными данными, но даже с тремя входными данными для окончательного получения выборок представлений во временной области, показанных на Фигуре 1g.
Кроме того, следует отметить, что выборки для представлений во временной области, например, для диапазона перекрытия OL23, получают путем применения процедур, применяемых в блоке 159, 160, ко второму блоку и третьему блоку. Соответственно, выборки для диапазона перекрытия OL0,1 рассчитываются путем выполнения процедур 159, 160 для соответствующих спектральных компонентов звукового поля Bi для определенного количества i для блока 0 и блока 1.
Кроме того, как уже отмечалось, представлением компонентов звукового поля может быть представление в частотной области, как показано на Фигуре 1f для 156 и 157. В альтернативном варианте осуществления настоящего изобретения, представлением компонентов звукового поля может быть представление во временной области, как показано на Фигуре 1g, при этом четыре компонента звукового поля представляют собой простые звуковые сигналы, имеющие последовательность выборок, связанных с определенной частотой выборок. Кроме того, представление в частотной области или представление во временной области компонентов звукового поля может быть закодировано. Это кодирование может выполняться отдельно, таким образом, что каждый компонент звукового поля кодируется как моносигнал, или кодирование может выполняться совместно, таким образом, что, например, четыре компонента звукового поля B1 - B4 считаются многоканальным сигналом, имеющим четыре канала. Таким образом, закодированное представление в частотной области или представление во временной области, закодированное посредством любого полезного алгоритма кодирования, также является представлением компонентов звукового поля.
Кроме того, даже представление во временной области перед плавным микшированием/перекрытием с суммированием, выполненным блоком 161, может быть полезным представлением компонентов звукового поля для конкретного варианта реализации настоящего изобретения. Кроме того, также может быть выполнено некоторое векторное квантование по блокам n для определенного компонента, например, для компонента 1, для сжатия представления в частотной области компонента звукового поля для передачи или хранения, или для других задач обработки.
Предпочтительные варианты осуществления настоящего изобретения
На Фигуре 2a показан новый подход, используемый Блоком (10), который позволяет синтезировать компонент системы Амбисоник желаемого порядка (уровня) и моды из сигналов группы (по меньшей мере, двух) микрофонов. В отличие от соответствующих подходов, используемых в существующем уровне техники, для микрофонных устройств не существует каких-либо ограничений. Это означает, что множество микрофонов могут быть расположены в произвольной форме, например, в виде совмещенного устройства, линейного массива, планарного массива или трехмерного массива. Кроме того, каждый микрофон может иметь всенаправленную или произвольную направленную направленность. Направленности различных микрофонов могут различаться.
Для того, чтобы получить желаемый компонент системы Амбисоник, множество микрофонных сигналов сначала преобразуют в частотно-временное представление с использованием Блока (101). Для этой цели можно использовать, например, фильтр-банк или кратковременное преобразование Фурье (STFT). Выходными данными Блока (101) являются множественные микрофонные сигналы в частотно-временной области. Заметим, что следующая обработка выполняется отдельно для частотно-временных плит.
После преобразования группы микрофонных сигналов в частотно-временной области мы определяем, по меньшей мере, одно направление звука (для частотно-временной плитки) в Блоке (102) из, по меньшей мере, двух микрофонных сигналов. Направления звука характеризуют, с какого направления в микрофонный массив поступает главный звук для частотно-временной плитки. Это направление обычно называют направлением поступления звука (DOA). В варианте осуществления настоящего изобретения, отличном от DOA, также можно рассмотреть направление распространения звука, которое является противоположным направлению DOA, или любое другое измерение, которое характеризует направление звука. По меньшей мере, одно направление звука или DOA оценивается в Блоке (102) с использованием, например, узкополосных оценивателей DOA существующего уровня техники, которые доступны практически для любого микрофонного устройства. Подходящие примерные оцениватели DOA перечислены в Варианте 1 осуществления настоящего изобретения. Количество направлений звука или DOA (по меньшей мере, одно), которые рассчитываются в Блоке (102), зависит, например, от допустимой вычислительной сложности, а также от возможностей используемого оценивателя DOA или формы микрофона. Направление звука можно оценить, например, в 2D-пространстве (представленном, например, в виде азимутального угла) или в 3D-пространстве (представленном, например, в виде азимутального угла и угла возвышения). В дальнейшем, большая часть описания основана на более общем 3D-случае, хотя понятно, что все этапы обработки применяются также и к 2D-случаю. Зачастую, пользователь указывает, сколько направлений звука или DOA (например, 1, 2 или 3) оценивается на одну частотно-временную плитку. В альтернативном варианте осуществления настоящего изобретения количество главных звуков может быть оценено с использованием подходов существующего уровня техники, например, с использованием подходов, которые объяснены в [SourceNum].
По меньшей мере, одно направление звука, которое было оценено в Блоке (102) для частотно-временной плитки, используется в Блоке (103) для вычисления для частотно-временной плитки, по меньшей мере, одного отклика пространственной базисной функции желаемого порядка (уровня) и моды. Один отклик вычисляется для каждого оцененного направления звука. Как объяснялось в предыдущем разделе, пространственная базисная функция может представлять собой, например, сферическую гармонику (например, если обработка выполняется в 3D-пространстве) или цилиндрическую гармонику (например, если обработка выполняется в 2D-пространстве). Отклик пространственной базисной функции представляет собой пространственную базисную функцию, оцененную в соответствующем оцененном направлении звука, как более подробно описано в первом варианте осуществления настоящего изобретения.
По меньшей мере, одно направление звука, которое оцениваются для частотно-временной плитки, далее используются в Блоке (201), а именно для вычисления для частотно-временной плитки, по меньшей мере, одного компонента системы Амбисоник желаемого порядка (уровня) и моды. Такой компонент системы Амбисоник синтезирует компонент системы Амбисоник для направленного звука, поступающего из оцененного звукового направления. Дополнительными входными данными для Блока (201) является, по меньшей мере, один отклик пространственной базисной функции, который был вычислен для частотно-временной плитки в Блоке (103), а также, по меньшей мере, один микрофонный сигнал для данной частотно-временной плитки. В Блоке (201) для каждого оцененного направления звука и соответствующего отклика пространственной базисной функции вычисляется один компонент системы Амбисоник желаемого порядка (уровня) и моды. Этапы обработки Блока (201) обсуждаются дополнительно в нижеупомянутых вариантах осуществления настоящего изобретения.
Настоящее изобретение (10) содержит необязательный Блок (301), который может вычислять для частотно-временной плитки компонент диффузного звука системы Амбисоник желаемого порядка (уровня) и моды. Этот компонент синтезирует компонент системы Амбисоник, например, для чисто диффузного звукового поля или для окружающего звука. Входные данные для Блока (301) представляют собой, по меньшей мере, одно направление звука, которое было оценено в Блоке (102), а также, по меньшей мере, один микрофонный сигнал. Этапы обработки Блока (301) дополнительно рассматриваются в последующих вариантах осуществления настоящего изобретения.
Компоненты диффузного звука системы Амбисоник, которые вычисляются в дополнительном Блоке (301), могут быть дополнительно декоррелированы в необязательном Блоке (107). Для этой цели можно использовать декорреляторы существующего уровня техники. Некоторые примеры перечислены в Варианте 4 осуществления настоящего изобретения. Как правило, можно применять различные декорреляторы или различные варианты декоррелятора для различных порядков (уровней) и мод. При этом декоррелированные компоненты диффузного звука системы Амбисоник различных порядков (уровней) и мод будут взаимно некоррелированы. Это эмулирует ожидаемое физическое поведение, а именно, то, что компоненты системы Амбисоник различных порядков (уровней) и мод – взаимно некоррелированы для диффузных звуков или окружающих звуков, как объясняется, например, в [SpCoherence].
По меньшей мере, один компонент системы Амбисоник (прямой звук) желаемого порядка (уровня) и моды, который был вычислен для частотно-временной плитки в Блоке (201), и соответствующий компонент диффузного звука системы Амбисоник, который был вычислен в Блоке (301), объединены в Блоке (401). Как описано в последующих Вариантах осуществления настоящего изобретения, объединение может быть реализовано, например, как (взвешенная) сумма. Выходные данные Блока (401) являются конечным синтезированным компонентом системы Амбисоник желаемого порядка (уровня) и моды для данной частотно-временной плитки. Понятно, что если только одиночный (прямой звук) компонент системы Амбисоник желаемого порядка (уровня) и моды был вычислен в Блоке (201) для частотно-временной плитки (и без компонента диффузного звука системы Амбисоник), то объединитель (401) является излишним.
После вычисления конечного компонента системы Амбисоник желаемого порядка (уровня) и моды для всех частотно-временных плиток, компонент системы Амбисоник может быть преобразован обратно во временную область с обратным частотно-временным преобразованием (20), которое может быть реализовано, например, как обратный фильтр-банк или обратное STFT. Заметим, что обратное частотно-временное преобразование не требуется в каждом применении, и поэтому оно не является частью настоящего изобретения. На практике можно вычислить компоненты системы Амбисоник для всех желаемых порядков и мод, чтобы получить желаемый сигнал системы Амбисоник желаемого высшего порядка (уровня).
На Фигуре 2b показана слегка модифицированная реализация настоящего изобретения. На этом фигуре обратное частотно-временное преобразование (20) применяется перед объединителем (401). Это возможно, поскольку обратное частотно-временное преобразование обычно является линейным преобразованием. Применяя обратное частотно-временное преобразование перед объединителем (401), можно, например, выполнить декорреляцию во временной области (вместо частотно-временной области, как на Фигуре 2а). Это может иметь практический эффект для некоторых применений при реализации настоящего изобретения.
Следует отметить, что обратный фильтр-банк также может находиться где-либо в другом месте. Как правило, объединитель и декоррелятор должны (и обычно, последний) применяться во временной области. Но оба или только один блок также могут применяться в частотной области.
Поэтому предпочтительные варианты осуществления настоящего изобретения содержат калькулятор диффузного компонента 301 для расчета, для каждой частотно-временной плитки из группы частотно-временных плиток, по меньшей мере, одного компонента диффузного звука. Кроме того, такие варианты осуществления настоящего изобретения содержат объединитель 401 для объединения информации диффузного звука и информации прямого звукового поля для получения представления в частотной области или представления во временной области компонентов звукового поля. Кроме того, в зависимости от варианта реализации настоящего изобретения калькулятор диффузных компонентов дополнительно содержит декоррелятор 107 для декоррелирования информации диффузного звука, при этом декоррелятор может быть реализован в пределах частотной области, так что корреляция выполняется с представлением частотно-временной плитки компонента диффузного звука. В альтернативном варианте осуществления настоящего изобретения декоррелятор выполнен с возможностью работы во временной области, как показано на Фигуре 2b, в результате чего выполняется декорреляция во временной области временного представления определенного компонента диффузного звука определенного порядка.
Другие варианты осуществления, относящиеся к настоящему изобретению, содержат частотно-временной преобразователь, например, частотно-временный преобразователь 101 для преобразования каждого из группы микрофонных сигналов временной области в частотное представление, имеющее множество частотно-временных плит. Другие варианты осуществления настоящего изобретения содержат частотно-временные преобразователи, например, блок 20 Фигуры 2а или Фигуры 2b для преобразования, по меньшей мере, одного компонента звукового поля или объединения, по меньшей мере, одного компонента звукового поля, то есть, компонентов прямого звукового поля и компонентов диффузного звука в представление во временной области компонента звукового поля.
В частности, частотно-временной преобразователь 20 выполнен с возможностью обработки, по меньшей мере, одного компонента звукового поля для получения группы компонентов звукового поля во временной области, где эти компоненты звукового поля во временной области являются компонентами прямого звукового поля. Кроме того, частотно-временной преобразователь 20 выполнен с возможностью обработки компонентов диффузного звука (поля) для получения группы диффузных компонентов (звукового поля) во временной области, а объединитель выполнен с возможностью выполнения объединения компонентов звукового поля (прямого) во временной области и диффузных компонентов (компонентов звукового поля) во временной области во временную область, как показано, например, на Фигуре 2b. В альтернативном варианте осуществления настоящего изобретения объединитель 401 выполнен с возможностью объединения, по меньшей мере, одного компонента звукового поля (прямого) для частотно-временной плитки и компонентов диффузного звука (поля) для соответствующей частотно-временной плитки в пределах частотной области, а частотно-временной преобразователь 20 затем выполнен с возможностью обработки результата объединителя 401 для получения компонентов звукового поля во временной области, то есть, представления компонентов звукового поля во временной области, например, как показано на Фигуре 2а.
Нижеупомянутые варианты осуществления настоящего изобретения более подробно описывают некоторые варианты реализации настоящего изобретения. Следует отметить, что в Вариантах 1-7 осуществления настоящего изобретения рассматривается одно направление звука на одну частотно-временную плитку (и, следовательно, только один отклик пространственной базисной функции и только один компонент прямого звука системы Амбисоник на уровень и моду, и на время и частоту). Вариант 8 осуществления настоящего изобретения описывает пример, в котором рассматривается более одного направления звука на одну частотно-временную плитку. Концепция этого варианта осуществления настоящего изобретения может быть применена простым способом ко всем другим вариантам осуществления настоящего изобретения.
Вариант 1 осуществления настоящего изобретения
На Фигуре 3a показан вариант осуществления настоящего изобретения, который позволяет синтезировать компонент системы Амбисоник желаемого порядка (уровня) и моды из сигналов группы (по меньшей мере, двух) микрофонов.
Входные данные по настоящему изобретению представляет собой сигналы группы (по меньшей мере, двух) микрофонов. Микрофоны могут быть расположены в произвольной форме, например, в виде совмещенного устройства, линейного массива, планарного массива или трехмерного массива. Кроме того, каждый микрофон может иметь всенаправленную или произвольную направленную направленность. Направленности различных микрофонов могут различаться.
Множественные микрофонные сигналы преобразуются в частотно-временную область в Блоке (101) с использованием, например, фильтр-банка или кратковременного преобразования Фурье (STFT). Выходные данные частотно-временное преобразования (101) представляет собой множественные микрофонные сигналы в частотно-временной области, которые обозначаются 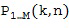 , где
, где 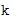 представляет собой частотный индекс,
представляет собой частотный индекс, 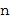 представляет собой временной индекс, а
представляет собой временной индекс, а 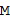 представляет собой количество микрофонов. Заметим, что нижеупомянутая обработка выполняется отдельно для частотно-временных плиток
представляет собой количество микрофонов. Заметим, что нижеупомянутая обработка выполняется отдельно для частотно-временных плиток 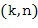 .
.
После преобразования микрофонных сигналов во временной области, выполняется оценка направления звука в Блоке (102) по времени и частоте с использованием, по меньшей мере, двух микрофонных сигналов . В этом варианте осуществления настоящего изобретения одно направление звука определяется по времени и частоте. Для оценки направления звука в (102) могут использоваться узкополосные оцениватели направления прихода (DOA) существующего уровня техники, которые доступны в литературе для различных форм микрофонных массивов. Например, можно использовать алгоритм MUSIC [MUSIC], который применим к произвольным микрофонным устройствам. В случае равномерных линейных массивов, неравномерных линейных массивов с эквидистантными точками сетки или кольцевых массивов всенаправленных микрофонов может быть применен алгоритм Root MUSIC [RootMUSIC1, RootMUSIC2, RootMUSIC3], который является более эффективным, с точки зрения проведения вычислений, чем MUSIC. Еще одним известным узкополосным оценивателем DOA, который может быть применен к линейным массивам или планарным массивам с вращательно-инвариантной структурой субмассива, является ESPRIT [ESPRIT].
В этом варианте осуществления настоящего изобретения выходными данными оценивателя направления звука (102) является направление звука для момента времени и частотного индекса . Направление звука может быть выражено, например, в виде вектора единичной нормы n(k,n) или в виде азимутального угла 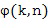 и/или угла возвышения
и/или угла возвышения 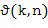 , которые связаны, например, как
, которые связаны, например, как
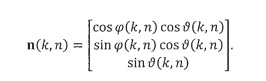
Если угол возвышения не оценен (2D-случай), мы можем предположить нулевое возвышение, то есть, 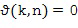 , на следующих этапах. В этом случае, вектор единичной нормы n(k,n) можно записать в виде
, на следующих этапах. В этом случае, вектор единичной нормы n(k,n) можно записать в виде
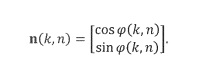
После оценки направления звука в Блоке (102) отклик пространственной базисной функции желаемого порядка (уровня) и моды определяется в Блоке (103) индивидуально по времени и частоте с использованием оцененной информации о направлении звука. Отклик пространственной базисной функции порядка (уровня) и моды обозначается 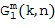 и рассчитывается как
и рассчитывается как
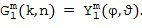
В данном документе 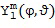 представляет собой пространственную базисную функцию порядка (уровня) и моды , которая зависят от направления, обозначенного вектором n(k,n) или азимутальным углом , и/или углом возвышения . Поэтому отклик характеризует отклик пространственной базисной функции на звук, поступающий из направления, обозначенного вектором n(k,n) или азимутальным углом , и/или углом места . Например, при рассмотрении вещественнозначных сферических гармоник с N3D-нормализацией в виде пространственной базисной функции, можно рассчитать как [SphHarm, Ambix, FourierAcoust]
представляет собой пространственную базисную функцию порядка (уровня) и моды , которая зависят от направления, обозначенного вектором n(k,n) или азимутальным углом , и/или углом возвышения . Поэтому отклик характеризует отклик пространственной базисной функции на звук, поступающий из направления, обозначенного вектором n(k,n) или азимутальным углом , и/или углом места . Например, при рассмотрении вещественнозначных сферических гармоник с N3D-нормализацией в виде пространственной базисной функции, можно рассчитать как [SphHarm, Ambix, FourierAcoust]

где
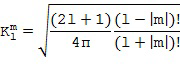
являются константами N3D-нормализации и 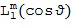 является присоединенным полиномом Лежандра порядка (уровня) и моды , в зависимости от угла возвышения, который определяется, например, в [FourierAcoust]. Заметим, что отклик пространственной базисной функции
является присоединенным полиномом Лежандра порядка (уровня) и моды , в зависимости от угла возвышения, который определяется, например, в [FourierAcoust]. Заметим, что отклик пространственной базисной функции 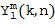 желаемого порядка (уровня) и моды также может быть предварительно вычислен для каждого азимутального угла и/или угла возвышения и сохранен в справочной таблице, а затем его можно выбрать, в зависимости от оцененного направления звука.
желаемого порядка (уровня) и моды также может быть предварительно вычислен для каждого азимутального угла и/или угла возвышения и сохранен в справочной таблице, а затем его можно выбрать, в зависимости от оцененного направления звука.
В этом варианте осуществления настоящего изобретения, без потери общности, первый микрофонный сигнал упоминаются как опорный микрофонный сигнал 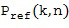 , то есть,
, то есть,
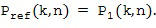
В этом варианте осуществления настоящего изобретения опорный микрофонный сигнал объединяется, например, путем умножения 115 для частотно-временной плитки на отклик пространственной базисной функции, определенной в Блоке (103), то есть,
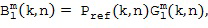
приводит к желаемому компоненту системы Амбисоник 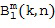 порядка (уровня) и моды для частотно-временной плитки . Полученные в результате компоненты системы Амбисоник , в конечном итоге, могут быть преобразованы обратно во временную область с использованием обратного фильтр-банка или обратного STFT, сохранены, переданы или использованы, например, для применений пространственного воспроизведения звука. На практике можно вычислить компоненты системы Амбисоник для всех желаемых порядков и мод, чтобы получить желаемый сигнал системы Амбисоник желаемого высшего порядка (уровня).
порядка (уровня) и моды для частотно-временной плитки . Полученные в результате компоненты системы Амбисоник , в конечном итоге, могут быть преобразованы обратно во временную область с использованием обратного фильтр-банка или обратного STFT, сохранены, переданы или использованы, например, для применений пространственного воспроизведения звука. На практике можно вычислить компоненты системы Амбисоник для всех желаемых порядков и мод, чтобы получить желаемый сигнал системы Амбисоник желаемого высшего порядка (уровня).
Вариант 2 осуществления настоящего изобретения
На Фигуре 3b показан другой вариант осуществления настоящего изобретения, который позволяет синтезировать компонент системы Амбисоник желаемого порядка (уровня) и моды из сигналов группы (по меньшей мере, двух) микрофонов. Этот вариант осуществления настоящего изобретения – аналогичен Варианту 1 осуществления настоящего изобретения, но он дополнительно содержит Блок (104) для определения опорного микрофонного сигнала из группы микрофонных сигналов.
Как и в Варианте 1 осуществления настоящего изобретения входные данные по настоящему изобретению представляет собой сигналы группы (по меньшей мере, двух) микрофонов. Микрофоны могут быть расположены в произвольной форме, например, в виде совмещенного устройства, линейного массива, планарного массива или трехмерного массива. Кроме того, каждый микрофон может иметь всенаправленную или произвольную направленную направленность. Направленности различных микрофонов могут различаться.
Как и в Варианте 1 осуществления настоящего изобретения множественные микрофонные сигналы преобразуются в частотно-временную область в Блоке (101) с использованием, например, фильтр-банка или кратковременного преобразования Фурье (STFT). Выходные данные частотно-временного преобразования (101) представляет собой микрофонные сигналы в частотно-временной области, которые обозначаются . Нижеупомянутая обработка выполняется отдельно для частотно-временных плиток .
Как и в Варианте 1 осуществления настоящего изобретения оценка направления звука выполняется в Блоке (102) по времени и частоте с использованием, по меньшей мере, двух микрофонных сигналов . Соответствующие оценки обсуждаются в Варианте 1 осуществления настоящего изобретения. Выходными данными оценивателя направления звука (102) является направление звука в момент времени и с частотным индексом . Направление звука может быть выражено, например, в виде вектора единичной нормы n(k,n) или в виде азимутального угла , и/или угла возвышения , которые связаны, как описано в Варианте 1 осуществления настоящего изобретения.
Как и в Варианте 1 осуществления настоящего изобретения отклик пространственной базисной функции желаемого порядка (уровня) и моды определяется в Блоке (103) по времени и частоте с использованием оцененной информации о направлении звука. Отклик пространственной базисной функции обозначается . Например, мы можем рассматривать вещественнозначные сферические гармоники с N3D-нормализацией в виде пространственной базисной функции, и можно определить, как описано в Варианте 1 осуществления настоящего изобретения.
В этом Варианте осуществления настоящего изобретения опорный микрофонный сигнал определяется из группы микрофонных сигналов в Блоке (104). Для этой цели Блок (104) использует информацию о направлении звука, которая была оценена в Блоке (102). Различные опорные микрофонные сигналы могут быть определены для различных частотно-временных плиток. Различные возможности существуют для определения опорного микрофонного сигнала из группы микрофонных сигналов на основе информации о направлении звука. Например, микрофон можно выбрать по времени и частоте из группы микрофонов, который находится ближе всего к оцененному направлению звука. Этот подход наглядно представлен на Фигуре 1b. Например, если предположить, что позиции микрофонов задаются позициями векторов 
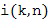 ближайшего микрофона, решив проблему
ближайшего микрофона, решив проблему
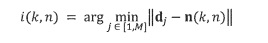
таким образом, опорный микрофонный сигнал для рассматриваемых времени и частоты задается
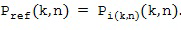
В примере на Фигуре 1b, опорный микрофон для частотно-временной плитки будет микрофоном номер 3, то есть, 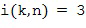 , поскольку
, поскольку 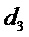
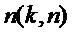 является применение многоканального фильтра к микрофонным сигналам, то есть,
является применение многоканального фильтра к микрофонным сигналам, то есть,
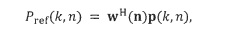
где w(n) является многоканальным фильтром, который зависит от оцененного направления звука, и вектор 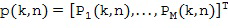 содержит множество микрофонных сигналов. Существует много различных оптимальных многоканальных фильтров w(n) в литературе, которые могут быть использованы для вычисления , например, фильтра задержки и суммирования, или фильтра LCMV (линейно ограниченная минимальная дисперсия), которые выводятся, например, в [OptArrayPr]. Использование многоканальных фильтров имеет различные преимущества и недостатки, которые объясняются в [OptArrayPr], например, они позволяют нам уменьшить уровень собственного шума микрофона.
содержит множество микрофонных сигналов. Существует много различных оптимальных многоканальных фильтров w(n) в литературе, которые могут быть использованы для вычисления , например, фильтра задержки и суммирования, или фильтра LCMV (линейно ограниченная минимальная дисперсия), которые выводятся, например, в [OptArrayPr]. Использование многоканальных фильтров имеет различные преимущества и недостатки, которые объясняются в [OptArrayPr], например, они позволяют нам уменьшить уровень собственного шума микрофона.
Как и в Варианте 1 осуществления настоящего изобретения опорный микрофонный сигнал , наконец, объединяют, например, путем умножения 115 на время и частоту с откликом пространственной базисной функции, определенной в Блоке (103), что приводит к желаемому компоненту системы Амбисоник порядка (уровня) и моды для частотно-временной плитки . Полученные в результате компоненты системы Амбисоник , в конечном итоге, могут быть преобразованы обратно во временную область с использованием обратного фильтр-банка или обратного STFT, сохранены, переданы или использованы, например, для применений пространственного воспроизведения звука. На практике можно вычислить компоненты системы Амбисоник для всех желаемых порядков и мод, чтобы получить желаемый сигнал системы Амбисоник желаемого высшего порядка (уровня).
Вариант 3 осуществления настоящего изобретения
На Фигуре 4 показан другой вариант осуществления настоящего изобретения, который позволяет синтезировать компонент системы Амбисоник желаемого порядка (уровня) и моды из сигналов группы (по меньшей мере, двух) микрофонов. Этот вариант осуществления настоящего изобретения аналогичен Варианту 1 осуществления настоящего изобретения, но он вычисляет компоненты системы Амбисоник для прямого звукового сигнала и диффузного звукового сигнала.
Как и в Варианте 1 осуществления настоящего изобретения входные данные по настоящему изобретению представляет собой сигналы группы (по меньшей мере, двух) микрофонов. Микрофоны могут быть расположены в произвольной форме, например, в виде совмещенного устройства, линейного массива, планарного массива или трехмерного массива. Кроме того, каждый микрофон может иметь всенаправленную или произвольную направленную направленность. Направленности различных микрофонов могут различаться.
Как и в Варианте 1 осуществления настоящего изобретения множественные микрофонные сигналы преобразуются в частотно-временную область в Блоке (101) с использованием, например, фильтр-банка или кратковременного преобразования Фурье (STFT). Выходные данные частотно-временного преобразования (101) представляет собой микрофонные сигналы в частотно-временной области, которые обозначаются . Нижеупомянутая обработка выполняется отдельно для частотно-временных плиток .
Как и в Варианте 1 осуществления настоящего изобретения оценка направления звука выполняется в Блоке (102) по времени и частоте с использованием, по меньшей мере, двух микрофонных сигналов . Соответствующие оценки обсуждаются в Варианте 1 осуществления настоящего изобретения. Выходными данными оценивателя направления звука (102) является направление звука в момент времени и с частотным индексом . Направление звука может быть выражено, например, в виде вектора единичной нормы n(k,n) или в виде азимутального угла , и/или угла возвышения , которые связаны, как описано в Варианте 1 осуществления настоящего изобретения.
Как и в Варианте 1 осуществления настоящего изобретения отклик пространственной базисной функции желаемого порядка (уровня) и моды определяется в Блоке (103) по времени и частоте с использованием оцененной информации о направлении звука. Отклик пространственной базисной функции обозначается . Например, мы можем рассматривать вещественнозначные сферические гармоники с N3D-нормализацией в виде пространственной базисной функции, и можно определить, как описано в Варианте 1 осуществления настоящего изобретения.
В этом варианте осуществления настоящего изобретения средний отклик пространственной базисной функции желаемого порядка (уровня) и моды , который не зависит от временного индекса , получают из Блока (106). Этот средний отклик обозначается 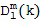 и характеризует отклик пространственной базисной функции для звуков, поступающих со всех возможных направлений (таких как, диффузные звуки или окружающие звуки). Одним из примеров определения среднего отклика является рассмотрение интеграла от квадрата величины пространственной базисной функции по всем возможным углам
и характеризует отклик пространственной базисной функции для звуков, поступающих со всех возможных направлений (таких как, диффузные звуки или окружающие звуки). Одним из примеров определения среднего отклика является рассмотрение интеграла от квадрата величины пространственной базисной функции по всем возможным углам  и/или
и/или  . Например, интегрируя по всем углам на сфере, мы получаем
. Например, интегрируя по всем углам на сфере, мы получаем
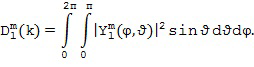
Такое определение среднего отклика можно интерпретировать следующим образом: Как поясняется в Варианте 1 осуществления настоящего изобретения, пространственная базисная функция может интерпретироваться, как направленность микрофона порядка . Для целей увеличения порядков, такой микрофон станет все более направленным, и поэтому меньшее количество диффузной звуковой энергии или окружающей звуковой энергии будет захвачено в практическом звуковом поле, по сравнению со всенаправленным микрофоном (микрофон порядка ). С определением , приведенным выше, средний отклик приведет к вещественнозначному коэффициенту, который характеризует, насколько диффузная звуковая энергия или окружающая звуковая энергия ослабляется в сигнале микрофона порядка , по сравнению со всенаправленным микрофоном. Ясно, что помимо интегрирования квадрата величины пространственной базисной функции 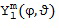 по направлениям сферы существуют различные альтернативные варианты для определения среднего отклика , например: интегрирование квадрата величины по направлениям на окружности, интегрирование квадрата величины по любому набору желаемых направлений
по направлениям сферы существуют различные альтернативные варианты для определения среднего отклика , например: интегрирование квадрата величины по направлениям на окружности, интегрирование квадрата величины по любому набору желаемых направлений 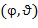 , получение средних значений квадрата величины по любому набору желаемых направлений , интегрирование или получение средних значений величины вместо квадрата величины, с учетом взвешенной суммы по любому набору желаемых направлений , или указание любого желаемого вещественнозначного номера для , что соответствует желаемой чувствительности вышеупомянутого воображаемого микрофона порядка, по отношению к диффузным звукам или окружающим звукам.
, получение средних значений квадрата величины по любому набору желаемых направлений , интегрирование или получение средних значений величины вместо квадрата величины, с учетом взвешенной суммы по любому набору желаемых направлений , или указание любого желаемого вещественнозначного номера для , что соответствует желаемой чувствительности вышеупомянутого воображаемого микрофона порядка, по отношению к диффузным звукам или окружающим звукам.
Отклик средней пространственной базисной функции также может быть предварительно рассчитан и сохранен в справочной таблице, и определение значений отклика выполняется путем доступа к справочной таблице и получения соответствующего значения.
Как и в Варианте 1 осуществления настоящего изобретения, без потери общности, первый микрофонный сигнал упоминаются как опорный микрофонный сигнал, то есть, 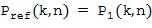 .
.
В этом варианте осуществления настоящего изобретения опорный микрофонный сигнал используется в Блоке (105) для вычисления прямого звукового сигнала, обозначенного 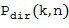 , и диффузного звукового сигнала, обозначенного
, и диффузного звукового сигнала, обозначенного 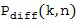 . В Блоке (105) прямой звуковой сигнал может быть рассчитан, например, путем применения одноканального фильтра
. В Блоке (105) прямой звуковой сигнал может быть рассчитан, например, путем применения одноканального фильтра 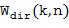 для опорного микрофонного сигнала, то есть,
для опорного микрофонного сигнала, то есть,
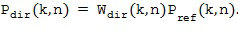
В литературе существуют различные возможности для вычисления оптимального одноканальный фильтра . Например, можно использовать хорошо известный фильтр квадратного корня Винера, который был определен, например, в [Victaulic] как
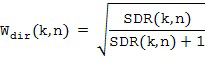
где 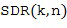 представляет собой соотношение сигнал-диффузия (SDR) в момент времени и с частотным индексом , которое характеризует соотношение мощности между прямым звуком и диффузным звуком, как описано в [VirtualMic]. SDR можно оценить, используя любые два микрофона из группы микрофонных сигналов с помощью оценки SDR существующего уровня техники, доступной в литературе, например, с помощью оценивателей, предложенных в [SDRestim], которые основаны на пространственной когерентности между двумя произвольными микрофонными сигналами. В Блоке (105) прямой звуковой сигнал может быть рассчитан, например, путем применения одноканального фильтра
представляет собой соотношение сигнал-диффузия (SDR) в момент времени и с частотным индексом , которое характеризует соотношение мощности между прямым звуком и диффузным звуком, как описано в [VirtualMic]. SDR можно оценить, используя любые два микрофона из группы микрофонных сигналов с помощью оценки SDR существующего уровня техники, доступной в литературе, например, с помощью оценивателей, предложенных в [SDRestim], которые основаны на пространственной когерентности между двумя произвольными микрофонными сигналами. В Блоке (105) прямой звуковой сигнал может быть рассчитан, например, путем применения одноканального фильтра 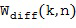 для опорного микрофонного сигнала, то есть,
для опорного микрофонного сигнала, то есть,
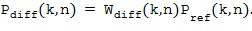
В литературе существуют различные возможности для вычисления оптимального одноканального фильтра . Например, можно использовать хорошо известный фильтр квадратного корня Винера, который может быть определен, например, в [Victaulic], как
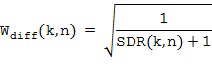
где представляет собой SDR, которое может быть оценено, как уже говорилось ранее.
В этом варианте осуществления настоящего изобретения прямой звуковой сигнал , определенный в Блоке (105), объединяется, например, путем умножения 115a на время и частоту, с откликом пространственной базисной функции, определенной в Блоке (103), то есть,

что приводит к компоненту прямого звука системы Амбисоник 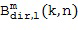 порядка (уровня) и моды для частотно-временной плитки . Кроме того, диффузный звуковой сигнал , определенный в Блоке (105), объединяют, например, путем умножения 115b на время и частоту, с откликом пространственной базисной функции, определенной в Блоке (106), то есть,
порядка (уровня) и моды для частотно-временной плитки . Кроме того, диффузный звуковой сигнал , определенный в Блоке (105), объединяют, например, путем умножения 115b на время и частоту, с откликом пространственной базисной функции, определенной в Блоке (106), то есть,
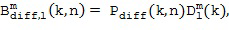
что приводит к компоненту диффузного звука системы Амбисоник 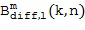 порядка (уровня) и моды для частотно-временной плитки .
порядка (уровня) и моды для частотно-временной плитки .
Наконец, компонент прямого звука системы Амбисоник и компонент диффузного звука системы Амбисоник объединяются, например, посредством операции суммирования (109), чтобы получить конечный компонент системы Амбисоник желаемого порядка (уровня) и режима для частотно-временной плитки , то есть,
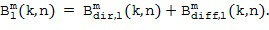
Полученные в результате компоненты системы Амбисоник , в конечном итоге, могут быть преобразованы обратно во временную область с использованием обратного фильтр-банка или обратного STFT, сохранены, переданы или использованы, например, для применений пространственного воспроизведения звука. На практике можно вычислить компоненты системы Амбисоник для всех желаемых порядков и мод, чтобы получить желаемый сигнал системы Амбисоник желаемого высшего порядка (уровня).
Важно подчеркнуть, что преобразование обратно во временную область с использованием, например, обратного фильтр-банка или обратного STFT, может быть выполнено перед вычислением , то есть, до операции (109). Это означает, что мы сначала можем преобразовать и 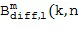 ) обратно во временную область, а затем суммировать оба компонента с операцией (109), чтобы получить конечный компонент системы Амбисоник
) обратно во временную область, а затем суммировать оба компонента с операцией (109), чтобы получить конечный компонент системы Амбисоник 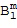 . Это возможно, поскольку обратный фильтр-банк или обратное STFT являются, в целом, линейными операциями.
. Это возможно, поскольку обратный фильтр-банк или обратное STFT являются, в целом, линейными операциями.
Заметим, что алгоритм в этом варианте осуществления настоящего изобретения может быть выполнен с возможностью, позволяющей вычислять компоненты прямого звука системы Амбисоник и компонент диффузного звука системы Амбисоник для различных мод (порядков) . Например, может быть вычислено до порядка  , тогда как может быть вычислено только до порядка (в этом случае, будет составлять ноль для порядков, которые больше ). Это имеет определенные преимущества, как описано в Варианте 4 осуществления настоящего изобретения. Если требуется, например, рассчитать только , а не для определенного порядка (уровня) или моды , тогда, например, Блок (105) может быть выполнен с возможностью, позволяющей диффузному звуковому сигналу стать равным нулю. Это может быть достигнуто, например, путем установления фильтра в уравнениях предварительно на 0 и фильтра на 1. В альтернативном варианте осуществления настоящего изобретения можно вручную установить SDR в предыдущих уравнениях на очень высокое значение.
, тогда как может быть вычислено только до порядка (в этом случае, будет составлять ноль для порядков, которые больше ). Это имеет определенные преимущества, как описано в Варианте 4 осуществления настоящего изобретения. Если требуется, например, рассчитать только , а не для определенного порядка (уровня) или моды , тогда, например, Блок (105) может быть выполнен с возможностью, позволяющей диффузному звуковому сигналу стать равным нулю. Это может быть достигнуто, например, путем установления фильтра в уравнениях предварительно на 0 и фильтра на 1. В альтернативном варианте осуществления настоящего изобретения можно вручную установить SDR в предыдущих уравнениях на очень высокое значение.
Вариант 4 осуществления настоящего изобретения
На Фигуре 5 показан другой вариант осуществления настоящего изобретения, который позволяет синтезировать компонент системы Амбисоник желаемого порядка (уровня) и моды из сигналов группы (по меньшей мере, двух) микрофонов. Этот вариант осуществления настоящего изобретения – аналогичен Варианту 3 осуществления настоящего изобретения, но он дополнительно содержит декорреляторы для диффузных компонентов системы Амбисоник.
Как и в Варианте 3 осуществления настоящего изобретения входные данные по настоящему изобретению представляет собой сигналы группы (по меньшей мере, двух) микрофонов. Микрофоны могут быть расположены в произвольной форме, например, в виде совмещенного устройства, линейного массива, планарного массива или трехмерного массива. Кроме того, каждый микрофон может иметь всенаправленную или произвольную направленную направленность. Направленности различных микрофонов могут различаться.
Как и в Варианте 3 осуществления настоящего изобретения множественные микрофонные сигналы преобразуются в частотно-временную область в Блоке (101) с использованием, например, фильтр-банка или кратковременного преобразования Фурье (STFT). Выходные данные частотно-временного преобразования (101) представляет собой микрофонные сигналы в частотно-временной области, которые обозначаются . Нижеупомянутая обработка выполняется отдельно для частотно-временных плиток .
Как и в Варианте 3 осуществления настоящего изобретения оценка направления звука выполняется в Блоке (102) по времени и частоте с использованием, по меньшей мере, двух микрофонных сигналов . Соответствующие оценки обсуждаются в Варианте 1 осуществления настоящего изобретения. Выходными данными оценивателя направления звука (102) является направление звука в момент времени и с частотным индексом . Направление звука может быть выражено, например, в виде вектора единичной нормы n(k,n) или в виде азимутального угла , и/или угла возвышения , которые связаны, как описано в Варианте 1 осуществления настоящего изобретения.
Как и в Варианте 3 осуществления настоящего изобретения отклик пространственной базисной функции желаемого порядка (уровня) и моды определяется в Блоке (103) по времени и частоте с использованием оцененной информации о направлении звука. Отклик пространственной базисной функции обозначается . Например, мы можем рассматривать вещественнозначные сферические гармоники с N3D-нормализацией в виде пространственной базисной функции, и можно определить, как описано в Варианте 1 осуществления настоящего изобретения.
Как и в Варианте 3 осуществления настоящего изобретения средний отклик пространственной базисной функции желаемого порядка (уровня) и моды , который не зависит от временного индекса , получают из Блока (106). Этот средний отклик обозначается и характеризует отклик пространственной базисной функции для звуков, поступающих со всех возможных направлений (таких как, диффузные звуки или окружающие звуки). Средний отклик может быть получен путем, который описан в Варианте 3 осуществления настоящего изобретения.
Как и в Варианте 3 осуществления настоящего изобретения, без потери общности, первый микрофонный сигнал упоминаются как опорный микрофонный сигнал, то есть, .
Как и в Варианте 3 осуществления настоящего изобретения, опорный микрофонный сигнал используется в Блоке (105) для расчета прямого звукового сигнала, обозначенного , и диффузного звукового сигнала, обозначенного . Объяснение вычислению и дано в Варианте 3 осуществления настоящего изобретения.
Как и в Варианте 3 осуществления настоящего изобретения, прямой звуковой сигнал , определенный в Блоке (105), объединяется, например, путем умножения 115a на время и частоту, с откликом пространственной базисной функции, определенной в Блоке (103), с получением компонента прямого звука системы Амбисоник порядка (уровня) и моды для частотно-временной плитки . Кроме того, диффузный звуковой сигнал , определенный в Блоке (105), объединяется, например, путем умножения 115b на время и частоту, со средним откликом пространственной базисной функции, определенной в Блоке (106), с получением компонента диффузного звука системы Амбисоник порядка (уровня) и моды для частотно-временной плитки .
В этом варианте осуществления настоящего изобретения рассчитанный компонент диффузного звука системы Амбисоник – декоррелирован в Блоке (107) с использованием декоррелятора, с получением декоррелированного компонента диффузного звука системы Амбисоник, обозначенного 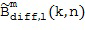 . Для декорреляция можно использовать методы декорреляции существующего уровня техники. Различные декорреляторы или варианты реализации декоррелятора обычно применяются к компоненту диффузного звука системы Амбисоник различного порядка (уровня) и моды , в результате чего полученные декоррелированные компоненты диффузного звука системы Амбисоник различного уровня и моды – взаимно некоррелированы. При этом компоненты диффузного звука системы Амбисоник обладают ожидаемым физическим поведением, а именно, компоненты системы Амбисоник различных порядков и мод – взаимно некоррелированы, если звуковое поле является окружающим или диффузным [SpCoherence]. Заметьте, что компонент диффузного звука системы Амбисоник может быть преобразован обратно во временную область, используя, например, обратный фильтр-банк или обратное STFT перед применением декоррелятора (107).
. Для декорреляция можно использовать методы декорреляции существующего уровня техники. Различные декорреляторы или варианты реализации декоррелятора обычно применяются к компоненту диффузного звука системы Амбисоник различного порядка (уровня) и моды , в результате чего полученные декоррелированные компоненты диффузного звука системы Амбисоник различного уровня и моды – взаимно некоррелированы. При этом компоненты диффузного звука системы Амбисоник обладают ожидаемым физическим поведением, а именно, компоненты системы Амбисоник различных порядков и мод – взаимно некоррелированы, если звуковое поле является окружающим или диффузным [SpCoherence]. Заметьте, что компонент диффузного звука системы Амбисоник может быть преобразован обратно во временную область, используя, например, обратный фильтр-банк или обратное STFT перед применением декоррелятора (107).
Наконец, компонент прямого звука системы Амбисоник и компонент диффузного звука системы Амбисоник объединяются, например, посредством операции суммирования (109), чтобы получить конечный компонент системы Амбисоник желаемого порядка (уровня) и моды для частотно-временной плитки , то есть,
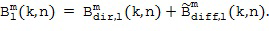
Полученные в результате компоненты системы Амбисоник , в конечном итоге, могут быть преобразованы обратно во временную область с использованием, например, обратного фильтр-банка или обратного STFT, сохранены, переданы или использованы, например, для пространственного воспроизведения звука. На практике можно вычислить компоненты системы Амбисоник для всех желаемых порядков и мод, чтобы получить желаемый сигнал системы Амбисоник желаемого высшего порядка (уровня).
Важно подчеркнуть, что преобразование обратно во временную область с использованием, например, обратного фильтр-банка или обратного STFT, может быть выполнено перед вычислением , то есть, до операции (109). Это означает, что мы сначала можем преобразовать и 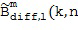 ) обратно во временную область, а затем суммировать оба компонента с операцией (109), чтобы получить конечный компонент системы Амбисоник . Это возможно, поскольку обратный фильтр-банк или обратное STFT являются, в целом, линейными операциями. Точно так же декоррелятор (107) может быть применен к компоненту диффузного звука системы Амбисоник
) обратно во временную область, а затем суммировать оба компонента с операцией (109), чтобы получить конечный компонент системы Амбисоник . Это возможно, поскольку обратный фильтр-банк или обратное STFT являются, в целом, линейными операциями. Точно так же декоррелятор (107) может быть применен к компоненту диффузного звука системы Амбисоник  после преобразования обратно во временную область. Это может быть выгодным с практической точки зрения, поскольку некоторые декорреляторы работают с сигналами во временной области.
после преобразования обратно во временную область. Это может быть выгодным с практической точки зрения, поскольку некоторые декорреляторы работают с сигналами во временной области.
Кроме того, следует отметить, что к Фигуре 5 можно добавить блок, например, обратный фильтр-банк перед декоррелятором, и обратный фильтр-банк можно добавить в любое место системы.
Как объяснялось в Варианте 3 осуществления настоящего изобретения, алгоритм в этом варианте осуществления настоящего изобретения может быть выполнен с возможностью, позволяющей вычислять компоненты прямого звука системы Амбисоник и компонент диффузного звука системы Амбисоник для различных мод (порядков) . Например, может быть вычислено до порядка , тогда как может быть вычислено только до порядка . Это уменьшит сложность вычислений.
Вариант 5 осуществления настоящего изобретения
На Фигуре 6 показан другой вариант осуществления настоящего изобретения, который позволяет синтезировать компонент системы Амбисоник желаемого порядка (уровня) и моды из сигналов группы (по меньшей мере, двух) микрофонов. Этот вариант осуществления настоящего изобретения – аналогичен Варианту 4 осуществления настоящего изобретения, но прямой звуковой сигнал и диффузный звуковой сигнал определяются из группы микрофонных сигналов и путем использования информации о направлении поступления.
Как и в Варианте 4 осуществления настоящего изобретения, входные данные по настоящему изобретению представляет собой сигналы группы (по меньшей мере, двух) микрофонов. Микрофоны могут быть расположены в произвольной форме, например, в виде совмещенного устройства, линейного массива, планарного массива или трехмерного массива. Кроме того, каждый микрофон может иметь всенаправленную или произвольную направленную направленность. Направленности различных микрофонов могут различаться.
Как и в Варианте 4 осуществления настоящего изобретения, множественные микрофонные сигналы преобразуются в частотно-временную область в Блоке (101) с использованием, например, фильтр-банка или кратковременного преобразования Фурье (STFT). Выходные данные частотно-временного преобразования (101) представляет собой микрофонные сигналы в частотно-временной области, которые обозначаются . Нижеупомянутая обработка выполняется отдельно для частотно-временных плиток .
Как и в Варианте 4 осуществления настоящего изобретения оценка направления звука выполняется в Блоке (102) по времени и частоте с использованием, по меньшей мере, двух микрофонных сигналов . Соответствующие оцениватели обсуждаются в Варианте 1 осуществления настоящего изобретения. Выходными данными оценивателя направления звука (102) является направление звука в момент времени и с частотным индексом . Направление звука может быть выражено, например, в виде вектора единичной нормы , и/или угла возвышения , которые связаны, как описано в Варианте 1 осуществления настоящего изобретения.
Как и в Варианте 4 осуществления настоящего изобретения, отклик пространственной базисной функции желаемого порядка (уровня) и моды определяется в Блоке (103) по времени и частоте с использованием оцененной информации о направлении звука. Отклик пространственной базисной функции обозначается . Например, мы можем рассматривать вещественнозначные сферические гармоники с N3D-нормализацией в виде пространственной базисной функции, и можно определить, как описано в Варианте 1 осуществления настоящего изобретения.
Как и в Варианте 4 осуществления настоящего изобретения, средний отклик пространственной базисной функции желаемого порядка (уровня) и моды , который не зависит от временного индекса, получают из Блока (106). Этот средний отклик обозначается и характеризует отклик пространственной базисной функции для звуков, поступающих со всех возможных направлений (таких как, диффузные звуки или окружающие звуки). Средний отклик может быть получен путем, который описан в Варианте 3 осуществления настоящего изобретения.
В этом варианте осуществления настоящего изобретения прямой звуковой сигнал и диффузный звуковой сигнал определяются в Блоке (110) по временному индексу и частотному индексу из, по меньшей мере, двух доступных микрофонных сигналов . Для этой цели Блок (110) использует информацию о направлении звука, которая была оценена в Блоке (102). В дальнейшем приводятся различные примеры Блока (110), которые описывают, как определять и .
В первом примере Блока (110) опорный микрофонный сигнал, обозначенный , определяется из группы микрофонных сигналов на основе информации о направлении звука, представленной Блоком (102). Опорный микрофонный сигнал может быть определен путем выбора микрофонного сигнала, который находится ближе всего к оцененному направлению звука для рассматриваемого времени и частоты. Этот способ выбора для определения микрофонного сигнала был разъяснен в Варианте 2 осуществления настоящего изобретения. После определения , прямой звуковой сигнал и диффузный звуковой сигнал могут быть вычислены, например, путем применения одноканальных фильтров и , соответственно, к опорному микрофонному сигналу . Этот подход и вычисление соответствующих одноканальных фильтров были разъяснены в Варианте 3 осуществления настоящего изобретения.
Во втором примере Блока (110) мы определяем опорный микрофонный сигнал , как в предыдущем примере, и вычисляем , путем применения одноканального фильтра - . Однако для того, чтобы определить диффузный сигнал мы выбираем второй опорный сигнал 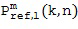 и применяем одноканальный фильтр ко второму опорному сигналу, то есть,
и применяем одноканальный фильтр ко второму опорному сигналу, то есть,

Фильтр может быть вычислен, как это объяснено на примере Варианта 3 осуществления настоящего изобретения. Второй опорный сигнал соответствует одному из доступных микрофонных сигналов . Однако для порядков и мод мы можем использовать различные микрофонные сигналы в качестве второго опорного сигнала. Например, для уровня и моды 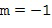 , мы можем использовать первый микрофонный сигнал микрофона в качестве второго опорного сигнала, то есть,
, мы можем использовать первый микрофонный сигнал микрофона в качестве второго опорного сигнала, то есть, 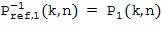 . Для уровня и моды
. Для уровня и моды  , мы можем использовать второй микрофонный сигнал, то есть,
, мы можем использовать второй микрофонный сигнал, то есть, 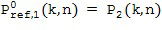 . Для уровня и моды
. Для уровня и моды  , мы можем использовать третий микрофонный сигнал, то есть,
, мы можем использовать третий микрофонный сигнал, то есть, 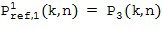 . Доступные микрофонные сигналы могут быть отнесены, например, случайным образом ко второму опорному сигналу для различных порядков и мод. Это – разумный практический подход, поскольку для диффузных или окружающих ситуаций с записыванием все микрофонные сигналы обычно содержат аналогичную звуковую мощность. Преимущество выбора различных сигналов второго опорного микрофона для различных порядков и мод состоит в том, что полученные диффузные звуковые сигналы зачастую (по меньшей мере, частично) являются взаимно некоррелированными для различных порядков и мод.
. Доступные микрофонные сигналы могут быть отнесены, например, случайным образом ко второму опорному сигналу для различных порядков и мод. Это – разумный практический подход, поскольку для диффузных или окружающих ситуаций с записыванием все микрофонные сигналы обычно содержат аналогичную звуковую мощность. Преимущество выбора различных сигналов второго опорного микрофона для различных порядков и мод состоит в том, что полученные диффузные звуковые сигналы зачастую (по меньшей мере, частично) являются взаимно некоррелированными для различных порядков и мод.
В третьем примере Блока (110) прямой звуковой сигнал определяется путем применения многоканального фильтра, обозначенного wdir(n), к множественным микрофонным сигналам , то есть,
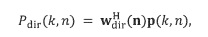
где многоканальный фильтр wdir(n) зависит от оцененного направления звука, и вектор 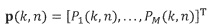 содержит множественные микрофонные сигналы. В литературе существует много различных оптимальных многоканальных фильтров wdir(n), которые могут быть использованы для вычисления из информации о направлении звука, например, фильтры, которые получены в [InformedSF]. Аналогичным образом, диффузный звуковой сигнал определяется путем применения многоканального фильтра, обозначенного wdiff (n), к множественным микрофонным сигналам , то есть,
содержит множественные микрофонные сигналы. В литературе существует много различных оптимальных многоканальных фильтров wdir(n), которые могут быть использованы для вычисления из информации о направлении звука, например, фильтры, которые получены в [InformedSF]. Аналогичным образом, диффузный звуковой сигнал определяется путем применения многоканального фильтра, обозначенного wdiff (n), к множественным микрофонным сигналам , то есть,
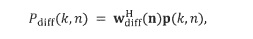
где многоканальный фильтр wdiff(n) зависит от оцененного направления звука. В литературе существует много различных оптимальных многоканальных фильтров wdiff (n), которые могут быть использованы для вычисления , например, фильтр, который получен в [DiffuseBF].
В четвертом примере Блока (110) мы определяем и , как в предыдущем примере, путем применения многоканальных фильтров wdir (n) и wdiff (n), соответственно, к микрофонным сигналам p (k,n). Однако мы используем различные фильтры wdiff(n) для различных порядков и мод таким образом, чтобы полученные в результате диффузные звуковые сигналы для различных порядков и режимов были взаимно некоррелированными. Эти различные фильтры wdiff(n), которые минимизируют корреляцию между выходными сигналами, могут быть вычислены, например, как описано в [CovRender].
Как и в Варианте 4 осуществления настоящего изобретения, прямой звуковой сигнал , определенный в Блоке (105), объединяется, например, путем умножения 115a на время и частоту, с откликом пространственной базисной функции, определенной в Блоке (103), с получением компонента прямого звука системы Амбисоник порядка (уровня) и моды для частотно-временной плитки . Кроме того, диффузный звуковой сигнал , определенный в Блоке (105), объединяется, например, путем умножения 115b на время и частоту, со средним откликом пространственной базисной функции, определенной в Блоке (106), с получением компонента диффузного звука системы Амбисоник порядка (уровня) и моды для частотно-временной плитки .
Как и в Варианте 3 осуществления настоящего изобретения, вычисленный компонент прямого звука системы Амбисоник и компонент диффузного звука системы Амбисоник объединяются, например, посредством операции суммирования (109), чтобы получить конечный компонент системы Амбисоник желаемого порядка (уровня) и моды для частотно-временной плитки . Полученные в результате компоненты системы Амбисоник , в конечном итоге, могут быть преобразованы обратно во временную область с использованием обратного фильтр-банка или обратного STFT, сохранены, переданы или использованы, например, для применений пространственного воспроизведения звука. На практике можно вычислить компоненты системы Амбисоник для всех желаемых порядков и мод, чтобы получить желаемый сигнал системы Амбисоник желаемого высшего порядка (уровня). Как поясняется в Варианте 3 осуществления настоящего изобретения, преобразование обратно во временную область может быть выполнено до вычисления , то есть, до операции (109).
Заметим, что алгоритм в этом варианте осуществления настоящего изобретения может быть выполнен с возможностью, позволяющей вычислять компоненты прямого звука системы Амбисоник и компонент диффузного звука системы Амбисоник для различных мод (порядков) . Например, может быть вычислено до порядка , тогда как может быть вычислено только до порядка (в этом случае, будет составлять ноль для порядков, которые больше ). Если желательно, например, рассчитать только , а не для определенного порядка (уровня) или моды , тогда, например, Блок (110) может быть выполнен с возможностью, позволяющей диффузному звуковому сигналу стать равным нулю. Это может быть достигнуто, например, путем установления фильтра в уравнениях предварительно на 0 и фильтра на 1. Аналогичным образом, фильтр 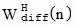 может быть установлен на ноль.
может быть установлен на ноль.
Вариант 6 осуществления настоящего изобретения
На Фигуре 7 показан другой вариант осуществления настоящего изобретения, который позволяет синтезировать компонент системы Амбисоник желаемого порядка (уровня) и моды из сигналов группы (по меньшей мере, двух) микрофонов. Этот вариант осуществления настоящего изобретения – аналогичен Варианту 5 осуществления настоящего изобретения, но он дополнительно содержит декорреляторы для диффузных компонентов системы Амбисоник.
Как и в Варианте 5 осуществления настоящего изобретения, входные данные по настоящему изобретению представляет собой сигналы группы (по меньшей мере, двух) микрофонов. Микрофоны могут быть расположены в произвольной форме, например, в виде совмещенного устройства, линейного массива, планарного массива или трехмерного массива. Кроме того, каждый микрофон может иметь всенаправленную или произвольную направленную направленность. Направленности различных микрофонов могут различаться.
Как и в Варианте 5 осуществления настоящего изобретения, множественные микрофонные сигналы преобразуются в частотно-временную область в Блоке (101) с использованием, например, фильтр-банка или кратковременного преобразования Фурье (STFT). Выходные данные частотно-временного преобразования (101) представляет собой микрофонные сигналы в частотно-временной области, которые обозначаются . Нижеупомянутая обработка выполняется отдельно для частотно-временных плиток .
Как и в Варианте 5 осуществления настоящего изобретения, оценка направления звука выполняется в Блоке (102) по времени и частоте с использованием, по меньшей мере, двух микрофонных сигналов . Соответствующие оцениватели обсуждаются в Варианте 1 осуществления настоящего изобретения. Выходными данными оценивателя направления звука (102) является направление звука в момент времени и с частотным индексом . Направление звука может быть выражено, например, в виде вектора единичной нормы n(k,n) или в виде азимутального угла , и/или угла возвышения , которые связаны, как описано в Варианте 1 осуществления настоящего изобретения.
Как и в Варианте 5 осуществления настоящего изобретения, отклик пространственной базисной функции желаемого порядка (уровня) и моды определяется в Блоке (103) по времени и частоте с использованием оцененной информации о направлении звука. Отклик пространственной базисной функции обозначается . Например, мы можем рассматривать вещественнозначные сферические гармоники с N3D-нормализацией в виде пространственной базисной функции, и можно определить, как описано в Варианте 1 осуществления настоящего изобретения.
Как и в Варианте 5 осуществления настоящего изобретения, средний отклик пространственной базисной функции желаемого порядка (уровня) и моды , который не зависит от временного индекса, получают из Блока (106). Этот средний отклик обозначается и характеризует отклик пространственной базисной функции для звуков, поступающих со всех возможных направлений (таких как, диффузные звуки или окружающие звуки). Средний отклик может быть получен путем, который описан в Варианте 3 осуществления настоящего изобретения.
Как и в Варианте 5 осуществления настоящего изобретения прямой звуковой сигнал и диффузный звуковой сигнал определяются в Блоке (110) по временному индексу и частотному индексу из, по меньшей мере, двух доступных микрофонных сигналов . Для этой цели Блок (110) использует информацию о направлении звука, которая была оценена в Блоке (102). Объяснение различным примерам Блока (110) дается в Варианте 5 осуществления настоящего изобретения.
Как и в Варианте 5 осуществления настоящего изобретения, прямой звуковой сигнал , определенный в Блоке (105), объединяется, например, путем умножения 115a на время и частоту, с откликом пространственной базисной функции, определенной в Блоке (103), с получением компонента прямого звука системы Амбисоник порядка (уровня) и моды для частотно-временной плитки . Кроме того, диффузный звуковой сигнал , определенный в Блоке (105), объединяется, например, путем умножения 115b на время и частоту, со средним откликом пространственной базисной функции, определенной в Блоке (106), с получением компонента диффузного звука системы Амбисоник порядка (уровня) и моды для частотно-временной плитки .
Как и в Варианте 4 осуществления настоящего изобретения, рассчитанный компонент диффузного звука системы Амбисоник – декоррелирован в Блоке (4) с использованием декоррелятора, с получением декоррелированного компонента диффузного звука системы Амбисоник, обозначенного . Обоснованность и способы декорреляции приведены в Варианте 4 осуществления настоящего изобретения. Как и в Варианте 4 осуществления настоящего изобретения, компонент диффузного звука системы Амбисоник может быть преобразован обратно во временную область, используя, например, обратный фильтр-банк или обратное STFT перед применением декоррелятора (107).
Как и в Варианте 4 осуществления настоящего изобретения, компонент прямого звука системы Амбисоник и декоррелированный компонент диффузного звука системы Амбисоник объединяются, например, посредством операции суммирования (109), чтобы получить конечный компонент системы Амбисоник желаемого порядка (уровня) и моды для частотно-временной плитки . Полученные в результате компоненты системы Амбисоник , в конечном итоге, могут быть преобразованы обратно во временную область с использованием обратного фильтр-банка или обратного STFT, сохранены, переданы или использованы, например, для применений пространственного воспроизведения звука. На практике можно вычислить компоненты системы Амбисоник для всех желаемых порядков и мод, чтобы получить желаемый сигнал системы Амбисоник желаемого высшего порядка (уровня). Как поясняется в Варианте 4 осуществления настоящего изобретения, преобразование обратно во временную область может быть выполнено до вычисления , то есть, до операции (109).
Как и в Варианте 4 осуществления настоящего изобретения, алгоритм в этом варианте осуществления настоящего изобретения может быть выполнен с возможностью, позволяющей вычислять компоненты прямого звука системы Амбисоник и компонент диффузного звука системы Амбисоник для различных мод (порядков) . Например, может быть вычислено до порядка , тогда как может быть вычислено только до порядка .
Вариант 7 осуществления настоящего изобретения
На Фигуре 8 показан другой вариант осуществления настоящего изобретения, который позволяет синтезировать компонент системы Амбисоник желаемого порядка (уровня) и моды из сигналов группы (по меньшей мере, двух) микрофонов. Вариант осуществления настоящего изобретения – аналогичен Варианту 1 осуществления настоящего изобретения, но он дополнительно содержит Блок (111), который применяет операцию сглаживания к вычисленному отклику пространственной базисной функции.
Как и в Варианте 1 осуществления настоящего изобретения входные данные по настоящему изобретению представляют собой сигналы группы (по меньшей мере, двух) микрофонов. Микрофоны могут быть расположены в произвольной форме, например, в виде совмещенного устройства, линейного массива, планарного массива или трехмерного массива. Кроме того, каждый микрофон может иметь всенаправленную или произвольную направленную направленность. Направленности различных микрофонов могут различаться.
Как и в Варианте 1 осуществления настоящего изобретения множественные микрофонные сигналы преобразуются в частотно-временную область в Блоке (101) с использованием, например, фильтр-банка или кратковременного преобразования Фурье (STFT). Выходные данные частотно-временного преобразования (101) представляет собой микрофонные сигналы в частотно-временной области, которые обозначаются . Нижеупомянутая обработка выполняется отдельно для частотно-временных плиток .
Как и в Варианте 1 осуществления настоящего изобретения, без потери общности, первый микрофонный сигнал упоминаются как опорный микрофонный сигнал, то есть, .
Как и в Варианте 1 осуществления настоящего изобретения оценка направления звука выполняется в Блоке (102) по времени и частоте с использованием, по меньшей мере, двух микрофонных сигналов . Соответствующие оцениватели обсуждаются в Варианте 1 осуществления настоящего изобретения. Выходными данными оценивателя направления звука (102) является направление звука в момент времени и с частотным индексом . Направление звука может быть выражено, например, в виде вектора единичной нормы 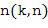 или в виде азимутального угла , и/или угла возвышения , которые связаны, как описано в Варианте 1 осуществления настоящего изобретения.
или в виде азимутального угла , и/или угла возвышения , которые связаны, как описано в Варианте 1 осуществления настоящего изобретения.
Как и в Варианте 1 осуществления настоящего изобретения отклик пространственной базисной функции желаемого порядка (уровня) и моды определяется в Блоке (103) по времени и частоте с использованием оцененной информации о направлении звука. Отклик пространственной базисной функции обозначается . Например, мы можем рассматривать вещественнозначные сферические гармоники с N3D-нормализацией в виде пространственной базисной функции, и можно определить, как описано в Варианте 1 осуществления настоящего изобретения.
В отличие от Варианта 1 осуществления настоящего изобретения, отклик используется в качестве входных данных для Блока (111), который применяет операцию сглаживания к . Выходные данные Блока (111) представляет собой функцию сглаженного отклика, обозначенную как 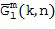 . Цель операции сглаживания заключается в уменьшении нежелательной вариации оценок значений , которая может произойти на практике, например, если направления звука и/или , оцененные в Блоке (102), являются шумовыми. Сглаживание, применяемое к , может выполняться, например, по времени и/или частоте. Например, временное сглаживание может быть достигнуто с использованием хорошо известного рекурсивного фильтра усреднения
. Цель операции сглаживания заключается в уменьшении нежелательной вариации оценок значений , которая может произойти на практике, например, если направления звука и/или , оцененные в Блоке (102), являются шумовыми. Сглаживание, применяемое к , может выполняться, например, по времени и/или частоте. Например, временное сглаживание может быть достигнуто с использованием хорошо известного рекурсивного фильтра усреднения
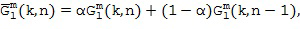
где 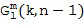 – функция отклика, вычисленная в предыдущем временном интервале. Кроме того,
– функция отклика, вычисленная в предыдущем временном интервале. Кроме того, 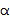 представляет собой вещественнозначное число между 0 и 1, которое контролирует эффективность временного сглаживания. Для значений , находящихся близко к 0, выполняется сильное временное усреднение, в то время как для значений , находящихся близко к 1, выполняется короткое временное усреднение. В практическом применении значение зависит от применения, и его можно установить таким образом, чтобы оно было постоянным, например,
представляет собой вещественнозначное число между 0 и 1, которое контролирует эффективность временного сглаживания. Для значений , находящихся близко к 0, выполняется сильное временное усреднение, в то время как для значений , находящихся близко к 1, выполняется короткое временное усреднение. В практическом применении значение зависит от применения, и его можно установить таким образом, чтобы оно было постоянным, например, 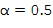 . В альтернативном варианте осуществления настоящего изобретения спектральное сглаживание может быть выполнено также в Блоке (111), что означает, что отклик усредняется по множеству полос частот. Такое спектральное сглаживание, например, в пределах так называемых ERB (Equivalent rectangular bandwidth – эквивалентный рекурсивный диапазон частот) полос, описано, например, в [ERBsmooth].
. В альтернативном варианте осуществления настоящего изобретения спектральное сглаживание может быть выполнено также в Блоке (111), что означает, что отклик усредняется по множеству полос частот. Такое спектральное сглаживание, например, в пределах так называемых ERB (Equivalent rectangular bandwidth – эквивалентный рекурсивный диапазон частот) полос, описано, например, в [ERBsmooth].
В этом варианте осуществления настоящего изобретения опорный микрофонный сигнал окончательно объединяется, например, путем умножения 115 на время и частоту, со сглаженным откликом пространственной базисной функции, определенной в Блоке (111), что приводит к желаемому компоненту системы Амбисоник порядка (уровня) и моды для частотно-временной плитки . Полученные в результате компоненты системы Амбисоник , в конечном итоге, могут быть преобразованы обратно во временную область с использованием обратного фильтр-банка или обратного STFT, сохранены, переданы или использованы, например, для применений пространственного воспроизведения звука. На практике можно вычислить компоненты системы Амбисоник для всех желаемых порядков и мод, чтобы получить желаемый сигнал системы Амбисоник желаемого высшего порядка (уровня).
Ясно, что усиление сглаживания в Блоке (111) может применяться также во всех вариантах осуществления настоящего изобретения.
Вариант 8 осуществления настоящего изобретения
Настоящее изобретение также может быть применено в так называемом многоволновом случае, где рассматривается более одного направления звука на частотно-временную плитку. Например, Вариант 2 осуществления настоящего изобретения, показанный на Фигуре 3b, может быть реализован в многоволновом случае. В этом случае Блок (102) оценивает 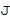 направления звука по времени и частоте, где представляет собой целое значение, которое больше одного, например,
направления звука по времени и частоте, где представляет собой целое значение, которое больше одного, например, 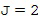 . Чтобы оценить множественные направления звука, можно использовать оценки существующего уровня техники, например, ESPRIT или Root MUSIC, которые описаны в [ESPRIT, RootMUSIC1]. В этом случае выходные данные Блока (102) представляет собой множественные направления звука, указанные, например, в форме множественных азимутальных углов
. Чтобы оценить множественные направления звука, можно использовать оценки существующего уровня техники, например, ESPRIT или Root MUSIC, которые описаны в [ESPRIT, RootMUSIC1]. В этом случае выходные данные Блока (102) представляет собой множественные направления звука, указанные, например, в форме множественных азимутальных углов 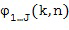 и/или углов возвышения
и/или углов возвышения 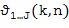 .
.
Множественные направления звука затем используются в Блоке (103) для вычисления множественных откликов 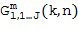 , по одному отклику для каждого оцененного направления звука, как описано, например, в Варианте 1 осуществления настоящего изобретения. Кроме того, множественные направления звука, рассчитанные в Блоке (102), используются в Блоке (104) для расчета множественных опорных сигналов
, по одному отклику для каждого оцененного направления звука, как описано, например, в Варианте 1 осуществления настоящего изобретения. Кроме того, множественные направления звука, рассчитанные в Блоке (102), используются в Блоке (104) для расчета множественных опорных сигналов 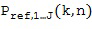 , по одному для каждого из множественных направлений звука. Каждый из множественных опорных сигналов может быть рассчитан, например, путем применения многоканальных фильтров
, по одному для каждого из множественных направлений звука. Каждый из множественных опорных сигналов может быть рассчитан, например, путем применения многоканальных фильтров 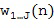 ко множественным микрофонным сигналам, аналогично тому, как описано в Варианте 2 осуществления настоящего изобретения. Например, первый опорный сигнал
ко множественным микрофонным сигналам, аналогично тому, как описано в Варианте 2 осуществления настоящего изобретения. Например, первый опорный сигнал 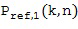 может быть получен путем применения многоканального фильтра
может быть получен путем применения многоканального фильтра 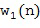 существующего уровня техники, который будет извлекать звуки из направления
существующего уровня техники, который будет извлекать звуки из направления 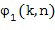 и/или
и/или 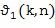 при ослаблении звуков из всех других направлений звука. Такой фильтр можно вычислить, например, как информационный фильтр LCMV (linearly constrained minimum variance – линейно ограниченная минимальная дисперсия), который поясняется в [InformedSF]. Множественные опорные сигналы затем умножают на соответствующие множественные отклики , чтобы получить множественные компоненты системы Амбисоник
при ослаблении звуков из всех других направлений звука. Такой фильтр можно вычислить, например, как информационный фильтр LCMV (linearly constrained minimum variance – линейно ограниченная минимальная дисперсия), который поясняется в [InformedSF]. Множественные опорные сигналы затем умножают на соответствующие множественные отклики , чтобы получить множественные компоненты системы Амбисоник 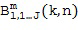 , например, -й компонент системы Амбисоник, соответствующий
, например, -й компонент системы Амбисоник, соответствующий  -му направление звука, и опорный сигнал, соответственно, рассчитывается как
-му направление звука, и опорный сигнал, соответственно, рассчитывается как

Наконец, компоненты системы Амбисоник суммируются для получения конечного желаемого компонента системы Амбисоник порядка (уровня) и моды для временной плитки , то есть,
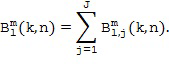
Ясно, что другие вышеупомянутые варианты осуществления настоящего изобретения могут распространяться и на многоволновой случай. Например, в Варианте 5 осуществления настоящего изобретения и в Варианте 6 осуществления настоящего изобретения мы можем рассчитать множественные прямые звуки 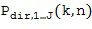 , по одному для каждого из множественных направлений звука, с использованием одних и тех же многоканальных фильтров, которые упомянуты в этом варианте осуществления настоящего изобретения. Затем множественные прямые звуки умножаются на соответствующие множественные отклики , приводящие ко множественным компонентам прямого звука системы Амбисоник
, по одному для каждого из множественных направлений звука, с использованием одних и тех же многоканальных фильтров, которые упомянуты в этом варианте осуществления настоящего изобретения. Затем множественные прямые звуки умножаются на соответствующие множественные отклики , приводящие ко множественным компонентам прямого звука системы Амбисоник 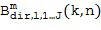 , которые можно суммировать для получения конечного желаемого компонента прямого звука системы Амбисоник .
, которые можно суммировать для получения конечного желаемого компонента прямого звука системы Амбисоник .
Следует отметить, что настоящее изобретение может быть применено не только к двухмерным (цилиндрическим) или трехмерным (сферическим) способам системы Амбисоник, но также и к любым другим способам, основанным на пространственных базисных функциях для расчета любых компонентов звукового поля.
Варианты осуществления настоящего изобретения списком
1.Преобразование множественных микрофонных сигналов в частотно-временную область.
2.Расчет, по меньшей мере, одного направления звука по времени и частоте из множественных микрофонных сигналов.
3.Вычисление для каждого времени и частоты, по меньшей мере, одной функции отклика, в зависимости от, по меньшей мере, одного направления звука.
4.Получение для каждого времени и частоты, по меньшей мере, одного опорного микрофонного сигнала.
5.Для каждого времени и частоты умножение, по меньшей мере, одного опорного микрофонного сигнала на, по меньшей мере, одну функцию отклика, чтобы получить, по меньшей мере, один компонент системы Амбисоник желаемого порядка и моды.
6.Если множественные компоненты системы Амбисоник были получены для желаемого порядка и моды, суммирование соответствующих компонентов системы Амбисоник для того, чтобы получить конечный желаемый компонент системы Амбисоник.
4.В некоторых Вариантах осуществления настоящего изобретения вычисление на Этапе 4, по меньшей мере, одного прямого звука и диффузного звука из множественных микрофонных сигналов вместо, по меньшей мере, одного опорного микрофонного сигнала.
5.Умножение, по меньшей мере, одного прямого звука и диффузного звука на, по меньшей мере, один соответствующий ответ прямого звука и ответ диффузного звука для получения, по меньшей мере, одного компонента прямого звука системы Амбисоник и компонента диффузного звука системы Амбисоник для желаемого порядка и моды.
6.Компоненты диффузного звука системы Амбисоник могут быть дополнительно декоррелированы для различных порядков и мод.
7.Суммирование компонентов прямого звука системы Амбисоник и компонентов диффузного звука системы Амбисоник для получения конечного желаемого компонента системы Амбисоник желаемого порядка и моды.
Ссылки
[Ambisonics] Р. К. Furness, “Ambisonics - An overview,” in AES 8th International Conference, April 1990, pp. 181–189.
[Ambix] C. Nachbar, F. Zotter, E. Deleflie, and A. Sontacchi, "AMBIX - A Suggested Ambisonics Format", Proceedings of the Ambisonics Symposium 2011.
[ArrayDesign] M. Williams and G. Le Du, “Multichannel Microphone Array Design,” in Audio Engineering Society Convention 108, 2008.
[CovRender] J. Vilkamo and V. Pulkki, "Minimization of Decorrelator Artifacts in Directional Audio Coding by Covariance Domain Rendering ", J. Audio Eng. SoC, vol. 61, no. 9, 2013.
[DiffuseBF] O. Thiergart and E. A. P. Habets, "Extracting Reverberant Sound Using a Linearly Constrained Minimum Variance Spatial Filter," IEEE Signal Processing Letters, vol. 21, no. 5, May 2014.
[DirAC] V. Pulkki, ''Directional audio coding in spatial sound reproduction and stereo upmixing,'' in Proceedings of The AES 28th International Conference, pp. 251-258, June, 2006.
[EigenMike] J. Meyer and T. Agnello, “Spherical microphone array for spatial sound recording,” in Audio Engineering Society Convention 115, October 2003
[ERBsmooth] A. Favrot and C. Faller, "Perceptually Motivated Gain Filter Smoothing for Noise Suppression", Audio Engineering Society Convention 123, 2007.
[ESPRIT] R. Roy, A. Paulraj, and T. Kailath, “Direction-of-arrival estimation by subspace rotation methods – ESPRIT,” in IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Stanford, CA, USA, April, 1986.
[FourierAcoust] E. G. Williams, “Fourier Acoustics: Sound Radiation and Nearfield Acoustical Holography," Academic Press, 1999.
[HARPEX] S. Berge and N. Barrett, "High Angular Resolution Planewave Expansion,'' in 2nd International Symposium on Ambisonics and Spherical Acoustics, May, 2010.
[InformedSF] O. Thiergart, G. Del Galdo, м. Taseska и е. а. P. Habets, "An Informed Parametric Spatial Filter Based on Instantaneous Direction-of-Arrival Estimates," IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 22, no. 12, December 2014.
[MicSetup3D] H. Lee and C. Gribben, “On the optimum microphone array configuration for height channels,” in 134 AES Convention, Rome, 2013.
[MUSIC] R. Schmidt, “Multiple emitter location and signal parameter estimation,” IEEE Transactions on Antennas and Propagation, vol. 34, no. 3, pp. 276–280, 1986.
[OptArrayPr] B. D. Van Veen and K. M. Buckley, "Beamforming: A versatile approach to spatial filtering", IEEE ASSP Magazine, vol. 5, no. 2, 1988.
[RootMUSIC1] B. Raoand and K .Hari, “Performance analysis of root-MUSIC,” in Signals, Systems and Computers, 1988. Twenty-Second Asilomar Conference on, vol. 2, 1988, pp. 578–582.
[RootMUSIC2] A. Mhamdi and A. Samet, “Direction of arrival estimation for nonuniform linear antenna,” in Communications, Computing and Control Applications (CCCA), 2011 International Conference on, March 2011, pp. 1–5.
[RootMUSIC3] M. Zoltowski and C. P. Mathews, “Direction finding with uniform circular arrays via phase mode excitation and beamspace root-MUSIC,” in Acoustics, Speech, and Signal Processing, 1992. ICASSP-92., 1992 IEEE International Conference on, vol. 5, 1992, pp. 245–248.
[SDRestim] O. Thiergart, G. Del Galdo, and E A. P. Habets, "On the spatial coherence in mixed sound fields and its application to signal-to-diffuse ratio estimation", The Journal of the Acoustical Society of America, vol. 132, no. 4, 2012.
[SourceNum] J.-S. Jiang and M.-A. Ingram, “Robust detection of number of sources using the transformed rotational matrix,” in Wireless Communications and Networking Conference, 2004. WCNC. 2004 IEEE, vol. 1, March, 2004.
[SpCoherence] D. P. Jarrett, O. Thiergart, E. A. P. Habets, and P. A. Naylor, “Coherence-Based Diffuseness Estimation in the Spherical Harmonic Domain,” IEEE 27th Convention of Electrical and Electronics Engineers in Israel (IEEEI), 2012.
[SphHarm] F. Zotter, "Analysis and Synthesis of Sound-Radiation with Spherical Arrays", PhD thesis, University of Music and Performing Arts Graz, 2009.
[VirtualMic] O. Thiergart, G. Del Galdo, M. Taseska, and E. A. P. Habets, "Geometry-based Spatial Sound Acquisition Using Distributed Microphone Arrays," IEEE Transactions on in Audio, Speech, and Language Processing, vol. 21, no. 12, De
Хотя некоторые аспекты были описаны в контексте устройства, очевидно, что эти аспекты также представляют собой описание соответствующего способа, где блок или устройство соответствуют этапу способа или характерной черте этапа способа. Аналогичным образом, аспекты, описанные в контексте этапа способа, также представляют собой описание соответствующего блока или элемента, или характерной черты соответствующего устройства.
Сигнал по настоящему изобретению может быть сохранен на цифровом носителе данных, или он может передаваться посредством передающей среды, такой как беспроводная передающая среда или проводная передающая среда, например, Интернет.
В зависимости от определенных требований реализации варианты осуществления настоящего изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может быть выполнена с использованием цифрового носителя данных, например гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или ФЛЭШ-памяти, имеющих электронно-считываемые управляющие сигналы, хранящиеся на них, которые взаимодействуют (или могут взаимодействовать) с программируемой компьютерной системой, в результате чего выполняется соответствующий способ.
Некоторые варианты осуществления настоящего изобретения содержат энергонезависимый носитель данных, имеющий электронно-считываемые управляющие сигналы, которые способны взаимодействовать с программируемой компьютерной системой, в результате чего выполняется один из способов, описанных в настоящем документе.
Как правило, варианты осуществления настоящего изобретения могут быть реализованы как продукт компьютерной программы с программным кодом, причем программный код работает для выполнения одного из способов, когда продукт компьютерной программы работает на компьютере. Например, программный код может храниться на машиночитаемом носителе информации.
Другие варианты осуществления настоящего изобретения содержат машиночитаемый носитель информации, на который записана программа для выполнения одного из способов, описанных в настоящем документе, хранящуюся на машиночитаемом носителе.
Другими словами, вариант осуществления способа по настоящему изобретению представляет собой, следовательно, компьютерную программу, имеющую программный код для выполнения одного из описанных в настоящем документе способов, когда компьютерная программа работает на компьютере.
Таким образом, дополнительным вариантом осуществления способов по настоящему изобретению является носитель данных (или цифровой носитель данных, или машиночитаемый носитель данных), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
Таким образом, дополнительным вариантом осуществления способа по настоящему изобретению является поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Поток данных или последовательность сигналов, например, могут быть выполнены с возможностью передачи посредством коммуникационного соединения передачи данных, например, посредством Интернета.
Дополнительный вариант осуществления настоящего изобретения содержит средство обработки, например компьютер, или программируемое логическое устройство, выполненное с возможностью или адаптированное для выполнения одного из способов, описанных в настоящем документе.
Дополнительный вариант осуществления настоящего изобретения содержит компьютер, на котором установлена компьютерная программа для выполнения одного из способов, описанных в настоящем документе.
В некоторых вариантах осуществления настоящего изобретения программируемое логическое устройство (например, программируемая пользователем матрица логических элементов) может использоваться для выполнения некоторых или всех функциональных возможностей способов, описанных в настоящем документе. В некоторых вариантах осуществления настоящего изобретения программируемая пользователем матрица логических элементов может взаимодействовать с микропроцессором для выполнения одного из способов, описанных настоящем документе. Как правило, в предпочтительном варианте осуществления настоящего изобретения способы выполняются любым устройством.
Вышеописанные варианты осуществления настоящего изобретения носят лишь иллюстративный характер в отношении принципов настоящего изобретения. Понятно, что модификации и варианты компоновки и детали, описанные в настоящем документе, будут очевидны для специалистов в данной области техники. Таким образом, целью является ограничение только объема готовящейся патентной формулы изобретения, а не конкретных деталей, представленных путем описания и объяснения вариантов осуществления настоящего изобретения в настоящем документе.
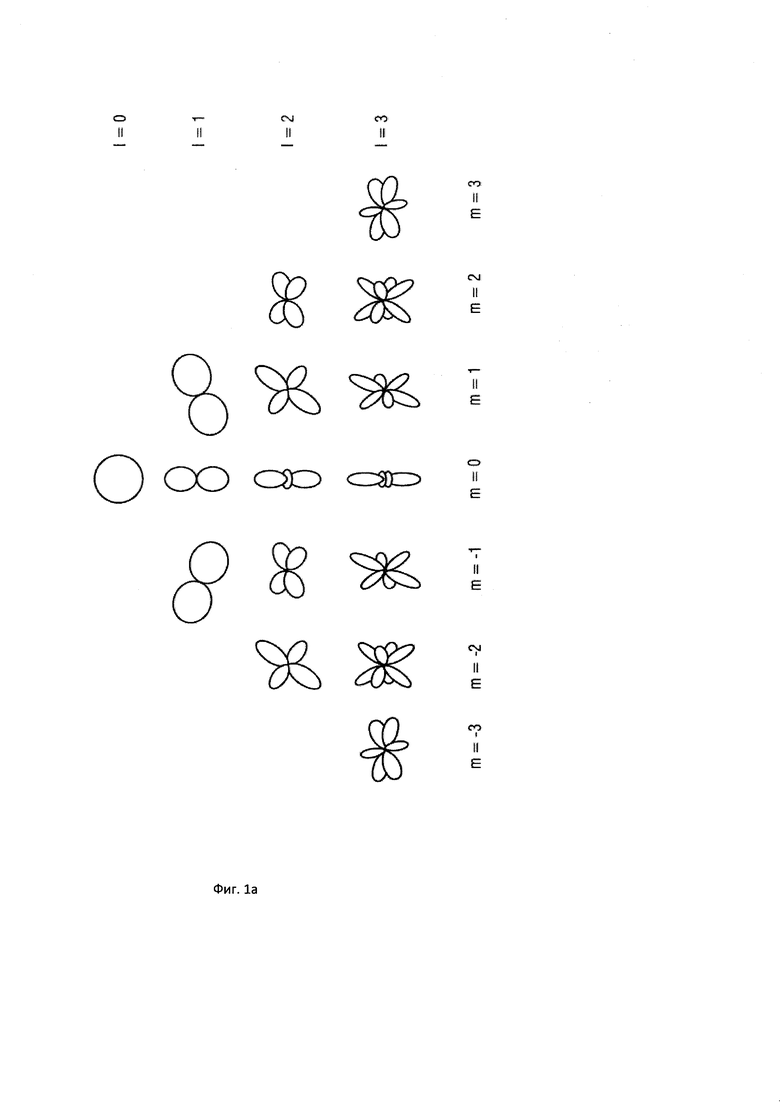
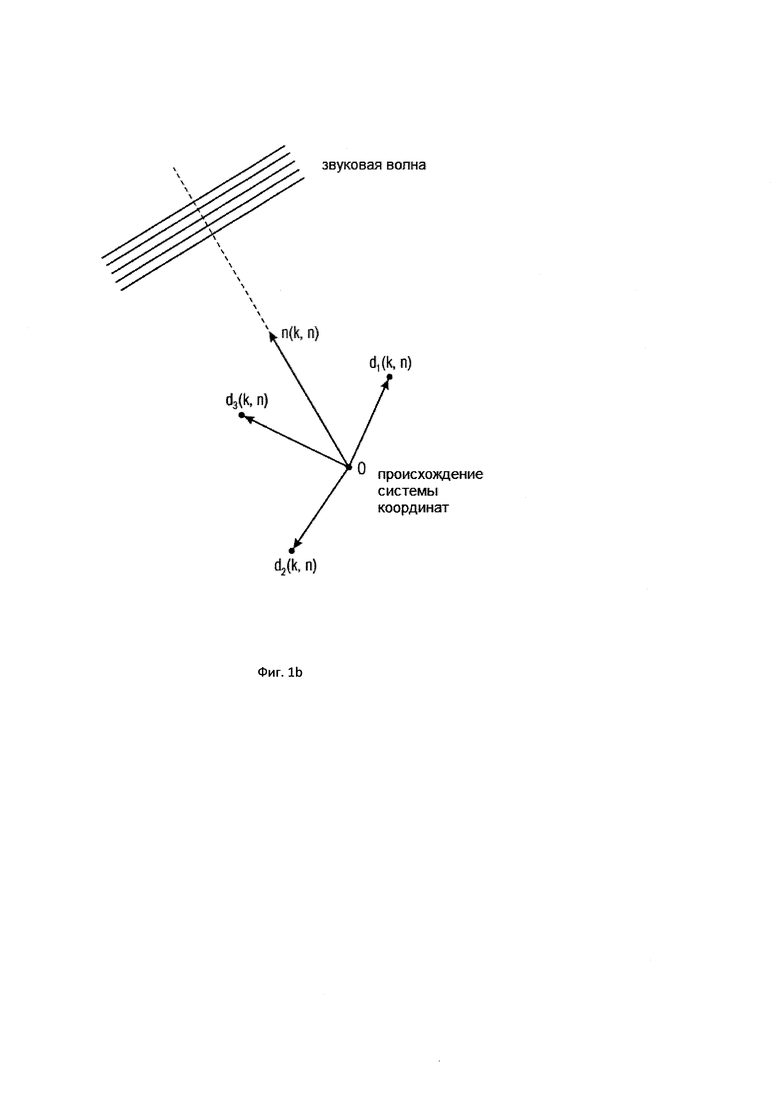
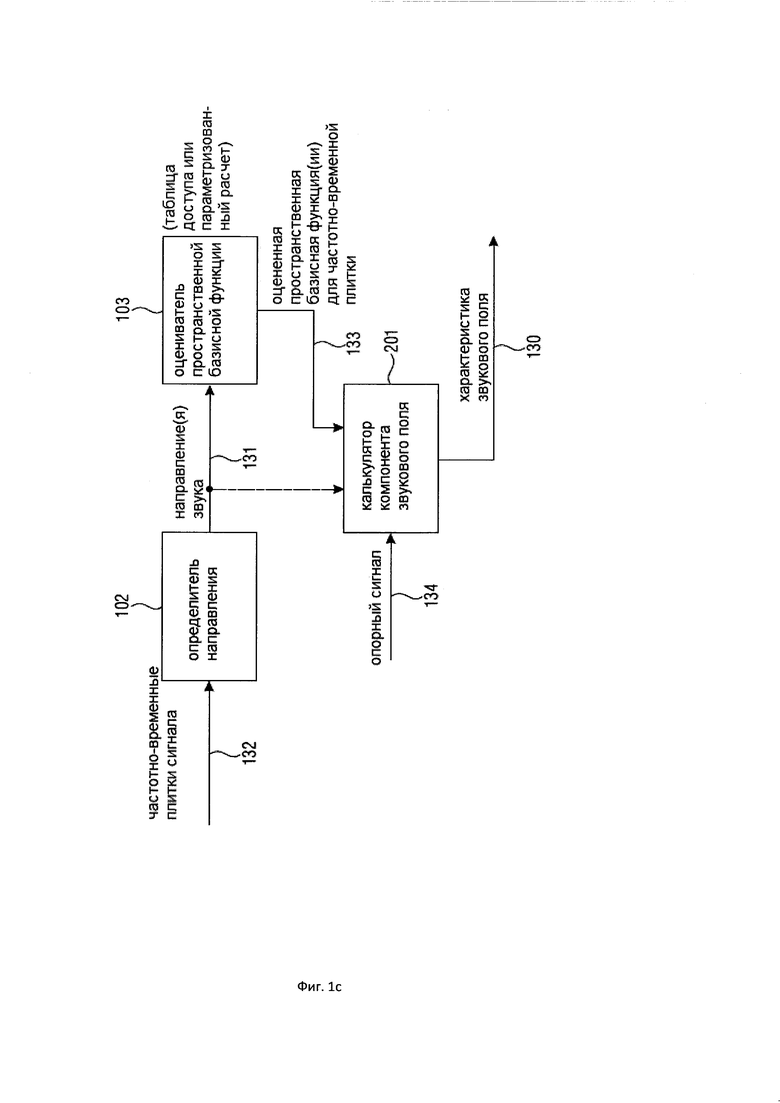
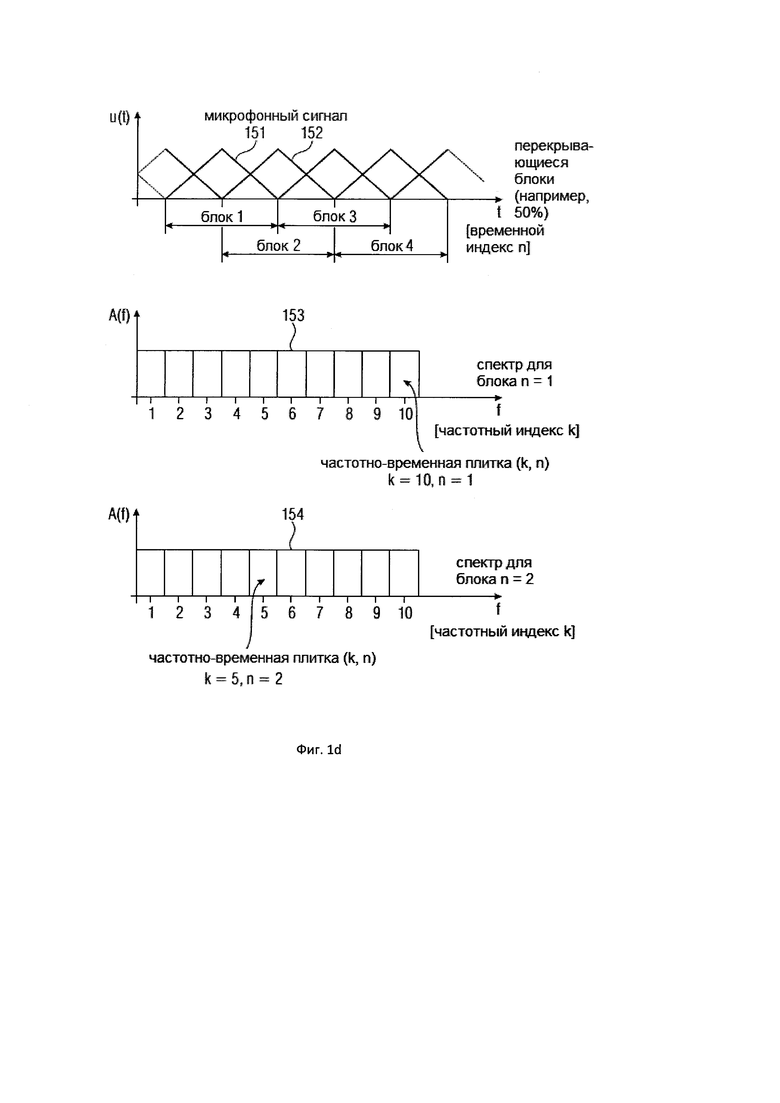

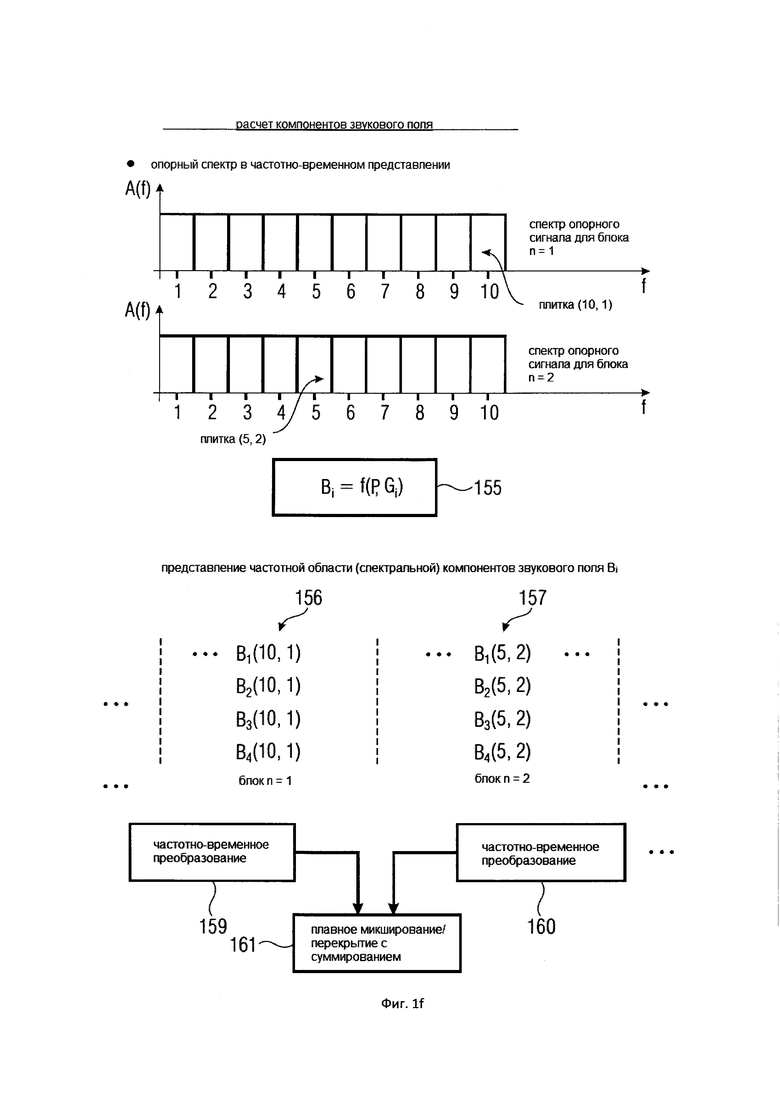
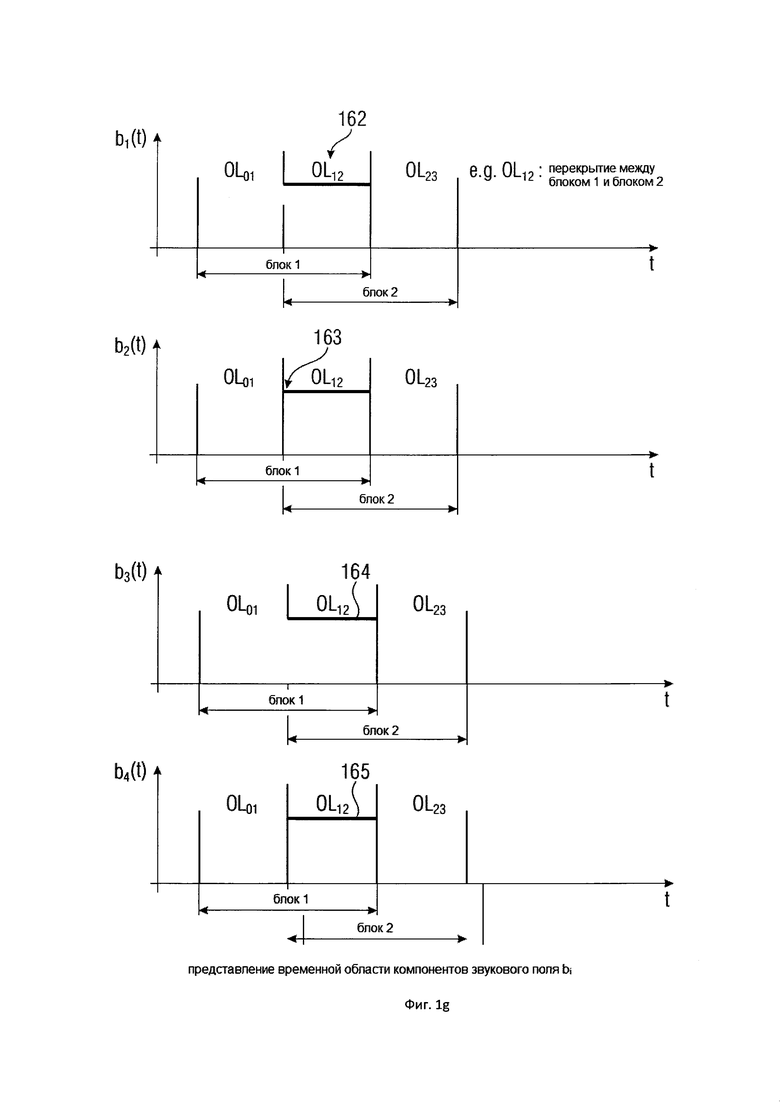
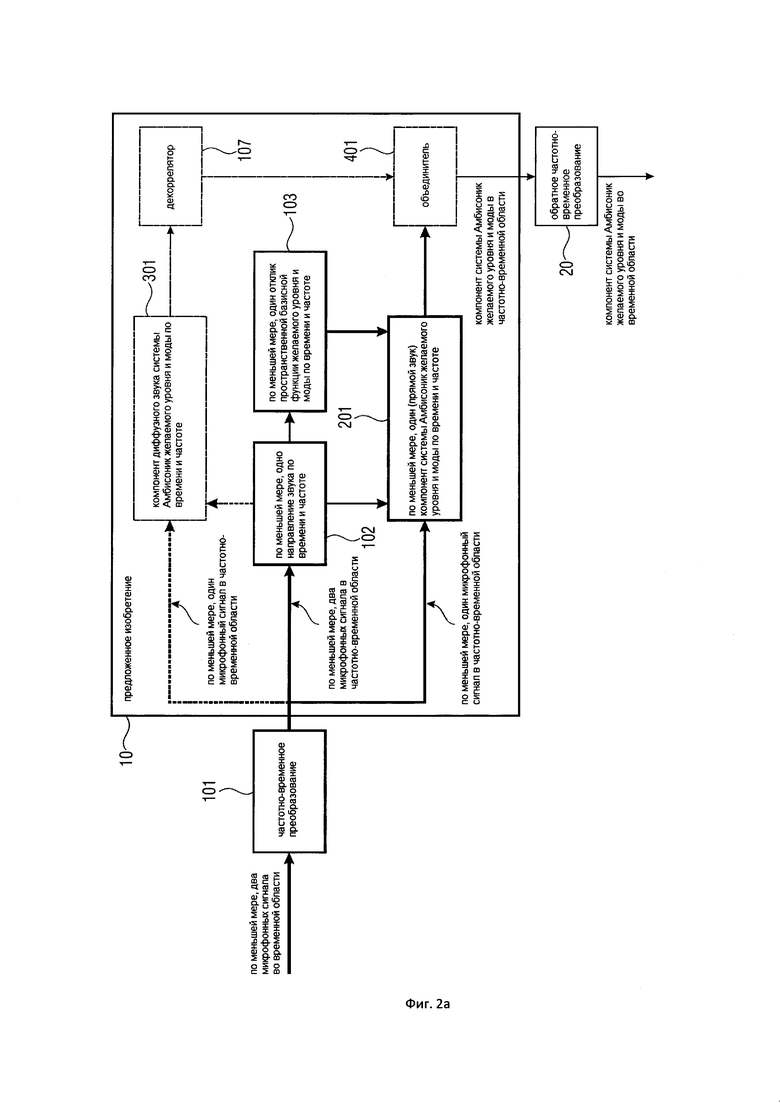
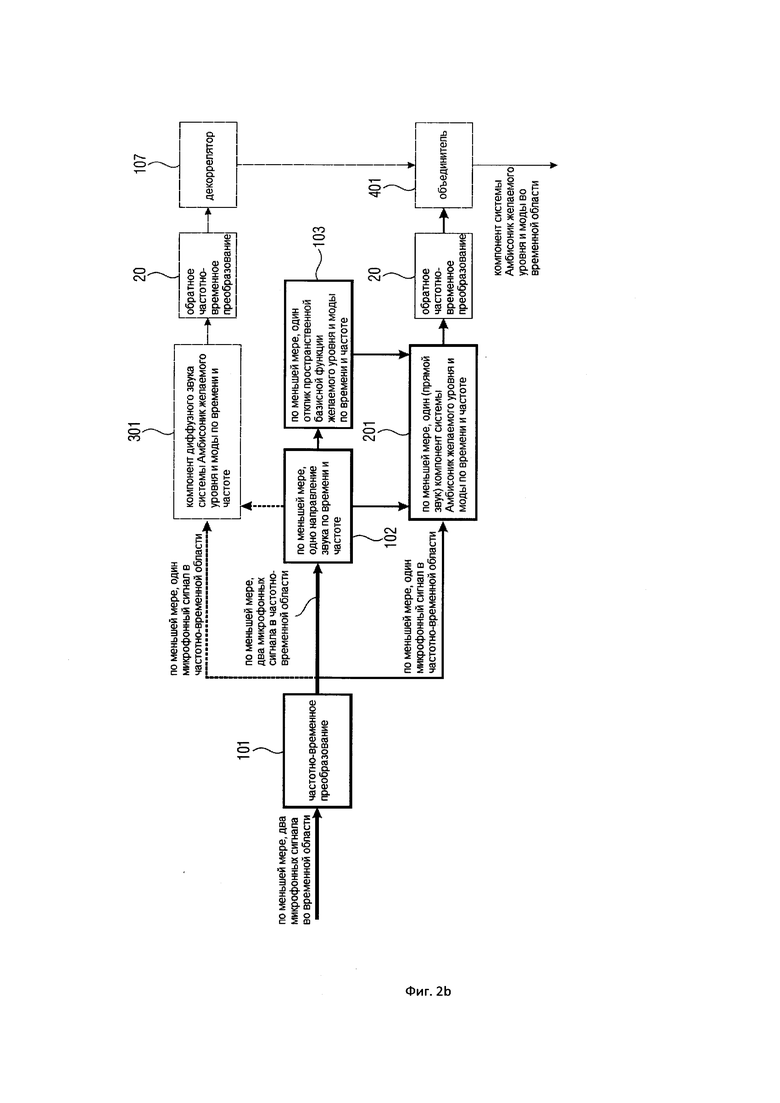
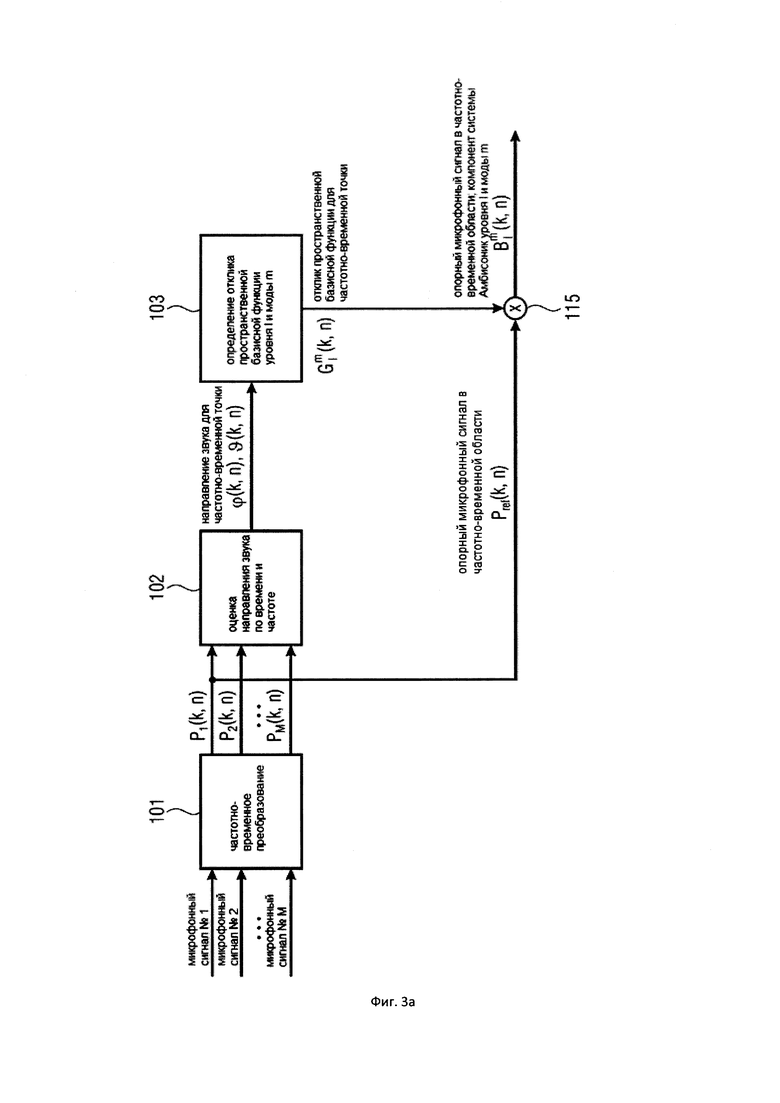
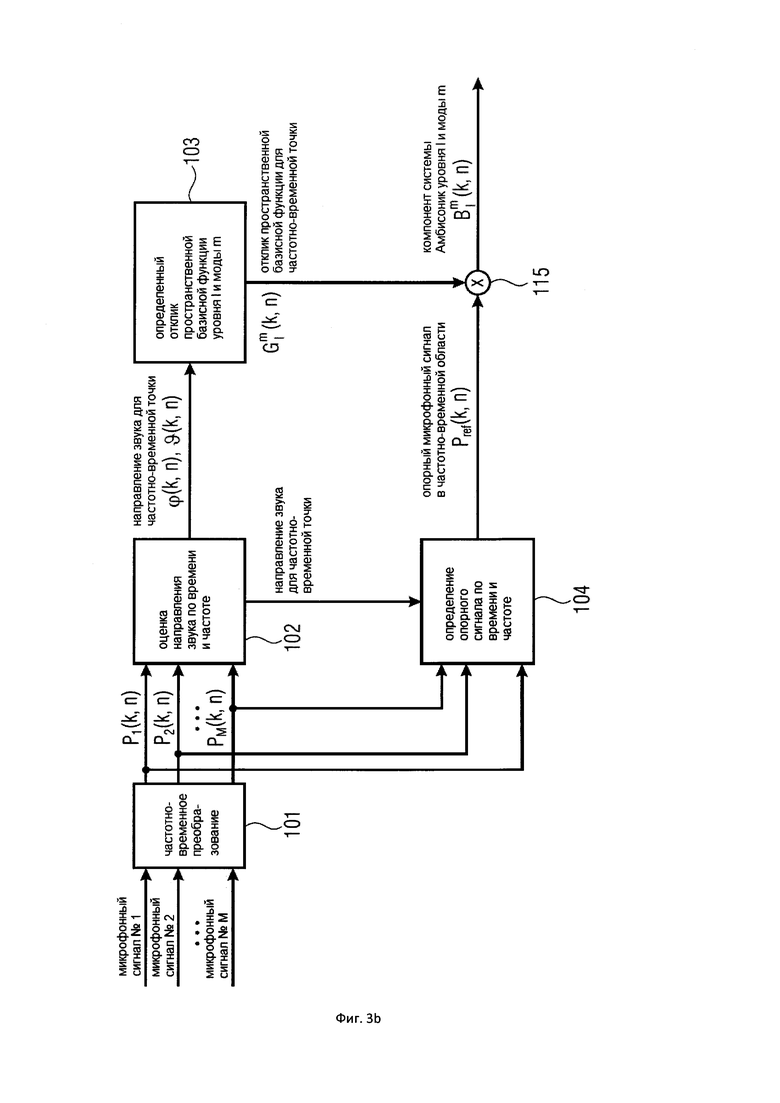
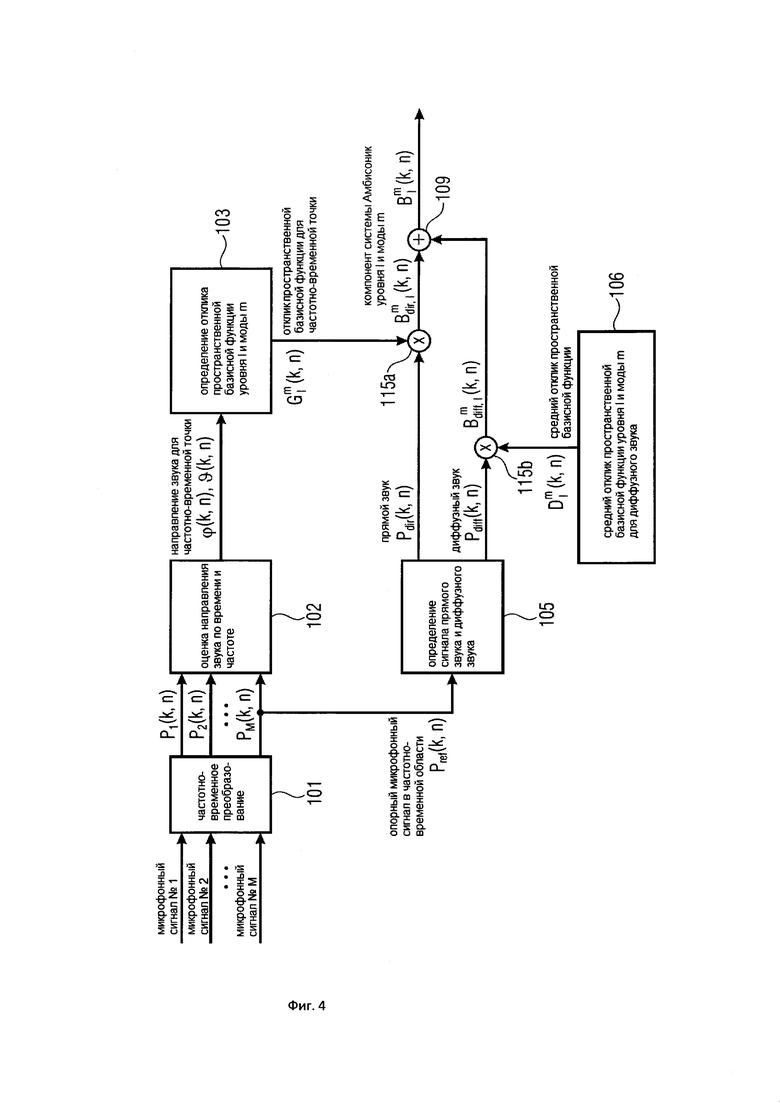
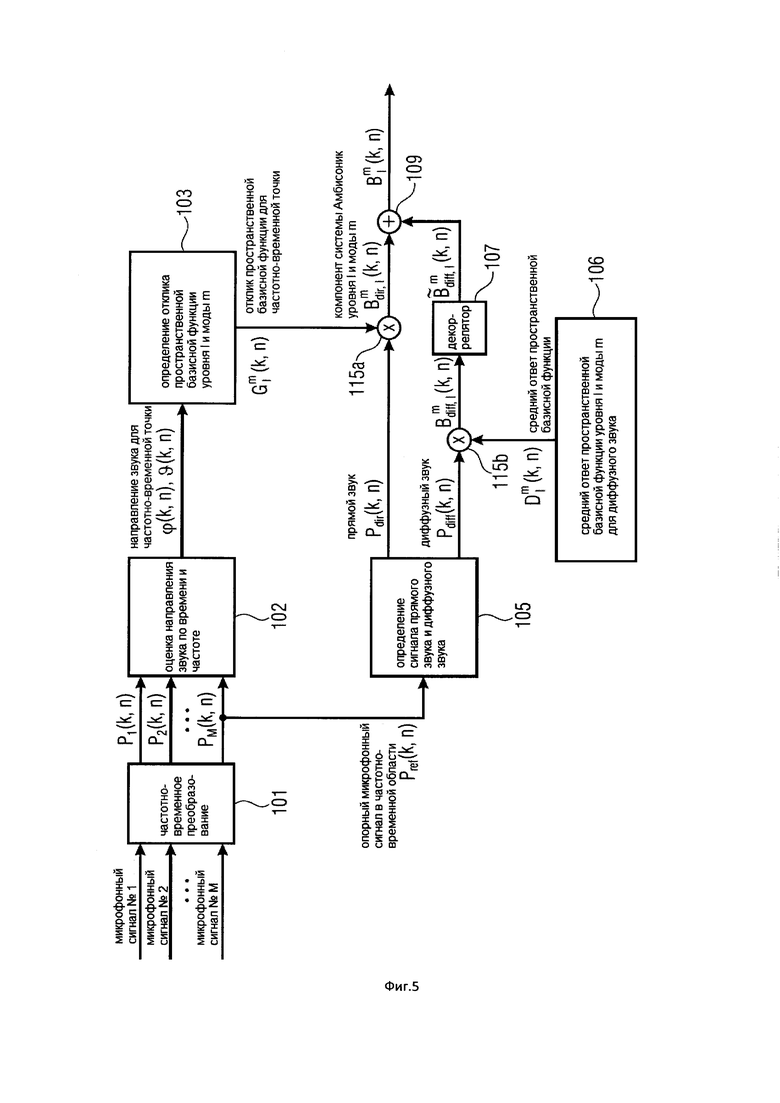
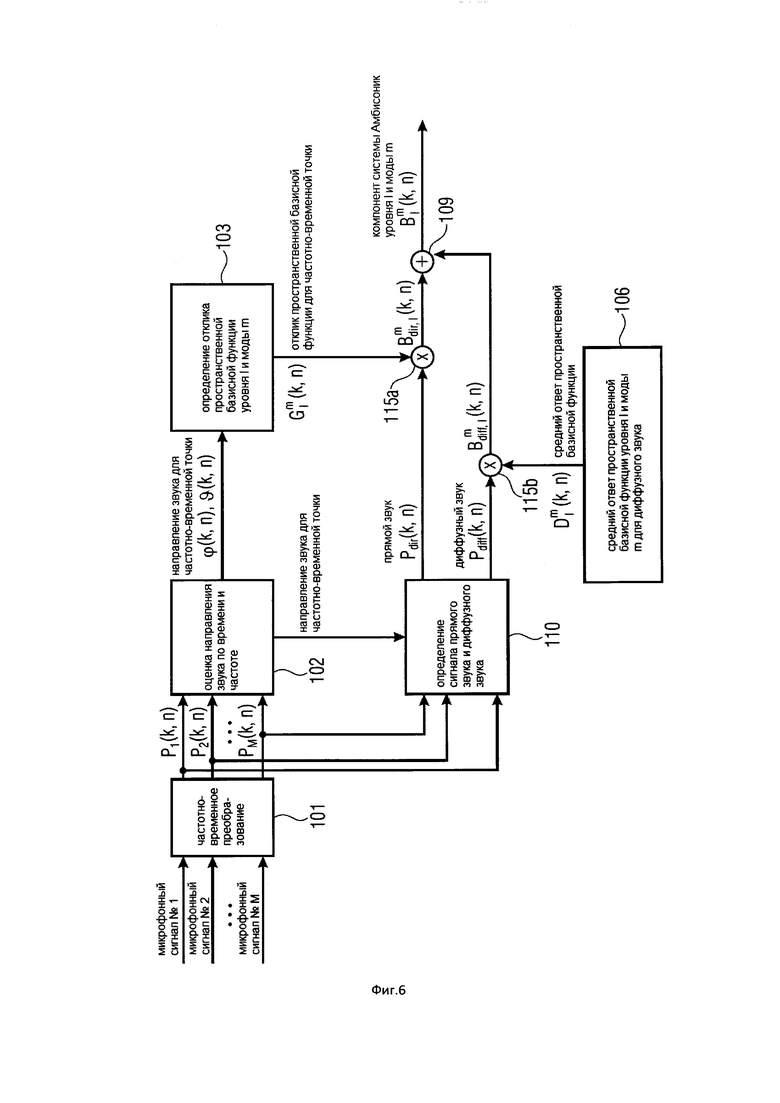
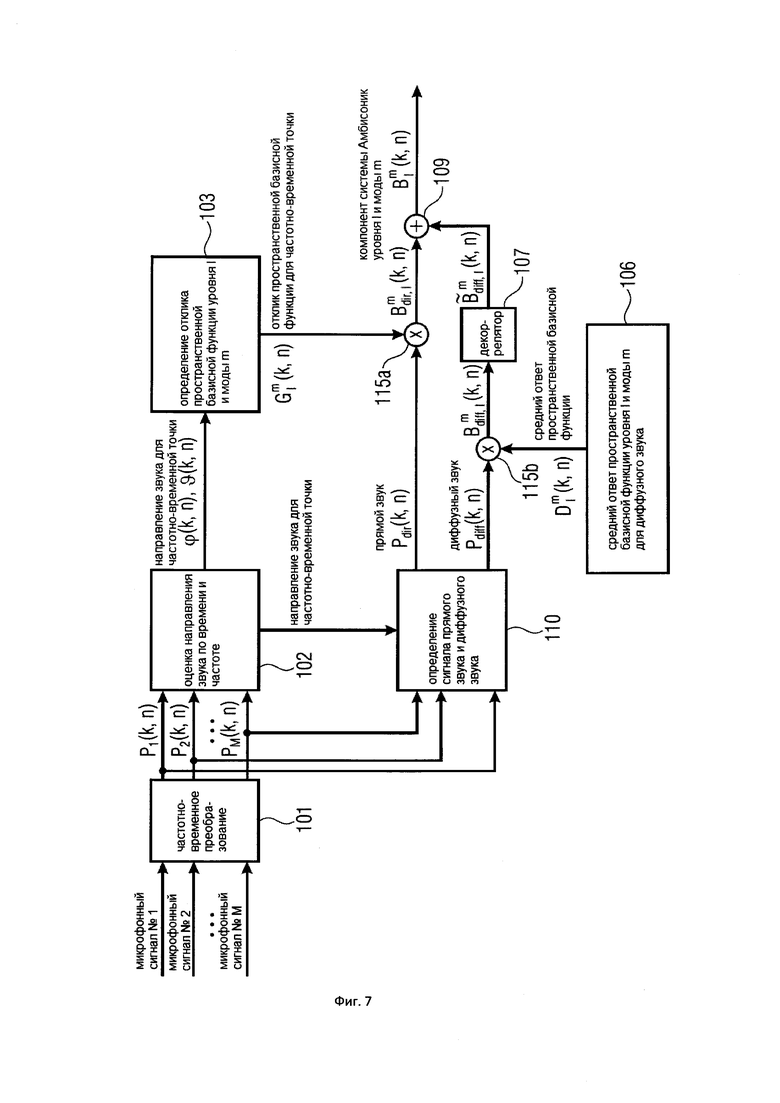
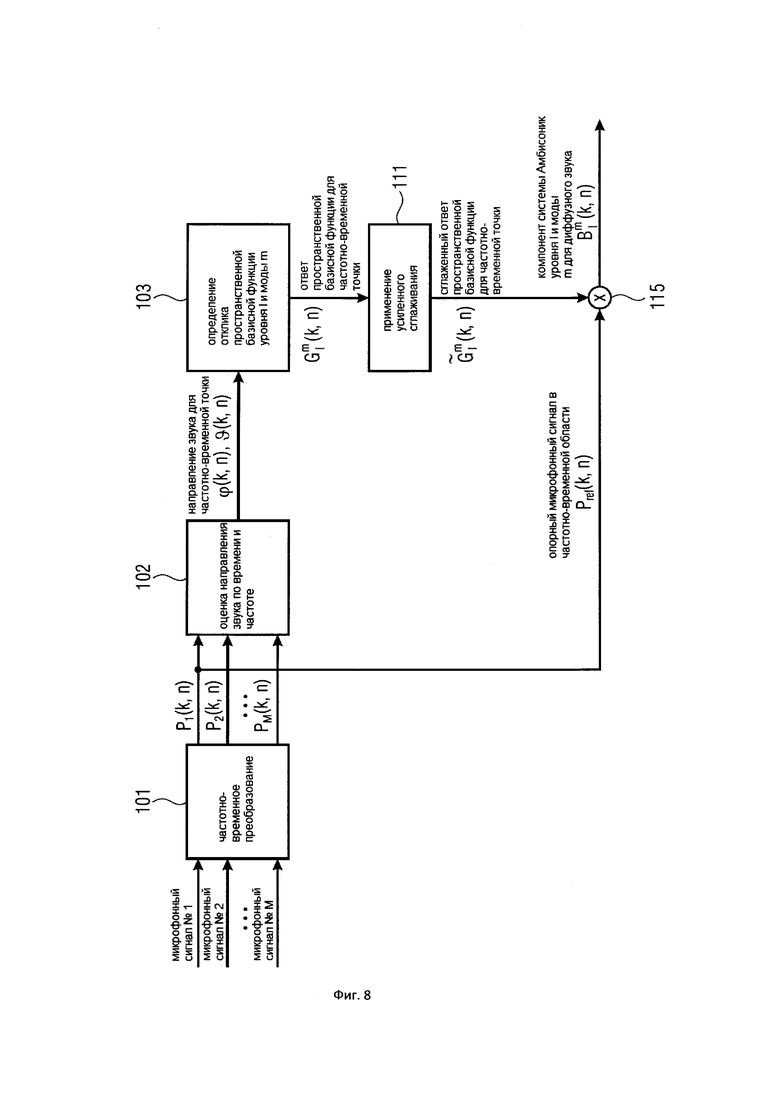
Изобретение относится к акустике, в частности к устройствам формирования звукового поля. Устройство содержит блок оценки направления на источник звука, блок вычисления базисной функции, блок формирования компонент звукового поля. Блок формирования компонент звукового поля вычисляет соответствующие компоненты на основе базисной функции, информации о направлении на источник звука и опорного сигнала, принимаемого с микрофона. Также устройство содержит блок вычисления составляющих диффузного звукового поля, блок объединения, выполненный с возможностью объединения компонент прямого и диффузного звукового полей. Блок вычисления диффузного звукового поля выполнен на основе декоррелятора звуковых сигналов. Также устройство содержит блок частотно-временного преобразования. Базисная функция вычисляется на основе азимута и угла возвышения. Технический результат – усовершенствование концепции формирования характеристик звукового поля. 3 н. и 21 з.п. ф-лы, 16 ил.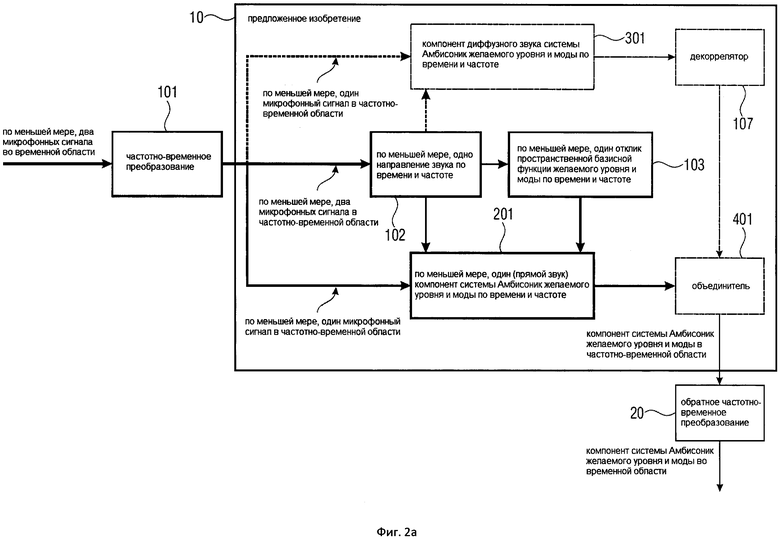
1. Устройство формирования характеристики звукового поля, имеющей представление компонентов звукового поля, включающее:
определитель направления (102), выполненный с возможностью определения, по меньшей мере, одного направления звука для каждой частотно-временной плитки из группы частотно-временных плиток группы микрофонных сигналов;
оцениватель пространственной базисной функции (103), выполненный с возможностью оценки для каждой частотно-временной плитки из группы частотно-временных плиток, по меньшей мере, одной пространственной базисной функции с использованием, по меньшей мере, одного направления звука;
калькулятор компонента звукового поля (201), выполненный с возможностью расчета для каждой частотно-временной плитки из группы частотно-временных плиток, по меньшей мере, одного компонента звукового поля, соответствующего, по меньшей мере, одной пространственной базисной функции, с использованием, по меньшей мере, одной пространственной базисной функции, оцененной с использованием, по меньшей мере, одного направления звука, и с использованием опорного сигнала для соответствующей частотно-временной плитки, при этом опорный сигнал выводится из, по меньшей мере, одного микрофонного сигнала из группы микрофонных сигналов.
2. Устройство по п. 1, дополнительно включающее:
калькулятор диффузного компонента (301), выполненный с возможностью расчета для каждой частотно-временной плитки из группы частотно-временных плиток, по меньшей мере, одного компонента диффузного звука; и
объединитель (401), выполненный с возможностью объединения информации диффузного звука и информации прямого звукового поля для получения представления в частотной области или во временной области компонентов звукового поля.
3. Устройство по п. 2, отличающееся тем, что калькулятор диффузного компонента (301) дополнительно содержит декоррелятор (107), выполненный с возможностью декоррелирования информации диффузного звука.
4. Устройство по п. 1, дополнительно включающее частотно-временной преобразователь (101), выполненный с возможностью преобразования каждого из группы микрофонных сигналов временной области в частотное представление, имеющее группу частотно-временных плиток.
5. Устройство по п. 1, дополнительно включающее частотно-временной преобразователь (20), выполненный с возможностью преобразования, по меньшей мере, одного компонента звукового поля или объединения, по меньшей мере, одного компонента звукового поля и компонента диффузного звука в представление во временной области компонентов звукового поля.
6. Устройство по п. 5, отличающееся тем, что частотно-временной преобразователь (20) выполнен с возможностью обработки, по меньшей мере, одного компонента звукового поля для получения группы компонентов звукового поля во временной области и обработки компонентов диффузного звука для получения группы компонентов диффузного звука во временной области, при этом объединитель (401) выполнен с возможностью объединения компонентов звукового поля во временной области и диффузных компонентов во временной области во временную область; или
объединитель (401) выполнен с возможностью объединения, по меньшей мере, одного компонента звукового поля для частотно-временной плитки и компонентов диффузного звука для соответствующей частотно-временной плитки в пределах частотной области, и при этом частотно-временной преобразователь (20) выполнен с возможностью обработки результата объединителя (401) для получения компонентов звукового поля во временной области.
7. Устройство по п. 1, дополнительно включающее калькулятор опорного сигнала (104), выполненный с возможностью расчета опорного сигнала из группы микрофонных сигналов,
посредством, по меньшей мере, одного направления звука,
выбора конкретного микрофонного сигнала из группы микрофонных сигналов, основанного, по меньшей мере, на одном направлении звука, или
многоканального фильтра, примененного к, по меньшей мере, двум микрофонным сигналам, при этом многоканальный фильтр зависит от, по меньшей мере, одного направления звука и отдельных позиций микрофонов, из которых получают группу микрофонных сигналов.
8. Устройство по п. 1, отличающееся тем, что оцениватель пространственной базисной функции (103) выполнен с возможностью использования, для пространственной базисной функции, параметризованного представления, при этом параметром параметризованного представления является направление звука, и вставления параметра, соответствующего направлению звука, в параметризованное представление для получения результата оценки для каждой пространственной базисной функции; или
оцениватель пространственной базисной функции (103) выполнен с возможностью использования справочной таблицы для каждой пространственной базисной функции, имеющей, в качестве входных данных, идентификацию пространственной базисной функции и направление звука и имеющей, в качестве выходных данных, результат оценки, и при этом оцениватель пространственной базисной функции (103) выполнен с возможностью определения для, по меньшей мере, одного направления звука, определенного определителем направления, соответствующего направления звука по входным данным справочной таблицы или вычисления среднего взвешенного или невзвешенного между двумя входными данными справочной таблицы, которые находятся рядом с, по меньшей мере, одним направлением звука, определенным определителем направления; или
оцениватель пространственной базисной функции (103) выполнен с возможностью использования, для пространственной базисной функции, параметризованного представления, при этом параметром параметризованного представления является направление звука, при этом направление звука является одномерным, таким как азимутальный угол, в двухмерной ситуации или двухмерным, таким как азимутальный угол и угол возвышения, в трехмерной ситуации, и вставления параметра, соответствующего направлению звука, в параметризованное представление, чтобы получить результат оценки для каждой пространственной базисной функции.
9. Устройство по п. 1, дополнительно включающее: определитель прямого или диффузного звука (105), выполненный с возможностью определения прямой части или диффузной части группы микрофонных сигналов в качестве опорного сигнала,
при этом калькулятор компонента звукового поля (201) выполнен с возможностью использования прямой части только при расчете, по меньшей мере, одного компонента прямого звукового поля.
10. Устройство по п. 9, дополнительно включающее определитель среднего отклика базисной функции (106), выполненный с возможностью определения среднего отклика пространственной базисной функции, при этом определитель содержит способ расчета или способ доступа к справочной таблице; и
калькулятор компонента диффузного звука (301), выполненный с возможностью расчета, по меньшей мере, одного компонента диффузного звукового поля, используя только диффузную часть в качестве опорного сигнала вместе со средним откликом пространственной базисной функции.
11. Устройство по п. 10, дополнительно включающее объединитель (109, 401), выполненный с возможностью объединения компонента прямого звукового поля;
и компонент диффузного звукового поля, выполненный с возможностью получения компонента звукового поля.
12. Устройство по п. 9, отличающееся тем, что калькулятор компонента диффузного звука (301) выполнен с возможностью расчета компонентов диффузного звука до предопределенного первого номера или порядка, а
калькулятор компонента диффузного звука (201) выполнен с возможностью расчета компонентов прямого звукового поля до предопределенного второго номера или порядка,
при этом предопределенный второй номер или порядок больше, чем предопределенный первый номер или порядок, и
предопределенный первый номер или порядок равен 1 или больше 1.
13. Устройство по п. 10, отличающееся тем, что калькулятор компонента диффузного сигнала (105) содержит декоррелятор (107), выполненный с возможностью декоррелирования компонента диффузного звука до или после объединения со средним откликом пространственной базисной функции в представлении частотной области или в представлении временной области.
14. Устройство по п. 9, отличающееся тем, что определитель прямого или диффузного звука (105) выполнен с возможностью:
расчета прямой части и диффузной части из сигнала одного микрофона, а калькулятор компонента диффузного звука (301) выполнен с возможностью расчета, по меньшей мере, одного компонента диффузного звука с использованием диффузной части в качестве опорного сигнала, и при этом калькулятор компонента звукового поля (201) выполнен с возможностью расчета, по меньшей мере, одного компонента прямого звукового поля с использованием прямой части в качестве опорного сигнала; или
расчета диффузной части из микрофонного сигнала, отличного от микрофонного сигнала, из которого рассчитывается прямая часть, и при этом калькулятор компонента диффузного звука выполнен с возможностью расчета, по меньшей мере, одного компонента диффузного звука с использованием диффузной части в качестве опорного сигнала, и при этом калькулятор компонента звукового поля (201) выполнен с возможностью расчета, по меньшей мере, одного компонента прямого звукового поля с использованием прямой части в качестве опорного сигнала; или
расчета диффузной части для другой пространственной базисной функции с помощью другого микрофонного сигнала, и при этом калькулятор компонента диффузного звука (301) выполнен с возможностью использования первой диффузной части в качестве опорного сигнала для среднего отклика пространственной базисной функции, соответствующего первому номеру, и использования другой второй диффузной части в качестве опорного сигнала, соответствующего среднему отклику пространственной базисной функции со вторым номером, при этом первый номер отличается от второго номера, и при этом первый номер и второй номер указывают на заданный порядок или уровень и моду, по меньшей мере, одной пространственной базисной функции; или
расчета прямой части с использованием первого многоканального фильтра, применяемого к группе микрофонных сигналов, и расчета диффузной части с использованием второго многоканального фильтра, применяемого к группе микрофонных сигналов, при этом второй многоканальный фильтр отличается от первого многоканального фильтра, и при этом калькулятор компонента диффузного звука (301) выполнен с возможностью расчета, по меньшей мере, одного компонента диффузного звука с использованием диффузной части в качестве опорного сигнала, и при этом калькулятор компонента звукового поля (201) выполнен с возможностью расчета, по меньшей мере, одного компонента прямого звукового поля с использованием прямой части в качестве опорного сигнала; или
расчета диффузных частей для различных пространственных базисных функций с использованием различных многоканальных фильтров для различных пространственных базисных функций, и при этом калькулятор компонента диффузного звука (301) выполнен с возможностью расчета, по меньшей мере, одного компонента диффузного звука с использованием диффузной части в качестве опорного сигнала, и при этом калькулятор компонента звукового поля (201) выполнен с возможностью расчета, по меньшей мере, одного компонента прямого звукового поля с использованием прямой части в качестве опорного сигнала.
15. Устройство по п. 1, отличающееся тем, что оцениватель пространственной базисной функции (103) содержит сглаживатель (111), работающий во временном направлении или в частотном направлении для сглаживания результатов оценки, и
при этом калькулятор компонента звукового поля (201) выполнен с возможностью использования сглаженных результатов оценки при расчете, по меньшей мере, одного компонента звукового поля.
16. Устройство по п. 1, отличающееся тем, что оцениватель пространственной базисной функции (103) выполнен с возможностью расчета, для частотно-временной плитки, для каждого направления звука из, по меньшей мере, двух направлений звука, определяемых определителем направления, результата оценки, для каждой пространственной базисной функции из одной или более двух пространственных базисных функций,
при этом калькулятор опорного сигнала (104) выполнен с возможностью расчета, для каждого направления звука, отдельных опорных сигналов,
при этом калькулятор компонента звукового поля (103) выполнен с возможностью расчета компонента звукового поля для каждого направления с использованием результата оценки для направления звука и опорного сигнала для направления звука, и
при этом калькулятор компонента звукового поля выполнен с возможностью добавления компонентов звукового поля для различных направлений, рассчитанных с использованием пространственной базисной функции для получения компонента звукового поля для пространственной базисной функции в частотно-временной плитке.
17. Устройство по п. 1, отличающееся тем, что оцениватель пространственной базисной функции (103) выполнен с возможностью использования, по меньшей мере, одной пространственной базисной функции для системы Амбисоник в двухмерной или трехмерной ситуации.
18. Устройство по п. 17, отличающееся тем, что калькулятор пространственной базисной функции (103) выполнен с возможностью использования, по меньшей мере, пространственных базисных функций, по меньшей мере, двух уровней или порядков или, по меньшей мере, двух мод.
19. Устройство по п. 18, отличающееся тем, что калькулятор компонента звукового поля (201) выполнен с возможностью расчета компонента звукового поля для, по меньшей мере, двух уровней группы уровней, содержащего уровень 0, уровень 1, уровень 2, уровень 3, уровень 4, или
при этом калькулятор компонента звукового поля (201) выполнен с возможностью расчета компонентов звукового поля для, по меньшей мере, двух мод группы мод, содержащих моду -4, моду -3, моду -2, моду -1, моду 0, моду 1, моду 2, моду 3, моду 4.
20. Устройство по п. 1, отличающееся тем, что калькулятор диффузного компонента (301) выполнен с возможностью расчета, для каждой частотно-временной плитки из группы частотно-временных плиток, по меньшей мере, одного компонента диффузного звука; и
объединитель (401) выполнен с возможностью объединения информации диффузного звука и информации прямого звукового поля для получения представления в частотной области или представления во временной области компонентов звукового поля,
при этом калькулятор диффузного компонента или объединитель выполнен с возможностью расчета или объединения диффузного компонента до определенного порядка, или номера определенного порядка, или номера, который меньше, чем порядок или номер, до которого калькулятор компонента звукового поля (201) настроен для расчета компонента прямого звукового поля.
21. Устройство по п. 20, отличающееся тем, что определенный порядок или номер составляет один или ноль, а порядок или номер, до которого калькулятор компонента звукового поля (201) настроен для того, чтобы рассчитать компонент звукового поля, составляет, по меньшей мере, 2.
22. Устройство по п. 1, отличающееся тем, что калькулятор компонента звукового поля (201) выполнен с возможностью умножения (115) сигнала в частотно-временной плитке опорного сигнала на результат оценки, полученный из пространственной базисной функции, для получения информации о компоненте звукового поля, связанном с пространственной базисной функцией, и умножения (115) сигнала в частотно-временной плитке опорного сигнала на следующий результат оценки, полученный из следующей пространственной базисной функции, для получения информации о следующем компоненте звукового поля, связанном со следующей пространственной базисной функцией.
23. Способ формирования характеристики звукового поля, имеющего представление компонентов звукового поля, включающий:
определение (102), по меньшей мере, одного направления для каждой частотно-временной плитки из группы частотно-временных плиток группы микрофонных сигналов;
оценивание (103) для каждой частотно-временной плитки из группы частотно-временных плиток, по меньшей мере, одной пространственной базисной функции с использованием, по меньшей мере, одного направления звука; и
проведение расчета (201) для каждой частотно-временной плитки из группы частотно-временных плиток, по меньшей мере, одного компонента звукового поля, соответствующего, по меньшей мере, одной пространственной базисной функции, с использованием, по меньшей мере, одной пространственной базисной функции, оцененной с использованием, по меньшей мере, одного направления звука, и с использованием опорного сигнала для соответствующей частотно-временной плитки, при этом опорный сигнал выводится из, по меньшей мере, одного микрофонного сигнала из группы микрофонных сигналов.
24. Машиночитаемый носитель информации для работы на компьютере или процессоре, содержащий записанный способ формирования характеристики звукового поля, содержащего компоненты звукового поля, по п. 23.
| US 20140358559 A1, 04.12.2014 | |||
| US 8374365 B2, 12.02.2013 | |||
| US 20110286609 A1, 24.11.2011 | |||
| УСТРОЙСТВО И СПОСОБ ИЗВЛЕЧЕНИЯ ПРЯМОГО СИГНАЛА/СИГНАЛА ОКРУЖЕНИЯ ИЗ СИГНАЛА ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ И ПРОСТРАНСТВЕННОЙ ПАРАМЕТРИЧЕСКОЙ ИНФОРМАЦИИ | 2011 |
|
RU2568926C2 |
| Устройство для определения горизонтальных усилий, действующих на рабочий орган сельскохозяйственной машины со стороны почвы | 2023 |
|
RU2800401C1 |

