Настоящее изобретение относится к области транскодирования аудиоформата [Транскодирование - преобразование файла из одного способа кодирования (т.е. формата файла) в другой. Транскодировщик - устройство, преобразующее один вид кодированных сигналов в другой], в частности к транскодированию форматов параметрического кодирования.
В последнее время были предложены несколько способов параметрического кодирования многоканальных/многообъектных аудиосигналов. Каждый способ имеет свои преимущества и недостатки по отношению к его характеристикам, таким как тип параметрической характеристики, зависимость/независимость от установки конкретного громкоговорителя и т.д. Различные параметрические способы оптимизируются для различных стратегий кодирования.
Например, Направленное Аудио Кодирование (DirAC), формат представления многоканального звукового сигнала на основе сжатия сигнала и дополнительной информации, содержащей направление звука и параметры диффузности [диффузность - рассеянное (диффузное) отражение звука] для ряда поддиапазонов частот. Благодаря такому способу параметризации DirAC системы могут быть легко использованы, например, для выполнения направленной фильтрации и, таким образом, выделения и усиления звука, который поступает в определенном направлении по отношению к микрофону. Таким образом, DirAC можно рассматривать как акустический интерфейс, способный выполнять определенную пространственную обработку.
В качестве еще одного примера можно назвать Пространственное Кодирование Аудио Объекта (SAOC) ISO/IEC," MPEG audio technologies - Part.2: Spatial Audio Object Coding (SAOC)", ISO/IEC JTC1/SC29/WG11 (MPEG) FCD 23003-2”From SAC to SAOC-Recent Developments in Parametric Coding of Spatial Audio", 22nd Regional UK AES Conference, Cambridge, UK, April 2007, J.Engdegard, B.Resch, C.Falch, O.Hellmuth, J.Hilpert, A.Holzer, L.Terentiev, J.Breebaart, J.Koppens, E.Schuijers and W.Oomen: "Spatial Audio Object Coding (SAOC) - The Upcoming MPEG Standard on Parametric Object Based Audio Coding", 124th AES Convention, Amsterdam 2008, Preprint 7377, являющееся параметрической системой кодирования, эффективной по отношению к битрейту [скорости передачи битов данных], представляющей аудиосценарии, содержащие множество аудиообъектов.
Здесь представление основано на сжатии сигнала и параметрической дополнительной информации. В отличие от системы DirAC, которая направлена на представление оригинального пространственного аудиосценария, воспринятого микрофоном, SAOC не выполняет реконструкцию исходного аудиосценария. Вместо этого необходимое количество аудиообъектов (аудиоисточников) передается и объединяется в SAOC декодировщике в целевой аудиосценарий в соответствии с предпочтениями пользователя в терминале декодировщика, то есть пользователь может свободно в интерактивном режиме управлять и изменять каждый из аудиообъектов.
Как правило, при многоканальном воспроизведении и прослушивании слушатель находится в окружении нескольких громкоговорителей. Существуют различные способы захвата аудиосигналов для конкретных случаев. Единственной общей целью при воспроизведении является воспроизведение пространственной композиции первоначально записанного сигнала, то есть расположение разделенных источников звука, например, таких как местоположение трубы в оркестре. Достаточно часто встречаются специальные установки воспроизведения, способные создавать различные пространственные впечатления. Без использования способов специальной доработки после изготовления известные двухканальные стереоустановки могут только воссоздать слуховые впечатления на линии между двумя громкоговорителями. Это стало возможным с помощью так называемой амплитудной панорамы, где амплитуда сигнала, связанного с одним аудиоисточником, распределяется между двумя динамиками в зависимости от расположения аудиоисточника по отношению к громкоговорителям. Это обычно делается во время записи или последующего смешивания (микширования). То есть аудиоисточник, поступающий слева по отношению к слушателю, будет воспроизводиться в основном левой акустической системой, в то время как аудиоисточник, находящийся перед слушателем, будет воспроизводиться с одинаковой амплитудой (уровнем) обоими громкоговорителями. Однако звук, приходящий по другим направлениям, не может быть воспроизведен.
Следовательно, при использовании большего числа громкоговорителей, которые расположены вокруг слушателя, могут быть воспроизведены несколько направлений и могут быть созданы более естественные пространственные впечатления. Вероятно, самое известное расположение многоканальных громкоговорителей использовано в стандарте 5,1 (ITU-R775-1), который состоит из 5 громкоговорителей, азимутальные углы которых по отношению к слушателю равны 0°, 30° и 110°. Это означает, что во время записи или микшировании сигнала, с учетом конкретной конфигурации громкоговорителей отклонения от стандартного расположения приведут к снижению качества воспроизведения.
Также были предложены многие другие системы с различным количеством громкоговорителей, расположенных в различных направлениях. Профессиональные системы, особенно в театрах и сложных аудиоустановках могут содержать громкоговорители на разных высотах.
Т.к. существуют различные установки воспроизведения, для ранее упомянутых акустических систем были разработаны и предложены несколько различных способов записи, для того чтобы записывать и воспроизводить пространственные впечатления при прослушивании таким же образом, как это было воспринято записывающим оборудованием. Теоретически идеальный способ записи пространственного звука для выбранной многоканальной акустической системы будет использовать такое же количество микрофонов, сколько имеется громкоговорителей. В таком случае диаграммы направленности микрофонов также должны соответствовать расположению громкоговорителей, так что звук с любого выделенного направления будет записан только небольшим количеством микрофонов (1, 2 или более). Каждый микрофон связан с конкретным громкоговорителем. Дополнительные громкоговорители, используемые при воспроизведении, должны соответствовать микрофонам с узкими диаграммами направленности. Однако микрофоны с узкими диаграммами направленности стоят довольно дорого и обычно имеют не плоские частотные характеристики, снижающие качество записанного звука нежелательным образом. Кроме того, использование в качестве входных данных для многоканального воспроизведения нескольких микрофонов со слишком широкими диаграммами направленности приводит к частотным искажениям и нарушению четкости слухового восприятия вследствие того, что звук, приходящий по одному направлению, всегда будет воспроизводиться большим числом громкоговорителей, чем это необходимо, как это могло бы быть записано микрофонами, связанными с различными динамиками. Как правило, современные микрофоны лучше всего подходят для двухканальной записи и воспроизведения, то есть они разработаны без цели воспроизведения окружающего пространственного впечатления.
С точки зрения разработки микрофонов были использованы несколько подходов для адаптации диаграммы направленности микрофона к требованиям пространственного воспроизведения звука. Как правило, все микрофоны воспринимают звук по-разному в зависимости от направления прихода звука к микрофону. То есть микрофоны имеют разную чувствительность в зависимости от направления прихода записываемого звука. В некоторых микрофонах этот эффект является незначительным, так что они улавливают звук почти независимо от направления. Эти микрофоны, как правило, называют всенаправленными микрофонами. В типичной конструкции микрофона чувствительная диафрагма герметично крепится к небольшому корпусу. Если диафрагма не прикреплена к корпусу и звук приходит к ней одинаковым образом с каждой стороны, то диаграмма направленности имеет две лопасти. То есть такой микрофон фиксирует аудио с одинаковой чувствительностью как из передней, так и с задней части диафрагмы, однако, с обратной полярностью. Такой микрофон не захватывает звук, идущий по направлению, совпадающему с плоскостью диафрагмы, т.е. перпендикулярно к направлению максимальной чувствительности. Такие диаграммы направленности называется дипольными и имеют форму «восьмерки».
Всенаправленный микрофон также может быть преобразован в направленный микрофон при использовании негерметичного корпуса. Корпус имеет особенность в том, что звуковые волны могут проходить через него и достигать диафрагмы, в которой некоторые направления распространения являются предпочтительными, так что диаграмма направленности такого микрофона имеет промежуточный тип между круговой и дипольной. Эти диаграммы направленности могут, например, иметь две области. Тем не менее, области могут иметь различную величину. Некоторые широко известные микрофоны имеют диаграммы направленности, которые имеют только одну область. Наиболее важным примером является диаграмма направленности в виде кардиоиды, у которой функция направленности D может быть выражена как D=1+cos (θ), где величина 9 задает направление прихода звука. Такая функция направленности показывает количественно, какая доля входящей амплитуды звука захватывается в зависимости от различных направлений.
Ранее обсуждавшиеся всенаправленные диаграммы направленности также называются диаграммами нулевого порядка, а другие диаграммы направленности, также упоминавшиеся ранее (дипольные и кардиоидные), называются диаграммами первого порядка. Все обсуждавшиеся ранее конструкции микрофона не позволяют формировать диаграммы направленности произвольного вида, так как форма диаграммы направленности полностью определяется механической конструкцией.
Чтобы частично решить эту проблему, были разработаны некоторые специализированные акустические структуры, которые могут использоваться для создания более узкой диаграммы направленности, чем у микрофонов первого порядка. Например, если в трубку с отверстиями устанавливается всенаправленный микрофон, может быть создан микрофон с узкой диаграммой направленности. Эти микрофоны называются «дробовиковыми» или «винтовочными» микрофонами. Тем не менее, они обычно не имеют ровную АЧХ, то есть диаграммы направленности сужаются за счет качества записанного звука. Кроме того, форма диаграммы направленности предопределена геометрической конструкцией и, таким образом, диаграмма направленности при записи с использованием таких микрофонов не может контролироваться после записи.
Таким образом, предложенные до настоящего времени различные способы частично позволяют изменять диаграмму направленности после фактической записи. Как правило, эти способы используют основную идею записи звука с помощью группы всенаправленных или направленных микрофонов с последующей обработкой сигнала. Недавно были предложены различные варианты таких способов. Можно рассмотреть довольно простой пример записи звука с двумя всенаправленными микрофонами, которые расположены близко друг к другу, с вычитанием одного сигнала из другого. Это позволяет создать виртуальный сигнал микрофона с диаграммой направленности, эквивалентной диполю.
В других, более сложных схемах, перед суммированием также могут быть использованы задержка сигналов микрофона или их фильтрация. При формирования сигнала соответствующий узкий пространственный луч создается с помощью фильтрации каждого сигнала микрофона с помощью специально разработанного фильтра с суммированием сигналов после фильтрации (суммирующий фильтр с формированием луча). Однако эти способы «не видят» самого сигнала, то есть они не знают направление прихода звука. Таким образом, предварительно определенная диаграмма направленности не будет зависеть от фактического наличия источника звука в заданном направлении. Как правило, оценка "направления прихода" звука является самостоятельной задачей.
С помощью вышеуказанных способов может быть сформировано большое число различных пространственных характеристик направленности. Тем не менее, формирование произвольных диаграмм направленности с избирательной пространственной чувствительностью (то есть формирование узкой диаграммы направленности) требует использования большого количества микрофонов.
Альтернативный способ создания многоканальных записей состоит в том, что микрофоны располагаются близко к каждому источнику звука (например, к инструменту), чтобы записать и воссоздать пространственные впечатления путем контроля уровней сигналов каждого микрофона при окончательном микшировании. Однако такая система требует большого количества микрофонов и взаимодействия с пользователем при создании окончательного сжатого сигнала.
Способом преодоления указанной проблемы является система DirAC, которая может быть использована с различными системами микрофонов и способна записывать и воспроизводить звук при произвольном расположении набора громкоговорителей. Цель DirAC заключается в как можно более точном воспроизведении пространственных впечатлений на имеющемся акустическом оборудовании, с использованием многоканальной акустической системы, имеющей произвольное геометрическое расположение. В записывающем оборудовании отклики среды (которые могут быть непрерывными записанными звуковыми сигналами или могут иметь импульсные характеристики) фиксируются с помощью всенаправленного микрофона (W) и набора микрофонов, позволяющих определять направление прихода и диффузность звука.
В последующих пунктах и в пределах всего изобретения термин "диффузность" следует понимать как меру для не-направленности звука. То есть звук, поступающий для прослушивания или записи, распределяется в равной степени во все стороны и максимально рассеивается. Распространенный способ количественной оценки диффузности заключается в использовании значений диффузности в интервале [0, …, 1], где значение 1 описывает максимально рассеянный звук, а значение 0 описывает абсолютно направленный звук, т.е. звук, прибывающий и отчетливо различимый только в определенном направлении. Одним из известных способов определения направления прихода звука является применение 3 микрофонов (X, Y, Z) с диаграммами направленности в виде «восьмерки», расположенных в соответствии с декартовыми осями координат. Были разработаны специальные микрофоны, так называемые микрофоны В-формата, которые непосредственно получают все желаемые отклики. Однако, как отмечалось выше, W, X, Y и Z сигналы могут также быть определены из набора дискретных всенаправленных микрофонов.
В DirAC анализе записанный звуковой сигнал разделяется на частотные каналы, которые соответствуют разрешающей способности по частоте слухового восприятия человека. То есть сигнал, например, обрабатывается набором фильтров или с помощью Фурье-преобразования, в результате чего сигнал разделяется на множество частотных каналов, имеющих пропускную способность, адаптированную к разрешающей способности по частоте слухового восприятия человека. Затем сигналы диапазонов частот анализируются для определения направления поступления звука и значения диффузности для каждого частотного канала с заданным разрешением по времени. Это разрешение по времени не имеет фиксированного значения и может, конечно, быть адаптировано к параметрам записи. В DirAC один или нескольких аудиоканалов записываются или передаются вместе с результатами анализа направления и данными о диффузности.
В процессе синтеза или декодирования аудиоканалы, поступающие в результате на громкоговорители, могут использовать всенаправленный канал W (запись с высоким качеством благодаря использованию всенаправленной диаграммы направленности микрофона), или могут формироваться сигналы, имеющие определенные характеристики направленности для каждого громкоговорителя, вычисленные как взвешенная сумма W, X, Y и Z. В соответствии с кодировкой, каждый аудиоканал разделяется на частотные каналы, которые затем могут разделяться на диффузные и недиффузные потоки, в зависимости от результатов анализа диффузности. Если измеренная диффузность будет высокой, диффузный поток может быть воспроизведен с помощью способов воспроизводства диффузного восприятия звука, таких как способы декорреляции, также используемые в Бинауральном Трековом Кодировании.
Недиффузный звук воспроизводится с помощью способа, целью которого является формирование точечных виртуальных источников звука, расположенных в направлении, указанном найденными при анализе данными о направлении, т.е. происходит генерация DirAC сигнала. То есть пространственное воспроизведение не адаптировано к одной конкретной, "идеальной" настройке громкоговорителя, как в известных до настоящего времени способах (например, 5.1). В частности, поступление звука задается с помощью параметров направления (т.е. описывается вектором), с использованием сведений о диаграммах направленности микрофонов, используемых при записи. Как обсуждалось выше, поступление звука в 3-мерном пространстве определяется частотно-избирательным способом. Таким образом, впечатление направленности может быть воспроизведено с высоким качеством для любой расстановки громкоговорителей, поскольку геометрия расстановки громкоговорителей известна. Следовательно, DirAC не ограничен специальной геометрией расстановки громкоговорителей и в целом допускает более гибкое пространственное воспроизведение звука.
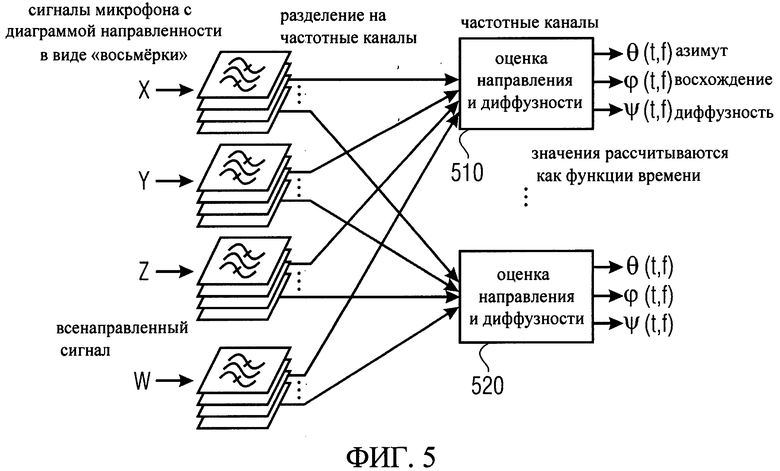
DirAC, см. Pulkki, V., Directional audio coding in spatial sound reproduction and stereo upmixing," In Proceedings of The AES' 28th International Conference, pp.251-258, Pitea, Sweden, June 30-July 2, 2006, представляет собой систему для представления пространственных аудиосигналов на основе одного или более сжатых сигналов, а также дополнительной информации. Дополнительная информация описывает, кроме прочих возможных аспектов, направление поступления звукового поля, степень его диффузности в ряде диапазонов частот, как это показано на фиг.5.
Фиг.5 иллюстрирует сигнал DirAC, который состоит из трех компонентов направленности, таких как, например, сигналы микрофона с диаграммой направленности в виде «восьмерки» X, Y, Z плюс всенаправленный сигнал W. Каждый из сигналов доступен в частотной области, которая показана на фиг.5 в виде нескольких наложенных друг на друга плоскостей для каждого из сигналов. На основе четырех сигналов может быть осуществлена оценка направления и диффузности в блоках 510 и 520, которые формируют результат оценки направления и диффузности для каждого из частотных каналов. Результат этих оценок определяется параметрами θ(t,f), θ(t,f) и θ(t,f), представляющими азимутальный угол, угол возвышения и диффузность для каждого из частотных слоев.
Параметризация DirAC может быть легко использована для реализации пространственного фильтра с требуемой пространственной характеристикой, например, только поступающего звука в направлении от говорящего в данный момент человека. Это может быть достигнуто путем использования направления/диффузности и, возможно, зависящего от частоты весового коэффициента, применяемого при сжатии сигналов, как показано на фиг.6 и 7.
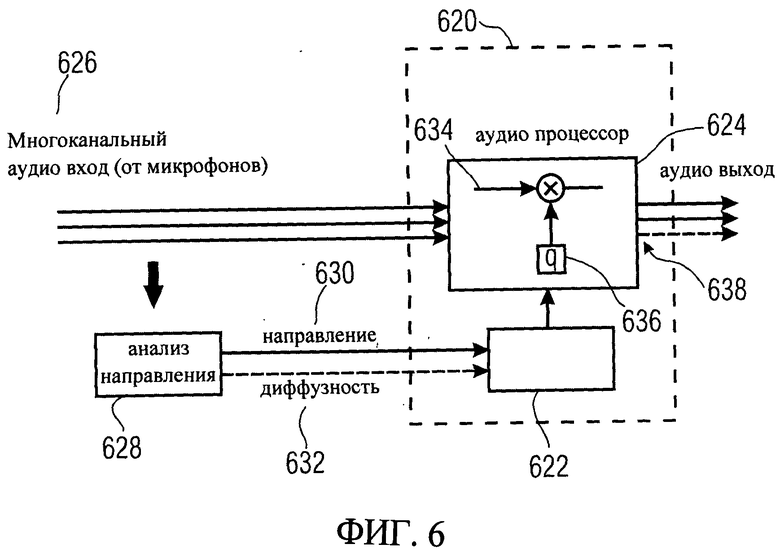
На фиг.6 показан декодировщик 620 для восстановления аудиосигнала. Декодировщик 620 включает в себя селектор направления 622 и аудиопроцессор 624. В соответствии с примером на фиг.6 многоканальный аудиовход 626, записанный с помощью нескольких микрофонов, анализируется анализатором направления 628, который формирует параметры направления, указывающие направление поступления части аудиоканалов, то есть направление поступления проанализированных частей сигнала. Выбирается направление, от которого большая часть энергии поступает на микрофон и записывается положение, определяемое для каждой конкретной части сигнала. Это можно также сделать, например, с помощью микрофонных технологий DirAC, как описано выше. Для проведения анализа могут быть использованы и другие способы анализа направления на основе записанной аудиоинформации. В результате анализатор направления 628 формирует параметры направления 630, указывающие направление поступления части звукового канала или многоканального сигнала 626. Кроме того, анализатор направления 628 может в текущий момент времени выдать параметр диффузности 632 для каждой части сигнала, например для каждого частотного интервала или для каждого промежутка времени сигнала.
Параметры направления 630 и, кроме того, параметр диффузности 632 передаются на селектор направления 620, который используется для выбора нужного направления поступления по отношению к местоположению записанной или восстановленной частей восстанавливаемого звукового сигнала. Информация о желаемом направлении передается на аудиопроцессор 624. Аудиопроцессор 624 получает, по крайней мере, один аудиоканал 634, имеющий составную часть, для которой были получены параметры направления. По крайней мере, один канал, измененный аудиопроцессором, может, например, быть сжатым многоканальным сигналом 626, полученным с помощью обычных алгоритмов многоканального сжатия. Один очень простой вариант может быть получен прямым суммированием сигналов многоканального аудиовхода 626. Однако такая концепция не ограничена количеством входных каналов, и все входные аудиоканалы 626 могут одновременно быть обработаны аудиодекодировщиком 620.
Аудиопроцессор 624 изменяет аудиоблоки для восстановления частей восстанавливаемого звукового сигнала, причем изменения включают в себя увеличение интенсивности части аудиоканала, имеющей параметры направления, указывающие направление поступления, близкое к желаемому направлению поступления по отношению к другой части аудиоканала, имеющей параметры направления, указывающие направление поступления, удаленное от желаемого направления поступления. В примере на фиг.6 изменение производится путем умножения коэффициента масштаба 636 (q) на часть аудиоканала, которая должна быть изменена. То есть если результаты анализа части аудиоканала показывают, что эта часть поступает от направления, близкого к выбранному желаемому направлению, при умножении на часть аудиоканала используется большой коэффициент масштаба 636. Таким образом, на выходе 638 аудиопроцессор формирует реконструированную часть восстанавливаемого звукового сигнала, соответствующую части аудиоканала, представленной на его входе. Кроме того, как указано пунктирными линиями на выходе 638 аудиопроцессора 624, такая процедура может быть выполнена не только для моно сигнала на выходе, но и для многоканальных выходных сигналов, для которых количество каналов на выходе не является фиксированным или определенным заранее.
Другими словами, аудиодекодировщик 620 принимает на свой вход такие результаты анализа направленности, какие используются, например, в DirAC. Аудиосигналы 626 от набора микрофонов могут быть разделены на диапазоны частот в зависимости от разрешающей способности по частоте слуховой системы человека. Направление звука и, кроме того, диффузность звука анализируется в зависимости от времени для каждого частотного канала. Такие параметры, как, например, углы направлений азимутальный (azi) и восхождения (ele), и индекс диффузности (ψ), который изменяется от нуля до единицы, передаются дальше.
Затем предназначенные или выбранные характеристики направленности вводятся в полученные сигналы с применением к ним операции взвешивания, которая зависит от углов направления (azi и ele) и, кроме того, от диффузности (ψ). Очевидно операция взвешивания может быть определена по-разному для различных частотных диапазонов, и, как правило, изменяется с течением времени.
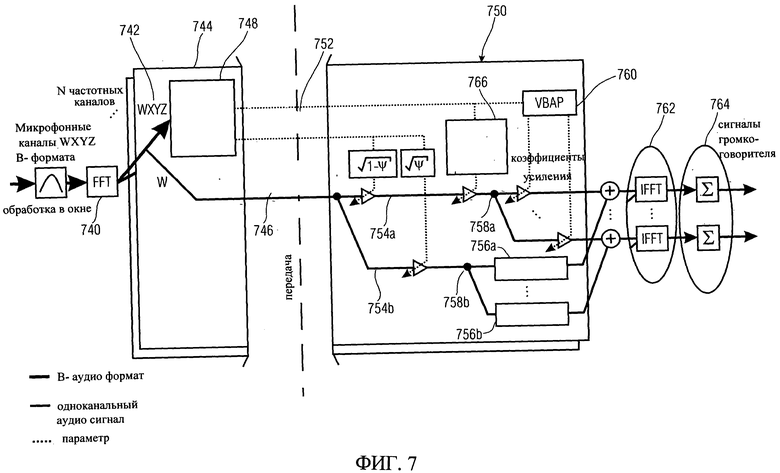
На фиг.7 показан еще один пример, основанный на DirAC синтезе. В этом смысле пример на фиг. 7 можно было бы интерпретировать как повышение производительности DirAC, позволяющее контролировать уровень звука в зависимости от результатов анализа направления. Это дает возможность усилить звук, приходящий от одного или нескольких направлений, или подавить звук от одного или нескольких направлений. При многоканальном воспроизведении возможна пост-обработка образа воспроизводимого звука. Если используется только один выходной канал, результат эквивалентен использованию во время записи сигнала направленного микрофона с произвольной диаграммой направленности. На фиг.7 показано получение параметров направления, а также одного передаваемого аудиоканала. Анализ проводится на основе микрофонных каналов В-формата: W, X, Y и Z, записанных, например, микрофоном звукового поля.
Обработка производится с использованием фреймов. То есть непрерывные звуковые сигналы разделяются на фреймы, которые масштабируются с помощью функции окна для того, чтобы избежать разрывов на границах фреймов. Фреймы оконного сигнала подвергаются преобразованию Фурье в блоке Фурье- преобразования 740, с разделением микрофонных сигналов на N диапазонов частот. Для простоты изложения обработка одного произвольного диапазона частот будет описана в следующих пунктах, а остальные частотные диапазоны обрабатываются аналогичным образом. Блок Фурье-преобразования 740 формирует коэффициенты, описывающие интенсивность частотных компонентов, присутствующих в каждом из каналов микрофона в В-формате: W, X, Y и Z в пределах анализируемого оконного фрейма. Эти частотные параметры 742 вводятся в аудиокодировщик 744 для вывода аудиоканала и связанных с ним параметров направления. В примере, показанном на фиг.7, передаваемый аудиоканал выбирается в качестве всенаправленного канала 746, располагающего информацией о сигналах со всех направлений. На основе коэффициентов 742 для всенаправленной и направленной частей каналов микрофона в В-формате проводится анализ направленности и диффузности с помощью блока анализа направления 748.
Направления поступления звука в анализируемой части аудиоканала передаются в аудиодекодировщик 750 для восстановления звукового сигнала вместе с всенаправленным каналом 746. Если присутствуют параметры диффузности 752, при прохождении сигнала он разбивается на недиффузный 754а и диффузный 754b участки. Недиффузный участок 754а масштабируется в соответствии с параметром диффузности, например, если диффузность Т мала, большая часть энергии или амплитуды будет перенесена в недиффузный участок. И наоборот, когда диффузность высокая, большая часть энергии будет перенесена на диффузный участок 754b. В диффузном участке 754b сигнал является некоррелированным или диффузным после обработки блоками декорреляции 756а или 756b. Декорреляцию можно выполнить с помощью обычных известных способов, таких как свертка с сигналом белого шума, причем сигнал белого шума может отличаться от одного частотного канала к другому. Поскольку декорреляция сохраняет энергию, конечный результат может быть восстановлен путем простого сложения сигналов недиффузного участка сигнала 754а и диффузного участка сигнала 754b на выходе, так как участки сигнала уже были масштабированы, как было задано параметром диффузности У.
Когда восстановление проводится для многоканального сигнала, прямой участок сигнала 754а, а также диффузный участок сигнала 754b разделены на некоторое число под-участков, соответствующих сигналам отдельных громкоговорителей, разделенных на позиции 758а и 758b. Разделение на позиции 758а и 758b можно интерпретировать как расширение по меньшей мере одного аудиоканала на нескольких каналов для воспроизведения через акустическую систему с несколькими громкоговорителями.
Поэтому каждый из нескольких каналов имеет часть канала из аудиоканала 746. Направление поступления отдельных частей звука восстанавливается блоком перенаправления 760, который кроме того увеличивает или уменьшает интенсивность или амплитуду части канала в соответствующих громкоговорителях при воспроизведении. Блок перенаправления 760 обычно требует знания о расстановке громкоговорителей, используемых для воспроизведения. Фактическое перераспределение (перенаправление) и вывод может быть связано с весовыми коэффициентами, например реализовано способом, использующим вектор амплитудной панорамы. Блок перераспределения 760 позволяет использовать различные геометрические расстановки громкоговорителей с произвольной конфигурацией воспроизводящих динамиков, в соответствии с вариантами изобретения, без потери качества воспроизведения. После нескольких обработок с помощью обратного преобразования Фурье в блоках 762 сигналы в частотной области преобразуются в сигналы во временной области, которые могут быть воспроизведены в отдельных громкоговорителях. Перед воспроизведением осуществляются процедуры перекрытия и сложения с использованием блоков суммирования 764 для объединения разделенных аудиофреймов и получения непрерывных сигналов во временной области, готовых для воспроизведения на громкоговорителях.
В соответствии с примером, показанным на фиг.7, в обработку сигналов DirAC внесены изменения, заключающиеся в том, что аудиопроцессор 766 изменяет часть уже обработанного аудиоканала и позволяет увеличить интенсивность части аудиоканала, имеющей параметры направления, указывающие, что направление поступления близко к желаемому направлению. Это достигается за счет применения дополнительного весового коэффициента для прямого участка сигнала. То есть если частота обрабатываемого участка поступает от желаемого направления, сигнал выделяется с использованием дополнительного усиления для определенной части сигнала. Усиление может быть выполнено до точки разделения 758а так, как эффект будет действовать на все части канала в равной степени.
Применение дополнительного весового коэффициента может быть реализовано в пределах блока перераспределения 760, который в этом случае использует перераспределение коэффициентов усиления с увеличением их на дополнительный весовой коэффициент.
При использовании направленного усиления при восстановлении многоканального сигнала воспроизведение может, например, быть выполнено в стиле DirAC рендеринга [рендеринг - термин в компьютерной графике, обозначающий процесс получения изображения по модели с помощью компьютерной программы], как показано на фиг.7. Аудиоканал, который будет воспроизводиться, разделен на диапазоны частот, равные тем, которые используются для анализа направленности. Эти диапазоны частот затем разбиваются на диффузные и недиффузные потоки. Диффузный поток воспроизводится, например, путем подачи звука на каждый громкоговоритель после свертки с 30 мс белый импульсным шумом. Шумовые импульсы различны для каждого динамика. Недиффузный поток применяется к направлению для избавления от результатов анализа направленности, который, конечно, зависит от времени. Для достижения направленного восприятия в многоканальных акустических системах может быть использована простая амплитудная панорама для пар или «троек» динамиков. Кроме того, каждый частотный канал умножается на коэффициент усиления или коэффициент масштабирования, которые зависят от результатов анализа направления. В целом, может быть указана функция, определяющая желаемую диаграмму направленности при воспроизведении. Может существовать, например, только одно направление, которое должно быть выделено. Тем не менее, диаграммы направленности произвольного вида могут быть легко реализованы в соответствии с фиг.7.
Далее описан еще один пример в виде списка этапов обработки. Обработка основана на предположении, что звук записывается микрофоном в В-формате, а затем обрабатывается для прослушивания при многоканальной или монофонической расстановке громкоговоритель с использованием DirAC стиля рендеринга или рендеринга, поддерживающего параметры направленности, указывающие направление поступления частей звукового канала.
Во-первых, сигналы микрофона можно разделить на диапазоны частот и проанализировать по направлению и, кроме того, диффузности в каждом диапазоне в зависимости от частоты. В качестве примера направление может быть параметризовано углами азимутальным и восхождения (Azi, ele).
Во-вторых, может быть указана функция F, которая описывает желаемую диаграмму направленности. Функция может иметь произвольный вид. Обычно это зависит от направления. Она, кроме того, может также зависеть от диффузности, если имеется информация о диффузности. Функция может иметь различный вид для различных частот, а также может изменяться в зависимости от времени. В каждом диапазоне частот из функции F может быть получен коэффициент направленности q для каждого промежутка времени, который затем используется для последующего взвешивания (масштабирования) звукового сигнала.
В-третьих, значения аудиовыборок можно умножить на значения коэффициентов направленности q, соответствующие каждому временному и частотному участку, для формирования выходного сигнала. Это может быть сделано во временной и/или частотной области. Кроме того, такая обработка может, например, быть выполнена как часть DirAC рендеринга с любым желаемым количеством каналов вывода.
Как описано выше, результат можно будет прослушивать с использованием многоканальных или монофонических акустических систем. В последнее время были предложены способы параметризации передачи/хранения аудиосценариев, эффективные по битрейту, содержащие несколько аудиообъектов, например Бинауральное Трековое Кодирование (тип 1), см. С.Faller and F.Baumgarte, "Binaural Cue Coding - Part II: Schemes and applications", IEEF Trans. on Speech and Audio Proc., vol.11, no.6, Nov.2003, or Joint Source Coding, cf. C.Faller, "Parametric Joint-Coding of Audio Sources", 120th AES Convention, Paris, 2006, Preprint 6752, and MPEG Spatial Audio Object Coding (SAOC), cf. J.Herre, S.Disch, J.Hilpert, O.Hellmuth: "From SAC to SAOC - Recent Developments in Parametric Coding of Spatial Audio", 22nd Regional UK AES Conference, Cambridge, UK, April 2007, J.Engdegard, B.Resch, C.Falch, O.Hellmuth, J.Hilpert, A.Holzer, L.Terentiev, J.Breebaart, J.Koppens, E.Schuijers and W.Oomen: "Spatial Audio Object Coding (SAOC) - The Upcoming MPEG Standard on Parametric Object Based Audio Coding", 124th AES Convention, Amsterdam 2008, Preprint 7377).
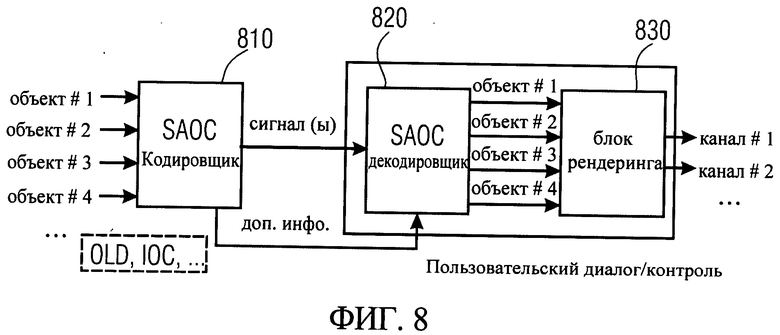
Эти способы направлены на реконструкцию желаемого восприятия аудиосценария на выходе, или, точнее, формы волны. На фиг. 8 показан вид такой системы (в данном случае MPEG SAOC). Фиг.8 представляет обзор MPEG SAOC системы. Система включает в себя SAOC кодировщик 810, декодировщик SAOC 820 и блок рендеринга 830. Общая обработка может осуществляться избирательно по частоте, обработка, представленная далее, может быть проведена в каждом отдельном диапазоне частот. Кодировщик SAOC на входе имеет число (N) входных сигналов аудиообъекта, которые декодируются как часть обработки в SAOC кодировщике. Кодировщик SAOC 810 формирует на выходах микшированный сигнал и дополнительную информацию. Дополнительная информация, извлеченная SAOC кодировщиком 810, представляет собой характеристики аудиообъектов на входе. Для MPEG SAOC амплитуда (мощность) объекта используется всеми аудиообъектами в качестве наиболее значимые компонент дополнительной информации. На практике вместо абсолютной мощности объекта передается относительная мощность, определяемая как разность уровней объектов (OLD). Согласованность/корреляция между парами объектов называется когерентностью между объектами (IOC) и далее может быть использована для описания свойств входных аудиообъектов.
Сжатый сигнал и дополнительная информация могут передаваться или храниться. Для этого сжатый аудиосигнал может быть сжат с использованием аудиокодировщиков с хорошим восприятием, таких как MPEG-1 Layer 2 или 3, также известных как МРЗ, MPEG с улучшенной аудиокодировкой (ААС) и т.д.
При воспроизведении SAOC декодировщик 820 пытается концептуально восстановить сигналы исходного объекта, к которому также относится объект разделения, использующий переданную дополнительную информацию. Эти сигналы, аппроксимирующие объект, затем смешиваются с целевым сценарием, представленным М выходными аудиоканалами с помощью матрицы рендеринга, используемой в блоке рендеринга 830. По сути, разделение объекта на сигналы никогда не выполняется, так как оба этапа разделения и смешивания объединены в один этап транскодирования, в результате чего достигается колоссальное сокращение вычислительной сложности.
Такая схема может быть очень эффективна не только с точки зрения битрейта, так как необходимо передавать только несколько сжатых каналов, плюс некоторую дополнительную информацию вместо N аудиосигналов объекта, а также информацию рендеринга или дискретной системы, но и с точки зрения сложности вычислений, сложность обработки связана, главным образом, с количеством выходных каналов, а не количеством аудиообъектов. Дополнительные преимущества для пользователя при воспроизведении заключаются в свободе выбора установки рендеринга, например выбор моно, стерео, объемный, виртуальных наушников в режимах воспроизведения и т.д., и особенность интерактивности: матрица рендеринга, и, следовательно, выход сценария могут быть установлены и изменены пользователем в интерактивном режиме в соответствии с личными предпочтениями или другими критериями, например можно поместить говорящих людей из одной группы в одну пространственную область, чтобы максимально отгородить их от оставшихся других говорящих. Эта интерактивность достигается путем предоставления пользователю интерфейса декодировщика.
Понятие условного транскодирования для транскодирования в формате MPEG SAOC объемного звучания (MPS) для многоканального рендеринга рассматривается далее. Как правило, декодирование SAOC может быть сделано с помощью процесса транскодирования. MPEG SAOC формирует целевой аудиосценарий, в состав которого входят все отдельные аудиообъекты, с настройками многоканального воспроизведения звука с помощью транскодирования сценария в соответствующий формат MPEG Surround, см. J.Негге, К.Kjorling, J.Breebaart, С.Faller, S.Disch, H.Pumhagen, J.Koppens, J.Hilpert, J.Roden, W.Oomen, K.Linzmeier, K.S.Chong: "MPEG Surround - The ISO/MPEG Standard for Efficient and Compatible Multichannel Audio Coding", 122nd AES Convention, Vienna, Austria, 2007, Preprint 7084.
В соответствии с фиг.9, дополнительная информация SAOC обрабатывается в блоке 910 и затем транскодируется в 920 вместе с поддерживаемыми пользователем данными о конфигурации воспроизведения и параметрах рендеринга объектов. Кроме того, параметры сжатия SAOC используются пре-процессором сжатия 930. Затем оба процесса сжатия и дополнительная информации MPS могут быть переданы MPS декодировщику 940 для окончательного рендеринга.
Обычные представления имеют недостаток в том, что они либо просто реализуются, как, например, в случае DirAC, но информация пользователя или индивидуальный рендеринг пользователя не могут быть применены, либо они более сложны в реализации, однако, имеют преимущество в том, что информация пользователя может использоваться как, например, в SAOC.
Объектом настоящего изобретения является обеспечение концепции аудиокодирования, которая может быть легко внедрена и позволяет пользователю выполнять индивидуальные действия.
Это достигается с помощью транскодировщика аудиоформата в соответствии с п.1 и способа транскодирования аудиоформата в соответствии с п.14.
Идея настоящего изобретения состоит в том, что возможности направленного аудиокодирования и пространственного кодирования аудиообъектов могут быть объединены. Еще одна идея настоящего изобретения заключается в том, что направленные аудиокомпоненты могут быть преобразованы в отдельные элементарные аудиоисточники или сигналы. Варианты изобретения могут обеспечить эффективное объединение возможностей DirAC и SAOC систем, тем самым создавая способ, который использует DirAC в качестве акустического фронта с встроенной возможностью пространственной фильтрации и применяет эту систему для разделения входящего звука на аудиообъекты, которые затем представляются и визуализируются (проводится рендеринг) с помощью SAOC. Кроме того, варианты изобретения имеют преимущество в том, что преобразование из представления DirAC в представление SAOC может быть выполнено чрезвычайно эффективным способом, путем преобразования двух типов дополнительной информации, и более предпочтительный вариант позволяет оставить сжатый сигнал неизмененным.
Воплощения изобретения будут подробно описаны с использованием сопровождающих фигур, на которых:
Фиг.1 представляет вариант транскодировщика аудиоформата;
На фиг.2 показан другой вариант транскодировщика аудиоформата;
На фиг.3 показан еще один вариант транскодировщика аудиоформата;
На фиг.4а показана суперпозиция направленных аудиокомпонент;
На фиг.4б показан пример весовой функции, используемой в воплощении изобретения;
На фиг.4с показан пример функции окна, используемой в воплощении;
Фиг.5 иллюстрирует алгоритм DirAC;
Фиг.6 иллюстрирует современный вариант направленного анализа;
Фиг.7 иллюстрирует современную схему направленного взвешивания в сочетании с DirAC рендерингом;
Фиг.8 показывает вид MPEG системы SAOC; и
Фиг.9 иллюстрирует современный вариант транскодирования из SAOC в MPS.
На фиг.1 показан транскодировщик аудиоформата 100 для транскодирования входного аудиосигнала, имеющего не менее двух направленных аудиокомпонентов. Транскодировщик аудиоформата 100 включает в себя преобразователь 110 для преобразования входного сигнала в преобразованный сигнал, имеющий представление преобразованного сигнала и направление поступления преобразованного сигнала. Кроме того, транскодировщик аудиоформата 100 содержит определитель положения 120 для определения, по крайней мере, двух пространственных положений, по крайней мере, двух пространственных источников звука. По крайней мере, два пространственных местоположения могут быть известны априори, то есть, например, быть заданными или введенными пользователем, или определенными, или обнаруженными на основе преобразованного сигнала. Более того, транскодировщик аудиоформата 100 включает в себя процессор 130 для обработки преобразованного сигнала, представленного на основе не менее двух пространственных местоположений, чтобы получить, по крайней мере, два разделенных элементарных аудиоисточника.
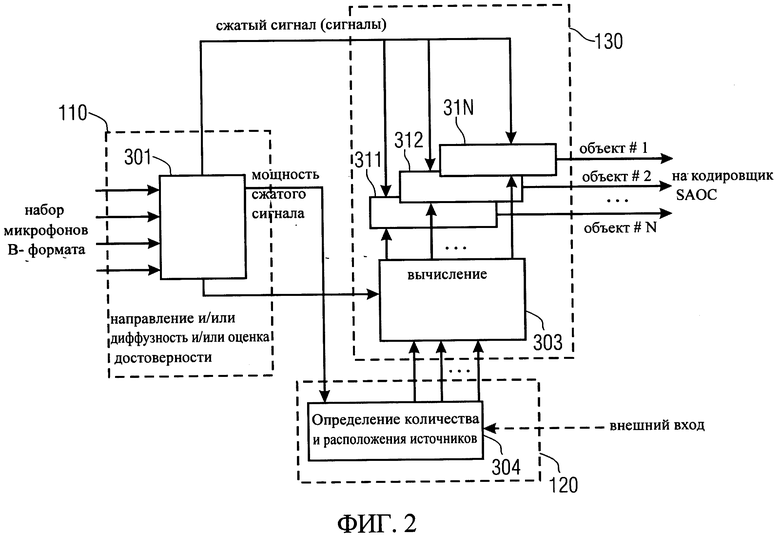
Варианты изобретения могут обеспечить возможность эффективного объединения возможностей DirAC и SAOC систем. Другим вариантом настоящего изобретения является воплощение, изображенное на фиг.2. На фиг.2 показан другой транскодировщик аудиоформата 100, в котором преобразователь 110 выполнен в виде этапа DirAC анализа 301. В воплощениях транскодировщик аудиоформата 100 может быть адаптирован для транскодирования входного сигнала в соответствии с сигналом DirAC, сигналом В-формата или сигналом с группы микрофонов. В воплощении, изображенном на фиг.2, DirAC можно использовать в качестве акустического фронта для получения пространственного аудиосценария с помощью В-формата микрофона или, альтернативно, группы микрофонов, как показано на этапе анализа DirAC или в блоке 301.
Как уже упоминалось выше, в воплощениях транскодировщик аудиоформата 100, преобразователь 110, определитель положения 120 и/или процессор 130 могут быть адаптированы для преобразования входного сигнала с точки зрения количества поддиапазонов частот и/или временных промежутков или временных фреймов.
В воплощениях преобразователь 110 может быть адаптирован для преобразования входного сигнала в преобразованный сигнал, включающий диффузность и/или оценку достоверности на частоте поддиапазона.
На фиг.2 представление преобразованного сигнала отмечено надписью "Сжатые сигналы". В варианте, изображенном на фиг.2, показаны принципы DirAC параметризации акустического сигнала по направлению, диффузности и, альтернативно, оценка достоверности в каждом поддиапазоне частот, которые могут быть использованы определителем положения 120, то есть "Определение количества и расположения источников " в блоке 304 для диагностики пространственных положений, в которых имеются активные источники звука. В соответствии с пунктирной линией с надписью "Мощность сжатого сигнала" на фиг.2 мощность сжатого сигнала может быть передана в определитель положения 120.
В варианте, изображенном на фиг.2, процессор 130 может использовать пространственные положения, и, возможно, другие априорные сведения, использовать набор пространственных фильтров 311, 312, 31N, для которых в блоке 303 рассчитываются весовые коэффициенты, чтобы изолировать или выделить каждый источник звука.
Другими словами, в воплощениях процессор 130 может быть адаптирован для определения весового коэффициента для каждого из, по крайней мере, двух разделенных источников звука. Более того, в воплощениях процессор 130 может быть адаптирован для обработки преобразованного сигнала, представленного, по крайней мере, двумя пространственными фильтрами, для аппроксимации, по крайней мере, двух разделенных источников звука, по крайней мере, для двух отдельных измерений аудиоисточников. Измерение аудиоисточников, например, может выражаться в соответствующих сигналах или мощностях сигналов.
В варианте, изображенном на фиг.2, случай двух источников звука расширен до N источников звука и соответствующих сигналов. Соответственно, на фиг.2, показаны N фильтров или этапов синтеза, т.е. 311, 312, …, 31N. В этих N пространственных фильтрах происходит DirAC сжатие всенаправленных компонентов, сигналы преобразуются к набору аппроксимированных разделенных источников звука, которые могут быть использованы в качестве входных в SAOC кодировщике. Другими словами, в вариантах изобретения разделенные источники звука можно интерпретировать как различные аудиообъекты, которые затем кодируются в SAOC кодировщике. Соответственно, в воплощениях транскодировщик аудиоформата 100 может включать в себя SAOC кодировщик для кодирования, по крайней мере, двух раздельных источников аудиосигналов для получения SAOC кодированного сигнала, включающего сжатый компонент SAOC и компонент дополнительной информации SAOC.
Описанные выше варианты могут реализовываться дискретной последовательностью DirAC направленной фильтрации с последующим SAOC кодированием, для которой далее будет представлена усовершенствованная структура, позволяющая уменьшить вычислительную сложность. Как объяснялось выше, N разделенных аудиосигналов источников могут быть восстановлены обычным образом с использованием N-DirAC наборов фильтров синтеза, 311, 31N, а затем проанализированы с помощью SAOC набора фильтров анализа в SAOC кодировщике. SAOC кодировщик может затем получить суммарный/микшированный сигнал из разделенных сигналов объекта. Более того, обработка реальных образцов сигнала может иметь большую вычислительную сложность, чем проведение вычислительной обработки в области параметров, которые могут иметь значительно более низкую частоту дискретизации и будут использованы в других вариантах изобретения.
Варианты могут обеспечить преимущество вследствие значительно более эффективной обработки и варианты могут включать в себя следующие два упрощения:
Во-первых, и DirAC и SAOC могут использовать набор фильтров, которые в некоторых воплощениях позволяют получить практически идентичные поддиапазоны частот для обеих схем. Преимущество состоит в том, что в нескольких вариантах для обеих схем может использоваться один и тот же набор фильтров. В этом случае DirAC синтез и набор фильтров анализа SAOC могут быть исключены, что приводит к снижению вычислительной сложности и алгоритмической задержки. Кроме того, варианты могут использовать два разных набора фильтров, которые формируют параметры с совпадающими сетками поддиапазонов частот. Экономия при расчетах в наборе фильтров в таких вариантах не может быть очень велика.
Во-вторых, в вариантах вместо явного вычисления разделенных сигналов источника эффект разделения может быть достигнут только за счет вычислений в области параметров. Другими словами, в вариантах процессор 130 может быть адаптирован для оценки информации о мощности, например мощности или нормированной мощности, для каждого из, по крайней мере, двух разделенных источников звука, как минимум для двух измерений раздельных источников звука. В вариантах может быть вычислена степень сжатия DirAC сигнала.
В вариантах для каждого желаемого/обнаруженного расположения источника звука направленное взвешивание/взвешенная фильтрация могут быть определены в зависимости от направления и, возможно, диффузности и использованы в характеристиках разделения. В вариантах мощность каждого источника звука из разделенных сигналов может быть оценена по произведению степени сжатия и коэффициента взвешивания мощности. В вариантах процессор 130 может быть адаптирован для преобразования мощностей, по крайней мере, двух разделенных источников звука в SAOC OLDs [SAOC Object Level Differences- кодировка SAOC с использованием разности уровней между объектами].
Варианты могут осуществлять описанный выше способ обработки потоков данных без привлечения какой-либо обработки реальных сжатых сигналов. Кроме того, в некоторых вариантах могут быть также вычислены когерентности между объектами (IOC). Это может быть достигнуто путем использования направленного взвешивания и сжатия сигналов до перехода в область преобразования.
В вариантах процессор 130 может быть адаптирован для вычисления IOC, по крайней мере, двух разделенных источников звука. Как правило, процессор (130) может быть адаптирован для вычисления IOC каждого из двух, по крайней мере, из двух разделенных источников звука. В вариантах определитель положения 120 может включать в себя детектор, адаптированный для обнаружения, двух пространственных положений, по крайней мере, двух пространственных источников звука на основе преобразованного сигнала. Кроме того, определитель положения/детектор 120 может быть адаптирован для обнаружения, по крайней мере, двух пространственных положений путем сложения нескольких последовательных временных сегментов входного сигнала. Определитель положения/детектор 120 также может быть приспособлен для обнаружения, по крайней мере, двух пространственных положений на основе оценки максимальной вероятности пространственной плотности мощности. Определитель положения/детектор 120 может быть адаптирован для обнаружения множества местоположений пространственных источников звука на основе преобразованного сигнала.
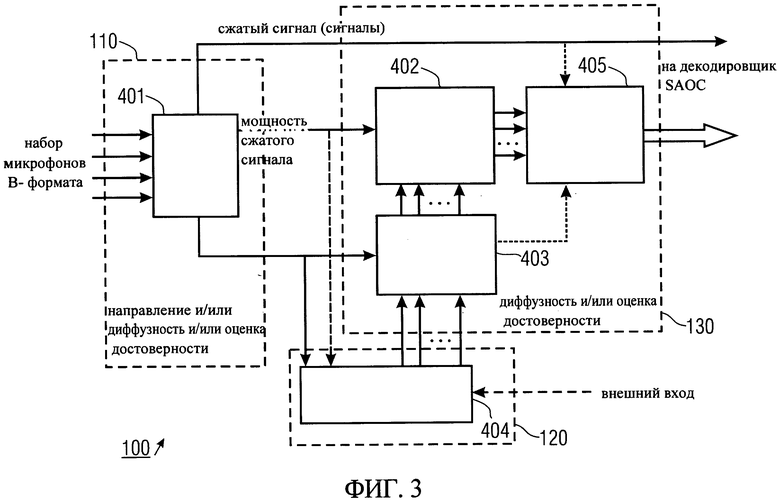
Фиг.3 иллюстрирует другой вариант транскодировщика аудиоформата 100. Аналогично воплощению, изображенному на фиг.2, преобразователь 110 выполнен в виде этапа 401 "DirAC анализ". Кроме того, определитель положения/детектор 120 представлен в виде этап 404 "расчет количества и местоположения источников". Процессор 130 включает в себя этап 403 "расчет весового коэффициента", этап 402 расчета разделенных источников мощности и этап 405 расчета SAOC OLDs и потока данных.
Как и ранее, в варианте, изображенном на фиг.3, сигнал, полученный с помощью набора микрофонов или, наоборот, микрофона в В-формате, и подается на этап 401 "DirAC анализа". Данный анализ предоставляет один или несколько сжатых сигналов и информацию о поддиапазонах частот для каждого обработанного временного фрейма, включая оценку мгновенной степени сжатия и направление. Кроме того, этап 401 "DirAC анализ" может обеспечить измерение диффузности и/или оценка достоверности определения направления. На основе этой информации и, возможно, других данных, таких как мгновенная степень сжатия, оценка количества источников звука и их местоположение, могут быть вычислены на этапе 404 определителем положения/детектором 120, соответственно, например, путем сложения измерений результатов обработки нескольких временных фреймов, которые располагаются последовательно во времени.
Процессор 130 может быть адаптирован для получения на этапе 403 направленных весовых коэффициентов для каждого источника звука и его местоположения по результатам оценки положения источника и направления и дополнительно значения диффузности и/или оценки достоверности для последовательных временных фреймов. В результате первого сложения на этапе 402 оценок степени сжатия и весовых коэффициентов на этапе 405 могут быть получены SAOC OLDs. Кроме того, в воплощениях может генерироваться полный поток битов SAOC. Кроме того, процессор 130 может быть адаптирован для вычисления SAOC IOCs с использованием сжатого сигнала и блока обработки 405 в варианте, изображенном на фиг.3. В вариантах сжатые сигналы и дополнительная информация SAOC затем могут храниться или передаваться вместе при декодировании SAOC или рендеринге.
"Величина диффузности" является параметром, который описывает для каждой частотно-временной последовательности "диффузность (рассеянность)" звукового поля. Без ограничения общности ее значение находится в пределах диапазона [0, 1], где диффузность = 0 указывает на совершенно когерентное звуковое поле, например идеальную плоскую волну, в то время как диффузность = 1 означает абсолютно диффузное звукового поле, например, полученное с большим числом пространственно распределенных аудиоисточников, излучающих взаимно некоррелированных шумы. Некоторые математические выражения можно использовать для оценки величины диффузности. Например, в Pulkki В., "Directional audio coding in spatial sound reproduction and stereo upmixing," in Proceedings of the AES 28th International Conference, pp.251-258, Pitea, Sweden, June 30 - July 2, 2006, диффузность вычисляется путем анализа энергии входных сигналов, сравнивая активной интенсивности звука энергетическое поле.
Далее будет представлена оценка достоверности. В зависимости от направления поступления используется оценка, которую можно измерить и которая выражает, насколько надежно определено каждое направление в каждой частотно-временной последовательности. Эта информация может быть использована при определении количества и месторасположения источников, а также при расчете весовых коэффициентов на этапах 403 и 404, соответственно.
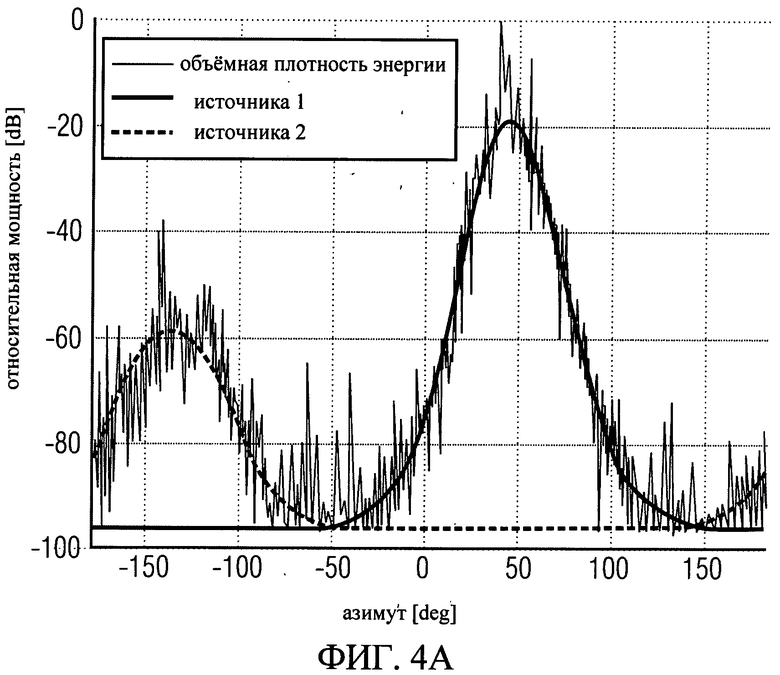
В следующем воплощения процессора 130, а также этап 404 "определение количества и месторасположения источников" будут подробно описаны. Количество и месторасположение источников звука для каждого временного фрейма может быть получено из априорных сведений, то есть эти параметры либо задаются на входе либо оцениваются автоматически. В последнем случае существует несколько подходов. Например, оценка максимальной вероятности объемной (пространственной) плотности мощности может быть использована в вариантах. В воплощениях плотность мощности входного сигнала может быть вычислена в зависимости от направления. В предположении, что источники звука имеют форму распределения по фон Мизесу, можно оценить, сколько имеется источников и где они расположены, выбрав решение с наибольшей вероятностью. Пример идеального пространственного распределения изображен на фиг.4а.
На фиг.4а показан график пространственной плотности мощности, создаваемой двумя аудиоисточниками. Фиг.4а показывает относительные мощности в дБ по оси ординат и азимутальный угол по оси абсцисс. Кроме того, на фиг.4а изображены три различных сигнала, один из которых представляет реальную пространственную плотность мощности, которая показана тонкой линией, при наличии шума. Кроме того, жирной линией показана теоретическая пространственной плотность мощности первого источника, а пунктирная линия показывает то же самое для второго источника. Модель, которая наилучшим образом соответствует практическим результатам, состоит из двух аудиоисточников, расположенных под углами 45° и -135° соответственно. В других моделях угол восхождения также может использоваться. В таких вариантах пространственная плотность мощности становится трехмерной функцией.
Далее представлена более подробная информация о реализации другого варианта процессора 130, особенно на этапе 403 расчета весовых коэффициентов. Блок обработки вычисляет весовые коэффициенты для каждого извлекаемого объекта. Весовые коэффициенты рассчитываются на основе данных, предоставленных на этапе 401 DirAC анализа вместе с информацией этапа 404 о количестве источников и их местоположении. Информация может быть обработана одновременно по всем источникам или по отдельности, так что весовой коэффициент для каждого объекта рассчитывается независимо от других.
Весовые коэффициенты для i-х объектов определяются для каждой временной и частотной последовательности, так что если γi(k,n) обозначает весовые коэффициенты для частотного индекса k, и временного индекса k, комплексный спектр сжатого сигнала i-го объекта может быть легко вычислен:
Wi(k,n)=W(k,n)×γi(k,n).
Как уже упоминалось выше, сигналы, полученные таким образом, могут быть направлены в SAOC кодировщик. Тем не менее, в вариантах этот этап может быть полностью исключен при вычислении SAOC параметров непосредственно из весовых коэффициентов γi(k,n).
Далее будет кратко объяснено, как в вариантах могут быть вычислены весовые коэффициенты γi(k,n). Если не указано иное, далее все величины зависят от (k,n), а именно от частотных и временных индексов.
Можно предположить, что диффузность Ψ или оценка достоверности определены в диапазоне [0, 1], где Ψ=1 соответствует полностью диффузному сигнала. Кроме того, θ обозначает направление поступления, в следующем примере это означает азимутальный угол. Расширение на 3D-пространство выполняется очень легко.
Также γi обозначает весовой коэффициент, с которым сжатый сигнал масштабируется при извлечении аудиосигнала из i-го объекта, W(k,n) обозначает комплексный спектр сигнала и сжатия, и Wi(k,n) обозначает комплексный спектр i-го извлеченного объекта.
В первом варианте двумерная функция определена в области (θ,Ψ). Упрощенное воплощение использует 2D функции Гаусса g(θ,Ψ) в соответствии с выражением:
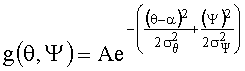
где α это направление, в котором находится объект, и 

Весовой коэффициент γi(k,n) может быть определено путем вычисления записанного выше уравнения для значений θ(k,n) и Ψ(k,n), полученного при DirAC обработке, т.е.
γi(k,n)=g(θ(k,n),Ψ(k,n)).
Идеальный вид функции показан на фиг.4б. Из фиг.4б видно, что большие значения весовых коэффициентов получаются при малых значениях диффузности. Для фиг.4б полагаем, что α=-π/4 рад (или -45 град), 
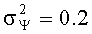
Весовой коэффициент будет максимальным для Ψ(k,n)=0 и θ=α. Для направления, сильно отличающегося от α, а также для больших значений диффузности весовой коэффициент уменьшается. При изменении параметров g(θ(k,n),Ψ(k,n)) могут быть построены несколько функций g(θ(k,n),Ψ(k,n)), которые извлекают объекты из различных направлений.
Если весовые коэффициенты, полученные от разных объектов, приводят к значениям полной энергии, большей, чем у сжатого сигнала, то есть если

то можно регулировать коэффициенты умножения А в функции g(θ(k,n),Ψ(k,n)), чтобы установить сумму квадратов меньше или равной 1.
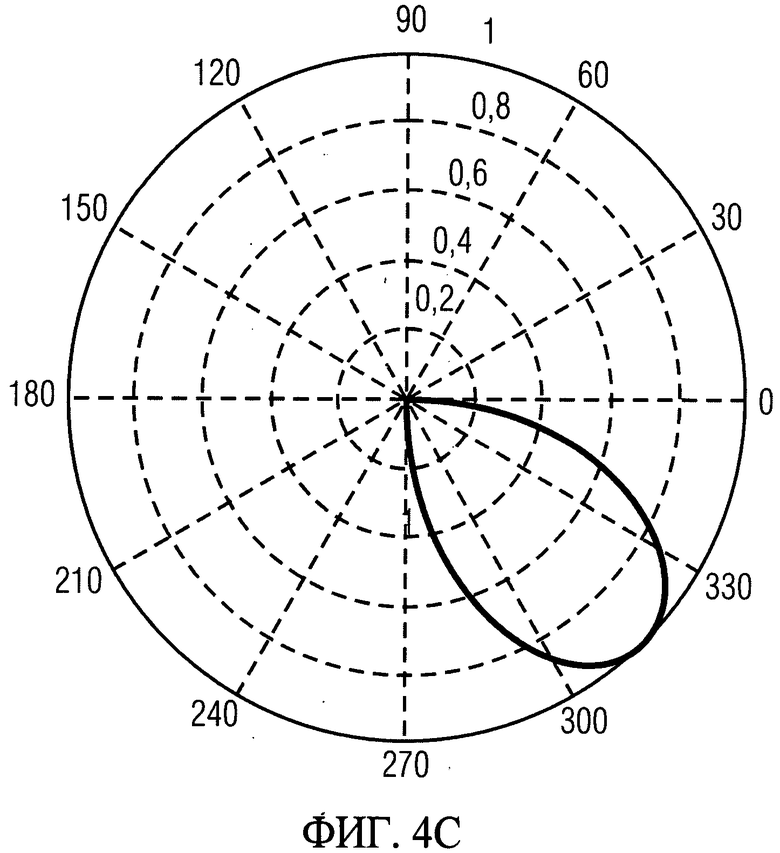
Во втором воплощении весовые коэффициенты для диффузной и недиффузной частей звукового сигнала могут быть определены с помощью различных весовых окон. Более подробную информацию можно найти в Markus Kallinger, Giovanni Del Galdo, Fabian Kuech, Dirk Mahne, Richard Schultz-Amling, "SPATIAL FILTERING USING DIRECTIONAL АУДИО CODING PARAMETERS", ICASSP 09.
Спектр i-го объекта может быть получен с помощью формулы:
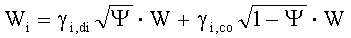
где γi,di и γi,co являются весовыми коэффициентами для диффузной и недиффузной (когерентной) частей, соответственно. Усиление для недиффузной части может быть получено из одномерного окна следующим образом:

где В - ширина окна.
Идеальный вид окна α=-π/4, В=π/4 изображен на фиг.4с.
Усиление для диффузной части, γi,di, может быть получено таким же образом. Соответствующие окна, например, кардиоиды или близкие к кардиоидам, направлены на α, или даже могут быть всенаправленными. После того как вычисляются значения усиления, γi,di и γi,co, весовой коэффициент γi может быть просто получен:

так что Wi=γi·W.
Если весовые коэффициенты, полученные для различных объектов, приводят к значениям полной энергии, большей, чем энергия сжатого сигнала, то есть если
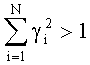
то можно соответственно масштабировать усиление γi.
Этот блок обработки может также получать весовые коэффициенты для дополнительного фонового (остаточного) объекта, для которого мощность рассчитывается в блоке 402. Фоновый объект содержит оставшуюся энергию, которая не была назначена любому другому объекту. Энергия может быть задана объекту второго плана, чтобы исключить неопределенность оценки направления. Например, определенное направление поступления в течение частотно-временного интервала оценивается по точности направления на определенный объект. Однако так как оценка имеет ошибку, небольшая часть энергии может быть назначена объекту второго плана.
Далее представлены подробные сведения о другом варианте процессора 130, особенно этап 402 "определение разделенных источников мощности". Этот блок обработки использует весовые коэффициенты, вычисленные в 403, и применяет их для расчета энергии каждого объекта, если γi(k,n) обозначает вес i-го объекта для частотно-временного интервала, определяется (k,n), затем легко определяется энергия Ei(k,n):
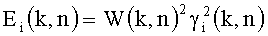
где W(k,n) - это комплексное частотно-временное представление сжатого сигнала.
В идеальном случае сумма энергий всех объектов равна энергии, присутствующей в сжатом сигнале, а именно:
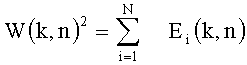
где N - это количество объектов.
Это может быть достигнуто различными способами. Один вариант может включать использование остаточного объекта, как уже упоминалось в контексте расчета весового коэффициента. Функция остаточного объекта для представления недостающей мощности в общем балансе мощности выходных объектов такова, что их общая мощность равна мощности сжатого сигнала в каждый момент времени/частоты.
Другими словами, в вариантах процессор 130 может быть адаптирован для последующего определения весового коэффициента для дополнительного фонового объекта, у которого весовые коэффициенты таковы, что сумма энергий, связанных, по крайней мере, с двумя разделенными источниками звука и дополнительного фонового объекта, равна энергии представления преобразованного сигнала.
В стандарте SAOC ISO/IEC, "MPEG аудио technologies - Part 2: Spatial Audio Object Coding (SAOC)," ISO/IECJTC1/SC29/WG11 (MPEG) FCD 23003-2), определен соответствующий механизм того, как выделить недостающую энергию. Другой пример стратегии может включать в себя соответствующее масштабирование весовых коэффициентов для достижения желаемого общего баланса энергии.
В общем, если этап 403 формирует весовые коэффициенты для фонового объекта, эта энергия может быть присвоена остаточному объекту. Далее представлена более подробная информация о расчете SAOC OLDs и, кроме того, IOCs и на этапе 405 формируется битовый поток таким образом, как это может быть выполнено в вариантах.
Этот блок выполняет дальнейшую обработку мощности аудиообъектов и преобразование ее в SAOC совместимые параметры, то есть OLDs. Для этого мощности объектов нормируются по отношению к мощности объекта с наибольшей мощностью, в результате чего получаются относительные значения мощности для каждого временного/частотного интервала. Эти параметры могут быть использованы непосредственно для последующей обработки в SAOC декодировщике или они могут квантоваться (дискретизироваться) и передаваться/храниться как часть битового потока SAOC. Кроме того, IOC параметры могут быть выведены или переданы/сохранены как часть SAOC битового потока.
В зависимости от определенных требований реализации изобретения предложенные способы могут быть реализованы в оборудовании или в программном обеспечении. Реализация может быть выполнена с использованием цифровых носителей, в частности дисков, DVD или компакт-дисков с читаемыми электронным способом управляющими сигналами, хранящимися на носителе, которые взаимодействуют с программной системой компьютера таким образом, что способы изобретения выполняются. Таким образом, изобретение является программным продуктом с программным кодом, хранящимся на машиночитаемом носителе, программным кодом, способным для выполнения способов изобретения, при запуске компьютерного программного продукта на компьютере. Другими словами, способы изобретения являются, таким образом, компьютерной программой, имеющей программные коды для выполнения хотя бы одного из способов изобретения, при запуске компьютерной программы.
Выше были подробно показаны и описаны способы изобретения со ссылкой на конкретные варианты их исполнения, однако специалистам в данной области будет понятно, что различные изменения в форме и деталях могут быть сделаны без отступления от основных идей изобретения. Следует понимать, что различные изменения могут быть сделаны в процессе адаптации к различным воплощениям, не отходя от более общих представлений, описанных выше, и изложенных далее в формуле изобретения.


Изобретение относится к транскодировщику аудиоформата (100) для транскодирования входного аудиосигнала. Технический результат заключается в эффективном объединении возможностей направленного и пространственного аудиокодирования. Входной звуковой сигнал имеет не менее двух направленных аудиокомпонентов. Транскодировщик аудиоформата (100) включает преобразователь (110) для преобразования входного аудиосигнала в преобразованный сигнал, имеющий представление преобразованного сигнала и направление поступления преобразованного сигнала. Транскодировщик аудиоформата (100) дополнительно содержит определитель положения (120) для определения, по крайней мере, двух пространственных местоположений, по крайней мере, двух пространственных источников звука. Транскодировщик аудиоформата (100) также содержит процессор (130) для обработки представления преобразованного сигнала с использованием не менее двух пространственных местоположений для получения. по крайней мере, двух измерений разделенных источников звука. 3 н. и 9 з.п. ф-лы, 11 ил.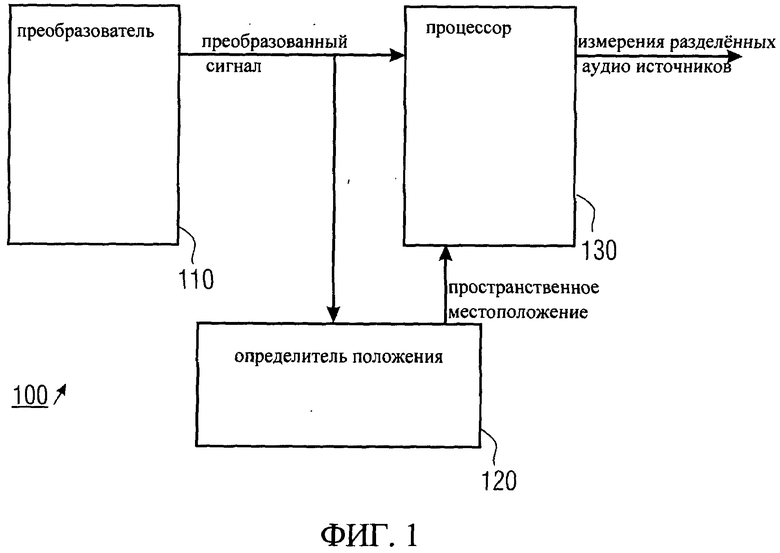
1 .Транскодировщик аудиоформата (100) для транскодирования входного аудиосигнала, имеющего не менее двух направлений аудиокомпонентов, включающий конвертер (110) для преобразования входного аудиосигнала в преобразованный сигнал, имеющий представление преобразованного сигнала и направление поступления преобразованного сигнала; определитель положения (120) для определения, по крайней мере, двух пространственных местоположений, по крайней мере, двух пространственных источников звука, а также процессор (130) для обработки представления преобразованного сигнала на основе не менее двух пространственных местоположений и направлений поступления преобразованного сигнала для получения, по крайней мере, двух измерений разделенных аудиоисточников, причем процессор (130) приспособлен для определения (303) весового коэффициента для каждого, по крайней мере, из двух разделенных источников звука, а также процессор (130) приспособлен для обработки представления преобразованного сигнала с помощью, по крайней мере, двух пространственных фильтров (311,312, 31N) в зависимости от весовых коэффициентов для аппроксимации, по крайней мере, двух отдельных источников звука, по крайней мере, двумя отдельными источниками аудиосигналов с помощью как минимум двух измерений отдельных источников звука, или процессор (130) приспособлен для оценки (402) мощности сигнала каждого, по крайней мере, из двух разделенных источников звука в зависимости от весовых коэффициентов с помощью как минимум двух измерений отдельных источников звука.
2. Транскодировщик аудиоформата (100) по п.1, в котором входной аудиосигнал, имеющий, по меньшей мере, два направленных аудиокомпонента, является направленным кодированным аудиосигналом DirAC, сигналом В-формата или сигналом от набора направленных микрофонов.
3. Транскодировщик аудиоформата (100) по п.1, в котором конвертер (110) приспособлен для преобразования входного аудиосигнала в сигнал с преобразованным числом частотных полос/подполос и/или интервалов времени/фреймов.
4. Транскодировщик аудиоформата (100) по п.3, в котором конвертер (110) приспособлен для преобразования входного аудиосигнала в преобразованный сигнал, содержащий, кроме указанных составляющих, значение диффузности и/или оценку достоверности по каждой полосе частот.
5. Транскодировщик аудиоформата (100) по п.1, дополнительно включающий кодировщик SAOC (Пространственное Кодирование Аудио Объекта) для кодирования, по крайней мере, двух раздельных аудиосигналов источников для получения SAOC кодированного сигнала, включающего SAOC компоненты сжатого сигнала и сведения о компонентах SAOC дополнительной информации.
6. Транскодировщик аудиоформата (100) по п.1, в котором процессор (130) для обработки представления преобразованного сигнала выполнен с возможностью пересчета показателей мощности, по меньшей мере, двух отдельных источников звука с получением значений разности уровней аудиообъектов пространственного кодирования OLD SAOC .
7. Транскодировщик аудиоформата (100) по п.6, в котором процессор (130) выполнен с возможностью обработки представления преобразованного сигнала для вычисления межобъектной когерентности IOC, по меньшей мере, двух отдельных источников звука.
8. Транскодировщик аудиоформата (100) по п.3, в котором определитель положения (120) как минимум двух источников пространственного звука включает детектор, рассчитанный на распознавание, по меньшей мере, двух положений в пространстве как минимум двух источников пространственного звука на основе преобразованного сигнала, при этом детектор, распознающий как минимум два пространственных положения, выполнен с возможностью такого распознавания путем комбинации множества последовательных временных интервалов/фреймов входного сигнала.
9. Транскодировщик аудиоформата (100) по п.8, в котором детектор адаптирован для обнаружения, по крайней мере, двух пространственных положений на основе оценки максимального значения вероятности пространственной плотности мощности преобразованного сигнала.
10. Транскодировщик аудиоформата (100) по п.1, в котором процессор (130) приспособлен для последующего определения весового коэффициента дополнительного фонового объекта, причем весовые коэффициенты таковы, что сумма энергий, соответствующая, по крайней мере, двум разделенным источникам звука и дополнительному фоновому объекту, равна энергии представления преобразованного сигнала.
11. Способ транскодирования аудиосигнала, входного аудиосигнала, имеющего не менее двух направлений аудиокомпонентов, включающий этапы преобразования входного аудиосигнала в преобразованный сигнал, имеющий представление преобразованного сигнала и направление поступления преобразованного сигнала; определения не менее двух пространственных местоположений, по меньшей мере, двух пространственных источников звука, а также обработки представления преобразованного сигнала на основе не менее двух пространственных положений для получения, по крайней мере, двух отдельных измерений аудиоисточников, в котором шаг обработки включает определение (303) весового коэффициента для каждого, по крайней мере, из двух разделенных источников звука, а также обработку представления преобразованного сигнала с использованием не менее двух пространственных фильтров (311, 312, 31N) в зависимости от весовых коэффициентов для аппроксимации, по крайней мере, двух отдельных источников звука, по крайней мере, двумя отдельными звуковыми сигналами источника, в виде, по крайней мере, двух отдельных измерений аудиоисточников, или оценку (402) мощности сигнала каждого по крайней мере из двух разделенных источников звука в зависимости от весовых коэффициентов, с помощью как минимум двух отдельных измерений источников звука.
12. Машиночитаемый носитель информации с записанной на нем компьютерной программой для осуществления способа по п.11 при условии выполнения компьютерной программы с использованием компьютерной или процессорной техники.
| WO 2006024977 A1, 09.03.2006 | |||
| EP 1890456 A1, 20.02.2008 | |||
| US 7260524 B2, 21.08.2007 | |||
| ПРЕОБРАЗОВАНИЕ ФОРМАТА АУДИОФАЙЛА | 2004 |
|
RU2335022C2 |
| WO 2005078707 A1, 25.08.2005 | |||

