Настоящее изобретение направлено на аудиокодирование и, в частности, на генерирование описания звукового поля из входного сигнала с использованием одного или более генераторов звуковых компонент.
Методика [1] направленного аудиокодирования (DirAC) представляет собой эффективный подход к анализу и воспроизведению пространственного звука. DirAC использует перцептивно-мотивированное представление звукового поля на основе направления прихода (DOA) и диффузности, измеряемых для каждой полосы частот. Оно основано на предположении, что в один момент времени и в одном критическом диапазоне пространственное разрешение слуховой системы ограничивается декодированием одного указателя для направления и другого - для межуральной согласованности. Затем пространственный звук представляется в частотной области посредством плавного микширования двух потоков: ненаправленного диффузного потока и направленного недиффузного потока.
DirAC изначально предназначалось для записанного звука в B-формате, но его также можно расширить для сигналов микрофона, соответствующих некоторой конкретной схеме громкоговорителей, такой как 5.1 [2], или любой конфигурации микрофонных решеток [5]. В последнем случае можно достичь большей гибкости, записывая сигналы не для некоторой конкретной схемы громкоговорителей, а вместо этого записывая сигналы промежуточного формата.
Такой промежуточный формат, хорошо зарекомендовавший себя на практике, представлен Амбисоникой/Ambisonics (более высокого порядка) [3]. Из амбисонического сигнала можно генерировать сигналы любой желаемой схемы громкоговорителей, в том числе бинауральные сигналы для воспроизведения через наушники. Для этого требуется специальный рендерер, который применяется к амбисоническому сигналу, используя либо линейный амбисонический рендерер [3], либо параметрический рендерер, такой как направленное аудиокодирование (DirAC).
Амбисонический сигнал может быть представлен как многоканальный сигнал, в котором каждый канал (именуемый амбисонической компонентой) эквивалентен коэффициенту так называемой пространственной базисной функции. С помощью взвешенной суммы этих пространственных базисных функций (с весами, соответствующими коэффициентам) можно воссоздать исходное звуковое поле в месте записи [3]. Следовательно, коэффициенты пространственной базисной функции (т.е. амбисонические компоненты) представляют собой компактное описание звукового поля в месте записи. Существуют различные типы пространственных базисных функций, например сферические гармоники (SH) [3] или цилиндрические гармоники (CH) [3]. CH могут быть использованы при описании звукового поля в 2D-пространстве (например, для воспроизведения 2D-звука), тогда как SH могут быть использованы для описания звукового поля в 2D- и 3D-пространстве (например, для воспроизведения 2D- и 3D-звука).
Например, аудиосигнал 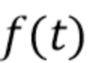 , который приходит с определенного направления
, который приходит с определенного направления 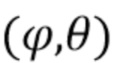 , приводит в результате к пространственному аудиосигналу
, приводит в результате к пространственному аудиосигналу 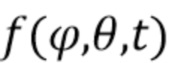 , который может быть представлен в амбисоническом формате путем расширения сферических гармоник вплоть до порядка отсечения H:
, который может быть представлен в амбисоническом формате путем расширения сферических гармоник вплоть до порядка отсечения H:
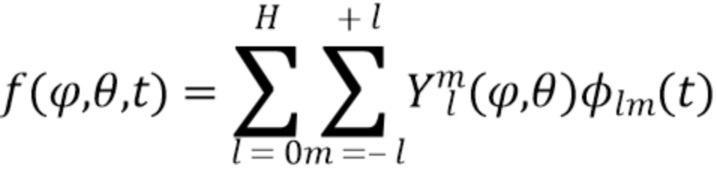
где 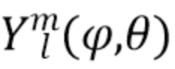 представляет собой сферические гармоники порядка l и моды (mode) m, а
представляет собой сферические гармоники порядка l и моды (mode) m, а 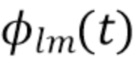 представляют собой коэффициенты расширения. С увеличением порядка отсечения H такое расширение приводит к более точному пространственному представлению. Сферические гармоники вплоть до порядка H=4 с индексом нумерации амбисонических каналов (ACN) проиллюстрированы на Фиг. 1a для порядка n и моды m.
представляют собой коэффициенты расширения. С увеличением порядка отсечения H такое расширение приводит к более точному пространственному представлению. Сферические гармоники вплоть до порядка H=4 с индексом нумерации амбисонических каналов (ACN) проиллюстрированы на Фиг. 1a для порядка n и моды m.
DirAC уже было расширено для доставки амбисонических сигналов более высокого порядка из амбисонического сигнала первого порядка (FOA, также именуемого как B-формат) или из различных микрофонных решеток [5]. Этот документ фокусируется на более эффективном способе синтеза амбисонических сигналов более высокого порядка из параметров DirAC и опорного сигнала. В этом документе опорный сигнал, также именуемый сигналом понижающего микширования, считается подмножеством амбисонического сигнала более высокого порядка или линейной комбинацией подмножества амбисонических компонент.
Кроме того, в настоящем изобретении рассматривается случай, в котором DirAC используется для передачи в параметрической форме аудиосцены. В этом случае сигнал понижающего микширования кодируется обычным базовым аудиокодером, в то время как параметры DirAC передаются в сжатом виде как вспомогательная информация. Преимущество настоящего способа состоит в учете ошибки квантования, возникающей при аудиокодировании.
Далее представлен обзор системы пространственного аудиокодирования на основе DirAC, разработанной для иммерсивных голосовых и аудиосервисов (IVAS). Это представляет один из различных контекстов, например обзор системы пространственного аудиокодера DirAC. Задача такой системы заключается в том, чтобы иметь возможность обрабатывать различные пространственные аудиоформаты, представляющие аудиосцену, и кодировать их с низкими битрейтами, а также воспроизводить исходную аудиосцену после передачи настолько верно, насколько это возможно.
Система может принимать в качестве входных данных различные представления аудиосцен. Входная аудиосцена может быть захвачена многоканальными сигналами, предназначенными для воспроизведения в различных положениях громкоговорителей, слышимыми объектами вместе с метаданными, описывающими положения этих объектов с течением времени, или амбисоническим форматом первого порядка или более высокого порядка, представляющим звуковое поле в положении слушателя или опорном положении.
Предпочтительно данная система основана на расширенных голосовых сервисах (EVS) 3GPP, поскольку ожидается, что такое решение будет работать с малой задержкой для обеспечения возможности разговорных сервисов в сетях мобильной связи.
Как показано на Фиг. 1b, кодер (кодер IVAS) может поддерживать различные аудиоформаты, передаваемые в систему по отдельности или в одно и то же время. Аудиосигналы могут быть акустическими по своей природе, воспринимаемыми микрофонами, или электрическими по своей природе, которые подлежат передачи на громкоговорители. Поддерживаемые аудиоформаты могут быть многоканальным сигналом, амбисоническими компонентами первого порядка и более высокого порядка, а также аудиообъектами. Сложная аудиосцена также может быть описана посредством объединения различных входных форматов. Затем все аудиоформаты передаются в анализатор DirAC, который извлекает параметрическое представление всей аудиосцены. Направление прихода и диффузность, измеряемые для каждой частотно-временной единицы, формируют параметры. За анализатором DirAC следует кодер пространственных метаданных, который квантует и кодирует параметры DirAC для получения параметрического представления низкого битрейта.
Наряду с этими параметрами сигнал понижающего микширования, выводимый из различных источников или входных аудиосигналов, кодируется для передачи с помощью обычного базового аудиокодера. В этом случае основанный на EVS аудиокодер применяется для кодирования сигнала понижающего микширования. Сигнал понижающего микширования состоит из разных каналов, именуемых транспортными каналами: сигнал может представлять собой, например, четыре сигнала коэффициентов, составляющие сигнал B-формата, стереопару или монофоническое понижающее микширование в зависимости от целевого битрейта. Кодированные пространственные параметры и кодированный битовый аудиопоток мультиплексируются перед передачей по каналу связи.
Сторона кодера пространственного аудиокодирования на основе DirAC, поддерживающего различные аудиоформаты, проиллюстрирована на Фиг. 1b. Акустический/электрический ввод (входные данные) 1000 вводится в интерфейс 1010 кодера, причем интерфейс кодера обладает определенной функциональностью для амбисоники первого порядка (FOA) или амбисоники высокого порядка (HOA), проиллюстрированной в 1013. Кроме того, интерфейс кодера обладает функциональностью для многоканальных (MC) данных, таких как стереоданные, данные 5.1 или данные, имеющие более двух или пяти каналов. Кроме того, интерфейс 1010 кодера обладает функциональностью для кодирования объектов, как, например, SAOC (пространственное кодирование аудиообъектов), проиллюстрированное 1011. Кодер IVAS содержит каскад 1020 DirAC с блоком 1021 анализа DirAC и блоком 1022 понижающего микширования (DMX). Сигнал, выводимый блоком 1022, кодируется базовым кодером 1040 IVAS, таким как кодер AAC или EVS, а метаданные, сгенерированные блоком 1021, кодируются с использованием кодера 1030 метаданных DirAC.
В декодере, показанном на Фиг. 2, транспортные каналы декодируются базовым декодером, тогда как метаданные DirAC сначала декодируются перед их передачей с декодированными транспортными каналами в блок синтеза DirAC. На данной стадии могут быть рассмотрены различные варианты. Может потребоваться воспроизвести определенную аудиосцену непосредственно на конфигурациях каких-либо громкоговорителей или наушников, как это обычно возможно в традиционной системе DirAC (MC на Фиг. 2).
Декодер также может доставлять отдельные объекты в том виде, в котором они были представлены на стороне кодера (Объекты на Фиг. 2).
В качестве альтернативы, также может потребоваться выполнить рендеринг сцены в амбисонический формат для других дальнейших манипуляций, таких как вращение, отражение или движение сцены (FOA/HOA на Фиг. 2) или для использования внешнего рендерера, не определенного в исходной системе.
Декодер пространственного аудиокодирования DirAC, доставляющий различные аудиоформаты, проиллюстрирован на Фиг. 2 и содержит декодер 1045 IVAS и подключенный далее интерфейс 1046 декодера. Декодер 1045 IVAS содержит базовый декодер 1060 IVAS, который сконфигурирован для того, чтобы выполнять операцию декодирования содержимого, закодированного базовым кодером 1040 IVAS с Фиг. 1b. Кроме того, предоставляется декодер 1050 метаданных DirAC, который обеспечивает функциональность декодирования для декодирования содержимого, закодированного кодером 1030 метаданных DirAC. Блок 1070 синтеза принимает данные из блока 1050 и 1060 и с помощью некоторой пользовательской интерактивности или без нее, вывод (выходные данные) вводится в интерфейс 1046 декодера, который генерирует данные FOA/HOA, как проиллюстрировано в 1083, многоканальные данные (данные MC), как проиллюстрировано в блоке 1082, или данные объектов, как проиллюстрировано в блоке 1081.
Традиционный синтез HOA с использованием парадигмы DirAC изображен на Фиг. 3. Входной сигнал, именуемый сигналом понижающего микширования, является частотно-временной единицей, анализируемой блоком частотных фильтров. Блок 2000 частотных фильтров может быть блоком комплекснозначных фильтров, таким как комплекснозначный QMF, или блочным преобразованием типа STFT. Синтез HOA генерирует на выходе амбисонический сигнал порядка H, содержащий 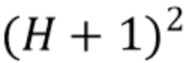 компонент. Опционально он также может выводить амбисонический сигнал, рендеринг которого выполняется с конкретной схемой громкоговорителей. Далее мы подробно рассмотрим, как получить компонент из сигнала понижающего микширования, сопровождаемого в некоторых случаях входными пространственными параметрами.
компонент. Опционально он также может выводить амбисонический сигнал, рендеринг которого выполняется с конкретной схемой громкоговорителей. Далее мы подробно рассмотрим, как получить компонент из сигнала понижающего микширования, сопровождаемого в некоторых случаях входными пространственными параметрами.
Сигнал понижающего микширования может представлять собой исходные микрофонные сигналы или смесь исходных сигналов, представляющих исходную аудиосцену. Например, если аудиосцена захватывается микрофоном звукового поля, сигнал понижающего микширования может представлять собой всенаправленную компоненту сцены (W), стереофоническое понижающее микширование (L/R) или амбисонический сигнал первого порядка (FOA).
Для каждого частотно-временного фрагмента, направление звука, также именуемое направлением прихода (DOA), и коэффициент диффузности оцениваются, соответственно, блоком 2020 оценки направления и блоком 2010 оценки диффузности, если сигнал понижающего микширования содержит достаточную информацию для определения таких параметров DirAC. Это так, например, если сигналом понижающего микширования является амбисонический сигнал первого порядка (FOA). В качестве альтернативы или если сигнала понижающего микширования недостаточно для определения таких параметров, параметры могут быть переданы непосредственно в синтез DirAC через входной битовый поток, содержащий эти пространственные параметры. Битовый поток может состоять, например, из квантованных и закодированных параметров, принимаемых в качестве вспомогательной информации в случае приложений передачи аудиоданных. В этом случае параметры выводятся вне модуля синтеза DirAC из исходных микрофонных сигналов или входных аудиоформатов, передаваемых модулю анализа DirAC на стороне кодера, как проиллюстрировано переключателем 2030 или 2040.
Направления звука используются блоком 2050 оценки направленных усилений для оценки, для каждого частотно-временного фрагмента из множества частотно-временных фрагментов, одного или более наборов из направленных усилений 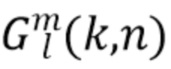 , где H представляет порядок синтезируемого амбисонического сигнала.
, где H представляет порядок синтезируемого амбисонического сигнала.
Направленные усиления могут быть получены посредством оценки пространственной базисной функции для каждого оцениваемого направления звука с желаемым порядком (уровнем) l и модой m амбисонического сигнала для синтеза. Направление звука может быть выражено, например, через вектор 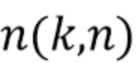 единичной нормы или через азимутальный угол
единичной нормы или через азимутальный угол 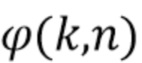 и/или угол
и/или угол 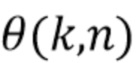 возвышения, которые связаны, например, как:
возвышения, которые связаны, например, как:
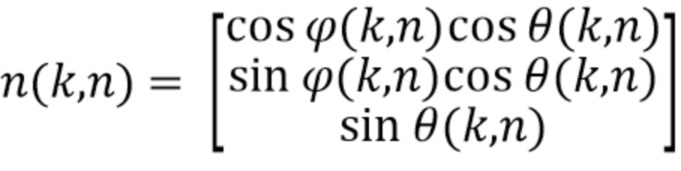
После оценки или получения направления звука ответ пространственной базисной функции желаемого порядка (уровня) l и моды m может быть определен, например, посредством рассмотрения действительнозначных сферических гармоник с SN3D нормализацией в качестве пространственной базисной функции:
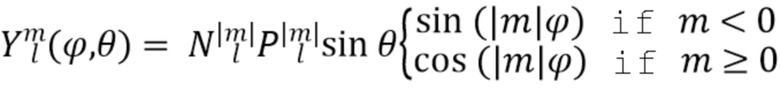
с диапазонами 0≤l≤H и −l≤m≤l. 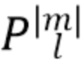 представляют собой функции Лежандра, а
представляют собой функции Лежандра, а 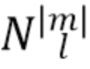 представляет собой член нормализации как для функций Лежандра, так и для тригонометрических функций, который принимает следующую форму для SN3D:
представляет собой член нормализации как для функций Лежандра, так и для тригонометрических функций, который принимает следующую форму для SN3D:
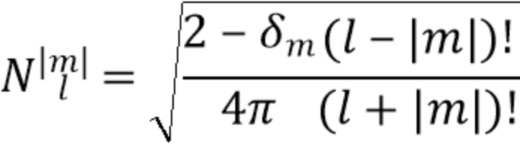
где дельта Кронекера 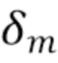 равна единице для m=0 и нулю в ином случае. Затем направленные усиления выводятся непосредственно для каждого частотно-временного фрагмента с индексами (k, n) как:
равна единице для m=0 и нулю в ином случае. Затем направленные усиления выводятся непосредственно для каждого частотно-временного фрагмента с индексами (k, n) как:
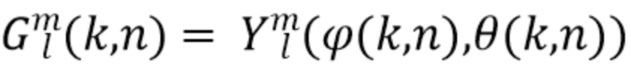
Амбисонические компоненты 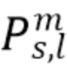 прямого звука вычисляются путем выведения опорного сигнала
прямого звука вычисляются путем выведения опорного сигнала 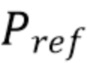 из сигнала понижающего микширования и умножаются на направленные усиления и коэффициентную функцию диффузности
из сигнала понижающего микширования и умножаются на направленные усиления и коэффициентную функцию диффузности 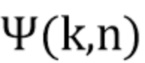 :
:

Например, опорный сигнал может быть всенаправленной компонентой сигнала понижающего микширования или линейной комбинацией K каналов сигнала понижающего микширования.
Амбисоническая компонента диффузного звука может быть смоделирована посредством использования ответа пространственной базисной функции для звуков, приходящих со всех возможных направлений. Одним из примеров является определение среднего ответа 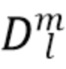 посредством рассмотрения интеграла квадрата абсолютной величины пространственной базисной функции
посредством рассмотрения интеграла квадрата абсолютной величины пространственной базисной функции 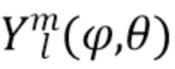 по всем возможным углам
по всем возможным углам 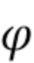 и
и 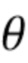 :
:
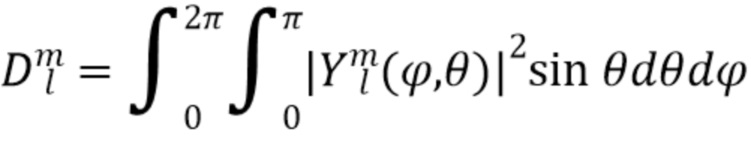
Амбисонические компоненты 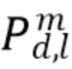 диффузного звука вычисляются из сигнала
диффузного звука вычисляются из сигнала 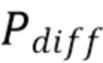 умноженного на средний ответ и коэффициентную функцию диффузности :
умноженного на средний ответ и коэффициентную функцию диффузности :
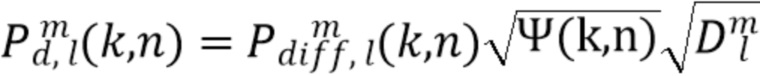
Сигнал 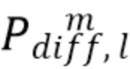 может быть получен с помощью различных декорреляторов, применяемых к опорному сигналу .
может быть получен с помощью различных декорреляторов, применяемых к опорному сигналу .
Наконец, амбисоническая компонента прямого звука и амбисоническая компонента диффузного звука объединяются 2060, например, посредством операции суммирования, чтобы получить окончательную амбисоническую компоненту 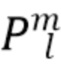 желаемого порядка (уровня) l и моды m для частотно-временного фрагмента (k, n), т.е.
желаемого порядка (уровня) l и моды m для частотно-временного фрагмента (k, n), т.е.
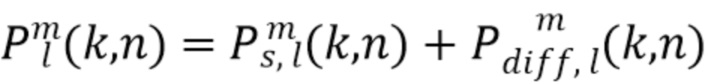
Полученные амбисонические компоненты могут быть преобразованы обратно во временную область с использованием блока 2080 обратных фильтров или обратного STFT, сохранены, переданы или использованы, например, для приложений пространственного воспроизведения звука. В качестве альтернативы, линейный амбисонический рендерер 2070 может быть применен для каждой полосы частот для получения сигналов, которые подлежат воспроизведению с конкретной схемой громкоговорителей или через наушники, перед преобразованием сигналов громкоговорителей или бинауральных сигналов во временную область.
Следует отметить, что [5] также указывает на возможность того, что компоненты 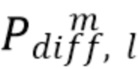 диффузного звука могут быть синтезированы только вплоть до порядка L, где L<H. Это снижает вычислительную сложность, одновременно с этим избегая синтетических артефактов из-за интенсивного использования декорреляторов.
диффузного звука могут быть синтезированы только вплоть до порядка L, где L<H. Это снижает вычислительную сложность, одновременно с этим избегая синтетических артефактов из-за интенсивного использования декорреляторов.
Целью настоящего изобретения является предоставление улучшенной схемы генерирования описания звукового поля из входного сигнала.
Эта цель достигается устройством для генерирования описания звукового поля по пункту 1, способом для генерирования описания звукового поля по пункту 20 или компьютерной программой по пункту 21.
Настоящее изобретение в соответствии с первым аспектом основано на обнаружении того, что нет необходимости выполнять синтез компонент звукового поля, в том числе вычисление диффузной части, для всех генерируемых компонент. Достаточно выполнить синтез диффузных компонент только до определенного порядка. Тем не менее, чтобы не было флуктуаций энергии или ошибок энергии, компенсация энергии выполняется при генерировании компонент звукового поля первой группы компонент звукового поля, которые имеют диффузную и прямую компоненту, при этом такая компенсация энергии зависит от данных о диффузности и по меньшей мере одного из числа компонент звукового поля во второй группе, максимального порядка компонент звукового поля первой группы и максимального порядка компонент звукового поля второй группы. В частности, в соответствии с первым аспектом настоящего изобретения устройство для генерирования описания звукового поля из входного сигнала, содержащего один или более каналов, содержит анализатор входного сигнала для получения данных о диффузности из входного сигнала и генератор звуковых компонент для генерирования из входного сигнала одной или более компонент звукового поля первой группы компонент звукового поля, имеющих для каждой компоненты звукового поля прямую компоненту и диффузную компоненту, и для генерирования из входного сигнала второй группы компонент звукового поля, имеющих только прямую компоненту. В частности, генератор звуковых компонент выполняет компенсацию энергии при генерировании первой группы компонент звукового поля, причем компенсация энергии зависит от данных о диффузности и по меньшей мере одного из числа компонент звукового поля во второй группе, числа диффузных компонент в первой группе, максимального порядка компонент звукового поля первой группы и максимального порядка компонент звукового поля второй группы.
Первая группа компонент звукового поля может содержать компоненты звукового поля низкого порядка и компоненты звукового поля среднего порядка, а вторая группа содержит компоненты звукового поля высокого порядка.
Устройство для генерирования описания звукового поля из входного сигнала, содержащего по меньшей мере два канала, в соответствии со вторым аспектом изобретения, содержит анализатор входного сигнала для получения данных о направлении и данных о диффузности из входного сигнала. Устройство, кроме того, содержит блок оценки для оценки первого связанного с энергией или амплитудой показателя для всенаправленной компоненты, выведенной из входного сигнала, и для оценки второго связанного с энергией или амплитудой показателя для направленной компоненты, выведенной из входного сигнала. Кроме того, устройство содержит генератор звуковых компонент для генерирования компонент звукового поля для звукового поля, причем генератор звуковых компонент выполнен с возможностью выполнения компенсации энергии направленной компоненты с использованием первого связанного с энергией или амплитудой показателя, второго связанного с энергией или амплитудой показателя, данных о направлении и данных о диффузности.
В частности, второй аспект настоящего изобретения основан на обнаружении того факта, что в ситуации, когда направленная компонента принимается устройством для генерирования описания звукового поля и в то же время также принимаются данные о направлении и данные о диффузности, данные о направлении и диффузности могут быть использованы для компенсации любых ошибок, вероятно, внесенных из-за квантования или любой другой обработки направленной или всенаправленной компоненты в кодере. Таким образом, данные о направлении и диффузности применяются не просто с целью генерирования описания звукового поля как таковые, но эти данные используются «второй раз» для корректировки направленной компоненты для того, чтобы устранить или по меньшей мере частично устранить и, следовательно, скомпенсировать потерю энергии направленной компоненты.
Предпочтительно, эта компенсация энергии выполняется для компонент низкого порядка, которые принимаются в интерфейсе декодера или которые генерируются из данных, принимаемых от аудиокодера, генерирующего входной сигнал.
В соответствии с третьим аспектом настоящего изобретения устройство для генерирования описания звукового поля с использованием входного сигнала, содержащего моносигнал или многоканальный сигнал, содержит анализатор входного сигнала, генератор низких аудиокомпонент, генератор компонент среднего порядка и генератор компонент высокого порядка. В частности, разные «суб»-генераторы выполнены с возможностью генерирования компонент звукового поля в соответствующем порядке на основе конкретной процедуры обработки, которая отличается для каждого из генератора компонент низкого, среднего или высокого порядка. Это гарантирует, что поддерживается оптимальный компромисс между требованиями к обработке, с одной стороны, требованиями к качеству аудио, с другой стороны, и практичностью процедур, с еще одной другой стороны. Посредством этой процедуры использование декорреляторов, например, ограничивается только генерированием компонент среднего порядка, но для генерирования компонент низкого порядка и генерирования компонент высокого порядка избегают любых декорреляторов, склонных к артефактам. С другой стороны, компенсация энергии предпочтительно выполняется для потери энергии диффузных компонент, и эта компенсация энергии выполняется только в пределах компонент звукового поля низкого порядка или только в пределах компонент звукового поля среднего порядка, или как в компонентах звукового поля низкого порядка, так и в компонентах звукового поля среднего порядка. Предпочтительно, чтобы компенсация энергии для направленной компоненты, формируемой в генераторе компонент низкого порядка, также выполнялась с использованием передаваемых данных направленной диффузности.
Предпочтительные варианты осуществления относятся к устройству, способу или компьютерной программе для синтеза амбисонического сигнала (более высокого порядка) с использованием парадигмы направленного аудиокодирования (DirAC), перцептивно-мотивированной методики для пространственной аудиообработки.
Варианты осуществления относятся к эффективному способу для синтезирования амбисонического представления аудиосцены из пространственных параметров и сигнала понижающего микширования. При применении способа, но не ограничиваясь этим, аудиосцена передается и, следовательно, кодируется для уменьшения объема передаваемых данных. Сигнал понижающего микширования после этого сильно ограничен в числе каналов и качестве битрейтом, который доступен для передачи. Варианты осуществления относятся к эффективному способу использования информации, содержащейся в передаваемом сигнале понижающего микширования, для уменьшения сложности синтезирования при одновременном повышении качества.
Другой вариант осуществления изобретения касается диффузной компоненты звукового поля, которая может быть ограничена только моделированием вплоть до предопределенного порядка синтезируемых компонент, чтобы избежать артефактов синтезирования. Вариант осуществления обеспечивает способ компенсации результирующей потери энергии путем усиления сигнала понижающего микширования.
Другой вариант осуществления касается направленной компоненты звукового поля, характеристики которой могут быть изменены в пределах сигнала понижающего микширования. Сигнал понижающего микширования может быть дополнительно нормализован по энергии, чтобы сохранить соотношение энергии, продиктованное переданным параметром направления, но нарушенное во время передачи из-за квантования или других введенных ошибок.
Далее предпочтительные варианты осуществления настоящего изобретения описаны со ссылкой на прилагаемые чертежи, на которых:
Фиг. 1a иллюстрирует сферические гармоники с нумерацией амбисонических каналов/компонент;
Фиг. 1b иллюстрирует сторону кодера процессора пространственного аудиокодирования на основе DirAC;
Фиг. 2 иллюстрирует декодер процессора пространственного аудиокодирования на основе DirAC;
Фиг. 3 иллюстрирует процессор синтеза амбисоники высокого порядка, известный из уровня техники;
Фиг. 4 иллюстрирует предпочтительный вариант осуществления настоящего изобретения с применением первого аспекта, второго аспекта и третьего аспекта;
Фиг. 5 иллюстрирует общую схему обработки для компенсации энергии;
Фиг. 6 иллюстрирует устройство для генерирования описания звукового поля в соответствии с первым аспектом настоящего изобретения;
Фиг. 7 иллюстрирует устройство для генерирования описания звукового поля в соответствии со вторым аспектом настоящего изобретения;
Фиг. 8 иллюстрирует устройство для генерирования описания звукового поля в соответствии с третьим аспектом настоящего изобретения;
Фиг. 9 иллюстрирует предпочтительную реализацию генератора компонент низкого порядка с Фиг. 8;
Фиг. 10 иллюстрирует предпочтительную реализацию генератора компонент среднего порядка с Фиг. 8;
Фиг. 11 иллюстрирует предпочтительную реализацию генератора компонент высокого порядка с Фиг. 8;
Фиг. 12а иллюстрирует предпочтительную реализацию вычисления компенсационного усиления в соответствии с первым аспектом;
Фиг. 12b иллюстрирует реализацию вычисления компенсационного усиления в соответствии со вторым аспектом; и
Фиг. 12c иллюстрирует предпочтительную реализацию компенсации энергии, объединяющую первый аспект и второй аспект.
Фиг. 6 иллюстрирует устройство для генерирования описания звукового поля в соответствии с первым аспектом изобретения. Устройство содержит анализатор 600 входного сигнала для получения данных о диффузности из входного сигнала, проиллюстрированного слева на Фиг. 6. Кроме того, устройство содержит генератор 650 звуковых компонент для генерирования из входного сигнала одной или более компонент звукового поля первой группы компонент звукового поля, имеющих для каждой компоненты звукового поля прямую компоненту и диффузную компоненту. Кроме того, генератор звуковых компонент генерирует из входного сигнала вторую группу компонент звукового поля, имеющую только прямую компоненту.
В частности, генератор 650 звуковых компонент выполнен с возможностью выполнять компенсацию энергии при генерировании первой группы компонент звукового поля. Компенсация энергии зависит от данных о диффузности и числа компонент звукового поля во второй группе или от максимального порядка компонент звукового поля первой группы или максимального порядка компонент звукового поля второй группы. В частности, в соответствии с первым аспектом изобретения, компенсация энергии выполняется для компенсации потери энергии из-за того, что для второй группы компонент звукового поля генерируются только прямые компоненты, а какие-либо диффузные компоненты не генерируются.
В противоположность этому, в первой группе компонент звукового поля прямая и диффузная части включаются в компоненты звукового поля. Таким образом, генератор 650 звуковых компонент генерирует, как проиллюстрировано верхней решеткой, компоненты звукового поля, которые имеют только прямую часть, а не диффузную часть, как проиллюстрировано, на других фигурах, посредством ссылочной позиции 830, и генератор звуковых компонент генерирует компоненты звукового поля, которые имеют прямую часть и диффузную часть, как проиллюстрировано ссылочными позициями 810, 820, которые поясняются ниже со ссылкой на другие фигуры.
Фиг. 7 иллюстрирует устройство для генерирования описания звукового поля из входного сигнала, содержащего по меньшей мере два канала, в соответствии со вторым аспектом изобретения. Устройство содержит анализатор 600 входного сигнала для получения данных о направлении и данных о диффузности из входного сигнала. Кроме того, обеспечен блок 720 оценки для оценки первого связанного с энергией или амплитудой показателя для всенаправленной компоненты, выведенной из входного сигнала, и для оценки второго связанного с энергией или амплитудой показателя для направленной компоненты, выведенной из входного сигнала.
Кроме того, устройство для генерирования описания звукового поля содержит генератор 750 звуковых компонент для генерирования компонент звукового поля для звукового поля, причем генератор 750 звуковых компонент выполнен с возможностью выполнения компенсации энергии направленной компоненты с использованием первого связанного с амплитудой показателя, второго связанного с энергией или амплитудой показателя, данных о направлении и данных о диффузности. Таким образом, генератор звуковых компонент генерирует, в соответствии со вторым аспектом настоящего изобретения, скорректированные/скомпенсированные направленные (прямые) компоненты и, если реализуются соответствующим образом, другие компоненты того же порядка, что и входной сигнал, такие как всенаправленные компоненты, которые предпочтительно не подвергаются компенсации энергии или подвергаются компенсации энергии только с целью компенсации диффузной энергии, как обсуждается в контексте Фиг. 6. Следует отметить, что связанный с амплитудой показатель также может быть нормой или величиной или абсолютным значением направленной или всенаправленной компоненты, такой как B0 и B1. Предпочтительно мощность или энергия, выводимая с помощью степени 2, является предпочтительной, как указано в уравнении, но другие мощности, применяемые к норме или величине или абсолютному значению, также могут быть использованы для получения связанного с энергией или амплитудой показателя.
В реализации устройство для генерирования описания звукового поля в соответствии со вторым аспектом выполняет компенсацию энергии направленной компоненты сигнала, включенной во входной сигнал, содержащий по меньшей мере два канала, так что направленная компонента включается во входной сигнал или может быть вычислена из входного сигнала, например, путем вычисления разности между двумя каналами. Это устройство может выполнять лишь корректировку без генерирования каких-либо данных более высокого порядка или подобного. Однако в других вариантах осуществления генератор звуковых компонент выполнен с возможностью также генерировать другие компоненты звукового поля из других порядков, как проиллюстрировано ссылочными позициями 820, 830, описанными ниже, но для этих (имеющих более высокий порядок) звуковых компонент, для которых в сигнал не было включено каких-либо дополняющих частей, компенсация энергии направленной компоненты не является обязательной к выполнению.
Фиг. 8 иллюстрирует предпочтительную реализацию устройства для генерирования описания звукового поля с использованием входного сигнала, содержащего моносигнал или многоканальный сигнал, в соответствии с третьим аспектом настоящего изобретения. Устройство содержит анализатор 600 входного сигнала для анализа входного сигнала для выведения данных о направлении и данных о диффузности. Кроме того, устройство содержит генератор 810 компонент низкого порядка для генерирования описания звукового поля низкого порядка из входного сигнала вплоть до предопределенного порядка и предопределенной моды, при этом генератор 810 компонент низкого порядка выполнен с возможностью выведения описания звукового поля низкого порядка посредством копирования или взятия входного сигнала или части входного сигнала как есть или посредством выполнения взвешенной комбинации каналов входного сигнала, когда входной сигнал является многоканальным сигналом. Кроме того, устройство содержит генератор 820 компонент среднего порядка для генерирования описания звукового поля среднего порядка выше упомянутого предопределенного порядка или с упомянутым предопределенным порядком и выше предопределенной моды и ниже или с первым порядком отсечения, используя синтез по меньшей мере одной прямой части и по меньшей мере одной диффузной части, с использованием данных о направлении и данных о диффузности, так что описание звукового поля среднего порядка содержит прямой вклад и диффузный вклад.
Устройство для генерирования описания звукового поля дополнительно содержит генератор 830 компонент высокого порядка для генерирования описания звукового поля высокого порядка, имеющего компоненту выше упомянутого первого порядка отсечения, используя синтез по меньшей мере одной прямой части, при этом описание звукового поля высокого порядка содержит только прямой вклад. Таким образом, в варианте осуществления синтез по меньшей мере одной прямой части выполняется без синтезирования каких-либо диффузных компонент, так что описание звукового поля высокого порядка содержит только прямой вклад.
Таким образом, генератор 810 компонент низкого порядка генерирует описание звукового поля низкого порядка, генератор 820 компонент среднего порядка генерирует описание звукового поля среднего порядка, а генератор компонент высокого порядка генерирует описание звукового поля высокого порядка. Описание звукового поля низкого порядка расширяется вплоть до определенного порядка и моды, как, например, в контексте амбисонических сферических компонент высокого порядка, как проиллюстрировано на Фиг. 1. Однако любое другое описание звукового поля, например описание звукового поля с цилиндрическими функциями или описание звукового поля с любыми другими компонентами, отличными от какого-либо амбисонического представления, также может быть сгенерировано в соответствии с первым, вторым и/или третьим аспектом настоящего изобретения.
Генератор 820 компонент среднего порядка генерирует компоненты звукового поля выше упомянутого предопределенного порядка или моды и вплоть до определенного порядка отсечения, который также обозначается как L в нижеследующем описании. Наконец, генератор 830 компонент высокого порядка выполнен с возможностью применения генерирования компонент звукового поля от порядка L отсечения вплоть до максимального порядка, обозначаемого как H в нижеследующем описании.
В зависимости от реализации, компенсация энергии, обеспечиваемая генератором 650 звуковых компонент с Фиг. 6, не может быть применена в генераторе 810 компонент низкого порядка или генераторе 820 компонент среднего порядка, как проиллюстрировано соответствующими ссылочными позициями на Фиг. 6, для компоненты прямого/диффузного звука. Кроме того, вторая группа компонент звукового поля, генерируемых компонентой звукового поля, генерируемых генератором 650 компонент звукового поля, соответствует выводу генератора 830 компонент высокого порядка с Фиг. 8, проиллюстрированному ссылочным номером 830 под надписью прямой/не диффузный на Фиг. 6.
Со ссылкой на Фиг. 7, показано, что компенсация энергии направленной компоненты предпочтительно выполняется в генераторе 810 компонент низкого порядка, проиллюстрированном на Фиг. 8, т.е. выполняется для некоторых или всех компонент звукового поля вплоть до предопределенного порядка и предопределенной моды, как проиллюстрировано ссылочной позицией 810 над верхней стрелкой, выходящей из блока 750. Генерирование компонент среднего порядка и компонент высокого порядка проиллюстрировано относительно верхней заштрихованной стрелки, выходящей из блока 750 на Фиг. 7, как проиллюстрировано ссылочными позициями 820, 830, указанными под этой верхней стрелкой. Таким образом, генератор 810 компонент низкого порядка с Фиг. 8 может применять компенсацию диффузной энергии в соответствии с первым аспектом и компенсацию направленного (прямого) сигнала в соответствии со вторым аспектом, тогда как генератор 820 компонент среднего порядка может выполнять только компенсацию диффузных компонент, поскольку этот генератор компонент среднего порядка генерирует выходные данные, имеющие диффузные части, которые могут быть улучшены относительно своей энергии, чтобы иметь более высокий бюджет энергии диффузных компонент в выходном сигнале.
Далее приводится ссылка на Фиг. 4, иллюстрирующую реализацию первого аспекта, второго аспекта и третьего аспекта настоящего изобретения в одном устройстве для генерирования описания звукового поля.
Фиг. 4 иллюстрирует входной анализатор 600. Входной анализатор 600 содержит блок 610 оценки направления, блок 620 оценки диффузности и переключатели 630, 640. Анализатор 600 входного сигнала выполнен с возможностью анализа входного сигнала, обычно следующего за блоком 400 фильтров анализа, чтобы искать для каждого фрагмента время/частота информацию о направлении, указываемую как DOA, и/или информацию о диффузности. Информация о направлении, DOA, и/или информация о диффузности также может происходить из битового потока. Таким образом, в ситуациях, когда эти данные не могут быть извлечены из входного сигнала, т.е. когда входной сигнал имеет только всенаправленную компоненту W, тогда анализатор входного сигнала извлекает данные о направлении и/или данные о диффузности из битового потока. Когда, например, входной сигнал является двухканальным сигналом, имеющим левый канал L и правый канал R, тогда может быть выполнен анализ, чтобы получить данные о направлении и/или диффузности. Когда входным сигналом является амбисонический сигнал первого порядка (FOA) или любой другой сигнал с более чем двумя каналами, такой как сигнал A-формата или сигнал B-формата, тогда может быть выполнен фактический анализ сигнала, выполняемый блоком 610 или 620. Однако, когда битовый поток анализируется для извлечения из битового потока данных о направлении и/или данных о диффузности, это также представляет собой анализ, выполняемый анализатором 600 входного сигнала, но без фактического анализа сигнала, как в другом случае. В последнем случае анализ выполняется над битовым потоком, а входной сигнал состоит как из сигнала понижающего микширования, так и из данных битового потока.
Кроме того, устройство для генерирования описания звукового поля, проиллюстрированное на Фиг. 4, содержит блок 410 вычисления направленных усилений, разделитель 420, объединитель 430, декодер 440 и блок 450 синтезирующих фильтров. Блок 450 синтезирующих фильтров принимает данные для амбисонического представления высокого порядка или сигнала, который подлежит воспроизведению наушниками, т.е. бинаурального сигнала, или сигнала, который подлежит воспроизведению громкоговорителями, расположенными в определенной конфигурации громкоговорителей, представляющей многоканальный сигнал, адаптированный под эту конкретную конфигурацию громкоговорителей, из описания звукового поля, которое обычно не зависит от конкретной конфигурации громкоговорителей.
Кроме того, устройство для генерирования описания звукового поля содержит генератор звуковых компонент, обычно состоящий из генератора 810 компонент низкого порядка, содержащего блок «генерирование компонент низкого порядка» и блок «микширование компонент низкого порядка». Кроме того, обеспечен генератор 820 компонент среднего порядка, состоящий из блока 821 генерируемого опорного сигнала, декорреляторов 823, 824 и блока 825 микширования компонент среднего порядка. И генератор 830 компонент высокого порядка также обеспечен и представлен на Фиг. 4, содержащий блок 822 микширования компонент высокого порядка. Кроме того, обеспечен блок вычисления (диффузных) компенсационных усилений, проиллюстрированный ссылочными позициями 910, 920, 930, 940. Ссылочные позиции с 910 по 940 дополнительно поясняются со ссылкой на Фиг. с 12a по 12c.
Хотя это не проиллюстрировано на Фиг. 4, по меньшей мере компенсация энергии диффузного сигнала выполняется не только в генераторе звуковых компонент для низкого порядка, что явно проиллюстрировано на Фиг. 4, но эта компенсация энергии также может быть выполнена в микшере 825 компонент среднего порядка.
Кроме того, Фиг. 4 иллюстрирует ситуацию, когда вся обработка выполняется для отдельных фрагментов время/частота, генерируемых блоком 400 фильтров анализа. Таким образом, определенное значение DOA, определенное значение диффузности и определенная обработка для применения этих значений, а также для применения различных компенсаций обеспечивается для каждого фрагмента время/частота. Кроме того, компоненты звукового поля также генерируются/синтезируются для отдельных фрагментов времени/частоты, и объединение, выполняемое объединителем 430, также происходит в области времени/частоты для каждого отдельного фрагмента времени/частоты, и, дополнительно, процедура декодера 440 HOA выполняется в области времени/частоты, и блок 450 синтезирующих фильтров затем генерирует сигналы временной области для полной полосы частот с компонентами HOA полного диапазона частот, с бинауральными сигналами полного диапазона частот для наушников или с сигналами громкоговорителей полного диапазона частот для громкоговорителей определенной конфигурации громкоговорителей.
В вариантах осуществления настоящего изобретения используются два основных принципа:
Амбисонические компоненты диффузного звука могут быть синтезированы с ограничением только для компонент низкого порядка синтезируемого амбисонического сигнала вплоть до порядка L<H.
Из сигнала понижающего микширования обычно могут быть извлечены K амбисонических компонент низкого порядка, для которых полный синтез не требуется.
В случае монофонического понижающего микширования, понижающее микширование обычно представляет собой всенаправленную компоненту W амбисонического сигнала.
В случае стереофонического понижающего микширования левый (L) и правый (R) каналы могут быть легко преобразованы в амбисонические компоненты W и Y.
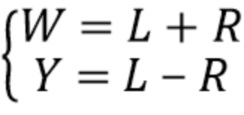
В случае понижающего микширования FOA амбисонические компоненты порядка 1 уже являются доступными. В качестве альтернативы, FOA может быть восстановлен из линейной комбинации 4-канального сигнала понижающего микширования, DMX, который, например, имеет A-формат:
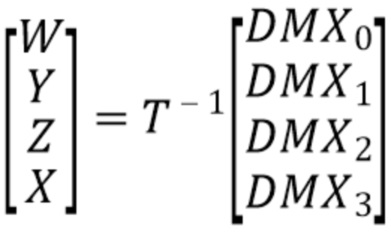
где
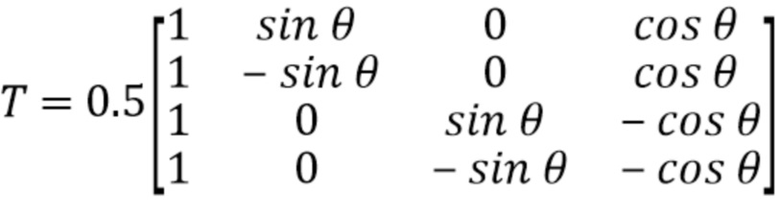
и
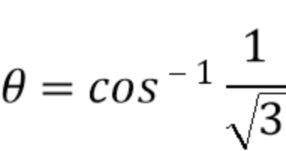
К этим двум принципам также можно применить два улучшения:
Потеря энергии из-за отсутствия моделирования амбисонических компонент диффузного звука до порядка H может быть компенсирована путем усиления K амбисонических компонент низкого порядка, извлекаемых из сигнала понижающего микширования.
В применениях передачи, в которых сигнал понижающего микширования кодируется с потерями, передаваемый сигнал понижающего микширования искажается ошибками квантования, которые могут быть устранены путем ограничения соотношения энергии K амбисонических компонент низкого порядка, извлекаемых из сигнала понижающего микширования.
Фиг. 4 иллюстрирует вариант осуществления нового способа. Одним из отличий от состояния, изображенного на Фиг. 3, является дифференциация процесса микширования, который различается в зависимости от порядка амбисонической компоненты, которая подлежит синтезированию. Компоненты низких порядков в основном определяются из компонент низкого порядка, извлекаемых непосредственно из сигнала понижающего микширования. Микширование компонент низкого порядка может быть таким же простым, как непосредственное копирование извлеченных компонент в вывод.
Однако в предпочтительном варианте извлеченные компоненты дополнительно обрабатываются посредством применения компенсации энергии, функции диффузности и порядков L и H отсечения, или посредством применения нормализации энергии, функции диффузности и направлений звука, или посредством применения обоих из них.
Микширование компонент среднего порядка фактически аналогично современному способу (за исключением опциональной компенсации диффузности) и генерирует и объединяет амбисонические компоненты как прямых, так и диффузных звуков вплоть до порядка L отсечения, но игнорируя K компонент низкого порядка, уже синтезированных путем микширования компонент низкого порядка. Микширование компонент высокого порядка состоит из генерирования оставшихся 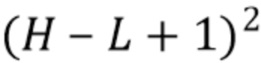 амбисонических компонент вплоть до порядка
амбисонических компонент вплоть до порядка 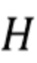 отсечения, но только для прямого звука, игнорируя диффузный звук. Далее подробно описывается микширование или генерирование компонент низкого порядка.
отсечения, но только для прямого звука, игнорируя диффузный звук. Далее подробно описывается микширование или генерирование компонент низкого порядка.
Первый аспект относится к компенсации энергии, в целом проиллюстрированной на Фиг. 6, представляющей общую схему по первому аспекту. Принцип поясняется для конкретного случая для 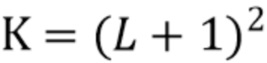 без потери общности.
без потери общности.
Фиг. 5 показывает общую схему обработки. Входной вектор 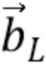 представляет собой физически корректный амбисонический сигнал с порядком
представляет собой физически корректный амбисонический сигнал с порядком  отсечения. Он содержит
отсечения. Он содержит 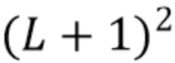 коэффициентов, обозначенных
коэффициентов, обозначенных 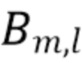 , где
, где 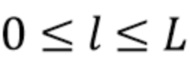 представляет собой порядок коэффициента, а
представляет собой порядок коэффициента, а 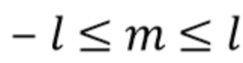 представляет собой моду. Обычно амбисонический сигнал представляется в частотно-временной области.
представляет собой моду. Обычно амбисонический сигнал представляется в частотно-временной области.
В блоке 820, 830 синтезирования HOA амбисонические коэффициенты синтезируются от вплоть до максимального порядка , где 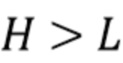 . Результирующий вектор
. Результирующий вектор  содержит синтезированные коэффициенты порядка
содержит синтезированные коэффициенты порядка 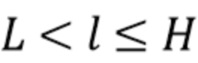 , обозначаемые
, обозначаемые 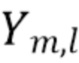 . Синтезирование HOA обычно зависит от диффузности
. Синтезирование HOA обычно зависит от диффузности 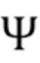 (или аналогичного показателя), которая описывает, насколько диффузным является звуковое поле для текущей частотно-временной точки. Обычно коэффициенты в синтезируются только в том случае, если звуковое поле становится недиффузным, тогда как в диффузных ситуациях коэффициенты становятся равными нулю. Это предотвращает появление артефактов в диффузных ситуациях, но также приводит к потере энергии. Подробности синтезирования HOA поясняются ниже.
(или аналогичного показателя), которая описывает, насколько диффузным является звуковое поле для текущей частотно-временной точки. Обычно коэффициенты в синтезируются только в том случае, если звуковое поле становится недиффузным, тогда как в диффузных ситуациях коэффициенты становятся равными нулю. Это предотвращает появление артефактов в диффузных ситуациях, но также приводит к потере энергии. Подробности синтезирования HOA поясняются ниже.
Чтобы компенсировать потерю энергии в упомянутых выше диффузных ситуациях, мы применяем компенсацию энергии к в блоке 650, 750 компенсации энергии. Результирующий сигнал обозначается как  и имеет тот же максимальный порядок , что и . Компенсация энергии зависит от диффузности (или аналогичного показателя) и увеличивает энергию коэффициентов в диффузных ситуациях, так что потеря энергии коэффициентов в компенсируется. Подробности поясняются далее.
и имеет тот же максимальный порядок , что и . Компенсация энергии зависит от диффузности (или аналогичного показателя) и увеличивает энергию коэффициентов в диффузных ситуациях, так что потеря энергии коэффициентов в компенсируется. Подробности поясняются далее.
В блоке объединения коэффициенты с компенсированной энергией в объединяются 430 с синтезированными коэффициентами в для получения выходного амбисонического сигнала  содержащего все
содержащего все 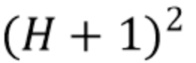 коэффициенты, т.е.
коэффициенты, т.е.
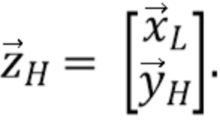
Далее синтезирование HOA объясняется как вариант осуществления. Существует несколько современных подходов к синтезированию коэффициентов HOA в , например, рендеринг на основе ковариации или прямой рендеринг с использованием направленного аудиокодирования (DirAC). В простейшем случае коэффициенты в синтезируются из всенаправленной компоненты  в с использованием
в с использованием
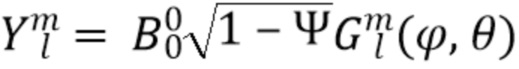 .
.
Здесь 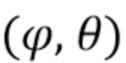 является направлением прихода (DOA) звука, а
является направлением прихода (DOA) звука, а 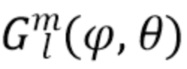 представляет собой соответствующее усиление амбисонического коэффициента порядка l и моды m. Обычно соответствует действительнозначной диаграмме направленности хорошо известной сферической гармонической функции порядка l и моды m, оцениваемой в DOA . Диффузность Ψ становится 0, если звуковое поле является недиффузным, и 1, если звуковое поле является диффузным. Следовательно, коэффициенты
представляет собой соответствующее усиление амбисонического коэффициента порядка l и моды m. Обычно соответствует действительнозначной диаграмме направленности хорошо известной сферической гармонической функции порядка l и моды m, оцениваемой в DOA . Диффузность Ψ становится 0, если звуковое поле является недиффузным, и 1, если звуковое поле является диффузным. Следовательно, коэффициенты 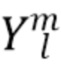 , вычисленные выше порядка L, становятся равными нулю в ситуациях диффузной записи. Обратите внимание, что параметры , и могут быть оценены из амбисонического сигнала
, вычисленные выше порядка L, становятся равными нулю в ситуациях диффузной записи. Обратите внимание, что параметры , и могут быть оценены из амбисонического сигнала  первого порядка на основе вектора активной интенсивности звука, как поясняется в исходных документах DirAC.
первого порядка на основе вектора активной интенсивности звука, как поясняется в исходных документах DirAC.
Далее обсуждается компенсация энергии компонентов диффузного звука. Чтобы получить компенсацию энергии, мы рассматриваем типичную модель звукового поля, в которой звуковое поле состоит из компоненты прямого звука и компоненты диффузного звука, т.е. всенаправленный сигнал может быть записан как
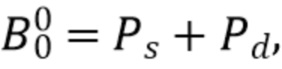
где 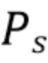 является прямым звуком (например, плоской волной), а
является прямым звуком (например, плоской волной), а 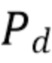 является диффузным звуком. Предполагая эту модель звукового поля и SN3D нормализацию амбисонических коэффициентов, ожидаемая мощность физически корректных коэффициентов определяется как
является диффузным звуком. Предполагая эту модель звукового поля и SN3D нормализацию амбисонических коэффициентов, ожидаемая мощность физически корректных коэффициентов определяется как
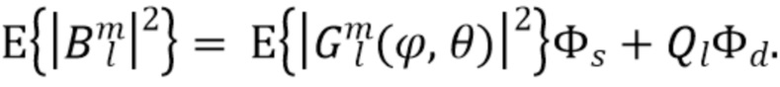
Здесь, 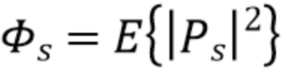 представляет собой мощность прямого звука, а
представляет собой мощность прямого звука, а 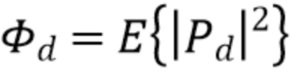 представляет собой мощность диффузного звука. Кроме того,
представляет собой мощность диффузного звука. Кроме того, 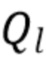 представляет собой фактор направленности коэффициентов l-го порядка, который определяется как
представляет собой фактор направленности коэффициентов l-го порядка, который определяется как 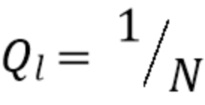 , где
, где 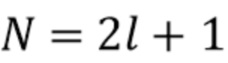 представляет собой число коэффициентов на порядок l. Чтобы вычислить компенсацию энергии, мы можем либо рассмотреть DOA (более точная компенсация энергии), либо предположить, что является равномерно распределенной случайной величиной (более практичный подход). В последнем случае ожидаемая мощность
представляет собой число коэффициентов на порядок l. Чтобы вычислить компенсацию энергии, мы можем либо рассмотреть DOA (более точная компенсация энергии), либо предположить, что является равномерно распределенной случайной величиной (более практичный подход). В последнем случае ожидаемая мощность 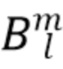 равна
равна
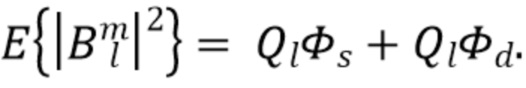
Далее пусть 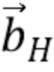 обозначает физически корректный амбисонический сигнал максимального порядка . Используя приведенные выше уравнения, общая ожидаемая мощность определяется как
обозначает физически корректный амбисонический сигнал максимального порядка . Используя приведенные выше уравнения, общая ожидаемая мощность определяется как
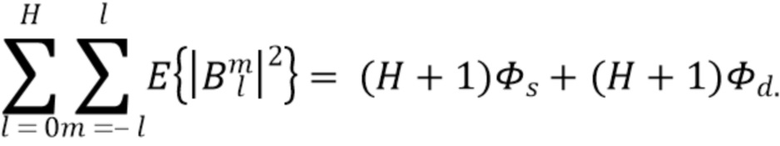
Аналогично, при использовании общего определения диффузности 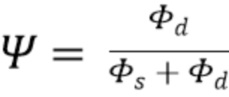 полная ожидаемая мощность синтезируемого амбисонического сигнала определяется как
полная ожидаемая мощность синтезируемого амбисонического сигнала определяется как
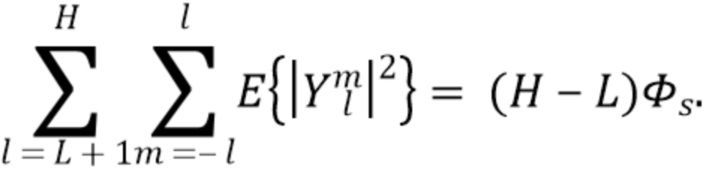
Компенсация энергии осуществляется путем умножения коэффициента  на , т.е.
на , т.е.
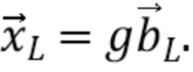
Общая ожидаемая мощность выходного амбисонического сигнала теперь определяется как
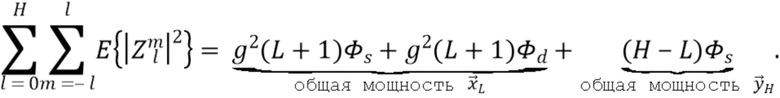
Общая ожидаемая мощность должна соответствовать общей ожидаемой мощности . Следовательно, квадрат коэффициента компенсации вычисляется как
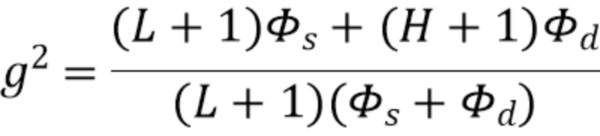
Это можно упростить до
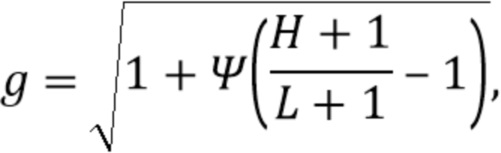
где 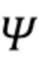 представляет собой диффузность, представляет собой максимальный порядок входного амбисонического сигнала, а представляет собой максимальный порядок выходного амбисонического сигнала.
представляет собой диффузность, представляет собой максимальный порядок входного амбисонического сигнала, а представляет собой максимальный порядок выходного амбисонического сигнала.
Можно применить тот же принцип и для 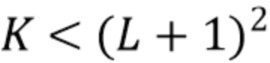 , где
, где 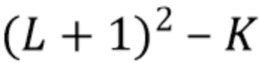 амбисонических компонент диффузного звука синтезируются с использованием декорреляторов и среднего диффузного ответа.
амбисонических компонент диффузного звука синтезируются с использованием декорреляторов и среднего диффузного ответа.
В определенных случаях 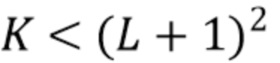 и никакие компоненты диффузного звука не синтезируются. Это особенно верно для высоких частот, где абсолютные фазы не слышны, а использование декорреляторов неуместно. Затем компоненты диффузного звука могут быть смоделированы с помощью компенсации энергии путем вычисления порядка Lk и числа мод mk, соответствующих K компонентам низкого порядка, при этом K представляет число диффузных компонент в первой группе:
и никакие компоненты диффузного звука не синтезируются. Это особенно верно для высоких частот, где абсолютные фазы не слышны, а использование декорреляторов неуместно. Затем компоненты диффузного звука могут быть смоделированы с помощью компенсации энергии путем вычисления порядка Lk и числа мод mk, соответствующих K компонентам низкого порядка, при этом K представляет число диффузных компонент в первой группе:
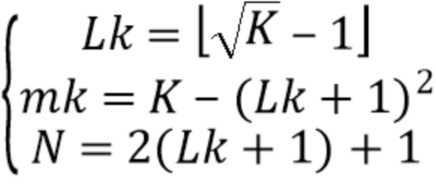
Компенсирующим усилением тогда становится:
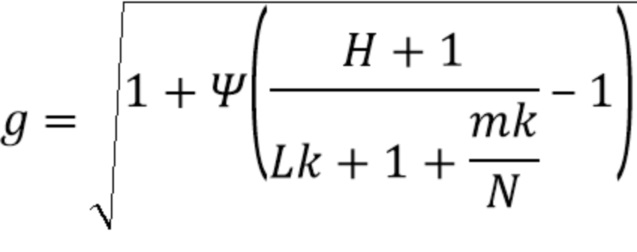
Далее представляются варианты осуществления нормализации энергии компонент прямого звука, соответствующие второму аспекту, в общем проиллюстрированному на Фиг. 7. Выше предполагалось, что входной вектор являлся физически корректным амбисоническим сигналом максимального порядка L. Однако на входной сигнал понижающего микширования могут оказывать влияние ошибки квантования, которые могут нарушать соотношение энергии. Это соотношение может быть восстановлено путем нормализации входного сигнала понижающего микширования:
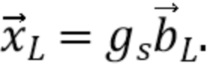
Учитывая направление звука и параметры диффузности, прямые и диффузные компоненты могут быть выражены как:
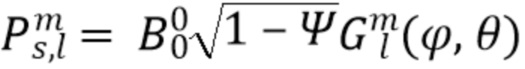
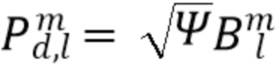
Ожидаемая мощность в соответствии с моделью затем может быть выражена для каждой из компонент как:
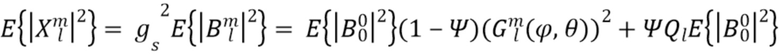
Компенсирующим усилением тогда становится:
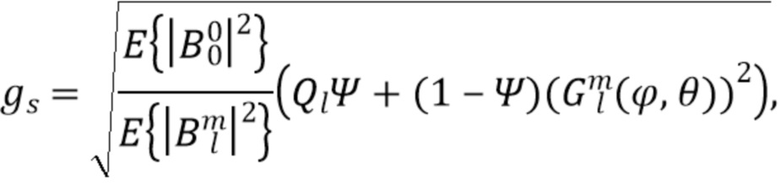
где 0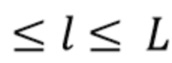 и
и 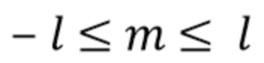
В качестве альтернативы, ожидаемая мощность в соответствии с моделью затем может быть выражена для каждой из компонент  как:
как:
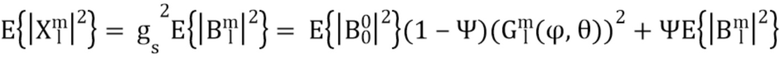
Компенсирующим усилением тогда становится:
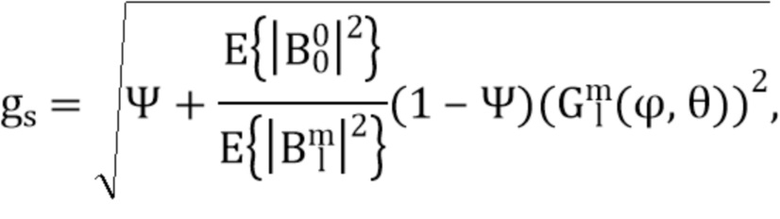
где 0 и
и являются комплексными значениями, и для вычисления 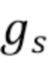 берется норма или величина или абсолютное значение или представление комплексного значения в полярных координатах и возводится в квадрат, чтобы получить ожидаемую мощность или энергию в качестве связанного с энергией или амплитудой показателя.
берется норма или величина или абсолютное значение или представление комплексного значения в полярных координатах и возводится в квадрат, чтобы получить ожидаемую мощность или энергию в качестве связанного с энергией или амплитудой показателя.
Компенсация энергии компонент диффузного звука и нормализация энергии компонент прямого звука могут быть достигнуты совместно, применяя усиление следующей формы:
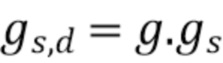
В реальной реализации полученное усиление нормализации, компенсационное усиление или их комбинация могут быть ограничены, чтобы избежать больших коэффициентов усиления, приводящих к серьезному выравниванию частотной характеристики, которое может привести к звуковым артефактам. Например, усиления могут быть ограничены диапазоном от -6 до +6 дБ. Кроме того, усиления можно сглаживать во времени и/или по частоте (с помощью скользящей средней или рекурсивной средней) для предотвращения резких изменений и для последующего процесса стабилизации.
Далее будут резюмированы некоторые выгоды и преимущества предпочтительных вариантов осуществления по сравнению с существующим уровнем техники.
Упрощенное (менее сложное) синтезирование HOA в DirAC.
Более прямое синтезирование без полного синтезирования всех амбисонических компонент.
Уменьшение количества требуемых декорреляторов и их влияния на финальное качество.
Уменьшение артефактов кодирования, вносимых в сигнал понижающего микширования во время передачи.
Разделение обработки на три разных порядка для достижения оптимального компромисса между качеством и эффективностью обработки.
Далее резюмируются некоторые аспекты изобретения, частично или полностью включенные в вышеприведенное описание, которые могут использоваться независимо друг от друга или в комбинации друг с другом, или только в определенной комбинации, объединяющей только два произвольно выбранных аспекта из упомянутых трех аспектов.
Первый аспект: Компенсация энергии для компонент диффузного звука
Настоящее изобретение исходит из того факта, что, когда описание звукового поля генерируется из входного сигнала, содержащего одну или более компонент сигнала, входной сигнал может быть проанализирован для получения, по меньшей мере, данных о диффузности для звукового поля, представленного входным сигналом. Анализ входного сигнала может представлять собой извлечение данных о диффузности, ассоциированных как метаданные с одной или более компонентами сигнала, или анализ входного сигнала может представлять собой анализ реального сигнала, когда, например, входной сигнал имеет две, три или даже более компонент сигнала, например полное представление первого порядка, такое как представление в B-формате или представление в A-формате.
Теперь имеется генератор звуковых компонент, который генерирует одну или более компонент звукового поля первой группы, которые имеют прямую компоненту и диффузную компоненту. И, дополнительно, генерируется одна или более компонент звукового поля второй группы, при этом для такой второй группы компонента звукового поля имеет только прямые компоненты.
В отличие от генерирования полного звукового поля, это приведет к ошибке в энергии при условии, что значение диффузности для текущего кадра или текущего рассматриваемого фрагмента времени/частоты имеет значение, отличное от нуля.
Чтобы компенсировать эту ошибку энергии, компенсация энергии выполняется при генерировании первой группы компонент звукового поля. Эта компенсация энергии зависит от данных о диффузности и числа компонент звукового поля во второй группе, представляющей потерю энергии из-за отсутствия синтезирования диффузных компонент для этой второй группы.
В одном варианте осуществления генератор звуковых компонент для первой группы может быть ветвью низкого порядка с Фиг. 4, которая извлекает компоненты звукового поля первой группы посредством копирования или выполнения взвешенного сложения, т.е. без выполнения оценки сложной пространственной базисной функции. Таким образом, компонента звукового поля первой группы не является доступной отдельно как прямая часть и диффузная часть. Однако увеличение всей компоненты звукового поля первой группы по отношению к ее энергии автоматически увеличивает энергию диффузной части.
В качестве альтернативы, генератор звуковых компонент для одной или более компонент звукового поля первой группы также может быть ветвью среднего порядка на Фиг. 4, полагающейся на раздельное синтезирование прямой части и синтезирование диффузной части. Здесь мы имеет отдельно доступную диффузную часть, и в одном варианте осуществления диффузная часть компоненты звукового поля увеличивается, но не прямая часть, чтобы компенсировать потерю энергии из-за второй группы. В качестве альтернативы, однако, в этом случае можно было бы увеличить энергию результирующей компоненты звукового поля после объединения прямой части и диффузной части.
В качестве альтернативы, генератор звуковых компонент для одной или более компонент звукового поля первой группы также может представлять собой ветви компонент низкого и среднего порядка на Фиг. 4. Тогда компенсация энергии может применяться только к компонентам низкого порядка или к компонентам как низкого, так и среднего порядка.
Второй аспект: Нормализация энергии компонент прямого звука
В этом изобретении исходят из предположения, что генерирование входного сигнала, который имеет две или более звуковых компонент, сопровождалось некоторым видом квантования. Как правило, при рассмотрении двух или более звуковых компонент, одна звуковая компонента входного сигнала может представлять собой всенаправленный сигнал, например всенаправленные микрофонные сигналы W в представлении B-формата, а другие звуковые компоненты могут представлять собой отдельные направленные сигналы, такие как сигналы X, Y, Z микрофона в форме восьмерки в представлении B-формата, то есть в амбисоническом представлении первого порядка.
Когда кодер сигнала попадает в ситуацию, когда требования к битрейту слишком высоки для идеальной операции кодирования, то типичная процедура состоит в том, что кодер кодирует всенаправленный сигнал как можно точнее, но кодер только тратит меньшее количество битов на направленные компоненты, которое может быть даже настолько низкими, что одна или более направленных компонент полностью сводятся к нулю. Это представляет собой такую потерю или несоответствие энергии в информации о направлении.
Теперь тем не менее может иметь место требование, которое, например, получают за счет наличия явной параметрической вспомогательной информации, указывающей, что определенный кадр или элемент разрешения по времени/частоте имеет определенную диффузность, меньшую единицы, и направление звука. Таким образом, может возникнуть ситуация, когда в соответствии с параметрическими данными имеется некоторая определенная недиффузная компонента с некоторым определенным направлением, в то время как, с другой стороны, передаваемый всенаправленный сигнал и направленные сигналы это направление не отражают. Например, всенаправленный сигнал мог бы передаваться без какой-либо существенной потери информации, в то время как направленный сигнал, Y, отвечающий за левое и правое направление, мог бы быть установлен равным нулю по причине отсутствия битов. В этом сценарии, даже если в исходной аудиосцене компонента прямого звука исходит слева, передаваемые сигналы будут отражать аудиосцену без какой-либо характеристики направленности лево-право.
Таким образом, в соответствии со вторым изобретением выполняется нормализация энергии для компонент прямого звука, чтобы компенсировать нарушение соотношения энергии с помощью данных о направлении/диффузности, которые либо явно включаются во входной сигнал, либо выводятся из самого входного сигнала.
Эта нормализация энергии может быть применена в контексте всех отдельных ветвей обработки с Фиг. 4 либо полностью, либо только по отдельности.
Это изобретение позволяет использовать дополнительные параметрические данные, либо принимаемые из входного сигнала, либо выводимые из ненарушенных частей входного сигнала, и, следовательно, ошибки кодирования, включенные во входной сигнал по какой-либо причине, могут быть уменьшены с использованием дополнительных данных о направлении и данных о диффузности, выводимых из входного сигнала.
В этом изобретении связанный с энергией или амплитудой показатель для всенаправленной компоненты, выводимой из входного сигнала, и дополнительный связанный с энергией или амплитудой показатель для направленной компоненты, выводимой из входного сигнала, оцениваются и используются для компенсации энергии вместе с данными о направлении и данными о диффузности. Таким связанным с энергией или амплитудой показателем может быть сама амплитуда или мощность, т.е. возведенные в квадрат и просуммированные амплитуды, или может быть энергия, например мощность, умноженная на определенный период времени, или может быть любой другой показатель, выводимый из амплитуды с показателем степени для амплитуды, отличным от единицы, и последующим суммированием. Таким образом, дополнительным связанным с энергией или амплитудой показателем также может быть громкость с показателем степени три по сравнению с мощностью с показателем степени два.
Третий аспект: Реализация системы с различными процедурами обработки для разных порядков
В третьем изобретении, которое проиллюстрировано на Фиг. 4, звуковое поле генерируется с использованием входного сигнала, содержащего моносигнал или многокомпонентный сигнал, имеющий две или более компоненты сигнала. Анализатор сигналов выводит данные о направлении и данные о диффузности из входного сигнала либо посредством явного анализа сигнала в случае, если входной сигнал имеет две или более компоненты сигнала, либо посредством анализа входного сигнала для извлечения данных о направлении и данных о диффузности, включенных во входной сигнал в качестве метаданных.
Генератор компонент низкого порядка генерирует звуковое описание низкого порядка из входного сигнала вплоть до предопределенного порядка и выполняет эту задачу для доступных мод, которые могут быть извлечены из входного сигнала, посредством копирования компоненты сигнала из входного сигнала или посредством выполнения взвешенной комбинации компонент во входном сигнале.
Генератор компонент среднего порядка генерирует звуковое описание среднего порядка, имеющее компоненты с порядком выше предопределенного порядка или с предопределенным порядком и выше предопределенной моды и ниже или с первым порядком отсечения, используя синтез по меньшей мере одной прямой компоненты и синтез по меньшей мере одной диффузной компоненты, с использованием данных о направлении и данных о диффузности, получаемых из анализатора, так что звуковое описание среднего порядка содержит прямой вклад и диффузный вклад.
Кроме того, генератор компонент высокого порядка генерирует звуковое описание высокого порядка, имеющее компоненты с порядками выше первого отсечения и ниже или равными второму порядку отсечения, используя синтез по меньшей мере одной прямой компоненты без синтеза какой-либо диффузной компоненты, так что звуковое описание высокого порядка имеет только прямой вклад.
Изобретение этой системы имеет значительные преимущества в том, что генерирование максимально точного звукового поля низкого порядка посредством использования информации, включенной во входной сигнал, выполняется как можно лучше, в то же время операции обработки для выполнения звукового описания низкого порядка требуют небольших затрат из-за того, что требуются только операции копирования или операции взвешенной комбинации, такие как взвешенные сложения. Таким образом, высококачественное звуковое описание низкого порядка выполняется с минимальным объемом требуемой мощности обработки.
Звуковое описание среднего порядка требует большей мощности обработки, но позволяет сгенерировать очень точное звуковое описание среднего порядка с прямым и диффузным вкладами с использованием анализируемых данных о направлении и данных о диффузности, как правило, вплоть до некоторого порядка, т.е. высокого порядка, ниже которого диффузный вклад в описание звукового поля все еще требуется с точки зрения восприятия.
Наконец, генератор компонент высокого порядка генерирует звуковое описание высокого порядка только путем выполнения прямого синтеза без выполнения диффузного синтеза. Это, опять же, снижает объем требуемой мощности обработки из-за того, что генерируются только прямые компоненты, тогда как в то же самое время исключение диффузного синтеза не является таким уж проблематичным с точки зрения восприятия.
Естественно, третье изобретение может быть объединено с первым и/или вторым изобретением, но даже когда по некоторым причинам компенсация за невыполнение диффузного синтеза генератором компонент высокого порядка не применяется, процедура, тем не менее приводит в результате к оптимальному компромиссу между мощностью обработки, с одной стороны, и качеством звука, с другой. То же самое верно и для выполнения нормализации энергии низкого порядка, компенсирующей кодирование, используемое для генерирования входного сигнала. В варианте осуществления эта компенсация выполняется дополнительно, но даже без этой компенсации получаются значительные нетривиальные преимущества.
Фиг. 4 в качестве символической иллюстрации параллельной передачи показывает число компонент, обрабатываемых каждым генератором компонент. Генератор 810 компонент низкого порядка, проиллюстрированный на Фиг. 4, генерирует описание звукового поля низкого порядка из входного сигнала вплоть до предопределенного порядка и предопределенной моды, при этом генератор 810 компонент низкого порядка выполнен с возможностью выведения описания звукового поля низкого порядка посредством копирования или взятия входного сигнала как есть или посредством выполнения взвешенной комбинации каналов входного сигнала. Как проиллюстрировано между блоком генератора компонент низкого порядка и блоком микширования компонент низкого порядка, K отдельных компонент обрабатываются этим генератором 810 компонент низкого порядка. Генератор 820 компонент среднего порядка генерирует опорный сигнал, и в качестве примерной ситуации указывается, что используется всенаправленный сигнал, включенный в сигнал понижающего микширования на входе или выходе блока 400 фильтров. Однако, когда входной сигнал имеет левый канал и правый канал, то моносигнал, получаемый путем сложения левого и правого каналов, вычисляется генератором 821 опорного сигнала. Кроме того, число (L+1)2 - K компонент генерируются генератором компонент среднего порядка. Кроме того, генератор компонент высокого порядка генерирует число (H+1)2 - (L+1)2 компонент, так что в конце, на выходе объединителя, находятся (H+1)2 компонент из одной или нескольких (небольшое число) компонент на входе в блок 400 фильтров. Разделитель выполнен с возможностью обеспечения раздельных данных о направлении/диффузности в соответствующие генераторы 810, 820, 830 компонент. Таким образом, генератор компонент низкого порядка принимает K элементов данных. На это указывает линия, соединяющая разделитель 420 и блок микширования компонент низкого порядка.
Кроме того, блок 825 микширования компонент среднего порядка принимает (L+1)2 - K элементов данных, а блок микширования компонент высокого порядка принимает (H+1)2 - (L+1)2 элементов данных. Соответственно, отдельные блоки микширования компонент предоставляют определенное число компонент звукового поля в объединитель 430.
Далее предпочтительная реализация генератора 810 компонент низкого порядка с Фиг. 4 иллюстрируется со ссылкой на Фиг. 9. Входной сигнал вводится в блок 811 исследования входного сигнала, и этот блок 811 исследования входного сигнала передает полученную информацию в блок 812 выбора режима обработки. Блок 812 выбора режима обработки выполнен с возможностью выбора множества различных режимов обработки, которые схематично проиллюстрированы как блок 813 копирования, обозначенный цифрой 1, блок 814 взятия (как есть), обозначенный цифрой 2, блок линейной комбинации (первый режим), обозначенный цифрой 3 и ссылочной позицией 815, и блок 816 линейной комбинации (второй режим), обозначенный цифрой 4. Например, когда блок 811 исследования входного сигнала определяет определенный вид входного сигнала, тогда блок 812 выбора режима обработки выбирает один из упомянутого множества различных режимов обработки, как показано в таблице на Фиг. 9. Например, когда входным сигналом является всенаправленный сигнал W или моносигнал, тогда выбирается копирование 813 или взятие 814. Однако, когда входным сигналом является стереосигнал с левым каналом или правым каналом, или многоканальный сигнал с 5.1 или 7.1 каналами, тогда блок 815 линейной комбинации выбирается для того, чтобы выводить из входного сигнала всенаправленный сигнал W посредством сложения левого и правого и посредством вычисления направленной компоненты посредством вычисления разности между левым и правым.
Однако, когда входным сигналом является объединенный стереосигнал, то есть срединное/боковое ("mid/side") представление, тогда выбирается либо блок 813, либо блок 814, поскольку срединный сигнал уже представляет всенаправленный сигнал, а боковой сигнал уже представляет направленную компоненту.
Аналогичным образом, когда определяется, что входной сигнал является амбисоническим сигналом первого порядка (FOA), то блок 812 выбора режима выбирает либо блок 813, либо блок 814. Однако, когда определено, что входной сигнал является сигналом A-формата, тогда блок 816 линейной комбинации (второй режим) выбирается для того, чтобы выполнить линейное преобразование над сигналом A-формата, чтобы получить амбисонический сигнал первого порядка, имеющий всенаправленную компоненту и компоненты трех направлений, представляющие блоки K компонент низкого порядка, сгенерированных блоком 810 на Фиг. 8 или Фиг. 6. Кроме того, на Фиг. 9 проиллюстрирован компенсатор 900 энергии, который выполнен с возможностью выполнения компенсации энергии для вывода из одного из блоков с 813 по 816, чтобы выполнить диффузную компенсацию и/или прямую компенсацию с соответствующими значениями g и gs усиления.
Следовательно, реализация компенсатора 900 энергии соответствует процедуре генератора 650 звуковых компонент или генератора 750 звуковых компонент с Фиг. 6 и Фиг. 7, соответственно.
Фиг. 10 иллюстрирует предпочтительную реализацию генератора 820 компонент среднего порядка с Фиг. 8 или части генератора 650 звуковых компонент для нижней стрелки с прямыми/диффузными (компонентами) из блока 650, относящимися к первой группе. В частности, генератор 820 компонент среднего порядка содержит генератор 821 опорного сигнала, который принимает входной сигнал и генерирует опорный сигнал посредством копирования или взятия его как есть, когда входным сигналом является моносигнал, или посредством выведения опорного сигнала из входного сигнала, выполняя вычисление согласно вышеописанному или тому, что представлено в заявке WO 2017/157803 A1, содержимое которой включено в настоящий документ по этой ссылке во всей своей полноте.
Кроме того, Фиг. 10 иллюстрирует вычислитель 410 направленного усиления, который выполнен с возможностью вычисления направленного усиления Glm из определенной информации DOA (Φ,θ) и из определенного номера m моды и определенного номера l порядка. В предпочтительном варианте осуществления, когда обработка выполняется в области времени/частоты для каждого отдельного фрагмента, который обозначается с помощью k, n, направленное усиление вычисляется для каждого такого фрагмента времени/частоты. Блок 820 весовой обработки принимает опорный сигнал и данные о диффузности для определенного фрагмента времени/частоты и результатом обработки блоком 820 весовой обработки является прямая часть. Диффузная часть генерируется обработкой, выполняемой фильтром 823 декорреляции и последующим блоком 824 весовой обработки, принимающим значение Ψ диффузности для определенного временного кадра и элемента разрешения по частоте и, в частности, принимающим средний ответ на определенную моду m и порядок l, указываемый как Dl и генерируемый блоком 826 обеспечения среднего ответа, который принимает в качестве ввода требуемую моду m и требуемый порядок l.
Результатом обработки блоком 824 весовой обработки является диффузная часть, и эта диффузная часть прибавляется к прямой части сумматором 825 для того, чтобы получить определенную компоненту звукового поля среднего порядка для определенной моды m и определенного порядка l. Предпочтительно применять диффузное компенсационное усиление, описанное со ссылкой на Фиг. 6, только к диффузной части, генерируемой блоком 823. Это может быть выгодно сделано в рамках процедуры, выполняемой блоком весовой обработки (диффузных компонент). Таким образом, в сигнале усиливается только диффузная часть, чтобы компенсировать потерю диффузной энергии, понесенную более высокими компонентами, которые не принимают полного синтеза, как проиллюстрировано на Фиг. 10.
Генерирование только прямой части проиллюстрировано на Фиг. 11 для генератора компонент высокого порядка. В своей основе, генератор компонент высокого порядка реализован таким же образом, что и генератор компонент среднего порядка по отношению к прямой ветви, но не содержит блоков 823, 824, 825 и 826. Таким образом, генератор компонент высокого порядка содержит только блок 822 весовой обработки (прямых компонент), принимающий входные данные от вычислителя 410 направленного усиления и принимающий опорный сигнал от генератора 821 опорного сигнала. Предпочтительно, чтобы для генератора компонент высокого порядка и генератора компонент среднего порядка генерировался только один опорный сигнал. Однако оба блока также могут иметь индивидуальные генераторы опорных сигналов, в зависимости от обстоятельств. Тем не менее предпочтительно иметь только один генератор опорного сигнала. Таким образом, обработка, выполняемая генератором компонент высокого порядка, является чрезвычайно эффективной, поскольку для фрагмента времени/частоты должна выполняться только одна операция взвешивания с определенным направленным усилением Glm с определенной информацией Ψ о диффузности. Таким образом, компоненты звукового поля высокого порядка могут быть сгенерированы чрезвычайно эффективно и быстро, а любая ошибка, связанная с отсутствием генерирования диффузных компонент или неиспользованием диффузных компонент в выходном сигнале, легко компенсируется за счет усиления компонент звукового поля низкого порядка или предпочтительно только диффузной части компонент звукового поля среднего порядка.
Обычно диффузная часть не будет доступна отдельно в компонентах звукового поля низкого порядка, генерируемых копированием или выполнением (взвешенной) линейной комбинации. Однако увеличение энергии таких компонент автоматически увеличивает энергию диффузной части. Как выяснили изобретатели, одновременное повышение энергии прямой части проблемой не является.
Далее делается ссылка на Фиг. с 12a по 12c для того, чтобы дополнительно проиллюстрировать вычисление отдельных компенсационных усилений.
Фиг. 12a иллюстрирует предпочтительную реализацию генератора 650 звуковых компонент с Фиг. 6. Компенсационное усиление (диффузное) вычисляется в одном варианте осуществления с использованием значения диффузности, максимального порядка H и порядка L отсечения. В другом варианте осуществления диффузное компенсационное усиление вычисляется с использованием параметра Lk, выводимого из числа компонент в ветви 810 обработки низкого порядка. Кроме того, параметр mk используется в зависимости от параметра lk и числа K компонент, фактически генерируемых генератором компонент низкого порядка. Кроме того, также используется значение N, зависящее от Lk. Оба значения H, L в первом варианте осуществления или H, Lk, mk обычно представляют число компонент звукового поля во второй группе (связанное с числом звуковых компонент в первой группе). Таким образом, чем больше компонент, для которых диффузная компонента не синтезируется, тем выше будет компенсационное усиление энергии. С другой стороны, чем больше число компонент звукового поля низкого порядка, которые могут быть компенсированы, т.е. умножены на коэффициент усиления, тем этот коэффициент усиления может быть ниже. Как правило, коэффициент g усиления всегда будет больше 1.
Фиг. 12a иллюстрирует вычисление коэффициента g усиления вычислителем 910 (диффузного) компенсационного усиления и последующее применение этого коэффициента усиления к компоненте (низкого порядка), которая подлежит «корректировке», как это делается блоком 900 применения компенсационного усиления. В случае линейных чисел блок применения компенсационного усиления будет умножителем, а в случае логарифмических чисел блок применения компенсационного усиления будет сумматором. Однако другие реализации применения компенсационного усиления могут быть реализованы в зависимости от конкретной природы и способа вычисления компенсационного усиления блоком 910. Таким образом, усиление не обязательно должно быть мультипликативным, но также может быть любым другим усилением.
Фиг. 12b иллюстрирует третью реализацию обработки (прямого) компенсационного усиления. Вычислитель 920 (прямого) компенсационного усиления принимает в качестве ввода связанный с энергией или амплитудой показатель для всенаправленной компоненты, указанный как «всенаправленная мощность» на Фиг. 12b. Кроме того, второй связанный с энергией или амплитудой показатель для направленной компоненты также вводится в блок 920 в качестве «направленной мощности». Кроме того, вычислитель 920 прямого компенсационного усиления дополнительно принимает информацию QL или, в качестве альтернативы, информацию N. N равно (2l+1), что является числом коэффициентов на порядок l, а Ql равно 1/N. Кроме того, направленное усиление Glm для некоторого фрагмента времени/частоты (k, n) также требуется для вычисления (прямого) компенсационного усиления. Направленное усиление представляет собой те же данные, которые, например, были выведены вычислителем 410 направленного усиления с Фиг. 4. (Прямое) компенсационное усиление gs пересылается из блока 920 в блок 900 применения компенсационного усиления, который может быть реализован аналогично блоку 900, т.е. принимает компоненту(ы), которая подлежит «корректировке», и выводит скорректированную компоненту(ы).
Фиг. 12c иллюстрирует предпочтительную реализацию комбинации компенсации энергии компонент диффузного звука и нормализации энергии компенсации компонент прямого звука, которые должны быть выполнены совместно. С этой целью (диффузное) компенсационное усиление g и (прямое) компенсационное усиление gs вводятся в объединитель 930 усилений. Результат объединителя усилений (т.е. объединенное усиление) вводится в блок 940 манипулирования усилением, который реализован как постпроцессор и выполняет ограничение минимальным или максимальным значением, или который применяет функцию сжатия для выполнения некоторого в своем роде более мягкого ограничения, или выполняет сглаживание временных или частотных фрагментов. Подвергнутое манипуляции усиление, которое ограничено, сжато, или сглажено или обработано другими способами постобработки, затем применяется блоком применения усиления к компоненте(ам) низкого порядка для получения скорректированной компоненты(компонент) низкого порядка.
В случае линейных усилений g, gs, объединитель 930 усилений реализуется как умножитель. В случае логарифмических усилений, объединитель усилений реализуется как сумматор. Кроме того, что касается реализации блока оценки с Фиг. 7, указанного ссылочной позицией 620, показано, что блок 620 оценки может обеспечивать любые связанные с энергией или амплитудой показатели для всенаправленной и направленной компонент до тех пор, пока степень, применяемая к амплитуде, больше 1. В случае мощности в качестве связанного с энергией или амплитудой показателя, показатель степени равняется 2. Однако также могут быть полезны показатели степени от 1,5 до 2,5. Кроме того, полезны даже более высокие показатели степени или степени, такие как степень 3, применяемая к амплитуде, соответствующей значению громкости, а не значению мощности. Таким образом, как правило, степени 2 или 3 являются предпочтительными для обеспечения связанных с энергией или амплитудой показателей, но также обычно предпочтительны степени от 1,5 до 4.
Далее кратко излагаются несколько примеров аспектов изобретения.
Основной пример 1a для первого аспекта (компенсация энергии для компонент диффузного звука)
1a. Устройство для генерирования описания звукового поля из входного сигнала, содержащего один или более каналов, причем устройство содержит:
анализатор входного сигнала для получения данных о диффузности из входного сигнала;
генератор звуковых компонент для генерирования из входного сигнала одной или более компонент звукового поля первой группы компонент звукового поля, имеющей для каждой компоненты звукового поля прямую компоненту и диффузную компоненту, и для генерирования из входного сигнала второй группы компонент звукового поля, имеющих только прямую компоненту,
при этом генератор звуковых компонент выполнен с возможностью выполнять компенсацию энергии при генерировании первой группы компонент звукового поля, причем компенсация энергии зависит от данных о диффузности и числа компонент звукового поля во второй группе.
Основной пример 1b для второго аспекта (нормализация энергии для прямых компонент сигнала)
1b. Устройство для генерирования описания звукового поля из входного сигнала, содержащего по меньшей мере два канала, причем устройство содержит:
анализатор входного сигнала для получения данных о направлении и данных о диффузности из входного сигнала;
блок оценки для оценки первого связанного с амплитудой показателя для всенаправленной компоненты, выведенной из входного сигнала, и для оценки второго связанного с амплитудой показателя для направленной компоненты, выведенной из входного сигнала, и
генератор звуковых компонент для генерирования компонент звукового поля для звукового поля, причем генератор звуковых компонент выполнен с возможностью выполнения компенсации энергии направленной компоненты с использованием первого связанного с амплитудой показателя, второго связанного с амплитудой показателя, данных о направлении и данных о диффузности.
Основной пример 1c для третьего аспекта: Реализация системы с ветвями разных генераторов
1c. Устройство для генерирования описания звукового поля с использованием входного сигнала, содержащего моносигнал или многоканальный сигнал, причем устройство содержит:
анализатор входного сигнала для анализа входного сигнала для выведения данных о направлении и данных о диффузности;
генератор компонент низкого порядка для генерирования звукового описания низкого порядка из входного сигнала вплоть до предопределенного порядка и моды, при этом генератор компонент низкого порядка выполнен с возможностью выведения звукового описания низкого порядка посредством копирования входного сигнала или посредством выполнения взвешенной комбинации каналов входного сигнала;
генератор компонент среднего порядка для генерирования звукового описания среднего порядка, которое выше предопределенного порядок или с предопределенным порядком и выше предопределенной моды и ниже или с первым порядком отсечения, используя синтез по меньшей мере одной прямой компоненты и по меньшей мере одной диффузной компоненты, с использованием данных о направлении и данных о диффузности, так что звуковое описание среднего порядка содержит прямой вклад и диффузный вклад; и
генератор компонент высокого порядка для генерирования звукового описания высокого порядка, имеющего компоненту, которая выше первого порядка отсечения, используя синтез по меньшей мере одной прямой компоненты без синтеза какой-либо диффузной компоненты, так что звуковое описание высокого порядка имеет только прямой вклад.
2. Устройство по примерам 1a, 1b, 1c,
в котором звуковое описание низкого порядка, звуковое описание среднего порядка или звуковое описание высокого порядка содержат компоненты звукового поля выходного звукового поля, которые являются ортогональными, так что любые два звуковых описания не содержат одни и те же компоненты звукового поля, или
при этом генератор компонент среднего порядка генерирует компоненты ниже или с первым порядком отсечения, не используемым генератором компонент низкого порядка.
3. Устройство по одному из предшествующих примеров, содержащее:
прием входного сигнала понижающего микширования, имеющего один или более аудиоканалов, которые представляют звуковое поле
прием или определение одного или более направлений звука, которые представляют звуковое поле;
оценку одной или более пространственных базисных функций с использованием одного или более направлений звука;
выведение первого набора одной или более компонент звукового поля из первой взвешенной комбинации каналов входного сигнала понижающего микширования.
выведение второго набора одной или более прямых компонент звукового поля из второй взвешенной комбинации каналов входного сигнала понижающего микширования и одной или более оцененных пространственных базисных функций.
объединение первого набора одной или более компонент звукового поля и второго набора одной или более компонент звукового поля.
4. Устройство по одному из предшествующих примеров, при этом первый и второй наборы компонент звукового поля ортогональны.
5. Устройство по одному из предшествующих примеров, при этом компоненты звукового поля являются коэффициентами ортогональных базисных функций.
6. Устройство по одному из предшествующих примеров, при этом компоненты звукового поля являются коэффициентами пространственных базисных функций.
7. Устройство по одному из предшествующих примеров, при этом компоненты звукового поля являются коэффициентами сферических или круговых гармоник.
8. Устройство по одному из предшествующих примеров, при этом компоненты звукового поля являются амбисоническими коэффициентами.
9. Устройство по одному из предшествующих примеров, при этом входной сигнал понижающего микширования имеет менее трех аудиоканалов.
10. Устройство по одному из предшествующих примеров, дополнительно содержащее:
прием или определение значения диффузности;
генерирование одной или более компонент диффузного звука в зависимости от значения диффузности; и
объединение одной или более компонент диффузного звука со вторым набором одной или более прямых компонент звукового поля;
11. Устройство по одному из предшествующих примеров, в котором генератор диффузных компонент дополнительно содержит декоррелятор для декорреляции информации о диффузном звуке.
12. Устройство по одному из предшествующих примеров, при этом первый набор одной или более компонент звукового поля выводятся из значения диффузности.
13. Устройство по одному из предшествующих примеров, при этом первый набор одной или более компонент звукового поля выводятся из одного или более направлений звука.
14. Устройство по одному из предшествующих примеров, которое осуществляет выведение зависимых от частоты и времени направлений звука.
15. Устройство по одному из предшествующих примеров, которое осуществляет выведение зависимых от частоты и времени значений диффузности.
16. Устройство по одному из предшествующих примеров, дополнительно содержащее: разложение множества каналов сигнала понижающего микширования во временной области в частотное представление, имеющее множество частотно-временных фрагментов.
17. Способ для генерирования описания звукового поля из входного сигнала, содержащего один или более каналов, содержащий:
получение данных о диффузности из входного сигнала;
генерирование из входного сигнала одной или более компонент звукового поля первой группы компонент звукового поля, имеющей для каждой компоненты звукового поля прямую компоненту и диффузную компоненту, и генерирование из входного сигнала второй группы компонент звукового поля, имеющих только прямую компоненту,
при этом генерирование содержит выполнение компенсации энергии при генерировании первой группы компонент звукового поля, причем компенсация энергии зависит от данных о диффузности и числа компонент звукового поля во второй группе.
18. Способ для генерирования описания звукового поля из входного сигнала, содержащего по меньшей мере два канала, содержащий:
получение данных о направлении и данных о диффузности из входного сигнала;
оценку первого связанного с амплитудой показателя для всенаправленной компоненты, выведенной из входного сигнала, и оценку второго связанного с амплитудой показателя для направленной компоненты, выведенной из входного сигнала, и
генерирование компонент звукового поля для звукового поля, при этом генератор звуковых компонент выполнен с возможностью выполнения компенсации энергии направленной компоненты с использованием первого связанного с амплитудой показателя, второго связанного с амплитудой показателя, данных о направлении и данных о диффузности.
19. Способ для генерирования описания звукового поля с использованием входного сигнала, содержащего моносигнал или многоканальный сигнал, причем способ содержит:
анализ входного сигнала для выведения данных о направлении и данных о диффузности;
генерирование звукового описания низкого порядка из входного сигнала вплоть до предопределенного порядка и моды, при этом генератор низкого порядка выполнен с возможностью выведения звукового описания низкого порядка посредством копирования входного сигнала или выполнения взвешенной комбинации каналов входного сигнала;
генерирование звукового описания среднего порядка, которое выше предопределенного порядка или с предопределенным порядком и выше предопределенной моды и ниже высокого порядка, используя синтез по меньшей мере одной прямой части и по меньшей мере одной диффузной части, с использованием данных о направлении и данных о диффузности, так что звуковое описание среднего порядка содержит прямой вклад и диффузный вклад; и
генерирование звукового описания высокого порядка, имеющего компоненту, которая имеет или выше высокого порядка, используя синтез по меньшей мере одной прямой части без синтеза какой-либо диффузной компоненты, так что звуковое описание высокого порядка содержит только прямой вклад.
20. Компьютерная программа для выполнения при работе на компьютере или процессоре способа по одному из примеров 17, 18 или 19.
Здесь следует упомянуть, что все альтернативы или аспекты, которые описаны выше, а также все аспекты, определенные независимыми пунктами в нижеследующей формуле изобретения, могут использоваться индивидуально, то есть без какой-либо другой альтернативы или объекта, кроме предполагаемой альтернативы, объекта или независимого пункта. Однако в других вариантах осуществления две или более альтернатив или аспектов или независимых пунктов формулы изобретения могут быть объединены друг с другом, а в других вариантах осуществления все аспекты или альтернативы и все независимые пункты формулы изобретения могут быть объединены друг с другом.
Кодированный согласно изобретению аудиосигнал может быть сохранен на цифровом носителе данных или энергонезависимом носителе данных или может быть передан в среде передачи, такой как беспроводная среда передачи, или проводная среда передачи, такая как Интернет.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствуют этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют собой описание соответствующего блока, элемента или признака соответствующего устройства.
В зависимости от определенных требований к реализации варианты осуществления изобретения могут быть реализованы аппаратно или программно. Реализация может быть выполнена с использованием цифрового носителя данных, например дискеты, DVD, CD, ROM, PROM, EPROM, EEPROM или FLASH-памяти, на которых хранятся электронно-читаемые управляющие сигналы, которые взаимодействуют между собой (или способны взаимодействовать) с программируемой компьютерной системой, чтобы выполнялся соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронно-читаемые управляющие сигналы, которые способны взаимодействовать с программируемой компьютерной системой, так что выполняется один из описанных в данном документе способов.
Как правило, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, причем программный код действует для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может, например, храниться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из описанных в данном документе способов, хранящуюся на машиночитаемом носителе или энергонезависимом запоминающем носителе.
Другими словами, вариант осуществления способа по настоящему изобретению представляет собой компьютерную программу, имеющую программный код для выполнения одного из описанных здесь способов, когда компьютерная программа выполняется на компьютере.
Следовательно, дополнительным вариантом осуществления способов согласно изобретению является носитель данных (или цифровой носитель данных, или считываемый компьютером носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в данном документе.
Таким образом, дополнительный вариант осуществления способа по настоящему изобретению представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в данном документе. Поток данных или последовательность сигналов могут, например, быть сконфигурированы для передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например компьютер, или программируемое логическое устройство, выполненное с возможностью или адаптированное для выполнения одного из способов, описанных в данном документе.
Еще один вариант осуществления включает в себя компьютер, на котором установлена компьютерная программа для выполнения одного из описанных в данном документе способов.
В некоторых вариантах осуществления можно использовать программируемое логическое устройство (например, программируемую пользователем вентильную матрицу) для выполнения некоторых или всех функциональных возможностей, описанных в данном документе способов. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из описанных в данном документе способов. Обычно способы предпочтительно выполняются с помощью любого аппаратного устройства.
Вышеописанные варианты осуществления являются просто иллюстрацией принципов настоящего изобретения. Понятно, что модификации и изменения компоновок и деталей, описанных в данном документе, будут очевидны другим специалистам в данной области техники. Таким образом, имеется намерение ограничиваться только объемом прилагаемой формулы изобретения, а не конкретными деталями, представленными в качестве описания и пояснения вариантов осуществления в данном описании.
Источники информации
[1] V. Pulkki, M-V Laitinen, J Vilkamo, J Ahonen, T Lokki and T Pihlajamäki, “Directional audio coding - perception-based reproduction of spatial sound”, International Workshop on the Principles and Application on Spatial Hearing, Nov. 2009, Zao; Miyagi, Japan.
[2] M. V. Laitinen and V. Pulkki, "Converting 5.1 audio recordings to B-format for directional audio coding reproduction," 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, 2011, pp. 61-64.
[3] R. K. Furness, "Ambisonics - An overview," in AES 8th International Conference, April 1990, pp. 181-189.
[4] C. Nachbar, F. Zotter, E. Deleflie, and A. Sontacchi, "AMBIX - A Suggested Ambisonics Format", Proceedings of the Ambisonics Symposium 2011.
[5] "APPARATUS, METHOD OR COMPUTER PROGRAM FOR GENERATING A SOUND FIELD DESCRIPTION" (соответствующая документу WO 2017/157803 A1).
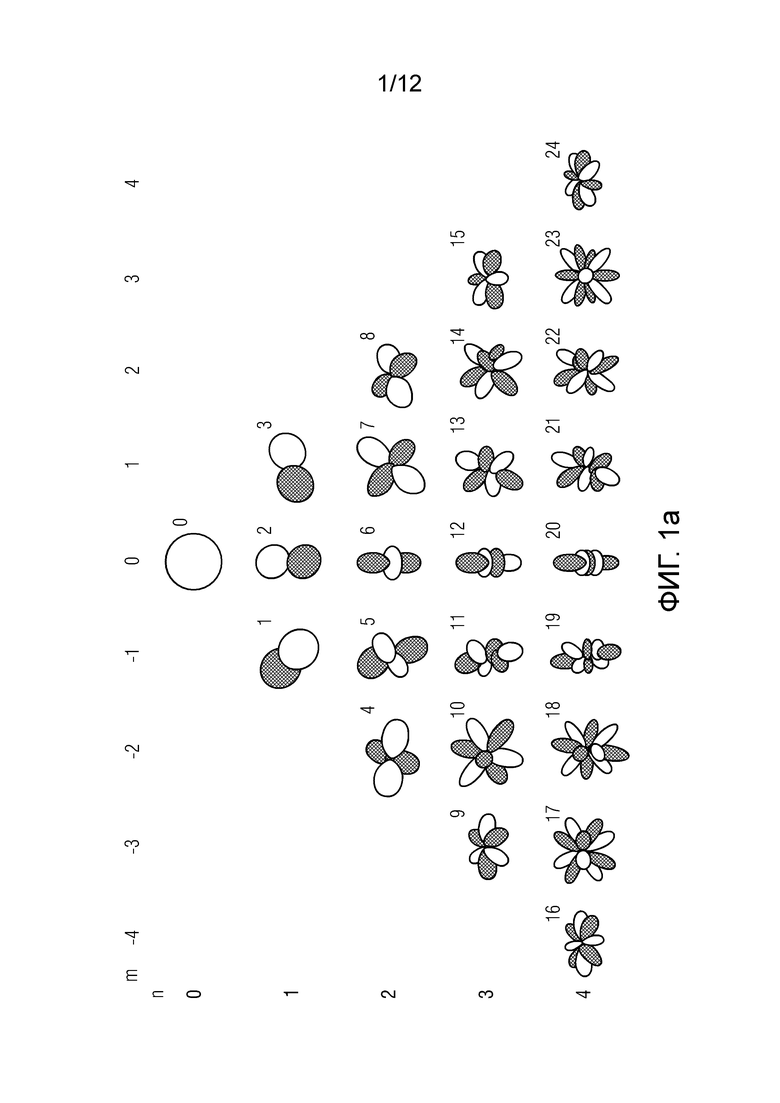
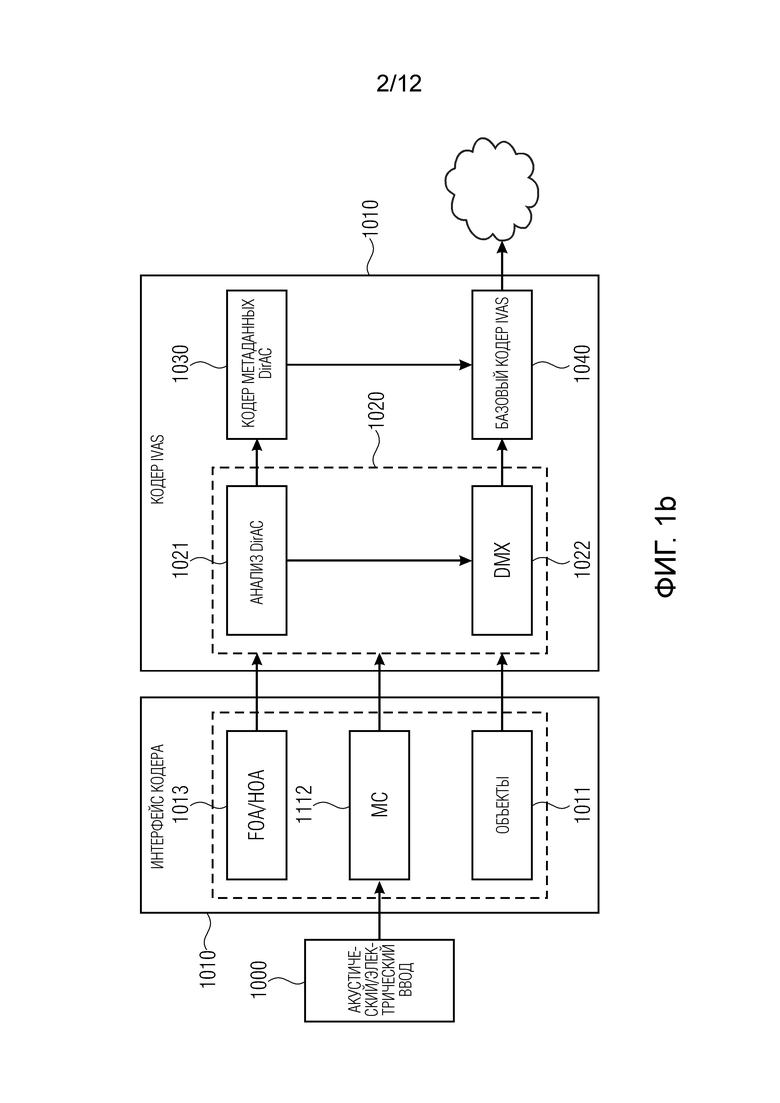
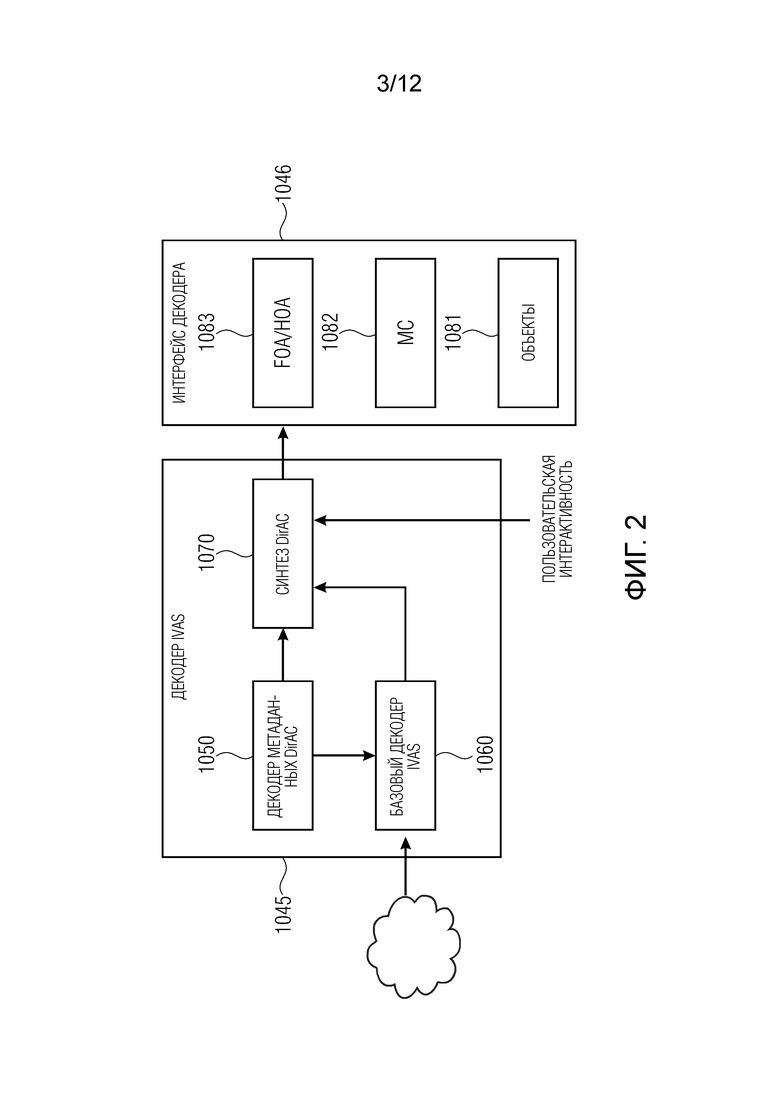
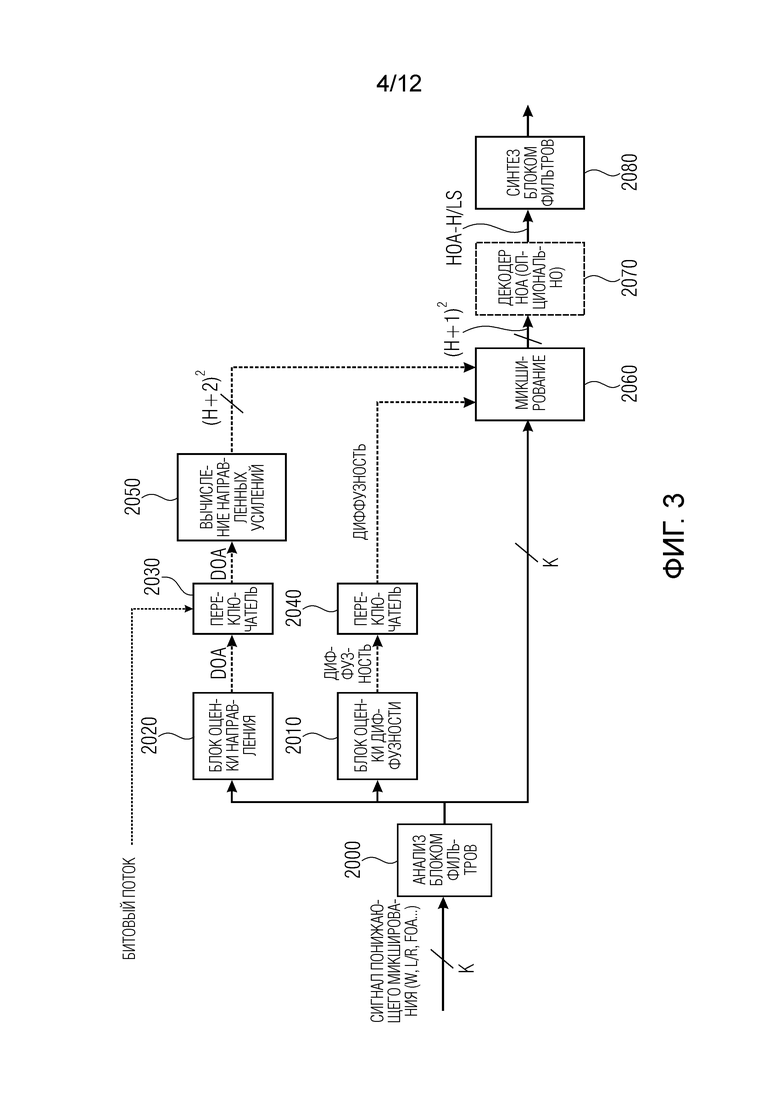
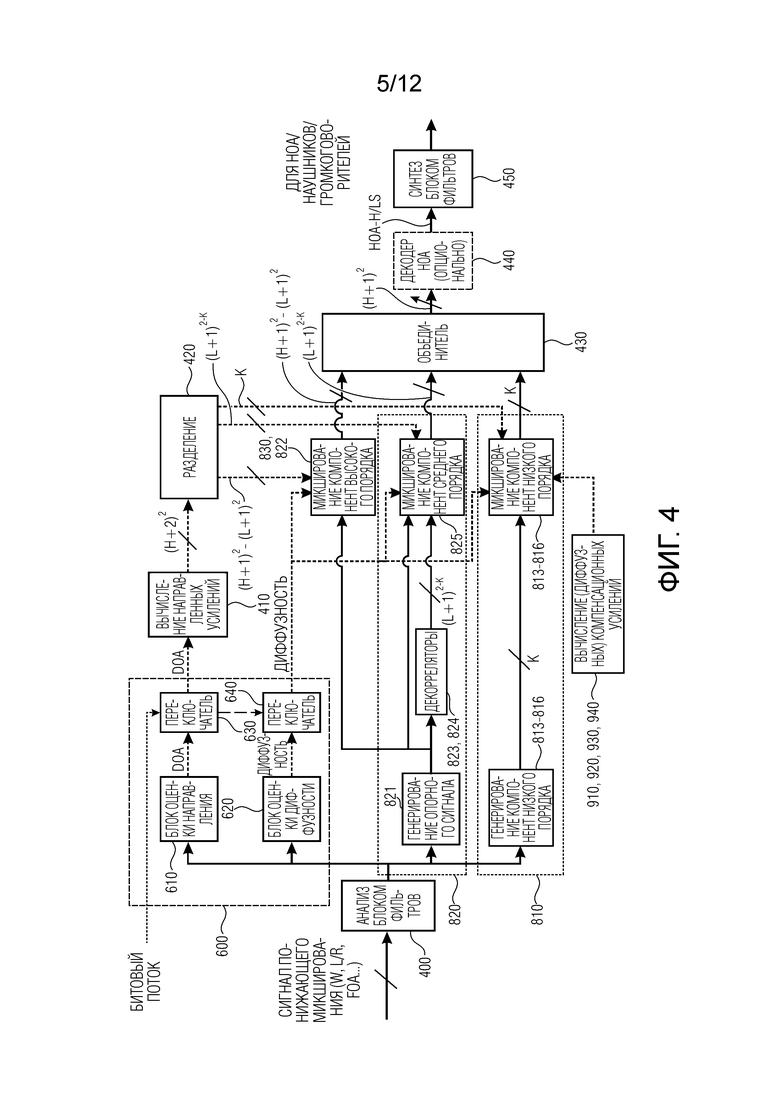
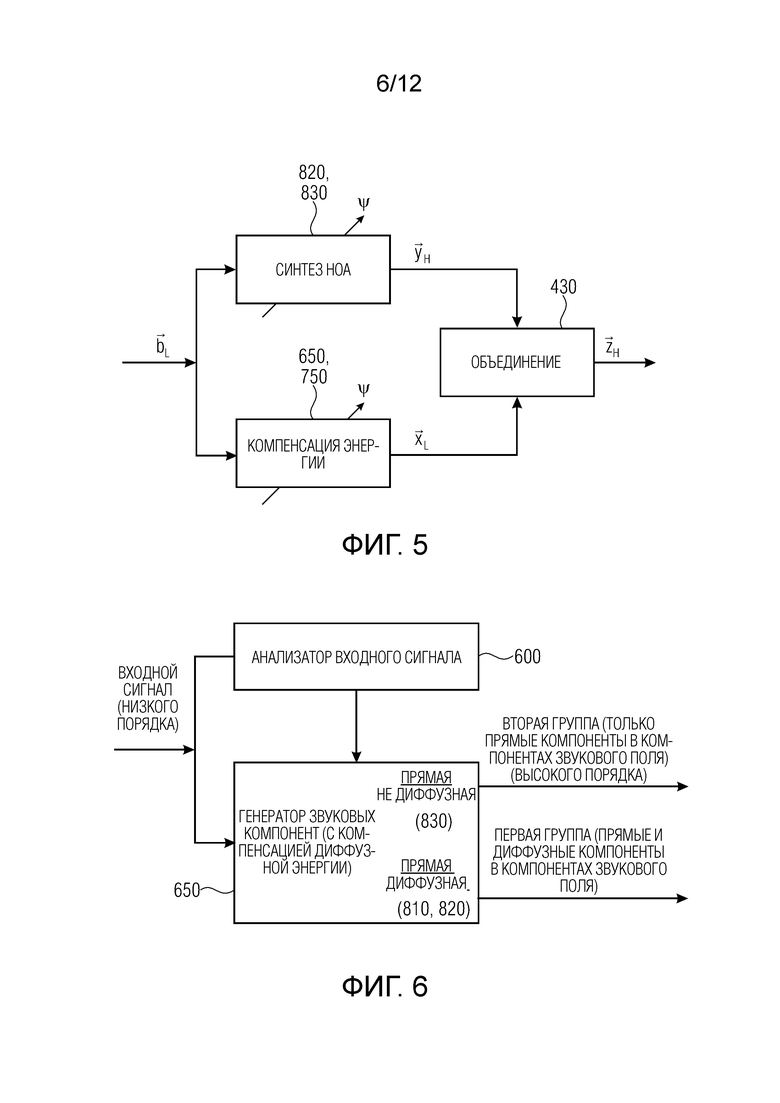
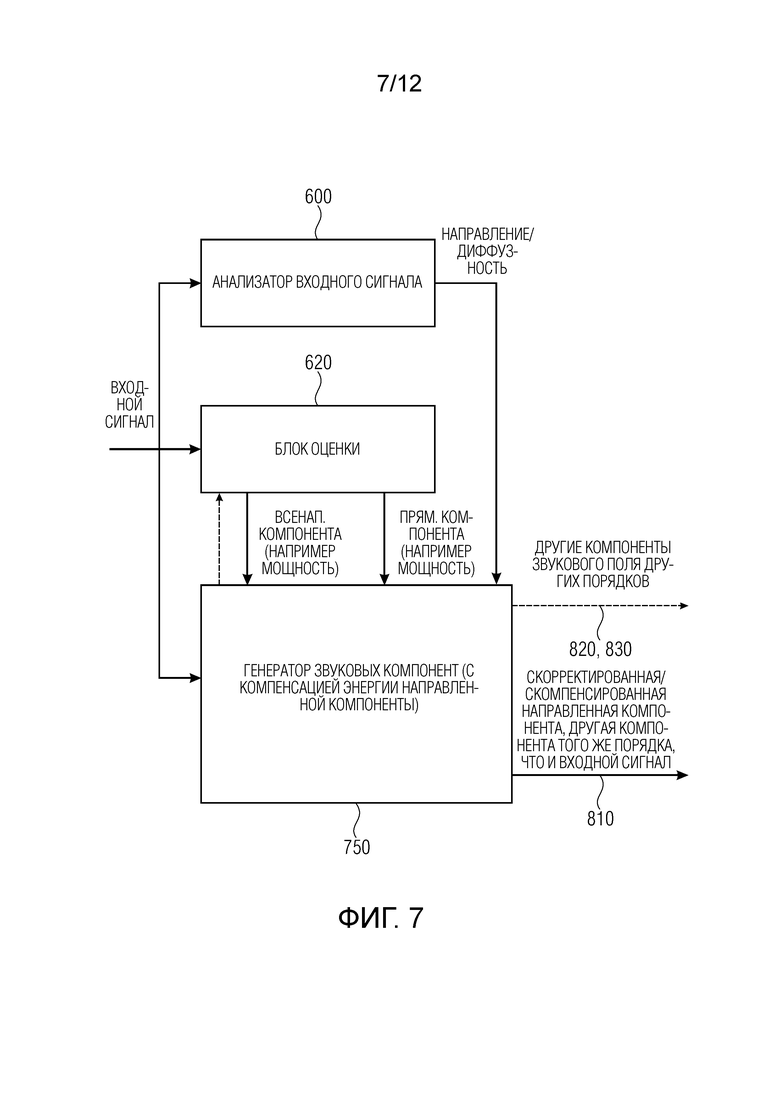
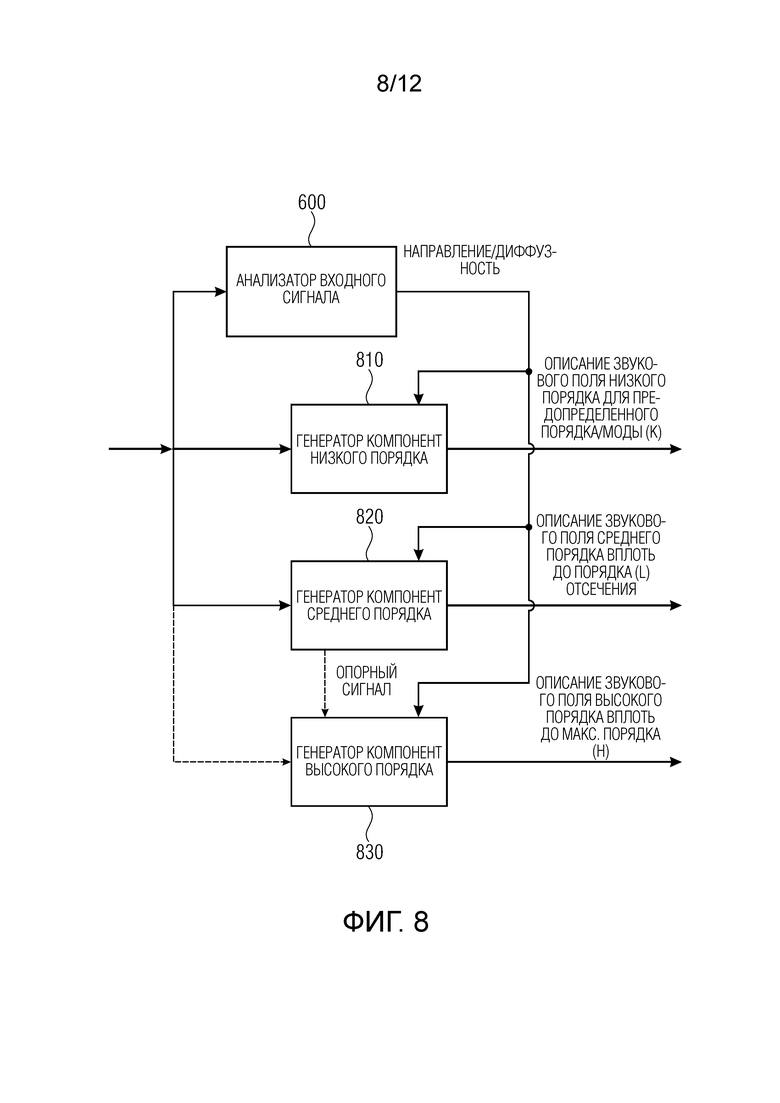
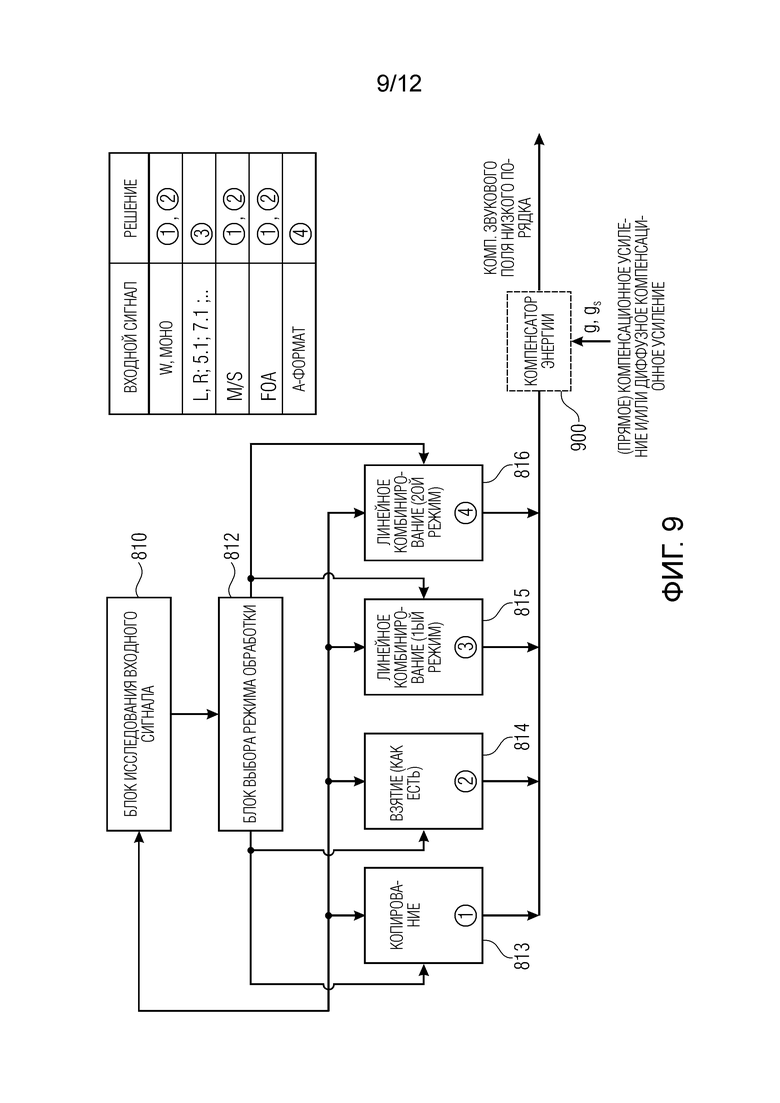
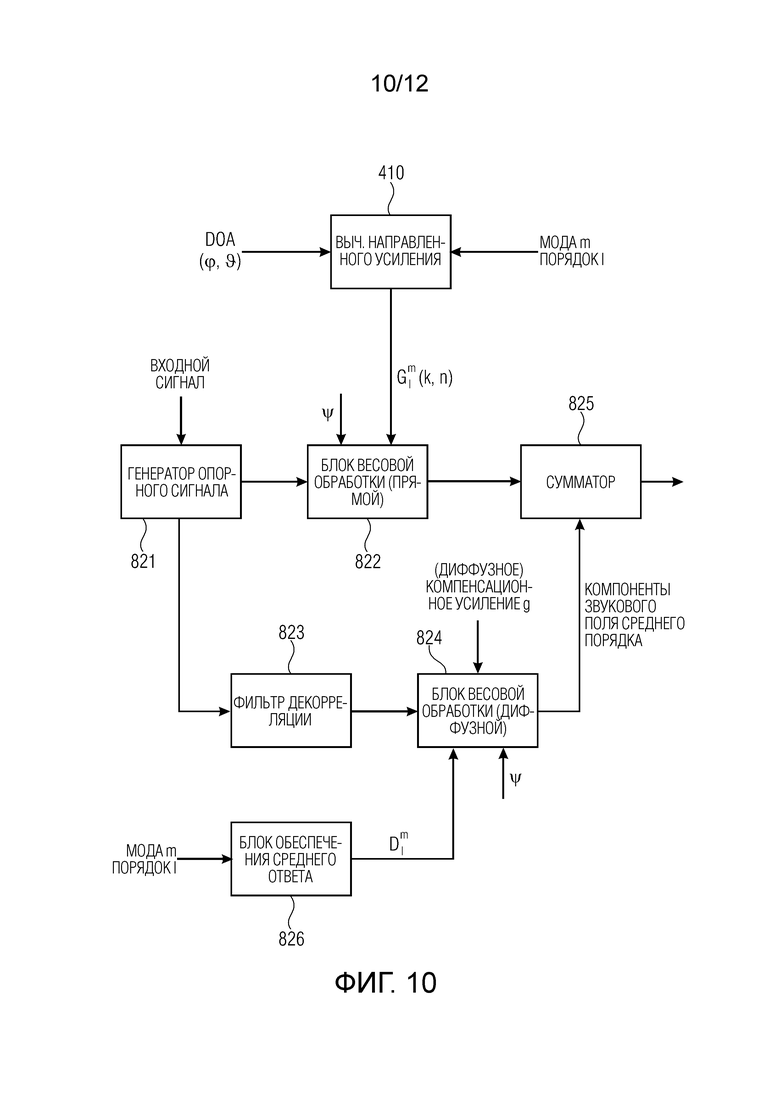
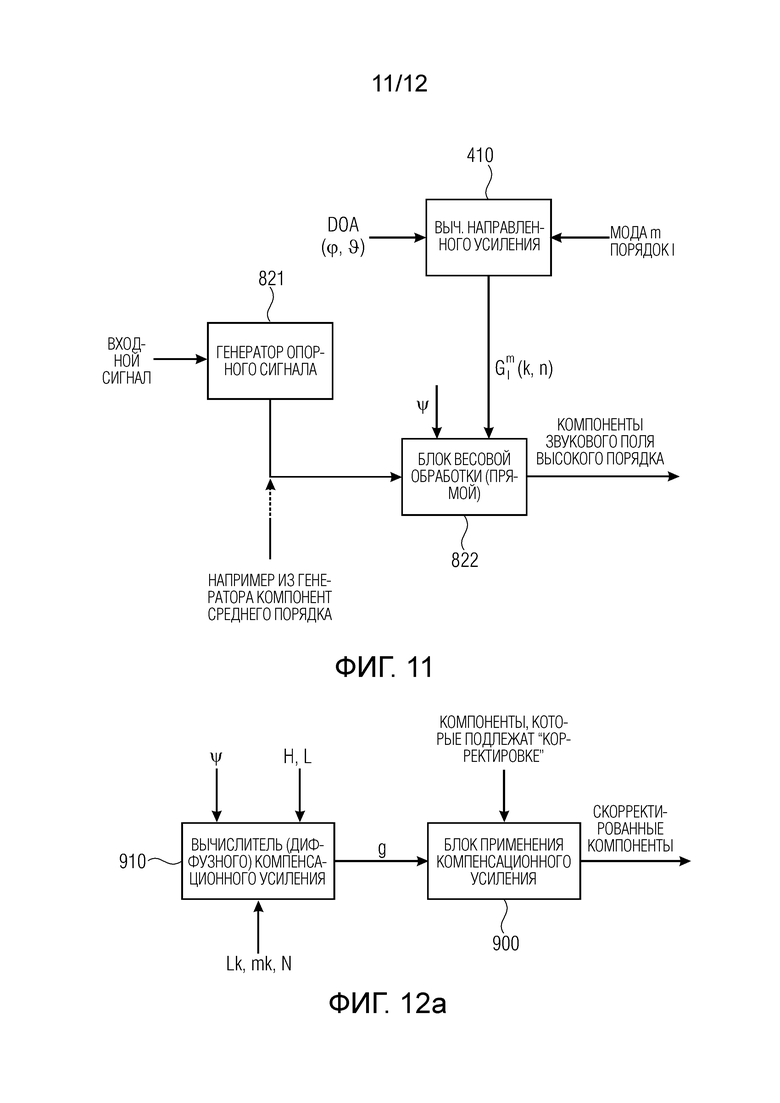
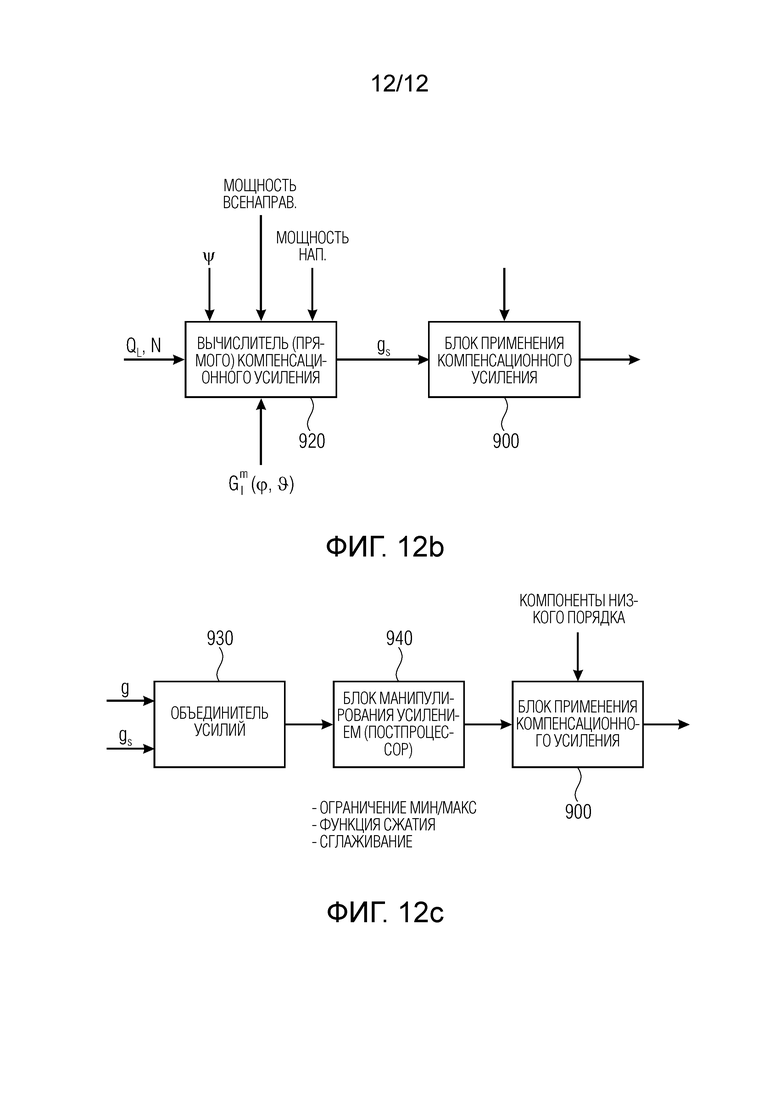
Изобретение относится к способам и устройствам аудиокодирования. Технический результат заключается в уменьшении ошибки квантования при кодировании аудиосигнала. Технический результат достигается за счет выполнения следующих этапов способа: получение данных о направлении и данных о диффузности из входного сигнала; оценка первого связанного с энергией или амплитудой показателя для всенаправленной компоненты, выводимой из входного сигнала, и оценку второго связанного с энергией или амплитудой показателя для направленной компоненты, выводимой из входного сигнала, и генерирование компонент звукового поля, при этом генератор звуковых компонент выполнен с возможностью выполнения компенсации энергии направленной компоненты с использованием первого связанного с энергией или амплитудой показателя, второго связанного с энергией или амплитудой показателя, данных о направлении и данных о диффузности. 3 н. и 19 з.п. ф-лы, 15 ил.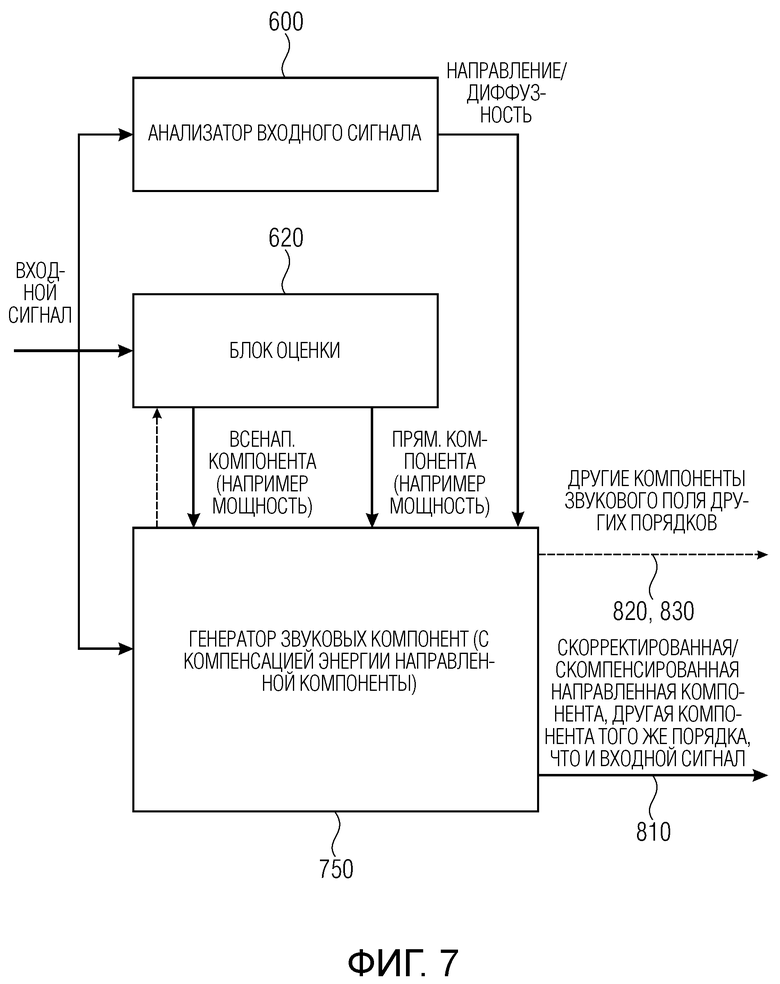
1. Устройство для генерирования описания звукового поля из входного сигнала, содержащего по меньшей мере два канала, причем устройство содержит:
анализатор (600) входного сигнала для получения данных о направлении и данных о диффузности из входного сигнала;
блок (620) оценки для оценки первого связанного с энергией или энергией или амплитудой показателя для всенаправленной компоненты, выводимой из входного сигнала, и для оценки второго связанного с энергией или амплитудой показателя для направленной компоненты, выводимой из входного сигнала, и
генератор (750) звуковых компонент для генерирования компонент звукового поля для звукового поля, при этом генератор звуковых компонент выполнен с возможностью выполнения компенсации энергии направленной компоненты с использованием первого связанного с энергией или амплитудой показателя, второго связанного с энергией или амплитудой показателя, данных о направлении и данных о диффузности.
2. Устройство по п. 1, в котором входной сигнал содержит по меньшей мере два канала, при этом блок (620) оценки выполнен с возможностью вычисления всенаправленной компоненты с использованием сложения по меньшей мере двух каналов, и вычисления направленной компоненты с использованием вычитания по меньшей мере двух каналов (815).
3. Устройство по п. 1, в котором входной сигнал содержит всенаправленную компоненту и одну или более направленных компонент, и в котором блок (620) оценки выполнен с возможностью вычисления первого связанного с амплитудой показателя для всенаправленной компоненты с использованием входного сигнала и вычисления второго связанного с энергией или амплитудой показателя для каждой из одной или более направленных компонент из входного сигнала.
4. Устройство по п. 1, в котором входной сигнал содержит представление A-формата или B-формата с по меньшей мере двумя каналами, и в котором блок (620) оценки выполнен с возможностью выведения (816) всенаправленной компоненты и направленных компонент с использованием взвешенного линейного комбинирования по меньшей мере двух каналов.
5. Устройство по п. 1, в котором анализатор (600) входного сигнала выполнен с возможностью извлечения данных о диффузности из метаданных, ассоциированных с входным сигналом, или с возможностью извлечения данных о диффузности из входного сигнала посредством анализа (610, 620) сигнала собственно входного сигнала, имеющего по меньшей мере два (две) канала или компоненты.
6. Устройство по п. 1, в котором блок (620) оценки выполнен с возможностью вычисления первого связанного с энергией или амплитудой показателя или второго связанного с энергией или амплитудой показателя из абсолютного значения комплексной амплитуды или величины, возведенной в степень, которая больше 1 и меньше 5 или равна 2 или 3.
7. Устройство по п. 1,
при этом генератор (750) звуковых компонент содержит компенсатор (900-940) энергии для выполнения компенсации энергии, причем компенсатор энергии содержит вычислитель (910, 920, 930, 940) компенсационного усиления для вычисления компенсационного усиления с использованием первого связанного с энергией или амплитудой показателя, второго связанного с энергией или амплитудой показателя, данных о направлении и данных о диффузности.
8. Устройство по п. 1, в котором генератор (750) звуковых компонент выполнен с возможностью вычисления (410) из данных о направлении направленного усиления и объединения (920) направленного усиления и данных о диффузности для выполнения компенсации энергии.
9. Устройство по п. 1, в котором блок (620) оценки выполнен с возможностью оценивать второй связанный с энергией или амплитудой показатель для первой направленной компоненты и третий связанный с энергией или амплитудой показатель для второй направленной компоненты, вычислять первое компенсационное усиление для первой направленной компоненты с использованием первого и второго связанных с энергией или амплитудой показателей, и вычислять второе компенсационное усиление для второй направленной компоненты с использованием первого и третьего связанных с энергией или амплитудой показателей.
10. Устройство по п. 9,
в котором вычислитель (910, 920) компенсационного усиления выполнен с возможностью вычисления (910) первого коэффициента усиления в зависимости от данных о диффузности и по меньшей мере одного из числа компонент звукового поля во второй группе, максимального порядка компонент звукового поля первой группы и максимального числа компонент звукового поля второй группы, вычисления (920) второго коэффициента усиления в зависимости от первого связанного с энергией или амплитудой показателя для всенаправленной компоненты, второго связанного с энергией или амплитудой показателя для направленной компоненты, данных о направлении и данных о диффузности, и вычисления (930) компенсационного усиления с использованием первого коэффициента усиления и второго коэффициента усиления,
при этом генератор (750) звуковых компонент выполнен с возможностью использования тех же самых данных о направлении и данных о диффузности для вычисления первого компенсационного усиления и второго компенсационного усиления.
11. Устройство по п. 7,
в котором вычислитель (910) компенсационного усиления выполнен с возможностью вычисления коэффициента усиления на основе следующего уравнения
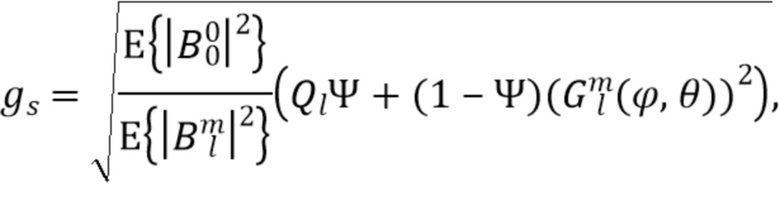 или
или
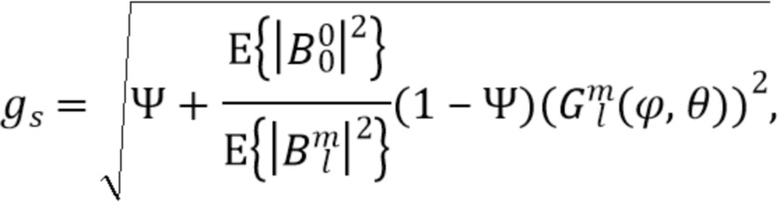
где Ψ представляет данные о диффузности, 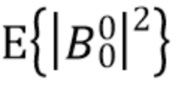 представляет первый связанный с энергией или амплитудой показатель,
представляет первый связанный с энергией или амплитудой показатель, 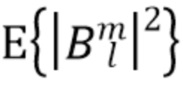 представляет второй связанный с энергией или амплитудой показатель,
представляет второй связанный с энергией или амплитудой показатель, 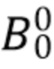 представляет собой всенаправленную компоненту,
представляет собой всенаправленную компоненту, 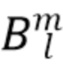 представляет собой направленную компоненту,
представляет собой направленную компоненту, 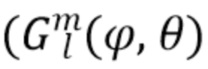 представляет собой усиление направления, выводимое из данных о направлении
представляет собой усиление направления, выводимое из данных о направлении 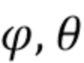 ,
, 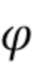 представляет собой азимутальный угол,
представляет собой азимутальный угол, 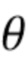 представляет собой угол возвышения,
представляет собой угол возвышения, 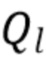 представляет собой коэффициент направленности порядка l, а gs представляет собой коэффициент усиления.
представляет собой коэффициент направленности порядка l, а gs представляет собой коэффициент усиления.
12. Устройство по п. 7, в котором вычислитель (910) компенсационного усиления выполнен с возможностью
увеличения компенсационного усиления при увеличении первого связанного с энергией или амплитудой показателя, или
уменьшения компенсационного усиления при увеличении второго связанного с энергией или амплитудой показателя, или
увеличения компенсационного усиления с увеличением усиления направления, или
увеличения компенсационного усиления при уменьшении числа направленных компонент.
13. Устройство по п. 7,
в котором генератор (650) звуковых компонент предназначен для генерирования из входного сигнала одной или более компонент звукового поля первой группы компонент звукового поля, имеющей для каждой компоненты звукового поля прямую компоненту и диффузную компоненту, и для генерирования из входного сигнала второй группы компонент звукового поля, имеющих только прямую компоненту,
при этом вычислитель (910) компенсационного усиления выполнен с возможностью вычисления компенсационного усиления с использованием данных о диффузности и по меньшей мере одного из числа компонент звукового поля во второй группе, числа диффузных компонент в первой группе, максимального порядка компонент звукового поля первой группы и максимального порядка компонент звукового поля второй группы.
14. Устройство по п. 7, в котором вычислитель (910, 920, 930, 940) компенсационного усиления выполнен с возможностью выполнения манипулирования (940) коэффициентом усиления с использованием ограничения с фиксированным максимальным порогом или фиксированным минимальным порогом, или с использованием функции сжатия для сжатия низких или высоких коэффициентов усиления до средних коэффициентов усиления, чтобы получить компенсационное усиление.
15. Устройство по п. 1,
при этом генератор (750) звуковых компонент выполнен с возможностью генерирования других компонент звукового поля других порядков, при этом объединитель (430) выполнен с возможностью объединения компонент звукового поля определенного звукового поля и других компонент звукового поля других порядков для получения описания звукового поля, имеющего порядок выше, чем порядок входного сигнала.
16. Устройство по п. 7, в котором компенсатор (910, 920, 930, 940) энергии содержит блок (900) применения компенсационного усиления для применения компенсационного усиления к по меньшей мере одной компоненте звукового поля.
17. Устройство по п. 1, в котором генератор (750) звуковых компонент содержит генератор (810) компонент низкого порядка для генерирования описания звукового поля низкого порядка из входного сигнала вплоть до предопределенного порядка и предопределенной моды, при этом генератор (810) компонент низкого порядка выполнен с возможностью выведения описания звукового поля низкого порядка посредством копирования или взятия входного сигнала или формирования взвешенной комбинации каналов входного сигнала,
при этом описание звукового поля низкого порядка содержит всенаправленную компоненту и направленную компоненту, генерируемую копированием, или взятием, или линейной комбинацией.
18. Устройство по п. 17, в котором генератор (750) звуковых компонент дополнительно содержит:
генератор (820) компонент среднего порядка для генерирования описания звукового поля среднего порядка выше упомянутого предопределенного порядка или с упомянутым предопределенным порядком и выше предопределенной моды и ниже или с первым порядком отсечения, используя синтез по меньшей мере одной прямой части и по меньшей мере одной диффузной части, с использованием данных о направлении и данных о диффузности, так что описание звукового поля среднего порядка содержит прямой вклад и диффузный вклад; и
генератор (830) компонент высокого порядка для генерирования описания звукового поля высокого порядка, имеющего компоненту выше упомянутого первого порядка отсечения, используя синтез по меньшей мере одной прямой части, при этом описание звукового поля высокого порядка содержит только прямой вклад.
19. Устройство по п. 1,
в котором первая группа компонент звукового поля вплоть до порядка l коэффициентов и вторая группа компонент звукового поля выше этого порядка l коэффициентов ортогональны друг другу, или в котором компоненты звукового поля являются по меньшей мере одними из коэффициентов ортогональных базисных функций, коэффициентов пространственных базисных функций, коэффициентов сферических или круговых гармоник и амбисонических коэффициентов.
20. Устройство по п. 1,
блок (400) фильтров анализа для генерирования одной или более компонент звукового поля для множества различных частотно-временных фрагментов, при этом анализатор (600) входного сигнала выполнен с возможностью получения элемента данных о диффузности для каждого частотно-временного фрагмента, и при этом генератор (750) звуковых компонент выполнен с возможностью выполнения компенсации энергии отдельно для каждого частотно-временного фрагмента.
21. Способ для генерирования описания звукового поля из входного сигнала, содержащего по меньшей мере два канала, содержащий:
получение данных о направлении и данных о диффузности из входного сигнала;
оценку первого связанного с энергией или амплитудой показателя для всенаправленной компоненты, выводимой из входного сигнала, и оценку второго связанного с энергией или амплитудой показателя для направленной компоненты, выводимой из входного сигнала, и
генерирование компонент звукового поля для звукового поля, при этом генератор звуковых компонент выполнен с возможностью выполнения компенсации энергии направленной компоненты с использованием первого связанного с энергией или амплитудой показателя, второго связанного с энергией или амплитудой показателя, данных о направлении и данных о диффузности.
22. Физический считываемый компьютером носитель данных, имеющий хранящуюся на нем компьютерную программу для выполнения при исполнении на компьютере или процессоре способа по п. 21.
| УСТРОЙСТВО И СПОСОБ МАСШТАБИРОВАНИЯ ЦЕНТРАЛЬНОГО СИГНАЛА И УЛУЧШЕНИЯ СТЕРЕОФОНИИ НА ОСНОВЕ ОТНОШЕНИЯ СИГНАЛ-ПОНИЖАЮЩЕЕ МИКШИРОВАНИЕ | 2014 |
|
RU2663345C2 |
| УСТРОЙСТВО ПАРАМЕТРИЧЕСКОГО СТЕРЕОФОНИЧЕСКОГО ПОВЫШАЮЩЕГО МИКШИРОВАНИЯ, ПАРАМЕТРИЧЕСКИЙ СТЕРЕОФОНИЧЕСКИЙ ДЕКОДЕР, УСТРОЙСТВО ПАРАМЕТРИЧЕСКОГО СТЕРЕОФОНИЧЕСКОГО ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ, ПАРАМЕТРИЧЕСКИЙ СТЕРЕОФОНИЧЕСКИЙ КОДЕР | 2009 |
|
RU2497204C2 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| US 8891797 B2, 18.11.2014 | |||
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 9691406 B2, 27.06.2017. | |||

