ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится к кодированию видео и декодированию видео, вовлекающим в себя соответственно арифметическое кодирование и арифметическое декодирование.
УРОВЕНЬ ТЕХНИКИ
По мере того, как разрабатываются и предоставляются аппаратные средства для воспроизведения и сохранения высококачественного видеоконтента высокого разрешения, растет потребность в видеокодеке для эффективного кодирования или декодирования высококачественного видеоконтента высокого разрешения. В традиционном видеокодеке видео кодируется согласно ограниченному способу кодирования на основе макроблока, имеющего предварительно определенный размер.
Данные изображений пространственной области преобразуются в коэффициенты частотной области посредством использования способа преобразования частоты. Видеокодек кодирует частотные коэффициенты в единицах блоков посредством разделения изображения на множество блоков, имеющих предварительно определенный размер, и выполнения дискретного косинусного преобразования (DCT) для быстрого осуществления преобразования частоты. Коэффициенты частотной области легко сжимаются по сравнению с данными изображений пространственной области. В частности, пиксельное значение изображения в пространственной области представляется как ошибка прогнозирования, и в силу этого, если преобразование частоты выполняется в отношении ошибки прогнозирования, большой объем данных может быть преобразован в 0. Видеокодек преобразует данные, которые формируются непрерывно и многократно, в небольшие данные, с тем чтобы уменьшать объем данных.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
ТЕХНИЧЕСКАЯ ЗАДАЧА
Настоящее изобретение предоставляет способ и устройство для выполнения арифметического кодирования и арифметического декодирования видео посредством классификации символа на битовые строки префикса и суффикса.
ТЕХНИЧЕСКОЕ РЕШЕНИЕ
Согласно аспекту настоящего изобретения, предусмотрен способ декодирования видео посредством декодирования символов, причем способ включает в себя: синтаксический анализ символов блоков изображений из принимаемого потока битов; классификацию текущего символа на битовую строку префикса и битовую строку суффикса на основе порогового значения, определяемого согласно размеру текущего блока; выполнение арифметического декодирования посредством использования способа арифметического декодирования, определяемого для каждой из битовой строки префикса и битовой строки суффикса; выполнение преобразования из двоичной формы (дебинаризации) посредством использования способа преобразования в двоичную форму (бинаризации), определяемого для каждой из битовой строки префикса и битовой строки суффикса; и восстановление блоков изображений посредством выполнения обратного преобразования и прогнозирования в отношении текущего блока посредством использования текущего символа, восстанавливаемого посредством арифметического декодирования и преобразования из двоичной формы.
ПРЕИМУЩЕСТВА ИЗОБРЕТЕНИЯ
Эффективность процесса кодирования/декодирования символов повышается посредством осуществления способа преобразования в двоичную форму, имеющего относительно небольшую нагрузку по объему вычислений, в отношении области суффикса или битовой строки суффикса, или посредством пропуска контекстного моделирования в ходе контекстного арифметического кодирования/декодирования для кодирования/декодирования символов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 является блок-схемой устройства кодирования видео, согласно варианту осуществления настоящего изобретения;
Фиг. 2 является блок-схемой устройства декодирования видео, согласно варианту осуществления настоящего изобретения;
Фиг. 3 и 4 являются схемами для описания арифметического кодирования посредством классификации символа на битовую строку префикса и битовую строку суффикса согласно предварительно определенному пороговому значению, согласно варианту осуществления настоящего изобретения;
Фиг. 5 является блок-схемой последовательности операций способа для описания способа кодирования видео, согласно варианту осуществления настоящего изобретения;
Фиг. 6 является блок-схемой последовательности операций способа для описания способа декодирования видео, согласно варианту осуществления настоящего изобретения;
Фиг. 7 является блок-схемой устройства кодирования видео на основе единиц кодирования, имеющих древовидную структуру, согласно варианту осуществления настоящего изобретения;
Фиг. 8 является блок-схемой устройства декодирования видео на основе единицы кодирования, имеющей древовидную структуру, согласно варианту осуществления настоящего изобретения;
Фиг. 9 является концептуальной схемой единиц кодирования, согласно варианту осуществления настоящего изобретения;
Фиг. 10 является блок-схемой кодера изображений на основе единиц кодирования согласно варианту осуществления настоящего изобретения;
Фиг. 11 является блок-схемой декодера изображений на основе единиц кодирования согласно варианту осуществления настоящего изобретения;
Фиг. 12 является схемой, показывающей единицы кодирования согласно глубинам и сегменты, согласно варианту осуществления настоящего изобретения;
Фиг. 13 является схемой для описания взаимосвязи между единицей кодирования и единицами преобразования, согласно варианту осуществления настоящего изобретения;
Фиг. 14 является схемой для описания информации кодирования единиц кодирования согласно глубинам, согласно варианту осуществления настоящего изобретения;
Фиг. 15 является схемой, показывающей более глубокие единицы кодирования согласно глубинам, согласно варианту осуществления настоящего изобретения;
Фиг. 16-18 являются схемами для описания взаимосвязи между единицами кодирования, единицами прогнозирования и единицами преобразования, согласно варианту осуществления настоящего изобретения; и
Фиг. 19 является схемой для описания взаимосвязи между единицей кодирования, единицей прогнозирования и единицей преобразования, согласно информации режима кодирования по таблице 1.
ЛУЧШИЙ ВАРИАНТ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Согласно аспекту настоящего изобретения, предусмотрен способ декодирования видео посредством декодирования символов, причем способ включает в себя: синтаксический анализ символов блоков изображений из принимаемого потока битов; классификацию текущего символа на битовую строку префикса и битовую строку суффикса на основе порогового значения, определяемого согласно размеру текущего блока; выполнение арифметического декодирования посредством использования способа арифметического декодирования, определяемого для каждой из битовой строки префикса и битовой строки суффикса; выполнение преобразования из двоичной формы посредством использования способа преобразования в двоичную форму, определяемого для каждой из битовой строки префикса и битовой строки суффикса; и восстановление блоков изображений посредством выполнения обратного преобразования и прогнозирования в отношении текущего блока посредством использования текущего символа, восстанавливаемого посредством арифметического декодирования и преобразования из двоичной формы.
Выполнение преобразования из двоичной формы может включать в себя восстановление области префикса и области суффикса символа посредством выполнения преобразования из двоичной формы согласно способу преобразования в двоичную форму, определяемому для каждой из битовой строки префикса и битовой строки суффикса.
Выполнение арифметического декодирования может включать в себя: выполнение арифметического декодирования для определения контекстного моделирования в отношении битовой строки префикса согласно местоположениям битов; и выполнение арифметического декодирования для пропуска контекстного моделирования в отношении битовой строки суффикса в обходном режиме.
Выполнение арифметического декодирования может включать в себя выполнение арифметического декодирования посредством использования контекста предварительно определенного индекса, который заранее выделяется местоположениям битов битовой строки префикса, когда символ является информацией конечной позиции коэффициента для коэффициента преобразования.
Текущий символ может включать в себя по меньшей мере одно из режима внутреннего прогнозирования и информации конечной позиции коэффициента текущего блока.
Способ преобразования в двоичную форму дополнительно может включать в себя по меньшей мере одно, выбранное из группы, состоящей из унарного преобразования в двоичную форму, усеченного унарного преобразования в двоичную форму, экспоненциального преобразования в двоичную форму Голомба и преобразования в двоичную форму фиксированной длины.
Согласно другому аспекту настоящего изобретения, предусмотрен способ кодирования видео посредством кодирования символов, причем способ включает в себя: формирование символов посредством выполнения прогнозирования и преобразования в отношении блоков изображений; классификацию текущего символа на область префикса и область суффикса на основе порогового значения, определяемого согласно размеру текущего блока; формирование битовой строки префикса и битовой строки суффикса посредством использования способа преобразования в двоичную форму, определяемого для каждой из области префикса и области суффикса; выполнение кодирования символов посредством использования способа арифметического кодирования, определяемого для каждой из битовой строки префикса и битовой строки суффикса; и вывод битовых строк, сформированных посредством кодирования символов, в форме потоков битов.
Выполнение кодирования символов может включать в себя: выполнение кодирования символов в отношении битовой строки префикса посредством использования способа арифметического кодирования для выполнения контекстного моделирования согласно местоположениям битов; и выполнение кодирования символов в отношении битовой строки суффикса посредством использования способа арифметического кодирования для пропуска контекстного моделирования в обходном режиме.
Выполнение кодирования символов может включать в себя выполнение арифметического кодирования посредством использования контекста предварительно определенного индекса, который заранее выделяется местоположениям битов битовой строки префикса, когда символ является информацией конечной позиции коэффициента для коэффициента преобразования.
Текущий символ может включать в себя по меньшей мере одно из режима внутреннего прогнозирования и информации конечной позиции коэффициента текущего блока.
Способ преобразования в двоичную форму дополнительно может включать в себя по меньшей мере одно, выбранное из группы, состоящей из унарного преобразования в двоичную форму, усеченного унарного преобразования в двоичную форму, экспоненциального преобразования в двоичную форму Голомба и преобразования в двоичную форму фиксированной длины.
Согласно другому аспекту настоящего изобретения, предусмотрено устройство для декодирования видео посредством декодирования символов, причем устройство включает в себя: синтаксический анализатор для синтаксического анализа символов блоков изображений из принимаемого потока битов; декодер символов для классификации текущего символа на битовую строку префикса и битовую строку суффикса на основе порогового значения, определяемого согласно размеру текущего блока, и выполнения арифметического декодирования посредством использования способа арифметического декодирования, определяемого для каждой из битовой строки префикса и битовой строки суффикса, и затем выполнения преобразования из двоичной формы посредством использования способа преобразования в двоичную форму, определяемого для каждой из битовой строки префикса и битовой строки суффикса; и модуль восстановления изображений для восстановления блоков изображений посредством выполнения обратного преобразования и прогнозирования в отношении текущего блока посредством использования текущего символа, восстанавливаемого посредством арифметического декодирования и преобразования из двоичной формы.
Согласно другому аспекту настоящего изобретения, предусмотрено устройство для кодирования видео посредством кодирования символов, причем устройство включает в себя: кодер изображений для формирования символов посредством выполнения прогнозирования и преобразования в отношении блоков изображений; кодер символов для классификации текущего символа на область префикса и область суффикса на основе порогового значения, определяемого согласно размеру текущего блока, и формирования битовой строки префикса и битовой строки суффикса посредством использования способа преобразования в двоичную форму, определяемого для каждой из области префикса и области суффикса, и затем выполнения кодирования символов посредством использования способа арифметического кодирования, определяемого для каждой из битовой строки префикса и битовой строки суффикса; и модуль вывода потоков битов для вывода битовых строк, сформированных посредством кодирования символов, в форме потоков битов.
Согласно другому аспекту настоящего изобретения, предусмотрен считываемый компьютером носитель записи, имеющий реализованную на нем компьютерную программу для исполнения способа декодирования видео посредством декодирования символов.
Согласно другому аспекту настоящего изобретения, предусмотрен считываемый компьютером носитель записи, имеющий реализованную на нем компьютерную программу для исполнения способа кодирования видео посредством кодирования символов.
ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Далее настоящее изобретение описывается более подробно со ссылкой на прилагаемые чертежи, на которых показаны примерные варианты осуществления изобретения. Такие выражения, как "по меньшей мере один из", предваряющие список элементов, модифицируют весь список элементов и не модифицируют отдельные элементы списка.
Со ссылкой на фиг. 1-6 описываются способ кодирования видео, вовлекающий в себя арифметическое кодирование, и способ декодирования видео, вовлекающий в себя арифметическое декодирование, согласно варианту осуществления настоящего изобретения. Кроме того, со ссылкой на фиг. 7-19 описываются способ кодирования видео, вовлекающий в себя арифметическое кодирование, и способ декодирования видео, вовлекающий в себя арифметическое декодирование на основе единиц кодирования, имеющих древовидную структуру, согласно варианту осуществления настоящего изобретения. В дальнейшем в этом документе, "изображение" может означать неподвижное изображение видео или фильм, т.е. само видео.
В дальнейшем в этом документе, со ссылкой на фиг. 1-6 описываются способ кодирования видео и способ декодирования видео, согласно варианту осуществления настоящего изобретения, на основе способа прогнозирования в режиме внутреннего прогнозирования.
Фиг. 1 является блок-схемой устройства 10 кодирования видео, согласно варианту осуществления настоящего изобретения.
Устройство 10 кодирования видео может кодировать видеоданные пространственной области через внутреннее (интра-) прогнозирование/внешнее (интер-) прогнозирование, преобразование, квантование и кодирование символов. В дальнейшем в этом документе, подробно описываются операции, выполняемые, когда устройство 10 кодирования видео кодирует символы, сформированные посредством внутреннего прогнозирования/внешнего прогнозирования, преобразования и квантования, через арифметическое кодирование.
Устройство 10 кодирования видео включает в себя кодер 12 изображений, кодер 14 символов и модуль 16 вывода потоков битов.
Устройство 10 кодирования видео может разбивать данные изображений видео на множество единиц данных и кодировать данные изображений согласно единицам данных. Единица данных может иметь квадратную форму или прямоугольную форму или может представлять собой произвольную геометрическую форму, но единица данных не ограничивается единицей данных, имеющей предварительно определенный размер. Согласно способу кодирования видео на основе единиц кодирования, имеющих древовидную структуру, единица данных может быть максимальной единицей кодирования, единицей кодирования, единицей прогнозирования, единицей преобразования и т.п. Пример, в котором способ арифметического кодирования/декодирования согласно варианту осуществления настоящего изобретения используется в способе кодирования/декодирования видео на основе единиц кодирования, имеющих древовидную структуру, описывается со ссылкой на фиг. 7-19.
Для удобства описания, подробно описывается способ кодирования видео для "блока", который является видом единицы данных. Тем не менее, способ кодирования видео согласно различным вариантам осуществления настоящего изобретения не ограничивается способом кодирования видео для "блока" и может использоваться для различных единиц данных.
Кодер 12 изображений выполняет такие операции, как внутреннее прогнозирование/внешнее прогнозирование, преобразование или квантование, в отношении блоков изображений, чтобы формировать символы.
Кодер 14 символов классифицирует текущий символ на область префикса и область суффикса на основе порогового значения, определяемого согласно размеру текущего блока, чтобы кодировать текущий символ из числа символов, сформированных согласно блокам. Кодер 14 символов может определять пороговое значение для классификации текущего символа на область префикса и область суффикса на основе по меньшей мере одного из ширины и высоты текущего блока.
Кодер 14 символов может определять способ кодирования символов для каждой из области префикса и области суффикса и кодировать каждую из области префикса и области суффикса согласно способу кодирования символов.
Кодирование символов может быть разделено на процесс преобразования в двоичную форму для преобразования символа в битовые строки и процесс арифметического кодирования для выполнения контекстного арифметического кодирования в отношении битовых строк. Кодер 14 символов может определять способ преобразования в двоичную форму для каждой из области префикса и области суффикса символа и выполнять преобразование в двоичную форму в отношении каждой из области префикса и области суффикса согласно способу преобразования в двоичную форму. Битовая строка префикса и битовая строка суффикса могут быть сформированы соответственно из области префикса и области суффикса.
Альтернативно, кодер 14 символов может определять способ арифметического кодирования для каждой из битовой строки префикса и битовой строки суффикса символа и выполнять арифметическое кодирование в отношении каждой из битовой строки префикса и битовой строки суффикса согласно способу арифметического кодирования.
Кроме того, кодер 14 символов может определять способ преобразования в двоичную форму для каждой из области префикса и области суффикса символа и выполнять преобразование в двоичную форму в отношении каждой из области префикса и области суффикса согласно способу преобразования в двоичную форму и может определять способ арифметического кодирования для каждой из битовой строки префикса и битовой строки суффикса символа и выполнять арифметическое кодирование в отношении битовой строки префикса и битовой строки суффикса согласно способу арифметического кодирования.
Кодер 14 символов согласно варианту осуществления настоящего изобретения может определять способ преобразования в двоичную форму для каждой из области префикса и области суффикса. Способы преобразования в двоичную форму, определенные для области префикса и области суффикса, могут отличаться друг от друга.
Кодер 14 символов может определять способ арифметического кодирования для каждой из битовой строки префикса и битовой строки суффикса. Способы арифметического кодирования, определенные для битовой строки префикса и битовой строки суффикса, могут отличаться друг от друга.
Соответственно, кодер 14 символов может преобразовывать в двоичную форму область префикса и область суффикса посредством использования различных способов только в процессе преобразования в двоичную форму процесса декодирования символов или может кодировать битовую строку префикса и битовую строку суффикса посредством использования различных способов только в процессе арифметического кодирования. Кроме того, кодер 14 символов может кодировать область префикса (битовую строку префикса) и область суффикса (битовую строку суффикса) посредством использования различных способов в процессах преобразования в двоичную форму и арифметического кодирования.
Выбранный способ преобразования в двоичную форму может представлять собой, по меньшей мере один из способов общего преобразования в двоичную форму, унарного преобразования в двоичную форму, усеченного унарного преобразования в двоичную форму, экспоненциального преобразования в двоичную форму Голомба и преобразования в двоичную форму фиксированной длины.
Кодер 14 символов может выполнять кодирование символов посредством выполнения арифметического кодирования для выполнения контекстного моделирования в отношении битовой строки префикса согласно местоположениям битов и посредством выполнения арифметического кодирования для пропуска контекстного моделирования в отношении битовой строки суффикса в обходном режиме.
Кодер 14 символов может по отдельности выполнять кодирование символов для области префикса и области суффикса относительно символов, включающих в себя по меньшей мере одно из режима внутреннего прогнозирования и информации конечной позиции коэффициента для коэффициента преобразования.
Кодер 14 символов также может выполнять арифметическое кодирование посредством использования контекста предварительно определенного индекса, который заранее выделяется битовой строке префикса. Например, кодер 14 символов может выполнять арифметическое кодирование посредством использования контекста предварительно определенного индекса, который заранее выделяется каждому местоположению битов битовой строки префикса, когда символ является информацией конечной позиции коэффициента для коэффициента преобразования.
Модуль 16 вывода потоков битов выводит битовые строки, сформированные посредством кодирования символов, в форме потоков битов.
Устройство 10 кодирования видео может выполнять арифметическое кодирование для символов блоков видео и выводить символы.
Устройство 10 кодирования видео может включать в себя центральный процессор (не показан) для общего управления кодером 12 изображений, кодером 14 символов и модулем 16 вывода потоков битов. Альтернативно, кодер 12 изображений, кодер 14 символов и модуль 16 вывода потоков битов могут управляться посредством процессоров (не показаны), соответственно, установленных в них, и устройство 10 кодирования видео может полностью управляться посредством систематической работы процессоров (не показаны). Альтернативно, кодер 12 изображений, кодер 14 символов и модуль 16 вывода потоков битов могут управляться посредством внешнего процессора (не показан) устройства 10 кодирования видео.
Устройство 10 кодирования видео может включать в себя по меньшей мере один модуль хранения данных (не показан) для сохранения данных, которые вводятся-выводятся в/из кодера 12 изображений, кодера 14 символов и модуля 16 вывода потоков битов. Устройство 10 кодирования видео может включать в себя контроллер запоминающего устройства (не показан) для управления вводом-выводом данных, сохраненных в модуле хранения данных (не показан).
Устройство 10 кодирования видео работает связанным с внутренним процессором кодирования видео или внешним процессором кодирования видео, чтобы выполнять кодирование видео, включающее в себя прогнозирование и преобразование, за счет этого выводя результат кодирования видео. Внутренний процессор кодирования видео устройства 10 кодирования видео может выполнять базовые операции кодирования видео не только посредством использования отдельного процессора, но также и посредством включения модуля обработки кодирования видео в устройство 10 кодирования видео, центральное управляющее устройство или графическое управляющее устройство.
Фиг. 2 является блок-схемой устройства 20 декодирования видео, согласно варианту осуществления настоящего изобретения.
Устройство 20 декодирования видео может декодировать видеоданные, кодированные посредством устройства 10 кодирования видео, посредством синтаксического анализа, декодирования символов, обратного квантования, обратного преобразования, внутреннего прогнозирования/компенсации движения и т.д., и восстанавливать видеоданные рядом с исходными видеоданными пространственной области. В дальнейшем в этом документе, описывается процесс, в котором устройство 20 декодирования видео выполняет арифметическое декодирование для синтаксически проанализированных символов из потока битов, чтобы восстанавливать символы.
Устройство 20 декодирования видео включает в себя синтаксический анализатор 22, декодер 24 символов и модуль 26 восстановления изображений.
Устройство 20 декодирования видео может принимать поток битов, включающий в себя кодированные данные видео. Синтаксический анализатор 22 может синтаксически анализировать символы блоков изображений из потока битов.
Синтаксический анализатор 22 может синтаксически анализировать символы, кодированные через арифметическое кодирование относительно блоков видео, из потока битов.
Синтаксический анализатор 22 может синтаксически анализировать символы, включающие в себя режим внутреннего прогнозирования блока видео, информацию конечной позиции коэффициента для коэффициента преобразования и т.д., из принимаемого потока битов.
Декодер 24 символов определяет пороговое значение для классификации текущего символа на битовую строку префикса и битовую строку суффикса. Декодер 24 символов может определять пороговое значение для классификации текущего символа на битовую строку префикса и битовую строку суффикса на основе размера текущего блока, т.е. по меньшей мере одного из ширины и высоты текущего блока. Декодер 24 символов определяет способ арифметического декодирования для каждой из битовой строки префикса и битовой строки суффикса. Декодер 24 символов выполняет декодирование символов посредством использования способа арифметического декодирования, определяемого для каждой из битовой строки префикса и битовой строки суффикса.
Способы арифметического декодирования, определенные для битовой строки префикса и битовой строки суффикса, могут отличаться друг от друга.
Декодер 24 символов может определять способ преобразования в двоичную форму для каждой из битовой строки префикса и битовой строки суффикса символа. Соответственно, декодер 24 символов может выполнять преобразование из двоичной формы для битовой строки префикса символа посредством использования способа преобразования в двоичную форму. Способы преобразования в двоичную форму, определенные для битовой строки префикса и битовой строки суффикса, могут отличаться друг от друга.
Кроме того, декодер 24 символов может выполнять арифметическое декодирование посредством использования способа арифметического декодирования, определяемого для каждой из битовой строки префикса и битовой строки суффикса символа, и может выполнять преобразование из двоичной формы посредством использования способа преобразования в двоичную форму, определяемого для каждой из битовой строки префикса и битовой строки суффикса, сформированной посредством арифметического декодирования.
Соответственно, декодер 24 символов может декодировать битовую строку префикса и битовую строку суффикса посредством использования различных способов только в процессе арифметического декодирования процесса декодирования символов или может выполнять преобразование из двоичной формы посредством использования различных способов только в процессе преобразования из двоичной формы. Кроме того, декодер 24 символов может декодировать битовую строку префикса и битовую строку суффикса посредством использования различных способов в процессах арифметического декодирования и преобразования из двоичной формы.
Способ преобразования в двоичную форму, определенный для каждой из битовой строки префикса и битовой строки суффикса символа, может представлять собой не только общий способ преобразования в двоичную форму, но также может представлять собой по меньшей мере один из способов унарного преобразования в двоичную форму, усеченного унарного преобразования в двоичную форму, экспоненциального преобразования в двоичную форму Голомба и преобразования в двоичную форму фиксированной длины.
Декодер 24 символов может выполнять арифметическое декодирование для выполнения контекстного моделирования в отношении битовой строки префикса согласно местоположениям битов. Декодер 24 символов может использовать способ арифметического декодирования для пропуска контекстного моделирования в отношении битовой строки суффикса в обходном режиме. Соответственно, декодер 24 символов может выполнять декодирование символов посредством арифметического декодирования, выполняемого в отношении каждой из битовой строки префикса и битовой строки суффикса символа.
Декодер 24 символов может выполнять арифметическое декодирование в отношении битовой строки префикса и битовой строки суффикса символов, включающих в себя по меньшей мере одно из режима внутреннего прогнозирования и информации конечной позиции коэффициента для коэффициента преобразования.
Декодер 24 символов может выполнять арифметическое декодирование посредством использования контекста предварительно определенного индекса, который заранее выделяется согласно местоположениям битов битовой строки префикса, когда символ является информацией относительно конечной позиции коэффициента для коэффициента преобразования.
Модуль 26 восстановления изображений может восстанавливать область префикса и область суффикса символа посредством выполнения арифметического декодирования и преобразования из двоичной формы в отношении каждой из битовой строки префикса и битовой строки суффикса. Модуль 26 восстановления изображений может восстанавливать символ посредством синтезирования области префикса и области суффикса символа.
Модуль 26 восстановления изображений выполняет обратное преобразование и прогнозирование в отношении текущего блока посредством использования текущего символа, восстанавливаемого посредством арифметического декодирования и преобразования из двоичной формы. Модуль 26 восстановления изображений может восстанавливать блоки изображений посредством выполнения таких операций, как обратное квантование, обратное преобразование или внутреннее прогнозирование/компенсация движения, посредством использования соответствующих символов для каждого из блоков изображений.
Устройство 20 декодирования видео согласно варианту осуществления настоящего изобретения может включать в себя центральный процессор (не показан) для общего управления синтаксическим анализатором 22, декодером 24 символов и модулем 26 восстановления изображений. Альтернативно, синтаксический анализатор 22, декодер 24 символов и модуль 26 восстановления изображений могут управляться посредством процессоров (не показаны), соответственно, установленных в них, и устройство 20 декодирования видео может полностью управляться посредством систематической работы процессоров (не показаны). Альтернативно, синтаксический анализатор 22, декодер 24 символов и модуль 26 восстановления изображений могут управляться посредством внешнего процессора (не показан) устройства 20 декодирования видео.
Устройство 20 декодирования видео может включать в себя по меньшей мере один модуль хранения данных (не показан) для сохранения данных, которые вводятся-выводятся в/из синтаксического анализатора 22, декодера 24 символов и модуля 26 восстановления изображений. Устройство 20 декодирования видео может включать в себя контроллер запоминающего устройства (не показан) для управления вводом/выводом данных, сохраненных в модуле хранения данных (не показан).
Устройство 20 декодирования видео работает связанным с внутренним процессором декодирования видео или внешним процессором декодирования видео, чтобы выполнять декодирование видео, включающее в себя обратное преобразование. Внутренний процессор декодирования видео устройства 20 декодирования видео может выполнять базовые операции декодирования видео не только посредством использования отдельного процессора, но также и посредством включения модуля обработки декодирования видео в устройство 20 декодирования видео, центральное управляющее устройство или графическое управляющее устройство.
Контекстно-адаптивное двоичное арифметическое кодирование (CABAC) широко используется в качестве способа арифметического кодирования/декодирования на основе контекста для кодирования/декодирования символов. Согласно контекстному арифметическому кодированию/декодированию, каждый бит битовой строки символа может быть ячейкой (бином) контекста, и местоположение каждого бита может отображаться в индекс ячейки. Длина битовой строки, т.е. длина ячейки, может варьироваться согласно размеру значения символа. Контекстное моделирование для определения контекста символа требуется для того, чтобы выполнять контекстное арифметическое кодирование/декодирование. Контекст обновляется согласно местоположениям битов битовой строки символа, т.е. в каждом индексе ячейки, чтобы выполнять контекстное моделирование, и в силу этого требуется сложный системный процесс.
Согласно устройству 10 кодирования видео и устройству 20 декодирования видео, описанным со ссылкой на фиг. 1 и 2, символ классифицируется на область префикса и область суффикса, и относительно простой способ преобразования в двоичную форму может использоваться для области суффикса по сравнению с областью префикса. Кроме того, арифметическое кодирование/декодирование через контекстное моделирование выполняется в отношении битовой строки префикса, и контекстное моделирование не выполняется в отношении битовой строки суффикса, и за счет этого может быть уменьшена нагрузка по объему вычислений для контекстного арифметического кодирования/декодирования. Соответственно, устройство 10 кодирования видео и устройство 20 декодирования видео могут повышать эффективность процесса кодирования/декодирования символов посредством осуществления способа преобразования в двоичную форму, имеющего относительно небольшую нагрузку по объему вычислений, для области суффикса или битовой строки суффикса, или посредством пропуска контекстного моделирования в ходе контекстного арифметического кодирования/декодирования для кодирования/декодирования символов.
В дальнейшем в этом документе, описываются различные варианты осуществления для арифметического кодирования, которое может быть выполнено посредством устройства 10 кодирования видео и устройства 20 декодирования видео.
Фиг. 3 и 4 являются схемами для описания арифметического кодирования посредством классификации символа на битовую строку префикса и битовую строку суффикса согласно предварительно определенному пороговому значению, согласно варианту осуществления настоящего изобретения.
Ссылаясь на фиг. 3, подробно описывается процесс выполнения кодирования символов, согласно варианту осуществления настоящего изобретения, для информации конечной позиции коэффициента символа. Информация конечной позиции коэффициента является символом, представляющим местоположение конечного коэффициента, не 0, из числа коэффициентов преобразования блока. Поскольку размер блока задается как ширина и высота, информация конечной позиции коэффициента может быть представлена посредством двумерных координат, т.е. x-координаты в направлении ширины и y-координаты в направлении высоты. Для удобства описания, фиг. 3 показывает случай, когда кодирование символов выполняется в отношении x-координаты в направлении ширины, из информации конечной позиции коэффициента, когда ширина блока составляет w.
Диапазон x-координаты информации конечной позиции коэффициента находится в пределах ширины блока, и в силу этого x-координата информации конечной позиции коэффициента равна или превышает 0 и равна или меньше w-1. Для арифметического кодирования символа символ может классифицироваться на область префикса и область суффикса на основе предварительно определенного порогового значения th. Таким образом, арифметическое кодирование может быть выполнено в отношении битовой строки префикса, в которой область префикса преобразуется в двоичную форму, на основе контекста, определенного через контекстное моделирование. Кроме того, арифметическое кодирование может быть выполнено в отношении битовой строки суффикса, в которой область суффикса преобразуется в двоичную форму в обходном режиме, в котором пропускается контекстное моделирование.
Здесь, пороговое значение th для классификации символа на область префикса и область суффикса может быть определено на основе ширины w блока. Например, пороговое значение th может быть определено как равное (w/2)-1, чтобы разделять битовую строку на два (формула 1 для определения порогового значения). Альтернативно, ширина w блока, в общем, имеет квадрат 2, и тем самым пороговое значение th может быть определено на основе значения логарифма ширины w (формула 2 для определения порогового значения).
Формула 1 для определения порогового значения: th=(w/2)-1;
формула 2 для определения порогового значения: th=(log2w<<1)-1;
На фиг. 3, согласно формуле 1 для определения порогового значения, когда ширина w блока равна 8, формула выдает пороговое значение th=(8/2)-1=3. Таким образом, в x-координате информации конечной позиции коэффициента, 3 может быть классифицировано в качестве области префикса, а остальные значения, отличные от 3, могут быть классифицированы в качестве области суффикса. Область префикса и область суффикса могут преобразовываться в двоичную форму согласно способу преобразования в двоичную форму, определяемому для каждой их области префикса и области суффикса.
Когда x-координата N текущей информации конечной позиции коэффициента равна 5, x-координата информации конечной позиции коэффициента может быть классифицирована как N=th+2=3+2. Другими словами, в x-координате информации конечной позиции коэффициента, 3 может быть классифицировано в качестве области префикса, а 2 может быть классифицировано в качестве области суффикса.
Согласно варианту осуществления настоящего изобретения, область префикса и область суффикса могут преобразовываться в двоичную форму согласно различным способам преобразования в двоичную форму, определенным соответственно для области префикса и области суффикса. Например, область префикса может преобразовываться в двоичную форму согласно способу унарного преобразования в двоичную форму, и область суффикса может преобразовываться в двоичную форму согласно общему способу преобразования в двоичную форму.
Соответственно, после того, как 3 преобразуется в двоичную форму согласно способу унарного преобразования в двоичную форму, битовая строка 32 префикса "0001" может быть сформирована из области префикса, и после того, как 2 преобразуется в двоичную форму согласно общему способу преобразования в двоичную форму, битовая строка 34 суффикса "010" может быть сформирована из области суффикса.
Кроме того, контекстное арифметическое кодирование может быть выполнено в отношении битовой строки 32 префикса "0001" через контекстное моделирование. Таким образом, индекс контекста может быть определен для каждой ячейки битовой строки 32 префикса "0001".
Арифметическое кодирование может быть выполнено в отношении битовой строки 34 суффикса "010" в обходном режиме без выполнения контекстного моделирования. Арифметическое кодирование может быть выполнено без выполнения контекстного моделирования при условии, что в обходном режиме, каждая ячейка имеет контекст равновероятностного состояния, т.е. контекст 50%.
Соответственно, контекстное арифметическое кодирование может быть выполнено в отношении каждой из битовой строки 32 префикса "0001" и битовой строки 34 суффикса "010", чтобы завершать кодирование символов относительно x-координаты N текущей информации конечной позиции коэффициента.
Хотя описан вариант осуществления, в котором кодирование символов выполняется через преобразование в двоичную форму и арифметическое кодирование, декодирование символов может быть выполнено таким же образом. Другими словами, синтаксически проанализированная битовая строка символа может классифицироваться на битовую строку префикса и битовую строку суффикса на основе ширины w блока, арифметическое декодирование может быть выполнено в отношении битовой строки 32 префикса через контекстное моделирование, и арифметическое декодирование может быть выполнено в отношении битовой строки 34 суффикса без выполнения контекстного моделирования. Преобразование из двоичной формы может быть выполнено в отношении битовой строки 32 префикса после арифметического декодирования посредством использования способа унарного преобразования в двоичную форму, и может быть восстановлена область префикса. Кроме того, преобразование из двоичной формы может быть выполнено в отношении битовой строки 34 суффикса после арифметического кодирования посредством использования общего способа преобразования в двоичную форму, и за счет этого может быть восстановлена область суффикса. Символ может быть восстановлен посредством синтезирования восстановленной области префикса и области суффикса.
Хотя описан вариант осуществления, в котором способ унарного преобразования в двоичную форму используется для области префикса (битовой строки префикса), и общий способ преобразования в двоичную форму используется для области суффикса (битовой строки суффикса), способ преобразования в двоичную форму не ограничен этим. Альтернативно, способ усеченного унарного преобразования в двоичную форму может использоваться для области префикса (битовой строки префикса), и способ преобразования в двоичную форму фиксированной длины может использоваться для области суффикса (битовой строки суффикса).
Хотя описан только вариант осуществления, связанный с информацией конечной позиции коэффициента в направлении ширины блока, также может быть использован вариант осуществления, связанный с информацией конечной позиции коэффициента в направлении высоты блока.
Кроме того, нет необходимости выполнять контекстное моделирование в отношении битовой строки суффикса для выполнения арифметического кодирования посредством использования контекста, имеющего фиксированную вероятность, но есть необходимость выполнять переменное контекстное моделирование для битовой строки префикса. Контекстное моделирование, которое должно быть выполнено в отношении битовой строки префикса, может быть определено согласно размеру блока.
В таблице контекстного отображения местоположение каждого номера соответствует индексу ячейки битовой строки префикса, и номер обозначает индекс контекста, который должен быть использован в местоположении соответствующего бита. Для удобства описания, например, в блоке 4×4, битовая строка префикса состоит всего из четырех битов, и когда k рано 0, 1, 2 и 3 согласно таблице контекстного отображения, индексы контекстов в 0, 1, 2 и 2 определяются для k-того индекса ячейки, и в силу этого может выполняться арифметическое кодирование на основе контекстного моделирования.
Фиг. 4 показывает вариант осуществления, в котором режим внутреннего прогнозирования включает в себя внутренний режим для сигнала яркости и внутренний режим для сигнала цветности, указывающий направление внутреннего прогнозирования блока сигнала яркости и блока сигнала цветности, соответственно. Когда режим внутреннего прогнозирования равен 6, битовая строка 40 символа "0000001" формируется согласно способу унарного преобразования в двоичную форму. В этом случае, арифметическое кодирование может быть выполнено в отношении первого бита 41 "0" битовой строки 40 символа режима внутреннего прогнозирования через контекстное моделирование, и арифметическое кодирование может быть выполнено в отношении остальных битов 45 "000001" битовой строки 40 символа в обходном режиме. Другими словами, первый бит 41 битовой строки 40 символа соответствует битовой строке префикса, а остальные биты 45 битовой строки 40 символа соответствуют битовой строке суффикса.
То, сколько битов битовой строки 40 символа кодируется при арифметическом кодировании в качестве битовой строки префикса через контекстное моделирование, и сколько битов битовой строки 40 символа кодируется при арифметическом кодировании в качестве битовой строки суффикса в обходном режиме, может быть определено согласно размеру блока или размеру набора блоков. Например, что касается блока 64×64, арифметическое кодирование может быть выполнено только в отношении первого бита из битовых строк режима внутреннего прогнозирования, и арифметическое кодирование может быть выполнено в отношении остальных битов в обходном режиме. Что касается блоков, имеющих другие размеры, арифметическое кодирование может быть выполнено в отношении всех битов битовых строк режима внутреннего прогнозирования в обходном режиме.
В общем, информация относительно битов рядом с младшим битом (LSB) является относительно менее важной, чем информация относительно битов рядом со старшим битом (MSB) битовой строки символа. Соответственно, устройство 10 кодирования видео и устройство 20 декодирования видео могут выбирать способ арифметического кодирования согласно способу преобразования в двоичную форму, имеющему относительно высокую точность относительно битовой строки префикса рядом с MSB, даже если существует нагрузка по объему вычислений, и может выбирать способ арифметического кодирования согласно способу преобразования в двоичную форму, допускающему выполнение простой операции относительно битовой строки суффикса рядом с LSB. Кроме того, устройство 10 кодирования видео и устройство 20 декодирования видео могут выбирать способ арифметического кодирования на основе контекстного моделирования относительно контекстного моделирования, и могут выбирать способ арифметического кодирования, без выполнения контекстного моделирования, относительно битовой строки суффикса рядом с LSB.
В вышеприведенном описании, описан вариант осуществления, в котором преобразование в двоичную форму выполняется в отношении битовой строки префикса и битовой строки суффикса информации конечной позиции коэффициента для коэффициента преобразования посредством использования различных способов, со ссылкой на фиг. 3. Кроме того, описан вариант осуществления, в котором арифметическое кодирование выполняется в отношении битовой строки префикса и битовой строки суффикса из битовых строк режима внутреннего прогнозирования посредством использования различных способов, со ссылкой на фиг. 4.
Тем не менее, согласно различным вариантам осуществления настоящего изобретения, способ кодирования символов, в котором используются способы преобразования в двоичную форму/арифметического кодирования, по отдельности определенные для битовой строки префикса и битовой строки суффикса, или используются различные способы преобразования в двоичную форму/арифметического кодирования, не ограничивается вариантами осуществления, описанными со ссылкой на фиг. 3 и 4, и различные способы преобразования в двоичную форму/арифметического кодирования могут использоваться для различных символов.
Фиг. 5 является блок-схемой последовательности операций способа, иллюстрирующей способ кодирования видео, согласно варианту осуществления настоящего изобретения.
На этапе 51, символы формируются посредством выполнения прогнозирования и преобразования в отношении блоков изображений.
На этапе 53, текущий символ классифицируется на область префикса и область суффикса на основе порогового значения, определяемого согласно размеру текущего блока.
На этапе 55, битовая строка префикса и битовая строка суффикса формируются посредством использования способов преобразования в двоичную форму, по отдельности определенных для области префикса и области суффикса символа.
На этапе 57, кодирование символов выполняется посредством использования способов арифметического кодирования, по отдельности определенных для битовой строки префикса и битовой строки суффикса.
На этапе 59, битовые строки, сформированные посредством кодирования символов, выводятся в форме потоков битов.
На этапе 57, кодирование символов может быть выполнено в отношении битовой строки префикса посредством использования способа арифметического кодирования для выполнения контекстного моделирования согласно местоположениям битов, и кодирование символов также может быть выполнено для битовой строки суффикса посредством использования способа арифметического кодирования для пропуска контекстного моделирования в обходном режиме.
На этапе 57, когда символ является информацией конечной позиции коэффициента для коэффициента преобразования, арифметическое кодирование может быть выполнено посредством использования контекста предварительно определенного индекса, который заранее выделяется местоположениям битов битовой строки префикса.
Фиг. 6 является блок-схемой последовательности операций способа, иллюстрирующей способ декодирования видео, согласно варианту осуществления настоящего изобретения.
На этапе 61, символы блоков изображений синтаксически анализируются из принимаемого потока битов.
На этапе 63, текущий символ классифицируется на битовую строку префикса и битовую строку суффикса на основе порогового значения, определяемого согласно размеру текущего блока.
На этапе 65, арифметическое декодирование выполняется посредством использования способа арифметического декодирования, определяемого для каждой из битовой строки префикса и битовой строки суффикса текущего символа.
На этапе 67, после арифметического декодирования, преобразование из двоичной формы выполняется посредством использования способа преобразования в двоичную форму, определяемого для каждой из битовой строки префикса и битовой строки суффикса.
Область префикса и область суффикса символа могут быть восстановлены посредством выполнения преобразования из двоичной формы посредством использования способа преобразования в двоичную форму, определяемого для каждой из битовой строки префикса и битовой строки суффикса.
На этапе 69, блоки изображений могут быть восстановлены посредством выполнения обратного преобразования и прогнозирования в отношении текущего блока посредством использования текущего символа, восстанавливаемого посредством арифметического декодирования и преобразования из двоичной формы.
На этапе 65, арифметическое декодирование для определения контекстного моделирования согласно местоположениям битов может быть выполнено в отношении битовой строки префикса, и арифметическое декодирование для пропуска контекстного моделирования может быть выполнено в отношении битовой строки суффикса в обходном режиме.
На этапе 65, когда символ является информацией конечной позиции коэффициента для коэффициента преобразования, арифметическое декодирование может быть выполнено посредством использования контекста предварительно определенного индекса, который заранее выделяется местоположениям битов битовой строки префикса.
В устройстве 10 кодирования видео согласно варианту осуществления настоящего изобретения и устройстве 20 декодирования видео согласно другому варианту осуществления настоящего изобретения, блоки, на которые разбиваются видеоданные, разбиваются на единицы кодирования, имеющие древовидную структуру, единицы прогнозирования используются для того, чтобы выполнять внутреннее прогнозирование в отношении единиц кодирования, и единица преобразования используется для того, чтобы преобразовывать единицы кодирования.
В дальнейшем в этом документе, описываются способ и устройство для кодирования видео, а также способ и устройство для декодирования видео на основе единицы кодирования, имеющей древовидную структуру, единицы прогнозирования и единицы преобразования.
Фиг. 7 является блок-схемой устройства 100 кодирования видео на основе единиц кодирования, имеющих древовидную структуру, согласно варианту осуществления настоящего изобретения.
Устройство 100 кодирования видео, заключающее в себе прогнозирование видео на основе единицы кодирования, имеющей древовидную структуру, включает в себя модуль 110 разбиения максимальной единицы кодирования, модуль 120 определения единиц кодирования и модуль 130 вывода. Для удобства описания, устройство 100 кодирования видео, заключающее в себе прогнозирование видео на основе единицы кодирования, имеющей древовидную структуру, упоминается как устройство 100 кодирования видео.
Модуль 110 разбиения максимальной единицы кодирования может разбивать текущую картинку на основе максимальной единицы кодирования для текущей картинки изображения. Если текущая картинка больше максимальной единицы кодирования, данные изображений текущей картинки могут разбиваться на по меньшей мере одну максимальную единицу кодирования. Максимальная единица кодирования согласно варианту осуществления настоящего изобретения может быть единицей данных, имеющей размер 32×32, 64×64, 128×128, 256×256 и т.д., при этом форма единицы данных является квадратом, имеющим ширину и длину в квадратах по 2. Данные изображений могут выводиться в модуль 120 определения единиц кодирования согласно по меньшей мере одной максимальной единице кодирования.
Единица кодирования согласно варианту осуществления настоящего изобретения может отличаться посредством максимального размера и глубины. Глубина обозначает число раз, которое единица кодирования пространственно разбивается от максимальной единицы кодирования, и по мере того, как глубина увеличивается, более глубокие единицы кодирования согласно глубинам могут разбиваться от максимальной единицы кодирования до минимальной единицы кодирования. Глубина максимальной единицы кодирования является самой верхней глубиной, а глубина минимальной единицы кодирования является самой нижней глубиной. Поскольку размер единицы кодирования, соответствующей каждой глубине, снижается по мере того, как увеличивается глубина максимальной единицы кодирования, единица кодирования, соответствующая верхней глубине, может включать в себя множество единиц кодирования, соответствующих нижним глубинам.
Как описано выше, данные изображений текущей картинки разбиваются на максимальные единицы кодирования согласно максимальному размеру единицы кодирования, и каждая из максимальных единиц кодирования может включать в себя более глубокие единицы кодирования, которые разбиваются согласно глубинам. Поскольку максимальная единица кодирования согласно варианту осуществления настоящего изобретения разбивается согласно глубинам, данные изображений пространственной области, включенные в максимальную единицу кодирования, могут быть иерархически классифицированы согласно глубинам.
Может быть предварительно определена максимальная глубина и максимальный размер единицы кодирования, которые ограничивают общее число раз, сколько высота и ширина максимальной единицы кодирования иерархически разбиваются.
Модуль 120 определения единиц кодирования кодирует по меньшей мере одну область разбиения, полученную посредством разбиения области максимальной единицы кодирования согласно глубинам, и определяет глубину, чтобы выводить конечные кодированные данные изображений согласно по меньшей мере одной области разбиения. Другими словами, модуль 120 определения единиц кодирования определяет кодированную глубину посредством кодирования данных изображений в более глубоких единицах кодирования согласно глубинам, согласно максимальной единице кодирования текущей картинки и выбора глубины, имеющей наименьшую ошибку кодирования. Определенная кодированная глубина и кодированные данные изображений согласно определенной кодированной глубине выводятся в модуль 130 вывода.
Данные изображений в максимальной единице кодирования кодируются на основе более глубоких единиц кодирования, соответствующих по меньшей мере одной глубине, равной или ниже максимальной глубины, и результаты кодирования данных изображений сравниваются на основе каждой из более глубоких единиц кодирования. Глубина, имеющая наименьшую ошибку кодирования, может быть выбрана после сравнения ошибок кодирования более глубоких единиц кодирования. По меньшей мере одна кодированная глубина может быть выбрана для каждой максимальной единицы кодирования.
Размер максимальной единицы кодирования разбивается по мере того, как единица кодирования иерархически разбивается согласно глубинам, и по мере того, как увеличивается число единиц кодирования. Кроме того, даже если единицы кодирования соответствуют идентичной глубине в одной максимальной единице кодирования, определяется то, разбивать или нет каждую из единиц кодирования, соответствующих идентичной глубине, до нижней глубины посредством измерения ошибки кодирования данных изображений каждой единицы кодирования, отдельно. Соответственно, даже когда данные изображений включаются в одну максимальную единицу кодирования, данные изображений разбиваются на области согласно глубинам, ошибки кодирования могут отличаться согласно областям в одной максимальной единице кодирования, и, таким образом, кодированные глубины могут отличаться согласно областям в данных изображений. Таким образом, одна или более кодированных глубин могут быть определены в одной максимальной единице кодирования, и данные изображений максимальной единицы кодирования могут быть разделены согласно единицам кодирования по меньшей мере одной кодированной глубины.
Соответственно, модуль 120 определения единиц кодирования может определять единицы кодирования, имеющие древовидную структуру, включенные в максимальную единицу кодирования. "Единицы кодирования, имеющие древовидную структуру" согласно варианту осуществления настоящего изобретения включают в себя единицы кодирования, соответствующие глубине, определенной как кодированная глубина, из всех более глубоких единиц кодирования, включенных в максимальную единицу кодирования. Единица кодирования кодированной глубины может быть иерархически определена согласно глубинам в идентичной области максимальной единицы кодирования и может быть независимо определена в различных областях. Аналогично, кодированная глубина в текущей области может быть независимо определена из кодированной глубины в другой области.
Максимальная глубина согласно варианту осуществления настоящего изобретения является индексом, связанным с числом разбиений, выполненных от максимальной единицы кодирования до минимальной единицы кодирования. Первая максимальная глубина согласно варианту осуществления настоящего изобретения может обозначать общее число разбиений, выполненных от максимальной единицы кодирования до минимальной единицы кодирования. Вторая максимальная глубина согласно варианту осуществления настоящего изобретения может обозначать общее число уровней глубины от максимальной единицы кодирования до минимальной единицы кодирования. Например, когда глубина максимальной единицы кодирования равна 0, глубина единицы кодирования, на которую максимальная единица кодирования разбивается один раз, может задаваться равной 1, а глубина единицы кодирования, на которую максимальная единица кодирования разбивается два раза, может задаваться равной 2. Здесь, если минимальная единица кодирования является единицей кодирования, на которую максимальная единица кодирования разбивается четыре раза, имеется 5 уровней глубины с глубинами 0, 1, 2, 3 и 4, и за счет этого первая максимальная глубина может задаваться равной 4, а вторая максимальная глубина может задаваться равной 5.
Прогнозирующее кодирование (с прогнозированием) и преобразование может выполняться согласно максимальной единице кодирования. Прогнозирующее кодирование и преобразование также выполняются на основе более глубоких единиц кодирования согласно глубине, равной, или глубинам, меньшим максимальной глубины, согласно максимальной единице кодирования.
Поскольку число более глубоких единиц кодирования увеличивается каждый раз, когда максимальная единица кодирования разбивается согласно глубинам, кодирование, включающее в себя прогнозирующее кодирование и преобразование, выполняется в отношении всех более глубоких единиц кодирования, сформированных по мере того, как увеличивается глубина. Для удобства описания, прогнозирующее кодирование и преобразование далее описываются на основе единицы кодирования текущей глубины в максимальной единице кодирования.
Устройство 100 кодирования видео может по-разному выбирать размер или форму единицы данных для кодирования данных изображений. Чтобы кодировать данные изображений, выполняются такие операции, как прогнозирующее кодирование, преобразование и энтропийное кодирование, и в это время, идентичная единица данных может использоваться для всех операций, или различные единицы данных могут использоваться для каждой операции.
Например, устройство 100 кодирования видео может выбирать не только единицу кодирования для кодирования данных изображений, но также и единицу данных, отличающуюся от единицы кодирования, с тем чтобы выполнять прогнозирующее кодирование для данных изображений в единице кодирования.
Чтобы выполнять прогнозирующее кодирование в максимальной единице кодирования, прогнозирующее кодирование может выполняться на основе единицы кодирования, соответствующей кодированной глубине, т.е. на основе единицы кодирования, которая более не разбивается на единицы кодирования, соответствующие нижней глубине. В дальнейшем в этом документе, единица кодирования, которая более не разбивается и становится базисной единицей для прогнозирующего кодирования, далее упоминается как "единица прогнозирования". Сегмент, полученный посредством разбиения единицы прогнозирования, может включать в себя единицу данных, полученную посредством разбиения по меньшей мере одной из высоты и ширины единицы прогнозирования. Сегмент представляет собой единицу данных, имеющую форму, в которую единица прогнозирования единицы кодирования разделяется, единица прогнозирования может быть сегментом, имеющим тот же размер, что и единица кодирования.
Например, когда единица кодирования в 2Nx2N (где N является положительным целым числом) более не разбивается и становится единицей прогнозирования в 2Nx2N, размер сегмента может составлять 2Nx2N, 2NxN, Nx2N или NxN. Примеры типа сегмента включают в себя симметричные сегменты, которые получаются посредством симметричного разбиения высоты или ширины единицы прогнозирования, сегменты, полученные посредством асимметричного разбиения высоты или ширины единицы прогнозирования, к примеру, 1:n или n:1, сегменты, которые получаются посредством геометрического разбиения единицы прогнозирования, и сегменты, имеющие произвольные формы.
Режим прогнозирования единицы прогнозирования может быть по меньшей мере одним из внутреннего режима, внешнего режима и режима пропуска. Например, внутренний режим или внешний режим могут выполняться в отношении сегмента в 2Nx2N, 2NxN, Nx2N или NxN. Кроме того, режим пропуска может выполняться только в отношении сегмента в 2Nx2N. Кодирование независимо выполняется в отношении одной единицы прогнозирования в единице кодирования, в силу этого выбирая режим прогнозирования, имеющий наименьшую ошибку кодирования.
Устройство 100 кодирования видео также может выполнять преобразование в отношении данных изображений в единице кодирования на основе не только единицы кодирования для кодирования данных изображений, но также и на основе единицы данных, которая отличается от единицы кодирования. Чтобы выполнять преобразование в единице кодирования, преобразование может выполняться на основе единицы преобразования, имеющей размер, меньший или равный единице кодирования. Например, единица преобразования может включать в себя единицу преобразования для внутреннего режима и единицу преобразования для внешнего режима.
Аналогично единице кодирования, единица преобразования в единице кодирования может быть рекурсивно разбита на области меньшего размера. Таким образом, остаточные данные в единице кодирования могут быть разделены согласно преобразованию, имеющему древовидную структуру согласно глубинам преобразования.
Глубина преобразования, указывающая число разбиений, чтобы достигать единицы преобразования посредством разбиения высоты и ширины единицы кодирования, также может задаваться в единице преобразования. Например, в текущей единице кодирования 2Nx2N, глубина преобразования может быть равна 0, когда размер единицы преобразования также составляет 2Nx2N, может быть равна 1, когда размер единицы преобразования составляет NxN, и может быть равна 2, когда размер единицы преобразования составляет N/2xN/2. Другими словами, единица преобразования, имеющая древовидную структуру, может задаваться согласно глубинам преобразования.
Информация кодирования согласно единицам кодирования, соответствующим кодированной глубине, требует не только информацию относительно кодированной глубины, но также и информацию, связанную с прогнозирующим кодированием и преобразованием. Соответственно, модуль 120 определения единиц кодирования не только определяет кодированную глубину, имеющую наименьшую ошибку кодирования, но также и определяет тип сегмента в единице прогнозирования, режим прогнозирования согласно единицам прогнозирования и размер единицы преобразования для преобразования.
Ниже подробно описываются единицы кодирования согласно древовидной структуре в максимальной единице кодирования и способ определения единицы прогнозирования/сегмента и единицы преобразования согласно вариантам осуществления настоящего изобретения со ссылкой на фиг. 7-19.
Модуль 120 определения единиц кодирования может измерять ошибку кодирования более глубоких единиц кодирования согласно глубинам посредством использования оптимизации искажения в зависимости от скорости передачи на основе множителей Лагранжа.
Модуль 130 вывода выводит данные изображений максимальной единицы кодирования, которая кодируется на основе по меньшей мере одной кодированной глубины, определенной посредством модуля 120 определения единиц кодирования, и информации относительно режима кодирования согласно кодированной глубине в потоках битов.
Кодированные данные изображений могут быть получены посредством кодирования остаточных данных изображения.
Информация относительно режима кодирования согласно кодированной глубине может включать в себя информацию относительно кодированной глубины, типа сегмента в единице прогнозирования, режима прогнозирования и размера единицы преобразования.
Информация относительно кодированной глубины может быть задана посредством использования информации разбиения согласно глубинам, которая указывает то, выполняется или нет кодирование в отношении единиц кодирования нижней глубины вместо текущей глубины. Если текущая глубина текущей единицы кодирования является кодированной глубиной, данные изображений в текущей единице кодирования кодируется и выводятся, и тем самым информация разбиения может быть задана так, чтобы не разбивать текущую единицу кодирования до нижней глубины. Альтернативно, если текущая глубина текущей единицы кодирования не является кодированной глубиной, кодирование выполняется в отношении единицы кодирования нижней глубины, и тем самым информация разбиения может быть задана так, чтобы разбивать текущую единицу кодирования, чтобы получать единицы кодирования нижней глубины.
Если текущая глубина не является кодированной глубиной, кодирование выполняется в отношении единицы кодирования, которая разбивается на единицу кодирования нижней глубины. Поскольку по меньшей мере одна единица кодирования нижней глубины существует в одной единице кодирования текущей глубины, кодирование многократно выполняется в отношении каждой единицы кодирования нижней глубины, и за счет этого кодирование может быть рекурсивно выполнено для единиц кодирования, имеющих идентичную глубину.
Поскольку единицы кодирования, имеющие древовидную структуру, определяются для одной максимальной единицы кодирования, и информация относительно по меньшей мере одного режима кодирования определяется для единицы кодирования кодированной глубины, информация относительно по меньшей мере одного режима кодирования может быть определена для одной максимальной единицы кодирования. Кроме того, кодированная глубина данных изображений максимальной единицы кодирования может отличаться согласно местоположениям, поскольку данные изображений иерархически разбиваются согласно глубинам, и тем самым информация относительно кодированной глубины и режима кодирования может задаваться для данных изображений.
Соответственно, модуль 130 вывода может назначать информацию кодирования относительно соответствующей кодированной глубины и режима кодирования по меньшей мере одной из единицы кодирования, единицы прогнозирования и минимальной единицы, включенной в максимальную единицу кодирования.
Минимальная единица согласно варианту осуществления настоящего изобретения является прямоугольной единицей данных, полученной посредством разбиения минимальной единицы кодирования, составляющей самую нижнюю кодированную глубину, на 4. Альтернативно, минимальная единица может быть максимальной прямоугольной единицей данных, которая может быть включена во все из единиц кодирования, единиц прогнозирования, единиц сегментирования и единиц преобразования, включенных в максимальную единицу кодирования.
Например, информация кодирования, выводимая через модуль 130 вывода, может классифицироваться на информацию кодирования согласно единицам кодирования и информацию кодирования согласно единицам прогнозирования. Информация кодирования согласно единицам кодирования может включать в себя информацию относительно режима прогнозирования и относительно размера сегментов. Информация кодирования согласно единицам прогнозирования может включать в себя информацию относительно оцененного направления внешнего режима, относительно индекса опорного изображения внешнего режима, относительно вектора движения, относительно компоненты сигнала цветности внутреннего режима и относительно способа интерполяции внутреннего режима. Кроме того, информация относительно максимального размера единицы кодирования, заданного согласно изображениям, слайсам (срезам) или группам изображений (GOP), и информация относительно максимальной глубины могут вставляться в набор параметров последовательности (SPS) или набор параметров изображения (PPS).
Кроме того, информация относительно максимального размера единицы преобразования, разрешенного для текущего видео, и информация относительно минимального размера единицы преобразования может выводиться через заголовок потока битов, SPS или PPS. Модуль 130 вывода может кодировать и выводить ссылочную информацию, информацию однонаправленного прогнозирования, информацию типов слайсов, включающую в себя четвертый тип слайса, и т.д., связанную с прогнозированием, описанным выше со ссылкой на фиг. 1-6.
В устройстве 100 кодирования видео, более глубокая единица кодирования может быть единицей кодирования, полученной посредством деления высоты или ширины единицы кодирования верхней глубины, которая на один слой выше, на два. Другими словами, когда размер единицы кодирования текущей глубины равен 2Nx2N, размер единицы кодирования нижней глубины равен NxN. Кроме того, единица кодирования текущей глубины, имеющая размер 2Nx2N, может включать в себя самое большее 4 единицы кодирования нижней глубины.
Соответственно, устройство 100 кодирования видео может формировать единицы кодирования, имеющие древовидную структуру, посредством определения единиц кодирования, имеющих оптимальную форму и оптимальный размер для каждой максимальной единицы кодирования, на основе размера максимальной единицы кодирования и максимальной глубины, определенной с учетом характеристик текущей картинки. Кроме того, поскольку кодирование может выполняться в отношении каждой максимальной единицы кодирования посредством использования любого из различных режимов прогнозирования и преобразований, оптимальный режим кодирования может быть определен с учетом характеристик единицы кодирования различных размеров изображения.
Таким образом, если изображение, имеющее высокое разрешение или большой объем данных, кодируется в традиционном макроблоке, число макроблоков в расчете на изображение чрезмерно увеличивается. Соответственно, число фрагментов сжатой информации, сформированной для каждого макроблока, увеличивается, и в силу этого трудно передавать сжатую информацию, и эффективность сжатия данных снижается. Тем не менее, посредством использования устройства 100 кодирования видео, эффективность сжатия изображений может быть повышена, поскольку единица кодирования регулируется с учетом характеристик изображения при увеличении максимального размера единицы кодирования с учетом размера изображения.
Устройство 100 кодирования видео по фиг. 7 может выполнять операции устройства 10 кодирования видео, описанного со ссылкой на фиг. 1.
Модуль 120 определения единиц кодирования может выполнять операции кодера 12 изображений устройства 10 кодирования видео. Модуль 120 определения единиц кодирования может определять единицу прогнозирования для внутреннего прогнозирования согласно единицам кодирования, имеющим древовидную структуру для каждой максимальной единицы кодирования, выполнять внутреннее прогнозирование в каждой единице прогнозирования, определять единицу преобразования для преобразования и выполнять преобразование в каждой единице преобразования.
Модуль 130 вывода может выполнять операции модуля 14 кодирования символов и модуля 16 вывода потоков битов устройства 10 кодирования видео. Формируются символы для различных единиц данных, таких как картинка, слайс, максимальная единица кодирования, единица кодирования, единица прогнозирования и единица преобразования, и каждый из символов классифицируется на область префикса и область суффикса согласно пороговому значению, определенному на основе размера соответствующей единицы данных. Модуль 130 вывода может формировать битовую строку префикса и битовую строку суффикса посредством использования способа преобразования в двоичную форму, определяемого для каждой из области префикса и области суффикса символа. Любое из общего преобразования в двоичную форму, унарного преобразования в двоичную форму, усеченного унарного преобразования в двоичную форму, экспоненциального преобразования в двоичную форму Голомба и преобразования в двоичную форму фиксированной длины выбирается для того, чтобы преобразовывать в двоичную форму область префикса и область суффикса, за счет этого формируя битовую строку префикса и битовую строку суффикса.
Модуль 130 вывода может выполнять кодирование символов посредством выполнения арифметического кодирования, определенного для каждой из битовой строки префикса и битовой строки суффикса. Модуль 130 вывода может выполнять кодирование символов посредством выполнения арифметического кодирования для выполнения контекстного моделирования согласно местоположениям битов в отношении битовой строки префикса и посредством выполнения арифметического кодирования для пропуска контекстного моделирования в отношении битовой строки суффикса в обходном режиме.
Например, когда кодируется конечная информация позиции коэффициента для коэффициента преобразования единицы преобразования, пороговое значение для классификации битовой строки префикса и битовой строки суффикса может быть определено согласно размеру (ширине или высоте) единицы преобразования. Альтернативно, пороговое значение может быть определено согласно размерам слайса, включающего в себя текущую единицу преобразования, максимальную единицу кодирования, единицу кодирования, единицу прогнозирования и т.д.
Альтернативно, может быть определено, посредством максимального индекса режима внутреннего прогнозирования, то, сколько битов битовой строки символа кодируется при арифметическом кодировании в качестве битовой строки префикса через контекстное моделирование в режиме внутреннего прогнозирования, и сколько битов битовой строки символа кодируется при арифметическом кодировании в качестве битовой строки суффикса в обходном режиме. Например, всего 34 режима внутреннего прогнозирования может использоваться для единиц прогнозирования, имеющих размеры 8×8, 16×16 и 32×32, всего 17 режимов внутреннего прогнозирования может использоваться для единицы прогнозирования, имеющей размер 4×4, и всего общее число режимов внутреннего прогнозирования может использоваться для единицы прогнозирования, имеющей размер 64×64. В этом случае, поскольку единицы прогнозирования, допускающие использование идентичного числа режимов внутреннего прогнозирования, рассматриваются как имеющие аналогичные статистические характеристики, первый бит из числа битовых строк в режиме внутреннего прогнозирования может быть кодирован через контекстное моделирование для арифметического кодирования относительно единиц прогнозирования, имеющих размеры 8×8, 16×16 и 32×32. Кроме того, все биты из числа битовых строк в режиме внутреннего прогнозирования могут быть кодированы в обходном режиме для арифметического кодирования относительно остальных единиц прогнозирования, т.е. единиц прогнозирования, имеющих размеры 4×4 и 64×64.
Модуль 130 вывода может выводить битовые строки, сформированные посредством кодирования символов, в форме потоков битов.
Фиг. 8 является блок-схемой устройства 200 декодирования видео на основе единицы кодирования, имеющей древовидную структуру, согласно варианту осуществления настоящего изобретения.
Устройство 200 декодирования видео, выполняющее прогнозирование видео на основе единицы кодирования, имеющей древовидную структуру, включает в себя приемное устройство 210, модуль 220 извлечения данных изображений и информации кодирования и декодер 230 данных изображений.
Определения различных терминов, таких как единица кодирования, глубина, единица прогнозирования, единица преобразования и информация относительно различных режимов кодирования, для различных операций устройства 200 декодирования видео являются идентичными определениям, описанным со ссылкой на фиг. 7 и устройство 100 кодирования видео.
Приемное устройство 210 принимает и синтаксически анализирует поток битов кодированного видео. Модуль 220 извлечения данных изображений и информации кодирования извлекает кодированные данные изображений для каждой единицы кодирования из синтаксически проанализированного потока битов, при этом единицы кодирования имеют древовидную структуру согласно каждой максимальной единице кодирования, и выводит извлеченные данные изображений в декодер 230 данных изображений. Модуль 220 извлечения данных изображений и информации кодирования может извлекать информацию относительно максимального размера единицы кодирования текущей картинки из заголовка относительно текущей картинки или SPS или PPS.
Кроме того, модуль 220 извлечения данных изображений и информации кодирования извлекает информацию относительно кодированной глубины и режима кодирования для единиц кодирования, имеющих древовидную структуру, согласно каждой максимальной единице кодирования из синтаксически проанализированного потока битов. Извлеченная информация относительно кодированной глубины и режима кодирования выводится в декодер 230 данных изображений. Другими словами, данные изображений в строке битов разбиваются на максимальные единицы кодирования так, что декодер 230 данных изображений декодирует данные изображений для каждой максимальной единицы кодирования.
Информация относительно кодированной глубины и режима кодирования согласно максимальной единице кодирования может задаваться для информации относительно по меньшей мере одной единицы кодирования, соответствующей кодированной глубине, и информация относительно режима кодирования может включать в себя информацию относительно типа сегмента соответствующей единицы кодирования, соответствующей кодированной глубине, режиму прогнозирования и размеру единицы преобразования. Кроме того, информация разбиения согласно глубинам может быть извлечена в качестве информации относительно кодированной глубины.
Информация относительно кодированной глубины и режима кодирования согласно каждой максимальной единице кодирования, извлеченной посредством модуля 220 извлечения данных изображений и информации кодирования, является информацией относительно определенной кодированной глубины и режима кодирования, чтобы формировать минимальную ошибку кодирования, когда кодер, такой как устройство 100 кодирования видео, многократно выполняет кодирование для каждой более глубокой единицы кодирования согласно глубинам согласно каждой максимальной единице кодирования. Соответственно, устройство 200 декодирования видео может восстанавливать изображение посредством декодирования данных изображений согласно кодированной глубине и режиму кодирования, который формирует минимальную ошибку кодирования.
Поскольку информация кодирования относительно кодированной глубины и режима кодирования может назначаться предварительно определенной единице данных из соответствующей единицы кодирования, единицы прогнозирования и минимальной единицы, модуль 220 извлечения данных изображений и информации кодирования может извлекать информацию относительно кодированной глубины и режима кодирования согласно предварительно определенным единицам данных. Предварительно определенные единицы данных, которым назначается идентичная информация относительно кодированной глубины и режима кодирования, могут логически выводиться как единицы данных, включенные в идентичную максимальную единицу кодирования.
Декодер 230 данных изображений восстанавливает текущее изображение посредством декодирования данных изображений в каждой максимальной единице кодирования на основе информации относительно кодированной глубины и режима кодирования согласно максимальным единицам кодирования. Другими словами, декодер 230 данных изображений может декодировать кодированные данные изображений на основе извлеченной информации относительно типа сегмента, режима прогнозирования и единицы преобразования для каждой единицы кодирования из единиц кодирования, имеющих в себя древовидную структуру, включенных в каждую максимальную единицу кодирования. Процесс декодирования может включать в себя прогнозирование, включающее в себя внутреннее прогнозирование и компенсацию движения, а также обратное преобразование.
Декодер 230 данных изображений может выполнять внутреннее прогнозирование или компенсацию движения согласно сегменту и режиму прогнозирования каждой единицы кодирования на основе информации относительно типа сегмента и режима прогнозирования единицы прогнозирования единицы кодирования согласно кодированным глубинам.
Кроме того, декодер 230 данных изображений может выполнять обратное преобразование согласно каждой единице преобразования в единице кодирования на основе информации относительно единицы преобразования согласно единицам кодирования, имеющим древовидную структуру, с тем чтобы выполнять обратное преобразование согласно максимальным единицам кодирования. Пиксельное значение пространственной области в единице кодирования может быть восстановлено через обратное преобразование.
Декодер 230 данных изображений может определять по меньшей мере одну кодированную глубину текущей максимальной единицы кодирования посредством использования информации разбиения согласно глубинам. Если информация разбиения указывает то, что данные изображений более не разбиваются при текущей глубине, текущая глубина является кодированной глубиной. Соответственно, декодер 230 данных изображений может декодировать кодированные данные по меньшей мере одной единицы кодирования, соответствующей каждой кодированной глубине в текущей максимальной единице кодирования, посредством использования информации относительно типа сегмента единицы прогнозирования, режима прогнозирования и размера единицы преобразования для каждой единицы кодирования, соответствующей кодированной глубине, и выводить данные изображений текущей максимальной единицы кодирования.
Другими словами, единицы данных, содержащие информацию кодирования, включающую в себя идентичную информацию разбиения, могут собираться посредством наблюдения набора информации кодирования, назначаемого для предварительно определенной единицы данных из единицы кодирования, единицы прогнозирования и минимальной единицы, и собранные единицы данных могут рассматриваться как одна единица данных, которая должна быть декодирована посредством декодера 230 данных изображений в одном режиме кодирования. Декодирование текущей единицы кодирования может быть выполнено посредством получения информации относительно режима кодирования для каждой единицы кодирования, определенного таким образом.
Кроме того, устройство 200 декодирования видео по фиг. 8 может выполнять операции устройства 20 декодирования видео, описанного выше со ссылкой на фиг. 2.
Приемное устройство 210 и модуль 220 извлечения данных изображений и информации кодирования могут выполнять операции синтаксического анализатора 22 и декодера 24 символов устройства 20 декодирования видео. Декодер 230 данных изображений может выполнять операции декодера 24 символов устройства 20 декодирования видео.
Приемное устройство 210 принимает поток битов изображения, и модуль 220 извлечения данных изображений и информации кодирования синтаксически анализирует символы блоков изображений из принимаемого потока битов.
Модуль 220 извлечения данных изображений и информации кодирования может классифицировать текущий символ на битовую строку префикса и битовую строку суффикса, на основе порогового значения, определяемого согласно размеру текущего блока. Например, когда декодируется конечная информация позиции коэффициента для коэффициента преобразования единицы преобразования, пороговое значение для классификации битовой строки префикса и битовой строки суффикса может быть определено согласно размеру (ширине или высоте) единицы преобразования. Альтернативно, пороговое значение может быть определено согласно размерам слайса, включающего в себя текущую единицу преобразования, максимальную единицу кодирования, единицу кодирования, единицу прогнозирования и т.д. Альтернативно, может быть определено, посредством максимального индекса режима внутреннего прогнозирования, то, сколько битов битовой строки символа кодируется при арифметическом кодировании в качестве битовой строки префикса через контекстное моделирование в режиме внутреннего прогнозирования, и сколько битов битовой строки символа кодируется при арифметическом кодировании в качестве битовой строки суффикса в обходном режиме.
Арифметическое декодирование выполняется посредством использования способа арифметического декодирования, определяемого для каждой из битовой строки префикса и битовой строки суффикса текущего символа. Арифметическое декодирование для определения контекстного моделирования согласно позициям битов может быть выполнено в отношении битовой строки префикса, и арифметическое декодирование для пропуска контекстного моделирования может быть выполнено в отношении битовой строки суффикса посредством использования обходного режима.
После арифметического декодирования выполняется преобразование из двоичной формы согласно способу преобразования в двоичную форму, определяемому для каждой из битовой строки префикса и битовой строки суффикса. Область префикса и область суффикса символа могут быть восстановлены посредством выполнения преобразования из двоичной формы согласно способу преобразования в двоичную форму, определяемому для каждой из битовой строки префикса и битовой строки суффикса.
Декодер 230 данных изображений может восстанавливать блоки изображений посредством выполнения обратного преобразования и прогнозирования в отношении текущего блока посредством использования текущего символа, восстанавливаемого посредством арифметического декодирования и преобразования из двоичной формы.
Следовательно, устройство 200 декодирования видео может получать информацию относительно по меньшей мере одной единицы кодирования, которая формирует минимальную ошибку кодирования, когда кодирование рекурсивно выполняется для каждой максимальной единицы кодирования, и может использовать эту информацию для того, чтобы декодировать текущее изображение. Другими словами, могут быть декодированы единицы кодирования, имеющие древовидную структуру, определенные как оптимальные единицы кодирования в каждой максимальной единице кодирования.
Соответственно, даже если данные изображений имеют высокое разрешение и большой объем данных, данные изображений могут быть эффективно декодированы и восстановлены посредством использования размера единицы кодирования и режима кодирования, которые адаптивно определяются согласно характеристикам данных изображений, посредством использования информации относительно оптимального режима кодирования, принимаемой из кодера.
Фиг. 9 является принципиальной схемой единиц кодирования согласно варианту осуществления настоящего изобретения.
Размер единицы кодирования может выражаться как "ширина x высота" и может составлять 64×64, 32×32, 16×16 и 8×8. Единица кодирования в 64×64 может разбиваться на сегменты в 64×64, 64×32, 32×64 или 32×32, единица кодирования в 32×32 может разбиваться на сегменты в 32×32, 32×16, 16×32 или 16×16, единица кодирования в 16×16 может разбиваться на сегменты в 16×16, 16×8, 8×16 или 8×8, и единица кодирования в 8×8 может разбиваться на сегменты в 8×8, 8×4, 4×8 или 4×4.
В видеоданных 310, разрешение составляет 1920×1080, максимальный размер единицы кодирования равен 64, и максимальная глубина равна 2. В видеоданных 320, разрешение составляет 1920×1080, максимальный размер единицы кодирования равен 64, и максимальная глубина равна 3. В видеоданных 330, разрешение составляет 352×288, максимальный размер единицы кодирования равен 16, и максимальная глубина равна 1. Максимальная глубина, показанная на фиг. 9, обозначает общее число разбиений от максимальной единицы кодирования до минимальной единицы декодирования.
Если разрешение является высоким, или объем данных является большим, максимальный размер единицы кодирования может быть большим, с тем чтобы не только повышать эффективность кодирования, но также и точно отражать характеристики изображения. Соответственно, максимальный размер единицы кодирования видеоданных 310 и 320, имеющих более высокое разрешение, чем видеоданные 330, может составлять 64.
Поскольку максимальная глубина видеоданных 310 равна 2, единицы 315 кодирования видеоданных 310 могут включать в себя максимальную единицу кодирования, имеющую размер по продольной оси равный 64, и единицы кодирования, имеющие размеры по продольной оси равные 32 и 16, поскольку глубины увеличиваются на два уровня посредством разбиения максимальной единицы кодирования два раза. Между тем, поскольку максимальная глубина видеоданных 330 равна 1, единицы кодирования 335 видеоданных 330 могут включать в себя максимальную единицу кодирования, имеющую размер продольной оси в 16, и единицы кодирования, имеющие размер продольной оси в 8, поскольку глубины увеличиваются на один уровень посредством разбиения максимальной единицы кодирования один раз.
Поскольку максимальная глубина видеоданных 320 равна 3, единицы 325 кодирования видеоданных 320 могут включать в себя максимальную единицу кодирования, имеющую размер продольной оси в 64, и единицы кодирования, имеющие размеры продольной оси в 32, 16 и 8, поскольку глубины увеличиваются на 3 уровня посредством разбиения максимальной единицы кодирования три раза. По мере того, как увеличивается глубина, подробная информация может точно выражаться.
Фиг. 10 является блок-схемой кодера 400 изображений на основе единиц кодирования согласно варианту осуществления настоящего изобретения.
Кодер 400 изображений выполняет операции модуля 120 определения единиц кодирования устройства 100 кодирования видео, чтобы кодировать данные изображений. Другими словами, модуль 410 внутреннего прогнозирования выполняет внутреннее прогнозирование в отношении единиц кодирования во внутреннем режиме из текущего кадра 405, и модуль 420 оценки движения и модуль 425 компенсации движения выполняют внешнюю оценку и компенсацию движения для единиц кодирования во внешнем режиме из текущего кадра 405 посредством использования текущего кадра 405 и опорного кадра 495.
Данные, выводимые из модуля 410 внутреннего прогнозирования, модуля 420 оценки движения и модуля 425 компенсации движения, выводятся в качестве квантованного коэффициента преобразования через преобразователь 430 и квантователь 440. Квантованный коэффициент преобразования восстанавливается в качестве данных в пространственной области через обратный квантователь 460 и обратный преобразователь 470, и восстановленные данные в пространственной области выводятся в качестве опорного кадра 495 после постобработки через модуль 480 удаления блочности и модуль 490 контурной фильтрации. Квантованный коэффициент преобразования может выводиться в качестве потока 455 битов через энтропийный кодер 450.
Для применения кодера 400 изображений в устройстве 100 кодирования видео, все элементы кодера 400 изображений, т.е. модуль 410 внутреннего прогнозирования, модуль 420 оценки движения, модуль 425 компенсации движения, преобразователь 430, квантователь 440, энтропийный кодер 450, обратный квантователь 460, обратный преобразователь 470, модуль 480 удаления блочности и модуль 490 контурной фильтрации выполняют операции на основе каждой единицы кодирования из единиц кодирования, имеющих древовидную структуру, с учетом максимальной глубины каждой максимальной единицы кодирования.
В частности, модуль 410 внутреннего прогнозирования, модуль 420 оценки движения и модуль 425 компенсации движения определяют сегменты и режим прогнозирования каждой единицы кодирования из единиц кодирования, имеющих древовидную структуру, с учетом максимального размера и максимальной глубины текущей максимальной единицы кодирования, и преобразователь 430 определяет размер единицы преобразования в каждой единице кодирования из единиц кодирования, имеющих древовидную структуру.
В частности, энтропийный кодер 450 может выполнять кодирование символов в отношении области префикса и области суффикса посредством классификации символа на область префикса и области суффикса согласно предварительно определенному пороговому значению и с использованием различных способов преобразования в двоичную форму и арифметического кодирования относительно области префикса и области суффикса.
Пороговое значение для классификации символа на область префикса и область суффикса может быть определено на основе размеров единиц данных символа, т.е. слайса, максимальной единицы кодирования, единицы кодирования, единицы прогнозирования, единицы преобразования и т.д.
Фиг. 11 является блок-схемой декодера 500 изображений на основе единицы кодирования согласно варианту осуществления настоящего изобретения.
Синтаксический анализатор 510 синтаксически анализирует кодированные данные изображений, которые должны быть декодированы, и информацию относительно кодирования, требуемую для декодирования, из потока 505 битов. Кодированные данные изображений выводятся в качестве обратно квантованных данных через энтропийный декодер 520 и обратный квантователь 530, и обратно квантованные данные восстанавливаются в данные изображений в пространственной области через обратный преобразователь 540.
Модуль 550 внутреннего прогнозирования выполняет внутреннее прогнозирование в отношении единиц кодирования во внутреннем режиме относительно данных изображений в пространственной области, и модуль 560 компенсации движения выполняет компенсацию движения в отношении единиц кодирования во внешнем режиме посредством использования опорного кадра 585.
Данные изображений в пространственной области, которые пропущены через модуль 550 внутреннего прогнозирования и модуль 560 компенсации движения, могут выводиться в качестве восстановленного кадра 595 после постобработки через модуль 570 удаления блочности и модуль 580 контурной фильтрации. Кроме того, данные изображений, которые постобрабатываются через модуль 570 удаления блочности и модуль 580 контурной фильтрации, могут выводиться в качестве опорного кадра 585.
Чтобы декодировать данные изображений в декодере 230 данных изображений устройства 200 декодирования видео, декодер 500 изображений может выполнять операции, которые выполняются после синтаксического анализатора 510.
Для применения декодера 500 изображений в устройстве 200 декодирования видео, все элементы декодера 500 изображений, т.е. синтаксический анализатор 510, энтропийный декодер 520, обратный квантователь 530, обратный преобразователь 540, модуль 550 внутреннего прогнозирования, модуль 560 компенсации движения, модуль 570 удаления блочности и модуль 580 контурной фильтрации выполняют операции на основе единиц кодирования, имеющих древовидную структуру, для каждой максимальной единицы кодирования.
В частности, модуль 550 внутреннего прогнозирования и модуль 560 компенсации движения выполняют операции на основе сегментов и режима прогнозирования для каждой из единиц кодирования, имеющих древовидную структуру, а обратный преобразователь 540 выполняет операции на основе размера единицы преобразования для каждой единицы кодирования.
В частности, энтропийный декодер 520 может выполнять декодирование символов для каждой из битовой строки префикса и битовой строки суффикса посредством классификации синтаксически проанализированной битовой строки символа на битовую строку префикса и битовую строку суффикса согласно предварительно определенному пороговому значению и с использованием различных способов преобразования в двоичную форму и арифметического декодирования относительно битовой строки префикса и битовой строки суффикса.
Пороговое значение для классификации битовой строки символа на битовую строку префикса и битовую строку суффикса может быть определено на основе размеров единиц данных символа, т.е. слайса, максимальной единицы кодирования, единицы кодирования, единицы прогнозирования, единицы преобразования и т.д.
Фиг. 12 является схемой, показывающей более глубокие единицы кодирования согласно глубинам и сегменты согласно варианту осуществления настоящего изобретения.
Устройство 100 кодирования видео и устройство 200 декодирования видео используют иерархические единицы кодирования с тем, чтобы учитывать характеристики изображения. Максимальная высота, максимальная ширина и максимальная глубина единиц кодирования могут быть адаптивно определены согласно характеристикам изображения или могут быть по-другому заданы пользователем. Размеры более глубоких единиц кодирования согласно глубинам могут быть определены согласно предварительно определенному максимальному размеру единицы кодирования.
В иерархической структуре 600 единиц кодирования согласно варианту осуществления настоящего изобретения, максимальная высота и максимальная ширина единиц кодирования составляют 64, а максимальная глубина составляет 4. Здесь, максимальная глубина означает общее число разбиений, выполняемых от максимальной единицы кодирования до минимальной единицы кодирования. Поскольку глубина увеличивается вдоль вертикальной оси иерархической структуры 600, разбиваются высота и ширина более глубокой единицы кодирования. Кроме того, единица прогнозирования и сегменты, которые являются базисами для прогнозирующего кодирования каждой более глубокой единицы кодирования, показаны вдоль горизонтальной оси иерархической структуры 600.
Другими словами, единица 610 кодирования является максимальной единицей кодирования в иерархической структуре 600, в которой глубина равна 0, а размер, т.е. высота на ширину, равен 64×64. Глубина увеличивается вдоль вертикальной оси, и существуют единица кодирования 620, имеющая размер 32×32 и глубину в 1, единица кодирования 630, имеющая размер 16×16 и глубину в 2, единица 640 кодирования, имеющая размер 8×8 и глубину 3, и единица кодирования 650, имеющая размер 4×4 и глубину 4. Единица 650 кодирования, имеющая размер 4×4 и глубину 4, является минимальной единицей кодирования.
Единица прогнозирования и сегменты единицы кодирования размещаются вдоль горизонтальной оси согласно каждой глубине. Другими словами, если единица 610 кодирования, имеющая размер 64×64 и глубину 0, является единицей прогнозирования, единица прогнозирования может разбиваться на сегменты, включенные в единицу 610 кодирования, т.е. на сегмент 610, имеющий размер 64×64, сегменты 612, имеющие размер 64×32, сегменты 614, имеющие размер 32×64, или сегменты 616, имеющие размер 32×32.
Аналогично, единица прогнозирования единицы 620 кодирования, имеющей размер 32×32 и глубину в 1, может разбиваться на сегменты, включенные в единицу 620 кодирования, т.е. на сегмент 620, имеющий размер 32×32, сегменты 622, имеющие размер 32×16, сегменты 624, имеющие размер 16×32, и сегменты 626, имеющие размер 16×16.
Аналогично, единица прогнозирования единицы 630 кодирования, имеющей размер 16×16 и глубину в 2, может разбиваться на сегменты, включенные в единицу 630 кодирования, т.е. на сегмент, имеющий размер 16×16, включенный в единицу 630 кодирования, сегменты 632, имеющие размер 16×8, сегменты 634, имеющие размер 8×16, и сегменты 636, имеющие размер 8×8.
Аналогично, единица прогнозирования единицы 640 кодирования, имеющей размер 8×8 и глубину 3, может разбиваться на сегменты, включенные в единицу 640 кодирования, т.е. на сегмент, имеющий размер 8×8, включенный в единицу 640 кодирования, сегменты 642, имеющие размер 8×4, сегменты 644, имеющие размер 4×8, и сегменты 646, имеющие размер 4×4.
Единица 650 кодирования, имеющая размер 4×4 и глубину 4, является минимальной единицей кодирования и единицей кодирования самой нижней глубины. Единица прогнозирования единицы 650 кодирования назначается только сегменту, имеющему размер 4×4.
Чтобы определять по меньшей мере одну кодированную глубину единиц кодирования, составляющих максимальную единицу 610 кодирования, модуль 120 определения единиц кодирования устройства 100 кодирования видео выполняет кодирование для единиц кодирования, соответствующих каждой глубине, включенной в максимальную единицу 610 кодирования.
Число более глубоких единиц кодирования согласно глубинам, включающим в себя данные в идентичном диапазоне и идентичного размера, увеличивается по мере того, как увеличивается глубина. Например, четыре единицы кодирования, соответствующие глубине 2, требуются для того, чтобы охватывать данные, которые включаются в одну единицу кодирования, соответствующую глубине 1. Соответственно, чтобы сравнивать результаты кодирования идентичных данных согласно глубинам, кодируются единица кодирования, соответствующая глубине 1, и четыре единицы кодирования, соответствующие глубине 2.
Чтобы выполнять кодирование для текущей глубины из глубин, наименьшая ошибка кодирования может быть выбрана для текущей глубины посредством выполнения кодирования для каждой единицы прогнозирования в единицах кодирования, соответствующих текущей глубине, вдоль горизонтальной оси иерархической структуры 600. Альтернативно, минимальная ошибка кодирования может находиться посредством сравнения наименьших ошибок кодирования согласно глубинам, посредством выполнения кодирования для каждой глубины по мере того, как глубина увеличивается вдоль вертикальной оси иерархической структуры 600. Глубина и сегмент, имеющие минимальную ошибку кодирования в единице 610 кодирования, могут быть выбраны в качестве кодированной глубины и типа сегмента единицы 610 кодирования.
Фиг. 13 является схемой для описания взаимосвязи между единицей кодирования и единицами преобразования, согласно варианту осуществления настоящего изобретения.
Устройство 100 или 200 кодирования видео кодирует или декодирует изображение согласно единицам кодирования, имеющим размеры, меньшие или равные максимальной единице кодирования для каждой максимальной единицы кодирования. Размеры единиц преобразования для преобразования во время кодирования могут быть выбраны на основе единиц данных, которые не больше соответствующей единицы кодирования.
Например, в устройстве 100 или 200 кодирования видео, если размер единицы 710 кодирования составляет 64×64, преобразование может выполняться посредством использования единиц 720 преобразования, имеющих размер 32×32.
Кроме того, данные единицы 710 кодирования, имеющей размер 64×64, могут быть кодированы посредством выполнения преобразования в отношении каждой из единиц преобразования, имеющих размер 32×32, 16×16, 8×8 и 4×4, которые меньше 64×64, а затем может быть выбрана единица преобразования, имеющая наименьшую ошибку кодирования.
Фиг. 14 является схемой для описания информации кодирования единиц кодирования согласно глубинам, согласно варианту осуществления настоящего изобретения.
Модуль 130 вывода устройства 100 кодирования видео может кодировать и передавать информацию 800 относительно типа сегмента, информацию 810 относительно режима прогнозирования и информацию 820 относительно размера единицы преобразования для каждой единицы кодирования, соответствующей кодированной глубине, в качестве информации относительно режима кодирования.
Информация 800 указывает информацию относительно формы сегмента, полученного посредством разбиения единицы прогнозирования текущей единицы кодирования, при этом сегмент является единицей данных для прогнозирующего кодирования текущей единицы кодирования. Например, текущая единица кодирования CU_0, имеющая размер 2Nx2N, может разбиваться на любой из сегмента 802, имеющего размер 2Nx2N, сегмента 804, имеющего размер 2NxN, сегмента 806, имеющего размер Nx2N, и сегмента 808, имеющего размер NxN. Здесь, информация 800 относительно типа сегмента задается так, что она указывает одно из сегмента 804, имеющего размер 2NxN, сегмента 806, имеющего размер Nx2N, и сегмента 808, имеющего размер NxN.
Информация 810 указывает режим прогнозирования каждого сегмента. Например, информация 810 может указывать режим прогнозирующего кодирования, выполняемого в отношении сегмента, указываемого посредством информации 800, т.е. внутренний режим 812, внешний режим 814 или режим 816 пропуска.
Информация 820 указывает единицу преобразования, на которой следует базироваться, когда преобразование выполняется в отношении текущей единицы кодирования. Например, единица преобразования может быть первой единицей 822 внутреннего преобразования, второй единицей 824 внутреннего преобразования, первой единицей внешнего преобразования 826 или второй единицей 828 внешнего преобразования.
Модуль 220 извлечения данных изображений и информации кодирования устройства 200 декодирования видео может извлекать и использовать информацию 800, 810 и 820 для декодирования согласно каждой более глубокой единице кодирования.
Фиг. 15 является схемой, показывающей более глубокие единицы кодирования согласно глубинам, согласно варианту осуществления настоящего изобретения.
Информация разбиения может быть использована для того, чтобы указывать изменение глубины. Информация разбиения указывает то, разбивается или нет единица кодирования текущей глубины на единицы кодирования нижней глубины.
Единица 910 прогнозирования для прогнозирующего кодирования единицы 900 кодирования, имеющей глубину 0 и размер 2N_0×2N_0, может включать в себя сегменты типа 912 сегмента, имеющего размер 2N_0×2N_0, типа 914 сегмента, имеющего размер 2N_0xN_0, типа 916 сегмента, имеющего размер N_0×2N_0, и типа 918 сегмента, имеющего размер N_0xN_0. Фиг. 15 иллюстрирует только типы 912-918 сегментов, которые получаются посредством симметричного разбиения единицы 910 прогнозирования, но тип сегмента не ограничен этим, и сегменты единицы 910 прогнозирования могут включать в себя асимметричные сегменты, сегменты, имеющие предварительно определенную форму, и сегменты, имеющие геометрическую форму.
Прогнозирующее кодирование многократно выполняется в отношении одного сегмента, имеющего размер 2N_0×2N_0, двух сегментов, имеющих размер 2N_0xN_0, двух сегментов, имеющих размер N_0×2N_0, и четырех сегментов, имеющих размер N_0xN_0, согласно каждому типу сегмента. Прогнозирующее кодирование во внутреннем режиме и внешнем режиме может выполняться в отношении сегментов, имеющих размеры 2N_0×2N_0, N_0×2N_0, 2N_0xN_0 и N_0xN_0. Прогнозирующее кодирование в режиме пропуска выполняется только в отношении сегмента, имеющем размер 2N_0×2N_0.
Ошибки кодирования, включающего в себя прогнозирующее кодирование, в типах 912-918 сегментов сравниваются, и определяется наименьшая ошибка кодирования для типов сегментов. Если ошибка кодирования является наименьшей в одном из типов 912-916 сегментов, единица 910 прогнозирования может не разбиваться на нижнюю глубину.
Если ошибка кодирования является наименьшей в типе 918 сегмента, глубина изменяется с 0 на 1, чтобы разбивать тип 918 сегмента, на этапе 920, и кодирование многократно выполняется для единиц 930 кодирования, имеющих глубину в 2 и размер N_0xN_0, чтобы выполнять поиск минимальной ошибки кодирования.
Единица 940 прогнозирования для прогнозирующего кодирования единицы 930 кодирования, имеющей глубину в 1 и размер 2N_1×2N_1 (=N_0xN_0), может включать в себя сегменты типа 942 сегмента, имеющего размер 2N_1×2N_1, типа 944 сегмента, имеющего размер 2N_1xN_1, типа 946 сегмента, имеющего размер N_1×2N_1, и типа 948 сегмента, имеющего размер N_1xN_1.
Если ошибка кодирования является наименьшей в типе 948 сегмента, глубина изменяется от 1 до 2, чтобы разбивать тип 948 сегмента, на этапе 950, и кодирование многократно выполняется в отношении единиц 960 кодирования, которые имеют глубину в 2 и размер N_2xN_2, чтобы выполнять поиск минимальной ошибки кодирования.
Когда максимальная глубина составляет d-1, единица кодирования согласно каждой глубине может разбиваться вплоть до того, когда глубина становится равной d-1, и информация разбиения может быть кодирована вплоть до того, когда глубина составляет одно из 0-d-2. Другими словами, когда кодирование выполняется вплоть до того, когда глубина составляет d-1 после того, как единица кодирования, соответствующая глубине d-2, разбивается на этапе 970, единица 990 прогнозирования для прогнозирующего кодирования единицы 980 кодирования, имеющей глубину d-1 и размер 2N_(d-1)x2N_(d-1) может включать в себя сегменты типа 992 сегмента, имеющего размер 2N_(d-1)x2N_(d-1), типа 994 сегмента, имеющего размер 2N_(d-1)xN_(d-1), типа 996 сегмента, имеющего размер N_(d-1)x2N_(d-1), и типа 998 сегмента, имеющего размер N_(d-1)xN_(d-1).
Прогнозирующее кодирование может многократно выполняться в отношении одного сегмента, имеющего размер 2N_(d-1)x2N_(d-1), двух сегментов, имеющих размер 2N_(d-1)xN_(d-1), двух сегментов, имеющих размер N_(d-1)x2N_(d-1), четырех сегментов, имеющих размер N_(d-1)xN_(d-1), из типов 992-998 сегментов, чтобы выполнять поиск типа сегмента, имеющего минимальную ошибку кодирования.
Даже когда тип 998 сегмента имеет минимальную ошибку кодирования, поскольку максимальная глубина составляет d, единица кодирования CU_(d-1), имеющая глубину d-1, более не разбивается до нижней глубины, и кодированная глубина для единиц кодирования, составляющих текущую максимальную единицу 900 кодирования, определяется как d-1, и тип сегмента текущей максимальной единицы 900 кодирования может быть определен как N_(d-1)xN_(d-1). Кроме того, поскольку максимальная глубина составляет d, и минимальная единица 980 кодирования, имеющая самую нижнюю глубину d-1, более не разбивается до нижней глубины, информация разбиения для минимальной единицы 980 кодирования не задается.
Единица 999 данных может быть "минимальной единицей" для текущей максимальной единицы кодирования. Минимальная единица согласно варианту осуществления настоящего изобретения может быть прямоугольной единицей данных, полученной посредством разбиения минимальной единицы 980 кодирования на 4. Посредством многократного выполнения кодирования, устройство 100 кодирования видео может выбирать глубину, имеющую наименьшую ошибку кодирования, посредством сравнения ошибок кодирования согласно глубинам единицы 900 кодирования, чтобы определять кодированную глубину и задавать соответствующий тип сегмента и режим прогнозирования в качестве режима кодирования кодированной глубины.
Также, минимальные ошибки кодирования согласно глубинам сравниваются во всех глубинах 1-d, и глубина, имеющая наименьшую ошибку кодирования, может быть определена в качестве кодированной глубины. Кодированная глубина, тип сегмента единицы прогнозирования и режим прогнозирования могут быть кодированы и переданы в качестве информации относительно режима кодирования. Кроме того, поскольку единица кодирования разбивается от глубины в 0 до кодированной глубины, только информация разбиения кодированной глубины задается равной 0, а информация разбиения глубин за исключением кодированной глубины задается равной 1.
Модуль 220 извлечения данных изображений и информации кодирования устройства 200 декодирования видео может извлекать и использовать информацию относительно кодированной глубины и единицы прогнозирования единицы 900 кодирования, чтобы декодировать сегмент 912. Устройство 200 декодирования видео может определять глубину, при которой информация разбиения равна 0, в качестве кодированной глубины посредством использования информации разбиения согласно глубинам и использовать информацию относительно режима кодирования соответствующей глубины для декодирования.
Фиг. 16-18 являются схемами для описания взаимосвязи между единицами кодирования, единицами прогнозирования и единицами преобразования, согласно варианту осуществления настоящего изобретения.
Единицы 1010 кодирования являются единицами кодирования, имеющими древовидную структуру согласно кодированным глубинам, определенным посредством устройства 100 кодирования видео, в максимальной единице кодирования. Единицы 1060 прогнозирования являются сегментами единиц прогнозирования каждой из единиц 1010 кодирования, и единицы 1070 преобразования являются единицами преобразования каждой из единиц 1010 кодирования.
Когда глубина максимальной единицы кодирования равна 0 в единицах 1010 кодирования, глубины единиц 1012 и 1054 кодирования равны 1, глубины единиц 1014, 1016, 1018, 1028, 1050 и 1052 кодирования равны 2, глубины единиц 1020, 1022, 1024, 1026, 1030, 1032 и 1048 кодирования равны 3, а глубины единиц 1040, 1042, 1044 и 1046 кодирования равны 4.
В единицах прогнозирования 1060, некоторые единицы 1014, 1016, 1022, 1032, 1048, 1050, 1052 и 1054 кодирования получаются посредством разбиения единиц кодирования в единицах 1010 кодирования. Другими словами, типы сегментов в единицах 1014, 1022, 1050 и 1054 кодирования имеют размер 2NxN, типы сегментов в единицах 1016, 1048 и 1052 кодирования имеют размер Nx2N, и тип сегмента единицы 1032 кодирования имеет размер NxN. Единицы прогнозирования и сегменты единиц 1010 кодирования меньше или равны каждой единицы кодирования.
Преобразование или обратное преобразование выполняется для данных изображений единицы 1052 кодирования в единицах 1070 преобразования в единице данных, которая меньше единицы 1052 кодирования. Кроме того, единицы 1014, 1016, 1022, 1032, 1048, 1050 и 1052 кодирования в единицах 1070 преобразования отличаются от единиц кодирования в единицах 1060 прогнозирования с точки зрения размеров и форм. Другими словами, устройства 100 и 200 кодирования и декодирования видео могут выполнять внутреннее прогнозирование, оценку движения, компенсацию движения, преобразование и обратное преобразование по отдельности в отношении единицы данных в идентичной единице кодирования.
Соответственно, кодирование рекурсивно выполняется в отношении каждой из единиц кодирования, имеющих иерархическую структуру в каждой области максимальной единицы кодирования, чтобы определять оптимальную единицу кодирования, и за счет этого могут быть получены единицы кодирования, имеющие рекурсивную древовидную структуру. Информация кодирования может включать в себя информацию разбиения относительно единицы кодирования, информацию относительно типа сегмента, информацию относительно режима прогнозирования и информацию относительно размера единицы преобразования. Таблица 1 показывает информацию кодирования, которая может задаваться посредством устройств 100 и 200 кодирования и декодирования видео.
(кодирование в отношении единицы кодирования, имеющей размер 2Nx2N и текущую глубину d)
Внешний
Пропуск (только 2Nx2N)
2NxN
Nx2N
NxN
2NxnD
nLx2N
nRx2N
(симметричный тип)
N/2xN/2
(асимметрич-ный тип)
Модуль 130 вывода устройства 100 кодирования видео может выводить информацию кодирования относительно единиц кодирования, имеющих древовидную структуру, и модуль 220 извлечения данных изображений и информации кодирования устройства 200 декодирования видео может извлекать информацию кодирования относительно единиц кодирования, имеющих древовидную структуру, из принимаемого потока битов.
Информация разбиения указывает то, разбивается или нет текущая единица кодирования на единицы кодирования нижней глубины. Если информация разбиения текущей глубины d равна 0, глубина, при которой текущая единица кодирования более не разбивается в нижнюю глубину, является кодированной глубиной, и тем самым информация относительно типа сегмента, режима прогнозирования и размера единицы преобразования может быть задана для кодированной глубины. Если текущая единица кодирования дополнительно разбивается согласно информации разбиения, кодирование независимо выполняется в отношении четырех единиц кодирования разбиения нижней глубины.
Режим прогнозирования может быть одним из внутреннего режима, внешнего режима и режима пропуска. Внутренний режим и внешний режим могут быть заданы во всех типах сегментов, а режим пропуска задается только в типе сегмента, имеющем размер 2Nx2N.
Информация относительно типа сегмента может указывать типы симметричных сегментов, имеющие размеры 2Nx2N, 2NxN, Nx2N и NxN, которые получаются посредством симметричного разбиения высоты или ширины единицы прогнозирования, и типы асимметричных сегментов, имеющих размеры 2NxnU, 2NxnD, nLx2N и nRx2N, которые получаются посредством асимметричного разбиения высоты или ширины единицы прогнозирования. Типы асимметричных сегментов, имеющие размеры 2NxnU и 2NxnD, могут быть, соответственно, получены посредством разбиения высоты единицы прогнозирования в 1:3 и 3:1, а типы асимметричных сегментов, имеющие размеры nLx2N, и nRx2N могут быть, соответственно, получены посредством разбиения ширины единицы прогнозирования в 1:3 и 3:1.
Размер единицы преобразования может задаваться как два типа во внутреннем режиме и два типа во внешнем режиме. Другими словами, если информация разбиения единицы преобразования равна 0, размер единицы преобразования может составлять 2Nx2N, что является размером текущей единицы кодирования. Если информация разбиения единицы преобразования равна 1, единицы преобразования могут быть получены посредством разбиения текущей единицы кодирования. Кроме того, если типом сегмента текущей единицы кодирования, имеющей размер 2Nx2N, является тип симметричного сегмента, размер единицы преобразования может составлять NxN, а если типом сегмента текущей единицы кодирования является тип асимметричного сегмента, размер единицы преобразования может составлять N/2xN/2.
Информация кодирования относительно единиц кодирования, имеющих древовидную структуру, может включать в себя по меньшей мере одну из единицы кодирования, соответствующей кодированной глубине, единицы прогнозирования и минимальной единицы. Единица кодирования, соответствующая кодированной глубине, может включать в себя по меньшей мере одну из единицы прогнозирования и минимальной единицы, содержащей идентичную информацию кодирования.
Соответственно, определяется то, включаются или нет смежные единицы данных в идентичную единицу кодирования, соответствующую кодированной глубине, посредством сравнения информации кодирования смежных единиц данных. Кроме того, соответствующая единица кодирования, соответствующая кодированной глубине, определяется посредством использования информации кодирования единицы данных, и за счет этого может быть определено распределение кодированных глубин в максимальной единице кодирования.
Соответственно, если текущая единица кодирования прогнозируется на основе информации кодирования смежных единиц данных, можно обращаться непосредственно к информации кодирования единиц данных в более глубоких единицах кодирования, смежных с текущей единицей кодирования, и она может использоваться.
Альтернативно, если текущая единица кодирования прогнозируется на основе информации кодирования смежных единиц данных, единицы данных, смежные с текущей единицей кодирования, ищутся с использованием кодированной информации единиц данных, и к искомым смежным единицам кодирования можно обращаться для прогнозирования текущей единицы кодирования.
Фиг. 19 является схемой для описания взаимосвязи между единицей кодирования, единицей прогнозирования и единицей преобразования, согласно информации режима кодирования по таблице 1.
Максимальная единица 1300 кодирования включает в себя единицы 1302, 1304, 1306, 1312, 1314, 1316 и 1318 кодирования кодированных глубин. Здесь, поскольку единица 1318 кодирования является единицей кодирования кодированной глубины, информация разбиения может задаваться равной 0. Информация относительно типа сегмента единицы 1318 кодирования, имеющей размер 2Nx2N, может задаваться как одно из типа 1322 сегмента, имеющего размер 2Nx2N, типа 1324 сегмента, имеющего размер 2NxN, типа 1326 сегмента, имеющего размер Nx2N, типа 1328 сегмента, имеющего размер NxN, типа 1332 сегмента, имеющего размер 2NxnU, типа 1334 сегмента, имеющего размер 2NxnD, типа 1336 сегмента, имеющего размер nLx2N, и типа 1338 сегмента, имеющего размер nRx2N.
Информация разбиения (флаг TU-размера) единицы преобразования представляет собой вид индекса преобразования, и размер единицы преобразования, соответствующий индексу преобразования, может варьироваться согласно типу единицы прогнозирования или сегмента единицы кодирования.
Например, когда тип сегмента задается как симметричный, т.е. тип 1322, 1324, 1326 или 1328 сегмента, единица 1342 преобразования, имеющая размер 2Nx2N, задается, если информация разбиения единицы преобразования равна 0, и единица 1344 преобразования, имеющая размер NxN, задается, если флаг TU-размера равен 1.
Когда тип сегмента задается как асимметричный, т.е. тип 1332, 1334, 1336 или 1338 сегмента, единица 1352 преобразования, имеющая размер 2Nx2N, задается, если флаг TU-размера равен 0, и единица 1354 преобразования, имеющая размер N/2xN/2 задается, если флаг TU-размера равен 1.
Ссылаясь на фиг. 19, флаг TU-размера является флагом, имеющим значение в 0 или 1, но флаг TU-размера не ограничивается 1 битом, и единица преобразования может иерархически разбиваться при наличии древовидной структуры, в то время как флаг TU-размера увеличивается от 0. Флаг TU-размера может быть использован в качестве варианта осуществления индекса преобразования.
В этом случае, если информация разбиения единицы преобразования используется вместе с размером максимальной единицы преобразования и размером минимальной единицы преобразования, может выражаться размер единицы преобразования, который фактически используется. Устройство 100 кодирования видео может кодировать информацию размера максимальных единиц преобразования, информацию размера минимальных единиц преобразования и информацию разбиения максимальных единиц преобразования. Кодированная информация размера максимальных единиц преобразования, информация размера минимальных единиц преобразования и информация разбиения максимальных единиц преобразования может вставляться в SPS. Устройство 200 декодирования видео может выполнять декодирование видео посредством использования информации размера максимальных единиц преобразования, информации размера минимальных единиц преобразования и информации разбиения максимальных единиц преобразования.
Например, если текущая единица кодирования имеет размер 64×64, и размер максимальной единицы преобразования равен 32×32, когда информация разбиения единиц преобразования равна 0, размер единицы преобразования может задаваться равным 32×32, когда информация разбиения единиц преобразования равна 1, размер единицы преобразования может задаваться равным 16×16, а когда информация разбиения единиц преобразования равна 2, размер единицы преобразования может задаваться равным 8×8.
Альтернативно, если текущая единица кодирования имеет размер 32×32, и размер минимальной единицы преобразования равен 32×32, когда информация разбиения единиц преобразования равна 1, размер единицы преобразования может задаваться равным 32×32, и поскольку размер единицы преобразования равен или превышает 32×32, информация разбиения единиц преобразования более не может задаваться.
Альтернативно, если текущая единица кодирования имеет размер 64×64, и информация разбиения максимальных единиц преобразования равна 1, информация разбиения единиц преобразования может задаваться равной 0 или 1, и другая информация разбиения единиц преобразования может не задаваться.
Соответственно, если информация разбиения максимальных единиц преобразования задается как MaxTransformSizeIndex, если размер минимальной единицы преобразования задается как MinTransformSize, и если размер единицы преобразования задается как RootTuSize, когда информация разбиения единиц преобразования равна 0, CurrMinTuSize, который является размером минимальной единицы преобразования, доступным в текущей единице кодирования, может быть задан посредством нижеприведенной формулы (1):
CurrMinTuSize=max(MinTransformSize, RootTuSize/(2^MaxTransformSizeIndex)) (1)
По сравнению с CurrMinTuSize, который является размером минимальной единицы преобразования, доступным в текущей единице кодирования, RootTuSize, который является размером единицы преобразования, когда информация разбиения единиц преобразования равна 0, может представлять размер максимальной единицы преобразования, который может приспосабливаться в системе. Другими словами, согласно формуле (1), RootTuSize/(2^MaxTransformSizeIndex) является размером единицы преобразования, на которую разбивается RootTuSize число раз, соответствующее информации разбиения максимальных единиц преобразования, а MinTransformSize является размером минимальной единицы преобразования, и в силу этого меньшее значение из RootTuSize/(2^MaxTransformSizeIndex) и MinTransformSize может составлять CurrMinTuSize, который является размером минимальной единицы преобразования, доступным в текущей единице кодирования.
RootTuSize, который является размером максимальной единицы преобразования, может варьироваться согласно режиму прогнозирования.
Например, если текущим режимом прогнозирования является внешний режим, то RootTuSize может быть определен согласно нижеприведенной формуле (2). В формуле (1), MaxTransformSize обозначает размер максимальной единицы преобразования, и PUSize обозначает размер текущей единицы прогнозирования.
RootTuSize=min(MaxTransformSize, PUSize) (2)
Другими словами, если текущим режимом прогнозирования является внешний режим, RootTuSize, который является размером единицы преобразования, когда информация разбиения единиц преобразования равна 0, может задаваться равным меньшему значению из размера максимальной единицы преобразования и размера текущей единицы прогнозирования.
Если режимом прогнозирования текущей единицы сегментирования является внутренний режим, RootTuSize может быть определен согласной нижеприведенной формуле (3). PartitionSize обозначает размер текущей единицы сегментирования.
RootTuSize=min(MaxTransformSize, PartitionSize) (3)
Другими словами, если текущим режимом прогнозирования является внутренний режим, RootTuSize может задаваться равным меньшему значению из размера максимальной единицы преобразования и размера текущей единицы сегментирования.
Тем не менее, размер RootTuSize текущей максимальной единицы преобразования, варьирующийся согласно режиму прогнозирования в единице сегментирования, является просто примером, и фактор для определения размера текущей максимальной единицы преобразования не ограничен этим.
Данные изображений пространственной области кодируются для каждой единицы кодирования, имеющей древовидную структуру, посредством использования способа кодирования видео на основе единиц кодирования, имеющих древовидную структуру, описанного выше со ссылкой на фиг. 7-19, и декодирование выполняется для каждой максимальной единицы кодирования посредством использования способа декодирования видео на основе единиц кодирования, имеющих древовидную структуру, и в силу этого восстанавливаются данные изображений пространственной области, за счет этого восстанавливая видео, которое является изображением и последовательностью изображений. Восстановленное видео может быть воспроизведено посредством устройства воспроизведения, может быть сохранено на носителе хранения данных или может быть передано через сеть.
Варианты осуществления настоящего изобретения могут быть записаны в качестве компьютерной программы и могут быть реализованы в цифровых компьютерах общего назначения, которые выполняют программы с использованием считываемого компьютером носителя записи. Примеры считываемого компьютером носителя записи включают в себя магнитные носители хранения данных (например, ROM, гибкие диски, жесткие диски и т.д.) и оптические носители записи (например, CD-ROM или DVD).
Хотя это изобретение конкретно показано и описано со ссылкой на его предпочтительные варианты осуществления, специалисты в данной области техники должны понимать, что различные изменения по форме и содержанию могут быть сделаны без отступления от сущности и объема изобретения, заданных посредством прилагаемой формулы изобретения. Предпочтительные варианты осуществления должны рассматриваться только в описательном смысле, а не в целях ограничения. Следовательно, объем изобретения задается не посредством подробного описания изобретения, а посредством прилагаемой формулы изобретения, и любые отличия в пределах объема должны истолковываться как включенные в настоящее изобретение.


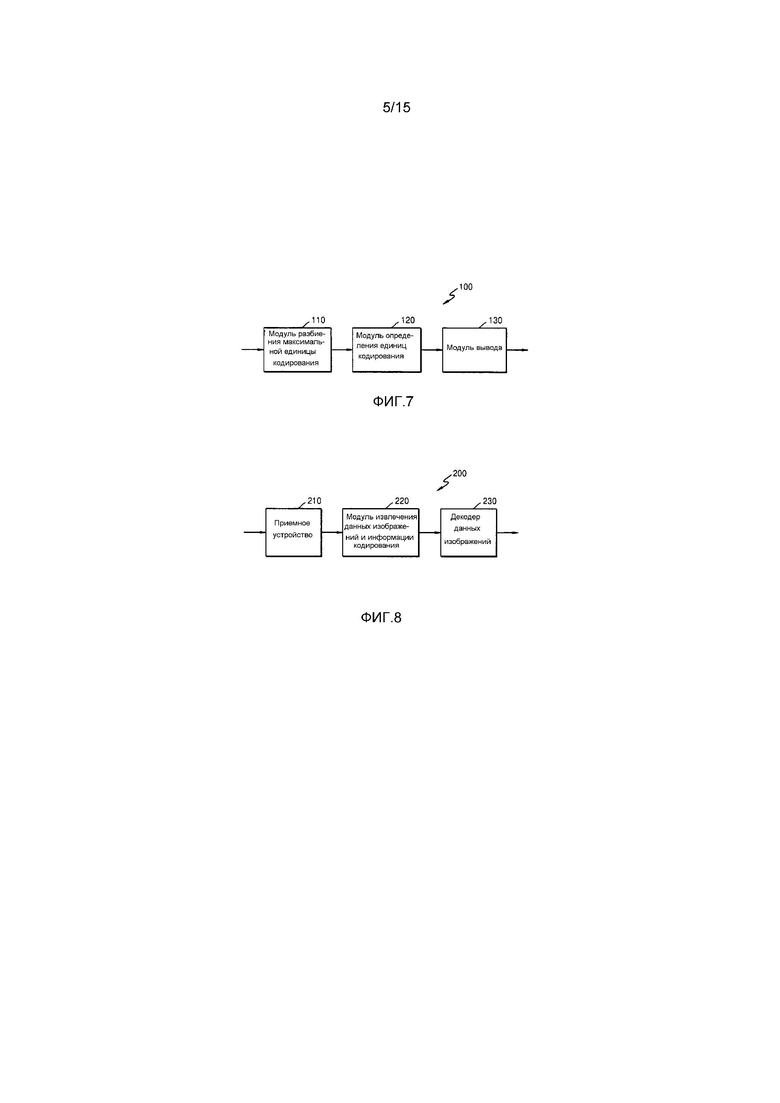
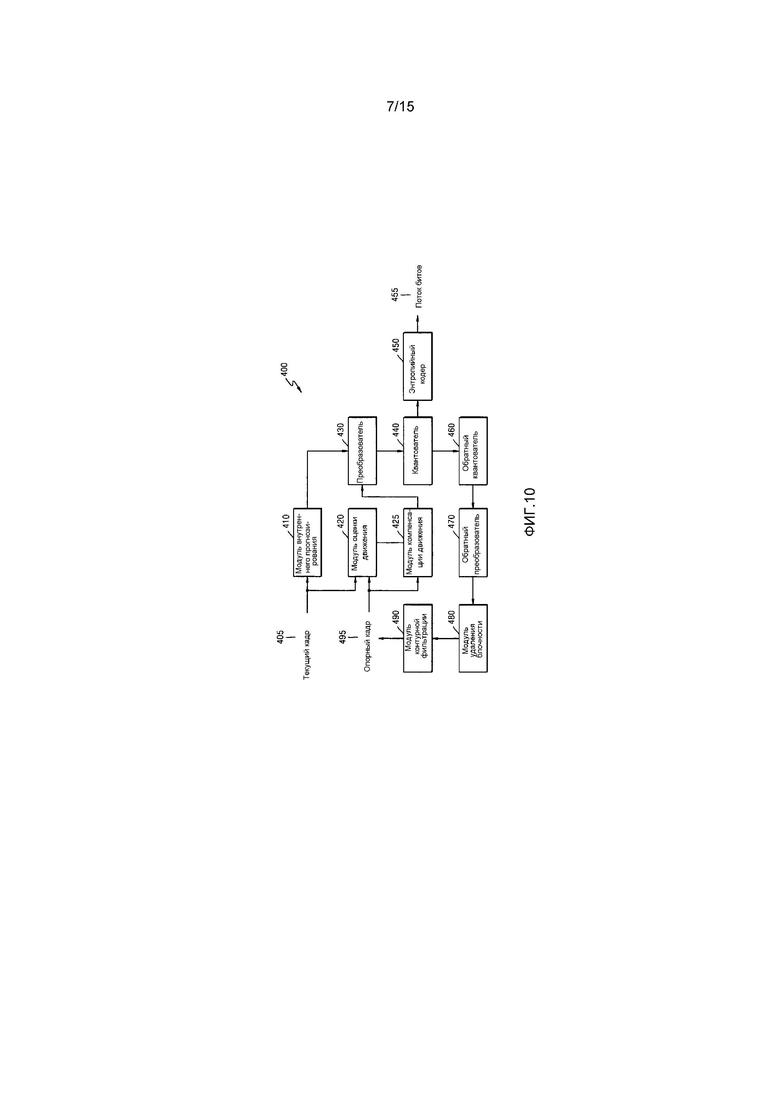
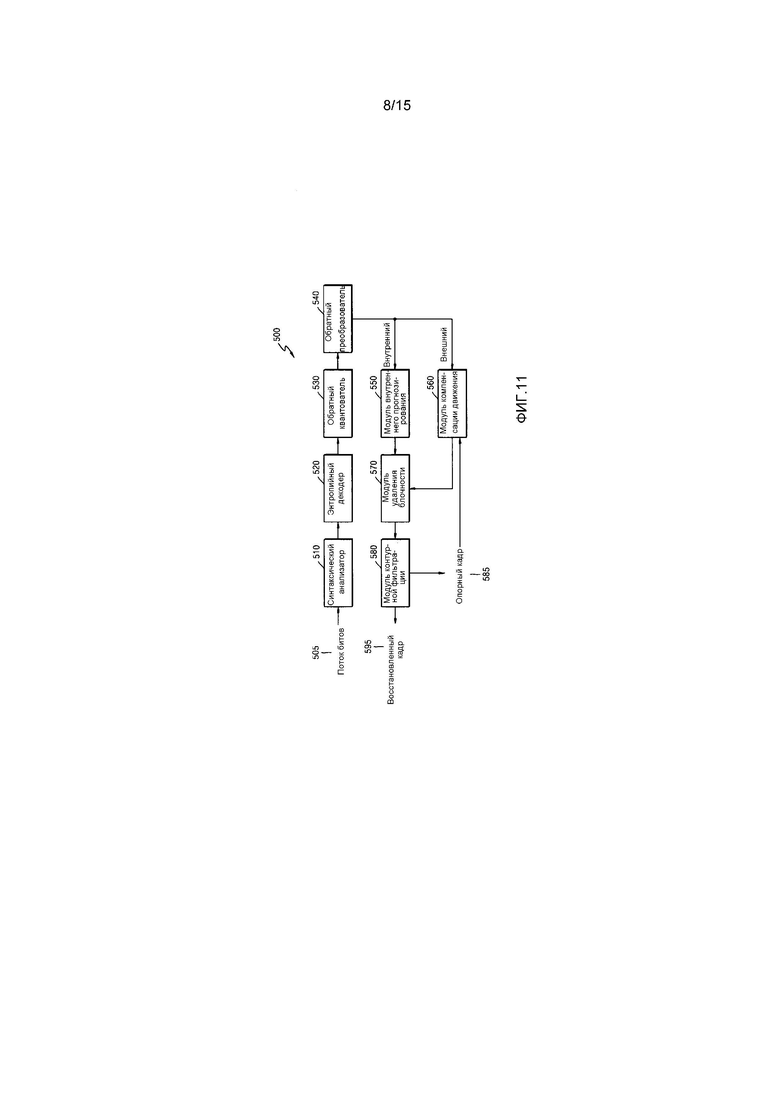
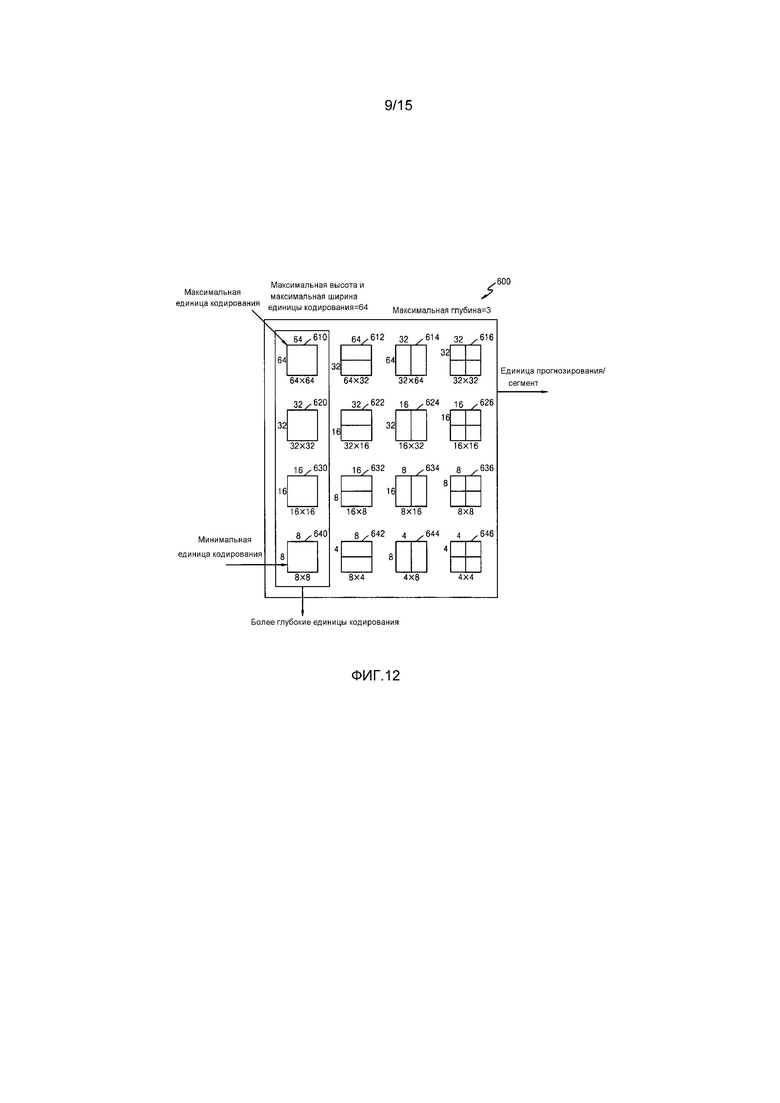
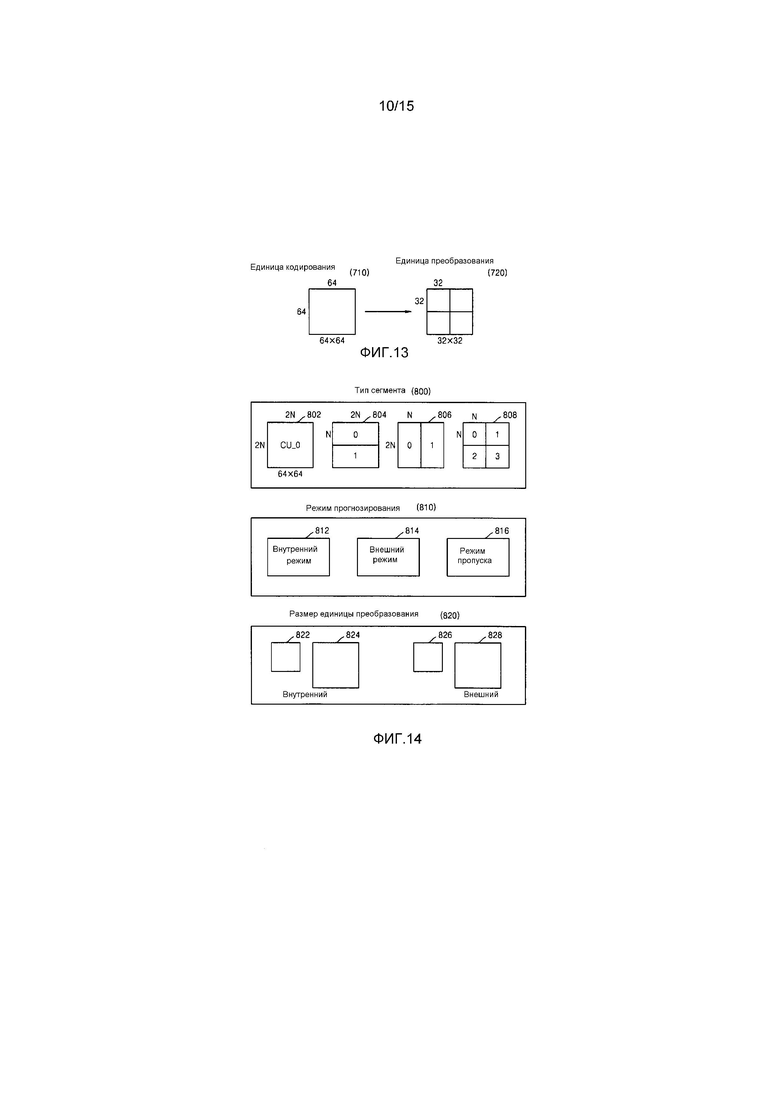
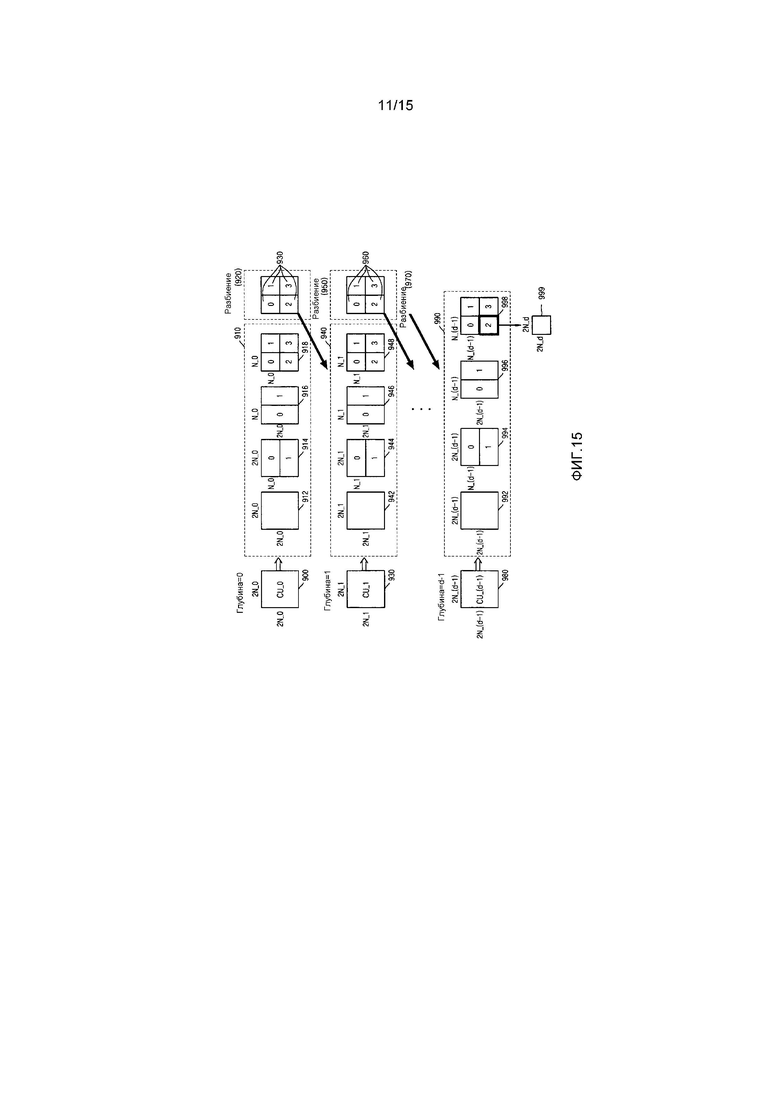
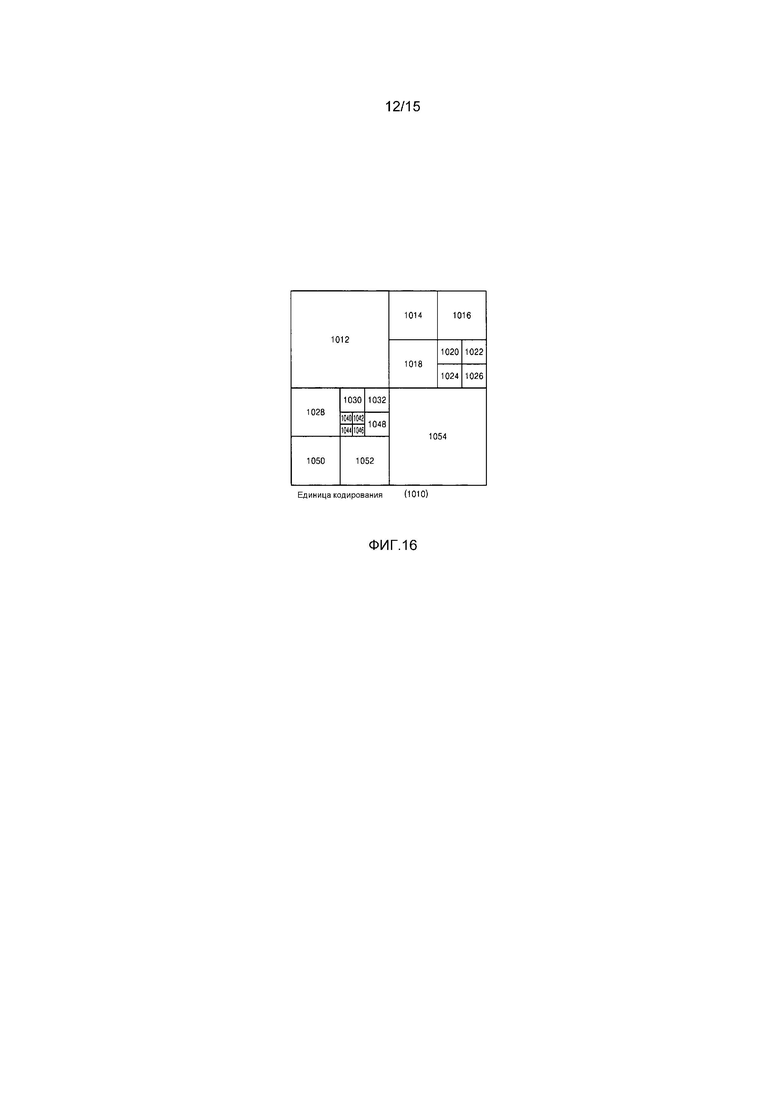
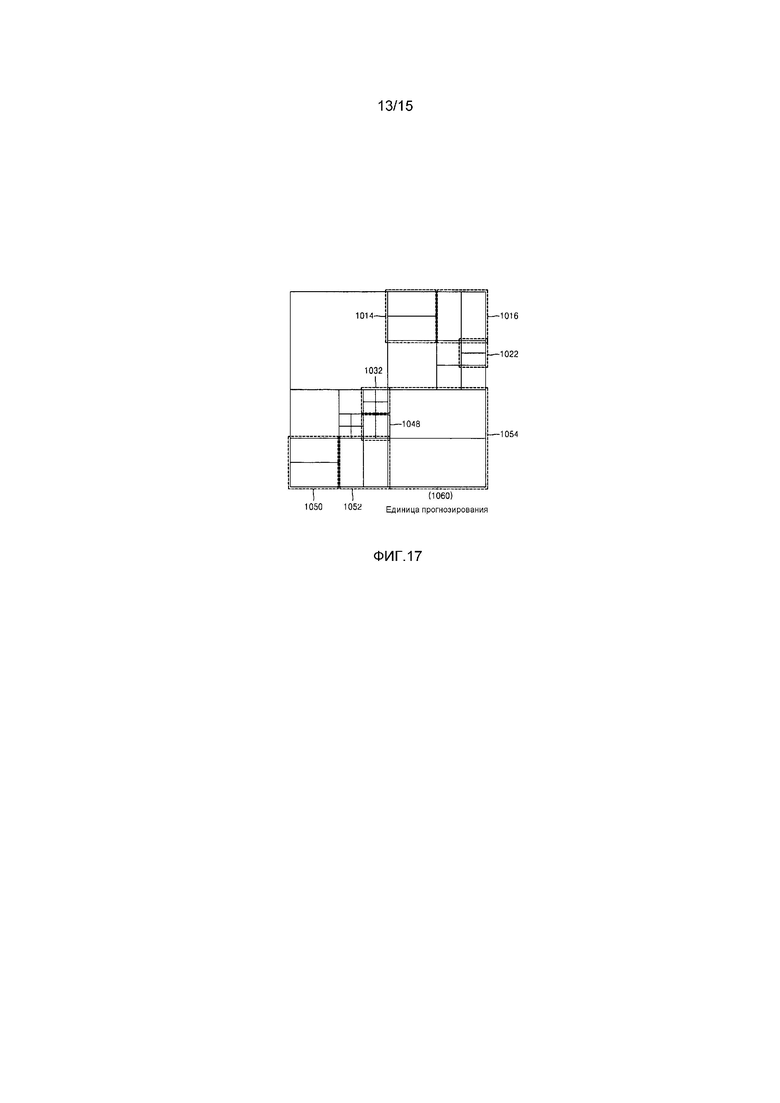

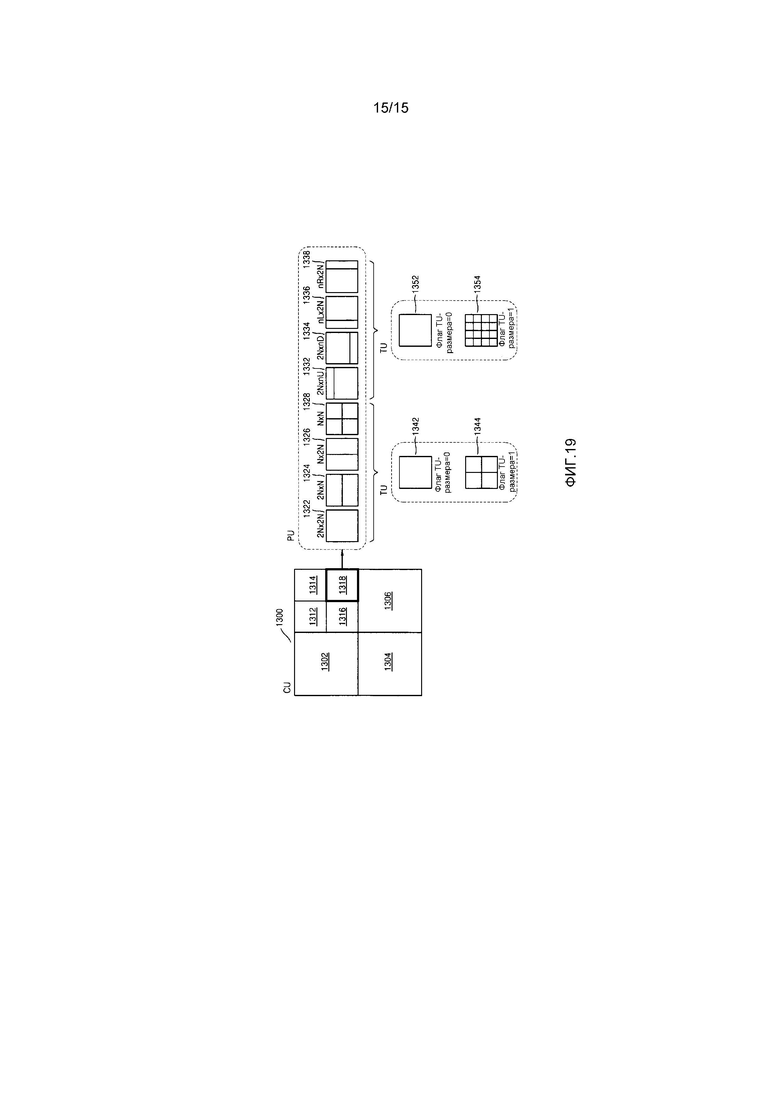
Изобретение относится к кодированию/декодированию видео на основе арифметического кодирования. Техническим результатом является повышение эффективности процесса декодирования символов. Предложен cпособ декодирования видео посредством декодирования символов, который включает: синтаксический анализ символов блоков изображений из принимаемого потока битов; классификацию текущего символа на битовую строку префикса и битовую строку суффикса на основе порогового значения, определяемого согласно размеру текущего блока; выполнение арифметического декодирования посредством использования способа арифметического декодирования, определяемого для каждой из битовой строки префикса и битовой строки суффикса; и выполнение преобразования из двоичной формы посредством использования способа преобразования в двоичную форму, определяемого для каждой из битовой строки префикса и битовой строки суффикса. 11 н.п. ф-лы, 19 ил., 2 табл.
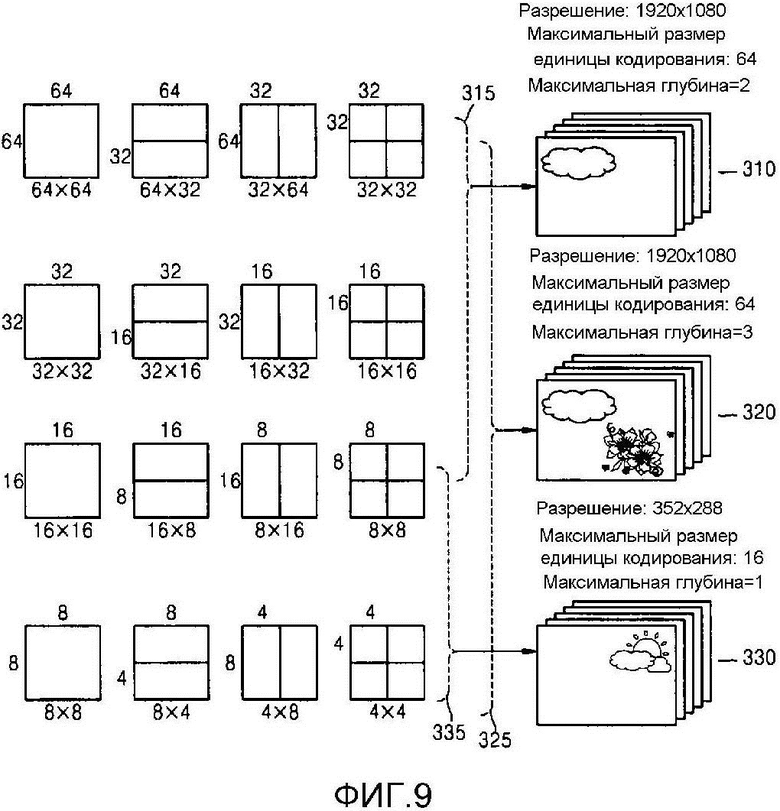
1. Способ декодирования видео, содержащий:
получение битовой строки префикса местоположения последнего коэффициента блока преобразования посредством выполнения контекстного арифметического декодирования в отношении принятого битового потока;
когда битовая строка префикса превышает предопределенное значение, получение из битового потока битовой строки суффикса согласно обходному режиму;
выполнение обратной бинаризации в отношении битовой строки префикса согласно схеме усеченной бинаризации для получения префикса, подвергнутого обратной бинаризации;
выполнение обратной бинаризации в отношении битовой строки суффикса согласно схеме бинаризации с фиксированной длиной для получения суффикса, подвергнутого обратной бинаризации; и
восстановление символа, указывающего местоположение последнего коэффициента блока преобразования, посредством использования префикса, подвергнутого обратной бинаризации, и суффикса, подвергнутого обратной бинаризации,
при этом диапазон значения префикса, подвергнутого обратной бинаризации, определяется на основе размера блока преобразования, и диапазон значения суффикса, подвергнутого обратной бинаризации, определяется на основе значения префикса, подвергнутого обратной бинаризации,
при этом значение символа, указывающего местоположение последнего коэффициента блока преобразования, восстанавливается посредством использования значения префикса, подвергнутого обратной бинаризации, и значения суффикса, подвергнутого обратной бинаризации, и
при этом контекстное арифметическое декодирование выполняется посредством использования индекса контекста, определяемого на основе размера блока преобразования.
2. Способ для кодирования видео, причем способ содержит:
формирование символа, указывающего местоположение последнего коэффициента блока преобразования;
выполнение бинаризации в отношении префикса символа согласно схеме усеченной бинаризации для формирования битовой строки префикса;
выполнение бинаризации в отношении суффикса символа согласно схеме бинаризации с фиксированной длиной для формирования битовой строки суффикса;
выполнение контекстного арифметического кодирования в отношении битовой строки префикса для формирования информации о префиксе местоположения последнего коэффициента; и
выполнение энтропийного кодирования в отношении битовой строки суффикса согласно обходному режиму для формирования информации о суффиксе местоположения последнего коэффициента,
при этом диапазон значения префикса символа определяется на основе размера блока преобразования и диапазон значения суффикса символа определяется на основе значения префикса символа.
3. Устройство кодирования видео, причем устройство содержит:
средство формирования символа, выполненное с возможностью формирования символа, указывающего местоположение последнего коэффициента блока преобразования; и
энтропийный кодер, выполненный с возможностью выполнения бинаризации в отношении префикса символа согласно схеме усеченной бинаризации для формирования битовой строки префикса, выполнения бинаризации в отношении суффикса символа согласно схеме бинаризации с фиксированной длиной для формирования битовой строки суффикса, выполнения контекстного арифметического кодирования в отношении битовой строки префикса для формирования информации о префиксе местоположения последнего коэффициента и выполнения энтропийного кодирования в отношении битовой строки суффикса согласно обходному режиму для формирования информации о суффиксе местоположения последнего коэффициента,
при этом диапазон значения префикса символа определяется на основе размера блока преобразования и диапазон значения суффикса символа определяется на основе значения префикса символа.
4. Способ для кодирования видео, причем способ содержит:
формирование символа, указывающего местоположение последнего коэффициента блока преобразования;
выполнение бинаризации в отношении префикса символа согласно схеме усеченной бинаризации для формирования битовой строки префикса;
выполнение бинаризации в отношении суффикса символа согласно схеме бинаризации с фиксированной длиной для формирования битовой строки суффикса;
выполнение контекстного арифметического кодирования в отношении битовой строки префикса для формирования информации о префиксе местоположения последнего коэффициента; и
выполнение энтропийного кодирования в отношении битовой строки суффикса согласно обходному режиму для формирования информации о суффиксе местоположения последнего коэффициента,
при этом диапазон значения префикса символа определяется на основе размера блока преобразования и диапазон значения суффикса символа определяется на основе значения префикса символа, и
при этом контекстное арифметическое кодирование выполняется посредством использования индекса контекста, определяемого на основе размера блока преобразования.
5. Устройство кодирования видео, причем устройство содержит:
средство формирования символа, выполненное с возможностью формирования символа, указывающего местоположение последнего коэффициента блока преобразования; и
энтропийный кодер, выполненный с возможностью выполнения бинаризации в отношении префикса символа согласно схеме усеченной бинаризации для формирования битовой строки префикса, выполнения бинаризации в отношении суффикса символа согласно схеме бинаризации с фиксированной длиной для формирования битовой строки суффикса, выполнения контекстного арифметического кодирования в отношении битовой строки префикса для формирования информации о префиксе местоположения последнего коэффициента и выполнения энтропийного кодирования в отношении битовой строки суффикса согласно обходному режиму для формирования информации о суффиксе местоположения последнего коэффициента,
при этом диапазон значения префикса символа определяется на основе размера блока преобразования и диапазон значения суффикса символа определяется на основе значения префикса символа, и
при этом контекстное арифметическое кодирование выполняется посредством использования индекса контекста, определяемого на основе размера блока преобразования.
6. Способ для кодирования видео, причем способ содержит:
разделение изображения на множество максимальных блоков кодирования;
иерархическое разделение одного из этих максимальных блоков кодирования на по меньшей мере один блок кодирования;
определение по меньшей мере одного блока преобразования, полученного иерархическим отделением от текущего блока кодирования;
формирование символа, указывающего местоположение последнего коэффициента блока преобразования из числа упомянутого по меньшей мере одного блока преобразования;
выполнение бинаризации в отношении префикса символа согласно схеме усеченной бинаризации для формирования битовой строки префикса;
выполнение бинаризации в отношении суффикса символа согласно схеме бинаризации с фиксированной длиной для формирования битовой строки суффикса;
выполнение контекстного арифметического кодирования в отношении битовой строки префикса для формирования информации о префиксе местоположения последнего коэффициента; и
выполнение энтропийного кодирования в отношении битовой строки суффикса согласно обходному режиму для формирования информации о суффиксе местоположения последнего коэффициента,
при этом диапазон значения префикса символа определяется на основе размера блока преобразования и диапазон значения суффикса символа определяется на основе значения префикса символа, и
при этом контекстное арифметическое кодирование выполняется посредством использования индекса контекста, определяемого на основе размера блока преобразования.
7. Долговременный считываемый компьютером носитель, хранящий битовый поток, причем битовый поток содержит:
информацию о префиксе местоположения последнего коэффициента, формируемую посредством выполнения контекстного арифметического кодирования в отношении битовой строки префикса местоположения последнего коэффициента блока преобразования; и
информацию о суффиксе местоположения последнего коэффициента, формируемую посредством выполнения энтропийного кодирования в отношении битовой строки суффикса местоположения последнего коэффициента блока преобразования согласно обходному режиму,
при этом битовая строка префикса местоположения последнего коэффициента формируется посредством выполнения бинаризации в отношении префикса символа местоположения последнего коэффициента согласно схеме усеченной бинаризации,
при этом битовая строка суффикса местоположения последнего коэффициента формируется посредством выполнения бинаризации в отношении суффикса символа местоположения последнего коэффициента согласно схеме бинаризации с фиксированной длиной, и
при этом диапазон значения префикса символа определяется на основе размера блока преобразования и диапазон значения суффикса символа определяется на основе значения префикса символа.
8. Долговременный считываемый компьютером носитель, хранящий битовый поток, причем битовый поток содержит:
информацию о префиксе местоположения последнего коэффициента, формируемую посредством выполнения контекстного арифметического кодирования в отношении битовой строки префикса местоположения последнего коэффициента блока преобразования; и
информацию о суффиксе местоположения последнего коэффициента, формируемую посредством выполнения энтропийного кодирования в отношении битовой строки суффикса местоположения последнего коэффициента блока преобразования согласно обходному режиму,
при этом битовая строка префикса местоположения последнего коэффициента формируется посредством выполнения бинаризации в отношении префикса символа местоположения последнего коэффициента согласно схеме усеченной бинаризации,
при этом битовая строка суффикса местоположения последнего коэффициента формируется посредством выполнения бинаризации в отношении суффикса символа местоположения последнего коэффициента согласно схеме бинаризации с фиксированной длиной, и
при этом диапазон значения префикса символа определяется на основе размера блока преобразования и диапазон значения суффикса символа определяется на основе значения префикса символа, и
при этом контекстное арифметическое кодирование выполняется посредством использования индекса контекста, определяемого на основе размера блока преобразования.
9. Долговременный считываемый компьютером носитель, хранящий битовый поток, причем битовый поток содержит:
информацию о префиксе местоположения последнего коэффициента, формируемую посредством выполнения контекстного арифметического кодирования в отношении битовой строки префикса местоположения последнего коэффициента блока преобразования; и
информацию о суффиксе местоположения последнего коэффициента, формируемую посредством выполнения энтропийного кодирования в отношении битовой строки суффикса местоположения последнего коэффициента блока преобразования согласно обходному режиму,
при этом битовая строка префикса местоположения последнего коэффициента формируется посредством выполнения бинаризации в отношении префикса символа местоположения последнего коэффициента согласно схеме усеченной бинаризации,
при этом битовая строка суффикса местоположения последнего коэффициента формируется посредством выполнения бинаризации в отношении суффикса символа местоположения последнего коэффициента согласно схеме бинаризации с фиксированной длиной,
при этом диапазон значения префикса символа определяется на основе размера блока преобразования и диапазон значения суффикса символа определяется на основе значения префикса символа, и
при этом контекстное арифметическое кодирование выполняется посредством использования индекса контекста, определяемого на основе размера блока преобразования, и индекса бина битовой строки префикса.
10. Долговременный считываемый компьютером носитель, хранящий битовый поток, причем битовый поток содержит:
информацию о префиксе местоположения последнего коэффициента, формируемую посредством выполнения контекстного арифметического кодирования в отношении битовой строки префикса местоположения последнего коэффициента блока преобразования; и
информацию о суффиксе местоположения последнего коэффициента, формируемую посредством выполнения энтропийного кодирования в отношении битовой строки суффикса местоположения последнего коэффициента блока преобразования согласно обходному режиму,
при этом:
битовая строка префикса местоположения последнего коэффициента формируется посредством выполнения бинаризации в отношении префикса символа местоположения последнего коэффициента согласно схеме усеченной бинаризации,
битовая строка суффикса местоположения последнего коэффициента формируется посредством выполнения бинаризации в отношении суффикса символа местоположения последнего коэффициента согласно схеме бинаризации с фиксированной длиной,
изображение разделяется на множество максимальных блоков кодирования, один из упомянутых максимальных блоков кодирования иерархически разделяется на по меньшей мере один блок кодирования,
по меньшей мере один блок преобразования иерархически отделяется от текущего блока кодирования;
причем блок преобразования является одним из числа упомянутого по меньшей мере одного блока преобразования, и
диапазон значения префикса символа определяется на основе размера блока преобразования и диапазон значения суффикса символа определяется на основе значения префикса символа.
11. Долговременный считываемый компьютером носитель, хранящий битовый поток, причем битовый поток содержит:
информацию о префиксе местоположения последнего коэффициента, формируемую посредством выполнения контекстного арифметического кодирования в отношении битовой строки префикса местоположения последнего коэффициента блока преобразования; и
информацию о суффиксе местоположения последнего коэффициента, формируемую посредством выполнения энтропийного кодирования в отношении битовой строки суффикса местоположения последнего коэффициента блока преобразования согласно обходному режиму,
при этом:
битовая строка префикса местоположения последнего коэффициента формируется посредством выполнения бинаризации в отношении префикса символа местоположения последнего коэффициента согласно схеме усеченной бинаризации,
битовая строка суффикса местоположения последнего коэффициента формируется посредством выполнения бинаризации в отношении суффикса символа местоположения последнего коэффициента согласно схеме бинаризации с фиксированной длиной,
изображение разделяется на множество максимальных блоков кодирования, один из упомянутых максимальных блоков кодирования иерархически разделяется на по меньшей мере один блок кодирования,
по меньшей мере один блок преобразования иерархически отделяется от текущего блока кодирования;
причем блок преобразования является одним из числа упомянутого по меньшей мере одного блока преобразования,
диапазон значения префикса символа определяется на основе размера блока преобразования и диапазон значения суффикса символа определяется на основе значения префикса символа, и
при этом контекстное арифметическое кодирование выполняется посредством использования индекса контекста, определяемого на основе размера блока преобразования.
| Способ дуговой точечной сварки | 1991 |
|
SU1797536A3 |
| WO 03094529 A2, 2003-11-13 | |||
| US 2005038837 A1, 2005-02-17 | |||
| US 2010040140 A1, 2010-02-18 | |||
| US 2007171985 A1, 2007-07-26 | |||
| СПОСОБЫ И СИСТЕМЫ ДЛЯ КОДИРОВАНИЯ ЗНАЧИМЫХ КОЭФФИЦИЕНТОВ ПРИ ВИДЕОСЖАТИИ | 2007 |
|
RU2406256C2 |

