Область техники, к которой относится изобретение
Настоящее изобретение относится к кодированию и декодированию данных.
Уровень техники
Предложенное здесь описание «предпосылок» к созданию изобретения предназначено, в общем случае, для общего представления контекста настоящего изобретения. Работы авторов настоящего изобретения в той степени, в какой они описаны в этом разделе предпосылок, равно как и аспекты этого изобретения, которые не могут быть иначе квалифицированы в качестве известных на момент подачи заявки, не противопоставляются, ни в явном, ни в неявном виде, настоящему изобретению.
Известны несколько различных систем сжатия и распаковки данных, использующих преобразование видеоданных к представлению в частотной области, квантование коэффициентов в частотной области и затем применение некоторого вида энтропийного кодирования к квантованным коэффициентам.
Энтропию в рассматриваемом контексте можно считать представлением информационного контента символа данных или последовательности символов. Целью энтропийного кодирования является кодирование последовательности символов данных без потерь с использованием (в идеале) наименьшего числа битов кодированных данных, необходимого для представления информационного контента этой последовательности символов данных. На практике энтропийное кодирование используется для кодирования квантованных коэффициентов, так что объем кодированных данных меньше (с точки зрения числа битов) объема данных в составе исходных квантованных коэффициентов. Более эффективная процедура энтропийного кодирования дает меньший объем выходных данных при таком же объеме входных данных.
Одним из способов энтропийного кодирования видеоданных является так называемый способ контекстно-адаптивного двоичного арифметического кодирования (CABAC (context adaptive binary arithmetic coding)).
Раскрытие изобретения
Настоящее изобретение предлагает устройство для декодирования данных, содержащее декодер для декодирования входных кодированных величин данных и преобразования их в декодированные величины данных, имеющие некоторую битовую глубину, при этом входные кодированные величины данных кодированы в виде наборов данных и кодов выхода для величин, не кодированных в виде наборов данных, здесь код выхода содержит префиксную часть, охватываемую максимальной длиной префикса, зависящей от битовой глубины величин данных, и неунарно кодированную суффиксную часть, длина которой в битах зависит от величины, кодированной посредством префиксной части, в соответствии с таким соотношением, что по меньшей мере для некоторых величины, кодированных посредством префиксной части, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части.
Далее, соответствующие аспекты и признаки изобретения определены в прилагаемой Формуле изобретения.
Следует понимать, что приведенное выше общее описание и последующее подробное описание являются примерами, но не ограничениями, настоящего изобретения.
Краткое описание чертежей
Более полная оценка настоящего изобретения и многочисленные преимущества, создаваемые им, могут быть легко получены, когда изобретение станет лучше понятно со ссылками на последующее подробное описание вариантов, рассматриваемое вместе с прилагаемыми чертежами, на которых:
Фиг. 1 схематично иллюстрирует систему передачи и приема аудио/видео (A/V) данных с использованием сжатия и расширения видеоданных;
Фиг. 2 схематично иллюстрирует систему отображения видео, использующую расширение видеоданных;
Фиг. 3 схематично иллюстрирует систему хранения аудио/видео данных с использованием сжатия и распаковки видеоданных;
Фиг. 4 схематично иллюстрирует видеокамеру с использованием сжатия видеоданных;
Фиг. 5 представляет упрощенную схему устройства сжатия и распаковки данных; Фиг. 6 схематично иллюстрирует генерирование прогнозируемых изображений;
Фиг. 7 схематично иллюстрирует наибольший модуль кодирования (largest coding unit (LCU));
Фиг. 8 схематично иллюстрирует группу из четырех модулей кодирования (coding unit (CU));
Фиг. 9 и 10 схематично иллюстрирует разбиение модулей кодирования, показанных на Фиг. 8, на модули кодирования меньшего размера;
Фиг. 11 схематично иллюстрирует матрицу модулей прогнозирования (prediction unit (PU));
Фиг. 12 схематично иллюстрирует матрицу модулей преобразования (transform unit (TU));
Фиг. 13 схематично иллюстрирует частично кодированное изображение;
Фиг. 14 схематично иллюстрирует набор возможных направлений прогнозирования;
Фиг. 15 схематично иллюстрирует набор режимов преобразования;
Фиг. 16 схематично иллюстрирует зигзагообразное сканирование;
Фиг. 17 схематично иллюстрирует модуль энтропийного кодирования согласно способу CABAC;
Фиг. 18 представляет упрощенную логическую схему, иллюстрирующую способ кодирования;
Фиг. 19 представляет упрощенную логическую схему, иллюстрирующую способ кодирования;
Фиг. 20 представляет упрощенную логическую схему, иллюстрирующую способ кодирования; и
Фиг. 21 представляет упрощенную логическую схему, иллюстрирующую способ кодирования.
Осуществление изобретения
На Фиг. 1-4 приведены схематичные иллюстрации устройств или систем, использующих устройства сжатия и/или распаковки данных, которые будут описаны ниже в связи с вариантами настоящего изобретения.
Все устройства сжатия и/или распаковки данных, которые будут описаны ниже, могут быть реализованы в виде аппаратуры, в виде загружаемого программного обеспечения, работающего в устройстве общего назначения для обработки данных, таком как компьютер общего назначения, в виде программируемой аппаратуры, такой как специализированная интегральная схема (application specific integrated circuit (ASIC)) или программируемая пользователем вентильная матрица (field programmable gate array (FPGA)), либо в виде сочетания перечисленных компонентов. В случаях, где варианты настоящего изобретения реализованы посредством загружаемого и/или встроенного программного обеспечения, следует понимать, что такое загружаемое и/или встроенное программное обеспечение и энергонезависимые машиночитаемые носители для хранения данных, на которых хранится или иным способом записано это загружаемое и/или встроенное программное обеспечение, считаются вариантами настоящего изображения.
Фиг. 1 схематично иллюстрирует систему передачи и приема аудио/видео данных с использованием сжатия и распаковки видеоданных.
Входной аудио/видео сигнал 10 поступает в устройство 20 сжатия видеоданных, которое сжимает по меньшей мере видео составляющую аудио/видео сигнала 10 для передачи по линии 30 передачи данных, такой как кабель, оптоволокно, беспроводная линия или другая подобная линия передачи. Сжатый сигнал обрабатывают в устройстве 40 распаковки для получения выходного аудио/видео сигнала 50. В обратном тракте устройство 60 сжатия осуществляет сжатие аудио/видео сигнала для передачи по линии 30 передачи данных в устройство 70 распаковки.
Устройство 20 сжатия и устройство 70 распаковки могут, таким образом, образовать один узел канала передачи данных. Устройство 40 распаковки и устройство 60 распаковки могут образовать другой узел канала передачи данных. Безусловно, в тех случаях, когда канал передачи данных является односторонним, только в одном из узлов может потребоваться устройство сжатия и только в другом из этих узлов потребуется устройство распаковки.
Фиг. 2 схематично иллюстрирует систему отображения видео, использующую распаковку видеоданных. В частности, сжатый аудио/видео сигнал 100 обрабатывают в устройстве 110 распаковки для получения распакованного сигнала, который может быть представлен на дисплее 120. Устройство 110 распаковки может быть реализовано в виде интегральной части дисплея 120, например, оно может быть выполнено в одном корпусе с устройством отображения. В качестве альтернативы, устройство 110 распаковки может быть реализовано (например) в виде так называемой приставки (set top box (STB)), отмечая при этом, что слова "set-top" (установленный сверху) не подразумевают требования, чтобы приставка была установлена в какой-либо конкретной ориентации или в каком-либо конкретном положении относительно дисплея 120; это просто термин, используемый в рассматриваемой области техники для обозначения устройства, соединяемого с дисплеем в качестве периферийного устройства.
Фиг. 3 схематично иллюстрирует систему хранения аудио/видео данных с использованием сжатия и распаковки видеоданных. Входной аудио/видео сигнал 130 поступает в устройство 140 сжатия, которое генерирует сжатый сигнал для сохранения в запоминающем устройстве 150, таком как дисковод с магнитным диском, дисковод с оптическим диском, устройство с магнитной лентой, твердотельное запоминающее устройство, такое как полупроводниковое запоминающее устройство, или другое запоминающее устройство. При воспроизведении сжатые данные считывают из запоминающего устройства 150 и передают в устройство 160 распаковки для осуществления распаковки данных с целью генерирования выходного аудио/видео сигнала 170.
Следует понимать, что сжатый или кодированный сигнал, а также носитель для хранения или передачи данных считаются здесь вариантами.
Фиг. 4 схематично иллюстрирует видеокамеру с использованием сжатия видеоданных. На Фиг. 4 показаны устройство 180 считывания изображения, такое как формирователь сигналов изображения на основе приборов с зарядовой связью (ПЗС (charge coupled device (CCD))), и соответствующая электронная схема управления и считывания, которые генерируют видеосигнал, передаваемый в устройство 190 сжатия. Микрофон (или несколько микрофонов) 200 генерирует аудио сигнал для передачи в устройство 190 сжатия. Это устройство 190 сжатия генерирует сжатый аудио/видео сигнал 210 для сохранения и/или передачи (показано в общем виде как каскад 220 схемы).
Способы, которые описаны ниже, относятся главным образом к сжатию видеоданных. Должно быть очевидно, что многие существующие способы могут быть использованы для сжатия аудиоданных в сочетании со способами сжатиями видеоданных, которые будут описаны далее, для генерирования сжатого аудио/видео сигнала. Соответственно, отдельное обсуждение сжатия аудио данных здесь приведено не будет. Также должно быть понятно, что скорость передачи данных, соответствующая видеоданным, и в частности, видеоданным «вещательного» качества, обычно очень сильно превышает скорость передачи данных, ассоциированную с аудиоданными (будь то сжатые или несжатые аудиоданные). Поэтому должно быть понятно, что несжатые аудиоданные могут сопровождать сжатые видеоданные, образуя вместе с этими видеоданными сжатый аудио/видео сигнал. Далее, должно быть также понятно, что хотя представленные примеры (показанные на Фиг. 1-4) относятся к аудио/видео данным, описываемые ниже способы могут найти применение в системах, которые просто имеют дело (иными словами сжимают, распаковывают, сохраняют, представляют на дисплее и/или передают) с видеоданными. Иными словами, эти варианты могут быть применены к сжатию видеоданных без всякой необходимости обрабатывать какие-либо аудиоданные, ассоциированные с этими видеоданными.
Фиг. 5 представляет упрощенную схему устройства сжатия и распаковки видеоданных, работающего под управлением контроллера 345.
Последовательные изображения из состава входного видеосигнала 300 поступают в сумматор 310 и в модуль 320 прогнозирования изображения. Этот модуль 320 прогнозирования изображения будет рассмотрен ниже более подробно со ссылками на Фиг. 6. Сумматор 310 на самом деле осуществляет операцию вычитания (отрицательного суммирования), в ходе которой он принимает входной видеосигнал 300 на положительный ("+") вход и выходной сигнал модуля 320 прогнозирования изображения на отрицательный ("-") вход, так что происходит вычитание прогнозируемого изображения из входного изображения. В результате происходит генерирование так называемого сигнала 330 остаточного изображения, представляющего разность между реальным и прогнозируемым изображениями.
Одна из причин генерирования сигнала остаточного изображения состоит в следующем. Описываемые ниже способы кодирования данных, иными словами, способы, которые будут применены к сигналу остаточного изображения, работают более эффективно, когда кодируемое изображение содержит меньше «энергии». Здесь термин «эффективно» означает генерирование меньшего объема кодированных данных; для любого конкретного уровня качества изображения желательно (и считается «эффективным») генерировать настолько маленький объем данных, насколько это практически возможно. Слова об «энергии» в остаточном изображении относятся к количеству информации, содержащейся в остаточном изображении. Если прогнозируемое изображение окажется идентичным реальному изображению, разница между этими двумя изображениями (иными словами, остаточное изображение) будет содержать нулевую информацию (нулевую энергию) и может быть очень легко кодирована с преобразованием в кодированные данные небольшого объема. В общем случае, если удастся добиться разумно эффективной работы процедуры прогнозирования, тогда остаточное изображение будет содержать меньше информации (меньше энергии), чем входное изображение, и соответственно будет легче кодировать это остаточное изображение путем преобразования его в кодированные данные небольшого объема.
Данные 330 остаточного изображения поступают в модуль 340 преобразования, который генерирует представление данных остаточного изображения, получаемое в результате дискретного косинусного преобразования (discrete cosine transform (DCT)). Способ преобразования DCT сам по себе хорошо известен и не будет здесь рассмотрен подробно. Однако некоторые аспекты способов, используемых в предлагаемом устройстве, будут более подробно рассмотрены ниже, и в частности, аспекты, относящиеся к выбору различных блоков данных, к которым применяется операция преобразования DCT. Эти аспекты будут обсуждаться ниже со ссылками на Фиг. 7-12.
Отметим, что в некоторых вариантах вместо преобразования DCT применяется дискретное синусное преобразование (discrete sine transform (DST)). В других вариантах может не применяться никакое преобразование. Это может быть сделано избирательно, так что этап преобразования может быть, по сути дела, обойден, например, под управления команды или режима «пропустить преобразование» ("transform skip").
Выходные данные модуля 340 преобразования, представляющие собой набор коэффициентов преобразования для каждого преобразованного блока данных изображения, поступают в модуль 350 квантования. В области сжатия видеоданных известны различные способы квантования, от простейшего умножения на масштабный коэффициент квантования до применения сложных преобразовательных таблиц под управлением параметра квантования. Общая цель является двоякой. Во-первых, процедура квантования уменьшает число возможных значений преобразованных данных. Во-вторых, процедура квантования может увеличить вероятность того, что величины преобразованных данных будут являться нулевыми. Оба эти фактора могут позволить процедуре энтропийного кодирования, которая будет рассмотрена ниже, работать более эффективно и генерировать небольшие объемы сжатых видеоданных.
Модуль 360 сканирования осуществляет процедуру сканирования данных. Целью процедуры сканирования является переупорядочение квантованных преобразованных данных таким образом, чтобы собрать как можно больше ненулевых квантованных коэффициентов преобразования вместе, и, конечно же, поэтому собрать как можно больше нулевых квантованных коэффициентов преобразования вместе. Этот может позволить эффективно применить так называемое кодирование длин серий или какой-либо аналогичный способ. Таким образом, процедура сканирования содержит выбор коэффициентов из квантованных преобразованных данных, и в частности, из блока коэффициентов, соответствующего блоку данных изображения, которые были преобразованы и квантованы, в соответствии с «порядком сканирования», так что (а) все коэффициенты выбирают только однажды как часть сканирования, и (b) сканирование стремится создать нужное переупорядочение. Способы выбора порядка сканирования будут рассмотрены ниже. Одним из примеров порядка сканирования, который может дать полезные результаты, является так называемое зигзагообразное сканирование.
Сканированные коэффициенты затем передают в модуль 370 энтропийного кодирования (ЕЕ). Здесь также могут быть использованы различные виды энтропийного кодирования. Два примера, которые будут рассмотрены ниже, представляют собой варианты так называемой системы контекстно-адаптивного двоичного арифметического кодирования (САВАС (Context Adaptive Binary Arithmetic Coding)) и варианты так называемой системы контекстно-адаптивного кодирования в коде переменной длины (CAVLC (Context Adaptive Variable-Length Coding)). В общем случае считается, что способ САВАС обладает более высокой эффективностью, а некоторые исследования показали, что этот способ дает уменьшение объема выходных кодированных данных на 10-20% при сопоставимом качестве изображения по сравнению со способом CAVLC. Однако считается, что способ CAVLC обладает намного меньшей сложностью (с точки зрения его реализации) по сравнению со способом САВАС. Способ САВАС будет обсуждаться ниже со ссылками на Фиг. 17.
Отметим, что процедура сканирования и процедура энтропийного кодирования показаны здесь как отдельные процедуры, но на деле они могут быть объединены или выполнены совместно. Иными словами, считывание данных для передачи в модуль энтропийного кодирования может происходить в порядке сканирования. Подобные же соображения применимы к соответствующим обратным процедурам, которые будут рассмотрены ниже.
Выходные данные модуля 370 энтропийного кодирования вместе с дополнительными данными (упомянутыми выше и/или обсуждаемыми ниже), например, данными, определяющими способ, каким модуль 320 прогнозирования генерирует прогнозируемое изображение, образуют сжатый выходной видеосигнал 380.
Однако здесь создан также обратный путь, поскольку работа самого модуля 320 прогнозирования зависит от расширенной версии сжатых выходных данных.
Причина этого состоит в следующем. На соответствующем этапе процедуры расширения (будет рассмотрена ниже) генерируют расширенную версию остаточных данных. Эти расширенные остаточные данные следует суммировать с прогнозируемым изображением для генерации выходного изображения (поскольку первоначальные остаточные данные представляли собой разность между входным изображением и прогнозируемым изображением). Для того, чтобы результаты этой процедуры были сопоставимы, как между стороной сжатия и стороной расширения, прогнозируемое изображение, генерируемое модулем 320 прогнозирования, должно быть одинаковым и во время процедуры сжатия, и во время процедуры расширения. Безусловно, при расширении устройство не имеет доступа к исходным входным изображениям, а ему доступны только расширенные изображения. Поэтому при сжатии модуль 320 прогнозирования базирует свои прогнозы (по меньшей мере, для межкадрового кодирования) на расширенных версиях сжатых изображений.
Процедура энтропийного кодирования, выполняемая модулем 370 энтропийного кодирования, считается кодированием «без потерь» в том смысле, что она может быть обращена с получением точно таких же самых данных, какие были переданы в модуль 370 энтропийного кодирования. Поэтому обратный путь может быть реализован прежде этапа энтропийного кодирования. Действительно, процедура сканирования, осуществляемая модулем 360 сканирования, также считается процедурой без потерь, но в рассматриваемом варианте обратный путь 390 соединяет выход модуля 350 квантования с входом комплементарного ему модуля 420 обратного квантования.
В общем случае, модуль 410 энтропийного декодирования, модуль 400 обратного сканирования, модуль 420 обратного квантования и модуль 430 обратного преобразования реализуют соответствующие обратные функции относительно функций модуля 370 энтропийного кодирования, модуля 360 сканирования, модуля 350 квантования 350 и модуля 340 преобразования. Сейчас обсуждение будет продолжено рассмотрением процедуры сжатия; а процедура расширения входного сжатого видеосигнала будет отдельно рассмотрена ниже.
В ходе процедуры сжатия сканированные коэффициенты передают по обратному пути 390 от модуля 350 квантования в модуль 420 обратного квантования, выполняющий операции, обратные операциям модуля 360 сканирования. Модули 420, 430 выполняют процедуры обратного квантования и обратного преобразования для генерации сжатого-расширенного сигнала 440 остаточного изображения.
Сигнал 440 изображения добавляют, в сумматоре 450, к выходному сигналу модуля 320 прогнозирования для генерации реконструированного выходного изображения 460. Это дает один из входных сигналов для модуля 320 прогнозирования изображения, как будет рассмотрено ниже.
Рассмотрим процедуру, применяемую к принимаемому сжатому видеосигналу 470, этот сигнал поступает в модуль 410 энтропийного декодирования и оттуда дальше в цепочку из модуля 400 обратного сканирования, модуля 420 обратного квантования и модуля 430 обратного преобразования перед суммированием с выходным сигналом модуля 320 прогнозирования изображения в сумматоре 450. Говоря прямо, выходной сигнал 460 сумматора 450 образует выходной распакованный видеосигнал 480. На практике, перед тем, как передать этот сигнал на выход может быть выполнена дополнительная фильтрация.
Хотя Фиг. 5 был рассмотрен в контексте модуля кодирования, следует понимать, что обратный путь декодирования (модули 400, 410, 420, 430, 450, 320 все работают под управлением контроллера 345) является примером модуля декодирования. Операции, описанные выше и рассмотренные ниже, представляют примеры этапов способа, относящиеся (как это применимо) к операциям кодирования и декодирования.
Фиг. 6 схематично иллюстрирует генерацию прогнозируемых изображений и, в частности, работу модуля 320 прогнозирования изображения.
Есть два основных режима прогнозирования: так называемое внутрикадровое прогнозирование и так называемое межкадровое прогнозирование или прогнозирование с компенсацией движения (motion-compensated (МС)).
Внутрикадровое прогнозирование основано на прогнозировании содержания блока изображения с использованием данных из состава самого этого изображения (кадра). Это соответствует так называемому кодированию I-кадра в других способах сжатия видео. В отличие от кодирования I-кадра, где все изображение кодируют внутрикадровым способом, в предлагаемых вариантах выбор между внутрикадровым и межкадровым кодированием может быть сделан для каждого блока отдельно (блок за блоком), хотя в других вариантах такой выбор по-прежнему осуществляется сразу для каждого кадра (кадр за кадром).
Прогнозирование с компенсацией движения использует информацию о движении, что означает попытки определить, где находится источник подробностей и деталей изображения, которые нужно кодировать в текущем изображении (кадре), - в другом, соседнем или близком изображении (кадре). Соответственно, в идеальном случае содержание блока данных изображения в составе прогнозируемого изображения может быть кодировано очень просто в виде ссылки (вектора движения), указывающей на соответствующий блок, находящийся в той же самой или в слегка отличной позиции в составе соседнего изображения (кадра).
На Фиг. 6 показаны две схемы прогнозирования изображения (соответствующие внутрикадровому и межкадровому прогнозированию), результаты работы которых выбирает мультиплексор 500 под управлением сигнала 510 режима с целью вывода блоков прогнозируемого изображения для передачи в сумматора 310 и 450, Выбор делается в зависимости от того, какой из вариантов дает наименьшую «энергию» (что, как обсуждается выше, можно рассматривать как информационное содержание, требующее кодирования), и об этом выборе сообщают модулю кодирования в составе кодированного выходного потока данных. Энергию изображения, в этом контексте, можно определить, например, посредством пробного вычитания области согласно двум версиям прогнозируемого изображения из входного изображения, возведения величины каждого пикселя в составе разностного изображения в квадрат, суммирования полученных квадратов величин пикселей и идентификации, какая из этих двух версий дает меньшую среднеквадратическую величину разностного изображения применительно к рассматриваемой области изображения.
В системе внутрикадрового прогнозирования реальное прогнозирование осуществляется на основе блоков изображения, принимаемых в составе сигнала 460, т.е. можно сказать, что прогнозирование основано на кодированных-декодированных блоках изображения, для того, чтобы точно такое же прогнозирование было выполнено в устройстве расширения. Однако данные могут быть получены из входного видеосигнала 300 посредством селектора 520 внутрикадрового режима для управления модулем 530 внутрикадрового прогнозирования изображения.
При межкадровом прогнозировании модуль 540 прогнозирования с компенсацией движения (motion compensated (МС)) использует информацию движения, такую как векторы движения, получаемые модулем 550 оценки движения из входного видеосигнала 300. Модуль 540 прогнозирования с компенсацией движения применяет эти векторы движения к обработанной версии реконструированного изображения 460 для генерирования блоков межкадрового прогнозирования.
Сейчас будет рассмотрена обработка, применяемая к сигналу 460. Сначала сигнал фильтруют посредством модуля 560 фильтрации. Сюда входит применение «деблокирующего» фильтра для устранения или по меньшей мере уменьшения эффектов поблочной обработки, осуществляемой модулем 340 преобразования, и последующие операции. Кроме того, применяют адаптивный контурный фильтр с использованием коэффициентов, получаемых путем обработки реконструированного сигнала 460 и входного видеосигнала 300. Адаптивный контурный фильтр представляет собой фильтр, который, используя известные способы, применяет адаптивные коэффициенты фильтрации к данным, которые нужно фильтровать. Иными словами, коэффициенты фильтрации могут изменяться в зависимости от различных факторов. Данные, определяющие, какие коэффициенты фильтрации следует использовать, входят составной частью в кодированный выходной поток данных.
Фильтрованный выходной сигнал от модуля 560 фильтрации фактически образует выходной видеосигнал 480. Видеосигнал записывают также в качестве буферизации в одном или нескольких запоминающих устройств 570 изображения; сохранение последовательных изображений является требованием прогнозирования с компенсацией движения, и в частности - требованием для генерации векторов движения. Для экономии места в памяти изображения, сохраняемые в запоминающих устройствах 570 изображения, могут храниться в сжатом виде, из которого их расширяют для использования при генерации векторов движения. Для этой конкретной цели может быть использована любая известная система расширения/сжатия. Сохраняемые изображения передают в интерполяционный фильтр 580, которые генерирует версию сохраняемых изображений с повышенным разрешением; в этом примере, генерируют промежуточные отсчеты (суб-отсчеты) таким образом, что разрешение интерполированного изображения с выхода интерполяционного фильтра 580 в 8 раз (по каждому измерению) выше разрешения изображений, хранящихся в запоминающих устройствах 570 изображения. Интерполированные изображения передают на вход модуля 550 оценки движения, а также в модуль 540 прогнозирования с компенсацией движения.
В некоторых вариантах может присутствовать в качестве опции дополнительный этап умножения величин данных входного видеосигнала на четыре с использованием умножителя 600 (эффективно путем простого сдвига этих величин данных на два бита влево) и затем применения соответствующей операции деления (сдвиг на два бита вправо) на выходе устройства с использованием делителя или схемы 610 сдвига вправо. Таким образом, сдвиг влево и сдвиг вправо изменяют данные только для внутренних операций устройства. Эта операция может обеспечить более высокую точность вычислений в устройстве, поскольку уменьшается эффект погрешностей округления данных.
Далее будет описан способ разбиения изображения для выполнения процедуры сжатия. На базовом уровне изображение, подлежащее сжатию, рассматривают как матрицу блоков или отсчетов. Для целей настоящего обсуждения наибольший такой рассматриваемый блок является так называемым наибольшим модулем кодирования (largest coding unit (LCU)) 700 (Фиг. 7), представляющим собой матрицу 64×64 отсчетов. Здесь обсуждение относится к яркостным отсчетам. В зависимости от режима цветности, такого как 4:4:4, 4:2:2, 4:2:0 или 4:4:4:4 (данные GBR плюс ключевые данные), может быть разное число цветностных отсчетов, соответствующих яркостному блоку.
Будут описаны три базовых типа блоков: модули кодирования, модули прогнозирования и модули преобразования. В общем случае рекурсивное разбиение модулей LCU позволяет секционировать входное изображение так, чтобы и размер блоков, и параметры кодирования блоков (такие как режимы прогнозирования или режимы кодирования остатка) можно было задать в соответствии с конкретными характеристиками изображения, которое нужно кодировать.
Модуль LCU может быть разбит на так называемые модули кодирования (coding unit (CU)). Модули кодирования всегда являются квадратными, а их размер может быть в пределах от 8×8 отсчетов до полного размера модуля LCU 700. Модули кодирования могут быть организованы в структуры типа дерева, так что в результате первого разбиения, показанного на Фиг. 8, будут получены модули 710 кодирования размером 32×32 отсчетов; последующие разбиения, выполняемые избирательно, могут дать некоторое количество модулей 720 кодирования размером 16×16 отсчетов (Фиг. 9) и потенциально некоторое количество модулей 730 кодирования размером 8×8 отсчетов (Фиг. 10). В целом этот процесс может создать дерево контентно-адаптивного кодирования из блоков CU, каждый из которых может быть таким большим, как модуль LCU или таким маленьким, как 8×8 отсчетов. Кодирование выходных видеоданных осуществляется на основе этой структуры модулей кодирования.
Фиг. 11 схематично иллюстрирует матрицу модулей прогнозирования (prediction unit (PU)). Модуль прогнозирования представляет собой базовый блок для передачи информации, относящейся к процедуре прогнозирования изображения, или, другими словами, дополнительных данных, добавляемых к энтропийно кодированным данным остаточного изображения, для образования выходного видеосигнала устройства, показанного на Фиг. 5. В общем случае, модули прогнозирования не ограничиваются квадратной формой. Они могут иметь и другую форму, и в частности иметь прямоугольную форму, составляющую половину одного из квадратных модулей кодирования, если размер соответствующего модуля кодирования больше минимального (8×8) размера. Цель состоит в том, чтобы позволить границам соседних модулей прогнозирования совпадать (насколько это возможно близко) с границами реальных объектов на изображении, так что к разным реальным объектам могут быть применены различные параметры прогнозирования. Каждый модуль кодирования может содержать один или более модулей прогнозирования.
Фиг. 12 схематично иллюстрирует матрицу модулей преобразования (transform unit (TU)). Модуль преобразования представляет собой базовый блок для процедуры преобразования и квантования. Модули преобразования всегда являются квадратными и могут иметь размер от 4×4 до 32×32 отсчетов. Каждый модуль кодирования может содержать один или более модулей преобразования. Сокращение SDIP-P на Фиг. 12 обозначает так называемый модуль разбиения при внутрикадровом прогнозировании на малой дальности. В такой конфигурации используются только одномерные преобразования, так что блок размером 4×N проходит через N преобразований, где входные данные для этих преобразований основаны на ранее декодированных соседствующих блоках и ранее декодированных соседних линиях в текущем модуле SDIP-Р прогнозирования.
Теперь будет обсуждаться процедура внутрикадрового прогнозирования. В общем случае, процедура внутрикадрового прогнозирования генерирует прогноз текущего блока (модуля прогнозирования) отсчетов на основе ранее кодированных и декодированных отсчетов того же самого изображения. Фиг. 13 схематично иллюстрирует частично кодированное изображение 800. Здесь изображение кодируют по направлению от верхнего левого угла к нижнему правому углу на основе единиц LCU. Пример LCU, кодированной частично посредством обработки всего изображения, показан в виде блока 810. Заштрихованная область 820 выше и слева от блока 810 уже была кодирована. Для внутрикадрового прогнозирования содержания блока 810 можно использовать заштрихованную область 820, но не использовать ничего из незаштрихованной области ниже блока 810.
Блок 810 представляет модуль LCU; как обсуждается выше, для целей внутрикадрового прогнозирования этот модуль может быть разбит на модули прогнозирования меньшего размера. Пример такого модуля 830 прогнозирования показан в пределах модуля LCU 810.
Внутрикадровое прогнозирование учитывает отсчеты, расположенные выше и/или слева от текущего модуля LCU 810. Исходные отсчеты, на основе которых прогнозируют требуемые отсчеты, могут быть расположены в различных позициях или в различных направлениях относительно текущего модуля прогнозирования в составе модуля LCU 810. Для принятия решения, какое направление подходит для текущего модуля прогнозирования, результаты пробного прогнозирования на основе каждого направления-кандидата сравнивают по порядку, чтобы определить, какое из направлений дает выходной результат, ближайший к соответствующему блоку входного изображения. Направление прогнозирования, которое дает ближайший результат, выбирают в качестве направления прогнозирования для этого модуля прогнозирования.
Кадр можно также кодировать на основе «срезов». В одном из примеров, срез представляет собой группу соседствующих один с другим по горизонтали модулей LCU. Но в более общих словах, все остаточное изображение может составлять один срез, либо срез может представлять собой один модуль LCU, либо срез может представлять собой строку модулей LCU и т.д. Срезы могут создавать некоторую устойчивость к ошибкам, поскольку их кодируют в качестве независимых блоков. На границе среза происходит полный сброс (начальная установка) состояний модуля кодирования и модуля декодирования. Например, внутрикадровое прогнозирование не осуществляется через границы срезов; для этого границы срезов рассматривают в качестве границ изображения.
Фиг. 14 схематично иллюстрирует набор возможных (кандидатов) направлений прогнозирования. Полный набор из 34 направлений-кандидатов доступен для модулей прогнозирования размером 8×8, 16×16 или 32×32 отсчетов. Для специальных случаев модулей прогнозирования размером 4×4 и 64×64 отсчетов доступен сокращенный набор направлений-кандидатов (17 направлений-кандидатов и 5 направлений-кандидатов, соответственно). Направления определяют путем горизонтального и вертикального смещения относительно текущего положения блока и кодируют в качестве «режимов» прогнозирования, набор которых показан на Фиг. 15. Отметим, что так называемый режим постоянной составляющей (DC) представляет простое среднее арифметическое окружающих отсчетов сверху и слева.
Фиг. 16 схематично иллюстрирует зигзагообразное сканирование, представляющее собой схему сканирования, которая может быть применена модулем 360 сканирования. На Фиг. 16 показана схема сканирования для примера блока из 8×8 коэффициентов преобразования, где коэффициент постоянной составляющей (DC) расположен в верхней левой позиции 840 блока, а возрастающие вертикальные и горизонтальные пространственные частоты представлены коэффициентами, расположенными на возрастающих расстояниях вниз и вправо от верхней левой позиции 840.
Отметим, что в некоторых вариантах коэффициенты можно сканировать в обратном порядке (от нижнего правого угла к верхнему левому углу с использованием порядка, показанного на Фиг. 16). Также следует отметить, что в некоторых вариантов сканирование может проходить слева направо через несколько (например, от одной до трех) самых верхних горизонтальных строк перед осуществлением зигзагообразное сканирование остальных коэффициентов.
Фиг. 17 схематично иллюстрирует модуль энтропийного кодирования согласно способу САВАС.
Посредством контекстно-адаптивного кодирования такого типа и согласно вариантам настоящего изобретения бит данных может быть кодирован с использованием вероятностной модели или контекста, представляющего ожидание или прогнозирование того, насколько правдоподобно, что бит данных равен единице или нулю. Для этого входному биту данных назначают кодовую величину в выбранном одном из двух (или, в более общем случае, из нескольких) комплементарных поддиапазонов диапазона кодовых величин, где размеры этих поддиапазонов (в вариантах, соответствующие пропроции поддиапазонов относительно набора кодовых величин) определяют на основе контекста (который в свою очередь определен контекстной переменной, ассоциированной с или другим способом относящейся к входной величине). Следующий этап предназначен для модификации всего диапазона, т.е., набора кодовых величин (для использования следующего входного бита данных или следующей величины данных) в ответ на назначенную кодовую величину и текущий размер выбранного поддиапазона. Если размер полученного модифицированного диапазона оказался меньше порога, представляющего заданный минимальный размер (например, половина исходного размера диапазона), увеличивают размер, например, вдвое (сдвигая влево), модифицированного диапазона, причем такое удвоение можно выполнять последовательно (больше одного раза), если нужно, до тех пор пока размер диапазон не достигнет по меньшей мере заданного минимального размера. В этот момент генерируют бит выходных кодированных данных для указания, что имеет место операция (или для каждой операции) удвоения или увеличения размера. Следующий этап содержит модификацию контекста (т.е., в некоторых вариантах, модификацию контекстной переменной) для использования с или в отношении следующего бита или величины входных данных (или, в некоторых вариантах, в отношении следующей группы битов или величин данных, подлежащих кодированию). Это может быть сделано с использованием текущего контекста и идентификации текущего «наиболее вероятного символа» (единицы или нуля, что именно, как это указывает контекст, имеет на текущий момент вероятность больше) в качестве указателя к преобразовательной таблице новых контекстных величин или в качестве входных переменных для подходящей математической формуле, из которой может быть выведена новая контекстная переменная. Модификация контекстной переменной может, в некоторых вариантах, увеличить пропорцию набора кодовых величин в поддиапазоне, который может быть выбран для текущей величины данных.
Модуль кодирования САВАС оперирует над двоичными данными, иными словами данными, представленными только двумя символами 0 и 1. Модуль кодирования использует так называемую процедуру контекстного моделирования, которая выбирает «контекст» или вероятностную модель для последующих данных на основе ранее кодированных данных. Выбор контекста осуществляется детерминистским способом, так что такое же определение, на основе ранее декодированных данных, может быть произведено в модуле декодирования без необходимости добавления других данных (определяющих контекст) в кодированный поток данных, передаваемый в модуль декодирования.
Как показано на Фиг. 17, входные данные, подлежащие кодированию, могут быть переданы в двоичный преобразователь 900, если они не находятся уже в двоичной форме; если данные уже находятся в двоичной форме, тогда эти данные направляют в обход преобразователя 900 (посредством показанного на схеме переключателя 910). В рассматриваемых вариантах преобразование в двоичную форму реально осуществляется путем выражения данных квантованных коэффициентов преобразования в виде последовательности двоичных «карт», что будет дополнительно описано ниже.
Двоичные данные могут быть затем обработаны в одном из двух процессорных трактов - «регулярном» и «обходном», (которые на схеме показаны как отдельные тракты, но могут быть, в обсуждаемых ниже вариантах, фактически реализованы в тех же самых процессорных каскадах, только с использованием слегка отличных параметров). Обходной тракт использует так называемый обходной модуль 920 кодирования, который совсем не обязательно использует контекстное моделирование в такой же форме, как регулярный тракт. В некоторых примерах кодирования способом САВАС этот обходной тракт может быть выбран, если выбран, если есть необходимость особенно быстрой обработки пакета данных, но в рассматриваемых вариантах отмечены только два признака так называемых «обходных» данных: во-первых, эти обходные данные обрабатывают в модуле кодирования способом САВАС (950, 960), но только с использованием фиксированной контекстной модели, представляющей вероятность 50%; и во-вторых, обходные данные относятся к некоторым категориям данным, одним из конкретных примеров которых являются данные знака коэффициентов. В противном случае, регулярный тракт выбирают посредством показанных на схеме переключателей 930, 940. Сюда входят данные, обрабатываемые блоком 950 моделирования контекста, за которым следует модуль 960 кодирования.
Модуль энтропийного кодирования, показанный на Фиг. 17, кодирует блок данных (иными словами, например, данные, соответствующие блоку коэффициентов, относящихся к блоку остаточного изображения) в виде одной величины, если блок образован целиком из нулевых данных. Для каждого блока, не попадающего в эту категорию, т.е. блока, содержащего по меньшей мере некоторые ненулевые данные, формируют «карту значимости». Карта значимости указывает, для каждой позиции в блоке данных, подлежащих кодированию, является ли соответствующий коэффициент в блоке данных ненулевым (так что есть пример карты значимости, указывающей позиции, относительно матрицы величин данных, наиболее значимых сегментов данных, являющихся ненулевыми). Карта значимости может содержать флаг данных, указывающий позицию, согласно заданному упорядочению в матрице величин данных, где наиболее значимые сегменты данных имеют ненулевую величину.
Данные карты значимости, будучи в двоичной форме, сами по себе кодированы способом САВАС. Использование карты значимости помогает сжатию, поскольку нет необходимости кодировать данные для коэффициента, который карта значимости обозначает как нулевой. Кроме того, карта значимости может содержать специальный код для указания последнего ненулевого коэффициента в блоке, так что все конечные высокочастотные/замыкающие нулевые коэффициенты могут быть исключены из кодирования. В кодированном потоке битов данных за картой значимости следуют данные, определяющие величины ненулевых коэффициентов, указанных картой значимости.
Кроме того, формируют и кодируют способом САВАС другие уровни карты данных. В качестве примера можно указать карту, которая определяет, посредством двоичной величины (1 = да, 0 = нет), имеют ли данные коэффициента в какой-либо позиции карты, которые карта значимости обозначила как «ненулевые», реально величину «единица». Другая карта указывает, имеют ли данные коэффициента в какой-либо позиции карты, которые карта значимости обозначила как «ненулевые», реально величину «два». Следующая карта указывает, для тех позиций карты, в которых карта значимости обозначила, что данные коэффициентов являются «ненулевыми», имеют ли эти данные коэффициентов величину «больше двух». Еще одна карта указывает, опять для данных, обозначенных как «ненулевые», знак соответствующей величины данных (с использованием предварительно заданной двоичной нотации, такой как 1 для «+», 0 для «-», или, безусловно, возможен какой-либо другой способ).
В некоторых вариантах карту значимости и другие карты генерируют на основе квантованных коэффициентов преобразования, например, посредством модуля 360 сканирования, и затем выполняют для этих коэффициентов процедуру зигзагообразного сканирования (или процедуру сканирования по какой-либо другой схеме, выбранной из совокупности схем зигзагообразного сканирования, горизонтального растрового и вертикального растрового сканирования, согласно режиму внутрикадрового прогнозирования) перед кодированием способом САВАС.
В некоторых вариантах модуль энтропийного кодирования с применением алгоритмов высокоэффективного видео кодирования (HEVC САВАС) осуществляет кодирование синтаксических элементов с использованием следующих процедур:
Кодируют позицию последнего значимого коэффициента (в порядке сканирования) в единице TU.
Кодируют для каждой группы коэффициентов размером 4×4 (группы обрабатывают в обратном порядке сканирования) флаг наличия значимых коэффициентов в этой группе, указывающий, содержит ли эта группа ненулевые коэффициенты. Это не требуется для группы, содержащей последний значимый коэффициент, а также предполагается, что такой флаг равен 1 для верхней левой группы (содержащей коэффициент постоянной составляющей (DC)). Если флаг равен 1, тогда сразу же после него кодируют следующие синтаксические элементы, относящиеся к рассматриваемой группе:
Карта значимости:
Для каждого коэффициента в группе кодируют флаг, указывающий, является ли этот коэффициент значимым (имеет ненулевую величину). Для коэффициента, обозначенного последней значимой позицией, флаг не нужен.
Карта величин «больше единицы»:
Для ряда коэффициентов (до восьми), для которых в карте значимости присутствует 1, (считая по направлению назад от конца группы) это указывает, превосходит ли величина 1.
Флаг величин «больше двух»:
Для коэффициента (не больше одного), для которого величина в карте «больше единицы» равна 1, (для коэффициента, ближайшего к концу группы) это указывает, превышает ли величина этого коэффициента 2.
Знаковые биты:
Для всех ненулевых коэффициентов знаковые биты кодируют в виде равновероятных групп САВАС, причем последний бит знака (в обратном порядке сканирования) возможно вместо этого выводят из данных четности, когда применяется сокрытие знаковых битов.
Коды выхода:
Для любого коэффициента, величина которого не описывается полностью предшествующими синтаксическими элементами, остаток кодируют в виде кода выхода.
Вообще говоря, кодирование способом САВАС использует прогнозирование контекста, или вероятностную модель, для следующего бита, подлежащего кодированию, на основе других ранее кодированных данных. Если следующий бит является таким же, как бит, идентифицированный вероятностной моделью в качестве «наиболее вероятного», тогда кодирование информации, что «следующий бит согласуется с вероятностной моделью», может быть осуществлено с большой эффективностью. Менее эффективно кодировать, что «следующий бит не согласуется с вероятностной моделью», так что вывод контекстных данных важен для хорошей работы модуля кодирования. Термин «адаптивный» означает, что контекстные или вероятностные модели адаптируются или изменяются в процессе кодирования с целью попытаться обеспечить хорошее согласование со следующими (еще не кодированными) данными.
Используя простую аналогию, в письменном английском языке буква "U" является относительно редкой, но в позиции текста сразу же после буквы "Q", эта буква "U" употребляется очень часто. Поэтому вероятностная модель может задать для вероятности буквы "U" очень маленькую величину, но если текущей буквой является буква "Q", в вероятностной модели для буквы "U" в качестве следующей буквы может быть задана очень высокая величина вероятности.
Способ кодирования САВАС используется в рассматриваемых вариантах по меньшей мере для карты значимости и для карт, указывающих, равна ли ненулевая величина единице или двум, хотя каждый из этих синтаксических элементов может и не быть кодирован для каждого коэффициента. Обработка в обходном тракте - которая в этих вариантах идентична кодированию способом САВАС, но с использованием вероятностной модели, описывающей равновероятное (0.5:0.5) распределение 1 и 0, применяется по меньшей мере для данных знака и для частей величин коэффициентов, которые не были описаны предшествующими синтаксическими элементами. Для тех позиций данных, которые идентифицированы как имеющие не полностью описанные части величин коэффициентов, может быть использовано отдельное, так называемое кодирование данных выхода с целью кодирования реальных остаточных величин данных, где реальная величина равна остаточной величине плюс величина сдвига, полученная из соответствующих кодированных синтаксических элементов. Сюда может относиться способ кодирования Голомба-Райса.
Процедура контекстного моделирования и кодирования способом САВАС более подробно описана в Рабочем проекте по высокоэффективному видео кодированию WD4: Working Draft 4 of High-Efficiency Video Coding, JCTVC-F803_d5, Draft ISO/IEC 23008-HEVC; 201x(E) 2011-10-28.
Другие способы, относящиеся к вариантам кодирования битов выхода, или связанные с этим способы будут рассмотрены применительно к Фиг. 18.
Сначала, однако, обсудим способы, используемые для кодирования кодов выхода.
В действующем стандарте высокоэффективного видео кодирования (HEVC) (на дату приоритета настоящей заявки) коды выхода кодируют с использованием двух механизмов:
1/ Кодирование Голомба-Райса с максимальной длиной префикса, равной 2.
2/ Если кодируемая величина не может быть полностью описана кодом Голомба-Райса, кодируют код «выход-выход» ("escape-escape") с использованием экспоненциального кода Голомба k-го порядка (exponential-Golomb-order-k).
Так называемое кодирование Голомба-Райса кодирует величину, v, в виде унарно кодированного префикса (переменное число 1, за которыми следует 0, или наоборот), после чего следуют k (иначе обозначаемое как rParam) битов суффикса.
Кодовое пространство разбито на интервалы, размеры которых определены параметром Райса - rParam, как:
размер интервала = 1 << rParam
Как обычно, запись "<< n" обозначает сдвиг влево на число битовых позиций (разрядов) равное величине n. Аналогичная запись >> n обозначает сдвиг вправо на n битовых позиций. Таким образом, например, когда параметр rParam равен 0, размер кодового интервала равен 1. Когда параметр rParam равен 3, размер кодового интервала равен 8, и т.д.
Модуль кодирования и модуль декодирования сохраняют величину параметра rParam по отдельности и модифицируют ее в соответствии с заданными условиями.
Префикс кодируют с применением унарного кодирования для указания, в какой кодовый интервал попадает конечная величина.
Например, величина префикса = 2, параметр rParam = 2, размер интервала = 4 и величина попадает в интервал 8-11 включительно. Это можно рассматривать как «грубую» часть величины.
Суффикс кодируют с применением двоичного кодирования (длина суффикса равна параметру rParam). Величина суффикса указывает, где в найденном конкретном интервале лежит конечная величина.
Например, величина префикса = 2, параметр rParam = 2, величина суффикса равна = 3; это означает, что конечная величина лежит в интервале 8-11. Величина суффикса, равная 0, будет указывать на конечную величину, равную 8; а величина суффикса, равная 3 (как в рассматриваемом примере) указывает на конечную величину, равную 11.
Суффикс, таким образом, можно считать «тонкой» (или точной) частью величины.
Пусть параметр prefix_length равен общему числу 1 в унарно кодированном префиксе. Пусть параметр K равен величине самых младших битов параметра rParam.
конечная величина = (prefix_length << rParam) + K
Как отмечено выше, в действующем стандарте высокоэффективного видео кодирования (HEVC) (на дату приоритета настоящей заявки) установлен предел (равный 2) максимальной длины префикса для кодирования Голомба-Райса (следовательно, может быть не более 3 интервалов). Если передан более длинный префикс, из величины этого префикса вычитают 3 (величина префикса равна его длине) и рассматривают этот префикс как префикс экспоненциального кода Голомба k-го порядка (где параметр rParam служит величиной k). Этот экспоненциальный код Голомба k-го порядка можно рассматривать как выход из обычного, нормального механизма кодирования выхода - код «выход-выход» ("escape-escape").
Следует понимать, что префикс Голомба-Райса с максимальной длиной, равной 2, за которым следует экспоненциальный код Голомба k-порядка, также эквивалентен префиксу Голомба-Райса с максимальной длиной 3, за которым следует экспоненциальный код Голомба (k+1)-го порядка.
Кроме того, конечную величину также модифицируют путем добавления (в модуле декодирования) или вычитания (в модуле кодирования) минимальной величины, которая не может быть кодирована с использованием способа Голомба-Райса, поскольку известно, что конечная величина является большой, так как применено кодирование типа выход-выход.
Теперь будут рассмотрены экспоненциальные коды Голомба k-го порядка. При таком кодировании число, подлежащее кодированию, разделяют на унарно кодированный префикс переменной длины и суффикс переменной длины. При этом число битов суффикса = prefix_length + k. Здесь параметр prefix_length опять равен числу 1 в унарном коде.
Как и в случае кодирования Голомба-Райса кодовое пространство разбивают на интервалы. Однако эти интервалы имеют неодинаковые размеры; напротив размеры интервалов увеличиваются экспоненциально (например, интервал 0 = 0, интервал 1 = 1-2, интервал 2 = 3-6 и т.д.).
Префикс кодируют способом унарного кодирования для указания, в какой кодовый интервал попадает конечная величина.
Суффикс кодируют способом двоичного кодирования, хотя здесь длина суффикса равна длине префикса. Величина суффикса указывает, где в найденном конкретном интервале лежит конечная величина.
Число дополнительных битов, равное k, кодируют с применением двоичного кодирования; эти биты служат дополнительными младшими (LSB) битами конечной величины.
Общее число битов в коде = prefix_length + 1 + prefix_length + k.
Пусть K равно величине, представленной последними k битами.
Когда параметр prefix_length равен 0, величина v будет равна K.
Когда параметр prefix_length равен 1, величина v будет между (1<<k)+K и (3<<k)+K (исключительно)
Когда параметр prefix_length равен 2, величина v будет между (3<<k)+K и (7<<k)+K (исключительно)
Когда параметр prefix_length равен 3, величина v будет между (7<<k)+K и (15<<k)+K (исключительно)
Поэтому v = ((2^prefix_length)-1)<<k) + suffix
Например: конечный двоичный код = 110011.
В этом примере, параметр rParam = 1; длина префикса = 2 (две 1 перед первым 0), кодовый интервал = 3-6; суффикс = 0b01 = 1, величина перед k = 4 = 0b100; дополнительный бит = 0b1 = 1, конечная величина = 0b1001 = 9. (Здесь 0b обозначает двоичное представление).
При высокоэффективном кодировании способом HEVC, как отмечено выше, используются и код Голомба-Райса, и экспоненциальный код Голомба. Если параметр prefix_length меньше трех, код интерпретируют как код Голомба-Райса. Однако если этот параметр prefix_length больше или равен 3, код интерпретируют как экспоненциальный код Голомба k-порядка, где указанная выше величина параметра rParam служит величиной k.
Префикс (в любой системе) представляет собой пример унарного кода. Суффикс в одном из примеров представляет собой неунарный код. Эти две системы представляют пример составленного из двух частей кода переменной длины.
В этом случае величину параметра prefix_length, используемого для декодирования экспоненциального кода Голомба, уменьшают на 3, а величину, полученную в результате операции декодирования, увеличивают посредством (3<<k), поскольку это наименьшая величина, которая не может быть представлена с использованием кода Голомба-Райса.
Величина "k" используемая для получения кодов выхода и выхода-выхода (Escape и Escape-Escape) при высокоэффективном кодировании (HEVC), изменяется. Для каждой группы из 16 коэффициентов эта величина к начинается с 0 и увеличивается каждый раз, когда величина коэффициента больше 3<<k. В такой ситуации величину k увеличивают максимум до 4. Отметим, что это обсуждение относится к величинам коэффициентов, поскольку знаковый бит, представляющий знак коэффициента, передают отдельно. Могут быть также применены и другие схемы инициализации и изменения величины k.
Фиг. 18 представляет упрощенную логическую схему, иллюстрирующую способ генерации кодов выхода, как обсуждается выше.
Способ может оперировать над группой величин данных, содержащей (например) последовательность преобразованных в частотную область коэффициентов изображения, или ненулевые составляющие этой последовательности, или ненулевые составляющие последовательности, где каждая величина данных была уменьшена на 1 (в этом последнем случае может быть сначала сформирована карта значимости, так что каждый коэффициент уменьшают на 1 перед дальнейшей обработкой, поскольку карта значимости учитывает величину 1).
На этапе 2000 устанавливают начальную величину параметра k в начале каждой группы. В обычной системе кодирования способом HEVC версия 1, величину k первоначально задают равной 0, хотя могут быть и альтернативные схемы, используемые для расширения стандарта HEVC. На этапе 2010 модуль кодирования САВАС проверяет, является ли текущая группа верхней левой группой, содержащей эквивалент коэффициента постоянной составляющей (DC), или группой, содержащей коэффициент, помеченный в более ранней процедуре как последний значимый коэффициент. Если это так, управление переходит к этапу 2030. Если это не так, на этапе 2020 модуль кодирования САВАС проверяет, содержит ли текущая группа ненулевые коэффициенты. Если не содержит, процедура завершается с кодированием флага значимости текущей группы как 0. Если ненулевые коэффициенты есть, управление переходит к этапу 2030 с кодированием флага значимости текущей группы как 1. На этапе 2030 генерируют карту значимости для каждого коэффициента в группе (хотя для группы, содержащей самый последний значимый коэффициент, для некоторых коэффициентов не требуются позиции в карте значимости, поскольку они могут быть выведены). На этапе 2040 генерируют карту «>1», которая указывает, для группы, содержащей до 8 коэффициентов, имеющих величину 1 в карте значимости и выбранных, считая назад от конца группы, превосходит ли величина этих коэффициентов 1. На этапе 2050 генерируют карту «>2». Для до 1 коэффициента, которому в карте «>1» соответствует величина 1 (коэффициент, ближайший к концу группы) эта карта «>2» указывает, превосходит ли величина этого коэффициента 2. На этапе 2060 генерируют знаковые биты для всех значимых коэффициентов (хотя может быть использована схема, называемая «сокрытие знаковых битов», для вывода последнего знакового бита, который в противном случае пришлось бы кодировать, на основе положительной и отрицательной четности кодовых величин в группе), а на этапе 1570 генерируют коды выхода для любого коэффициента, величина которого не полностью описана предыдущим синтаксическим элементом (иными словами, данными, сформированными на каком-либо из этапов 2030-2060). Отметим, что на Фиг. 18, в некоторых примерах реализации алгоритма HEVC, нет необходимости генерировать все карты для каждого коэффициента. Например, в группе из (скажем) 16 коэффициентов могут быть один или несколько коэффициентов, для которых некоторые карты не генерируют.
Эти карты являются примерами карты «больше единицы», указывающей позиции, относительно матрицы величин данных, в которых старшие (наиболее значимые) сегменты величин данных превышают 1; и карты «больше двух», указывающей позиции, относительно матрицы величин данных, в которых старшие (наиболее значимые) сегменты величин данных превышают 2.
На этапе 2070, если нужен код выхода, его генерируют на основе текущей величины k с использованием только что описанных способов. В частности, коэффициент, который требует применения кода выхода, сначала обрабатывают с использованием карты значимости и, в качестве опции, одной или нескольких других карт. Отметим, что в случае коэффициента, для которого требуется кодирование выхода, любая из используемых карт - карта значимости, карта «>1» и карта «>2» будет помечена флагом "1". Это происходит потому, что любой из коэффициентов, для которого требуется кодирование выхода, по определению больше величины, какая может быть кодирована с применением каких-либо карт, имеющихся для этого коэффициента.
Код выхода нужен, когда текущая величина данных не может быть полностью кодирована. Здесь термин «полностью» означает, что величина данных, меньшая чем уже кодированные величины (посредством карт или посредством карт плюс фиксированные биты, например), равна нулю. Другими словами, величина данных является полностью кодируемой с использованием уже сформированных компонентов, если остаточная величина от этой величины данных, полученная с учетом указанных компонентов, равна нулю.
Таким образом, в предположении, что для примера коэффициента имеются карта значимости, карта «>1» и карта «>2», каждая из этих карт будет помечена флагом как «значимая» ("significant"), ">1" и ">2" для этого коэффициента.
Это означает (в рассматриваемом примере), что указанный коэффициент должен быть равен по меньшей мере 3.
Поэтому величина 3 может быть, без потери информации, вычтена из коэффициента перед кодированием выхода. Эту величину 3 (или в более общем смысле, переменный базовый уровень (base_level), указывающий числовой диапазон, определяемый картами, применимыми к этому коэффициенту) восстанавливают при декодировании.
Принимая десятичную величину 15 коэффициента (1111 в двоичном представлении) в качестве примера, получаем: значение в карте значимости равно "1", значение в карте «>1» равно "1" и значение в карте «>2» равно "1". Величина параметра base_level равна 3. Этот базовый уровень (base_level) вычитают из величины коэффициента для получения десятичной величины 12 (1100 - в двоичном представлении), передаваемой для кодирования выхода.
Величина k (см. выше) теперь определяет число битов в суффиксе. Биты суффикса берут от самых младших битов величины коэффициента после вычитания параметра base_level. Если (например) k=2, тогда два самых младших бита остатка 1100 рассматривают, как биты суффикса, иными словами биты суффикса в этом примере представляют собой 00. Оставшиеся биты (11 в рассматриваемом примере) кодируют в качестве префикса.
Таким образом, суммируя, процедура, ассоциированная с кодом выхода, содержит:
генерирование одной или множества карт, определяющих один или более младших битов коэффициента, так что (если требуется код выхода) коэффициент должен иметь величину, равную по меньшей мере базовому уровню (base_level);
вычитание параметра base_level из коэффициента;
кодирование младших k битов оставшейся части коэффициента в качестве битов суффикса; и
кодирование оставшихся старших битов указанной оставшейся части коэффициента в качестве префикса.
Варианты настоящего изобретения рассматривают распознавание длины кода по худшему случаю, который может происходить при кодировании кода выхода для коэффициента.
При использовании обработки с повышенной точностью для 16-разрядного видео диапазон коэффициента в модуле энтропийного кодирования maxTrDynamicRange равен 22 разрядам, следовательно можно показать, что при использовании такой схемы максимальное число битов кода выхода, которые могут быть кодированы для коэффициента, достигается, когда параметр rParam равен 0 и величина коэффициента находится на максимуме (1 << 22), в виде:

При высокоэффективном кодировании (HEVC) в экспоненциальном коде Голомба эта величина требует 21-битового суффикса (и потому 21-битового префикса), равно как 1-битового разделителя и 3 дополнительных битов префикса, чтобы сигнализировать, что это не является кодом Голомба-Райса. Это приводит в худшем случае всего к 46 бит, что может оказаться слишком большой нагрузкой для модуля декодирования.
Варианты настоящего изобретения предлагают одну или нескольких альтернативных схем для части кодирования выхода согласно экспоненциальному коду Голомба, что может уменьшить длину кода выхода по худшему случаю до 32 бит, что совпадает с длиной кода выхода по худшему случаю для высокоэффективного кодирования в коде HEVC версия 1. Потенциально длину кода можно уменьшить еще больше, хотя это становится предметом компромисса между длиной кода и эффективности кодирования. Поскольку модуль декодирования версии 2 должен будет поддерживать версию 1, нет необходимости снижать максимальную длину кода в расширенных профилях модуля декодирования версия 2 до уровня меньше максимальной длины кода в стандартной версии 1.
Как обсуждается выше, в текущем стандарте HEVC (по состоянию на дату приоритета настоящей заявки), коды выхода (любую часть величины коэффициента, не описываемуя синтаксическим элементом, кодированным способом САВАС) кодируют посредством состоящего из двух частей кода Голомба-Райса/экспоненциального кода Голомба. При кодировании 16-разрядного видео с использованием повышенной точности этот способ приводит к максимальной длине кода выхода, равной 46 бит, как выведено выше, что может создать значительную нагрузку при декодировании одного коэффициента.
В некоторых вариантах, путем модификации отображения между длинами префикса и суффикса в части схемы кодирования кодов выхода, соответствующей экспоненциальному коду Голомбу, длину по худшему случаю можно уменьшить, например, до 32 бит, без существенного нежелательного воздействия на эффективность кодирования или эффективность обработки. В других вариантах можно скорректировать кодирование по Голомбу-Райсу или даже исключить полностью.
При кодировании 16-разрядного видео с использованием так называемой повышенной точности динамический диапазон модуля преобразования и квантования и, следовательно, коэффициентов, поступающих в модуль энтропийного кодирования, (maxTrDynamicRange) равен 16+6=22. В результате этого максимальная величина коэффициента составляет 222 = 4194304. При коррекции путем вычитания 1 для входа в карту значимости и 3 для кода Голомба-Райса (параметр Райса rParam в худшем случае равен 0) максимальная величина, которая может быть кодирована с использованием экспоненциального кода Голомба, равна 4194300.
Можно показать, что для кодирования этой величины с использованием экспоненциального кода Голомба согласно HEVC требуется 21-битовый суффикс (и потому 21-битовый префикс) в дополнение к однобитовому разделителю и трем дополнительным битам префикса для сигнализации, что используется экспоненциальное кодирование Голомба. В результате этого общая длина кода в худшем случае равна 46.
Однако вместо того, чтобы просто отобразить длину префикса прямо на длину суффикса (как в отображении 1:1), здесь предложены различные альтернативные схемы.
В некоторых вариантах длина суффикса может быть функцией (такой как экспоненциальная функция) длины префикса. Примером такой экспоненциальной функции является suffixLength = (1 << prefixLength) >> 1. Таким способом, например, только 5 бит префикса нужно передать, чтобы сигнализировать о 16 бит суффикса; может также потребоваться разделитель '0' в зависимости от того, применяется ли унарное кодирование или усеченное унарное кодирование с максимум 5 разрядами. Это пример структуры, где величина, кодированная префиксной частью, ассоциирована с длиной неунарно кодированной суффиксной части, так что длина неунарно кодированной суффиксной части представляет собой экспоненциальную функцию величины, кодированной посредством префиксной части.
В некоторых вариантах префикс может сам по себе представлять собой экспоненциальный код Голомба, а не унарный код.
В некоторых вариантах длина префикса может быть отображена в длину суффикса с использованием таблицы. Этот способ позволяет адаптировать набор размеров интервалов к данным. Таблица может быть задана заранее (иными словами, заранее вписана в модуль кодирования и в модуль декодирования) или передана в составе или в связи с кодированным потоком данных (так что соотношение между длиной префиксной части и длиной суффиксной части определено информацией, передаваемой в ассоциации с данными, подлежащими кодированию), или выведена из ранее кодированных коэффициентов иди других данных, или получена с использованием сочетания этих и других способов (например, выбрана из набора заданных таблиц с использованием данных, переданных в потоке). В некоторых вариантах величина, кодированная префиксной частью, и длина неунарно кодированной суффиксной части ассоциированы с одной или несколькими таблицами. Некоторые варианты содержат этап выбора одной из таблиц, ассоциирующих величину, кодированную префиксной частью, и длину неунарно кодированной суффиксной части согласно одной или несколькими группам, содержащим: (i) флаг данных, ассоциированный с кодированными величинами данных; и (ii) параметр, выводимый из одной или нескольких ранее кодированных величин данных.
Некоторые другие варианты могут работать следующим образом. При кодировании 16-разрядного видео с использованием повышенной точности динамический диапазон модуля преобразования и квантования и, следовательно, коэффициентов, поступающих в модуль энтропийного кодирования, (maxTrDynamicRange) равен 16+6=22. Как обсуждается выше, в результате этого максимальная величина коэффициента составляет 222 = 4194304. При коррекции путем вычитания 1 для входа в карту значимости и 3 для кода Голомба-Райса (параметр Райса rParam в худшем случае равен 0) максимальная величина, которая может быть кодирована с использованием экспоненциального кода Голомба, равна 4194300, а общая длина кода в худшем случае равна 46, как обсуждается выше.
Однако вместо того, чтобы просто позволить длине префикса увеличиваться без ограничений, может быть использована альтернативная схема, в которой применяется обработка с повышенной точностью и которая ограничивает число префиксных битов, необходимое для передачи сигнала в худшем случае. Максимальная длина префикса равна:
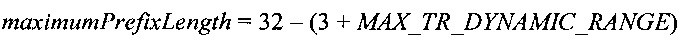
Когда достигнута эта длина префикса, соответствующая длина суффикса тогда равна:
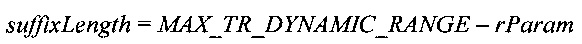
Далее, поскольку максимальная длина префикса известна уже в начале кодирования/декодирования, префикс может быть кодирован с применением усеченного унарного кодирования - исключая разделитель, если достигнута эта максимальная длина префикса.
Следовательно, длина кода выхода для худшего случая уменьшается до:

Это позволяет «вписать» любой код выхода в одно 32-разрядное целое число и сделать максимальную длину кода выхода такой же, как в стандарте высокоэффективного кодирования HEVC версия 1. Отметим, что модуль декодирования в стандарте HEVC, поддерживающий работу с большой битовой глубиной, (такой, как использование 16-разрядного видео) должен будет по-прежнему, по меньшей мере в некоторых вариантах, поддерживать использование данных, кодированных с применением стандарта высокоэффективного кодирования HEVC версия 1, так что это ограничивает число битов в составе кода выхода максимально допустимым числом согласно стандарту HEVC версия 1, а это означает, что в таких конфигурациях длина кода выхода не превышает уже поддерживаемой максимальной длины.
Эти варианты могут предоставлять преимущества, аналогичные тем, какие дают описанные выше системы с таблицами отображения, однако предлагаемые примеры способны добиться такого же эффекта уменьшения максимальной длины кода в худшем случае и такой же производительности кодирования, но без необходимости в использовании преобразовательной таблицы. Однако общий принцип ограничения длины префикса максимальной длиной в зависимости от битовой глубины величин данных (подлежащих кодированию или декодированию) может быть также использован в сочетании с одной или несколькими таблицами, как обсуждается выше, или с другими соотношениями между длиной префикса или длиной суффикса.
Эти варианты, таким образом, составляют пример способа, в котором длина префикса ограничена некой максимальной величиной. Например, максимальная величина префикса может зависеть от величины maxTrDynamicRange, представляющей динамический диапазон величин данных для кодирования. В некоторых примерах максимальная длина префикса равна 29- maxTrDynamicRange. В другом примере, максимальная длина префикса равна 28- maxTrDynamicRange.
Отметим, что другой вариант выражения некоторых из этих способов состоит в том, что видеоданные имеют некоторую битовую глубину (такую как 16 бит, выражают число битов на один отсчет в каждом канале). Эта битовая глубина применяется к отсчетам исходных видеоданных (иными словами, отсчеты для кодирования в модуле кодирования), и также применяется соответственно к отсчетам, декодируемым в модуле декодирования. Битовая глубина может быть выражена в неявном виде и выделена из структуры данных, поступающей в модуль кодирования или в модуль декодирования, или может быть задана флагом или как-то другим способом обозначена для модуля кодирования или модуля декодирования посредством одного или нескольких индикаторов, таких как флаги или параметры. В некоторых примерах ширину динамического диапазона, maxTrDynamicRange, задают равной битовой глубине плюс сдвиг, такой как сдвиг 6 бит, (например, в ситуации, где битовая глубина равна 16 бит, например, переменная ширина maxTrDynamicRange динамического диапазона может быть равна 16+6=22 бит) а длина префикса поэтому ограничена некоторой максимальной длиной префикса, зависящей от битовой глубины величин кодируемых или декодируемых данных применительно к конкретной ситуации. Более конкретно, в некоторых примерах длина префикса, таким образом, ограничена некоторой максимальной длиной префикса в зависимости от битовой глубины величин кодируемых или декодируемых данных, например, плюс шесть бит.
Соответственно, такая схема может предоставить примеры систем и способов кодирования или декодирования, где максимальная длина префикса равна заданной константе минус величина, равная ширине динамического диапазона величин данных, подлежащих кодированию. Например, эта заданная константа может быть равна 29 или эта заданная константа может быть равна 28.
Может быть использовано сочетание этих способов и/или способов, которые будут обсуждаться ниже.
Контроллер 345 может работать (в случае модуля декодирования или модуля кодирования или в случае соответствующих способов) для определения каких-либо параметров, от которых зависит длина префикса и/или соотношение между длиной префикса и длиной суффикса, а также для задания или по другому установления максимальной длины префикса и соотношения между длиной префикса и длиной суффикса.
Все эти схемы являются вариантами способа, согласно которому устройство для кодирования данных осуществляет кодирование матрицы величин данных в виде наборов данных и кодов выхода для величин, не кодированных наборами данных, где код выхода содержит префиксную часть и неунарно кодированную суффиксную часть, так что длина суффиксной части в битах зависит от величины, кодированной префиксной частью, согласно такому соотношению, что по меньшей мере для некоторых величин, кодированных префиксной частью, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части. Описываемые здесь примеры предлагают варианты способа, в котором длина префикса ограничена максимальной длиной префикса, зависящей от битовой глубины величин кодируемых или декодируемых данных.
С точки зрения соответствующей операции декодирования (в модуле декодирования или в декодирующем тракте модуля кодирования) все эти схемы являются вариантами способа, согласно которому устройство для декодирования данных осуществляет декодирование входных кодированных величин данных, каковые были кодированы в виде наборов данных и кодов выхода для величин, не кодированных наборами данных, где код выхода содержит префиксную часть и неунарно кодированную суффиксную часть, так что длина суффиксной части в битах зависит от величины, кодированной префиксной частью, согласно такому соотношению, что по меньшей мере для некоторых величин, кодированных префиксной частью, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части.
Варианты охватывают устройство для кодирования и/или декодирования, осуществляющее такие способы, загружаемое программное обеспечение, при выполнении которого компьютер осуществляет эти способы, энергонезависимый машиночитаемый носитель для хранения информации, на котором поставляют это загружаемое программное обеспечение (такой как магнитный или оптический диск), а также устройство для съемки (считывания) видеоданных, передачи, представления на дисплее и/или хранения информации, содержащие указанные выше устройство для кодирования или декодирования данных, программное обеспечение и носитель.
Как обсуждается, префиксная часть может содержать унарно кодированную величину.
В некоторых вариантах, когда активизирована обработка данных с повышенной точностью, может быть использовано отображение, позволяющее уменьшить число битов в префиксе, необходимое для передачи сигнала в худшем случае. Такое отображение представлено в следующей таблице, которая отображает длины суффиксов в длины префиксов для обработки данных с повышенной точностью.

Схема (i) воспроизводит обычное экспоненциальное кодирование Голомба.
Схема (ii) эмулирует длину суффикса, являющуюся экспоненциальной функцией длины префикса, как обсуждается выше.
Можно заметить, что схема (ii) способна уменьшить число битов в худшем случае для 16-разрядного видео кодирования (где параметр MAX_TR_DYNAMIC_RANGE равен 22 бит) от 46 бит (схема (i) с унарным кодированием) до 31 бит, если используется унарное кодирование префикса, или 30 бит, если применяется усеченной унарное кодирование префикса, при максимум 5 бит префикса, хотя это ведет к большим потерям эффективности кодирования, чем в схеме (iii), поскольку точность интервала теряется для небольших величин. Однако если применить способы адаптации параметров кодирования Голомба-Райса, описанные в заявке GB1320775.8, (содержание которой включено сюда посредством ссылки) потери для этих схем можно уменьшить.
При использовании схемы (iii) обеспечивается наличие мелкоструктурных интервалов кодирования для небольших величин, но при этом требуется не больше 7 бит в префиксе (вместо 21) для сигнализации о наибольшем возможном суффиксе. Кроме того, поскольку максимальная длина префикса известна, этот префикс можно кодировать с использованием усеченного унарного кодирования в виде усеченной унарно кодированной величины - исключив разделитель, если достигнута максимальная длина префикса. Максимальная длина суффикса равна maxTrDynamicRange, хотя если параметр rParam не равен 0, максимальная длина суффикса равна is maxTrDynamicRange - rParam, причем после суффикса следуют биты параметра rParam. Следовательно, в некоторых вариантах этой схемы некоторые или все величины в таблице являются функцией параметра rParam.
Контроллер 345 может быть конфигурирован для доступа к одной или нескольким группам таблиц (таким как таблицы (i)-(iii) выше) с целью определения подходящего соотношения между длиной префикса и длиной суффикса.
Длина кода выхода в худшем случае, таким образом, уменьшена до 7 (префикс) + 22 (максимальный суффикс) + 3 (биты, не относящиеся к коду Голомба-Райса) = 32, поскольку для усеченного унарного префикса нет разделителя, можно любой код выхода «вписать» в одно 32-битовое целое число.
Некоторые варианты имеют следующие дополнительные признаки:
Поскольку максимальная длина суффикса известна, префикс может быть передан с использованием усеченного унарного кодирования вместо простого унарного кодирования (иными словами, если достигнуто максимальное число битов префикса, разделитель, обычно вставляемый между префиксом и суффиксом, становится не нужен).
В схемах, где длина префикса может быть отображена в длину суффикса, которая больше, чем нужно, (например, больше параметра maxTrDynamicRange) эта длина суффикса может быть «обрезана» до этой величины, так что получаемые посредством соотношения между длиной префикса и длиной суффикса величины, превосходящие параметр maxTrDynamicRange, задают равными этому параметру maxTrDynamicRange. В общем случае, соотношение между величиной, кодированной префиксной частью, и длиной неунарно кодированной суффиксной части таково, что максимальная длина неунарно кодированной суффиксной части не превышает указанного максимального числа битов для каждой из подлежащих кодированию величин данных.
В конфигурациях, где параметр maxTrDynamicRange меньше 16 бит, величину 16 можно исключить, например, путем задания максимальной длины суффикса в приведенном выше соотношении равной 15. В качестве примера, это может быть использовано для интерпретации экспоненциального префикса, равного 4. Что в противном случае потребовало бы 16-битового суффикса.
Теперь обсудим первый рабочий пример.
Входными данными для этой процедуры являются запрос проведения табличной бинаризации синтаксического элемента с не имеющей знака величиной synVal, параметром Райса riceParam и флагом isChroma, указывающим, относится ли текущий синтаксический элемент к цветностному коэффициенту.
Выходными данными этой процедуры является результат табличной бинаризации синтаксического элемента synVal.
Переменную maxTrDynamicRange определяют следующим образом:
Если флаг isChroma равен 0, тогда переменная maxTrDynamicRange = extended_precision_processing_flag ? Мах( 15, BitDepthY + 6): 15
В противном случае, maxTrDynamicRange = extended_precision_processing_flag ? Max (15, BitDepthC + 6): 15
Здесь использованы следующие обозначения. "А = flag ? В : С" обозначает, что переменной А присвоена величина В или величина С в зависимости от того, находится ли двоичная величина «флаг» ("flag") в состоянии «истинно» или «ложно», соответственно. Max (D, Е) выбирает большую из величин D и Е. BitDepthY обозначает битовую глубину яркостного или зеленого канала; BitDepthC обозначает битовую глубину цветностного или синего или красного канала. Величина параметра extended_precision_processing_fiag представляет собой флаг, указывающий, активизирована ли обработка данных с повышенной точностью.
Переменные suffixLength[x] и minimumUncodeableValue[x], величину, указывающую минимальное значение кода выход-выход, как обсуждается выше, получают из следующей таблицы (в качестве примера):

Двоичная строка процедуры табличной бинаризации синтаксического элемента synVal определена следующим образом, где каждый вызов функции put(X), при X равно 0 или 1, добавляет двоичную величину X в конце двоичной строки:

Процедура бинаризации параметра coeff_abs_level_remaining
Переменную сМах получают из параметра cRiceParam, эквивалентного параметру rParam, используемому выше, как:
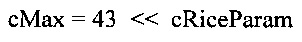
Бинаризация синтаксического элемента coeff_abs_level_remaining[n] представляет собой конкатенацию двоичной префиксной строки и (если есть) двоичной суффиксной строки.
Для вывода двоичной префиксной строки применимо следующее:
Величину префикса cu_qp_delta_abs, prefixVal получают следующим образом:
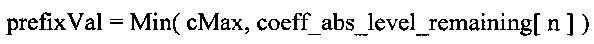
Двоичную префиксную строку задают с привлечением процедуры TR-бинаризации к префиксу prefixVal с переменными сМах и cRiceParam в качестве входных величин.
Когда двоичная префиксная строка равна битовой строке длиной 43, где все биты равны 1, тогда двоичная суффиксная строка присутствует и определяется следующим образом:
Величину суффикса of cu_qp_delta_abs, suffixVal, выводят следующим образом:
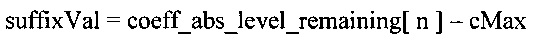
Когда флаг extended_precision_processing_flag равен 1, двоичную суффиксную строку задают путем привлечения двоичной бинаризации к суффиксу suffixVal, где переменную isChroma задают равной 1, если параметр cIdx больше 0, и 0 в противном случае.
В противном случае (флаг extended_precision_processing_flag равен 0) двоичную суффиксную строку задают путем привлечения EGk-бинаризации для суффикса suffixVal, где порядок к экспоненциального кодирования Голомба задают равным cRiceParam.
Теперь будет рассмотрен еще один рабочий пример, относящийся к вариантам, где длина префикса ограничена. Входными данными для этой процедуры являются запрос ограниченной бинаризации экспоненциального кода Голомба для синтаксического элемента с не имеющей знака величиной synVal, параметром riceParam Райса и флагом isChroma, указывающим, относится ли текущий синтетический элемент к цветностному коэффициенту. Выходными данными этой процедуры является результат бинаризации ограниченного экспоненциального кода Голомба k-порядка для синтаксического элемента synVal.
Переменную maxTrDynamicRange получают следующим образом:
Если флаг isChroma равен 0, тогда параметр maxTrDynamicRange = extended_precision_processing_flag ? Мах( 15, BitDepthy + 6): 15
В противном случае параметр maxTrDynamicRange = extended_precision_processing_flag ? Max(15, BitDepthc + 6): 15
Переменную maximumPrefixLength задают равной (29 - maxTrDynamicRange).
Двоичную строку результата бинаризации ограниченного экспоненциального кода Голомба k-порядка для синтаксического элемента synVal задают следующим образом, где каждый вызов функции put(X), при X равно 0 или 1, добавляет двоичную величину X в конце двоичной строки:

В обычном экспоненциальном коде Голомба, как обсуждается выше, суффикс получают путем вычитания минимальной величины, которая не может быть кодирована суффиксом меньшей длины, из величины, подлежащей кодированию. Например, для кодирования величины 9 (0b1001) (здесь префикс 0b обозначает двоичное представление) при k=0 (или без применения k), отметим, что:
0-бит префикс/суффикс кодирует до 0
1-бит префикс/суффикс кодирует до 2
2-бит префикс/суффикс кодирует до 6
Следовательно нужен 3-битовый префикс/суффикс (кодирует до 14). Наименьшая величина, которая не может быть кодирована 2-битовым префиксом/суффиксом равна 7 (6+1) - так что суффикс образован как 9-7 = 2 (0b010) размером 3 бит, что дает конечную кодированную величину 111-0-010.
В рамках настоящего изобретения длина суффикса, ассоциированная с максимальной длиной префикса, является (по необходимости) достаточно большой, чтобы это вычитание не требовалось - так что суффикс мог бы быть просто равен величине, подлежащей кодированию.
Например, максимальная длина префикса = 3, ассоциированная с этим длина суффикса = 4.
Тогда кодированная величина равна усеченному унарному префиксу, за которым следует суффикс, равный величине, подлежащей кодированию. Например, десятичное число 9 может быть кодировано в виде 111-1001.
Еще в одном рабочем примере, число 1, используемых для сигнализации «это не код Голомба-Райса», равно 4, но тогда код интерпретируется как экспоненциальный код Голомба (k+1)-го порядка. Максимальная длина префикса для обсуждаемого выше способа определяется как:

Рассмотрим следующие коды:
(i) 110X…
(ii) 1110Х…
(iii) 111Х…
(где X означает «не заботьтесь о том, какова величина этого бита»)
Код (i), где число единиц в начале кода равно 2, ни одна из приведенных выше схем не интерпретирует, как экспоненциальный код Голомба.
Код (ii), где число единиц в начале кода равно 3, система описанная вые первой интерпретирует как экспоненциальный код Голомба, а система, описанная второй, - нет. Однако поскольку здесь в начале кода присутствуют ровно 3 единицы, длина префикса экспоненциального кода Голомба равна 0 (нет 1 перед первым 0). Но если длина префикса равна 0, интерпретация экспоненциального кода Голомба k-го порядка является такой же, как интерпретация кода Голомба-Райса k-го порядка.
Код (iii), где число единиц в начале кода равно 4, оба способа интерпретируют как экспоненциальный код Голомба-Райса. В первой системе это будет интерпретировано как код k-го порядка с длиной префикса по меньшей мере 1. Во второй системе это будет интерпретировано как код (k+1)-го порядка с длиной префикса по меньшей мере 0. В обоих случаях длина префикса зависит от числа дополнительных 1 после начала кода. Но поскольку биты префикса экспоненциального кода Голомба эффективно добавляются к величине k, можно видеть, что обе интерпретации эквивалентны. Это, таким образом, эквивалентно увеличению порога «это не код Голомба-Райса» на (не более чем) 1 в предположении, что величина k при декодировании экспоненциального кода Голомба также увеличивается на 1.
На Фиг. 19 представлена упрощенная логическая схема, иллюстрирующая способ кодирования. На этапе 2200 задают длину префикса и/или максимальную длину префикса (например, посредством контроллера 345, в ответ на один или несколько параметров, таких как битовая глубина данных) каким-либо из способов, обсуждавшихся выше. На этапе 2210 кодируют одну или несколько величин данных в соответствии с заданной так длиной префикса.
На Фиг. 20 представлена упрощенная логическая схема, иллюстрирующая способ кодирования. На этапе 2220 префикс кодируют и представляют в виде унарно кодированной величины (примером является усеченная унарно кодированная величина). На этапе 2230 кодируют соответствующий суффикс.
На Фиг. 21 представлена упрощенная логическая схема, иллюстрирующая способ кодирования. На этапе 2240 обращение к таблице, обсуждавшейся выше, для получения (на этапе 2250) длины суффикса.
Соответствующие способы применяют на соответствующих этапах декодирования.
Другие аспекты и признаки настоящего изобретения определены следующими пронумерованными статьями:
(1) Способ функционирования устройства кодирования данных, содержащий этапы, на которых:
кодируют с помощью устройства кодирования данных матрицы величин данных в виде наборов данных и кодов выхода для величин, не кодированных в виде наборов данных, при этом код выхода содержит префиксную часть и неунарно кодированную суффиксную часть, длина которой, в битах, зависит от величины, кодированной посредством префиксной части, в соответствии с таким соотношением, что по меньшей мере для некоторых величин, кодированных посредством префиксной части, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части.
2420-549892RU/55
УСТРОЙСТВО КОДИРОВАНИЯ ИЗОБРАЖЕНИЯ, СПОСОБ КОДИРОВАНИЯ ИЗОБРАЖЕНИЯ И ПРОГРАММА, И УСТРОЙСТВО ДЕКОДИРОВАНИЯ ИЗОБРАЖЕНИЯ, СПОСОБ ДЕКОДИРОВАНИЯ ИЗОБРАЖЕНИЯ И ПРОГРАММА
(2) Способ по (1), в котором префиксная часть содержит унарно кодированную величину.
(3) Способ по (2), в котором префиксная часть содержит усеченную унарно кодированную величину.
(4) Способ по любому из (1)-(3), в котором соотношение между длиной префиксной части и длиной суффиксной части задано на основе информации, переданной в связи с данными, подлежащими кодированию.
(5) Способ по любому из (1)-(4), в котором величина, кодированная посредством префиксной части, и длина неунарно кодированной суффиксной части ассоциированы посредством одной или более таблиц.
(6) Способ по (5), содержащий этап, на котором выбирают одну из таблиц, ассоциирующих величину, кодированную посредством префиксной части, с длиной неунарно кодированной суффиксной части согласно одному или более параметрам из группы, содержащей: (i) флаг данных, ассоциированный с кодированными величинами данных; и (ii) параметр, получаемый на основе одной или более ранее кодированных величин данных.
(7) Способ по любому из (1)-(6), в котором величина, кодированная посредством префиксной части, ассоциирована с длиной неунарно кодированной суффиксной части так, что длина неунарно кодированной суффиксной части представляет собой экспоненциальную функцию величины, кодированной посредством префиксной части.
(8) Способ по любому из (1)-(7), в котором соотношение между величиной, кодированной посредством префиксной части, и длиной неунарно кодированной суффиксной части таково, что максимальная длина неунарно кодированной суффиксной части не превышает максимальной величины, выбранной из: максимального числа битов в каждой из величин данных, подлежащих кодированию; и заданной максимальной величины.
(9) Способ по любому из (1)-(8), в котором префиксная часть сама по себе кодирована в экспоненциальном коде Голомба.
(10) Способ по любому из (1)-(9), в котором длина префиксной части ограничена максимальной величиной длины префикса.
(11) Способ по (10), в котором максимальная величина длины префикса зависит от величины параметра maxTrDynamicRange, представляющего собой динамический диапазон величин данных для кодирования.
(12) Способ по 11, в котором максимальная длина префикса равна 29-maxTrDynamicRange.
(13) Способ по любому из (1)-(12), в котором один из наборов данных представляет собой карту значимости, указывающую позиции, в матрице величин данных, старших (наиболее значимых) сегментов данных, являющихся ненулевыми.
(14) Способ по (13), в котором карта значимости содержит флаг, указывающий позицию, согласно заданному упорядочению матрицы величин данных, последнего из старших (наиболее значимых) сегментов данных, имеющих ненулевую величину.
(15) Способ по 13, в котором наборы данных содержат:
карту «больше единицы», указывающую позиции, относительно матрицы величин данных, старших (наиболее значимых) сегментов данных, которые больше 1; и
карту «больше двух», указывающую позиции, относительно матрицы величин данных, старших (наиболее значимых) сегментов данных, которые больше 2.
(16) Способ функционирования устройства декодирования данных, содержащий этапы, на которых:
декодируют с помощью устройства декодирования данных входных кодированных величин данных, кодированных в виде наборов данных и кодов выхода для величин, не кодированных в виде наборов данных, при этом код выхода содержит префиксную часть и неунарно кодированную суффиксную часть, длина которой, в битах, зависит от величины, кодированной посредством префиксной части, в соответствии с таким соотношением, что по меньшей мере для некоторых величин, кодированных посредством префиксной части, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части.
(17) Компьютерное программное обеспечение, при выполнении которого компьютер осуществляет способ по любому из (1)-(16).
(18) Устройство кодирования данных, содержащее:
модуль кодирования для кодирования матрицы величин данных в виде наборов данных и кодов выхода для величин, не кодированных в виде наборов данных, при этом код выхода содержит префиксную часть и неунарно кодированную суффиксную часть, длина которой, в битах, зависит от величины, кодированной посредством префиксной части, в соответствии с таким соотношением, что по меньшей мере для некоторых величин, кодированных посредством префиксной части, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части.
(19) Устройство декодирования данных, содержащее:
модуль декодирования для декодирования входных кодированных величин, кодированных в виде наборов данных и кодов выхода для величин, не кодированных в виде наборов данных, для величин, не кодированных в виде наборов данных, код выхода содержит префиксную часть и неунарно кодированную суффиксную часть, длина которой, в битах, зависит от величины, кодированной посредством префиксной части, в соответствии с таким соотношением, что по меньшей мере для некоторых величин, кодированных посредством префиксной части, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части.
(20) Устройство съемки видеоданных, передачи, представления на дисплее и/или сохранения видеоданных согласно статье 18 или статье 19.
Далее соответствующие аспекты и признаки настоящего изобретения определены следующими пронумерованными статьями:
(1) Устройство декодирования данных, содержащее:
модуль декодирования для декодирования входных кодированных величин данных и преобразования их в декодированные величины данных, имеющие битовую глубину, при этом входные кодированные величины данных кодированы в виде наборов данных и кодов выхода для величин, не кодированных в виде наборов данных, причем код выхода содержит префиксную часть, так что длина префикса ограничена максимальной длиной префикса, зависящей от битовой глубины величин данных, и неунарно кодированную суффиксную часть, длина которой, в битах, зависит от величины, кодированной посредством префиксной части, в соответствии с соотношением, что по меньшей мере для величин, кодированных посредством префиксной части, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части.
(2) Устройство по (1), в котором префиксная часть содержит унарно кодированную величину.
(3) Устройство по (2), в котором префиксная часть содержит усеченную унарно кодированную величину.
(4) Устройство по любому из (1)-(3), содержащее контроллер, для доступа к одной или более таблицам, в которых величина, кодированная префиксной частью, ассоциирована с длиной неунарно кодированной суффиксной части.
(5) Устройство согласно (4), в котором контроллер выполнен с возможностью выбора одной из таблиц, ассоциирующих величину, кодированную посредством префиксной части, с длиной неунарно кодированной суффиксной части согласно одному или более параметрам из группы, содержащей: (i) флаг данных, ассоциированный с кодированными величинами данных; и (ii) параметр, получаемый на основе одной или более ранее кодированных величин данных.
(6) Устройство по любому из (1)-(3), в котором величина, кодированная посредством префиксной части, ассоциирована с длиной неунарно кодированной суффиксной части так, что длина неунарно кодированной суффиксной части представляет собой экспоненциальную функцию величины, кодированной посредством префиксной части.
(7) Устройство по любому из (1)-(3), в котором соотношение между величиной, кодированной посредством префиксной части, и длиной неунарно кодированной суффиксной части таково, что максимальная длина неунарно кодированной суффиксной части не превышает максимальной величины, выбранной из списка, содержащего: максимальное число битов в каждой из величин данных, подлежащих кодированию; и заданную максимальную величину.
(8) Устройство по любому из (1)-(7), в котором префиксная часть сама по себе кодирована в экспоненциальном коде Голомба.
(9) Устройство по любому из (1)-(8), в котором префиксная часть ограничена максимальной величиной длины префикса, зависящей от битовой глубины величин данных плюс шесть.
(10) Устройство по любому из (1)-(9), в котором максимальная длина префикса равна заданной константе минус величина, равная динамическому диапазону величин данных для кодирования.
(11) Устройство по (10), в котором указанная заданная константа равна 29.
(12) Устройство по (10), в котором указанная заданная константа равна 28.
(13) Устройство по любому из (1)-(12), в котором один из наборов данных представляет собой карту значимости, указывающую позиции, в матрице величин данных, старших (наиболее значимых) сегментов данных, которые являются ненулевыми.
(14) Устройство по (13), в котором карта значимости содержит флаг данных, указывающий позицию, согласно заданному упорядочению матрицы величин данных, последнего из старших (наиболее значимых) сегментов данных, имеющих ненулевую величину.
(15) Способ функционирования устройства декодирования данных, содержащий этапы, на которых:
декодируют с помощью устройства декодирования данных входные кодированные величины данных и преобразуют их в декодированные величины данных, имеющие битовую глубину, при этом входные кодированные величины данных кодированы в виде наборов данных и кодов выхода для величин, не кодированных в виде наборов данных, а код выхода содержит префиксную часть, так что длина префикса ограничена максимальной длиной префикса, зависящей от битовой глубины величин данных, и неунарно кодированную суффиксную часть, длина которой, в битах, зависит от величины, кодированной посредством префиксной части, в соответствии с таким соотношением, что по меньшей мере для величин, кодированных посредством префиксной части, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части.
(16) Компьютерное программное обеспечение, вызывающее, при исполнении компьютером осуществление способа согласно (15).
(17) Энергонезависимый машиночитаемый носитель для хранения информации, хранящий компьютерное программное обеспечение по (16).
(18) Устройство кодирования данных, содержащее:
модуль кодирования для кодирования матрицы величин данных, имеющих некоторую битовую глубину, в виде наборов данных и кодов выхода для величин, не кодированных в виде наборов данных, при этом код выхода содержит префиксную часть, длина которой ограничена максимальной длиной префикса, зависящей от битовой глубины величин данных, и неунарно кодированную суффиксную часть, длина которой, в битах, зависит от величины, кодированной посредством префиксной части, в соответствии с таким соотношением, что по меньшей мере для величин, кодированных посредством префиксной части, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части.
(19) Устройство по (18), в котором префиксная часть содержит унарно кодированную величину.
(20) Устройство по (19), в котором префиксная часть содержит усеченную унарно кодированную величину.
(21) Устройство по любому из (18)-(20), содержащее контроллер, выполненный с возможностью доступа к одной или более таблицам, в которых величина, кодированная префиксной частью, ассоциирована с длиной неунарно кодированной суффиксной части.
(22) Устройство по (21), в котором контроллер выполнен с возможностью выбора одной из таблиц, ассоциирующих величину, кодированную посредством префиксной части, с длиной неунарно кодированной суффиксной части согласно одному или более параметрам из группы, содержащей: (i) флаг данных, ассоциированный с кодированными величинами данных; и (ii) параметр, получаемый на основе одной или более ранее кодированных величин данных.
(23) Устройство по любому из (18)-(20), в котором величина, кодированная посредством префиксной части, ассоциирована с длиной неунарно кодированной суффиксной части так, что длина неунарно кодированной суффиксной части представляет собой экспоненциальную функцию величины, кодированной посредством префиксной части.
(24) Устройство по любому из (18)-(20), в котором соотношение между величиной, кодированной посредством префиксной части, и длиной неунарно кодированной суффиксной части таково, что максимальная длина неунарно кодированной суффиксной части не превышает максимальной величины, выбранной из списка, содержащего: максимальное число битов в каждой из величин данных, подлежащих кодированию; и заданную максимальную величину.
(25) Устройство по любому из (18)-(24), в котором префиксная часть сама по себе кодирована в экспоненциальном коде Голомба.
(26) Устройство по любому из (18)-(25), в котором максимальная длина префикса равна заданной константе минус величина, равная динамическому диапазону величин данных для кодирования.
(27) Устройство по (26), в котором указанная заданная константа равна 29.
(28) Устройство по (26), в котором указанная заданная константа равна 28.
(29) Устройство по (18)-(28), в котором один из наборов данных представляет собой карту значимости, указывающую позиции, в матрице величин данных, старших (наиболее значимых) сегментов данных, которые являются ненулевыми.
(30) Устройство согласно (29), в котором карта значимости содержит флаг данных, указывающий позицию, согласно заданному упорядочению матрицы величин данных, последнего из старших (наиболее значимых) сегментов данных, имеющих ненулевую величину.
(31) Устройство по (29) или (30), в котором наборы данных содержат:
карту «больше единицы», указывающую позиции, относительно матрицы величин данных, старших (наиболее значимых) сегментов данных, которые больше 1; и
карту «больше двух», указывающую позиции, относительно матрицы величин данных, старших (наиболее значимых) сегментов данных, которые больше 2.
(32) Способ функционирования устройства кодирования данных, содержащий этапы, на которых:
кодируют с помощью устройства кодирования данных матрицы величин данных в виде наборов данных, имеющих битовую глубину, и кодов выхода для величин, не кодированных в виде наборов данных, при этом код выхода содержит префиксную часть, длина которой ограничена максимальной длиной префикса, зависящей от битовой глубины величин данных, и неунарно кодированную суффиксную часть, длина которой, в битах, зависит от величины, кодированной посредством префиксной части, в соответствии с таким соотношением, что по меньшей мере для некоторых величин, кодированных посредством префиксной части, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части.
(33) Компьютерное программное обеспечение, вызывающее, при исполнении компьютером, осуществление способа по (32).
(34) Энергонезависимый машиночитаемый носитель хранения информации, хранящий компьютерное программное обеспечение по (33).
(35) Оборудование для съемки видеоданных, передачи, представления на дисплее и/или сохранения видеоданных по любому из (1)-(14) и (18)-(31).
Следует понимать, что функции модуля декодирования или модуля кодирования, либо функциональные этапы способа декодирования или способа кодирования с целью выбора или другим способом установления соотношения между длиной префикса или длиной суффикса и/или выбора или установления другим способом максимальной длины префикса, могут быть выполнены контроллером или другим подобным устройством, таким как (в некоторых примерах, описанных выше) контроллер 345.
Как обсуждается выше, должно быть понятно, что признаки устройства, перечисленные в приведенных выше статьях, могут быть реализованы соответствующими признаками модуля кодирования или модуля декодирования, как это обсуждалось раньше.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ ЗНАЧАЩИХ КОЭФФИЦИЕНТОВ В ЗАВИСИМОСТИ ОТ ПАРАМЕТРА УКАЗАННЫХ ЗНАЧАЩИХ КОЭФФИЦИЕНТОВ | 2014 |
|
RU2637879C2 |
| КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ ЗНАЧАЩИХ КОЭФФИЦИЕНТОВ В ЗАВИСИМОСТИ ОТ ПАРАМЕТРА УКАЗАННЫХ ЗНАЧАЩИХ КОЭФФИЦИЕНТОВ | 2014 |
|
RU2751570C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2019 |
|
RU2755020C2 |
| СПОСОБ КОДИРОВАНИЯ ИЗОБРАЖЕНИЯ, УСТРОЙСТВО КОДИРОВАНИЯ ИЗОБРАЖЕНИЯ, СПОСОБ ДЕКОДИРОВАНИЯ ИЗОБРАЖЕНИЯ И УСТРОЙСТВО ДЕКОДИРОВАНИЯ ИЗОБРАЖЕНИЯ | 2012 |
|
RU2714377C2 |
| СПОСОБ КОДИРОВАНИЯ ИЗОБРАЖЕНИЯ, УСТРОЙСТВО КОДИРОВАНИЯ ИЗОБРАЖЕНИЯ, СПОСОБ ДЕКОДИРОВАНИЯ ИЗОБРАЖЕНИЯ И УСТРОЙСТВО ДЕКОДИРОВАНИЯ ИЗОБРАЖЕНИЯ | 2012 |
|
RU2610249C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2018 |
|
RU2699677C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2012 |
|
RU2642373C1 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2012 |
|
RU2595934C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2022 |
|
RU2839276C2 |
| ИНИЦИАЛИЗАЦИЯ КОНТЕКСТА ПРИ ЭНТРОПИЙНОМ КОДИРОВАНИИ | 2021 |
|
RU2779898C1 |
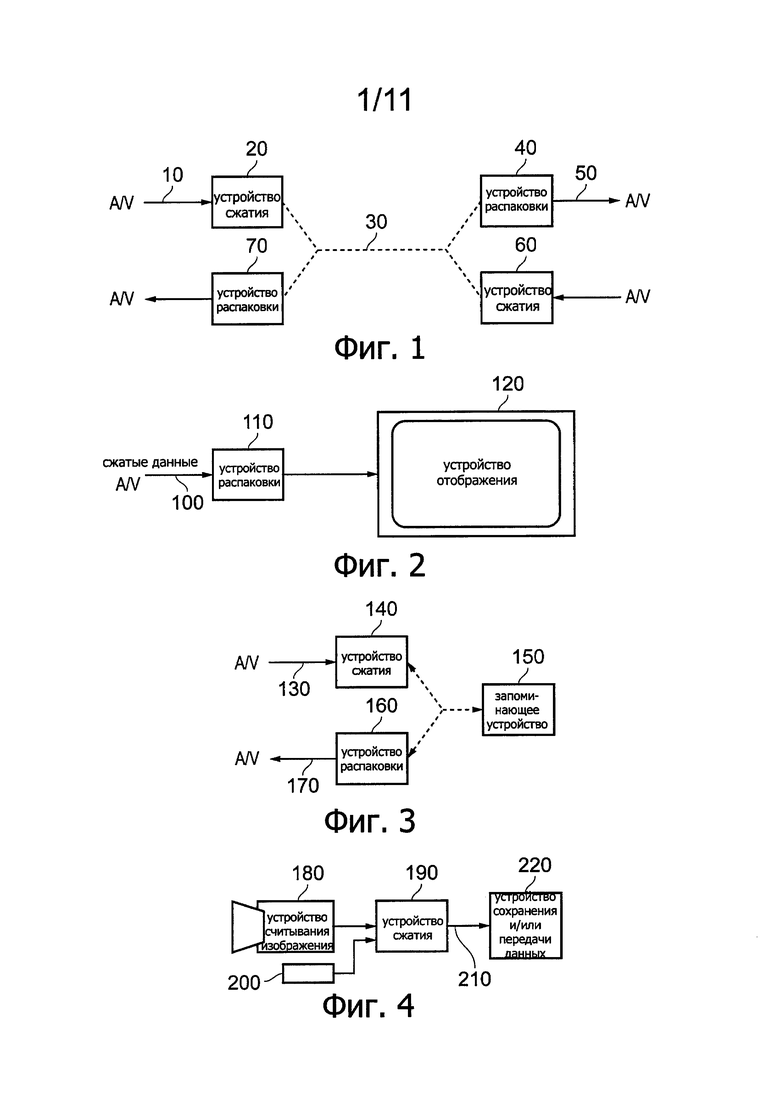
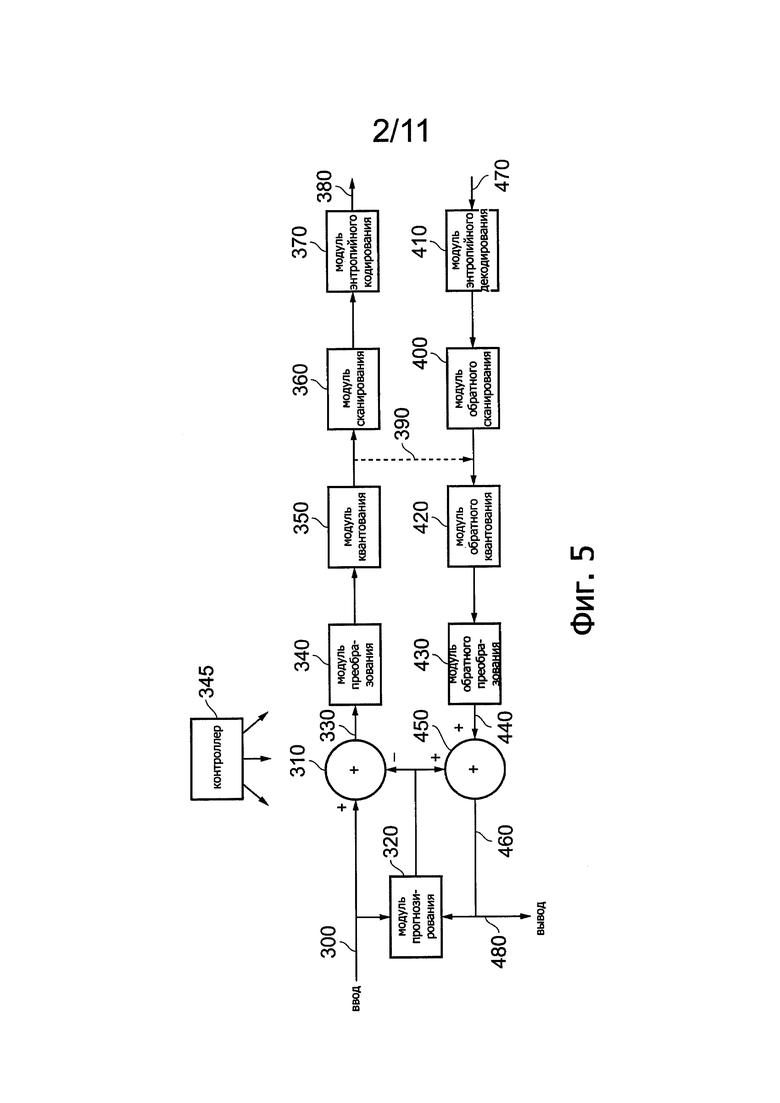
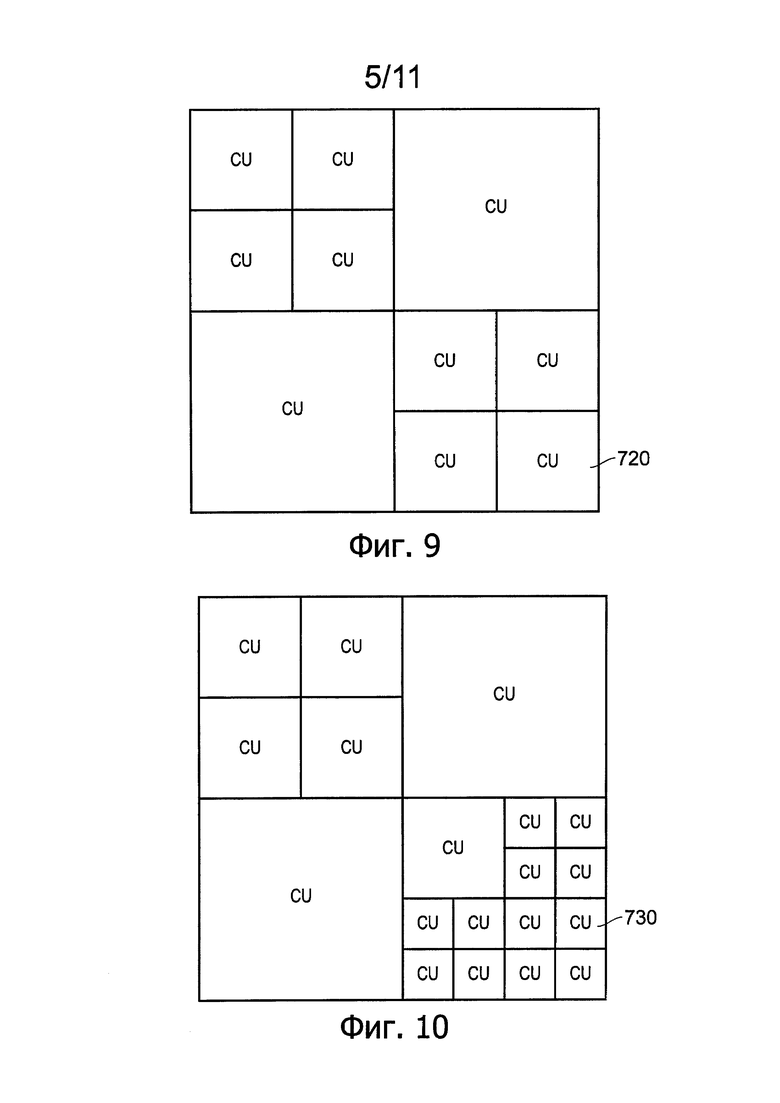
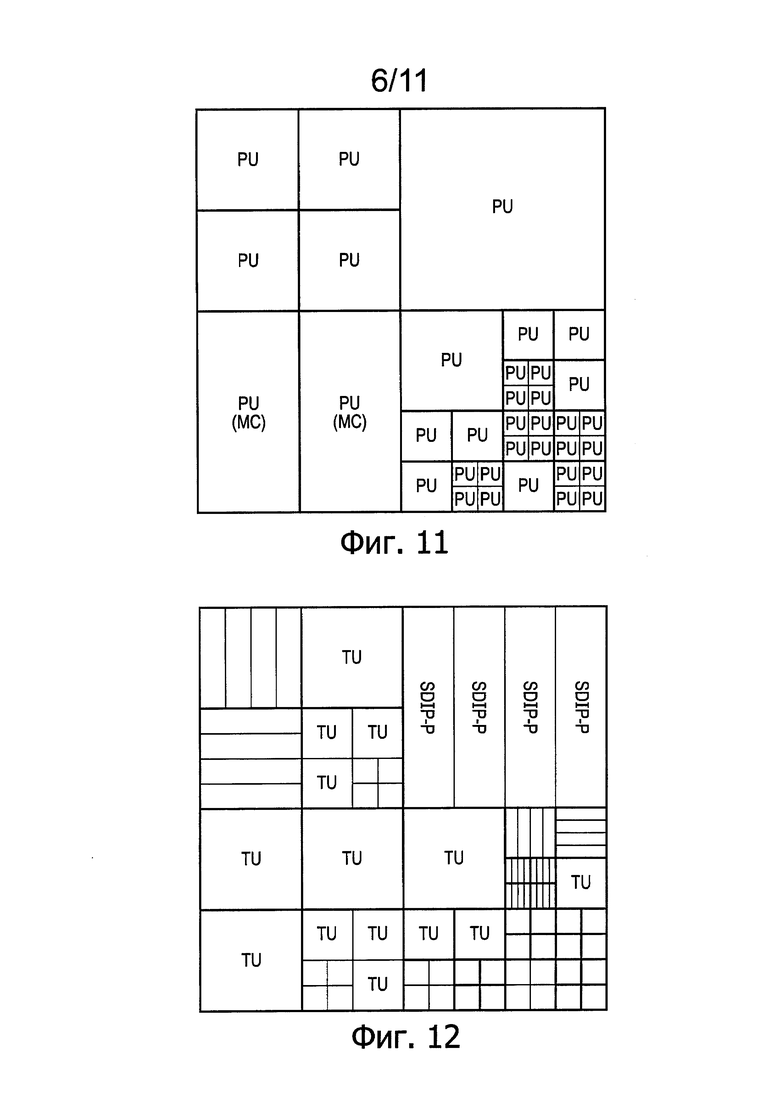
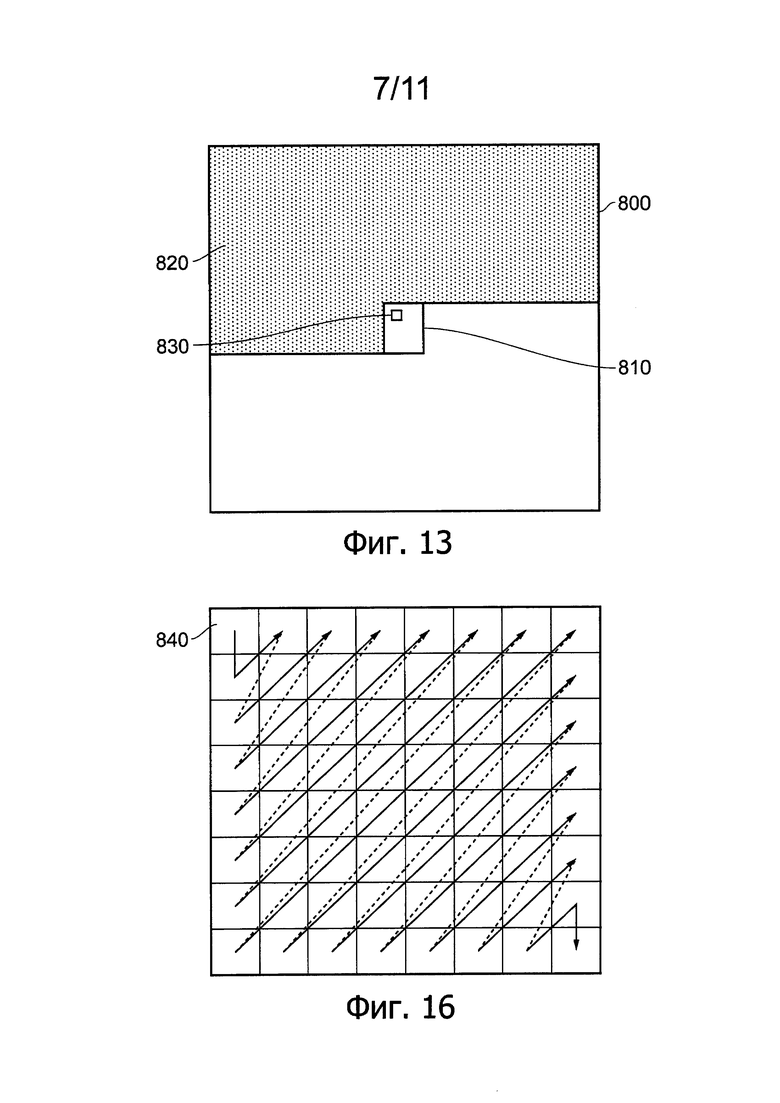
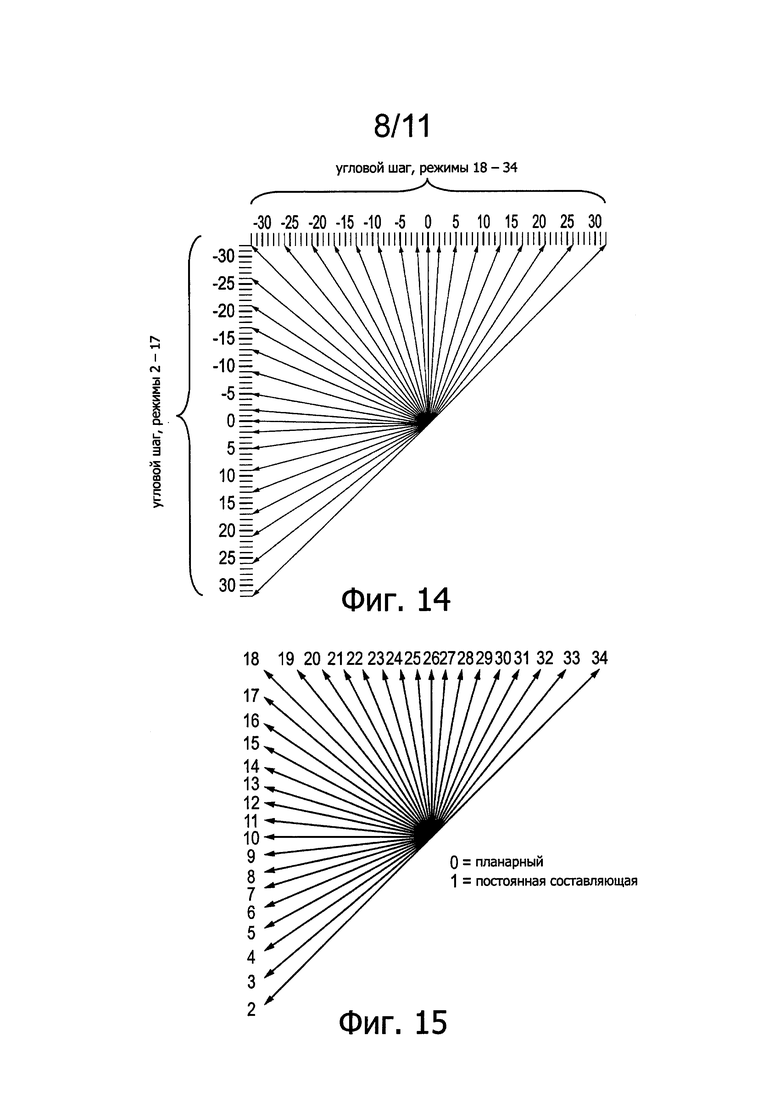
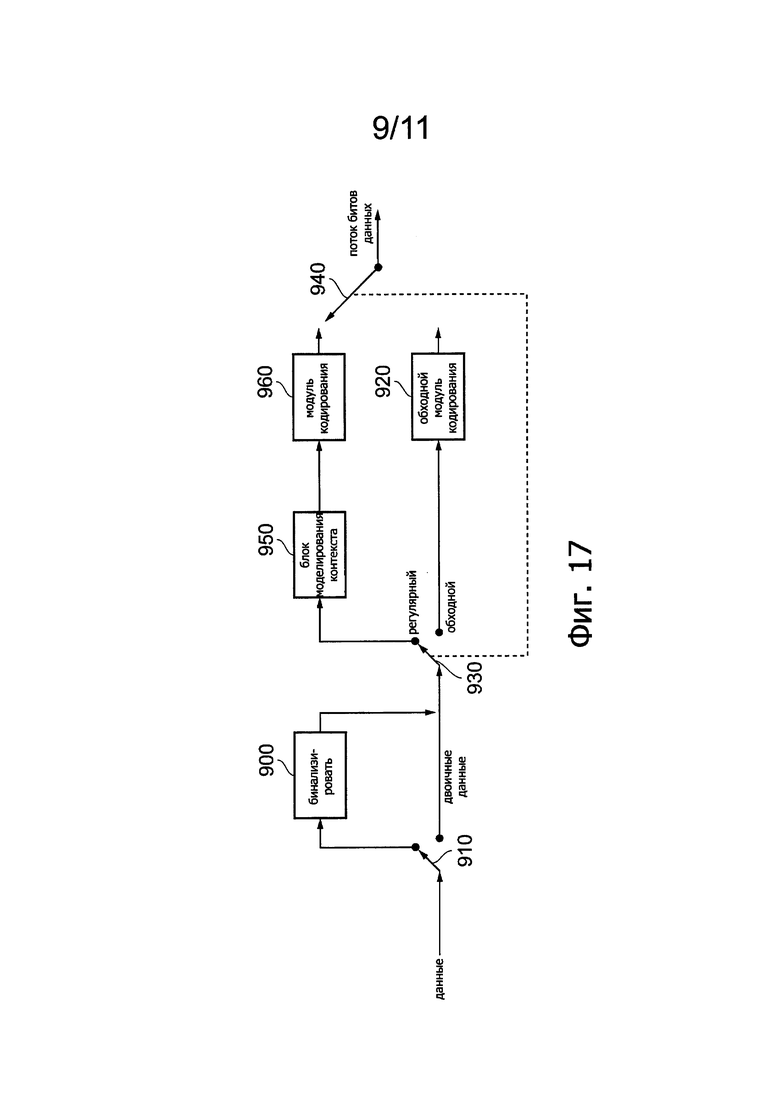
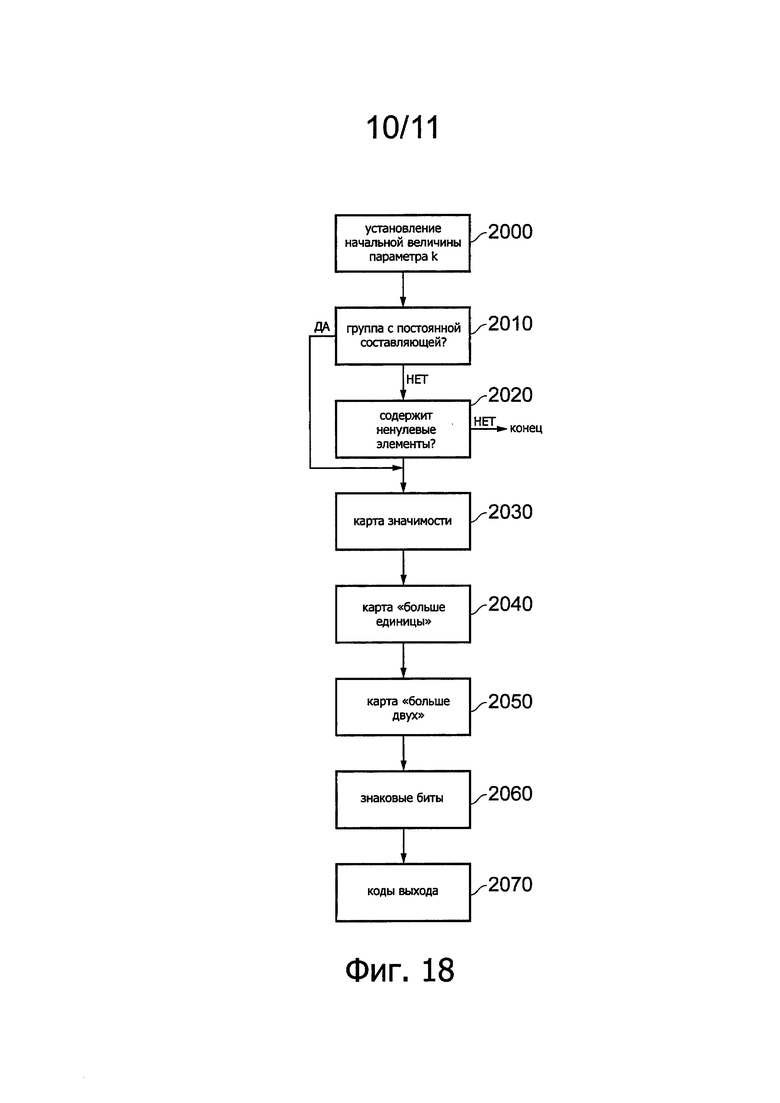
Изобретение относится к вычислительной технике. Технический результат заключается в уменьшении максимальной длины кода при сохранении производительности кодирования. Устройство декодирования данных содержит модуль декодирования для декодирования входных кодированных величин данных в декодированные величины данных, имеющие битовую глубину, при этом входные кодированные величины данных кодированы в виде наборов данных и кодов выхода для величин, не кодированных в виде наборов данных, причем код выхода содержит префиксную часть, имеющую длину префикса, ограниченную максимальной длиной префикса, зависящей от битовой глубины величин данных, и неунарно кодированную суффиксную часть, имеющую длину, в битах, зависящую от величины, кодированной посредством префиксной части, в соответствии с таким соотношением, что по меньшей мере для величин, кодированных посредством префиксной части, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части. 7 н. и 26 з.п. ф-лы, 21 ил.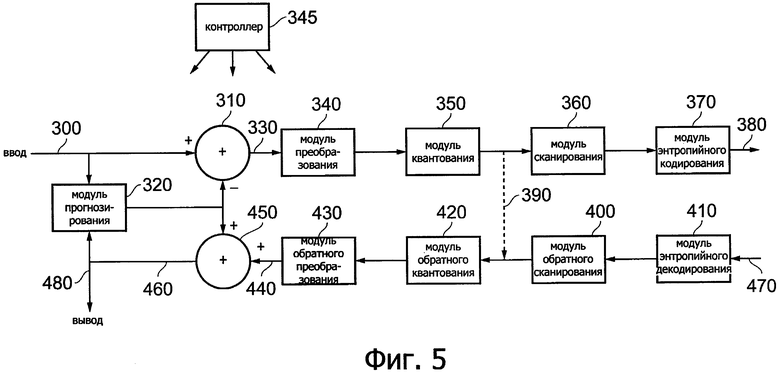
1. Устройство декодирования данных, содержащее:
модуль декодирования для декодирования входных кодированных величин данных в декодированные величины данных, имеющие битовую глубину, при этом входные кодированные величины данных кодированы в виде наборов (2030, 2040, 2050) данных и кодов (2070) выхода для величин, не кодированных в виде наборов данных, причем код выхода содержит префиксную часть, имеющую длину префикса, ограниченную максимальной длиной префикса, зависящей от битовой глубины величин данных, и неунарно кодированную суффиксную часть, имеющую длину, в битах, зависящую от величины, кодированной посредством префиксной части, в соответствии с таким соотношением, что по меньшей мере для величин, кодированных посредством префиксной части, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части.
2. Устройство по п. 1, в котором префиксная часть содержит унарно кодированную величину.
3. Устройство по п. 2, в котором префиксная часть содержит усеченную унарно кодированную величину.
4. Устройство по п. 1, содержащее контроллер, выполненный с возможностью доступа к одной или более таблицам, в которых величина, кодированная префиксной частью, ассоциирована с длиной неунарно кодированной суффиксной части.
5. Устройство по п. 4, в котором контроллер выполнен с возможностью выбора одной из таблиц, ассоциирующих величину, кодированную посредством префиксной части, с длиной неунарно кодированной суффиксной части согласно одному или более параметрам из группы, содержащей: (i) флаг данных, ассоциированный с кодированными величинами данных; и (ii) параметр, получаемый на основе одной или более ранее кодированных величин данных.
6. Устройство по п. 1, в котором величина, кодированная посредством префиксной части, ассоциирована с длиной неунарно кодированной суффиксной части так, что длина неунарно кодированной суффиксной части представляет собой экспоненциальную функцию величины, кодированной посредством префиксной части.
7. Устройство по п. 1, в котором соотношение между величиной, кодированной посредством префиксной части, и длиной неунарно кодированной суффиксной части таково, что максимальная длина неунарно кодированной суффиксной части не превышает максимальной величины, выбранной из списка, содержащего: максимальное число битов в каждой из величин данных, подлежащих кодированию; и заданную максимальную величину.
8. Устройство по п. 1, в котором префиксная часть сама по себе кодирована в экспоненциальном коде Голомба.
9. Устройство по п. 1, в котором префиксная часть ограничена максимальной величиной длины префикса, зависящей от битовой глубины величин данных, плюс шесть.
10. Устройство по п. 1, в котором максимальная длина префикса равна заданной константе минус величина, равная динамическому диапазону величин данных для кодирования.
11. Устройство по п. 10, в котором указанная заданная константа равна 29.
12. Устройство по п. 10, в котором указанная заданная константа равна 28.
13. Устройство по п. 1, в котором один из наборов данных представляет собой карту значимости, указывающую позиции, в матрице величин данных, старших сегментов данных, являющихся ненулевыми.
14. Устройство по п. 13, в котором карта значимости содержит флаг данных, указывающий позицию, согласно заданному упорядочению матрицы величин данных, последнего из старших сегментов данных, имеющих ненулевую величину.
15. Способ функционирования устройства декодирования данных, содержащий этапы, на которых:
декодируют с помощью устройства декодирования данных входные кодированные величины данных и преобразуют их в декодированные величины данных, имеющие битовую глубину, при этом входные кодированные величины данных кодированы в виде наборов данных и кодов выхода для величин, не кодированных в виде наборов данных, причем код выхода содержит префиксную часть, имеющую длину префикса, ограниченную максимальной длиной префикса, зависящей от битовой глубины величин данных, и неунарно кодированную суффиксную часть, имеющую длину, в битах, зависящую от величины, кодированной посредством префиксной части, в соответствии с таким соотношением, что по меньшей мере для величин, кодированных посредством префиксной части, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части.
16. Энергонезависимый машиночитаемый носитель хранения информации, хранящий компьютерное программное обеспечение, вызывающее при исполнении компьютером осуществление способа по п. 15.
17. Устройство кодирования данных, содержащее:
модуль кодирования для кодирования матрицы величин данных, имеющих битовую глубину, в виде наборов данных и кодов выхода для величин, не кодированных в виде наборов данных, при этом код выхода содержит префиксную часть, имеющую длину, ограниченную максимальной длиной префикса, зависящей от битовой глубины величин данных, и неунарно кодированную суффиксную часть, имеющую длину, в битах, зависящую от величины, кодированной посредством префиксной части, в соответствии с таким соотношением, что по меньшей мере для величин, кодированных посредством префиксной части, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части.
18. Устройство по п. 17, в котором префиксная часть содержит унарно кодированную величину.
19. Устройство по п. 18, в котором префиксная часть содержит усеченную унарно кодированную величину.
20. Устройство по п. 17, содержащее контроллер, выполненный с возможностью доступа к одной или более таблицам, в которых величина, кодированная префиксной частью, ассоциирована с длиной неунарно кодированной суффиксной части.
21. Устройство по п. 20, в котором контроллер выполнен с возможностью выбора одной из таблиц, ассоциирующих величину, кодированную посредством префиксной части, с длиной неунарно кодированной суффиксной части согласно одному или более параметрам из группы, содержащей: (i) флаг данных, ассоциированный с кодированными величинами данных; и (ii) параметр, получаемый на основе одной или более ранее кодированных величин данных.
22. Устройство по п. 17, в котором величина, кодированная посредством префиксной части, ассоциирована с длиной неунарно кодированной суффиксной части так, что длина неунарно кодированной суффиксной части представляет собой экспоненциальную функцию величины, кодированной посредством префиксной части.
23. Устройство по п. 17, в котором соотношение между величиной, кодированной посредством префиксной части, и длиной неунарно кодированной суффиксной части таково, что максимальная длина неунарно кодированной суффиксной части не превышает максимальной величины, выбранной из списка, содержащего: максимальное число битов в каждой из величин данных, подлежащих кодированию; и заданную максимальную величину.
24. Устройство по п. 17, в котором префиксная часть сама по себе кодирована в экспоненциальном коде Голомба.
25. Устройство по п. 17, в котором максимальная длина префикса равна заданной константе минус величина, равная динамическому диапазону величин данных для кодирования.
26. Устройство по п. 25, в котором указанная заданная константа равна 29.
27. Устройство по п. 25, в котором указанная заданная константа равна 28.
28. Устройство по п. 17, в котором один из наборов данных представляет собой карту значимости, указывающую позиции, в матрице величин данных, старших сегментов данных, являющихся ненулевыми.
29. Устройство по п. 28, в котором карта значимости содержит флаг данных, указывающий позицию, согласно заданному упорядочению матрицы величин данных, последнего из старших сегментов данных, имеющих ненулевую величину.
30. Устройство по п. 28, в котором наборы данных содержат:
карту «больше единицы», указывающую позиции, относительно матрицы величин данных, наиболее значимых сегментов данных, которые больше 1; и
карту «больше двух», указывающую позиции, относительно матрицы величин данных, наиболее значимых сегментов данных, которые больше 2.
31. Способ функционирования устройства кодирования данных, содержащий этапы, на которых:
кодируют с помощью устройства кодирования данных матрицу величин данных в виде наборов данных, имеющих битовую глубину, и кодов выхода для величин, не кодированных в виде наборов данных, при этом код выхода содержит префиксную часть, имеющую длину, ограниченную максимальной длиной префикса, зависящей от битовой глубины величин данных, и неунарно кодированную суффиксную часть, имеющую длину, в битах, зависящую от величины, кодированной посредством префиксной части, в соответствии с таким соотношением, что по меньшей мере для величин, кодированных посредством префиксной части, длина неунарно кодированной суффиксной части больше длины, в битах, префиксной части.
32. Энергонезависимый машиночитаемый носитель хранения информации, хранящий компьютерное программное обеспечение, вызывающее, при исполнении компьютером, осуществление способа по п. 31.
33. Устройство обработки видеоданных, содержащее:
устройство, выполненное с возможностью осуществления по меньшей мере одного из съемки, передачи, отображения и хранения видеоданных; и
по меньшей мере одно из устройства декодирования данных по п. 1 и устройства кодирования данных по п. 17.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Устройство для управления шаговым двигателем | 1984 |
|
SU1267582A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| ПОДОБНАЯ ИНТЕРПОЛЯЦИИ ФИЛЬТРАЦИЯ ПОЛОЖЕНИЙ ЦЕЛОЧИСЛЕННЫХ ПИКСЕЛЕЙ ПРИ ВИДЕОКОДИРОВАНИИ | 2009 |
|
RU2477577C2 |

