УРОВЕНЬ ТЕХНИКИ
[1] Активизируемые голосом человеко-машинные диалоговые системы, например голосовое взаимодействие с развлекательными системами или личными устройствами, зависят от точного распознавания речи пользователя. Например, эффективные приложения голосового поиска должны точно распознавать отправленные пользователем запросы или другие взаимодействия, чтобы возвращенная пользователю информация коррелировала с намерением пользователя при отправке запроса или действия. В рамках последовательности взаимодействий или "реплик" с одной из этих систем пользователь может отправить несколько запросов. Как правило, содержание тех запросов меняется на уровне слова, или лексическом, от одной реплики к следующей, но часто имеет некоторую связанность на семантическом или уровне намерений в одном и том же сеансе. Например, пользователь может спросить о фильме, а затем захотеть узнать о ближайших местоположениях кинотеатра, где показывают этот фильм.
[2] Этот сценарий особенно распространен в структурированных областях, например развлекательных системах или приложениях персональных помощников, где пользователи могут задавать несколько порций информации для завершения задачи. (Например, для задачи бронирования авиабилета это могло бы включать в себя задание местоположений отправления и прибытия, даты рейса, предпочтительного времени, предпочтительной авиакомпании и т. п.). Но даже когда плановое намерение пользователя меняется от одной реплики к следующей, все же может иметь место некоторая связанность или корреляция между последовательными запросами; например, резервирование прокатного автомобиля или поиск гостиницы после покупки авиабилетов.
[3] Включая эту информацию о контексте сеанса пользователя в модели языков, используемые диалоговыми системами для распознавания речи, можно повышать точность систем путем предоставления лучшего моделирования цели и моделирования с предсказанием. Однако сбор этой информации на семантическом уровне при ограниченных данных за прошлое время (например, прошлые запросы в определенном сеансе вплоть до настоящего времени) требует усилий. Кроме того, существующие попытки моделирования контекста сеанса рассматривают только прошлые запросы в текущем сеансе и предполагают, что весь сеанс ориентирован только на одну определенную тему или намерение. Кроме того, эти подходы не моделируют последовательные действия, предпринятые пользователем в каждом сеансе.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[4] Данная Сущность изобретения предоставляется для знакомства с набором идей в упрощенном виде, которые дополнительно описываются ниже в Подробном описании. Данная Сущность изобретения не предназначена для определения ключевых признаков или существенных признаков заявленного предмета изобретения, и также не предназначена для использования в качестве содействия в определении объема заявленного предмета изобретения.
[5] Варианты осуществления изобретения ориентированы на системы и способы для улучшения моделей языков и моделей понимания естественного языка (SLU) для распознавания речи путем приспособления источников знаний, используемых моделями, к контекстам сеансов. В частности, источник знаний, например граф знаний, может использоваться для сбора и моделирования динамического контекста сеанса на основе информации о взаимодействии с пользователем из истории использования, например журналов сеансов, которая отображается в источник знаний. Как будет дополнительно описано, в одном варианте осуществления источник знаний приспосабливается к контексту сеанса для некоторого пользователя путем включения информации о взаимодействии с пользователем из истории использования у этого пользователя или других похожих пользователей. Например, информацию из взаимодействий пользователя или "реплик" с приложением или устройством можно отобразить в источник знаний. На основе последовательностей отображенных взаимодействий с пользователем определяется модель последовательности намерений. Затем модель последовательности намерений можно использовать для построения или приспособления моделей языков и моделей SLU на основе контекста сеанса, включая формирование и интерполяцию моделей в реальном масштабе времени, посредством этого функционирующих в качестве моделей контекста сеанса. Таким образом, модель может использоваться для определения набора вероятных следующих реплик, принимая во внимание идущую реплику или реплики. Затем к модели (моделям) языка для набора вероятных следующих реплик можно обращаться или формировать ее для упрощения точного распознавания следующей реплики.
[6] Некоторые варианты осуществления включают в себя приспособление источника знаний к моделированию контекста сеанса глобально для всех пользователей или только для определенной группы пользователей. Например, информацию об истории использования, включенную в источник (источники) знаний, можно приспособить к пользователям с похожими интересами или намерениями на основе данных социальных сетей пользователей, журналов пользователей или другой пользовательской информации. Таким образом, модели контекста сеанса можно строить на основе характеристик совокупности, общих для похожих пользователей.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[7] Настоящее изобретение иллюстрируется в качестве примера, а не ограничения, на прилагаемых чертежах, на которых одинаковые номера ссылок указывают похожие элементы и на которых:
[8] Фиг. 1 - блок-схема примерной архитектуры системы, в которой может применяться вариант осуществления изобретения;
[9] Фиг. 2 изображает части одного примера персонализированного графа знаний в соответствии с вариантом осуществления изобретения;
[10] Фиг. 3 изображает пояснительное представление одного аспекта модели контекста сеанса в соответствии с вариантом осуществления изобретения;
[11] Фиг. 4-6 изображают блок-схемы алгоритмов способов для приспособления модели языка к контексту сеанса на основе истории пользователя для лучшего понимания будущих взаимодействий в соответствии с вариантами осуществления настоящего изобретения;
[12] Фиг. 7-8 изображают блок-схемы алгоритмов способов для предоставления модели контекста сеанса на основе информации об истории пользователя в соответствии с вариантами осуществления настоящего изобретения;
[13] Фиг. 9 изображает блок-схемы алгоритмов способа для использования источника знаний, персонализированного с помощью информации о контексте сеанса, чтобы предоставить модель языка в соответствии с вариантами осуществления настоящего изобретения; и
[14] Фиг. 10 - блок-схема примерной вычислительной среды, подходящей для использования при реализации вариантов осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
[15] Предмет настоящего изобретения описывается здесь со спецификой, чтобы соответствовать требованиям закона. Однако само описание не имеет целью ограничить объем этого патента. Скорее, авторы изобретения предположили, что заявленный предмет изобретения также можно было бы воплотить другими способами, чтобы включить другие этапы или сочетания этапов, аналогичных описанным в этом документе, вместе с другими существующими или будущими технологиями. Кроме того, хотя термин "этап" может использоваться в этом документе для ассоциации с разными элементами применяемых способов, термин не следует интерпретировать как предполагающий какой-нибудь конкретный порядок среди или между различными этапами, раскрытыми в этом документе, за исключением случая, когда явно описывается порядок отдельных этапов.
[16] Аспекты описанной в этом документе технологии в целом ориентированы на системы, способы и компьютерные носители информации для улучшения, в том числе, моделей языков для распознавания речи путем приспособления используемых моделями языков источников знаний к контекстам сеансов. В частности, источник знаний, например граф знаний, может использоваться для сбора и моделирования динамического контекста сеанса на основе информации о взаимодействии с пользователем из истории использования, например журналов сеансов, которая отображается в источник знаний. Источник знаний можно приспособить к контексту сеанса для некоего пользователя путем отображения или согласования с источником знаний информации о взаимодействии с пользователем из личной истории использования у этого пользователя или похожих пользователей, посредством этого персонализируя источник знаний для пользователя или набора пользователей. Из отображений можно определить намерение пользователя, соответствующее каждому взаимодействию, на основе возможных типов сущностей и связанной информации из областей, охватывающих отображение. На основе последовательностей или шаблонов из отображенной информации о взаимодействии с пользователем можно определить и использовать последовательности намерений более высокого уровня для создания моделей, которые предвидят похожие намерения, но с другими аргументами, включая аргументы, которые не обязательно появляются в истории использования. В одном варианте осуществления модель включает в себя набор вероятностей переходов, указывающий правдоподобие перехода от первого взаимодействия ко второму взаимодействию.
[17] Модель контекста сеанса может использоваться для определения информации о вероятном будущем взаимодействии с пользователем, например отправленном пользователем запросе или другом взаимодействии с пользователем, на основе идущей информации о взаимодействии с пользователем. На основе информации о вероятном будущем взаимодействии может формироваться модель языка или модель SLU или приспосабливаться для улучшения распознавания речи и понимания, ассоциированных со следующим взаимодействием.
[18] В качестве примера в варианте осуществления информация о взаимодействии с пользователем, например информация из журнала запросов пользователя, отображается в семантические отношения источника знаний, например в граф знаний. Информация о взаимодействии с пользователем может содержать последовательности (или шаблоны) событий взаимодействия с пользователем из одного или более сеансов между пользователем и приложением либо устройством. Из отображения может определяться вероятное намерение пользователя, ассоциированное с каждым отображенным событием взаимодействия с пользователем, на основе семантических отношений (например, одной или более сущностей, типа (типов) сущностей или отношения (отношений)) и/или другой информации в источнике знаний, соответствующем отображенному событию взаимодействия. На основе отображения и последовательности (или шаблонов) событий взаимодействия с пользователем в сеансах связанной с взаимодействием с пользователем информации может определяться и использоваться последовательность (или шаблон) вероятных намерений пользователя для модели последовательности намерений. В варианте осуществления модель последовательности намерений включает в себя статистики для переходов намерений в последовательности (или шаблоне) намерений, например набор вероятностей переходов намерений, который представляет собой правдоподобие последующих намерений пользователя, принимая во внимание одно или более идущих намерений. Модель последовательности намерений можно использовать для построения или приспособления моделей языков и моделей SLU на основе контекста сеанса, включая формирование и интерполяцию моделей языков и SLU в реальном масштабе времени, посредством этого создавая модель контекста сеанса. Таким образом, модель контекста сеанса может использоваться для определения набора вероятных следующих реплик, принимая во внимание идущую реплику или реплики. Затем к модели (моделям) языка для набора вероятных следующих реплик можно обращаться или формировать ее для упрощения точного распознавания следующей реплики.
[19] Например, в первой реплике пользователь спрашивает свое личное устройство "Who is the director of Life is Beautiful?" ("Кто режиссер фильма "Жизнь прекрасна"?"). Этот запрос можно отобразить в часть источника знаний, соответствующую семантическому отношению фильм-режиссер (например, Жизнь прекрасна - кто режиссер - Роберто Бениньи). Из модели контекста сеанса на основе источника знаний, которая заполнена идущей информацией о личной истории использования, можно определить, что после запроса типа "режиссер-фильм" существует вероятность 0,4 того, что в следующей реплике пользователь спросит об актерском составе фильма, вероятность 0,2 того, что пользователь спросит дальше об "Оскарах" или наградах, и вероятность 0,1 того, что пользователь спросит далее о национальности режиссера. На основе этих вероятностей переходов можно интерполировать модели языков, соответствующие переходам (например, актерский состав "Жизнь прекрасна", его награды или национальность режиссера), чтобы лучше распознавать или понимать следующую реплику. С каждой последующей репликой модель контекста сеанса использует область и намерения из идущей реплики (реплик) для предсказания правдоподобия следующих реплик, чтобы можно было приспособить модели языков и модели SLU для предсказания.
[20] Варианты осуществления изобретения можно считать "персонализирующими" источник знаний путем отображения или согласования личной истории использования, включая информацию о взаимодействии с пользователем, с более общим источником знаний. Информация о взаимодействии с пользователем в качестве примера и без ограничения может включать в себя один или более запросов пользователя, фрагменты (речи), включая устные запросы, другие комбинированные или контекстные данные, например фрагменты речи пользователя в некоторые моменты времени в рамках сеанса, действия пользователя или то, что отображается пользователю в рамках сеанса, и другую связанную с взаимодействием с пользователем информацию. Как описано выше, информация о взаимодействии с пользователем может поступать из личной истории использования, которая в качестве примера и без ограничения может включать в себя журналы веб-запросов пользователя, журналы запросов с настольного ПК или личного устройства, взаимодействия в социальных сетях, посещенные веб-сайты или аналогичную информацию о взаимодействии с пользователем. Соответственно, в варианте осуществления личная история использования отображается в обобщенный или менее персонализированный источник знаний для его персонализации, и из этого определяются последовательности намерений. В другом варианте осуществления подмножество или части личной истории использования, включая информацию о взаимодействии с пользователем, отображаются в обобщенный (или менее персонализированный) источник знаний для его персонализации на основе связанной с взаимодействием с пользователем информации. Из персонализированного источника знаний определяются последовательности намерений для модели последовательностей намерений.
[21] Кроме того, при создании персонализированного источника знаний могут использоваться различные личные источники информации для пользователя и более обобщенные (менее персонализированные) источники знаний, например базы данных доменов и графы знаний. В некоторых вариантах осуществления персонализированные источники знаний могут использоваться в качестве персонализированных моделей языков, например, путем обучения модели языка на запросах, соответствующих сущностям или парам сущностей, которые появляются в информации об истории использования у пользователя. Персонализированные источники знаний также могут использоваться для определения моделей последовательностей намерений путем определения последовательностей (или шаблонов) сущностей и пар сущностей, соответствующих последовательностям или шаблонам информации о взаимодействии с пользователем из информации об истории использования. Вероятности, ассоциированные с переходами намерений в модели последовательностей намерений, можно затем использовать для регулирования взвешивания персонализированных моделей языков, посредством этого создавая модель контекста сеанса.
[22] Некоторые варианты осуществления дополнительно включают в себя приспособление источника знаний к моделированию контекста сеанса глобально для всех пользователей или только для определенной группы пользователей. Например, персонализированные источники знаний могут использоваться для идентификации пользователей с похожими интересами или намерениями, например, путем кластеризации. Таким образом, модели контекста сеанса можно строить на основе характеристик совокупности, общих для похожих пользователей. Кроме того, источник знаний, персонализированный для целевого пользователя, можно расширить или улучшить на основе источников знаний, персонализированных для похожих пользователей. Таким образом, там, где личная история использования для нового пользователя разрежена или неизвестна, информацию от похожих пользователей, включая, например, информацию о сущности, парах сущность-связь, намерениях или популярности сущности, можно использовать для обучения модели контекста сеанса для нового пользователя.
[23] Обращаясь теперь к фиг. 1, предоставляется блок-схема, показывающая аспекты примерной архитектуры системы, подходящей для реализации варианта осуществления изобретения и обозначенной в целом как система 100. Нужно понимать, что эта и другие компоновки, описанные в этом документе, излагаются только в качестве примеров. Таким образом, система 100 представляет только один пример подходящих архитектур вычислительных систем. Другие компоновки и элементы (например, пользовательские устройства, хранилища данных и т. п.) могут использоваться в дополнение к показанным или вместо них, и некоторые элементы могут вообще не включаться для ясности. Более того, многие элементы, описанные в этом документе, являются функциональными сущностями, которые могут быть реализованы как обособленные или распределенные компоненты либо в сочетании с другими компонентами, и в любом подходящем сочетании и расположении. Различные функции, описанные в этом документе как выполняемые одним или несколькими сущностями, могут выполняться аппаратными средствами, микропрограммным обеспечением и/или программным обеспечением. Например, некоторые функции могут выполняться процессором, исполняющим инструкции, сохраненные в запоминающем устройстве.
[24] Среди прочих не показанных компонентов система 100 включает в себя сеть 115, коммуникационно соединенную с одним или несколькими пользовательскими устройствами (например, элементами 102 и 104), хранилищем 106 и генератором 120 персонализированного источника знаний. Показанные на фиг. 1 компоненты можно реализовать с использованием одного или более вычислительных устройств, например вычислительного устройства 1000, описанного в связи с фиг. 10. Сеть 115 может включать в себя одну или более локальных сетей (LAN) и/или глобальных сетей (WAN) без ограничения. Такие сетевые среды - обычное явление в офисах, корпоративных компьютерных сетях, сетях интранет и в Интернете. Следует понимать, что в рамках объема настоящего изобретения в системе 100 может применяться любое количество пользовательских устройств, компонентов хранения и генераторов персонализированных источников знаний. Каждый может быть выполнен в виде одиночного устройства или более устройств, сотрудничающих в распределенной среде. Например, генератор 120 персонализированного источника знаний может предоставляться посредством нескольких устройств, организованных в распределенную среду, которые вместе предоставляют описанные в этом документе функциональные возможности. Более того, другие не показанные компоненты также могут включаться в сетевую среду. Например, также может предоставляться хранилище данных графа знаний для отдельного хранения графов знаний, к которому можно легко обращаться посредством описанных в этом документе вариантов осуществления.
[25] Примерные пользовательские устройства 102 и 104 выполнены в виде любого типа пользовательского устройства, допускающего приема ввода от пользователя, например, описанного ниже. Хотя фиг. 1 показывает два примерных пользовательских устройства 102 и 104, пользователь может ассоциироваться только с одним пользовательским устройством или более чем с двумя устройствами. В некоторых вариантах осуществления пользовательское устройство, принимающее ввод от пользователя, ассоциируется с идентификатором пользователя для пользователя.
[26] В одном варианте осуществления пользовательские устройства 102 и 104 могут иметь тип вычислительного устройства, описанного в этом документе относительно фиг. 10. В качестве примера, а не ограничения, пользовательское устройство можно воплотить в виде персонального цифрового помощника (PDA), мобильного устройства, переносного компьютера, планшета, пульта дистанционного управления, развлекательной системы, компьютерной системы транспортного средства, встраиваемого контроллера системы, бытового прибора, бытовой электроники или другого электронного устройства, допускающего прием ввода от пользователя. Ввод может приниматься одной из многих различных модальностей, таких как (в качестве примера, а не ограничения) голос или звук, текст, касание, нажатие, жесты, физическая среда пользователя или другие технологии ввода, описанные в связи с фиг. 10. Например, пользователь может использовать поисковую систему в сеансе для ввода одного или более запросов, намереваясь принять релевантную тем запросам информацию. Либо пользователь может взаимодействовать с одним или несколькими веб-сайтами социальных сетей и предоставлять ввод, которым пользователь намеревается поделиться с друзьями или даже посторонними. Пользователь также может взаимодействовать с веб-сайтами социальных сетей, указывающими, что пользователь прочитал и отмечает понравившимся сообщение другого пользователя. Еще пользователь может использовать голосовые команды с игровой системой, телевизором и т. п. Все эти виды ввода, а также другие, конкретно не упомянутые в этом документе, рассматриваются как входящие в объем настоящего изобретения.
[27] Хранилище 106 хранит, как правило, один или более источников 107 знаний и личных источников 109, которые в одном варианте осуществления используются для построения моделей контекста сеанса для приспособления моделей языков, чтобы улучшать распознавание речи, например, чтобы точно определять вероятность следующего фрагмента речи пользователя. В некоторых вариантах осуществления одна или более моделей (не показаны), включая модели, построенные из источников 107 знаний, и/или модели, построенные из источников 107 знаний и личных источников 109, также хранятся в хранилище 106. Кроме того, хотя изображено в виде одного компонента хранения данных, хранилище 106 можно воплотить в виде одного или более хранилищ данных, либо оно может находиться в облаке.
[28] Источники 107 знаний в одном варианте осуществления включают в себя реляционные базы данных, включающие базы данных доменов, базы знаний, графы знаний или аналогичные источники информации. В одном варианте осуществления источники 107 знаний выполнены в виде структурированной базы семантических знаний, например Семантической Сети. Для справки: Семантическую Сеть (или аналогичные структурированные базы знаний, или семантические графы масштаба Сети) можно представить с использованием Среды описания ресурса (RDF), которая является структурой ассоциации на основе триплетов, которая обычно включает в себя две сущности, связанные некоторым отношением, и похожа на общеизвестную предикатно-аргументную структуру. Примером был бы "directed_by (Avatar, James Cameron)". Так как использование и популярность RDF выросли, появились хранилища триплетов (называемые базами знаний или графами знаний), охватывающие различные области, например Freebase.org. В одном варианте осуществления источники 107 знаний включают в себя один или более графов знаний (или графов отношений), которые включают в себя наборы триплетов, указывающие отношение между двумя сущностями (например, Аватар - кто режиссер - Джеймс Кэмерон), и которые можно собирать в структуру графа. На фиг. 2 предоставляется примерный граф знаний, который иллюстрирует примерные сущности и их отношения и будет подробнее обсуждаться в этом документе.
[29] В одном случае источник знаний идентифицирует по меньшей мере одну сущность. При использовании в данном документе термин "сущность" в широком понимании включает в себя любой тип элемента, включая понятие или объект, который имеет возможные отношения с другими элементами. Например, сущность могла бы быть фильмом "Жизнь прекрасна", режиссером "Роберто Бениньи" или наградой "Оскар". Коллекции сущностей, имеющие похожее синтаксическое или семантическое значение, содержат типы сущностей (например, названия фильмов, песни, выражения времени и т. п.). Кроме того, связанные типы сущностей можно организовать в области, которые можно рассматривать как категорию сущностей, например фильмы, упражнение, музыка, спорт, предприятия, изделия, организации и т. п. Например, в области фильмов фильм "Жизнь прекрасна" снял режиссер "Роберто Бениньи", и фильм также получил Оскара.
[30] Личные источники 109 включают в себя один или более источников информации для пользователя. В качестве примера, а не ограничения, такая пользовательская информация может включать в себя журналы запросов пользователя, включающие отправленные запросы, результаты запросов и/или выбранные результаты; посещенные веб-сайты и история обозревателя; история онлайн-покупок; взаимодействия в социальных сетях; и другая информация о взаимодействии с пользователем или история использования. В одном варианте осуществления пользовательская информация включает в себя действия, предпринятые на пользовательском устройстве (например, элементах 102 или 104), которые можно соотнести с ID пользователя.
[31] Хранилище 106 также может хранить персонализированные источники знаний или расширенные персонализированные источники знаний, сформированные в соответствии с описанными в этом документе вариантами осуществления. Например, как будет описываться дополнительно, персонализированный источник знаний настраивается для конкретного пользователя и может использоваться для определения модели контекста сеанса для пользователя, а также для приспособления модели языка для улучшения распознавания речи для того конкретного пользователя. Расширенный персонализированный источник знаний настраивается для конкретного пользователя, но также включает в себя отображения от других пользователей, обладающих интересами, сходными с пользователем, ассоциированным с персонализированным источником знаний. Когда в этом документе ссылаются на отображения, ссылаются на процесс излечения данных из одного или более личных источников и их согласования или отображения в источник знаний.
[32] В одном варианте осуществления, где данные включают в себя определенную сущность или тип сущности, можно идентифицировать ту сущность или тип сущности в персонализированном источнике знаний, например графе знаний, и к той сущности или типу сущности добавляется подсчет. Таким образом, персонализированный источник знаний становится вероятностным персонализированным источником знаний. Например, если данные включают в себя название фильма "Жизнь прекрасна", то это название фильма находят в персонализированном графе знаний пользователя, и текущий подсчет у той сущности увеличивается на единицу. Другие способы отображения также рассматриваются как входящие в объем вариантов осуществления изобретения. Например, может использоваться некий алгоритм для предоставления или вычисления веса для каждой сущности и/или типа сущности. В таких вариантах осуществления алгоритм может использовать способ взаимно-однозначного подсчета либо может учитывать разные факторы, например, из какого источника упоминалась сущность или тип сущности, как пользователь указал интерес к той сущности или типу сущности, и т. п. В одном варианте осуществления, где расширяется персонализированный источник знаний целевого пользователя, может использоваться взвешивание из персонализированного источника знаний для масштабирования подсчетов некоторых N-грамм, поступающих из запросов других пользователей, чтобы представлялись, кроме того, интересы или намерения целевого пользователя.
[33] Генератор 120 персонализированного источника знаний содержит компонент 122 сбора истории пользователя, компонент 124 анализа истории пользователя, компонент 126 расширения источника знаний, компонент 128 отображения и компонент 130 определения последовательностей намерений. В некоторых вариантах осуществления генератор 120 персонализированного источника знаний может включать в себя меньшее количество компонентов, например, компонент 124 анализа, компонент 128 отображения и компонент 130 определения последовательностей намерений. Как показано в варианте осуществления из фиг. 1, генератор 120 персонализированного источника знаний конфигурируется для формирования персонализированных источников знаний, при этом расширенные персонализированные источники знаний используют личные исходные данные от конкретного пользователя или от других пользователей, определенных как похожие на конкретного пользователя, и для определения последовательностей намерений в отображенной информации о взаимодействии с пользователем, которые могут использоваться для модели последовательностей намерений. В одном варианте осуществления генератор 120 персонализированного источника знаний можно реализовать на одном или более пользовательских устройствах, например пользовательских устройствах 102 и 104, на сервере или серверном компоненте (не показан) либо на распределенной платформе (не показана) в облаке.
[34] На верхнем уровне персонализированный источник знаний в одном варианте осуществления создается путем отображения личных исходных данных в обобщенный (неперсонализированный) источник знаний либо персонализированный источник знаний, который можно персонализировать дополнительно. В частности, компонент 122 сбора истории пользователя конфигурируется для извлечения или иного сбора персонализированной истории пользователя для конкретного пользователя. Эта персонализированная история пользователя может собираться из ряда личных источников 109. В одном варианте осуществления может использоваться любой источник при условии, что его можно связать с конкретным пользователем, например источник, требующий идентификации пользователя или иным образом ассоциированный с конкретным пользователем. Сбор данных из таких источников позволяет системе собирать личные интересы и намерения пользователя, которые затем можно использовать для моделирования контекстов сеансов и предсказания или определения правдоподобия неизвестных запросов (например, голосовых запросов) для использования при персонализированном моделировании языка. Поэтому понимание интересов и намерений пользователя помогает предсказывать, чем может интересоваться пользователь, или о чем пользователь может спросить в будущих запросах.
[35] В дополнение к истории пользователя, ассоциированной только с конкретным пользователем, компонент 122 сбора истории пользователя в некоторых вариантах осуществления также отвечает за сбор истории по отношению к другим пользователям, похожим на конкретного пользователя, например другим пользователям с похожей историей пользователя, включая их интересы, намерения и/или последовательности намерений. В частности, там, где история пользователя для конкретного пользователя разрежена или неизвестна, может быть полезно подкрепить персонализированный источник знаний пользователя данными от других пользователей, которые разделяют интересы, намерения или последовательности намерений, похожие на того конкретного пользователя. В качестве примера, а не ограничения, можно определить, что конкретный пользователь сильно интересуется фильмами в целом и часто ищет в Сети информацию об актерском составе для различных фильмов. Более того, история пользователя для этого пользователя указывает, что пользователь имеет склонность время от времени покупать фильмы. Поэтому там, где определяется, что другой пользователь или группа пользователей обладают похожими интересами к фильмам, ищут актерские составы фильмов и также имеют склонность покупать фильмы, данные из истории другого пользователя или группы пользователей можно отобразить в персонализированный источник знаний, ассоциированный с конкретным пользователем, чтобы подкрепить пригодность персонализированного источника знаний для распознавания речи. Также там, где определяется, что другой пользователь или группа пользователей обладают похожими последовательностями намерений, данные из истории другого пользователя или группы пользователей можно отобразить в персонализированный источник знаний, ассоциированный с конкретным пользователем.
[36] Компонент 124 анализа истории пользователя в целом конфигурируется для анализа вероятных больших объемов данных, извлеченных или собранных компонентом 122 сбора истории пользователя, чтобы идентифицировать любую связанную с сущностью или связанную с действием пользователя информацию, включая события взаимодействия с пользователем. Взаимодействия с пользователем или действия при использовании в данном документе относятся к действию, предпринятому пользователем, которое может предоставлять информацию о намерении пользователя и уровне интереса пользователя, ассоциированных с конкретной сущностью и/или типом сущности. Событие взаимодействия с пользователем относится к определенному взаимодействию с пользователем. Например, продолжая с вышеприведенным примером, если пользователь интересуется фильмами и имеет склонность совершать нерегулярные покупки фильмов через веб-сайт, то действие совершения покупок фильмов можно идентифицировать, проанализировать и отобразить в личный источник знаний пользователя.
[37] Связанная с действием пользователя информация может быть особенно полезна для расширения персонализированного графа знаний пользователя с использованием данных от других пользователей, потому что действия можно использовать для определения, обладают ли другие пользователи интересами или намерениями, похожими на таковые у конкретного пользователя. Другое примерное действие пользователя включает в себя пользователя, предоставляющего указание, что ему или ей "нравится" некоторый элемент (например, общественный деятель, знаменитость, книга, фильм, сообщение от другого пользователя), например, на сайте социальных сетей. В некоторых вариантах осуществления сущности, ассоциированные со всем, что "понравилось" пользователю, можно идентифицировать с помощью компонента 124 анализа истории пользователя.
[38] В дополнение к анализу персонализированной истории пользователя, ассоциированной с конкретным пользователем, компонент 124 анализа истории пользователя в некоторых вариантах осуществления также отвечает за анализ данных, ассоциированных с другими пользователями с интересами и/или намерениями, похожими на конкретного пользователя, как описано в этом документе. В таких вариантах осуществления проанализированные данные, ассоциированные с другими пользователями, затем можно отобразить в персонализированный граф знаний конкретного пользователя.
[39] Компонент 126 расширения источника знаний конфигурируется для определения, следует ли расширять персонализированный источник знаний конкретного пользователя, и в некоторых вариантах осуществления - как его можно расширить и до какой степени. В одном варианте осуществления, где персонализированный источник знаний пользователя не сильно заполнен отображениями информации из истории пользователя, например, если подсчеты или веса сущностей в источнике знаний не особенно высоки или не соответствуют пороговой величине, то можно определить, что персонализированный источник знаний пользователя следует расширять. Компонент 126 расширения источника знаний также может отвечать за определение, как следует расширять личный источник знаний. Один аспект этого определения может включать в себя идентификацию других пользователей или групп пользователей, которые похожи на конкретного пользователя. В одном варианте осуществления похожие пользователи могут иметь общие характеристики совокупности, например интерес к определенной области, типы выполненных запросов (например, поиск актерского состава фильмов), действия пользователя (например, покупка фильмов), последовательности намерений (или шаблоны, включая последовательности типов намерений), и т. п.
[40] В одном варианте осуществления расширение личного источника знаний включает в себя взвешивание сущностей и отношений между сущностями в персонализированном источнике знаний целевого пользователя. Взвешивание может основываться на количестве раз, которое определенные сущности и отношения были отображены из данных истории пользователя. Похожее взвешивание может применяться по отношению к персонализированным источникам знаний других пользователей. Если сущности и отношения между сущностями в определенной части персонализированного источника знаний целевого пользователя имеют вес (например, соответствуют минимальной пороговой величине взвешенных значений), аналогичный таким же сущностям и отношениям между сущностями в такой же части персонализированных источников знаний других пользователей, то можно определить, что конкретный пользователь и другие пользователи обладают похожим интересом к предмету из той части графа знаний.
[41] В другом варианте осуществления используется популярность сущностей в источнике знаний вместо или в дополнение к подсчету того, сколько раз была отображена сущность. Например, там, где определенная сущность обладает особенно высокой популярностью (например, ее часто запрашивают, упоминают, публикуют на сайтах социальных сетей) для группы других пользователей, можно предсказать, что конкретный пользователь также имеет интерес к той популярной сущности. Соответственно, персонализированный источник знаний конкретного пользователя можно расширить в отношении той сущности, и он может включать в себя указание, что конкретный пользователь интересуется (или, скорее всего, интересуется) частью персонализированного источника знаний для той сущности.
[42] В еще одном варианте осуществления персонализированный источник знаний пользователя может использоваться для определения уровня интереса пользователя к первой части персонализированного источника знаний, например к конкретной сущности или отношению между сущностями. Например, определение уровня интереса может содержать определение, соответствует ли пользователь некоторой пороговой величине, указывающей правдоподобие того, что пользователь (или другие пользователи) интересуется некоторой частью источника знаний. В качестве альтернативы или в дополнение может быть несколько уровней интереса, которым можно соответствовать для количественного выражения интереса пользователя к части источника знаний.
[43] Компонент 128 отображения в генераторе 120 персонализированного источника знаний конфигурируется для отображения данных в источник знаний. Как описано в этом документе, компонент 124 анализа истории пользователя, как правило, идентифицирует и извлекает из личных источников данные истории пользователя, например сущности и действия пользователя. Эти данные затем отображаются в источник знаний, посредством этого приспосабливая или персонализируя источник знаний для пользователя. Отображение этих данных может происходить разными способами. Например, как описано выше, каждый раз, когда конкретная сущность или тип сущности идентифицируется в личной информации об истории пользователя, можно увеличить подсчет для той сущности или типа сущности в источнике знаний, так что в любой конкретный момент сущность или тип сущности имеет ассоциированный с ней (с ним) подсчет. Таким образом, если сущность была отображена десять раз, то ассоциированный с сущностью подсчет в персонализированном источнике знаний может быть равен 10. Либо в одном варианте осуществления в качестве альтернативы может использоваться алгоритм для вычисления веса для каждой сущности вместо взаимно-однозначного подсчета. Алгоритм может учитывать другие факторы, например, где и/или как сущность (или тип сущности) упоминается или иным образом связывается с пользователем или контекстом. Соответственно, при использовании в данном документе термины "отображение", "отображенный в" или "согласованный" используются в широком смысле для обозначения увеличения подсчета, взвешивания или создания ассоциации с сущностью, отношением, парой сущность-сущность или типом сущности в источнике знаний или другом индикаторе для представления интереса пользователя к определенной части источника знаний на основе информации об истории пользователя.
[44] Компонент 130 определения последовательностей намерений конфигурируется для определения последовательностей или шаблонов намерений пользователя (включая области). При использовании в данном документе термин "последовательности намерений" содержит последовательность или шаблон одного или более намерений пользователя или типов намерений, которые можно представить одной или несколькими областями.
[45] В некоторых вариантах осуществления может допускаться, что пользователи будут часто взаимодействовать с диалоговыми системами в соответствии с их общими намерениями, чтобы выполнить некую задачу (например, организация действий на вечер пятницы). Таким образом, пользователи в определенном сеансе, вероятно, будут придерживаться похожих последовательностей намерений или типов намерений. Для разных пользователей аргументы намерений могли бы отличаться, однако они могут использовать похожие последовательности типов намерений (например, сначала бронируя обед, затем проверяя расписания фильмов или баров с "живой" музыкой, отправляя электронное письмо друзьям, чтобы поделиться подробностями планов, и т. п.). Соответственно, собирая последовательности намерений пользователей более высокого уровня, например, путем отображения последовательностей или шаблонов информации о взаимодействии с пользователем, которые можно принимать из их журналов сеансов, можно создавать модели, например модели последовательностей намерений, которые предвидят похожие намерения, но с другими аргументами (например, такими аргументами, как определенные сущности или определенные отношения, которые не появлялись в журналах сеансов или другой информации об истории использования).
[46] В варианте осуществления последовательности намерений определяются на основе последовательностей или шаблонов взаимодействий с пользователем в информации о сеансе пользователя, присутствующей в данных, отображенных в источник знаний. Как описывалось ранее, отображенные в источник знаний данные могут включать в себя информацию о взаимодействии с пользователем, например, события взаимодействия с пользователем из одного или более сеансов между пользователем и прикладным устройством. Из отображения, выполняемого компонентом 128 отображения, могут определяться вероятные намерения пользователя, ассоциированные с каждым отображенным событием взаимодействия с пользователем. В варианте осуществления вероятные намерения пользователя определяются на основе семантических отношений (например, одной или более сущностей, типов сущностей или отношений) и/или другой информации в источнике знаний, соответствующей отображенной информации о взаимодействии с пользователем, например области того подпространства источника знаний. Таким образом, последовательность или шаблон намерений пользователя может определяться на основе последовательности или шаблона отображенных взаимодействий с пользователем. В одном варианте осуществления последовательности или шаблоны намерений используются компонентом 130 для формирования модели последовательностей намерений, которая включает в себя статистики для переходов намерений или областей в последовательности или шаблоне. Например, в одном варианте осуществления статистики могут содержать набор вероятностей переходов намерений, который представляет собой вероятность следующего намерения пользователя (или последующих намерений пользователя), принимая во внимание одно или более идущих намерений. Кроме того, как дополнительно описано в связи с фиг. 3, вероятности переходов в модели последовательности намерений могут использоваться для построения или приспособления персонализированных моделей языков или моделей SLU, включая формирование и интерполяцию моделей языков и SLU в реальном масштабе времени, посредством этого создавая модель контекста сеанса.
[47] Обращаясь теперь к фиг. 2, изображаются аспекты персонализированного источника знаний в соответствии с вариантами осуществления изобретения. В качестве примера персонализированный источник знаний из фиг. 2 содержит персонализированный граф знаний и в целом называется графом 200 знаний. Граф 200 знаний представляет один пример источника знаний, который можно персонализировать для конкретного пользователя. В частности, как описано ниже, фиг. 2 иллюстрирует пример согласования информации об истории пользователя (в этом случае - прошлых фрагментов речи пользователя) с графом 200 знаний и взвешивания отношений на графе в соответствии с личными статистиками использования из истории пользователя.
[48] Граф знаний можно разделить на несколько частей, при этом каждая часть называется подграфом. На фиг. 2 показаны два подграфа примерного графа 200 знаний: часть, соответствующая области 202 фильмов, и часть, соответствующая области 204 книг. Для ясности область 202 фильмов и область 204 книг показывают только подмножество сущностей и отношений между сущностями в области. В частности, область 202 фильмов показана в центре сущности фильма "Жизнь прекрасна", а область книг 204 показана в центре сущности книги "Левиафан". Как указывают три точки (элементы 214 и 216), присутствуют и другие подразделы графа знаний (например, другие фильмы, другие книги), но они не показаны.
[49] Также на фиг. 2 показан прямоугольник 206 с информацией об истории пользователя. В этом примере информация об истории пользователя включает в себя прошлые взаимодействия с пользователем, например идущий запрос, отправленный пользователем, спрашивающим о фильмах режиссера Роберто Бениньи. Здесь сущность "Роберто Бениньи" и отношение сущности "режиссер" идентифицируются из фрагмента речи пользователя и отображаются (стрелка 209) в граф 200 знаний. Второй пример показывает действие пользователя, указывающее, что пользователь купил копию фильма "Жизнь прекрасна". Стрелка 211 показывает, как это действие пользователя согласуется с сущностью "Жизнь прекрасна" на графе 200 знаний. Аналогичным образом прямоугольник 206 показывает примеры других запросов пользователя, которые могут поступать из одного или более журналов запросов, ассоциированных с пользователем. Эти запросы включают в себя, например, запрос фильмов, получивших "Оскара". Здесь "Оскар" можно идентифицировать как сущность и отобразить в сущность 210 "Оскар, лучшая мужская роль" на графе знаний и/или, как здесь показано, в отношение сущность-сущность "награда", соединенное с сущностью 210 "Оскар, лучшая мужская роль", потому что намерение пользователя состоит в установлении фильмов, которым присужден Оскар. Следующий пример представляет запрос из журнала запросов настольного ПК (или пользовательского устройства), который включает в себя прошлые запросы от пользователя, выполненные на пользовательском устройстве. Здесь пользователь искал книги, сохраненные локально на его или ее пользовательском устройстве, которые являются беллетристикой. Таким образом, "беллетристика" распознается как сущность, и ее можно отобразить в сущность беллетристики и/или в отношение сущности "жанр", соединенное с беллетристикой, поскольку намерение пользователя состояло в нахождении книг, которые относятся к беллетристике.
[50] Наконец, предоставляется примерное событие взаимодействия с пользователем у пользователя, отправляющего запрос "книги Пола Остера". Как показано, сущность "Пол Остер" можно отобразить в персонализированный граф знаний пользователя как сущность или как отношение между книгой (сущность) "Левиафан", имеющей автора (сущность) "Пол Остер". Таким образом, в результате отображения в граф 200 знаний примерной информации об истории пользователя, предоставленной в прямоугольнике 206, граф 200 знаний становится персонализированным для пользователя.
[51] Как дополнительно показано на фиг. 2, некоторые сущности, например "Премия Медичи" 208, "Роберто Бениньи" 212 и "Оскар, лучшая мужская роль" 210, могут определяться как более интересующие этого конкретного пользователя, что указано овальными формами, помещаемыми под сущность каждый раз (например, представляя собой подсчет), когда происходит отображение в ту сущность. В качестве альтернативы подсчеты или веса, ассоциированные с некоторыми сущностями, парами сущность-сущность или отношениями, могут предоставлять другое указание (например, ассоциированное значение), что пользователь интересуется теми сущностями, парами сущность-сущность или отношениями.
[52] Со ссылкой на фиг. 3 предоставляется пример, показывающий один аспект модели контекста сеанса на основе персонализированного графа 300 знаний. Фиг. 3 изображает три подграфа персонализированного графа 300 знаний, причем каждый подграф включает в себя различные сущности и отношения сущностей (например, пару сущностей 313 и 317, связанных в соответствии со стрелкой 314), например, описанные в связи с фиг. 2. Фиг. 3 также изображает первую часть 305 графа знаний, показывающую семантическое отношение 304 между сущностями 303 и 307, и набор вторых частей 315, 325 и 335 графа знаний, показывающий семантические отношения 314, 324 и 334 соответственно между сущностями 313 и 317, 323 и 327, и 333 и 337.
[53] Каждая часть 305, 315, 325 и 335 соответствует отображению события взаимодействия с пользователем из отображенной информации об истории пользователя и представляет собой семантическое отношение на графе знаний. Из каждого отображения можно определить вероятное намерение пользователя, ассоциированное с отображенным событием взаимодействия с пользователем, на основе семантического отношения (отношений), например одной или более сущностей, типа (типов) сущностей или отношения (отношений), и/или на основе другой информации, которая может присутствовать в источнике знаний, соответствующем местоположению отображенного события. Таким образом, каждая часть 305, 315, 325 и 335 также соответствует вероятному намерению пользователя для отображенной информации о взаимодействии с пользователем.
[54] Как описано в связи с фиг. 1, в некоторых вариантах осуществления изобретения последовательность намерений может определяться (например, компонентом 130 определения последовательностей намерений) на основе последовательностей или шаблонов информации о взаимодействии с пользователем в информации о сеансе пользователя, присутствующей в данных, отображенных в персонализированный источник знаний. Соответственно, первая часть 305 графа 300 знаний соответствует первому намерению на основе первого события взаимодействия с пользователем (отображенного в источник знаний), а части 315, 325 и 335 соответствуют второму намерению (посредством этого создавая набор вторых намерений) на основе второго события взаимодействия с пользователем, происходящего после первого события взаимодействия с пользователем в сеансе. Стрелки 310, 320 и 330 указывают переходы от первого намерения (соответствующего части 305) к набору вторых намерений (части 315, 325 и 335 соответственно) и могут представляться в виде вероятности или правдоподобия того, что конкретное второе намерение (например, второе намерение, соответствующее части 335) последует за первым намерением (соответствующим части 305). Набор переходов 310, 320 и 330 соответственно представляет собой набор вероятностей переходов намерений между первым намерением и вторым намерением и может использоваться для модели последовательности намерений.
[55] Предположим, например, что информация об истории пользователя включает в себя журнал запросов, который содержит один или более сеансов с отправленными пользователем запросами между пользователем и приложением персонального помощника, работающим на мобильном устройстве, причем каждый сеанс включает в себя последовательность запросов. Предположим, что десять из тех сеансов включают в себя отправленный пользователем запрос, спрашивающий о режиссере фильма (например, "Кто режиссер фильма "Жизнь прекрасна"?"). Предположим, что в трех из этих десяти сеансов следующий отправленный пользователем запрос спрашивал о национальности режиссера фильма; в пяти из этих десяти сеансов следующий отправленный пользователем запрос спрашивал об актерском составе фильма; и в двух из этих десяти сеансов следующий отправленный пользователем запрос спрашивал о наградах, которые получил фильм. Используя примерный персонализированный источник 300 знаний, можно определить набор вероятностей переходов намерений на основе этих последовательностей запросов. В частности, часть 305 соответствует первому намерению на основе первого события взаимодействия с пользователем (пользователь отправил запрос, связанный с режиссером фильма - то есть "Кто режиссер фильма "Жизнь прекрасна"?"). Части 315, 325 и 335 соответствуют второму намерению на основе второго взаимодействия с пользователем, происходящего после первого события взаимодействия с пользователем в сеансе. Здесь части 315, 325 и 335 пусть соответствуют отправленным позднее запросам о национальности режиссера, актерском составе и наградах соответственно. Поэтому вероятности переходов, ассоциированные со стрелками 310, 320 и 330, могут определяться как равные 0,3 (то есть в трех из десяти сеансов следующий запрос был о национальности режиссера), 0,5 (то есть следующий запрос был об актерском составе пять раз из десяти сеансов) и 0,2 (следующий запрос был о наградах в двух из 10 сеансов). Эти вероятности переходов (0,5, 0,3 и 0,2) могут использоваться для модели последовательностей намерений. (В этом случае модель содержала бы для ясности только два намерения в последовательности: первое намерение, соответствующее запросу о режиссере фильма, и второе намерение, соответствующее второму запросу о национальности режиссера, актерском составе фильма либо наградах фильма). Для этой модели последовательностей намерений, где первое намерение имеет отношение к режиссеру фильма, существует вероятность 0,3 того, что следующим намерением будет национальность режиссера, вероятность 0,5 того, что следующее намерение будет относиться к актерскому составу, и вероятность 0,2 того, что следующее намерение будет относиться к наградам. В некоторых вариантах осуществления модель последовательностей намерений представляет собой переходы от пар сущность-сущность к другим парам сущность-сущность (как показано на фиг. 3), от отношений к другим отношениям или от намерений/области к другим намерениям/области.
[56] На основе модели последовательностей намерений при необходимости можно интерполировать модели языков или модели SLU, посредством этого создавая модели контекста сеанса. Например, для данного источника знаний предположим, что веса, соответствующие сущностям и отношениям сущностей, одинаковы (то есть равномерные распределения). (Такое распределение может быть маловероятным, но предоставляется с целью объяснения). Таким образом, модель языка, которая основывается на этом источнике знаний, имела бы равные вероятности для всех возможных следующих фрагментов на основе идущего фрагмента. Предположим теперь, что источник знаний персонализируется с помощью информации о взаимодействии с пользователем, как описано выше, чтобы определить модель последовательностей намерений. Теперь веса можно регулировать на основе вероятностей переходов, ассоциированных с этой моделью последовательностей намерений. Таким образом, вероятности возможных следующих фрагментов изменяются на основе идущего фрагмента или фрагментов, посредством этого создавая модель контекста сеанса. Веса можно регулировать любым способом, известным в данной области техники. Например, в некоторых вариантах осуществления веса можно регулировать путем усреднения, например усреднения начального значения и значений соответствующих вероятностей переходов намерений. В некоторых вариантах осуществления веса можно регулировать путем уменьшения или увеличения значений на основе, соответственно, уменьшенных или увеличенных соответствующих вероятностей переходов намерений.
[57] В некоторых вариантах осуществления модель контекста сеанса формируется в реальном масштабе времени или при необходимости, когда модели языков или модели SLU интерполируются на основе модели последовательности намерений. В некоторых вариантах осуществления модель контекста сеанса определяется из персонализированного источника знаний, который изменен (например, путем регулирования взвешивания в узлах или отношениях), чтобы представлять переходы от пар сущность-сущность к другим парам сущность-сущность, от отношений к другим отношениям или от намерений/области к другим намерениям/области (то есть вероятности переходов). Модель контекста сеанса также можно воплотить в виде набора вероятностей переходов намерений, ассоциированного с источником знаний, так что для данной сущности или семантического отношения, идентифицированных из первой реплики, можно определить вероятную вторую реплику (или набор вероятных вторых реплик) с помощью модели контекста сеанса на основе вероятностей переходов намерений и взвешивания, ассоциированных с конкретной сущностью или семантическим отношением в источнике знаний. В некоторых вариантах осуществления модель контекста сеанса можно воплотить, например, в виде таблицы, ассоциированной с графом знаний, как часть реляционной базы данных, представляющей источник знаний, или набора вероятностей, ассоциированного с семантическими отношениями.
[58] Фиг. 4-9 предоставляют набор блок-схем алгоритмов, иллюстрирующих примерные варианты осуществления способа из изобретения. В частности, фиг. 4-6 ориентированы на способы для персонализации источника знаний для конкретного пользователя или набора пользователей на основе истории использования, которая может включать в себя информацию о взаимодействии с пользователем. Фиг. 7-9 ориентированы на способы включения информации о контексте сеанса, например данных из последовательности или шаблона взаимодействий с пользователем, в источник знаний (или с использованием источника знаний, персонализированного с помощью информации о контексте сеанса) для моделирования контекста сеанса. Предполагается, что любой из процессов, описанных в вариантах осуществления для персонализации источника знаний, обсуждаемых в связи с фиг. 4-6, может применяться к способам включения информации о контексте сеанса, обсуждаемым в связи с фиг. 7-9.
[59] Обращаясь теперь к фиг. 4, предоставляется блок-схема алгоритма, иллюстрирующая один примерный способ 400 для персонализации источника знаний для конкретного целевого пользователя на основе информации об истории пользователя. Персонализированный источник знаний, созданный в соответствии со способом 400, может использоваться для персонализации моделей языков для распознавания речи целевого пользователя, например путем предсказания будущих неизвестных запросов (например, голосовых запросов), отправляемых пользователем. Персонализированный источник знаний также может использоваться для создания модели последовательности намерений путем определения последовательностей (или шаблонов) сущностей и пар сущностей, соответствующих последовательностям или шаблонам информации о взаимодействии с пользователем из истории пользователя. Статистики, ассоциированные с переходами намерений в модели последовательностей намерений, можно затем использовать для регулирования взвешивания персонализированных моделей языков, посредством этого создавая модель контекста сеанса.
[60] Соответственно, на верхнем уровне варианты осуществления способа 400 сначала создают персонализированный источник знаний, используя различные личные источники информации для целевого пользователя, а также доступные источники знаний, которые могут включать в себя неперсонализированные источники знаний либо источники знаний, допускающие персонализацию для целевого пользователя. Информация, извлеченная из прошлых фрагментов, взаимодействий с пользователем и других личных источников информации об истории пользователя, согласуется с источником знаний. Например, основанное на сущностях сходство прошлых фрагментов речи пользователей с частями графа знаний можно идентифицировать и отобразить в те части. Можно отслеживать сущности и типы сущностей, которые появляются в истории пользователя, а их подсчеты можно использовать при построении персонализированных моделей языков. Один вариант осуществления дополнительно включает в себя использование заданных моделей понимания естественного языка для предметных областей, чтобы оценивать вероятность конкретной области, принимая во внимание прошлый фрагмент речи пользователя (или другой элемент данных пользователя), и/или вероятность намерения пользователя и конкретного отношения, принимая во внимание прошлый фрагмент речи пользователя.
P(область | прошлый фрагмент речи пользователя), P(намерение & отношение | прошлый фрагмент речи пользователя)
Вероятности могут использоваться для повышения подсчетов определенных частей источника знаний при построении персонализированных моделей языков, например, как показано на фиг. 2.
[61] Продолжая с фиг. 4, на этапе 410 информация об истории использования для целевого пользователя принимается из одного или более личных источников. история использования включает в себя данные, соотнесенные с целевым пользователем, которые собираются из одного или более личных источников, например личных источников 109, описанных в связи с фиг. 1; например, прошлые запросы пользователя из журналов запросов, взаимодействия с веб-сайтами, действия пользователя и т. п., выполняемые целевым пользователем посредством пользовательского устройства. Намерение пользователя можно вывести из прошлого поведения, которое представляется историей использования.
[62] В одном варианте осуществления история использования собирается и хранится в хранилище данных, например хранилище 106 из фиг. 1. Например, можно собирать и ассоциировать с пользователем место, где целевой пользователь входит в пользовательское устройство, приложение, работающее на устройстве, или определенный веб-сайт либо веб-службу, например поисковую систему, информацию об истории использования. В одном варианте осуществления можно хранить адреса или указатели на информацию об истории использования, чтобы на следующем этапе можно было принять историю использования и проанализировать определенную информацию из истории использования.
[63] На этапе 420 анализируется информация об истории использования, чтобы идентифицировать одну или более сущностей и/или действий пользователя, которые могут быть частью последовательности или шаблона взаимодействий с пользователем, например отправленные пользователем запросы, фрагменты речи или действия пользователя. В одном варианте осуществления этап 420 включает в себя извлечение сущностей, включая пары сущность-сущность и отношения сущностей, и/или действий пользователя из информации об истории использования, ассоциированной с целевым пользователем. В одном варианте осуществления проанализированная информация об истории использования идентифицирует одну или более последовательностей событий взаимодействия с пользователем.
[64] На этапе 430 проанализированные данные, например связанная с сущностью или связанная с действием пользователя информация из события взаимодействия с пользователем, отображаются в источник знаний, посредством этого создавая персонализированный источник знаний и указывая части источника знаний, представляющие наибольший интерес для целевого пользователя. Таким образом, личные интересы и намерения пользователя, которые представлены историей использования, собираются в персонализированный источник знаний, а затем могут использоваться для персонализированного моделирования языка, например, предсказания будущих неизвестных запросов (например, голосовых запросов). Например, фрагменты речи пользователя или прошлые взаимодействия целевого пользователя можно согласовать с графом знаний, например, описанным в связи с фиг. 2.
[65] В одном варианте осуществления этап 430 содержит приспособление существующих моделей языков, которые можно представить с помощью источника знаний, к истории использования у целевого пользователя, например, к прошлым фрагментам. Предполагая, что у пользователей обычно есть запросы для диалоговых систем в соответствии с их общими интересами, они могут повторять запросы из похожих областей и с похожими намерениями, но аргументы намерения отличаются. Соответственно, путем сбора интересов и намерений пользователя более высокого уровня, в некоторых вариантах осуществления включающих в себя последовательности намерений, можно создавать модели языков, которые предвидят похожие намерения, но с другими аргументами (то есть аргументами, которые не появляются в истории использования). В результате включения информации о последовательности намерений модели языков приспосабливаются к контекстам сеансов и, таким образом, становятся точнее. Как описано выше, в одном варианте осуществления это достигается путем идентификации основанных на сущностях сходствах истории использования с частями источника знаний и их отображения в соответствующую часть источника знаний. Таким образом, отслеживаются сущности и типы сущностей, которые появляются в истории пользователя, а их подсчеты используются при построении персонализированных моделей языков. В некоторых вариантах осуществления персонализированный источник знаний, определенный на этом этапе, представляет собой вероятностный источник знаний, потому что статистики использования из истории пользователя использовались для взвешивания отношений и сущностей источника знаний (или добавления к ним подсчетов).
[66] На этапе 440 персонализированный источник знаний может использоваться для персонализации (или обучения) модели языка для целевого пользователя. На верхнем уровне вариант осуществления этапа 440 может содержать включение персонализированного вероятностного источника знаний в персонализированную модель языка, например, путем обучения модели языка (например, N-граммы) на запросах, соответствующих сущностям или парам сущность-сущность, которые были идентифицированы в истории использования. Модель языка можно дополнительно обучить для целевого пользователя сначала путем обучения модели для запросов целевого пользователя, а затем ее интерполяции по запросам для той же сущности или пар сущность-сущность, поступающих от всех пользователей. В качестве альтернативы модель языка для всех пользователей, например универсальную модель языка (ULM), можно обучить для пространства источника знаний целевого пользователя. В обоих случаях веса из источника знаний целевого пользователя могут использоваться для масштабирования подсчетов некоторых N-грамм, поступающих из запросов других пользователей, чтобы представлялись, кроме того, интересы или намерения целевого пользователя.
[67] В некоторых вариантах осуществления персонализированный источник знаний используется для определения набора вероятностей переходов намерений путем определения последовательностей или шаблонов отображенной сущности или информации о действии пользователя, из которых можно вывести намерение пользователя. Вероятности переходов могут использоваться для регулирования весов (или подсчетов) отношений и сущностей источника знаний, посредством этого создавая модель контекста сеанса. Таким образом, персонализированные модели языков на основе источников знаний приспосабливаются к модели контекст сеанса.
[68] В одном варианте осуществления способа 400 анализируются персонализированные графы знаний, ассоциированные с другими пользователями. Из этих персонализированных графов знаний можно идентифицировать одного или более этих других пользователи как обладающего интересами и/или намерениями, похожими на целевого пользователя, например, отобразив сущности и отношения между сущностями в таковые у целевого пользователя. Таким образом, сущности и/или действия пользователя, ассоциированные с другими похожими пользователями, можно отобразить в персонализированный граф знаний целевого пользователя. Это дополняет персонализированный граф знаний целевого пользователя, так что персонализированная модель языка пользователя лучше подходит для улучшения распознавания речи. В одном варианте осуществления сходство интереса и/или намерения между двумя пользователями или группой пользователей может определяться путем сравнения двух пространств вероятностных графов знаний, ассоциированных с каждым пользователем или группой, где каждое пространство представляется вероятностным графом. Используя этот показатель сходства, можно оценить веса интерполяции для определения, какие веса будут использоваться для интерполяции персонализированного источника знаний целевого пользователя по источникам похожих пользователей или групп пользователей.
[69] Некоторые варианты осуществления способа 400 включают в себя использование взаимодействий в социальных сетях или других пользовательских введенных данных в аналогичных сетях для персонализации модели языка путем сбора, анализа и отображения этих взаимодействий в источник знаний, как описано выше. В некоторых вариантах осуществления источник знаний уже персонализирован для целевого пользователя и может быть дополнительно персонализирован или расширен путем отображения взаимодействия с социальными сетями. В таких вариантах осуществления или в вариантах осуществления, где персонализированный источник знаний целевого пользователя расширяется на основе сходства с другими пользователями, модели языков для других похожих пользователей или друзей в социальных сетях могут использоваться для интерполяции персонализированной модели языка целевого пользователя. Затем новая персонализированная модель языка может использоваться для предсказания будущих запросов целевого пользователя, предполагая, что друзья в социальных сетях окажут некоторое влияние на будущие запросы от целевого пользователя.
[70] Теперь со ссылкой на фиг. 5 предоставляется блок-схема алгоритма, иллюстрирующая примерный способ 500 для персонализации источника знаний для конкретного целевого пользователя на основе информации об истории пользователя и информации от похожих пользователей. Персонализированный источник знаний может использоваться для персонализации моделей языков для распознавания речи целевого пользователя, например, путем предсказания будущих неизвестных запросов, отправляемых целевым пользователем. Персонализированный источник знаний также может использоваться для создания модели контекста сеанса, которая описана в этом документе.
[71] На верхнем уровне варианты осуществления способа 500 могут использоваться для "расширения" источника знаний, персонализированного для целевого пользователя, путем включения информации из источников знаний, персонализированных для похожих пользователей и/или друзей в социальных сетях. Одним из способов, которым можно расширить персонализированный граф знаний, является использование известных личных взаимоотношений. Примерное отношение может включать в себя триплеты типа "работа в <компания>" или "является отцом <контакт>". Тогда подграфы графа знаний масштаба Сети, которые активизированы идущей историей использования, можно добавить к этому расширенному личному графу знаний. В таких вариантах осуществления узлы и ветви (например, сущности и отношения между сущностями на графе знаний) взвешиваются относительн об истории использования, чтобы обучение модели языка могло сразу извлечь выгоду. Затем эти веса могут определять веса N-граммы, используемой для активизации той части графа. Кроме того, как только пользователь получил расширенный персонализированный источник знаний, персонализированные источники знаний других пользователей можно использовать для улучшения источника знаний целевого пользователя. Например, модель языка целевого пользователя можно приспособить с использованием модели языка других пользователей с прежним весом на основе частоты контактов.
[72] Аналогичным образом персонализированный источник знаний можно расширить путем использования источников знаний других пользователей, похожих на целевого пользователя. Например, предполагая, что у каждого пользователя есть персонализированная модель языка, которая может предоставляться вероятностным персонализированным источником знаний, определенным на основе ег об истории использования и метаданных, например, описанных в связи с фиг. 4, можно создавать модели языков для разных характеристик совокупности пользователей. В одном варианте осуществления похожих пользователей можно идентифицировать путем кластеризации моделей языков, соответствующих персонализированным источникам знаний пользователей. Может применяться любое количество различных методик для кластеризации, известных специалистам в данной области техники. В одном варианте осуществления применяется восходящая кластеризация, при которой пара моделей языков, которые больше всего похожи друг на друга по отношению к некоторому показателю, объединяются итерационно (в одном варианте осуществления объединяются с равными весами). Может использоваться симметричное расстояние Кульбака-Лейблера, которое обычно используется для вычисления расстояния между двумя распределениями вероятностей, или похожий показатель. В другом варианте осуществления применяется кластеризация методом K-средних, где возможные модели языков сначала разделяются на N групп для N кластеров. Модель языка вычисляется с использованием линейной интерполяции моделей языков внутри ее. Каждая модель языка затем перемещается в группу, которая наиболее похожа, опять с использованием некоторого расстояния или показателя сходства.
[73] В качестве дополняющего подхода в некоторых вариантах осуществления в дополнение к лексической информации могут использоваться способы кластеризации на основе сходства графов для кластеризации персонализированных графов знаний, чтобы идентифицировать группы пользователей с похожими интересами или намерениями. Эти варианты осуществления, которые могут опираться на шаблоны действий пользователей, получают в результате семантически кластеризованных пользователей. В одном варианте осуществления могут использоваться способы для кластеризации записей базы данных, например скрытое семантическое индексирование (LSI). В некоторых случаях, где источник знаний является графом знаний, граф можно перевести в таблицы отношений семантических триплетов (отношение/пары сущностей, например "Кэмерон-режиссер-Аватар"). В этих вариантах осуществления вместо кластеризации элементов графа пользователи кластеризуются на основе их использования триплетов с помощью простого преобразования таблиц. Как только определяются кластеры, их можно использовать для предоставления более однородных моделей языков, потому что модели можно обучать на больших количествах похожих данных.
[74] Продолжая с фиг. 5, на этапе 510 из истории использования у целевого пользователя идентифицируется первый набор данных, содержащий по меньшей мере одну сущность или по меньшей мере одно действие пользователя. По меньшей мере одна сущность может включать в себя одну или более сущностей, пар сущность-сущность или отношений сущностей, соответствующих источнику знаний. В некоторых вариантах осуществления история использования из одного или более личных источников информации для целевого пользователя анализируется для идентификации первого набора данных, а в некоторых вариантах осуществления первый набор данных анализируется из истории использования, как описано на этапе 420 из фиг. 4.
[75] На этапе 520 первый набор данных отображается в персонализированный источник знаний для целевого пользователя. В варианте осуществления источник знаний выполнен в виде обобщенного (неперсонализированного) источника знаний, который становится персонализированным после отображения первого набора данных. В качестве альтернативы в другом варианте осуществления первый набор данных отображается в источник знаний, который уже персонализирован для целевого пользователя, например, персонализированный источник знаний, созданный в соответствии со способом 400 из фиг. 4. В вариантах осуществления первый набор данных, который содержит по меньшей мере одну сущность или действие пользователя, можно отобразить, как описано на этапе 430 из фиг. 4.
[76] На этапе 530 определяется набор пользователей, похожих на целевого пользователя. В одном варианте осуществления один или более похожих пользователей определяются путем кластеризации, например, описанной выше. В одном варианте осуществления этап 530 включает в себя взвешивание сущностей и отношений между сущностями в персонализированном источнике знаний целевого пользователя. Взвешивание может основываться на количестве раз, которое определенные сущности и отношения были отображены из данных истории пользователя. Похожее взвешивание может применяться по отношению к персонализированным источникам знаний других пользователей. Если сущности и отношения между сущностями в определенной части персонализированного источника знаний целевого пользователя имеют вес (например, соответствуют минимальной пороговой величине взвешенных значений), аналогичный таким же сущностям и отношениям между сущностями в такой же части персонализированных источников знаний других пользователей, то можно определить, что целевой пользователь и другие пользователи обладают похожим интересом к предмету из той части графа знаний.
[77] В другом варианте осуществления используется популярность сущностей в источнике знаний вместо подсчета того, сколько раз была отображена сущность. Например, если определенная сущность обладает особенно высокой популярностью (например, ее часто запрашивают, упоминают, публикуют на сайтах социальных сетей) для группы друзей целевого пользователя в социальных сетях, то может увеличиться правдоподобие того, что целевой пользователь также имеет интерес к той популярной сущности. Соответственно, персонализированный источник знаний целевого пользователя можно расширить (как описано на этапе 540) в отношении той сущности, и он может включать в себя указание, что конкретный пользователь интересуется (или, скорее всего, интересуется) частью персонализированного источника знаний для той сущности.
[78] В другом варианте осуществления уровень интереса целевого пользователя и других пользователей определяется с использованием персонализированного источника знаний целевого пользователя и персонализированных источников знаний других пользователей. Например, уровень интереса можно сравнить в первой части соответствующих источников знаний для определения, существуют ли похожие или частично совпадающие интересы между пользователями. В одном случае можно определить, соответствует ли определенный уровень интереса минимальной пороговой величине, а также то, что группа других пользователей обладает сопоставимым уровнем интереса к первой части источника знаний с уровнем интереса целевого пользователя. Хотя в одном варианте осуществления имеется одна пороговая величина, используемая для определения уровней интереса пользователей, в другом варианте осуществления используется больше одной пороговой величины, чтобы, например, имелась пороговая величина низкого уровня интереса, пороговая величина среднего уровня интереса, пороговая величина высокого уровня интереса и т. п. Пользователи, которые содержат набор пользователей, которые разделяют похожие интересы с целевым пользователем, в одном варианте осуществления обладают общими друг с другом интересами. Другие способы для определения сходства пользователей, конкретно не раскрытые в этом документе, рассматриваются как входящие в объем изобретения.
[79] На этапе 540 второй набор данных, соответствующий набору пользователей, похожих на целевого пользователя, отображается в персонализированный источник знаний целевого пользователя, посредством этого расширяя персонализированный источник знаний целевого пользователя. Второй набор данных содержит по меньшей мере одну сущность (включая пару сущность-сущность либо отношение сущности) или действие пользователя. В некоторых вариантах осуществления второй набор данных идентифицируется и извлекается из персонализированных источников знаний похожих пользователей. В одном варианте осуществления второй набор данных включает в себя информацию о сущности и/или связанные метаданные, которые чаще возникают в персонализированных источниках знаний в наборе похожих пользователей, что может определяться пороговой величиной. На этапе 550 персонализированный источник знаний для целевого пользователя, который расширен, используется для персонализации (или обучения) модели языка для целевого пользователя. Варианты осуществления этапа 450 похожи на варианты осуществления, описанные в связи с этапом 440 способа 400 (фиг. 4).
[80] Обращаясь к фиг. 6, предоставляется блок-схема алгоритма, иллюстрирующая примерный способ 600 для расширения графа знаний, персонализированного для целевого пользователя. Расширенный персонализированный граф знаний может использоваться для персонализации модели языка для целевого пользователя. Персонализированная модель языка может использоваться для распознавания речи целевого пользователя, например, путем предсказания будущих неизвестных запросов, отправляемых целевым пользователем.
[81] На этапе 610 агрегируется история использования из одного или более личных источников, ассоциированных с первым пользователем. история использования включает в себя данные, соотнесенные с первым пользователем, из одного или более личных источников, например личных источников 109, описанных в связи с фиг. 1. Например, прошлые запросы пользователя из журналов запросов, взаимодействия с веб-сайтами, действия пользователя и т. п., выполняемые первым пользователем посредством пользовательского устройства.
[82] На этапе 620 сущность и информация о действии пользователя извлекаются из агрегированной истории использования у первого пользователя. Сущность и информация о действии пользователя могут включать в себя одну или более сущностей, пар сущность-сущность, отношений сущностей или связанную с действием пользователя информацию. В одном варианте осуществления сущность и информация о действии пользователя анализируются из агрегированной истории использования, как описано на этапе 420 способа 400 (фиг. 4).
[83] На этапе 630 сущность и информация о действии пользователя, извлеченные на этапе 620, отображаются в первый граф знаний, ассоциированный с первым пользователем, посредством этого персонализируя первый граф знаний для того пользователя. В одном варианте осуществления операция отображения, выполняемая на этапе 630, похожа на операцию отображения, описанную на этапе 430 способа 400 (фиг. 4), где источник знаний является графом знаний.
[84] На этапе 640 определяется второй пользователь, похожий на первого пользователя. В одном варианте осуществления этап 640 содержит идентификацию второго пользователя, похожего на первого пользователя, путем определения, что персонализированный граф знаний для второго пользователя похож на персонализированный граф знаний первого пользователя. В одном варианте осуществления второй пользователь состоит в наборе похожих пользователей, определенных путем кластеризации или другими способами, как описано на этапе 530 способа 500 (фиг. 5). Как описывалось ранее, на основе определенного сходства между первым и вторым пользователем можно предсказать, что первый и второй пользователь, скорее всего, разделяют похожие интересы и намерения.
[85] На этапе 650 персонализированный граф знаний первого пользователя расширяется для включения информации из персонализированного графа знаний, ассоциированного со вторым (похожим) пользователем, определенным на этапе 640. В варианте осуществления этап 650 содержит отображение сущности или информации о действии пользователя из персонализированного графа знаний второго пользователя в персонализированный граф знаний первого пользователя. Некоторые варианты осуществления этапа 650 похожи на варианты осуществления, описанные в связи с этапом 540 способа 500 (фиг. 5), где источником знаний является граф знаний. В одном варианте осуществления второй персонализированный граф знаний развит лучше (включает в себя больше информации), нежели первый персонализированный граф знаний перед расширением первого графа. В некоторых вариантах осуществления способа 600 расширенный персонализированный граф знаний может использоваться для персонализации модели языка и/или модели контекста сеанса для первого пользователя, например, описанной на этапе 550 способа 500 (фиг. 5).
[86] Обращаясь к фиг. 7, предоставляется блок-схема алгоритма, иллюстрирующая примерный способ 700 для приспособления модели языка к контексту сеанса на основе истории пользователя. На верхнем уровне в одном варианте осуществления способ 700 включает в источник знаний информацию о контексте сеанса, например последовательности (или шаблоны) взаимодействий с пользователем из журналов сеансов пользователя. На основе последовательностей взаимодействий может определяться последовательность намерений или типов намерений более высокого уровня, соответствующих взаимодействиям, с помощью набора статистик переходов, представляющего правдоподобие того, что встретится конкретное, позднее возникающее намерение, принимая во внимание определенное идущее намерение. На основе этих статистик можно интерполировать веса, соответствующие сущностям и отношениям сущностей в источнике знаний, посредством этого создавая модель контекста сеанса. В варианте осуществления из модели контекста сеанса можно предоставить одну или более моделей языков на основе интерполированных теперь весов источника знаний.
[87] На этапе 710 информация об истории использования принимается из одного или более личных источников. Информация об истории использования включает в себя одну или более последовательностей или шаблонов событий взаимодействия с пользователем. В варианте осуществления информация об истории использования включает в себя комбинированные данные и может приниматься из одного или более журналов сеансов. В варианте осуществления информацию об истории использования можно проанализировать (например, как описано на этапе 420 из фиг. 4), чтобы определить одну или более последовательностей или шаблонов событий взаимодействия с пользователем.
[88] На этапе 720 для каждого события в одной или более последовательностях событий взаимодействия с пользователем определяется вероятное намерение пользователя, соответствующее событию. В варианте осуществления этап 720 содержит отображение события в источник знаний, например, описанное на этапе 430 (фиг. 4), и определение намерения на основе семантического отношения (отношений) или другой информации, ассоциированной с частью источника знаний при отображении. В варианте осуществления намерение можно вывести на основе информации о сущности и отношении, включающей в себя тип (типы) сущности и типы отношений или другую информацию о семантических отношениях, ассоциированную с частью источника знаний при отображении. В варианте осуществления намерение может определяться только для подмножества событий взаимодействия, например, событий взаимодействия в последовательностях, или содержащих определенные сущности, либо отношения сущностей, либо интерес, или подобных целевому пользователю. В варианте осуществления, где источник знаний не содержит сущности или отношения сущности, соответствующих отображаемому событию взаимодействия с пользователем, их можно добавить (либо, в случае графа знаний, можно создать узел (узлы) сущности и ветвь (ветви) отношения); например, на основе сущностей или отношений сущностей, идентифицированных в информации об истории использования, ассоциированной с событием. Например, если реплика пользователя спрашивает о режиссере недавно вышедшего фильма, который еще не включен в источник знаний, то можно вывести семантическое отношение режиссер-фильм, и в источник знаний можно добавить сущность, соответствующую фильму, и отношение "режиссер", ассоциированное с фильмом.
[89] На этапе 730 на основе намерения, определенного для каждого события взаимодействия с пользователем в одной или более последовательностях, определяется набор вероятностей переходов намерений. В варианте осуществления вероятность перехода представляет собой правдоподобие того, что конкретное намерение возникнет после идущего намерения. В варианте осуществления этапа 730 одна или более последовательностей намерений высокого уровня могут определяться на основе одной или более последовательностей событий взаимодействия с пользователем, где каждое намерение в последовательности намерений соответствует событию в последовательности событий взаимодействия с пользователем. Из одной или более этих последовательностей намерений может определяться набор вероятностей переходов намерений на основе вероятности определенного намерения, возникающего после данного намерения. Например, вероятность перехода могла бы указывать правдоподобие, что в следующей реплике пользователь спросит об актерском составе фильма, с учетом того, что в идущей реплике пользователь спросил об определенном режиссере определенного фильма.
[90] В варианте осуществления набор вероятностей переходов намерений содержит модель последовательности намерений, содержащую отношение по меньшей мере двух намерений и вероятность второго намерения с учетом первого намерения. Модель последовательности намерений в некоторых вариантах осуществления может использоваться для интерполяции моделей языков для использования при распознавании следующей реплики сеанса пользователя, например следующего запроса, произносимого пользователем. В варианте осуществления взвешивание, ассоциированное с частью источника знаний, соответствующей намерению, к которому осуществляется переход (второе намерение из отношения по меньшей мере двух намерений), можно регулировать по меньшей мере частично на основе вероятности перехода.
[91] На этапе 740 набор вероятностей переходов намерений используется для предоставления модели языка. В варианте осуществления модели языков интерполируются при необходимости на основе вероятностей переходов намерений и ранее принятой реплики (реплик) пользователя. В варианте осуществления набор вероятностей переходов намерений может использоваться для определения или изменения весов, ассоциированных с сущностью или отношением сущности в источнике знаний, посредством этого персонализируя (или дополнительно персонализируя) источник знаний и создавая модель контекста сеанса. Тогда модель контекста сеанса может использоваться для создания, при необходимости, одной или более моделей языков на основе одного или более идущих фрагментов речи пользователя или взаимодействий. В некоторых вариантах осуществления модель языка предоставляется из персонализированного источника знаний, например, описанного на этапе 440 (фиг. 4).
[92] Теперь со ссылкой на фиг. 8 предоставляется блок-схема алгоритма, иллюстрирующая примерный способ 800 для предоставления модели контекста сеанса на основе информации об истории пользователя для использования при распознавании речи или понимании естественного языка. Модель контекста сеанса может использоваться для предоставления одной или более моделей языков (или моделей SLU), используемых для распознавания (или понимания) второй реплики, произносимой пользователем, принимая во внимание уже принятую от пользователя первую реплику. Например, на верхнем уровне и в одном варианте осуществления после приема первого устного взаимодействия с пользователем (первой реплики) часть источника знаний (в этом примере называемая "частью первой реплики") определяется соответствующей сущностям и отношениям сущностей, идентифицированным в первой реплике. На основе набора вероятностей переходов, ассоциированного с той определенной частью первой реплики источника знаний, может определяться одна или более частей вероятной второй реплики источника знаний, где части второй реплики соответствуют вероятным следующим репликам (следующим устным взаимодействиям с пользователем), принимаемым от пользователя. Затем можно предоставить модель языка (или модель SLU) на основе каждой из этих частей вероятной второй реплики или подмножества частей второй реплики (например, частей наиболее вероятной второй реплики). В варианте осуществления каждая из этих предоставленных моделей языков (или моделей SLU) основывается на весах или распределениях, ассоциированных с сущностями и/или отношениями сущностей в части второй реплики. Кроме того, эти используемые моделями веса можно интерполировать на основе вероятности перехода у перехода к той конкретной части второй реплики от части первой реплики источника знаний.
[93] Другими словами, модель контекста сеанса может при необходимости использоваться для формирования определенных моделей языков на основе вероятной следующей реплики, принимаемой от пользователя, с учетом идущей реплики или реплик. Таким образом, в качестве примера предположим, что весьма вероятно (то есть высокая вероятность перехода), что если пользователь сначала спрашивает о режиссере фильма в первой реплике, то пользователь далее спросит (во второй реплике) либо об актерском составе фильма, либо о наградах фильма. После того, как пользователь спрашивает сначала "Кто режиссер фильма "Жизнь прекрасна"?", можно сформировать первую модель языка и предоставить для распознавания следующей (последующей) реплики, которая может быть принята от пользователя, где предполагается, что пользователь спросит об актерском составе "Жизнь прекрасна". (Например, эту первую модель языка можно приспособить для более точного распознавания последующего фрагмента речи пользователя, например "Он также играл главную роль в фильме?", где "он" относится к Роберто Бениньи - режиссеру, поскольку пользователь только что спросил о том, кто режиссер). Аналогичным образом после того, как пользователь спрашивает сначала "Кто режиссер фильма "Жизнь прекрасна"?", можно сформировать вторую модель языка и предоставить для распознавания следующей (последующей) реплики, которая может быть принята от пользователя, где предполагается, что пользователь спросит о полученных фильмом "Жизнь прекрасна" наградах. (Например, эту вторую модель языка можно приспособить для более точного распознавания последующего фрагмента речи пользователя, например "Он выдвигался на Оскар?", где "он" относится к "Жизнь прекрасна" - фильму, поскольку пользователь только что спросил о том, кто режиссер "Жизнь прекрасна", а "Оскар" является наградой).
[94] Продолжая с фиг. 8, на этапе 810 принимается информация об истории использования, содержащая одну или более последовательностей взаимодействий с пользователем. В варианте осуществления история использования принимается из одного или более личных источников, например журнала сеанса пользователя, и может содержать комбинированную информацию. Одна или более последовательностей взаимодействий с пользователем включают в себя информацию по меньшей мере о первом взаимодействии с пользователем и втором взаимодействии с пользователем; например, первом отправленном пользователем запросе или реплике и втором запросе (или второй реплике), отправленном пользователем позднее. В варианте осуществления второе взаимодействие является следующим происходящим взаимодействием (непосредственно последующим) после первого взаимодействия. В варианте осуществления информацию об истории использования можно проанализировать (например, как описано на этапе 420 из фиг. 4), чтобы определить одну или более последовательностей или взаимодействий с пользователем.
[95] На этапе 820 для каждого первого взаимодействия с пользователем в одной или более последовательностях взаимодействий с пользователем определяется часть первой реплики источника знаний, соответствующая первому взаимодействию, посредством этого создавая набор частей первой реплики источника знаний. Например, в варианте осуществления часть источника знаний, соответствующая взаимодействию с пользователем, может определяться путем отображения взаимодействия с пользователем (или информации об истории использования, ассоциированной с взаимодействием с пользователем) в источник знаний, например, описанный на этапе 430 (фиг. 4). На основе отображения может определяться часть (части) источника знаний, релевантная или соответствующая взаимодействию с пользователем (то есть часть источника знаний, в которую отображается взаимодействие).
[96] На этапе 830 похожее определение выполняется для второго взаимодействия с пользователем. В частности, на этапе 830 для каждого второго взаимодействия с пользователем в одной или более последовательностях взаимодействий с пользователем определяется часть второй реплики источника знаний, соответствующая второму взаимодействию, посредством этого создавая набор частей второй реплики источника знаний. Различные варианты осуществления этапа 830 похожи на варианты осуществления, описанные на этапе 820. В одном варианте осуществления этапы 820 и 830 дополнительно содержат определение взвешивания каждой из частей первой реплики и второй реплики на основе количества первых и вторых взаимодействий с пользователем, соответствующих частям первой реплики и второй реплики соответственно. В одном варианте осуществления веса или распределения, ассоциированные с сущностями или отношениями сущностей, которые включаются в каждую часть источника знаний, задаются или изменяются на основе количества первых и вторых взаимодействий с пользователем, соответствующих частям первой реплики и второй реплики соответственно.
[97] На этапе 840 определяется тип намерения, ассоциированный с каждой частью первой реплики, посредством этого создавая набор типов намерений первой реплики, и определяется тип намерения, ассоциированный с каждой частью второй реплики, посредством этого создавая набор типов намерений второй реплики. В варианте осуществления тип намерения является намерением пользователя или намерением более высокого уровня, которое соответствует действию, предпринятому пользователем, например взаимодействию с пользователем. В варианте осуществления могут определяться типы намерений, ассоциированные с каждой из частей первой реплики и второй реплики, на основе информации о сущности и отношении в соответствующих частях источника знаний, как описано на этапе 720 способа 700 (фиг. 7).
[98] На этапе 850 определяется набор вероятностей переходов, причем каждая вероятность перехода представляет собой правдоподобие того, что возникнет конкретный тип намерения второй реплики с учетом определенного типа намерения первой реплики. В одном варианте осуществления вероятность перехода представляет собой правдоподобие того, что возникнет тип намерения второй реплики в реплике или взаимодействии с пользователем, следующих непосредственно за типом намерения первой реплики. Например, в варианте осуществления вероятность перехода могла бы представлять вероятность того, что пользователь спросит дальше, кто играет главную роль в "Жизнь прекрасна" (соответственно, тип намерения второй реплики - об актерском составе фильма), после того как спрашивает о режиссере "Жизнь прекрасна" (соответственно, тип намерения первой реплики - режиссер фильма). В одном варианте осуществления набор вероятностей переходов содержит модель последовательности намерений, например, описанную на этапе 730 способа 700 (фиг. 7), которая может использоваться в некоторых вариантах осуществления для интерполяции моделей языков для использования при распознавании следующей реплики в сеансе пользователя, например, следующего запроса, произносимого пользователем.
[99] В варианте осуществления взвешивание, ассоциированное с частью второй реплики графа знаний, можно регулировать по меньшей мере частично на основе вероятности перехода от части первой реплики источника знаний к той части второй реплики. Соответственно, на этапе 860 одна или более моделей языков (или моделей SLU) предоставляются по меньшей мере частично на основе набора вероятностей переходов. Например, как описывалось ранее, в одном варианте осуществления после приема первого устного взаимодействия с пользователем (первой реплики) может определяться часть первой реплики источника знаний, соответствующая сущностям и отношениям сущностей, идентифицированным в первой реплике. На основе набора вероятностей переходов, ассоциированного с той определенной частью первой реплики источника знаний (как определено на основе одной или более последовательностей из истории использования на идущих этапах способа 800), могут определяться части вероятной второй реплики источника знаний, где эти части второй реплики соответствуют вероятным следующим репликам (следующим устным взаимодействиям с пользователем), ожидаемым от пользователя. Тогда на основе этого можно предоставить модели языков (модели SLU) для каждой из частей вероятной второй реплики, используя веса, ассоциированные с сущностями и/или отношениями сущностей в определенной части второй реплики. Кроме того, используемые моделями веса можно интерполировать на основе вероятности перехода у перехода к той конкретной части второй реплики от части первой реплики источника знаний. (Другими словами, определенные модели языков могут формироваться при необходимости на основе вероятной следующей реплики, принимаемой от пользователя, с учетом идущей реплики или реплик).
[100] Обращаясь к фиг. 9, предоставляется блок-схема алгоритма, иллюстрирующая примерный способ 900 для использования источника знаний, персонализированного с помощью информации о контексте сеанса, чтобы предоставить модель языка (или модель SLU), приспособленную к контексту сеанса. Модель языка или модель SLU может использоваться для более точного распознавания или понимания следующего фрагмента (следующей реплики), принятого от пользователя. Варианты осуществления способа 900 используют источник знаний, который персонализирован с помощью информации о контексте сеанса. Источник знаний можно персонализировать в соответствии с вариантами осуществления, описанными в связи с фиг. 4-8.
[101] В одном варианте осуществления, как только источник знаний персонализируется (например, путем отображения журналов сеансов в сущности или пары сущность-сущность на графе знаний), можно собирать статистики о переключении с одного намерения на другое намерение или с одной области на другую область. Статистики можно представить в источнике знаний в виде дополнительных переходов; например, вероятности того, что пользователь останется в поиске одного жанра музыки, в сравнении с переключением на другой жанр или область. Соответственно, когда пользователь начинает говорить в личное устройство (или другую человеко-машинную диалоговую систему), после пары реплик некоторые варианты осуществления способа 900 идентифицируют сначала соответствующие подпространства (то есть части) в источнике знаний. Затем вероятности переходов, ассоциированные с этими подпространствами, могут использоваться в качестве весов переходов (которые представляют собой отношения или изменения намерения/области), которые могут использоваться в качестве весов интерполяции для моделей языков, представляющих другие подпространства, которые рассматриваются (то есть те подпространства, переход к которым вероятен в следующей реплике). Например, в первой реплике пользователь произносит "Когда сегодня вечером играют Giants?". Вариант осуществления изобретения обнаруживает "Giants" в качестве сущности, отображает ее в источник знаний (или создает запись для этой сущности в источнике знаний, если отсутствует), и повышает вероятность или вес, ассоциированные с тем подпространством (то есть частью источника знаний), указывая, что пользователь интересуется понятиями или действиями касательно этой сущности (Giants) в источнике знаний. На основе того подпространства вычисляются все возможные переходы (или только вероятные переходы) от сущности Giants. Затем оперативно интерполируются модели языков, соответствующие этим переходам.
[102] Продолжая с этим примером, предположим, что имеется вероятность 0,8 того, что следующая реплика перейдет к конкретному игроку (например, пользователь спросит далее о Серхио Ромо), и вероятность 0,2 того, что следующая реплика перейдет к командным футболкам (например, пользователь спросит далее "Сколько стоит футболка от Giant?"). Можно предоставить и использовать две модели языков на основе двух подпространств, соответствующих Серхио Ромо и футболке Giant (или связанным с Giant товарам), для более точного определения следующего фрагмента от пользователя, так что веса или распределения каждой модели языка интерполируются на основе вероятностей переходов. (В этом случае одна из моделей языков интерполируется с 0,8, а другая модель языка - с 0,2).
[103] Предположим далее, что во второй реплике пользователь спрашивает "Как сыграл Серхио Ромо?". (Таким образом, пользователь высказал одну из двух вероятных следующих реплик, обсуждаемых в идущем абзаце). Здесь вариант осуществления изобретения обнаруживает имя игрока в качестве сущности, отображает ее в источник знаний (или создает запись для этой сущности в источнике знаний, если отсутствует), и повышает вероятность или вес, ассоциированные с тем подпространством, указывая, что пользователь интересуется понятиями или действиями касательно этой сущности (Серхио Ромо) в источнике знаний. На основе подпространства и на основе идущих реплик и намерений/областей, например подпространства спортивных команд (Giants) из первой реплики, вычисляются все возможные переходы (или только вероятные переходы) от настоящего подпространства (подпространства, соответствующего Серхио Ромо). Затем модели языков, соответствующие этим новым переходам, интерполируются и используются для более точного распознавания следующего фрагмента (третьей реплики), принятого от пользователя.
[104] Продолжая с фиг. 9, на этапе 910 принимается первый запрос. Запрос может быть принят от пользователя, участвующего в сеансе с пользовательским устройством, например устройствами 102 и 104 из фиг. 1, или человеко-машинной диалоговой системой. В варианте осуществления первый запрос предоставляется пользователем в виде устного запроса или другого фрагмента речи.
[105] На этапе 920 первый запрос отображается в первое подпространство (или часть) источника знаний, персонализированного с помощью информации о контексте сеанса. В варианте осуществления персонализированный источник знаний включает в себя множество подпространств, которые связаны с другими подпространствами, так что каждый набор связанных подпространств (или "набор связанных подпространств") содержит по меньшей мере первое подпространство, одно или более вторых подпространств, соответствующих следующим репликам или взаимодействиям с пользователем, и статистику переходов, ассоциированную с каждым вторым подпространством, представляющую собой правдоподобие того, что в конкретное второе подпространство переходят из первого подпространства в наборе связанных подпространств. Таким образом, после отображения первого запроса в первую часть или подпространство можно определить одно или более вторых подпространств, переход к которым вероятен из первого подпространства, а также одну или более статистик переходов, ассоциированных с каждым из вторых подпространств (как описано на этапе 930). В варианте осуществления статистики переходов определяются на основе информации о прошлых периодах, включенной в персонализированное пространство знаний, и соответствуют последовательностям взаимодействий с пользователем. В варианте осуществления набор связанных подпространств включает в себя отношение первой пары сущность-сущность ко второй паре сущность-сущность, первого отношения сущности ко второму отношению сущности, первого намерения (намерений)/области ко второму намерению (намерениям)/области или первой пары/отношения/намерения (намерений)/области сущностей ко второй паре/отношению/намерению (намерениям)/области сущностей. В варианте осуществления запрос можно отобразить, как описано на этапе 430 способа 400 (фиг. 4).
[106] На этапе 930 на основе отображения, определенного на этапе 920, определяется первый набор статистик переходов, который соответствует будущему запросу (второму запросу), прием которого от пользователя вероятен. В варианте осуществления первый набор статистик переходов содержит статистики переходов, ассоциированные с каждым из одного или более вторых подпространств, в которые можно перейти из первого подпространства. В варианте осуществления статистики переходов содержат набор вероятностей переходов и определяются, например, как описано на этапе 850 способа 800 (фиг. 8) или этапе 730 способа 700 (фиг. 7).
[107] На этапе 940 на основе набора статистик переходов предоставляется одна или более моделей языков (или моделей SLU) для использования со вторым запросом или взаимодействием (второй репликой), ожидаемым от пользователя. В варианте осуществления одна или более моделей языков предоставляются для более точного определения последующего фрагмента от пользователя. В варианте осуществления веса или распределения моделей языков интерполируются на основе набора статистик переходов.
[108] В одном варианте осуществления способа 900 множество наборов связанных подпространств в персонализированном источнике знаний дополнительно содержит одно или более третьих подпространств, соответствующих третьим репликам или взаимодействиям с пользователем, где статистика перехода также представляет собой правдоподобие того, что в конкретное третье подпространство переходят из конкретного второго подпространства, принимая во внимание переход из конкретного первого подпространства в конкретное второе подпространство. Более того, в одном варианте осуществления второй запрос принимается и отображается в персонализированный источник знаний, например, описанный на этапах 910 и 920. На основе отображения первого и второго запросов вариант осуществления определяет второй набор статистик переходов, который соответствует будущему запросу (третьему запросу), прием которого от пользователя вероятен. Кроме того, на основе второго набора статистик переходов предоставляется одна или более моделей языков для использования с третьим запросом или взаимодействием (третьей репликой), ожидаемым от пользователя. В варианте осуществления эти "модели языков третьей реплики" могут предоставляться, как описано на этапе 940.
[109] Соответственно, описаны различные аспекты технологии, ориентированной на системы и способы для улучшения моделей языков и моделей SLU, которые могут использоваться для распознавания речи и систем понимания разговорной речи, путем персонализации источников знаний, используемых моделями, для включения в них информации о контексте сеанса.
[110] Подразумевается, что различные признаки, подкомбинации и изменения вариантов осуществления, описанных в этом документе, полезны и могут применяться в других вариантах осуществления без ссылки на другие признаки или подкомбинации. Кроме того, порядок и последовательности этапов, показанные в примерных способах 400, 500, 600, 700, 800 и 900, никоим образом не предназначены для ограничения объема настоящего изобретения, и этапы фактически могут совершаться в различных последовательностях в рамках вариантов осуществления. Такие разновидности и сочетания также предполагаются входящими в объем вариантов осуществления изобретения. Например, как описывалось ранее, предполагается, что любой из процессов, описанных в способах 400, 500 и 600 для персонализации источника знаний, может использоваться со способами 700, 800 и 900.
[111] Описав различные варианты осуществления изобретения, теперь описывается примерная вычислительная среда, подходящая для реализации вариантов осуществления изобретения. Со ссылкой на фиг. 10 предоставляется примерное вычислительное устройство и в целом называется вычислительным устройством 1000. Вычислительное устройство 1000 является лишь одним примером подходящей вычислительной среды и не предназначено для предложения какого-нибудь ограничения в отношении области применения или функциональных возможностей изобретения. Вычислительное устройство 1000 не следует интерпретировать ни как обладающее какой-либо зависимостью, ни требованием относительно любого проиллюстрированного компонента или сочетания компонентов.
[112] Варианты осуществления изобретения могут описываться в общем контексте машинного кода или используемых машиной инструкций, включая используемые компьютером или исполняемые компьютером инструкции, например программные модули, исполняемые компьютером или другой машиной, например персональным цифровым помощником, смартфоном, планшетным ПК или другим карманным устройством. Как правило, программные модули, включающие в себя процедуры, программы, объекты, компоненты, структуры данных и т. п., относятся к коду, который выполняет конкретные задачи или реализует конкретные абстрактные типы данных. Варианты осуществления изобретения можно применять на практике в ряде конфигураций систем, включая карманные устройства, бытовую электронику, универсальные компьютеры, вычислительные устройства с большей специализацией и т. д. Варианты осуществления изобретения также можно применять на практике в распределенных вычислительных средах, где задачи выполняются устройствами дистанционной обработки, которые связаны через сеть связи. В распределенной вычислительной среде программные модули могут быть расположены как на локальных, так и на удаленных компьютерных носителях информации, включающих в себя запоминающие устройства.
[113] Со ссылкой на фиг. 10 вычислительное устройство 1000 включает в себя шину 1010, которая напрямую или косвенно соединяет следующие устройства: запоминающее устройство 1012, один или более процессоров 1014, один или более компонентов 1016 представления, один или более портов 1018 ввода/вывода (I/O), один или более компонентов 1020 ввода/вывода и пояснительный источник 1022 питания. Шина 1010 представляет собой то, что может быть одной или несколькими шинами (например, адресной шиной, шиной данных или их сочетанием). Хотя различные блоки фиг. 10 для ясности показаны линиями, в действительности эти блоки представляют собой логические, не обязательно действующие компоненты. Например, можно считать компонент представления, например устройство отображения, компонентом ввода/ввода. Также процессоры обладают запоминающими устройствами. Авторы этого изобретения признают, что это является свойством данной области техники, и повторяют, что схема фиг. 10 является всего лишь пояснительной для примерного вычислительного устройства, которое может использоваться применительно к одному или нескольким вариантам осуществления настоящего изобретения. Не делается различия между такими категориями, как "рабочая станция", "сервер", "переносной компьютер", "карманное устройство" и т. д., так как все они рассматриваются в рамках фиг. 10 и со ссылкой на "вычислительное устройство".
[114] Вычислительное устройство 1000 обычно включает в себя ряд считываемых компьютером носителей. Считываемые компьютером носители могут быть любыми доступными носителями, к которым можно обращаться с помощью вычислительного устройства 1000, и включают в себя как энергозависимые и энергонезависимые носители, так и съемные и несъемные носители. В качестве примера, а не ограничения, считываемые компьютером носители могут быть выполнены в виде компьютерных носителей информации и средств связи. Компьютерные носители информации включают в себя как энергозависимые и энергонезависимые, так и съемные и несъемные носители, реализованные по любому способу или технологии для хранения информации, такой как считываемые компьютером инструкции, структуры данных, программные модули или другие данные. Компьютерные носители информации включают в себя, но не ограничиваются, RAM, ROM, EEPROM, флэш-память или другую технологию памяти, компакт-диск, универсальные цифровые диски (DVD) или другой накопитель на оптических дисках, магнитные кассеты, магнитную ленту, накопитель на магнитных дисках или другие магнитные запоминающие устройства, или любой другой носитель, который может использоваться для хранения нужной информации и к которому можно обращаться с помощью вычислительного устройства 1000. Компьютерные носители информации не содержат сигналы как таковые. Средства связи обычно реализуют считываемые компьютером инструкции, структуры данных, программные модули или другие данные в модулированном сигнале данных, таком как несущая или другой транспортный механизм, и включают в себя любые средства доставки информации. Термин "модулированный сигнал данных" означает сигнал, который имеет одну или более своих характеристик, установленных или измененных таким образом, чтобы кодировать информацию в сигнале. В качестве примера, а не ограничения, средства связи включают в себя проводные средства, такие как проводная сеть или прямое проводное соединение, и беспроводные средства, такие как акустические, радиочастотные, инфракрасные и другие беспроводные средства. Сочетания любого из вышеприведенного также следует включить в область считываемых компьютером носителей.
[115] Запоминающее устройство 1012 включает в себя компьютерные носители информации в виде энергозависимого и/или энергонезависимого запоминающего устройства. Запоминающее устройство может быть съемным, несъемным или их сочетанием. Примерные аппаратные устройства включают в себя твердотельное запоминающее устройство, жесткие диски, накопители на оптических дисках и т. д. Вычислительное устройство 1000 включает в себя один или более процессоров 1014, которые считывают данные из различных объектов, например запоминающего устройства 1012 или компонентов 1020 ввода/вывода. Компонент (компоненты) 1016 представления представляют показания данных пользователю или другому устройству. Примерные компоненты представления включают в себя устройство отображения, динамик, печатающий компонент, вибрационный компонент и т. п.
[116] Порты 1018 ввода/вывода позволяют вычислительному устройству 1000 логически соединяться с другими устройствами, включая компоненты 1020 ввода/вывода, некоторые из которых могут быть встраиваемыми. Пояснительные компоненты включают в себя микрофон, джойстик, игровой планшет, спутниковую тарелку, сканер, принтер, компонент связи (например, компонент сетевой связи, компонент радио- или беспроводной связи или т. п.) и т. п. Компоненты 1020 ввода/вывода могут предоставлять естественный интерфейс пользователя (NUI), который обрабатывает жесты в воздухе, голос или другие физиологические входные данные, сформированные пользователем. В некоторых случаях входные данные могут передаваться подходящему сетевому элементу для дополнительной обработки. NUI может реализовывать любое сочетание из распознавания речи, распознавания касания и пера, распознавания лиц, биометрического распознавания, распознавания жестов на экране и рядом с экраном, жестов в воздухе, отслеживания движений головы и глаз и распознавания касания, ассоциированных с отображениями на вычислительном устройстве 1000. Вычислительное устройство 1000 может быть оснащено камерами глубины, например системами стереоскопических камер, системами камер в ИК-области, системами RGB-камер и их сочетаниями, для обнаружения и распознавания жестов. Более того, вычислительное устройство 1000 может быть оснащено акселерометрами или гироскопами, которые дают возможность обнаружения движения. Вывод акселерометров или гироскопов может предоставляться на дисплей вычислительного устройства 1000 для визуализации дополненной реальности или виртуальной реальности с эффектом присутствия.
[117] Возможны многие другие компоновки различных изображенных компонентов, а также не показанные компоненты без отклонения от объема нижеприведенной формулы изобретения. Варианты осуществления настоящего изобретения описаны с намерением быть пояснительными, а не ограничивающими. Альтернативные варианты осуществления станут очевидны рецензентам этого раскрытия изобретения после и вследствие его прочтения. Альтернативное средство реализации вышеупомянутого может быть выполнено без отклонения от объема нижеприведенной формулы изобретения. Некоторые признаки и подкомбинации представляют полезность и могут применяться без ссылки на другие признаки и подкомбинации, и рассматриваются в рамках объема формулы изобретения.
[118] Соответственно, в одном аспекте вариант осуществления изобретения ориентирован на один или более считываемых компьютером носителей с воплощенными на них исполняемыми компьютером инструкциями, которые при исполнении вычислительной системой, содержащей процессор и запоминающее устройство, побуждают вычислительную систему выполнить способ для предоставления модели языка, приспособленной к контексту сеанса на основе истории пользователя. Способ включает в себя прием информации об истории использования, содержащей одну или более последовательностей событий взаимодействия с пользователем, и определение вероятного намерения пользователя, соответствующего событию, для каждого события в одной или более последовательностях. Способ также включает в себя определение набора вероятностей переходов намерений на основе вероятных намерений пользователя, определенных для каждого события; и использование набора вероятностей переходов намерений, чтобы предоставить модель языка.
[119] В другом аспекте предоставляется один или более считываемых компьютером носителей с воплощенными на них исполняемыми компьютером инструкциями, которые при исполнении вычислительной системой, содержащей процессор и запоминающее устройство, побуждают вычислительную систему выполнить способ для предоставления модели контекста сеанса на основе информации об истории пользователя. Способ включает в себя прием информации об истории использования, содержащий информацию об одной или более последовательностях взаимодействий с пользователем, причем каждая последовательность включает в себя по меньшей мере первое и второе взаимодействие, и определение части первой реплики источника знаний, соответствующей первому взаимодействию, для каждого первого взаимодействия в одной или более последовательностях. Способ также включает в себя определение части второй реплики источника знаний, соответствующей второму взаимодействию, для каждого второго взаимодействия в одной или более последовательностях, посредством этого создавая набор частей второй реплики; и определение типа намерения, ассоциированного с каждой частью первой реплики и каждой частью второй реплики, посредством этого создавая набор типов намерений первой реплики и набор типов намерений второй реплики. Способ дополнительно включает в себя определение набора вероятностей переходов на основе наборов типов намерений первой реплики и типов намерений второй реплики и одной или более последовательностей взаимодействий с пользователем.
[120] В некоторых вариантах осуществления способ дополнительно включает в себя определение набора моделей языков, соответствующих части второй реплики в подмножестве набора частей второй реплики, по меньшей мере частично на основе набора вероятностей переходов, посредством этого создавая модель контекста сеанса. В некоторых вариантах осуществления способ дополнительно включает в себя определение взвешивания, ассоциированного по меньшей мере с одной частью второй реплики источника знаний, и предоставление модели языка на основе взвешивания. В некоторых вариантах осуществления способ дополнительно включает в себя определение взвешивания части первой реплики на основе количества соответствующих первых взаимодействий для каждой части первой реплики; и определение взвешивания части второй реплики на основе количества соответствующих вторых взаимодействий для каждой части второй реплики.
[121] В еще одном аспекте предоставляется один или более считываемых компьютером носителей с воплощенными на них исполняемыми компьютером инструкциями, которые при исполнении вычислительной системой, содержащей процессор и запоминающее устройство, побуждают вычислительную систему выполнить способ для предоставления модели языка, приспособленной к контексту сеанса. Способ включает в себя прием первого запроса, отображение первого запроса в первое подпространство персонализированного источника знаний, и определение первого набора статистик переходов, соответствующего второму запросу, на основе отображения и персонализированного источника знаний. Способ также включает в себя предоставление одной или более моделей языков на основе первого набора статистик переходов для использования со вторым запросом.
[122] В некоторых вариантах осуществления персонализированный источник знаний включает в себя множество наборов связанных подпространств, причем каждый набор связанных подпространств содержит первое подпространство, одно или более вторых подпространств, причем каждое второе подпространство соответствует вероятному второму запросу, и статистику переходов, ассоциированную с каждым вторым подпространством, представляющую собой правдоподобие того, что во второе подпространство переходят из первого подпространства. Более того, в некоторых вариантах осуществления набор связанных подпространств дополнительно содержит одно или более третьих подпространств, причем каждое третье подпространство соответствует вероятному третьему запросу, и где статистика перехода также представляет собой правдоподобие того, что в конкретное третье подпространство переходят из конкретного второго подпространства, принимая во внимание переход из первого подпространства в конкретное второе подпространство. В некоторых вариантах осуществления способ дополнительно включает в себя прием второго запроса; отображение второго запроса в одно из одного или более вторых подпространств персонализированного источника знаний; определение второго набора статистик переходов, соответствующего третьему запросу, на основе отображения и персонализированного источника знаний; и предоставление одной или более моделей языков третьей реплики для использования с третьим запросом на основе второго набора статистик переходов.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ ОРФАННЫХ ВЫСКАЗЫВАНИЙ | 2015 |
|
RU2699399C2 |
| КОНТЕКСТНЫЕ ЗАПРОСЫ | 2011 |
|
RU2573764C2 |
| ИСПОЛЬЗОВАНИЕ КОНТЕКСТНОЙ ИНФОРМАЦИИ ДЛЯ ОБЛЕГЧЕНИЯ ОБРАБОТКИ КОМАНД В ВИРТУАЛЬНОМ ПОМОЩНИКЕ | 2012 |
|
RU2542937C2 |
| МАШИННОЕ ОБУЧЕНИЕ | 2005 |
|
RU2391791C2 |
| ПОДДЕРЖАНИЕ КОНТЕКСТНОЙ ИНФОРМАЦИИ МЕЖДУ ПОЛЬЗОВАТЕЛЬСКИМИ ВЗАИМОДЕЙСТВИЯМИ С ГОЛОСОВЫМ ПОМОЩНИКОМ | 2018 |
|
RU2785950C2 |
| СИСТЕМА КОМПОЗИЦИИ ЗАПРОСОВ | 2016 |
|
RU2691851C1 |
| ВЫВЕДЕНИЕ НАМЕРЕНИЯ ПОЛЬЗОВАТЕЛЯ НА ОСНОВЕ ПРЕДЫДУЩИХ ВЗАИМОДЕЙСТВИЙ С ГОЛОСОВЫМ ПОМОЩНИКОМ | 2011 |
|
RU2544787C2 |
| ОРКЕСТРОВКА СЛУЖБ ДЛЯ ИНТЕЛЛЕКТУАЛЬНОГО АВТОМАТИЗИРОВАННОГО ПОМОЩНИКА | 2011 |
|
RU2556416C2 |
| ПЕРСОНАЛИЗИРОВАННЫЙ СЛОВАРЬ ДЛЯ ЦИФРОВОГО ПОМОЩНИКА | 2011 |
|
RU2541219C2 |
| ОПРЕДЕЛЕНИЕ НАМЕРЕНИЯ ПОЛЬЗОВАТЕЛЯ НА ОСНОВЕ ОНТОЛОГИЙ ПРЕДМЕТНЫХ ОБЛАСТЕЙ | 2011 |
|
RU2541221C2 |
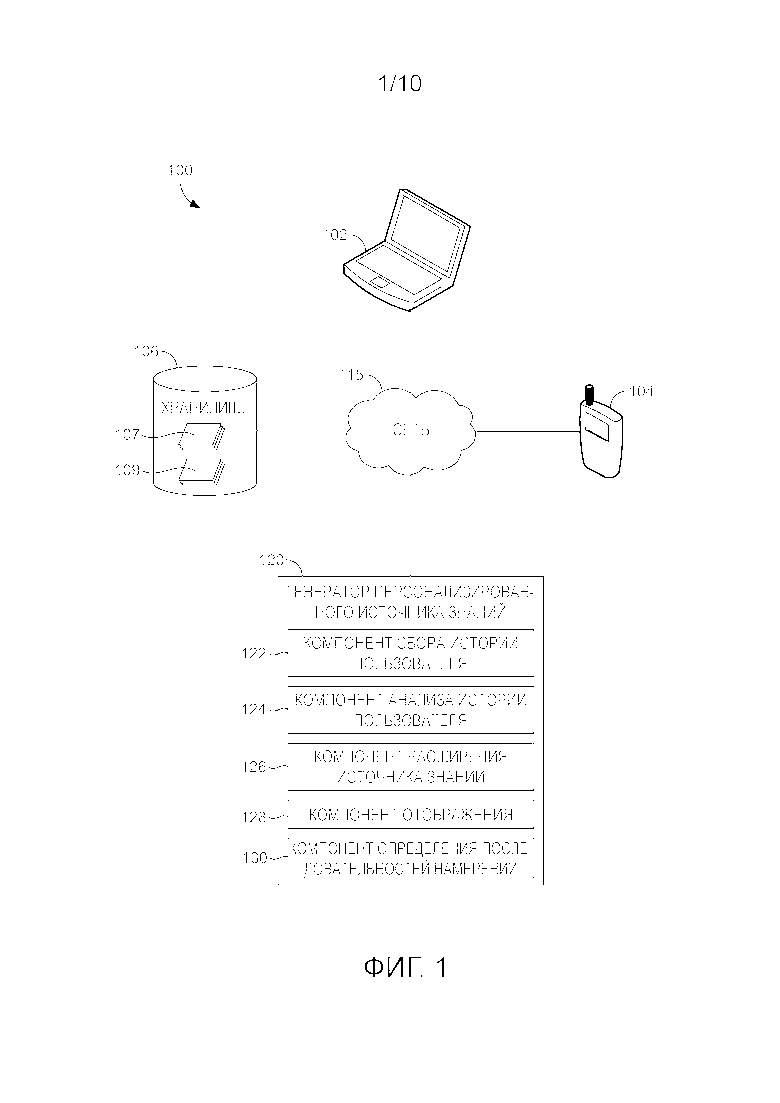
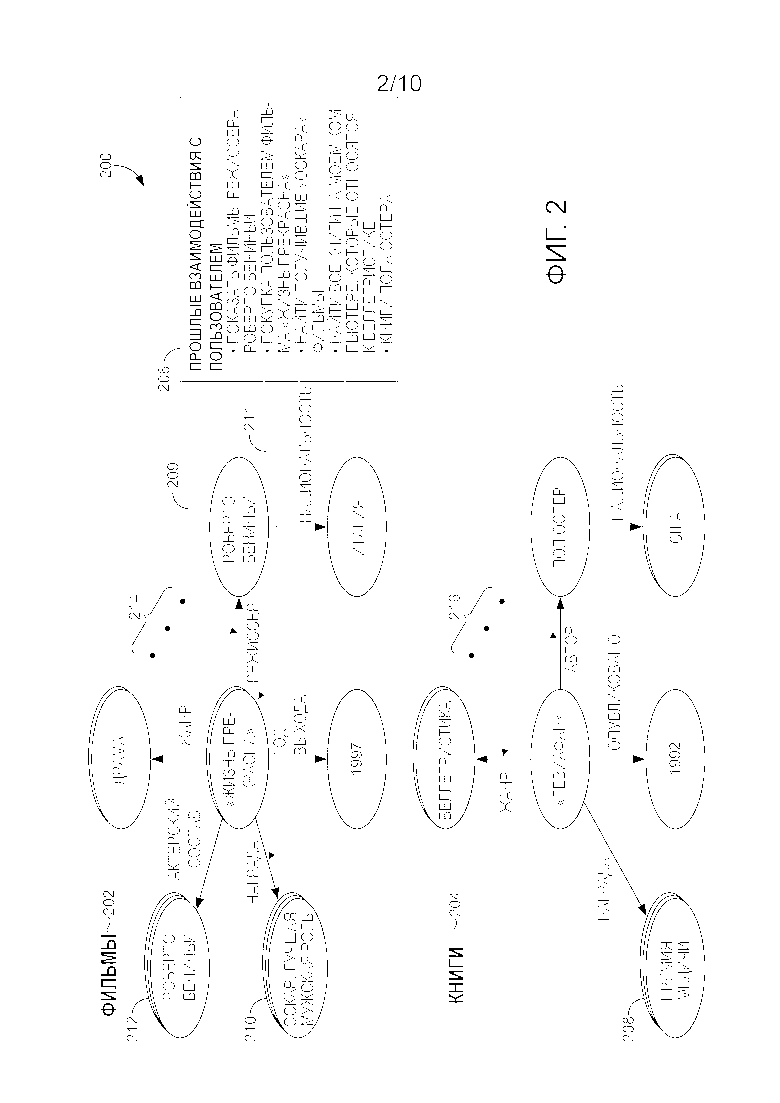
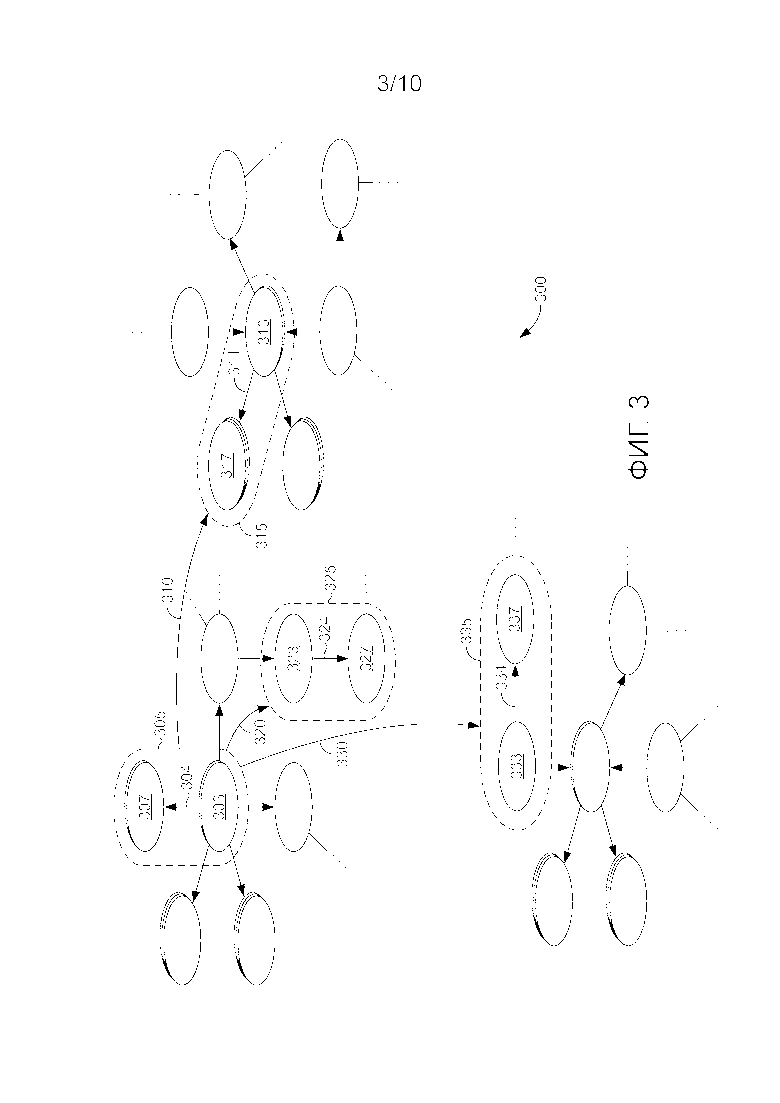

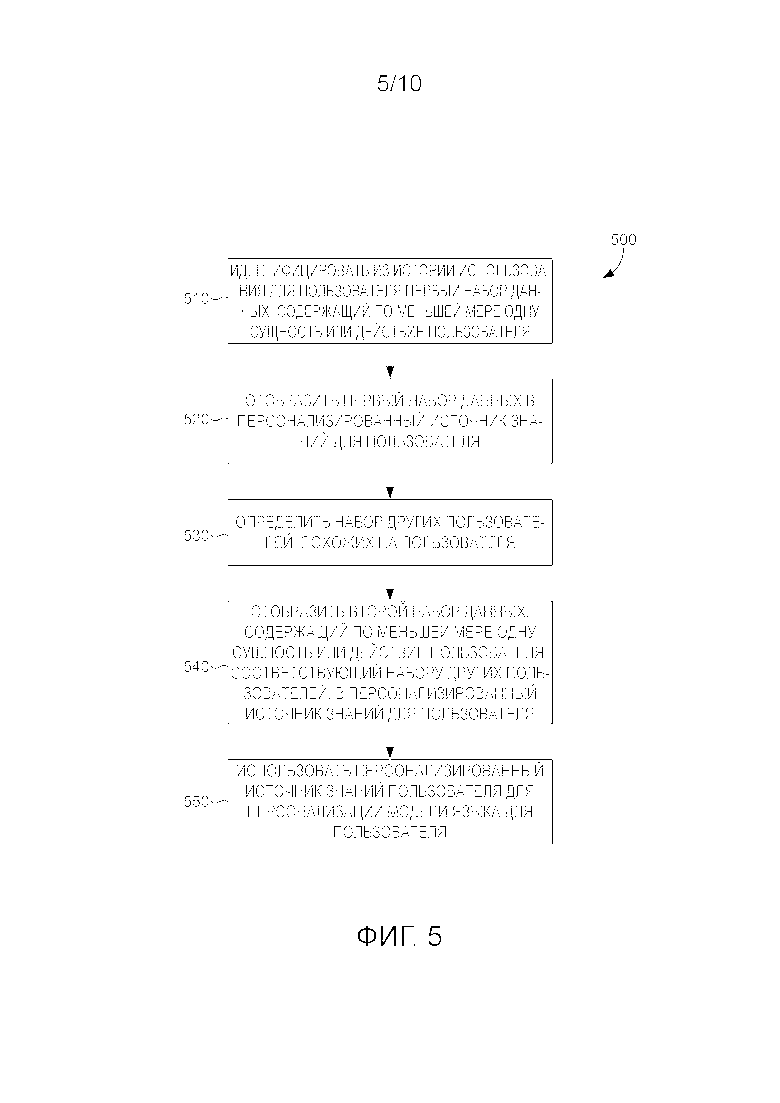

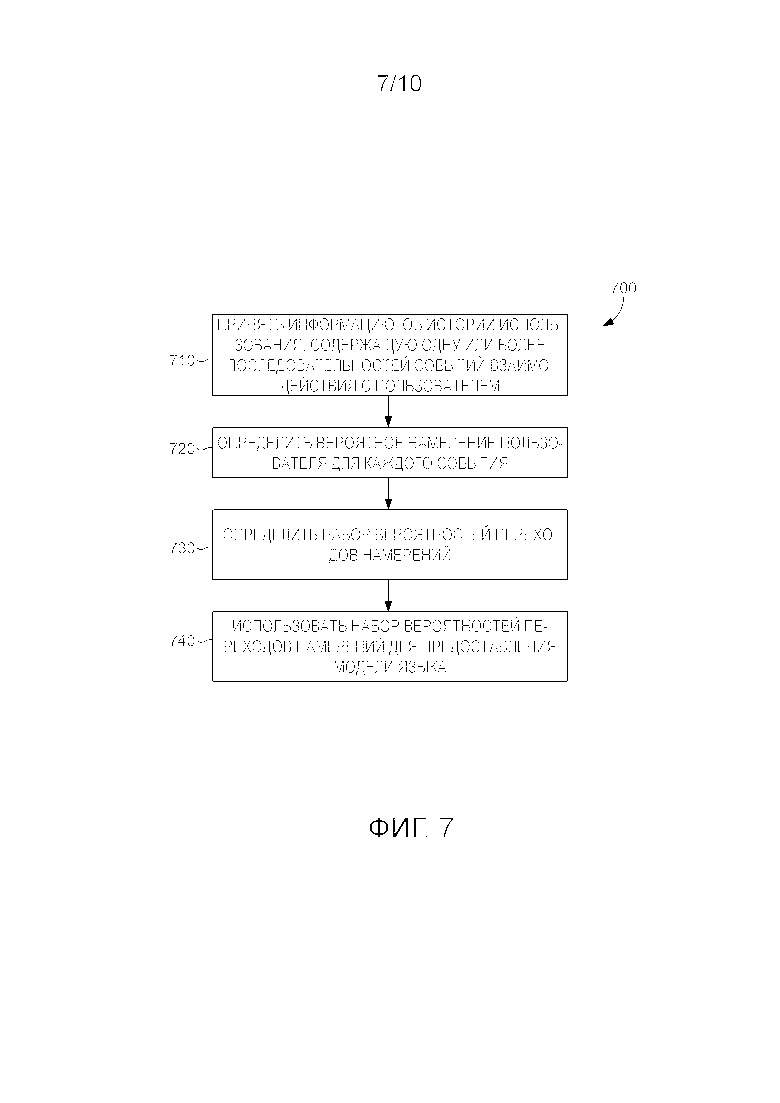

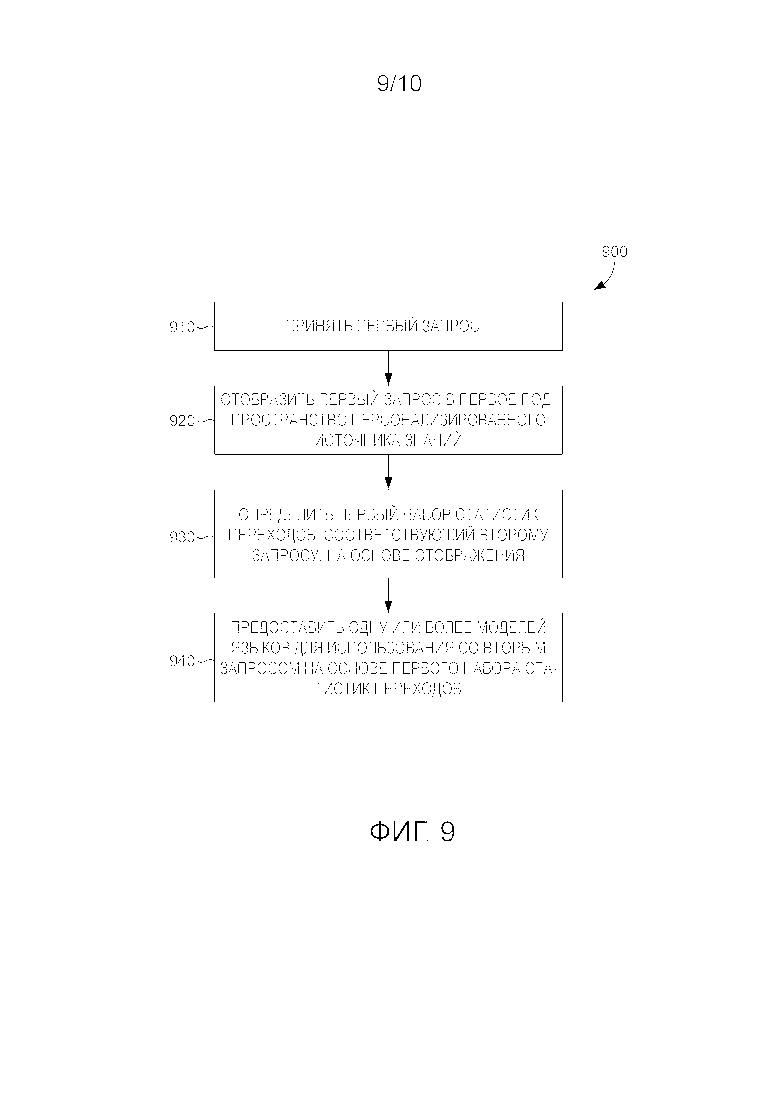
Изобретение относится к области вычислительной техники для распознавания речи пользователя. Технический результат заключается в повышении точности формирования персонализированной для пользователя модели языка. Технический результат достигается за счет приема информации об истории использования, содержащей одну или более последовательностей событий взаимодействия с пользователем; определения вероятного намерения пользователя, соответствующего событию, для каждого события в одной или более последовательностях; определения набора вероятностей переходов намерений на основе вероятных намерений пользователя, определенных для каждого события; и использования набора вероятностей переходов намерений для формирования персонализированной для пользователя модели языка. 2 н. и 3 з.п. ф-лы, 10 ил.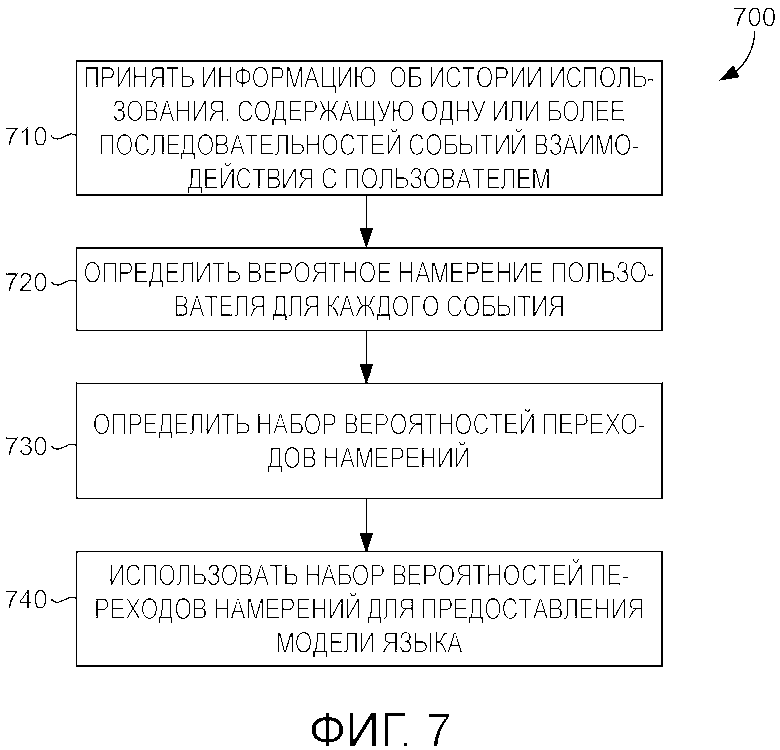
1. Один или более считываемых компьютером носителей с воплощенными на них исполняемыми компьютером инструкциями, которые при исполнении вычислительной системой, содержащей процессор и запоминающее устройство, побуждают вычислительную систему выполнить способ для предоставления модели языка, приспособленной к контексту сеанса на основе истории пользователя, причем способ содержит этапы, на которых:
принимают информацию об истории использования, содержащую одну или более последовательностей событий взаимодействия с пользователем;
определяют вероятное намерение пользователя, соответствующее событию, для каждого события в одной или более последовательностях;
определяют набор вероятностей переходов намерений на основе вероятных намерений пользователя, определенных для каждого события; и
используют набор вероятностей переходов намерений для формирования персонализированной для пользователя модели языка.
2. Один или более считываемых компьютером носителей по п. 1, при этом информация об истории использования содержит один или более журналов сеансов пользователя.
3. Один или более считываемых компьютером носителей по п. 1, при этом каждая вероятность перехода в наборе вероятностей переходов представляет собой вероятность перехода от первого намерения, соответствующего первому событию в первой последовательности из одной или более последовательностей, ко второму намерению, соответствующему второму событию в первой последовательности в одной или более последовательностях.
4. Один или более считываемых компьютером носителей по п. 1, при этом предоставленная модель языка интерполируется по меньшей мере частично на основе подмножества вероятностей переходов намерений в наборе вероятностей переходов намерений.
5. Вычислительная система, сконфигурированная для выполнения способа для предоставления модели языка, приспособленной к контексту сеанса на основе истории пользователя, причем способ содержит этапы, на которых:
принимают информацию об истории использования, содержащую одну или более последовательностей событий взаимодействия с пользователем;
определяют вероятное намерение пользователя, соответствующее событию, для каждого события в одной или более последовательностях;
определяют набор вероятностей переходов намерений на основе вероятных намерений пользователя, определенных для каждого события; и
используют набор вероятностей переходов намерений для формирования персонализированной для пользователя модели языка.
| US 8352246 B1, 08.01.2013 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| ПОСЛЕДОВАТЕЛЬНЫЙ МУЛЬТИМОДАЛЬНЫЙ ВВОД | 2004 |
|
RU2355045C2 |

