ОБЛАСТЬ ТЕХНИКИ
[001] Настоящее изобретение в целом относится к вычислительным системам, а точнее - к системам и способам сегментации документов на блоки различного типа.
УРОВЕНЬ ТЕХНИКИ
[002] Изображение может содержать документ или часть документа. Этот документ может включать различные типы сегментов или блоков, например, блоки заголовков, блоки текста, блоки диаграмм, блоки таблиц и т.д. Система обработки изображений может быть использована для выявления на изображении блоков различного типа.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[003] В соответствии с одним или более вариантами реализации настоящего изобретения пример способа может включать: получение изображения, содержащего, как минимум, часть документа; выявление множества точек деления, разделяющих изображение на потенциальные сегменты; создание графа линейного деления (ГЛД), содержащего множество вершин, использующих множество точек деления, и множество ребер, соединяющих множество вершин; выявление пути в ГЛД со значением метрики качества выше порогового значения, где путь выбирается из множества путей в ГЛД и содержит одно или более ребер из множества ребер, и значение метрики качества порождается с помощью нейронной сети, классифицирующей множество пикселей изображения; и создание одного или более блоков изображения, где каждый из одного или более блоков соответствует ребру из одного или более ребер выявленного пути и соответствует части изображения, ассоциированной с одним из типов объекта.
[004] В соответствии с одним или более вариантами реализации настоящего изобретения пример системы может включать запоминающее устройство, в котором хранятся инструкции; обрабатывающее устройство, соединенное с запоминающим устройством, причем это обрабатывающее устройство предназначено для выполнения команд для: получения изображения, содержащего, как минимум, часть документа; выявления множества точек деления, разделяющих изображение на потенциальные сегменты; создания графа линейного деления (ГЛД), содержащего множество вершин, использующих множество точек деления, и множество ребер, соединяющих множество вершин; выявления пути в ГЛД со значением метрики качества выше порогового значения, где путь выбирается из множества путей в ГЛД и содержит одно или более ребер из множества ребер, и значение метрики качества порождается с помощью нейронной сети, классифицирующей множество пикселей изображения; и создания одного или более блоков изображения, где каждый из одного или более блоков соответствует ребру из одного или более ребер выявленного пути и соответствует части изображения, ассоциированной с одним из типов объекта.
[005] В соответствии с одним или более вариантами реализации настоящего изобретения пример постоянного машиночитаемого носителя данных может включать исполняемые команды, которые при исполнении их обрабатывающим устройством приводят к выполнению обрабатывающим устройством операций, включающих: получение изображения, содержащего, как минимум, часть документа; выявление множества точек деления, разделяющих изображение на потенциальные сегменты; создание графа линейного деления (ГЛД), содержащего множество вершин, использующих множество точек деления, и множество ребер, соединяющих множество вершин; выявление пути в ГЛД со значением метрики качества выше порогового значения, где путь выбирается из множества путей в ГЛД и содержит одно или более ребер из множества ребер, и значение метрики качества порождается с помощью нейронной сети, классифицирующей множество пикселей изображения; и создание одного или более блоков изображения, где каждый из одного или более блоков соответствует ребру из одного или более ребер выявленного пути и соответствует части изображения, ассоциированной с одним из типов объекта.
[006] КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[007] Для более полного понимания настоящего изобретения ниже приводится подробное описание, в котором для примера, а не способом ограничения, оно иллюстрируется со ссылкой на чертежи, на которых:
[008] На Фиг. 1 изображена схема компонентов верхнего уровня для примера архитектуры системы в соответствии с одним или более вариантами реализации настоящего изобретения.
[009] На Фиг. 2 приведена блок-схема одного иллюстративного примера способа сегментации документа на блоки различного типа в соответствии с одним или более вариантами реализации настоящего изобретения.
[0010] На Фиг. 3 приведен один иллюстративный пример изображения, содержащего страницу документа для сегментации документа на блоки различного типа, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0011] На Фиг. 4A приведен иллюстративный пример выявления точек деления для разделения изображения, содержащего страницу документа, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0012] На Фиг. 4B приведен иллюстративный пример выявления точек деления с использованием гистограмм, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0013] На Фиг. 4C приведен иллюстративный пример создания графа линейного деления для изображения, содержащего страницу документа, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0014] На Фиг. 5A-5C приведены примеры карт вероятности, созданных нейронной сетью для изображения, содержащего документ, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0015] На Фиг. 6 приведен иллюстративный пример вычисления априорной оценки для ребра графа линейного деления, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0016] На Фиг. 7 приведен иллюстративный пример вычисления качества частичного пути для графа линейного деления, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0017] На Фиг. 8A-8C приведены примеры результатов анализа различных путей в графе линейного деления, в соответствии с одним или более вариантами реализации настоящего изобретения.
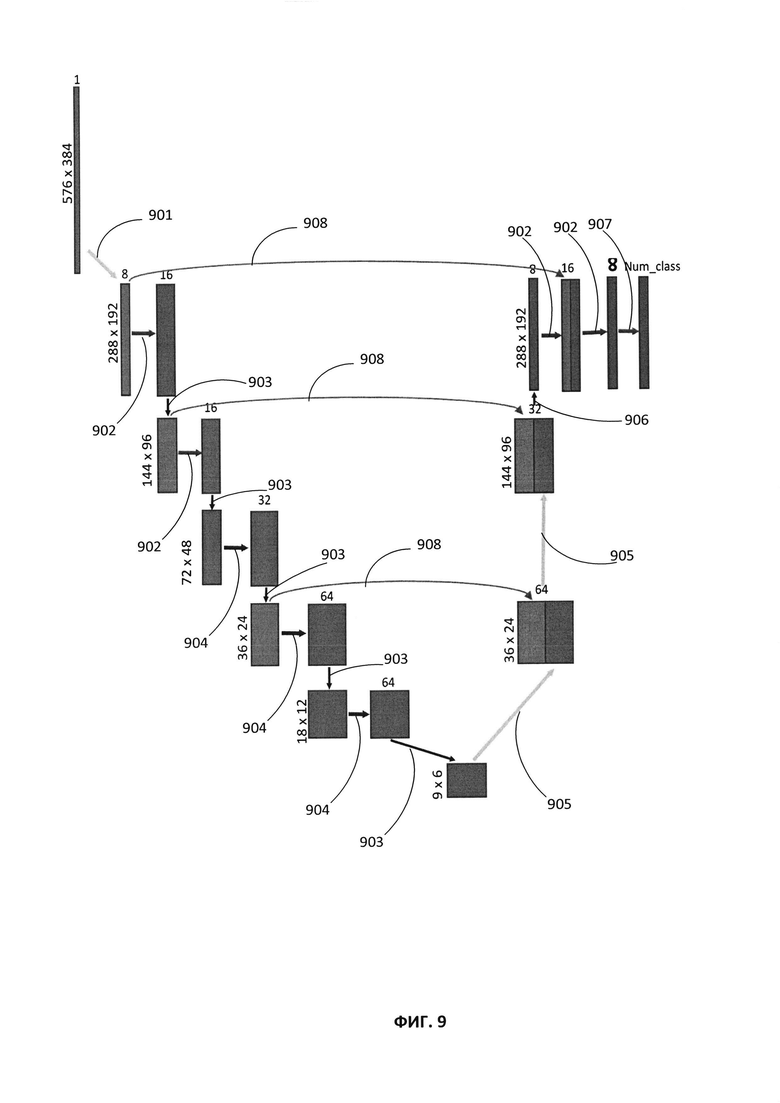
[0018] На Фиг. 9 приведен иллюстративный пример топологии нейронной сети в соответствии с одним или более вариантами реализации настоящего изобретения.
[0019] На Фиг. 10 приведен пример вычислительной системы, которая может выполнять один или более способов, описанных в настоящем документе, в соответствии с одним или более вариантами реализации настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[0020] Как обсуждалось ранее, страница документа может содержать различные типы сегментов или блоков. Каждый блок может быть ассоциирован с отдельным типом элементарных объектов, включая, но не ограничиваясь, заголовки, текст, диаграммы, таблицы, графику и др. Для анализа изображения, содержащего страницу документа, с целью сегментации страницы документа на блоки различного типа, могут использоваться различные способы.
[0021] Обычно для получения решения проблем сегментации изображения могут использоваться низкоуровневые и (или) высокоуровневые механизмы. Низкоуровневыми механизмами называются механизмы, которые в основном работают непосредственно с изображениями. Например, в низкоуровневом механизме изображение может быть предварительно обработано (например, путем удаления текстуры), на изображении могут быть выделены атомарные объекты (например, связные компоненты, разделители и т.д.), и может быть выполнена классификация элементарных компонентов. Механизмы более высокого уровня, чем низкоуровневые механизмы, описанные выше, могут не работать непосредственно с изображениями, вместо этого они могут работать с атомарными объектами, выделенными механизмами низкого уровня.
[0022] На самых высоких уровнях механизмы могут использовать «модельный» подход. В модельном подходе отдельные признаки изображения или объектов изображения могут интерпретироваться на основе их основных характеристик и (или) связей с ближайшими объектами, а также на основании роли этих признаков или объектов в документе, содержащемся на изображении. Например, это может определяться тем, насколько каждый из извлеченных атомарных объектов соответствует логической структуре документа. Такая интерпретация может выполняться наложением моделей на «контексты». Контекст может быть определен, например, как данный регион изображения. Модель может отражать, как могут выглядеть отдельные признаки изображения, при условии, что тип документа на изображении определен. В одном из примеров «одноколоночной модели» может предполагаться, что документ имеет «одноколоночную структуру», в которой объекты на изображении имеют ориентацию в одну и ту же сторону (например, объекты ориентированы вертикально или горизонтально). Одноколоночная модель может предполагать, что содержимое изображения может быть разделено на элементарные объекты (то есть таблицы, текст и др.), которые не пересекаются, например, по вертикали. Качество модели может зависеть оттого, насколько хорошо модель определяет и выявляет характеристики каждого объекта на изображениях. В другом примере «многоколоночная модель» может работать, используя предположение о том, что содержимое изображения представляет собой документ, который содержит несколько колонок. Каждая колонка сама по себе может иметь одноколоночную структуру, однако несколько колонок могут иметь структуру, в которой объекты ориентированы в разных направлениях. В таких типах моделей наложение моделей может выполняться в два этапа. На первом этапе определяется основная структура документа для выявления каждой из нескольких колонок, а на втором этапе каждая из колонок анализируется по отдельности (например, в каждой отдельной колонке выявляются строки текста или таблицы). Таким образом, многоколоночная структура может быть проанализирована путем разбиения изображения на множество одно колоночных структур и применения анализа одноколоночной модели к каждой одноколоночной структуре.
[0023] В некоторых примерах для анализа одноколоночных регионов изображения может применяться алгоритм, работающий по принципу «снизу вверх». Алгоритм «снизу вверх» может включать использование независимых механизмов для анализа элементарных объектов различного типа, так что каждый из механизмов будет использоваться для поиска элементарных объектов определенного типа. Например, для поиска абзаца по принципу «снизу вверх» потенциальные извлекаемые символы изображения могут объединяться в потенциальные слова, потенциальные слова могут далее объединяться в потенциальные строки, и потенциальные строки могут объединяться в параграфы, обеспечивая конечный результат поиска для поиска параграфов. В других примерах в их упрощенном описании поиск таблиц может выполняться объединением линий; поиск диаграмм может выполняться по связным компонентам и т.д. Результат может быть составлен из объектов, которые не пересекаются в одном направлении (например, по вертикали, по горизонтали и т.д.). Однако недостаток подхода «снизу-вверх» в том, что он использует жадный алгоритм. Жадный алгоритм на каждом этапе попытки нахождения глобально оптимального решения делает локально оптимальный выбор. Во многих задачах жадный алгоритм может найти глобальное решение за разумное время; однако он может не давать наилучшего глобального решения. В текущей ситуации подход «снизу-вверх» с использованием индивидуальных механизмов может быть жадным, поскольку каждый отдельный механизм может искать и выдавать результаты для определенного типа объектов, но не осведомлен о результатах работы других механизмов для других типов объектов внутри того же региона изображения. Например, механизм поиска текста для региона изображения не принимает во внимание результаты механизма поиска таблицы для того же региона изображения. Таким образом, подход «снизу-вверх» может быть не в состоянии дать наилучшее решение для сегментации.
[0024] Описанные в настоящем документе системы и способы представляют значительные улучшения, позволяя обеспечить более точную сегментацию одноколоночного региона документа на блоки элементарных объектов разного типа, предлагая различные варианты возможной сегментации одноколоночного региона документа как путей в графе линейного деления (ГЛД). Поиск в ГЛД может производиться для определения оптимального пути среди вариантов потенциальной сегментации с использованием результатов классификации каждого пикселя изображения нейронными сетями и сравнением результатов каждого из путей, то есть общее решение не базируется на изолированных примерах анализа; напротив, решение может иметь информацию о результатах анализа каждого из путей вариантов возможной сегментации. Этот механизм может включать получение изображения, содержащего, как минимум, часть документа, для которого различные блоки могут быть выявлены. Множество точек деления можно идентифицировать с помощью характеристик изображения. Например, для выявления точек деления можно использовать гистограммы черных и (или) цветных пикселей. Множество точек деления можно использовать для разделения изображения на варианты потенциальных сегментов. Граф линейного деления (ГЛД) можно построить с помощью множества точек деления. ГЛД может содержать вершины и ребра, при этом точки деления выбираются в качестве вершин ГЛД, а ребра образуются путем соединения вершин. В некоторых примерах вершины могут выбираться путем фильтрации точек деления, исходя из различных факторов, ребра могут также селективно размещаться между выбранными вершинами, исходя из различных факторов. После построения ГЛД может производиться поиск различных путей в ГЛД для выявления полного пути ГЛД, который обеспечивает оптимальное качество сегментации. Полный путь является отдельным случаем из множества возможных частичных путей. Частичные пути представляют собой пути, которые начинаются с верхней вершины, но могут не всегда доходить до нижней вершины. Частичный путь может рассматриваться как полный путь, если он заканчивается в нижней вершине. Определение полного пути может базироваться на метрике качества, вычисляемой механизмом. Метрика качества для частичных и полных путей может вычисляться в несколько этапов. Этапы могут включать выявление для каждого ребра априорной оценки принадлежности к определенному типу объектов, и для наиболее перспективных ребер - апостериорного качества (более подробное описание см. ниже), исходя из дополнительных вычислений на основе результатов анализа ребер. Для вычисления значений метрики качества может использоваться нейронная сеть, классифицирующая множество пикселей изображения. Исходя из выявленного полного пути ГЛД для получения результата сегментации документа могут быть созданы один или более блоков изображения. Каждый из этих одного или более блоков соответствуют ребру, входящему в выявленный путь, и соответствует части изображения, ассоциированного с определенным типом объекта.
[0025] Возможен поиск для определения оптимального разбиения колонок на блоки и выбора оптимального результата анализа блоков. Описанные в настоящем документе способы представляют более высококачественные результаты анализа одноколоночного региона по сравнению с результатами работы жадных алгоритмов, таких как подход «снизу-вверх». Использование нейронной сети для предсказания вероятности того, что каждый пиксель изображения принадлежит к определенному классу объектов, также повышает общую скорость алгоритма сегментации.
[0026] Различные аспекты упомянутых выше способов и систем подробно описаны ниже в этом документе с помощью примеров, а не способом ограничения.
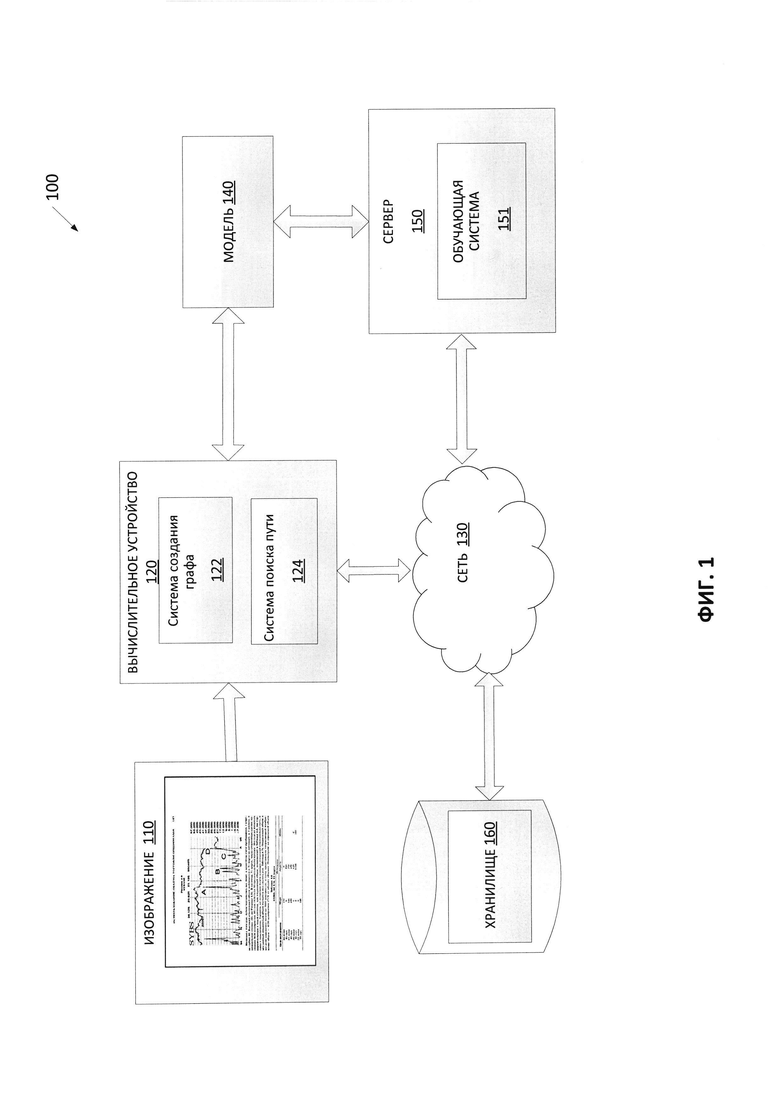
[0027] На Фиг. 1 изображена диаграмма компонентов верхнего уровня для пояснения системной архитектуры 100 в соответствии с одним или более вариантами реализации настоящего изобретения. Системная архитектура 100 включает вычислительное устройство 120, хранилище 160 и сервер 150, подключенный к сети 130. Сеть 130 может быть общественной сетью (например, Интернет), частной сетью (например, локальная сеть (LAN, local area network) или распределенной сетью (WAN, wide area network)), а также их комбинацией.
[0028] Вычислительное устройство 120 может производить сегментацию изображения документа. В одном из вариантов реализации изобретения вычислительное устройство 120 может быть настольным компьютером, портативным компьютером, смартфоном, планшетным компьютером, сервером, сканером или любым подходящим вычислительным устройством, способным использовать технологии, описанные в этом изобретении. Вычислительное устройство 120 может получать одно или более изображений. В одном из примеров изображение 110 может быть получено вычислительным устройством 120. Изображение 110 может содержать изображение документа, страницы документа или части страницы документа. В одном из примеров может возникнуть необходимость выявления различных блоков внутри документа. Страница документа или часть страницы документа с изображения 110 может иметь одноколоночную структуру. Изображение 110 может быть подано на вход вычислительного устройства 120. Вычислительное устройство 120 может определять оптимальный вариант сегментации и создавать в качестве результата один или более блоков изображения, представляющих собой части изображения 110, ассоциированные с различными типами объектов.
[0029] В одном из вариантов реализации изобретения вычислительное устройство 120 может включать систему создания графа 122 и систему поиска пути 124. Система создания графа 122 и система поиска пути 124 могут содержать инструкции, хранящиеся на одном или более физических машиночитаемых носителях данных вычислительного устройства 120 и выполняемые на одном или более устройствах обработки вычислительного устройства 120. В одном из вариантов реализации изобретения система создания графа 122 может создавать граф линейного деления (ГЛД), исходя из изображения 110. Например, ГЛД может содержать множество вершин и ребер, причем вершины могут быть порождены с использованием точек деления, выявленных в изображении 110, а ребра могут быть порождены путем соединения этих вершин.
[0030] В одном из вариантов реализации изобретения система поиска пути 124 может использовать обученную модель машинного обучения 140, которая была обучена и использована для классификации пикселей изображения 110 на различные классы элементарных объектов. Модель 140 машинного обучения может быть обучена с использованием обучающей выборки изображений и соответствующих классов объектов для каждого пикселя. В некоторых вариантах реализации изобретения модель 140 машинного обучения может быть частью системы поиска пути 124 или располагаться на другой машине с обеспечением доступа к ней (например, на сервере 150) системы поиска пути 124. Исходя из результатов (например, карт вероятности для пикселей изображения) обученной модели 140 машинного обучения, система поиска пути 124 может искать путь в ГЛД, созданной системой создания графа 122, для выявления пути, ассоциированного со значением метрики качества, соответствующего пороговому значению, для получения оптимального пути в ГЛД. Система поиска пути 124 может также создавать один или более блоков, соответствующих одному или более ребрам выявленного пути так, что каждый блок может представлять тип объекта.
[0031] Сервер 150 может быть стоечным сервером, маршрутизатором, персональным компьютером, карманным персональным компьютером, мобильным телефоном, портативным компьютером, планшетным компьютером, фотокамерой, видеокамерой, нетбуком, настольным компьютером, медиацентром или их сочетанием. Сервер 150 может содержать систему обучения 151. Модель машинного обучения 140 может ссылаться на артефакт модели, созданный обучающей системой 151 с использованием обучающих данных, которые содержат обучающие входные данные и соответствующие искомые выходные данные (правильные ответы на соответствующие обучающие входные данные). В процессе обучения могут быть найдены шаблоны обучающих данных, которые преобразуют входные данные обучения в искомый результат (ответ, который следует предсказать) и впоследствии могут быть использованы моделями машинного обучения 140 для будущих прогнозов. Как более подробно будет описано ниже, модель машинного обучения 140 может быть составлена, например, из одного уровня линейных или нелинейных операций (например, машина опорных векторов [SVM, support vector machine]) или может представлять собой глубокую сеть, то есть модель машинного обучения, составленную из нескольких уровней нелинейных операций. Примерами глубоких сетей являются нейронные сети, включая сверточные нейронные сети, рекуррентные нейронные сети с одним или более скрытыми слоями и полносвязные нейронные сети.
[0032] Как отмечалось выше, модель машинного обучения 140 может быть обучена определять вероятность того, что пиксели изображения принадлежат к заранее определенному классу объектов, используя учебные данные, как более подробно будет описано ниже. После обучения модели 140 машинного обучения она может быть передана в систему поиска пути 124 для анализа изображения 110. Например, система поиска изображения 124 для каждого ребра, содержащего часть изображения 110, может запрашивать результат анализа части изображения от модели 140 машинного обучения. В некоторых примерах модель 140 может содержать сверточную нейронную сеть. Система поиска пути 124 может получать от модели машинного обучения 140 один или более результатов. Результатом может быть набор карт вероятности принадлежности к различным классам объектов.
[0033] Хранилище 160 может быть постоянной памятью, которая в состоянии сохранять изображение 110, а также структуры данных для разметки, организации и индексации изображения 110. Хранилище 160 может располагаться на одном или более запоминающих устройствах, таких как основное запоминающее устройство, магнитные или оптические запоминающие устройства на основе дисков, лент или твердотельных накопителей, NAS, SAN и т.д. Несмотря на то что хранилище изображено отдельно от вычислительного устройства 120, в одной из реализаций изобретения хранилище 160 может быть частью вычислительного устройства 120. В некоторых вариантах реализации хранилище 160 может представлять собой подключенный к сети файловый сервер, в то время как в других вариантах реализации изобретения хранилище 160 может представлять собой какой-либо другой тип энергонезависимого запоминающего устройства, такой как объектно-ориентированная база данных, реляционная база данных и т.д., которая может находиться на сервере или на одной или более различных машинах, подключенных к нему через сеть 130.
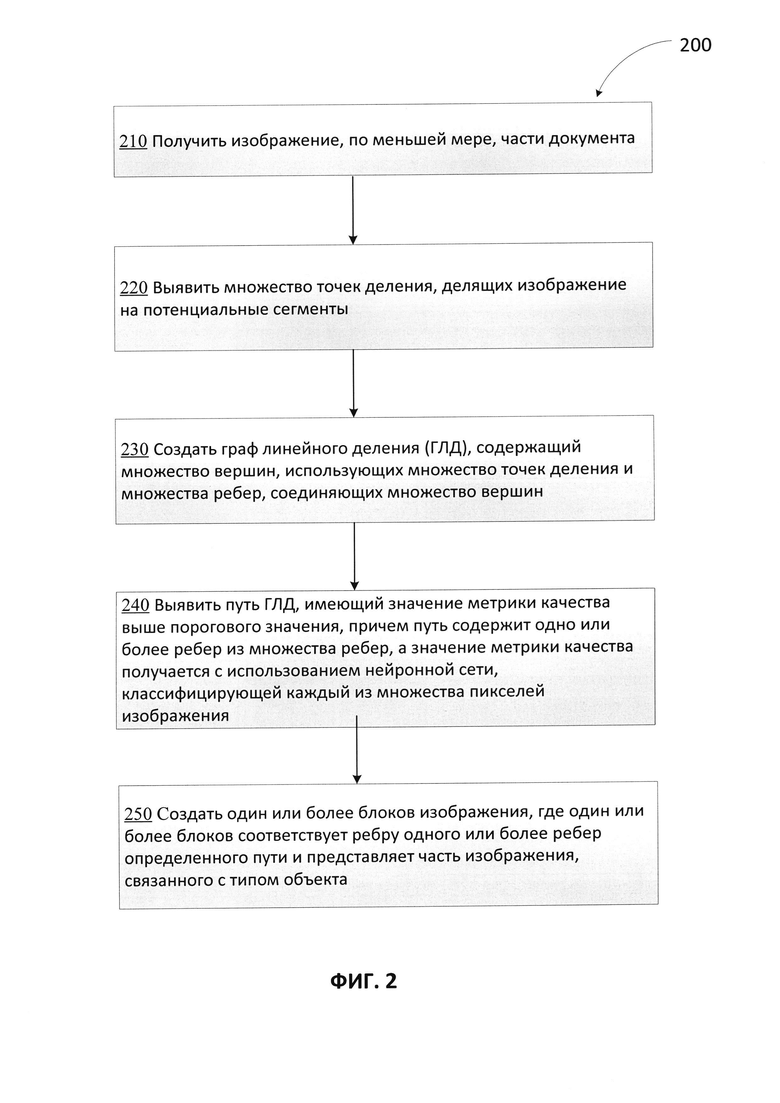
[0034] На Фиг. 2 приведена блок-схема одного иллюстративного примера способа сегментации документа на блоки различного типа в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 200 и (или) каждая из его отдельно взятых функций, процедур, подпрограмм или операций могут осуществляться с помощью одного или более процессоров вычислительной системы (например, вычислительной системы 1000 на Фиг. 10), реализующей этот способ. В некоторых вариантах реализации способ 200 может быть реализован в одном потоке обработки. Кроме того, способ 200 может выполняться, используя два или более потоков обработки, причем каждый поток выполняет одну или более отдельных функций, процедур, подпрограмм или операций способа. В качестве иллюстративного примера потоки обработки, реализующие способ 200, могут быть синхронизированы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). В качестве альтернативы реализующие способ 200 потоки обработки могут выполняться асинхронно по отношению друг к другу. Таким образом, несмотря на то, что Фиг. 2 и соответствующее описание содержат список операций для способа 200 в определенном порядке, в различных вариантах реализации способа, как минимум, некоторые из описанных операций могут выполняться параллельно и (или) в случайно выбранном порядке. В одном из вариантов реализации способ 200 может выполняться с помощью одного или более компонентов на Фиг. 1, например, системы построения графа 122, системы поиска пути 124 и т.п.
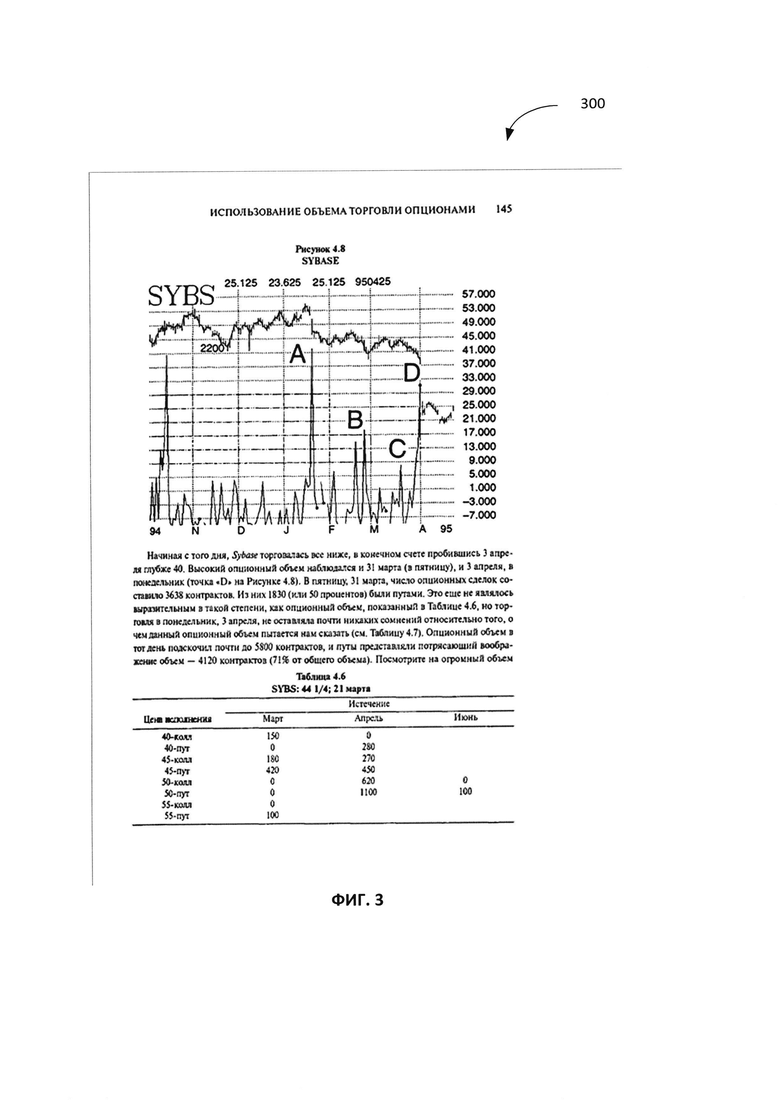
[0035] На шаге 210 вычислительная система, реализующая способ, может получать изображение. Изображение может содержать, как минимум, часть документа. Эта часть документа может включать одноколоночную структуру. Одноколоночная структура может содержать в части документа объекты, имеющие одинаковую ориентацию. Документ может быть печатным документом, цифровым документом и т.д. На Фиг. 3 показан пример изображения, содержащего документ 300 для сегментации на различные блоки. Все элементарные объекты (то есть строки текста, абзацы, таблицы, диаграммы и т.д.) внутри документа 300 изображены как ориентированные в горизонтальном направлении, объекты не пересекаются по вертикали. Документ 300 может быть страницей документа с одноколоночной структурой или регионом страницы многоколоночного документа с одноколоночной структурой. В одном из примеров, если документ является страницей с двухколоночной структурой, он может быть обработан так, чтобы в нем были выявлены два одноколоночных региона. Каждый из двух одноколоночных регионов может быть получен вычислительной системой, реализующей этот способ для сегментации.
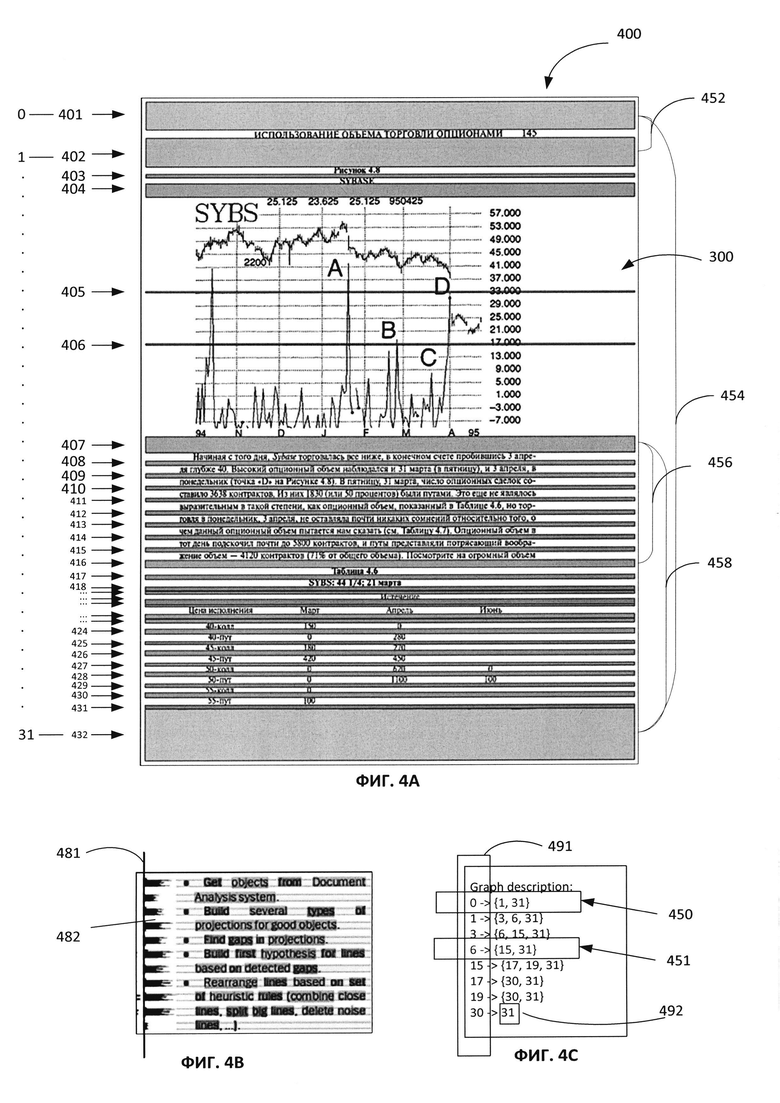
[0036] Обращаясь вновь к Фиг. 2, на шаге 220 вычислительная система может выявлять множество точек деления, разделяющих изображение на потенциальные сегменты. Например, на Фиг. 4A приведен пример выявления точек деления для разделения изображения 400, содержащего документ 300 с Фиг. 3. Множество точек деления может быть выявлено с помощью характеристик, признаков или элементарных объектов, извлеченных из изображения 400. Например, для выявления точек деления могут использоваться гистограммы черных и цветных пикселей. Фиг. 4B содержит пример выявления точек деления с помощью гистограмм. Гистограмма черных пикселей может проектироваться на вертикальную ось 481. Эта гистограмма может содержать пустые области, то есть области с нулевым количеством черных пикселей. Пустые области (например, пустая область 482) на гистограмме могут указывать на пустые области изображения, соответствующие точкам на вертикальной оси. Пустые области могут рассматриваться как точки деления. Обращаясь вновь к Фиг. 4A, точки деления могут выявляться там, где на изображении 400 между элементарными объектами (например, текстом, картинками и т.д.) находятся пустые области. Каждая пустая область между объектами изображения 400 может быть определена в качестве точки деления. На Фиг. 4A каждая горизонтальная пустая область на изображении 400, помеченная прямоугольниками 401-432, определена в качестве точки деления. Точки деления далее помечаются числами от «0» до «31», причем число «0» соответствует прямоугольнику 401 и представляет собой начальную точку среди точек деления, а число «31» соответствует прямоугольнику 432 и представляет собой конечную точку среди точек деления. Эти числа используются для ссылки на вершины ГЛД. В некоторых вариантах реализации изобретения точки деления могут быть получены в виде элементарных объектов, извлеченных из изображения низкоуровневыми механизмами, и могут передаваться вместе с изображением 400 для дальнейшей обработки.
[0037] Согласно Фиг. 2, на шаге 230 вычислительная система может создавать граф линейного деления (ГЛД). ГЛД может содержать множество вершин и множество ребер (дуг). Множество вершин может быть получено с использованием множества точек деления. Множество ребер может быть получено путем соединения множества вершин. В одном из примеров ГЛД может быть направленным ациклическим графом (DAG от англ. directed acyclic graph), в котором имеется источник в самой верхней точке деления и приемник в самой нижней точке деления, и каждая направлена из предыдущей точки в следующую точку графа. Каждая из выявленных точек деления может стать вершиной (узлом) ГЛД. Некоторые или все вершины могут отслеживаться сверху вниз и соединяться, образуя ребро.
[0038] В некоторых вариантах реализации ГЛД может создаваться путем выбора всех точек деления в качестве множества вершин ГЛД. В некоторых вариантах реализации ГЛД может создаваться путем фильтрации точек деления для выбора подмножества из множества точек деления в качестве множества вершин ГЛД. Выявленные точки деления могут классифицироваться для получения качества каждой точки деления. Например, классификатор может использовать следующие признаки: средние размеры области, соответствующей точке деления (то есть ширину области, деленную на среднюю высоту строки текста в документе, или ширину области в см (дюймах и т.д.); максимальное качество разделителей, которые пересекают область (то есть непрерывность области); взвешенное качество разделителей, которые пересекают область и т.д. Также при выборе вершин во внимание могут приниматься дополнительные факторы. В некоторых вариантах реализации может быть задано предельное количество вершин. Например, может быть установлено предельное максимальное количество 15 вершин, выбираемых из имеющихся точек деления.
[0039] Аналогичным образом, в некоторых примерах ГЛД может создаваться путем выбора пар вершин из имеющихся вершин ГЛД и соединения каждой из выбранных пар вершин для образования каждого из множества ребер ГЛД. Таким образом, не всегда расположенная ниже вершина (то есть точка деления) может иметь входящее ребро. Ребра могут быть созданы между вершинами, если ребро имеет высокую вероятность представления части изображения, соответствующую точной сегментации блоков. Выбор пар вершин для образования ребер может базироваться на различных факторах. В некоторых примерах реализации пары вершин (то есть точек деления) могут классифицироваться, исходя из одного или более факторов, таких как, максимальный индикатор качества точек деления заключенных между парой вершин; относительные размеры (то есть ширина, высота) частей изображения (например, пустых областей), соответствующих точкам деления, взвешенное качество точек деления, заключенных между парой вершин, и т.д. Исходя из результата классификации точек деления, выбираются пары вершин, которые при соединении образуют ребра ГЛД. Для текущей точки деления, рассматриваемой для использования в ребре, в качестве парной для образования ребра может оцениваться точка деления, расположенная ниже. В одном из примеров выбор может быть основан на качестве точек деления, расположенных ниже текущей точки деления, количество выбранных точек деления М<=min (5, k), где k - количество точек деления, расположенных ниже текущей точки деления. В различных вариантах реализации ребра могут фильтроваться таким образом, чтобы ограничить размер ГЛД. Может быть установлено предельное максимальное количество ребер. Например, максимальное предельное количество может быть равно 5 ребрам, образуемым из каждой данной вершины.
[0040] Фиг. 4A и 4C демонстрируют создание ГЛД путем выбора вершин и ребер, соединяющих эти вершины. Используя описанные выше факторы, в качестве вершин ГЛД можно выбрать точки деления 0-31. На Фиг. 4C прямоугольники 491 и 492 включают множество вершин ГЛД, которые соединены ребрами попарно. В примере на Фиг. 4C вершины, образующие ребро, включают подмножество из 9 точек деления: 0, 1, 3, 6, 15, 17, 19, 30 и 31.
[0041] Далее вершины ГЛД соединяются, образуя ребра ГЛД. Как обсуждалось ранее, не все 9 вершин соединяются друг с другом, образуя ребра; выбираются пары вершин, которые образуют ребра ГЛД. Пары вершин выбираются таким образом, чтобы включить наиболее вероятные ребра, соответствующие правильной сегментации изображений на блоки, исходя из описанных выше факторов. Например, на Фиг. 4A показаны ребра, выходящие из точки деления 401 (вершина 0) и 407 (вершина 6). Как там показано, из вершины 0 (точка деления 401) выходят два ребра. Первое ребро 452 образуется путем соединения пары вершин, вершины 0 (точка деления 401) и вершины 1 (точка деления 402). Второе ребро 454 образуется путем соединения другой пары вершин, вершины 0 (точка деления 401) и вершины 31 (точка деления 432). На Фиг. 4С описание графа содержит эти два ребра 452 и 454, так что вершина 0 имеет два ребра, представленные первой строкой 450 описания графа «0 - > {1, 31}.» Таким образом, имеется ребро, выходящее из вершины 0 в вершину 1, и другое ребро, выходящее из вершины 0 в вершину 31. В другом примере Фиг. 4A демонстрирует два ребра, исходящих из точки деления 407 (вершина 6). Ребро 456 образуется соединением пары вершин, вершины 6 (точка деления 407) и вершины 15 (точка деления 416). Ребро 458 образуется путем соединения другой пары вершин, вершины 6 (точка деления 407) и вершины 31 (точка деления 432). На Фиг. 4C описание графа содержит эти два ребра 456 и 458, так что вершина 6 имеет два ребра, представленные строкой 451 описания графа «6 - >{15, 31}.» Таким образом, имеется ребро, выходящее из вершины 6 в вершину 15, и другое ребро, выходящее из вершины 6 в вершину 31.
[0042] Вернемся к Фиг. 2, на шаге 240 вычислительная система может выявлять путь в ГЛД со значением метрики качества выше порогового значения. Этот путь может включать одно или более ребер из множества ребер. Значение метрики качества может быть получено с помощью нейронной сети, классифицирующей каждый из множества пикселей изображения. Пороговое значение может быть получено, исходя из количества наибольших значений метрики качества, связанных с одним или более путями в ГЛД, где диапазон значений для наибольших значений находится в определенном диапазоне. Выявленный путь может быть выбран из множества путей, имеющих значения метрики качества выше порогового значения. Выбор пути может основываться на попарном сравнении каждого из множества путей. Значения метрики качества для множества ребер могут быть получены, исходя из исходной (априорной) оценки вероятностей того, что каждое ребро из множества ребер соответствует каждому объекту из множества заранее определенных типов объектов. Вероятности могут оцениваться, исходя из подмножества множества пикселей изображения, соответствующих каждому ребру из множества ребер, исходя из нейронной сети, классифицирующей каждый из множества пикселей изображения. Это изображение может быть подано на вход нейронной сети. Множество вероятностей может быть получено в качестве результата работы нейронной сети для каждого из множества пикселей изображения, принадлежащих каждому из множества заранее определенных классов объектов, соответствующих каждому из множества заранее определенных типов объектов. Значения метрики качества частичного пути и полного пути далее могут быть получены, исходя из максимального значения априорной оценки вероятностей для каждого ребра из множества ребер, соответствующих каждому из множества заранее определенных типов объектов (более подробное описание см. ниже).
[0043] Создание ГЛД может допускать выявление оптимального полного пути (т.е. пути с максимальным общим значением метрики качества ребер, включенных в путь), соединяющего верхнюю и нижнюю точки деления изображения. Кроме выявления оптимального полного пути, сегментирующего изображение на различные блоки, каждое ребро полного пути анализируется для определения типа блока, которому соответствует ребро. Таким образом, этот анализ может давать результат, показывающий, что одно или более ребер полного пути соответствуют блоку таблицы, другое ребро полного пути соответствует блоку текста и т.д. Поиск оптимального полного пути может выполняться в несколько этапов. В некоторых вариантах реализации поиск для выявления оптимального пути в ГЛД может включать вычисление априорной оценки и апостериорной оценки качества ребер в ГЛД. Поиск оптимального пути может включать использование алгоритма поиска «А*» в ГЛД. А* - это алгоритм информированного поиска для обхода и поиска пути в графах. Он формулируется в терминах взвешенных графов: начиная с определенного начального узла графа, он направлен на поиск пути к заданному целевому узлу, который имеет наименьшую цену (минимальное пройденное расстояние, минимальное время и т.д.) или максимальную метрику качества в способе, описываемом здесь. Это обеспечивается поддержанием дерева путей, исходящих из начального узла, и продолжением этих путей по одному ребру за раз до выполнения критерия останова.
[0044] Вычислительная система может вычислять априорную оценку (то есть исходную оценку) для каждого ребра из множества ребер ГЛД. Эта априорная оценка может обеспечить оценку вероятности для каждого ребра из множества ребер, соответствующую каждому из множества заранее определенных типов объектов до выполнения А* - поиска в ГЛД. Вычисление априорной оценки может включать использование на ребрах ГЛД различных анализаторов. Например, анализаторы могут включать анализаторы заранее определенных типов объектов, такие как анализаторы текста, анализаторы диаграмм, анализаторы изображений, анализаторы таблиц и т.д. Каждый из этих анализаторов обеспечивает оценку вероятности того, что ребро, анализируемое конкретным анализатором, принадлежит к типу объектов, соответствующему анализатору. Например, анализатор таблиц может показывать для отдельного ребра, что оценка вероятности того, что это ребро соответствует типу объекта «таблица», равна 0,8. При наличии N заранее определенных типов объектов с N анализаторами, используемыми на каждом ребре, для каждого ребра количество априорных оценок вероятностей будет равно N. Например, если N равно 4, то есть при наличии 4 заранее определенных типов объектов (например, анализатора текста, анализатора диаграмм, анализатора изображений и анализатора таблиц), для каждого ребра ГЛД будет получено 4 априорные оценки.
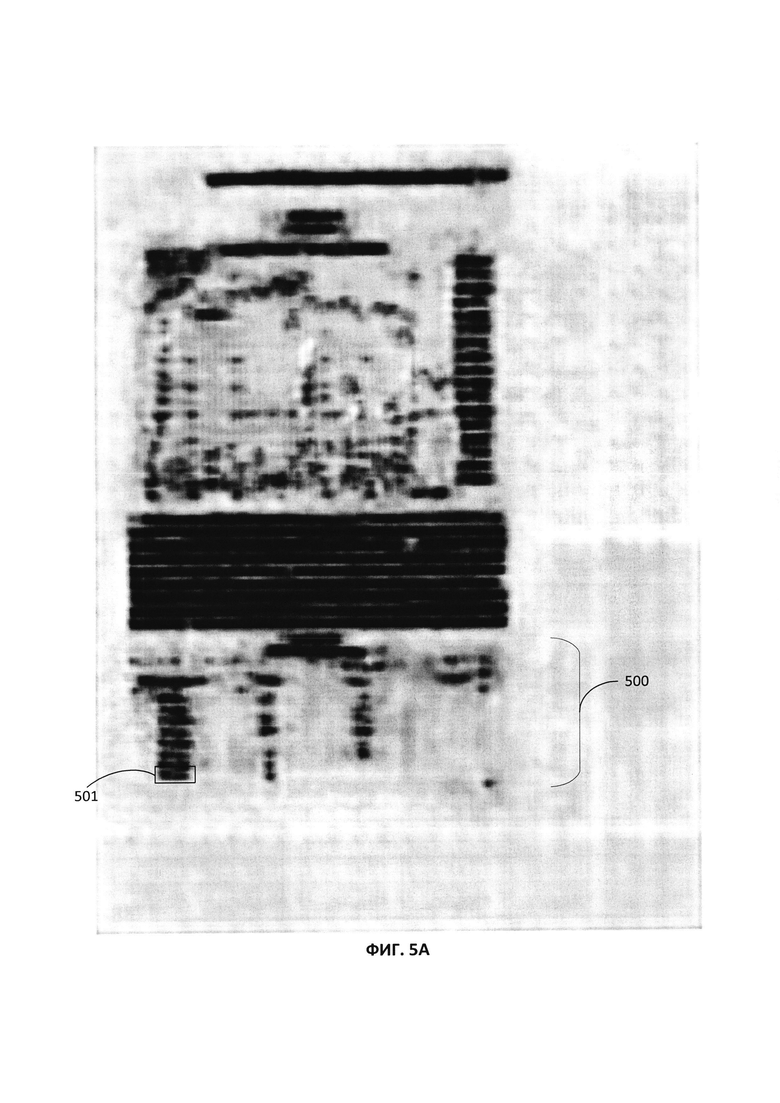
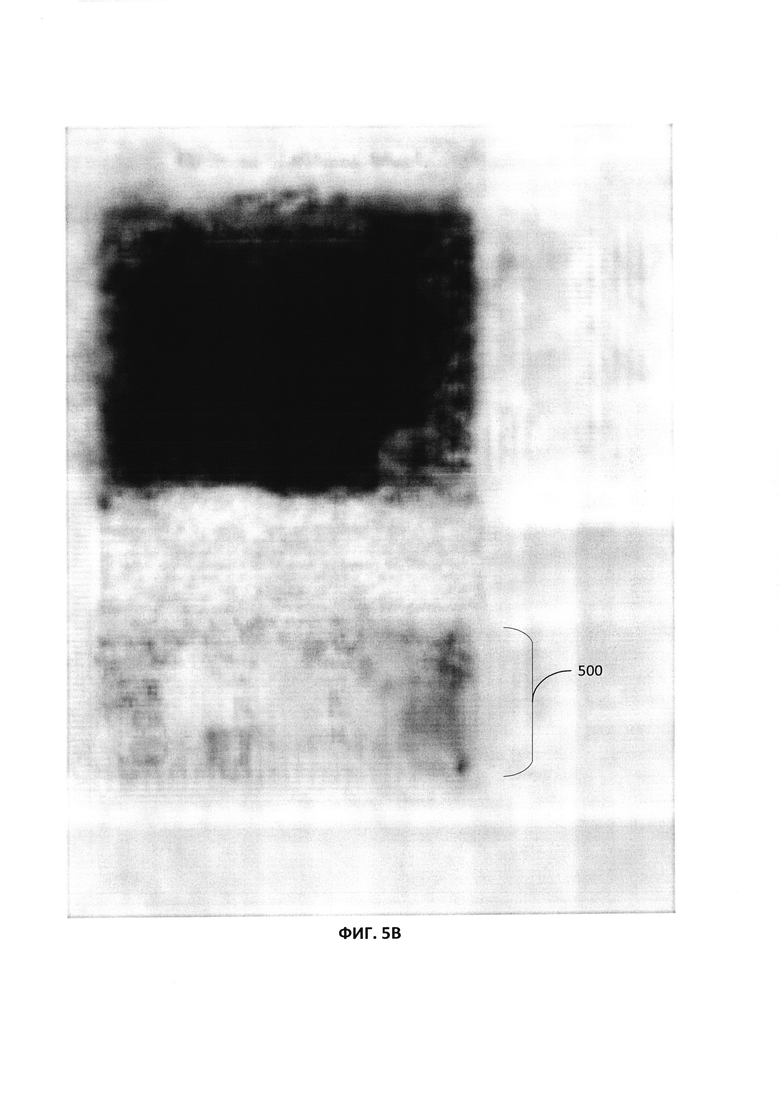
[0045] Априорная оценка вероятностей может быть вычислена, исходя из анализа изображения страницы документа нейронной сетью (например, сверточной нейронной сетью). Априорная оценка является быстрой и малозатратной оценкой вероятности принадлежности каждого ребра из множества ребер к каждому из множества заранее определенных типов объектов. Априорная оценка выполняется для каждого ребра ГЛД. Полученное изображение может быть подано на вход нейронной сети. Нейронная сеть может выдать в качестве выходных данных множество вероятностей. Множество вероятностей может указывать для каждого пикселя из большого числа пикселей данного изображения вероятности того, что данный пиксель принадлежит к каждому из предопределенных классов объектов, определенных в нейронной сети. Предопределенные классы объектов могут соответствовать предопределенным типам объектов анализаторов. Количество предопределенных классов объектов может также быть равно N или числу предопределенных типов объектов для анализаторов. Например, предопределенные классы объектов для нейронной сети могут содержать классы для текста, картинок, диаграмм, таблиц и т.д. Нейронная сеть может быть обучена с использованием обучающих изображений и классификации каждого пикселя обучающих изображений в предопределенные классы объектов. Таким образом, при вводе изображения в нейронную сеть на выходе можно получить значение вероятности, согласно которому конкретный пиксель данного изображения принадлежит к определенному классу объектов. Например, нейронная сеть может определить для каждого пикселя вероятность того, что пиксель будет принадлежать к классу «Таблица», «Текст», «Картинка» и т.д. На Фиг. 5A-5C изображены карты вероятностей множества вероятностей, генерируемых нейронной сетью для каждого пикселя изображения 400. На Фиг. 5A показан пример карты вероятностей класса «Текст» для региона 500, содержащего подмножество пикселей. Каждый пиксель региона 500 анализируется нейронной сетью. Нейронная сеть определяет вероятности принадлежности пикселей региону 500 к классу «Текст». Темные области изображения, такие как область 501, указывают на высокую вероятность того, что пиксель принадлежит к классу «Текст». Аналогичным образом на Фиг. 5B показана карта вероятности типа «Картинка» для региона 500 с использованием в ней темных зон, а на Фиг. 5C показана карта вероятности класса «Таблица» для региона 500 с использованием в ней темных зон. Дальнейшее описание топологии нейронной сети показано со ссылкой на Фиг. 9 ниже.
[0046] Априорная оценка или исходная оценка вероятностей могут быть вычислены с использованием подмножества множества пикселей изображения, соответствующего каждому ребру из множества ребер, анализируемых для априорной оценки, на основе нейронной сети, классифицирующей каждый из множества пикселей изображения. В примере каждый анализатор может рассматривать выход нейронной сети для подмножества пикселей в регионе, охватываемой конкретным ребром, который анализатор анализирует в настоящее время. Например, регион может быть частью, подобной прямоугольнику, определенного размера, который соответствует конкретному ребру. Используя пиксели в регионе, соответствующие ребру, анализатор может провести априорную оценку того, что регион принадлежит типу объекта, представленного анализатором. В одном из примеров если пороговый процент пикселей в регионе классифицирован нейронной сетью как имеющий высокую вероятность принадлежности к определенному классу, то анализатор, соответствующий этому конкретному классу объекта, может обеспечить высокую априорную оценку того, что ребро соответствует этому конкретному типу объекта. В другом примере, если большинство пикселей в регионе классифицируются нейронной сетью как имеющие низкую вероятность принадлежности к определенному классу, то анализатор, соответствующий этому конкретному классу объекта, может обеспечить низкую априорную оценку того, что ребро соответствует этому конкретному типу объекта. Например, текстовый анализатор может анализировать ребро, охватывающее регион с высокой вероятностью принадлежности к классу «Таблица». То есть большинство пикселей в регионе классифицировано выходом нейронной сети как принадлежащих с высокой вероятностью к классу «Таблица». Априорная оценка вероятности того, что ребро, соответствующее региону, является текстом, будет низкой.
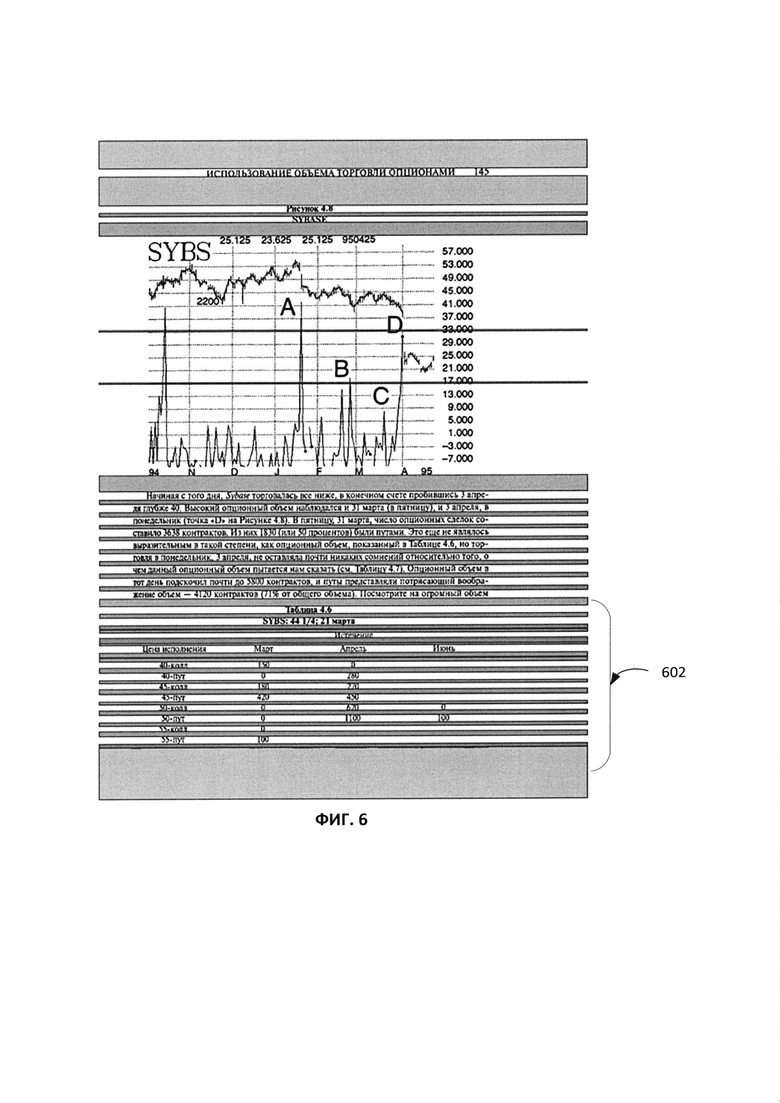
[0047] На Фиг. 6 показан иллюстративный пример вычисления априорной оценки ребра ГЛД. Априорная оценка для ребра 602 вычисляется с использованием выхода нейронной сети для соответствующего региона изображения 400. Выходы нейронной сети для каждого класса (например, текст, картинка, таблица), как показано на Фиг. 5A-5C, используются каждым анализатором, соответствующим этому классу. Если ребро 602 анализируется анализатором класса «Текст», он дает низкую априорную оценку вероятности того, что ребро соответствует типу объекта «Текст». Оценка основана на выходе нейронной сети для соответствующего региона 500 на Фиг. 5A, который предоставил карту вероятностей для пикселей в регионе 500, которые принадлежат к классу «Текст». Оценка невысока, поскольку большинство пикселей не отмечены как имеющие высокую вероятность принадлежности к классу «Текст», определенную темными областями. Аналогичным образом если ребро 602 анализируется анализатором типа «Картинка», он обеспечивает низкую априорную оценку вероятности того, что ребро соответствует типу объекта «Картинка» на основе выхода нейронной сети для соответствующего региона 500 на Фиг. 5B, которая предоставила карту вероятности для пикселей в регионе 500, которые принадлежат к классу «Картинка». Однако если ребро 602 анализируется анализатором типа «Таблица», он обеспечивает высокую априорную оценку вероятности того, что ребро соответствует типу объекта «Таблица». Оценка основана на выходе нейронной сети для соответствующего региона 500 на Фиг. 5C, который предоставил карту вероятностей для пикселей в регионе 500, которые принадлежат к классу «Таблица». Оценка высока, поскольку большинство пикселей отмечены как имеющие высокую вероятность принадлежности к классу «Таблица», определенную темными зонами в регионе 500.
[0048] Впоследствии может быть получено апостериорное качество ребер и выбран один или более оптимальных полных путей. Апостериорное качество может быть получено путем запуска анализатора, соответствующего конкретному классу объекта, такого как текстовый анализатор, анализатор диаграмм, анализатор картинок, анализатор таблиц и т.д. Каждый из анализаторов анализирует ребро, используя соответствующий механизм, обеспечивающий апостериорное качество того, что ребро, анализируемое конкретным анализатором, относится к типу объекта, представленному анализатором. Каждый механизм, который используется для обеспечения апостериорного качества для ребра, является более ресурсоемким, чем быстрый анализ ребра, путем сравнения с выходными данными сверточной нейронной сети, которая используется для обеспечения априорного качества ребра (более подробное описание см. выше). Например, для апостериорной оценки качества текстового ребра (ребра, анализируемого текстовым анализатором) используется механизм, который собирает абзацы из строк. В некоторых примерах при вычислении апостериорной оценки, учитываются такие факторы, как качество собранных абзацев, их выравнивание, пересекаются ли они с вертикальными разделителями, и если да, то как часто и т.д. В другом примере для апостериорной оценки качества ребра картинки используется механизм, который собирает картинку из связных компонентов и может также оценивать их с помощью специализированного классификатора. При расчете апостериорной оценки ребра картинки учитываются такие факторы, как качество собранной картинки, фрагменты слов, попадающих в регион ребра, но не включаемые в область картинки. В другом примере для апостериорной оценки качества ребра таблицы используется механизм, который находит структуру таблицы (например, разбиение таблицы на ячейки). Далее апостериорное качество рассчитывается на основе этой структуры. Например, насколько хорошо текст размещается в ячейках, является ли структура ячейки регулярной или нет, существуют ли пустые ячейки, есть ли в ячейках картинки и т.д.
[0049] В некоторых реализациях оптимальный путь может быть определен с использованием итеративного процесса. В некотором примере итеративный процесс может содержать вычисление метрики качества, связанного с каждым частичным путем ГЛД, начинающимся от верхней вершины и заканчивающимся в текущей вершине, рассматриваемой для частичного пути. Частичный путь, который заканчивается в текущей вершине, которая является самой нижней вершиной, определяется как полный путь. То есть для вычисления метрики качества для каждой итерации итерационного процесса текущая вершина выбирается из множества вершин, образующих ребра ГЛД. Определяется частичный путь между самой верхней вершиной и текущей вершиной. В некоторых реализациях на этом этапе может быть выполнена апостериорная оценка качества для ребер, которые исходят из верха наибольшей вершины и заканчиваются в текущей вершине. Метрика качества для частичного пути может быть рассчитана на основе 1) апостериорного качества ребер между верхом наибольшей вершины (например, начальной вершины) и текущей вершиной; 2) вспомогательной величины, соответствующей текущей вершине. Апостериорное качество ребер может быть получено путем вычисления произведения апостериорных значений качества множества ребер между самой верхней вершиной и текущей вершиной. Вспомогательная величина, соответствующая текущей вершине, может быть получена на основе качества вспомогательных путей, которые соединяют текущую вершину и самую нижнюю вершину (например, конечную вершину). Качество вспомогательных путей соответствует априорному качеству каждого ребра, включенного во вспомогательные пути. Если в пути существует несколько ребер, их априорные значения качества умножаются для получения общего априорного качества пути. Вспомогательная величина соответствует максимальному априорному качеству пути, который начинается с текущей вершины и заканчивается в нижней части вершины. В некоторых вариантах реализации метрика качества выводится путем вычисления произведения значения апостериорного качества ребер между самой верхней вершиной и текущей вершиной и вспомогательной величиной, соответствующим текущей вершине, на основе априорного качества ребер между текущей вершиной и самой нижней вершиной.
[0050] В одной реализации алгоритм вычисления метрики качества для частичного пути и полного пути для выбора одного или более оптимальных полных путей может быть следующим. Ациклический направленный граф (или направленный ациклический граф) может быть выражен как: (V, А), где V={ν0, … , νn-1} - множество вершин с номером 0 до n-1 согласно порядку топологической сортировки, а A - множество ребер. Каждое ребро «a» в множестве ребер A может быть связано с априорной оценкой качества, 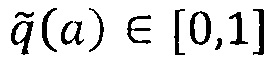 где априорная оценка качества
где априорная оценка качества 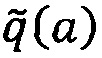 - это оценка, созданная каждым анализатором для каждого ребра с использованием сравнения с выходными данными сверточной нейронной сети, и где априорная оценка качества может варьировать между значениями 0 и 1 и может включать в себя значения 0 и 1.
- это оценка, созданная каждым анализатором для каждого ребра с использованием сравнения с выходными данными сверточной нейронной сети, и где априорная оценка качества может варьировать между значениями 0 и 1 и может включать в себя значения 0 и 1.
[0051] Вспомогательные величины могут быть выражены как: {rt, t=0, … ,n-1}, где rt - максимальное априорное качество пути, который начинается в вершине νt и заканчивается в вершине νn-1. Эти величины могут быть рассчитаны с использованием динамического программирования в течение времени O (|A|) следующими способами:
[0052] Предполагается, что rn-1=1. То есть предполагается, что максимальное априорное качество пути от последней вершины до той же последней вершины равно единице.
[0053] Вычисления для значений rt+1, … , rn-1 могут быть выполнены заранее. Для данной вершины νt может исходить множество ребер ai. Множество ребер может быть выражено как: 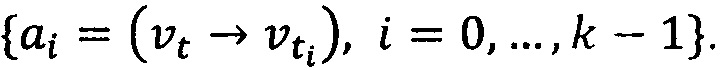 Тогда максимальное значение априорной оценки качества может быть выражено как:
Тогда максимальное значение априорной оценки качества может быть выражено как:
[0054] 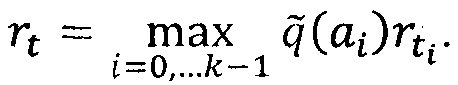
[0055] Путь может относится к частичному пути, если он начинается в вершине ν0 (например, в самой верхней вершине) и заканчивается в некоторой вершине νt,t∈{1,n-1}, то есть значения t варьируют от 1 до n-1. Частичный путь называется полным путем, если он заканчивается в вершине νn-1.
[0056] Качество частичного пути p=<ν0, а0, ν1, а1, … , at-1, νt> может быть рассчитано, как указано в «формуле (1)» следующим образом:
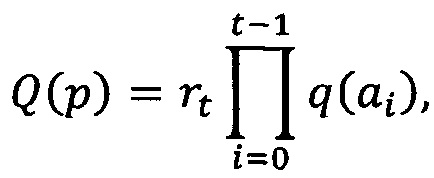
[0057] где q(ai) - апостериорное качество ребра, то есть качество результата анализа ребра, полученное в процессе поиска путей для одного или более оптимальных путей. Этот расчет скорее может быть более сложной операцией наложения блока на изображение, чем операцией, выполняемой на каждом ребре для получения априорной оценки. Например, чтобы получить апостериорное качество таблицы, необходимо проанализировать таблицу путем разбивки таблицы на ячейки и расчета качества ее структуры с использованием различных эвристических механизмов. Апостериорное качество ребра не превышает его априорной оценки качества.
[0058] В некоторых вариантах реализации при поиске частичных и/или полных путей может использоваться алгоритм А*. Такой алгоритм может включать в себя следующие операционные шаги:
[0059] 1. Н - приоритетная очередь путей может быть установлена так, что путь с более высоким качеством может иметь более высокую приоритетную позицию в очереди. Изначально очередь может быть пуста, то есть пути не введены в очередь.
[0060] 2. Для каждого ребра а в ГЛД, исходящего из самой верхней вершины ν0, ребро а может быть проанализировано на апостериорное качество, метрика качества соответствующего частичного пути может быть подсчитана и частичный путь, состоящий из ребра а, может быть добавлен в соответствующее приоритетное положение в очередь Н.
[0061] 3. Критерий останова может быть установлен таким образом, что если критерий выполняется, то операции заканчиваются. Если критерий останова не выполнен, должны повториться последующие шаги. Критерий останова может иметь место, например, когда количество полных путей, полученных из очереди, соответствует заданному порогу.
[0062] 4. Следующий частичный путь p, существующий в очереди Н, может быть получен, где путь заканчивается в вершине νt.
[0063] 5. Если частичный путь p не является полным путем, то для каждого ребра а, выходящего из вершины νt, ребро а может быть проанализировано на апостериорное качество, и метрика качества соответствующего частичного пути состоящего из частично пути р и ребра а может быть подсчитана и путь, состоящий из пути p и ребра а, может быть добавлен в очередь Н.
[0064] 6. Если путь р является полным путем, он может быть возвращен алгоритмом в качестве результата.
[0065] В некоторых примерах с помощью поиска можно идентифицировать более одного полного пути в ГЛД. Вышеупомянутый алгоритм может возвращать множество полных путей в порядке невозрастания значений метрики качества. То есть значения метрики качества для путей могут быть равными или уменьшаться в значениях внутри очереди.
[0066] В некоторых примерах некоторые из идентифицированного множества полных путей могут представлять варианты сегментации, которые близки друг к другу. Компьютерная система может идентифицировать один полный путь из множества полных путей для выбора лучшего варианта сегментации для полученного изображения. Каждый из полных путей может быть связан со значениями метрики качества. Метрика качества может обеспечивать качество одного или более ребер в совокупности. Один полный путь может характеризоваться значением метрики качества. Пороговое значение метрики качества может выбираться. Полный путь ГЛД, который имеет значение метрики качества выше порогового значения, может быть выбран в качестве полного пути, идентифицированного как обеспечивающий лучший вариант сегментации. В некоторых примерах пороговое значение может быть получено, исходя из некоторого количества наибольших значений метрики качества, связанных с одним или более путями в ГЛД, где диапазон значений для наибольших значений находится в определенном диапазоне. Например, может быть пять полных путей, идентифицированных в ГЛД, а значения метрики качества, связанные с пятью полными путями, могут варьироваться от 0,5 до 0,9. В этом примере пороговое значение может быть получено на основе верхних значений пяти полных путей, где верхние значения варьируются в пределах заданного диапазона значений 0,05. То есть верхние значения в диапазоне от 0,9 до 0,85 могут быть рассмотрены для выбора порогового значения. Исходя из доступных верхних значений в указанном диапазоне, пороговое значение может быть выбрано как 0,85. Любой путь, который превышает пороговое значение 0,85, может быть включен в рассмотрение для определения оптимального полного пути ГЛД. Например, три из пяти полных путей могут быть выше порогового значения 0,85. Один из этих трех полных путей может быть выбран как окончательный полный путь. В некоторых примерах выбор пути может основываться на попарном сравнении каждого из множества полных путей. Для сравнения результатов пары полных путей для оценки типов блоков в паре полных путей может использоваться компаратор. Компаратор может принимать в качестве входных данных два результата сегментации (например, два полных пути) со всеми ребрами от обоих анализируемых результатов, исследовать различия в путях и в качестве вывода дать оценку того, какой из двух результатов лучше в терминах точности идентификации типов блоков. Каждый компаратор может исследовать очень специфические сценарии (например, состоят ли анализируемые компаратором таблицы, по существу, из одной таблицы или двух таблиц и т.д.) и вычислить собственную оценку для сценария. Оценки могут использоваться для выбора одного из двух полных путей, проанализированных компаратором. Каждый полный путь может пройти этот анализ, и в конечном итоге полный путь с наилучшим результатом может быть выбран как один полный путь, обозначенный как лучший путь.
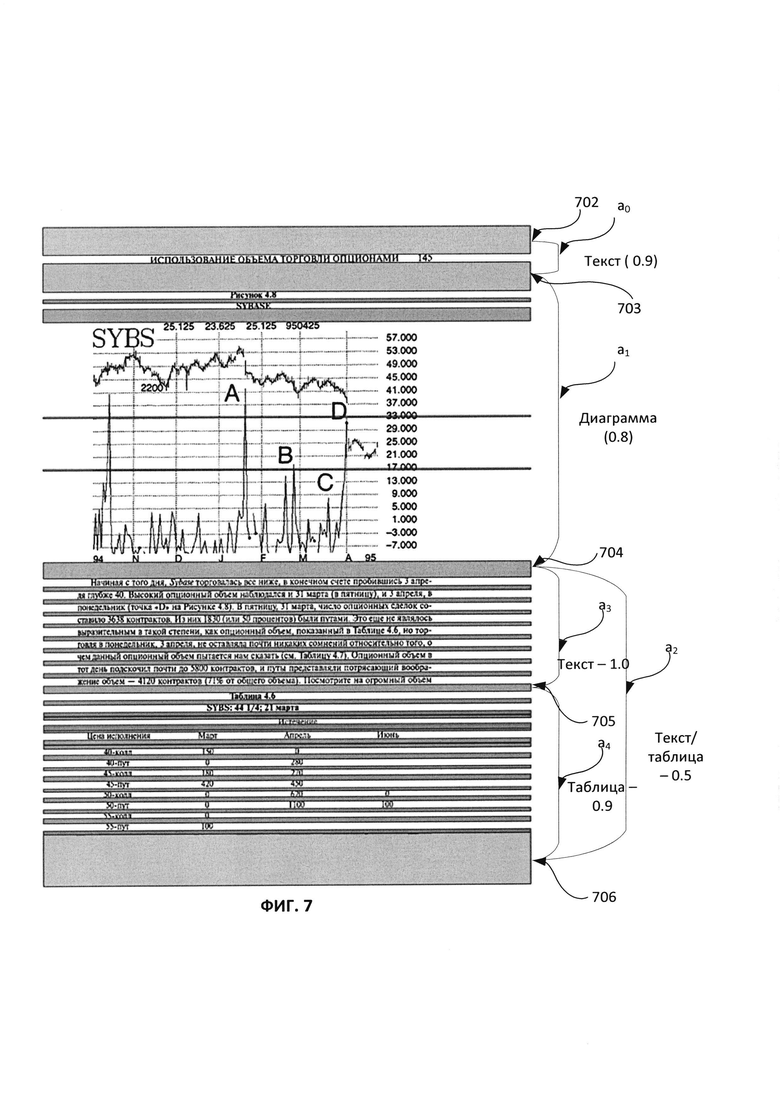
[0067] На Фиг. 7 показан пример расчета качества пути графа линейного деления. В этом примере вычисляется качество частичного пути, начинающегося в самой верхней вершине ν0, то есть вершине 702, и заканчивающегося в текущей вершине νt. Расчет может быть выполнен с использованием формулы (1), как определено ранее. В соответствии с формулой вычисляются апостериорные качества двух ребер между начальной вершиной ν0 и текущей вершиной νt (то есть вершиной 702 и вершиной 704) и умножаются на вспомогательную величину rt, соответствующую текущей вершине νt (вершина 704). Для вычисления апостериорных качеств ребер между вершиной 702 и вершиной 704 вычисляется произведение апостериорного качества ребра а0 между вершиной 702 и вершиной 703 и апостериорного качества ребра а1 между вершиной 703 и вершиной 704. Для текстового ребра а0, начинающегося с вершины 702 и заканчивающегося в вершине 703, апостериорное качество было равно 0,9. Аналогичным образом для ребра диаграммы а1, начинающегося с вершины 703 и заканчивающейся в вершине 704, апостериорное качество было равно 0,8, и значение было получено от анализатора диаграмм. Соответственно, произведение значений качества отдельных ребер а0 and а1 является произведением значений 0,9 и 0,8, которое представляет апостериорные качества ребер между начальной вершиной ν0 и текущей вершиной νt (то есть ребер между вершиной 702 и вершиной 704).
[0068] Вспомогательная величина rt вычисляется путем нахождения максимально возможного качества пути из текущей вершины νt (вершины 704) и конечной вершины νn-1 (вершины 706), что, в свою очередь, соответствует максимальному априорному качеству пути, начинающегося с текущей вершины νt (вершина 704) и конечной вершины νn-1 (вершина 706). Существуют два возможных пути, начинающиеся с вершины 704 и заканчивающиеся вершиной 706. Первый вариант состоит из двух ребер: первое ребро а3 между вершинами 704 и 705 с априорным значением качества 1,0, полученным из текстового анализатора, и второе ребро а4 между вершинами 705 и 706 с априорным значением качества 0,9, полученным от анализатора таблицы. Общее качество пути между вершинами 704 и 706 затем вычисляется как произведение этих значений качества 1,0 и 0,9, что приводит к 0,9. Второй вариант для пути, начинающегося из вершины 704 и заканчивающегося в вершине 706, представляет собой одиночное ребро а2, начинающееся из вершины 704 и заканчивающееся в вершине 706, которая имеет априорное значение качества 0,5, полученное от анализатора текста и анализатора таблицы. Таким образом, первый вариант имеет более высокое априорное значение качества 0,9 из двух возможных вариантов пути с априорными значениями 0,9 и 0,5 и выбирается, как имеющее максимально возможное качество (вспомогательная величина rt)) пути от текущей вершины νt (вершина 704) и конечной вершины νn-1 (вершина 706). Таким образом, качество частичного пути, начинающегося из вершины 702 и заканчивающегося в вершине 704, является произведением апостериорных качеств двух ребер между начальной вершиной ν0 и текущей вершиной νt (то есть 0,9 X 0,8) и вспомогательной величины rt, соответствующей текущей вершине νt (то есть 0,9), и равно:
[0069] 0,9 X 0,8 X 0,9=0,648.
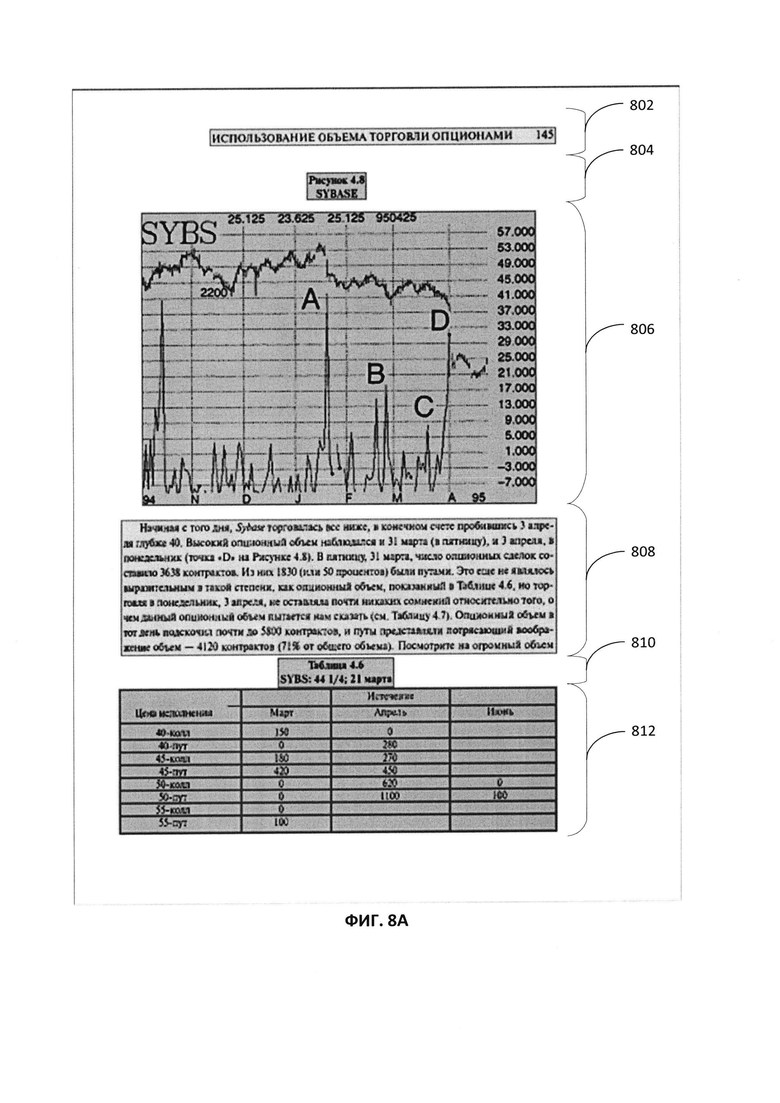
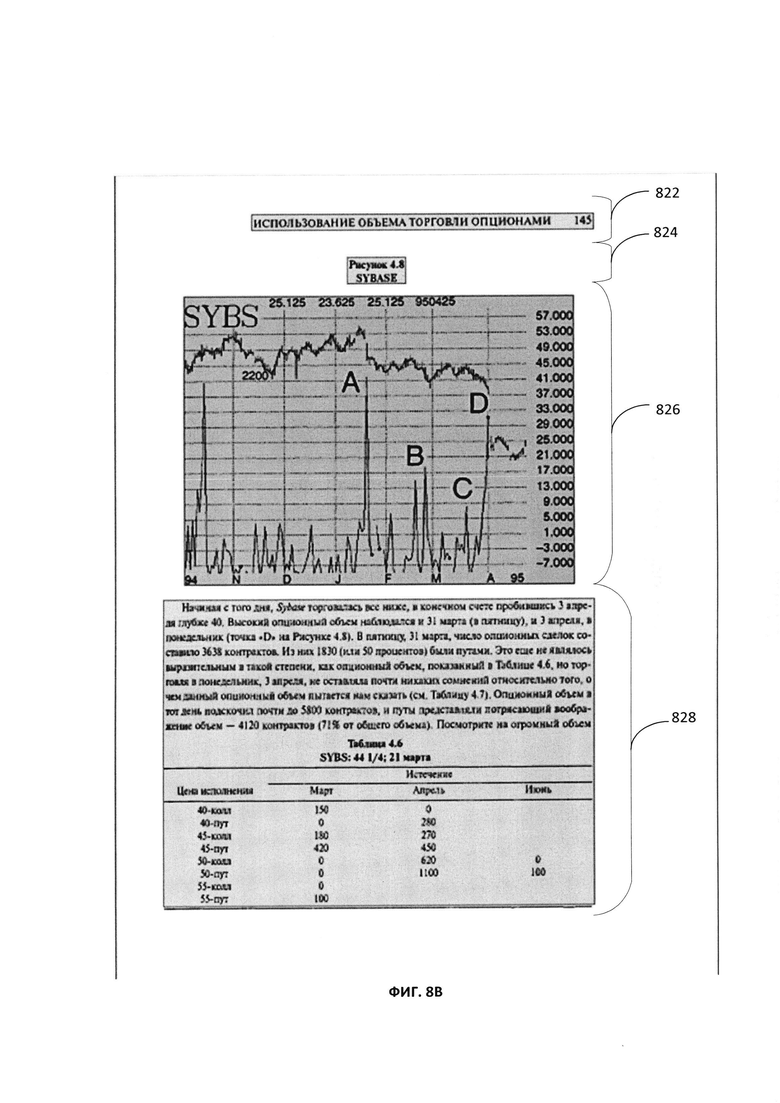
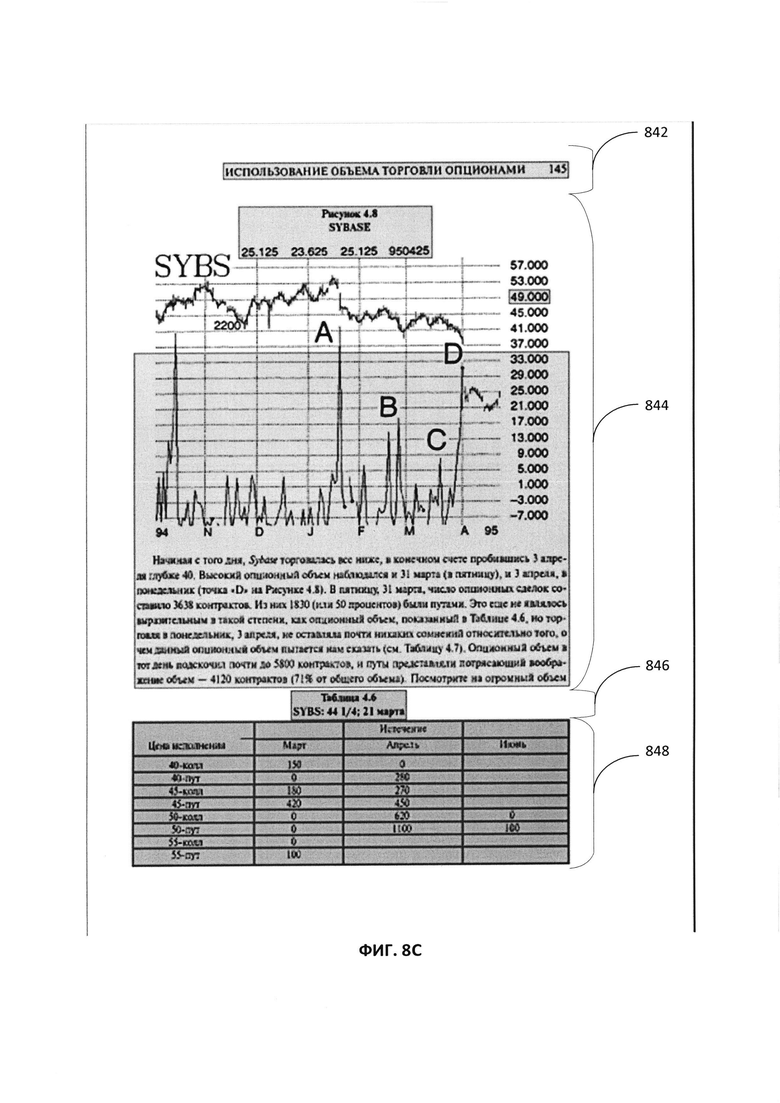
[0070] Если несколько полных путей определено с достаточно близкими значениями качества, то компараторы используются для парного сравнения между полными путями, а наилучший полный путь выбирается компараторами. Например, на Фиг. 8A-8C показаны примеры результатов анализа различных путей графа линейного деления (ГЛД). В результате анализа на Фиг. 8A был определен полный путь, содержащий множество ребер с 802 по 812. Аналогично, на Фиг. 8B полный путь содержит множество ребер с 822 по 828, а на Фиг. 8C полный путь содержит множество ребер с 842 по 848. В одном примере полный путь, определенный на Фиг. 8A, имеет самое высокое значение метрики качества, рассчитанное для полного пути, и выбран в качестве истинного пути, определяющего сегментацию изображения по всем путям Фиг. 8B и 8C. В другом примере каждый из полных путей на Фиг. 8A-8C может иметь значение метрики качества, которые близки друг к другу (например, в пределах заданного диапазона значений). Затем все пути сравниваются друг с другом с помощью парных компараторов для выбора конечного истинного пути (например, лучший путь, представляющий точную функцию сегментации), и выбирается полный путь на Фиг. 8A.
[0071] Вновь ссылаясь на Фиг. 2, на шаге 250 компьютерная система может генерировать один или более блоков изображения. Каждый из этих одного или более блоков может соответствовать ребру из одного или более ребер выявленного пути и представлять часть изображения, связанного с типом объекта. Например, как показано на Фиг. 8A, несколько блоков в полученном изображении генерируются в результате анализа каждого ребра в пределах выявленного полного пути. Определенный полный путь на Фиг. 8A содержит несколько сгенерированных блоков. Каждый из блоков соответствует ребру множества ребер с 802 по 812, включенных в выявленный путь. Каждый из блоков представляет часть полученного изображения, которое связано с конкретным типом объекта. Например, блоки, соответствующие ребрам 802 и 808, представляют собой фрагмент текста. Блоки, соответствующие ребрам 804 и 810, представляют собой заголовки. Блок, соответствующий ребру 806, представляет диаграмму, а блок, соответствующий ребру 812, представляет таблицу. В некоторых реализациях данные результаты сегментации могут быть переданы в модуль распознавания, который для компьютерной системы, выполняющей сегментацию, может быть внутренним или внешним.
[0072] На Фиг. 9 приведен иллюстративный пример топологии нейронной сети в соответствии с одним или более вариантами реализации настоящего изобретения. Нейронная сеть может соответствовать модели 140 и обучающему механизму 151, описанному на Фиг. 1, и (или) использоваться для создания карт вероятностей, изображенных на Фиг. 5A-5C. Как обсуждалось выше, априорные оценки присваиваются каждому ребру на основе анализа страницы документа нейронной сетью, такой как сверточная нейронная сеть. Например, серое изображение фиксированного размера может быть введено в нейронную сеть, используя входную матрицу X, Y и Z, где X и Y представляют соответственно ширину и высоту изображения, a Z представляет число каналов. Для серого изображения количество каналов для входа равно 1. На выходе могут быть предсказаны вероятности того, что каждый пиксель, соответствующий изображению, принадлежит каждому из N классов, которые могут быть предопределены. Например, в одном из вариантов реализации изобретения, N может быть равно числу 3, а классы соответствовать тексту, картинке и таблице. Каждый пиксель может с различными вероятностями приписываться к нескольким классам. Выходом может быть матрица размера 288×192×N, где N - количество каналов, представляющих количество классов. Пример сетевой топологии, используемой сверточной сетью, можно описать с точки зрения операций, выполняемых сетью над изображениями с использованием конкретных размеров фильтра, размеров заполнения (padding) и размер шага. Пример, показанный на Фиг. 9, имеет следующие операции: стрелка 901 выполняет свертку и операцию ReLu (Rectifier Linear Unit - Блок линейной ректификации) с использованием размера фильтра 3×3, размера заполнения 1×1 и 2 шага. Каждая стрелка 902 выполняет свертку и операцию ReLu, используя размер фильтра 3×3, размер заполнения 1×1 и 1 шаг. Каждая стрелка 904 выполняет операцию свертывания свертки с использованием размеров фильтров 1×9, 9×1 и 3×3, размеров заполнения 0×4, 4×0 и 1×1 и 1 шаг. Каждая стрелка 903 выполняет максимальную операцию объединения с использованием размера фильтра 2×2, размера заполнения 0×0 и 2 шага. Каждая стрелка 905 выполняет транспонированную свертку и операцию ReLu с использованием размера фильтра 4×4, размера заполнения 0×0 и 4 шага. Стрелка 906 выполняет транспонированную свертку и операцию ReLu, используя размер фильтра 6×6, размер заполнения 2×2 и 1 шаг. Стрелка 907 выполняет свертку и операцию сигмоида с использованием размера фильтра 3×3, размера заполнения 1×1 и 1 шаг. А каждая стрелка 908 выполняет операцию конкатенации каналов. Поскольку топология относится к Фиг. 5A-5C, на Фиг. 5A-5C показаны срезы выходной матрицы 288×192×N, где N=3: канал 1 (текст), канал 2 (картинка) и канал 3 (таблица). Каждый канал представляет собой серое изображение, описываемое цифрами от 0 до 1, которое можно интерпретировать следующим образом: 0 - белый цвет, а 1 - черный цвет (например, чем пиксель определяется более уверенно или с большей вероятностью интерпретируется, тем цвет может быть темнее).
[0073] На Фиг. 10 приведен пример вычислительной системы 1000, которая может выполнять один или более способов, описанных в настоящем документе, в соответствии с одним или более вариантами реализации настоящего изобретения. В одном из примеров вычислительная система 1000 может соответствовать вычислительному устройству, способному выполнять способ 200, представленный на Фиг. 2. Эта вычислительная система 1000 может быть подключена (например, по сети) к другим вычислительным системам в локальной сети, сети интранет, сети экстранет или сети Интернет. Данная вычислительная система 1000 может выступать в качестве сервера в сетевой среде клиент-сервер. Эта вычислительная система 1000 может представлять собой персональный компьютер (ПК), планшетный компьютер, телевизионную приставку (STB, set-top box), карманный персональный компьютер (PDA, Personal Digital Assistant), мобильный телефон, фотоаппарат, видеокамеру или любое устройство, способное выполнять набор команд (последовательно или иным способом), который определяется действиями этого устройства. Кроме того, несмотря на то, что показана система только с одним компьютером, термин «компьютер» также включает любой набор компьютеров, которые по отдельности или совместно выполняют набор команд (или несколько наборов команд) для выполнения любого из описанных здесь способа или нескольких таких способов.
[0074] Пример вычислительной системы 1000 включает процессор 1002, запоминающее устройство 1004 (например, постоянное запоминающее устройство (ROM, read-only memory) или динамическое оперативное запоминающее устройство (DRAM, dynamic random access memory)) и устройство хранения данных 1018, которые взаимодействуют друг с другом по шине 1030.
[0075] Обрабатывающее устройство 1002 представляет собой один или более обрабатывающих устройств общего назначения, например, микропроцессоров, центральных процессоров или аналогичных устройств. В частности, устройство обработки 1002 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор со сверхдлинным командным словом (VLIW) или процессор, в котором реализованы другие наборов команд, или процессоры, в которых реализована комбинация наборов команд. Устройство обработки 1002 также может представлять собой одно или несколько устройств обработки специального назначения, такое как специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Устройство обработки 1002 реализовано с возможностью выполнения инструкций в целях выполнения рассматриваемых в этом документе операций и шагов.
[0076] Вычислительная система 1000 может дополнительно включать устройство сопряжения с сетью 1022. Компьютерная система 1000 также может содержать блок видеодисплея 1010 (например, жидкокристаллический дисплей (ЖК-дисплей) или электронно-лучевую трубку (ЭЛТ)), буквенно-цифровое устройство ввода 1012 (например, клавиатуру), устройство управления курсором 1014 (например, мышь) и устройство, подающее сигналы 1016 (например, громкоговоритель). В одном иллюстративном примере видеодисплей 1010, устройство буквенно-цифрового ввода 1012 и устройство управления курсором 1014 могут быть объединены в один модуль или устройство (например, сенсорный жидкокристаллический дисплей).
[0077] Устройство хранения данных 1018 может содержать машиночитаемый носитель данных 1024, в котором хранятся инструкции 1026, реализующие одну или более методик или функций, описанных в настоящем документе. Инструкции 1026 могут также находиться полностью или, по меньшей мере, частично в основном запоминающем устройстве 1004 и (или) в устройстве обработки 1002 во время их выполнения вычислительной системой 1000, основным запоминающим устройством 1004 и устройством обработки 1002, также содержащим машиночитаемый носитель информации. Инструкции 1026 могут дополнительно передаваться или приниматься по сети через устройство сопряжения с сетью 1022.
[0078] Несмотря на то что машиночитаемый носитель данных 1024 показан в иллюстративных примерах как единичный носитель, термин «машиночитаемый носитель данных» следует понимать и как единичный носитель, и как несколько таких носителей (например, централизованная или распределенная база данных, и (или) связанные кэши и серверы), на которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также следует понимать как включающий любой носитель, который может хранить, кодировать или переносить набор команд для выполнения машиной и который обеспечивает выполнение машиной любой одной или более методик настоящего изобретения. Соответственно, термин «машиночитаемый носитель данных» следует понимать как содержащий, среди прочего, устройства твердотельной памяти, оптические и магнитные носители.
[0079] Несмотря на то что операции способов показаны и описаны в настоящем документе в определенном порядке, порядок выполнения операций каждого способа может быть изменен таким образом, чтобы некоторые операции могли выполняться в обратном порядке или чтобы некоторые операции могли выполняться, по крайней мере, частично, одновременно с другими операциями. В некоторых вариантах реализации изобретения команды или подоперации различных операций могут выполняться с перерывами и (или) попеременно.
[0080] Следует понимать, что приведенное выше описание носит иллюстративный, а не ограничительный характер. Различные другие варианты реализации станут очевидны специалистам в данной области техники после прочтения и понимания приведенного выше описания. Поэтому область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, которые покрывает формула изобретения.
[0081] В приведенном выше описании изложены многочисленные детали. Однако специалистам в данной области техники должно быть очевидно, что варианты реализации изобретения могут быть реализованы на практике и без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем, а не подробно, чтобы не усложнять описание настоящего изобретения.
[0082] Некоторые части описания предпочтительных вариантов реализации выше представлены в виде алгоритмов и символического изображения операций с битами данных в компьютерной памяти. Такие описания и представления алгоритмов являются средством, используемым специалистами в области обработки данных, чтобы наиболее эффективно передавать сущность своей работы другим специалистам в данной области. Приведенный здесь (и в целом) алгоритм сформулирован как непротиворечивая последовательность шагов, ведущих к нужному результату. Эти шаги требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[0083] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если прямо не указано иное, как видно из последующего обсуждения, следует понимать, что во всем описании такие термины, как «прием» или «получение», «определение» или «обнаружение», «выбор», «хранение», «настройка» и т.п., относятся к действиям компьютерной системы или подобного электронного вычислительного устройства или к процессам в нем, причем такая система или устройство манипулирует данными и преобразует данные, представленные в виде физических (электронных) величин, в регистрах компьютерной системы и памяти в другие данные, также представленные в виде физических величин в памяти или регистрах компьютерной системы или в других подобных устройствах хранения, передачи или отображения информации.
[0084] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, или оно может содержать универсальный компьютер, который избирательно активируется или дополнительно настраивается с помощью компьютерной программы, хранящейся в компьютере. Такая вычислительная программа может храниться на машиночитаемом носителе данных, включая, среди прочего, диски любого типа, в том числе гибкие диски, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), программируемые ПЗУ (EPROM), электрически стираемые ППЗУ (EEPROM), магнитные или оптические карты или любой тип носителя, пригодный для хранения электронных команд, каждый из которых соединен с шиной вычислительной системы.
[0085] Алгоритмы и изображения, приведенные в этом документе, не обязательно связаны с конкретными компьютерами или другими устройствами. Различные системы общего назначения могут использоваться с программами в соответствии с изложенной здесь информацией, возможно также признание целесообразным сконструировать более специализированные устройства для выполнения шагов способа. Структура разнообразных систем такого рода определяется в порядке, предусмотренном в описании. Кроме того, изложение вариантов реализации изобретения не предполагает ссылок на какие-либо конкретные языки программирования. Следует принимать во внимание, что для реализации принципов настоящего изобретения могут быть использованы различные языки программирования.
[0086] Варианты реализации настоящего изобретения могут быть представлены в виде вычислительного программного продукта или программы, которая может содержать машиночитаемый носитель данных с сохраненными на нем инструкциями, которые могут использоваться для программирования вычислительной системы (или других электронных устройств) в целях выполнения процесса в соответствии с сущностью изобретения. Машиночитаемый носитель данных включает процедуры хранения или передачи информации в машиночитаемой форме (например, компьютером). Например, машиночитаемый (считываемый компьютером) носитель данных содержит машиночитаемый (например, компьютер) носитель данных (например, постоянное запоминающее устройство (ПЗУ), оперативное запоминающее устройство (ОЗУ), накопитель на магнитных дисках, накопитель на оптическом носителе, устройства флэш-памяти и т.д.) и т.п.
[0087] Слова «пример» или «примерный» используются здесь для обозначения использования в качестве примера отдельного случая или иллюстрации. Любой вариант реализации или конструкция, описанные в настоящем документе как «пример», не должны обязательно рассматриваться как предпочтительные или преимущественные по сравнению с другими вариантами реализации или конструкциями. Слово «пример» лишь предполагает, что идея изобретения представляется конкретным образом. В этой заявке термин «или» предназначен для обозначения включающего «или», а не исключающего «или». Если не указано иное или не очевидно из контекста, то «X включает A или B» используется для обозначения любой из естественных включающих перестановок. То есть если X включает в себя A; X включает в себя B; или X включает A и B, то высказывание «X включает в себя A или B» является истинным в любом из указанных выше случаев. Кроме того, артикли «а» и «an», использованные в англоязычной версии этой заявки и в прилагаемой формуле изобретения, должны, как правило, означать «один или более», если иное не указано или из контекста не следует, что это относится к форме единственного числа. Использование терминов «вариант реализации», или «один вариант реализации», или «реализация», или «одна реализация» не означает одинаковый вариант реализации, если это не указано в явном виде. В описании термины «первый», «второй», «третий», «четвертый» и т.д. используются как метки для обозначения различных элементов и не обязательно имеют смысл порядка в соответствии с их числовым обозначением.
| название | год | авторы | номер документа |
|---|---|---|---|
| Программно-аппаратный комплекс, предназначенный для обработки аэрокосмических изображений местности с целью обнаружения, локализации и классификации до типа авиационной и сухопутной техники | 2021 |
|
RU2811357C2 |
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ ПАТОЛОГИЙ ЛЕГКИХ ПО РЕНТГЕНОВСКИМ ИЗОБРАЖЕНИЯМ | 2023 |
|
RU2840009C1 |
| СИСТЕМА И СПОСОБ ДИАГНОСТИКИ ПАТОЛОГИЙ ЛЕГКИХ ПО РЕНТГЕНОВСКИМ ИЗОБРАЖЕНИЯМ | 2023 |
|
RU2840011C1 |
| ИЗВЛЕЧЕНИЕ НЕСКОЛЬКИХ ДОКУМЕНТОВ ИЗ ЕДИНОГО ИЗОБРАЖЕНИЯ | 2020 |
|
RU2764705C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫЯВЛЕНИЯ ОБЪЕМНЫХ ОБРАЗОВАНИЙ ПОЧЕК НА КОМПЬЮТЕРНЫХ ТОМОГРАММАХ БРЮШНОЙ ПОЛОСТИ | 2024 |
|
RU2839531C1 |
| СПОСОБ, АППАРАТ И УСТРОЙСТВО ДЛЯ СЕГМЕНТАЦИИ ИЗОБРАЖЕНИЯ | 2014 |
|
RU2577188C1 |
| СПОСОБ ВИЗУАЛИЗАЦИИ 3D ПОРТРЕТА ЧЕЛОВЕКА С ИЗМЕНЕННЫМ ОСВЕЩЕНИЕМ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ НЕГО | 2021 |
|
RU2757563C1 |
| РЕКОНСТРУКЦИЯ ДОКУМЕНТА ИЗ СЕРИИ ИЗОБРАЖЕНИЙ ДОКУМЕНТА | 2017 |
|
RU2659745C1 |
| Сегментация многостолбцового документа | 2014 |
|
RU2647671C2 |
| Система и способ диагностики патологий придаточных пазух носа по рентгеновским изображениям | 2023 |
|
RU2825958C1 |

В настоящем документе представлены системы и способы для получения изображения, по меньшей мере, части документа и определения множества точек деления, делящих изображение на потенциальные сегменты; создания графа линейного деления (ГЛД), содержащего множество вершин с использованием множества точек деления и множества ребер, соединяющих множество вершин; идентификации пути ГЛД, имеющего значение метрики качества выше порогового значения, где путь выбирается из множества путей ГЛД и содержит одно или более ребер, а значение метрики качества выводится с использованием нейронной сети, классифицирующей каждый из множества пикселей изображения; а также создания одного или более блоков изображения, где каждый из одного или более блоков соответствует ребру идентифицированного пути и представляет часть изображения, связанного с типом объекта. 3 н. и 17 з.п. ф-лы, 10 ил.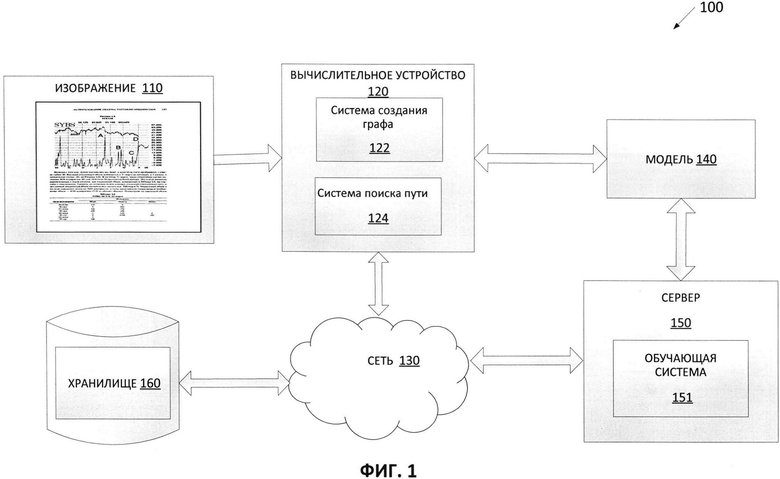
1. Способ сегментации документа на блоки различного типа, включающий:
получение изображения, по меньшей мере, части документа с помощью устройства обработки;
выявление множества точек деления, делящих изображение на потенциальные сегменты;
создание графа линейного деления (ГЛД), содержащего множество вершин, использующих множество точек деления и множества ребер, соединяющих множество вершин;
выявление пути ГЛД, имеющего значение метрики качества выше порогового значения, причем путь выбирается из множества путей LPG и содержит одно или несколько ребер из множества ребер, а значение метрики качества получается с использованием нейронной сети, классифицирующей каждый из множества пикселей изображения; а также
создание одного или более блоков изображения, когда один или более блоков соответствует ребру одного или более ребер выявленного пути и представляет часть изображения, связанного с типом объекта.
2. Способ по п. 1, в котором пороговое значение выводится на основе количества верхних значений метрики качества, связанных с одним или несколькими путями LPG, причем диапазон значений для верхних значений находится в пределах заданного диапазона.
3. Способ по п. 1, в котором выявленный путь выбирается из множества путей, имеющих значения метрики качества выше порогового значения, причем выбор основан на попарном сравнении каждого из множества путей.
4. Способ по п. 1, в котором ГЛД является направленным ациклическим графом.
5. Способ по п. 1, в котором создание ГЛД включает в себя выбор подмножества множества точек деления как множества вершин ГЛД на основе одного или более из следующих факторов:
средней ширины области, соответствующей каждой из множества точек деления; максимального качества разделителей, которые пересекают область; или взвешенного качества разделителей, которые пересекают область.
6. Способ по п. 1, в котором создание ГЛД включает: выбор пар вершин из множества вершин ГЛД, а также
соединение каждой из выбранных пар вершин для формирования каждого из множества ребер ГЛД.
7. Способ по п. 6, в котором выбор пар вершин основывается на одном или более следующих факторах:
относительные размеры частей изображения, соответствующих точкам деления;
максимальный показатель качества точек деления, охваченных парами вершин;
взвешенное количество точек деления, охваченных парами вершин;
качество соединенных пар вершин; или
количество точек деления под рассматриваемой в настоящий момент точкой деления.
8. Способ по п. 1, в котором значения метрики качества для множества путей ГЛД производятся на основе априорной оценки вероятностей соответствия каждого ребра из множества ребер каждому из числа заданных типов объектов.
9. Способ по п. 8, в котором априорная оценка вероятностей оценивается на основе подмножества множества пикселей изображения, соответствующих каждому ребру из множества ребер на основе нейронной сети, классифицирующей каждый из множества пикселей изображения.
10. Способ по п. 9, в котором изображение предоставляется нейронной сети в качестве ввода и набор вероятностей получают как вывод из нейронной сети для каждого из множества пикселей изображения, принадлежащих каждому из множества заранее определенных классов объектов, соответствующих каждому из числа заданных типов объектов.
11. Способ по п. 8, в котором значения метрики качества для одного или более ребер множества ребер выводятся на основе итеративного процесса, причем для каждой итерации итерационного процесса текущая вершина выбирается из множества вершин, а апостериорная величина качества производится для ребер между начальной вершиной ГЛД и текущей вершиной.
12. Способ по п. 11, в котором значения метрики качества дополнительно выводятся на основе вспомогательной величины, соответствующей текущей вершине, указывающей максимальное значение априорной оценки вероятностей для ребер между текущей вершиной и конечной вершиной ГЛД.
13. Способ по п. 12, в котором значения метрики качества вычисляют путем умножения апостериорного значения качества и вспомогательной величины, соответствующего текущей вершине.
14. Способ по п. 1, в котором часть документа содержит одноколоночную структуру, в которой объекты внутри части документа имеют ориентацию в одном направлении.
15. Система сегментации документа на блоки различного типа, включающая следующие компоненты:
запоминающее устройство, в котором хранятся инструкции;
устройство обработки, подключенное к запоминающему устройству, причем устройство обработки предназначено для выполнения инструкций для:
получения изображения, по меньшей мере, части документа;
выявления множества точек деления, делящих изображение на потенциальные сегменты;
создания графа линейного деления (ГЛД), содержащего множество вершин, использующих множество точек деления и множества ребер, соединяющих множество вершин;
выявления пути ГЛД, имеющего значение метрики качества выше порогового значения, причем путь выбирается из множества путей ГЛД и содержит одно или более ребер из множества ребер, а значение метрики качества получается с использованием нейронной сети, классифицирующей каждый из множества пикселей изображения; а также
создания одного или более блоков изображения, где один или более блоков соответствует ребру одного или более ребер выявленного пути и представляет часть изображения, связанного с типом объекта.
16. Система по п. 15, в которой значения метрики качества для множества путей ГЛД производятся на основе априорной оценки вероятностей соответствия каждого ребра из множества ребер каждому из числа заданных типов объектов.
17. Система по п. 16, в которой априорная оценка вероятностей оценивается на основе подмножества множества пикселей изображения, соответствующих каждому ребру из множества ребер на основе нейронной сети, классифицирующей каждый из множества пикселей изображения.
18. Система по п. 17, в которой изображение предоставляется нейронной сети в качестве ввода и набор вероятностей получают как вывод из нейронной сети для каждого из множества пикселей изображения, принадлежащих каждому из множества заранее определенных классов объектов, соответствующих каждому из числа заданных типов объектов.
19. Постоянный машиночитаемый носитель данных, содержащий инструкции, направленные на выполнение способа сегментации документа на блоки различного типа, которые при обращении к ним обрабатывающего устройства приводят к выполнению обрабатывающим устройством следующих операций:
получение изображения, по меньшей мере, части документа;
выявление множества точек деления, делящих изображение на потенциальные сегменты;
создание графа линейного деления (ГЛД), содержащего множество вершин, используя множество точек деления и множества ребер, соединяя множество вершин;
выявление пути ГЛД, имеющего значение метрики качества выше порогового значения, причем путь выбирается из множества путей ГЛД и содержит одно или более ребер из множества ребер, а значение метрики качества получается с использованием нейронной сети, классифицирующей каждое из множества пикселей изображения; а также
создание одного или более блоков изображения, когда один или более блоков соответствует ребру одного или более ребер выявленного пути и представляет часть изображения, связанного с типом объекта.
20. Постоянный машиночитаемый носитель данных по п. 19, в котором значения метрики качества для множества путей ГЛД производятся на основе априорной оценки вероятностей соответствия каждого ребра из множества ребер каждому из числа заданных типов объектов.
| US 2015199821 16.07.2015 | |||
| СПОСОБ РАЗДЕЛЕНИЯ ТЕКСТОВ И ИЛЛЮСТРАЦИЙ В ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ ДЕСКРИПТОРА СПЕКТРА ДОКУМЕНТА И ДВУХУРОВНЕВОЙ КЛАСТЕРИЗАЦИИ | 2017 |
|
RU2656708C1 |
| US 2018322339 08.11.2018 | |||
| US 2011222769 15.09.2011. | |||

