Область техники
[0001] Настоящее изобретение относится к анализу и обработке изображений документов. Более конкретно, настоящее изобретение относится к разделению на области текста и области иллюстраций изображений документов, как например научных статей, патентных документов, бизнес-документов, которые помимо простого текста содержат схематические чертежи, блок-схемы, схемы, графики, химические формулы и любые другие виды бизнес-графики, которые могут также содержать текстовые части. После выполнения разделения изображений документов на области текста и области иллюстраций, области текста могут быть использованы, например, в оптическом распознавании символов (OCR) для целей обработки естественного языка (NLP) и текстового поиска, области иллюстраций могут быть использованы, например, для целей поиска изображений, распознавания изображений, или сжатия изображений.
Уровень техники
[0002] Проблема разделения текста и изображений имеет значение для различных задач анализа и обработки изображений документов, например, индексирование и поиск документов, обнаружение и распознавание объектов документа, OCR, сжатие документов и многое другое. Корректная классификация областей интереса (ROI) в один из двух классов - текст или иллюстрация, имеет большое значение в таких задачах, поскольку она может значительно уменьшить объем данных, подлежащих обработке на последующих этапах, путем удаления нерелевантных областей (например, нетекстовых областей для OCR или текстовых областей для индексации или поиска изображений).
[0003] Большинство подходов, предлагаемых для решения этой проблемы, полагаются на продуманное конструирование построенного вручную дескриптора ROI, создающего легко различимые признаковые векторы для текстовых и нетекстовых областей. Такие подходы часто демонстрируют высокую частоту ошибочной классификации на таких классах иллюстраций, которые не полностью соответствуют принципам, лежащим в основе признаков таких дескрипторов (или эвристик, используемых для классификации этих признаков).
[0004] Еще одно семейство подходов опирается на алгоритмы машинного обучения с учителем, обучаемые на наборах размеченных вручную данных. Эффективность классификации в таких подходах в значительной степени зависит от репрезентативности обучающего набора данных, получение которого становится очень трудным, если необходима обработка очень разнообразного набора сильно изменчивых классов иллюстраций.
[0005] Способ разделения текстов и иллюстраций в соответствии с настоящим изобретением сочетает в себе сильные стороны обоих семейств подходов, пытаясь устранить или смягчить их недостатки. Благодаря этому достигается повышенная точность разделения текстов и иллюстраций, а также минимизация ошибок такого разделения. Кроме того, благодаря настоящему изобретению можно избежать уменьшения объема релевантных данных, подлежащих обработке на последующих этапах, тем самым обеспечив повышенную эффективность таких последующих этапов обработки. Для этих целей в настоящем изобретении алгоритмы машинного обучения без учителя применяются к основанным на форме признакам, извлекаемым из областей интереса документов, с последующей классификацией согласно операции логического вывода разметки или операции распространения разметки с частичным привлечением учителя.
Описание связанных документов уровня техники
[0006] Одно из самых популярных семейств способов разделения текст или не текст основано на извлечении простых признаков из ROI, а затем классификации этих признаков с помощью нескольких продуманных, построенных вручную эвристик, направленных на отделение текстовых областей от нетекстовых областей. Типичные признаки, используемые в таких подходах, основаны на компонентах связности, статистике по длинам серий, взаимной корреляции между линиями сканирования, проекционных профилях или распределении пикселей черного цвета. Одним экземпляром такого семейства подходов является патент США US 6,937,766, опубликованный 30 августа 2005 года, в котором текст извлекают из видеопоследовательности (см. реферат патента `766). Такие подходы являются быстрыми и эффективными для такого материала, в котором иллюстрациями являются фотографии, картины, кадры видеопоследовательности или другие виды красочных изображений, которые существенно отличаются от текста по своей структуре. Однако, для схематических чертежей, особенно текстовых блок-схем, электрических схем и подобного материала, такие подходы часто демонстрируют гораздо более худшую точность. Одним из их основных недостатков является то, что их эвристики обычно выводятся из наблюдений, относящихся к иллюстрациям, принадлежащим некоторому конкретному классу (или классам), и могут плохо обобщаться для других классов, что является особенно проблематичным для документов, содержащих очень разнообразный набор классов иллюстраций (например, для иллюстраций в патентных документах), в которых некоторые из классов не полностью соответствуют таким эвристикам. В качестве примера, способы, основанные на гистограммах длин серий, могут неправильно классифицировать в качестве текстовых областей блок-схемы, содержащие большие объемы текста.
[0007] Этот недостаток решается другим семейством подходов, основанных на алгоритмах машинного обучения с учителем, применяемых либо к признакам того же типа, что и описан выше, или к данным пикселей изображения. Поскольку задача разделения текста и иллюстраций может быть сформулирована как проблема бинарной классификации, подходы этого семейства обычно используют обучение на наборе размеченных вручную данных, чтобы изучить различие между текстовыми и нетекстовыми областями. В данном семействе подходов применяется классификация основанных на форме признаков, использующая классификатор k-ближайших соседей (KNN), многослойный перцептрон (MLP) или классификатор по методу опорных векторов (SVM), использующий основанный на градиенте дескриптор T-HOG. Одним экземпляром такого семейства подходов является патент США US 7,570,816, для корректного обучения классификатора которого требуется большой набор размеченных вручную данных (см. абзац [0008] патента `816).
[0008] Такие подходы могут по-прежнему страдать от недостаточной различающей способности построенных вручную признаков, которая не может быть компенсирована классификатором. Таким образом, были разработаны более эффективные подходы в работе с данными пикселей изображения или низкоуровневыми признаками. Один заметный подход такого рода основан на методах разреженного кодирования. Например, был предложен анализ морфологическиx компонент (MCA), использующий два предварительно построенных различающих переопределенных словаря (curvelet-преобразование для графики и вейвлет-преобразование для текста).
[0009] Тем не менее, основанные на обучении с учителем алгоритмы часто являются чрезмерно медленными на больших наборах данных (что имеет место в случае, например, патентных документов, содержащих миллионы областей), и они лучше всего работают, когда в обучающем наборе данных все релевантные классы иллюстраций представлены в достаточной степени так, чтобы алгоритм обучения знал, как отличить каждый из указанных классов от текста. Такой обучающий набор данных может не быть легкодоступным для многих видов документов, например, когда классы иллюстраций настолько многочисленны и обладают очень высокой изменчивостью внутри класса, создание такого набора данных с помощью ручной разметки (маркировки областей) было бы непомерно трудоемким (см., например, абзац [0008] патента `816). Чтобы устранить необходимость в обучающем наборе размеченных вручную данных были разработаны основанные на обучении без учителя способы, в которых в частности может быть использован алгоритм k-средних для кластеризации статистических признаков, вычисляемых с использованием, например, высокочастотных вейвлет-коэффициентов или карт краев. Такие способы описаны в работах C. Liu, C. Wang и R. Dai «Text detection in images based on unsupervised classification of edge-based features» (2005 год) и J. Gallavata, R. Ewerth и B. Freisleben «Text detection in images based on unsupervised classification of high-frequency wavelet coefficients» (2004 год). Далее в этой заявке будет продемонстрированно, что алгоритм k-средних сам по себе неспособен работать с невыпуклыми, вложенными и удлиненными кластерами, а также обладает рядом недостатков в вопросе разделения текста и иллюстраций, особенно при использовании Евклидова расстояния. Вследствие этого, эти способы также не приспособлены для разделения текста и схематических чертежей, особенно текстовых блок-схем, электрических схем или подобной бизнес-графики.
[0010] Наконец, в отношении ранее разработанных способов и настоящего изобретения необходимо отметить следующую важную информацию: большинство из ранее разработанных способов сконцентрированы особенно на задаче извлечения текста, в то время как настоящее изобретение сконцентрировано на извлечении иллюстраций из изображений документов. Кроме того, большинство вышеописанных способов обычно работают над естественными сценами (фотографиями или видеопоследовательностями). Тем не менее, такой тип данных сильно отличаются по своей структуре и свойствам содержащейся в них графики от структуры и свойств иллюстраций, например, схематических чертежей, возможно также имеющих некоторый текст в своем составе, в документах, подобных патентным документам, которые находятся в центре настоящего изобретения. Также необходимо обратить внимание на то, что во многих предыдущих работах используются хорошо известные наборы данных UW-III и ICDAR 2009 для создания построенных вручную признаков или обучения классификаторов, что может отрицательно повлиять на возможности обобщения как признаков, так и классификаторов в контексте задачи настоящего изобретения, поскольку эти наборы данных содержат только небольшое подмножество классов иллюстраций, присутствующих в документах, подобных патентным документам.
[0011] Различные другие реализации известны в данной области техники, но, насколько можно разумно установить из их доступной документации, эти реализации не могут адекватно решить все проблемы, решаемые описанным в данной заявке изобретением.
Сущность изобретения
[0012] В предпочтительном варианте осуществления настоящего изобретения предложен способ разделения текстов и иллюстраций в изображениях страниц документов, содержащий этапы, на которых получают изображения страниц документов; сегментируют изображения страниц документов на области интереса; извлекают признаковый вектор для каждой области интереса; и классифицируют каждый из извлеченных признаковых векторов в один из двух классов: текст или иллюстрация.
[0013] В этом предпочтительном варианте осуществления способа сегментирование изображения страниц документов на области интереса содержит подэтапы, на которых заполняют серии пикселей фона, длины которых ниже некоторого порогового значения, как в горизонтальном, так и в вертикальном направлениях и выбирают ограничительные рамки полученных в результате компонент связности как области интереса.
[0014] Кроме того, в этом предпочтительном варианте осуществления способа извлечение признакового вектора для каждой области интереса содержит подэтапы, на которых: изменяют размер области интереса до размера 500×500 пикселей с сохранением соотношения ее сторон; извлекают компоненты связности из области интереса измененного размера и вычисляют их центроиды; находят ближайших соседей для каждого центроида; строят двумерную гистограмму нормализованных расстояний и углов для всех пар, состоящих из центроида и каждого из его пяти ближайших соседних центроидов; и переформировывают двумерную гистограмму в признаковый вектор.
[0015] Наконец, в этом предпочтительном варианте осуществления способа классификация каждого из извлеченных признаковых векторов в один из двух классов: текст или иллюстрация, содержит подэтапы, на которых: осуществляют аппроксимирующее ядро преобразование признаковых векторов; осуществляют кластеризацию первого уровня преобразованных признаковых векторов с использованием алгоритма мини-пакетных k-средних для получения кластеров преобразованных признаковых векторов и их центроидов; осуществляют кластеризацию второго уровня центроидов кластеров, полученных на предшествующем подэтапе, с использованием усовершенствованного алгоритма кластеризации для получения соответствующих им суперкластеров; и проверяют, больше ли число полученных суперкластеров, чем два: если нет - используют операцию логического вывода разметки (S103.4.1) для классификации каждого из этих двух суперкластеров в один из двух классов: текст или иллюстрация; или если да - используют операцию распространения разметки с частичным привлечением учителя для классификации каждого из этих более двух суперкластеров в один из двух классов: текст или иллюстрация.
[0016] Такой способ разделения текстов и иллюстраций согласно настоящему изобретению сочетает в себе сильные стороны подходов, известных из уровня техники, тем самым устраняя или смягчая их недостатки. В свете этого настоящим способом достигается повышенная точность разделения текстов и иллюстраций, а также минимизация ошибок такого разделения.
Краткое описание чертежей
[0017] Другие благоприятные эффекты настоящего изобретения станут очевидны обычному специалисту в данной области техники после ознакомления с нижеследующим подробным описанием различных вариантов его осуществления, а также с чертежами, на которых:
[Фиг. 1] Фигура 1 иллюстрирует предпочтительный вариант осуществления способа разделения текстов и иллюстраций в изображениях страниц документов.
[Фиг. 2] Фигура 2 иллюстрирует подэтапы этапа сегментирования (S101) изображения страниц документов на области интереса согласно предпочтительному варианту осуществления настоящего изобретения.
[Фиг. 3] Фигура 3 иллюстрирует подэтапы этапа извлечения (S102) признакового вектора для каждой области интереса согласно предпочтительному варианту осуществления настоящего изобретения.
[Фиг. 4] Фигура 4 иллюстрируют подэтапы этапа классифицирования (S103) каждого из извлеченных признаковых векторов в один из двух классов: текст или иллюстрация согласно предпочтительному варианту осуществления настоящего изобретения.
[Фиг. 5] Фигура 5(а) иллюстрирует оригинальную страницу патента с пятью иллюстрациями; Фигура 5(б) иллюстрирует результат применения алгоритма RLSO к странице, показанной на фигуре 5(а): заполненные пиксели фона окрашены серым цветом, компоненты связности выделены четырехугольными ограничительными рамками.
[Фиг. 6] Фигура 6 иллюстрирует области интереса, извлекаемые посредством алгоритма RLSO из изображения страницы патента, в содержимом которой имеются как текст, так и иллюстрации.
[Фиг. 7] Фигура 7 иллюстрирует пары ближайших соседних центроидов компонент связности типичной ROI иллюстрации.
[Фиг. 8] Фигура 8 иллюстрирует пары ближайших соседних центроидов компонент связности типичной ROI текста.
[Фиг. 9] Фигуры 9(а)-(б) иллюстрируют используемые в настоящем изобретении Docstrum-дескрипторы: Docstrum-дескриптор (гистограмма слева - Фигура 9(а)) ROI иллюстрации; Docstrum-дескриптор (гистограмма справа - Фигура 9(б)) ROI текста. Данные Docstrum-дескрипторы вычислялись для областей интереса (ROI), размер которых составлял 500×500 пикселей, с использованием 64 бинов углов и 20 бинов расстояния.
[Фиг. 10] Фигуры 10(а)-(б) иллюстрируют используемые в настоящем изобретении Docstrum-дескрипторы: Docstrum-дескриптор (гистограмма слева - Фигура 10(а)) ROI иллюстрации и Docstrum-дескриптор (гистограмма справа - Фигура 10(б)) ROI текста. Данные Docstrum-дескрипторы вычислялись для областей интереса (ROI), размер которых составлял 300×300 пикселей, с использованием 16 бинов углов и 20 бинов расстояния.
[Фиг. 11] Фигура 11 иллюстрирует подэтапы этапа классифицирования (S103) каждого из извлеченных признаковых векторов в один из двух классов: текст или иллюстрация, с добавленной ветвью оценки качества классификации.
[Фиг. 12] Фигура 12 иллюстрирует архитектуру сиамской нейронной сети, используемой для обучения отображения признаков для аппроксимации ядра Жаккара.
[Фиг. 13] Фигура 13 иллюстрирует примеры кластеров, получаемых в результате выполнения подэтапа (S103.2) способа, на котором осуществляют кластеризацию первого уровня преобразованных признаковых векторов с использованием алгоритма мини-пакетных k-средних.
[Фиг. 14] Фигуры 14(а)-(б) иллюстрируют кривые точность - полнота для варианта с аппроксимированным ядром раскрытого способа. Фигура 14(а): кривые точность - полнота для разных алгоритмов кластеризации второго уровня. Фигура 14(б): кривые точность - полнота для разных аппроксимированных ядер. Маркеры указывают лучшие точки F1.
[Фиг. 15] Фигуры 15(а)-(б) иллюстрируют кривые точность - полнота для варианта с точным ядром раскрытого способа. Фигура 15(а): кривые точность - полнота для разных алгоритмов кластеризации второго уровня. Фигура 15(б): кривые точность - полнота для разных ядер. Маркеры указывают лучшие точки F1.
[Фиг. 16] Фигура 16 иллюстрирует точечную диаграмму компонент t-SNE, вычисленных для Docstrum-признаковых векторов ROI, классифицированных как ROI текста и ROI иллюстраций согласно раскрытому способу.
Подробное описание вариантов осуществления изобретения
[0018] Предпочтительные варианты осуществления настоящего изобретения теперь будут описаны более подробно со ссылкой на чертежи, на которых идентичные элементы на разных фигурах, по возможности, идентифицируются одинаковыми ссылочными позициями. Эти варианты осуществления представлены посредством пояснения настоящего изобретения, которое, однако, не следует ими ограничивать. Специалисты в данной области техники поймут после ознакомления с настоящим подробным описанием и чертежами, что могут быть сделаны различные модификации и варианты.
[0019] Поскольку изображения страниц патентных документов обладают вышеупомянутыми свойствами (крупномасштабный набор данных с очень разнообразным набором классов иллюстраций с очень высокой изменчивостью внутри класса), в нижеследующем подробном описании возможности, работа и реализации конкретных этапов раскрытого способа объясняются и демонстрируются на примере работы с изображениями страниц, извлеченными из случайно выбранного подмножества патентов из патентной базы данных USPTO. Однако, специалист поймет, что раскрытый способ подходит для других классов документов, содержащих бизнес-иллюстрации, аналогичные тем, которые используются в патентах.
[0020] Поскольку разделение текста и иллюстраций обычно используется в качестве стадии предварительной обработки для подготовки данных для последующих гораздо более сложных стадии, специалист в данной области поймет, что в идеале такой способ разделения должен быть относительно быстрым и легким (по сравнению с последующими стадиями, которыми, например, могут быть OCR или механизм индексирования и поиска изображений). Это требование подразумевает использование легкого алгоритма извлечения глобального дескриптора (а не более дорогостоящую агрегацию локальных дескрипторов, таких как VLAD или Fisher Vector для SIFT-дескрипторов), создающего низкоразмерные признаковые векторы. В случае черно-белых (бинарных) изображений документов (например, патентов) также вполне логично использовать алгоритм извлечения дескриптора, специально предназначенный для и приспособленный под изображения документов, содержащих области текста и иллюстраций, возможно, по меньшей мере частично, также наполненных текстом.
[0021] Другое требование, связанное с огромным количеством (миллионы) доступных патентов, заключается в том, что алгоритм классификации должен быть подходящим для обработки крупномасштабных наборов данных. Из-за отсутствия достаточно репрезентативного размеченного набора данных для иллюстраций из патентов классификационный алгоритм должен обеспечивать либо операцию распространения разметки с частичным привлечением учителя (при которой только небольшую часть признаковых векторов размечают и используют для распространения меток на неразмеченные данные), либо операцию логического вывода разметки (при которой разметка набора данных не требуется вовсе).
[0022] Наконец, для того, чтобы последующая обработка областей текста или иллюстраций, была полной и эффективной, необходим алгоритм разделения текста и иллюстраций, который обеспечивает высокий уровень полноты (recall) и хорошую точность (precision). Поскольку основной акцент в настоящем изобретении делается на выделение иллюстраций из изображений документов для их последующей индексации и использования в поиске, автор настоящего изобретения установил минимальные уровни для показателя полноты ROI иллюстраций на ~ 90%, а для показателя точности на ~ 75%, что означает, что теряется не более 10% иллюстраций, содержащихся во всех обрабатываемых заявленным способом изображениях документов, и допустимым является не более 25% насыщенности текстом в некотором выбранном наборе ROI. Поддержание как показателя полноты, так и показателя точности, по меньшей мере, на таком высоком уровне имеет решающее значение для задачи поиска иллюстраций, поскольку низкий показатель полноты приведет в результате к тому, что слишком много иллюстраций не будет проиндексировано, тогда как низкий показатель точности значительно увеличит избыточные вычисления, выполненные для текстовых ROI. Далее приведены детали способа разделения текстов и иллюстраций в изображениях страниц документов в соответствии с настоящим изобретением.
[0023] Фигура 1 иллюстрирует предпочтительный вариант осуществления способа разделения текстов и иллюстраций в изображениях страниц документов. Далее по тексту заявки наряду с подробным описанием каждого этапа и подэтапа будут описаны основные требования к каждому из этапов и подэтапов способа, которые мотивировали выбор автором настоящего изобретения алгоритмов, используемых на этих этапах.
[0024] На этапе (S100) способа получают изображения страниц документов. Данный этап может быть реализован любым известным из уровня техники способом.
[0025] На этапе (S101) способа сегментируют изображения страниц документов на области интереса (ROI). Поскольку страницы патентного документа представляют собой черно-белые (бинарные) изображения документов, которые обычно используют Манхэттенскую схему размещения текста и иллюстраций, в предпочтительном варианте осуществления данного этапа может быть использован алгоритм сегментации, использующий сглаживание по длинам серий с операцией логическое ИЛИ (RLSO). Подходящий для настоящего изобретения алгоритм RLSO может быть вариантом алгоритма сглаживания по длинам серий (RLSA). Детали подэтапов данного этапа ниже будут подробно описаны и проиллюстрированы со ссылкой на фигуры 2, 5(a), 5(б), 6.
[0026] На этапе (S102) способа извлекают признаковый вектор для каждой области интереса (ROI). Для ROI изображений, извлеченных с помощью упрощенного алгоритма RLSO, были опробованы несколько глобальных дескрипторов изображений, предназначенных для черно-белых изображений документов: моменты Ху (Hu), признаки Харалика (Haralick), дескриптор контекста формы (SCD), гистограмма длин серий (RLH), локальные бинарные шаблоны (LBP), адаптивная иерархическая гистограмма плотности (AHDH) и дескриптор спектра документа (далее упоминаемый как Docstrum-дескриптор). В результате было определено, что наиболее отчетливое и стойкое различие между признаковыми векторами для областей текста и иллюстраций из анализируемого набора данных обеспечивается Docstrum-дескриптором. Этот результат вполне оправдан, поскольку моменты Ху, признаки Харалика и LBP разрабатывались в основном для классификации текстур, SCD направлен на сопоставление форм, а RLH и AHDH хорошо подходят для поиска документов, тогда как Docstrum-дескриптор предназначен для анализа разметки и компоновки страницы в содержащих только текст документах. Таким образом, Docstrum-дескриптор может быть использован на данном этапе (S102) для извлечения признакового вектора для каждой ROI согласно предпочтительному варианту осуществления настоящего изобретения. Однако, специалисту будет понятно, что в других вариантах осуществления данного этапа (S102) любой из вышеперечисленных глобальных дескрипторов может быть использован вместо или вместе с Docstrum-дескриптором для извлечения признакового вектора, хоть и не столь эффективно. Использование Docstrum-дескриптора приводит в результате к тому, что для нетекстовых областей этап (S102) извлекает более ʺхаотичныеʺ признаковые векторы, делая их легко отличимыми от более «регулярных» признаковых векторов, извлекаемых для текстовых областей. Детали подэтапов данного этапа ниже будут подробно описаны и проиллюстрированы со ссылкой на фигуры 3, 7, 8, 9(а), 9(б), 10(а), 10(б).
[0027] Фигура 2 иллюстрирует подэтапы этапа сегментирования (S101) изображения страниц документов на области интереса согласно предпочтительному варианту осуществления настоящего изобретения.
[0028] На подэтапе (S101.1) способа заполняют цветом переднего плана горизонтальные серии пикселей фона, длины которых ниже некоторого предварительно установленного порогового значения.
[0029] На подэтапе (S101.2) способа заполняют цветом переднего плана вертикальные серии пикселей фона, длины которых ниже некоторого предварительно установленного порогового значения. На подэтапе (S101.3) способа применяют операцию логическое ИЛИ к изображениям, полученным в результате упомянутых заполнений. На подэтапе (S101.4) способа извлекают компоненты связности из изображения, полученного в результате применения операции логическое ИЛИ.
[0030] На подэтапе (S101.5) способа выбирают ограничительные рамки полученных в результате компонент связности в качестве областей интереса. Слишком маленькие ROI, площадь которых (в пикселях) менее 0,1% от всей площади изображения, но без ограничения упомянутым значением процента, могут быть отброшены.
[0031] Используемый в предпочтительном варианте осуществления данных подэтапов алгоритм RLSO отличается от известного алгоритма RLSA тем, что первый использует логическую операцию ИЛИ между сглаженными по горизонтали и по вертикали изображениями вместо логической операции И. Таким образом, используемая в предпочтительном варианте осуществления настоящего изобретения модификация RLSO еще больше упрощает данные подэтапы, заменяя сложную оценку пороговых значений сглаживания вычислением 90-го и 80-го процентилей длин серий пикселей фона, соответственно, для горизонтального и вертикального сглаживания. Однако, специалист поймет, что в других вариантах осуществления вместо вышеуказанный процентилей могут быть использованы другие процентили длин серий пикселей фона, соответственно, для горизонтального и вертикального сглаживания, без выхода за рамки настоящего раскрытия.
[0032] Пример применения алгоритма RLSO к иллюстрациям патента проиллюстрирован на фигурах 5(а), 5(б), а на фигуре 6 проиллюстрированы области интереса (ROI), извлеченные из изображения страницы патента, в содержимом которой имеются как текст, так и иллюстрации. В целях иллюстрации на фигуре 5(б) позицией 501 показана компонента связности, а позицией 502 ограничительная рамка. В целях иллюстрации на фигуре 6 позицией 601 показана область интереса.
[0033] Фигура 3 иллюстрирует подэтапы этапа извлечения (S102) признакового вектора для каждой области интереса согласно предпочтительному варианту осуществления настоящего изобретения.
[0034] На подэтапе (S102.1) способа изменяют размер области интереса до размера 500×500 пикселей с сохранением соотношения ее сторон. Другими словами, в предпочтительном варианте осуществления настоящего изобретения размер ROI изменяется на размер 500×500 пикселей, но без ограничения упомянутым значением размера, при сохранении пропорций такой ROI, то есть сначала ROI изменяют таким образом, чтобы больший размер (либо ширина, либо высота) был равен 500 пикселей, а затем по меньшему размеру область интереса (ROI) дополнялась до 500 пикселей, используя значение пикселя фона.
[0035] На подэтапе (S102.2) способа извлекают компоненты связности из области интереса измененного размера и вычисляют их центроиды. Данный подэтап может включать в себя дополнительную операцию, на которой отфильтровывают компоненты связности, у которых ширина или высота ограничительных рамок менее 1%, но без ограничения упомянутым значением процента, от соответствующей размерности ROI измененного размера.
[0036] На подэтапе (S102.3) способа находят ближайших соседей для каждого центроида, а на подэтапе (S102.4) способа строят двумерную гистограмму нормализованных расстояний и углов для всех пар, состоящих из центроида и каждого из его пяти ближайших соседних центроидов. Двумерная гистограмма нормализованных расстояний и углов пар ближайших соседних центроидов отражает структуру взаимного расположения областей связности. В качестве расстояния между двумя центроидами используется евклидово расстояние между точками на двумерной плоскости, угол для пары центроидов вычисляется как угол между прямой, соединяющим эти центроиды и горизонтальной линией. Количество используемых на данных подэтапах ближайших соседей центроидов может изменяться. Однако, если количество центроидов слишком мало (скажем ниже 4), используется, по существу, равномерно распределенная гистограмма. В предпочтительном варианте осуществления данных подэтапов расстояния нормализуют путем деления на среднее расстояние всех пар ближайших соседних центроидов.
[0037] На подэтапе (S102.5) способа переформировывают двумерную гистограмму в Docstrum - признаковый вектор. На данном подэтапе двумерная гистограмма может быть дополнительно нормализована так, чтобы ее L1-норма была равна 1. Docstrum - признаковый вектор, получаемый из двумерной гистограммы путем разворачивания ее в вектор на данном подэтапе и, в одном варианте осуществления, нормировки по L1-норме может альтернативно именоваться Docstrum-дескриптором в целях кратности и ясности.
[0038] Важно отметить, что изменение размера области интереса на подэтапе (S102.1) способа и нормализация расстояний при построении двумерной гистограммы на подэтапе (S102.4) способа отличает используемую в настоящем изобретении версию Docstrum-дескриптора от известного оригинального алгоритма, описанного в работе L. O'Gorman, «The Document Spectrum for Page Layout Analysis» IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 15, no. 11, pp. 1162-1173, 1993. Эти подэтапы используются в предпочтительном варианте осуществления заявленного способа для следующего: изменение размера ROI используется, чтобы уменьшить вычислительную сложность способа (поскольку большинство ROI имеют размеры намного больше, чем 500×500 пикселей), нормализация расстояний используется, чтобы сделать дескриптор инвариантным к масштабированию. Кроме того, сохранение соотношения сторон ROI при изменении ее размера на подэтапе (S102.1) способа используется для предотвращения перекоса распределения расстояний и углов вследствие неизотропного изменения размера ROI. Целевой размер ROI (в предпочтительном варианте осуществления - 500×500 пикселей) для использования на подэтапе изменения размера может быть выбран как компромисс между вычислительной сложностью дескриптора и сохранением деталей иллюстраций. Также может быть использован размер ROI 300×300 или любой размер ROI NxN, выбираемый из диапазона размеров ROI от 300×300 пикселей до 500×500 пикселей. Для того, чтобы построить двумерную гистограмму расстояний и углов в предпочтительном варианте осуществления способа используют 64 бина угла и 20 бинов расстояния, что приводит в результате к 1280-мерному признаковому вектору. «Бин» может быть определен как интервал гистограммы. Эти параметры могут быть выбраны как компромисс между размерностью дескриптора и его различающей способностью для различения текста и иллюстраций в изображениях документов.
[0039] Примеры пар ближайших соседних центроидов компонент связности для типичной ROI иллюстрации и типичной ROI текста показаны, соответственно, на фигурах 7 и 8. В целях иллюстрации на фигуре 7 позицией 701 показана пара ближайших соседних центроидов, а позициями 702 показаны соответствующие ей компоненты связности. В целях иллюстрации на фигуре 8 позицией 801 показана пара ближайших соседних центроидов, а позициями 802 показаны соответствующие ей компоненты связности.
[0040] Docstrum-дескрипторы (изображенные как одномерные гистограммы), вычисленные с использованием вышеуказанных предпочтительных параметров для тех же самых типичной ROI иллюстрации и типичной ROI текста с фигур 7 и 8 показаны, соответственно, на фигурах 9(а) и 9(б). Как можно видеть на фигурах 9(а) и 9(б), гистограмма для типичной ROI текста демонстрирует регулярно-разнесенные пики, в отличие от гистограммы для типичной ROI иллюстрации, которая выглядит намного более хаотичной.
[0041] Кроме того, в других вариантах осуществления настоящего изобретения размерность дескриптора может быть уменьшена (и, следовательно, вычислительная сложность вычисления и обработки дескриптора может быть уменьшена) путем дальнейшего уменьшения размера ROI и размерности гистограммы в бинах. Например, в варианте осуществления настоящего изобретения, в котором используют 16 бинов углов и 20 бинов расстояния, могут быть получены 320-мерные признаковые векторы. Docstrum-дескрипторы, использующие такие параметры и вычисленные для тех же самых типичных ROI, размер которых составляет 300×300 пикселей, проиллюстрированы на фигурах 10(а) и 10(б). Несмотря на то, что различающая способность таких дескрипторов с такими альтернативными параметрами видится ухудшенной (т.е. гистограмма для ROI текста имеет менее регулярную структуру), гистограммы по-прежнему являются достаточно подходящими для задачи отделения текста от иллюстраций согласно настоящему изобретению.
[0042] Фигура 4 иллюстрируют подэтапы этапа классифицирования (S103) каждого из извлеченных признаковых векторов в один из двух классов: текст или иллюстрация согласно предпочтительному варианту осуществления настоящего изобретения. В общем, в предпочтительном варианте осуществления раскрытого способа этот этап (S103) осуществляют следующим образом: сначала, признаковые векторы дескриптора преобразуют с помощью аппроксимирующего ядро (kernel, скалярное произведение) отображения признаков, затем осуществляют кластеризацию полученных в результате преобразованных признаковых векторов, используя алгоритм мини-пакетных k-средних, затем осуществляют кластеризацию центроидов кластеров, полученных в результате выполнения предшествующего подэтапа, используя один из возможных более сложных алгоритмов кластеризации. Полученные в результате кластеры центроидов, по сути, агрегируют кластеры, соответствующие таким центроидам (выходные данные с кластеризации 1-го уровня), в суперкластер (который может именоваться как «больший кластер»). Наконец, полученные суперкластеры классифицируют посредством либо операции логического вывода разметки (Zero-Shot Label Inference), либо операции распространения разметки с частичным привлечением учителя (Semi-Supervised Label Propagation), которая использует подмножество размеченных признаковых векторов.
[0043] Для оценки качества классификации в настоящем изобретении к блок-схеме с фигуры 4 может быть добавлена параллельная ветвь оценки качества классификации как показано на фигуре 11. Более подробное описание этой ветви оценки качества классификации и результатов этой оценки приведено ниже со ссылкой на фигуру 11.
[0044] Ниже по тексту приводится подробное описание вариантов осуществления подэтапов этапа (S103).
[0045] На подэтапе (S103.1) способа осуществляют аппроксимирующее ядро преобразование признаковых векторов. Под «ядром» здесь понимается обобщенное действительное скалярное произведение, т.е. действительнозначная функция, определенная на парах признаковых векторов, являющаяся симметричной и положительно-определенной, но не обязательно линейной. Этот подэтап хоть и не является обязательным, но отличает способ классификации дескрипторов согласно настоящему изобретению от способов классификации дескрипторов, известных из уровня техники. Поскольку Docstrum-дескриптор представляет собой гистограмму, Евклидовы расстояния (или скалярные произведения), используемые на последующих подэтапах этапа (S103) не являются достаточно адекватными в качестве меры схожести признаковых векторов. Популярными ядрами [от англ. «a kernel»] для основанных на гистограммах дескрипторов, которые широко используются в областях машинного зрения и машинного обучения, являются ядра Хеллингера, χ2, пересечения [от англ. «Intersection»] и Дженсена-Шеннона. Эти ядра описаны в работе A. Vedaldi, и A. Zisserman, «Efficient Additive Kernels via Explicit Feature Maps», IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 34, no. 3, pp. 480-492, 2012 (Далее упоминаемая как «Vedaldi»). Упомянутые ядра вместе с соответствующими им расстояниями определены в таблице 1, в которую также включена мера Жаккара (адаптированная для гистограмм), которая, насколько известно автору настоящего изобретения, не является широко используемой в областях машинного зрения, но, как будет показано далее, заслуживает внимания в контексте целей настоящей заявки.
Таблица 11
Ориентированные на гистограммы ядра и расстояния

KL - дивергенция Кульбака-Лейблера.
[0046] Однако, поскольку последующий подэтап кластеризации первого уровня (S103.2)- с использованием мини-пакетных k-средних, в состоянии использовать только Евклидовы расстояния между признаковыми векторами, в способе необходимо осуществлять преобразование Docstrum-признаковых векторов, используя подходящее аппроксимирующее ядро отображение признаков. Такое отображение признаков может быть определено как следующее отображение Ψ: ℜD → ℜN, такое, что для любых x, y ∈ ℜD: K (x, y) ≈〈Ψ(x), Ψ(y)〉, то есть линейное (Евклидово) скалярное произведение в преобразованном признаковом пространстве ℜN аппроксимирует нелинейное ядро K (x, y) в исходном признаковом пространстве ℜD. Поскольку положительно определенное ядро K (x, y) соответствует расстоянию D (x, y), заданному D2 (x, y)=K (x, x)+K (y, y) - 2K (x, y), легко понять, что для любых x, y ∈ ℜD: D2 (x, y) ≈║ Ψ(x), Ψ(y)║2, где ║·║2 - квадрат Евклидова расстояния в ℜN, поэтому расстояние, соответствующее ядру, также аппроксимируется тем же самым отображением признаков.
[0047] Поскольку ядра Хеллингера, χ2, пересечения и Дженсена-Шеннона являются аддитивными и γ-однородными, аппроксимирующие их отображения признаков могут быть выведены в аналитическом виде. Для ядра Хеллингера используется точное сохраняющее размерность отображение, которое берет квадратный корень каждой компоненты вектора, тогда как для ядер χ2, пересечения и Дженсена-Шеннона используются аппроксимирующие отображения из вышеуказанной работы Vedaldi с 5 компонентами, что в результате приводит к отображению следующего вида Ψ: ℜ1280→ ℜ6400 (5 раз 1280). Для признаковых векторов в используемом наборе данных такие отображения обеспечивают точность аппроксимации расстояния 6%.
[0048] В сравнении с другими ориентированными на гистограммы ядрами, ядро Жаккара не является ни аддитивным, ни γ-однородным (или стационарным), поэтому получение аппроксимирующего отображения признаков для него в аналитическом виде является гораздо более сложным. Таким образом, в настоящем изобретении для ядра Жаккара может быть использована сиамская нейронная сеть для обучения аппроксимирующего отображения признаков для этого ядра. Архитектура такой нейронной сети, используемой для обучения отображения признаков для аппроксимации ядра Жаккара, показана на фигуре 12. Заштрихованные слои сети на этой фигуре имеют разделяемые весовые коэффициенты и составляют отображение Ψ признаков, обученное этой сетью. Там, где имеет место размерность вывода слоя на фигуре 12, такая размерность приводится в круглых скобках.
[0049] На вход сети подают два случайно выбранных Docstrum-признаковых вектора x и y (каждый из которых является 1280-мерным). Каждый из этих двух векторов подается на свой собственный полносвязный (FC) слой, имеющий в качестве активации параметрическое усеченное линейное преобразование (PReLU) и 5000 выходов. Активация PReLU может быть реализована в соответствии с работой K. He, X. Zhang, S. Ren и J. Sun, «Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification» Proceedings of the IEEE International Conference on Computer Vision, pp. 1026-1034, 2015. Оба слоя FC+PReLU разделяют все весовые коэффициенты во время обучения, поэтому каждый из них фактически выполняет одно и то же отображение признаков Ψ: ℜ1280→ ℜ5000, обучение которого проводится этой сетью. Выходы слоев FC+PReLU, Ψ(x) и Ψ(y), подаются на слой вычисления L2-расстояния, который вычисляет квадрат Евклидова расстояния ║Ψ(x) - Ψ(y)║2 и не содержит обучаемых параметров. Полученный в результате квадрат расстояния является выходом сети. Этот квадрат D2 (x, y) расстояния ядра Жаккара используется в качестве целевого выхода во время обучения, тогда как средняя абсолютная ошибка в процентах (MAPE) используется в качестве функции потерь. Весовые коэффициенты FC-слоя могут быть инициализированы с помощью равномерной инициализации по методу Глоро, параметры PReLU могут быть инициализированы в нуль, а в качестве алгоритма оптимизации может быть использован Nesterov ADAM. После обучения в течение 300 эпох с использованием размера пакета, равного 10000 пар признаковых векторов, сеть достигает тестовой точности 7% (MAPE) в аппроксимации расстояния Жаккара, что сопоставимо с точностью аппроксимации других ядер.
[0050] Важно отметить, что в настоящем изобретении по-прежнему используется Евклидово расстояние (которое также может именоваться «линейным ядром») для последующих подэтапов обработки признаковых векторов, наряду с другими вышеупомянутыми ядрами, и в случае с ним данный этап аппроксимации ядра не используется. Другими словами, вместе с перечисленными выше нелинейными ядрами используется обычное евклидово скалярное произведение (и соответствующее ему евклидово расстояние), оно же «линейное ядро». При его использовании этап аппроксимации не нужен.
[0051] На подэтапе (S103.2) способа осуществляют кластеризацию первого уровня преобразованных признаковых векторов с использованием алгоритма мини-пакетных k-средних для получения кластеров преобразованных признаковых векторов и их центроидов. Алгоритм мини-пакетных k-средних выбран для предпочтительного варианта осуществления данного подэтапа из-за его высокой производительности, пригодности для крупномасштабной обработки и, как правило, хорошего качества результирующей кластеризации.
[0052] Однако, этот алгоритм, как и стандартный алгоритм k-средних, не способен правильно обрабатывать невыпуклые или удлиненные кластеры, которые вполне могут образовываться при реализации поставленной в настоящем изобретении задачи. Эта гипотеза может быть проверена посредством запуска кластеризации по k-средним, выполненной с настройкой на вывод небольшого количества кластеров (от 2 до 10) в отношении преобразованных Docstrum-дескрипторов, и визуального осмотра ROI, соответствующих признаковым векторам получаемых в результате кластеров. Такая проверка демонстрирует, что получаемые в результате кластеры содержат смесь как ROI текста, так и ROI иллюстраций без явного преобладания одного из этих классов. Однако, при увеличении числа кластеров до 20 и выше, в выводимых кластерах начинают преобладать либо ROI текста, либо ROI иллюстраций, что подтверждает вышеописанную гипотезу, поскольку большее количество запрошенных кластеров позволяет алгоритму k-средних разделить невыпуклые или удлиненные кластеры текста или иллюстраций на меньшие выпуклые и изотропные субкластеры без значительного их смешения. Путем варьирования числа запрошенных кластеров от 2 до 1000 и визуального осмотра результатов, было обнаружено, что 100 кластеров являются оптимальным компромиссом между чистотой кластера и вычислительной сложностью кластеризации по k-средним. Таким образом, в предпочтительном варианте осуществления подэтапа (S103.2) способа кластеризацию первого уровня преобразованных признаковых векторов с использованием алгоритма мини-пакетных k-средних осуществляют для получения 100 соответствующих им кластеров и их центроидов.
[0053] Как указано выше, на данном подэтапе алгоритм мини-пакетных k-средних, выполненный с возможностью вывода 100 кластеров с размером мини-пакета, составляющим 1000 признаковых векторов, за период в 100 эпох используется до тех пор, пока инерция мини-пакетов, усредненная по нескольким последним мини-пакетам, перестает существенно улучшаться.
[0054] Примеры получаемых в результате кластеров (составленных из отдельных ROI, соответствующих признаковым векторам кластеров) показаны на фигуре 13. На фигуре 13 представлены три вида типичных кластеров: текстовый кластер, кластер иллюстраций и смешанный кластер. Видно, что текстовый кластер и кластер иллюстраций почти на 100% чисты (содержат ROI только одного класса - текст или иллюстрацию), в то время как в типичном смешанном кластере преобладает один класс и содержится не более 30% примеси из другого класса. Автором настоящего изобретения был проведен ручной анализ таких смешанных кластеров, который показал, что они содержат менее 10% всех признаковых векторов иллюстративного набора данных, поэтому общий процент примесей составляет менее 3%, чем можно безопасно пренебречь в контексте задачи настоящего изобретения. Таким образом, для дальнейшей обработки и анализа считаем, что кластеризация первого уровня выводит, по существу, чистые текстовые кластеры и кластеры иллюстраций.
[0055] Также следует отметить, что наименьшая примесь достигается при использовании ядра Жаккара, при использовании ядер χ2 и Дженсена-Шеннона достигается значительно более высокая примесь, тогда как ядро пересечения и линейное ядро являются наихудшими с точки зрения кластерных примесей. Что касается ядра Хеллингера, так как оно обеспечивает результаты кластеризации даже хуже, чем у линейного ядра (не предлагая при этом никаких преимуществ по производительности), это ядро не используется для дальнейших подэтапов способа согласно настоящему изобретению (за исключением варианта осуществления заявленного способа с точным ядром).
[0056] На подэтапе (S103.3) способа осуществляют кластеризацию второго уровня центроидов кластеров, полученных на предшествующем подэтапе (S103.2), с использованием усовершенствованного алгоритма кластеризации для получения соответствующих им суперкластеров. Суперкластер именуется так, поскольку его размер превышает размер любого кластера, полученного на предшествующем подэтапе (S103.2).
[0057] Поскольку кластеризация по k-средним выдает выпуклые кластеры, которые имеют тенденцию быть изотропными и такая геометрия кластера, вероятнее всего, не соответствует геометрии кластеров Docstrum-признаковых векторов, которые соответствуют ROI текста и иллюстраций, необходимо агрегировать кластеры, полученные в результате кластеризации первого уровня, в суперкластеры с помощью алгоритма кластеризации, способного обрабатывать невыпуклые неизотропные кластеры. Поскольку большинство таких алгоритмов плохо масштабируется под наборы данных большого объема, автор настоящего изобретения решил применить их к центроидам кластеров, выдаваемых в результате кластеризации первого уровня, а не к гораздо более многочисленным фактическим признаковым векторам. Поскольку число таких центроидов составляет 100 (или менее), такое техническое решение позволяет избежать ограничения требованием пригодности для крупномасштабной обработки.
[0058] Для выполнения данного подэтапа (S103.3) было опробовано несколько алгоритмов кластеризации второго уровня: k-средних с инициализацией по k-средних++ (см., например, D. Arthur, and S. Vassilvitskii, ʺk-means++: The Advantages of Careful Seeding,ʺ Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Society for Industrial and Applied Mathematics, pp. 1027-1035, 2007), распространение близости (см., например, B.J. Frey, and D. Dueck, ʺClustering by Passing Messages Between Data Points,ʺ Science, vol. 315, no. 5814, pp. 972-976, 2007), сдвиг среднего [ от англ. ʺmean shiftʺ] (см., например, D. Comaniciu, and P. Meer, ʺMean Shift: A Robust Approach toward Feature Space Analysis,ʺ IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 24, no. 5, pp. 603-619, 2002), спектральная кластеризация (см., например, A.Y. Ng, M.I. Jordan, and Y. Weiss, ʺOn Spectral Clustering: Analysis and an Algorithm,ʺ Advances in Neural Information Processing Systems, vol. 2, pp. 849-856, 2002), агломеративная кластеризация с использованием нескольких методов связи (см., например, D. Müllner, ʺModern Hierarchical, Agglomerative Clustering Algorithmsʺ, arXiv preprint arXiv:1109.2378, 2011), DBSCAN (см., например, M. Ester, H.P. Kriegel, J. Sander, and X. Xu, ʺA Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise,ʺ Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, vol. 96, no. 34, pp. 226-231, 1996.), иерархический DBSCAN (HDBSCAN) (см., например, R. J. Campello, D. Moulavi, и J. Sander, ʺDensity-Based Clustering Based on Hierarchical Density Estimatesʺ, Pacific-Asia Conference on Knowledge Discovery and Data Mining, Springer Berlin Heidelberg, pp. 160-172, 2013), BIRCH (см., например, T. Zhang, R. Ramakrishnan и M. Livny, ʺBIRCH: An Efficient Data Clustering Method for Very Lange Databasesʺ, ACM Sigmod Record, vol. 25, no. 2, pp. 103-114, ACM, 1996) и одноклассовый SVM (см., например, B. Schölkopf, J.C. Platt, J. Shawe-Taylor, A.J. Smola, и R.C. Williamson, ʺEstimating the Support of a High-Dimensional Distribution,ʺ Neural Computation, vol. 13, no. 7, pp. 1443-1471, 2001) с использованием линейного, RBF- и сигмоидного ядер (которые фактически объединены с одним из ориентированных на гистограмму ядер, приведенных в Таблице 1, вследствие выполнения на подэтапе (S103.1) аппроксимирующего ядро признакового отображения). Следует отметить, что последний алгоритм из вышеперечисленных на самом деле является алгоритмом обнаружения новизны, который требует чистого набора данных для обучения, но было обнаружено, что он все же неплохо работает для задачи настоящего изобретения. Кроме того, также был опробован еще один алгоритм обнаружения новизны и выбросов, заключающийся в построении эллиптической огибающей для данных с использованием метода оценки минимального определителя ковариационной матрицы (P.J. Rousseeuw, and K.V. Driessen, ʺA Fast Algorithm for the Minimum Covariance Determinant Estimator,ʺ Technometrics, vol. 41, no. 3, pp. 212-223, 1999), однако, он не сработал, поскольку распределение данных в иллюстративном наборе не унимодальное и не симметричное.
[0059] Необходимо отметить, что поскольку для ядер χ2, пересечения, Дженсена-Шеннона и Жаккара размерность преобразованного признакового пространства в несколько раз превышает размерность исходного Docstrum-дескриптора, кластеризация первого уровня для этих ядер, которая является самой затратной по времени в раскрытом способе, занимает в 2-3 раза больше времени, чем для линейного ядра (т.е. для исходных Docstrum-признаковых векторов). Таким образом, одним из очевидных способов улучшить вычислительную производительность раскрытого способа является пропуск подэтапа (S103.1) способа, на котором осуществляют аппроксимирующее ядро преобразование признаковых векторов, но использование одного из ориентированных на гистограмму ядер во время кластеризации второго уровня на описываемом в данный момент подэтапе (S103.3). Этого можно достичь с помощью алгоритма кластеризации, который может принимать на вход матрицу ядер (или матрицу расстояний для основанных на расстояниях алгоритмов) вместо признаковых векторов, поскольку такая матрица для центроидов кластеров, выдаваемых в результате кластеризации первого уровня, существенно меньше (всего 100×100), чем для крупномасштабного набора данных, подаваемого на вход подэтапа кластеризации первого уровня (который может содержать миллионы векторов). Такие алгоритмы могут включать в себя распространение близости, агломеративную кластеризацию с использованием методов одиночной, полной, средней и взвешенной связи, DBSCAN, HDBSCAN, одноклассовый SVM и спектральную кластеризацию. Тут необходимо отметить, что в варианте осуществления с точным ядром могут использоваться все те же ядра, что и в варианте с аппроксимированным ядром. В случае варианта осуществления с точным ядром матрица ядер/расстояний может быть вычислена напрямую, как матрица (точных) попарных ядер/расстояний для всех пар центроидов, полученных методом мини-пакетных k-средних (то есть Kij=K(ci, cj), где Kij - элемент матрицы ядер/расстояний на пересечении i-ой строки и j-го столбца, K(ci, cj) -ядро/расстояние между i-ым и j-ым центроидами), затем эта матрица может подаваться на вход алгоритма кластеризации второго уровня: размер ее может составлять, но без ограничения упомянутым значением, 100×100, а перечисленные выше алгоритмы выполнены с возможностью использования этой матрицы, точнее, часть из упомянутых алгоритмов может использовать матрицу ядер (все, кроме DBSCAN, HDBSCAN), остальные - матрицу расстояний (DBSCAN, HDBSCAN). До этапа аппроксимации ядра варианты с точным и аппроксимированным ядром полностью идентичны, т.е. точно так же извлекаются признаковые вектора. Поскольку в этом варианте осуществления используются точные ядра и расстояния, применяемые к парам Docstrum-признаковых векторов, а не их приближения, данный вариант осуществления именуется в дальнейшем «вариант с точным ядром», в отличие от «варианта с аппроксимированным ядром», который был описан выше. В настоящем изобретении могут быть использованы как «вариант с точным ядром», так и «вариант с аппроксимированным ядром». Результаты работы и сравнение характеристик этих вариантов будут приведены ниже.
[0060] Для каждого из алгоритмов кластеризации второго уровня автор настоящего изобретения варьировал самые важные параметры в широком диапазоне, чтобы найти комбинации значений параметров, обеспечивающих наилучшую производительность в отношении точности, полноты и F1-показателей. Нижеследующая таблица 2 иллюстрирует эти варьируемые параметры и диапазоны их значений для алгоритмов кластеризации второго уровня. Также необходимо обратить внимание, что для агломеративной кластеризации использовались как неструктурированные, так и структурированные варианты, причем в последнем из упомянутых использовалась матрица связности, вычисленная по графу k-соседей.
Таблица 2
Варьируемые параметры алгоритмов кластеризации второго уровня
3 Используемые SVM-ядра: линейное, RBF- и сигмоидное.
4 Используемые стратегии назначения меток: k-средних и дискретизация.
[0061] На подэтапе (S103.4) способа проверяют, больше ли число полученных суперкластеров, чем два.
[0062] На подэтапе (S103.4.1) способа если число полученных суперкластеров равно двум, используют операцию логического вывода разметки для классификации каждого из этих двух суперкластеров в один из двух классов: текст или иллюстрация.
[0063] Или на подэтапе (S103.4.2) способа если число полученных суперкластеров больше двух, используют операцию распространения разметки с частичным привлечением учителя для классификации каждого из этих суперкластеров в один из двух классов: текст или иллюстрация.
[0064] Подэтап (S103.3) кластеризации второго уровня как правило выдает небольшое число суперкластеров. Чтобы классифицировать эти суперкластеры в класс «текст» или «иллюстрация», в настоящем изобретении используется дополнительный источник информации об этих классах. В зависимости от вывода с подэтапа (S103.3) кластеризации второго уровня в раскрытом способе используются два режима назначения разметки суперкластера: 1) режим логического вывода разметки (S103.4.1) используют, когда два суперкластера выведено с подэтапа (S103.3), 2) иначе используют режим распространения разметки с частичным привлечением учителя (S103.4.2) (т.е. когда с подэтапа (S103.3) выведено более 2 суперкластеров). Число выведенных суперкластеров может быть проверено на (опциональном) подэтапе (S103.4) способа, на котором проверяют, больше ли число полученных суперкластеров кластеров, чем два.
[0065] В режиме логического вывода разметки используют общую статистическую информацию о классах: например, в случае ROI из патентных документов используют наблюдение, что ROI текста количественно преобладают, таким образом, больший из двух суперкластеров может быть классифицирован как текстовый суперкластер, в то время как меньший из этих двух суперкластеров будет соответствовать суперкластеру иллюстраций.
[0066] В режиме распространения разметки с частичным привлечением учителя может быть использовано небольшое размеченное подмножество набора исходных данных, полученное из наблюдения, что имеется некоторое число патентных документов без иллюстраций (фигур), которые могут быть с легкостью идентифицированы по отсутствию в их полнотекстовых версиях выражений ʺfigʺ, ʺфигʺ, ʺdrawingʺ, ʺчертежʺ, ʺ##strʺ, но без ограничения упомянутыми выражениями. Все ROI (и их соответствующие Docstrum-признаковые векторы) из таких патентов размечают как текстовые. Затем для каждого суперкластера может быть вычислена его «насыщенность текстом», то есть доля его ROI, которые принадлежат к этому размеченному как текст подмножеству. Классификацию суперкластера затем выполняют как разметку суперкластеров, имеющих насыщенность текстом выше некоторого порогового значения, как соответствующих ROI текста, и разметку оставшихся суперкластеров как соответствующих ROI иллюстраций (тем самым осуществляют распространение текстовой разметки с упомянутого небольшого размеченного подмножества на весь суперкластер, имеющий высокую насыщенность текстом). Значение упомянутого порогового значения может быть вычислено как процентиль насыщенностей текстом всех суперкластеров, тогда как само значение процентиля может варьироваться от 0 до 100% вместе с параметрами алгоритма кластеризации второго уровня (см. подробное описание подэтапа S103.3 выше). Поскольку содержащие только текст патентные документы содержат ROI текста, которые являются достаточно репрезентативными для всего набора ROI текста патентных документов, то есть содержат все классы текстовых областей, специфичных для патентных документов (текст заголовка, текст таблицы, регулярные текстовые поля и т. д.), такое распространение разметки демонстрирует хорошие результаты в контексте решения задачи настоящего изобретения.
[0067] Следует отметить, что режим логического вывода разметки вообще не использует никаких размеченных данных, а только общую априорную информацию о распределении ROI текста и иллюстраций в наборе данных. Режим же распространения разметки с частичным привлечением учителя использует лишь небольшое подмножество (менее 1% всех данных) набора данных, размеченное как данные, принадлежащие некоторому одному классу (ROI текста в вышеописанном предпочтительном варианте), с использованием дополнительной побочной информации. Следует отметить, что режим распространения разметки именно с частичным привлечением учителя, а не с полным привлечением учителя, именуется так, поскольку в нем применяются размеченные данные только для одного класса из двух интересуемых.
[0068] Фигура 11 иллюстрирует подэтапы этапа классифицирования (S103) каждого из извлеченных признаковых векторов в один из двух классов: текст или иллюстрация, с добавленной ветвью оценки качества классификации. Данная фигура 11 соответствует фигуре 4, за исключением того, что к ней добавлена ветвь оценки качества классификации, обеспечиваемая подэтапами S103.5 и S103.6. Таким образом, повторное описание подэтапов S103.1 - S103.4 здесь приводиться не будет в целях ясности и краткости. На подэтапе (S103.5) способа размечают кластер вручную. На подэтапе (S103.6) способа сравнивают разметку, предсказанную способом, с разметкой, обеспеченной вручную, и вычисляют на основе этого сравнения показатель полноты, показатель точности и F1-показатель. Далее приведены и подробно описаны результаты оценки качества классификации раскрытым в настоящей заявке способом.
[0069] Чтобы количественно оценить качество разделения текста и иллюстраций, обеспечиваемое в различных вариантах осуществления настоящего изобретения, необходима однозначно истинная разметка набора данных. Классификация всех страниц патентных документов в виде либо текстовых, либо содержащих иллюстрации, доступная в USPTO или Google Patents, не обеспечивает точной разметки ROI, поскольку страница патентного документа может содержать ROI обоих классов: например, страницы иллюстраций содержат текстовые элементы (номера патентов, позиционные обозначения, подписи и т. д.), а страницы текста патентных документов, связанных с химией, часто содержат иллюстрации химических составов, смешанные с текстовыми областями. Другая мотивация не использовать внешнюю разметку заключается в том, что может отсутствовать внешний источник такой разметки для других классов документов, требующих разделения текста и иллюстраций согласно настоящему изобретению.
[0070] Таким образом, для целей оценки качества классификации используется правильная разметка, полученная вручную путем визуального осмотра и разметки случайных подмножеств ROI для каждого из кластеров, полученных в результате выполнения подэтапа (S103.2) кластеризации первого уровня (это становится возможно из-за относительно небольшого количества кластеров, выводимых с данного подэтапа). Поскольку, как упомянуто выше, в большинстве этих кластеров преобладают ROI одного класса (текст или иллюстрация), все ROI таких кластеров размечают как принадлежащие к упомянутому преобладающему классу этого кластера. Как отмечено ранее, такой подход будет страдать от неточной разметки в приемлемо малой степени (менее нескольких процентов ошибочно размеченных ROI).
[0071] Вручную разметив все ROI в наборе данных, оценивают качество разделения текста и иллюстраций с использованием широко используемых метрик качества классификации, таких как полнота, точность и F1-показатель, вычисляемых путем сравнения меток, предсказанных раскрытым способом, и меток, обеспеченных ручной маркировкой (далее ROI иллюстраций рассматриваются как положительные образцы и ROI текста как отрицательные). Однако, следует отметить, что представленные ниже результаты по упомянутым метрикам являются приблизительными в силу вышеупомянутой неточной разметки, хоть и в приемлемо малой степени.
[0072] Следует отметить, что ручная маркировка использовалась только для оценки качества классификации и для поиска оптимальных параметров заявленного способа, тогда как сам способ является полностью автоматическим и не полагается на какую-либо ручную работу.
Условия проведения экспериментов
[0073] Использовалась реализация способа на языке Python с применением пакетов NumPy и SciPy. Scikit-learn и fastcluster использовались для реализации этапов аппроксимации ядра и кластеризации, а Keras использовался для построения и обучения сиамской нейронной сети, тогда как данные изображения и дескриптора были сохранены в формате HDF5 с использованием пакета PyTables. Scikit-image использовался для операций обработки изображений.
[0074] В тестовой системе использовался 8-ядерный процессор AMD FX-8350 и графический процессор NVIDIA GeForce GTX 780 (использовался для обучения нейронной сети).
[0075] Набор данных, используемый для этих экспериментов, состоял из 12100 случайно выбранных патентов, загруженных с сайта USPTO (без каких-либо ограничений по теме). Патенты были взяты за период с 2005 по 2013 год. Такой подход привел к весьма разнообразному набору патентных иллюстраций из самых разных областей (электроника, строительство, оборудование, химия и т. д.). В общей сложности 1,1 миллиона ROI было извлечено из страниц этих патентов в результате выполнения этапа S101 раскрытого способа. Из этих 12100 патентов только 197 были только текстовыми патентами, из которых были извлечены 10458 ROI текста (менее 1% от всех ROI).
Время работы отдельных этапов, подэтапов и их реализаций
[0076] Самая трудоемкая часть раскрытого способа заключалась в обучении сиамской нейронной сети для получения аппроксимирующего ядро отображения для ядра Жаккара (более 20 часов). Вычисление Docstrum-дескриптора и преобразование Docstrum-признаковых векторов с использованием аппроксимирующего ядро признакового отображения заняло около 1,5 часов. Кроме того, подэтап (S103.2) кластеризации первого уровня занял около 3 часов для линейного ядра, около 7 часов для каждого из ядер χ2, пересечения, Дженсена-Шеннона и около 10,5 часов для ядра Жаккара. Все последующие подэтапы (кластеризация второго уровня (S103.2) и классификация суперкластеров (S103.4, S103.4.1, S103.4.2) заняли пренебрежимо малое время (несколько секунд) по сравнению с предыдущими подэтапами. Таким образом, большая часть времени потреблялась кластеризацией первого уровня (особенно при использовании нелинейного ядра).
[0077] Такое распределение времени обработки подтверждает решение автора настоящего изобретения разбить кластеризацию на два отдельных подэтапа, выполняемых различными алгоритмами (быстрый алгоритм мини-пакетных k-средних для кластеризации первого уровня и один из более сложных алгоритмов для кластеризации второго уровня), поскольку в противном случае кластеризация была бы запредельно медленной для любого из эффективно работающих алгоритмов.
Результаты варианта с аппроксимированным ядром
[0078] Автор настоящего изобретения оценил качество классификации варианта осуществления способа с аппроксимированным ядром для всех комбинаций значений варьируемых параметров, участвующих в подэтапах кластеризации второго уровня (см. Таблицу 2) и классификации суперкластеров. Общее количество опробованных комбинаций значений параметров для данного варианта составило 406665.
[0079] В нижеследующей Таблице 3 приведены результаты оценки качества классификации для этого варианта: каждая ячейка таблицы содержит результаты (F1, точность и полноту) для комбинации значений параметров, которая обеспечивает наивысшую F1-оценку для соответствующей пары алгоритма кластеризации второго уровня и аппроксимированного ядра (которые указаны, соответственно, в строках и столбцах Таблицы 3). Для каждого алгоритма кластеризации второго уровня лучший результат (исходя из F1-оценки) обозначен жирным шрифтом.
Таблица 35
Результаты оценки качества классификации для варианта с аппроксимированным ядром

[0080] Из этой таблицы видно, что из числа опробованных ядер наилучшие результаты обеспечиваются ядрами Жаккара, пересечения и χ2, тогда как из числа алгоритмов кластеризации второго уровня наилучшие результаты обеспечиваются агломеративной кластеризацией, BIRCH, DBSCAN, HDBSCAN и спектральной кластеризацией. В целом лучший результат достигается комбинацией DBSCAN с ядром пересечения. Эта комбинация может использоваться в предпочтительном варианте осуществления способа с аппроксимацией ядра.
[0081] Следует обратить внимание, что результаты для линейного ядра существенно хуже, чем результаты для нелинейных ядер для всех используемых алгоритмов кластеризации второго уровня, что подтверждает правильность выбора автором настоящего изобретения использования преобразования, аппроксимирующего одно из нелинейных ядер, в качестве первого подэтапа (S103.1) этапа (S103) классифицирования каждого из извлеченных признаковых векторов в один из двух классов: текст или иллюстрация.
[0082] Для визуализации результатов точность-полнота использовался следующий подход: для каждого алгоритма кластеризации второго уровня (или каждого аппроксимированного ядра) вычисляли выпуклую оболочку всех точек точности-полноты, связанных с этим алгоритмом (или ядром), и строили верхние правые сегменты этой выпуклой оболочки (которые соответствуют лучшим результатам, т.е. как более высокая точность, так и более высокая полнота). Фигуры 14(а)-(б) иллюстрируют кривые точности-полноты, показанные с использованием этого подхода для варианта с аппроксимированным ядром раскрытого способа. Эти кривые наглядно подтверждают выводы, сделанные в отношении результатов оценки, приведенных выше в отношении Таблицы 3.
[0083] Для дальнейшего анализа были выбраны три наилучших результата (они подчеркнуты в вышеприведенной Таблице 3): DBSCAN с ядром пересечения, спектральная кластеризация с ядром χ2 и агломеративная кластеризация с методом полной связи и ядром χ2. Несмотря на то, что некоторые другие комбинации значений параметров обеспечивают лучшую F1-оценку, чем последние два из выбранных результатов, они не обеспечивают никакого улучшения по сравнению с результатом DBSCAN с ядром пересечения по точности и полноте, тогда как агломеративная кластеризация с ядром χ2 демонстрирует лучший показатель полноты (ценой худшей точности), а спектральная кластеризация с ядром χ2 обеспечивает хороший компромисс между ними.
Результаты варианта с точным ядром
[0084] Для варианта раскрытого способа с точным ядром общее число опробованных комбинаций значений параметров составило 438170. В нижеследующей Таблице 4 показаны результаты оценки качества классификации для этого варианта.
Таблица 46
Результаты оценки качества классификации для варианта с точным ядром
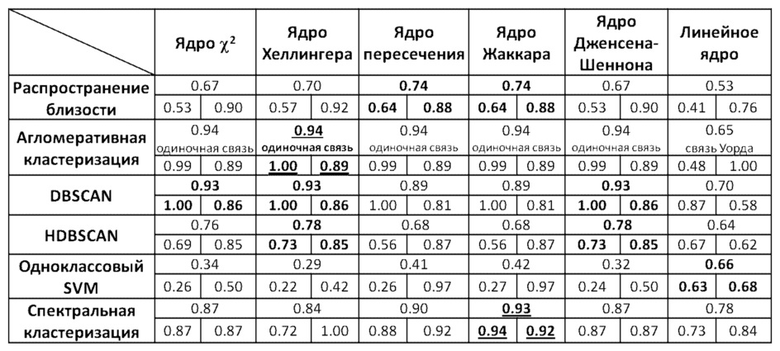
[0085] Из этой таблицы видно, что из числа ядер наилучшие результаты демонстрируют ядра Жаккара и χ2 (как и для варианта с аппроксимированным ядром), а также ядра Хеллингера и Дженсена-Шеннона. Из числа алгоритмов кластеризации второго уровня наилучшие результаты демонстрируют алгоритмы агломеративной кластеризации, DBSCAN и спектральной кластеризации (как и для варианта с аппроксимированным ядром). Фигуры 15(а)-(б) иллюстрируют кривые точности-полноты для варианта с точным ядром.
[0086] Из показанных результатов ясно, что этот вариант является жизнеспособной альтернативой гораздо более сложному по вычислениям варианту с аппроксимированным ядром, поскольку наиболее затратный по времени подэтап S103.2 (кластеризация первого уровня) для линейного ядра более, чем в два раза быстрее, чем для любого из нелинейных ядер.
Описание лучших конфигураций раскрытого способа
[0087] Поскольку кластеризация первого уровня, использующая линейное ядро (используемая в варианте с точным ядром) выдает большее число смешанных кластеров (тем самым обеспечивая менее чистое разделение), чем при использовании нелинейных ядер, автор настоящего изобретения выбрал для последующего анализа три лучшие конфигурации из всех конфигураций, опробованных для варианта с аппроксимированным ядром.
[0088] Сводка значений параметров алгоритма кластеризации второго уровня, а также значений параметров классификации суперкластеров (значение процентиля), обеспечивающих наилучшие результаты в варианте с аппроксимированным ядром, приведена в нижеследующей Таблице 5.
Таблица 5
Сводка по лучшим конфигурациям
(Nclusters=5)
[0089] Из этой таблицы видно, что с точки зрения эффективности по точности и полноте эти три варианта обеспечивают два крайних случая и компромисс между ними: один из этих крайних случаев - неструктурированная агломеративная кластеризация с ядром χ2, демонстрирующая 100% полноту (и 75% точность), другой из этих крайних случаев - DBSCAN с ядром пересечения, демонстрирующий 100% точность (и 89% полноту), тогда как спектральная кластеризация с ядром χ2 достигает промежуточные 82% точности и 95% полноты.
[0090] Для агломеративной кластеризации с ядром χ2 оптимальное количество (супер)кластеров равно двум, что позволяет использовать эту конфигурацию для классификации c логическим выводом разметки (см. подэтап S103.4.1) [от англ. ʺzero-shot classificationʺ]. Этот результат вполне закономерен для алгоритма агломеративной кластеризации с методом полной связи, который известен своим поведением «богатые становятся богаче», приводящим к небольшому количеству кластеров неравномерного размера. Для двух оставшихся конфигураций количество выходных суперкластеров составляет 10 (спектральная кластеризация) и 5 (DBSCAN), что не позволяет использовать режим логического вывода разметки для их классификации.
[0091] Важной обеспокоенностью специалиста в данной области может стать возможная зависимость оптимальных значений параметров, приведенных в Таблице 5 выше, от свойств конкретного набора данных, для которого их получают, и, следовательно, применимость этих оптимальных значений параметров в общем случае для других наборов данных. Для первой конфигурации (с использованием агломеративной кластеризации) оптимальные значения параметров включают в себя задание числа кластеров, равным двум, и использование метода полной связи. Обе эти настройки являются идеально общими для решения задачи настоящего изобретения, поскольку цель раскрытого способа состоит в разделении двух разных кластеров, один из которых является преобладающим, поэтому метод полной связи, способствующий поведению «богатые становятся богаче», здесь является естественным выбором. Для третьей конфигурации (с использованием кластеризации DBSCAN) оптимальные настройки включают настройку радиуса окрестности (который определяется свойствами Docstrum-дескриптора, используемого ядра и разделяемых классов, а не свойствами набора данных) и числа точек в окрестности некоторой точки, необходимого, чтобы можно было рассматривать ее как базовую точку (для этого числа общее значение по умолчанию, равное 5, представляется оптимальным). Общий параметр для всех конфигураций - значение процентиля для первой и третьей конфигураций, равное нулю, означает, что один суперкластер, имеющий минимальную насыщенность текстом, помечают как суперкластер иллюстраций, что также можно рассматривать в качестве довольно общей настройки. Чтобы подтвердить теоретические рассуждения, изложенные выше, раскрытый способ был применен, используя оптимальные значения параметров из Таблицы 5 (для первой и третьей конфигураций), к случайным подмножествам приемлемого размера из набора данных, и его вывод был проверен путем визуального осмотра. Этот эксперимент показал хорошее разделение текста и иллюстраций для разных видов патентных иллюстраций и текстовых областей, что подтвердило применимость указанных в Таблице 5 оптимальных настроек для общего случая.
[0092] Однако, для второй конфигурации (с использованием спектральной кластеризации) оптимальные значения параметров (Nclusters=10 и значение процентиля=12,5%) не демонстрируют такой стабильности для разных подмножеств использованного набора данных, а также не имеют убедительного теоретического обоснования их универсальности, поскольку Nclusters, которое выше двух, в действительности может указывать на число подклассов основных классов, представленных в конкретном наборе данных (например, различные виды ROI текста или иллюстраций). Таким образом, эта конфигурация должна быть использована с осторожностью на наборах данных, которые существенно отличаются от набора данных ROI патентных документов, который использовался в данном раскрытии в качестве иллюстративного набора данных.
[0093] Наконец, следует отметить, что вышеуказанные результаты сравнения эффективности классификации для алгоритмов кластеризации второго уровня хорошо коррелируют с поведением различных алгоритмов кластеризации, проиллюстрированных в работе Scikit-learn developers, ʺComparing Different Clustering Algorithms on Toy Datasets,ʺ Scikit-learn User Guide, http://scikit-learn.org/0.18/auto_examples/cluster/plot_cluster_comparison.html. 2016: только три алгоритма кластеризации были способны правильно обрабатывать оба тестовых набора данных с невыпуклыми кластерами (один из которых также содержит вложенные кластеры): агломеративная кластеризация, спектральная кластеризация и DBSCAN, эти алгоритмы кластеризации и являются тремя наиболее эффективными алгоритмами кластеризации второго уровня в варианте раскрытого способа с аппроксимированным ядром. Это наблюдение позволяет предположить, что использованный в настоящем раскрытии набор данных может иметь подобную геометрию суперкластеров (невыпуклую и, возможно даже, вложенную). Чтобы получить более точное представление о геометрии кластеров текста и иллюстраций, нелинейное сокращение размерности было выполнено над Docstrum-признаковыми векторами, преобразованными посредством отображения, аппроксимирующего ядро пересечения, используя метод t-SNE, и полученное в результате двумерное вложенное пространство было использовано для визуализации облаков точек, соответствующих признаковым векторам, помеченным как «текст» и «иллюстрация» раскрытым способом с использованием третьей конфигурации из Таблицы 5 (лучшая конфигурация по F1-оценке). Точечная диаграмма этих облаков точек в двумерном вложенном пространстве проиллюстрирована на фигуре 16.
[0094] На фигуре 16 видно, что «текстовые» точки образуют несколько кластеров, некоторые из которых имеют сложную невыпуклую геометрию и находятся довольно далеко друг от друга, в то время как большинство точек «иллюстраций» образует плотный хорошо локализованный кластер, окруженный кластерами текста. Хотя это вложенное пространство может и не давать полного представления об оригинальной геометрии кластеров, показанный на фигуре 16 график все же может быть использован для поддержки правильности сделанного выше предположения и, следовательно, выбора лучших алгоритмов кластеризации второго уровня. Эта сложная геометрия кластеров также может быть ответственной за низкую эффективность классификации конфигураций, использующих одноклассовый SVM. Поскольку одноклассовый SVM является методом обнаружения новизны, он также является естественным выбором для решения задачи настоящего изобретения; в раскрытых примерах изобретения использовалось обучающее подмножество для текстового класса и целью являлась идентификация класса иллюстраций как выбросов по отношению к текстовому классу. Однако, даже при использовании обобщенных RBF и сигмоидных ядер (посредством комбинации ориентированного на гистограмму ядра на подэтапе аппроксимирующего ядро признакового отображения и RBF или сигмоидного ядра в самом SVM), одноклассовый SVM не может обеспечить эффективность классификации алгоритмов, которые являются особенно эффективными в обработке кластеров сложной геометрии (например, DBSCAN или агломеративная кластеризация).
Выводы
[0095] Предложен новый способ разделения текста и иллюстраций для черно-белых изображений документов, содержащих очень разнообразный набор классов иллюстраций (например, как в патентных документах). Предложенный способ дает значительные преимущества по сравнению с подходами из уровня техники: он может разделять многие классы иллюстраций, ошибочно классифицируемые как текст более простыми способами, подходит для обработки крупномасштабных наборов данных и способен работать либо в режиме логического вывода разметки (используя лишь общую априорную информацию о распределении текста и иллюстраций в наборе данных) или в режиме с частичным привлечением учителя (используя небольшое подмножество данных, размеченных как текст). Эти преимущества проистекают из использования Docstrum-дескриптора, аппроксимирующих ядра отображений признаков для различных ориентированных на гистограмму ядер (в том числе ядер χ2, пересечения и Жаккара) и эффективной двухуровневой кластеризации (с использованием алгоритмов мини-пакетных k-средних, агломеративной кластеризации и DBSCAN).
[0096] Показана эффективность раскрытого способа на очень большом и разнообразном наборе данных изображений страниц патентных документов, где он достигает значений F1-оценки 0,86 при логическом выводе разметки и 0,94 при режиме с частичным привлечением учителя. Оптимальные значения параметров для различных подэтапов раскрытого способа получены с использованием расширенной оптимизации параметров, выполненной на этом наборе данных. Экспериментальные результаты использования раскрытого способа были проанализированы и лучшие его конфигурации были обоснованы как теоретическими рассуждениями, так и экспериментальными доказательствами.
[0097] Раскрытый способ может быть использован в качестве этапа предварительной обработки для различных задач обработки изображений документов: индексация и поиск документов, обнаружение и распознавание объектов документа, OCR, сжатие документов и многое другое, что станет очевидным для обычного специалиста в данной области после ознакомления с данным раскрытием.
[0098] Хотя данное изобретение было описано с определенной степенью детализации, следует понимать, что настоящее раскрытие было сделано только в качестве иллюстрации и что к многочисленным изменениям в деталях и компоновке этапов способа можно прибегать, не выходя за рамки объема изобретения, который определяется нижеследующей формулой изобретения.
Промышленная применимость
[0099] Раскрытое изобретение является промышленно применимым. Настоящее изобретение может быть применено при поиске документов. Для этого может быть обеспечено облачное окружение, содержащее по меньшей мере облачный сервер, механизм поиска документов, базу текстовых данных, базу данных иллюстраций. Множество пользовательских устройств может взаимодействовать с облачным сервером для отправки на него запроса на поиск документа(ов) как по его тексту, так и по его иллюстрациям. Документ может быть передан облачным сервером в механизм поиска документов, который реализует способ согласно настоящему раскрытию для обработки изображения документа, содержащегося в упомянутом запросе, для получения текстовых областей и областей иллюстраций этого документа. Затем, механизм поиска документов способен проводить поиск отдельно по текстовым областям и областям иллюстраций упомянутого документа и передавать на пользовательские устройства результаты поиска через облачный сервер. Пользовательским устройством может быть любое устройство, например, но без ограничения упомянутыми устройствами, компьютер, принтер, устройство мобильной связи, вычислительное устройство, планшет, сканер и т.д. При такой реализации обеспечивается быстрый отклик на запрос, экономия питания на осуществляемые вычисления, улучшенная релевантность результатов поиска.
[0100] Кроме того, настоящее изобретение может быть применено для разделения текстов и иллюстраций в изображениях страниц документов на пользовательском устройстве для последующих OCR, обработки изображений, или поиска по тексту или иллюстрациям. Для этого пользовательское устройство может быть реализовано с возможностью осуществления раскрытого в данном документе способа. Такая реализация может быть выполнена с использованием традиционного аппаратного обеспечения пользовательского устройства, включающего в себя процессор, постоянную память, оперативную память, экран, камеру, батарею, а также инструкций, записанных в памяти и реализующих заявленный способ с привлечением процессора, экрана и камеры пользовательского устройства. Пользовательским устройством может быть любое устройство, например, но без ограничения упомянутыми устройствами, компьютер, принтер, устройство мобильной связи, вычислительное устройство, планшет, сканер и т.д. При такой реализации обеспечивается ускорение обработки изображений страниц документов, а также более длительный срок службы батареи пользовательского устройства.
[0101] Настоящее изобретение также может быть применено для поиска по иллюстрациям или рукописным вводам на пользовательском устройстве или для автоматизированной категоризации документов на пользовательском устройстве или любом другом устройстве, хранящем эти документы. Другие возможные области применения раскрытого в данном документе способа и соответствующие реализации станут очевидными для обычного специалиста в данной области после изучения данного раскрытия.
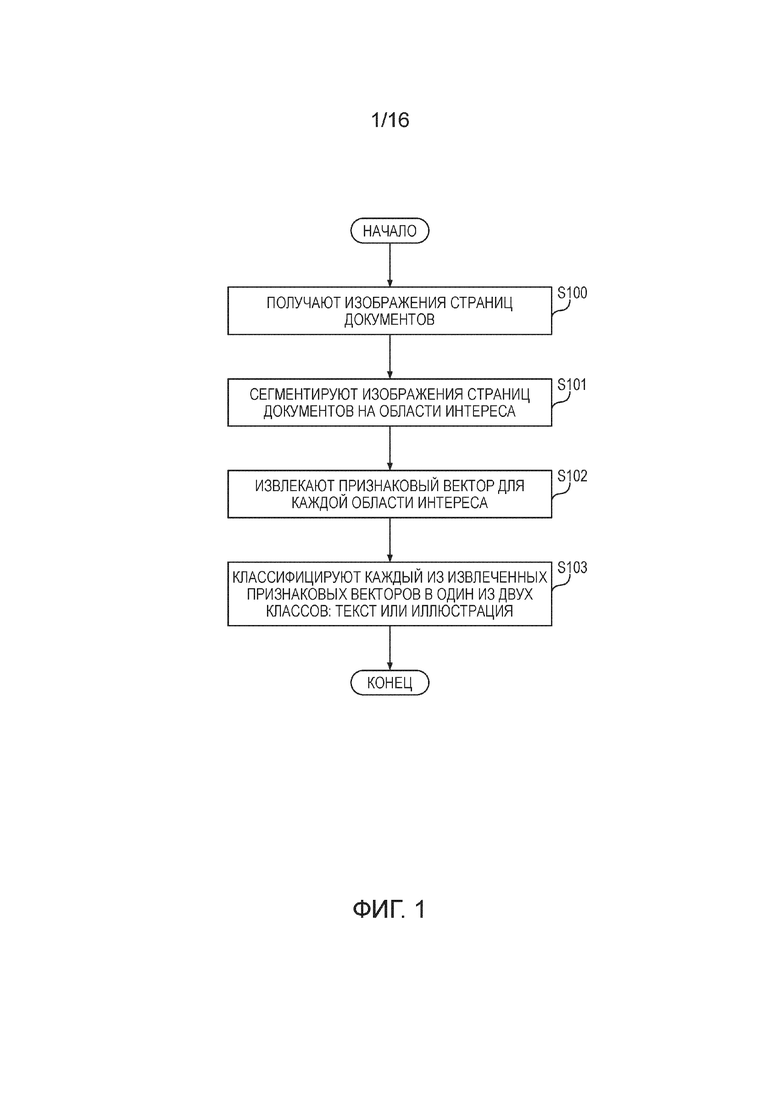
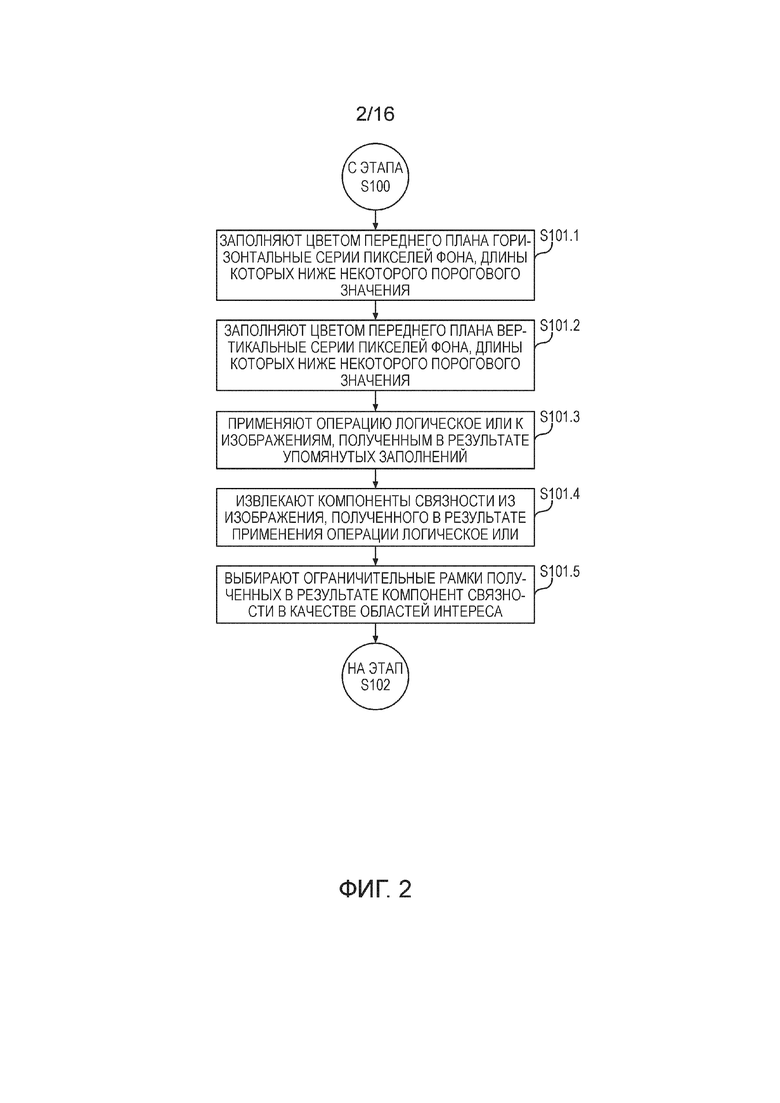




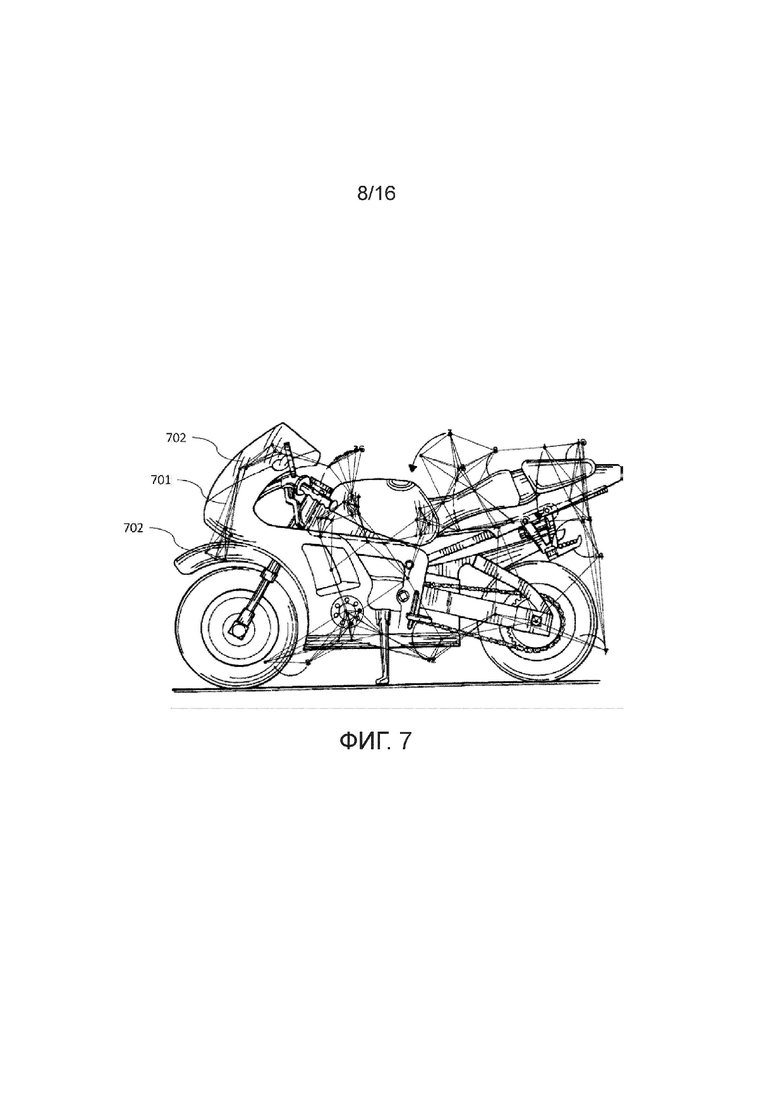

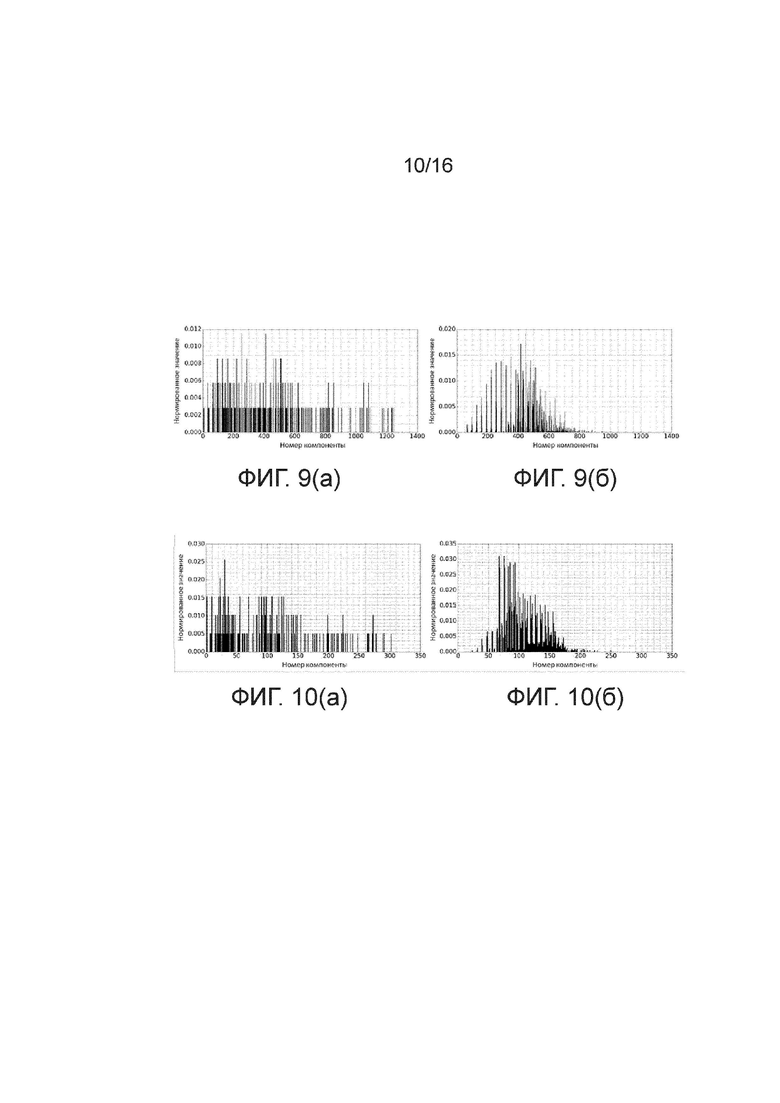




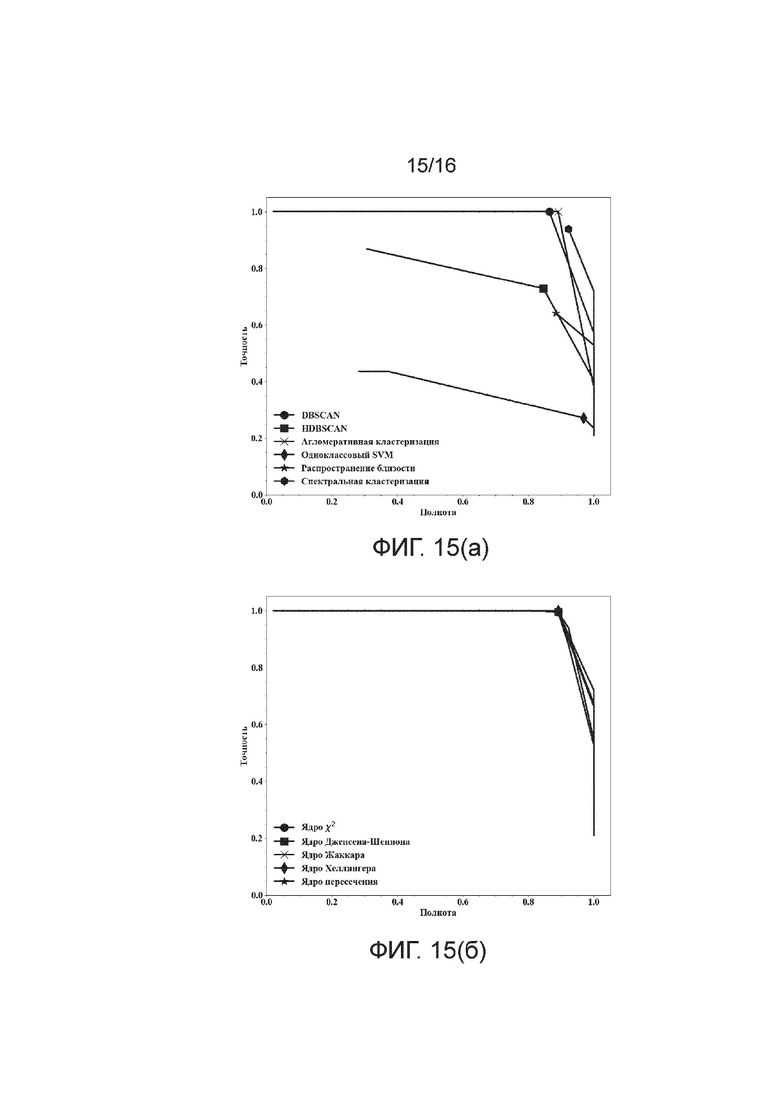
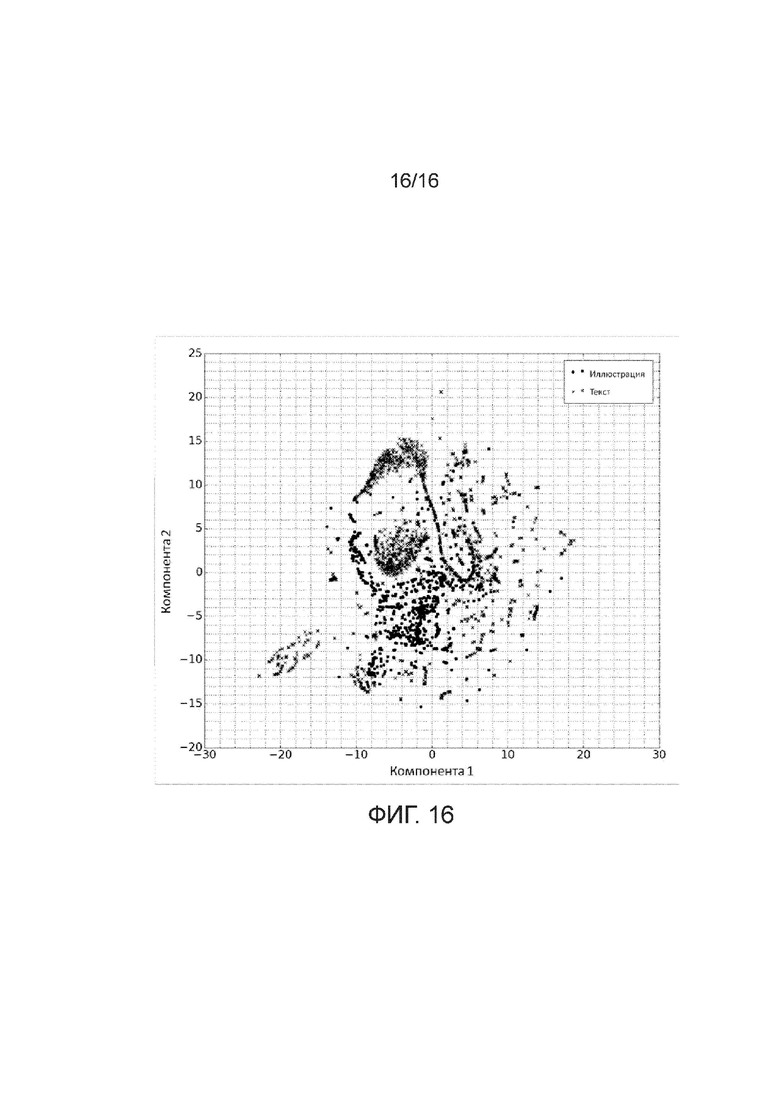
Изобретение относится к области анализа и обработки изображений документов. Технический результат – повышение точности разделения текстов и иллюстраций в изображениях документов и минимизация ошибок такого разделения. Способ разделения текстов и иллюстраций в изображениях страниц документов содержит этапы, на которых: получают изображения страниц документов; сегментируют изображения страниц документов на области интереса; извлекают признаковый вектор для каждой области интереса; и классифицируют каждый из извлеченных признаковых векторов в один из двух классов: текст или иллюстрация; при этом этап извлечения признакового вектора содержит подэтапы, на которых: изменяют размер области интереса с сохранением соотношения ее сторон; извлекают компоненты связности из области интереса измененного размера и вычисляют их центроиды; находят ближайших соседей для каждого центроида; строят двумерную гистограмму нормализованных расстояний и углов для всех пар, состоящих из центроида и каждого из его пяти ближайших соседних центроидов; и переформировывают двумерную гистограмму в признаковый вектор. 2 н. и 14 з.п. ф-лы, 21 ил., 5 табл. 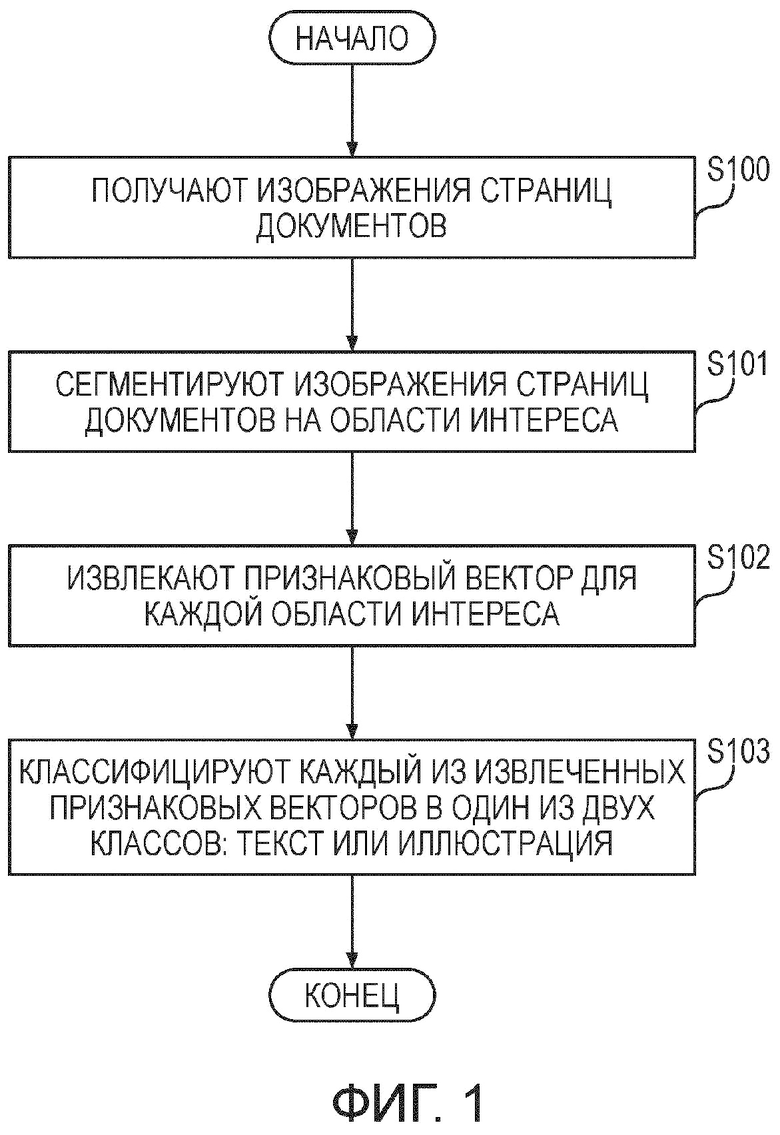
1. Способ разделения текстов и иллюстраций в изображениях страниц документов, содержащий этапы, на которых:
получают (S100) изображения страниц документов;
сегментируют (S101) изображения страниц документов на области интереса;
извлекают (S102) признаковый вектор для каждой области интереса; и
классифицируют (S103) каждый из извлеченных признаковых векторов в один из двух классов: текст или иллюстрация,
при этом этап, на котором извлекают (S102) признаковый вектор для каждой области интереса, содержит подэтапы, на которых:
изменяют (S102.1) размер области интереса до размера 300×300 или 500×500 пикселей с сохранением соотношения ее сторон;
извлекают (S102.2) компоненты связности из области интереса измененного размера и вычисляют их центроиды;
находят (S102.3) ближайших соседей для каждого центроида;
строят (S102.4) двумерную гистограмму нормализованных расстояний и углов для всех пар, состоящих из центроида и каждого из его пяти ближайших соседних центроидов; и
переформировывают (S102.5) двумерную гистограмму в Docstrum - признаковый вектор.
2. Способ по п. 1, в котором этап, на котором сегментируют (S101) изображения страниц документов на области интереса, содержит подэтапы, на которых:
заполняют (S101.1) цветом переднего плана горизонтальные серии пикселей фона, длины которых ниже некоторого порогового значения;
заполняют (S101.2) цветом переднего плана вертикальные серии пикселей фона, длины которых ниже некоторого порогового значения;
применяют (S101.3) операцию логическое ИЛИ к изображениям, полученным в результате упомянутых заполнений;
извлекают (S101.4) компоненты связности из изображения, полученного в результате применения операции логическое ИЛИ; и
выбирают (S101.5) ограничительные рамки полученных в результате компонент связности в качестве областей интереса.
3. Способ по п. 2, в котором отбрасывают области интереса, площадь которых в пикселях меньше некоторого порогового значения от всей площади сегментируемого изображения страницы документа.
4. Способ по п. 1, в котором изменение (S102.1) размера области интереса до размера 300×300 или 500×500 пикселей с сохранением соотношения ее сторон содержит:
изменение размера области интереса таким образом, чтобы ее больший размер по одному из ширины или высоты равнялся 300 или 500 пикселям, а ее меньший размер по другому из ширины или высоты дополнялся до 300 или 500 пикселей соответственно.
5. Способ по п. 1, в котором извлечение (S102.2) компонент связности из области интереса измененного размера и вычисление их центроидов дополнительно содержит
отфильтровывание компонент связности, ширина или высота ограничительных рамок которых меньше некоторого порогового значения.
6. Способ по п. 1, в котором нормализацию расстояний при построении (S102.4) двумерной гистограммы осуществляют путем деления каждого расстояния на среднее расстояние всех пар ближайших соседних центроидов.
7. Способ по п. 1, в котором переформировывание (S102.5) двумерной гистограммы в признаковый вектор дополнительно содержит
нормализацию двумерной гистограммы так, чтобы ее L1-норма была равна 1.
8. Способ по п. 1, в котором двумерную гистограмму нормализованных расстояний и углов для всех пар строят (S102.4) c использованием 64 бинов угла и 20 бинов расстояния, обеспечивая в результате переформирования (S102.5) такой двумерной гистограммы 1280-мерный признаковый вектор.
9. Способ по п. 1, в котором этап, на котором классифицируют (S103) каждый из извлеченных признаковых векторов в один из двух классов: текст или иллюстрация, содержит подэтапы, на которых:
осуществляют аппроксимирующее ядро преобразование (S103.1) признаковых векторов;
осуществляют кластеризацию первого уровня (S103.2) преобразованных признаковых векторов с использованием алгоритма мини-пакетных k-средних для получения кластеров преобразованных признаковых векторов и их центроидов;
осуществляют кластеризацию второго уровня (S103.3) центроидов кластеров, полученных на предшествующем подэтапе, с использованием усовершенствованного алгоритма кластеризации для получения соответствующих им суперкластеров; и
проверяют (S103.4), больше ли число полученных суперкластеров, чем два:
если число полученных суперкластеров равно двум, используют операцию логического вывода разметки (S103.4.1) для классификации каждого из этих двух суперкластеров в один из двух классов: текст или иллюстрация; или
если число полученных суперкластеров больше двух, используют операцию распространения разметки с частичным привлечением учителя (S103.4.2) для классификации каждого из этих более двух суперкластеров в один из двух классов: текст или иллюстрация.
10. Способ по п. 9, в котором аппроксимируемым ядром во время осуществления аппроксимирующего ядро преобразования (S103.1) признаковых векторов является одно из ядра Хеллингера, ядра χ2, ядра пересечения и ядра Дженсена-Шеннона, при этом
когда аппроксимируемым ядром является ядро Хеллингера, используют точное сохраняющее размерность отображение, или
когда аппроксимируемым ядром является одно из ядра χ2, ядра пересечения и ядра Дженсена-Шеннона, используют отображение с 5 компонентами.
11. Способ по п. 9, в котором аппроксимируемым ядром во время осуществления аппроксимирующего ядро преобразования (S103.1) признаковых векторов является ядро Жаккара, при этом
для обучения аппроксимирующего отображения признаков для этого ядра Жаккара используют сиамскую нейронную сеть.
12. Способ по п. 9, в котором кластеризацию первого уровня (S103.2) преобразованных признаковых векторов с использованием алгоритма мини-пакетных k-средних осуществляют для получения 100 кластеров преобразованных признаковых векторов и их центроидов, при этом
размер мини-пакета составляет 1000 признаковых векторов.
13. Способ по п. 9, в котором осуществление кластеризации второго уровня (S103.3) центроидов кластеров с использованием усовершенствованного алгоритма кластеризации агрегирует 100 центроидов кластеров, полученных в результате кластеризации первого уровня, в суперкластеры, при этом
усовершенствованный алгоритм кластеризации выбирают из группы, состоящей из распространения близости, агломеративной кластеризации, BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies, сбалансированные итеративные сокращения и кластеризация с использованием иерархий), DBSCAN (Density-Based Spatial Clustering of Applications with Noise, основанная на плотности пространственная кластеризация приложений с шумом), HDBSCAN (Hierarchical DBSCAN, иерархическая DBSCAN), сдвига среднего, одноклассового SVM (Support Vector Machine, метод опорных векторов), спектральной кластеризации,
используемый в агломеративной кластеризации метод связи выбирают из группы, состоящей из одиночного, полного, среднего, взвешенного, Уорда, центроидного и медианного,
используемое в одноклассовом SVM SVM-ядро выбирают из группы, состоящей из линейного ядра, RBF (Radial Basis Function, радиальная базисная функция)-ядра и сигмоидного ядра, и
используемую в спектральной кластеризации стратегию назначения меток выбирают из группы, состоящей из k-средних и дискретизации.
14. Способ по п. 9, в котором операцию логического вывода разметки осуществляют на основе общей статистической информации, размечая больший суперкластер как текстовый суперкластер или суперкластер иллюстраций в зависимости от того, что из текста или иллюстраций преобладает в типе документа, изображения страниц которого разделяют на текст и иллюстрации данным способом.
15. Способ по п. 9, в котором операцию распространения разметки с частичным привлечением учителя осуществляют с использованием размеченного подмножества набора изображений страниц документа, которые разделяют на текст и иллюстрации данным способом,
причем размеченное подмножество набора изображений страниц документа получают, идентифицируя по отсутствию в полнотекстовых версиях этих документов некоторых выражений и размечая все области интереса таких документов как текстовые, затем
для каждого суперкластера вычисляют его насыщенность текстом, отражающую долю его областей интереса, которые принадлежат к упомянутому размеченному как текст подмножеству, и
классифицируют суперкластеры, выполняя разметку суперкластеров, имеющих насыщенность текстом выше некоторого порогового значения, как соответствующих областям интереса текста, и разметку оставшихся суперкластеров как соответствующих областям интереса иллюстраций.
16. Способ разделения текстов и иллюстраций в изображениях страниц документов, содержащий этапы, на которых:
получают изображения страниц документов;
сегментируют изображения страниц документов на области интереса;
извлекают признаковый вектор для каждой области интереса; и
классифицируют каждый из извлеченных признаковых векторов в один из двух классов: текст или иллюстрация,
при этом этап, на котором классифицируют каждый из извлеченных признаковых векторов в один из двух классов: текст или иллюстрация, содержит подэтапы, на которых:
осуществляют кластеризацию первого уровня признаковых векторов с использованием алгоритма мини-пакетных k-средних для получения кластеров признаковых векторов и их центроидов;
вычисляют матрицу попарных ядер/расстояний для всех пар центроидов, полученных в результате кластеризации первого уровня;
осуществляют кластеризацию второго уровня центроидов кластеров по вычисленной матрице попарных ядер/расстояний для всех пар центроидов с использованием усовершенствованного алгоритма кластеризации, способного работать с матрицей ядер/расстояний, для получения соответствующих им суперкластеров; и
проверяют, больше ли число полученных суперкластеров, чем два:
если число полученных суперкластеров равно двум, используют операцию логического вывода разметки для классификации каждого из этих двух суперкластеров в один из двух классов: текст или иллюстрация, или
если число полученных суперкластеров больше двух, используют операцию распространения разметки с частичным привлечением учителя для классификации каждого из этих более двух суперкластеров в один из двух классов: текст или иллюстрация.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 8509534 B2, 13.08.2013 | |||
| БЛОК СПИРАЛЕЙ ДЛЯ МОБИЛЬНОГО ЗАГРАЖДЕНИЯ | 2006 |
|
RU2315159C1 |
| US 7570816 B2, 04.08.2009 | |||
| US 6937766 B1, 30.08.2005 | |||
| СИСТЕМА И СПОСОБ ИСПОЛЬЗОВАНИЯ ДАННЫХ ПРЕДЫДУЩЕГО КАДРА ДЛЯ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ КАДРОВ ВИДЕОМАТЕРИАЛОВ | 2014 |
|
RU2595559C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБЕСПЕЧЕНИЯ ПОИСКА ИЗОБРАЖЕНИЯ ПО СОДЕРЖИМОМУ | 2009 |
|
RU2533441C2 |

