Область изобретения
Изобретение относится к способам обнаружения текста на полутоновых цифровых изображениях и связанных с ними способами сегментации изображений по признаку наличия текста (площади занимаемой текстом в кадре) и выявления спама содержащегося в цифровом изображении.
Уровень техники
Известен способ обнаружения текста на изображениях [Y. Kunishige, F. Yaokai, S. Uchida, Scenery Character Detection with Environmental Context // The 11th International Conference on Document Analysis and Recognition (ICDAR), 2011, Pages: 1049-1053.] который заключается в использовании «контекста окружения» (environmental context). Основная мысль заключается в использовании информации о том, что окружает область-«кандидата». Иными словами, предлагается анализировать тот фон, на котором находится регион изображения, возможно, являющийся текстовым. Идея базируется на эмпирическом предположении, что вероятность наличия текста, например, на травяном покрове или на небе - низка.
Основной недостаток данного способа заключается в том, что он исключает наличие в кадре сложного фона и ориентирован только на работу с ограниченным набором фоновых рисунков.
Также известен способ [S. Uchida, Y. Shigeyoshi, Y. Kunishige, F. Yaokai, A Keypoint-Based Approach Toward Scenery Character Detection // The 11th International Conference on Document Analysis and Recognition (ICDAR), 2011, Pages: 819-823.] который заключается в детектировании на изображении так называемых SURF-точек. Предполагается, что если на исследуемом изображении присутствуют буквы, то они будут плотно такими точками покрыты. Дополнительно к этому вычисляется визуальная заметность (visual saliency). Вместе SURF и saliency будут представлять собой (128+1)-мерный вектор признаков. На этом векторе предполагается провести обучение классификатора.
Основной недостаток данного способа заключается в том, что метод детектирования точек дает плохие результаты по обнаружению текста при работе на сложных фонах (рекламные щиты, вывески магазинов, автомобильные номера).
Также известен способ [Y. Du, Н. Ai, S. Lao, Dot Text Detection Based on FAST Points // The 11th International Conference on Document Analysis and Recognition (ICDAR), 2011, Pages: 435-439.] который заключается в поиске точечного текста, но для обнаружения точек, составляющих буквы, применяется хорошо известный алгоритм FAST. Затем производится эвристическая фильтрация ложных кандидатов, объединение точек в буквы, букв - в слова, после чего применяется классификатор SVM для детектирования текстовых областей.
Основной недостаток данного способа заключается в том, что метод детектирования точек, как и в рассмотренном выше способе, дает плохие результаты при работе на сложных фонах (рекламные щиты, вывески магазинов, автомобильные номера).
В качестве прототипа выбран способ обнаружения текста в растровом изображении и способ выявления спама, содержащего растровые изображения (по патенту РФ №2363047, МПК G06K 9/36 (2007/10) опубликован 27.07.2009).
Он заключается в том, что на изображении распознается фоновый цвет, далее приводят изображение к двухцветному виду, находят границы замкнутого контура, описанного вокруг каждого из отдельных рисунков слитых пикселов цвета, отличных от упомянутого фонового цвета, и запоминают его координаты, сравнивают размеры каждого из упомянутых контуров с первыми заранее заданными пределами, интерпретируют каждый из оставшихся замкнутых контуров как контур текстового символа, находят предполагаемые строки текстовых символов, по замкнутым контурам, интерпритированым как контуры текстовых символов, разбивают найденные предполагаемые строки текстовых символов на наборы, интерпритируемые как найденные слова, сравнивают количество упомянутых контуров, интерпритированных как контуры текстовых символов, в каждом из упомянутых вероятных слов со вторыми заранее заданными пределами, исключают из дальнейшего рассмотрения те вероятностные слова, в которых количество упомянутых слов контуров, не попадает в упомянутые вторые заранее заданные пределы, сравнивают количество оставшихся вероятных слов в каждой упомянутой предполагаемой строке с третьими заранее заданными пределами, исключают из дальнейшего рассмотрения те из упомянутых предполагаемых строк, в которых количество вероятных слов не попадает в упомянутые третьи заранее заданные пределы, считают факт наличия оставшихся предполагаемых строк с вероятными словами обнаружением текста в упомянутом изображении.
Недостатком известного способа является низкая скорость работы, обусловленная многоэтапной обработкой, низкая вероятность правильного обнаружения, обусловленная тем, что выбор порога не учитывает статистические характеристики именно текста (буквы), а выбирается на основе гистограммы всего кадра.
Техническим результатом заявленного изобретения является повышение скорости обнаружение текстовых форм на изображении и увеличении вероятности правильного обнаружения за счет учета статистических характеристик текста.
Указанный технический результат достигается тем, что в известном способе производят формирование последовательности изображений, преобразования их к полутоновому представлению и обнаружение текстовых форм.
Сущность изобретения заключается в том, что согласно изобретению выделяют соседние кадры полутоновых изображений последовательности изображений, удаляют постоянную составляющую яркости изображения выделенных кадров, выполняют двойное пространственное горизонтальное дифференцирование, производят корреляционную обработку изображения с эталоном, рассчитывают порог, сравнивают результаты корреляционной обработки с порогом и при условии обнаружения текстовых форм определяют их параметры.
Удаление постоянной составляющей позволит сузить динамический диапазон яркости изображения, что позволит более качественно выделять перепады яркости, данную операцию можно осуществить, например, при помощи программных средств, программно-аппаратных средств, либо их комбинации.
Двойное пространственное горизонтальное дифференцирование, данная операция позволяет определить области, содержащие большое число резких перепадов яркости на ограниченном участке, в большинстве случаев области, содержащие текстовую форму, имеют ярко выраженный горизонтальный перепад яркости между буквами и фоновым рисунком.
Данная операция реализуется за счет вычитания двух соседних изображений сдвинутых относительно друг друга на один столбец и затем повторного вычитания двух преобразованных таким способом кадров.
Данную операцию можно осуществить, например, при помощи программных средств, программно-аппаратных средств.
Переходят к абсолютным значениям яркости, это обусловлено тем, что физически значения яркости могут принимать только положительные значения, а после проведения операции вычитания соседних изображений граница текстовой формы будет описываться, как положительными, так и отрицательными скачками яркости. Переход к абсолютным значениям яркости позволяет при дальнейшей обработке избежать потери части сигнала за счет суммирования с противоположным знаком составляющих, описывающих границы текстовой формы при помощи положительных и отрицательных скачков.
Переход к абсолютным значениям возможно осуществить например, при помощи инвертирующего усилителя для отрицательных значений сигнала, либо программно.
Формируют достаточную статистику, для чего осуществляют корреляционную обработку с эталоном. Если эталон будет точно соответствовать изображению строки текста, то достаточная статистика будет обеспечивать максимум отношения текст/фон [А.В. Коренной, Юдаков Д.С. Обнаружение и локализация текстовых форм на изображениях // Радиотехника №12, 2015 г. стр. 162-168].
Реализовать коррелятор возможно например, при помощи устройства умножения, линий задержки и интегратора, либо программно.
Рассчитывают порог обнаружения, на основе критерия Неймана-Пирсона при учете статистических характеристик достаточной статистики. В качестве фона рассматривается весь кадр изображения, принимая во внимание, что текст занимает относительно малую площадь и на статистические характеристики распределения яркости во всем кадре значения не оказывает А.В. Коренной, Юдаков Д.С. Обнаружение и локализация текстовых форм на изображениях // Радиотехника №12, 2015 г. стр. 162-168]. Порог определяется по табличным значениям плотности распределения вероятности с учетом заданной вероятности ложной тревоги.
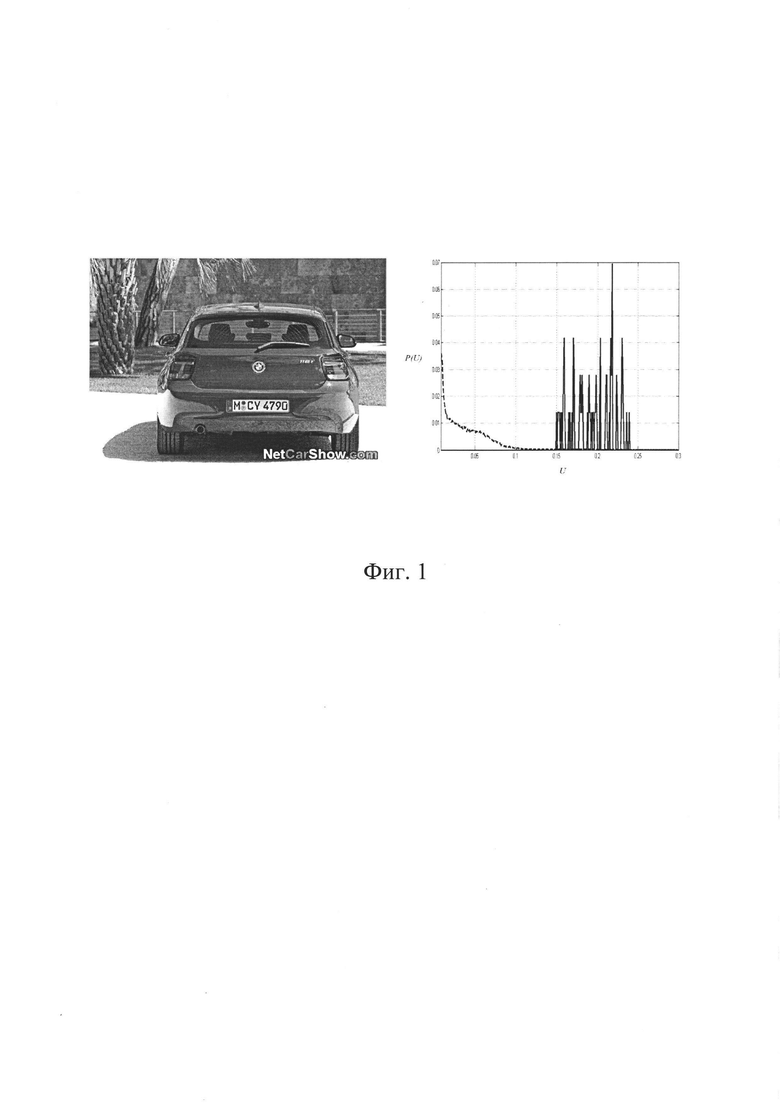
На фигуре 1 приведена гистограмма достаточной статистики всего изображения и участка изображения, соответствующего автомобильному номеру (сплошная линия).
Производят процедуру обнаружения путем сравнения результатов корреляционной обработки с порогом, результатом обнаружения текстовой формы будет являться бинарное изображение.
Производят операцию определения параметров обнаруженных текстовых форм. К полученному бинарному изображению, применяется морфологическая операция наращивания для удаления разрывов обнаруженных областей (Гонсалес Р., Вудс Р. Цифровая обработка изображений / Р. Гонсалес, Р. Вудс. - М.: Техносфера, 2005. - 1072 с.). После проведения данной операции производится определение параметров обнаруженных текстовых форм (координаты, длина, ширина и т.д.) на основе алгоритма поиска связных контуров. Каждый обнаруженный блок текста нумеруется и подсчитывается количество пикселей, входящих в данный блок (площадь), а также вычисляются его координаты (координаты верхней левой точки) и геометрические размеры (длина и ширина).
На фигуре 2 представлены результаты работы предложенного способа. Результат обнаружения текстовой формы, определения ее местоположения и размеров отображаются на исходном изображении в виде рамки соответствующего размера с номером в верхнем левом углу.
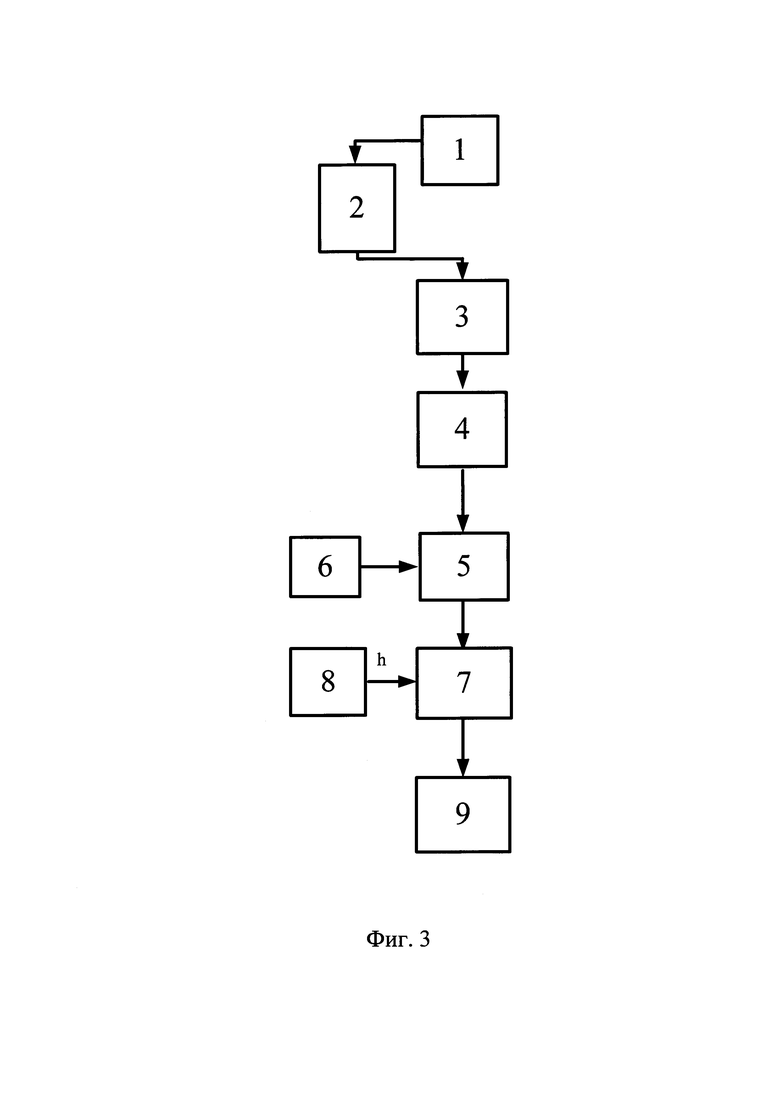
Способ может быть реализован, например, с помощью устройства, структурная схема которого приведена на фигуре 3, где обозначено: 1 - оптический датчик; 2 - аналого-цифровой преобразователь; 3 - блок удаления постоянной составляющей, предназначен для удаления постоянной составляющей яркости кадра; 4 - блок пространственного дифференцирования, предназначен для вычисления второй пространственной производной яркости кадра изображения; 5 - коррелятор предназначен для вычисления достаточной статистики изображения; 6 - блок эталонов, предназначен для хранения эталонов, может быть реализован на запоминающем устройстве; 7 - пороговое устройство, предназначено для обнаружения областей изображения содержащих текст; 8 - блок формирования порога, предназначен для формирования порога обнаружения; 9 - блок вторичной обработки, предназначен для вычисления параметров обнаруженных текстовых форм, может быть реализован программно на программируемом спецпроцессоре.
Устройство работает следующим образом: сигнал изображения, поступает в приемник оптического сигнала. С выхода приемника оптического сигнала изображение поступает на вход АЦП, на выходе АЦП получается оцифрованное изображение, далее с выхода АПЦ изображение поступает в блок удаления постоянной составляющей, где происходит вычисление постоянной составляющей яркости поступившего на вход изображения и вычитание из значений яркости каждого пикселя, с выхода БУП сигнал поступает на вход блока пространственного дифференцирования в котором производится вычисление вторых горизонтальных дискретных разностей для каждого кадра, с выхода БПД сигнал поступает на вход блока коррелятора, на второй вход коррелятора подается сигнал соответствующий эталону, с выхода коррелятора сигнал поступает в пороговое устройство, на второй вход которого подается сигнал соответствующий выбранному порогу, порог формируется в блоке формирования порога, на выходе порогового устройства получаем бинарное изображение, где значения пикселей превысивших порог задаются белым цветом, а не превысившие порог черным, с выхода порогового устройства сигнал поступает в блок вторичной обработки, где вычисляются параметры текстовых форм.
Таким образом, техническим результатом заявленного изобретения является повышение скорости обнаружение текстовых форм на изображении и увеличении вероятности правильного обнаружения за счет учета статистических характеристик текста.
Этот способ полезен при решения задач поиска текстовой информации на изображениях содержащих пестрый фоновый рисунок.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ОБНАРУЖЕНИЯ ТЕКСТА В РАСТРОВОМ ИЗОБРАЖЕНИИ (ВАРИАНТЫ) И СПОСОБ ВЫЯВЛЕНИЯ СПАМА, СОДЕРЖАЩЕГО РАСТРОВЫЕ ИЗОБРАЖЕНИЯ | 2007 |
|
RU2363047C1 |
| СПОСОБ И СИСТЕМА ПРЕОБРАЗОВАНИЯ МОМЕНТАЛЬНОГО СНИМКА ЭКРАНА В МЕТАФАЙЛ | 2013 |
|
RU2534005C2 |
| CПОСОБ АВТОМАТИЧЕСКОГО РАСПОЗНАВАНИЯ ОБЪЕКТОВ НА ИЗОБРАЖЕНИИ | 2013 |
|
RU2528140C1 |
| СПОСОБ ВЫЯВЛЕНИЯ СПАМА В РАСТРОВОМ ИЗОБРАЖЕНИИ | 2011 |
|
RU2453919C1 |
| СПОСОБ И СИСТЕМА ЭФФЕКТИВНОЙ ПОДГОТОВКИ СОДЕРЖАЩИХ ТЕКСТ ИЗОБРАЖЕНИЙ К ОПТИЧЕСКОМУ РАСПОЗНАВАНИЮ СИМВОЛОВ | 2016 |
|
RU2636097C1 |
| Способ помехоустойчивого градиентного выделения контуров объектов на цифровых полутоновых изображениях | 2018 |
|
RU2695417C1 |
| СПОСОБ И СИСТЕМА ПОДГОТОВКИ СОДЕРЖАЩИХ ТЕКСТ ИЗОБРАЖЕНИЙ К ОПТИЧЕСКОМУ РАСПОЗНАВАНИЮ СИМВОЛОВ | 2016 |
|
RU2628266C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2021 |
|
RU2768544C1 |
| СПОСОБ, СИСТЕМА, ЦИФРОВАЯ ФОТОКАМЕРА И СИС, ОБЕСПЕЧИВАЮЩИЕ ГЕОМЕТРИЧЕСКОЕ ПРЕОБРАЗОВАНИЕ ИЗОБРАЖЕНИЯ НА ОСНОВАНИИ ПОИСКА ТЕКСТОВЫХ СТРОК | 2006 |
|
RU2412482C2 |
| СПОСОБ И СИСТЕМА УЛУЧШЕНИЯ ТЕКСТА ПРИ ЦИФРОВОМ КОПИРОВАНИИ ПЕЧАТНЫХ ДОКУМЕНТОВ | 2012 |
|
RU2520407C1 |

Изобретение относится к способам обнаружения текста на полутоновых цифровых изображениях и связанным с ними способам сегментации изображений по признаку наличия текста. Техническим результатом является повышение точности обнаружения текстовых форм на изображениях, содержащих сложный фон. Способ включает в себя выделение соседних кадров полутоновых изображений последовательности изображений, удаление постоянной составляющей яркости изображения выделенных кадров, двойное пространственное горизонтальное дифференцирование, корреляционную обработку изображения с эталоном, расчет значения порога, сравнение результатов корреляционной обработки с порогом и при условии обнаружения текстовых форм определение их параметров. 3 ил.
Способ обнаружения и локализации текстовых форм на изображениях, включающий формирование последовательности изображений, преобразование их к полутоновому представлению и обнаружение текстовых форм, отличающийся тем, что согласно изобретению выделяют соседние кадры полутоновых изображений, считывая значения яркости пикселей с оптического датчика путем фиксации времени накопления между соседними кадрами для оптического датчика, при помощи аналого-цифрового преобразователя значения яркости каждого пикселя каждого из цветовых каналов изображения преобразуются в цифровую форму, преобразуют значения яркостных каналов в полутона программно при помощи вычислительного устройства путем сложения оцифрованных значений яркости каждого канала цвета для каждого пикселя умноженных на соответствующий коэффициент, удаляют постоянную составляющую яркости изображения выделенных кадров путем вычисления среднего значения яркости оцифрованных пикселей в кадре, складывая значения яркости всех пикселей кадра и деля на их количество на основе программы, выполняемой в вычислительном устройстве, вычитают среднее значение яркости из значений яркости каждого пикселя на основе программы, выполняемой в вычислительном устройстве, выполняют двойное пространственное горизонтальное дифференцирование путем двукратного последовательного вычитания в вычислительном устройстве друг из друга значений яркости пикселей соседних строк, производят построчную корреляционную обработку изображения с эталоном, рассчитывают порог по табличным значениям, в пороговом блоке формируют постоянное значение, соответствующее уровню рассчитанного порога, сравнивают значения для пикселей изображения, полученные на выходе коррелятора со значением порога, при условии превышения порога считается, что пиксель принадлежит текстовой форме, при условии обнаружения текстовых форм определяют их параметры.
| Колосоуборка | 1923 |
|
SU2009A1 |
| СПОСОБ ОБНАРУЖЕНИЯ ТЕКСТА В РАСТРОВОМ ИЗОБРАЖЕНИИ (ВАРИАНТЫ) И СПОСОБ ВЫЯВЛЕНИЯ СПАМА, СОДЕРЖАЩЕГО РАСТРОВЫЕ ИЗОБРАЖЕНИЯ | 2007 |
|
RU2363047C1 |
| US 8280157 B2, 02.10.2012 | |||
| US 8189917 B2, 29.05.2012 | |||
| УСТРОЙСТВО ВЫДЕЛЕНИЯ ВЫСОКОДЕТАЛИЗИРОВАННЫХ ОБЪЕКТОВ НА ИЗОБРАЖЕНИИ СЦЕНЫ | 2013 |
|
RU2542876C2 |
| US 8223395 B2, 17.07.2012. | |||

