Область техники, к которой относится изобретение
Настоящее изобретение относится к способу и устройству для рендеринга аудиосигнала и, более конкретно, к способу рендеринга и устройству для понижающего микширования (микширования с понижением числа каналов) многоканального сигнала в соответствии с типом рендеринга.
Уровень техники
Благодаря развитию технологий обработки изображений и звука было создано большое количество контента с высококачественными изображениями и звуком. Пользователи, которые требуют контент с высококачественными изображениями и звуком, хотят реалистичные изображения и звук, и, таким образом, активно ведутся исследования в области пространственных изображений и стереофонического звука.
Стереофонический звук означает звук, который дает чувство пространственного окружения путем воспроизведения не только высоты и тона звука, но также и трехмерного (3D) направления, включая горизонтальное и вертикальное направления и чувство расстояния, и имеющий дополнительную пространственную информацию, с помощью которой у аудитории, которая находится не в том пространстве, где генерируется источник звука, возникает чувство направления, чувство расстояния и чувство пространства.
Когда выполняется рендеринг многоканального сигнала, такого как 22.2-канальный сигнал, как 5.1-канального сигнала с использованием технологии виртуального рендеринга, 3D стереофонический звук может быть воспроизведен посредством двумерного (2D) выходного канала.
Подробное описание изобретения
Техническая задача
Когда выполняется рендеринг многоканального сигнала, такого как 22.2-канальный сигнал, как 5.1-канального сигнала с использованием технологии виртуального рендеринга, хотя трехмерные (3D) аудиосигналы могут быть воспроизведены с использованием двумерного (2D) выходного канала, он может не подходить для применения виртуального рендеринга в соответствии с характеристиками сигналов.
Настоящее изобретение относится к способу и устройству для воспроизведения стереофонического звука и, более конкретно, к способу воспроизведения многоканального аудиосигнала, включая звуковой сигнал с возвышением в окружении с горизонтальной схемой расположения, таким образом получая параметр рендеринга в соответствии с типом рендеринга и конфигурируя матрицу понижающего микширования.
Техническое решение
Показательная конфигурация настоящего изобретения для решения описанной выше задачи имеет следующий вид.
В соответствии с одним аспектом варианта осуществления способ рендеринга аудиосигнала включает в себя этапы, на которых: принимают многоканальный сигнал, содержащий множество входных каналов, которые должны быть преобразованы во множество выходных каналов; определяют тип рендеринга для рендеринга с возвышением на основании параметра, определенного из характеристики многоканального сигнала; и осуществляют рендеринг по меньшей мере одного высотного входного канала в соответствии с определенным типом рендеринга, при этом параметр включен в битовый поток многоканального сигнала.
Полезные эффекты изобретения
Когда осуществляется рендеринг многоканального сигнала, такого как 22.2-канальный сигнал, как 5.1-канального сигнала с использованием технологии виртуального рендеринга, хотя трехмерные (3D) аудиосигналы могут быть воспроизведены посредством двумерного (2D) выходного канала, он может не подходить для применения виртуального рендеринга в соответствии с характеристиками сигналов.
Настоящее изобретение относится к способу воспроизведения многоканального аудиосигнала, включающего в себя звуковой сигнал с возвышением, в окружении с горизонтальной схемой расположения, таким образом получая параметр рендеринга в соответствии с типом рендеринга и конфигурируя матрицу понижающего микширования, и, таким образом, может быть получена высокая производительность рендеринга в отношении аудиосигнала, который не подходит для применения виртуального рендеринга.
Описание чертежей
Фиг. 1 является блок-схемой, изображающей внутреннюю структуру устройства воспроизведения стереофонического аудио в соответствии с вариантом осуществления.
Фиг. 2 является блок-схемой, изображающей конфигурацию декодера и трехмерного (3D) акустического средства рендеринга в устройстве воспроизведения стереофонического аудио в соответствии с вариантом осуществления.
Фиг. 3 изображает схему расположения каналов, когда множество входных каналов подвергаются понижающему микшированию во множество выходных каналов в соответствии с вариантом осуществления.
Фиг. 4 является блок-схемой главных компонентов преобразователя формата средства рендеринга в соответствии с вариантом осуществления.
Фиг. 5 изображает конфигурацию селектора, который выбирает тип рендеринга и матрицу понижающего микширования на основании параметра определения типа рендеринга в соответствии с вариантом осуществления.
Фиг. 6 изображает синтаксис, который определяет конфигурацию типа рендеринга на основании параметра определения типа рендеринга в соответствии с вариантом осуществления.
Фиг. 7 является блок-схемой последовательности операций способа рендеринга аудиосигнала в соответствии с вариантом осуществления.
Фиг. 8 является блок-схемой последовательности операций способа рендеринга аудиосигнала на основании типа рендеринга в соответствии с вариантом осуществления.
Фиг. 9 является блок-схемой последовательности операций способа рендеринга аудиосигнала на основании типа рендеринга в соответствии с другим вариантом осуществления.
Лучший вариант осуществления
Показательные конфигурации настоящего изобретения для решения описанной выше задачи имеют следующий вид.
В соответствии с одним аспектом варианта осуществления способ рендеринга аудиосигнала включает в себя этапы, на которых: принимают многоканальный сигнал, содержащий множество входных каналов, которые должны быть преобразованы во множество выходных каналов; определяют тип рендеринга для рендеринга с возвышением на основании параметра, определенного из характеристики многоканального сигнала; и осуществляют рендеринг по меньшей мере одного высотного входного канала в соответствии с определенным типом рендеринга, при этом параметр включен в битовый поток многоканального сигнала.
Многоканальный сигнал может декодироваться основным декодером.
Этап, на котором определяют тип рендеринга, может включать в себя этап, на котором: определяют тип рендеринга для каждого из кадров многоканального сигнала.
Этап, на котором осуществляют рендеринг по меньшей мере одного высотного входного канала может включать в себя этап, на котором: применяют различные матрицы понижающего микширования, полученные в соответствии с определенным типом рендеринга, по меньшей мере к одному высотному входному каналу.
Способ может дополнительно включать в себя этапы, на которых: определяют, выполнить ли виртуальный рендеринг для выходного сигнала, при этом если для выходного сигнала не выполняется виртуальный рендеринг, этап, на котором определяют тип рендеринга, содержит этап, на котором: определяют тип рендеринга для того, чтобы не выполнять рендеринг с возвышением.
Этап, на котором выполняют рендеринг, может включать в себя этапы, на которых: выполняют пространственную фильтрацию тембра по меньшей мере для одного высотного входного канала, если определенный тип рендеринга является трехмерным (3D) типом рендеринга, выполняют пространственное панорамирование местоположения по меньшей мере для одного высотного входного канала; и если определенный тип рендеринга является двумерным (2D) типом рендеринга, выполняют общее панорамирование по меньшей мере для одного высотного входного канала.
Этап, на котором выполняют пространственную фильтрацию тембра, может включать в себя этап, на котором: корректируют тембр звука на основании функции моделирования восприятия звука человеком (HRTF).
Этап, на котором выполняют пространственное панорамирование местоположения, может включать в себя этап, на котором: генерируют верхнее звуковое изображение путем панорамирования многоканального сигнала.
Этап, на котором выполняют общее панорамирование, может включать в себя этап, на котором: генерируют звуковое изображение в горизонтальной плоскости путем панорамирования многоканального сигнала на основании азимутального угла.
Параметр может быть определен на основании атрибута аудиосцены.
Атрибут аудиосцены может включать в себя по меньшей мере одно из: корреляции между каналами входного аудиосигнала или ширину полосы частот входного аудиосигнала.
Параметр может создаваться в кодере.
В соответствии с одним аспектом другого варианта осуществления устройство для рендеринга аудиосигнала включает в себя: приемный блок для приема многоканального сигнала, содержащего множество входных каналов, которые должны быть преобразованы во множество выходных каналов; блок определения для определения типа рендеринга для рендеринга с возвышением на основании параметра, определенного из характеристики многоканального сигнала; и блок рендеринга для рендеринга по меньшей мере одного высотного входного канала в соответствии с определенным типом рендеринга, при этом параметр включен в битовый поток многоканального сигнала.
Устройство может дополнительно включать в себя: основной декодер, причем многоканальный сигнал декодируется основным декодером.
Блок определения может определять тип рендеринга для каждого из кадров многоканального сигнала.
Блок рендеринга может применять различные матрицы понижающего микширования, полученные в соответствии с определенным типом рендеринга, по меньшей мере к одному высотному входному каналу.
Устройство может дополнительно включать в себя: блок определения для определения, выполнять ли виртуальный рендеринг для выходного сигнала, при этом если для выходного сигнала не выполняется виртуальный рендеринг, блок определения определяет тип рендеринга так, чтобы не выполнять рендеринг с возвышением.
Блок рендеринга может выполнять пространственную фильтрацию тембра по меньшей мере для одного высотного входного канала, если определенный тип рендеринга является 3D типом рендеринга, дополнительно выполнять пространственное панорамирование местоположения по меньшей мере для одного высотного входного канала, и если определенный тип рендеринга является 2D типом рендеринга, дополнительно выполнять общее панорамирование по меньшей мере для одного высотного входного канала.
Пространственная фильтрация тембра может корректировать тембр звука на основании функции моделирования восприятия звука человеком (HRTF).
Пространственное панорамирование местоположения может генерировать верхнее звуковое изображение путем панорамирования многоканального сигнала.
Общее панорамирование может генерировать звуковое изображение в горизонтальной плоскости путем панорамирования многоканального сигнала на основании азимутального угла.
Параметр может быть определен на основании атрибута аудиосцены.
Атрибут аудиосцены может включать в себя по меньшей мере одно из: корреляции между каналами входного аудиосигнала и ширины полосы частот входного аудиосигнала.
Параметр может создаваться в кодере.
В соответствии с одним аспектом другого варианта осуществления компьютерно-читаемый носитель информации имеет записанную на нем программу для исполнения способа, описанного выше.
Кроме того, дополнительно обеспечены другой способ и другая система для реализации настоящего изобретения и компьютерно-читаемый носитель информации, имеющий записанную на нем компьютерную программу для исполнения способа.
Вариант осуществления изобретения
Подробное описание настоящего изобретения, которое будет представлено ниже, ссылается на прилагаемые чертежи, показывающие, в качестве примеров, конкретные варианты осуществления, с помощью которых может быть выполнено настоящее изобретение. Эти варианты осуществления описаны в достаточной мере подробно, чтобы специалисты в области техники могли осуществить настоящее изобретение. Следует понимать, что различные варианты осуществления настоящего изобретения отличаются друг от друга, но не являются исключающими друг друга.
Например, конкретная форма, структура и характеристика, изложенная в настоящем описании, может изменяться от одного варианта осуществления к другому варианту осуществления, не отступая от сущности и объема настоящего изобретения. Кроме того, следует понимать, что местоположения или схема расположения отдельных компонентов в каждом варианте осуществления также может быть изменена, не отступая от сущности и объема настоящего изобретения. Поэтому подробное описание, которое будет представлено, предназначено не для ограничения, и следует понимать, что объем настоящего изобретения включает в себя заявленный объем формулы изобретения и все объемы, эквивалентные заявленному объему.
Одинаковые номера позиций на чертежах обозначают одинаковые или аналогичные элементы в различных аспектах. Кроме того, на чертежах несущественные для описания части опущены для более ясного описания настоящего изобретения, и одинаковые номера позиций обозначают одинаковые элементы на протяжении всего описания.
Далее будут подробно описаны варианты осуществления настоящего изобретения со ссылкой на прилагаемые чертежи так, чтобы специалисты в области техники, к которой принадлежит настоящее изобретение, могли легко выполнить настоящее изобретение. Однако настоящее изобретение может быть реализовано во всевозможных различных формах и не ограничивается вариантами осуществления, описанными в настоящем описании.
На протяжении этого описания, когда написано, что определенный элемент «соединен» с другим элементом, это включает в себя случай «непосредственного соединения» и случай «электрического соединения» через другой элемент посередине. Кроме того, когда некоторая часть «включает в себя» некоторый компонент, это означает, что часть может дополнительно включать в себя другой компонент вместо исключения другого компонента, если специально не указано иное.
Далее настоящее изобретение описывается подробно со ссылкой на прилагаемые чертежи.
Фиг. 1 является блок-схемой, изображающей внутреннюю структуру устройства 100 воспроизведения стереофонического звука в соответствии с вариантом осуществления.
Устройство 100 воспроизведения стереофонического звука в соответствии с вариантом осуществления может иметь на выходе многоканальный аудиосигнал, в котором множество входных каналов микшируются во множество выходных каналов, которые должны быть воспроизведены. В этом случае, если число выходных каналов меньше, чем число входных каналов, входные каналы подвергаются понижающему микшированию, чтобы соответствовать числу выходных каналов.
Стереофонический звук означает звук, создающий чувство пространственного окружения путем воспроизведения не только высоты и тона звука, но также и направления и чувства расстояния, и имеющий дополнительную пространственную информацию, с помощью которой у аудитории, которая находится не в том пространстве, где генерируется источник звука, возникает чувство направления, чувство расстояния и чувство пространства.
В описании ниже выходные каналы аудиосигнала могут указывать число громкоговорителей, через которые выводится звук. Чем больше число выходных каналов, тем больше число громкоговорителей, через которые выводится звук. В соответствии с вариантом осуществления устройство 100 воспроизведения стереофонического звука может выполнять рендеринг и микшировать многоканальный акустический входной сигнал в выходные каналы, которые должны быть воспроизведены так, чтобы многоканальный аудиосигнал, имеющий большее число входных каналов, мог быть выведен и воспроизведен в окружении, имеющем меньшее число выходных каналов. В этом случае многоканальный аудиосигнал может включать в себя канал, в котором может выводиться звук с возвышением.
Канал, в котором может выводиться звук с возвышением, может означать канал, в котором аудиосигнал может выводиться громкоговорителем, расположенным выше голов аудитории, так, чтобы аудитория ощущала возвышение по вертикали. Горизонтальный канал может означать канал, в котором аудиосигнал может выводиться громкоговорителем, расположенным на горизонтальной поверхности к аудитории.
Описанное выше окружение, имеющее меньшее число выходных каналов, может означать окружение, в котором звук может выводиться громкоговорителями, расположенными на горизонтальной поверхности без выходных каналов, через которые может выводиться звук с возвышением.
Кроме того, в описании ниже горизонтальный канал может означать канал, включающий в себя аудиосигнал, который может быть выведен громкоговорителем, расположенным на горизонтальной поверхности. Верхний канал может означать канал, включающий в себя аудиосигнал, который может выводиться громкоговорителем, расположенным в местоположении с возвышением над горизонтальной поверхностью для вывода звука с возвышением.
Обращаясь к фиг. 1, устройство 100 воспроизведения стереофонического аудио в соответствии с вариантом осуществления может включать в себя аудио-ядро 110, средство 120 рендеринга, микшер 130 и блок 140 постобработки.
В соответствии с вариантом осуществления устройство 100 воспроизведения стереофонического аудио может иметь на выходе каналы, которые должны быть воспроизведены путем рендеринга и микширования многоканальных входных аудиосигналов. Например, многоканальный входной аудиосигнал может быть 22.2-канальным сигналом, а выходные каналы, которые должны быть воспроизведены, могут быть каналами 5.1 или 7.1. Устройство 100 воспроизведения стереофонического аудио может выполнять рендеринг путем определения выходного канала, соответствующего каждому каналу многоканального входного аудиосигнала, и микшировать сформированные аудиосигналы путем синтезирования сигналов каналов, соответствующих каналу, который должен быть воспроизведен, и выводить синтезированный сигнал в качестве конечного сигнала.
Кодированный аудиосигнал подается на вход аудио-ядра 110 в формате битового потока. Аудио-ядро 110 декодируют входной аудиосигнал путем выбора инструмента декодера, подходящего для схемы, с помощью которой был закодирован аудиосигнал. Аудио-ядро 110 может использоваться в том же значении, что и основной декодер.
Средство 120 рендеринга может выполнять рендеринг многоканального входного аудиосигнала в многоканальный выходной канал в соответствии с каналами и частотами. Средство 120 рендеринга может выполнять трехмерный (3D) рендеринг и 2D рендеринг многоканального аудиосигнала, в том числе верхний канал и горизонтальный канал. Конфигурация средства рендеринга и конкретный способ рендеринга будет описан более подробно со ссылкой на фиг. 2.
Микшер 130 может выводить конечный сигнал путем синтезирования сигналов каналов, соответствующих горизонтальному каналу с помощью средства 120 рендеринга. Микшер 130 может микшировать сигналы каналов для каждой секции набора. Например, микшер 130 может микшировать сигналы каналов для каждого I-кадра.
В соответствии с вариантом осуществления микшер 130 может выполнять микширование на основании значений мощности сигналов, сформированных в соответствующие каналы, которые должны быть воспроизведены. Другими словами, микшер 130 может определить амплитуду конечного сигнала или усиление, которое должно быть применено к конечному сигналу, на основании значения мощности сигналов, сформированных в соответствующие каналы, которые должны быть воспроизведены.
Блок 140 постобработки выполняет управление динамическим диапазоном и бинаурализацию многополосного сигнала для выходного сигнала микшера 130, чтобы подходить для каждого воспроизводящего устройства (громкоговоритель или наушники). Выходной аудиосигнал, выводимый из блока 140 постобработки, выводится устройством, таким как громкоговоритель, и выходной аудиосигнал может воспроизводиться 2D или 3D образом в соответствии с обработкой каждого компонента.
Устройство 100 воспроизведения стереофонического аудио в соответствии с вариантом осуществления на фиг. 1 показано на основе конфигурации аудиодекодера, и вспомогательная конфигурация опущена.
Фиг. 2 является блок-схемой, изображающей конфигурацию основного декодера 110 и 3D акустического средства 120 рендеринга в устройстве 100 воспроизведения стереофонического аудио в соответствии с вариантом осуществления.
Обращаясь к фиг. 2, в соответствии с вариантом осуществления устройство 100 воспроизведения стереофонического звука показано на основе конфигурации декодера 110 и 3D акустического средства 120 рендеринга, а другие конфигурации опущены.
Аудиосигнал, который подается на вход устройства 100 воспроизведения стереофонического аудио, является кодированным сигналом и подается на вход в формате битового потока. Декодер 110 декодирует входной аудиосигнал путем выбора инструмента декодера, подходящего для схемы, с помощью которой аудиосигнал был закодирован, и передает декодированный аудиосигнал 3D акустическому средству 120 рендеринга.
Если выполняется рендеринг с возвышением, виртуальное 3D изображение звука с возвышением может быть получено с помощью 5.1-канальной схемы расположения, включающей в себя только горизонтальные каналы. Такой алгоритм рендеринга с возвышением включает в себя пространственную фильтрацию тембра и процесс панорамирования пространственного местоположения.
3D акустическое средство 120 рендеринга включает в себя блок 121 инициализации для получения и обновления коэффициента фильтра и коэффициента панорамирования и блок 123 рендеринга для выполнения фильтрации и панорамирования.
Блок 123 рендеринга выполняет фильтрацию и панорамирование аудиосигнала, переданного от основного декодера 110. Блок 1231 пространственной фильтрации тембра обрабатывает информацию о местоположении звука так, чтобы сформированный аудиосигнал воспроизводился в желаемом месте. Блок 1232 пространственного панорамирования местоположения обрабатывает информацию о тоне звука так, чтобы сформированный аудиосигнал имел тон, подходящий для желаемого места.
Блок 1231 пространственной фильтрации тембра предназначен для коррекции тона звука на основании функции моделирования восприятия звука человеком (HRTF), моделирующей и отражающей разность маршрута, через который входной канал распространяется в выходной канал. Например, блок 1231 пространственной фильтрации тембра может корректировать тон звука для усиления энергии относительно сигнала полосы частот 1 ~ 10 кГц и уменьшения энергии относительно других полос частот, тем самым получая более естественный тон звука.
Блок 1232 пространственного панорамирования местоположения предназначен для обеспечения верхнего звукового изображения посредством многоканального панорамирования. Различные коэффициенты панорамирования (усиления) применяются к входным каналам. Хотя верхнее звуковое изображение может быть получено путем выполнения пространственного панорамирования местоположения, подобие между каналами может увеличиться, что увеличивает корреляции всех аудиосцен. Когда виртуальный рендеринг выполняется над сильно нескоррелированной аудиосценой, тип рендеринга может быть определен на основании характеристики аудиосцены для предотвращения ухудшения качества рендеринга.
Альтернативно, когда аудиосигнал производится, тип рендеринга может быть определен в соответствии с намерением производителя (создателя) аудиосигнала. В этом случае производитель аудиосигнала может вручную определить информацию относительно типа рендеринга аудиосигнала и может включить параметр для определения типа рендеринга в аудиосигнал.
Например, кодер генерирует дополнительную информацию, такую как rendering3DType, которая является параметром для определения типа рендеринга в кадре кодированных данных, и передает дополнительную информацию декодеру 110. Декодер 110 может подтвердить информацию rendering3DType, если rendering3DType указывает тип 3D рендеринга, выполнить пространственную фильтрацию тембра и пространственное панорамирование местоположения и, если rendering3DType указывает тип 2D рендеринга, выполнить пространственную фильтрацию тембра и общее панорамирование.
В этом отношении общее панорамирование может выполняться для многоканального сигнала на основании информации об азимутальном угле, не учитывая информацию об угле возвышения входного аудиосигнала. Аудиосигнал, к которому применяется общее панорамирование, не обеспечивает звуковое изображение, имеющее чувство возвышения по вертикали, и, таким образом, пользователю передается 2D звуковое изображение в горизонтальной плоскости.
Пространственное панорамирование местоположения, примененное к 3D рендерингу, может иметь различные коэффициенты панорамирования для каждой частоты.
В связи с этим коэффициент фильтра, который должен использоваться для фильтрации, и коэффициент панорамирования, который должен использоваться для панорамирования, передается из блока 121 инициализации. Блок 121 инициализации включает в себя блок 1211 получения параметра рендеринга c возвышением и блок 1212 обновления параметра рендеринга с возвышением.
Блок 1211 получения параметра рендеринга с возвышением получает инициализирующее значение параметра рендеринга с возвышением путем использования конфигурации и схемы расположения выходных каналов, то есть, громкоговорителей. В связи с этим инициализирующее значение параметра рендеринга с возвышением вычисляется на основании конфигурации выходных каналов в соответствии со стандартной схемой расположения и конфигурации входных каналов в соответствии с установкой рендеринга с возвышением, или для инициализирующего значения параметра рендеринга с возвышением предварительно считывается записанное в память инициализирующее значение в соответствии с отображающей зависимостью между входными/выходными каналами. Параметр рендеринга с возвышением может включать в себя коэффициент фильтра, который должен использоваться блоком 1231 пространственной фильтрации тембра, или коэффициент панорамирования, который должен использоваться блоком 1232 пространственного панорамирования местоположения.
Однако, как описано выше, может иметься отклонение между заданным значением возвышения для рендеринга с возвышением и настройками входных каналов. В этом случае, когда используется фиксированное заданное значение возвышения, становится трудно достичь цели виртуального рендеринга 3D аудиосигнала по воспроизведению 3D аудиосигнала более близко к исходному звуку 3D аудиосигнала через выходные каналы, имеющие конфигурацию, отличающуюся от конфигурации входных каналов.
Например, когда чувство возвышения по вертикали слишком высокое, может произойти феномен, когда звуковое изображение является маленьким, и качество звука ухудшается, а когда чувство возвышения по вертикали слишком низкое, может случиться проблема, что трудно ощутить эффект виртуального рендеринга. Поэтому необходимо настраивать чувство возвышения по вертикали в соответствии с настройками пользователя или степенью виртуального рендеринга, подходящей для входного канала.
Блок 1212 обновления параметра рендеринга с возвышением обновляет параметр рендеринга с возвышением путем использования инициализирующих значений параметра рендеринга с возвышением, которые получены блоком 1211 получения параметра рендеринга с возвышением на основании информации о возвышении входного канала или заданного пользователем возвышения. В связи с этим, если схема расположения громкоговорителей для выходных каналов имеет отклонение по сравнению со стандартной схемой расположения, может быть добавлен процесс для корректировки влияния в соответствии с отклонением. Отклонение выходных каналов может включать в себя информацию об отклонении в соответствии с разностью угла возвышения или разностью азимутального угла.
Выходной аудиосигнал, фильтрованный и панорамированный блоком 123 рендеринга с использованием параметра рендеринга с возвышением, полученного и обновленного блоком 121 инициализации, воспроизводится через громкоговоритель, соответствующий каждому выходному каналу.
Фиг. 3 изображает схему расположения каналов, когда множество входных каналов подвергается понижающему микшированию до множества выходных каналов в соответствии с вариантом осуществления.
Чтобы обеспечить такое же или усиленное чувство реализма и чувство погружения в реальность как в 3D изображении, были разработаны методики для обеспечения 3D стереофонического звука вместе с 3D стереоскопическим изображением. Стереофонический звук означает звук, в котором сам аудиосигнал дает чувство возвышения по вертикали и чувство пространства звука, и для воспроизведения такого стереофонического звука необходимо по меньшей мере два громкоговорителя, то есть выходных канала. Кроме того, за исключением бинаурального стереофонического звука с использованием HRTF, необходимо большее число выходных каналов для более точного воспроизведения чувства возвышения по вертикали, чувства расстояния и чувства пространства звука.
Поэтому была предложена и разработана стереосистема, имеющая два выходных канала, и различные многоканальные системы, такие как 5.1-канальная система, система Auro 3D, 10.2-канальная система Холмана, 10.2-канальная система ETRI/Samsung и 22.2-канальная система NHK.
Фиг. 3 изображает случай, в котором 22.2-канальный 3D аудиосигнал воспроизводится 5.1-канальной выходной системой.
5.1-канальная система является общим названием многоканальной аудиосистемы объемного звучания с пятью каналами, и она является системой, наиболее широко используемой в качестве аудиосистем домашних кинотеатров. В общей сложности 5.1 каналов включают в себя передний левый (FL) канал, центральный (C) канал, передний правый (FR) канал, левый канал объемного звучания (SL), и правый канал объемного звучания (SR). Как показано на фиг. 3, так как все выходы 5.1 каналов находятся в одной и той же плоскости, 5.1-канальная система физически соответствует 2D системе, и чтобы воспроизводить 3D аудиосигнал с использованием 5.1-канальной системы, должен быть выполнен процесс рендеринга для добавления 3D эффекта в сигнал, который должен быть воспроизведен.
5.1-канальная система широко используется в различных областях, не только в области фильмов, но также и в области DVD-изображений, области DVD-звука, области улучшенных аудио компакт-дисков (SACD) или области цифрового вещания. Однако, хотя 5.1-канальная система обеспечивает улучшенное чувство пространства по сравнению со стереосистемой, имеется несколько ограничений в формировании более широкого пространства для прослушивания по сравнению со способом представления многоканального звука, таким как в 22.2-канальных системах. В частности, так как зона наилучшего восприятия является узкой, когда выполняется виртуальный рендеринг, и вертикальное аудио изображение, имеющее угол возвышения, не может быть обеспечено, когда выполняется общий рендеринг, 5.1-канальная система не может быть подходящей для широкого пространства для прослушивания, такого как в кино.
22.2-канальная система, предложенная NHK, включает в себя три уровня выходных каналов, как показано на фиг. 3. Верхний уровень 310 включает в себя канал «голос бога» (VOG), канал T0, канал T180, канал TL45, канал TL90, канал TL135, канал TR45, канал TR90 и канал TR135. В настоящем описании индекс T, который является первым символом названия каждого канала, указывает верхний уровень, индексы L и R указывают левую и правую стороны, соответственно, а число после букв указывает азимутальный угол от центрального канала. Верхний уровень обычно называют вышележащим уровнем.
Канал VOG является каналом, присутствующим над головами аудитории, имеет угол возвышения 90° и не имеет никакого азимутального угла. Однако, когда канал VOG даже немного неправильно расположен, у канала VOG имеется азимутальный угол и угол возвышения, который отличается от 90°, и, таким образом, канал VOG не может больше выступать в качестве канала VOG.
Средний уровень 320 находится в той же самой плоскости, что и существующие 5.1 каналы и включает в себя канал ML60, канал ML90, канал ML135, канал MR60, канал MR90 и канал MR135 помимо выходных каналов для каналов 5.1. С связи с этим индекс M, который является первым символом названия каждого канала, указывает средний уровень, а следующее далее число указывает азимутальный угол от центрального канала.
Нижний уровень 330 включает в себя канал L0, канал LL45 и канал LR45. С связи с этим индекс L, который является первым символом названия каждого канала, указывает нижний уровень, а следующее далее число указывает азимутальный угол от центрального канала.
В каналах 22.2 средний уровень называют горизонтальным каналом, а каналы VOG, T0, T180, M180, L и C, соответствующие азимутальному углу 0° или 180°, называют вертикальными каналами.
Когда 22.2-канальный входной сигнал воспроизводится с использованием 5.1-канальной системы в соответствии с самым общим способом, межканальный сигнал может быть распределен с использованием выражения понижающего микширования. Альтернативно, может быть выполнен рендеринг для обеспечения виртуального чувства возвышения по вертикали так, чтобы 5.1-канальная система воспроизводила аудиосигнал, имеющий чувство возвышения по вертикали.
Фиг. 4 является блок-схемой основных компонентов средства рендеринга в соответствии с вариантом осуществления.
Средство рендеринга является понижающим число каналов микшером, который преобразовывает многоканальный входной сигнал, имеющий Nin каналов, в формат воспроизведения, имеющий Nout каналов, и называется преобразователем формата. В связи с этим Nout<Nin. Фиг. 4 является блок-схемой основных компонентов преобразователя формата, сконфигурированного из средства рендеринга, в отношении понижающего микширования.
Кодированный аудиосигнал подается на вход основного декодера 110 в формате битового потока. Сигнал, подаваемый на вход основного декодера 110, декодируется инструментом декодера, подходящим для схемы кодирования, и подается на вход преобразователя 125 формата.
Преобразователь 125 формата включает в себя два основных блока. Первый основной блок является блоком 1251 конфигурации понижающего микширования, который выполняет алгоритм инициализации, который отвечает за статические параметры, такие как входной и выходной форматы. Второй основной блок является блоком 1252 понижающего микширования, который выполняет понижающее микширование выходного сигнала микшера на основании параметра понижающего микширования, полученного с использованием алгоритма инициализации.
Блок 1251 конфигурации понижающего микширования генерирует параметр понижающего микширования, который оптимизирован на основании выходной схемы расположения для микшера, соответствующей схеме расположения сигнала входного канала, и схемы расположения воспроизведения, соответствующей схеме расположения выходного канала. Параметр микшера с понижением числа каналов может быть матрицей понижающего микширования, и он определяется доступной комбинацией данного входного формата и выходного канала.
В связи с этим алгоритм, который выбирает выходной громкоговоритель (выходной канал), применяется к каждому входному каналу с помощью самого подходящего правила соответствия, включенного в список правил соответствия с учетом психологических аспектов звука. Правило соответствия предназначено для постановки в соответствие одному входному каналу одного выходного громкоговорителя или множества выходных громкоговорителей.
Входной канал может ставиться в соответствие одному выходному каналу или может панорамироваться на два выходных канала. Входной канал, такой как канал VOG, может распределяться по множеству выходных каналов. Альтернативно, входной сигнал может панорамироваться на множество выходных каналов, имеющих различные коэффициенты панорамирования в соответствии с частотами, и формироваться с созданием эффекта присутствия, чтобы дать чувство окружающего пространства. Выходной канал, имеющий только горизонтальный канал, такой как канал 5.1, должен иметь канал виртуального возвышения (высоту), чтобы дать чувство окружающего пространства, и, таким образом, к выходному каналу применяется рендеринг с возвышением.
Оптимальное соответствие каждого входного канала выбирается в соответствии со списком выходных громкоговорителей, рендеринг которых может быть осуществлен в желаемом выходном формате. Сгенерированный параметр соответствия может включать в себя не только усиление понижающего микширования для входного канала, но также и коэффициент эквалайзера (фильтра тембра).
Во время процесса генерации параметра понижающего микширования, когда выходной канал выходит за пределы стандартной схемы расположения, например, когда выходной канал имеет не только отклонение по возвышению или по азимуту, но также и отклонение по расстоянию, может быть добавлен процесс обновления или корректировки параметра понижающего микширования с учетом этого.
Блок 1252 понижающего микширования определяет режим рендеринга в соответствии с параметром, который определяет тип рендеринга, включенный в выходной сигнал основного декодера 110, и выполняет понижающее микширование выходного сигнала микшера основного декодера 110 в соответствии с определенным режимом рендеринга. В связи с этим параметр, который определяет тип рендеринга, может быть определен кодером, который кодирует многоканальный сигнал, и может быть включен в многоканальный сигнал, декодированный основным декодером 110.
Параметр, который определяет тип рендеринга, может быть определен для каждого кадра аудиосигнала и может быть сохранен в поле кадра, который отображает дополнительную информацию. Если число типов рендеринга, которые могут выполняться средством рендеринга, ограничено, параметр, который определяет тип рендеринга, может быть небольшим битовым числом, и, например, если отображаются два типа рендеринга, может быть сконфигурирован как флаг, имеющий 1 бит.
Блок 1252 понижающего микширования выполняет понижающее микширование в частотной области и области поддиапазона гибридного квадратурного зеркального фильтра (QMF), и, чтобы предотвратить ухудшение сигнала из-за дефекта гребенчатой фильтрации, окрашивания или модуляции сигнала, выполняет фазовую синхронизацию и нормализацию энергии.
Фазовая синхронизация является процессом синхронизации фаз входных сигналов, которые имеют корреляцию, но различные фазы перед понижающим микшированием входных сигналов. Процесс фазовой синхронизации синхронизирует только связанные каналы относительно соответствующих частотно-временных ячеек, и он не должен изменять никакую другую часть входного сигнала. Следует отметить, что для того, чтобы предотвратить дефекты во время фазовой синхронизации, так как интервал фазовой коррекции быстро изменяется для синхронизации.
Если выполняется процесс фазовой синхронизации, узкой спектральной высоты тона, которая возникает из-за ограниченного разрешения по частоте и которую невозможно компенсировать, можно избежать с помощью нормализации энергии, и, таким образом, качество выходного сигнала может быть улучшено. Кроме того, отсутствует необходимость усиливать сигнал во время сохраняющей энергию нормализации, и, таким образом, может быть уменьшен дефект модуляции.
При рендеринге возвышения фазовая синхронизация не выполняется для точной синхронизации сформированного многоканального сигнала относительно входного сигнала высокочастотной полосы.
Во время понижающего микширования нормализация энергии выполняется для сохранения входной энергии, и она не выполняется, когда сама матрица понижающего микширования выполняет масштабирование энергии.
Фиг. 5 изображает конфигурацию селектора, который выбирает тип рендеринга и матрицу понижающего микширования на основании параметра определения типа рендеринга в соответствии с вариантом осуществления.
В соответствии с вариантом осуществления тип рендеринга определяется на основании параметра, который определяет тип рендеринга, и рендеринг выполняется в соответствии с определенным типом рендеринга. Если параметр, который определяет тип рендеринга, является флагом rendering3DType, имеющим размер в 1 бит, селектор работает так, чтобы выполнять 3D рендеринг, если rendering3DType равен 1 (ИСТИНА), и выполнять 2D рендеринг, если rendering3DType равен 0 (ЛОЖЬ), и он переключается в соответствии со значением rendering3DType.
В связи с этим M_DMX выбирается как матрица понижающего микширования для 3D рендеринга, и M_DMX2 выбирается как матрица понижающего микширования для 2D рендеринга. Каждая из матриц M_DMX и M_DMX2 понижающего микширования выбирается блоком 121 инициализации на фиг. 2 или блоком 1251 конфигурации понижающего микширования на фиг. 4. M_DMX является основной матрицей понижающего микширования для пространственного рендеринга с возвышением, включающей в себя коэффициент (усиление) понижающего микширования, который является неотрицательным вещественным числом. Размер M_DMX равен (Nout×Nin), где Nout обозначает число выходных каналов, а Nin обозначает число входных каналов. M_DMX2 является основной матрицей понижающего микширования для тембрального рендеринга с возвышением, включающей в себя коэффициент (усиление) понижающего микширования, который является неотрицательным вещественным числом. Размер M_DMX2 равен (Nout×Nin), как и для M_DMX.
Входной сигнал подвергается понижающему микшированию для каждого частотного поддиапазона гибридного QMF путем использования матрицы понижающего микширования, подходящей для каждого типа рендеринга в соответствии с выбранным типом рендеринга.
Фиг. 6 изображает синтаксис, который определяет конфигурацию типа рендеринга на основании параметра определения типа рендеринга в соответствии с вариантом осуществления.
Таким же образом, как показано на фиг. 5, параметр, который определяет тип рендеринга, является флагом rendering3Dtype, имеющим размер в 1 бит, и RenderingTypeConfig() задает соответствующий тип рендеринга для преобразования формата.
Rendering3Dtype может генерироваться кодером. В связи с этим rendering3Dtype может определяться на основании аудиосцены аудиосигнала. Если аудио сцена является широкополосным сигналом или является сильно декоррелированным сигналом, таким как звук дождя или звук аплодисментов и т.д., то rendering3Dtype является ЛОЖЬЮ, и, таким образом, многоканальный сигнал подвергается понижающему микшированию путем использования M_DMX2, которая является матрицей понижающего микширования для 2D рендеринга. В других случаях rendering3Dtype является ИСТИНОЙ в отношении общей аудиосцены, и, таким образом, многоканальный сигнал подвергается понижающему микшированию путем использования M_DMX, которая является матрицей понижающего микширования для 3D рендеринга.
Альтернативно, rendering3Dtype может определяться в соответствии с намерением производителя (создателя) аудиосигнала. Создатель выполняет понижающее микширование аудиосигнала (кадра), для которого задано выполнение 2D рендеринга, путем использования M_DMX2, которая является матрицей понижающего микширования для 2D рендеринга. В других случаях rendering3Dtype является ИСТИНОЙ в отношении общей аудиосцены, и, таким образом, создатель выполняет понижающее микширование аудиосигнала (кадра) путем использования M_DMX, которая является матрицей понижающего микширования для 3D рендеринга.
В связи с этим, когда выполняется 3D рендеринг, выполняются и пространственная фильтрация тембра, и пространственное панорамирование местоположения, тогда как когда выполняется 2D рендеринг, выполняется только пространственная фильтрация тембра.
Фиг. 7 является блок-схемой последовательности операций способа рендеринга аудиосигнала в соответствии с вариантом осуществления.
Если многоканальный сигнал, декодированный основным декодером 110, подается на вход преобразователя 125 формата или средства 120 рендеринга, инициализирующее значение параметра рендеринга получается на основании стандартной схемы расположения входных каналов и выходных каналов (операция 710). В связи с этим полученное инициализирующее значение параметра рендеринга может быть определено по-другому в соответствии с типом рендеринга, который, вероятно, должен быть выполнен средством 120 рендеринга, и может быть сохранено в энергонезависимой памяти, такой как постоянное запоминающее устройство (ROM) системы воспроизведения аудиосигнала.
Инициализирующее значение параметра рендеринга с возвышением вычисляется на основании конфигурации выходных каналов в соответствии со стандартной схемой расположения и конфигурации входных каналов в соответствии с установкой рендеринга с возвышением, или для инициализирующего значения параметра рендеринга с возвышением считывается предварительно записанное в память инициализирующее значение в соответствии с отображающей зависимостью между входными/выходными каналами. Параметр рендеринга с возвышением может включать в себя коэффициент фильтра, который должен использоваться блоком 1231 пространственной фильтрации тембра на фиг. 2, или коэффициент панорамирования, который должен использоваться блоком 1232 пространственного панорамирования местоположения на фиг. 2.
В связи с этим, если схемы расположения входных/выходных каналов идентичны всем стандартным схемам расположения, рендеринг может быть выполнен с использованием инициализирующего значения параметра рендеринга, полученного в 710. Однако, когда существует отклонение между заданным значением возвышения для рендеринга и настройками входных каналов или существует отклонение между схемой расположения, в которой фактически установлен громкоговоритель, и стандартной схемой расположения выходных каналов, если для рендеринга используется инициализирующее значение, полученное в операции 710, как есть, то происходит явление, в котором искаженный или сформированный сигнал звукового изображения выводится в местоположении, которое не является исходным местоположением.
Поэтому параметр рендеринга обновляется на основании отклонения между стандартной схемой расположения входных/выходных каналов и фактической схемой расположения (операция 720). В связи с этим обновленный параметр рендеринга может быть определен по-другому в соответствии с типом рендеринга, который, вероятно, должен выполняться средством 120 рендеринга.
Обновленный параметр рендеринга может иметь формат матрицы, имеющей размер Nin×Nout для каждого поддиапазона гибридного QMF в соответствии с каждым типом рендеринга. Nin обозначает число входных каналов. Nout обозначает число выходных каналов. В связи с этим матрица, представляющая параметр рендеринга, называется матрицей понижающего микширования. M_DMX обозначает матрицу понижающего микширования для 3D рендеринга. M_DMX2 обозначает матрицу понижающего микширования для 2D рендеринга.
Если матрицы M_DMX и M_DMX2 понижающего микширования определены, тип рендеринга, подходящий для текущего кадра, определяется на основании параметра, который определяет тип рендеринга (операция 730).
Параметр, который определяет тип рендеринга, может быть включен в битовый поток, подаваемый на вход основному декодеру, он генерируется, когда кодер кодирует аудиосигнал. Параметр, который определяет тип рендеринга, может быть определен в соответствии с характеристикой аудиосцены текущего кадра. Когда аудиосигнал имеет много транзиентных сигналов, таких как звук аплодисментов или звук дождя, так как присутствует много коротких и временных сигналов, аудиосцена имеет характеристику низкой корреляции между каналами.
Когда имеется сильно декоррелированный сигнал между каналами или атональный широкополосный сигнал во множестве входных каналов, уровни сигналов аналогичны для каждого канала, или импульсная форма короткой секции повторяется, если сигнал множества каналов подвергается понижающему микшированию до одного канала, то имеет место явление «phaseyness», при котором происходит эффект смещения из-за взаимной частотной интерференции, так что тон звука изменяется, и явление искажения тембра, при котором увеличивается число транзиентных сигналов для одного канала, так что происходит придание звуку черт белого шума.
В этом случае может быть предпочтительно выполнить тембральный рендеринг возвышения как 2D рендеринг, а не пространственный рендеринг возвышения как 3D рендеринг.
Поэтому, в результате анализа характеристик аудиосцены, тип рендеринга может быть определен как 3D тип рендеринга в нормальном случае, и тип рендеринга может быть определен как 2D тип рендеринга, если имеется широкополосный сигнал или имеется сильно декоррелированный сигнал между каналами.
Если тип рендеринга, подходящий для текущего кадра, определен, получается тип рендеринга на основании определенного типа рендеринга (операция 740). Выполняется рендеринг текущего кадра на основании полученного типа рендеринга (операция 750).
Если определенный тип рендеринга является 3D типом рендеринга, блок хранения данных, который хранит матрицу понижающего микширования, может получить M_DMX, которая является матрицей понижающего микширования для 3D рендеринга. Матрица M_DMX понижающего микширования выполняет понижающее микширование сигнала Nin входных каналов относительно одного поддиапазона гибридного QMF в Nout выходных каналов с использованием матрицы, имеющей размер Nin×Nout, для каждого поддиапазона гибридного QMF.
Если определенный тип рендеринга является 2D типом рендеринга, блок хранения данных, который хранит матрицу понижающего микширования, может получить M_DMX2, которая является матрицей понижающего микширования для 2D рендеринга. Матрица M_DMX2 понижающего микширования выполняет понижающее микширование сигнала Nin входных каналов относительно одного поддиапазона гибридного QMF в Nout выходных каналов с использованием матрицы, имеющей размер Nin×Nout, для каждого поддиапазона гибридного QMF.
Процесс определения типа рендеринга, подходящего для текущего кадра, (операция 730), получение типа рендеринга на основании определенного типа рендеринга (операция 740) и рендеринг текущего кадра на основании полученного типа рендеринга (операция 750) многократно выполняются для каждого кадра до тех пор, пока не кончится подаваемый на вход многоканальный сигнал, декодируемый основным декодером.
Фиг. 8 является блок-схемой последовательности операций способа рендеринга аудиосигнала на основании типа рендеринга в соответствии с вариантом осуществления.
В варианте осуществления на фиг. 8 добавлена операция 810 определения, возможен ли рендеринг возвышения, по взаимосвязи между входными/выходными каналами.
Возможен ли рендеринг возвышения, определяется на основании приоритета правил понижающего микширования в соответствии с входными каналами и схемой расположения воспроизведения.
Если рендеринг с возвышением не выполняется на основании приоритета правил понижающего микширования в соответствии с входными каналами и схемой расположения воспроизведения, получается (операция 850) параметр рендеринга для рендеринга без возвышения для выполнения рендеринга без возвышения.
Если рендеринг с возвышением возможен как результат определения в операции 810, тип рендеринга определяется из параметра типа рендеринга с возвышением (операция 820). Если параметр типа рендеринга с возвышением указывает 2D рендеринг, тип рендеринга определяется как 2D тип рендеринга, и получается параметр 2D рендеринга для 2D рендеринга (операция 830). Между тем, если параметр типа рендеринга с возвышением указывает 3D рендеринг, тип рендеринга определяется как 3D тип рендеринга, и получается параметр 3D рендеринга для 3D рендеринга (операция 840).
Параметр рендеринга, полученный посредством процесса, описанного выше, является параметром рендеринга для одного входного канала. Параметр рендеринга для каждого канала получается путем повторения того же самого процесса для каждого входного канала и используется для получения всех матриц понижающего микширования относительно всех входных каналов (операция 860). Матрица понижающего микширования является матрицей для рендеринга входного сигнала путем понижающего микширования сигнала входного канала в сигнал выходного канала и имеет размер Nin×Nout для каждого поддиапазона гибридного QMF.
Если матрица понижающего микширования получена, сигнал входного канала подвергается понижающему микшированию с использованием полученной матрицы понижающего микширования (операция 870) для генерации выходного сигнала.
Если параметр типа рендеринга с возвышением существует для каждого кадра декодированного сигнала, процесс операций 810-870 на фиг. 8 многократно выполняется для каждого кадра. Если процесс окончен на последнем кадре, заканчивается весь процесс рендеринга.
В связи с этим, когда выполняется рендеринг без возвышения, активное понижающее микширование выполняется на всех полосах частот. Когда выполняется рендеринг с возвышением, фазовая синхронизация выполняется только в полосе низких частот и не выполняется в полосе высоких частот. Фазовая синхронизация не выполняется в полосе высоких частот из-за точной синхронизации сформированного многоканального сигнала, как было описано выше.
Фиг. 9 является блок-схемой последовательности операций способа рендеринга аудиосигнала на основании типа рендеринга в соответствии с другим вариантом осуществления.
В варианте осуществления на фиг. 9 добавлена операция 910 определения, является ли выходной канал виртуальным каналом. Если выходной канал не является виртуальным каналом, так как нет необходимости выполнять рендеринг с возвышением или виртуальный рендеринг, рендеринг без возвышения выполняется на основании приоритета допустимых правил понижающего микширования. Таким образом, получается (операция 960) параметр рендеринга для рендеринга без возвышения для выполнения рендеринга без возвышения.
Если выходной канал является виртуальным каналом, возможен ли рендеринг с возвышением, определяется по взаимосвязи между входными/выходными каналами (операция 920). Возможен ли рендеринг с возвышением, определяется на основании приоритета правил понижающего микширования в соответствии с входными каналами и схемой расположения воспроизведения.
Если рендеринг с возвышением не выполняется на основании приоритета правил понижающего микширования в соответствии с входными каналами и схемой расположения воспроизведения, получается (операция 960) параметр рендеринга для рендеринга без возвышения для выполнения рендеринга без возвышения.
Если рендеринг с возвышением возможен в результате определения в операции 920, определяется тип рендеринга по параметру типа рендеринга с возвышением (операция 930). Если параметр типа рендеринга с возвышением указывает 2D рендеринг, тип рендеринга определяется как 2D тип рендеринга, и получается (операция 940) параметр 2D рендеринга для 2D рендеринга. Между тем, если параметр типа рендеринга с возвышением указывает 3D рендеринг, тип рендеринга определяется как 3D тип рендеринга, и получается (операция 950) параметр 3D рендеринга для 3D рендеринга.
2D рендеринг и 3D рендеринг соответственно используются вместе с тембральным рендерингом с возвышением и пространственным рендерингом с возвышением.
Параметр рендеринга, полученный посредством процесса, описанного выше, является параметром рендеринга для одного входного канала. Параметр рендеринга для каждого канала получается путем повторения того же самого процесса для каждого входного канала и используется для получения всех матриц понижающего микширования относительно всех входных каналов (операция 970). Матрица понижающего микширования является матрицей для рендеринга входного сигнала путем понижающего микширования сигнала входного канала в сигнал выходного канала и имеет размер Nin×Nout для каждого поддиапазона гибридного QMF.
Если матрица понижающего микширования получена, сигнал входного канала подвергается понижающему микшированию с использованием полученной матрицы понижающего микширования (операция 980) для генерации выходного сигнала.
Если параметр типа рендеринга с возвышением существует для каждого кадра декодированного сигнала, процесс операций 910-980 на фиг. 9 многократно выполняется для каждого кадра. Если процесс окончен на последнем кадре, заканчивается весь процесс рендеринга.
Описанные выше варианты осуществления настоящего изобретения могут быть реализованы как машинные команды, которые могут быть исполнены с помощью различных компьютерных средств и записаны на компьютерно-читаемый носитель информации. Компьютерно-читаемый носитель информации может включать в себя команды программы, файлы данных, структуры данных или их комбинацию. Команды программы, записанные на компьютерно-читаемом носителе информации, могут быть специально предназначены и созданы для настоящего изобретения или могут быть известны и применимы специалистами обычной квалификации в области программного обеспечения. Примеры компьютерно-читаемого носителя включают в себя магнитные носители, такие как жесткие диски, гибкие диски и магнитные ленты, оптические носители информации, такие как компактные CD-ROM и DVD, магнитооптические носители, такие как флоптические диски, и аппаратные устройства, которые специально выполнены с возможностью хранения и выполнения команд программы, такие как ROM, RAM и флэш-память. Примеры команд программы включают в себя код языка высокого уровня, который может быть исполнен компьютером, использующим интерпретатор, а также машинный код, сделанный компилятором. Аппаратные устройства могут быть заменены на один или несколько программных модулей для выполнения обработки в соответствии с настоящим изобретением и наоборот.
Хотя настоящее изобретение было описано со ссылкой на конкретные признаки, такие как детализированные компоненты, ограниченные варианты осуществления и чертежи, они обеспечены только для того, чтобы помочь общему пониманию настоящего изобретения, и настоящее изобретение не ограничивается этими вариантами осуществления, и специалисты в области техники, к которой принадлежит настоящее изобретение, могут выполнить различные изменения и модификации вариантов осуществления, описанных в настоящем описании.
Поэтому идея настоящего изобретения не должна определяться только вариантами осуществления, описанными выше, и прилагаемая формула изобретения, ее эквиваленты или весь объем, эквивалентно получаемый путем изменений из нее, входят в объем идеи настоящего изобретения.









Изобретение относится к обработке аудиосигналов, в частности, к способу воспроизведения многоканального аудиосигнала, включающего в себя звуковой сигнал с возвышением в окружении с горизонтальной схемой расположения, тем самым получая параметр рендеринга в соответствии с типом рендеринга и конфигурируя матрицу понижающего микширования. Технический результат – обеспечение высокой производительности рендеринга в отношении аудиосигнала, который не подходит для применения виртуального рендеринга. Данный способ включает в себя этапы, на которых принимают многоканальный сигнал, содержащий множество входных каналов, которые должны быть преобразованы во множество выходных каналов; определяют тип рендеринга для рендеринга с возвышением на основании параметра, определенного из характеристики многоканального сигнала; и осуществляют рендеринг по меньшей мере одного высотного входного канала в соответствии с упомянутым определенным типом рендеринга, при этом параметр включен в битовый поток многоканального сигнала. 2 н. и 1 з.п. ф-лы, 9 ил.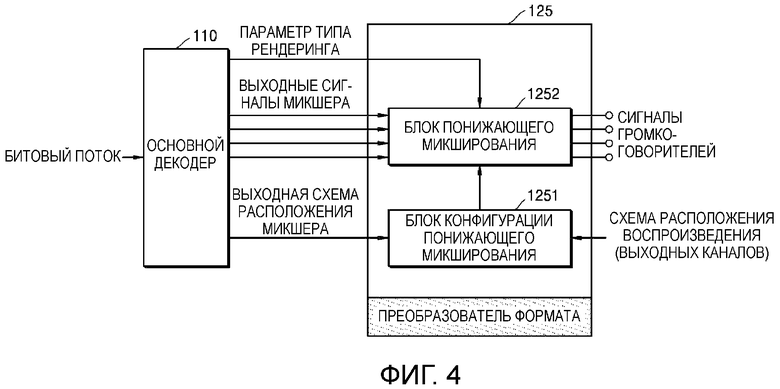
1. Способ рендеринга аудиосигнала, содержащий этапы, на которых:
принимают дополнительную информацию и множество сигналов входных каналов, включая по меньшей мере один сигнал высотного входного канала;
определяют, является ли выходной канал, соответствующий сигналу входного канала из множества сигналов входных каналов, виртуальным каналом;
определяют, является ли возможным рендеринг с возвышением на основе предварительно заданной таблицы для отображения сигнала входного канала на множество сигналов выходных каналов;
когда выходной канал, соответствующий сигналу входного канала, является виртуальным каналом и рендеринг с возвышением является возможным, получают параметр рендеринга с возвышением;
когда выходной канал, соответствующий сигналу входного канала, не является виртуальным каналом, получают параметр рендеринга без возвышения; и
получают первую матрицу понижающего микширования и вторую матрицу понижающего микширования на основе по меньшей мере одного из параметра рендеринга с возвышением и параметра рендеринга без возвышения; и
проводят рендеринг множества сигналов входных каналов во множество сигналов выходных каналов, используя одну из первой матрицы понижающего микширования и второй матрицы понижающего микширования, выбранную в соответствии с дополнительной информацией,
при этом рендеринг содержит:
рендеринг множества сигналов входных каналов посредством использования первой матрицы понижающего микширования, если дополнительная информация представляет тип рендеринга для общего режима; и
рендеринг множества сигналов входных каналов посредством использования второй матрицы понижающего микширования, если дополнительная информация представляет тип рендеринга для множества сигналов входных каналов, включающих в себя сильно декоррелированные широкополосные сигналы,
причем дополнительная информация принимается для каждого кадра.
2. Способ по п.1, в котором схема расположения на основе множества сигналов выходных каналов является одной из 5.1-канальной схемы расположения или 5.0-канальной схемы расположения.
3. Устройство для рендеринга аудиосигнала, содержащее:
по меньшей мере один процессор, выполненный с возможностью:
принимать дополнительную информацию и множество сигналов входных каналов, включая по меньшей мере один сигнал высотного входного канала;
определять, является ли выходной канал, соответствующий сигналу входного канала из множества сигналов входных каналов, виртуальным каналом;
определять, является ли возможным рендеринг с возвышением на основе предварительно заданной таблицы для отображения сигнала входного канала на множество сигналов выходных каналов;
когда выходной канал, соответствующий сигналу входного канала, является виртуальным каналом и рендеринг с возвышением является возможным, получать параметр рендеринга с возвышением;
когда выходной канал, соответствующий сигналу входного канала, не является виртуальным каналом, получать параметр рендеринга без возвышения; и
получать первую матрицу понижающего микширования и вторую матрицу понижающего микширования на основе по меньшей мере одного из параметра рендеринга с возвышением и параметра рендеринга без возвышения; и
проводить рендеринг множества сигналов входных каналов во множество сигналов выходных каналов, используя одну из первой матрицы понижающего микширования и второй матрицы понижающего микширования, выбранную в соответствии с дополнительной информацией,
при этом процессор дополнительно выполнен с возможностью:
рендеринга множества сигналов входных каналов посредством использования первой матрицы понижающего микширования, если дополнительная информация представляет тип рендеринга для общего режима; и
рендеринга множества сигналов входных каналов посредством использования второй матрицы понижающего микширования, если дополнительная информация представляет тип рендеринга для множества сигналов входных каналов, включающих в себя сильно декоррелированные широкополосные сигналы,
причем дополнительная информация принимается для каждого кадра.

