ОБЛАСТЬ ТЕХНИКИ
Техническое решение относится к области устройств или методов цифровых вычислений или обработки данных, специально предназначенные для специфических функций, а также к области информационных технологий и вычислительной техники, в частности, к средствам сбора, обработки и распределения данных и информации, а именно - к способу построения распределенной информационной системы.
УРОВЕНЬ ТЕХНИКИ
В настоящее время практически все большие программные системы являются распределенными. Распределенная система - система, в которой обработка информации сосредоточена не на одной вычислительной машине, а распределена между несколькими компьютерами. При проектировании распределенных систем, которое имеет много общего с проектированием программного обеспечения следует учитывать некоторые специфические особенности.
Существует шесть основных характеристик распределенных систем.
Совместное использование ресурсов. Распределенные системы допускают совместное использование как аппаратных (жестких дисков, принтеров), так и программных (файлов, компиляторов) ресурсов.
Открытость. Это возможность расширения системы путем добавления новых ресурсов.
Параллельность. В распределенных системах несколько процессов могут одновременно выполняться на разных компьютерах в сети. Эти процессы могут взаимодействовать во время их выполнения.
Масштабируемость. Под масштабируемостью понимается возможность добавления новых свойств и методов.
Отказоустойчивость. Наличие нескольких компьютеров позволяет дублирование информации и устойчивость к некоторым аппаратным и программным ошибкам. Распределенные системы в случае ошибки могут поддерживать частичную функциональность. Полный сбой в работе системы происходит только при сетевых ошибках.
Прозрачность. Пользователям предоставляется полный доступ к ресурсам в системе, в то же время от них скрыта информация о распределении ресурсов по системе.
Распределенные системы обладают и рядом недостатков.
Сложность. Намного труднее понять и оценить свойства распределенных систем в целом, их сложнее проектировать, тестировать и обслуживать. Также производительность системы зависит от скорости работы сети, а не отдельных процессоров. Перераспределение ресурсов может существенно изменить скорость работы системы.
Безопасность. Обычно доступ к системе можно получить с нескольких разных машин, сообщения в сети могут просматриваться и перехватываться. Поэтому в распределенной системе намного труднее поддерживать безопасность.
Управляемость. Система может состоять из разнотипных компьютеров, на которых могут быть установлены различные версии операционных систем. Ошибки на одной машине могут распространиться непредсказуемым образом на другие машины.
Непредсказуемость. Реакция распределенных систем на некоторые события непредсказуема и зависит от полной загрузки системы, ее организации и сетевой нагрузки. Так как эти параметры могут постоянно изменяться, поэтому время ответа на запрос может существенно отличаться от времени.
Из этих недостатков можно увидеть, что при проектировании распределенных систем возникает ряд проблем, которые надо учитывать разработчикам.
Из уровня техники известно техническое решение, описанное в RU 2656841 «Способ построения единого информационного пространства и система для его осуществления», опубликовано: 23.01.2018, патентообладатель Федеральное государственное автономное образовательное учреждение высшего образования "Санкт-Петербургский государственный университет аэрокосмического приборостроения" (RU). В документе описана система построения единого информационного пространства, содержащая соединенную с локальными и/или удаленными источниками информации сеть передачи данных, связанную с модулем коммуникационного интерфейса в каждом из локальных центров обработки данных и знаний и в каждом из управляющих центров обработки данных и знаний, подключенным к блоку аккомодации, предназначенному для конвертации метаданных и интегрирования в метаданные единого информационного пространства, и в каждом из центров с подключенной к блоку аккомодации информационной среде предприятия, представляющей технические и программные средства обработки информации системой автоматического проектирования для ввода данных и запросов, модулем электронного архива и информационной моделью изделия.
Из уровня техники известно техническое решение, описанное в RU 2637993 «Способ интеграции информационных ресурсов неоднородной вычислительной сети», опубликовано: 28.11.2017, патентообладатель Федеральное государственное казенное военное образовательное учреждение высшего образования "Военная академия связи имени Маршала Советского Союза СМ. Буденного" Министерства обороны Российской Федерации (RU). В документе описан способ интеграции информационных ресурсов неоднородной вычислительной сети, представленной в виде двух соединенных сетью связи вычислительных установок (ВУ), по меньшей мере, одна из которых снабжена отличной от других операционной системой (ОС), и в контексте этой ОС функционирует конечное приложение данной ВУ, заключающийся в том, что на первом этапе инсталлируют на каждой ВУ общесистемное программное обеспечение (ОСПО) путем доустановки базового набора транспортных протоколов, предназначенных для адресации узлов и маршрутизации пакетов, а также набора форматов обмена данными прикладного уровня, устанавливают на каждой ВУ однотипные средства межмашинного информационного обмена, реализующие физическую связность всех ВУ, формируют очереди исходящих и входящих сообщений для достижения гарантированного защищенного взаимодействия в информационном пространстве между конечными приложениями ВУ, повторяют операции добавления/удаления ссылок витрин данных каждой вычислительной установки в централизованное хранилище данных.
Недостатком вышеуказанных технических решений является отсутствие возможности обеспечить устойчивую и надежную работу большого числа одновременно подключенных пользователей в случае наличия больших групп пользователей, сильно удаленных друг от друга и географически распределенных.
СУЩНОСТЬ ТЕХНИЧЕСКОГО РЕШЕНИЯ
Задачей заявленного технического решения является устранение недостатков, присущих существующим аналогам.
Технический результат от использования данного технического решения заключается в повышении скорости обмена данными в распределенной информационной системе и обеспечении устойчивости, надежности и отказоустойчивости при одновременном соединении и работы в ней больших групп пользователей, сильно удаленных друг от друга и географически распределенных.
Данные технический результат достигается за счет создания такой модели кластерной архитектуры распределенной информационной системы, при которой, пользователи в одном регионе подключаются к узлу кластера, расположенному в этом регионе, но имеют доступ к функциональности и данным всей системы в целом.
В одном из предпочтительных вариантов реализации предложен способ построения распределенной информационной системы, характеризующийся тем, что: уточняют параметры распределенной информационной системы, такие как: количество пользователей, географическое месторасположение основных групп пользователей системы, состав функциональных модулей, востребованность функций конкретных модулей у конкретных групп пользователей, тип и структуру подсистемы хранения данных; на основе уточненных ранее параметров распределенной информационной системы определяют структуру кластера проектируемой информационной системы, а именно: количество географически распределенных узлов в кластере, количество и характеристики серверов в узле, состав конкретных функциональных модулей системы, размещаемых на отдельных серверах в узле; определяют необходимость дублирования конкретных функциональных модулей на серверах географически распределенных узлов в кластере распределенной информационной системы; осуществляют размещение функциональных модулей относительно определенной структуры кластера распределенной информационной системы и необходимости дублирования конкретных функциональных модулей на серверах географически распределенных узлов; определяют и настраивают взаимодействие функциональных модулей распределенной информационной системы с подсистемой хранения данных и репозиторием файлов; определяют и настраивают поиск и индексирование данных в распределенной информационной системе; осуществляют процедуру реплицирования кэша данных среди всех узлов кластера распределенной информационной системы; осуществляют процедуру аутентификации и авторизации пользователей распределенной информационной системы по признакам географического месторасположения и востребованности функций конкретных модулей.
Подсистема хранения данных в распределенной информационной системе может быть организована таким образом, что все узлы кластера ссылаются на одну базу данных.
Подсистема хранения данных в распределенной информационной системе может использовать конфигурацию Read-Writer database.
Подсистема хранения данных в распределенной информационной системе может распределять данные между различными базами данных.
В качестве репозитория файлов в распределенной информационной системе может использоваться File System store.
В качестве репозитория файлов в распределенной информационной системе может использоваться Advanced File System store.
В качестве репозитория файлов в распределенной информационной системе может использоваться репозиторий, реализующий доступ по протоколу CMIS.
Функции поиска и индексирования в распределенной информационной системе может выполнять подключаемая внешняя поисковая система Solr.
В распределенной информационной системе может использоваться централизованное расположение поискового индекса.
Может производиться синхронизация полнотекстовых индексов между всеми узлами кластера распределенной информационной системы.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 - блок-схема способа построения распределенной информационной системы;
Фиг. 2 - схема размещения функциональных модулей распределенной информационной системы в трех географически разнесенных локациях с использованием единой СУБД.
ПОДРОБНОЕ ОПИСАНИЕ ТЕХНИЧЕСКОГО РЕШЕНИЯ
В данном техническом решении под системой подразумевается компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность операций (действий, инструкций).
Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных. В роли устройства хранения данных могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, ПЗУ (постоянное запоминающее устройство), твердотельные накопители (SSD), оптические приводы.
Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
Ниже будут рассмотрены некоторые термины, которые в дальнейшем будут использоваться при описании технического решения.
Распределенная информационная система - любая информационная система, позволяющая организовать взаимодействие независимых, но связанных между собой ЭВМ. Под распределенными понимаются ИС, которые не располагаются на одной контролируемой территории, на одном объекте. Эти системы предназначены для автоматизации таких объектов, которые характеризуются территориальной распределенностью пунктов возникновения и потребления информации.
Кластер - группа компьютеров, объединенных высокоскоростными каналами связи, представляющая с точки зрения пользователя единый аппаратный ресурс.Кластер - слабо связанная совокупность нескольких вычислительных систем, работающих совместно для выполнения общих приложений, и представляющихся пользователю единой системой. Кластер - это разновидность параллельной или распределенной системы, которая:
- состоит из нескольких связанных между собой компьютеров;
- используется как единый, унифицированный компьютерный ресурс.
Обычно различают следующие основные виды кластеров:
-отказоустойчивые кластеры (High-availability clusters, НА, кластеры высокой доступности);
- кластеры с балансировкой нагрузки (Load balancing clusters);
- вычислительные кластеры (High performance computing clusters, HPC);
- системы распределенных вычислений.
Репозиторий (хранилище) - место, где хранятся и поддерживаются какие-либо данные. Чаще всего данные в репозиторий хранятся в виде файлов, доступных для дальнейшего распространения по сети. Существуют различные автоматизированные системы создания репозиториев.
Кэш - промежуточный буфер с быстрым доступом, содержащий информацию, которая может быть запрошена с наибольшей вероятностью. Доступ к данным в кэше осуществляется быстрее, чем выборка исходных данных из более медленной памяти или удаленного источника, однако ее объем существенно ограничен по сравнению с хранилищем исходных данных.
Распределенный кэш - система хранения данных, в которой информация хранится более чем на одном сервере, но при этом обеспечивается доступ ко всему объему данных сразу. Основным преимуществом подобного рода систем является возможность хранить огромные объемы данных без разбиения их на куски, ограниченные объемами конкретных накопителей или даже целых серверов. Чаще всего такие системы позволяют динамически наращивать объемы хранения посредством добавления новых серверов в систему распределенного хранения. Чтобы иметь возможность изменять топологию кластера (добавлять и удалять серверы), а также балансировать данные, используется принцип партиционирования (секционирования) данных.
Реплицирование (репликация) - механизм синхронизации содержимого нескольких копий объекта (например, содержимого базы данных). Репликация - это процесс, под которым понимается копирование данных из одного источника на другой (или на множество других) и наоборот. При репликации изменения, сделанные в одной копии объекта, могут быть распространены в другие копии.
Система управления базами данных (СУБД) - совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
Данное техническое решение обеспечивает повышение скорости обмена данными в распределенной информационной системе, а также устойчивости, надежности и отказоустойчивости при одновременном соединении и работы в ней больших групп пользователей, сильно удаленных друг от друга и географически распределенных, за счет создания такой модели кластерной архитектуры распределенной информационной системы, при которой, пользователи в одном регионе подключаются к узлу кластера, расположенному в этом регионе, но имеют доступ к функциональности и данным всей системы в целом.
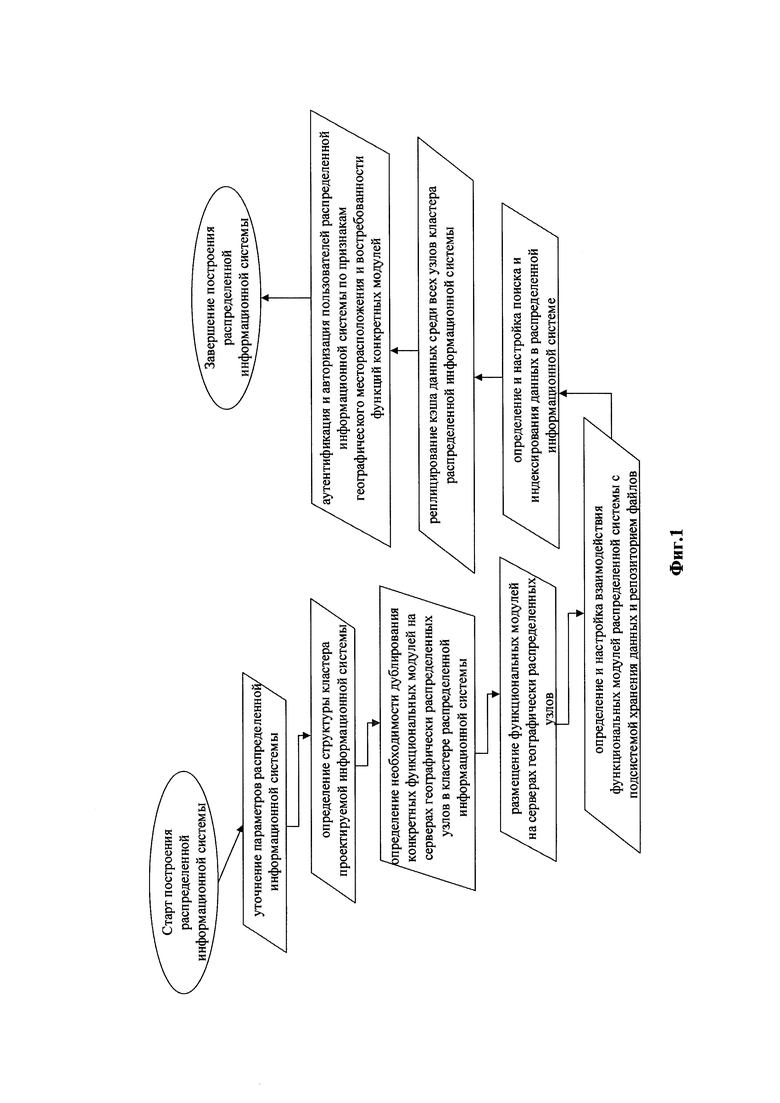
Согласно предлагаемому техническому решению, способ построения распределенной информационной системы заключается в выполнении следующих этапов (блок-схема изображена на Фиг. 1).
Уточняют параметры распределенной информационной системы, такие как: количество пользователей, географическое месторасположение основных групп пользователей системы, состав функциональных модулей, востребованность функций конкретных модулей у конкретных групп пользователей, тип и структуру подсистемы хранения данных.
На основе уточненных ранее параметров распределенной информационной системы определяют структуру кластера проектируемой информационной системы, а именно: количество географически распределенных узлов в кластере, количество и характеристики серверов в узле, состав конкретных функциональных модулей системы, размещаемых на отдельных серверах в узле.
Определяют необходимость дублирования конкретных функциональных модулей на серверах географически распределенных узлов в кластере распределенной информационной системы.
Осуществляют размещение функциональных модулей относительно определенной структуры кластера распределенной информационной системы и необходимости дублирования конкретных функциональных модулей на серверах географически распределенных узлов.
Определяют и настраивают взаимодействие функциональных модулей распределенной информационной системы с подсистемой хранения данных и репозиторием файлов.
Определяют и настраивают поиск и индексирование данных в распределенной информационной системе.
Осуществляют процедуру реплицирования кэша данных среди всех узлов кластера распределенной информационной системы.
Осуществляют процедуру аутентификации и авторизации пользователей распределенной информационной системы по признакам географического месторасположения и востребованности функций конкретных модулей.
Рассмотрим частный случай реализации описываемого способа, где распределенная информационная система представляет собой кроссплатформенное программное решение, построенное на модульной архитектуре.
Все компоненты подобной системы являются, например, отдельными программными OSGI-модулями, которые построены по единым правилам и технологиям, и могут быть подключаемыми (или отключаемыми) к основному ядру системы.
OSGI - спецификация динамической модульной системы и сервисной платформы для Java-приложений, разрабатываемая консорциумом OSGi Alliance. Спецификации дают модель для построения приложения из компонентов, связанных вместе посредством сервисов. Суть данной модели заключается в возможности переустанавливать динамически компоненты и составные части приложения без необходимости останавливать и перезапускать его.
Размещение отдельных модулей возможно на географически разнесенных серверах, образующих единый кластер распределенной информационной системы. При этом определенные модули размещаются на серверах, в локациях которых к ним имеется наиболее повышенный спрос, но также допускается дублирование модулей на различных узлах кластера, в случае, если их функциональность востребована во всех локациях использования распределенной информационной системы.
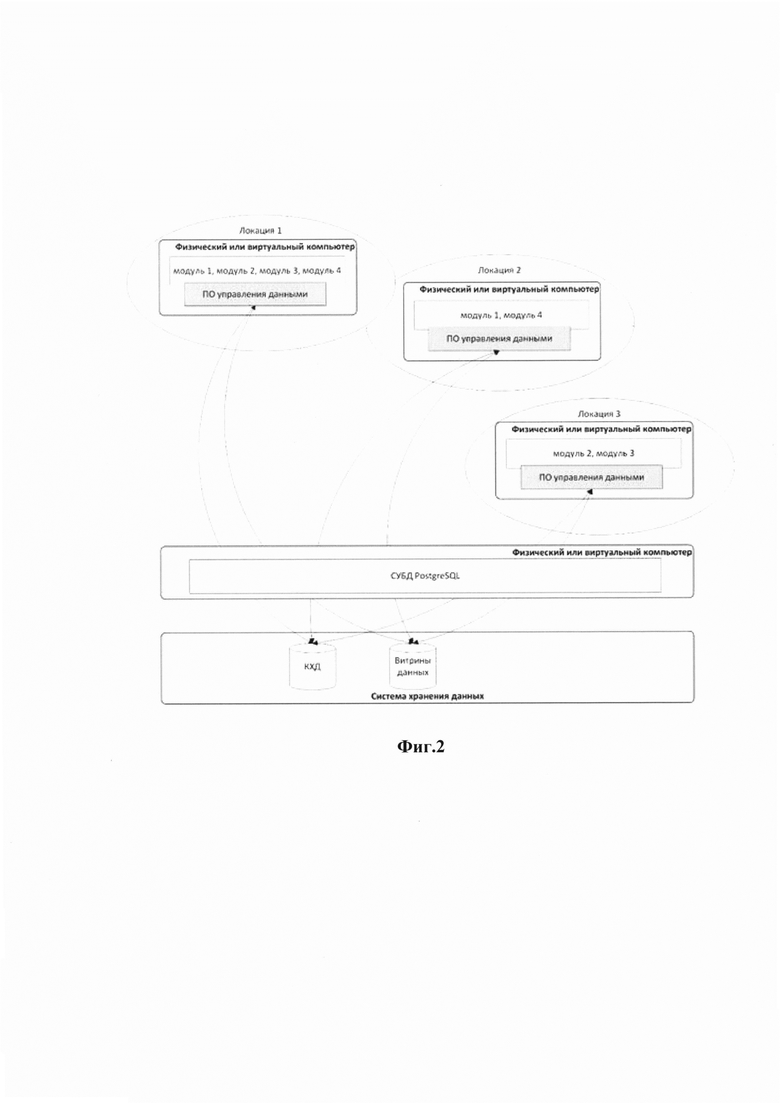
Географически разнесенные модули могут использовать как единую базу данных для управления данными, так и различные, синхронизированные между собой посредством репликации данных экземпляры баз данных.
На Фиг. 2 как частный случай реализации описываемого технического решения отображена схема размещения функциональных модулей распределенной информационной системы в трех географически разнесенных локациях с использованием единой СУБД.
Как видно из схемы, в этом примере распределенная информационная система построена на трех географически разнесенных локациях.
На каждом из узлов кластера размещены определенные наборы функциональных модулей, при этом определенные модули размещаются именно на тех узлах кластера, где они наиболее востребованы. При этом пользователи производят аутентификацию на экземплярах (instances) системы, в своей географической локации, что позволяет получить быстрый отзыв системы, пользуются именно тем набором модулей, которые востребованы в данной географической локации, но также и имеют доступ ко всему набору функциональности и данным, который имеет распределенная информационная система.
В частном случае реализации описываемого способа, распределенная информационная система представляет собой открытую платформу, вся функциональность которой доступна через API-интерфейсы (REST-сервисы). Она поддерживает веб-сервисы (SOAP), JSON, RMI, а также RMI по HTTP/HTTPS. Если в организации (компании, на предприятии и т.д.), где используется данная система, уже используются открытые приложения, поддерживающие доступ через сервисы или API-интерфейс, их можно будет интегрировать с данной распределенной информационной системой, которая также поддерживает широкие возможности масштабируемости и кластеризации.
Кластеризация подразделяется на следующие зоны:
1) Базы данных, возможны следующие варианты:
- Все узлы кластера ссылаются на одну и ту же базу данных. В данном случае каждый экземпляр физически обращается к одному и тому же экземпляру базы данных. Распределение же данных и ресурсов отдается на откуп конкретной СУБД, поддерживающей механизмы кластеризации;
- Read-Writer database configuration - Данный подход подразумевает, что создаются две базы данных: одна, оптимизированная под запросы на чтение данных, а другая, оптимизированная под запросы на запись. Далее, в свойствах системы указываются свойства соединения с обеими базами, а уже самостоятельно переадресует запросы на чтение в одну базу данных, а запросы на запись в другую;
- Database sharding - подразумевается распределение данных между различными базами данных, так называемое "горизонтальное разделение". Таким образом, каждая база данных содержит в себе лишь часть данных, что положительно сказывается на производительности всей системы.
2) Репозиторий файлов, возможны следующие варианты, причем имеется возможностью работать сразу с несколькими различными репозиториями одновременно:
- File System store - данный вид репозитория хранит все данные в файловой системе. Данные располагаются в строго определенной структуре подкаталогов относительно коренной директории репозитория. Эта структура подкаталогов строится по строгому алгоритму, который переводит идентификатор документа, присвоенный ему в базе данных, в структуру подкаталогов. Для обеспечения согласованности данных между различными узлами необходимо воспользоваться средствами ОС и смонтировать коренную директорию на все сервера. Таким образом, все экземпляры системы будут работать с централизованным репозиторием. Все возможные конфликты и блокировки одновременного доступа должны предотвращаться файловой системой;
- Advanced File System store - отличается от предыдущего вида репозитория только алгоритмом размещения документов в файловой системе (создает меньшее количество файлов в отдельной поддиректории, что положительно сказывается на времени доступа).
- CMIS (Content Management Interoperability Services) store - вместо встроенного репозитория можно использовать любой другой, реализующий доступ по протоколу CMIS. Протокол CMIS имеет средства управления одновременным доступом и предотвращает возникновение конфликтов и блокировок. Таким образом нам необходимо установить внешний репозиторий, а затем настроить систему на его использование в качестве встроенного.
3) Поиск и индексирование данных - при кластерной организации системы возможны три варианта построения поисковых механизмов:
- Подключаемая внешняя поисковая система Solr - данный вариант считается самым верным решением организации поиска, во-первых, он подразумевает выделение отдельной машины для нужд полнотекстовой индексации и поиска документов, что, несомненно, дает прирост производительности, во-вторых, он исключает трудности синхронизации поисковых индексов, так как все узлы обращаются к централизованному серверу.
- Синхронизация полнотекстовых индексов Lucene между всеми узлами - данный вариант предлагает настроить систему так, чтобы каждое произведенное изменение распространялось сразу на все узлы.
- Общий поисковый индекс - данный подход подразумевает централизованное расположение всего поискового индекса. Для этого придется выбрать между хранением индекса в базе данных и файловой системе.
4) Кэширование данных - кэш должен быть реплицирован среди всех узлов кластера. В системе в качестве системы кэширования использует Ehcache, и включены механизмы организации репликации кэша. Таким образом, для включения механизма реплицирования кэша достаточно установить только одно свойство в конфигурации системы. Механизм реплицирования кэша организован следующим образом: при изменении данных кэша на одном из узлов происходит передача изменений на все остальные узлы кластера по протоколу RMI.
Специалисту в данной области, очевидно, что конкретные варианты осуществления способа построения распределенной информационной системы были описаны здесь в целях иллюстрации, допустимы различные модификации, не выходящие за рамки и сущности объема технического решения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА УПРАВЛЕНИЯ ЭЛЕКТРОННЫМ ДОКУМЕНТООБОРОТОМ | 2018 |
|
RU2702505C1 |
| СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ (СУБД) | 2018 |
|
RU2704873C1 |
| СПОСОБ ЗАШИФРОВАННОЙ СВЯЗИ С ИСПОЛЬЗОВАНИЕМ ДЕЦЕНТРАЛИЗОВАННОЙ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЫ | 2024 |
|
RU2838643C1 |
| Интегрированный программно-аппаратный комплекс | 2016 |
|
RU2646312C1 |
| ПЕРСОНАЛИЗИРОВАННЫЙ РЕПОЗИТОРИЙ ОБЪЕКТОВ | 2016 |
|
RU2696225C1 |
| СПОСОБ ПРЕОБРАЗОВАНИЯ ДАННЫХ ГЕОИНФОРМАЦИОННЫХ СИСТЕМ (ГИС), СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ И СПОСОБ ПОИСКА ПО СФОРМИРОВАННОЙ ЭТИМ СПОСОБОМ БАЗЕ ДАННЫХ | 2017 |
|
RU2669143C1 |
| СИСТЕМА И СПОСОБ ВЫПОЛНЕНИЯ ПОИСКА | 2014 |
|
RU2597476C2 |
| Способ адаптивного выбора путей передачи данных пользователя | 2019 |
|
RU2739862C2 |
| ХРАНИЛИЩЕ ДАННЫХ ДЛЯ ОСНОВАННОЙ НА ЗНАНИЯХ СИСТЕМЫ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ДАННЫХ | 2003 |
|
RU2297665C2 |
| ИНТЕЛЛЕКТУАЛЬНОЕ УТОЧНЕНИЕ ПОИСКА | 2014 |
|
RU2665302C2 |
Изобретение относится к области вычислительной техники. Технический результат заключается в повышении скорости обмена данными в распределенной информационной системе. Способ содержит этапы, на которых: уточняют параметры распределенной информационной системы; определяют структуру кластера проектируемой информационной системы; определяют необходимость дублирования конкретных функциональных модулей на серверах географически распределенных узлов в кластере распределенной информационной системы; осуществляют размещение функциональных модулей; определяют и настраивают взаимодействие функциональных модулей распределенной информационной системы с подсистемой хранения данных и репозиторием файлов; определяют и настраивают поиск и индексирование данных в распределенной информационной системе; осуществляют процедуру реплицирования кэша данных среди всех узлов кластера распределенной информационной системы; осуществляют процедуру аутентификации и авторизации пользователей. 9 з.п. ф-лы, 2 ил. 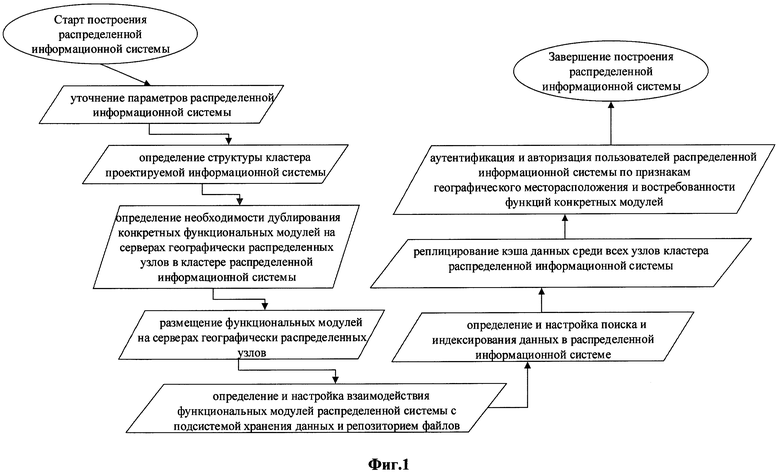
1. Способ построения распределенной информационной системы, характеризующийся тем, что:
уточняют параметры распределенной информационной системы, такие как: количество пользователей, географическое месторасположение основных групп пользователей системы, состав функциональных модулей, востребованность функций конкретных модулей у конкретных групп пользователей, тип и структуру подсистемы хранения данных;
на основе уточненных ранее параметров распределенной информационной системы определяют структуру кластера проектируемой информационной системы, а именно: количество географически распределенных узлов в кластере, количество и характеристики серверов в узле, состав конкретных функциональных модулей системы, размещаемых на отдельных серверах в узле;
определяют необходимость дублирования конкретных функциональных модулей на серверах географически распределенных узлов в кластере распределенной информационной системы;
осуществляют размещение функциональных модулей относительно определенной структуры кластера распределенной информационной системы и необходимости дублирования конкретных функциональных модулей на серверах географически распределенных узлов;
определяют и настраивают взаимодействие функциональных модулей распределенной информационной системы с подсистемой хранения данных и репозиторием файлов;
определяют и настраивают поиск и индексирование данных в распределенной информационной системе;
осуществляют процедуру реплицирования кэша данных среди всех узлов кластера распределенной информационной системы;
осуществляют процедуру аутентификации и авторизации пользователей распределенной информационной системы по признакам географического месторасположения и востребованности функций конкретных модулей.
2. Способ по п. 1, характеризующийся тем, что подсистема хранения данных в распределенной информационной системе организована таким образом, что все узлы кластера ссылаются на одну базу данных.
3. Способ по п. 1, характеризующийся тем, что подсистема хранения данных в распределенной информационной системе использует конфигурацию Read-Writer database.
4. Способ по п. 1, характеризующийся тем, что подсистема хранения данных в распределенной информационной системе распределяет данные между различными базами данных.
5. Способ по п. 1, характеризующийся тем, что в качестве репозитория файлов в распределенной информационной системе используется File System store.
6. Способ по п. 1, характеризующийся тем, что в качестве репозитория файлов в распределенной информационной системе используется Advanced File System store.
7. Способ по п. 1, характеризующийся тем, что в качестве репозитория файлов в распределенной информационной системе используется репозиторий, реализующий доступ по протоколу CMIS.
8. Способ по п. 1, характеризующийся тем, что функции поиска и индексирования в распределенной информационной системе выполняет подключаемая внешняя поисковая система Solr.
9. Способ по п. 1, характеризующийся тем, что в распределенной информационной системе используется централизованное расположение поискового индекса.
10. Способ по п. 1, характеризующийся тем, что производится синхронизация полнотекстовых индексов между всеми узлами кластера распределенной информационной системы.
| RU 2016129564 A, 23.01.2018 | |||
| RU 2016119888 A, 28.11.2017 | |||
| Колосоуборка | 1923 |
|
SU2009A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |

