ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0001] Настоящее изобретение относится, в общем, к области тематического моделирования и, в частности, к устройству и способу для тематического моделирования с априорными параметрами тональности на основе распределенных представлений.
УРОВЕНЬ ТЕХНИКИ
[0002] Тематическое моделирование стало предпочтительной моделью для ряда приложений, которые выполняют анализ больших текстовых коллекций без учителя. Базовая модель латентного размещения Дирихле (Latent Dirichlet Allocation) (Blei et al., 2003; Griffiths and Steyvers, 2004) получила множество развитий в различных целях, таких как моделирование взаимосвязанных тем (Li, 2009; Chang and Blei, 2010), эволюция темы во времени (Wang and McCallum, 2006; Blei and Lafferty, 2006; Wang et al., 2008), методы с переменной отклика с учителем (Blei and McAuliffe, 2007) и т.д.
[0003] Одним из важных применений тематических моделей стало их применение в области анализа тональности. В последнее время тематические модели были успешно применены в аспектно-ориентированном анализе мнений: тематические модели способны без учителя идентифицировать скрытые тематические аспекты с тональностями по отношению к ним в текстовых документах (текстах) и других эмоционально-оценочных наборах данных (Titov and McDonald, 2008; Moghaddam and Ester, 2012). В недавних исследованиях аспект обычно определяют как атрибут или признак продукта, который был прокомментирован в текстовом документе и может быть кластеризован в связные темы или аспекты (Moghaddam and Ester, 2012; Lin et al., 2012; Yang et al., 2015b), например, "кекс" и "стейк" являются частью темы "еда" для ресторанов.
[0004] Тематические модели, осуществляющие анализ тональности, обычно включают в себя тональные метки для отдельных слов. В таких тематических моделях, как JST и Reverse-JST (Lin et al., 2012), ASUM (Yohan and H., 2011) и USTM (Yang et al., 2015b), используются существующие словари оценочных слов для задания априорных параметров β тональности отдельным словам в определенных темах. Tutubalina and Nikolenko (2015) предложили новый метод, который начинается с исходного словаря оценочных слов, а затем обучаются новые априорные параметры β тональности с использованием метода максимизации ожидания. Этот подход позволяет обнаружить новые оценочные слова, особенно аспектно-ориентированные оценочные слова, которые не могли быть перечислены в словаре, имеют разные априорные параметры тональности для одних и тех же слов в различных аспектах, и было продемонстрировано общее улучшение классификации по тональностям.
[0005] С другой стороны, последние достижения в распределенных представлениях слов сделали их предпочтительным подходом к современной обработке естественного языка (Goldberg, 2015). В этом методе слова представляются в виде векторов в евклидовом пространстве, чтобы попытаться уловить семантические отношения с геометрией этого семантического пространства. Начиная с работ Mikolov et al. (2013a; 2013b), распределенные представления слов применялись для многочисленных задач обработки естественного языка, включая классификацию текста, извлечение тональной лексики, морфологическую разметку, синтаксический анализ и т.д. В частности, Wang et al. (2015) успешно применили сети краткосрочной памяти (LSTM) к векторным представлениям слов для анализа тональности, а Kalchbrenner et al. (2014) использовали для анализа тональности сверточные сети, нацеленные на выявление локальных признаков (например, в данном случае оценочных слов). Уже предложено несколько методов, объединяющих тематические модели и векторы слов, например, нейронные тематические модели Cao et al. (2015) и тематические модели с гауссовой смесью Yang et al. (2015a), однако они еще не получили развития на тематические модели для анализа тональности.
[0006] В традиционных аспектно-ориентированных подходах к анализу тональности извлекаются фразы, содержащие слова из предопределенных и обычно созданных вручную лексиконов или слова, на которые указали обученные классификаторы, чтобы предсказать полярность тональности. В этих работах обычно различают эмоциональные слова, выражающие чувства ("счастливый", "разочарованный"), и оценочные слова, выражающие тональность в отношении определенной вещи или аспекта ("идеальный", "ужасный"); эти слова берутся из известного словаря, и предполагается, что данная модель объединяет тональности отдельных слов в общую оценку всего текста и отдельные оценки конкретных аспектов. В работе (Liu, 2015) представлен недавний обзор анализа мнений; в большинстве методов центральную роль играет словарь оценочной лексики.
[0007] В последнее время было предложено несколько тематических моделей, которые были успешно использованы для анализа тональности. Вероятностные тематические модели, обычно основанные на латентном размещении Дирихле (LDA) и его развитиях (Lin et al., 2012; Yohan and H., 2011; Yang et al., 2015b; Lu et al., 2011), предполагают, что существует специфическое для документов распределение над тональностями, поскольку тональность зависит от документа, а априорные параметры модели основаны на лексиконе.
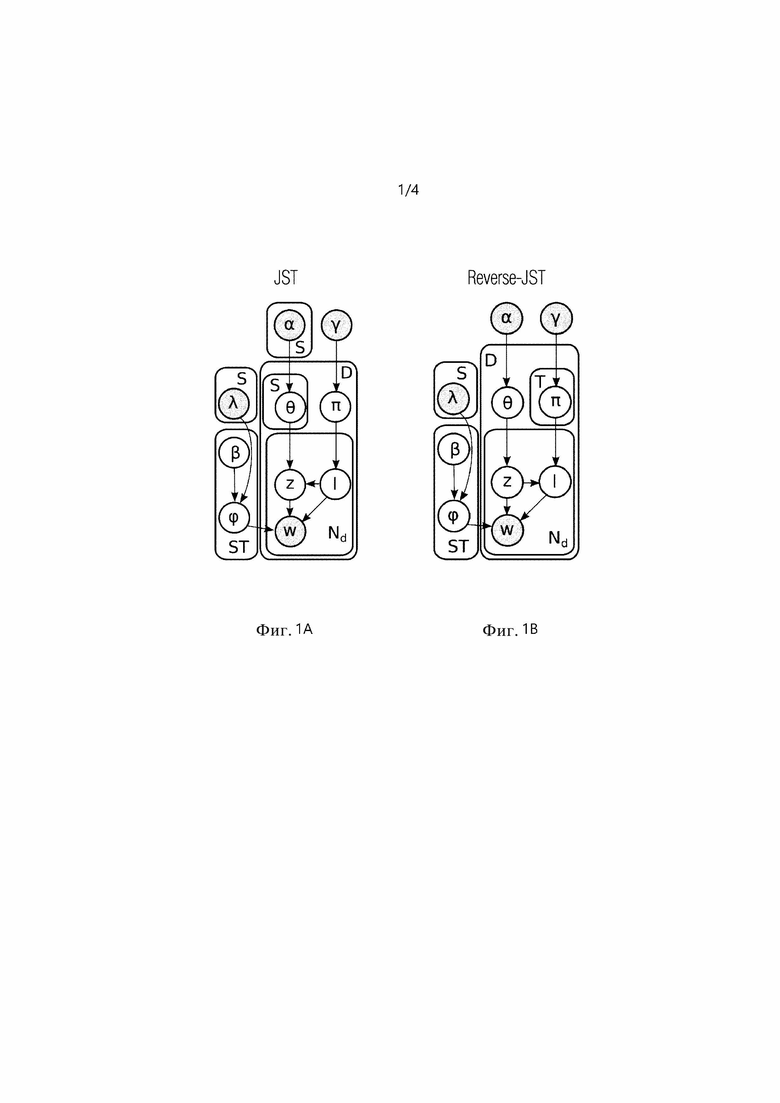
[0008] На фиг. 1A, 1B показаны предложенные Lin et al. (2012) тональностные модификации модели LDA: тональность-тема (Joint Sentiment-Topic, далее JST) и тема-тональность (Reverse Joint Sentiment-Topic, далее Reverse-JST), которые построены на основном предположении, что в модели JST темы зависят от тональностей из распределения d тональностей документа и слова порождаются условно на парах тональность-тема, тогда как в модели Reverse-JST тональности порождаются условно на распределении θd темы документа. Lin et al. (2012) вывели распределения сэмплирования по Гиббсу для обеих моделей.
[0009] Подобно JST, Jo and Oh (2011) предложили объединенную модель аспект-тональность (Aspect and Sentiment Unification Model, далее ASUM), в которой все слова в предложении порождаются из одной темы с одинаковой тональностью. Темы (аспекты из текстовых документов) порождаются из распределения предложений над тональностями. Модель ASUM показала более высокое качество по сравнению с классификаторами с учителем и другими генеративными моделями, включая JST.
[0010] В работе Yang et al. (2015b) представлены модели User-Aware Sentiment Topic Models (USTM), которые содержат метаданные пользователя вместе с темами и тональностями. В этой модели темы зависят от тегов документа, а слова обусловлены латентными темами, тональностями и тегами. USTM показывает существенно лучшие результаты по сравнению с JST и ASUM в предсказании тональности текстовых документов, однако авторы не анализировали минимальное количество тегов, необходимое для эффективного обучения без возникновения переобучения.
[0011] Следует также упомянуть непараметрическое иерархическое расширение ASUM, названное HASM (Kim et al., 2013), и непараметрические расширения моделей USTM - USTM-DP (W) и USTM-DP (S) (Yang et al., 2015b).
[0012] Существующие тематические модели для аспектно-ориентированного анализа тональности почти всегда предполагают наличие предопределенного словаря оценочных слов, обычно включающего эту информацию в априорные параметры β для распределений слово-тема в модели LDA. Было обнаружено, что асимметричное априорное распределение Дирихле на подокументные пропорции тематической тональности обеспечивает лучшую классификацию по сравнению с моделями с симметричными априорными распределениями (Yang et al., 2015b). Tutubalina and Nikolenko (2015) предлагают новый метод для автоматических обновлений тональных меток отдельных слов в режиме с частичным привлечением учителя, берущий начало с небольшого исходного словаря с оптимизацией на основе ожидания-максимизации. На каждом E-шаге априорные параметры тональности βkw обновляются пропорционально количеству слов w, порожденных с тональной меткой k в корпусе, коэффициентом, который уменьшается с числом итераций во избежание переобучения. Однако этот метод рассматривает каждое слово как независимую меру, и в целом, по-видимому, страдает от слишком большого количества независимых переменных.
[0013] Обучение априорных параметров β тональности можно рассматривать как часть усилий по оптимизации априорных параметров в тематических моделях. В смежной работе тематические гиперпараметры α были оптимизированы простой итерацией для максимизации логарифмического доказательства (Minka, 2000). Seaghdha and Teufel (2014) используют гиперпараметры байесовской модели с латентными переменными для исследования риторического и тематического языка, сэмплируя их гамильтоновым методом Монте-Карло. Hong et al. (2012) используют смесь ЕМ и сэмплирования Монте-Карло для эффективного изучения всех параметров в вариационном выводе. Другая группа методов оптимизации для параметров тональностной модели минимизирует погрешности между наблюдаемыми и прогнозируемыми рейтингами. Diao et al. (2014) используют градиентный спуск для минимизации целевой функции, которая состоит из ошибки предсказания на пользовательских рейтингах и вероятности изучения текста, зависящего от априорных параметров. Li et al. (2014) строят тематическую модель "пользователь-элемент" с учителем, которая оптимизирует априорные параметры и другие параметры, используя текстовое тематическое распределение и применяет латентные факторы пользователя и элемента для предсказания рейтингов. В данной работе не рассматриваются тематические модели с наблюдаемыми метками с учителем, однако они упоминаются как возможное направление для будущей работы.
[0014] И наконец, в настоящем изобретении используются распределенные представления слов, то есть модели, которые отображают каждое слово, встречающееся в словаре, в евклидовом пространстве, пытаясь захватить семантические взаимосвязи между словами как геометрические отношения в евклидовом пространстве. Обычно сначала создается словарь с унитарными представлениями отдельных слов, где каждое слово соответствует своей собственной мере, а затем, исходя из него, обучаются представления для отдельных слов, по существу, как задача уменьшения размерности (Mikolov et al., 2013b). Для этой цели исследователи обычно используют модель с одним скрытым слоем, которая пытается предсказать следующее слово на основе окна нескольких предыдущих слов. Затем представления, полученные на скрытом слое, принимаются за признаки слова; другие варианты включают GloVe (Global Vectors for Word Representation) (Pennington et al., 2014) и другие методы (Al-Rfou et al., 2013).
[0015] Было предпринято несколько попыток использовать распределенные представления слов для построения тематических моделей. Нейронная тематическая модель, разработанная Cao et al. (2015), моделирует распределения тема-слово и тема-документ с помощью нейронных сетей путем обучения векторных представлений n-граммы вместе с векторными представлениями документ-тема; эта модель была также расширена до настройки с учителем. Yang et al. (2015a) рассматривают тему, как кластер, заданный Гауссовым распределением, в семантическом пространстве, тем самым превращая тематическую модель в гауссову смесь. Другой способ принятия тематического моделирования в нейронную модель был предложен в работе Wu et al., 2016, где модификация TweetLDA, LDA для коротких текстов (Quercia et al., 2012) использовалась для порождения тем и тематических ключевых слов в качестве дополнительной информации для входного сообщения в сверточную нейронную сеть.
СПИСОК БИБЛИОГРАФИЧЕСКИХ ДАННЫХ
[0016] Rami Al-Rfou, Bryan Perozzi, and Steven Skiena. 2013. Polyglot: Distributed word representations for multilingual nlp. In Proceedings of the Seven teenth Conference on Computational Natural Lan guage Learning, pages 183-192, Sofia, Bulgaria. Association for Computational Linguistics.
[0017] N. Arefyev, A. Panchenko, A. Lukanin, O. Lesota, and P. Romanov. 2015. Evaluating three corpus-based semantic similarity systems for russian. In Proceedings of International Conference on Computational Linguistics Dialogue.
[0018] James Bergstra, Olivier Breuleux, Frederic Bastien, Pascal Lamblin, Razvan Pascanu, Guillaume Des jardins, Joseph Turian, David Warde-Farley, and Yoshua Bengio. 2010. Theano: a cpu and gpu math expression compiler. In Proceedings of the Python for scientific computing conference (SciPy), volume 4, page 3. Austin, TX.
[0019] David M. Blei and John D. Lafferty. 2006. Dynamic topic models. In Proceedings of the 23rd Inter national Conference on Machine Learning, pages 113-120, New York, NY, USA. ACM.
[0020] David M. Blei and JonD. McAuliffe. 2007. Supervised topic models. Advances in Neural Information Pro cessing Systems, 22.
[0021] David M. Blei, Andrew Y. Ng, and Michael I. Jordan. 2003. Latent Dirichlet allocation. Journal of Ma chine Learning Research, 3(4-5):993-1022.
[0022] Ziqiang Cao, Sujian Li, Yang Liu, Wenjie Li, and Heng Ji. 2015. A novel neural topic model and its super vised extension. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, January 25-30, 2015, Austin, Texas, USA., pages 2210-2216.
[0023] Jonathan Chang and David M. Blei. 2010. Hierarchical relational models for document networks. Annals of Applied Statistics, 4(1):124-150.
[0024] Qiming Diao, Minghui Qiu, Chao-Yuan Wu, Alexander J Smola, Jing Jiang, and Chong Wang. 2014. Jointly modeling aspects, ratings and sentiments for movie recommendation (jmars). In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 193-202. ACM.
[0025] Yoav Goldberg. 2015. A primer on neural network models for natural language processing. CoRR, abs/1510.00726.
[0026] Tom Griffiths and Mark Steyvers. 2004. Finding scientific topics. Proceedings of the National Academy of Sciences, 101 (Suppl. 1):5228-5335.
[0027] Liangjie Hong, Amr Ahmed, Siva Gurumurthy, Alexander J Smola, and Kostas Tsioutsiouliklis. 2012. Discovering geographical topics in the twitter stream. In Proceedings of the 21st international conference on World Wide Web, pages 769-778. ACM.
[0028] Nal Kalchbrenner, Edward Grefenstette, and Phil Blun-som. 2014. A convolutional neural network for modelling sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 655-665, Baltimore, Maryland. Association for Computational Linguistics.
[0029] Suin Kim, Jianwen Zhang, Zheng Chen, Alice H. Oh, and Shixia Liu. 2013. A hierarchical aspect-sentiment model for online reviews. In Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence, July 14-18, 2013, Bellevue, Washington, USA.
[0030] Fangtao Li, Sheng Wang, Shenghua Liu, and Ming Zhang. 2014. Suit: A supervised user-item based topic model for sentiment analysis. In Twenty-Eighth AAAI Conference on Artificial Intelligence.
[0031] S. Z. Li. 2009. Markov Random Field Modeling in Image Analysis. Advances in Pattern Recognition. Springer, Berlin Heidelberg.
[0032] Chenghua Lin, Yulan He, Richard Everson, and Stefan Ruger. 2012. Weakly supervised joint sentiment-topic detection from text. IEEE Transactions on Knowledge and Data Engineering, 24(6):1134 -1145.
[0033] Bing Liu. 2015. Sentiment Analysis: Mining Opinions, Sentiments, and Emotions. Cambridge University Press.
[0034] B. Lu, M. Ott, C. Cardie, andB.K. Tsou. 2011. Multiaspect sentiment analysis with topic models. Data Mining Workshops (ICDMW), 2011 IEEE 11thInter-national Conference, pages 81-88.
[0035] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013 a. Efficient estimation of word representations in vector space. CoRR, abs/1301.3781.
[0036] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013b. Distributed representations of words and phrases and their compositionality. CoRR, abs/1310.4546.
[0037] Thomas Minka. 2000. Estimating a dirichlet distribution.
Samaneh Moghaddam and Martin Ester. 2012. On the design of lda models for aspect-based opinion mining. In Proceedings of the 21st ACM international conference on Information and knowledge management, pages 803-812. ACM.
[0038] A. Panchenko, N.V Loukachevitch, D. Ustalov, D. Pa-perno, C. M. Meyer, and N. Konstantinova. 2015. Russe: The first workshop on russian semantic similarity. In Proceedings of the International Conference on Computational Linguistics and Intellectual Technologies (Dialogue), pages 89-105.
[0039] Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1532-1543, Doha, Qatar. Association for Computational Linguistics.
[0040] Daniele Quercia, Harry Askham, and Jon Crowcroft. 2012. TweetLDA: supervised topic classification and link prediction in twitter. In WebSci, pages 247-250. ACM.
[0041] Radim Rehhrek and Petr Sojka. 2010. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, pages 45-50, Valletta, Malta. ELRA. http://is.muni.cz/publication/884893/en.
[0042] Diarmuid O Seaghdha and Simone Teufel. 2014. Unsupervised learning of rhetorical structure with untopic models. In COLING, pages 2-13.
[0043] Ivan Titov and Ryan McDonald. 2008. Modeling online reviews with multi-grain topic models. In Proceedings of the 17th international conference on World Wide Web, pages 111-120. ACM.
[0044] Elena Tutubalina and Sergey I. Nikolenko. 2015. Inferring sentiment-based priors in topic models. In Proc. 14th Mexican International Conference on Artificial Intelligence, volume 9414 of Lecture Notes in Computer Science, pages 92-104. Springer.
[0045] Chong Wang, David M. Blei, and David Heckerman. 2008. Continuous time dynamic topic models. In Proceedings of the 24th Conference on Uncertainty in Artificial Intelligence.
[0046] Hongning Wang, Yue Lu, and Chengxiang Zhai. 2011. Latent aspect rating analysis without aspect keyword supervision. In Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 618-626. ACM.
[0047] Xin Wang, Yuanchao Liu, Chengjie Sun, Baoxun Wang, and Xiaolong Wang. 2015. Predicting polarities of tweets by composing word embeddings with long short-term memory. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1343-1353, Beijing, China. Association for Computational Linguistics.
[0048] Xuerui Wang and Andrew McCallum. 2006. Topics over time: a non-Markov continuous-time model of topical trends. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 424-433, New York, NY, USA. ACM.
[0049] Theresa Wilson, Janyce Wiebe, and Paul Hoffmann. 2005. Recognizing contextual polarity in phrase-level sentiment analysis. In Proceedings of the conference on human language technology and empirical methods in natural language processing, pages 347-354. Association for Computational Linguistics.
[0050] Yu Wu, Wei Wu, Zhoujun Li, and Ming Zhou. 2016. Topic augmented neural network for short text conversation. arXiv preprint arXiv:1605.00090.
[0051] Min Yang, Tianyi Cui, and Wenting Tu. 2015a. Ordering-sensitive and semantic-aware topic modeling. CoRR, abs/1502.0363.
[0052] Zaihan Yang, Alexander Kotov, Aravind Mohan, and Shiyong Lu. 2015b. Parametric and non-parametric user-aware sentiment topic models. In Proceedings of the 38-th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 413-422. ACM.
[0053] Jo Yohan and Oh Alice H. 2011. Aspect and sentiment unification model for online review analysis. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, WSDM '11, pages 815-824, New York, NY, USA. ACM.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0054] В настоящем изобретении предложен подход, в котором априорные параметры тональности обучаются в пространстве векторных представлений слов; это позволяет выявить больше аспектно-ориентированных тональных слов и дополнительно улучшить классификацию.
[0055] В отличие от нейронных тематических моделей в настоящем изобретении предложен способ, который более точно соответствует существующим подходам к тональностно-ориентированному тематическому моделированию; используются уже существующие, ранее обученные векторные представления слов, и они применяются для улучшения классификации тональности. Во-первых, это позволяет использовать векторные представления слов, обученные на очень больших корпусах и охватывающие множество примеров для различных языков, гораздо больше, чем может обеспечить любая тональностно-ориентированная база данных. Во-вторых, этот подход легче применять и расширять в практических ситуациях: для английского языка можно загрузить высококачественные векторные представления слов, обученные на огромных корпусах, таких как Википедия, а для других языков можно обучать векторные представления слов с использованием существующих библиотек, таких как word2vec (Mikolov et al., 2013a) и ее новые реализации ((Řehůřek and Sojka, 2010).
[0056] В соответствии с настоящим изобретением предлагается объединить преимущества тематических моделей и распределенных представлений посредством обучения тональностно-ориентированной тематической модели априорным параметрам, основанным на векторных представлениях слов. Основная идея заключается в том, что вместо обучения отдельных априорных параметров β независимо для каждого слова априорный параметр тональности обучается на основе семантически связных слов в семантическом пространстве, которое автоматически распространяется на очень похожие, взаимозаменяемые слова. Такой подход позволяет существенно расширить обученные словари тональности и усовершенствовать классификацию тональности. Кроме того, вместо одного унифицированного предсказания тональности, обеспечиваемого, например, LSTM, этот подход выдает специфичные позитивные и негативные слова для отдельных аспектов в текстовом документе, что обеспечивает более подробный и легко интерпретируемый взгляд на оценку тональности.
[0057] В настоящем изобретении предложен метод автоматического обновления априорных параметров тональности для взаимозаменяемых слов на основе распределенных представлений. Экспериментальная оценка показала, что эта идея приводит к улучшению классификации тональности и предсказания пользовательских атрибутов по сравнению с тематическими моделями, основанными на предопределенных априорных параметрах, и моделями, которые обновляют априорные параметры тональности для отдельных слов. Качественный анализ обнаруженных тем также показывает, что предлагаемая модель с измененными априорными параметрами может находить связные темы с высокой точностью. Кроме того, существует возможность обеспечения взаимодействия между априорными параметрами тональности в расширениях LDA и распределенными представлениями слов, можно будет включать распределенные представления слов непосредственно в другие априорные параметры.
[0058] Согласно одному аспекту настоящего изобретения предложен способ тематического моделирования с априорными параметрами тональности на основе распределенных представлений, содержащий этапы, на которых: вводят текстовый документ (текст) в тематическую модель; и посредством тематической модели: определяют представление для каждого слова в текстовом документе, причем представлениями являют векторы слов в семантическом пространстве; и оценивают эти представления с использованием априорных параметров тональности для определения темы, соответствующей данному текстовому документу, причем тематическая модель содержит априорные параметры тональности, обученные на основе представлений, распределенных с использованием регуляризатора, который задает одинаковую тональность словам, имеющим подобные векторы слов, и причем каждый априорный параметр тональности один и тот же для слов, имеющих подобные векторы слов.
[0059] Согласно следующему аспекту предложен способ, в котором при обучении априорных параметров тональности: вводят набор слов в тематическую модель, и посредством тематической модели: определяют набор ближайших соседей для каждого слова, определяют представление для каждого слова, причем представлениями являются векторы слов в семантическом пространстве; вычисляют коэффициент регуляризации упомянутого регуляризатора для задания регуляризатора путем оценки для каждого слова вероятностей встречаемости этого слова в тональности с помощью некоторых счетчиков, используя представления и набор ближайших соседей; задают одинаковую тональность словам, имеющим подобные векторы слов, используя регуляризатор; распределяют представления согласно результатам задания; и вычисляют априорные параметры тональности, используя распределенные представления.
[0060] Согласно следующему аспекту изобретения предложен способ, в котором при обучении априорных параметров тональности дополнительно: предсказывают пользовательские атрибуты посредством тематической модели, используя априорные параметры тональности, обученные на основе представлений, распределенных с использованием регуляризатора, причем пользовательские атрибуты включают в себя, по меньшей мере, одно из местоположения, пола и возраста пользователя; и обновляют априорные параметры тональности на основе предсказанных пользовательских атрибутов.
[0061] Согласно следующему аспекту изобретения предложен способ, в котором оценка представлений с использованием априорных параметров тональности включает в себя максимизацию правдоподобия тематической модели, содержащий этапы, на которых: обновляют коэффициент регуляризации, и обновляют априорные параметры тональности с использованием регуляризатора, имеющего обновленный коэффициент регуляризации.
[0062] Согласно другому аспекту настоящего изобретения предложено устройство для тематического моделирования с априорными параметрами тональности на основе распределенных представлений, содержащее: процессор и память, содержащую тематическую модель и команды, предписывающие процессору: вводить текстовый документ в тематическую модель; определять посредством тематической модели представление для каждого слова в текстовом документе, причем представлениями являются векторы слов в семантическом пространстве; и оценивать посредством тематической модели представления с использованием априорных параметров тональности, чтобы определить тему, соответствующую данному текстовому документу, при этом тематическая модель содержит априорные параметры тональности, обученные на основе представлений, распределенных с использованием регуляризатора, который задает одинаковую тональность словам, имеющим подобные векторы слов, и причем каждый априорный параметр тональности один и тот же для слов, имеющих подобные векторы слов.
[0063] Согласно следующему аспекту изобретения предложено устройство, в котором для обучения априорных параметров тональности память дополнительно содержит команды, предписывающие процессору: вводить набор слов в тематическую модель, и посредством тематической модели: определять набор ближайших соседей для каждого слова, определять представление для каждого слова, причем представлениями являются векторы слов в семантическом пространстве; вычислять коэффициент регуляризации упомянутого регуляризатора, чтобы задать регуляризатор посредством оценки для каждого слова вероятностей встречаемости данного слова в тональности с помощью некоторых счетчиков, используя представления и набор ближайших соседей; задавать одинаковую тональность словам, имеющим подобные векторы слов, используя регуляризатор; распределять представления в соответствии с результатами задания; и вычислять априорные параметры тональности, используя распределенные представления.
[0064] Согласно следующему аспекту изобретения предложено устройство, в котором для обучения априорных параметров тональности память дополнительно содержит команды, предписывающие процессору: предсказывать пользовательские атрибуты посредством тематической модели, используя априорные параметры тональности, обученные на основе представлений, распределенных с использованием регуляризатора, причем пользовательские атрибуты включают в себя, по меньшей мере, одно из местоположения, пола и возраста пользователя; и обновлять априорные параметры тональности на основе предсказанных пользовательских атрибутов.
[0065] Согласно следующему аспекту изобретения предложено устройство, в котором память дополнительно содержит команды, предписывающие процессору: при оценке представлений с использованием априорных тональности выполнять максимизацию правдоподобия тематической модели, при которой: обновляют коэффициент регуляризации; и обновляют априорные параметры тональности, используя регуляризатор, имеющий обновленный коэффициент регуляризации.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0066] Описанные выше и другие аспекты, существенные признаки и преимущества настоящего изобретения будут более понятны из следующего подробного описания в совокупности с прилагаемыми чертежами, на которых:
[0067] Фиг. 1A изображает тональностные расширения LDA для модели Joint Sentiment-Topic (JST).
[0068] Фиг. 1B изображает тональностные расширения LDA для модели Reverse Joint Sentiment-Topic (JST).
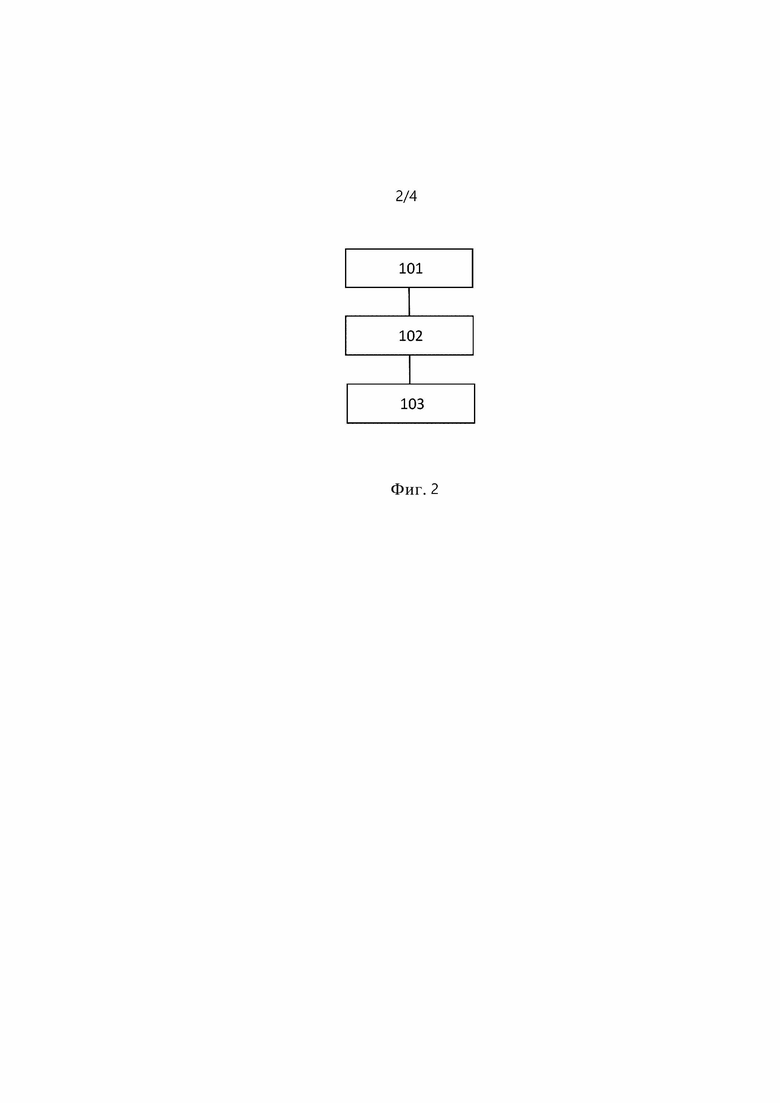
[0069] Фиг. 2 изображает блок-схему, иллюстрирующую способ тематического моделирования с априорными параметрами тональности на основе распределенных представлений.
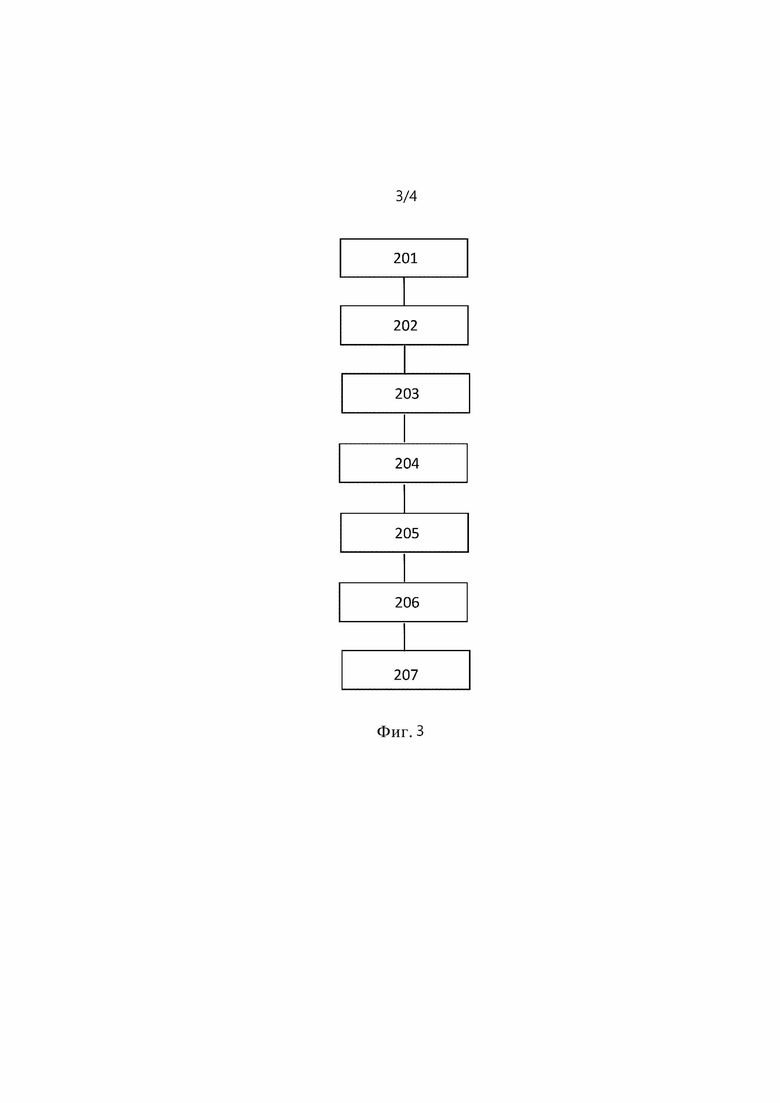
[0070] Фиг. 3 изображает блок-схему, иллюстрирующую обучение априорных параметров тональности в тематической модели.
[0071] Фиг. 4 изображает схему, иллюстрирующую точность предсказания тональности путем изменения коэффициента регуляризации a (набор данных Amazon-Tools).
[0072] В последующем описании, если не указано иное, одни и те же ссылочные позиции используются для одинаковых элементов, изображенных на разных чертежах, и их описание не дублируется.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0073] Дальнейшее описание со ссылками на прилагаемые чертежи представлено для обеспечения полного понимания различных вариантов осуществления настоящего изобретения, которые определены формулой изобретения и ее эквивалентами. Оно включает в себя различные конкретные детали, способствующие этому пониманию, однако эти детали следует рассматривать только как примерные. Соответственно, специалистам в данной области техники будет понятно, что различные изменения и модификации разных вариантов осуществления, описанных в данном документе, могут быть осуществлены не выходя за рамки объема настоящего раскрытия. Кроме того, описания известных функций и конструкций могут быть опущены для ясности и краткости изложения.
[0074] Термины и слова, используемые в следующем описании и формуле изобретения, не ограничены их библиографическими значениями, а используются автором только для обеспечения ясного и полного понимания настоящего раскрытия. Соответственно, специалистам в данной области будет понятно, что последующее описание различных вариантов осуществления настоящего раскрытия приводится только в целях иллюстрации.
[0075] Следует понимать, что формы единственного числа включают в себя и множественное число, если в контексте явно не указано иное. Таким образом, например, упоминание "области глаза" включает в себя упоминание одного или нескольких таких изображений.
[0076] Следует понимать, что хотя в данном документе могут использоваться термины "первый", "второй" и т.п. в отношении элементов настоящего изобретения, не следует истолковывать эти элементы как ограниченные данными терминами. Эти термины используются только для различия между элементами.
[0077] Кроме того, понятно, что термины "содержит", "содержащий", "включает" и/или "включающий", используемые в настоящем документе, указывают на наличие упомянутых признаков, целых чисел, операций, элементов и/или компонентов, но не исключают наличия или добавления одного или нескольких других признаков, целых чисел, операций, элементов, компонентов и/или их групп.
[0078] В различных вариантах осуществления настоящего раскрытия "модуль" или "блок" может выполнять по меньшей мере одну функцию или операцию и может быть реализован в аппаратном виде, программном обеспечении или их комбинации. "Множество модулей" или "множество блоков" может быть реализовано, по меньшей мере, в одном процессоре (не показан) посредством его интеграции с, по меньшей мере, одним модулем, отличным от "модуля" или "блока", который необходимо реализовать с помощью конкретного аппаратного элемента.
[0079] Далее будут более подробно описаны различные варианты осуществления настоящего изобретения со ссылками на прилагаемые чертежи.
Априорные параметры тональности как распределения в семантическом пространстве
[0080] Ранее априорные параметры тональности вводились в модель либо в виде предопределенных значений априорных параметров, взятых из словаря, либо в виде набора независимых значений βkw априорных параметров тональности, которые необходимо было обучать отдельно на E-шаге EM-алгоритма. В настоящем изобретении базовая модель априорных параметров βkw тональности изменена: вместо полностью независимых значений βkw априорных параметров для каждого значения k тональности и каждого слова w предполагается, что βkw должно быть одинаковым для слов, которые одинаковы в семантическом евклидовом пространстве векторных представлений слов. Предположим, что для каждого слова w найден набор Nei(w) ближайших соседей. Этот набор Nei(w) может, например, быть результатом модели кластеризации или просто выбора по порогу ближайших соседей с расстоянием, настроенным на обеспечение хороших семантических соответствий. Семантические соответствия являются хорошими, если пороги сходства e для расстояний d(w,w') превышают заданный порог.
[0081] Для обучения априорных параметров тональности используется ЕМ- алгоритм. На E-шаге оцениваются вероятности pkw того, что слово w встречается с тональностью k в корпусе, с помощью счетчиков nkw из процесса сэмплирования Гиббса. Затем к значениям pkw добавляется новый регуляризатор, который фиксирует, что pkw ≈ pkw' для  , т.е. слова с очень похожими векторами должны, по всей вероятности, иметь одинаковую тональность. В результирующей задаче оптимизации логарифмическое правдоподобие модели увеличивается на E-шаге, что в данном случае является мультиномиальным распределением
, т.е. слова с очень похожими векторами должны, по всей вероятности, иметь одинаковую тональность. В результирующей задаче оптимизации логарифмическое правдоподобие модели увеличивается на E-шаге, что в данном случае является мультиномиальным распределением 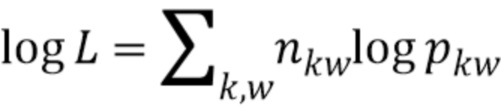 с регуляризатором R(p), который учитывает это предположение; для удобства оптимизации регуляризатор R(p) представлен в логарифмическом виде как:
с регуляризатором R(p), который учитывает это предположение; для удобства оптимизации регуляризатор R(p) представлен в логарифмическом виде как:
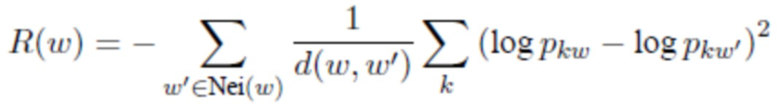 .
.
[0082] В целом, на E-шаге максимизация выполняется как:
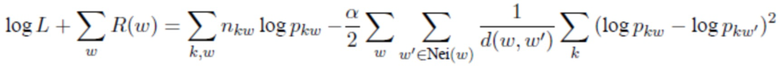 '
'
где α - коэффициент регуляризации, а d(w,w') - расстояние между векторами слов для w и w' в семантическом пространстве при ограничениях, что 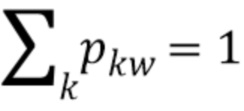 для каждого w. Расстояния могут быть евклидовыми и косинусными. Это задача квадратичной оптимизации на
для каждого w. Расстояния могут быть евклидовыми и косинусными. Это задача квадратичной оптимизации на 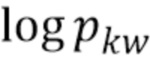 , поэтому ее можно решить с помощью готовых квадратичных оптимизаторов. Можно использовать другие возможные формы регуляризатора вектора слов.
, поэтому ее можно решить с помощью готовых квадратичных оптимизаторов. Можно использовать другие возможные формы регуляризатора вектора слов.
[0083] После нахождения pkw можно установить 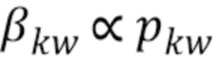 . Для данной тематической модели полезно использовать разрежающее априорное распределение с малыми параметрами βkw, чтобы нормализовать
. Для данной тематической модели полезно использовать разрежающее априорное распределение с малыми параметрами βkw, чтобы нормализовать 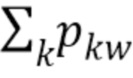 к максимальной сумме фиксированных априорных параметров βkw на основе Nei(w).
к максимальной сумме фиксированных априорных параметров βkw на основе Nei(w).
[0084] На фиг. 2 представлена блок-схема, иллюстрирующая способ тематического моделирования с априорными параметрами βkw тональности на основе распределенных представлений. Здесь тематическое моделирование выполняется тематической моделью, содержащей априорные параметры βkw тональности, обученные на основе представлений, распределенных с использованием регуляризатора R(p). Регуляризатор R(p) задает одинаковую тональность k словам w, имеющим подобные векторы слов. Каждая априорный параметр βkw тональности одинакова для слов w, имеющих подобные векторы слов. На этапе 101 в тематическую модель вводится текстовый документ. На этапе 102 тематическая модель определяет представление для каждого слова w в текстовом документе. Представления определяются как векторы слов в семантическом пространстве. На этапе 103 представления, определенные как векторы слов в семантическом пространстве, оцениваются с использованием априорных параметров βkw тональности, содержащихся в тематической модели, чтобы определить тему, соответствующую данному текстовому документу. Эта тематическая модель может быть основана на любых подходящих средствах искусственного интеллекта.
[0085] На фиг. 3 показан процесс обучения априорных параметров βkw тональности. На этапе 201 в тематическую модель вводится набор слов w. Затем тематическая модель выполняет этапы 202-207. На этапе 202 для каждого слова w определяется набор Nei(w) ближайших соседей. На этапе 203 для каждого слова w определяется представление в виде векторов слов в семантическом пространстве. На этапе 204 задается регуляризатор R(p) путем вычисления коэффициента регуляризации α регуляризатора R(p). При вычислении коэффициента регуляризации α для каждого слова w вероятности pkw встречаемости слова w в тональности k с помощью некоторых счетчиков nkw оцениваются с использованием представлений и набора Nei(w) ближайших соседей. На этапе 205 одинаковая тональность k задается словам w, имеющим подобные векторы слов, с помощью регуляризатора R(p). На этапе 206 эти представления распределяются в соответствии с результатами задания. На этапе 207 вычисляются априорные параметры βkw тональности с использованием распределенных представлений.
[0086] Процесс обучения может включать в себя этапы предсказания пользовательских атрибутов тематической моделью с использованием априорных параметров βkw тональности, обученных на основе представлений, распределенных с помощью регуляризатора, и обновления априорных параметров βkw тональности на основе предсказанных пользовательских атрибутов. Пользовательские атрибуты включают в себя по меньшей мере одно из местоположения, пола и возраста пользователя.
[0087] Этап 103 может дополнительно включать в себя выполнение максимизации правдоподобия тематической модели. При этой максимизации обновляют коэффициент регуляризации α регуляризатора R(p), и обновляют априорные параметры βkw тональности, используя регуляризатор R(p), имеющий обновленный коэффициент регуляризации α.
[0088] Предложено устройство для тематического моделирования с априорными параметрами тональности на основе распределенных представлений. Устройство выполнено с возможностью выполнения способа тематического моделирования с априорными параметрами тональности на основе распределенных представлений. Устройство содержит процессор и память, содержащую тематическую модель и команды. Команды предписывают процессору вводить текстовый документ в тематическую модель, определять посредством тематической модели представление в виде векторов слов в семантическом пространстве для каждого слова w в текстовом документе; и оценивать посредством тематической модели эти представления, используя априорные параметры βkw тональности, для определения темы, соответствующей данному текстовому документу. Тематическая модель содержит априорные параметры βkw тональности, обученные на основе представлений, распределенных с использованием регуляризатора R(p), имеющего коэффициент регуляризации α. Регуляризатор задает одинаковую тональность k словам w, имеющим подобные векторы слов. Каждая априорный параметр βkw тональности одинакова для слов w, имеющих подобные векторы слов.
[0089] Память дополнительно содержит команды, предписывающие процессору обучать априорные параметры βkw тональности. Эти команды предписывают процессору вводить набор слов w в тематическую модель, и посредством тематической модели: определять набор Nei(w) ближайших соседей для каждого слова w, определять представление как векторы слов в семантическом пространстве для каждого слова w; вычислять коэффициент регуляризации α регуляризатора R(p) для задания регуляризатора R(p) посредством оценки для каждого слова w вероятности pkw встречаемости слова w в тональности k с помощью некоторых счетчиков nkw, используя представления и набор Nei(w) ближайших соседей; задавать одинаковую тональность k словам w, имеющим подобные векторы слов, используя регуляризатор R(p); распределять представления в соответствии с результатами задания; и вычислять априорные параметры βkw тональности, используя распределенные представления.
[0090] Память дополнительно содержит команды, предписывающие процессору обучать априорные параметры βkw тональности для обновления априорных параметров βkw тональности на основе пользовательских атрибутов. Пользовательские атрибуты включают в себя по меньшей мере одно из местоположения, пола и возраста пользователя. Команды предписывают процессору предсказывать пользовательские атрибуты посредством тематической модели, используя априорные параметры βkw тональности, обученные на основе представлений, распределенных с использованием регуляризатора R(p); и обновлять априорные параметры βkw тональности на основе предсказанных пользовательских атрибутов.
[0091] Команды, предписывающие процессору оценивать представления с использованием априорных параметров βkw тональности, могут дополнительно содержать команды, предписывающие процессору выполнять максимизацию правдоподобия тематической модели, при которой: обновляют коэффициент регуляризации α, и обновляют априорные параметры βkw тональности, используя регуляризатор R(p), имеющий обновленный коэффициент регуляризации α.
[0092] Поскольку варианты осуществления настоящего изобретения были описаны как реализуемые, по меньшей мере частично, программно-управляемым устройством обработки данных, следует понимать, что постоянный машиночитаемый носитель с этим программным обеспечением, такой как оптический диск, магнитный диск, полупроводниковое запоминающее устройство или тому подобное, также рассматривается в качестве варианта осуществления настоящего раскрытия.
Наборы данных и параметры настройки
[0093] Предложенный этап оптимизации описывается с использованием шести наборов данных, доступных по адресу https://yadi.sk/d/82jgiXddsEtCG. Набор данных "Hotel" состоит из текстовых документов об отелях вместе с именами авторов на сайте TripAdvisor.com. В работе Yang et. al. (2015b) использовалось всего 808 текстовых документов с 5 верхними тегами местоположения, поэтому был принят набор данных из работы Wang et al., 2011. Для применения модели USTM были отобраны метаданные авторов текстовых документов из более чем 300 000 текстовых документов, и порядка половины авторов были исключены из рассмотрения в силу того, что их метаданные не содержали местоположение, пол или возраст; дополнительно были отфильтрованы авторы, которые не относились к 50 самым популярным местам проживания. Чтобы избежать проблемы разреженности, были рассмотрены 15 верхних тегов местоположения, а также 5 тегов возраста и 2 тега пола. Набор данных Amazon содержит текстовые документы о товарах с Amazon.com (https://snap.stanford.edu/data/web-Amazon.html), касающиеся компьютеров, автомобилей и бытовой техники (далее называемых AmazonComp, AmazonAuto и AmazonTools, соответственно). Для применения модели USTM для каждого набора данных были просмотрены метаданные авторов текстовых документов, такие как местоположение, и отфильтрованы до 25 верхних наиболее распространенных местоположений. В таблице 1 представлена статистика по шести наборам данных. Столбец "Dataset" в таблице 1 отображает используемый набор данных, столбец "# reviews" отображает количество текстовых документов в наборах данных, столбец "voc. size" отображает размер словаря, то есть количество уникальных слов в наборах данных, столбец "#tokens" отображает количество токенов в наборах данных, столбец "avg.lenʺ отображает среднюю длину текстовых документов в наборах данных.
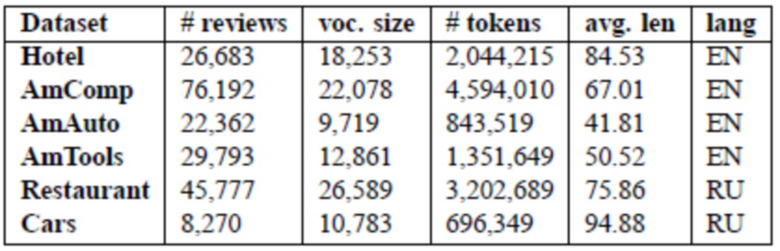
Таблица 1: Сводная статистика для наборов данных по текстовым документам.
[0094] Наборы данных "Restaurant" и "Cars" состоят из текстовых документов на русском языке, взятых с интернет-сайтов текстовых документов Otzovik.com и Restoclub.ru, соответственно; в них отсутствует информация об авторах текстовых документов. При предварительной обработке удаляется пунктуация, токены слов преобразуются в нижний регистр, удаляются стоп-слова, взятые из https://pypi.python.org/pypi/stop-words, за исключений отрицаний not (нет) и no (не); отфильтровываются редкие слова, имеющие встречаемость в наборе данных менее 5 раз, и часто встречающиеся слова, имеющие вхождение в более чем 30% текстовых документов, и применяется лемматизация для русских текстов с использованием библиотеки Mystem, расположенной по адресу https://tech.yandex.ru/mystem/. В таблице 1 представлена подробная информация о каждом наборе данных.
[0095] Что касается векторных представлений слов, то использовались модели "непрерывный мешок со словами" (continuous bag-of-words, далее CBOW) и skip n-gram word2vec, обученные на большом русскоязычном корпусе с примерно 14G токенами в 2,5 млн. документов (Arefyev et al., 2015; Panchenko et al., 2015).
[0096] Информация о тональности интегрируется в описанные модели с использованием асимметричных априорных распределений β. Созданный вручную лексикон для русского языка состоит из 1079 позитивных слов и 1474 негативных слов, а для английского языка принят MPQA Lexicon (Wilson et al., 2005), содержащий 2718 позитивных и 4911 негативных слов. Для других слов (возможно, нейтральных), которые не найдены в исходном словаре, используются симметричные априорные распределения. Таким образом, априорные параметры тональности делятся на три разные значения: нейтральное, позитивное и негативное. Сначала априорные параметры β для всех слов в корпусе задаются как βkw=0,01; затем, если слово принадлежит исходному словарю тональной лексики, для позитивного слова априорные параметры тональности задаются β*w=(1, 0,01, 0,001) (1 для позитивного, 0,1 для нейтрального и 0,001 для негативного); для негативного слова β*w=(0,001, 0,01, 1). Апостериорный вывод для всех моделей был сделан с применением 1000 итераций Гиббса с K=10, α=50/K и γ=0,1.
Результаты
[0097] Для каждого набора данных обучаются четыре тематические модели: JST, Reverse-JST, ASUM и USTM. В таблице 2 представлены результаты обучения JST, Reverse-JST, ASUM и USTM. Столбец "Dataset" в таблице 2 показан использованный набор данных, подстолбцы "pos.", "neg.", "neutr." в столбце " Labels" отображают количество позитивных, негативных и нейтральных меток для наборов данных текстового документа, соответственно, а подстолбцы "pos.", "neg." в столбце "#tokens" отображают количество позитивных, негативных токенов в наборах данных, соответственно.
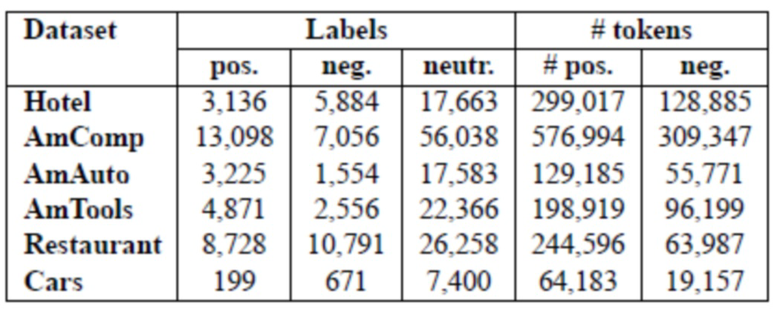
Таблица 2: Сводная статистика позитивных, негативных и нейтральных меток для наборов данных в текстовых документах.
[0098] Четыре обученные тематические модели сравниваются в трех вариантах: (i) фиксированном (без какой-либо оптимизации); (ii) с ЕМ-оптимизацией, как описано в работе (Tutubalina and Nikolenko, 2015) (отмечено "+ЕМ"); (iii) с предложенным этапом оптимизации (отмечено "+W2V"). Априорные параметры тональности обновляются через каждые 50 итераций.
[0099] В качестве контрольной выборки для задания коэффициента регуляризации α используется 20% обучающего набора, касающегося отелей и ресторанов. Для обучения априорных параметров βkw тональности выполняется градиентный спуск со скоростью обучения 10-6 с использованием библиотеки Theano (Bergstra et al., 2010). Для обоих корпусов коэффициент регуляризации α установлен на 1,0 для всех наборов данных.
[0100] Для оценки 10% текстовых документов используются в целях тестирования, а остальные 90% - для обучения тематических моделей. Коэффициенты сходства между парами слов с противоположными полярностями, такими как хороший [good] -плохой [bad], трудно [hard] -нетрудно [not hard], ругать [abuse] - хвалить [praise], анализируются вручную, и пороги сходства е для расстояний d(w,w') выбираются равными 0,77 для русского языка и 0,72 для английского языка.
[0101] В наборе данных "Restaurant" каждый текстовый документ связан с набором рейтингов, представляющим баллы от 0 (самый низкий) до 10 (самый высокий) в отношении продуктов питания, интерьера и услуг. Эти текстовые документы помечены тональностью "позитивный", если средний балл рейтинга равен или выше 7. Текстовые документы помечены тональностью "негативный", если рейтинг равен или меньше 4. В других наборах данных каждый текстовый документ связан с общим рейтингом от 0 (самый низкий) до 5 (самый высокий). Эти текстовые документы помечаются из 5 наборов данных позитивной или негативной тональностью, если балл рейтинга равен или больше 4 или балл рейтинга равен или меньше 2. Непомеченные текстовые документы рассматриваются как нейтральные. В таблице 2 представлены статистические данные по корпусам.
[0102] В соответствии с работой (Yang et al., 2015b), вероятности p(l|d) вычисляли на основе распределения φ тема-тональность-слово. В экспериментах текстовый документ d классифицируется как позитивный, если вероятность его позитивной метки p(lpos|d) выше вероятностей его негативных и нейтральных меток p(lneg|d) и p(lneu|d), и наоборот. Поскольку модели ASUM, JST и RJS учитывают только позитивные или негативные тональности, результаты всех моделей оцениваются только на основании текстовых документов с реальными позитивными или негативными метками. В таблице 3 представлены результаты классификации. Представленные результаты подвергнуты макро-усреднению на основе 5-проходной перекрестной проверки. В таблице 3 столбец " Model" отображает используемый метод, столбцы ʺHotelʺ, ʺAmazonComputerʺ, ʺAmazonAutoʺ отображают наборы данных, подстолбцы "P", "R", "F1", "Acc" отображают точность классификации, полноты в классификации, F-меру, т.е. меру точности теста, аккуратности, соответственно.
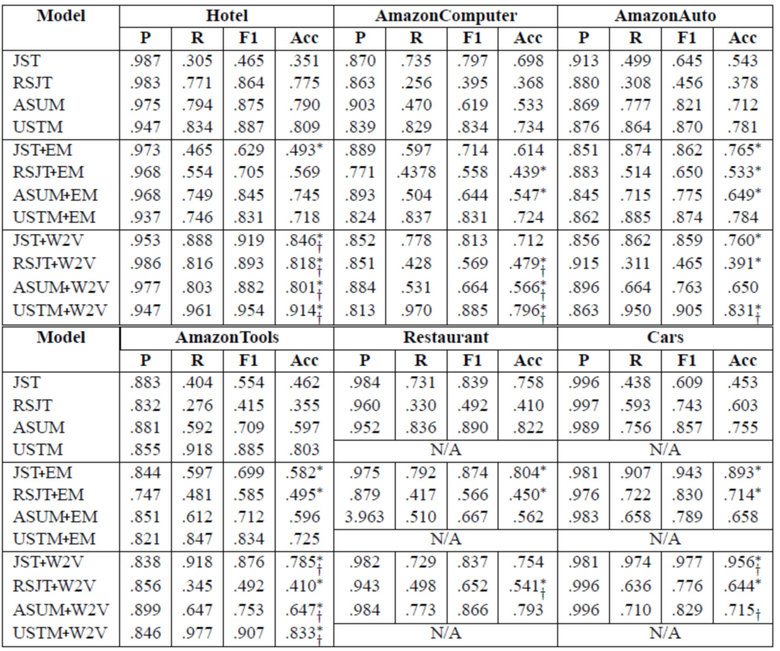
Таблица 3: Сравнение тематических моделей на нескольких реальных наборах данных; символы * и † над точностью указывают на статистически значимые улучшения по сравнению с соответствующей моделью со статическим βs и βs, оптимизированным EM-алгоритмом, соответственно, измеренные посредством критерия знаковых рангов Уилкоксона.

Таблица 4: Темы, обнаруженные в наборе данных моделью RJST+W2V.
[0103] Из результатов в таблице 3 можно сделать несколько важных выводов. Во-первых, результаты четырех моделей на наборе данных Hotel имеют высокую корреляцию с результатами работы Yang et al., 2015b. Модель USTM, являющаяся прототипом, дала лучшие результаты, чем модели RJST, JST и ASUM на четырех английских наборах данных. Во-вторых, результаты для USTM ясно показывают, что USTM+W2V обеспечивают лучшие результаты, чем исходные модели с априорными параметрами тональности, основанными на предопределенной оценочной лексике, и USTM+EM. Для JST и RJST результаты смешаны: JST+W2V и RJST+W2V обеспечили более высокую точность и F1-меру, чем JST+EM и RJST+EM, соответственно, в половине экспериментов. Результаты ASUM+EM и ASUM+W2V лишь немного лучше или хуже, чем у исходной ASUM, что имеет смысл, поскольку ASUM предполагает, что все слова в предложении порождаются из одной и той же тональности, и согласно изобретению обеспечивается обучение априорных параметров тональности для отдельных слов.
Предсказание пользовательских атрибутов
[0104] Согласно изобретению атрибуты автора текстового документа предсказываются на основе лексического содержания текстового документа, как в работе Yang et al., 2015b. Для этого используется набор данных Hotel с трехмерными пользовательскими атрибутами, такими как местоположение, пол и возраст. В качестве меры оценки используется средняя точность Mean Average Precision (MAP). Результаты представлены в таблице 5.
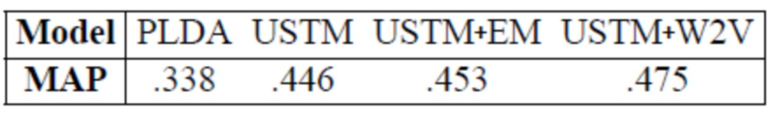
Таблица 5: Результаты тематических моделей на задаче предсказания атрибутов авторов текстовых документов.
[0105] Как и в задаче предсказания тональности тематическая модель с предложенной оптимизацией USTM+W2V дала лучшие результаты, чем базовые модели PLDA и USTM.
Влияние порога сходства и коэффициента регуляризации α
[0106] Согласно изобретению предложена оптимизация априорных параметров тональности β на основе распределенных представлений. Для демонстрации влияния порогового расстояния между векторами слов в семантическом пространстве и коэффициента регуляризации α в функции R(w) используется модель USTM, которая дала лучшие результаты в задаче классификации.
[0107] Во-первых, обеспечивается проверка эффективности порога сходства от 0,55 до 0,80 в наборе данных Hotel; результаты оценки представлены в таблице 6. Очевидно, что чем меньше выбранное пороговое значение, тем больше число слов, имеющих по меньшей мере одного ближайшего соседа. Этот порог контролирует плотность кластеризации априорных параметров ближайших слов. Количество уникальных слов с |Nei(w)|≥1 составило 13496, 11493, 8801, 4789 и 1177 для e равного 0,55, 0,60, 0,65, 0,72 и 0,80, соответственно. На основании этих результатов можно сделать несколько выводов. Во-первых, USTM+W2V с самыми низкими порогами e=0,55 и e=0,60 дают лучшие результаты, чем USTM (см. таблицу 3). Во-вторых, USTM+W2V с e=0,80 использует всего 6,45% словарного запаса для максимизации функции на E-шаге, и показала самые низкие результаты в таблице 6, тогда как наилучшие результаты были получены моделью USTM+W2V, которая использует 26,23%.
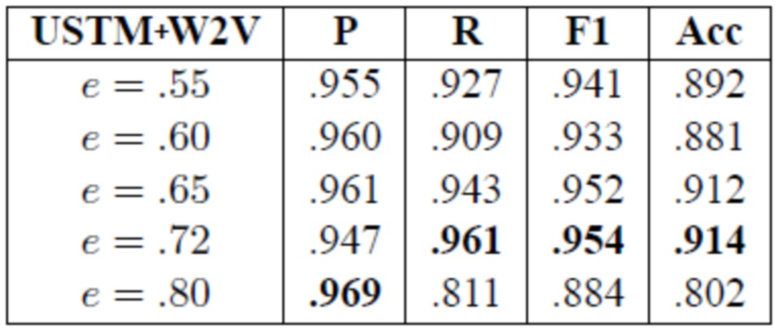
Таблица 6: Результаты USTM+W2V с изменяющимся порогом коэффициента сходства e (набор данных Hotel).
[0108] Далее исследуется влияние коэффициента регуляризации на набор данных AmazonTools. На фиг. 4 представлены результаты этого эксперимента для четырех моделей; на ней видно, что для всех моделей точность предсказания тональности достигает максимального значения, когда коэффициент а установлен на величину от 0,5 до 1,5.
Сравнение векторных представлений слов
[0109] Поскольку обучались векторы слов, использующие модели word2vec для русских текстов, был проведен ряд экспериментов для сравнения различных векторных представлений слов. Несколько векторных представлений слов обучались с применением высокопроизводительной реализации GPU модели CBOW, найденной по адресу https://github.com/ChenglongChen/word2vec_cbow, с различными параметрами s (размер вектора), w (длина локального контекста), n (негативное сэмплирование) и v (отсечка словаря: минимальная частота слова, которое следует включить в словарь). В таблице 7 приведены результаты классификации для некоторых характерных примеров для модели Reverse-JST. В общем, увеличение размера векторных представлений слов до примерно 300 улучшает результаты, в то время как параметры n и v оказывают очень слабое влияние.
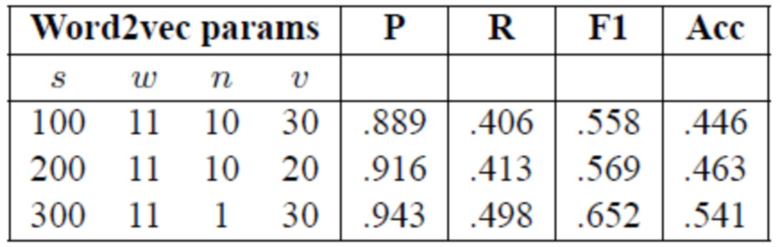
Таблица 7: Результаты модели Reverse-JST с различными векторными представлениями (набор данных Restaurant, e=0.77).
[0110] Для USTM также изучались общедоступные векторы слов GloVe, обученные на 6 миллиардах слов из текстовых данных новостных лент и из Википедии (Pennington et al., 2014). Как видно из таблицы 8, векторных представлений GloVe размерности 200 немного улучшились по сравнению с векторными представлениями word2vec на наборе данных Hotel. Как видно из таблицы 9, ручные проверки априорных параметров тональности различных слов подтверждают, что значения априорных параметров тональности более точны для векторов размерности 200 по сравнению с векторами размерности 100.
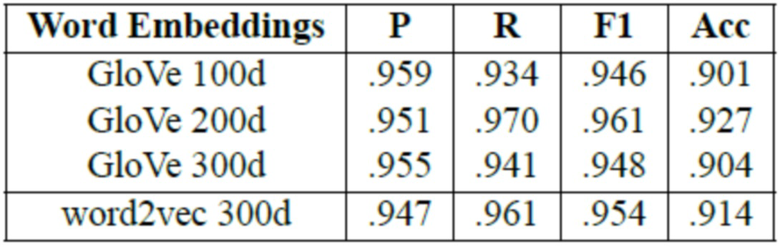
Таблица 8: Результаты USTM с различными векторными представлениями слов (набор данных Hotel, e=0,72).
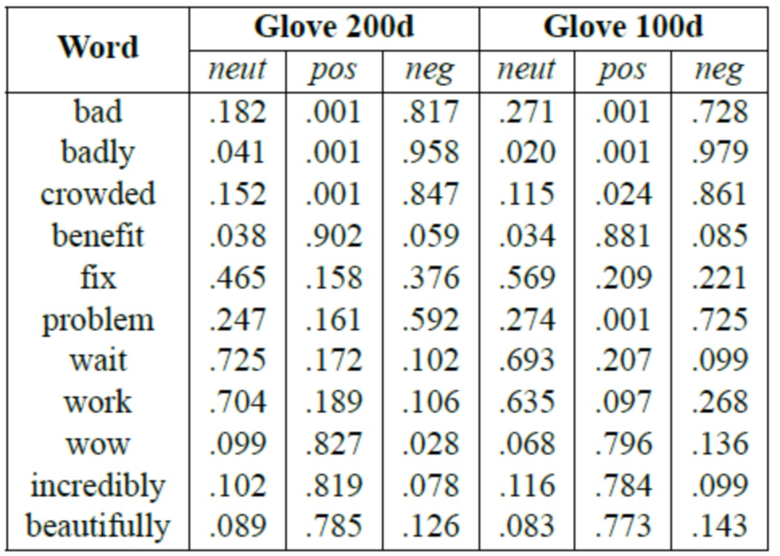
Таблица 9: Априорные параметры тональности USTM после обучения с оптимизацией на основе векторов Glove 200d и Glove 100d (набор данных Hotel).
Качественный анализ
[0111] В этом разделе представлен качественный анализ на темах, обнаруженных моделью RJST с этапом оптимизации на основе w2v. Основная цель изменения априорных параметров тональности на основе распределенных представлений слов состоит в вычислении аналогичных априорных параметров для семантически связанных слов, чтобы они имели более высокие вероятности представления связанных аспектов и подобной тональности. Для анализа результатов в соответствии с этой целью в таблице 4 приведены примеры обнаруженных тональностных тем. Проиллюстрированы термины самого высокого ранга для конкретных связанных с тональностью тем.
[0112] В таблице 4 показано, что модель RJST+W2V выделяет в основном относящиеся к семантике аспекты из текстовых документов, представляющие существительные типа автомобильных брендов на английском и русском языках (например, Volkswagen, toyota, ford, форд [ford]). Во-вторых, негативные темы показывают, что люди плохо относятся к российскому автопрому, старым автомобилям и ремонту автомобилей (негативные подтемы #2 и #3). И наконец, позитивный сэмпл, извлеченный моделью RJST+W2V, содержит определенные аспекты, такие как передача управляемости (трансмиссия, быстрый, привод), в то время как нейтральные подтемы описывают конфигурацию автомобиля (например, зеркало, сзади, панель, стекло) или процесс покупки (например, деньги, выбор, найти).
[0113] Представленные выше описания вариантов осуществления изобретения являются иллюстративными, и объем настоящего изобретения включает в себя модификации конфигурации и реализации. В частности, хотя варианты осуществления изобретения описаны, в общем, со ссылками на фигуры 1-9, эти описания являются примерными. Хотя объект изобретения описан на языке, характерном для конструктивных признаков или технологических действий, понятно, что объект, охарактеризованный в прилагаемой формуле изобретения, не обязательно ограничен конкретными признаками или действиями, описанными выше. Напротив, описанные выше конкретные признаки и действия раскрыты как примерные формы реализации формулы изобретения. Кроме того, изобретение не ограничено проиллюстрированной последовательностью этапов осуществления способа, которая может быть изменена специалистом без творческих усилий. Некоторые или все этапы способа могут выполняться последовательно или одновременно. Соответственно, объем изобретения ограничен только следующей формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ОПРЕДЕЛЕНИЯ ПРОФИЛЯ ПОЛЬЗОВАТЕЛЯ МОБИЛЬНОГО УСТРОЙСТВА НА САМОМ МОБИЛЬНОМ УСТРОЙСТВЕ И СИСТЕМА ДЕМОГРАФИЧЕСКОГО ПРОФИЛИРОВАНИЯ | 2016 |
|
RU2647661C1 |
| МЕТОД АНАЛИЗА ТОНАЛЬНОСТИ ТЕКСТОВЫХ ДАННЫХ | 2014 |
|
RU2571373C2 |
| СИСТЕМА И СПОСОБ АВТОМАТИЗИРОВАННОЙ ОЦЕНКИ НАМЕРЕНИЙ И ЭМОЦИЙ ПОЛЬЗОВАТЕЛЕЙ ДИАЛОГОВОЙ СИСТЕМЫ | 2020 |
|
RU2762702C2 |
| БАЙЕСОВСКОЕ РАЗРЕЖИВАНИЕ РЕКУРРЕНТНЫХ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2702978C1 |
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2016 |
|
RU2630427C2 |
| ОБУЧЕНИЕ КЛАССИФИКАТОРОВ, ИСПОЛЬЗУЕМЫХ ДЛЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2018 |
|
RU2691855C1 |
| СПОСОБ СЕМАНТИЧЕСКОГО ХЕШИРОВАНИЯ ТЕКСТОВЫХ ДАННЫХ | 2023 |
|
RU2822863C1 |
| ОБУЧЕНИЕ КЛАССИФИКАТОРОВ, ИСПОЛЬЗУЕМЫХ ДЛЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2018 |
|
RU2681356C1 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИОННЫХ ОБЪЕКТОВ С ИСПОЛЬЗОВАНИЕМ КОМБИНАЦИИ КЛАССИФИКАТОРОВ, АНАЛИЗИРУЮЩИХ ЛОКАЛЬНЫЕ И НЕЛОКАЛЬНЫЕ ПРИЗНАКИ | 2018 |
|
RU2686000C1 |
| ПОДБОР ПАРАМЕТРОВ ТЕКСТОВОГО КЛАССИФИКАТОРА НА ОСНОВЕ СЕМАНТИЧЕСКИХ ПРИЗНАКОВ | 2016 |
|
RU2628431C1 |

Изобретение относится к средствам для тематического моделирования с априорными параметрами тональности на основе распределенных представлений. Технический результат заключается в выявлении большего количества аспектно-ориентированных тональных слов и дополнительном улучшении классификации. Вводят текстовый документ в тематическую модель и посредством тематической модели определяют представление для каждого слова в текстовом документе, причем представлениями являются векторы слов в семантическом пространстве. Оценивают представления с использованием априорных параметров тональности для определения темы, соответствующей данному текстовому документу, причем тематическая модель содержит априорные параметры тональности, обученные на основе представлений, распределенных с использованием регуляризатора, который задает одинаковую тональность словам, имеющим подобные векторы слов, и причем каждый априорный параметр тональности один и тот же для слов, имеющих подобные векторы слов. 2 н. и 6 з.п. ф-лы, 5 ил., 9 табл.
1. Способ тематического моделирования с априорными параметрами тональности на основе распределенных представлений, содержащий этапы, на которых:
вводят текстовый документ в тематическую модель, и
посредством тематической модели:
определяют представление для каждого слова в текстовом документе, причем представлениями являются векторы слов в семантическом пространстве, и
оценивают упомянутые представления с использованием априорных параметров тональности для определения темы, соответствующей упомянутому текстовому документу,
причем тематическая модель содержит априорные параметры тональности, обученные на основе представлений, распределенных с использованием регуляризатора, причем регуляризатор задает одинаковую тональность словам, имеющим подобные векторы слов, и
причем каждый априорный параметр тональности один и тот же для слов, имеющих подобные векторы слов.
2. Способ по п. 1, в котором обучение априорных параметров тональности содержит этапы, на которых:
вводят набор слов в тематическую модель, и
посредством тематической модели:
определяют набор ближайших соседей для каждого слова,
определяют представление для каждого слова, причем представлениями являются векторы слов в семантическом пространстве;
вычисляют коэффициент регуляризации упомянутого регуляризатора для задания регуляризатора путем оценки для каждого слова вероятностей встречаемости этого слова в тональности с помощью некоторых счетчиков, используя представления и набор ближайших соседей;
задают одинаковую тональность словам, имеющим подобные векторы слов, используя регуляризатор;
распределяют представления согласно результатам задания; и
вычисляют априорные параметры тональности, используя распределенные представления.
3. Способ по п. 2, в котором обучение априорных параметров тональности дополнительно содержит этапы, на которых:
предсказывают пользовательские атрибуты посредством тематической модели, используя априорные параметры тональности, обученные на основе представлений, распределенных с использованием регуляризатора, причем пользовательские атрибуты включают в себя по меньшей мере одно из местоположения, пола и возраста пользователя, и
обновляют априорные параметры тональности на основе предсказанных пользовательских атрибутов.
4. Способ по одному из пп. 1-3, в котором
оценка представлений с использованием априорных параметров тональности содержит максимизацию правдоподобия тематической модели, содержащую этапы, на которых:
обновляют коэффициент регуляризации, и
обновляют априорные параметры тональности с использованием регуляризатора, имеющего обновленный коэффициент регуляризации.
5. Устройство для тематического моделирования с априорными параметрами тональности на основе распределенных представлений, содержащее:
процессор; и
память, содержащую тематическую модель и команды, предписывающие процессору:
вводить текстовый документ в тематическую модель;
определять посредством тематической модели представление для каждого слова в текстовом документе, причем представлениями являются векторы слов в семантическом пространстве, и
оценивать посредством тематической модели представления с использованием априорных параметров тональности для определения темы, соответствующей данному текстовому документу;
причем тематическая модель содержит априорные параметры тональности, обученные на основе представлений, распределенных с использованием регуляризатора, причем регуляризатор задает одинаковую тональность словам, имеющим подобные векторы слов, и
причем каждый априорный параметр тональности один и тот же для слов, имеющих подобные векторы слов.
6. Устройство по п. 5, в котором для обучения априорных параметров тональности память дополнительно содержит команды, предписывающие процессору:
вводить набор слов в тематическую модель, и
посредством тематической модели:
определять набор ближайших соседей для каждого слова,
определять представление для каждого слова, причем представлениями являются векторы слов в данном семантическом пространстве;
вычислять коэффициент регуляризации упомянутого регуляризатора, чтобы задать регуляризатор посредством оценки для каждого слова вероятностей встречаемости данного слова в тональности с помощью некоторых счетчиков, используя представления и набор ближайших соседей;
задавать одинаковую тональность словам, имеющим подобные векторы слов, используя регуляризатор;
распределять представления в соответствии с результатами задания; и
вычислять априорные параметры тональности, используя распределенные представления.
7. Устройство по п. 6, в котором для обучения априорных параметров тональности память дополнительно содержит команды, предписывающие процессору:
предсказывать пользовательские атрибуты посредством тематической модели, используя априорные параметры тональности, обученные на основе представлений, распределенных с использованием регуляризатора, причем пользовательские атрибуты включают в себя по меньшей мере одно из местоположения, пола и возраста пользователя; и
обновлять априорные параметры тональности на основе предсказанных пользовательских атрибутов.
8. Устройство по любому из пп. 5-7, в котором память дополнительно содержит команды, предписывающие процессору:
при оценке представлений с использованием априорных параметров тональности выполнять максимизацию правдоподобия тематической модели, содержащую:
обновление коэффициента регуляризации, и
обновление априорных параметров тональности, используя регуляризатор, имеющий обновленный коэффициент регуляризации.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| US 7788087 B2, 31.08.2010 | |||
| МЕТОД АНАЛИЗА ТОНАЛЬНОСТИ ТЕКСТОВЫХ ДАННЫХ | 2014 |
|
RU2571373C2 |
| КЛАССИФИКАЦИЯ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ НА ОСНОВЕ СЕМАНТИЧЕСКИХ ПРИЗНАКОВ | 2016 |
|
RU2628436C1 |

