Изобретение относится к области теории кодирования в частности к системам для объединенного кодирования с исправлением и обнаружением ошибок с целью повышения эффективности использования спектра при передаче данных в цифровой системе радиосвязи.
Актуальной является задача не только исправление ошибок при канальном кодировании, но и обнаружения неисправленных ошибок и организация автоматического запроса повторения (АЗП) с целью исправить подобные ошибки за счет дополнительной передачи минимально возможного числа кодовых символов.
Широко известен параллельный сверточный турбокод [ Berrou C. Near Shannon limit error – correcting coding and decoding / C. Berrou, A. Glaviex, P. Thitimajshina // IEEE International Communications Conference : Proc. 1993. – Geneva (Switzerland), 1993. – P. 1064–1070], позволивший приблизиться к потенциально достижимым характеристикам помехоустойчивого кодирования. Способ характеризуется следующим. На вход первого кодера подается информационная последовательность, на вход второго подается та же последовательность, но после перемежителя. Тем самым достигается статистическая независимость, особенно при больших размерах кодового блока. Итеративный подход заключается в том, что результаты одного декодирования с мягким выходом могут использоваться при другом декодировании, как априорная информация. Однако турбокод не является более эффективным, чем сверточный код, декодируемый по алгоритму Витерби, при размере фрейма менее 200 бит.
Аналогом заявляемого способа является продукт фирмы Trellis Ware код F-LDPC [Halford, Thomas & Bayram, Metin & Kose, Cenk & M. Chugg, Keith & Polydoros, Andreas. (2008). The F-LDPC Family: High-Performance Flexible Modern Codes for Flexible Radio. 376 - 380. 10.1109/ISSSTA.2008.75.]. Достоинством этого решения является глубокая интеграция протокола автоматического запроса повторной передачи (АЗП) с алгоритмом помехоустойчивого кодирования. Утверждается, что решение обладает максимально гибкими возможностями, одно ядро кодер/декодер поддерживает 40 кодовых скоростей (1/2–32/33) при этом допустимые размеры фрейма: 128, 256, 512, …, 16384 бит. Однако, например, для голосовых данных, размеры фреймы, производимые вокодером, могут составлять 16, 40, 80, 172 бита, таким образом невозможность работать с блоками от 20 бит является недостатком кода F-LDPC.
Классическая АЗП (ARQ), которая при ошибочном декодировании кадра предусматривает стирание принятых данных, полную повторную передачу кадра и независимое декодирование вновь полученного кадра не эффективна, т.к. приводит к слишком большой избыточной передаче данных. В настоящее время все большое распространение получает гибридная повторная передача [Error Control Coding: Fundamentals and Applications/ S. Lin, D. J. Costello, Jr. – NJ: Englewood Cliffs. – 1983. – 603 p.]. Суть метода в том, что более эффективной является такая стратегия, которая предусматривает при ошибочном декодировании сохранение данных кадра, получение от передатчика некоторой дополнительной информации, и повторное декодирование кадра с использованием этой дополнительной информации. Если объем дополнительной информации меньше объема целого кадра, то эффективность использования канала связи существенно увеличивается. Данный подход исследован Хагенауэром [J. Hagenauer. Rate Compatible Punctured Convolutional Codes (RCPC Codes) and their Applications. // IEEE Trans. Commun. – Vol. 36. – Apr. 1988. – P. 389-400.] и Чейзом [D. Chase. Code Combining A MaximumLikelihood Decoding Approach for Combining an Arbitrary Number of Noisy Packets. // IEEE Trans. Comm. – Vol. 33. – May 1985. – P. 385393] с разных позиций.
Рассмотрим классификацию рассмотренных схем АЗП (ARQ):
• Гибридная АЗП Типа 1 (НARQ-1 – суммирование Чейза). Данная стратегия повторной передачи характеризуется тем, что повторно передается тот же самый кадр.
• Гибридная АЗП Типа 2 (НARQ-2 – наращивание избыточности). Данная стратегия повторной передачи характеризуется тем, что число бит для повторной передачи меньше, чем в исходном кадре. Копия для повторной передачи не может быть декодируема самостоятельно.
• Гибридная АЗП Типа 3 (НARQ-3). Копия для повторной передачи может декодироваться самостоятельно. Однако кадр для повторной передачи может отличаться от первоначально переданного кадра, то есть может быть закодирован другим кодом.
Данную классификацию можно обобщить следующим образом:
• АЗП (ARQ) с полной передачей (к ней относится Тип 1 и Тип 3).
• АЗП (ARQ) с частичной передачей (Тип 2).
Темой дальнейшего исследования будет частичная передача – гибридная АЗП типа 2 (HARQ-2).
Возможны несколько подходов к реализации подобной стратегии АЗП (ARQ):
1. Повторная передача части ранее переданных кодовых символов кадра и их оптимальное сложение с кодовыми символами, сохраненными в памяти приемника.
2. Использование кодов с нарастающей сложностью. В случае ошибочного декодирования на передающей стороне вычисляются новые (дополнительные) проверочные символы, которые передаются приемнику.
В классе линейных блоковых кодов можно особо выделить подкласс кодов с низкой плотностью проверок на четность [Gallager R. “Low Density Parity Check Codes”// MIT Press 1963], превосходящий по своим характеристикам турбокод. Особенностью данного кода является наличие простой графической модели алгоритма декодирования определяемого как декодирование на графе (фиг. 1). Декодирование на графе следует понимать в том смысле, что граф определяет разбиение всего кодового слова на более короткие коды, причем короткие коды могут перекрываться друг с другом. Избежать данных перекрытий можно путем повторения перекрывающихся кодовых символов. Разные копии принятого кодового символа или мягкого решения об этом символе входят в различные кодовые слова более короткого кода, при этом все кодовые слова короткого кода могут быть декодированы независимо. Такая структура может быть представлена в виде двудольного графа один тип вершин, которого ассоциирован с кодовыми символами, причем количество ребер исходящих из каждой вершины соответствует количеству повторений кодового символа (переменная вершина – обозначена прямоугольником). Другой тип вершин соответствует коротким кодам, причем каждая вершина есть кодовое слово с количеством кодовых символов равным числу входящих ребер (проверочная вершина – обозначена кругом). Каждой проверочной вершине может быть приписана контрольная сумма, как индикатор наличия ошибок в коротком коде. Переменные вершины могут быть соединены только с проверочными вершинами, и, наоборот, проверочные вершины могут быть соединены только с переменными вершинами, что позволяет рассматривать граф как двудольный.
Такой двудольный граф называют графом Таннера [Tanner R.M. A Recursive Approach to Low Complexity Codes / R.M. Tanner // IEEE Transaction on Information Theory. – 1981. –Vol. IT27, № 9. – P. 533547]. По сути, для линейного блокового кода, граф Таннера является графическим представлением проверочной матрицы. Безошибочное декодирование характеризуется равенством нулю всех контрольных сумм – кодовых ограничений.
Код с низкой плотностью проверок на четность может быть декодирован в мягких решениях, используя алгоритм обмена сообщений (фиг. 1). Алгоритм обмена сообщениями [Gallager R. “Low Density Parity Check Codes”// MIT Press 1963] инициализируют каждый переменную вершину информацией о достоверности приема каждого символа (мягким решением), полученной из канала.
1. Вычисляют значение исходящего сообщения от переменной вершины равного апостериорной вероятности для кодового символа принять определенное значение кодового символа, отнесенного к этому переменной вершине для каждого ребра двудольного графа.
2. В каждом проверочной вершине модифицируют исходящие сообщения от тех переменных вершин, с которым они связаны ребром двудольного графа, и для которого они являются входящими, ставя в соответствие каждому ребру исходящие сообщения проверочной вершине, которые равны второму набору вероятностей для кодового символа принять определенное значение.
3. Обновляют исходящие сообщение переменной вершине входящими сообщениями, которые являются исходящими сообщениями проверочной вершине.
4. Повторяют итерации определенное число раз или до тех пор, пока кодовые ограничения не будут выполнены.
Знак исходящего сообщения выбирают таким, чтобы удовлетворить кодовым ограничениям. Абсолютное значение исходящего сообщения вычисляют при помощи функции  . Эта функция является решающей функцией или логарифмом отношения правдоподобия. Функция обладает коммутативностью:
. Эта функция является решающей функцией или логарифмом отношения правдоподобия. Функция обладает коммутативностью:

Есть несколько методов для определения функции  . Наиболее простой известен как алгоритм “min-sum”. Абсолютное значение исходящего сообщения равно минимальному абсолютному значению среди входящих сообщений за исключением сообщения от той вершины, для которого предназначено данное исходящее сообщение:
. Наиболее простой известен как алгоритм “min-sum”. Абсолютное значение исходящего сообщения равно минимальному абсолютному значению среди входящих сообщений за исключением сообщения от той вершины, для которого предназначено данное исходящее сообщение:

Другой метод задания функции состоит в определении функции через функцию  , применяемую в LOG MAP алгоритме [Pietrobon S.S. Implementation and Performance of a Turbo/MAP Decoder / S.S. Pietrobon // International J. of Satellite Communication. – 1998. Vol. 16 (Jan-Feb). – P. 23-46]. Функция может быть задана как:
, применяемую в LOG MAP алгоритме [Pietrobon S.S. Implementation and Performance of a Turbo/MAP Decoder / S.S. Pietrobon // International J. of Satellite Communication. – 1998. Vol. 16 (Jan-Feb). – P. 23-46]. Функция может быть задана как:

Где функция  , может быть представлена в виде таблицы.
, может быть представлена в виде таблицы.
Существует модификация предложенного метода, где дополнительное слагаемое  определено как:
определено как:

Модификации этого алгоритма приведена в [W.K Leung,W.L Lee,A.Wu,L.Ping,“ Efficient implementation technique of LDPC decoder ”Electron.Lett..,vol.37(20),pp.1231-1232,Sept2001]. Данный метод не требует таблицы, но приводит к некоторому ухудшению характеристик, но зато позволяет сократить число операций при декодировании.
Известен способ декодирования на графе, включающий в себя построение двудольного графа известен из патента US 4295218 Tanner “Error-correcting coding system” , Oct.13, 1981, G06F 11/10. Данный способ характеризуется следующей последовательностью действий:
на передающей стороне:
• формируют пакеты данных, каждый из которых содержит упорядоченную последовательность информационных символов;
• определяют подкоды для последовательности информационных символов и для каждого подкода формируют проверочные символы;
• формируют кодовое слово путем добавления проверочных символов к информационным символам;
на приемной стороне:
• формируют принятые корреляционные отклики на каждый из переданных кодовых символов;
• выполняют оценку шумового параметра смеси сигнал плюс шум, которая приближенно равна величине стандартного отклонения эквивалентного гауссовского белого шума, которым аппроксимируются помехи в канале;
• формируют мягкие решения о принятых кодовых символах, используя полученную оценку шумового параметра смеси сигнал плюс шум;
• разделяют мягкие решения о принятых кодовых символах на решения об информационных символах и решения о проверочных символах;
• формируют кодовые слова подкодов кода обобщенной проверки на четность;
• для каждого мягкого решения, входящего в каждое кодовое слово кода обобщенной проверки на четность, формируют модифицированное мягкое решение, которое является исходящим сообщением кодового слова кода обобщенной проверки на четность, таким образом, что исходящее сообщение кодового слова кода обобщенной проверки на четность представляет собой результат функционального преобразования исходных мягких решений - входящих сообщений кодового слова кода обобщенной проверки на четность;
• применяют полученные исходящие сообщения кодового слова кода обобщенной проверки на четность к тем переменным вершинам, с которыми подкоды кода обобщенной проверки на четность связаны посредством ребер двудольного графа и формируют подкоды кода повторений;
• для каждого мягкого решения, входящего в каждое кодовое слово обобщенного кода повторения, формируют модифицированное мягкое решение, которое является исходящим сообщением кодового обобщенного кода повторения, представляющее собой результат функционального преобразования над входящими сообщениями кодового слова обобщенного кода повторения;
• итеративно повторяют процесс обмена исходящими и входящими сообщениями таким образом, что исходящее сообщение кодового слова обобщенного кода повторений является входящим сообщением кодового слова кода обобщенной проверки на четность, а исходящее сообщение кода обобщенной проверки на четность является входящим сообщением кодового слова обобщенного кода повторений, формируя на каждой итерации последовательность модифицированных мягких решений;
• из последовательности модифицированных мягких решений формируют декодированные кодовые слова;
• умножают каждое декодированное кодовое слово на проверочную матрицу, получая упорядоченную последовательность контрольных сумм.
Однако следует отметить, что применяемое повторение кодовых символов может быть обобщенным, то есть вместо повторения может использоваться кодирование или отображением одного кодового символа в отличные от него  символов, возможно, другого алфавита.
символов, возможно, другого алфавита.
Операцию определения подкодов могут, например, составлять следующие действия:
• каждый информационный символ повторяют определенное число раз, в зависимости от его номера по порядку в последовательности символов, формируя последовательность повторенных информационных символов, причем количество повторений определяется заранее;
• осуществляют перемежение в последовательности повторенных информационных символов, добиваясь достаточного разнесения идущих подряд повторенных информационных символов и формируя последовательность перемеженных повторенных информационных символов;
• разбивают перемеженные повторенные информационные символы на группы таким образом, что каждая группа образует кодовое слово подкода.
Формирование подкодов из последовательности принятых мягких решений на приемной стороне можно определить как следующую последовательность действий:
• повторяют мягкие решения об информационных символах в соответствии с шаблоном повторения информационных символов;
• повторяют мягкие решения о проверочных символах, по крайней мере, два раза за исключением последнего проверочного символа;
• для мягких решений об информационных символах выполняют перемежение аналогичное перемежению на передающей стороне;
• формируют группы перемеженных мягких решений об информационных символах аналогичные группам соответствующих информационных символов на передающей стороне, образующие кодовое слово подкода обобщенной проверки на четность.
Применение полученных исходящих сообщений к исходной повторенной последовательности может быть реализовано путем выполнения следующей последовательности действий:
• деперемежают исходящие сообщения кодового слова кода обобщенной проверки на четность таким образом, что каждой копии мягкого решения о кодовом символе ставят в соответствие исходящее сообщение кодового слова кода обобщенной проверки на четность, соответствующее копии мягкого решения об этом символе;
• группируют исходящие сообщения кодового слова подкода обобщенной проверки на четность с мягкими решениями о принятых кодовых символах так, что в каждую группу входят мягкое решение о соответствующем кодовом символе и исходящие сообщение кодового слова кода обобщенной проверки на четность, соответствующее копии мягкого решения об этом символе, формируя, таким образом, кодовое слово обобщенного кода повторения, ставя каждое кодовое слово обобщенного кода повторения в соответствие кодовому символу, таким образом, что каждое исходящее сообщения кодового слова кода обобщенной проверки на четность является входящим сообщением кодового слова обобщенного кода повторения.
Таким образом, операции на графе Таннера, представляющего собой графическую модель разбиения кода на подкоды могут быть описаны в виде повторения, перемежения, группирования, а шаблоны повторения, группирования и правило перемежения однозначно задают двудольный граф.
Так турбокоды удобнее описывать в терминах повторения и перемежения, а коды с низкой плотностью проверок на четность в виде двудольного графа.
Учитывая пример с линейным блоковым кодом, где короткий код – это проверка на четность или сложения всех кодовых символов по модулю 2, будем называть применяемый короткий код на графе обобщенной проверкой на четность, которая будет заключаться в суммировании всех кодовых символов в поле Галуа или суммировании чисел по заданному модулю. Если в процессе передачи ошибок нет, то все подобные контрольные суммы должны быть равны нулю.
Однако если код является систематическим и может быть разделен на проверочную и информационную составляющие, то вышеупомянутому методу присущ следующий недостаток. При ошибке декодирования только в проверочной части кодового слова и отсутствии ошибок в информационной части фрейм все равно будет помечен как ошибочный и стерт, а контрольная сумма CRC позволяет контролировать ошибки только в информационной составляющей кодового слова.
Следуя терминологии из [П. Камерон, Дж. Ван Линт “Теория графов теория кодирования и блок-схемы”// M. Наука 1980], определим путь на графе как последовательность вершин, в которой соседние вершины смежные. Цикл – это путь, где начальные и конечные точки совпадают. Граф связен, если между любыми двумя вершинами существует путь, а метрикой расстояния между двумя вершинами будем считать длину кратчайшего пути между ними. Диаметром графа будем считать наибольшее значение расстояния между двумя любыми вершинами в графе, а обхватом графа – длину кратчайшего цикла без повторяющихся ребер при условии, что такой цикл существует. Валентностью вершины будем называть количество ребер, исходящих из этой вершины или количество вершин смежных данной. Если все вершины графа имеют одинаковую валентность, то граф будем называть регулярным. Хроматическим числом графа будем называть наименьшее количество цветов, в которые могут быть раскрашены все ребра графа таким образом, что любые два ребра, имеющие общую вершину, окрашены в разные цвета. Гамильтоновым путем или гамильтоновым циклом будем называть замкнутый цикл, без повторяющихся ребер, проходящий по всем вершинам графа единственный раз.
Граф должен иметь обхват не ниже 4 для применения в рассмотренном методе декодирования Таннера. В качестве примера на фиг. 2 приведен код, построенный на графе Петерсона, имеющего диаметр 6 и обхват 10. Однако недостатком такого подхода является ограниченное число вершин в подобных известных графах, а также трудность построения графов, содержащих более 100 вершин, обладающих заданными свойствами. Эффективность декодирования на графе в первую очередь зависит от структуры графа, а именно от наличия на графе дефектов в виде структур, приводящим к кодовым словам с низким весом. Одним из таких дефектов является “останавливающее множество” [Tom Richardson y Rudiger Urbanke “The Capacity of Low-Density Parity-Check Codes under Message-Passing Decoding”// March 9, 2001], а так же петель или циклов [David MacKay, Good Error-Correcting Codes Based on Very Sparse Matrices// IEEE Transaction on information theory, Vol 45, march 1999], где “останавливающее множество” как подмножество проверочных вершин, для которого не существует переменных вершин, соединенных единственным ребром с каким-либо из проверочных вершин, входящих в это подмножество. Множество переменных вершин, соединенных с останавливающим подмножеством, содержит наиболее вероятные комбинации ошибок. Однако, как было отмечено выше, граф может быть задан путем отдельного задания шаблона повторения и группирования, а также закона перемежения. Причем, предполагая идеальное перемежение, получены оптимизированные шаблоны повторения-группирования, которые основаны на неравномерном повторении [H. Jin, A. Khandekar and R. J. McEliece, “Irregular repeat-accumulate codes," Proceedings of the Second International Symposium on Turbo Codes and Related Topics, pp. 18, Brest, France, September 2000], [Thomas J. Richardson and Rüdiger L Urbanke . Efficient Encoding of Low-Density Parity Check Codes]. В связи с этим актуальной является задача отдельной разработки перемежителя, позволяющего построить по известным оптимизированным шаблонам повторения-группирования двудольный граф, содержащий наименьшее число дефектов.
В настоящее время широкую известность получил класс “турбо-образных” (“turbo-like”) кодов, среди которых выделяются коды с “повторением – накоплением”, известные из [H. Jin, A. Khandekar and R. J. McEliece, “Irregular repeat-accumulate codes," Proceedings of the Second International Symposium on Turbo Codes and Related Topics, pp. 1-8, Brest, France, September 2000]. Кодирование кодов с “повторением – накоплением” осуществляют в следующем порядке: повторение каждого информационного символа, перемежение повторенных символов, накопление суммы по модулю 2 перемеженных символов. Данные коды обладают свойствами, как турбо-кодов, так и кодов с низкой плотностью проверок на четность и могут быть декодированы как в параллельном режиме – алгоритм обмена сообщениями, так и в последовательном режиме – алгоритм MAP. Следует отметить, что в последнем случае алгоритм по существу является гибридным, состоящим из MAP алгоритма декодирования сверточного кода с двумя состояниями и алгоритма обмена сообщениями с неравномерно повторенными информационными символами [J. Li, Low-Complexity, Capacity-Approaching Coding Schemes: Design, Analysis and Applications, Ph.D. dissertation, Texas A&M University, 2002. ]. Из [ H. Jin, A. Khandekar and R. J. McEliece, “Irregular repeat-accumulate codes," Proceedings of the Second International Symposium on Turbo Codes and Related Topics, pp. 1-8, Brest, France, September 2000] известно, что наибольшая эффективность от применения достигается неравномерным или иррегулярным повторением информационных символов. Кроме того, характеристики кодов повторения с накоплением в большой степени характеризуются перемежителем, который совместно с шаблоном иррегулярного повторения и шаблоном накопления контрольных сумм определяют граф Таннера для данного кода. Требования к перемежителю заключаются в том, чтобы обеспечить достаточное разнесение повторенных символов, обеспечив тем самым отсутствие или малое число кодовых слов с низким весом.
Существуют два класса перемежителей: случайный и детерминистический. Для формирования случайного перемежителя применяют датчик случайных чисел, при помощи которого определяют номер перемежаемого символа в последовательности после перемежения. Последовательность получаемых номеров подвергают проверке на достаточность разнесения подряд идущих повторенных информационных символов с выбраковкой (откатом назад) последовательностей, не прошедших подобной проверки. Известен, в частности, алгоритм S-random [S. Dolinar and D. Divsalar “Weight Distribution for turbo codes using random and non-random permutation” JPL Progress report 42-122 pp 56-65 Aug 15,1995]. Известен патент [United States Patent 6,453,442 Sadjadpour, et al., September 17, 2002 Two stage S--Random interleaver], где реализован модифицированный S-random алгоритм.
Известен способ [Пат. 2427491 CA (0237743 WO), МКИ H04L1/18. Automatic Request Protocol Based Packet Transmission Using Punctured Codes / R. Wang, Ming J., A. Garmonov, A. Savinkov, A. Zhdanov. –PST Gazette. – 2002, May 19. – P. 9340], где подобная стратегия не приводит к снижению пропускной способности поскольку дополнительные кодовые символы или частичную повторную передача передают в составе следующего пакета, где проводят дополнительное перфорирование, освобождая место для проверочных кодовых символов для пакета в котором обнаружена ошибка, таким образом, ошибка в одном пакете исправляется за счет избыточности другого.
Примером системы передачи данных, использующей перемежитель DRP (States Patent 6,857,087), является способ и устройство из патента US 7673213, Keith ChuggPaul Gray, "Method and apparatus for communications using improved turbo like codes". В совокупности с адаптивным способом выравнивания скорости в зависимости от ошибок в канале [US 7975189 Cenk Kose Error rate estimation/application to code-rate adaption] система носит коммерческое название F-LDPC.
Способ по патенту US 7673213 состоит в следующем.
На передающей стороне:
– кодирование битов данных в соответствии с внешним сверточным кодом для создания последовательности внешних кодированных бит;
– обработку последовательности внешних кодированных бит с использованием перемежителя и одного модуля проверки на четность (SPC) для создания последовательности промежуточных бит;
– кодирование последовательности промежуточных битов в соответствии с внутренним сверточным кодом для создания последовательности внутренних кодированных бит;
– обработку последовательности внутренних закодированных битов с использованием модуля выкалывания для получения выколотых бит; а также
– объединение последовательности бит данных и последовательности выколотых битов для получения последовательности кодированных выходных бит.
На приемной стороне:
– получение мягких решений из канала;
– разделение мягких решений на систематическую и проверочную части;
– обработку проверочной части путем добавления нулевых бит на места выколотых;
а также
– итеративное декодирование с мягким входом мягким выходом проверочной и систематической части внешним декодером сверточного кода, внутренним декодером сверточного кода, декодером контроля четности (SPC), с использованием перемежителя и деперемежителя для создания последовательности декодированных бит.
Способ по патенту US 7975189 состоит в следующем:
– передачу первого набора данных, закодированных с первой скоростью передачи данных, причем первый блок данных включает в себя первое количество бит данных и первое количество бит четности;
– прием первого оцененного количества битовых ошибок для первого набора данных из приемника;
– определение первой мгновенной скорости передачи битов (BER) для первого набора данных на основе оценочного количества ошибок в битах, полученных от приемника;
– определение второй скорости передачи данных в зависимости от первой скорости передачи данных и первого мгновенного BER;
– передачу второго набора данных, закодированных со второй скоростью передачи данных.
На приемной стороне:
– принимают первый набор данных, закодированных с первой скоростью передачи данных от передатчика, причем первый набор данных включает в себя первое количество бит данных и первое количество бит четности;
– определяют первое оценочное количество битовых ошибок для первого набора данных, принимаемых приемником;
– определяют первую мгновенную частоту ошибок в битах для первого набора данных на основе оценочного количества бит-ошибок в первом блоке данных;
– определяют вторую скорость передачи данных в зависимости от первой скорости передачи данных и первой мгновенной частоты ошибок;
– передают сообщение обратной связи передатчику, указывающее, что передатчик должен передавать последующие блоки данных в приемник с использованием второй скорости передачи данных; а также
– принимают второй блок данных от передатчика, закодированного со второй скоростью передачи данных.
Из анализа патента US 7673213 видно, что это последовательное объединение сверточного кода и кода проверки на четность, то есть коммерческое название F-LDPC (гибкий код с низкой плотностью проверок на четность) не соответствует истине, так как при последовательном каскадировании кодов обычно не выполняется условие низкой плотности проверок на четность. Для последовательно соединенных кодов характерна зависимость от точности оценки дисперсии шума в канале. При неточной оценке эффективность итеративного декодирования декодерами с мягким входом мягким выходом резко падает из-за резкого роста метрик в системе декодеров, охваченных положительной обратной связью.
В основе способа классический иррегулярный код повторений с накоплениями с низкой плотностью проверок на четность [D. Divsalar, H. Jin, and R. J. McEliece. "Coding theorems for ‘turbo-like’ codes." Proc. 36th Allerton Conf. on Communication, Control and Computing, Allerton, Illinois, Sept. 1998, pp. 201–210.], где применен новый эффективный перемежитель, и производят оценку качества декодирования, то есть выносится решение о правильности приема
Недостатком классической схемы при декодировании по алгоритму "распространение сообщений" является то, что затруднено согласование скоростей посредством перфорирования или выкалывания. При замене выколотого символа нулем и приходе этого нуля на проверочный узел декодирования в качестве исходящего сообщения будут выданы все нули, что снижает эффективность декодирования.
Наиболее близким аналогом по технической сущности к предлагаемому является способ передачи голосовых данных в системе цифровой радиосвязи по патенту РФ 2323520, H03M 13/00, принятый за прототип.
Особенностью способа-прототипа является то, что производят оценку качества декодирования без применения циклической контрольной суммы. Для чего рассматривают последовательность не равных нулю контрольных сумм. При превышении значения порога пакет объявляет декодированным недостоверно.
Способ-прототип заключается в следующем.
На передающей стороне:
• формируют пакеты данных, каждый из которых содержит упорядоченную последовательность информационных символов;
• каждый информационный символ повторяют определенное число раз, в зависимости от его номера по порядку в последовательности символов, формируя последовательность повторенных информационных символов, причем количество повторений определяется заранее;
• осуществляют перемежение в последовательности повторенных информационных символов, добиваясь достаточного разнесения идущих подряд повторенных информационных символов, и формируя последовательность перемеженных повторенных информационных символов;
• разбивают перемеженные повторенные информационные символы на группы таким образом, что первый проверочный символ получают путем суммирования по заданному модулю начального значения переменной суммирования со всеми перемеженными повторенными информационными символами из первой группы, а проверочный символ  путем суммирования по заданному модулю проверочного символа
путем суммирования по заданному модулю проверочного символа  со всеми перемеженными повторенными информационными символами из группы
со всеми перемеженными повторенными информационными символами из группы 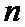 ;
;
• запоминают полученные проверочные символы;
• формируют кодовое слово путем добавления проверочных символов к информационным символам;
на приемной стороне:
• формируют принятые корреляционные отклики на каждый из переданных кодовых символов;
• выполняют оценку шумового параметра смеси сигнал плюс шум, которая приближенно равна величине стандартного отклонения эквивалентного гауссовского белого шума, которым аппроксимируются помехи в канале;
• формируют мягкие решения о принятых кодовых символах, используя полученную оценку шумового параметра смеси сигнал плюс шум;
• разделяют мягкие решения о принятых кодовых символах на решения об информационных символах и решения о проверочных символах;
• повторяют мягкие решения об информационных символах в соответствии с шаблоном повторения информационных символов;
• повторяют мягкие решения о проверочных символах, по крайней мере, два раза за исключением последнего проверочного символа;
• для мягких решений об информационных символах выполняют перемежение аналогичное перемежению на передающей стороне;
• формируют группы перемеженных мягких решений об информационных символах аналогичные группам соответствующих информационных символов на передающей стороне;
• первую группу перемеженных мягких решений дополняют мягким решением, соответствующим начальному значению переменной суммирования, и первой копией мягкого решения о первом проверочном символе, образуя первое кодовое слово кода обобщенной проверки на четность;
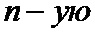 • группу перемеженных мягких решений дополняют второй копией
• группу перемеженных мягких решений дополняют второй копией  проверочного символа и первой копией мягкого решения об
проверочного символа и первой копией мягкого решения об  проверочном символе, образуя
проверочном символе, образуя 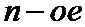 кодовое слово кода обобщенной проверки на четность;
кодовое слово кода обобщенной проверки на четность;
• для каждого мягкого решения, входящего в каждое кодовое слово кода обобщенной проверки на четность, формируют модифицированное мягкое решение, которое является исходящим сообщением кодового слова кода обобщенной проверки на четность, таким образом, что исходящее сообщение кодового слова кода обобщенной проверки на четность представляет собой результат функционального преобразования исходных мягких решений - входящих сообщений кодового слова кода обобщенной проверки на четность;
• деперемежают исходящие сообщения кодового слова кода обобщенной проверки на четность таким образом, что каждой копии мягкого решения о кодовом символе ставят в соответствие исходящее сообщение кодового слова кода обобщенной проверки на четность соответствующее копии мягкого решения об этом символе;
• группируют исходящие сообщения кодового слова кода обобщенной проверки на четность с мягкими решениями о принятых кодовых символах, так что в каждую группу входят мягкое решение о соответствующем кодовом символе и исходящие сообщение кодового слова кода обобщенной проверки на четность, соответствующее копии мягкого решения об этом символе, формируя, таким образом, кодовое слово обобщенного кода повторения, ставя каждое кодовое слово обобщенного кода повторения в соответствие кодовому символу, таким образом, что каждое исходящее сообщения кодового слова кода обобщенной проверки на четность является входящим сообщением кодового слова обобщенного кода повторения;
• для каждого мягкого решения входящего в каждое кодовое слово обобщенного кода повторения формируют модифицированное мягкое решение, которое является исходящим сообщением кодового обобщенного кода повторения представляющее собой результат функционального преобразования над входящими сообщениями кодового слова обобщенного кода повторения;
• итеративно повторяют процесс обмена исходящими и входящими сообщениями таким образом, что исходящее сообщение кодового слова обобщенного кода повторений является входящим сообщением кодового слова кода обобщенной проверки на четность, а исходящее сообщение кода обобщенной проверки на четность является входящим сообщением кодового слова обобщенного кода повторений формируя на каждой итерации последовательность модифицированных мягких решений;
• из последовательности модифицированных мягких решений формируют декодированные кодовые слова;
• умножают каждое декодированное кодовое слово на проверочную матрицу, получая упорядоченную последовательность контрольных сумм;
• если все контрольные суммы равны нулю, то кодовое слово считают декодированным верно;
• если количество контрольных сумм отличных от нуля нечетно и последняя контрольная сумма отлична от нуля, то заменяют ее нулем;
• если количество контрольных сумм отличных от нуля нечетно и последняя в последовательности контрольная сумма равна нулю, то ее заменяют любым отличным от нуля значением;
• разбивают последовательность контрольных сумм на пары, в которые входят элементы последовательности, идущие подряд, причем каждая контрольная сумма входит только в единственную пару;
• в каждой паре вычисляют разность номеров контрольных сумм;
• складывают все полученные разности номеров контрольных сумм;
• сравнивают полученное число с заданным порогом, если число превышает установленный порог, то информационную часть кодового слова считают декодированной неверно;
• если полученное число меньше заданного порога, то информационную часть кодового слова считают декодированной верно.
В прототипе реализована не только функция исправления ошибок, но также функция обнаружения ошибок без циклической контрольной суммы. Однако эффективность обнаружения ошибок существенно уступает алгоритму с циклической контрольной суммой. Тем не менее, функция обнаружения ошибок может быть использована для увеличения энергетического выигрыша кодирования путем применения алгоритма гибридного запроса-повторения без потери пропускной способности и не прибегая к перфорированию последовательности кодовых символов. Таким образом, задача увеличения энергетического выигрыша кодирования путем применения алгоритма гибридного запроса-повторения исключительно на физическом уровне является актуальной.
Для решения поставленной задачи в способе передачи данных в цифровой системе связи, заключающемся в том, что на передающей стороне формируют пакеты данных, каждый из которых содержит упорядоченную последовательность информационных символов, каждый информационный символ повторяют определенное число раз, в зависимости от его номера по порядку в последовательности символов, формируя последовательность повторенных информационных символов, причем, количество повторений определяется заранее, осуществляют перемежение в последовательности повторенных информационных символов, добиваясь достаточного разнесения идущих подряд повторенных информационных символов, и формируя последовательность перемеженных повторенных информационных символов, разбивают перемеженные повторенные информационные символы на группы таким образом, что первый проверочный символ получают путем суммирования по заданному модулю начального значения переменной суммирования со всеми перемеженными повторенными информационными символами из первой группы, а проверочный символ  путем суммирования по заданному модулю проверочного символа
путем суммирования по заданному модулю проверочного символа  со всеми перемеженными повторенными информационными символами из группы , запоминают полученные проверочные символы, формируют кодовое слово путем добавления проверочных символов к информационным символам, на приемной стороне формируют принятые корреляционные отклики на каждый из переданных кодовых символов, выполняют оценку шумового параметра смеси сигнал плюс шум, формируют мягкие решения о принятых кодовых символах, используя полученную оценку шумового параметра смеси сигнал плюс шум, разделяют мягкие решения о принятых кодовых символах на решения об информационных символах и решения о проверочных символах, повторяют мягкие решения об информационных символах в соответствии с шаблоном повторения информационных символов, повторяют мягкие решения о проверочных символах, по крайней мере, два раза за исключением последнего проверочного символа, для мягких решений об информационных символах выполняют перемежение аналогичное перемежению на передающей стороне, формируют группы перемеженных мягких решений об информационных символах, аналогичные группам соответствующих информационных символов на передающей стороне, первую группу перемеженных мягких решений дополняют мягким решением, соответствующим начальному значению переменной суммирования, и первой копией мягкого решения о первом проверочном символе, образуя первое кодовое слово кода обобщенной проверки на четность,
со всеми перемеженными повторенными информационными символами из группы , запоминают полученные проверочные символы, формируют кодовое слово путем добавления проверочных символов к информационным символам, на приемной стороне формируют принятые корреляционные отклики на каждый из переданных кодовых символов, выполняют оценку шумового параметра смеси сигнал плюс шум, формируют мягкие решения о принятых кодовых символах, используя полученную оценку шумового параметра смеси сигнал плюс шум, разделяют мягкие решения о принятых кодовых символах на решения об информационных символах и решения о проверочных символах, повторяют мягкие решения об информационных символах в соответствии с шаблоном повторения информационных символов, повторяют мягкие решения о проверочных символах, по крайней мере, два раза за исключением последнего проверочного символа, для мягких решений об информационных символах выполняют перемежение аналогичное перемежению на передающей стороне, формируют группы перемеженных мягких решений об информационных символах, аналогичные группам соответствующих информационных символов на передающей стороне, первую группу перемеженных мягких решений дополняют мягким решением, соответствующим начальному значению переменной суммирования, и первой копией мягкого решения о первом проверочном символе, образуя первое кодовое слово кода обобщенной проверки на четность,  группу перемеженных мягких решений дополняют второй копией
группу перемеженных мягких решений дополняют второй копией  проверочного символа и первой копией мягкого решения об
проверочного символа и первой копией мягкого решения об  проверочном символе, образуя
проверочном символе, образуя  кодовое слово кода обобщенной проверки на четность, для каждого мягкого решения, входящего в каждое кодовое слово кода обобщенной проверки на четность, формируют модифицированное мягкое решение, которое является исходящим сообщением кодового слова кода обобщенной проверки на четность таким образом, что исходящее сообщение кодового слова кода обобщенной проверки на четность представляет собой результат функционального преобразования исходных мягких решений, представляющих собой входящие сообщения кодового слова кода обобщенной проверки на четность, деперемежают исходящие сообщения кодового слова кода обобщенной проверки на четность таким образом, что каждой копии мягкого решения о кодовом символе ставят в соответствие исходящее сообщение кодового слова кода обобщенной проверки на четность соответствующее копии мягкого решения об этом символе, группируют исходящие сообщения кодового слова кода обобщенной проверки на четность с мягкими решениями о принятых кодовых символах, так что в каждую группу входят мягкое решение о соответствующем кодовом символе и исходящие сообщение кодового слова кода обобщенной проверки на четность, соответствующее копии мягкого решения об этом символе, формируя, таким образом, кодовое слово обобщенного кода повторения, ставя каждое кодовое слово обобщенного кода повторения в соответствие кодовому символу, таким образом, что каждое исходящее сообщение кодового слова кода обобщенной проверки на четность является входящим сообщением кодового слова обобщенного кода повторения, для каждого мягкого решения, входящего в каждое кодовое слово обобщенного кода повторения, формируют модифицированное мягкое решение, которое является исходящим сообщением кодового обобщенного кода повторения, представляющее собой результат функционального преобразования над входящими сообщениями кодового слова обобщенного кода повторения, итеративно повторяют процесс обмена исходящими и входящими сообщениями таким образом, что исходящее сообщение кодового слова обобщенного кода повторений является входящим сообщением кодового слова кода обобщенной проверки на четность, а исходящее сообщение кода обобщенной проверки на четность является входящим сообщением кодового слова обобщенного кода повторений, формируя на каждой итерации последовательность модифицированных мягких решений, из последовательности модифицированных мягких решений формируют декодированные кодовые слова, умножают каждое декодированное кодовое слово на проверочную матрицу, получая упорядоченную последовательность контрольных сумм, если все контрольные суммы равны нулю, то кодовое слово считают декодированным верно, если количество контрольных сумм отличных от нуля нечетно и последняя контрольная сумма отлична от нуля, то заменяют ее нулем, если количество контрольных сумм отличных от нуля нечетно, и последняя в последовательности контрольная сумма равна нулю, то ее заменяют любым отличным от нуля значением, разбивают последовательность контрольных сумм на пары, в которые входят элементы последовательности, идущие подряд, причем каждая контрольная сумма входит только в единственную пару, в каждой паре вычисляют разность номеров контрольных сумм, складывают все полученные разности номеров контрольных сумм, сравнивают полученное число с заданным порогом, если число превышает установленный порог, то информационную часть кодового слова считают декодированной неверно, если полученное число меньше заданного порога, то информационную часть кодового слова считают декодированной верно, согласно изобретению, если информационная часть кодового слова декодирована неверно то формируют сигнал запроса повторной передачи по каналу обратной связи для передающей стороны, на передающей стороне при получении сигнала запроса повторной передачи формируют пакет с кодово-сопряженной частью, для чего в очередном кодированном пакете часть кодовых символов заменяют суммой по модуля два с кодовыми символами ранее переданного и ошибочно декодированого пакета, формируя тем самым кодово-сопряженную часть, при получении текущего пакета с кодово-сопряженной частью декодируют его совместно с ранее принятым ошибочно декодированным пакетом для чего восстанавливают, возможно, с ошибками, последовательность мягких решений ошибочного пакета, модифицируют мягкие решения в кодово-сопряженной части в тех позициях, в которых заменяли кодовые символы суммой символов разных пакетов для чего заменяют знак на противоположный у принятого мягкого решения, если восстановленный кодовый символ предыдущего пакета соответствует логической единице, получая мягкие решения текущего пакета, декодируют мягкие решения текущего пакета, восстанавливают последовательность мягких решений текущего пакета, модифицируют мягкие решения в кодово-сопряженной части в тех позициях, в которых заменяли кодовые символы суммой символов разных пакетов для чего заменяют знак на противоположный у принятого мягкого решения если восстановленный кодовый символ текущего пакета соответствует логической единице, получая модифицированную последовательность мягких решений для ошибочного пакета, повторно декодируют ошибочный пакет, используя модифицированную последовательность мягких решений для ошибочного пакета как дополнительную информацию в тех позициях, в которых заменяли кодовые символы суммой символов разных пакетов, передают по каналу обратной связи сигналы, характеризующие результативность декодирования кодово-сопряженных пакетов.
кодовое слово кода обобщенной проверки на четность, для каждого мягкого решения, входящего в каждое кодовое слово кода обобщенной проверки на четность, формируют модифицированное мягкое решение, которое является исходящим сообщением кодового слова кода обобщенной проверки на четность таким образом, что исходящее сообщение кодового слова кода обобщенной проверки на четность представляет собой результат функционального преобразования исходных мягких решений, представляющих собой входящие сообщения кодового слова кода обобщенной проверки на четность, деперемежают исходящие сообщения кодового слова кода обобщенной проверки на четность таким образом, что каждой копии мягкого решения о кодовом символе ставят в соответствие исходящее сообщение кодового слова кода обобщенной проверки на четность соответствующее копии мягкого решения об этом символе, группируют исходящие сообщения кодового слова кода обобщенной проверки на четность с мягкими решениями о принятых кодовых символах, так что в каждую группу входят мягкое решение о соответствующем кодовом символе и исходящие сообщение кодового слова кода обобщенной проверки на четность, соответствующее копии мягкого решения об этом символе, формируя, таким образом, кодовое слово обобщенного кода повторения, ставя каждое кодовое слово обобщенного кода повторения в соответствие кодовому символу, таким образом, что каждое исходящее сообщение кодового слова кода обобщенной проверки на четность является входящим сообщением кодового слова обобщенного кода повторения, для каждого мягкого решения, входящего в каждое кодовое слово обобщенного кода повторения, формируют модифицированное мягкое решение, которое является исходящим сообщением кодового обобщенного кода повторения, представляющее собой результат функционального преобразования над входящими сообщениями кодового слова обобщенного кода повторения, итеративно повторяют процесс обмена исходящими и входящими сообщениями таким образом, что исходящее сообщение кодового слова обобщенного кода повторений является входящим сообщением кодового слова кода обобщенной проверки на четность, а исходящее сообщение кода обобщенной проверки на четность является входящим сообщением кодового слова обобщенного кода повторений, формируя на каждой итерации последовательность модифицированных мягких решений, из последовательности модифицированных мягких решений формируют декодированные кодовые слова, умножают каждое декодированное кодовое слово на проверочную матрицу, получая упорядоченную последовательность контрольных сумм, если все контрольные суммы равны нулю, то кодовое слово считают декодированным верно, если количество контрольных сумм отличных от нуля нечетно и последняя контрольная сумма отлична от нуля, то заменяют ее нулем, если количество контрольных сумм отличных от нуля нечетно, и последняя в последовательности контрольная сумма равна нулю, то ее заменяют любым отличным от нуля значением, разбивают последовательность контрольных сумм на пары, в которые входят элементы последовательности, идущие подряд, причем каждая контрольная сумма входит только в единственную пару, в каждой паре вычисляют разность номеров контрольных сумм, складывают все полученные разности номеров контрольных сумм, сравнивают полученное число с заданным порогом, если число превышает установленный порог, то информационную часть кодового слова считают декодированной неверно, если полученное число меньше заданного порога, то информационную часть кодового слова считают декодированной верно, согласно изобретению, если информационная часть кодового слова декодирована неверно то формируют сигнал запроса повторной передачи по каналу обратной связи для передающей стороны, на передающей стороне при получении сигнала запроса повторной передачи формируют пакет с кодово-сопряженной частью, для чего в очередном кодированном пакете часть кодовых символов заменяют суммой по модуля два с кодовыми символами ранее переданного и ошибочно декодированого пакета, формируя тем самым кодово-сопряженную часть, при получении текущего пакета с кодово-сопряженной частью декодируют его совместно с ранее принятым ошибочно декодированным пакетом для чего восстанавливают, возможно, с ошибками, последовательность мягких решений ошибочного пакета, модифицируют мягкие решения в кодово-сопряженной части в тех позициях, в которых заменяли кодовые символы суммой символов разных пакетов для чего заменяют знак на противоположный у принятого мягкого решения, если восстановленный кодовый символ предыдущего пакета соответствует логической единице, получая мягкие решения текущего пакета, декодируют мягкие решения текущего пакета, восстанавливают последовательность мягких решений текущего пакета, модифицируют мягкие решения в кодово-сопряженной части в тех позициях, в которых заменяли кодовые символы суммой символов разных пакетов для чего заменяют знак на противоположный у принятого мягкого решения если восстановленный кодовый символ текущего пакета соответствует логической единице, получая модифицированную последовательность мягких решений для ошибочного пакета, повторно декодируют ошибочный пакет, используя модифицированную последовательность мягких решений для ошибочного пакета как дополнительную информацию в тех позициях, в которых заменяли кодовые символы суммой символов разных пакетов, передают по каналу обратной связи сигналы, характеризующие результативность декодирования кодово-сопряженных пакетов.
Графические материалы, используемые в описании:
Фиг. 1 – алгоритм декодирования на графе: обмен сообщениями.
Фиг. 2 – граф Петерсона и заданный на нем код по способу Таннера.
Фиг. 3 – вариант реализации передающей части цифровой системы связи для передачи данных.
Фиг. 4 – вариант реализации приемной части цифровой системы связи для передачи данных.
Фиг. 5 – вариант реализации итеративного декодера.
Фиг. 6 – способ обнаружения ошибок без CRC.
Фиг. 7 – способ перемежения кодовых символов.
Фиг. 8 – результаты моделирования.
Заявляемый способ передачи данных в цифровой системе связи, заключается в том, что
на передающей стороне:
– формируют пакеты данных, каждый из которых содержит упорядоченную последовательность информационных символов;
– каждый информационный символ повторяют определенное число раз, в зависимости от его номера по порядку в последовательности символов, формируя последовательность повторенных информационных символов, причем, количество повторений определяется заранее;
– осуществляют перемежение в последовательности повторенных информационных символов, добиваясь достаточного разнесения идущих подряд повторенных информационных символов, и формируя последовательность перемеженных повторенных информационных символов;
– разбивают перемеженные повторенные информационные символы на группы таким образом, что первый проверочный символ получают путем суммирования по заданному модулю начального значения переменной суммирования со всеми перемеженными повторенными информационными символами из первой группы, а проверочный символ 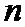 путем суммирования по заданному модулю проверочного символа
путем суммирования по заданному модулю проверочного символа 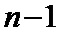 со всеми перемеженными повторенными информационными символами из группы
со всеми перемеженными повторенными информационными символами из группы 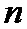 ;
;
– запоминают полученные проверочные символы;
– формируют кодовое слово путем добавления проверочных символов к информационным символам;
на приемной стороне:
– формируют принятые корреляционные отклики на каждый из переданных кодовых символов;
– выполняют оценку шумового параметра смеси сигнал плюс шум, которая приближенно равна величине стандартного отклонения эквивалентного гауссовского белого шума, которым аппроксимируются помехи в канале;
– формируют мягкие решения о принятых кодовых символах, используя полученную оценку шумового параметра смеси сигнал плюс шум;
– разделяют мягкие решения о принятых кодовых символах на решения об информационных символах и решения о проверочных символах;
– повторяют мягкие решения о информационных символах в соответствии с шаблоном повторения информационных символов;
– повторяют мягкие решения о проверочных символах по крайней мере два раза за исключением последнего проверочного символа;
– для мягких решений об информационных символах выполняют перемежение аналогичное перемежению на передающей стороне;
– формируют группы перемеженных мягких решений об информационных символах аналогичные группам соответствующих информационных символов на передающей стороне;
– первую группу перемеженных мягких решений дополняют мягким решением, соответствующим начальному значению переменной суммирования, и первой копией мягкого решения о первом проверочном символе, образуя первое кодовое слово кода обобщенной проверки на четность;
–  группу перемеженных мягких решений дополняют второй копией
группу перемеженных мягких решений дополняют второй копией  проверочного символа и первой копией мягкого решения об
проверочного символа и первой копией мягкого решения об  проверочном символе, образуя
проверочном символе, образуя 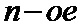 кодовое слово кода обобщенной проверки на четность;
кодовое слово кода обобщенной проверки на четность;
– для каждого мягкого решения, входящего в каждое кодовое слово кода обобщенной проверки на четность, формируют модифицированное мягкое решение, которое является исходящим сообщением кодового слова кода обобщенной проверки на четность, таким образом, что исходящее сообщение кодового слова кода обобщенной проверки на четность представляет собой результат функционального преобразования исходных мягких решений – входящих сообщений кодового слова кода обобщенной проверки на четность;
– деперемежают исходящие сообщения кодового слова кода обобщенной проверки на четность таким образом, что каждой копии мягкого решения о кодовом символе ставят в соответствие исходящее сообщение кодового слова кода обобщенной проверки на четность соответствующее копии мягкого решения об этом символе;
– группируют исходящие сообщения кодового слова кода обобщенной проверки на четность с мягкими решениями о принятых кодовых символах, так что в каждую группу входят мягкое решение о соответствующем кодовом символе и исходящие сообщение кодового слова кода обобщенной проверки на четность, соответствующее копии мягкого решения об этом символе, формируя, таким образом, кодовое слово обобщенного кода повторения, ставя каждое кодовое слово обобщенного кода повторения в соответствие кодовому символу, таким образом, что каждое исходящее сообщения кодового слова кода обобщенной проверки на четность является входящим сообщением кодового слова обобщенного кода повторения;
– для каждого мягкого решения входящего в каждое кодовое слово обобщенного кода повторения формируют модифицированное мягкое решение, которое является исходящим сообщением кодового обобщенного кода повторения представляющее собой результат функционального преобразования над входящими сообщениями кодового слова обобщенного кода повторения;
– итеративно повторяют процесс обмена исходящими и входящими сообщениями таким образом, что исходящее сообщение кодового слова обобщенного кода повторений является входящим сообщением кодового слова кода обобщенной проверки на четность, а исходящее сообщение кода обобщенной проверки на четность является входящим сообщением кодового слова обобщенного кода повторений формируя на каждой итерации последовательность модифицированных мягких решений;
– из последовательности модифицированных мягких решений формируют декодированные кодовые слова;
– умножают каждое декодированное кодовое слово на проверочную матрицу, получая упорядоченную последовательность контрольных сумм;
– если все контрольные суммы равны нулю, то кодовое слово считают декодированным верно;
– если количество контрольных сумм отличных от нуля нечетно и последняя контрольная сумма отлична от нуля, то заменяют ее нулем;
– если количество контрольных сумм отличных от нуля нечетно и последняя в последовательности контрольная сумма равна нулю, то ее заменяют любым отличным от нуля значением;
– разбивают последовательность контрольных сумм на пары, в которые входят элементы последовательности идущие подряд, причем каждая контрольная сумма входит только в единственную пару;
– в каждой паре вычисляют разность номеров контрольных сумм;
– складывают все полученные разности номеров контрольных сумм;
– сравнивают полученное число с заданным порогом, если число превышает установленный порог, то информационную часть кодового слова считают декодированной неверно;
– если полученное число меньше заданного порога, то информационную часть кодового слова считают декодированной верно;
– если информационная часть кодового слова декодирована неверно то формируют сигнал запроса повторной передачи по каналу обратной связи для передающей стороны;
– на передающей стороне при получении сигнала запроса повторной передачи формируют пакет с кодово-сопряженной частью, для чего в очередном кодированном пакете часть кодовых символов заменяют суммой по модуля два с кодовыми символами ошибочно декодированного пакета;
– при получении текущего пакета с кодово-сопряженной частью декодируют его совместно с ранее принятым ошибочно декодированным пакетом для чего восстанавливают, возможно, с ошибками, последовательность мягких решений ошибочного пакета;
– вычитают из кодово-сопряженной части пакета восстановленные мягкие решения в тех позициях, в которых заменяли кодовые символы суммой символов разных пакетов, получая мягкие решения текущего пакета;
– декодируют мягкие решения текущего пакета;
– восстанавливают последовательность мягких решений решений текущего пакета;
– вычитают из кодово-сопряженной части текущего пакета восстановленные мягкие решения текущего пакета в тех позициях, в которых заменяли кодовые символы суммой символов разных пакетов получая модифицированную последовательность мягких решений для ошибочного пакета;
– повторно декодируют ошибочный пакет используя модифицированную последовательность мягких решений для ошибочного пакета как дополнительную информацию, в тех позициях, в которых заменяли кодовые символы суммой символов разных пакетов;
– передают по каналу обратной связи сигналы, характеризующие результативность декодирования кодово сопряженных пакетов.
Для реализации заявляемого способа может быть использована система связи, передающее устройство (передающая сторона) которой представлено на фиг.3, а приемное устройство (приемная сторона) – на фиг. 4.
Передающее устройство, представленное на фиг. 3, содержит последовательно соединенные блок повторения информационных символов 1, блок перемежения информационных символов 2, блок разделения проверочных символов на группы 3, блок суммирования 5, блок памяти 8, блок межпакетного суммирования 7 и мультиплексор 6, выход которого соединен с каналом связи 9. Кроме того, передающее устройство содержит блок управления 4, сигналы с выходов которого являются управляющими сигналами, которые, в том числе, обеспечивают синхронизацию остальных блоков. Первый выход блока управления 4 соединен со вторым входом блока повторения информационных символов 1, второй выход блока управления 4 соединен со вторым входом блока перемежения информационных символов 2, третий выход блока управления 4 соединен со вторым входом блока разделения проверочных символов на группы 3, четвертый выход блока управления 4 соединен со вторым входом блока суммирования 5, пятый выход блока управления 4 соединен со вторым входом блока памяти 8, шестой выход блока управления 4 соединен со вторым входом блока межпакетного суммирования 7, седьмой выход блока управления 4 соединен со вторым входом мультиплексора 6. Второй выход блока памяти 8 соединен с третьим входом блока межпакетного суммирования 7 и третьим входом мультиплексора 6.
Первый вход блока повторения информационных символов 1 является первым входом передающего устройства, на который поступают пакеты данных, этот же вход соединен с первым входом мультиплексора 6. Первый вход блока управления 4 является входом сигнала обратной связи на автоматический запрос повторение, он же является вторым входом передающего устройства.
Через канал связи 9 сигнал поступает на приемное устройство.
Приемное устройство, представленное на фиг. 4, содержит последовательно соединенные блок формирования корреляционных откликов и оценки шумового параметра 10, блок разделения мягких решений 11, блок повторения проверочных символов 12, блок формирования перемеженных мягких решений 15, первый итеративный декодер 16, блок вычисления контрольных сумм в декодированном кодовом слове 17, блок контроля ошибок в декодированном кодовом слове 18, выход которого является первым выходом приемного устройства. Выход блока разделения мягких решений 11 через последовательно соединенные блок повторения информационных символов 13 и блок перемежения информационных символов 14 соединен со вторым входом блока формирования перемеженных мягких решений 15, выход которого соединен с входом блока хранения и вычитания мягких решений 19, первый вход-выход которого через последовательно соединенные второй итеративный декодер 20, блок вычисления контрольных сумм в декодированном кодовом слове 21 и блок контроля ошибок в декодированном кодовом слове 22 соединен с входом канала обратной связи 23. При этом второй выход блока контроля ошибок в декодированном кодовом слове 22 соединен со вторым входом второго итеративного декодера 20. Второй вход-выход блока хранения и вычитания мягких решений 19 соединен с входом-выходом первого итеративного декодера 16, второй вход которого подсоединен к третьему выходу блока контроля ошибок в декодированном кодовом слове 18, второй выход которого соединен со вторым входом канала обратной связи 23. Второй выход блока формирования корреляционных откликов и оценки шумового параметра 10 соединен третьим входом блока формирования перемеженных мягких решений 15.
Входом приемного устройства является вход блока формирования корреляционных откликов и оценки шумового параметра 10, на который поступает сигнал с передающего устройства через канал связи 9. Второй выход блока контроля ошибок в декодированном кодовом слове 22 является вторым выходом приемного устройства.
Итеративные декодеры 16 и 20 идентичны, поэтому рассмотрим вариант реализации первого итеративного декодера 16, представленный на фиг. 5. Первый итеративный декодер 16 содержит блок декодирования обобщенной проверки на четность 24, первый деперемежитель 25, второй деперемежитель 26, блок декодирования кода повторений 27, блок управления декодера 28, блок памяти 29, первый коммутатор 30, перемежитель 31 и второй коммутатор 32.
Первый вход первого коммутатора 30 соединен с выходом блока формирования перемеженных мягких решений 15 (фиг. 4), второй вход коммутатора 30 соединен с первым выходом блока управления декодера 28, вход которого соединен с выходом блока контроля ошибок в декодированном кодовом слове 18. Третий вход первого коммутатора 30 является входом/выходом блока памяти 29. Первый выход первого коммутатора 30 является выходом мягких решений из каждого кодового слова кода обобщенной проверки на четность и соединен с входом блока декодирования обобщенной проверки на четность 24, выход которого через первый деперемежитель 25 соединен с первым входом блока декодирования кода повторений 27. Второй выход первого коммутатора 30 является выходом мягких решений о кодовом символе сохраненных в блоке памяти 29 и через деперемежитель 26 соединен со вторым входом блока декодирования кода повторений 27. Первый выход блока декодирования кода повторений 27, который является выходом исходящих сообщений кодового обобщенного кода, соединен через первый вход второго коммутатора 32 со входом перемежителя 31, выход которого соединен с четвертым входом первого коммутатора 30. Второй выход блока декодирования кода повторений 27, который является выходом декодированного кодового слова, соединен со вторым входом второго коммутатора 32, третий вход которого является входом управления и соединен со вторым выходом блока управления декодера 28. Выход второго коммутатора 32 соединен со входом блока вычисления контрольных сумм в декодированном кодовом слове 17. Сигналы синхронизации на фиг.5 для упрощения схемы не показаны.
Работает устройство следующим образом.
На передающей стороне сформированные пакеты данных, каждый из которых содержит упорядоченную последовательность информационных символов, поступают вход блока повторения информационных символов 1 и одновременно на первый вход мультиплексора 6. В блоке повторения информационных символов 1 каждый информационный символ повторяют определенное число раз, в зависимости от его номера по порядку в последовательности символов, формируя последовательность повторенных информационных символов, причем, количество повторений определяется заранее. Последовательность повторенных информационных символов с выхода блока повторения информационных символов 1 поступает на вход блока перемежения информационных символов 2, где осуществляют перемежение в последовательности повторенных информационных символов, добиваясь достаточного разнесения идущих подряд повторенных информационных символов и формируя последовательность перемеженных повторенных информационных символов. В блоке разделения проверочных символов на группы 3 разбивают перемеженные повторенные информационные символы на группы, затем в блоке суммирования 5 получают первый проверочный символ путем суммирования по заданному модулю начального значения переменной суммирования со всеми перемеженными повторенными информационными символами из первой группы, а проверочный символ путем суммирования по заданному модулю проверочного символа  со всеми перемеженными повторенными информационными символами из группы . Полученные проверочные символы запоминают блоке памяти 8. Запомненные проверочные символы поступают в мультиплексор 6, где формируют кодовое слово путем добавления проверочных символов к информационным символам. Через канал связи 9 сформированное кодовое слово передают на приемное устройство. В случае получения по каналу обратной связи сигнала запроса на повторную передачу формируют пакет с кодово-сопряженной частью, для чего в блоке межпакетного суммирования 7 суммируют кодовые символы текущего пакета с кодовыми символами ошибочно декодированного пакета, сохраненного в блоке памяти 8. В мультиплексоре 6 мультиплексируют кодово-сопряженную часть пакета, полученную с блока межпакетного суммирования 7 и кодовые символы текущего пакета, которые также сохраняют в блоке памяти 8.
со всеми перемеженными повторенными информационными символами из группы . Полученные проверочные символы запоминают блоке памяти 8. Запомненные проверочные символы поступают в мультиплексор 6, где формируют кодовое слово путем добавления проверочных символов к информационным символам. Через канал связи 9 сформированное кодовое слово передают на приемное устройство. В случае получения по каналу обратной связи сигнала запроса на повторную передачу формируют пакет с кодово-сопряженной частью, для чего в блоке межпакетного суммирования 7 суммируют кодовые символы текущего пакета с кодовыми символами ошибочно декодированного пакета, сохраненного в блоке памяти 8. В мультиплексоре 6 мультиплексируют кодово-сопряженную часть пакета, полученную с блока межпакетного суммирования 7 и кодовые символы текущего пакета, которые также сохраняют в блоке памяти 8.
На приемной стороне сформированное в передатчике кодовое слово поступает на вход блока формирования корреляционных откликов и оценки шумового параметра 10, где формируют принятые корреляционные отклики на каждый из переданных кодовых символов и выполняют оценку шумового параметра смеси сигнал плюс шум, которая приближенно равна величине стандартного отклонения эквивалентного гауссовского белого шума, которым аппроксимируются помехи в канале, а затем формируют мягкие решения о принятых кодовых символах, используя полученную оценку шумового параметра смеси сигнал плюс шум. Полученные мягкие решения поступают на вход блока разделения мягких решений 11, где происходит разделение мягких решений о принятых кодовых символах на решения об информационных символах и решения о проверочных символах. Мягкие решения об информационных символах с блока разделения мягких решений 11 поступают на вход блока повторения информационных символов 13, где повторяют мягкие решения об информационных символах в соответствии с шаблоном повторения информационных символов. Мягкие решения о проверочных символах с блока разделения мягких решений 11 поступают на вход блока повторения проверочных символов 12, где повторяют мягкие решения о проверочных символах, по крайней мере, два раза за исключением последнего проверочного символа. Для мягких решений об информационных символах выполняют перемежение аналогичное перемежению на передающей стороне в блоке перемежения информационных символов 14. Затем в блоке формирования перемеженных мягких решений 15 формируют группы перемеженных мягких решений об информационных символах аналогичные группам соответствующих информационных символов на передающей стороне, используя сигналы с блока проверочных символов 12 и с блока формирования корреляционных откликов и оценки шумового параметра 10, причем первую группу перемеженных мягких решений дополняют мягким решением, соответствующим начальному значению переменной суммирования, и первой копией мягкого решения о первом проверочном символе, образуя первое кодовое слово кода обобщенной проверки на четность,  группу перемеженных мягких решений дополняют второй копией
группу перемеженных мягких решений дополняют второй копией 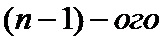 проверочного символа и первой копией мягкого решения об
проверочного символа и первой копией мягкого решения об  проверочном символе, образуя
проверочном символе, образуя  кодовое слово кода обобщенной проверки на четность. Сформированные перемеженные мягкие решения поступают на первый вход первого итеративного декодера 16 (на первый коммутатор 26 фиг. 5), в котором формируется декодированное кодовое слово. Каждое декодированное кодовое слово в блоке вычисления контрольных сумм в декодированном кодовом слове 17 умножают на проверочную матрицу, получая упорядоченную последовательность контрольных сумм, если все контрольные суммы равны нулю, то кодовое слово считают декодированным верно, если количество контрольных сумм отличных от нуля нечетно и последняя контрольная сумма отлична от нуля, то заменяют ее нулем, если количество контрольных сумм отличных от нуля нечетно и последняя в последовательности контрольная сумма равна нулю, то ее заменяют любым отличным от нуля значением, разбивают последовательность контрольных сумм на пары, в которые входят элементы последовательности, идущие подряд, причем каждая контрольная сумма входит только в единственную пару, в каждой паре вычисляют разность номеров контрольных сумм, складывают все полученные разности номеров контрольных сумм. Затем в блоке контроля ошибок в декодированном кодовом слове 18 сравнивают полученное число с заданным порогом, если число превышает установленный порог, то информационную часть кодового слова считают декодированной неверно, если полученное число меньше заданного порога, то информационную часть кодового слова считают декодированной верно.
кодовое слово кода обобщенной проверки на четность. Сформированные перемеженные мягкие решения поступают на первый вход первого итеративного декодера 16 (на первый коммутатор 26 фиг. 5), в котором формируется декодированное кодовое слово. Каждое декодированное кодовое слово в блоке вычисления контрольных сумм в декодированном кодовом слове 17 умножают на проверочную матрицу, получая упорядоченную последовательность контрольных сумм, если все контрольные суммы равны нулю, то кодовое слово считают декодированным верно, если количество контрольных сумм отличных от нуля нечетно и последняя контрольная сумма отлична от нуля, то заменяют ее нулем, если количество контрольных сумм отличных от нуля нечетно и последняя в последовательности контрольная сумма равна нулю, то ее заменяют любым отличным от нуля значением, разбивают последовательность контрольных сумм на пары, в которые входят элементы последовательности, идущие подряд, причем каждая контрольная сумма входит только в единственную пару, в каждой паре вычисляют разность номеров контрольных сумм, складывают все полученные разности номеров контрольных сумм. Затем в блоке контроля ошибок в декодированном кодовом слове 18 сравнивают полученное число с заданным порогом, если число превышает установленный порог, то информационную часть кодового слова считают декодированной неверно, если полученное число меньше заданного порога, то информационную часть кодового слова считают декодированной верно.
Восстановленные проверочные символы пакета, в котором детектирована ошибка, сохраняют в блоке хранения и вычитания мягких решений 19, где и вычитают из кодово-сопряженной части пакета восстановленные мягкие решения в тех позициях, в которых заменяли кодовые символы суммой символов разных пакетов, получая мягкие решения текущего пакета, которые используют как дополнительную информацию при декодировании текущего пакета первым итеративным декодером 16. Восстановленную последовательность мягких решений текущего пакета сохраняют в блоке хранения и вычитания мягких решений 19, там же вычитают из кодово-сопряженной части текущего пакета восстановленные мягкие решения текущего пакета в тех позициях, в которых заменяли кодовые символы суммой символов разных пакетов, получая модифицированную последовательность мягких решений для ошибочного пакета. Повторно декодируют ошибочный пакет вторым итеративным декодером 20, используя модифицированную последовательность мягких решений для ошибочного пакета, как дополнительную информацию в тех позициях, в которых заменяли кодовые символы суммой символов разных пакетов. Передают по каналу обратной связи 23 сигналы, характеризующие результативность декодирования кодово-сопряженных пакетов.
Алгоритм обнаружения ошибок в кодовом слове представлен на фиг. 6.
Обнаружение ошибок в заявляемом способе передачи данных в цифровой системе связи может быть пояснено следующим примером. Пусть мы имеем код “повторение с накоплением” заданный двудольным регулярным графом. Рассмотрим различные конфигурации ошибок. Отметим, случай, когда существуют ошибочно декодированные переменные вершины, но все контрольные суммы равны нулю. Это случай необнаружимой ошибки. Рассмотрим также случай, когда ошибки только в проверочной части кодового слова. Заметим, что каждая ошибка в проверочной части вызывает неравенство нулю двух соседних контрольных сумм. Однако неравные нулю контрольные суммы при ошибке в информационной части разнесены на расстояние пропорциональное параметру разнесения интерливера. Таким образом, при наличии единственной ошибки легко определить к какому символу она относится: информационному или проверочному. Для этого достаточно рассмотреть разность номеров проверочных вершин соответствующих неравным нулю контрольным суммам. Если таковая разность равна 1, то ошибочный символ однозначно можно отнести к проверочным символам, если больше, то ошибочный символ информационный.
Переходя к случаю многих ошибок, алгоритм состоит в следующем:
• если число отличных от нуля контрольных сумм нечетно, то изменяют контрольное значение последней суммы, добиваясь четного числа контрольных сумм;
• последовательно разбивают контрольные суммы на пары, вычисляют сумму разностей адресов проверочных вершин;
• сравнивают полученное значение с порогом, если оно меньше порога, то относят ошибки только к проверочным символам.
Таким образом, обнаружение ошибок осуществляют без CRC, тем самым повышая качество радиосвязи за счет снижения количества избыточных передаваемых кодовых символов, обеспечивая одновременно обнаружение и исправление ошибок.
Первый итеративный декодер 16, представленный на фиг. 5, работает следующим образом.
По сигналу с блока управления декодера 28 коммутатор 30 коммутирует мягкие решения из каждого кодового слова кода обобщенной проверки на четность на вход блока декодирования кода обобщенной проверки на четность и сохраняют их в блоке памяти 29. В блоке декодирования кода обобщенной проверки на четность 24 для каждого мягкого решения, входящего в каждое кодовое слово кода обобщенной проверки на четность, формируют модифицированное мягкое решение, которое является исходящим сообщением кодового слова кода обобщенной проверки на четность, таким образом, что исходящее сообщение кодового слова кода обобщенной проверки на четность представляет собой результат функционального преобразования исходных мягких решений – входящих сообщений кодового слова кода обобщенной проверки на четность. В деперемежителе 25 деперемежают исходящие сообщения кодового слова кода обобщенной проверки на четность таким образом, что каждой копии мягкого решения о кодовом символе ставят в соответствие исходящее сообщение кодового слова кода обобщенной проверки на четность соответствующее копии мягкого решения об этом символе. Мягкие решения о кодовом символе, сохраненные в блоке памяти 29, через коммутатор 30 деперемежают в деперемежителе 26 таким образом, что каждой копии мягкого решения о кодовом символе, сохраненной в блоке памяти 29, ставят в соответствие исходящее сообщение кодового слова кода обобщенной проверки на четность деперемеженной в блоке 25 соответствующее копии мягкого решения об этом символе. Деперемеженные мягкие решения с блоков 25 и 26 поступают в блок декодирования кода повторений 27, для каждого мягкого решения входящего в каждое кодовое слово обобщенного кода повторения формируют модифицированное мягкое решение, которое является исходящим сообщением кодового обобщенного кода повторения, представляющее собой результат функционального преобразования над входящими сообщениями кодового слова обобщенного кода повторения. По управляющему сигналу с блока управления декодера 28 коммутатор 32 пропускает на перемежитель 31 исходящих сообщений кодового слова обобщенного кода повторения, где происходит их перемежение, либо сформированные в блоке декодирования кода повторений 27 декодированные кодовые слова по соответствующему сигналу блока управления 28 коммутатор 32 на блок вычисления контрольных сумм в декодированном кодовом слове 17. .Итеративно повторяют процесс обмена исходящими и входящими сообщениями таким образом, что исходящее сообщение кодового слова обобщенного кода повторений является входящим сообщением кодового слова кода обобщенной проверки на четность, а исходящее сообщение кода обобщенной проверки на четность является входящим сообщением кодового слова обобщенного кода повторений, формируя на каждой итерации последовательность модифицированных мягких решений, из последовательности модифицированных мягких решений формируют декодированные кодовые слова.
Все блоки, входящие в систему связи могут быть реализованы на процессоре, ПЛИС, специализированной микросхеме.
Для заявляемого способа передачи данных в системе цифровой радиосвязи на основе кодов с низкой плотностью проверок на четность используется предлагаемый способ перемежения кодовых символов.
Известен способ перемежения последовательности кодовых символов по патенту РФ 2323520, H03M 13/00, (пункт 6 формулы изобретения), в котором последовательность кодовых символов разбивают на множество подпоследовательностей, в каждой из которых осуществляют перемежение при помощи пилотной псевдослучайной последовательности, которую задают посредством задания Гамильтонова пути на регулярном четырехвалентном графе. Пилотную псевдослучайную последовательность задают следующим образом. Пусть в графе существует гамильтонов путь, и нумерация вершин графа соответствует порядку прохождения данного пути. Пилотная псевдослучайная последовательность определена, если существует другой Гамильтонов путь, проходящий не по участвовавшим в первом пути ребрам графа. При прохождению по второму Гамильтонову пути получают последовательность номеров пройденных вершин, заданных при прохождению по первому пути, которая определяет пилотную псевдослучайную последовательность.
Недостатком данного способа перемежения является несколько худшие характеристики помехоустойчивости по сравнению со следующим вариантом перемежения кодовых символов (патент РФ 2323520, H03M 13/00, перемежение кодовых символов по п. 9)
Наиболее близким аналогом по технической сущности к предлагаемому является "Способ передачи голосовых данных в системе цифровой радиосвязи и способ перемежения последовательности кодовых символов (варианты)", патент РФ 2323520, H03M 13/00, перемежение кодовых символов по п. 9, принятый за прототип.
Способ-прототип заключается в следующем:
• разбивают последовательность символов для перемежения на подпоследовательности символов для перемежения;
• осуществляют обмен кодовыми символами между и/или внутри подпоследовательностей, образуя перемеженные подпоследовательности кодовых символов;
• формируют из подпоследовательностей финальную перемеженную последовательность;
• разбивают последовательность  символов для перемежения на две подпоследовательности символов для перемежения в первую из которых входят
символов для перемежения на две подпоследовательности символов для перемежения в первую из которых входят  символов для перемежения, а во вторую
символов для перемежения, а во вторую  символов для перемежения, причем формируют первую и вторую подпоследовательность таким образом, что в первой подпоследовательности выполняется условие
символов для перемежения, причем формируют первую и вторую подпоследовательность таким образом, что в первой подпоследовательности выполняется условие  ,
,
а во второй подпоследовательности выполняется условие 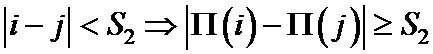 , где
, где  – номера кодовых символов до перемежения, а
– номера кодовых символов до перемежения, а  – номера кодовых символов после перемежения,
– номера кодовых символов после перемежения,  – целые положительные числа;
– целые положительные числа;
• – производя отбор символов в первую подпоследовательность по первым адресам, заданным в пилотной псевдослучайной последовательности и производя отбор последних  символов во вторую подпоследовательность по последним
символов во вторую подпоследовательность по последним  адресам, заданным в пилотной псевдослучайной последовательности, для определения которой формируют множество номеров
адресам, заданным в пилотной псевдослучайной последовательности, для определения которой формируют множество номеров  от
от  до
до  , где – количество символов для перемежения следующим образом:
, где – количество символов для перемежения следующим образом:
– устанавливают начальное значение параметра разнесения  , где – целые положительные числа и выполняется
, где – целые положительные числа и выполняется 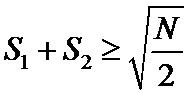 %;
%;
• формируют множество пар чисел  , определяющих закон взаимно однозначного соответствия между первоначальной последовательностью символов и перемеженной последовательностью символов, состоящее из одной пары чисел, где первое число – номер последовательности до перемежения, а второе число – номер элемента в последовательности после перемежения, где в вышеупомянутой паре чисел первое равно нулю и второе равно случайным образом выбранному номеру из множества
, определяющих закон взаимно однозначного соответствия между первоначальной последовательностью символов и перемеженной последовательностью символов, состоящее из одной пары чисел, где первое число – номер последовательности до перемежения, а второе число – номер элемента в последовательности после перемежения, где в вышеупомянутой паре чисел первое равно нулю и второе равно случайным образом выбранному номеру из множества  , который при этом исключают из множества
, который при этом исключают из множества  ;
;
• инициализируют  ;
;
• случайным образом выбирают из множества  элемент
элемент  и ставят ему во взаимно однозначное соответствие элемент
и ставят ему во взаимно однозначное соответствие элемент 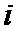 , определяя таким образом преобразование
, определяя таким образом преобразование  ;
;
• выполняют проверку дистанционного разнесения перемеженных символов для чего для всех 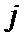 таких, что
таких, что  ,
, 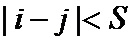 вычисляют значение
вычисляют значение 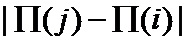 ;
;
• если все полученные значения больше или равны  , то увеличивают значение
, то увеличивают значение  , исключают элемент
, исключают элемент  из множества
из множества  и добавляют в множество
и добавляют в множество  пару
пару  ;
;
• если хотя бы одна разность оказывается меньше, чем , то повторно выбирают другой элемент  из множества
из множества  и повторяют для него проверку дистанционного разнесения перемеженных символов;
и повторяют для него проверку дистанционного разнесения перемеженных символов;
• при невозможности найти элемент, удовлетворяющий проверке дистанционного разнесения перемеженных символов, повторяют весь алгоритм заново с измененным параметром разнесения ;
• при достижении значения  присваивают
присваивают 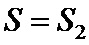 ;
;
• повторяют процедуру до тех пор, пока множество  не станет пустым, а множество
не станет пустым, а множество  не будет содержать
не будет содержать  пар чисел;
пар чисел;
• формируют из подпоследовательностей финальную перемеженную последовательность.
Недостатком прототипа является последовательный характер процедуры перемежения: кодовые символы могут быть перемежены только один за другим, что займет значительное время, а достоинством прототипа хорошие характеристики помехоустойчивости. Прототип является модификацией алгоритма S-random [S. Dolinar and D. Divsalar “Weight Distribution for turbo codes using random and non-random permutation” JPL Progress report 42-122 pp 56-65 Aug 15,1995], распространенной на случай малой длины пакета.
Требования к перемежителю заключаются в том, чтобы обеспечить достаточное разнесение повторенных символов, обеспечив тем самым отсутствие или малое число кодовых слов с низким весом. Существуют два класса перемежителей: псевдослучайный и детерминистический. Для формирования случайного перемежителя применяют датчик случайных чисел, при помощи которого определяют номер перемежаемого символа в последовательности после перемежения. Последовательность получаемых номеров подвергают проверке на достаточность разнесения подряд идущих повторенных информационных символов с выбраковкой (откатом назад) последовательностей, не прошедших подобной проверки.
Псевдослучайные перемежители требуют много памяти для хранения и не могут быть сгенерированы на приемной и передающей стороне независимо или же такая генерация потребует больших вычислительных и временных затрат. От этого недостатка свободны детерминистические перемежители, где способ взаимно однозначного соответствия перемежения определяется путем задания параметризованного алгоритма. Такие перемежителя могут формироваться “на лету”, то есть непосредственно в процессе декодирования, и задаются путем определения параметров алгоритма (несколько положительных целых чисел).
Примером является решение, представляющее собой взаимно простой интерливер, [United States Patent 6,857,087 Crozier, et al. February 15, 2005 High-performance low-memory interleaver banks for turbo-codes]. Такой способ, известный как DRP перемежитель, заключается в перемежении последовательности  упорядоченных элементов, сформированных как
упорядоченных элементов, сформированных как 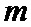 подпоследовательностей, где каждая подпоследовательность содержит в среднем
подпоследовательностей, где каждая подпоследовательность содержит в среднем 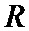 элементов. При этом
элементов. При этом
1. перемежают элементы в каждой из подпоследовательностей для формирования последовательности из упорядоченных элементов по правилу, установленному в пилотной подпоследовательности, формируя пилотную псевдослучайную подпоследовательность;
2. перемежают элементов в пилотной псевдослучайной последовательности из упорядоченных элементов для формирования перемеженной последовательности, сформированной как подпоследовательностей, имеющих размер в среднем  элементов;
элементов;
3. перемежают элементы внутри каждой из подпоследовательности для получения перемеженной последовательности из упорядоченных элементов.
Существенной особенностью данного способа является то, что шаг 2 выполняют путем взаимно-простого перемежителя, соответствующего преобразованию вида  , где количество перемежаемых элементов, а
, где количество перемежаемых элементов, а 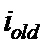 – старый номер в первой перемеженной последовательности
– старый номер в первой перемеженной последовательности  – число взаимно простое с . Подобный подход также известен из [S. Dolinar and D. Divsalar “Weight Distribution for turbo codes using random and non-random permutation” JPL Progress report 42-122 pp 56-65 Aug 15,1995] как алгебраический интерливер. Подбор чисел
– число взаимно простое с . Подобный подход также известен из [S. Dolinar and D. Divsalar “Weight Distribution for turbo codes using random and non-random permutation” JPL Progress report 42-122 pp 56-65 Aug 15,1995] как алгебраический интерливер. Подбор чисел  целесообразно таким образом, чтобы обеспечить наименьшее число кодовых слов с минимальным весом, что так же отвечает критерию минимума циклов длиной 4 на графе Таннера. Данный способ перемежения используют для турбокодов и он неприменим к кодам с низкой плотностью проверок на четность. Однако, взаимно-простой перемежитель допускает параллельное выполнение алгоритма перемежения несколькими процессорами.
целесообразно таким образом, чтобы обеспечить наименьшее число кодовых слов с минимальным весом, что так же отвечает критерию минимума циклов длиной 4 на графе Таннера. Данный способ перемежения используют для турбокодов и он неприменим к кодам с низкой плотностью проверок на четность. Однако, взаимно-простой перемежитель допускает параллельное выполнение алгоритма перемежения несколькими процессорами.
Для того чтобы схема параллельного перемежения была реализуемой, работа каждого из процессоров не должна приводить к конфликтам при доступе к памяти. К числу таких конфликтов можно, например, отнести попытку одновременной записи и чтения отдельной ячейки памяти. Память обычно реализуют в виде блоков (“банков”) памяти, таким образом, что к каждому блоку за один квант времени возможен либо доступ на запись (по указанному адресу), либо доступ на чтение.
Таким образом, видно, что актуальной является задача разработки алгоритма перемежения, который с одной стороны может быть реализован как результат параллельного перемежения последовательности кодовых символов несколькими процессорами, а с другой обеспечивать характеристики помехоустойчивости, сравнимые с прототипом.
Для решения поставленной задачи в способе перемежения последовательности кодовых символов, состоящем в том, что разбивают последовательность символов для перемежения на подпоследовательности символов для перемежения, осуществляют обмен кодовыми символами между и/или внутри подпоследовательностей, образуя перемеженные подпоследовательности кодовых символов, формируют из подпоследовательностей финальную перемеженную последовательность, последовательность символов для перемежения количеством разбивают на равные подпоследовательности установленного размера  , в каждой из подпоследовательностей производят перемежение по установленному правилу перемежения подпоследовательностей, согласно изобретению, формируют пилотную псевдослучайную подпоследовательность таким образом, что в пилотной подпоследовательности выполняется условие
, в каждой из подпоследовательностей производят перемежение по установленному правилу перемежения подпоследовательностей, согласно изобретению, формируют пилотную псевдослучайную подпоследовательность таким образом, что в пилотной подпоследовательности выполняется условие
 , где
, где  – номера кодовых символов до перемежения, а
– номера кодовых символов до перемежения, а  – номера тех же кодовых символов после перемежения,
– номера тех же кодовых символов после перемежения,  – целое положительное число; для определения пилотной псевдослучайной подпоследовательности номеров формируют множество номеров от до
– целое положительное число; для определения пилотной псевдослучайной подпоследовательности номеров формируют множество номеров от до 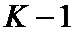 , где
, где  – количество символов для перемежения следующим образом: устанавливают начальное целые положительные значение параметра разнесения
– количество символов для перемежения следующим образом: устанавливают начальное целые положительные значение параметра разнесения  , формируют множество пар чисел , определяющих закон взаимно однозначного соответствия между первоначальной последовательности символов и перемеженной подпоследовательности символов, состоящее из одной пары чисел, где первое число – номер в подпоследовательности до перемежения, а второе число – номер элемента в подпоследовательности после перемежения, где в вышеупомянутой паре чисел первое равно нулю и второе равно случайным образом выбранному номеру из множества , который при этом исключают из множества , инициализируют , случайным образом выбирают из множества элемент и ставят ему во взаимно однозначное соответствие элемент , определяя таким образом, преобразование , выполняют проверку дистанционного разнесения перемеженных символов для чего для всех таких, что , , вычисляют значение , если все полученные значения разные, то увеличивают значение ; исключают элемент из множества и добавляют в множество пару , если хотя бы две разности оказываются равны, то повторно выбирают другой элемент из множества и повторяют для него проверку дистанционного разнесения перемеженных символов, при невозможности найти элемент, удовлетворяющий проверке дистанционного разнесения перемеженных символов, повторяют весь алгоритм заново с уменьшенным параметром разнесения , повторяют процедуру до тех пор, пока множество не станет пустым, а множество не будет содержать
, формируют множество пар чисел , определяющих закон взаимно однозначного соответствия между первоначальной последовательности символов и перемеженной подпоследовательности символов, состоящее из одной пары чисел, где первое число – номер в подпоследовательности до перемежения, а второе число – номер элемента в подпоследовательности после перемежения, где в вышеупомянутой паре чисел первое равно нулю и второе равно случайным образом выбранному номеру из множества , который при этом исключают из множества , инициализируют , случайным образом выбирают из множества элемент и ставят ему во взаимно однозначное соответствие элемент , определяя таким образом, преобразование , выполняют проверку дистанционного разнесения перемеженных символов для чего для всех таких, что , , вычисляют значение , если все полученные значения разные, то увеличивают значение ; исключают элемент из множества и добавляют в множество пару , если хотя бы две разности оказываются равны, то повторно выбирают другой элемент из множества и повторяют для него проверку дистанционного разнесения перемеженных символов, при невозможности найти элемент, удовлетворяющий проверке дистанционного разнесения перемеженных символов, повторяют весь алгоритм заново с уменьшенным параметром разнесения , повторяют процедуру до тех пор, пока множество не станет пустым, а множество не будет содержать 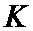 пар чисел; формируют перемеженные подпоследовательности, располагая элементы в соответствии с их новыми номерами в каждой подпоследовательности, используя пилотную псевдослучайную последовательность номеров, объединяют перемеженные подпоследовательности в первую перемеженную последовательность, в первой перемеженной последовательности выполняют второе перемежение для чего для каждого символа в последовательности формируют его новый номер в последовательности по порядку путем выполнения преобразования вида
пар чисел; формируют перемеженные подпоследовательности, располагая элементы в соответствии с их новыми номерами в каждой подпоследовательности, используя пилотную псевдослучайную последовательность номеров, объединяют перемеженные подпоследовательности в первую перемеженную последовательность, в первой перемеженной последовательности выполняют второе перемежение для чего для каждого символа в последовательности формируют его новый номер в последовательности по порядку путем выполнения преобразования вида  , где – количество перемежаемых элементов, а – старый номер в первой перемеженной последовательности, число взаимно простое с ; формируют вторую перемеженную последовательность, располагая элементы первой перемеженной последовательности в соответствии с новыми номерами, формируют третью перемеженную последовательность, для чего осуществляют преобразование
, где – количество перемежаемых элементов, а – старый номер в первой перемеженной последовательности, число взаимно простое с ; формируют вторую перемеженную последовательность, располагая элементы первой перемеженной последовательности в соответствии с новыми номерами, формируют третью перемеженную последовательность, для чего осуществляют преобразование  , где
, где  – последовательность значений из К элементов; формируют финальную перемеженную последовательность, располагая элементы в соответствии с их новыми номерами.
– последовательность значений из К элементов; формируют финальную перемеженную последовательность, располагая элементы в соответствии с их новыми номерами.
Предлагаемый способ перемежения последовательности кодовых символов заключается в следующем:
• разбивают последовательность символов для перемежения на подпоследовательности символов для перемежения;
• осуществляют обмен кодовыми символами между и/или внутри подпоследовательностей, образуя перемеженные подпоследовательности кодовых символов;
• формируют из подпоследовательностей финальную перемеженную последовательность;
• последовательность символов для перемежения количеством разбивают на равные подпоследовательности установленного размера ;
• в каждой из подпоследовательностей производят перемежение по установленному правилу перемежения подпоследовательностей, для этого формируют пилотную псевдослучайную подпоследовательность таким образом, что в пилотной подпоследовательности выполняется условие  , где – номера кодовых символов до перемежения, а – номера тех же кодовых символов после перемежения, – целое положительное число;
, где – номера кодовых символов до перемежения, а – номера тех же кодовых символов после перемежения, – целое положительное число;
• для определения пилотной псевдослучайной подпоследовательности номеров формируют множество номеров от до , где – количество символов для перемежения следующим образом:
устанавливают начальное целые положительные значение параметра разнесения , формируют множество пар чисел , определяющих закон взаимно однозначного соответствия между первоначальной последовательностью символов и перемеженной подпоследовательностью символов, состоящее из одной пары чисел, где первое число – номер в подпоследовательности до перемежения, а второе число – номер элемента в подпоследовательности после перемежения, где в вышеупомянутой паре чисел первое равно нулю и второе равно случайным образом выбранному номеру из множество , который при этом исключают из множества ;
• инициализируют ;
• случайным образом выбирают из множества элемент и ставят ему в взаимно однозначное соответствие элемент , определяя таким образом преобразование ;
• выполняют проверку дистанционного разнесения перемеженных символов для чего для всех таких, что , вычисляют значение ;
• если все полученные значения разные, то увеличивают значение , исключают элемент из множества и добавляют в множество пару ;
• если хотя бы две разности оказываются равны, то повторно выбирают другой элемент из множества и повторяют для него проверку дистанционного разнесения перемеженных символов;
• при невозможности найти элемент, удовлетворяющий проверке дистанционного разнесения перемеженных символов, повторяют весь алгоритм заново с уменьшенным параметром разнесения ;
• повторяют процедуру до тех пор, пока множество не станет пустым, а множество не будет содержать пар чисел;
• формируют перемеженные подпоследовательности, располагая элементы в соответствии с их новыми номерами в каждой подпоследовательности, используя пилотную псевдослучайную последовательность номеров;
• объединяют перемеженные подпоследовательности в первую перемеженную последовательность;
• в первой перемеженной последовательности выполняют второе перемежение для чего для каждого символа в последовательности формируют его новый номер в последовательности по порядку путем выполнения преобразования вида , где – количество перемежаемых элементов, а – старый номер в первой перемеженной последовательности, – число взаимно простое с ;
• формируют вторую перемеженную последовательность, располагая элементы первой перемеженной последовательности в соответствие с новыми номерами;
• для каждого -го элемента, начиная с первого, получают новый номер во второй перемеженной последовательности, где новый номер равен  , при этом номера остальных элементов последовательности не изменяют;
, при этом номера остальных элементов последовательности не изменяют;
• формируют третью перемеженную последовательность, для чего осуществляют преобразование  , где последовательность значений из К элементов;
, где последовательность значений из К элементов;
• формируют финальную перемеженную последовательность, располагая элементы в соответствии с их новыми номерами.
Предлагаемый способ перемежения последовательности кодовых символов может быть реализован на цифровом сигнальном процессоре, массиве цифровых сигнальных процессоров, ПЛИС, на специализированной микросхеме. Алгоритм перемежения представлен на фиг. 7.
Рассмотрим алгоритм, как алгоритм перемежения в прямоугольном перемежителе. Сущность алгоритма в том, что на первой стадии перемежения осуществляют перемежение внутри каждой из подпоследовательностей или перемежение в каждой строке, а на второй стадии – взаимно-простое перемежение, на третьей – циклический сдвиг в столбцах. Все три операции могут быть осуществлены параллельно.
Отличительными (новыми) признаками заявляемого способа передачи данных в цифровой системе радиосвязи относительно прототипа являются следующие признаки:
- новый способ перемежения кодовых символов;
-новый способ кодового сопряжения пакетов;
-новый способ декодирования кодово-сопряженных пакетов.
Сопоставительный анализ заявляемых способов с прототипом показывает, что предлагаемое изобретение существенно отличается от известных решений, так как позволяют повысить качество радиосвязи за счет снижения количества избыточных передаваемых кодовых символов, путем кодового сопряжения пакетов при автоматическом запросе-повторении, а также используя новый оптимизированный способы перемежения, увеличить быстродействие и пропускную способность устройства – за счет параллельной обработки пакетов данных.
Таким образом, технический результат состоит в получении энергетического выигрыша кодирования в среднем 0.5 дБ, а также в упрощении поиска псевдослучайной последовательности перемежения кодовых символов.
Для этого в способе применяют кодовое сопряжение пакетов и новый способ перемежения кодовых символов.
Таким образом, заявляемый способ позволяет достичь энергетического выигрыша кодирования в среднем 0.5 дБ по сравнению с прототипом. Кроме того, заявляемый способ позволяет существенно упростить поиск псевдослучайной последовательности перемежения кодовых символов, а также допускает параллельную реализацию декодирующего устройства без потери характеристик помехоустойчивости.



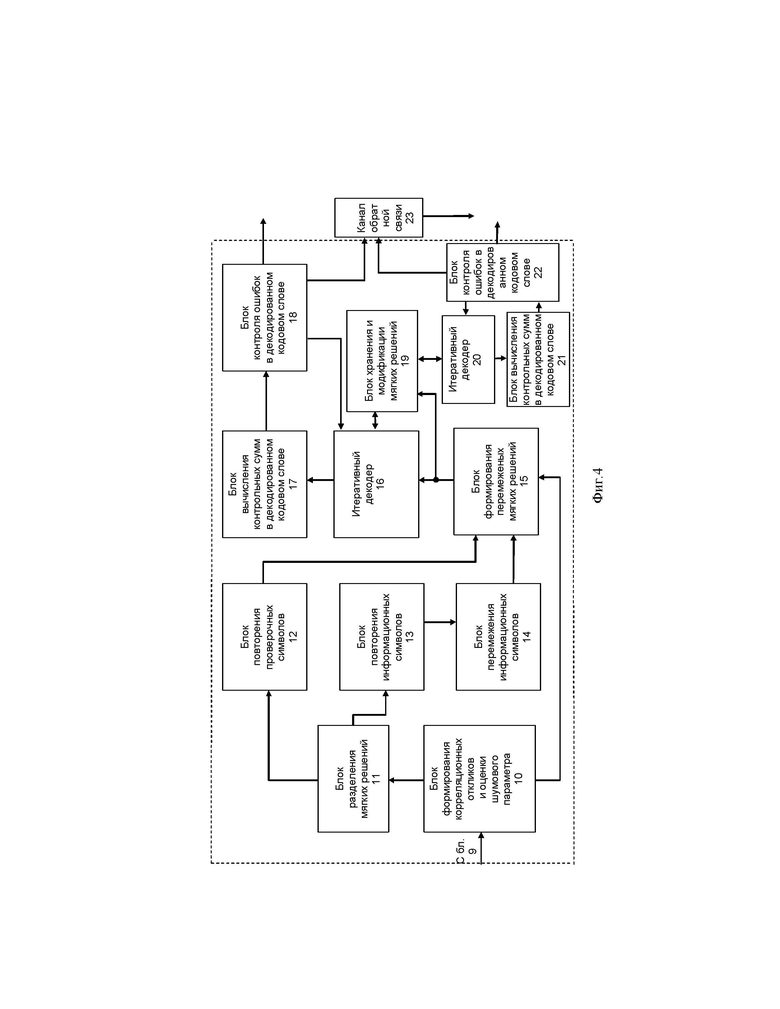
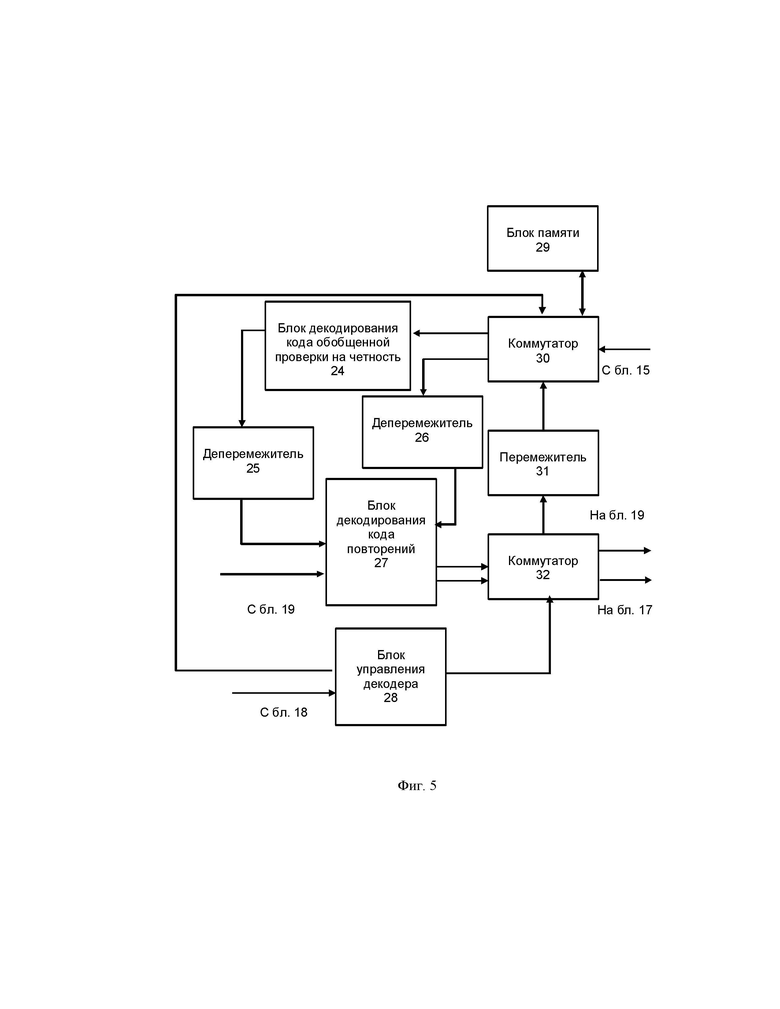
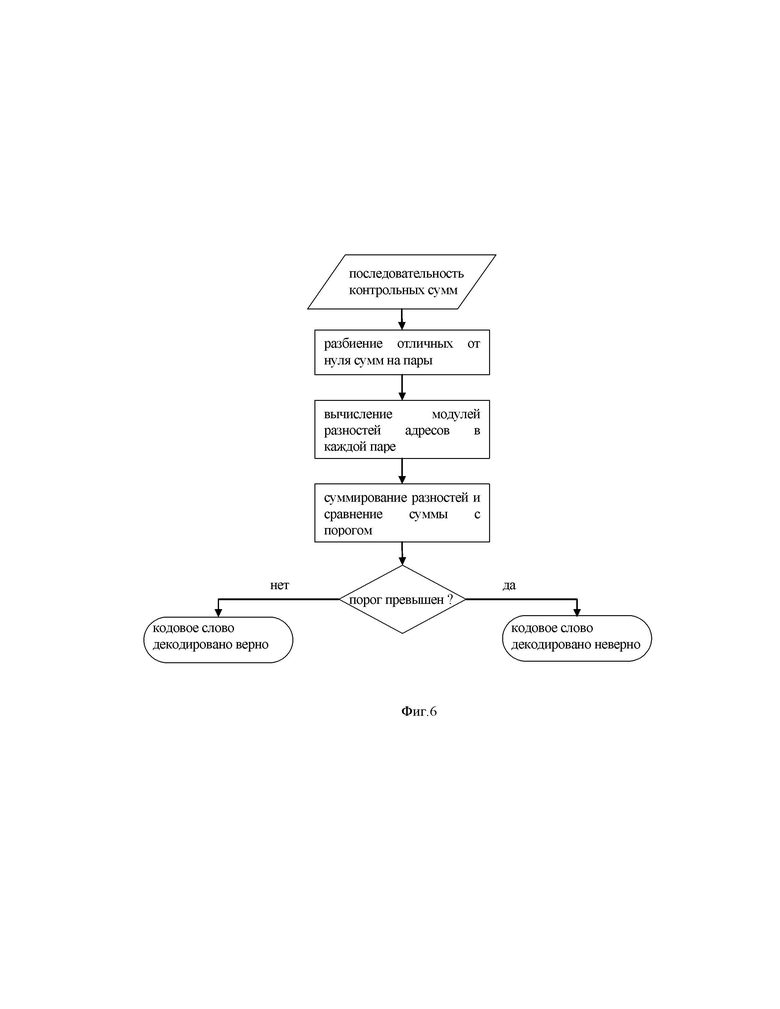


Изобретение относится к средствам для передачи данных в системе цифровой радиосвязи на основе кодов с низкой плотностью проверок на четность. Технический результат заключается в повышении эффективности кодирования. На передающей стороне формируют пакеты данных, каждый из которых содержит упорядоченную последовательность информационных символов. Каждый информационный символ повторяют определенное число раз, в зависимости от его номера по порядку в последовательности символов, формируя последовательность повторенных информационных символов. Количество повторений определяется заранее. Осуществляют перемежение в последовательности повторенных информационных символов, добиваясь разнесения идущих подряд повторенных информационных символов и формируя последовательность перемеженных повторенных информационных символов. Разбивают перемеженные повторенные информационные символы на группы таким образом, что первый проверочный символ получают путем суммирования по заданному модулю начального значения переменной суммирования со всеми перемеженными повторенными информационными символами из первой группы. 2 н. и 4 з.п. ф-лы, 8 ил.
1. Способ передачи данных в цифровой системе связи, заключающийся в том, что на передающей стороне формируют пакеты данных, каждый из которых содержит упорядоченную последовательность информационных символов, каждый информационный символ повторяют определенное число раз, в зависимости от его номера по порядку в последовательности символов, формируя последовательность повторенных информационных символов, причем количество повторений определяется заранее, осуществляют перемежение в последовательности повторенных информационных символов, добиваясь достаточного разнесения идущих подряд повторенных информационных символов и формируя последовательность перемеженных повторенных информационных символов, разбивают перемеженные повторенные информационные символы на группы таким образом, что первый проверочный символ получают путем суммирования по заданному модулю начального значения переменной суммирования со всеми перемеженными повторенными информационными символами из первой группы, а проверочный символ n - путем суммирования по заданному модулю проверочного символа n-1 со всеми перемеженными повторенными информационными символами из группы n, запоминают полученные проверочные символы, формируют кодовое слово путем добавления проверочных символов к информационным символам, на приемной стороне формируют принятые корреляционные отклики на каждый из переданных кодовых символов, выполняют оценку шумового параметра смеси сигнал плюс шум, формируют мягкие решения о принятых кодовых символах, используя полученную оценку шумового параметра смеси сигнал плюс шум, разделяют мягкие решения о принятых кодовых символах на решения об информационных символах и решения о проверочных символах, повторяют мягкие решения об информационных символах в соответствии с шаблоном повторения информационных символов, повторяют мягкие решения о проверочных символах по крайней мере два раза за исключением последнего проверочного символа, для мягких решений об информационных символах выполняют перемежение, аналогичное перемежению на передающей стороне, формируют группы перемеженных мягких решений об информационных символах, аналогичные группам соответствующих информационных символов на передающей стороне, первую группу перемеженных мягких решений дополняют мягким решением, соответствующим начальному значению переменной суммирования, и первой копией мягкого решения о первом проверочном символе, образуя первое кодовое слово кода обобщенной проверки на четность, n-ю группу перемеженных мягких решений дополняют второй копией (n-1)-го проверочного символа и первой копией мягкого решения об n-м проверочном символе, образуя n-е кодовое слово кода обобщенной проверки на четность, для каждого мягкого решения, входящего в каждое кодовое слово кода обобщенной проверки на четность, формируют модифицированное мягкое решение, которое является исходящим сообщением кодового слова кода обобщенной проверки на четность таким образом, что исходящее сообщение кодового слова кода обобщенной проверки на четность представляет собой результат функционального преобразования исходных мягких решений, представляющих собой входящие сообщения кодового слова кода обобщенной проверки на четность, деперемежают исходящие сообщения кодового слова кода обобщенной проверки на четность таким образом, что каждой копии мягкого решения о кодовом символе ставят в соответствие исходящее сообщение кодового слова кода обобщенной проверки на четность, соответствующее копии мягкого решения об этом символе, группируют исходящие сообщения кодового слова кода обобщенной проверки на четность с мягкими решениями о принятых кодовых символах, так что в каждую группу входят мягкое решение о соответствующем кодовом символе и исходящее сообщение кодового слова кода обобщенной проверки на четность, соответствующее копии мягкого решения об этом символе, формируя таким образом кодовое слово обобщенного кода повторения, ставя каждое кодовое слово обобщенного кода повторения в соответствие кодовому символу таким образом, что каждое исходящее сообщения кодового слова кода обобщенной проверки на четность является входящим сообщением кодового слова обобщенного кода повторения, для каждого мягкого решения, входящего в каждое кодовое слово обобщенного кода повторения, формируют модифицированное мягкое решение, которое является исходящим сообщением кодового обобщенного кода повторения, представляющее собой результат функционального преобразования над входящими сообщениями кодового слова обобщенного кода повторения, итеративно повторяют процесс обмена исходящими и входящими сообщениями таким образом, что исходящее сообщение кодового слова обобщенного кода повторений является входящим сообщением кодового слова кода обобщенной проверки на четность, а исходящее сообщение кода обобщенной проверки на четность является входящим сообщением кодового слова обобщенного кода повторений, формируя на каждой итерации последовательность модифицированных мягких решений, из последовательности модифицированных мягких решений формируют декодированные кодовые слова, умножают каждое декодированное кодовое слово на проверочную матрицу, получая упорядоченную последовательность контрольных сумм, если все контрольные суммы равны нулю, то кодовое слово считают декодированным верно, если количество контрольных сумм, отличных от нуля, нечетно и последняя контрольная сумма отлична от нуля, то заменяют ее нулем, если количество контрольных сумм, отличных от нуля, нечетно и последняя в последовательности контрольная сумма равна нулю, то ее заменяют любым отличным от нуля значением, разбивают последовательность контрольных сумм на пары, в которые входят элементы последовательности, идущие подряд, причем каждая контрольная сумма входит только в единственную пару, в каждой паре вычисляют разность номеров контрольных сумм, складывают все полученные разности номеров контрольных сумм, сравнивают полученное число с заданным порогом, если число превышает установленный порог, то информационную часть кодового слова считают декодированной неверно, если полученное число меньше заданного порога, то информационную часть кодового слова считают декодированной верно, отличающийся тем, что если информационная часть кодового слова декодирована неверно, то формируют сигнал запроса повторной передачи по каналу обратной связи для передающей стороны, на передающей стороне при получении сигнала запроса повторной передачи формируют пакет с кодово-сопряженной частью, для чего в очередном кодированном пакете часть кодовых символов заменяют суммой по модуля два с кодовыми символами ранее переданного и ошибочно декодированого пакета, формируя тем самым кодово-сопряженную часть, при получении текущего пакета с кодово-сопряженной частью декодируют его совместно с ранее принятым ошибочно декодированным пакетом, для чего восстанавливают, возможно с ошибками, последовательность мягких решений ошибочного пакета, модифицируют мягкие решения в кодово-сопряженной части в тех позициях, в которых заменяли кодовые символы суммой символов разных пакетов, для чего заменяют знак на противоположный у принятого мягкого решения, если восстановленный кодовый символ предыдущего пакета соответствует логической единице, получая мягкие решения текущего пакета, декодируют мягкие решения текущего пакета, восстанавливают последовательность мягких решений текущего пакета, модифицируют мягкие решения в кодово-сопряженной части в тех позициях, в которых заменяли кодовые символы суммой символов разных пакетов, для чего заменяют знак на противоположный у принятого мягкого решения, если восстановленный кодовый символ текущего пакета соответствует логической единице, получая модифицированную последовательность мягких решений для ошибочного пакета, повторно декодируют ошибочный пакет, используя модифицированную последовательность мягких решений для ошибочного пакета как дополнительную информацию в тех позициях, в которых заменяли кодовые символы суммой символов разных пакетов, передают по каналу обратной связи сигналы, характеризующие результативность декодирования кодово-сопряженных пакетов.
2. Способ по п. 1, отличающийся тем, что оценку шумового параметра смеси сигнал плюс шум определяют как величину стандартного отклонения эквивалентного Гауссовского белого шума, которым аппроксимируются помехи в канале.
3. Способ по п. 1, отличающийся тем, что итеративное декодирование выполняют в параллельном режиме, обрабатывая сообщения в каждом из кодовых слов обобщенного кода повторений или кодовых слов кода обобщенной проверки на четность независимо друг друга, а процедуру обмена сообщениями между контрольными и переменными вершинами осуществляют один раз за итерацию.
4. Способ по п. 1, отличающийся тем, что итеративное декодирование выполняют в последовательном режиме, последовательно обрабатывая сообщения в кодовых словах обобщенного кода повторений и кодовых словах кода обобщенной проверки на четность, причем по крайней мере одно исходящее сообщение от обрабатываемого кодового слова одного кода является входящим сообщением для кодового слова другого кода.
5. Способ по п. 1, отличающийся тем, что итеративное декодирование выполняют в последовательно-параллельном режиме, выделяя среди всего множество кодовых слов кодов обобщенного кода повторений и кода обобщенной проверки на четность подмножество кодовых слов, обрабатываемых в параллельном режиме и подмножество кодовых слов, обрабатываемых в последовательном режиме.
6. Способ перемежения последовательности кодовых символов, состоящий в том, что разбивают последовательность символов для перемежения на подпоследовательности символов для перемежения, осуществляют обмен кодовыми символами между и/или внутри подпоследовательностей, образуя перемеженные подпоследовательности кодовых символов, формируют из подпоследовательностей финальную перемеженную последовательность, последовательность символов для перемежения количеством N разбивают на равные подпоследовательности установленного размера K, в каждой из подпоследовательностей производят перемежение по установленному правилу перемежения подпоследовательностей, отличающийся тем, что формируют пилотную псевдослучайную подпоследовательность таким образом, что в пилотной подпоследовательности выполняется условие
 , где i,j1,2 – номера кодовых символов до перемежения, а
, где i,j1,2 – номера кодовых символов до перемежения, а  – номера тех же кодовых символов после перемежения, S – целое положительное число; для определения пилотной псевдослучайной подпоследовательности номеров формируют множество номеров M от 0 до K-1, где K - количество символов для перемежения следующим образом: устанавливают начальное целые положительные значение параметра разнесения S, формируют множество пар чисел Θ, определяющих закон взаимно однозначного соответствия между первоначальной последовательностью символов и перемеженной подпоследовательностью символов, состоящее из одной пары чисел, где первое число – номер в подпоследовательности до перемежения, а второе число – номер элемента в подпоследовательности после перемежения, где в вышеупомянутой паре чисел первое равно нулю и второе равно случайным образом выбранному номеру из множества М, который при этом исключают из множества М, инициализируют i=1, случайным образом выбирают из множества М элемент iп и ставят ему во взаимно однозначное соответствие элемент i, определяя таким образом преобразование
– номера тех же кодовых символов после перемежения, S – целое положительное число; для определения пилотной псевдослучайной подпоследовательности номеров формируют множество номеров M от 0 до K-1, где K - количество символов для перемежения следующим образом: устанавливают начальное целые положительные значение параметра разнесения S, формируют множество пар чисел Θ, определяющих закон взаимно однозначного соответствия между первоначальной последовательностью символов и перемеженной подпоследовательностью символов, состоящее из одной пары чисел, где первое число – номер в подпоследовательности до перемежения, а второе число – номер элемента в подпоследовательности после перемежения, где в вышеупомянутой паре чисел первое равно нулю и второе равно случайным образом выбранному номеру из множества М, который при этом исключают из множества М, инициализируют i=1, случайным образом выбирают из множества М элемент iп и ставят ему во взаимно однозначное соответствие элемент i, определяя таким образом преобразование 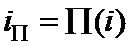 , выполняют проверку дистанционного разнесения перемеженных символов, для чего для всех j таких, что j<i,
, выполняют проверку дистанционного разнесения перемеженных символов, для чего для всех j таких, что j<i,  , вычисляют значение
, вычисляют значение  , если все полученные значения разные, то увеличивают значение i=i+1; исключают элемент iП из множества M и добавляют в множество Θ пару i,iП, если хотя бы две разности оказываются равны, то повторно выбирают другой элемент
, если все полученные значения разные, то увеличивают значение i=i+1; исключают элемент iП из множества M и добавляют в множество Θ пару i,iП, если хотя бы две разности оказываются равны, то повторно выбирают другой элемент  из множества M и повторяют для него проверку дистанционного разнесения перемеженных символов, при невозможности найти элемент, удовлетворяющий проверке дистанционного разнесения перемеженных символов, повторяют весь алгоритм заново с уменьшенным параметром разнесения S, повторяют процедуру до тех пор, пока множество M не станет пустым, а множество Θ не будет содержать K пар чисел; формируют перемеженные подпоследовательности, располагая элементы в соответствии с их новыми номерами в каждой подпоследовательности, используя пилотную псевдослучайную последовательность номеров, объединяют перемеженные подпоследовательности в первую перемеженную последовательность, в первой перемеженной последовательности выполняют второе перемежение, для чего для каждого символа в последовательности формируют его новый номер в последовательности по порядку путем выполнения преобразования вида
из множества M и повторяют для него проверку дистанционного разнесения перемеженных символов, при невозможности найти элемент, удовлетворяющий проверке дистанционного разнесения перемеженных символов, повторяют весь алгоритм заново с уменьшенным параметром разнесения S, повторяют процедуру до тех пор, пока множество M не станет пустым, а множество Θ не будет содержать K пар чисел; формируют перемеженные подпоследовательности, располагая элементы в соответствии с их новыми номерами в каждой подпоследовательности, используя пилотную псевдослучайную последовательность номеров, объединяют перемеженные подпоследовательности в первую перемеженную последовательность, в первой перемеженной последовательности выполняют второе перемежение, для чего для каждого символа в последовательности формируют его новый номер в последовательности по порядку путем выполнения преобразования вида 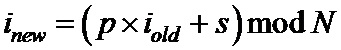 , где N – количество перемежаемых элементов, а iold – старый номер в первой перемеженной последовательности, p - число, взаимно простое с N; формируют вторую перемеженную последовательность, располагая элементы первой перемеженной последовательности в соответствии с новыми номерами, формируют третью перемеженную последовательность, для чего осуществляют преобразование
, где N – количество перемежаемых элементов, а iold – старый номер в первой перемеженной последовательности, p - число, взаимно простое с N; формируют вторую перемеженную последовательность, располагая элементы первой перемеженной последовательности в соответствии с новыми номерами, формируют третью перемеженную последовательность, для чего осуществляют преобразование 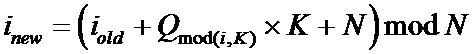 , где Q – последовательность значений из K элементов; формируют финальную перемеженную последовательность, располагая элементы в соответствии с их новыми номерами.
, где Q – последовательность значений из K элементов; формируют финальную перемеженную последовательность, располагая элементы в соответствии с их новыми номерами.
| СПОСОБ ПЕРЕДАЧИ ГОЛОСОВЫХ ДАННЫХ В СИСТЕМЕ ЦИФРОВОЙ РАДИОСВЯЗИ И СПОСОБ ПЕРЕМЕЖЕНИЯ ПОСЛЕДОВАТЕЛЬНОСТИ КОДОВЫХ СИМВОЛОВ (ВАРИАНТЫ) | 2006 |
|
RU2323520C2 |
| ТОРМОЗНАЯ КОЛОДКА ЖЕЛЕЗНОДОРОЖНОГО ТРАНСПОРТНОГО СРЕДСТВА | 2010 |
|
RU2427491C1 |
| US 6857087 B2, 15.02.2005 | |||
| US 7975189 B2, 05.07.2011 | |||
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| СПОСОБ ПЕРЕДАЧИ ИНФОРМАЦИИ С ИСПОЛЬЗОВАНИЕМ АДАПТИВНОГО ПЕРЕМЕЖЕНИЯ | 2003 |
|
RU2265960C2 |
| УСТРОЙСТВО И СПОСОБ ГЕНЕРИРОВАНИЯ И ДЕКОДИРОВАНИЯ КОДОВ В СИСТЕМЕ СВЯЗИ | 2002 |
|
RU2236756C2 |

