Изобретение относится к радиотехнике, а именно, к способам декодирования сигналов, полученных при использовании низкоплотностного кода, и предназначено для использования в области передачи цифровой информации.
Под помехоустойчивым кодированием понимается кодирование символов цифрового сигнала данных, характеризующихся использованием кодовых комбинаций, позволяющих обнаруживать и (или) исправлять ошибки в этом сигнале (ГОСТ 17657-79 Передача данных. Термины и определения, с.9).
Под помехоустойчивым декодированием понимается операция обратная кодированию символов цифрового сигнала данных (ГОСТ 17657-79 Передача данных. Термины и определения, с.9).
Под кодом проверки на четность с низкой плотностью понимается такой код, проверочная матрица которого имеет большинство элементов, равных нулю, и меньшинство - равных единице (Robert G. Gallager Low-Density Parity-Check Codec, p.7 1963).
Под параллельным каскадным кодом понимается схема кодирования, состоящая из двух параллельно соединенных через перемежитель кодов (Р.Морелос-Сарагоса Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение, с.238, Москва: Техносфера, 2005 г.).
Известен способ декодирования низкоплотностного кода - алгоритм распространения доверия (или минимум суммы) (Р.Морелос-Сарагоса Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение, с.262-263, Москва; Техносфера, 2005 г.). Сущность данного алгоритма заключается в вычислении на основе мягких решений демодулятора логарифмического отношения правдоподобия (LLR) для каждого бита кодового слова:
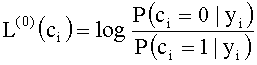 ,
,
где L(0)(ci) - логарифмическое отношения правдоподобия i индекса, нулевой итерации;
Р(ci=0|yi) - условная вероятность того, что был принят 0, при условии, что передавался yi;
Р(ci=1|yi) - условная вероятность того, что была принята 1, при условии, что передавался yi;
В конце каждой итерации формируется вектор LLR:
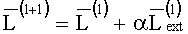 ,
,
где 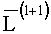 - вектор логарифмического отношения правдоподобия на l+1 итерации;
- вектор логарифмического отношения правдоподобия на l+1 итерации;
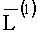 - вектор логарифмического отношения правдоподобия на l итерации;
- вектор логарифмического отношения правдоподобия на l итерации;
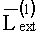 - сторонняя информация на l итерации.
- сторонняя информация на l итерации.
На выходе алгоритма после выполнения l итераций формируется вектор LLR:
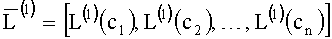 .
.
На основе данного вектора принимается жесткое решение - вектор V.
Синдром кодового слова V рассчитывается по формуле
S=V·HT,
где вектор S состоит из n-k компонент (n - полная длина кодового слова, k - информационная длина кодового слова) и рассчитывается по n-k проверочным уравнениям. В случае, если вектор V является кодовым словом, все n-k компонент равны 0, т.е все n-k проверочных уравнений равны 0.
Недостатком данного способа является высокая вероятность отказа декодирования при низких соотношениях сигнал/шум на входе демодулятора из-за влияния коротких циклов, которые возникают при построении графа Таннера низкоплотностного кода.
Также известен способ использования низкоплотностного кода в составе каскадной конструкции, где в качестве первого компонентного кода используется низкоплотностный код, декодируемый по алгоритму распространения доверия, а в качестве второго компонентного кода - блочный двоичный код БЧХ (ETSI EN 302 307 v1.1.1, Digital Video Broadcasting (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other broadband satellite applications: pp.19-23, 2004).
Недостатком данного способа является высокая вероятность отказа декодирования при низких соотношениях сигнал/шум на входе демодулятора из-за влияния коротких циклов, которые возникают при построении графа Таннера низкоплотностного кода.
Наиболее близким по технической сущности к заявляемому изобретению (прототипом) является способ кодирования/декодирования канала с использованием параллельного каскадного кода проверки на четность с низкой плотностью (Патент РФ №2310274, МПК Н03М 13/11, опубл. 10.11.2007 г.), заключающийся в том, что из информационных бит и первых бит проверок формируют первый компонентный код и выполняют его декодирование, затем выделяют информационную часть кодового слова и в зависимости от значения синдрома кодового слова принимают жесткое решение бит из информационной части или перемежают ее и из перемеженной информационной части и вторых бит проверок формируют второй компонентный код и выполняют его декодирование, после чего выделяют информационную часть кодового слова и над ней выполняют второе перемежение, обратное первому закону перемежения, и в зависимости от значения синдрома кодового слова принимают жесткое решение бит из информационной части или направляют ее на формирование первого компонентного кода, после чего повторяют весь цикл снова.
Недостатком данного способа является высокая вероятность отказа декодирования при низких соотношениях сигнал/шум на входе демодулятора из-за влияния коротких циклов, которые возникают при построении графа Таннера низкоплотностного кода.
Задачей изобретения является снижение вероятности отказа декодирования сигналов, полученных с использованием параллельного каскадного кода проверки на четность с низкой плотностью.
Задача изобретения решается тем, что известный способ помехоустойчивого декодирования сигналов, полученных с использованием параллельного каскадного кода проверки на четность с низкой плотностью, заключающийся в том, что из информационных бит и первых бит проверок формируют первый компонентный код и выполняют его декодирование, затем выделяют информационную часть кодового слова и в зависимости от значения синдрома кодового слова принимают жесткое решение бит из информационной части или перемежают ее и из перемеженной информационной части и вторых бит проверок формируют второй компонентный код и выполняют его декодирование, после чего выделяют информационную часть кодового слова и над ней выполняют второе перемежение, обратное первому закону перемежения, и в зависимости от значения синдрома кодового слова принимают жесткое решение бит из информационной части или направляют ее на формирование первого компонентного кода, после чего повторяют весь цикл снова, согласно изобретению дополнен тем, что перед операцией первого перемежения в зависимости от значения синдрома кодового слова осуществляют операцию обнаружения и устранения ситуаций «зацикливания» в первом компонентном коде и снова декодируют первый компонентный код, а после декодирования второго компонентного кода в зависимости от значения синдрома кодового слова осуществляют операцию обнаружения и устранения ситуаций «зацикливания» во втором компонентном коде и снова декодируют второй компонентный код или выполняют второе перемежение.
Перечисленная новая совокупность существенных признаков позволяет снизить вероятность отказа декодирования при низких соотношениях сигнал/шум за счет учета особенностей построения низкоплотностного кода.
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного технического решения, отсутствуют, что указывает на соответствие изобретения условию патентоспособности «новизна».
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного объекта, показали, что они не следуют явным образом из уровня техники. Из уровня техники также не выявлена известность влияния предусматриваемых существенными признаками заявленного изобретения преобразований на решение указанной задачи. Следовательно, заявленное изобретение соответствует условию патентоспособности «изобретательский уровень».
«Промышленная применимость» способа обусловлена наличием элементной базы, на основе которой могут быть выполнены устройства, реализующие данный способ с достижением указанного в изобретении назначения.
Заявленный способ поясняется чертежами, на которых показаны:
фиг.1 - последовательность операций способа помехоустойчивого декодирования сигналов, полученных с использованием параллельного каскадного кода проверки на четность с низкой плотностью;
1 - операция декодирования первого компонентного кода;
2 - процедура обнаружения и устранения ситуации «зацикливания» в первом компонентном коде;
3 - операция первого перемежения;
4 - операция декодирования второго компонентного кода;
5 - процедура обнаружения и устранения ситуации «зацикливания» во втором компонентном коде;
6 - операция второго перемежения, обратного первому;
7 - операция принятия жесткого решения бит.
Р1 - проверки первого кода;
P2 - проверки второго кода;
U - информационная часть кодового слова, принятого из канала связи;
U” - перемеженная информационная часть кодового слова, принятого из канала связи;
Ucorrect - исправленная информационная часть кодового слова.
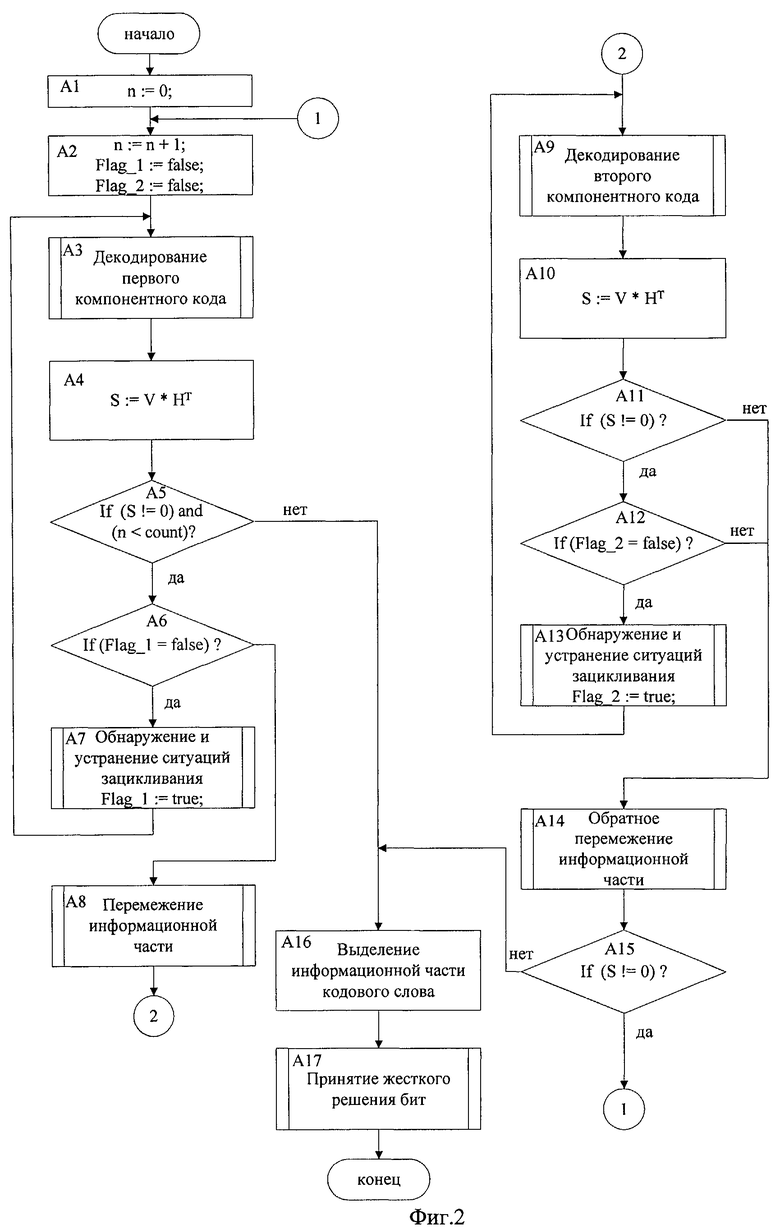
Фиг.2 - общий алгоритм способа помехоустойчивого декодирования сигналов, полученных с использованием параллельного каскадного кода проверки на четность с низкой плотностью.
А1 - инициализация алгоритма декодирования;
А2 - инициализация текущей итерации декодирования;
A3 - декодирование первого компонентного кода;
А4 - расчет синдрома кодового слова;
А5 - проверка условия неравенства синдрома кодового слова нулю;
А6 - проверка условия: выполнялась операция обнаружение и устранение ситуаций «зацикливания» в первом компонентном коде на данной итерации или нет;
А7 - обнаружение и устранение ситуаций «зацикливания» в первом компонентном коде;
A8 - перемежение информационной части;
А9 - декодирование второго компонентного кода;
А10 - расчет синдрома кодового слова;
A11 - проверка условия неравенства синдрома кодового слова нулю;
А12 - проверка условия: выполнялась операция обнаружение и устранение ситуаций «зацикливания» во втором компонентном коде на данной итерации или нет;
А13 - обнаружение и устранение ситуаций «зацикливания» в первом компонентном коде;
А14 - обратное перемежение информационной части;
А15 - проверка условия неравенства синдрома кодового слова нулю;
А16 - выделение информационной части кодового слова;
А17 - принятие жесткого решения бит.
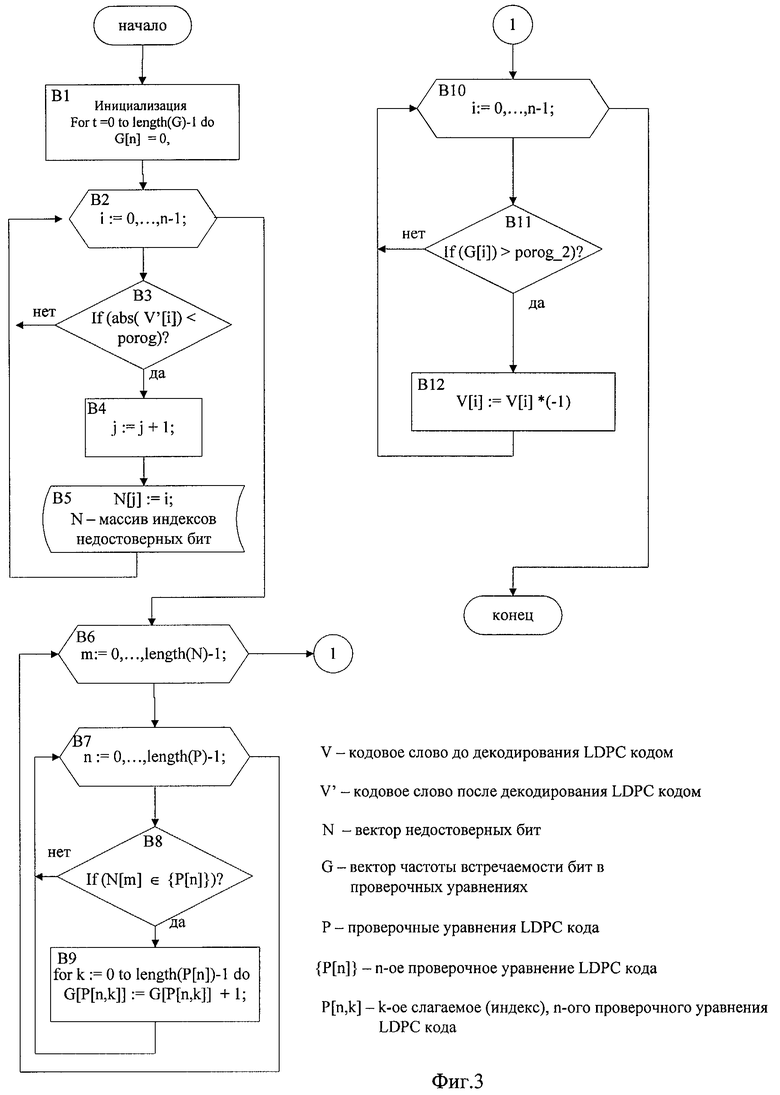
Фиг.3 - алгоритм процедуры обнаружения и устранения ситуаций зацикливания в низкоплотностном коде, реализованный во вновь введенных операциях (2 и 5).
В1 - инициализация процедуры обнаружения и устранения ситуаций зацикливания в низкоплотностном коде;
В2 - цикл, перебирающий все мягкие значения бит кодового слова;
B3 - проверка условия: больше или меньше порогового значения абсолютное значение мягкого бита;
B4 - счетчик недостоверных бит;
B5 - запись индекса недостоверного бита;
B6 - цикл, перебирающий все недостоверные индексы;
B7 - цикл, перебирающий все проверочные уравнения;
B8 - проверка условия: присутствует данный недостоверный индекс в текущем проверочном уравнении, или нет;
В9 - построение гистограммы частот встречаемости индексов бит кодового слова;
B10 - цикл, перебирающий все проверочные уравнения;
B11 - проверка условия: больше или меньше порогового значения частота появления недостоверного индекса;
B12 - инвертирование знака в текущем недостоверном индексе.
Фиг.4 - гистограмма частоты встречаемости индексов бит кодового слова.
На фиг.1 представлена последовательность операций способа декодирования сигналов, полученных с использованием параллельного каскадного кода проверки на четность с низкой плотностью. Из принятых информационных бит (U) и первых бит проверок (Р1) формируется первый компонентный код, который декодируется алгоритмом распространения доверия (блок 1). В случае, если после декодирования синдром кодового слова равен нулю, то информационная часть через ключ поступает на операцию принятия жесткого решения бит (блок 7), иначе результат декодирования первого компонентного кода через ключ поступает на блок 2, где выполняется операция обнаружения и устранения ситуаций «зацикливания» в первом компонентном коде. После чего скорректированное кодовое слово снова декодируется первым компонентным кодом, и результат декодирования поступает на ключ, где в случае нулевого синдрома кодового слова первого компонентного кода принимается решение о прекращении дальнейшего декодирования и информационная часть первого компонентного кода через ключ поступает на блок 7, где принимается жесткое решение бит. В противном случае, информационная часть первого компонентного кода через ключ поступает снова на блок 2, но так как процедура обнаружения и устранения ситуаций «зацикливания» в первом компонентном коде уже выполнялась на данной итерации декодирования, то информационная часть первого компонентного кода сразу поступает на операцию перемежения (блок 3), где выполняется первое перемежение информационной части, обновленной после декодирования первым компонентным кодом, и поступает на блок 4, где из перемеженной информационной части (U”) и вторых бит проверок (Р2) формируется второй компонентный код и декодируется. Если в результате декодирования второго компонентного кода полученный синдром не равен нулю, то результат декодирования через ключ поступает на блок 5, где выполняется процедура обнаружения и устранения ситуаций «зацикливания» во втором компонентном коде. После чего скорректированное кодовое слово снова декодируется вторым компонентным кодом, и информационная часть второго компонентного кода транслируется на блок 6, где выполняется второе перемежение, обратное первому закону перемежения. Если после декодирования второго компонентного кода синдром равен нулю, то в блоке 5 не выполняется процедура обнаружения и устранения ситуаций «зацикливания» во втором компонентном коде, а информационная часть второго компонентного кода просто транслируется на операцию второго перемежения (блок 6). После чего в зависимости от значения синдрома кодового слова результат обратного перемежения поступает на блок 7, где принимается жесткое решение бит, или вновь поступает на формирование и декодирование первого компонентного кода (блок 1).
Общий алгоритм способа декодирования сигналов с использованием параллельного каскадного кода проверки на четность с низкой плотностью представлен на фиг.2. На начальном этапе декодирования сигнала текущее число итераций ставится равным нулю: n=0 (блок А1). Далее происходит инициализация текущей итерации декодирования (блок А2): текущее число итераций увеличивается на единицу; булевым переменным Flag_1 и Flag_2 присваивается значение false, это означает, что на данной итерации декодирования процедуры обнаружения и устранения ситуаций «зацикливания» в низкоплотностном коде первого и второго компонентного кода не выполнялись. После инициализации выполняется декодирование первого компонентного кода (блок A3). Результат декодирования умножается на транспонированную проверочную матрицу (блок А4). В случае, если результат перемножения равен нулю (блок А5) или номер текущей итерации превышает допустимое количество итераций, то результат декодирования поступает на выход, где выделяется информационная часть кодового слова (блок А16). Иначе проверяется, выполнялась ли для первого компонентного кода процедура обнаружения и устранения ситуаций зацикливания на данной итерации (Flag_1=true) или нет (Flag_1=false) (блок А6). Ели данная процедура не выполнялась, то она выполняется и переменной Flag_1 присваивается значение true (блок А7). В противном случае осуществляется перемежение информационной части первого компонентного кода (блок А8). Из перемеженной информационной части и проверок второго компонентного кода формируется второй компонентный код и осуществляется процесс декодирования (блок А9). Результат декодирования перемножается на транспонированную проверочную матрицу (блок А10). В случае, если результат равен нулю (блок А11), то из кодового слова выделяется информационная часть и осуществляется обратное перемежение (блок А14). Иначе проверяется, выполнялась ли для второго компонентного кода процедура обнаружения и устранения ситуаций зацикливания на данной итерации (Flag_2=true) или нет (Flag_2=false) (блок А12). Ели данная процедура не выполнялась, то она выполняется и переменной Flag_2 присваивается значение true (блок А13). В противном случае информационная часть второго компонентного кода подвергается второму перемежению, осуществляемому по закону, обратному первому перемежению (блок А14). После обратного перемежения, в случае если синдром второго компонентного кода не равен нулю (блок А15), то результат второго перемежения поступает на блок А2, где число текущей итерации увеличивается на единицу, переменным Flag_1 и Flag_1 присваивается значение false и снова формируется кодовое слово первого компонентного кода и осуществляется его декодирование (блок A3). После чего повторяется весь выше изложенный цикл.
На фиг.3 представлен алгоритм, реализующий в способе процедуру обнаружения и устранения ситуаций зацикливания в низкоплотностном коде (операции 2 и 5). На начальном этапе выполнения алгоритма процедуры обнаружения и устранения ситуаций «зацикливания» выполняется инициализация: частоты встречаемости индексов устанавливаются в ноль (блок В1). Далее выполняется цикл от 0 до (n-1), где n - длина кодового слова (блок В2), в котором последовательно перебираются все мягкие решения бит, полученные в результате декодирования алгоритмом распространения доверия, и сравниваются их абсолютные значения с пороговыми (блок В3). В случае, если значение меньше порогового, то массив недостоверных бит увеличивается на единицу (изначально его длина равна 0) (блок В4) и записывается индекс данного мягкого решения (блок В5). В результате после того, как отработает цикл (блок В2), получается массив N недостоверных бит. Далее выполняется цикл от 0 до length(N)-1 (блок В6), где перебираются все индексы недостоверных бит и последовательно сравниваются со всеми проверочными уравнениями данного низкоплотностного кода (блок В7). В случае, если данный недостоверный индекс присутствует в проверочном уравнении (блок В8), то в гистограмме частот встречаемости значение по этому индексу увеличивается на единицу (блок В9). Таким образом, после того, как отработает цикл (блок В6), получается гистограмма частот G, которая показывает, какие из недостоверных индексов чаще всего участвуют в формировании мягких решений для других бит кодового слова. Далее необходимо выбрать наиболее часто встречаемые индексы в гистограмме G и изменить в них знак на противоположный в кодовом слове, которое поступало на декодирование. Осуществляется это следующим образом, выполняется цикл от 0 до (n-1), где n - длина кодового слова (блок В10), в котором последовательно перебираются элементы гистограммы G[i] и сравниваются с пороговым значением (блок В11). В случае, если значение больше порогового, то в кодовом слове до декодирования значение мягкого бита в индексе i умножается на (-1) (блок В12).
Для оценки эффективности предлагаемого способа помехоустойчивого декодирования по сравнению с существующим способом, описанным в прототипе, была разработана программная модель декодера в среде Microsoft Visual Studio 2008, в которой реализуется алгоритм предлагаемого способа помехоустойчивого декодирования. По результатам декодирования алгоритмом распространения доверия определяется множество недостоверных бит. Основываясь на частоте использования бит кодового слова в проверочных уравнениях, из всего множества недостоверных бит выделяется подмножество - те биты, которые вносят наибольший вклад в вычисления значений оценок других бит. Результатом на данном шаге будет гистограмма частот G(g0, g1,…, gn), где n - длина кодового слова, a gi - частота встречаемости i индекса кодового слова в тех проверочных уравнениях, в которых присутствуют индексы недостоверных бит. На фиг.4 представлена одна из возможных реализаций построения гистограммы G(g0, g1,…, gn).
Далее в кодовом слове, которое изначально поступало на декодер, изменяется знак на противоположный в индексах, на которых гистограмма частот G имеет значение больше порогового и к полученной последовательности мягких бит снова применяется алгоритм распространения доверия; результаты декодирования передаются декодеру второго кода. Если исправляющей способности второго кода недостаточно для коррекции слова, т.е. если при произведении декодированного слова на транспонированную проверочную матрицу кода частные компоненты полученного вектора неравны 0 (S=V·HT), то вновь по декодируемому слову строится гистограмма частот G и заново выполняются выше изложенные действия.
Для построения гистограммы G необходимо проверять, последовательно перебирая проверочные уравнения кода, присутствует ли в данном уравнении недостоверный индекс или нет. В случае, если присутствует, то в гистограмме G увеличить на единицу те значения, которые имеют индексы, входящие в данное проверочное уравнение. Элементы гистограммы G, имеющие максимальные значения, с большой вероятностью будут указывать на места расположения реально произошедших ошибок. Таким образом, в предлагаемом способе декодирования учитывается статистическая особенность построения низкоплотностного кода, что позволяет существенно понизить вероятность отказа декодирования при низких соотношениях сигнал/шум.
Эксперимент показал, что при использовании модуляции QPSK и скорости кодирования ½ в канале с аддитивным белым гауссовым шумом при соотношении сигнал/шум 3.1 дБ и при использовании способа декодирования, изложенного в прототипе, 83% кодовых слов имеют отказ декодирования. А при использовании предлагаемого способа декодирования, при том же соотношении сигнал/шум, отказ декодирования кодовых слов составляет 11%. Под отказом декодирования понимается ситуация, при которой синдром первого компонентного кода не равен нулю, а число итераций декодирования превышает заданное. Таким образом, переходя к энергетическим характеристикам, то предлагаемый декодер позволяет достигнуть вероятность ошибки на выходе, равной 10-6 при соотношении сигнал/шум 2.7 дБ, а способ, изложенный в прототипе, дает такую же вероятность ошибки при соотношении сигнал/шум 3.2 дБ. Таким образом, использование предлагаемой схемы дает выигрыш минимум 0.5 дБ.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО ПОМЕХОУСТОЙЧИВОГО ДЕКОДИРОВАНИЯ СИГНАЛОВ, ПОЛУЧЕННЫХ С ИСПОЛЬЗОВАНИЕМ КОДА ПРОВЕРКИ НА ЧЕТНОСТЬ С НИЗКОЙ ПЛОТНОСТЬЮ | 2013 |
|
RU2522299C1 |
| СПОСОБ ОПРЕДЕЛЕНИЯ ПАРАМЕТРОВ ПОМЕХОУСТОЙЧИВОГО КОДА | 2016 |
|
RU2628191C2 |
| СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ СООБЩЕНИЙ | 2015 |
|
RU2613021C1 |
| СПОСОБ ДЕКОДИРОВАНИЯ ТУРБОКОДА (ВАРИАНТЫ) | 2006 |
|
RU2340090C2 |
| Способ передачи данных в системе цифровой радиосвязи на основе кодов с низкой плотностью проверок на четность и способ перемежения кодовых символов | 2018 |
|
RU2700398C1 |
| Способ передачи данных на основе кодов с низкой плотностью проверок на четность | 2019 |
|
RU2708349C1 |
| Способ перемежения кодовых символов в коде с низкой плотностью проверок на четность | 2021 |
|
RU2755295C1 |
| СПОСОБ ДЕКОДИРОВАНИЯ ПОСЛЕДОВАТЕЛЬНОГО КАСКАДНОГО КОДА (ВАРИАНТЫ) | 2006 |
|
RU2340091C2 |
| Способ кодирования канала в системе связи, использующей LDPC-код | 2022 |
|
RU2791717C1 |
| Устройство передачи данных на основе кодов с низкой плотностью проверок на четность | 2019 |
|
RU2713573C1 |

Изобретение относится к передаче цифровой информации, а именно к способам декодирования сигналов с использованием параллельного каскадного кода проверки на четность с низкой плотностью. Способ помехоустойчивого декодирования указанных сигналов заключается в том, что из информационных бит и первых бит проверок декодируют первый компонентный код, затем выделяют информационную часть кодового слова и в зависимости от значения синдрома кодового слова принимают жесткое решение бит из информационной части или перемежают ее и из перемеженной информационной части и вторых бит проверок декодируют второй компонентный код, после чего выделяют информационную часть кодового слова и выполняют второе перемежение, обратное первому закону перемежения, и в зависимости от значения синдрома кодового слова принимают жесткое решение бит из информационной части или направляют ее на формирование первого компонентного кода, после чего повторяют весь цикл снова, причем перед первым перемежением в зависимости от значения синдрома кодового слова осуществляют обнаружение и устранение ситуаций «зацикливания» в первом компонентном коде, который снова декодируют, а после декодирования второго компонентного кода в зависимости от значения синдрома кодового слова осуществляют обнаружение и устранение ситуаций «зацикливания» во втором компонентном коде, который снова декодируют или выполняют второе перемежение. Технический результат - снижение вероятности ошибочного декодирования и вероятности отказа декодирования сигналов. 4 ил.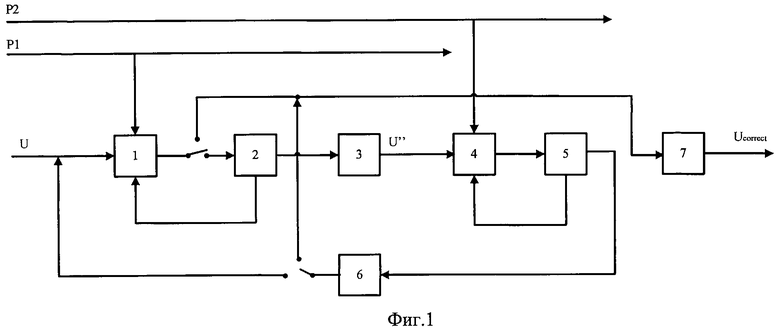
Способ помехоустойчивого декодирования сигналов, полученных с использованием параллельного каскадного кода проверки на четность с низкой плотностью, в котором из информационных бит и первых бит проверок формируют первый компонентный код и выполняют его декодирование, затем выделяют информационную часть кодового слова и в зависимости от значения синдрома кодового слова принимают жесткое решение бит из информационной части или перемежают ее и из перемеженной информационной части и вторых бит проверок формируют второй компонентный код и выполняют его декодирование, после чего выделяют информационную часть кодового слова и над ней выполняют второе перемежение, обратное первому закону перемежения, и в зависимости от значения синдрома кодового слова принимают жесткое решение бит из информационной части или направляют ее на формирование первого компонентного кода, после чего повторяют весь цикл снова, отличающийся тем, что перед операцией первого перемежения в зависимости от значения синдрома кодового слова осуществляют процедуру обнаружения и устранения ситуаций «зацикливания» в первом компонентном коде и снова декодируют первый компонентный код, а после декодирования второго компонентного кода в зависимости от значения синдрома кодового слова осуществляют процедуру обнаружения и устранения ситуаций «зацикливания» во втором компонентном коде и снова декодируют второй компонентный код или выполняют второе перемежение.
| УСТРОЙСТВО И СПОСОБ КОДИРОВАНИЯ/ДЕКОДИРОВАНИЯ КАНАЛА С ИСПОЛЬЗОВАНИЕМ ПАРАЛЛЕЛЬНОГО КАСКАДНОГО КОДА ПРОВЕРКИ НА ЧЕТНОСТЬ С НИЗКОЙ ПЛОТНОСТЬЮ | 2004 |
|
RU2310274C1 |
| WO 206082923 A1, 10.08.2006 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ ДЕПЕРЕМЕЖЕНИЯ ПОТОКА ПЕРЕМЕЖЕННЫХ ДАННЫХ В СИСТЕМЕ СВЯЗИ | 2003 |
|
RU2274951C2 |
| US 6854077 B2, 08.02.2005 | |||
| EP 1233524 A2, 21.08.2002. | |||

