УРОВЕНЬ ТЕХНИКИ
[0001] Запросы к поисковой машине часто недостаточно определены или неоднозначны. В примере пользователь, который дает запрос "bulls" ("быки"), может ссылаться на биржевые бумаги, животных, спортивную команду, мероприятие в Памплоне и т.п. Традиционные поисковые машины испытывают трудности с устранением неоднозначности у намерения информационного поиска (IR) пользователя и поэтому могут предоставлять результаты поиска, которые не релевантны для пользователя. Это, в свою очередь, может отталкивать пользователя от поисковой машины, посредством этого побуждая пользователя использовать другую поисковую машину.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0002] Нижеследующее является кратким изложением предмета изобретения, который подробнее описывается в этом документе. Данное краткое изложение сущности изобретения не предназначено для ограничения в отношении объема, определяемого формулой изобретения.
[0003] В этом документе описывается вычислительная система. Вычислительная система включает в себя процессор и запоминающее устройство, где запоминающее устройство содержит систему применения правил, которая исполняется процессором. Система применения правил конфигурируется для назначения контекста запросу в ответ на прием запроса. Система применения правил также конфигурируется для идентификации правила извлечения контента на основе запроса и контекста, назначенного запросу, где правило извлечения контента соотносит сочетание запроса и контекста с одним из контента и переформулирования запроса. Система применения правил дополнительно конфигурируется для исполнения правила извлечения контента в ответ на идентификацию правила извлечения контента.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0004] Фиг. 1 - функциональная блок-схема примерной вычислительной системы, которая облегчает создание и анализ правил извлечения контента.
[0005] Фиг. 2 - функциональная блок-схема примерной системы формирования правил, которая конфигурируется для формирования правил извлечения контента на основе журналов поисковой машины.
[0006] Фиг. 3 изображает примерную диаграмму Венна, которая иллюстрирует различающий подход для идентификации возможных пар переформулирования запросов.
[0007] Фиг. 4 изображает примерную диаграмму Венна, которая иллюстрирует порождающий подход для идентификации возможных пар переформулирования запросов.
[0008] Фиг. 5 - функциональная блок-схема системы анализа правил, которая конфигурируется для оценки эффективности соответствующих правил извлечения контента на основе журналов поисковой машины.
[0009] Фиг. 6 - функциональная блок-схема примерной вычислительной системы, которая конфигурируется для идентификации применимого правила извлечения контента в ответ на прием запроса.
[0010] Фиг. 7 - функциональная блок-схема примерной системы применения правил, которая конфигурируется для назначения контекста принятому запросу и идентификации правила извлечения контента на основе запроса и назначенного контекста.
[0011] Фиг. 8 - функциональная блок-схема примерной поисковой системы, которая конфигурируется для выполнения поиска на основе правила извлечения контента.
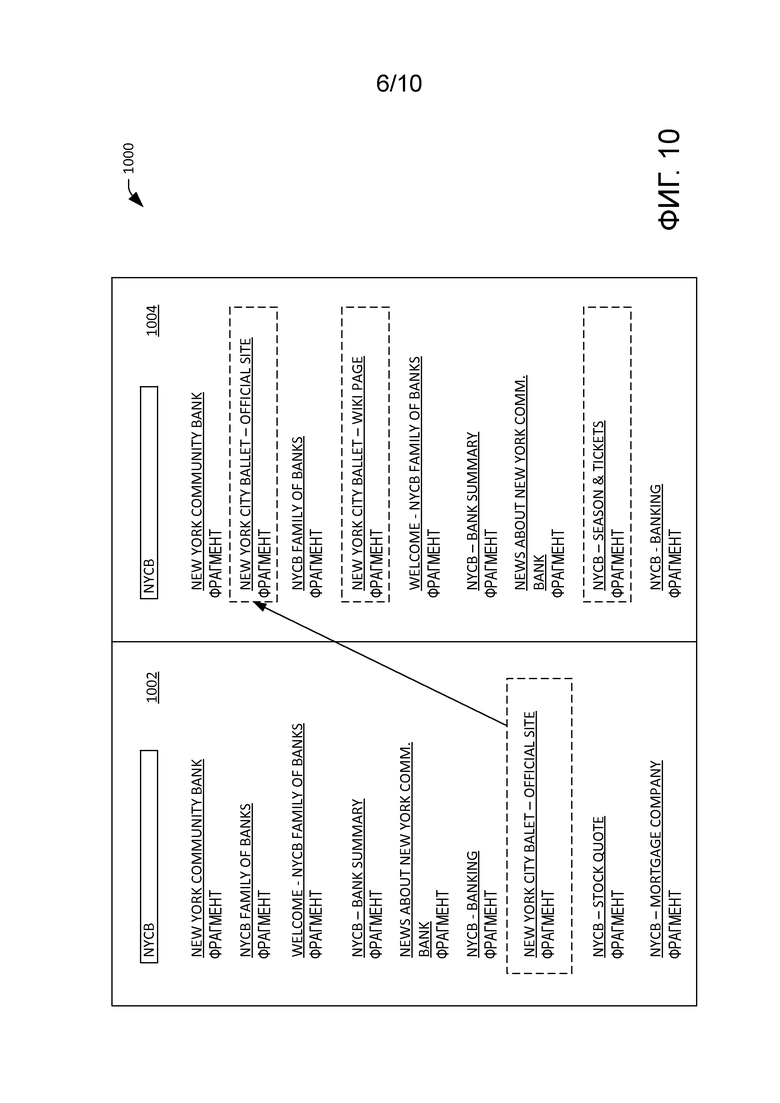
[0012] Фиг. 9 - примерный графический интерфейс пользователя, который изображает страницу результатов поисковой машины (SERP), где SERP содержит результаты поиска, извлеченные на основе правила извлечения контента.
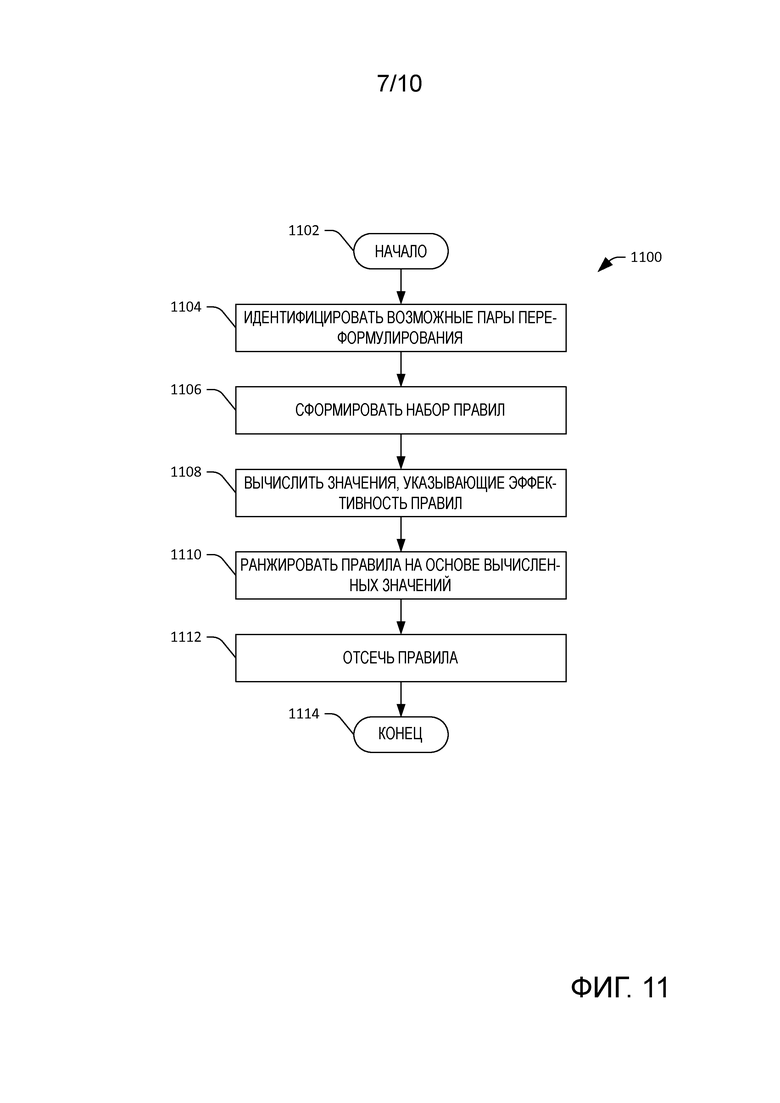
[0013] Фиг. 10 - примерный графический интерфейс пользователя, который изображает пару SERP с целью сравнения.
[0014] Фиг. 11 - блок-схема, которая иллюстрирует примерную методологию для формирования правил извлечения контента.
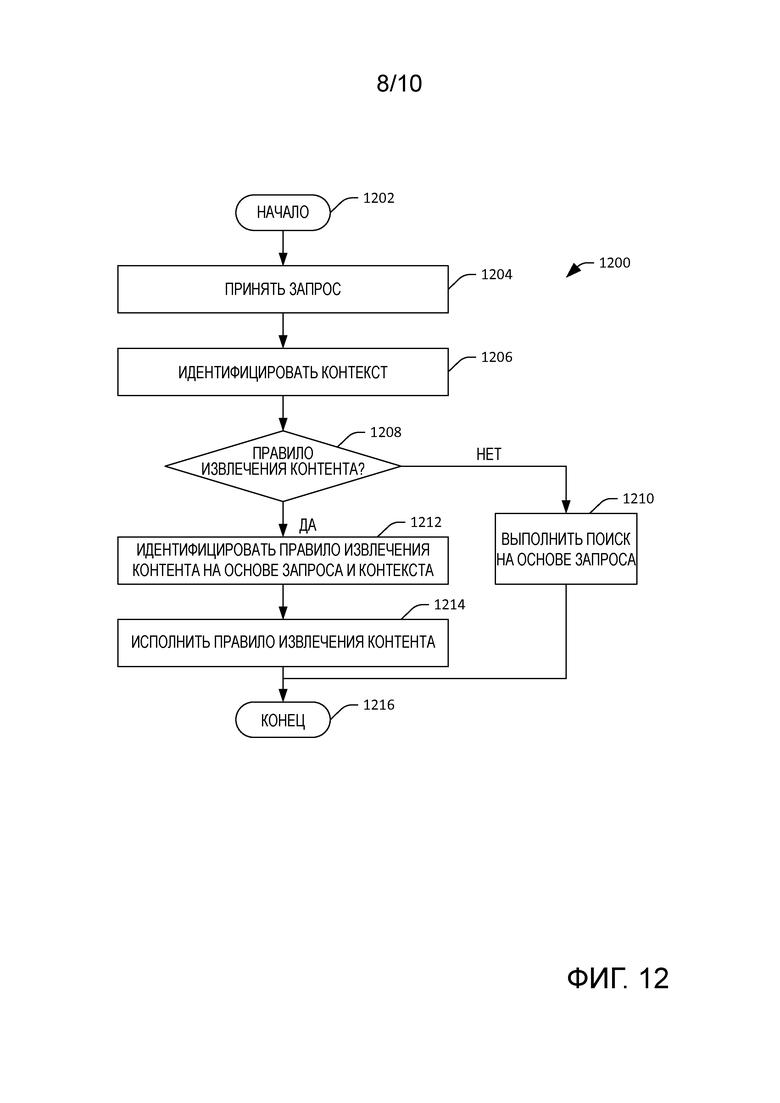
[0015] Фиг. 12 - блок-схема, иллюстрирующая примерную методологию для идентификации и исполнения правила извлечения контента.
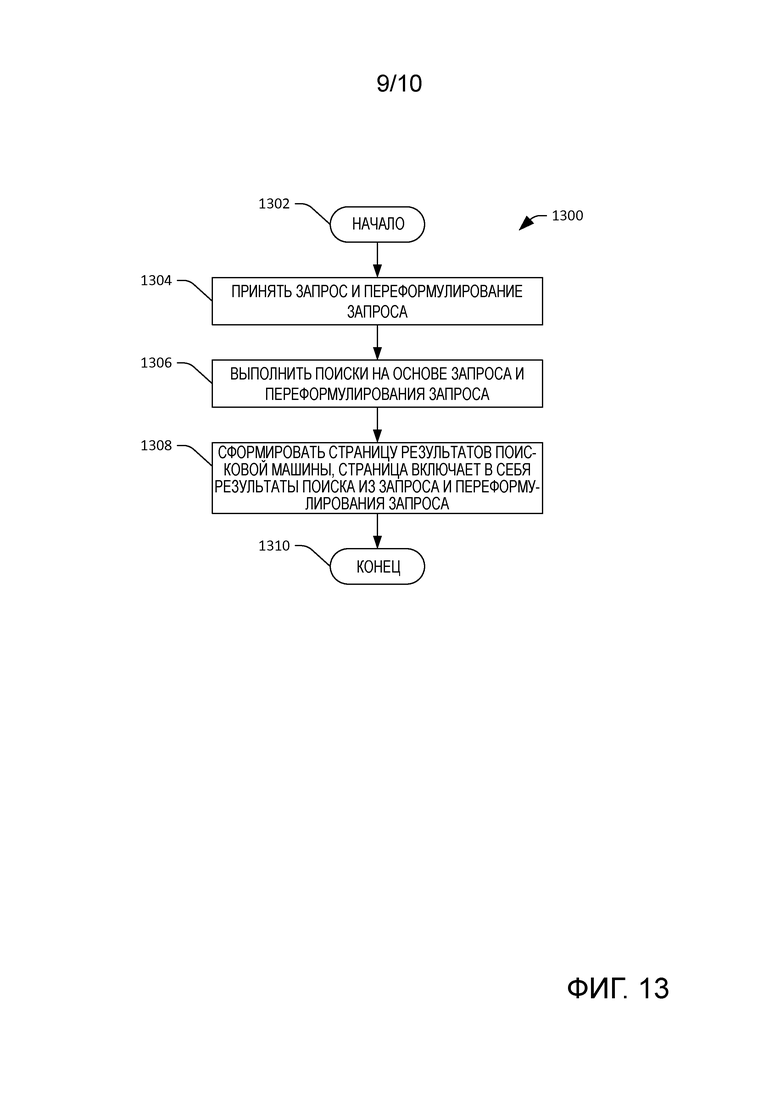
[0016] Фиг. 13 - блок-схема, которая иллюстрирует примерную методологию для формирования SERP на основе принятого запроса и переформулирования запроса.
[0017] Фиг. 14 - примерная вычислительная система.
ПОДРОБНОЕ ОПИСАНИЕ
[0018] Различные технологии, имеющие отношение к формированию и применению правил извлечения контента, описываются сейчас со ссылкой на чертежи, на которых одинаковые номера ссылок используются для ссылки на одинаковые элементы по всему описанию. В нижеследующем описании для целей пояснения излагаются многочисленные характерные подробности, чтобы обеспечить всестороннее понимание одного или нескольких аспектов. Тем не менее может быть очевидным, что такой аспект (аспекты) можно применять на практике без этих характерных подробностей. В иных случаях широко известные структуры и устройства показываются в виде блок-схемы, чтобы облегчить описание одного или нескольких аспектов. Кроме того, нужно понимать, что функциональные возможности, которые описываются как выполняемые некоторыми компонентами системы, могут выполняться несколькими компонентами. Аналогичным образом, например, компонент может конфигурироваться для выполнения функциональных возможностей, которые описываются как выполняемые несколькими компонентами.
[0019] Кроме того, термин "или" имеет целью обозначать включающее "или", а не исключающее "или". То есть, пока не указано иное или не ясно из контекста, фраза "X применяет A или B" имеет целью означать любую из естественных включающих перестановок. То есть фраза "X применяет A или B" выполняется любым из следующих случаев: X применяет A; X применяет B; или X применяет как A, так и B. К тому же при использовании в этой заявке и прилагаемой формуле изобретения единственное число следует в целом толковать означающим "один или несколько", пока не указано иное или из контекста не станет ясно, что предписывается форма единственного числа.
[0020] Кроме того, при использовании в данном документе термины "компонент" и "система" предназначены для включения в себя машиночитаемого хранилища данных, которое снабжается исполняемыми компьютером командами, которые побуждают выполнение некоторых функциональных возможностей при их исполнении процессором. Исполняемые компьютером команды могут включать в себя процедуру, функцию или т.п. Также нужно понимать, что компонент или систему можно расположить на одном устройстве или распределить по нескольким устройствам. Кроме того, при использовании в данном документе термин "примерный" имеет целью обозначать "служащий в качестве иллюстрации или примера чего-либо" и не имеет целью указывать предпочтение.
[0021] Теперь со ссылкой на фиг. 1 иллюстрируется примерная вычислительная система 100, которая конфигурируется для формирования правил извлечения контента. Как подробнее будет описываться в этом документе, правила извлечения контента формируются на основе соответствующих контекстов пользователей, которые дают запросы поисковой машине. Вычислительная система 100 может быть вычислительным устройством или распределенной вычислительной системой. Например, вычислительная система 100 может быть вычислительной системой предприятия, центром обработки данных и т. п. либо может включаться в них. Соответственно, элементы вычислительной системы 100 могут включаться в одиночное устройство либо распределяться по нескольким вычислительным устройствам.
[0022] Вычислительная система 100 содержит хранилище 102 данных. Хранилище 102 данных включает в себя хронологические журналы 104 поиска в поисковой машине. Журналы 104 поиска могут включать в себя, но не ограничиваются: 1) идентификаторы для соответствующих пользователей (например, где идентификаторы идентифицируют пользователей анонимно); 2) запросы, выданные пользователями; 3) удостоверения результатов поиска, представленных пользователям на основе выданных запросов; 4) удостоверения результатов поиска, выбранных пользователями; 5) метки, назначенные результатам поиска, идентифицированным как удовлетворяющие намерение IR пользователей (например, результат поиска можно пометить как удовлетворяющий намерение IR пользователя, если пользователь задерживается на нем в течение некоторого порогового количества времени (например, 30 секунд), или если результат поиска является последним результатом поиска, просмотренным в поисковом сеансе); и 6) отметки времени, назначенные запросам, которые указывают, когда были выданы запросы; 7) отметки времени, назначенные выбранным пользователями результатам поиска, которые указывают, когда результаты поиска были выбраны; 8) отметки времени, назначенные выбранным пользователями результатам поиска, которые указывают, сколько пользователи задержались на результатах поиска, и т. п. Журналы 104 поиска дополнительно могут включать в себя удостоверения конкретных поисковых сеансов, где поисковый сеанс можно задать как взаимодействие пользователя с поисковой машиной. Например, взаимодействия в последовательности взаимодействий могут задавать поисковый сеанс, где продолжительность времени между каждым последовательным взаимодействием меньше предопределенной пороговой длительности, например пяти минут, десяти минут, двадцати минут, тридцати минут или т.п. Таким образом, в поисковом сеансе пользователь "постоянно" взаимодействует с поисковой машиной. Кроме того, хотя и не показано, хранилище 102 данных может включать в себя информацию, не собираемую поисковой машиной напрямую, например посещенные пользователями веб-страницы, демографическую информацию о пользователях, данные социальных сетей (например, указания явных одобрений от пользователей) и т.п.
[0023] Хранилище 102 данных также может включать в себя данные 106 контекстов, которые включают в себя контексты, которые можно назначать данным в журналах 104 поиска. Например, веб-страница, включенная в журналы 104 поиска, может иметь по меньшей мере один назначенный ей контекст. Например, такой контекст может основываться на метке, назначенной веб-странице посредством Политики открытых данных (ODP), на распознавании поименованных сущностей (NER), на информации, полученной из wiki-страницы, или т.п. Кроме того, запросы в журналах 104 поиска могут иметь по меньшей мере один назначенный им контекст. Например, назначенный запросу контекст может основываться на контексте, назначенном результату поиска (например, веб-странице), посещенному пользователем, который дал запрос (например, где результат поиска удовлетворяет намерение IR пользователя).
[0024] Система 100 дополнительно включает в себя процессор 108 и запоминающее устройство 110, осуществляющее связь с процессором 108. Запоминающее устройство 110 может включать в себя систему 112 формирования правил и систему 114 анализа правил. Вкратце, система 112 формирования правил конфигурируется для формирования правил извлечения контента на основе журналов 104 поиска и данных 106 контекстов. Система 112 формирования правил может побуждать сохранение этих правил в хранилище 102 данных в виде правил 116. Система 114 анализа правил конфигурируется для оценки эффективности этих правил 116 на основе журналов 104 поиска и данных 106 контекстов.
[0025] Теперь предоставляется краткое объяснение правил 116 и примера правил 116. Запросы к поисковой машине часто не определены точно либо неоднозначны. Часто контекст или исходные данные о лице, выдавшем запрос (пользователе), могут предоставлять информацию, которая устраняет неоднозначность информационной потребности пользователя и может использоваться для автоматического предсказания более эффективного запроса (и, соответственно, извлечения) для пользователя. Правило, изученное системой 112 формирования правил и включенное в правила 116, может иметь следующий формат:
[КОНТЕКСТ] ЗАПРОС→ПЕРЕФОРМУЛИРОВАНИЕ ЗАПРОСА или КОНТЕНТ.
Примерными правилами извлечения контента, соответственно, могут быть:
1) [Виды спорта] bulls→Chicago Bulls; И
2) [Виды спорта] bulls→www.ChicagoBulls.com
[0026] Правило 1) можно интерпретировать следующим образом: когда пользователь просматривал недавно веб-страницы о видах спорта, и дает запрос "bulls", сделать вывод, что пользователь фактически подразумевал запрос "Chicago Bulls". Второе правило можно интерпретировать следующим образом: когда пользователь нажимал недавно на веб-страницы о видах спорта, и дает запрос "bulls", извлечь веб-страницу www.ChicagoBulls.com для пользователя. С учетом того, что фактическое намерение пользователя выводится точнее, для пользователя можно извлекать лучшие результаты. Как подробнее будет описываться в этом документе, результаты об измененном запросе, исходном запросе или их смеси можно извлекать и предоставлять пользователю.
[0027] Поэтому можно установить, что правило извлечения контента соотносит сочетание контекста и запроса с переформулированным запросом либо контентом. Контекст не имеет целью ограничиваться тематическим контекстом для поискового сеанса. Например, контекст может быть, но не ограничивается, тематическим контекстом конкретного поискового сеанса, долговременным тематическим контекстом, кратковременным тематическим контекстом, социальными показателями (например, самоопределившиеся группы на сайтах социальных сетей, которым принадлежит пользователь, школы, в которых обучался пользователь, контент, явно одобренный пользователем, и т.п.), местоположением пользователя, местоположением, соответствующим содержимому выбранных пользователем веб-страниц, временем года (например, весна, лето, осень, зима), относящимися ко времени событиями и т.п. Описанный в этом документе подход в отношении правил извлечения контента может быть применим к рекламе, контекстно-зависимому исправлению орфографических ошибок и изменениям помимо добавления слов, а также к ряду элементов, которые могут включаться в страницу результатов поисковой машины (SERP) или чей запуск влияет на состав SERP, например мгновенные ответы (запуск и ранжирование), связанные с областью сущностей поиски, объяснения взаимодействия с пользователем (UX) и мультимедийные вертикали, например изображения и видео.
[0028] Система правил анализа 114 в целом конфигурируется для оценки эффективности правила извлечения контента, сформированного системой 112 формирования правил. Например, как подробнее будет описываться в этом документе, система 114 анализа правил может конфигурироваться для анализа SERP, сформированной на основе запущенного переформулированного запроса, и для вычисления значения, указывающего качество SERP и, соответственно, качество запущенного правила извлечения контента. Впоследствии, когда принимается запрос и идентифицируются правила извлечения контента, которые применяются к запросу, качество правил извлечения контента может применяться для ранжирования правил, так что в среднем в ответ на прием запросов будут использоваться самые эффективные правила извлечения контента.
[0029] Хотя система 112 формирования правил и система 114 анализа правил иллюстрируются как включаемые в вычислительную систему 100, нужно понимать, что система 112 формирования правил и система 114 анализа правил могут включаться в отдельные вычислительные системы. Например, система 112 формирования правил может находиться в первой вычислительной системе и может выводить набор правил во вторую вычислительную систему, которая включает в себя систему 114 анализа правил.
[0030] Теперь со ссылкой на фиг. 2 иллюстрируется функциональная блок-схема системы 112 формирования правил. Система 112 формирования правил, как указано выше, обладает доступом к журналам 104 поиска и данным 106 контекстов. Система 112 формирования правил включает в себя компонент 202 идентификации возможных правил, который конфигурируется для формирования возможных правил извлечения контента. С этой целью компонент 202 идентификации возможных правил может идентифицировать возможные (QA, QB) пары (в этом документе называемые "парами переформулирования запросов"), где QA - начальный запрос, а QB - переформулирование начального запроса. Для каждой пары переформулирования запроса компонент 202 идентификации возможных правил может идентифицировать соответствующий QA контекст (контексты) в паре переформулирования запроса.
[0031] Существует несколько подходов, рассматриваемых для идентификации возможных пар переформулирования запросов. Например, компонент 202 идентификации возможных правил может использовать различающий способ для идентификации возможных пар переформулирования запросов. В другом примере компонент 202 идентификации возможных правил может использовать порождающий способ для идентификации возможных пар переформулирования запросов. Когда компонент 202 идентификации возможных правил использует порождающий подход, условное распределение вероятностей используется для идентификации возможных пар переформулирования запросов. Наоборот, когда компонент 202 идентификации возможных правил использует различающий подход, совместное распределение вероятностей используется для идентификации возможных пар переформулирования запросов.
[0032] В соответствии с примером компонент 202 идентификации правил может идентифицировать пороговое количество наиболее часто принимаемых запросов в журналах 104 поиска (например, 100 самых распространенных запросов, которые вычислены из выборки журналов 104 поиска), 1000 самых популярных запросов (которые вычислены из выборки журналов 104 поиска) и т.п. Затем компонент 202 идентификации возможных правил может идентифицировать пары переформулирования запросов на основе журналов 104 поиска, где пара переформулирования запроса включает в себя один из самых частых запросов в качестве начального запроса (QA) и соответствующее переформулирование (QB).
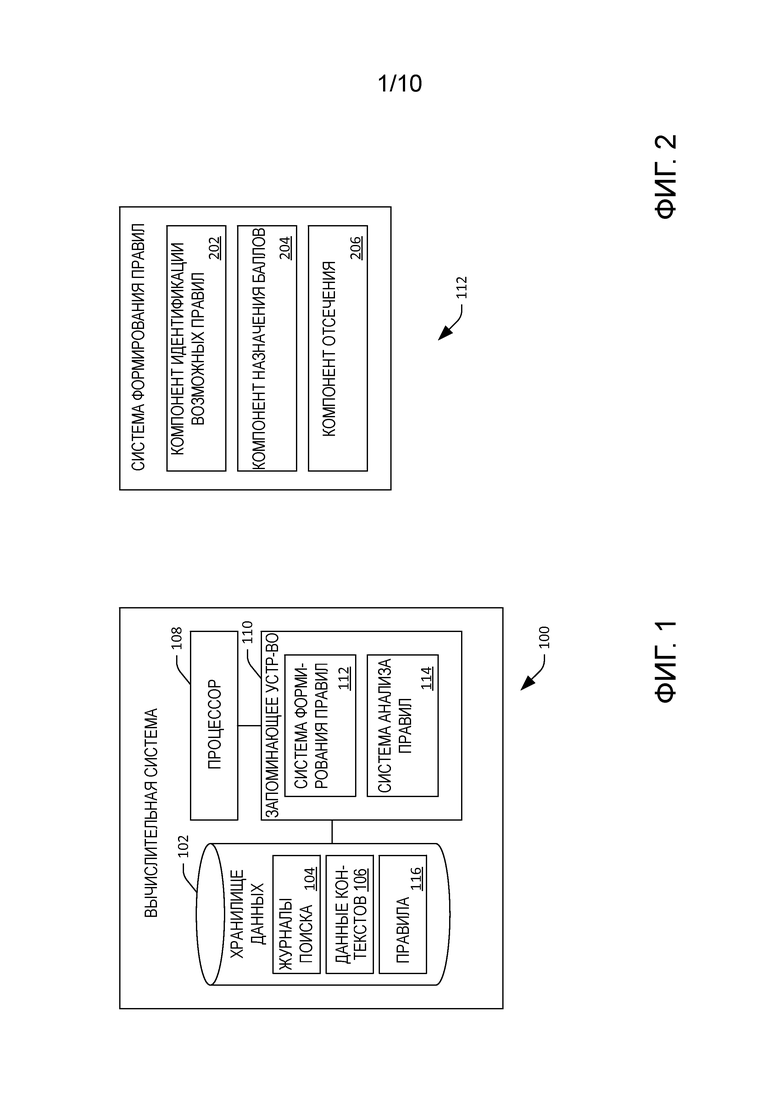
[0033] Дополнительные подробности относительно примерного различающего способа для идентификации возможных правил извлечения контента излагаются теперь по отношению к фиг. 3. Фиг. 3 иллюстрирует диаграмму 300 Венна, которая графически изображает пространство A запросов, пространство B переформулирования запросов и пространство C категорий в журналах 104 поиска. Как правило, компонент 202 идентификации возможных правил при применении различающего способа идентифицирует возможные пары переформулирования на основе перекрывающейся области между пространством A запросов, пространством B переформулирования и пространством C категорий: P(A, B, C).
[0034] В примере компонент 202 идентификации возможных правил может выбрать популярный запрос QA из пространства A запросов, и QA может использоваться в качестве задающего запроса. Компонент 202 идентификации возможных правил может идентифицировать расширения в QA (из пространства B переформулирования), когда QA представляет, например, неоднозначно поименованный субъект. Эти расширения можно получить из различных источников знаний, например wiki-страниц, ODP, словаря, который соотносит неоднозначные термины с поименованными субъектами и т.п. В другом примере компонент 202 идентификации возможных правил может идентифицировать возможную пару переформулирования на основе отношений между запросами, например перекрытия терминов между QA и QB или перекрытия в результатах поиска, обнаруженного поисковой машиной для запросов QA и QB в одном и том же поисковом сеансе. В еще одном примере компонент 202 идентификации возможных правил может использовать отношение подмножеств для идентификации возможной пары переформулирования. Например, компонент 202 идентификации возможных правил может рассмотреть QA и QB как возможную пару переформулирования, когда оба запроса совершаются в одном поисковом сеансе, и QB (выданный в поисковом сеансе после QA) включает в себя все термины из QA плюс один или несколько дополнительных терминов (например; соответственно, QA и QB находятся в перекрывающейся области A, B и C). Восприятие этого подхода состоит в том, что при использовании контекста можно автоматически предсказывать термины, которые пользователь добавил, чтобы улучшить свой запрос. Результатом является пара возможных запросов (QA, QB) на перекрытии между пространством A запросов, пространством B переформулирования и пространством C категорий, где пара включает в себя более ранний запрос QA и более поздний запрос QB. Компонент 202 идентификации возможных правил с тем же успехом может рассмотреть (QA, QA) как возможную пару. Этот тип собственного переформулирования может быть полезен для сравнения и определения, будет ли переформулирование запроса успешнее, чем сохранение начального запроса.
[0035] Как указано выше, в другом примере компонент 202 идентификации возможных правил может использовать порождающий способ, чтобы идентифицировать возможные пары переформулирования на основе журналов 104 поиска, что в целом представлено на фиг. 4. Фиг. 4 иллюстрирует диаграмму 400 Венна, которая изображает пространство A запросов, переформулирование B и пространство C контекстов. В порождающем способе запросы переформулирования в пространстве B переформулирования идентифицируются на основе условия запросов в пространстве A запросов, имеющих некоторую категорию в пространстве категорий: P(B|A, C). Например, как указывалось ранее, запросу QA в журналах 104 поиска можно назначить контекстные данные (категорию) в пространстве C категорий, где эти данные могут основываться на контекстных данных (категориях), назначенных результатам поиска, извлеченным поисковой машиной на основе запроса. Компонент 202 идентификации возможных правил, принимая во внимание пару (QA, C), может конфигурироваться для предсказания вероятности переформулирований QA, который может быть выдан параллельно. Например, компонент 202 идентификации возможных правил может вычислить вероятность того, что пользователь, давший запрос QA, позже даст запрос QB, с учетом того, что наблюдалось (QA, C).
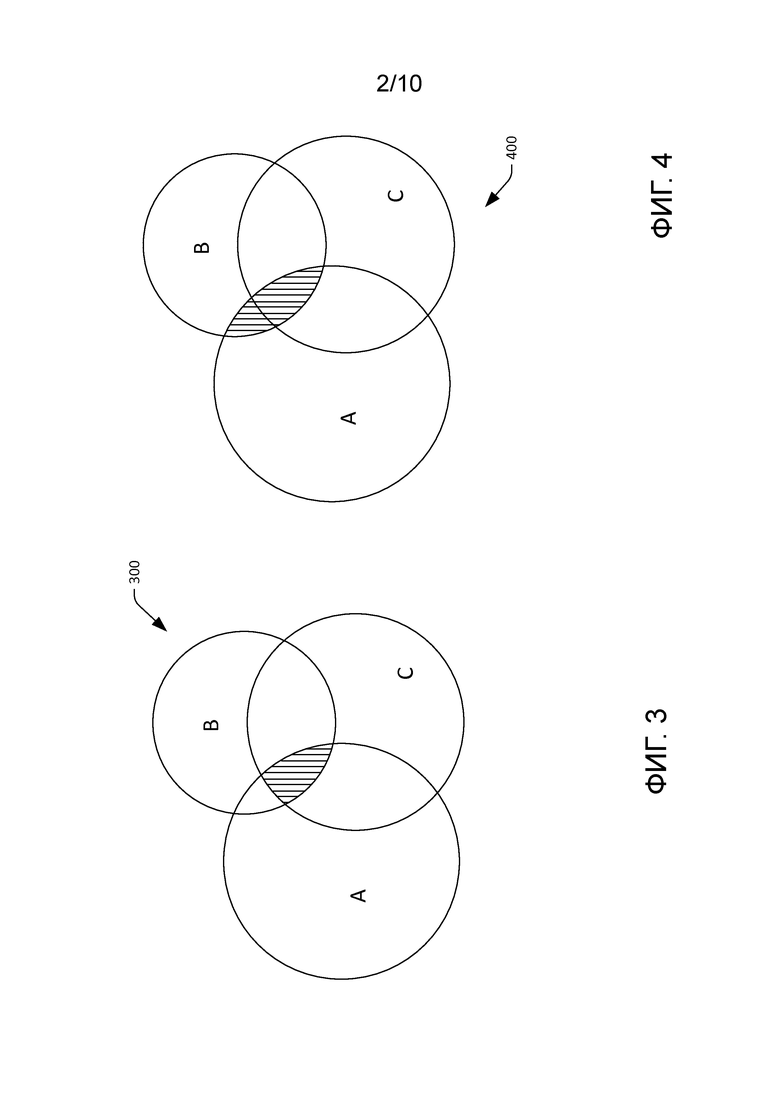
[0036] В другом примере компонент 202 идентификации возможных правил может идентифицировать или ранжировать возможные пары переформулирования в соответствии с их взаимной информацией. В этом случае взаимная информация между A, B и C может задаваться следующим образом:
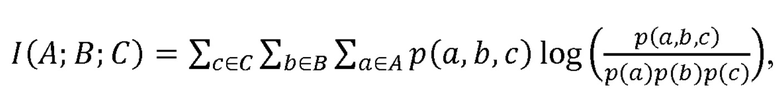
где p(a, b, c) - функция совместного распределения вероятностей у A, B и C, а p(a), p(b) и p(c) - функции маргинального распределения вероятностей у A, B и C соответственно.
[0037] В ответ на идентификацию возможных пар переформулирования запросов (с использованием порождающего или различающего подхода) компонент 202 идентификации возможных правил для каждой идентифицированной возможной пары переформулирования может сформировать набор контекстов, доступных в момент, где давался запрос QA. Примерные контексты включают в себя, но не ограничиваются: 1) пустой контекст; 2) класс "самых популярных" - это относится к наиболее частой теме (категории) результатов поиска, на которые нажимают в поисковом сеансе вплоть до момента, когда давался запрос QA; 3) класс "N самых популярных" - этот контекст представляет, что тема (категория) является одной из верхних N тем результатов поиска, на которые нажимают в поисковом сеансе вплоть до момента, где давался запрос QA; 4) класс "уверенность больше пороговой величины" - этот контекст отражает ситуацию, когда уверенность у темы (категории) результатов поиска, на которые нажимают в поисковом сеансе вплоть до момента, где давался запрос QA, превышает (заданную) пороговую величину. Другие контексты, которые можно назначить паре переформулирования запроса с помощью компонента 202 идентификации возможных правил, включают в себя: местоположение (город, штат, страна и т.п. в качестве контекста); на основе адреса (например, в качестве контекста включается часть сетевого адреса вычислительного устройства, применяемого пользователем); социальный контекст (в качестве контекста могут использоваться субъекты, которые "понравились" пользователю); долговременный тематический интерес, который аналогичен тематическому контексту поискового сеанса, но на большем диапазоне взаимодействий пользователя (например, за несколько недель поведения поиска и нажатия, а не за поисковый сеанс); предыдущие запросы, выданные пользователем (за множество периодов), или другие представления тем поисковых сеансов. В этом случае в качестве контекста могут использоваться темы запросов или все возвращенные документы в поисковой машине, а не только документы, на которые нажимают. Как только компонент 202 идентификации возможных правил назначает контекст паре переформулирования запроса, формируется правило извлечения контента. Используя примерные изложенные выше подходы, компонент 202 идентификации возможных правил может автоматически формировать множество правил извлечения контента на основе журналов 104 поиска.
[0038] Кроме того, в примере компонент 202 идентификации возможных правил может назначать уверенности контекстам в момент, где давался запрос QA. Например, на основе атрибутов пользователя, документов, выбранных во время поискового сеанса, и т.п. компонент 202 идентификации возможных правил может назначать баллы уверенности контекстам, назначенным паре переформулирования запроса - таким образом, пара переформулирования запроса может иметь несколько назначенных ей контекстов, каждый со своим значением уверенности.
[0039] Система 112 формирования правил также включает в себя компонент 204 назначения баллов, который может конфигурироваться для назначения соответствующего балла каждому правилу извлечения контента, выводимому компонентом 202 идентификации возможных правил. Балл, назначенный правилу извлечения контента, может указывать эффективность правила при исполнении и может основываться на содержимом журналов 104 поиска. Например, правило может считаться эффективным, если изменение запроса приводит пользователя к релевантному документу. Например, в журналах 104 поиска релевантный документ можно задать в качестве результата поиска, на котором задержался пользователь в течение некоторого порогового количества времени, или результата поиска, который завершил поисковый сеанс (например, пользователь прекращает взаимодействовать с поисковой машиной после просмотра результата поиска). Для формирования балла эффективности компонент 204 назначения баллов может анализировать журналы 104 поиска и агрегировать поисковые сеансы, где наблюдалось анализируемое правило (например, наблюдается совпадающий запрос и контекст, после чего пользователь дает изменение запроса). Компонент 204 назначения баллов может подсчитать количество раз, которое наблюдалось правило, а также количество раз, которое правило оказалось эффективным.
[0040] Компонент 204 назначения баллов может использовать такие подсчеты для ранжирования правил для данного запроса в показателях средней эффективности правил. Например, компонент 204 назначения баллов может ранжировать правила на основе назначенной им средней эффективности. Тем не менее также предполагаются другие подходы, например верхняя граница эффективности, что может быть полезно для принятия решения, может ли правило быть эффективным, если не наблюдалось часто. Соответственно, компонент 204 назначения баллов может для каждого сочетания запрос - контекст выводить ранжированный список правил извлечения контента.
[0041] Система 112 формирования правил при необходимости может включать в себя компонент 206 отсечения, который может фильтровать одно или несколько правил извлечения контента для повышения точности конечного набора правил, выводимого системой 112 формирования правил, посредством этого ограничивая выводимые правила только контекстными перезаписями. Фильтры, которые могут применяться компонентом 206 отсечения при отсечении правил, включают в себя, но не ограничиваются: 1) удаление правил, не наблюдаемых достаточное количество раз в журналах 104 поиска (например, компонент 206 отсечения может обеспечивать, что остаются только правила извлечения контента, которые наблюдались пороговое количество раз в журналах 104 поиска); 2) удаление возможных правил, чей показатель успешности в журналах 104 поиска не превышал показателя успешности, наблюдаемого, когда давался исходный запрос; 3) удаление возможных правил, чей показатель успешности в журналах 104 поиска не превышал контекстно-зависимого собственного переформулирования; 4) удаление возможных правил, чей показатель успешности в журналах 104 поиска не превышал QB, выдаваемого свободно от контекста; 5) удаление возможных правил извлечения контента, где показатель успешности, соответствующий QB, не превышает показателя успешности, соответствующего QA, на некоторую пороговую величину; 6) удаление возможных правил, где контекстное переформулирование (QB) совершается менее некоторой доли времени, которое происходит запрос QA, и 7) удаление правил, где их предсказанная производительность поиска (качество) предполагается низкой (это также можно выполнять оперативно во время извлечения: то есть можно игнорировать результаты, возвращенные из переформулирования, если оценивается, что они имеют низкое качество).
[0042] В еще одном примере неоднозначные запросы можно идентифицировать отдельно, и после этого система 112 формирования правил может изучать правила переформулирования запросов. Например, система 112 формирования правил может включать в себя классификатор, который обучается маркировать запрос как неоднозначный или однозначный. Например, классификатору можно предоставить N наиболее часто возникающих запросов в журналах 104 поиска, и классификатор может идентифицировать подмножество тех запросов, которые идентифицируются как неоднозначные. После этого система 112 формирования правил может формировать правила извлечения контента с использованием изложенных выше методик.
[0043] Ссылаясь теперь на фиг. 5, иллюстрируется функциональная блок-схема системы 114 анализа правил. Система 114 анализа правил включает в себя компонент 502 выборки, который может обращаться к журналам 104 поиска и извлекать оттуда поисковые сеансы. Как указывалось ранее, поисковый сеанс задается последовательностью постоянной активности пользователя по отношению к поисковой машине. Компонент 504 сопоставления принимает поисковый сеанс, идентифицированный компонентом 502 выборки, и идентифицирует по меньшей мере одно правило извлечения контента из правил извлечения контента, выводимых системой 112 формирования правил. Система 114 анализа правил также включает в себя компонент 506 создания страницы результатов поисковой машины (SERP), который создает SERPA на основе QA в журналах поиска и дополнительно создает по меньшей мере одну SERPB, инициированную идентифицированным правилом извлечения контента. Компонент 506 создания SERP может дополнительно создавать гипотетическую SERPF, которая включает в себя ранжированный список результатов поиска, который может быть смесью результатов поиска на SERPA и SERPB. Более того, компонент 506 создания SERP может включать рекламные объявления, мгновенный ответ, карточку субъекта и т. п. в SERPF.
[0044] Система 114 анализа правил также включает в себя компонент 508 оценки, который может принимать SERPF, а также по меньшей мере SERPA, предоставленную пользователю поискового сеанса, когда пользователь дал запрос QA. Компонент 508 оценки может выводить балл, указывающий эффективность набора правил, на основе взаимодействий пользователя, которые идентифицированы в поисковом сеансе в журналах 104 поиска. Например, если SERPF включает в себя результат поиска, который не включался в SERPA, но после того, как пользователем в журнале поиска было выбрано переформулирование сформулированного пользователем запроса, SERPF можно назначить балл, который указывает улучшение по сравнению с SERPA. Компонентом 508 оценки может применяться ряд методик для назначения балла, который указывает улучшение SERPF по сравнению с SERPA, которая была предоставлена пользователю.
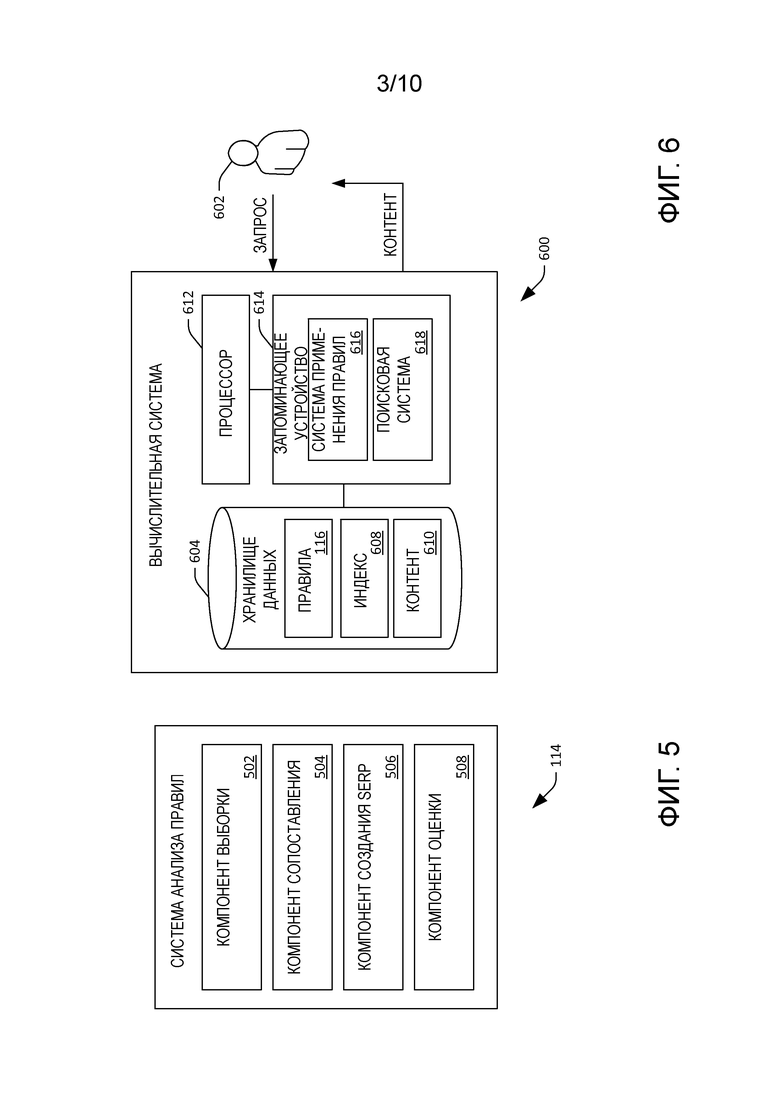
[0045] Теперь со ссылкой на фиг. 6 иллюстрируется примерная вычислительная система 600, которая конфигурируется для предоставления контента пользователю 602 посредством применения правила извлечения контента. Вычислительная система 600, например, может включаться в поисковую машину или использоваться для создания экземпляра поисковой машины. Поэтому вычислительная система 600 может быть вычислительной системой предприятия, центром обработки данных (например, частным центром обработки данных) и т.п. Вычислительная система 600 включает в себя хранилище 604 данных, где хранилище 604 данных содержит правила 116, сформированные системой 112 формирования правил. Снова форматом правил может быть [C] QA→QB или контент. Например, вместо правила извлечения контента, указывающего на переформулирование запроса, можно понять, что система 112 формирования правил может конфигурироваться для идентификации конкретного контента на основе выданного запроса и контекста (например, веб-страницы, которую обычно посещают). Хранилище 604 данных также может включать в себя индекс 608 с возможностью поиска, например, индекс веб-страниц, доступных через "Всемирную паутину" (Интернет). Хранилище 604 данных может дополнительно включать в себя контент 610, который может непосредственно предоставляться пользователю 602, например, мгновенные ответы, карточки сущностей, отдельные веб-страницы и т.п.
[0046] Вычислительная система 600 дополнительно включает в себя процессор 612 и запоминающее устройство 614, которое содержит системы и компоненты, которые исполняются процессором 612. Хотя вычислительная система 600 иллюстрируется как обособленная от вычислительной системы 100, нужно понимать, что вычислительные системы 100 и 600 могут включаться в одну и ту же вычислительную систему.
[0047] Запоминающее устройство 614 включает в себя систему 616 применения правил, которая конфигурируется для идентификации правила извлечения контента в ответ на прием запроса от пользователя 602. Система 616 применения правил дополнительно конфигурируется для исполнения идентифицированного правила. Запоминающее устройство 614 также может включать в себя поисковую систему 618, которая осуществляет связь с системой 616 применения правил. Поисковая система 618 в примере может принимать переформулирование запроса (и исходный запрос) и может выполнять поиск по индексу 608 на основе запроса и/или переформулирования запроса. В качестве альтернативы поисковая система 618 может предоставлять контент из контента 610 пользователю 602 на основе правила извлечения контента.
[0048] Точнее говоря, пользователь 602 может давать запрос для поисковой системы 618. Система 616 применения правил может принимать запрос и назначать принятому запросу один или несколько контекстов. Как указано выше, этот контекст может основываться на веб-страницах, посещенных пользователем 602 во время поискового сеанса, который включает в себя запрос, веб-страницы, обычно просматриваемые пользователем по прошествии времени (вне поискового сеанса), взаимодействия пользователя 602 в приложении социальных сетей, предыдущие запросы, выданные пользователем 602, и т.п. Нужно понимать, что в примере информация, применяемая системой 616 применения правил для назначения контекста запросу, может явно одобряться пользователем 602 для такого использования. Кроме того, система 602 применения правил может назначать несколько контекстов запросу, при этом контексты имеют назначенные им баллы уверенности. Например, система 602 применения правил может назначить запросу вероятность 0,8 того, что контекстом является "виды спорта".
[0049] В ответ на идентификацию контекстов, которые можно назначить запросу, система 616 применения правил ищет в правилах 116 по меньшей мере одно правило извлечения контента, которое запускается на основе запроса и контекстов. Когда можно запустить несколько правил, система 616 применения правил может выбрать некоторое пороговое количество правил с назначенными им наивысшими баллами эффективности. То есть система 616 применения правил может идентифицировать некоторое пороговое количество самых высокоранжированных правил из правил 116, которые применяют, принимая во внимание запрос и назначенные запросу контексты. Как только идентифицировано правило, система 616 применения правил может исполнить правило, что может включать в себя передачу поисковой системе 618 переформулированного запроса, идентифицированного в правиле (и, при необходимости, исходного запроса). Затем поисковая система 618 может доставить контент пользователю 602 (побудить отображение контента на дисплее вычислительного устройства, применяемого пользователем 602) на основе переформулирования запроса. Исполнение правила также предназначено для выполнения отложенного извлечения контента - например, исполнение правила может привести к запросу, показываемому как предложение (совет) запроса, которое может выбираться пользователем для извлечения контента.
[0050] Теперь со ссылкой на фиг. 7 иллюстрируется функциональная блок-схема системы 616 применения правил. Как указывалось ранее, система 616 применения правил принимает потенциально неоднозначный запрос. Система 616 применения правил включает в себя компонент 702 идентификации контекста, который конфигурируется для назначения контекста запросу в ответ на прием такого запроса. В примере компонент 702 идентификации контекста может назначать контекст запросу на основе наблюдений за пользователем 602. Например, наблюдения за пользователем 602 могут включать в себя наблюдения за поисковым сеансом, в котором дается запрос (например, выбранные пользователем результаты поиска или не выбранные пользователем результаты поиска), наблюдения в течение более длительного времени (например, неделя), наблюдения в течение еще большего времени (например, от трех до шести месяцев) и т.п. Наблюдения могут дополнительно включать в себя, но не ограничиваются, ранее выданные пользователем 602 запросы, посещенные пользователем 602 веб-страницы, взаимодействие пользователя по отношению к веб-страницам социальных сетей (например, "понравившиеся" пользователю субъекта) и т.п. Кроме того, наблюдения за пользователем 602 могут включать в себя атрибуты пользователя, например демографическую информацию о пользователе 602 (например, возраст, пол, расовая принадлежность, …), рост пользователя 602, цвет волос пользователя 602 и так далее. Более того, наблюдения могут включать в себя местоположение пользователя 602, сетевой адрес вычислительного устройства пользователя 602, время дня, день недели, время года и т.п.
[0051] Компонент 704 сопоставления может принимать запрос и назначенный запросу контекст от компонента 702 идентификации контекста и может идентифицировать правило в правилах 606, которое соотносится с сочетанием запроса и контекста. В некоторых случаях запросу можно назначить более одного контекста, что может привести к идентификации более одного правила в правилах 606.
[0052] Система 616 применения правил также может включать в себя компонент 706 передачи, который, например, передает идентифицированные правила в поисковую систему 618. Дополнительно или в качестве альтернативы компонент 706 передачи может конфигурироваться для ранжирования правил, выводимых компонентом 704 сопоставления. Как указывалось ранее, правила могут иметь назначенные им баллы эффективности, и компонент 706 передачи может ранжировать правила на основе их соответствующих баллов эффективности. Тогда поисковая система 618 может выполнять поиск по меньшей мере на основе самого высокоранжированного правила в правилах.
[0053] Ссылаясь на фиг. 8, иллюстрируется функциональная блок-схема поисковой системы 618. Поисковая система 618 включает в себя поисковый компонент 802, который принимает сформулированный пользователем 602 запрос и переформулированный запрос, идентифицированный правилом извлечения контента. Соответственно, поисковый компонент 802 может выполнять по меньшей мере два поиска: поиск на основе исходного запроса, выданного пользователем 602, и другой поиск на основе переформулированного запроса, идентифицированного системой 616 применения правил.
[0054] Поисковая система 618 может дополнительно включать в себя смешивающий компонент 804, который может принимать набор результатов поиска на основе поиска и другой набор результатов поиска на основе другого поиска и формировать SERP, которая включает в себя по меньшей мере один результат поиска в наборе результатов поиска и по меньшей мере один результат поиска в другом наборе результатов поиска. Таким образом, смешивающий компонент 804 может смешивать результаты поиска, извлеченные на основе разных запросов. Смешивающий компонент 804 может использовать любую подходящую методику при выполнении такого смешивания. Например, результаты поиска могут иметь баллы релевантности, назначенные им соответствующим образом для запроса. Смешивающий компонент 804 может смешивать результаты поиска из двух наборов результатов поиска на основе соответствующих баллов релевантности, назначенных результатам поиска в двух наборах результатов поиска.
[0055] В другом примере смешивающий компонент 804 может побудить показ на SERP реализуемого компьютером рекламного объявления на основе переформулированного запроса. Такое рекламное объявление может включать в себя рекламное объявление, отображенное в боковой врезке, баннерное рекламное объявление и т.п. В еще одном примере смешивающий компонент 804 может побудить отображение на SERP карточки субъекта на основе переформулированного запроса. Карточка субъекта может включать в себя информацию о субъекте, которая может отображаться на SERP. Например, субъект может быть человеком, местом или вещью, и карточка субъекта может отображать атрибуты человека, места или вещи. В еще одном примере, когда переформулированный запрос имеет отношение к местоположению, смешивающий компонент 804 может побудить показ на SERP карты того местоположения. В примере, когда исходным запросом является "bulls", а переформулированным запросом является "Chicago Bulls", смешивающий компонент 804 может побудить показ карты Чикаго на SERP. Более того, смешивающий компонент 804 может побудить показ мгновенного ответа на SERP на основе переформулированного запроса. В еще одном примере смешивающий компонент 804 может побудить выделение ключевых слов в переформулированном запросе (но не в исходном запросе) в результатах поиска, показанных на странице результатов поиска, посредством этого предоставляя пользователю визуальное указание переформулированного запроса. Более того, смешивающий компонент 804 может отображать переформулированный запрос как предлагаемый запрос, где после выбора пользователем переформулированного запроса поисковый компонент 802 может выполнять поиск исключительно на основе переформулированного запроса.
[0056] Поисковая система 618 дополнительно включает в себя компонент 806 вывода, который побуждает показ SERP, сформированной смешивающим компонентом 804, на дисплее вычислительного устройства, применяемого пользователем 602.
[0057] Теперь со ссылкой на фиг. 9 иллюстрируется примерный графический интерфейс 900 пользователя для SERP, которая может формироваться смешивающим компонентом 804 и выводиться компонентом 806 вывода. Графический интерфейс 900 пользователя включает в себя поле 902 запроса. Как можно убедиться, пользователь сформулировал исходный запрос "eagles" в поле 902 поиска. В примере, изображенном в графическом интерфейсе 900 пользователя, назначенным запросу "eagles" контекстом является "N самых популярных видов спорта", и идентифицируется правило извлечения контента, которое соотносит сочетание "eagles" и контекста "N самых популярных видов спорта" с переформулированным запросом "Philadelphia Eagles". Поисковый компонент 802 может выполнить два поиска: поиск на основе запроса "eagles" и другой поиск на основе запроса "Philadelphia Eagles". Смешивающий компонент 804 смешивает результаты поиска, а компонент 806 вывода выводит SERP, показанную в графическом интерфейсе 900 пользователя. В этом примере SERP включает в себя карточку 904 субъекта для субъекта "Philadelphia Eagles". Карточка 904 субъекта включает в себя атрибуты о "Philadelphia Eagles", включая, например, действующих игроков, стадион, дату основания, тренера и т. п. SERP также включает в себя несколько результатов поиска. Результаты поиска могут включать в себя результат поиска, который весьма релевантен переформулированному запросу, в верхних результатах поиска на SERP. Однако другие результаты поиска могут основываться на более неоднозначном запросе "eagles". Например, один результат поиска на SERP может относиться к музыкальной группе, The Eagles.
[0058] Ссылаясь теперь на фиг. 10, иллюстрируется пара графических интерфейсов 1002 и 1004 пользователя. Первый графический интерфейс 1002 пользователя изображает SERP, которая включает в себя результаты поиска на основе запроса "nycb", который может быть отчасти неоднозначным. Например, запрос может быть аббревиатурой, которая может описывать New York Community Bank, биржевой символ для New York Community Bank, ипотечную компанию New York Community Bank, New York City Ballet и т.п. Однако запрос "nycb" может быть сформулирован в конкретном контексте - например, пользователь, который дал запрос, просматривал связанные с искусством веб-страницы. Сочетание "nycb" и контекста может запустить правило извлечения контента, которое включает в себя запрос "New York City Ballet". SERP показанная в графическом интерфейсе 1004 пользователя, является SERP, выведенной смешивающим компонентом 804, которая включает в себя результаты поиска как для запроса "nycb", так и для переформулированного запроса "New York City Ballet". Как можно определить путем сравнения SERP, показанной в графическом интерфейсе 1002 пользователя, с SERP, показанной в графическом интерфейсе 1004 пользователя, графический интерфейс 1004 пользователя изображает несколько результатов поиска, которые относятся к New York City Ballet, тогда как графический интерфейс 1002 пользователя включает в себя один результат поиска, связанный с New York City Ballet (и ранжированный в результатах поиска сравнительно низко). В сущности, лицу, выдавшему запрос, с большей вероятностью предоставляются результаты поиска, которые интересуют пользователя, не требуя при этом, чтобы пользователь фактически переформулировал свой запрос.
[0059] Фиг. 11-13 иллюстрируют примерные методологии, относящиеся к правилам извлечения контента. Хотя методологии показываются и описываются как ряд действий, которые выполняются в некой последовательности, нужно понимать и принимать во внимание, что методологии не ограничиваются порядком той последовательности. Например, некоторые действия могут происходить в ином порядке, нежели описывается в этом документе. К тому же действие может происходить одновременно с другим действием. Кроме того, в некоторых случаях не все действия могут быть необходимы для реализации описанной в этом документе методологии.
[0060] Кроме того, описанные в этом документе действия могут быть исполняемыми компьютером командами, которые можно реализовать одним или несколькими процессорами и/или сохранить на машиночитаемом носителе или носителях. Исполняемые компьютером команды могут включать в себя процедуру, подпрограмму, программы, поток исполнения и/или т.п. Более того, результаты действий в методологиях можно сохранять на машиночитаемом носителе, отображать на устройстве отображения и/или т.п.
[0061] Ссылаясь теперь на фиг. 11, иллюстрируется примерная методология 1100 для вывода правил извлечения контента. Методология 1100 начинается с этапа 1102, и на этапе 1104 идентифицируются возможные пары переформулирования. Возможные пары переформулирования можно идентифицировать с использованием любой из рассмотренных выше методик относительно компонента 202 идентификации возможных правил. Например, можно использовать порождающие способы и различающие способы для изучения переформулирований запросов на данных журналов поиска.
[0062] На этапе 1106 формируется набор правил извлечения контента для каждой пары переформулирования запроса. Примерные методики для формирования набора правил описаны выше относительно компонента 202 идентификации возможных правил.
[0063] На этапе 1108 могут вычисляться значения, указывающие эффективность правил. В соответствии с примером могут использоваться подходы типа "многорукого бандита" для ранжирования предложенных правил извлечения контента либо по баллу эффективности, либо по верхней границе балла эффективности. На этапе 1110 правила ранжируются на основе значений, вычисленных на этапе 1108, и на этапе 1112 правила извлечения контента отсекаются при необходимости. Например, правила могут отсекаться, как описано выше относительно компонента 206 отсечения. Методология 1100 завершается на этапе 1114.
[0064] Ссылаясь теперь на фиг. 12, иллюстрируется примерная методология 1200, которая облегчает исполнение правила извлечения контента. Методология 1200 начинается с этапа 1202, и на этапе 1204 принимается запрос. На этапе 1206 идентифицируется контекст для запроса. На этапе 1208 выполняется определение, соотнесен ли запрос и контекст с правилом извлечения контента. Если отсутствует правило извлечения контента для сочетания запроса и контекста, то методология 1200 переходит к этапу 1210, где выполняется поиск на основе запроса, принятого на этапе 1204. Если на этапе 1208 определяется, что правило извлечения контента соотносится в запрос, принятый на этапе 1204, и контекст, идентифицированный на этапе 1206, то на этапе 1212 идентифицируется правило извлечения контента на основе запроса и контекста. Правило извлечения контента может идентифицировать, например, переформулирование запроса, который может передаваться в поисковую систему. На этапе 1214 переформулирование запроса, идентифицированное в правиле извлечения контента, передается в поисковую машину, которая выполняет поиск на основе запроса, принятого на этапе 1204, и переформулирования запроса. Методология 1200 завершается на этапе 1216.
[0065] Ссылаясь теперь на фиг. 13, иллюстрируется примерная методология 1300, которая облегчает формирование SERP на основе правила извлечения контента. Методология 1300 начинается с этапа 1302, и на этапе 1304 принимаются запрос и переформулирование запроса. Переформулирование запроса идентифицировано на основе правила извлечения контента, которое соотносит сочетание запроса и его контекст с переформулированным запросом. На этапе 1306 выполняются поиски на основе, соответственно, запроса и переформулирования запроса. На этапе 1308 формируется SERP, которая включает в себя результаты поиска на основе запроса и результаты поиска на основе переформулирования запроса. То есть SERP включает в себя смесь результатов поиска из двух отдельных поисков. Методология 1200 завершается на этапе 1210.
[0066] Теперь излагаются различные примеры.
[0067] Пример 1: Вычислительная система, содержащая: процессор; и запоминающее устройство, которое содержит систему применения правил, которая исполняется процессором, причем система применения правил сконфигурирована для: назначения контекста запросу в ответ на прием запроса; идентификации правила извлечения контента на основе запроса и контекста, назначенного запросу, правило извлечения контента соотносит сочетание запроса и контекста с одним из контента и переформулирования запроса; и исполнения правила извлечения контента в ответ на идентификацию правила извлечения контента.
[0068] Пример 2: Вычислительная система в соответствии с примером 1, в которой правило извлечения контента соотносит сочетание запроса и контекста с переформулированным запросом, и система применения правил сконфигурирована для передачи переформулированного запроса в поисковую систему, которая выполняет переформулированный запрос по индексу.
[0069] Пример 3: Вычислительная система в соответствии с любым из примеров 1-2, в которой поисковая система выполняет запрос и переформулированный запрос, и в которой поисковая система конфигурируется для возврата страницы результатов поисковой машины, причем страница результатов поисковой машины содержит контент, извлеченный поисковой системой на основе запроса и переформулированного запроса.
[0070] Пример 4: Вычислительная система в соответствии с примером 3, причем контент содержит результаты поиска, извлеченные поисковой системой на основе запроса, и другие результаты поиска, извлеченные поисковой системой на основе переформулированного запроса.
[0071] Пример 5: Вычислительная система в соответствии с примером 3, причем контент содержит по меньшей мере одно из карты, карточки субъекта или рекламного объявления, которое извлекается поисковой системой на основе переформулированного запроса.
[0072] Пример 6: Вычислительная система в соответствии с примером 1, в которой правило извлечения контента соотносит сочетание запроса и контекста в контент, контент является веб-страницей.
[0073] Пример 7: Вычислительная система в соответствии с примером 1, в которой система применения правил содержит компонент идентификации контекста, который назначает контекст запросу на основе наблюдений за пользователем, который дал запрос.
[0074] Пример 8: Вычислительная система в соответствии с примером 7, в которой компонент идентификации контекста назначает контекст для текущего поискового сеанса.
[0075] Пример 9: Вычислительная система в соответствии с примером 7, в которой наблюдения за пользователем дополнительно содержат по меньшей мере одно из взаимодействия с приложением социальной сети, предыдущего запроса, выданного пользователем, или сетевого адреса вычислительного устройства пользователя.
[0076] Пример 10: Вычислительная система в соответствии с любым из примеров 1-9, причем запоминающее устройство дополнительно содержит систему формирования правил, которая формирует множество правил извлечения контента на основе журналов поиска поисковой машины, при этом множество правил извлечения контента содержит правило извлечения контента.
[0077] Пример 11: Вычислительная система в соответствии с примером 10, в которой система формирования правил содержит компонент назначения баллов, который назначает соответствующие баллы множеству правил извлечения контента, где правило извлечения контента назначается запросу на основе балла, назначенного правилу извлечения контента.
[0078] Пример 12: Способ, содержащий: назначение контекста принятому запросу на основе наблюдений за лицом, выдавшим запрос; идентификацию правила извлечения контента на основе запроса и контекста, назначенного запросу, правило извлечения контента соотносит сочетание запроса и контекста с одним из переформулирования запроса и контента; и исполнение правила извлечения контента в ответ на идентификацию правила извлечения контента.
[0079] Пример 13: Способ в соответствии с примером 12, в котором правило извлечения контента соотносит сочетание запроса и контекста в переформулирование запроса, при этом способ дополнительно содержит: выполнение поиска на основе запроса; и выполнение другого поиска на основе переформулирования запроса.
[0080] Пример 14: Способ в соответствии с примером 13, дополнительно содержащий: вывод страницы результатов поисковой машины на основе поиска и другого поиска, причем страница результатов поисковой машины включает в себя результат поиска, извлеченный при поиске, и результат другого поиска, извлеченный при другом поиске.
[0081] Пример 15: Способ в соответствии с примером 14, дополнительно содержащий: выделение ключевого слова переформулированного запроса в результате другого поиска, при этом запрос не содержит выделенного ключевого слова.
[0082] Пример 16: Способ в соответствии с примером 12, в котором правило извлечения контента соотносит сочетание запроса и контекста с переформулированием запроса, при этом способ дополнительно содержит: выполнение поиска на основе запроса; формирование страницы результатов поисковой машины на основе запроса; и представление переформулирования запроса на странице результатов поисковой машины в качестве предлагаемого запроса.
[0083] Пример 17: Способ в соответствии с примером 12, в котором правило извлечения контента соотносит сочетание запроса и контекста в контент, и в котором выполнение правила извлечения контента содержит побуждение отображения контента лицу, выдавшему запрос, на дисплее.
[0084] Пример 18: Способ в соответствии с любым из примеров 12-17, в котором наблюдения за лицом, выдавшим запрос, содержат демографические характеристики лица, выдавшего запрос.
[0085] Пример 19: Способ в соответствии с любым из примеров 12-18, в котором наблюдения за лицом, выдавшим запрос, содержат предыдущие запросы, сформулированные лицом, выдавшим запрос, и результаты поиска, выбранные или не выбранные лицом, выдавшим запрос.
[0086] Пример 20: Машиночитаемый носитель информации, содержащий команды, которые при исполнении процессором побуждают процессор выполнить действия, содержащие: идентификацию правила извлечения контента на основе запроса и контекста, назначенного запросу, причем контекст указывает тему, наблюдаемую в прошлом как интересующую лицо, выдавшее запрос; идентификацию предопределенного соотнесения между сочетанием запроса и контекста и переформулированием запроса; и побуждение показа контента на дисплее на основе переформулирования запроса в ответ на идентификацию предопределенного отображения.
[0087] Пример 21: Система, содержащая средство для назначения контекста принятому запросу на основе наблюдений за лицом, выдавшим запрос; средство для идентификации правила извлечения контента на основе запроса и контекста, назначенного запросу, правило извлечения контента соотносит сочетание запроса и контекста с одним из переформулирования запроса и контента; и средство для исполнения правила извлечения контента.
[0088] Ссылаясь теперь на фиг. 14, приводится высокоуровневая иллюстрация примерного вычислительного устройства 1400, которое может использоваться в соответствии с системами и методологиями, раскрытыми в этом документе. Например, вычислительное устройство 1400 может использоваться в системе, которая поддерживает формирование правил извлечения контента. В качестве другого примера вычислительное устройство 1400 может использоваться в системе, которая поддерживает применение правил извлечения контента. Вычислительное устройство 1400 включает в себя по меньшей мере один процессор 1402, который исполняет команды, которые хранятся в запоминающем устройстве 1404. Команды могут быть, например, командами для реализации функциональных возможностей, описанных как осуществляемые одним или несколькими рассмотренными выше компонентами, или командами для реализации одного или нескольких описанных выше способов. Процессор 1402 может обращаться к запоминающему устройству 1404 посредством системной шины 1406. В дополнение к хранению исполняемых команд запоминающее устройство 1404 также может хранить индекс, правила извлечения контента, контент и т.п.
[0089] Вычислительное устройство 1400 дополнительно включает в себя хранилище 1408 данных, которое доступно процессору 1402 посредством системной шины 1406. Хранилище 1408 данных может включать в себя исполняемые команды, правила извлечения контента, индекс, контент и т.п. Вычислительное устройство 1400 также включает в себя входной интерфейс 1410, который позволяет внешним устройствам осуществлять связь с вычислительным устройством 1400. Например, входной интерфейс 1410 может использоваться для приема команд от внешнего компьютерного устройства, от пользователя и т.п. Вычислительное устройство 1400 также включает в себя выходной интерфейс 1412, который сопрягает вычислительное устройство 1400 с одним или несколькими внешними устройствами. Например, вычислительное устройство 1400 может отображать текст, изображения и т.п. посредством выходного интерфейса 1412.
[0090] Предполагается, что внешние устройства, которые осуществляют связь с вычислительным устройством 1400 через входной интерфейс 1410 и выходной интерфейс 1412, можно включить в среду, которая предоставляет практически любой тип интерфейса пользователя, с которым может взаимодействовать пользователь. Примеры типов интерфейса пользователя включают в себя графические интерфейсы пользователя, естественные интерфейсы пользователя и так далее. Например, графический интерфейс пользователя может принимать ввод от пользователя, применяющего такое устройство (устройства) ввода, как клавиатура, мышь, пульт дистанционного управления или т.п., и предоставлять вывод на таком устройстве вывода, как дисплей. Кроме того, естественный интерфейс пользователя может дать пользователю возможность взаимодействовать с вычислительным устройством 1400 без ограничений, накладываемых устройством ввода, например клавиатурами, мышами, пультами дистанционного управления и т.п. Точнее, естественный интерфейс пользователя может опираться на распознавание речи, распознавание касания и пера, распознавание жестов на экране и рядом с экраном, жесты в воздухе, отслеживание движений головы и глаз, голос и речь, зрение, касание, жесты, искусственный интеллект и так далее.
[0091] Более того, хотя и проиллюстрировано в виде одиночной системы, нужно понимать, что вычислительное устройство 1400 может быть распределенной системой. Таким образом, например, несколько устройств могут осуществлять связь посредством сетевого соединения и могут вместе выполнять задачи, описанные как выполняемые вычислительным устройством 1400.
[0092] Различные функции, описанные в этом документе, могут быть реализованы в аппаратных средствах, программном обеспечении или любом их сочетании. При реализации в программном обеспечении функции могут храниться или передаваться в виде одной или нескольких команд либо кода на машиночитаемом носителе. Машиночитаемые носители включают в себя машиночитаемые носители информации. Машиночитаемые носители информации могут быть любыми доступными носителями информации, к которым можно обращаться с помощью компьютера. В качестве примера, а не ограничения, такие машиночитаемые носители информации могут быть выполнены в виде RAM, ROM, EEPROM, компакт-диска или другого накопителя на оптических дисках, накопителя на магнитных дисках или других магнитных запоминающих устройств, либо любого другого носителя, который может использоваться для перемещения или хранения необходимого программного кода в виде команд или структур данных, и к которому [носителю] можно обращаться с помощью компьютера. Диски при использовании в данном документе включают в себя компакт-диск (CD), лазерный диск, оптический диск, цифровой универсальный диск (DVD), гибкий диск и диск Blu-ray (BD), где магнитные диски обычно воспроизводят данные магнитным способом, а оптические диски обычно воспроизводят данные оптически с помощью лазеров. Кроме того, распространяемый сигнал не включается в область машиночитаемых носителей информации. Машиночитаемые носители также включают в себя средства связи, включающие любой носитель, который способствует переносу компьютерной программы из одного места в другое. Соединение, например, может быть средством связи. Например, если программное обеспечение передается с веб-сайта, сервера или другого удаленного источника с использованием коаксиального кабеля, волоконно-оптического кабеля, витой пары, цифровой абонентской линии (DSL) или беспроводных технологий, например ИК-связи, радиочастотной связи и СВЧ-связи, то коаксиальный кабель, волоконно-оптический кабель, витая пара, DSL или беспроводные технологии, например ИК-связь, радиочастотная связь и СВЧ-связь, включаются в определение средства связи. Сочетания вышеперечисленного также следует включить в область машиночитаемых носителей.
[0093] В качестве альтернативы или дополнительно функциональные возможности, описанные в этом документе, могут по меньшей мере частично выполняться одним или несколькими компонентами аппаратной логики. Например, и без ограничения, пояснительные типы компонентов аппаратной логики, которые можно использовать, включают в себя программируемые пользователем вентильные матрицы (FPGA), специализированные интегральные схемы (ASIC), стандартные части специализированной ИС (ASSP), системы на кристалле (SOC), сложные программируемые логические устройства (CPLD) и т.п.
[0094] То, что описано выше, включает в себя примеры одного или нескольких вариантов осуществления. Конечно, невозможно описать каждое мыслимое изменение и переделку вышеприведенных устройств или методик в целях описания вышеупомянутых аспектов, однако специалист в данной области техники может признать, что допустимы многие дополнительные изменения и перестановки различных аспектов. Соответственно, описанные аспекты подразумеваются охватывающими все такие переделки, изменения и вариации, которые входят в пределы сущности и объема, определяемого прилагаемой формулой изобретения. Кроме того, в случае, когда термин "включает в себя" используется либо в описании подробностей, либо в формуле изобретения, такой термин предназначен быть включающим в некотором смысле аналогично термину "содержащий", поскольку "содержащий" интерпретируется, когда применяется в качестве переходного слова в формуле изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Система и способ для формирования обучающего набора для алгоритма машинного обучения | 2020 |
|
RU2790033C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ РАНЖИРОВАННЫХ ПОЗИЦИЙ ЭЛЕМЕНТОВ СИСТЕМОЙ РАНЖИРОВАНИЯ | 2020 |
|
RU2781621C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ АНОМАЛЬНЫХ ПОСЕЩЕНИЙ ВЕБ-САЙТОВ | 2019 |
|
RU2775824C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ФОРМИРОВАНИЯ ПОДСКАЗОК ПО РАСШИРЕНИЮ ПОИСКОВЫХ ЗАПРОСОВ В ПОИСКОВОЙ СИСТЕМЕ | 2019 |
|
RU2744111C2 |
| ФОРМИРОВАНИЕ ПОИСКОВОГО ЗАПРОСА НА ОСНОВЕ КОНТЕКСТА | 2013 |
|
RU2633115C2 |
| Способ и система для формирования карточки объекта | 2018 |
|
RU2739554C1 |
| Способ и сервер для формирования расширенного запроса | 2021 |
|
RU2813582C2 |
| Система и способ формирования обучающего набора для алгоритма машинного обучения | 2018 |
|
RU2744029C1 |
| СПОСОБ И СЕРВЕР ДЛЯ КЛАССИФИКАЦИИ ВЕБ-РЕСУРСА | 2017 |
|
RU2658878C1 |
| КОНТЕКСТНЫЙ ПОИСК В МУЛЬТИМЕДИЙНОМ КОНТЕНТЕ | 2015 |
|
RU2726864C2 |

Изобретение относится к области вычислительной техники. Технический результат заключается в повышении качества информационного поиска. Способ содержит этапы, на которых: во время поискового сеанса пользователя с поисковой машиной принимают запрос от клиентского вычислительного устройства посредством сетевого соединения; назначают тему упомянутому запросу на основе упомянутого предыдущего запроса; идентифицируют правило извлечения контента; в ответ на упомянутую идентификацию правила извлечения контента, выполняют поиск по совокупности документов с использованием упомянутого переформулированного запроса, чтобы получить ранжированный список результатов поиска; передают ранжированный список результатов поиска в клиентское вычислительное устройство. 3 н. и 17 з.п. ф-лы, 14 ил. 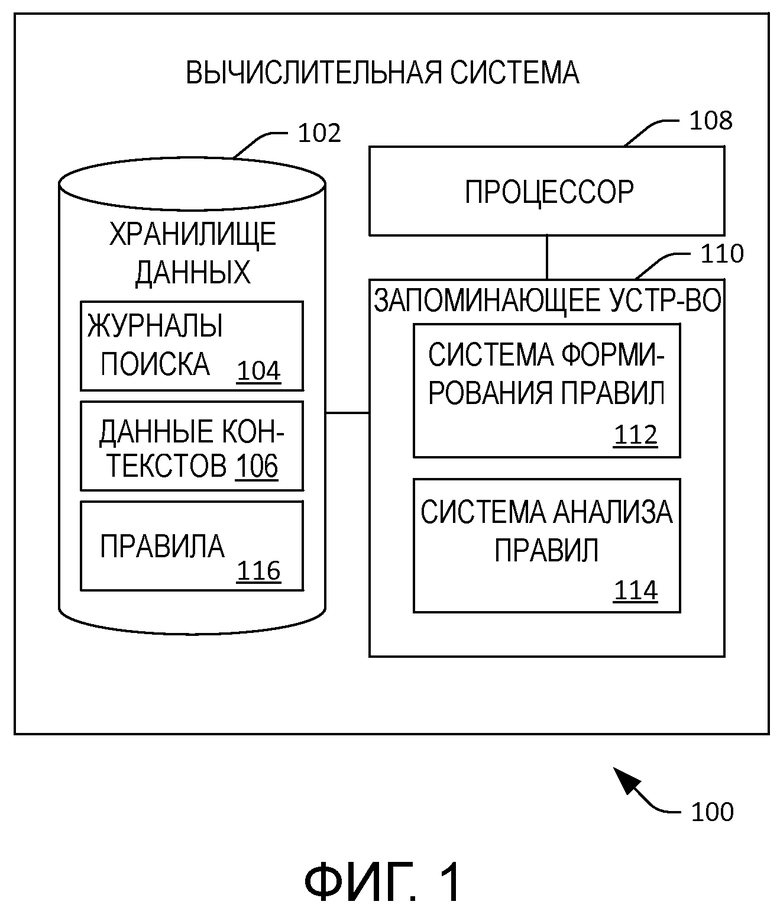
1. Вычислительная система, содержащая:
процессор; и
запоминающее устройство, которое содержит инструкции, которые при их исполнении процессором, предписывают процессору выполнять действия, содержащие:
во время поискового сеанса с поисковой машиной, прием запроса от клиентского вычислительного устройства, которое находится на сетевой связи с вычислительной системой;
в ответ на упомянутый прием запроса, назначение темы этому запросу из множества заранее заданных тем, причем по данной теме пользователем клиентского вычислительного устройства осуществляется поиск во время поискового сеанса, при этом данная тема назначается на основе предыдущего запроса, принятого от клиентского вычислительного устройства во время поискового сеанса, причем упомянутые запрос и предыдущий запрос помечаются как принадлежащие поисковому сеансу на основе того, что упомянутый запрос принимается в пределах пороговой величины времени от того момента, когда был принят упомянутый предыдущий запрос;
в ответ на упомянутое назначение темы запросу, идентификацию правила извлечения контента в базе данных правил извлечения контента на основе сочетания упомянутых запроса и темы, назначенной запросу, при этом правило извлечения контента соотносит это сочетание запроса и темы с переформулированием запроса;
в ответ на упомянутую идентификацию правила извлечения контента, выполнение поиска по совокупности документов с использованием упомянутого переформулированного запроса, чтобы получить ранжированный список результатов поиска; и
передачу ранжированного списка результатов поиска в клиентское вычислительное устройство, при этом клиентское вычислительное устройство отображает ранжированный список результатов поиска на своем дисплее в ответ на прием ранжированного списка результатов поиска.
2. Вычислительная система по п. 1, в которой упомянутый поиск выполняется поисковой машиной с использованием обоих из упомянутых запроса и переформулированного запроса, при этом ранжированный список результатов поиска включен в страницу результатов поисковой машины, причем ранжированный список результатов поиска содержит контент, извлеченный поисковой машиной на основе упомянутых запроса и переформулированного запроса.
3. Вычислительная система по п. 2, при этом ранжированный список результатов поиска содержит первый набор результатов поиска, который основывается на упомянутом запросе, и второй набор результатов поиска, который основывается на упомянутом переформулированном запросе.
4. Вычислительная система по п. 2, при этом страницу результатов поисковой машины содержит по меньшей мере одно из карты, карточки субъекта и рекламного объявления, которые извлекаются на основе упомянутого переформулированного запроса.
5. Вычислительная система по п. 1, в которой упомянутая тема назначается упомянутому запросу на основе множества запросов, ранее поданных пользователем, которым были поданы упомянутые запрос и предыдущий запрос, причем каждый запрос в этом множестве запросов помечается как принадлежащий поисковому сеансу.
6. Вычислительная система по п. 5, в которой упомянутая тема назначается упомянутому запросу дополнительно на основе по меньшей мере одного из взаимодействия пользователя с приложением социальной сети и сетевого адреса вычислительного устройства пользователя.
7. Вычислительная система по п. 1, в которой действия дополнительно содержат формирование множества правил извлечения контента на основе журналов поиска поисковой машины, причем данное множество правил извлечения контента содержит упомянутое правило извлечения контента.
8. Вычислительная система по п. 7, в которой действия дополнительно содержат назначение соответствующих баллов упомянутому множеству правил извлечения контента, при этом упомянутое правило извлечения контента назначается упомянутому запросу на основе балла, назначенного упомянутому правилу извлечения контента.
9. Компьютерно-реализуемый способ осуществления тематического поиска, содержащий этапы, на которых:
во время поискового сеанса пользователя с поисковой машиной, принимают запрос от клиентского вычислительного устройства посредством сетевого соединения, причем поисковый сеанс содержит предыдущий запрос, представленный пользователем в поисковую машину, при этом упомянутые запрос и предыдущий запрос помечаются как принадлежащие поисковому сеансу на основе того, что упомянутый запрос подается пользователем в поисковую машину в пределах пороговой величины времени от того момента, когда упомянутый предыдущий запрос был подан пользователем в поисковую машину;
назначают тему упомянутому запросу на основе упомянутого предыдущего запроса, представленного пользователем во время поискового сеанса, при этом данная тема назначается из множества заранее заданных тем, причем по данной теме пользователем осуществляется поиск во время поискового сеанса;
идентифицируют правило извлечения контента, которое соотнесено с сочетанием упомянутых запроса и темы, назначенной запросу, причем правило извлечения контента соотносит данное сочетание запроса и темы с переформулированием запроса; и
в ответ на упомянутую идентификацию правила извлечения контента, выполняют поиск по совокупности документов с использованием упомянутого переформулированного запроса, чтобы получить ранжированный список результатов поиска; и
передают ранжированный список результатов поиска в клиентское вычислительное устройство, при этом клиентское вычислительное устройство отображает ранжированный список результатов поиска на своем дисплее в ответ на прием ранжированного списка результатов поиска.
10. Способ по п. 9, дополнительно содержащий этап, на котором выполняют еще один поиск по упомянутой совокупности документов с использованием упомянутого запроса.
11. Способ по п. 10, дополнительно содержащий этап, на котором выдают страницу результатов поисковой машины на основе упомянутых поиска и еще одного поиска, при этом страница результатов поисковой машины включает в себя ранжированный список результатов поиска, причем ранжированный список результатов поиска включает в себя результат поиска, полученный в упомянутом поиске, и другой результат поиска, полученный в упомянутом еще одном поиске.
12. Способ по п. 11, дополнительно содержащий этап, на котором выделяют ключевое слово упомянутого переформулированного запроса в упомянутом другом результате поиска, причем данного ключевого слова нет в упомянутом запросе.
13. Способ по п. 9, дополнительно содержащий этапы, на которых:
выполняют второй поиск по упомянутой совокупности документов на основе упомянутого запроса;
генерируют страницу результатов поисковой машины на основе упомянутого запроса; и
представляют упомянутый переформулированный запрос на странице результатов поисковой машины в качестве предлагаемого запроса, причем упомянутый поиск по совокупности документов на основе переформулированного запроса выполняется только после выбора упомянутого переформулированного запроса.
14. Способ по п. 9, в котором упомянутая тема назначается упомянутому запросу дополнительно на основе демографической информации о лице, подавшем упомянутый запрос.
15. Способ по п. 9, в котором упомянутая тема назначается упомянутому запросу дополнительно на основе возвращенных поисковой машиной результатов поиска, которые были выбраны или не были выбраны лицом, подавшим упомянутый запрос, когда подавался упомянутый предыдущий запрос.
16. Машиночитаемый носитель информации, содержащий инструкции, которые при их исполнении процессором предписывают процессору выполнять действия, содержащие:
в то время как пользователь клиентского вычислительного устройства участвует в поисковом сеансе с поисковой машиной, прием запроса от клиентского вычислительного устройства;
в ответ на упомянутый прием запроса, назначение темы этому запросу из множества заранее заданных тем, причем эта тема назначается данному запросу на основе предыдущего запроса, принятого от клиентского вычислительного устройства во время поискового сеанса, при этом упомянутые запрос и предыдущий запрос помечаются как принадлежащие поисковому сеансу на основе того, что упомянутый запрос принимается в пределах пороговой величины времени от того момента, когда был принят упомянутый предыдущий запрос, причем по упомянутой теме пользователем клиентского вычислительного устройства осуществляется поиск во время поискового сеанса;
в ответ на упомянутое назначение темы запросу, идентификацию правила извлечения контента, которое соотнесено с сочетанием упомянутых запроса и темы, назначенной запросу, причем правило извлечения контента задает переформулирование запроса для упомянутого запроса;
выполнение поиска по совокупности документов на основе упомянутого переформулированного запроса, причем результатом этого выполнения поиска является формирование ранжированного списка результатов поиска; и
передачу ранжированного списка результатов поиска в клиентское вычислительное устройство, при этом клиентское вычислительное устройство отображает ранжированный список результатов поиска на своем дисплее в ответ на прием ранжированного списка результатов поиска.
17. Машиночитаемый носитель информации по п. 16, при этом упомянутое множество заранее заданных тем основывается на темах, назначенных веб-страницам в журналах поиска поисковой машины.
18. Машиночитаемый носитель информации по п. 16, при этом упомянутая тема назначается упомянутому запросу дополнительно на основе демографической информации о пользователе, который подал упомянутый запрос.
19. Машиночитаемый носитель информации по п. 16, при этом упомянутая тема назначается упомянутому запросу дополнительно на основе тем, назначенных другим запросам, помеченным как принадлежащие поисковому сеансу.
20. Машиночитаемый носитель информации по п. 16, в котором действия дополнительно содержат выполнение второго поиска по упомянутой совокупности документов на основе упомянутого запроса, при этом ранжированный список результатов поиска содержит по меньшей мере один результат, идентифицированный во втором поиске.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| RU 2008139483 A, 20.04.2010. | |||

