Область техники, к которой относится изобретение
[001] Настоящая технология в целом относится к расширению запросов и, в частности, к способу и серверу для формирования расширенного запроса для пользователя электронного устройства.
Уровень техники
[002] Сеть Интернет обеспечивает доступ к разнообразным ресурсам, таким как, видеофайлы, файлы изображений, аудиофайлы или веб-страницы. Для поиска этих ресурсов используются поисковые системы. Например, после получения отправленного пользователем запроса поисковая система может определять цифровые изображения, соответствующие информационным потребностям пользователя. Пользовательские запросы могут состоять из одного или нескольких терминов. Поисковая система выбирает и ранжирует результаты поиска в зависимости от их соответствия пользовательскому запросу и их важности или качества по сравнению с другими результатами поиска и предоставляет пользователю лучшие результаты поиска.
[003] Поисковые системы могут расширять пользовательский опыт и предлагать пользователям варианты запросов или подсказки, помогая пользователям удовлетворять их информационные потребности. Например, предлагаемый вариант может использоваться как дополнение для частично введенного пользовательского запроса, применяемое для уточнения поиска или стратегии поиска. Некоторые поисковые системы по мере ввода пользователем желательного запроса предлагают варианты в виде списка. В другом примере в ответ на пользовательский запрос на странице результатов поисковой системы (SERP, Search Engine Results Page) могут отображаться подсказки, позволяющие пользователю ознакомиться с текущими результатами поиска и выбрать следующий запрос, если он не удовлетворен текущими результатами поиска. Предоставление возможных вариантов запроса или подсказок, желательных для пользователя, представляет собой непростую задачу.
[004] В патентном документе US2011258148 описаны системы для прогнозирования цели поиска на основе данных о поведении пользователя при просмотре ресурсов. Например, из поведения пользователя при просмотре могут быть получены схемы поиска пользователя, который просматривает веб-страницу и вскоре после этого выполняет запрос. Запросы из схем поиска могут быть ранжированы на основе вероятности инициирования поиска, указывающей на то, что контент веб-страницы побуждает пользователя выполнять поиск.
Раскрытие изобретения
[005] Разработчики настоящей технологии обнаружили определенные технические недостатки, связанные с существующими поисковыми системами. Традиционные системы могут предлагать расширенные запросы, слишком похожие друг на друга.
[006] Согласно аспектам настоящей технологии, разработчики настоящей технологии реализовали способы и серверы для инициирования отображения множества расширенных запросов для пользователя электронного устройства. В одном примере расширенные запросы могут представлять собой дополнения для запроса или предлагаемые варианты запроса. Такой расширенный запрос представляет собой дополненный запрос, который содержит текущий запрос пользователя и отображается пользователю (например, в раскрывающемся меню строки поиска) во время ввода пользователем запроса до отображения результатов поиска пользователю. В другом примере расширенный запрос может представлять собой переформулированный текущий запрос, отправленный пользователем, или дополнительный запрос. Такой расширенный запрос часто отображается в специально выделенной части или в специализированном меню страницы SERP, соответствующей текущему запросу, отправленному пользователем. В некоторых случаях такие расширенные запросы могут содержать или не содержать части текущего запроса, отправленного пользователем, и отображаются пользователю для удобного инициирования им дополнительного поиска, если страница SERP не содержит удовлетворительных результатов поиска. В некоторых вариантах осуществления изобретения такие расширенные запросы могут отображаться в виде активируемых значков в области, расположенной в верхней части страницы SERP. В других вариантах осуществления изобретения такие расширенные запросы могут отображаться в меню, представленном в виде списка, в области, расположенной в нижней части страницы SERP.
[007] Независимо от конкретного вида расширенного запроса, подлежащего отображению пользователю, отображение чрезмерно схожих друг с другом расширенных запросов нежелательно. В одном примере в результате отображения пользователю схожих расширенных запросов неэффективно используется полезная площадь экрана пользовательского устройства. В другом примере расширенные запросы, приводящие к схожим результатам поиска, избыточны с точки зрения удовлетворения потребностей пользователя в поиске.
[008] Разработчики настоящей технологии разработали способы повышения вероятности удовлетворения потребностей пользователя в поиске путем отображения расширенных запросов, обеспечивающих более разнообразные результаты поиска. Безотносительно какой-либо конкретной теории, разработчики настоящей технологии установили, что благодаря отфильтровыванию кандидатов (на расширенные запросы) на основе степени сходства соответствующих результатов поиска пользователь может получать доступ к более разнообразным результатам поиска с использованием демонстрируемых ему расширенных запросов.
[009] Согласно первому аспекту настоящей технологии реализован способ формирования расширенного запроса для пользователя электронного устройства. Способ выполняется сервером, связанным с электронным устройством. На сервере размещена поисковая система. Способ включает в себя получение сервером от электронного устройства указания на пользовательский запрос, связанный с данными запроса. Способ включает в себя формирование сервером, использующим первую модель, первой строки-кандидата и второй строки-кандидата, представляющих собой соответствующих кандидатов для расширенного запроса, на основе данных запроса. Способ включает в себя определение сервером, использующим вторую модель, того, что первая строка-кандидат и вторая строка-кандидат представляют собой пару схожих строк-кандидатов, при этом вторая модель обучена в парной конфигурации на основе обучающего набора. Обучающий набор содержит первую обучающую строку, представляющую собой первый обучающий запрос, вторую обучающую строку, представляющую собой второй обучающий запрос, и метку. Метка указывает на сходство первой обучающей строки и второй обучающей строки и определена на основе сравнения первого обучающего документа, релевантного первому обучающему запросу, и второго обучающего документа, релевантного второму обучающему запросу. Способ включает в себя инициирование сервером отображения на электронном устройстве в качестве расширенного запроса лишь одной строки из пары схожих строк-кандидатов.
[010] В некоторых вариантах осуществления способа метка указывает на сходство первой обучающей строки и второй обучающей строки, если первый обучающий документ совпадает со вторым обучающим документом.
[011] В некоторых вариантах осуществления способа первый обучающий документ представляет собой первое множество обучающих документов, а второй обучающий документ представляет собой второе множество обучающих документов. Первое множество обучающих документов содержит N документов, наиболее релевантных первому обучающему запросу. Второе множество обучающих документов содержит M документов, наиболее релевантных второму обучающему запросу, а метка указывает на то, что первая обучающая строка подобна второй обучающей строке, если в первом множестве обучающих документов и во втором множестве обучающих документов содержится по меньшей мере заранее заданное количество одинаковых обучающих документов.
[012] В некоторых вариантах осуществления способа N документов, наиболее релевантных первому обучающему запросу, и M документов, наиболее релевантных второму обучающему запросу, определяются поисковой системой в автономном режиме до обучения второй модели.
[013] В некоторых вариантах осуществления способа первая модель представляет собой модель ранжирования, способную формировать ранжированный список строк-кандидатов, а первая строка-кандидат и вторая строка-кандидат ранжируются в ранжированном списке строк-кандидатов. При этом инициирование включает в себя инициирование сервером отображения на электронном устройстве в качестве расширенного запроса строки-кандидата с бóльшим рангом из числа первой строки-кандидата и второй строки-кандидата.
[014] В некоторых вариантах осуществления способа первая модель представляет собой углубленную модель семантического сходства (DSSM, Deep Semantic Similarity Model).
[015] В некоторых вариантах осуществления способа вторая модель представляет собой модель DSSM.
[016] В некоторых вариантах осуществления способа расширенный запрос представляет собой дополненный запрос, содержащий запрос. При этом инициирование включает в себя инициирование сервером отображения на электронном устройстве дополненного запроса без отображения страницы SERP, соответствующей запросу.
[017] В некоторых вариантах осуществления способа расширенный запрос представляет собой переформулированный запрос. При этом инициирование включает в себя инициирование сервером отображения на электронном устройстве страницы SERP, соответствующей запросу и содержащей часть с переформулированным запросом.
[018] В некоторых вариантах осуществления способа расширенный запрос представляет собой дополненный запрос, содержащий запрос. При этом инициирование включает в себя инициирование сервером отображения на электронном устройстве страницы SERP, соответствующей запросу и содержащей часть с переформулированным запросом.
[019] Согласно второму аспекту настоящей технологии реализован способ формирования расширенного запроса для пользователя электронного устройства. Способ выполняется сервером, связанным с электронным устройством и содержащим поисковую систему. Способ включает в себя получение сервером данных запроса, связанных с запросом, отправленным пользователем. Способ включает в себя формирование сервером, использующим первую модель, первой строки-кандидата и второй строки-кандидата, которые представляют собой соответствующих кандидатов для расширенного запроса, на основе данных запроса. Способ включает в себя определение сервером в реальном времени на основе первой строки-кандидата первого множества документов, содержащего документы, релевантные первой строке-кандидату. Способ включает в себя определение сервером в реальном времени на основе второй строки-кандидата второго множества документов, содержащего документы, релевантные второй строке-кандидату. Способ включает в себя определение сервером того, что первая строка-кандидат и вторая строка-кандидат представляют собой пару схожих строк, если в первом множестве документов и во втором множестве документов содержится по меньшей мере заранее заданное количество одинаковых документов. Способ включает в себя инициирование сервером отображения на электронном устройстве в качестве расширенного запроса лишь одной строки из пары строк-кандидатов.
[020] В некоторых вариантах осуществления способа первая модель представляет собой модель ранжирования, способную формировать ранжированный список строк-кандидатов, а первая строка-кандидат и вторая строка-кандидат ранжируются в ранжированном списке строк-кандидатов. При этом инициирование включает в себя инициирование сервером отображения на электронном устройстве в качестве расширенного запроса строки-кандидата с бóльшим рангом из числа первой строки-кандидата и второй строки-кандидата.
[021] В некоторых вариантах осуществления способа модель представляет собой модель DSSM.
[022] В некоторых вариантах осуществления способа расширенный запрос представляет собой дополненный запрос, содержащий запрос. При этом инициирование включает в себя инициирование сервером отображения на электронном устройстве дополненного запроса без отображения страницы SERP, соответствующей запросу.
[023] В некоторых вариантах осуществления способа расширенный запрос представляет собой переформулированный запрос. При этом инициирование включает в себя инициирование сервером отображения на электронном устройстве страницы SERP, соответствующей запросу и содержащей часть с переформулированным запросом.
[024] В некоторых вариантах осуществления способа расширенный запрос представляет собой дополненный запрос, содержащий запрос. При этом инициирование включает в себя инициирование сервером отображения на электронном устройстве страницы SERP, соответствующей запросу и содержащей часть с переформулированным запросом.
[025] Согласно третьему аспекту настоящей технологии реализован сервер для формирования расширенного запроса для пользователя электронного устройства, при этом сервер связан с электронным устройством и содержит поисковую систему. Сервер способен получать от электронного устройства указание на пользовательский запрос, связанный с данными запроса. Сервер способен с использованием первой модели формировать на основе данных запроса первую строку-кандидата и вторую строку-кандидата, которые представляют собой соответствующих кандидатов для расширенного запроса. Сервер способен с использованием второй модели определять, что первая строка-кандидат и вторая строка-кандидат представляют собой пару схожих строк-кандидатов, при этом вторая модель обучена в парной конфигурации на основе обучающего набора. Обучающий набор содержит первую обучающую строку, представляющую собой первый обучающий запрос, вторую обучающую строку, представляющую собой второй обучающий запрос, и метку. Метка указывает на сходство первой обучающей строки и второй обучающей строки и определена на основе сравнения первого обучающего документа, релевантного первому обучающему запросу, и второго обучающего документа, релевантного второму обучающему запросу. Сервер способен инициировать отображение на электронном устройстве в качестве расширенного запроса лишь одной строки из пары схожих строк-кандидатов.
[026] В некоторых вариантах осуществления сервера метка указывает на сходство первой обучающей строки и второй обучающей строки, если первый обучающий документ совпадает со вторым обучающим документом.
[027] В некоторых вариантах осуществления сервера первый обучающий документ представляет собой первое множество обучающих документов, а второй обучающий документ представляет собой второе множество обучающих документов. Первое множество обучающих документов содержит N документов, наиболее релевантных первому обучающему запросу. Второе множество обучающих документов содержит M документов, наиболее релевантных второму обучающему запросу. Метка указывает на то, что первая обучающая строка подобна второй обучающей строке, если в первом множестве обучающих документов и во втором множестве обучающих документов содержится по меньшей мере заранее заданное количество одинаковых обучающих документов.
[028] В некоторых вариантах осуществления сервера N документов, наиболее релевантных первому обучающему запросу, и M документов, наиболее релевантных второму обучающему запросу, определяются поисковой системой в автономном режиме до обучения второй модели.
[029] В некоторых вариантах осуществления сервера первая модель представляет собой модель ранжирования, способную формировать ранжированный список строк-кандидатов, а первая строка-кандидат и вторая строка-кандидат ранжируются в ранжированном списке строк-кандидатов. При этом способность сервера к инициированию включает в себя способность к инициированию отображения на электронном устройстве в качестве расширенного запроса строки-кандидата с бóльшим рангом из числа первой строки-кандидата и второй строки-кандидата.
[030] В некоторых вариантах осуществления сервера первая модель представляет собой модель DSSM.
[031] В некоторых вариантах осуществления сервера вторая модель представляет собой модель DSSM.
[032] В некоторых вариантах осуществления сервера расширенный запрос представляет собой дополненный запрос, содержащий запрос. При этом способность сервера к инициированию включает в себя способность к инициированию отображения на электронном устройстве дополненного запроса без отображения страницы SERP, соответствующей запросу.
[033] В некоторых вариантах осуществления сервера расширенный запрос представляет собой переформулированный запрос. При этом способность сервера к инициированию включает в себя способность к инициированию отображения на электронном устройстве страницы SERP, соответствующей запросу и содержащей часть с переформулированным запросом.
[034] В некоторых вариантах осуществления сервера расширенный запрос представляет собой дополненный запрос, содержащий запрос. При этом способность сервера к инициированию включает в себя способность к инициированию отображения на электронном устройстве страницы SERP, соответствующей запросу и содержащей часть с переформулированным запросом.
[035] В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, из устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему, что не существенно для настоящей технологии. В настоящем контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая конкретная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
[036] В контексте настоящего описания термин «устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что устройство, функционирующее как устройство согласно данному контексту, также может функционировать как сервер для других устройств. Использование термина «устройство» не исключает использования нескольких устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо последовательностей любых задач, запросов или шагов любого описанного здесь способа.
[037] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, где реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
[038] В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д., но не ограничивается ими.
[039] В контексте настоящего описания выражение «компонент» включает в себя обозначение программного обеспечения (подходящего для определенных аппаратных средств), необходимого и достаточного для выполнения определенной функции или нескольких функций.
[040] В контексте настоящего описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого рода и вида, включая оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
[041] В контексте настоящего описания числительные «первый», «второй», «третий» и т.д. используются лишь для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает наличие «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента в действительности могут быть одним и тем же элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - различные программные и/или аппаратные средства.
[042] Каждый вариант осуществления настоящей технологии относится к по меньшей мере одной из вышеупомянутых целей и/или аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
[043] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления настоящей технологии содержатся в дальнейшем описании, на приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[044] Дальнейшее описание приведено для лучшего понимания настоящей технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
[045] На фиг. 1 приведена схема системы, пригодной для реализации не имеющих ограничительного характера вариантов осуществления настоящей технологии.
[046] На фиг. 2 приведены три разных представления окна браузера браузерного приложения пользовательского устройства системы, представленной на фиг. 1, согласно некоторым вариантам осуществления настоящей технологии.
[047] На фиг. 3 приведено представление процесса, используемого сервером системы, представленной на фиг. 1, для формирования списка расширенных запросов согласно некоторым вариантам осуществления настоящей технологии.
[048] На фиг. 4 приведено представление одной итерации обучения модели машинного обучения, используемой в процессе, представленном на фиг. 3, для определения того, является ли пара строк-кандидатов парой схожих строк-кандидатов, согласно некоторым вариантам осуществления настоящей технологии.
[049] На фиг. 5 приведено представление процесса, используемого сервером системы, представленной на фиг. 1, для формирования списка расширенных запросов согласно другим вариантам осуществления настоящей технологии.
[050] На фиг. 6 приведена блок-схема способа, выполняемого сервером, представленным на фиг. 1, согласно некоторым вариантам осуществления настоящей технологии.
Осуществление изобретения
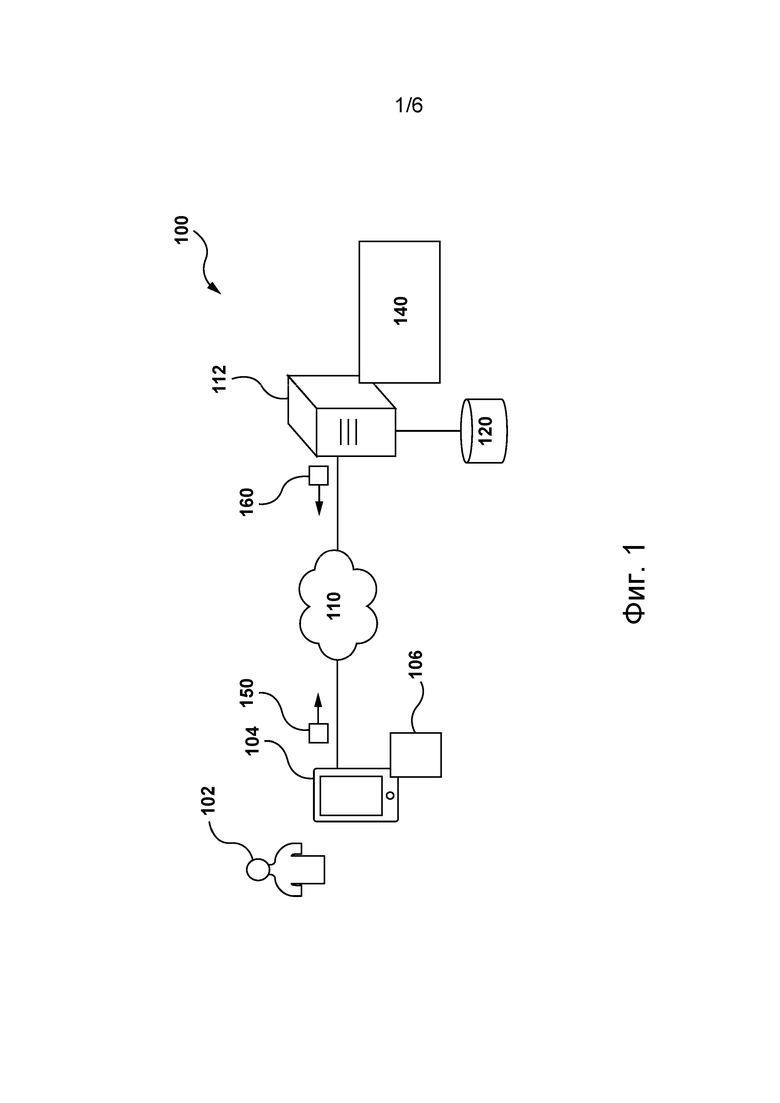
[051] На фиг. 1 представлена схема системы 100, пригодной для реализации не имеющих ограничительного характера вариантов осуществления настоящей технологии. Очевидно, что система 100 приведена лишь для демонстрации варианта реализации настоящей технологии. Таким образом, дальнейшее описание системы представляет собой описание примеров, иллюстрирующих настоящую технологию. Это описание не предназначено для определения объема или границ настоящей технологии. В некоторых случаях приводятся полезные примеры модификаций системы 100. Они способствуют пониманию, но также не определяют объема или границ настоящей технологии. Эти модификации не составляют исчерпывающего перечня. Как должно быть понятно специалисту в данной области, вероятно, возможны и другие модификации. Кроме того, если в некоторых случаях модификации не описаны (т.е. примеры модификаций отсутствуют), это не означает, что они невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии. Специалисту в данной области должно быть понятно, что это не обязательно. Кроме того, следует понимать, что система 100 в некоторых случаях может представлять собой упрощенную реализацию настоящей технологии и что такие варианты представлены для того, чтобы способствовать лучшему ее пониманию. Специалистам в данной области должно быть понятно, что другие варианты осуществления настоящей технологии могут быть значительно сложнее.
[052] В общем случае система 100 способна предоставлять результаты поиска устройству 104 для их отображения пользователю 102 в ответ на запросы, отправленные пользователем 102. Система 100 содержит устройство 104, связанное с пользователем 102. Устройство 104 иногда может называться электронным устройством, оконечным устройством, клиентским электронным устройством или просто устройством. Следует отметить, что связь электронного устройства 104 с пользователем 102 не означает необходимости предлагать или подразумевать какой-либо режим работы, например, вход в систему, регистрацию и т.п.
[053] На реализацию устройства 104 не накладывается каких-либо особых ограничений. Например, устройство 104 может быть реализовано как персональный компьютер (настольный, ноутбук, нетбук и т.д.), беспроводное устройство связи (смартфон, сотовый телефон, планшет и т.д.) или как сетевое оборудование (маршрутизатор, коммутатор, шлюз и т.д.). Устройство 104 содержит известные в данной области техники аппаратные средства и/или прикладное программное обеспечение и/или встроенное программное обеспечение (либо их сочетание) для выполнения браузерного приложения 106. Браузерное приложение 106 обеспечивает пользователю 102 доступ к одному или нескольким веб-ресурсам. На реализацию браузерного приложения 106 не накладывается каких-либо особых ограничений. Например, браузерное приложение 106 может быть реализовано в виде браузера Yandex™.
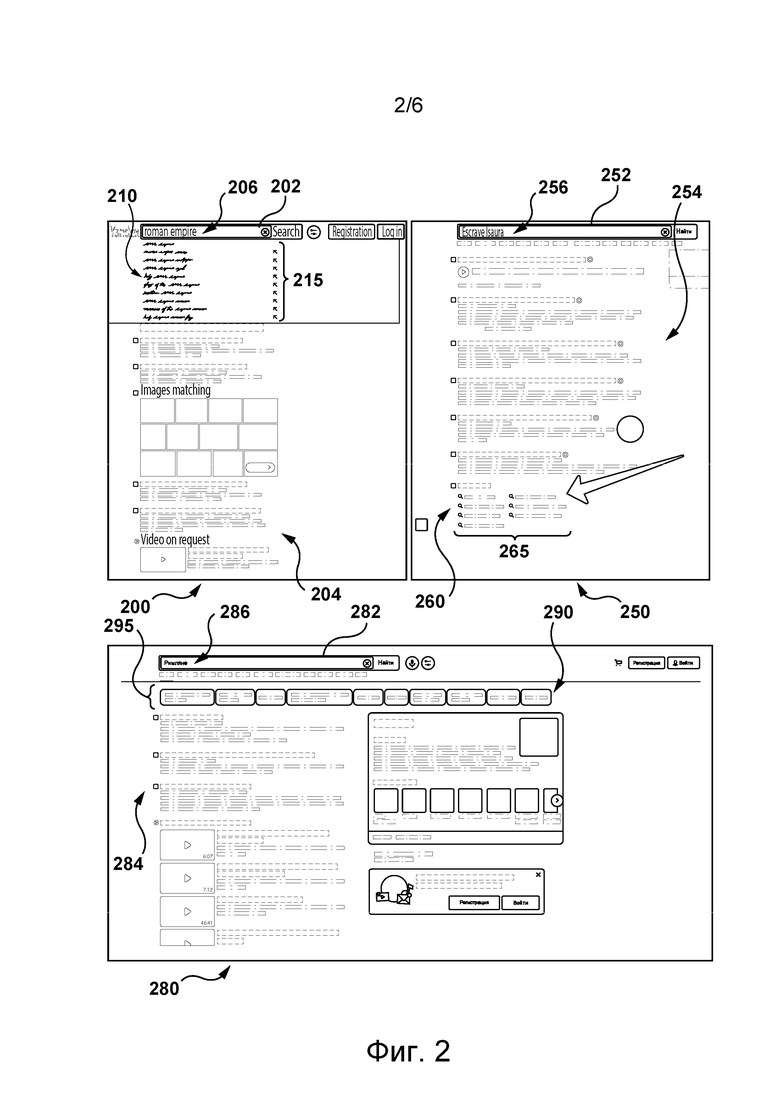
[054] На фиг. 2 приведены три представления 200, 250 и 280 окна браузера (без числового обозначения) браузерного приложения 106, отображаемого устройством 104 пользователю 102, в различных вариантах осуществления настоящей технологии. Каждое представление 200, 250 и 280 окна браузера содержит соответствующую строку поиска. Например, первое представление 200 содержит строку 202 поиска, второе представление 250 содержит строку 252 поиска, третье представление 280 содержит строку 282 поиска.
[055] Следует отметить, что строка поиска позволяет пользователю 102 печатать (или вводить) и отправлять запросы для поиска конкретной информации. Например, пользователь 102 может с помощью строки поиска отправлять запрос, который может передаваться устройством 104 поисковой системе для поиска конкретной информации, связанной с этим запросом. В результате устройство 104 может, среди прочего, получать эту конкретную информацию и отображать ее пользователю 102 на странице SERP в окне браузера.
[056] Предполагается, что строка поиска может быть реализована в виде омнибокса браузерного приложения 106 без выхода за границы настоящей технологии. Иными словами, функции описанной здесь строки поиска могут быть реализованы с использованием омнибокса браузерного приложения 106.
[057] В некоторых вариантах осуществления настоящей технологии, как показано в представлении 200, строка 202 поиска обеспечивает функции расширения запроса и, таким образом, позволяет передавать частичный запрос, когда пользователь 102 не напечатал полностью (или не ввел полностью) желательный пользовательский запрос в строке 202 поиска, для приема в ответ предлагаемых вариантов расширения запроса.
[058] Как показано в представлении 200, окно браузера содержит множество 204 результатов поиска, предоставленных пользователю 102 в ответ на предыдущий запрос, отправленный пользователем 102. Пусть пользователь 102 намеревается отправить поисковой системе новый запрос. Для этого пользователь 102 начинает вводить новый частичный запрос 206. Пока пользователь 102 вводит новый частичный запрос 206, пользователю 102 отображается меню 210 предлагаемых вариантов расширения запроса, содержащее множество 215 предлагаемых вариантов расширения.
[059] Можно сказать, что множество 215 предлагаемых вариантов расширения содержит расширенные версии нового частичного запроса 206, поскольку предлагаемые варианты расширения содержат новый частичный запрос 206 и один или несколько дополнительных терминов, которые, в определенном смысле, расширяют новый частичный запрос 206. Предполагается, что множество 215 предлагаемых вариантов расширения может содержать один или несколько дополнительных терминов, расположенных до терминов нового частичного запроса 206, после них и/или между ними.
[060] Пользователь 102 может выбрать один вариант из множества 215 предлагаемых вариантов расширения в качестве нового запроса для отправки поисковой системе. Предполагается, что меню 210 предлагаемых вариантов расширения запроса может представлять собой временное меню, которое отображается пользователю 102, пока пользователь 102 вводит новый частичный запрос 206, и может обновляться в реальном времени с использованием различных предлагаемых вариантов расширения по мере ввода пользователем 102 дополнительных терминов.
[061] В других вариантах осуществления настоящей технологии, как показано в представлении 250, в нижней части страницы SERP, отображаемой пользователю 102 в окне браузера, может располагаться меню 260 подсказок. Например, в ответ на отправленный пользователем 102 запрос 256 пользователю 102 может отображаться множество 254 результатов поиска. Если пользователь 102 не удовлетворен множеством 254 результатов поиска, он может выбрать подсказку из множества подсказок 265, отображаемых в меню 260 подсказок, для выполнения нового поиска с использованием выбранной подсказки в качестве нового запроса.
[062] Можно сказать, что множество подсказок 265 представляет собой переформулированные запросы, которые могут содержать или не содержать один или несколько терминов из запроса 256. Подсказка из множества подсказок 265 обеспечивает пользователю 102 возможность удобного запуска нового поиска при попытке удовлетворить потребности пользователя 102 в поиске, если пользователь 102 не удовлетворен одним или несколькими результатами из множества 254 результатов поиска. Отображаемые подсказки 265 содержат список потенциальных новых запросов в нижней части текущей страницы SERP, которые пользователь 102 может использовать для начала нового поиска после ознакомления со множеством 254 результатов поиска.
[063] В других вариантах осуществления настоящей технологии, как показано в представлении 280, в верхней части страницы SERP, отображаемой пользователю 102 в окне браузера, может располагаться множество активируемых значков 290. Например, в ответ на отправленный пользователем 102 запрос 286 пользователю 102 может отображаться множество 284 результатов поиска. Если пользователь 102 не удовлетворен одним или несколькими результатами из множества 284 результатов поиска, то пользователь 102 может выбрать запрос из множества 295 дополнительных запросов, отображаемых на множестве активируемых значков 290, для выполнения дополнительного поиска для выбранного дополнительного запроса.
[064] Можно сказать, что множество 295 дополнительных запросов представляет собой переформулированные запросы, которые могут содержать или не содержать один или несколько терминов из запроса 286. Запрос из множества 295 дополнительных запросов обеспечивает пользователю 102 возможность удобного запуска дополнительного поиска при попытке удовлетворить потребности пользователя 102 в поиске, если пользователь 102 не удовлетворен одним или несколькими результатами из множества 284 результатов поиска. В верхней части текущей страницы SERP отображается множество активируемых значков 290, которые пользователь 102 может выбирать для запуска дополнительного поиска.
[065] В контексте настоящей технологии пользователю 102 отображается один или несколько расширенных запросов для удовлетворения потребностей пользователя 102 в поиске. В некоторых вариантах осуществления изобретения расширенный запрос может представлять собой предлагаемый вариант завершения запроса, такой как вариант из множества 215 предлагаемых вариантов завершения. В других вариантах осуществления изобретения расширенный запрос может представлять собой подсказку относительно запроса, такую как подсказка из множества подсказок 265. В других вариантах осуществления изобретения расширенный запрос может представлять собой дополнительный запрос, такой как запрос из множества 295 дополнительных запросов. Ниже более подробно описано формирование и отображение для пользователя 102 расширенного запроса системой 100.
[066] Представленное на фиг. 1 устройство 104 соединено с сетью 110 связи для доступа к серверу 112 и/или к другим веб-ресурсам (не показаны). В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в качестве сети 110 связи может использоваться сеть Интернет. В других не имеющих ограничительного характера вариантах осуществления данной технологии сеть 110 связи может быть реализована иначе, например, в виде любой глобальной сети связи, локальной сети связи, частной сети связи и т.п. Реализация линии связи (без числового обозначения) между устройством 104 и сетью 110 связи зависит, среди прочего, от реализации устройства 104.
[067] Лишь в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления настоящей технологии, где устройство 104 реализовано как беспроводное устройство связи (такое как смартфон), линия связи может быть реализована как беспроводная линия связи (такая как канал сети связи 3G, канал сети связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.). В тех примерах, где устройство 104 реализовано как ноутбук, линия связи может быть беспроводной (такой как Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.д.) или проводной (такой как соединение на основе Ethernet).
[068] Сервер 112 может быть реализован в виде традиционного компьютерного сервера. В примере осуществления настоящей технологии сервер 112 может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сервер 112 может быть реализован с использованием любых других подходящих аппаратных средств, прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 112 представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 112 могут быть распределены между несколькими серверами.
[069] В целом, сервер 112 может управляться и/или администрироваться поставщиком услуг поисковой системы (не показан), таким как оператор поисковой системы Yandex™. В общем случае поисковая система представляет собой компьютерную систему, предназначенную для выполнения веб-поисков. Систематический поиск конкретной информации, указанной в запросе на веб-поиск, выполняется в сети Интернет. Результаты поиска обычно представляются в ранжированном виде и часто называются страницами SERP. Информация может представлять собой сочетание ссылок на веб-страницы, изображения, видеоматериалы, инфографику, статьи, научные работы и файлы других видов. Некоторые поисковые системы также извлекают данные, доступные в базах данных или открытых каталогах. Как известно в данной области техники, поисковые системы могут поддерживать обновление информации о веб-документах путем выполнения алгоритма обхода веб-ресурсов. На сервере 112 размещена поисковая система 140, связанная со строкой поиска и/или с браузерным приложением 106 (см. фиг. 1). Таким образом, сервер 112 способен выполнять один или несколько поисков, соответствующих желательным пользовательским запросам, отправленным с использованием строки поиска и/или браузерного приложения 106.
[070] Сервер 112 может получать данные от электронного устройства 104 с использованием пакета 150 данных запроса и отправлять данные электронному устройству с использованием пакета 160 данных ответа. Например, пакет 150 данных запроса может содержать информацию, указывающую на запрос, отправленный пользователем 102, и/или на частичный запрос, вводимый в текущий момент времени пользователем 102. В том же примере пакет 160 данных ответа может содержать информацию, указывающую на один или несколько расширенных запросов для пользователя 102 и/или на один или несколько результатов поиска, соответствующих отправленному запросу, и информацию для отображения одного или нескольких расширенных запросов и/или одного или нескольких результатов поиска в браузерном приложении 106.
[071] Сервер 112 связан с базой 120 данных. База 120 данных может быть реализована в одной базе данных. База 120 данных может быть разделена на несколько распределенных хранилищ данных. В целом, база 120 данных способна получать с сервера 112 данные, которые были получены либо иным образом определены или сформированы сервером 112 во время обработки, для временного и/или постоянного хранения и выдавать сохраненные данные серверу 112 для их использования.
[072] Как более подробно описано далее, сервер 112 способен использовать архивную информацию, собранную из большого количества прошлых пользовательских запросов. Таким образом, база 120 данных может хранить информацию, связанную с переданными серверу 112 прошлыми пользовательскими запросами. Иными словами, база 120 данных может содержать одну или несколько коллекций данных, относящихся к прошлым пользовательским запросам, которые пользователь 102 и/или другие пользователи поисковой системы ранее отправляли серверу 112.
[073] Сервер 112 способен предоставлять результаты поиска после получения желательного пользовательского запроса. Таким образом, база 120 данных может хранить информацию, связанную с по меньшей мере некоторыми возможными результатами поиска, которые сервер 112 способен предоставлять после получения желательных пользовательских запросов. На виды результатов поиска не накладывается каких-либо особых ограничений. Достаточно указать, что сервер 112 может получать набор результатов поиска из базы 120 данных для запроса, отправленного серверу 112 пользователем 102 устройства 104 (или любым другим пользователем поисковой системы), а также может предоставлять набор результатов поиска устройству 104 для их отображения пользователю 102 (или любому другому пользователю поисковой системы).
[074] Предполагается, что база 120 данных может содержать инвертированный индекс, связанный с поисковой системой 140. В общем случае инвертированный индекс содержит большое количество списков вхождений и представляет собой индекс базы данных, в котором хранятся данные о сопоставлении контента, такого как слова или числа, с соответствующими местоположениями в таблице или в документе либо в наборе документов. Инвертированный индекс позволяет быстрее получать результаты поиска в ответ на запрос. Инвертированные индексы представляют собой популярные структуры данных, используемые в системах поиска документов, в частности, в поисковых системах.
[075] Сервер 112 способен реализовывать один или несколько алгоритмов машинного обучения (MLA, Machine Learning Algorithm) для выполнения одной или нескольких функций поисковой системы 140. В общем случае алгоритмы MLA способны обучаться и осуществлять прогнозирование на основе данных. Алгоритмы MLA обычно используются для первоначального построения модели на основе обучающих входных данных, чтобы затем на основе данных формировать прогнозы или решения, выраженные в виде выходных данных, а не выполнять статические машиночитаемые команды. В данной области техники известны алгоритмы MLA различных видов с различными структурами или топологиями.
[076] Одна группа алгоритмов MLA содержит нейронные сети (NN, Neural Network). В общем случае сеть NN состоит из взаимосвязанных групп искусственных «нейронов», которые обрабатывают информацию с использованием коннекционного подхода к вычислениям. Сети NN используются для моделирования сложных взаимосвязей между входными и выходными данными (без фактической информации о взаимосвязях) или для поиска закономерностей в данных. Сети NN сначала адаптируются на этапе обучения, когда они обеспечиваются известным набором входных данных и информацией для адаптации сети NN, с целью формирования соответствующих выходных данных (для ситуации, в отношении которой выполняется попытка моделирования). На этапе обучения сеть NN адаптируется к изучаемой ситуации и изменяет свою структуру так, чтобы обеспечивать адекватные предсказанные выходные данные для входных данных в новой ситуации (на основе того, что было выучено). Таким образом, вместо попытки определения сложных статистических распределений или математических алгоритмов для ситуации сеть NN пытается предоставить «интуитивный» ответ на основе «восприятия» ситуации. Таким образом, сеть NN представляет собой своего рода обученный черный ящик, который может быть использован в ситуациях, когда содержимое ящика не имеет значения, а важно лишь то, что этот ящик предоставляет адекватные ответы для входных данных. Сети NN широко используются во многих таких ситуациях, где важно получать выходные данные на основе входных данных, и менее важна или вовсе неважна информация о том, как получаются выходные данные.
[077] Вкратце можно сказать, что реализация алгоритма MLA может быть разделена на два основных этапа: этап обучения и этап использования. Сначала алгоритм MLA обучается на этапе обучения. Затем, когда алгоритму MLA известно, какие предполагаются входные данные и какие должны выдаваться выходные данные, этот алгоритм MLA выполняется с реальными данными на этапе использования.
[078] В контексте настоящей технологии сервер 112 способен использовать один или несколько алгоритмов MLA с целью формирования расширенных запросов для пользователей поисковой системы 140. В некоторых вариантах осуществления настоящей технологии сервер 112 способен формировать расширенный запрос для пользователя 102 согласно описанию, проиллюстрированному на фиг. 3 и 4. В других вариантах осуществления настоящей технологии сервер 112 способен формировать расширенный запрос для пользователя 102 согласно описанию, проиллюстрированному на фиг. 5.
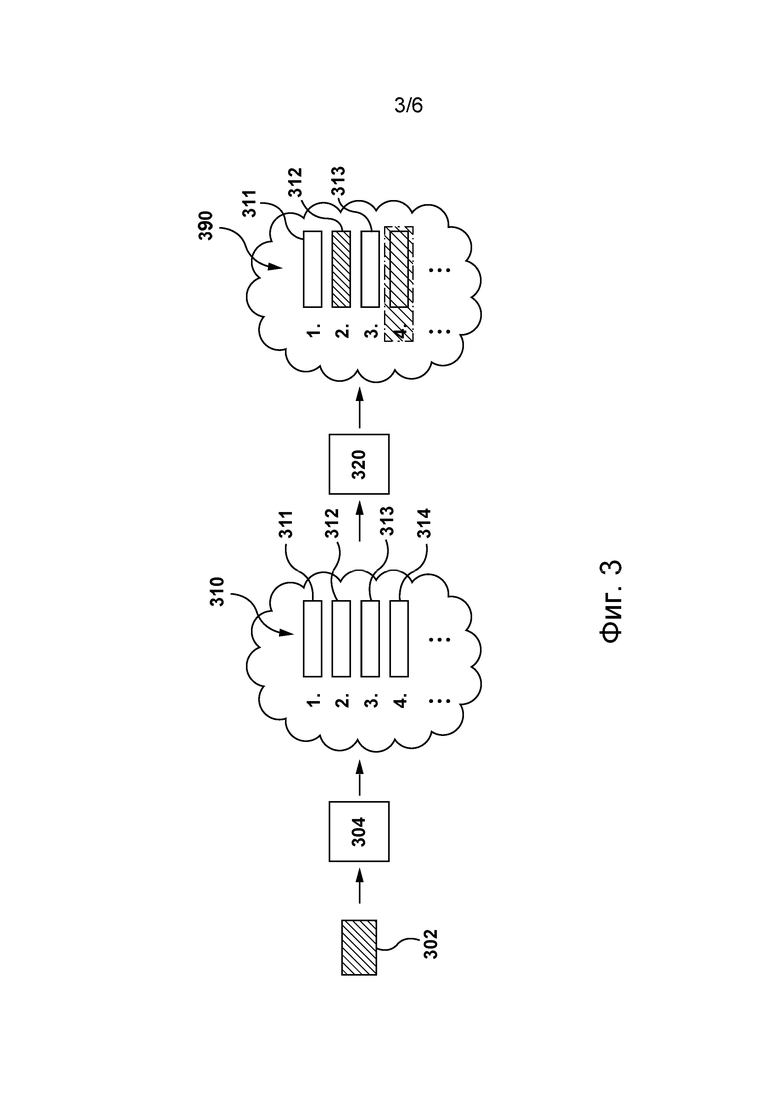
[079] На фиг. 3 приведено представление процесса, используемого сервером 112, способным формировать список 390 расширенных запросов для пользователя 102, в некоторых вариантах осуществления настоящей технологии. В этих вариантах осуществления изобретения сервер 112 способен выполнять первую модель 304 и вторую модель 320. Первая модель 304 и вторая модель 320 могут быть реализованы в виде соответствующих алгоритмов MLA. В по меньшей мере одном варианте осуществления изобретения первая модель 304 и вторая модель 320 могут быть реализованы в виде соответствующих углубленных структурированных семантических моделей (DSSM, Deep Structured Semantic Model).
[080] В общем случае модель DSSM, которая также называется углубленной моделью семантического сходства (Deep Semantic Similarity Model), представляет собой глубокую нейронную сеть (DNN, Deep Neural Network), используемую для представления текстовых строк (предложений, запросов, предикатов, упоминаний об объектах и т.д.) в непрерывном семантическом пространстве и для моделирования семантического сходства двух текстовых строк (например, в виде Sent2Vec). Модели DSSM применяются в разных областях, включая ранжирование результатов информационного поиска и веб-поиска, выбор или определение релевантности рекламных объявлений, контекстный поиск объектов, формулирование знаний, снабжение изображений субтитрами и машинный перевод.
[081] Сервер 112 способен получать данные 302 запроса, связанные с запросом пользователя 102. В некоторых вариантах осуществления изобретения данные 302 запроса могут указывать на текущий запрос, отправленный пользователем 102. В других вариантах осуществления изобретения данные 302 запроса могут, например, указывать на частичный запрос, который пользователь в текущий момент времени вводит в строке поиска.
[082] В некоторых вариантах осуществления настоящей технологии данные 302 запроса могут содержать текстовую строку, представляющую собой пользовательский запрос и/или частичный пользовательский запрос. Предполагается, что данные запроса могут содержать один или несколько дополнительных признаков, связанных с пользовательским запросом и/или с частичным пользовательским запросом. Например, сервер 112 способен обращаться к базе 120 данных и получать информацию, хранящуюся в сочетании с пользовательским запросом и/или с частичным пользовательским запросом. Таким образом, сервер 112 способен получать данные предыстории, например, связанные с пользовательским запросом и/или с частичным пользовательским запросом, и использовать их в качестве одного или нескольких дополнительных признаков в данных 302 запроса.
[083] Первая модель 304, выполняемая сервером 112, может использовать данные 302 запроса для формирования списка 310 строк-кандидатов. Например, список 310 строк-кандидатов содержит строки-кандидаты 311, 312, 313 и 314. Строка-кандидат из списка является соответствующим кандидатом для расширенного запроса, подлежащего предоставлению пользователю 102. В некоторых вариантах осуществления настоящей технологии строки в списке 310 строк-кандидатов могут быть взаимно упорядочены, т.е. список 310 строк-кандидатов может представлять собой ранжированный список, в котором строка-кандидат связана с соответствующим рангом в этом ранжированном списке.
[084] В по меньшей мере некоторых вариантах осуществления настоящей технологии сервер 112 способен обучать и использовать первую модель 304 подобно тому, как описано в патенте этого же заявителя US10846340 «Method and server for predicting a query-completion suggestion for a partial user-entered query» (выдан 24.11.2020), содержание которого полностью включено в настоящий документ посредством ссылки.
[085] Сформировав список 310 строк-кандидатов с помощью первой модели 304, сервер 112 может использовать вторую модель 320. Вторая модель 320 предназначена для определения схожих строк-кандидатов из списка 310 строк-кандидатов. Иными словами, сервер 112 может использовать вторую модель 320 для определения пар схожих строк-кандидатов из списка 310 строк-кандидатов. Сервер 112 может использовать эту информацию, чтобы исключать из списка 390 строк-кандидатов своего рода «дубликаты» (или с точки зрения семантики «приблизительные дубликаты» в результатах поиска, формируемых для строки-кандидата из списка 310 строк-кандидатов) так, чтобы пользователю 102 в качестве расширенного запроса предоставлялась лишь одна строка из соответствующей пары схожих строк-кандидатов.
[086] В представленном на фиг. 3 не имеющем ограничительного характера примере сервер 112 может использовать вторую модель 320 для определения того, что строки-кандидаты 312 и 314 представляют собой пару схожих строк. В этом случае сервер 112 способен исключать строку из пары схожих строк из списка 390 расширенных запросов, предоставляемых пользователю 102.
[087] Разработчики настоящей технологии установили, что сходство пары строк-кандидатов может быть определено на основе степени сходства результатов поиска, получаемых в случае их использования в качестве запросов. Иными словами, в некоторых вариантах осуществления изобретения разработчики настоящей технологии разработали способы и серверы, использующие сходство результатов поиска в качестве заменяющего признака для определения сходства соответствующей пары строк-кандидатов.
[088] Можно сказать, что сервер 112 может использовать вторую модель 320 для удаления дубликатов строк-кандидатов из списка 310 строк-кандидатов таким образом, чтобы расширенные запросы, предоставляемые пользователю 102, обеспечивали более разнообразные результаты поиска для пользователя 102. Благодаря такому удалению дубликатов строк-кандидатов при определении расширенных запросов, вероятность удовлетворения потребностей пользователя 102 в поиске может быть увеличена за счет по меньшей мере одного из расширенных запросов вследствие разнообразия соответствующих результатов поиска.
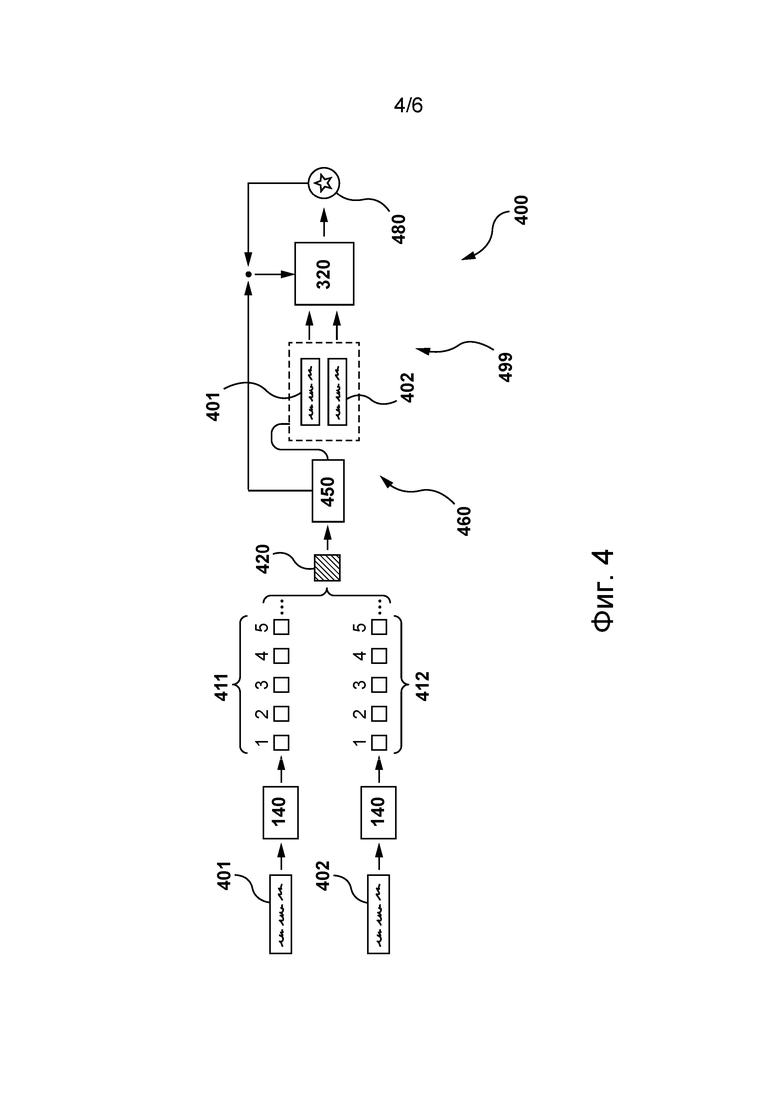
[089] Ниже со ссылкой на фиг. 4 описано обучение сервером 112 второй модели 320 для определения пар схожих строк-кандидатов. При этом представлена одна итерация 499 обучения второй модели 320 на основе обучающего набора 460. Следует отметить, что сервер 112 способен обучать вторую модель 320 в автономном режиме. Можно сказать, что сервер 112 способен обучать вторую модель 320 до ее использования для определения строк-кандидатов из списка 310 строк кандидатов, представляющих собой схожие строки-кандидаты. Также следует отметить, что, несмотря на то, что на фиг. 4 представлена лишь одна итерация 499 обучения, на этапе обучения второй модели 320 сервером 112 в отношении второй модели 320 может быть выполнено большое количество итераций обучения, подобных одной итерации 499 обучения.
[090] Как описано выше, вторая модель 320 обучается на основе обучающего набора 460, содержащего пару (без числового обозначения) обучающих строк, включая первую обучающую строку 401, вторую обучающую строку 402 и метку 450. Можно сказать, что вторая модель 320 обучается в парной конфигурации на основе пары обучающих строк и соответствующей метки.
[091] Перед выполнением одной итерации 499 обучения сервер 112 способен формировать и сохранять обучающий набор 460. С этой целью сервер 112 может получать первую обучающую строку 401 и вторую обучающую строку 402 из базы 120 данных. Сервер 112 способен использовать поисковую систему 140 для формирования первого множества 411 результатов поиска для первой обучающей строки 401 (используется в качестве запроса) и для формирования второго множества 412 результатов поиска для второй обучающей строки 402 (используется в качестве запроса).
[092] В других вариантах осуществления изобретения в базе 120 данных может храниться множество предыдущих результатов поиска, сформированных для первой обучающей строки 401, и множество предыдущих результатов поиска, сформированных для второй обучающей строки 402. В этих вариантах осуществления изобретения сервер 112 способен вместо формирования первого множества 411 результатов поиска и второго множества 412 результатов поиска в процессе формирования обучающего набора получать из базы 120 данных множество предыдущих результатов поиска для первой обучающей строки 401 и для второй обучающей строки 402, соответственно.
[093] Результаты поиска из первого множества 411 результатов поиска и из второго множества 412 результатов поиска могут быть представлены в различном виде. Можно сказать, что результат поиска представляет собой цифровой документ, релевантный соответствующей обучающей строке. Например, цифровой документ может представлять собой веб-страницу, цифровое изображение, новостную статью и т.п.
[094] Сервер 112 способен сравнивать первое множество 411 результатов поиска со вторым множеством 412 результатов поиска. В некоторых вариантах осуществления изобретения сервер 112 может выполнять функцию 420 сравнения первого множества 411 результатов поиска и второго множества 412 результатов поиска с целью формирования метки 450 для пары, состоящей из первой обучающей строки 401 и второй обучающей строки 402.
[095] В некоторых вариантах осуществления изобретения функция 420 сравнения может определять, совпадают ли N результатов поиска с наибольшим рангом из первого множества 411 результатов поиска с N результатами поиска с наибольшим рангом из второго множества 412 результатов поиска. Если N результатов поиска с наибольшим рангом совпадают, то сервер 112 может определять, что первая обучающая строка 401 и вторая обучающая строка 402 представляют собой пару схожих обучающих строк.
[096] В других вариантах осуществления изобретения первое множество 411 результатов поиска содержит N наиболее релевантных первой обучающей строке 401 документов, а второе множество 412 результатов поиска содержит M документов, наиболее релевантных второй обучающей строке 402. В этих вариантах осуществления изобретения функция 420 сравнения может определять, что первая обучающая строка 401 схожа со второй обучающей строкой 402, если в первом множестве 411 результатов поиска и во втором множестве 412 результатов поиска содержится по меньшей мере заранее заданное количество одинаковых результатов поиска и/или заранее заданное количество одинаковых результатов поиска с наибольшим рангом.
[097] В других вариантах осуществления изобретения сервер 112 способен сравнивать наиболее релевантный результат поиска из первого множества 411 результатов поиска с наиболее релевантным результатом поиска из второго множества 412 результатов поиска для определения их совпадения (одинакового результата поиска).
[098] Пусть в одном варианте осуществления изобретения три результата поиска с наибольшим рангом из первого множества 411 результатов поиска совпадают с тремя результатами поиска с наибольшим рангом из второго множества 412 результатов поиска. В этом варианте осуществления изобретения сервер 112 может определить, что первая обучающая строка 401 и вторая обучающая строка 402 представляют собой пару схожих строк. Таким образом сервер может сформировать метку 450 для пары обучающих строк, указывающую на то, что они представляют собой пару схожих обучающих строк.
[099] Сервер 112 способен сохранять сформированный таким образом обучающий набор 460 в базе 120 данных. Сервер 112 может сохранять большое количество сформированных таким образом обучающих наборов, основываясь на соответствующих парах обучающих строк и путем анализа соответствующих результатов поиска с целью определения того, являются соответствующие пары обучающих строк парами схожих обучающих строк или парами несхожих обучающих строк. Следует отметить, что количество результатов поиска, которые должны совпадать в первом множестве 411 результатов поиска и во втором множестве 412 результатов поиска для определения того, что пара обучающих строк представляет собой пару схожих строк, может, среди прочего, зависеть от конкретных вариантов реализации настоящей технологии. Независимо от конкретной функции сравнения, используемой сервером 112 для формирования метки 450, можно сказать, что сервер 112 способен на основе совпадения (или частичного совпадения) наиболее релевантного результата (или результатов) поиска определять схожесть обучающих строк в паре для каждой пары обучающих строк.
[0100] Во время одной итерации 499 обучения сервер 112 может вводить первую обучающую строку 401 и вторую обучающую строку 402 во вторую модель 320.
[0101] В некоторых вариантах осуществления изобретения вторая модель 320 может быть обучена прогнозированию вероятности схожести первой обучающей строки 401 и второй обучающей строки 402 (например, с применением регрессии). В этих вариантах осуществления изобретения выходное значение 480 может указывать на вероятность того, что первая обучающая строка 401 схожа со второй обучающей строкой 402. Сервер 112 может применять штрафную функцию (не показана) для сравнения метки 450 с выходным значением 480. В этих вариантах осуществления изобретения метка 450 может соответствовать значению 0, например, указывающему на несхожую пару, или значению 1, например, указывающему на схожую пару. В этих вариантах осуществления изобретения выходное значение может представлять собой непрерывное значение в диапазоне между 0 и 1. Сервер 112 может использовать один или несколько способов машинного обучения, чтобы, в определенном смысле, корректировать вторую модель 320 для формирования лучшего прогноза в будущем. Например, сервер 112 может использовать способ обратного распространения на основе сравнения метки 450 и выходного значения 480.
[0102] В других вариантах осуществления изобретения вторая модель 320 может быть обучена прогнозированию схожести первой обучающей строки 401 и второй обучающей строки 402 (например, с применением классификации). Сервер 112 может применять штрафную функцию (не показана) для сравнения метки 450 с выходным значением 480. В этих вариантах осуществления изобретения выходное значение 480 может указывать на прогнозируемый класс для пары обучающих строк, например, такой как класс «схожие» или класс «несхожие». В этих вариантах осуществления изобретения метка 450 может указывать на контрольный класс для пары. Сервер 112 может использовать один или несколько способов машинного обучения, чтобы, в определенном смысле, корректировать вторую модель 320 для формирования лучшего прогноза. Например, сервер 112 может использовать способ обратного распространения на основе сравнения метки 450 и выходного значения 480.
[0103] Обучив таким образом вторую модель 320, сервер 112 может использовать ее в реальном времени для предоставления одного или нескольких расширенных запросов пользователю 102. Сервер 112 может вводить соответствующие пары строк-кандидатов из списка 310 строк-кандидатов во вторую модель 320 (см. фиг. 3). Вторая модель 320 способна для каждой введенной пары строк-кандидатов определять, является ли введенная пара парой схожих строк.
[0104] Пусть сервер 112 вводит строку-кандидата 312 и строку-кандидата 314 во вторую модель 320 и вторая модель 320 определяет, что строка-кандидат 312 и строка-кандидат 314 представляют собой пару схожих строк. В этом случае сервер 112 способен исключать строку-кандидата 312 или строку-кандидата 314 из списка 390 расширенных запросов.
[0105] В тех вариантах осуществления изобретения, где список 310 строк-кандидатов представляет собой ранжированный список строк-кандидатов, сервер 112 может исключать из пары схожих строк строку-кандидата с рангом меньшим, чем у другой строки-кандидата в этой паре. Таким образом, в представленном на фиг. 3 не имеющем ограничительного характера примере сервер 112 может исключить строку-кандидата 314 из списка 390 расширенных запросов, которые могут быть предоставлены пользователю 102.
[0106] Вкратце, вторая модель 320 может быть обучена в автономном режиме на основе множества обучающих наборов. Обучающие наборы могут быть сформированы и сохранены заранее, а затем могут быть использованы для обучения второй модели 320 в автономном режиме. Можно сказать, что вторая модель 320 может быть обучена до получения данных 302 запроса и может применяться сервером 112 на этапе ее использования после формирования списка 310 строк-кандидатов. Иными словами, в этих вариантах осуществления изобретения серверу 112 не требуется фактически определять множество результатов поиска для соответствующих строк-кандидатов из списка 310 строк-кандидатов при определении того, являются соответствующие пары строк-кандидатов парами схожих строк-кандидатов или нет.
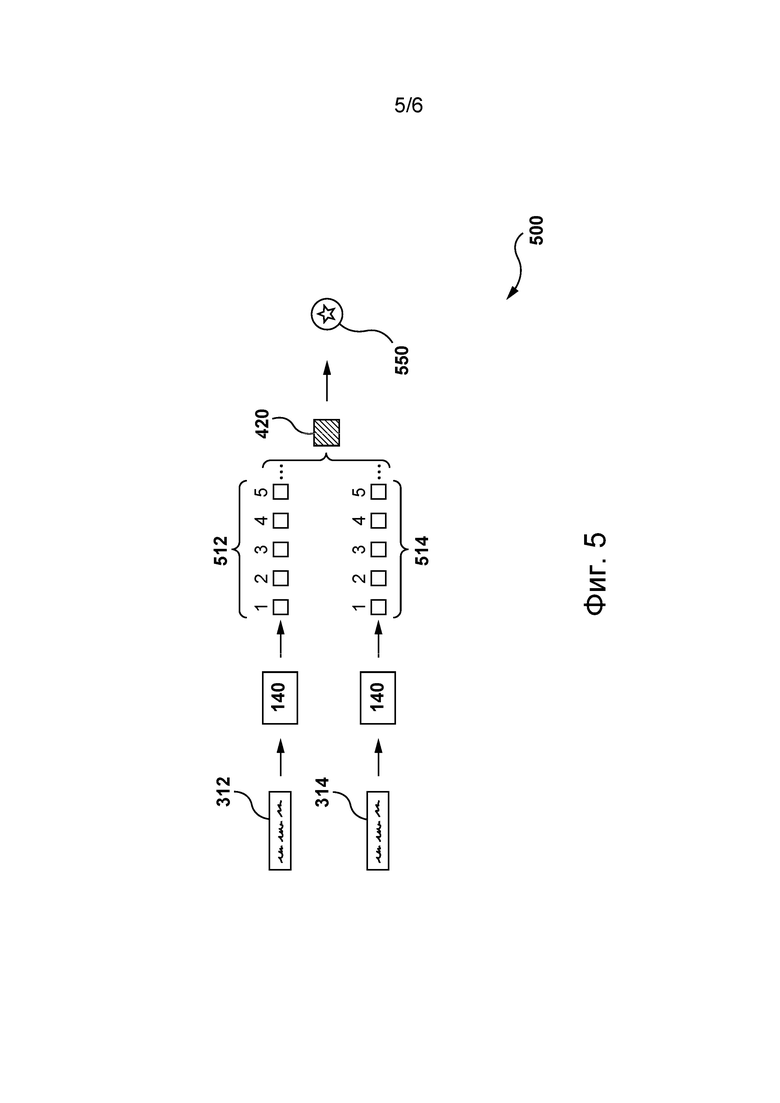
[0107] На фиг. 5 приведено представление 500 процесса, используемого сервером 112 для определения того, является ли пара строк-кандидатов парой схожих строк-кандидатов, согласно другим вариантам осуществления настоящей технологии.
[0108] В этих вариантах осуществления изобретения сервер 112 может использовать строку-кандидата 312 для формирования в реальном времени множества 512 результатов поиска и использовать строку-кандидата 314 для формирования в реальном времени множества 514 результатов поиска. Затем сервер 112 может использовать функцию 420 сравнения для определения параметра 550, указывающего на то, являются ли строки-кандидаты 312 и 314 парой схожих строк-кандидатов. В этих вариантах осуществления изобретения можно сказать, что вместо использования второй модели 320, обученной до получения данных 302 запроса, сервер 112 может формировать в реальном времени множество результатов поиска для соответствующих строк-кандидатов из списка 310 строк-кандидатов (без отображения их пользователю) для определения строк, составляющих пары схожих строк-кандидатов. Если параметр 550 указывает на схожесть строки-кандидата 312 со строкой-кандидатом 314, то сервер 112 может исключить строку-кандидата 312 или строку-кандидата 314 из списка 390 расширенных запросов.
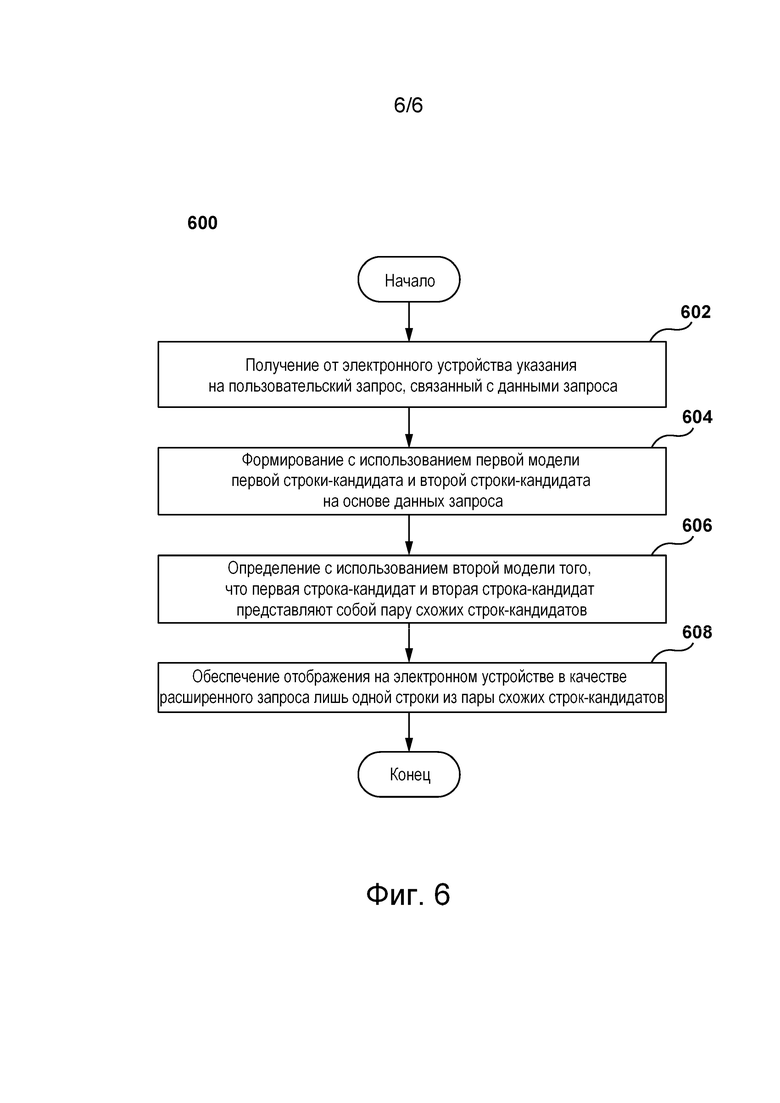
[0109] На фиг. 6 представлена блок-схема способа 600, выполняемого сервером 112 в по меньшей мере некоторых вариантах осуществления настоящей технологии. Далее подробно описаны различные шаги способа 600.
Шаг 602: получение от электронного устройства указания на пользовательский запрос, связанный с данными запроса.
[0110] Способ 600 начинается с шага 602, на котором сервер 112 может получать указание на пользовательский запрос от электронного устройства 104. Пользовательский запрос связан с данными запроса. Например, пользовательский запрос может представлять собой запрос, отправленный пользователем 102. В другом примере пользовательский запрос может представлять собой запрос, частично введенный пользователем 102.
[0111] В некоторых вариантах осуществления настоящей технологии данные запроса могут содержать текстовую строку, представляющую собой пользовательский запрос и/или частичный пользовательский запрос. Предполагается, что данные запроса могут содержать один или несколько дополнительных признаков, связанных с пользовательским запросом и/или с частичным пользовательским запросом. Например, сервер 112 способен обращаться к базе 120 данных и получать информацию, хранящуюся в сочетании с пользовательским запросом и/или с частичным пользовательским запросом. Таким образом, сервер 112 способен получать данные предыстории, например, связанные с пользовательским запросом и/или с частичным пользовательским запросом, и использовать их в качестве одного или нескольких дополнительных признаков в данных запроса.
Шаг 604: формирование с использованием первой модели первой строки-кандидата и второй строки-кандидата на основе данных запроса.
[0112] Способ продолжается на шаге 604, на котором сервер 112 путем использования первой модели может формировать первую строку-кандидата и вторую строку-кандидата на основе данных запроса. Например, сервер 112 может использовать первую модель 304 для формирования множества строк-кандидатов на основе данных запроса. Первая строка-кандидат и вторая строка-кандидат представляют собой соответствующих кандидатов для расширенного запроса.
[0113] В некоторых вариантах осуществления изобретения первая модель 304 может представлять собой модель ранжирования, способную формировать множество строк кандидатов и ранжировать их в ранжированном списке строк-кандидатов. Предполагается, что первая модель 304 может быть реализована в виде модели DSSM.
Шаг 606: определение с использованием второй модели того, что первая строка-кандидат и вторая строка-кандидат представляют собой пару схожих строк-кандидатов.
[0114] Способ продолжается на шаге 606, на котором сервер 112 путем использования второй модели 320 способен определять, что первая строка-кандидат и вторая строка-кандидат представляют собой пару схожих строк-кандидатов.
[0115] В некоторых вариантах осуществления настоящей технологии вторая модель 320 может представлять собой модель DSSM, обученную на основе обучающего набора 460. Вторая модель 320 может быть обучена ранее в парной конфигурации на основе обучающего набора 460, как описано выше со ссылкой на фиг. 4.
[0116] Предполагается, что обучающий набор для второй модели 320 содержит первую обучающую строку, представляющую собой первый обучающий запрос, вторую обучающую строку, представляющую собой второй обучающий запрос, и метку. Метка указывает на сходство первой обучающей строки и второй обучающей строки и определена на основе сравнения первого обучающего документа, релевантного первому обучающему запросу, и второго обучающего документа, релевантного второму обучающему запросу.
[0117] В некоторых вариантах осуществления изобретения метка может указывать на сходство первой обучающей строки и второй обучающей строки, если первый обучающий документ совпадает со вторым обучающим документом.
[0118] В других вариантах осуществления изобретения первый обучающий документ может представлять собой первое множество обучающих документов, а второй обучающий документ может представлять собой второе множество обучающих документов. Первое множество обучающих документов содержит N документов, наиболее релевантных первому обучающему запросу, а второе множество обучающих документов содержит M документов, наиболее релевантных второму обучающему запросу. В этих вариантах осуществления изобретения метка может указывать на то, что первая обучающая строка схожа со второй обучающей строкой, если в первом множестве обучающих документов и во втором множестве обучающих документов содержится по меньшей мере заранее заданное количество одинаковых обучающих документов. Это заранее заданное количество может быть определено оператором поисковой системы 140.
[0119] В других вариантах осуществления изобретения N документов, наиболее релевантных первому обучающему запросу, и M документов, наиболее релевантных второму обучающему запросу, может быть определено поисковой системой 140 в автономном режиме до обучения второй модели 320. В других вариантах осуществления изобретения наиболее релевантные документы для соответствующих обучающих запросов могут быть получены из базы 120 данных.
Шаг 608: обеспечение отображения на электронном устройстве в качестве расширенного запроса лишь одной строки из пары схожих строк-кандидатов.
[0120] Способ 600 продолжается на шаге 608, на котором сервер 112 способен обеспечивать отображение на электронном устройстве 104 в качестве расширенного запроса лишь одной строки из пары схожих строк-кандидатов. Сервер 112 может формировать пакет данных для передачи электронному устройству 104 через сеть 110 связи. Пакет данных может содержать по меньшей мере информацию, указывающую на строку из пары схожих строк-кандидатов, и команды для отображения строки из пары схожих строк-кандидатов на дисплее электронного устройства 104.
[0121] Следует отметить, что на электронном устройстве 104 может отображаться несколько расширенных запросов. Тем не менее, лишь одна строка из пары схожих строк-кандидатов отображается в качестве соответствующего расширенного запроса.
[0122] В некоторых вариантах осуществления изобретения сервер 112 может обеспечивать отображение на электронном устройстве 104 в качестве расширенного запроса строки-кандидата с бóльшим рангом из числа первой строки-кандидата и второй строки-кандидата из ранжированного списка строк-кандидатов, сформированного первой моделью 304.
[0123] Для специалиста в данной области могут быть очевидными возможные изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии. Предшествующее описание приведено лишь в иллюстративных целях, а не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ОБРАБОТКИ ПОИСКОВОГО ЗАПРОСА | 2015 |
|
RU2640639C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ РАНЖИРОВАНИЮ ОБЪЕКТОВ | 2020 |
|
RU2782502C1 |
| СПОСОБ И СИСТЕМА РАНЖИРОВАНИЯ МНОЖЕСТВА ДОКУМЕНТОВ НА СТРАНИЦЕ РЕЗУЛЬТАТОВ ПОИСКА | 2017 |
|
RU2677380C2 |
| Система и способ для формирования обучающего набора для алгоритма машинного обучения | 2020 |
|
RU2790033C2 |
| СПОСОБ И СЕРВЕР ОБРАБОТКИ ПОИСКОВОГО ПРЕДЛОЖЕНИЯ | 2015 |
|
RU2609079C2 |
| СПОСОБ И СЕРВЕР ГЕНЕРИРОВАНИЯ МЕТА-ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ | 2018 |
|
RU2721159C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ НЕЙРОННОЙ СЕТИ ФОРМИРОВАНИЮ ТЕКСТОВОЙ ВЫХОДНОЙ ПОСЛЕДОВАТЕЛЬНОСТИ | 2020 |
|
RU2798362C2 |
| СПОСОБ (ВАРИАНТЫ) И СЕРВЕР РАНЖИРОВАНИЯ ПОИСКОВЫХ РЕЗУЛЬТАТОВ НА ОСНОВЕ ПАРАМЕТРА ПОЛЕЗНОСТИ | 2015 |
|
RU2632138C2 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСШИРЕНИЯ ПОИСКОВЫХ ЗАПРОСОВ С ЦЕЛЬЮ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2018 |
|
RU2720905C2 |
Настоящее изобретение относится к области вычислительной техники. Технический результат заключается в повышении точности поиска информации за счёт возможности предоставления пользователю спрогнозируемых расширенных поисковых запросов. Технический результат достигается за счёт того, что сервер получает указание на пользовательский запрос, использует первую модель для формирования первой строки-кандидата и второй строки-кандидата, которые представляют собой соответствующих кандидатов для расширенного запроса, использует вторую модель для определения того, что первая строка-кандидат и вторая строка-кандидат представляют собой пару схожих строк-кандидатов, и инициирует отображение на электронном устройстве в качестве расширенного запроса лишь одной строки из пары схожих строк-кандидатов. Вторая модель обучается в парной конфигурации на основе обучающего набора. Обучающий набор содержит первую и вторую обучающие строки и метку. Метка указывает на сходство первой обучающей строки и второй обучающей строки. Метка определяется на основе сравнения обучающего документа или нескольких документов, релевантных первой и второй обучающей строке. 3 н. и 23 з.п. ф-лы, 6 ил.
1. Способ формирования расширенного запроса для пользователя электронного устройства, выполняемый сервером, связанным с электронным устройством и содержащим поисковую систему, и включающий в себя:
- получение сервером от электронного устройства указания на пользовательский запрос, связанный с данными запроса;
- формирование сервером, использующим первую модель, первой строки-кандидата и второй строки-кандидата, которые представляют собой соответствующих кандидатов для расширенного запроса, на основе данных запроса;
- определение сервером, использующим вторую модель, того, что первая строка-кандидат и вторая строка-кандидат представляют собой пару схожих строк-кандидатов, при этом вторая модель обучена в парной конфигурации на основе обучающего набора, который содержит первую обучающую строку, представляющую собой первый обучающий запрос, вторую обучающую строку, представляющую собой второй обучающий запрос, и метку, которая указывает на сходство первой обучающей строки и второй обучающей строки и определена на основе сравнения первого обучающего документа, релевантного первому обучающему запросу, и второго обучающего документа, релевантного второму обучающему запросу; и
- инициирование сервером отображения на электронном устройстве в качестве расширенного запроса лишь одной строки из пары схожих строк-кандидатов.
2. Способ по п. 1, отличающийся тем, что метка указывает на сходство первой обучающей строки и второй обучающей строки, если первый обучающий документ совпадает со вторым обучающим документом.
3. Способ по п. 1, отличающийся тем, что первый обучающий документ представляет собой первое множество обучающих документов, а второй обучающий документ представляет собой второе множество обучающих документов, при этом первое множество обучающих документов содержит N документов, наиболее релевантных первому обучающему запросу, второе множество обучающих документов содержит M документов, наиболее релевантных второму обучающему запросу, а метка указывает на то, что первая обучающая строка схожа со второй обучающей строкой, если в первом множестве обучающих документов и во втором множестве обучающих документов содержится по меньшей мере заранее заданное количество одинаковых обучающих документов.
4. Способ по п. 3, отличающийся тем, что N документов, наиболее релевантных первому обучающему запросу, и M документов, наиболее релевантных второму обучающему запросу, определяются поисковой системой в автономном режиме до обучения второй модели.
5. Способ по п. 1, отличающийся тем, что первая модель представляет собой модель ранжирования, способную формировать ранжированный список строк-кандидатов, первая строка-кандидат и вторая строка-кандидат ранжируются в ранжированном списке строк-кандидатов, а инициирование включает в себя инициирование сервером отображения на электронном устройстве в качестве расширенного запроса строки-кандидата с большим рангом из числа первой строки-кандидата и второй строки-кандидата.
6. Способ по п. 1, отличающийся тем, что первая модель представляет собой углубленную модель семантического сходства (DSSM).
7. Способ по п. 1, отличающийся тем, что вторая модель представляет собой модель DSSM.
8. Способ по п. 1, отличающийся тем, что расширенный запрос представляет собой дополненный запрос, содержащий запрос, а инициирование включает в себя инициирование сервером отображения на электронном устройстве дополненного запроса без отображения страницы результатов поисковой системы (SERP), соответствующей запросу.
9. Способ по п. 1, отличающийся тем, что расширенный запрос представляет собой переформулированный запрос, а инициирование включает в себя инициирование сервером отображения на электронном устройстве страницы SERP, соответствующей запросу и содержащей часть с переформулированным запросом.
10. Способ по п. 1, отличающийся тем, что расширенный запрос представляет собой дополненный запрос, содержащий запрос, а инициирование включает в себя инициирование сервером отображения на электронном устройстве страницы SERP, соответствующей запросу и содержащей часть с переформулированным запросом.
11. Способ формирования расширенного запроса для пользователя электронного устройства, выполняемый сервером, связанным с электронным устройством и содержащим поисковую систему, и включающий в себя:
- получение сервером данных запроса, связанных с запросом, отправленным пользователем;
- формирование сервером, использующим первую модель, первой строки-кандидата и второй строки-кандидата, которые представляют собой соответствующих кандидатов для расширенного запроса, на основе данных запроса;
- определение сервером в реальном времени на основе первой строки-кандидата первого множества документов, содержащего документы, релевантные первой строке-кандидату;
- определение сервером в реальном времени на основе второй строки-кандидата второго множества документов, содержащего документы, релевантные второй строке-кандидату;
- определение сервером того, что первая строка-кандидат и вторая строка-кандидат представляют собой пару схожих строк, если в первом множестве документов и во втором множестве документов содержится по меньшей мере заранее заданное количество одинаковых документов; и
- инициирование сервером отображения на электронном устройстве в качестве расширенного запроса лишь одной строки из пары схожих строк-кандидатов.
12. Способ по п. 11, отличающийся тем, что первая модель представляет собой модель ранжирования, способную формировать ранжированный список строк-кандидатов, первая строка-кандидат и вторая строка-кандидат ранжируются в ранжированном списке строк-кандидатов, а инициирование включает в себя инициирование сервером отображения на электронном устройстве в качестве расширенного запроса строки-кандидата с большим рангом из числа первой строки-кандидата и второй строки-кандидата.
13. Способ по п. 11, отличающийся тем, что первая модель представляет собой модель DSSM.
14. Способ по п. 11, отличающийся тем, расширенный запрос представляет собой дополненный запрос, содержащий запрос, а инициирование включает в себя инициирование сервером отображения на электронном устройстве дополненного запроса без отображения страницы SERP, соответствующей запросу.
15. Способ по п. 11, отличающийся тем, что расширенный запрос представляет собой переформулированный запрос, а инициирование включает в себя инициирование сервером отображения на электронном устройстве страницы SERP, соответствующей запросу и содержащей часть с переформулированным запросом.
16. Способ по п. 11, отличающийся тем, что расширенный запрос представляет собой дополненный запрос, содержащий запрос, а инициирование включает в себя инициирование сервером отображения на электронном устройстве страницы SERP, соответствующей запросу и содержащей часть с переформулированным запросом.
17. Сервер для формирования расширенного запроса для пользователя электронного устройства, связанный с электронным устройством, содержащий поисковую систему, и способный:
- получать от электронного устройства указание на пользовательский запрос, связанный с данными запроса;
- формировать с использованием первой модели первую строку-кандидата и вторую строку-кандидата, которые представляют собой соответствующих кандидатов для расширенного запроса, на основе данных запроса;
- определять с использованием второй модели, что первая строка-кандидат и вторая строка-кандидат представляют собой пару схожих строк-кандидатов, при этом вторая модель обучена в парной конфигурации на основе обучающего набора, который содержит первую обучающую строку, представляющую собой первый обучающий запрос, вторую обучающую строку, представляющую собой второй обучающий запрос, и метку, которая указывает на сходство первой обучающей строки и второй обучающей строки и определена на основе сравнения первого обучающего документа, релевантного первому обучающему запросу, и второго обучающего документа, релевантного второму обучающему запросу; и
- инициировать отображение на электронном устройстве в качестве расширенного запроса лишь одной строки из пары схожих строк-кандидатов.
18. Сервер по п. 17, отличающийся тем, что метка указывает на сходство первой обучающей строки и второй обучающей строки, если первый обучающий документ совпадает со вторым обучающим документом.
19. Сервер по п. 17, отличающийся тем, что первый обучающий документ представляет собой первое множество обучающих документов, а второй обучающий документ представляет собой второе множество обучающих документов, при этом первое множество обучающих документов содержит N документов, наиболее релевантных первому обучающему запросу, второе множество обучающих документов содержит M документов, наиболее релевантных второму обучающему запросу, а метка указывает на то, что первая обучающая строка схожа со второй обучающей строкой, если в первом множестве обучающих документов и во втором множестве обучающих документов содержится по меньшей мере заранее заданное количество одинаковых обучающих документов.
20. Сервер по п. 19, отличающийся тем, что N документов, наиболее релевантных первому обучающему запросу, и M документов, наиболее релевантных второму обучающему запросу, определяются поисковой системой в автономном режиме до обучения второй модели.
21. Сервер по п. 17, отличающийся тем, что первая модель представляет собой модель ранжирования, способную формировать ранжированный список строк-кандидатов, первая строка-кандидат и вторая строка-кандидат ранжируются в ранжированном списке строк-кандидатов, а способность сервера выполнять инициирование включает в себя способность инициировать отображение на электронном устройстве в качестве расширенного запроса строки-кандидата с большим рангом из числа первой строки-кандидата и второй строки-кандидата.
22. Сервер по п. 17, отличающийся тем, что первая модель представляет собой модель DSSM.
23. Сервер по п. 17, отличающийся тем, что вторая модель представляет собой модель DSSM.
24. Сервер по п. 17, отличающийся тем, что расширенный запрос представляет собой дополненный запрос, содержащий запрос, а способность сервера выполнять инициирование включает в себя способность инициировать отображение на электронном устройстве дополненного запроса без отображения страницы SERP, соответствующей запросу.
25. Сервер по п. 17, отличающийся тем, что расширенный запрос представляет собой переформулированный запрос, а способность сервера выполнять инициирование включает в себя способность инициировать отображение на электронном устройстве страницы SERP, соответствующей запросу и содержащей часть с переформулированным запросом.
26. Сервер по п. 17, отличающийся тем, что расширенный запрос представляет собой дополненный запрос, содержащий запрос, а способность сервера выполнять инициирование включает в себя способность инициировать отображение на электронном устройстве страницы SERP, соответствующей запросу и содержащей часть с переформулированным запросом.
| СПОСОБ И СИСТЕМА ДЛЯ ФОРМИРОВАНИЯ ПОДСКАЗОК ПО РАСШИРЕНИЮ ПОИСКОВЫХ ЗАПРОСОВ В ПОИСКОВОЙ СИСТЕМЕ | 2019 |
|
RU2744111C2 |
| US 8280886 B2, 02.10.2012 | |||
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| СПОСОБ ФОРМИРОВАНИЯ ПОЛЬЗОВАТЕЛЬСКОГО ЗАПРОСА | 2016 |
|
RU2677379C2 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| ФОРМИРОВАНИЕ ПОИСКОВОГО ЗАПРОСА НА ОСНОВЕ КОНТЕКСТА | 2013 |
|
RU2633115C2 |
