В атомной промышленности наметилась сильная тенденция перехода к КИП-системам и модулям безопасности на базе FPGA в противоположность используемым в настоящее время системам на базе CPU.
FPGA предлагают множество преимуществ, особенно в контексте сложных систем с множеством параллельных входных и выходных сигналов. В настоящее время все конкретные для проекта задачи по инженерному обеспечению для КИП-платформ на базе CPU могут выполняться неспециалистами в электронике с помощью ориентированных на поток сигналов читаемых человеком диаграмм. Комплекс инструментальных средств автоматически переводит эти схемы в C-код, который может быть скомпилирован и запущен в КИП-системе безопасности на базе CPU.
Эта методология может быть сертифицирована для прикладных задач безопасности, поскольку двоичные результаты всего комплекса инструментальных средств являются очень прогнозируемыми. Это, однако, отличает подход на базе CPU от подхода на базе FPGA: вследствие природы FPGA и их комплексов инструментальных средств даже небольшие изменения на начальном уровне проекта могут вести к ранее непрогнозированным, полностью отличающимся временным характеристикам конечной микросхемы. Следовательно, отрасль КИП безопасности не следовала подходу на базе схем вместе с внутренним FPGA до сих пор. Вместо этого специалистам по электронике необходимо выполнять соответствующее введение технического решения FPGA с помощью хорошо известных методик на основе языков описания аппаратных средств, таких как VHDL. Это ведет либо к фиксированным техническим решениям, которые должны быть повторно использованы при отличающихся обстоятельствах, либо к очень сложным задачам по инженерному обеспечению проекта, затрагивающих специалистов не только из атомной прикладной области, но также из области технических решений FPGA. Кроме того, каждое FPGA-техническое решение нуждается в очень тщательной сертификации посредством применения тщательно спроектированных процессов разработки и подтверждения правильности.
В другом контексте, за пределами атомной отрасли, была предложена частичная переконфигурация для множества FPGA. См., например, патент США 7 669 168 B1: "Method and apparatus for dynamically connecting modules in a programmable device".
Основная идея здесь заключается в наличии базы данных локально предварительно маршрутизированных низкоуровневых логических блоков, которые могут индивидуально быть объединены в битовый поток, который конфигурирует FPGA.
В принципе, частичная переконфигурация будет решением для данной проблемы, если применяется правильно, но:
- Сложно и, таким образом, трудно, сертифицировать комплекс инструментальных средств, который должен обслуживать этот характерный признак, который в настоящее время широко не предоставляется и не очень стабилен.
- Некоторый модуль устанавливается только в конкретный слот (местоположение) на микросхеме с помощью специализированных соединений с некоторыми штырьковыми выводами. Если, например, блок голосования необходим на штырьковых выводах 1-4, а фильтрующий блок необходим на штырьковых выводах 10-20, необходимая библиотека модулей будет содержать блок голосования точно на тех штырьковых выводах (плюс блоки голосования на других комбинациях выводов). То же применяется к фильтрующим блокам и всем другим логическим функциональным блокам, таким образом, приводя в результате к тому, что предварительно сертифицированная библиотека будет очень большой: Все виды блоков необходимы для потенциально большого числа слотов.
- Слоты для блоков, которые соединяются с конкретными штырьковыми выводами, имеют фиксированный размер - таким образом, простая вентильная схема расходует столько же логических ресурсов, сколько сложная функция фильтра. Таким образом, будет необходима группировка классов размеров для логических блоков, которая будет дополнительно ограничивать пригодные комбинации штырьковых выводов-функций.
- Было множество других практических проблем с существующими инструментальными средствами, таких как, например, ограничения синхронизации (не каждый блок может использовать каждый тактовый сигнал) или гранулярность (блоки должны быть скорее большими с конкретными границами, таким образом также только большие микросхемы могут быть разделены на несколько слотов).
- Только несколько различных FPGA поддерживают частичную переконфигурацию, а именно, FPGA на базе флэш-технологии или на базе антиперемычек нормально ее не поддерживают, хотя, к несчастью, именно они особенно подходят для данного контекста.
В итоге, частичная переконфигурация является элегантным и мощным решением для множества проблем, но не вполне приспособлена к данному решению, которому явно не нужна полная мощность всех динамически (пере-)конфигурируемых логических блоков, а только несколько динамических соединений штырьковых выводов с функциональными блоками. Основным фокусом частичной переконфигурации является динамически (пере-)конфигурируемые части FPGA после включения в смысле временного мультиплексирования логических блоков, чтобы уменьшать необходимые аппаратные ресурсы или учитывать обновления на месте эксплуатации. Это очевидно не планируется в данном применении. Дополнительно, она не может рассматриваться в качестве испытанной технологии и, следовательно, вряд ли подходит для атомных КИП-систем, которые должны поддерживаться в течение десятилетий.
Следовательно, целью настоящего изобретения является сохранение доказавшего свою пригодность схемно-ориентированного, специфического для проекта инженерного подхода, в то же время все еще получая преимущества FPGA-технологии и в то же время избегая вышеупомянутых проблем в отношении технологии частичной переконфигурации.
Согласно изобретению эта цель достигается посредством компоновки схемы с помощью отличительных признаков из пункта 1 и пункта 2 формулы изобретения.
Предпочтительные варианты осуществления и улучшения являются предметом зависимых пунктов формулы и последующего подробного описания.
Очень простыми словами, концепцией, лежащей в основе настоящего изобретения, является развитие общей идеи, что вся логика, которая должна быть реализована, может быть разделена на несколько устройств, тогда как одно (или некоторые) из них являются фиксированными, а одно (или некоторые) из них должны быть адаптированы к специфическим для проекта (специализированным) нуждам.
Основной идеей согласно настоящему изобретению является ограничение степеней свободы для динамичной для проекта FPGA-части системы для того, чтобы упрощать комплекс инструментальных средств (что также облегчает сертификацию).
Подход основывается на идее разработки одного или более предварительно сертифицированных FPGA-технических решений, содержащих расширенный набор потенциально необходимых логических функций. Другими словами, существует универсальная предварительно сконфигурированная FPGA с множеством специфичных для области применения (т.е., подходящих для КИП-задач на атомной электростанции), но типовых по применению логических функций. Они не приспосабливаются для специфических для проекта нужд, но они могут быть применены достаточно гибким образом, чтобы все еще применять последовательность действий технического проектирования на основе схем, имея возможность соединять соответствующие функциональные элементы или блоки друг с другом специфическим для проекта образом.
Одним предварительным условием является тот факт, что многие текущие FPGA-устройства предлагают громадные объемы логики по сравнению с тем, что типично необходимо для КИП-прикладных задач безопасности. Это предоставляет возможность им развивать (и тщательно сертифицировать) FPGA-проектные решения, которые содержат расширенный набор логических блоков, которые могут быть необходимы для различных проектов.
Примеры таких проектных решений могут включать в себя следующие характеристики:
- базовые цифровые сигналы, например, включающие в себя десятки: логических функций (И/ИЛИ/исключающее ИЛИ...), блоков голосования, блоков задержки, сигнальных блоков, объединяющих шинных интерфейсов...
- фильтр и контроллер: фильтрующие блоки, блоки контроллеров (PID, PI,...), сигнальный интегратор, сигнальный дифференциатор, RMS-блоки,...
- специальные функции: алгоритмы, например, относящиеся к некоторым ядерным аспектам
- базовые аналоговые сигналы, например, десятки: последовательных цифровых интерфейсов (SPI, I2S,...), блоков сравнения, блоков вычисления (сложения, вычитания,...), блоков задержки, объединяющих шинных интерфейсов.
Применительно к практике, эталонные образы FPGA могут, конечно, также содержать функциональные блоки из других областей (цифровые, аналоговые), которые группируются вместе, чтобы соответствовать некоторым типичным прикладным задачам.
Такие эталонные FPGA-образы могут быть использованы для КИП-прикладных задач следующими способами:
a) CPLD-подход
Идея заключается в объединении большой FPGA с большим числом штырьковых выводов (например, 500 пользовательских I/O) с одним или более CPLD, окружающими ее. Эталонный образ(ы) FPGA полностью замораживаются и проектируются способом, когда все штырьковые выводы FPGA связаны с хорошо определенными функциями. CPLD работает(ют) в качестве программируемой коммутационной матрицы, которая соединяет, например, 50-60 входных/выходных штырьковых выводов дочерней платы сложного логического устройства с штырьковыми выводами FPGA специфическим для проекта способом, включая в себя все соединения между несколькими функциями FPGA.
В противоположность FPGA, CPLD предлагают гораздо меньше аппаратных ресурсов (что делает их фактически непригодными в качестве первичного программируемого логического устройства - даже для данной прикладной задачи), но они предлагают строго прогнозируемую синхронизацию и, следовательно, сравнительно простой комплекс инструментальных средств. Только конфигурация CPLD(множества CPLD) (плюс некоторые предварительно запрограммированные контрольные значения, если применимы, см. ниже) определяет специфическую для проекта функцию и, следовательно, все сигналы платы FPGA. Динамические (=схемно-ориентированные) комплексы инструментальных средств CPLD, следовательно, являются гораздо более легко управляемыми и предлагают более простую сертификацию, чем комплексы инструментальных средств FPGA. CPLD могут дополнительно выполнять проверки целостности, например, непрерывно считывая (и проверяя) конфигурацию FPGA или связываясь с другими реализованными с помощью FPGA механизмами проверки целостности. Таким образом, возможно разрабатывать специфическую для проекта последовательность действий по техническому проектированию, которая предоставляет возможность (полу-)автоматического создания соответствующих образов CPLD.
Главные преимущества этого подхода включают в себя:
- Техническое проектирование может оставаться таким же, что и для текущих КИП-платформ на базе CPU - (почти) аналогичные входные каскадные схемы могут даже быть реализованы разнообразно на базе CPU и базе FPGA.
- Потенциал FPGA-технологии может быть почти полностью использован. Вследствие того факта, что конкретные функции привязываются к конкретным штырьковым выводам, могут быть ситуации, когда этот подход уступает "классическому" FPGA-подходу.
- Низкие по стандартам FPGA затраты на техническое проектирование, при этом имеется высокая степень гибкости, чтобы удовлетворять различным потребностям проекта.
- Низкие трудозатраты по техническому обслуживанию, поскольку необходимо позаботиться только о нескольких эталонных образах и комплексе инструментальных средств разработки.
- Концептуально высокие степени сложности являются разрешимыми - число доступных штырьковых выводов на коммерческих устройствах выглядит ограничивающим фактором.
Недостатки, с другой стороны, включают в себя:
- "Реальные" CPLD явно находятся на пути к устареванию и могут не быть легко доступными в отдаленном будущем.
- CPLD с высоким числом штырьковых выводов редко встречаются (если вообще доступны), при этом, возможно, более одного CPLD необходимо для каждой FPGA.
- Затраты на дополнительное CPLD являются непроизводительными расходами.
Однако, недостатки не усложняют возможность технической реализации концепции фундаментальным образом, и преимущества несомненно перевешивают недостатки.
b) Подход с внешним матричным коммутатором/FPGA
Вместо CPLD могут быть применены специализированная ИС матричного коммутатора или даже другая "распределительная" FPGA - предпочтительно с очень специализированным, жестко контролируемым комплексом инструментальных средств, который может лишь создавать образы конфигурации коммутатора - которые конфигурируются с помощью энергонезависимой памяти или локального CPU.
Если специализированная FPGA просто применяется для распределения, даже комплекс инструментальных средств с неизвестными свойствами является пригодным (это также справедливо для CPLD-подхода, описанного выше):
- Автоматический VHDL-генератор создает необходимый код распределительной матрицы для FPGA, который компилируется в двоичный поток посредством специфического для поставщика комплекса инструментальных средств.
- Для того, чтобы сертифицировать специфические для проекта распределительные устройства, разрабатывается типовая система измерения/сертификации (например, PCB), которая содержит тот же тип распределительного устройства, окруженного тестовой инфраструктурой. Эта система сертификации служит лишь цели автоматического определения 100% каких-либо характеристик образа коммутационной матрицы (например, выполненных соединений, моментов времени ввода-вывода) и создает отчет о них. 100%-определение характеристик естественно включает в себя также 100%-тестирование.
-Инженерам проекта необходимо тестировать их окончательный образ распределительного коммутатора с помощью упомянутых сертифицированных, специализированных тестовых аппаратных средств (которые, конечно, могут быть повторно использованы), чтобы доказывать, что комплекс инструментальных средств с неизвестными свойствами работал правильно.
-Следовательно, сложный комплекс инструментальных средств FPGA больше не является предметом обсуждения, и большие, удобные FPGA могут быть использованы вместо старого/отработанного CPLD или других экзотических устройств.
-Кроме того, устаревание также не является проблемой, поскольку эта концепция работает для любой FPGA, пока доступен стенд сертификации/испытания для этого конкретного типа FPGA.
Этот подход имеет все преимущества CPLD-подхода, упомянутые выше, и предоставляет эффективный способ управлять процессом устаревания, поскольку он не привязан к конкретным устройствам и может быть мигрирован на другие устройства по причинам устаревания или разнообразия. Недостатки, главным образом, касаются несколько более сложной разработки подходящих инструментальных программных средств и испытательных устройств.
Кроме того, устройства типовой матричной логики (GAL) могут быть рассмотрены для простой сертификации, если все еще существуют доступные устройства, которые не будут вскоре сняты с производства.
c) Подход ASIC с перемычкой/антиперемычкой
Этот подход аналогичен предыдущему с одним исключением, что вместо сортирующей FPGA предлагается однократно программируемая ASIC с перемычкой/антиперемычкой. Предпосылкой для этой концепции является тот факт, что FPGA с перемычкой/антиперемычкой предлагают множество преимуществ, поскольку они представляют реальные аппаратные средства таким образом, что их "программирование" является просто последним этапом производства аппаратных средств. Однако, FPGA на основе перемычек больше легко не доступны на рынке, а FPGA на основе антиперемычек являются достаточно дорогими. В качестве способа исправления проблемы можно прибегнуть к разработке собственного (изготовленного на заказ) маршрутизирующего устройства с перемычкой/антиперемычкой, которое является достаточно простым, поскольку ему не нужно содержать какие-либо логические элементы, а "только" программируемые маршруты. Необходимые методики являются достаточно старыми и хорошо испытанными и протестированными различными способами.
Преимущества этого подхода включают в себя:
-Распределение реализуется в реальных аппаратных средствах без проблем включения питания или одиночных сбоев, которые не должны приниматься во внимание.
-Поскольку это решение является однократно программируемым, достижимый уровень кибербезопасности потенциально выше, чем с другими решениями.
Связанные недостатки могут включать в себя соответствующие трудозатраты по разработке и проблемы долговременной стабильности относительно множества ASIC.
d) PCB-подход
Этот подход аналогичен предыдущему. Он ориентирован на идею использования платы печатного монтажа (PCB) вместо CPLD или FPGA, чтобы обеспечивать преобразование данных для главной FPGA. Опять же, ожидаются значительные трудозатраты для разработки, производства и сертификации подходящих (изготовленных на заказ) PCB. С другой стороны, необходимые методики также хорошо проверены и испытаны.
e) Подход с исправлением двоичного потока:
В этом подходе FPGA проектируется аналогично варианту a), но функциональные блоки не соединяются с штырьковыми выводами FPGA. Вместо этого они маршрутизируются к четко определенным маршрутизирующим коммутаторам в FPGA-изделии. FPGA предлагают несколько видов ресурсов разводки, чтобы взаимосвязывать различные части схемы, которые могут различаться между локальными соединениями и прямыми соединениями. Они размещаются в архитектуре матричного коммутатора, объединяющей группы коммутаторов, установка которых формирует неотъемлемую часть всей конфигурации FPGA.
Идея, стоящая за этим подходом, заключается в наличии зафиксированного эталонного образа, который может быть изменен только посредством обработки предварительно определенного небольшого набора разводящих (маршрутизирующих) коммутаторов (например, 50 частей на FPGA, обладающей тысячами частей). Это выполняется непосредственно на уровне файла конфигурации с помощью низкоуровневых инструментальных средств обработки двоичного потока. Эти инструментальные средства естественно должны реализовывать средство обеспечения целостности всей схемы. Выбор коммутаторов и фиксированной маршрутизации всех других логических ресурсов должен гарантировать достаточные резервы синхронизации во всех обстоятельствах, независимо от того, как коммутаторы установлены. Специфическая для проекта последовательность операций технического проектирования, таким образом, поддерживает статическую корректировку эталонных FPGA-образов, чтобы охватывать специфическую для прикладной задачи конфигурацию.
f) Подход с программируемой коммутационной матрицей:
В этом подходе эталонный FPGA-образ содержит дополнительно логический блок программируемой коммутационной матрицы (мультиплексора), который считывает конфигурацию из внешней по отношению к FPGA энергонезависимой памяти и переключает соединение со всеми логическими блоками в FPGA соответствующим образом. Однако, необходимые структуры мультиплексора применимы только для довольно небольшого числа вводов и выводов. Это необязательно препятствует использованию в данном контексте, поскольку полный NxM матричный коммутатор не нужен: детально продуманное разделение штырьковых выводов и функций может уменьшать необходимые ресурсы логики и маршрутизации до легко управляемого количества.
Общим для всех этих способов является то, что FPGA может считывать контрольные значения (например, необходимые для компараторов) из энергонезависимой памяти, также соединенной с FPGA. Если использует(-ют)ся FGPA на базе SRAM, этот блок памяти может также содержать несколько эталонных образов, которые могут быть выбраны посредством, например, DIP-переключателей, перемычек и т.д. Для того, чтобы гарантировать целостность контрольных значений и/или образов, могут быть применены алгоритмы шифрования.
Таким образом, преимущества, относящиеся к настоящему изобретению, включают в себя, но не только, тот факт, что используемая в настоящее время методология технического проектирования КИП среди систем на базе CPU остается пригодной в FPGA-инфраструктуре со всеми своими преимуществами:
-Специалисты по электронике не нужны для специфического для проекта технического проектирования.
-Нет специфического для проекта HDL-кода, который гораздо труднее сертифицировать, чем самообъясняющие схемы. Это приводит в результате к чрезвычайно уменьшенным затратам специфического для проекта технического проектирования.
-Высокая гибкость относительно сценариев применения по сравнению с фиксированными проектными решениями, привязанными к конкретным типам реактора или конкретным КИП-системам и функциям.
Примерный вариант осуществления изобретения затем описывается относительно сопровождающих чертежей, которые изображают исключительно схематичным и очень упрощенным образом:
Фиг. 1 - сложную логическую плату КИП-системы безопасности,
Фиг. 2 - дочернюю плату на базе FPGA для логической платы согласно фиг. 1,
Фиг. 3 - детальный чертеж для фиг. 2, и
Фиг. 4 - схематичное представление последовательности операций технического проектирования в соединении с разработкой компоновки схемы, которая должна быть реализована на дочерней плате согласно фиг. 2.
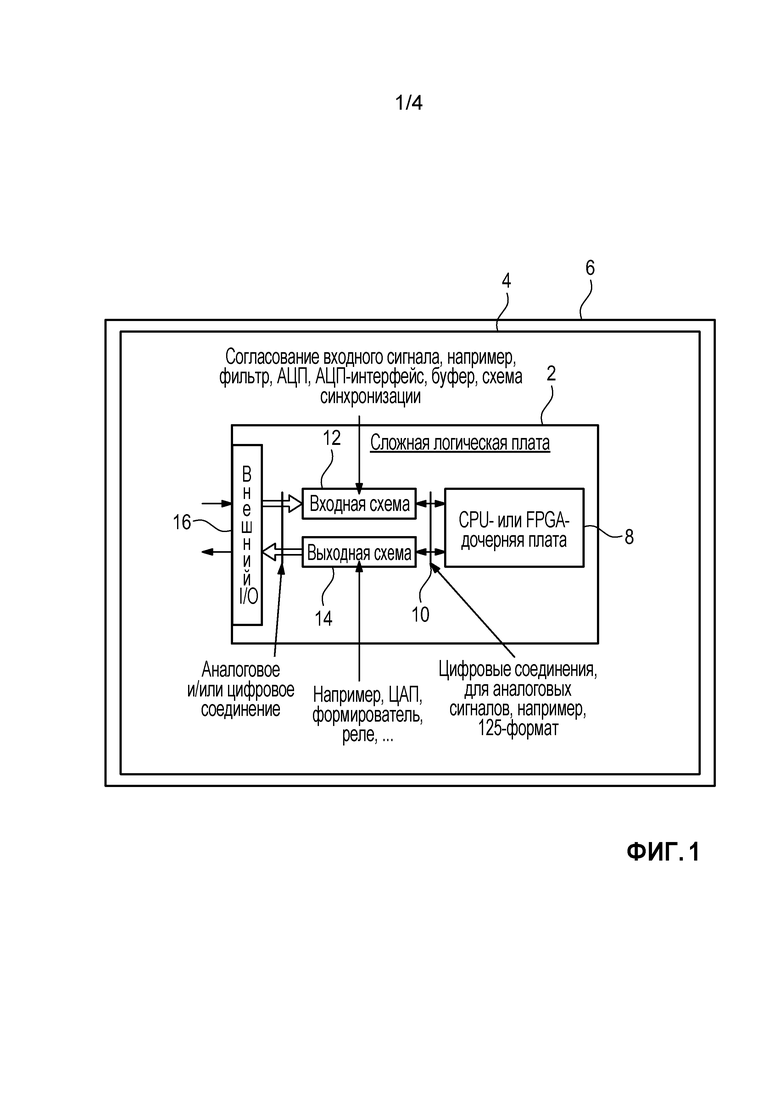
Фиг. 1 изображает, в стиле ориентировочного плана, сложную логическую плату 2 системы 4 контроля и управления (КИП) для безопасности, которая должна быть использована на атомной электростанции 6. Эта плата также называется материнской платой. Фактическая логика может быть реализована на дочерней плате 8, соединенной заменяемым образом с материнской платой 2. Традиционно, дочерняя плата 8 (если присутствует) основана на CPU, т.е., содержит центральный процессор (CPU) с фиксированным набором инструкций и последовательным порядком работы в качестве главного вычислительного ресурса. Дочерняя плата 8 соединяется, через подходящий цифровой интерфейс 10 через разъемы, с входной схемой 12 с одной стороны и выходной схемой 14 с другой стороны. Входная схема 12 предоставляет средство для согласования аналоговых и/или цифровых входных сигналов, предоставляемых через внешние разъемы 16 ввода/вывода (I/O). Это средство типично содержит аналого-цифровые преобразователи (ADC), соответствующие интерфейсы, фильтры, буферы, схемы синхронизации и т.п. Соответственно, выходная схема 14 преобразует цифровые выходные сигналы дочерней платы 8 в подходящие аналоговые и/или цифровые сигналы для периферийных устройств, в конкретных объектах, которые соединяются с материнской платой 2 через внешние I/O 16. Для этого, выходная схема 14 типично содержит цифро-аналоговые преобразователи, (DAC), формирователи, реле и т.п.
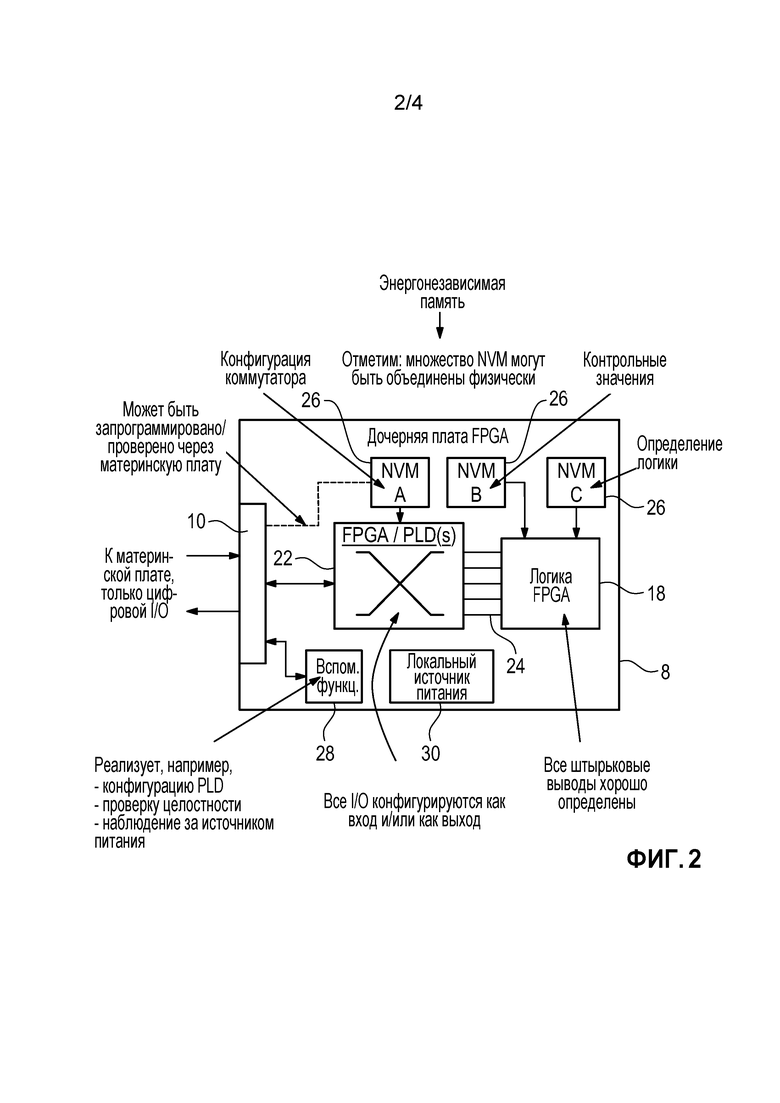
В то время как логика для КИП-архитектур безопасности традиционно реализовывалась в системах на базе CPU, существует растущий тренд по направлению к системам на базе FPGA, в частности, вследствие их большей гибкости в контексте сложных систем с множеством параллельных входных и выходных сигналов. Однако, основное внимание должно быть уделено тому, чтобы соответствовать строгим требованиям в атомной промышленности с точки зрения приемочных испытаний (V&V), также называемых сертификацией, для входных/выходных установок и характеристик логических устройств. Фиг. 2 изображает дочернюю плату 8 на базе FPGA для использования с материнской платой 2 на фиг. 1, проектное решение которой особенно хорошо подходит, чтобы справляться с этой проблемой. Фиг. 3 отбирает важные детали из фиг. 2. Конечно, отдельная дочерняя плата может не быть необходимой, если вся схема, включающая периферию и/или внешние интерфейсы, реализуется на одной главной плате вместо этого.
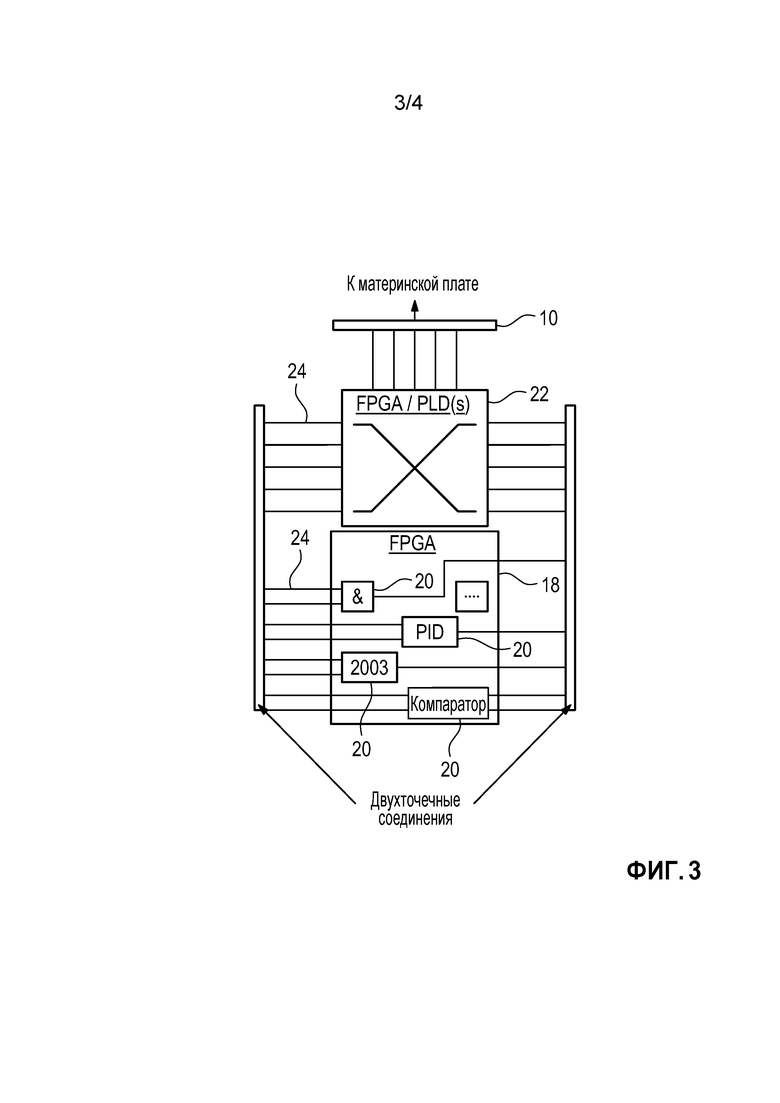
Как показано на фиг. 3, дочерняя плата 8 удерживает типичную программируемую пользователем вентильную матрицу (FPGA) 18 с большим числом логических функций, предоставляемых посредством соответствующих логических функциональных элементов 20 или блоков логических функций (вкратце: логических элементов или логических блоков), в частности, простых логических вентилей, и, если необходимо, также более сложной функцией типа сумматоров, компараторов, контроллеров пропорционально-интегрально-дифференцированного регулирования (PID) и других контроллеров, фильтров и т.п. Логические элементы 20, следовательно, состоят из/содержат/объединяют несколько ресурсов элементарной логики или логических блоков FPGA. FPGA 18 также содержит набор (пере-)конфигурируемых внутренних ресурсов маршрутизации (программируемых коммутаторов), которые обычно предоставляют возможность специфичных для проекта взаимных соединений логических элементов 20.
Однако, вследствие ограничений, упомянутых выше, внутренние ресурсы маршрутизации FPGA не используются, чтобы соединять логические элементы 20 друг с другом в системе согласно фиг. 2 и 3. Вместо этого, программируемое логическое устройство (PLD) 22, штырьковые выводы которого соединяются с соответствующими штырьковыми выводами FPGA 18 через дорожки 24 схемы дочерней платы 8 (двухточечные соединения), действует в качестве внешней для FPGA коммутационной матрицы и, таким образом, предоставляет конфигурируемые функции маршрутизации, которые необходимы для специфического для проекта межсоединения логических элементов 20 FPGA. Следовательно, PLD 22 может также называться "вспомогательным PLD" или "распределительным PLD" или "PLD коммутационной матрицы" или "коммутирующим PLD" для (типично > 50 или даже > 200) двухточечных соединений между штырьковыми выводами FPGA 18 и штырьковыми выводами PLD 22 и, следовательно, для упомянутых логических функциональных элементов 20 FPGA 18. Следовательно "коммутирующий PLD" 22 просто действует как программируемая проволочная сетка.
PLD 22, который действует как коммутационная матрица для логических элементов 20 типичной FPGA 18, может быть изготовленной на заказ специализированной интегральной схемой (ASIC) или платой печатного монтажа (PCB). В предпочтительном варианте осуществления, однако, это (по меньшей мере, одно или даже несколько из них) - сложное программируемое логическое устройство (CPLD), и даже более предпочтительно FPGA, которая программируется согласно преобладающим специфическим для проекта нуждам и, следовательно, предоставляет необходимые межсоединения между логическими элементами 20 типовой FPGA 18. В то время как распределительное PLD 22 может содержать значительное количество логических ресурсов само по себе, они фактически не используются вообще или только в небольшом ограниченном диапазоне самое большее. Вместо этого, фактически используемые признаки вспомогательного PLD 22 по существу ограничиваются операциями маршрутизации/коммутационной матрицы для типовой FPGA 18, как описано выше. Таким образом, V&V соответствующих инструментальных средств разработки/программирования для PLD 22 значительно облегчается, как обсуждается более подробно ниже.
Предпочтительно, вспомогательный PLD 22 не только взаимосвязывает логические элементы 20 типовой FPGA 18 подходящим, специфическим для проекта образом, но также маршрутизирует внешние для FPGA цифровые входные/выходные сигналы от/к материнской плате 2 через цифровой I/O-интерфейс 10. Согласно коммутационной матрице, запрограммированной в PLD 22, любой штырьковый вывод FPGA 18 может быть сконфигурирован в качестве входного и/или выходного штырькового вывода.
Дочерняя плата 8 может также быть оснащена множеством модулей энергонезависимой памяти (NVM) 26. В качестве примера, один из этих NVM 26 содержит предварительно определенную конфигурацию переключения, которая загружается в PLD 22 во время включения питания или настройки. Она может быть запрограммирована/проверена через материнскую плату 2, как указано пунктирной линией на фиг. 2. Другая NVM 26 содержит предварительно определенные логические определения, которые должны быть загружены в FPGA 18 во время включения питания. Третья NVM 26 может содержать набор контрольных/значений параметров, которые должны быть загружены в FPGA 18 во время включения питания. NVM 26 могут быть объединены физически.
Вспомогательный модуль 28 может содержать некоторые функции помощника, например, для конфигурации PLD, проверки целостности или наблюдение за блоком питания, включающее в себя наблюдение за локальным блоком 30 питания дочерней платы. Альтернативно, такие функции могут, по меньшей мере, частично быть реализованы в PLD 22 в качестве исключения для общего правила не использовать логические ресурсы PLD.
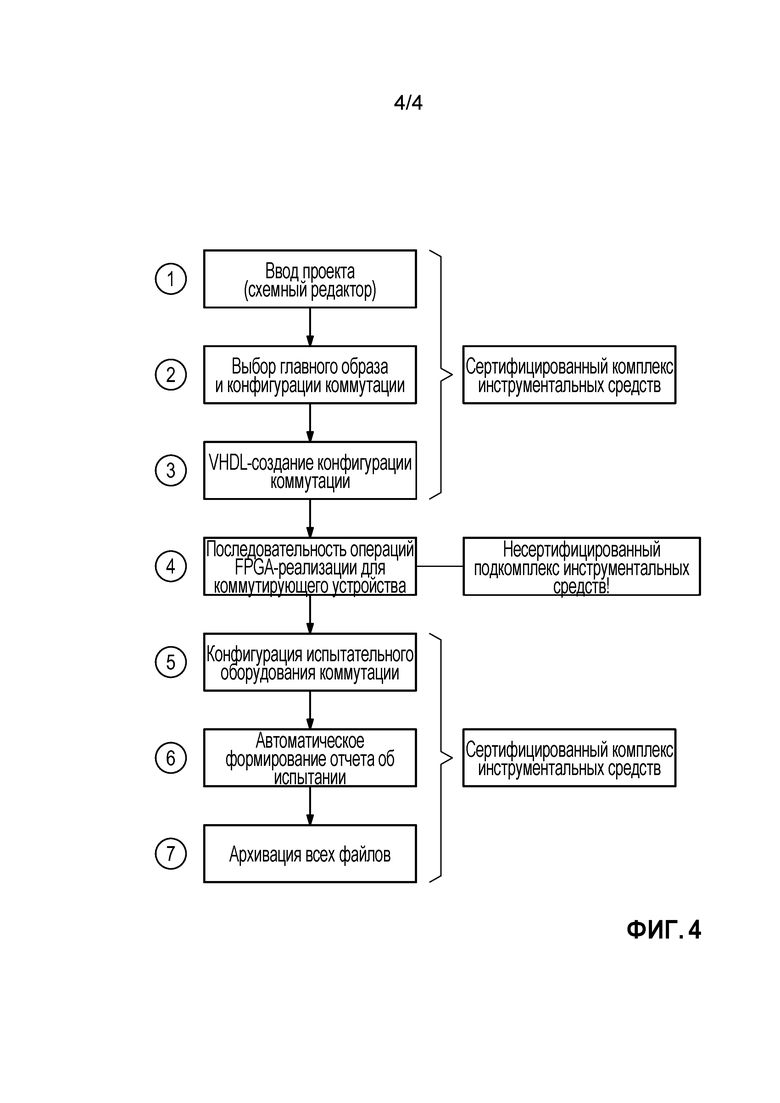
Кроме того, фиг. 4 иллюстрирует примерную последовательность операций технического проектирования, относящуюся к разработке, программированию и подтверждения правильности системы, иллюстрированной на предыдущих чертежах. Содержимое семи блоков блок-схемы последовательности операций должно пониматься следующим образом:
1. Ввод проектного решения аналогичен сегодняшним способам - используется схемный редактор (например, графический редактор блок-схем), который предоставляет возможность создания схем, состоящих из конструктивных блоков (библиотека функций, например, сумматор, компаратор, блок голосования), которые соединены друг с другом специфическим для проекта образом. Результирующая принципиальная электрическая схема может тогда следовать доказавшему свою пригодность процессу подтверждения правильности (V&V), который включает в себя неавтоматизированные осмотры. На этой стадии различие между принципиальной электрической схемой, которая будет реализована в системе на базе CPU, и принципиальной электрической схемой, которая будет реализована в системах на базе FPGA, не существует или является малозначительным.
2. Новая часть программного обеспечения "компилирует" эту схему, выбирая одну или более главных FPGA (разделяя результирующее проектное решение) и определяя необходимые соединения штырьковых выводов используемых образов главной FPGA.
3. Автоматический VHDL-генератор создает необходимый код распределительной матрицы для FPGA. Результирующий VHDL является тривиальным, поскольку он лишь содержит соединения, а не логику - хотя, в качестве последнего варианта он может изменяться в пользу некоторых фиксированных логических блоков в этой коммутационной FPGA - которая, например, выполняет функции типа конфигурации включения питания или самотестирования.
4. Фактический двоичный поток конфигурации создается посредством трудно сертифицируемого, специфичного для поставщика комплекса инструментальных средств, включающего в себя базовые V&V-механизмы, такие как анализ статических рисков сбоя.
5. Результирующий образ загружается в независимые испытательные аппаратные средства, которые содержат то же FPGA-устройство, что и конечная целевая система, и единственной которых целью является V&V распределительных FPGA. Это испытательное оборудование выполняет 100% тестирование распределительной FPGA - тогда как термин "100%" тестирование должен быть определен в соответствии с компетентными органами и органами по сертификации. Может быть необходимо разрабатывать/применять разнородные/избыточные испытательные системы, чтобы заранее исключать типичные причины ошибок в отношении испытательного оборудования. В любом случае, проверка вводов и выводов независимо от комплекса инструментальных средств является одним надежным способом сертифицировать в ином случае трудно сертифицируемый комплекс инструментальных средств.
6. Это испытательное оборудование также (полу-)автоматически создает отчет об испытании, который может (автоматически) быть сравнен со спецификацией с этапа 2.
7. Все уместные файлы теперь архивируются и готовы к использованию в конечной аппаратной платформе.
Наконец, в то время как изобретение было, главным образом, описано в контексте КИП-системы безопасности для атомной электростанции, другие промышленные или военные применения, конечно, также возможны.
Словарь
FPGA (Программируемая пользователем вентильная матрица):
Современная мелкомодульная программируемая интегральная схема, которая проектируется, чтобы конфигурироваться потребителем или проектировщиком после производства - отсюда происходит определение "программируемая пользователем". Она содержит множество конфигурируемых логических ресурсов (логических блоков) с внутренними поисковыми таблицами (LUT) и гибкими ресурсами маршрутизации, т.е., с иерархией переконфигурируемых межсоединений, которые предоставляют возможность блокам быть "связанными вместе". В принципе, каждая логическая схема может быть поставлена в соответствие с ресурсами FPGA.
CPLD (Сложное программируемое логическое устройство):
Прежняя крупномодульная программируемая интегральная схема, которая содержит несколько макроячеек (матрицы И и ИЛИ, триггеры и т.д.). В принципе, каждая логическая схема может быть поставлена в соответствие с ресурсами CPLD, но вследствие ограничений размера она лучше подходит для простых задач.
PLD (Программируемое логическое устройство):
Обобщенный термин классификации для FPGA, CPLD и других программируемых логических устройств.
VHDL (Язык описания аппаратных средств быстродействующих интегральных схем):
Язык, который используется, чтобы описывать логические схемы, которые должны затем быть поставлены в соответствие с ресурсами PLD. Также используется для создания испытательных стендов для множества PLD.
CPU (Центральный процессор):
Главный процессор (например, компьютера) с фиксированным набором инструкций и последовательным порядком работы. Последовательность инструкций для CPU называется программой или, на более высоком уровне, программным обеспечением.
ASIC (Специализированная интегральная схема):
Микросхема с фиксированным логическим проектным решением, подходящим для конкретного применения. CPU или FPGA также являются ASIC, но поскольку их применение должно программироваться конечным пользователем, конечный пользователь должен программировать желаемый характер поведения в микросхему.
PCB (Плата печатного монтажа):
Плата, состоящая из одного или более слоев, чтобы соединять смонтированные компоненты друг с другом или с разъемами. Типичным примером для PCB является материнская плата компьютера, где устанавливаются CPU, набор микросхем, память, разъемы и т.д.
КИП безопасности (контрольно-измерительные приборы безопасности):
Система для безопасного применения, которая собирает информацию о текущем состоянии прикладной задачи (например, температуру в ядерном энергетическом реакторе), оценивает эту информацию (например, температура в ядерном реакторе выше предварительно определенного порогового значения?) и действует соответственно, чтобы удерживать прикладную задачу в безопасном состоянии (например, уменьшать выходную мощность ядерного реактора, когда температура является слишком высокой).
Список ссылочных символов
2 сложная логическая плата/материнская плата
4 КИП-система безопасности
6 атомная электростанция
8 дочерняя плата
10 цифровой интерфейс
12 входная схема
14 выходная схема
16 внешний I/O
18 FPGA
20 логический функциональный элемент/блок
22 PLD
24 дорожка схемы
26 NVM
28 вспомогательный модуль
30 локальный источник питания
| название | год | авторы | номер документа |
|---|---|---|---|
| МОДУЛЬ ЛОГИКИ ПРИОРИТЕТОВ | 2011 |
|
RU2595908C2 |
| Высокопроизводительная вычислительная платформа на базе процессоров с разнородной архитектурой | 2016 |
|
RU2635896C1 |
| УСТРОЙСТВА, СИСТЕМЫ И СПОСОБЫ, ОТНОСЯЩИЕСЯ К PLC | 2007 |
|
RU2419826C2 |
| УСТРОЙСТВА И СПОСОБЫ ДЛЯ ДИАГНОСТИКИ ОСНОВАННЫХ НА ЭЛЕКТРОНИКЕ ПРОДУКТОВ | 2013 |
|
RU2562418C2 |
| УСТРОЙСТВА, СИСТЕМЫ И СПОСОБЫ ДЛЯ НАЗНАЧЕНИЯ АДРЕСА PLC-МОДУЛЯ | 2007 |
|
RU2419825C2 |
| Программно-аппаратная платформа и способ ее реализации для беспроводных средств связи | 2016 |
|
RU2626550C1 |
| ПОДКЛЮЧАЕМЫЙ ПОРТАТИВНЫЙ СОПРОЦЕССОР С ИЗМЕНЯЕМОЙ СИСТЕМОЙ КОМАНД И СПОСОБ ЕГО ПРИМЕНЕНИЯ | 2009 |
|
RU2411575C1 |
| ИСПОЛЬЗОВАНИЕ АППАРАТНО-ОБЕСПЕЧИВАЕМОЙ ЗАЩИЩЕННОЙ ИЗОЛИРОВАННОЙ ОБЛАСТИ ДЛЯ ПРЕДОТВРАЩЕНИЯ ПИРАТСТВА И МОШЕННИЧЕСТВА В ЭЛЕКТРОННЫХ УСТРОЙСТВАХ | 2017 |
|
RU2744849C2 |
| МОДУЛЬНЫЙ МАСШТАБИРУЕМЫЙ КОММУТАТОР И СПОСОБ РАСПРЕДЕЛЕНИЯ КАДРОВ В СЕТИ БЫСТРОГО ETHERNET | 2001 |
|
RU2257678C2 |
| УСТРОЙСТВО УПРАВЛЕНИЯ РАСПРОСТРАНЕНИЕМ КОНТЕНТА, ТЕРМИНАЛ, ПРОГРАММА И СИСТЕМА РАСПРОСТРАНЕНИЯ СОДЕРЖИМОГО | 2008 |
|
RU2456768C2 |
Изобретение относится к компоновке схемы для КИП-системы (4) безопасности атомной электростанции. Технический результат заключается в обеспечении FPGA-технологии применительно к условиям эксплуатации атомных электростанций. Для этого компоновка схемы согласно изобретению содержит: типовую FPGA (18) с некоторым числом логических блоков (20) и, по меньшей мере, одно специализированное PLD (22), которое работает как специализированная коммутационная матрица для упомянутых логических блоков (20). 2 н. и 9 з.п. ф-лы, 4 ил.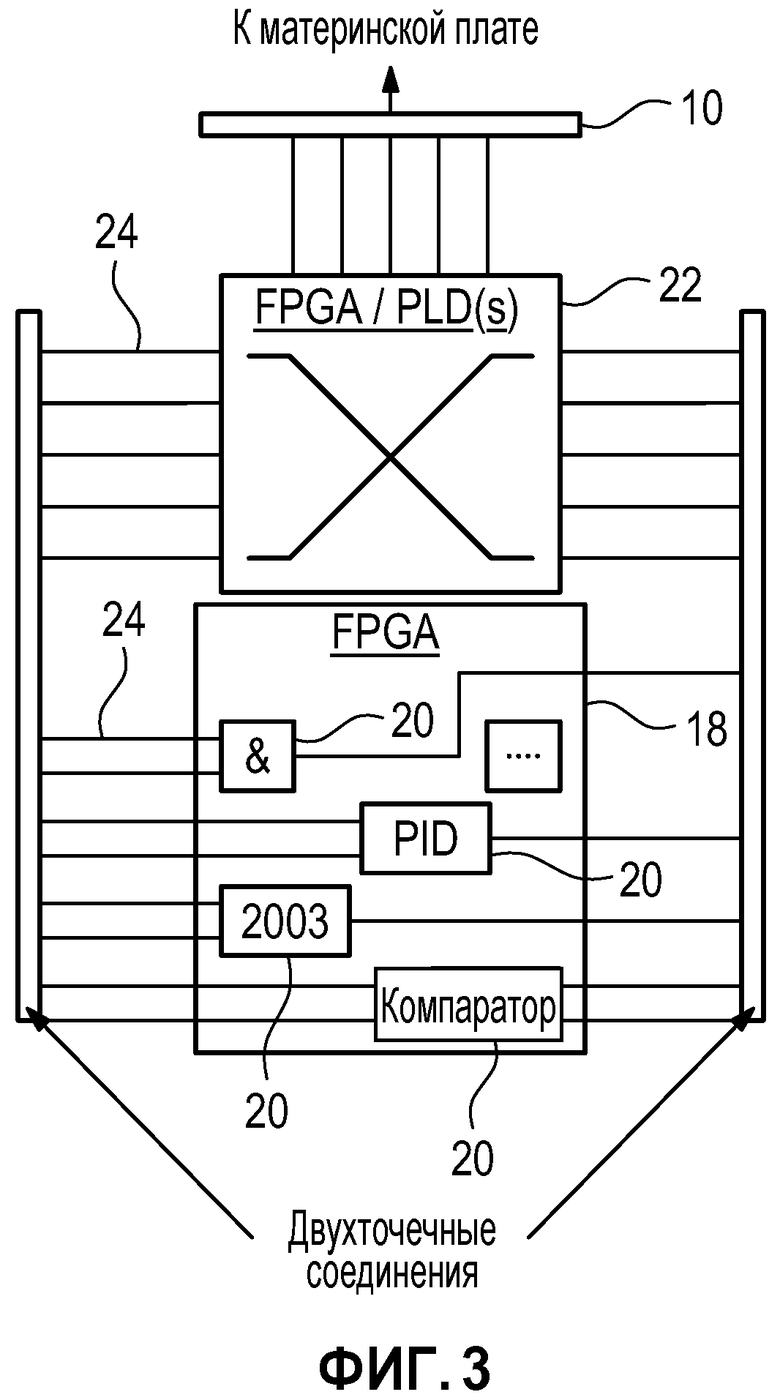
1. Схема модуля безопасности КИП-системы (4) безопасности атомной электростанции (6), размещенная на логической плате (2) и содержащая:
типовую FPGA (18) с некоторым числом логических функциональных элементов (20), каждый из которых содержит вводы и выводы, набор внутренних ресурсов маршрутизации для межсоединений между вводами и выводами логических функциональных элементов (20) и множество штырьковых выводов,
по меньшей мере одно специализированное PLD (22) с множеством штырьковых выводов и
множество двухточечных соединений между штырьковыми выводами FPGA (18) и штырьковыми выводами PLD (22) через дорожки (24) схемы логической платы (2),
при этом PLD (22) работает как специализированная, внешняя по отношению к FPGA коммутационная матрица для упомянутых двухточечных соединений и, следовательно, для упомянутых вводов и выводов упомянутых логических функциональных элементов (20), причем PLD (22) предоставляет конфигурируемые функции маршрутизации, которые необходимы для специфического для проекта межсоединения логических функциональных элементов (20) FPGA.
2. Схема по п. 1, в которой используемый диапазон функций, обеспечиваемых посредством PLD (22), главным образом или исключительно ограничивается ролью коммутационной матрицы для FPGA (18).
3. Схема по п.1 или 2, в которой коммутационная матрица для логических функциональных элементов (20) FPGA (18) реализована исключительно посредством PLD (22).
4. Схема по п.1 или 2, в которой FPGA (18) и PLD (22) размещены на общей монтажной плате и штырьковым образом соединены друг с другом через дорожки схемы.
5. Схема по п.1 или 2 с точно одним PLD (22), выделенным для FPGA (18).
6. Схема по п.1 или 2, в которой соответствующее PLD (22) является CPLD.
7. Схема по п.1 или 2, в которой соответствующее PLD (22) является FPGA.
8. Схема по п.1 или 2, в которой соответствующее PLD (22) является ASIC.
9. Схема по п.1 или 2, в которой соответствующее PLD (22) является PCB.
10. Схема по п.1 или 2, в которой число двухточечных соединений больше 50, в частности больше 200.
11. КИП-система (4) безопасности атомной электростанции (6) с по меньшей мере одной схемой модуля безопасности по любому из предшествующих пунктов.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| US 7673087 B1, 02.03.2010 | |||
| Предохранительное устройство для паровых котлов, работающих на нефти | 1922 |
|
SU1996A1 |
| ПЛАНИРОВЩИК С УЧЕТОМ ПАКЕТОВ В СИСТЕМАХ БЕСПРОВОДНОЙ СВЯЗИ | 2005 |
|
RU2348119C2 |
| МЕХАНИЗМ ПОДАЧИ ШЛИФОВАЛЬНОЙ ГОЛОВК3Cti.;orv.>&oH>&vTT j11А1П!П1о-'Г1^;;Г":нАЯ|ЬИ&,ПИОТсКА I | 0 |
|
SU356111A1 |

