Изобретение относится к устройству кодирования для обработки входного сигнала и к устройству декодирования для обработки кодированного сигнала. Изобретение также относится к соответствующим способам и к компьютерной программе.
Центральной частью кодеков для речевых сигналов и аудиокодеков являются их перцептивные модели, которые описывают относительную перцептивную важность ошибок в разных элементах представления сигнала. На практике перцептивные модели состоят из зависимых от сигнала весовых коэффициентов, которые используются при квантовании каждого элемента. Для оптимального функционирования желательно использовать такую же перцептивную модель в декодере. Хотя перцептивная модель является зависимой от сигнала, однако она заранее не известна в декодере, в результате чего аудиокодеки в общем случае передают эту модель явно, за счет увеличения потребления битов.
Приближается эпоха «Интернета вещей» (IoT), в силу чего следующее поколение кодеров речевых сигналов и аудиокодеров должно охватывать его. Однако цели разработки IoT-систем плохо стыкуются с классическим проектированием кодеров речевых сигналов и аудиокодеров, в результате чего требуется большая модернизация кодеров.
Во-первых, тогда как современный кодер речевых сигналов и аудиокодер, такой как AMR-WB, EVS, USAC и AAC, состоит из интеллектуальных и сложных кодеров и относительно простых декодеров [1-4], в «Интернете вещей», поскольку он должен поддерживать распределенные узлы-датчики низкой сложности, предпочтительно, чтобы кодеры были простыми.
Во-вторых, поскольку узлы-датчики кодируют один и тот же сигнал источника, применение одинакового квантования в каждом узле-датчике будет представлять избыточное кодирование и потенциально серьезную потерю эффективности. В частности, поскольку перцептивная модель должна быть более или менее одинаковой в каждом узле, ее передача от каждого узла является почти чистым избыточным кодированием.
Традиционные способы кодирования речевых сигналов и аудиосигналов состоят из трех частей:
1. перцептивная модель, которая определяет относительное воздействие ошибок в различных параметрах кодека,
2. модель источника, которая описывает диапазон и вероятность различной входной информации, и
3. энтропийный кодер, который использует модель источника для минимизации перцептивного искажения [5].
Кроме того, перцептивная модель может быть применена любым из следующих двух способов.
1. Параметры сигнала могут быть взвешены в соответствии с перцептивной моделью, в результате чего все параметры могут быть квантованы с одинаковой точностью. Тогда перцептивная модель должна быть передана декодеру, чтобы взвешивание могло быть устранено.
2. Перцептивная модель в качестве альтернативы может быть применена в качестве модели оценки, в которой выходная информация синтеза разных квантований сравнивается, будучи взвешенной посредством перцептивной модели, в итерации анализа через синтез. Хотя в этом случае перцептивная модель не должна передаваться, этот подход имеет недостаток в том, что формы ячеек квантования образуются не регулярно, что сокращает эффективность кодирования. Однако важно еще отметить, что для нахождения оптимального квантования должен использоваться сложный в вычислительном отношении поиск с полным перебором разных квантований.
Поскольку подход анализа через синтез тем самым приводит к сложному в вычислительном отношении кодеру, он не является целесообразной альтернативой для IoT. Таким образом, декодер должен иметь доступ к перцептивной модели. Однако, как отмечено выше, явная передача перцептивной модели (или эквивалентно модели огибающей спектра сигнала) не желательна, поскольку это понижает эффективность кодирования.
Задача изобретения состоит в создании способа восстановления перцептивной модели в декодере из переданного сигнала без вспомогательной информации относительно перцептивной модели.
Задача решается посредством устройства кодирования для обработки входного сигнала, а также устройства декодирования для обработки кодированного сигнала. Задача также решается посредством соответствующих способов и системы, содержащей устройство кодирования и устройство декодирования.
Изобретение является особенно полезным в сетях распределенных датчиков и в «Интернете вещей», где дополнительные расходы на потребление битов от передачи перцептивной модели увеличиваются с количеством датчиков.
Изобретение в соответствии с одним вариантом осуществления также может быть обозначено как слепое восстановление перцептивных моделей в распределенном кодировании речевых сигналов и аудиосигналов.
Входной сигнал здесь является речевым сигналом и/или аудиосигналом, который будет кодирован устройством кодирования.
Задача решается посредством устройства кодирования для обработки входного сигнала. Устройство кодирования предпочтительно обеспечивает кодированный сигнал.
Устройство кодирования содержит блок перцептивного взвешивания и блок квантования.
Блок перцептивного взвешивания содержит блок обеспечения модели и блок применения модели. Блок обеспечения модели выполнен с возможностью обеспечения модели с перцептивным взвешиванием на основе входного сигнала. Блок применения модели выполнен с возможностью обеспечения перцептивно взвешенного спектра посредством применения модели с перцептивным взвешиванием к спектру на основе входного сигнала.
Блок квантования выполнен с возможностью квантования перцептивно взвешенного спектра и для обеспечения битового потока. Блок квантования содержит блок применения случайной матрицы и блок вычисления функции знака. Блок применения случайной матрицы выполнен с возможностью применения случайной матрицы к перцептивно взвешенному спектру, чтобы обеспечить преобразованный спектр. Блок вычисления функции знака выполнен с возможностью функции вычисления знака (signum) компонентов преобразованного вектора, чтобы обеспечить битовый поток.
Квантование содержит по меньшей мере два этапа. На первом этапе перцептивно взвешенный спектр объединяется со случайной матрицей. Такая случайная матрица имеет преимущество в том, что для каждого входного сигнала используется своя матрица. Это становится полезным, когда несколько датчиков охватывают один и тот же источник аудиосигналов, и нужно избежать избыточного кодирования. Второй этап включает в вычисление функции знака компонентов преобразованного вектора.
В одном варианте осуществления блок обеспечения модели выполнен с возможностью обеспечения модели с перцептивным взвешиванием на основе сжатия спектра на основе входного сигнала.
В устройстве кодирования изобретения перцептивное взвешивание входного сигнала основано в одном варианте осуществления на сжатии входного сигнала. В варианте осуществления перцептивное взвешивание основано на сжатии огибающей спектра магнитуды входного сигнала (огибающая является непрерывной, обычно гладкой формой, описывающей характеристику сигнала, его спектр магнитуды). На основе сжатия получается модель с перцептивным взвешиванием, которая в итоге используется для перцептивного взвешивания спектра входного сигнала.
Устройство кодирования в одном варианте осуществления обеспечивает битовый поток со вспомогательной информацией, охватывающей некоторые аспекты процесса кодирования.
В варианте осуществления информация о квантовании обеспечена как вспомогательная информация посредством вывода кодированного сигнала устройством кодирования в качестве результата процесса кодирования.
В дополнительном варианте осуществления блок перцептивного взвешивания содержит блок вычисления огибающей. Блок вычисления огибающей выполнен с возможностью обеспечения огибающей спектра магнитуды на основе входного сигнала.
В одном варианте осуществления блок обеспечения модели выполнен с возможностью вычисления функции сжатия, описывающей сжатие огибающей. Кроме того, блок обеспечения модели выполнен с возможностью вычисления модели с перцептивным взвешиванием на основе функции сжатия. В этом варианте осуществления блок обеспечения модели выполняет сжатие огибающую и вычисляет функцию, описывающую это сжатие. На основе этой функции получается модель с перцептивным взвешиванием. В этом варианте осуществления сжатие огибающей спектра основано на входном сигнале, т.е. диапазон магнитуды сокращается и, таким образом, становится меньше, чем перед сжатием. Посредством сжатия огибающей спектр также подвергается сжатию, т.е. диапазон магнитуды спектра сокращается.
В другом варианте осуществления модель с перцептивным взвешиванием или функция сжатия вычисляется непосредственно из входного сигнала или магнитуды/мощности спектра на основе входного сигнала.
В соответствии с вариантом осуществления блок обеспечения модели выполнен с возможностью вычисления функции сжатия, описывающей сжатие спектра на основе входного сигнала, или описывающей сжатие огибающей спектра магнитуды на основе входного сигнала. Сжатие сокращает диапазон магнитуды спектра на основе входного сигнала или сокращает диапазон магнитуды огибающей. Кроме того, блок обеспечения модели выполнен с возможностью вычисления модели с перцептивным взвешиванием на основе функции сжатия.
В варианте осуществления функция сжатия - например, для сжатия спектра или огибающей - отвечает двум следующим критериям.
Во-первых, функция сжатия является строго возрастающей. Это подразумевает, что для любой положительной скалярной величины и произвольно малого значения значение функции для положительной скалярной величины меньше значения функции для суммы положительной скалярной величины и произвольно малого значения.
Во-вторых, для первой положительной скалярной величины и второй положительной скалярной величины, которая больше первой положительной скалярной величины, разность между значением функции для второй положительной скалярной величины и значением функции для первой положительной скалярной величины меньше разности между второй положительной скалярной величиной и первой положительной скалярной величиной.
Задача решается посредством способа обработки входного сигнала. Этот входной сигнал предпочтительно является аудиосигналом и/или речевым сигналом.
Способ обработки входного сигнала, являющегося аудиосигналом и/или речевым сигналом, содержит по меньшей мере следующие этапы:
вычисление модели с перцептивным взвешиванием на основе входного сигнала,
обеспечение перцептивно взвешенного спектра посредством применения модели с перцептивным взвешиванием к спектру на основе входного сигнала, и
квантование перцептивно взвешенного спектра для обеспечения битового потока,
причем квантование перцептивно взвешенного спектра содержит:
применение случайной матрицы к перцептивно взвешенному спектру для обеспечения преобразованного спектра, и
вычисление функции знака компонентов преобразованного спектра для обеспечения битового потока.
В варианте осуществления выполняются следующие этапы:
вычисление огибающей спектра магнитуды на основе входного сигнала,
вычисление модели с перцептивным взвешиванием на основе сжатия огибающей.
Варианты осуществления устройства кодирования также могут быть выполнены посредством этапов способа и соответствующих вариантов осуществления способа. Таким образом, объяснения, данные для вариантов осуществления устройства, также относятся к способу.
Задача также решается посредством способа обработки входного сигнала,
содержащего:
обеспечение модели перцептивного взвешивания на основе входного сигнала,
взвешивание спектра входного сигнала посредством применения модели перцептивного взвешивания к спектру входного сигнала, и
квантование взвешенного спектра посредством вычисления функции знака случайных проекций взвешенного спектра.
Способ в варианте осуществления дополнительно содержит:
получение случайных проекций взвешенного спектра посредством применения случайной матрицы к взвешенному спектру.
В варианте осуществления обеспечение модели перцептивного взвешивания содержит сжатие огибающей спектра магнитуды входного сигнала.
В соответствии с вариантом осуществления способ дополнительно содержит:
получение огибающей посредством использования набора фильтров и диагональной матрицы, содержащей коэффициенты нормализации для каждой полосы.
Задача также решается посредством устройства декодирования для обработки кодированного сигнала.
Устройство декодирования содержит по меньшей мере блок обратного квантования и блок устранения перцептивного взвешивания.
Блок обратного квантования выполнен с возможностью выполнения обратного квантования битового потока, содержащегося в кодированном сигнале, и обеспечения вычисленного перцептивно взвешенного спектра. Кроме того, блок обратного квантования выполнен с возможностью выполнения обратного квантования битового потока посредством применения псевдоинверсии случайной матрицы к битовому потоку. Блок обратного квантования отменяет эффекты квантования, имевшего место во время процесса кодирования. За блоком обратного квантования следует блок устранения перцептивного взвешивания, в результате чего спектр, полученный в результате обратного квантования, подвергается устранению перцептивного взвешивания. Вычисленный перцептивно взвешенный спектр принимается блоком устранения перцептивного взвешивания, чтобы подвергнуться устранению перцептивного взвешивания. Наконец полученный спектр тем самым представляет собой подвергнутый устранению перцептивного взвешивания подвергнутый обратному квантованию битовый поток, содержащийся во входном сигнале.
Блок устранения перцептивного взвешивания отменяет эффекты перцептивного взвешивания, которое произошло во время процесса кодирования, что приводит к кодированному сигналу. Это делается в одном варианте осуществления без вспомогательной информации кодированного сигнала, содержащей модель с перцептивным взвешиванием. Модель восстанавливается из кодированного аудиосигнала как такового.
Блок устранения перцептивного взвешивания содержит блок аппроксимации спектра и блок аппроксимации модели.
Восстановление модели в одном варианте осуществления выполняется посредством итеративного способа, для которого требуются начальные значения. Следовательно, блок обеспечения исходного предположения, содержащийся в блоке устранения перцептивного взвешивания, выполнен с возможностью обеспечения данных для исходного предположения модели с перцептивным взвешиванием, с которой связан кодированный сигнал. Данные для исходного предположения в одном варианте осуществления содержат вектор с диагональными элементами матрицы, описывающей модель с перцептивным взвешиванием.
Блок аппроксимации спектра выполнен с возможностью вычисления приближения спектра на основе вычисленного перцептивно взвешенного спектра. Кроме того, блок аппроксимации модели выполнен с возможностью вычисления приближения модели с перцептивным взвешиванием, связанной с кодированным сигналом (т.е. которая использовалась для кодирования входного сигнала, тем самым формируя кодированный сигнал) на основе приближения спектра.
В варианте осуществления блок устранения перцептивного взвешивания содержит блок обеспечения исходного предположения. Блок обеспечения исходного предположения выполнен с возможностью обеспечения данных для исходного предположения модели с перцептивным взвешиванием. Блок аппроксимации спектра выполнен с возможностью вычисления приближения спектра на основе кодированного сигнала и исходного предположения или приближения модели с перцептивным взвешиванием. Кроме того, приближение спектра в варианте осуществления основано либо на исходном предположении, либо на специально вычисленном приближение модели с перцептивным взвешиванием. Этот выбор зависит от факта, началась ли итерация только что с исходного предположения, или уже произошла по меньшей мере одна итерация по меньшей мере с одним улучшением приближения, ведущим к приближению модели с перцептивным взвешиванием. В одном варианте осуществления итерация выполняется, пока не будет достигнут критерий сходимости.
Блок обратного квантования в одном варианте осуществления выполнен с возможностью выполнения обратного квантования битового потока, содержащегося в кодированном сигнале, на основе вспомогательной информации о случайной матрице, содержащейся в кодированном сигнале. Этот вариант осуществления относится к процессу кодирования, в котором квантование выполняется с использованием случайной матрицы. Информация об используемой случайной матрице содержится во вспомогательной информации кодированного сигнала. В одном варианте осуществления вспомогательная информация содержит только начальное значение столбцов случайной матрицы.
В одном варианте осуществления множество кодированных сигналов обрабатывается совместно. Каждый кодированный сигнал содержит битовый поток со вспомогательной информацией относительно по меньшей мере информации о квантовании, выполненном при обеспечении соответствующего кодированного сигнала. С этой целью блок обратного квантования выполнен с возможностью принимать множество входных сигналов и обеспечивать в одном варианте осуществления только один вычисленный перцептивно взвешенный спектр на основе множества входных сигналов. Входные сигналы предпочтительно относятся аудиосигналу/речевому сигналу, исходящему из одного и того же источника сигнала.
В другом варианте осуществления устройство декодирования выполнено с возможностью применения моделирования источника. Модель источника описывает диапазон и вероятность различной входной информации.
Задача также решается посредством способа обработки кодированного сигнала. Этот кодированный сигнал предпочтительно является кодированным аудиосигналом и/или кодированным речевым сигналом.
Способ обработки (или декодирования) кодированного сигнала содержит по меньшей мере следующие этапы:
обратное квантование битового потока, содержащегося в кодированном сигнале, и обеспечение вычисленного перцептивно взвешенного спектра,
причем обратное квантование битового потока содержит применение псевдоинверсии случайной матрицы к битовому потоку,
вычисление приближения спектра на основе вычисленного перцептивно взвешенного спектра, и
вычисление приближения модели с перцептивным взвешиванием, с которой связан кодированный сигнал (т.е. которая была использована для формирования кодированного сигнала), на основе приближения спектра.
В одном варианте осуществления способ содержит следующие этапы:
вычисление приближения спектра либо на основе вычисленного перцептивно взвешенного спектра и исходного предположения, либо на основе вычисленного перцептивно взвешенного спектра и приближения модели с перцептивным взвешиванием, с которой связан кодированный сигнал.
Вычисленные приближения модели с перцептивным взвешиванием предпочтительно используются для следующего вычисления приближения спектра.
Задача также решается посредством способа обработки кодированного сигнала,
содержащего:
обеспечение квантованного перцептивного сигнала посредством применения псевдоинверсии случайной матрицы к кодированному сигналу,
вычисление оценки спектра на основе квантованного перцептивного сигнала, и
вычисление приближения модели перцептивного взвешивания, используемой для обеспечения кодированного сигнала, на основе приближения спектра.
В соответствии с вариантом осуществления способ дополнительно содержит:
обеспечение нулевого приближения модели перцептивного взвешивания с использованием исходного предположения, и
вычисление нулевой оценки спектра на основе нулевого приближения модели перцептивного взвешивания.
В дополнительном варианте осуществления способ дополнительно содержит:
получение исходного предположения посредством использования набора фильтров и диагональной матрицы, содержащей коэффициенты нормализации для каждой полосы.
Варианты осуществления устройства также могут быть выполнены посредством этапов способа и соответствующих вариантов осуществления способа. Таким образом, объяснения, данные для вариантов осуществления устройства, также относятся к способу.
Задача также решается посредством системы, содержащей по меньшей мере одно устройство кодирования и устройство декодирования. В одном варианте осуществления используется множество устройств кодирования, которые в одном варианте осуществления соответствуют узлам-датчикам, например, микрофонам.
Задача также решается посредством компьютерной программы для выполнения способа любого из предыдущих вариантов осуществления, когда она исполняется на компьютере или процессоре.
Далее изобретение будет разъяснено относительно прилагаемых чертежей и вариантов осуществления, изображенных на прилагаемых чертежах.
Фиг.1 показывает блок-схему системы первого варианта осуществления, содержащей устройство кодирования и устройство декодирования,
Фиг.2 показывает блок-схему варианта осуществления устройства кодирования,
Фиг.3 оказывает блок-схему блока перцептивного взвешивания как части устройства кодирования,
Фиг.4 показывает сигналы, принадлежащие процессу кодирования,
Фиг.5 показывает блок-схему второго варианта осуществления системы, содержащей множество устройств кодирования,
Фиг.6 показывает более подробную блок-схему третьего варианта осуществления системы,
Фиг.7 показывает блок-схему варианта осуществления устройства декодирования,
Фиг.8 показывает блок-схему другого варианта осуществления устройства декодирования,
Фиг.9 показывает вариант осуществления блока устранения перцептивного взвешивания как части устройства декодирования,
Фиг.10 показывает сигналы, принадлежащие процессу декодирования,
Фиг.11 показывает средние значения отношения SNR с разными битовыми скоростями для экспериментальных данных, и
Фиг.12 показывает разностные оценки MUSHRA для экспериментальных данных.
Фиг.1 показывает систему для обработки входного сигнала 3, который является речевым сигналом и/или аудиосигналом. Этот входной сигнал 3 кодируется устройством 1 кодирования. Кодированный сигнал 4, предпочтительно являющийся битовым потоком, например, передается через Интернет устройству 2 декодирования, которое декодирует кодированный сигнал 4 и обеспечивает слушателю извлеченный аудиосигнал 5 (не показан).
Устройство 1 кодирования использует модель с перцептивным взвешиванием для обработки входного сигнала 3, но эта модель не передается посредством кодированного сигнала 4. Устройство 2 декодирования извлекает модель из кодированного сигнала 4, чтобы отменить эффекты модели.
Устройство 1 кодирования, показанное на фиг.2, содержит преобразователь 15, блок 10 перцептивного взвешивания 10 и блок 14 квантования.
Преобразователь 15 обеспечивает спектр s на основе входного сигнала 3, который является временным сигналом. Это делается, например, посредством оконного преобразования Фурье (STFT).
Спектр s подвергается перцептивному взвешиванию посредством блока перцептивного взвешивания 10 и становится перцептивно взвешенным спектром x. Этот спектр x подается на блок 14 квантования, который квантует его и обеспечивает квантованный сигнал 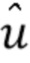 , являющийся битовым потоком. Этот квантованный сигнал в этом варианте осуществления объединяется с соответствующей вспомогательной информацией, охватывающей информацию о квантовании, но в этом варианте осуществления не о модели с перцептивным взвешиванием, чтобы обеспечить кодированный сигнал 4.
, являющийся битовым потоком. Этот квантованный сигнал в этом варианте осуществления объединяется с соответствующей вспомогательной информацией, охватывающей информацию о квантовании, но в этом варианте осуществления не о модели с перцептивным взвешиванием, чтобы обеспечить кодированный сигнал 4.
Фиг.3 показывает вариант осуществления блока 10 перцептивного взвешивания.
Блок 10 перцептивного взвешивания принимает входной сигнал 3 или соответствующий спектр после преобразования входного сигнала 3 в частотную область и обеспечивает перцептивно взвешенный спектр x. С этой целью блок 10 перцептивного взвешивания содержит блок 11 вычисления огибающей, блок 12 обеспечения модели и блок 13 применения модели.
Блок 11 вычисления огибающей принимает входной сигнал 3 или соответствующий спектр и обеспечивает огибающую y спектра магнитуды |x| на основе входного сигнала 3. В показанном варианте осуществления блок 11 вычисления огибающей обеспечивает огибающую y посредством матрицы A и диагональной матрицы Λ. The матрица A является набором фильтров, и диагональная матрица (содержит коэффициенты нормализации для каждой полосы используемого набора фильтров. Огибающая y затем получается на основе спектра магнитуды |x| входного сигнала 3 посредством уравнения 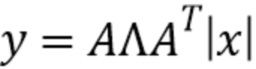 , тогда как
, тогда как 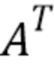 является транспонированием матрицы A.
является транспонированием матрицы A.
На основе этой огибающей y блок 12 обеспечения модели осуществляет сжатие огибающей y. Цель сжатия состоит в том, чтобы получить функцию, которая приближает перцептивное функционирование уха. Далее обсуждается вариант осуществления, в котором огибающая сжата посредством возведения y степень p. Когда, например, p равно 0,3, тогда диапазон yp будет меньше диапазона первоначального y. Величина сжатия в этом примере, таким образом, зависит от значения p. Например, огибающая сокращается до желаемого диапазона. В одном варианте осуществления функция сокращении диапазона или сжатия для сжатия огибающей y задается посредством 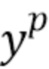 , где
, где 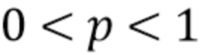 . Это означает, что сжатие выполнено посредством экспоненциальной функции огибающей с экспонентой больше нуля и меньше единицы. Это сжатие выполняется по отсчетам в одном варианте осуществления.
. Это означает, что сжатие выполнено посредством экспоненциальной функции огибающей с экспонентой больше нуля и меньше единицы. Это сжатие выполняется по отсчетам в одном варианте осуществления.
Функция сжатия 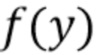 описывает вектор w, т.е.
описывает вектор w, т.е. 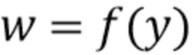 , который дает диагональные элементы модели W с перцептивным взвешиванием. Здесь входная информация y задана как вектор, и функция f применяется ко всем отсчетам вектора y, приводя к вектору w. Таким образом, если k-ым отсчетом y является yk, то k-ым отсчетом w=f(y) является wk=f(yk).
, который дает диагональные элементы модели W с перцептивным взвешиванием. Здесь входная информация y задана как вектор, и функция f применяется ко всем отсчетам вектора y, приводя к вектору w. Таким образом, если k-ым отсчетом y является yk, то k-ым отсчетом w=f(y) является wk=f(yk).
Следовательно, на основе функции сжатия может быть получена модель W с перцептивным взвешиванием, в данном случае в форме матрицы.
Другими словами: огибающая спектра магнитуды подвергается сжатию, и из функции, описывающей сжатую огибающую, вычисляется модель с перцептивным взвешиванием, которая применяется для перцептивного взвешивания спектра.
Блок 13 применения модели применяет модель W с перцептивным взвешиванием к спектру s на основе входного сигнала 3. В показанном варианте осуществления блок 13 применения модели применяет матрицу модели W с перцептивным взвешиванием к вектору на основе спектра.
Перцептивное моделирование теперь будет разъяснено еще раз.
Кодеки для речевых сигналов и аудиокодеки основаны на эффективном моделировании человеческого слухового восприятия. Цель состоит в том, чтобы получить такое взвешивание ошибок квантования, что оптимизация отношения сигнал-шум во взвешенной области дает наилучшее по восприятию качество.
Аудиокодеки в общем случае работают в спектральной области, когда спектр входного кадра s может быть перцептивно взвешен с помощью диагональной матрицы W, в результате чего взвешенный спектр 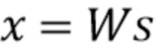 может быть квантован
может быть квантован 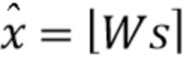 , где скобки
, где скобки  обозначают квантование.
обозначают квантование.
В декодере может быть восстановлена обратная операция 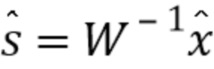 .
.
В частности, модель перцептивного взвешивания состоит из двух частей.
i) Фиксированная часть, соответствующая пределам восприятия в различных частотных полосах. Перцептивные модели, такие как барк-шкала и ERB-шкала, моделируют плотность частот, в результате чего искаженная ось имеет однородную перцептивную точность [17]. Однако, поскольку цель состоит в том, чтобы измерить энергию ошибки в искаженном масштабе, магнитуда спектральных компонентов может быть эквивалентно масштабирована таким образом, что можно избежать сложной в вычислительном отношении операции [18]. Эта операция также сходна с операцией предыскажения, применяемой в речевых кодеках [1-3]. Поскольку эта часть взвешивания является фиксированной, ее не требуется явно передавать. Она может быть применена в кодере и непосредственно применена в обратном направлении в декодере.
ii) Адаптивная относительно сигнала часть перцептивной модели соответствует маскирующим частоту свойствам восприятия. А именно, компоненты сигнала с высокой энергией замаскируют компоненты с более низкой энергией и, таким образом, воспроизводит их неслышимыми, если они оба будут достаточно близки по частоте [5]. Форма маскирующей частоту кривой, таким образом, равна форме огибающей сигнала, но с меньшей магнитудой.
Если |x| является спектром магнитуды входного сигнала, его огибающая спектра y может быть получена в варианте осуществления посредством , где матрица A является набором фильтров, например, как на фиг.4(a).
В отличие от обычных наборов фильтров типа MFCC [19], в одном варианте осуществления используются окна типа асимметричного окна Ханна с наложением, простирающимся от k-ого фильтра до (k - 2)-ого и (k+2)-ого фильтров (см. фиг.4(a)).
Диагональная матрица (содержит коэффициенты нормализации для каждой полосы, в результате чего получается единичное усиление.
В зависимости от варианта осуществления используются мел-шкала, барк-шкала или ERB-шкала с подходящим количеством полос.
При частоте дискретизации 12,8 кГц здесь использовался набор мел-фильтров с 20 полосами.
Альтернативой для матрицы набора фильтров типа MFCC является использование расширения с помощью фильтрации, в результате чего A становится матрицей свертки. Поскольку операции фильтрации являются хорошо проработанными способами цифровой обработки сигналов, их обратные операции также могут быть найдены без затруднений.
Перцептивные весовые коэффициенты моделируют эффект маскировки частоты, который в свою очередь соответствует расширению и масштабированию энергии по частотам [20, 5]. Матрица A модели огибающей уже достигает эффекта расширения, тогда как масштабирование энергии еще должно быть смоделировано.
Масштабирование энергии соответствует сжатию сигнала и сокращает диапазон магнитуды огибающей (см. фиг.4(b)). Следовательно, если спектр s умножен на матрицу W перцептивного взвешивания, получается спектр , который имеет сокращенный диапазон (см. фиг.4(c)).
Перцептивное взвешивание, таким образом, сокращает диапазон или сглаживает спектр, но оно не производит спектр с совершенно плоской огибающей. Диапазон огибающей сокращается, в результате чего часть ее диапазона сохраняется, и этот оставшийся диапазон может использоваться для восстановления первоначального сигнала после расширенной огибающей.
Функция сокращения диапазона или сжатия для огибающей y (где вектор w дает диагональные элементы W) может быть применена, например, по отсчетам как экспонента 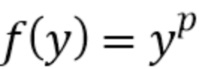 , где .
, где .
Для спектра s и его k-ого отсчета sk взвешивание применяется посредством умножения xk=wk * sk, где xk - k-ый отсчет взвешенного спектра x, и wk - k-ый отсчет вектора w взвешивания. Такая же операция может быть выражена как матричная операция посредством формирования матрицы W, которая имеет значения взвешивания на диагонали Wkk=wk, и матрица является нулевой во всех других позициях. Из этого следует, что x=W*s.
Хотя возможно использовать любую функцию, которая сжимает диапазон y, возведение в степень обладает преимуществом в том, что оно приводит к простому аналитическому выражению при восстановлении огибающей в декодере.
Подходящие функции f() сжатия выполняют следующие требования:
1. функции сжатия являются строго возрастающими, т.е. f(t)<f(t+eps), где t - любая положительная скалярная величина, и eps - произвольно малое значение,
2. для любых положительных скалярных величин (первая и вторая скалярная величина, t1, t2) t1<t2 выполняется условие f(t2) - f(t1)<t2 - t1. Другими словами, любая функция, которая сокращает расстояние между такими двумя положительными скалярными величинами t2 - t1, является подходящей функцией.
В дополнение к возведению в степень f(y)=yp с малой экспонентой p в другом варианте осуществления функция сжатия является логарифмом, то есть f(y)=log(y).
Алгоритм кодера как способ кодирования или реализованный устройством кодирования в одном варианте осуществления является следующим.
1. Вычислить огибающую спектра магнитуды.
2. Выполнить сжатие огибающей для получения модели перцептивного взвешивания.
3. Примените взвешивание к спектру .
4. Выполнить квантование и передать взвешенный спектр 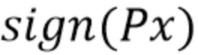 .
.
Этот алгоритм применяется независимо в каждом узле-датчике.
За перцептивным взвешиванием следует квантование.
Таким образом, изобретение состоит из двух частей:
1. распределенное квантование входного сигнала с использованием случайных проекций и 1-битного квантования, и
2. неявная передача перцептивной модели.
Посредством квантования случайных проекций каждый переданный бит кодирует уникальный фрагмент информации и предотвращается избыточное кодирование.
Перцептивная модель формируется независимо в каждом узле-датчике (например, содержащем микрофон), и передается квантованный перцептивно взвешенный сигнал. Перцептивное взвешивание делает сигнал более плоским, но базовая форма сохраняется. Таким образом, на стороне декодера можно сделать обратный вывод, какой должна быть первоначальная огибающая, даже из перцептивно взвешенного сигнала.
Далее следует обсуждение распределенного квантования.
Хотя распределенное кодирование источника является хорошо изученным предметом (например, [7, 8]), и оно применялось в других приложениях, таких как видеокодирование [9], было сделано лишь несколько разработок для распределенного аудиокодирования (например, [10-13]), и ни одна из них, однако, не занимается проблемой избыточного кодирования относительно перцептивных моделей и моделей огибающей. Даже подход с масштабируемым кодированием в [14] включает в себя кодирование огибающей с масштабными коэффициентами. Также подход кодирования с множеством описаний был применено только к маскированию потери пакетов [15, 16].
Далее следует легко реализуемая схема квантования. См. способ 1-битного квантования, который использовался в системах распознавания со сжатием (compressive sensing) [6].
Цель блока квантования и процесса квантования состоит в том, чтобы обеспечить возможность квантования в независимых датчиках, в результате чего гарантируется, тот каждый переданный бит улучшает качество, без осуществления связи между узлами-датчиками. Датчик может отправить исключительно только один бит, и этот единственный бит может использоваться для улучшения качества.
Предложенная схема квантования одного варианта осуществления основана на случайных проекциях действительнозначного представления спектра сигнала и передачи знака каждого измерения.
Пусть x - действительнозначный вектор N x 1, содержащий спектр входного сигнала, и 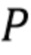 - случайная матрица K x N, столбцы которой нормализованы к единичной длине. Затем x будет преобразован посредством
- случайная матрица K x N, столбцы которой нормализованы к единичной длине. Затем x будет преобразован посредством 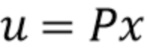 . Далее следует квантование знака каждого компонента u, то есть квантование представляет собой
. Далее следует квантование знака каждого компонента u, то есть квантование представляет собой 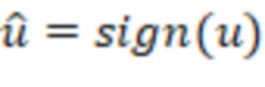 , которое может быть передано без потерь с помощью K битов.
, которое может быть передано без потерь с помощью K битов.
Количество битов битового потока, таким образом, определяет одно измерение случайной матрицы.
Отсчеты P предпочтительно являются псевдослучайными значениями, и это означает, что они похожи на случайные значения, но на самом деле сформированы некоторой сложной математической формулой или алгоритмом. Генераторы псевдослучайных чисел являются стандартными математическими инструментами, которые имеет каждый компьютер и каждая математическая программная библиотека. Справедливо то, что матрица P должна быть известна и в кодере, и в приемнике/декодере, и что распределение случайных чисел является одинаковым для всех отсчетов в P.
Восстановление как приближение x может без затруднений быть вычислено посредством
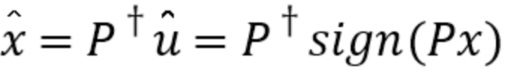 (1)
(1)
где 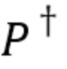 - псевдообратная матрица случайной матрицы .
- псевдообратная матрица случайной матрицы .
При условии, что начальное значение для псевдослучайных столбцов является известным в декодере, декодер может тем самым декодировать сигнал только на основе . Следовательно, в одном варианте осуществления начальное значение псевдослучайных столбцов задано как вспомогательная информация кодированного сигнала. Генераторы псевдослучайных чисел обычно формируют последовательности случайных значений таким образом, что для предыдущего значения x(k) в последовательности они формируют следующий случайный отсчет x(k+1)=f(x(k)). Таким образом, если начальная точка x(1), называемая «начальным значением» псевдослучайной последовательности, известна, то возможно сформировать всю последовательность. Следовательно, на сторонах кодирования и декодирования используется одна и та же функция для формирования случайных отсчетов.
В случае нескольких узлов-датчиков предполагается, что входной сигнал x представляет собой одинаковые или шумные версии одного и того же сигнала, но каждый датчик имеет свою собственную случайную матрицу Pk. В декодере случайные матрицы могут быть сведены в одну большую матрицу P=[P1, P2, …], в результате чего уравнение 1 остается неизменным.
Известно, что если K<<N, то является приблизительно ортонормальным, 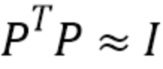 , и квантование является почти оптимальным.
, и квантование является почти оптимальным.
Здесь K не обязательно более меньше N, в результате чего ортонормальность становится менее точной. Использование транспонирования вместо псевдообратной матрицы уменьшает алгоритмическую сложность и эффективность кодирования, но не налагает ограничение на наши эксперименты по перцептивному моделированию, поскольку каждый переданный бит по-прежнему улучшает точность выходного сигнала.
Можно ожидать, что затем на стороне декодера будет применена модель источника, и что такая модель увеличит точность восстановления. Однако, не обязательно реализовывать модель источника, поскольку ее эффект может быть эмулирован увеличением точности посредством отправки большего количества битов.
Блок-схема последовательности варианта осуществления системы (за исключением перцептивной модели) проиллюстрирована на фиг.5. Показаны n микрофонов, захватывающих аудиосигналы из одного источника аудиосигналов. Последующие устройства 1 кодирования находятся в показанной части варианта осуществления соответствующего узла-микрофона или узла-датчика.
n входных сигналов 3 преобразуются преобразователями 15 из n устройств 1 кодирования 1 в n спектров s, которые конвертируются в n перцептивно взвешенных спектров 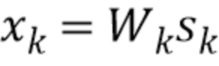 , и здесь это делается не показанными блоками перцептивного взвешивания.
, и здесь это делается не показанными блоками перцептивного взвешивания.
n перцептивно взвешенных спектров xk подаются на n блоков 14 квантования.
Каждый блок 14 квантования содержит блок 16 применения случайной матрицы и блок 17 вычисления функции знака.
Блоки 16 применения случайной матрицы применяют случайную матрицу 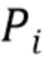 , представляющую собой матрицу с размерами K x N, к вектору N x 1 на основе соответствующего перцептивно взвешенного спектра xi, где i=1, 2, …, n. N - целое скалярное значение, соответствующее количеству отсчетов в спектре x. K - целое скалярное значение, соответствующее количеству рядов в рандомизированном спектре. Посредством квантования с помощью оператора знака каждый ряд квантуется с помощью одного бита, в результате чего количество переданных битов равно K. Когда используются несколько кодеров - например, микрофонов - тогда каждый кодер имеет свои собственные матрицы Pk, которые имеют размер Kk x N. Таким образом, каждый кодер отправляет декодеру Kk битов, причем количество битов может изменяться от кодера к кодеру.
, представляющую собой матрицу с размерами K x N, к вектору N x 1 на основе соответствующего перцептивно взвешенного спектра xi, где i=1, 2, …, n. N - целое скалярное значение, соответствующее количеству отсчетов в спектре x. K - целое скалярное значение, соответствующее количеству рядов в рандомизированном спектре. Посредством квантования с помощью оператора знака каждый ряд квантуется с помощью одного бита, в результате чего количество переданных битов равно K. Когда используются несколько кодеров - например, микрофонов - тогда каждый кодер имеет свои собственные матрицы Pk, которые имеют размер Kk x N. Таким образом, каждый кодер отправляет декодеру Kk битов, причем количество битов может изменяться от кодера к кодеру.
Преобразованные спектры заданы как: 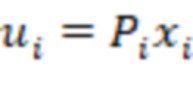 .
.
Блок 17 вычисления функции знака вычисляет знак или функцию знака (sign) соответствующего преобразованного спектра: 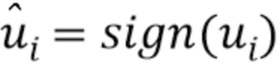 . Это делается с K компонентами преобразованных спектров и дает в результате K битов, передаваемых по каналу передачи.
. Это делается с K компонентами преобразованных спектров и дает в результате K битов, передаваемых по каналу передачи.
Фиг.6 показывает одно устройство 1 кодирования, включающее в себя блок 10 перцептивного взвешивания и блок 14 квантования.
Аудиосигнал 3 преобразовывается преобразователем 15 в спектр sk. Блок 10 перцептивного взвешивания применяет матрицу W перцептивного взвешивания к спектру sk, чтобы обеспечить перцептивно взвешенный спектр xk, который квантуется блоком 14 квантования.
Блок 14 квантования содержит блоки 16 применения случайных матриц, которые принимают перцептивно взвешенный спектр xk и применяют к нему случайную матрицу Pk через Pkxk. Компоненты полученного в результате преобразованного спектра uk квантуются блоком 17 вычисления функции знака через вычисление функции знака каждого компонента. Это дает в результате битовые потоки с количеством битов, равным количеству компонентов преобразованного спектра. Кодированный сигнал 4, таким образом, задается посредством битового потока 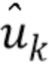 .
.
Далее следует обсуждение методов декодирования кодированных сигналов.
Фиг.7 показывает вариант осуществления устройства 2 декодирования для обработки кодированного сигнала 4.
Кодированный сигнал 4 находится в форме битового потока , подвергается обратному квантованию блоком 20 обратного квантования.
Кодированный сигнал 4 подвергается обратному квантованию посредством использования псевдообратной для случайной матрицы . Информация о случайной матрице извлекается из вспомогательной информации кодированного сигнала 4. Вычисленный перцептивно взвешенный спектр задается как: 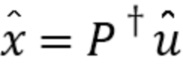 .
.
Вычисленный перцептивно взвешенный спектр 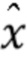 подвергается устранению перцептивного взвешивания блоком 21 устранения перцептивного взвешивания. Вычисленный спектр
подвергается устранению перцептивного взвешивания блоком 21 устранения перцептивного взвешивания. Вычисленный спектр 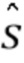 , обеспеченный блоком 21 устранения перцептивного взвешивания, преобразовывается блоком 22 обратного преобразования (например, через обратное оконное преобразования Фурье, STFT-1) во временной сигнал, который представляет собой извлеченным аудиосигнал 5.
, обеспеченный блоком 21 устранения перцептивного взвешивания, преобразовывается блоком 22 обратного преобразования (например, через обратное оконное преобразования Фурье, STFT-1) во временной сигнал, который представляет собой извлеченным аудиосигнал 5.
Фиг.8 показывает вариант осуществления, в котором блок 20 обратного квантования принимает множество кодированных сигналов 4 из разных узлов-датчиков, т.е. от разных микрофонов. Отдельные случайные матрицы Pk сводятся в одну большую матрицу P=[P1, P2, …].
Один вычисленный перцептивно взвешенным спектр тогда задается как: 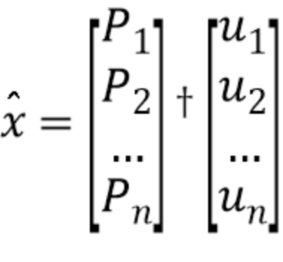 .
.
В альтернативном варианте осуществления битовые потоки инвертируются с помощью их соответствующих случайных матриц 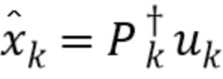 , и спектры затем сливаются.
, и спектры затем сливаются.
Полученный вычисленный перцептивно взвешенный спектр обрабатывается, как описано для варианта осуществления, показанного на фиг.7.
На фиг.9 показан вариант осуществления блока 21 устранения перцептивного взвешивания как части устройства декодирования.
Блок 21 устранения перцептивного взвешивания принимает от блока 20 обратного квантования вычисленный перцептивно взвешенный спектр , который представляет собой подвергнутый обратному квантованию битовый поток кодированного сигнала 4.
Блок 21 устранения перцептивного взвешивания восстанавливает модель W с перцептивным взвешиванием, использованную во время кодирования входного сигнала 3, посредством использования итеративного алгоритма. Здесь Wk - k-ое приближение или предположение модели W с перцептивным взвешиванием.
Алгоритм начинается с блока 23 обеспечения исходного предположения. Блок 23 обеспечения исходного предположения обеспечивает нулевую оценку W0 модели W с перцептивным взвешиванием.
В показанном варианте осуществления используется вектор wk, который содержит диагональные элементы соответствующей матрицы Wk. Такой вектор использовался c функцией сжатия огибающей спектра магнитуды во время перцептивного взвешивания входного сигнала.
Следовательно, задано нулевое предположение вектора w0, и соответствующим образом установлено нулевое приближение W0 модели W с перцептивным взвешиванием.
Исходное предположение вектора w0 приближения устанавливается в одном варианте осуществления посредством использования уравнение, используемого для вычисления огибающей y спектра магнитуды.
Так, исходное предположение становится: 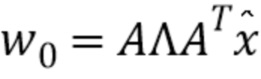 с матрицей A и диагональной матрицей Λ.
с матрицей A и диагональной матрицей Λ.
Матрица A представляет собой набор фильтров, и диагональная матрица (содержит коэффициенты нормализации для каждой группы используемого набора фильтров. Выбор матрицы A является проектным решением, которое, как правило, заранее фиксировано. В варианте осуществления, в котором матрица A не изменяется со временем, она жестко встроена и в кодер, и в декодер. Это подразумевает, что и кодер, и декодер используют одну и ту же известную матрицу A. В другом варианте осуществления матрица, используемая для кодирования, передается как часть кодированного сигнала. В одном варианте осуществления выбор относительно матрицы A передается на этапе инициализации или конфигурации, прежде чем начнется фактическая передача данных. Сказанное выше также относится к диагональной матрице Λ.
Матрица W0 исходного предположения подается на блок 24 аппроксимации спектра. С этого также начинается фактическая итерация с переменным индексом k, установленным равным 0.
Блок 24 аппроксимации спектра на основе данных w0 для исходного предположения W0 модели W с перцептивным взвешиванием вычисляет приближение спектра.
Это делается через применение инверсии матрицы W0 исходного предположения к вектору, содержащему вычисленный перцептивно взвешенный спектр .
Спектр аппроксимируется на этом шаге с k=0 посредством 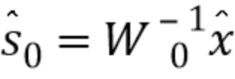 .
.
Аппроксимированный спектр  подается на блок 25 аппроксимации модели, который вычисляет новое приближение W1 для модели W с перцептивным взвешиванием.
подается на блок 25 аппроксимации модели, который вычисляет новое приближение W1 для модели W с перцептивным взвешиванием.
Это основано на знании, что вектор диагональных элементов wk является функцией спектра  .
.
В одном варианте осуществления функция f() сжатия, которая используется во время кодирования для формирования матрицы W, известна на стороне декодирования. Как обсуждалось ранее относительно матрицы A, функция f() сжатия либо установлена на обеих сторонах, например, фиксирована в соответствующем программном обеспечении для кодирования и декодирования, либо передается как часть кодированного сигнала.
Следовательно, следующее приближение вектора вычисляется через: 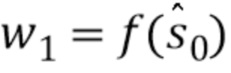 , и получается следующее - здесь первое - приближение W1.
, и получается следующее - здесь первое - приближение W1.
Это приближение W1 возвращается блоку 24 аппроксимации спектра для вычисления следующего аппроксимированного спектра 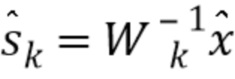 . Индекс k соответствующим образом увеличивается.
. Индекс k соответствующим образом увеличивается.
Это приближение служит далее для получения следующего приближения Wk+1 модели W с перцептивным взвешиванием на основе вектора с диагональными элементами, заданного уравнением: 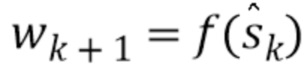 .
.
Это повторяется, пока не будет достигнута сходимость. Сходимость обычно проверяется посредством сравнения текущего выданного вектора w(k) с предыдущим вектором w(k-1). Если разность ||w(k) - w(k-1)|| меньше некоторого предварительно заданного порога, то итерация сошлась, и итерации могут быть остановлены.
Полученный наконец приближенный спектр является выходом блока 21 устранения перцептивного взвешивания и представляет собой приближение спектра первоначального входного сигнала.
Восстановление перцептивной модели разъясняется еще раз.
На стороне декодера оценка перцептивного сигнала x (см. уравнение 1) может быть восстановлена посредством 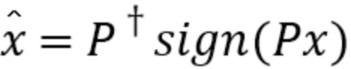 , где
, где 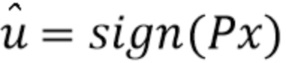 - квантованный перцептивно взвешенный спектр x. Это выполняется посредством блока 20 обратного квантования.
- квантованный перцептивно взвешенный спектр x. Это выполняется посредством блока 20 обратного квантования.
Главная задача состоит в том, чтобы тем самым восстановить оценку первоначального сигнала s из квантованного перцептивного сигнала .
Перцептивно взвешенный спектр x основан на спектре входного сигнала через модель W с перцептивным взвешиванием посредством уравнения: .
Цель состоит в том, что оценка была равна спектру, т.е. 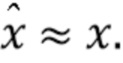
Следовательно, 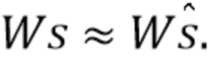
Кроме того, вектор w, задающий диагональные элементы матрицы W, является функцией спектра s входного сигнала: w=f(s).
Таким образом, с помощью оценки w может быть оценен 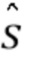 , в результате чего может быть оценен w. Это может повторяться, пока не будет достигнута сходимость.
, в результате чего может быть оценен w. Это может повторяться, пока не будет достигнута сходимость.
Таким образом, это алгоритм максимизации ожидания, который может быть описан следующим образом:
1. Получить исходное предположение w0, например, и соответствующим образом установить w0.
2. Повторять от k=0, пока не будет достигнута сходимость:
(a) Вычислить .
(b) Вычислить 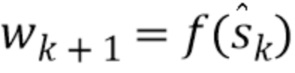 и соответствующим образом установить Wk+1.
и соответствующим образом установить Wk+1.
(c) Увеличить k.
Последние значения и Wk являются окончательными оценками и 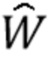 .
.
Как правило, для сходимости требуется меньше 20 итераций.
Разные варианты осуществления устройства декодирования 2 также показаны на фиг.5 и фиг.6. Устройство 2 декодирования на фиг.5 показано без устранения взвешивания. На фиг.6 аппроксимация модели W с перцептивным взвешиванием задается и используется для устранения взвешивания подвергнутого обратному квантованию спектра . Это подчеркивает, что декодирование включает в себя восстановление модели W на основе кодированного сигнала.
Для оценки функционирования каждой части предложенной системы были выполнены следующие эксперименты.
Были сравнены три версии входных аудиоданных:
квантованный и восстановленный сигнал 1) без перцептивного моделирования и 2) с перцептивным моделированием, известным в декодере,
а также 3) перцептивно квантованный сигнал, причем восстановление выполняется со вслепую оцениваемой перцептивной моделью в соответствии с изобретением.
В качестве тестового материала были использованы случайные речевые отсчеты из набора данных NTT-AT [21] (см. верхний ряд на фиг.10). Входные сигналы были передискретизированы на частоте 12,8 кГц, преобразование STFT было реализовано с дискретным косинусным преобразованием для получения действительнозначного спектра, и использовалась модель огибающей с 20 полосами, распределенными в соответствии с мел-шкалой [20, 5].
В качестве первого приближения перцептивной модели использовалась функция сокращения диапазона с p=0,5. Эта перцептивная модель была выбрана лишь в качестве способа демонстрации функционирования слепого восстановления, и ее нельзя рассматривать как налаженный готовый продукт.Функционирование модели огибающей, а также перцептивной модели уже было проиллюстрировано на фиг.4.
Сначала будет оценено перцептивное отношение SNR для квантования, предложенного без слепого восстановления (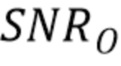 ) и со слепым восстановлением (
) и со слепым восстановлением (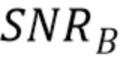 ) перцептивной модели, соответственно:
) перцептивной модели, соответственно:
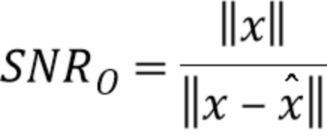 и
и 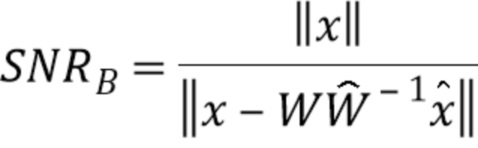 (2)
(2)
Фиг.10 иллюстрирует перцептивное отношение SNR для речевого файла, квантованного разными способами (K=3000).
Ясно, что когда перцептивная модель известна (подход с предсказанием), отношение SNR близко к 8,4 дБ. Слепое восстановление перцептивной модели (вслепую) явно уменьшает качество, особенно для звонких фонем. Однако отношение SNR системы без перцептивной модели (без п.модели) более чем в два раза хуже, чем со слепым восстановлением.
Чтобы дополнительно количественно оценить преимущество слепого восстановления вместо отсутствия перцептивного моделирования, было измерено среднее отношение SNR с разными битовыми скоростями K (см. фиг.11).
Подходы со слепым восстановлением и без перцептивной модели в среднем на 1,1 дБ и на 5,8 дБ хуже, чем подход с предсказанием. Очевидно, отношение SNR улучшается с битовой скоростью, хотя случай без перцептивной модели улучшается медленнее, чем с перцептивной моделью. Кроме того, с увеличением отношения SNR слепое восстановление асимптотически приближается к качеству подхода с предсказанием.
Наконец, чтобы оценить субъективное качество, был выполнен тест на прослушивание MUSHRA с восемью слушателями и шестью случайно выбранными позициями из набора данных NTT-AT. Сигнал подвергался квантованию с 3 кбит на кадр. Это относительно малое количество с учетом того, что для экспериментов не использовалось моделирование источника, в результате чего выходное отношение SNR также является относительно малым. Этот сценарий был выбран, чтобы продемонстрировать проблематичное условие, и предполагается, что функционирование значительно улучшится на более высоких битовых скоростях, а также при применении модели источника.
На основе разностных оценок MUSHRA на фиг.12 можно видеть, что для всех позиций перцептивное моделирование улучшает качество для оценки с предсказанием, и для слепой оценки на 29,9 и 22,3 пунктов в среднем, соответственно. Статистическая значимость разностей была подтверждена с помощью t-критерия Стьюдента при p>99%.
Предложенная схема 1-битного квантования и кодирования - либо объединенная в одном варианте осуществления, либо в отдельных вариантах осуществления - имеет несколько интересных последствий и свойств.
Во-первых, для анализа свойств квантования следует отметить, что каждый столбец матрицы P является проекцией на 1-мерное подпространство N-мерного пространства вектора x.
Посредством кодирования знака одной проекции N-мерное пространство разбивается на две части. Посредством повторяющегося кодирования знаков 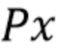 N-мерное пространство разбивается на еще более мелкие ячейки квантования. Поскольку P является случайной матрицей, ее столбцы приблизительно ортогональны друг другу, в результате чего ячейки квантования остаются почти оптимальными.
N-мерное пространство разбивается на еще более мелкие ячейки квантования. Поскольку P является случайной матрицей, ее столбцы приблизительно ортогональны друг другу, в результате чего ячейки квантования остаются почти оптимальными.
В системе с одним узлом может быть разработан подход квантования, который является более эффективным. Однако в распределенной системе это становится сложнее - нужен простой способ предотвращения того, чтобы узлы кодировали одинаковую информацию, то есть нужно избежать избыточного кодирования, сохраняя низкую алгоритмическую сложность. Квантование в изобретении является очень простым и обеспечивает почти оптимальную производительность.
Во-вторых, не использовались способы кодирования источника.
Однако известно, что такое моделирование может использоваться для значительного улучшения эффективности кодирования. Моделирование источника может быть применено на стороне декодера посредством моделирования распределения вероятности речевых сигналов и аудиосигналов (например, [22]). Моделирование источника возможно, поскольку квантованный сигнал может рассматриваться как наблюдение при наличии шумов за «истинным» сигналом, в результате чего посредством применения предшествующего распределения источника может быть применена оптимизация наибольшего правдоподобия (или сходная оптимизация), чтобы аппроксимировать «истинный» сигнал. Поскольку эта оптимизация применяется в сети или в декодере, узлы-датчики предохранены от вычислительной нагрузки, и узлы-датчики могут оставаться маломощными.
В-третьих, с точки зрения конфиденциальности возможно разработать способ случайной проекции с очень эффективным шифрованием.
Если подслушивающий не будет знать начальное значение для случайной матрицы, то данные будут казаться совершенно случайными и бессмысленными. В предположении, что случайное начальное значение передается безопасным образом, только кодер и намеченный приемник могут расшифровать сообщение. Этот подход отличается от таких подходов, которые даны в [12, 13], где намеренно используется связь между узлами. Хотя такое сотрудничество между узлами может использоваться для улучшения перцептивного отношения SNR, труднее гарантировать конфиденциальность. Даже в предположении, что узлы-датчики работают по безопасной сети, возможно взять только один взломанный узел, чтобы получить доступ ко всему обмену данными. Напротив, в предложенном подходе, если подслушивающий получает доступ к одному узлу-датчику, он взламывает данные только этого узла, поскольку узлы могут и должны использовать разные начальные значения. Чтобы ограничить мощность передачи узлов-датчиков, можно, однако, разрешить узлам ретранслировать пакеты, поскольку пакеты остаются читаемыми только намеченным получателем, и, таким образом, конфиденциальность не ставится под угрозу.
Способ изобретения в одном варианте осуществления основан на идее 1-битного квантования, когда на стороне кодера перцептивно взвешенный входной сигнал проецируется на случайное подпространство, и затем передается знак каждого измерения. Декодер может инвертировать квантование с помощью псевдообратной матрицы и т.п., чтобы получить квантованный перцептивно взвешенный сигнал.
Основной частью предложенного способа является последующее восстановление оценки первоначального сигнала, когда мы имеем доступ только к перцептивно взвешенному сигналу. Подход основан на алгоритме максимизации оценки (EM), в котором итеративно чередуются оценка перцептивной модели и первоначального сигнала.
Предложенный распределенный алгоритм кодирования речевых сигналов и аудиосигналов, таким образом, является целесообразным подходом для приложений «Интернета вещей». Он предлагает масштабируемое функционирование для любого количества узлов-датчиков и уровня потребления энергии. Кроме того, алгоритм безопасен по своему замыслу, поскольку конфиденциальность канала связи может быть гарантирована посредством зашифрованной передачи случайного начального значения.
Представленное изобретение включает в себя по меньшей мере следующие признаки, аспекты, а также очевидные применения и расширения. Таким образом, список относится к другому варианту осуществления и допускает различные комбинации упомянутых признаков.
1. Система распределенного кодирования речевых сигналов и аудиосигналов с одним или несколькими кодерами, которые могут быть реализованы на масштабируемых, гибких, маломощных и недорогих процессорах с ограниченными пропускной способностью передачи, вычислительной способностью и другими ресурсами.
1.1. Распределенные кодеры могут быть выполнены с возможностью кодирования информации таким образом, что информация от каждого узла кодера может быть независимо квантована, в результате чего объем информации от коллекции узлов может быть максимизирован, например,
1.1.1. посредством того, что каждый узел кодера кодирует информацию, которая является ортогональной или приблизительно ортогональной по отношению к другим узлам,
1.1.2. посредством использования алгоритмов случайного квантования, которые могут являться или не являться ортогональными или приблизительно ортогональными по отношению к другим узлам,
1.1.3. посредством использования способов энтропийного кодирования для сжатия квантованной информации.
1.2. Распределенные кодеры могут быть выполнены с возможностью кодирования информации в перцептивной области, которая аппроксимирует перцептивную точность слуховой системы человека,
1.2.1. причем преобразование в перцептивную область может быть сделано обратимым, в результате чего узлы кодера могут (вслепую) восстановить перцептивную модель без явной передачи перцептивной модели,
1.2.2. причем некоторые или все параметры перцептивных моделей могут быть явно переданы от некоторых или всех узлов кодера как вспомогательная информация.
1.2.3. причем перцептивные модели могут быть описаны с использованием моделей огибающей, таких как модели с линейным предсказанием, наборы фильтров, матричные преобразования или полосы масштабных коэффициентов (кусочно-постоянных или интерполированных), и они могут быть реализованы как матричные операции или операции фильтрации.
1.2.4. причем перцептивные модели могут иметь постоянные и адаптивные части, где постоянные части всегда являются одинаковыми, и адаптивные части зависят от входного сигнала, и/или конфигурации системы, и/или количества доступных ресурсов (аппаратных ресурсов, вычислительных ресурсов, ресурсов для передачи, мощности батареи и т.д.).
1.3. Распределенные кодеры могут быть выполнены с возможностью кодирования информации таким образом, что ошибка квантования минимизирована в перцептивной области, например, как цикл анализа через синтез в кодеках CELP.
1.4. Распределенные кодеры могут быть выполнены с возможностью кодирования информации с использованием шифрования, чтобы предотвратить подслушивание, например,
1.4.1. посредством шифрования финального или промежуточного описания сигнала перед передачей с использованием способов, которые являются алгоритмическими или основаны на таблицах поиска,
1.4.2. посредством использования квантования с рандомизацией, такой как случайные преобразования или проекции, когда рандомизация достигается посредством алгоритма или таблицы поиска с известным начальным значением (стартовой точкой).
1.5. Распределенные кодеры, конфигурация которых может быть гибкой и модифицироваться в режиме онлайн, например,
1.5.1. на основе местоположения и движения звуковых источников (таких как говорящие люди), узлов-датчиков, а также доступности ресурсов, узлы-датчики могут независимо или совместно решать, какие узлы активны или не активны,
1.5.2. на основе местоположения и движения звуковых источников (таких как говорящие люди), узлов-датчиков, а также доступности ресурсов, узлы-датчики могут независимо или совместно решать регулировать распределение ресурсов, например, таким образом, чтобы узел-датчик с микрофоном около говорящего использовал больше ресурсов, чем тот, который находится дальше.
1.6. Особый случай предложенной системы - когда существует только один кодер, в результате чего система сводится к классической архитектуре кодеков для речевых сигналов и аудиокодеков. Однако важно отметить, что случайное квантование и слепое восстановление перцептивной модели - аспекты текущего изобретения - могут использоваться также в классической структуре кодера и декодера, например, в интересах эффективности кодирования, для получения кодера низкой сложности и для шифрования связи.
2. Система распределенного кодирования речевых сигналов и аудиосигналов, в которой ввод от кодеров сливается в одном или нескольких сетевых узлах (с использованием способов обработки в сети) или в одном или нескольких узлах декодера/приемника.
2.1. Декодер или блоки обработки могут быть выполнены с возможностью выполнять обратное квантование, например,
2.1.1. точное обратное преобразование, псевдоинверсию или приближенную инверсию, такую как транспонирование случайной матрицы,
2.1.2. оценку входного сигнала посредством методов оптимизации, таких как распознавание со сжатием,
2.1.3. битовые потоки 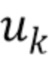 из узлов
из узлов 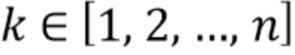 могут быть слиты посредством совместной инверсии, такой как , или битовые потоки могут быть сначала инвертированы , и только потом слиты. Преимущество последнего состоит в том, что тогда мы можем применить моделирование, такое как перцептивная модель, модель источника, пространственная модель и модель датчика, отдельно или совместно на каждом узле.
могут быть слиты посредством совместной инверсии, такой как , или битовые потоки могут быть сначала инвертированы , и только потом слиты. Преимущество последнего состоит в том, что тогда мы можем применить моделирование, такое как перцептивная модель, модель источника, пространственная модель и модель датчика, отдельно или совместно на каждом узле.
2.2. Декодер или блоки обработки могут быть выполнены с возможностью инвертирования перцептивную модель посредством использования переданной вспомогательной информации и/или посредством ее слепой оценки на основе восстановленного (перцептивного) сигнала, например, посредством
2.2.1. прямых методов, когда перцептивная модель получается непосредственно из квантованного сигнала,
2.2.2. итеративных методов, когда оценка перцептивной модели последовательно улучшается с каждой итерацией.
2.3. Декодер или блоки обработки могут быть выполнены с возможностью использования модели источник и модели узла-датчика, чтобы улучшить качество декодированного сигнала.
2.3.1. Посредством моделирования статистических свойства сигналов источника и узлов-датчиков мы можем оптимизировать вероятность наблюдения (квантованного сигнала) с учетом предшествующего распределения сигнала и/или источника.
2.3.1.1. Признаки смоделированного источника могут включать в себя одну или несколько моделей огибающей спектра (модели с линейным предсказанием, квантование распределения, масштабные коэффициенты и т.д.), гармонические модели (гребенчатые фильтры, долговременные прогнозы и т.д.), временные огибающие (модели с линейным предсказанием, квантование распределения, масштабные коэффициенты и т.д.), пространственные огибающие и пространственные модели движения.
2.3.1.2. Признаки могут быть смоделированы с помощью поиска в таблице, такой как кодовые книги или векторное квантование, или с помощью параметрических моделей, таких как физические (речеобразование и т.д.), перцептивные (модели маскирования, критические полосы и т.д.) или статистические модели (одномерные или многомерные распределения вероятностей).
2.3.1.3. Признаки могут описывать акустические и пространственные признаки источников, но также и признаки узлов-датчиков, такие как качество сигнала (например, высокое или низкое отношение SNR) и пространственные признаки (например, стационарный, движущийся, носимый и т.д.).
2.3.2. Посредством определения перцептивно раздражающих искажений выходного сигнала мы можем модифицировать выходной сигнал, например, посредством способов последующей фильтрации.
2.4. Декодер или блоки обработки могут быть выполнены с возможностью использовать способы улучшения сигнала, такие как ослабление шума, формирование диаграммы направленности и способы разделения источников, чтобы улучшить качество сигнала.
2.4.1. Способы с несколькими микрофонами, такие как формирование диаграммы направленности, могут использоваться, чтобы получить выгоду от пространственной конфигурации датчиков для извлечения пространственно разделенных источников звука и другой информации об акустике помещения. Важно отметить, что способы с несколькими микрофонами, как правило, могут включать в себя оценку задержки и/или оценку взаимной корреляции.
2.4.2. Способы ослабления шума могут использоваться для подавления нежелательных источников, таких как фоновый шум.
2.4.3. Способы разделения источников могут использоваться для различения нескольких источников звука.
3. Система распределенного кодирования речевых сигналов и аудиосигналов, в которой информация сигнальной информации может быть передана, ретранслирована и обработана посредством выбора устройств/узлов в системе.
3.1. Узлы-датчики (устройства с датчиками) принимают необработанный сигнал и могут быть выполнены с возможностью либо кодирования (квантования и кодирования) сигнала, либо его передачи в необработанном формате.
3.2. Любой узел (как правило, узел-датчик), который имеет доступ к необработанному сигналу, может кодировать сигнал и передать его.
3.3. Любой узел может быть выполнен с возможностью ретрансляции информации от других узлов.
3.4. Любой узел (как правило, узел-приемник), который имеет доступ к кодированному сигналу (и к факультативной информации шифрования-декодирования), может быть выполнен с возможностью декодирования сигнала.
3.5. Промежуточный узел, такой как серверное устройство на стороне декодера, может быть выполнен с возможностью слияния информации из доступных потоков в один или несколько потоков. Комбинированный поток (потоки) может представлять, например, первоначальное акустическое представление (например, музыкальный спектакль) или отдельные источники звука (например, отдельные выступающие на телеконференции). Комбинированный поток может быть затем воспроизведен посредством динамиков, сохранен, передан как таковой или кодирован тем же самым или некоторым другим инструментом кодирования речевых сигналов и аудиосигналов.
3.6. Конфигурация сети может быть выполнена как статичная или динамичная, чтобы она оптимизировала, например, один или несколько из следующих критериев: качество звука, распределение ресурсов, безопасность/конфиденциальность.
4. Предполагаемые приложения включают в себя по меньшей мере
4.1. Телефонные приложения, в которых выбор поддерживающих устройств используется для сбора желаемого речевого сигнала и аудиосигнала (сигналов).
4.1.1. Домашние и офисные приложения, в которых выбор поддерживающих устройств используется для сбора желаемого речевого сигнала и аудиосигнала (сигналов) и передаются одному или нескольким удаленным местоположениям.
4.1.2. Приложения телеконференций, в которых выбор поддерживающих устройств используется для сбора желаемого речевого сигнала и аудиосигнала (сигналов) и передаются одному или нескольким удаленным местоположениям.
4.1.3. Системы автомобильного телефона, в которых фиксированные микрофоны в автомобиле и/или поддерживающие устройства в автомобиле используются для сбора желаемого речевого сигнала и аудиосигнала (сигналов) и передаются одному или нескольким отдаленным местоположениям.
4.2. Игры и приложения виртуальной/дополненной реальности, в которых звуковая сцена игрока передается другим игрокам или серверу.
4.3. Рабочие приложения для концерта, выступления, театральной постановки, оперы, представления, спортивного мероприятия и другого события, в которых звуки исполнителей, игроков, аудитории или полной звуковой сцены записываются или передаются с помощью системы распределенного кодирования речевых сигналов и аудиосигналов.
4.3.1. Приложение может быть разработано с низкой или сверхнизкой задержкой, чтобы обеспечить взаимодействие и/или одновременное воспроизведение и усиление.
4.3.2. Приложение может быть разработано для обеспечения взаимодействия между исполнителями в аудитории или между всеми участниками.
4.4. Приложения безопасности, в которых звуковая сцена отслеживается для обнаружения опасных событий (например, паника на стадионе), несчастных случаев дома (например, падающий пожилой человек) и т.д.
4.5. Мультимедийные приложения, в которых речевые сигналы и аудиосигналы объединены с видеоинформацией и/или другой информацией.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где модуль или устройство соответствуют этапу способа или признаку этапа способа. Аналогичным образом аспекты, описанные в контексте этапа способа, также представляют описание соответствующего модуля, или элемента, или признака соответствующего устройства. Некоторые или все этапы способа могут быть исполнены (или использовать) аппаратное устройство, как, например, микропроцессор, программируемый компьютер или электронная схема. В некоторых вариантах осуществления некоторый один или более из самых важных этапов способа могут быть исполнены таким устройством.
В изобретении переданный или кодированный сигнал может быть сохранен на цифровом запоминающем носителе или может быть передан в передающем носителе, таком как беспроводной передающий носитель или проводной передающий носитель, например, Интернет.
В зависимости от некоторых требований реализации варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может быть выполнена с использованием цифрового запоминающего носителя, например гибкого диска, DVD, Blu-ray, CD, ПЗУ (ROM), ППЗУ (PROM), СППЗУ (EPROM), ЭСППЗУ (EEPROM) или флэш-памяти, имеющих сохраненные на них читаемые в электронном виде управляющие сигналы, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой, в результате чего выполняется соответствующий способ. Таким образом, цифровой запоминающий носитель может являться машиночитаемым.
Некоторые варианты осуществления в соответствии с изобретением содержат носитель данных, имеющий в читаемые в электронном виде управляющие сигналы, которые способны взаимодействовать с программируемой компьютерной системой, в результате чего выполняется один из способов, описанных в настоящем документе.
Обычно варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, программный код выполнен с возможностью выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных в настоящем документе, сохраненных на машиночитаемом носителе.
Другими словами, вариант осуществления способа изобретения, таким образом, представляет собой компьютерную программу, имеющую программный код для выполнения одного из способов, описанных в настоящем документе, когда компьютерная программа выполняется на компьютере.
Дополнительный вариант осуществления способов изобретения, таким образом, представляет собой носитель данных (или запоминающий носитель долговременного хранения, такой как цифровой запоминающий носитель или машиночитаемый носитель) содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Носитель данных, цифровой запоминающий носитель или носитель с записанными данными обычно являются материальными и/или долговременного хранения.
Дополнительный вариант осуществления способа изобретения, таким образом, представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Поток данных или последовательность сигналов, например, могут быть выполнены с возможностью быть перенесенными через соединение передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например компьютер или программируемое логическое устройство, выполненное с возможностью или адаптированное для выполнения одного из способов, описанных в настоящем документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
Дополнительный вариант осуществления в соответствии с изобретением содержит устройство или систему, выполненную с возможностью переносить (например, в электронном или оптическом виде) компьютерную программу для выполнения одного из способов, описанных в настоящем документе, к приемнику. Приемник, например, может являться компьютером, мобильным устройством, запоминающим устройством и т.п.Устройство или система, например, могут содержать файловый сервер для переноса компьютерной программы к приемнику.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторой или всей функциональности способов, описанных в настоящем документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из способов, описанных в настоящем документе. Обычно способы предпочтительно выполняются любым аппаратным устройством.
Описанные выше варианты осуществления являются лишь иллюстрацией принципов настоящего изобретения. Подразумевается, что модификации и вариации размещений и подробностей, описанных в настоящем документе, будут очевидны для других специалистов в области техники. Таким образом, подразумевается, что изобретение ограничено только объемом последующей патентной формулы изобретения, а не конкретными подробностями, представленными посредством описания и разъяснения представленных в настоящем документе вариантов осуществления.
Литература
[1] TS 26.445, EVS Codec Detailed Algorithmic Description; 3GPP Technical Specification (Release 12), 3GPP, 2014.
[2] TS 26.190, Adaptive Multi-Rate (AMR-WB) speech codec, 3GPP, 2007.
[3] ISO/IEC 23003-3:2012, ʺMPEG-D (MPEG audio technologies), Part 3: Unified speech and audio coding, (2012.
[4] M. Bosi, K. Brandenburg, S. Quackenbush, L. Fielder, K. Akagiri, H. Fuchs, and M. Dietz, ʺISO/IEC MPEG-2 advanced audio coding, (Journal of the Audio engineering society, vol. 45, no. 10, pp.789-814, 1997.
[5] M. Bosi and R. E. Goldberg, Introduction to Digital Audio Coding and Standards. Dordrecht, The Netherlands: Kluwer Academic Publishers, 2003.
[6] P. T. Boufounos and R. G. Baraniuk, ʺ1-bit compressive sensing, (in Information Sciences and Systems, 2008. CISS 2008. 42nd Annual Conference on. IEEE, 2008, pp.16-21.
[7] Z. Xiong, A. D. Liveris, and S. Cheng, ʺDistributed source coding for sensor networks, (IEEE Signal Process. Mag., vol. 21, no. 5, pp.80-94, 2004.
[8] Z. Xiong, A. D. Liveris, and Y. Yang, ʺDistributed source coding, (Handbook on Array Processing and Sensor Networks, pp.609- 643, 2009.
[9] B. Girod, A. M. Aaron, S. Rane, and D. Rebollo-Monedero, ʺDistributed video coding, (Proc. IEEE, vol. 93, no. 1, pp.71-83, 2005.
[10] A. Majumdar, K. Ramchandran, and L. Kozintsev, ʺDistributed coding for wireless audio sensors, (in Applications of Signal Processing to Audio and Acoustics, 2003 IEEE Workshop on. IEEE, 2003, pp.209-212.
[11] H. Dong, J. Lu, and Y. Sun, ʺDistributed audio coding in wireless sensor networks, (in Computational Intelligence and Security, 2006 International Conference on, vol. 2. IEEE, 2006, pp.1695-1699.
[12] A. Zahedi, J. ∅stergaard, S. H. Jensen, P. Naylor, and S. Bech, ʺCoding and enhancement in wireless acoustic sensor networks, (in Data Compression Conference (DCC), 2015. IEEE, 2015, pp. 293-302.
[13] A. Zahedi, J. ∅stergaard, S. H. Jensen, S. Bech, and P. Naylor, ʺAudio coding in wireless acoustic sensor networks, (Signal Processing, vol. 107, pp.141-152, 2015.
[14] US 7,835,904.
[15] G. Kubin and W. B. Kleijn, ʺMultiple-description coding (MDC) of speech with an invertible auditory model, (in Speech Coding, IEEE Workshop on, 1999, pp.81-83.
[16] V. K. Goyal, ʺMultiple description coding: Compression meets the network, (IEEE Signal Process. Mag., vol. 18, no. 5, pp.74- 93, 2001.
[17] J. O. Smith III and J. S. Abel, ʺBark and ERB bilinear transforms, (IEEE Trans. Speech Audio Process., vol. 7, no. 6, pp.697-708, 1999.
[18] T. Bäckström, ʺVandermonde factorization of Toeplitz matrices and applications in filtering and warping, (IEEE Trans. Signal Process., vol. 61, no. 24, pp.6257-6263, Dec. 2013.
[19] F. Zheng, G. Zhang, and Z. Song, ʺComparison of different implementations of MFCC, (Journal of Computer Science and Technology, vol. 16, no. 6, pp.582-589, 2001.
[20] H. Fastl and E. Zwicker, Psychoacoustics: Facts and models. Springer, 2006, vol. 22.
[21] NTT-AT, ʺSuper wideband stereo speech database, (http://www.ntt-at.com/product/widebandspeech, accessed: 09.09.2014. [Online]. Available: http://www.ntt-at.com/product/ widebandspeech
[22] S. Korse, T. Jähnel, and T. Bäckström, ʺEntropy coding of spectral envelopes for speech and audio coding using distribution quantization, (in Proc. Interspeech, 2016.
| название | год | авторы | номер документа |
|---|---|---|---|
| АУДИОКОДЕР И ДЕКОДЕР | 2015 |
|
RU2696292C2 |
| СПОСОБ И УСТРОЙСТВО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИОСИГНАЛОВ (ВАРИАНТЫ) | 2012 |
|
RU2505921C2 |
| КОДЕР ДЛЯ КОДИРОВАНИЯ АУДИОСИГНАЛА, СИСТЕМА ПЕРЕДАЧИ АУДИО И СПОСОБ ОПРЕДЕЛЕНИЯ ЗНАЧЕНИЙ КОРРЕКЦИИ | 2014 |
|
RU2643646C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2008 |
|
RU2562375C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2008 |
|
RU2456682C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2019 |
|
RU2793725C2 |
| УСТРОЙСТВО И СПОСОБ ДЕКОДИРОВАНИЯ КОДИРОВАННОГО ЗВУКОВОГО СИГНАЛА | 2009 |
|
RU2483366C2 |
| КВАНТОВАНИЕ КОЭФФИЦИЕНТОВ УСИЛЕНИЯ ДЛЯ РЕЧЕВОГО КОДЕРА ЛИНЕЙНОГО ПРОГНОЗИРОВАНИЯ С КОДОВЫМ ВОЗБУЖДЕНИЕМ | 2001 |
|
RU2257556C2 |
| КОДИРОВАНИЕ СПЕКТРАЛЬНЫХ КОЭФФИЦИЕНТОВ СПЕКТРА АУДИОСИГНАЛА | 2014 |
|
RU2638734C2 |
| СПОСОБ ОБРАБОТКИ ЗВУКОВОГО СИГНАЛА | 2011 |
|
RU2464649C1 |
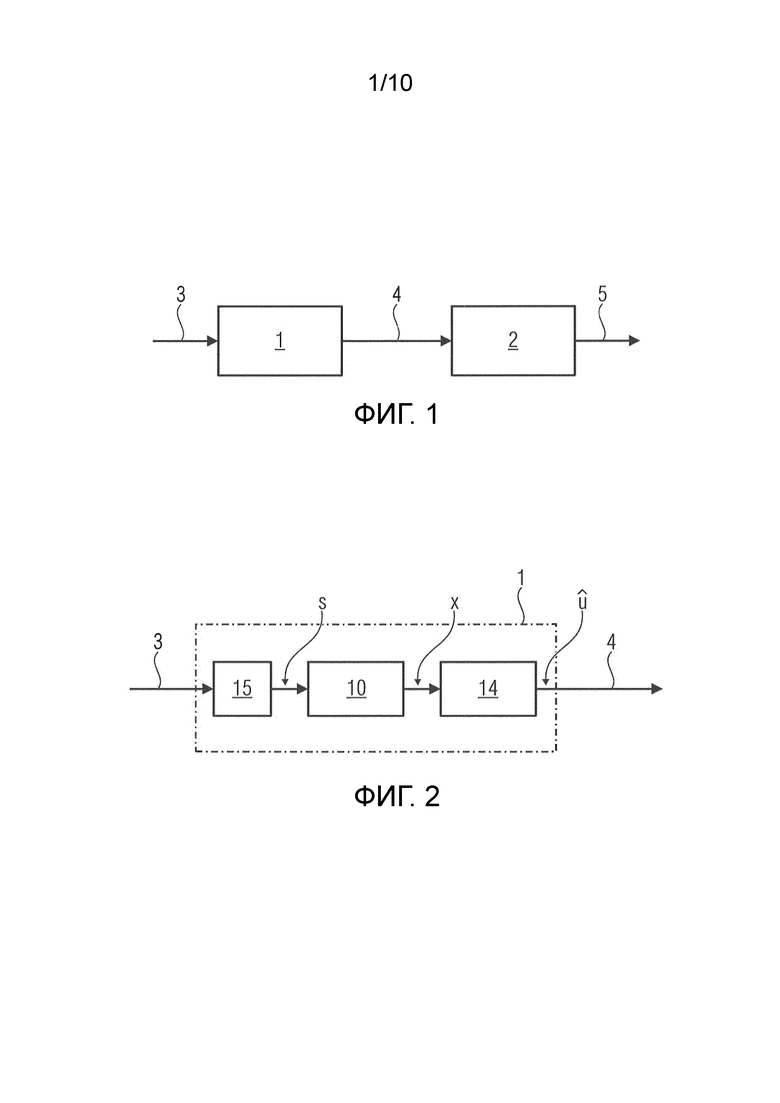
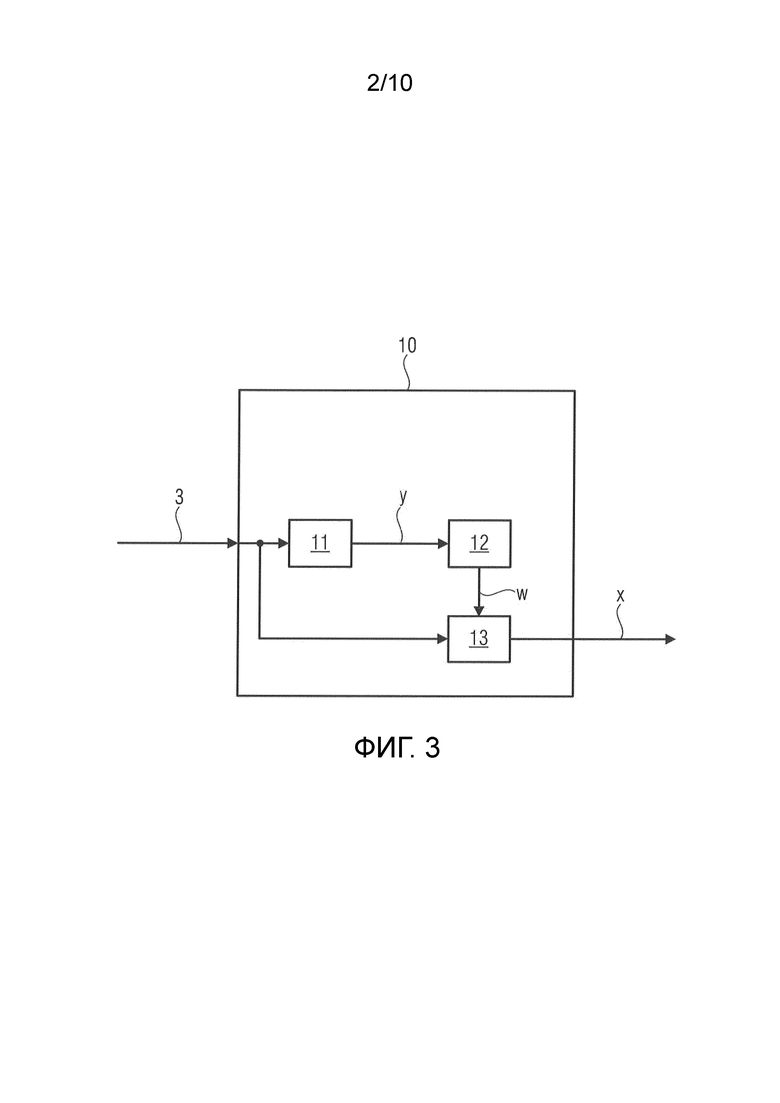
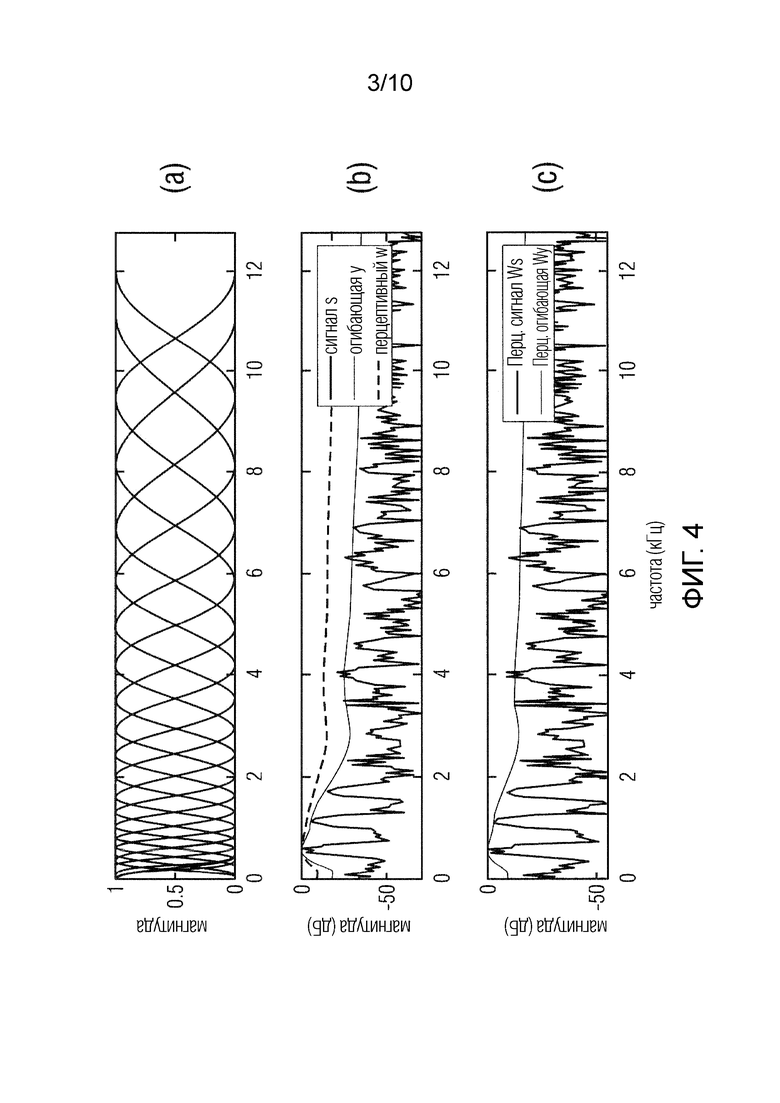
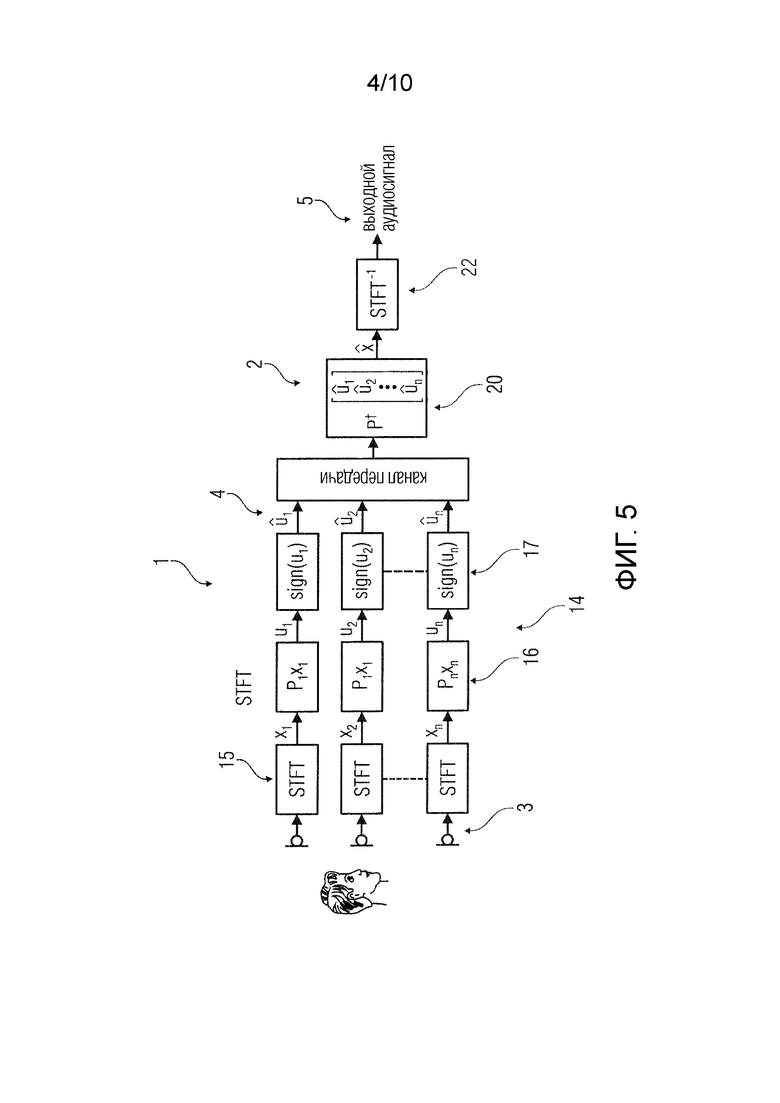
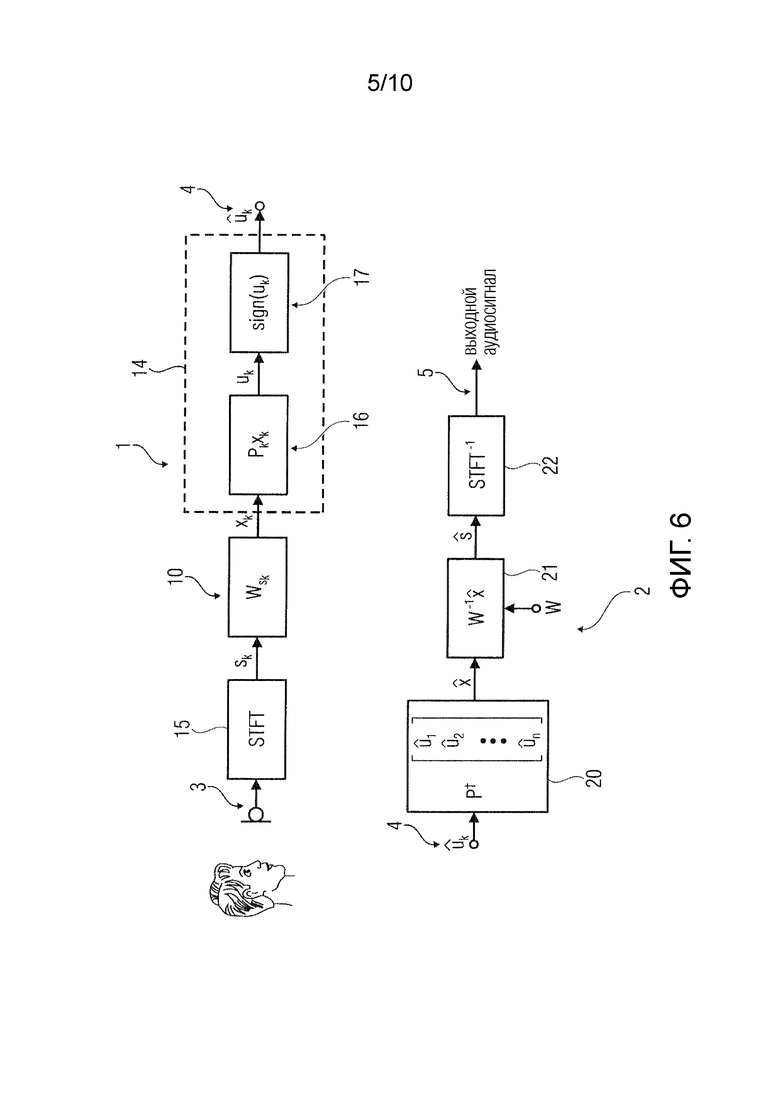
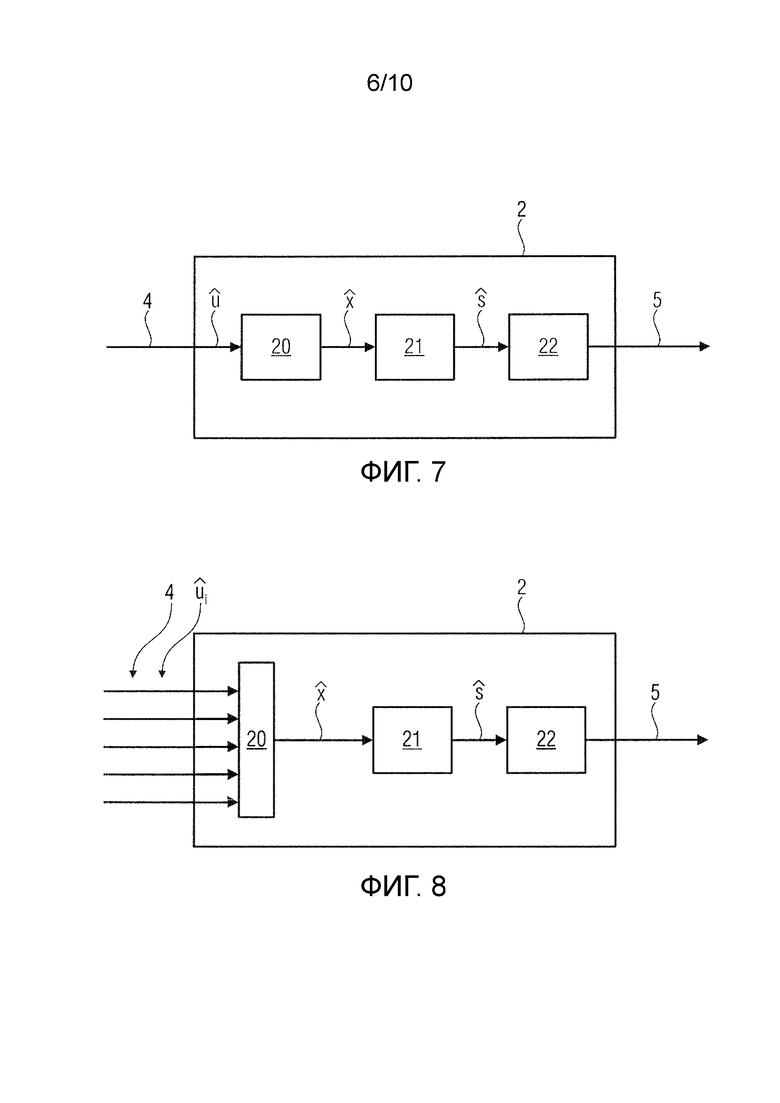
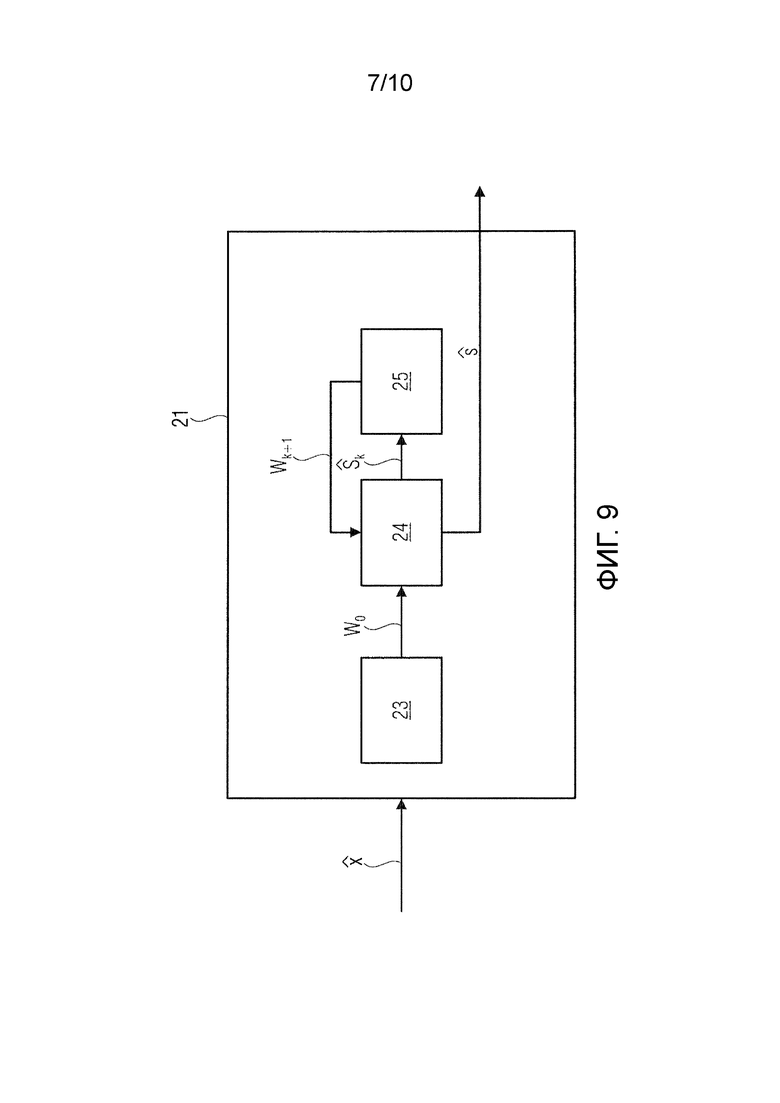
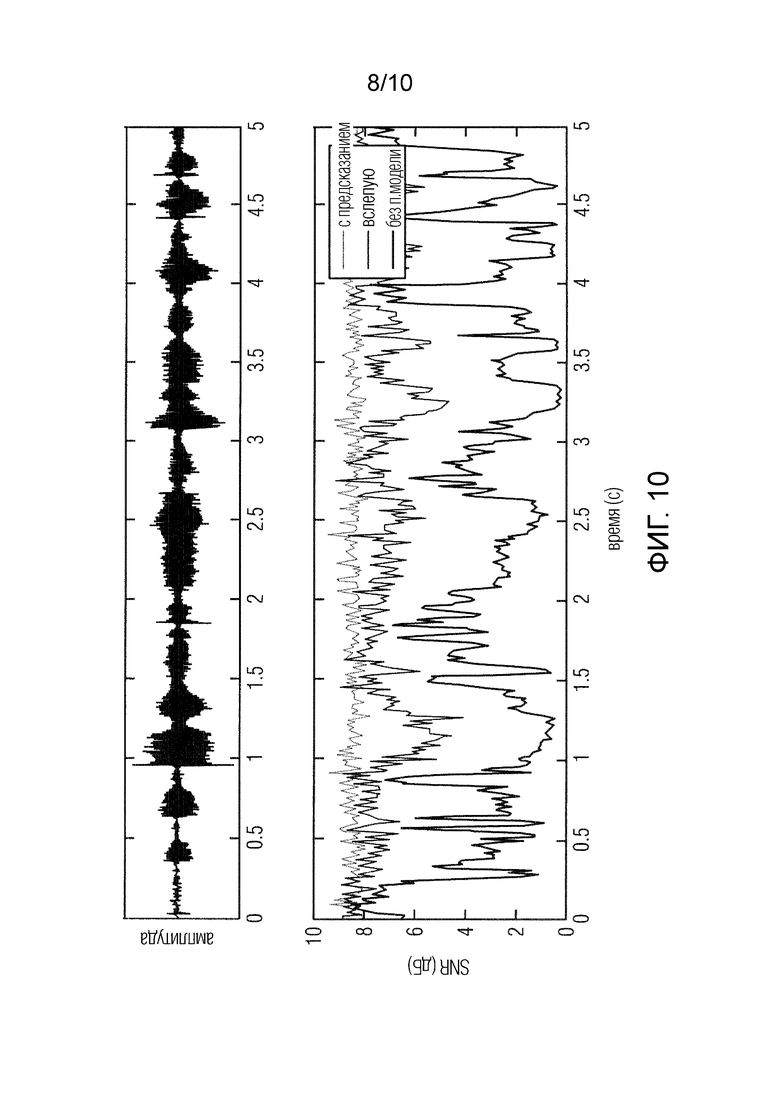
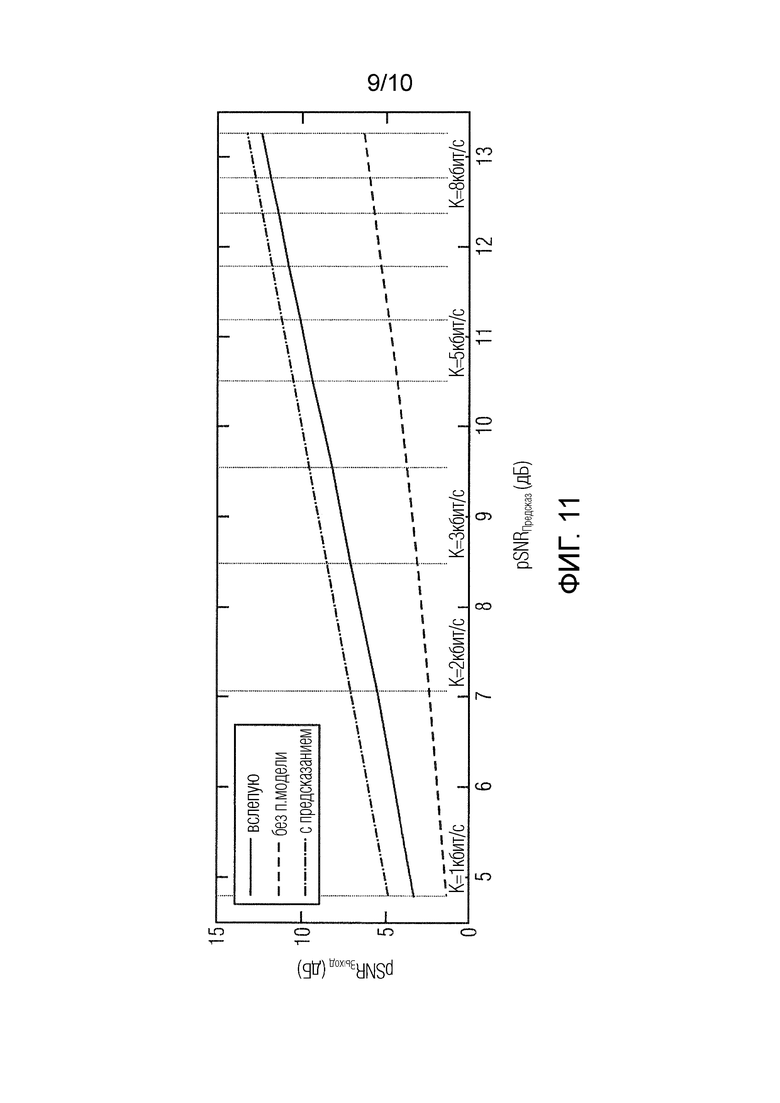

Изобретение относится к области кодирования/декодирования сигналов. Технический результат изобретения заключается улучшении эффективности кодирования/декодирования сигналов за счет перцептивного взвешивания на основе входного сигнала. Устройство кодирования для обработки входного сигнала содержит блок перцептивного взвешивания и блок квантования, причём блок перцептивного взвешивания содержит блок обеспечения модели и блок применения модели. Блок обеспечения модели выполнен с возможностью обеспечения модели (W) перцептивного взвешивания на основе входного сигнала, блок применения модели выполнен с возможностью обеспечения перцептивно взвешенного спектра (x) посредством применения модели (W) перцептивного взвешивания к спектру (s) на основе входного сигнала. Причём блок квантования выполнен с возможностью квантования перцептивно взвешенного спектра (x) и обеспечения битового потока (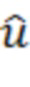 ) и содержит блок применения случайной матрицы и блок вычисления функции знака. Блок применения случайной матрицы выполнен для обеспечения преобразованного спектра (u), блок вычисления функции знака выполнен для обеспечения битового потока (
) и содержит блок применения случайной матрицы и блок вычисления функции знака. Блок применения случайной матрицы выполнен для обеспечения преобразованного спектра (u), блок вычисления функции знака выполнен для обеспечения битового потока (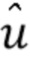 ). 6 н. и 15 з.п. ф-лы, 12 ил.
). 6 н. и 15 з.п. ф-лы, 12 ил.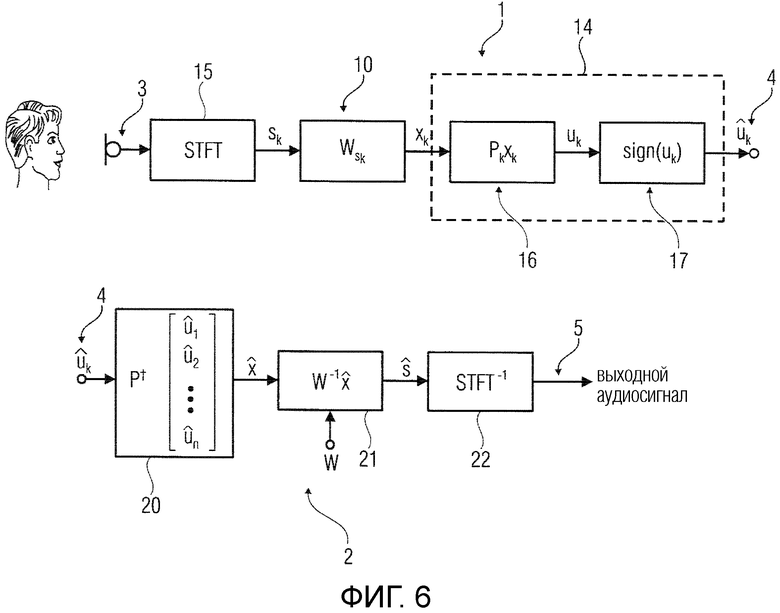
1. Устройство (1) кодирования для обработки входного сигнала (3),
содержащее блок (10) перцептивного взвешивания и
блок (14) квантования,
причём блок (10) перцептивного взвешивания содержит блок (12) обеспечения модели и блок (13) применения модели,
причём блок (12) обеспечения модели выполнен с возможностью обеспечения модели (W) перцептивного взвешивания на основе входного сигнала (3),
и при этом блок (13) применения модели выполнен с возможностью обеспечения перцептивно взвешенного спектра (x) посредством применения модели (W) перцептивного взвешивания к спектру (s) на основе входного сигнала (3),
причём блок (14) квантования выполнен с возможностью квантования перцептивно взвешенного спектра (x) и обеспечения битового потока ( ),
),
причём блок (14) квантования содержит блок (16) применения случайной матрицы и блок (17) вычисления функции знака,
причём блок (16) применения случайной матрицы выполнен с возможностью применения случайной матрицы (P) к перцептивно взвешенному спектру (x), чтобы обеспечить преобразованный спектр (u), и
при этом блок (17) вычисления функции знака выполнен с возможностью вычисления функции знака компонентов преобразованного спектра (u), чтобы обеспечить битовый поток ( ), и
), и
при этом блок (12) обеспечения модели выполнен с возможностью вычисления огибающей (y) спектра (|x|) магнитуды входного сигнала (3), применения функции (f()) сжатия к огибающей (y) спектра (|x|) магнитуды и вычисления модели (W) перцептивного взвешивания на основе результата применения функции (f()) сжатия.
2. Устройство (1) кодирования по п. 1,
в котором функция (f()) сжатия является строго возрастающей,
причём для любой положительной скалярной величины (t) и произвольно малого значения (eps) значение функции (f(t)) для положительной скалярной величины (t) меньше значения функции (f(t+eps)) для суммы (t+eps) положительной скалярной величины (t) и произвольно малого значения (eps), и
при этом для первой положительной скалярной величины (t1) и второй положительной скалярной величины (t2), которая больше первой положительной скалярной величины (t1), разность между значением функции (f(t2)) для второй положительной скалярной величины (t2) и значением функции (f(t1)) для первой положительной скалярной величины (t1) меньше разности между второй положительной скалярной величиной (t2) и первой положительной скалярной величиной (t1).
3. Устройство (2) декодирования для обработки кодированного сигнала (4),
содержащее блок (20) обратного квантования и
блок (21) устранения перцептивного взвешивания,
причём блок (20) обратного квантования выполнен с возможностью обратного квантования битового потока (), содержащегося в кодированном сигнале (4), и обеспечения вычисленного перцептивно взвешенного спектра ( ),
),
причём блок (20) обратного квантования выполнен с возможностью обратного квантования битового потока () посредством применения псевдообратной матрицы (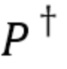 ) случайной матрицы (
) случайной матрицы (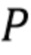 ) к битовому потоку (),
) к битовому потоку (),
причём блок (21) устранения перцептивного взвешивания содержит блок (24) аппроксимации спектра и блок (25) аппроксимации модели,
причём блок (24) аппроксимации спектра выполнен с возможностью вычисления аппроксимации спектра (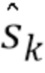 ) на основе вычисленного перцептивно взвешенного спектра (), и
) на основе вычисленного перцептивно взвешенного спектра (), и
при этом блок (25) аппроксимации модели выполнен с возможностью вычисления аппроксимации (Wk) модели (W) перцептивного взвешивания, с которым связан кодированный сигнал (4), на основе аппроксимации спектра (), причём блок (21) устранения перцептивного взвешивания содержит блок (23) обеспечения исходного предположения,
причём блок (23) обеспечения исходного предположения выполнен с возможностью обеспечения данных (w0) для исходного предположения (W0) модели (W) перцептивного взвешивания, и
при этом блок (24) аппроксимации спектра выполнен с возможностью итерационного вычисления аппроксимации спектра () на основе вычисленного перцептивно взвешенного спектра () и исходного предположения (W0) модели перцептивного взвешивания или аппроксимации (Wk) модели (W) перцептивного взвешивания.
4. Устройство (2) декодирования по п. 3, в котором блок (24) аппроксимации спектра выполнен с возможностью
вычисления исходной аппроксимации спектра (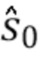 ) на основании исходного предположения (W0) модели перцептивного взвешивания и вычисленного перцептивно взвешенного спектра (), и вычисления первой аппроксимации (W1) модели перцептивного взвешивания с использованием первой аппроксимации спектра (
) на основании исходного предположения (W0) модели перцептивного взвешивания и вычисленного перцептивно взвешенного спектра (), и вычисления первой аппроксимации (W1) модели перцептивного взвешивания с использованием первой аппроксимации спектра (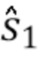 ), и
), и
вычисления первой аппроксимации спектра () на основании первой аппроксимации (W1) модели перцептивного взвешивания и вычисленного перцептивно взвешенного спектра (), и вычисления второй аппроксимации (W2) модели перцептивного взвешивания с использованием первой аппроксимации спектра ().
5. Устройство (2) декодирования по п. 4, в котором блок (24) аппроксимации спектра выполнен с возможностью
вычисления первой аппроксимации (W1) модели перцептивного взвешивания с использованием вычисления оценки (w1) огибающей исходной аппроксимации спектра () или вычисления второй аппроксимации (W2) модели перцептивного взвешивания с использованием вычисления оценки (w2) огибающей первой аппроксимации спектра ().
6. Устройство (2) декодирования по п. 5, в котором блок (24) аппроксимации спектра выполнен с возможностью
вычисления оценки (w1) огибающей исходной аппроксимации спектра () с использованием вычисления спектральной огибающей исходной аппроксимации спектра () и применения функции (f()) сжатия к спектральной огибающей исходной аппроксимации спектра () или вычисления оценки (w2) огибающей первой аппроксимации спектра () с использованием вычисления спектральной огибающей первой аппроксимации спектра () и применения функции (f()) сжатия к спектральной огибающей первой аппроксимации спектра ().
7. Устройство (2) декодирования по п. 3, в котором блок (24) аппроксимации спектра выполнен с возможностью итерационного вычисления аппроксимации спектра (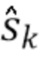 ) до тех пор, пока не будет выполнен критерий сходимости, причём аппроксимация спектра (), полученная на последнем этапе k итерации, является декодированным аудиосигналом.
) до тех пор, пока не будет выполнен критерий сходимости, причём аппроксимация спектра (), полученная на последнем этапе k итерации, является декодированным аудиосигналом.
8. Устройство (2) декодирования по п. 7, в котором блок (24) аппроксимации спектра выполнен с возможностью проверки в качестве критерия сходимости результата сравнения выданного вектора w(k) текущего этапа k итерации с выданным вектором w(k-1) предыдущего этапа k-1 итерации.
9. Устройство (2) декодирования по п. 8, в котором блок (24) аппроксимации спектра выполнен с возможностью определения сходимости для итерационного вычисления, когда разность между выданным вектором w(k) текущего этапа k итерации и выданным вектором w(k-1) предыдущего этапа k-1 итерации ниже предварительно установленной пороговой величины.
10. Устройство (2) декодирования по п. 8 или 9, в котором блок (24) аппроксимации спектра выполнен с возможностью вычисления в качестве выданного вектора оценки (wk) огибающей для аппроксимации спектра () на текущем этапе k итерации и оценки (wk-1) огибающей для аппроксимации спектра (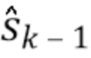 ) на предыдущем этапе k-1 итерации.
) на предыдущем этапе k-1 итерации.
11. Устройство (2) декодирования по любому из пп. 3-10,
в котором блок (20) обратного квантования выполнен с возможностью обратного квантования битового потока () на основе вспомогательной информации о случайной матрице (P), содержащейся в кодированном сигнале (3).
12. Устройство (2) декодирования по любому из пп. 3-11,
в котором блок (20) обратного квантования выполнен с возможностью приема множества битовых потоков (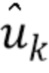 ) и обеспечения вычисленного перцептивно взвешенного спектра () на основе множества битовых потоков ().
) и обеспечения вычисленного перцептивно взвешенного спектра () на основе множества битовых потоков ().
13. Устройство (2) декодирования по любому из пп. 5-12,
причем устройство (2) декодирования выполнено с возможностью применения моделирования источника.
14. Способ обработки входного сигнала (3),
содержащий этапы, на которых:
обеспечивают модель (W) перцептивного взвешивания на основе входного сигнала (3),
взвешивают спектр (s) входного сигнала (3) посредством применения модели (W) перцептивного взвешивания к спектру (s) входного сигнала (3) и
выполняют квантование взвешенного спектра (x) посредством вычисления функции знака случайных проекций взвешенного спектра (x),
причём обеспечение модели (W) перцептивного взвешивания содержит этап, на котором вычисляют огибающую (y) для спектра (|x|) магнитуды входного сигнала (3), применяют функцию (f()) сжатия к огибающей (y) спектра (|x|) магнитуды и вычисляют модель (W) перцептивного взвешивания на основе результата упомянутого применения.
15. Способ по п. 14,
дополнительно содержащий этап, на котором:
получают случайные проекции взвешенного спектра (x) посредством применения случайной матрицы (P) к взвешенному спектру (x).
16. Способ по п. 15,
дополнительно содержащий этап, на котором:
получают огибающую (y) посредством использования набора (A) фильтров и диагональной матрицы (Λ), содержащей коэффициенты нормализации для каждой полосы.
17. Способ обработки кодированного сигнала (4),
содержащий этапы, на которых:
обеспечивают квантованный перцептивный сигнал () посредством применения псевдообратной матрицы () случайной матрицы () к кодированному сигналу (4),
вычисляют оценку спектра () на основе квантованного перцептивного сигнала () и
вычисляют аппроксимацию (Wk) модели (W) перцептивного взвешивания, используемой для обеспечения кодированного сигнала (4), на основе аппроксимации спектра (),
причём вычисление приближения (Wk) модели (W) перцептивного взвешивания содержит этап, на котором обеспечивают данные (w0) для исходного предположения (w0) модели перцептивного взвешивания, и
при этом вычисление оценки спектра () содержит этап, на котором итерационно вычисляют аппроксимацию спектра () на основе вычисленного перцептивно взвешенного спектра (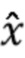 ) и исходного предположения (W0) модели перцептивного взвешивания или аппроксимации (Wk) модели (W) перцептивного взвешивания.
) и исходного предположения (W0) модели перцептивного взвешивания или аппроксимации (Wk) модели (W) перцептивного взвешивания.
18. Способ по п. 17,
в котором вычисление оценки спектра () содержит этап, на котором вычисляют исходную аппроксимацию спектра () на основе исходного предположения (w0) модели (W) перцептивного взвешивания.
19. Способ по п. 17, дополнительно содержащий этапы, на которых:
получают данные (w0) для исходного предположения (w0) модели перцептивного взвешивания посредством использования набора (A) фильтров и диагональной матрицы (Λ), содержащей коэффициенты нормализации для каждой полосы.
20. Машиночитаемый носитель данных, на котором сохранена компьютерная программа для выполнения способа по п. 14, когда она исполняется на компьютере или в процессоре.
21. Машиночитаемый носитель данных, на котором сохранена компьютерная программа для выполнения способа по п. 17, когда она исполняется на компьютере или в процессоре.
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Обучающее устройство | 1979 |
|
SU858067A1 |
| EP 0658876 B1, 15.09.1999 | |||
| СПОСОБЫ И УСТРОЙСТВО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ЧАСТИ РЕЧЕВОГО СИГНАЛА ДИАПАЗОНА ВЫСОКИХ ЧАСТОТ | 2006 |
|
RU2402826C2 |

