Область техники, к которой относится изобретение
Настоящее изобретение в целом относится к области обработки изображений, и более конкретно, к кодированию и декодированию цифровых изображений и последовательностей цифровых изображений.
Изобретение, таким образом, в частности, предназначено для кодирования видеоданных, воплощенного в современных (MPEG, H.264 и т.д.) или будущих кодерах видеоданных (ITU-T/VCEG (Н.265) или ISO/MPEG (HEVC)).
Уровень техники
В современных кодерах видеоданных (MPEG, H.264 и т.д.) используется представление в виде блоков видеопоследовательности. Изображения разделяют на макроблоки, причем каждый макроблок сам разделен на блоки, и каждый блок или макроблок кодируют, используя прогнозирование внутри изображения или между изображениями. Таким образом, некоторые изображения кодируют, используя пространственное прогнозирование (внутрикадровое прогнозирование), в то время как другие изображения кодируют, используя временное прогнозирование (межкадровое прогнозирование) в отношении одного или более опорных кодируемых - декодируемых изображений, используя компенсацию движения, как известно для специалиста в данной области техники.
Для каждого блока кодируют остаточный блок, также называемый остатком прогнозирования, соответствующий оригинальному блоку, уменьшенному в ходе прогнозирования. Остаточные блоки преобразуют, используя преобразование типа дискретного косинусного преобразования (DCT), затем квантуют, используя, например, квантование скалярного типа. В конце этапа квантования получают коэффициенты, некоторые из которых являются положительными, а другие отрицательными. Затем их пробегают, обычно в зигзагообразном порядке считывания (как в стандарте JPEG), обеспечивая, таким образом, возможность использования существенного количества нулевых коэффициентов при высоких частотах. В конце упомянутого выше пробегания получают одномерный список коэффициентов, который можно назвать "квантованным остатком". Коэффициенты из этого списка затем кодируют, используя энтропийное кодирование.
Энтропийное кодирование (например, арифметическое кодирование или кодирование типа Хаффмана) выполняют следующим образом:
- элемент информации подвергают энтропийному кодирования для указания положения последнего ненулевого коэффициента в списке,
- для каждого коэффициента, расположенного перед последним ненулевым коэффициентом, элемент информации энтропийно кодируют для указания, равен или нет этот коэффициент нулю,
- для каждого ненулевого коэффициента, указанного ранее, энтропийно кодируют элемент информации для указания, равен или нет этот коэффициент единице,
- для каждого коэффициента, который не равен нулю и не равен единице и который был расположен перед последним ненулевым коэффициентом, энтропийно кодируют элемент информации амплитуды (абсолютное значение коэффициента, значение которого было уменьшено вдвое),
- для каждого ненулевого коэффициента назначенный для него знак кодируют как "0" (для знака"+") или как "1" (для знака "-").
В соответствии с технологией Н.264, например, когда макроблок разделяют на блоки, сигнал данных, соответствующий каждому блоку, передают в декодер. Такой сигнал содержит:
- квантованные остатки, содержащиеся в упомянутом выше списке,
- элементы информации, представляющие используемый режим кодирования, в частности:
• режим прогнозирования (внутрикадровое прогнозирование, межкадровое прогнозирование, принятое по умолчанию прогнозирование, с помощью которого получают прогнозирование, для которого не передают информацию в декодер (называется "пропуском");
• информация, устанавливающая тип прогнозирования (ориентация, опорное изображение и т.д.);
• тип разделения на участки;
• тип преобразования, например, 4×4 DCT, 8×8 DCT и т.д.;
• «информация о движении, в случае необходимости;
• и т.д.
Декодирование выполняют изображение за изображением, и для каждого изображения макроблок за макроблоком. Для каждого участка макроблока считывают соответствующие элементы потока. Обратное квантование и обратное преобразование коэффициентов блоков выполняют для получения декодированного остатка прогнозирования. Затем рассчитывают прогнозирование участка, и участок восстанавливают путем добавления прогнозирования к декодированному остатку прогнозирования.
Кодирование внутри кадра или между кадрами, в результате конкуренции друг с другом, как воплощено в стандарте Н.264, таким образом, основано на размещении различных элементов информации кодирования, таких как упомянутые выше, так, чтобы они конкурировали с целью выбора лучшего режима, то есть, режима, который оптимизирует кодирование рассматриваемого участка, в соответствии с заданным критерием рабочих характеристик, например, стоимостью случайного искажения, как хорошо известно специалисту в данной области техники.
Элементы информации, представляющие выбранный режим кодирования, содержатся в сигнале данных, передаваемом кодером в декодер. Декодер, таким образом, выполнен с возможностью идентификации режима кодирования, выбранного в кодере, с последующим применением прогнозирования, которое соответствует этому режиму.
В документе "Data Hiding of Motion Information in Chroma and Luma Samples for Video Compression", J.-M. Thiesse, J. Jung and M. Antonini, International workshop on multimedia signal processing, 2011 представлен способ сокрытия данных, который воплощается во время сжатия видеоданных.
Более конкретно, предложено избегать включения в сигнал, предназначенный для передачи в декодер по меньшей мере одного индекса конкуренции, вырабатываемого из множества индексов конкуренции, предназначенных для передачи. Такой индекс представляет собой, например, индекс MVComp, который представляет элемент информации, для идентификации предиктора вектора движения, используемого для блока, межкадрового прогнозирования. Такой индекс, который может принимать значение 0 или 1, не включают непосредственно в сигнал кодированных элементов данных, но передают посредством четности суммы коэффициентов квантованного остатка. Формируется связь между четностью квантованного остатка и индексом MVComp. В качестве примера, четное значение квантованного остатка ассоциируют со значением 0 индекса MVComp, в то время как нечетное значение квантованного остатка ассоциируют с индексом MVComp со значением 1. При этом могут возникнуть два случая. В первом случае, если четность квантованного остатка уже соответствует четности индекса MVComp, который требуется передать, квантованный остаток кодируют обычным образом. Во втором случае, если четность квантованного остатка отличается от четности индекса MVComp, который требуется передать, квантованный остаток модифицируют таким образом, чтобы его четность была такой же, как у индекса MVComp.Такая модификация включает в себя постепенное увеличение или уменьшение одного или больше коэффициентов квантованного остатка на нечетное значение (например, +1, -1, +3, -3, +5, -5 и т.д.) и поддержание только модификации, которая оптимизирует заданный критерий, в данном случае, ранее упомяну тую стоимость случайного искажения.
В декодере индекс MVComp не считывают в сигнале. Декодер довольствуется просто обычным определением остатка. Если значение такого остатка будет четным, индекс MVComp устанавливают равным 0. Если значение этого остатка будет нечетным, индекс MVComp устанавливают в 1.
В соответствии с технологией, которая была представлена выше, коэффициенты, которые подвергаются модификации, не всегда выбираются оптимально, так, что применяемая модификация приводит к нарушениям сигнала, передаваемого в декодер. Такие нарушения неизбежно оказывают отрицательное влияние на эффективность сжатия видеоданных.
Раскрытие изобретения
Одна из целей изобретения состоит в том, чтобы устранить недостатки упомянутого выше предшествующего уровня техники.
Таким образом, цель настоящего изобретения относится к способу кодирования по меньшей мере одного изображения, разделенного на участки, такой способ реализует следующие этапы:
- выполняют прогнозирование элементов данных текущего участка как функцию по меньшей мере одного опорного участка, уже кодированного, а затем декодированного, выводя прогнозируемый участок;
- определяют набор остаточных элементов данных путем сравнения элементов данных, относящихся к текущему участку и прогнозируемому участку, причем остаточные элементы данных соответственно связаны с различными элементами цифровой информации, для которых требуется выполнить энтропийное кодирование,
- генерируют сигнал, содержащий кодированные элементы информации. Способ, в соответствии с изобретением, характеризуется тем, что реализует, перед этапом генерирования сигнала, следующие этапы:
- определяют из определенного набора остаточных элементов данных поднабор, содержащий элементы остаточных данных, пригодных для модификации,
- рассчитывают значение функции, представляющей элементы остаточных данных упомянутого определенного поднабора,
- сравнивают рассчитанное значение со значением по меньшей мере одного из элементов цифровой информации,
- в зависимости от результата сравнения выполняют модификацию или не выполняют модификацию по меньшей мере одного из элементов остаточных данных в поднаборе,
- в случае модификации, выполняют энтропийное кодирование упомянутого по меньшей мере одного элемента модифицированных остаточных данных.
Такая последовательность обеспечивает возможность применения технологии скрытия данных в уменьшенном наборе элементов остаточных данных, и в этом наборе элементы остаточных данных пригодны для их модификации.
В соответствии с изобретением, следует понимать, что выражение "элементы остаточных данных" означает элементы данных, для которых применение модификации не приводит к десинхронизации между кодером и декодером.
Таким образом, в соответствии с изобретением, элементы остаточных данных, которые предназначены для их модификации, выбирают намного более надежно, чем в ранее процитированном предшествующем уровне техники, обеспечивая, таким образом, возможность получения лучшего качества восстановления изображения в декодере.
Кроме того, возможность модификации уменьшенного количества элементов остаточных данных обеспечивает возможность ускорения кодирования.
В конкретном варианте осуществления этапы, которые следуют за этапом определения поднабора элементов остаточных данных воплощают только, если удовлетворяется заданный критерий, зависящий от элементов остаточных данных, пригодных для их модификации.
Такая последовательность дополнительно обеспечивает для кодера возможность рационального определения, следует или нет применять в отношении данных технологию скрытия. Такой этап определения имеет преимущество ею применения только для ограниченного набора элементов остаточных данных, пригодных для их модификации. Таким образом, обеспечивается то, что технология скрытия данных применяется намного более соответствующим образом, чем в ранее процитированном предшествующем уровне техники, в частности, для наилучшего выбранного количества элементов остаточных данных, для которых точно определили, что после модификации этих элементов данных нарушение сигнала, генерируемого в результате такой модификации, не будет оказывать отрицательное влияние на качество восстановления изображения в декодере.
В другом частном варианте осуществления заданный критерий определения зависит от результата сравнения между числом элементов остаточных данных, пригодных для их модификации, и заданным числом.
Такая последовательность обеспечивает улучшение характеристик сжатия арифметического кодера при эффективном уменьшении затрат на передачу сигналов. В частности, такая последовательность обеспечивает возможность точного детектирования числа элементов остаточных данных, из которых было бы целесообразно применить технологию скрытия данных так, чтобы последняя не приводила к высоким уровням нарушений в сигнале, предназначенном для передачи в декодер.
В еще одном частном варианте осуществления, если множество элементов цифровой информации рассматривают во время этапа сравнения, последний приводит к сравнению рассчитанного значения функции, представляющей элементы остаточных данных определенного поднабора, со значением функции, представляющей множество элементов цифровой информации.
Такая последовательность обеспечивает оптимизацию рабочих характеристик арифметического кодера при оптимизации уменьшения затрат на передачу сигналов, поскольку она обеспечивает скрытие нескольких элементов цифровой информации в сигнале, предназначенном для передачи в декодер.
В еще одном частном варианте осуществления по меньшей мере один элемент цифровой информации соответствует знаку остаточного элемента данных.
Знак представляет собой особенно ценный элемент информации, который требуется скрыть, вследствие того факта, что вероятность появления положительного или отрицательного знака является равновероятной. Также, учитывая, что знак обязательно кодирован в одном бите, таким образом, становится возможным, путем скрытия этой информации, сэкономить один бит в сигнале для передачи в декодер, существенно уменьшая, таким образом, стоимость передачи сигналов. Уменьшение такой стоимости будет тем более высоким, когда возможно, в соответствии с изобретением, скрыть множество знаков, и, поэтому, множество битов.
Соответственно, изобретение относится также к устройству кодирования по меньшей мере одного изображения, разделенного на участки, такое устройство, содержит:
- средство прогнозирования элементов данных текущего участка как функции по меньшей мере одного опорного участка, уже кодированного с последующим декодированием с предоставлением прогнозируемого участка,
- средство определения набора остаточных элементов данных, пригодных для сравнения элементов данных, относящихся к текущему участку и прогнозирован ному участку, элементы остаточных данных связаны, соответственно, с различными элементами цифровой информации, для которых требуется выполнить энтропийное кодирование,
- средство генерирования сигнала, содержащего элементы кодированной информации.
Такое устройство кодирования характеризуется тем, что оно содержит, перед средством генерирования, средство обработки, которое выполнено с возможностью:
- определять, из определенного набора элементов остаточных данных, поднабор, содержащий элементы остаточных данных, пригодных для их модификации,
- рассчитывать значение функции, представляющей элементы остаточных данных определенного поднабора,
- сравнивать рассчитанное значение со значением по меньшей мере одного из элементов цифровой информации,
- модифицировать или не модифицировать упомянутый по меньшей мере один из элементов остаточных данных определенного поднабора в зависимости от результата модификации,
а также средство энтропийного кодирования по меньшей мере одного элемента модифицированных остаточных данных в случае модификации средством обработки.
Соответствующим образом изобретение относится также к способу декодирования сигнала данных, представляющего по меньшей мере одно изображение, разделенное на участки, которое было ранее кодировано, содержащему этап получения путем энтропийного декодирования данных сигнала, элементов цифровых данных, связанных с элементами остаточных данных, которые относятся по меньшей мере к одному ранее кодированному участку.
Такой способ декодирования характеризуется тем, что он содержит следующие этапы:
- определяют, из элементов остаточных данных, поднабор, содержащий элементы остаточных данных, выполненных с возможностью их модификации во время предыдущего кодирования,
- рассчитывают значение функции, представляющей элементы остаточных данных, упомянутого определенного поднабора,
- из рассчитанного значения определяют значение по меньшей мере одного элемента цифровой информации, которое отличается от тех, которые были получены путем энтропийного декодирования.
В частном варианте осуществления этапы, которые следуют после этапа определения поднабора элементов остаточных данных, реализуют только, если удовлетворяется заданный критерий, зависящий от элементов остаточных данных, подлежащих модификации.
В другом частном варианте осуществления заданный критерий определения зависит от результата сравнения между числом элементов остаточных данных, которые могли быть модифицированы, и заданным числом.
В еще одном частном варианте осуществления множество значений, связанных, соответственно, с множеством элементов цифровых данных, которые отличаются от полученных в результате энтропийного декодирования, получают из упомянутого рассчитанного значения.
В еще одном частном варианте осуществления упомянутый по меньшей мере один элемент цифровой информации соответствует знаку элемента остаточных данных.
Соответственно изобретение также относится к устройству декодирования сигнала данных, представляющего по меньшей мере одно разделение изображения на участки, которые были ранее кодированы, содержащее средство получения, путем энтропийного декодирования элементов данных сигнала, элементов цифровой информации, связанных с остаточными элементами данных, в отношении по меньшей мере одного ранее кодированного участка.
Такое устройство декодирования отличается тем, что оно содержит средство обработки, которое выполнено с возможностью:
- определять, из упомянутых остаточных элементов данных, поднабор, содержащий остаточные элементы данных, которые могли быть модифицированы во время предыдущего кодирования,
- рассчитывать значение функции, представляющей элементы остаточных данных определенного поднабора,
- из рассчитанного значения получать значение по меньшей мере одного элемента цифровой информации, который отличается от полученных в результате энтропийного декодиронаиия.
Изобретение также относится к компьютерной программе, включающей в себя команды для исполнения этапов представленного выше способа кодирования или декодирования, когда программа исполняется компьютером.
В такой программе может использоваться любой язык программирования, и она может быть представлена в форме исходного кода, объектного кода или кода, промежуточного между исходным кодом и объектным кодом, например, в частично компилированной форме или в любой друтой требуемой форме.
Еще один другой объект изобретения представляет собой считываемый компьютером носитель записи, включающий в себя команды компьютерной программы, как упомянуто выше.
Носитель записи может представлять собой любой объект или устройство, выполненное с возможностью сохранения программы. Например, такой носитель может включать в себя средство сохранения, такое как ROM, например, CD-ROM или ROM в микроэлектронных цепях, или средство магнитной записи, например, гибкий диск или жесткий диск.
С другой стороны, такой носитель записи может представлять собой среду передачи, такую как электрический или оптический сигнал, который может быть передан через электрический или оптический кабель, через радиоканал или через другое средство. Программа, в соответствии с изобретением, в частности, может быть зафужена через сеть типа Интернет.
В качестве альтернативы, такой носитель записи может представлять собой интегральную схему, в которую встроена программа, схема выполнена с возможностью исполнения рассматриваемого способа или может использоваться при исполнении последнего.
Устройство кодирования, способ декодирования, устройство декодирования и компьютерные программы, упомянутые выше, проявляют по меньшей мере те же преимущества, что и те, которые предоставляются способом кодирования, в соответствии с настоящим изобретением.
Краткое описание чертежей
Другие свойства и преимущества будут понятны при чтении двух предпочтительных вариантов осуществления, описанных со ссылкой на чертежи, на которых:
на фиг. 1 представлены основные этапы способа кодирования, в соответствии с изобретением,
на фиг. 2 представлен вариант осуществления устройства декодирования в соответствии с изобретением,
на фиг. 3 представлены основные этапы способа декодирования в соответствии с изобретением,
на фиг. 4 представлен вариант осуществления устройства декодирования в соответствии с изобретением.
Подробное описание кодирующей части
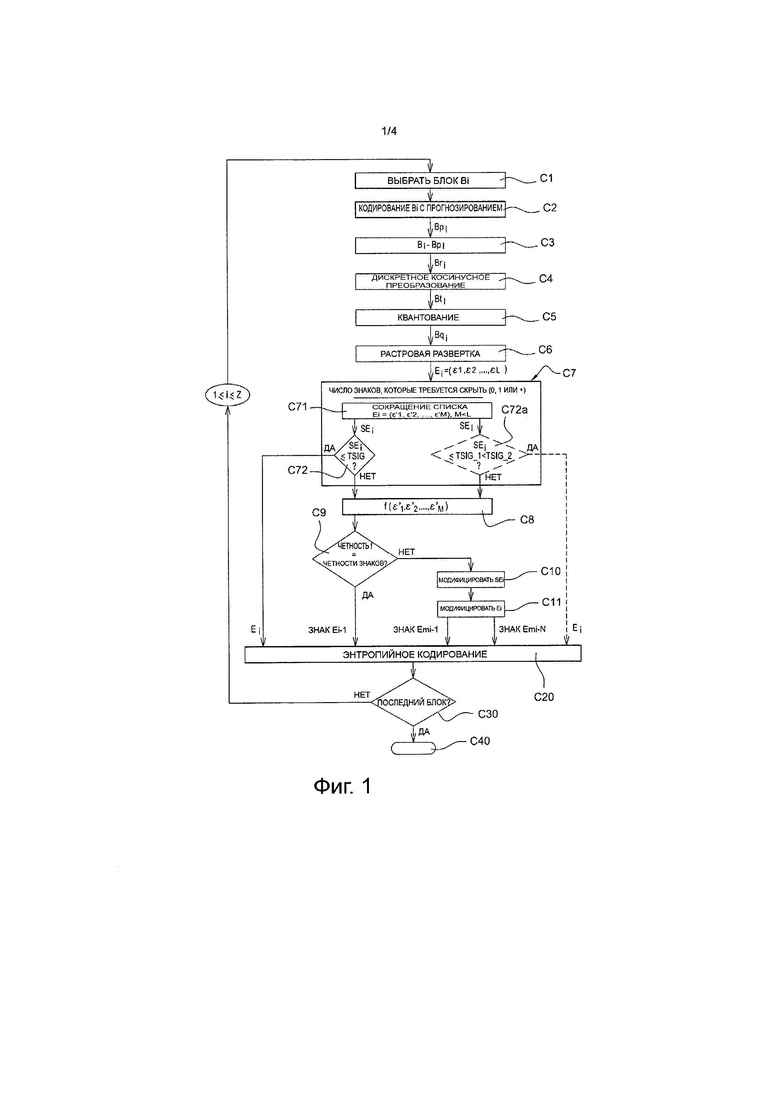
Ниже будет описан вариант осуществления изобретения, в котором используется способ кодирования, в соответствии с изобретением, для кодирования последовательности изображений в соответствии с двоичным потоком, близко к тому, что получают путем кодирования в соответствии со стандартом H.264/MPEG-4 AVC. В этом варианте осуществления способ кодирования, в соответствии с изобретением, например, воплощен в виде программных средств или в форме аппаратных средств путем модификаций кодера, первоначально соответствующего стандарту Н. 264/MPEG-4 AVC. Способ кодирования, в соответствии с изобретением, представлен в форме алгоритма, включающего в себя этапы от С1 до С40, представленные на фиг. 1.
В соответствии с вариантом осуществления изобретения, способ кодирования, в соответствии с изобретением, воплощен в устройстве кодирования или в кодере СО, вариант осуществления которого представлен на фиг. 2.
В соответствии с изобретением, перед фактическим этапом кодирования, изображение IE последовательности изображений, предназначенное для кодирования в заданном порядке, разделяют на множество Z участков В1, В2, …, Bi, Bz, как представлено на фиг. 2.
Следует отметить, что в смысле изобретения, термин "участок" означает модуль кодирования. Такая последняя терминология, в частности, используется в стандарте HEVC/II.265, черновик которого, например, представлен в документе, доступном по следующему адресу в Интернет:
<http://phenix.int-evrv.fr/ict/doc_end_user/current_document.php?id-3286>
В частности, такие группы модулей кодирования вместе устанавливают пиксели прямоугольной или квадратной формы, также называемые блоками, макроблоками или наборами пикселей, которые имеют другие геометрические формы.
В примере, представленном на фиг. 2, упомянутые участки представляют собой блоки, которые имеют квадратную форму, и все из которых имеют одинаковый размер. В зависимости от размера изображения, который не обязательно составляет кратное размера блока, последние блоки слева и последние блоки снизу не обязательно должны быть квадратной формы. В альтернативном варианте осуществления блоки могут, например, иметь прямоугольную форму и/или могут не быть выровнены друг с другом.
Каждый блок или макроблок, кроме того, может быть сам разделен на подблоки, которые сами после этого могут быть подразделены.
Такое разделение выполняют с помощью модуля PCO разделения, представленного на фиг. 2, в котором используется, например, алгоритм разделения, хорошо известный сам по себе.
После упомянутого этапа разделения, кодируют каждый из текущих участков Bi (где i представляет собой целое число, такое, как 1≤i≤Z) упомянутого изображения IE.
В примере, представленном на фиг. 2, такое кодирование применяют последовательно для каждого из блоков B1-Bz, текущего изображения IE. Блоки кодируют, например, в соответствии с разверткой, такой как растровая развертка, которая известна специалисту в данной области техники.
Кодирование, в соответствии с изобретением, воплощают в прохраммном модуле МС_СО кодирования кодера СО, как представлено на фиг. 2.
Во время этапа С1, представленного на фиг. 1, модуль МС_СО кодирования по фиг. 2 выбирает, в качестве текущего блока B1, первый блок В1, предназначенный для кодирования текущего изображения IE. Как представлено на фиг. 2, он представляет собой первый блок слева от изображения IE.
Во время этапа С2, представленного на фиг. 1, выполняют кодирование с прогнозированием текущего блока B1, используя известные технологии внутрикадрового и/или межкадрового прогнозирования, в течение которого выполняют прогнозирование, используя кодирование с прогнозированием блока В1 в отношении по меньшей мере одного ранее кодированного и декодированного блока. Такое прогнозирование выполняют, используя модуль программного обеспечения прогнозирования PRED_СО, как представлено на фиг. 2.
Само собой разумеется, возможны другие режимы внутрикадрового прогнозирования, предложенные в стандарте Н.264.
Для текущего блока В1 также можно выполнять кодирование с прогнозированием в межкадровом режиме, в течение которого текущий блок прогнозируют в отношении блока из ранее колированного и декодированного изображения. Другие типы прогнозирования также могут быть предусмотрены. Среди вариантов прогнозирования, возможных для текущего блока, выбирают оптимальное прогнозирование в соответствии с критериями случайного искажения, которые известны специалисту в данной области техники.
Упомянутый этап кодирования с прогнозированием обеспечивает возможность кодирования с прогнозированием блока Вр1 который представляет собой аппроксимацию текущего блока В1. Элементы информации, относящиеся к такому кодированию с прогнозированием, будут включены в сигнал, для передачи в декодер. Такие элементы информации содержат, в частности, тип прогнозирования (межкадровый или внутрикадровый), и, в случае необходимости, режим внутрикадрового прогнозирования, типы разделения блока или макроблоков, если последние были подразделены, индекс опорного изображения и вектор движения, которые использовали в режиме межкадрового прогнозирования. Такие элементы информации сжимают с помощью кодера СО.
Во время следующего этапа С3, представленного на фиг. 1, модуль PRED_CO прогнозирования сравнивает элементы данных, относящиеся к текущему блоку В1, с элементами данных прогнозируемого блока Bp1. Более конкретно, во время этого этапа, обычно блок Bp1 прогнозирования вычитают из текущего блока В1 для получения остаточного блока Br1.
В течение следующего этапа С4, представленного на фиг. 1, остаточный блок Br1 преобразуют в соответствии с обычной операцией прямого преобразования, такой, как, например, тип дискретного косинусного преобразования DCT, для получения преобразованного блока Bt1. Такая операция выполняется программным модулем МТ_СО преобразования, как представлено на фиг. 2.
Во время следующего этапа С5, представленного на фиг. 1, преобразованный блок Bt1 квантуют в соответствии с обычной операцией квантования, такой как, например, скалярное квантование. Затем получают блок Bq1 квантованных коэффициентов. Такой этап выполняют, используя программный модуль MQ_CO квантования, как представлено на фиг. 2.
Во время следующего этапа С6, представленного на фиг. 1, для квантованных коэффициентов блока Bq1 выполняют развертку в заданном порядке. В представленном примере такая развертка представляет собой обычную зигзагообразную развертку. Этот этап выполняют, используя программный модуль ML_СО считывания, как представлено на фиг. 2. В конце этапа С6 получают одномерный список E1=(ε1, ε2, …, εL) коэффициентов, обычно известный, как "квантованный остаток", где L представляет собой целое число, большее чем или равное 1. Каждый из коэффициентов в списке E1 взаимосвязан с различными элементами цифровой информации, для которых предполагается выполнить энтропийное кодирование. Такие элементы цифровой информации описаны ниже в качестве примера.
Предположим, что в представленном примере, L=16, и что список Е1 содержит следующие шестнадцать коэффициентов: Е1 - (0, +9, -7, 0, 0, +1, 0, -1, +2, 0, 0, +1, 0,0, 0, 0).
В данном случае:
- для каждого коэффициента, расположенного перед последним ненулевым коэффициентом в списке Е1, элемент цифровой информации, такой как бит, должен быть энтропийно кодирован для обозначения, равен или нет этот коэффициент нулю: если этот коэффициент равен нулю, будет кодирован, например, бит со значением 0, в то время как, если коэффициент не равен нулю, будет кодирован бит со значением 1;
- для каждого ненулевого коэффициента +9, -7, +1, -1, +2, +1, элемент цифровой информации, такой как бит, должен быть подвергнут энтропийному кодированию для обозначения, равно или нет абсолютное значение коэффициента единице: если оно равно 1, тогда будет кодировано, например, значении бита с величиной 1, в то время как, если оно не равно 1, будет кодирован бит со значением 0;
- для каждого ненулевого коэффициента и для которого абсолютное значение не равно единице, и который расположен перед последним ненулевым коэффициентом, таким, как коэффициенты со значениями +9, -7, +2, элемент информации амплитуды (абсолютное значение коэффициента, из которого вычли значение два) подвергают энтропийному кодированию;
- для каждого ненулевого коэффициента знак, назначенный ему, кодируют, используя элемент цифровой информации, такой как бит, например, устанавливают в '0' (для знака "+") или устанавливают в '1' (для знака "-").
Ниже, со ссылкой на фиг. 1, будут описаны конкретные этапы кодирования, в соответствии с изобретением.
В соответствии с изобретением определяют, что следует исключить энтропийное кодирование по меньшей мере одного из упомянутых выше элементов информации. По причинам, которые пояснялись выше в описании, в предпочтительном варианте воплощения, определяют, что не следует выполнять энтропийное кодирование по меньшей мере для одного знака одного из упомянутых коэффициентов в списке E1.
В качестве альтернативного примера, в частности, можно было бы определить необходимость энтропийного кодирования по меньшей мере младшего значащего бита двоичного представления амплитуды первого ненулевого коэффициента в упомянутом списке Е1.
С этой целью, во время этапа С7, представленного на фиг. 1, выбирают количество знаков, которое требуется скрыть при выполнении более позднего этапа энтропийного кодирования. Такой этап выполняется, используя программный модуль MTR_CO обработки, как представлено на фиг. 2.
В предпочтительном варианте осуществления количество знаков, которые требуется скрыть, равно одному или нулю. Кроме того, в соответствии с упомянутым предпочтительным вариантом осуществления, предполагается скрыть знак первого ненулевого коэффициента, который предназначен быть скрытым. Поэтому, в представленном примере, скрыт знак коэффициента ε2=+9.
В альтернативном варианте осуществления количество знаков, которые должны быть скрыты, равно либо нулю, единице, двум, трем или больше.
В соответствии с предпочтительным вариантом осуществления, на этапе С7, во время первого подэтапа С71, представленного на фиг. 1, подсписок SE1, содержащий коэффициенты, пригодные для их модификации, ε'1, ε'2, …, ε'M, где М<L, определяют из упомянутого списка Е1. Такие коэффициенты будут называться ниже в описании модифицируемыми коэффициентами.
В соответствии с изобретением, коэффициент является модифицируемым, если модификация его квантованного значения не приводит к десинхронизации в декодере при обработке этого модифицированного коэффициента декодером. Таким образом, модуль MTR_CO обработки изначально конфигурируют так, чтобы он не выполнял модификацию:
- нулевого коэффициента или коэффициентов, расположенных перед первым списком из ненулевых коэффициентов таким образом, что декодер не влияет на значение скрытого знака в этом или в этих нулевых коэффициентах,
- и по причинам вычислительной сложности, нулевого коэффициента или коэффициентов, расположенных после последнего ненулевого коэффициента.
В представленном примере, в конце подэтапа С71, получают подсписок SE1 таким образом, что SE1=(9, -7, 0, 0, 1, 0, -1, 2, 0, 0, 1). Следовательно, получают одиннадцать модифицированных коэффициентов.
Во время следующего подэтапа С72, представленного на фиг. 1, модуль MTR_CO обработки переходит к сравнению количества модифицированных коэффициентов с заданным пороговым значением TSIG. В предпочтительном варианте осуществления TSIG имеет значение 4.
Если количество модифицированных коэффициентов меньше, чем пороговое значение TSIG, то во время этапа С20, представленного на фиг. 1, выполняют обычное энтропийное кодирование коэффициентов в списке Е1, такое, как выполняют, например, в кодере CABAC, обозначенном ссылкой СЕ_СО на фиг. 2. С этой целью, знак каждого ненулевого коэффициента в списке Е1 подвергают энтропийному кодированию.
Если количество модифицированных коэффициентов больше, чем пороговое значение TS1G, тогда во время этапа С8, представленного на фиг. 1, модуль MTR_CO обработки рассчитывает значение функции f, которое представляет коэффициенты в подсписке SE1.
В предпочтительном варианте осуществления, в котором предполагается скрывать только один знак в сигнале, предназначенном для декодера, функция f представляет собой четность суммы коэффициентов в подсписке SE1.
Во время этапа С9, представленного на фиг. 1, модуль MTR_CO обработки проверяет, соответствует ли четность значения знака, который должен быть скрыт, четности суммы коэффициентов в подсписке SE1, в соответствии с установленным заранее определенным в кодере СО условием.
В предложенном примере упомянутое соглашение является таким, что положительный знак ассоциируют с битом со значением равным нулю, в то время, как отрицательный знак ассоциирован с битом со значением равным единице.
Если, в соответствии с условием, принятым в кодере СО, в соответствии с изобретением, знак является положительным, что соответствует значению бита кодирования равного нулю, и если сумма коэффициентов в подсписке SE1 является четной, тогда выполняют этап С20 для энтропийного кодирования коэффициентов в упомянутом выше списке E1, за исключением знака коэффициента ε2.
Если, все еще, в соответствии с соглашением, принятым в кодере СО, в соответствии с изобретением, знак будет отрицательным, что соответствует значению бита кодирования, равному единице, и если сумма коэффициентов в подсписке SE1 нечетная, тогда также выполняют этап С20 для энтропийного кодирования коэффициентов в упомянутом выше списке E1, за исключением знака коэффициента ε2.
Если, в соответствии с соглашением, принятым в кодере СО, в соответствии с изобретением, знак будет положительным, что соответствует значению бита кодирования, равным нулю, и если сумма коэффициентов в подсписке SE1 будет нечетной, то во время этапа С10, представленного на фиг. 1, модифицируют по меньшей мере один модифицируемый коэффициент в подсписке SE1.
Если, все еще в соответствии с соглашением, принятым в кодере СО, в соответствии с изобретением, знак будет отрицательным, что соответствует значению бита кодирования, равному единице, и если сумма коэффициентов в подсписке SE1 четная, тогда также на этапе С10 модифицируют по меньшей мере один модифицируемый коэффициент в подсписке SE1.
Такую операцию модификации выполняют с помощью модуля MTR_CO обработки по фиг. 2.
В примерном варианте осуществления, в котором SE1=(+9, -7, 0, 0, +1, 0, -1, +2, 0, 0, +1), общая сумма f коэффициентов равна 5, и, поэтому, она нечетная. Для того, чтобы декодер мог реконструировать положительный знак, назначенный для первого ненулевого коэффициента ε2=+9, без кодера СО, чтобы передать этот коэффициент в декодер, четность суммы должна стать четной. Следовательно, модуль MTR_CO обработки тестирует, во время упомянутого этапа С10, различные модификации коэффициентов в подсписке SE1, все с целью изменения четности суммы коэффициентов. В предпочтительном варианте осуществления добавляют +1 или -1 к каждому модифицированному коэффициенту, и модификацию выбирают среди этих полученных модификаций.
В предпочтительном варианте осуществления в результате такого выбора формируется оптимальное прогнозирование, в соответствии с критерием рабочих характеристик, который, например, представляет собой критерий случайного искажения, как хорошо известно специалисту в данной области техники. Такой критерий выражается уравнением (1), представленным ниже:

где D представляет собой искажение между оригинальным макроблоком и реконструированным макроблоком, R представляет стоимость кодирования в битах элементов информации кодирования, и λ представляет множитель Лагранжа, значение которого может быть фиксировано перед кодированием.
В предложенном примере модификация, которая приводит к оптимальному прогнозированию, в соответствии с упомянутым выше критерием случайного искажения, представляет собой добавление значения 1 ко второму коэффициенту -7 в подсписке SE1.
Следовательно, в конце этапа С10 модифицируемый подсписок получает модифицированный подсписок SEm1=(+9, -6, 0, 0, +1, 0, -1, +2, 0, 0, +1).
Следует отметить, что во время этого этапа, определенные модификации запрещены. Таким образом, если бы первый ненулевой коэффициент ε2 имел значение +1, было бы невозможно добавить к нему -1, поскольку он при этом слал бы равным нулю, и таким образом, потерял бы свою характеристику первого ненулевого коэффициента в списке E1. Декодер при этом должен связать декодируемый знак (путем расчета четности суммы коэффициентов) с другим коэффициентом, и при этом возникла бы ошибка декодирования.
Во время этапа С11, представленного на фиг. 1, модуль MTR_СО обработки выполняет соответствующую модификацию в списке Е1. Затем получают следующий модифицированный список Em1=(0, +9, -6, 0, 0, +1, 0, -1, +2, 0, 0, +1, 0, 0, 0, 0).
Затем, на этапе С20, для энтропийного кодирования коэффициентов в упомянутом выше списке, выполняют Em1, за исключением знака коэффициента ε2, который представляет собой знак "+" коэффициента 9 в представленном примере, и этот знак скрыт в четности суммы коэффициентов.
Следует отметить, что набор амплитуд коэффициентов в списке Е1 или в модифицированном списке Em1 кодируют перед набором знаков, за исключением знака первого ненулевого коэффициента ε2, который не кодируют, как пояснялось выше.
Во время следующего этапа С30, представленного на фиг. 1, модуль МС_СО кодирования на фиг. 2 тестирует, является ли текущий блок кодирования последним блоком изображения IE.
Если текущий блок представляет собой последний блок изображения IE, тогда во время этапа С40, представленного на фиг. 1, способ кодирования заканчивается.
Если это не так, выбирают следующий блок Bi который затем кодируют в соответствии с порядком ранее упомянутой растровой развертки, путем повторения этапов от С1 до С20, для 1≤i≤Z.
После выполнения энтропийного кодирования всех блоков В1-Bz, конструируют сигнал F, представляющий, в двоичной форме, упомянутые кодированные блоки.
Построение двоичного сигнала F воплощено в программном модуле CF построения потока, как представлено на фиг. 2.
Поток F затем передают через сеть передачи данных (не показана) в удаленный терминал. Последний включает в себя декодер, который будет более подробно описан ниже в этом описании.
Далее, в основном, со ссылкой на фиг. 1, будет описан другой вариант осуществления изобретения.
Этот другой вариант осуществления отличается от предыдущего только количеством коэффициентов, которые должны быть скрыты, которое равно либо 0, или N, где N представляет собой целое число, такое, как N≥2.
С этой целью, упомянутый выше подэтап С72 сравнения заменяют подэтапом С72а, представленным пунктирной линией на фиг. 1, во время которого множество модифицируемых коэффициентов сравнивают с несколькими заданными пороговыми значениями 0 < TSIG_1 < TSIG 2 < TSIG 3 …, таким образом, что, если множество модифицированных коэффициентов находится между TSIG_N и TSIG_N+1, предполагается скрыть N знаков.
Если множество модифицируемых коэффициентов меньше, чем первое пороговое значение TSIG_1, тогда во время упомянутого выше этапа С20 выполняют обычное энтропийное кодирование коэффициентов в списке Е1. С этой целью знак каждого ненулевого коэффициента в списке Е1 подвергают энтропийному кодированию.
Если множество модифицированных коэффициентов находится между порогами TSIG_N и TSIG_N+1, тогда во время этапа С8, представленного на фиг. 1, модуль MTR_CO обработки рассчитывает значение функции f, которое представляет коэффициенты в подсписке Е1.
В этом другом варианте осуществления, поскольку решение в кодере состоит в том, чтобы скрыть N знаков, функция f представляет собой остаток от модуля 2N суммы коэффициентов в подсписке SE1. Предполагается, в предложенном примере, что N=2, два знака, которые должны быть скрыты, представляют собой два первых знака двух первых ненулевых коэффициентов, соответственно, то есть, ε2 и ε3.
Во время следующего этапа С9, представленного на фиг. 1, модуль MTR_СО обработки проверяет, соответствует ли конфигурация из N знаков, то есть, 2N возможных конфигураций, значению остатка модуля 2N суммы коэффициентов в подсписке SE1.
В предложенном примере, где N=2, существуют 22=4 разных конфигураций знаков.
Эти четыре конфигурации соответствуют соглашению в кодере СО, причем это соглашение определено, например, следующим образом:
- остаток, равный нулю, соответствует двум последовательным положительным знакам: +, +;
- остаток, равный единице, соответствует последовательным положительному знаку и отрицательному знаку: +, -;
- остаток, равный двум, соответствует последовательным отрицательному знаку и положительному знаку: -, +;
- остаток, равный трем, соответствует двум последовательным отрицательным знакам:
Если конфигурация из N знаков соответствует значению остатка по модулю 2N от суммы коэффициентов в подсписке SE1, то этап С20 для энтропийного кодирования коэффициентов в упомянутом выше списке E1 выполняется, за исключением знаков коэффициента ε2 и коэффициента ε3, причем эти знаки скрыты в четности суммы модуля 2N коэффициентов.
Если это не так, тогда выполняют этап С10 для модификации по меньшей мере одного модифицированного коэффициента в подсписке SE1. Такую модификацию выполняют с помощью модуля MTR_CO обработки на фиг. 2 таким образом, что модуль остатка 2N суммы модифицированных коэффициентов в подсписке SE1 достигает значения каждого из двух знаков, которые должны быть скрыты.
Во время ранее упомянутого этапа С11 модуль MTR_СО обработки выполняет соответствующую модификацию списка Е1. Таким образом, получают модифицированный список Em1.
Затем выполняют этап С20 для энтропийного кодирования коэффициентов в упомянутом выше списке Em1, за исключением знака коэффициента ε2 и знака коэффициента ε3, и эти знаки скрыты в четности суммы модуля 2N коэффициентов.
Подробное описание декодирующей части
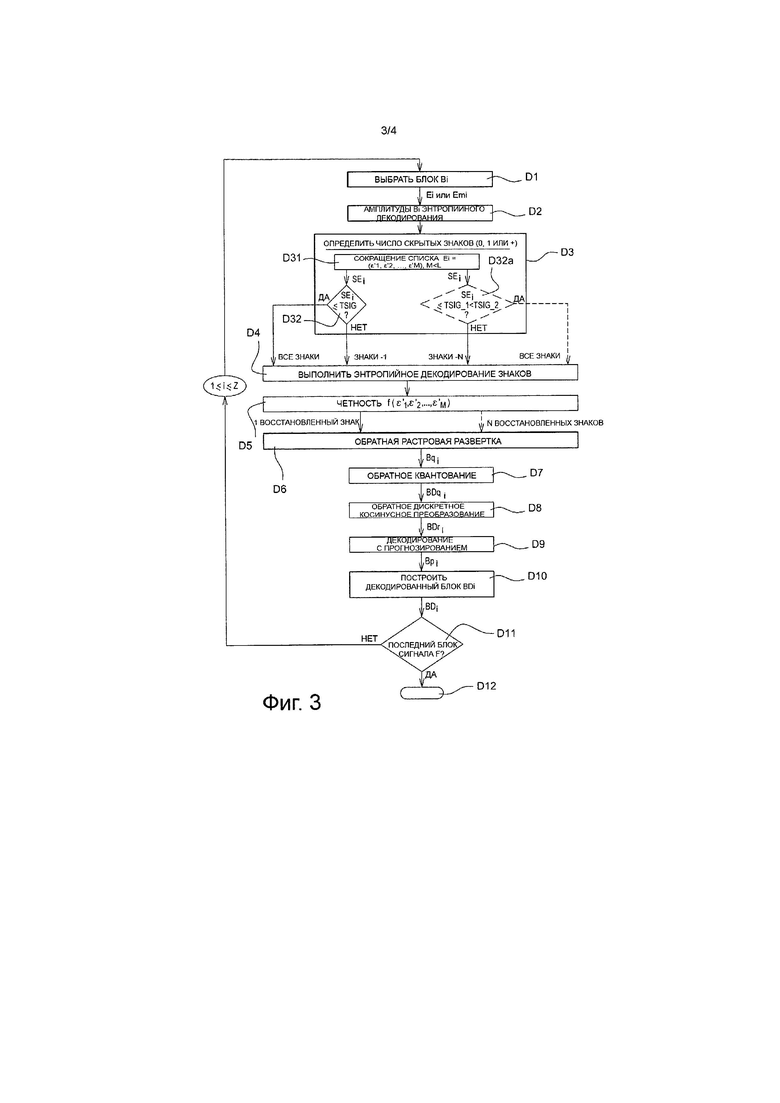
Вариант осуществления способа декодирования, в соответствии с изобретением, будет описан ниже, в котором способ декодирования воплощен в виде программных средств или в форме аппаратных средств, путем модификации декодера, который первоначально соответствует стандарту H.264/MPEG-4 AVC.
Способ декодирования, в соответствии с изобретением, представлен в форме алгоритма, включающего в себя этапы D1 - D12, представленные на фиг. 3.
В соответствии с вариантом осуществления изобретения способ декодирования, в соответствии с изобретением, воплощен в устройстве декодирования или в декодере DO, как представлено на фиг. 4.
Во время предварительного этапа, который не представлен на фиг. 3, в принятом сигнале F данных, идентифицируют участки B1-Bz, которые были кодированы ранее кодером СО. В предпочтительном варианте осуществления, упомянутые участки представляют собой блоки, которые имеют квадратную форму, и все имеют одинаковый размер. В зависимости от размера изображения, который не обязательно должен составлять целочисленное кратное размера блоков, последние блоки слева и последние блоки снизу не обязательно должны иметь квадратную форму. В альтернативном варианте осуществления блоки могут быть, например, прямоугольными и/или могут не быть выровнены друг с другом.
Каждый блок или макроблок, кроме того, сам по себе может быть разделен на подблоки, которые сами по себе могут быть подразделены.
Такая идентификация выполняется с помощью программного модуля EX_DO анализа потока, как представлено на фиг. 4.
Во время этапа D1, представленного на фиг. 3, модуль EX_DO на фиг. 4 выбирают в качестве текущего блока В1, первый блок В1 предназначен для декодирования. Такой выбор состоит, например, в размещении указателя считывания в сигнале F, в начале элементов данных первого блока В1.
Затем выполняют декодирование каждого из выбранных блоков кодирования.
В примере, представленном на фиг. 3, такое декодирование применяют последовательно к каждому из кодированных блоков от B1 до Bz. Блоки декодируют, например, в соответствии с растровой разверткой, как хорошо известно специалисту в данной области техники.
Декодирование, в соответствии с изобретением, воплощают в программном модуле MD_DO декодирования декодера DO, как представлено на фиг. 4.
Во время этапа D2, представленного на фиг. 3, выполняют первое энтропийное декодирование первого выбранного текущего блока B1. Такую операцию выполняют с помощью модуля DE_DO энтропийного декодирования, представленного на фиг. 4, например, типа CABAC. Во время этого этапа модуль DF_DO выполняет энтропийное декодирование элементов цифровой информации, соответствующих амплитуде каждого из кодированных коэффициентов в списке Е1 или в модифицированном списке Em1. На данном этапе не декодируют только знаки коэффициентов в списке Е1 или в модифицированном списке Em1.
Во время этапа D3, представленного на фиг. 3, определяют множество знаков, для которых возможно их скрытие во время предыдущего этапа С20 энтропийного кодирования. Такой этап D3 выполняют с помощью программного модуля MTR_DO обработки, как представлено на фиг. 4. Этап D3 аналогичен упомянутому выше этапу С7 для определения количества знаков, которые должны быть скрыты.
В предпочтительном варианте осуществления количество скрытых знаков равно единице или нулю. Кроме того, в соответствии с упомянутым предпочтительным вариантом осуществления, скрытым является знак первого ненулевого коэффициента. В представленном примере, поэтому, он представляет собой положительный знак коэффициента ε2=+9.
В альтернативном варианте осуществления количество скрытых знаков равно нулю, одному, двум, трем или больше.
В соответствии с предпочтительным вариантом осуществления этапа D3, во время первого подэтапа D31, представленного на фиг. 3, подсписок, содержащий коэффициенты ε'1, ε'2, ε'М, где М<L, которые позволяют выполнять их модификацию при кодировании, определяют из упомянутого списка Е1 или из модифицированного списка Em1.
Такое определение выполняют так же, как и на упомянутом выше этапе С7 кодирования.
Аналогично упомянутому выше модулю MTR_СО обработки, модуль MTR_DO обработки первоначально конфигурируют, так, чтобы модифицировать:
- нулевой коэффициент или коэффициенты, расположенные перед первым ненулевым коэффициентом,
- и по причинам сложности расчетов, нулевой коэффициент или коэффициенты, расположенные после последнего ненулевого коэффициента.
В представленном примере, в конце подэтапа D31, находится подсписок SEm1 такой, как SEm1=(9, -6, 0, 0, 1, 0, -1, 2, 0, 0, 1). Следовательно, получают одиннадцать коэффициентов, которые могли бы быть модифицированы.
Во время следующего подэтапа D32. представленного на фиг. 3, модуль MTR_DO обработки переходит к сравнению количества коэффициентов, которые могли бы быть модифицированы с заданным пороговым значением TSIG. В предпочтительном варианте осуществления TSIG имеет значение 4.
Если количество коэффициентов, которые могли быть модифицированы, меньше, чем пороговое значение TSIG, тогда во время этапа D4, представленного на фиг. 3, выполняют обычное энтропийное декодирование для всех знаков коэффициентов в списке Е1. Такое декодирование выполняют с помощью декодера САВАС, обозначенного опорным значением DE_DO на фиг. 4. С этой целью, знак каждого ненулевого коэффициента в списке E1 подвергают энтропийному декодированию.
Если количество коэффициентов, которое может быть модифицировано, больше, чем пороговое значение TSIG, тогда во время упомянутого этапа D4 выполняют обычное энтропийное декодирование всех знаков коэффициентов в списке Em1, за исключением знака первого ненулевого коэффициента ε2.
Во время этапа D5, представленного на фиг. 3, модуль MTR_DO обработки рассчитывает значение функции f, которое представляет коэффициенты в подсписке SEm, для определения, является ли рассчитанное значение четным или нечетным.
В предпочтительном варианте осуществления, где скрыт только один знак в сигнале F, функция f представляет собой четность суммы коэффициентов в подсписке SEm1.
В соответствии с соглашением, используемым в кодере СО, который является таким же, как и в декодере DO, четное значение суммы коэффициентов в подсписке SEm1 означает, что знак первого ненулевого коэффициента в модифицированном списке Em1 является положительным, в то время, как нечетное значение суммы коэффициентов в подсписке SEm1 означает, что знак первого ненулевого коэффициента в модифицированном списке Em1 является отрицательным.
В примерном варианте осуществления, в котором SEm1=(+9, -6, 0, 0, +1, 0, -1, +2, 0, 0, +1), общая сумма коэффициентов равна 6, и, поэтому, является четной. Следовательно, в конце этапа D5, модуль MTR_DO обработки выводит из него, что скрытый знак первого ненулевого коэффициента ε2 является положительным.
Во время этапа D6, представленного на фиг. 3, и с помощью всех реконструированных элементов цифровой информации во время этапов D2, D4 и D5, квантованные коэффициенты блока Bq1 реконструируют в заданном порядке. В представленном примере он представляет собой обратную зигзагообразную развертку в отношении зигзагообразной развертки, выполненной во время упомянутого выше этапа С6 кодирования. Такой этап выполняют с помощью программного модуля ML_DO считывания, как представлено на фиг. 4. Более конкретно, модуль ML_DO продолжает обработку, так, чтобы включить коэффициенты списка E1 (одномерный) в блок Bq1 (двумерный), используя упомянутый порядок обратной зигзагообразной развертки.
Во время этапа D7, представленного на фиг. 3, квантованный остаточный блок Bq1 подвергают обратному квантованию, в соответствии с обычной операцией обратного квантования, которая представляет собой обратную операцию квантования, выполненную на упомянутом выше этапе С5 кодирования, для получения декодированного деквантованного блока BDq1. Такой этап исполняют с помощью программного модуля MDQ_DO обратного квантования, как представлено на фиг. 4.
Во время этапа D8, представленного на фиг. 3, выполняют обратное преобразование деквантованного блока BDq1, которое представляет собой операцию, обратную для прямого преобразования, выполненного при кодировании на упомянутом выше этапе С4. Таким образом, получают декодированный остаточный блок BDr1. Такую операцию выполняют с помощью программного модуля MTI_DO обратного преобразования, как представлено на фиг. 4.
Во время этапа D9, представленного на фиг. 3, выполняют декодирование с прогнозированием текущего блока В1. Такое декодирование с прогнозированием обычно выполняют, используя известные технологии внутрикадрового и/или межкадрового прогнозирования, во время которых блок В1 прогнозируют в отношении по меньшей мере одного ранее декодированного блока. Такую операцию выполняют с помощью модуля PRED_DO декодирования с прогнозированием, как представлено на фиг. 4.
Само собой разумеется, что возможны другие режимы внутрикадрового прогнозирования, как предложено в стандарте Н.264.
Во время этого этапа выполняют прогнозирование декодирования, используя декодированные элементы синтаксиса на предыдущем этапе, и, в частности, содержащем тип прогнозирования (межкадровое или внутрикадровое), и, в случае необходимости, режим внутри кадрового прогнозирования, тип разделения блока или макроблока, если последний был разделен, индекс опорного изображения и вектор движения, которые используются в режиме межкадрового прогнозирования.
Упомянутый выше этап декодирования с прогнозированием обеспечивает построение прогнозируемого блока Вр1.
Во время этапа D10, представленного на фиг. 3, декодированный блок BD1 строят путем добавления декодированного остаточного блока BDr1 к прогнозируемом у блоку Bp1. Такую операцию исполняют с помощью программного модуля MR_DO реконструкции, представленного на фиг. 4.
Во время этапа D11, представленного на фиг. 3, модуль MD_DO декодирования проверяет, является ли текущий декодированный блок последним блоком, идентифицированным в сигнале F.
Если текущий блок представляет собой последний блок в сигнале F, тогда во время этапа D12, представленного на фиг. 3, способ декодирования заканчивается.
Если это не так, выбирают следующий блок В1 как блок, который должен быть декодирован, в соответствии с порядком упомянутой выше растровой развертки, путем повторения этапов D1-D10, для 1≤i≤Z.
Далее, со ссылкой на фиг. 3, будет описан другой вариант осуществления изобретения.
Этот другой вариант осуществления отличается от предыдущего только количеством скрытых коэффициентов, которое не является равным ни 0, ни N, где N представляет собой целое число такое, как N≥2.
С этой целью, ранее упомянутый подэтап D32 сравнения заменяют подэтапом D32a, представленным пунктирной линией на фиг. 3, во время которого количество коэффициентов, которые могли бы быть модифицированными, сравнивают с несколькими заданными пороговыми значениями 0 < TSIG_1 < TSIG_2 < TSIG_3 …, таким образом, что если множество упомянутых коэффициентов находится в пределах от TSIG_N до TSIG_N+1, могут быть скрыты N знаков.
Если количество упомянутых коэффициентов меньше, чем первое пороговое значение TSIG_1, тогда во время ранее упомянутого этапа D4 выполняют обычное энтропийное декодирование всех знаков коэффициентов в списке Е1. С этой целью, знак каждого ненулевого коэффициента в списке Е1 подвергают энтропийному декодированию.
Если количество упомянутых коэффициентов находится между порогом TSIG_N и TSIG_N+1, тогда во время ранее упомянутого этапа D4, выполняют обычное энтропийное декодирование всех знаков коэффициентов в списке Е1, за исключением N соответствующих знаков первых ненулевых коэффициентов в упомянутом модифицированном списке Em1, упомянутые N знаков скрывают.
В другом варианте осуществления модуль MTR_DO обработки рассчитывает, во время этапа D5, значение функции f, которое представляет собой остаток модуля 2N суммы коэффициентов в подсписке SEm1. В предложенном примере это N=2.
MTR_DO модуля обработки, следовательно, выводит из него конфигурацию двух скрытых знаков, которые назначены для каждого из двух первых ненулевых коэффициентов ε2 и ε3, соответственно, в соответствии с соглашением, используемым при кодировании.
После реконструкции этих двух знаков, выполняют этапы D6 - D12, описанные выше.
Само собой разумеется, что варианты осуществления, которые были описаны выше, были представлены исключительно в качестве показателя, а не для ограничения, и что специалист в данной области техники может легко разработать множество модификаций без выхода, таким образом, за пределы объема изобретения.
Таким образом, например, в соответствии с упрощенным вариантом осуществления в отношении того, что представлено на фиг. 1, кодер СО мог бы быть сконфигурирован так, чтобы он скрывал по меньшей мере N' заданных знаков, где N'≥1, вместо либо нуля, одного или N заданных знаков. В этом случае этап С72 или С72а сравнения можно было бы исключить. Соответствующим образом, в соответствии с упрощенным вариантом осуществления в отношении того, что представлено на фиг. 3, декодер DO мог бы быть сконфигурирован так, чтобы он реконструировал N' заданных знаков вместо либо нуля, одного или N заданных знаков. В этом случае, можно было бы устранить этап D32 или D32a сравнения.
Кроме того, критерий определения, применяемый на этапе С72 кодировании или на этапе D32 декодирования, может быть заменен другим типом критерия. С этой целью, вместо сравнения множества модифицированных коэффициентов или множества коэффициентов, которые были модифицированы с пороговым значением, модуль MTR_CO или MTR_DO обработки мог бы применять критерий выбора, который представляет собой функцию суммы амплитуд коэффициентов, которые являются модифицированными или могли бы быть модифицированы, соответственно, или количества нулей, присутствующих среди коэффициентов, которые являются модифицированными и которые могли быть модифицированными, соответственно.


Изобретение относится к области кодирования и декодирования изображений. Технический результат заключается в повышении точности кодирования и декодирования изображений. Технический результат достигается за счет набора коэффициентов, закодированных с помощью контекстного адаптивного двоичного арифметического кодирования (CABAC), которые должны быть декодированы декодером для генерирования набора коэффициентов, представляющего остаточный блок для блока, обладающего возможностью сокрытия данных знака, причем набор коэффициентов включает в себя некоторый конкретный ненулевой коэффициент, который не имеет указания знака, при этом на основе операции, представляющей деление между суммой ненулевых коэффициентов в упомянутом наборе коэффициентов и некоторым конкретным числом, данные остатка используются для указания знака для упомянутого конкретного ненулевого коэффициента. 8 з.п. ф-лы, 4 ил.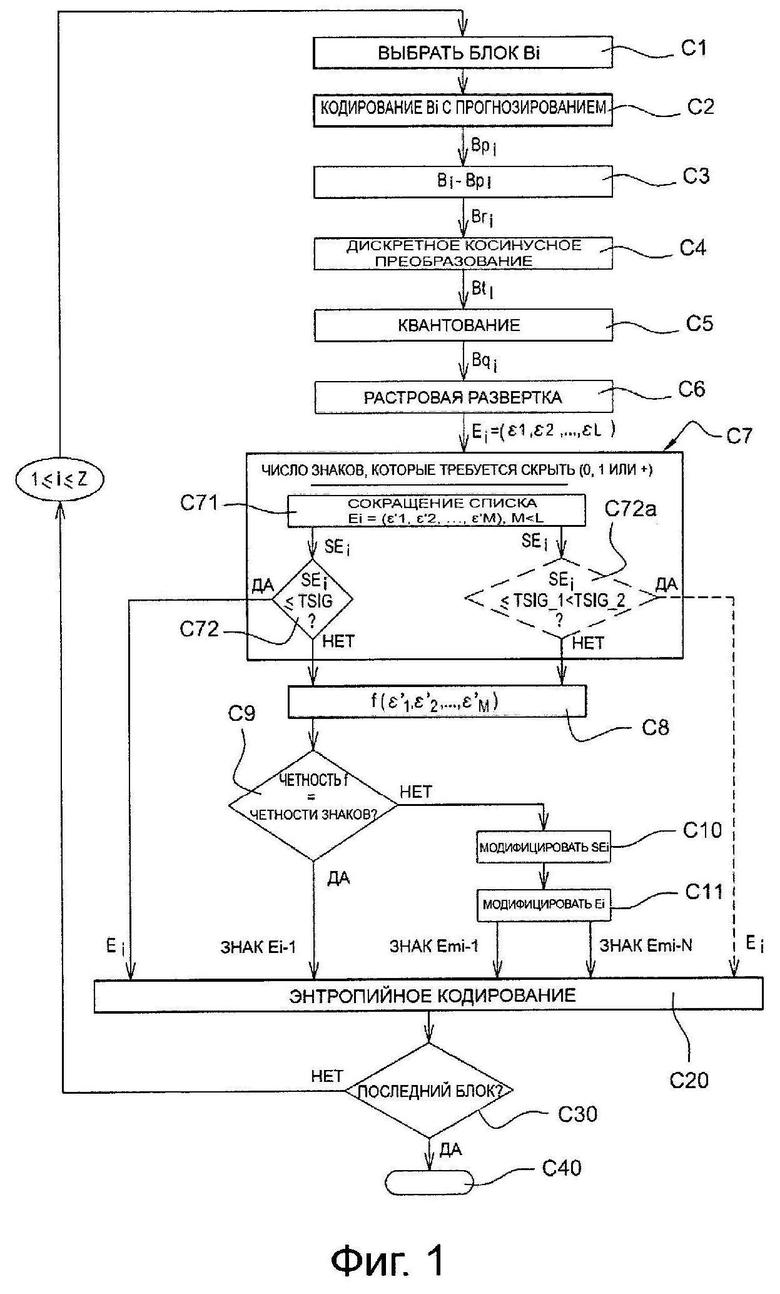
1. Долговременный считываемый компьютером носитель для хранения данных, представляющих блок изображения, обладающий возможностью сокрытия данных знака, содержащий:
битовый поток, записанный на упомянутый долговременный считываемый компьютером носитель, причем битовый поток содержит набор коэффициентов, закодированных с помощью контекстного адаптивного двоичного арифметического кодирования (CABAC), которые должны быть декодированы декодером для генерирования набора коэффициентов, представляющего остаточный блок для блока, обладающего возможностью сокрытия данных знака, причем набор коэффициентов включает в себя некоторый конкретный ненулевой коэффициент, который не имеет указания знака,
при этом на основе операции, представляющей деление между суммой ненулевых коэффициентов в упомянутом наборе коэффициентов и некоторым конкретным числом, данные остатка используются для указания знака для упомянутого конкретного ненулевого коэффициента.
2. Считываемый компьютером носитель по п. 1, при этом сумма ненулевых коэффициентов в наборе коэффициентов вычисляется с использованием суммы абсолютных значений ненулевых коэффициентов в наборе коэффициентов.
3. Считываемый компьютером носитель по п. 1, при этом данные остатка являются данными контроля четности суммы ненулевых коэффициентов в наборе коэффициентов.
4. Считываемый компьютером носитель по п. 3, при этом если данные контроля четности являются четными, знак для упомянутого конкретного ненулевого коэффициента является положительным, а если данные контроля четности являются нечетными, знак для упомянутого конкретного ненулевого коэффициента является отрицательным.
5. Считываемый компьютером носитель по п. 1, при этом набор коэффициентов, закодированных с помощью CABAC, должен быть декодирован декодером для генерирования второго набора коэффициентов, представляющего указания знака одного или более других ненулевых коэффициентов в наборе коэффициентов, причем каждый из них имеет указание знака.
6. Считываемый компьютером носитель по п. 1, при этом упомянутой операцией является операция деления по модулю.
7. Считываемый компьютером носитель по п. 1, при этом упомянутое конкретное число имеет значение, равное двум.
8. Считываемый компьютером носитель по п. 1, при этом упомянутый конкретный ненулевой коэффициент является ненулевым коэффициентом, который упорядочен как последний ненулевой коэффициент в обратном порядке сканирования остаточного блока.
9. Считываемый компьютером носитель по п. 1, при этом значение по меньшей мере одного из ненулевых коэффициентов было модифицировано из исходного значения перед кодированием для того, чтобы обеспечить возможность использования упомянутой операции для указания знака для упомянутого конкретного ненулевого коэффициента.
| ЭФФЕКТИВНОЕ ПО ИСПОЛЬЗОВАНИЮ ПАМЯТИ АДАПТИВНОЕ БЛОЧНОЕ КОДИРОВАНИЕ | 2007 |
|
RU2413360C1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |

