Область техники, к которой относится изобретение
Настоящее изобретение, в общем, относится к области обработки изображений, и более конкретно, к кодированию и декодированию цифровых изображений и последовательностей цифровых изображений.
Изобретение, таким образом, в частности, предназначено для кодирования видеоданных, воплощенного в существующих (MPEG, H. 264 и т.д.) или будущих кодерах видеоданных (ITU-T/VCEG (H. 265) или ISO/MPEG (HEVC)).
Уровень техники
В современных кодерах видеоданных (MPEG, H. 264 и т.д.) используется поблочное представление видеопоследовательности. Изображения разделяют на макроблоки, причем каждый макроблок также разделен на блоки, и каждый блок или макроблок кодируют, используя прогнозирование внутри изображения или между изображениями. Таким образом, некоторые изображения кодируют, используя пространственное прогнозирование (внутрикадровое прогнозирование), в то время как другие изображения кодируют, используя временное прогнозирование (межкадровое прогнозирование) в отношении одного или больше опорных кодируемых - декодируемых изображений, используя компенсацию движения, как известно для специалиста в данной области техники.
Для каждого блока кодируют остаточный блок, также называемый остатком прогнозирования, соответствующий оригинальному блоку, уменьшенному в ходе прогнозирования. Остаточные блоки преобразуют, используя преобразование типа дискретного косинусного преобразования (DCT), затем квантуют, используя, например, квантование скалярного типа. В конце этапа квантования получают коэффициенты, некоторые из которых являются положительными, а другие отрицательными. Затем выполняют их обход в порядке считывания, обычно в зигзагообразном порядке (как в стандарте JPEG), обеспечивая, таким образом, возможность использования существенного количества нулевых коэффициентов на высоких частотах. В конце упомянутого выше обхода получают одномерный список коэффициентов, который можно назвать "квантованным остатком". Коэффициенты из этого списка затем кодируют, используя энтропийное кодирование.
Энтропийное кодирование (например, арифметическое кодирование или кодирование типа Хаффмана) выполняют следующим образом:
- элемент информации подвергают энтропийному кодированию для обозначения положения последнего ненулевого коэффициента в списке,
- для каждого коэффициента, расположенного перед последним ненулевым коэффициентом, элемент информации энтропийно кодируют для обозначения, равен или нет этот коэффициент нулю,
- для каждого обозначенного ранее коэффициента, который не равен нулю, энтропийно кодируют элемент информации для обозначения, равен или нет этот коэффициент единице,
- для каждого ненулевого коэффициента, который не равен единице, расположенного перед последним ненулевым коэффициентом, энтропийно кодируют элемент амплитуды информации (абсолютное значение коэффициента, значение которого было уменьшено вдвое),
- для каждого ненулевого коэффициента назначенный для него знак кодируют как "0" (для знака"+") или как "1" (для знака"-").
В соответствии с технологией Н. 264, например, когда макроблок разделяют на блоки, сигнал данных, соответствующий каждому блоку, передают в декодер. Такой сигнал содержит:
- квантованные остатки, содержащиеся в упомянутом выше списке,
- информацию, представляющую используемый режим кодирования, в частности:
- режим прогнозирования (внутрикадровое прогнозирование, межкадровое прогнозирование, принятое по умолчанию прогнозирование, выполняющее прогнозирование, для которого не передают элемент информации в декодер "пропуск");
- информацию, устанавливающую тип прогнозирования (ориентация, опорное изображение и т.д.);
- тип разделения;
- тип преобразования, например, 4×4 DCT, 8×8 DCT и т.д.;
- информация о движении, в случае необходимости;
- и т.д.
Декодирование выполняют изображение за изображением и для каждого изображения макроблок за макроблоком. Для каждого участка макроблока считывают соответствующие элементы потока. Обратное квантование и обратное преобразование коэффициентов блоков выполняют для получения декодированного остатка прогнозирования. Затем вычисляют прогнозирование участка, и участок реконструируют путем добавления прогнозирования к декодированному остатку прогнозирования.
Внутрикадровое или межкадровое кодирование с конкуренцией, как воплощено в стандарте Н. 264, таким образом, основано на различных элементах информации кодирования, таких как упомянутые выше, для которых устанавливают конкуренцию с целью выбора наилучшего режима, то есть режима, который оптимизирует кодирование рассматриваемого участка, в соответствии с заданным критерием рабочих характеристик, например, скорость передачи битов/стоимость искажения, как хорошо известно специалисту в данной области техники.
Информация, представляющая выбранный режим кодирования, содержится в сигнале данных, передаваемом кодером в декодер. Декодер, таким образом, выполнен с возможностью идентификации выбранного в кодере режима кодирования, с последующим применением прогнозирования, которое соответствует этому режиму.
В документе "Data Hiding of Motion Information in Chroma and Luma Samples for Video Compression", J. - M. Thiesse, J. Jung and M. Antonini, International workshop on multimedia signal processing, 2011 представлен способ скрытия данных, который воплощается во время сжатия видеоданных.
Более точно, предложено избегать включения в сигнал, предназначенный для передачи в декодер по меньшей мере одного индекса конкуренции, вырабатываемого из множества индексов конкуренции, предназначенных для передачи. Такой индекс представляет собой, например, индекс MVComp, который представляет элемент информации, для идентификации предиктора вектора движения, используемого для блока, прогнозируемого в межкадровом режиме. Такой индекс, который может принимать значение 0 или 1, не включен непосредственно в сигнал кодированных данных, но его транспортируют через четность сумм коэффициентов квантованного остатка. Ассоциация формируется между четностью квантованного остатка и индексом MVComp.В качестве примера, четное значение квантованного остатка ассоциируют со значением 0 индекса MVComp, в то время как нечетное значение квантованного остатка ассоциируют с индексом MVComp со значением 1. При этом могут возникнуть два случая. В первом случае, если четность квантованного остатка уже соответствует четности индекса MVComp, который требуется передать, квантованный остаток кодируют обычным образом. Во втором случае, если четность квантованного остатка отличается от четности индекса MVComp, который требуется передать, квантованный остаток модифицируют таким образом, чтобы его четность была такой же, как у индекса MVComp. Такая модификация состоит в последовательном увеличении или уменьшении одного или более коэффициентов квантованного остатка на нечетное значение (например,+1, -1, +3, -3, +5, -5 и т.д.) и поддержании только модификации, которая оптимизирует заданный критерий, в данном случае, ранее упомянутую выше скорость передачи битов/стоимость искажения.
В декодере индекс MVComp не считывают в сигнале. Декодер просто выполняет определение путем обычного определения остатка. Если значение такого остатка будет четным, индекс MVComp устанавливают равным 0. Если значение этого остатка будет нечетным, индекс MVComp устанавливают в 1.
В соответствии с технологией, которая была представлена выше, коэффициенты, которые подвергаются модификации, не всегда выбирается оптимально, таким образом, что применяемая модификация приводит к нарушениям сигнала, передаваемого в декодер. Такие нарушения неизбежно оказывают отрицательное влияние на эффективность сжатия видеоданных.
Кроме того, индекс MVComp не составляет самый полезный элемент информации, который должен быть скрыт, поскольку вероятности того, что этот индекс будет равен 0 или 1, не равны между собой. Следовательно, если этот индекс будет кодирован обычным способом, используя энтропийное кодирование, то он будет представлен в сжатом файле, предназначенном для передачи в декодер, с меньшим количеством данных, чем один бит на переданный индекс MVComp. Следовательно, если индекс MVComp будет передан в четности квантованного остатка, количество данных, сэкономленных, таким образом, будет меньше, чем один бит за индекс MVComp, тогда как четность остатка могла бы позволить транспортировать единицу информации в один бит на индекс.
Следовательно, снижение стоимости передачи сигналов, так же как эффективность сжатия, являются не оптимальными.
Раскрытие изобретения
Одна из целей изобретения состоит в том, чтобы устранить недостатки упомянутого выше предшествующего уровня техники.
С этой целью предмет настоящего изобретения относится к способу кодирования по меньшей мере одного изображения, разделенного на области, при этом текущая область, предназначенная для кодирования, содержит данные по меньшей мере одного элемента данных, которому назначен знак.
Способ в соответствии с изобретением, в частности, состоит в том, что в нем реализуются, для упомянутого выше текущего участка, следующие этапы:
- вычисляют значения функции, представляющие данные упомянутого текущего участка, за исключением знака,
- сравнивают расчетное значение с заданным значением знака,
- как функцию результата сравнения выполняют модификацию или другое изменение по меньшей мере одних из данных текущего участка,
- в случае модификации кодируют по меньшей мере один модифицированный элемент данных.
Такая компоновка обеспечивает возможность успешного применения технологии скрытия данных для знаков данных кодируемого участка. Знак действительно представляет собой элемент информации, который особенно уместно скрывать из-за того факта, что вероятность появления положительного знака или отрицательного знака равновероятна. Поэтому, учитывая, что знак обязательно кодируют как один бит, таким образом возможно, скрывая этот элемент информации, сэкономить один бит в сигнале, передаваемом в декодер, таким образом, существенно уменьшая стоимость передачи сигналов.
Следует отметить, что среди информации (знак, амплитуда, и т.д.), ассоциированной с элементом данных изображения, очень немногие из них равновероятны. Таким образом, для знака, который представляет собой равновероятный элемент информации, особенно предпочтительно скрывать элемент информации этого типа, таким образом, позволяя повысить характеристики сжатия.
В конкретном варианте осуществления в случае, когда множество знаков учитывают в ходе вышеупомянутого этапа сравнения, последний состоит в сравнении расчетного значения функции, представляющей данные текущего участка, со значением функции, представляющей множество знаков.
Такая компоновка позволяет оптимизировать характеристики сжатия арифметического кодера, оптимизируя снижение стоимости передачи сигналов, поскольку это позволяет скрыть несколько знаков в сигнале, который будет передан в декодер.
Соотносительно, изобретение относится к устройству кодирования по меньшей мере одного изображения, разделенного на области, причем текущая область, предназначенная для кодирования, содержит данные по меньшей мере одного элемента данных, которому выделен знак.
Такое устройство кодирования примечательно тем, что оно содержит средство обработки, которое для текущей области, подлежащей кодированию, выполнено с возможностью:
- вычисления значения функции, представляющей данные текущего участка, за исключением знака,
- сравнения вычисленного значения с заданным значением знака,
- модификации или другой обработки по меньшей мере одних данных текущей области в качестве функции результата сравнения,
и тем, что содержит средство кодирования по меньшей мере одного модифицируемого элемента данных в случае модификации средством обработки.
Соответствующим образом изобретение также относится к способу декодирования сигнала данных, представляющего по меньшей мере одно изображение, разделенное на участки, которые были ранее кодированы, текущий участок, предназначенный для декодирования, содержащий данные по меньшей мере одному элементу данных, для которого выделен знак.
Такой способ декодирования примечателен тем, что он содержит для текущего участка следующие этапы:
- декодируют данные текущей области, за исключением знака,
- вычисляют значения функции, представляющей декодируемые данных текущей области,
- получают на основе расчетного значения значение знака.
В конкретном варианте осуществления множество значений, ассоциированных, соответственно, с множеством знаков, получают на основе расчетного значения.
Соответственно, изобретение относится к устройству декодирования представителя сигнала данных по меньшей мере одного изображения, разделенного на области, которые были ранее кодированы, причем текущая область, которая подлежит декодированию, содержащая данные по меньшей мере одного элемента данных, для которого выделен знак.
Такое устройство декодирования примечательно тем, что оно содержит средство обработки, которое для текущей области, которая подлежит декодированию, выполнено с возможностью:
- декодирования данных текущей области, с исключением знака,
- вычисления значения функции, представляющей декодируемые данные текущей области,
- получать на основе расчетного значения значение знака.
Изобретение также относится к компьютерной программе, включающей в себя инструкции для исполнения этапов представленного выше способа кодирования или декодирования, когда программа исполняется компьютером.
В такой программе может использоваться любой язык программирования, и она может быть представлена в форме исходного кода, объектного кода или кода, промежуточного между исходным кодом и объектным кодом, например, в частично компилированной форме или в любой другой требуемой форме.
Еще один другой предмет изобретения представляет собой считываемый компьютером носитель записи, хранящий инструкции компьютерной программы упомянутой выше.
Носитель записи может представлять собой любой объект или устройство, выполненное с возможностью хранения программы. Например, такой носитель может включать в себя средство хранения, такое как ROM, например CD-ROM или ROM в микроэлектронных цепях, или средство магнитной записи, например гибкий диск или жесткий диск.
Кроме того, такой носитель записи может представлять собой среду передачи, такую как электрический или оптический сигнал, который может быть передан через электрический или оптический кабель, через радиоканал или через другое средство. Программа, в соответствии с изобретением, в частности, может быть загружена через сеть типа Интернет.
В качестве альтернативы, такой носитель записи может представлять собой интегральную схему, в которую встроена программа, схема выполнена с возможностью исполнения рассматриваемого способа или может использоваться при исполнении последнего.
Устройство кодирования, способ декодирования, устройство декодирования и компьютерные программы, упомянутые выше, проявляют по меньшей мере те же преимущества, что и те, которые предоставляются способом кодирования, в соответствии с настоящим изобретением.
Краткое описание чертежей
Другие свойства и преимущества будут понятны при чтении двух предпочтительных вариантов осуществления, описанных со ссылкой на чертежи, на которых:
на фиг. 1 представлены общие этапы способа кодирования, в соответствии с изобретением,
на фиг. 2 представлено устройство кодирования, в соответствии с изобретением, выполненное с возможностью выполнения этапов способа кодирования по фиг. 1,
на фиг. 3 представлен конкретный вариант осуществления способа кодирования в соответствии с изобретением,
на фиг. 4 представлен конкретный вариант осуществления устройства кодирования в соответствии с изобретением,
на фиг. 5 представлены общие этапы способа декодирования, в соответствии с изобретением,
на фиг. 6 представлено устройство декодирования, в соответствии с изобретением, выполненное с возможностью выполнения этапов способа декодирования по фиг. 5,
на фиг. 7 представлен конкретный вариант осуществления способа декодирования в соответствии с изобретением,
на фиг. 8 представлен конкретный вариант осуществления устройства декодирования в соответствии с изобретением,
Осуществление изобретения
Подробное описание участка кодирования
Ниже будет описан вариант осуществления изобретения, в котором способ кодирования, в соответствии с изобретением, используется для кодирования последовательности изображений, в соответствии с бинарным потоком, близким к тому, который получают путем кодирования, в соответствии со стандартом H. 264/MPEG-4 AVC. В этом варианте осуществления способ кодирования, в соответствии с изобретением, например, воплощен в виде программных средств или аппаратных средств путем модификации кодера, первоначально соответствующего стандарту Н. 264/MPEG-4 AVC.
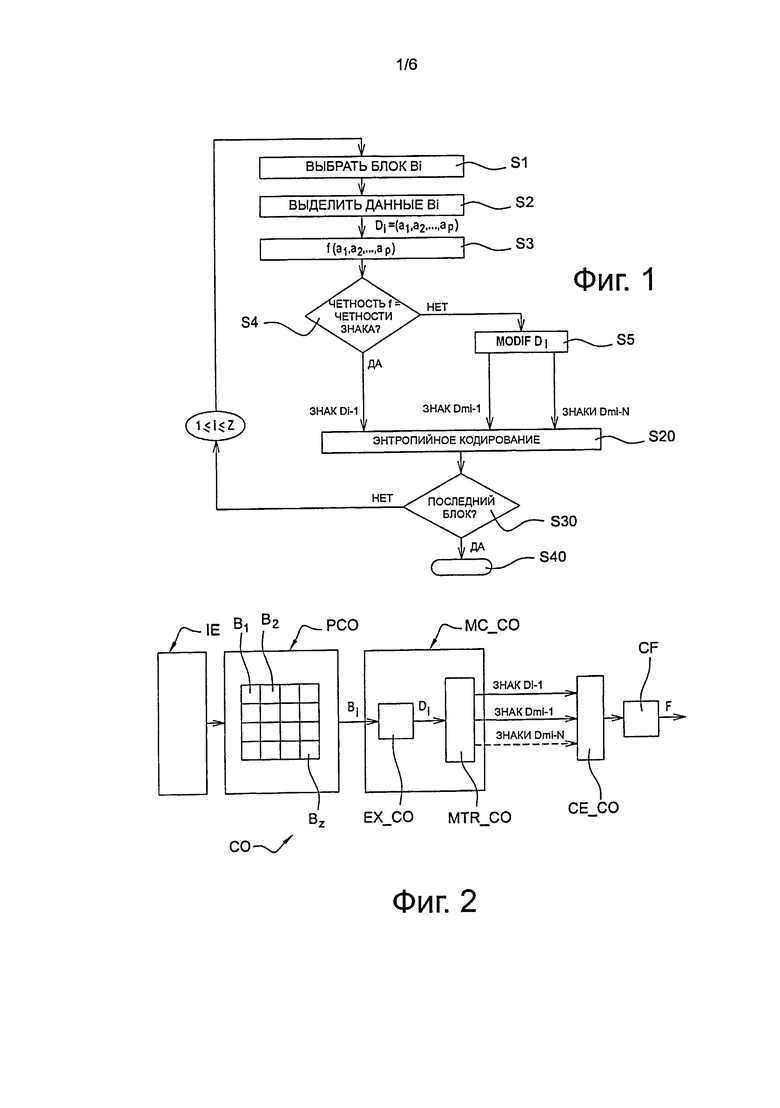
Способ кодирования, в соответствии с изобретением, представлен в форме алгоритма, включающего в себя этапы от С1 до С40, показанные на фиг. 1.
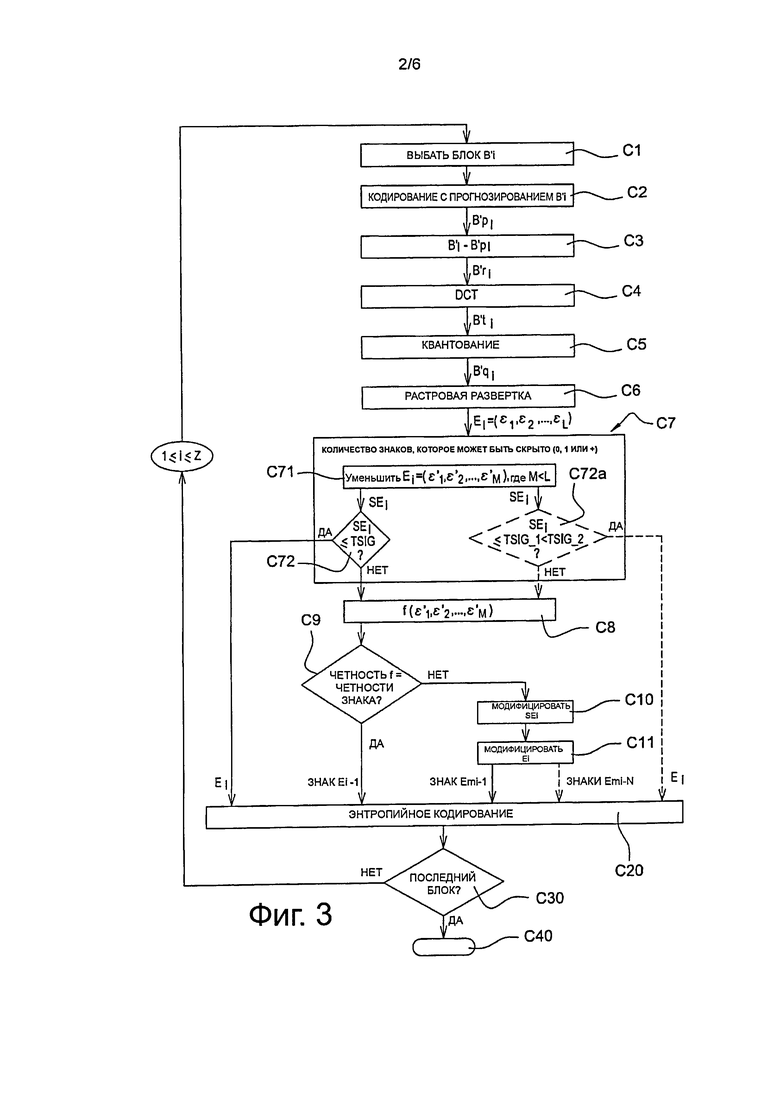
В соответствии с вариантом осуществления изобретения способ кодирования, в соответствии с изобретением, воплощен в устройстве кодирования или в кодере СО, вариант осуществления которого представлен на фиг. 2.
В соответствии с изобретением, перед фактическим этапом кодирования выполняют разделение изображения IE, состоящего из последовательности изображений, предназначенных для кодирования в заданном порядке, на множество Z областей B1, B2, …, Bi, …, BZ, как представлено на фиг. 2.
Следует отметить, что в пределах значения изобретения, термин "область" означает модуль кодирования. Такая терминология, в частности, используется в стандарте HEVC/H. 265, который в настоящее время находится в разработке, например, в документе, доступном по следующему адресу Интернет:
<http://phenix.int-evry.fr/jct/doc_end_user/current_document.php?id=3286>
В частности, такие модули кодирования группируют вместе в наборах пикселей прямоугольной или квадратной формы, также называемых блоками, макроблоками или наборах пикселей, имеющих другие геометрические формы.
В примере, представленном на фиг. 2, упомянутые участки представляют собой блоки, которые имеют квадратную форму, и все из которых имеют одинаковый размер. В зависимости от размера изображения, который не обязательно составляет кратное значение размера блоков, последние блоки слева и последние блоки снизу не обязательно должны быть квадратной формы. В альтернативном варианте осуществления блоки могут, например, иметь прямоугольную форму и/или могут не быть выровнены друг с другом.
Каждый блок или макроблок, кроме того, может быть сам разделен на подблоки, которые сами после этого могут быть подразделены.
Такое разделение выполняют с помощью модуля РСО разделения, представленного на фиг. 2, в котором используется, например, алгоритм разделения, хорошо известный сам по себе.
После упомянутого этапа разделения выполняют кодирование каждой из текущих областей Bi (где i представляет собой целое число, такое как 1≤i≤Z) упомянутого изображения IE.
В примере, представленном на фиг. 2, такое кодирование применяют последовательно для каждого из блоков B1-BZ текущего изображения IE. Блоки кодируют, например, в соответствии с обходом, таким как обход в виде растровой развертки, как хорошо известно для специалиста в данной области техники.
Кодирование, в соответствии с изобретением, воплощено в программном модуле кодирования МС_СО кодера СО, такого как представлен на фиг. 2.
В ходе этапа С1, представленного на фиг. 1, модуль МС_СО кодирования на фиг. 2 выбирает, в качестве текущего блока В1, первый блок В1, предназначенный для кодирования текущего изображения IE. Как представлено на фиг.2, он представляет собой первый левый блок изображения IE.
В ходе этапа S2, представленного на фиг.1, предпринимается выделение данных текущего блока В1 в форме списка D1=(a1, a2, …, ар). Такое выделение выполняют с помощью программного модуля ЕХ_СО, как представлено на фиг. 2. Такие данные, например, представляют собой данные пикселя, при этом каждым ненулевым данным пикселя назначают либо положительный знак, или отрицательный знак.
Каждые из данных списка D1 ассоциированы с различными элементами цифровой информации, которая предназначена для выполнения энтропийного кодирования. Элементы цифровой информации, такие как эти, описаны ниже в качестве примера:
- для каждого из элемента данных, расположенного перед последним ненулевым элементом данных списка, D1, цифровой элемент информации, такой как бит, предназначен для энтропийного кодирования для обозначения, равен или нет элемент данных нулю: если элемент данных равен нулю, например, будет кодировано значение бита, равное 0, в то время как, если элемент данных не равен нулю, будет кодировано значение бита, равное 1;
- для каждого ненулевого элемента данных цифровой элемент информации, такой как бит, предназначен для энтропийного кодирования для обозначения, равно или абсолютное значение элемента данных единице: если оно равно 1, будет кодировано, например, значение бита, равное 1, в то время как, если оно не равно 1, будет кодировано значение бита, равное 0;
- для каждого ненулевого элемента данных, абсолютное значение которого не равно единице и который расположен перед последним ненулевым элементом данных, энтропийно кодируют элемент амплитуды информации,
- для каждого ненулевого элемента данных знак, который ему выделяют, кодируют с помощью цифрового элемента информации, такой как, например, бит, установленный в "0" (для знака +) или в "1" (для знака -).
Этапы абсолютного кодирования, в соответствии с изобретением, будут описаны ниже со ссылкой на фиг. 1.
В соответствии с изобретением, определяют, что требуется исключить энтропийное кодирования по меньшей мере одного знака одних из упомянутых данных списка D1.
В соответствии с предпочтительным вариантом осуществления, именно знак первого ненулевого элемента данных должен быть скрыт. Такой знак представляет собой, например, положительный знак, и его выделяют первому ненулевому элементу данных, такому как, например, элемент а2 данных.
В ходе этапа S3, представленного на фиг. 1, модуль MTR_CO обработки вычисляет значение функции f, которое является репрезентативным для данных списка D1.
В предпочтительном варианте осуществления, где одиночный знак должен быть скрыт в сигнале, предназначенном для передачи в декодер, функция f представляет собой четную сумму данных в списке D1.
В ходе этапа S4, представленного на фиг. 1, модуль MTR_CO обработки проверяет, соответствует ли значение знака, который должен быть скрыт, четности суммы данных списка D1, используя соглашение, определенное заранее в кодере СО.
В предложенном примере упомянутое соглашение выполняется таким образом, что положительный знак ассоциируют с битом значения, равного нулю, в то время как отрицательный знак ассоциируют с битом значения, равного единице.
Если, в соответствии с соглашением, принятым в кодере СО, в соответствии с изобретением, знак будет положительным, таким образом, соответствующим значению бита кодирования нуля, и если сумма данных списка D1 будет четной, выполняют этап S20 энтропийного кодирования данных упомянутого выше списка D1, за исключением знака первого ненулевого элемента a2 данных. Такой этап S20 представлен на фиг. 1.
Если, все еще, в соответствии с соглашением, принятым в кодере СО, в соответствии с изобретением, знак будет отрицательным, соответствующим, таким образом, одному из значения бита кодирования, и если сумма данных списка D1 будет нечетной, также выполняют этап S20 энтропийного кодирования данных упомянутого выше списка D1, за исключением знака первого ненулевого элемента а2 данных.
Если, в соответствии с соглашением, принятым в кодере СО, в соответствии с изобретением, знак будет положительным, соответствующим, таким образом, нулевому значению бита кодирования, и если сумма данных списка D1 будет нечетной, выполняют в ходе этапа S5, представленного на фиг. 1, модификацию по меньшей мере одного модифицируемого элемента данных списка D1.
Если, все еще, в соответствии с соглашением, принятым в кодере СО, в соответствии с изобретением, знак будет отрицательным, соответствующим, таким образом, одному из значения бита кодирования, и если сумма данных списка D1 будет четной, также выполняют этап S5 модификации по меньшей мере одного модифицируемого элемента данных списка D1.
В соответствии с изобретением, элемент данных является модифицируемым, если модификация его значения не приводит к какой-либо десинхронизации в декодере, как только этот модифицируемый элемент данных будет обработан декодером. Таким образом, модуль MTR_CO обработки первоначально выполнен так, чтобы не модифицировать:
- нулевой элемент данных или данные, расположенные перед первым ненулевым элементом данных, таким образом, что декодер не выделяет значение скрытого знака для этих или тех нулевых данных,
- и по причинам сложности расчетов, элемент нулевых данных или данные, расположенные после последнего ненулевого элемента данных.
Такая операция модификации выполняется модулем MTR_CO обработки по фиг. 2.
В предложенном примерном варианте осуществления предполагается, что полная сумма данных списка D1 равна 5 и поэтому является нечетной. То есть, декодер может реконструировать положительный знак, выделенный первому ненулевому элементу а2 данных, без передачи кодером СО этого элемента данных в декодер, при этом необходимо, чтобы значение четности суммы было четным. Следовательно, модуль MTR_CO обработки проверяет, в ходе упомянутого этапа S5, различные модификации данных списка D1, все из которых направлены на изменение четности суммы данных. В предпочтительном варианте осуществления предпринимается добавление +1 или -1 к каждому модифицируемому элементу данных и делают выбор, в соответствии с заданным критерием, модификации среди всех выполненных.
Затем получают модифицированный список Dm1=(a’1, a’2,..., a’P) после окончания этапа S5.
Следует отметить, что в ходе этого этапа определенные модификации запрещены. Таким образом, в случае, когда первый ненулевой элемент данных равен +1, было бы невозможно добавить к нему -1, поскольку он стал бы равен нулю, и при этом потерял бы свою характеристику первого ненулевого элемента данных списка D1. Декодер затем впоследствии выделил бы декодированный знак (путем расчета четности суммы данных) другому элементу данных, и тогда могла бы возникнуть ошибка декодирования.
После этого выполняют этап S20 энтропийного кодирования данных упомянутого выше списка Dm1, за исключением положительного знака первого ненулевого элемента a2 данных, и этот знак скрыт в четности суммы данных.
Следует отметить, что набор амплитуд данных списка D1 или модифицированного списка Dm1 кодируют перед набором знаков, за исключением знака первого ненулевого элемента данных, который не кодируют, как пояснялось выше.
В ходе следующего этапа S30, представленного на фиг. 1, модуль МС_СО кодирования по фиг. 2 проверяет, является ли текущий кодированный блок последним блоком изображения IE.
Если текущий блок представляет собой последний блок изображения IE, в ходе этапа S40, представленного на фиг. 1, способ кодирования прекращают.
Если это не так, предпринимают выбор следующего блока Bi, который затем кодируют в соответствии с упомянутым выше порядком растровой развертки при выполнении обхода, с последовательным приращением этапов от S1 до S20, для 1≤i≤Z.
После выполнения энтропийного кодирования для всех блоков от B1 до BZ предпринимается построение сигнала F, представляющего в двоичной форме упомянутые кодированные блоки.
Построение двоичного сигнала F воплощают в модуле CF программного построения потока, таком как представлено на фиг. 2.
Поток F после этого передают через сеть передачи данных (не представлена) на удаленное оконечное устройство. Последнее содержит декодер, который будет более подробно описан в последующем описании.
Далее, в основном, со ссылкой на фиг. 1, будет описан другой вариант осуществления изобретения.
Такой другой вариант осуществления отличается от предыдущего исключительно количеством знаков, которые будут скрыты, которое составляет N, N представляет собой целое число, такое как N≥2.
С этой целью функция f представляет собой модуль 2N остатка суммы данных списка D1. При этом предполагается, что в предложенном примере, N=2, два знака, которые должны быть скрыты, представляют собой первые два знака первых двух ненулевых данных в списке D1, например, а2 и а3.
В ходе этапа S4, представленного на фиг. 1, модуль MTR_CO обработки проверяет, соответствует ли конфигурация из N знаков, то есть 2N возможных конфигураций, значению модуля 2N остатка суммы данных списка D1.
В предложенном примере, где N=2, существуют 22=4 разных конфигураций знаков.
Эти четыре конфигурации подчиняются соглашению в кодере СО, которое, например, определено следующим образом:
- остаток, равный нулю, соответствует двум последовательным положительным знакам: +, +;
- остаток, равный единице, соответствует последовательным положительному знаку и отрицательному знаку: +, -;
- остаток, равный двум, соответствует последовательным отрицательному знаку и положительному знаку: -, +;
- остаток, равный трем, соответствует двум последовательным отрицательным знакам: -, -.
Если конфигурация N знаков соответствует значению модуля 2N остатка суммы данных списка D1, выполняется этап S20 энтропийного кодирования данных упомянутого выше списка D1, за исключением соответствующего знака первых двух ненулевых данных а2 и а3, и эти знаки скрыты в четности модуля 2N суммы данных в списке D1.
Если это не так, выполняют этап S5 модификации по меньшей мере одного модифицируемого элемента данных списка D1. Такую модификацию выполняют с помощью модуля MTR_CO обработки по фиг. 2 таким образом, что модуль 2N остатка суммы модифицируемых данных списка D1 получает значения каждого из двух знаков, которые должны быть скрыты.
Затем получают модифицированный список Dm1=(‘1,’2, …, a’P).
После этого выполняют этап S20 энтропийного кодирования данных упомянутого выше списка Dm1, за исключением знака первого ненулевого элемента а2 данных и знака второго ненулевого элемента а3 данных, знаки которых скрыты в четности суммы модуля 2N данных.
Конкретный вариант осуществления изобретения будет описан ниже, в котором способ кодирования, в соответствии с изобретением, все еще используется для кодирования последовательности изображений, в соответствии с двоичным потоком, близким к тому, который получают в результате кодирования, в соответствии со стандартом H. 264/MPEG-4 AVC. В этом варианте осуществления способ кодирования, в соответствии с изобретением, например, воплощен в программном обеспечении или в аппаратных средствах путем модификации кодера, первоначально соответствующего стандарту H. 264/MPEG-4 AVC.
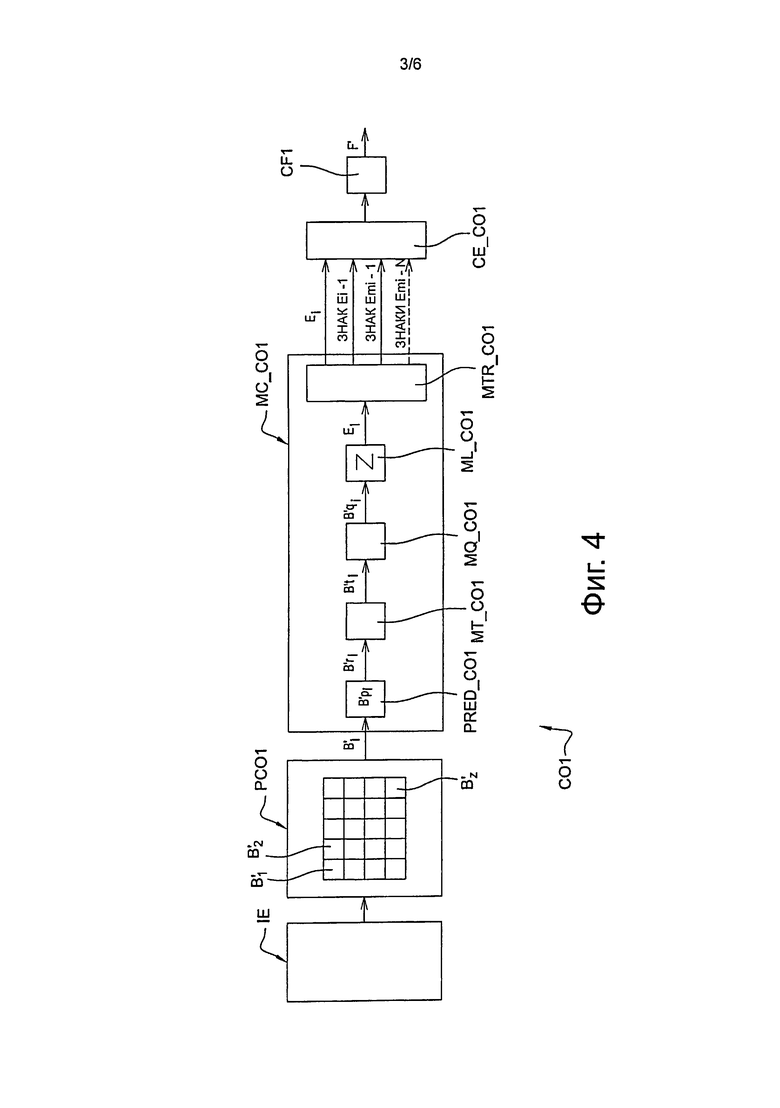
Способ кодирования, в соответствии с изобретением, представлен в форме алгоритма, содержащего этапы С1 - С40, такие как показаны на фиг. 3.
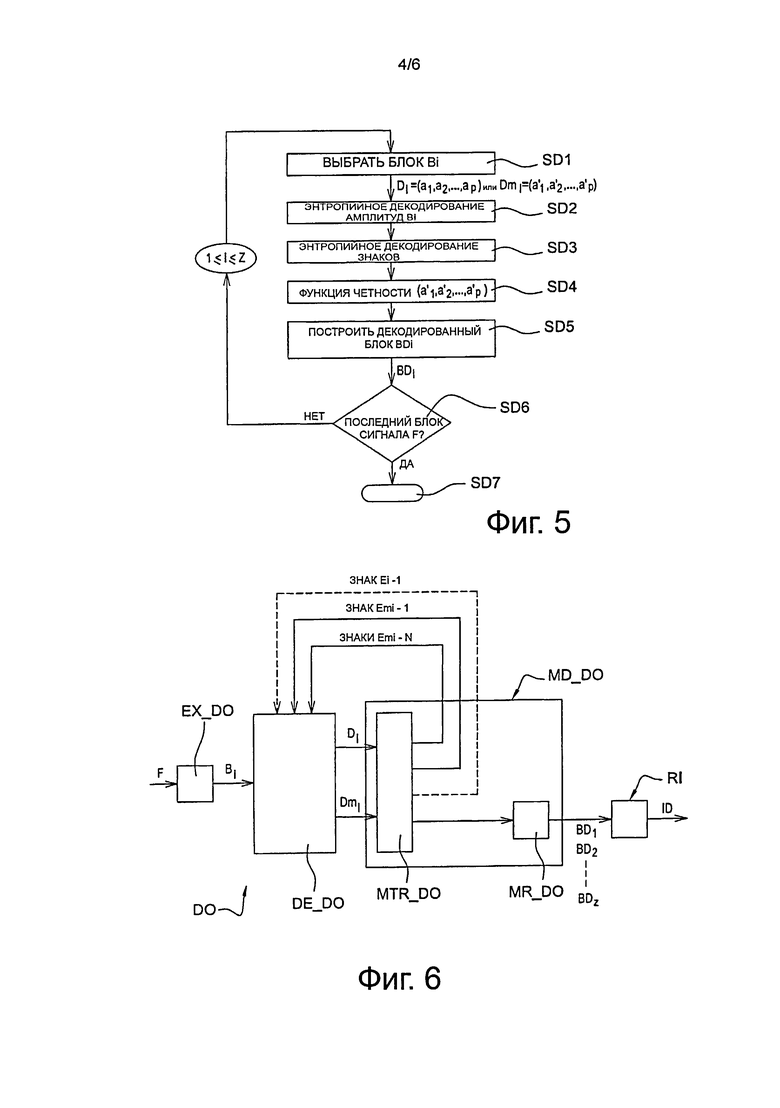
В соответствии с вариантом осуществления изобретения, способ кодирования воплощен в устройстве кодирования или в кодере CO1, вариант осуществления которого представлен на фиг. 4.
В соответствии с изобретением, и как описано в предыдущих примерах, выполняют, перед соответствующим кодированием, разделение изображения IE из последовательности изображений, предназначенных для кодирования в заданном порядке, на множество Z областей B’1, В’2, …, B’i, …, B’Z, как представлено на фиг. 4.
В примере, представленном на фиг. 4, упомянутые области представляют собой блоки, которые имеют квадратную форму, и все имеют одинаковый размер. В качестве функции размера изображения, которое не обязательно должно составлять кратное число размера блоков, последние блоки слева и последние блоки снизу могут не быть квадратными. В альтернативном варианте осуществления блоки могут, например, иметь прямоугольную форму и/или могут не быть выравнены друг с другом.
Каждый блок или макроблок может, кроме того, сам по себе быть разделенным на подблоки, которые сами по себе могут быть подразделены дополнительно.
Такое разделение выполняют с помощью программного модуля PCO1 разделения, представленного на фиг. 4, который идентичен модулю РСО разделения, представленному на фиг. 2.
После упомянутого этапа разделения выполняют кодирование каждой из текущих областей B’i (i представляет собой целое число, такое как 1≤i≤Z) упомянутого изображения IE.
В примере, представленном на фиг. 4, такое кодирование выполняют последовательно для каждого из блоков B’1 - B’Z текущего изображения IE. Блоки кодируют в соответствии с обходом, таким как, например, обход с "растровой разверткой", как хорошо известно для специалиста в данной области техники.
Кодирование, в соответствии с изобретением, воплощают в модуле МС_CO1 программного обеспечения кодирования кодера CO1, как представлено на фиг. 4.
В ходе этапа С1, представленного на фиг. 3, блок МС_CO1 кодирования на фиг. 4 выбирает в качестве текущего блока B’i первый блок B’1, предназначенный для кодирования текущего изображения IE. Как представлено на фиг. 4, он представляет собой первый левый блок изображения IE.
В ходе этапа С2, представленного на фиг. 3, выполняется предиктивное кодирование текущего блока B’1, используя известные технологии внутри кадрового и/или межкадрового прогнозирования, в ходе которого блок B’1 прогнозируют в отношении по меньшей мере одного ранее кодированного и декодированного блока. Такое прогнозирование выполняется с помощью программного модуля PRED_CO1 прогнозирования, такого как представлен на фиг. 4.
Само собой разумеется, что возможны другие режимы внутрикадрового прогнозирования, такие как предложены в стандарте Н. 264.
Текущий блок B’1 также может быть подвергнут кодированию с прогнозированием межкадровом режиме, в ходе которого текущий блок прогнозируют на основе блока, возникающего из ранее кодированного и декодированного изображения. Другие типы прогнозирования, конечно, могут быть рассмотрены. Среди возможных вариантов прогнозирования для текущего блока выбирают оптимальное прогнозирование, в соответствии с критерием скорости/искажения, хорошо известного для специалиста в данной области техники.
Упомянутый выше этап кодирования с прогнозированием возможен для построения прогнозируемого блока B’p1, который представляет собой аппроксимацию текущего блока B’1. Информация, относящаяся к этому кодированию с прогнозированием, предназначена для описания в сигнале, который должен быть передан в декодер. Такая информация, в частности, содержит тип прогнозирования (межкадровый или внутрикадровый), и, если соответствует, режим внутрикадрового прогнозирования, тип разделения на области блока или макроблока, если последний был подразделен, индекс опорного изображения и вектор смещения, используемый в режиме межкадрового прогнозирования. Эта информация сжимается с помощью кодера CO1.
В течение следующего этапа С3, представленного на фиг. 3, модуль PRED_CO1 прогнозирования сравнивает данные, относящиеся к текущему блоку B’1, с данными прогнозируемого блока B’p1. Более точно, в течение этого этапа обычно выполняется вычитание блока B’p1 прогнозирования из текущего блока B’1, для получения остаточного блока B’r1.
В течение следующего этапа С4, представленного на фиг. 3, выполняют преобразование остаточного блока B’r1, в соответствии с обычной операцией прямого преобразования, такой, например, как дискретное косинусное преобразование DCT, для формирования преобразованного блока B’t1. Такую операцию выполняют с помощью модуля МТ_CO1 программного преобразования, такого как представлен на фиг. 4.
В течение следующего этапа С5, представленного на фиг. 3, выполняют квантование преобразованного блока B’t1, в соответствии с обычной операцией квантования, такой как, например, скалярное квантование. Затем получают блок B’q1 квантованных коэффициентов. Такой этап выполняют, используя модуль MQ_CO1 программного квантования, такой как представлен на фиг. 4.
В течение следующего этапа С6, представленного на фиг. 3, выполняют обход, в заданном порядке, квантованных коэффициентов блока B’q1. В представленном примере это приводит к обычному зигзагообразному обходу. Такой этап выполняют путем считывания программного модуля ML_C01, такого как представлен на фиг. 4. По окончании этапа С6 получают одномерный список E1=(ε1, ε2, …, εL) коэффициентов, более известных под термином "квантованный остаток", где L представляет собой целое число, большее или равное 1. Каждый из коэффициентов списка E1 ассоциирован с различными элементами цифровой информации, которые предназначены для выполнения с ними энтропийного кодирования. Такие элементы цифровой информации описаны ниже в качестве примера.
Предположим, что в представленном примере L=16 и что список E1 содержит следующие шестнадцать коэффициентов: E1=(0, +9, -7, 0, 0, +1, 0, -1, +2, 0, 0, +1, 0, 0, 0, 0).
В этом случае:
- для каждого коэффициента, расположенного перед последним ненулевым коэффициентом списка E1, цифровой элемент информации, такой как бит, предназначен для энтропийного кодирования для обозначения, равен или нет коэффициент нулю: если коэффициент равен нулю, он представляет собой, например, бит со значением 0, который будет кодирован, в то время как, если коэффициент не равен нулю, он представляет собой бит со значением 1, который будет кодирован;
- для каждого ненулевого коэффициента +9, -7, +1, -1, +2, +1, цифровой элемент информации, такой как бит, предназначен для энтропийного кодирования для обозначения, равно или нет абсолютное значение коэффициента единице: если оно равно 1, оно представляет собой, например, бит со значением 1, который будет кодирован, в то время как, если оно не равно 1, оно представляет собой бит со значением 0, которое будет кодировано;
- для каждого ненулевого коэффициента, абсолютное значение которого не равно единице, и который расположен перед последним ненулевым коэффициентом, таким как коэффициенты со значением +9, -7, +2, элемент амплитуды информации (абсолютное значение коэффициента, из которого вычитают значение два) кодируют энтропийно,
- для каждого ненулевого коэффициента знак, который выделяют для него, кодируют, используя цифровой элемент информации, такой как бит, например, установленный в "0" (для знака +) или в "1" (для знака -).
Конкретные этапы кодирования, в соответствии с изобретением, будут описаны со ссылкой на фиг. 3.
В соответствии с изобретением, определяют, что требуется исключить энтропийное кодирование по меньшей мере одного из упомянутых выше элементов цифровой информации, которые представляют собой по меньшей мере один знак одного из упомянутых коэффициентов списка E1.
С этой целью в ходе этапа С7, представленного на фиг. 3, выполняют выбор количества знаков, которые должны быть скрыты в ходе последующего этапа энтропийного кодирования. Такой этап выполняют с помощью модуля MTR_C01 программной обработки, такого как представлено на фиг. 4.
В предпочтительном варианте осуществления количество знаков, которое должно быть скрыто, равно единице или нулю. Кроме того, в соответствии с упомянутым предпочтительным вариантом осуществления, именно знак первого ненулевого коэффициента должен быть скрыт. В представленном примере это поэтому влечет скрытие знака коэффициента ε2=+9.
В альтернативном варианте осуществления количество знаков, которое должно быть скрыто, равно либо нулю, либо одному, или двум, или трем, или больше.
В соответствии с предпочтительным вариантом осуществления этапа С7, в ходе первого подэтапа С71, представленного на фиг.3, выполняется определение, на основе упомянутого списка E1, подсписка SE1, содержащего коэффициенты, выполненные с возможностью их модификации ε’1, ε’2, …, ε’М, где М<L. Такие коэффициенты в последующем описании будут называться пригодными для модификации коэффициентами.
В соответствии с изобретением, коэффициент является пригодным для модификации, если модификация его квантованного значения не приводит к десинхронизации в декодере, после того, как такой модифицируемый коэффициент будет обработан декодером. Таким образом, модуль MTR_CO1 обработки первоначально выполнен так, что он не модифицирует:
- нулевой коэффициент или коэффициенты, расположенные перед первым ненулевым коэффициентом, таким образом, что декодер не выделяет значение скрытого знака для этого или этих нулевых коэффициентов,
- и, по причинам сложности расчетов, нулевой коэффициент или коэффициенты, расположенные после последнего ненулевого коэффициента.
В представленном примере после окончания подэтапа С71 полученный подсписок SE1 является таким, что SE1=(9, -7, 0, 0, 1, 0, -1, 2, 0, 0, 1). Следовательно, получают одиннадцать пригодных для модификации коэффициентов.
В течение следующего подэтапа С72, представленного на фиг. 3, модуль MTR_CO1 обработки выполняет сравнение количества модифицируемых коэффициентов с заданным порогом TSIG. В предпочтительном варианте осуществления TSIG равно 4.
Если количество модифицируемых коэффициентов будет меньше, чем пороговое значение TSIG, в течение этапа С20, представленного на фиг. 3, выполняют обычное энтропийное кодирование коэффициентов по списку E1, такое как выполняется, например, в кодере САВАС, обозначенном ссылочной позицией СЕ_CO1 на фиг. 4. С этой целью знак каждого ненулевого коэффициента в списке E1 кодируют энтропийно.
Если количество модифицируемых коэффициентов больше, чем пороговое значение TSIG, в ходе этапа С8, представленного на фиг. 3, модуль MTR_CO1 обработки рассчитывает значение функции f, которая представляет коэффициенты подсписка SE1.
В предпочтительном варианте осуществления, где один знак предназначен для скрытия в сигнале, который должен быть передан в декодер, функция f представляет собой четность суммы коэффициентов подсписка SE1.
В ходе этапа С9, представленного на фиг. 3, модуль MTR_CO1 обработки проверяет, соответствует ли четность значения знака, предназначенного для скрытия, четности суммы коэффициентов подсписка SE1, в соответствии с соглашением, определенным ранее в кодере CO1.
В предложенном примере упомянутое соглашение является таким, что положительный знак ассоциируют с битом значения, равным нулю, в то время как отрицательный знак ассоциируют с битом значения, равным единице.
Если, в соответствии с соглашением, принятым в кодере CO1, в соответствии с изобретением, знак будет положительным, так что он, таким образом, соответствует нулевому значению бита кодирования, и если сумма коэффициентов подсписка SE1 будет четной, выполняется этап С20 энтропийного кодирования коэффициентов упомянутого выше списка E1, за исключением знака коэффициента ε2.
Если, все еще в соответствии с соглашением, принятым в кодере CO1, в соответствии с изобретением, знак будет отрицательным, соответствуя, таким образом, одному из значения бита кодирования, и если сумма коэффициентов подсписка SE1 будет нечетной, также выполняется этап С20 энтропийного кодирования коэффициентов упомянутого выше списка E1, за исключением знака коэффициента ε2.
Если, в соответствии с соглашением, принятым в кодере CO1, в соответствии с изобретением, знак будет положительным, соответствуя, таким образом, нулевому значению бита кодирования, и если сумма коэффициентов подсписка E1 будет нечетной, в ходе этапа С10, представленного на фиг. 3, выполняется модификация по меньшей мере одного пригодного для модификации коэффициента подсписка SE1.
Если, все еще в соответствии с соглашением, принятым в кодере CO1, в соответствии с изобретением, знак будет отрицательным, соответствуя, таким образом, одному из значений бита кодирования, и если сумма коэффициентов подсписка SE1 будет четной, также выполняют этап С10 модификации по меньшей мере одного пригодного к модификации коэффициента подсписка SE1.
Такая операция модификации выполняется модулем MTR_CO1 обработки по фиг. 4.
В примерном варианте осуществления, где SE1=(+9, -7, 0, 0, +1, 0, -1, +2, 0, 0, +1), общая сумма коэффициентов равна 5 и поэтому является нечетной. Таким образом, декодер может реконструировать положительный знак, выделенный для первого ненулевого коэффициента, ε2=+9, без передачи кодером CO1 этого коэффициента в декодер, при этом четность суммы может стать четной. Следовательно, модуль MTR_CO1 обработки тестирует, в ходе упомянутого этапа С10, различные модификации коэффициентов подсписка SE1, все из которых направлены на изменение четности суммы коэффициентов. В предпочтительном варианте осуществления выполняется добавление +1 или -1 к каждому пригодному для модификации коэффициенту и выполняется выбор модификации среди всех них.
В предпочтительном варианте осуществления такой выбор составляет оптимальное прогнозирование в соответствии с критерием рабочих характеристик, которые, например, представляют собой критерий нарушения скорости передачи битов, хорошо известный для специалиста в данной области техники. Такой критерий выражен уравнением (1), представленным ниже:
(l)J=D+λR, где
D представляет искажение между исходным макроблоком и реконструированным макроблоком, R представляет стоимость в битах кодирования информации кодирования, и λ представляет множитель Лагранжа, значение которого может быть фиксировано перед кодированием.
В предложенном примере модификация, которая приводит к повышению оптимального прогнозирования в соответствии с упомянутым выше критерием скорости передачи битов/искажения, представляет собой добавление значения 1 ко второму коэффициенту -7 из подсписка SE1.
Модифицированный подсписок SEm1=(+9, -6, 0, 0, +1, 0, -1, +2, 0, 0, +1) затем получают по окончании этапа С10.
Следует отметить, что в ходе этого этапа определенные модификации запрещены. Таким образом, в случае, когда первый ненулевой коэффициент ε2 должен был быть равен +1, было бы невозможно добавить -1 к нему, поскольку он стал бы равным нулю, и при этом потерял бы свою характеристику первого ненулевого коэффициента списка E1. Декодер затем впоследствии выделил бы декодированный знак (путем расчета четности суммы коэффициентов) для другого коэффициента, и при этом возникла бы ошибка декодирования.
В ходе этапа С11, представленного на фиг. 3, модуль MTR_CO1 обработки выполняет соответствующую модификацию списка E1. Затем получают следующий модифицированный список Em1=(0, +9, -6, 0, 0, +1, 0, -1, +2, 0, 0, +1, 0, 0, 0, 0).
После этого выполняют этап С20 энтропийного кодирования коэффициентов упомянутого выше списка Em1, за исключением знака коэффициента ε2, который представляет собой знак + коэффициента 9 в предложенном примере, и этот знак скрыт в четности суммы коэффициентов.
Следует отметить, что набор амплитуд коэффициентов списка E1 или модифицированного списка Em1 кодируют перед набором знаков, за исключением знака первого ненулевого коэффициента ε2, который не кодируют, как пояснялось выше.
В ходе следующего этапа С30, представленного на фиг. 3, модуль МС_CO1 кодирования по фиг. 4 тестирует, является ли кодированный текущий блок последним блоком в изображении IE.
Если текущий блок представляет собой последний блок изображения IE, в ходе этапа С40, представленного на фиг. 3, способ кодирования прекращается.
Если это не так, выполняется выбор блока, следующего после B’i, который затем кодируют в соответствии с упомянутым выше порядком обхода в виде растровой развертки, путем итерации этапов С1 - С20, для 1≤i≤Z.
После того, как энтропийное кодирование всех блоков B’1 - B’Z будет выполнено, выполняется построение сигнала F’, представляющего, в бинарной форме, упомянутые кодированные блоки.
Построение двоичного сигнала F’ воплощают в программном модуле CF1 построения потока, таком как представлен на фиг. 4.
Поток F’ после этого передают с помощью сети передачи данных (не представлена) на удаленное оконечное устройство. Последний содержит декодер, который будет более подробно описан в последующем описании.
Далее, со ссылкой на фиг. 3, будет описан другой вариант осуществления изобретения.
Этот другой вариант осуществления отличается от предыдущего исключительно количеством коэффициентов, которые будут скрыты, которое равно либо 0, или N, причем N представляет собой целое число, такое как N≥2.
С этой целью упомянутый выше подэтап С72 сравнения заменяют подэтапом С72а, представленным пунктиром на фиг.3, в ходе которого выполняют сравнение количества модифицированных коэффициентов с несколькими заданными пороговыми значениями 0<TSIG_1<TSIG_2<TSIG_3 …, таким образом, что, если количество модифицированных коэффициентов находится между TSIG_N и TSIG__N+1, N знаков должны быть скрыты.
Если количество модифицированных коэффициентов меньше, чем первое пороговое значение TSIG_1, в ходе упомянутого выше этапа С20 выполняют обычное энтропийное кодирование коэффициентов списка E1. С этой целью знак каждого ненулевого коэффициента списка E1 подвергают энтропийному кодированию.
Если количество модифицированных коэффициентов находится между пороговым значением TSIG_N и TSIG_N+1, в ходе этапа С8, представленного на фиг. 3, модуль MTR_CO1 обработки рассчитывает значение функции f, которое представляет коэффициенты подсписка SE1.
В этом другом варианте осуществления решение в кодере направлено на скрытие N знаков, функция f представляет собой модуль 2N остатка суммы коэффициентов подсписка SE1. При этом предполагается, что в предложенном примере N=2, два знака, которые должны быть скрыты, представляют собой первые два знака первых двух ненулевых коэффициентов, соответственно, а именно ε2 и ε3.
В ходе следующего этапа С9, представленного на фиг. 3, модуль MTR_CO1 обработки проверяет, соответствует ли конфигурация N знаков, то есть 2N возможных конфигураций, значению модуля 2N остатка суммы коэффициентов подсписка SE1.
В предложенном примере, где N=2, существуют 22=4 разных конфигураций знаков.
Эти четыре конфигурации соответствуют условиям соглашения в кодере CO1, которое, например, определено следующим образом;
- остаток, равный нулю, соответствует двум последовательным положительным знакам: +, +;
- остаток, равный единице, соответствует последовательному положительному знаку и отрицательному знаку: +, -;
- остаток, равный двум, соответствует последовательному отрицательному знаку и положительному знаку: -, +;
- остаток, равный трем, соответствует двум последовательным отрицательным знакам: -, -.
Если конфигурация N знаков соответствует значению модуля 2N остатка суммы коэффициентов подсписка SE1, выполняется этап С20 энтропийного кодирования коэффициентов упомянутого выше списка E1, за исключением знака коэффициента ε2 и коэффициента ε3, и эти знаки скрыты в четности модуля 2N суммы коэффициентов.
Если это не так, выполняется этап С10 модификации по меньшей мере одного пригодного для модификации коэффициента подсписка SE1. Такую модификацию выполняют с помощью модуля MTR_CO1 обработки по фиг. 4, таким образом, что модуль 2N остатка суммы пригодных для модификации коэффициентов подсписка SE1 получает значения каждого из двух знаков, которые должны быть скрыты.
В ходе упомянутого выше этапа С11 модуль MTR_C01 обработки выполняет соответствующую модификацию списка E1. В результате получают модифицированный список Em1.
После этого выполняют этап С20 энтропийного кодирования коэффициентов упомянутого выше списка Em1, за исключением знака коэффициента ε2 и знака коэффициента ε3, и эти знаки скрыты в модуле 2N четности суммы коэффициентов.
Подробное описание участка декодирования
Общий вариант осуществления способа декодирования, в соответствии с изобретением, будет описан ниже, в котором способ декодирования воплощен в виде программного обеспечения или в аппаратных средствах путем модификации декодера, первоначально соответствующего стандарту H.264/MPEG-4 AVC.
Способ декодирования, в соответствии с изобретением, представлен в форме алгоритма, содержащего этапы SD1 - SD7, показанные на фиг. 5.
В соответствии с общим вариантом осуществления изобретения, способ декодирования, в соответствии с изобретением, воплощен в устройстве декодирования или в декодере DO, таком как представлено на фиг.6, который пригоден для потока F, подаваемого кодером СО по фиг. 2.
В ходе предварительного этапа, не представленного на фиг. 5, выполняется идентификация принятого сигнала F данных для участков B1 - BZ, которые были предварительно кодированы кодером СО. В предпочтительном варианте воплощения упомянутые участки представляют собой блоки, которые имеют квадратную форму, и все имеют одинаковый размер. Как функция размера изображения, который не обязательно должен быть кратным размеру блоков, последние блоки слева и последние блоки снизу могут не быть квадратными. В альтернативном варианте осуществления блоки могут иметь, например, прямоугольную форму и/или могут быть не выравнены друг с другом.
Каждый блок или макроблок может, кроме того, сам быть разделен на подблоки, которые сами по себе могут быть подразделены.
Такую идентификацию выполняют, используя программный модуль EX_DO анализа потока, такой, как представлено на фиг. 6.
В ходе этапа SD1, представленного на фиг. 5, модуль EX_DO по фиг. 6 выбирает, как текущий блок Вi первый блок B1 для декодирования. Такой выбор состоит, например, в установке указателя для считывания в сигнале F в начале данных первого блока B1.
После этого выполняется декодирование каждого из выбранных кодированных блоков.
В примере, представленном на фиг.5, такое декодирование последовательно применяют к каждому из кодированных блоков B1 - BZ. Блоки декодируют, в соответствии с, например, обходом в виде "растровой развертки", как хорошо известно специалисту в данной области техники.
Декодирование, в соответствии с изобретением, воплощено в программном модуле MDJDO декодирования декодера DO, так как представлено на фиг. 6.
В ходе этапа SD2, представленного на фиг. 5, вначале выполняют энтропийное декодирование первого текущего блока B1, который был выбран. Такую операцию выполняют с помощью модуля DEJDO энтропийного декодирования, представленного на фиг. 6, например, типа САВАС. В ходе выполнения этого этапа модуль DE_DO выполняет энтропийное декодирование элементов цифровой информации, соответствующих амплитуде каждых из кодированных данных списка D1 или модифицированного списка Dm1. В данный момент, только знаки данных списка D1 или модифицированного списка Dm1 не будут декодированы.
В случае, когда модуль MTR_DO обработки принимает список D1=(a1, a2, …, aP), в ходе этапа SD3, представленного на фиг. 5, выполняют обычное энтропийное декодирование всех знаков данных списка D1. Такое декодирование выполняют с помощью декодера САВАС, обозначенного, как DE_DO на фиг. 6. С этой целью знак каждого ненулевого элемента данных списка D1 подвергают энтропийному декодированию.
В случае, когда модуль MTR_DO обработки принимает модифицированный список Dm1=(a’1, a’2,..., a’P), в ходе упомянутого этапа SD3, выполняют обычное энтропийное декодирование всех знаков данных из списка Dm1, за исключением знака первого ненулевого элемента а2 данных.
В ходе этапа SD4, представленного на фиг. 5, модуль MTR_DO обработки рассчитывает значение функции f, которая представляет данные списка Dm1, для определения, является ли расчетное значение четным или нечетным.
В предпочтительном варианте осуществления, когда одиночный знак скрыт в сигнале F, функция f представляет собой четность суммы данных списка Dm1.
В соответствии с соглашением, используемым в кодере СО, которое является таким же, как и в декодере DO, четное значение суммы данных этого списка Dm1 обозначает, что знак первого ненулевого элемента данных модифицированного списка Dm1 будет положительным, в то время как нечетное значение суммы данных списка Dm1 обозначает, что знак первого ненулевого элемента данных модифицированного списка Dm1 будет отрицательным.
В примерном варианте осуществления общая сумма данных является четной. Следовательно, по окончанию этапа SD4, модуль MTR_DO обработки выводит из этого, что скрытый знак первого ненулевого элемента а2 данных является положительным.
В ходе этапа SD5, представленного на фиг. 5, выполняется построение декодированного блока BD1. Такую операцию выполняют с помощь программного модуля MR_DO реконструкции, представленного на фиг. 6.
В ходе этапа SD6, представленного на фиг. 5, модуль MD_DO декодирования проверяет, является ли декодированный текущий блок последним блоком, идентифицированным в сигнале F.
Если текущий блок представляет собой последний блок в сигнале F, в ходе этапа SD7, представленного на фиг. 5, способ декодирования прекращается.
Если это не так, выполняется выбор следующего блока Bi, предназначенного для декодирования, в соответствии с упомянутым выше порядком растровой развертки при обходе, при последующем приращении этапов SD1 - SD5, для 1≤i≤Z.
Другой вариант осуществления изобретения будет описан ниже, в основном, со ссылкой на фиг. 5.
Этот другой вариант осуществления отличается от предыдущего исключительно количеством скрытых знаков, которое теперь равно N, где N представляет собой целое число, такое что N≥2.
С этой целью в ходе упомянутого выше этапа SD3 выполняется обычное энтропийное декодирование всех знаков данных списка, Dm1, за исключением N соответствующих знаков первых нескольких ненулевых данных упомянутого модифицированного списка Dm1, упомянутые N знаков являются скрытыми.
В этом другом варианте осуществления модуль MTR_DO обработки рассчитывает, в ходе этапа SD4, значение функции f, которое представляет собой модуль 2N остатка суммы данных списка Dm1. Предполагается, что в предложенном примере N=2.
Модуль MTR_DO обработки затем выводит из этого конфигурацию двух скрытых знаков, которые назначены, соответственно, для каждых из первых двух ненулевых данных а2 и а3, в соответствии с соглашением, используемым при кодировании.
После реконструкции одного из двух знаков выполняют этапы SD5 - SD7, описанные выше.
Конкретный вариант осуществления способа декодирования, в соответствии с изобретением, будет описан ниже, в котором способ декодирования воплощен в программных или в аппаратных средствах путем модификации декодера, первоначально соответствующего стандарту H.264/MPEG-4 AVC.
Способ декодирования, в соответствии с изобретением, представлен в форме алгоритма, содержащего этапы D1 - D12, показанные на фиг. 7.
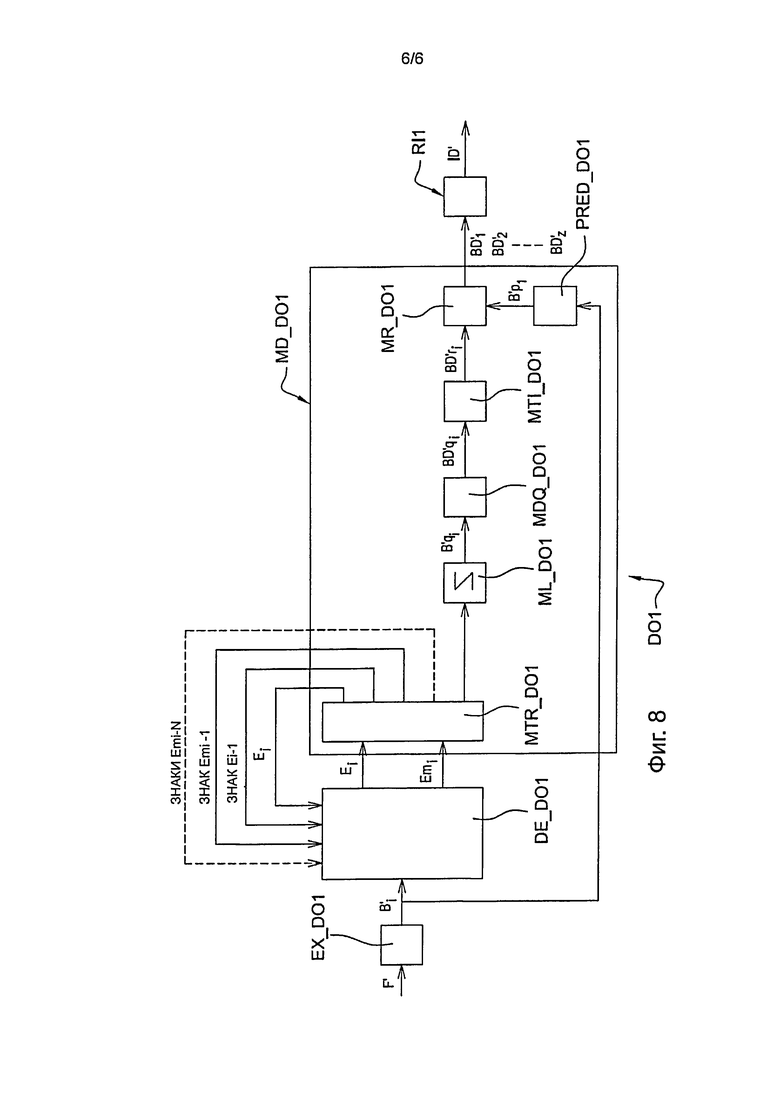
В соответствии с вариантом осуществления изобретения, способ декодирования, в соответствии с изобретением, воплощен в устройстве декодирования или в декодере DO1, таком как представлено на фиг.8, который может обрабатывать сигнал F’, подаваемый кодером CO1 по фиг. 4.
В ходе предварительного этапа, который не представлен на фиг.7, выполняют идентификацию принятого сигнала F’ данных, для областей B’1 - B’Z, которые ранее были кодированы кодером CO1. В предпочтительном варианте осуществления упомянутые области представляют собой блоки, которые имеют квадратную форму, и все имеют одинаковый размер. Как функция размера изображения, которая не обязательно представляет собой кратное размера блоков, последние блоки слева и последние блоки снизу могут не быть квадратными. В альтернативном варианте осуществления блоки могут, например, иметь прямоугольный размер и/или могут не быть выравнены друг с другом.
Каждый блок или макроблок может, кроме этого, сам быть разделен на подблоки, которые сами по себе также могут быть разделены дополнительно.
Такая идентификация выполняется с помощью модуля EX_DO1 программного обеспечения для анализа потока, такого как представлен на фиг. 8.
В ходе этапа D1, представленного на фиг. 7, модуль EX_D01 по фиг. 8 выбирает, как текущий блок B’i первый блок B’1, предназначенный для декодирования. Такой выбор состоит, например, в помещении указателя для считывания сигнала F’ в начале данных первого блока B’1.
После этого выполняют декодирование каждого из выбранных кодированных блоков.
В примере, представленном на фиг. 7, такое декодирование применяют последовательно для каждого из кодированных блоков B’1 - B’Z. Блоки декодируют в соответствии с примером обхода "растровой развертки", как хорошо известно специалисту в данной области техники.
Декодирование, в соответствии с изобретением, осуществляется в программном модуле MD_DO1 декодирования декодера D01, такого как представлен на фиг. 8.
В ходе этапа D2, представленного на фиг. 7, вначале выполняют энтропийное декодирование первого текущего блока B’1, который был выбран. Такую операцию выполняют с помощью модуля DE_DO1 энтропийного декодирования, представленного на фиг. 8, например, типа САВАС. В ходе этого этапа модуль DE_D01 выполняет энтропийное декодирование цифровой информации, соответствующей амплитуде каждого из кодированных коэффициентов списка E1 или модифицированного списка Em1. В данный момент, только знаки коэффициентов в списке E1 или в модифицированном списке Em1 не будут декодированы.
В ходе выполнения этапа D3, представленного на фиг. 7, выполняется определение количества знаков, которые могли быть скрыты в ходе предыдущего этапа С20 энтропийного кодирования. Такой этап D3 выполняется модулем MTR_DO1 программной обработки, таким как представлено на фиг. 8. Этап D3 аналогичен упомянутому выше этапу С7 определения количества знаков, которые должны быть скрыты.
В предпочтительном варианте воплощения количество скрытых знаков равно единице или нулю. Кроме того, в соответствии с упомянутым предпочтительным вариантом осуществления, скрывают знак первого ненулевого коэффициента. В представленном примере это поэтому приводит к положительному знаку коэффициента ε2=+9.
В альтернативном варианте осуществления количество скрытых знаков равно или нулю, или одному, или двум, или трем, или больше.
В соответствии с предпочтительным вариантом осуществления этапа D3, в ходе первого подэтапа D31, представленного на фиг. 7, выполняют определение, на основе упомянутого списка E1 или модифицированного списка Em1, подсписка, содержащего коэффициенты ε’1, ε’2, …, ε’М, где M<L, который может быть модифицирован при кодировании.
Такое определение выполняют таким же образом, как и на упомянутом выше этапе С7 кодирования.
Аналогично упомянутому выше модулю MTR_CO1 обработки, модуль MTR_DO1 обработки изначально выполнен так, чтобы он не модифицировал:
- нулевой коэффициент или коэффициенты, расположенные перед первым ненулевым коэффициентом,
- и, по причинам сложности расчетов, нулевой коэффициент или коэффициенты, расположенные после последнего ненулевого коэффициента.
В представленном примере, по окончании подэтапа D31, это приводит к подсписку SEm1, такому как SEm1=(9, -6, 0, 0, 1, 0, -1, 2, 0, 0, 1). Следовательно, получают одиннадцать коэффициентов, которые могут быть модифицированы.
В ходе следующего подэтапа D32, представленного на фиг.7, модуль MTR_DO1 обработки выполняет сравнение количества коэффициентов, которые могут быть модифицированы, с заданным пороговым значением TSIG. В предпочтительном варианте осуществления TSIG равно 4.
Если количество коэффициентов, пригодных для модификации, меньше, чем пороговое значение TSIG, в ходе этапа D4, представленного на фиг. 7, выполняют обычное энтропийное декодирование всех знаков коэффициентов списка E1. Такое декодирование выполняют с помощью декодера САВАС, который обозначен ссылочным обозначением DE_D01 на фиг. 8. С этой целью знак каждого ненулевого коэффициента в списке E1 подвергают энтропийному декодированию.
Если количество коэффициентов, которые могут быть модифицированы, больше, чем пороговое значение TSIG, в ходе упомянутого этапа D4, выполняют обычное энтропийное декодирование всех знаков коэффициентов списка Em1, за исключением знака первого ненулевого коэффициента ε2.
В ходе этапа D5, представленного на фиг. 7, модуль MTR_DO1 обработки рассчитывает значение функции f, которое представляет коэффициенты подсписка SEm1, для определения, является ли расчетное значение четным или нечетным.
В предпочтительном варианте осуществления, где одиночный знак скрыт в сигнале F’, функция f представляет собой четность суммы коэффициентов подсписка SEm1.
В соответствии с соглашением, используемым в кодере CO1, которое является таким же, как и в декодере DO1, четное значение суммы коэффициентов подсписка SEm1 обозначает, что знак первого ненулевого коэффициента модифицированного списка Em1 является положительным, в то время как нечетное значение суммы коэффициентов подсписка SEm1 обозначает, что знак первого ненулевого коэффициента модифицированного списка Em1 является отрицательным.
В примерном варианте осуществления, где SEm1=(+9, -6, 0, 0, +1, 0, -1, +2, 0, 0, +1), общая сумма коэффициентов равна 6 и поэтому является четной. Следовательно, по окончании этапа D5 модуль MTR_DO1 обработки выводит из этого, что скрытый знак первого ненулевого коэффициента ε2 является положительным.
В ходе этапа D6, представленного на фиг. 7, и с помощью всех элементов цифровой информации, реконструированных в ходе этапов D2, D4 и D5, выполняется реконструкция квантованных коэффициентов блока B’q1 в заданном порядке. В представленном примере это приводит к зигзагообразному обходу, обратному зигзагообразному обходу, выполняемому в ходе упомянутого выше этапа С6 кодирования. Такой этап выполняется с помощью считывающего программного модуля ML_D01, такого как представлен на фиг. 8. Более точно, модуль MLJD01 выполняет запись коэффициентов списка E1 (одномерного) в блок B’q1 (двумерный), используя упомянутый обратный обход в зигзагообразном порядке.
В ходе этапа D7, представленного на фиг. 7, выполняется деквантование квантованного остаточного блока B’q1 в соответствии с обычной операцией деквантования, которая представляет собой операцию, обратную для квантования, выполняемого при кодировании на упомянутом выше этапе С5, для получения декодированного деквантованного блока BD’q1. Такой этап выполняется с использованием программного модуля MDQ_D01 деквантования, такого как представлен на фиг. 8.
В ходе этапа D8, представленного на фиг. 7, выполняется обратное преобразование деквантованного блока BD’q1, который представляет собой операцию, обратную для прямого преобразования, выполняемого при кодировании упомянутого выше этапа С4. Затем получают декодированный остаточный блок BD’r1. Такая операция выполняется с помощью программного модуля MTI_DO1 деквантования, такого как представлен на фиг. 8.
В ходе этапа D9, представленного на фиг. 7, выполняют предиктивное декодирование текущего блока B’1. Предиктивное декодирование, такое как это выполняется обычно с помощью известных технологий внутрикадрового и/или межкадрового прогнозирования, в ходе которого блок B’1 прогнозируют в отношении по меньшей мере одного ранее декодированного блока. Такую операцию выполняют с помощью модуля PRED_DO1 предиктивного декодирования, такого как представлено на фиг. 8.
Само собой разумеется, что возможны другие режимы внутрикадрового прогнозирования, такие как предложены в стандарте Н. 264.
В ходе этого этапа предиктивное декодирование выполняют, используя элементы синтаксиса, декодированные на предыдущем этапе и содержащие, в частности, тип прогнозирования (межкадровое или внутрикадровое), и, если соответствует, режим внутрикадрового прогнозирования, тип разделения блока или макроблока, если последний был подразделен, индекс опорного изображения и вектор смещения, используемый в режиме межкадрового прогнозирования.
Упомянутый выше этап предиктивного декодирования позволяет построить прогнозированный блок B’p1.
В ходе этапа D10, представленного на фиг. 7, выполняется построение декодированного блока BD’1 путем добавления декодированного остаточного блока BD’1 к прогнозированному блоку B’p1. Такую операцию выполняют с помощью модуля MR_DO1 программного обеспечения реконструкции, представленного на фиг. 8.
В ходе этапа D11, представленного на фиг. 7, модуль MD_DO1 декодирования тестирует, является ли декодированный текущий блок последним блоком, идентифицированным в сигнале F’.
Если текущий блок представляет собой последний блок сигнала F’, в ходе этапа D12, представленного на фиг. 7, способ декодирования прекращается.
Если это не так, выполняется выбор следующего блока В’i, который должен быть декодирован, в соответствии с упомянутым выше порядком растровой развертки в поперечном направлении, путем итерационных этапов D1 - D10, для 1≤i≤Z.
Другой вариант осуществления изобретения будет описан ниже, в основном, со ссылкой на фиг. 7.
Такой другой вариант осуществления отличается от предыдущего исключительно количеством скрытых коэффициентов, которые равны либо 0, или N, причем N представляет собой целое число, такое как N≥2.
С этой целью упомянутый выше подэтап D32 сравнения заменяют подэтапом D32a, представленным пунктиром на фиг. 7, в ходе которого выполняется сравнение количества коэффициентов, которые могут быть модифицированы с рядом заданных пороговых значений 0<TSIG_1<TSIG_2<TSIG_3 …, таким образом, что, если количество упомянутых коэффициентов находится между TSIG_N и TSIG_N+1, может быть скрыто N знаков.
Если количество упомянутых коэффициентов меньше, чем первое пороговое значение TSIG_1, в ходе упомянутого выше этапа D4 выполняется обычное энтропийное декодирование всех знаков коэффициентов списка E1. С этой целью знак каждого ненулевого коэффициента списка E1 подвергают энтропийному декодированию.
Если количество упомянутых коэффициентов находится между порогом TSIG_N и TSIG_N+1, в ходе упомянутого выше этапа D4 выполняют обычное энтропийное декодирование всех знаков коэффициентов списка E1, за исключением N соответствующих знаков первых ненулевых коэффициентов упомянутого модифицированного списка Em1, при этом упомянутые N знаков скрыты.
В этом другом варианте осуществления модуль MTRJD01 обработки рассчитывает, в ходе этапа D5, значение функции f, которая представляет собой модуль 2N остатка суммы коэффициентов подсписка SEm1. Предполагается, что в представленном примере N=2.
Модуль MTR_DO1 обработки затем выводит из них конфигурации двух скрытых знаков, которые, соответственно, выделены для каждого из первых двух ненулевых коэффициентов ε2 и ε3, в соответствии с соглашением, принятым при кодировании.
После реконструкции этих двух знаков выполняют описанные выше этапы D6 - D12.
Само собой разумеется, что варианты осуществления, которые были описаны выше, были представлены исключительно в качестве представления и никоим образом не являются ограничительными и что различные модификации могут быть легко выполнены специалистом в данной области техники, однако, без выхода за пределы объема изобретения.
Таким образом, например, в соответствии с упрощенным вариантом осуществления относительно того, что представлено на фиг. 4, кодер CO1 может быть выполнен так, чтобы он срывал по меньшей мере N’ заданных знаков, при N’≥1, либо вместо нуля, или единицы, или N заданных знаков. В этом случае этап С72 или С72а сравнения мог бы быть исключен. Соответствующим образом, в соответствии с упрощенным вариантом осуществления относительно того, что представлено на фиг. 8, декодер DO1 мог бы быть выполнен с возможностью реконструкции N’ заданных знаков либо вместо нуля, или вместо единицы, или N заданных знаков. В этом случае этап D32 или D32a сравнения мог бы быть исключен. Кроме того, критерий определения, применяемый на этапе С72 кодирования и на этапе D32 декодирования, мог бы быть заменен другим типом критерия.
С этой целью вместо сравнения с пороговым значением количества модифицированных коэффициентов или количества коэффициентов, которые могли бы быть модифицированы, модуль MTR_CO1 или MTR_DO1 обработки мог бы применять критерий определения, который, соответственно, зависит от суммы амплитуд коэффициентов, которые могут быть модифицированы или которые пригодны для модификации, или либо количество нулей, представляют коэффициенты, которые могут быть модифицированы или которые пригодны для модификации.

Изобретение относится к технологиям обработки изображений. Техническим результатом является уменьшение объема переданных данных за счет сокрытия данных знака. Предложен считываемый компьютером носитель, имеющий инструкции, хранимые на нем. Инструкции побуждают по меньшей мере один процессор выполнять этап, включающий в себя получение набора коэффициентов, представляющих остаточный блок раздела, поддерживающего сокрытие данных знака, изображения, упомянутый набор коэффициентов включает в себя первый ненулевой коэффициент, который не имеет указания знака, а также этап, направленный на вычисление суммы ненулевых коэффициентов в упомянутом наборе коэффициентов. Кроме того, по меньшей мере один процессор осуществляет вычисление данных четности с использованием упомянутой суммы ненулевых коэффициентов и указание знака для упомянутого первого ненулевого коэффициента на основе данных четности. 2 н. и 11 з.п. ф-лы, 8 ил.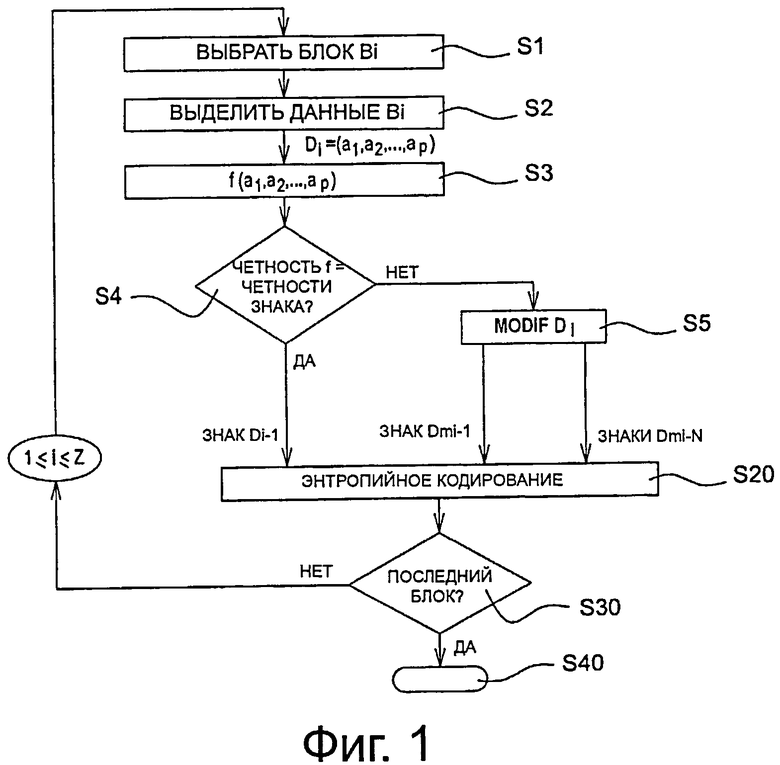
1. Считываемый компьютером носитель, хранящий инструкции, которые при исполнении одним или более процессорами побуждают упомянутый один или более процессоров выполнять операции, содержащие:
получение набора коэффициентов, представляющих остаточный блок раздела, поддерживающего сокрытие данных знака изображения, упомянутый набор коэффициентов включает в себя первый ненулевой коэффициент, который не имеет указания знака;
вычисление суммы ненулевых коэффициентов в упомянутом наборе коэффициентов;
вычисление данных четности с использованием упомянутой суммы ненулевых коэффициентов; и
указание знака для упомянутого первого ненулевого коэффициента на основе данных четности.
2. Считываемый компьютером носитель по п.1, при этом указание знака для упомянутого первого ненулевого коэффициента содержит:
определение, что значение данных четности равно некоторому конкретному значению, назначенному положительному знаку; и
в ответ на определение, что значение данных четности равно упомянутому конкретному значению, назначенному положительному знаку, указание положительного знака для упомянутого первого ненулевого коэффициента.
3. Считываемый компьютером носитель по п.1, при этом указание знака для упомянутого первого ненулевого коэффициента содержит:
определение, что значение данных четности равно некоторому конкретному значению, назначенному отрицательному знаку; и
в ответ на определение, что значение данных четности равно упомянутому конкретному значению, назначенному отрицательному знаку, указание отрицательного знака для упомянутого первого ненулевого коэффициента.
4. Считываемый компьютером носитель по п.1, при этом операции содержат:
определение, что подсчет ненулевых коэффициентов в упомянутом наборе коэффициентов удовлетворяет некоторому порогу; и
в ответ на определение, что подсчет ненулевых коэффициентов в упомянутом наборе коэффициентов удовлетворяет упомянутому порогу, определение, что упомянутый первый ненулевой коэффициент не имеет указания знака.
5. Считываемый компьютером носитель по п.1, при этом операции содержат:
определение, что кодирование с сокрытием данных знака разрешено для упомянутого набора коэффициентов.
6. Считываемый компьютером носитель, хранящий инструкции, которые при исполнении одним или более процессорами побуждают упомянутый один или более процессоров выполнять операции, содержащие:
получение первого набора коэффициентов, представляющих раздел изображения, упомянутый первый набор коэффициентов включает в себя первый ненулевой коэффициент, имеющий знак, который является положительным или отрицательным;
вычисление суммы ненулевых коэффициентов в упомянутом первом наборе коэффициентов;
вычисление данных четности с использованием упомянутой суммы ненулевых коэффициентов в упомянутом первом наборе коэффициентов;
генерирование выходных данных на основе данных четности;
сравнение выходных данных со значением, назначенным знаку упомянутого первого ненулевого коэффициента;
определение, что сравнение не удовлетворяет некоторому критерию;
в ответ на определение, что сравнение не удовлетворяет упомянутому критерию, модификацию по меньшей мере некоторого конкретного ненулевого коэффициента в упомянутом первом наборе коэффициентов; и
кодирование второго набора коэффициентов, в том числе (i) упомянутого первого ненулевого коэффициента без знака, (ii) модифицированного конкретного ненулевого коэффициента и (iii) других коэффициентов в упомянутом первом наборе коэффициентов.
7. Считываемый компьютером носитель по п.6, при этом модификация ненулевого коэффициента в упомянутом первом наборе коэффициентов содержит:
определение, что модификация конкретного ненулевого коэффициента в упомянутом первом наборе коэффициентов обеспечивает оптимальное предсказание на основе критерия производительности; и
в ответ на определение, что модификация конкретного ненулевого коэффициента в упомянутом первом наборе коэффициентов обеспечивает оптимальное предсказание, выбор конкретного ненулевого коэффициента для модификации.
8. Считываемый компьютером носитель по п.7, при этом критерий производительности включает в себя критерий искажения битрейта.
9. Считываемый компьютером носитель по п.6, при этом модификация по меньшей мере конкретного ненулевого коэффициента в упомянутом первом наборе коэффициентов содержит модификацию конкретного ненулевого коэффициента для генерирования второго ненулевого коэффициента.
10. Считываемый компьютером носитель по п.6, при этом операции дополнительно содержат:
определение, что подсчет ненулевых коэффициентов в упомянутом первом наборе коэффициентов удовлетворяет некоторому порогу; и
в ответ на определение, что подсчет ненулевых коэффициентов в упомянутом первом наборе коэффициентов удовлетворяет упомянутому порогу, определение некоторого числа ненулевых коэффициентов для сокрытия знака на основе упомянутого порога.
11. Считываемый компьютером носитель по п.6, при этом кодирование упомянутого второго набора коэффициентов содержит:
энтропийное кодирование упомянутого второго набора коэффициентов; и
передачу энтропийно закодированного второго набора коэффициентов.
12. Считываемый компьютером носитель по п.6, при этом конкретный ненулевой коэффициент является упомянутым первым ненулевым коэффициентом.
13. Считываемый компьютером носитель по п.6, при этом конкретный ненулевой коэффициент не является упомянутым первым ненулевым коэффициентом.
| статья S | |||
| Djukanovic et al | |||
| "Detection optimization fo the DCT-domain image watermarking system", опубликованная 23.08.2010, 5 стр | |||
| Токарный резец | 1924 |
|
SU2016A1 |
| КОМПЛЕКСЫ 1-МЕТИЛТЕТРАБЕНЗООКТАДЕГИДРОКОРРИНА С ЦИНКОМ, МЕДЬЮ И ГИДРОКСИЛАНТАНОМ | 2007 |
|
RU2360915C1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| ОСНОВАННОЕ НА КОНТЕКСТЕ АДАПТИВНОЕ НЕРАВНОМЕРНОЕ КОДИРОВАНИЕ ДЛЯ АДАПТИВНЫХ ПРЕОБРАЗОВАНИЙ БЛОКОВ | 2003 |
|
RU2330325C2 |

