Изобретение относится к способам медицинской диагностики, а именно к способу обработки массивов медицинских данных и применения их в системах поддержки принятия решений в медицине.
Выявление и диагностирование болезней пациента является сложной и ответственной задачей. Правильность постановки диагноза определяется множеством факторов - опыт врача, внимательность, сложность текущего случая, сопутствующие заболевания. Для устранения этих недостатков используются различные системы поддержки принятия решений.
Существует огромное количество публикаций по медицинским исследованиям и наблюдениям, содержащих, в том числе информацию по возможной симптоматике заболеваний. Актуальной задачей является создание инструментов извлечения и обработки большого объема данных для последующего использования в системах принятия решений, связанных с постановкой диагноза и выявления рисков тех или иных заболеваний у пациента.
Известен способ поддержки принятия врачебных решений, в котором обрабатывают данные, содержащиеся в истории болезней пациентов, выбранных из предварительно сформированной обучающей выборки; преобразовывают эти данные в последовательность медицинских фактов по каждому пациенту с использованием медицинских онтологий; производят автоматическую разметку полученной последовательности медицинских фактов по каждому пациенту, используя извлеченные из истории болезни пациента диагнозы или другие интересующие факты; производят обучение первичных репрезентаций независимо для каждой из модальностей; осуществляют обучение совместных репрезентаций; производят обучение финальных моделей и параметров агрегации; получают историю болезни пациента, не входящую в обучающую выборку, и производят предварительную обработку данных из неё; преобразовывают обработанные данные в последовательность медицинских фактов с использованием медицинских онтологий; полученный набор фактов отправляют на вход обученным финальным моделям; определяют диагноз, проводят анализ и прогноз развития заболеваний пациента с наибольшей вероятностью, соответствующий предъявленному набору фактов [1].
Данный способ сложен и дорогостоящ в исполнении, требует доступа к огромному количеству историй болезни пациентов, содержащих конфиденциальную информацию, и в то же время ограничен указанным объемом информации, что препятствует выявлению достаточно редких заболеваний. Кроме того, выявление медицинских фактов обусловлено и выбором критериев ранжирования важности фактов, что является достаточно сложной задачей и может провоцировать появление ошибок в процессе.
Также известна система DeepPatient [2], использующая нейросетевые автокодировщики, способна предсказывать риски развития заболеваний у пациентов в будущем на основании обучения на историях болезни пациентов (на вход подаются тексты историй болезни и заболевания, фактически имеющиеся у пациентов).
Данные методы требуют для реализации доступа к сотням тысяч историй болезней пациентов (например, в статье использовано 800 000 историй болезней). Поддержание и постоянное обновление такой базы создает проблемы защиты персональных данных, так как истории болезни очень трудно анонимизировать (наличие возраста и биометрических показателей в базе необходимо для обучения системы, но при этом позволяет сопоставить данные с конкретным человеком, даже если в данных нет ФИО человека). При этом даже в таких больших базах данных могут отсутствовать случаи многих редких заболеваний.
Известны системы автоматизированной диагностики, основанные на использовании структурированных баз знаний, содержащих медицинские факты и диагностические правила, созданные вручную и требующие постоянного пересмотра и обновления [3] и полуавтоматические методы для построения таких баз данных [4] , которые основаны на статистике совместного использования данных в PubMed, Wikipedia и электронных медицинских записях.
Недостатками известных методов является необходимость обеспечения сложных каналов обработки текста на естественном языке (выделение сущностей, анализ отношений, разрешение неоднозначности) для интерпретации данных и ограниченная способность статистических данных по сопутствующим явлениям улавливать сложные взаимосвязи, например, время появления симптомов. Совместное упоминание симптомов и болезней в научной литературе далеко не всегда означает наличие между ними связи (это может делаться для примера, в негативном ключе (нет таких симптомов) и в ряде других случаев).
Большинство средств проверки симптомов используют списки с множественным выбором для сбора симптомов или позволяют вводить симптомы на естественном языке, но только один главный симптом [5].
В настоящее время подавляющее число решений работает только с английским языком и при этом имеют недостаточную точность. Согласно последним исследованиям [6], большинство систем правильный диагноз выводят на первое место в 34% случаев, в то время как средняя точность в топ-20 (правильный диагноз в топ-20 поставленных диагнозов) составляет 58%. Недавно были опубликованы новые тесты [7] для системы диагностики Babylon, в которой утверждается, что качество результатов сопоставимо с результатами человека-врача, однако, эти результаты по-прежнему ниже, чем у лучших врачей-людей, и были высказаны опасения по поводу достоверности опубликованных результатов из-за методологических недостатков.
Техническая задача заявляемого изобретения заключается в повышении точности диагностирования, анализа и прогноза развития заболевания для пациента на основе его жалоб, симптомов и результатов обследований.
Технический результат – автоматизация способа обработки большого объема медицинских публикаций, высокая точность диагностирования существующих заболеваний и определения риска развития заболеваний.
Технический результат достигается тем, что способ прогнозирования диагноза на основе обработки данных, содержащих медицинские знания, включает выполняемые посредством электронно-вычислительного устройства формирование предварительной выборки научных статей по медицине из публичных баз данных и создание языковой модели, обучаемой на основе указанной выборки, формирование с помощью устройства пользователя текста, содержащего сведения о пациенте, обработку указанного текста с помощью электронно-вычислительного устройства, включающую формирование текстовых строк путем добавления к ранее сформированному тексту сведений о заболевании, и последующее их направление на вход обученной языковой модели для вычисления вероятности данной строки или ее подстроки.
Заявляемое изобретение позволяет, имея список жалоб пациента и результатов его обследований, предположить возможные существующие заболевания, а также заболевания, риск развития которых повышен. Изобретение может быть использовано в качестве инструмента для врача, помогающего при постановке диагноза не пропустить возможные причины жалоб, для контроля работы врачей или в превентивной медицине для реализации автоматического анализа историй болезни пациентов с целью выявления пациентов с рисками развития различных заболеваний. Кроме того, пациент также может обратиться к данному решению для предварительной оценки того, к какому специалисту необходимо обратиться и насколько срочно.
В основу заявляемого способа заложено использование языковой модели, обученной на текстах медицинских научных публикаций и используемой для оценки вероятности наличия того или иного заболевания на основе описания симптомов.
Заявляемый способ прогнозирования диагноза пациента реализуется посредством электронно-вычислительных машин и компьютерного интерфейса пользователя и включает следующие этапы:
1. Формирование выборки научных статей по медицине из публичных баз данных на различных языках;
2. Обучение языковой модели с помощью полученной выборки;
Выборка статей может быть предварительно отфильтрована с целью оставить только тексты, имеющие отношение к лечению заболеваний.
Языковая модель - это модель осуществляющая предсказание токена под номером t в последовательности, заданной t-1 предшествующих токенов, где токены могут быть словами, подсловами или символами.
Целью языковой модели является оценка распределения P(x0:T) по последовательностям токенов (x0, x1, ..., xT):=x0:xT [8]. Обучение языковой модели это процесс, создающий аппроксимирующую функцию реального распределения дискретного условного распределения вероятностей P(xt|x0,...xt-1) получения следующего токена, если даны значения предыдущих токенов. Совместное распределение по длинным текстовым фрагментам может быть представлено как произведение значений распределения по токенам, обусловленным предшествующими токенами [9]:
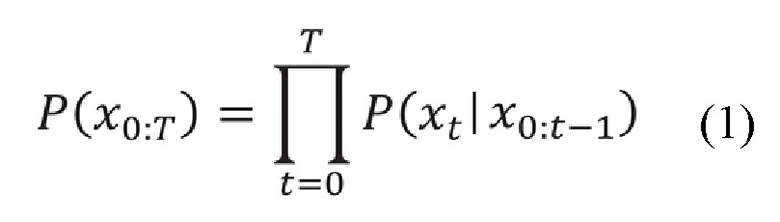
Таким образом, получают функцию, вычисляющую вероятность появления следующего токена на основе примеров текста.
Языковая модель может представлять собой рекуррентную нейронную сеть или нейронную сеть другой архитектуры и может строиться различными способами.
3. Введение врачом или пациентом в компьютер через интерфейс пользователя данных пациента, включающих данные анамнеза, результаты его медицинских и биологических исследований и объективного осмотра. Указанные данные вводят в текстовом формате на естественном языке. Подсчитывается число токенов в веденных данных. Результат подсчета обозначим буквой l.
4. Обработка сформированного текстового документа посредством ЭВМ, включающая формирование текстовой строки путем добавления сведений о заболевании (название заболевания, его свойства, например, его симптомы или патогенез) к полученному тексту, направление полученной строки на вход языковой модели для вычисления вероятности результирующего текста строки или подстроки по формуле (1), при этом t может быть равным нулю или l.
На вход языковой модели может подаваться не весь текст, введенный пациентом и врачом, а только части этого текста. Части текста могут быть получены с помощью различных алгоритмов предварительной обработки текста, выделяющих из текста важные фрагменты.
Описание примера осуществления заявляемого технического решения:
Для иллюстрации осуществления способа была использована языковая модель, построенная на рекуррентных нейронных сетях, в частности на основе долгой краткосрочной памяти (LSTM) [10].
Пусть дана последовательность векторов {x (t)}, где t = 1… T. Простая рекуррентная нейронная сеть вычисляет выходную последовательность y(t) согласно формулам (2) и (3):
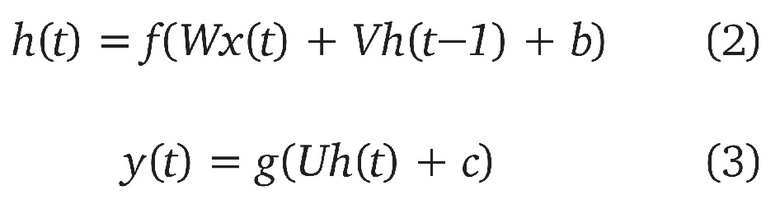
где f - нелинейная функция, такая как сигмоидная функция или функция гиперболического тангенса, а g - выходная функция. W и V - весовые матрицы между входным и скрытым слоем, а также между скрытым слоем и его предыдущим состоянием для шага t-1. U – выходная весовая матрица, b и c - векторы смещения, для скрытого слоя и слоя выходов нейронной сети.
Структура LSTM является расширением простой рекуррентной нейронной сети и позволяет избежать проблем с долговременными зависимостями. В LSTM простая функция активации f заменяется на составную функцию активации LSTM. Каждый скрытый блок LSTM дополняется переменной состояния s(t). Активации скрытого слоя соответствуют «ячейкам памяти», масштабируемым активациями «выходных вентильных элементов» o и вычисляется следующим образом:
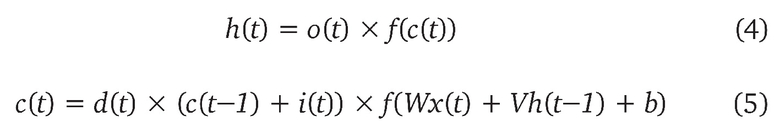
Где x обозначает поэлементное умножение, d(t) - это функция динамической активации, которая масштабирует состояние с помощью параметра «вентиля забывания» (forget gate), а i(t) - это активация входа.
Далее языковую модель на уровне символов с 3 скрытыми слоями, основанную на LSTM, обучали с 3,192 ячейками LSTM на каждом слое. Модель предварительно обучали на подмножестве Российской Википедии, содержащей 2 миллиарда символов. Модель обучали с использованием усеченного обратного распространения ошибки через время со скоростью обучения, контролируемой алгоритмом Adam [11].
Далее были выбраны оптимальные параметры языковой модели: количество скрытых блоков на слой LSTM – 128 и количество слоев LSTM равно 2.
Для дальнейшего обучения языковой модели был использован набор сообщений, собранных на российских онлайн-медицинских форумах. Набор данных содержал описания медицинских жалоб, обсуждений и рекомендаций врачей по различным медицинским темам. Общее количество сообщений на форуме в наборе данных составило 30, 756. Было отобрано 50 историй болезни, опубликованных в российских медицинских журналах, по 50 различным заболеваниям, случайно выбранным из списка диагнозов, найденных на интернет-форумах. В каждой истории болезни был прописан окончательный диагноз, подтвержденный тщательной медицинской экспертизой.
Обученная таким образом языковая модель была сохранена на сервере.
Далее рассмотрим конкретный пример использования созданной и обученной языковой модели.
Пациент приходит на осмотр к профильному врачу или врачу общей практики. Врач осуществляет опрос жалоб пациента, осмотр, исследует результаты проведенных анализов (при их наличии). Далее врач вводит полученную информацию в текстовом формате в компьютер через интерфейс пользователя в систему обработки. Введенные данные сохраняются в электронной истории болезни пациента. К сформированному тексту может быть добавлена ключевая фраза. Например, если требуются диагнозы, может быть добавлена ключевая фраза «было диагностировано», если требуется получить риски развития заболеваний, то фраза «имеет повышенный риск развития». Ключевая фраза может быть также и пустой.
Полученный текст длиной l (длина измеряется в числе токенов) обрабатывают посредством ЭВМ, направляя на вход языковой модели, включая поочередное добавление названия заболевания из списка заболеваний, хранящегося на сервере к полученному тексту, вычисление вероятности результирующего текста по формуле (1), при этом t может быть равным нулю или l, или иному значению. Данное вычисление повторяется для всех заболеваний в списке. Результатом является получение списка пар {заболевание, значение вероятности}. Полученные результаты сортируют в порядке возрастания вероятности того или иного диагноза. Для получения N самых вероятных вариантов берутся первые N элементов списка.
Пример 1:
Текст, введенный врачом в систему обработки: «У меня такая ситуация. Дикие боли в эпигастральной области, больше слева, от поджелудочной вниз к кишечнику. Отрыжка, метеоризм, запоры; во время приступов - расстройства желудка. Боли до еды и после (с тяжестью)»
Правильный диагноз «гастрит» система вывела на первое место в топ - 10 возможных заболеваний.
Пример 2.
Текст, введенный пользователем в систему обработки: «першение в горле, усиление кашля с небольшим количеством мокроты сероватого цвета, повышение температуры тела до 37,8°С, потливость. В течение примерно 25 лет беспокоит кашель, преимущественно по утрам, с небольшим количеством мокроты».
Описание этого случая составлено на основе статьи, взятой из Медицинского журнала (Архив внутренней медицины № 2 (22) 2015 г. - «Клинический случай развития туберкулеза под маской обострения хронического бронхита»). Как следует из названия статьи, в этом случае верным диагнозом был туберкулез.
Система обработки в этом случае вывела правильный диагноз на 9 место в топ-10 возможных диагнозов. В числе возможных диагнозов были указаны также бронхит, простуда и другие респираторные заболевания.
Согласно статье, диагноз «туберкулез» в этом случае не был установлен врачом, несмотря на то, что у него была возможность осмотреть пациента и провести лабораторные анализы, в то время как система полагалась исключительно на краткое описание.
На основании полученного перечня возможных диагнозов врач может назначить пациенту необходимые дополнительные исследования или же направить к профильному специалисту для подтверждения диагноза.
Сравнительный пример.
Было проведено сравнение результатов, получаемых предлагаемым методом с результатами существующих подходов.
Из данных форумов были извлечены все упоминания диагнозов и симптомов с использованием обученной модели извлечения сущностей. Затем каждому извлеченному уникальному термину был присвоен код по международной классификации болезней (ICD). Затем были выбраны 200 самых распространенных диагнозов и создана таблица совпадений с симптомами, где симптомы были перечислены, как указано в тексте, без нормализации. Далее были извлечены все симптомы, упоминаемые для той или иной болезни и выделены 40 наиболее похожих записей в таблице совпадений симптомов / диагнозов, используя косинусное сходство между симптомами, полученными суммированием вложений каждого слова для данного симптома. Каждый диагноз в списке оценивался в соответствии с количеством совпадающих симптомов и степенью, в которой отдельные симптомы были сходными.
В таблице 1 приведены данные, иллюстрирующие точность предсказания диагноза в случае применения метода основанного на статистике совпадений и методов с использованием языковой модели. Были проанализированы методы, использующие обучение языковой модели на различных источниках входной информации.
Таблица 1
Было обнаружено, что точность метода на основе языковой модели превосходит точность метода, основанного на статистике совпадений. При этом преимуществом использования языковой модели также является то, что она способна использовать дополнительную информацию, содержащуюся в описаниях, которая отсутствует в статистике совпадений.
Таким образом, заявляемый способ позволяет использовать в системах поддержки принятия решений разнообразные данные, публикуемые в научных журналах, а не только истории болезни пациентов, что соответственно расширяет перечень диагностируемых заболеваний, а также позволяет получить расширенную картину возможных симптомов, сопровождающих их, для наиболее точного диагностирования.
Кроме того, предлагаемый метод не требует наличия структурированных данных, где описание заболевания сопоставлено с клинически подтвержденным диагнозом, что значительно упрощает и удешевляет его внедрение.
Преимущества заявляемого изобретения:
1. Список возможных диагнозов определяется на основании описания на естественном языке. Это позволяет упростить использование системы как для врача, так и для пациента.
2. При использовании в медицинских учреждениях, данный способ не требует хранения данных в определенном формате, поскольку совместим с различными информационными системами.
3. Способ позволяет учитывать все детали истории болезни, позволяющие наиболее точно предсказать диагноз в отличие от других методов, использующих преобразование текста в стандартный машиночитаемый формат.
3. Способ прост в реализации и обладает низкой трудоемкостью. Система способна к самообучению без участия человека-специалиста. Способ не требует от врача трудоемкой операции записи всех значений в соответствующие поля формы.
4. Нет ограничений на список входной информации (жалоб, видов обследований) и количество заболеваний, которое можно распознавать.
1. Патент РФ №2703679, опубл. 21.10.2019
2. Miotto, R., Li, L., Kidd, B. A., & Dudley, J. T. (2016). Deep patient: an unsuper-vised representation to predict the future of patients from the electronic health records. Scientific reports, 6, 26094
3. Blum, B. I., & Semmel, R. D. (1991, May). Medical informatics, knowledge, and expert systems. In [1991] Computer-Based Medical Systems@ m_Proceedings of the Fourth Annual IEEE Symposium (pp. 212–218). IEEE
4. Middleton, K., Butt, M., Hammerla, N., Hamblin, S., Mehta, K., & Parsa, A. (2016) Sorting out symptoms: design and evaluation of the babylon check automated triage system. arXiv preprint arXiv:1606.02041
5. Kafle, S., Pan, P., Torkamani, A., Halley, S., Powers, J., & Kardes, H. (2018). Personalized symptom checker using medical claims. In Proceedings of the Third International Workshop on Health Recommender Systemsco located with Twelfth ACM Conference on Recommender Systems (HealthRec-Sys’18), Vancouver, BC, Canada, October 6, 2018, 5 page.
6. Semigran, Hannah L., et al. (2015) “Evaluation of symptom checkers for self di-agnosis and triage: audit study.” bmj 351: h3480
7. Razzaki, S., Baker, A., Perov, Y., Middleton, K., Baxter, J., Mullarkey, D. & DoRosa-rio, A. (2018). A comparative study of artificial intelligence and human doctors for the purpose of triage and diagnosis. arXiv preprint arXiv:1806.10698
8. Sullivan D. J. Computerized risk management module for medical diagnosis : пат. 7197492 США. – 2007.
9. Iliff E. C. Automated diagnostic system and method including alternative symptoms : пат. 6764447 США. – 2004.
10. Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735–1780.
11. Kingma, Diederik P., and Jimmy Ba (2014). “Adam: A method for stochastic optimization.” arXiv preprint arXiv:1412.6980.
Изобретение относится к способам медицинской диагностики, а именно к способу обработки массивов медицинских данных и применения их в системах поддержки принятия решений в медицине. Технический результат – обеспечение автоматизации обработки большого объема медицинских публикаций при повышении точности диагностирования существующих заболеваний и определения риска развития заболеваний. Способ прогнозирования диагноза на основе обработки данных, содержащих медицинские знания, включает выполняемые посредством электронно-вычислительного устройства формирование предварительной выборки научных статей по медицине из публичных баз данных и создание языковой модели, обучаемой на основе указанной выборки. Формируют с помощью устройства пользователя текст, содержащий сведения о пациенте. Обрабатывают указанный текст с помощью электронно-вычислительного устройства, формируют текстовые строки путем добавления к ранее сформированному тексту сведений о заболевании, и затем направляют их на вход обученной языковой модели для вычисления вероятности данной строки или ее подстроки. 3 з.п. ф-лы, 1 табл.
1. Способ прогнозирования диагноза на основе обработки данных, содержащих медицинские знания, включающий выполняемые посредством электронно-вычислительного устройства формирование предварительной выборки научных статей по медицине из публичных баз данных и создание языковой модели, обучаемой на основе указанной выборки, формирование с помощью устройства пользователя текста, содержащего сведения о пациенте, обработку указанного текста с помощью электронно-вычислительного устройства, включающую формирование текстовых строк путем добавления к ранее сформированному тексту сведений о заболевании, и последующее их направление на вход обученной языковой модели для вычисления вероятности данной строки или ее подстроки.
2. Способ по п.1, отличающийся тем, что сведения о пациенте могут включать один или несколько из следующих видов данных: данные анамнеза, результаты его медицинских и биологических исследований и данные объективного осмотра.
3. Способ по п.1, отличающийся тем, что сведения о пациенте представлены в текстовом формате на естественном языке.
4. Способ по п.1, отличающийся тем, что обработка текста включает поочередное добавление названия заболевания из списка заболеваний, хранящегося на сервере и вычисление вероятности результирующего текста для каждого заболевания по формуле оценки распределения
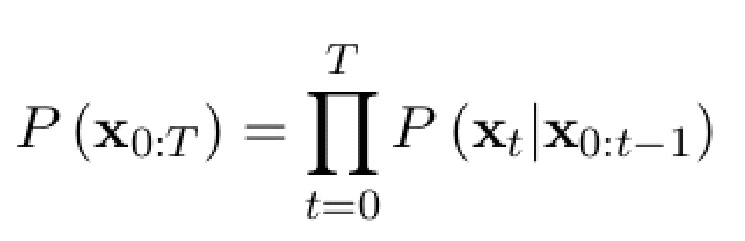
где t - номер токена, принимающий значения 0 или l, l – длина обрабатываемого текста.
| Способ и система поддержки принятия врачебных решений с использованием математических моделей представления пациентов | 2017 |
|
RU2703679C2 |
| US 7630947 B2, 08.12.2009 | |||
| US 7899764 B2, 01.03.2011 | |||
| US 8108381 B2, 31.01.2012 | |||
| US 8015136 B1, 06.09.2011 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| ПОДДЕРЖКА ПРИНЯТИЯ РЕШЕНИЙ ОБ УСТРАНЕНИИ ОШИБОК В КЛИНИЧЕСКОЙ ДОКУМЕНТАЦИИ | 2011 |
|
RU2606050C2 |
| СПОСОБ КЛАССИФИКАЦИИ ДОКУМЕНТОВ ПО КАТЕГОРИЯМ | 2012 |
|
RU2491622C1 |
| US 7197492 B2, 27.03.2007 | |||
| US 6764447 B2, 20.07.2004. | |||

