Изобретение относится к области образовательных систем с компьютерными технологиями, в частности к методам оценки глубины знаний и способности к логическим рассуждениям учащихся и специалистов.
Самый распространенный способ тестирования знаний — это тестирование с выбором варианта ответов, в котором учащиеся оценивают предложенные варианты ответа на тестовое задание и выбирают один (или несколько) верных. Если выбранный студентом вариант совпадает с отмеченным разработчиком тестового задания как правильный, то студент получает определенное число баллов, иначе, если вариант неправильный или вопрос пропущен, то тестируемый не получает никаких баллов. Главным преимуществом этого метода является возможность стандартизации и автоматизации процесса оценки (исключение фактора участия человека в проверке задания).
Данный способ обладает известными недостатками:
1. Составление тестовых заданий трудоемкая задача, при этом для объективности оценки каждый раз необходимо составлять новые тестовые задания, поскольку предыдущие задания могут стать известными для учащихся и потеряют свою ценность. Кроме того, новые задания приходится составлять если в процессе развития науки старые знания устаревают.
2. Составитель теста может допустить ошибки или составить тесты, проверяющие несущественные аспекты учебной программы. Составитель теста может сам быть некомпетентен, и его знания невозможно объективно проверить иначе, чем использованием других тестов.
3. Неоднозначные формулировки заданий и ответов могут привести к искажению результатов.
4. Задача выбора из вариантов ответов проверяет пассивные знания (способность опознать правильный ответ) и не проверяет способность рассуждать логически и применять полученные знания.
5. Тестирование не устойчиво к списыванию из учебников или поиску ответов в сети Интернет, из-за чего для его проведения требуются строгие меры контроля списывания. В то время, как на практике часто требуется проверить не запоминания фактов, а способность обучаемого найти нужные факты в литературе и применить их.
Для решения задачи снижения трудоемкости процесса создания теста существуют подходы к автоматизации создания тестов. Известны подходы к компьютерной генерации тестов с помощью базы фактов (онтологии) [1], а также более современные решения позволяющие перефразировать предложения текста в вопрос с помощью семантического анализа [2, 3] или глубоких нейронных сетей [4] (например «Куликовская битва была в 1380 году → «Что было в 1380 году?») и генерации заведомо неправильных ответов для получения теста. Эти решения не устраняют проблему ошибок в тестах, поскольку уровень алгоритмов уступает человеческому интеллекту, качество теста снижается и требует последующей проверки человеком. Кроме того, не решается проблема глубокой проверки способности рассуждать и применять знания. Вероятнее всего, автоматизация составления тестов такого рода требует наличия искусственного интеллекта, не уступающего по возможностям человеку-специалисту, что на текущем уровне развития науки невозможно. Тесты, где необходимо вписать недостающее слово в предложение страдают от тех же проблем, усугубляющихся трудностью оценки (могут подходить по смыслу разные слова).
Другим известным направлением является автоматизация оценки заданий выраженных в свободной форме (сочинения, эссе), например оценка уникальности [5] и соответствия теме [6]. Но ни одно из известных решений не способно автоматически проверить содержательную часть сочинения или даже реферата на достаточном уровне, по причине изложенной выше (требует наличия искусственного интеллекта, не уступающего по возможностям человеку-специалисту).
Технической задачей заявляемого изобретения является получение способа создания тестовых заданий для проверки знаний, обеспечивающего возможность проверки способности учащихся и специалистов к рассуждениям.
Технический результат – автоматизация процесса создания тестовых заданий, обеспечивающих возможность проверки способности учащихся и специалистов к рассуждениям.
Технический результат достигается тем, что способ создания тестовых заданий для проверки глубины знаний и способности к рассуждениям учащихся и специалистов включает получение с помощью электронно-вычислительного устройства выборки текстов по заданной теме, создание на ее основе языковой модели в виде функции условного распределения вероятности, модификацию распределения с использованием числового значения параметра сложности, с последующим формированием на его основе автоматически генерируемых текстов путем получения следующего токена в тексте с учетом значений предыдущих токенов в соответствии с функцией распределения, получение текстов из реальных источников информации, схожих по установленной функции сходства с упомянутыми автоматически сгенерированными текстами и формирование тестовых заданий, содержащих упомянутые автоматически сгенерированные тексты и схожие тексты из реальных источников информации.
Заявляемый способ основан на использовании в составе тестовых заданий автоматически сгенерированных текстов, содержащих фактические и логические ошибки с заданным уровнем и частотой ошибок. В процессе тестирования тестируемый должен выявить из предложенных текстов те, которые сгенерированы автоматически, т.е. содержат ошибки. Для того, чтобы опознать автоматически сгенерированный текст необходимо иметь знания и навыки, чтобы выявить в нем логические ошибки. Таким образом, основная проблема автоматизации проверки знаний, заключающаяся в отсутствии идеального искусственного интеллекта обходится, поскольку в данном случае ошибки компьютерных алгоритмов являются основой самого метода.
Осуществление изобретения.
Способ создания тестовых заданий для проверки знаний и способности к рассуждениям учащихся и специалистов согласно заявляемому изобретению включает формирование тестовых заданий с применением ЭВМ и языковой модели, представляющих собой сочетание автоматически генерируемых текстов и текстов из реальных источников информации (например, источников научной информации, учебников, энциклопедий). Сформированные тестовые задания предоставляют обучающимся, задача которых состоит в выборе текстов, сгенерированных автоматически, подсчет правильных ответов обучающегося.
Формирование автоматически генерируемых текстов осуществляется следующим образом:
С помощью ЭВМ создается выборка текстов по заданной тематике с использованием научных статей, учебников, энциклопедий, находящихся в открытом доступе в Интернете, или используя недоступные публично базы данных (например, если тестирование создается для проверки знания сотрудниками внутренних документов компании).
С помощью полученной выборки с использованием ЭВМ осуществляется обучение языковой модели.
Языковая модель - это модель осуществляющая предсказание токена под номером t в последовательности, заданной t-1 предшествующих токенов, где токены могут быть словами, подсловами или символами.
Целью языковой модели является оценка распределения P(x0:T) по последовательностям токенов (x0, x1, ..., xT):=x0:xT [8]. Обучение языковой модели это процесс, создающий аппроксимирующей реальное распределение функции дискретного условного распределения вероятностей P(xt|x0,...xt-1) получения следующего токена, если даны значения предыдущих токенов. Совместное распределение по длинным текстовым фрагментам может быть представлено как произведение значений распределения по токенам, обусловленным предшествующими токенами [9]:
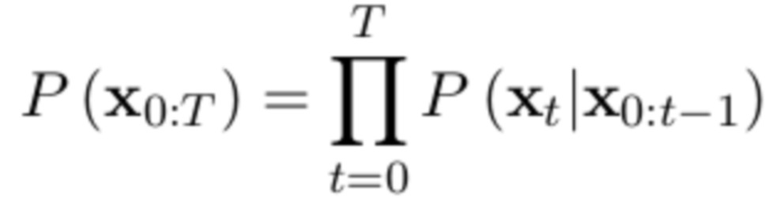
Таким образом, получают функцию, вычисляющую вероятность появления следующего токена на основе примеров текста.
Языковая модель может представлять собой рекуррентную нейронную сеть или нейронную сеть другой архитектуры и может строиться различными способами.
Для проверки результата с помощью ЭВМ и языковой модели генерируется несколько текстов небольшой длины, путем последовательного предсказания следующего токена на основании распределения P(x0: T). Предсказание может осуществляться как путем выбора самого вероятного токена, так и путем случайного выбора токена из распределения P(x0:T), или из распределения pτi, вычисляемого на основании P(x0: T) согласно формуле:
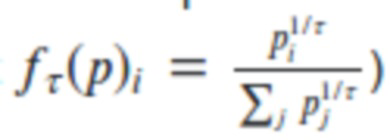
где τ — значение температуры (условный показатель), i - номер токена для которого производится вычисление, j - индекс, по которому производится суммирование, он принимает значения от 0 до количества токенов.
Как следует из формулы, при τ= 1 текст генерируется из исходного распределения, при τ>1 повышается элемент случайности и при очень высоких значениях τ текст станет просто случайным набором символов (токенов). Для целей настоящего метода показатель τ используется как один из способов регулирования сложности теста. Сложность теста также возможно регулировать другими способами, изменяющими выходное распределение P(x0:T), например путем добавления к активациям скрытых слоев нейронной сети случайного шума с заданной амплитудой A.
Подбор значений τ и A может осуществляться различными методами. При отсутствии возможности проведения процедуры подбора параметра значение τ принимается равным 1, а А равным нулю и текст генерируется из исходного распределения P(x0:T).
Значения параметров могут быть выбраны эмпирически: осуществляется генерация текстов с использованием различных параметров, затем специалист в предметной области просматривает полученные фрагменты и выбирает уровень сложности, который он считает приемлемым для проведения проверки знаний учащихся.
В другом варианте осуществления изобретения значения параметров могут быть выбраны путем статистического подбора: осуществляется генерация текстов с использованием различных значений параметров А или τ, затем с использованием полученных текстов, а также текстов из реальных источников информации формируют тестовые задания, предоставляемые двум группам испытуемых, одна из которых является экспертами в теме тестирования, а вторая контрольной (группа может быть набрана из обучающихся, еще не знакомых с темой теста). Выбирается значение параметра, показавшего наибольшую разницу в средних баллах между группой экспертов и контрольной группой.
Для создания теста по выбранной теме ряд автоматически-сгенерированных текстов перемешиваются в случайном порядке с похожими фрагментами из реальных источников информации (учебников, научных статей и других).
Похожие фрагменты могут быть получены путем осуществления автоматизированного поиска с помощью ЭВМ сходных согласно некоторой функции сходства фрагментов (абзацев) в реальных источниках информации. Функция сходства может быть определена различным образом. Одним из вариантов реализации данного процесса является вычисление процента совпадений уникальных слов (или словосочетаний заданной длины) сгенерированного фрагмента текста и абзацев реальных источников информации с последующим поиском среди них абзаца, для которого данная величина максимальна. Таким образом, выбираются похожие фрагменты, которые имеют наибольшее число совпадающих слов со сгенерированным примером. Другим способом реализации функции сходства является использование функций, предназначенных для поиска информации таких как TF/IDF, BM25 [10]. Также могут использоваться метрики сходства текстов, такие как BLEU [11], нейросетевые обучаемые модели для вычисления сходства текстовых фрагментов [12-14], или другие функции с фиксированными, подбираемыми или обучаемыми параметрами. Тексты также могут быть подобраны вручную или с использованием поисковых систем в сети Интернет.
Данный процесс можно повторять многократно для получения любого необходимого количества тестов.
Полученный тест наносится на бумагу или другой носитель, и предъявляется тестируемому. Задача обучающегося определить тексты, которые сгенерированы автоматически. После выполнения тестового задания вручную или с помощью ЭВМ производится подсчет правильных ответов, полученное число является числом баллов, полученных за тест.
Для превращения числа баллов в оценку используются существующие методы калибровки тестов с множественным выбором, например [7], которые позволяют оценить вероятность случайного правильного прохождения теста и найти соответствие между баллами и уровнем знаний.
Примеры осуществления изобретения:
Пример 1.
Языковая модель на базе нейронной сети Long Short-Term Memory (LSTM) [15] была обучена для предсказания следующего символа (модель на уровне символов, где токенами являются отдельные символы) на выборке текстов художественных книг (5Gb данных), после чего была дообучена на выборке текстов по истории. Модель содержала в себе 4 слоя LSTM ячеек по 3192 ячейки в каждом слое. Выходным множеством токенов были символы русского алфавита. При генерации текста, значение параметра τ было принято равным 1. Был получен следующий текст:
1. «Полковник Корнилов родился в 1891 году в семье старого полковника. В 1918 году он был призван в армию и получил приказ от командования войск НКВД подготовить почву для подготовки к войне. В 1921 году он принял участие в операции по проведению военных действий в районе Сталинграда. В 1941 году он был назначен командиром 1-й танковой дивизии и получил приказ от командования 1-й танковой армии от 15 июня 1941 года принять участие в боях под Москвой. В 1942 году он был награжден орденом Красного Знамени. В 1942 году в районе Сталинграда был обнаружен труп майора Василия Сергеевича Сталина. В 1942 году он был признан виновным в убийстве Сталина. В 1942 году он был приговорен к смертной казни за убийство»
После этого второй текст был подобран из реальных источников информации по принципу наибольшего сходства со сгенерированным с использованием метрики сходства на базе ключевых слов:
2. «Полковник Корнилов родился 18 (30) августа 1870 г. в семье хорунжего. Он окончил Сибирский кадетский корпус, Михайловское артиллерийской училище, а также Николаевскую академию Генштаба (с золотой медалью). В 1904-1905 гг. занимал должность штаб-офицера и фактически выполнял обязанности начальника штаба. Был награжден за доблесть в Мукденском сражении и произведен в полковники. Л.Г. Корнилов попал в плен в 1915 г. во время отступления армий, его дивизия понесла серьезные потери”
Оба текста содержат изложение фактов биографии исторического лица, однако текст номер 1 содержит ряд фактических ошибок (военные действия в районе Сталинграда в 1921 году, несуществующие исторические лица, другие нарушения хронологии), что позволяет человеку с базовыми знаниями истории опознать его как ошибочный.
Пример 2.
Языковая модель на базе нейросетевой архитектуры Transformer [16,17] была обучена на 10 Gb текста научных статей из медицинских журналов. Текст был разбит на токены с помощью метода Byte-Pair Encoding [18], был использован словарь из 64000 токенов. Был сгенерирован текст из 20 текстов, 10 из которых являются сгенирированными с помощью языковой модели и 10 — найдены в реальных научных статьях по принципу сходства начала первого предложения в каждом тексте. Тестируемому было предложено определить, какие из фрагментов сгенерированы автоматически.
Пример сгенерированного фрагмента:
“Настоящее исследование было разработано для изучения влияния одной внутрибрюшинной инъекции неселективного антагониста 5-НТ-рецептора метизергида (10 мг / кг) на антиноцицептивное действие морфина у крысы. Антиноцицептивный эффект метизергида оценивали в тесте принудительного плавания”.
В данном случае предметом проверки знаний является экспериментальная биохимия. Приведенный выше текст сгенерирован автоматически и очень похож на настоящий. Однако, он содержит логическую ошибку (тест принудительного плавания используется для оценки эффективности антидепрессантов и не может быть использован для описанной в фрагменте цели, потому что в нем нет болевого стимула). В данном случае студент должен не только знать факты специфической предметной области, но и представить себе описываемый в фрагменте опыт, чтобы понять, что нужный результат в нем получен не будет. При этом наличие под рукой справочной информации не помогает однозначно определить ошибку, если человек не имеет достаточного уровня понимания и способности к логическим рассуждениям в заданной области.
Заявляемый способ обладает следующими преимуществами:
- позволяет снизить трудозатраты на создание тестовых заданий;
- позволяет исключить случайные ошибки при создании и проверке тестовых заданий;
- обеспечивает возможность создания заданий заданного уровня сложности;
- позволяет минимизировать вероятность случайного правильного прохождения теста тестируемым;
- учитывает не только знание определенных фактов в изучаемой дисциплине, но и способность к логическим рассуждениям и выводам тестируемого.
1. Papasalouros, Andreas, Konstantinos Kanaris, and Konstantinos Kotis. "Automatic Generation Of Multiple Choice Questions From Domain Ontologies." e-Learning. 2008.
2. Kantor, Arthur, Jan Kleindienst, and Martin Schmid. "Automatic question generation from natural text." U.S. Patent No. 9,904,675. 27 Feb. 2018.
3. Международная заявка WO2018165579, опубл. 13.09.2018г.
4. Subramanian, Sandeep, et al. "Neural models for key phrase detection and question generation." arXiv preprint arXiv:1706.04560 (2017).
5.Zubarev D.V., Sochenkov I.V (2019). Cross-Language Text Alignment for Plagiarism Detection Based on Contextual and Context-Free Models. Computational Linguistics and Intellectual Technologies: Proceedings of Annual International Conference “Dialogue”, Issue 18
6. Tikhomirov M. M., Loukachevitch N. V., Dobrov B. V (2019). Assessing Theme Adherence in Student Thesis. Computational Linguistics and Intellectual Technologies: Proceedings of Annual International Conference “Dialogue”, Issue 18
7. Ercikan, Kadriye, et al. "Calibration and scoring of tests with multiple-choice and constructed-response item types." Journal of Educational Measurement 35.2 (1998): 137-154.
8. Ronald Rosenfeld. 2000. Two decades of statistical language modeling: Where do we go from here? Proceedings of the IEEE, 88(8):1270–1278
9. Akbik, Alan, Duncan Blythe, and Roland Vollgraf. "Contextual string embeddings for sequence labeling." Proceedings of the 27th International Conference on Computational Linguistics. 2018.
10. Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze. An Introduction to Information Retrieval, Cambridge University Press, 2009, p. 233
11. Papineni, K.; Roukos, S.; Ward, T.; Zhu, W. J. (2002). BLEU: a method for automatic evaluation of machine translation (PDF). ACL-2002: 40th Annual meeting of the Association for Computational Linguistics. pp. 311–318.
12. He H., Gimpel K., Lin J. Multi-perspective sentence similarity modeling with convolutional neural networks //Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. – 2015. – С. 1576-1586.
13. Neculoiu, Paul, Maarten Versteegh, and Mihai Rotaru. "Learning text similarity with siamese recurrent networks." Proceedings of the 1st Workshop on Representation Learning for NLP. 2016.
14. Amiri, Hadi, et al. "Learning text pair similarity with context-sensitive autoencoders." Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016.
15. Sepp Hochreiter; Jürgen Schmidhuber (1997). "Long short-term memory". Neural Computation. 9 (8): 1735–1780. doi:10.1162/neco.1997.9.8.1735. PMID 9377276.
16. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
17. Radford, Alec, et al. "Improving language understanding by generative pre-training." URL: https://s3-us-west-2.amazonaws.com/openai-assets/researchcovers/languageunsupervised/language understanding paper. Pdf (2018).
18. Sennrich, Rico, Barry Haddow, and Alexandra Birch. "Neural machine translation of rare words with subword units." arXiv preprint arXiv:1508.07909 (2015).
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПРОГНОЗИРОВАНИЯ ДИАГНОЗА НА ОСНОВЕ ОБРАБОТКИ ДАННЫХ, СОДЕРЖАЩИХ МЕДИЦИНСКИЕ ЗНАНИЯ | 2019 |
|
RU2723674C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА ДЛЯ ЦИФРОВОГО АССИСТЕНТА | 2022 |
|
RU2796208C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА | 2023 |
|
RU2817524C1 |
| ICL-тест - инструмент по измерению информационно-коммуникационной компетентности в цифровой среде | 2017 |
|
RU2656699C1 |
| СПОСОБ И СИСТЕМА ПЕРЕФРАЗИРОВАНИЯ ТЕКСТА | 2023 |
|
RU2814808C1 |
| ТЕМАТИЧЕСКИЕ МОДЕЛИ С АПРИОРНЫМИ ПАРАМЕТРАМИ ТОНАЛЬНОСТИ НА ОСНОВЕ РАСПРЕДЕЛЕННЫХ ПРЕДСТАВЛЕНИЙ | 2018 |
|
RU2719463C1 |
| Способ оценки знаний учащегося при компьютерном тестировании | 2016 |
|
RU2640709C1 |
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ ТЕКСТА | 2022 |
|
RU2818693C2 |
| СИСТЕМА И МЕТОД АВТОМАТИЧЕСКОГО СОЗДАНИЯ ШАБЛОНОВ | 2018 |
|
RU2697647C1 |
| Система критериально-ориентированного тестирования | 2016 |
|
RU2649550C2 |
Изобретение относится к области образовательных систем с компьютерными технологиями, в частности к методам оценки глубины знаний и способности к логическим рассуждениям учащихся и специалистов. Технический результат - автоматизация процесса создания тестовых заданий, обеспечивающих возможность проверки способности учащихся и специалистов к рассуждениям. Компьютерный автоматизированный способ создания тестовых заданий для проверки глубины знаний и способности к рассуждениям учащихся и специалистов включает получение с помощью электронно-вычислительного устройства выборки текстов по заданной теме, создание на ее основе языковой модели в виде функции условного распределения вероятности, модификацию распределения с использованием числового значения параметра сложности последующим формированием на его основе автоматически генерируемых текстов путем получения следующего токена в тексте с учетом значений предыдущих токенов, получение текстов из реальных источников информации, схожих по установленной функции сходства с упомянутыми автоматически сгенерированными текстами и формирование тестовых заданий, содержащих упомянутые автоматически сгенерированные тексты и схожие тексты из реальных источников информации. 5 з.п. ф-лы.
1. Компьютерный автоматизированный способ создания тестовых заданий для проверки глубины знаний и способности к рассуждениям учащихся и специалистов, включающий получение с помощью электронно-вычислительного устройства выборки текстов по заданной теме, создание на ее основе языковой модели в виде функции условного распределения вероятности, модификацию распределения с использованием числового значения параметра сложности последующим формированием на его основе автоматически генерируемых текстов путем получения следующего токена в тексте с учетом значений предыдущих токенов, получение текстов из реальных источников информации, схожих по установленной функции сходства с упомянутыми автоматически сгенерированными текстами и формирование тестовых заданий, содержащих упомянутые автоматически сгенерированные тексты и схожие тексты из реальных источников информации.
2. Способ по п.1, отличающийся тем, что в качестве токена используют слово, часть слова или символ.
3. Способ по п.1, отличающийся тем, что определение распределения осуществляют с помощью нейронных сетей.
4. Способ по п.1, отличающийся тем, что числовое значение параметра сложности определяется эмпирическим методом посредством выбора специалистом в предметной области приемлемого уровня сложности на основе ряда автоматически сгенерированных текстов.
5. Способ по п.1, отличающийся тем, что числовое значение параметра сложности определяется статистическим методом посредством выполнения тестовых заданий с различными уровнями сложности контрольной и экспертной группами и выбора значения параметра сложности, показавшего наибольшую разницу в средних баллах между группами.
6. Способ по п.1, отличающийся тем, что в качестве функции сходства используют максимальное совпадение слов или комбинаций слов сгенерированного текста и текста реальных источников информации.
| Устройство для контроля знаний обучаемых | 1979 |
|
SU873263A1 |
| СПОСОБ ИЗВЛЕЧЕНИЯ ФАКТОВ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2016 |
|
RU2637992C1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| СПОСОБ КОНТРОЛЯ И ОЦЕНКИ ЗНАНИЙ | 2018 |
|
RU2695829C1 |

