Группа изобретений относится к области корректировки орфографических ошибок, а именно автоматической проверке правописания и исправлению опечаток в любой текстовой среде.
Исправление опечаток – одна из важнейших задач компьютерной лингвистики. На ее решение направлены многочисленные технические решения, начиная с известных интегрированных программных компонентов – проверка правописания в текстовом редакторе MS Word, автоисправление в виртуальной клавиатуре портативных мобильных устройств, использующие встроенные, либо наполняемые пользовательским вводом словари – и до сложных разработок на основе машинного обучения и языковых моделей, таких как Aspell (http:// aspell.net/), Hunspell (http://hunspell.github.io/), ispell (https://www.cs.hmc. edu/~geoff/ ispell.html). Однако указанные системы не учитывают контекст корректируемого текста.
Известна также система levenshtein_corrector_ru, разработанная в библиотеке DeepPavlov, которую использует KenLM в качестве языковой модели и LevenshteinSearcher для генерации кандидатов. Однако KenLM как языковая модель не чувствительна к перестановкам слов, что может быть критично для языков с мягким порядком слов (включая русский).
Языковая модель Brill-Moore, требовательна к обучающей выборке. В связи с этим система, раскрытая в патенте US 7047493B1 (приоритет 2000-03-31, МПК G06F17/21) отличается долгим и сложным механизмом обучения при низких, по сравнению с существующими аналогами, показателях корректировки ошибок.
Другое известное решение, Yandex.Speller (https://yandex.ru/dev/speller/), для обнаружения ошибки и подбора замены использует библиотеку машинного обучения CatBoost. Благодаря CatBoost он может расшифровывать искажённые до неузнаваемости слова («адникасниеи» → «одноклассники») и учитывать контекст при поиске опечаток («скучать музыку» → «скачать музыку»). Однако указанная система ограничена использованием в браузерах и веб-приложениях, и не определят ошибки новых слов, ещё не попавших в словари.
Следующее известное решение – US 20190197099 A1 (дата публикации 27 июня 2019 г., МПК G06F17 / 27). При разработке аналога разработчики отметили, что можно создать алгоритм машинного обучения (MLA) для исправления опечатки, независимо от причины опечатки, при условии, что оно обучено на соответствующих данных обучения. И варианты осуществления указанной технологии были разработаны на основе предположения, что путем искусственного создания переформулировок слов эти перестановки могут быть использованы для обучения вышеупомянутого MLA. По меньшей мере, некоторые не ограничивающие варианты осуществления настоящей технологии направлены на создание «реалистичных опечаток» (которые пользователь с большей вероятностью сделает при вводе поискового запроса и т.п.), которые можно использовать для обучения MLA. Используя эти переформулировки, MLA обучается ранжировать и выбирать переформулированное слово, которое является правильно набранным словом. Система использует слова и символы-кандидаты и присваивает им рейтинг и оценку для определения вероятности опечатки. Недостаток указанной системы в ее нацеленности на веб-ресурсы и целевое формирование словаря замены из истории запросов пользователя.
Наиболее близким аналогом является решение, описанное в US 10115055 B2 (дата публикации 30 октября 2018 г., МПК G06F17 / 27). Данное изобретение максимально подробно описывает систему и процесс обучения нейронной сети с целью глубокого изучения основанного на естественном языке, в котором: модель / машина корректирования токенизации и орфографии слова может генерировать выходные данные исправленных наборов слов; и / или модель / машина деривации семантики слова может генерировать семантически маркированные выходные данные предложений на основе соответствующих входных данных наборов слов. Указанные система и способ имеют несколько вариантов реализации в зависимости от материалов обучения - словари, пользовательский ввод, шум, базы правописания и правок, но неизменным остается результат – откорректированное предложение и процессы обучения, токенизации, семантического распознавания и маркировки лексических единиц. Достоинством аналога является широкий набор баз и методов для обучения модели, нацеленной на обработку текста из любых источников – от газет до научных текстов, а также внедрение токенизации. Однако из описания системы не ясно, каким образом принимается итоговое решение о корректировке ошибок для вывода орфографически верного решения и автоматической замены слов с опечатками. Нет проработки ошибок и их оценки, что имеет значение при машинном обучении системы.
В связи с этим актуальной является задача по созданию системы корректировки орфографии, применимой в любой текстовой среде, где на входе система получает текстовый материал с ошибками, и на выходе выдает орфографически корректный текст. Для этой цели в предложенном решении в отличие от аналогов используется существенный этап оценки правдоподобия исправлений системой и автоматическое принятие решений об исправлении по результатам предыдущих этапов.
Таким образом, технический результат предложенного решения заключается в повышении эффективности корректировки орфографических ошибок.
Предлагаемое решение заключается в том, чтобы с помощью блока языковой модели и блока модели ошибок, опираясь на ранжированные результаты обработки токенизированного текста, предоставленные языковой модели модулем генерации исправлений, система автоматически подбирала такие варианты предложений, которые бы повышали правдоподобие выходного предложения, оценивала правдоподобие предложения и отдельных слов в нем, прогнозировала модель исправления ошибок с оценкой правдоподобия исправления любой подстроки в предложении на другую подстроку и автоматически заменяла лексические единицы с ошибками на орфографически корректные.
Краткое описание чертежей.
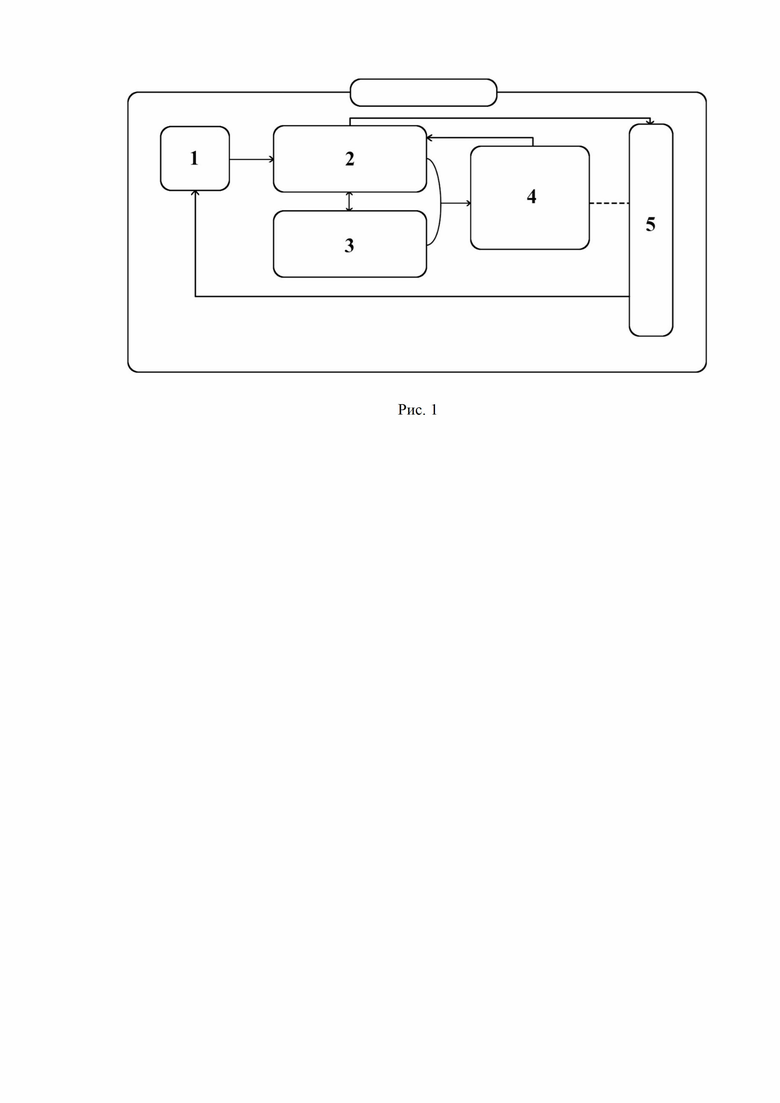
Рис.1 - Представляет схему, иллюстрирующую положение и взаимосвязь блоков и модулей;
Рис.2 – схема, иллюстрирующая порядок действий способа;
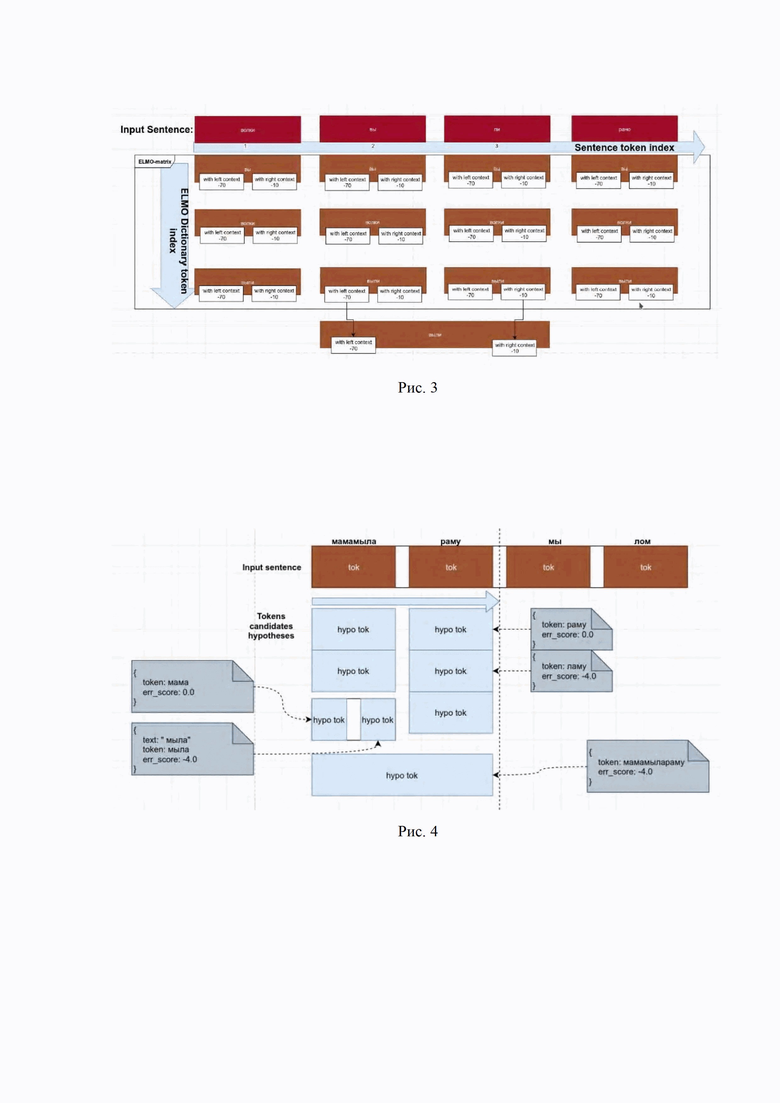
Рис.3 – иллюстрация – пример генерации гипотез исправлений сегментов предложения с оценкой штрафов за исправления;
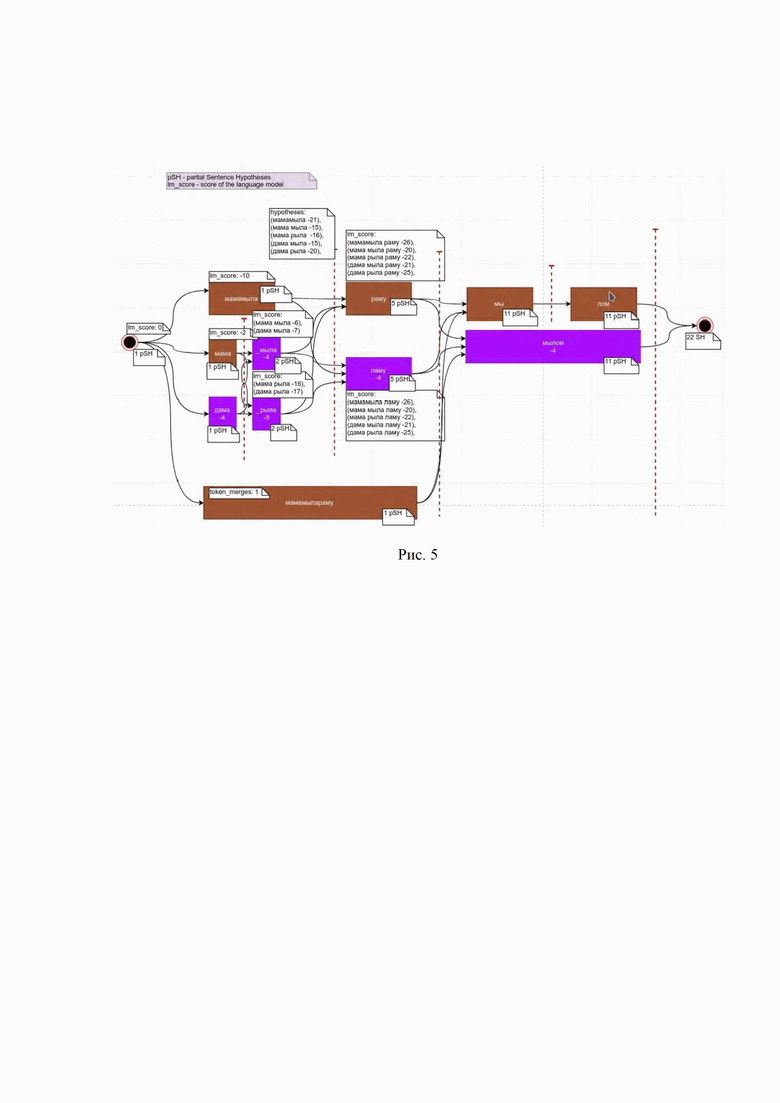
Рис.4 – иллюстрация – пример построения графа гипотез-предложений;
Рис.5 – иллюстрация – пример оценки левого и правого правдоподобий при изменении токенной длины предложения при использовании в качестве блока 4 языковой модели ELMO.
Далее со ссылками на представленные иллюстрирующие материалы 1-4 подробно раскрыта предложенная группа изобретений.
Ссылаясь на Рис. 1, система корректировки орфографических ошибок представляет собой тесное взаимодействие заложенных в нее модулей и блоков, а именно:
Модуль считывания и преобразования текста 1 представляет собой компонент системы на основе программного обеспечения и отвечает за подготовку текстового материала к считыванию остальными блоками и модулями системы (2-5). В указанную подготовку входит: токенизация предложений, понижение регистра букв и депунктуирование. Дополнительной функцией модуля является возвращение в первоначальный вид, но уже исправленного текста после выполнения всех процессов: повышение регистра букв и расстановка пунктуации по прежним местам.
Модуль генерации исправлений 2, представляющий собой компонент системы на основе программного обеспечения, осуществляет считывание токенов предложения и генерацию гипотез-сегментов. На этом этапе системное правило для каждого токена предложения генерирует кандидаты слова (и кандидаты биграммы похожие на исходный токен) близкие по взвешенному расстоянию Левенштейна. Затем проводится генерация исправлений на основе склейки слов в одно (исправление ошибочных пробелов). Для базовой гипотезы также проводится изучение «является ли токен аббревиатурой». Модуль генерации исправлений 2 принимает на вход токенизированный текст с модуля считывания и преобразования текста 1 и на выходе выдает множество гипотез токенов ранжированных по стоимости исправления. Исправления могут состоять из композиции замен, удалений, вставок, транспозиций отдельных букв слова, а также включать склейку слов в одно слово и расклейку слов в (два) слова. На этом этапе указанный модуль тесно взаимодействует с блоком модели ошибок 3.
Модель ошибок 3 является блоком системы на основе программного обеспечения и вместе с блоком языковой модели 4 влияют на нейросеть-составляющую системы, т.е результаты, полученные указанными блоками, являются приоритетными для системы. Блок модели ошибок 3 при взаимодействии с модулем генерации исправлений 2 по паре строк s1 и s2 дает оценку логарифмической вероятности преобразования s1 в s2: P(s1|s2) Например, вероятность P(мвма|мама) > P(мвма|гиппопотам), то есть вероятность исправления строки “мвма” на “мама” больше, чем вероятность, что автор строки “мвма” хотел написать “гиппопотам”. В предлагаемом решении используется модель ошибок, которая инкрементирует штрафы за всякое исправление. В используемом решении учитываются штрафы для специальных частотных подстрок “чо-нить” на “что-нибудь”, которые дают более низкий штраф за частотные ошибки, чем для случайных исправлений. Базовый штраф за замену буквы - 4. Однако вставка и удаление пробела, транспозиция пары смежных букв имеют более низкий штраф. Это является вышеуказанной стоимостью исправления, в соответствии со значением которой модуль генерации исправлений 2 ранжирует результаты. Дополнительно система использует оценки частотности опечаток.
Блок языковой модели 4 является сердцем системы, так как выбор языковой модели напрямую влияет на финальное качество корректировки. В преимущественном варианте осуществления и для опытной практической реализации системы была использована языковая модель ELMO. Блок языковой модели представляет собой программное обеспечение и считывает результаты модуля генерации исправлений 2 и блока модели ошибок 3. На основе этих данных образуется языковая матрица, и обсчет языковой матрицы токенизированного предложения, где для каждой токен-позиции в предложении генерируется распределение вероятностей по словарю с учетом контекста остальных слов предложения. Эта матрица позволяет оценить правдоподобие замены слова в предложении на произвольное слово из словаря языковой модели. Имея гипотезы исправлений для каждого сегмента предложения, модель оценивает языковой выигрыш каждой гипотезы (languagemodeladvantage) и итоговый выигрыш (advantage). Языковой выигрыш оценивает прирост вероятности от замены исходного сегмента на гипотезу по оценке языковой модели. Итоговый выигрыш оценивается как сумма языкового выигрыша и штрафа за исправление ошибки.
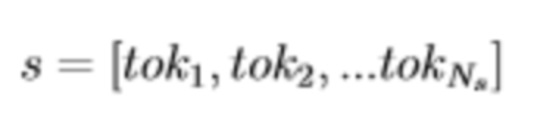 Алгоритм оценки правдоподобия слов в предложении для каждой позиции слова в конкретном предложении строит распределение вероятностей слов.
Алгоритм оценки правдоподобия слов в предложении для каждой позиции слова в конкретном предложении строит распределение вероятностей слов.
Входное предложение:
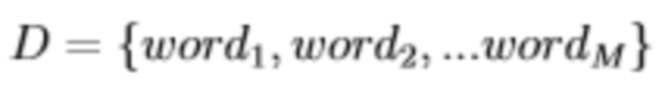
Словарь языковой модели:
Распределение на выходе из модели это множество условных распределений – языковая матрица для предложения s):
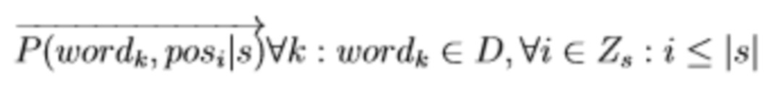
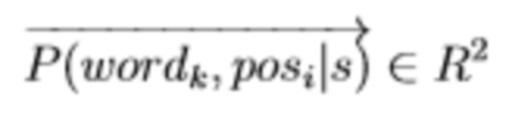
Для каждого токена wordk стоящего в токен-позиции posi в предложении s языковая модель оценивает левое и правое правдоподобия. Левое правдоподобие это оценка правдоподобия токена при условии наличия токенов слева (у которых posj: j < i). Аналогично правое правдоподобие — это правдоподобие токена при условии правого контекста (j > i).
Так как блок языковой модели 4 основывается на базе токенов, то орфографические ошибки, решаемые преобразованием двух или нескольких слов склеиванием нескольких токенов в один, меняют токен-индексацию в предложении - уменьшают количество токенов. Для этой ситуации применяется другая формула. При объединении двух токенов в один находящихся на позициях i и i+1 левое правдоподобие итогового токена берется из языковой матрицы на позиции i (при условии, что итоговый токен есть в словаре), а правое правдоподобие берется из колонки матрицы на позиции i + 1.
При увеличении количества токенов после исправления для точной оценки необходим перерасчет матрицы полученного предложения. Но с потерей точности можно оценить правдоподобие такой расклейки без переоценки языковой моделью. Для этого модель использует левое правдоподобие левого токена и правое правого токена. Левое правдоподобие правого токена и правое правдоподобие левого токена неизвестны. Модель вводит штраф за расклейку слов и считает кумулятивный выигрыш по сравнению со склеенным словом суммируя известные оценки языковой модели и штраф за расклейку (и прочие штрафы за правки, если они имеют место быть). Затем система вновь обращается к модулю генерации исправлений 2 для оценки выигрышей сегментов-гипотез.
После подсчета оценок вероятности, выигрышей и правдоподобия, выполненного предыдущими модулями и блоками, все данные передаются на модуль принятия решений 5, представляющего собой системный компонент на основе алгоритма. В процессе считывания подготовленных числовых значений, алгоритм параметризуется минимальным отступом уверенности для исправления, идет последовательно по сегментам предложения и оценивает наилучшую замену по значению итогового выигрыша. Затем принимает решение об исправлении, либо сохранении написания слова и по завершении процедуры, после команды исправить/оставить, процесс переключается обратно на модуль считывания и преобразования текста 1, который возвращает текст в первоначальный вид, не затрагивая исправленные орфографические ошибки - повышает регистр букв и расставляет пунктуацию по прежним местам.
Система работает в режиме последовательно-параллельных задач, этапы идут друг за другом, где каждый опирается на результаты предыдущего, но разбор токенизированного предложения идет целиком, так как каждое слово-токен рассматривается в контексте других слов-токенов.
Детальное описание способа корректировки орфографических ошибок по указанной системе, ссылаясь на Рис.2:
1. С помощью описанной системы в автоматизированном режиме посредством модуля считывания и преобразования текста 1 осуществляют препроцессинг: токенизируют предложение, понижают регистр букв и осуществляют депунктуацию.
2. Через модуль генерации исправлений 2 осуществляют считывание токенизированного предложения и, используя словарь языка и взвешенную метрику Левенштейна, находят кандидаты-исправления, которые образуют ранжированное пространство гипотез слов для корректировки.
3. Осуществляют анализ предложения языковой моделью. Вводят данные токенизированного предложения и пространства гипотез-слов, а блок языковой модели 4 в результате анализа выдает матрицу правдоподобий слов и исправлений в предложении в зависимости от их позиции.
4. При помощи того же блока производят оценку правдоподобий исправлений, изменяющих количество токенов в предложении (исправления связанные с уменьшением количества слов и исправления связанные с увеличением числа слов в предложении). В результате этих шагов получают пространство сегментов-гипотез (включая нуль-гипотезы – сегменты без исправлений) предложения с оценками правдоподобий сегментов в контексте рассматриваемого предложения.
5. После этапа генерации гипотез и анализа предложения возвращаются к помощи модуля генерации исправлений 2 производят оценку выигрышей сегментов-гипотез. В простой реализации оценка представляет собой суммирование правдоподобий сегментов-гипотез и правдоподобий исправлений и вычет правдоподобия нуль-гипотезы (гипотезы без исправления), для получения выигрыша над нуль-гипотезой. Если выигрыш положительный — значит исправление правдоподобно. Если выигрыш отрицательный, то исправление неправдоподобно.
6. Далее с помощью модуля принятия решений 5 об исправлениях проходят по пространству оцененных гипотез слева-направо по предложению и принимают решение о внесении правки на одну из гипотез для данного сегмента или выборе нуль-гипотезы (оставляет сегмент предложения как в исходном предложении).
7. Финальным шагом способа является постпроцессинг посредством модуля считывания и преобразования текста 1, при котором происходит склеивание сегментов в строку-предложение и восстановление регистра слов и пунктуации в исправленном предложении.
Результатом использования настоящего изобретения являются следующие преимущества:
- Быстрая проверка орфографических ошибок;
- Единовременная корректировка ошибок;
- Обучаемая гибкая система на основе нейросети и языковой модели постоянно обрабатывает данные о найденных и возможных ошибках, все время совершенствуясь и сводя орфографические ошибки на нет;
- Система способна запоминать новые правила, таким образом есть возможность применения системы и в случаях с аббревиатурами и иными сложными ситуациями компьютерной лингвистики.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ ТЕКСТА | 2022 |
|
RU2818693C2 |
| СПОСОБ И СИСТЕМА ПЕРЕФРАЗИРОВАНИЯ ТЕКСТА | 2023 |
|
RU2814808C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА | 2023 |
|
RU2817524C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА ДЛЯ ЦИФРОВОГО АССИСТЕНТА | 2022 |
|
RU2796208C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ОТВЕТА НА ПОИСКОВЫЙ ЗАПРОС | 2024 |
|
RU2834217C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫСТРАИВАНИЯ ДИАЛОГА С ПОЛЬЗОВАТЕЛЕМ В УДОБНОМ ДЛЯ ПОЛЬЗОВАТЕЛЯ КАНАЛЕ | 2018 |
|
RU2688758C1 |
| СПОСОБ И СИСТЕМА ПОЛУЧЕНИЯ ВЕКТОРНЫХ ПРЕДСТАВЛЕНИЙ ДАННЫХ В ТАБЛИЦЕ С УЧЁТОМ СТРУКТУРЫ ТАБЛИЦЫ И ЕЁ СОДЕРЖАНИЯ | 2024 |
|
RU2839037C1 |
| СИСТЕМА И СПОСОБ АВТОМАТИЗИРОВАННОЙ ОЦЕНКИ НАМЕРЕНИЙ И ЭМОЦИЙ ПОЛЬЗОВАТЕЛЕЙ ДИАЛОГОВОЙ СИСТЕМЫ | 2020 |
|
RU2762702C2 |
| СИСТЕМА И МЕТОДИКА АВТОМАТИЧЕСКОГО ОБУЧЕНИЯ ЯЗЫКАМ НА ОСНОВЕ ЧАСТОТНОСТИ СИНТАКСИЧЕСКИХ МОДЕЛЕЙ | 2015 |
|
RU2632656C2 |
| СПОСОБ И СИСТЕМА ИЗВЛЕЧЕНИЯ ИМЕНОВАННЫХ СУЩНОСТЕЙ | 2020 |
|
RU2760637C1 |

Изобретение относится к системе и способу корректировки орфографических ошибок. Технический результат заключается в повышении эффективности корректировки орфографических ошибок за счет реализации оценки правдоподобия исправлений и принятия решений об исправлении ошибок. Способ включает подготовительный этап по токенизации, уменьшению регистра букв и депунктуации, финальный этап по увеличению регистра букв и возвращению пунктуации, отличающийся тем, что через модуль генерации исправлений осуществляют считывание токенизированного предложения и, используя словарь языка и взвешенную метрику Левенштейна, находят кандидаты-исправления, которые образуют ранжированное пространство гипотез слов для корректировки, затем осуществляют анализ предложения с помощью блока языковой модели, вводят данные токенизированного предложения и пространства гипотез-слов и получают матрицу правдоподобий слов и исправлений в предложении, при помощи того же блока производят оценку правдоподобий исправлений, получают пространство сегментов-гипотез с оценками правдоподобий сегментов в контексте, возвращаются к помощи модуля генерации исправлений и производят оценку выигрышей сегментов-гипотез, получают вывод о правдоподобности, далее с помощью модуля принятия решений об исправлениях проходят по пространству оцененных гипотез слева-направо по предложению и принимают решение о внесении правки или сохранении состояния без правки, получают откорректированный текст. 2 н. и 2 з.п. ф-лы, 5 ил.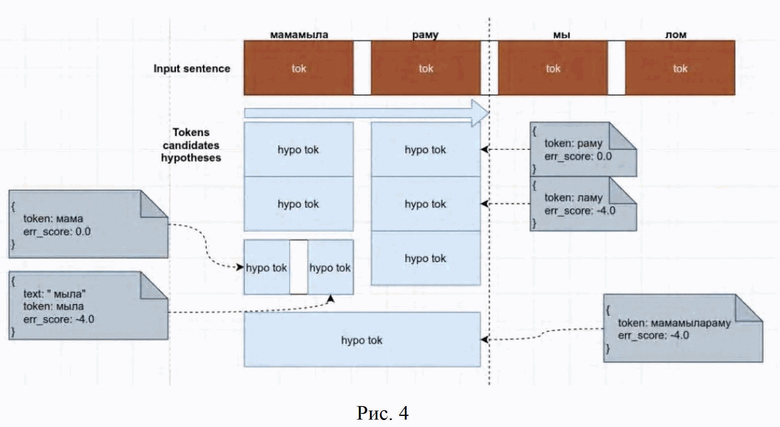
1. Система корректировки орфографических ошибок, характеризующаяся наличием модуля считывания и преобразования текста, отвечающего за токенизацию, изменение пунктуации, изменение регистра букв и блока языковой модели, производящего анализ предложений, отличающаяся тем, что содержит:
- модуль генерации исправлений, который на основе токенизированных предложений генерирует кандидаты слова, близкие по взвешенному расстоянию Левенштейна, и производит оценку выигрышей сегментов-гипотез,
- блок модели ошибок, который просчитывает вероятности исправления и инкрементирует штрафы за каждое исправление,
- модуль принятия решений, который оценивает наилучшую замену по данным от других модулей и блоков и осуществляет замену при положительном результате,
при этом модуль генерации исправлений взаимосвязан с блоком языковой модели, который в свою очередь взаимосвязан с блоком модели ошибок.
2. Система по п. 1, отличающаяся тем, что блок языковой модели выполнен с возможностью генерации матрицы правдоподобий слов и исправлений.
3. Система по п. 1, отличающаяся тем, что блок языковой модели выполнен на основе языковой модели ELMO.
4. Способ корректировки орфографических ошибок с помощью указанной по п. 1 формулы системы, включающий подготовительный этап по токенизации, уменьшению регистра букв и депунктуации, финальный этап по увеличению регистра букв и возвращению пунктуации, отличающийся тем, что через модуль генерации исправлений осуществляют считывание токенизированного предложения и, используя словарь языка и взвешенную метрику Левенштейна, находят кандидаты-исправления, которые образуют ранжированное пространство гипотез слов для корректировки, затем осуществляют анализ предложения с помощью блока языковой модели, вводят данные токенизированного предложения и пространства гипотез-слов и получают матрицу правдоподобий слов и исправлений в предложении, при помощи того же блока производят оценку правдоподобий исправлений, получают пространство сегментов-гипотез с оценками правдоподобий сегментов в контексте, возвращаются к помощи модуля генерации исправлений и производят оценку выигрышей сегментов-гипотез, получают вывод о правдоподобности, далее с помощью модуля принятия решений об исправлениях проходят по пространству оцененных гипотез слева-направо по предложению и принимают решение о внесении правки или сохранении состояния без правки, получают откорректированный текст.
| US 10115055 B2, 30.10.2018 | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| US 7047493 B1, 16.05.2006 | |||
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| US 9384389 B1, 05.07.2016 | |||
| US 9600469 B2, 21.03.2017 | |||
| US 9734234 B2, 15.08.2017 | |||
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |

