Область техники, к которой относится изобретение
Настоящее изобретение относится к способу записи слуховых вызванных потенциалов (Auditory Evoked Potential, AEP), в частности, стационарных слуховых реакций (Auditory Steady State Response, ASSR). Изобретение относится конкретно к способу записи слуховых вызванных потенциалов пациента (являющегося человеком). Изобретение также относится к системе обработки данных, содержащей процессор и средство программного кода, чтобы побуждать процессор выполнять, по меньшей мере, некоторые из этапов способа.
Изобретение дополнительно относится к системе записи слуховых вызванных потенциалов пациента и к ее использованию.
Варианты осуществления изобретения могут, например, быть полезны при таких применениях, как диагностические инструменты для проверки правильности настройки слухового устройства.
Уровень техники
Когда пациенту подают кратковременные звуковые сигналы, суммарная реакция множества дистанционно разнесенных нейронов в мозге может записываться с помощью неинвазивных электродов (например, прикрепленных к коже головы и/или расположенных в наружном слуховом проходе пациента). Эти слуховые вызванные потенциалы (AEP) могут записываться на всех уровнях слухового канала, например, от слухового нерва (суммарный биопотенциал, CAP); от ствола головного мозга (слуховая характеристика ствола головного мозга, ABR); до коры головного мозга (корковый слуховой вызванный потенциал, CAEP) и т. д. Эти классические AEP получают, подавая кратковременные акустические стимулы с малой частотой повторения. При более высоких частотах реакции на каждый стимул накладываются на реакции, вызванные предыдущим стимулом, чтобы сформировать стабильную реакцию (как определено в работе Picton и др., 1987). В ранних исследованиях такие стабильные слуховые реакции (ASSR) также вызывались синусоидально амплитудно модулированными (АМ) чистыми тонами. Благодаря тонотопической организации внутреннего уха (улитки внутреннего уха) и слуховому каналу, несущая частота для AM-тональных сигналов определяет область базилярной мембраны внутри улитки внутреннего уха, создающей вызванные реакции, которые следуют частоте модуляции. Таким образом, доказано, что ASSR является эффективным инструментом тестирования местоположений на различных частотах в пределах слухового канала. AM-тональные сигналы являются самыми простыми стимулами на конкретных частотах, используемыми для вызова ASSR, но они стимулируют только небольшое количество слуховых нервных волокон, приводя в результате к относительно малой амплитуде реакции. Эта малая реакция может проблематична для разрешающей способности реакции, поэтому были разработаны различные способы увеличения области стимуляции в улитке внутреннего уха, чтобы использовать больше слуховых нервных волокон и увеличить амплитуду реакции и, следовательно, улучшить обнаружение и точность реакции.
Документ WO2006003172A1 (US 8 591 433 B2) описывает конструкцию электрических или акустических стимулов на конкретных частотах для записи ASSR, как совокупность последовательности многочисленных спектральных компонент (то есть, чистых тонов), разработанную для оптимизации амплитуд реакции. Это было достигнуто предварительной компенсацией частотно-зависимой задержки, создаваемой внутренним ухом (улиткой внутреннего уха), чтобы получить в результате более синхронизированное возбуждение по частоте слухового нерва. Основная характеристика слуховой вызванной реакции состоит в том, что величина реакции зависит от количества слуховых единиц/нервных волокон, которые синхронно активируются стимулом (как определено в работе [Eggermont, 1977]). Компенсируя частотно-зависимую задержку улитки внутреннего уха и конкретно определяя величину и фазу каждой из многочисленных спектральных составляющих, можно создать периодически повторяющееся изменение по частоте или чирпированный сигнал. Частота повторения этой последовательности чирпированных сигналов определяется частотным промежутком между спектральными компонентами, используемыми при ее формировании, и ширина полосы управляется выбранным количеством компонент. Таким образом, может быть создан очень гибкий и эффективный стимул для записи ASSR (сравните, например, с работами [Elberling, 2005], [Elberling и др. 2007a], [Elberling и др. 2007b] и [Cebulla и др., 2007]).
Одним из главных преимуществ ASSR является возможность выполнения одновременных многополосных записей, то есть, подача многочисленных стимулов на различных несущих частотах на оба уха, причем с разными частотами повторения, и, следовательно, обнаружение и наблюдение этих потенциалов обычно делаются в частотной области. Создавая стимул периодическим, стимул и структура реакции в частотной области становятся четко определенными и, что существенно, предсказуемыми, и, таким образом, ASSR хорошо подходит для алгоритмов автоматического обнаружения, основанных на наборах гармоник частот повторения.
В настоящее время, ASSR в клинике и при исследованиях стимулируются, используя повторяющиеся последовательности широкополосных и узкополосных чирпированных сигналов, амплитудно-модулированные тональные сигналы, объединенные амплитудно- и частотно-модулированные тональные сигналы и последовательности щелчков и тональных пакетов. В результате очень успешных универсальных программ скрининга новорожденных во многих странах педиатрические аудиологи теперь обычно наблюдают пациентов в пределах первых нескольких недель после рождения [(Chang и др., 2012)]. Поэтому предпочтительно разработать протоколы настройки слухового устройства для юных младенцев, поскольку, чем раньше начнется вмешательство, тем лучше будут результаты. Таким образом, использование ASSR для оценки аудиометрического порога является быстрым способом продвижения вперед для использования с новорожденными, попадающими в программу скрининга. Определение порогов для этих пациентов через поведенческие средства очень ненадежно или невозможно, поэтому существует потребность в объективных физиологических способах. Для вычисления ожидаемой разности между физиологическими и поведенческими порогами на каждом звуковом уровне существует статистика регрессии. Точная оценка порога зависит от способности определения, существует ли малая реакция в присутствии остаточного фонового шума. В дополнение к младенцам, ASSR и объективные меры с трудом используются для тестирования взрослых, то есть, взрослых с серьезным умственными или физическими нарушениями.
При настройке слухового устройства для конкретногоу пользователя необходимо регулировать параметры, например, чтобы гарантировать, что коэффициент усиления установлен так, что речевой спектр усиливается в пределах динамического диапазона слуха пациента. При добросовестной практике проверка правильности такой настройки должна делаться, чтобы гарантировать, что она фактически имеет место. Это особенно важно для младенцев из-за их неспособности принимать участие в поведенческом тестировании и потому, что акустические свойства очень малых наружных слуховых проходов младенцев индивидуально существенно различны [Bagatto и др., 2002]. Следовательно, надежный объективный способ выполнения такой процедуры весьма важен. Все слуховые вызванные потенциалы звукового поля, такие как ABR, CAEP и ASSR, были предложены в качестве потенциальных способов проведения такой процедуры. Было показано, что ABR являются неприемлемыми, поскольку стимулы, используемые для вызывания реакции, обычно очень короткие (<10 мс) и процесс настройки слухового устройства искажает стимул, делая форму сигнала реакции трудной для интерпретации.
В настоящее время растет популярность CAEP для проверки настройки слухового устройства. В частности CAEP, вызванные кратковременными фонемами и речеподобными стимулами, обсуждаются для отражения нейронного кодирование речи и обеспечения объективного свидетельства, что усиленная речь была обнаружена. Для CAEP документированы недостатки, а именно, что на них сильно влияет внимание пациента, которым трудно управлять у младенцев. Кроме того, объективное обнаружение форм сигнала реакции является проблемным, поскольку формы сигнала/вызванные потенциалы значительно зависят от индивидуальных пациентов. Наконец, даже при том, что они более длительны по продолжительности, чем стимулы ABR, типичные стимулы для вызывания CAEP все же являются относительно короткими и, следовательно, подверженными тем же самым искажениям и недостаткам, которые описаны выше.
Раскрытие изобретения
Настоящее изобретение относится к области записи слуховых вызванных потенциалов (AEP) у людей-пациентов. Настоящее изобретение направлено на уменьшение, по меньшей мере, некоторых из недостатков решений предшествующего уровня техники. Конкретно, изобретение сосредоточено на новой технологии стимулирования стабильных слуховых реакций более речеподобным сигналом, содержащим вариации амплитуды во времени, которые подобны свободно произносимой речи.
Настоящее изобретение относится к созданию более речеподобного стимула ASSR, при этом все еще сохраняя его предпочтительные свойства. Оно может использоваться при проверке проверки правильности настройки слухового устройства с помощью описанного выше приложения, поскольку обходит некоторые из проблем, связанных с корковыми вызванными реакциями. Однако способ в равной степени может использоваться для записи реакции при выключенном устройстве, с преимуществом стимуляции слуховой системы сигналом, пригодным для оценки его способности обрабатывать речь.
В соответствии с предложениями [John & Picton (2004)], настоящее изобретение использует спектрально формируемые многополосные стимулы, чтобы иметь нормальный долговременный речевой спектр. Его наложение будет создаать низкочастотную амплитудную модуляцию, подобную огибающей, видимой при свободно произносимой речи (сравните, например, с [Plomp; 1984]). Для звуков, несущих информацию, такую как речь, большая часть информации переносится в изменениях стимула, а не в частях звукового сигнала, которые относительно устойчивы. Нормальная многополосная ASSR с различными отдельными несущими частотами или полосами для каждой полосы будет иметь разную частоту повторения. Это позволяет многополосное обнаружение реакции в частотной области. Разные частоты повторения и полосы, объединенные во временной области, будут давать в результате стимул, имеющий форму сигнала, которая будет меняться во времени. Настоящее изобретение предлагает дополнительно несколько способов применения низкочастотной амплитудной модуляции в диапазоне нормального модуляционного спектра речи (сравните, например, с [Plomp; 1984]... <20 Гц), чтобы сделать стимул более речеподобным, то есть, имеющим реалистичные флюктуации амплитуды, подобные свободно произносимой речи. [John & Picton, 2004] предложили применять широкополосную огибающую с величинами, подобными величинам реальной речевой огибающей. Однако, реальные речевые модуляции неодинаковы по всему частотному диапазону, как это ясно видно на спектрах конкретной речевой модуляции в полосе частот, представленных в работе [Holube и др., 2010]. Поэтому в настоящем изобретении предлагается применять независимые речевые огибающие к каждой из полос стимула, описанных выше. Дополнительно, предлагается использовать огибающие, оцениваемые непосредственно из реальной речи, для создания стимула, более схожего с реальной речью.
То, как слуховое устройство (HA) обрабатывает входящие слуховые стимулы, чрезвычайно важно, если желаемое применение заключается в использовании ASSR для проверки правильности настройки. HA является медицинским устройством, предназначенным для усиления входящих звуков, чтобы сделать их слышимыми для носящих их владельцев и улучшить для них разборчивость речи. Современные цифровые HA являются сложными нелинейными и нестабильными (зависящими от времени) устройствами, которые изменяют свое состояние или режим работы, основываясь на непрерывно продолжающейся оценке типа и характеристик подаваемого на них звука. Например, величина применяемого динамического усиления может зависеть от того, является ли стимулом речь, музыка, хаотический шум или динамические звуки окружающей среды, объективно оцениваемые в алгоритмах обработки сигналов HA. При проверке правильности применений настройки у младенцев и у трудных для тестирования пациентов (например, взрослых), мы интересуемся, главным образом, тем, программируются ли HA этих пациентов таким образом, что речь при нормальных уровнях прослушивания усиливается так, чтобы попадать в пределы звукового диапазона слушателя. Затем важно, чтобы любой новый стимул ASSR обрабатывался на HA способом, схожим с реальной свободно произносимой речью. В настоящем изобретении предлагается модифицировать стимулы ASSR, чтобы они были более схожими с речью, например, вводя соответствующие изменения амплитуды во времени. Измерения коэффициентов усиления вставки для различных HA может делаться согласно IEC 60118-15 (2012), чтобы подтвердить, что стимулы правильно обрабатываются речеподобным способом.
Точное место расположения нейрофизиологического генератора при ASSR является неопределенным, поскольку при возбуждении реагирует вся слуховая система. Изменение частот повторения многополосного стимула стимула ASSR смещает область слуховой системы, в которой доминирует мощность реакции, которая регистрируется на поверхности черепа. Стабильные слуховые реакции на частотах повторения <20 1/с, как полагают, преобладающе имеют корковое происхождение. Для частот >20 1/с обычно считается, что источником реакции являются кора головного мозга и ствол головного мозга, причем сила корковой деятельности уменьшается с увеличением частоты повторения. Выше приблизительно 50 Гц доминирующим источником реакции является ствол головного мозга. Специальное упоминание следует сделать в отношении частот вблизи 40 1/с, где реакции формируются как стволом головного мозга, так и первичными слуховыми корковыми и таламокортикальными схемами (сравните, например, с [Picton и др., 2003]; и [Kuwada и др., 2002]). На реакции в слуховом канале на частотах выше, чем обусловленные стволом головного мозга, влияют внимание и состояние активации. Также существует значительный эффект созревания корковых реакций - для новорожденных, имеющих за счет этого малую амплитуду ASSR на частоте 40 1/с. Однако, частоты в диапазоне примерно 70 1/с - 100 1/с создают устойчивые и длительные реакции, на которые не оказывают серьезного влияния состояние активации и, конечно, отсутствия внимания, эффекты созревания, относящиеся к нервной незрелости и экспериментальным изменениям в акустике наружного слухового прохода или среднего уха. Поэтому, изменяя частоту повторения, можно смещать расположение механизма формирования ASSR в различные места в слуховом проходе (то есть, от ствола головного мозга к коре головного мозга) в зависимости от того, что необходимо для рассматриваемого применения.
Предложенное здесь изменение стимула ASSR, представляет новый подход для получения речеподобного стимула. В вариантах осуществления изобретения информация о нейронном кодировании речевых побудителей может быть извлечена, сохраняя превосходную статистику обнаружения при записи ASSR.
Задача настоящего изобретения заключается в возбуждении слуховой системы сигналом, пригодным для оценки возможности слуховой системы обрабатывать речь. Дополнительная задача вариантов осуществления изобретения состоит в создании стимула для управления слуховым устройством речеподобным способом, чтобы объективно оценить способность слуха пользователя при ношении слухового устройства. Дополнительная задача вариантов осуществления изобретения состоит в создании стимула, который в дополнение к вышеупомянутым преимуществам позволяет одновременную оценку вспомогательной электрофизиологической реакции при нескольких различных уровнях речи. Эта информация может использоваться для управления изменениями установок усиления слухового устройства. В конечном счете, эта информация может использоваться при автоматизированной процедуре настройки слухового устройства.
Задачи приложения решаются изобретением, описанным в сопровождающей формуле изобретения и описанным далее.
Способ записи стабильных слуховых реакций
В одном варианте настоящего изобретения задача изобретения решается способом записи стабильных слуховых реакций пациента способом, содержащим этапы, на которых: a) обеспечивают акустический стимулирующий сигнал для уха пациента, b) записывают стабильные слуховые реакции пациента, происходящие за счет подачи упомянутого акустического стимулирующего сигнала. Способ обеспечивает присутствие речеподобного стимула в акустическом стимулирующем сигнале. Предпочтительно, способ содержит обеспечение речеподобного стимула в виде совокупности (например, суммы или взвешенной суммы) последовательности стимулов на конкретных частотах, каждый из которых имеет конкретную (например, заданную) ширину полосы частот, частоту повторения, амплитуду и амплитудную модуляцию.
Преимущество изобретения состоит в том, что оно позволяет клиническую оценку действия слухового устройства в нормальном режиме работы, то есть, при обработке речевых стимулов.
Задача настоящего изобретения состоит в обеспечении нового способа вызова ASSR, используя речеподобный стимул, сохраняя при этом преимущества традиционных подходов, где структура стимула и реакции в частотной области четко определены и предсказуемы. Это, например, достигается при использовании автоматических алгоритмов обнаружения или оценки амплитуды (мощности), основываясь на наборе гармоник частот повторения в пределах различных частотных диапазонов стимула (такие полосы частот в дальнейшем упоминаются как "полосы частот стимула").
В варианте осуществления способ содержит этапы, на которых
a1) проектируют электрический сигнал стимула, представляющий собой речеподобный сигнал;
a2) преобразуют упомянутый электрический сигнал стимула в акустический сигнал стимула;
a3) применяют упомянутый акустический сигнал к уху пациента.
Предпочтительно, применение акустического стимула к уху пациента выполняется в конфигурации свободного поля (от громкоговорителя, например, от направленного громкоговорителя, расположенного снаружи слухового прохода пациента). Альтернативно, акустический стимул может прикладываться к барабанной перепонке пациента (только) громкоговорителем слухового устройства, которое носят на ухе или внутри уха пользователя. В последнем случае стимулы могут передаваться в слуховое устройство или формироваться в слуховом устройстве.
В варианте осуществления способ содержит запись упомянутых слуховых вызыванных реакций пациента
- когда пациент носит слуховое устройство в ухе; а также,
- когда пациент не носит слуховое устройство в ухе.
Предполагается, что пациент имеет ухудшение слуха в одном или в обоих ушах и что слуховое устройство выполнено с возможностью компенсации ухудшения слуха уха пациента, имеющего такое ухудшение слуха.
Подразумевается, что слуховое устройство включено, когда подвергается воздействию акустического стимула. В варианте осуществления пациент имеет ухудшение слуха в одном или обоих ушах. Предпочтительно, слуховое устройство (например, слуховой аппарат) выполнено с возможностью компенсации ухудшения слуха этого уха пациента.
В варианте осуществления речеподобный стимул создается как электрический сигнал стимула, который преобразуется в акустический сигнал (например, электроакустическим преобразователем, типа вибропреобразователя или громкоговорителя). В варианте осуществления речеподобный стимул создается как акустический сигнал, состоящий из множества индивидуальных компонент акустического сигнала, которые в совокупности (например, при смешивании, например, посредством сложения) представляют речеподобный стимул.
В варианте осуществления способ выполнен с возможностью изменения частот повторения индивидуальных стимулов на конкретных частотах. В варианте осуществления способ выполнен с возможностью предоставления различных частот повторения индивидуальных стимулов на конкретных частотах и выбора их так, чтобы они были пригодны для записи слуховых вызванных реакций в ответ на многочисленные, одновременно действующие стимулы на конкретных частотах, и для получения реакций от соответствующих структур слухового канала. Выбирая различные частоты повторения для различных полос частот стимула (например, шириной в одну октаву) можно одновременно тестировать различные частотные области слуховой системы. Спектр реакции ASSR в одиночной полосе содержит ряд гармоник на кратных частотах повторения. Таким образом, если многочисленные полосы будут представляться одновременно, но каждая полоса частот будет иметь свою собственную уникальную частоту повторения, то физиологическая вызванная реакция будет содержать ряд многочисленных гармоник, но, что важно, на индивидуальных частотах. Это позволит разделить реакции, полученные в разных полосах.
В варианте осуществления способа объединенный амплитудный спектр индивидуальных стимулов на конкретных частотах соответствует долговременному амплитудному спектру нормальной речи. В варианте осуществления объединенный амплитудный спектр является совокупностью множества (например, трех или более, таких как четыре или более или восемь или более) индивидуальных стимулов на конкретных частотах. В варианте осуществления каждый из стимулов на конкретных частотах (например, четыре чирч-стимула шириной в одну октаву, например, [Elberling и др., 2007b]) взвешивается таким образом, что общий широкополосный стимул имеет долговременный спектр, приближающийся к спектру нормальной речи.
В варианте осуществления способ содержит случай, когда любой из совокупных широкополосных индивидуальных стимулов на конкретных частотах или индивидуальные стимулы на конкретных частотах являются амплитудно-модулированными в соответствии с низкочастотной модуляцией, происходящей в нормальной речи. В варианте осуществления низкочастотная амплитудная модуляция, присущая свободно произносимой речи, применяется к сформированному широкополосному ASSR-стимулу речевого спектра. Низкочастотная амплитудная модуляция и долговременный речевой спектр предпочтительно гарантируют, что слуховые устройства будут обрабатывать объединенный стимул способом, подобным свободно произносимой речи. В варианте осуществления термин "низкочастотная модуляция, происходящая в нормальной речи" применяется, например, для обозначения результирующего стимула, имеющего модуляционный спектр, сравнимый с нормальной речью, например, с максимумом на частоте приблизительно 4 Гц при измерении в полосе 1/октавы (сравните, например, с [Plomp, 1984]). В варианте осуществления "низкочастотная модуляция, происходящая в нормальной речи", например, применяется для обозначения огибающей, определенный из реально произносимого речевого сигнала или искусственного речевого сигнала, такого, как ISTS (Holube и др., 2010).
В варианте осуществления способ обеспечивает соответствие долгосрочного амплитудного спектра и низкочастотной амплитудной модуляции индивидуальных стимулов на конкретных частотах, соответствующей речи, произносимой с определенной силой звука. В варианте осуществления примеры речи, произносимой с определенной силой звука, представляются как тихая, нормальная, повышенная и крик. В варианте осуществления объединенный широкополосный стимул, имеющий долговременный усредненный спектр, обеспечивается на уровнях, определенных с точки зрения конкретной силы звука согласно ANSI S3.5. (1997). Это выгодно для клинических применений, предназначенных для тестирования на стандартизированных речевых уровнях.
В варианте осуществления способ обеспечивает индивидуальный стимул на конкретных частотах, состоящий из чирпированных сигналов с ограниченной полосой. В варианте осуществления индивидуальные чирпированные сигналы на конкретных частотах имеют ширину спектра в одну октаву. В варианте осуществления индивидуальные чирпированные сигналы выполнены с возможностью перекрытия частотного диапазона, важного для разборчивости речи, например, адаптируясь к конкретному пациенту, например, перекрытие диапазона частот между 200 Гц и 8 кГц, например, диапазона приблизительно между 350 Гц и 5600 Гц. В варианте осуществления стимул на конкретных частотах состоит из четырех чирпированных сигналов шириной в одну октаву, имеющих центральные частоты 500, 1000, 2000 и 4000 Гц (определяющие четыре полосы частот стимула), соответственно, перекрывающие, таким образом, частотный диапазон приблизительно от 350 Гц до 5600 Гц. В варианте осуществления способ обеспечивает, что индивидуальные стимулы на конкретных частотах являются независимо амплитудно модулированными огибающей, представляющей модуляции речевым сигналом в конкретной полосе. В варианте осуществления модуляции речевым сигналом в конкретной полосе могут определяться из реального речевого сигнала или искусственного речевого сигнала, отфильтрованного полосовым фильтром с полосами частот, соответствующими полосам частот стимула, описанным выше, и где речевые огибающие определяются независимо для каждой полосы.
В варианте осуществления способ обеспечивает квантование по времени и/или по уровню наложенной речеподобной модуляции. Применение речеподобных амплитудных модуляций к повторяющимся стимулам ASSR означает, что индивидуальные повторения основного стимула будут представлены на множестве разных уровней. Это может активно использоваться для выполнения оценки ASSR, соответствующей нескольким различным уровням стимула одновременно, на основе одного проводимого измерения. Это, однако, кардинально зависит от возможности сортировки входящих блоков записи ("длительности периодов") результата измерения ASSR в различных "уровневых накопителях", соответствующих различным уровням стимула. Понятно, что дополнительные преимущества могут быть получены при следующем:
1. Квантование (конкретная полоса частот) по времени коэффициентов усиления огибающей, чтобы сделать их постоянными для каждого периода для минимизации временного искажения индивидуальных стимулов (или минимизации размывания спектра в частотной области).
2. Квантование коэффициентов усиления огибающей для получения конкретных желаемых уровней стимула.
Квантование модуляций по уровню может, например, соответствовать уровням Leq+10 дБ, Leq, Leq - 10 дБ, и Leq - 20 дБ, где Leq является долговременным средним уровнем (потенциально отфильтрованным полосовым фильтром) речевого сигнала, используемого для создания огибающей. Таким образом, квантование модуляций по времени, а также по уровням, вместе с соответствующей сортировкой периодов измеренных реакций на этапе обнаружения способа ASSR позволяет одновременно оценивать электрофизиологическую реакцию на конкретные части речевого сигнала с точки зрения уровня, например, "громкий"(Leq+10 дБ), "средний"(Leq), "тихий" (Leq - 10 дБ) и "очень тихий"(Leq - 20 дБ).
В варианте осуществления способ обеспечивает, что квантованный по уровню стимул, который приводит к оценкам электрофизиологической реакции на речь на нескольких различных уровнях, используется для автоматизированной настройки слухового устройства. Это достигается автоматическим увеличением усиления слухового устройства в частотных диапазонах, где электрофизиологическая реакция ниже нормативных значений, и наоборот.
В варианте осуществления способ обеспечивает, что запись упомянутых слуховых вызванных реакций содержит запись стабильных слуховых реакций, ASSR.
Способ проектирования стимулов
В варианте обеспечивается способ проектирования стимулов для системы ASSR. Способ содержит этапы, на которых:
- определяют множество различных стимулов на конкретных частотах, каждый из которых имеет конкретную частоту или центральную частоту и полосу (и располагается в различных полосах частот стимулов);
- определяют индивидуальную частоту повторения для каждого из множества различных стимулов на конкретных частотах;
- спектрально формируют амплитудный спектр каждого из множества различных стимулов на конкретных частотах, чтобы обеспечить сформированные по частоте стимулы на конкретных частотах;
- модулируют по амплитуде каждый из спектрально сформированных стимулов на конкретных частотах или объединенный широкополосный сигнал реальной или с моделированной огибающей текущей речи;
- объединяют спектрально сформированные стимулы на конкретных частотах, чтобы обеспечить объединенный широкополосный сигнал;
где спектральное формирование амплитудного спектра каждого из множества различных стимулов на конкретных частотах выполнено с возможностью обеспечения соответствия объединенного сигнала долговременному спектру текущей речи, произносимой с определенной силой звука.
Подразумевается, что некоторые или все признаки процесса способа записи слуховых вызванных реакций, описанных выше в разделе "Осуществление изобретения" или в формуле изобретения, при необходимости могут быть объединены с вариантами осуществления способа проектирования стимулов для системы ASSR и наоборот.
В варианте осуществления способ содержит квантование амплитудных модуляций по времени и/или по уровню.
В варианте осуществления количество стимулов на конкретных частотах больше или равно двум, как например, больше трех, например, равно четырем. В варианте осуществления количество и частоты или центральные частоты стимулов на конкретных частотах адаптируются таким образом, чтобы перекрыть заданный диапазон частот, например, диапазон работы определенного слухового устройства или диапазон частот, важный для разборчивости речи, например, часть диапазона частот между 20 Гц и 8 кГц, например, между 250 Гц и 6 кГц.
В варианте осуществления способ содержит применение независимых речевых огибающих к каждой из полос частот стимула. Другими словами, способ содержит извлечение речеподобной огибающей независимо для различных полос частот стимула.
В варианте осуществления способ содержит выполнение результирующего объединенного сигнала, содержащего речеподобный стимул, с возможностью гарантии, что слуховой устройство входит в речевой режим работы (например, программа, специально адаптированная для обработки речи), одновременно позволяя измерение ASSR, когда речеподобные стимулы принимаются слуховым устройством.
Система стимуляции
В варианте обеспечивается система стимуляции для проектирования и формирования стимулов для системы ASSR. Система стимуляции содержит:
- генератор стимуляции для формирования множества различных стимулов на конкретных частотах, каждый из которых имеет конкретную частоту или центральную частоту и полосу частот, и (генератор стимуляции) выполнен с возможностью применения индивидуальной частоты повторения к каждому из множества различных стимулов с конкретными частотами;
- блок формирования спектра для спектрального формирования амплитуд каждого из множества различных стимулов с конкретными частотами;
- блок объединения для объединения спектрально сформированных стимулов с конкретными частотами для обеспечения объединенного широкополосного сигнала;
- блок амплитудной модуляции для модуляции амплитуды каждого из спектрально сформированных стмулов с конкретными частотами или объединенного широкополосного сигнала с реальной или моделированной огибающей текущей речи; и
в которой формирование спектра амплитуд каждого из множества различных стимулов с конкретными частотами выполнено с возможностью обеспечения соответствия объединенного сигнала долговременному спектру текущей речи, произносимой с определенной силой звука.
Подразумевается, что некоторые или все признаки процесса способа проектирования стимулов для системы ASSR, описанной выше в разделе "Осуществление изобретения" или в формуле изобретения, могут при необходимости объединяться с вариантами осуществления системы проектирования стимулов для системы ASSR и наоборот.
В варианте осуществления система стимуляции содержит блок квантования модуляций амплитуды по времени и/или по уровню:
В варианте осуществления система стимуляции выполнена с возможностью применения независимых речевых огибающих к каждой из полос частот стимула (полос стимуляции, содержащих стимул с конкретной частотой).
В варианте осуществления система стимуляции адаптируется, чтобы обеспечить, что результирующий объединенный сигнал, содержащий речеподобные стимулы, выполнен с возможностью гарантии, что слуховое устройство включает речевой режим работы (например, программу, специально адаптированную для обработки речи), позволяя в то же время измерение ASSR, когда речеподобные стимулы принимаются слуховым устройством.
Система обработки данных
В одном варианте настоящего изобретения дополнительно обеспечивается система обработки данных, содержащая процессор и средство программного кода, чтобы побуждать процессор выполнять, по меньшей мере, некоторые (как пример, большинство или все) этапы способа, описанного выше в разделе "Осуществление изобретения" и в формуле изобретения.
Считываемый компьютером носитель
В одном варианте настоящего изобретения дополнительно обеспечивается материальный машиночитаемый носитель, хранящий компьютерную программу, содержащую средство программного кода, чтобы побуждать систему обработки данных выполнять, по меньшей мере, некоторые (как пример, большинство или все) этапы способа, описанного выше в разделе "Осуществление изобретения" и в формуле изобретения, когда упомянутая компьютерная программа выполняется в системе обработки данных.
Диагностическая система
В одном варианте настоящего изобретения дополнительно обеспечивается диагностическая система для записи стабильных слуховых реакций пациента, причем система содержит блок стимуляции для обеспечения акустического сигнала стимула для уха пациента и блок записи для записи стабильных слуховых реакций пациента, возникающих под действием упомянутого акустического сигнала стимула. Блок стимуляции выполнен с возможностью обеспечения присутствия в акустическом сигнале речеподобного стимула. Речеподобный стимул предпочтительно обеспечивается как комбинация последовательностей стимулов на конкретных частотах, каждый из которых имеет конкретные (например, заданные) ширину полосы, частоту повторения, амплитуду и амплитудную модуляцию и, возможно, квантован по времени и/или по уровню.
Подразумевается, что некоторые или все признаки процесса способа, описанного выше в разделе "Осуществление изобретения" или в формуле изобретения, могут объединяться с вариантами осуществления диагностической системы, когда должным образом заменяются соответствующим структурным признаком, и наоборот. Варианты осуществления диагностической системы имееют те же самые преимущества, что и соответствующие способы.
В варианте осуществления блок стимуляции содержит:
- генератор стимуляции для формирования множества различных стимулов на конкретных частотах, каждый из которых имеет конкретную частоту или центральную частоту и полосу частот (которые располагаются в различных полосах частот стимула) и выполнен с возможностью применения индивидуальной частоты повторения к каждому из различных стимулов на конкретных частотах;
- блок формирования спектра для спектрального формирования амплитудного спектра каждого из различных стимулов с конкретными частотами, чтобы обеспечить спектрально сформированные стимулы на конкретных частотах;
- блок объединения для объединения спектрально сформированных стимулов на конкретных частотах для обеспечения объединенного широкополосного сигнала;
- блок амплитудной модуляции для амплитудной модуляции каждого из спектрально сформированных стимулов с конкретными частотами или объединенного широкополосного сигнала с реальной или моделированной огибающей текущей речи, чтобы обеспечить упомянутый речеподобный стимул; и
в котором формирование спектра для амплитудного спектра каждого из различных стимулов с конкретной частотой выполняется с возможностью обеспечения соответствия объединенного сигнала долговременному спектру текущей речи, произносимой с определенной силой звука.
В варианте осуществления блок стимуляции содержит блок квантования амплитудных модуляций.
В варианте осуществления блок стимуляции выполнен с возможностью примения независимых речевых огибающих к каждой из полос частот стимула.
В варианте осуществления блок объединения содержит или состоит из блока суммирования для сложения индивидуальных спектрально сформированных символов (с ограниченной полосой) на конкретных частотах, чтобы обеспечить объединенный широкополосный сигнал. В варианте осуществления блок объединения содержит или состоит из блока суммирования.
В варианте осуществления диагностическая система выполнена с возможностью записи слуховых вызванных реакций (например, ASSR) пациента:
- когда пациент носит слуховое устройство в ухе; а также,
- когда пациент не носит слуховое устройство в ухе.
Объединенная система
Как вариант, в разделе "Осуществление изобретения" и в формуле изобретения дополнительно обеспечивается система объединения, содержащая диагностическую систему, описанную выше, и слуховое устройство для компенсации ухудшения слуха пользователя.
В варианте осуществления слуховое устройство выполнено с возможностью обеспечения частотно-зависимого коэффициента усиления и/или коэффициента усиления, зависящего от уровня сжатия и/или переноса (со сжатием или без сжатия спектра) одного или более частотных диапазонов в один или более другие частотные диапазоны, чтобы, например, компенсировать ухудшение слуха пользователя. В варианте осуществления слуховое устройство содержит блок обработки сигналов для улучшения входных сигналов и обеспечения обработанного выходного сигнала. Предпочтительно, слуховое устройство выполнено с возможностью, по меньшей мере, в определенном режиме работы, улучшения разборчивость речи для пользователя.
В варианте осуществления объединенная система выполнена с возможностью гарантии, что слуховое устройство включается в речевой режим работы (например, посредством программы, специально приспособленной для обработки речи), одновременно позволяя измерение ASSR, когда слуховым устройством принимаются речеподобные стимулы, соответствующие настоящему изобретению.
Применение
Как вариант, в разделе "Осуществление изобретения" и в формуле изобретения, помимо прочего, представляется применение описанной выше диагностической системы. В варианте осуществления обеспечивается применение диагностической системы для подтверждения правильности настройки слухового устройства. В варианте осуществления обеспечивается использование диагностической системы для записи ASSR на пациенте, носящем слуховое устройство (выполненное с возможностью компенсации ухудшения слуха у пациента) (включенное измерение). В варианте осуществления обеспечивается использование диагностической системы записи ASSR на пациенте, не носящем слуховое устройство (выключенное измерение).
Слуховое устройство
Как вариант, дополнительно обеспечивается слуховое устройство. Слуховое устройство содержит входное устройство и выходной преобразователь. Слуховое устройство выполнено с возможностью приема или формирования различных стимулов на конкретных частотах, сформированных так, как это определено способом проектирования стимулов для системы ASSR, описанным в разделе "Осуществление изобретения" или в формуле изобретения. Слуховое устройство дополнительно выполнено с возможностью подачи различных стимулов на конкретных частотах в качестве акустического стимула через упомянутый выходной преобразователь слухового устройства.
В варианте осуществления слуховое устройство выполнено с возможностью включения речевого режима работы (например, программы, конкретно адаптированной для обработки речи), одновременно позволяя измерение ASSR, когда слуховое устройство принимает речеподобные стимулы, соответствующие настоящему изобретению. Таким образом обеспечивается, что стимулы, когда подаются пользователю, были обработаны слуховым устройством таким же способом, которым обрабатываются обычные речевые сигналы. Записанные сигналы, вызванные стимулами, таким образом, представляют восприятие пользователем речи.
В варианте осуществления слуховое устройство содержит или состоит из слухового устройства.
В варианте осуществления входное устройство слухового устройства содержит один или более микрофонов для восприятия звука окружающей среды, в том числе, например, акустического стимула от громкоговорителя диагностической системы, соответствующей настоящему изобретению. В варианте осуществления слуховое устройство выполнено с возможностью приема различных стимулов на конкретных частотах от диагностической системы через радиолинию. В варианте осуществления слуховое устройство содержит комбинированный блок объединения, позволяющий подавать пользователю различные стимулы на конкретных частотах через выходной преобразователь (например, громкоговоритель), в одиночку или в комбинации с электрическими звуковыми сигналами, воспринимаемыми или принимаемыми входным устройством.
Определения
Термин "речеподобный сигнал" или "речеподобные стимулы" в настоящем контексте представляется как означающий сигнал (или стимул), имеющий долговременный спектр и амплитудные вариации во времени, подобные свободно произносимой речи (как например, определено в стандарте IEC 60118-15. (2012)). Предпочтительно, речеподобный сигнал (или стимул) выполняется с возможностью демонстрации флюктуаций уровня (низкочастотные амплитудные модуляции) с динамическим диапазоном во времени в свободном поле, соответствующем речи, как например, определено в стандарте IEC60118-15 (например, при анализе в полосе 1/3 октавы).
В настоящем контексте "слуховое устройство" относится к устройству, такому, как например, слуховой инструмент или активное устройство для защиты ушей, или к другому устройству аудиообработки, выполненному с возможностью улучшения, усиления и/или защиты способности пользователя слушать, принимая акустические сигналы из окружающей среды пользователя, формируя соответствующие аудиосигналы, возможно, модифицируя аудиосигналы и подавая возможно модифицированные аудиосигналы в качестве звуковых сигналов, по меньшей мере, одному уху пользователя. "Слуховое устройство" дополнительно относится к такому устройству, как наушник или гарнитура, выполненному с возможностью электронного приема аудиосигналов, возможно модифицируя аудиосигналы и подавая возможно модифицированные аудиосигналы в качестве звуковых сигналов, по меньшей мере, одному уху пользователя. Такие звуковые сигналы могут подаваться, например, в форме акустических сигналов, излучаемых извне в уши пользователя, акустических сигналов, передаваемых в виде механических вибраций внутрь ушей пользователя через структуру кости головы пользователя и/или через части среднего уха, а также электрических сигналов, передаваемых прямо или косвенно кохлеарному нерву пользователя.
Слуховое устройство может быть выполнено с возможностью ношения любым известным способом, например, в виде блока, расположенного за ухом с трубкой, направляющей излученные акустические сигналы в наружный слуховой проход, или с громкоговорителем, расположенным вблизи или внутри наружного слухового прохода, в виде блока, полностью или частично расположенного в ушной раковине и/или в наружном слуховом проходе, в виде блока, прикрепленного к приспособлению, имплантированному в кость черепа, в виде полностью или частично имплантированного блока и т. д. Слуховое устройство может содержать единый блок или несколько блоков, электронно сообщающихся друг с другом.
В более широком смысле, слуховое устройство содержит входной преобразователь для приема акустического сигнала из среды пользователя и подачи соответствующего входного аудиосигнала и/или принятого сигнала для электронного (то есть, проводного или беспроводного) приема входного аудиосигнала, схему обработки сигналов для обработки входного аудиосигнала и средство вывода для подачи звукового сигнала пользователю в зависимости от обработанного аудиосигнала. В некоторых слуховых устройствах схема обработки сигнала может быть представлена усилителем. В некоторых слуховых устройствах средство вывода может содержать выходной преобразователь, такой как, например, громкоговоритель для обеспечения акустического сигнала воздушной проводимости или вибропреобразователь для обеспечения акустического сигнала костной проводимости или жидкостной проводимости. В некоторых слуховых устройствах средство вывода может содержать один или более выходных электродов для подачи электрических сигналов.
В некоторых слуховых устройствах вибропреобразователь может быть выполнен с возможностью подачи акустического сигнала костной проводимости чрескожно или подкожным образом к кости черепа. В некоторых слуховых устройствах вибропреобразователь может имплантироваться в среднее ухо и/или во внутреннее ухо. В некоторых слуховых устройствах вибропреобразователь может быть выполнен с возможностью подачи проводимого костной структурой акустического сигнала к кости среднего уха и/или к ушной улитке. В некоторых слуховых устройствах вибропреобразователь может быть выполнен с возможностью подачи проводимого текучей средой акустического сигнала в кохлеарную жидкость, например, через овальное окно. В некоторых слуховых устройствах выходные электроды могут имплантироваться в ушную улитку или во внутреннюю часть кости черепа и могут быть выполнены с возможностью подачи электрических сигналов к волосковым сенсорным клеткам ушной улитки, к одному или более слуховым нервам, к слуховой зоне коры головного мозга и/или к другим частям коры головного мозга.
Краткое описание чертежей
Варианты изобретения могут наилучшим образом стать понятны из последующего подробного описания, рассматриваемого в сочетании с сопроводительными чертежами. Чертежи являются схематическими и упрощенными для ясности и они показывают только те подробности, которые улучшают понимание пунктов формулы изобретения, тогда как другие подробности не показываются. Повсеместно одни и те же ссылочные позиции используются для идентичных или соответствующих частей. Индивидуальные признаки каждого варианта могут объединяться с любыми признаками других вариантов. Эти и другие варианты, признаки и/или технический эффект должны быть очевидны из приведенного подробного описания, сделанного со ссылкой на чертежи, описанные здесь далее, на которых:
Фиг. 1A - вариант осуществления способа формирования сигнала речеподобного стимула, и фиг. 1B - вариант осуществления диагностической системы для записи слухового вызыванного потенциала в соответствии с настоящим изобретением,
Фиг. 2A, 2B, 2C, 2-D, 2E, 2F - примерные компоненты индивидуальных сигналов, из которых формируют результирующий сигнал речеподобного стимула, показанный на фиг. 2G, соответствующий настоящему изобретению,
Фиг. 3 - пример способа по стандарту IEC60118-15, (2012), для определения коэффициента усиление вставки слухового устройства и соответствующий динамический диапазон уровня для речеподобных стимулов,
Фиг. 4A и 4B - две примерные настройки диагностической системы для того, чтобы (вместе) проверить настройку слухового устройства, на фиг. 4A показано измерение AEP, где пользователь носит слуховое устройство в нормальном режиме (включено), и на фиг. 4B показано измерения AEP, где пользователь не носит (выключено) слуховое устройство, стимуляция при обеих настройках обеспечивается посредством громкоговорителя диагностической системы,
Фиг. 5A - вариант осуществления диагностической системы, и
Фиг. 5B - вариант осуществления диагностической системы, стимулирующей слуховое устройство при его ношении пациентом, стимуляция обеспечивается громкоговорителем диагностической системы,
Фиг. 6A - вариант осуществления блока стимуляции, соответствующего настоящему изобретению,
Фиг. 6B - пример коэффициентов усиления огибающей стимула, квантованной по времени и по уровню,
Фиг. 7A - первый сценарий измерения AEP, где пользователь носит слуховое устройство в нормальном режиме (включено) и где стимулы подаются на слуховое устройство для воспроизведения пользователю через громкоговоритель слухового устройства,
Фиг. 7B - второй сценарий измерения AEP, где пользователь носит слуховое устройство в нормальном режиме (включено) и где стимулы подаются на слуховое устройство для воспроизведения пользователю через громкоговоритель слухового устройства,
Фиг. 7C - третий сценарий измерения AEP, где пользователь носит первое и второе слуховые устройства биноуральной слуховой системы в нормальном режиме (включено) и где стимулы подаются на слуховые устройства для воспроизведения левому и правому ушам пользователя через громкоговорители слухового устройства.
Фиг. 8 - вариант осуществления диагностической системы, стимулирующей слуховое устройство при его ношении пациентом, в котором стимуляция обеспечивается через громкоговоритель слухового устройства.
Фиг. 9 - блок-схема последовательности выполнения операций способа проектирования стимулов для системы AEP, например, для системы ASSR.
Осуществление изобретения
Подробное описание, изложенное ниже в сочетании с приложенными чертежами, предназначено служить описанием различных конфигураций. Подробное описание содержит конкретные детали с целью обеспечения полного понимания различных концепций. Однако, специалистам в данной области техники должно быть очевидно, что эти концепции на практике могут реализовываться без этих конкретных деталей. Несколько вариантов устройств и способов описываются с помощью различных блоков, функциональных блоков, модулей, компонент, схем, этапов, процессов, алгоритмов и т. д. (все вместе называемые "элементы"). В зависимости от конкретного применения, конструктивных ограничений или других причин, эти элементы могут реализовываться, используя электронное аппаратурное обеспечение, компьютерную программу или любую их комбинацию.
Электронное аппаратурное обеспечение может содержать микропроцессоры, микроконтроллеры, цифровые сигнальные процессоры (DSP), программируемые логические интегральные схемы (FPGA), программируемые логические устройства (PLD), вентильную логику, дискретные аппаратурные схемы и другое соответствующее аппаратное обеспечение, выполненное с возможностью обеспечения различных функциональных возможностей, описанных в ходе этого раскрытия. Термин "компьютерная программа" должен истолковываться широко, чтобы означать команды, наборы команд, код, кодовые сегменты, управляющую программу, программы, подпрограммы, программные модули, приложения, программные приложения, пакеты программного обеспечения, стандартные программы, стандартные подпрограммы, объекты, исполнимые программы, потоки управления, процедуры, функции и т. д., независимо от того, относятся ли они к программному обеспечению, встроенному микропрограммному обеспечению, промежуточному программному обеспечению, микрокоду, языку описания аппаратурного обеспечения или чему-либо иному.
На фиг. 1A показан вариант осуществления способа формирования сигнала речеподобного стимула. На фиг. 1B показан вариант осуществления диагностической системы для записи слухового вызванного потенциала, соответствующей настоящему изобретению.
На фиг. 1A показан принцип и предпочтительный вариант осуществления формирования стимула в настоящем раскрытии. На левой стороне (блок "Чирпированные сигналы с шириной полосы в октаву"), в качестве примера, показаны четыре чирпированные сигнала с шириной полосы в октаву, сформированные на центральных частотах 500, 1000, 2000 и 4000 Гц. Стимулы подаются с разными частотами стимуляции (смотрите, например, фиг. 2A, 2B, 2C, 2D) и могут использоваться для одновременной стимуляции ASSR на множестве конкретных частот (сравните, например, с документом WO2006003172A1, [Elberling и др., 2007b]. Четыре чирпированные сигнала являются следующими (сравните с блоком "Формирование спектра"), спектрально сформированными таким образом, что амплитудный спектр объединенного сигнала соответствует долговременному спектру текущей речи, произносимой с определенной силой звука (здесь, в качестве примера, сила звука является "нормальной" - ANSI S3.5. (1997)).
Затем (сравните с блоком "Модуляция") объединенный и спектрально сформированный сигнал вводится в амплитудный модулятор, который модулирует либо каждый из стимулов с ограниченной полосой, либо объединенный широкополосный сигнал реальной или моделированной огибающей текущей речи (сравните, например, Plomp, 1984). Наконец (сравните с этапом "Моделированный речевой сигнал") моделированный речевой сигнал подается на преобразователь стимула (здесь, в качестве примера показан громкоговоритель) с требуемым уровнем подачи.
На фиг. 1A ссылки сделаны на подробные временные формы сигнала, показанные на фиг. 2A-2G.
На фиг. 1A схематично показан вариант осуществления стимулирующей части (представленной на фиг. 1B как STU и OT) диагностической системы. На фиг. 1B схематично показан вариант осуществления диагностической системы (DMS), содержащей блок стимуляции (STU), выходной преобразователь (OT) и блок записи (REC), соединенные с множеством электродов записи (rec-elec). Фиг. 1B дополнительно содержит пользователя (U), носящего слуховое устройство (HD) в первом ухе (1st ear) и ушную пробку (plug) во втором ухе (2nd ear). На фиг. 1B показано "свободное поле", вспомогательное при измерении с помощью диагностической системы, соответствующей настоящему изобретению. Слуховое устройство выполнено с возможностью восприятия звука от окружающей среды, чтобы обеспечить электрический входной сигнал, и содержит блок обработки сигналов для обеспечения улучшенного сигнала, применяя к входному сигналу зависящий от уровня и от частоты коэффициент усиления, чтобы компенсировать ухудшение слуха первого уха пользователя, и выходной блок, чтобы подать улучшенный сигнал в качестве выходного стимула, воспринимаемого пользователем как звук. Ушная пробка (plug) выполнена с возможностью блокирования прохождения звука во второе ухо на нейроны, вызывающие реакцию в слуховой системе. Когда электрические стимулы (stim), сформированные блоком стимуляции (STU) и преобразованные в акустические стимулы (ac-stim) выводятся через выходной преобразователь (OT), акустические стимулы (ac-stim) воспринимаются входным преобразователем слухового устройства (HD) в первом ухе (1st ear) пользователя (U), обрабатываются блоком обработки сигналов и подаются в слуховую систему (Auditory system) пользователя через выходной блок слухового устройства. Стимулы от выходного блока слухового устройства вызывают реакции (aep) слуховой системы (слуховая система). Вызванные реакции (aep) записываются блоком записи (REC) через записывающие электроды (rec-el), смонтированный на голове пользователя (HEAD), например, прикрепляются к коже и/или к ткани скальпа или к наружному слуховому проходу пользователя. Блоки записи (REC) и стимуляции (СТУ) соединены (сравните, прохождение сигнала), например, чтобы управлять временными соотношениями между формированием стимулов блоком стимуляции и обнаружением и обработкой вызванных реакций (ASSR) блоком записи.
На фиг. 2A, 2B, 2C, 2D, 2E, 2F показаны примерные компоненты индивидуальных сигналов, из которых формируется сигнал результирующий речеподобного стимула (как показано на фиг. 2G).
На фиг. 2A-2G показаны подробности временных сигналов на различных этапах варианта осуществления предложенного изобретения. Сверху вниз: сначала показаны четыре стимула на конкретных частотах, используя масштаб времени 100 мс (фиг. 2A-2D). Разные частоты стимуляции указываются слева и, в качестве примера, варьируются от 84,0 1/с до 90,6 1/с. На фиг. 2A показывает узкополосный чирпированный сигнал на частоте 500 Гц с частотой повторения 86,0 Гц. На фиг. 2B показан узкополосный чирпированный сигнал на частоте 1000 Гц с растотой стимуляции 90,6 Гц. На фиг. 2C показан узкополосный чирпированный сигнал на частоте 2000 Гц с частотой стимуляции 84,0 Гц. На фиг. 2D показан узкополосный чирпированный сигнал на частоте 4000 Гц с частотой стимуляции 88,6 Гц. Каждый из узкополосных чирпированных сигналов формируется соответствующей фильтрацией (полосовым фильтром с шириной полосы в 1 октаву) широкополосного линейного чирпированного сигнала на частотах между минимальной частотой (например, 350 Гц) и максимальной частотой (например, 11,3 кГц) (сравните, Elberling & Don, 2010). Спектрально сформированный объединенный широкополосный сигнал показан на фиг. 2E как "Сумма взвешенных чирпированных сигналов ". На фиг. 2A-2G четыре стимула на конкретных частотах, каждый из которых содержит периодически повторяющийся (с шириной полосы в одну октаву) узкополосный чирпированный сигнал, используются для формирования объединенного широкополосного сигнала. Альтернативно, может использоваться другое количество узкополосных чирпированных сигналов, например, 12 узкополосных чирпированных сигналов (с шириной полосы в 1/3 октавы), перекрывающих тот же самый частотный диапазон от приблизительно 350 Гц до приблизительно 5600 Гц.
Затем, используя масштаб времени 10 с, на фиг. 2F показан пример "Моделированная речевая огибающая" и, наконец, соответствующий модулированный выходной сигнал показан как "Моделированный речевой сигнал" на фиг. 2G. Моделированная речевая огибающая на фиг. 2E формируется, например, как огибающая примерной свободно произносимой речи.
На фиг. 3 согласно стандарту IEC60118-15, (2012) показан пример способа определения коэффициента усиления вставки слухового устройства и соответствующий динамический диапазон уровня для речеподобных стимулов.
На фиг. 3 приводится взятый из стандарта IEC60118-15, (2012), пример способа определения коэффициента усиления вставки слухового устройства и соответствующий динамический диапазон уровня (дБ SPL) относительно частоты (Гц)) для речеподобных стимулов. На левой стороне чертежа (обозначенной как "Выключено") показано изменение уровня стандартизированного речевого тестового стимула (Holube и др., 2010), записанного в тестовом поле слухового устройства (Interacoustics TB25). Изменение уровня для каждой полосы шириной 1/3 октавы обозначается как 30, 65 и 99 процентилей соответствующего распределения амплитудных значений короткого периода (125 мс). Также показан долговременный амплитудный речевой спектр (LTASS) в полосах одной трети октавы. На среднем чертеже (обозначенном "Включено") показан выходной сигнал педиатрического слухового устройства, измеренный в тестовом боксе, используя средство моделирования перекрытого уха (IEC 60318-4, 2010). На правом чертеже (обозначенном EIG=Aided-unaided@65 dB SPL) показан предполагаемый коэффициент усиления вставки (EIG). Заметим, что предполагаемый коэффициент усиления вставки для сигнальных компонент, имеющих относительно более низкие входные уровни (представленные 30-типроцентным процентилем), больше, чем предполагаемый коэффициент усиления вставки сигнальных компонент, имеющих относительно более высокие входные уровни (представленные 99-процентным процентилем). Это имеет место, например, за счет алгоритма сжатия, который имеет тенденцию усиливать низкие входные уровни больше, чем высокие входные уровни. Предпочтительный вариант осуществления настоящего изобретения должен использовать способы, изложенные в стандарте IEC 60118-15, (2012), чтобы продемонстрировать речеподобную обработку новых стимулов ASSR на цифровых слуховых устройствах.
На фиг. 4A и 4B показаны примерные настройки диагностической системы для проверки правильности настройки слухового устройства, причем фиг. 4A И 4B показывают измерение AEP, когда пользователь носит слуховое устройство в нормальном режиме (включен) и когда пользователь не носит слуховое устройство (выключено), соответственно. Диагностическая система содержит компоненты, обсуждавшиеся в связи с фиг. 1B, и находится на фиг. 4A в состоянии использования при включенном измерении, где акустические стимулы (ac-stim1)свободного поля от выходного преобразователя (OT, здесь это громкоговоритель) воспринимаются слуховым устройством (HD1), выполненным с возможностью расположения внутри или на первом ухе (ear1) пользователя (U) (или полностью или частично имплантированным в голову пользователя). Слуховое устройство содержит входной блок (IU, здесь показан микрофон), блок обработки сигналов (не показан) для применения коэффициента усиления, зависимого от уровня и частоты, к входному сигналу со стороны входного блока и подачи такого улучшенного сигнала к выходному блоку (OU, здесь показан выходной преобразователь (громкоговоритель)). Выходной преобразователь слухового устройства, в целом, выполнен с возможностью подачи стимула (основываясь на сигнале, воспринимаемом входным устройством IU), который воспринимается пользователем как звук. Слуховая система пользователя схематично показана на фиг. 4A И 4B как барабанная перепонка и среднее ухо (М-ear), ушная улитка (cochlea) и кохлеарный нерв (neurons). Нервные связи от соответствующих кохлеарных нервов до слуховых центров мозга (основной слуховой зоны коры головного мозга, показанных как центр, обозначенный PAC на фиг. 4A и 4B и на фиг. 7A-7C), обозначены на фиг. 4A и 4B полужирными штриховыми кривыми. Диагностическая система содержит блок стимуляции (СТУ), выполненный с возможностью подачи сигнала электрического стимула (stim1), содержащего множество индивидуально повторяющихся стимулов на конкретных частотах, которые объединяются и спектрально формируются в амплитуду, чтобы эмулировать длиннолатентный спектр текущей речи (с определенной силой звука), и амплитуда, модулируемая во времени, чтобы обеспечить огибающую стимулов, эквивалентна амплитуде текущей речи. Диагностическая система дополнительно содержит блок записи (REC) для записи слуховой вызванной реакции пациента, возникающей в результате действия упомянутого акустического сигнала стимула ac-stim1. В сценарии на фиг. 4B акустический сигнал стимула ac-stim1 в свободном поле принимается ухом пациента и слуховой системой (без средства слухового устройства, т.е. в "выключенном" режиме). В сценарии на фиг. 4A акустический сигнал стимула ac-stim1 в свободном поле воспринимается, обрабатывается и подается в слуховую систему пациента слуховым устройством (то есть, находящимся во "включенном" режиме. При обеих настройках, во включенном и в выключенном режимах, стамуляция подается в одно ухо (правое ухо, ear1), а в другое ухо (левое ухо, ear2) вставляется ушная пробка (plug), чтобы перекрыть прохождение звука для этого уха и не вызывать реакцию нейронов в слуховой системе. Блок записи содержит или оперативно соединяется с электродами (ACQ), выполненными с возможностью восприятия сигналов мозговых волн (rec0, rec1, rec2) (например, AEP), когда они должным образом располагаются на голове пользователя. В вариантах осуществления, показанных на фиг. 4A И 4B, три электрода (ACQ) показаны расположенными на скальпе пользователя (U). Блок записи и блок стимуляции связаны друг с другом (signal cont), чтобы, например, управлять синхронизацией между стимуляцией и записью. Блок записи содержит соответствующую схемотехнику для усиления, обработки и обнаружения, позволяющую обеспечивать конкретные данные ASSR.
На фиг. 5A показан вариант осуществления одной только диагностической системы и на фиг. 5B показан вариант осуществления диагностической системы, стимулирующей слуховое устройство во время ношения его пациентом.
На фиг. 5A показана блок-схема диагностической системы (DMS), которая также показывается и описывается в сочетании с фиг. 4A и 4B и на фиг. 1B. Диагностическая система имеет электродную часть (ACQ, содержащую множество Ne электродов для восприятия вызванных потенциалов recn от слуховой системы и мозга, когда они монтируются на голове пользователя. Вызванные потенциалы recn, воспринимаемые электродами, подаются на блок записи (REC) для обработки и оценки. Электрические стимулы stim (например, управляемые (к примеру, инициируемые) блоком записи (REC) через управляющий сигнал cont), соответствующие настоящему изобретению, формируются блоком стимуляции (STIM) и преобразуются в акустические стимулы (свободного поля) ac-stim выходным преобразователем (громкоговорителем) системы. На фиг. 5B показана диагностическая система (DMS), используемый во "включенном" режиме (как показано и обсуждалось в связи с фиг. 4A), где пациент, носящий слуховое устройство (HD), подвергается воздействию акустических стимулов (ac-stim) диагностической системы в одном ухе. Акустические стимулы (ac-stim) воспринимаются звуковым входным блоком (Sound-in) слухового устройства, расположенного в ухе. Акустические стимулы (ac-stim) преобразуются в электрический входной сигнал микрофоном слухового устройства и обрабатываются на пути прохождения сигнала слухового устройства к громкоговорителю, представляющему обработанные стимулы пользовател. в виде выходного звука (Sound-out). Путь прохождения сигнала слухового устройства (HD) содержит, например, аналогово-цифровой преобразователь (AD), обеспечивающий оцифрованный электрический входной сигнал (IN), блок обработки сигналов (SPU) для обработки оцифрованного электрического входного сигнала, например, в режиме обработки речи, и предоставления обработанного сигнала, который преобразован в аналоговый сигнал цифро-аналоговым преобразователем (DA) перед тем, как будет преобразован в звуковой сигнал громкоговорителем слухового устройства. Выходной звук (Sound-out) от слухового устройства представляет собой обработанную версию речеподобных акустических стимулов (ac-stim) от диагностической системы (как она подается слуховым устройством). Слуховая система пользователя воспринимает выходной звук (Sound-out) от слухового устройства (HD) и вызывает потенциалы (AEP), которые воспринимаются электродами (ACQ) диагностической системы (DMS). Диагностическая система (DMS) и слуховое устройство (HD) вместе представляет собой объединенную систему (CS). Слуховое устройство (HD) может быть любого вида (типа (воздушной проводимости, костной проводимости, кохлеарный имплантат (или их комбинации), стиля (позади уха, в ухе и т.д.) или изготовления) и быть способно улучшать речевой (или речеподобный) входной сигнал в соответствии с потребностями пользователя. В варианте осуществления способность слухового устройства обрабатывать речеподобные сигналы стимулов от диагностической системы, таких как обычная речь, проверяется при отдельном измерении (например, в измерительнои боксе с малым отражением), например, согласно стандарту IEC 60118-15 (2012), дополнительно, сравните ниже.
Пример
В качестве примера, стимул ASSR, соответствующий настоящему изобретению, может быть сформирован четырьмя последовательными узкополосными (NB) чирпированными сигналами ASSR шириной в одну октаву, созданными согласно способам, описанным в документе US 8 591 433 B2, с центральными частотами 500, 1000, 2000 и 4000 Гц и частотами повторения 86,0 1/с, 90,6 1/с, 84,0 1/с, и 88,6 1/с, соответственно. Эти примеры показаны на фиг. 2(A-D). Чтобы сделать стимул речеподобным, целевой уровень звукового давления должен предпочтительно соответствовать нормальным речевым уровням в полосах октавы. Стимул должен предпочтительно должен подаваться в помещении с очень малыми отражениями (например, безэховом). Каждая полоса частот затем взвешивается в соответствии с ANSI S3.5. (1997) для речи с нормальной звуковой силой, измеренной на расстоянии 1 м от источника (например, от громкоговорителя). Согласно стандарту ANSI уровни звукового давления в полосе октавы затем устанавливаются как 59,8, 53,5, 48,8 и 43,9 дБ SPL для полос в октаве 500, 1000, 2000 и 4000 Гц, соответственно. Полосы затем объединяются (смотрите фиг. 2E), с тем, чтобы сумма индивидуальных полос дала в результате широкополосный стимул с длиннолатентным спектром, идентичным речи при нормальной звуковой силе, соответствующей уровню звукового давления в свободном поле приблизительно 62,5 дБ SPL.
Затем широкополосный стимул подается на модулятор и применяется моделированная речевая огибающая. Это показано на фиг. 2F как отфильтрованная низкочастотным фильтром (частота среза 4 Гц) огибающая гауссова белого шума. Модулятор перемножает широкополосный стимул ASSR с моделированной речевой огибающей и результат показан на фиг. 2G.
При подаче через слуховое устройство, cопутствующая модуляция мощности огибающей по полосам и флюктуация мощности в полосе будет, в принципе, возбуждать устройство в режиме работы, подобном речи. При использовании стандарта IEC 60118-15 (2012), соответствующие акустические измерения в анализаторе слухового устройства могут быть проделаны, чтобы продемонстрировать, что стимул обрабатывается слуховым устройством речеподобным способом. Нормальная речь имеет присущие ей флюктуации уровня (амплитудная модуляция), причем их динамический диапазон во времени в свободном поле является важной характеристикой речи и анализируется в полосе шириной 1/3 октавы согласно стандарту IEC60118-15. Если новый стимул ASSR имеет тот же самый входной динамический диапазон, что и стандартизированный речевой стимул, это гарантирует, что слуховое устройство стимулируется правильно. Выходной сигнал слухового устройства и предполагаемый коэффициент усиления также определяются, чтобы количественно определить их соотношение и дополнительно продемонстрировать, что слуховое устройство обрабатывает стимул речеподобным способом. Пример такой процедуры представлен на фиг.3.
В настоящем примере AM применяется к объединенному широкополосному стимулу (сравните фиг. 2A-2G). Альтернативно, AM может применяться таким образом, чтобы моделировать сопутствующую модуляцию при нормальной речи, то есть, иметь узкополосные области с общей модуляцией, а не по всей области широкополосного стимула. Это можно просто сделать, используя набор фильтров и многочисленные модуляторы перед объединением в единый широкополосный стимул. Это показано на фиг. 6A.
На фиг. 6A показан вариант осуществления блока стимуляции (STU), соответствующего настоящему изобретению. Блок стимуляции (STU), показанный на фиг. 6A, содержит генератор символов на конкретных частотах (FSSG), например, узкополосных стимулов, как показано на фиг. 1A, 1B, 2A-2G, но, альтернативно, и других стимулов на конкретных частотах, например, стимулов, сформированных индивидуальной амплитудой чистого тона из числа чистых тонов, модулированной более низкой частотной несущей. Генератор стимулов на конкретных частотах (FSSG) обеспечивает сигналы стимулов fs-stim. Блок стимуляции (STU) дополнительно содержит блок формирования спектра (SSU), который формирует стимулы на конкретных частотах fs-stim, чтобы обеспечить соответствие амплитудного спектра результирующего объединенного сигнала ss-stim длиннолатентному спектру текущей речи, например, произносимой с определенной силой звука. Блок стимуляции (STU) дополнительно содержит набор фильтров для анализа (AFB), который разделяет стимулы на сформированных частотах ss-stim на множество N полос частот стимула, обеспечивая (меняющуюся во времени) сигналы в полосе со сформированной частотой shst1, shst2, …, shstN. Блок стимуляции (STU) дополнительно содержит модуляторы полосы-уровня (обозначенные как "x" на фиг. 6A) для модулированных по амплитуде сигналов со сформированной по частоте полосой, shst1, shst2, …, shstN с индивидуальными частотами модуляции полосы-уровня rsam1, rsam2, …, rsamN, предоставляемые блоком модуляции частоты-уровня (BLM), выполненным с возможностью обеспечения, что результирующие амплитудно модулированные сигналы со сформированной по частоте полосой smst1, smst2, …, smstN имеют огибающую, эквивалентную огибающей текущей речи. Например, BLM может получить свои огибающие из реального речевого сигнала или из искусственного речевого сигнала, такого как ISTS (Holube и др., 2010), посредством полосовой фильтрации речевого сигнала соответствующими широкополосными полосовыми фильтрами, с центральной частотой в N полосах частот стимулов A-FB, и извлечения огибающих конкретных частот из этих N стимулов с полосами частот из этих N сигналов с ограниченной полосой. Блок стимуляции (STU) дополнительно содержит блок объединения (здесь в форме блока SUM) для объединения сигналов smst1, smst2, …, smstN полосы-уровня, чтобы обеспечить результирующий сигнал стимуляции stim во временной области. Результирующие электрические стимулы stim могут затем быть преобразованы в акустические стимулы (сравните, ac-stim на фиг. 1B, 4 и 5) электроакустическим преобразователем (сравните, например, OT на фиг. 1B), например, громкоговорителем (сравните, например, с громкоговорителем на фиг. 1A, 4, 5).
BLM может дополнительно содержать этап квантования, на котором N огибающих квантуются по времени и по уровню. Это может быть достигнуто следующим образом. Сначала, речевой сигнал, из которого получают огибающую, растягивается во времени, так чтобы его длительность равнялась целому числу периодов немодулированного стимула. После фильтрации речевого сигнала по N полос частот стимула и извлечения огибающих, огибающие сначала квантуются по времени, так что каждая огибающая полосы является постоянной на каждом периоде немодулированного стимула. Затем огибающие квантуются по уровням, например, соответствующим Leq+10 дБ, Leq, Leq - 10 дБ и Leq - 20 дБ, где Leq является длиннолатентным средним уровнем отфильтрованного полосовым фильтром речевого сигнала. На фиг. 6B показывает пример временных траекторий коэффициентов усиления огибающих, полученных из сигнала ISTS продолжительностью 60 секунд для полос частот стимула шириной в одну октаву с центральной частотой 500, 1000, 2000 и 4000 Гц. В этом примере период (длительность периода) немодулируемого стимула составляет 136,53 мс и вся длительность, показанная на фиг. 6B, расширена на 440 длительностей периода, соответствуя 60,075 с. Квантование по уровню соответствует Leq+10 дБ, Leq, Leq - 10 дБ и Leq - 20 дБ с более низкими кроэффициентами усиления, остающимися неизменными.
Следует заметить, что длительность периода, выбранная для этого примера, существенно короче чем, та, которая типична для стимула ASSR. Это, однако, предпочтительно, чтобы иметь возможность представить модуляции в частотном диапазоне, относящемся к речи. Модуляционный спектр речи лемонстрирует характерный размытый максимум вблизи 4 Гц. Чтобы представить модуляции в этом частотном диапазоне, траектории огибающей необходимо менять, по меньшей мере, каждые 1/4 Гц=250 мс, что устанавливает верхний предел длительности периода.
Траектории огибающих, показанные на фиг. 6B, являются ступенчатыми функциями, которые подразумевают разрывы на каждой ступени траектории. Может быть предпочтительным ввести плавные переходы от одной ступени к другой, например, посредством нарастающего косинусного фронта с компромиссом между спектральными помехами стимулам в пределах каждого периода и артефактами перехода между периодами.
Уровни квантования для этого примера были выбраны так, чтобы обеспечить категории уровней, которые могут быть клинически важны для оценки доступа к различным частям речи и позволить важные регулировки настроек слухового устройства. Однако, другие категории уровней точно также могут быть выбраны.
Деление периодов огибающей на выбранные категории делалось раздельно для каждой полосы частот стимула, сортируя все квантованные по времени значения периода огибающей и затем определяя границы, с тем, чтобы средний уровень огибающей в пределах каждого набора границ ("уровневых накопителей") был насколько возможно близок к Leq+10 дБ, Leq, Leq - 10 дБ и Leq - 20 дБ. Все коэфициенты усиления огибающей в пределах уровневого накопителя были затем установлены на номинальный уровень накопителя и возвращались к их первоначальной позиции во времени в траектории.
Таким образом, фиксированный вид траекторий огибающих создавался через 60,075 с длительности растянутого во времени речевого сигнала, из которого получают огибающие. Этот вид огибающих, как предполагается, должен повторяться, пока не закончится запись ASSR.
На фиг. 7A, 7B и 7C показаны сценарии, подобные сценариям, показанным на фиг. 4A, описанным выше. Разность, тем не менее, состоит в том, что стимулы, сформированные блоком стимуляции (STU) диагностической системы в вариантах осуществления, показанных на фиг. 4A, передаются (проводным или беспроводным способом) напрямую к слуховому устройству(-ам) или формируются в слуховом устройстве(-ах) (вместо того, чтобы воспроизводиться через громкоговоритель диагностической системы и восприниматься микрофоном(-ами) слухового устройства(-в)). В обоих случаях стимулы подаются пользователю (U) через громкоговоритель (OT) слухового устройства (HD1).
На фиг. 7A показан первый сценарий измерения AEP, где пользователь (U) носит слуховое усипрйство (HD1) в нормальном режиме (включенном) и где стимулы stim1 подаются блоком стимуляции (STU) диагностической системы напрямую к слушающему устройству (HD1) для воспроизведения пользователю (U) посредством громкоговорителя (OT) слухового устройства (HD1). Соединение между диагностической системой и слуховым устройством может быть проводным соединением беспроводного соединения (например, основанным на Bluetooth или другой стандартизированной или собственной технологии).
На фиг. 7B показан второй сценарий измерения AEP, где пользователь (U) носит слуховое устройство (HD1) в нормальном режиме (включен) и где стимулы stim1 подаются напрямую (электрически) на слуховое устройство для воспроизведения пользователю громкоговорителем слухового устройства. Вариант осуществления, показанный на фиг. 7B, подобен варианту осуществления, показанному на фиг. 7A. Различие состоит только в том, что стимулы, формируемые на фиг. 7A блоком стимуляции (STU) диагностической системы, вместо этого формируются в слуховом устройстве (HD1). Блок стимуляции (STU) располагается в слуховом устройстве (HD1) и управляется диагностической системой через управляющий сигнал cont (здесь) от блока записи (REC) диагностической системы.
На фиг. 7C показан третий сценарий измерения AEP. Вариант осуществления, показанный на фиг. 7C, подобен варианту осуществления, показанному на фиг. 7B. Разница состоит в том, что в варианте осуществления, показанном на фиг. 7C, пользователь носит первое и второе слуховые устройства (HD1, HD2) бинауральной слуховой системы в нормальном режиме (включенном) (вместо одиночного слухового устройства в одном из ушей). Оба слуховых устройства (HD1, HD2) содержат блок стимуляции (STU), которым управляет диагностическая система через управляющий сигнал cont (здесь) от блока записи (REC) диагностической системы.
Преимущество вариантов осуществления, показанных на фиг. 7A, 7B и 7C, по сравнению с вариантом осуществления, показанным на фиг. 4A, состоит в том, что стимулы обеспечиваются электрически для громкоговорителя слухового устройства (не через промежуточное электрическое звено на акустический преобразователь (громкоговоритель диагностической системы) и акустическое звено к электрическому преобразователю (микрофон слухового устройства)).
На фиг. 8 показан вариант осуществления объединенной системы (CS), содержащей диагностическую систему (DMS), стимулирующую слуховое устройство (HD), когда его носит пациент (U), где стимуляция stim передается непосредственно на слуховое устройство (HD) и подается через громкоговоритель (OT) слухового устройства (HD). Вариант осуществления, показанный на фиг. 8, подобен варианту осуществления, показанному на фиг. 5B. Прямой путь прохождения сигнала для слухового устройства (HD) содержит входной преобразователь (здесь микрофон), аналогово-цифровой преобразователь (AD), блок обработки сигналов (SPU), блок объединения (CU), цифро-аналоговый преобразователь (DA) и выходной преобразователь (здесь, громкоговоритель). Отличие от варианта осуществления, показанного на фиг. 5B, состоит в том, что в варианте осуществления, показанном на фиг. 8, сигнал стимуляции stim посылается непосредственно от блока стимуляции (STIM) диагностической системы (DMS) на блок объединения (CU) слухового устройства (HD) через интерфейс (IF), (например, беспроводной интерфейс). Блок объединения (CU) выполнен с возможностью разрешения предоставить сигнал стимуляции stim, полученный от диагностической системы (DMS), пользователю (U) через громкоговоритель (и преобразователь DA (DA)) слухового устройства (в одиночку или вместе (смешанным) с обработанным сигналом PS от блока обработки сигналов (SPU) прямого пути прохождения сигнала слухового устройства (HD). Блоком объединения может управлять диагностическая система (например, сигналом, переданным через (например, беспроводной) интерфейс (IF)).
На фиг. 9 показана блок-схема последовательности выполнения операций способа проектирования стимулов для применения в системе записи слуховых вызванных потенциалов (AEP), в частности, в системе записи стабильных слуховых реакций (ASSR). Способ содержит этапы, на которых:
S1. Определяют много различных стимулов на конкретных частотах, каждый из которых имеет конкретную частоту или центральную частоту и ширину полосы, определяющую соответствующие полосы частот стимула;
S2. Определяют индивидуальную частоту повторения для каждого из различных стимулов на конкретных частотах;
S3. Спектрально формируют амплитудный спектр каждого из различных стимулов на конкретных частотах, чтобы обеспечить частотно сформированные стимулы на конкретных частотах;
S4. Амплитудно модулируют каждый из спектрально сформированных стимулов на конкретных частотах или объединенный широкополосный сигнал реальной или моделированной огибающей текущей речи;
S5. Объединяют спектрально сформированные стимулы на заданных (конкретных) частотах, чтобы обеспечить объединенный широкополосный сигнал;
S6. В котором спектральное формирование амплитудного спектра каждого из различных стимулов на конкретных частотах выполняется с возможностью обеспечения соответствия объединенного сигнала длиннолатентному спектру текущей речи, произносимой с определенной звуковой силой.
В варианте осуществления способ содержит применение независимых речевых огибающих к каждой из полос частот стимула. В варианте осуществления индивидуальные стимулы на заданных (конкретных) частотах являются независимо амплитудно модулированными огибающей, представляющей речевые модуляции в конкретных полосах.
В варианте осуществления способ содержит квантование по времени и/или по уровню наложенных речеподобных модуляций. В варианте осуществления способ содержит обеспечение синхронности модуляций во времени с периодичностью немодулированного стимула, с тем, чтобы на спектральные свойства стимула в пределах каждого периода не оказывали влияния приложенные речеподобные модуляции.
В варианте осуществления способ содержит обеспечение системы записи AEP, например, ASSR, выполненной с возможностью применения стимулов, разработанных по способу проектирования стимулов, определенному этапами S1-S6.
Подразумевается, что структурные признаки устройств, описанных выше в подробном описании и/или в формуле изобретения, могут объединяться с этапами способа, когда должным образом заменяются соответствующим процессом, или наоборот.
При использовании здесь подразумевается, что единственное число содержит в себе также и множественное число (то есть, должно иметь смысл "по меньшей мере один"), если явно не заявляется иное. Дополнительно следует понимать, что термины "содержат", "включают в себя", "содержащий" и/или "включающий в себя", когда используются в настоящем описании, указывают на присутствие установленных признаков, целых чисел, этапов, операций, элементов и/или компонентов, но не препятствуют присутствию или добавлению одной или более других функций, целых чисел, этапов, операций, элементов, компонентов и/или их групп. Следует также понимать, что когда элемент упоминается как "соединенный" или "связанный" с другим элементом, он может быть напрямую соединен или связан с другим элементом, но могут также присутствовать и промежуточные элементы, если явно не заявлено иное. Дополнительно, термины "соединенный" или "связанный", как они используются здесь, могут содержать "соединенный беспроводным способом" или "связанный беспроводным способом". Термин "и/или", как он используется здесь, содержит любую и все комбинации одного или более соответственных перечисленных терминов. Этапы любого раскрытого способа не ограничиваются заявленным здесь точным порядком, если явно не заявляется иное.
Следует понимать, что ссылка повсеместно в этом описании на "один из вариантов осуществления" или на "вариант осуществления" или на "вариант" или на признаки, содержащиеся как "может", означает, что конкретный признак, структура или характеристика, описанные в связи с вариантом осуществления, содержатся по меньшей мере в одном варианте осуществления изобретения. Дополнительно, конкретные признаки, структуры или характеристики могут быть объединены как подходящие в одном или более вариантах осуществления изобретения. Предыдущее описание предоставляется, чтобы позволить любому специалисту, квалифицированному в данной области техники, практически реализовать различные описанные здесь различные варианты. Различные изменения в этих вариантах будут легко очевидны специалистам в данной области техники и универсальные принципы, определенные здесь, могут применяться к другим вариантам.
Пункты формулы изобретения не предназначены служить ограничениями показанных здесь вариантов, а состоят в том, чтобы быть в полном объеме согласованными с языком пунктов формулы изобретения, где ссылка на элемент в единственном числе не предназначена означать "один и только один", если это конкретно не заявлено", а скорее "один или более". Если конкретно не заявлено иное, термин "некоторый" означает "один или более".
Соответственно, контекст должен рассматриваться с точки зрения следующих далее пунктов формулы изобретения.
Литература
- ANSI S3.5. (1997), American National Standard: ʹMethods for Calculation of the Speech Intelligibility Indexʹ.
- [Bagatto et al., 2002] Bagatto, M. P., Scollie, S. D., Seewald, R. C., Moodie, K. S., & Hoover, B. M. (2002). Real-ear-to-coupler difference predictions as a function of age for two coupling procedures. Journal of the American Academy of Audiology, 13(8), 407-415.
- [Cebulla et al., 2007] Cebulla, M., Stürzebecher, E., Elberling, C., and Müller, J. (2007), ʹNew clicklike stimuli for hearing testingʹ, J. Am. Acad. Audiol., 18, 725-738.
- [Chang et al.; 2012] Chang H.-W., Dillon, H., Carter, L., Van Dun, B., and Young, S.-T. (2012), ʹThe relationship between cortical auditory evoked potential (CAEP) detection and estimated audibility in infants with sensorineural hearing lossʹ, Int. J. Audiol., 51, 663-670.
- [Elberling, 2005], Elberling, C. (2005), ʹMethod to design acoustic stimuli in spectral domain for the recording of auditory steady-state responses (ASSR)ʹ, Patent No.: US 8,591,433 B2 (Nov. 26, 2013).
- [Elberling et al., 2007a], Elberling, C., Don, M., Cebulla, M., and Stürzebecher, E. (2007), ʹAuditory steady-state responses to chirp stimuli based on cochlear traveling wave delayʹ, J. Acoust. Soc. Am., 122(5), 2772-2785.
- [Elberling et al., 2007b] Elberling, C., Cebulla, M., & Stürzebecher, E. (2007), ʹSimultaneous multiple stimulation of the ASSRʹ. In: 1st International Symposium on Auditory and Audiological Research (ISAAR 2007): Auditory signal processing in hearing-impaired listeners. Eds. T Dau, JM Buchholz, JM Harte, TU Christensen. Centertryk A/S, Denmark. ISBN 87-990013-1-4. pg. 201-209.
- [Elberling & Don, 2010] Elberling, C. and Don, M. (2010), ʹA direct approach for the design of chirp stimuli used for the recording of auditory brainstem responsesʹ, J. Acoust. Soc. Am., 128(5): 2955-2964.
- IEC 60118-15. (2012), Electroacoustics - Hearing aids - Part 15: ʹMethods for characterising signal processing in hearing aids with a speech-like signalʹ (International Electrotechnical Commission, Geneva, Switzerland).
- IEC 60318-4. (2010), Electroacoustics-Simulators of Human Head and Ear-Part 4: ʹOccluded-Ear Simulator for the Measurement of Earphones Coupled to the Ear by Means of Ear Insertsʹ (International Electrotechnical Commission, Geneva, Switzerland).
- [Holube et al., 2010] Holube, I., Fredelake, S., Vlaming, M., & Kollmeier, B. (2010). Development and analysis of an International Speech Test Signal (ISTS). International Journal of Audiology, 49(12), 891-903.
- [John & Picton, 2004] John, MS. & Picton, TW. (2004). System and method for objective evaluation of hearing using auditory steady-state responses. US patent 2004/0064066A1.
- [Kuwada et al.; 2002] Kuwada, S., Anderson, J.S., Batra, R., Fitzpatrick, D.C., Teisser, N. and DʹAngelo, W.R. (2002), ʹSouraces of the Scalp-Recorded Amplitude Modulation Following Responseʹ, J. Am. Acad. Audiol., 13, 188-204.
- [Picton et al., 1987] Picton, T.W., Skinner, C.R., Champagne, S.C., Kellett, A.J.C., and Maiste, A.C. (1987), ʹPotentials evoked by the sinusoidal modulation of the amplitude or frequency of a toneʹ, J. Acoust. Soc. Am., 82(1), 165-178.
- [Plomp; 1984] Plomp, R. (1984), ʹPerception of Speech as a Modulated Signalʹ, In Proc. Of the 10th Int. Cong. Of Phon. Sci., Eds. Van der Broecke and Cohen,29-40.
- US 8,591,433 B2 (Maico Diagnostic) 26.11.2013.
- WO2006003172A1 (Maico Diagnostic) 12.01.2006
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ настройки речевого процессора системы кохлеарной имплантации | 2017 |
|
RU2652733C1 |
| СПОСОБ ОПРЕДЕЛЕНИЯ ОПТИМАЛЬНЫХ ПАРАМЕТРОВ СЛУХОПРОТЕЗИРОВАНИЯ | 2010 |
|
RU2414168C1 |
| СПОСОБ КОДИРОВАНИЯ СТИМУЛИРУЮЩЕГО СИГНАЛА В КОХЛЕАРНОМ ИМПЛАНТЕ | 2017 |
|
RU2657941C1 |
| СПОСОБ ПЕРЕДАЧИ РЕЧЕВЫХ СИГНАЛОВ | 1993 |
|
RU2049456C1 |
| СПОСОБ ОПРЕДЕЛЕНИЯ ОПТИМАЛЬНЫХ ПАРАМЕТРОВ НАСТРОЙКИ СЛУХОВОГО АППАРАТА | 2019 |
|
RU2722875C1 |
| Способ определения динамического диапазона слуха у пациентов со слуховыми аппаратами | 2015 |
|
RU2610829C1 |
| УСТРОЙСТВО ДЛЯ ПРИЕМА РЕЧЕВЫХ СИГНАЛОВ | 1993 |
|
RU2049426C1 |
| СПОСОБ НАСТРОЙКИ КОХЛЕАРНОГО ИМПЛАНТА | 2007 |
|
RU2352084C1 |
| СПОСОБ НАСТРОЙКИ КОХЛЕАРНОГО ИМПЛАНТА | 2005 |
|
RU2297111C1 |
| Способ диагностического исследования слуха у детей первого года жизни | 2022 |
|
RU2803386C1 |
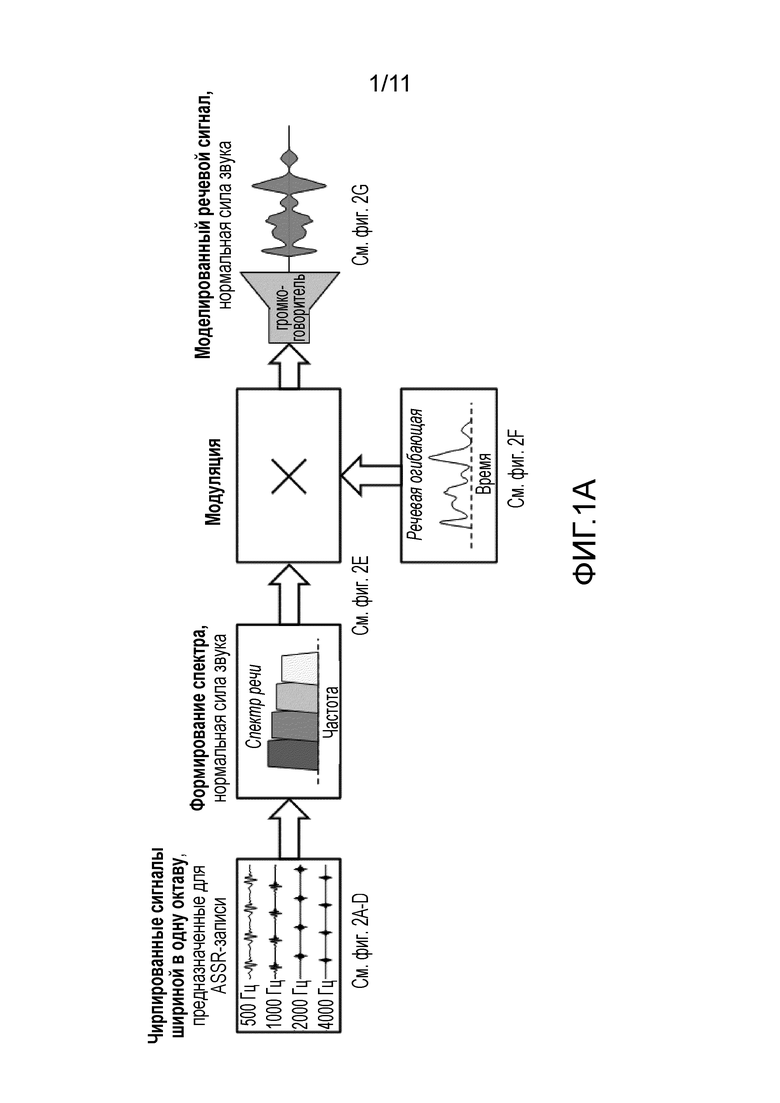
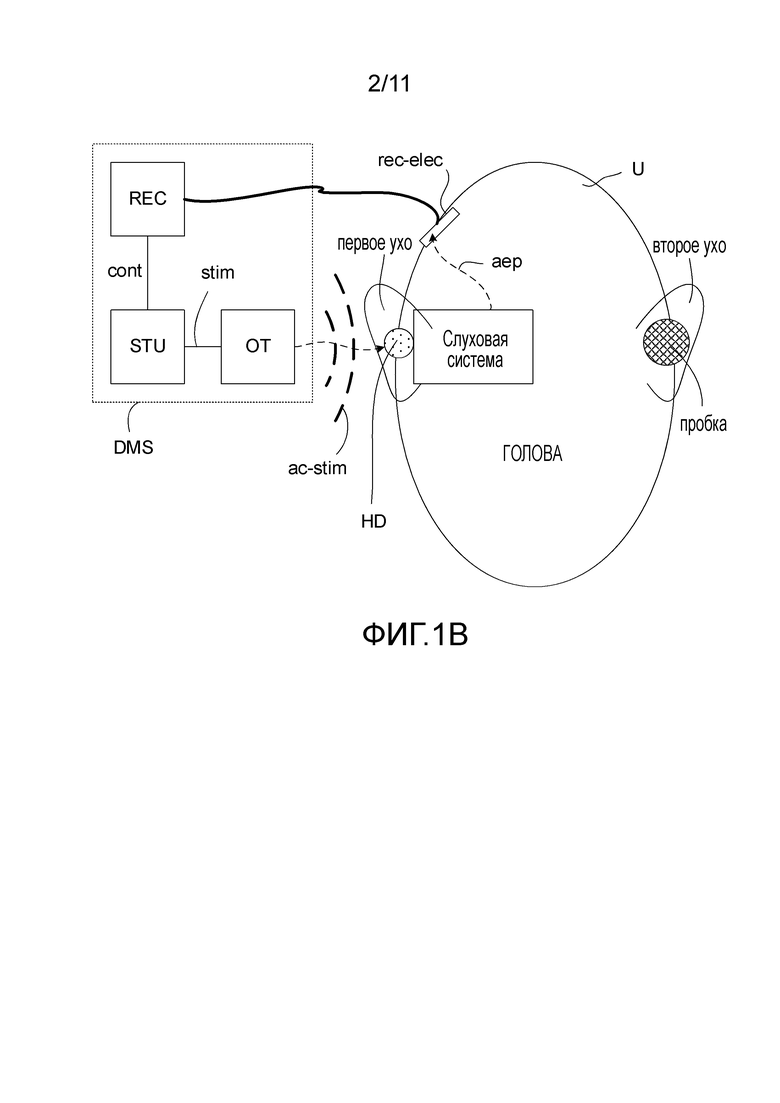
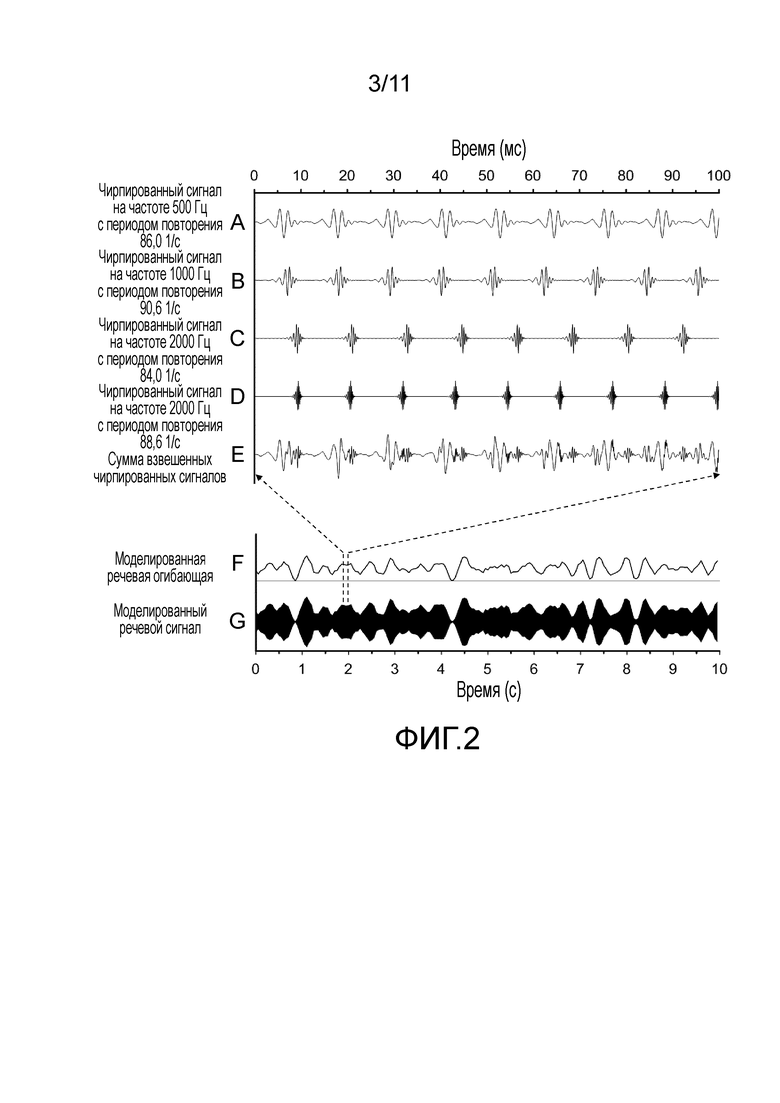
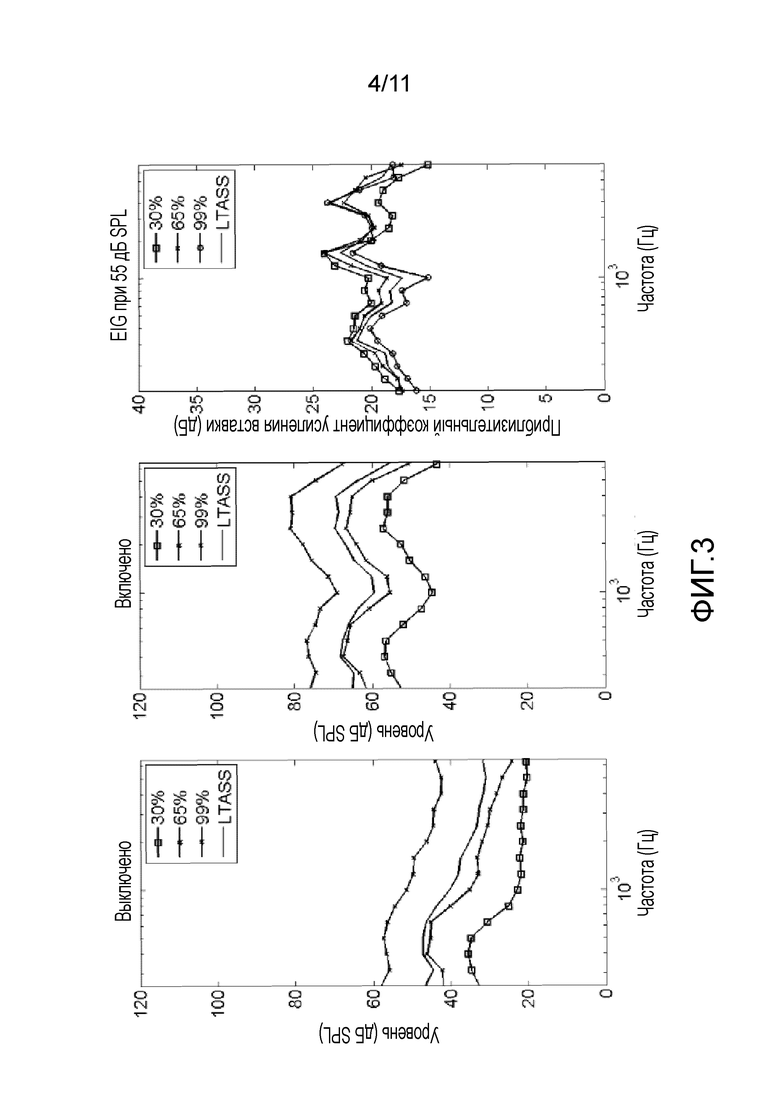
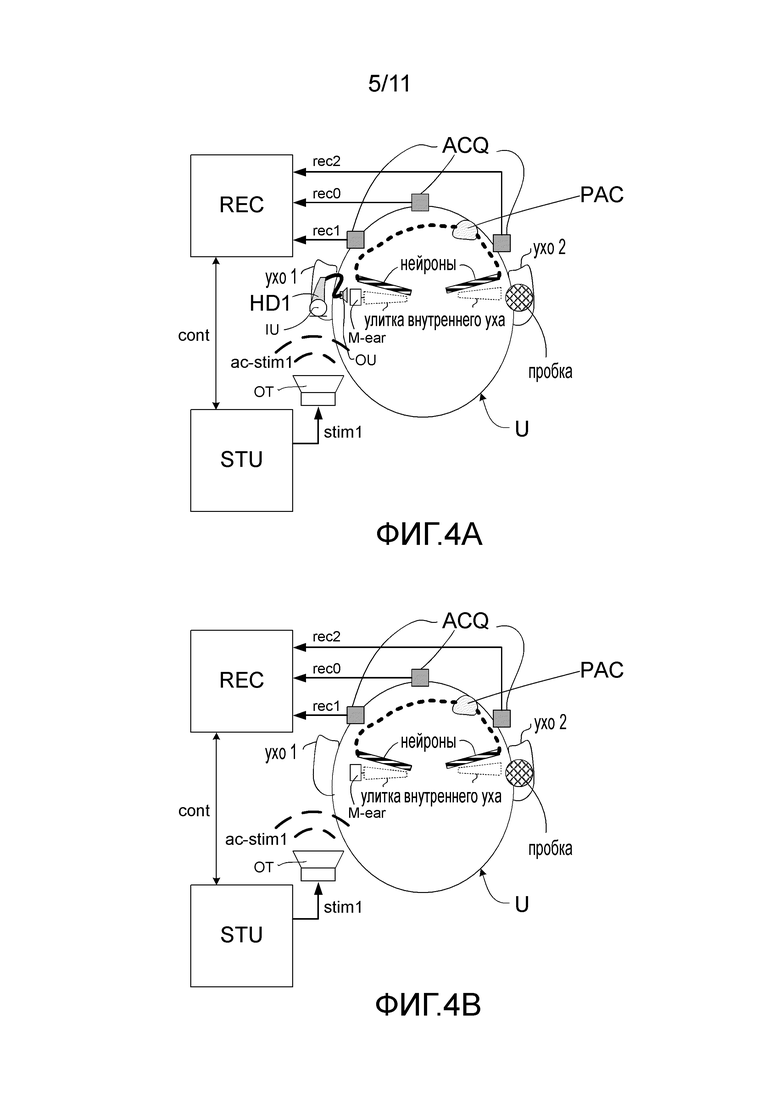
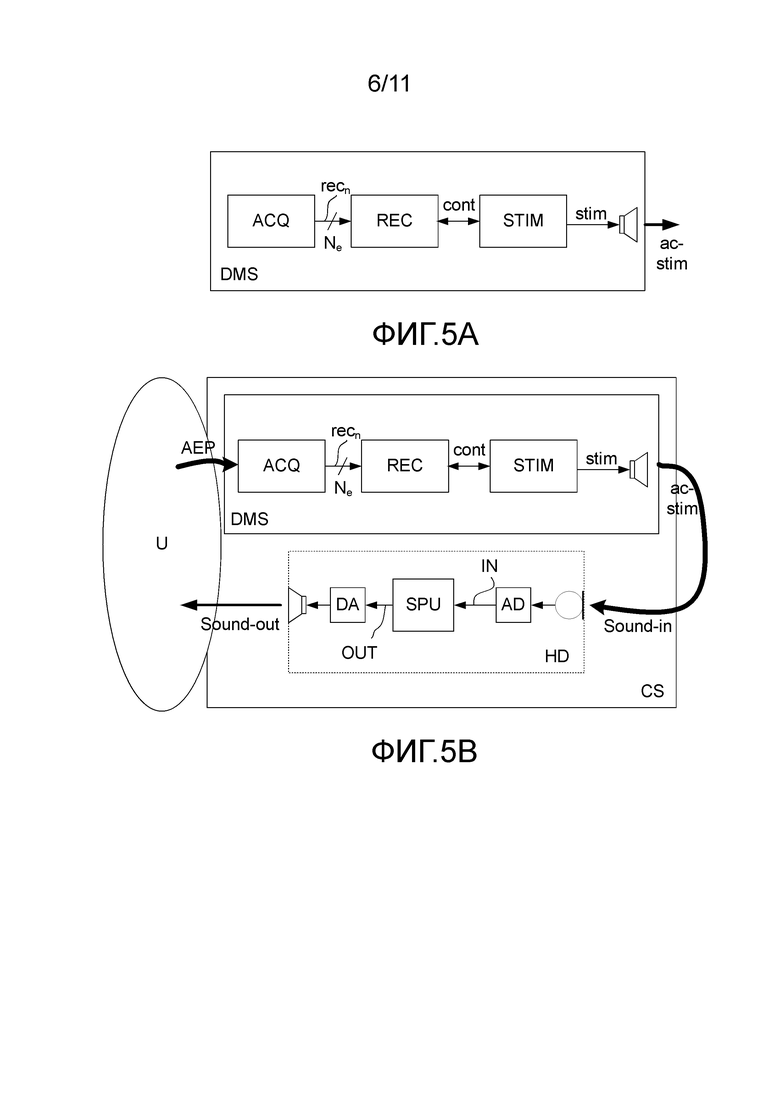
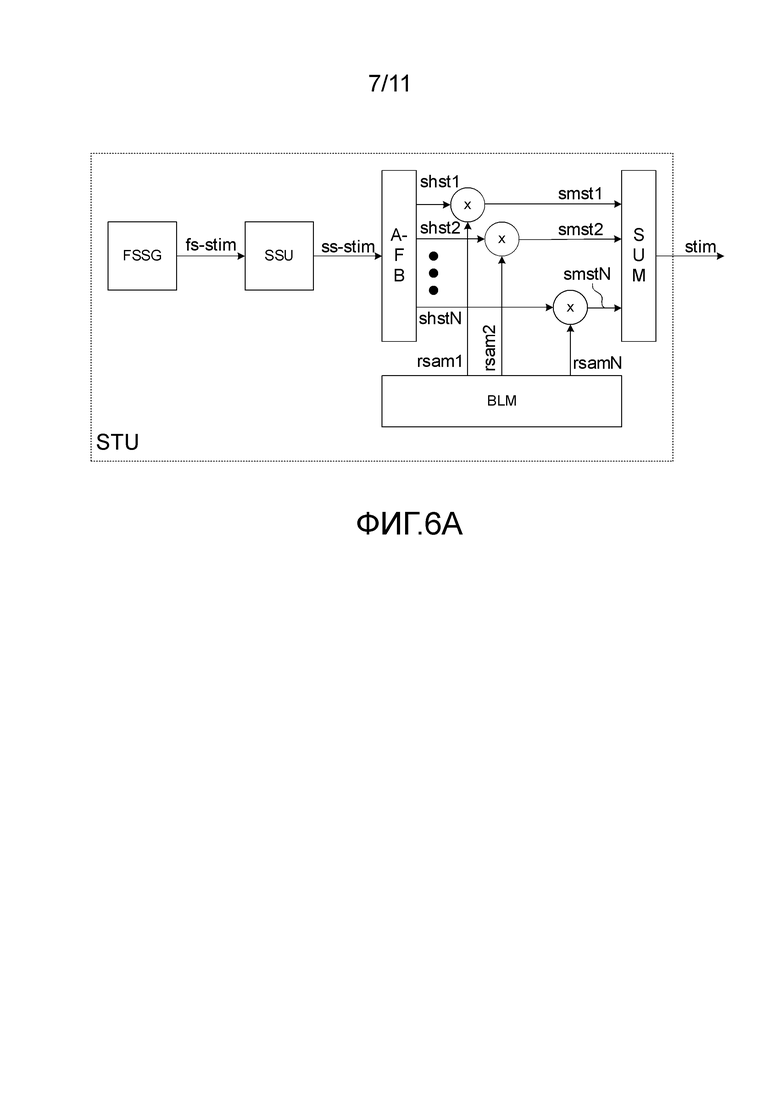

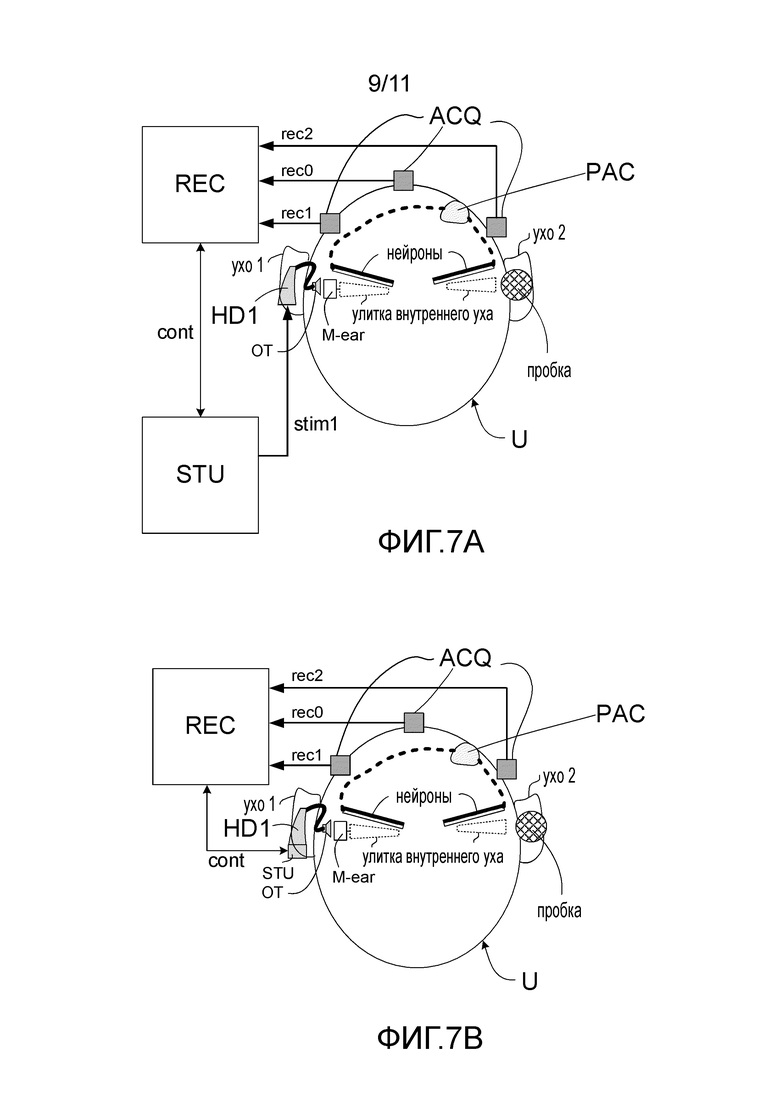
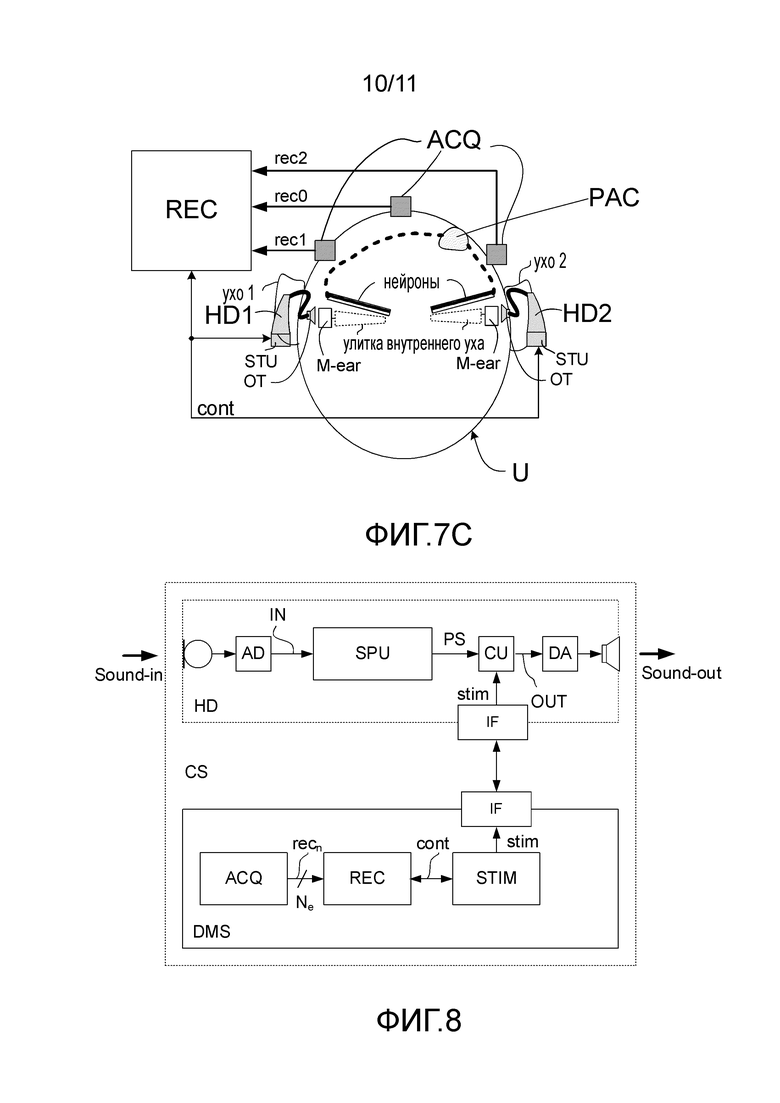
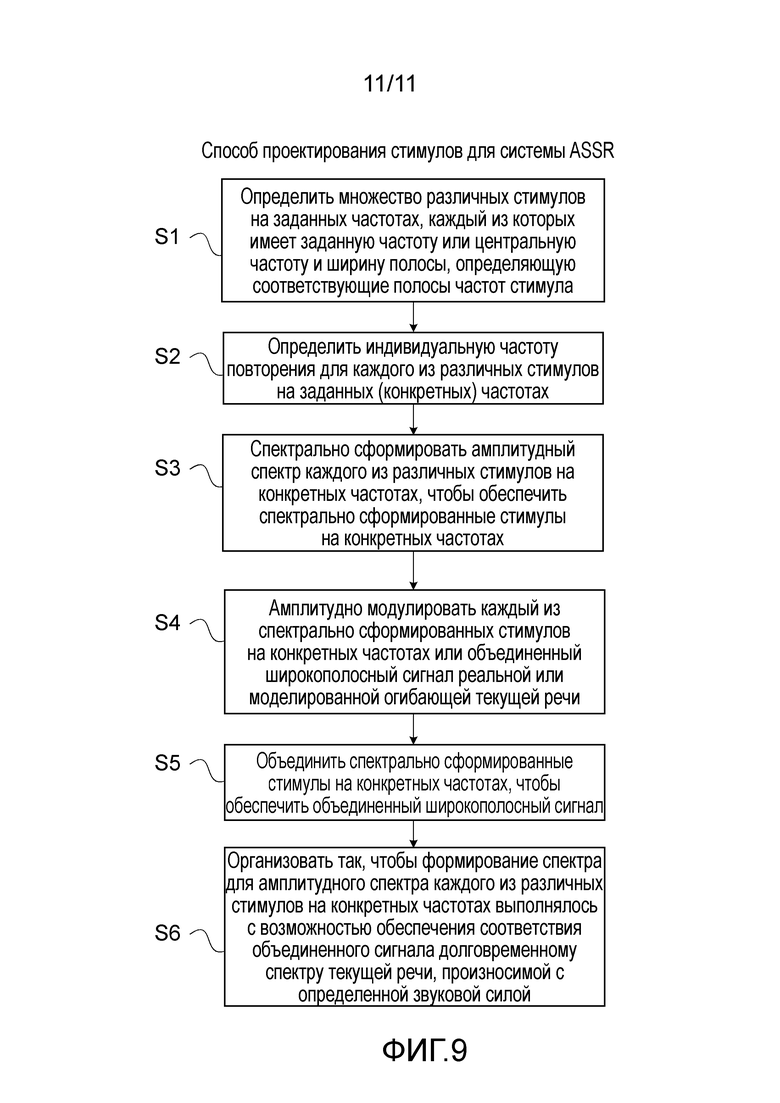
Группа изобретений относится к медицине, а именно к способу и диагностической системе для записи стабильных слуховых реакций пациента. Диагностическая система содержит блок стимуляции для обеспечения подачи акустического сигнала стимула к уху пациента и блок записи для записи стабильных слуховых реакций пациента, возникающих под действием стимула. При этом подают акустический сигнал стимула к уху пациента. Записывают стабильные слуховые реакции пациента, вызванные сигналом стимула. Акустический сигнал содержит речеподобный стимул, обеспечиваемый как комбинация последовательности индивидуальных стимулов на заданных частотах, каждый из которых имеет заданную полосу частот, частоту повторения, амплитуду и амплитудную модуляцию. Индивидуальные стимулы на заданных частотах и частоты повторения индивидуальных стимулов на заданных частотах различны и выбираются так, чтобы быть пригодными для записи вызванных слуховых реакций в ответ на стимулы и для получения реакции от соответствующих структур слухового прохода. Объединенный амплитудный спектр индивидуальных стимулов на заданных частотах соответствует долговременному амплитудному спектру речи. Обеспечивается стимуляция речеподобными сигналами с вариациями амплитуды во времени, которые подобны свободно произносимой речи и позволяют осуществлять одновременную оценку вспомогательной электрофизиологической реакции при нескольких различных уровнях речи. 5 н. и 20 з.п. ф-лы, 9 ил.
1. Способ записи стабильных слуховых реакций пациента, причем упомянутый способ содержит этапы, на которых
a) подают акустический сигнал стимула к уху пациента,
b) записывают стабильные слуховые реакции пациента, вызванные упомянутым акустическим сигналом стимула,
при этом акустический сигнал стимула содержит речеподобный стимул, обеспечиваемый как комбинация последовательности индивидуальных стимулов на заданных частотах, каждый из которых имеет заданную полосу частот, частоту повторения, амплитуду и амплитудную модуляцию;
при этом указанные индивидуальные стимулы на заданных частотах и частоты повторения индивидуальных стимулов на заданных частотах различны и выбираются так, чтобы быть пригодными для записи вызванных слуховых реакций в ответ на указанные стимулы на заданных частотах и для получения реакции от соответствующих структур слухового прохода, и
при этом объединенный амплитудный спектр индивидуальных стимулов на заданных частотах соответствует долговременному амплитудному спектру речи.
2. Способ по п. 1, содержащий этапы, на которых
a1) проектируют электрический сигнал стимула, представляющий собой речеподобный сигнал;
a2) преобразуют упомянутый электрический сигнал стимула в упомянутый акустический сигнал стимула;
a3) подают упомянутый акустический сигнал стимула к уху пациента.
3. Способ по п. 1 или 2, содержащий этап, на котором записывают упомянутые стабильные слуховые реакции пациента
- когда упомянутый пациент носит слуховое устройство, которое в активном режиме работы выполнено с возможностью улучшения акустического сигнала в упомянутом ухе; а также
- когда упомянутый пациент не носит слуховое устройство в упомянутом ухе.
4. Способ по п. 1, в котором частоты повторения индивидуальных стимулов на заданных частотах различны и выбираются так, чтобы быть пригодными для записи стабильных слуховых реакций в ответ на многочисленные одновременные стимулы на заданных частотах и чтобы получить реакции от соответствующих структур слухового прохода.
5. Способ по п. 1, в котором объединенный широкополосный стимул из индивидуальных стимулов на заданных частотах или индивидуальные стимулы на заданных частотах являются амплитудно-модулированными согласно соответствующей низкочастотной модуляции, возникающей в речи.
6. Способ по п. 5, в котором указанная низкочастотная модуляция, возникающая в речи, является огибающей, определенной из реально произносимого речевого сигнала или искусственного речевого сигнала, такого как Международный Речевой Тестовый Сигнал (ISTS).
7. Способ по п. 1, в котором долговременный амплитудный спектр и амплитудная модуляция индивидуальных стимулов на заданных частотах соответствуют речи, произносимой с звуковой силой.
8. Способ по п. 1, в котором индивидуальный стимул на заданной частоте состоит из чирпированных сигналов с ограниченной полосой.
9. Способ по п. 1, содержащий этапы, на которых:
- определяют множество различных стимулов на заданных частотах, каждый из которых имеет заданную частоту или центральную частоту и ширину полосы, определяющую соответствующие полосы частот стимула;
- определяют индивидуальную частоту повторения для каждого из различных стимулов на заданных частотах;
- модулируют по амплитуде каждый из спектрально сформированных стимулов на заданных частотах или объединенный широкополосный сигнал реальной или моделированной огибающей текущей речи;
- спектрально формируют амплитудный спектр каждого из различных стимулов на заданных частотах, чтобы обеспечить спектрально сформированные стимулы на заданных частотах;
- объединяют спектрально сформированные стимулы на заданных частотах, чтобы обеспечить объединенный широкополосный сигнал;
при этом этап спектрального формирования амплитудного спектра каждого из различных стимулов на заданных частотах выполняют так, чтобы обеспечить соответствие объединенного сигнала долговременному спектру текущей речи, произносимой с звуковой силой.
10. Способ по п. 9, содержащий этап, на котором применяют независимые речевые огибающие к каждой из полос частот стимула.
11. Способ по п. 1, содержащий этап, на котором обеспечивают независимую амплитудную модуляцию индивидуальных стимулов на заданных частотах огибающей, представляющей собой речевые модуляции в заданной полосе.
12. Способ по п. 1, содержащий этап, на котором обеспечивают квантование наложенных речеподобных модуляций по времени и/или по уровню.
13. Способ по п. 12, содержащий этап, на котором обеспечивают синхронность модуляций по времени с периодичностью немодулируемого стимула, чтобы спектральные свойства стимула в пределах каждого периода не подвергались влиянию наложенных речеподобных модуляций.
14. Способ по п. 12, содержащий этап, на котором обеспечивают соответствие квантования модуляций по уровню значениям Leq+10 дБ, Leq, Leq - 10 дБ, и Leq - 20 дБ, где Leq является долговременным средним уровнем речевого сигнала, используемого для создания огибающей.
15. Способ по п. 12, содержащий этап, на котором используют квантованный по уровню стимул, который дает оценки электрофизиологической реакции на речь на нескольких отдельных уровнях, для автоматизированной настройки слухового устройства.
16. Диагностическая система записи стабильных слуховых реакций пациента, причем упомянутая система содержит блок стимуляции для обеспечения подачи акустического сигнала стимула к уху пациента и блок записи для записи стабильных слуховых реакций пациента, возникающих под действием упомянутого акустического сигнала стимула,
при этом блок стимуляции выполнен с возможностью обеспечения содержания в акустическом сигнале стимула речеподобного стимула, обеспечиваемого как комбинация последовательности индивидуальных стимулов на заданных частотах, каждый из которых имеет заданную полосу частот, частоту повторения, амплитуду и амплитудную модуляцию,
при этом индивидуальные стимулы на заданных частотах и частоты повторения индивидуальных стимулов на заданных частотах различны и выбираются так, чтобы быть пригодными для записи вызванных слуховых реакций в ответ на указанные стимулы на заданных частотах и для получения реакции от соответствующих структур слухового прохода, и
при этом объединенный амплитудный спектр индивидуальных стимулов на заданных частотах соответствует долговременному амплитудному спектру речи.
17. Диагностическая система по п. 16, в которой блок стимуляции содержит
- генератор стимуляции для формирования множества различных стимулов на заданных частотах, каждый из которых имеет заданную частоту или центральную частоту и полосу частот и выполнен с возможностью применения индивидуальной частоты повторения к каждому из различных стимулов на заданных частотах;
- блок спектрального формирования для спектрального формирования амплитудного спектра каждого из различных стимулов на заданных частотах, чтобы обеспечить спектрально сформированные стимулы на заданных частотах;
- блок объединения для объединения спектрально сформированных стимулов на заданных частотах, чтобы обеспечить объединенный широкополосный сигнал; и
- блок амплитудной модуляции для амплитудной модуляции каждого из спектрально сформированных стимулов на заданных частотах или объединенного широкополосного сигнала реальной или смоделированной огибающей текущей речи, чтобы обеспечить упомянутый речеподобный стимул,
при этом спектральное формирование амплитудного спектра каждого из различных стимулов на заданных частотах выполнено с возможностью обеспечения соответствия объединенного сигнала долговременному спектру текущей речи, произносимой с звуковой силой.
18. Диагностическая система по п. 16 или 17, содержащая блок квантования амплитудных модуляций.
19. Диагностическая система по п. 16, в которой блок стимуляции выполнен с возможностью применения независимых речевых огибающих к каждой из полос частот стимула.
20. Объединенная система, содержащая диагностическую систему по любому из пп. 16-19 и слуховое устройство для компенсации ухудшения слуха пользователя.
21. Объединенная система по п. 20, выполненная с возможностью предоставления пользователю акустического сигнала стимула через громкоговоритель.
22. Объединенная система по п. 20 или 21, в которой различные стимулы на заданных частотах передаются слуховому устройству как электрические сигналы или формируются в слуховом устройстве перед подачей пользователю через громкоговоритель слухового устройства в качестве акустического сигнала стимула.
23. Объединенная система по п. 20 или 21, в которой различные стимулы на заданных частотах воспроизводятся громкоговорителем диагностической системы, внешней по отношению к слуховому устройству, и воспринимаются микрофоном слухового устройства, посредством которого акустический сигнал стимула подается пользователю через громкоговоритель слухового устройства.
24. Система обработки данных, содержащая процессор и средство программного кода для обеспечения выполнения процессором этапов способа по любому из пп. 1-15.
25. Машиночитаемый носитель, хранящий компьютерную программу, содержащую средство программного кода для обеспечения выполнения системой обработки данных по меньшей мере некоторых или всех этапов способа по любому из пп. 1-15, когда упомянутая компьютерная программа выполняется на системе обработки данных.
| US 2004064066 A1, 01.04.2004 | |||
| CN 102137624 B, 10.09.2014 | |||
| WO 2006062480 A1, 15.06.2006 | |||
| СПОСОБ ДИАГНОСТИКИ РЕТРОКОХЛЕАРНЫХ И ЦЕНТРАЛЬНЫХ СЛУХОВЫХ НАРУШЕНИЙ | 2009 |
|
RU2402266C1 |
| СПОСОБ ОПРЕДЕЛЕНИЯ ОПТИМАЛЬНЫХ ПАРАМЕТРОВ СЛУХОПРОТЕЗИРОВАНИЯ | 2010 |
|
RU2414168C1 |
| СПОСОБ ОЦЕНКИ ЗВУКОВОСПРИЯТИЯ У ПАЦИЕНТОВ С ПАТОЛОГИЕЙ СРЕДНЕГО УХА | 2013 |
|
RU2534877C1 |

