ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение относится в целом к способам и системам автоматизированного ответа на вопросы, которые могут в режиме реального времени давать напоминающие человеческие ответы на вопросы из разных областей знаний.
УРОВЕНЬ ТЕХНИКИ
[0002] Люди все чаще задают вопросы автоматизированным системам, предназначенным для выдачи ответов. Как правило, вопросы, которые задают люди, являются субъективными со свойственными им предвзятостью, предпочтениями и другими сложностями, которые делают проблематичной точную автоматизированную выдачу ответа.
[0003] Автоматические ответы на вопросы (Question Answering, QA) является популярной областью исследований в обработке естественного языка. Обычно это сложная вычислительная задача, которая включает в себя несколько компонентов, таких как понимание вопроса, идентификация фокуса вопроса и формирование ответа. Как правило, вопросы, задаваемые люди, являются субъективными и со свойственными им предвзятостью, предпочтениями, эмоциями и другими сложностями, которые делают проблематичной точную автоматизированную выдачу ответа. Помимо проблем, связанных с идентификацией субъективности, эмоции и фокуса вопроса, QA-системы должны давать ответ в режиме реального времени, зачастую менее чем за минуту. Сформированный ответ должен также напоминать человеческий, т. е. должен быть не только правильными, но и структурированным подобно обычному ответу человека и грамматически правильным. Также желательно, чтобы предоставленный ответ был лаконичным.
[0004] Существующие QA-системы главным образом сконцентрированы на выдаче ответов на основанные на знаниях вопросы фактоидного типа, которые являются сфокусированными, менее неоднозначными и основанными на событиях, которые обычно содержат выражение для ответа. Фактоидные вопросы не столь подвержены влиянию субъективности и мнениям человека, и поэтому на них проще отвечать. Эти существующие QA-системы обычно не понимают фокуса соответствующего вопроса и не осознают или не оценивают эмоционального или субъективного компонента вопроса. Соответственно, существующие QA-системы не в состоянии предоставлять информацию, исходя из фокуса, эмоции или субъективности автора вопроса.
РАСКРЫТИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
[0005] Остается актуальной потребность в автоматизированных вопросно-ответных системах и способах, которые могут в режиме реального времени давать напоминающие человеческие ответы на вопросы из разных областей знаний по самым разным темам.
[0006] Настоящее изобретение относится к обладающим признакам изобретения способам и системам автоматизированного ответа на вопросы. Различные варианты реализации и осуществления, приведенные в настоящем документе, относятся к системе, которая разлагает на части вопрос пользователя за счет понимания области знаний и фокуса вопроса. Предварительно натренированная модель идентификации области знаний вопроса может применять основанный на глубоком обучении ансамблевый метод и может использовать двунаправленную, основанную на рекуррентной нейронной сети (РНС) архитектуру кодер-декодер, где кодер преобразует описание вопроса в вектор фиксированный длины, из которого декодер формирует соответствующие слова данной области знаний. Для разложенного вопроса выполняют поиск в семантическом пространстве латентно-семантического анализа (ЛСА)/латентного размещения Дирихле (ЛРД), построенном с использованием существующих корпусов. После того, как идентифицирован вопрос, имеющий сильное сходство с вопросом, заданным пользователем, система извлекает ответы, данные на наиболее сходные вопросы, заданные ранее, и ранжирует их на основе перекрытия с идентифицированным фокусом и областью знаний. Наилучший ответ, данный на этот вопрос, реконструируют с учетом идентифицированных фокуса и области знаний. В соответствии с вариантом реализации система может быть оптимизирована для краткого ответа на вопросы в режиме реального времени.
[0007] В целом в соответствии с одним аспектом предложена система для автоматического ответа на вопросы. Система включает в себя: семантическое пространство, сформированное из корпуса вопросов и ответов, пользовательский интерфейс, выполненный с возможностью приема вопроса от пользователя, и процессор, содержащий:
(i) движок разложения вопроса, выполненный с возможностью разложения принятого вопроса на по меньшей мере одну область знаний, одно ключевое слово и одно фокусное слово;
(ii) формирователь сходства с вопросом, выполненный с возможностью идентификации одного или более вопросов в семантическом пространстве с использованием разложенного вопроса, причем идентифицированные один или более вопросов определяют как сходные с принятым вопросом;
(iii) движок извлечения и ранжирования ответов, выполненный с возможностью извлечения из семантического пространства ответов, связанных с одним или более идентифицированных вопросов, и идентификации одного или более извлеченных ответов в качестве наилучшего ответа; и
(iv) движок доработки ответа, выполненный с возможностью доработки идентифицированного наилучшего ответа с использованием одного или более из указанной по меньшей мере одной области знаний, одного ключевого слова и одного фокусного слова; причем доработанный ответ предоставляют пользователю посредством пользовательского интерфейса.
[0008] В соответствии с одним вариантом реализации система дополнительно включает в себя корпус вопросов и ответов, причем по меньшей мере некоторые вопросы связаны с соответствующим ответом.
[0009] В соответствии с одним вариантом реализации система дополнительно содержит движок предварительной обработки, выполненный с возможностью предварительной обработки принятого вопроса, включающей в себя одно или более из извлечения текста из принятого вопроса, сегментирования предложения принятого вопроса и исправления правописания принятого вопроса.
[0010] В соответствии с одним вариантом реализации система дополнительно включает в себя базу данных семантического пространства, выполненную с возможностью хранения семантического пространства.
[0011] В соответствии с одним вариантом реализации система дополнительно включает в себя движок синтаксической и семантической связанности, выполненный с возможностью ранжирования одного или более идентифицированных вопросов на основе сходства с принятым вопросом.
[0012] В целом в соответствии с одним аспектом предложен способ для автоматического ответа на вопросы. Способ включает следующие этапы:
(i) предоставление автоматизированной вопросно-ответной системы, содержащей пользовательский интерфейс, процессор и сформированное семантическое пространство;
(ii) прием посредством пользовательского интерфейса вопроса, на который требуется ответ;
(ii) разложение с помощью процессора принятого вопроса на по меньшей мере одну область знаний, одно ключевое слово и одно фокусное слово;
(iv) идентификация с помощью процессора одного или более вопросов в семантическом пространстве с использованием разложенного вопроса, причем идентифицированные один или более вопросов определяют как сходные с принятым вопросом;
(v) ранжирование с помощью процессора одного или более идентифицированных вопросов на основе сходства с принятым вопросом;
(vi) извлечение с помощью процессора из семантического пространства ответов, связанных с одним или более идентифицированных вопросов;
(vii) идентификация с помощью процессора одного или более извлеченных ответов в качестве наилучшего ответа;
(viii) доработка с помощью процессора идентифицированного наилучшего ответа с использованием одного или более из указанной по меньшей мере одной области знаний, одного ключевого слова и одного фокусного слова и
(ix) предоставление посредством пользовательского интерфейса доработанного наилучшего ответа в качестве ответа на принятый вопрос.
[0013] В соответствии с одним вариантом реализации способ дополнительно включает в себя этап формирования семантического пространства из корпуса вопросов и ответов, причем по меньшей мере некоторые вопросы связаны с соответствующим ответом.
[0014] В соответствии с одним вариантом реализации сформированное семантическое пространство сохраняют в базе данных.
[0015] В соответствии с одним вариантом реализации вопросы в семантическом пространстве представляют собой вектор, и разложенный вопрос представляет собой вектор, причем векторы вопросов в семантическом пространстве сравнивают с вектором разложенного вопроса, и при этом вопрос в семантическом пространстве идентифицируют как сходный, если результат сравнения векторов выше заданного порогового значения. В соответствии с одним вариантом реализации заданное пороговое значение содержит значение косинуса.
[0016] В соответствии с одним вариантом реализации способ дополнительно включает в себя этап предварительной обработки принятого вопроса процессором, включающей одно или более из извлечения текста из принятого вопроса, сегментирования предложения принятого вопроса и исправления правописания принятого вопроса.
[0017] В соответствии с одним вариантом реализации этап ранжирования одного или более идентифицированных вопросов на основе сходства с принятым вопросом включает семантический и/или синтаксический анализ идентифицированных вопросов.
[0018] В соответствии с одним вариантом реализации этап идентификации одного или более извлеченных ответов в качестве наилучшего ответа включает ранжирование извлеченных ответов.
[0019] В соответствии с одним вариантом реализации система дополнительно содержит предварительно натренированный классификатор областей знаний вопросов, а принятый вопрос разлагают по меньшей мере частично на основе предварительно натренированного классификатора областей знаний вопросов.
[0020] В различных вариантах реализации процессор или контроллер может быть связан с одним или более носителей информации (упоминаемых в настоящем документе просто как «память», например, энергозависимая и энергонезависимая память компьютера, такая как ОЗУ, ППЗУ, СППЗУ и ЭСППЗУ, гибкие диски, компакт-диски, оптические диски, магнитная лента и т. п.). В некоторых вариантах реализации носители информации могут быть закодированы с помощью одной или более программ, которые при исполнении одним или более процессоров и/или контроллеров, выполняют по меньшей мере некоторые из функций, обсуждаемых в настоящем документе. Различные носители информации могут быть зафиксированы внутри процессора или контроллера или могут быть выполнены с возможностью переноса, чтобы одну или более хранящихся на них программ можно было загружать в процессор или контроллер для осуществления различных аспектов настоящего изобретения, обсуждаемых здесь. Используемые в настоящем документе термины «программа» или «компьютерная программа» в общем смысле относятся к любому типу компьютерного кода (например, к программному обеспечению или микрокоду), который может быть использован для программирования одного или более процессоров или контроллеров.
[0021] Используемый в настоящем документе термин «сеть» относится к любому взаимному соединению двух или более устройств (включая контроллеры или процессоры), которое обеспечивают передачу информации (например, для управления устройствами, хранения данных, обмена данными и т. д.) между любыми двумя или более устройствами и/или среди нескольких устройств, соединенных в сеть. Как нетрудно понять, различные реализации сетей, пригодных для взаимного соединения нескольких устройств, могут включать в себя множество сетевых топологий и использовать любой из множества протоколов связи. Кроме того, в различных сетях в соответствии с настоящим изобретением любое одно соединение между двумя устройствами может быть представлено специализированным соединением между двумя системами или, в альтернативном варианте реализации, неспециализированным соединением. Помимо переноса информации, предназначенной для двух устройств, такое неспециализированное соединение может переносить информацию, необязательно предназначенную для любого из двух устройств (например, открытое сетевое соединение). Кроме того, легко понять, что различные сети устройств, которые обсуждаются в настоящем документе, могут использовать один или более беспроводных, проводных/кабельных и/или оптоволоконных каналов, обеспечивающих передачу информации по всей сети.
[0022] Следует понимать, что все сочетания вышеупомянутых понятий и дополнительных понятий, обсуждаемых более подробно ниже (при условии, что такие понятия не являются взаимно несовместимыми), рассматриваются как часть объекта изобретения, описанного в настоящей заявке. В частности, все сочетания заявленного объекта изобретения в конце данного описания рассматриваются как часть объекта изобретения, описанного в настоящей заявке. Также следует понимать, что терминологии, используемой в явной форме в настоящем документе, которая может также встретиться в любом описании, включенном посредством ссылки, следует придавать смысл, наиболее согласующийся с конкретными понятиями, описанными в настоящем документе.
[0023] Эти и другие особенности настоящего изобретения очевидны из вариантов реализации, описанных ниже в настоящем документе, и будут пояснены со ссылкой на данные варианты реализации.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0024] На чертежах аналогичные номера позиций, как правило, относятся к одним и тем же деталям на всех различных видах. Кроме того, чертежи необязательно выполнены в масштабе, вместо этого упор в основном делается на иллюстрацию принципов изобретения.
[0025] На ФИГ. 1 приведена блок-схема способа автоматического ответа на вопросы в соответствии с вариантом реализации.
[0026] На ФИГ. 2 приведена блок-схема способа создания семантического пространства в соответствии с вариантом реализации.
[0027] На ФИГ. 3 приведена блок-схема способа разложения вопроса в соответствии с вариантом реализации.
[0028] На ФИГ. 4 приведена блок-схема способа разложения вопроса в соответствии с вариантом реализации.
[0029] На ФИГ. 5 приведена блок-схема способа идентификации вопросов в семантическом пространстве в соответствии с вариантом реализации.
[0030] На ФИГ. 6 приведена блок-схема способа идентификации вопросов в семантическом пространстве в соответствии с вариантом реализации.
[0031] На ФИГ. 7 приведена блок-схема способа ранжирования идентифицированных вопросов в соответствии с вариантом реализации.
[0032] На ФИГ. 8 приведена блок-схема способа ранжирования и доработки извлеченных ответов в соответствии с вариантом реализации.
[0033] На ФИГ. 9 приведена блок-схема способа автоматического ответа на вопросы в соответствии с вариантом реализации.
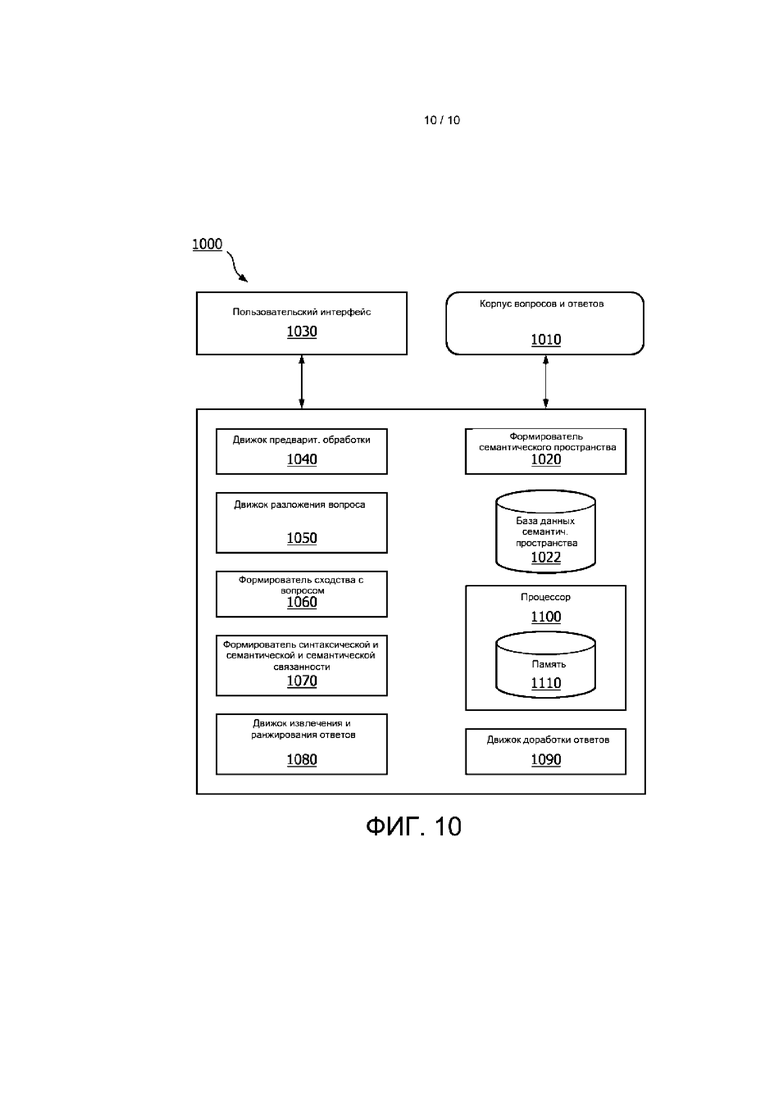
[0034] На ФИГ. 10 приведено схематическое представление системы для автоматического ответа на вопросы в соответствии с вариантом реализации.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
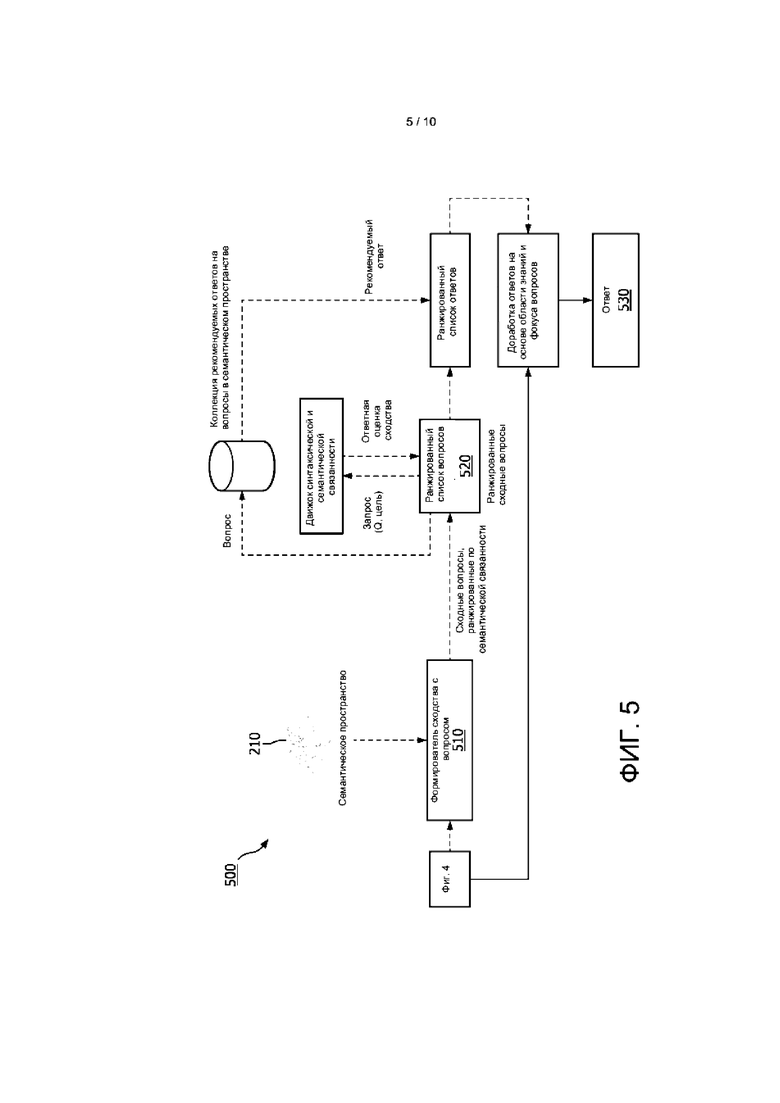
[0035] В настоящем описании раскрыты различные варианты реализации автоматизированной вопросно-ответной системы. В частности, заявитель осознал и понял, что было бы полезно создать систему, которая более точно дает напоминающие человеческие ответы на субъективные вопросы в режиме реального времени. Автоматизированная вопросно-ответная система принимает вопрос пользователя и извлекает одну или более областей знаний, фокусных слов и/или ключевых слов. Система проводит сравнение разложенного вопроса по всему семантическому пространству и идентифицирует хранящиеся вопросы, которые сильно сходны с поставленным вопросом. Затем система извлекает ответы на эти вопросы, которые наиболее сходны с поставленным вопросом, и ранжирует эти ответы на основе сходства или перекрытия с извлеченными фокусными словами и областями знаний. Наилучший ответ идентифицируют и предоставляют пользователю.
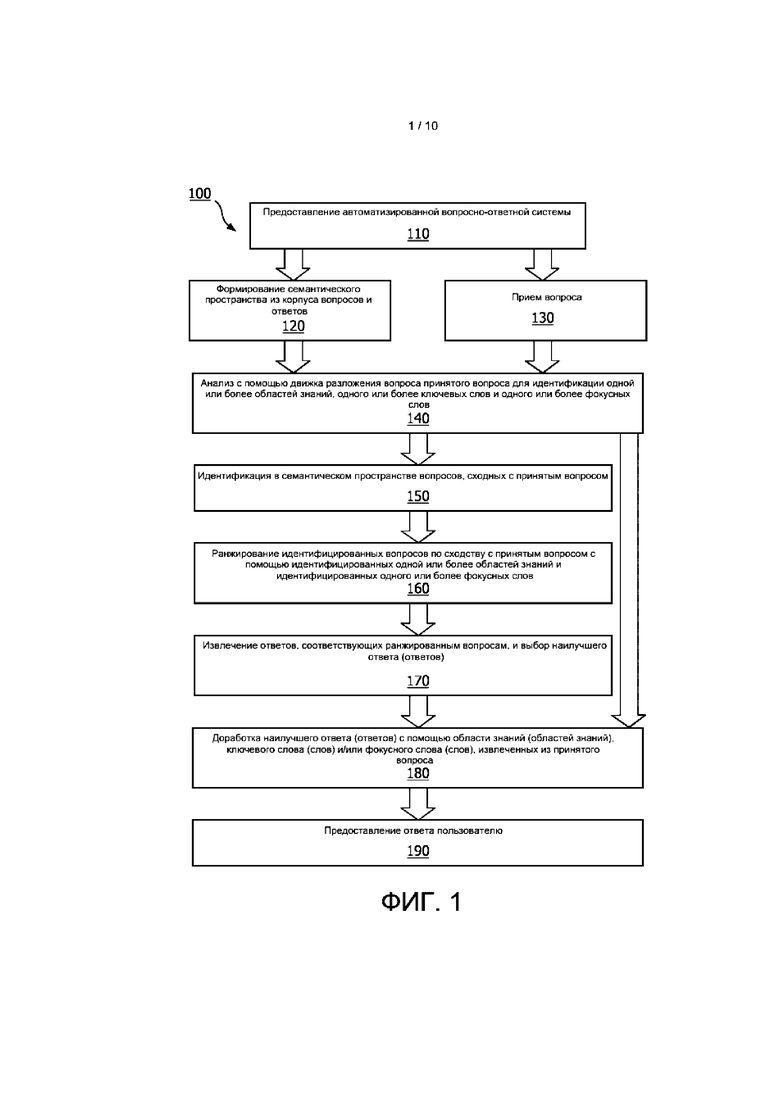
[0036] На ФИГ. 1 представлена используемая в одном варианте реализации блок-схема способа 100 для автоматизированной вопросно-ответной системы. На этапе 110 способа предоставляют автоматизированную вопросно-ответную систему. Автоматизированная вопросно-ответная система может быть любой из систем, описанных или иным образом предполагаемых в настоящем документе.
[0037] На этапе 120 способа создают семантическое пространство из существующего или формируемого корпуса вопросов и/или ответов. В соответствии с вариантом реализации семантическое пространство является основой для представления значения слова, как правило, даваемого в виде математического представления. Семантическое пространство полезно для обработки естественного языка, в том числе для извлечения информации. Слова и/или выражения могут быть представлены в виде векторов высокой размерности, а сравнения между словами или выражениями могут быть выполнены, в качестве лишь примера, путем сравнения косинуса угла между векторами, представляющими слова или выражения, хотя возможны также множество других способов. В соответствии с вариантом реализации этап 120 способа может быть выполнен один раз для создания семантического пространства, которое используют для многочисленных анализов вопросов/ответов. В альтернативном варианте реализации семантическое пространство могут создавать повторно или обновлять на регулярной и/или постоянной основе.
[0038] Одним из способов создания семантического пространства является латентно-семантический анализ (ЛСА). ЛСА представляет собой форму обработки естественного языка, в которой слова, сходные по смыслу, будут появляться в похожем тексте. При сравнении косинуса угла между двумя векторами, представляющими два слова, результат близкий к 1, представляет сходные слова, тогда как результат, близкий к 0, представляет несходные слова. Еще одним способом создания семантического пространства является латентное размещение Дирихле (ЛРД). ЛРД представляет собой форму обработки естественного языка, при которой формируют статистическую модель для получения возможности объяснения наблюдений ненаблюдаемыми группами, объясняющими, почему некоторые части данных схожи. В дополнение к ЛСА и ЛРД или в качестве альтернативы к ЛСА или ЛРД возможны другие способы и алгоритмы создания семантического пространства, в том числе без ограничений основанная на WordNet семантика и формирование меры сходства.
[0039] Любой существующий или формируемый корпус вопросов и ответов, используемый для создания семантического пространства, может быть получен из любого общедоступного и/или частного источника. В соответствии с вариантом реализации семантическое пространство можно построить, взяв, например, миллионный корпус вопросов и ответов Yahoo® 4.4 или любую другую коллекцию вопросов/ответов. В некоторых таких вариантах реализации могут быть выбраны все заголовки вопросов, очищены путем удаления стандартного стоп-слова, и затем из них могут быть извлечены основы слов. В качестве лишь одного примера в различных вариантах реализации может быть построено семантическое пространство размерности 300, хотя возможны более высокие или более низкие размерности. В других вариантах реализации может быть использован этот же или подобный процесс очистки и выделения основ.
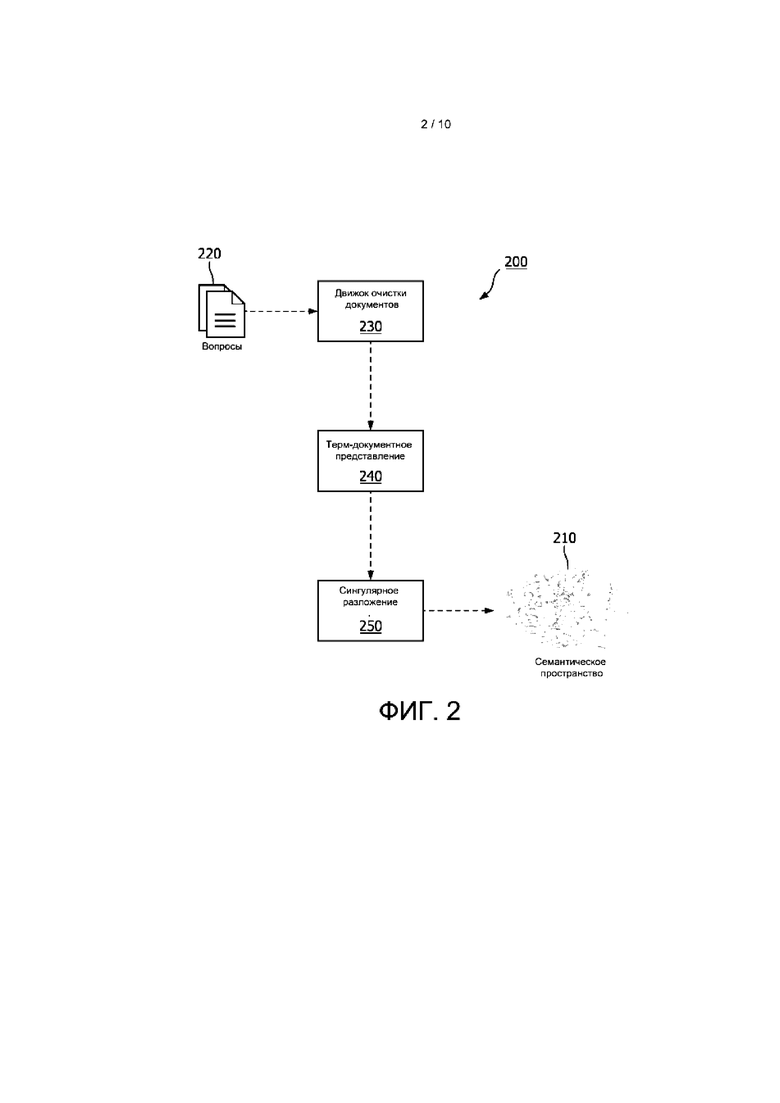
[0040] На ФИГ. 2 представлена используемая в одном варианте реализации блок-схема способа 200 создания семантического пространства 210. В соответствии с вариантом реализации способ 200 выполняют с помощью одного или более процессоров систем, описанных в настоящем документе. В альтернативном варианте реализации способ 200 может быть выполнен удаленным или не являющимся частью системы процессором, и сформированное семантическое пространство может быть использовано алгоритмами или процессорами систем, описанных в настоящем документе. На этапе 220 система принимает корпус вопросов и/или ответов. Система очищает документ или документы, составляющие корпус вопросов и/или ответов на этапе 230, который может быть выполнен с помощью любого ныне известного или будущего способа подготовки или очистки документов. На этапе 240 система выполняет анализ терм-документного представления, в котором термины и документы представляют матрицей. Например, каждому из уникальных терминов в коллекции документов может быть назначена строка в матрице, а каждому документу в коллекции может быть назначен столбец в матрице. На этапе 250 способа выполняют сингулярное разложение (СР). СР - это математический подход, в котором из большого фрагмента текста строят матрицу, содержащую количества слов в абзаце, где строки представляют уникальные слова, а столбцы представляют каждый абзац. В соответствии с вариантом реализации могут быть выполнены либо этап 240, либо этап 250, либо оба этапа.
[0041] На этапе 130 способа принимают вопрос. Вопрос может быть принят с использованием любого способа или системы или любого источника. Например, вопрос может быть принят от пользователя в режиме реального времени, например, из мобильного устройства, переносного компьютера, настольного компьютера, носимого устройства, домашнего вычислительного устройства или любого другого вычислительного устройства. Вопрос может быть принят из любого пользовательского интерфейса, который позволяет принимать информацию, такого как микрофон или текстовый ввод среди множества других типов пользовательских интерфейсов. В альтернативном варианте реализации вопрос может быть принят из вычислительного устройства или автоматизированной системы. Например, смартфон пользователя может быть запрограммирован на запрос системы о темах, относящихся к действиям, движениям, местоположению или другим аспектам пользователя.
[0042] Вопрос может быть по любой теме. Например, в число вопросов могут входить: «Следует ли мне продать свой дом?», «Где мне лучше всего работать?», «Где припаркован мой автомобиль?», «Зачем мне вкладывать средства на пенсию?» среди многих и многих других типов, форм и вариантов вопросов. Вопрос может быть очень узким и связанным с конкретным фактом с известным и постоянным ответом («Почему небо голубое?») или может быть широким и ничем не ограниченным с возможно неизвестным и непостоянным ответом («Могут ли быть приведения в моем доме?»).
[0043] Вопрос может быть принят непосредственно автоматизированной вопросно-ответной системой или может быть принят дистанционно и передан или иным образом сообщен системе. Например, автоматизированная вопросно-ответная система может содержать пользовательский интерфейс, который принимает вопросы напрямую. В альтернативном варианте реализации автоматизированная вопросно-ответная система может содержать модуль связи, который принимает вопросы из любой проводной и/или беспроводной сети, такой как внутренняя сеть или Интернет.
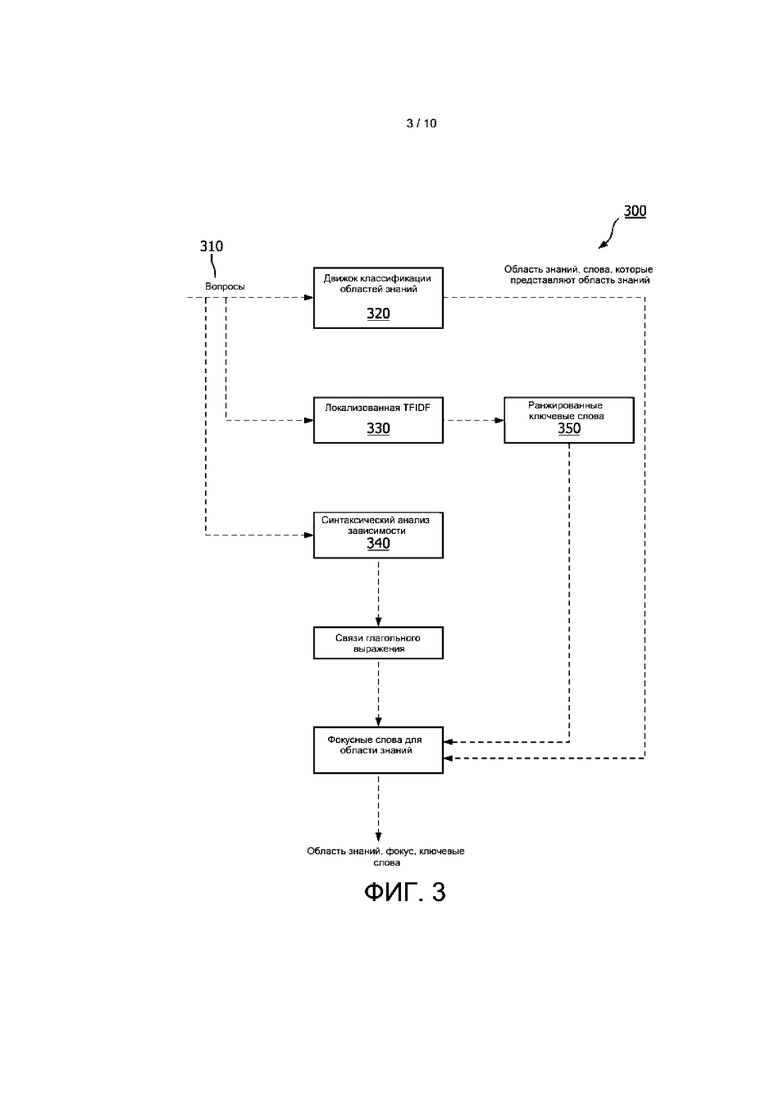
[0044] На этапе 140 способа движок разложения вопроса анализирует принятый вопрос для идентификации в вопросе одного или более элементов, таких как одна или более областей знаний, одно или более ключевых слов и одно или более фокусных слов. На ФИГ. 3 представлена блок-схема способа 300 разложения вопроса. Вопрос 310 принимают и анализируют с помощью одного или более движков 320 классификации области знаний, локализованного движка 330 частоты термина-обратной частоты документа (TFIDF) и/или синтаксического анализатора 340 зависимости.
[0045] В соответствии с вариантом реализации движок 320 классификации области знаний анализирует принятый вопрос 310 с использованием предварительно натренированной модели идентификации областей знаний вопросов, построенной ансамблевым методом на основе глубокого обучения. В различных вариантах реализации используют двунаправленную, основанную на рекуррентной нейронной сети (РНС) архитектуру кодер-декодер, где кодер преобразует описание вопроса в вектор фиксированный длины, из которого декодер формирует соответствующие слова области знаний.
[0046] В соответствии с вариантом реализации локализованный движок 330 частоты термина-обратной частоты документа анализирует вопрос для определения того, насколько важно слово для документа, и может быть использован как весовой коэффициент. Например, значение TFIDF может снижать вес рассматриваемого слова, если это слово часто встречается в тренировочном корпусе. TFIDF может формировать список ранжированных ключевых слов 350, которые могут быть использованы для формирования фокусных слов для вопроса.
[0047] В соответствии с вариантом реализации синтаксический анализатор 340 зависимости анализирует определенные ключевые слова и слова, которые изменяют эти ключевые слова. Выходные данные синтаксического анализатора 340 зависимости помимо других анализов могут быть дополнительно проанализированы для идентификации связей глагольного выражения.
[0048] В соответствии с вариантом реализации выходными данными движка разложения вопроса могут быть один или более элементов, таких как одна или более областей знаний, одно или более ключевых слов и/или одного или более фокусных слов принятого вопроса.
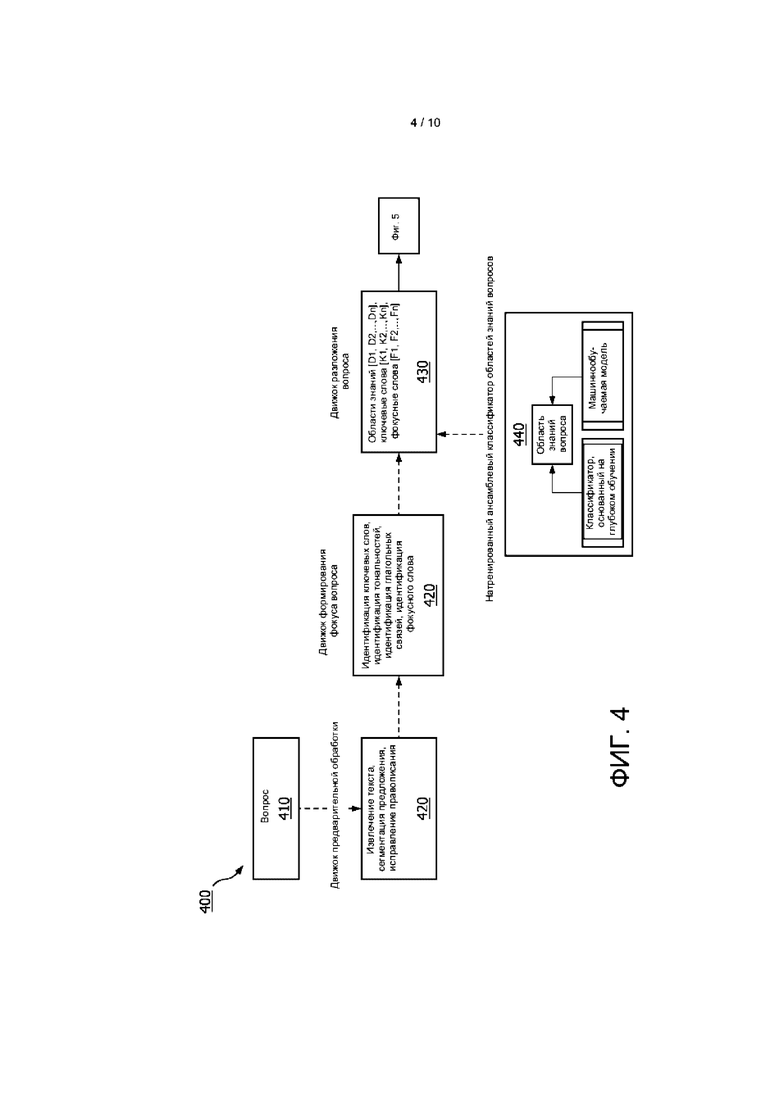
[0049] На ФИГ. 4 представлена другая блок-схема способа 400 разложения вопроса. Вопрос 410 принимают и анализируют с помощью движка 420 предварительной обработки, который идентифицирует и/или извлекает текст из принятого вопроса (например, преобразованием звукового файла в текст), сегментирует предложение и/или исправляет правописание в тексте. Движок 430 формирования фокуса вопроса анализирует предварительно обработанный вопрос для идентификации одного или более ключевых слов, одной или более тональностей или одной или более глагольных связей, или одного или более ключевых слов. Движок 430 разложения вопроса, описанный более полно выше со ссылкой на ФИГ. 3, идентифицирует в вопросе один или более элементов, таких как одна или более областей знаний, одно или более ключевых слов и одно или более фокусных слов.
[0050] В соответствии с вариантом реализации с целью очистки вопроса в различных вариантах реализации основное внимание может быть уделено удалению искаженных символов, исправлению правописания и/или сегментации предложения. Язык, используемый в вопросах, может быть, например, неформальным социальным медийным языком или сленгом. Для очистки тела и заголовка вопроса в различных вариантах реализации используются одни и те же этапы. После очистки вопроса в вариантах реализации может быть выполнено разложение вопроса за счет сосредоточения внимания на идентификации ключевых слов, идентификации тональностей и/или формирования фокусных слов.
[0051] В соответствии с вариантом реализации движок 430 разложения вопроса использует предварительно натренированный ансамблевый классификатор 440 областей знаний вопросов. Классификатор 440 может содержать предварительно натренированный модуль идентификации областей знаний вопросов, построенный с использованием ансамблевого метода на основе глубокого обучения. Например, классификатор 440 может использовать двунаправленную, основанную на рекуррентной нейронной сети (РНС) архитектуру кодер-декодер, где кодер преобразует описание вопроса в вектор фиксированный длины, из которого декодер формирует соответствующие слова области знаний. Возможны другие способы формирования классификатора областей знаний вопросов.
[0052] На этапе 150 способа, изображенного на ФИГ. 1, выполняют поиск по разложенному вопросу в сформированном семантическом пространстве, чтобы идентифицировать в этом пространстве вопросы, имеющие сильное сходство, например, в семантической структуре и/или фокусе, с принятым вопросом. Поиск по разложенному вопросу, который может содержать одну или более областей знаний, одно или более ключевых слов и/или одно или более фокусных слов, в семантическом пространстве может быть осуществлен с использованием самых разных способов. Вопросы в семантическом пространстве, сходные с принятым вопросом, могут быть идентифицированы с использованием самых разных способов.
[0053] На ФИГ. 5 представлена используемая в одном варианте реализации блок-схема способа 500 идентификации в семантическом пространстве вопросов, сходных с принятым вопросом. Разложенный вопрос, содержащий одну или более областей знаний, одно или более ключевых слов и/или одно или более фокусных слов, принимают из движка 430 разложения вопроса и выполняют по нему поиск в семантическом пространстве 201 с помощью формирователя 510 сходства с вопросом. Например, в различных вариантах реализации способа, описанных или иным образом предполагаемых в настоящем документе, в семантическом пространстве могут быть идентифицированы вопросы, которые имеют косинусное сходство больше, чем 0,7, хотя возможны другие значения. В некоторых вариантах реализации после экспериментирования, экспертной оценки или анализа, машинного обучения или других подходов может быть выбрано пороговое значения. Затем идентифицированные вопросы могут быть ранжированы с использованием идентифицированных одной или более областей знаний, одного или более ключевых слов и/или одного или более фокусных слов.
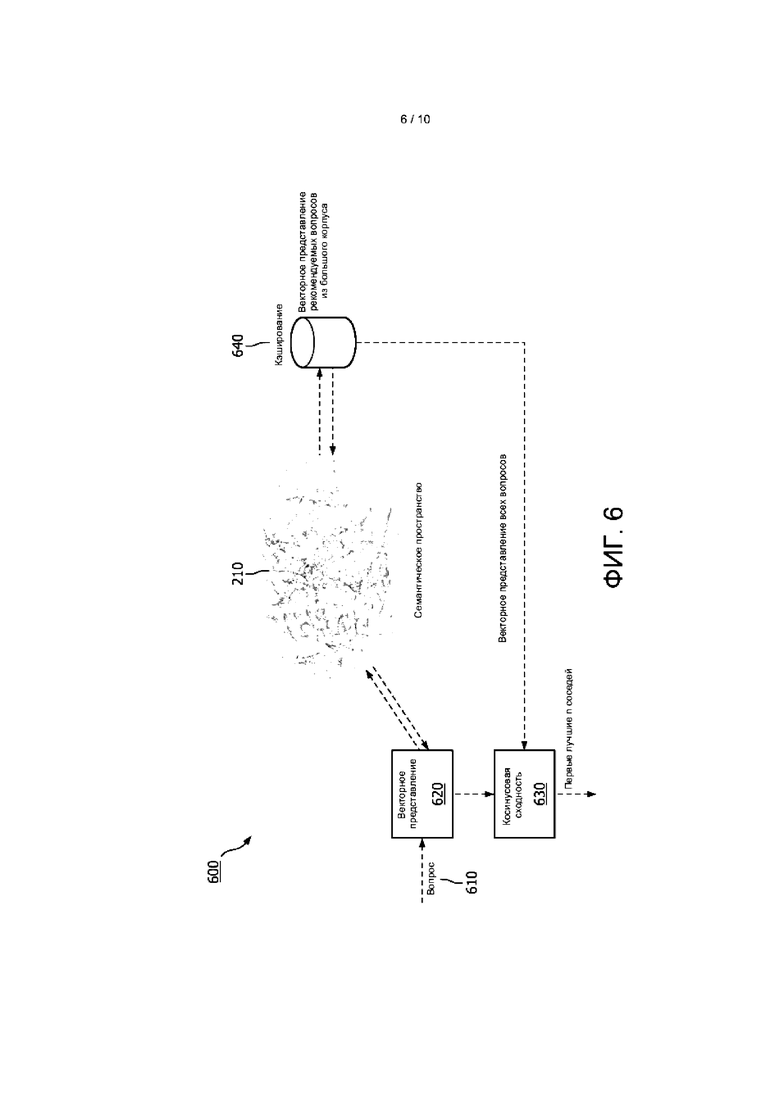
[0054] На ФИГ. 6 представлена используемая в одном варианте реализации блок-схема способа 600 идентификации в семантическом пространстве вопросов, сходных с принятым вопросом. На этапе 620 разобранный или разложенный вопрос 610, содержащий одну или более областей знаний, одно или более ключевых слов и/или одно или более фокусных слов, принимают и преобразуют в векторное представление. В альтернативном варианте реализации разобранный или разложенный вопрос предварительно преобразуют, изменяют или анализируют для формирования векторного представления, и это векторное представление принимается системой. Затем векторное представление принятого вопроса сравнивают со сформированными векторами вопросов в семантическом пространстве 210. В соответствии с вариантом реализации выполняют сравнения с вопросами в пределах семантического пространства, при этом идентифицируют векторы, которые имеют косинусное сходство больше заданного порогового значения. Заданное пороговое значение может быть предварительно запрограммировано, основано на пользовательской настройке, выведено из машинного обучения, основано по меньшей мере частично на одном или более из идентифицированных одной или более областей знаний, одном или более ключевых слов и/или одном или более фокусных слов, или установлено с помощью другого механизма или параметра. В соответствии с вариантом реализации векторы вопросов из семантического пространства 210 хранят в базе 640 данных для быстрого извлечения и анализа.
[0055] Результатом этой фильтрации является ранжированный список семантически сходных вопросов. Этот список вопросов может не точно относиться к вопросу с точки зрения полярности и направления действия, поскольку он представляет собой модель «мешок слов». Чтобы выделить сходный вопрос, как по смыслу, так и по синтаксису, список вопросов может быть, в числе прочих анализов, дополнительно обработан на предмет сходных ключевых слов и порядка слов на основе мер сходности.
[0056] На этапе 160 способа вопросы, идентифицированные на этапе 150, затем ранжируют с использованием, например, идентифицированных одной или более областей знаний, одного или более ключевых слов и/или одного или более фокусных слов, чтобы сформировать ранжированный список вопросов 520, как показано на ФИГ. 5.
[0057] В соответствии с вариантом реализации локализованное извлечение ключевых слов на основе предварительно натренированных с помощью корпуса оценок TFIDF может способствовать идентификации важных слов в вопросах. Эти слова используют для получения оценки перекрытия слов и повторного ранжирования вопросов, которые получены с этапа семантического сходства. Для локализованного извлечения ключевых слов в различных вариантах реализации могут быть использованы один или более алгоритмов извлечения ключевых слов.
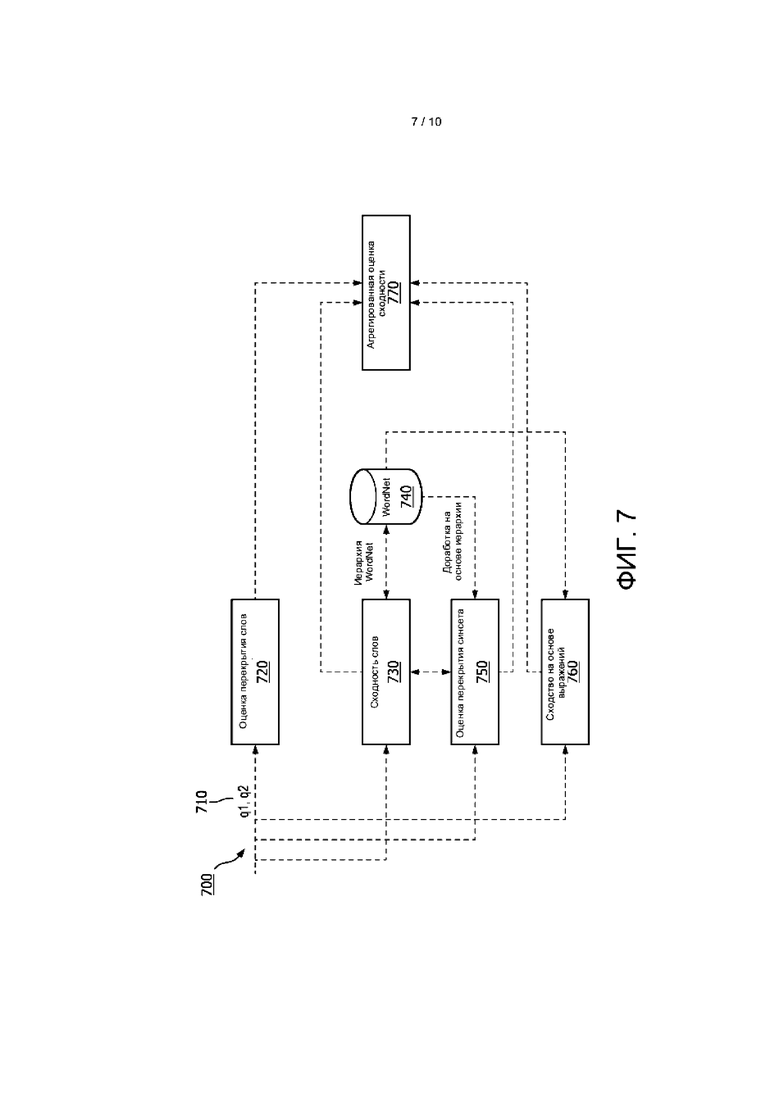
[0058] После идентификации ранжированного списка вопросов, которые семантически наиболее близки к вопросу, заданному пользователем, в различных вариантах реализации могут быть использованы один или более способов или алгоритмов для дальнейшего надежного идентификации сходности между вопросами. В соответствии с одним способом процесс анализа может сильно зависеть от порядка слов и может использовать WordNet для определения прочности взаимосвязи между словами. Например, слова, принадлежащие к одному и тому же "синсету", или синонимичные слова, обладающие одинаковым смыслом или значением, могут иметь более высокий вес, чем слова, принадлежащие разным синсетам.
[0059] Кроме того, если слова имеют общую гиперонимическую или гипонимическую взаимосвязь, то этим словам могут быть присвоены меньшие веса по сравнению с синонимичными словами. Чем выше разница в уровне взаимосвязи, тем ниже вес. Поскольку данный способ может зависеть от длины предложений, он может быть вычислительноемким, и, следовательно, в различных вариантах реализации может быть использован механизм кэширования для улучшения скорости вычислений алгоритма.
[0060] На ФИГ. 7 представлена используемая в одном варианте реализации блок-схема способа 700 ранжирования идентифицированных вопросов на этапе 160. Список вопросов (q1, q2) 710 формируют и/или принимают с помощью системы и анализируют с использованием одного или более процессов. Например, список вопросов может быть проанализирован на предмет оценки перекрытия слов на этапе 720, на похожесть слов на этапе 730, причем может быть использован или не использован WordNet на этапе 740, на перекрытие синсета на этапе 750 и основанную на выражении похожесть на этапе 760. Результатом данного процесса является список ранжированных идентифицированных вопросов с агрегированной оценкой 770 сходности.
[0061] На этапе 170 способа выделяют и ранжируют ответы в пределах семантического пространства, связанного с ранжированными идентифицированными вопросами, причем ранжирование может быть основано по меньшей мере частично на перекрытии с идентифицированным фокусом и/или областью знаний. Например, после приема окончательного ранжированного списка вопросов с предыдущего этапа в различных вариантах реализации выделяют ответы, ранее данные на эти вопросы. Затем система может ранжировать ответы на основе перекрытия с ключевым словом и совпадения с фокусом вопроса. Если ответы ограничены определенной длиной, такой как 1000 символов или менее, то в некоторых вариантах реализации могут быть выбраны одно или более предложений, которые наиболее репрезентативны для фокуса и взвешенных ключевых слов, извлеченных из заголовка вопроса и тела вопроса. В вариантах реализации могут выбирать наилучший ответ, который имеет вопрос, тоже ранжированный высоко и совпадающих по характеристикам с ответом.
[0062] На этапе 180 способа наилучший ответ или ответы, идентифицированные на этапе 170, дорабатывают с использованием идентифицированных одной или более областей знаний, одного или более ключевых слов и одного или более фокусных слов, извлеченных из принятого вопроса.
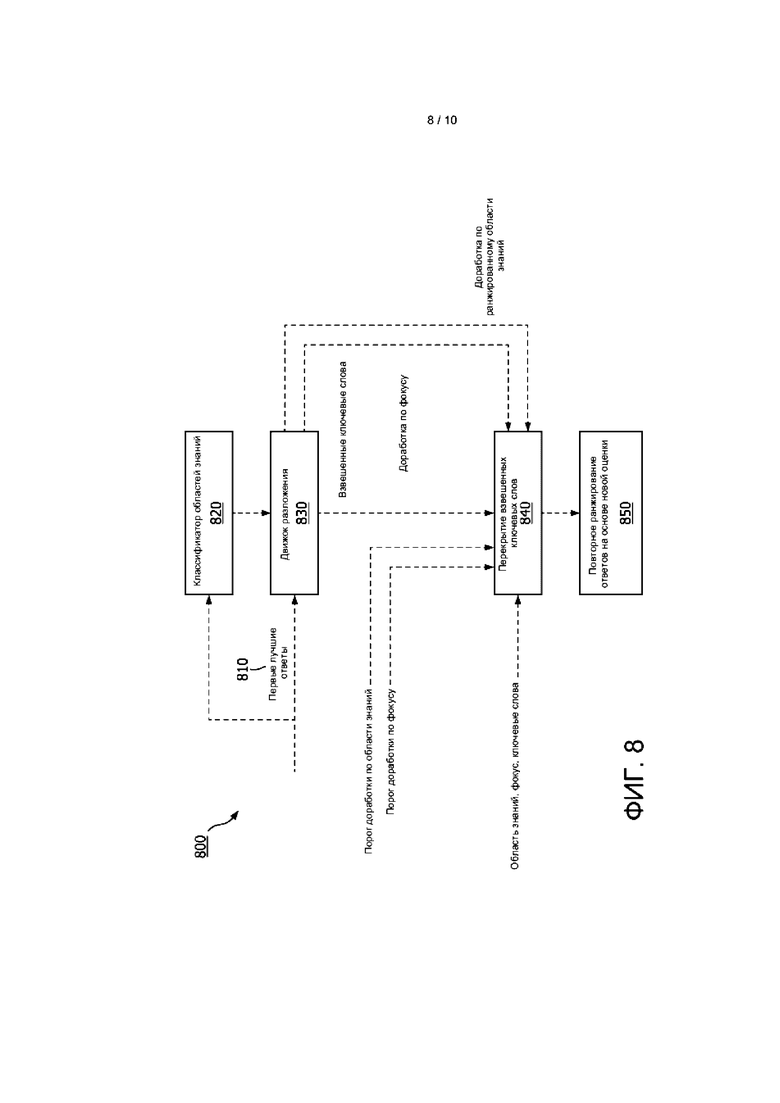
[0063] На ФИГ. 8 представлена используемая в одном варианте реализации блок-схема способа 800 ранжирования и доработки извлеченных ответов. Ответы 810 на один или более ранжированных идентифицированных вопросов предоставляют в систему или иным образом принимаются ею. Эти ответы подают в классификатор 820 областей знаний для идентификации одной или более областей знаний этих вопросов, и подают в движок 830 разложения для разложения ответов. Движок разложения создает одно или более взвешенных ключевых слов из одного или более ответов, которые затем анализируют на перекрытие на этапе 840. Кроме того, на этапе 840 обеспечивают идентифицированные одну или более областей знаний, одно или более ключевых слов и одно или более фокусных слов, извлеченных из принятого вопроса.
[0064] Затем на этапе 850 один или более ответов повторно ранжируют на основе по меньшей мере частично доработки и идентифицируют один наилучший ответ.
[0065] На этапе 190 способа пользователю предоставляют окончательный ответ. Например, как показано на ФИГ. 5, после доработки ответа (ответов) пользователю предоставляют окончательный ответ 530. Ответ может быть предоставлен пользователю посредством любого пользовательского интерфейса, который позволяет передавать информацию, такого как динамик или экран среди множества других типов пользовательских интерфейсов. В альтернативном варианте реализации ответ может быть предоставлен из вычислительного устройства или автоматизированной системы. Например, смартфон пользователя может быть запрограммирован на автоматический запрос системы относительно тем, относящихся к действиям, движениям, местоположению или другим аспектам пользователя, и будет автоматически принимать ответ для предоставления пользователю по мере надобности, по запросу или иным образом.
[0066] В соответствии с вариантом реализации окончательный ответ предоставляют пользователю в течение 60 секунд или менее, 30 секунд или менее, 10 секунд или менее, или в течение любого более или менее длительного промежутка времени. Этот промежуток времени может быть предварительно определенным или может быть основан на одной или более пользовательских настроек, изученных машиной параметрах или любых других параметрах. Например, пользователь может указать промежуток времени посредством пользовательского интерфейса или пользовательской настройки. Этот указанный пользователем промежуток времени может влиять на один или более этапов способа, описанных в настоящем документе, например, ограничивая объем обработки, выполняемой на одном или более этапах.
[0067] На ФИГ. 9 представлена используемая в одном варианте реализации блок-схема способа 900 для автоматизированной вопросно-ответной системы, аналогичного способам, описанным выше. На этапе 910 выбранный наилучший ответ анализируют в точке принятия решения, где ответ анализируют, чтобы определить, является ли он наилучшим ответом. Данный способ может быть применен, например, в случаях, когда в принимаемом вопросе упоминается специфический объект и/или имеется фактический или известный ответ. Например, вопрос может быть вопросом с известным или основанном на объекте ответом («Кто такая Мэри Поппинс?»), но для которого семантическое пространство может не иметь наилучшего ответа. Соответственно, система может сравнивать ответ с базой данных или другой системой и определять, что она ответила правильно или, вероятно, ответила правильно, и в таком случае ответ предоставляют пользователю. В альтернативном варианте реализации, если система определяет, что ответ дан неверно или вряд ли дан верно, система может запросить в базе данных известные или основанные на объекте ответы на этапе 920, чтобы идентифицировать ответ, который является наилучшим ответов, или, скорее всего, является лучшим ответом.
[0068] На ФИГ. 10 приведено схематическое представление системы 1000 для автоматического ответа на вопросы в соответствии с вариантом реализации. Система 1000 может включать в себя любой из элементов, движков, баз данных, процессоров и/или других компонентов, описанных или иным образом предполагаемых в настоящем документе. В соответствии с вариантом реализации система 1000 содержит пользовательский интерфейс 1030 для приема вопроса и/или выдачи ответа. Пользовательский интерфейс может представлять собой любое устройство или систему, которые позволяют передавать и/или принимать информацию, такие как динамик или экран среди множества других типов пользовательских интерфейсов. Информация может быть также передана в вычислительное устройство или автоматизированную систему и/или принята из них. Пользовательский интерфейс может находиться вместе с одним или более другими компонентами системы, или может находиться удаленно от системы и обмениваться данными посредством проводной и/или беспроводной сети связи.
[0069] В соответствии с вариантом реализации система 1000 содержит корпус 1010 вопросов и ответов или поддерживает связь с ним, или принимает его. Как описано или иным образом предполагается в настоящем документе, формирователь 1020 семантического пространства использует корпус вопросов и ответов для формирования семантического пространства. Сформированное семантическое пространство может быть сохранено в базе 1022 данных семантического пространства, которая может находиться вместе с одним или более другими компонентами системы, или может находиться удаленно от системы и обмениваться данными посредством проводной и/или беспроводной сети связи.
[0070] В соответствии с вариантом реализации система 1000 содержит движок 1040 предварительной обработки, который идентифицирует и/или извлекает текст из принятого вопроса, сегментирует предложение и/или исправляет правописание в тексте. Движок 1040 предварительной обработки может содержать движок формирования фокуса вопроса, который анализирует предварительно обработанный вопрос для идентификации одного или более ключевых слов, одной или более тональностей, или одной или более глагольных связей, или одного или более ключевых слов. Движок 1040 предварительной обработки может подавать свои выходные данные в качестве входных данных в движок формирования фокуса вопроса.
[0071] В соответствии с вариантом реализации система 1000 содержит движок 1050 разложения вопроса, который идентифицирует два или более элементов, таких как одна или более областей знаний, одно или более ключевых слов и/или одного или более фокусных слов, из вопроса.
[0072] В соответствии с вариантом реализации система 1000 содержит формирователь 1060 сходства с вопросом, который принимает разложенный вопрос, содержащий одну или более областей знаний, одно или более ключевых слов и/или одно или более фокусных слов, и выполняет по нему поиск в сформированном семантическом пространстве, чтобы идентифицировать вопросы, которые сходны с разложенным вопросом. Сходство может быть определено, например, на основе сравнения косинусов векторов вопросов семантического пространства и принятого вопроса, среди прочих способ. Затем идентифицированные вопросы могут быть ранжированы с использованием идентифицированных одной или более областей знаний, одного или более ключевых слов и/или одного или более фокусных слов.
[0073] В соответствии с вариантом реализации система 1000 содержит движок 1070 синтаксической и семантической связанности. Движок синтаксической и семантической связанности может идентифицировать вопросы, которые семантически наиболее близки к вопросу, заданному пользователем. Движок может дополнительно или в качестве альтернативы определять, имеют ли вопросы или слова в вопросе общую гиперонимическую, гипонимическую или синонимическую взаимосвязь, и может после этого корректировать вес вопроса соответствующим образом.
[0074] В соответствии с вариантом реализации система 1000 содержит движок 1080 извлечения и ранжирования ответов. Движок извлечения и ранжирования ответов идентифицирует ответы в пределах семантического пространства, связанного с ранжированными идентифицированными вопросами, причем ранжирование может быть основано по меньшей мере частично на перекрытии с выявленным фокусом и/или областью знаний. Возможны другие способы ранжирования извлеченных ответов.
[0075] В соответствии с вариантом реализации система 1000 содержит движок 1090 доработки ответа, который дорабатывает идентифицированные и ранжированные ответы, используя идентифицированные одну или более областей знаний, одно или более ключевых слов и/или одного или более фокусных слов, извлеченных из принятого вопроса. Возможны другие способы доработки извлеченных ответов. Выходные данные движка 1090 доработки ответа могут быть предоставлены пользователю посредством пользовательского интерфейса 1030.
[0076] В соответствии с вариантом реализации система 1000 содержит процессор, который выполняет один или более этапов способа и может включать в себя один или более движков или формирователей. Процессор 1100 может быть образован одним или несколькими модулями и может содержать, например, память 1110. Процессор 1100 может принимать любую подходящую форму, в том числе без ограничений микроконтроллера, нескольких микроконтроллеров, электрической схемы, одного процессора или множества процессоров. Память 1110 может принимать любую подходящую форму, в том числе энергонезависимой памяти и/или ОЗУ, Энергонезависимая память может включать в себя постоянное запоминающее устройство (ПЗУ), накопитель на жестких магнитных дисках (НЖМД) или твердотельный накопитель (ТТН). Память может хранить, среди прочего, операционную систему. ОЗУ используется процессором для временного хранения данных. В соответствии с вариантом реализации операционная система может содержать код, который при исполнении его процессором управляет работой одного или более компонентов системы 1000.
[0077] Все определения, сформулированные и используемые в настоящем документе, следует понимать как имеющие преимущество перед определениями в словарях, определениями в документах, включенных путем ссылки, и/или обычными значениями определяемых терминов.
[0078] Используемые в настоящем описании и формуле изобретения средства выражения единственного числа следует понимать как означающие «по меньшей мере один/одна/одно», если только иное не указано в явной форме.
[0079] Используемую в настоящем описании и формуле изобретения выражение «и/или» следует понимать как означающую «любой из двух или оба» из элементов, соединенных таких образом, т. е. элементов, которые в некоторых случаях представлены в конъюнктивной форме, а других случаях в дизъюнктивной форме. Несколько элементов, перечисленных с помощью «и/или», следует понимать таким же образом, т. е. «один или более» из элементов, соединенных таким образом. Могут, необязательно, присутствовать другие элементы, отличные от элементов, специально указанных с помощью выражения «и/или», вне зависимости от того, относятся ли она или не относятся к этим специально указанным элементам.
[0080] Используемый в настоящем описании и формуле изобретения союз «или» следует понимать, как имеющий то же значение, что и выражение «и/или», определенная выше. Например, при разделении элементов в списке «или» или «и/или» следует понимать как включающие, т. е. включение по меньшей мере одного, но также включение более, чем одного, из числа или списка элементов и, необязательно, дополнительных неперечисленных элементов. Только выражения, в явном виде указывающие противоположное, такие как «только один/одна/одно из» или «ровно один/одна/одно из», или выражение «состоящий/состоящая/состоящее из», используемая в формуле изобретения, будут относиться ровно к одном элементу из числа или списка элементов. Как правило, используемый в настоящем документе термин «или» следует понимать только как указывающий исключительные варианты (т. е. «один или другой, но не оба»), когда ему предшествуют термины исключения, такие как «один из двух», «один из», «только один из» или «ровно один из».
[0081] Используемую в настоящем описании и формуле изобретения выражение «по меньшей мере один» в отношении списка из одного или более элементов следует понимать как означающую по меньшей мере один элемент, выбранный из одного или более элементов в этом списке элементов, но, необязательно, включая по меньшей мере один из каждого и каждый элемент, конкретно перечисленные в списке элементов, и не исключая никаких комбинаций элементов в списке элементов. Это определение также допускает, необязательно, присутствие элементов, отличных от элементов, конкретно указанных в списке элементов, к которым относится выражение «по меньшей мере один», вне зависимости от того, относится ли она или не относится к этим элементам, указанным конкретно.
[0082] Также следует понимать, что если иное не указано в явной форме, во всех способах, заявленных в настоящем описании, которые содержат более одного этапа или действия, порядок этапов или действий способа необязательно ограничен порядком, в котором этапы и действия способа изложены.
[0083] В формуле изобретения, а также в приведенном выше описании, все переходные выражения, такие как «содержащий», «включающий в себя», «имеющий», «охватывающий», «заключающий в себе», «подразумевающий» и т. п. необходимо понимать как неограничивающие, т. е. означающие включение, но не ограничение. Только переходные выражения «состоящий из» и «состоящий по существу из» должны быть ограничивающими или полуограничивающими переходными выражениями, соответственно.
Хотя в настоящей заявке описаны и проиллюстрированы несколько вариантов реализации изобретения, специалисты в данной области могут без труда представить себе целый ряд других средств и/или структур для выполнения функции и/или достижения результатов и/или одного или более преимуществ, описанных в настоящей заявке, подразумевается, что каждое из таких изменений и/или модификаций находится в пределах объема вариантов реализации изобретения, описанных в настоящей заявке. В частности, специалистам в данной области вполне понятно, что все параметры, размеры, материалы и конфигурации, описанные в настоящей заявке, предназначены в качестве примера, и что фактические параметры, размеры, материалы и/или конфигурации будут зависеть от определенной области или областей применения, в которых используют идеи настоящего изобретения. Специалисты в данной области техники узнают или смогут выявить, путем всего лишь обычного экспериментирования, множество эквивалентов конкретных вариантов осуществления изобретения, описанных в настоящей заявке. Поэтому понятно, что вышеуказанные варианты реализации приведены только в качестве примера, и что в пределах объема приложенной формулы изобретения и ее эквивалентов варианты реализации изобретения могут быть осуществлены на практике иным образом, чем описано и заявлено. Варианты реализации настоящего изобретения относятся к каждому отдельному признаку, системе, изделию, материалу, комплекту и/или способу, описанному в настоящей заявке. Кроме того, любая комбинация из двух или более таких признаков, систем, изделий, материалов, комплектов и/или способов, если такие признаки, системы, изделия, материалы, комплекты и/или способы не являются взаимно несовместимыми, включена в объем настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ СОЗДАНИЯ МОДЕЛИ АНАЛИЗА ДИАЛОГОВ НА БАЗЕ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ДЛЯ ОБРАБОТКИ ЗАПРОСОВ ПОЛЬЗОВАТЕЛЕЙ И СИСТЕМА, ИСПОЛЬЗУЮЩАЯ ТАКУЮ МОДЕЛЬ | 2019 |
|
RU2730449C2 |
| ПОИСК ИЗОБРАЖЕНИЙ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2688271C2 |
| РАЗРЕШЕНИЕ КОРЕФЕРЕНЦИИ В ЧУВСТВИТЕЛЬНОЙ К НЕОДНОЗНАЧНОСТИ СИСТЕМЕ ОБРАБОТКИ ЕСТЕСТВЕННОГО ЯЗЫКА | 2008 |
|
RU2480822C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБРАБОТКИ ПОЛЬЗОВАТЕЛЬСКОГО РАЗГОВОРНОГО РЕЧЕВОГО ФРАГМЕНТА | 2019 |
|
RU2757264C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ОТВЕТА НА ПОИСКОВЫЙ ЗАПРОС | 2024 |
|
RU2834217C1 |
| СПОСОБ ПРЕДСТАВЛЕНИЯ РЕЗУЛЬТАТОВ ПОИСКА В СООТВЕТСТВИИ С ПОИСКОВЫМ ЗАПРОСОМ В СЕТИ ИНТЕРНЕТ | 2014 |
|
RU2598789C2 |
| СПОСОБ И СИСТЕМА ОБУЧЕНИЯ СИСТЕМЫ ЧАТ-БОТА | 2023 |
|
RU2820264C1 |
| СПОСОБ И СИСТЕМА УПРАВЛЕНИЯ ДИАЛОГОВЫМ АГЕНТОМ В КАНАЛЕ ВЗАИМОДЕЙСТВИЯ С ПОЛЬЗОВАТЕЛЕМ | 2019 |
|
RU2818036C1 |
| РЕЗЮМИРОВАНИЕ ПОТОКОВ СООБЩЕНИЙ | 2012 |
|
RU2621005C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРЕДОСТАВЛЕНИЯ РЕЧЕВОГО ИНТЕРФЕЙСА | 2009 |
|
RU2494476C2 |

Настоящее изобретение относится к области вычислительной техники. Технический результат заключается в улучшении скорости вычислений алгоритма автоматизированного ответа на вопросы. Система для автоматизированного ответа на вопросы, содержащая: семантическое пространство, сформированное из корпуса вопросов и ответов; пользовательский интерфейс, выполненный с возможностью приема вопроса; процессор, содержащий: движок разложения вопроса, выполненный с возможностью разложения вопроса на область знаний, ключевое слово и фокусное слово; формирователь сходства с вопросом, выполненный с возможностью идентификации одного или более вопросов в семантическом пространстве с использованием разложенного вопроса; движок извлечения и ранжирования ответов, выполненный с возможностью: извлечения из семантического пространства одного или более ответов, связанных с одним или более идентифицированных вопросов; и идентификация одного или более извлеченных ответов в качестве наилучшего ответа; и движок доработки ответа, выполненный с возможностью доработки наилучшего ответа; причем доработанный ответ предоставляют пользователю посредством пользовательского интерфейса. 2 н. и 13 з.п. ф-лы, 10 ил. 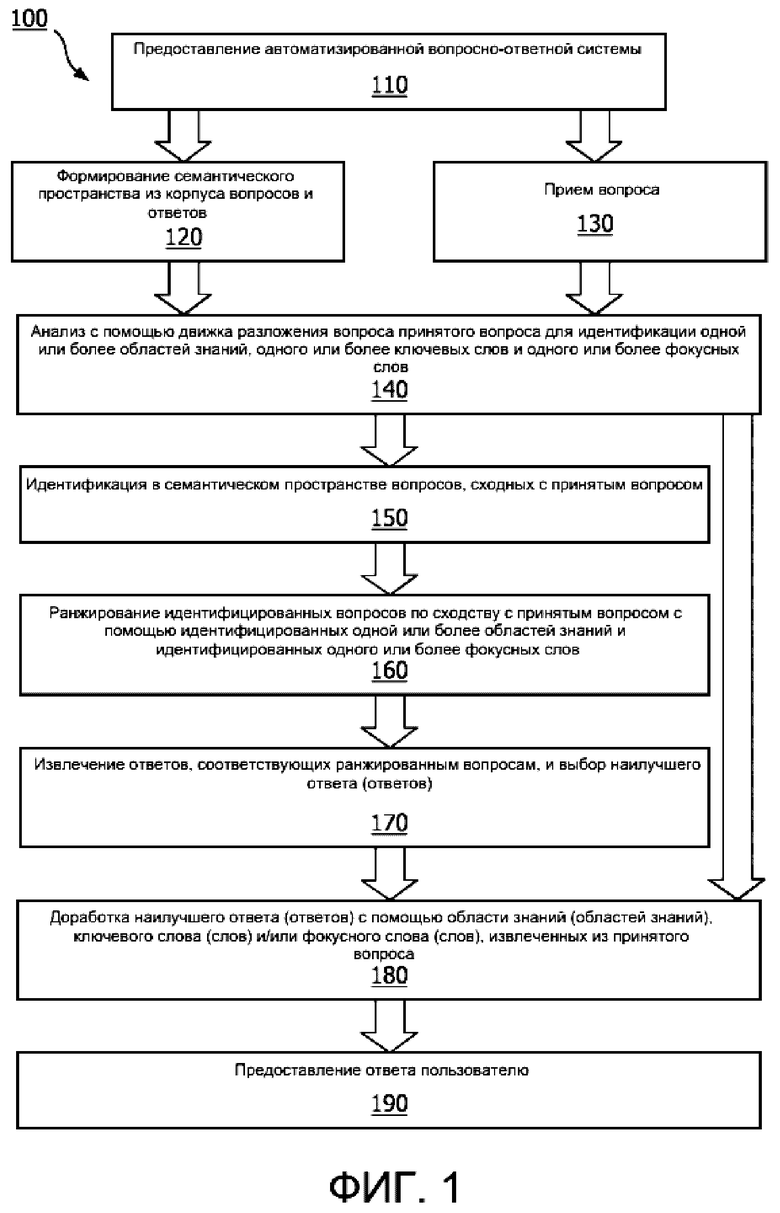
1. Система (1000) для автоматизированного ответа на вопросы в течение заданного промежутка времени, содержащая:
семантическое пространство (210), формируемое из корпуса вопросов и ответов;
пользовательский интерфейс (1030), выполненный с возможностью приема вопроса от пользователя; и
процессор (1100) для идентификации и доработки ответа на вопрос в течение заданного промежутка времени, содержащий следующее:
движок (1050) разложения вопроса, выполненный с возможностью разложения принятого вопроса по меньшей мере на одну область знаний, одно ключевое слово и одно фокусное слово;
формирователь (1060) сходства с вопросом, выполненный с возможностью идентификации одного или более вопросов в семантическом пространстве (210) с использованием разложенного вопроса, причем идентифицированные один или более вопросов определяют как сходные с принятым вопросом;
движок (1080) извлечения и ранжирования ответов, выполненный с возможностью: (i) извлечения из семантического пространства (210) ответов, связанных с одним или более идентифицированными вопросами, причем извлеченные ответы ограничены определенной длиной в зависимости от заданного промежутка времени, и одно или более предложений ответов из семантического пространства (210), которые являются наиболее репрезентативными для по меньшей мере одного фокусного слова и одного ключевого слова, выбраны в качестве извлеченных ответов; (ii) идентификации одного или более извлеченных ответов в качестве наилучшего ответа; и
движок (1090) доработки ответа, выполненный с возможностью доработки идентифицированного наилучшего ответа с использованием одного или более из указанной по меньшей мере одной области знаний, одного ключевого слова и одного фокусного слова для повторного ранжирования наилучших ответов и для идентификации одного наилучшего ответа;
причем один наилучший ответ предоставлен пользователю посредством пользовательского интерфейса (1030) в течение заданного промежутка времени.
2. Система (1000) по п. 1, дополнительно содержащая корпус (1010) вопросов и ответов, причем по меньшей мере некоторые вопросы связаны с соответствующим ответом.
3. Система (1000) по п. 1, дополнительно содержащая движок (1040) предварительной обработки, выполненный с возможностью предварительной обработки принятого вопроса, включающей в себя одно или более из извлечения текста из принятого вопроса, сегментирования предложения принятого вопроса и исправления правописания принятого вопроса.
4. Система (1000) по п. 1, дополнительно содержащая базу (1022) данных семантического пространства, выполненную с возможностью хранения семантического пространства (210).
5. Система (1000) по п. 1, дополнительно содержащая движок (1070) синтаксической и семантической связанности, выполненный с возможностью ранжирования одного или более идентифицированных вопросов на основе сходства с принятым вопросом.
6. Система (1000) по п. 1, в которой вопросы в семантическом пространстве (210) содержат вектор и разложенный вопрос содержит вектор,
обеспечено сравнение векторов вопросов в семантическом пространстве (210) с вектором разложенного вопроса, и
при этом вопрос в семантическом пространстве (210) идентифицирован как сходный, если результат сравнения векторов выше заданного порогового значения.
7. Компьютеризированный способ (100) автоматизированного ответа на вопросы в течение заданного промежутка времени, включающий следующие этапы:
предоставление (110) автоматизированной вопросно-ответной системы (1000), содержащей пользовательский интерфейс (1030), процессор (1100) и сформированное семантическое пространство (210);
прием (130) посредством пользовательского интерфейса (1030) вопроса от пользователя, на который запрашивается ответ в течение заданного промежутка времени;
разложение (140) с помощью процессора (1100) принятого вопроса по меньшей мере на одну область знаний, одно ключевое слово и одно фокусное слово;
идентификация (150) с помощью процессора (1100) одного или более вопросов в сформированном семантическом пространстве (210) с использованием разложенного вопроса, причем идентифицированные один или более вопросов определяют как сходные с принятым вопросом;
ранжирование (160) с помощью процессора (1100) одного или более идентифицированных вопросов на основе сходства с принятым вопросом;
извлечение (170) с помощью процессора (1100) из семантического пространства (210) ответов, связанных с одним или более идентифицированных вопросов, причем извлеченные ответы ограничены определенной длиной в зависимости от заданного промежутка времени, и одно или более предложений ответов из семантического пространства (210), которые являются наиболее репрезентативными для по меньшей мере одного фокусного слова и одного ключевого слова, выбраны в качестве извлеченных ответов;
идентификация (170) с помощью процессора (1100) одного или более извлеченных ответов в качестве наилучшего ответа;
доработка (180) с помощью процессора (1100) идентифицированного наилучшего ответа с использованием одного или более из указанной по меньшей мере одной области знаний, одного ключевого слова и одного фокусного слова, причем наилучшие ответы повторно ранжируют и идентифицируют один наилучший ответ, и
предоставление (190) посредством пользовательского интерфейса (1030) одного наилучшего ответа в качестве ответа на принятый вопрос в течение заданного промежутка времени.
8. Способ по п. 7, дополнительно включающий этап формирования (120) семантического пространства (210) из корпуса (1010) вопросов и ответов, причем по меньшей мере некоторые вопросы связаны с соответствующим ответом.
9. Способ по п. 8, в котором сформированное семантическое пространство (210) сохраняют в базе (1022) данных.
10. Способ по п. 7, в котором вопросы в семантическом пространстве (210) содержат вектор, и разложенный вопрос содержит вектор, векторы вопросов в семантическом пространстве (210) сравнивают с вектором разложенного вопроса, и при этом вопрос в семантическом пространстве (210) идентифицируют как сходный, если результат сравнения векторов выше заданного порогового значения.
11. Способ по п. 10, в котором заданное пороговое значение содержит значение косинуса.
12. Способ по п. 7, дополнительно включающий этап предварительной обработки процессором (1100) принятого вопроса, включающей одно или более из извлечения текста из принятого вопроса, сегментирования предложения принятого вопроса и исправления правописания принятого вопроса.
13. Способ по п. 7, в котором этап ранжирования (160) одного или более идентифицированных вопросов на основе сходства с принятым вопросом включает семантический и/или синтаксический анализ идентифицированных вопросов.
14. Способ по п. 7, в котором этап идентификации (170) одного или более извлеченных ответов в качестве наилучшего ответа включает ранжирование извлеченных ответов.
15. Способ по п. 7, в котором система (1000) дополнительно содержит предварительно натренированный классификатор (440) областей знаний вопросов, и в котором принятый вопрос разлагают по меньшей мере частично на основе предварительно натренированного классификатора областей знаний вопросов (440).
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| ПРОВЕРКА РЕЛЕВАНТНОСТИ МЕЖДУ КЛЮЧЕВЫМИ СЛОВАМИ И СОДЕРЖАНИЕМ ВЕБ-САЙТА | 2005 |
|
RU2375747C2 |

