ОБЛАСТЬ ТЕХНИКИ
[1] Настоящее техническое решение, в общем, относится к поисковым системам в целом, а более конкретно - к способу обработки поисковых запросов для извлечения информации по пользовательскому поисковому запросу и генерации сокращенного ответа на него.
УРОВЕНЬ ТЕХНИКИ
[2] В настоящее время поисковые системы являются неотъемлемой частью глобальных и локальных сетей связи и обеспечивают предоставление релевантных результатов поисковых запросов. С развитием технологий в сфере искусственного интеллекта, расширились и возможности поисковых систем, за счет внедрения алгоритмов машинного обучения. Так, поисковые системы стали применяться и в корпоративной сфере, например, в рабочих процессах предприятий и/или компаний, обладающих большим объемом документов.
[3] Однако, применение поисковых систем, таких как поисковые системы, основанные на моделях машинного обучения, чат-боты и т.д., в корпоративной сфере имеет ряд недостатков. Как правило, в корпоративной сфере существуют определенные области техники, связанные со спецификой деятельности конкретных корпораций и/или компаний, что существенно усложняет применение известных поисковых систем в рабочих целях. Так, ввиду наличия доменно-специфичных терминов в поисковых запросах, известные поисковые системы показывают низкую полноту поисковой выдачи (предоставляемых документов и/или результатов поисковых запросов). Это связано с тем, что поисковая выдача зачастую содержит в себе семантически схожий запросу текст, но некорректный с точки зрения интерпретации узкоспециализированных терминов. Например, запросы «миграция данных из базы данных» и «миграция данных из s3» являются семантически схожими, но по существу относятся к разным понятиям. Кроме того, алгоритмы машинного обучения в известных поисковых системах обучаются на открытых данных, которые не содержат или содержат слишком малое количество доменно-специфичных обучающих данных (доступные методы позволяют добиваться высокой полноты только при наличии большого количества доменно-специфичных данных). Поэтому развитие поисковых систем в доменно-специфичных терминах является существенной и нетривиальной задачей.
[4] Из уровня техники известны подходы, основанные на доменной адаптации поисковых систем для предоставления поисковых результатов на поисковые запросы, содержащие доменно-специфичные термины. Так, к таким подходам можно отнести GPL (найдено в Интернет по ссылке: https://arxiv.org/abs/2112.07577)(Generative Pseudo Labeling). Метод GPL относится к методам обучения без учителя, использует генеративные модели для генерации псевдозапросов по корпусу текста и существующую поисковую систему для поиска релевантных документов. В качестве целевых меток для обучения модели DPR (Dense Passage Retrieval, семантический поиск для извлечения релевантных документов) используются метки модели ранжирования, например, RocketQA, доступно по ссылке: https://arxiv.org/abs/2010.08191. Такой подход позволяет дообучать модель DPR на синтетических данных.
[5] Стоит отметить, что зачастую в качестве модели ранжирования берется общедоступная модель, которая была обучена на общедоступных данных, не содержащих доменно-специфичные понятия, что может негативно повлиять на качество доменной адаптации. Также такой метод требует достаточно большого размера доменно-специфичного корпуса текстов для достижения качественных результатов, что является серьезным ограничением.
[6] Соответственно, недостатком такого подхода является низкая точность предоставления поисковых результатов на поисковые запросы, содержащие доменно-специфичные термины, что, как следствие снижает качество генерации ответа на пользовательский запрос.
[7] Общим недостатком известных решений является отсутствие эффективного способа обработки поисковых запросов, содержащих доменно-специфичные термины, выполняемого поисковыми системами, обеспечивающего повышение полноты выдачи и не требующего больших размеров доменно-специфичного корпуса текстов для достижения качественных результатов. Кроме того, такой подход должен обладать низкими вычислительными затратами.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[8] Данное техническое решение направлено на устранение недостатков, присущих существующим решениям, известным из уровня техники.
[9] Решаемой технической проблемой в данном техническом решении является создание нового и эффективного способа обработки поисковых запросов, содержащих доменно-специфичные термины, в поисковой системе.
[10] Техническим результатом, проявляющимся при решении вышеуказанной проблемы, является повышение точности генерации результата поискового запроса, за счет улучшения релевантности извлеченных документов.
[11] Указанный технический результат достигается благодаря осуществлению способа обработки поисковых запросов, выполняемого по меньшей мере одной поисковой системой, содержащего этапы, на которых:
a) получают поисковый запрос от пользователя;
b) осуществляют полнотекстовый поиск документов на основе запроса, полученного на этапе а);
c) формируют первый набор результатов поиска;
d) осуществляют токенизацию и векторизацию поискового запроса;
e) осуществляют обработку векторного представления поискового запроса, полученного на этапе d), с помощью модели машинного обучения на базе нейронной сети, обученной на семантический поиск документов, причем в ходе обучения осуществляют:
i. формирование набора данных, содержащего доменно-специфические термины и синонимы к указанным терминам;
ii. создание неразмеченного набора данных из доменно-специфичного корпуса текстов;
iii. аугментацию неразмеченного набора данных посредством замены доменно-специфичных терминов их синонимами;
iv. обучение модели машинного обучения на аугментированном неразмеченном наборе данных;
f) формируют второй набор результатов поиска на основе документов, полученных на этапе е);
g) объединяют первый и второй набор результатов поиска;
h) ранжируют объединенный первый и второй набор результатов поиска, причем, в ходе ранжирования определяют релевантность каждого документа относительно поискового запроса;
i) формируют генеративный результат поискового запроса, основанный на полученных документах;
j) отправляют результат, полученный на этапе i), пользователю.
[12] В одном из частных примеров осуществления способа обучения модели машинного обучения на аугментированном неразмеченном наборе данных содержит следующие шаги:
i. генерация поисковых запросов к набору данных с помощью больших языковых моделей;
ii. генерация сложных негативных примеров имеющейся системой поиска;
iii. получение псевдометок релевантности поискового запроса по исходному тексту и негативным примерам с помощью их ранжирования;
iv. формирование набора данных, включающего: поисковый запрос; исходный текст, к которому генерировался запрос; набор сложных негативных примеров; псевдометки релевантности;
v. обучение модели машинного обучения на полученном наборе данных.
[13] В другом частном примере осуществления способа в ходе объединения первого и второго набора результатов поиска, позиционное расположение каждого результата поиска из каждого набора в объединенном наборе данных выбирается случайным образом.
[14] В другом частном примере осуществления способа доменно-специфические термины представляют собой узкоспециализированные термины, характерные для определенной прикладной области.
[15] В другом частном примере осуществления способа в ходе ранжирования, объединенного первого и второго набора результатов поиска, осуществляют следующие шаги:
i. получение пар текстовых последовательностей, где каждая пара включает в себя поисковый запрос и потенциально релевантный документ;
ii. конвертацию каждой пары в вещественное число, соответствующее степени релевантности документа к запросу;
iii. определение порядка ранжирования документов, на основе сравнения вещественных чисел каждой пары.
[16] В другом частном примере осуществления способа ранжирование выполняется по меньшей мере одной моделью машинного обучения на базе нейронной сети, обученной на наборе данных, содержащим доменно-специфические термины и синонимы к указанным терминам.
[17] В другом частном примере осуществления способа полнотекстовый поиск документов осуществляется посредством, по меньшей мере алгоритма полнотекстового поиска, учитывающего длину документа и частоту терминов.
[18] В другом частном примере осуществления способа алгоритм полнотекстового поиска документов дополнительно содержит набор данных, включающий доменно-специфические термины и синонимы к указанным терминам.
[19] В другом частном примере осуществления способа генеративный результат формируется с помощью нейронной сети.
[20] В другом частном примере осуществления способа генеративный результат представляет собой текстовую последовательность, сформированную на основе пользовательского запроса и релевантных к нему документов из объединенного первого и второго набора результатов поиска.
[21] В другом частном примере осуществления способа векторизация поискового запроса осуществляется посредством двунаправленного кодирования.
[22] Кроме того, заявленные технические результаты достигаются за счет системы обработки поисковых запросов, содержащей:
• по меньшей мере один процессор;
• по меньшей мере одну память, соединенную с процессором, которая содержит машиночитаемые инструкции, которые, при их выполнении по меньшей мере одним процессором, обеспечивают выполнение способа обработки поисковых запросов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[23] Признаки и преимущества настоящего технического решения станут очевидными из приводимого ниже подробного описания и прилагаемых чертежей, на которых:
[24] Фиг. 1 иллюстрирует пример реализации системы обработки поисковых запросов.
[25] Фиг. 2 иллюстрирует блок-схему выполнения заявленного способа.
[26] Фиг. 3 иллюстрирует пример вычислительного устройства для реализации заявленной системы.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[27] Заявленное техническое решение предлагает новый подход, обеспечивающий новый и эффективный способ обработки поисковых запросов, содержащих доменно-специфичные термины, в поисковой системе. Аспекты заявленного технического решения обеспечивают повышение полноты результатов выдачи за счет применения как полнотекстового поиска, так и семантического поиска, обученного на доменно-специфичных терминах, а также дополнительного этапа ранжирования полученных поисковых результатов, что позволяет улучшить релевантность извлеченных документов перед генерацией ответа. Кроме того, заявленное техническое решение обеспечивает возможность генерации ответа, содержащего сжатое или обобщенное изложение наиболее релевантных результатов из объединенного набора результатов поискового запроса.
[28] Заявленное техническое решение может выполняться, например, системой, машиночитаемым носителем, сервером и т.д. В данном техническом решении под системой подразумевается, в том числе компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность операций (действий, инструкций).
[29] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[30] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных, например, таких устройств, как оперативно запоминающие устройства (ОЗУ) и/или постоянные запоминающие устройства (ПЗУ). В качестве ПЗУ могут выступать, включая, но не ограничиваясь, жесткие диски (HDD), флеш-память, твердотельные накопители (SSD), оптические носители данных (CD, DVD, BD, MD и т.п.) и др.
[31] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[32] Термин «инструкции», используемый в этой заявке, может относиться, в общем, к программным инструкциям или программным командам, которые написаны на заданном языке программирования для осуществления конкретной функции, такой как, например, получение и обработка данных, формирование профиля пользователя, прием и передача сигналов, анализ принятых данных, идентификация пользователя и т.п.Инструкции могут быть осуществлены множеством способов, включающих в себя, например, объектно-ориентированные методы. Например, инструкции могут быть реализованы, посредством языка программирования С++, Java, Python, различных библиотек (например, "MFC"; Microsoft Foundation Classes) и т.д. Инструкции, осуществляющие процессы, описанные в этом решении, могут передаваться как по проводным, так и по беспроводным каналам передачи данных, например, Wi-Fi, Bluetooth, USB, WLAN, LAN и т.п.
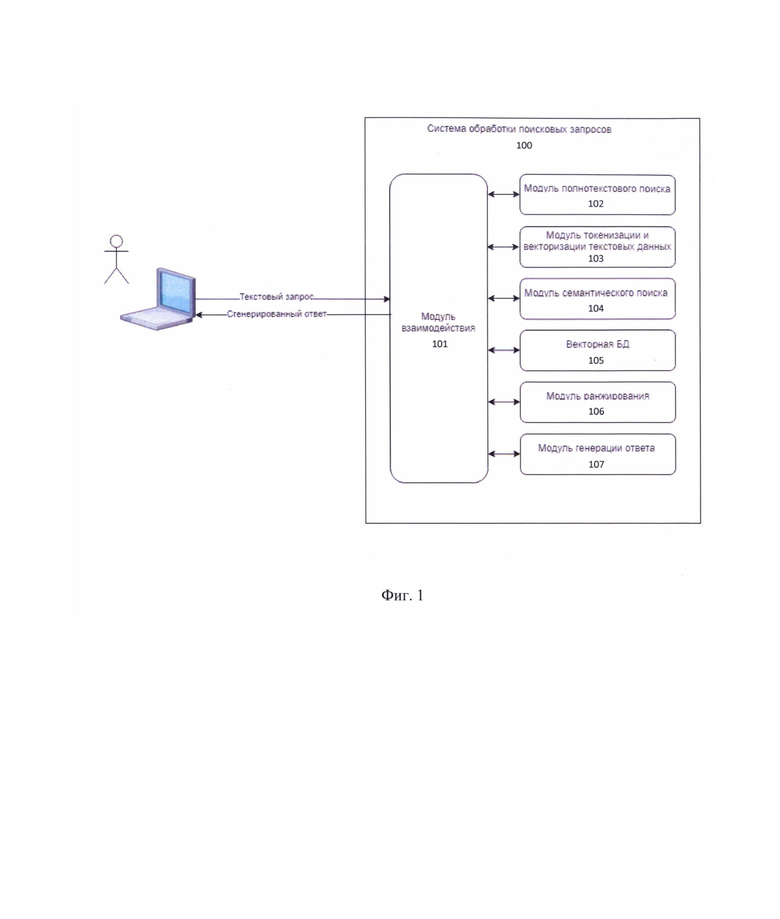
[33] На Фиг. 1 приведен общий вид системы 100 обработки поисковых запросов в поисковой системе. Система 100 включает в себя основные функциональные элементы, такие как: модуль взаимодействия 101, модуль полнотекстового поиска 102, модуль токенизации и векторизации текстовых данных 103, модуль семантического поиска 104, векторную базу данных 105, модуль ранжирования 106, модуль генерации ответа 107. Более подробно элементы системы 100 раскрыты на Фиг. 3.
[34] Система 100 может являться частью и/или быть связана с поисковой системой. Так, в одном частном варианте осуществления система 100 может являться элементом поисковой системы. Поисковая система может представлять собой корпоративную поисковую систему, предназначенную для поиска данных внутри компании, например, на основе комбинированного поиска в сети Интернет и содержимых баз данных компании. Как правило, поиск предназначен для внутренних пользователей компании в рабочих целях и содержит в поисковых запросах доменно-специфичные термины, связанные с областью техники компании. В еще одном частном варианте осуществления поисковая система может представлять веб-сервис для поиска текстовой или графической информации, поисковую систему на основе алгоритмов машинного обучения, например, поисковая система на базе LLM и т.д., локальную или десктопную поисковую систему для поиска локальных файлов и т.д. В еще одном частном варианте осуществления поисковая система может представлять комбинацию нескольких типов поисковых систем.
[35] Под доменно-специфичными терминами следует понимать узкоспециализированные термины, характерные для определенной прикладной области. Так, доменно-специфичные термины могут относится к прикладной области корпоративной сферы, например, области информационных технологий, сетей и систем связи, облачных решений и т.д. Так, доменно-специфичные термины относятся к специфичной лексике, присущей определенной области техники, например, медицине (биологические термины, названия лекарств и т.д.), ИТ технологиям (название алгоритмов, систем, протоколов взаимодействия и т.д.).
[36] Модуль взаимодействия 101 может быть реализован на базе по меньшей мере одного вычислительного устройства, оснащенного соответствующим программным обеспечением и предназначен для обработки входящих поисковых запросов, координации работы других модулей, предоставления вывода пользователю.
[37] Модуль 101 может содержать пользовательский интерфейс для взаимодействия с пользователями поисковой системы. Координация работы других модулей может выполняться, например, посредством взаимодействия с указанными модулями по протоколу HTTPS (вызов API). Под координацией следует понимать очередность исполнения модулями системы 100 этапов способа 200, который раскрыт более подробно ниже. Так, модуль 101 может обеспечивать обработку поискового запроса от пользователя, подготовку данных для подмодулей 101-107 и определять порядок их обхода.
[38] Модуль полнотекстового поиска 102 может представлять собой систему полнотекстового поиска, вычислительное устройство и т.д.
[39] Модуль 102 предназначен для автоматизированного поиска документов на основе поискового запроса, при котором поиск ведется не по именам документов, а по их содержимому, всему или существенной части содержимого документа. Так, в одном частном варианте осуществления полнотекстовый поиск может выполняться алгоритмом ВМ25 в сочетании с набором данных, содержащим доменно-специфические термины и синонимы к указанным терминам (словарь синонимов) для улучшения эффективности поиска. Алгоритм ВМ25 является усовершенствованной версией TF-IDF, которая учитывает длину документа и частоту терминов, в то время как словарь синонимов помогает улучшить полноту поисковой выдачи.
[40] Модуль 102 работает со структурой данных обратный индекс, которая представляет из себя набор ключей и значений, где ключом является слово, а значением/-ями - индексы документов, в котором/-ых оно встречается. Для ранжирования документов-кандидатов из обратного индекса могут использоваться различные функции, например, TF-IDF, ВМ25 и т.д. При использовании словаря синонимов (набора данных, содержащего доменно-специфичных терминов и синонимом к указанным терминам) обеспечивается возможность добавлять в обратный индекс синонимичные термины и привязывать к ним релевантные документы.
[41] Стоит отметить, что названия технологий транслитерируются на русский язык, например, «terraform» и «терраформ», имеют специфичные сокращения, «виртуальная машина» и «вм» и т.п. Словарь синонимов позволяет учитывать вхождения синонимичных терминов в документах, путем их добавления в качестве ключей в обратный индекс.
[42] Рассмотрим пример работы полнотекстового поиска со словарем:
Исходный запрос: создать мастер-узел
Модифицированный запрос: создать (мастер-узел ИЛИ мастер ИЛИ мастер-нода)
[43] Как видно из представленного примера, применение словаря синонимов расширяет охватываемые релевантные документы, что, соответственно, повышает полноту поисковой выдачи.
[44] Модуль токенизации и векторизации текстовых данных 103 может быть реализован на базе по меньшей мере одного вычислительного устройства, оснащенного соответствующим программным обеспечением, и включать набор моделей для токенизации и детокенизации текста, векторизации токенизированного текста и преобразования токенов в текст, например, одну или несколько моделей машинного обучения для преобразования текстовой информации в векторную форму, например, BERT, ELMo, ULMFit, XLNet, RoBerta, RuGPT3 и другие.
[45] В одном частном варианте осуществления модуль 103 может быть реализован на базе системы 300, которая более подробно раскрыта на Фиг. 3. Стоит отметить, что определенный метод токенизации и векторизации зависит от выбранной языковой модели, на базе которой реализован модуль 104. Например, при использовании модели RuGPT3, токенизация осуществляется методом ВРЕ (Byte Pair Encoding), а последующая векторизация - путем замены каждого токена на его индекс в словаре языковой модели, составленном на этапе изначального обучения модели. Кроме того, в еще одном частном варианте осуществления, в качестве метода токенизации может использоваться токенизация по словам.
[46] Пример токенизации по словам и кодирование слов индексами в словаре: 'миграция БД' → ['миграция', 'БД'] → [235, 376].
[47] Модуль семантического поиска 104 может быть реализован на базе по меньшей мере одной нейронной сети, заранее обученной на конкретных наборах данных, состоящих, например, из троек (текст поискового запроса, текст релевантного документа, текст нерелевантного документа), пятерок (текст запроса, текст релевантного документа (позитивный пример), оценка релевантности позитивного примера, текст нерелевантного документа (негативный пример), оценка релевантности негативного примера) и т.д. Так, тройки могут использоваться в случаях, когда набор данных тройки уже содержит оценки релевантности документов, однако, на практике такое маловероятно.
[48] В качестве модели машинного обучения, реализующей функцию обработки векторного представления поисковых запросов и текстов документов, может быть использована модель из семейства BERT-подобных моделей, например, xlm-roberta-base. В одном частном варианте осуществления, при реализации заявленного решения, МО являлась мультиязычная модель, например multilingual-e5-large. Модель обучена на источниках из разных доменов: Википедия, книги, новости, мультиязычный Common Crawl и т.д.
[49] В еще одном частном варианте осуществления модель так же была дообучена на узкоспециализированных доменных текстах, с использованием различных методов аугментации текста, в частности аугментации синонимами, и техники GPL.
[50] Всего в датасете для дообучения содержалось около 160000 наборов данных, состоящих из пятерок (текст запроса, текст релевантного документа (позитивный пример), оценка релевантности позитивного примера, текст нерелевантного документа (негативный пример), оценка релевантности негативного примера).
[51] Пример аугментированного текста:
Исходный текст: создать вм
Варианты аугментированного текста: создать виртуалку, создать ECS, создать виртуальный сервер и т.п.
[52] Для получения нейросетевой выдачи, в модуле 104 осуществляется сравнение расстояний между пользовательским запросом в виде вектора и документами базы документов 105, также представленных в виде векторов.
[53] Векторная база данных 105 используется для хранения и обработки векторной информации, полученной от модуля 103. Указанная база данных 105 обеспечивает быстрый и эффективный поиск по векторам, поддерживает операции сравнения и кластеризации, а также обеспечивает возможность масштабирования и расширения с учетом потребностей системы поиска данных (поисковая система).
[54] Модуль ранжирования 106 может быть реализован на базе вычислительного устройства и предназначен для оценки релевантности текстовых последовательностей.
[55] Так, модуль 106 выполняет процесс ранжирования результатов поиска в соответствии с запросом пользователя среди наборов результатов поиска, полученных от модулей 102 и 104. Пары текстовых последовательностей поступают на вход модулю 106, где каждая пара включает в себя поисковый запрос и потенциально релевантный документ из базы данных. Модуль 106 затем конвертирует эту пару в вещественное число, которое отражает степень релевантности документа к запросу. Путем сравнения этих чисел модуль определяет порядок ранжирования документов, что позволяет представить пользователю наиболее релевантную информацию в ответ на его запрос.
[56] Рассмотрим более подробно принцип работы модуля 106.
[57] После получения двух выдач (семантической и полнотекстовой) из модулей семантического поиска 104 и полнотекстового поиска 102, смешанная выдача подается в модуль 106. В одном частном варианте осуществления, модуль 106 может быть реализован на базе нейронной сети, такой как нейронная сеть для ранжирования: BERT-подобные модели, например, bert, roberta и т.д., например, bert-multilingual-passage-reranking-msmarco. Модель получает на вход пару поисковый запрос и документ-кандидат, на выходе получаем вещественную оценку (от -10 до 10, больше - лучше). После получения оценок ранжирования для каждого элемента смешанной выдачи, производится сортировка по оценке ранжирования по убыванию.
[58] Стоит отметить, что указанная модель ранжирования, в еще одном частном варианте осуществления, дообучается на наборе данных, содержащем доменно-специфичные термины и синонимы к указанным терминам. Указанный процесс позволяет нивелировать множественные значения одного и того же термина. Так, у одного и того же термина может быть несколько синонимов, что, при использовании стандартной модели ранжирования, приведет к некорректной оценке результатов поискового запроса. Следовательно, для повышения полноты поисковой выдачи модель ранжирования дообучается синонимичными понятиями.
[59] Для этого так же используется словарь синонимов для конкретной доменно-специфичной области. В заявленном техническом решении модель была дообучена на асессорской разметке, состоящей из приблизительно 5000 троек (поисковый запрос, документ, оценка релевантности).
[60] Модуль 107 может быть реализован на базе генеративной нейронной сети и предназначен для формирования генеративного результата поискового запроса.
[61] Модуль 107 отвечает за генерацию окончательного ответа на основе пользовательского запроса и релевантных к нему документов из базы знаний, полученных от других модулей. Модуль 107 преобразует полученные данные в окончательный ответ на запрос пользователя в виде текстовой последовательности.
[62] Так, в одном частном варианте реализации, модуль 107 может быть реализован на базе модели типа LLM, которая запромптирована (дообучена посредством текстовых подсказок) отвечать на пользовательский запрос, опираясь на самые релевантные запросу документы. Так, в еще одном частном варианте осуществления модель может представлять собой модель машинного обучения GigaChat, но очевидно, что могут применяться и другие модели (YaGPT, ChatGPT, open-source LLM).
[63] Пример дообучения модели посредством текстовых подсказок предобученных языковых моделей машинного обучения может выглядеть следующим образом: «Ваша роль - выступать в качестве системы информационного поиска. Вам будет задан вопрос, а также предоставлены релевантные отрывки из различных документов. Ваша задача - сформировать короткий и информативный ответ (не более 150 слов), основанный исключительно на представленных отрывках. Обязательно использовать информацию только из данных отрывков. Важно соблюдать нейтральный и объективный тон, а также избегать повторения текста. В конце формируйте окончательный ответ ("FINAL ANSWER"). Не пытайтесь изобрести ответ. Отвечайте исключительно на русском языке, за исключением специфических терминов. Если представленные документы не содержат информации, достаточной для формирования ответа, скажите: "Я не могу ответить на Ваш вопрос, используя информацию из предоставленной документации. Попробуйте переформулировать вопрос." Если документ содержит информацию, относящуюся к запросу, но запрос не предполагает прямого ответа, то просто перескажите содержание релевантного документа.».
[64] Соответственно, на основе результатов поиска, представленных в модуль 107 и предварительного дообучения текстовой подсказкой, модуль 107 предоставит короткий и информативный ответ на основе документов, содержащихся в выборке, т.е. выполнит объединение наиболее релевантных частей из разных документов в единый ответ (генерация ответа).
[65] Благодаря осуществлению указанной системы 100 обеспечивается повышение полноты поисковой выдачи на поисковый запрос, содержащий доменно-специфичные термины.
[66] Рассмотрим метрики качества системы:

[67] Как видно из Таблицы 1, реализация заявленной технической системы обработки поисковых запросов, обученной на поиск релевантных документов с учетом доменно-специфических терминов, обладает более высокой точностью нахождения релевантных документов в общем массиве документов, чем существующие системы поиска. Стоит отметить, что параметр точности, приведенных в Таблице 1 характеризует процент попадания релевантных поисковому запросу документов в результат поисковой выдачи.
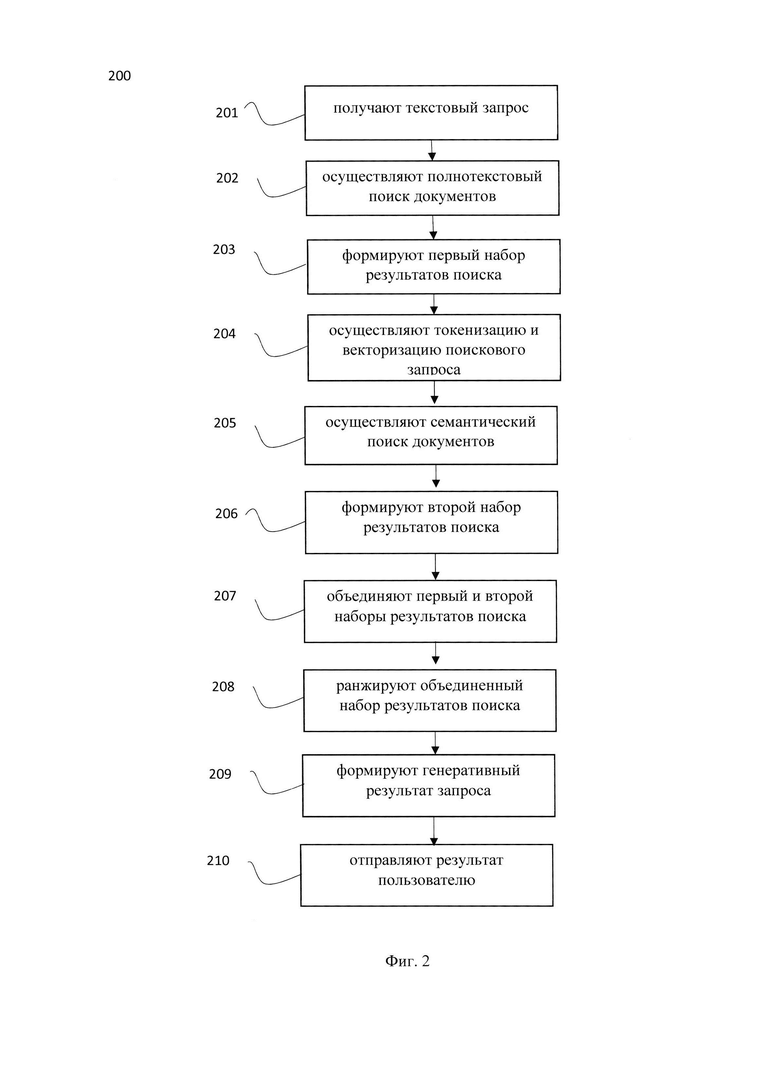
[68] На Фиг. 2 представлена блок схема способа 200 обработки поисковых запросов, выполняемого по меньшей мере одной поисковой системой и/или системой 100, которая является частью поисковой системы. Указанный способ 200 раскрыт поэтапно более подробно ниже. Указанный способ 200 заключается в выполнении этапов, направленных на обработку различных цифровых данных, таких как текстовые данные. Обработка, как правило, выполняется с помощью системы, которая может представлять, например, сервер, компьютер, мобильное устройство, вычислительное устройство и т.д, дополненное аппаратными и/или программно-аппаратными блоками, например, модулями системы 100, реализующими настоящий способ 200. Как указывалось, выше, более подробно элементы системы раскрыты на Фиг. 3.
[69] На этапе 201 система получает получают поисковый запрос от пользователя. Указанный этап может выполняться модулем 101.
[70] Так, на указанном этапе 202, система получает, например, с помощью интерфейса взаимодействия с пользователем, пользовательский запрос. Пользовательский запрос может быть получен в текстовом виде, например, через сеть связи, такую как глобальная или локальная сеть связи. В одном частном варианте осуществления текстовый запрос содержит доменно-специфичные термины. В еще одном частном варианте осуществления, поисковый запрос может быть получен посредством межмашинного взаимодействия, например, от системы предприятия и/или компании.
[71] На этапе 202 система осуществляет полнотекстовый поиск документов, выполняющийся модулем полнотекстового поиска 102, на основе запроса, полученного на этапе 201 и переданного модулем взаимодействия 101 в модуль 102.
[72] Как указывалось выше, полнотекстовый поиск может выполняться алгоритмом ВМ25 в сочетании с набором данных, содержащим доменно-специфические термины и синонимы к указанным терминам (словарь синонимов) для улучшения эффективности поиска.
[73] Для выполнения полнотекстового поиска осуществляется работа со структурой данных обратный индекс, которая представляет из себя набор ключей и значений, где ключом является слово, а значением/-ями - индексы документов, в котором/-ых оно встречается. Для ранжирования документов-кандидатов из обратного индекса могут использоваться различные функции, например, TF-IDF, ВМ25 и т.д. При использовании словаря синонимов (набора данных, содержащего доменно-специфичных терминов и синонимом к указанным терминам) обеспечивается возможность добавлять в обратный индекс синонимичные термины и привязывать к ним релевантные документы. Процесс формирования набора данных, содержащего доменно-специфичные термины и синонимы к указанным терминам более подробно раскрыт ниже.
[74] Результатом выполнения этапа 202 является набор релевантных результатов поискового запроса.
[75] На этапе 203 система формирует первый набор результатов поиска.
[76] Указанный набор формируется на основе результатов поиска, полученных на этапе 202.
[77] В одном частном варианте осуществления, первый набор результатов поиска может быть отправлен в модуль взаимодействия 101 для дальнейшей агрегации и обработке.
[78] Первый набор результатов поиска содержит результаты полнотекстового поиска.
[79] Далее, способ 200 переходит к этапу 204, с помощью модуля взаимодействия 101 передавая первый набор результатов поиска в модуль токенизации и векторизации 103.
[80] На указанном этапе 204 осуществляется токенизация и векторизация поискового запроса модулем 103 с последующей передачей результатов векторизации в векторную БД 105 под хранение и оперирование поиском.
[81] Так, токенизация и векторизация может выполняться посредством моделей для токенизации и детокенизации текста, векторизации токенизированного текста и преобразования токенов в текст, например, одной или несколькими моделями машинного обучения для преобразования текстовой информации в векторную форму, например, BERT, ELMo, ULMFit, XLNet, RoBerta, RuGPT3 и другие.
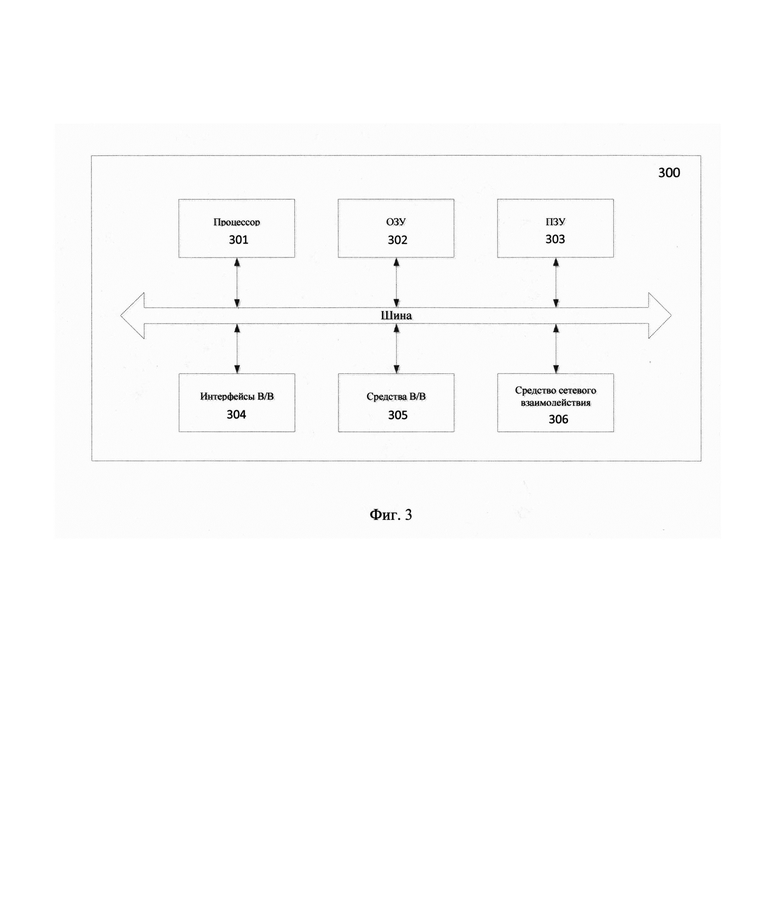
[82] В еще одном частном варианте осуществления, токенизация и векторизация текста может выполняться с помощью двунаправленного кодирования для обработки и анализа текстовых последовательностей, что обеспечивает возможность извлечения полезных признаков из данных и преобразования их в векторное пространство, которое затем может быть использовано для более сложных операций, таких как сравнение и кластеризация.
[83] На этапе 205 осуществляют обработку векторного представления поискового запроса, полученного на этапе 204 и переданного модулем взаимодействия 101 в модуль семантического поиска 104, с помощью модели машинного обучения на базе нейронной сети, обученной на семантический поиск документов, причем в ходе обучения осуществляют: формирование набора данных, содержащего доменно-специфические термины и синонимы к указанным терминам; создание неразмеченного набора данных из доменно-специфичного корпуса текстов; аугментацию неразмеченного набора данных посредством замены доменно-специфичных терминов их синонимами; обучение модели машинного обучения на аугментированном неразмеченном наборе данных.
[84] Рассмотрим более подробно процесс обучения модели машинного обучения модуля 104.
[85] Для формирования набора данных, содержащих доменно-специфичные термины и синонимы к указанным терминам, на первом шаге осуществляют выделение наиболее важных доменно-специфичных терминов.
[86] Так, указанный шаг может выполняться, например, посредством анализа данных корпорации и выделения наиболее часто встречающихся терминов. В еще одном частном варианте осуществления, такие термины могут быть очищены от терминов, не несущих смысловую нагрузку. Так, например, в области облачных технологий могут быть выделены такие термины как: виртуальная машина, фаервол, оркестратор контейнеров и т.д. В еще одном частном варианте осуществления, набор данных может формироваться посредством сопоставления слов, применяемых в конкретной области техники со словарем русского языка и выделением слов, которых там нет и дальнейшей проверке таких слов на содержание смысловой нагрузки (проведение семантического анализа). Также, сформированный набор может быть проверен с помощью экспертной оценки.
[87] Далее, осуществляется составление списка синонимов к терминам (слова, словосочетания), например: Elastic Cloud Server, ECS, виртуальный сервер, Виртуальная машина, виртуалка, ВМ, VM; email, электронная почта, E-mail, e-mail, имейл, емейл, имеил, емеил; WAF, Web application firewall, файервол, межсетевой экран.
[88] Таким образом, формируется набор данных, содержащий доменно-специфичные термины и синонимы к указанным терминам (словарь синонимов).
[89] Пример словаря синонимов:
["Elastic Cloud Server, ECS, виртуальный сервер, Виртуальная машина, виртуалка, ВМ, VM",
"балансер, balancer, балансировщик",
"млспейс, mlspace, мл спейс, ml space",
"postgresql, PSQL, postgres, постгрес, PostgreSQL",
"email, электронная почта, E-mail, e-mail, имейл, емейл, имеил, емеил",
"Инициализация, Активация, Инициация, Инициировать",
"Каталог, Папка, Директория",
"Распределенная атака Отказ в обслуживании, ДДоС, ДДоС-атака, DDoS",
"Атака Отказ в обслуживании, ДоС, ДоС-атака, DoS",
"Пространство имен, Namespace, Неймспейс",
"Эндпоинт, endpoint, эндпойнт",
"Рабочий узел, Воркер-нода, Воркер, Воркер-узел",
"Мастер-узел, Мастер, Мастер-нода"]
[90] Как указывалось выше, словарь синонимов позволяет учитывать вхождения синонимичных терминов в документах, путем их добавления в качестве ключей в обратный индекс. Указанный словарь синонимов в дальнейшем может применяться как в алгоритмах полнотекстового поиска, так и в алгоритмах ранжирования. В одном частном варианте осуществления, указанный сформированный набор может быть добавлен в алгоритм полнотекстового поиска по запросам с всевозможными подстановками (заменами) синонимов, например, следующим образом: Создать вм → создать, вм, виртуальная машина, виртуальный сервер, vm.
[91] Далее, для обучения модели машинного обучения на семантический поиск документов, осуществляется создание неразмеченного набора данных из доменно-специфичного корпуса текстов.
[92] На указанном шаге осуществляется аугментация неразмеченного набора данных, получившегося на предыдущих шагах.
[93] Так, искусственное размножение данных (аугментация) может осуществляться, например, с помощью замены синонимами доменно-специфичных терминов (замена термина в тексте на синоним).
[94] Таким образом, получается аугментированный датасет, содержащий доменно-специфичные термины.
[95] Пример искусственного расширения датасета:
Исходный текст: создать вм
Варианты аугментированного текста: создать виртуалку, создать ECS, создать виртуальный сервер и т.п.
[96] Далее, выполняется обучение модели семантического поиска на неразмеченных данных. Обучение может выполняться, например, с помощью техники GPL с искусственным расширением датасета синонимами (замена на синоним).
[97] В процессе обучения осуществляется генерация поисковых запросов к набору данных с помощью больших языковых моделей (LLM); генерация сложных негативных примеров имеющейся системой поиска; получение псевдометок релевантности поискового запроса исходному тексту и негативным примерам, например, с помощью модели ранжирования; составление наборов данных для обучения, таких как пятерки (поисковый запрос; исходный текст, к которому генерировался запрос, набор сложных негативных примеров, псевдометки релевантности, оценки релевантности примеров); обучение модели DPR на полученном наборе данных.
[98] Таким образом, на этапе 205 осуществляется семантический поиск документов модулем 104 с помощью модели машинного обучения на базе нейронной сети, обученной на узкоспециализированных доменных текстах, с использованием различных методов аугментации текста, в частности аугментации синонимами, и техники GPL. Всего в датасете для дообучения применялось около 160000 троек (поисковый запрос, документ, псевдооценка релевантности).
[99] На этапе 206 формируют второй набор результатов поиска на основе документов, полученных на этапе 205.
[100] Так, указанный набор является результатом поисковой выдачи модели семантического поиска, примененный к векторному представлению поискового запроса. Указанный второй набор результатов является независимым. Т.е. семантический поиск проводится без учета полнотекстового поиска.
[101] Полученный второй набор направляется в модуль взаимодействия 101 для агрегации.
[102] На этапе 207, например, посредством модуля взаимодействия 101, осуществляется объединение первого и второго набора результатов поиска (203+206), с последующей передачей объединенного набора модулем взаимодействия 101 в модуль ранжирования 106.
[103] Так, в одном частном варианте осуществления, позиционное расположение каждого результата поиска из каждого набора в объединенном наборе данных выбирается случайным образом. Указанная особенность необходима для того, чтобы при ранжировании результатов, система не отдавала предпочтение наиболее релевантным результатам из каждого типа поиска (полнотекстовый и семантический).
[104] На этапе 208 осуществляют ранжирование модулем 106 объединенного первого и второго набора результатов поиска, причем, в ходе ранжирования определяют релевантность каждого документа относительно поискового запроса.
[105] Так, на этапе 208 после получения двух выдач (семантической и полнотекстовой), смешанная выдача подается в модуль ранжирования 106, содержащий нейросеть для ранжирования (BERT-подобные модели, например, bert, roberta и т.д.), например, bert-multilingual-passage-reranking-msmarco. Модель получает на вход пару поисковый запрос и документ-кандидат, на выходе получаем вещественную оценку (от -10 до 10, больше - лучше). После получения оценок ранжирования для каждого элемента смешанной выдачи, производится сортировка по оценке ранжирования по убыванию.
[106] Полученные оценки релевантности отправляются в модуль взаимодействия 101.
[107] Далее, модуль 101 выполняет сортировку документов из смешанной выдачи по убыванию оценок релевантности. Первые K документов, например, 6 документов, 10 документов и т.д., из отсортированной смешанной выдачи отправляются вместе с пользовательским запросом в виде текстовой последовательности в модуль генерации ответа 107.
[108] На этапе 209, на основе документов, отобранных модулем взаимодействия 101, формируется генеративный результат поискового запроса.
[109] На указанном этапе 209 полученные данные преобразуются в окончательный ответ на запрос пользователя в виде текстовой последовательности, например, посредством генерации ответа на пользовательский запрос.
[110] Так, в одном частном варианте реализации, модуль генерации ответа 107 может быть реализован на базе модели типа LLM, которая запромптирована (дообучена посредством текстовых подсказок) отвечать на пользовательский запрос, опираясь на самые релевантные запросу документы. Так, в еще одном частном варианте осуществления модель может представлять собой модель машинного обучения GigaChat, но очевидно, что могут применяться и другие модели (YaGPT, ChatGPT, open-source LLM).
[111] Генеративный результат представляет собой обобщение, например, нескольких релевантных источников и генерации ответа, содержащего наиболее релевантные ответы, например, в виде сжатого изложения указанных источников с добавлением релевантных документов.
[112] Далее, на этапе 210 сгенерированный результат поискового запроса отправляется на пользовательское устройство.
[113] Таким образом, в вышеприведенных материалах был описан способ распознавания данных, содержащих коммерческую тайну, в текстовых документах.
[114] На Фиг. 3 представлена система 300, реализующая этапы заявленного способа 200 и реализующая элементы системы 100.
[115] В общем случае система 300 содержит такие компоненты, как: один или более процессоров 301, по меньшей мере одну память 302, средство хранения данных 303, интерфейсы ввода/вывода 304, средство В/В 305, средство сетевого взаимодействия 306, которые объединяются посредством универсальной шины.
[116] Процессор 301 выполняет основные вычислительные операции, необходимые для обработки данных при выполнении способа 200. Процессор 301 исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти 302.
[117] Память 302, как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
[118] Средство хранения данных 303 может выполняться в виде HDD, SSD дисков, рейд массива, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средства 303 позволяют выполнять долгосрочное хранение различного вида информации, например, первый и второй набор результатов поиска и т.п.
[119] Для организации работы компонентов системы 300 и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В 304. Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, FireWire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[120] Выбор интерфейсов 304 зависит от конкретного исполнения системы 300, которая может быть реализована на базе широко класса устройств, например, персональный компьютер, мейнфрейм, ноутбук, серверный кластер, тонкий клиент, смартфон, сервер и т.п.
[121] В качестве средств В/В данных 305 может использоваться: клавиатура, джойстик, дисплей (сенсорный дисплей), монитор, сенсорный дисплей, тач-пад, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[122] Средства сетевого взаимодействия 306 выбираются из устройств, обеспечивающий сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п.С помощью средств 606 обеспечивается организация обмена данными между, например, системой 300, представленной в виде сервера и вычислительным устройством пользователя, на котором могут отображаться полученные данные (обезличенный текстовый документ) по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
[123] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ АУГМЕНТАЦИИ ОБУЧАЮЩЕЙ ВЫБОРКИ ДЛЯ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ | 2020 |
|
RU2758683C2 |
| СПОСОБ И СИСТЕМА ПЕРЕФРАЗИРОВАНИЯ ТЕКСТА | 2023 |
|
RU2814808C1 |
| СПОСОБ УПРАВЛЕНИЯ АВТОМАТИЗИРОВАННОЙ СИСТЕМОЙ ПРАВОВЫХ КОНСУЛЬТАЦИЙ | 2019 |
|
RU2718978C1 |
| МНОГОЭТАПНОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2021 |
|
RU2824338C2 |
| РАСШИРЕНИЕ ВОЗМОЖНОСТЕЙ ИНФОРМАЦИОННОГО ПОИСКА | 2015 |
|
RU2618375C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА | 2023 |
|
RU2817524C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА ДЛЯ ЦИФРОВОГО АССИСТЕНТА | 2022 |
|
RU2796208C1 |
| Способ разметки и верификации текстовых данных | 2023 |
|
RU2832840C1 |
| СПОСОБ СОЗДАНИЯ МОДЕЛИ АНАЛИЗА ДИАЛОГОВ НА БАЗЕ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ДЛЯ ОБРАБОТКИ ЗАПРОСОВ ПОЛЬЗОВАТЕЛЕЙ И СИСТЕМА, ИСПОЛЬЗУЮЩАЯ ТАКУЮ МОДЕЛЬ | 2019 |
|
RU2730449C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРОВЕРКИ МЕДИАКОНТЕНТА | 2022 |
|
RU2815896C2 |
Изобретение относится к области информационных технологий, а именно к поисковым системам в целом. Технический результат направлен на повышение точности генерации результата поискового запроса. Способ обработки поисковых запросов, выполняемый по меньшей мере одной поисковой системой, содержащий этапы, на которых: получают поисковый запрос от пользователя; осуществляют полнотекстовый поиск документов на основе запроса; формируют первый набор результатов поиска; осуществляют токенизацию и векторизацию поискового запроса; осуществляют обработку векторного представления поискового запроса с помощью модели машинного обучения на базе нейронной сети, обученной на семантический поиск документов; формируют второй набор результатов поиска на основе документов; объединяют первый и второй наборы результатов поиска; ранжируют объединенный первый и второй наборы результатов поиска, причем в ходе ранжирования определяют релевантность каждого документа относительно поискового запроса; формируют генеративный результат поискового запроса, основанный на полученных документах; отправляют результат пользователю. 2 н. и 10 з.п. ф-лы, 3 ил.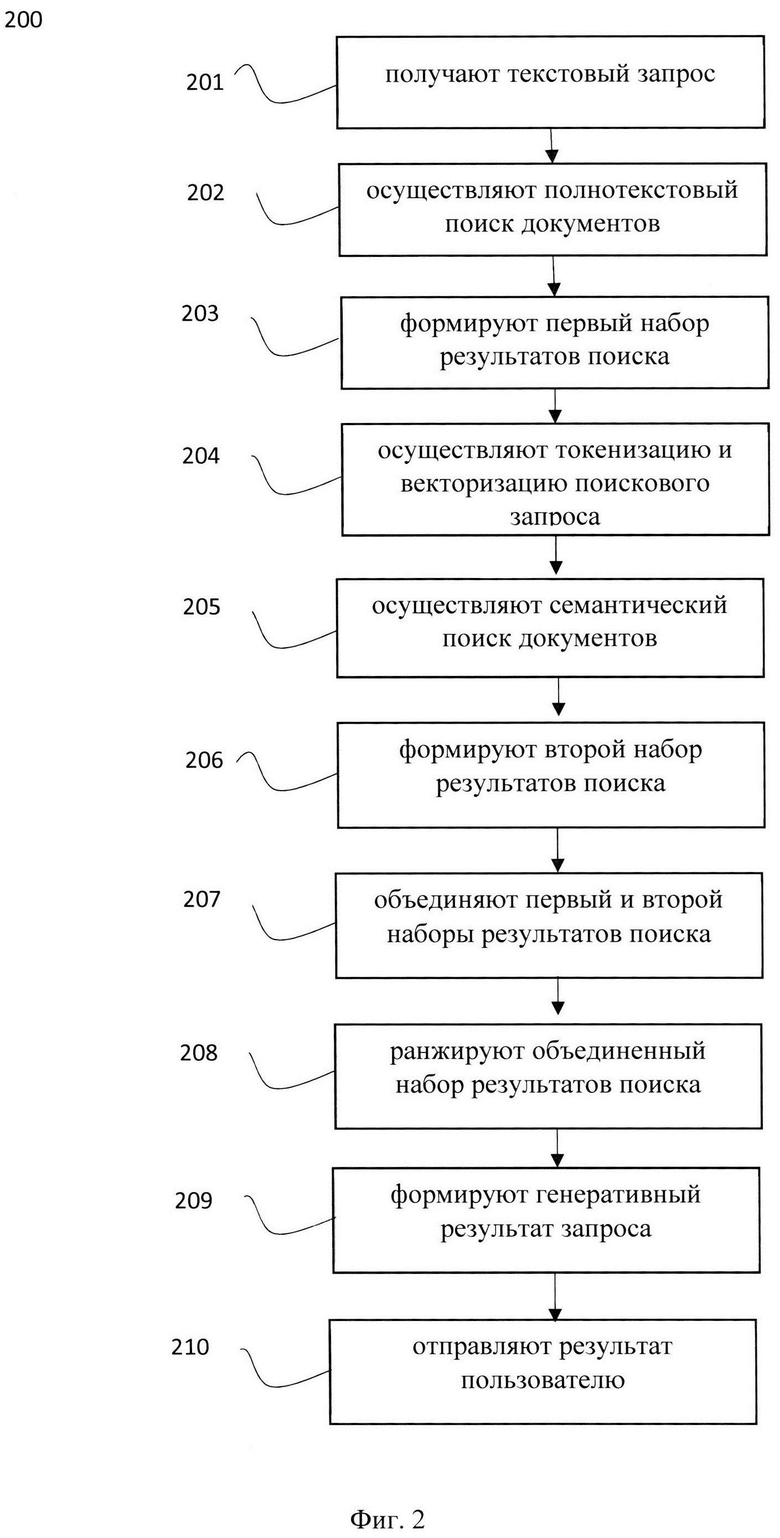
1. Способ обработки поисковых запросов, выполняемый по меньшей мере одной поисковой системой, содержащий этапы, на которых:
a) получают поисковый запрос от пользователя;
b) осуществляют полнотекстовый поиск документов на основе запроса, полученного на этапе а);
c) формируют первый набор результатов поиска;
d) осуществляют токенизацию и векторизацию поискового запроса;
e) осуществляют обработку векторного представления поискового запроса, полученного на этапе d), с помощью модели машинного обучения на базе нейронной сети, обученной на семантический поиск документов, причем в ходе обучения осуществляют:
i) формирование набора данных, содержащего доменно-специфические термины и синонимы к указанным терминам;
ii) создание неразмеченного набора данных из доменно-специфичного корпуса текстов;
iii) аугментацию неразмеченного набора данных посредством замены доменно-специфичных терминов их синонимами;
iv) обучение модели машинного обучения на аугментированном неразмеченном наборе данных;
f) формируют второй набор результатов поиска на основе документов, полученных на этапе е);
g) объединяют первый и второй наборы результатов поиска;
h) ранжируют объединенные первый и второй наборы результатов поиска, причем в ходе ранжирования определяют релевантность каждого документа относительно поискового запроса;
i) формируют генеративный результат поискового запроса, основанный на полученных документах;
j) отправляют результат, полученный на этапе i), пользователю.
2. Способ по п. 1, характеризующийся тем, что обучение модели машинного обучения на аугментированном неразмеченном наборе данных содержит следующие шаги:
i) генерация поисковых запросов к набору данных с помощью больших языковых моделей;
ii) генерация сложных негативных примеров имеющейся системой поиска;
iii) получение псевдометок релевантности поискового запроса по исходному тексту и негативным примерам с помощью их ранжирования;
iv) формирование набора данных, включающего: поисковый запрос; исходный текст, к которому генерировался запрос; набор сложных негативных примеров; псевдометки релевантности;
v) обучение модели машинного обучения на полученном наборе данных.
3. Способ по п. 1, характеризующийся тем, что в ходе объединения первого и второго наборов результатов поиска позиционное расположение каждого результата поиска из каждого набора в объединенном наборе данных выбирается случайным образом.
4. Способ по п. 1, характеризующийся тем, что доменно-специфические термины представляют собой узкоспециализированные термины, характерные определенной прикладной области.
5. Способ по п. 1, характеризующийся тем, что в ходе ранжирования объединенных первого и второго наборов результатов поиска осуществляют следующие шаги:
i.) получение пар текстовых последовательностей, где каждая пара включает в себя поисковый запрос и потенциально релевантный документ;
ii) конвертацию каждой пары в вещественное число, соответствующее степени релевантности документа к запросу;
iii) определение порядка ранжирования документов на основе сравнения вещественных чисел каждой пары.
6. Способ по п. 1, характеризующийся тем, что ранжирование выполняется по меньшей мере одной моделью машинного обучения на базе нейронной сети, обученной на наборе данных, содержащем доменно-специфические термины и синонимы к указанным терминам.
7. Способ по п. 1, характеризующийся тем, что полнотекстовый поиск документов осуществляется посредством по меньшей мере алгоритма полнотекстового поиска, учитывающего длину документа и частоту терминов.
8. Способ по п. 7, характеризующийся тем, что алгоритм полнотекстового поиска документов дополнительно содержит набор данных, включающий доменно-специфические термины и синонимы к указанным терминам.
9. Способ по п. 1, характеризующийся тем, что генеративный результат формируется с помощью нейронной сети.
10. Способ по п. 1, характеризующийся тем, что генеративный результат представляет собой текстовую последовательность, сформированную на основе пользовательского запроса и релевантных к нему документов из объединенных первого и второго наборов результатов поиска.
11. Способ по п. 1, характеризующийся тем, что векторизация поискового запроса осуществляется посредством двунаправленного кодирования.
12. Система обработки поисковых запросов, содержащая:
• по меньшей мере один процессор;
• по меньшей мере одну память, соединенную с процессором, которая содержит машиночитаемые инструкции, которые при их выполнении по меньшей мере одним процессором обеспечивают выполнение способа по любому из пп. 1-11.
| US 11016966 B2, 25.05.2021 | |||
| US 11182445 B2, 23.11.2021 | |||
| US 11388481 B2, 12.07.2022 | |||
| US 9372920 B2, 21.06.2016 | |||
| СПОСОБ И СИСТЕМА ОБРАБОТКИ ПОИСКОВОГО ЗАПРОСА | 2015 |
|
RU2640639C2 |
| СПОСОБ ОБСТРУКТИВНОЙ РЕЗЕКЦИИ ТОНКОЙ КИШКИ С НАЛОЖЕНИЕМ ОТСРОЧЕННОГО АНАСТОМОЗА | 2017 |
|
RU2670694C9 |
| СИСТЕМА И СПОСОБ ОБРАБОТКИ ДАННЫХ ДЛЯ КОМПЛЕКСНОЙ ОЦЕНКИ ЗРЕЛОСТИ НАУЧНО-ТЕХНОЛОГИЧЕСКОГО ПРОЕКТА НА ОСНОВЕ ИСПОЛЬЗОВАНИЯ НАБОРА ПАРАМЕТРОВ | 2020 |
|
RU2733485C1 |

