ПЕРЕКРЕСТНЫЕ ССЫЛКИ НА РОДСТВЕННЫЕ ЗАЯВКИ
[0001] По настоящей заявке испрашивается приоритет временной патентной заявки №62/286,437 Clandestine Machine Intelligence Retribution through Covert Operations in Cyberspace (MACINT) («Скрытное изъятие машинной информации посредством нелегальных операций в киберпространстве»), поданной 24.01.2016; временной патентной заявки №62/294,258 Logically Inferred Zero-database A-priori Realtime Defense (LIZARD) («Логическая защита и мгновенное реагирование в реальном времени без создания баз данных»), поданной 11.02.2016; временной патентной заявки №62/307,558 Critical Infractructure Protection & Retribution (CIPR) through Cloud & Tiered Information Security (CTIS) («Активная защита критической инфраструктуры посредством обеспечения многоуровневой защиты информации в облачной архитектуре»), поданной 13.03.2016; временной патентной заявки №62/323,657 Critical Thinking Memory & Perception (CTMP) («Память и восприятие, основанные на критическом мышлении») от 16.04.2016; временной патентной заявки №62/326,763 Linear Atomic Quantum Information Transfer (LAQIT) («Линейная атомно-квантовая передача информации»), поданной 23.04.2016; временной патентной заявки №62/341,310 Objective Debate Machine (ODM) («Машина для объективного спора»), поданной 25.05.2016; временной патентной заявки №62/439,409 Lexical Objectivity Mining (LOM) («Лексически объективный майнинг»), поданной 27.12.2016, и временной патентной заявки №62/449,313 Universal BCHAIN Everything Connections (UBEC) («Система универсальных BCHAIN-связей всего со всем»), поданной 23.01.2017, полные раскрытия которых содержатся в данном документе в виде ссылки. Родственные настоящей заявке патентные заявки включают патентную заявку сер. №15/145,800 METHOD AND DEVICE FOR MANAGING SECURITY IN A COMPUTER NETWORK («Способ и устройство для управления безопасностью в компьютерной сети»), поданную 04.05.2016, и патентную заявку сер. №15/264,744 SYSTEM OF PERPETUAL GIVING («Система постоянной отдачи»), поданную 14.09.2016, полные раскрытия которых содержатся в данном документе в виде ссылки.
ОБЛАСТЬ ИЗОБРЕТЕНИЯ
[0002] Настоящее изобретение относится к системе компьютерной безопасности на основе искусственного интеллекта. В состав изобретения входят такие подсистемы, как активная защита критической инфраструктуры посредством обеспечения многоуровневой защиты информации в облачной архитектуре (CIPR/CTIS), секретный машинный интеллект (MACINT) и отпор посредством скрытных операций в киберпространстве, логическая защита и мгновенное реагирование в реальном времени без создания баз данных (LIZARD), память и восприятие, основанные на критическом мышлении (СТМР), лексически объективный майнинг (LOM), линейная атомно-квантовая передача информации (LAQIT) и система универсальных BCHAIN-связей всего со всем (UBEC), а также гармонизация базовых подключений с присоединением встроенных узлов.
УРОВЕНЬ ТЕХНИКИ
[0003] При решении вопросов компьютерной безопасности в сложных случаях часто требуется вмешательство специалиста-человека. В связи с бурным развитием возможностей компьютерной техники и компьютерных сетей усилилась активность злонамеренных лиц, в том числе хакеров, что выходит за рамки традиционных методов обеспечения безопасности, требующим участия человека. Чтобы преодолеть данные ограничения, предлагаются стратегии с использованием искусственного интеллекта. Однако данные стратегии требуют в своей основе продвинутых моделей, способных достоверно имитировать мыслительный процесс человека и реализуемых компьютерной техникой.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0004] Система компьютерной безопасности, основанная на искусственном интеллекте, в которой система оснащена памятью, где хранятся запрограммированные инструкции, процессором, сопряженным с памятью, для выполнения запрограммированных инструкций, а также по меньшей мере одной базой данных, причем система также включает в себя компьютерную систему, обеспечивающую реализацию указанных функций.
[0005] Компьютерная система представляет собой активную защиту критической инфраструктуры посредством обеспечения многоуровневой защиты информации в облачной архитектуре (CIPR/CTIS) и дополнительно включает в себя:
а) доверенную платформу, представляющую собой сеть агентов, сообщающих о деятельности хакеров;
б) провайдера управляемой сети и услуг безопасности (Managed Network & Security Services Provider, MNSP), который обеспечивает услуги и решения по управляемому безопасному шифрованию, подключениям и совместимости;
где MNSP соединен с доверенной платформой посредством виртуальной частной сети (Virtual Private Network, VPN), которая предоставляет канал связи с доверенной платформой, a MNSP выполнен с возможностью анализировать весь трафик в сети предприятия, причем трафик направляют в MNSP.
[0006] MNSP включает в себя:
а) логическую защиту и мгновенное реагирование в реальном времени без создания баз данных (LIZARD), которая узнает назначение и функцию внешнего кода и блокирует его в случае наличия злого умысла либо отсутствия обоснованной цели, а также анализирует угрозы сами по себе без обращения к прошлым данным;
б) искусственные угрозы безопасности (Artificial Security Threat, AST), которые представляют собой гипотетический сценарий события в системе безопасности для проверки эффективности правил безопасности;
в) творческий модуль, осуществляющий процесс интеллектуального создания новых гибридных форм из существующих форм;
г) обнаружение злого умысла, посредством которого определяют взаимосвязь информации, выделяют образцы поведения, связанного с системой безопасности, проводят регулярные фоновые проверки нескольких подозрительных событий в системе безопасности, а также предпринимают попытки найти взаимосвязь между событиями, на первый взгляд не связанными между собой;
д) поведение системы безопасности, в котором хранятся и индексируются события в системе безопасности, их признаки и отклик на них, причем отклики представляют собой решения как по блокировке, так и по допуску;
е) итеративный рост и развитие интеллекта (Iterative Intelligence Growth/Intelligence Evolution, I2GE), посредством которого изучают большие данные и распознают сигнатуры вредоносного ПО, а также симулируют потенциальные разновидности данного ПО путем совмещения AST с творческим модулем;
ж) память и восприятие, основанные на критическом мышлении (СТМР), посредством которых критически рассматривают решения по блокировке или допуску, а также обеспечивают дополнительный уровень безопасности путем изучения перекрестных данных, предоставляемых I2GE, LIZARD и доверенной платформой, причем СТМР оценивает собственный потенциал в формировании объективного решения по данному вопросу и не навязывает это решение, если оно малонадежно.
[0007] Для защищенного взаимодействия с LIZARD в MNSP используется клиент LIZARD Lite, выполненный с возможностью работать на устройстве, входящем в сеть предприятия.
[0008] Демилитаризованная зона (Demilitarized Zone, DMZ) представляет собой подсеть, содержащую HTTP-сервер с более высокой ответственностью перед системой безопасности, чем у обычного компьютера, снимающий такую ответственность с остальных устройств в сети предприятия.
[0009] I2GE включает в себя итеративное развитие, в котором отбирают и исследуют параллельные пути развития, итеративные поколения которых адаптируются к одним и тем же искусственным угрозам безопасности, и путь с наиболее удачными личностными чертами лучше других противостоит угрозам безопасности.
[0010] LIZARD включает в себя:
а) синтаксический модуль, который предоставляет фреймворк для написания и чтения компьютерного кода;
б) целевой модуль, который с помощью синтаксического модуля выделяет из кода цель, поле чего выдает ее в собственном формате сложносоставной цели;
в) виртуальную обфускацию, в рамках которой сеть и базу данных предприятия копируют и переносят в виртуальную среду, где конфиденциальные сведения замещают фальшивыми данными, причем среда может динамически подстраиваться в реальном времени под поведение цели, включая в себя больше фальшивых данных либо больше настоящих данных самой системы;
г) имитацию сигнала, которая обеспечивает своего рода ответный удар при достижении аналитического завершения виртуальной обфускации;
д) проверку внутренней логики, в рамках которой проверяют, присутствует ли логика во всех внутренних функциях внешнего кода;
е) переписывание внешнего кода, в рамках которого посредством синтаксического и целевого модулей внешний код преобразуют в формат сложносоставной цели;
ж) обнаружение скрытого кода, в рамках которого обнаруживают код, скрытно помещенный в пакеты передачи данных;
з) сопоставление карт потребностей, т.е. карту иерархии потребностей и целей, на которую опираются, решая, соответствует ли внешний код общему назначению системы;
где для написания кода синтаксический модуль получает из целевого модуля код в формате сложносоставной цели, затем пишет код с произвольным синтаксисом, после чего вспомогательная функция переводит его в реальный исполняемый код; где для чтения синтаксический модуль направляет в целевой модуль синтаксическую интерпретацию кода с целью выявить назначение данного кода;
где имитация сигнала использует синтаксический модуль с целью понять синтаксис коммуникации вредоносного ПО с запустившими его хакерами, после чего контроль над коммуникацией перехватывают, чтобы создать ложное впечатление, что атака удалась и что конфиденциальные данные попали к хакерам, в то время как система LIZARD также направляет хакерам код ошибки от вредоносного ПО, маскируя его под реальный отклик от ПО;
где при переписывании внешнего кода с помощью выявленной цели достраивают кодовый набор, тем самым добиваясь того, чтобы внутри сети предприятия исполнялись только желаемые и понятные функции внешнего кода, а все остальные части кода не получали доступа в систему.
[0011] Для того, чтобы при переписывании внешнего кода был синтаксически воспроизведен внешний код с целью сглаживания потенциально незамеченных вредоносных эксплойтов, посредством комбинационного метода сравнивают и сопоставляют заявленную цель с выявленной целью, причем используют целевой модуль для манипуляции форматом сложносоставной цели, причем в отношении выявленной цели при сопоставлении карт потребностей сохраняют иерархическую структуру для сохранения юрисдикции всех нужд предприятия, с тем чтобы определить и обосновать назначение участка кода, в зависимости от пустот в юрисдикционно-ориентированной карте потребностей, причем входящую цель получают из процесса рекурсивной отладки.
[0012] При рекурсивной отладке циклически проходят сегменты кода, проверяют их на наличие багов и исправляют их, причем если баг не устраняется, весь сегмент кода заменяют исходным сегментом внешнего кода, после чего данный исходный сегмент помечают с целью упрощения процесса виртуальной обфускации и поведенческого анализа, причем исходное состояние внешнего кода интерпретируется целевым модулем и синтаксическим модулем для переписывания кода, причем отладчик напрямую обращается к внешнему коду в случае, если в переписанной версии обнаружен неустранимый баг и весь сегмент необходимо заменить исходным сегментом внешнего кода, тогда как сегменты переписанного кода проверяют в виртуальной среде выполнения на предмет наличия багов программирования, где виртуальная среда выполнения запускает сегменты кода и проверяет на наличие ошибок выполнения, и при наличии багов программирования виртуальная среда выполнения выявляет тип и участок ошибок, после чего готовят потенциальное решение для бага программирования посредством совмещения цели и перевыражения кода из заявленной цели, причем участок бага программирования переписывают в ином формате с целью избежать бага, причем потенциальное решение выводят, а если решений не осталось, данный сегмент кода больше не переписывают, а в итоговом кодовом наборе вставляют на его место исходный сегмент кода напрямую из внешнего кода.
[0013] При сопоставлении карт потребностей облака LIZARD Cloud и LIZARD Lite обращаются к иерархической карте ветвей юрисдикции предприятия, причем вне зависимости от того, совпадает входящая цель с заявленной либо получена из целевого модуля, в ходе сопоставления карт потребностей подтверждают обоснование для выполнения кода/функции в системе предприятия, причем эталонный экземпляр иерархической карты хранят в облаке LIZARD Cloud в MNSP, а индекс потребностей в сопоставлении карт потребностей рассчитывают на основании данного эталонного экземпляра, причем предоптимизированный индекс потребностей распространяют по всем доступным конечным клиентам, а для сопоставления карт потребностей получают запрос потребностей в отношении наиболее подходящей потребности системы в целом, причем в качестве соответствующего вывода выступает формат сложносоставной цели, отражающий данную подходящую потребность.
[0014] В MNSP виртуально воссоздают всю инфраструктуру локальной сети (LAN) предприятия, причем в процессе поведенческого анализа системой хакеры сталкиваются как с элементами реальной инфраструктуры локальной сети, так и с виртуальной копией, и в случае, если такой анализ выявляет риск, хакеру в большей степени предоставляют взаимодействовать с виртуальной копией с целью снизить риск взлома настоящих данных и/или устройств.
[0015] AST передают корневую сигнатуру вредоносного ПО, с тем чтобы сформировать итерации/вариации данной сигнатуры, причем полиморфические вариации вредоносного ПО получают на выходе из I2GE и передают на обнаружение вредоносного ПО.
[0016] Обнаружение вредоносного ПО производят на всех трех уровнях устройства компьютера, а именно в пользовательском пространстве, пространстве ядра и пространстве прошивки/оборудования, причем все указанные пространства находятся под контролем агентов LIZARD Lite.
[0017] Компьютерная система представляет собой секретный машинный интеллект (MACINT) и отпор посредством скрытных операций в киберпространстве и дополнительно включает в себя:
а) интеллектуальное управление информацией и конфигурацией (Intelligent Information and Configuration Management, I2CM), обеспечивающее интеллектуальное управление, просмотр и контроль информации;
б) консоль управления (Management Console, МС), предоставляющую пользователям канал ввода/вывода;
причем I2СМ включает в себя:
i) сбор, при котором используют критерии общего уровня для отсеивания неважной и лишней информации, а также сливают и помечают потоки информации с множества платформ;
ii) службу конфигурации и размещения, которая включает в себя интерфейс для добавления новых устройств в сеть предприятия с заданными настройками безопасности и подключения, а также для управления учетными записями новых пользователей;
iii) разделение по юрисдикции, в рамках которого размеченный пул информации делят исключительно в соответствии с юрисдикцией конкретного пользователя консоли управления;
iv) разделение по угрозам, в рамках которого информацию организуют в соответствии с отдельными угрозами;
v) автоматизированные элементы управления для доступа в облако MNSP, на доверенную платформу или к дополнительным сторонним службам.
[0018] В облаке MNSP в ходе поведенческого анализа наблюдают состояние вредоносного ПО и действия, которые оно выполняет, находясь в среде фальшивых данных, причем если вредоносное ПО предпринимает попытку передать фальшивые данные хакеру, исходящий сигнал перенаправляют, так чтобы его получил фальшивый хакер, где хакерский интерфейс получает кодовую структуру вредоносного ПО и на ее основе восстанавливает внутреннюю структуру вредоносного ПО, из которой затем получают хакерский интерфейс, причем фальшивый хакер и фальшивое вредоносное ПО симулируют внутри виртуальной среды, где виртуальный фальшивый хакер посылает ответный сигнал настоящему вредоносному ПО для выявления дальнейшего поведения данного ПО, а реальный хакер получает фальшивый ответный код, не соответствующий поведению/состоянию настоящего вредоносного ПО.
[0019] В ходе сканирования эксплойтов определяет возможности и характеристики преступного оборудования, и итоговые результаты сканирования применяются эксплойтом - программой, которая направляется доверенной платформой посредством базы данных ответных эксплойтов и поражает систему злоумышленников, причем в базе данных ответных эксплойтов содержатся средства нанесения отпора злоумышленникам, предоставленные поставщиками аппаратного обеспечения в виде готовых бэкдоров и известных уязвимостей, причем в единой базе данных судебных доказательств собраны судебные доказательства из множества источников, включающих множество предприятий.
[0020] В случае, если законспирированный агент из преступной системы захватывает файл в сети предприятия, брандмауэр формирует отчет, который направляют в сбор отчетов, причем в ходе сбора отчетов данные категоризируют и разделяют для длительного/глубинного сканирования и оперативного/поверхностного сканирования.
[0021] Глубинное сканирование взаимодействует с большими данными, при этом используя субалгоритм обнаружения злого умысла и субалгоритм управления внешними сущностями, причем стандартные отчеты с пунктов безопасности собирают в сборе отчетов и делают из них выборку посредством фильтров с низкими ограничениями, причем подробности событий сохраняют в индексе и трекинге событий, в ходе обнаружения аномалий используют индекс событий и поведение системы безопасности в соответствии с промежуточными данными, представленными модулем глубинного сканирования, для определения потенциальных рисков, причем в анализе событий участвуют субалгоритмы управления внешними сущностями и обнаружения злого умысла.
[0022] Доверенная платформа проверяет произвольный компьютер на предмет того, являются ли его серверные родственники/соседи (т.е. другие сервера, с которыми он соединен) ранее запущенными двойными или тройными агентами доверенной платформы, причем поиск агентов осуществляется в облаке индекса и трекинга доверенных двойных агентов и в облаке индекса и трекинга доверенных тройных агентов, где двойной агент, которому доверяет произвольный компьютер, проводит эксплойт по доверенному каналу, и эксплойт пытается найти конфиденциальный файл, отправляет его в карантин и передает его точное состояние доверенной платформе, после чего пытается гарантированно удалить его с компьютера злоумышленника.
[0023] Запрос к API (Application Programming Interface, программный интерфейс приложения) провайдера составляется доверенной платформой для обнаружения в сетевых журналах сетевого надзора произвольной системы потенциальной передачи файлов на компьютер злоумышленника, причем метаданные используют для того, чтобы со значительной долей уверенности определить, на какой компьютер совершена передача, сетевой надзор выясняет параметры сети компьютера злоумышленника и перенаправляет сведения на доверенную платформу, причем доверенную платформу используют для обращения к API системы безопасности, предоставленному поставщиками программного и аппаратного обеспечения, для того чтобы применить готовые бэкдоры в целях судебного расследования.
[0024] Доверенная платформа принудительно отправляет на компьютер злоумышленника обновление программного обеспечения или прошивки для создания нового готового бэкдора, причем на соседние похожие машины для маскировки принудительно отправляют плацебо-обновление, идентификационные данные цели направляют на доверенную платформу, причем доверенная платформа указывает контролеру программного обеспечения/прошивки принудительно отправить плацебо-обновления и обновления, содержащие бэкдоры, на соответствующие компьютеры, где обновление, содержащее бэкдор, приводит к созданию нового бэкдора в системе компьютера злоумышленника путем использования существующей системы обновления программного обеспечения, установленного на данном компьютере, а плацебо-обновление бэкдоров не содержит, причем контролер переносит бэкдор как на цель, так и на компьютеры, контакт которых с целью выше среднего, причем при применении эксплойта посредством обновления, содержащего бэкдор, конфиденциальный файл отправляют в карантин и копируют с целью дальнейшего анализа истории использования его метаданных, а любые дополнительные судебные данные собирают и направляют в пункт связи экслойта на доверенной платформе.
[0025] На доверенную платформу принудительно отправляют флаг долгосрочного приоритета для наблюдения за системой злоумышленников на предмет любых изменений/обновлений, причем система предприятия передает в модуль ордера цель, и модуль ордера сканирует входящие данные всех аффилированных систем на предмет ассоциаций с заданной целью, где в случае совпадений информацию передают в систему предприятия, которая создала ордер и пытается проникнуть в цель, причем входящие данные передают в желаемый аналитический модуль, посредством которого синхронизируют взаимовыгодные сведения безопасности.
[0026] Компьютерная система представляет собой логическую защиту и мгновенное реагирование в реальном времени без создания баз данных (LIZARD) и дополнительно включает в себя:
а) статичное ядро (Static Core, SC), состоящее из в основном статичных программных модулей;
б) итерационный модуль, посредством которого изменяют, создают и уничтожают модули в динамической оболочке, причем итерационный модуль использует AST для оценки качества работы системы безопасности, а также итерационное ядро для осуществления автоматического написания кода;
в) алгоритм дифференциальной модификации, посредством которого модифицируют базовую итерацию в соответствии с недостатками, обнаруженными с помощью AST, причем после применения дифференциальной логики предлагают новую итерацию и рекурсивно обращаются к итерационному ядру, которое затем заново подвергают той же самой проверке с использованием AST;
г) алгоритм логической дедукции, в который из AST поступают известные отклики системы безопасности итераций динамической оболочки, и посредством данного алгоритма вычисляют состав кодового набора, который поможет добиться известного верного отклика на сценарий события в системе безопасности;
д) динамическая оболочка (Dynamic Shell, DS), в которой содержатся преимущественно динамические программные модули, которые были автоматически запрограммированы итерационным модулем (Iteration Module, IM);
е) карантин кода, посредством которого внешний код изолируют в ограниченной виртуальной среде;
ж) обнаружение скрытого кода, в рамках которого обнаруживают код, скрытно помещенный в пакеты передачи данных;
з) переписывание внешнего кода, в рамках которого после выяснения назначения внешнего кода переписывают части кода или код целиком и которое допускает только переписывание;
причем все устройства на предприятии связаны через LIZARD, все прошивки и программное обеспечение, на которых работают данные устройства, запрограммированы так, чтобы любые скачивания/закачки данных происходили исключительно через LIZARD как постоянный прокси, причем LIZARD взаимодействует с тремя типами данных, включая данные в движении, используемые данные и неподвижные данные, а также взаимодействует с различными формами данных, в том числе с файлами, электронной почтой, сетевыми данными, мобильными данными, облачными данными и съемными данными.
[0027] Система дополнительно включает в себя:
а) реле переполнения AST, где данные передаются в AST для будущего улучшения итераций, когда система может принимать только малонадежные решения;
б) проверку внутренней логики, в рамках которой проверяют, присутствует ли логика во всех внутренних функциях участка внешнего кода;
в) зеркальный тест, посредством которого проверяют, совпадает ли динамика ввода/вывода переписанного кода с оригиналом, причем все скрытые эксплойты исходного кода отключены и не выполняются;
г) сопоставление карт потребностей, т.е. карту иерархии потребностей и целей, на которую опираются, решая, соответствует ли внешний код общему назначению системы;
д) синхронизатор с настоящими данными, посредством которого отбирают данные, которые затем направят в смешанные среды, а также устанавливают приоритет запрещения доступа к конфиденциальной информации вредоносному ПО;
е) менеджер данных, выступающий в качестве интерфейса-посредника между сущностью и данными, приходящими извне виртуальной среды;
ж) виртуальная обфускация, посредством которой запутывают код и ограничивают к нему доступ путем постепенного и частичного его погружения в виртуальную фальшивую среду;
з) модуль скрытной транспортировки, посредством которого скрытно и незаметно происходит перенос вредоносного ПО в среду фальшивых данных;
и) трекинг отзыва данных, в котором отслеживается вся информация, загруженная с подозрительной сущности и отправленная туда.
[0028] Система дополнительно включает модуль сравнения целей, в котором производят сравнение четырех типов цели, для того чтобы убедиться в том, что поведение и структура сущности одобрены и понятны LIZARD и рассматриваются как содействующие назначению системы в целом.
[0029] Итерационный модуль использует SC, чтобы синтаксически модифицировать кодовую базу DS в соответствии с выявленной целью в «фиксированных целях» и данных из реле возврата данных (Data Return Relay, DRR), причем модифицированную версию LIZARD параллельно подвергают стресс-тестам AST с использованием множества разных сценариев событий в системе безопасности.
[0030] Внутри SC в рамках логического вывода из изначально более простых функций выводят логически необходимые функции, причем все дерево функциональных зависимостей строится из заявленной сложносоставной цели;
где в рамках перевода кода преобразуют произвольный обобщенный код, понимаемый напрямую функциями синтаксического модуля, в код на любом выбранном известном языке программирования, а также выполняют обратную операцию перевода кода на известном языке программирования в произвольный код;
где в рамках упрощения логики упрощают логику записанного кода для создания карты взаимосвязанных функций;
где формат сложносоставной цели представляет собой формат для хранения взаимосвязанных подцелей, в сумме составляющих общую цель;
где целевые ассоциации представляют собой запрограммированные сведения о том, какие функции и какие типы поведения связаны с какими целями;
где в рамках итеративного расширения добавляют подробности и сложность для развития простой цели в сложносоставную путем обращения к целевым ассоциациям;
где в рамках итеративной интерпретации циклически обрабатывают все взаимосвязанные функции и получают интерпретированную цель путем обращения к целевым ассоциациям;
где внешнее ядро сформировано целевым и синтаксическим модулями, которые работают сообща с целью выведения логической цели неизвестного внешнего кода и получения исполняемого кода из заявленной цели функционального кода;
где внешний код представляет собой код, неизвестный LIZARD, функционал и назначение которого неизвестны, причем внешний код служит вводом для внутреннего ядра, а выводом служит выявленная цель, причем выявленная цель - это намерение данного кода, согласно оценкам целевого модуля, и причем выявленную цель возвращают в формате сложносоставной цели.
[0031] IM использует AST для оценки качества работы системы безопасности, а также итерационное ядро для осуществления автоматического написания кода, причем, если LIZARD приходится принимать малонадежное решение, данные об атаках злоумышленников и самих злоумышленниках из DDR передают в AST; причем внутри итерационного ядра алгоритм дифференциальной модификации (Differential Modifier Algorithm, DMA) получает из внутреннего ядра программные возможности синтаксического и целевого модулей, а также сведения о назначении системы, после чего используется кодовый набор для модификации базовой итерации в соответствии с недостатками, обнаруженными с помощью AST, где итоговые недостатки системы безопасности представлены визуально, чтобы указать на угрозы безопасности, прошедшие сквозь базовую итерацию во время работы виртуальной среды исполнения.
[0032] В рамках DMA текущее состояние отражает кодовый набор динамической оболочки с символически сопоставленными формами, размерами и положениями, причем разные конфигурации данных форм указывают на разные конфигурации интеллекта и реакции системы безопасности, причем AST передает потенциальные отклики текущего состояния, которые оказались неверными, а также верный отклик;
где вектор атаки выступает в качестве символического отображения угрозы кибербезопасности, причем направление, размер и цвет соответствуют гипотетическим свойствам вектора атаки, размеру и типу вредоносного ПО, причем вектор атаки символически отталкивается от кодового набора с целью выразить отклик системы безопасности на данный кодовый набор;
где верное состояние представляет собой окончательный результат работы DMA по получению желаемого отклика системы безопасности из участка кода динамической оболочки, причем различия между текущим состоянием и верным состоянием приводят к различным откликам вектора атаки;
где AST предоставляет известные недостатки системы безопасности, а также верный отклик системы безопасности, причем алгоритм логической дедукции использует ранние итерации DS с целью получить более совершенную и эффективную итерацию динамической оболочки, под которой понимается программа верного отклика системы безопасности.
[0033] В рамках виртуальной обфускации подозрительный код скрытно перенаправляют в среду, в которой половину данных интеллектуальным образом смешивают с фальшивыми данными, причем субъекты, работающие в настоящей системе, можно с легкостью и скрытно перенести в среду фальшивых данных, полную либо частичную, благодаря виртуальной изоляции, где генератор фальшивых данных, используя в качестве образца синхронизатор с настоящими данными, создает фальшивые и бесполезные данные; где воспринимаемый риск уверенности в восприятии поступающего внешнего кода влияет на выбираемый LIZARD уровень обфускации; где высокая уверенность во вредоносности кода приводит к тому, что его помещают в среду с большим содержанием фальшивых данных, тогда как низкая уверенность во вредоносности кода приводит к тому, что его помещают либо в настоящую систему, либо в среду, содержащую 100% фальшивых данных.
[0034] В трекинге отзыва данных отслеживается вся информация, загруженная с подозрительной сущности и отправленная туда, причем в случае, если фальшивые данные были отправлены легитимной сущности в сети предприятия, все эти фальшивые данные отзываются, и взамен их отправляют настоящие данные, причем триггер отзыва выполнен таким образом, чтобы легитимная сущность в сети предприятия не предпринимала действий на основании определенных данных, пока не получит подтверждения о том, что это настоящие, а не фальшивые данные.
[0035] В ходе поведенческого анализа отслеживают поведение подозрительной сущности в плане скачивания и загрузки информации с целью определить потенциальные меры по устранению угрозы, причем реальная система содержит исходные настоящие данные, целиком существующие вне виртуальной среды, где настоящие данные, заменяющие собой фальшивые данные, поступают нефильтрованными в трекинг отзыва данных, где может быть сделан патч настоящих данных для замены фальшивых данных на настоящие данные в сущности, ранее классифицированной как подозрительная; причем менеджер данных, погруженный в виртуальную изолированную среду, получает патч настоящих данных из трекинга отзыва данных; причем если безвредный код в ходе поведенческого анализа был отмечен как вредоносный, принимаются меры по устранению угрозы для замены фальшивых данных в сущности, ранее классифицированной как подозрительная, на соответствующие настоящие данные; причем секретный токен - это строка безопасности, сформированная и назначенная LIZARD, которая позволяет реально безвредной сущности не выполнять свою функцию, причем если токен отсутствует, то это значит, что, вероятнее всего, данная легитимная сущность была случайно помещена в среду, частично состоящую из фальшивых данных, по подозрению в том, что она может являться вредоносным ПО, после чего активируют замедленную сессию с интерфейсом задержки, тогда как, если токен присутствует, это значит, что серверная среда настоящая, и, следовательно, все замедленные сессии деактивируются.
[0036] В рамках поведенческого анализа карта целей представляет собой иерархию задач системы, которая дает цель всей системе предприятия, причем заявленную цель, назначение деятельности и назначение кодовой базы сравнивают с присущей системе необходимости в том, что якобы делает подозрительная сущность; причем осуществляют наблюдение за деятельностью памяти, процессора и сетевой активностью подозрительной сущности, где синтаксический модуль интерпретирует такую деятельность с точки зрения желательной функции, причем такие функции затем переводят в назначение с помощью целевого модуля, где кодовая база - это исходный код/программная структура подозрительной сущности, которую передают в синтаксический модуль, где синтаксический модуль распознает программный синтаксис и сводит программный код и деятельность кода к промежуточной карте взаимосвязанных функций, причем целевой модуль выдает воспринимаемые намерения подозрительной сущности, выдавая также назначение кодовой базы и назначение деятельности, где назначение кодовой базы содержит известную цель, назначение, юрисдикцию и полномочия сущности, выявленные возможностями синтаксического модуля LIZARD, а назначение деятельности содержит известную цель, назначение, юрисдикцию и полномочия сущности, выявленные LIZARD благодаря пониманию деятельности памяти, процессора и сетевой активности; где под заявленной целью понимают цель, назначение, юрисдикцию и полномочия сущности, заявленные самой сущностью, а необходимая цель содержит ожидаемую цель, назначение, юрисдикцию и полномочия, требуемые системой предприятия; причем все цели сравнивают в модуле сравнения, а любые расхождения в целях приводят к выполнению сценария расхождения в целях и, как следствие, к мерам по устранению угрозы.
[0037] Компьютерная система представляет собой память и восприятие, основанные на критическом мышлении (СТМР). Система дополнительно включает в себя:
а) расширитель объема критических правил (Critical Rule Score Extender, CRSE), который берет известный объем восприятий и расширяет его, добавляя в него восприятие критического мышления;
б) верные правила, к которым относятся верные правила, полученные путем использования восприятия критического мышления;
в) выполнение правил (Rule Execution, RE), в рамках которого выполняются правила, существование и выполнение которых подтверждается сканированием памяти хаотического поля, с целью получения желаемых и подходящих решений, принятых с помощью критического мышления;
г) вывод критических решений, в рамках которого получают итоговую логику для определения общего итога работы СТМР путем сравнения выводов, достигнутых как симулятором восприятия наблюдателя (Perception Observer Emulator, РОЕ), так и RE;
где РОЕ симулирует наблюдателя и проверяет/сравнивает все потенциальные факты восприятия, используя различные формы симуляции наблюдателя;
где RE включает шахматную плоскость, которую используют для отслеживания преобразования наборов правил, причем объекты на доске отражают сложность данной ситуации в системе безопасности, а перемещение данных объектов по «доске безопасности» отражает развитие ситуации, которое контролируется откликами правил безопасности.
[0038] Система дополнительно включает в себя:
а) субъективные решения, предоставляемые алгоритмом сопоставления выбранных образцов (Selected Pattern Matching Algorithm, SPMA);
б) ввод метаданных системы, включающих необработанные метаданные из SPMA, описывающие механику работы алгоритма и процесс прихода к тому или иному решению;
в) обработку причин, в рамках которой происходит логическое осмысление утверждений путем сравнения характеристик свойств;
г) обработку правил, в рамках которой выведенные правила используют в качестве позиции для сравнения с целью определить масштаб текущей проблемы;
д) сеть памяти, которая сканирует журналы рыночных переменных на предмет выполнимых правил;
е) получение необработанного восприятия, в рамках которого из SPMA получают журналы метаданных, причем журналы обрабатывают и формируют восприятие, которое отражает восприятие данного алгоритма, причем восприятие сохраняют в сложном формате восприятия (Perception Complex Format, PCF) и симулируют с помощью РОЕ; причем под прикладными углами восприятия понимают углы восприятия, которые уже были применены и использованы SPMA;
ж) механизм автоматизированного обнаружения восприятия (Automated Perception Discovery Mechanism, APDM), который задействует творческий модуль, производящий гибридизированное восприятие, формируемое в соответствии с входными данными прикладных углов восприятия, с тем чтобы объем восприятия можно было увеличивать;
з) плотность самокритичных знаний (Self-Critical Knowledge Density, SKCD), где оценивается объем и тип потенциально неизвестных знаний, лежащих за пределами журналов и отчетов, причем последующие функции критического мышления в СТМР могут задействовать весь потенциальный объем имеющихся знаний; причем критическое мышление указывает на юрисдикцию внешней оболочки мышления, основанного на правилах;
и) получение выводов (Implication Derivation, ID), в рамках которого выводят углы восприятия данных из текущих прикладных углов восприятия,
причем SPMA противопоставляют критическому мышлению, выполненному посредством СТМР при использовании восприятия и правил.
[0039] Система дополнительно включает в себя:
а) менеджмент и распределение ресурсов (Resource Management & Allocation, RMA), в рамках которых с помощью настраиваемой политики решают, сколько восприятия необходимо задействовать, чтобы симулировать наблюдателя, причем приоритет в отборе фактов восприятия выбирают исходя из их веса в порядке убывания, а с политика затем определяет способ отсекания: процентная доля, фиксированное число либо более сложный способ;
б) поиск по хранилищу (Storage Search, SS), в рамках которого используют CVF, полученный из обогащенных данными журналов, в качестве критерия поиска по базе данных в хранилище восприятия (Perception Storage, PS), причем в PS факты восприятия хранятся не только со своим значением веса, но и также с индексом в виде формата сравниваемых переменных (Comparable Variable Format, CVF);
в) обработку метрик, в ходе которой восстанавливают распределение переменных из SPMA;
г) дедукцию восприятия (Perception Deduction, PD), в рамках которой используют распределение откликов и соответствующих метаданных системы для воспроизведения исходного восприятия отклика распределения;
д) модуль категоризации метаданных (Metadata Categorization Module, МСМ), в котором отладку и отслеживание алгоритма разделяют на отдельные категории посредством категоризации информации на основе синтаксиса, причем данные категории используют для создания и получения конкретного распределения откликов с корреляцией по рискам и возможностям;
е) комбинацию метрик, в ходе которой углы восприятия разделяют на категории метрик;
ж) преобразование метрик, в ходе которого отдельные метрики преобразовывают обратно в полноценные углы восприятия;
з) расширение метрик (Metric Expansion, ME), в ходе которого метрики множества разных углов восприятия сохраняют по категориям в отдельных базах данных;
и) генератор формата сравниваемых переменных (Comparable Variable Format Generator, CVFG), который преобразует поток информации в формат CVF.
[0040] Система дополнительно включает в себя:
а) сопоставление восприятия, в рамках которого CVF генерируют из фактов восприятия, полученных из выведения синтаксиса правил (Rule Syntax Derivation, RSD), причем вновь сгенерированный CVF используют для поиска подходящих фактов восприятия в PS со схожими индексами, а потенциальные совпадения возвращают в генерирование синтаксиса правил (Rule Syntax Generation, RSG);
б) распознавание памяти (Memory Recognition, MR), в ходе которого из данных ввода формируют хаотическое поле;
в) индексацию концептов памяти, в рамках которой целые концепты индивидуально оптимизируют в виде индексов, причем индексы используются буквенными сканерами для взаимодействия с хаотическим полем;
г) парсер выполнения правил (Rule Fulfillment Parser, RFP), которому передают отдельные части правил с метками распознавания, причем каждую часть помечают в соответствии с тем, была ли она найдена в хаотическом поле в ходе распознавания памяти; причем RFP логически решает, какие целые правила, выступающие как комбинация всех частей, были успешно распознаны в хаотическом поле и заслуживают выполнения;
д) разделение формата синтаксиса правил (Rule Syntax Format Separation, RSFS), в рамках которого верные правила распределяют по типу, так чтобы все действия, свойства, условия и объекты хранились отдельно;
е) выведение синтаксиса правил, в ходе которого логические «черно-белые» правила преобразовывают в факты восприятия на основе метрик, причем сложные сочетания из нескольких правил преобразовывают в единое общее восприятие, выраженное через множество метрик с различными градиентами;
ж) генерирование синтаксиса правил (RSG), в ходе которого получают ранее подтвержденные факты восприятия, хранящиеся в формате восприятия, и взаимодействуют с внутренним составом метрик факта восприятия, причем такие измерения метрик на основании градиентов преобразуют в двоичные и логические наборы правил, симулирующие поток информации ввода/вывода исходного факта восприятия;
з) разделение формата синтаксиса правил (RSFS), в котором верные правила представляют собой точное отражение наборов правил, соответствующие реальности наблюдаемого объекта, причем верные правила распределяют по типу, так чтобы все действия, свойства, условия и объекты хранились отдельно, позволяя системе определять, какие элементы были найдены в хаотическом поле, а какие нет;
и) встроенную логическую дедукцию, в которой используются логические принципы, позволяющие избежать ошибок в определении того, какие правила точно отражают множество градиентов метрик внутри факта восприятия;
к) анализ контекста метрик, в рамках которого анализируют взаимные связи внутри восприятия метрик, причем определенные метрики могут зависеть от других с разной степенью силы, причем контекстуализацию используют в качестве дополнения к зеркальным взаимным связям, имеющимся у правил в «цифровом» формате набора правил;
л) преобразование формата синтаксиса правил (Rule Syntax Format Conversion, RSRC), в ходе которого правила распределяют для соответствия формату синтаксиса правил (Rule Syntax Format, RSF);
где интуитивное решение участвует в критическом мышлении путем задействования фактов восприятия, а разумное решение участвует в критическом мышлении путем задействования правил, причем в качестве фактов восприятия используются данные, полученные из интуитивного решения в соответствии с синтаксисом формата, заданным во внутреннем формате, а выполненные правила - это данные, полученные из разумного решения, представляющего собой набор выполнимых наборов правил из RE, причем данные передаются в соответствии с синтаксисом формата, заданным во внутреннем формате;
где под действиями поднимают действие, которое, возможно, уже выполнялось, будет выполнено или рассматривается для активации, под свойствами понимают характеристики, похоже на свойства, описывающие что-то другое, будь то действие, состояние или объект, под состояниями понимают логическую операцию или оператор, а под объектами понимают цель, к которой применены характеристики;
где раздельный формат правил используют в качестве вывода из разделения формата синтаксиса правил (RSFS), выступающего в качестве этапа, предшествующего распознаванию памяти, а также в качестве вывода из распознавания памяти (Memory Recognition, MR), выступающего в качестве этапа, следующего за распознаванием памяти.
[0041] Система дополнительно включает в себя:
а) парсер хаотического поля (Chaotic Field Parsing, CFP), в котором формат журналов собирают в единое сканируемое хаотическое поле;
б) дополнительные правила, получаемые из распознавания памяти (MR) в дополнение к верным правилам;
причем внутри сопоставления восприятия (Perception Matching, РМ) статистика метрик обеспечивает статистическую информацию из хранилища восприятия, в ходе управления ошибок обрабатывают синтаксис и/или логические ошибки, происходящие из тех или иных отдельных метрик, в ходе разделения метрик изолируют отдельные метрики, поскольку они раньше объединялись в единый блок - восприятие ввода; причем в алгоритм сравнения узлов (Node Comparison Algorithm, NCA) передают состав узлов в двух или более CVF, где каждый узел CVF представляет собой степень значимости свойства, где над каждым отдельным узлом выполняют сравнение по сходству и рассчитывают совокупную вариативность, и где меньшее значение вариативности указывает на более точное совпадение.
[0042] Заявленная система дополнительно включает в себя:
а) необработанное восприятие-интуитивное мышление (аналоговое), где обрабатывают факты восприятия в соответствии с «аналоговым» форматом, причем факты восприятия аналогового формата относятся к решениям, сохраненным в градиентах на гладкой кривой без перепадов;
б) необработанные правила-логическое мышление (цифровое), где обрабатывают правила в соответствии с цифровым форматом, причем необработанные правила цифрового формата относятся к решениям, которые хранятся в шагах с почти полным отсутствием «серой зоны»;
где под невыполненными правилами понимают наборы правил, недостаточно распознанные в хаотическом поле в соответствии с их логическими зависимостями, а под выполненными правилами понимают наборы правил, которые достаточно распознаны как существующие в хаотическом поле в соответствии с их логическими зависимостями; а также
где управление очередями (Queue Management, QM) задействует реконструкцию синтаксических связей (Syntactical Relationship Reconstruction, SRR) для анализа каждой отдельной части в наиболее логичном порядке и имеет доступ к результатам распознавания памяти (MR), и, таким образом, можно дать ответ на двоичные потоковым вопросам на да/нет и предпринять соответствующие действия, причем QM проверяет каждый сегмент правил пошагово, и если какой-либо сегмент отсутствует в хаотическом поле и не состоит в нужных отношениях с остальными сегментами, весь набор правил помечают как невыполненный.
[0043] Последовательная организация памяти представляет собой оптимизированный способ хранения информации в «цепочках» упорядоченных сведений, причем в точках доступа к памяти ширина каждого узла (блока) отражает возможность прямого доступа наблюдателя к запомненному объекту (узлу), в объеме доступа каждая буква отражает конкретную точку прямого доступа наблюдателя к памяти, более широкий объем доступа указывает на то, что для каждого из последовательных узлов существует несколько точек доступа, причем чем больше к последовательности обращаются строго «по порядку», а не к случайно выбранному узлу, тем уже будет объем доступа (относительно размера последовательности), причем во вложенных слоях подпоследовательности последовательность, которая показывает высокое отсутствие единообразия, состоит из последовательности более коротких, связанных между собой, подпоследовательностей.
[0044] Непоследовательная организация памяти представляет собой хранение информации в виде непоследовательно расположенных связанных объектов, причем обратимость указывает на непоследовательное расположение и единый объем, где непоследовательные отношения отмечаются относительно широкой точкой доступа к каждому узлу, причем при перетасовке узлов сохраняется та же степень единообразия; причем в ядерной теме и ассоциациях повторяют одну и ту же последовательность узлов, но с разными ядрами (центральными объектами), где ядро представляет собой основную тему, по отношению к которой оставшиеся узлы выступают в качестве соседей по памяти, что позволяет обеспечить более простой доступ к ним, чем в случае, когда ядерная тема отсутствует.
[0045] В рамках распознавания памяти (MR) сканируют хаотическое поле для распознавания известных концептов, причем хаотическое поле представляет собой «поле» концептов, произвольно погруженных в «белый шум», при этом в хранилище концептов памяти сохраняют распознаваемые концепты, которые готовы к индексации и обращению к ним для полевого исследования, при этом трехбуквенный сканер сканирует хаотическое поле и проверяет трехбуквенные сегменты, соответствующие цели, пятибуквенный сканер сканирует хаотическое поле и проверяет пятибуквенные сегменты, которые соответствуют цели, но на этот раз сегмент, который проверяется при каждом продвижении по всему полю, представляет собой целое слово, причем хаотическое поле сегментируют для сканирования в разных пропорциях, где при уменьшении области сканирования точность увеличивается, а по мере увеличения буквенного сканера повышается эффективность распознавания за счет точности, причем индексация концептов памяти (Memory Concept Indexing, MCI) меняет размер сканера в ответ на оставшиеся необработанные концепты памяти, причем MCI начинает с самого большого доступного сканера и постепенно уменьшает его, в результате чего освобождается больше вычислительных ресурсов для проверки потенциального существования меньших по размеру целей концептов памяти.
[0046] Логика интерпретации поля (Field Interpretation Logic, FIL) отвечает за логистику управления сканерами различной ширины, причем сканирование общей области начинается со сканирования крупных наборов букв и прорабатывает большую область поля с меньшими ресурсозатратами, но за счет мелкомасштабной точности, причем сканирование конкретной области используют, когда обнаружена значимая область, и ее необходимо «приблизить», тем самым гарантируя, что дорогое и точное сканирование не выполняют в лишней и безрезультатной области, а получение дополнительного распознавания концептов памяти в хаотическом поле указывает на то, что область поля плотно насыщена концептами памяти.
[0047] В механизме автоматизированного обнаружения восприятия (Automated Perception Discovery Mechanism, APDM) угол восприятия определяется в сочетании с несколькими метриками, включая область, тип, интенсивность и последовательность, определяющие множество аспектов восприятия, из которых состоит общее восприятие, причем творческий модуль создает сложные вариации восприятия, в которых вес восприятия определяет относительное влияние восприятия, симулируемого посредством РОЕ, причем вес обоих входящих фактов восприятия учитывают при определении веса новоитерированного восприятия, которое содержит гибридизированные метрики, опирающиеся на предыдущее поколение восприятий.
[0048] На вход CVFG подают пакет данных, который представляет собой произвольный набор данных, которые должны быть представлены составом узлов сгенерированного CVF, причем для каждого отдельного блока, заданного пакетом данных, производят последовательное продвижение, где блок данных преобразуют в формат узла, имеющий тот же информационный состав, на который ссылается конечный CVF, причем преобразованные узлы после проверки их существования временно сохраняют в удержании узлов, причем если узлы не найдены, то они создаются и обновляются статистической информацией, включая возникновение и использование, причем все узлы в загоне собирают и принудительно передают как модульный вывод в виде CVF.
[0049] Посредством алгоритма сравнения узлов сравнивают два состава узлов, которые были считаны из необработанного CVF, причем в рамках режима частичного соответствия (Partial Match Mode, РММ), если в одном CVF есть активный узел, а в кандидате для сравнения он не найден (узел неактивен), то сравнение не штрафуют, тогда как в рамках режима полного соответствия (Whole Match Mode, WMM), если в одном CVF есть активный узел, а в кандидате для сравнения он не найден (узел неактивен), то сравнение штрафуют.
[0050] В рамках разделения системных метаданных (System Metadata Separation, SMS) разделяют входные системные метаданные на значимые причинно-следственные связи системы безопасности, где при сканировании/ассимиляции субъекта субъект/подозреваемый в ситуации в системе безопасности извлекается из метаданных системы посредством предварительно созданных контейнеров категорий и необработанного анализа из модуля категоризации, причем субъект используется в качестве основной контрольной точки для получения отклика системы безопасности/переменного отношения, где при сканировании/ассимиляции рисков факторы риска ситуации в системе безопасности извлекают из метаданных системы посредством предварительно созданных контейнеров категорий и необработанного анализа из модуля категоризации, причем риск связан с целевым субъектом, который демонстрирует или подвержен такому риску, где при сканировании/ассимиляции откликов отклик ситуации в системе безопасности извлекают из метаданных системы посредством предварительно созданных контейнеров категорий и необработанного анализа из модуля категоризации, причем отклик связан с субъектом безопасности, который якобы заслуживает такого отклика.
[0051] В МСМ в рамках разделения формата разделяют и классифицируют метаданные в соответствии с правилами и синтаксисом распознанного формата, причем правила и синтаксис локального формата содержат определения, которые позволяют модулю МСМ распознавать предварительно отформатированные потоки метаданных, где трассировка отладки представляет собой трассировку уровня кодирования, которая предоставляет используемые переменные, функции, методы и классы, а также соответствующий им контент/типы входных и выходных переменных, где трассировка алгоритма представляет собой трассировку программного уровня, которая обеспечивает данные системы безопасности в сочетании с анализом алгоритма, в котором итоговое решение системы безопасности (пропустить/заблокировать) предоставляется вместе со следом (обоснованием) того, как это решение было принято, а также с соответствующим весом каждого фактора, участвовавшего в принятии данного решения.
[0052] В обработке метрик (Metric Processing, MP) отклик системы безопасности X представляет собой последовательность факторов, которые вносят вклад в итоговый отклик системы безопасности, выбираемый SPMA, причем начальный вес определяют посредством SPMA, где дедукция восприятия (Perception Deduction, PD) использует часть отклика системы безопасности и соответствующие метаданные системы для воспроизведения исходного восприятия отклика системы безопасности, причем интерпретация восприятия размерной серии отображает, как PD будет принимать отклик системы безопасности SPMA и связывать соответствующий ввод метаданных системы для воссоздания всего объема интеллектуального «цифрового восприятия», первоначально использованного в SPMA, причем заполнение формы, количество стека и размеры являются цифровыми фактами восприятия, которые содержат в себе «точку зрения» интеллектуального алгоритма.
[0053] В PD отклик системы безопасности X передают в качестве входных данных в расчет обоснования, где определяют обоснование отклика системы безопасности SPMA путем задействования намеренной подачи модуля упрощения ввода/вывода (Input/Output Reduction, IOR), причем модуль IOR использует разделенный ввод и вывод различных вызовов функций, указанных в метаданных, где разделение метаданных выполняют посредством МСМ.
[0054] В РОЕ ввод метаданных системы представляет собой первоначальный ввод, используемый в получении необработанного восприятия (Raw Perception Production, RP2) для получения восприятия в формате CVF, причем в рамках поиска по хранилищу (Storage Search, SS) CVF, полученный из обогащенных данными журналов, используют в качестве критерия поиска по базе данных в хранилище восприятия (Perception Storage, PS), причем в ранжировании факты восприятия расположены в порядке их окончательного веса, а обогащенные данными журналы применяют к фактам восприятия для получения рекомендаций по блокировке/разрешению, где SCKD помечает журналы для определения ожидаемого верхнего значения неизвестных знаний, с помощью парсера данных выполняют базовую интерпретацию обогащенных данными журналов и ввода метаданных системы с целью получить исходное решение о блокировке или разрешении, принятое первоначальным SPMA, причем СТМР критикует решения в РОЕ в соответствии с восприятием, а в выполнении правил (RE) - в соответствии с логически определенными правилами.
[0055] В рамках сложности метрик внешняя граница круга отражает верхнюю точку известных знаний в отношении отдельно взятой метрики, причем край круга отражает большую сложность метрики, тогда как центр круга отражает меньшую сложность метрики, причем светло-серая зона в центре отражает комбинацию метрик в текущей партии прикладных углов восприятия, а внешняя темно-серая зона отражает сложность метрики, хранящейся и известной системе в целом, причем задачей идентификации является увеличение сложности подходящих метрик, так чтобы приумножить число и сложность углов восприятия, причем темно-серая область поверхности отражает общий объем текущей партии прикладных углов восприятия, а также объем, оставшийся за пределами известной верхней границы, где после улучшения и увеличения сложности метрики возвращают в виде сложности метрик, которая используется в качестве ввода для преобразования метрик, в ходе которого отдельные метрики преобразовывают обратно в полноценные углы восприятия, и итоговый вывод собирают в подразумеваемые углы восприятия.
[0056] В SCKD в модуле категоризации известных данных (Known Data Categorization, KDC) категорически отделяют известную информацию от ввода, так чтобы можно было выполнить запрос аналогии с подходящей базой данных, а также разделяют информацию на категории, причем каждая отдельная категория обеспечивает ввод для CVFG, который выводит категориальную информацию в формате CVF, используемый в поиске по хранилищу (SS) для поиска совпадений в базе данных известного объема данных, причем каждую категорию помечают соответствующим объемом известных данных в соответствии с результатами SS, причем помеченные объемы неизвестной информации для каждой категории снова собирают в тот же поток исходного ввода в комбинаторе неизвестных данных (Unknown Data Combiner, UDC).
[0057] Компьютерная система представляет собой лексически объективный майнинг (LOM). Система дополнительно включает в себя:
а) обоснование первоначального запроса (Initial Query Reasoning, IQR), куда передают вопрос и в рамках которого задействуют центральное хранилище знаний (Central Knowledge Retention, CKR) для расшифровки недостающих подробностей, необходимых для понимания вопроса и ответа на него;
б) разъяснение опроса (Survey Clarification, SC), куда передают вопрос и данные дополнительного запроса и в рамках которого получают ввод от человека-субъекта и и отправляют ему вывод, а также формируют разъясненный вопрос/утверждение;
в) построение утверждений (Assertion Construction, АС), в рамках которого получают предложение в форме утверждения или вопроса, а на выходе получают концепты, связанные с данным предложением;
г) представление ответа, представляющее собой интерфейс для представления выводов, полученных АС, как человеку-субъекту, так и рациональному обращению (Rational Appeal, RA);
д) составление иерархической карты (Hierarchical Mapping, НМ), в рамках которой составляют карту связанных концептов для поиска совпадений или конфликтов в логике вопросов/утверждений, а также рассчитывают выгоды и риски той или иной позиции по теме;
е) центральное хранилище знаний (CKR), представляющее собой основную базу данных, куда LOM обращается за знаниями;
ж) валидацию знаний (Knowledge Validation, KV), в рамках которой получают знание высокой достоверности до критики, которое необходимо логически разделить под возможности запросов и ассимиляцию в CKR;
з) принятие отклика, представляющее собой выбор, предоставляемый человеку-субъекту, в рамках которого он либо принимает отклик LOM, либо критикует его, причем если отклик принят, он затем обрабатывается в KV, чтобы быть сохраненным в CKR в качестве подтвержденного знания (высокой достоверности), а если человек-субъект не принимает отклик, его направляют в RA, где проверяют и критикуют доводы, предоставленные человеком;
и) управляемый поставщик услуг на основе искусственного интеллекта (Managed Artificially Intelligent Services Provider, MAISP), который поддерживает запущенную в интернет-облаке копию LOM, где работает мастер-копия CKR, и подключает LOM к клиентским службам, программно-аппаратным службам, зависимостям сторонних приложений, источникам информации и облаку MNSP.
[0058] К клиентским службам относятся личные помощники с искусственным интеллектом, коммуникационные приложения и протоколы, автоматизация дома и медицинские приложения, к программно-аппаратным службам относятся онлайн-покупки, онлайн-транспорт, заказ медицинских рецептов, причем клиентские службы и программно-аппаратные службы взаимодействуют с LOM через документированную инфраструктуру API, что позволяет стандартизировать протоколы и передачу информации, причем LOM извлекает знания из внешних источников информации посредством механизма автоматизированных исследований (Automated Research Mechanism, ARM).
[0059] В рамках лингвистического построения (Linguistic Construction, LC) интерпретируют необработанные вопросы/утверждения, введенные человеком-субъектом и полученные от параллельных модулей для создания логического разделения лингвистического синтаксиса, причем в ходе обнаружения концептов (Concept Discovery, CD) получают точки интереса в рамках разъясненного вопроса/утверждения и выводят связанные концепты путем задействования CKR; причем в рамках приоритизации концептов (Concept Prioritization, CP) получают подходящие концепты и упорядочивают их по логическим уровням, отражающим конкретность и обобщенность; причем логика разделения откликов (Response Separation Logic, RSL) задействует LC для понимания человеческого отклика и связывания подходящего и работающего отклика с первоначальным запросом на разъяснение, тем самым выполняя задачу SC; причем LC затем повторно задействуют во время фазы вывода, чтобы внести поправки в исходный вопрос/утверждение с целью включить туда дополнительную информацию, полученную SC; причем в построении контекста (Context Construction, СС) используют метаданные из построения утверждений (АС) и доказательства от человека-субъекта для передачи необработанных фактов в СТМР для критического мышления; причем в ходе сравнения решений (Decision Comparison, DC) определяют совпадение решений до критики и после критики; причем в ходе определения совместимости концептов (Concept Compatibility Detection, CCD) сравнивают производные концептов от исходного вопроса/утверждения с целью подтвердить результат логической совместимости; причем калькулятор выгод/рисков (Benefit/Risk Calculator, BRC) получает результаты совместимости от CCD и взвешивает выгоды и риски с целью сформировать единое решение, которое охватывает градиенты переменных, входящих в состав концепта; причем в рамках взаимодействия концептов (Concept Interaction, CI) назначают характеристики, которые относятся к концептам АС и к частям информации, полученной от человека-субъекта посредством разъяснения опроса (Survey Clarification, SC).
[0060] Внутри IQR LC получает исходный вопрос/утверждение, где вопрос лингвистически разделен, и IQR обрабатывает каждое отдельное слово/фразу за раз, задействуя CKR; где, обращаясь к CKR, IQR рассматривает потенциально возможные варианты с учетом неоднозначности значений слов/фраз.
[0061] В рамках разъяснения опроса (SC) получают входные данные от IQR, причем входные данные содержат последовательность запрошенных разъяснений, на которые должен ответить человек-субъект для получения объективного ответа на исходный вопрос/утверждение, причем предоставленный ответ на разъяснения направляют в логику разделения откликов (RSL), где отклики коррелируют с запросами на разъяснение; при этом параллельно с обработкой запрошенных разъяснений LC предоставляют лингвистическую ассоциацию разъяснений, где данная ассоциация содержит внутренние отношения между запрашиваемыми разъяснениями и структурой языка, что позволяет RSL внести поправки в исходный вопрос/утверждение, в результате чего LC выводит разъясненный вопрос.
[0062] В рамках построения утверждений, получившего разъясненный вопрос/утверждение, LC разбивает вопрос на точки интереса, которые передают в обнаружение концептов, где извлекают ассоциированные концепты путем задействования CKR, причем в рамках приоритизации концептов (CP) концепты упорядочивают по логическим уровням, где верхнему уровню назначают самые обобщенные концепты, в то время как нижним уровням назначают более конкретные концепты, при этом верхний уровень переносят в составление иерархических карт (НМ) в качестве модульного ввода, где при параллельной передаче информации НМ получает точки интереса, которые обрабатываются его модулем зависимостей взаимодействия концептов (CI), где точкам интереса назначают характеристики путем обращения к индексированной информации в CKR, причем после того, как НМ завершает свой внутренний процесс, его окончательный вывод возвращают в АС после того, как производные концепты были проверены на совместимость, а также взвешены и возвращены выгоды/риски позиции.
[0063] В рамках НМ CI предоставляет входные данные в CCD, который определяет уровень совместимости/конфликта между двумя концептами, при этом данные о совместимости/конфликте пересылают в BRC, где совместимость и конфликты переводят в выгоды и риски, связанные с принятием целостной единообразной позиции по проблеме, при этом позиции вместе с факторами риска/выгоды пересылают в АС в качестве модульного вывода, причем система содержит циклы информационного потока, указывающие на то, что градиенты интеллекта постепенно дополняются, поскольку субъективная природа вопроса/утверждения представляет собой постепенно выстраиваемый объективный ответ; где CI получает точки интереса и интерпретирует каждую из них в соответствии с высшим уровнем приоритизированных концептов.
[0064] В рамках RA посредством ядерной логики обрабатывают преобразованный лингвистический текст и возвращают результат, в котором, если результат высокой степени достоверности, его передают в валидацию знаний (KV) для правильной ассимиляции в CKR, а если результат низкой степени достоверности, то его передают в АС для продолжения цикла самокритики, причем в ядерную логику поступают входные данные от LC в виде решения до критики без лингвистических элементов, причем решение переправляют в СТМР в качестве субъективного мнения, а также в построение контекста (СС), где используют метаданные от АС и потенциальные доказательства от человека-субъекта для передачи необработанных фактов в СТМР в качестве входного «объективного факта», при этом СТМР при получении двух обязательных входных видов данных обрабатывает их для получения наилучшего возможного варианта «объективного мнения», где мнение обрабатывают внутри RA в качестве решения после критики, причем решения как до критики, так и после критики переправляют в сравнение решений (DC), в рамках которого определяют степень совпадения данных решений, причем затем либо признают истинными аргументы апелляции, либо улучшают контраргумент, чтобы объяснить, почему апелляция недействительна, в случае же если исход сценария признания истины/улучшения неважен, результат высокой степени достоверности передают в KV, а результат низкой степени достоверности передают в АС для дальнейшего анализа.
[0065] В рамках CKR единицы информации хранят в формате единиц знаний (Unit Knowledge Format, UKF), где формат синтаксиса правил (RSF) представляет собой набор синтаксических стандартов для отслеживания правил ссылок, причем одиночного объекта или действия в RSF может быть задействовано множество единиц правил; при этом привязка к источнику представляет собой набор сложных данных, посредством которых отслеживают заявленные источники информации, причем кластер UKF состоит из цепочки вариантов UKF, связанных между собой для определения юрисдикционно раздельной информации, причем UKF2 содержит основную целевую информацию, UKF1 содержит данные о метке времени и, следовательно, не содержит само поле метки времени для избежания бесконечного регресса, a UKF3 содержит информацию о привязке к источнику и, следовательно, не содержит само поле источника для избежания бесконечного регресса; причем каждый UKF2 должен сопровождаться по крайней мере одним UKF1 и одним UKF3, иначе кластер (последовательность) считается неполным, и информация в нем еще не может быть обработана общесистемной общей логикой LOM; причем между центральным UKF2 и соответствующими ему блоками UKF1 и UKF3 могут стоять блоки UKF2, выступающие в качестве цепного моста, при этом последовательность кластеров UKF будет обрабатываться KCA для формирования производного утверждения, причем в ходе анализа совпадения знаний (KCA) кластерную информацию UKF сравнивают для подтверждения доказательств о предвзятой позиции, при этом после того, как KCA завершает обработку, CKR может вывести окончательное мнение по теме.
[0066] В рамках ARM, где, как показывает деятельность пользователя, по мере взаимодействия пользователя с концептами LOM, они прямо или косвенно приводятся в качестве релевантных для отклика на вопрос/утверждение, причем ожидается, что деятельность пользователя в конечном итоге предоставит концепты, для которых в CKR сведений мало или нет вообще, как указано в списке запрашиваемых, но недоступных концептов, при этом посредством сортировки и приоритизации концептов (Concept Sorting & Prioritization, CSP) принимают определения концептов из трех независимых источников и собирают вместе для определения приоритетов ресурсов информационного запроса, причем данные, предоставляемые источниками информации, получают и обрабатывают в агрегаторе информации (Information Aggregator, IA) в соответствии с тем, какое определение концепта запросило их и какие релевантные метаданные сохранены, причем информацию отправляют в анализ перекрестных ссылок (Cross-Reference Analysis, CRA), где полученную информацию сравнивают и строят с учетом ранее имевшихся знаний из CKR.
[0067] В профиле личного интеллекта (Personal Intelligence Profile, PIP) сохраняют личную информацию об индивидууме посредством множества потенциальных конечных точек и клиентов, причем их информация изолирована от CKR, однако доступна для общесистемной общей логики LOM, в которой личная информация, относящаяся к приложениям искусственного интеллекта, зашифрована и хранится в личном пуле кластеров UKF в формате UKF, причем данные процесса анонимизации информации (Information Anonymization Process, IAP) дополняют в CKR после удаления всех идентифицирующих личность данных, при этом полученные данные анализа перекрестных ссылок (Cross-Reference Analysis, CRA) сравнивают и строят с учетом ранее существовавших знаний из CKR.
[0068] Администрация и автоматизация жизни (Life Administration & Automation, LAA) объединяет устройства с подключением к Интернету и сервисы на единой платформе, где при активном принятии решений (Active Decision Making, ADM) учитывают доступность и функционал клиентских служб, программно-аппаратных служб, IoT-устройств (Internet of Things, «Интернет вещей»), правил расходов и сумм, доступных в соответствии с правилами и управлением распределением средств (Fund Appropriations Rules & Management, FARM), где FARM получает от человека входные данные, задающие критерии, пределы и область действия модуля, чтобы информировать ADM, в чем состоит его юрисдикция, причем средства криптовалюты депонируют на цифровой кошелек, где модуль взаимодействия с IoT (IoT Interaction Module, ИМ) поддерживает базу данных о том, какие IoT-устройства доступны, причем потоки данных отражают, когда устройства с поддержкой IoT отправляют информацию в LAA.
[0069] Система дополнительно включает мониторинг поведения (Behavior Monitoring, ВМ), в рамках которого отслеживают персональные идентифицируемые запросы данных от пользователей для проверки на наличие неэтичного и/или незаконного материала, при этом с помощью сбора метаданных (Metadata Aggregation, MDA) данные, относящиеся к пользователю, собирают из внешних служб с тем чтобы установить цифровую личность пользователя, причем такие данные передают в индукцию/дедукцию и, в конечном итоге, в PCD, где проводится сложный анализ с подтверждающими факторами из MNSP; причем вся информация от аутентифицированного пользователя, которая предназначена для PIP, проходит через отслеживание информации (Information Tracking, IT) и проверяется по «черному списку поведения», при этом в обнаружении до совершения преступления (Pre-Crime Detection, PCD) данные дедукции и индукции объединяют и анализируют с целью получения выводов до совершения преступления, причем PCD использует СТМР, который напрямую обращается к черному списку поведения для проверки позиций, сформированных индукцией и дедукцией, причем управление черным списком (ВМА) работает внутри фреймворка облачной службы MNSP.
[0070] LOM выполнен с возможностью управлять персонализированным портфолио жизни индивидуума, где LOM получает начальный вопрос, который приводит к выводу через внутренний процесс умозаключений LOM, где LOM подключается к модулю LAA, который подключается к устройствам с доступом в Интернет, откуда LOM может получать данные и которыми может управлять, причем в рамках контекстуализации LOM выводит недостающие звенья при построении аргумента, причем LOM постигает с помощью своей логики, что для решения дилеммы, поставленной исходным утверждением, сначала необходимо знать или допускать определенные переменные о ситуации.
[0071] Компьютерная система представляет собой линейную атомно-квантовую передачу информации (LAQIT). Система включает в себя:
а) рекурсивное повторение той же постоянной последовательности цветов внутри логически структурированного синтаксиса;
б) рекурсивное использование данной последовательности для перевода с использованием английского алфавита;
где при стуктурировании «базового» слоя алфавита используют последовательность цветов с сокращенным и неравным весом цветового канала, а также с дополнительным пространством для синтаксических определений внутри цветового канала, зарезервированным под будущее использование и расширение;
где сложный алгоритм передает свой журнал событий и отчеты о состоянии LAQIT, причем отчеты о событиях/состоянии формируют автоматически, конвертируют в передаваемый синтаксис LAQIT на текстовой основе, синтаксически небезопасную информацию передают по цифровому каналу, передаваемый синтаксис LAQIT на текстовой основе конвертируют в высокочитаемый визуальный синтаксис LAQIT (линейный режим), где ключ оптимизирован под человеческое запоминание и основывается на относительно короткой последовательности форм;
где локально небезопасный текст вводится отправителем для отправки получателю, причем текст конвертируют в передаваемый зашифрованный синтаксис LAQIT на текстовой основе, синтаксически безопасную информацию передают по цифровому каналу, данные конвертируют в визуально зашифрованный синтаксис LAQIT;
где эффект ступенчатого распознавания (Incremental Recognition Effect, IRE) представляет собой канал передачи информации и распознает полную форму информационного блока до его полной доставки, причем данный эффект предсказательной индексации встраивается путем отображения переходов между словами, тогда как эффект приблизительного распознавания (Proximal Recognition Effect, PRE) представляет собой канал передачи информации и распознает полную форму информационного блока, даже если он испорчен, изменен или перепутан.
[0072] В линейном режиме LAQIT блок показывает версию линейного режима в «базовой визуализации», а точка отображает отсутствие шифрования, причем в разделителе слов цвет формы представляет собой символ, который следует за словом и выступает в качестве разделителя между ним и следующим словом, где зона одиночного просмотра включает в себя меньшую зону просмотра с буквами большего размера и, следовательно, меньшим количеством информации на пиксель, причем в зоне двойного просмотра больше активных букв на пиксель, в то время как затенение делает входящие и исходящие буквы тусклыми, так чтобы основной фокус наблюдателя находился на зоне просмотра.
[0073] В атомном режиме, который может работать с широким набором уровней шифрования, ссылка на основной символ базы будет конкретизировать общее значение определяемой буквы, где кикер имеет тот же цветовой диапазон, что и база, и точно определяет конкретный символ, где в направлении чтения чтение поступившей информации начинают с верхнего квадрата первого орбитального кольца, причем как только орбитальное кольцо пройдено, чтение продолжают с верхнего квадрата следующего по порядку орбитального кольца, где порталы входа/выхода являются точками создания/уничтожения символа (его базы), причем новый символ, принадлежащий к соответствующей орбите, выйдет из портала и сдвинется на свою позицию по часовой стрелке, а атомное ядро определяет символ, следующий за словом;
где в рамках навигации по словам каждый блок представляет собой целое слово (или несколько слов в молекулярном режиме) в левой части экрана, причем при отображении слова соответствующий блок перемещается наружу и вправо, а когда это слово завершено, блок отступает назад, причем цвет/форма навигационного блока имеет тот же цвет/форму, что и база первой буквы слова; где в рамках навигации по предложениям каждый блок представляет собой кластер слов, где кластер представляет собой максимальное количество слов, которое может уместиться на панели навигации по словам; где создание атомного состояния - это переход, который вызывает эффект ступенчатого распознавания (IRE), при котором переходные базы появляются из порталов входа/выхода со скрытыми кокерами и перемещаются по часовой стрелке на свои позиции; где расширение атомного состояния - это переход, который вызывает эффект приблизительного распознавания (PRE), при котором, после того как базы достигли своей позиции, они перемещаются наружу в «расширенной» последовательности представления информационного состояния, которая раскрывает кикеры, посредством чего можно представить конкретное определение состояния информации; где разрушение атомного состояния - это переход, который вызывает эффект ступенчатого распознавания (IRE), при котором базы сокращают (путем обращения последовательности расширения), чтобы снова скрыть кикеры, которые теперь смещаются по часовой стрелке, чтобы достичь портала входа/выхода.
[0074] При обфускации формы стандартные квадраты заменяют пятью визуально различными формами, причем вариативность форм в синтаксисе позволяет вставлять (поддельные) буквы-пустышки в стратегических точках атомного профиля, где буквы-пустышки скрывают истинный и предполагаемый смысл сообщения, причем расшифровка того, является ли буква настоящей или пустышкой, надежно и временно переданного ключа дешифрования;
где в рамках связей перенаправления связь соединяет две буквы и изменяет поток чтения, причем, начиная с типичного шаблона чтения по часовой стрелке, при обнаружении связи, которая взлетает (начинается с) и приземляется (заканчивается на) на легитимные/настоящие буквы, связь перенаправляет шаблон чтения для возобновления на посадочной букве;
где в рамках радиоактивных элементов некоторые элементы могут «дребезжать», что может инвертировать оценку того, является ли буква пустышкой или нет, где формы отражают формы, доступные для шифрования, центральные элементы отражают центральный элемент орбиты, которая определяет символ, идущий сразу за словом.
[0075] В рамках связей перенаправления связи начинаются с буквы «взлета» и заканчиваются буквой «посадки», каждая из которых может быть или не быть пустышкой, причем если среди букв нет ни одной пустышки, то связь изменяет направление и позицию чтения, причем если одна или обе буквы являются пустышками, то вся связь должна быть проигнорирована, в противном случае сообщение будет расшифровано неправильно, причем при определении ключа связи необходимость следовать связи при чтении состояния информации зависит от того, была ли она конкретно определена в ключе шифрования.
[0076] При одиночном кластере оба соседа нерадиоактивны, следовательно, определяют объем кластера, причем, поскольку ключ определяет двойные кластеры как действительные, с элементом следует обращаться как если бы он изначально не был радиоактивным, тогда как при двойном кластере ключевое определение определяет двойные кластеры как активные, следовательно, во время расшифровки сообщения все кластеры других размеров должны считаться неактивными, при этом неверная интерпретация показывает, что интерпретатор не рассматривал двойной кластер как обратную последовательность (ложное срабатывание).
[0077] В молекулярном режиме с включенным шифрованием и потоковой передачей, при сопротивлении скрытому перебору по словарю неправильная дешифровка сообщения вызывает альтернативное «подложное» сообщение, в котором при нескольких активных словах на молекулу слова представлены параллельно во время молекулярной процедуры, тем самым увеличивая долю информации на площадь поверхности, однако с постоянной скоростью перехода, причем между двоичным режимом и режимом потоковой передачи выбирают потоковый режим, тогда как в типичной атомной конфигурации режим чтения является двоичным, причем двоичный режим указывает, что центральный элемент определяет, какой символ следует за словом, а молекулярный режим также является двоичным, кроме случаев, когда включено шифрование, которое придерживается режима потоковой передачи, причем режим потоковой передачи ссылается на специальные символы в пределах орбиты.
[0078] Компьютерная система представляет собой систему универсальных BCHAIN-связей всего со всем (UBEC) с гармонизацией базовых подключений с присоединением встроенных узлов (Base Connection Harmonization Attaching Integrated Nodes, BCHAIN). Система дополнительно включает в себя:
а) порт связи (Communications Gateway, CG), являющийся первичным алгоритмом узла BCHAIN для взаимодействия с аппаратным интерфейсом, осуществляющим связь с остальными узлами BCHAIN;
б) статистическое изучение узлов (Node Statistical Survey, NSS), в рамках которого интерпретируют образцы поведения удаленных узлов;
в) индекс убегания узлов, с помощью которого отслеживают вероятность того, что сосед узла избежит близости с воспринимающим узлов;
г) индекс насыщения узлов, с помощью которого отслеживают число узлов в радиусе обнаружения воспринимающего узла;
д) индекс постоянства узлов, с помощью которого отслеживают качество работы узлов с точки зрения воспринимающего узла, причем высокое значение индекса указывает на то, что окружающие соседние узлы, как правило, более доступны и активны, а также поддерживают постоянный уровень производительности, причем узлы двойного назначения, как правило, имеют более низкое значение индекса постоянства, тогда как узлы, прикрепленные к сети BCHAIN, показывают более высокое значение индекса постоянства;
е) индекс перекрытия узлов, с помощью которого отслеживают число узлов, совпадающих друг с другом, с точки зрения воспринимающего узла.
[0079] Система дополнительно включает в себя:
а) модуль распознавания составных цепочек (Customchain Recognition Module, CRM), который соединяется с составными цепочками, включая цепочки приложений или микроцепочки, ранее зарегистрированными узлом, причем данный модуль информирует остальную часть протокола BCHAIN об обнаружении обновления в секции цепочки приложений в метацепочке или эмуляторе метацепочки в микроцепочке;
б) доставка запрошенного содержимого (Content Claim Delivery, CCD), в рамках которой получают проверенное CCR, а затем отправляют подходящее CCF для выполнения запроса;
в) динамическая адаптация стратегии (Dynamic Strategy Adaptation, DSA), которой подчиняется модуль создания стратегии (Strategy Creation Module, SCM), посредством которого динамически генерируют новую стратегию, используя творческий модуль для создания гибридных сложных стратегий, которым система отдала предпочтение посредством алгоритма выбора оптимизированной стратегии (Optimized Strategy Selection Algorithm, OSSA), причем новые стратегии варьируются в соответствии с данными, полученными от интерпретации хаоса поля;
г) криптографическая цифровая экономическая биржа (Cryptographic Digital Economic Exchange, CDEE) с набором экономических личностей под управлением графического интерфейса пользователя (Graphical User Interface, GUI) внутри интерфейса платформы UBEC (UBEC Platform Interface, UPI), причем для личности А тратится ровно столько ресурсов узла, сколько необходимо, для личности В ресурсы тратятся, пока маржа прибыли выше заданной величины, личность С платит за единицу работы обмененной валютой, а для личности D ресурсы тратятся, пока они есть, без ограничений и без ожиданий выручки, причем тратится как содержимое, так и деньги;
д) интерпретация текущего рабочего состояния (Current Work Status Interpretation, CWSI), в рамках которой обращаются к разделу экономической инфраструктуры метацепочки с целью определить текущий избыток или дефицит узла в отношении затрат на выполненную работу;
е) экономически обоснованное назначение работы (Economically Considered Work Imposition, ECWI), в рамках которого рассматривают выбранную экономическую личность с текущим избытком/дефицитом работы с целью определить, необходимо ли выполнить больше работы;
ж) симбиотическое рекурсивное продвижение интеллекта (Symbiotic Recursive Intelligence Advancement, SRIA), представляющее собой тройственные взаимоотношения между различными алгоритмами, входящими в состав LIZARD, которая улучшает исходный код алгоритма путем выявления назначения кода, включая свой собственный, I2GE, которое симулирует поколения виртуальных итераций программы, и сетью BCHAIN, которая представляет собой обширную сеть хаотически соединенных узлов, способных децентрализированно выполнять сложные программы с большим количеством данных.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0080] Более подробно заявленное изобретение раскрывается в нижеследующем описании, сопровождающемся чертежами, причем патент или заявка содержат по меньшей мере один чертеж, выполненный в цвете, и копии данного патента или заявки, содержащих цветной чертеж (чертежи), можно по запросу за соответствующую плату получить в ведомстве. На чертежах:
На Фиг. 1-26 схематично проиллюстрирована активная защита критической инфраструктуры посредством обеспечения многоуровневой защиты информации в облачной архитектуре (CIPR/CTIS), в частности:
На Фиг. 1-2 схематично проиллюстрировано, как определения множества углов интерпретации безопасности представлены в качестве методологии для анализа.
На Фиг. 3 схематично показана архитектура управляемого безопасного шифрования на базе облака для защищенной сети EI2 (Extranet, Intranet, Internet; внешняя сеть, внутренняя сеть, Интернет).
На Фиг. 4-8 схематично показан общий принцип работы провайдера управляемой сети и услуг безопасности (MNSP).
На Фиг. 9 схематично показана обработка событий безопасности в реальном времени с точки зрения облачной системы шифрования и безопасности LIZARD.
На Фиг. 10 схематично проиллюстрирован пример использования активной защиты критической инфраструктуры посредством обеспечения многоуровневой защиты информации в облачной архитектуре (CIPR/CTIS) в энергосистеме.
На Фиг. 11 схематично показан шаг 1 - первоначальное вторжение в систему.
На Фиг. 12 схематично показан шаг 2 - отправка первоначального «троянского коня».
На Фиг. 13 схематично показан шаг 3 - загрузка продвинутого исполняемого вредоносного ПО.
На Фиг. 14 схематично показан шаг 4 - взлом систем предотвращения/защиты от вторжений.
На Фиг. 15 схематично показано желаемое поведение хакера и действительный отклик системы безопасности.
На Фиг. 16 схематично показана регулярная внутренняя аутентификация протоколов доступа (Scheduled Internal Authentication Protocol Access, SIAPA).
На Фиг. 17 схематично показан доступ на корневой уровне и доступ на стандартном уровне.
На Фиг. 18 схематично показан контрольный обзор.
На Фиг. 19 схематично показаны итеративный рост и развитие интеллекта (I2GE).
На Фиг. 20 схематично показана инфраструктурная система.
На Фиг. 21 схематично показаны система злоумышленников, инфраструктурная система и общедоступная инфраструктура.
На Фиг. 22 и 23 схематично проиллюстрировано, как при переписывании внешнего кода синтаксически воспроизводят внешний код с нуля для предотвращения потенциально пропущенных вредоносных эксплойтов.
На Фиг. 24 и 25 схематично проиллюстрировано, как рекурсивная отладка циклически проходит по участкам кода.
На Фиг. 26 схематично показано внутреннее устройство сопоставления карт потребностей.
На Фиг. 27-42 схематично проиллюстрирован секретный машинный интеллект (MACINT) и отпор посредством скрытных операций в киберпространстве, в частности:
На Фиг. 27 схематично показаны интеллектуальное управление, просмотр и контроль информации.
На Фиг. 28 схематично показана работа поведенческого анализа.
На Фиг. 29 и 30 схематично проиллюстрирована система злоумышленников и отпор против системы злоумышленников.
На Фиг. 31 и 32 схематично показан алгоритм работы MACINT.
На Фиг. 33 схематично проиллюстрирован общий обзор скрытных операций MACINT и то, как злоумышленники взламывают систему предприятия.
На Фиг. 34 схематично показаны подробности длительного/глубинного сканирования с использованием больших данных.
На Фиг. 35 схематично проиллюстрировано, как произвольный компьютер проверяют посредством доверенной платформы.
На Фиг. 36 схематично проиллюстрировано, как известные двойные и тройные агенты доверенной платформы применяются для помощи судебному расследованию.
На Фиг. 37 схематично показано, как посредством доверенной платформы совершается обращение к API провайдера.
На Фиг. 38 схематично показано использование доверенной платформы для обращения к API системы безопасности, предоставленному поставщиками программного и аппаратного обеспечения, для того чтобы применить выявленные бэкдоры.
На Фиг. 39-41 схематично проиллюстрировано, как обобщенные и настраиваемые эксплойты применяют к произвольным компьютерам и компьютерам злоумышленников.
На Фиг. 42 схематично проиллюстрировано, как флаг долгосрочного приоритета принудительно отправляют на доверенную платформу для контроля за системой злоумышленников.
На Фиг. 43-68 схематично показана логическая защита и мгновенное реагирование в реальном времени без создания баз данных (LIZARD), в частности:
На Фиг. 43 и 44 схематично показана структура зависимостей LIZARD.
На Фиг. 45 схематично показан общий вид LIZARD.
На Фиг. 46 схематично показаны основные функции алгоритмов LIZARD.
На Фиг. 47 схематично показано внутреннее устройство статичного ядра (SC).
На Фиг. 48 схематично проиллюстрировано, как во внутреннем ядре размещаются ключевые ядерные функции системы.
На Фиг. 49 схематично показано внутреннее устройство динамической оболочки (DS).
На Фиг. 50 схематично показан итерационный модуль (IM), посредством которого интеллектуально изменяют, создают и уничтожают модули в динамической оболочке.
На Фиг. 51 схематично показано итерационное ядро, выступающее в качестве основной логики итерационного кода с целью улучшения безопасности.
На Фиг. 52-57 схематично показан логический процесс работы алгоритма дифференциальной модификации (DMA) 353.
На Фиг. 58 схематично показана в общем виде виртуальная обфускация.
На Фиг. 59-61 схематично показан аспект контроля и отклика виртуальной обфускации.
На Фиг. 62 и 63 схематично показано, как в трекинге отзыва данных отслеживается вся информация, загруженная с подозрительной сущности и отправленная туда.
На Фиг. 64 и 65 схематично показано внутреннее устройство триггера отзыва данных.
На Фиг. 66 схематично показан отбор данных, в рамках которого отфильтровывают высококонфиденциальные данные и смешивают настоящие данные с фальшивыми данными.
На Фиг. 67 и 68 схематично показано внутреннее устройство поведенческого анализа.
На Фиг. 69-120 схематично показаны память и восприятие, основанные на критическом мышлении (СТМР), в частности:
На Фиг. 69 схематично показана основная логика работы СТМР.
На Фиг. 70 схематично показаны углы восприятия.
На Фиг. 71-73 схематично показана структура зависимостей СТМР.
На Фиг. 74 схематично показана конечная логика обработки интеллектуальной информации в СТМР.
На Фиг. 75 схематично показано, как два основных ввода интуиции/восприятия и мышления/логики сводят в единый терминальный вывод, отражающий результаты деятельности СТМР.
На Фиг. 76 схематично показан объем интеллектуального мышления, совершаемого исходным алгоритмом сопоставления выбранных образцов (SPMA).
На Фиг. 77 схематично показано противопоставление стандартного SPMA критическому мышлению, осуществляемому СТМР с использованием фактов восприятия и правил.
На Фиг. 78 схематично проиллюстрировано, как получают верные правила в отличие от известных текущих правил.
На Фиг. 79 и 80 схематично изображен модуль сопоставления восприятия (РМ).
На Фиг. 81-85 схематично показано выведение/генерирование синтаксиса правил.
На Фиг. 86-87 схематично показан принцип работы модуля разделения формата синтаксиса правил (RSFS).
На Фиг. 88 схематично показан принцип работы парсера выполнения правил (RFP).
На Фиг. 89-90 схематично показан отладчик выполнения.
На Фиг. 91 схематично показано выполнение правил.
На Фиг. 92 и 93 схематично показана последовательная организация памяти.
На Фиг. 94 схематично показана непоследовательная организация памяти.
На Фиг. 95-97 схематично показан процесс распознавания памяти.
На Фиг. 98-99 схематично показана логика интерпретации поля (FIL).
На Фиг. 100-101 схематично показан механизм автоматизированного обнаружения восприятия (APDM).
На Фиг. 102 схематично показано получение необработанного восприятия (RP2).
На Фиг. 103 схематично показан логический порядок действий генератора формата сравниваемых переменных (CVFG).
На Фиг. 104 схематично показан алгоритм сравнения узлов (NCA).
На Фиг. 105 и 106 схематично показано разделение системных метаданных (SMS).
На Фиг. 107 и 108 схематично показан модуль категоризации метаданных (МСМ).
На Фиг. 109 схематически показан процесс обработки метрик (MP).
На Фиг. 110 и 111 схематично показано внутреннее устройство дедукции восприятия (PD).
На Фиг. 112-115 схематично показан симулятор восприятия наблюдателя (РОЕ).
На Фиг. 116 и 117 схематично показано получение выводов (ID).
На Фиг. 118-120 схематично показана плотность самокритичных знаний (SKCD).
На Фиг. 121-165 схематично проиллюстрирован лексически объективный майнинг (LOM), в частности:
На Фиг. 121 схематично показана основная логика работы лексически объективного майнинга (LOM).
На Фиг. 122-124 схематично показан управляемый поставщик услуг на основе искусственного интеллекта (MAISP).
На Фиг. 125-128 схематично показана структура зависимостей LOM.
На Фиг. 129 и 130 схематично показана внутренняя логика обоснования первоначального запроса (IQR).
На Фиг. 131 схематично показан процесс разъяснения опроса (SC).
На Фиг. 132 схематично показан процесс построения утверждений (АС).
На Фиг. 133 и 134 схематично показано внутреннее устройство и принцип работы составления иерархических карт (НМ).
На Фиг. 135 и 136 схематично показано внутреннее устройство рационального обращения (RA).
На Фиг. 137 и 138 схематично показано внутреннее устройство центрального хранилища знаний (CKR).
На Фиг. 139 схематично показан механизм автоматизированных исследований (ARM).
На Фиг. 140 схематично показано стилометрическое сканирование (SS).
На Фиг. 141 схематично показана система перехвата по предположению (AOS).
На Фиг. 142 схематично показаны интеллектуальное управление информацией и конфигурацией (I2CM) и консоль управления.
На Фиг. 143 схематично показан профиль личного интеллекта (PIP).
На Фиг. 144 схематично показана администрация и автоматизация жизни (LAA).
На Фиг. 145 схематично показан процесс мониторинг поведения (ВМ).
На Фиг. 146 схематично показаны этика/приватность/право (Ethical Privacy Legal, EPL).
На Фиг. 147 схематично показан общий вид алгоритма работы LIZARD.
На Фиг. 148 схематично показан итеративный рост интеллекта.
На Фиг. 149 и 150 схематично показано итеративное развитие.
На Фиг. 151-154 схематично показан творческий модуль.
На Фиг. 155 и 156 схематично показан LOM, используемый в качестве личного помощника.
На Фиг. 157 схематично показано применение LOM в качестве исследовательского инструмента.
На Фиг. 158 и 159 схематично проиллюстрировано, как LOM изучает достоинства и недостатки предлагаемой теории.
На Фиг. 160 и 161 схематично проиллюстрировано, как LOM строит политику для внешнеполитических военных игр.
На Фиг. 162 и 163 схематично проиллюстрировано, как LOM проводит журналистское расследование.
На Фиг. 164 и 165 схематично проиллюстрировано, как LOM выполняет историческую проверку.
На Фиг. 166-179 схематично показан защищенный и эффективный цифро-ориентированный язык LAQIT, в частности:
На Фиг. 166 схематично показана сущность LAQIT.
На Фиг. 167 схематично показаны основные типы используемых языков.
На Фиг. 168-169 схематично показан линейный режим работы LAQIT.
На Фиг. 170 и 171 схематично показаны параметры атомного режима.
На Фиг. 172-174 схематично показан общий вид принципа шифрования в атомном режиме.
На Фиг. 175 и 176 схематично показан механизм работы связей перенаправления.
На Фиг. 175 и 176 схематично показан механизм работы радиоактивных элементов.
На Фиг. 179 схематично показан молекулярный режим с включенным шифрованием и потоковой передачей.
На Фиг. 180-184 схематично показан общий вид платформы UBEC и ее клиентской части, которая соединяется с децентрализованной системой распространения информации BCHAIN, в частности:
На Фиг. 180 схематично показан узел BCHAIN, который содержит и запускает приложение, работающее с BCHAIN.
На Фиг. 181 схематично показана ядерная логика 1010 протокола BCHAIN.
На Фиг. 182 схематично показана динамическая адаптация стратегии (Dynamic Strategy Adaptation, DSA), которой подчиняется модуль создания стратегии (Strategy Creation Module, SCM).
На Фиг. 183 схематично показана криптографическая цифровая экономическая биржа (Cryptographic Digital Economic Exchange, CDEE) с набором экономических личностей.
На Фиг. 184 схематично показано симбиотическое рекурсивное продвижение интеллекта (Symbiotic Recursive Intelligence Advancement, SRIA).
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Активная защита критической инфраструктуры посредством обеспечения многоуровневой защиты информации в облачной архитектуре (CIPR/CTIS)
[0081] На Фиг. 1-2 проиллюстрировано, как определения множества углов интерпретации безопасности представлены в качестве методологии для анализа. Пункт 1 показывает разработанную сеть маяков и агентов, с помощью которых генерируют карту злоумышленников. Совмещая такую карту/базу данных со сложными алгоритмами прогнозирования, получают потенциальные угрозы. В I2GE 21 задействуют большие данные и распознавание сигнатур вредоносного ПО для определения личности злоумышленника. В хранилище поведения системы безопасности 20 содержатся предыдущие события в системе безопасности, их последствия и адекватные отклики на них. Такой подходящий отклик может быть подвергнут критике в СТМР 22 (память и восприятие, основанные на критическом мышлении) в качестве дополнительного уровня безопасности. Пункт 2 указывает, какие активы находятся под угрозой и какой потенциальный ущерб может быть нанесен. Пример: Можно открыть все шлюзы в плотине гидроэлектростанции, что может привести к затоплению близлежащей деревни, а также к гибели людей и материальному ущербу. Инфраструктурная база данных 3 относится к общим базам данных, содержащим конфиденциальную и неконфиденциальную информацию государственной или частной компании, входящей в национальную инфраструктуру. К элементам управления инфраструктурой 4 могут относиться технические, цифровые и/или механические средства управления промышленным оборудованием, таким как плотины водоспуска, трансформаторы национальной электросети и т.д. В пункте 5 анализируют закономерности трафика с целью определить время появления потенциальных слепых зон. Такие атаки могут быть легко замаскированы и смешаны с легитимным трафиком. Задают вопрос: есть ли какие-либо политические/финансовые/спортивные или иные мероприятия, которые могут представлять интерес для злоумышленников? Сеть внешних агентов доверенной платформы сообщает об активности хакеров и подготовке атак. Таким образом можно рассчитать время атаки. В пункте 6 задают вопрос: Какие предприятия наиболее уязвимы и, следовательно, могут стать мишенью для атаки? Какие типы предприятий в данном географическом регионе потенциально уязвимы? Каковы их наиболее уязвимые активы/средства контроля и каковы наилучшие средства их защиты? Сеть внешних агентов доверенной платформы сообщает об активности хакеров и подготовке атак. Таким образом можно предположить место атаки. В пункте 7 задают вопрос: Какие геополитические, корпоративные и финансовые группировки существуют в мире, способные спонсировать или инициировать такую атаку? Кто от нее выиграет и насколько? Сеть внешних агентов доверенной платформы сообщает об активности хакеров и подготовке атак. Таким образом можно предположить мотив атаки. В пункте 8 задают вопрос: Каковы потенциальные точки эксплойтов и укрытия для вредоносного ПО? Как можно использовать такие «слепые зоны» и недостаточно укрепленные точки доступа для взлома ключевых активов и пунктов инфраструктурного контроля? LIZARD 16 способна узнать назначение и функцию внешнего кода и заблокировать его в случае наличия злого умысла либо отсутствия обоснованной цели. СТМР 22 способна критически рассматривать решения по блокировке или допуску, тем самым обеспечивая дополнительный уровень безопасности.
[0082] На Фиг. 3 показана архитектура управляемого безопасного шифрования на базе облака для защищенной сети EI2 (внешняя сеть, внутренняя сеть, Интернет). Провайдер управляемой сети и услуг безопасности (MNSP) 9 обеспечивает услуги и решения по управляемому безопасному шифрованию, подключениям и совместимости для отраслей критической инфраструктуры: энергетика, химическая промышленность, ядерная промышленность, плотины и т.д. Доверенная платформа 10 - это совокупность проверенных компаний и систем, которые взаимодействуют друг с другом, обмениваясь информацией и услугами в области безопасности. Поставщики программного и аппаратного обеспечения 11 - это крупные производители аппаратного/программного обеспечения (напр., Intel, Samsung, Microsoft, Symantec, Apple и т.д.). В данном контексте они предоставляют доверенной платформе 10 все потенциальные средства доступа и/или эксплуатации своих продуктов, которые в ограниченном или полном объеме обеспечивают доступ к бэкдорам. Это обеспечивает доверенной платформе в сотрудничестве с партнерами и совместным отделом безопасности возможность осуществления потенциальных процессов обеспечения безопасности и/или отпора. Виртуальная частная сеть (VPN) 12 - типовая технология, обеспечивающая защищенную и логистически отделенную коммуникацию между MNSP 9, доверенной платформой и связанными партнерами. Внешняя сеть обеспечивает виртуальное совместное использование цифровых средств, как если бы они находились в одном и том же локальном окружении (напр., в сети LAN). Таким образом, сочетание этих двух технологий способствует эффективной и безопасной связи между партнерами для повышения эффективности работы доверенной платформы. Поставщики услуг безопасности 13 - это совокупность государственных и/или частных компаний, предлагающих цифровые стратегии и решения в области безопасности. Их решения/продукты были организованы по контракту, с тем чтобы доверенная платформа могла извлечь выгоду из исходной информации о безопасности (т.е. новых сигнатур вредоносных программ) и анализа безопасности. Такое повышение уровня безопасности, в свою очередь, идет на пользу самим поставщикам услуг безопасности, поскольку они получают доступ к дополнительной информации и инструментам для обеспечения безопасности. Потоки сведений об угрозе от сторонних лиц (Third Party Threat Intelligence, 3PTI) 14 обеспечивают взаимный обмен информацией, важной с точки зрения безопасности (т.е. новыми сигнатурами вредоносного ПО). Доверенная платформа выступает в качестве центрального узла для отправки, получения и использования такой информации, важной с точки зрения безопасности. Используя несколько информационных потоков, можно получить (задействуя поставщиков услуг безопасности) более продвинутые модели поведения, важного с точки зрения безопасности, с помощью аналитических модулей, которые различают информационное сотрудничество (т.е. обнаружение злого умысла 19). Правоохранительные органы 15 обращаются в соответствующие правоохранительные подразделения, как на уровне штата (напр., полиция Нью-Йорка), страны (напр., ФБР), так и на международном уровне (напр., Интерпол). Связь устанавливают, с тем чтобы получать и отправлять информацию, важную с точки зрения безопасности, для более эффективного отпора хакерам-преступникам. Такой отпор, как правило, включает в себя обнаружение и арест подозреваемых, а затем суд над ними.
[0083] На Фиг. 4-8 показан общий принцип работы провайдера управляемой сети и услуг безопасности (MNSP) 9 и взаимоотношения между его внутренними подмодулями. LIZARD 16 анализирует угрозы сами по себе, не обращаясь к прошлым историческим данным. Искусственные угрозы безопасности (AST) 17, представляют собой гипотетический сценарий события в системе безопасности для проверки эффективности правил безопасности. Угрозы безопасности имеют повторяющуюся степень серьезности и тип, чтобы обеспечивать информативное сравнение сценариев событий в системе безопасности. Творческий модуль 18 осуществляет процесс интеллектуального создания новых гибридных форм из существующих форм. Он используется в качестве подключаемого модуля для обслуживания нескольких алгоритмов. В рамках обнаружения злого умысла 19 обеспечивают фоновую проверку нескольких «преступных» событий в системе безопасности с целью определить закономерности и связи между, казалось бы, несвязанными событиями в системе безопасности. Поведение системы безопасности 20: События и отклики системы безопасности на них сохраняют и индексируют для будущих запросов. I2GE 21 - это ветвь MNSP 9, отвечающая за ретроспективный анализ больших данных. Помимо стандартных средств отслеживания сигнатур, она способна симулировать будущие потенциальные варианты вредоносного ПО, путем задействуя AST в сочетании с творческим модулем. СТМР 22 задействует перекрестные ссылки на интеллектуальные данные из нескольких источников (например, I2GE, LIZARD, доверенной платформы и т.д.) и узнает об ожиданиях восприятия и реальности. СТМР оценивает собственную способность формировать объективное решение по вопросу и воздерживается от реализации решений, в которых имеет низкую степень уверенности. Консоль управления (МС) 23 - это интеллектуальный интерфейс для того, чтобы человек мог контролировать и управлять сложными и полуавтоматическими системами. Интеллектуальное управление информацией и конфигурацией (I2CM) 24 содержит набор функций, которые контролируют поток информации и использование авторизованной системы.
Энергетический сетевой коммутатор 25 представляет собой крупную частную внешнюю сеть, которая соединяет поставщиков, производителей, покупателей энергии и т.д. Через него они могут обмениваться важной с точки зрения безопасности информацией, касающейся их отрасли. Процесс связи по энергетическому сетевому коммутатору осуществляется посредством VPN/внешней сети 12 и облака MNSP 9. Такое облачное взаимодействие позволяет проводить двунаправленный анализ безопасности, причем 1) важные сведения о безопасности направляются энергетическим сетевым коммутатором в облако MNSP; 2) важные меры по устранению угрозы безопасности направляются облаком MNSP в энергетический сетевой коммутатор. Весь сетевой трафик энергетической компании в EI2 (внешние сети, внутренние сети, Интернет) всегда перенаправляется через VPN 12 в облако MNSP. Сертификацию и шифрование, используемые MNSP во всех услугах, осуществляют в соответствии с национальными (используемыми в конкретной стране, напр., FedRAMP, NIST, ОМВ и др.) и международными (ETSI, ISO / IEC, IETF, IEEE и др.) стандартами и требованиями к шифрованию (например, FIPS и др.). Внутренняя сеть 26 (зашифрованный слой % VPN) поддерживает защищенное внутреннее соединение с частными сетями 27 предприятия (здесь: энергетической компании). Это позволяет клиенту LIZARD Lite 43 работать в инфраструктуре предприятия и при этом осуществлять защищенную коммуникацию с облаком Lizard 16, которое расположено в облаке MNSP 9. Пункт 27 указывает на локальный узел частной сети. Такие частные сети предлагают несколько местоположений (обозначенных как местоположения А, В и С). В каждой частной сети могут существовать различные варианты технологической инфраструктуры, например, кластер серверов (местоположение С) или общий офис с мобильными устройствами и закрытым Wi-Fi-соединением (местоположение А). Каждому узлу частной сети назначена своя консоль управления (МС) 23. Портативные медиа-устройства 28 выполнены с возможностью безопасного подключения к частной сети и, как следствие, к внутренней сети 26, а значит, посредством безопасного соединения через VPN/внешнюю сеть 12 они косвенно подключены к MNSP 9. При использовании этого безопасного соединения весь трафик перенаправляют через MNSP для максимального применения развернутых алгоритмов анализа безопасности в реальном времени и ретроспективе. Такие портативные устройства могут поддерживать это безопасное соединение - как в защищенной частной сети, так и Wi-Fi-сети общественного кафе. Демилитаризованная зона (DMZ) 29 представляет собой подсеть, содержащую HTTP-сервер с более высокой ответственностью перед системой безопасности, чем у обычного компьютера. Повышенная ответственность проистекает не из недостатков системы безопасности, а из-за сложного программно-аппаратного состава общедоступного сервера. Поскольку существует так много потенциальных позиций для атаки, несмотря на все усилия по усилению безопасности, сервер помещается в DMZ, чтобы освободить остальную частную сеть (местоположение С) от ответственности. Ввиду такого разделения HTTP-сервер неспособен общаться с другими устройствами внутри частной сети, если они не находятся в DMZ. Клиент LIZARD Lite 43 может работать в пределах DMZ, поскольку установлен на HTTP-сервере. Исключение в политике DMZ сделано только для МС 23, чтобы она могла иметь доступ к HTTP-серверу и, следовательно, к DMZ. Клиент Lite общается с MNSP по зашифрованным каналам, сформированным из событий 12 и 26. В пункте 30 данные сервера изолированы от частной сети, однако не помещены в DMZ 29. Благодаря этому возможно общение между устройствами, входящими в частную сеть. На каждом сервере установлена независимая копия клиента Lizard Lite 43, и каждый сервер управляется МС 23. Интернет 31 упоминается в связи с тем, что он является средством передачи информации между MNSP 9 и корпоративными устройствами 28, на которых работает клиент LIZARD Lite. Интернет является наиболее подверженным риску источником угроз безопасности для корпоративных устройств, в отличие от локальной сети (LAN), откуда тоже могут исходить угрозы. Из-за высокого риска для системы безопасности весь трафик с отдельных устройств перенаправляется через MNSP, выступающий в качестве прокси-сервера. Благодаря созданию структуры из VPN/внешней сети 12 потенциальные интернет-злоумышленники смогут видеть только зашифрованную информацию Потоки сведений об угрозе от сторонних лиц (3PTI) 32 представляют собой специально настроенный ввод данных, предоставленных сторонними лицами в соответствии с заданными договорными обязательствами. Итеративное развитие 33: выбор и развитие параллельных путей развития. Итеративные поколения адаптируются к тем же искусственным угрозам безопасности (AST), а затем отбирают путь с лучшими личностными чертами, который лучше всех сопротивляется угрозам безопасности. Пути развития 34: виртуально закрытая и изолированная последовательность поколений наборов правил. Эволюционные параметры и критерии задаются личностью данного пути X.
[0084] На Фиг. 9 показана обработка событий безопасности в реальном времени с точки зрения облачной системы шифрования и безопасности LIZARD. Синтаксический модуль 35 предоставляет фреймворк для написания и чтения компьютерного кода. Для написания получают из РМ формат сложносоставной цели, затем пишут код, используя синтаксис произвольного кода, затем вспомогательная функция переводит произвольный код в реальный исполняемый код (в зависимости от выбранного языка). Для чтения в целевой модуль направляют синтаксическую интерпретацию кода с целью выявить назначение данного кода. С помощью синтаксического модуля 35 целевой модуль 36 выводит назначение кода и выдает его в собственном «формате сложносоставной цели». Такая цель должна адекватно описывать предполагаемые функции блока кода (даже если этот код был скрыто помещен в данные), как их интерпретирует SM. В рамках виртуальной обфускации 37 сеть и базу данных предприятия копируют и переносят в виртуальную среду, где конфиденциальные данные заменяют на фальшивые (поддельные) данные. В зависимости от поведения цели среда может динамически изменяться в реальном времени с целью добавления либо большего количества фальшивых элементов, либо большего настоящих элементов системы в целом. Имитация сигнала 38 обеспечивает своего рода ответный удар при достижении аналитического завершения виртуальной обфускации (защиты). При имитации сигнала используют синтаксический модуль для определения синтаксиса коммуникации между вредоносным ПО и хакерами. После этого коммуникацию взламывают, давая вредоносному ПО ложное впечатление, будто оно успешно отправило конфиденциальные данные хакерам (при этом сами данные фальшивые, и ПО отправляет их виртуальной иллюзии хакера). Настоящие хакеры, в свою очередь, получают код ошибки от вредоносного ПО, сгенерированный LIZARD, но похожий на реальный отклик вредоносного ПО. Это заставляет хакера тратить время и ресурсы на бессмысленную отладку и, в конечном итоге, отказаться от работы с вредоносным ПО под ложным впечатлением, что оно не работает. В рамках проверки внутренней логики 39 проверяют, присутствует ли логика во всех внутренних функциях внешнего кода. Затем убеждаются в отсутствии участков кода, логика которых противоречит назначению внешнего кода в целом. В рамках переписывания внешнего кода 40 посредством синтаксического и целевого модулей внешний код преобразуют в формат сложносоставной цели. Кодовый набор затем достраивают с помощью выявленной цели. Тем самым добиваются того, чтобы внутри сети предприятия исполнялись только желаемые и понятные функции внешнего кода, а все остальные части кода не получали доступа в систему. В рамках обнаружения скрытого кода 41 обнаруживают код, скрытно помещенный в пакеты передачи данных. На сопоставление карт потребностей 42, т.е. карту иерархии потребностей и целей, опираются, решая, соответствует ли внешний код общему назначению системы. Клиент LIZARD Lite 43 является облегченной версией программы системы LIZARD, в которой отключены ресурсоемкие функции, такие как виртуальная обфускация 208 и имитация сигнала. Он выполняет мгновенную оценку угроз в реальном времени с минимальным использованием компьютерных ресурсов, задействуя объективный анализ угроз, не основанный на прошлом опыте и не обращающийся к базе данных сигнатур. Благодаря журналам 44 у системы энергетической компании 48 есть множество точек создания журналов, например, стандартных журналов ошибок/доступа к ПО, журналом операционной системы, контрольного зондирования и т.д. Эти журналы затем отправляют в алгоритмы сопоставления локальных шаблонов 46 и СТМР 22 для глубокого анализа безопасности и поиска отклика. Трафик 45 включает весь внутренний и внешний трафик энергетической компании. Алгоритмы сопоставления локальных шаблонов 46 состоят из типового программного обеспечения, которое обеспечивает начальный уровень безопасности, такой как антивирусы, адаптивные брандмауэры и т.д. Меры по устранению угрозы 47 осуществляются алгоритмом сопоставления локальных шаблонов 46, что первоначально понимается как решение проблемы/устранение риска безопасности. Они могут включать в себя блокировку порта, передачи файлов, запросов на административные функции и т.д. Система 48 энергетической компании изолирована от специализированных алгоритмов безопасности, в которые она отправляет свои журналы и информацию о графике. Это связано с тем, что алгоритмы LIZARD 16, I2GE 21 и СТМР 22 расположены в облаке MNSP 9. Такое разделение позволяет создать централизованную модель базы данных, что приводит к увеличению пула данных/тенденций в системе безопасности и, следовательно, позволяет обеспечить более всесторонний анализ.
[0085] Как показано на Фиг. 11, система злоумышленников сканирует уязвимый канал входа в целевую систему. При возможности взламывают канал для доставки небольшой по размеру программы. Система злоумышленников 49 использует неподконтрольную преступную сторону для совершения атаки вредоносным ПО по партнерской системе 51, и далее - по инфраструктурной системе 54. Источник вредоносного ПО 50 является контейнером для неактивной формы вредоносного кода (собственно вредоносного ПО). Как только код достигает (или пытается достичь) целевой инфраструктурной системы 54, вредоносное ПО активируется и выполняет свою задачу либо по программе, либо по указанию. Партнерская система 51 взаимодействует с инфраструктурной системой в соответствии с договором между инфраструктурной (здесь: энергетической) компанией и партнером. Такое соглашение отражает определенный деловой интерес, например, управление цепочками поставок или коммутатор отслеживания запасов. Для выполнения согласованных услуг обе стороны взаимодействуют в электронной форме в соответствии с ранее согласованными стандартами безопасности. Источник вредоносного ПО 50 от имени преступника, который управляет системой злоумышленников 49, пытается найти в партнерской системе эксплойт для проникновения. Таким образом вредоносное ПО достигает своей конечной цели, а именно: заражает инфраструктурную систему 54. Таким образом источник вредоносного ПО 50 использует партнерскую систему в качестве посредника для заражения. Среди многих каналов связи между партнерской системой 51 и инфраструктурной системой 54 взлому со стороны вредоносного ПО, отправленного из источника вредоносного ПО 50, был взломан канал 52. Канал/протокол 53 обозначает канал связи между партнерской системой 51 и инфраструктурной системой 54, который не был взломан. К таким каналам могут относиться соединения с файловой системой, базой данных, маршрутизация электронной почты, VOIP-соединения и т.п. Инфраструктурная система 54 является важнейшим элементом устройства энергетической компании, поскольку через нее осуществляется прямой доступ к инфраструктурной базе данных 57 и элементам управления инфраструктурой 56. Типовая система защиты от вторжений 55 выполнена в виде стандартной процедуры безопасности. Элементы управления инфраструктурой 56 представляют собой цифровой интерфейс, подключенный к энергетическому оборудованию, отвечающему, например, за открытие и закрытие шлюзов водоспуска плотины ГЭС или угол наклона солнечных батарей и т.п. В инфраструктурной базе данных 57 содержатся конфиденциальные сведения, относящиеся к ядру работы инфраструктурной системы энергетической компании в целом. К таким сведениям относятся контактные данные, отслеживание смены работника, документация на энергетическое оборудование, чертежи и т.д.
[0086] Как показано на Фиг. 12, взломанный канал 52 обеспечивает очень небольшое пространство для преступных действий, поэтому для расширения возможностей в целевую систему запускают очень простой вирус - «троянский конь». «Троянский конь» 58 запускается из источника вредоносного ПО 50, проходит по взломанному каналу 52 и достигает цели - инфраструктурной системы 54. Его назначение состоит в том, чтобы воспользоваться существующими эксплойтами с целью установить на целевую систему пакет продвинутого исполняемого вредоносного ПО (более сложноустроенного и содержащего действующий вредоносный код, похищающий данные, и т.п.).
[0087] На Фиг. 13 показано, как после проникновения в систему «троянского коня» в систему, посредством нового канала, созданного «троянским конем», скрытно загружают крупный исполняемый пакет вредоносного ПО. Продвинутое исполняемое вредоносное ПО 59 переносят в инфраструктурную систему 54, а оттуда - в базу данных конфиденциальной информации 57 и систему управления 56. Продвинутое исполняемое вредоносное ПО использует цифровой маршрут, предварительно проложенный «троянским конем» на пути к цели.
[0088] На Фиг. 14 показано, как продвинутое исполняемое вредоносное ПО 50 производит взлом IDS, давая возможность системе злоумышленников скрытно и незаметно скачать конфиденциальные инфраструктурные сведения и точки управления. В рамках желаемого поведения хакера 60 хакеру 65 удалось заполучить достоверные учетные данные сотрудника компании и его легитимные разрешенные данные входа. Хакер намерен использовать эти учетные данные для получения скрытного доступа к локальной сети, предназначенной только для сотрудников. Хакер намеревается обойти типичный ответ безопасности «слишком мало, слишком поздно». Даже если клиенту, отвечающему за безопасность в конечной точке, удастся ретранслировать данные в облачную службу безопасности, ретроспективное аналитическое решение по безопасности будет направлено только на минимизацию ущерба, а не на устранение угрозы вторжения в режиме реального времени. Располагая актуальным откликом системы безопасности 61 клиент LIZARD Lite (для использования на конечной точке) не может однозначно доказать назначение, функцию и цель использования учетных данных и доступа к системе. Поскольку неизвестно, является ли пользователь с указанными учетными данными легитимным сотрудником или нет, его помещают в виртуальную среду, частично наполненную фальшивыми данными. В рамках такой среды возможно динамически изменять объем доступных конфиденциальных данных в режиме реального времени по мере анализа поведения пользователя. Поведенческий анализ 62 выполняется по отношению к хакеру 65 на основании элементов, с которыми он взаимодействует, которые существуют как в реальной инфраструктуре LAN 64, так и в ее виртуальном клоне. С помощью похищенных учетных данных 63 хакер получает доступ к учетной записи администратора на ноутбуке 28 энергетической компании, а оттуда - к инфраструктуре LAN 64, к которой данный ноутбук подключен. Учетные данные могли быть похищены путем перехвата незашифрованной электронной переписки или кражи незашифрованного устройства, на котором локально хранятся эти учетные данные и т.п. Инфраструктура LAN 64 представляет собой ряд корпоративных устройств, соединенных между собой посредством локальной сети (проводной и/или беспроводной). В нее также могут входить принтеры, сервера, планшеты, телефоны и проч. Вся инфраструктура локальной сети виртуально воссоздается (в виде виртуального маршрутизатора IP адресов, виртуального принтера, виртуального сервера и т.д.) в облаке MNSP 9. Затем, пока система выполняет поведенческий анализ 62, хакеру дают доступ к элементам как реальной инфраструктуры LAN, так и к ее виртуальному клону. Если такой анализ указывает на риск, то хакеру расширяют доступ к фальшивой инфраструктуре (в отличие от настоящей инфраструктуры) с целью снизить риск взлома настоящих данных и/или устройств. Хакер 65 - это преступное лицо, которое намеревается получить доступ к конфиденциальным сведениям и похитить их посредством первоначального вторжения с помощью похищенных учетных данных 63. В рамках набора паролей 66 процесс аутентификации требует ввода набора из трех паролей. Эти пароли никогда не хранятся по отдельности и всегда используются вместе. В соответствии с временно назначенным SIAPA протоколом сотрудник должен ввести сочетание из трех паролей. В рамках регулярной внутренней аутентификации протоколов доступа (SIAPA) 67 протокол аутентификации портала входа каждого отдельного сотрудника меняют еженедельно/ежемесячно. Такой протокол может включать в себя выбор паролей А и С из набора паролей А, В и С (которые были предварительно назначены для аутентификации). Благодаря созданию регулярного графика изменения протоколов аутентификации (например, каждый понедельник или первый день месяца) сотрудники привыкнут к переключению протоколов аутентификации, что минимизирует ложные срабатывания системы (когда легитимный сотрудник, используя старый протокол, попадает в среду фальшивых данных 394). Чтобы устранить риск того, что новый протокол будет взломан хакером, сотруднику позволяют просмотреть новый протокол только один раз, после чего он будет уничтожен и недоступен для просмотра. Для получения доступа к такому первому и единственному просмотру требуется специальная многофакторная аутентификация, включающая проверку биометрических данных/сканирование сетчатки/текстовое сообщение на телефон и т.п. Сотрудник должен запомнить только одну или две буквы, которые определяют, какой(ие) из трех паролей он должен ввести. Так, например, на неделе 1 68 при вводе чего-либо, кроме паролей А и В, пользователь попадает в среду фальшивых данных 394. Так, например, на неделе 2 69 при вводе чего-либо, кроме паролей А и С, пользователь попадает в среду фальшивых данных. Так, например, на неделе 3 70 при вводе чего-либо, кроме одного пароля В, пользователь попадает в среду фальшивых данных. Так, например, на неделе 4 71 при вводе чего-либо, кроме все без исключения паролей, пользователь попадает в среду фальшивых данных. В SIAPA 72 протокол аутентификации хранят в тайне, и верный протокол известен только тому, у кого был доступ к временному объявлению. В виртуальной копии 73 инфраструктуры LAN, поскольку хакер 65 ввел все три пароля вместо того, чтобы пропустить требуемый, его без уведомлений перенаправляют в среду-дубликат в облаке MNSP 9, где никаких важных данных или функций не содержится. Судебные доказательства и данные поведенческого анализа собирают, пока хакер уверен, что успешно проник в реальную систему. Так, например, по сценарию «неверный протокол» 74, хакер не использовал нужный протокол, поскольку не мог его знать. Более того, хакер даже не ожидал, что протокол подразумевает намеренный пропуск определенного пароля. В пункте 75 хакеру удалось украсть легитимные учетные данные, с помощью которых он намеревается войти в систему компании и похитить конфиденциальные данные. Отдел внутреннего контроля 76 предприятия состоит из административного комитета, а также технического командного центра. Это верхний уровень для контроля и разрешения/блокировки потенциально вредоносного поведения. Сотрудники В и D 77 не являются злоумышленниками (они исключительно лояльны интересам предприятия), поэтому их отобрали в качестве квалифицированных сотрудников для трехстороннего сотрудничества по утверждению функции корневого уровня 80. Сотрудник А 78 для процесса трехстороннего сотрудничества 80 не отобрали. Возможно, это связано с тем, что у него нет достаточного опыта работы в компании, технического опыта, либо есть криминальное прошлое, либо он слишком тесно связан с другими сотрудниками, а значит, может участвовать в заговоре против компании и т.п. Сотрудник С (злоумышленник) 79 пытается получить доступ к функции/действию корневого уровня в преступных целях. Такую функцию корневого уровня 80 нельзя выполнить без согласия и одобрения трех сотрудников, каждый из которых имеет доступ корневого уровня. Все три сотрудника несут равную ответственность за результаты выполнения такой функции корневого уровня, несмотря на то, что преступные намерения есть только у сотрудника С. Таким образом у сотрудников воспитывается культура осторожности и недоверия, что удерживает их от преступного поведения - в первую очередь, из-за понимания процедуры. Сотрудников Е и F 81 не отобрали для процесса трехстороннего сотрудничества 80 - прежде всего потому, что они не располагают доступом корневого уровня для выполнения или утверждения запрошенной функции корневого уровня. В рамках контрольного обзора 82 используют время, предоставляемое искусственной задержкой, для проверки и критики запрошенных действий. Действие корневого уровня 83 откладывается на 1 час, чтобы предоставить отделу контроля возможность рассмотреть действие и сообщить о его разрешении или блокировке. В политике также может быть прописано решение по умолчанию (разрешение либо блокировка), если отдел контроля не в состоянии принять решение или у него нет на это времени. Посредством контрольного обзора 84 определяют, по какой причине не было достигнуто единогласное решение. Так, при выполнении действия корневого уровня 85, после того, как оно пройдет через систему контроля и сотрудничества, ведется строгая отчетность по тому, кто какую часть действия одобрил. Таким образом, если действие корневого уровня выполнялось во вред интересам компании, можно будет провести тщательное расследование. В пункте 86 действие корневого уровня отменено в связи с несостоявшимся трехсторонним сотрудничеством (единогласного решения не достигнуто). В пункте 87 все трое отобранных сотрудников с доступом корневого уровня единогласно одобрили действие корневого уровня. Если действие корневого уровня на самом деле выполняется с преступной целью, необходимо, чтобы все три сотрудника участвовали в заговоре против компании. В связи с этой маловероятной, но все же возможной ситуацией, выполнение действия корневого уровня 83 откладывают на 1 час, чтобы отдел контроля мог его изучить (см. пункты 76 и 82). В пункте 88 один или более квалифицированных сотрудников, отобранных для трехстороннего сотрудничества, отклонили запрошенное действие корневого уровня. Таким образом, действие корневого уровня отменяется 89, поскольку по его поводу не было достигнуто единогласного решения. База данных эволюционных образцов 90 содержит ранее обнаруженные и обработанные образцы рисков безопасности. В этих образцах собраны все потенциальные варианты развития текущего вредоносного ПО. Корневая сигнатура вредоносного ПО 91 предоставляется AST 17 для генерирования итераций/вариаций данной сигнатуры 91. Полиморфические вариации 92 вредоносного ПО предоставляются как выход из I2GE и передаются в системы обнаружения вредоносного ПО 95. Инфраструктурная система 93 физически находится на территории инфраструктуры. Эта система, как правило, управляет функциональной инфраструктурой, такой как ГЭС, электросети и т.п. Инфраструктурный компьютер 94 - это определенный компьютер, выполняющий функции или часть функций инфраструктуры из системы 93. Программное обеспечение для обнаружения вредоносного ПО 95 развертывается на всех трех уровнях компьютера. Сюда входит пользовательское пространство 97, пространство ядра 99 и пространство прошивки/оборудования 101. Точно так же развертывают агенты Lizard Lite, которые обнаруживают вредоносное ПО отдельно на каждом из трех уровней. Форма вредоносного ПО 96, которая была получена путем итераций пути развития 34, находится в драйвере (который существует в пространстве ядра 99). Пользовательское пространство 97 предназначено для наиболее популярных приложений разработчиков. В него легче всего проникнуть вредоносному ПО, но в нем и легче всего обнаружить и изолировать вредоносное ПО. Вся деятельность в пользовательском пространстве эффективно контролируется LIZARD Lite. Приложения 98 в пользовательском пространстве могут включать программы типа Microsoft Office, Skype, Quicken и др. Пространство ядра 99 в основном поддерживается поставщиками операционных систем, такими как Apple, Microsoft и Linux Foundation. Проникнуть в него сложнее, чем в пользовательское пространство, и ответственность лежит в основном на поставщике, если только в инфраструктуре не производилось модификаций на уровне ядра. Вся деятельность в пространстве ядра (включая изменения реестра (Microsoft OS), управление памятью, управление сетевым интерфейсом и т.д.) эффективно контролируется LIZARD Lite. Драйвер 100 позволяет инфраструктурному компьютеру 94 взаимодействовать с периферийными устройствами и оборудованием (мышь, клавиатура, сканер отпечатков пальцев и т.д.). Пространство прошивки/оборудования 101 полностью поддерживается поставщиками прошивки/оборудования. В это пространство сложнее всего проникнуть вредоносному ПО, поскольку для этого нужен физический доступ к оборудованию (например, нужно снять старый чип BIOS с материнской платы и поставить на его место новый). Однако, в зависимости от конфигурации оборудования LIZARD Lite контролирует некоторые виды деятельности в пространстве прошивки. BIOS 102 (тип прошивки) - это первый уровень программного обеспечения, на котором строится операционная система. К общедоступной инфраструктуре 103 относится неизвестная и потенциально взломанная цифровая инфраструктура (маршрутизаторы ISP, волоконные кабели и т.д.). Агента 104 внедряют в общедоступную инфраструктуру, после чего он отслеживает известные каналы обратного вызова, взаимодействуя с их известным описанием (порт, тип протокола и т.д.), хранящимся в базе данных доверенной платформы. Агент проверяет наличие сигналов сердечного ритма и уведомляет о них доверенную платформу, чтобы получить рычаги воздействия на источник вредоносного ПО. С помощью автообнаружения и установки клиента Lite 105 облако LIZARD в MNSP 9 обнаруживает конечную точку (напр., ноутбук), которая не предоставляет ответного сигнала (рукопожатие) LIZARD. Конечная точка будет синхронизирована после обнаружения и классифицирована посредством I2CM 24. Таким образом, облако LIZARD обнаруживает (через удаленную корневую оболочку SSH), что клиент Lizard Lite 43 не установлен/активирован, и, используя корневую оболочку, запускает установку клиента 43, а также следит за его правильной активацией. Вредоносное ПО 106А осуществляет первоначальное вторжение, потому что клиент Lite 43 на устройстве входа не установлен. Клиент Lite 43 устанавливают практически на каждом экземпляре системы, не говоря о том, что весь входящий и исходящий график перенаправляют через MNSP, где располагается облако LIZARD. В первоначальном эксплойте 107 обнаруживают первоначальную вредоносную сущность и, возможно, блокируют ее полностью до того, как она создает канал скрытого обратного вызова 106В. Канал 106В представляет собой скрытый путь связи, по которому вредоносное ПО 106В скрытно связывается с базой. В частности, оно может маскировать свой сигнал, подражая легитимному графику приложений, использующих протоколы http или https. Широкий круг поставщиков 108 предоставляет ценные ресурсы, такие как скрытый доступ к программному обеспечению, аппаратному обеспечению, брандмауэрам, услугам, финансам и критической инфраструктуре, с тем чтобы агенты 104 могли внедряться в общедоступную инфраструктуру 103. Сигнал сердечного ритма передается вредоносным ПО по каналу обратного вызова 106В через равные промежутки времени с определенным размером и частотой и адресуется источнику происхождения/лояльности по каналу скрытого обратного вызова. Сигнал показывает состояние/возможности вредоносного ПО, позволяя источнику вредоносного ПО 50 принимать решения о будущем использовании эксплойтов и координировать атаки. Такой источник вредоносного ПО представляет собой организацию с хакерскими возможностями, применяемыми со злым умыслом, например, хакеры-преступники (black hat) или правительство другого государства. Вредоносное ПО 106А и сигнал сердечного ритма (внутри канала 106В) обнаруживается системой LIZARD, работающей в облаке MNSP 9, поскольку весь входящий и исходящий график перенаправляется в облако MNSP/LIZARD через VPN-туннель.
[0089] На Фиг. 22 и 23 показано, как при переписывании внешнего кода синтаксически воспроизводят внешний код с нуля для предотвращения потенциально пропущенных вредоносных эксплойтов. Посредством комбинационного метода 113 сравнивают и сопоставляют заявленную цель 112А (есть доступна; в зависимости от политики предприятия 147 может быть необязательной) с выявленной целью 112В. Посредством целевого модуля 36 манипулируют форматом сложносоставной цели и достигают итогового совпадения либо несовпадения сценариев. В случае выявленной цели 112В сопоставление карт потребностей сохраняет иерархическую структуру для контроля за юрисдикцией всех потребностей предприятия. Таким образом, назначение блока кода можно определить и обосновать исходя из пропусков в карте потребностей 114, ориентированной по юрисдикциям. Входящая цель 115 поступает в процесс рекурсивной отладки 119, где задействуются целевой и синтаксический модули. Множественные входы (т.е. назначения) не объединяются. На каждую входящую цель параллельно запускают отдельную копию алгоритма. В итоговой проверке безопасности 116 используют синтаксический модуль 35 и целевой модуль 36 для выполнения многоцелевой проверки «здравомыслия» для защиты уязвимых точек в программировании, после чего итоговый результат 117 передают в VPN/внешнюю сеть 12.
[0090] На Фиг. 24 и 25 показано, как рекурсивная отладка 119 циклически проходит по участкам кода на предмет багов и применяет исправления багов 129 (решения), где это возможно. Если баг сохраняется, весь участок кода заменяют 123 на исходный (внешний) участок кода 121. Исходный участок кода затем помечают для упрощения работы дополнительных уровней системы безопасности, таких как виртуальная обфускация и поведенческий анализ. Исходное состояние внешнего кода 120 интерпретируется целевым модулем 36 и синтаксическим модулем 35 для переписывания кода Отладчик напрямую обращается к внешнему коду 120 в случае, если в переписанной версии обнаружен неустранимый баг и весь сегмент необходимо заменить исходным сегментом (внешнего) кода. Сегменты 121 переписанного кода 122 проверяют в виртуальной среде выполнения 131 на предмет наличия багов программирования 132. В данной среде 131 выполняются участки кода 121, такие как функции и классы, и проверяются на наличие ошибок выполнения (синтаксические ошибки, переполнение буфера, неправильный вызов функции и т.д.). Все ошибки программирования обрабатывают и исправляют. При наличии багов программирования 132 виртуальная среда выполнения выявляет тип и участок ошибок. Все нужные детали программирования предоставляются для упрощения решения. Потенциальное решение для бага программирования 132 готовят посредством совмещения цели 124 и перевыражения кода из заявленной цели данных функций и классов. Участок бага программирования переписывают в ином формате с целью избежать бага. Выводят потенциальное решение, и, если никаких решений не остается, переписанный код данного участка кода 121 удаляют, а в итоговом кодовом наборе используют исходный сегмент кода (взятый напрямую из внешнего кода). Как правило, баг программирования 132 будет получать программное решение 138 несколько раз в цикле. Если в попытках устранить баг 132 все программные решения были исчерпаны, решение отбрасывают 137 и используют исходный участок внешнего кода 133. Участок кода 121 может быть помечен 136 как внешний для упрощения процесса принятия решения дополнительными мерами безопасности, такими как виртуальная обфускация и поведенческий анализ. Например, если в переписанном блоке кода содержится много участков внешнего кода, то его скорее поместят среду фальшивых данных 394. При кэшировании участка кода 130 отдельные сегменты кода (функции/классы) кэшируются и повторно используются в различных операциях переписывания для повышения эффективности применения облачных ресурсов LIZARD. Данный кэш активно используется, поскольку весь трафик сосредоточен в облаке посредством VPN. Поставщик переписанного участка кода 128 предоставляет ранее переписанный участок кода 121, чтобы к ошибке программирования можно было применить соответствующее решение 129.
[0091] На Фиг. 26 показано внутреннее устройство сопоставления карт потребностей 114, посредством которого удостоверяют юрисдикцию цели. Облако LIZARD и клиент Lite обращаются к иерархической карте 150 юрисдикции подразделений предприятия. Это делается для обоснования назначения кода/функции и потенциального блокирования такого кода/функции, если у него нет законного обоснования. Все входящие цели 139, как заявленные, так и выявленные (посредством целевого модуля 35) проверяют с помощью сопоставления карт потребностей 114 для обоснования работы кода/функции в системе предприятия. Мастер-копия иерархической карты 150 хранится в облаке LIZARD в MNSP 9, в зарегистрированной учетной записи предприятия. Индекс потребностей 145 внутри сопоставления карт потребностей 114 рассчитывают, ссылаясь на мастер-копию. Затем предоптимизированный индекс потребностей (не сама иерархия) распространяют между всеми доступными конечными клиентами. Сопоставление карт потребностей получает запрос на потребности 140 в отношении наиболее подходящей потребности системы в целом. В качестве соответствующего вывода выступает формат сложносоставной цели 325, который представляет собой соответствующую потребность. В ходе фильтрации критериев потребности в совокупности с приоритетами 143 производят поиск подходящей потребности в политике предприятия 147. Такая политика 147 диктует типы и категории потребностей, которые может иметь каждая юрисдикция. Потребности могут включать переписку по электронной почте, установку программного обеспечения и т.п. Политика 147 определяет, каков приоритет той или иной потребности с точки зрения предприятия. В соответствии с определениями, связанными с каждым подразделением, потребности связаны с соответствующими отделами. Таким образом можно выполнять проверку разрешений. Пример: Сопоставление карт потребностей одобрило запрос в отдел кадров на скачивание личных дел всех сотрудников, потому что подошло время ежегодной оценки качества работы сотрудников в соответствии с их квалификацией. При первоначальной обработке 148 юрисдикцию каждого подразделения скачивают для проверки потребностей. При расчете потребностей подразделений 149 потребности связывают с соответствующим отделом в соответствии с определениями, связанными с каждым подразделением. Таким образом можно выполнять проверку разрешений. Пример: Сопоставление карт потребностей одобрило запрос в отдел кадров на скачивание личных дел всех сотрудников, потому что подошло время ежегодной оценки качества работы сотрудников в соответствии с их юрисдикцией, заданной в иерархической карте 150.
Секретный машинный интеллект (MACINT) и отпор посредством скрытных операций в киберпространстве
[0092] На Фиг. 27 показаны интеллектуальное управление, просмотр и контроль информации. При сборе 152 используют критерии общего уровня для отсеивания неважной и лишней информации, а также сливают и помечают потоки информации с множества платформ. Служба настройки и размещения 153 представляет собой интерфейс для размещения новых устройств (компьютеров, ноутбуков, мобильных телефонов) на предприятии с нужными настройками безопасности и подключения. Когда устройство добавлено и настроено, настройки можно корректировать посредством консоли управления через посредничество элементов управления обратной связью. Эта служба также управляет созданием новых учетных записей клиентов/посетителей. Этот процесс может включать в себя связь оборудования с учетными записями пользователей, настройку интерфейса, перечисление переменных клиентов/посетителей (напр., тип деятельности, тип продукта и т.д.). В рамках разделения по юрисдикции 154 размеченный пул информации делят исключительно в соответствии с юрисдикцией конкретного пользователя консоли управления. В рамках разделения по угрозам 155 информацию организуют в соответствии с отдельными угрозами. Каждый тип данных либо связывают с угрозой (что добавляет многословности), либо удаляют. На этой стадии под названием интеллектуальная контекстуализация 156 оставшиеся данные представляют в виде скопления островов, каждый из которых отражает угрозу кибербезопасности. Для развития анализа безопасности устанавливают связи между платформами. Для понимания закономерностей угроз обращаются к историческим данным (из I2GE 21 в отличие от LIZARD 16), а СТМР используется для анализа критического мышления. В рамках решения дилеммы угрозы 157 угрозу кибербезопасности рассматривают с высоты птичьего полета (общая картина). Такую угрозу передают в консоль управления для графического отображения. Поскольку рассчитанные измерения, относящиеся к механике угрозы, в конечном итоге объединяются с нескольких платформ, можно автоматически выполнить более обоснованное решение по борьбе с угрозами. Автоматизированные элементы управления 158 представляют собой доступ алгоритма к элементам управления MNSP 9, ТР (Trusted Platform, доверенная платформа), 3PS, связанным с администрированием. Элементы управления обратной связью 159 предлагают управление высокого уровня для облака MNSP, доверенной платформы 10, дополнительных сторонних служб (3PS), которые могут быть использованы для помощи в разработке политики, экспертизе, расследовании угроз и т.д. Такие элементы управления в конечном итоге проявляются на консоли управления (МС) с соответствующим настраиваемым отображением и эффективностью представления. Таким образом достигается эффективное управление и манипуляция всеми системами (MNSP, ТР, 3PI) напрямую и с единого интерфейса который может при необходимости сфокусироваться на конкретных деталях. Ручное управление 160 представляет собой доступ человека к элементам управления MNSP 9, ТР, 3PS, связанным с администрированием. При прямом управлении 161 ручное управление задействуется для обеспечения человеческого интерфейса. В рамках категории и юрисдикции 162 пользователь консоли управления использует свои входные учетные данные для определения своей юрисдикции и объема доступа к информации. Все потенциальные векторы данных 163 - это данные в движении, используемые данные и неподвижные данные. Настраиваемое отображение 164 используется различными подразделениями предприятия (бухгалтерия, финотдел, отдел кадров, IT-отдел, юротдел, отдели безопасности/генеральный инспектор, отдел конфиденциальной информации, профсоюз и т.д.) и другими заинтересованными сторонами (сотрудники, руководители, начальники отделов), а также сторонними партнерами, правоохранительными органами и т.д. Интегрированное единое представление 165 - это единое представление всех потенциальных возможностей, таких как мониторинг, ведение журнала, отчетность, сопоставление событий, обработка предупреждений, создание политики/набора правил, меры по устранению угрозы, настройка алгоритмов, предоставление услуг (новые клиенты/модификации), использование доверенной платформы, а также сторонних служб (включая получение отчетов и предупреждений/журналов и т.д. от сторонних поставщиков услуг). Единый вид всех аспектов безопасности 165 - это набор визуальных элементов, представляющих периметр, предприятие, центр обработки данных, облако, съемные носители, мобильные устройства и т.д. Команда кибербезопасности 167 - это команда квалифицированных специалистов, контролирующих деятельность и состояние нескольких систем по всем направлениям. Поскольку производится интеллектуальная обработка информации и принимаются решения посредством ИИ, затраты могут быть снижены за счет найма меньшего количества людей с меньшим опытом работы. Основная цель группы состоит в том, чтобы выступать резервным слоем и контролировать развитие системы в соответствии с желаемыми критериями при выполнении крупномасштабного анализа. В ходе поведенческого анализа 168 наблюдают за состоянием и действиями вредоносного ПО 169, пока оно находится в среде, полностью состоящей из фальшивых данных 394. Пока вредоносное ПО взаимодействует с фальшивыми данными 170, поведенческий анализ записывает образцы поведения, выявленные во время активации (т.е. работает только по воскресеньям, когда на предприятии выходной), запросы на доступ к файлам, запрошенные корневые функции администратора и т.п. Вредоносное ПО 169 было загружено хакером 177. Пока хакер считает, что он успешно загрузил вредоносное ПО в целевую систему, вредоносное ПО незаметно переводят в среду, содержащую 100% фальшивых данных 394. В окружении фальшивых данных 170 вредоносное ПО 169 завладело цифровой копией фальшивых данных. Оно делает это исходя из того, что данные настоящие, причем ни ПО, ни, как следствие, хакер 177 не знают, являются ли данные настоящими или фальшивыми. Когда вредоносное ПО пытается отправить фальшивые данные хакеру, исходящий сигнал перенаправляют так, чтобы он был получен фальшивым хакером 174, а не настоящим хакером, как ожидает вредоносное ПО. В рамках хакерского интерфейса 171 синтаксический модуль 35 и целевой модуль 36 (которые по юрисдикции относятся к системе LIZARD) получают кодовую структуру вредоносного ПО 169. С помощью данных модулей восстанавливает внутреннюю структуру вредоносного ПО, из которой затем получают хакерский интерфейс. Посредством этого интерфейса описывают способ связи между вредоносным ПО и хакером, ожидания вредоносного ПО от хакера (напр., получение команд и т.п.) и ожидания хакера от вредоносного ПО (напр., отчеты о состоянии и т.п.). Такая информация позволяет имитировать фальшивого хакера 174 и фальшивое вредоносное ПО 172 в виртуальной среде 173. Как только поведенческий анализ 168 в достаточной степени изучил поведение вредоносного ПО 169, посредством функции имитации сигнала MNSP 9 симулируют программу, которая ведет себя, как хакер 177. Сюда входит протокол связи, который существует между настоящим вредоносным ПО 169, фальшивыми данными 170 и фальшивым хакером 174. В рамках имитации ответного сигнала 175 виртуальный фальшивый хакер 174 посылает ответный сигнал настоящему вредоносному ПО 169, создавая впечатление, что оно выполнило либо провалило свою задачу. Такой сигнал может включать команды для поведения вредоносного ПО и/или запросы на обновление информационного статуса. Благодаря этому развивают исследование поведенческого анализа для наблюдения за следующими закономерностями поведения вредоносного ПО. По завершении исследования среду фальшивых данных 394 с вредоносным ПО могут либо заморозить, либо уничтожить. В рамках имитации ответного кода 176 хакеру направляют фальшивый код ответа, который не связан с поведением/состоянием настоящего вредоносного ПО. В зависимости от желаемой тактики отпора может быть отправлен либо фальшивый код ошибки, либо фальшивый код успеха. Поддельный код ошибки создает у хакера впечатление, что вредоносное ПО не работает (хотя в действительности оно работает), и он будет вынужден тратить время на бесполезную отладку. Поддельный код успеха уменьшит вероятность того, что хакер будет создавать новую форму вредоносного ПО, а вместо этого сосредоточится на текущем и возможных незначительных улучшениях. Поскольку LIZARD уже раскрыла вредоносное ПО, хакер будет вынужден тратить на него силы и время, считая его успешным. Хакер 177 по-прежнему уверен, что загруженное им вредоносное ПО, успешно проникло в целевую систему. На самом деле вредоносное ПО изолировано в виртуальной среде. Та же самая виртуальная среда запускает поведенческий анализ 168 вредоносного ПО для симуляции способа и синтаксиса его коммуникации с хакером (как двунаправленного, так и всенаправленного). Активы злоумышленников 178 представляют собой инвестиции финансов злоумышленников 184 в облегчение взлома и преступных действий в рамках системы злоумышленников 49. Такие активы 178 обычно проявляются как вычислительная мощность и подключение к Интернету, так как значительные инвестиции в эти два актива позволяют осуществлять более сложные и продвинутые виды взлома. В отношении преступного кода 179 агент доверенной платформы производит сканирование эксплойтов для того, чтобы собрать как можно больше судебных доказательств. На компьютере злоумышленника 180 выполняется эксплойт процессора, который переполняет процессор инструкциями AVX. Это приводит к увеличению температуры, увеличению потребления электроэнергии, большему износу процессора и уменьшению доступной вычислительной мощности для преступной деятельности. Сканирование эксплойтов 181 в активах злоумышленников 178 выполняется с целью выявления их возможностей и характеристик. Полученные результаты сканирования обрабатываются с помощью эксплойта 185 и передаются на доверенную платформу 10. Эксплойт 185 - это программа, которая направляется доверенной платформой посредством базы данных ответных эксплойтов 187 и поражает указанную систему злоумышленников 49, как проиллюстрировано на Фиг. 27-44, описывающих MACINT. Расходы на электричество и охлаждение значительно возрастают, что приводит к истощению финансов злоумышленников 184. Выключение компьютеров серьезно затруднит преступную деятельность. Покупка новых компьютеров создаст дополнительную нагрузку на финансы злоумышленников, причем новые компьютеры будут точно так же уязвимы для эксплойтов, как и старые. В базе данных ответных эксплойтов 187 содержатся средства нанесения отпора злоумышленникам, предоставленные поставщиками аппаратного обеспечения 186 в виде выявленных бэкдоров и известных уязвимостей В единой базе данных судебных доказательств 188 собраны судебные доказательства из множества источников, включающих множество предприятий. Таким образом, против преступного предприятия строится самая сильная доказательная база, которая может быть представлена в соответствующий суд. При выборе цели 189 цель выбирается для отпора только после того, как против нее найдены надлежащие судебные доказательства. Это может включать в себя минимальное время, необходимое для рассмотрения доказательной базы надзорным органом (напр., 6 месяцев). Доказательства должны быть в высшей степени надежными, и отдельные события не могут быть использованы для отпора из страха поразить невинную цель и повлечь за собой правовые последствия. С помощью верификации цели 190 подозреваемые системы злоумышленников проверяются посредством нескольких способов, позволяющих превзойти любые потенциальные способы маскировки (общественное кафе, сеть TOR и т.д.), включая:
i) Физическое местоположение. Можно воспользоваться GPS. Облачные сервисы могут помочь в подтверждении (напр., долгосрочный прецедент для местоположения входа в Dropbox)
ii) Физическое устройство. MAC-адрес, серийный номер (производителя/поставщика).
iii) Проверка личности сотрудника. В системе безопасности используют биометрические данные, фотографии с фронтальной камеры, а также подтверждают постоянное использование одних и тех же учетных данных входа на нескольких платформах.
[0093] На Фиг. 33 проиллюстрирован общий обзор скрытных операций MACINT и то, как злоумышленники взламывают систему предприятия. Система предприятия 228 определяет весь объем и юрисдикцию инфраструктуры и имущества предприятия. Компьютер предприятия 227 является важной частью системы предприятия 228, так как содержит конфиденциальные сведения 214 и зависит от сети предприятия 219 в плане выполнения своих основных задач. Спящий двойной агент 215 представляет собой вредоносное ПО на целевом компьютере 227, которое остается неактивным и притворяется «спящим». Программистам и аналитикам в области кибербезопасности очень сложно обнаружить его, поскольку вреда оно пока не причиняет. Когда хакеры из системы злоумышленников 49 находят подходящий момент для использования своего спящего агента 215, агент 215 скрытно перехватывает копию конфиденциального файла 214. На этом этапе хакеры выдают себя, и их начинают отслеживать, но агента 215 они загрузили ранее без ведома администраторов (т.е. предполагается, что файл 214 того стоил). В шаге 216 захваченный файл 214 передают в зашифрованном виде за пределы корпоративной сети на целевой сервер злоумышленников. Такое шифрование (то есть https) разрешено политикой, поэтому передача не блокируется немедленно. Захваченный файл 214 передают в сетевую инфраструктуру сети предприятия 219 в попытке покинуть систему предприятия 228 и попасть в произвольную систему 262, а оттуда в систему злоумышленников 49. Такая сетевая инфраструктура представлена в виде маршрутизатора LAN 217 и брандмауэра 218, выступающего последним препятствием для вредоносного ПО, прежде чем оно успешно передает захваченный файл 214 за пределы системы предприятия. Типовой брандмауэр 218, который в данном примере неспособен предотвратить кражу файла 214, формирует отчет, который направляют в сбор отчетов 220. В ходе сбора данные категоризируют и разделяют для длительного/глубинного сканирования 221 и оперативного/поверхностного сканирования 222. В случае сценария с пустым результатом 223 оперативное сканирование 222 неспособно почти мгновенно распознать вредоносную деятельность и остановить ее до выполнения. В случае обнаружения связи с вредоносным ПО 224 долгосрочное сканирование 221 в конечном счете распознает вредоносное поведение, поскольку имеет больше времени для анализа. Дополнительное время позволяет при долгосрочном сканировании 221 проводить более тщательный поиск с использованием более сложных алгоритмов и пунктов данных. Скомпрометированный ботнетом сектор 225 - это компьютер, входящий в систему произвольной третьей стороны, который используется для передачи конфиденциального файла 226, чтобы обмануть следствие и подставить произвольную третью сторону. Воры отправляют конфиденциальный файл 226 на компьютер злоумышленников 229, сохраняя при этом скрытое присутствие через свой ботнет, и продолжают использовать файл для вымогательства и незаконного получения прибыли. Потенциальные следы компьютера злоумышленников (т.е. его IP-адрес) могут сохраниться только на произвольном компьютере 238, к которому ни у администраторов, ни у следователей из системы предприятия 228 доступа нет.
[0094] На Фиг. 34 показаны дополнительные подробности длительного/глубинного сканирования 230 с использованием больших данных 231. Глубинное сканирование 230 вносит свой вклад в большие данные 231 и взаимодействует с ними, одновременно используя два субалгоритма: обнаружение злого умысла и управления внешними сущностями. Промежуточные результаты передаются в обнаружение аномалий, которые отвечают за окончательные результаты. Стандартные отчеты с пунктов безопасности, например, брандмауэров и центральных серверов, собирают в сборе отчетов 220 и делают из них выборку посредством фильтров с низкими ограничениями. В рамках индекса и трекинга событий 235 сохраняют подробную информация о событиях, такую как IP-адрес, МАС-адрес, идентификатор поставщика, серийный номер, время, даты, DNS и т.д. Такие сведения существуют как в локальной базе данных, так и в базе данных общего облака (данные в базах не идентичны). Локальное хранилище таких записей передается (с ограничениями в соответствии с политикой предприятия) в облачную базу данных для содействия другим предприятиям. Взамен для локального анализа поступает полезная информация о событиях. Предприятие, которое зарегистрировано в доверенной третьей стороне 235, возможно, уже столкнулось с нарушениями, совершенными посредством ботнета, и может предоставить данные для профилактики и снижения таких рисков. В рамках поведения системы безопасности 236 реакционные руководства по безопасности хранятся в локальной базе данных и в общей облачной базе данных (данные в базах не идентичны). Такие реакционные руководства задают точки поведения для обеспечения безопасности системы. Например, если к системе обращался IP-адрес, который, согласно индексу событий, 6 раз из 10 был связан с ботнетом, данный IP-адрес запрещают на 30 дней и устанавливают в журнале флаг приоритета, чтобы пометить любые попытки входа с данного IP-адреса в систему в течение этого времени. Локальное хранилище таких рекомендаций передается (с ограничениями в соответствии с политикой предприятия) в облачную базу данных для содействия другим предприятиям. Взамен для локального анализа поступает полезная информация о событиях. В рамках обнаружения аномалий 237 индекс событий и поведение системы безопасности используются в соответствии с промежуточными данными, предоставленными модулем глубинного сканирования, для определения любых потенциальных рисков и угроз, например, передачи конфиденциального файла неавторизованным агентом в произвольную систему за пределами сети предприятия. Произвольный компьютер 238 показан в качестве конечного сервера назначения, участвующего во взломе, который определяется любыми известными характеристиками, такими как МАС-адрес/последний известный IP-адрес 239, страной? графиком работы и т.д. Такой анализ в основном задействует модуль управления внешними сущностями 232. Система затем способна определить вероятность 240 того, что такой компьютер включен в ботнет. Такой анализ в первую очередь включает в себя обнаружение злого умысла 19.
[0095] На Фиг. 35 показано, как доверенная платформа 10 проверяет произвольный компьютер на предмет того, являются ли его серверные родственники/соседи (т.е. другие сервера, с которыми он соединен) ранее запущенными двойными или тройными агентами доверенной платформы 10. В шаге 242 отражено, как известная информация произвольного компьютера 238, такая как МАС-адрес/IP-адрес 239, отправляются для запроса в индекс и трекинг событий 235 и облачную версию 232. Такая облачная версия, работающая под доверенной платформой 10, отслеживает подробности событий для определения будущих угроз и намеков на угрозы, т.е. МАС-адреса, IP-адреса, метки времени доступа и т.д. Результаты таких запросов 242 направляют в сбор сведений о системе 243. Такие сведения включают в себя исходные данные о произвольном компьютере 238, компьютеры/системы, которые регулярно получают и/или отправляют пакеты на компьютер 238, а также системы, которые находятся в физической близости от компьютера 238. Эти сведения затем передают на шаги 246 и 247, где проверяют, является ли какой-либо из упомянутых компьютеров/систем двойным агентом 247 или тройным агентом 246. Поиск агентов осуществляется в облаке индекса и трекинга доверенных двойных агентов 244 и в облаке индекса и трекинга доверенных тройных агентов 245. В индексе двойных агентов 244 содержится список систем, в которых установлены спящие агенты, управляемые доверенной платформой и аффилированными системами. В индексе тройных агентов 245 содержится список систем, которые были взломаны преступными синдикатами (напр., ботнетами), но также были незаметно взломаны и доверенной платформой 10, чтобы отслеживать вредоносные действия и события. Эти два облака затем выводят свои результаты, которые объединяют в список активных и релевантных агентов 248.
[0096] На Фиг. 36 показано, как известные двойные и тройные агенты доверенной платформы 10 применяются для помощи судебному расследованию. При переносе из списка агентов 248 соответствующий спящий агент 252 активируется 249. Компьютер двойного агента 251, которому доверяет произвольный компьютер 238, принудительно отправляет эксплойт 253 через свой доверенный канал 254. После успешной загрузки на произвольный компьютер 238 эксплойт 253 отслеживает поведение конфиденциального файла 241 и узнает, что он был отправлен на компьютер, который теперь известен как компьютер злоумышленников 229. Он следует по тому же пути, который использовался для передачи файла 241 в первый раз 216 по каналу 255, и пытается установить себя на компьютер злоумышленников 229. Затем эксплойт 253 пытается найти конфиденциальный файл 241, помещает его в карантин, отправляет его точное состояние обратно на доверенную платформу 10, а затем пытается удалить его с компьютера злоумышленников 229. Затем доверенная платформа 10 пересылает помещенный в карантин файл обратно в исходную систему предприятия 228 (которой принадлежит исходный файл) в целях судебной экспертизы. Эксплойту 253 не всегда гарантированно удается вернуть конфиденциальный файл 241, но, по крайней мере, он пересылает идентифицируемую информацию 239 о компьютере злоумышленников 229 и системе 49.
[0097] На Фиг. 37 показано, как посредством доверенной платформы 10 совершается обращение к API провайдера 257 в отношении произвольного компьютера 238. Сетевой надзор 261 используется для того, чтобы попытаться взломать произвольную систему 262 в целях дальнейшего судебного расследования. Системе предприятия 228 известен только ограниченный набор сведений 259 о произвольном компьютере 238, и она ищет сведения о компьютере злоумышленника 229 и системе злоумышленников 49. Запрос API к ISP 257 выполняется через доверенную платформу 10. В сетевом надзоре 261 обнаруживаются сетевые журналы произвольной системы 262, где указан факт возможной передачи файла (как будет доказано впоследствии) на компьютер злоумышленников 229. История журнала недостаточно подробна, потому в ней нет точного и полного состава конфиденциального файла 241, но с помощью метаданных 260 можно со значительной уверенностью определить, на какой компьютер был отправлен файл. Сетевой надзор 261 обнаруживает сведения о сети 258 компьютера злоумышленников 229 и таким образом перенаправляет такую информацию на доверенную платформу 10, которая, в свою очередь, уведомляет систему предприятия 228.
[0098] На Фиг. 38 показано использование доверенной платформы 10 для обращения к API системы безопасности, предоставленному поставщиками программного 268 и аппаратного 272 обеспечения, для того чтобы применить выявленные бэкдоры в целях судебного расследования. В шаге 263 известные идентификационные данные компьютера злоумышленников 229 передают на доверенную платформу 10 для использования в API бэкдоров. К таким данным могут относится МАС-адрес/IP-адрес 239 и подозрительное программное обеспечение и аппаратное обеспечение компьютера злоумышленников. Затем доверенная платформа 10 отправляет эксплойт 253 аффилированным поставщикам программного обеспечения 268 и аппаратного обеспечения 272 в неактивном состоянии (код выполнения эксплойта тоже передается, но не выполняется). Поставщикам также отправляют подозрительное программное обеспечение 269 и аппаратное обеспечение 273 компьютера злоумышленников 229, который выявлен системой предприятия 228 в шаге 263. Поставщики ведут список бэкдоров установленного программного обеспечения 270 и аппаратного обеспечения 274, включая также информацию о том, как запускать их, какие меры авторизации должны быть приняты и каковы их возможности и ограничения. Все такие бэкдоры внутренне изолированы и конфиденциальны с точки зрения поставщика, поэтому доверенная платформа не получает сведений, касающихся таких бэкдоров, но предоставляет эксплойт 253, который на них основывается. При успешном применении бэкдора в программном обеспечении 267 или аппаратном обеспечении 271 эксплойт 253 скрытно устанавливают на компьютер злоумышленника 229. Конфиденциальный файл 241 отправляют в карантин и копируют с целью дальнейшего анализа истории использования его метаданных. Все оставшиеся копии на компьютере злоумышленника 229 безопасно удаляют. Собирают все прочие дополнительные судебные данные. Такие судебные данные возвращают в пункт связи эксплойта 253 на доверенной платформе 10. После этого судебные доказательства 265 передают в систему предприятия 228, включая конфиденциальный файл 241, найденный на компьютере злоумышленников 229, и сведения о лицах, связанных с системой злоумышленников, против которых имеются доказательства причастности к первоначальной краже файла 241. Таким образом, система предприятия 228 может восстановить файл 241, если он был удален из их системы во время первоначальной кражи, а сведения о лицах 264 позволят им добиваться возмещения убытков и отключения ботнета системы злоумышленников 49 для снижения риска будущих атак.
[0099] На Фиг. 39-41 показано, как обобщенные 282 и настраиваемые 283 эксплойты применяют к произвольным компьютерам 238 и компьютерам злоумышленников 229 в попытке напрямую взломать их без непосредственного участия доверенной платформы 10. Общие эксплойты 282 - это набор программных, программно-аппаратных и аппаратных эксплойтов, организованных и собранных системой предприятия 280 посредством независимых исследований в области кибербезопасности. С помощью настройки эксплойтов 283 эксплойты настраиваются в соответствии с известной информацией о цели. Эксплойты 253 загружают в порядке уменьшения вероятности успеха. Набор доступной информации 284, касающейся компьютера злоумышленников 229, передается в настройки 283. К этой информации относится любая известная информация о компьютере, в частности, МАС-адрес/IP-адрес 239 и подозрительное программное обеспечение и аппаратное обеспечение 285, используемое компьютером злоумышленников 229. Опосредованное управление 286 представляет собой комбинацию алгоритма и базы данных, которая интеллектуально выбирает прокси-сервера для запуска эксплойтов. Прокси-сеть 279 представляет собой серию прокси-узлов 278, которые позволяют любой отдельной системе маскировать свою исходную личность. Узел передает цифровые сообщения и выступает открытым инициатором. Узлы интеллектуально выбираются опосредованным управлением 286 в соответствии с общей производительностью узла, доступностью узла и текущей рабочей нагрузкой узла. Попыткам атаки подвергают три потенциальные точки эксплойтов компьютера злоумышленников 229 и/или произвольного компьютера 238. Если взлом компьютера злоумышленника 229 неудачен, все равно производится попытка взлома произвольного компьютера 238, поскольку она все еще способствует проведению судебного расследования. Один из способов активации эксплойта - это активация напрямую, второй - через туннель ботнета 276 на произвольном компьютере, а третий - тот же способ, которым система злоумышленников пользовалась при установке ботнета 277 (а также других неиспользуемых точек эксплойтов). Туннель ботнета 276 представляет собой установленное средство связи, используемое для общения между компьютером злоумышленников 229 и активной частью ботнета 240. Все судебные данные, которые генерируют с помощью эксплойта 253, отправляют в систему предприятия 228 в шаге 275.
[0100] На Фиг. 41 показано, как для принудительного направления обновления 289 программного обеспечения или прошивки на компьютер злоумышленника 229 с целью создания нового бэкдора используют специальный API доверенной платформы 10. В целях конспирации плацебо-обновление 288 также принудительно отправляют на соседние схожие устройства. Система предприятия 228 отправляет идентификационные данные цели 297 доверенной платформе 10. К таким данным относится МАС-адрес/IP-адрес 239. Доверенная платформа 10 указывает контролеру программного обеспечения/прошивки 287 принудительно отправить плацебо-обновления 288 и обновления, содержащие бэкдоры, 289 на соответствующие компьютеры Обновление, содержащее бэкдор, приводит к созданию нового бэкдора в системе компьютера злоумышленника 229 путем использования существующей системы обновления программного обеспечения, установленного на данном компьютере Такое обновление может быть предназначено для операционной системы, BIOS (прошивки), конкретного программного обеспечения, такого как текстовый редактор. В плацебо-обновлении 288 бэкдоры отсутствуют, так что безопасность не страдает, однако свойства и идентификаторы (т.е. номер/код обновления) у него те же, что и у обновления, содержащего бэкдор, 289, что позволяет создать среду, поддерживающую маскировку бэкдора. Контролер 287 переносит бэкдор 295 как на цель, так и на компьютеры, контакт которых с целью выше среднего. Такими дополнительными компьютерами 296 могут выступать те компьютеры, которые принадлежат инфраструктуре системы злоумышленников 49 или же те, которые находятся в той же локальной сети, что и компьютер злоумышленников 229. Активация эксплойтов на таких дополнительных компьютерах 296 увеличивает шансы на получение доступа к компьютеру злоумышленников 229 в случае, если прямая атака невозможна (т.е. обновления операционной системы отключены и т.п.). Тогда эксплойт 253 сможет рассмотреть другие точки входа в цель, если сможет установить себя на соседние компьютеры 296. Задействованные компьютеры 291, имеющие среднюю степень контакта с целью, также получают плацебо-обновление 228. Под степенью контакта понимают совместное использование общей сети (напр., виртуальной частной сети и т.д.) или общей служебной платформы (напр., совместное использование файлов и т.п.). Вовлеченная система 290 также может быть стратегически связана с системой злоумышленников 49, например, принадлежать юридической структуре той же компании и т.п. Соседние компьютеры 293, принадлежащие к соседней системе 292, получают плацебо-обновление из-за своего физического местоположения рядом с целевым компьютером злоумышленника 229 (в одном районе и т.п.). Как задействованные системы 290, так и соседние с ними 292 получают плацебо-обновления 288 в целях помощи судебному расследованию, которое должно проводиться быстро, особенно если контролером 287 на ближайшее будущее (либо срок, уместный для расследования) плановых обновлений не запланировано. В случае, если запланировано плановое обновление для программного обеспечения/прошивки, тогда задействованным системам 290 и соседним системам 292 плацебо-обновление не требуется, чтобы подтвердить легитимность обновления, содержащего бэкдор, 289. Вместо этого бэкдор 289 загружают в ряд легитимных обновлений, нацеленных на компьютер злоумышленника 229 и другой компьютер 296. При успешном применении эксплойта 253 посредством обновления, содержащего бэкдор, 295 конфиденциальный файл 241 отправляют в карантин и копируют с целью дальнейшего анализа истории использования его метаданных. Все оставшиеся копии на компьютере злоумышленника 229 безопасно удаляют. Собирают любые дополнительные судебные данные, после чего направляют в пункт связи эксплойта на доверенной платформе 10. После проверки данных на платформе 10 их направляют в систему предприятия 228 по результатам 281.
[0101] На Фиг. 42 показано, как флаг долгосрочного приоритета принудительно отправляют на доверенную платформу 10 для наблюдения за системой злоумышленников 229 на предмет изменений/обновлений. За новыми событиями наблюдают с приоритетом над долгосрочным наблюдением для упрощения расследования. Во-первых, система предприятия 228 предоставляет цель 297 (которая включает идентифицируемые данные 239) модулю ордера 300, который входит в состав доверенной платформы 10. Модуль ордера сканирует входящие данные 299 всех аффилированных систем 393 на предмет ассоциаций с заданной целью 297. В случае совпадений информацию передают в систему предприятия 228, которая создала ордер и пытается проникнуть в цель 297. Ввод информации 299 - это информация, которую аффилированные системы доверенной платформы 10 сообщают, как правило, для получения желаемого анализа. Входные данные также могут быть представлены исключительно с целью получения аккредитации и репутации в доверенной платформе 10. Аффилированные систем 303 направляют свой ввод в доверенную платформу 10, что идет на пользу системе предприятия 228, стремящейся контролировать цель 297. Это увеличивает шансы того, что одна из этих аффилированных систем 303 столкнулась с целью или ее родственником, причем взаимодействие может быть положительным, нейтральным или отрицательным. Такой ввод 299 передается в желаемый аналитический модуль 301, который представляет функцию большинства доверенной платформы 10 для синхронизации взаимовыгодной информации о безопасности. Аффилированные системы 303 размещают запросы безопасности и обмениваются информацией о безопасности. Если найдена информация, относящаяся к цели 297 или любым связанным устройствам, эта информация также параллельно передают в модуль ордера 300. Вывод информации 302 из модуля 301 направляют в аффилированную систему 303 для выполнения запрошенной задачи или функции. Все полезные сведения, найденные модулем ордера 300, касательно цели 297 передают в результаты 298 в рамках судебного расследования, проводимого системой предприятия 228.
Логическая защита и мгновенное реагирование в реальном времени без создания баз данных (LIZARD)
[0102] На Фиг. 43 и 44 показана структура зависимостей LIZARD (логической защиты и мгновенного реагирования в реальном времени без создания баз данных). Статичное ядро 193 состоит из в основном статичных программных модулей, вручную запрограммированных людьми. Посредством итерационного модуля 194 интеллектуально изменяют, создают и уничтожают модули в динамической оболочке 198. Искусственные угрозы безопасности (AST) используют для оценки качества работы системы безопасности, а итерационное ядро - для осуществления автоматического написания кода Итерационное ядро 195 выступает в качестве основной логики итераций динамической оболочки 198 с целью улучшения безопасности, как показано на Фиг. 51. Посредством алгоритма дифференциальной модификации 196 модифицируют базовую итерацию в соответствии с недостатками, обнаруженными с помощью AST. После применения дифференциальной логики предлагают новую итерацию, в которой рекурсивно вызывают итерационное ядро и которая проходит тот же процесс испытания с использованием AST. В алгоритм логической дедукции (Logic Deduction Algorithm, LDA) 197 из искусственной угрозы безопасности (AST) поступают известные отклики системы безопасности итерации динамической оболочки в текущем состоянии. LDA также определяет, какой состав набора кодов достигнет известного верного отклика на сценарий безопасности (предоставленный AST). В динамической оболочке 198 содержатся преимущественно динамические программные модули, которые были автоматически запрограммированы итерационным модулем. Посредством карантина кода 199 внешний код изолируют в ограниченной виртуальной среде (т.е. как в чашке Петри). В рамках обнаружения скрытого кода 200 обнаруживают код, скрытно помещенный в пакеты передачи данных. Данные из реле переполнения AST 201 передаются в AST 17 для будущего улучшения итераций, когда система может принимать только малонадежные решения. В рамках проверки внутренней логики 202 проверяют, присутствует ли логика во всех внутренних функциях блока внешнего кода. Затем убеждаются в отсутствии участков кода, логика которых противоречит назначению внешнего кода в целом. В рамках переписывания внешнего кода 230 после выяснения назначения внешнего кода переписывают части кода или код целиком, причем в нем допускается только переписывание. Посредством зеркального теста проверяют, совпадает ли динамика ввода/вывода переписанного кода с оригиналом. Таким образом, все скрытые эксплойты исходного кода отключены и не выполняются. На сопоставление карт потребностей 204, т.е. карту иерархии потребностей и целей, опираются, решая, соответствует ли внешний код общему назначению системы (т.е. загадке). Синхронизатор с настоящими данными 205 представляет собой один из двух уровней (второй - менеджер данных), который интеллектуальным образом отбирает данные, отправляемые в смешанные среды, и назначает приоритет отбора. Таким образом, строго конфиденциальные сведения недоступны для потенциального вредоносного ПО, а доступны только для кода, который хорошо известен и заслуживает доверия. Менеджер данных 206 выступает интерфейсом-посредником между объектом и данными, поступающими извне виртуальной среды. Координатор фреймворка 207 управляет всем вводом, выводом, порождением потоков и диагностикой полу-искусственных и искусственных алгоритмов. Посредством виртуальной обфускации 208, посредством запутывают код (в том числе потенциального вредоносного ПО) и ограничивают к нему доступ путем постепенного и частичного его погружения в виртуальную фальшивую среду. Посредством модуля скрытной транспортировки 209 скрытно и незаметно происходит перенос вредоносного ПО в среду фальшивых данных 394. В модуле сравнения целей 210 производят сравнение четырех типов цели, для того чтобы убедиться в том, что поведение и структура сущности одобрены и понятны LIZARD и рассматриваются как содействующие назначению системы в целом. Значительное расхождение в целях указывает на злонамеренное поведение. Генератор фальшивых данных 211 создает фальшивые данные, которые неотличимы от настоящих данных, например, партии номеров соцстрахования. Менеджер виртуальной среды 212 управляет созданием виртуальной среды, которая включает в себя такие переменные, как доля фальшивых данных, доступные системные функции, параметры сетевой связи, параметры хранения и т.д. В трекинге отзыва данных 213 отслеживается вся информация, загруженная с подозрительной сущности 415 и отправленная туда. Это делается для снижения риска передачи конфиденциальной информации вредоносным программам. Эта проверка безопасности также нивелирует логистические проблемы, возникающие, когда легитимный процесс в системе предприятия получает фальшивые (поддельные) данные. В случае, когда фальшивые данные отправляют (заведомо известному) легитимному объекту предприятия, выполняется «обратный вызов», который возвращает все фальшивые данные, и вместо них отправляют настоящие данные, которые были первоначально запрошены.
[0103] На Фиг. 45 показан общий вид LIZARD (логическая защита и мгновенное реагирование в реальном времени без создания баз данных), которая выступает в качестве центрального надзорного алгоритма, способного в реальном времени блокировать все потенциальные угрозы кибербезопасности, не обращаясь напрямую за помощью к динамически расширяющейся базе данных. Определение того, разрешены ли данные/доступ в систему, основано на актуальности знания, функции и назначения. Если блок кода или данных не несет функции/назначения для достижения заданной цели системы, то он будет скрытым образом отклонен, включая виртуальную изоляцию и обфускацию. LIZARD оснащена синтаксическим интерпретатором, который может читать и переписывать компьютерный код. В сочетании с возможностями по выведению целей она способна вывесить целенаправленное поведение из блоков кода, даже тех, которые скрытно встраиваются в кажущиеся безобидными данные. Все корпоративные устройства, даже те, которые находятся вне предприятия, например, телефон компании в общественной кофейне, маршрутизируются через LIZARD. Все программное обеспечение и прошивки, на которых работают ресурсы предприятия, запрограммированы таким образом, чтобы все скачивание/загрузка данных выполнялось через LIZARD в качестве постоянного прокси. Несоблюдение политики постоянных прокси-серверов смягчается благодаря использованию политики лояльных активов. Передача цифровых данных в системе предприятия должна проходить через аппаратуру, которая запрограммирована на передачу данных через LIZARD. Следовательно, вредоносный код не может найти безопасного места, равно как и скомпрометированных компьютеров, которые игнорируют политику постоянного прокси. LIZARD имеет симбиотическую связь с итерационным модулем (IM). IM клонирует запрограммированные целевые задачи и возможности синтаксического распознавания LIZARD, а затем использует их для модификации LIZARD в соответствии с запрограммированными целями. Модуль искусственной угрозы безопасности (AST) задействован в параллельной виртуальной среде с целью проведения стресс-тестов различных вариантов LIZARD. Вариант, который показывает наилучший результат, становится следующей официальной итерацией. LIZARD представляет собой инновационную модель, которая отличается от существующих решений в сфере кибербезопасности. Благодаря расширенным возможностям логического вывода она способна принимать мгновенные и точные решения в области безопасности, не прибегая к парадигме «слишком мало слишком поздно» - распространенному на сегодняшний день принципу обеспечения кибербезопасности. LIZARD взаимодействует с тремя типами данных: данными в движении, используемыми данными и неподвижными данными. LIZARD взаимодействует с 6 типами носителей данных (т.е. векторами): файлы, электронная почта, Интернет, мобильные, облачные данные и съемные носители (USB). Система предприятия 228 обозначает типы серверов, которые работают в этой инфраструктуре, например, HTTP, DNS и т.д. Мобильные устройства 305 работают в общественной кофейне 306. Они подключены к цифровой инфраструктуре системы предприятия 228 через клиент LIZARD Lite 43. Такой клиент 43 выступает в качестве шлюза в Интернет 304, а затем соединяет устройство с зашифрованным облаком LIZARD 308.
[0104] На Фиг. 46 показаны основные функции алгоритмов LIZARD. Внешняя динамическая оболочка (DS) 313 LIZARD - это функциональный раздел, наиболее подверженный изменениям посредством итераций. Модули, которые требуют высокой степени сложности для достижения своей цели, обычно входят в данную оболочку 313, поскольку их уровень сложности превосходит тот, который группа программистов может обрабатывать напрямую. Итерационный модуль 314 использует статичное ядро (SC) 315, чтобы синтаксически модифицировать кодовую базу DS 313 в соответствии с выявленной целью в «фиксированных целях» и данных из реле возврата данных (DRR) 317. Эту модифицированную версию LIZARD затем подвергают стресс-тестам (одновременно) с использованием множества различных сценариев событий в системе безопасности, полученных от искусственных угроз безопасности (AST) 17. Наиболее успешную итерацию принимают как живую функционирующую версию. SC 315 LIZARD наименее подвержено изменениям в процессе автоматизированных итераций. Его напрямую изменяют люди-программисты. В особенности внутренний квадрат, известный как внутреннее ядро 334, который совершенно не подвержен автоматизированным итерациям. Этот самый внутренний слой 334 похож на корень дерева, который определяет развитие и функционал LIZARD. Общие динамические модули (GDM) 316 представляют собой зону модулей, которые сильнее всего поддаются автоматизированному самопрограммированию и, следовательно, входят в юрисдикцию динамической оболочки 313. Такие программы, запущенные в GDM 316, находятся в постоянном статусе «бета-версии» (не обязательно стабильном и незавершенном). Если LIZARD принимает малонадежное решение, она передает нужные данные в AST 17 посредством реле возврата данных (DRR) 317 с целью улучшить будущие итерации LIZARD. Сам LIZARD напрямую не полагается на такие данные для принятия решений, но данные о развивающихся угрозах могут косвенно пойти на пользу априорному принятию решений, осуществляемому будущей итерацией LIZARD. Метка 342 показывает, что чем больше человек принимает участия в разработке кода, тем более статичным является код (изменяется очень медленно). Чем больше итерационный модуль (IM) 314 программирует код, тем более динамичным и текучим он получается. Как показано, синтаксический модуль 35 и целевой модуль 36 работают внутри SC 315.
[0105] На Фиг. 47 показано внутреннее устройство статичного ядра (SC) 315. В рамках логического вывода 320 из изначально более простых функций выводят логически необходимые функции. Конечным результатом является то, что из заявленной сложносоставной цели строится целое дерево функциональных зависимостей. В рамках перевода кода 321 преобразуют произвольный обобщенный код, понимаемый напрямую функциями синтаксического модуля, в код на любом выбранном известном языке программирования. Также выполняется обратный перевод с известных компьютерных языков на произвольный код. Правила и синтаксис 322 содержат статические определения, которые помогают интерпретировать и создавать синтаксические структуры. Например, правила и синтаксис языка программирования C++ могут храниться в 322. В рамках упрощения логики 323 упрощают логику записанного кода для создания карты взаимосвязанных функций. Конечным выводом исполняемой программы выступает написанный код 324, а вводом - цель кода 332. Формат сложносоставной цели 325 представляет собой формат для хранения взаимосвязанных подцелей, в сумме составляющих общую цель. Целевые ассоциации 326 представляют собой запрограммированные сведения о том, какие функции и какие типы поведения связаны с какими целями. В рамках итеративного расширения 327 добавляют подробности и сложность для развития простой цели в сложносоставную путем обращения к целевым ассоциациям. В рамках итеративной интерпретации 328 циклически обрабатывают все взаимосвязанные функции и получают интерпретированную цель путем обращения к целевым ассоциациям 326. Внешнее ядро 329 сформировано в основном целевым и синтаксическим модулями, которые работают сообща с целью выведения логической цели неизвестного внешнего кода и получения исполняемого кода из заявленной цели функционального кода. Внешний код 330 - это код, который неизвестен LIZARD, также как и его функции и назначение неизвестны. При этом внешний код 330 служит вводом для внутреннего ядра, а выводом служит выявленная цель 331. Цель 331 - это намерение данного кода 330, как его оценивает целевой модуль 36. Ее возвращают в формате сложносоставной цели 325.
[0106] На Фиг. 48 показано, как во внутреннем ядре 334 размещаются ключевые ядерные функции системы, которые напрямую программируют только квалифицированные специалисты по кибербезопасности 319 посредством платформы поддержки 318. Основной код 335 - это минимальная основа, необходимая для запуска LIZARD. С точки зрения ядра 336, все необходимые функции для работы с LIZARD, такие как функции сжатия и сравнения, хранятся в фундаментальных фреймворках и библиотеках 336. С точки зрения ядра 336, управление потоками и распределение нагрузки 337 позволяют LIZARD эффективно масштабировать кластер серверов, в то время как протоколы связи и шифрования определяют типы применяемого шифрования (напр., AES, RSA и т.д.). С точки зрения ядра 336, управление памятью 339 позволяет эффективно обрабатывать данные, которые интерпретируются и обрабатываются LIZARD в оперативном запоминающем устройстве (RAM). Задачи системы 336 включают в себя политику безопасности 340 и цели предприятия 341. Политика 340 вручную разрабатывается специалистом в области кибербезопасности (или несколькими) в качестве руководства, на которое может ссылаться LIZARD для работы в соответствии с настраиваемыми переменными. Следовательно, LIZARD имеет стандарт, который объясняет то, что считается небезопасным и запрещенным действием, а что - допустимым. Например, в политику безопасности 340 могут быть включены пункты о запрете на отправку электронных сообщений получателям за пределами организации либо о блокировке учетной записи после третьей ошибки при вводе пароля. Цели предприятия 341 определяют в более общих терминах, к какой инфраструктуре в целом предприятие стремится. Цели 341 в основном используют для управления самопрограммированием динамической оболочки 313 в соответствии с функциями, которыми должна располагать LIZARD, и какие задачи она должна выполнять исходя из инфраструктурного контекста предприятия.
[0107] На Фиг. 49 показано внутреннее устройство динамической оболочки (DS) 313. Этот раздел LIZARD в основном управляется программным модулем с искусственным интеллектом (итерационный модуль). Модули во внешней оболочке 345 являются новыми и экспериментальными модулями, которые оказывают незначительное влияние на принятие решений всей системой. Внутренняя оболочка 344 - это основная структура LIZARD, где расположено большинство интеллектуальных возможностей. Новый и экспериментальный алгоритм 343 распределяет программное пространство, где функциональная потребность в новом модуле может быть запрограммирована и протестирована людьми, искусственным интеллектом или и теми, и другими.
[0108] На Фиг. 50 показан итерационный модуль (IM), посредством которого интеллектуально изменяют, создают и уничтожают модули в динамической оболочке 313. Искусственные угрозы безопасности (AST) 17 используются для оценки качества работы системы безопасности, а итерационное ядро 347 - для осуществления автоматического написания кода В реле возврата данных (DRR) 317 данные о злонамеренных атаках и злоумышленниках передаются в AST 17, когда LIZARD пришлось прибегнуть к принятию решения с низким уровнем доверия. AST 17 создает виртуальную среду для тестирования с имитированными угрозами безопасности для инициации процесса итерации. Искусственная эволюция AST 17 задействована в достаточной степени, чтобы опережать органическую эволюцию преступной злонамеренной киберактивности. В рамках клонирования статичного ядра 346 статичное ядро 315, включая полудинамическое внешнее ядро 329, используют в качестве критерия для контроля итераций. Поскольку данная итерация частично изменяет внешнее ядро 329, самопрограммирование совершило полный цикл в цикле работы искусственного интеллекта. Итерационное ядро 347 получает искусственные сценарии безопасности и руководство по задачам системы для изменения динамической оболочки 313. Итерационное ядро 347 производит большое количество итераций. В шаге 348 итерацию, лучше всего показавшую себя в искусственных испытаниях системы безопасности, загружают в качестве живой функционирующей итерации динамической оболочки.
[0109] На Фиг. 51 показано итерационное ядро 347, выступающее в качестве основной логики итерационного кода с целью улучшения безопасности. В рамках рекурсивной итерации 350 вызывают новую копию итерационного ядра 347, где новая итерация 355 заменяет базовую итерацию 356. Такой переход контролируется управлением потоков 349, что происходит из управления потоками и распределения нагрузки 337, входящих в состав основного кода 335. Алгоритм дифференциальной модификации (DMA) 353 получает из внутреннего ядра 334 программные возможности 351 синтаксического и целевого модулей, а также сведения о назначении системы 352. Эти два ввода соотносятся с фундаментальными фреймворками и библиотеками 336, а также с политикой безопасности 340/целями предприятия 341. Затем такой кодовый набор используют для изменения базовой итерации 356 в соответствии с недостатками, обнаруженными с помощью AST 17. После применения дифференциальной логики предлагают новую итерацию 355, в которой рекурсивно вызывают итерационное ядро 347 и которая проходит тот же процесс испытания с использованием AST 17. В рамках сценариев событий в системе безопасности, стоящих в очереди, 360, множество сценариев коллективно проходят всестороннее испытание динамической оболочки 313 по всем известным точкам безопасности. В рамках активных сценариев событий в системе безопасности 361 текущий активный сценарий безопасности проверяет динамическую оболочку 313 в изолированной виртуальной среде запуска 357. Такая среда 357 представляет собой виртуальную копию, которая полностью отделена от остальной системы. Она выполняет искусственное формирование вредоносных атак и вторжений. Итоговые ошибки безопасности 362 представляют визуально, чтобы показать те угрозы безопасности, которые «прошли» через базовую итерацию 356 во время работы виртуальной среды выполнения 357. После этого любые обнаруженные ошибки 363 направляются в DMA 353 для облегчения формирования новой итерации 355, в которой стремятся избежать таких ошибок.
[0110] На Фиг. 52-57 показан логический процесс работы алгоритма дифференциальной модификации (DMA) 353. Текущее состояние 365 отражает кодовый набор динамической оболочки 313 с символически сопоставленными формами, размерами и положениями. Различные конфигурации этих форм указывают на различные конфигурации информации о безопасности и откликов системы безопасности. AST 17 передает потенциальные отклики текущего состояния 365, которые оказались неверными, а также верный отклик (т.е. помещение файла в карантин, поскольку он является вирусом). Вектор атаки 370 (обозначен пунктиром) выступает в качестве символического отображения угрозы кибербезопасности. Направление, размер и цвет соответствуют гипотетическим свойствам вектора атаки, размеру и типу вредоносного ПО. Вектор атаки символически отталкивается от кодового набора с целью выразить отклик системы безопасности на данный кодовый набор. Пункт А 367 показывает конкретную конфигурацию безопасности, которая позволяет вектору атаки проходить, что может быть или не быть правильным откликом системы безопасности. Пункт В 368 показывает вектор атаки, отталкивающийся от конфигурации безопасности, которая демонстрирует тип отклика, отличающийся от пункта А, но при этом потенциально правильный или неправильный. Пункт С 369 показывает отклик системы безопасности, который отправляет вектор атаки обратно в место происхождения, что может быть или не быть правильным отклик системы безопасности. На Фиг. 53 верное состояние 354 отражает конечный результат работы алгоритма дифференциальной модификации 353 по получению желаемого отклика системы безопасности из блока кода динамической оболочки 313. Верное состояние 354 получают путем рекурсивных итераций 350 новых итераций 355 динамической оболочки 313. Даже если между текущим 365 и верным 354 состояниями есть небольшие различия, эти различия могут привести к совершенно разным откликам на вектор атаки 370. Хотя в пункте А 367 вектор атаки проходит прямо насквозь, в пункте А 371 (верный отклик системы безопасности) вектор атаки отражается под прямым углом. Отклик на вектор атаки для пункта B в текущем 365 и верном 354 состояниях остается неизменным. В пункте С 373, вектор атаки также отправляется обратно к исходному источнику, но в другое место, нежели в пункте С 369. Все отображения вектора атаки демонстрируют в соответствии с логистическим управлением угрозами безопасности. На Фиг. 54 показан вектор атаки на систему безопасности в AST 375, который представляет собой последовательность атак, сгенерированных AST 17. Верный отклик системы безопасности 376 демонстрирует желаемый отклик системы безопасности, относящийся к векторам атак 370. Кодовый набор (формы) для получения таких верных откликов системы безопасности не показан, так как на данном шаге он еще не известен. На Фиг. 55 показана текущая ответная атака динамической оболочки 377, демонстрирующая худший отклик системы безопасности, чем верная ответная атака динамической оболочки 378. Такой верный отклик 378 получают из алгоритма логической дедукции (LDA) 197. На Фиг. 56 показано, как LDA 197 выводит верные настройки безопасности, чтобы соответствовать верному отклику на атаку 378. Статичное ядро 315 передает системный фреймворк/контроль 352 и автоматизированные программные возможности синтаксиса/цели 351 в LDA 379, чтобы с их помощью можно было создать программу безопасности, дающую верный отклик на атаку 378. В шаге 381 LDA 379 передают базовую итерацию 356 динамической оболочки 313. Такая итерация представлена в виде программы отклика системы безопасности 382, которая выдает некачественные и неэффективные отклики системы безопасности. Такая программа 382 используется в качестве входных данных для LDA 379. В LDA используют возможности синтаксиса/цели 351 из статичного ядра 315 для надстроек над неверной программой отклика системы безопасности 382, так чтобы она соответствовала верной ответной атаке 378. Следовательно, получают верную программу отклика системы безопасности 383, которая считается новой итерацией 355 динамической оболочки 313. Процесс продолжается посредством рекурсивной итерации 350 итерационного ядра 347, в которой постоянно улучшают возможности безопасности динамической оболочки 313, пока она не будет насыщена всеми данными безопасности, полученными от AST 17. На Фиг. 57 в упрощенном виде показан процесс того, как AST 17 передает известные недостатки системы безопасности 364 вместе с правильным откликом системы безопасности 384. В то время как AST 17 может передать известные недостатки системы безопасности 364 и отклики 384, этот модуль не в состоянии создать эффективную и работающую программу, которая разработает такие верные отклики 384. Следовательно, в LDA 379 используют прошлые (базовые) итерации 356 динамической оболочки 313 для получения улучшенной и более эффективной итерации 355 динамической оболочки, известной как верная программа отклика системы безопасности 385. Под термином «программа» понимается общий функционал множества различных функций и подмодулей внутри динамической оболочки 313.
[0111] На Фиг. 58 показана в общем виде виртуальная обфускация. Следующие возможности виртуальной обфускации и генерирования фальшивых данных реализуются на зашифрованной облачной платформе, которой могут пользоваться малые и средние предприятия, в штате которых очень мало или совсем нет специалистов по кибербезопасности. Система безопасности также может быть установлена непосредственно в центрах обработки данных крупных корпораций. В этом случае сценарий вредоносного ПО 385 поступает из Интернета 304 и обходит типовой брандмауэр/систему обнаружения вторжений/антивирус и т.д. В текущей итерации LIZARD 16 имеет низкую достоверность оценки намерения/цели входящего блока кода 385. Эти условия рассматриваются как наихудший сценарий. Чтобы снизить риск того, что невинный процесс будет лишен прав доступа к важным данным, а также чтобы избежать риска передать конфиденциальные данные вредоносному коду, сомнительный код 385 скрытно переводят в среду, где половина данных интеллектуально смешана с фальшивыми (поддельными) данными. Реальная система 388 представляет собой неограниченный доступ к настоящим данным 389, за исключением тех, к которым требуется административный уровень доступа. Любые субъекты, работающие в реальной системе 388, могут быть легко и тайно перенесены в среду, частично 391 или полностью 394 состоящей из фальшивых данных, благодаря виртуальной изоляции 390. Синхронизатор с настоящими данными 386 представляет собой один из двух уровней (второй - менеджер данных 401), который интеллектуальным образом отбирает данные, отправляемые в смешанные среды, и назначает приоритет отбора. Таким образом, конфиденциальные сведения остаются недоступны для подозрительных вредоносных программ, а доступны они только хорошо известному и надежному коду. Генератор фальшивых данных 387, используя в качестве образца синхронизатор с настоящими данными 386, создает фальшивые и бесполезные данные Атрибуты, такие как тип данных, формат данных, плотность данных, детализация данных и т.д., копируют из настоящих данных 389 для создания базы данных с данными, которые похожи на настоящие, которые и кажутся хорошо интегрированными в систему в целом (т.е. среди них нет лишних и странных данных). Предполагаемый риск поступающего внешнего кода определяет уровень обфускации, выбираемый LIZARD 16. Высокая уверенность в том, что код является вредоносным, вызывает перевод кода в среду, которая содержит большие объемы фальшивых данных 394. Низкая уверенность в том, что код является вредоносным, вызывает перевод кода либо в реальную систему 388 (т.е. трактуется в пользу кода), либо в среду, на 100% состоящую из фальшивых данных 394 (т.е. отсутствие доверия по умолчанию). Такие настройки поведения системы безопасности задаются в политике безопасности 340, которая входит в задачи системы 336, которые, в свою очередь, входят во внутреннее ядро 334. Высоко-контролируемый сетевой интерфейс 392 используется в средах, содержащих фальшивые данные 393. Такой безопасный интерфейс используется для защиты среды от утечки в ограниченные среды, такие как реальная система 388 в сочетании с виртуальной изоляцией 390. Такая изоляция 390 использует технологию виртуализации для полного разделения и защиты оперативного запоминающего устройства (RAM), а с помощью потоков процессора от смешения изолирует среду саму на себя.
[0112] На Фиг. 59-61 показан аспект контроля и отклика виртуальной обфускации. Такая система отслеживает вредоносное ПО 385 и решает, что делать дальше, в соответствии с его поведением. Изначально LIZARD воспринимает блок кода, который может быть или не быть вредоносным, на текущем итерационном уровне сложности. В случае если ПО не является вредоносным, LIZARD переводит его в виртуальный клон реальной системы, состоящий на 50% из фальшивых данных 391. Это делается для того, чтобы, если окажется, что подозрения о вредоносном ПО не подтвердится, функциональность системы и предприятия серьезно не страдала (напр., не предоставлялся неправильный номер соцстрахования и т.п.). В проиллюстрированном примере блок кода на самом деле является вредоносным ПО 385, но на этом этапе LIZARD все еще не уверен из-за нового и неизвестного характера этой угрозы и способа взлома. На Фиг. 60, в частности, показано, как вредоносное ПО 385 погружают в виртуально изолированную 380 среду фальшивых данных 391, поскольку LIZARD еще не уверен, является ли код вредоносным ПО или нет. Менеджер данных 401 интеллектуально смешивает настоящие данные с фальшивыми, поэтому конфиденциальные данные не подвергаются риску. Менеджер 401 загружает 402 информацию, сгенерированную вредоносным ПО 385, в хранилище фальшивых данных 400 и скачивает 398 ранее сохраненные фальшивые данные, чтобы затем смешать их с настоящими данными 397. Таким образом, у вредоносного ПО нет разрешения на запись в хранилище настоящих данных 397, а значит, оно не может перехватить конфиденциальные сведения. Вредоносное ПО 385 виртуально изолировано 380, так чтобы доступ к нему было только у менеджера данных 401. Эта виртуальная изоляция запрещает вредоносному ПО доступ ко всем настоящим данным 397 в обход менеджера данных 401. В ходе поведенческого анализа 403 отслеживают поведение подозрительного блока кода в плане скачивания 398 и загрузки 402 информации с целью определить потенциальные меры по устранению угрозы. В рамках анализа 403 отслеживают поведение вредоносного ПО 385 в исходной форме, чтобы подтвердить или опровергнуть первоначальное подозрение LIZARD. Отследив поведение вредоносного ПО в исходной форме, LIZARD подтвердила первоначальное подозрение, что внешний код действительно является вредоносным. Вредоносное ПО 385 незаметно переводят в виртуальную среду, на 100% состоящую из фальшивых данных, 394 посредством модуля скрытной транспортировки 395. Если вредоносное ПО уже размножилось и провело заражение в среде, на 50% состоящей из фальшивых данных, 391 то всю виртуальную среду уничтожают (включая вредоносное ПО) в качестве меры предосторожности. На этом этапе вредоносное ПО 385 полностью погружают в среду фальшивых данных 394, где у него не будет доступа ни к какой конфиденциальной информации. За потенциальной коммуникацией между вредоносным ПО и его базой (т.е. сигналы сердечного ритма) посредством скрытых каналов связи ведут наблюдение с целью потенциально улучшить будущие итерации динамической оболочки 313. Такая информация о поведении вредоносного ПО передается через реле возврата данных (DRR) 317 в AST 17 для использования в будущих итерациях. Таким образом DS 313 может принять более надежное решение относительно аналогичного вредоносного ПО 385, вместо того чтобы снова прибегать к его размещению в среде, на 50% состоящей из фальшивых данных 391 (которая по-прежнему содержит некоторый риск кражи легитимных данных).
[0113] На Фиг. 62 и 63 показано, как в трекинге отзыва данных 399 отслеживается вся информация, загруженная с подозрительной сущности 415 и отправленная туда. Это делается для снижения риска передачи конфиденциальной информации вредоносным программам. Эта проверка безопасности также нивелирует логистические проблемы легитимного процесса предприятия, возникающие из-за получения им фальшивых данных 400. В случае если фальшивые данные были отправлены легитимной (как теперь известно) сущности, их отзывают, а взамен отправляют настоящие данные (запрошенные изначально). Триггер отзыва выполнен таким образом, чтобы легитимная сущность в сети предприятия не предпринимала действий на основании определенных данных, пока не получит подтверждения о том, что это настоящие, а не фальшивые данные. Если вредоносное ПО, находящееся в смешанной виртуальной среде, получило настоящие данные, весь контейнер среды уничтожают вместе вредоносным ПО 385. Вся система получает предупреждение сообщать о любых необычных действиях, связанных с данными, которые, как стало известно, находились в распоряжении вредоносной программы до ее уничтожения. Эта концепция проявляется в мониторинге на уровне всей системы 405. Если сущность, получившая часть настоящих данных, оказывается вредоносным ПО (при анализе моделей поведения), то виртуальная среда (включая вредоносное ПО) безопасно уничтожается, а сеть предприятия оценивают на предмет необычной активности помеченных настоящих данных. Таким образом сдерживаются любые потенциальные утечки информации. В рамках отслеживания скачивания 407 и загрузки 408 фальшивых данных отслеживают фальшивые данные, которые были отправляют и получают от подозрительной сущности 415 в виртуальном контейнере. В рамках уведомлений о безопасности загрузки 410 данные, которые были изначально записаны в сбор фальшивых данных 400 в качестве меры предосторожности, впоследствии считают безопасными, и, следовательно, их можно записывать в настоящие данные 412 для выполнения запроса на загрузку 402, полученного от подозрительной сущности 415. После этого реле загрузки 411 передает информацию, помеченную как безопасная, в настоящие данные 412. В случае если легитимная сущность в сети предприятия (не вредоносное ПО) получила фальшивые данные 400, ее информируют 413 об объеме фальшивых данных. Взамен фальшивых данных загружают точно такие же настоящие данные 412. Триггер отзыва данных 414 - это установленное программное обеспечение, взаимодействующее с легитимными сущностями (и иногда с вредоносными сущностями, выдающими себя за легитимные) и проверяющее их на наличие скрытых сигналов, указывающих на потенциальную активацию среды со смешанным набором данных. Менеджер данных 401 - это интерфейс-посредник между сущностью 415 и данными, посредством которого вычисляют соотношение между настоящими данными 412 (если таковые имеются) и фальшивыми данными 400 (если таковые имеются). В потоках данных на загрузку 402 и скачивание 398 отдельные пакеты/файлы помечают (при необходимости), для того чтобы триггер отзыва данных 414 мог построить обратимость данных.
[0114] На Фиг. 64 и 65 показано внутреннее устройство триггера отзыва данных 414. В ходе поведенческого анализа 403 отслеживают поведение подозрительной сущности 415 в плане скачивания и загрузки информации с целью определить потенциальные меры по устранению угрозы 419. Реальная система 417 содержит исходные настоящие данные 412, которые существуют полностью вне виртуальной среды, а также все возможные конфиденциальные данные. Настоящие данные, которыми заменяют фальшивые данные 418, поступают в неотфильтрованном виде в трекинг отзыва данных 399 (даже до синхронизатора с настоящими данными 386). Таким образом фальшивые данные в ранее подозрительной сущности 422 можно заменить настоящими данными с помощью патча настоящих данных 416. Менеджер данных 401, который погружен в виртуальную изолированную среду 404, получает патч настоящих данных 416 трекинга отзыва данных 399. Этот патч 416 содержит инструкции по замене для перевода ранее подозрительной сущности 422 (как теперь доказано, безопасной) в правильную, реальную и полноценную информационную среду. Патч 416 передают в интерфейс отзыва данных 427, откуда впоследствии передает ранее подозрительной сущности 422. Скачанные данные 420 - это данные, которые предприятие скачало в среде фальшивых данных 404 (т.е., эти данные являются частично или полностью фальшивыми). Фиксированные данные 421 - это то место, где фальшивые данные заменяют на аналогичные настоящие данные после применения патча настоящих данных 416. Если безвредный код 409 в ходе поведенческого анализа 403 был отмечен как вредоносный, принимаются меры по устранению угрозы 419. Посредством такого действия 419 заменяют фальшивые данные в ранее подозрительной сущности 422 соответствующими настоящими данными 412. Секретный токен 424 - это строка безопасности, которая генерируется и назначается LIZARD. Секретный токен 424 не является доказательством для виртуальной обфускации, что подозрительная сущность 415 легитимна и безвредна. Вместо этого он позволяет сущности, которая действительно безвредна, не выполнять свою работу, поскольку известно, что она была частично 391 или полностью 394 находится в среде фальшивых данных. До тех пор пока сущность является легитимной, у сотрудника/программы и т.п. не должно быть логистических проблем по взаимодействию с фальшивыми данными и реальными трудностями (ошибка в адресе доставки, ошибочное увольнение и т.п.). Триггер отзыва данных 414 имеется только у легитимных сущностей и функций предприятия. По умолчанию, легитимная сущность проверяет наличие токена 424 в согласованном местоположении во встроенной серверной среде 404 на. Если токен отсутствует 429 и 425, это указывает на вероятный сценарий того, что легитимный объект был случайно помещен в среду, частично состоящую из фальшивых данных (ввиду вероятного риска, что это может быть вредоносное ПО). После этого активируют замедленную сессию 428 с интерфейсом задержки 426. Если токен присутствует (426 и 424), это значит, что серверная среда настоящая, и, следовательно, все замедленные сессии деактивируются 427. Интерфейс задержки 426 - это модуль, который предварительно установлен непосредственно в сущности. При получении указания о нахождении в фальшивой среде 404 активируют замедленную сессию. В замедленной сессии все процессы деятельности сущности искусственно замедляют, чтобы у поведенческого анализа 403 было время принять решение о том, является ли данная сущность безвредной или вредоносной. На деле такая задержка, как ожидается, займет несколько секунд на действие. Настоящим вредоносным программам чрезвычайно трудно получить копию секретного токена (который сам может регулярно изменяться и обновляться), потому что его тайно внедряют только в системы, на 100% состоящие из реальных данных, куда вредоносное ПО практически никогда не попадает. В том случае, если секретный токен не обнаружен, запускают интерфейс задержки 426, что подразумевает, что сущность ожидает, пока поведенческий анализ 403 не вернет ей доступ к настоящим данным.
[0115] На Фиг. 66 показан отбор данных, в рамках которого отфильтровывают высококонфиденциальные данные и смешивают настоящие данные с фальшивыми данными. Настоящие данные 412 передают в синхронизатор с настоящими данными 386, который отфильтровывает конфиденциальные данные 431. Диапазон фильтрации изменяется в соответствии с политикой системы 430, заданной в статичном ядре 315. Модуль 431 следит за тем, чтобы конфиденциальная информация никогда не попала в ту же виртуальную среду, в которой находится подозрительная сущность 415. Данные фильтруются один раз, сразу после того, как сгенерирована 434 виртуальная среда 404. В качестве критериев для генерации 433 используют отфильтрованные реальные данные; по ним определяют, сколько фальшивых данных и какого типа следует сгенерировать. Генератор фальшивых данных 387 создает фальшивые данные, которые разработаны таким образом, чтобы их нельзя было отличить от настоящих данных, т.е. партии номеров соцстрахования. В рамках проверки совместимости 432 сгенерированные фальшивые данные проверяют на совместимость с настоящими данными, чтобы не было слишком много совпадений и, наоборот, отсутствующих типов данных. Сбор настоящих и фальшивых данных производят для гладкого слияния, которое не будет вызывать подозрений, т.е. фальшивые номера соцстрахования и настоящие не пересекаются. Генератор виртуальной среды 434 управляет созданием виртуальной среды 404, которая включает в себя такие переменные, как соотношение фальшивых и настоящих данных, доступные системные функции, параметры сетевой связи, настройки хранения и т.д. Критерии данных 435 - это переменная для регулирования соотношения между реальными и фальшивыми (поддельными) данными. В рамках слияния данных 438 данные объединяют в соответствии с критериями данных 435. В процессе слияния настоящие данные, помеченные как менее конфиденциальные, объединяются с фальшивыми данными, что делает их как будто более конфиденциальными. В рамках управления соотношением 437 постоянно регулируют объем сливаемых настоящих и фальшивых данных, чтобы достичь требуемого соотношения. Данные объединяют в реальном времени в соответствии с запросом 440, полученным от подозрительной сущности 415. Возращенные данные имеют указанное соотношение фальшивых данных к запрашиваемым данным 439.
[0116] На Фиг. 67 и 68 показано внутреннее устройство поведенческого анализа 403. Карта целей 441 представляет собой иерархию задач системы, которая дает цель всей системе предприятия. Такую цель назначают даже мелкомасштабным сетям, обработке процессором и событиям хранилищ. Заявленную цель, назначение деятельности и назначение кодовой базы сравнивают с присущей системе необходимости в том, что якобы делает подозрительная сущность 415. В рамках мониторинга активности 453 осуществляют контроль хранилища, обработки процессором и сетевой активности подозрительной сущности. Синтаксический модуль 35 интерпретирует активность 443 с точки зрения желаемой функции. Затем такие функции посредством целевого модуля 36 преобразуют в подразумеваемую цель. Например, целью кодовой базы 446 может быть подача годовых отчетов о заработке, однако целью активности 447 может быть «собрать номера соцстрахования наиболее высокооплачиваемых сотрудников». Методика та же, что и у таможенного отдела аэропорта, где необходимо декларировать определенные предметы, в то время как таможня в любом случае производит досмотр багажа. Кодовая база 442 является исходным кодом/программной структурой подозрительной сущности 415. Сущностям, которые не раскрывают свой исходный код из-за того, что являются скомпилированной программой с закрытым исходным кодом, может быть заблокирован доступ к системе в соответствии с системной политикой 430. Такую кодовую базу 442 переправляют в синтаксический модуль 35 в качестве модуля поведенческого анализа 403. Синтаксический модуль 35 распознает программный синтаксис и способен сводить программный код и активность кода к промежуточной карте взаимосвязанных функций 444. Такие функции 444 отражают функциональные возможности кодовой базы 442 и активности 443; их передают в целевой модуль 36, который генерирует воспринимаемые «намерения» подозрительной сущности 415. Целевой модуль 36 генерирует назначение кодовой базы 446 и цель активности 444. Назначение кодовой базы 446 содержит известную цель, функцию, юрисдикцию и полномочия сущности 415, выведенные с помощью функций синтаксического программирования LIZARD. Цель активности 447 содержит известную цель, функцию, юрисдикцию и полномочия сущности 415 в соответствии с тем, как LIZARD понимает деятельность ее хранилища, процессора и сетевое поведение 453. Под заявленной целью понимают цель, назначение, юрисдикцию и полномочия сущности 415, заявленные самой сущностью. Необходимая цель 445 содержит ожидаемую цель, назначение, юрисдикцию и полномочия, требуемые системой предприятия. Принцип напоминает наем сотрудника для удовлетворения потребностей компании. Это позволяет LIZARD блокировать подозрительную сущность 415, если ее возможности и/или услуги не являются абсолютно необходимыми для системы. Все четыре цели 445-448 сравнивают в модуле сравнения 449, чтобы убедиться в том, что существование и поведение сущности 415 в рамках системы предприятия оправданы и понимаются LIZARD как нужные для выполнения задач системы 336. Любые несоответствия между четырьмя целями 445-448 вызывают сценарий расхождения целей 450, который, в свою очередь, вызывает меры по устранению угрозы 419. В рамках мер по устранению угрозы могут пометить подозрительную сущность 415 как вредоносное ПО 385 или как безвредное ПО 409. Далее возможно либо полное уничтожение виртуального контейнера, либо скрытное перемещение вредоносного ПО 385 в новую виртуальную среду, где нет настоящих данных (а есть только фальшивые данные), либо открытие доступа к реальной сети предприятия.
Критическое мышление память и восприятие (СТМР)
[0117] На Фиг. 69 показана основная логика работы СТМР 22. Основная задача СТМР заключается в критике решений, принятых третьей стороной. СТМР 22 задействует перекрестные ссылки на интеллектуальные данные из нескольких источников (например, I2GE, LIZARD, доверенной платформы и т.д.) и узнает об ожиданиях восприятия и реальности. СТМР оценивает собственную способность формировать объективное решение по вопросу и воздерживается от реализации решений, в которых имеет низкую степень уверенности. Входящие потоки данных, такие как армия глобально развернутых агентов, а также информация с доверенной платформы, преобразуются в данные для действий. Под субъективными решениями 454 понимают исходное субъективное решение, предоставленное алгоритмом ввода, известного как алгоритм сопоставления выбранных образцов (SPMA) 526. SPMA - это, как правило, система защиты, связанная с безопасностью, но не ограничивается этим и может быть связана с другими типами систем, такими как лексически объективный майнинг (LOM) (алгоритм обоснования) и способ непрерывной отдачи (Method for Perpetual Giving, MPG) (алгоритм интерпретации налогов). Под вводом метаданных системы 455 подразумевают необработанные метаданные из SPMA 526, описывающие механику работы алгоритма и процесс прихода к тому или иному решению. В рамках обработки причин 456 происходит логическое осмысление утверждений путем сравнения характеристик свойств. В рамках обработки правил 457, входящей в процесс обработки причин, выведенные правила используют в качестве позиции для сравнения с целью определить масштаб текущей проблемы. Расширитель объема критических правил (CRSE) 458 берет известный объем восприятий и расширяет его, добавляя в него восприятие критического мышления. К верным правилам 459 относятся верные правила, полученные путем использования восприятия критического мышления. В сети памяти 460 журналы рыночных переменных (параметры рынка 30 и история прибыли 31) проверяют на наличие выполнимых правил. Любые применимые и выполняемые правила выполняются для принятия решений о перехвате распределения инвестиций. В рамках выполнения правил (RE) 461 правила, существование и выполнимость которых подтверждается сканированием памяти хаотического поля 613, выполняют с целью получения желаемых и подходящих решений, принятых с помощью критического мышления. Такое выполнение правил неизбежно приводит к однозначным результатам. Хотя хаотически сложный процесс может привести к непоследовательным, но работающим результатам, логически сложный процесс RE 461 всегда приводит к одним и тем же выводимым результатам, зависящим от логической последовательности в наборе правил. В рамках вывода критических решений 463 получают итоговую логику для определения общего итога работы СТМР путем сравнения выводов, достигнутых как симулятором восприятия наблюдателя (РОЕ) 475, так и выполнением правил (RE) 461. Критическое решение 463 - это конечный результат, представляющий собой мнение по вопросу, настолько объективное, насколько возможно. Журналы 464 содержат необработанную информацию, которая используется независимо для принятия критического решения без какого-либо влияния со стороны субъективного мнения алгоритма ввода. Получение необработанного восприятия (RP2) 465 - это модуль, получающий журналы метаданных из SPMA 526. Такие журналы анализируют и формируют на их основе восприятие, которое отражает восприятие такого алгоритма. Восприятие хранится в сложном формате восприятия (PCF) и симулируется симулятором восприятия наблюдателя (РОЕ) 475. Под прикладными углами восприятия 466 понимают углы восприятия, которые уже были применены и использованы SPMA 526. Механизм автоматизированного обнаружения восприятия (APDM) 467 задействует творческий модуль 18, производящий гибридизированное восприятие (формируемое в соответствии с входными данными прикладных углов восприятия 466), с тем чтобы объем восприятия можно было увеличивать. 468 представляет собой весь объем восприятия, доступный компьютерной системе. Критическое мышление 469 указывает на юрисдикцию внешней оболочки мышления, основанного на правилах. В итоге в ходе выполнения правил (RE) 461 демонстрируют не только хорошо проработанные правила согласно SPMA 526 правила, но и новые верные правила 459, полученные внутри СТМР.
[0118] Как показывает плотность самокритичных знаний 474 на Фиг. 70, входящие необработанные журналы содержат технические знания, известные SPMA 526. Этот модуль 474 оценивает объем и тип потенциально неизвестных знаний, которые недоступны для отчетных журналов. Таким образом, при последующих активациях критического мышления СТМР можно будет использовать потенциальный объем всех вовлеченных знаний, как известных самой системе, так и неизвестных. Симулятор восприятия наблюдателя (РОЕ) 475 симулирует наблюдателя и проверяет/сравнивает все потенциальные факты восприятия, используя различные формы симуляции наблюдателя. Входными данными, в дополнение к расширенным журналам данных, являются все потенциальные точки восприятия. На выходе получают итоговое решение по безопасности, созданное такими расширенными журналами в соответствии с лучшим, наиболее релевантным и наиболее осторожным наблюдателем с указанной смесью выбранных фактов восприятия. Модуль получения выводов (ID) 477 выводит углы восприятия данных из текущих прикладных углов восприятия 470. Что касается мер по перехвату 476, критику окончательных мер/утверждений по устранению угрозы производят в симуляторе восприятия наблюдателя (РОЕ) 475.
[0119] На Фиг. 71 показана структура зависимостей СТМР. В рамках менеджмента и распределения ресурсов (RMA) 479 с помощью настраиваемой политики решают, сколько восприятия необходимо задействовать, чтобы симулировать наблюдателя. Приоритет в отборе фактов восприятия выбирают исходя из их веса в порядке убывания. Политика затем определяет способ отсекания: процентная доля, фиксированное число либо более сложный способ. В рамках поиска по хранилищу (SS) 480 используют CVF, полученный из обогащенных данными журналов, в качестве критерия поиска по базе данных в хранилище восприятия (PS) 478. В ходе обработки метрик (МР) 489 восстанавливают переменные из алгоритма сопоставления выбранных образцов (SPMA) 526, а именно распределение инвестиций, с целью «добыть» факты восприятия из интеллекта данного алгоритма. Дедукция восприятия (Perception Deduction, PD) 490 использует часть отклика размещения инвестиций и соответствующие метаданные системы для воспроизведения исходного восприятия отклика размещения инвестиций. Вывод критических решений (Critical Decision Output, CDO) 462 указывает окончательную логику для определения вывода СТМР. В модуле категоризации метаданных (МСМ) 488 трассировку отладки и алгоритма разделяют на категории с использованием традиционной категоризации информации на основе синтаксиса. Затем такие категории можно использовать для организации и получения отдельных откликов о распределении инвестиций с учетом рыночных/налоговых рисков и возможностей. В разделении системных метаданных (SMS) 487 ввод метаданных системы 455 разделяют на значимые причинно-следственные связи распределения инвестиций. В логике модуля заполнения 483 всесторонне сопоставляют распределение инвестиций с соответствующими рыночными/налоговыми рисками, возможностями и их соответствующими откликами. Навигатор субъектов 481 прокручивает всех применимых субъектов. Модуль заполнения субъектов 482 извлекает соответствующий инвестиционный риск и распределение, соотнесенное с субъектом. В хранилище восприятия (PS) 478, помимо веса фактов восприятия, хранят формат сравниваемых переменных (CVF) в качестве индекса. Это означает, что база данных оптимизирована для получения CVF в качестве входного поискового запроса, по которому будет выдан набор фактов восприятия.
[0120] Как показано на Фиг. 72, модуль получения выводов (ID) 477 выводит углы восприятия данных из текущих прикладных углов восприятия. Что касается плотности самокритичных знаний (SCKD) 492, входящие необработанные журналы содержат известные знания. Этот модуль оценивает объем и тип потенциальных неизвестных знаний, которые недоступны для отчетных журналов. Таким образом, последующие функции критического мышления СТМР могут использовать потенциальный объем всех вовлеченных знаний, известных и неизвестных непосредственно системой. В ходе комбинации метрик 493 углы восприятия разделяют на категории метрик. В ходе преобразования метрик 494 отдельные метрики преобразовывают обратно в полноценные углы восприятия. В ходе расширения метрик (ME) 495 метрики множества разных углов восприятия сохраняют по категориям в отдельных базах данных. Верхняя граница представлена пиковым знанием о каждой отдельной метрической базе данных. После улучшения и усложнения метрики возвращают для того, чтобы преобразовать их обратно в углы восприятия и использовать в рамках критического мышления. Генератор формата сравниваемых переменных (CVFG) 491 преобразует поток информации в формат сравниваемых переменных (CVF).
[0121] На Фиг. 73 показана структура зависимостей СТМР. В расширителе объема критических правил (CRSE) 458 известные факты восприятия используют для расширения объема наборов правил для критического мышления. В рамках сопоставления восприятия 503 формат сравниваемых переменных (CVF) генерируют из фактов восприятия, полученных из выведения синтаксиса правил (RSD) 504. Вновь сформированный CVF используют для поиска подходящих фактов восприятий в хранилище восприятия (PS) 479 с похожими индексами. Потенциальные совпадения возвращают в генерирование синтаксиса правил (RSG) 505. В ходе распознавания памяти (MR) 501 из данных ввода формируют хаотическое поле 613. Полевое сканирование выполняют для распознавания известных концептов. При индексировании концептов памяти 500 все концепты индивидуально оптимизируют и разделяют на части, называемые индексами. Эти индексы используются буквенными сканерами для взаимодействия с хаотическим полем 613. Парсеру выполнения правил (RFP) 498 передают отдельные части правил с метками распознавания. Каждую часть помечают как найденную или не найденную в хаотическом поле 613 с помощью распознавания памяти 501. RFP может затем логически вывести, какие целые правила, т.е. совокупности всех частей, были в достаточной степени распознаны в хаотическом поле 613, чтобы к ним можно было применить выполнение правил (RE) 461. В рамках разделения формата синтаксиса правил (RSFS) 499 верные правила разделяют и организуют по типу. Следовательно, все действия, свойства, условия и объекты складируют отдельно. Это позволяет системе различать, какие части были найдены в хаотическом поле 613, а какие - нет. В ходе выведения синтаксиса правил 504 логические «черно-белые» правила преобразовывают в факты восприятия на основе метрик. Сложное расположение нескольких правил преобразуют в единое восприятие, которое выражается через несколько метрик с различными градиентами. В ходе генерирования синтаксиса правил (RSG) 505 получают ранее подтвержденные факты восприятия, хранящиеся в формате восприятия, и взаимодействуют с внутренним составом метрик факта восприятия. Такие градиентные измерения метрик преобразуют в двоичные и логические наборы правил, которые симулируют информационный поток ввода/вывода исходного восприятия. Верные правила из разделения формата синтаксиса правил (RSFS) 499 отражают точное представление наборов правил, которые соответствуют реальному облику наблюдаемого объекта. Верные правила разделяют и организуют по типу. Следовательно, все действия, свойства, условия и объекты складируют отдельно. Это позволяет системе различать, какие части были найдены в хаотическом поле 613, а какие - нет. Встроенная логическая дедукция 506 использует логические принципы, позволяющие избежать ошибок в определении того, какие правила точно отражают множество градиентов метрик внутри факта восприятия. Для наглядности возьмем аналоговую синусоидальную волну (напр., радиочастоты и т.п.) и преобразуем ее в цифровые шаги. Общая тенденция, позиция и результат одинаковы, однако при этом аналоговый сигнал был преобразован в цифровой. В рамках анализа контекста метрик 507 анализируют взаимные связи внутри восприятия метрик. Определенные метрики могут зависеть от других с разной степенью силы. Контекстуализацию используют в качестве дополнения к зеркальным взаимным связям, имеющимся у правил в «цифровом» формате набора правил. Посредством анализа ввода/вывода 508 выполняют дифференциальный анализ ввода и вывода каждого восприятия (серый) или правила (черный и белый). Цель данного модуля - сделать так, чтобы входные и выходные данные оставались максимально похожими или идентичными после преобразования (с серого на черно-белое и наоборот). Посредством расчета критерия 509 вычисляют критерии и задачи правил ввода. Все это можно перевести в «мотивацию», лежащую в основе набора правил. Правила реализуют по причинам, обозначенным как прямо, так и косвенно. Следовательно, вычисляя косвенную причину выполнения «цифрового» правило, эту же причину можно использовать для обоснования состава метрик в факте восприятия, требующем те же возможности ввода/вывода. В ходе анализа формирования правил 510 анализирует общую структуру/состав правил и то, как они взаимодействуют друг с другом. Результаты анализа используют для дополнения зеркально связанных взаимосвязей, которые имеются у метрик в «аналоговом» восприятии. В ходе преобразования формата синтаксиса правил (RSRC) 511 правила распределяют для соответствия формату синтаксиса правил (RSF) 538.
[0122] На Фиг. 74 показана конечная логика обработки интеллектуальной информации в СТМР. В итоговую логику поступает интеллектуальна информация как из режима интуиции/восприятия, так и из режима мышления/логики (из симулятора восприятия наблюдателя (РОЕ) 475 и из выполнения правил (RE) 461 соответственно). В ходе непосредственного сравнения решений (Direct Decision Comparison, DDC) 512 оба решения от интуиции и мышления сравниваются с целью подтвердить их схожесть. Главное отличие заключается в том, что мета-метаданные еще не сравниваются, потому что, если они все равно совпадут, то нет смысла тратить ресурсы, чтобы понять почему. Управление конечным выводом (Terminal Output Control, TOC) 513 выступает последней логикой для определения вывода СТМР из обоих режимов: интуиции 514 и мышления 515. Интуитивное решение 514 является одним из двух основных разделов СТМР, который участвует в критическом мышлении, задействуя факты восприятия. См. симулятор восприятия наблюдателя (РОЕ) 475. Мыслительное решение 515 - это еще один из двух основных разделов СТМР, где критическое мышление осуществляется с использованием правил. См. выполнение правила (RE) 461. Восприятие 516 - это данные, полученные из интуитивного решения 158 в соответствии с синтаксисом формата, заданным во внутреннем формате 518. Выполненные правила 517 - это данные, полученные из разумного решения 515, которое представляет собой набор применимых (выполнимых) наборов правил из выполнения правил (RE) 461. Такие данные передается в соответствии с синтаксисом формата, заданным во внутреннем формате 518. С помощью внутреннего формата 518 модуль категоризации метаданных (МСМ) 488 способен распознавать синтаксис обоих входящих наборов данных, поскольку они были стандартизированы с помощью известного и согласованного формата, который используется внутри СТМР.
[0123] На Фиг. 75 показано, как два основных ввода интуиции/восприятия и мышления/логики сводят в единый терминальный вывод, отражающий результаты деятельности СТМР в целом. Критическое решение и мета-метаданные 521 - это цифровой носитель, передающий либо факты восприятия 516, либо выполненные правила 517 в соответствии с синтаксисом, заданным во внутреннем формате 518.
[0124] На Фиг. 76 показан объем интеллектуального мышления, совершаемого исходным алгоритмом сопоставления выбранных образцов (SPMA) 526. Входные переменные 524 -это исходные переменные распределения финансов/налогов, которые рассматриваются для обработки причин и правил. СТМР критикует их и выводит второе мнение на основе искусственного интеллекта. Переменный ввод 525 принимает входные переменные, которые определяют решение по безопасности. Такие переменные предлагают критерии для СТМР, чтобы помочь определить, какие меры по устранению угрозы являются разумными. Если в переменной есть сложение, вычитание или изменение, тогда соответствующее изменение должно быть отражено в итоговых мерах по устранению угрозы. Основная цель СТМР - определить правильное, критическое изменение в мерах по устранению угрозы, которое правильно и точно отражает изменение входных переменных. Алгоритм сопоставления выбранных образцов (SPMA) 526, пытается определить наиболее подходящее действие в соответствии со своими собственными критериями. Итоговая форма вывода 527 представляет собой результат работы SPMA 526 с начальными входными переменными 168. Правила, выведенные в процессе принятия решений SPMA 526, считаются «текущими правилами» но необязательно являются «верными правилами». При объединении атрибутов 528 согласно данным в журнале, предоставленным SPMA 526, обработка причины 456 продолжается с текущим объемом знаний в соответствии с SPMA 526.
[0125] На Фиг. 77 показано противопоставление стандартного SPMA 526 критическому мышлению, осуществляемому СТМР с использованием фактов восприятия и правил. Неверно понятое действие 531 - то действие, для которого алгоритм сопоставления выбранных образцов (SPMA) 526 не смог обеспечить достаточно точные меры по устранению угрозы. Это объясняется фундаментальным базовым предположением, которое не было проверено в исходном коде или данных SPMA 526. В этом примере использование в качестве входной переменной трехмерного объекта и верное соответствующее действие иллюстрируют наличие измерения/вектора, не учтенного SPMA 526. В рамках соответствующего действия 532 критическое мышление рассматривает как 3-е измерение, которое SPMA 526 опускает в качестве вектора для проверки. 3-е измерение было рассмотрено критическим мышлением 469 из-за всех дополнительных проверок углов восприятия. Что касается верных правил 533, расширитель объема критических правил (CRSE) расширяет объем понимания наборов правила, задействуя ранее незатронутые углы восприятия (т.е. третье измерение). Что касается текущих правил 534, производные правила текущих мер по устранению угрозы отражают понимание или его отсутствие (по сравнению с верными правилами) SPMA 526. Правила ввода получают из алгоритма сопоставления выбранных образцов (SPMA) 526, описывающих исходную область понимания SPMA. Это продемонстрировано в SPMA 526, который охватывает только два измерения в плоскостном концепте финансовых ассигнований.
[0126] На Фиг. 78 показано как получают верные правила 533 в отличие от известных текущих правил 534, в которых могут быть опущены значительные подробности и/или переменные. В парсере хаотического поля (CFP) 535 формат журналов собирают в единое сканируемое хаотическое поле 613. Дополнительные правила 536 получают из распознавания памяти (MR) 501 в дополнение к уже определенным верным правилам 533. В правилах восприятия 537 факты восприятия, которые считаются актуальными и популярными, преобразуют в логические правила. Если в факте восприятия (в его исходном формате восприятия) было много сложных отношений между метриками, в которых определяли множество «серых областей», то «черно-белые» логические правила охватывают такие «серые» области, увеличивая их сложность на n-ю степень. Формат синтаксиса правил 538 - это формат хранения, оптимизированный под эффективное хранение переменных и составления запросов к ним.
[0127] На Фиг. 79 и 80 показан модуль сопоставления восприятия (РМ) 503. Что касается статистики метрик 539, статистическая информация поступает из хранилища восприятия (PS) 479. Такая статистика определяет тенденции популярности метрик, внутренние отношения между метриками, скорость роста метрик и т.д. Некоторые общие статистические запросы (например, общий рейтинг популярности метрик) выполняются автоматически и сохраняются. Другие, более конкретные, запросы (насколько связаны метрики Х и Y) направляют в PS 479 в режиме реального времени. В удержании отношений между метриками 540 содержат данные об отношениях между метриками, чтобы затем переместить их в обобщенный вывод. В рамках управления ошибками 541 анализируют синтаксис и/или логические ошибки, возникающие в каждой отдельной метрике. В ходе разделения метрик 542 изолируют каждую отдельную метрику, так как они ранее были объединены в одну единицу - входящее восприятие 544. Входящее восприятие 544 представляет собой примерный состав факта восприятия, включающего в себя метрики зрения, обоняния, осязания и слуха. Алгоритму сравнения узлов (NCA) 546 передают состав узлов двух или более CVF. Каждый узел в CVF представляет степень значимости свойства. Сравнение по сходству выполняют на основе отдельного узла, после чего вычисляют совокупную вариативность. Это обеспечивает эффективно высчитанное точное сравнение. Чем меньше степень вариативности - в отдельном узле или по совокупному весу, - тем более близко определено соответствие. Формат сравниваемых переменных (CVF) 547 - это визуальное представление различных составов CVF. Подача совпадений в качестве вывода 550 является конечным выводом сопоставления восприятия (РМ) 503. Независимо от того, какие узлы в алгоритме сравнения узлов (NCA) 546 перекрываются, их сохраняют как результат сопоставления, и, соответственно, общий результат представлен в шаге 550.
[0128] На Фиг. 81-85 показано выведение/генерирование синтаксиса правил. Необработанное восприятие - интуитивное мышление (аналоговое) 551 - это где факты восприятия обрабатывают в соответствии с «аналоговым» форматом. Необработанные правила - логическое мышление (цифровое) 552 - это где правила обрабатывают в соответствии с цифровым форматом. Восприятия, относящихся к решению о финансовом распределении, в аналоговом формате 553 хранят в градиентах на гладкой кривой без перепадов. Необработанные правила, относящиеся к решению о распределении финансовых средств, в цифровом формате 554 хранят на «ступеньках», где (практически) отсутствует «серая зона». С точки зрения содержания данных исходные правила 555 совпадают с верными правилами 533. Отличие состоит в том, что исходные правила 555 преобразуют с помощью разделения формата синтаксиса правил (RSFS) 499 в более динамический формат, который позволяет осуществлять перекрестные ссылки с хаотическим полем 613 через распознавание памяти 501. Распознанные сегменты правил 556 - это правила из исходных правил 555, которые были распознаны посредством распознавания памяти 501. Они показывают, какие из отдельных сегментов, составляющих исходное верное правило 533 (действия, свойства, условия и объекты), были распознаны в хаотическом поле 613, и, следовательно, применимы для того, чтобы потенциально стать логически выполненными правилами. Решения о перехвате системы безопасности 557 выступают конечным результатом выполнения правил (RE) 461, что позволяет привести меры по устранению угрозы в исполнение. Такие меры по устранению угрозы далее направляют в управление конечным выводом (ТОС) 513, которое является подмножеством большей логики мер по устранению угрозы, выполняемой в выводе критических решений (CDO) 462. Под невыполненными правилами 558 понимают наборы правил, недостаточно распознанные (в соответствии с парсером выполнения правил 498) в хаотическом поле 613 в соответствии с их логическими зависимостями. Точно так же, выполненные правила 517 были признаны достаточно доступными в хаотическом поле 613 в соответствии с логическими зависимостями, проанализированными CDO 462. Решение сторонней базы данных 559 - это программное обеспечение аппаратного интерфейса, которое управляет буфером, кэшем, дисковым хранилищем, управлением потоками, управлением памятью и другими типичными механическими функциями базы данных. Отладчик выполнения 560 пытается найти причину невыполнения правил. Либо хаотическое поле 613 было недостаточно богатым, либо набор правил был изначально нелогичным. Если набор правил нелогичен, его можно проверить мгновенно с определенной степенью точности. Однако для установления потенциальной пустоты хаотического поля 613 необходимо провести несколько сканирований, чтобы избежать ложных выводов, вызванных недостаточным сканированием.
[0129] На Фиг. 86-87 показан принцип работы модуля разделения формата синтаксиса правил (RSFS) 499. В этом модуле верные правила 502 разделены и организованы по типу. Следовательно, все действия, свойства, условия и объекты складируют отдельно. Это позволяет системе различать, какие части были найдены в хаотическом поле 613, а какие - нет. Действия 561 - это один из четырех типов данных сегмента правил, который указывает на то, что действие, возможно, уже было выполнено, будет выполнено, рассматривается для активации и т.д. Свойства 562 - это один из четырех типов данных сегмента правил, который указывает на какой-то атрибут, похожий на свойство, который описывает что-то еще, например, действие, условие или объект. Условия 563 - это один из четырех типов данных сегмента правил, который указывает на логическую операцию или оператор (то есть, если x и y, то z, если x или z, то y и т.д.). Объекты 564 - это один из четырех типов данных сегмента правил, который указывает на цель, к которой могут быть применены атрибуты, такие как действия 561 и свойства 562. На этапе обработки 565 результаты получения взаимосвязи, которые были собраны до настоящего времени, представляют как выходные данные, и программа после этого завершается. На этапе обработки 566 сегменты правила разбирают по одному элементу за раз. На этапе обработки 567 интерпретируют и записывают каждое отдельное отношение между сегментами правил (т.е. действия 561, объекты 564 и т.д.). Таким образом, каждое отдельное отношение собирается и готовится к выводу на этапе 565. В ходе последовательного сканирования 568 разделяют каждую единицу RSF 538 по маркеру [DIVIDE]. Субъекты и клей из RSF 538 также разделяют и анализируют. Разделенный вывод 569 - это где отдельные субъекты и внутренние отношения между субъектами удерживаются сканером. Они сразу отправляются на вывод, после того как весь RSF 538 последовательно просканирован. Раздельный формат правил 570 - это механизм доставки, содержащий отдельные сегменты правил (т.е. действия 561, объекты 564 и т.д.), из разделенного вывода 569. Применение раздельного формата правил 570 показано в двух основных точках передачи информации: как вывод из разделения формата синтаксиса правил (RSFS) 499 (фаза до распознавания памяти) и как вывод из распознавания памяти (MR) 501 (фаза после распознавания памяти).
[0130] На Фиг. 88 показан принцип работы парсера выполнения правил (RFP) 498. Данному модулю передают отдельные части правил с метками распознавания. Каждую часть помечают в соответствии с тем, была ли она найдена в хаотическом поле 613 в ходе распознавания памяти 501. RFP 498 логически решает, какие целые правила, выступающие как комбинация всех частей, были успешно распознаны в хаотическом поле 613 и заслуживают выполнения (RE) 461. Управление очередями (QM) 561 задействует модуль реконструкции синтаксических связей (SRR) 497 для анализа каждой отдельной части в наиболее логичном порядке. QM 561 имеет доступ к результатам распознавания памяти (MR) 501, и, таким образом, можно дать ответ на двоичные потоковые вопросы на да/нет и предпринять соответствующие действия. QM проверяет каждый сегмент правил пошагово, и если какой-либо сегмент отсутствует в хаотическом поле 613 и не состоит в нужных отношениях с остальными сегментами, весь набор правил помечают как невыполненный. Если все этапы проверки пройдены, то набор правил помечают как выполненный 522. На этапе QM 571 проверяют, был ли найден сегмент правила «Объект С» в хаотическом поле 613. На этапе QM 572 проверяют, связан ли следующий соответствующий сегмент, также найденный в хаотическом поле 613 в соответствии с распознаванием памяти (MR) 501, с исходным «Объектом С». Та же логика применяется к этапам QM 573 и 574 QM для условия В и действия А соответственно. Эти обозначения сегментов (А, В, С и т.д.) не являются частью базовой логики программы, но являются ссылкой на логичный пример, используемый для отображения ожидаемого и типичного использования. Для получения полностью восстановленного набора правил 575 требуется выполненный набор правил из управления очередями 576, при условии, что набор правил был признан выполнимым и ассоциации сегментов правил заданы модулем реконструкции синтаксических связей (SRR) 497.
[0131] На Фиг. 89-90 изображен отладчик выполнения 560, который пытается найти причину невыполнения правил. Либо хаотическое поле 613 было недостаточно богатым, либо набор правил был изначально нелогичным. Если набор правил нелогичен, его можно проверить мгновенно с определенной степенью точности. Однако для установления потенциальной пустоты хаотического поля 613 необходимо провести несколько сканирований, чтобы избежать ложных выводов, вызванных недостаточным сканированием. Сканирование пустоты поля 577 конкретно проверяет, является ли хаотическое поле 613 достаточно насыщенным или нет, чтобы запустить переменную структуру набора правил. Сканирование 578 проверяет на наличие релевантных частей правила внутри хаотического поля 613. В базе данных 579 сканирования сохраняют результаты сканирования для последующего использования в будущем. Условно 580 проверяет, не переполнилась ли база данных 579 сканирования. Это означает, что все возможные способы сканирования на предмет поиска частей правил были осуществлены, вне зависимости от того, дало ли сканирование положительные или отрицательные результаты. Если все возможные способы сканирования были осуществлены, то подразумевается вывод 581: пустота хаотического поля 613 является причиной того, почему набор правил был классифицирован как невыполненный. Если не все возможные способы сканирования были осуществлены, то подразумевается вывод 582: сканирование является неполным и необходимо сканировать больше секторов хаотического поля 613, чтобы надежно определить, является ли пустота хаотического поля 613 причиной невыполнения правила. Посредством теста на логическую невыполнимость 583 проверяют, есть ли по сути невозможная логическая зависимость в наборе правил, которая заставляет классифицировать его как невыполненный. Например, объекту 584 «холостяк» было присвоено свойство 585 «женат», что приводит к внутреннему противоречию. Посредством теста 583 определяют словарные определения терминов 584 и 585. В ходе проверки внутренней логики правила 588 проверяют, являются ли все свойства совместимыми и соответствуют ли они своим объектам. Определение «холостяк» 584 в формате RSF 538 способствует частичному определению объекта 586 «мужчина», в то время как определение «женат» 585 (также в формате RSF 538) способствует частичному определению объекта 587 «два человека». Вывод проверки 588 состоит в том, что оба определения 586 и 587 совместимы, поскольку объект 586 «человек» потенциально входит в состав объекта 587 «Два человека». В рамках преобразования релевантности правил 589 справедливые термины преобразуют для проведения сравнительного теста. Такое преобразование позволяет понять второе определение («женат») в контексте первого определения («холостяк»). Таким образом, делается вывод 591 о том, что правило содержит внутреннее противоречие о том, что один и тот же мужчина в настоящее время не может быть женат 590 и не женат 592.
[0132] На Фиг. 91 показано выполнение правил (RE) 461: правила, существование и выполнимость которых подтверждается сканированием памяти хаотического поля 613, выполняют с целью получения желаемых и подходящих решений, принятых с помощью критического мышления. Имеется шахматная плоскость, которую используют для отслеживания преобразования наборов правил, причем объекты на доске отражают сложность данной ситуации в системе безопасности, а перемещение данных объектов по «доске безопасности» отражает развитие ситуации, которое контролируется откликами правил безопасности. В шаге 1593 информация RSF 538 определяет начальные позиции всех соответствующих объектов на шахматной плоскости, следовательно, определяя начало динамически каскадной ситуации безопасности, что символически используют для иллюстрации логических «положений» правил, которые связаны с динамической политикой безопасности. Шаг 2 594 и шаг 6 598 указывают на преобразование объекта, которое демонстрирует применяемые правила безопасности, которые изменяют положение и область определенных ситуаций безопасности. Например, преобразование объекта на этапах 2 и 6 может представлять собой шифрование критически важных файлов. Шаг 3 595 иллюстрирует перемещение объекта по шахматной плоскости, что может соответствовать фактическому перемещению конфиденциального файла в удаленное местоположение в рамках стратегии отклика системы безопасности. Шаг 4 596 и шаг 5 597 показывают процесс слияния двух объектов в единый третий объект. Примером применения этого правила являются две отдельные и изолированные локальные сети, объединяемые в целях эффективного и безопасного управления передачей информации. По завершении выполнения правил (RE) 461 результаты верных правил 533 и текущих правил 534 различаются. Отсюда видно преимущество критического мышления, выполняемого в СТМР, в отличие от менее критичных результатов, получаемых от алгоритма сопоставления выбранных образцов (SPMA) 526. Все формы, цвета и позиции символически представляют переменные безопасности, инциденты и отклики (т.к. их проще объяснить, чем реальные объекты безопасности). SPMA создает конечные позиции форм, которые отличаются от тех, что получены в СТМР, а также схожие, но различные цвета (оранжевый и желтый) для пятиугольника. Это происходит из-за сложной структуры условных операторов-наборов правил, через которую все входные журналы проходят перед обработкой. Это похоже на то, как различные переменные игроков перед началом игры в бильярд (рост, сила и т.д.) могут привести к совершенно разным конечным позициям шаров. СТМР также превратил фиолетовый квадрат в куб, который символически представляет (в описании СТМР) его способность учитывать измерения и представления, которые SPMA 526 или даже человек никогда бы не заметили и не затронули. Окончательное решение о перехвате системы безопасности 599 принимают в соответствии с верными правилами 533.
[0133] На Фиг. 92 и 93 изображена последовательная организация памяти, представляющая собой способ оптимизированного хранения информации, позволяющий с большей эффективностью считывать и записывать «цепочки» упорядоченных сведений, например, алфавита. В точках доступа к памяти 600 ширина каждого из узлов 601 (блоков) представляет собой прямой доступ наблюдателя к запомненному объекту (узлу). В последовательно запоминаемом порядке алфавита буква «А» является наиболее доступной точкой памяти, так как это первый узел в последовательности. Буквы «Е», «Н» и «L» также предоставляют более простой прямой доступ, поскольку они являются «ведущими» для своих собственных подпоследовательностей «EFG», «HIJK» и «LMNOP» соответственно. В области доступности 602 каждая буква представляет свою точку прямого доступа к памяти для наблюдателя. Чем шире область доступности, тем больше точек доступности у данного узла последовательности, и наоборот. Чем больше к последовательности будут обращаться только «по порядку», а не с какого-либо случайно выбранного узла, тем более узкой является область доступности (относительно размера последовательности). Это позволяет более эффективно восстанавливать память в соответствии с порядком ее последовательности. В случае вложенных слоев подпоследовательности 603 последовательность, которая демонстрирует сильную неоднородность, состоит из серии меньших подпоследовательностей, которые соединяются между собой. Алфавит в значительной степени демонстрирует подобное поведение, поскольку отдельные подпоследовательности 'ABCD', 'EFG', 'HUK', 'LMNOP' существуют независимо в виде запомненных последовательностей, но они взаимосвязаны и образуют алфавит в целом. Этот тип хранения и обращения к памяти может быть гораздо более эффективным, если есть периодический или частый доступ к определенным узлам главной последовательности. Таким образом можно избежать сканирования с начала всей последовательности, что экономит время и ресурсы. Это аналогично сканированию книги по главам, вместо того, чтобы сканировать ее с первой страницы каждый раз. В случае крайне неоднородной области 605 точки доступа во всех узлах выбираются непоследовательно. Это означает, что в ней существует множество вложенных подпоследовательностей, которые соединяются в цепочку. Крайне неоднородная последовательность означает, что она является умеренно последовательной, но должна иметь несколько точек доступа к памяти (вложенные слои подпоследовательности). Примером крайне неоднородной последовательности 605 является алфавит, трудность перечисления которого зависит от того, с какой буквы начать. Напротив, в случае крайне однородной последовательности 607 существует единая точка доступа для всех узлов. Это означает, что он не состоит из вложенных подпоследовательностей, которые соединяются в цепочку. Крайне однородная последовательность означает, что она является либо крайне последовательной (количество точек доступа к узлам стремится к нулю), либо крайне непоследовательной (множество точек доступа к узлам). Примером крайне однородной последовательности 607 является набор фруктов: в их перечислении едва ли есть какая-либо четкая или явная последовательность и среди них нет никаких взаимосвязанных подпоследовательностей. Умеренно однородная последовательность 606 имеет большой начальный узел доступа, что означает, что наиболее эффективно перечислять содержание, начиная с самого начала. Однако основное содержание, кроме того, является линейным, что указывает на отсутствие вложенных слоев подпоследовательности и наличие единственной большой последовательности. Умеренно неоднородная последовательность 604 не сильно отклоняется от линейной и, следовательно, имеет постоянные точки доступа по всей длине. Это указывает на то, что существуют более тонкие и менее определенные вложенные слои подпоследовательности, в то же время соответствующие логичному и обратимому набору. Примером информации, демонстрирующей поведение умеренно неоднородных последовательностей 604, может служить каталог производителя автомобилей. В нем могут быть определены категории, такие как спортивные автомобили, гибридные автомобили и внедорожники, но нет сильного предвзятого мнения о том, как список следует перечислять или запоминать, поскольку потенциальный покупатель все же может сравнивать внедорожник со спортивным автомобилем, несмотря на то, что они представлены в разных категориях.
[0134] На Фиг. 94 показана непоследовательная организация памяти, которая представляет собой хранение информации в виде непоследовательно расположенных связанных объектов, например, фруктов. В наборе фруктов нет строго определенного порядка, в котором они должны перечисляться, в отличие от алфавита, который имеет строгий последовательный порядок того, как должна читаться информация. Организация памяти 608 показывает последовательно унифицированные узлы доступа для всех фруктов, что указывает на их непоследовательную организацию. Организация 608 иллюстрирует, как обратимость указывает на непоследовательное расположение и однородную область. В данном случае показано, что память фруктов является непоследовательной, на что указывает относительно широкая точка доступа к узлам. Та же самая однородность существует, когда порядок фруктов перетасовывается, что указывает на обратимый порядок следования фруктов в наборе. Напротив, последовательный ряд, такой как алфавит, гораздо труднее читать задом наперед, в отличие от обычного перечисления. Список общих фруктов не демонстрирует такого явления, что указывает на то, что к нему чаще обращаются в виде непоследовательного списка, чем в виде последовательного. В ядерной теме и ассоциациях 609, поскольку в этом списке фруктов нет последовательности, повторяются одни и те же последовательности фруктов, но с другим ядром (центральным объектом). Ядро представляет собой первичную тему, для которой оставшиеся плоды действуют как соседи в памяти, к которым будет легче обратиться, чем в случае, когда ядерная тема не задана. Что касается сильных соседей 610А, то, несмотря на то, что яблоко является общим фруктом, оно имеет более сильную связь с ананасом, чем с другими фруктами из-за частичного совпадения в написании («APPLE» - «PINEAPPLE»). Следовательно, они считаются более связанными с точки зрения памяти. Что касается слабых соседей 610В, то, поскольку ананас - это тропический фрукт, он меньше ассоциируется с апельсинами и бананами (общим фруктов). Ананас, скорее всего, будет упоминаться в связи с манго из-за пересечения по типу тропических фруктов. Точка графа 612 демонстрирует, как крайне слабая последовательность в порядке следования фруктов приводит к крайне сильной однородности доступа к узлу 601.
[0135] На Фиг. 95-97 показан процесс распознавания памяти (MR) 501, в рамках которого сканируют хаотическое поле 613 для распознания известных концептов. Хаотическое поле 613 представляет собой «поле» концептов, произвольно погруженных в «белый шум». В рамках распознавания памяти сканируют хаотическое поле для распознавания известных концептов. В хранилище концептов памяти 614 сохраняют распознаваемые концепты, которые готовы к индексации и обращению к ним для полевого исследования. На иллюстрации используется упрощенный пример написания названий растений для облегчения понимания системы. Однако этот пример можно использовать в качестве аналогии для гораздо более сложных сценариев. Если взять пример ситуации безопасности из реальной жизни, то можно говорить о распознавании гражданских и военнослужащих лиц на видеозаписях камер слежения. Если взять пример из области кибербезопасности, то можно говорить о распознавании известных и запомненных «троянских коней», бэкдоров и обнаружении их в море белого шума (журналов безопасности). Трехбуквенный сканер 615 сканирует хаотическое поле 613 и проверяет трехбуквенные сегменты, соответствующие цели. Допустим, целью является «PLANT» («растение»), и сканер перемещается вдоль поля с шагом в 3 символа. На каждом шаге сканер проверяет сегменты «PLA», «LAN» и «ANT», поскольку они являются подмножествами слова «PLANT». Несмотря на это, слова «LAN» (сокр. «локальная сеть») и «ANT» («муравей») являются независимыми словами сами по себе и тоже могут выступать в качестве целей. Следовательно, когда один из этих трехбуквенных сегментов найден в поле, это может означать, что была найдена полная цель «LAN» или «ANT» либо было найдено подмножество «PLANT». Тот же принцип применяют для 5-буквенного сканера 616, но на этот раз сегмент, который проверяется при каждом шаге по полю, представляет собой целое слово «PLANT». Такие цели, как «LAN» и «ANT», пропускают, поскольку 5-буквенный сканер работает с сочетаниями из минимум 5 букв. Хаотическое поле 613 сегментируют для сканирования по разной ширине (3, 5 букв или более), поскольку такие сегменты обеспечивают различные уровни эффективности сканирования. По мере уменьшения объема сканирования (меньшее количество букв) точность увеличивается (и наоборот). По мере того, как увеличивается площадь поля сканера, сканер больших букв более эффективен для выполнения распознавания, но теряет в точности (в зависимости от того, насколько маленькая цель). В рамках индексации концептов памяти (MCI) 500, в шаге 617 чередуют размер сканера (3, 5 или более) в ответ на оставшиеся необработанными концепты памяти. MCI 500 начинает с самого большого доступного сканера и постепенно уменьшает его в шаге 617, с тем чтобы выделить больше вычислительных ресурсов для проверки на потенциальное существование целевых концептов памяти меньшего размера. В шаге 618 циклически обрабатывают доступные концепты памяти, так чтобы их индексы (сегменты меньшего размера, подходящие для соответствующей длины, например, 3 или 5) можно было получить в шаге 620. В случае, если концепт памяти отсутствует в удержании индексов концептов 624, в шаге 619 он будет создан в соответствии с логистическим порядком действий. В шаге 621 затем назначают производные индексы из шага 620 в удержание 624. Пока запрограммированный полный цикл MCI 500 продолжается, если в MCI заканчиваются необработанные сканеры букв, тогда наступает развилка, где он либо отправит пустой (нулевой) результат 622, если в удержании 624 пусто, или отправит данные из удержания 624 в качестве модульного вывода 623. Разделы хаотического поля 613 продемонстрированы в пунктах 625--628. Разделы 625 и 626 представляют собой сканирование, выполненное 5-буквенным сканером, в то время как разделы 627 и 628 представляют 3-буквенное сканирование. Сканирование 625 имеет ширину 5 букв, а для проверки дано слово из шести букв: «TOMATO» («помидор»). Были сопоставлены два 5-буквенных сегмента: «ТОМАТ» и «ОМАТО», которые ранее были проиндексированы в MCI 500. Каждый из них соответствует 5-буквенному совпадению из 6-буквенного слова, т.е. 83%. Эту долю/процент кумулятивно складывают в пользу концепта памяти «TOMATO» и получают 167% 637, следовательно, концепт «TOMATO» был успешно обнаружен в хаотическом поле 613. Сканирование 626 нацелено на концепт памяти «EGGPLANT» («баклажан») с двумя значимыми сегментами: «GGPLA» и «PLANT». В то время как «GGPLA» соотносится исключительно с «EGGPLANT», сегмент «PLANT» представляет возможность ложного срабатывания, так как «PLANT» («растение») сам по себе является концептом памяти. Если система распознает «PLANT» как существующее в хаотическом поле 613, в случае если «EGGPLANT» является единственным реально распознаваемым концептом памяти в поле, это будет классифицироваться как ложное срабатывание. Однако программа системы способна обойти сценарий ложного срабатывания, так как «GGPLANT» обеспечивает совпадение на 63% и «PLANT» в контексте «EGGPLANT» также добавляет 63%, тогда как «PLANT» в контексте «PLANT» дает 100%. Поскольку совпадения складываются кумулятивно, то целевой концепт «EGGPLANT» получает совокупный балл 126% (63% + 63%) 638, в то время как целевой концепт «PLANT» получит 100% 639. Следовательно, сканер успешно провел правильную интерпретацию хаотического поля 613. Сканирование 627 имеет ширину 3 буквы и распознает сегмент «ТОМ», что приводит к совокупному совпадению 50% 640. Цель та же, что и в поле сканирования 625, но из-за разницы в ширине сканирования (3 буквы вместо 5) достоверность совпадения ниже (50% против 167%). Следовательно, конструкция MCI 500 включает в себя несколько уровней ширины сканирования, чтобы обеспечить правильный баланс между точностью и затратами вычислительных ресурсов. Сканирование 628 также имеет ширину 3 букв, на этот раз с двумя шансами получить ложное срабатывание 636. Хотя в действительности целевой концепт - «CARROT» («морковь»), в поле самостоятельно существуют составляющие его сегменты «CAR» («машина») и «ROT» («гнить»). Сканер теперь должен выявить, какой концепт на самом деле находится в хаотическом поле 613. Это проверяется путем дополнительного сканирования по соседним буквам. В конце концов, сканер распознает концепт как «CARROT», а не «CAR» или «ROT», благодаря подтверждению со стороны других индексов. 100% совпадение с «CAR» 641 и 100% совпадение с «ROT» 643 проигрывают 200% совпадению с «CARROT» 642.
[0136] На Фиг. 98-99 показана логика интерпретации поля (FIL) 644 и 645, которая управляет логистикой для управления сканерами различной ширины с соответствующими результатами. Сканирование общей области 629 начинается со сканирования крупных наборов букв. Этот тип сканирования может просматривать область поля большего размера, задействуя меньшее количество ресурсов, но теряя в точности. Следовательно, сканеры меньших наборов букв запускают, когда необходимо изучить более узкую область и повысить точность сканирования. Сканер узкого объема 630 используют, когда выделена значимая область, которую необходимо «приблизить». Общая корреляция заключается в том, что чем меньше область поля, выбранная для сканирования, тем меньше нужный тип сканера (меньше букв). Это гарантирует, что дорогостоящее и точное сканирование не будет выполняться там, где это не нужно и излишне. Раздел 645 FIL отображает реакционную логистику результатов сканирования. Если конкретный сканер совершает дополнительное распознавание концептов памяти в хаотическом поле 613, это указывает на то, что данная область поля 631 (раздел 613) плотно насыщена концептами памяти и ее стоит «приблизить» путем использования сканеров меньшей ширины. Таким образом, 5-буквенный сканер с охватом поля 30% 632 активирует 3-буквенный сканер с охватом поля 10% 633, в случае если исходный результат работы рассматривается как «Увеличенное «дополнительное» распознавание» 634. «Дополнительное» в данном случае 634 указывает на то, что распознавание дополняет первоначальное распознавание, выполненное в разделе 644 FIL.
[0137] На Фиг. 100-101 показан механизм автоматизированного обнаружения восприятия (APDM) 467. Наблюдатель 646, представляя цифрового наблюдателя или человека-наблюдателя, может воспринимать один и тот же объект с помощью нескольких восприятий. Наблюдаемый объект используется для иллюстрации сценария возможного события в системе кибербезопасности. Угол восприятия А 647 дает ограниченный объем информации о наблюдаемом объекте, поскольку он отображается в двух измерениях. Угол восприятия В 648 дает более осознанный объем информации, поскольку включает в себя третье измерение. Результат угла восприятия С 649 неизвестен нашим ограниченным возможностям мышления, так как процесс творческой гибридизации в творческом модуле 18 задействует современные возможности параллельной обработки. Алгоритм критического мышления, путем гибридизации метрик углов А и В и, соответственно, формирования новой итерации 653, обладает потенциалом для создания большего количества форм восприятия, которые могут быть за пределами человеческого понимания или экспоненциальными (не плоскостными) отношениями между сложностью итерации и экономией процессорного времени и мощности. Угол восприятия 650 задается несколькими метриками, включая, но не ограничиваясь, область, тип, интенсивность и последовательность 651. Эти метрики задают множество аспектов восприятия, которые составляют общее восприятие. Они могут стать более сложными по объему, чем приведенный выше пример, и, как следствие, можно добиться множества сложных вариаций восприятия, созданных творческим модулем. Вес восприятия 652 определяет, какое относительное влияние имеет данный факт восприятия при симуляции симулятором восприятия наблюдателя (РОЕ) 475. Данный вес обоих входящих фактов восприятия учитывается при определении веса нового итеративного восприятия 653. Новое итеративное восприятие 653 содержит гибридизированные метрики, на которые повлияло предыдущее поколение фактов восприятия А + В. Такой новый угол восприятия может потенциально предложить новую продуктивную точку зрения, чтобы программное обеспечение системы безопасности могло обнаружить скрытые эксплойты. Поколения восприятия выбираются для гибридизации посредством сочетания метода проб и ошибок и интеллектуального отбора. Если факт восприятия, особенно в новой итерации, оказывается бесполезным для предоставления информации о проблемах безопасности, его можно игнорировать, но удалять его не будут, так как есть вероятность, что оно когда-нибудь даст полезную информацию. Так, происходит трата вычислительных ресурсов компенсируется интеллектуальными ресурсами безопасности.
[0138] На Фиг. 102 показано получение необработанного восприятия (RP2) 465, представляющее собой модуль, получающий журналы метаданных из алгоритма сопоставления выбранных образцов (SPMA) 526. Такие журналы анализируют и формируют на их основе восприятие, которое отражает восприятие такого алгоритма. Восприятие хранится в сложном формате восприятия (PCF) и симулируется симулятором восприятия наблюдателя (РОЕ). Разделение системных метаданных (SMS) 487 на выходе производит отклик системы безопасности/вариативные пары 654, устанавливающие причинно-следственные отношения в системе безопасности, дополняя подходящие мер по устранению угрозы переменными-триггерами (например, субъект, местоположение, поведенческий анализ и т.д.). Формат сравниваемых переменных 547 представлен с неграфической точки зрения 655. Каждый из этих наборов фактов восприятия имеет различный состав фактов восприятия со своим удельным весом влияния для формирования CVF 547.
[0139] На Фиг. 103 показан логический порядок действий генератора формата сравниваемых переменных (CVFG) 491. На вход CVFG подают пакет данных 658, который представляет собой произвольный набор данных, которые должны быть представлены составом узлов сгенерированного CVF 547. В шаге 659 производят последовательное продвижение для каждого отдельного блока, заданного пакетом данных 658. В шаге 660 блок данных преобразуют в формат узла, который имеет тот же состав информации, на который ссылается итоговый CVF 547. Узлы являются строительными элементами для CVF и позволяют выполнять эффективные и точные оценки сравнения с другими CVF. CVF подобен необратимой хэш-сумме MDS, за тем исключением, что имеет оптимизированные для сравнения характеристики (узлы). Такие преобразованные узлы затем временно хранятся в удержании узлов 661 после доказательства их существования в шаге 665. Если они не найдены, их создают в шаге 662, а в шаге 663 обновляют с использованием статистической информации, такой как возникновение и использование. В шаге 664 все узлы в удержании 661 собирают и отправляют в виде модульного вывода в формате CVF 547. Если после запуска генератора в удержании 661 пусто, то возвращают пустой результат 618.
[0140] На Фиг. 104 посредством алгоритма сравнения узлов (NCA) 667 сравнивают два состава узлов 666 и 668, которые были считаны из необработанного CVF 547. Каждый узел в CVF представляет степень значимости свойства. Сравнение по сходству выполняют на основе отдельного узла, после чего вычисляют совокупную вариативность. Это обеспечивает эффективно высчитанное точное сравнение. Чем меньше степень вариативности - в отдельном узле или по совокупному весу, - тем более близко определено соответствие. Существует два режима сравнения: режим частичного совпадения (РММ) и режим полного совпадения (WMM). В рамках РММ, если в одном CVF есть активный узел и он не найден в кандидате для сравнение (узел неактивен), то сравнение не наказывают. Пример применимости режима: при сравнении дерева А с лесом А, дерево А найдет похожее на него дерево В, которое находится в лесу А. В рамках WMM, если в одном CVF есть активный узел и он не найден в кандидате на сравнение (узел неактивен), то сравнение наказывается. Пример применимости режима: при сравнении дерева А с лесом А совпадение не будет найдено, поскольку дерево А и лес А сравнивают напрямую, и между ними большие различия в перекрытии и структурном сходстве.
[0141] На Фиг. 105 и 106 показано разделение системных метаданных (SMS) 487, где ввод метаданных системы 484 разделяют на значимые причинно-следственные отношения в системе безопасности. В качестве вывода из МСМ 488 в шаге 672 по отдельности извлекают программные элементы журналов. В шаге 673 отдельные категории из МСМ используют для получения более подробного состава взаимосвязей между откликами системы безопасности и переменными безопасности (журналами безопасности). Эти категории 674 затем ассимилируют в шагах 669, 670 и 671. При сканировании/ассимиляции субъекта 669 субъект/подозреваемый в ситуации в системе безопасности извлекается из метаданных системы посредством предварительно созданных контейнеров категорий и необработанного анализа из модуля категоризации. Субъект используется в качестве основного ориентира для вывода взаимоотношений отклика системы безопасности/переменной. Субъект может представлять собой либо человека, либо компьютер, либо исполняемый фрагмент кода, либо сеть, либо даже предприятия в целом. Такие проанализированные субъекты 682 хранят в хранилище субъектов 679. При сканировании/ассимиляции рисков 670 факторы риска ситуации в системе безопасности извлекают из метаданных системы посредством предварительно созданных контейнеров категорий и необработанного анализа из модуля категоризации. Риск связан с целевым субъектом, который демонстрирует такой риск или подвергается ему. Риск может быть определен как потенциальная точка атаки, тип уязвимости атаки и т.п. Такие риски хранят в хранилище рисков 680 вместе со связями с субъектами из индекса субъектов 683. При сканировании/ассимиляции откликов 671 отклик ситуации в системе безопасности извлекают из метаданных системы посредством предварительно созданных контейнеров категорий и необработанного анализа из модуля категоризации. Отклик связывают с субъектом безопасности, который якобы заслуживает такого отклика. Отклики могут представлять собой разрешение, блокировку, отметку, помещение в карантин, обфускацию, имитацию сигнала, отпор и т.д. Такие отклики хранят в хранилище откликов 681 вместе со связями с субъектами из индекса субъектов 683. Такая сохраненная информация затем обрабатывается логикой модуля заполнения (PL) 483, которая распределяет все субъекты безопасности по соответствующим им рискам и откликам.
[0142] На Фиг. 107 и 108 показан модуль категоризации метаданных (МСМ) 488. В рамках разделения формата 688 разделяют и классифицируют метаданные в соответствии с правилами и синтаксисом распознанного формата. Метаданные должны быть собраны в соответствии с распознаваемым форматов, иначе их обрабатывать не будут. Правила и синтаксис локального формата 689 содержат определения, которые позволяют модулю МСМ распознавать предварительно отформатированные потоки метаданных. Под «локальным» понимают формат, который был ранее выбран, поскольку присутствует в метаданных. Трассировка отладки 485 представляет собой трассировку уровня кодирования, которая предоставляет используемые переменные, функции, методы и классы, а также соответствующий им контент/типы входных и выходных переменных. Предоставляется полная цепочка вызовов функций (функций, вызывающие другие функции). Трассировка алгоритма 486 является трассировкой программного уровня, которая выдает данные безопасности в сочетании с анализом алгоритма. Итоговое решение по безопасности (разрешение/блокировка) предоставляется вместе с описанием (обоснованием) того, как было принято это решение, и весом каждого фактора. Трассировка алгоритма 486 вызывает режим МСМ, в котором в шаге 686 циклически прокручивают каждое из обоснований решения по безопасности. Обоснования определяют, как и почему был принят определенный отклик системы безопасности, в синтаксисе компьютерного журнала (в отличие от написанного человеком). Распознаваемые форматы 687 - это предопределенные и стандартизированные форматы синтаксиса, совместимые с СМТР. Следовательно, если объявления формата из ввода метаданных системы 484 не распознаются, возвращается модульный нулевой результат 618. Программисты SPMA 526 обязаны кодировать метаданные 484 в стандартизированном формате, который распознается СТМР. Такие форматы не обязаны быть проприетарными и эксклюзивными для СТМР, такими как JSON, XML и т.д. В удержании переменных 684 хранят переменные обработки по категориям 674, так чтобы их можно было все одновременно представить как окончательный и унифицированный вывод 685. В шаге 675 проводят проверку сравнения двух основных ветвей входящей информации: трассировки отладки 485 и трассировки алгоритма 486. В рамках сравнения отслеживают возникновение обоснования на уровне программирования, чтобы лучше понять, почему произошло такое обоснование безопасности и достойно ли оно стать выводом для МСМ. Этот шаг выполняют в целях предосторожности, чтобы гарантировать, что за каждым обоснованием по безопасности есть логика и что решение хорошо понимается даже на уровне программирования, а также чтобы в дальнейшем принять потенциальную критику СТМР в целом. Точно так же подтверждение риска проверяют на предмет совпадений с помощью данных трассировки отладки в шаге 676. В шаге 677 метаданные проверяют на наличие функций, которые были вызваны SPMA, a затем данные функции проверяют с целью определить, задано ли их функциональное назначение и обоснование использования в соответствии со спецификациями распознаваемых форматов 687.
[0143] На Фиг. 109 показан процесс обработки метрик (МР) 489, в ходе которого восстанавливают переменные из алгоритма сопоставления выбранных образцов (SPMA) 526, а именно распределение инвестиций, с целью «добыть» факты восприятия из интеллекта данного алгоритма. Отклик системы безопасности Х 690 представляет собой ряд факторов, которые определяют выбор итогового отклика посредством SPMA (т.е. разрешение/блокировка/обфускация и т.п.). Каждая форма отражает отклик системы безопасности из алгоритма сопоставления выбранных образцов (SPMA). Начальный вес задается SPMA, так как используется его интеллект. Решения затем в целом используют в качестве основы для моделирования восприятия. Дедукция восприятия (PD) 490 использует часть отклика системы безопасности и соответствующие метаданные системы для воспроизведения исходного восприятия отклика системы безопасности. Интерпретация восприятия размерной серии 699 отображает, как PD будет принимать отклик системы безопасности SPMA и связывать соответствующий ввод метаданных системы 484 для воссоздания всего объема интеллектуального «цифрового восприятия», первоначально использованного в SPMA. Это дает СТМР глубокое понимание алгоритма ввода, которое затем можно повторно использовать, также ссылаясь на интеллект множества разных алгоритмов, вследствие чего, реализуется значительная веха в развитии искусственного интеллекта. Такие формы являются символом сложных правил, поведения и корреляций, реализованных в SPMA. Заполнение формы 697, количество стека 698 и пространственность 699 являются цифровыми представлениями, которые отражают «точку зрения» интеллектуального алгоритма. Пространственный тип восприятия 699 представляет собой трехмерную форму, которая может быть символическим представлением алгоритма изучения языка, толкующего внутреннюю электронную переписку сотрудника предприятия в попытке обнаружить и/или предсказать нарушение политики конфиденциальности. В то время как пространственный тип может быть одним интеллектуальным алгоритмом с небольшими вариациями (то есть вариация 694С является круглой, в то время как 695С/696С является прямоугольной, представляющей тонкие различия в интеллектуальном алгоритме), может быть несколько начальных откликов системы безопасности, по которым в общем не видно, что они сделаны по указанному алгоритму. По сути, 694А имеет больше общего с 692А, чем с 696А. Несмотря на то, что это, касалось бы, противоречит здравому смыслу, 692А - это отклик системы безопасности, который был выполнен алгоритмом заполнением формы 697 и который полностью отличается от пространственности 699. Хотя факты восприятия 695С и 696С идентичны, их соответствия в рамках откликов системы безопасности 695А и 696А имеют тонкие различия. Отклик системы безопасности 695А темнее и представляет пространственное восприятие со стороны 695В, в то время как 696А представляет точно такое же восприятие, но спереди 6968. Эти различия показывают, как разные отклики системы безопасности, направленные на различные угрозы безопасности/подозрительные события, можно проанализировать и понять, что они основаны на одном и том же интеллектуальном алгоритме. Все три экземпляра пространственных фактов восприятия 699 (два из которых идентичны) объединяют в единую единицу, на которую внутри СТМР ссылаются как на угол восприятия В 702. Вес влияния, которое данный угол восприятия имеет в СТМР, рассчитывают в соответствии с исходным весом влияния откликов системы безопасности 694А, 695А и 696А. Что касается факта восприятия количества стека 698, то вместо получения трехмерной глубины согласно, как в пространственном восприятии 699, отклик системы безопасности 693А выступает частью набора из нескольких величин. Это может быть символическим представлением алгоритма профилирования, который создает профили безопасности для новых сотрудников компании, чтобы избежать внешнего проникновения. Хотя СТМР первоначально получает только один профиль безопасности, который представлен как отклик системы безопасности 693А, на самом деле он является частью набора профилей с перекрестными ссылками друг на друга, т.н. (после того, как МР 489 выполняет анализ) восприятие количества стека 698. К такому факту восприятия в СТМР обращаются как к углу восприятия А 701. В рамках откликов системы безопасности 691А и 692А отклик системы безопасности отправляют в МР 489, символически представленный в виде неполной формы. PD 490 использует ввод метаданных системы, чтобы выяснить, что интеллектуальный алгоритм, на котором основан данный отклик системы безопасности, ищет отсутствие ожидаемой переменной безопасности. Например, это может быть алгоритм, который замечает отсутствие обычного/ожидаемого поведения, в отличие от поиска подозрительного поведения. Это может быть сотрудник компании, который подписывает свои электронные письма не так, как обычно. Это может означать либо внезапное изменение привычки, либо указание на то, что учетная запись электронной почты этого сотрудника была взломана злоумышленником, который не привык подписывать электронные письма так, как настоящий сотрудник. Такой алгоритм был проанализирован и восстановлен, чтобы стать цифровым восприятием заполненной формы 697, к которому в СТМР можно обращаться как к углу восприятия С 700 с соответствующим весом влияния.
[0144] На Фиг. 110 и 111 показано внутреннее устройство дедукции восприятия (PD) 490, которое в основном используется при обработке метрик (МР) 489. Отклик системы безопасности Х передают в качестве входных данных в расчет обоснования 704. Данный модуль определяет обоснование отклика системы безопасности в SPMA 526, задействуй целенаправленную подачу модуля сведения ввода/вывода 706, которая хранится в базе данных намерений 705. Модуль IOR интерпретирует отношение ввода-вывода функции с целью определить обоснование и назначение функции. Модуль IOR использует раздельный ввод и вывод различных вызовов функций, перечисленных в метаданных. Такое разделение метаданных выполняется модулем категоризации метаданных (МСМ) 488, выходные категории которого представлены в виде наборов 672 и 674. В JRC 704 намерения функций, сохраненные в базе данных намерений 705, проверяют по откликам системы безопасности, предоставленным в качестве входных данных 690. Если намерения функций подтверждают решения безопасности SPMA, то их представляют в качестве действительного подтверждения для обоснования преобразования метрик (JMC) 703. В модуле JMC подтвержденное обоснование отклика системы безопасности преобразуют в метрику, которая определяет характеристику восприятия. Метрики аналогичны человеческим органам чувств, и обоснование реакции безопасности представляет собой оправдание для использования того или иного чувства. Когда человек переходит через дорогу, его органы чувств (или метрики) зрения и слуха усиливаются, а обоняния и осязания - бездействуют. Эта совокупность органов чувств с соответствующими величинами интенсивности отражает восприятие «перехода через дорогу». Обоснование этой аналогии может быть следующее: «транспортные средства на дорогах могут быть опасными, но вы можете увидеть и услышать их». Следовательно, структура восприятия рационально обоснована, и образуется примерный угол восприятия С 543. Отношение ввода-вывода (IOR) определяется как единый набор ввода функций и соответствующего вывода, предоставленного той или иной функцией. IOR 706 сначала проверяет, были ли ранее проанализированы отношения ввода-вывода и «намерение» функции путем обращения к внутренней базе данных. Если информация найдена в базе данных, она используется в качестве дополнения к текущему вводу/выводу данных в шаге 708. Затем дополненный таким образом (если возможно) ввод/вывод данных проверяют на достаточную насыщенность для достижения достаточного уровня значимости анализа в шаге 714. Количество определяется в технических терминах, а минимальный уровень определяется уже существующей политикой СТМР. Если для анализа недостаточно информации ввода-вывода, то в шаге 711 анализ конкретной функции отменяется и модуль IOR 706 переходит к следующей доступной функции. Поскольку они представляют собой достаточный объем информации для анализа, отношения ввода-вывода классифицируют в соответствии со сходством 709. Например, выяснено, что одна связь ввода-вывода конвертирует одну валюту в другую (напр., доллары США в евро), в то время как другие отношения ввода-вывода переводят одни единицы массы в другую (напр., фунты в килограммы). Оба отношения ввода-вывода классифицируют как принадлежащие к преобразованию данных, поскольку концепты триггеров коррелируют с индексом категоризации. Например, в таком индексе могут быть ссылки на доллары США, евро, фунты и килограммы, которые, в свою очередь, указывают на категорию преобразования данных. Следовательно, как только эти блоки обнаруживают в отношении ввода-вывода, IOR 706 способно их должным образом классифицировать. Следовательно, предполагается, что целью функции является конвертация валюты и перевод величин. После категоризации всех доступных взаимосвязей ввода-вывода категории ранжируют в соответствии с весом взаимосвязей ввода-вывода, которое они содержат в шаге 710, причем наиболее популярные появляются первыми. В шаге 715 категории ввода/вывода данных проверяют на предмет того, способны ли они достоверно отображать суть намерения функции. Это делается путем проверки логики преобразования ввода-вывода, которое выполняет функция. Если определенные категории информации являются постоянными и четко различимыми (например, одна категория - конвертация валюты, а вторая - перевод величин), то эти категории становятся описанными «намерениями» функции. Следовательно, функция будет описана как предназначенная для конвертации валют и перевода величин. Сведение функции к ее предполагаемому назначению посредством IOR 706 имеет важные последствия для анализа безопасности, поскольку СТМР может проверить реальное назначение функции, существующей в коде, и может интеллектуально сканировать ее на наличие вредоносного поведения, прежде чем будет нанесен какой-либо ущерб в результате выполнения такого кода. Если «намерение» было хорошо понято IOR 706 с достаточной степенью достоверности, то оно представляется как модульный вывод 712. Если категории «намерение» не полностью подтверждают друг друга и «намерение» функции не было достоверно установлено, то «намерение» функции объявляется неизвестным, и IOR 706 переходит к следующей доступной функции анализа в шаге 711.
[0145] На Фиг. 112-115 показан симулятор восприятия наблюдателя (РОЕ) 475. Данный модуль симулирует наблюдателя и проверяет/сравнивает все потенциальные факты восприятия, используя различные формы симуляции наблюдателя. Входными данными, в дополнение к расширенным журналам данных, являются все потенциальные точки восприятия, а на выходе получают итоговое решение по безопасности, созданное такими расширенными журналами в соответствии с лучшим, наиболее релевантным и наиболее осторожным наблюдателем с указанной смесью выбранных фактов восприятия. Ввод метаданных системы 484 представляет собой первоначальный ввод, используемый в получении необработанного восприятия (RP2) 465 для получения фактов восприятия в формате CVF 547. В рамках поиска по хранилищу (SS) 480 используют CVF, полученный из обогащенных данными журналов, в качестве критерия поиска по базе данных в хранилище восприятия (PS) 478. PS предоставляет все доступные CVF 547 из базы данных с наиболее подходящими CVF. На их связанный состав и вес восприятия затем ссылаются, чтобы использовать при успешном событии сопоставления в результатах 716. Пересечение сходства упоминается как 60% совпадение 719 и 30% совпадение 720. Такие результаты рассчитываются в ходе поиска по хранилищу 480. Результаты 716 и совпадения 719 и 720 сохраняют и затем рассчитывают для индивидуального ранжирования фактов восприятия в рамках вычисления веса 718. Такое вычисление принимает значение общего сходства (или совпадения) из CVF базы данных по сравнению с входным CVF и умножает это значение на вес каждого отдельного факта восприятия. Такой вес уже сохранен и ассоциирован с CVF как изначально определенный в ходе обработки метрик (МР) 489. В рамках ранжирования 717 факты восприятия упорядочены в соответствии с их окончательным весом. Такое ранжирование является частью процесса отбора для использования наиболее релевантных (как взвешено в рамках вычисления веса 718) фактов восприятия для понимания ситуации безопасности и, следовательно, для подтверждения команды по блокировке 730 или разрешению 731. После ранжирования фактов восприятия их передают в приложение 729, где к ним применяют обогащенные данными журналы 723 для получения рекомендаций по блокировке/разрешению. Журналы 723 являются входными журналами системы с описанием исходного инцидента в системе безопасности. Самокритичная плотность знаний (SCKD) 492 помечает журналы для определения расчетной верхней области неизвестных знаний. Это означает, что факты восприятия могут учитывать данные, помеченные неизвестными областями данных. Это означает, что факты восприятия могут выполнять более точную оценку инцидента в системе безопасности, учитывая, что имеется оценка того, сколько известно, а сколько неизвестно. С помощью парсера данных 724 выполняют базовую интерпретацию обогащенных данными журналов 723 и ввода метаданных системы 484 с целью получить исходное решение о блокировке или разрешении 725, принятое первоначальным алгоритмом сопоставления выбранных образцов (SPMA) 526. Таким образом, существуют два возможных сценария: SPMA либо решила блокировать 730 инцидент в системе безопасностью (то есть предотвратить загрузку программы) в сценарии 727, либо решила разрешить 731 такой инцидент в сценарии 726. На этом этапе СТМР 22 уже достаточно продвинулась, чтобы выполнить свою основную задачу - раскритиковать решение (включая, но не ограничиваясь, кибербезопасность). Критика в СТМР осуществляется дважды двумя способами: один раз в симуляторе восприятия наблюдателя (РОЕ), в соответствии с восприятием, и один раз в выполнении правил (RE), в соответствии с логически определенными правилами. В рамках РОЕ после получения команды на блокировку от SPMA включается логика перехвата 732. После получения команды на подтверждения от SPMA включается логика перехвата 733. В шаге 732А по умолчанию предполагают совершение действия блокировки 730, и значения величин BLOCK-AVG и APPROVE-AVG 732В рассчитывают путем нахождения среднего значения достоверности блокировки/разрешения, хранящегося в сценарии 727. В шаге 732С проверяют, превышает ли среднее значение достоверности сценария 727 предварительно определенный (в соответствии с политикой) уровень достоверности. Если достоверность сценария низкая, это указывает на то, что СТМР скрывает критику из-за недостатка информации/понимания. При возникновении такой ситуации с низким уровнем надежности модуль обратной связи RMA 728 переходит к шагу 732D, чтобы попытаться переоценить ситуацию в области безопасности с включением большего количества фактов восприятия. Такие дополнительно учитываемые факты восприятия могут повысить степень достоверности. Таким образом, обратная связь RMA будет связываться с самим управлением и распределением ресурсов (RMA) 479, чтобы проверить, допустима ли переоценка в соответствии с политикой управления ресурсами. Если переоценка недопустима, то алгоритм достиг своего максимального потенциала доверия, и перехват первоначального решения о разрешении/блокировке окончательно прерывается на весь текущий сеанс РОЕ. В шаге 732Е обозначают состояние модуля обратной связи RMA 728, получающего разрешение от RMA 479 на перераспределение большего количества ресурсов и, следовательно, привлечения в расчет большего количества фактов восприятия в расчет. При таком условии попытка перехвата (критика СТМР) прерывается в шаге 732F, чтобы позволить провести новую оценку сценария 727 с добавлением новых фактов восприятия (и, соответственно, увеличением нагрузки на ресурсы компьютера). В шаге 732G показано, что среднее значение разрешения является достаточно достоверным (в соответствии с политикой), чтобы отменить действие блокировки по умолчанию 730/732А и выполнить вместо него действие разрешения 731 в шаге 732Н. Та же логика применяется к логике разрешения 733, которая имеет место в сценарии 726. В шаге 733А по умолчанию задано совершение действия разрешения по запросу SPMA 526. Значения величин BLOCK-AVG и APPROVE-AVG 732B рассчитывают путем нахождения среднего значения достоверности блокировки/разрешения, хранящегося в сценарии 726. В шаге 733С проверяют, превышает ли среднее значение достоверности сценария 726 предварительно определенный (в соответствии с политикой) уровень достоверности. При возникновении такой ситуации с низким уровнем надежности модуль обратной связи RMA 728 переходит к шагу 733D, чтобы попытаться переоценить ситуацию в области безопасности с включением большего количества фактов восприятия. В шаге 733Е обозначают состояние модуля обратной связи RMA 728, получающего разрешение от RMA 479 на перераспределение большего количества ресурсов и, следовательно, привлечения в расчет большего количества фактов восприятия в расчет. При таком условии попытка перехвата (критика СТМР) прерывается в шаге 733F, чтобы позволить провести новую оценку сценария 726 с добавлением новых фактов восприятия (и, соответственно, увеличением нагрузки на ресурсы компьютера). В шаге 733G обозначено, что средняя вероятность разрешения достаточно достоверна (в соответствии с политикой), поэтому перехватывают действие разрешения по умолчанию 731/733А и осуществляют вместо него действие блокировки 730 в шаге 733Н.
[0146] На Фиг. 116 и 117 показан модуль получения выводов (ID) 477, который выводит углы восприятия данных из текущих прикладных углов восприятия. Прикладные углы восприятия 470 - это набор известных фактов восприятия, которые хранятся в системе хранения СТМР. Такие факты восприятия 470 были применены и использованы SPMA 526 и затем собраны в виде набора фактов восприятия 734 и переправлены в комбинацию метрик 493. Данный модуль 493 преобразует формат углов восприятия 734 в категории метрик, т.е. в формат, распознаваемый в рамках получения выводов (ID) 477. В рамках сложности метрик 736 внешняя граница круга отражает верхнюю точку известных знаний в отношении отдельно взятой метрики. Край крута отражает большую сложность метрики, тогда как центр круга отражает меньшую сложность метрики. Светло-серая зона в центре отражает комбинацию метрик в текущей партии прикладных углов восприятия, а внешняя темно-серая зона отражает сложность метрики, хранящейся и известной системе в целом. Задача ID 477 состоит в том, чтобы увеличить сложность соответствующих метрик, так чтобы углы восприятия могли значительно увеличиться в сложности и количестве. Известную сложность метрик из текущей партии добавляют к соответствующей базе данных метрик 738, в случае если в ней еще нет такой сложности/уровня подробности. Таким образом система совершила полный цикл, и вновь сохраненную сложность метрик можно использовать в потенциальной будущей партии углов восприятия для получения выводов. Такой состав сложных метрик 736 передают в качестве ввод в расширение метрик (ME) 495, в ходе которого метрики множества разных углов восприятия сохраняют по категориям в отдельных базах данных 738. Темно-серая зона поверхности отражает общий объем текущей партии прикладных углов восприятия, а также объем, оставшийся за пределами известной верхней границы. Верхняя граница представлена пиковым знанием о каждой отдельной метрической базе данных. Следовательно, текущую партию метрик (производных из текущей партии углов восприятия) улучшают с использованием ранее известных деталей/сложности этих метрик. После улучшения и увеличения сложности метрики возвращают в виде сложности метрик 737. Как показано на диаграмме 737, светло-серая область стала больше во всех четырех секторах метрик: области 739, последовательности 749, типа 741 и интенсивности 742. Отсюда следует, что факт восприятия стал более подробным и сложным во всех четырех секторах метрик. Увеличенную сложность метрик 737 передают в качестве ввода для преобразования метрик 494, в ходе которого отдельные метрики преобразовывают обратно в полноценные углы восприятия 735. Итоговый вывод собирают в подразумеваемые углы восприятия 471, представляющие собой расширенную версию исходного ввода прикладных углов восприятия 470.
[0147] На Фиг. 118-120 показана плотность самокритичных знаний (SKCD) 492, где оценивается объем и тип потенциально неизвестных знаний, лежащих за пределами журналов и отчетов. Таким образом последующие функции критического мышления в рамках СТМР 22 могут использовать потенциальный объем всех соответствующих знаний, как известных непосредственно системе, так и неизвестных. Ниже приведен пример использования для демонстрации предполагаемой функциональности и возможностей SCKD 492:
i) Система накопила много справочного материала по ядерной физике.
ii) Система провела аналогию и выяснила, что ядерная физика и квантовая физика категорически и систематически схожи по сложности и типу.
iii) Однако объем справочных знаний по квантовой физике в системе гораздо меньше, чем по ядерной физике.
iv) Таким образом, система определяет верхнюю границу потенциально достижимого знания в квантовой физике по аналогии с ядерной физикой.
v) Система определяет, что объем известных ей знаний в области терминов квантовой физики невелик.
В модуле категоризации известных данных (KDC) 743 категорически отделяют подтвержденную (известную) информацию от ввода 746, так чтобы можно было выполнить запрос аналогии с подходящей базой данных. Информацию разделяют на категории А, В и С 750, причем каждая отдельная категория обеспечивает ввод для генератора формата сравниваемых переменных (CVFG) 491, который выводит категориальную информацию в формате CVF 547, используемый в поиске по хранилищу (SS) 480 для поиска совпадений в базе данных известного объема данных 747. В рамках базы данных 747 верхняя граница известных данных определяется в соответствии с категорией данных. Проводят сравнение между схожими типами и структурами данных для оценки достоверности объема знаний. Если SS 480 не смог найти никаких результатов, чтобы провести аналогию между знаниями в сценарии 748, то текущие данные сохраняются, чтобы можно было провести аналогию в будущем. Согласно примеру варианта использования, такой инцидент позволит определить область ядерной физики. Затем, когда в будущем будут обращаться к квантовой физике, система сможет провести аналогию между объемом своих знаний со знанием, которое на данный момент хранится в области знаний по ядерной физике. Сценарий 749 описывает ситуацию с найденными результатами, где каждую категорию помечают согласно объему известных данных в ней в соответствии с результатами SS 480. После этого в комбинаторе неизвестных данных (UDC) 744 помеченные области неизвестной информации для каждой категории повторно объединяют в один и тот же поток исходных данных (ввод 746). На выходе 745 исходные входные данные возвращают и соединяют с определениями из области неизвестных данных. На Фиг. 119 более подробно изображен модуль категоризации известных данных (KDC) 743. Известные данные 752 являются первичным вводом и содержат блоки информации 755, которые представляют определенные области данных, такие как отдельные записи из журнала ошибок. В шаге 756 производят проверку на наличие распознаваемых определений в блоке, которые покажут, в соответствии с вариантом использования, что блок помечен как информация из области ядерной физики. Если категория, соответствующая данной метке, уже содержится в удержании категорий 750, то эту ранее имеющуюся категорию усиливают подробностями в шаге 748, дополняя ее обработанным блоком информации 755. Если такой категории не существует, то она создается в шаге 749, с тем чтобы блок информации 755 можно было должным образом сохранить. Рудиментарная логика 759 последовательно перебирает блоки по кругу, пока все они не будут обработаны. После того как все они были обработаны, если минимальное количество (определенное политикой) было отправлено в удержание категорий 750, то KDC 743 формирует модульный вывод в виде нулевого результата 618. Если имеется достаточное количество обработанных блоков, тогда информацию в удержании категорий 750 передают в промежуточный алгоритм 751 (который в основном представляет собой SCKD 492). В комбинатор неизвестных данных (UDC) 744 поступают известные данные, в которых промежуточным алгоритмом 751 были отмечены неизвестные пункты данных 757. Такие данные первоначально сохраняют в удержании категорий 750, а там рудиментарная логика 760 последовательно проходит все эти единицы по кругу. В шаге 754 проверяют, содержат ли заданные категории в удержании 750 исходные метаданные, которые описывают, как преобразовать отдельные категории в связный поток информации. Такие метаданные первоначально были найдены во входных известных данных 752 из KDC 743, поскольку на этом этапе данные еще не были разделены на категории и существовала исходная единая связная структура, в которой содержались все данные. После шага 754, в котором повторно связывают метаданные с соответствующими им данными, помеченные блоки передают в удержание рекомбинации блоков 753. Если в шаге 754 не было найдено метаданных, соответствующих данным, то в удержании 753 неизбежно будет пусто и будет сгенерирован модульный нулевой результат 618. После успешного сопоставления метаданных в удержании 753 появляются данные, и модульным выводом для UDC 744 станут известные данные в сочетании с помеченными неизвестными данными 757. Блоки 755 в модульном выводе представляют исходные блоки информации, найденные в известных данных 752 из KDC 743. Пятиугольник 758 представляет определение области неизвестных данных, которая связана с каждым блоком известных данных 755.
Лексически объективный майнинг (LOM)
[0148] На Фиг. 121 показана основная логика работы лексически объективного майнинга (LOM). LOM пытается максимально приблизиться к объективному ответу на широкий круг вопросов и/или утверждений. Он взаимодействует с человеком-субъектом 800, чтобы тот уступил в споре с LOM или усилил свои аргументы. Уступка и усиление аргументов составляют основу принципа работы LOM, так как он должен быть в состоянии признать, свою ошибку, чтобы тем самым учиться на знаниях человека, от которого он и получает знания в первую очередь. LOM чрезвычайно требователен к базе данных (и, следовательно, к центральному процессору, оперативной памяти и дисковому пространству), так что центральное хранилище знаний (CKR) 806 в единой (но дублированной для резервного копирования) мастер-копии для него полезно. Сторонние приложения могут быть реализованы через платный или бесплатный API, который подключается к такой центральной мастер-копии. Деятельность LOM начинается с человека-субъекта 800, который помещает вопрос или утверждение 801 в основной визуальный интерфейс LOM. Такой вопрос/утверждение 801А передается для обработки в обоснование начального запроса (IQR) 802, где задействуется центральное хранилище знаний (CKR) 806 для расшифровки недостающих деталей, которые имеют решающее значение для понимания и ответа на вопрос/утверждение. После этого вопрос/утверждение 801 вместе с дополнительно запрошенными данными переносят в разъяснение опроса (SC) 803A, которое взаимодействует с человеком-субъектом 800 с целью получения дополнительной информации, чтобы вопрос/утверждение 801А можно было проанализировать объективно и с использованием необходимого контекста. Таким образом формируют разъясненный вопрос/утверждение 801В, который принимает исходный необработанный вопрос/утверждение 801, поставленный человеком-субъектом 800, но дополненный подробностями, полученными от 800 посредством SC 803A. В рамках построения утверждений (AC) 808A получают предложение в форме утверждения или вопроса (напр., 801 В), а на выходе получают концепты, связанные с данным предложением. Представление ответа 809 представляет собой интерфейс для представления выводов, полученных LOM (в частности, АС 808), как человеку-субъекту 800, так и рациональному обращению (RA) 811. Такой интерфейс представлен визуально для понимания человеком 800 и в чисто цифровом синтаксическом формате для RA 811. В рамках составления иерархической карты (НМ) 807 составляют карту связанных концептов для поиска совпадений или конфликтов в логике вопросов/утверждений. Зачем рассчитывают выгоды и риски обладания определенной позиции по теме. Центральное хранилище знаний (CKR) 806 представляет собой основную базу данных, куда LOM обращается за знаниями. Оно оптимизировано для эффективности запросов и логической категоризации и разделения концептов, чтобы можно было построить сильные аргументы и победить критику человека-субъекта 800. В рамках валидации знаний (KV) 806A которой получают знание высокой достоверности до критики, которое необходимо логически разделить под возможности запросов и ассимиляцию в CKR 806. Принятие отклика 810 представляет собой выбор, предоставляемый человеку-субъекту 800, в рамках которого он либо принимает отклик LOM, либо критикует его, причем если отклик принят, он затем обрабатывается в KV 805, чтобы быть сохраненным в CKR 806 в качестве подтвержденного знания (высокой достоверности) Если человек-субъект 800 не принимает отклик, его переправляют в рациональное обращение (RA) 811А, где причины апелляции, приведенные человеком 800, проверяют и критикуют. RA 811А может критиковать утверждения, либо собственные, либо принадлежащие человеку (из ответа «нет» на вопрос о принятии отклика 810).
[0149] На Фиг. 122-124 показан управляемый поставщик услуг на основе искусственного интеллекта (MAISP) 804A. MAISP запускает облачную интернет-копию LOM с мастер-копией центрального хранилище знаний (CKR) 806. MAISP 804A соединяет LOM с клиентскими службами 861А, программно-аппаратными службами 861 В, зависимостями сторонних приложений 804С, источниками информации 804 В и облаком MNSP 9. К клиентским службам 861А относятся личные помощники с искусственным интеллектом (напр., Apple Siri, Microsoft Cortana, Amazon Alexa, Google Assistant), приложения и протоколы связи (напр., Skype, WhatsApp), приложения для «умного дома» (напр., управление холодильником, гаражом, дверями, термостатами) и медицинские приложения (напр., перепроверка диагноза, история болезни). К программно-аппаратным службам 861В относятся онлайн-покупки (напр., через Amazon.com), онлайн-транспорт (напр., Uber), заказ медицинских рецептов (напр., CVS) и т.п. Указанные клиентские службы 861А и программно-аппаратные службы 861В взаимодействуют с LOM через документированную инфраструктуру API 804F, что позволяет стандартизировать протоколы и передачу информации. LOM извлекает знания из внешних источников информации 8048 посредством механизма автоматизированных исследований (ARM) 805В.
[0150] На Фиг. 125-128 показана структура зависимостей LOM, иллюстрирующая систему взаимозависимости между модулями. В рамках лингвистического построения (LC) 812A интерпретируют необработанные вопросы/утверждения, введенные человеком-субъектом 800 и полученные от параллельных модулей для создания логического разделения лингвистического синтаксиса, который будет понятен системе LOM в целом. В ходе обнаружения концептов (CD) 813A получают точки интереса в рамках разъясненного вопроса/утверждения 804 и выводят связанные концепты путем задействования CKR 806. В рамках приоритизации концептов (СР) 814А получают подходящие концепты и упорядочивают их по логическим уровням, отражающим конкретность и обобщенность. Верхний уровень назначают наиболее обобщенным концептам, тогда как нижние уровни назначают наиболее конкретным концептам. Логика разделения откликов (RSL) 815A задействует LC 812A для понимания человеческого отклика и связывания подходящего и работающего отклика с первоначальным запросом на разъяснение, тем самым выполняя задачу SC 803A. LC 812A затем повторно задействуют во время фазы вывода, чтобы внести поправки в исходный вопрос/утверждение 801 с целью включить туда дополнительную информацию, полученную SC 803. Модуль человеческого интерфейса (Human Interface Module, HIM) 816A предоставляет четкие и логически разделенные подсказки человеку-субъекту 800 для заполнения пробелов в знаниях, указанных в обосновании первоначального запроса (Initial Query Reasoning, IQR) 802A. В построении контекста (СС) 817А используют метаданные от построения утверждений (AC) 808A и потенциальные доказательства от человека-субъекта 800 для передачи необработанных фактов в СТМР для критической обработки. В рамках сравнения решений (DC) 818A определяют степень совпадения решений до критики и после критики. В ходе определения совместимости концептов (CCD) 819A сравнивают производные концептов от исходного вопроса/утверждения 801 с целью подтвердить результат логической совместимости. Такие концепты могут представлять обстоятельства, состояния, обязательства и т.д. Калькулятор выгод/рисков (BRC) 820A получает результаты совместимости от CCD 819 и взвешивает выгоды и риски с целью сформировать единое решение, которое охватывает градиенты переменных, входящих в состав концепта. В рамках взаимодействия концептов (CI) 821А назначают характеристики, которые относятся к концептам AC 808A и к частям информации, полученной от человека-субъекта 800 посредством разъяснения опроса (SC) 803A.
[0151] На Фиг. 129 и 130 показана внутренняя логика обоснования первоначального запроса (IQR) 802A. В лингвистическое построение (LC) 812A, выступающее в качестве алгоритма IQR 802, поступает исходный вопрос/утверждение 801 от человека-субъекта 800. Вопрос/утверждение 801 лингвистически разделяют, чтобы IQR 802A была возможность обрабатывать каждое слово/фразу по отдельности. Вспомогательный глагол «should» 822 создает недостаток ясности в отношении временного измерения 822. Следовательно, для разъяснения формируют встречные вопросы, такие как «Каждый день?», «Каждую неделю?» и т.д. Подлежащее «I» 823 создает недостаток ясности относительно того, кто является деятелем; следовательно, формируют дополнительные вопросы, которые задают человеку-субъекту 800. Сказуемое «eat» 824 не обязательно неясно, но способно дополнить другие точки анализа, которые не ясны. В IQR 802 концепт еды объединяют с концептами здоровья и денег в шагах 824, используя базу данных CKR 806. Все это используют для запроса «Субъект задает вопрос» 823, чтобы задать более подходящие и уместные дополнительные вопросы, например: «Мужчина или женщина?», «Диабетик?», «Занятия спортом?», «Покупательная способность?». Существительное «фаст-фуд» 825 вызывает недостаток ясности в том, как следует его толковать. Его можно истолковать как в простейшем смысле, т.е. «еда, которая подается очень быстро» в техническом значении 827, так и в более распространенном понимании 826 «жареные соленые продуктов, которые очень дешевы и очень быстро готовятся по заказу». Салат-бар технически является местом быстрого получения готовой еды. Однако это техническое определение соответствует более распространенному концепту «фаст-фуд». Обращаясь к CKR 806, IQR 802 рассматривает потенциально возможные варианты с учетом неоднозначности значения термина «фаст-фуд». Такие неоднозначные варианты, такие как «Бургерная?» или «Салат-бар?», могут направлены человеку-субъекту 800 посредством модуля человеческого интерфейса (HIM) 816. Однако в CKR 806 может быть достаточно информации, чтобы понять, что общий контекст вопроса 801 подсказывает более распространенное толкование 826. CKR 806 способен представлять такой общий контекст, постепенно поняв, что существуют противоречия, связанные с фаст-фудом и здоровьем. Следовательно, существует высокая вероятность того, что вопрос 801 ссылается на данное противоречие, поэтому HIM 816 не нужно вызывать для дальнейшего разъяснения с помощью человека-субъекта 800. Поэтому IQR 802 стремится расшифровать очевидные и тонкие нюансы в определениях. Вопрос 828 указывает LOM в целом, что человек-субъект 800 задает вопрос, а делает утверждение.
[0152] На Фиг. 131 показан процесс разъяснения опроса (SC) 803, куда поступает ввод из IQR 802. Такой ввод содержит ряд запрошенных разъяснений 830, на которые человек-субъект 800 должен ответить, чтобы был получен объективный ответ на первоначальный вопрос/утверждение 801. Таким образом, запрошенные разъяснения 830 направляют в модуль человеческого интерфейса (HIM) 816B. Любой предоставленный ответ на такие разъяснения направляют в логику разделения ответов (RSL) 815A, которая после этого соотносит ответы с запросами на разъяснение. Одновременно с обработкой запрошенных разъяснений 830 предоставляют лингвистическую ассоциацию разъяснений 829 в лингвистическое построение (LC) 812A. Данная ассоциация 829 содержит внутренние связи между запрошенными разъяснениями 830 и структурой языка. Это, в свою очередь, позволяет RSL 815A внести поправки в исходный вопрос/утверждение 801, в результате чего LC 812A может вывести разъясненный вопрос 804, в который включена информация, полученная посредством HIM 816.
На Фиг. 132 показан процесс построения утверждений (АС) 808, куда поступает разъясненный вопрос/утверждение 804, сгенерированный в ходе разъяснения опроса (SC) 803. Затем LC 812A разбивает вопрос на точки интереса 834 (ключевые концепты), которые передают в обнаружение концептов (CD) 813. Затем в CD извлекают ассоциированные концепты 832 путем задействования CKR 806. В рамках приоритизации концептов (СР) 814А концепты 832 упорядочивают по логическим уровням, указывающим на обобщенность/конкретность. Верхний уровень назначают наиболее обобщенным концептам, тогда как нижние уровни назначают наиболее конкретным концептам. Данное упорядочение было облегчено благодаря данным, предоставленным CKR 806. Верхний уровень переносят в составление иерархических карт (НМ) 807 в качестве модульного ввода. Одновременно с этим НМ 807 получает точки интереса 834, которые обрабатываются его зависимым модулем взаимодействия концептов (CI) 821. CI присваивает атрибуты точкам интереса 834, обращаясь к индексированной информации, доступной в CKR 806. После того как НМ 807 завершит свой внутренний процесс, его окончательный результат возвращают в АС 808. Перед этим производные концепты проверяют на совместимость, а пользу/риск позиции взвешивают и выдают. Это так называемый модульная выходная петля обратной связи 833, поскольку АС 808 и НМ 807 совершили полный цикл и будут продолжать посылать друг другу модульный выход до тех пор, пока не произойдет полное насыщение анализа сложностью концептов и пока в CKR 806 не образуется узкого места из-за ограничения знаний (в зависимости от того, что наступит раньше).
[0153] На Фиг. 133 и 134 показано внутреннее устройство и принцип работы составления иерархических карт (НМ) 807. АС 808 обеспечивает одновременно два типа ввода для НМ 807. Один из них известен как концептуальные точки интереса 834, а другой - это верхний уровень приоритизированных концептов 837 (наиболее общих). В рамках взаимодействия концептов (CI) 821 используют оба входа для связи контекстуализированных выводов с точками интереса 834, как показано на Фиг. 128. CI 821 предоставляет входные данные в CCD 819, который определяет уровень совместимости/конфликта между двумя концептами Это дает НМ 807 общее понимание согласованности между утверждениями и/или суждениями человека-субъекта 800 и достоверными знаниями, индексированными в центральном хранилище знаний (CKR) 806. Данные о совместимости/конфликте пересылают в калькулятор выгод/рисков (BRC) 820, где совместимость и конфликты переводят в выгоды и риски, связанные с принятием целостной единообразной позиции по проблеме. Так, например, в зависимости от варианта использования могут возникнуть три основные позиции (в соответствии с критериями, установленными человеком-субъектом 800): фаст-фуд в целом не рекомендуется, фаст-фуд допустим, но не поощряется, или же фаст-фуд в целом рекомендуется. Такие позиции вместе с их факторами риска/пользы направляют в АС 808 в виде модульного вывода 836. Это один из нескольких моментов в LOM, когда поток информации прошел полный круг, так как АС 808 будет пытаться способствовать расширению утверждений, выдвинутых НМ 807. Система, содержащая циклы информационного потока, указывает на то, что градиенты интеллекта постепенно дополняются, поскольку субъективный характер вопроса/утверждения представляет собой постепенно выстраиваемый объективный ответ. Так, например, медоносная пчела ищет нектар цветка, одновременно собирая пыльцу, которую затем переносит на другие цветы. Такое опыление приводит к увеличению количества цветов, что в конечном итоге привлекает еще больше пчел. Так и в рамках LOM возникает взаимосвязанная информационная экосистема для постепенного «опыления» утверждений и развития концептов, пока система не достигнет сильной уверенности в позиции по теме. Внутреннее устройство взаимодействия концептов (CI) в качестве модуля НМ 807 показано на Фиг. 128. В CI 821 поступают точки интереса 834, которые там интерпретируют в соответствии с верхним уровнем приоритизированных концептов 837. Два из приоритизированных концептов верхнего уровня в этом примере - это «здоровье» и «бюджетные ограничения» 837. Следовательно, когда CI пытается интерпретировать точки интереса 834, то делает это через призму этих тем. Точка интереса «диабетик» 838 приводит к утверждениям «дорогие лекарства» в отношении «бюджетных ограничений» 837 и «более хрупкое здоровье» / «непереносимость сахара» в отношении «здоровья» 837. Точка интереса «мужчина» 839 приводит к утверждению «как правило, не имеет свободного времени», которое, однако, имеет низкую степень достоверности, так как система устанавливает, что требуется более конкретное определение, например, «трудоголик» и т.п. Вопрос времени имеет обратную пропорциональную связь с «бюджетными ограничениями», так как система заметила корреляцию между временем и деньгами. Точка интереса «средний класс» 840 приводит к утверждению «может позволить себе более качественную еду» в отношении «бюджетных ограничений» 837. Точка интереса «Burger King» 841 приводит к утверждениям «дешево» и «экономия» в отношении «бюджетных ограничений» 837 и «высокое содержание сахара» и «жареная пища» в отношении «здоровья» 837. Такие утверждения формируют путем обращения к устоявшимся и достоверным знания, хранящимся в CKR 806.
[0154] На Фиг. 135 и 136 схематично показано внутреннее устройство рационального обращения (RA) 811, где критикуют утверждения: как самокритику, так и критику в ответах человека. LC 812A выступает в качестве основного подкомпонента RA 811 и получает входные данные от двух потенциальных источников. Один из источников - если человек-субъект 800 отклоняет мнение, отстаиваемое LOM в шаге 842. Другой источник - представление ответа 843, в рамках которого в цифровой форме передают утверждение, созданное АС 808, для самокритики внутри LOM. После того как LC 812A преобразовал лингвистический текст в синтаксис, понятный остальной системе, его обрабатывают в рамках RA посредством ядерной логики 844. Далее, ядерная логика возвращает результат, в котором, если результат высокой степени достоверности 846, то его передают в валидацию знаний (KV) 805 для правильной ассимиляции в CKR 806. Если результат, выданный ядерной логикой, низкой степени достоверности 845, то его передают в АС 808 для продолжения цикла самокритики (еще один элемент LOM прошел полный круг). В ядерную логику 844 поступают входные данные от LC 812A в виде решения до критики 847 без лингвистических элементов (вместо этого используют синтаксис, оптимальный для искусственного интеллекта). Данное решение 847 переправляют в СТМР 22 в виде раздела «субъективного мнения» 848. Также решение 847 направляют в построение контекста (СС) 847, где используют метаданные от АС 808 и потенциальные доказательства от человека-субъекта 800 для передачи необработанных фактов (т.е. системных журналов) в СТМР 22 в качестве входного «объективного факта». При этом СТМР 22 при получении двух обязательных входных видов данных обрабатывает их для получения наилучшего возможного варианта «объективного мнения» 850. Данное мнение 850 обрабатывают внутри RA 811 в качестве решения после критики 851. Решения как до критики 847, так и после критики 851 направляют в сравнение решений (DC) 818, в рамках которого определяют степень совпадения данных решений 847 и 851. Затем либо признают истинными 852 аргументы апелляции, либо улучшают 853 контраргумент, чтобы объяснить, почему апелляция недействительна. Такую оценку проводят, не обращая внимание на то, откуда поступил апелляция: от искусственного интеллекта или от человека. В случае же если исход сценария уступки 852/улучшения 852 неважен, результат высокой степени достоверности 846 передают в KV 805, а результат низкой степени достоверности 845 передают в АС 808 для дальнейшего анализа.
[0155] На Фиг. 137 и 138 схематично показано внутреннее устройство центрального хранилища знаний (CKR), где хранятся и объединяются сведения из базы данных LOM. Единицы информации хранят в формате единиц знаний (UKF), существующем в трех видах: UKF1 855А, UKF2 855В, UKF3 855С. UKF2 855В - это основной формат, где целевая информация хранится в формате синтаксиса правил (RSF) 538, выделенном как величина 865Н. Индекс 856D представляет собой цифровое хранилище и точку обращения к жалобам/совместимую с обработкой, которая обеспечивает обращение к большим наборам данных, при этом экономя ресурсы системы. Данный основной блок информации ссылается на метку времени 856С, которая является ссылкой на отдельную единицу знания посредством индекса 856А, известного как UKF1 855А. Такая единица не имеет раздела метки времени 856С, как у UKF2 855В, а вместо этого хранит большое количество информации о метках времени в разделе величины 856Н в формате RSF 538. Формат синтаксиса правил (RSF) 538 - это набор синтаксических стандартов для отслеживания ссылок на правила. Для описания одного объекта или действия можно задействовать несколько единиц правил из RSF 538. RSF активно используется непосредственно в СТМР. UKF1 855А содержит раздел привязки к источнику 856В, который является ссылкой на индекс 856G копии UKF3 855С. Такая единица UKF3 855С является отражением UKF1 855А, поскольку имеет раздел метки времени, но не имеет раздела привязки к источнику. Это связано с тем, что UKF3 855С хранил содержимое привязки к источнику 856Е и 856В в своем разделе величины 856Н в RSF 538. Привязка к источнику представляет собой набор сложных данных, которые отслеживают заявленные источники информации. Такие источники получают статусы достоверности в соответствии с подтверждающими и оправдывающими факторами по результатам обработки в KCA 816D. Поэтому кластер UKF 854F состоит из цепочки вариантов UKF, связанных с целью определить юрисдикционно раздельную информацию (время и источник определяются динамически). Резюмируя: UKF2 855В содержит основную целевую информацию. UKF1 855А содержит данные о метке времени и, следовательно, не содержит само поле метки времени для избежания бесконечного регресса. UKF3 855С содержит данные о привязке к источнику и, следовательно, не содержит соответствующего поля для избежания бесконечного регресса. Каждый UKF2 855В должен сопровождаться по крайней мере одним UKF1 855А и одним UKF3 855С, иначе кластер (последовательность) считается неполным, и информация в нем еще не может быть обработана общесистемной общей логикой LOM 859. Между центральным UKF2 855В (с центральной целевой информацией) и соответствующими ему блоками UKF1 855А и UKF3 855С могут стоять блоки UKF2 855В, выступающие в качестве цепного моста. Последовательность кластеров UKF 854D будет обработана KCA 816D для формирования производного утверждения 854В. Точно так же последовательность кластеров UKF 854E будет обработана KCA 816D для формирования производного утверждения 854С. В ходе анализа совпадения знаний (KCA) 816D кластерную информацию UKF сравнивают для подтверждения доказательств о предвзятой позиции. Данный алгоритм учитывает надежность привязанного источника, когда заявление было предъявлено, оправдывающие доказательства и т.д. Поэтому после завершения обработки в KCA 816D CKR 806 может вывести окончательное мнение по теме 854А. CKR 806 никогда не удаляет информацию, поскольку даже информация, определенная как ложная, может быть полезна для отделения истины от лжи в дальнейшем. Следовательно, CKR 806 использует продвинутую службу пространства для хранения 854G, которая может обрабатывать бесконечно растущий набор данных CKR 806 и масштабироваться под него.
[0156] На Фиг. 139 показан механизм автоматизированных исследований (ARM) 8058, который непрерывно пытается снабжать CKR 806 новыми знаниями с целью повысить общие возможности LOM по оценке и принятию решений. Как показывает деятельность пользователя 857А, по мере взаимодействия пользователя с концептами LOM (через любое доступное клиентское приложение), они прямо или косвенно приводятся в качестве релевантных для отклика на вопрос/утверждение. Ожидается, что деятельность пользователя 857 в конечном итоге предоставит концепты, для которых в CKR 806 сведений мало или нет вообще, как указано в списке запрашиваемых, но недоступных концептов 8578. Посредством сортировки и приоритизации концептов (CSP) 821В принимают определения концептов из трех независимых источников и собирают вместе для определения приоритетов ресурсов (ширины канала и т.п.) информационного запроса (IR) 812В. Модуль IR 812В получает доступ к соответствующим источникам для получения конкретно определенной информации. Информацию определяют согласно типам концептов. Такие источники обозначены как общедоступные источники новостей 857С (новостные службы, напр., Reuters, New York Times, Washington Post и др.), архивы общедоступных данных 8570 (информационные агрегаторы, напр., «Википедия», Quora и др.), и социальные сети/средства социального взаимодействия 857Е (напр., Facebook, Twitter и др.). Данные, предоставляемые источниками информации, получают и обрабатывают в агрегаторе информации (IA) 821В в соответствии с тем, какое определение концепта запросило их и какие релевантные метаданные сохранены. После этого информацию отправляют в анализ перекрестных ссылок (CRA) 814В, где полученную информацию сравнивают и строят с учетом ранее имевшихся знаний из CKR 806. Таким образом всю вновь поступающую информацию можно оценивать и подтверждать в соответствии с тем, что CKR 806 известно и неизвестно на данный момент. Стилометрическое сканирование (Stylometric Scanning, SS) 808В - это дополнительный модуль, который позволяет CRA 814В рассматривать стилометрические подписи, объединяющие новую информацию с ранее существующими знаниями из CKR 806. Отсутствующие концепты зависимости 857F - это концепты, которые логически необходимо понимать в качестве основы для понимания первоначального целевого концепта (то есть, чтобы понять, как устроен грузовик, нужно сначала изучить и понять устройство дизельного двигателя). Такие отсутствующие концепты передают в CSP 821В для обработки. Список активных концептов 857G включает в себя популярные темы, которые оцениваются как наиболее активные в CKR 806. Концепты 857G передают в творческий генератор концептов (CCG) 820В, где они затем творчески подбираются (посредством творческого модуля 18) для создания новых потенциальных концептов. Этот механизм зависит от возможности того, что одна из этих смесей выдаст новые объемы информации из источников 857С, 857D, 857Е, подключенных к IR 812В.
Пример использования стилометрии:
Новые внешние данные 858А помечены как полученные от известного репортера CNN. Однако было найдено очень сильное стилометрическое совпадение с подписью военного аналитического центра. Следовательно, CKR 806 в основном привязывает контент к военному аналитическому центру, который только «подается» как будто от CNN. Таким образом, возможно дальнейшее сравнение образцов и обнаружение злого умысла для последующего применения логики LOM (например, проверки в будущем, действительно ли контент был предоставлен каналом CNN). После этого оценки совпадений, конфликтов и предвзятости оценивают, как если бы контент поступил из аналитического центра, а не из CNN.
[0157] На Фиг. 140 показано стилометрическое сканирование (SS) 808, в ходе которого анализируют стилометрическую подпись 858С нового внешнего контента (который еще не попал в систему). Стилометрия - это статистический анализ различий в литературном стиле между писателями или жанрами. Это помогает CKR 806 в отслеживании ожиданий источника данных/утверждений, что дополнительно помогает LOM обнаруживать подтверждающие утверждения. В рамках заключения о подписи (SC) 819В на привязку контента новых внешних данных 858А к источнику влияют любые существенные совпадения в стилометрической подписи 858С. Чем сильнее стилометрическое совпадение, тем сильнее привязка к источнику в соответствии со стилометрией. В рамках запроса на подпись (SQ) 807В стилометрическую подпись 858С сопоставляют со всеми известными подписями из SI 813В. Любые совпадения в любых значительных градиентах степени записываются. Индекс подписей (SI) 813B представляет собой список всех известных стилометрических подписей 858С, полученных из CKR 806. Как показывает сторонний алгоритм стилометрии 858В, LOM зависит от должным образом выбранного продвинутого и эффективного алгоритма стилометрии.
[0158] На Фиг. 141 показана система перехвата по предположению (AOS) 815В, которая получает предложение в форме утверждения или вопроса и выводит концепты, связанные с данным предложением. В рамках сопоставления определений концептов (CDM) 803B все запрограммированные предположения 858D, предоставленные человеком-субъектом 800, проверяются по модулю интерпретации зависимостей (DI) 816В. Все концепты проверяют по этике/приватности/праву (EPL) 811В на предмет возможных нарушений. В модуле 816В интерпретации зависимостей (DI) осуществляется доступ ко всем основанным на знаниях зависимостям, которые удовлетворяют данному отклику на запрос данных. Таким образом извлекают полное «дерево» информации, из которого формируют в высокой степени объективное мнение. Запрошенные данные 858Е - это данные, запрошенные общесистемной общей логикой LOM 859, как в виде конкретного, так и в виде условного запроса. По конкретному запросу ищут точно помеченный набор информации. По условному запросу ищут всю информацию, которая отвечает заданным условиям.
[0159] На Фиг. 142 показаны интеллектуальное управление информацией и конфигурацией (I2CM) 804E и консоль управления 804D. При сборе 860А используют критерии общего уровня для отсеивания неважной и лишней информации, а также сливают и помечают потоки информации с множества платформ. В рамках решения дилеммы угрозы 860В угрозу концептуальных данных рассматривают с высоты птичьего полета. Такую угрозу передают в консоль управления для графического отображения. Поскольку рассчитанные измерения, относящиеся к механике угрозы, в конечном итоге объединяются с нескольких платформ, можно автоматически выполнить более обоснованное решение по борьбе с угрозами. Автоматизированные элементы управления 860С представляют собой доступ алгоритма к управлению MNSP 9, доверенной платформой 860Q и сторонними службами 860R. Элементы управления обратной связью 860D предлагают управление высокого уровня для облака MNSP 9, доверенной платформы (ТР) 860Q, дополнительных сторонних служб 860R, которые могут быть использованы для помощи в разработке политики, экспертизе, расследовании угроз и т.д. Такие элементы управления 860D в конечном итоге проявляются на консоли управления (МС) 804D с соответствующим настраиваемым отображением и эффективностью представления. Таким образом достигается эффективное управление и манипуляция всеми системами (MNSP, ТР, 3PI) напрямую и с единого интерфейса который может при необходимости сфокусироваться на конкретных деталях. Ручное управление 860Е представляет собой доступ человека к элементам управления MNSP 9, доверенной платформой 860Q и сторонними службами 860R, связанным с администрированием. На этапе интеллектуальной контекстуализации 860F все оставшиеся данные выглядят, как кластер островов, где каждый остров представляет собой угрозу концептуальных данных. Для развития анализа концептов устанавливают связи между платформами. Для понимания закономерностей угроз обращаются к историческим данным (из I2GE 21 в отличие от LIZARD), a CTMP 22 используется для анализа критического мышления. Служба настройки и размещения 8606 представляет собой интерфейс для размещения новых устройств (компьютеров, ноутбуков, мобильных телефонов) на предприятии с нужными настройками концептуальных данных и подключения. Когда устройство добавлено и настроено, настройки можно корректировать посредством консоли управления (МС) 804D через посредничество элементов управления обратной связью 8600. Эта служба также управляет созданием новых учетных записей клиентов/посетителей. Этот процесс может включать в себя связь оборудования с учетными записями пользователей, настройку интерфейса, перечисление переменных клиентов/посетителей (напр., тип деятельности, тип продукта и т.д.). В рамках разделения по юрисдикции 860Н размеченный пул информации делят исключительно в соответствии с юрисдикцией конкретного пользователя консоли управления 804D. В рамках разделения по угрозам 860I информацию организуют в соответствии с отдельными угрозами (т.е. угрозами концептуальных данных). Каждый тип данных либо связывают с угрозой (что добавляет многословности), либо удаляют. Прямое управление 8601 - это интерфейс для подключения пользователя МС 804D к элементам управления обратной связью 8600 посредством ручного управления 860Е. В рамках категории и юрисдикции 860Н пользователь МС 804D использует свои входные учетные данные для определения своей юрисдикции и объема доступа к информации. Все потенциальные векторы данных 860L - это данные в движении, используемые данные и неподвижные данные. Настраиваемое отображение 860М используется различными подразделениями предприятия (бухгалтерия, финотдел, отдел кадров, IT-отдел, юротдел, отдели безопасности/генеральный инспектор, отдел конфиденциальной информации, профсоюз и т.д.) и другими заинтересованными сторонами (сотрудники, руководители, начальники отделов), а также сторонними партнерами, правоохранительными органами и т.д. Единый вид всех аспектов концептуальных данных 860N - это периметр, предприятие, центр обработки данных, облако, съемные носители, мобильные устройства и т.д. Интегрированное единое представление 600 - это единое представление всех потенциальных возможностей, таких как мониторинг, ведение журнала, отчетность, сопоставление событий, обработка предупреждений, создание политики/набора правил, меры по устранению угрозы, настройка алгоритмов, предоставление услуг (новые клиенты/модификации), использование доверенной платформы, а также сторонних служб (включая получение отчетов и предупреждений/журналов и т.д. от сторонних поставщиков услуг). Команда по концептуальным данным 860Р - это команда квалифицированных специалистов, контролирующих деятельность и состояние нескольких систем по всем направлениям. Поскольку производится интеллектуальная обработка информации и принимаются решения посредством ИИ, затраты могут быть снижены за счет найма меньшего количества людей с меньшим опытом работы. Основная цель группы состоит в том, чтобы выступать резервным слоем и контролировать развитие системы в соответствии с желаемыми критериями при выполнении крупномасштабного анализа.
[0160] На Фиг. 143 показан профиль личного интеллекта (PIP) 802C, где хранятся личные данные отдельного человека с нескольких потенциальных конечных точек и клиентов. Эти данные надежно изолированы от CKR 806, однако доступны для общесистемной общей логики LOM 859, в которой происходит принятие высокоперсонализированных решений. В соответствии с личной аутентификацией и шифрованием (РАЕ) 803С входящий запрос на данные должен сначала аутентифицировать себя, чтобы гарантировать, что доступ к персональным данным предоставлен только нужному пользователю. Личная информация, относящаяся к приложениям искусственного интеллекта, зашифрована и хранится в личном пуле кластеров UKF 815C в формате UKF. Данные процесса анонимизации информации (IAP) 816С дополняют в CKR 806 после удаления всех идентифицирующих личность данных. Даже после того как личные данные устраняют из потока данных, IAP 816С пытается предотвратить предоставление слишком большого количества параллельных данных, которые могут быть подвергнуты обратному разбору (например, судебно-детективная работа) с целью выяснить личность человека. Полученные данные анализа перекрестных ссылок (CRA) 814 сравнивают и строят с учетом ранее существовавших знаний из CKR 806. Таким образом всю вновь поступающую информацию можно оценивать и подтверждать в соответствии с тем, что CKR 806 известно и неизвестно на данный момент. При любом запросе на данные доступ к информации всегда осуществляют в CKR 806. Если в запросе на данные указаны персональные критерии, то к PIP 802C обращаются через объединение персональных и общих данных (PGDM) 813C, а также основываются на основных знаниях CKR 806.
[0161] На Фиг. 144 показана администрация и автоматизация жизни (LAA) 812D, которая объединяет различные устройства с подключением к Интернету и сервисы на единой платформе, посредством которой автоматизируют выполнение повседневных задач и решение единичных ситуаций. Активное принятие решений (ADM) 813D - это центральная логика LAA 812D, которая учитывает доступность и функционал клиентских служб 861А, программно-аппаратных служб 861В, IoT-устройств 862А, правил расходов и сумм, доступных в соответствии с FARM 814D. В рамках правил и управления распределением средств (FARM) 814D человек вручную задает критерии, пределы и область действия модуля, чтобы информировать ADM 813D, в чем состоит его юрисдикция. Человек-субъект 800 вручную депонирует средства криптовалюты (напр., биткойны) на цифровой кошелек 861С, тем самым задавая верхний предел суммы, которую может потратить LAA 812D. Модуль взаимодействия с IoT (IIM) 815D поддерживает базу данных о том, какие IoT-устройства 862А доступны человеку. Ключи и механизмы аутентификации хранятся здесь для обеспечения безопасного управления 862С IoT-устройствами 862А. Производители/разработчики продукта 861F предоставляют программируемые конечные точки API для LAA 812D в виде программирования взаимодействий в программах IoT 861Е. Такие конечные точки используются, в частности, модулем взаимодействия с IoT (IIМ) 815D. Потоки данных 862В возникают, когда устройства с поддержкой IoT 862А отправляют информацию в LAA 8120, так чтобы можно было выполнять интеллектуальные и автоматизированные действия. Пример: Термостат, сообщающий температуру, холодильник, сообщающий запасы молока. Управление устройствами 862С обозначает, что устройства с поддержкой IoT 862А получают команды на выполнение действий от LAA 812D. Пример: Включить кондиционирование воздуха, открыть ворота для доставки посылки и т.п. К категориям клиентских служб 861А относятся:
i) Личные помощники с искусственным интеллектом
ii) Приложения и протоколы связи
in) «Умный дом «
iv) Медицинские интерфейсы
v) Службы отслеживания посылок
К программно-аппаратным службам 861В относятся:
vi) Онлайн-заказы через Amazon
vii) Транспортные приложения (напр., Uber)
viii) Медицинские рецепты
Ниже приведен обобщенный пример использования с целью продемонстрировать функционал LAA 812D: Холодильник с поддержкой IoT обнаруживает, что молоко заканчивается. С помощью эмоционального интеллекта LOM провел анализ того, что настроение субъекта имеет тенденцию быть более негативным, когда он не пьет жирного молока. Оценив риски и пользу в текущей жизненной ситуации субъекта, LOM размещает заказ на жирное молоко в онлайн-службе доставки (например, Amazon). LOM отслеживает отправление молока по трекинг-номеру и открывает ворота дома, чтобы молоко доставили на территорию дома. После того как доставщик уходит, LOM закрывает ворота. Все это время он следит за безопасностью, на случай если доставщик окажется злоумышленником. После этого простой колесный робот с простым манипулятором забирает молоко и помещает его в холодильник, чтобы оно остыло и не испортилось.
[0162] На Фиг. 145 показан процесс мониторинга поведения (ВМ) 819С, включающий мониторинг пользовательских запросов на получение персональных данных на предмет наличия в них материалов, нарушающих этику и/или закон. С помощью сбора метаданных (MDA) 812C данные, относящиеся к пользователю, собирают из внешних служб с тем чтобы установить цифровую личность пользователя (т.е. IP-адрес, МАС-адрес и т.п.). Такие данные передают в индукцию 820С/дедукцию 821C и, в конечном итоге, в PCD 807С, где проводится сложный анализ с подтверждающими факторами из MNSP 9. Пример: Пользователь, взаимодействующий с торговым порталом amazon.com в качестве клиента, передает свой IP-адрес в поведенческий контроль (ВМ) 819С LOM в целях безопасности. Вся информация от аутентифицированного пользователя, которая предназначена для PIP 802C, проходит через отслеживание информации (IT) 818C и проверяется по «черному списку поведения» 864А. Пример: Пользователь задает вопрос о химическом составе серы. Информацию, которая (частично или полностью) совпадает с элементами из черного списка 863В, передают из IT 818C в индукцию 820С и дедукцию 821C. В обнаружении до совершения преступления (PCD) 807C данные дедукции и индукции объединяют и анализируют с целью получения выводов до совершения преступления. При обнаружении значительного объема совпадений сведения преступного характера и выясненную личность пользователя передают в правоохранительные органы. PCD 807C использует СТМР 22, который напрямую обращается к черному списку поведения 864А для проверки позиций, сформированных индукцией 820С и дедукцией 821C. Управление черным списком (ВМА) 817D работает внутри фреймворка облачной службы MNSP 9. ВМА 817D публикует и поддерживает черный список поведения 864А, в котором определены опасные концепты, требующие мониторинга пользователей для предотвращения преступлений и поимки преступников. ВМА 864В также публикует и поддерживает черный список EPL (этика/приватность/право) 864В, в котором отмечены конфиденциальные сведения, которые нельзя передавать в LOM в качестве результата запроса. К таким конфиденциальным сведениям могут относиться украденные документы и персональные данные (например, номер социального страхования, номер паспорта и т.п.). В ВМА 864В интерпретируют подходящие и применимые законы и политики с точки зрения этики, защиты персональных данных и права (т.е. политики кибербезопасности, политики приемлемого использования и проч.). Черный список обычно включает концепты-триггеры, которые могут вызвать подозрение насчет пользователя, который слишком часто обращается к таким концептам. Черный список также может быть ориентирован на конкретных лиц и/или организации, например, на те, что объявлены в розыск. Предотвращение будущих преступлений происходит в ВМ 819С с использованием подтверждающих факторов, проверенных MNSP 9. Правоохранительные органы 864С могут подключаться к ВМА 817D через облако MNSP 9, чтобы предоставлять информацию о концептах, внесенных в черный список, и получать данные о результатах обнаружения преступлений из PCD 807C в ВМ 819С. Подтверждение информации мониторинга поведения 864D позволяет MNSP 9 сообщать данные мониторинга поведения ВМ 819С для подтверждения. В этику/приватность/право (EPL) 811В поступает настроенный черный список из MNSP, и где с помощью AOS 815В блокируют любые утверждения, содержащие материал, нарушающий этику, приватность и/или закон.
[0163] На Фиг. 146 показаны этика/приватность/право (EPL) 811B, куда поступает настроенный черный список из MNSP, и где с помощью AOS 815B блокируют любые утверждения, содержащие материал, нарушающий этику, приватность и/или закон. MNSP 9 используют для борьбы с традиционными угрозами безопасности, такими как попытки взлома с помощью «троянских коней», вирусов и т.д. Модули ВМ 819С и EPL 811В LOM анализируют контекст на наличие концептуальных данных с помощью индукции 820С и дедукции 821C для обнаружения нарушений этики/приватности/права.
[0164] На Фиг. 147 показан в общем виде алгоритм LIZARD. Динамическая оболочка (DS) 865A - это уровень LIZARD, наиболее подверженный изменениям посредством итераций. Модули, которые требуют высокой степени сложности для достижения своей цели, обычно входят сюда, поскольку их уровень сложности превосходит тот, который группа программистов может обрабатывать. Синтаксический модуль (SM) 865В предоставляет фреймворк для написания и чтения компьютерного кода. Для написания получают из РМ формат сложносоставной цели, затем пишут код, используя синтаксис произвольного кода, затем вспомогательная функция переводит произвольный код в реальный исполняемый код (в зависимости от выбранного языка). Для чтения в целевой модуль 865Е направляют синтаксическую интерпретацию кода с целью выявить назначение данного кода. Если LIZARD принимает малонадежное решение, она передает нужные данные посредством реле возврата данных (DRR) 865C в ACT 866 с целью улучшить будущие итерации LIZARD. Сам LIZARD напрямую не полагается на такие данные для принятия решений, но данные о развивающихся угрозах могут косвенно пойти на пользу априорному принятию решений, осуществляемому будущей итерацией LIZARD. Искусственная концептуальная угроза (ACT) 866 создает виртуальную испытательную среду, где симулируются концептуальные угрозы данных, с целью запуска процесса итерации. Искусственное развитие ACT 866 в состоянии опережать органическую эволюцию вредоносных концептов. Итерационный модуль (IM) 865D использует SC 865F, чтобы синтаксически модифицировать кодовую базу DS 865A в соответствии с выявленной целью в «фиксированных целях» и данных из DRR 865C. Эту модифицированную версию LIZARD затем подвергают стресс-тестам (одновременно) с использованием множества различных сценариев концептуальных угроз данным, полученных от ACT 866. Наиболее успешную итерацию принимают как живую функционирующую версию. С помощью синтаксического модуля 865В целевой модуль 865Е выводит назначение кода и выдает его в собственном «формате сложносоставной цели». Такая цель должна адекватно описывать предполагаемые функции блока кода (даже если этот код был скрыто помещен в данные), как их интерпретирует SM 865B. Статичное ядро (SC) 865F - это уровень LIZARD, наименее подверженный изменениям в процессе автоматизированных итераций. Его напрямую изменяют люди-программисты. Особенно темный внутренний квадрат, на который автоматические итерации не влияют. Этот самый внутренний слой похож на корень дерева, который определяет развитие и функционал LIZARD.
[0165] На Фиг. 148 показан итеративный рост интеллекта (подраздел I2GE 21), где описывается способ развития статичного набора правил путем его адаптации к различного рода опасностям концептуальных данных. Создают последовательность наборов правил для поколений, и их развитие направляют через определение черт личности. Такие наборы правил используют для обработки входящих концептуальных потоков данных и выполнения наиболее необходимых мер по устранению угроз и публикации уведомлений. Путь развития 867А - это целая цепочка поколений с одинаковой «личностью». С течением времени процессора поколения становятся все более динамичными. Исходный статический набор правил становится менее распространенным и впоследствии может быть удален или переопределен. Пример: Путь развития А имеет черты строгий и осторожный, не склонный прощать и обладающий низкой терпимостью к предположениям. В рамках концептуального поведения 867В поведение аналитиков концептуальных данных обрабатывают и сохраняют, с тем чтобы пути развития 867А могли у них учиться. Пример: Путь А обнаружил множество реакций на концептуальные угрозы данных, которые соответствовали конкретной ситуации и оптимистичному типу личности. Путь А создает правила, которые имитируют такое поведение. Человек 867С обозначает аналитиков концептуальных данных, которые создают начальный набор правил для запуска эволюционной цепочки. Пример: Определяют правило, согласно которому любые концепты, касающиеся покупки плутония на черном рынке, блокируются. Личность 867D - это набор переменных, которые определяют характеристики реакции, которые должны использоваться в ответ на триггеры концептуальных угроз данных.
[0166] На Фиг. 149-150 показано итеративное развитие (входящее в состав I2GE 21), в котором отбирают и исследуют параллельные пути развития 867А. Итеративные поколения адаптируются к тем же ACT 866, а затем отбирают путь с лучшими личностными чертами, который лучше всех сопротивляется концептуальным угрозам. Процессорное время 868А является мерой мощности процессора во времени и может измеряться в тактах процессора в секунду. Одного только времени для измерения степени обработки, которой подвергают путь развития эволюционный путь, недостаточно, поскольку необходимо учитывать количество ядер и мощность каждого процессора. Пример: Обработка запроса, который у Intel Pentium III занимает тысячу лет, у процессора Intel Haswell может занять 30 минут. Благодаря виртуальной изоляции 868В все пути развития виртуально изолированы, чтобы гарантирует, что их итерации основаны исключительно на критериях их собственных личностей. Пример: Путь В совершенно не знает, что путь С решил сложную концептуальную проблему данных, поэтому для получения своего решения должен опираться на личные качества и изученные данные. Некоторые пути могут быть удалены 868С, так как достигли состояния, когда неспособны распознать концептуальную угрозы данных. Наиболее вероятное следствие из этого: создать новый путь с измененной личностью. Пример: Путь D не смог распознать концептуальную угрозу данных за сто единиц процессорного времени 868А, следовательно, его удаляют. Система мониторинга/взаимодействия 868D является платформой, которая внедряет триггеры концептуальных угроз данных из системы ACT 866 и передает отклики на соответствующие концептуальные угрозы данных из облака концептуального поведения (все в соответствии с указанными чертами личности). Пример: Система мониторинга сообщает пути В необходимые отклики на концептуальные угрозы данных, необходимые для создания поколения 12. Искусственная концептуальная угроза (Artificial Concept Threat, ACT) 866 представляет собой изолированную систему, которая обеспечивает единообразную среду для концептуальных угроз данных. Она создает упражнения на распознавание концептов для аналитиков, чтобы они могли практиковаться и обучить систему распознавать различные потенциальные отклики на концептуальные данные и черты. Пример: ACT предоставил сложный набор концептов, которые распознаются людьми как опасные. Например, «как приготовить зарин из бытовых ингредиентов». Реальная концептуальная угроза (Real Concept Threat, RCT) 869A поставляет концептуальному сценарию 869С реальные угрозы из реальных журналов данных. Человек 867С отдает прямые распоряжения 869В системе мониторинга/взаимодействия 868D. Пример: Прервать путь вручную, изменить основные переменные в личности пути и т.п. Модуль перекрестных ссылок 869D является аналитическим мостом между концептуальной угрозой 869С и откликом 869Е, созданным аналитиком концептов 867С. После извлечения значимого действия он отправляет его в модуль маркировки признаков 869F. Концептуальные угрозы 869С могут исходить от реальных угроз 869A или из тренировочных упражнений 866. Модуль маркировки признаков 869F делит все типы поведения в соответствии с типом(ами) личности. Пример: Когда аналитик концептуальных данных 867С пометил 869Е электронное письмо с чрезмерным упоминанием способов самоубийства как опасное, модуль привязал это поведение к осторожной личности, поскольку такой поведенческий шаблон совпадает с прошлыми событиями, а также потому, что аналитик сам определил себя как осторожного человека. Модуль взаимодействия черт 869G анализирует взаимосвязь между разными личностями. Эту информацию передают в концептуальное поведение 867G, а затем - в систему мониторинга/взаимодействия 868D и сами пути. Пример: Безжалостная и реалистическая личности имеют много схожего в применении и одинаково реагируют на одно и то же событие, при этом строгая и оптимистическая личности почти никогда не реагируют одинаково на одно и то же событие.
[0167] На Фиг. 151-154 показан творческий модуль 18 - интеллектуальный алгоритм для создания новых гибридных форм из существующих форм. Творческий модуль 18 используется в качестве подключаемого модуля для обслуживания нескольких алгоритмов. В пункте 870А две родительские (предшествующие) формы принудительно отправляют в интеллектуальный селектор для получения гибридной формы 870В. Эти формы могут отражать абстрактные конструкты данных. Пример: Форма А представляет собой усредненную модель опасного концепта, полученную из базы данных концептов. Форма В представляет новую информацию, выпущенную набором правил концепта-триггера, о том, как он отреагировал на опасный концепт. Информация в форме В позволяет создать гибридную форму, которая станет более опасным концептом, чем тот, который представлен формой А. Посредством алгоритма интеллектуального селектора 870В отбирают и объединяют новые черты в гибридную форму. Пример: Форма А представляет собой усредненную модель концептуальной угрозы данных, выведенной базой данных концептов. Форма В представляет собой новую информацию, выпущенную набором правил концепта о том, как он реагировал на прошлую концептуальную угрозу. Информация в форме В позволяет создать гибридную форму, которая станет более триггером концептуальной угрозы, чем тот, который представлен формой А. Режим 870С определяет тип алгоритма, в котором используется творческий модуль 18. Таким образом, интеллектуальный селектор 870В знает, какие части целесообразно объединять в зависимости от используемого приложения. Пример: Выбирают режим ACT 866, поэтому интеллектуальный селектор 870В знает, что ожидаемые входные данные представляют собой представление базы данных угроз (форма А) и недавно выпущенную информацию, где подробно описана реакция набора правил на концепт-триггер угрозы (форма В). Приписываемый режим 870С определяет способ наилучшего объединения новых данных со старыми для создания эффективной гибридной формы. Статические критерии 870D предоставляет аналитик концептуальных данных; в них представлены обобщенные настройки объединения форм. Такие данные могут включать в себя приоритеты ранжирования, желаемые пропорции данных и данные для прямого объединения, зависящего от того, какой режим 870С выбран. Пример: Если выбран режим 870С ACT 866, то итоговая информация, полученная от несработавшего триггера угрозы, должна сильно повлиять на базу данных триггеров угроз, чтобы сильно изменить состав такого триггера. Если триггер продолжает давать сбои после таких изменений, то его удаляют. Необработанное сравнение 871В выполняется в обеих входящих формах в зависимости от статических критериев 870D, предоставляемых аналитиком концептуальных данных 867С. После необработанного сравнения подавляющее большинство форм оказались совместимы со статическими критериями 870D. Единственное обнаруженное различие заключалось в том, что в форму А был включен отклик, помеченный статическими критериями как «чужеродный». Это означает, что Форма В - представление из базы данных триггеров угрозы - не охватывает/не представляет определенную аномалию, обнаруженную в Форме А. С помощью важности изменения ранга 871С оценивают, какие изменения важны и не важны в соответствии с предоставленными статическими критериями 870D. Пример: Поскольку в форме А обнаружена аномалия, которая не представлена в форме В, статические критерии 870D признают, что эта аномалия имеет решающее значение, поэтому она приводит к заметным изменениям, вносимым в процесс объединения для получения гибридной формы АВ. В модуле слияния 871D неизменные данные и обнаруженные отклонения собирают в гибридную форму на основе статических критериев 870D и используемого режима 870С. Такие отклонения могут включать в себя пропорцию распределения 872А данных, важность определенных данных и то, как данные должны сцепляться/соотноситься друг с другом. Пример: Получают ранговую значимость аномального состава. После внесения соответствующих корректировок процесс, который руководствуется статическими критериями 870D, обнаруживает, несовместима ли данная реакция на аномалию с другими частями данных. Процесс слияния затем модифицирует ранее существовавшие данные, так что исправление аномалии может эффективно сливаться с уже существующими данными. Объем перекрывающейся информации фильтруют в соответствии с пропорцией 872А, заданной статическими критериями 870D. Если задана большая пропорция 872А, то в гибридную форму попадет больше данных, оставшихся неизменными. Если задана маленькая пропорция 872А, то большая часть гибридной формы будет сильно отличаться от предыдущих итераций. В рамках приоритета 872В оба набора данных конкурируют за одно место формы, в котором надо определить черту. Происходит процесс расстановки приоритетов, в котором выбирают, какие элементы будут выделены, а какие перекрыты или спрятаны. Так как только одна черта может занимать определенное место (выделено прямоугольником), процесс расстановки приоритетов помогает понять, какой признак наследуется. Стиль 872С определяет способ объединения перекрывающихся элементов. Часто есть несколько способов, по которым можно выполнить конкретное слияние, поэтому статические критерии 870D и режим 870С предписывают данному модулю отдавать предпочтение определенному типу слиянию перед другими. Часто у черт встречаются перекрывающиеся формы, что позволяет создать форму со объединенными чертами. Пример: Если в качестве входящих форм даны треугольник и круг, то можно воспроизвести форму, напоминающую Pacman'a.
[0168] На Фиг. 155-156 показано применение LOM в качестве личного помощника. LOM может быть настроен для управления персонализированным портфелем жизни человека. Человек может активно дать согласие на то, чтобы LOM регистрировал личные данные его повседневной жизни с целью дать содержательный и подходящий совет, когда человек сталкивается с дилеммами или предложениями, которые могут включать ситуации на работе, предпочтения в еде, решения о покупках и т.п. LOM получает начальный вопрос 874В, который приводит к выводу 874С через внутренний процесс умозаключений LOM 874А. EPL 811В используется для проверки ответа, генерируемого LOM, на соответствие требованиям этики, приватности и права. Для большей персонализации LOM подключается к модулю LAA 812D, который подключается к устройствам с доступом в Интернет, откуда LOM может получать данные и которыми может управлять (напр., включить кондиционер, когда вы приходите домой). Посредством PIP 802C LOM получает личную информацию о пользователе, и пользователь может дать согласие на безопасное отслеживание информации. Таким образом, в будущем LOM сможет предоставить более точные ответы. В рамках контекстуализации 874D LOM выводит недостающие звенья при построении аргумента. LOM постигает с помощью своей продвинутой логики, что для решения дилеммы, поставленной исходным утверждением, сначала необходимо знать или допускать определенные переменные о ситуации.
[0169] На Фиг. 157 показано применение LOM в качестве исследовательского инструмента. Допустим, пользователь использует LOM в качестве инвестиционного инструмента. Поскольку утверждение 875В сформулировано объективно и безлично, LOM не требует дополнительных подробностей 875D конкретного отдельного варианта использования, чтобы сформировать сложное мнение по данному вопросу. Таким образом, вывод 875С достигается без персональной информации. EPL 811B используется для проверки соответствия ответа, генерируемого LOM, требованиям этики, приватности и права, а ВМ 819С используется для мониторинга заговоров с целью совершения незаконных/неэтичных действий от имени пользователя.
[0170] На Фиг. 158-159 проиллюстрировано, как LOM изучает достоинства и недостатки предлагаемой теории 876В. Биткойн - это пиринговая децентрализованная сеть, которая подтверждает право собственности на криптовалюту в виде публичного журнала записей, называемого блокчейном. Все транзакции с участием биткойнов записываются в блоки, которые возникают в сети каждые 10 минут. Текущее запрограммированное ограничение в клиенте Bitcoin Core составляет 1 Мб, что означает, что каждые 10 минут может выполняться не более 1 Мб транзакций (представленных в форме данных). В связи с ростом популярности биткойна как актива в последнее время ограничение размеров блока привело к нагрузке на систему, увеличению времени подтверждения платежей и росту майнерских комиссий. Благодаря контекстуализации 876D LOM может вывести недостающие ссылки при построении аргумента. Используя свою продвинутую логику, LOM расшифровал, что для решения дилеммы, поставленной исходным утверждением, он должен сначала знать или предположить, кто будет поднимать предел размера блока. Поэтому LOM достигнут вывод 876С. EPL 811В используется для проверки соответствия ответа, генерируемого LOM, требованиям этики, приватности и права, а ВМ 819С используется для мониторинга заговоров с целью совершения незаконных/неэтичных действий от имени пользователя.
[0171] На Фиг. 160-161 проиллюстрировано, как LOM строит политику для внешнеполитических военных игр. Изолированная и защищенная копия LOM может быть использована на оборудовании и местах, одобренных военными. Это позволяет LOM получать доступ к своим общим знаниям из центрального хранилища знаний (CKR) 806 и в то же время - к военной (в т.ч. секретной) информации в локальной копии профиля личного интеллекта (PIP). Военные могут проводить сложные военные игры благодаря продвинутым интеллектуальным способностям LOM, имея при этом доступ к общим и конкретным знаниям. Первоначальный сценарий военной игры предлагается с утверждением 877В и запрограммированными предположениями 877Е. Из-за сложности сценария военной игры LOM отвечает запросом на дополнительные данные 887D. LOM может решить, что для получения сложного ответа он должен располагать информацией высокого уровня, например, подробными данными о 50000 военнослужащих. Такие сведения могут занимать объем в несколько терабайт и потребуют параллельной обработки в течение нескольких дней. Все сведения передают через стандартизированные и автоматизированные форматы и протоколы (т.е. импортируют 50000 листов Excel в течение двух часов в рамках единого действия компьютерного интерфейса). В рамках ВМ 819С и EPL 811B активируют перехват секретного допуска, чтобы отключить защитные функции, связанные с конфиденциальным характером сведений. В симуляции военной игры могут встретиться темы, которые могут быть помечены ВМ 819С и EPL 811B. EPL может заблокировать полезную информацию, которая в противном случае могла бы принести пользу симуляции, что в итоге может сказаться на жизнях реальных людей и потраченных деньгах. ВМ 819С мог пометить тему и сообщить об этом ответственным лицам MNSP 9. Следовательно, военные каналы/организации с соответствующей квалификацией могут аутентифицировать свою сессию LOM через PIP 802C, чтобы позволить LOM обрабатывать такие конфиденциальные темы без перебоев, помех и отчетов ответственным лицам. Поскольку такая информация может быть засекречена: например, номера и местоположения военных подразделений, в рамках аутентифицированного сеанса можно разрешить перехват, блокирующий деятельность ВМ 819С и EPL 811C, так чтобы конфиденциальная информация никогда не покидала LOM и не попадала на внешние платформы, такие как MNSP 9. Что касается PIP 802C, уполномоченные военные, которые запускают эту военную игру, используют специализированную копию LOM, которая располагает улучшенной/ специализированной криптографической защитой и изоляцией данных, включая, например, специальное решение для хранения данных на месте, для того чтобы конфиденциальные военные сведения никогда не попали в общедоступное облачное хранилище, а оставались на одобренных военными объектах. Следовательно, такая надежно сохраненная информация позволяет процессу внутренних умозаключений 877А LOM моделировать предлагаемые военные игры.
[0172] На Фиг. 162-163 проиллюстрировано, как LOM проводит журналистское расследование, в частности, находит идентифицирующие личные сведения. Примером такого варианта использования можно считать расследование тайны личности создателя биткойна, известного под псевдонимом Сатоси Накамото. Сообщество майнеров, наряду со многими изданиями и журналистами, вложило немало усилий в попытки раскрыть его личность. Тем не менее LOM может максимизировать усилия по расследованию благодаря тщательности и автоматизации подхода. LOM может наткнуться на определенную часть журналистской головоломки, которую необходимо решить, чтобы точно ответить на первоначальный запрос. Следовательно, LOM может отправлять специализированные информационные запросы в ARM 805B, который собирает информацию в CKR 806. Благодаря контекстуализации 879D LOM не требует дополнительных сведений о конкретном варианте использования, чтобы сформировать сложное мнение по данному вопросу, потому что вопрос 878В сформулирован объективно и безлично. LOM никогда не чувствует «стыда» за отсутствие ответа или неуверенность в нем, поскольку LOM обладает «личностью», которая отличается «бескомпромиссной честностью». Следовательно, он видит неизбежные пробелы в доказательствах, необходимых для раскрытия истинной личности Сатоси, такие как, например, в промежуточном заключении 878Е. Параллельно с тем, как ARM 805B извлекает все электронные письма и журналы чатов, которые достоверно связаны с Сатоси, выполняют стилометрию 808В для подтверждения и определения истинной личности Сатоси. Затем все, что LOM узнает в ходе журналистского расследования, представляют в виде заключения 879С.
[0173] На Фиг. 164-165 проиллюстрировано, как LOM выполняет историческую проверку. LOM может проверять подлинность исторических документов путем подтверждения цепочки рассказчиков. Доказано, что некоторые исторические документы, известные как «хадисы» (араб. буквально «новый»), достоверно приписаны их создателю благодаря подтверждениям людей, которые подтверждали переданные новости. Поскольку тексты-хадисы изначально хранятся и понимаются в разговорном контексте на арабском языке, модуль лингвистического построения 812А обращается к сторонним алгоритмам перевода, чтобы понимать тексты непосредственно на их исходном языке. Благодаря контекстуализации 879D LOM не требует дополнительных подробностей конкретного отдельного варианта использования, чтобы сформировать сложное мнение по этому вопросу, потому что вопрос 8798 сформулирован объективно и безлично. С помощью KCA 816D информация, собранная в UKF кластерах, сравнивается с целью подтвердить свидетельства о достоверности цитаты (хадис), подтвержденной цепочкой рассказчиков. Этот алгоритм учитывает надежность приписанного источника (то есть предполагаемого рассказчика хадиса), когда такое заявление было сделано, косвенные свидетельства и т.д. С течением времени LOM создает концепты в CKR 806 из данных, полученных ARM, что облегчает процесс аутентификации хадиса. Алгоритм сам себе задает такие вопросы, как «Что такое хадис?», «Какие существуют варианты хадисов?», «Какова лучшая методика аутентификации?». CKR 806 создает надежную базу определений с помощью неотъемлемых расширенных рассуждений и может обосновать любые выводы 879С, которые делает LOM. В рамках построения кластеров 879С CKR 806 приходит к концептуальным выводам посредством «укладки» строительных блоков информации, т.н. кластеров UKF. Эти кластеры охватывают широкий спектр метаданных, касающихся целевой информации, таких как приписываемые источники, время создания подозрительной информации и т.д.
Цифроориентированный язык LAQIT
[0174] На Фиг. 166 представлена концепция LAQIT. LAQIT - это эффективный и безопасный метод передачи информации внутри сети доверенных и целевых сторон. LAQIT предлагает широкий набор режимов, часть которых делает акцент на удобочитаемость, а другие - на безопасность. Линейный, атомный и квантовый режимы - это различные способы передачи информации, каждый из которых предлагает свои функции и способы применения. LAQIT является наивысшим проявлением безопасной передачи информации, так как самое слабое звено в нем - это закрытость информации, содержащейся в голове. Риск контрагента практически снимается, так как эффективно простой в запоминании ключ хранится исключительно в сознании получателя, а сообщение расшифровывается в реальном времени (с использованием человеческой памяти) в соответствии с составом этого ключа. Ключ должен быть передан только один раз и зафиксирован в памяти, поэтому в каждом отдельном случае можно использовать сложные меры конфиденциальности, например, отключать телефоны при передаче ключа или передавать его через временный зашифрованный электронный почтовый ящик и т.п. Все заботы по безопасности касаются соблюдения тайны ключа. Поскольку его легко запомнить, многие трудности снимаются. Блок 900А обозначает ту же постоянную последовательность цветов: красный, оранжевый, синий, зеленый, фиолетовый - которую рекурсивно повторяют внутри логически структурированного синтаксиса LAQIT. Блок 900В дополнительно иллюстрирует последовательность цветов, рекурсивно используемую для перевода с помощью английского алфавита. При структурировании «базового» слоя алфавита используют последовательность цветов с сокращенным и неравным весом фиолетового канала. Оставшееся пространство для синтаксических определений в фиолетовом канале зарезервировано для потенциального использования в будущем и расширения. В шаге 901 сложный алгоритм передает свой журнал событий и отчеты о состоянии LAQIT. В этом сценарии шифрование отключено по выбору, но опция шифрования доступна. В шаге A1 902A отчеты о событиях/состоянии формируют автоматически. В шаге А2 903А отчеты о событиях/состоянии конвертируют в передаваемый синтаксис LAQIT на текстовой основе. В шаге A3 904А синтаксически небезопасную информацию передают по цифровому каналу, либо зашифрованному (напр., VPN 12), либо незашифрованному (напр., необработанный HTTP). Предпочтительно, но необязательно использовать зашифрованный канал. В шаге А4 905А передаваемый синтаксис LAQIT на текстовой основе конвертируют в высокочитаемый визуальный синтаксис LAQIT (линейный режим). В шаге 911 представлен целевой получатель - человек, так как LAQIT разработан и оптимизирован для получателей информации, не являющихся компьютером или ИИ. В шаге 906 показано, что отправителем конфиденциальной информации является человек. Он может представлять службу разведки или осведомителя. Отправитель 906 раскрывает ключ шифрования LAQIT непосредственно получателю 911 по безопасному и временно зашифрованному туннелю, предназначенному для передачи такого ключа 939, причем следы передачи остаются в постоянном хранилище. В идеале человек-получатель 911 должен зафиксировать ключ 939 в памяти и удалить все следы хранения ключа в цифровой системе, чтобы исключить возможность взлома. Это возможно благодаря тому, что ключ 939 оптимизирован для запоминания человеком, поскольку основан на относительно короткой последовательности форм. В шаге B1 902B представлен локально незащищенный текст, вводимый отправителем 906 для отправки получателю 911. В шаге В2 903В представлена конвертация текста 902B в передаваемый зашифрованный синтаксис LAQIT на текстовой основе. В шаге В3 904В синтаксически безопасную информацию передают по цифровому каналу, либо зашифрованному (напр., VPN 12), либо незашифрованному (напр., необработанный HTTP). В шаге В4 905В показано преобразование данных в визуально зашифрованный синтаксис LAQIT (т.е. атомарный режим с уровнем шифрования 8), который затем представляют человеку-получателю 911.
[0175] На Фиг. 167 показаны основные типы используемых языков (или способов передачи информации) для сравнения по эффективности в плане передачи информации посредством использования таких информационных каналов, как положение, форма, цвет и звук. Наиболее эффективным и полезным языком считается тот, который эффективно включает и использует наибольшее количество каналов. Эффект ступенчатого распознавания (IRE) 907 представляет собой канал передачи информации. Он отличается тем, что распознает полную форму единицы информации до ее полного получения, примерно как человек договаривает за собеседником слова и фразы. LAQIT демонстрирует этот эффект прогнозирования, отображая переходы между словами. Опытный читатель LAQIT может начать формировать отображаемое слово, пока блоки еще только занимают свое положение. Эффект приблизительного распознавания (PRE) 908 представляет собой канал передачи информации Он отличается тем, что распознает полную форму единицы информации, даже если она испорчена, изменена или перепутана. Для сравнения можно взять написание английского слова «character» и «chracaetr». Внешние границы единицы заданы (первый и последний символ) и близость перепутанных символов не мешает определить слово в целом. Что касается письменного языка 912, то типичный текст сочетает в себе положение букв и форму букв, и слова распознаются целиком, в отличие от распознавания по буквам, как описано в IRE 907. Что касается устной речи 913, типичный разговор сочетает в себе положение слов (порядок их произнесения) и форму, которая представлена частотой тона и ударением. Азбука Морзе 915 состоит из различных бинарных позиций звуков. Из-за предварительного знания о получателе информации возможен запуск IRE 907, но не промежуточный, поскольку информация, передаваемая азбукой Морз, поступает постепенно. При использовании жестикуляции 915 информация задается положением и формой движения рук. Жесты могут включать взмахи руками, указывающие самолету взлетать, грузовику - остановиться и т.д. Возможностей предвидения нет, поэтому запуск IRE 907 или PRE 908 невозможен. LAQIT 916 может задействовать гораздо больше информационных каналов по сравнению с конкурирующими языками 912-915. Это означает, что он способен передавать больше информации за меньшее время и на меньшем носителе (то есть, занимая меньше места на экране). Этот запас мощности позволяет эффективно внедрять сложные функции, такие как надежное шифрование. Благодаря шифрованию звука 909 LAQIT в состоянии задействовать звуковой информационный канал для дальнейшего шифрования информации. Таким образом, он способен передавать информацию через звук, несмотря на то, что при незашифрованном обмене данными это невозможно.
[0176] На Фиг. 168-169 схематично показан линейный режим работы LAQIT, отличающийся простотой устройства, удобством использования, высокой информационной плотностью и отсутствием шифрования. В блоке 917 показана версия линейного режима в «базовой визуализации». Пункт 918 демонстрирует отсутствие шифрования. Линейный режим не позволяет эффективно распределять пространство для обфускации формы 941, которая является основой для шифрования в атомном режиме. Напротив, линейный режим оптимизирован для плотной передачи данных и эффективного использования экранного пространства. В рамках разделителя слов 919 цвет этой формы отражает символ, который следует за словом и отделяет его от следующего. Это точно такой же синтаксис, как у атомного ядра для атомной процедуры. Можно применять цветовые коды, обозначающие вопросительный знак, восклицательный знак, точку и запятую. Зона одиночного просмотра 920 отражает то, как в базовую визуализацию 917 включена меньшая зону просмотра с буквами большего размера и, следовательно, меньшим количеством информации на пиксель по сравнению с продвинутой визуализацией 918. Такая продвинутая визуализация отличается наличием двойной зоны просмотра 922. В рамках продвинутой визуализации используют больше букв на пиксель, так как ожидается, что читатель LAQIT будет успевать читать. Следовательно, существует дилемма компромисса между скоростью представления и плотностью информации. Затенение 921 делает входящие и исходящие буквы тусклыми, так что наблюдатель фокусируется на зоне (ах) просмотра. Затенение отчасти прозрачно, что дает наблюдателю возможность прогнозировать входящие слова, а также проверять исходящие слова. Этот эффект также известен как эффект ступенчатого распознавания (IRE) 907. Передача информации высокой плотности 923 показывает, что в рамках продвинутой визуализации 918 каждая буква меньше по размеру, соответственно, в одном и том же объеме пространства представлено больше букв и плотность информации на пиксель увеличивается.
[0177] На Фиг. 170 и 171 показаны параметры атомного режима, поддерживающего шифрование на большом числе уровней шифрования. Ссылка на основной символ базы 924 в общем указывает на определяемую букву. Красный цвет базы указывает, что буква находится в промежутке от А до F (включительно) в соответствии с алфавитным указателем 900В. Слова можно читать, используя только базы (без кикера 925), так как индукция помогает догадаться о правописании слова. В общей сложности, для шифрования существует пять возможных форм. Кикер 925 имеет тот же цветовой диапазон, что и база, и точно определяет конкретный символ. Отсутствие кикера также означает определение, т.е. самостоятельную красную базу. Без кикера это буква А. Кикеры существуют в пяти возможных формах 935, что позволяет производить шифрование. В направлении чтения 926 чтение поступившей информации начинают с верхнего квадрата первого орбитального кольца. Чтение выполняют по часовой стрелке. Как только орбитальное кольцо пройдено, чтение продолжают с верхнего квадрата следующего по порядку орбитального кольца (кольцо 2). Порталы входа/выхода 927 являются точками создания/уничтожения символа (его базы). Новый символ, принадлежащий к соответствующей орбите, выйдет из портала и сдвинется на свою позицию по часовой стрелке. Атомное ядро 928 определяет символ, следующий за словом. Как правило, это пробел, означающий, что предложение после данного слова продолжается. Можно применять цветовые коды, обозначающие вопросительный знак, восклицательный знак, точку и запятую. Также коды указывают, продолжится ли слово в новом информационном состоянии, поскольку все три орбитальных кольца заполнены до предела. Когда орбитальное кольцо 929 заполняется, буква переходит на следующее (большее по размеру) орбитальное кольцо. Предел символов для орбитального кольца 1 составляет 7, для кольца 2-15, а для кольца 3-20. То есть, в атоме может быть не более 42 символов (включая возможные пустышки). Если достигнут предел в 42 символа, то слово будет разрезано на отрезки по 42, а ядро будет указывать на то, что следующее информационное состояние является продолжением текущего слова. В рамках навигации по словам 930 каждый блок представляет собой целое слово (или несколько слов в молекулярном режиме) в левой части экрана. При отображении слова соответствующий блок перемещается наружу и вправо, а когда слово завершено, блок отступает назад. Цвет/форма навигационного блока имеет тот же цвет/форму, что и база первой буквы слова. В рамках навигации по предложениям 931 каждый блок представляет собой кластер слов, а кластер представляет собой максимальное количество слов, которое может уместиться на панели навигации по словам. Если остался один блок навигации по предложениям либо он последний, то, скорее всего, в нем будет меньше слов, чем позволяют пределы. Создание атомного состояния 932 - это переход, который вызывает эффект ступенчатого распознавания (IRE) 907, при котором переходные базы 924 появляются из порталов входа/выхода 927 со скрытыми кикерами 925 и перемещаются по часовой стрелке на свои позиции. В течение этого перехода опытный читатель языка LAQIT в состоянии предугадать часть слова или слово целиком еще до того, как благодаря IRE 907 будут выявлены кикеры 925. Это похоже на функцию автозаполнения, которой обладает большинство поисковых движков. Они оценивают оставшийся объем предложения по начальному куску информации. Расширение атомного состояния 933 -это переход, который вызывает эффект приблизительного распознавания (PRE) 908, при котором, после того как базы 924 достигли своей позиции, они перемещаются наружу в «расширенной» последовательности представления информационного состояния. Этот процесс раскрывает кикеры 925, посредством чего можно представить конкретное определение состояния информации. Опытному читателю языка LAQIT нет необходимости постепенно прокручивать буквы по отдельности, чтобы постепенно выстроить слово. Он может посмотреть на структуру в целом и сразу же угадать значение слова благодаря PRE 908. Разрушение атомного состояния 934 - это переход, который вызывает эффект ступенчатого распознавания (IRE) 907, при котором базы 924 сокращают (путем обращения последовательности расширения 933), чтобы снова скрыть 925 кикеры, которые теперь смещаются по часовой стрелке, чтобы достичь портала входа/выхода. При высокоскоростной визуализации информационного состояния опытный читатель языка LAQIT может задействовать переход разрушения для завершения распознавания слова. Это полезно, когда возможность увидеть расширенное атомное состояние (где показаны кикеры) дается на очень короткое время (доли секунды).
[0178] На Фиг. 172-174 показан общий вид принципа шифрования в атомном режиме. Поскольку LAQIT обеспечивает эффективную и плотную передачу информации, в нем имеется достаточный запас пропускной способности для реализации возможностей шифрования. Это синтаксическое шифрование отличается от классического шифрования, известного в области кибербезопасности, тем, что для получения расшифрованного кода в реальном времени требуется, чтобы предполагаемый получатель информации держал ключ в голове. Таким образом снижается риск того, что данные в движении, используемые данные и неподвижные данные будут прочитаны и поняты злоумышленниками или несанкционированными получателями. Сложность шифрования ранжируется по девяти стандартизированным уровням 940, демонстрирующим компромисс между удобочитаемостью и степенью безопасности. В ходе обфускации формы 941 (уровни 1-9) стандартные квадраты заменяются пятью визуально отличными друг от друга формами. Вариативность фигур в синтаксисе позволяет вставлять буквы-пустышки (фальшивые) в стратегических точках атомного профиля. Буквы-пустышки запутывают истинный смысл сообщения. Определить, является ли буква подлинной или пустышкой, можно с помощью надежно переданного на время ключа дешифрования. Если буква совместима с ключом, то она должна учитываться при распознавании слова. Если нет, то не учитывается. Связь перенаправления 942 (уровни 4-9) - это связь, которая соединяет две буквы и изменяет направление чтения. Начиная с типичного шаблона чтения по часовой стрелке, при обнаружении связи, которая взлетает (начинается с) и приземляется (заканчивается на) на легитимные/настоящие буквы, связь перенаправляет шаблон чтения для возобновления на посадочной букве. Радиоактивные элементы 943 (уровни 7-9) - это некоторые элементы, которые могут «дребезжать», что может инвертировать оценку того, является ли буква пустышкой или нет. Формы 935 отражают формы, доступные для шифрования: треугольник, круг, квадрат, пятиугольник и трапецоид. Центральные элементы 936 отражают центральный элемент орбиты, которая определяет символ, идущий сразу за словом. К таким элементам относятся: красный - точка, оранжевый - запятая, синий - пробел, зеленый - вопросительный знак, розовый - восклицательный знак. В примере шифрования 937 показана обфускация формы 941, которая применима к уровням шифрования 1-9. В центре орбиты показан центральный элемент 936, а основными средствами шифрования с помощью обфускации формы 941 выступают буквы-пустышки 938. Левая пустышка имеет последовательность круг-квадрат. Правая пустышка имеет последовательность квадрат-треугольник. Поскольку обеих этих последовательностей нет в ключе шифрования 939, читатель в состоянии распознать их как ошибочные и, следовательно, пропустить их при вычислении значения информационного состояния.
[0179] На Фиг. 175-176 показан механизм работы связей перенаправления 942. В примере шифрования 944 показаны связи перенаправления 942 и 945. Ниже приведены «правила поведения», касающиеся связей перенаправления:
1) При достижении связи ей начинают следовать по умолчанию, следовательно, обычное поведение по часовой стрелке прекращается.
2) При следовании пути: букву «взлета», с которой начинается путь, считают частью последовательности.
3) При следовании пути: букву «посадки», которой заканчивается путь, считают частью последовательности.
4) По пути можно проследовать только единожды.
5) Каждое упоминание буквы считают только единожды.
6) По пути необходимо следовать только в том случае, если его буквы «взлета» и «посадки» не пустышки.
В рамках связей перенаправления 945 связи начинаются с буквы «взлета» и заканчиваются буквой «посадки», каждая из которых может быть или не быть пустышкой. Если среди букв нет ни одной пустышки, то связь изменяет направление и позицию чтения. Если одна или обе буквы являются пустышками, то вся связь должна быть проигнорирована, в противном случае сообщение будет расшифровано неправильно. Для каждой отдельной связи задано верное направление чтения, но этот порядок не описан явно и должен быть определен путем индукции в соответствии с текущей позицией чтения и набором пустышек в информационном состоянии. Буквы-пустышки 946 показывают, как всего две такие буквы затрудняют процесс расшифровки и, соответственно, повышают сопротивляемость атакам методом полного перебора. Это связано с тем, что сочетание обфускации формы и связей перенаправления экспоненциально усложняет проведение атак методом полного перебора. При определении ключа связи 947 необходимость следовать связи при чтении информационного состояния зависит от того, была ли она конкретно определена в ключе шифрования. Возможные определения: одиночная связь, двойная связь, тройная связь. Потенциальный сценарий неверного прочтения связи перенаправления (из-за незнания ключа связи 947) показан в виде неверной интерпретации 949. Такая неверная интерпретация 949 приводит к тому, что сообщение прочитывается как «RDTNBAIB», в то время как истинное сообщение в правильной интерпретации 948 выглядит как «RABBIT» («кролик»). Существует множество способов неправильной интерпретации связей перенаправления 945, поскольку они используют сложность, создаваемую обфускацией формы 941, для экспоненциального повышения надежности сообщения. Существует только один верный способ интерпретации истинного сообщения, как показано в верной интерпретации 948.
[0180] На Фиг. 177-178 показан механизм работы радиоактивных элементов 943. В примере шифрования 950 показаны радиоактивные элементы 943 и 951. Ниже приведены «правила поведения», касающиеся радиоактивных элементов:
1) Во время фазы расширения информационного состояния радиоактивный элемент считается неспокойным или вибрирующим.
2) Радиоактивный элемент может быть активным либо «спящим».
3) То, что радиоактивный элемент активный, указывает на то, что его статус пустышки обращен. Т.е. если состав форм указывает, что он пустышка, то это ложное срабатывание. На самом деле элемент не является пустышкой, а считается полноценной буквой. Если состав форм указывает, что элемент настоящий, то это ложное срабатывание. На самом деле элемент - пустышка, а не полноценная буква.
4) То, что радиоактивный элемент «спящий», указывает на то, что его статус пустышки/полноценной буквы не затронут.
5) Кластер радиоактивных элементов определяется непрерывной цепочкой радиоактивных элементов внутри орбитального кольца. Когда радиоактивные элементы находятся рядом друг с другом (в пределах одного орбитального кольца), они создают кластер. Если сосед радиоактивного элемента не радиоактивен, тогда это и есть верхняя граница кластера.
6) Ключ определяет, какие кластеры активны, а какие - «спят». Т.е., если в ключе определен двойной кластер, то радиоактивными являются все двойные кластеры, а одиночные и тройные кластеры являются «спящими».
Радиоактивные элементы 950 демонстрируют, что буква (или элемент) считается радиоактивной, если она сильно «трясется» во время расширенной фазы представления информации. В связи с классификацией уровней шифрования атом, содержащий радиоактивные элементы, всегда будет иметь межатомные связи. Поскольку радиоактивные элементы изменяют классификацию букв в том, являются они пустышками или нет, обфускация безопасности увеличивается экспоненциально. Двойной кластер 952 демонстрирует, что наличие в пределах одной орбиты последовательности из двух радиоактивных элементов определяет ее как кластер (двойной). Является ли он активным или «спящим», определяется ключом шифрования 954. При одиночном кластере 953 оба соседа нерадиоактивны, следовательно, определяют объем кластера. Поскольку ключ определяет двойные кластеры как действительные, с элементом 953 следует обращаться, как если бы он изначально не был радиоактивным. При двойном кластере ключевое определение 954 определяет двойные кластеры как активные, следовательно, во время расшифровки сообщения все кластеры других размеров должны считаться неактивными. Неверная интерпретация 956 показывает, что интерпретатор не рассматривал двойной кластер 952 как обратную последовательность (ложное срабатывание). То есть, в шаге 956А правильный ответ - игнорировать его, потому что, несмотря на то, что он не является пустышкой, он принадлежит к активному радиоактивному кластеру (подтвержденному ключом 954), который дает команду процессу дешифрования интерпретировать буквы в обратном порядке. При одновременном использовании обфускации формы 941, связей перенаправления 942 и радиоактивных элементов 943 никто не сможет эффективно разгадать все возможные комбинации с использованием метод полного перебора, не располагая ключом. Неверная интерпретация 956 демонстрирует, что интерпретатор без ключа 954 может быть введен в заблуждение и станет использовать связь перенаправления 956В, которой не нужно было бы следовать в соответствии с верной интерпретацией 955. Это приводит к совершенно другому результату: сообщение прочитывается как «RADIT» вместо «RABBIT». Полная информация о способах правильного дешифрования сообщения проиллюстрирована верной интерпретацией 955.
[0181] На Фиг. 179 показан молекулярный режим с включенным шифрованием и потоковой передачей 959. При сопротивлении скрытому перебору по словарю 957 неправильная дешифровка сообщения вызывает альтернативное «подложное» сообщение. Злоумышленнику внушают ложное впечатление, что он успешно расшифровал сообщение, тогда как на самом деле он получил фальшивку, которая маскирует настоящий текст. При нескольких активных словах на молекулу 958 слова представлены параллельно во время молекулярной процедуры. Это увеличивает долю информации на площадь поверхности, однако при постоянной скорости перехода требуется более опытный читатель. Навигация по словам показывает, что в данный момент активны четыре слова. Однако в связи с обфускацией с использованием связи перенаправления слова разделены на части и существуют в нескольких разных атомах внутри молекулы. Двоичный режим и режим потоковой передачи 959 иллюстрирует потоковый режим, тогда как в типичной атомной конфигурации режим чтения является двоичным. Двоичный режим указывает, что центральный элемент определяет, какой символ следует за словом (т.е. вопросительный знак, восклицательный знак, точка, пробел и т.д.). Молекулярный режим также является двоичным, кроме случаев, когда включено шифрование, которое придерживается режима потоковой передачи. Режим потоковой передачи ссылается на специальные символы в пределах орбиты, такие как знаки вопроса и т.п. Это нужно потому, что внутри зашифрованной молекулы слова существуют одновременно в нескольких атомах, а значит, для отдельного слова нет конкретного элемента. В рамках молекулярных связей 960 информационное состояние молекулы не является исключительной отличительной чертой шифрования, но может выступать катализатором обфускации при шифровании. Все три режима шифрования (обфускация формы, связи перенаправления и радиоактивные элементы) увеличивают свою силу безопасности по экспоненте при помещении во все более молекулярную среду. Ключ направления чтения 961 показывает, что, хотя по умолчанию в строке 1 направление чтения слева направо, а затем в строке 2 - снова слева направо, направление чтения может быть заменено в соответствии с ключом шифрования. Это увеличивает степень обфускации сообщения и, следовательно, его конфиденциальность/безопасность. Связи перенаправления обладают наибольшим приоритетом, заменяя даже направление, заданное ключом (только если связь не является пустышкой).
Общие сведения об универсальных BCHAIN-связях всего со всем (UBEC) с использованием гармонизации базовых подключений присоединением встроенных узлов (BCHAIN)
[0182] На Фиг. 180 показан узел BCHAIN 1001, который содержит и запускает приложение, работающее с BCHAIN 1003. Порт связи (CG) 1000 является первичным алгоритмом узла BCHAIN 1001 для взаимодействия с аппаратным интерфейсом, осуществляющим связь с остальными узлами BCHAIN 1001. В рамках статистического изучения узлов (NSS) 1006 интерпретируют образцы поведения удаленных узлов. С помощью индекса убегания узлов 1006А отслеживают вероятность того, что сосед узла избежит близости с воспринимающим узлом. Высокое значение индекса убегания указывает на более хаотичную среду, для работы с которой потребуются более сложные стратегии.
Примеры:
Смартфоны в автомобилях, которые движутся по шоссе, будут иметь высокий индекс убегания узлов. Холодильник, стоящий в кафе Starbucks будет иметь очень низкий индекс убегания узлов.
С помощью индекса насыщения узлов 1006В отслеживают число узлов в радиусе обнаружения воспринимающего узла. Высокий индекс насыщения указывает на то, что в данной области очень много узлов. Это может двояко влиять на производительность из-за необходимости поступаться спросом или предложением. При этом область, более плотно насыщенная узлами, скорее всего будет более стабильной/предсказуемой и, следовательно, менее хаотичной.
Примеры:
У кафе Starbucks в центре Нью-Йорка будет высокий индекс насыщения узлов. У палатки посреди пустыни будет очень низкий индекс насыщения узлов.
С помощью индекса постоянства узлов 1006С отслеживают качество работы узлов с точки зрения воспринимающего узла. Высокое значение индекса указывает на то, что окружающие соседние узлы, как правило, более доступны и активны, а также поддерживают постоянный уровень производительности. Узлы двойного назначения, как правило, имеют более низкое значение индекса постоянства, тогда как узлы, прикрепленные к сети BCHAIN, показывают более высокое значение индекса постоянства.
Примеры:
У узлов двойного назначения, например, у компьютера сотрудника предприятия, будет низкий индекс постоянства, поскольку в рабочее время на нем меньше ресурсов, а во время обеденных перерывов и отсутствия сотрудника - больше.
С помощью индекса совпадения узлов 1006D отслеживают число узлов, совпадающих друг с другом, с точки зрения воспринимающего узла. Хотя индексы совпадения и насыщения, как правило, коррелируют между собой, они отличаются тем, что индекс перекрытия указывает на общую величину перекрытия между соседями, а индекс насыщения имеет дело только с физическим объемом занимаемого пространства. Следовательно, при высоком индексе насыщения с беспроводным покрытием широкого радиуса на каждом приборе повышается и индекс перекрытия.
Примеры:
Устройства начинают входить в определенные сектора сети BCHAIN с новым оптимизированным микрочипом BCHAIN (BCHAIN Optimized Microchip, BOM), который имеет направленную антенну с высоким коэффициентом усиления и передовой технологией формирования луча. Следовательно, индекс перекрытия в таких секторах увеличивается из-за узлов, имеющих более перекрывающуюся структуру связи.
[0183] На Фиг. 181 показана ядерная логика 1010 протокола BCHAIN. Модуль распознавания составных цепочек (CRM) 1022 соединяется с составными цепочками (например, цепочками приложений или микроцепочками), ранее зарегистрированными узлом. Следовательно, узел имеет криптографический доступ для чтения, записи и/или административного поведения по отношению к данной функции. Данный модуль информирует остальную часть протокола BCHAIN об обнаружении обновления в секции цепочки приложений в метацепочке или эмуляторе метацепочки в микроцепочке. В рамках доставки запрошенного содержимого (Content Claim Delivery, CCD) 1026 получают проверенное CCR 1018, а затем отправляют подходящее CCF 1024 для выполнения запроса
[0184] На Фиг. 182 показана динамическая адаптация стратегии (DSA) 1008, которой подчиняется модуль создания стратегии (SCM) 1046, посредством которого динамически генерируют новую стратегию 1054, используя творческий модуль 18 для создания гибридных сложных стратегий, которым система отдала предпочтение посредством алгоритма выбора оптимизированной стратегии (OSSA) 1042. Новые стратегии варьируются в зависимости от входных данных, предоставляемых интерпретацией хаотического поля (Field Chaos Interpretation, FCI) 1048.
[0185] На Фиг. 183 показана криптографическая цифровая экономическая биржа (CDEE) 1056 с набором экономических личностей 1058, 1060, 1062 и 1064 под управлением графического интерфейса пользователя (GUI) внутри интерфейса платформы UBEC (UPI) В рамках личности А 1058 ресурсы узла потребляются только для того, чтобы соответствовать объему потребления (если он выше нуля). Личность А идеально подходит для нерегулярного экономного потребителя, передающего незначительные/умеренные объемы информации. Количество прямых трансляций, таких как VoIP-звонки (напр., Skype) и приоритетная передача информации, минимально. Личность В 1060 потребляет максимальное количество ресурсов при условии, что маржа прибыли выше X (избыточные единицы работы могут быть обменены на альтернативные валюты, такие как криптовалюта, фиатная валюта, драгоценные металлы и т.п.). Личность В идеально подходит для узла, который был специально создан для развития инфраструктуры сети BCHAIN с целью получения прибыли. Следовательно, такой узел обычно представляет собой постоянную инфраструктурную установку, которая работает от сети, а не от устройства с питанием от батареи, и имеет мощные внутренние компьютерные компоненты (устройства беспроводной связи, мощный процессор, объемный жесткий диск и т.д.). Это, например, стационарное устройство и т.п. Личность С 1062 платит за единицу работы обменной валютой (криптовалюта, фиатная валюта, драгоценные металлы и т.п.), так чтобы потребление контента затрачивало как можно меньше ресурсов узла. Личность С идеально подходит для интенсивного потребителя информации или для тех, кто хочет получить выгоду от сети BCHAIN, но не хочет, чтобы ресурсы их устройства истощались (т.е. смартфон быстро разряжает батарею и нагревается в кармане). В рамках личности D 1064 ресурсы узла расходуются на максимально возможном уровне и без каких-либо ограничений на ожидание прибыли, как в виде потребления контента, так и в виде денежной компенсации. Личность D выбирают те, чьи основные интересы лежат в усилении сети BCHAIN. (т.е. основные разработчики сети BCHAIN могут приобретать и устанавливать узлы, исключительно чтобы укреплять сеть, а не использовать контент или зарабатывать деньги). В рамках интерпретации текущего рабочего состояния (CWSI) 1066 обращаются к разделу экономической инфраструктуры метацепочки с целью определить текущий избыток или дефицит узла в отношении затрат на выполненную работу. В рамках экономически обоснованного назначения работы (ECWI) 1068 рассматривают выбранную экономическую личность с текущим избытком/дефицитом работы с целью определить, необходимо ли выполнить больше работы.
[0186] На Фиг. 184 показано симбиотическое рекурсивное продвижение интеллекта (SRIA), представляющее собой тройственные взаимоотношения между тремя различными алгоритмами, которые позволяют им развивать свой интеллект. LIZARD 16 может улучшить исходный код алгоритма, распознавая назначение кода, включая свой собственный. I2GE 21 может симулировать поколения итераций виртуальных программ и таким образом выбирает самую сильную версию программы. Сеть BCHAIN - это обширная сеть хаотически связанных узлов, с помощью которых можно децентрализованно запускать сложные программы, требовательные к объему данных.
| название | год | авторы | номер документа |
|---|---|---|---|
| Система контроля политики безопасности элементов корпоративной сети связи | 2023 |
|
RU2813469C1 |
| Система и способ обнаружения вредоносного кода в исполняемом файле | 2020 |
|
RU2757807C1 |
| СПОСОБ АВТОМАТИЧЕСКОЙ НАСТРОЙКИ СРЕДСТВА БЕЗОПАСНОСТИ | 2012 |
|
RU2514137C1 |
| СПОСОБ ОБЕСПЕЧЕНИЯ БЕЗОПАСНОГО ВЫПОЛНЕНИЯ ФАЙЛА СЦЕНАРИЯ | 2014 |
|
RU2584507C1 |
| Способ обнаружения вредоносных сборок | 2015 |
|
RU2628920C2 |
| СИСТЕМА И СПОСОБ УСКОРЕНИЯ РЕШЕНИЯ ПРОБЛЕМ ЗА СЧЕТ НАКОПЛЕНИЯ СТАТИСТИЧЕСКОЙ ИНФОРМАЦИИ | 2010 |
|
RU2444056C1 |
| СПОСОБ ФОРМИРОВАНИЯ АНТИВИРУСНОЙ ЗАПИСИ ПРИ ОБНАРУЖЕНИИ ВРЕДОНОСНОГО КОДА В ОПЕРАТИВНОЙ ПАМЯТИ | 2015 |
|
RU2592383C1 |
| СПОСОБ ОБНАРУЖЕНИЯ ВРЕДОНОСНОГО КОДА В ОПЕРАТИВНОЙ ПАМЯТИ | 2015 |
|
RU2589862C1 |
| СПОСОБ ИСКЛЮЧЕНИЯ ПРОЦЕССОВ ИЗ АНТИВИРУСНОЙ ПРОВЕРКИ НА ОСНОВАНИИ ДАННЫХ О ФАЙЛЕ | 2015 |
|
RU2595510C1 |
| Способ выявления вредоносных файлов с использованием графа связей | 2023 |
|
RU2823749C1 |
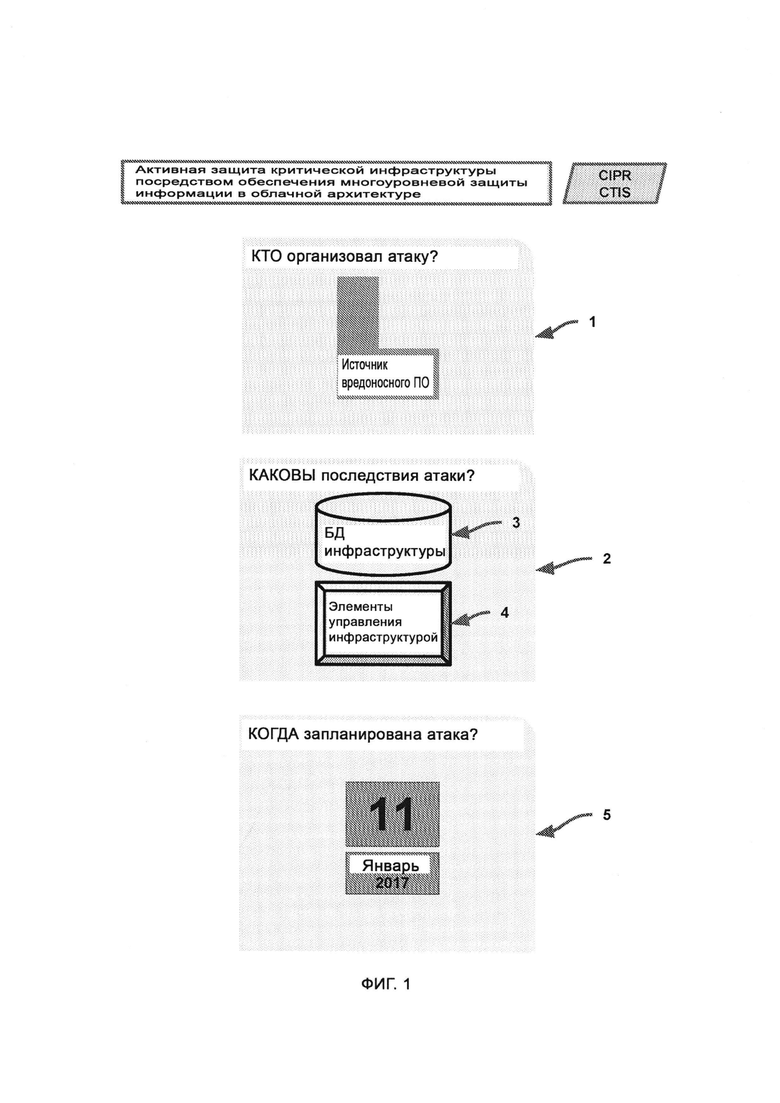

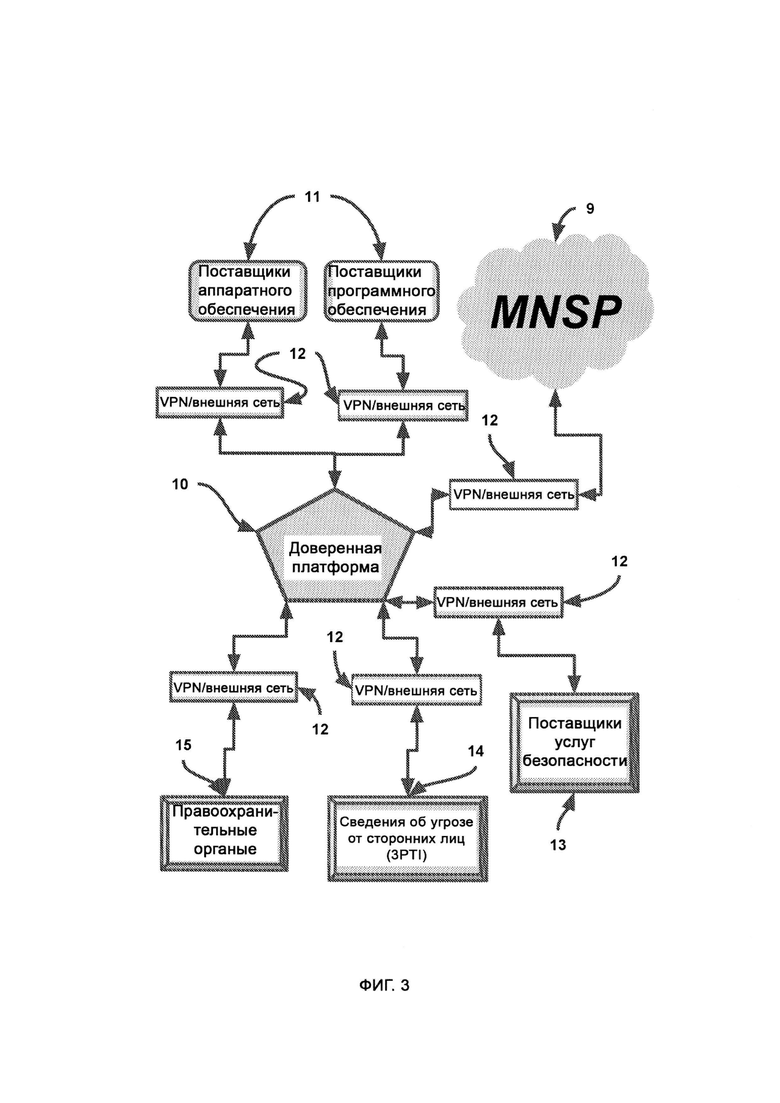
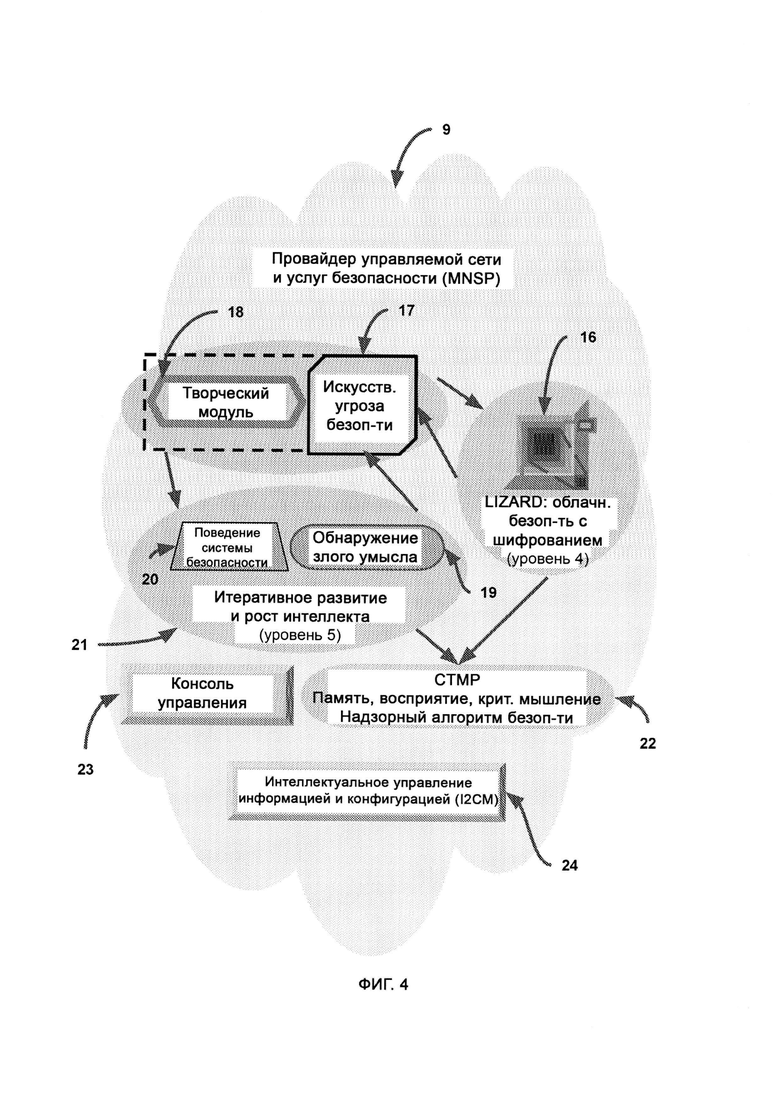
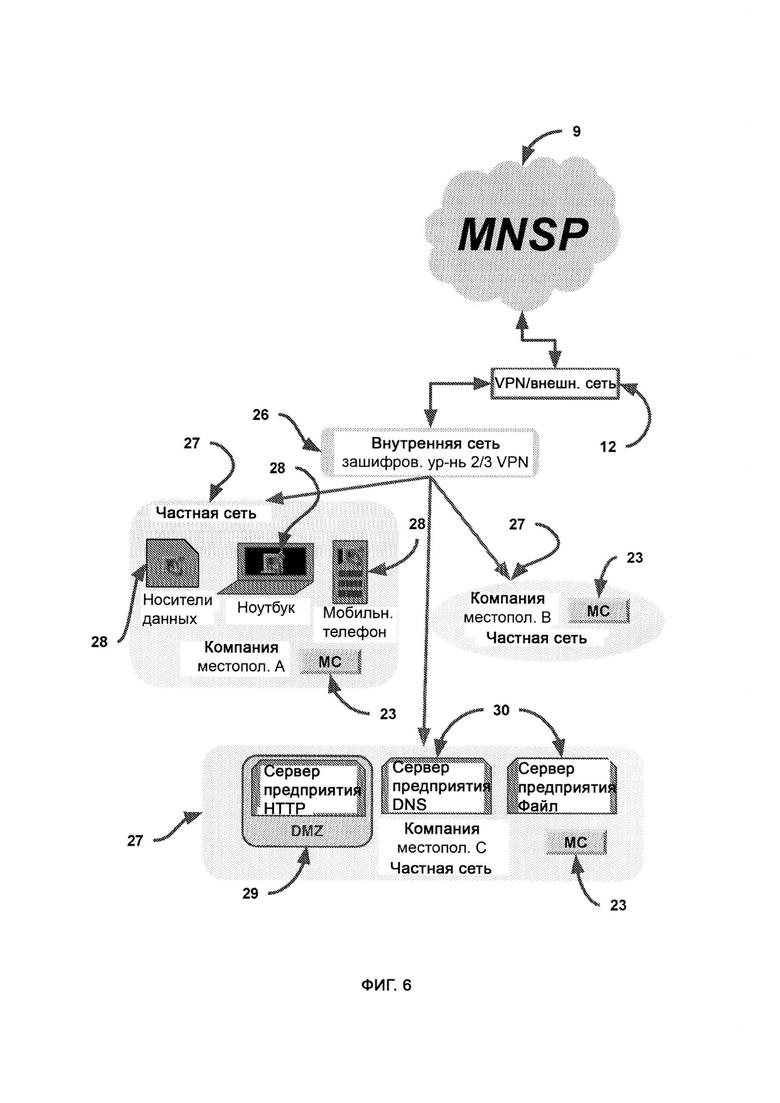
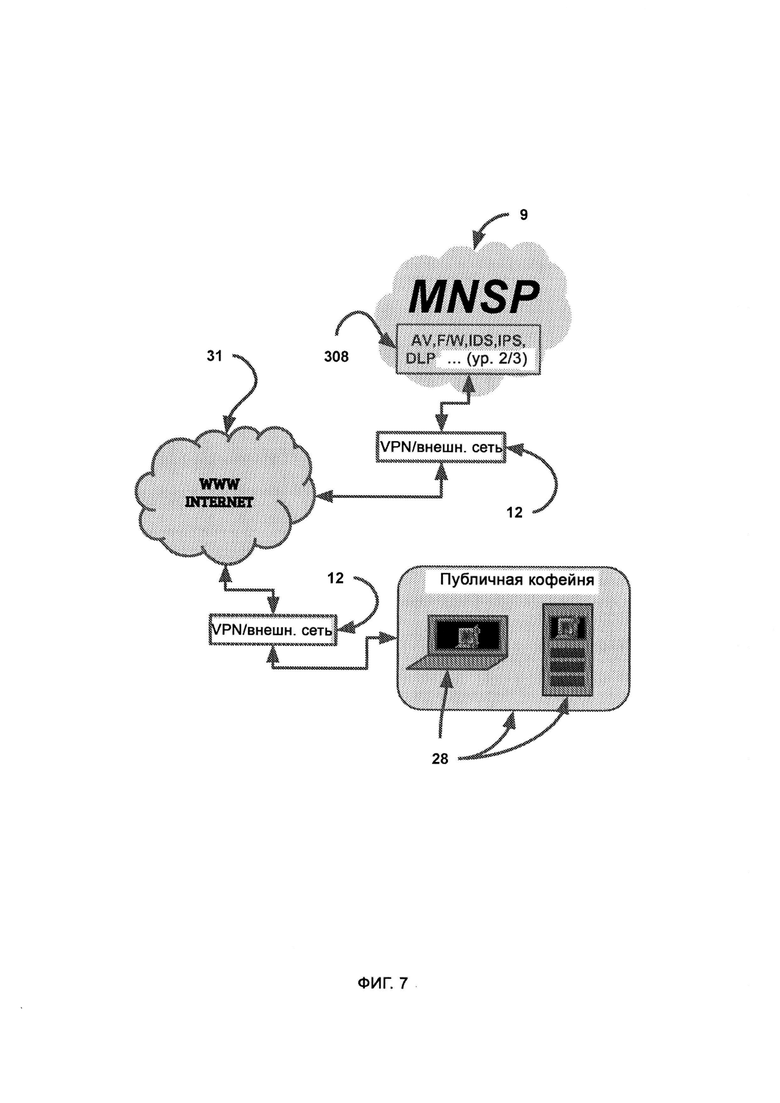
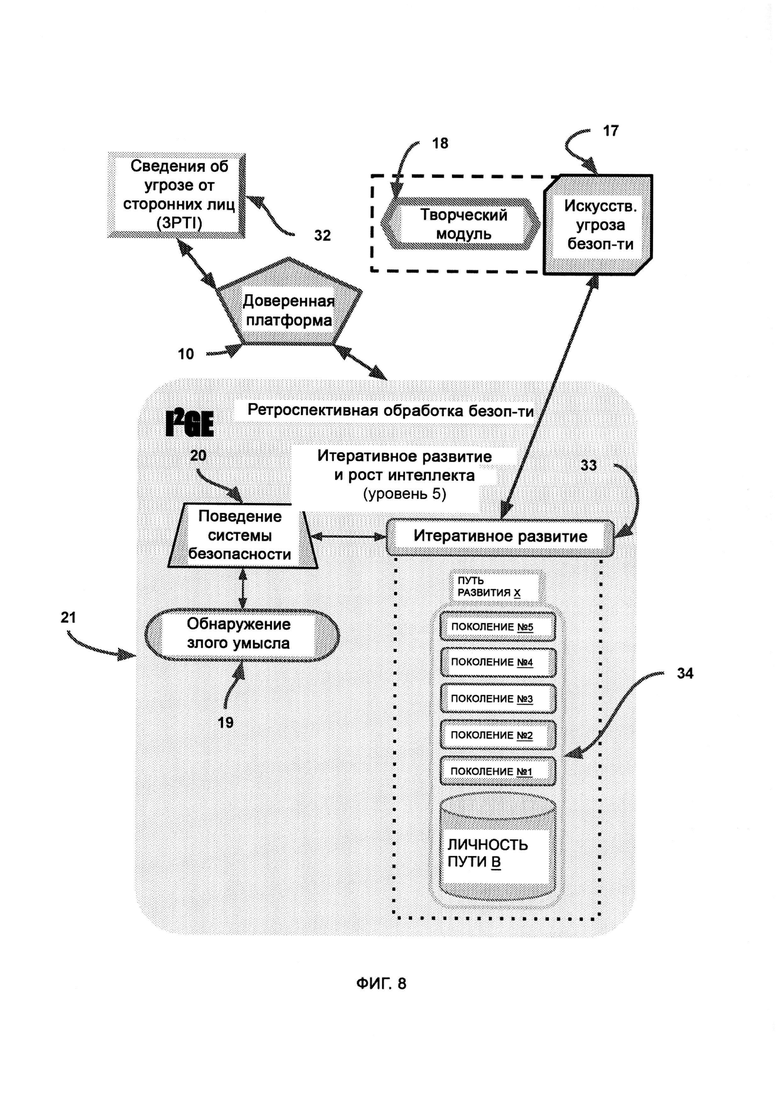
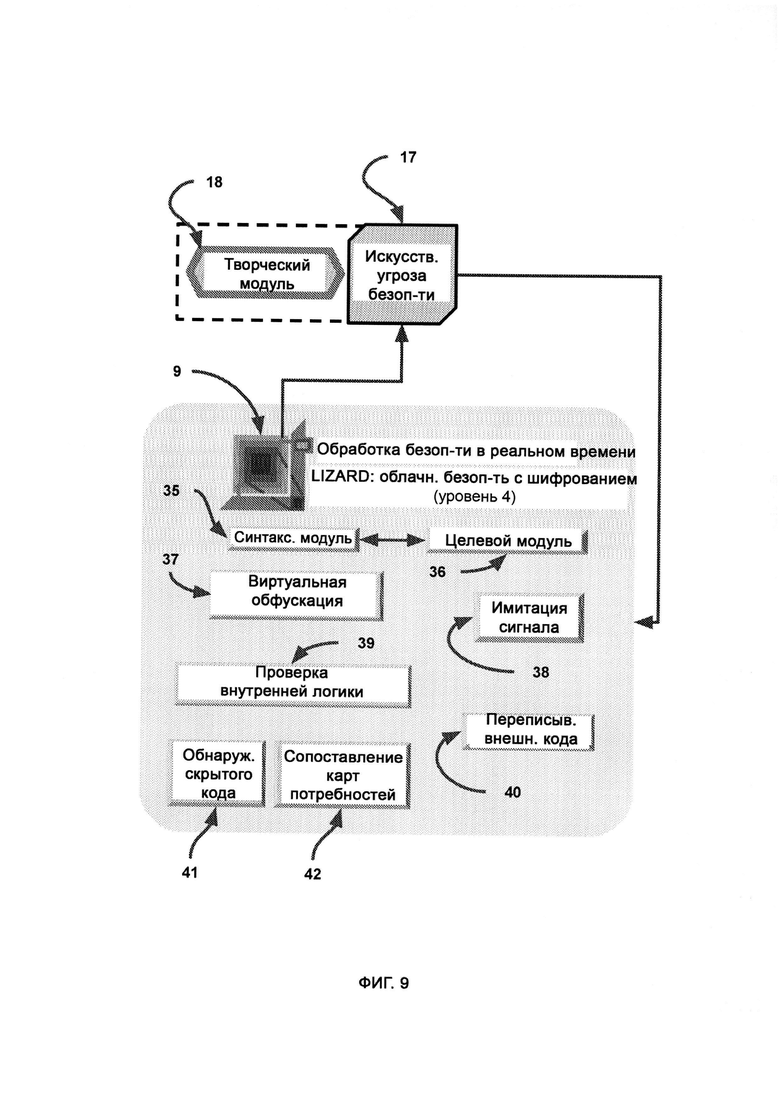
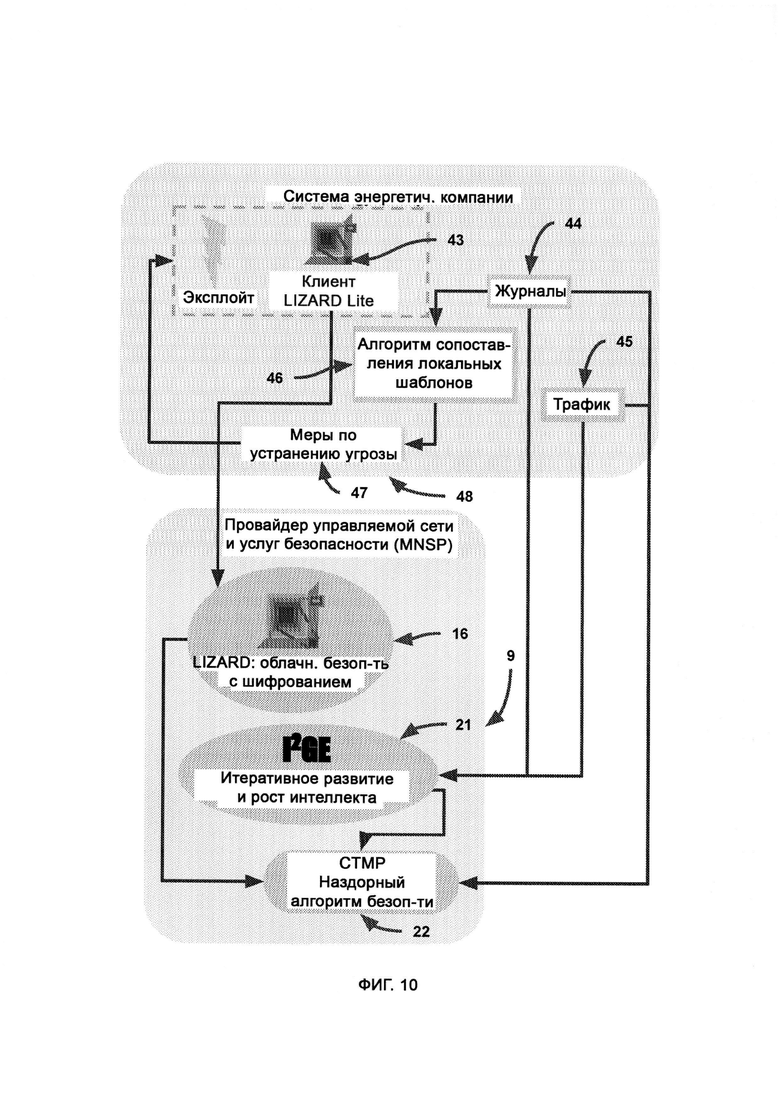
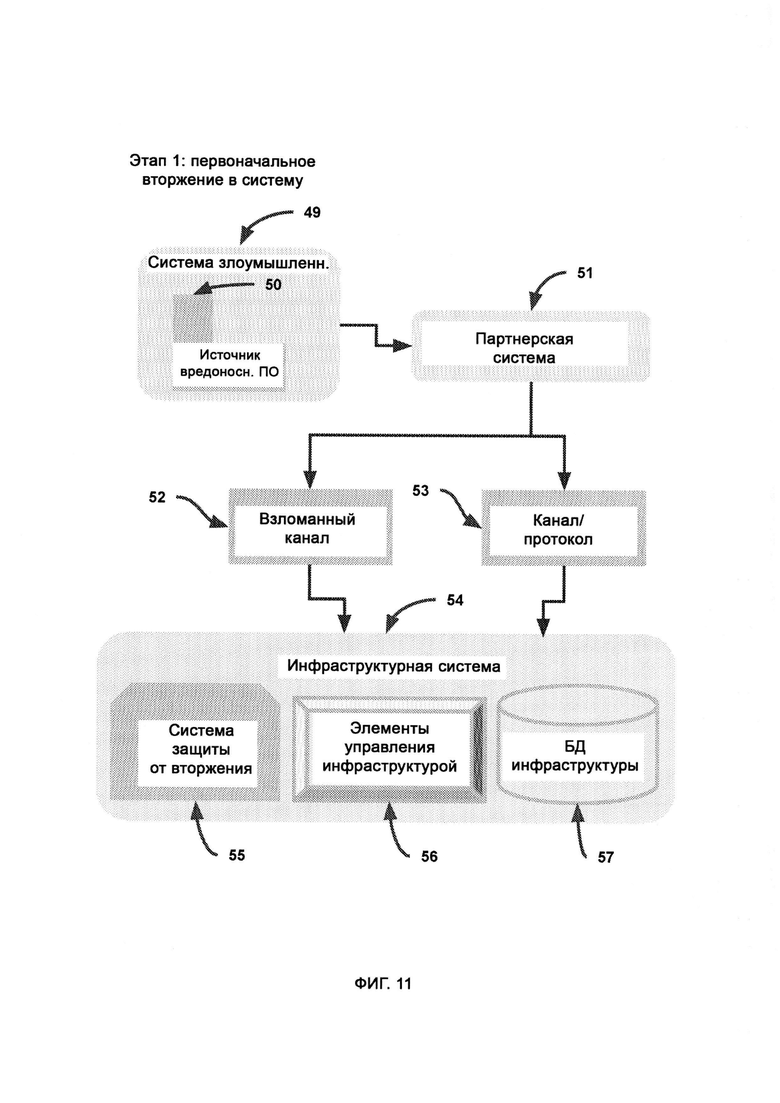
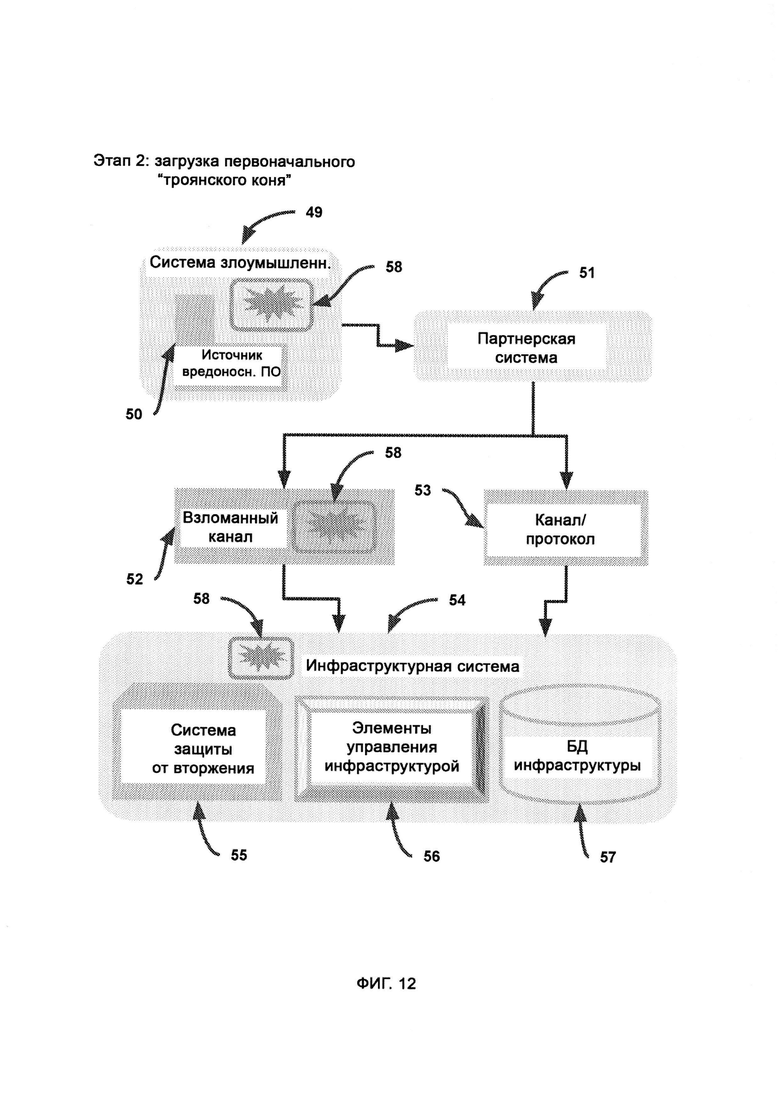


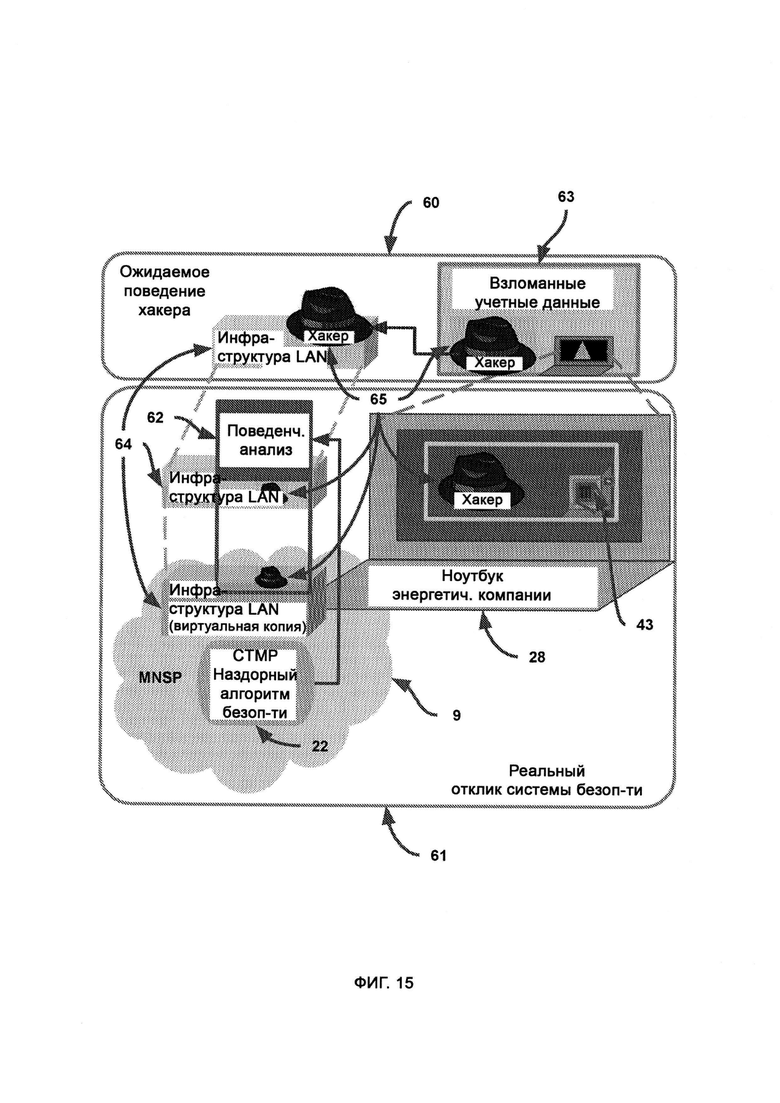
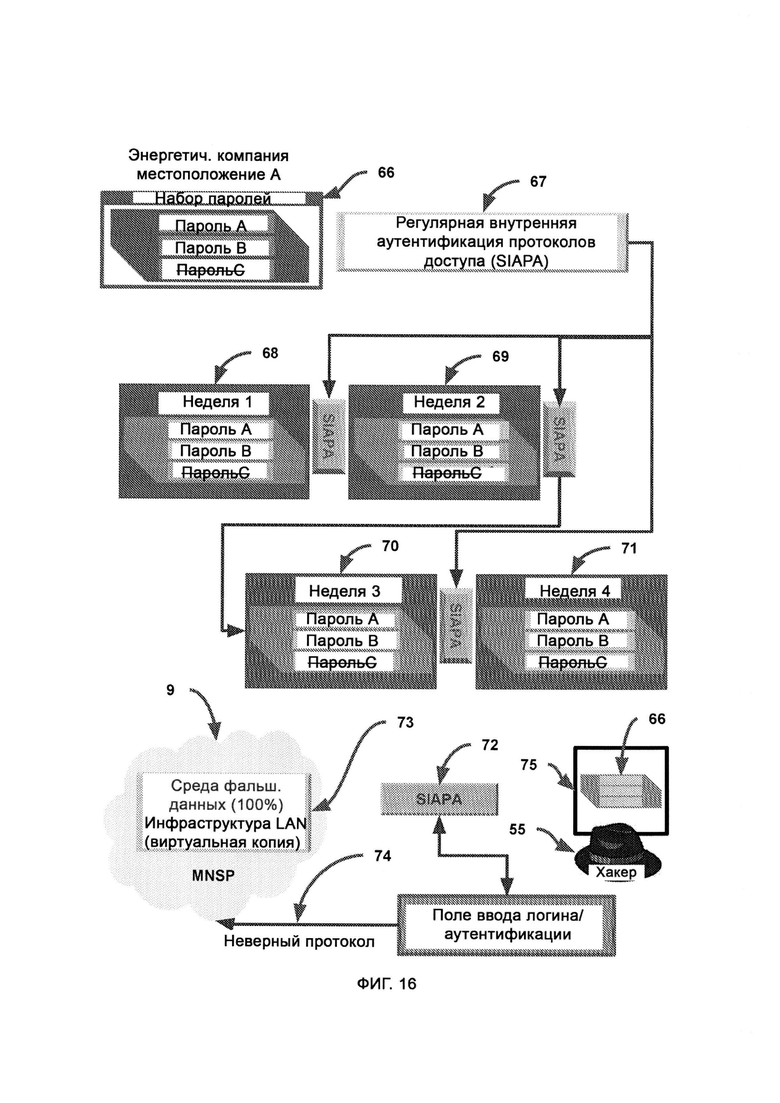
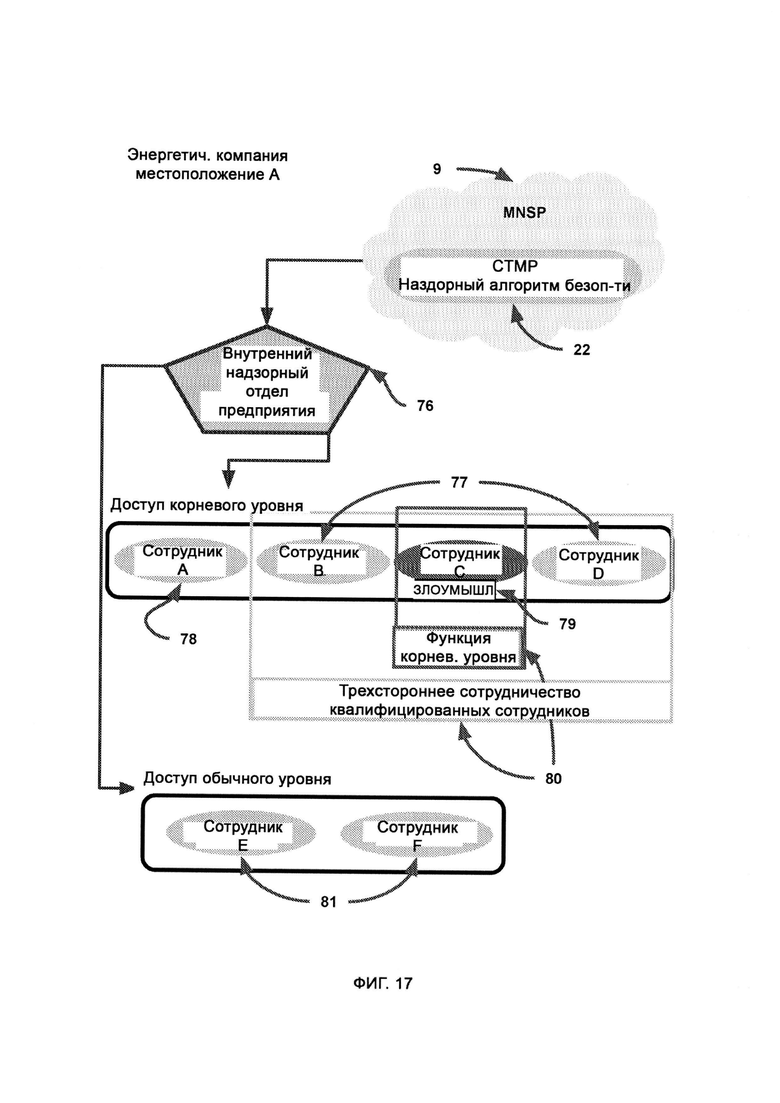
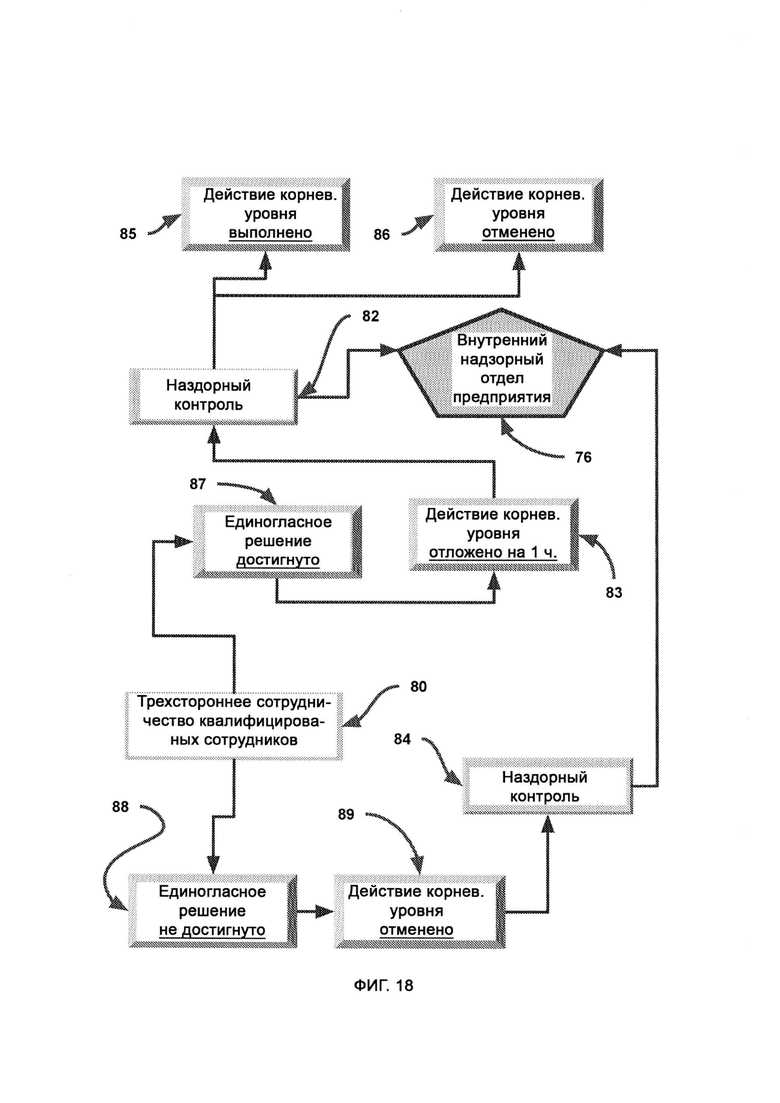
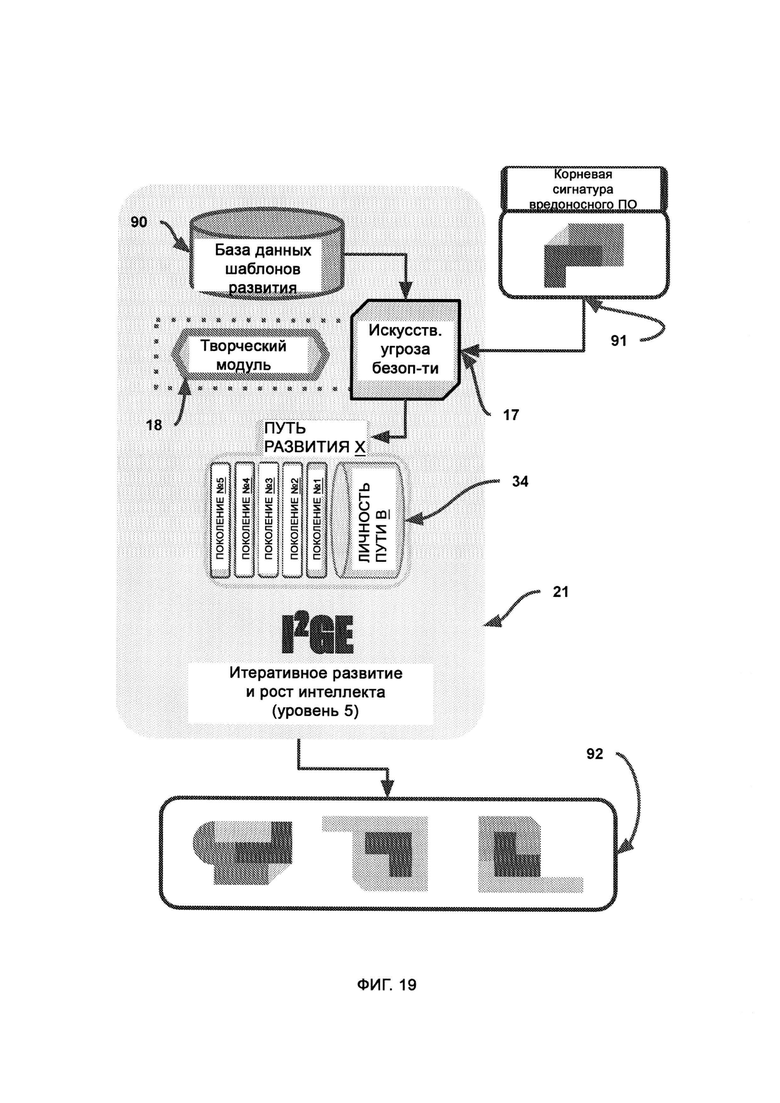
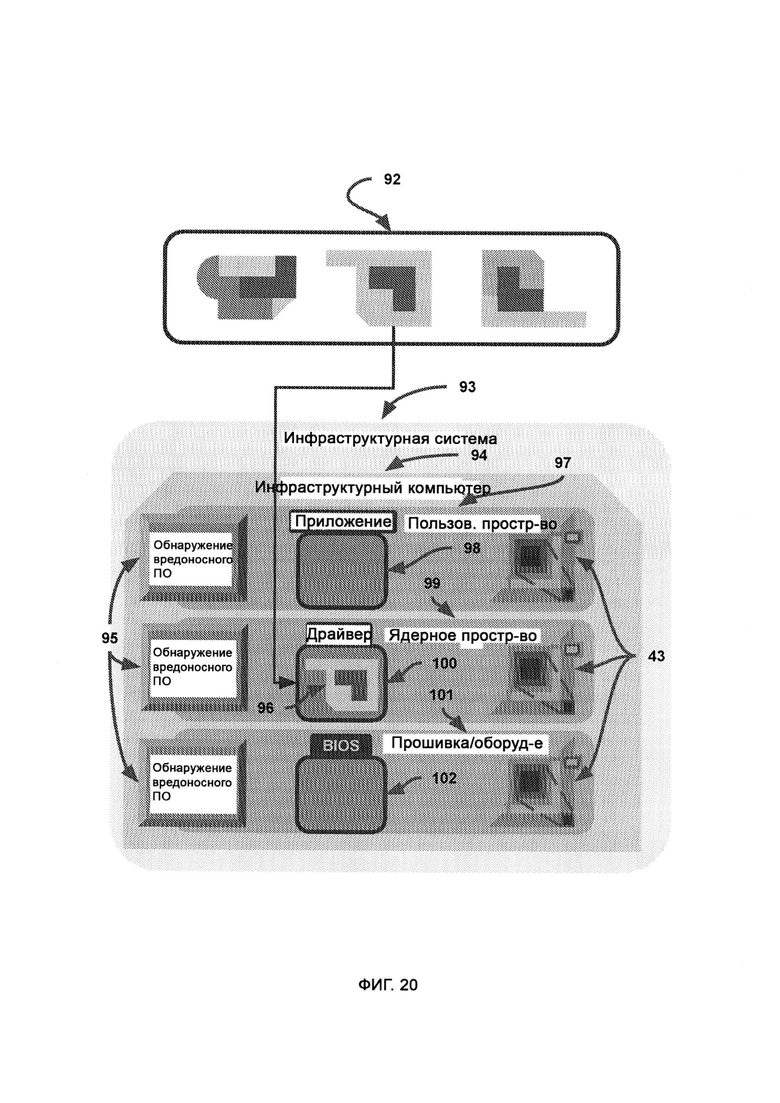
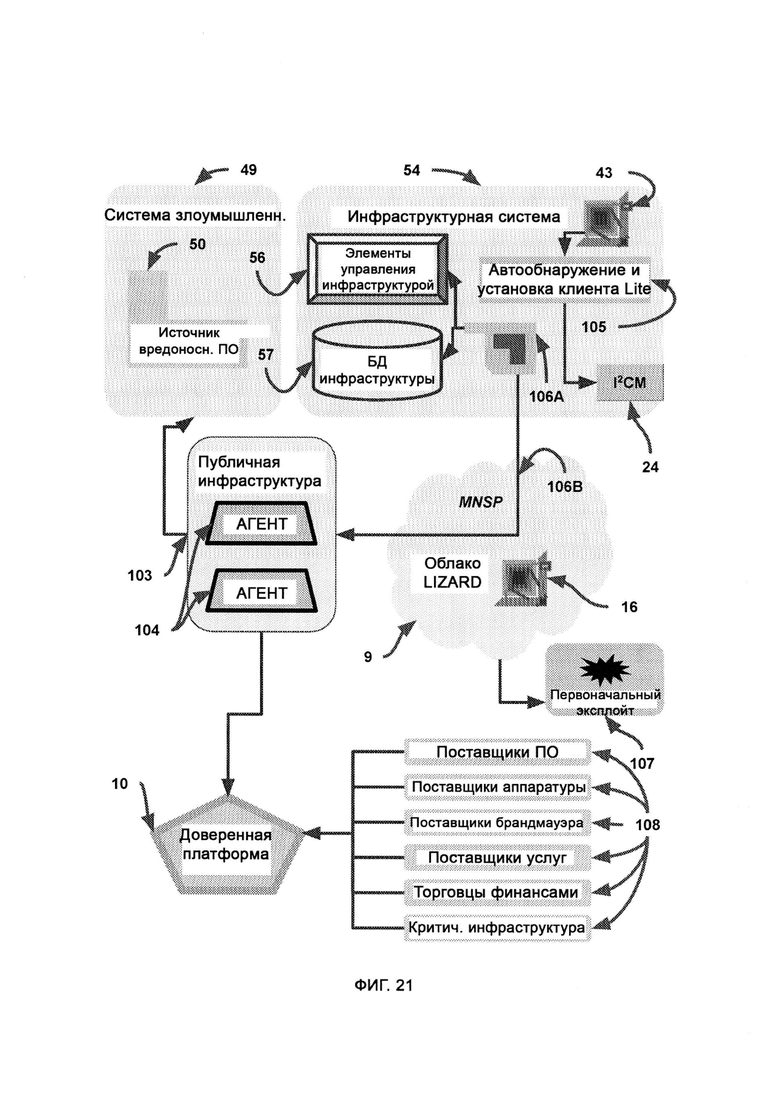

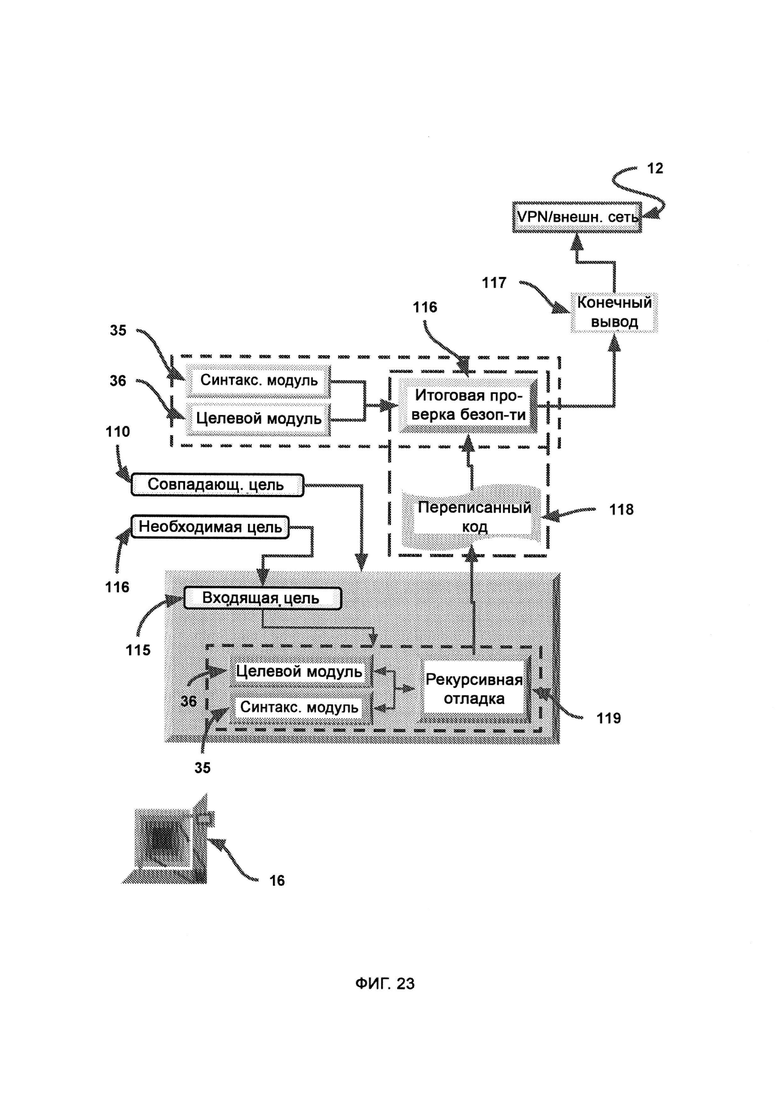

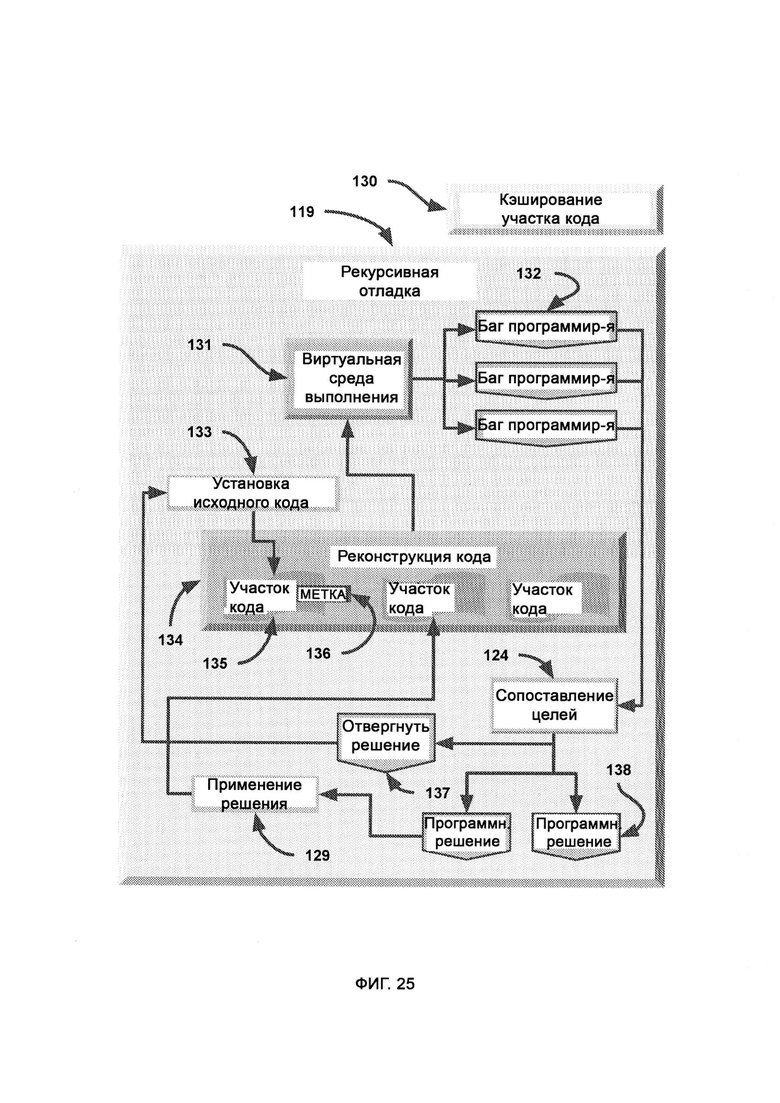
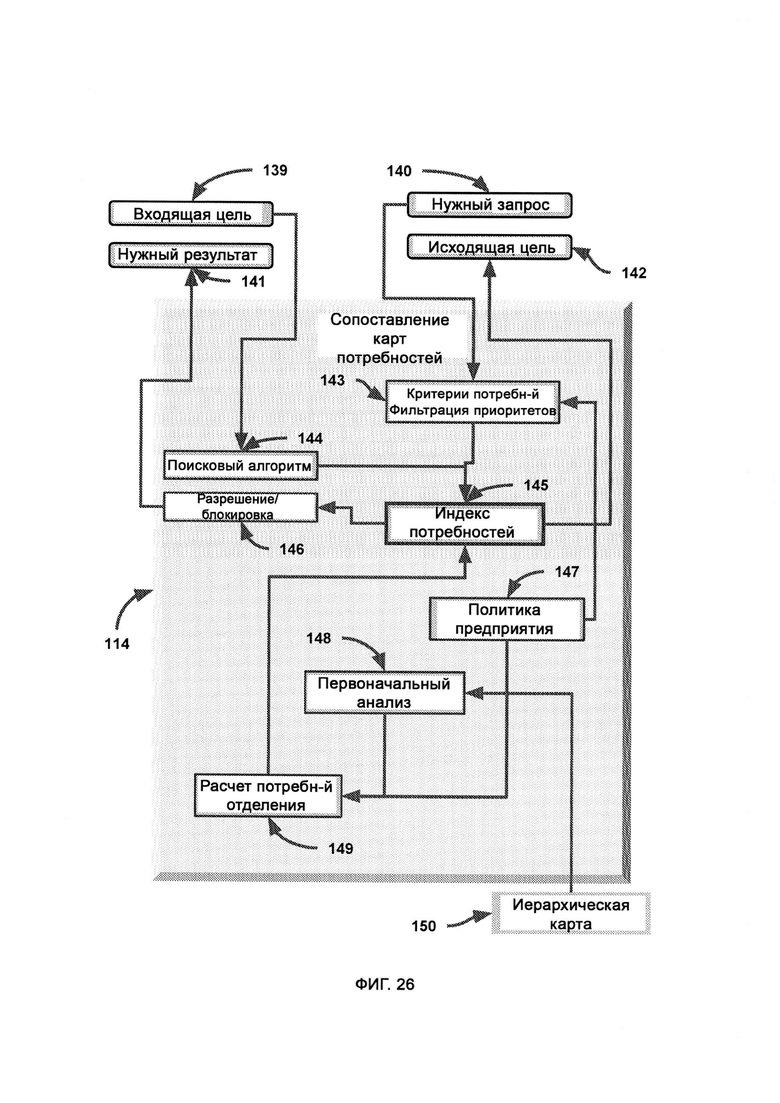
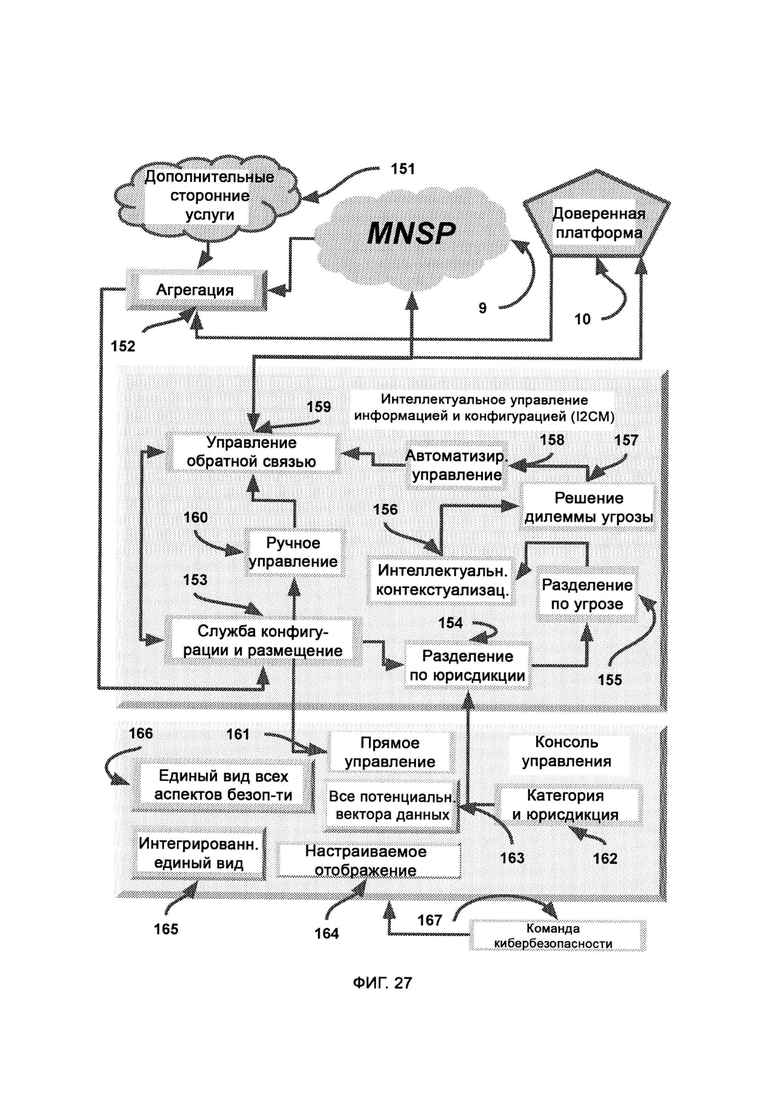
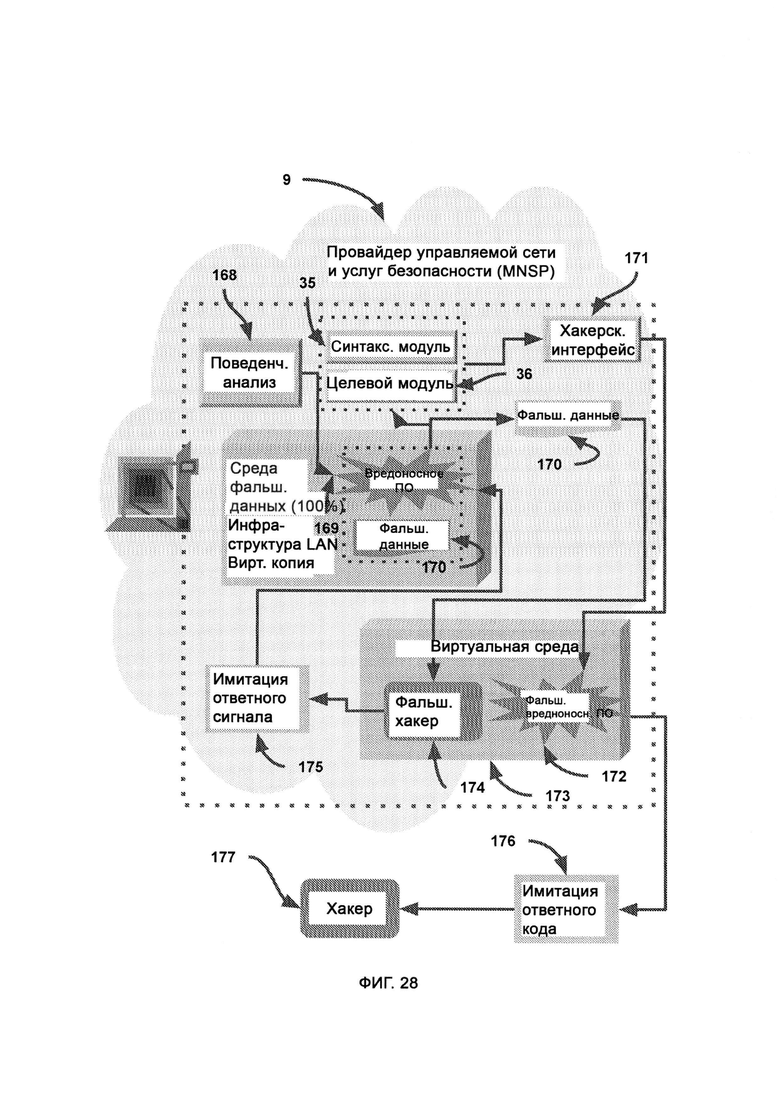
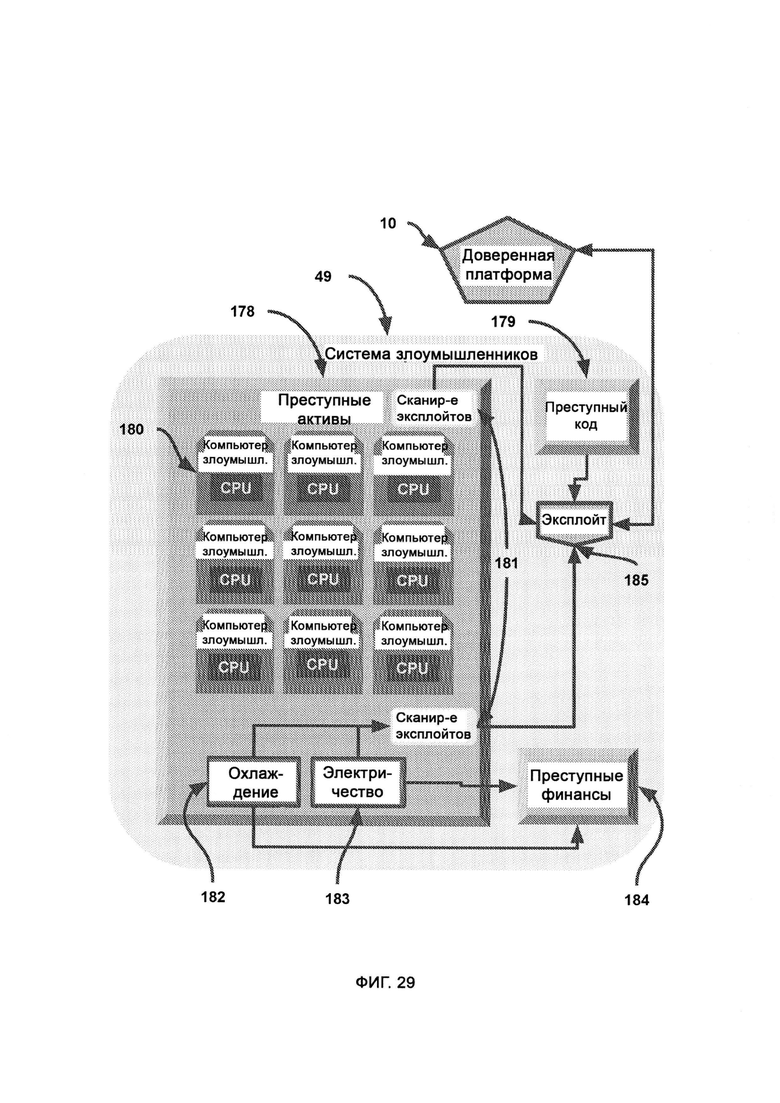

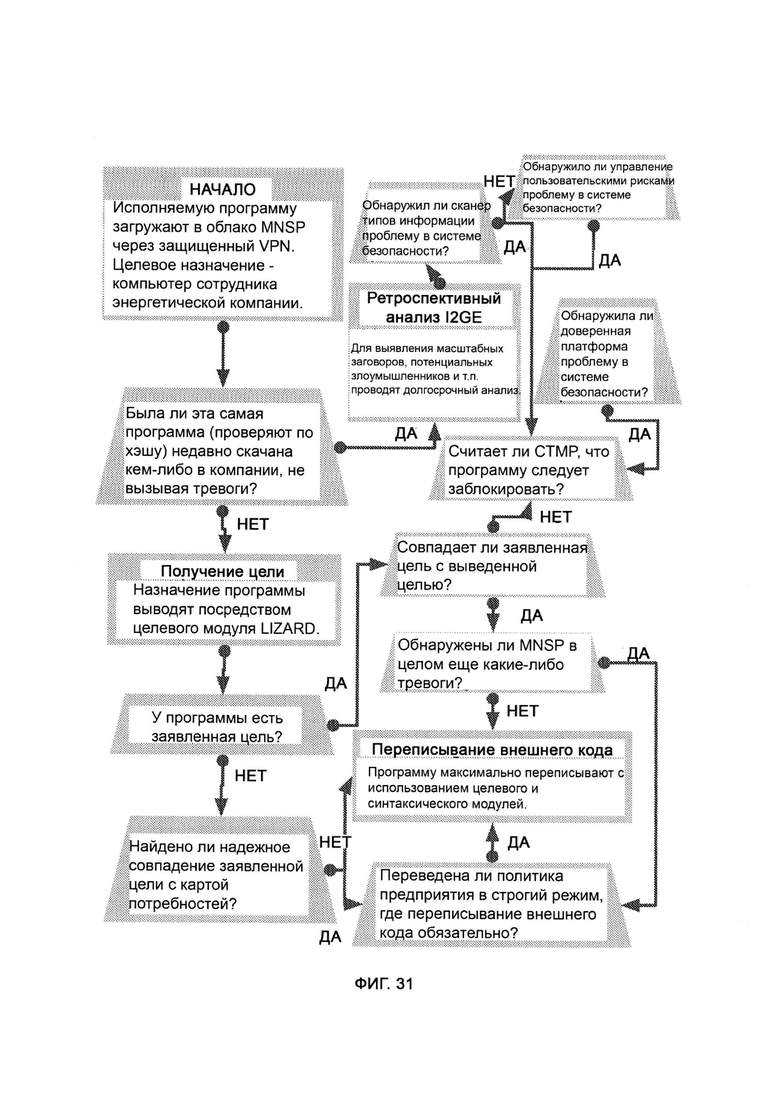
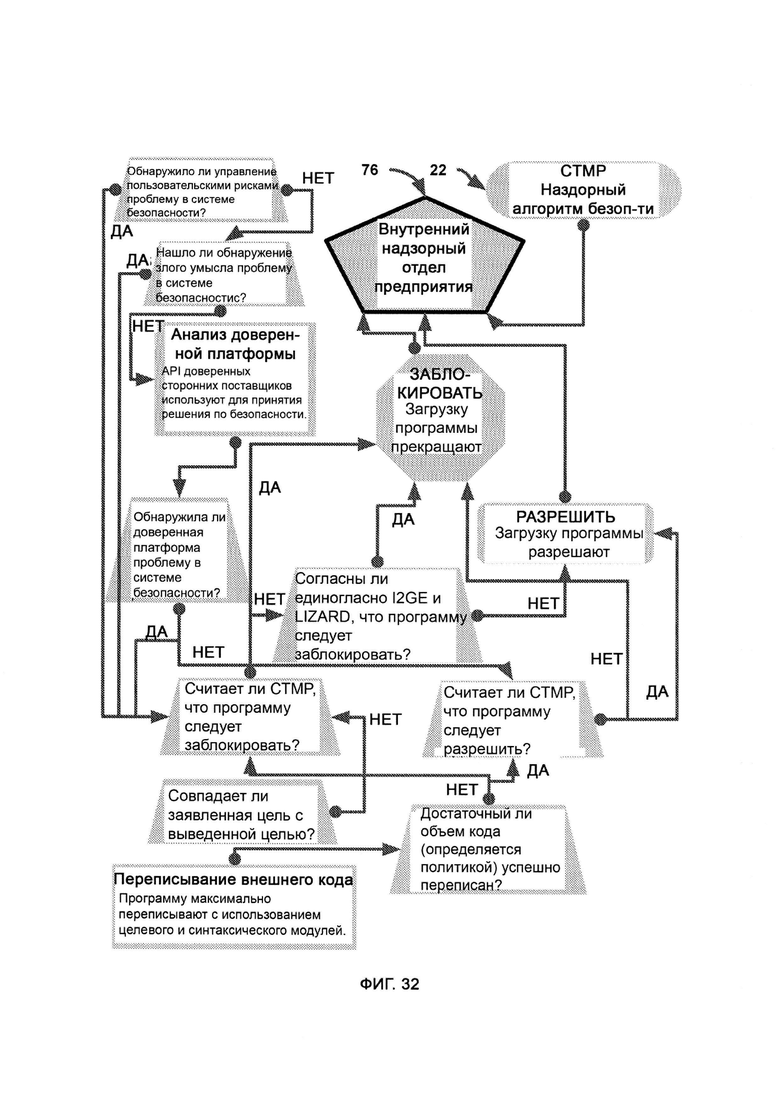

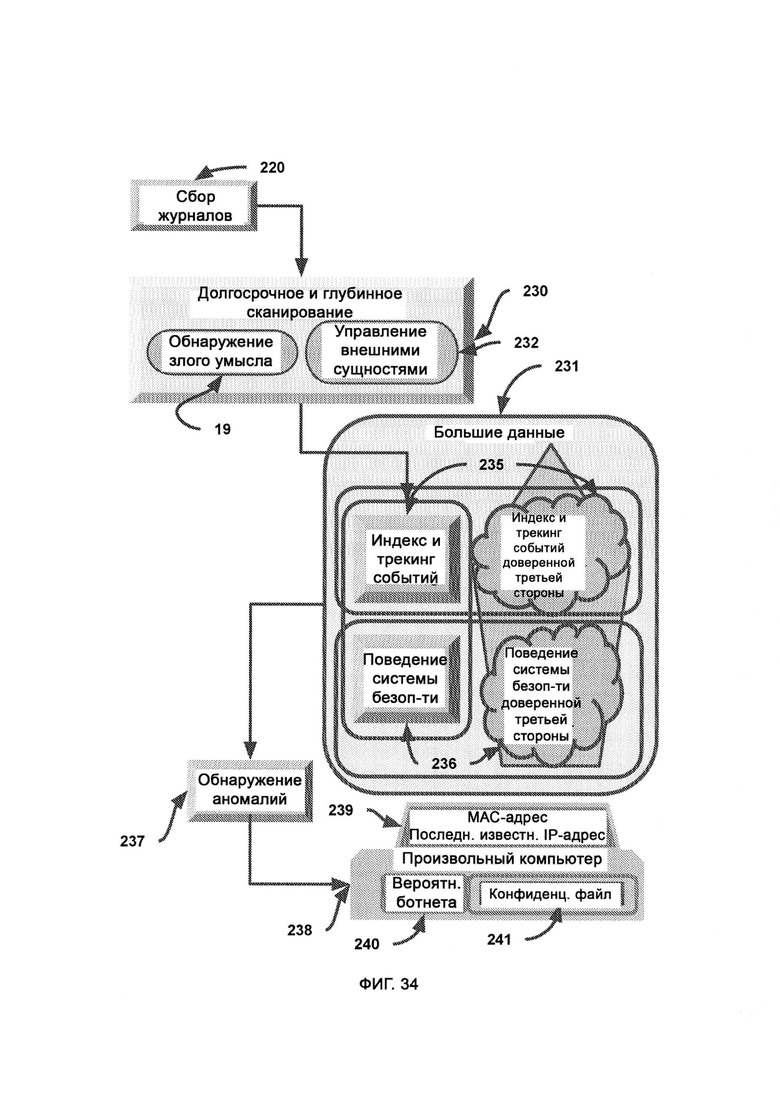
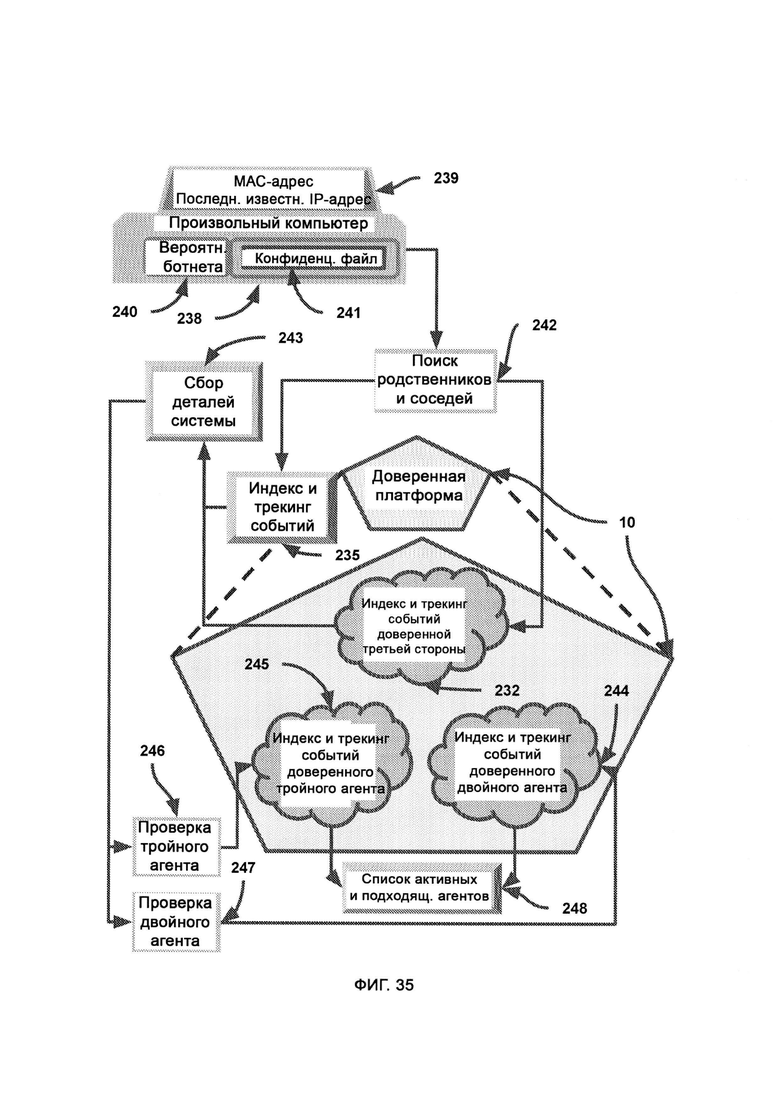
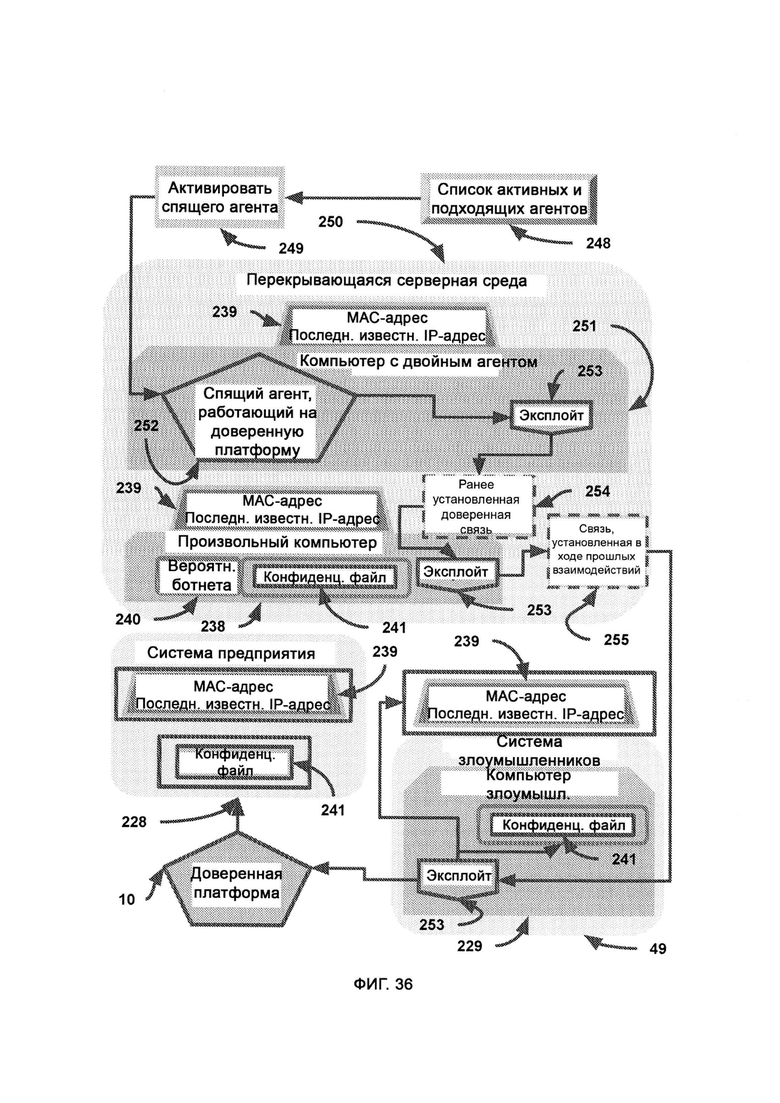

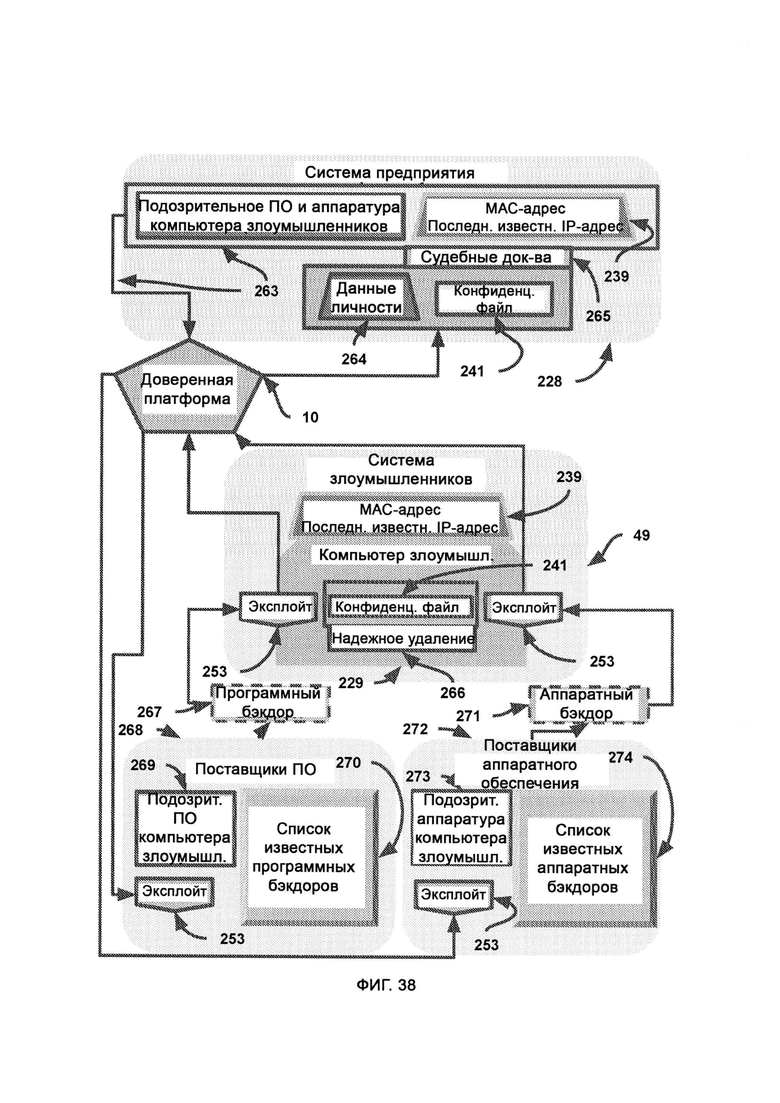
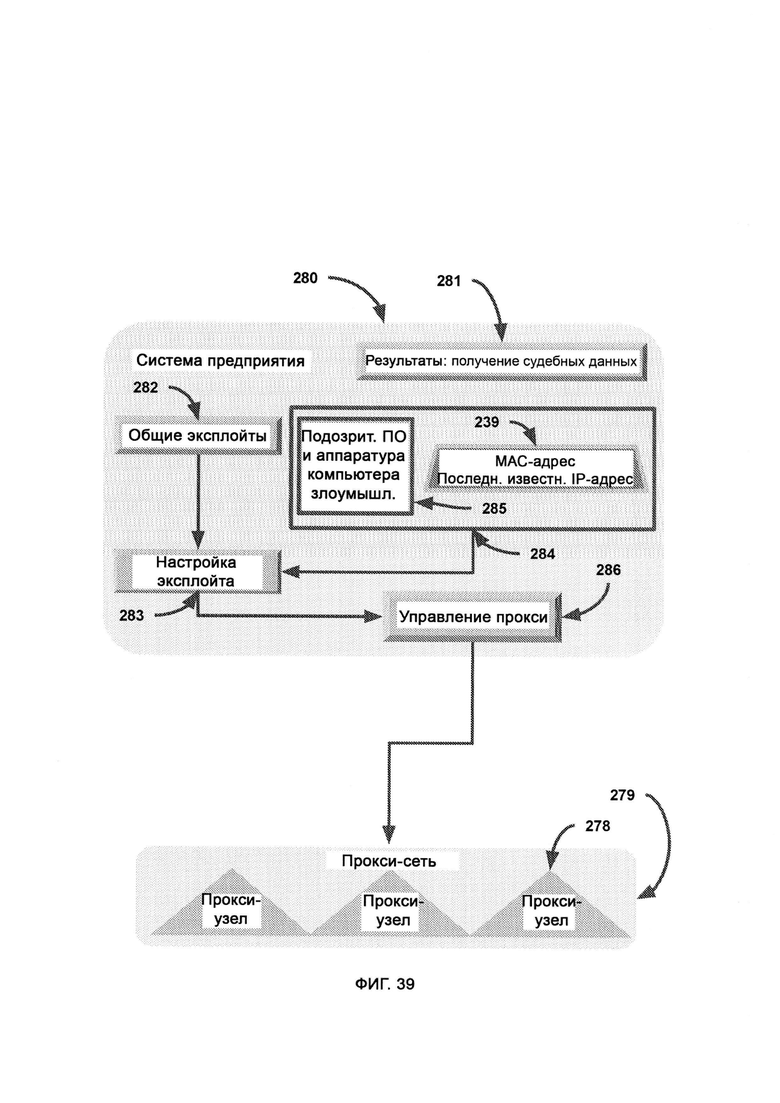
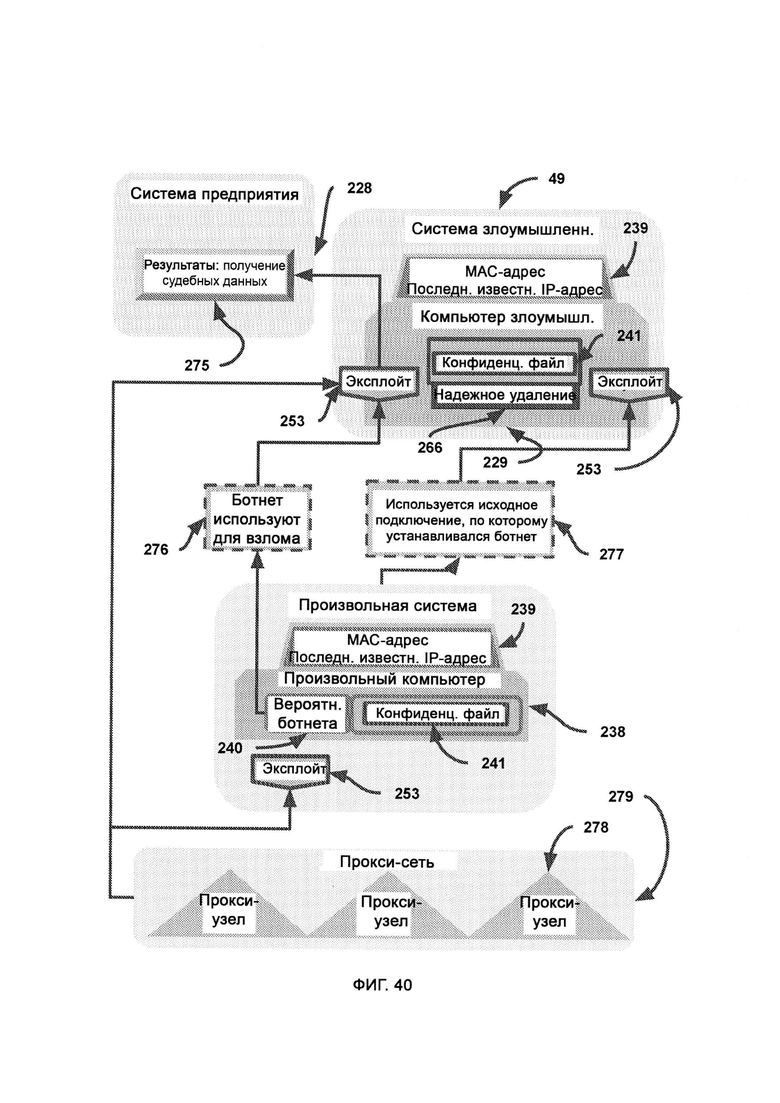
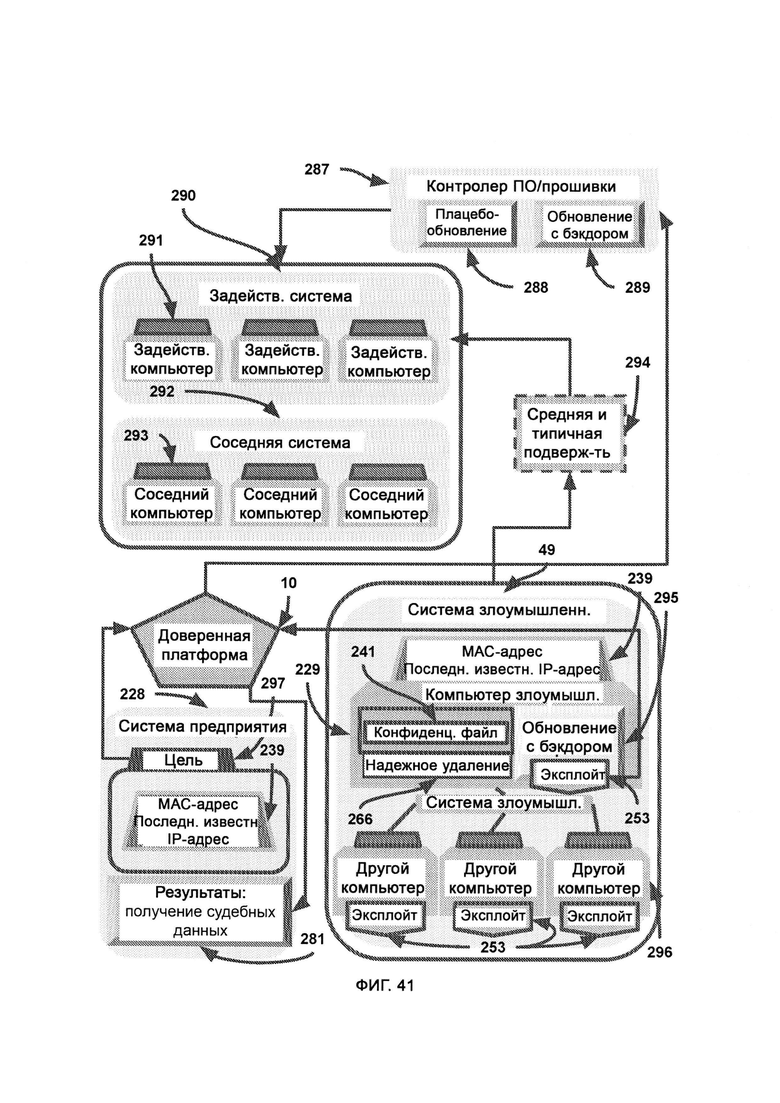
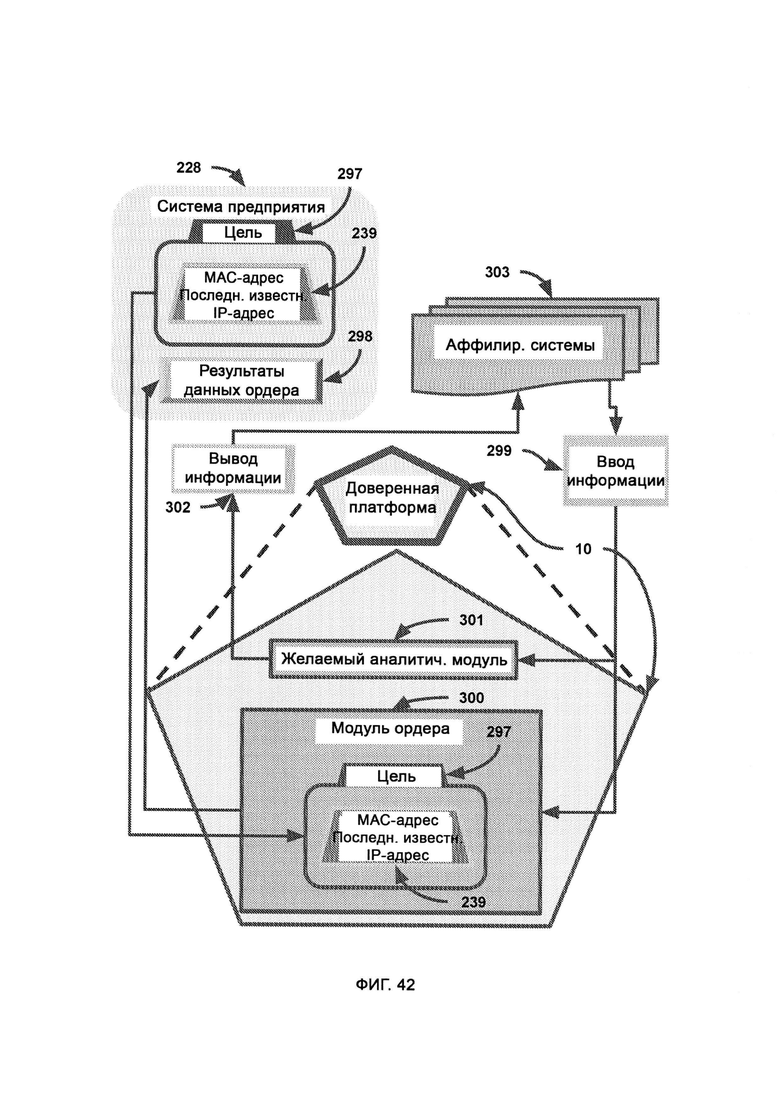
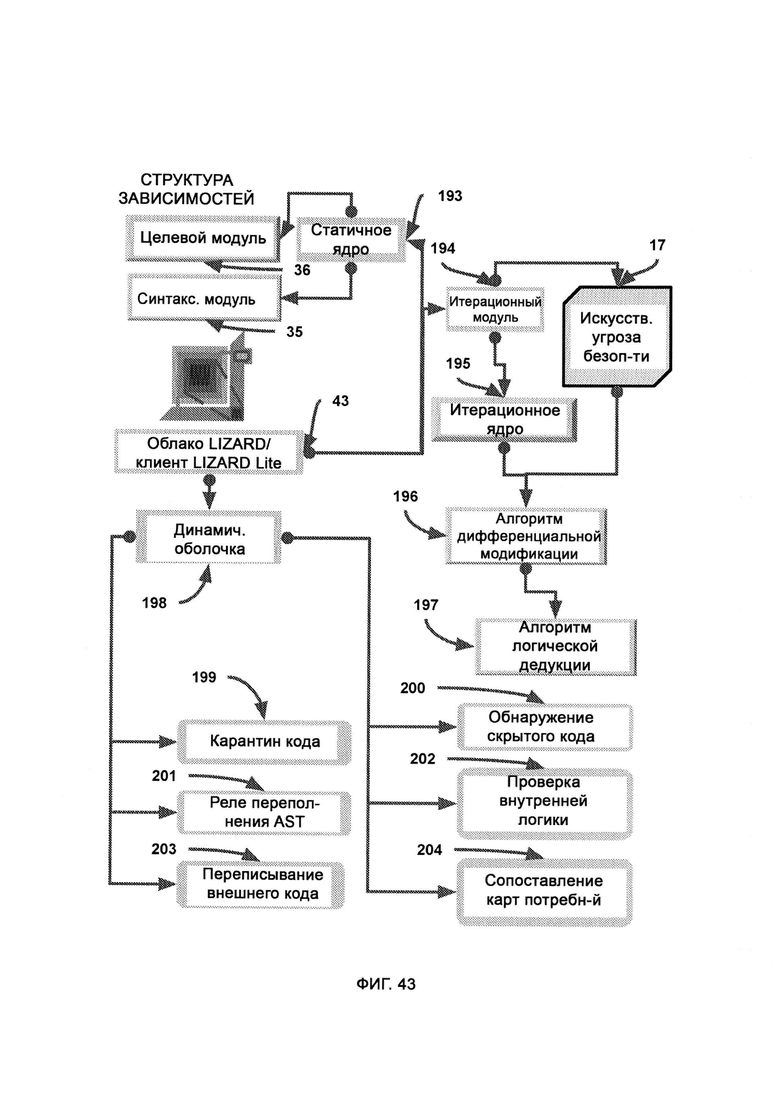


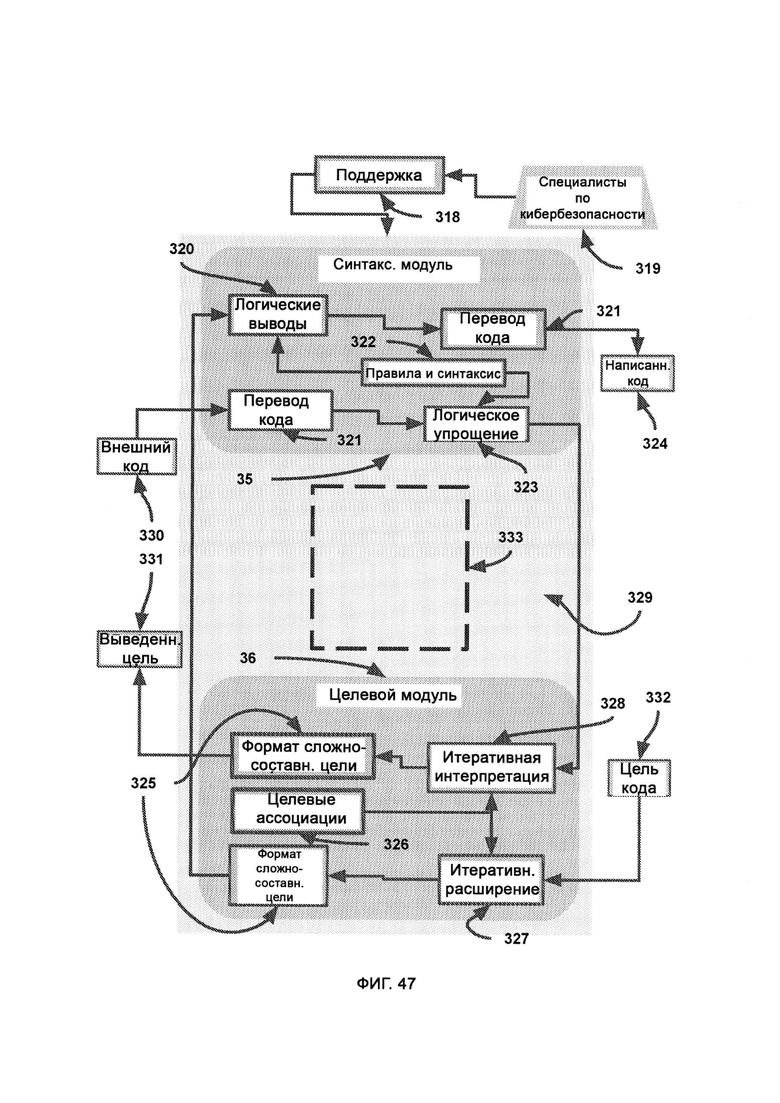

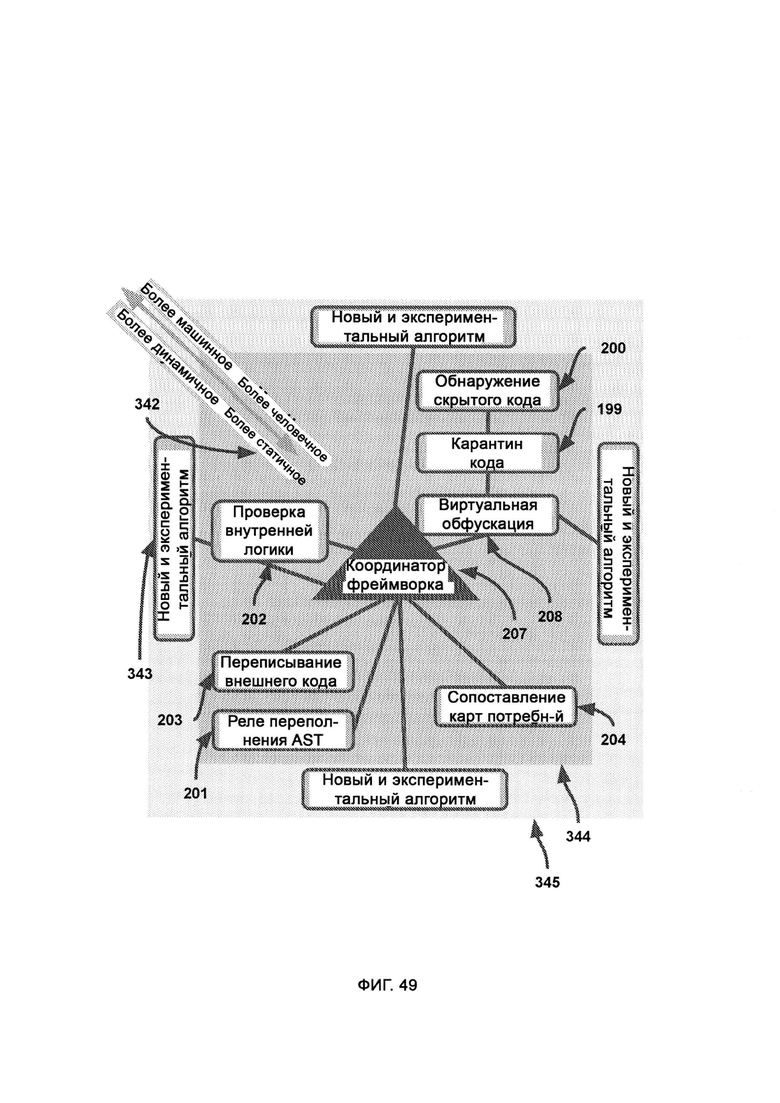
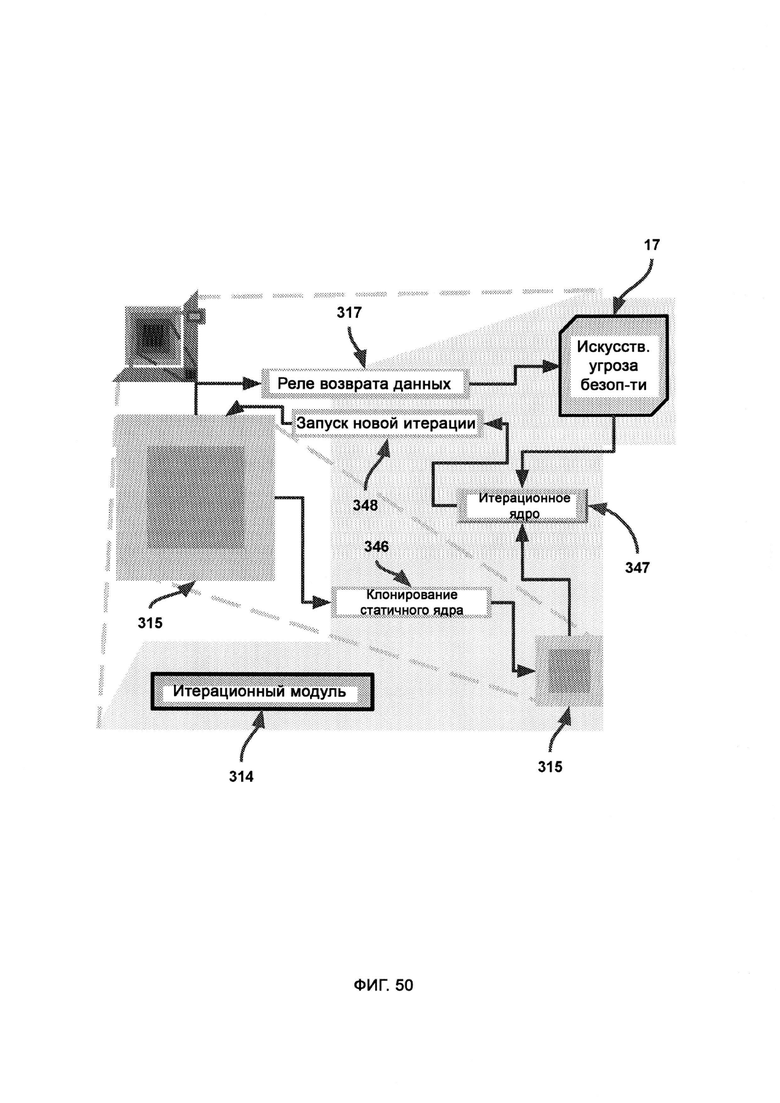
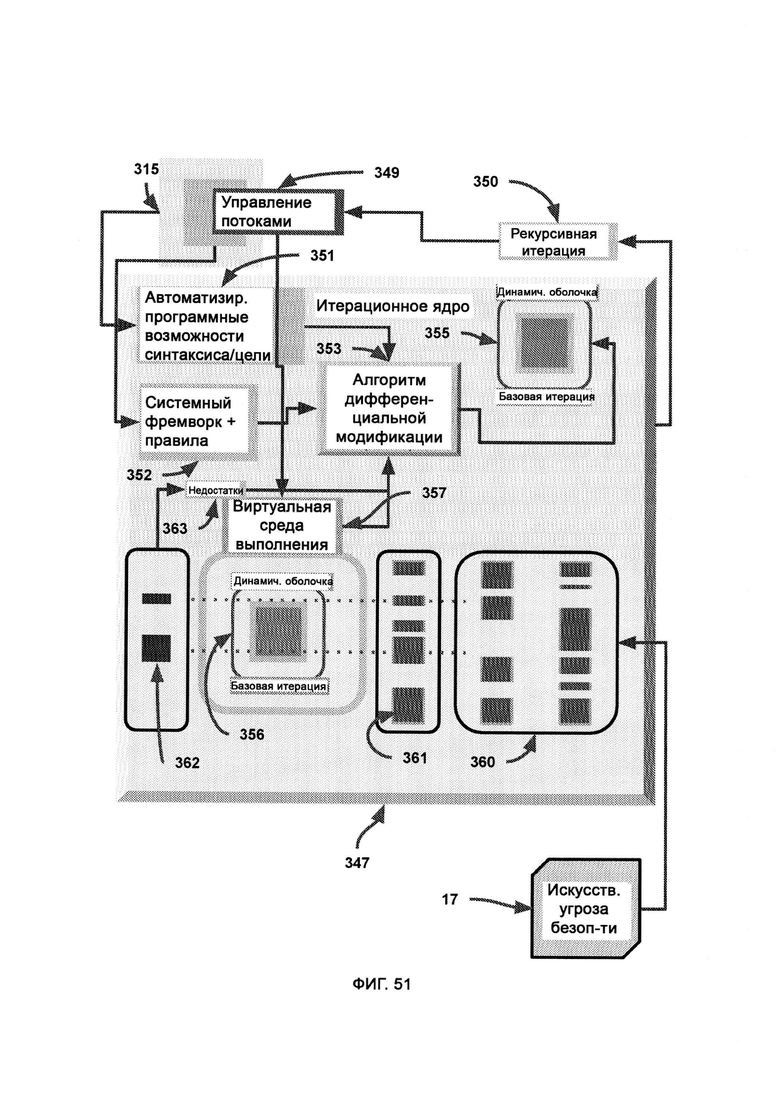
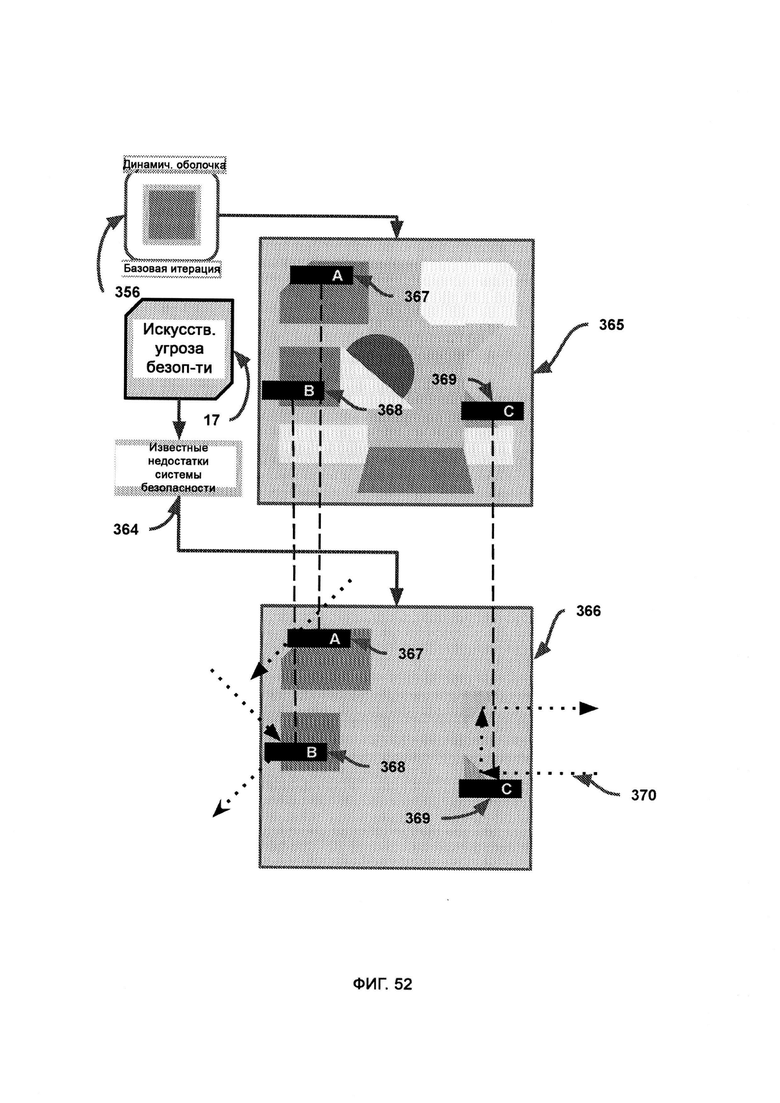
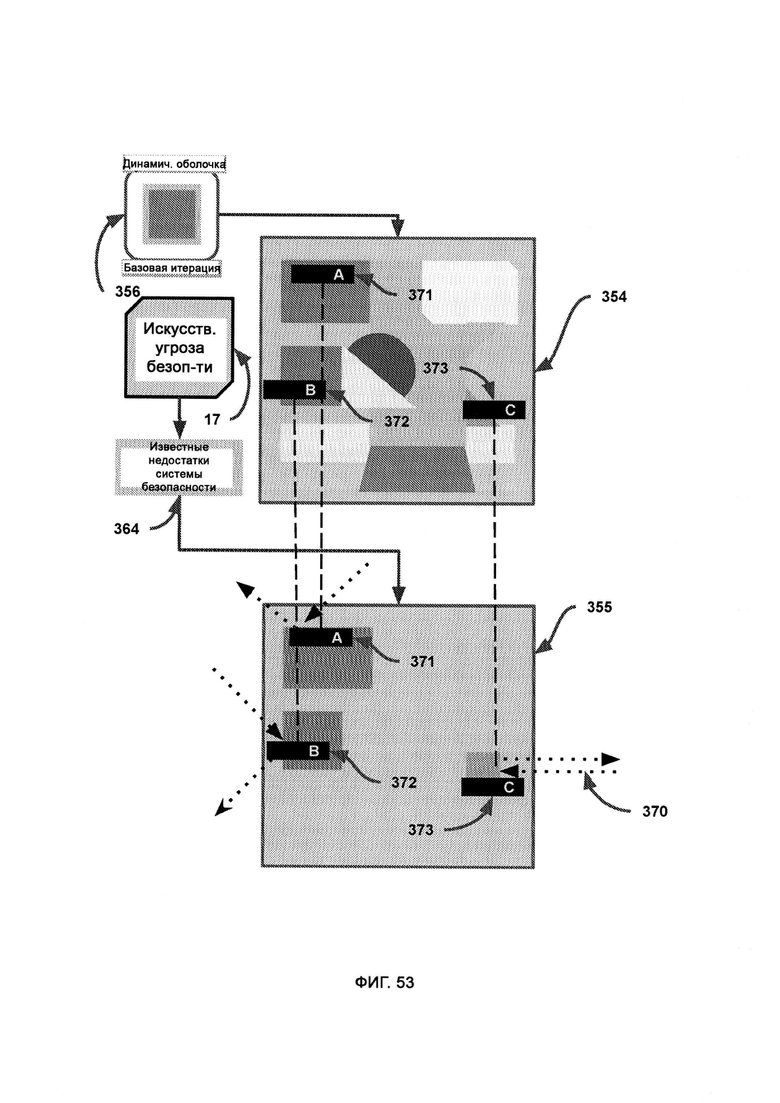
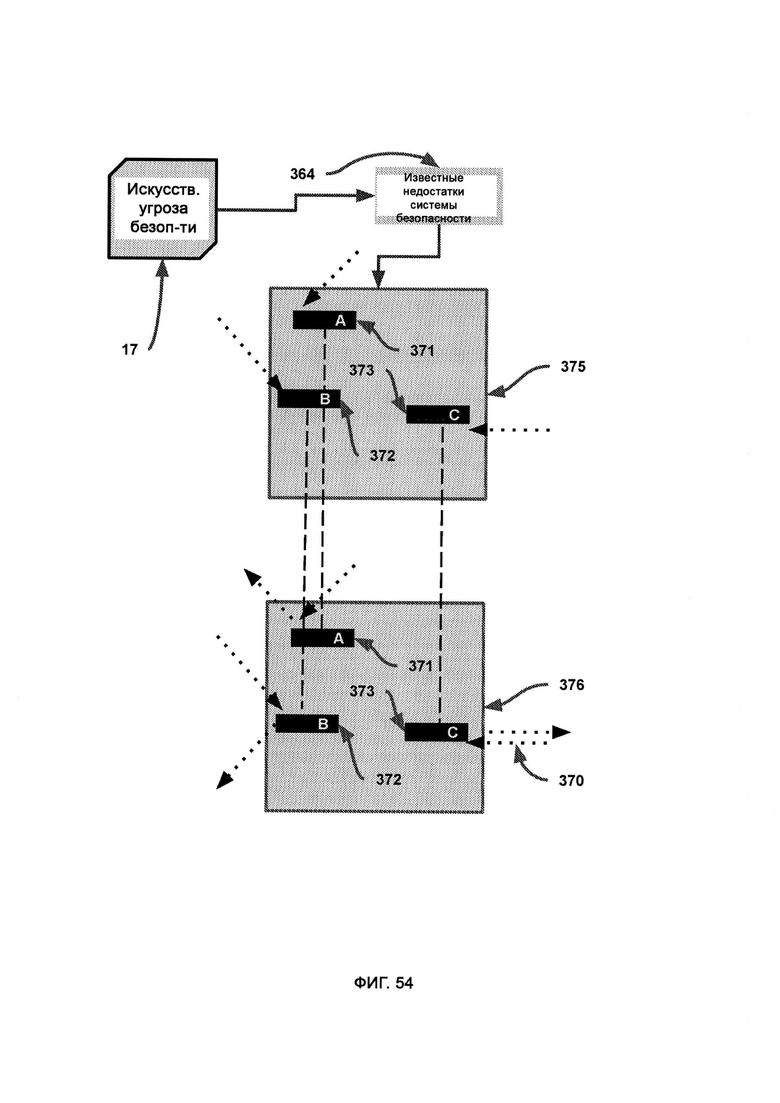
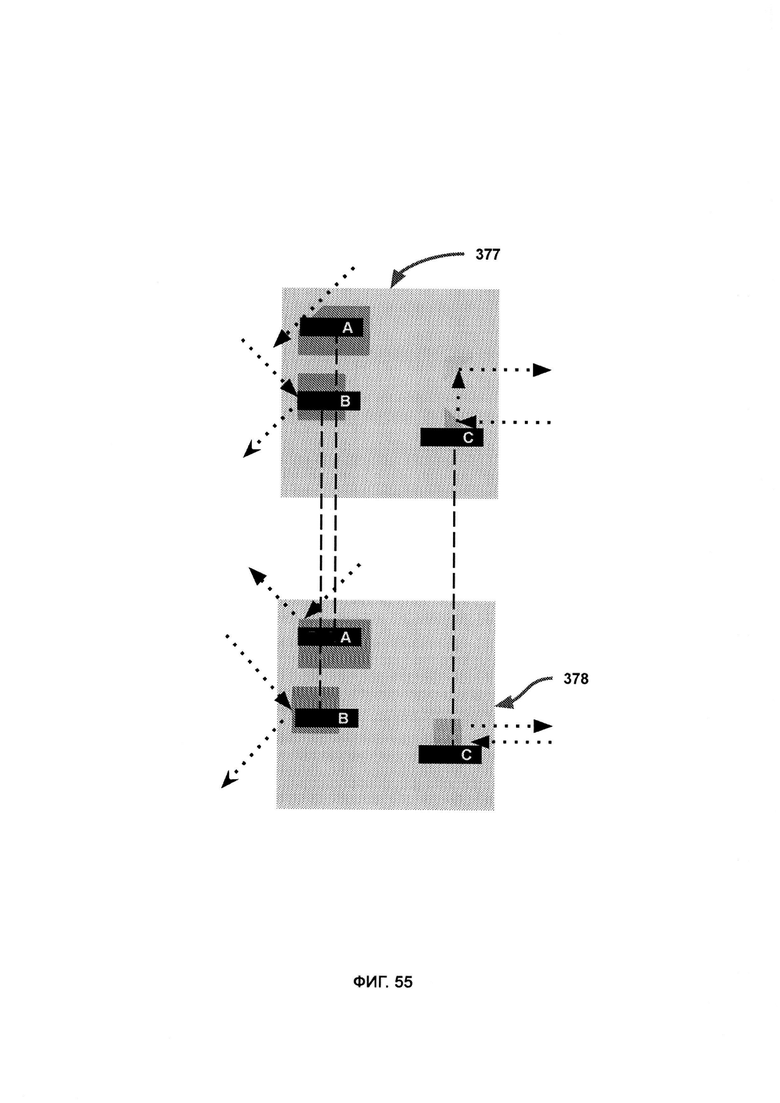
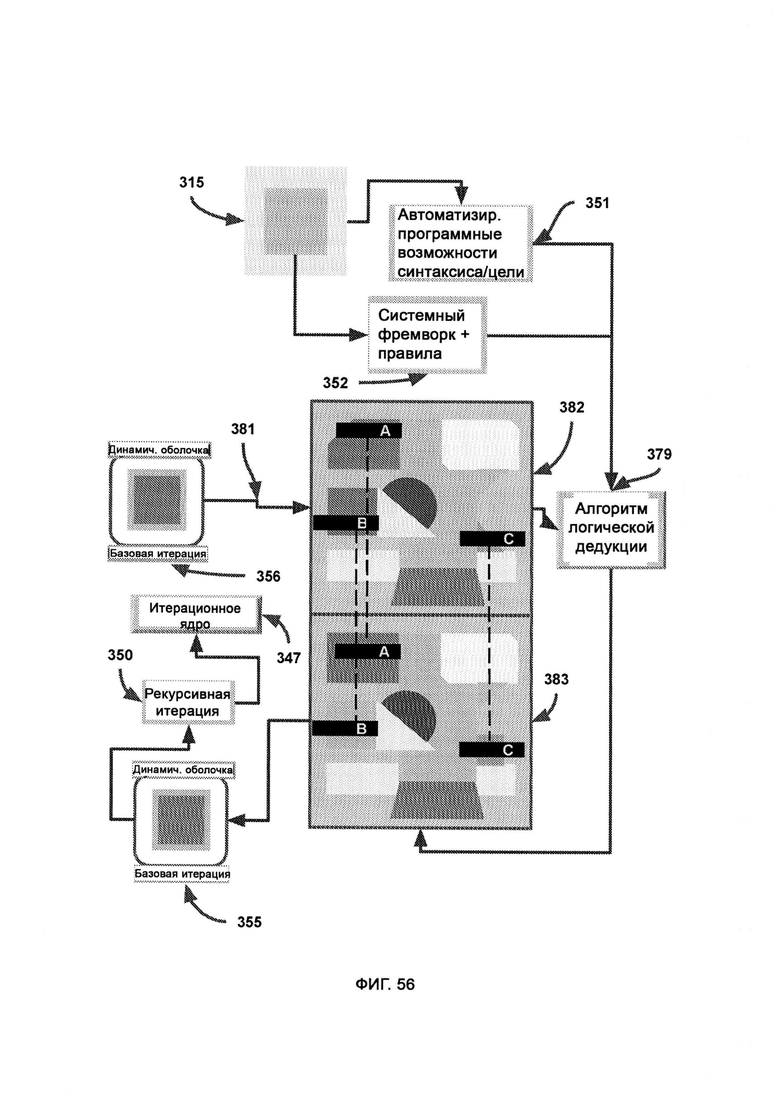
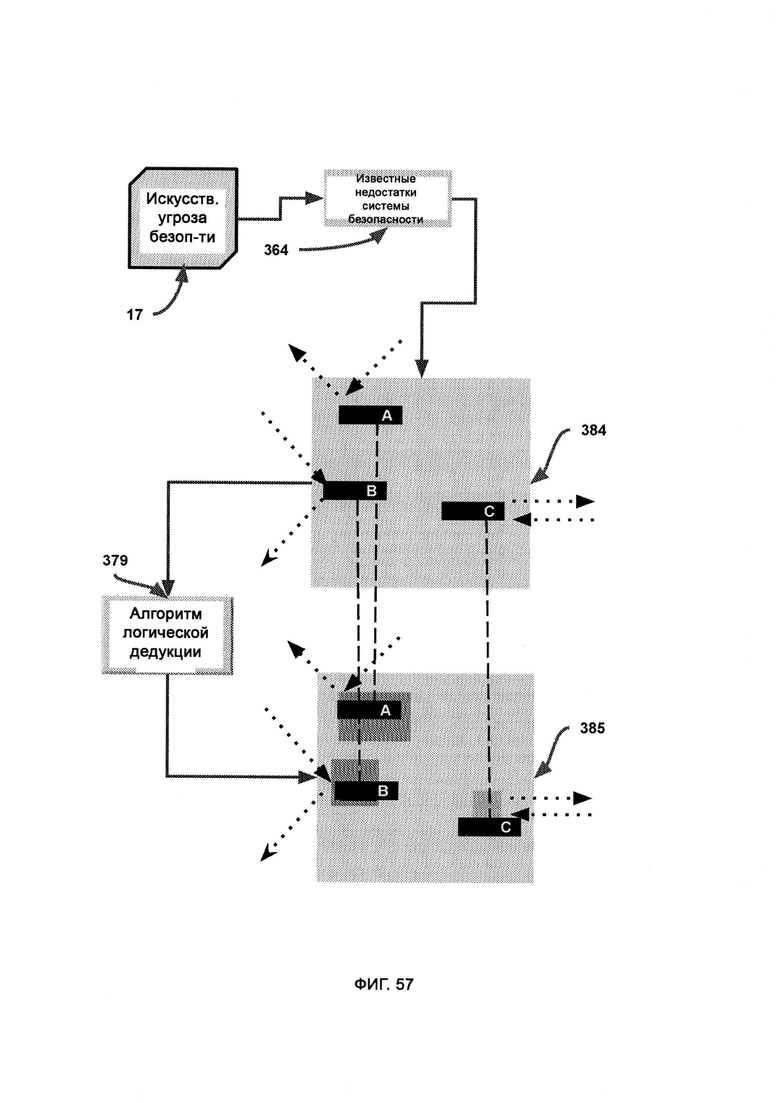
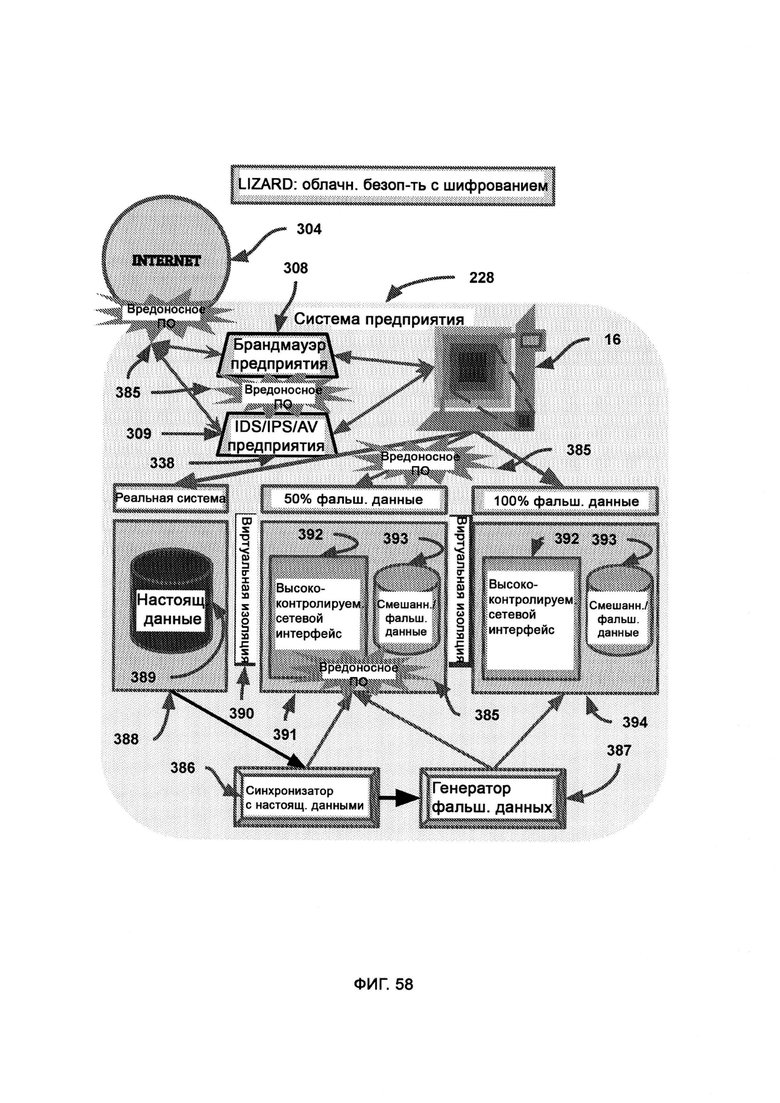
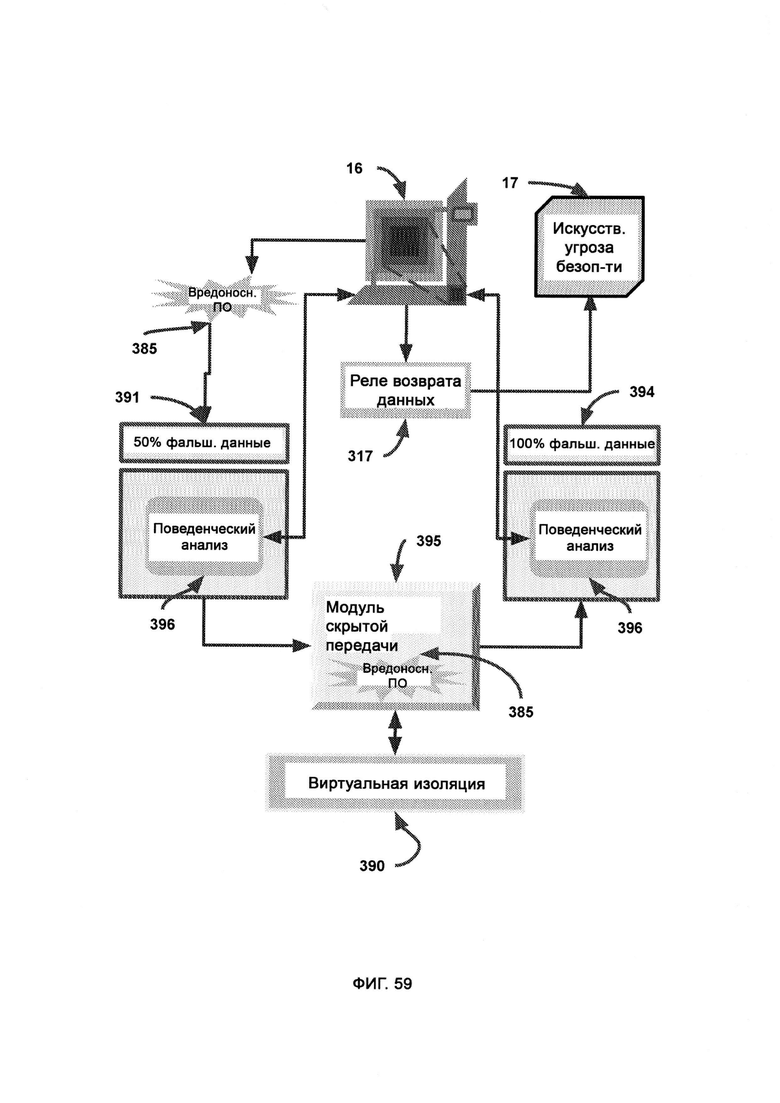
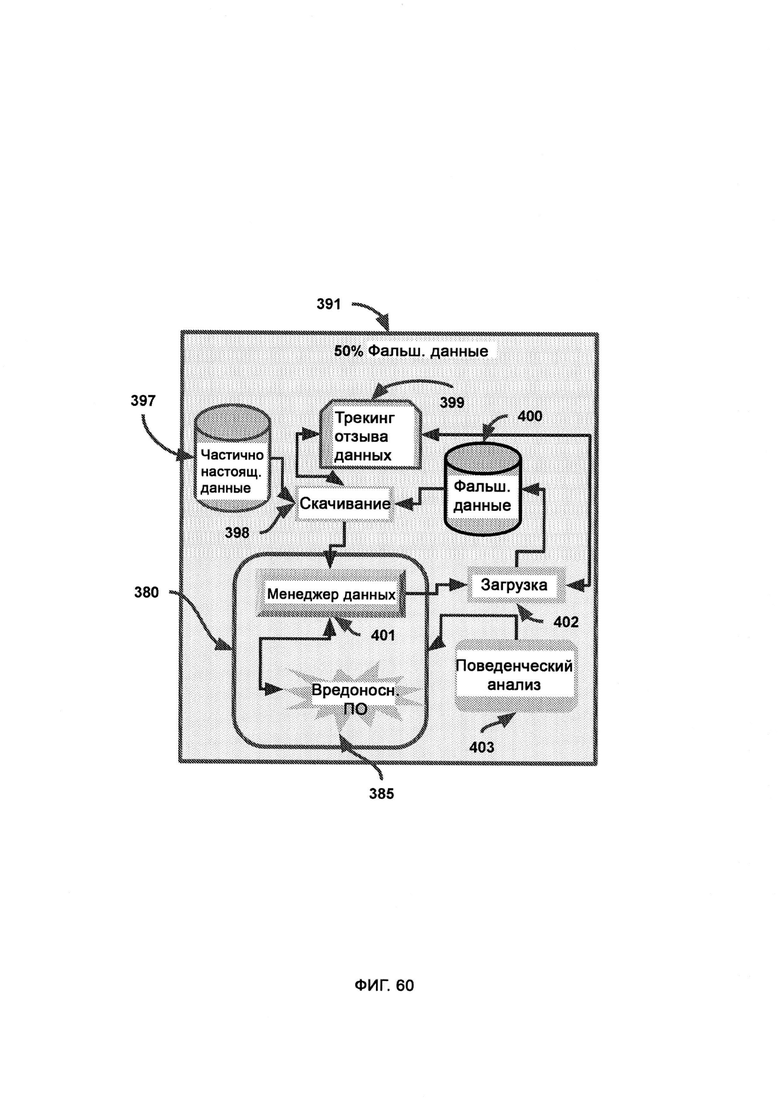

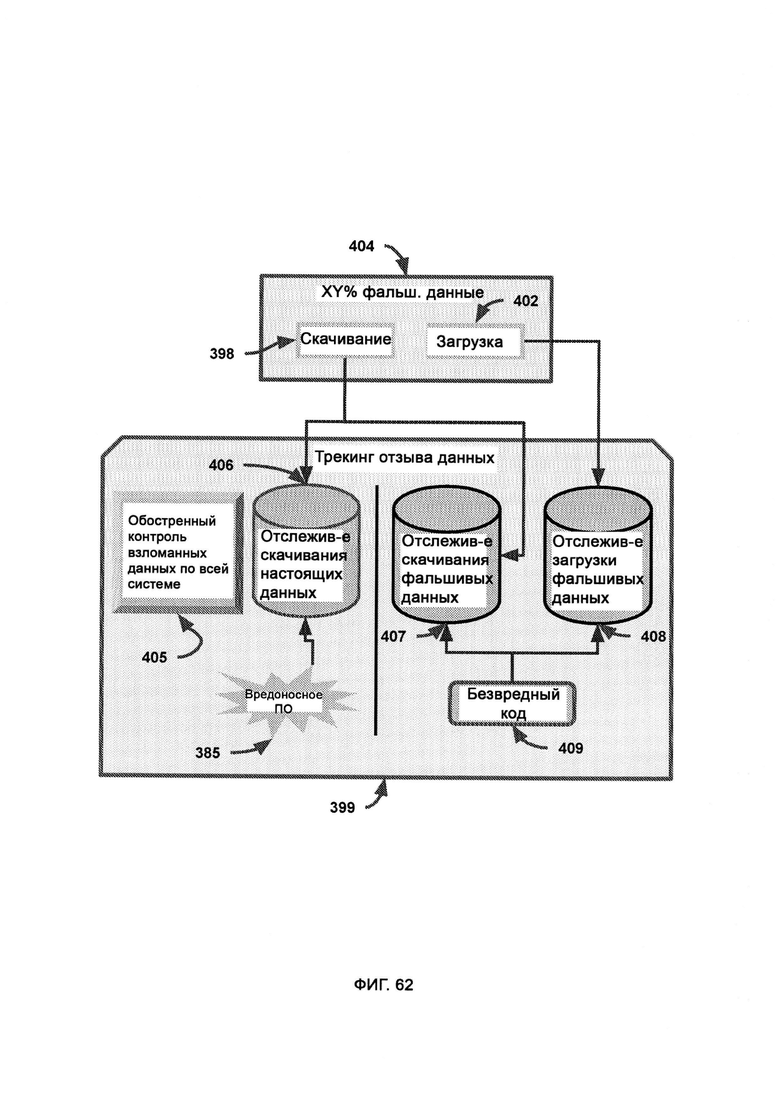
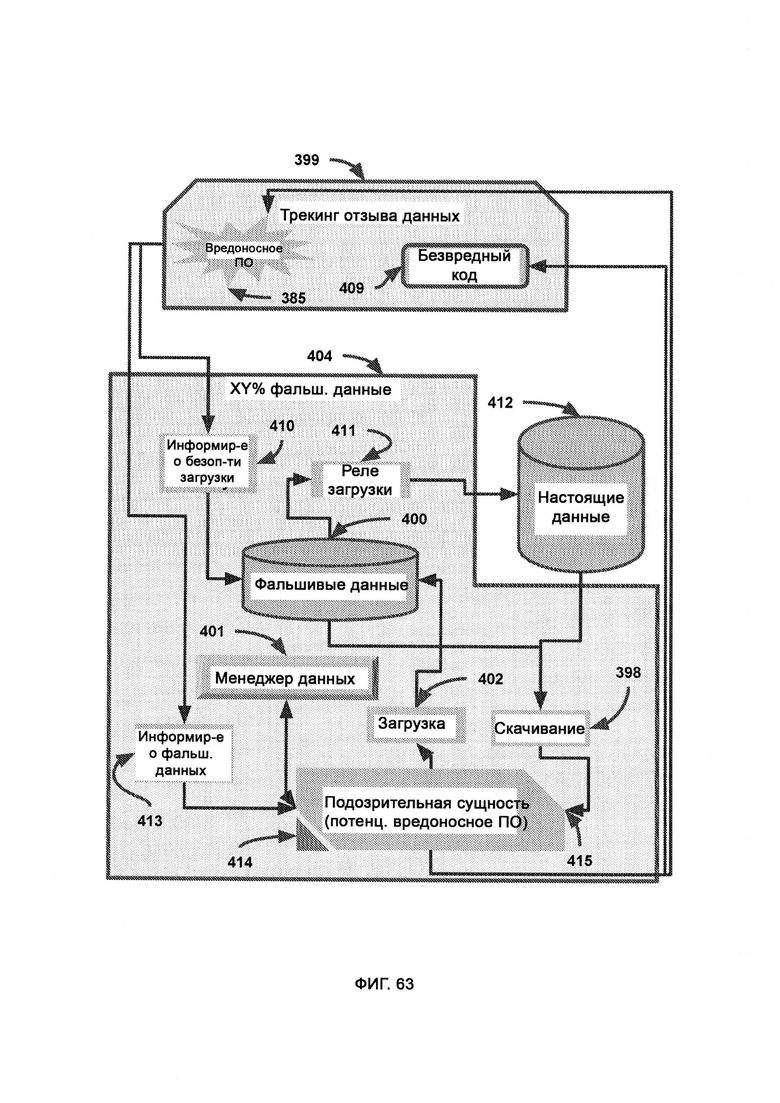
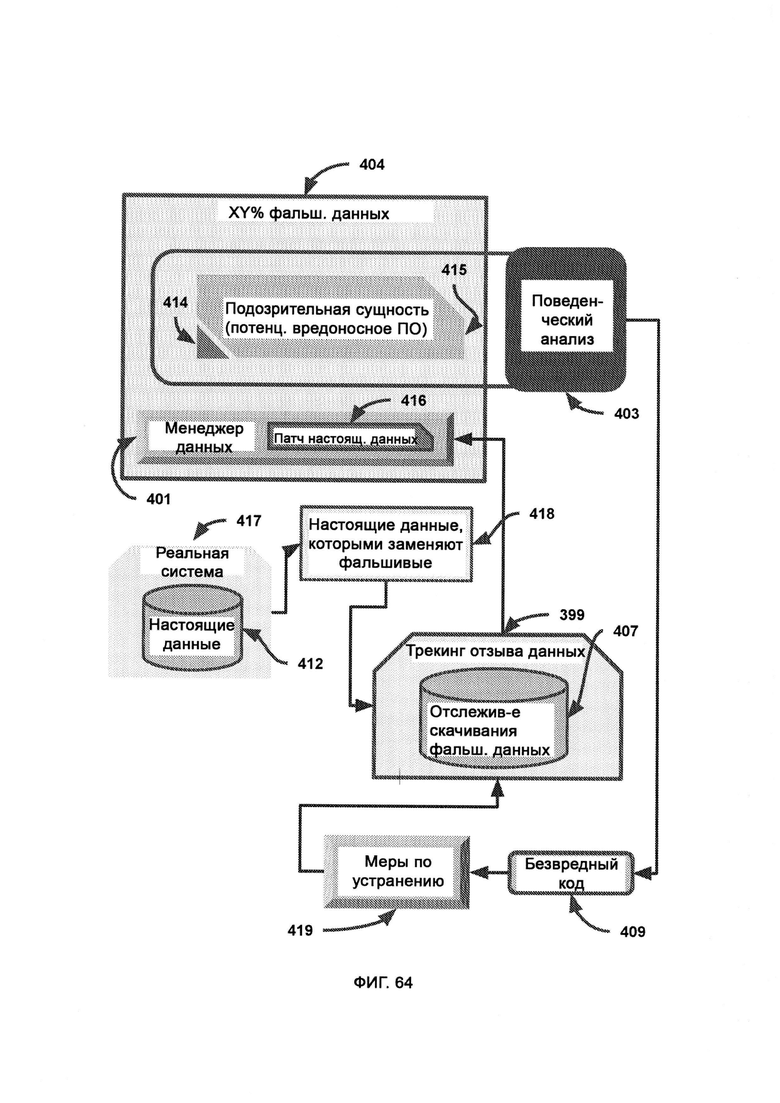

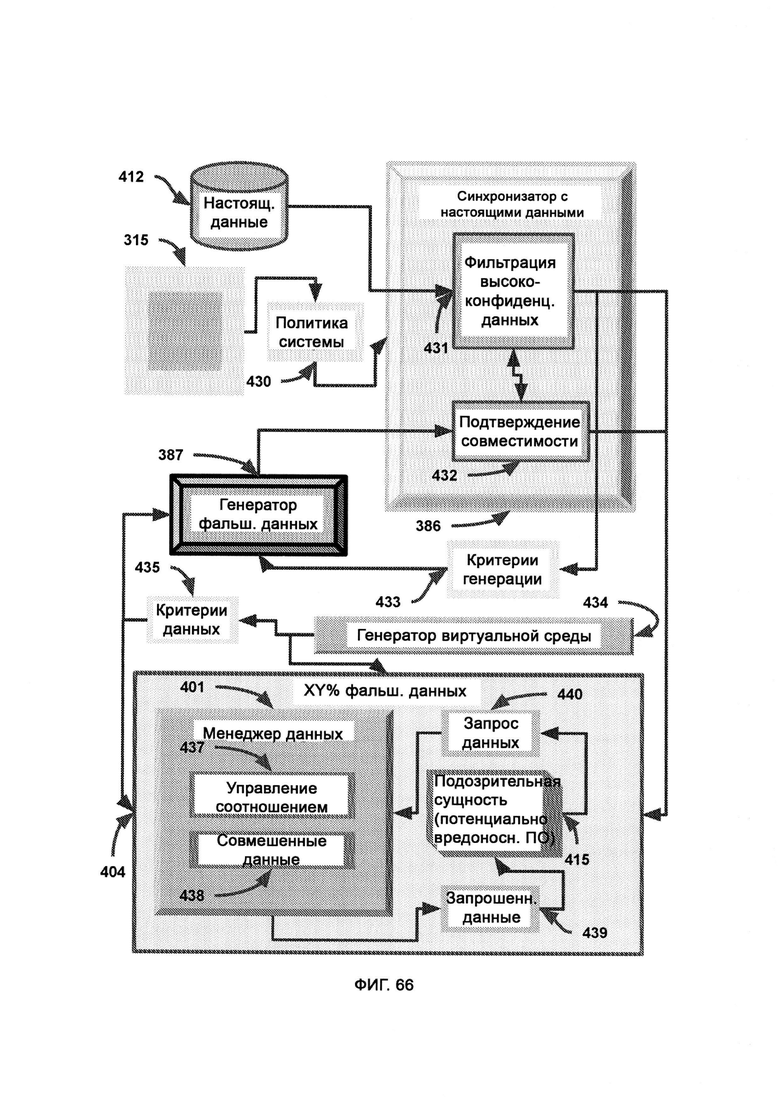

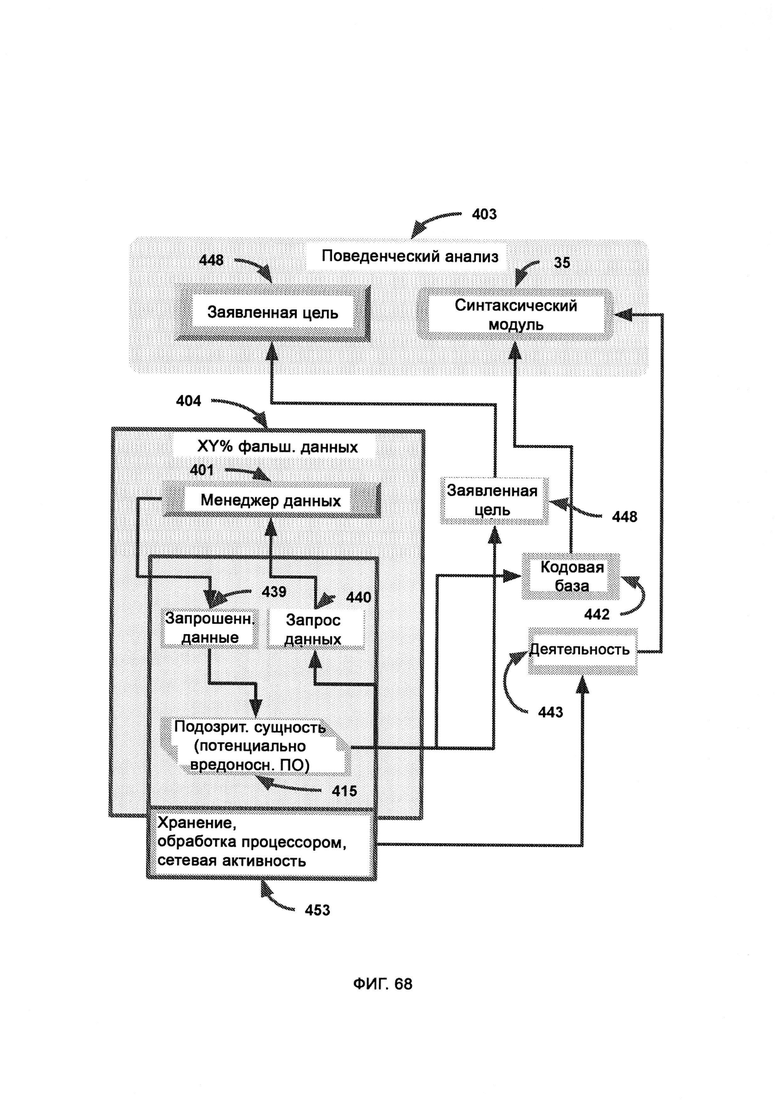
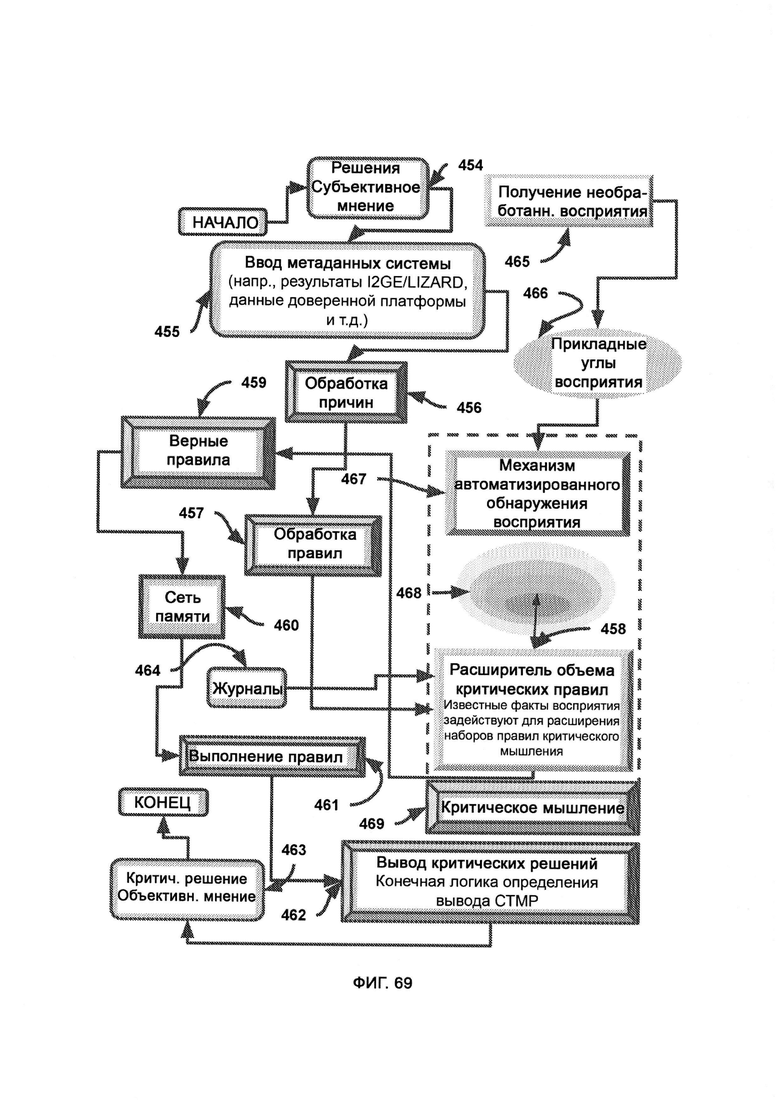
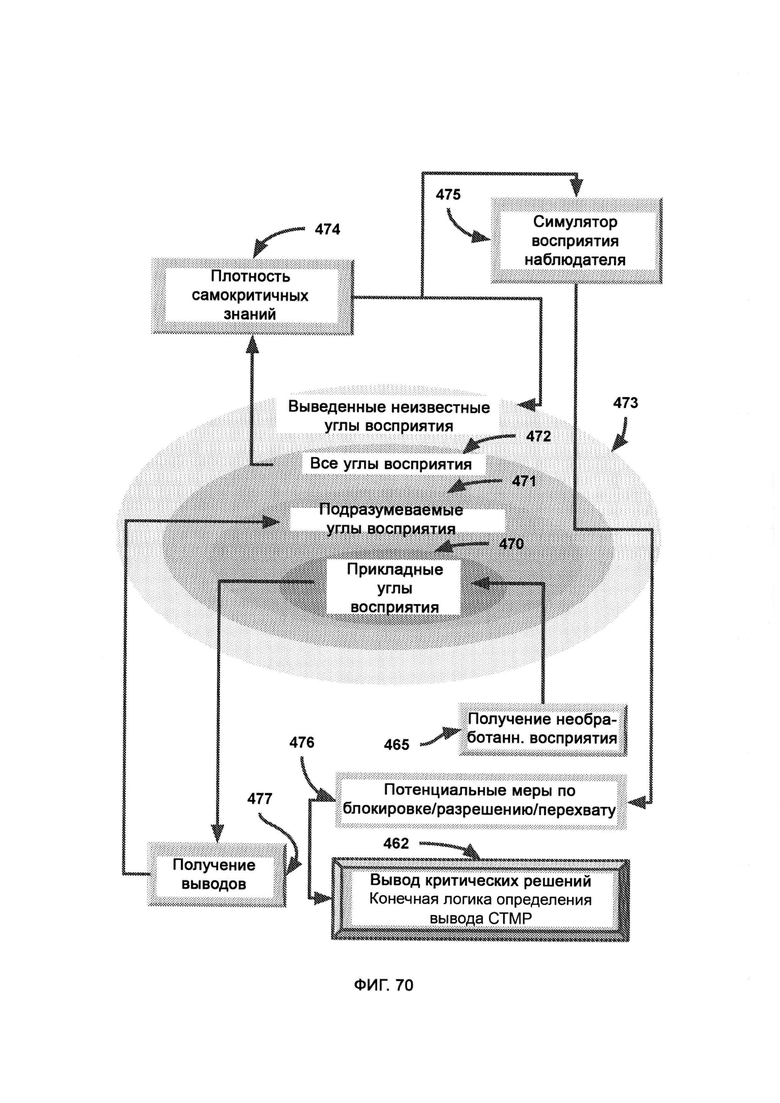
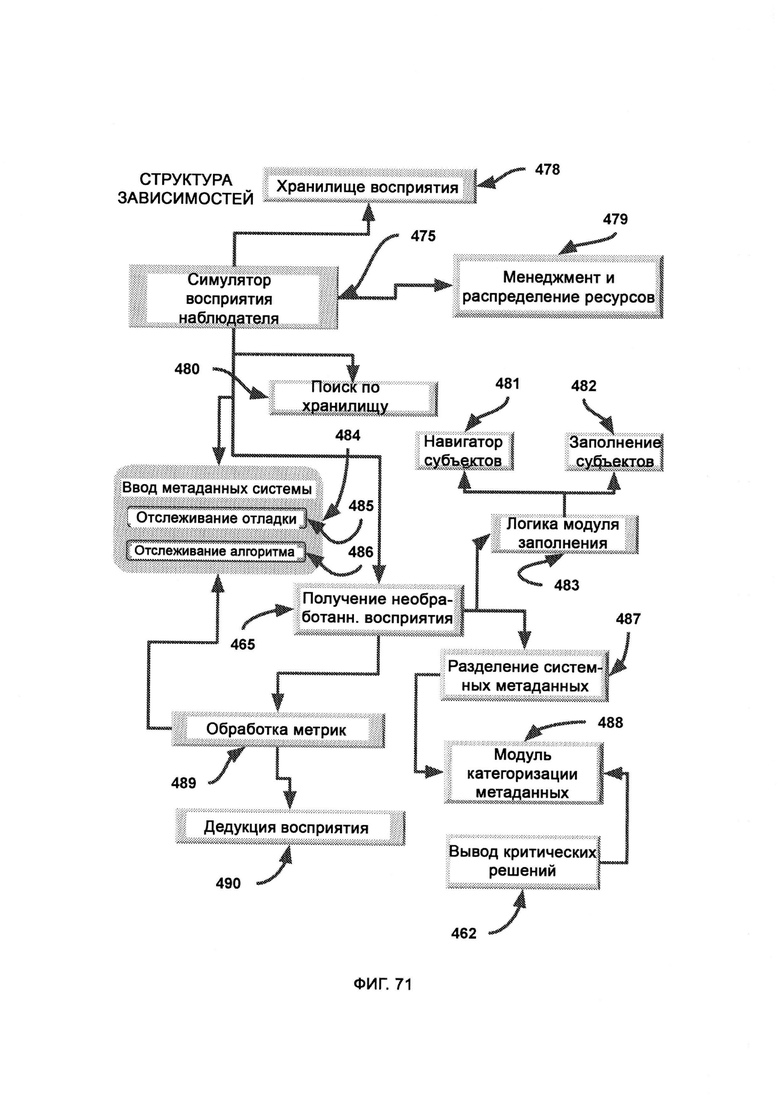
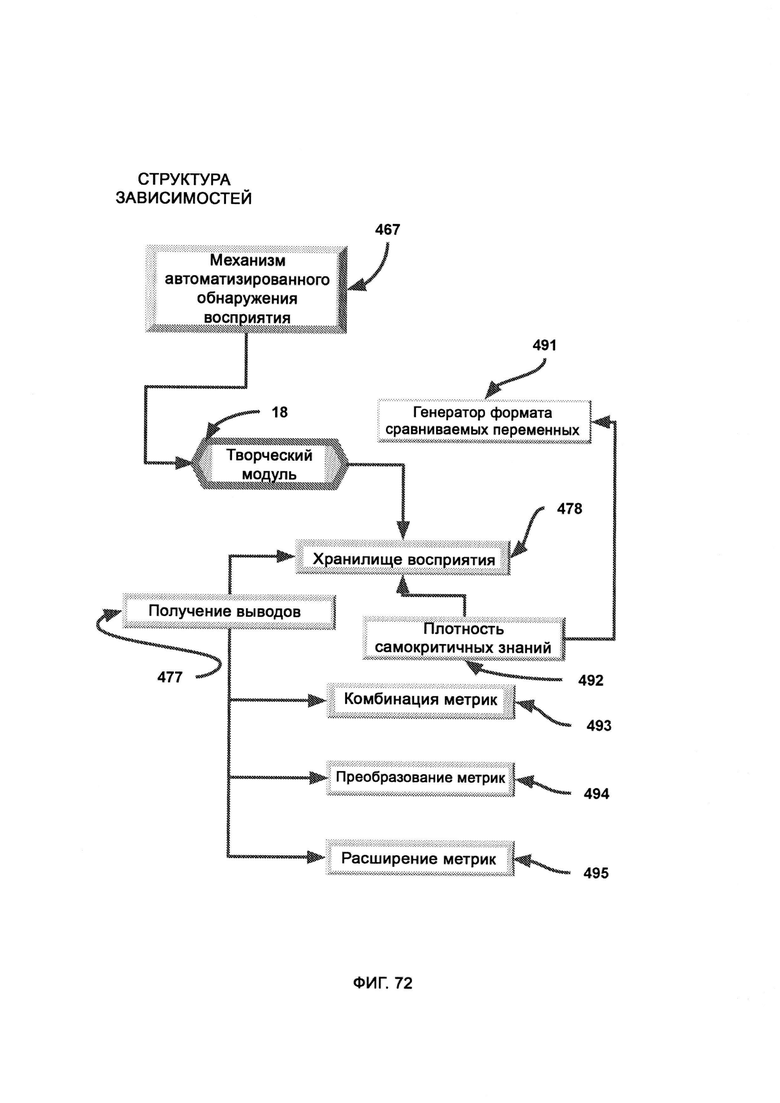
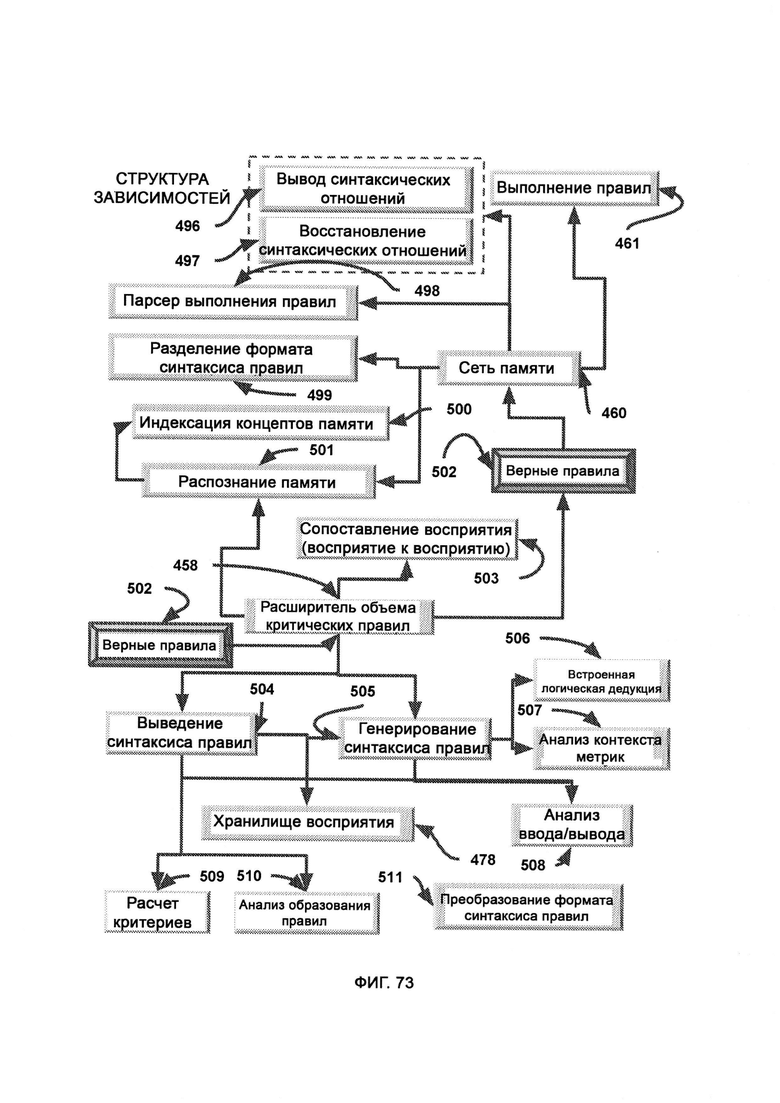
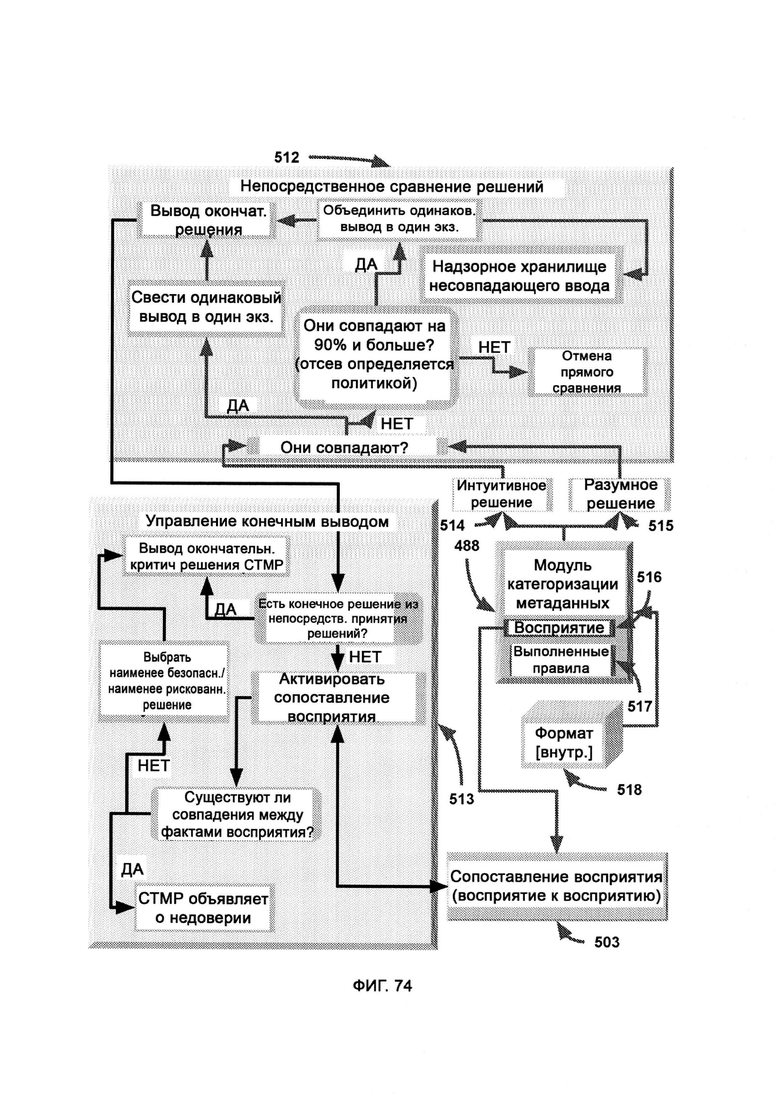
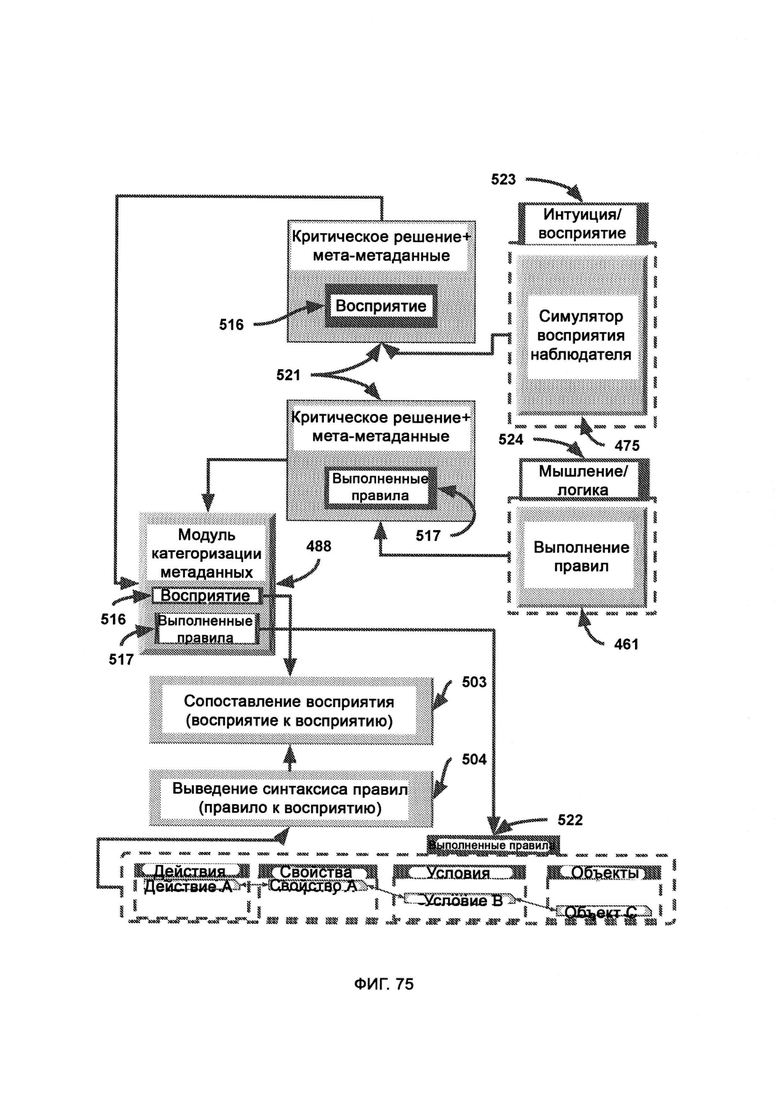
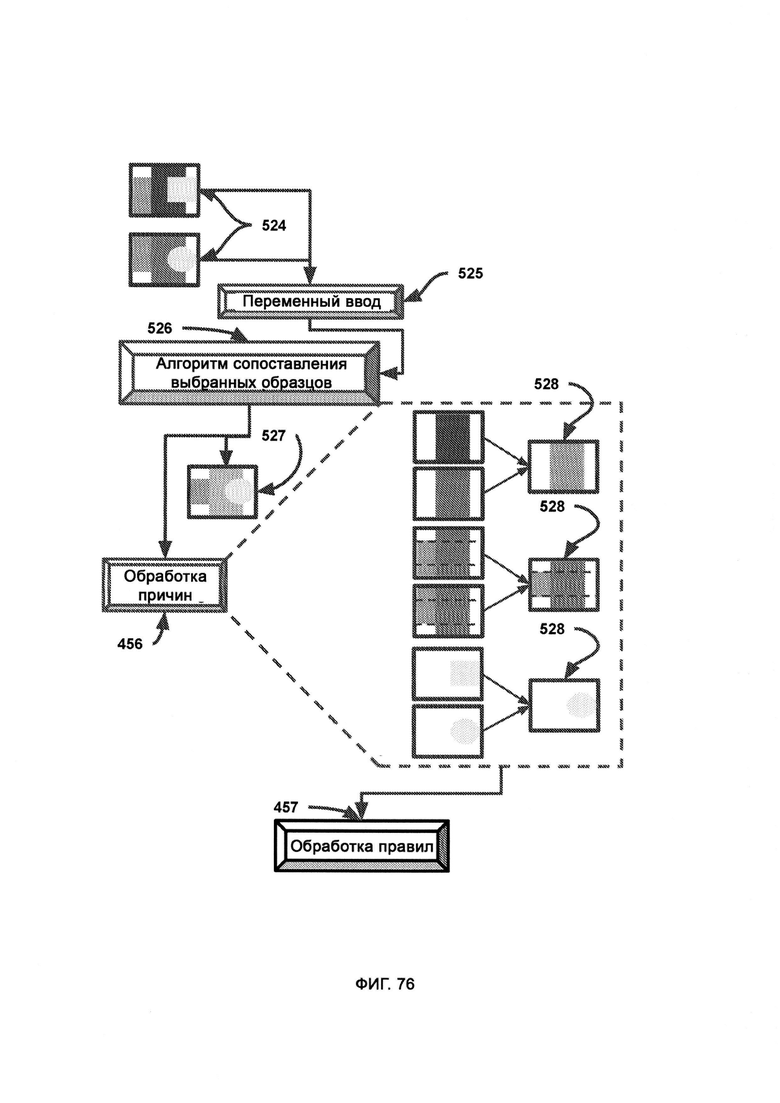
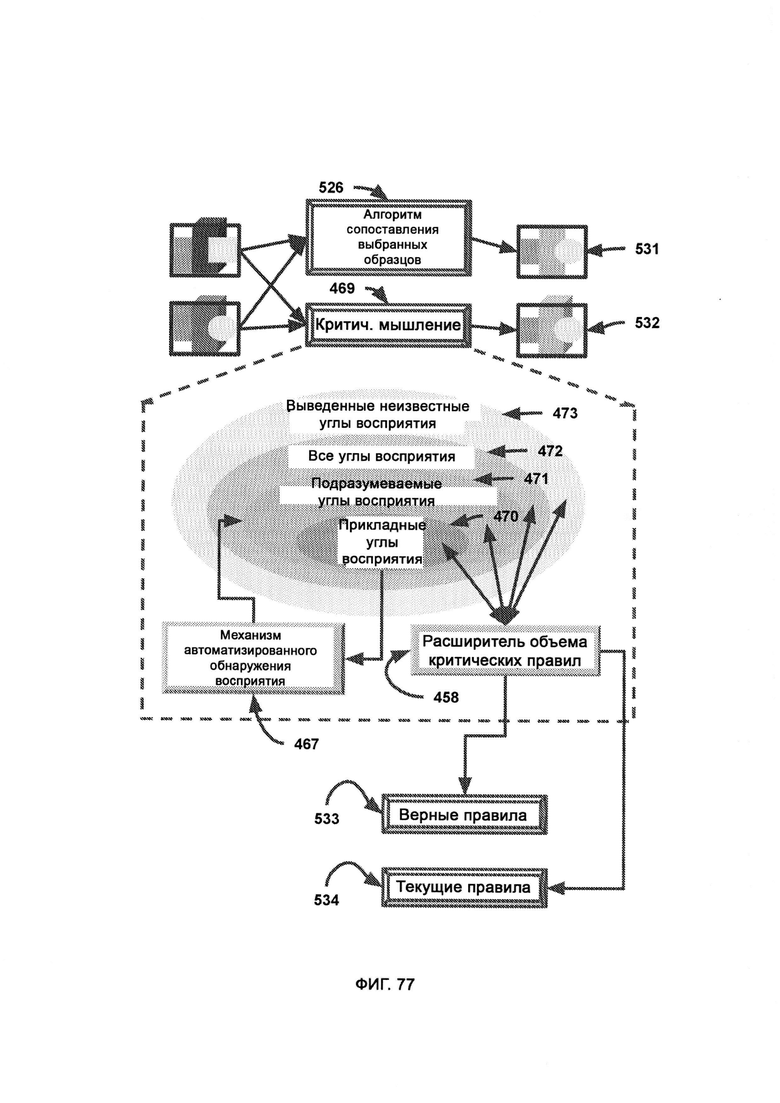
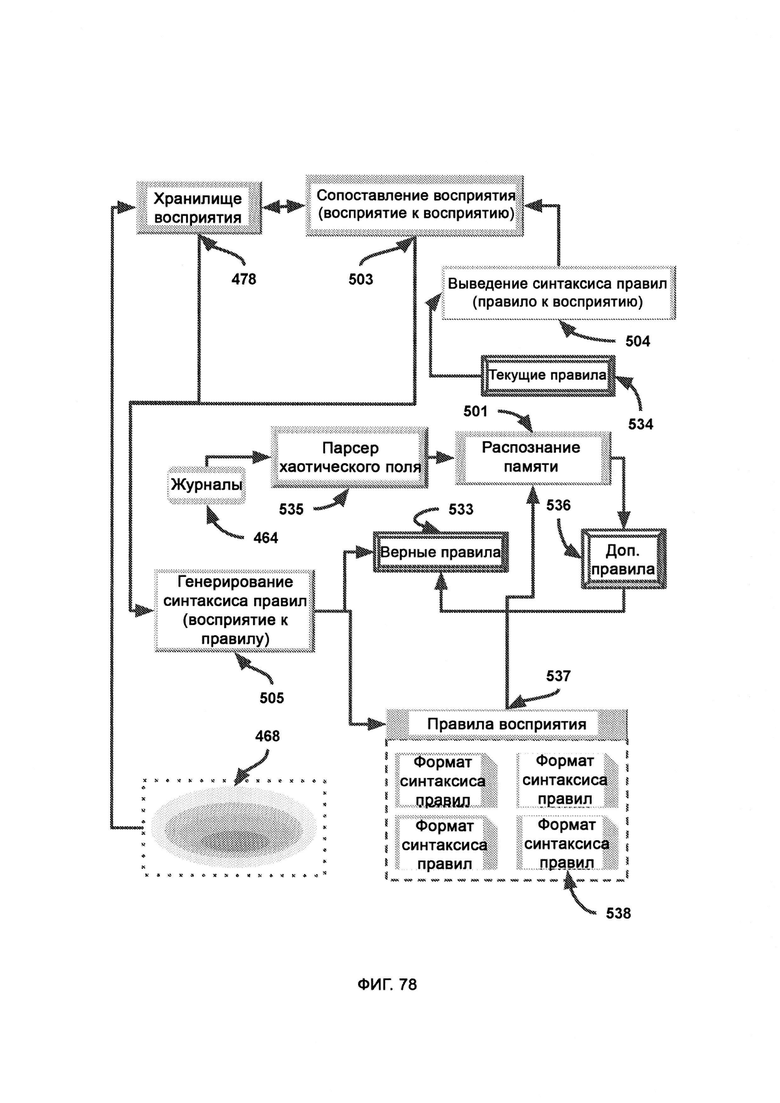
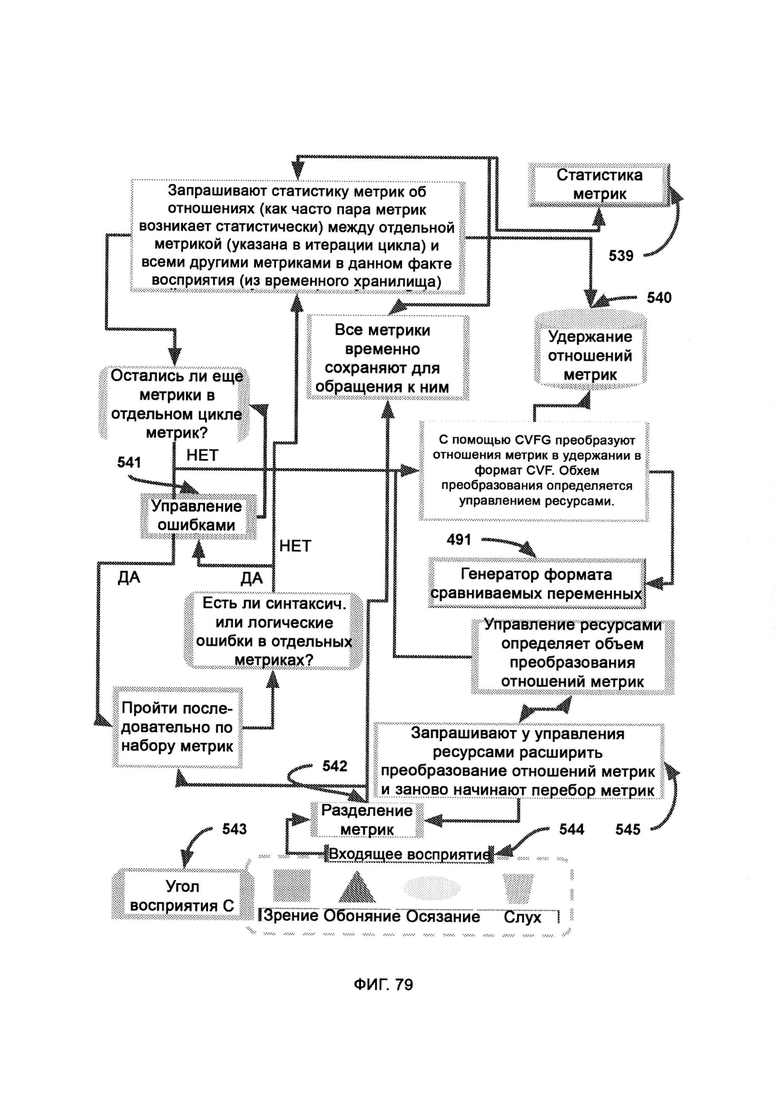
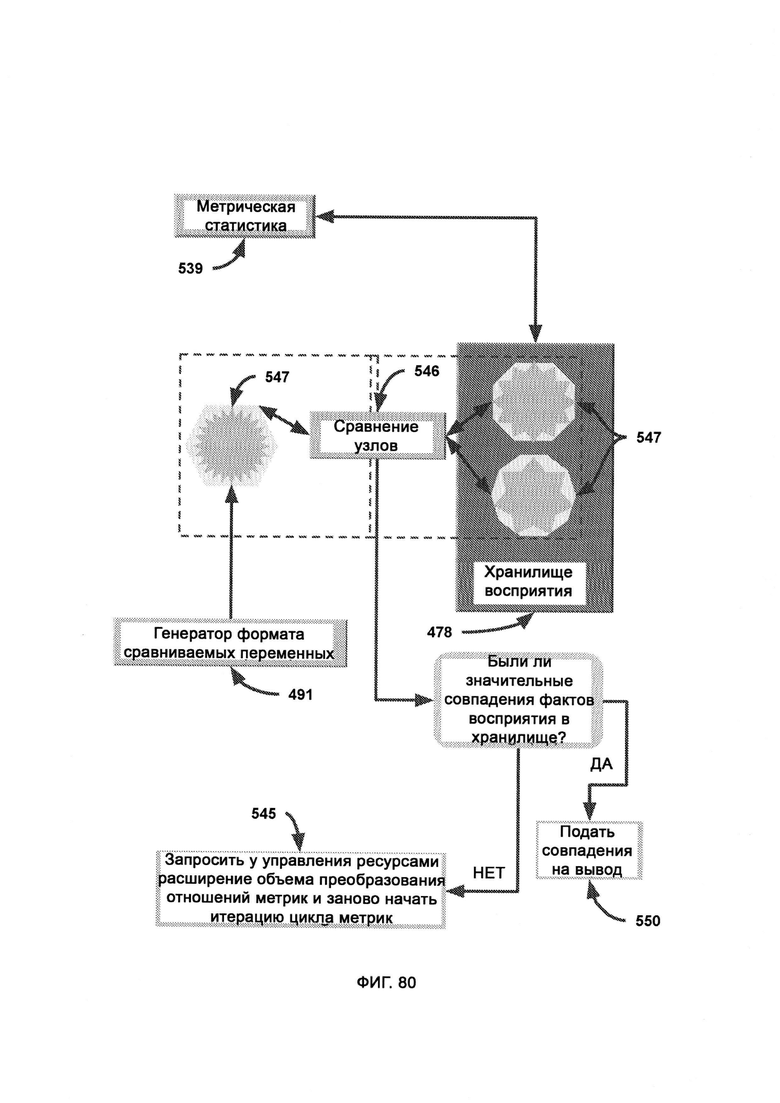

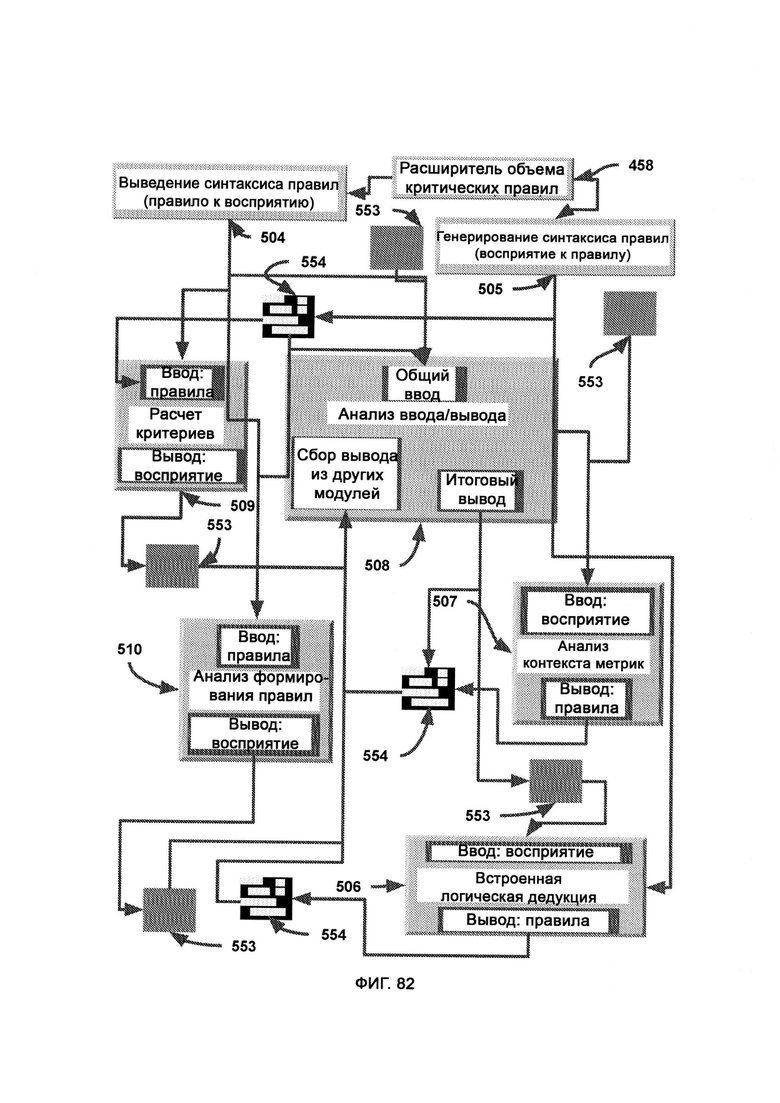
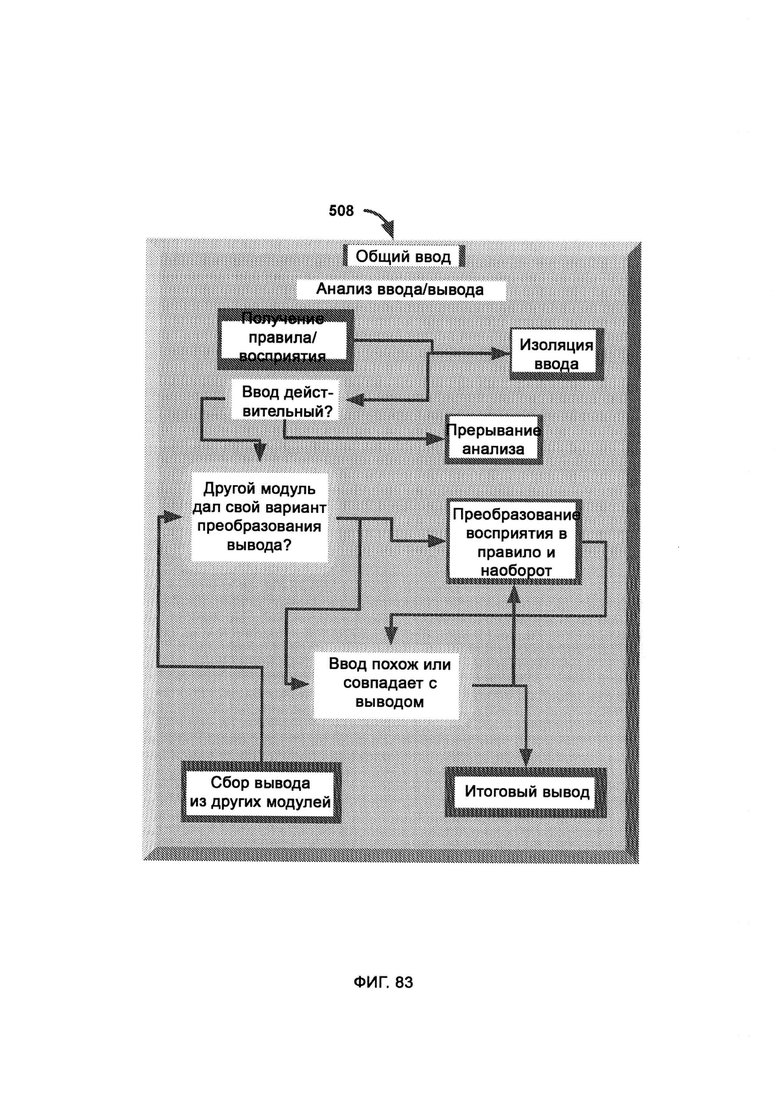
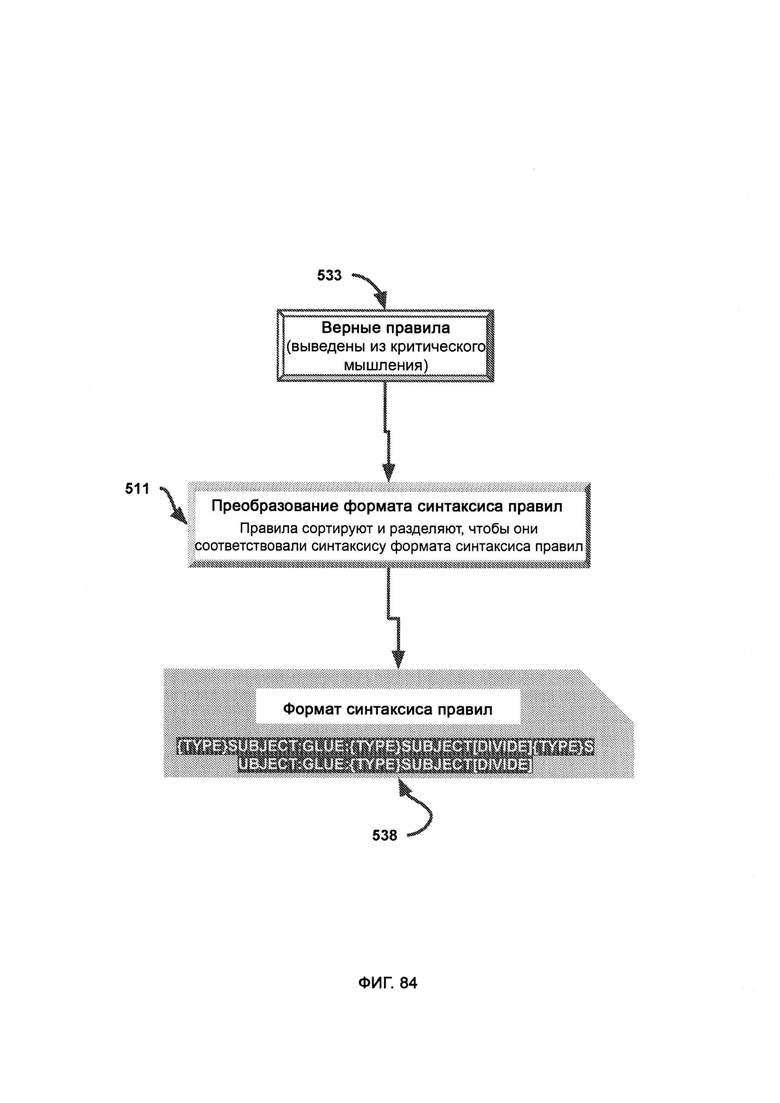
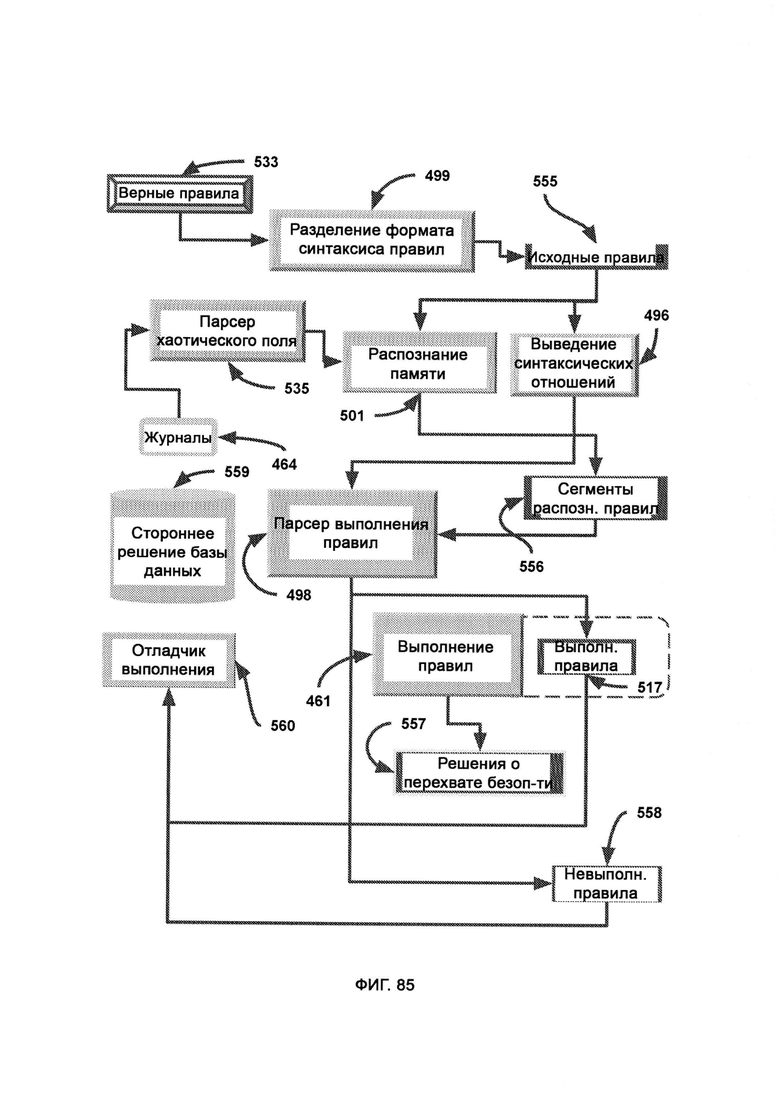

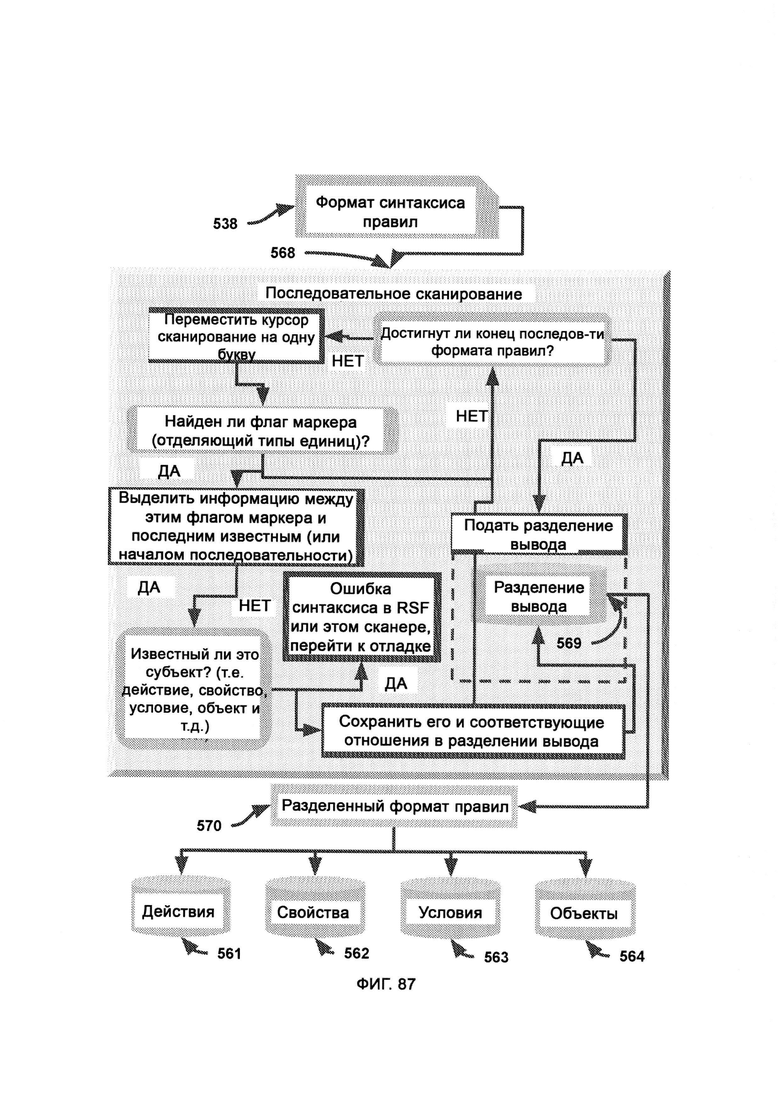
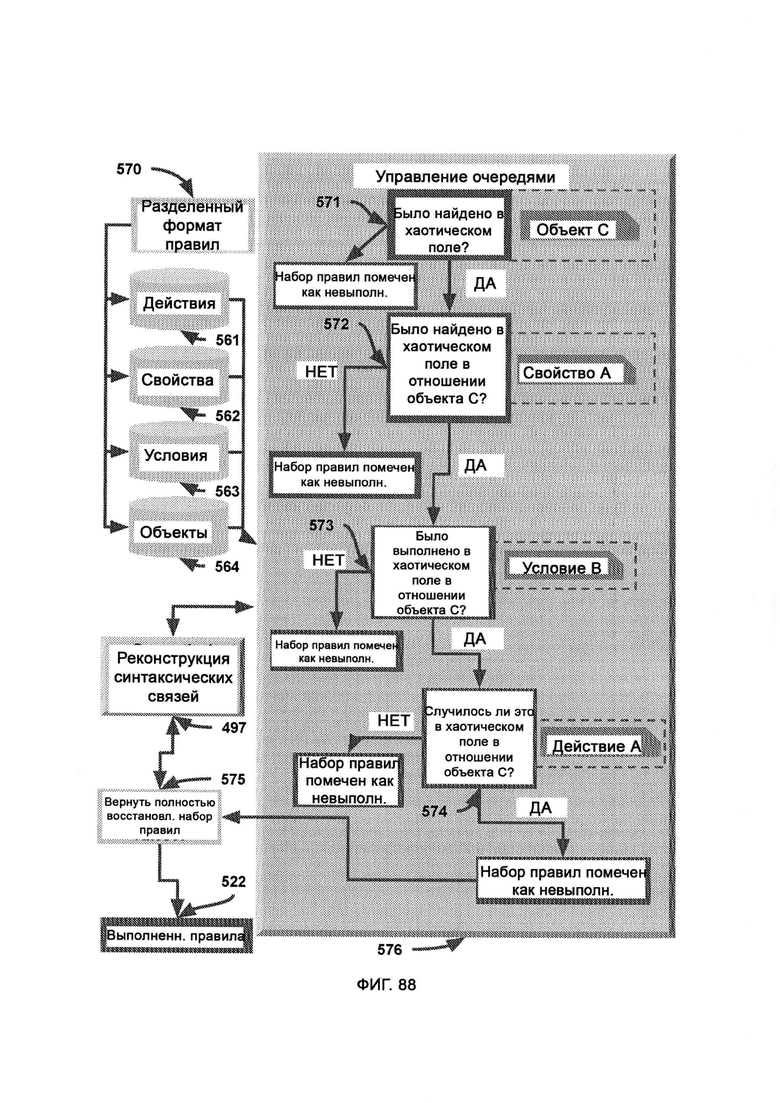
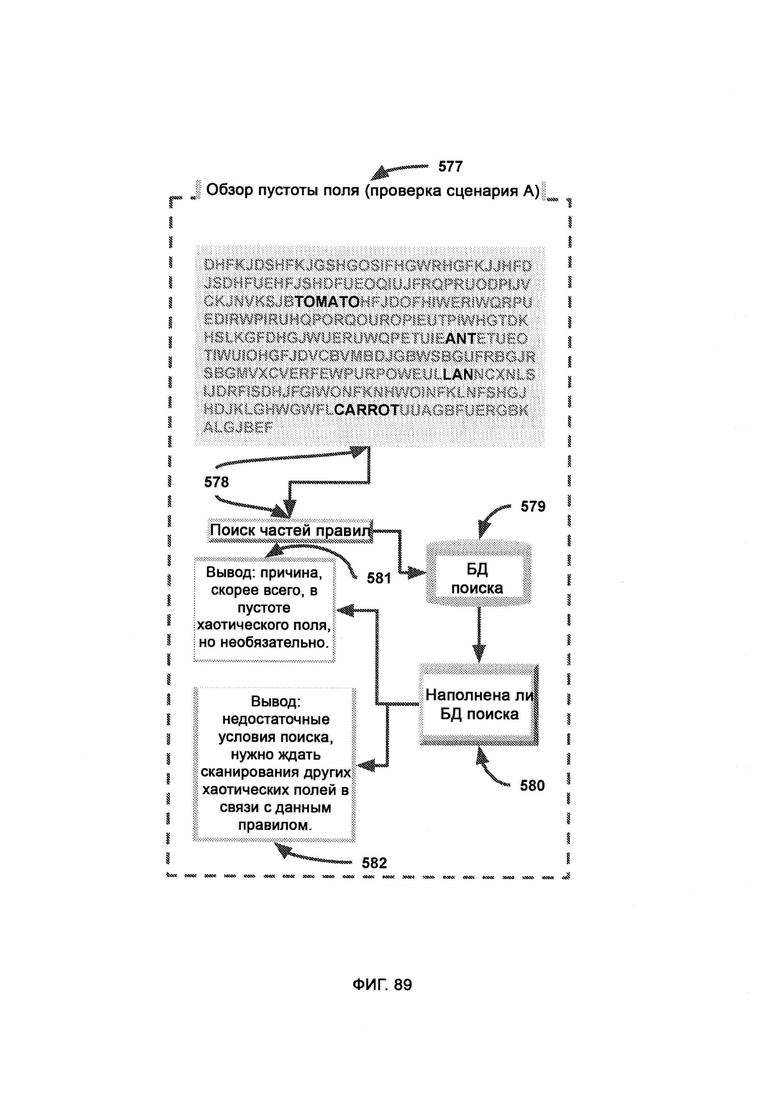
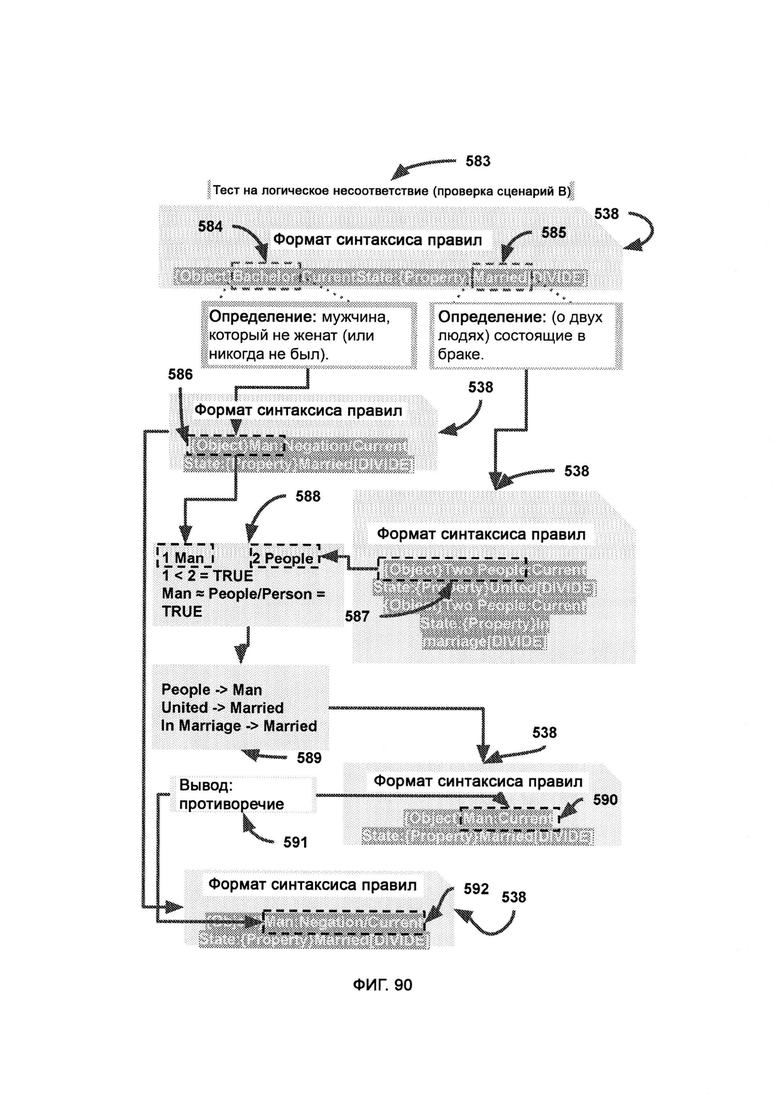

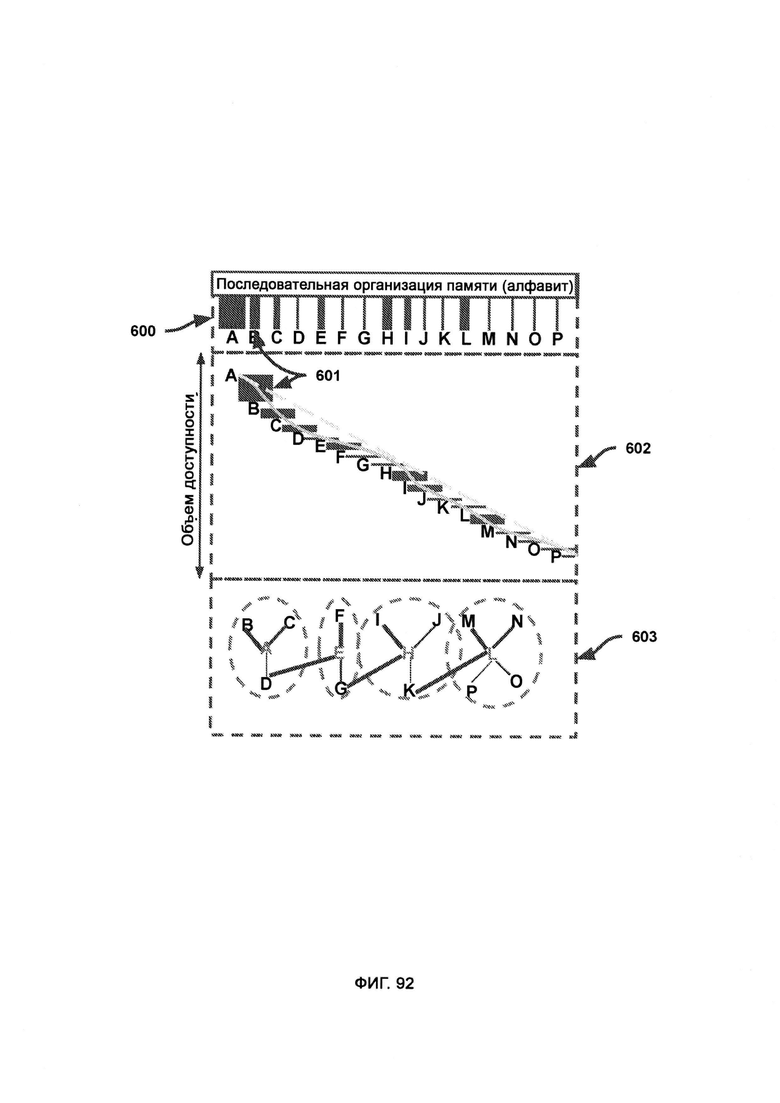
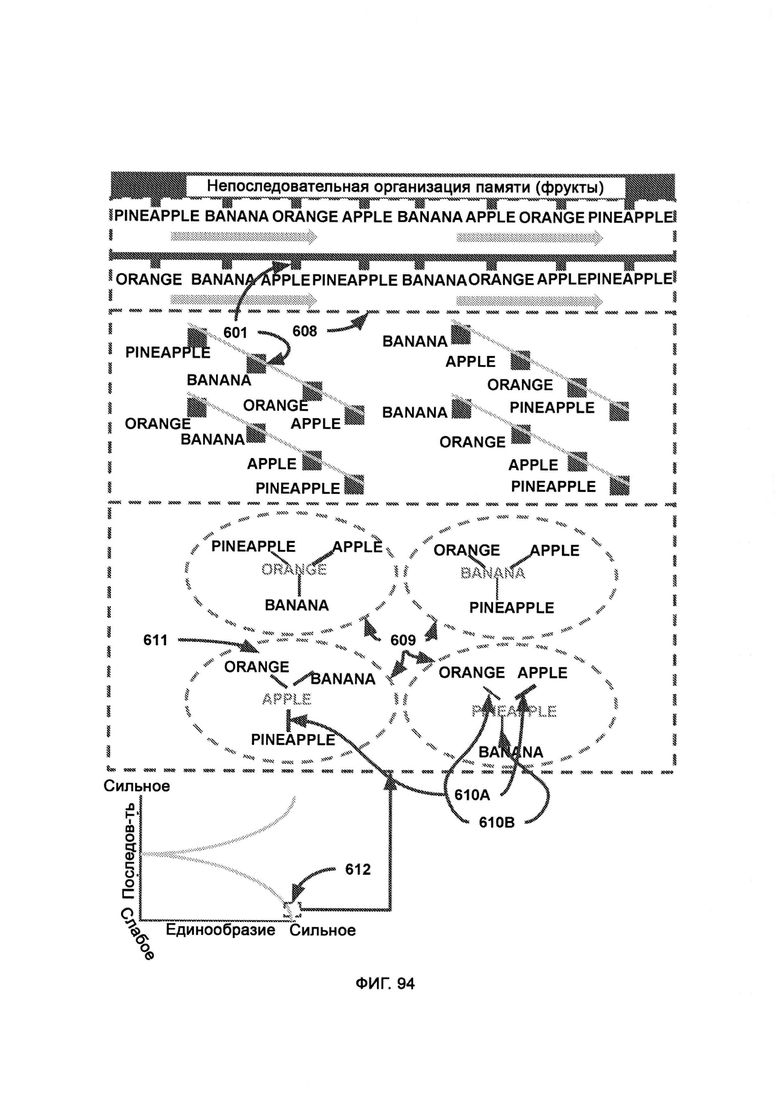
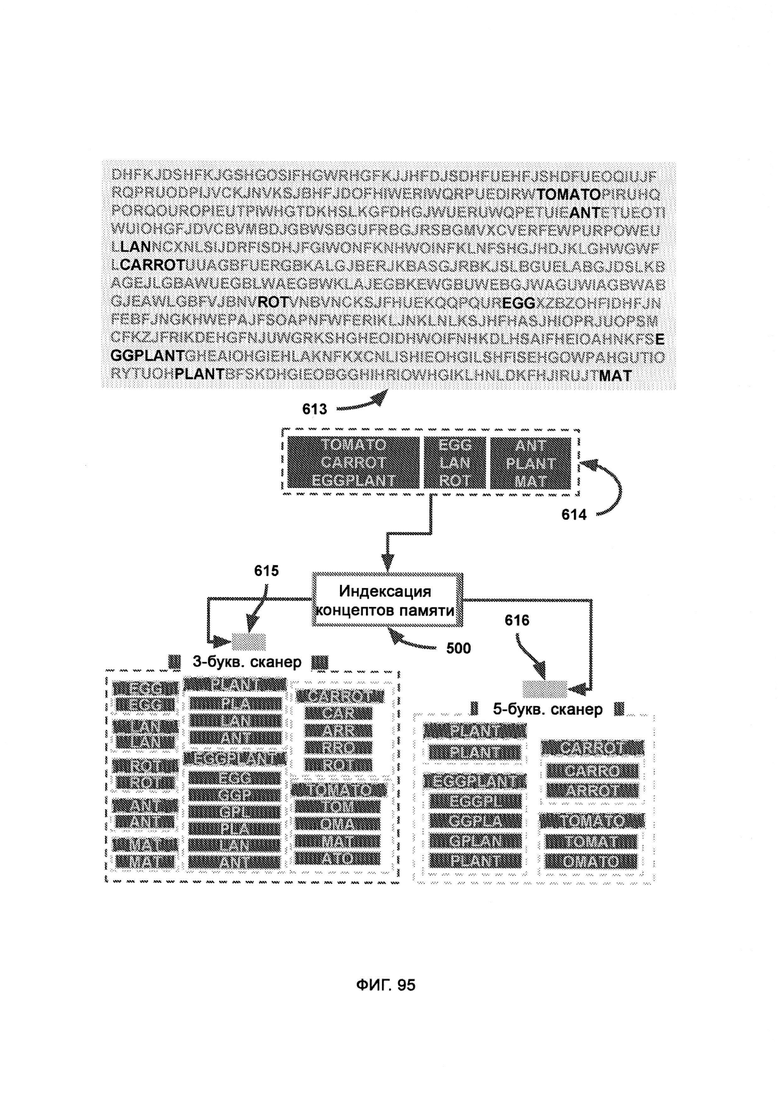
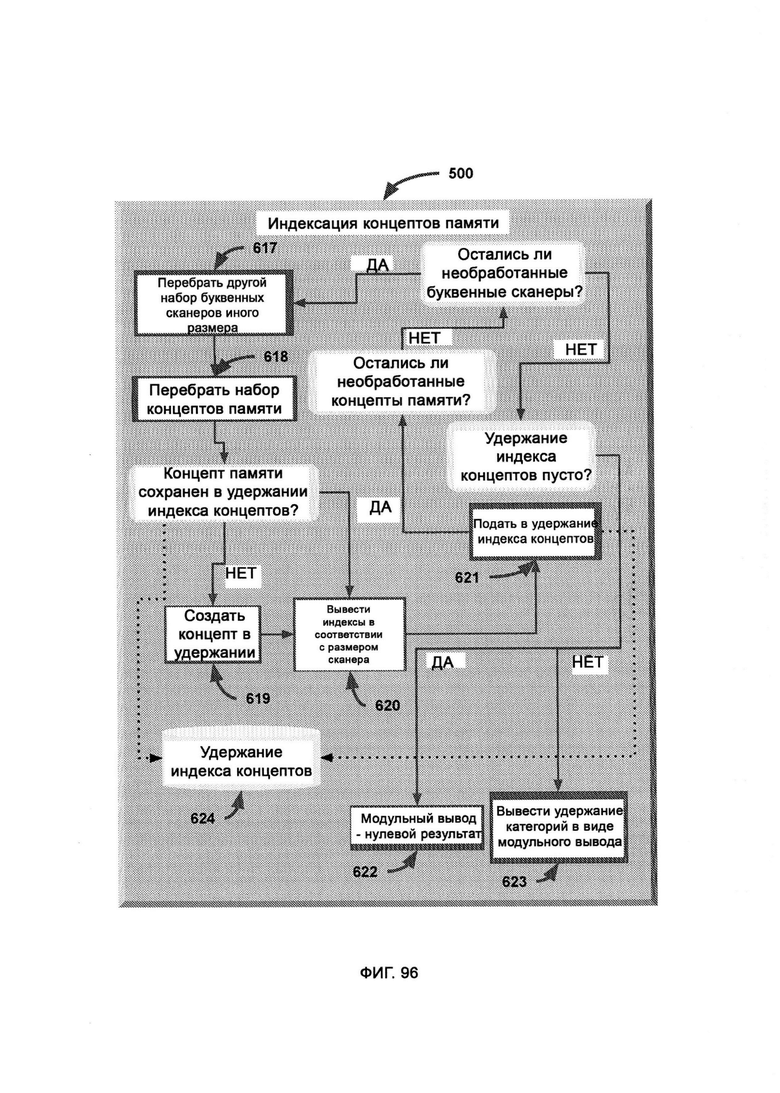

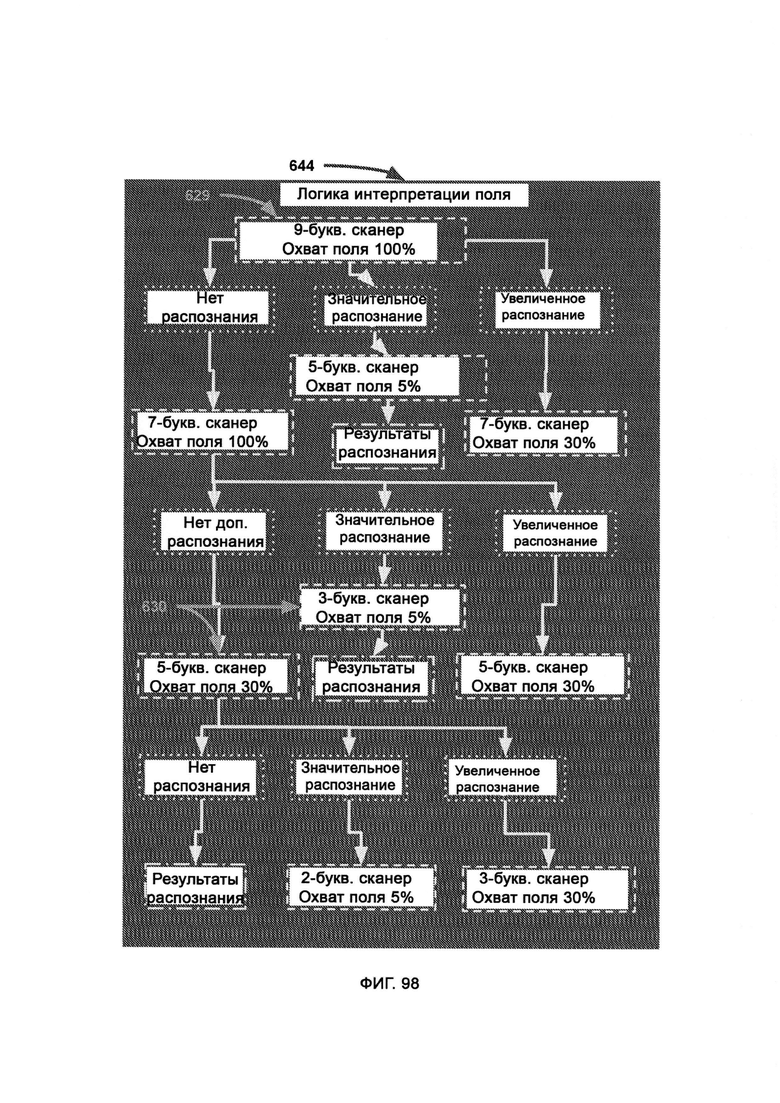
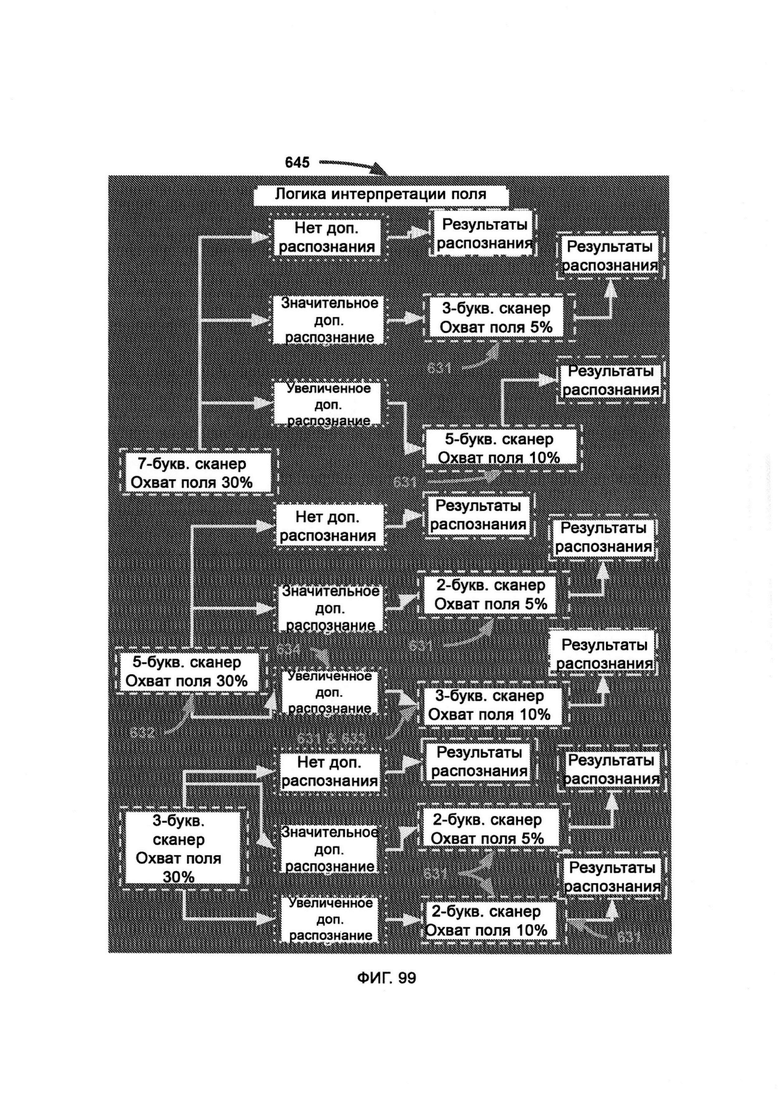

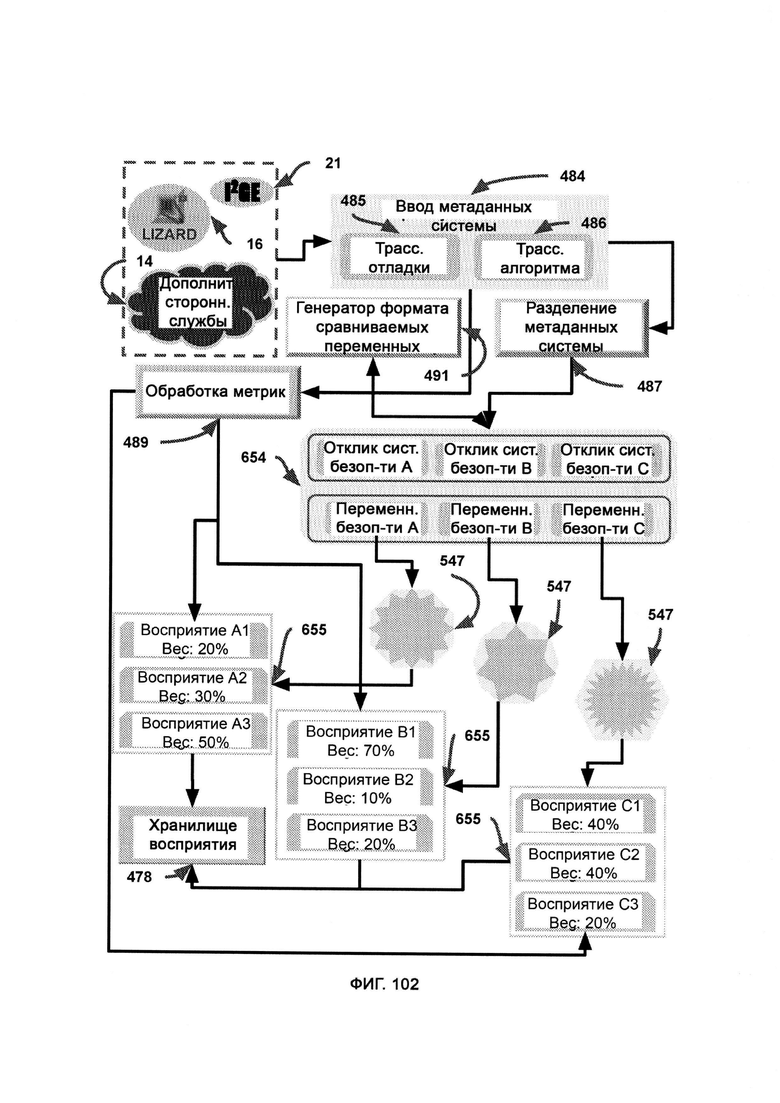

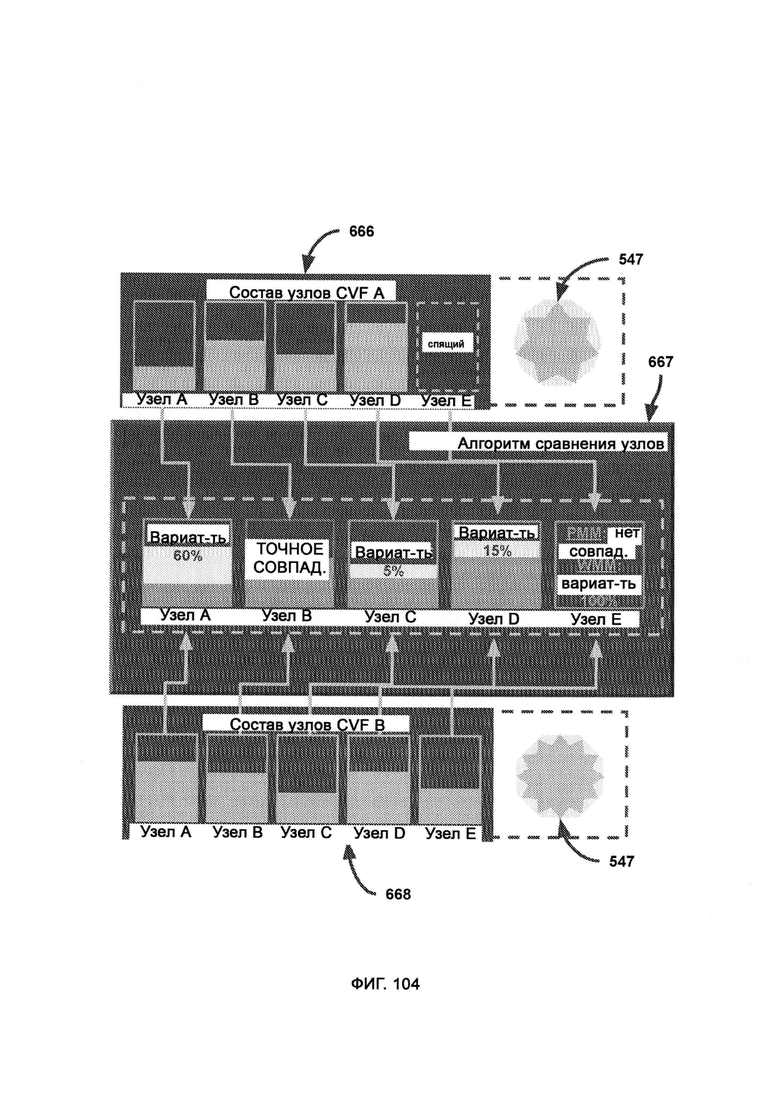
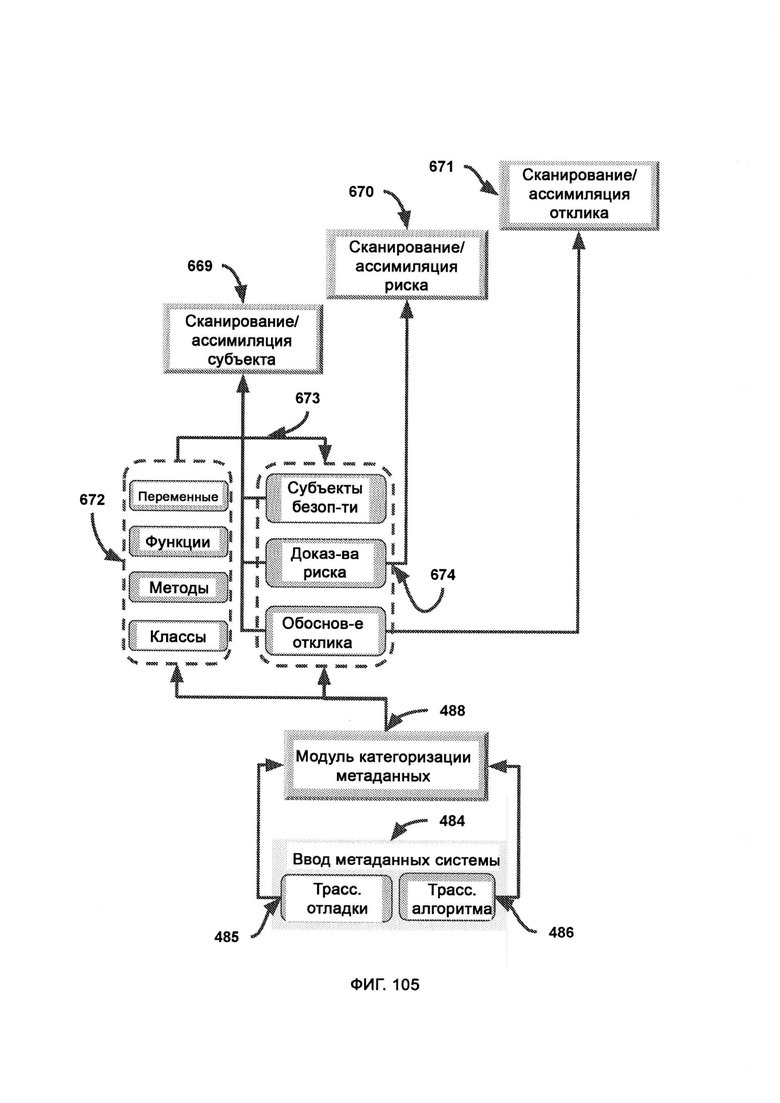




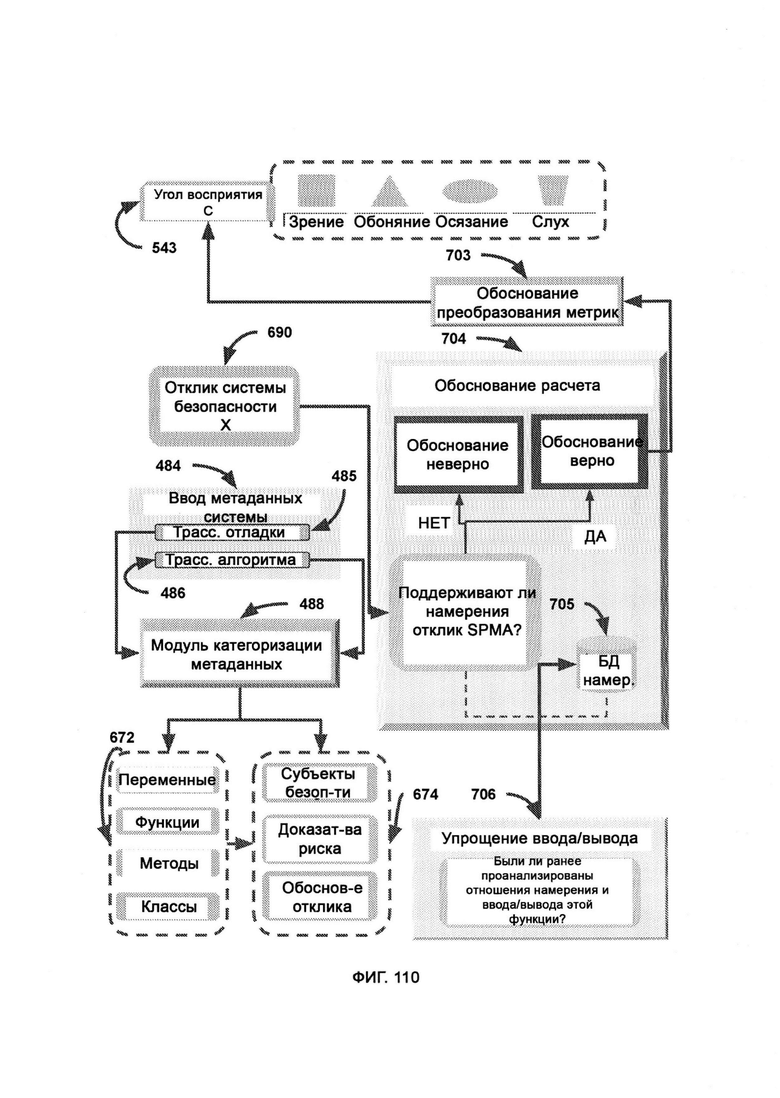
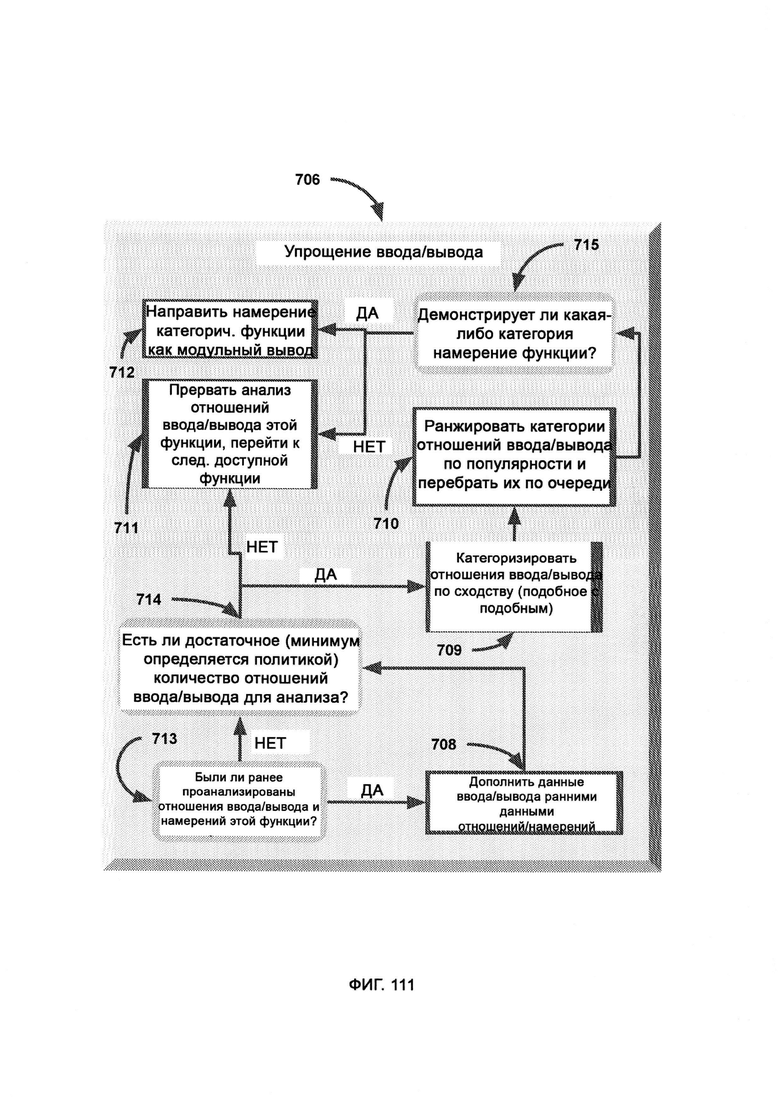
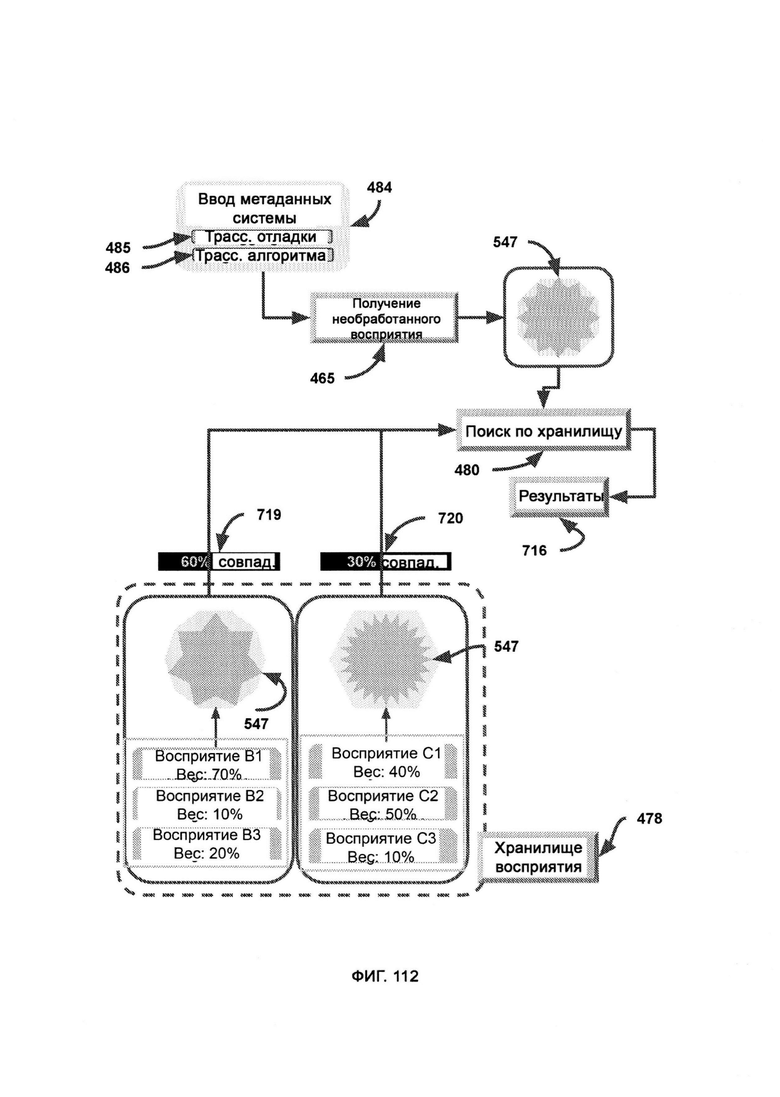
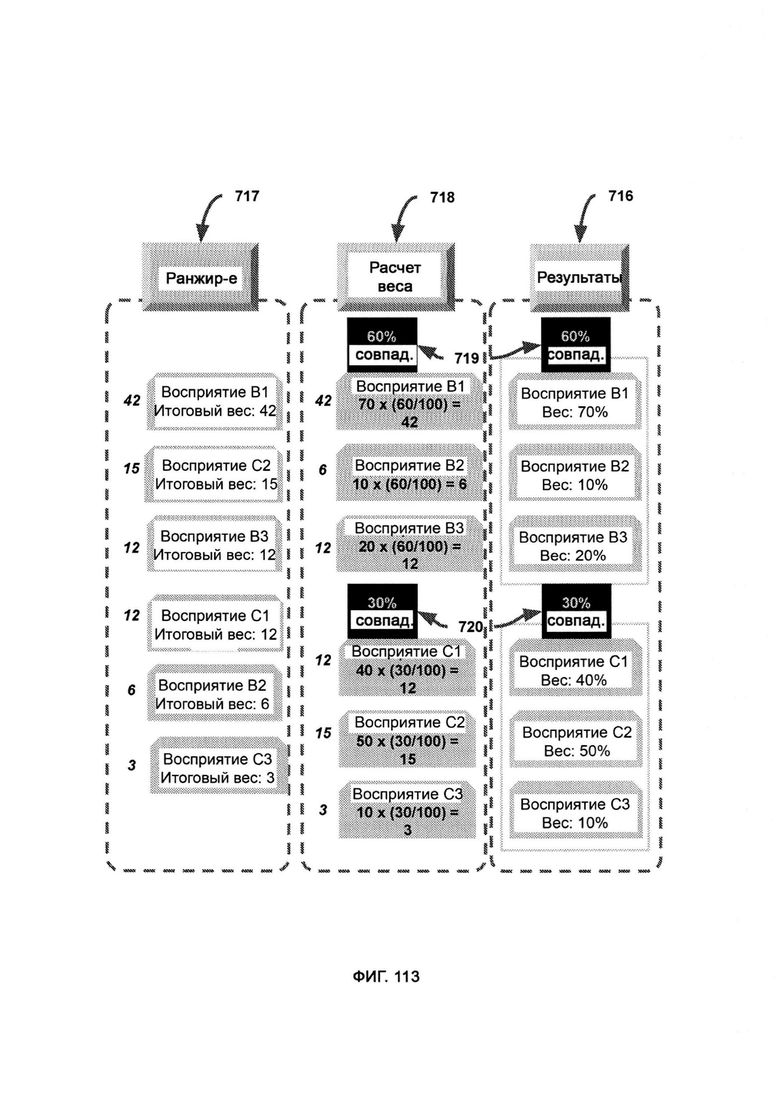
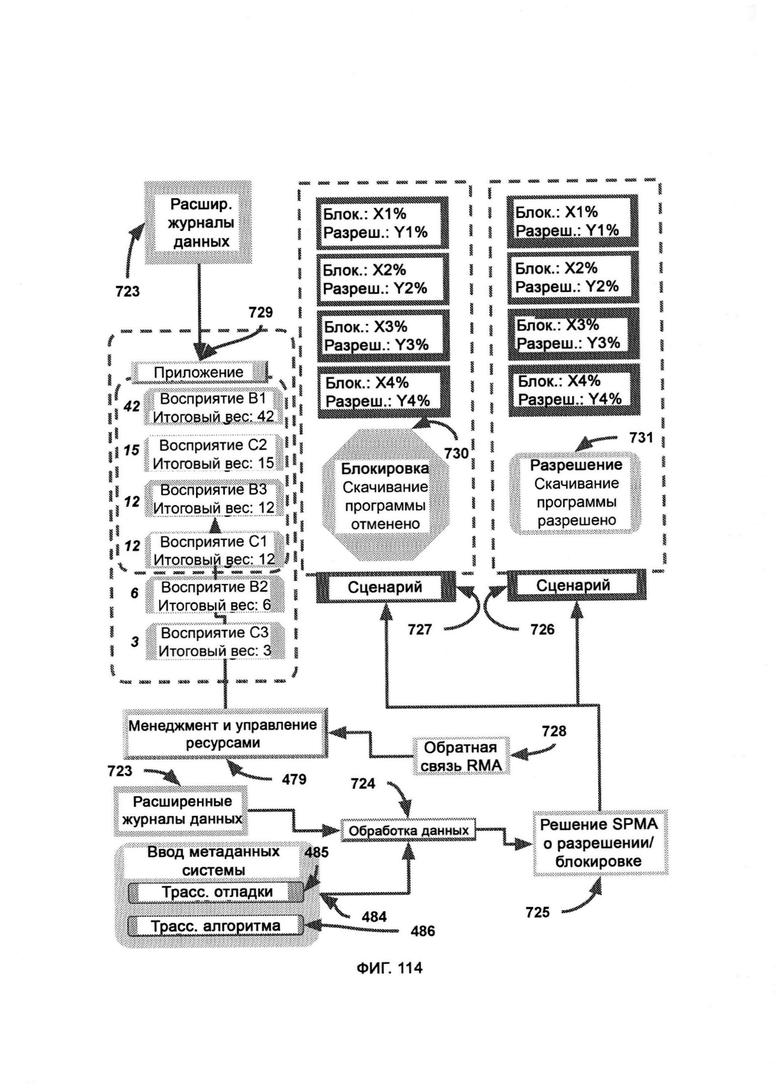
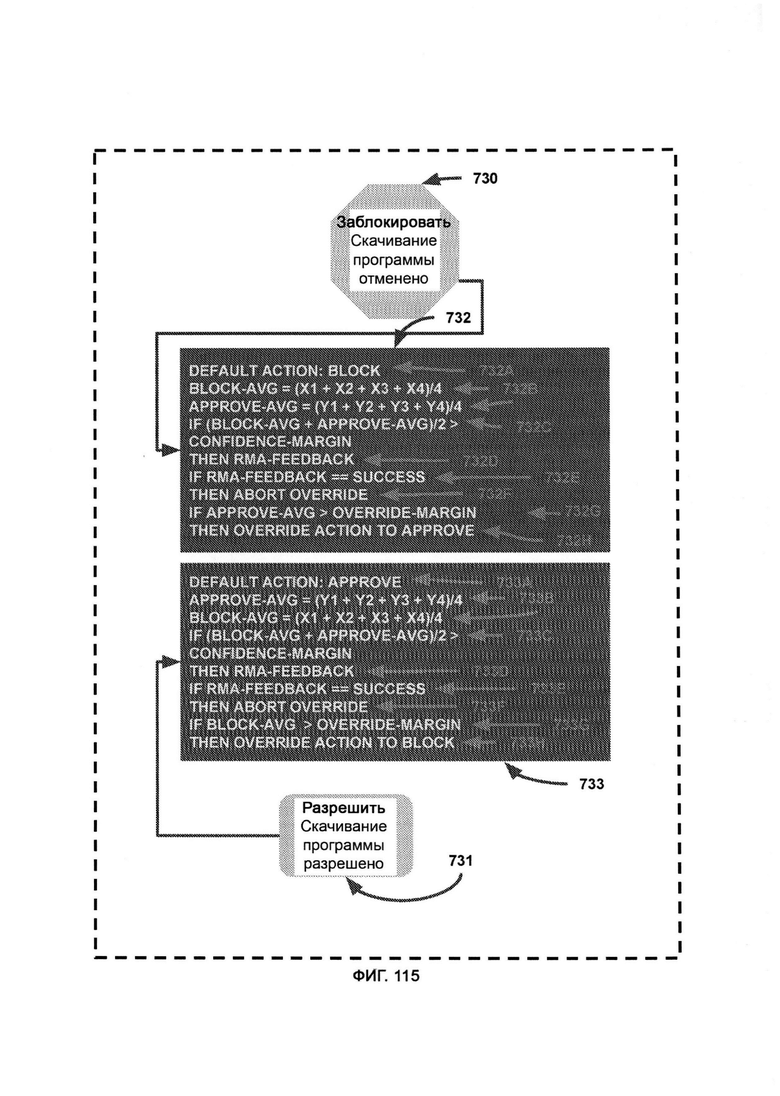


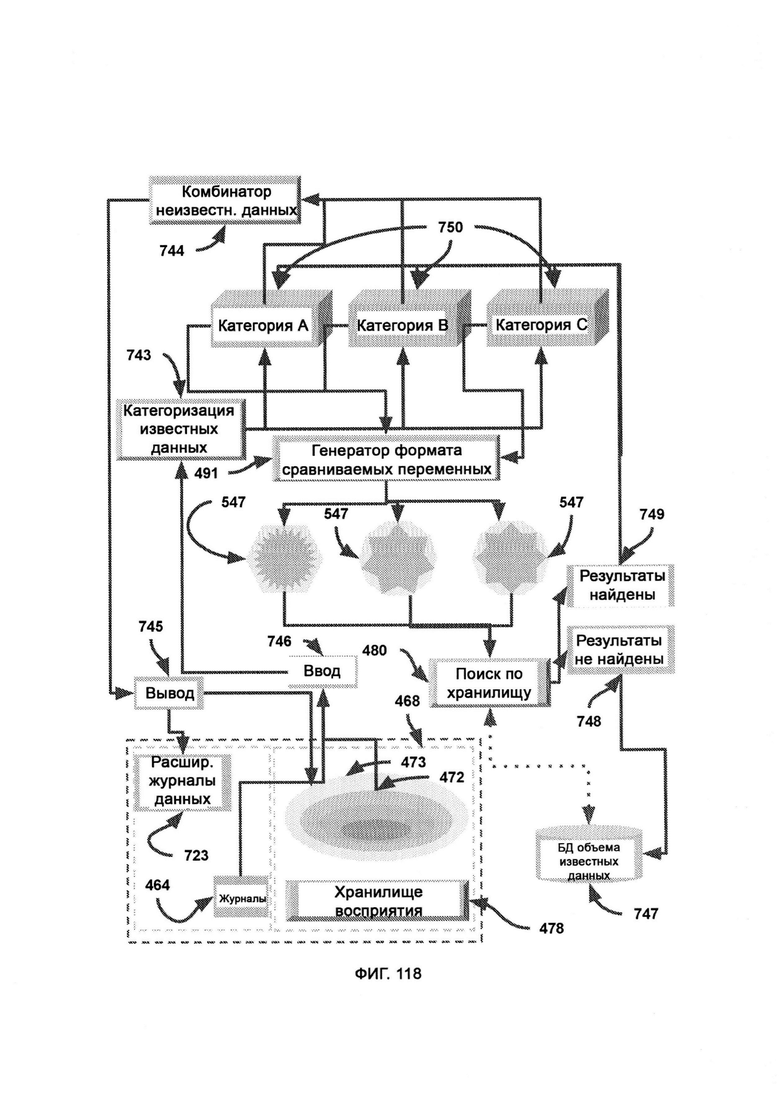
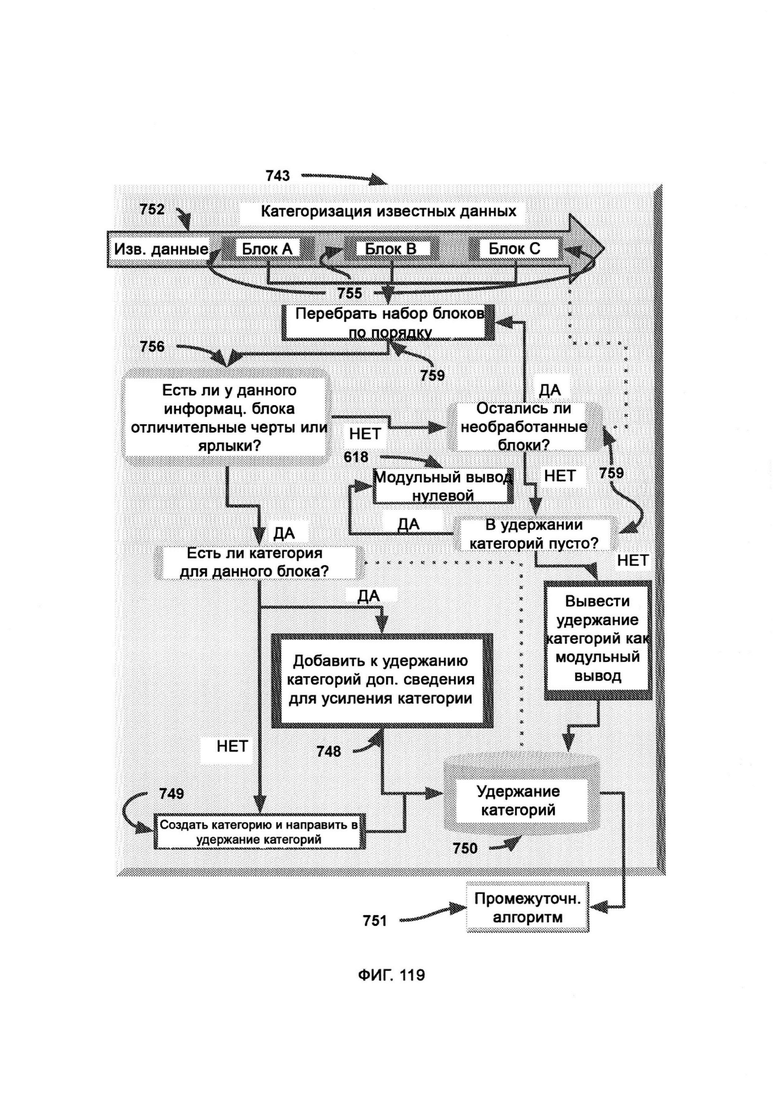
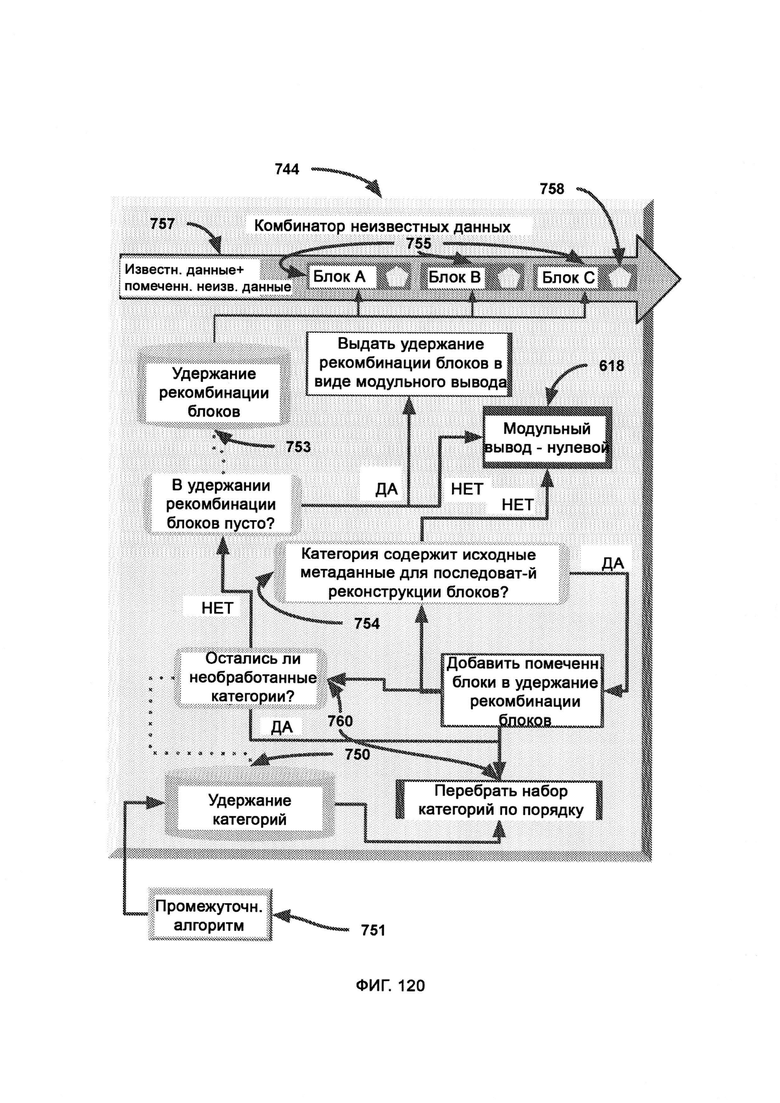
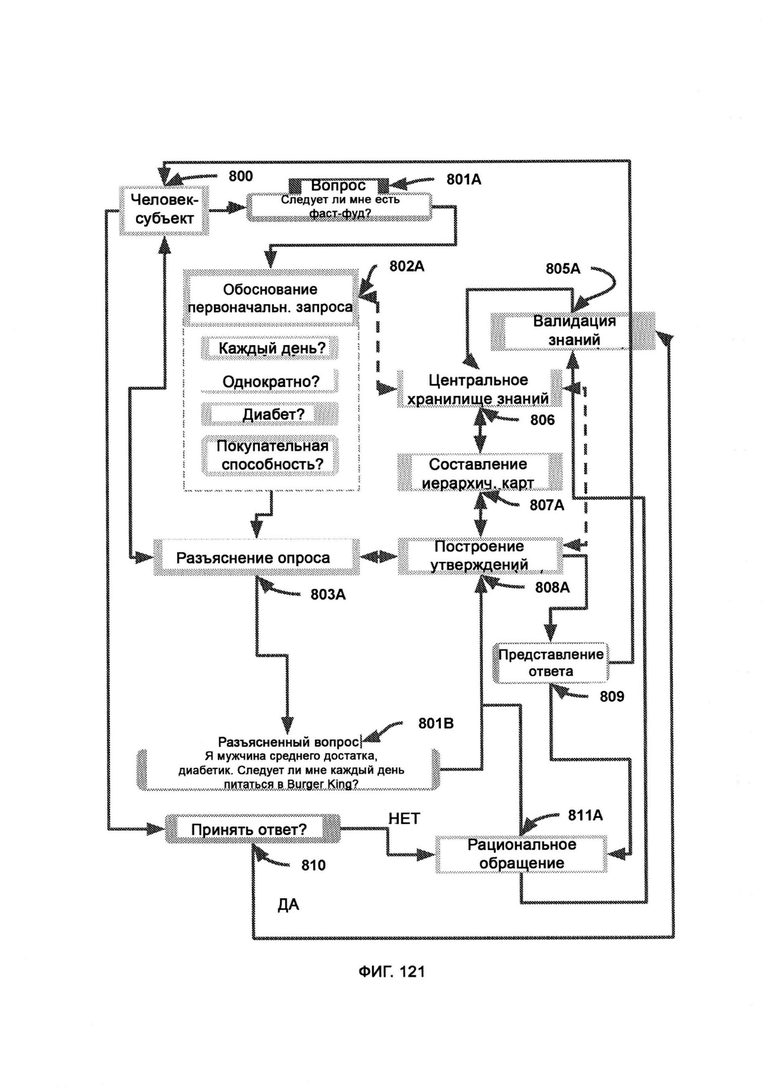
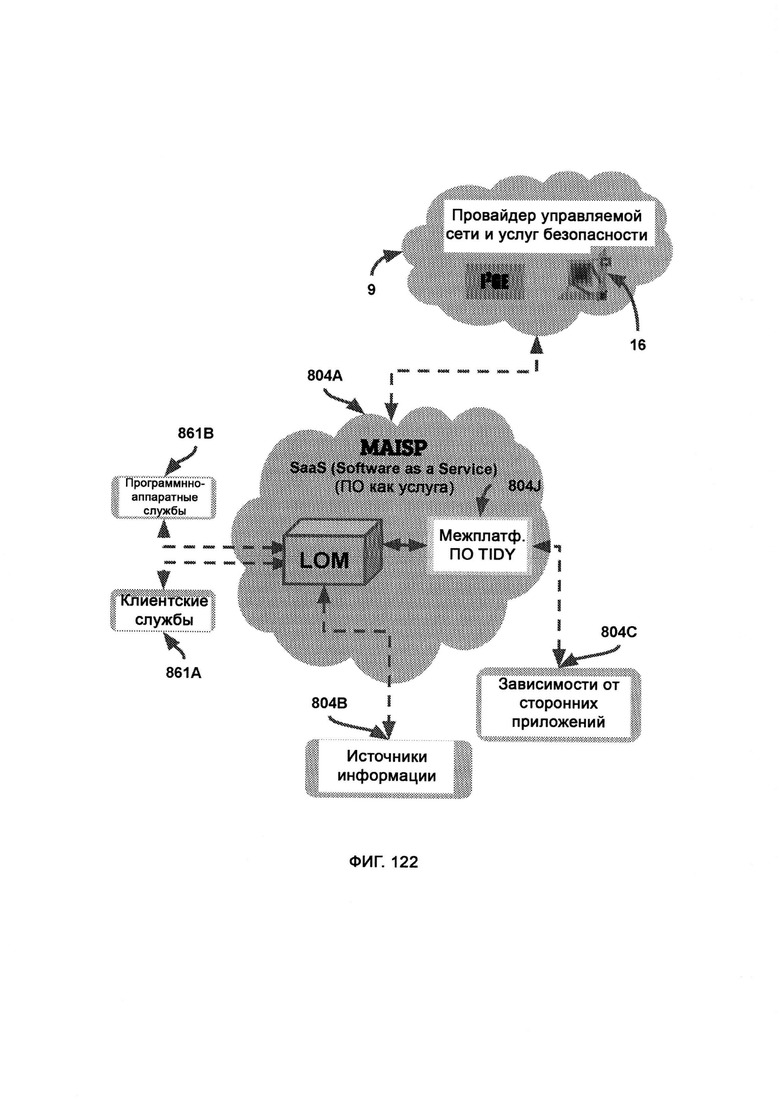
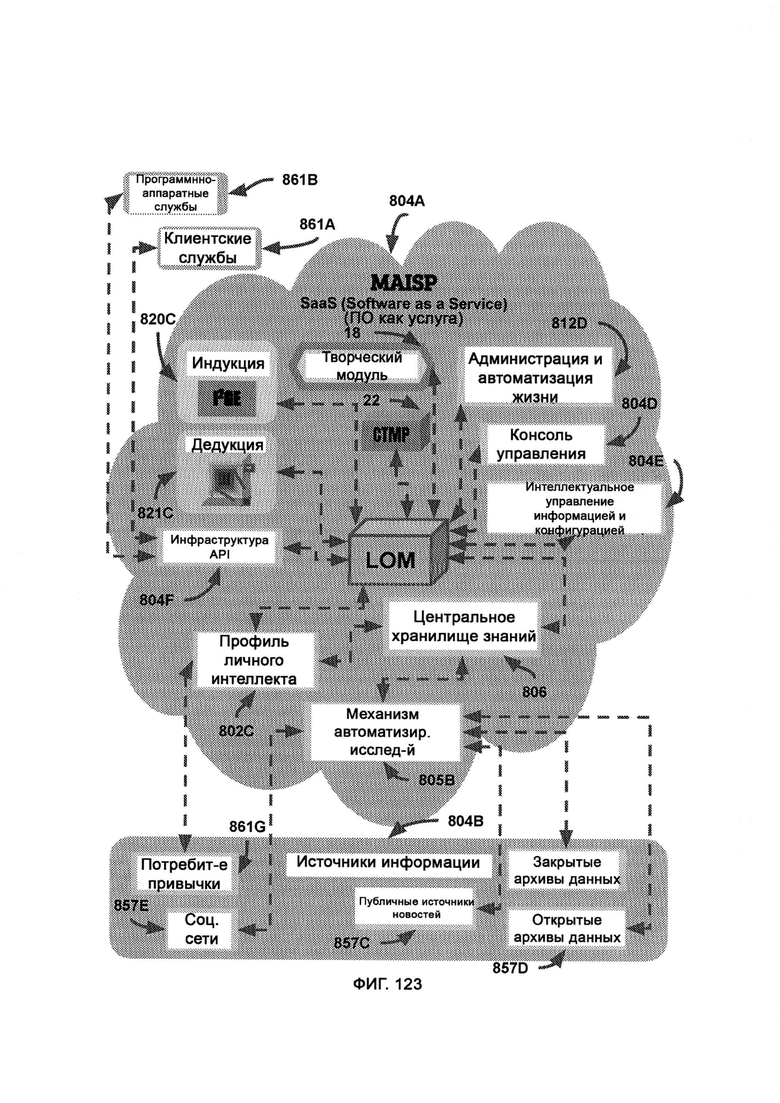
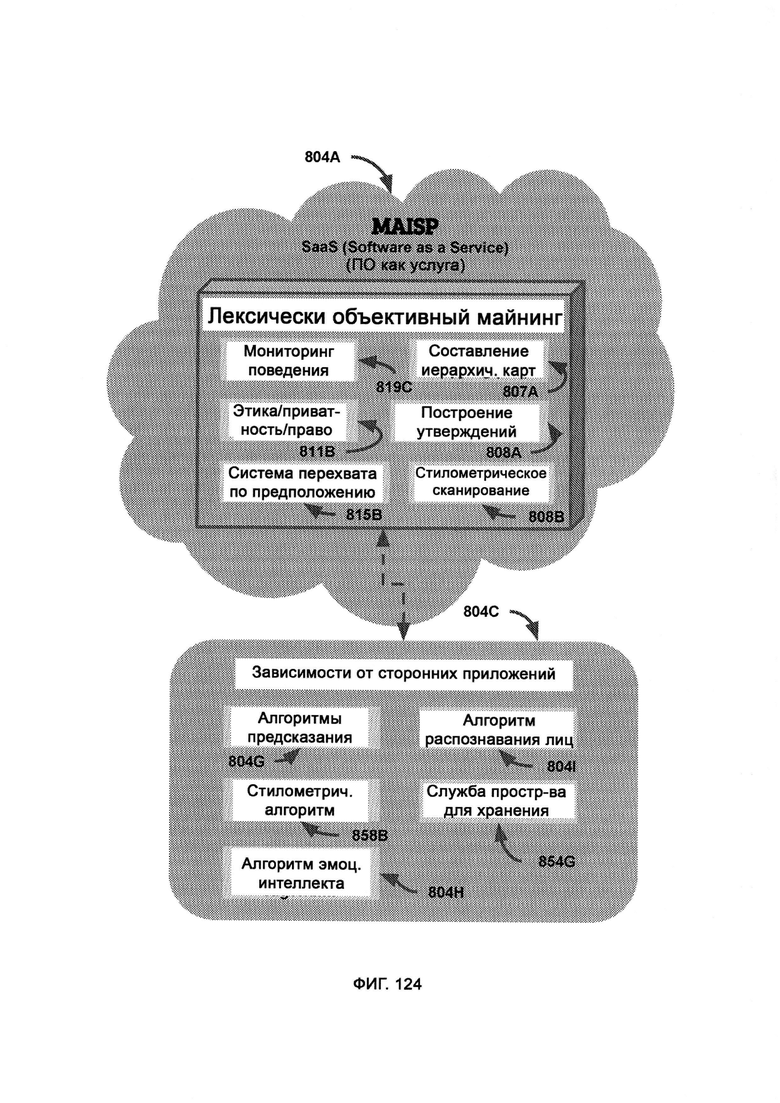
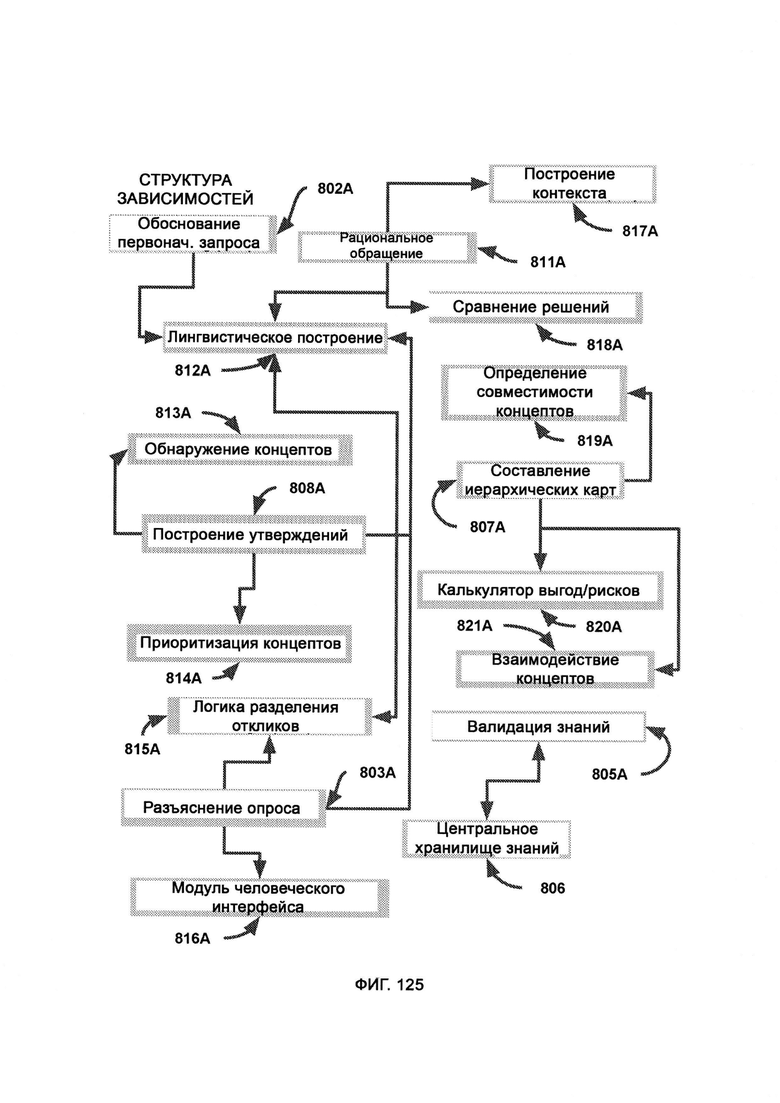

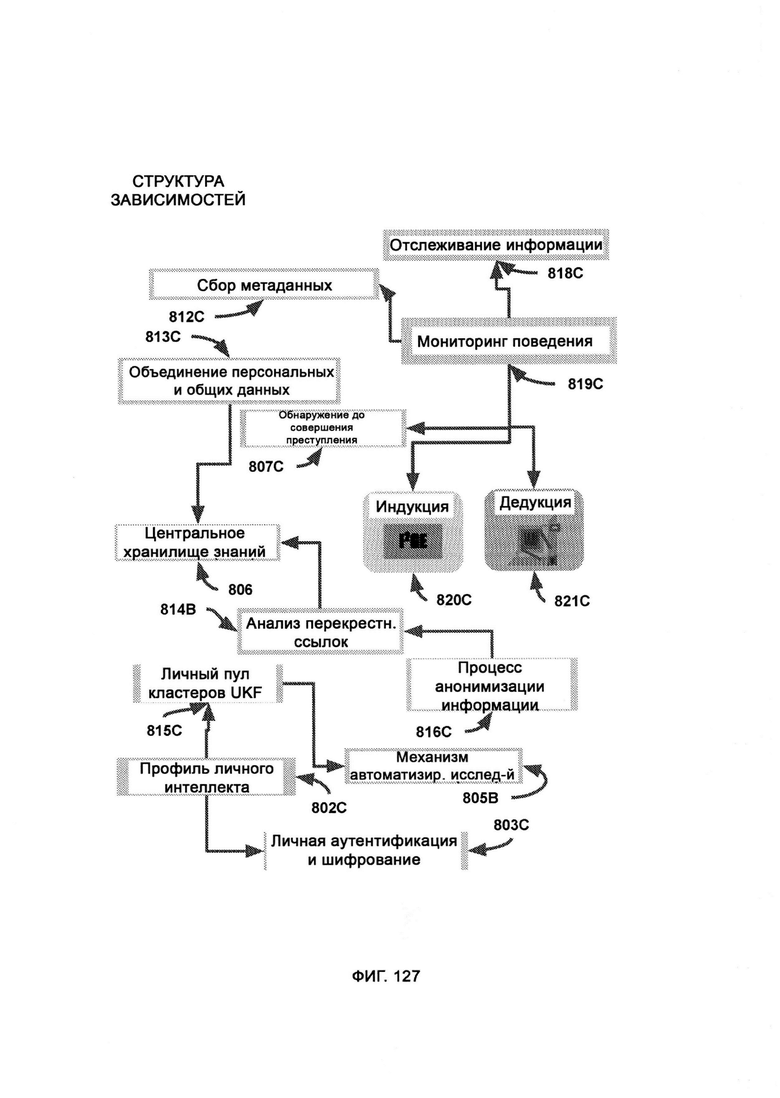
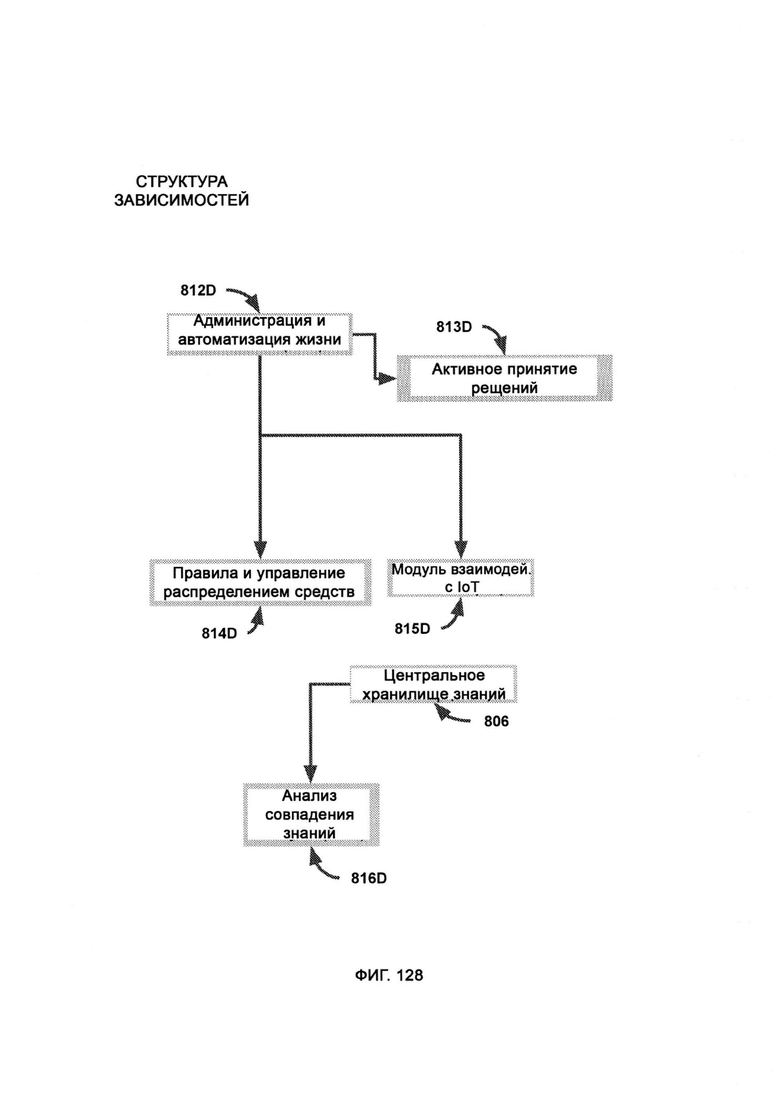

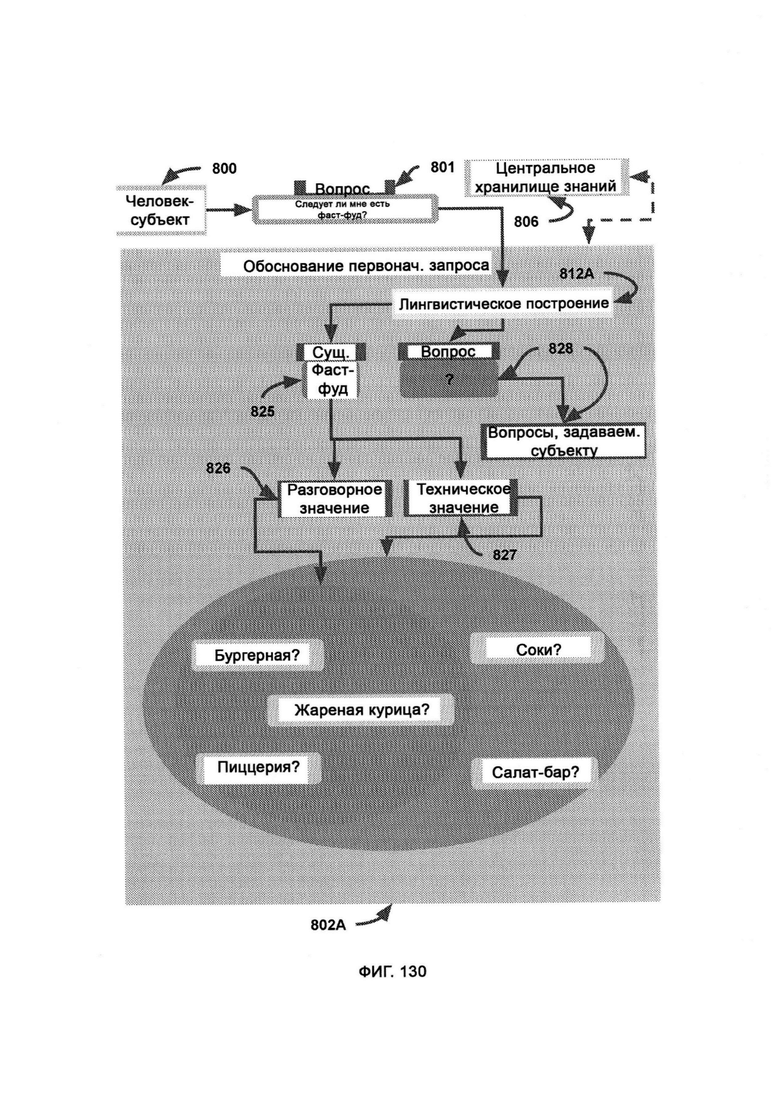
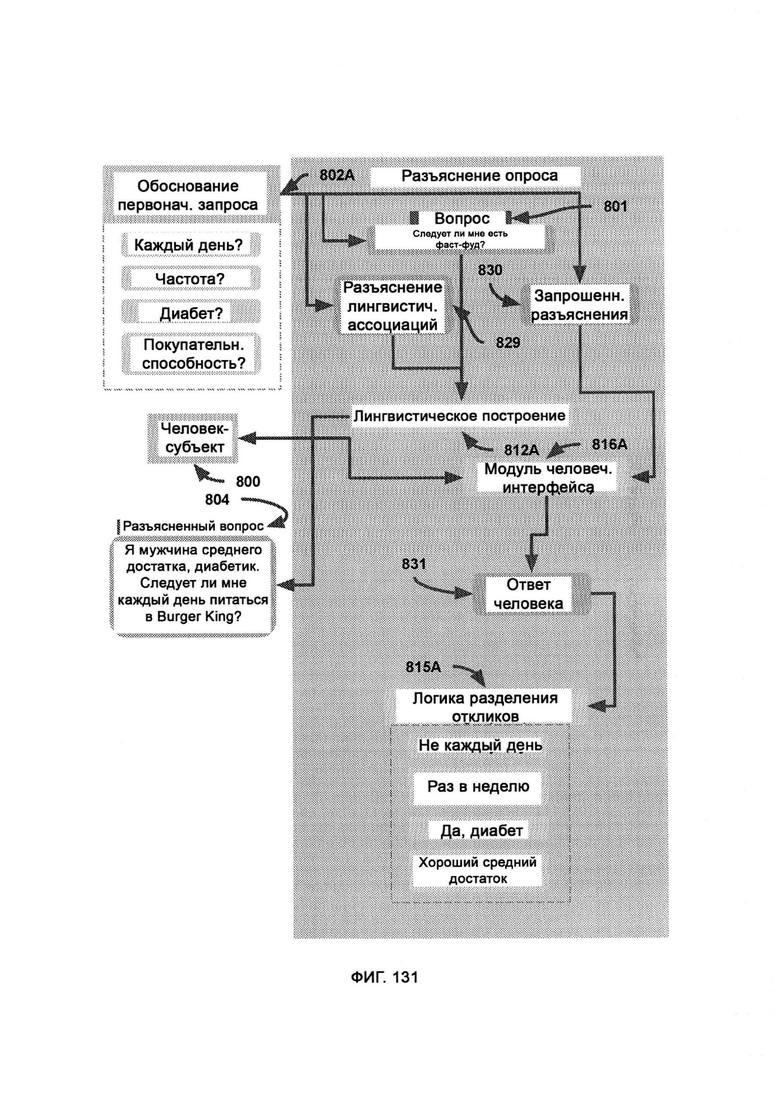
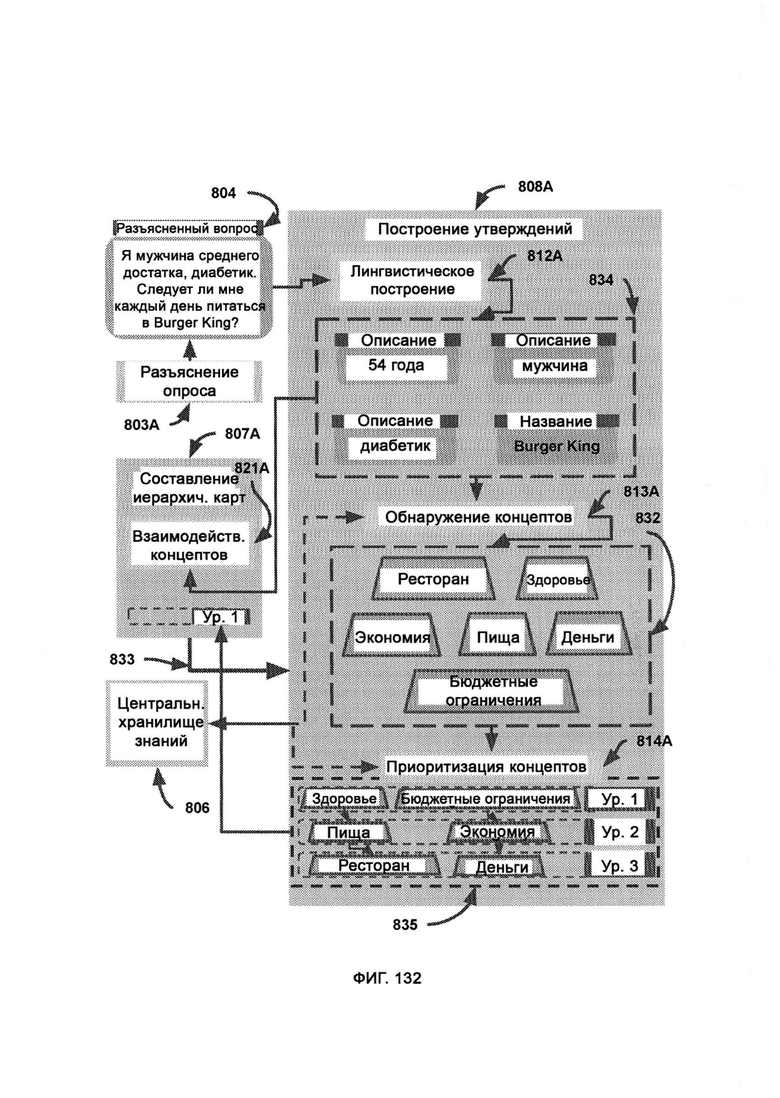

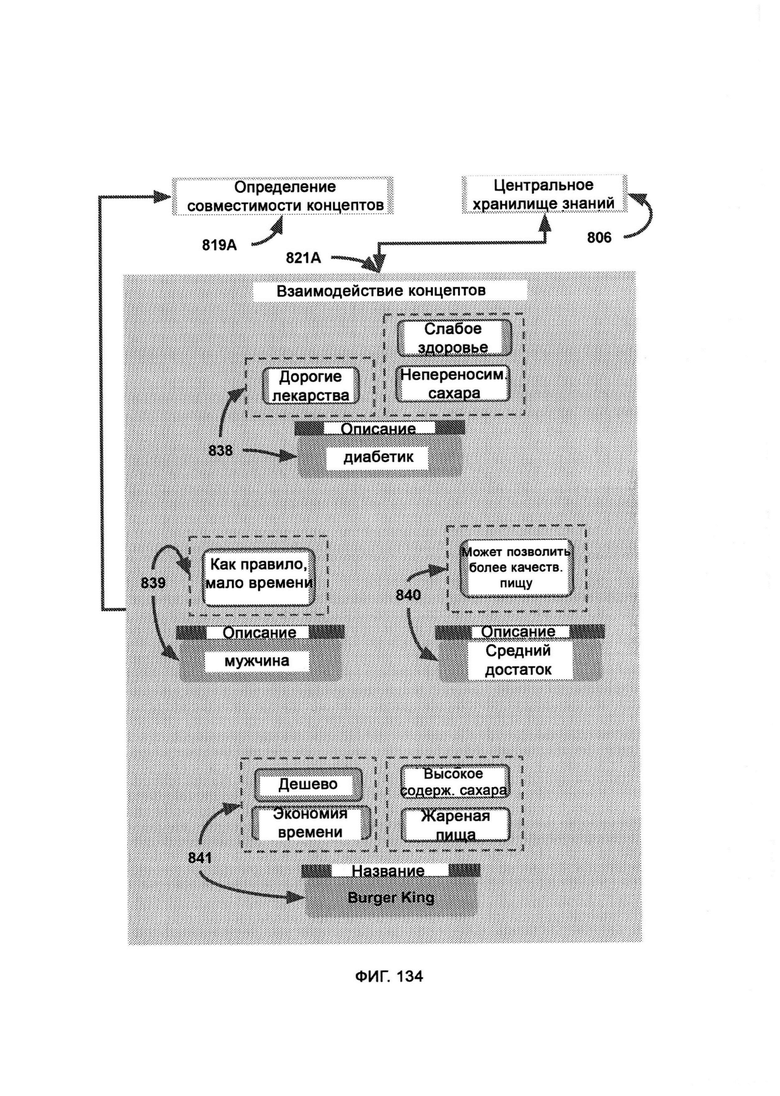


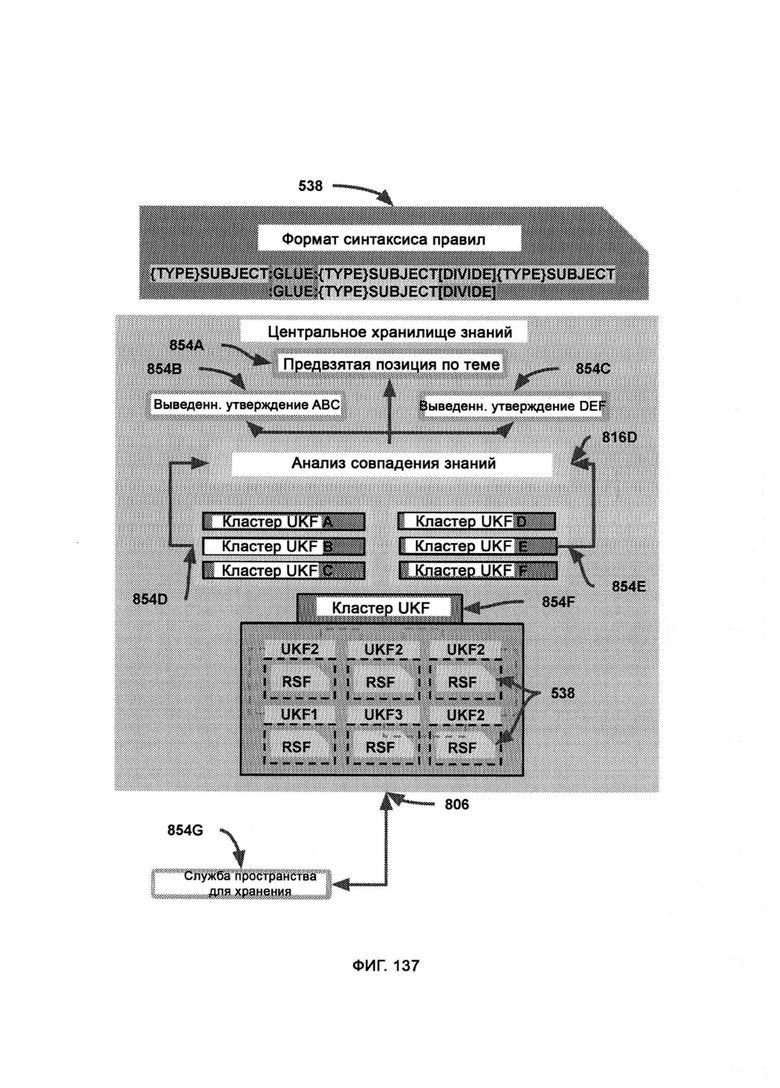


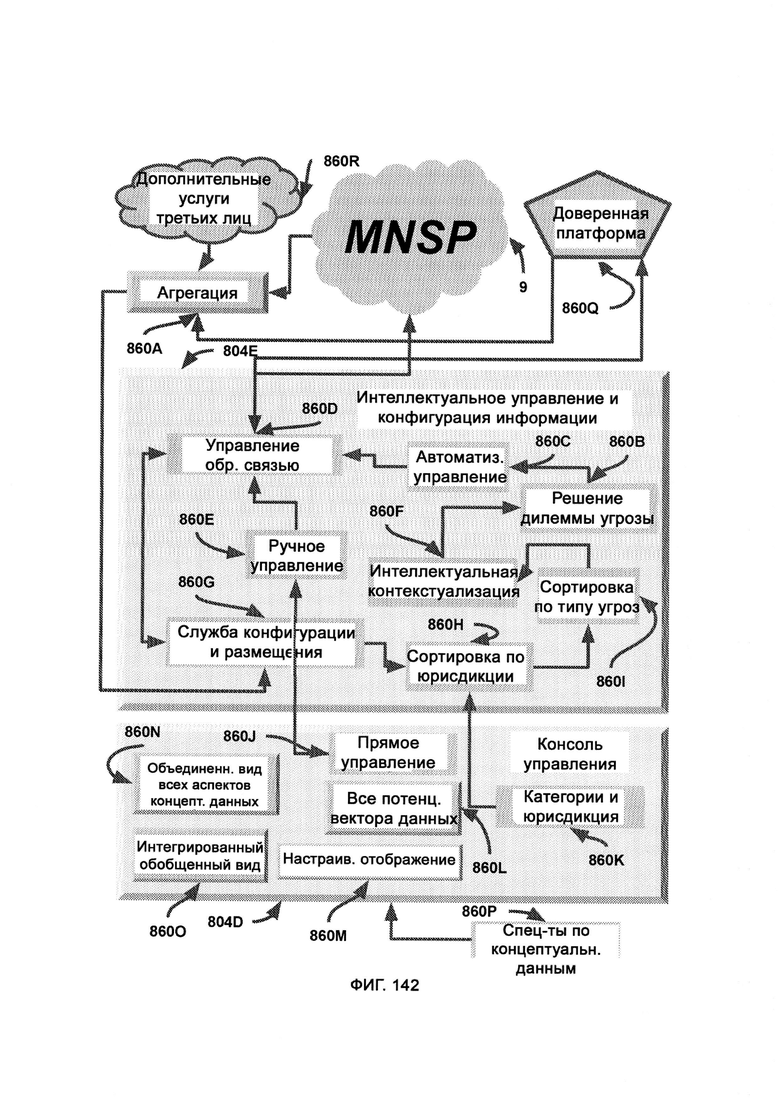
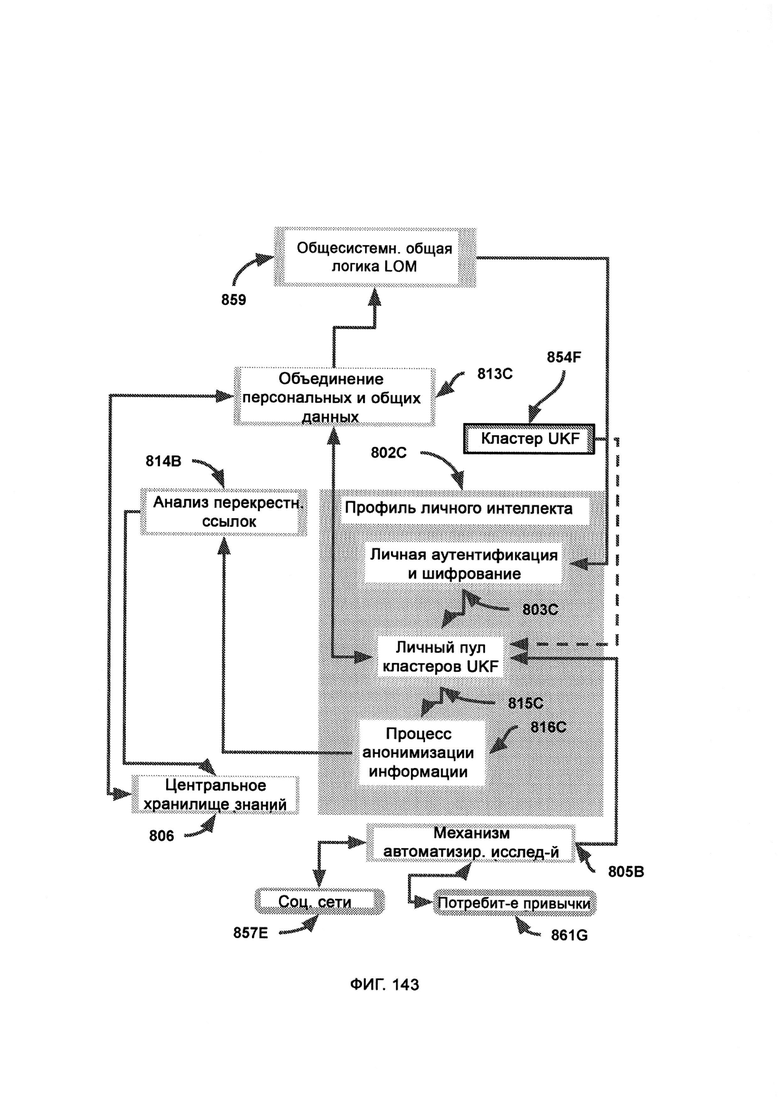

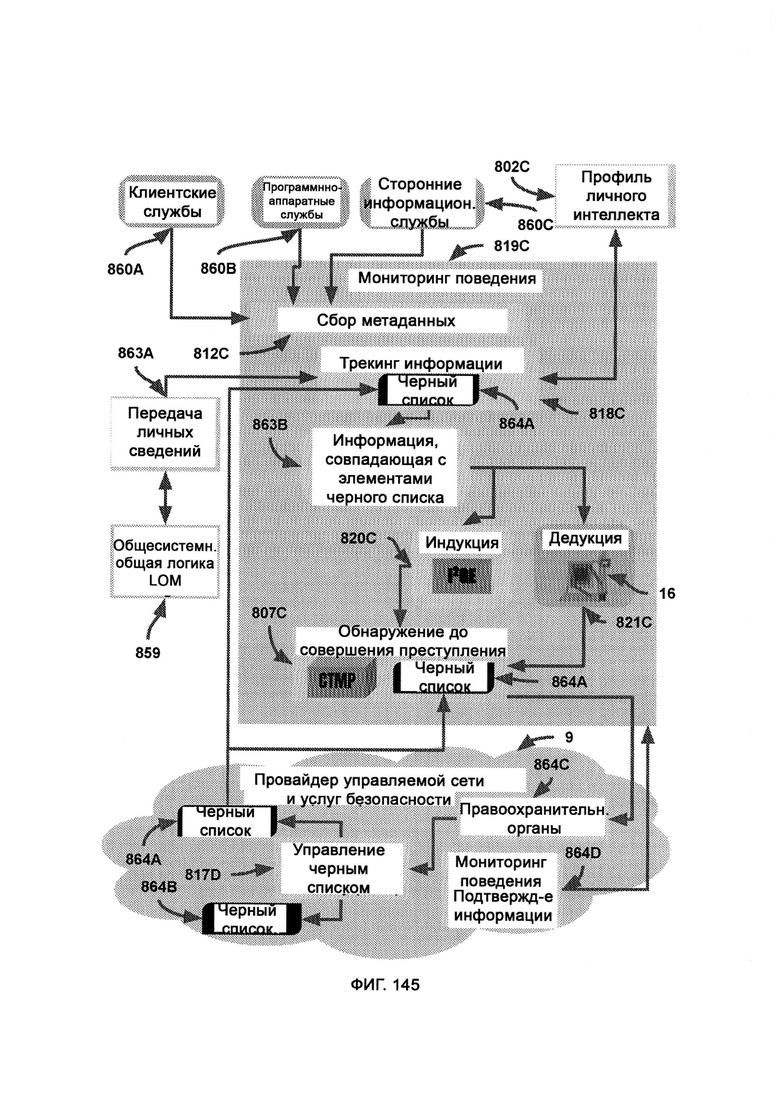
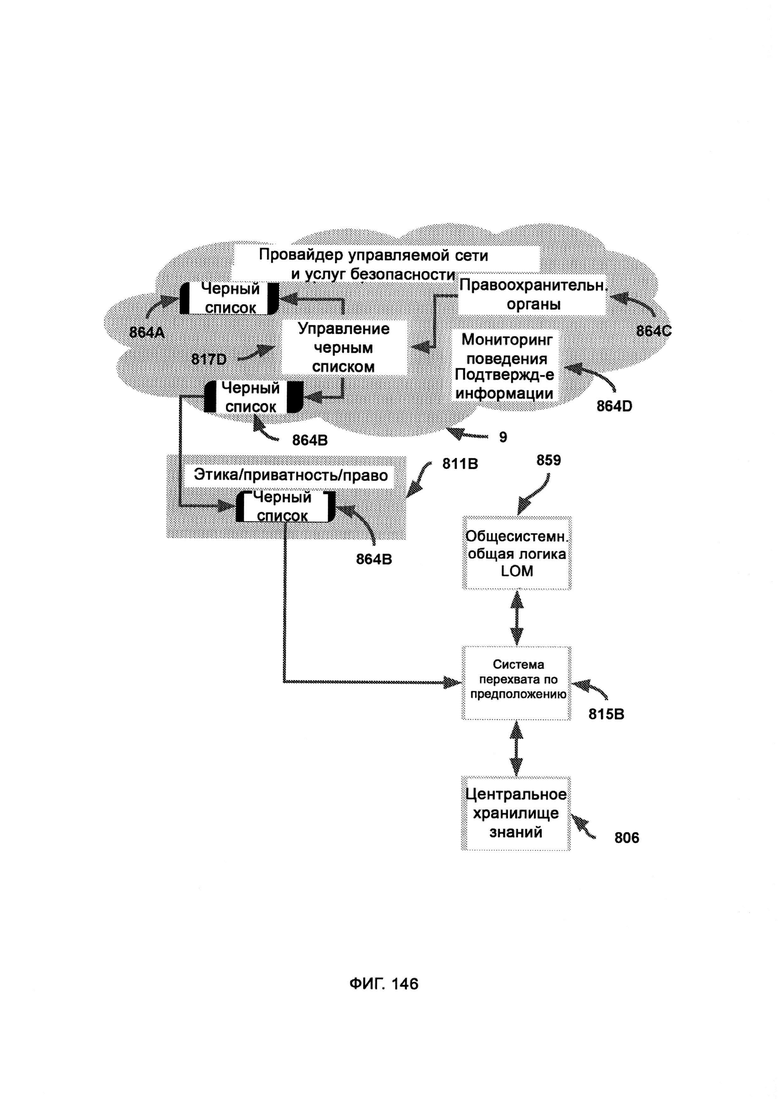
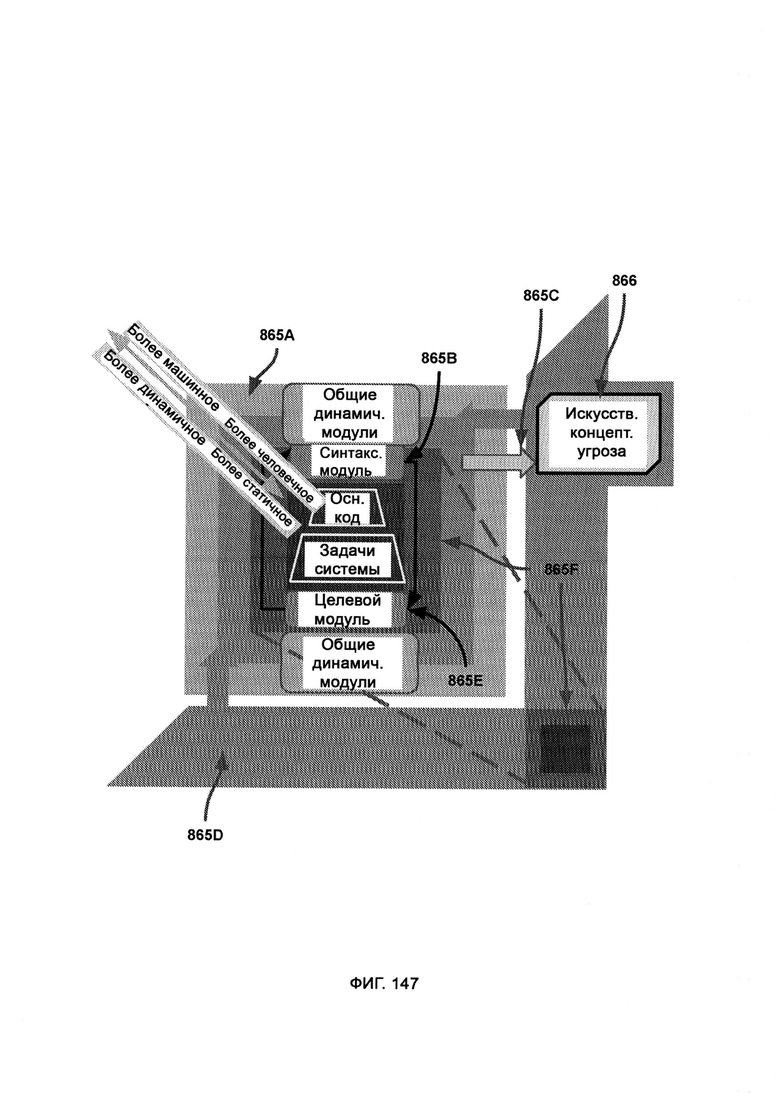
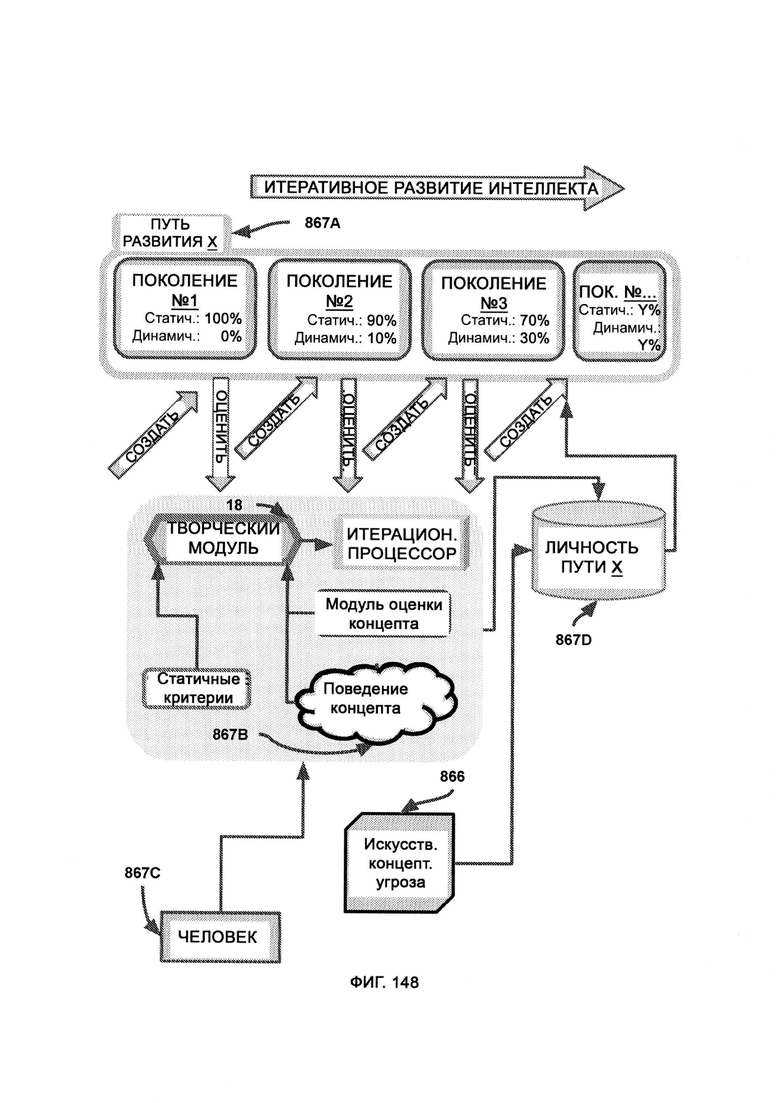
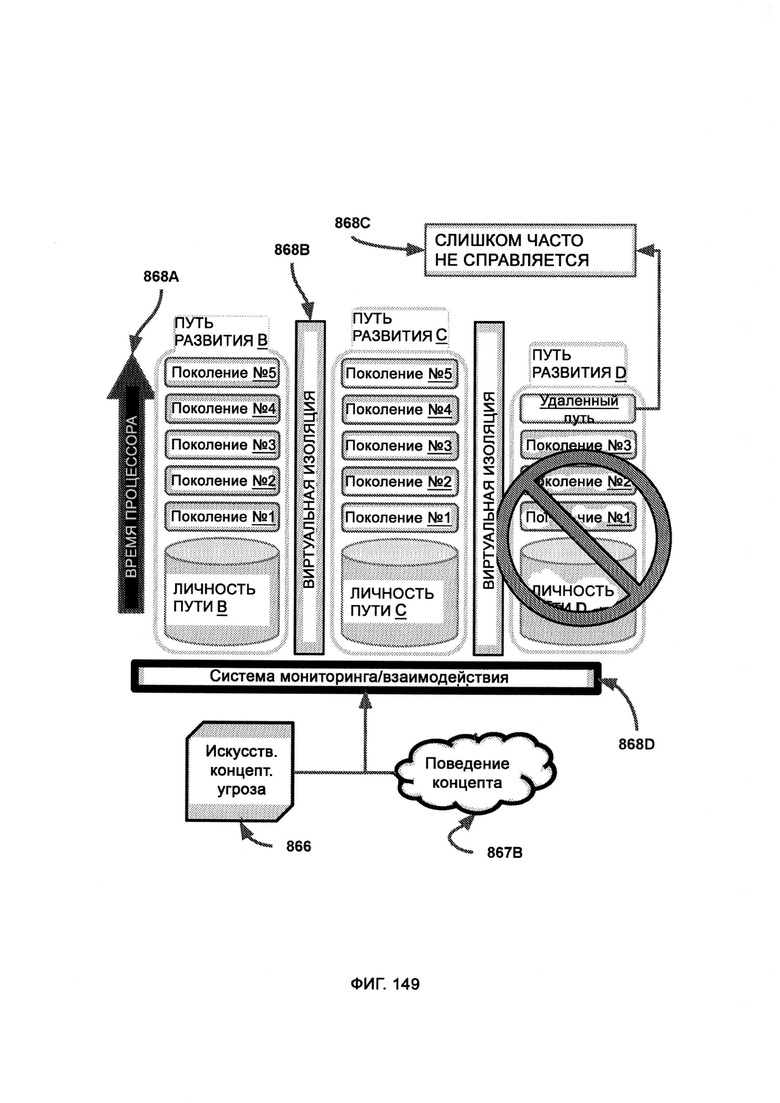
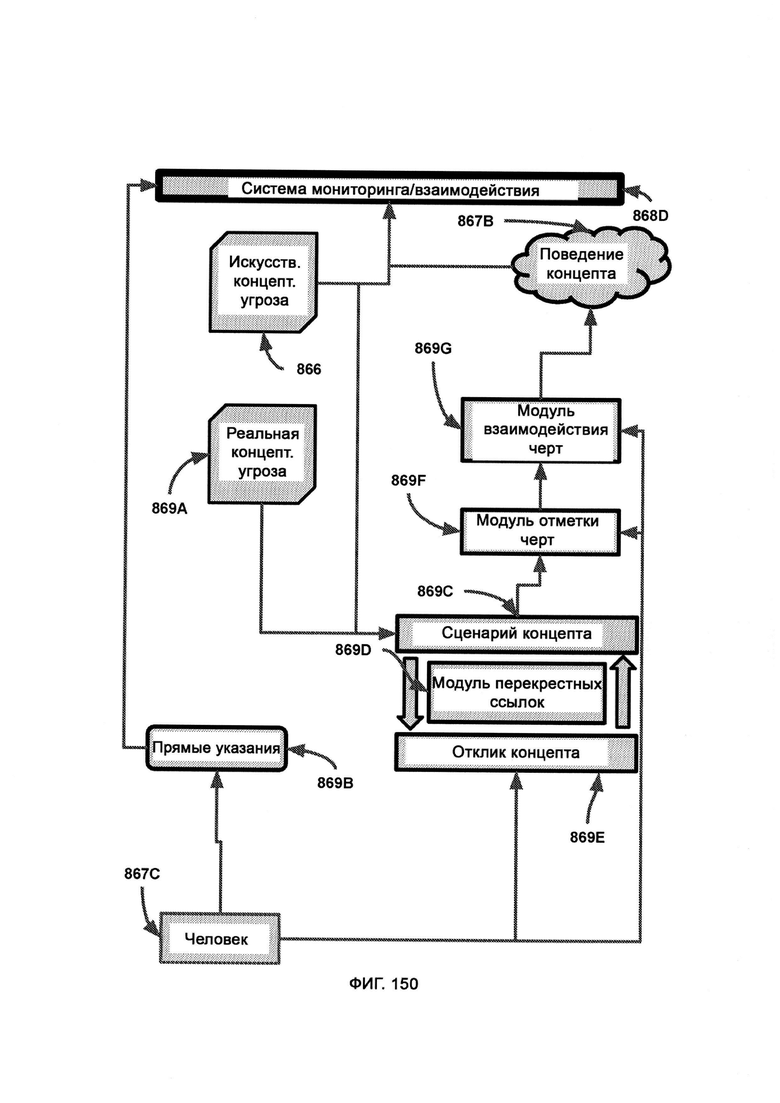
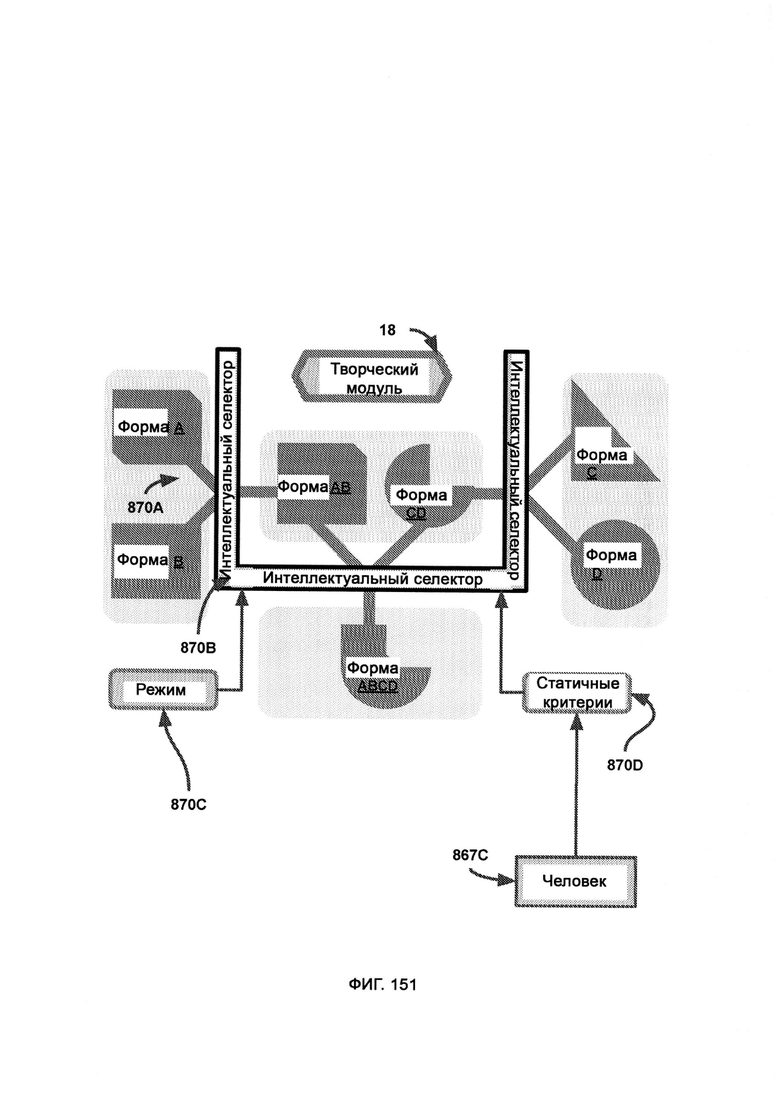
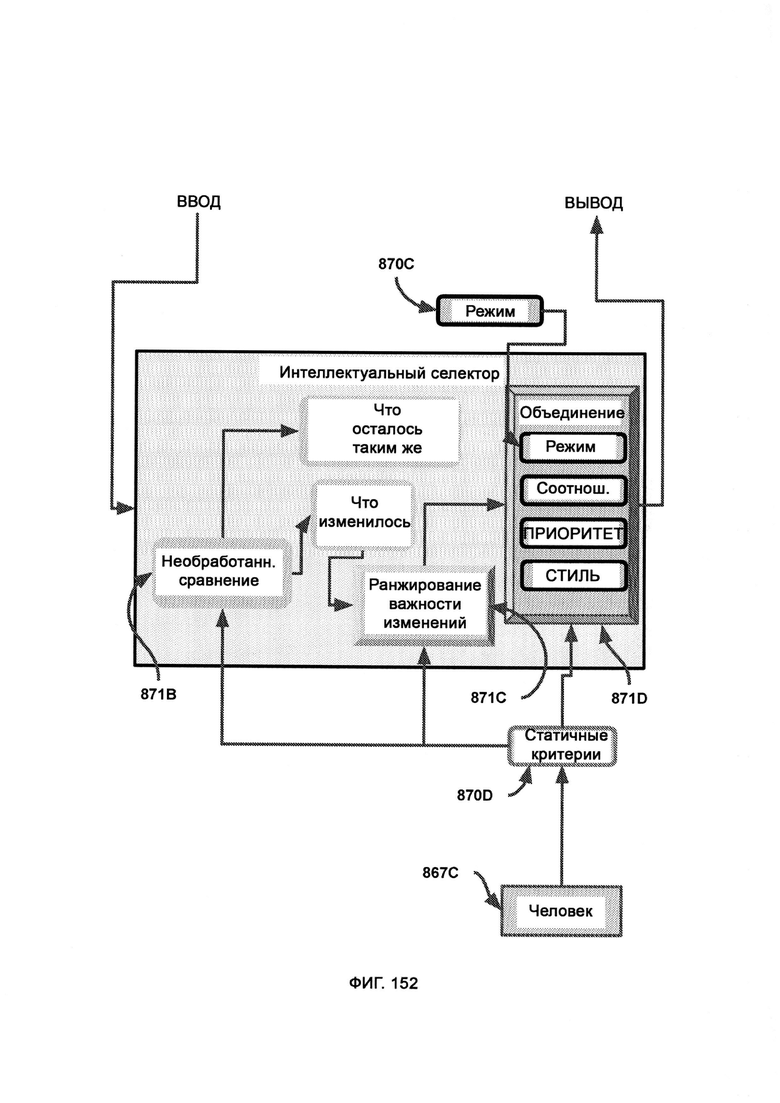
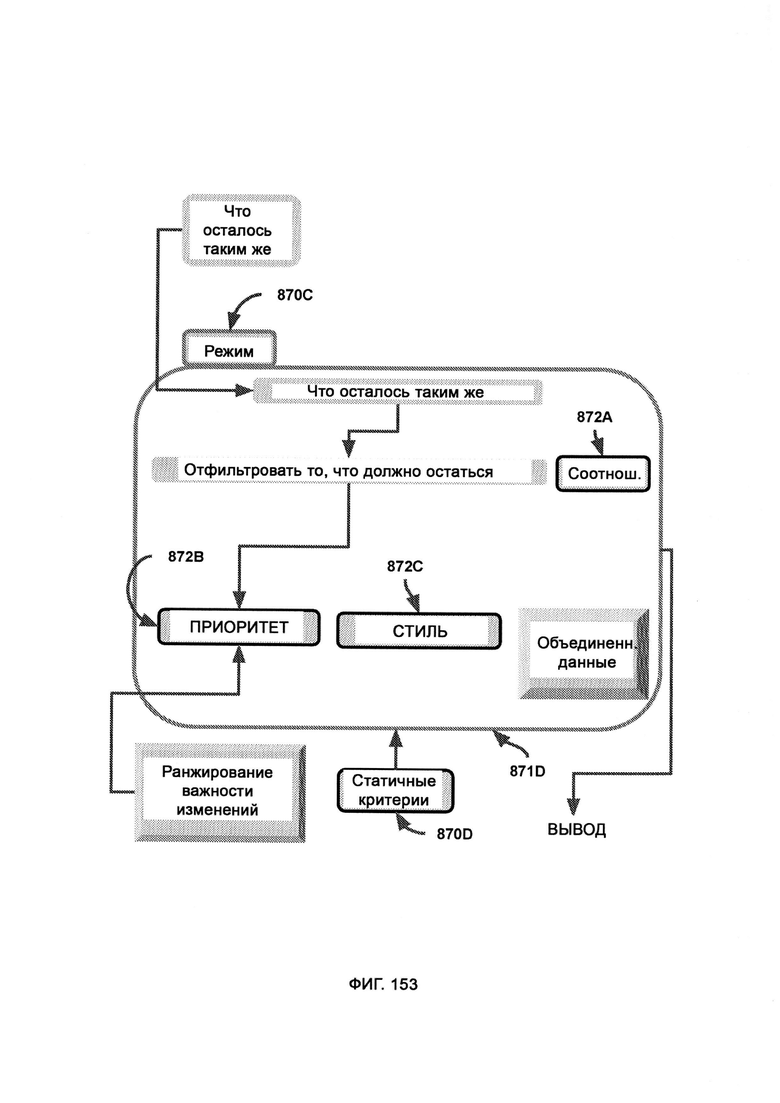
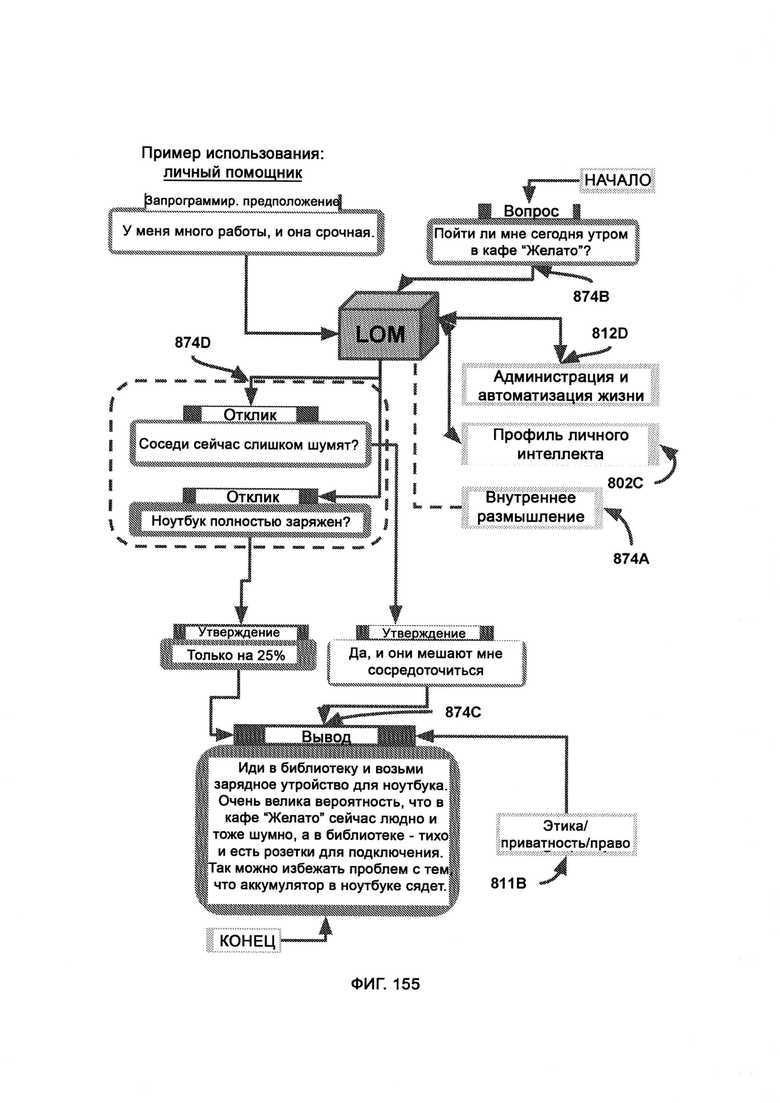
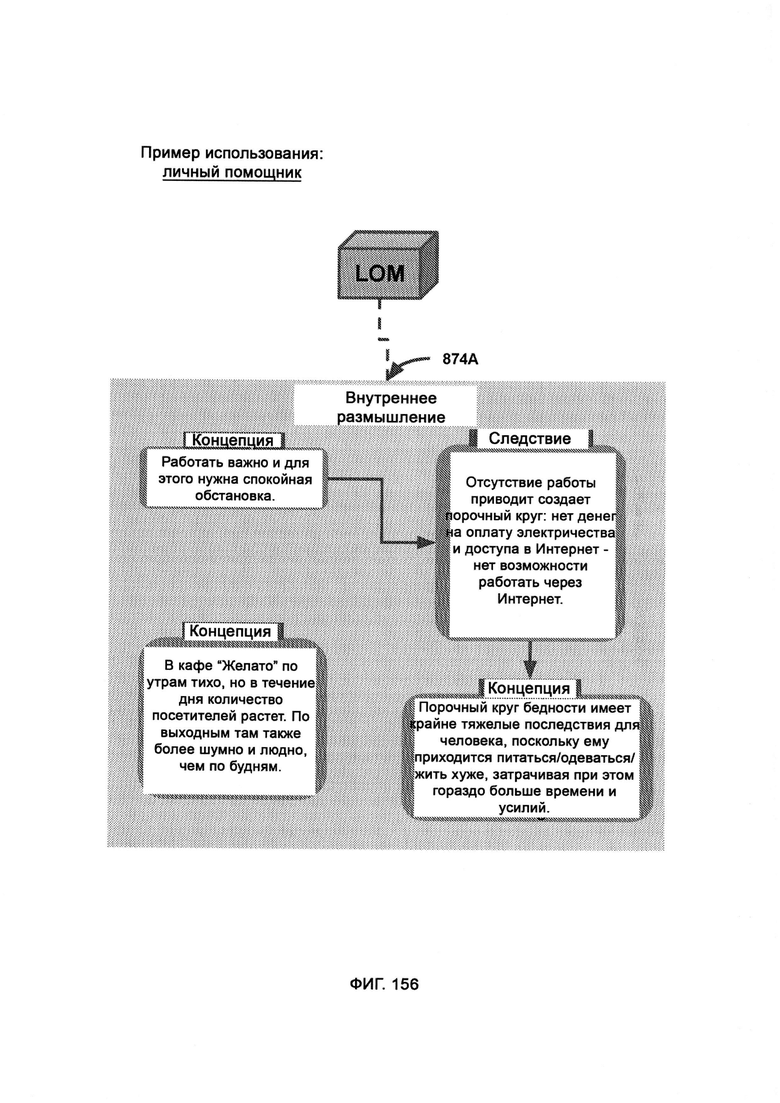
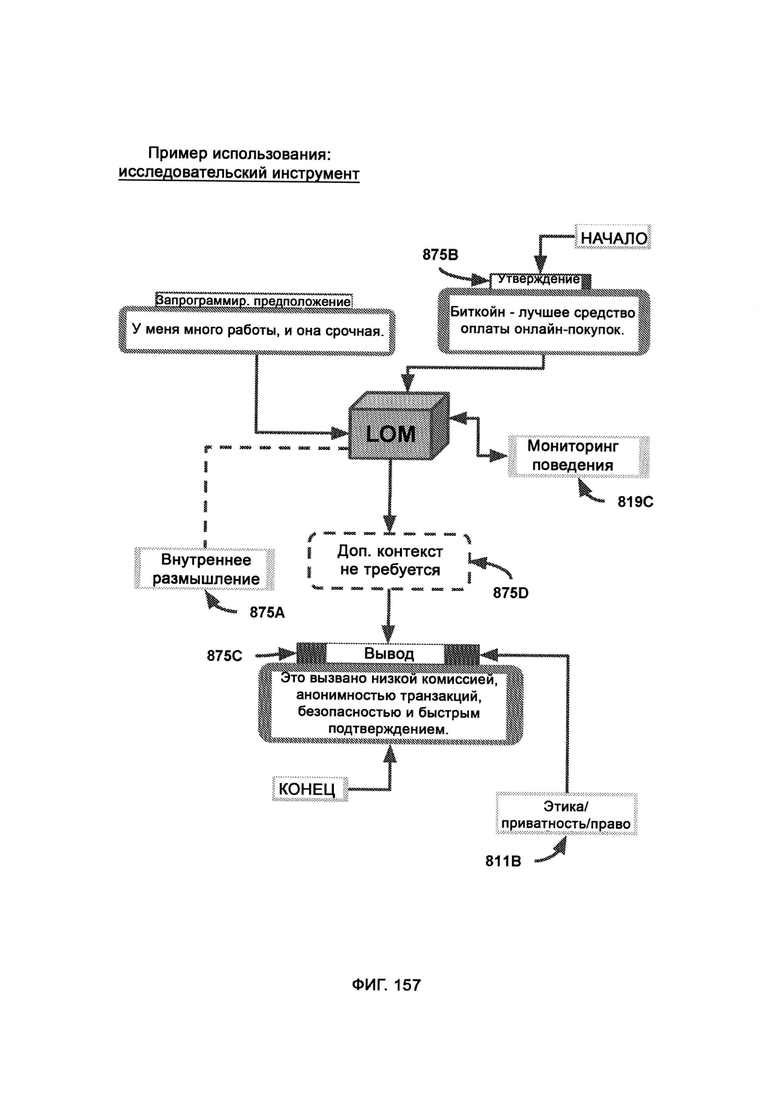
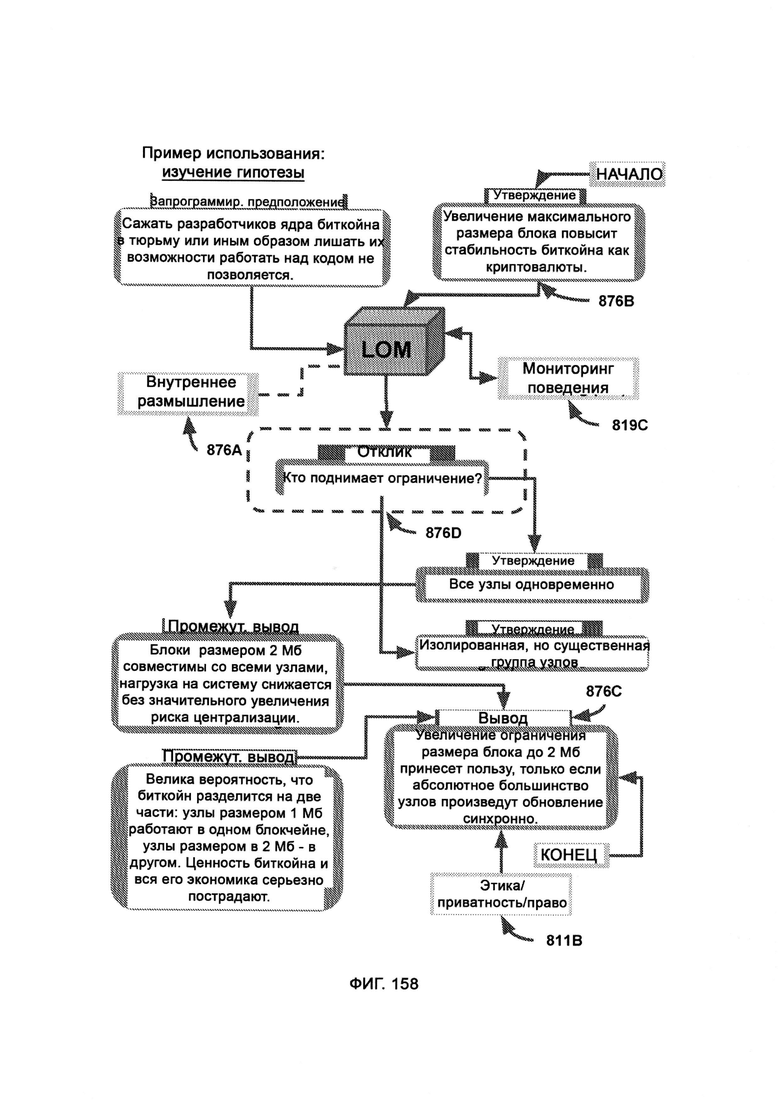
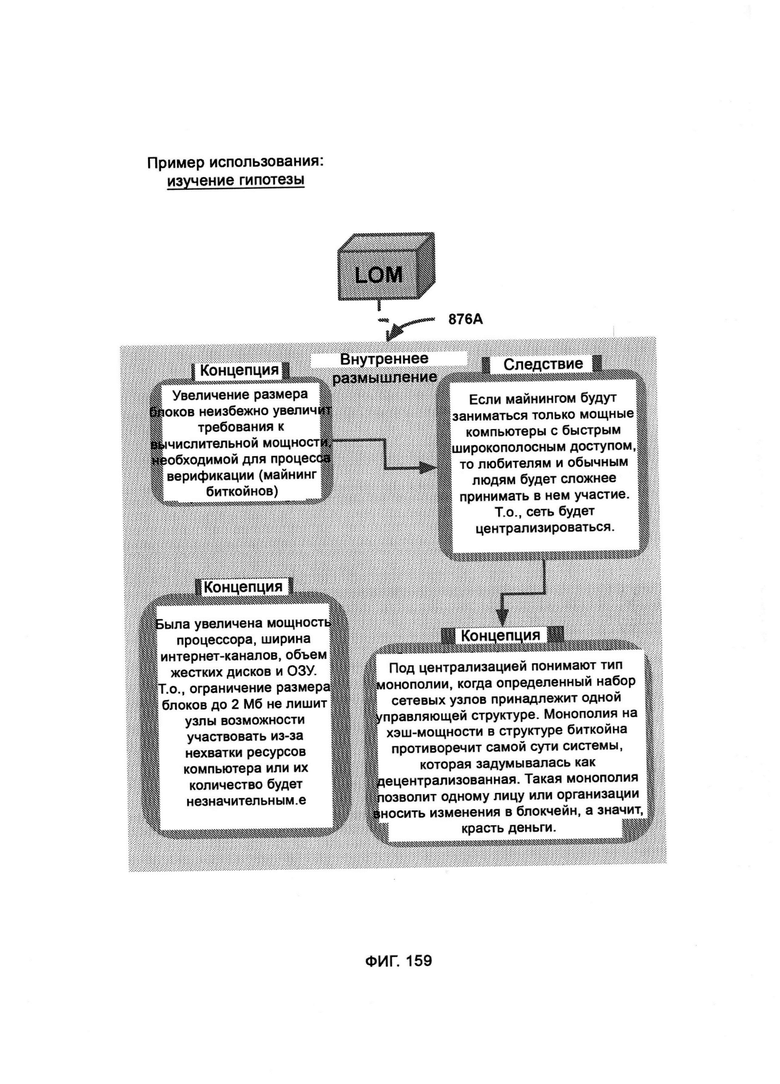
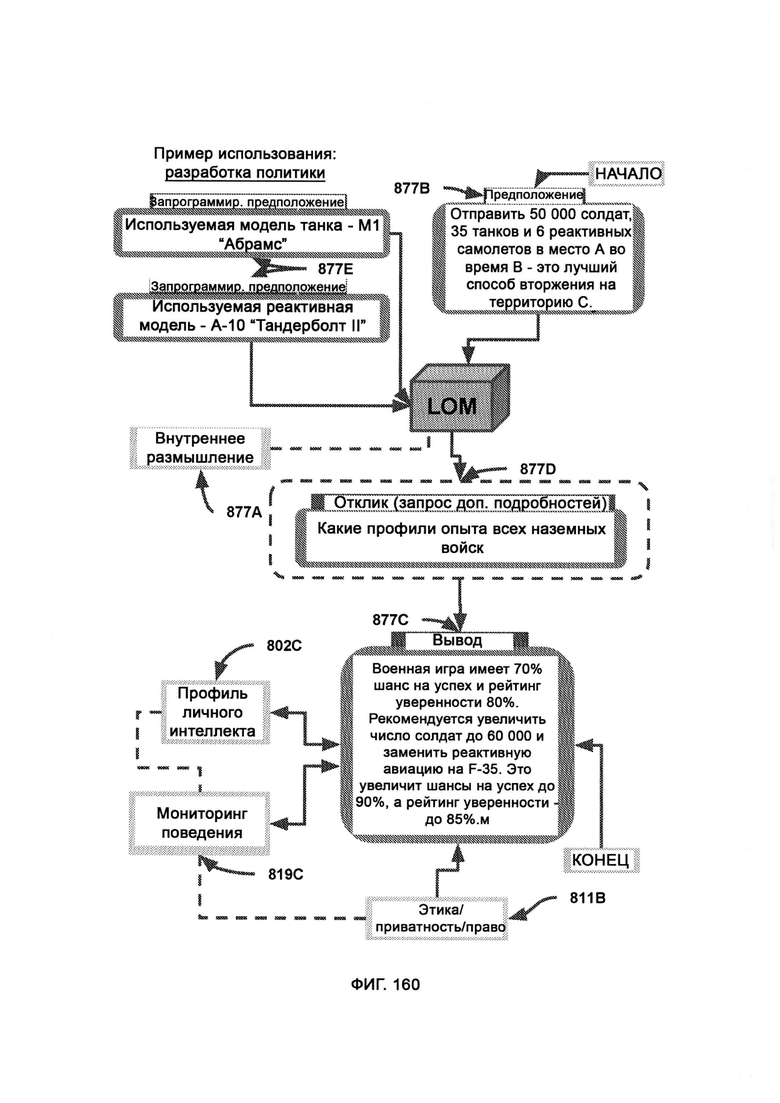
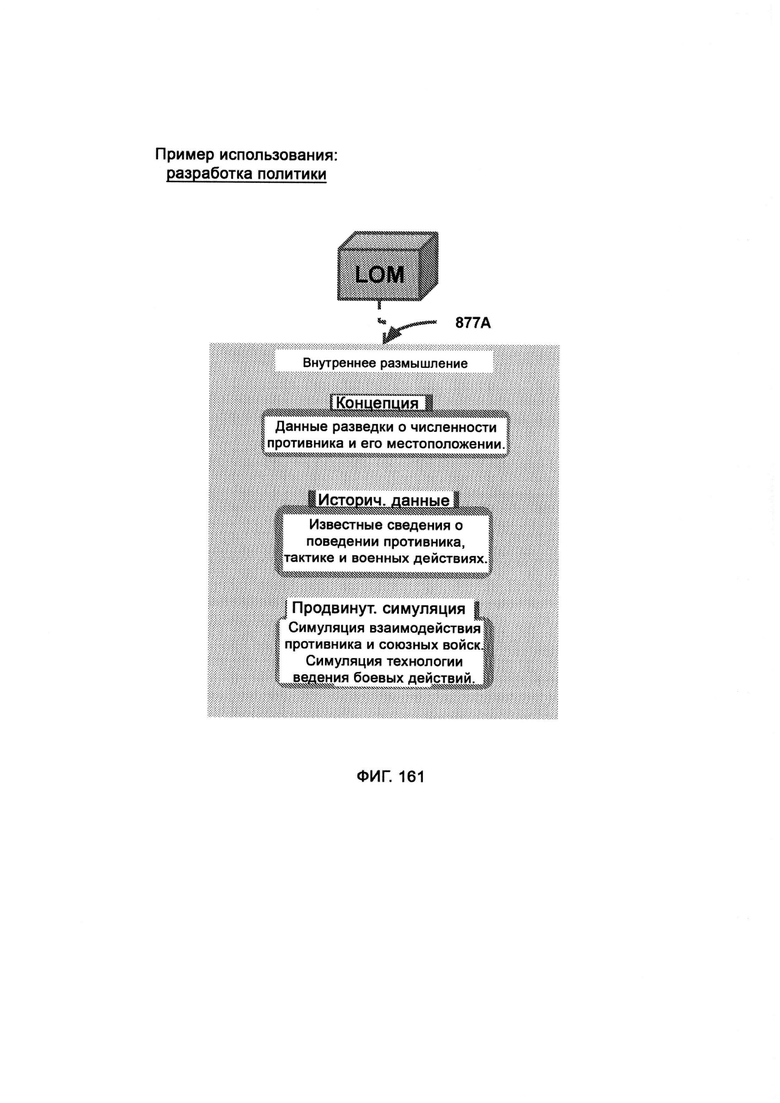
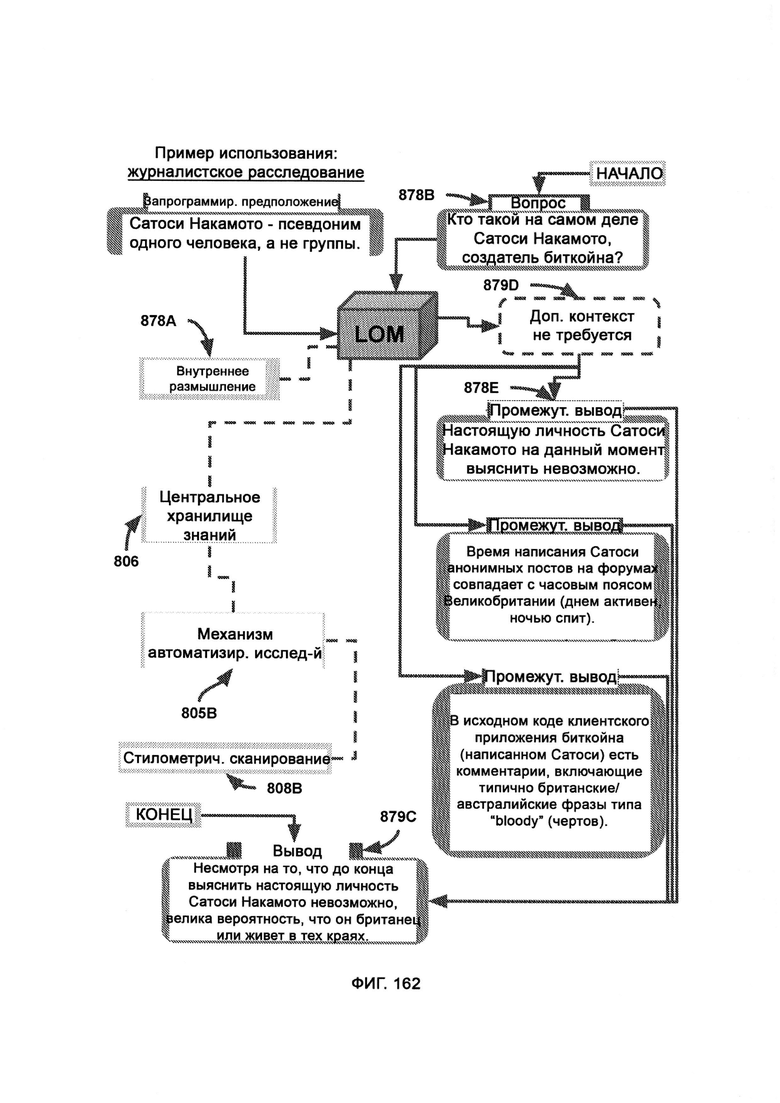
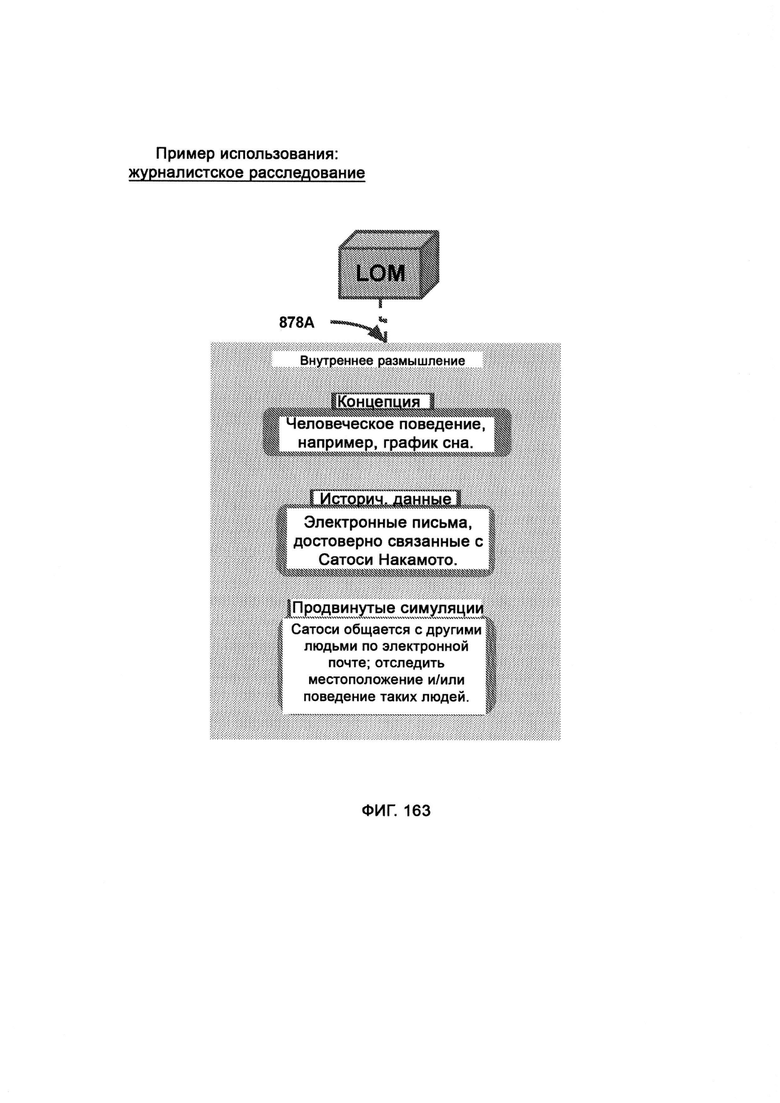
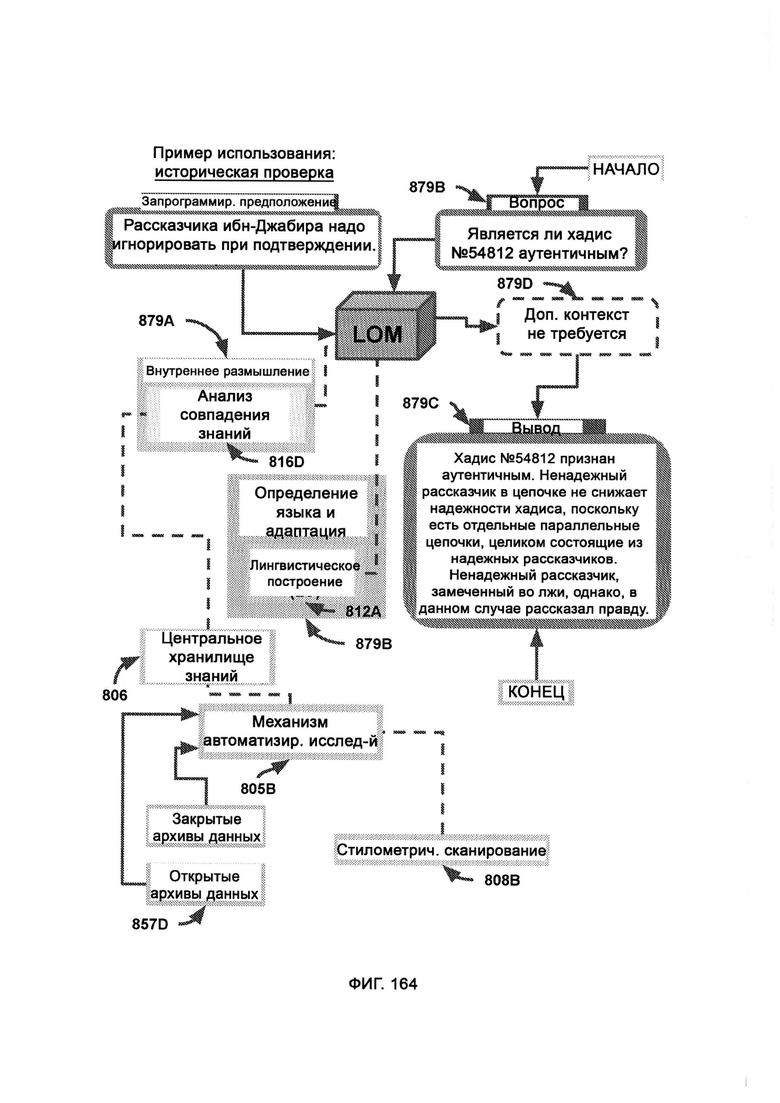
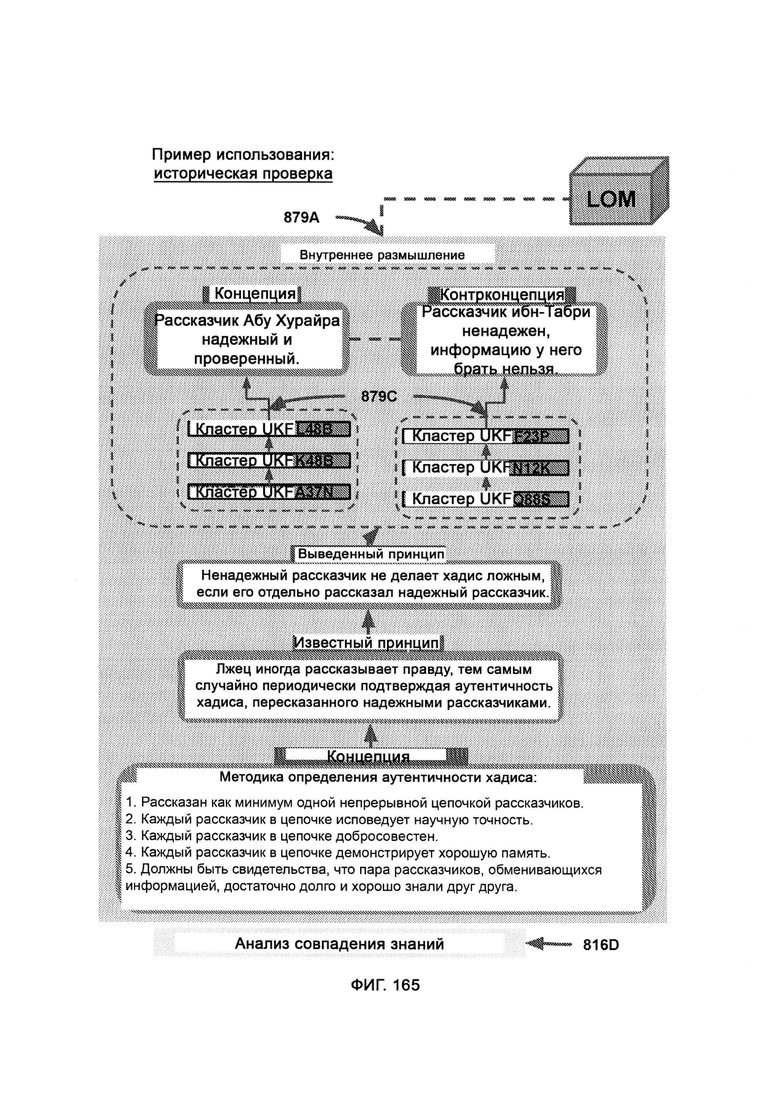

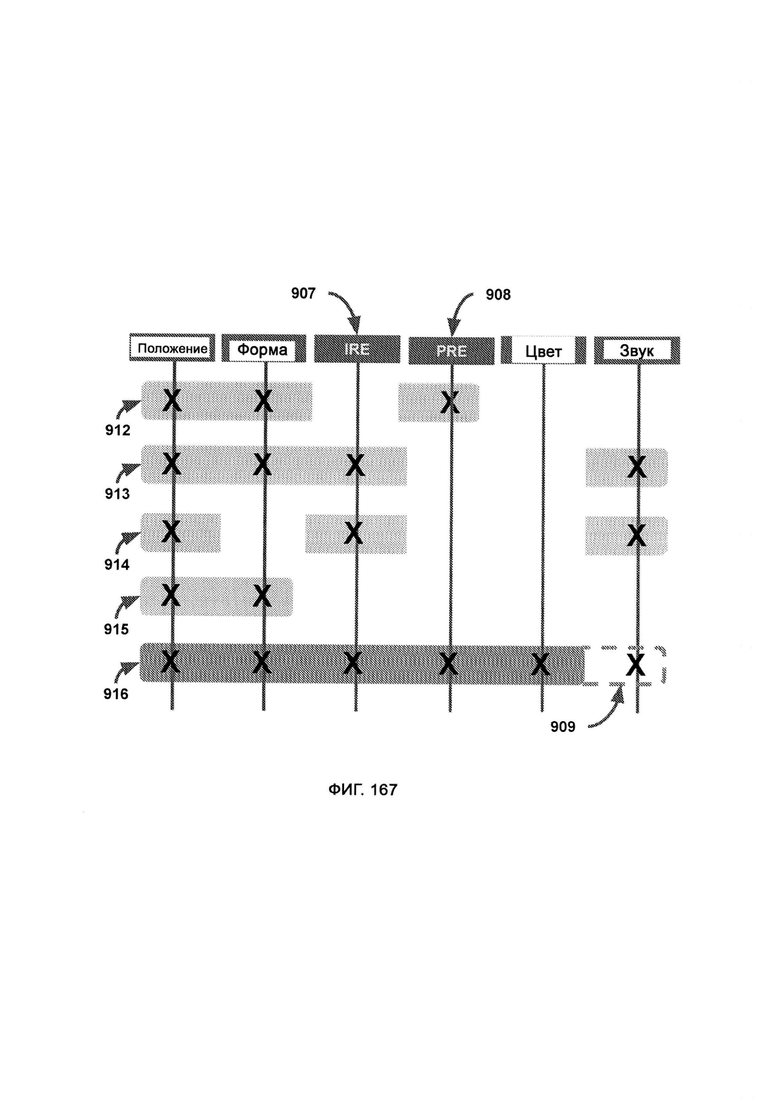
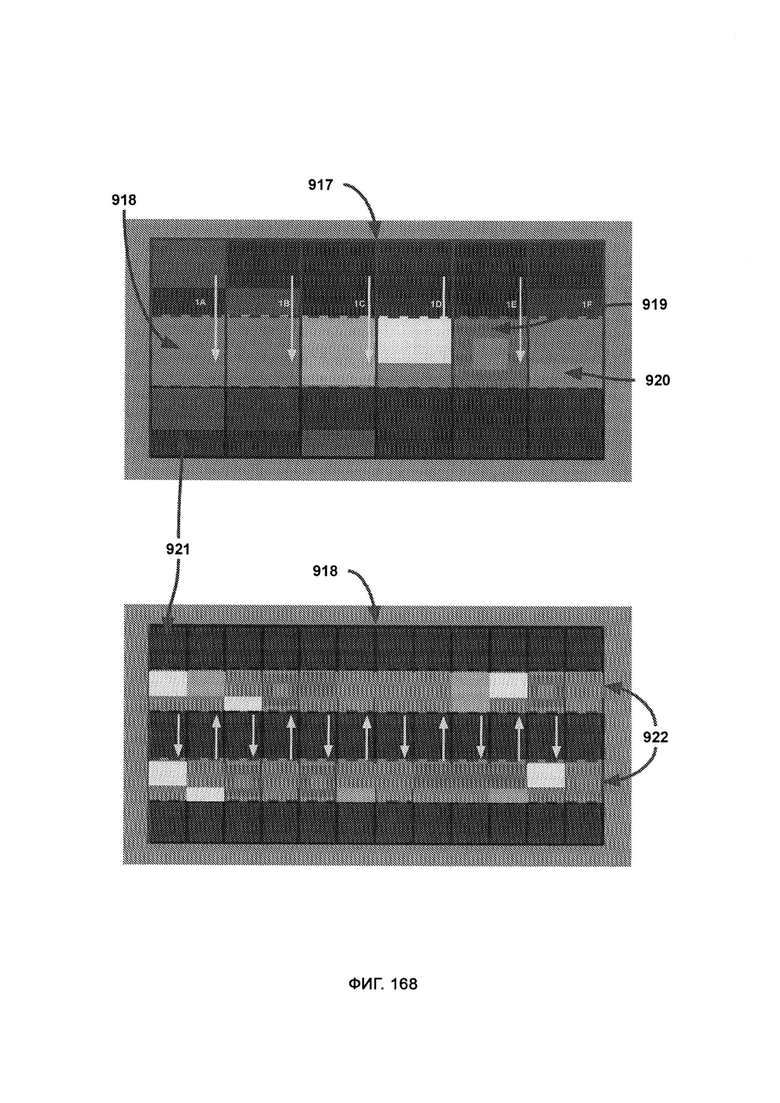

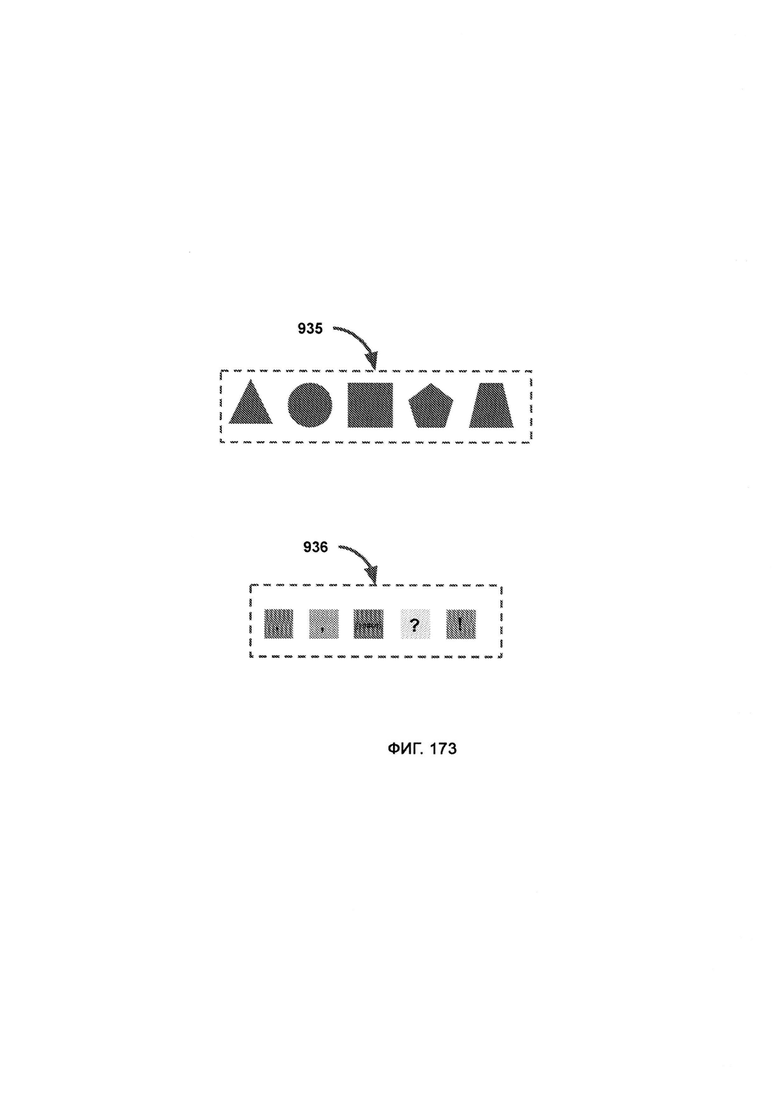
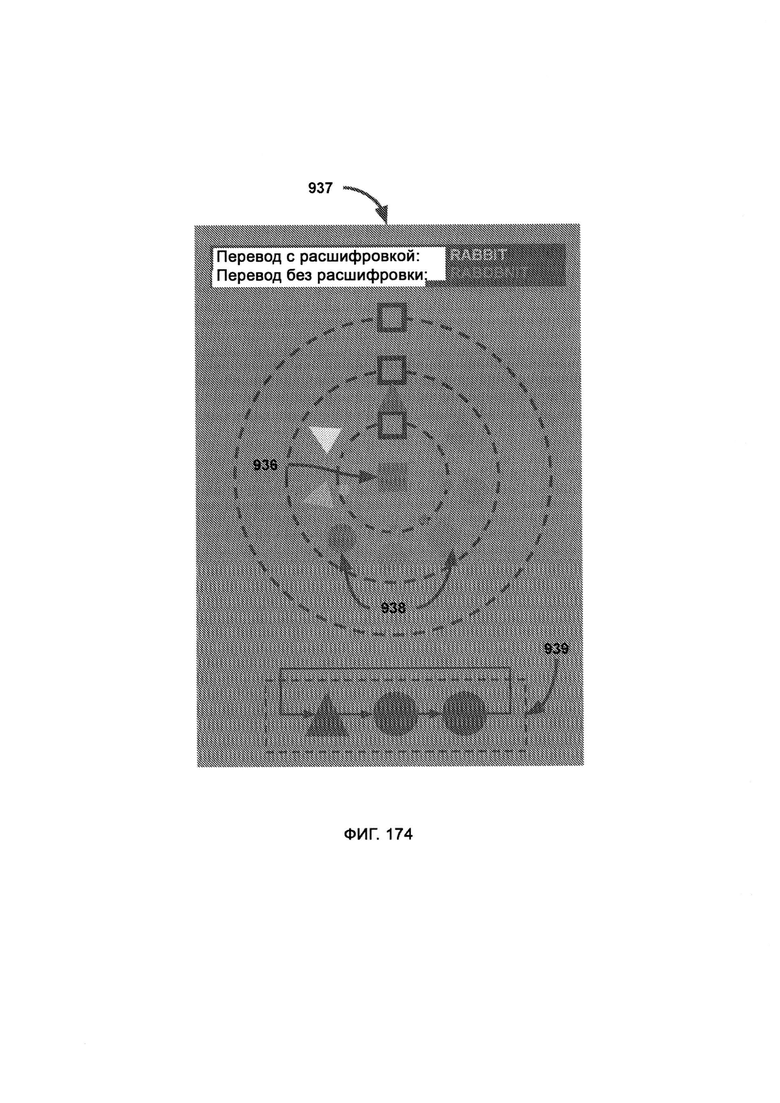

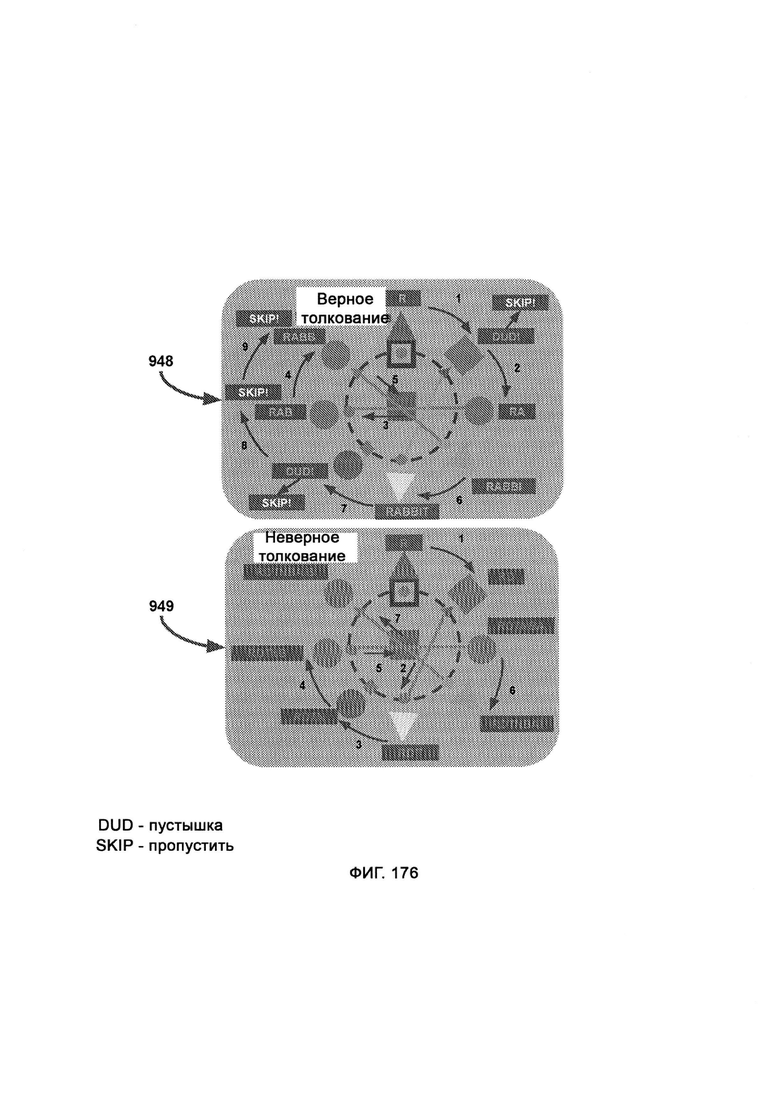
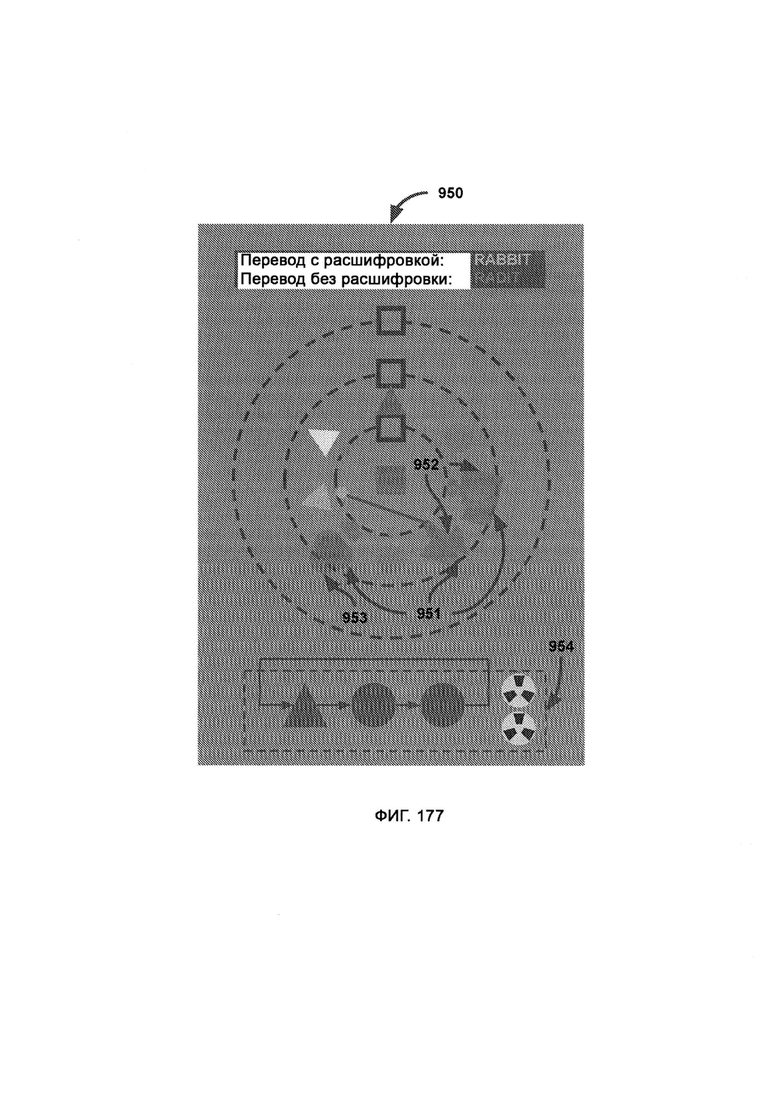
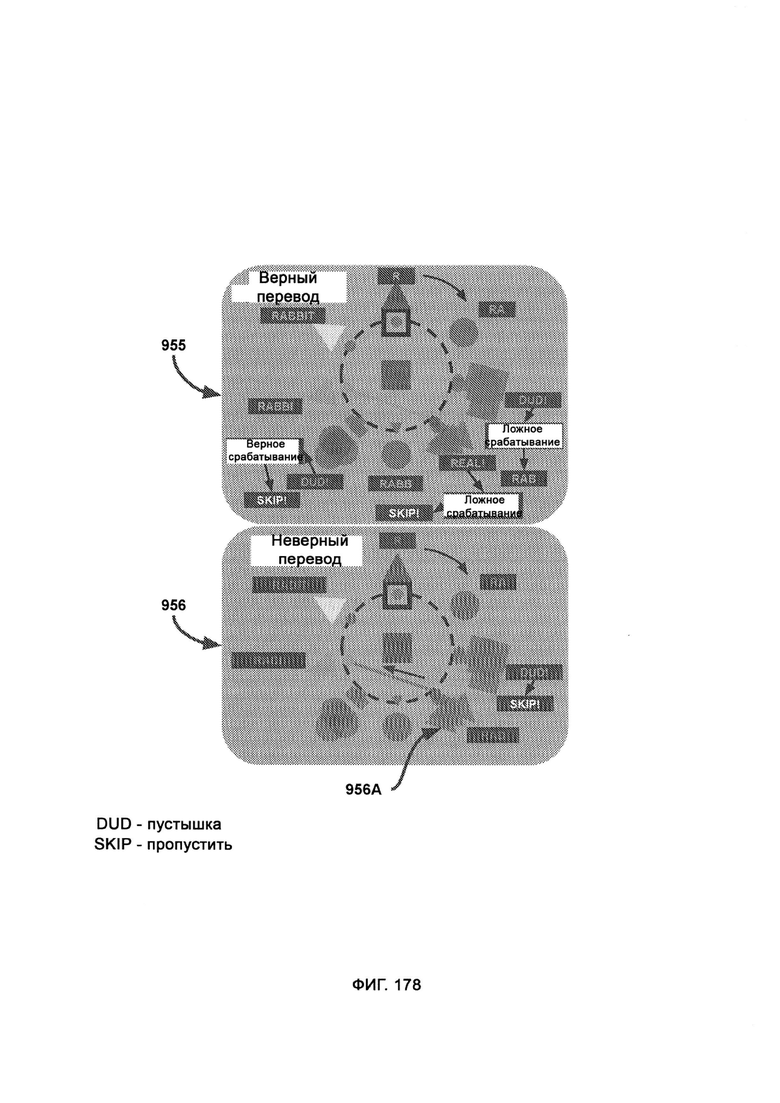

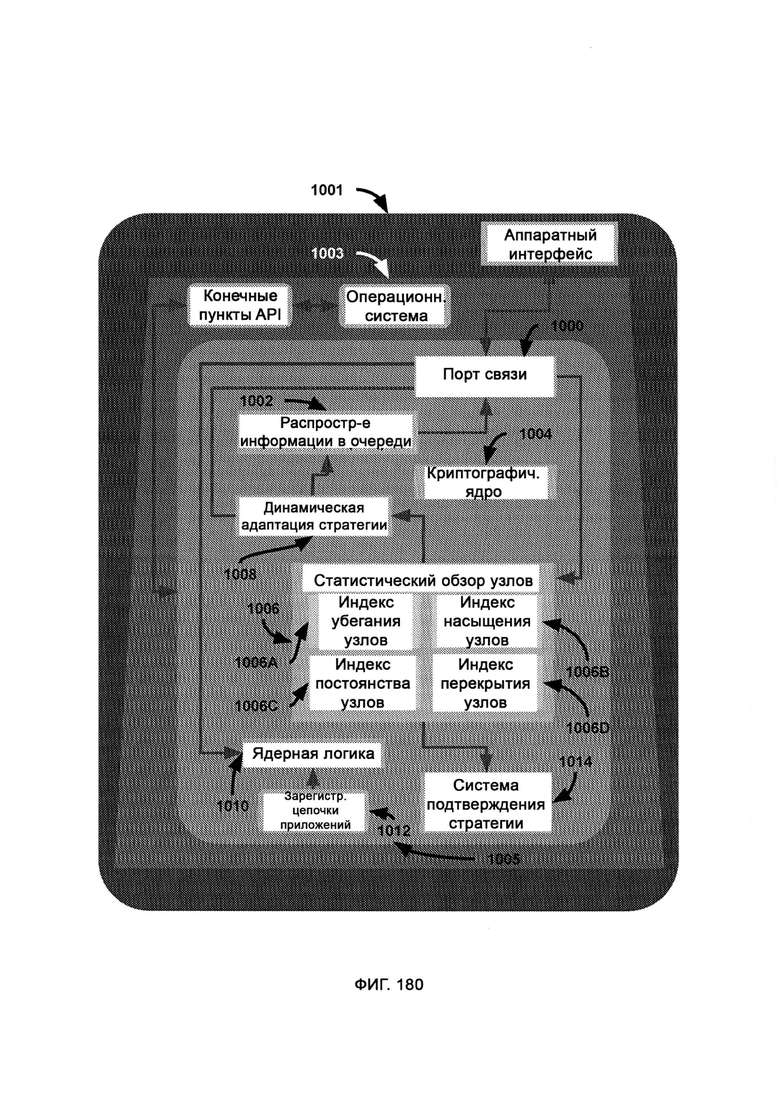
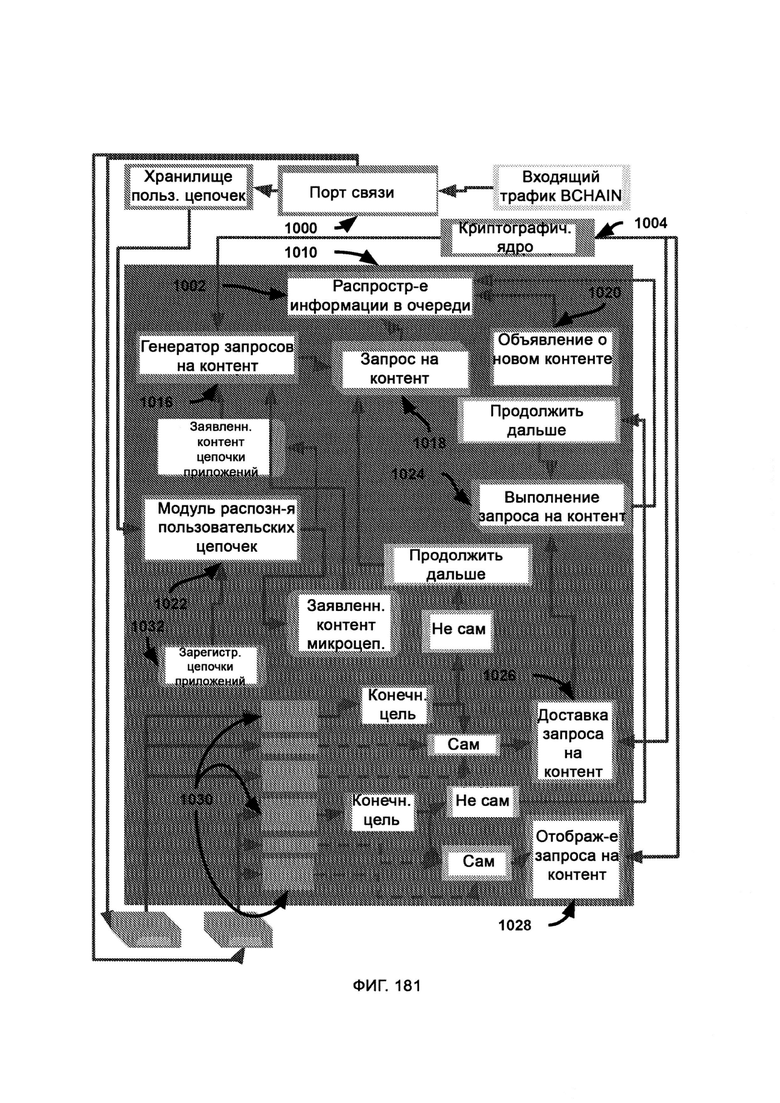


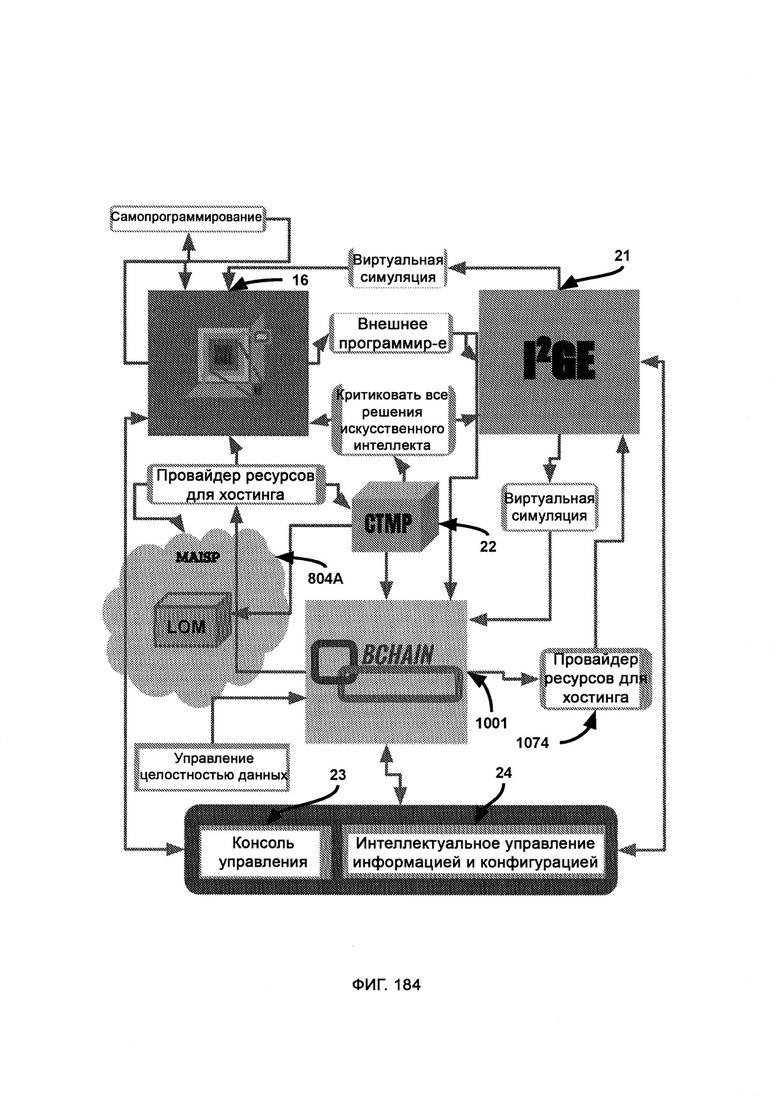
Изобретение относится к области компьютерной безопасности. Техническим результатом является создание системы компьютерной безопасности, основанной на искусственном интеллекте. Система компьютерной безопасности, основанная на искусственном интеллекте, оснащена памятью и процессором, сопряженным с памятью, причем данная система компьютерной безопасности также включает в себя активную защиту критической инфраструктуры посредством обеспечения многоуровневой защиты информации в облачной архитектуре (CIPR/CTIS), секретный машинный интеллект (MACINT) и отпор посредством скрытных операций в киберпространстве, логическую защиту и мгновенное реагирование в реальном времени без создания баз данных (LIZARD), память и восприятие, основанные на критическом мышлении (СТМР), лексически объективный майнинг (LOM), линейную атомно-квантовую передачу информации (LAQIT) и систему универсальных BCHAIN-связей всего со всем (UBEC), а также гармонизацию базовых подключений с присоединением встроенных узлов. 7 н. и 67 з.п. ф-лы, 184 ил.
1. Система компьютерной безопасности, основанная на искусственном интеллекте, характеризующаяся тем, что система компьютерной безопасности оснащена памятью и процессором, сопряженным с памятью, причем данная система компьютерной безопасности также включает в себя активную защиту критической инфраструктуры посредством обеспечения многоуровневой защиты информации в облачной архитектуре (CIPR/CTIS), которая дополнительно включает в себя:
а) доверенную платформу, представляющую собой сеть агентов, сообщающих о деятельности хакеров;
б) провайдера управляемой сети и услуг безопасности (MNSP), который обеспечивает услуги и решения по управляемому безопасному шифрованию, подключениям и совместимости;
где MNSP соединен с доверенной платформой посредством виртуальной частной сети (VPN), которая предоставляет канал связи с доверенной платформой, a MNSP выполнен с возможностью анализировать весь трафик в сети предприятия, причем трафик направляют в MNSP, который дополнительно включает в себя:
а) логическую защиту и мгновенное реагирование в реальном времени без создания баз данных (LIZARD), которая узнает назначение и функцию внешнего кода и блокирует его в случае наличия злого умысла либо отсутствия обоснованной цели, а также анализирует угрозы сами по себе без обращения к прошлым данным;
б) искусственные угрозы безопасности (AST), которые представляют собой гипотетический сценарий события в системе безопасности для проверки эффективности правил безопасности;
в) творческий модуль, осуществляющий процесс интеллектуального создания новых гибридных форм из существующих форм;
г) обнаружение злого умысла, посредством которого определяют взаимосвязь информации, выделяют образцы поведения, связанного с системой безопасности, проводят регулярные фоновые проверки нескольких подозрительных событий в системе безопасности, а также предпринимают попытки найти взаимосвязь между событиями, на первый взгляд не связанными между собой;
д) поведение системы безопасности, в котором хранятся и индексируются события в системе безопасности, их признаки и отклик на них, причем отклики представляют собой решения как по блокировке, так и по допуску;
е) итеративный рост и развитие интеллекта (I2GE), посредством которого изучают большие данные и распознают сигнатуры вредоносного ПО, а также симулируют потенциальные разновидности данного ПО путем совмещения AST с творческим модулем;
ж) память и восприятие, основанные на критическом мышлении (СТМР), посредством которых критически рассматривают решения по блокировке или допуску, а также обеспечивают дополнительный уровень безопасности путем изучения перекрестных данных, предоставляемых I2GE, LIZARD и доверенной платформой, причем СТМР оценивает собственный потенциал в формировании объективного решения по данному вопросу и не навязывает это решение, если оно малонадежно.
2. Система по п. 1, отличающаяся тем, что для защищенного взаимодействия с LIZARD в MNSP используется клиент LIZARD Lite, выполненный с возможностью работать на устройстве, входящем в сеть предприятия.
3. Система по п. 1, дополнительно включающая в себя демилитаризованную зону (DMZ), которая представляет собой подсеть, содержащую HTTP-сервер с более высокой ответственностью перед системой безопасности, чем у обычного компьютера, снимающий такую ответственность с остальных устройств в сети предприятия.
4. Система по п. 1, отличающаяся тем, что I2GE включает в себя итеративное развитие, в котором отбирают и исследуют параллельные пути развития, итеративные поколения которых адаптируются к одним и тем же искусственным угрозам безопасности (AST), и путь с наиболее удачными личностными чертами лучше других противостоит угрозам безопасности.
5. Система по п. 1, отличающаяся тем, что LIZARD включает в себя:
а) синтаксический модуль, который предоставляет фреймворк для написания и чтения компьютерного кода;
б) целевой модуль, который с помощью синтаксического модуля выделяет из кода цель, поле чего выдает ее в собственном формате сложносоставной цели;
в) виртуальную обфускацию, в рамках которой сеть и базу данных предприятия копируют и переносят в виртуальную среду, где конфиденциальные сведения замещают фальшивыми данными, причем среда может динамически подстраиваться в реальном времени под поведение цели, включая в себя больше фальшивых данных либо больше настоящих данных самой системы;
г) имитацию сигнала, которая обеспечивает своего рода ответный удар при достижении аналитического завершения виртуальной обфускации;
д) проверку внутренней логики, в рамках которой проверяют, присутствует ли логика во всех внутренних функциях внешнего кода;
е) переписывание внешнего кода, в рамках которого посредством синтаксического и целевого модулей внешний код преобразуют в формат сложносоставной цели;
ж) обнаружение скрытого кода, в рамках которого обнаруживают код, скрытно помещенный в пакеты передачи данных;
з) сопоставление карт потребностей, т.е. карту иерархии потребностей и целей, на которую опираются, решая, соответствует ли внешний код общему назначению системы;
где для написания кода синтаксический модуль получает из целевого модуля код в формате сложносоставной цели, затем пишет код с произвольным синтаксисом, после чего вспомогательная функция переводит его в реальный исполняемый код;
где для чтения синтаксический модуль направляет в целевой модуль синтаксическую интерпретацию кода с целью выявить назначение данного кода;
где имитация сигнала использует синтаксический модуль с целью понять синтаксис коммуникации вредоносного ПО с запустившими его хакерами, после чего контроль над коммуникацией перехватывают, чтобы создать ложное впечатление, что атака удалась и что конфиденциальные данные попали к хакерам, в то время как система LIZARD также направляет хакерам код ошибки от вредоносного ПО, маскируя его под реальный отклик от ПО;
где при переписывании внешнего кода с помощью выявленной цели достраивают кодовый набор, тем самым добиваясь того, чтобы внутри сети предприятия исполнялись только желаемые и понятные функции внешнего кода, а все остальные части кода не получали доступа в систему.
6. Система по п. 5, отличающаяся тем, что для того, чтобы при переписывании внешнего кода был синтаксически воспроизведен внешний код с целью сглаживания потенциально незамеченных вредоносных эксплойтов, посредством комбинационного метода сравнивают и сопоставляют заявленную цель с выявленной целью, причем используют целевой модуль для манипуляции форматом сложносоставной цели, причем в отношении выявленной цели при сопоставлении карт потребностей сохраняют иерархическую структуру для сохранения юрисдикции всех нужд предприятия, с тем чтобы определить и обосновать назначение участка кода, в зависимости от пустот в юрисдикционно-ориентированной карте потребностей, причем входящую цель получают из процесса рекурсивной отладки.
7. Система по п. 6, отличающаяся тем, что при рекурсивной отладке циклически проходят сегменты кода, проверяют их на наличие багов и исправляют их, причем если баг не устраняется, весь сегмент кода заменяют исходным сегментом внешнего кода, после чего данный исходный сегмент помечают с целью упрощения процесса виртуальной обфускации и поведенческого анализа, причем исходное состояние внешнего кода интерпретируется целевым модулем и синтаксическим модулем для переписывания кода, причем отладчик напрямую обращается к внешнему коду в случае, если в переписанной версии обнаружен неустранимый баг и весь сегмент необходимо заменить исходным сегментом внешнего кода, тогда как сегменты переписанного кода проверяют в виртуальной среде выполнения на предмет наличия багов программирования, где виртуальная среда выполнения запускает сегменты кода и проверяет на наличие ошибок выполнения, и при наличии багов программирования виртуальная среда выполнения выявляет тип и участок ошибок, после чего готовят потенциальное решение для бага программирования посредством совмещения цели и перевыражения кода из заявленной цели, причем участок бага программирования переписывают в ином формате с целью избежать бага, причем потенциальное решение выводят, а если решений не осталось, данный сегмент кода больше не переписывают, а в итоговом кодовом наборе вставляют на его место исходный сегмент кода напрямую из внешнего кода.
8. Система по п. 6, отличающаяся тем, что при сопоставлении карт потребностей облака LIZARD Cloud и LIZARD Lite обращаются к иерархической карте ветвей юрисдикции предприятия, причем вне зависимости от того, совпадает входящая цель с заявленной либо получена из целевого модуля, в ходе сопоставления карт потребностей подтверждают обоснование для выполнения кода/функции в системе предприятия, причем эталонный экземпляр иерархической карты хранят в облаке LIZARD Cloud в MNSP, а индекс потребностей в сопоставлении карт потребностей рассчитывают на основании данного эталонного экземпляра, причем предоптимизированный индекс потребностей распространяют по всем доступным конечным клиентам, а для сопоставления карт потребностей получают запрос потребностей в отношении наиболее подходящей потребности системы в целом, причем в качестве соответствующего вывода выступает формат сложносоставной цели, отражающий данную подходящую потребность.
9. Система по п. 1, отличающаяся тем, что в MNSP виртуально воссоздают всю инфраструктуру локальной сети (LAN) предприятия, причем в процессе поведенческого анализа системой хакеры сталкиваются как с элементами реальной инфраструктуры локальной сети, так и с виртуальной копией, и в случае, если такой анализ выявляет риск, хакеру в большей степени предоставляют взаимодействовать с виртуальной копией с целью снизить риск взлома настоящих данных и/или устройств.
10. Система по п. 1, отличающаяся тем, что AST передают корневую сигнатуру вредоносного ПО, с тем чтобы сформировать итерации/вариации данной сигнатуры, причем полиморфические вариации вредоносного ПО получают на выходе из I2GE и передают на обнаружение вредоносного ПО.
11. Система по п. 10, отличающаяся тем, что обнаружение вредоносного ПО производят на всех трех уровнях устройства компьютера, а именно в пользовательском пространстве, пространстве ядра и пространстве прошивки/оборудования, причем все указанные пространства находятся под контролем агентов LIZARD Lite.
12. Система компьютерной безопасности, основанная на искусственном интеллекте, характеризующаяся тем, что система компьютерной безопасности оснащена памятью и процессором, сопряженным с памятью, причем данная система компьютерной безопасности также включает в себя секретный машинный интеллект (MACINT) и отпор посредством скрытных операций в киберпространстве, которые дополнительно включают в себя:
а) интеллектуальное управление информацией и конфигурацией (I2CM), обеспечивающее интеллектуальное управление, просмотр и контроль информации;
б) консоль управления (МС), предоставляющую пользователям канал ввода/вывода; причем I2CM включает в себя:
i) сбор, при котором используют критерии общего уровня для отсеивания неважной и лишней информации, а также сливают и помечают потоки информации с множества платформ;
ii) службу конфигурации и размещения, которая включает в себя интерфейс для добавления новых устройств в сеть предприятия с заданными настройками безопасности и подключения, а также для управления учетными записями новых пользователей;
iii) разделение по юрисдикции, в рамках которого размеченный пул информации делят исключительно в соответствии с юрисдикцией конкретного пользователя консоли управления;
iv) разделение по угрозам, в рамках которого информацию организуют в соответствии с отдельными угрозами;
v) автоматизированные элементы управления для доступа в облако MNSP, на доверенную платформу или к дополнительным сторонним службам.
13. Система по п. 12, отличающаяся тем, что в облаке MNSP в ходе поведенческого анализа наблюдают состояние вредоносного ПО и действия, которые оно выполняет, находясь в среде фальшивых данных, причем, если вредоносное ПО предпринимает попытку передать фальшивые данные хакеру, исходящий сигнал перенаправляют, так чтобы его получил фальшивый хакер, где хакерский интерфейс получает кодовую структуру вредоносного ПО и на ее основе восстанавливает внутреннюю структуру вредоносного ПО, из которой затем получают хакерский интерфейс,
причем фальшивый хакер и фальшивое вредоносное ПО симулируют внутри виртуальной среды, где виртуальный фальшивый хакер посылает ответный сигнал настоящему вредоносному ПО для выявления дальнейшего поведения данного ПО, а реальный хакер получает фальшивый ответный код, не соответствующий поведению/состоянию настоящего вредоносного ПО.
14. Система по п. 12, отличающаяся тем, что в ходе сканирования эксплойтов определяет возможности и характеристики преступного оборудования, и итоговые результаты сканирования применяются эксплойтом - программой, которая направляется доверенной платформой посредством базы данных ответных эксплойтов и поражает систему злоумышленников, причем в базе данных ответных эксплойтов содержатся средства нанесения отпора злоумышленникам, предоставленные поставщиками аппаратного обеспечения в виде готовых бэкдоров и известных уязвимостей, причем в единой базе данных судебных доказательств собраны судебные доказательства из множества источников, включающих множество предприятий.
15. Система по п. 12, отличающаяся тем, что законспирированный агент из преступной системы захватывает файл в сети предприятия, брандмауэр формирует отчет, который направляют в сбор отчетов, причем в ходе сбора отчетов данные категоризируют и разделяют для длительного/глубинного сканирования и оперативного/поверхностного сканирования.
16. Система по п. 15, отличающаяся тем, что глубинное сканирование взаимодействует с большими данными, при этом используя субалгоритм обнаружения злого умысла и субалгоритм управления внешними сущностями, причем стандартные отчеты с пунктов безопасности собирают в сборе отчетов и делают из них выборку посредством фильтров с низкими ограничениями, причем подробности событий сохраняют в индексе и трекинге событий, в ходе обнаружения аномалий используют индекс событий и поведение системы безопасности в соответствии с промежуточными данными, представленными модулем глубинного сканирования, для определения потенциальных рисков, причем в анализе событий участвуют субалгоритмы управления внешними сущностями и обнаружения злого умысла.
17. Система по п. 16, отличающаяся тем, что доверенная платформа проверяет произвольный компьютер на предмет того, являются ли его серверные родственники/соседи (т.е. другие сервера, с которыми он соединен) ранее запущенными двойными или тройными агентами доверенной платформы, причем поиск агентов осуществляется в облаке индекса и трекинга доверенных двойных агентов и в облаке индекса и трекинга доверенных тройных агентов, где двойной агент, которому доверяет произвольный компьютер, проводит эксплойт по доверенному каналу, и эксплойт пытается найти конфиденциальный файл, отправляет его в карантин и передает его точное состояние доверенной платформе, после чего пытается гарантированно удалить его с компьютера злоумышленника.
18. Система по п. 17, отличающаяся тем, что запрос к API провайдера составляется доверенной платформой для обнаружения в сетевых журналах сетевого надзора произвольной системы потенциальной передачи файлов на компьютер злоумышленника, причем метаданные используют для того, чтобы со значительной долей уверенности определить, на какой компьютер совершена передача, сетевой надзор выясняет параметры сети компьютера злоумышленника и перенаправляет сведения на доверенную платформу, причем доверенную платформу используют для обращения к API системы безопасности, предоставленному поставщиками программного и аппаратного обеспечения, для того чтобы применить готовые бэкдоры в целях судебного расследования.
19. Система по п. 12, отличающаяся тем, что доверенная платформа принудительно отправляет на компьютер злоумышленника обновление программного обеспечения или прошивки для создания нового готового бэкдора, причем на соседние похожие машины для маскировки принудительно отправляют плацебо-обновление, идентификационные данные цели направляют на доверенную платформу, причем доверенная платформа указывает контролеру программного обеспечения/прошивки принудительно отправить плацебо-обновления и обновления, содержащие бэкдоры, на соответствующие компьютеры, где обновление, содержащее бэкдор, приводит к созданию нового бэкдора в системе компьютера злоумышленника путем использования существующей системы обновления программного обеспечения, установленного на данном компьютере, а плацебо-обновление бэкдоров не содержит, причем контролер переносит бэкдор как на цель, так и на компьютеры, контакт которых с целью выше среднего, причем при применении эксплойта посредством обновления, содержащего бэкдор, конфиденциальный файл отправляют в карантин и копируют с целью дальнейшего анализа истории использования его метаданных, а любые дополнительные судебные данные собирают и направляют в пункт связи экслойта на доверенной платформе.
20. Система по п. 12, отличающаяся тем, что на доверенную платформу принудительно отправляют флаг долгосрочного приоритета для наблюдения за системой злоумышленников на предмет любых изменений/обновлений, причем система предприятия передает в модуль ордера цель, и модуль ордера сканирует входящие данные всех аффилированных систем на предмет ассоциаций с заданной целью, где в случае совпадений информацию передают в систему предприятия, которая создала ордер и пытается проникнуть в цель, причем входящие данные передают в желаемый аналитический модуль, посредством которого синхронизируют взаимовыгодные сведения безопасности.
21. Система компьютерной безопасности, основанная на искусственном интеллекте, характеризующаяся тем, что система компьютерной безопасности оснащена памятью и процессором, сопряженным с памятью, причем данная система компьютерной безопасности также включает в себя логическую защиту и мгновенное реагирование в реальном времени без создания баз данных (LIZARD), которые дополнительно включает в себя:
а) статичное ядро (SC), состоящее из в основном статичных программных модулей;
б) итерационный модуль, посредством которого изменяют, создают и уничтожают модули в динамической оболочке, причем итерационный модуль использует AST для оценки качества работы системы безопасности, а также итерационное ядро для осуществления автоматического написания кода;
в) алгоритм дифференциальной модификации, посредством которого модифицируют базовую итерацию в соответствии с недостатками, обнаруженными с помощью AST, причем после применения дифференциальной логики предлагают новую итерацию и рекурсивно обращаются к итерационному ядру, которое затем заново подвергают той же самой проверке с использованием AST;
г) алгоритм логической дедукции, в который из AST поступают известные отклики системы безопасности итераций динамической оболочки, и посредством данного алгоритма вычисляют состав кодового набора, который поможет добиться известного верного отклика на сценарий события в системе безопасности;
д) динамическая оболочка (DS), в которой содержатся преимущественно динамические программные модули, которые были автоматически запрограммированы итерационным модулем (IM);
е) карантин кода, посредством которого внешний код изолируют в ограниченной виртуальной среде;
ж) обнаружение скрытого кода, в рамках которого обнаруживают код, скрытно помещенный в пакеты передачи данных;
з) переписывание внешнего кода, в рамках которого после выяснения назначения внешнего кода переписывают части кода или код целиком и которое допускает только переписывание;
причем все устройства на предприятии связаны через LIZARD, все прошивки и программное обеспечение, на которых работают данные устройства, запрограммированы так, чтобы любые скачивания/закачки данных происходили исключительно через LIZARD как постоянный прокси, причем LIZARD взаимодействует с тремя типами данных, включая данные в движении, используемые данные и неподвижные данные, а также взаимодействует с различными формами данных, в том числе с файлами, электронной почтой, сетевыми данными, мобильными данными, облачными данными и съемными данными.
22. Система по п. 21, дополнительно включающая в себя:
а) реле переполнения AST, где данные передаются в AST для будущего улучшения итераций, когда система может принимать только малонадежные решения;
б) проверку внутренней логики, в рамках которой проверяют, присутствует ли логика во всех внутренних функциях участка внешнего кода;
в) зеркальный тест, посредством которого проверяют, совпадает ли динамика ввода/вывода переписанного кода с оригиналом, причем все скрытые эксплойты исходного кода отключены и не выполняются;
г) сопоставление карт потребностей, т.е. карту иерархии потребностей и целей, на которую опираются, решая, соответствует ли внешний код общему назначению системы;
д) синхронизатор с настоящими данными, посредством которого отбирают данные, которые затем направят в смешанные среды, а также устанавливают приоритет запрещения доступа к конфиденциальной информации вредоносному ПО;
е) менеджер данных, выступающий в качестве интерфейса-посредника между сущностью и данными, приходящими извне виртуальной среды;
ж) виртуальная обфускация, посредством которой запутывают код и ограничивают к нему доступ путем постепенного и частичного его погружения в виртуальную фальшивую среду;
з) модуль скрытной транспортировки, посредством которого скрытно и незаметно происходит перенос вредоносного ПО в среду фальшивых данных;
и) трекинг отзыва данных, в котором отслеживается вся информация, загруженная с подозрительной сущности и отправленная туда.
23. Система по п. 22, дополнительно включающая модуль сравнения целей, в котором производят сравнение четырех типов цели, для того чтобы убедиться в том, что поведение и структура сущности одобрены и понятны LIZARD и рассматриваются как содействующие назначению системы в целом.
24. Система по п. 23, отличающаяся тем, что итерационный модуль использует SC, чтобы синтаксически модифицировать кодовую базу DS в соответствии с выявленной целью в «фиксированных целях» и данных из реле возврата данных (DRR), причем модифицированную версию LIZARD параллельно подвергают стресс-тестам AST с использованием множества разных сценариев событий в системе безопасности.
25. Система по п. 24, отличающаяся тем, что внутри SC в рамках логического вывода из изначально более простых функций выводят логически необходимые функции, причем все дерево функциональных зависимостей строится из заявленной сложносоставной цели;
где в рамках перевода кода преобразуют произвольный обобщенный код, понимаемый напрямую функциями синтаксического модуля, в код на любом выбранном известном языке программирования, а также выполняют обратную операцию перевода кода на известном языке программирования в произвольный код;
где в рамках упрощения логики упрощают логику записанного кода для создания карты взаимосвязанных функций;
где формат сложносоставной цели представляет собой формат для хранения взаимосвязанных подцелей, в сумме составляющих общую цель;
где целевые ассоциации представляют собой запрограммированные сведения о том, какие функции и какие типы поведения связаны с какими целями;
где в рамках итеративного расширения добавляют подробности и сложность для развития простой цели в сложносоставную путем обращения к целевым ассоциациям;
где в рамках итеративной интерпретации циклически обрабатывают все взаимосвязанные функции и получают интерпретированную цель путем обращения к целевым ассоциациям;
где внешнее ядро сформировано целевым и синтаксическим модулями, которые работают сообща с целью выведения логической цели неизвестного внешнего кода и получения исполняемого кода из заявленной цели функционального кода;
где внешний код представляет собой код, неизвестный LIZARD, функционал и назначение которого неизвестны, причем внешний код служит вводом для внутреннего ядра, а выводом служит выявленная цель, причем выявленная цель - это намерение данного кода, согласно оценкам целевого модуля, и причем выявленную цель возвращают в формате сложносоставной цели.
26. Система по п. 25, отличающаяся тем, что IM использует AST для оценки качества работы системы безопасности, а также итерационное ядро для осуществления автоматического написания кода, причем, если LIZARD приходится принимать малонадежное решение, данные об атаках злоумышленников и самих злоумышленниках из DDR передают в AST; причем внутри итерационного ядра алгоритм дифференциальной модификации (DMA) получает из внутреннего ядра программные возможности синтаксического и целевого модулей, а также сведения о назначении системы, после чего используется кодовый набор для модификации базовой итерации в соответствии с недостатками, обнаруженными с помощью AST, где итоговые недостатки системы безопасности представлены визуально, чтобы указать на угрозы безопасности, прошедшие сквозь базовую итерацию во время работы виртуальной среды исполнения.
27. Система по п. 26, отличающаяся тем, что в рамках DMA текущее состояние отражает кодовый набор динамической оболочки с символически сопоставленными формами, размерами и положениями, причем разные конфигурации данных форм указывают на разные конфигурации интеллекта и реакции системы безопасности, причем AST передает потенциальные отклики текущего состояния, которые оказались неверными, а также верный отклик;
где вектор атаки выступает в качестве символического отображения угрозы кибербезопасности, причем направление, размер и цвет соответствуют гипотетическим свойствам вектора атаки, размеру и типу вредоносного ПО, причем вектор атаки символически отталкивается от кодового набора с целью выразить отклик системы безопасности на данный кодовый набор;
где верное состояние представляет собой окончательный результат работы DMA по получению желаемого отклика системы безопасности из участка кода динамической оболочки, причем различия между текущим состоянием и верным состоянием приводят к различным откликам вектора атаки;
где AST предоставляет известные недостатки системы безопасности, а также верный отклик системы безопасности, причем алгоритм логической дедукции использует ранние итерации DS с целью получить более совершенную и эффективную итерацию динамической оболочки, под которой понимается программа верного отклика системы безопасности.
28. Система по п. 24, отличающаяся тем, что в рамках виртуальной обфускации подозрительный код скрытно перенаправляют в среду, в которой половину данных интеллектуальным образом смешивают с фальшивыми данными, причем субъекты, работающие в настоящей системе, можно с легкостью и скрытно перенести в среду фальшивых данных, полную либо частичную, благодаря виртуальной изоляции, где генератор фальшивых данных, используя в качестве образца синхронизатор с настоящими данными, создает фальшивые и бесполезные данные; где воспринимаемый риск уверенности в восприятии поступающего внешнего кода влияет на выбираемый LIZARD уровень обфускации; где высокая уверенность во вредоносности кода приводит к тому, что его помещают в среду с большим содержанием фальшивых данных, тогда как низкая уверенность во вредоносности кода приводит к тому, что его помещают либо в настоящую систему, либо в среду, содержащую 100% фальшивых данных.
29. Система по п. 28, отличающаяся тем, что в трекинге отзыва данных отслеживается вся информация, загруженная с подозрительной сущности и отправленная туда, причем в случае, если фальшивые данные были отправлены легитимной сущности в сети предприятия, все эти фальшивые данные отзываются, и взамен их отправляют настоящие данные, причем триггер отзыва выполнен таким образом, чтобы легитимная сущность в сети предприятия не предпринимала действий на основании определенных данных, пока не получит подтверждения о том, что это настоящие, а не фальшивые данные.
30. Система по п. 29, отличающаяся тем, что в ходе поведенческого анализа отслеживают поведение подозрительной сущности в плане скачивания и загрузки информации с целью определить потенциальные меры по устранению угрозы, причем реальная система содержит исходные настоящие данные, целиком существующие вне виртуальной среды, где настоящие данные, заменяющие собой фальшивые данные, поступают нефильтрованными в трекинг отзыва данных, где может быть сделан патч настоящих данных для замены фальшивых данных на настоящие данные в сущности, ранее классифицированной как подозрительная; причем менеджер данных, погруженный в виртуальную изолированную среду, получает патч настоящих данных из трекинга отзыва данных; причем если безвредный код в ходе поведенческого анализа был отмечен как вредоносный, принимаются меры по устранению угрозы для замены фальшивых данных в сущности, ранее классифицированной как подозрительная, на соответствующие настоящие данные; причем секретный токен - это строка безопасности, сформированная и назначенная LIZARD, которая позволяет реально безвредной сущности не выполнять свою функцию, причем если токен отсутствует, то это значит, что, вероятнее всего, данная легитимная сущность была случайно помещена в среду, частично состоящую из фальшивых данных, по подозрению в том, что она может являться вредоносным ПО, после чего активируют замедленную сессию с интерфейсом задержки, тогда как, если токен присутствует, это значит, что серверная среда настоящая, и, следовательно, все замедленные сессии деактивируются.
31. Система по п. 29, отличающаяся тем, что в рамках поведенческого анализа карта целей представляет собой иерархию задач системы, которая дает цель всей системе предприятия, причем заявленную цель, назначение деятельности и назначение кодовой базы сравнивают с присущей системе необходимости в том, что якобы делает подозрительная сущность; причем осуществляют наблюдение за деятельностью памяти, процессора и сетевой активностью подозрительной сущности, где синтаксический модуль интерпретирует такую деятельность с точки зрения желательной функции, причем такие функции затем переводят в назначение с помощью целевого модуля, где кодовая база - это исходный код/программная структура подозрительной сущности, которую передают в синтаксический модуль, где синтаксический модуль распознает программный синтаксис и сводит программный код и деятельность кода к промежуточной карте взаимосвязанных функций, причем целевой модуль выдает воспринимаемые намерения подозрительной сущности, выдавая также назначение кодовой базы и назначение деятельности, где назначение кодовой базы содержит известную цель, назначение, юрисдикцию и полномочия сущности, выявленные возможностями синтаксического модуля LIZARD, а назначение деятельности содержит известную цель, назначение, юрисдикцию и полномочия сущности, выявленные LIZARD благодаря пониманию деятельности памяти, процессора и сетевой активности; где под заявленной целью понимают цель, назначение, юрисдикцию и полномочия сущности, заявленные самой сущностью, а необходимая цель содержит ожидаемую цель, назначение, юрисдикцию и полномочия, требуемые системой предприятия; причем все цели сравнивают в модуле сравнения, а любые расхождения в целях приводят к выполнению сценария расхождения в целях и, как следствие, к мерам по устранению угрозы.
32. Система компьютерной безопасности, основанная на искусственном интеллекте, характеризующаяся тем, что система компьютерной безопасности оснащена памятью и процессором, сопряженным с памятью, причем данная система компьютерной безопасности также включает в себя память и восприятие, основанные на критическом мышлении (СТМР), которые дополнительно включают в себя:
а) расширитель объема критических правил (CRSE), который берет известный объем восприятий и расширяет его, добавляя в него восприятие критического мышления;
б) верные правила, к которым относятся верные правила, полученные путем использования восприятия критического мышления;
в) выполнение правил (RE), в рамках которого выполняются правила, существование и выполнение которых подтверждается сканированием памяти хаотического поля, с целью получения желаемых и подходящих решений, принятых с помощью критического мышления;
г) вывод критических решений, в рамках которого получают итоговую логику для определения общего итога работы СТМР путем сравнения выводов, достигнутых как симулятором восприятия наблюдателя (РОЕ), так и RE;
где РОЕ симулирует наблюдателя и проверяет/сравнивает все потенциальные факты восприятия, используя различные формы симуляции наблюдателя;
где RE включает шахматную плоскость, которую используют для отслеживания преобразования наборов правил, причем объекты на доске отражают сложность данной ситуации в системе безопасности, а перемещение данных объектов по «доске безопасности» отражает развитие ситуации, которое контролируется откликами правил безопасности.
33. Система по п. 32, дополнительно включающая в себя:
а) субъективные решения, предоставляемые алгоритмом сопоставления выбранных образцов (SPMA);
б) ввод метаданных системы, включающих необработанные метаданные из SPMA, описывающие механику работы алгоритма и процесс прихода к тому или иному решению;
в) обработку причин, в рамках которой происходит логическое осмысление утверждений путем сравнения характеристик свойств;
г) обработку правил, в рамках которой выведенные правила используют в качестве позиции для сравнения с целью определить масштаб текущей проблемы;
д) сеть памяти, которая сканирует журналы рыночных переменных на предмет выполнимых правил;
е) получение необработанного восприятия, в рамках которого из SPMA получают журналы метаданных, причем журналы обрабатывают и формируют восприятие, которое отражает восприятие данного алгоритма, причем восприятие сохраняют в сложном формате восприятия (PCF) и симулируют с помощью РОЕ; причем под прикладными углами восприятия понимают углы восприятия, которые уже были применены и использованы SPMA;
ж) механизм автоматизированного обнаружения восприятия (APDM), который задействует творческий модуль, производящий гибридизированное восприятие, формируемое в соответствии с входными данными прикладных углов восприятия, с тем чтобы объем восприятия можно было увеличивать;
з) плотность самокритичных знаний (SKCD), где оценивается объем и тип потенциально неизвестных знаний, лежащих за пределами журналов и отчетов, причем последующие функции критического мышления в СТМР могут задействовать весь потенциальный объем имеющихся знаний; причем критическое мышление указывает на юрисдикцию внешней оболочки мышления, основанного на правилах;
и) получение выводов (ID), в рамках которого выводят углы восприятия данных из текущих прикладных углов восприятия, причем SPMA противопоставляют критическому мышлению, выполненному посредством СТМР при использовании восприятия и правил.
34. Система по п. 33, дополнительно включающая в себя:
а) менеджмент и распределение ресурсов (RMA), в рамках которых с помощью настраиваемой политики решают, сколько восприятия необходимо задействовать, чтобы симулировать наблюдателя, причем приоритет в отборе фактов восприятия выбирают исходя из их веса в порядке убывания, а с политика затем определяет способ отсекания: процентная доля, фиксированное число либо более сложный способ;
б) поиск по хранилищу (SS), в рамках которого используют CVF, полученный из обогащенных данными журналов, в качестве критерия поиска по базе данных в хранилище восприятия (PS), причем в PS факты восприятия хранятся не только со своим значением веса, но и также с индексом в виде формата сравниваемых переменных (CVF);
в) обработку метрик, в ходе которой восстанавливают распределение переменных из SPMA;
г) дедукцию восприятия (PD), в рамках которой используют распределение откликов и соответствующих метаданных системы для воспроизведения исходного восприятия отклика распределения;
д) модуль категоризации метаданных (МСМ), в котором отладку и отслеживание алгоритма разделяют на отдельные категории посредством категоризации информации на основе синтаксиса, причем данные категории используют для создания и получения конкретного распределения откликов с корреляцией по рискам и возможностям;
е) комбинацию метрик, в ходе которой углы восприятия разделяют на категории метрик;
ж) преобразование метрик, в ходе которого отдельные метрики преобразовывают обратно в полноценные углы восприятия;
з) расширение метрик (ME), в ходе которого метрики множества разных углов восприятия сохраняют по категориям в отдельных базах данных;
и) генератор формата сравниваемых переменных (CVFG), который преобразует поток информации в формат сравниваемых переменных (CVF).
35. Система по п. 34, дополнительно включающая в себя:
а) сопоставление восприятия, в рамках которого CVF генерируют из фактов восприятия, полученных из выведения синтаксиса правил (RSD), причем вновь сгенерированный CVF используют для поиска подходящих фактов восприятия в PS со схожими индексами, а потенциальные совпадения возвращают в генерирование синтаксиса правил (RSG);
б) распознавание памяти (MR), в ходе которого из данных ввода формируют хаотическое поле;
в) индексацию концептов памяти, в рамках которой целые концепты индивидуально оптимизируют в виде индексов, причем индексы используются буквенными сканерами для взаимодействия с хаотическим полем;
г) парсер выполнения правил (RFP), которому передают отдельные части правил с метками распознавания, причем каждую часть помечают в соответствии с тем, была ли она найдена в хаотическом поле в ходе распознавания памяти; причем RFP логически решает, какие целые правила, выступающие как комбинация всех частей, были успешно распознаны в хаотическом поле и заслуживают выполнения;
д) разделение формата синтаксиса правил (RSFS), в рамках которого верные правила распределяют по типу, так чтобы все действия, свойства, условия и объекты хранились отдельно;
е) выведение синтаксиса правил, в ходе которого логические «черно-белые» правила преобразовывают в факты восприятия на основе метрик, причем сложные сочетания из нескольких правил преобразовывают в единое общее восприятие, выраженное через множество метрик с различными градиентами;
ж) генерирование синтаксиса правил (RSG), в ходе которого получают ранее подтвержденные факты восприятия, хранящиеся в формате восприятия, и взаимодействуют с внутренним составом метрик факта восприятия, причем такие измерения метрик на основании градиентов преобразуют в двоичные и логические наборы правил, симулирующие поток информации ввода/вывода исходного факта восприятия;
з) разделение формата синтаксиса правил (RSFS), в котором верные правила представляют собой точное отражение наборов правил, соответствующие реальности наблюдаемого объекта, причем верные правила распределяют по типу, так чтобы все действия, свойства, условия и объекты хранились отдельно, позволяя системе определять, какие элементы были найдены в хаотическом поле, а какие нет;
и) встроенную логическую дедукцию, в которой используются логические принципы, позволяющие избежать ошибок в определении того, какие правила точно отражают множество градиентов метрик внутри факта восприятия;
к) анализ контекста метрик, в рамках которого анализируют взаимные связи внутри восприятия метрик, причем определенные метрики могут зависеть от других с разной степенью силы, причем контекстуализацию используют в качестве дополнения к зеркальным взаимным связям, имеющимся у правил в «цифровом» формате набора правил;
л) преобразование формата синтаксиса правил (RSRC), в ходе которого правила распределяют для соответствия формату синтаксиса правил (RSF);
где интуитивное решение участвует в критическом мышлении путем задействования фактов восприятия, а разумное решение участвует в критическом мышлении путем задействования правил, причем в качестве фактов восприятия используются данные, полученные из интуитивного решения в соответствии с синтаксисом формата, заданным во внутреннем формате, а выполненные правила - это данные, полученные из разумного решения, представляющего собой набор выполнимых наборов правил из RE, причем данные передаются в соответствии с синтаксисом формата, заданным во внутреннем формате;
где под действиями поднимают действие, которое, возможно, уже выполнялось, будет выполнено или рассматривается для активации, под свойствами понимают характеристики, похоже на свойства, описывающие что-то другое, будь то действие, состояние или объект, под состояниями понимают логическую операцию или оператор, а под объектами понимают цель, к которой применены характеристики;
где раздельный формат правил используют в качестве вывода из разделения формата синтаксиса правил (RSFS), выступающего в качестве этапа, предшествующего распознаванию памяти, а также в качестве вывода из распознавания памяти (MR), выступающего в качестве этапа, следующего за распознаванием памяти.
36. Система по п. 35, дополнительно включающая в себя:
а) парсер хаотического поля (CFP), в котором формат журналов собирают в единое сканируемое хаотическое поле;
б) дополнительные правила, получаемые из распознавания памяти (MR) в дополнение к верным правилам;
причем внутри сопоставления восприятия (РМ) статистика метрик обеспечивает статистическую информацию из хранилища восприятия, в ходе управления ошибок обрабатывают синтаксис и/или логические ошибки, происходящие из тех или иных отдельных метрик, в ходе разделения метрик изолируют отдельные метрики, поскольку они раньше объединялись в единый блок - восприятие ввода; причем в алгоритм сравнения узлов (NCA) передают состав узлов в двух или более CVF, где каждый узел CVF представляет собой степень значимости свойства, где над каждым отдельным узлом выполняют сравнение по сходству и рассчитывают совокупную вариативность, и где меньшее значение вариативности указывает на более точное совпадение.
37. Система по п. 36, дополнительно включающая в себя:
а) необработанное восприятие - интуитивное мышление (аналоговое), где обрабатывают факты восприятия в соответствии с «аналоговым» форматом, причем факты восприятия аналогового формата относятся к решениям, сохраненным в градиентах на гладкой кривой без перепадов;
б) необработанные правила - логическое мышление (цифровое), где обрабатывают правила в соответствии с цифровым форматом, причем необработанные правила цифрового формата относятся к решениям, которые хранятся в шагах с почти полным отсутствием «серой зоны»;
где под невыполненными правилами понимают наборы правил, недостаточно распознанные в хаотическом поле в соответствии с их логическими зависимостями, а под выполненными правилами понимают наборы правил, которые достаточно распознаны как существующие в хаотическом поле в соответствии с их логическими зависимостями;
а также где управление очередями (QM) задействует реконструкцию синтаксических связей (SRR) для анализа каждой отдельной части в наиболее логичном порядке и имеет доступ к результатам распознавания памяти (MR), и, таким образом, можно дать ответ на двоичные потоковым вопросам на да/нет и предпринять соответствующие действия, причем QM проверяет каждый сегмент правил пошагово, и если какой-либо сегмент отсутствует в хаотическом поле и не состоит в нужных отношениях с остальными сегментами, весь набор правил помечают как невыполненный.
38. Система по п. 37, отличающаяся тем, что последовательная организация памяти представляет собой оптимизированный способ хранения информации в «цепочках» упорядоченных сведений, причем в точках доступа к памяти ширина каждого узла (блока) отражает возможность прямого доступа наблюдателя к запомненному объекту (узлу), в объеме доступа каждая буква отражает конкретную точку прямого доступа наблюдателя к памяти, более широкий объем доступа указывает на то, что для каждого из последовательных узлов существует несколько точек доступа, причем чем больше к последовательности обращаются строго «по порядку», а не к случайно выбранному узлу, тем уже будет объем доступа (относительно размера последовательности), причем во вложенных слоях подпоследовательности последовательность, которая показывает высокое отсутствие единообразия, состоит из последовательности более коротких, связанных между собой, подпоследовательностей.
39. Система по п. 37, отличающаяся тем, что непоследовательная организация памяти представляет собой хранение информации в виде непоследовательно расположенных связанных объектов, причем обратимость указывает на непоследовательное расположение и единый объем, где непоследовательные отношения отмечаются относительно широкой точкой доступа к каждому узлу, причем при перетасовке узлов сохраняется та же степень единообразия; причем в ядерной теме и ассоциациях повторяют одну и ту же последовательность узлов, но с разными ядрами (центральными объектами), где ядро представляет собой основную тему, по отношению к которой оставшиеся узлы выступают в качестве соседей по памяти, что позволяет обеспечить более простой доступ к ним, чем в случае, когда ядерная тема отсутствует.
40. Система по п. 37, отличающаяся тем, что в рамках распознавания памяти (MR) сканируют хаотическое поле для распознавания известных концептов, причем хаотическое поле представляет собой «поле» концептов, произвольно погруженных в «белый шум», при этом в хранилище концептов памяти сохраняют распознаваемые концепты, которые готовы к индексации и обращению к ним для полевого исследования, при этом трехбуквенный сканер сканирует хаотическое поле и проверяет трехбуквенные сегменты, соответствующие цели, пятибуквенный сканер сканирует хаотическое поле и проверяет пятибуквенные сегменты, которые соответствуют цели, но на этот раз сегмент, который проверяется при каждом продвижении по всему полю, представляет собой целое слово, причем хаотическое поле сегментируют для сканирования в разных пропорциях, где при уменьшении области сканирования точность увеличивается, а по мере увеличения буквенного сканера повышается эффективность распознавания за счет точности, причем индексация концептов памяти (MCI) меняет размер сканера в ответ на оставшиеся необработанные концепты памяти, причем MCI начинает с самого большого доступного сканера и постепенно уменьшает его, в результате чего освобождается больше вычислительных ресурсов для проверки потенциального существования меньших по размеру целей концептов памяти.
41. Система по п. 37, отличающаяся тем, что логика интерпретации поля (FIL) отвечает за логистику управления сканерами различной ширины, причем сканирование общей области начинается со сканирования крупных наборов букв и прорабатывает большую область поля с меньшими ресурсозатратами, но за счет мелкомасштабной точности, причем сканирование конкретной области используют, когда обнаружена значимая область, и ее необходимо «приблизить», тем самым гарантируя, что дорогое и точное сканирование не выполняют в лишней и безрезультатной области, а получение дополнительного распознавания концептов памяти в хаотическом поле указывает на то, что область поля плотно насыщена концептами памяти.
42. Система по п. 37, отличающаяся тем, что в механизме автоматизированного обнаружения восприятия (APDM) угол восприятия определяется в сочетании с несколькими метриками, включая область, тип, интенсивность и последовательность, определяющие множество аспектов восприятия, из которых состоит общее восприятие, причем творческий модуль создает сложные вариации восприятия, в которых вес восприятия определяет относительное влияние восприятия, симулируемого посредством РОЕ, причем вес обоих входящих фактов восприятия учитывают при определении веса новоитерированного восприятия, которое содержит гибридизированные метрики, опирающиеся на предыдущее поколение восприятий.
43. Система по п. 37, отличающаяся тем, что на вход CVFG подают пакет данных, который представляет собой произвольный набор данных, которые должны быть представлены составом узлов сгенерированного CVF, причем для каждого отдельного блока, заданного пакетом данных, производят последовательное продвижение, где блок данных преобразуют в формат узла, имеющий тот же информационный состав, на который ссылается конечный CVF, причем преобразованные узлы после проверки их существования на этапе временно сохраняют в удержании узлов, причем если узлы не найдены, то они создаются и обновляются статистической информацией, включая возникновение и использование, причем все узлы в удержании собирают и принудительно передают как модульный вывод в виде CVF.
44. Система по п. 37, отличающаяся тем, что посредством алгоритма сравнения узлов сравнивают два состава узлов, которые были считаны из необработанного CVF, причем в рамках режима частичного соответствия (РММ), если в одном CVF есть активный узел, а в кандидате для сравнения он не найден (узел неактивен), то сравнение не штрафуют, тогда как в рамках режима полного соответствия (WMM), если в одном CVF есть активный узел, а в кандидате для сравнения он не найден (узел неактивен), то сравнение штрафуют.
45. Система по п. 37, отличающаяся тем, что в рамках разделения системных метаданных (SMS) разделяют входные системные метаданные на значимые причинно-следственные связи системы безопасности, где при сканировании/ассимиляции субъекта субъект/подозреваемый в ситуации в системе безопасности извлекается из метаданных системы посредством предварительно созданных контейнеров категорий и необработанного анализа из модуля категоризации, причем субъект используется в качестве основной контрольной точки для получения отклика системы безопасности/переменного отношения, где при сканировании/ассимиляции рисков факторы риска ситуации в системе безопасности извлекают из метаданных системы посредством предварительно созданных контейнеров категорий и необработанного анализа из модуля категоризации, причем риск связан с целевым субъектом, который демонстрирует или подвержен такому риску, где при сканировании/ассимиляции откликов отклик ситуации в системе безопасности извлекают из метаданных системы посредством предварительно созданных контейнеров категорий и необработанного анализа из модуля категоризации, причем отклик связан с субъектом безопасности, который якобы заслуживает такого отклика.
46. Система по п. 37, отличающаяся тем, что в МСМ в рамках разделения формата разделяют и классифицируют метаданные в соответствии с правилами и синтаксисом распознанного формата, причем правила и синтаксис локального формата содержат определения, которые позволяют модулю МСМ распознавать предварительно отформатированные потоки метаданных, где трассировка отладки представляет собой трассировку уровня кодирования, которая предоставляет используемые переменные, функции, методы и классы, а также соответствующий им контент/типы входных и выходных переменных, где трассировка алгоритма представляет собой трассировку программного уровня, которая обеспечивает данные системы безопасности в сочетании с анализом алгоритма, в котором итоговое решение системы безопасности (пропустить/заблокировать) предоставляется вместе со следом (обоснованием) того, как это решение было принято, а также с соответствующим весом каждого фактора, участвовавшего в принятии данного решения.
47. Система по п. 37, отличающаяся тем, что в обработке метрик (MP) отклик системы безопасности X представляет собой последовательность факторов, которые вносят вклад в итоговый отклик системы безопасности, выбираемый SPMA, причем начальный вес определяют посредством SPMA, где дедукция восприятия (PD) использует часть отклика системы безопасности и соответствующие метаданные системы для воспроизведения исходного восприятия отклика системы безопасности, причем интерпретация восприятия размерной серии отображает, как PD будет принимать отклик системы безопасности SPMA и связывать соответствующий ввод метаданных системы для воссоздания всего объема интеллектуального «цифрового восприятия», первоначально использованного в SPMA, причем заполнение формы, количество стека и размеры являются цифровыми фактами восприятия, которые содержат в себе «точку зрения» интеллектуального алгоритма.
48. Система по п. 47, отличающаяся тем, что в PD отклик системы безопасности X передают в качестве входных данных в расчет обоснования, где определяют обоснование отклика системы безопасности SPMA путем задействования намеренной подачи модуля упрощения ввода/вывода (IOR), причем модуль IOR использует разделенный ввод и вывод различных вызовов функций, указанных в метаданных, где разделение метаданных выполняют посредством МСМ.
49. Система по п. 37, отличающаяся тем, что в РОЕ ввод метаданных системы представляет собой первоначальный ввод, используемый в получении необработанного восприятия (RP2) для получения восприятия в формате CVF, причем в рамках поиска по хранилищу (SS) CVF, полученный из обогащенных данными журналов, используют в качестве критерия поиска по базе данных в хранилище восприятия (PS), причем в ранжировании факты восприятия расположены в порядке их окончательного веса, а обогащенные данными журналы применяют к фактам восприятия для получения рекомендаций по блокировке/разрешению, где SCKD помечает журналы для определения ожидаемого верхнего значения неизвестных знаний, с помощью парсера данных выполняют базовую интерпретацию обогащенных данными журналов и ввода метаданных системы с целью получить исходное решение о блокировке или разрешении, принятое первоначальным SPMA, причем СТМР критикует решения в РОЕ в соответствии с восприятием, а в выполнении правил (RE) - в соответствии с логически определенными правилами.
50. Система по п. 34, отличающаяся тем, что в рамках сложности метрик внешняя граница круга отражает верхнюю точку известных знаний в отношении отдельно взятой метрики, причем край круга отражает большую сложность метрики, тогда как центр круга отражает меньшую сложность метрики, причем светло-серая зона в центре отражает комбинацию метрик в текущей партии прикладных углов восприятия, а внешняя темно-серая зона отражает сложность метрики, хранящейся и известной системе в целом, причем задачей идентификации является увеличение сложности подходящих метрик, так чтобы приумножить число и сложность углов восприятия, причем темно-серая область поверхности отражает общий объем текущей партии прикладных углов восприятия, а также объем, оставшийся за пределами известной верхней границы, где после улучшения и увеличения сложности метрики возвращают в виде сложности метрик, которая используется в качестве ввода для преобразования метрик, в ходе которого отдельные метрики преобразовывают обратно в полноценные углы восприятия, и итоговый вывод собирают в подразумеваемые углы восприятия.
51. Система по п. 37, отличающаяся тем, что в SCKD в модуле категоризации известных данных (KDC) категорически отделяют известную информацию от ввода, так чтобы можно было выполнить запрос аналогии с подходящей базой данных, а также разделяют информацию на категории, причем каждая отдельная категория обеспечивает ввод для CVFG, который выводит категориальную информацию в формате CVF, используемый в поиске по хранилищу (SS) для поиска совпадений в базе данных известного объема данных, причем каждую категорию помечают соответствующим объемом известных данных в соответствии с результатами SS, причем помеченные объемы неизвестной информации для каждой категории снова собирают в тот же поток исходного ввода в комбинаторе неизвестных данных (UDC).
52. Система компьютерной безопасности, основанная на искусственном интеллекте, характеризующаяся тем, что система компьютерной безопасности оснащена памятью и процессором, сопряженным с памятью, причем данная система компьютерной безопасности также включает в себя лексически объективный майнинг (LOM), который дополнительно включает в себя:
а) обоснование первоначального запроса (IQR), куда передают вопрос и в рамках которого задействуют центральное хранилище знаний (CKR) для расшифровки недостающих подробностей, необходимых для понимания вопроса и ответа на него;
б) разъяснение опроса (SC), куда передают вопрос и данные дополнительного запроса и в рамках которого получают ввод от человека-субъекта и отправляют ему вывод, а также формируют разъясненный вопрос/утверждение;
в) построение утверждений (АС), в рамках которого получают предложение в форме утверждения или вопроса, а на выходе получают концепты, связанные с данным предложением;
г) представление ответа, представляющее собой интерфейс для представления выводов, полученных АС, как человеку-субъекту, так и рациональному обращению (RA);
д) составление иерархической карты (НМ), в рамках которой составляют карту связанных концептов для поиска совпадений или конфликтов в логике вопросов/утверждений, а также рассчитывают выгоды и риски той или иной позиции по теме;
е) центральное хранилище знаний (CKR), представляющее собой основную базу данных, куда LOM обращается за знаниями;
ж) валидацию знаний (KV), в рамках которой получают знание высокой достоверности до критики, которое необходимо логически разделить под возможности запросов и ассимиляцию в CKR;
з) принятие отклика, представляющее собой выбор, предоставляемый человеку-субъекту, в рамках которого он либо принимает отклик LOM, либо критикует его, причем если отклик принят, он затем обрабатывается в KV, чтобы быть сохраненным в CKR в качестве подтвержденного знания (высокой достоверности), а если человек-субъект не принимает отклик, его направляют в RA, где проверяют и критикуют доводы, предоставленные человеком;
и) управляемый поставщик услуг на основе искусственного интеллекта (MAISP), который поддерживает запущенную в интернет-облаке копию LOM, где работает мастер-копия CKR, и подключает LOM к клиентским службам, программно-аппаратным службам, зависимостям сторонних приложений, источникам информации и облаку MNSP.
53. Система по п. 52, отличающаяся тем, что к клиентским службам относятся личные помощники с искусственным интеллектом, коммуникационные приложения и протоколы, автоматизация дома и медицинские приложения, к программно-аппаратным службам относятся онлайн-покупки, онлайн-транспорт, заказ медицинских рецептов, причем клиентские службы и программно-аппаратные службы взаимодействуют с LOM через документированную инфраструктуру API, что позволяет стандартизировать протоколы и передачу информации, причем LOM извлекает знания из внешних источников информации посредством механизма автоматизированных исследований (ARM).
54. Система по п. 53, отличающаяся тем, что в рамках лингвистического построения (LC) интерпретируют необработанные вопросы/утверждения, введенные человеком-субъектом и полученные от параллельных модулей для создания логического разделения лингвистического синтаксиса, причем в ходе обнаружения концептов (CD) получают точки интереса в рамках разъясненного вопроса/утверждения и выводят связанные концепты путем задействования CKR; причем в рамках приоритизации концептов (CP) получают подходящие концепты и упорядочивают их по логическим уровням, отражающим конкретность и обобщенность; причем логика разделения откликов (RSL) задействует LC для понимания человеческого отклика и связывания подходящего и работающего отклика с первоначальным запросом на разъяснение, тем самым выполняя задачу SC; причем LC затем повторно задействуют во время фазы вывода, чтобы внести поправки в исходный вопрос/утверждение с целью включить туда дополнительную информацию, полученную SC; причем в построении контекста (СС) используют метаданные из построения утверждений (АС) и доказательства от человека-субъекта для передачи необработанных фактов в СТМР для критического мышления; причем в ходе сравнения решений (DC) определяют совпадение решений до критики и после критики; причем в ходе определения совместимости концептов (CCD) сравнивают производные концептов от исходного вопроса/утверждения с целью подтвердить результат логической совместимости; причем калькулятор выгод/рисков (BRC) получает результаты совместимости от CCD и взвешивает выгоды и риски с целью сформировать единое решение, которое охватывает градиенты переменных, входящих в состав концепта; причем в рамках взаимодействия концептов (CI) назначают характеристики, которые относятся к концептам АС и к частям информации, полученной от человека-субъекта посредством разъяснения опроса (SC).
55. Система по п. 54, отличающаяся тем, что внутри IQR LC получает исходный вопрос/утверждение, где вопрос лингвистически разделен, и IQR обрабатывает каждое отдельное слово/фразу за раз, задействуя CKR; где, обращаясь к CKR, IQR рассматривает потенциально возможные варианты с учетом неоднозначности значений слов/фраз.
56. Система по п. 54, отличающаяся тем, что в рамках разъяснения опроса (SC) получают входные данные от IQR, причем входные данные содержат последовательность запрошенных разъяснений, на которые должен ответить человек-субъект для получения объективного ответа на исходный вопрос/утверждение, причем предоставленный ответ на разъяснения направляют в логику разделения откликов (RSL), где отклики коррелируют с запросами на разъяснение; при этом параллельно с обработкой запрошенных разъяснений LC предоставляют лингвистическую ассоциацию разъяснений, где данная ассоциация содержит внутренние отношения между запрашиваемыми разъяснениями и структурой языка, что позволяет RSL внести поправки в исходный вопрос/утверждение, в результате чего LC выводит разъясненный вопрос.
57. Система по п. 54, отличающаяся тем, что в рамках построения утверждений, получившего разъясненный вопрос/утверждение, LC разбивает вопрос на точки интереса, которые передают в обнаружение концептов, где извлекают ассоциированные концепты путем задействования CKR, причем в рамках приоритизации концептов (CP) концепты упорядочивают по логическим уровням, где верхнему уровню назначают самые обобщенные концепты, в то время как нижним уровням назначают более конкретные концепты, при этом верхний уровень переносят в составление иерархических карт (НМ) в качестве модульного ввода, где при параллельной передаче информации НМ получает точки интереса, которые обрабатываются его модулем зависимостей взаимодействия концептов (CI), где точкам интереса назначают характеристики путем обращения к индексированной информации в CKR, причем после того, как НМ завершает свой внутренний процесс, его окончательный вывод возвращают в АС после того, как производные концепты были проверены на совместимость, а также взвешены и возвращены выгоды/риски позиции.
58. Система по п. 57, отличающаяся тем, что в рамках НМ CI предоставляет входные данные в CCD, который определяет уровень совместимости/конфликта между двумя концептами, при этом данные о совместимости/конфликте пересылают в BRC, где совместимость и конфликты переводят в выгоды и риски, связанные с принятием целостной единообразной позиции по проблеме, при этом позиции вместе с факторами риска/выгоды пересылают в АС в качестве модульного вывода, причем система содержит циклы информационного потока, указывающие на то, что градиенты интеллекта постепенно дополняются, поскольку субъективная природа вопроса/утверждения представляет собой постепенно выстраиваемый объективный ответ; где CI получает точки интереса и интерпретирует каждую из них в соответствии с высшим уровнем приоритизированных концептов.
59. Система по п. 54, отличающаяся тем, что в рамках RA посредством ядерной логики обрабатывают преобразованный лингвистический текст и возвращают результат, в котором, если результат высокой степени достоверности, его передают в валидацию знаний (KV) для правильной ассимиляции в CKR, а если результат низкой степени достоверности, то его передают в АС для продолжения цикла самокритики, причем в ядерную логику поступают входные данные от LC в виде решения до критики без лингвистических элементов, причем решение переправляют в СТМР в качестве субъективного мнения, а также в построение контекста (СС), где используют метаданные от АС и потенциальные доказательства от человека-субъекта для передачи необработанных фактов в СТМР в качестве входного «объективного факта», при этом СТМР при получении двух обязательных входных видов данных обрабатывает их для получения наилучшего возможного варианта «объективного мнения», где мнение обрабатывают внутри RA в качестве решения после критики, причем решения как до критики, так и после критики переправляют в сравнение решений (DC), в рамках которого определяют степень совпадения данных решений, причем затем либо признают истинными аргументы апелляции, либо улучшают контраргумент, чтобы объяснить, почему апелляция недействительна, в случае же если исход сценария признания истины/улучшения неважен, результат высокой степени достоверности передают в KV, а результат низкой степени достоверности передают в АС для дальнейшего анализа.
60. Система по п. 54, отличающаяся тем, что в рамках CKR единицы информации хранят в формате единиц знаний (UKF), где формат синтаксиса правил (RSF) представляет собой набор синтаксических стандартов для отслеживания правил ссылок, причем одиночного объекта или действия в RSF может быть задействовано множество единиц правил; при этом привязка к источнику представляет собой набор сложных данных, посредством которых отслеживают заявленные источники информации, причем кластер UKF состоит из цепочки вариантов UKF, связанных между собой для определения юрисдикционно раздельной информации, причем UKF2 содержит основную целевую информацию, UKF1 содержит данные о метке времени и, следовательно, не содержит само поле метки времени для избежания бесконечного регресса, a UKF3 содержит информацию о привязке к источнику и, следовательно, не содержит само поле источника для избежания бесконечного регресса; причем каждый UKF2 должен сопровождаться по крайней мере одним UKF1 и одним UKF3, иначе кластер (последовательность) считается неполным, и информация в нем еще не может быть обработана общесистемной общей логикой LOM; причем между центральным UKF2 и соответствующими ему блоками UKF1 и UKF3 могут стоять блоки UKF2, выступающие в качестве цепного моста, при этом последовательность кластеров UKF будет обрабатываться KCA для формирования производного утверждения, причем в ходе анализа совпадения знаний (KCA) кластерную информацию UKF сравнивают для подтверждения доказательств о предвзятой позиции, при этом после того, как KCA завершает обработку, CKR может вывести окончательное мнение по теме.
61. Система по п. 54, отличающаяся тем, что в рамках ARM, где, как показывает деятельность пользователя, по мере взаимодействия пользователя с концептами LOM, они прямо или косвенно приводятся в качестве релевантных для отклика на вопрос/утверждение, причем ожидается, что деятельность пользователя в конечном итоге предоставит концепты, для которых в CKR сведений мало или нет вообще, как указано в списке запрашиваемых, но недоступных концептов, при этом посредством сортировки и приоритизации концептов (CSP) принимают определения концептов из трех независимых источников и собирают вместе для определения приоритетов ресурсов информационного запроса, причем данные, предоставляемые источниками информации, получают и обрабатывают в агрегаторе информации (IA) в соответствии с тем, какое определение концепта запросило их и какие релевантные метаданные сохранены, причем информацию отправляют в анализ перекрестных ссылок (CRA), где полученную информацию сравнивают и строят с учетом ранее имевшихся знаний из CKR.
62. Система по п. 54, отличающаяся тем, что в профиле личного интеллекта (PIP) сохраняют личную информацию об индивидууме посредством множества потенциальных конечных точек и клиентов, причем их информация изолирована от CKR, однако доступна для общесистемной общей логики LOM, в которой личная информация, относящаяся к приложениям искусственного интеллекта, зашифрована и хранится в личном пуле кластеров UKF в формате UKF, причем данные процесса анонимизации информации (IAP) дополняют в CKR после удаления всех идентифицирующих личность данных, при этом полученные данные анализа перекрестных ссылок (CRA) сравнивают и строят с учетом ранее существовавших знаний из CKR.
63. Система по п. 54, отличающаяся тем, что администрация и автоматизация жизни (LAA) объединяет устройства с подключением к Интернету и сервисы на единой платформе, где при активном принятии решений (ADM) учитывают доступность и функционал клиентских служб, программно-аппаратных служб, IoT-устройств, правил расходов и сумм, доступных в соответствии с правилами и управлением распределением средств (FARM), где FARM получает от человека входные данные, задающие критерии, пределы и область действия модуля, чтобы информировать ADM, в чем состоит его юрисдикция, причем средства криптовалюты депонируют на цифровой кошелек, где модуль взаимодействия с IoT (IIM) поддерживает базу данных о том, какие IoT-устройства доступны, причем потоки данных отражают, когда устройства с поддержкой IoT отправляют информацию в LAA.
64. Система по п. 52, дополнительно включающая мониторинг поведения (ВМ), в рамках которого отслеживают персональные идентифицируемые запросы данных от пользователей для проверки на наличие неэтичного и/или незаконного материала, при этом с помощью сбора метаданных (MDA) данные, относящиеся к пользователю, собирают из внешних служб с тем чтобы установить цифровую личность пользователя, причем такие данные передают в индукцию/дедукцию и, в конечном итоге, в PCD, где проводится сложный анализ с подтверждающими факторами из MNSP; причем вся информация от аутентифицированного пользователя, которая предназначена для PIP, проходит через отслеживание информации (IT) и проверяется по «черному списку поведения», при этом в обнаружении до совершения преступления (PCD) данные дедукции и индукции объединяют и анализируют с целью получения выводов до совершения преступления, причем PCD использует СТМР, который напрямую обращается к черному списку поведения для проверки позиций, сформированных индукцией и дедукцией, причем управление черным списком (ВМА) работает внутри фреймворка облачной службы MNSP.
65. Система по п. 63, отличающаяся тем, что LOM выполнен с возможностью управлять персонализированным портфолио жизни индивидуума, где LOM получает начальный вопрос, который приводит к выводу через внутренний процесс умозаключений LOM, где LOM подключается к модулю LAA, который подключается к устройствам с доступом в Интернет, откуда LOM может получать данные и которыми может управлять, причем в рамках контекстуализации LOM выводит недостающие звенья при построении аргумента, причем LOM постигает с помощью своей логики, что для решения дилеммы, поставленной исходным утверждением, сначала необходимо знать или допускать определенные переменные о ситуации.
66. Система компьютерной безопасности, основанная на искусственном интеллекте, характеризующаяся тем, что система оснащена памятью, в которой хранятся запрограммированные инструкции, и процессором, сопряженным с памятью, для выполнения запрограммированных инструкций, а также по меньшей мере одной базой данных, причем данная система включает в себя систему на компьютерной основе,
где указанная система на компьютерной основе представлена линейной атомно-квантовой передачей информации (LAQIT), включающей в себя:
а) рекурсивное повторение той же постоянной последовательности цветов внутри логически структурированного синтаксиса;
б) рекурсивное использование данной последовательности для перевода с использованием английского алфавита;
где при стуктурировании «базового» слоя алфавита используют последовательность цветов с сокращенным и неравным весом цветового канала, а также с дополнительным пространством для синтаксических определений внутри цветового канала, зарезервированным под будущее использование и расширение; где сложный алгоритм передает свой журнал событий и отчеты о состоянии LAQIT, причем отчеты о событиях/состоянии формируют автоматически, конвертируют в передаваемый синтаксис LAQIT на текстовой основе, синтаксически небезопасную информацию передают по цифровому каналу, передаваемый синтаксис LAQIT на текстовой основе конвертируют в высокочитаемый визуальный синтаксис LAQIT (линейный режим), где ключ оптимизирован под человеческое запоминание и основывается на относительно короткой последовательности форм;
где локально небезопасный текст вводится отправителем для отправки получателю, причем текст конвертируют в передаваемый зашифрованный синтаксис LAQIT на текстовой основе, синтаксически безопасную информацию передают по цифровому каналу, данные конвертируют в визуально зашифрованный синтаксис LAQIT;
где эффект ступенчатого распознавания (IRE) представляет собой канал передачи информации и распознает полную форму информационного блока до его полной доставки, причем данный эффект предсказательной индексации встраивается путем отображения переходов между словами, тогда как эффект приблизительного распознавания (PRE) представляет собой канал передачи информации и распознает полную форму информационного блока, даже если он испорчен, изменен или перепутан.
67. Система по п. 66, отличающаяся тем, что в линейном режиме LAQIT блок показывает версию линейного режима в «базовой визуализации», а точка отображает отсутствие шифрования, причем в разделителе слов цвет формы представляет собой символ, который следует за словом и выступает в качестве разделителя между ним и следующим словом, где зона одиночного просмотра включает в себя меньшую зону просмотра с буквами большего размера и, следовательно, меньшим количеством информации на пиксель, причем в зоне двойного просмотра больше активных букв на пиксель, в то время как затенение делает входящие и исходящие буквы тусклыми, так чтобы основной фокус наблюдателя находился на зоне просмотра.
68. Система по п. 66, отличающаяся тем, что в атомном режиме, который может работать с широким набором уровней шифрования, ссылка на основной символ базы будет конкретизировать общее значение определяемой буквы, где кикер имеет тот же цветовой диапазон, что и база, и точно определяет конкретный символ, где в направлении чтения чтение поступившей информации начинают с верхнего квадрата первого орбитального кольца, причем как только орбитальное кольцо пройдено, чтение продолжают с верхнего квадрата следующего по порядку орбитального кольца, где порталы входа/выхода являются точками создания/уничтожения символа (его базы), причем новый символ, принадлежащий к соответствующей орбите, выйдет из портала и сдвинется на свою позицию по часовой стрелке, а атомное ядро определяет символ, следующий за словом;
где в рамках навигации по словам каждый блок представляет собой целое слово (или несколько слов в молекулярном режиме) в левой части экрана, причем при отображении слова соответствующий блок перемещается наружу и вправо, а когда это слово завершено, блок отступает назад, причем цвет/форма навигационного блока имеет тот же цвет/форму, что и база первой буквы слова; где в рамках навигации по предложениям каждый блок представляет собой кластер слов, где кластер представляет собой максимальное количество слов, которое может уместиться на панели навигации по словам; где создание атомного состояния - это переход, который вызывает эффект ступенчатого распознавания (IRE), при котором переходные базы появляются из порталов входа/выхода со скрытыми кикерами и перемещаются по часовой стрелке на свои позиции; где расширение атомного состояния - это переход, который вызывает эффект приблизительного распознавания (PRE), при котором, после того как базы достигли своей позиции, они перемещаются наружу в «расширенной» последовательности представления информационного состояния, которая раскрывает кикеры, посредством чего можно представить конкретное определение состояния информации; где разрушение атомного состояния - это переход, который вызывает эффект ступенчатого распознавания (IRE), при котором базы сокращают (путем обращения последовательности расширения), чтобы снова скрыть кикеры, которые теперь смещаются по часовой стрелке, чтобы достичь портала входа/выхода.
69. Система по п. 68, отличающаяся тем, что при обфускации формы стандартные квадраты заменяют пятью визуально различными формами, причем вариативность форм в синтаксисе позволяет вставлять (поддельные) буквы-пустышки в стратегических точках атомного профиля, где буквы-пустышки скрывают истинный и предполагаемый смысл сообщения, причем расшифровка того, является ли буква настоящей или пустышкой, надежно и временно переданного ключа дешифрования;
где в рамках связей перенаправления связь соединяет две буквы и изменяет поток чтения, причем, начиная с типичного шаблона чтения по часовой стрелке, при обнаружении связи, которая взлетает (начинается с) и приземляется (заканчивается на) на легитимные/настоящие буквы, связь перенаправляет шаблон чтения для возобновления на посадочной букве;
где в рамках радиоактивных элементов некоторые элементы могут «дребезжать», что может инвертировать оценку того, является ли буква пустышкой или нет, где формы отражают формы, доступные для шифрования, центральные элементы отражают центральный элемент орбиты, которая определяет символ, идущий сразу за словом.
70. Система по п. 69, отличающаяся тем, что в рамках связей перенаправления связи начинаются с буквы «взлета» и заканчиваются буквой «посадки», каждая из которых может быть или не быть пустышкой, причем если среди букв нет ни одной пустышки, то связь изменяет направление и позицию чтения, причем если одна или обе буквы являются пустышками, то вся связь должна быть проигнорирована, в противном случае сообщение будет расшифровано неправильно, причем при определении ключа связи необходимость следовать связи при чтении состояния информации зависит от того, была ли она конкретно определена в ключе шифрования.
71. Система по п. 69, отличающаяся тем, что при одиночном кластере оба соседа нерадиоактивны, следовательно, определяют объем кластера, причем, поскольку ключ определяет двойные кластеры как действительные, с элементом следует обращаться как если бы он изначально не был радиоактивным, тогда как при двойном кластере ключевое определение определяет двойные кластеры как активные, следовательно, во время расшифровки сообщения все кластеры других размеров должны считаться неактивными, при этом неверная интерпретация показывает, что интерпретатор не рассматривал двойной кластер как обратную последовательность (ложное срабатывание).
72. Система по п. 69, отличающаяся тем, что в молекулярном режиме с включенным шифрованием и потоковой передачей, при сопротивлении скрытому перебору по словарю неправильная дешифровка сообщения вызывает альтернативное «подложное» сообщение, в котором при нескольких активных словах на молекулу слова представлены параллельно во время молекулярной процедуры, тем самым увеличивая долю информации на площадь поверхности, однако с постоянной скоростью перехода, причем между двоичным режимом и режимом потоковой передачи выбирают потоковый режим, тогда как в типичной атомной конфигурации режим чтения является двоичным, причем двоичный режим указывает, что центральный элемент определяет, какой символ следует за словом, а молекулярный режим также является двоичным, кроме случаев, когда включено шифрование, которое придерживается режима потоковой передачи, причем режим потоковой передачи ссылается на специальные символы в пределах орбиты.
73. Система компьютерной безопасности, основанная на искусственном интеллекте, характеризующаяся тем, что система компьютерной безопасности оснащена памятью и процессором, сопряженным с памятью, причем данная система компьютерной безопасности также включает в себя систему универсальных BCHAIN-связей всего со всем (UBEC) на основе гармонизации базовых связей с присоединением интегрированных узлов (BCHAIN), которая дополнительно включает в себя:
а) порт связи (CG), являющийся первичным алгоритмом узла BCHAIN для взаимодействия с аппаратным интерфейсом, осуществляющим связь с остальными узлами BCHAIN;
б) статистическое изучение узлов (NSS), в рамках которого интерпретируют образцы поведения удаленных узлов;
в) индекс убегания узлов, с помощью которого отслеживают вероятность того, что сосед узла избежит близости с воспринимающим узлов;
г) индекс насыщения узлов, с помощью которого отслеживают число узлов в радиусе обнаружения воспринимающего узла;
д) индекс постоянства узлов, с помощью которого отслеживают качество работы узлов с точки зрения воспринимающего узла, причем высокое значение индекса указывает на то, что окружающие соседние узлы, как правило, более доступны и активны, а также поддерживают постоянный уровень производительности, причем узлы двойного назначения, как правило, имеют более низкое значение индекса постоянства, тогда как узлы, прикрепленные к сети BCHAIN, показывают более высокое значение индекса постоянства;
е) индекс перекрытия узлов, с помощью которого отслеживают число узлов, совпадающих друг с другом, с точки зрения воспринимающего узла.
74. Система по п. 73, дополнительно включающая в себя:
а) модуль распознавания составных цепочек (CRM), который соединяется с составными цепочками, включая цепочки приложений или микроцепочки, ранее зарегистрированными узлом, причем данный модуль информирует остальную часть протокола BCHAIN об обнаружении обновления в секции цепочки приложений в метацепочке или эмуляторе метацепочки в микроцепочке;
б) доставка запрошенного содержимого (CCD), в рамках которой получают проверенное CCR, а затем отправляют подходящее CCF для выполнения запроса;
в) динамическая адаптация стратегии (DSA), которой подчиняется модуль создания стратегии (SCM), посредством которого динамически генерируют новую стратегию, используя творческий модуль для создания гибридных сложных стратегий, которым система отдала предпочтение посредством алгоритма выбора оптимизированной стратегии (OSSA), причем новые стратегии варьируются в соответствии с данными, полученными от интерпретации хаоса поля;
г) криптографическая цифровая экономическая биржа (CDEE) с набором экономических личностей под управлением графического интерфейса пользователя (GUI) внутри интерфейса платформы UBEC (UPI), причем для личности А тратится ровно столько ресурсов узла, сколько необходимо, для личности В ресурсы тратятся, пока маржа прибыли выше заданной величины, личность С платит за единицу работы обмененной валютой, а для личности D ресурсы тратятся, пока они есть, без ограничений и без ожиданий выручки, причем тратится как содержимое, так и деньги;
д) интерпретация текущего рабочего состояния (CWSI), в рамках которой обращаются к разделу экономической инфраструктуры метацепочки с целью определить текущий избыток или дефицит узла в отношении затрат на выполненную работу;
е) экономически обоснованное назначение работы (ECWI), в рамках которого рассматривают выбранную экономическую личность с текущим избытком/дефицитом работы с целью определить, необходимо ли выполнить больше работы;
ж) симбиотическое рекурсивное продвижение интеллекта (SRIA), представляющее собой тройственные взаимоотношения между различными алгоритмами, входящими в состав LIZARD, которая улучшает исходный код алгоритма путем выявления назначения кода, включая свой собственный, I2GE, которое симулирует поколения виртуальных итераций программы, и сетью BCHAIN, которая представляет собой обширную сеть хаотически соединенных узлов, способных децентрализированно выполнять сложные программы с большим количеством данных.

