В обычных проводных сетях тема маршрутизации данных считается сложившейся областью исследований, в которой существуют эффективные и надежные решения, как, впрочем, и выделенное аппаратное обеспечение размещается в сети исключительно для данной конкретной задачи (маршрутизаторы). Однако, из-за уникальных свойств беспроводных самоорганизующихся сетей, таких как динамическая топология, беспроводная среда передачи, как, впрочем, и ограничения по энергопотреблению и вычислительные ограничения, задача разработки эффективной схемы многосегментной (multi-hop) маршрутизации становится нетривиальной.
Исследовательские институты и отрасль, столкнувшиеся с такими проблемами, разработали большое количество алгоритмов маршрутизации для беспроводных самоорганизующихся сетей, которые работают с разной эффективностью в конкретных сетях.
Основной класс протоколов маршрутизации самоорганизующейся сети предназначен для минимизации таких основных атрибутов сети, как служебная нагрузка от управления, коэффициент потери пакетов, задержка пакетов и показатель энергопотребления, при максимальном увеличении пропускной способности сети [1].
Обычно, этот класс протоколов делится на три больших подкласса на основании лежащей в их основе логики обнаружения маршрута:
- реактивные, также называемые протоколы по запросу:
Эти протоколы основаны на стратегиях по запросу, т.е. маршрут (сетевой путь) создается только когда узел-источник запрашивает передачу данных к некоторому узлу-получателю в сети. С этой целью процедура обнаружения маршрута должна вызываться каждый раз, когда должен быть передан объект данных. В течение фазы обнаружения маршрута, узел-источник отправляет сообщение запроса маршрута RREQ и ожидает сообщения ответа маршрута RREP от его непосредственных соседей. Когда первое сообщение RREQ прибывает в узел-получатель, он отправляет обратно упомянутое сообщение RREP, содержащее некоторую информацию о пути. Таким образом, создается маршрут, когда источник принимает обратно пакет RREP от узла-получателя, и может быть инициирована передача данных. Когда передача данных закончена, созданный маршрут становится неактивным после некоторого предопределенного интервала лимита времени.
Некоторые хорошо известные реактивные самоорганизующиеся протоколы маршрутизации описаны в [2] и [3].
- проактивные или протоколы с табличным управлением:
Эти протоколы основаны на обычных методиках маршрутизации «с табличным управлением», когда информация о маршрутах от каждого узла до всех возможных получателей собирается на лету в течение передачи данных. В данном случае, каждый узел имеет свою собственную таблицу маршрутизации, содержащую информацию о путях от него до всех других узлов в сети. Глобальная информация маршрутизации непрерывно обновляется и осуществляется ее обмен между узлами путем широковещательной передачи пакетов управления в сеть. В итоге все узлы в сети получают фактическую глобальную таблицу маршрутов так, что классический алгоритм маршрутизации (Беллмана-Форда, Дейкстра) из теории графов может быть использован узлом для нахождения пути к любому возможному получателю в сети.
Механизм обновления маршрута в проактивных протоколах становится сложной проблемой в условиях беспроводных самоорганизующихся сетей из-за их характерных особенностей, таких как ограничения энергопотребления, динамическая топология, шумная беспроводная среда. Таким образом, они не используются широко в самоорганизующихся сетях в их первоначальной концепции, однако, надлежащие модификации данной проактивной схемы были реализованы и описаны в [4] и [5], так что теперь они чаще всего используются для маршрутизации в самоорганизующихся сетях. Также [6] описывает хорошо известный проактивный протокол маршрутизации.
- гибридные протоколы:
Эти протоколы используют как реактивные, так и проактивные методики, в зависимости от текущей среды передачи. Примеры таких протоколов описаны в [7]. Эти протоколы указаны для использования в стандарте IEEE 802.11s ячеистой WLAN.
Другой тип алгоритма маршрутизации основан на Обучении с Подкреплением, которое принадлежит к области Машинного Обучения. Теория Машинного Обучения описана в [8, 9]. В целом она может быть описана следующим образом. Присутствует объект «агент», который обладает некоторым набором «действий», из которых агент может осуществлять выбор. Каждое действие ассоциировано с некоторым «значением оценки», которое говорит агенту, «насколько хорошо это действие», если это действие будет выбрано/инициировано. Эти значения оценки динамически модифицируются в течение процесса взаимодействия, когда агент выбирает некоторое действие, и принимает некоторое «вознаграждение» от него. Это значение вознаграждения играет решающую роль, поскольку оно непосредственно влияет на соответствующее значение оценки этого действия - в целом, чем ниже значение оценки, тем будет ниже вероятность выбора этого действия.
В качестве общего и наиболее частого примера, описывающего логику Обучения с Подкреплением, используется задача «N-рукого бандита». Задача «N-рукого бандита» ставит целью максимальную величину вознаграждения от машины N-рукого бандита, используемой в игорном доме, где «N-рукий» означает, что присутствует некоторое логичное количество рычагов, которое может иметь машина (1, 2, 5, 10 и т.д. количество уровней). Игрок может выбирать одну «руку» (рычаг) из всех доступных и тянуть за нее для того, чтобы получить выигрышные очки/вознаграждение. В книге Р. Саттона «Reinforcement Learning: An Introduction» [8] «игра» определяется как событие, когда игрок тянет за рычаг, и результат этого события определяется как «вознаграждение». Таким образом задача состоит в максимальном увеличении ожидаемого общего вознаграждения за некоторое количество игр, другими словами, выборов действия.
В качестве параметра максимизации используется «значение оценки 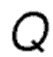 », которое, в целом, может быть вычислено, как:
», которое, в целом, может быть вычислено, как:
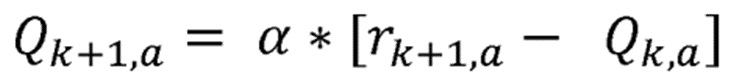 (1)
(1)
где:
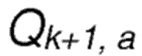 является ожидаемым значением вознаграждения для действия а;
является ожидаемым значением вознаграждения для действия а;
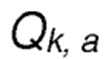 является оценочным значением вознаграждения действия а за последнее событие;
является оценочным значением вознаграждения действия а за последнее событие;
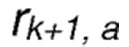 является фактическим значением вознаграждения, полученным для действия а;
является фактическим значением вознаграждения, полученным для действия а;
α является параметром размера шага;
k является текущим номером шага.
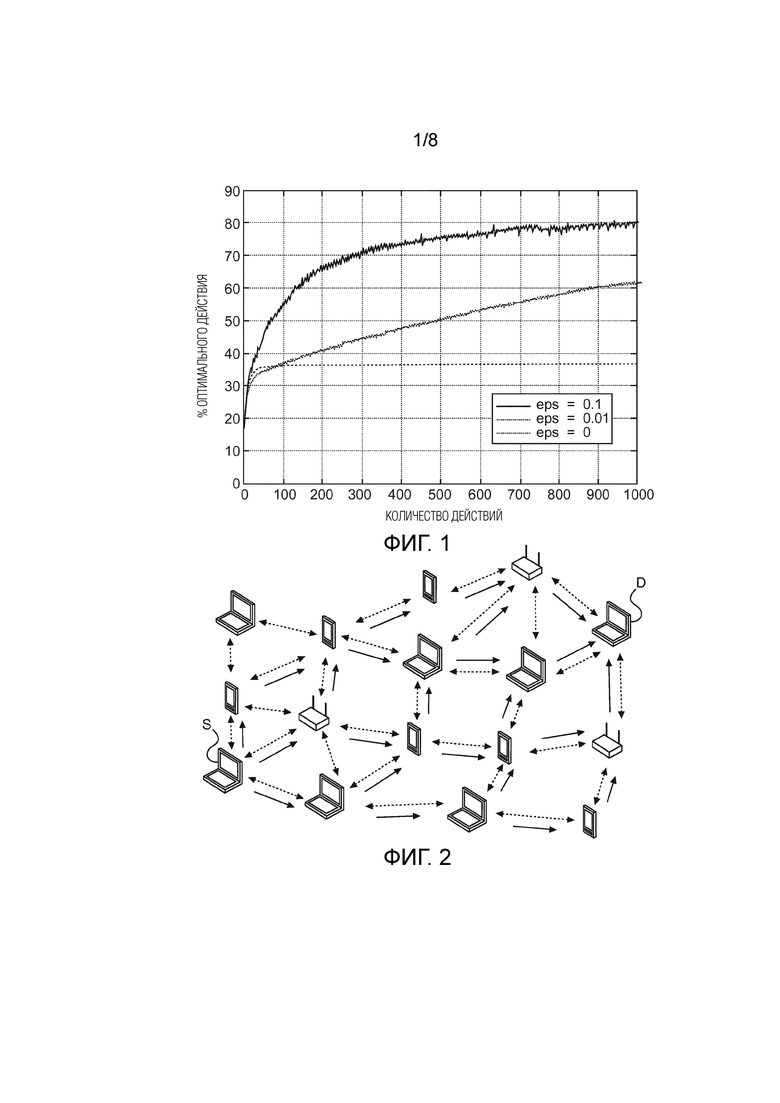
Существует много «способов выбора», на основании которых выполняется принятие решения о действии. Это может быть простым «Жадным» способом, который всегда выбирает действие а с максимальным значением . Фиг. 1 показывает распределение оптимального коэффициента выбора, когда используется е-Жадный способ выбора. Три кривые соответствуют изменению e-Жадного параметра eps между 0, 0.001 и 0.1, как указано на чертеже. Такие кривые имитируют результаты e-Жадного способа выбора по 1000 игр для модели 10-рукого бандита, усредненные по 2000 задач.
Беспроводные ячеистые сети могут быть использованы, в частности, в ситуациях, в которых сетевые узлы являются подвижными или портативными и требуется высокая гибкость при конфигурировании сети. Одной формой беспроводных ячеистых сетей являются беспроводные мобильные самоорганизующиеся сети. Это само-конфигурируемые, динамические сети, в которых узлы могут свободно перемещаться. В беспроводных самоорганизующихся сетях отсутствует сложность настройки и администрирования инфраструктуры, позволяя устройствам создавать и присоединяться к сетям «на лету» - в любом месте, в любое время.
Одним примером, в котором может быть использована технология беспроводной ячеистой сети, несмотря на тот факт, что участники не являются подвижными, является область интеллектуального уличного освещения. В интеллектуальном уличном освещении, также упоминаемом как адаптивное уличное освещение, светильники уличного освещения приглушаются, когда не обнаруживается активность, но их яркость увеличивается, когда обнаруживается движение. Такие интеллектуальные светильники уличного освещения оборудованы камерой или датчиком для распознавания объекта и средствами обработки и связи. Когда обнаруживается прохожий, то светильник уличного освещения будет сообщать это соседним светильникам уличного освещения, яркость которых будет увеличиваться таким образом, что люди всегда окружены безопасным кругом света на их пути. Подробное описание такой концепции представлено в документе DE 10 2010 049 121 B8.
Из WO 2007/001286 A1 известен способ выявления маршрутов в сетях беспроводной связи. Данный способ содержит этап выявления маршрута через множество узлов сети связи. Первый узел осуществляет широковещательную передачу кадра запроса маршрута (RREQ). Кадр RREQ генерируется для выявления маршрута. Второй узел принимает кадр RREQ. Второй узел осуществляет одноадресную передачу кадра PING в первый узел, чтобы удостовериться в целостности канала беспроводной связи между первым узлом и вторым узлом. Затем второй узел осуществляет одноадресную передачу кадра ответа маршрута (RREP), только если удостоверена целостность беспроводного канала.
Из WO 2015/052248 A1 известна станция для использования в ячеистой сети, в которой обеспечена усовершенствованная функция нахождения пути. Данная станция содержит контроллер, выполненный с возможностью принимать из передающей станции запрос пути на предмет пути от первой станции до второй станции, определять предлагаемый путь между первой станцией и второй станцией и определять стоимость предлагаемого пути. Контроллер выполнен с возможностью получать уровень выходной мощности для передающей станции и включать уровень заряда батареи питания в определение стоимости для предлагаемого пути, причем повышение уровня выходной мощности приводит к увеличению стоимости для предлагаемого пути.
Авторы изобретения идентифицировали разные проблемы с этими описанными выше подходами. Одна проблема относится к проблеме инициализации таблицы маршрутов, которая настраивается в узле для принятия решения о следующем сегменте (hop) при маршрутизации пакетов в направлении к получателю.
Одна проблема с этими подходами состоит в том, что в случаях, когда аналогичные значения вознаграждения возвращаются обратно на фазе обнаружения пути, существует относительно высокая вероятность того, что выбирается путь, который является относительно неэффективным.
Вследствие этого существует потребность в улучшенном подходе для настройки таблицы маршрутов на фазе обнаружения пути. Это соответствует проблеме изобретения.
Данная цель достигается посредством способа адаптивного выбора маршрута в узле беспроводной ячеистой сети связи по пункту 1, соответствующего устройства для выполнения способа адаптивного выбора маршрута по пункту 14, и соответствующей компьютерной программы по пункту 15. Зависимые пункты формулы изобретения включают в себя преимущественные дополнительные разработки и улучшения изобретения, как описано ниже.
Предложение касается улучшения способа адаптивного выбора маршрута в узле беспроводной ячеистой сети связи, при этом используется методика основанной на RL маршрутизации. Предложение касается улучшения процедуры обнаружения пути, которая используется для настройки таблиц маршрутов для отражения текущего состояния сети. В процедуре обнаружения пути осуществляется широковещательная передача сообщения запроса маршрута (RREQ) узлом-источником. Соседний узел, принимающий такое сообщение RREQ, будет осуществлять повторную широковещательную передачу данного сообщения дальше в сеть. Это происходит снова и снова некоторое количество сегментов до тех пор, пока RREQ-сообщение в конечном итоге не принимается адресуемым узлом-получателем. Когда это происходит, узел-получатель осуществляет широковещательную передачу сообщения ответа маршрута (RREP) в ответ на прием упомянутого RREQ-сообщения, в отношении которого аналогично осуществляется повторная широковещательная передача некоторое количество сегментов посредством промежуточных узлов, принимающих RREP-сообщение маршрута. В данном процессе узел, который принял упомянутое RREQ-сообщение, обновляет таблицу маршрутов соответствующими оценочными значениями вознаграждения для соответствующего действия. То же самое происходит в узле, принимающем RREP-сообщение. Конкретная функция вознаграждения предлагается для оценки упомянутых значений вознаграждения в процедуре обнаружения пути. Предложение включает в себя то, что функция вознаграждения зависит от индикатора силы принимаемого сигнала RSSI, измеренного в течение приема упомянутого сообщения запроса маршрута или сообщения ответа маршрута, и количества сегментов, которое сообщение запроса маршрута или сообщение ответа маршрута распространялось в сети для достижения принимающего узла. Данное предложение обладает преимуществом в том, что на первоначальной стадии отдается предпочтение более коротким маршрутам с сильным сигналом приема.
В одном предпочтительном варианте осуществления функция вознаграждения определяется в форме:
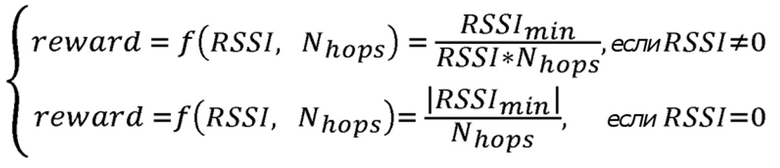
где  является результирующим оценочным значением вознаграждения для действия по отправке сообщения следующему соседу, от которого было принято сообщение запроса маршрута или сообщение ответа маршрута, и
является результирующим оценочным значением вознаграждения для действия по отправке сообщения следующему соседу, от которого было принято сообщение запроса маршрута или сообщение ответа маршрута, и
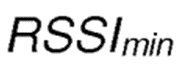 является минимальным возможным значением индикатора силы принятого сигнала RSSI, которое может быть измерено беспроводным сетевым интерфейсом.
является минимальным возможным значением индикатора силы принятого сигнала RSSI, которое может быть измерено беспроводным сетевым интерфейсом.
Здесь, в дополнительном варианте осуществления изобретения измеряется в значениях дБм, которые меняются в диапазоне [-100,0], где ноль соответствует самому сильному принятому сигналу.
В улучшенном варианте осуществления предложения основанная на RL маршрутизация также применяется для обычной маршрутизации пакетов в отсутствие фазы обнаружения пути. Здесь, функция вознаграждения обратной связи используется для оценки значений вознаграждения, при этом упомянутая функция вознаграждения обратной связи определяется в форме:
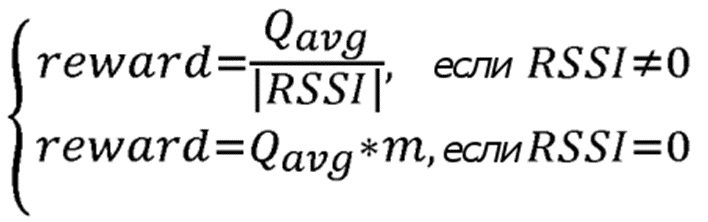
где m является коэффициентом умножения, который увеличивает значение вознаграждения, когда индикатор силы принятого сигнала 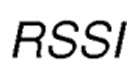 достигает максимального значения ноль, при этом коэффициент умножения находится в диапазоне: [1, 100];
достигает максимального значения ноль, при этом коэффициент умножения находится в диапазоне: [1, 100];
где 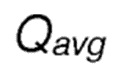 является вычисленным средним оценочным значением вознаграждения, которое принимается в отправляющем узле в сообщении обратной связи (ACK) для передачи от отправляющего узла.
является вычисленным средним оценочным значением вознаграждения, которое принимается в отправляющем узле в сообщении обратной связи (ACK) для передачи от отправляющего узла.
Более того, предлагается вычислять среднее оценочное значение вознаграждения в соответствии с формулой:
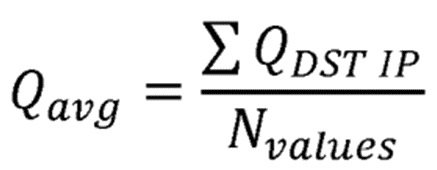
где 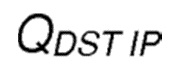 является оценочным значением вознаграждения для передачи от отправляющего узла в направлении узла-получателя, где
является оценочным значением вознаграждения для передачи от отправляющего узла в направлении узла-получателя, где 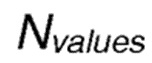 является количеством значений, по которым должно быть вычислено среднее. Оба предложения приводят к существенно более хорошему поведению времени восстановления маршрута в сравнении с традиционными схемами маршрутизации.
является количеством значений, по которым должно быть вычислено среднее. Оба предложения приводят к существенно более хорошему поведению времени восстановления маршрута в сравнении с традиционными схемами маршрутизации.
Дополнительной предпочтительной мерой является то, что узел принимает решение о следующем сегменте на номере t шага на основании функции распределения вероятностей 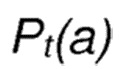 , где соответствует вероятности выбора для отбора действия а на номере t шага.
, где соответствует вероятности выбора для отбора действия а на номере t шага.
В данном предложенном варианте предпочтительным является, если функция распределения вероятностей соответствует функции распределения Гиббса-Больцмана в соответствии с формулой:
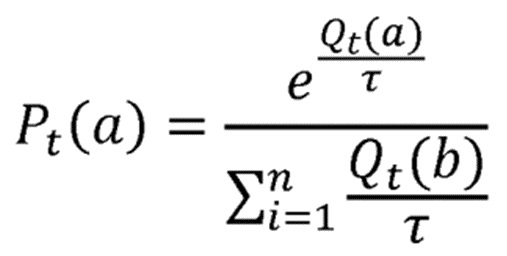
с 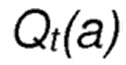 , являющимся оценочным значением вознаграждения действия а на текущем шаге t,
, являющимся оценочным значением вознаграждения действия а на текущем шаге t,
с 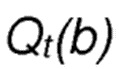 , являющимся оценочным значением вознаграждения альтернативного действия
, являющимся оценочным значением вознаграждения альтернативного действия 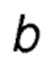 на текущем шаге t и
на текущем шаге t и
τ , являющимся положительным параметром температуры для распределения Гиббса-Больцмана, и i, являющимся значением индекса. Высокие значения параметра температуры τ делают выборы действий равномерно вероятными, т.е. вероятности выбора всех возможных действий будут равными или очень близкими друг к другу. С другой стороны, низкие температуры вызывают большие различия в вероятностях выбора между действиями. Таким образом, определяется параметр управления τ, который может быть использован для регулирования поведения маршрутизации.
В одном дополнительном варианте осуществления предлагается, чтобы параметр температуры адаптивно определялся в зависимости от текущего коэффициента потери пакетов PLR. Высокие значения параметра температуры τ делают выборы действий равномерно вероятными, т.е. вероятности выбора всех возможных действий будут равными или очень близкими друг к другу. С другой стороны, низкие температуры вызывают большую разницу в вероятностях выбора между действиями.
Здесь предпочтительным является то, чтобы параметр температуры τ адаптивно определялся в соответствии с формулой:
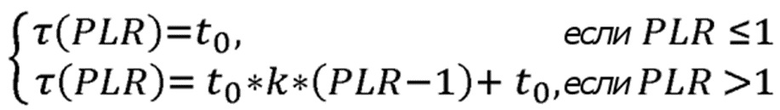
где k является коэффициентом роста, равным 0.5 по умолчанию, и который меняется в диапазоне [0, 1];
и 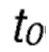 является первоначальным значением параметра температуры, который взят из диапазона [0, 1000].
является первоначальным значением параметра температуры, который взят из диапазона [0, 1000].
Также предпочтительным является, если текущий коэффициент потери пакетов  вычисляется в соответствии с формулой
вычисляется в соответствии с формулой
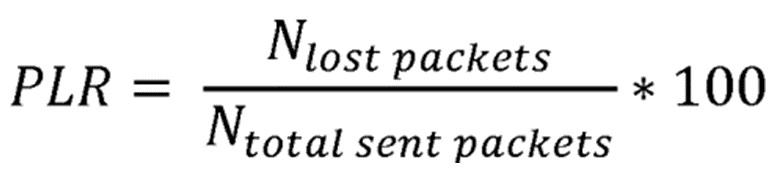
где 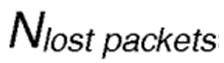 является текущим количеством потерянных пакетов, а количество суммарных отправленных пакетов
является текущим количеством потерянных пакетов, а количество суммарных отправленных пакетов  находится в диапазоне [0, 100]. При продолжающемся процессе выборов соседа и последующей переадресации пакета, значение PLR может меняться непредсказуемым образом, тем самым оказывая воздействие на надежность созданных маршрутов. В таком сценарии, предпочтительным является модификация параметра температуры τ в соответствии с вышеупомянутой формулой.
находится в диапазоне [0, 100]. При продолжающемся процессе выборов соседа и последующей переадресации пакета, значение PLR может меняться непредсказуемым образом, тем самым оказывая воздействие на надежность созданных маршрутов. В таком сценарии, предпочтительным является модификация параметра температуры τ в соответствии с вышеупомянутой формулой.
Другим предложенным улучшением, обеспечивающим преимущество в основанной на RL маршрутизации, является мера, по которой в случае, когда пакет теряется, отправляющий узел формирует отрицательное значение вознаграждения и использует его в процессе для обновления своей таблицы маршрутов для того, чтобы пометить выбранный маршрут, как менее привлекательный для дальнейших передач.
Здесь предпочтительным является введение экспоненциального увеличения при вычислении отрицательного значения вознаграждения, когда происходят последовательные потери пакетов.
Экспоненциальное увеличение отрицательного значения вознаграждения может быть вычислено в соответствии с формулой:
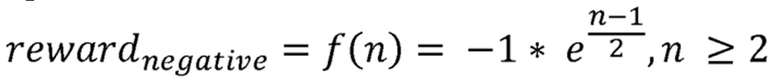
где n соответствует количеству последовательных событий потери пакетов, при этом для 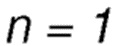 отрицательное значение вознаграждения устанавливается в -1. Это приводит к значительному преимуществу в наблюдаемых значениях Коэффициента Потери Пакетов, в сравнении с традиционной схемой маршрутизации.
отрицательное значение вознаграждения устанавливается в -1. Это приводит к значительному преимуществу в наблюдаемых значениях Коэффициента Потери Пакетов, в сравнении с традиционной схемой маршрутизации.
Изобретение также касается соответственно выполненного устройства для выполнения способа адаптивного выбора маршрута.
Изобретение также касается соответственно выполненной компьютерной программы с инструкциями, которая выполняет способ для выбора маршрута, когда выполняется в вычислительной системе.
В нижеследующем изобретение будет описано посредством предпочтительных вариантов осуществления при обращении к фигурам некоторого количества чертежей. Здесь:
Фиг. 1 показывает иллюстрацию средней эффективности e-Жадного способа выбора действия в имитации игры 10-рукого бандита для разных e-Жадных параметров;
Фиг. 2 показывает пример создания беспроводной ячеистой сети с помощью портативных устройств;
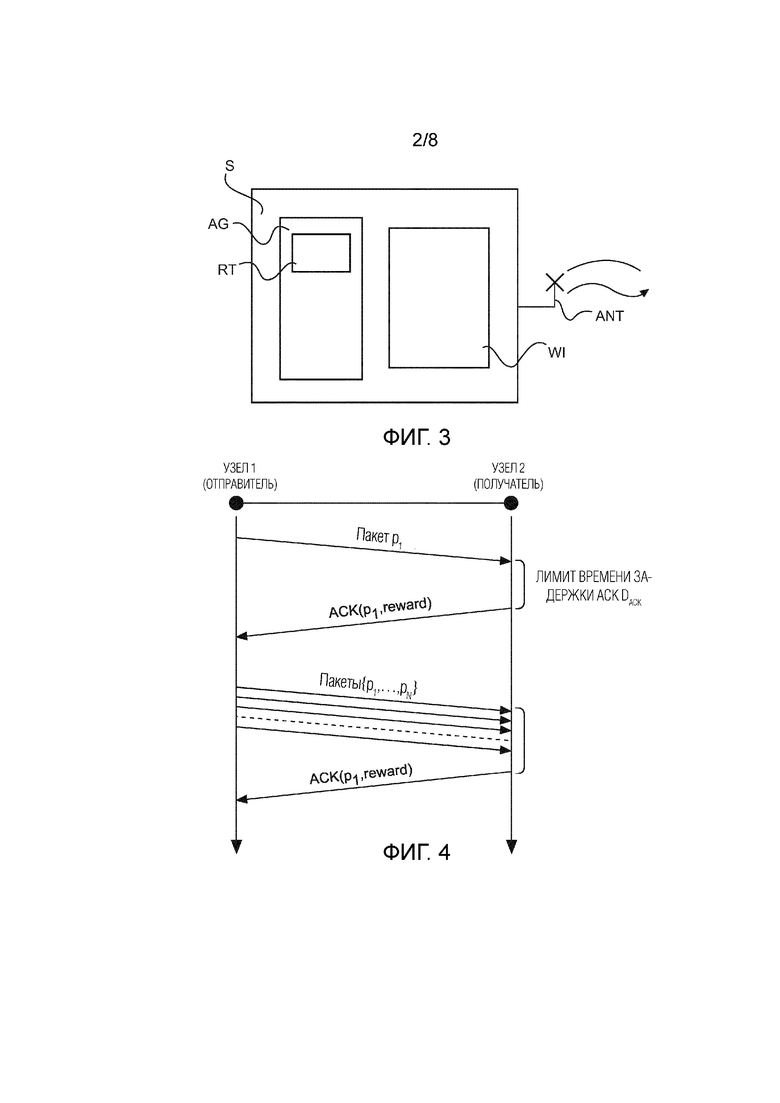
Фиг. 3 показывает упрощенную структурную схему узла;
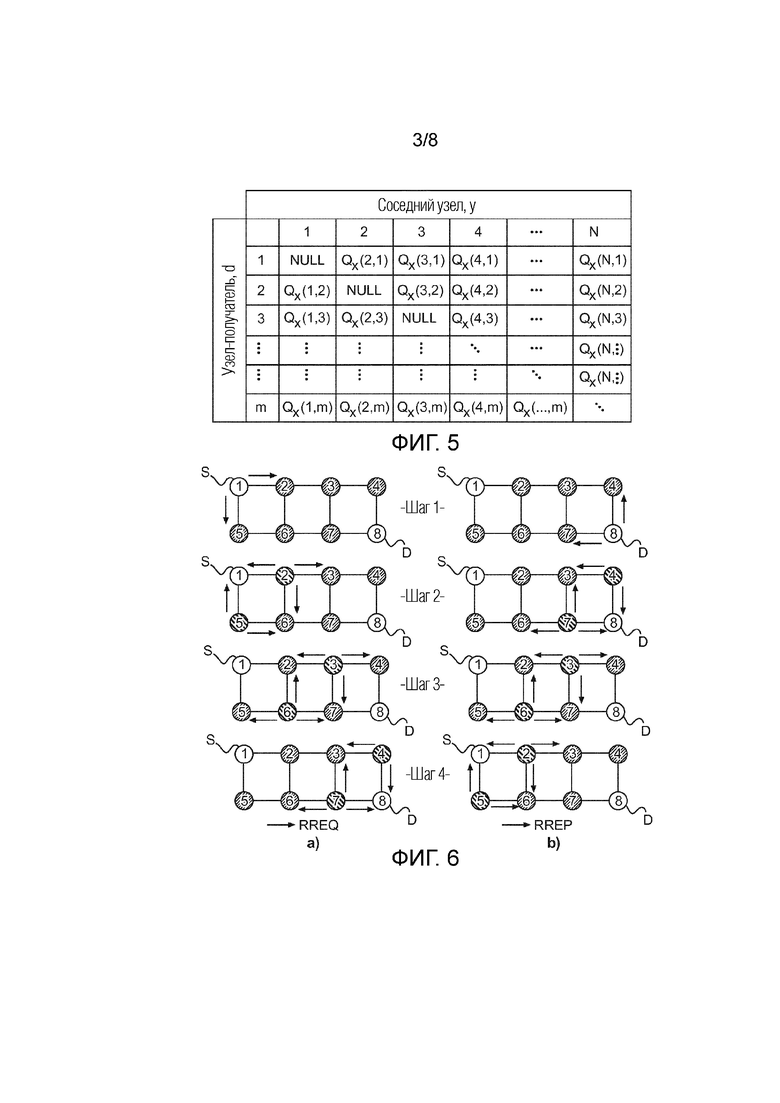
Фиг. 4 показывает общую схему переадресации пакета и приема информации обратной связи в сообщении ACK;
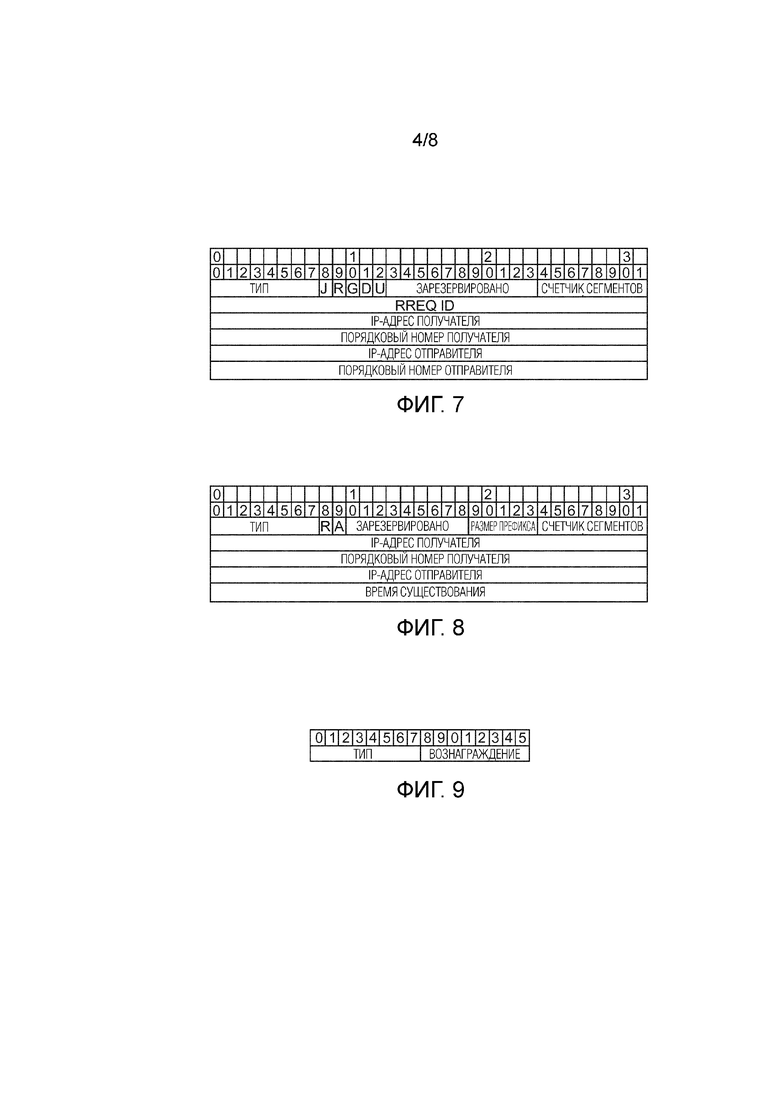
Фиг. 5 показывает принципиальную структуру таблицы маршрутов с оценочными значениями 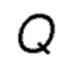 для действий переадресации пакета непосредственным соседям;
для действий переадресации пакета непосредственным соседям;
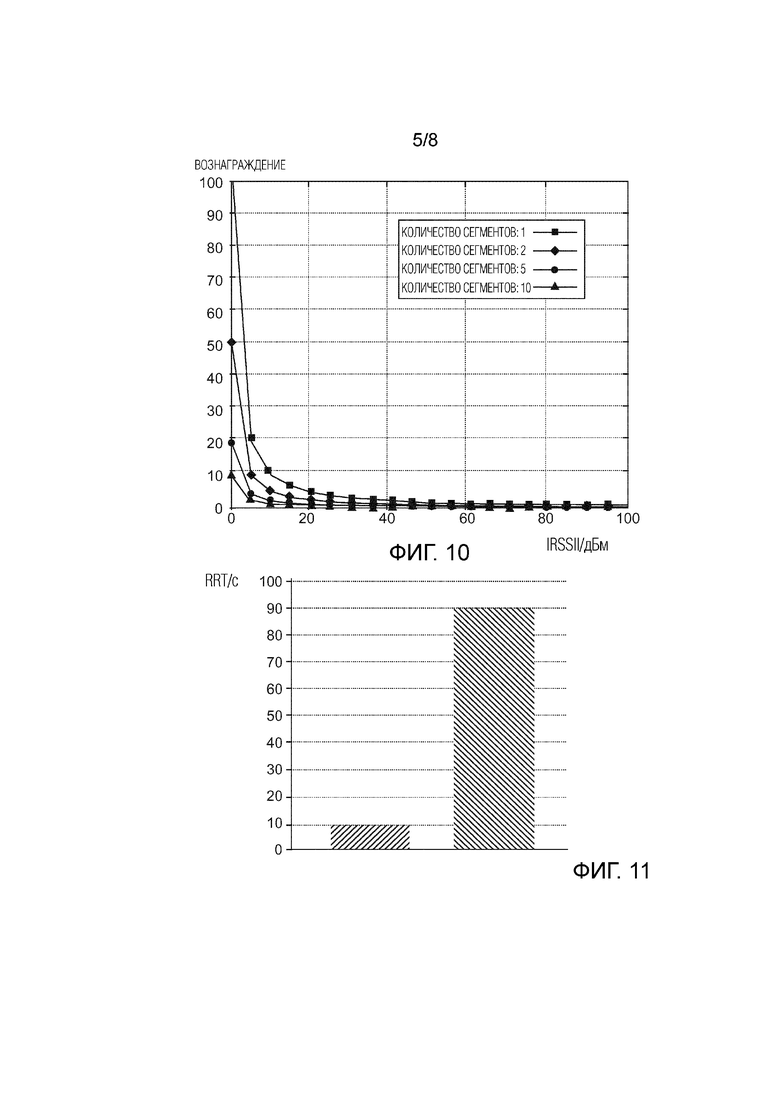
Фиг. 6 показывает шаги широковещательной передачи сообщения RREQ от узла-источника к узлу-получателю через некоторое количество сегментов на виде a), и шаги широковещательной передачи сообщения RREP от узла-получателя к узлу-источнику через некоторое количество сегментов на виде b);
Фиг. 7 показывает формат поля полезной нагрузки в сообщении RREQ;
Фиг. 8 показывает формат поля полезной нагрузки в сообщении RREP;
Фиг. 9 показывает формат поля полезной нагрузки в сообщении ACK;
Фиг. 10 показывает пример изменения оценочных значений вознаграждения в зависимости от значения RSSI для разных случаев с разным количеством сегментов;
Фиг. 11 показывает улучшение результирующих значений времени обнаружения маршрута RRT в сравнении с традиционной схемой маршрутизации;
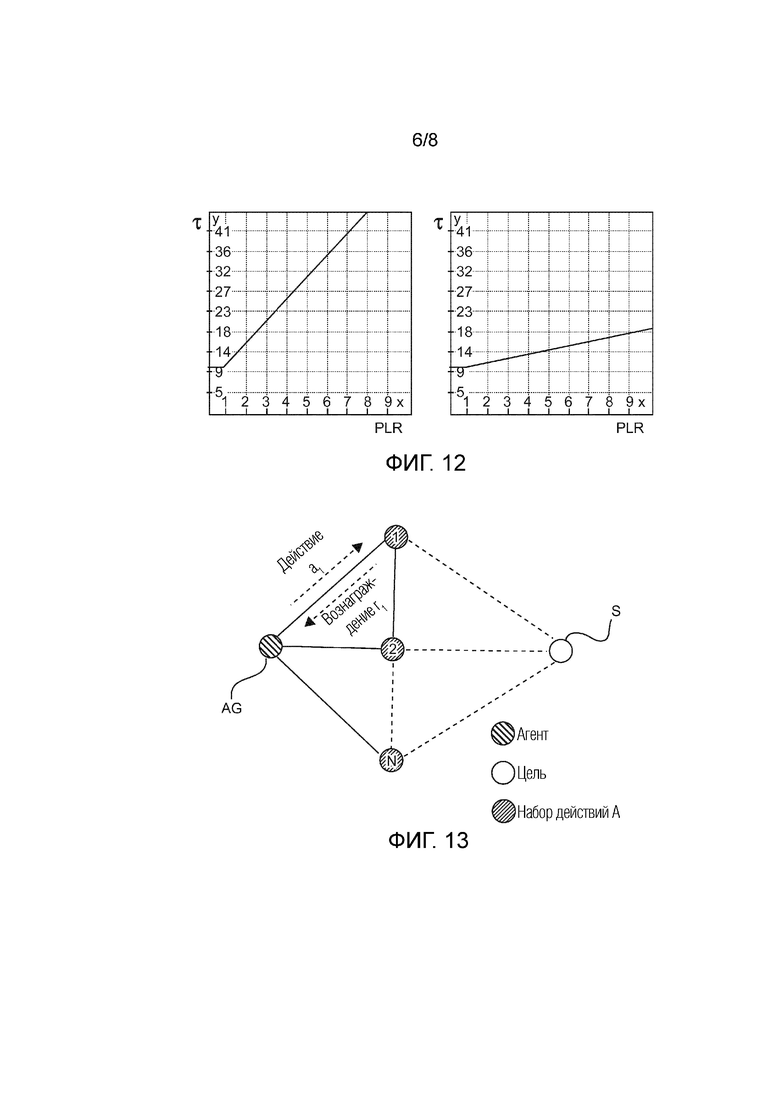
Фиг. 12 показывает примеры предложенной функции температуры для распределения Гиббса-Больцмана с коэффициентом роста k равным 0.5 с левой стороны и k равным 0.1 с правой стороны;
Фиг. 13 иллюстрирует общую задачу переадресации пакета в многосегментной сети при применении процесса маршрутизации на основании подхода обучения с подкреплением;
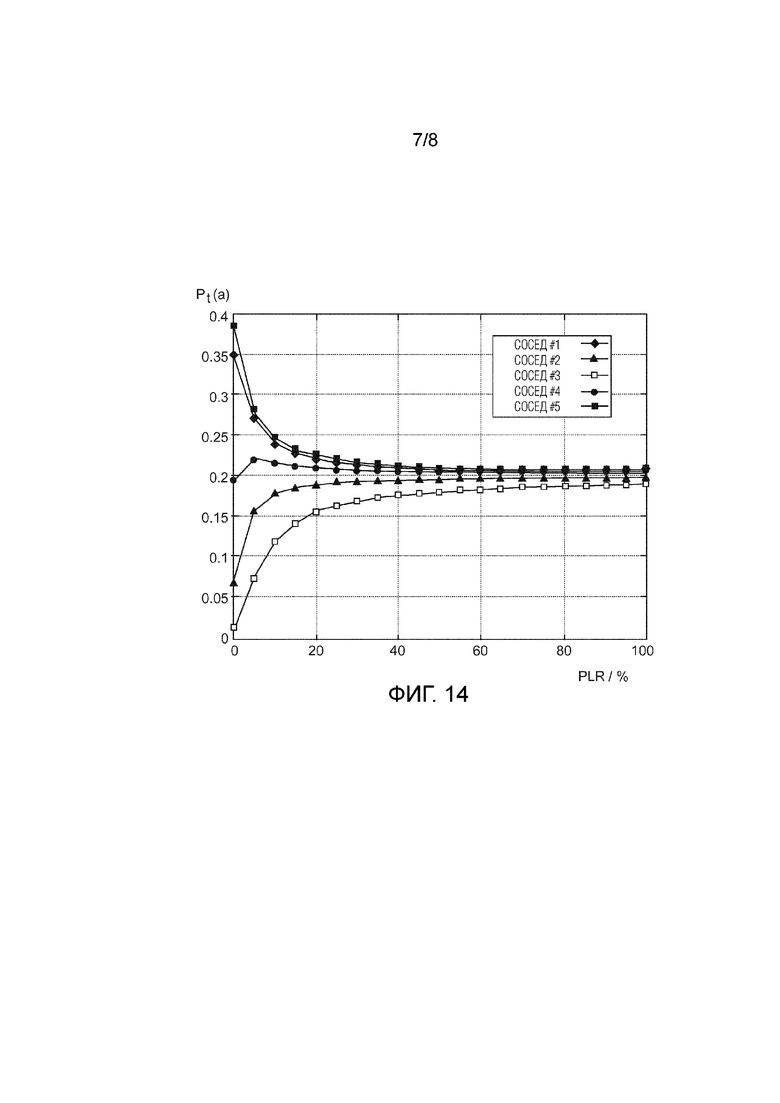
Фиг. 14 показывает пример изменения вероятностей выбора соседа 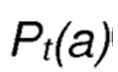 в зависимости от значения коэффициента потери пакетов PLR;
в зависимости от значения коэффициента потери пакетов PLR;
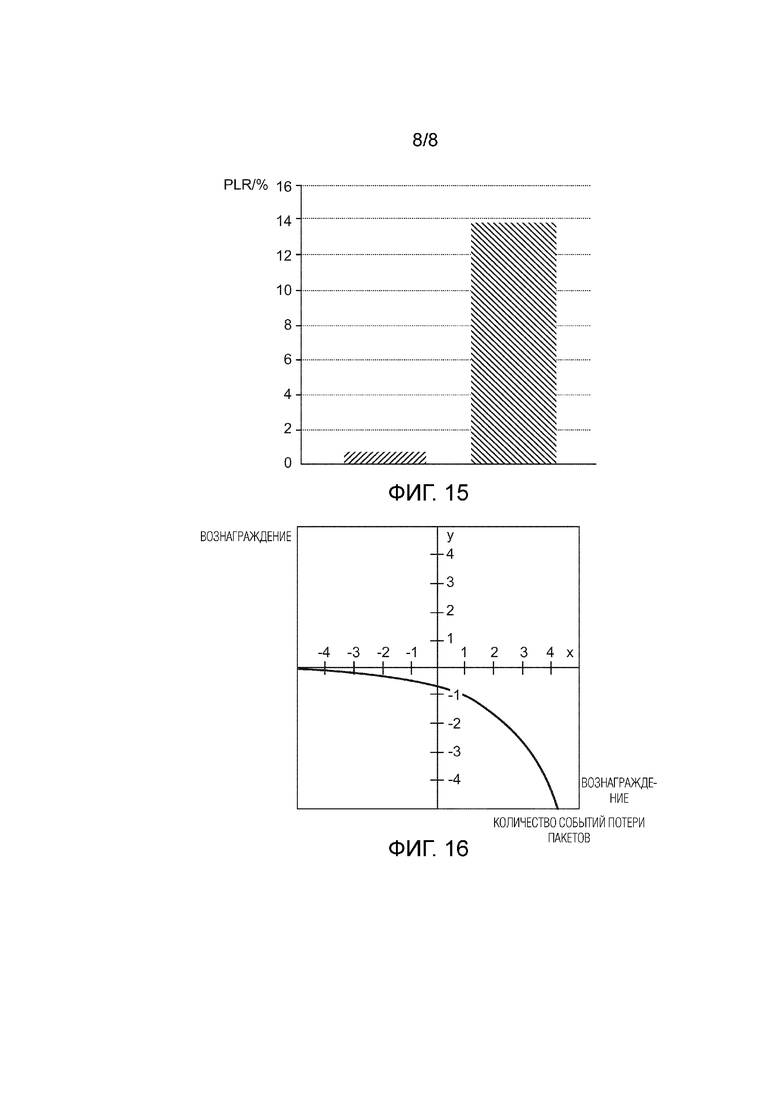
Фиг. 15 показывает улучшение результирующего коэффициента потери пакетов при использовании предложенного алгоритма основанной на RL маршрутизации в сравнении с традиционной схемой маршрутизации; и
Фиг. 16 показывает пример улучшения отрицательного значения вознаграждения в соответствии с дополнительным предложением в зависимости от количества последовательных потерь пакетов.
Настоящее описание иллюстрирует принципы настоящего изобретения. Таким образом, следует принимать во внимание, что специалисты в соответствующей области техники смогут разработать различные компоновки, которые, несмотря на то, что явно не описано или не показано в данном документе, воплощают принципы изобретения.
Все примеры и условные формулировки, приведенные в данном документе, предназначены для образовательных целей, чтобы помочь читателю понять принципы изобретения и концепции, внесенные автором изобретения в развитие области техники, и должны толковаться как не ограничивающие такие конкретно приведенные примеры и условия.
Более того, все формулировки в данном документе, которые приводят принципы, аспекты и варианты осуществления изобретения, как, впрочем, и их конкретные примеры, предназначены для охвата как их структурных, так и функциональных эквивалентов. Дополнительно, предполагается, что такие эквиваленты включают в себя как известные в настоящий момент эквиваленты, так и, впрочем, эквиваленты, разработанные в будущем, т.е. любые разработанные элементы, которые выполняют ту же самую функцию, независимо от структуры.
Таким образом, например, специалистам в соответствующей области техники должно быть понятно, что схемы, представленные в данном документе, представляют концептуальные виды иллюстративных схем, воплощающих принципы изобретения.
Функции различных элементов, показанных на фигурах, могут быть обеспечены посредством использования выделенного аппаратного обеспечения, как, впрочем, и аппаратного обеспечения, выполненного с возможностью исполнения программного обеспечения в ассоциации с подходящим программным обеспечением. Когда обеспечиваются процессором, функции могут быть предоставлены одним выделенным процессором, одним совместно используемым процессором или множеством отдельных процессоров, некоторые из которых могут быть совместно используемыми. Более того, явное использование понятия «процессор» или «контроллер» не следует толковать, как обращенное исключительно к аппаратному обеспечению, выполненному с возможностью исполнения программного обеспечения, и может неявным образом включать, без ограничения, аппаратное обеспечение цифрового сигнального процессора (DSP), постоянную память (ROM) для хранения программного обеспечения, память с произвольным доступом (RAM) и энергонезависимое хранилище.
Также может быть включено другое аппаратное обеспечение, обычное и/или специализированное. Аналогичным образом, любые переключатели, показанные на фигурах, являются лишь концептуальными. Их функция может быть выполнена посредством операции программной логики, посредством выделенной логики, посредством взаимодействия программного управления и выделенной логики, или даже вручную, причем конкретная методика, выбирается исполнителем, как более конкретно понятная из контекста.
В формуле изобретения подразумевается, что любой элемент, выраженный как средство для выполнения указанной функции, охватывает любой способ выполнения той функции, включая, например, a) сочетание элементов схемы, которые выполняют ту функцию, или b) программное обеспечение в любой форме, включая, вследствие этого, встроенное программное обеспечение, микрокод или аналогичное, объединенные с подходящей схемой для исполнения того программного обеспечения для выполнения функции. Изобретение, определенное такими пунктами формулы изобретения, основано на том факте, что функциональные возможности, обеспечиваемые различными перечисленными средствами, объединяются и собираются вместе так, как того требует формула изобретения. Таким образом, считается, что любые средства, которые могут обеспечить эти функциональные возможности, эквивалентны тем, что показаны в данном документе.
Пример беспроводной самоорганизующейся сети, изображается на Фиг. 2. Данный чертеж показывает множество портативных устройств, таких как лэптопы или планшетные компьютеры и интеллектуальные телефоны (смартфоны) и маршрутизаторы. Непосредственные линии связи между этими устройства изображены с помощью пунктирных линий. Одна станция-источник в левой стороне помечена ссылочным знаком S. Одна станция-получатель в правой стороне помечена ссылочным знаком D. В отношении пакета данных, отправленного узлом-источником S, должна быть осуществлена маршрутизация через сеть к узлу-получателю D. Возможные сетевые пути с 5 сегментами, по которым может быть осуществлена маршрутизация пакета, указаны стрелками. Считается, что все участники в сети связи, изображенной на Фиг. 2, оборудованы интерфейсом WLAN в соответствии с одним из стандартов семейства стандартов IEEE 802.11xx, например, стандартом IEEE 802.11s.
В соответствии с предложением, используется технология основанной на обучении с подкреплением маршрутизации. Главная логика концепции обучения с подкреплением состоит в том факте, что присутствует действие, которое выбирается из набора действий, и что существует обратная связь в форме вознаграждения по выбранному действию, которая модифицирует некоторые критерии выбора (значение оценки) для данного действия в будущем. На Фиг. 3 концепция обучения с подкреплением иллюстрируется в форме структурной схемы беспроводного сетевого узла. Это может быть любым сетевым узлом, но тот что показан, соответствует узлу-источнику S. В нем присутствует агент AG, который принимает решение о том, по какому пути пакет от узла-источника S к получателю D должен быть отправлен в дальнейшем. Чтобы иметь возможность принимать такое решение, агент AG обновляет таблицу маршрутизации RT, в которой для каждой линии связи до непосредственного соседа данного узла записано значение оценки , представляющее собой коэффициент успешности, когда пакет, маршрутизации которого осуществлялась в данном направлении, достигает узла-получателя D. Для каждого пакета агент AG принимает решение о маршрутизации, приводящее к передаче пакета через схему WLAN WI и антенну ANT, причем агент AG ожидает приема обратно пакета квитирования ACK, в котором значение вознаграждения возвращается от соседа, который принимает тот пакет. Агент AG по приему обратно пакета квитирования, или по обнаружению потери такого пакета, обновляет свою таблицу маршрутизации RT. Все эти задачи агента теперь будут объяснены более подробно. Агент может быть реализован в форме прикладной программы, которая инсталлируется в памяти сетевого узла и выполняется процессором сетевого узла.
Сначала, общая концепция обучения с подкреплением (RL) приводится в соответствие с алгоритмом адаптивной переадресации пакетов следующим образом:
- для каждого адреса-получателя, по которому должен быть доставлен пакет:
-- в каждом узле присутствует агент, как в концепции RL
-- непосредственные соседи узла соответствуют набору действий a, которые агент может предпринять
-- таблица маршрутов RT соответствует набору значений оценки
-- когда узел отправляет пакет выбранному соседу, то это соответствует выбранному и инициированному действию
-- принятое сообщение ACK, в ответ на отправленный пакет данных, от выбранного соседа соответствует принятому значению вознаграждения.
Когда узел, с пакетом для адреса получателя, выбирает «узел следующего сегмента» из списка его непосредственных соседей и отправляет туда пакет, он затем ожидает сообщение квитирования ACK от данного соседа, которое содержит некоторое значение вознаграждения для выбора данного соседа. Данный процесс отправки пакета p1 и приема обратно пакета квитирования ACK(p1, reward) иллюстрируется на Фиг. 4. Могут быть отправлены дополнительные пакеты с p2 по pN и могут ожидаться дополнительные пакеты квитирования. Существует период лимита времени задержки ACK, который требуется в принимающем узле для обработки, пока пакет ACK сможет быть отправлен обратно. Такая обработка включает в себя вычисление значения вознаграждения, которое возвращается обратно в пакете ACK.
Существует три возможных результата, которые могут произойти в течение фазы передачи:
- пакет данных или пакет ACK теряется во время передачи:
В данном случае, отправляющий узел не примет пакет ACK, таким образом он автоматически назначит некоторое отрицательное значение вознаграждения для выбранного действия. Это справедливо, потому что, если пакет или пакет ACK постоянно теряется при отправке конкретному соседу, то это означает, что, либо узел перешел в автономный режим, либо узел вышел из диапазона передачи при перемещении, либо беспроводная линия связи стала слишком ненадежной (по различным причинам, связанным с проблемами беспроводной передачи), либо узел слишком перегружен входящим трафиком.
В любом случае, имеет смысл уменьшить вероятность выбора этого конкретного соседа для передачи пакетов данных с заданным адресом получателя. Это делается путем назначения отрицательного значения вознаграждения для вычисления обновленной оценочной записи значения в таблице маршрутов.
- ACK принимается с низким значением вознаграждения:
Это означает, что сосед, который принял пакет данных, имеет путь к получателю, но этот путь либо неоптимальный по длине (слишком много сегментов), либо качество дальнейших линий связи плохое. Таким образом, узел будет медленно уменьшать значение оценки для данного конкретного выбора в долгосрочной перспективе, увеличивая вероятности выбора других соседей.
- ACK принимается с высоким значением вознаграждения:
Если принятый пакет ACK содержит высокое значение вознаграждения, то это означает, что этот сосед имеет хороший путь к узлу-получателю, таким образом, ему может отдаваться предпочтение как хорошему решению переадресации. При отправке пакетов такому соседу и получении обратно пакетов ACK с высокими значениями вознаграждения, общее значение оценки данного соседа будет увеличиваться в долгосрочной перспективе, вследствие чего, вероятность выбора данного действия будет увеличиваться, обеспечивая хорошую маршрутизацию данных по этой линии связи.
Пример таблицы маршрутов RT с постоянно обновляемыми оценочными значениями иллюстрируется на Фиг. 5.
Далее будет объяснено, каким образом будет инициализирован процесс основанной на RL маршрутизации. Первоначальное распределение значений вознаграждения для путей по всей сети имеет место на фазе обнаружения маршрута, проиллюстрированной на Фиг. 6. Узел осуществляет широковещательную передачу сообщения запроса маршрута RREQ его непосредственным соседям, и соседи осуществляют повторную широковещательную передачу данного RREQ дальше в сеть. Это процесс иллюстрируется на Фиг. 6a. Данная методика широковещательной передачи часто называется «веерной рассылкой» на современном техническом уровне, поскольку RREQ-сообщение в основном переадресовывается каждому узлу в сети, до тех пор, пока либо не достигается счетчик времени существования широковещательной передачи TTL, либо дублированное сообщение RREQ не принимается узлом, который уже отправил это сообщение RREQ ранее. Формат сообщения RREQ показан на Фиг. 7. Отмечается, что показывается только поле полезной нагрузки сообщения RREQ. Таким образом, каждый узел в сети обновляет свою собственную таблицу маршрутизации RT актуальной информацией о маршруте в направлении адреса источника RREQ-сообщения (на адрес узла-источника на Фиг. 7).
Возврат обратно сообщений ответа маршрута RREP начинается, как только узел-получатель D принял RREQ-сообщение. Переадресация RREP-сообщения происходит аналогичным образом, но в противоположном направлении. Прямой процесс RREP-сообщения иллюстрируется на Фиг. 6b. Формат RREP-сообщения показан на Фиг. 8. В дополнение, формат сообщения ACK показан на Фиг. 9. Отмечается, что первый байт в поле полезной нагрузки сообщения ACK содержит тип ACK. Второй байт содержит значение вознаграждения.
На нулевой стадии, когда узел-источник S не обладает информацией о маршруте в направлении узла-получателя D, его значения оценки для передач в направлении адреса получателя устанавливаются в первоначальное значение 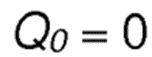 по умолчанию. В другом варианте осуществления доступный диапазон оценочных значений вознаграждения для инициализации определяется как:
по умолчанию. В другом варианте осуществления доступный диапазон оценочных значений вознаграждения для инициализации определяется как:
[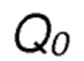 , |
, |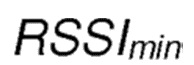 |], где:
|], где:
является минимальным возможным значением индикатора силы принятого сигнала, которое агент может принять от физического сетевого интерфейса, по приему соответствующего сообщения RREQ/RREP. Запись RSSI может быть считана с помощью соответствующей команды в программном обеспечении драйвера беспроводного сетевого адаптера, причем значение представляет силу сигнала в дБм.
После этого первого этапа инициализации, инициируется процедура «обнаружения пути», где осуществляется передача широковещательных сообщений RREQ и сообщения RREP возвращаются обратно также в режиме широковещательной связи. В то время, как сообщения распространяются по сети, каждый узел, который принял RREQ-сообщение с адресом узла-источника S и адресом узла-получателя D, см. Фиг. 5a, обновляет таблицу маршрутов оценочным значением вознаграждения, вычисленным в принимающем узле, в соответствии со следующей функцией вознаграждения:
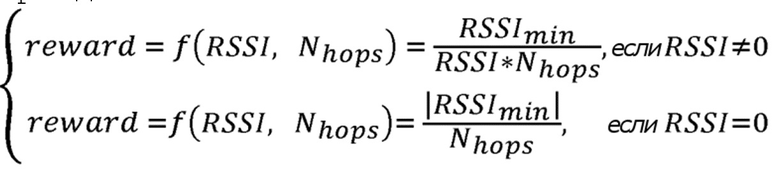 (2)
(2)
где:
 является оценочным значением вознаграждения для действия передачи в направлении соседа, который достигается за количество сегментов
является оценочным значением вознаграждения для действия передачи в направлении соседа, который достигается за количество сегментов 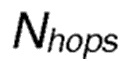 ,
,
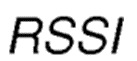 является Индикатором Силы Принятого Сигнала в дБм, который меняется в диапазоне [-100, 0], где 0 соответствует самому сильному принятому сигналу;
является Индикатором Силы Принятого Сигнала в дБм, который меняется в диапазоне [-100, 0], где 0 соответствует самому сильному принятому сигналу;
является количеством сегментов, которое прошло сообщение RREQ от узла-источник к узлу-получателю, соответственно.
То же самое происходит, когда сообщение RREP принимается в узле. В конце данного процесса таблица маршрутов RT полностью инициализируется, т.е. каждый узел обладает для всех своих непосредственных соседей записью в таблице маршрутов касательно оценочного значения , отражающего результат фазы обнаружения пути.
Фиг. 10 показывает зависимость между вычисленным значением вознаграждения и , с количеством сегментов [1, 2, 5, 10]. Минимальное значение RSSI соответствует 10дБм.
Таким образом, когда заканчивается процедура обнаружения пути, все узлы, включая источник и получатель, получили оценочные значения вознаграждения в направлении адреса получателя, как, впрочем, и в направлении адреса источника. С учетом формулы выше, значения оценки распределяются на основании значения счетчика сегментов от источника/получателя, как, впрочем, и индикатора RSSI. Таким образом, на первоначальной стадии отдается предпочтение более коротким маршрутам с сильными значениями принятого сигнала.
Механизм формирования вознаграждения играет важную роль во всей процедуре переадресации пакета, поскольку он определяет степень «гибкости» в решениях переадресации пакета. Например, если значения вознаграждения сильно не меняются между «хорошими» и «плохими» маршрутами, то узлы просто не будут использовать более оптимальные пути большую часть времени, взамен, существует высокая вероятность того, что пакеты будут идти самым неэффективным образом, вызывая больше потерь пакетов и задержек. Таким же образом, если вознаграждение с очень небольшим отрицательным значением будет формироваться после неудачи приема сообщения ACK, то соответствующая запись будет уменьшать значение ошибки для этого маршрута слишком медленно, так что последующие пакеты буду вероятно отправляться и теряться по тому же самому маршруту с более высокой вероятностью.
Для решения данной проблемы предлагается следующее поведение: Когда узел принимает пакет от отправляющего узла, он вычисляет свое среднее значение оценки в направлении адреса получателя принятого пакета и отправляет его обратно в сообщении ACK. Принимающий узел получает среднее значение, и делит его на абсолютное значение принятого сообщения. Таким образом, предлагается следующая функция вознаграждения обратной связи:
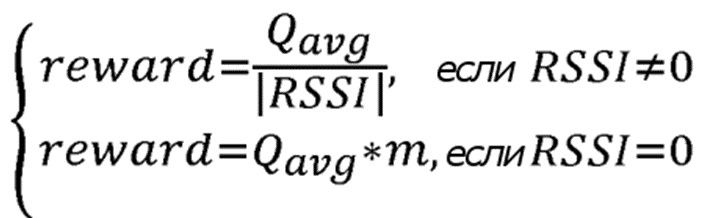 (3)
(3)
где:
является индикатором силы принятого сигнала в дБм, который меняется в диапазоне [-100, 0], где 0 соответствует самому сильному принятому сигналу;
m является коэффициентом умножения, который увеличивает вознаграждение, когда сила принятого сигнала достигает максимального значения (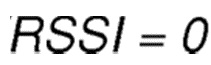 ), и меняется в диапазоне: [1, 100];
), и меняется в диапазоне: [1, 100];
где
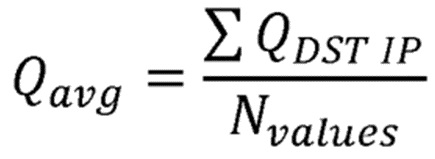
является вычисленным средним оценочным значением вознаграждения для наблюдаемых передач в направлении IP-адреса получателя, которое отправляется обратно отправителю в сообщении ACK.
Данная формула соответствует конкретному случаю оценки первоначальных значений с количеством сегментов равным 1, см. формулу (2). После приема сообщения ACK, узел-отправитель получает общую информацию о том «насколько хорош данный сосед для такого получателя» или «насколько хороши маршруты данного соседа» в направлении адреса получателя. Если среднее значение оценки высокое, это означает, что данный сосед располагается ближе к получателю, или он обладает многими другими хорошими возможностями для переадресации пакета дальше. В противоположность, если среднее значение низкое, тогда либо сосед располагается дальше от получателя, либо он имеет слишком мало возможностей переадресации для заданного получателя. В любом случае, узел, после приема ACK, обновляет свою собственную запись маршрута в направлении данного соседа либо высоким, либо низким значением вознаграждения.
Фиг. 11 показывает более хорошее значение RRT (Время Восстановления Маршрута) с левой стороны в сравнении с традиционной схемой маршрутизации с правой стороны.
Дополнительное улучшение касается способа выбора следующего сегмента, где предлагается основывать это решение на функции распределения вероятностей Гиббса-Больцмана, которая имеет следующую формулу:
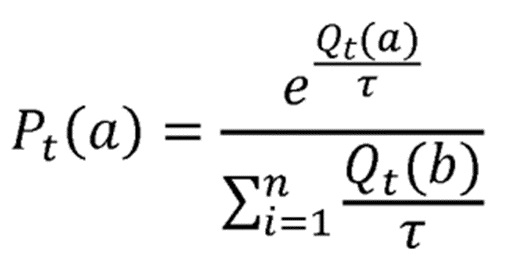 (4)
(4)
где:
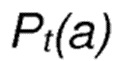 соответствует вероятности выбора действия a на текущем шаге t;
соответствует вероятности выбора действия a на текущем шаге t;
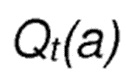 соответствует оценочному значению вознаграждения действия a на текущем шаге t;
соответствует оценочному значению вознаграждения действия a на текущем шаге t;
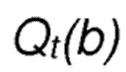 соответствует оценочному значению вознаграждения альтернативного действия
соответствует оценочному значению вознаграждения альтернативного действия 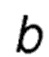 на текущем шаге t; и
на текущем шаге t; и
τ соответствует положительному параметру в функции вероятности Гиббса-Больцмана, который называется температурой.
Высокие значения параметра температуры τ делают выборы действий равномерно вероятными, т.е. вероятности выбора всех возможных действий будут равными или очень близкими друг к другу. С другой стороны, низкие температуры вызывают большие различия в вероятностях выбора между действиями.
Если 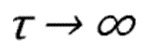 , то способ обращается в классический способ Жадного выбора.
, то способ обращается в классический способ Жадного выбора.
Предлагается, чтобы вероятности выбора адаптивно определялись из текущего значения Коэффициента Потери Пакетов (PLR), путем изменения параметра температуры τ следующим образом:
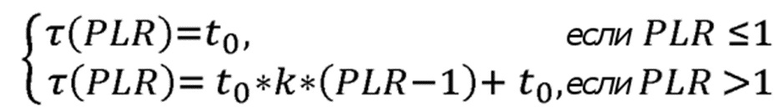 (5)
(5)
где:
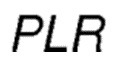 соответствует Коэффициенту Потери Пакетов, со значениями в диапазоне [0, 100]. Значение PLR вычисляется по формуле:
соответствует Коэффициенту Потери Пакетов, со значениями в диапазоне [0, 100]. Значение PLR вычисляется по формуле:
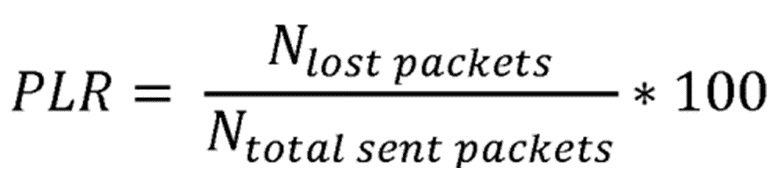
τ соответствует параметру температуры из распределения Гиббса-Больцмана;
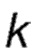 соответствует предложенному коэффициенту роста, равному 0.5 по умолчанию, и который меняется в диапазоне: [0, 1];
соответствует предложенному коэффициенту роста, равному 0.5 по умолчанию, и который меняется в диапазоне: [0, 1];
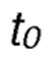 соответствует первоначальному значению параметра τ, которое меняется в диапазоне: [0, 1000].
соответствует первоначальному значению параметра τ, которое меняется в диапазоне: [0, 1000].
Пример функции 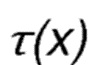 изображен на Фиг. 12, где x соответствует значению PLR. Слева функция показана для значения равного 0.5, а с правой стороны для значения равного 0.1.
изображен на Фиг. 12, где x соответствует значению PLR. Слева функция показана для значения равного 0.5, а с правой стороны для значения равного 0.1.
Таким образом, предложенная функция определяет форму распределения весовых коэффициентов (вероятностей) выбора заданного действия, в зависимости от текущих значения PLR, что является целью данного предложения. Далее предоставляется пример.
Фиг. 13 показывает беспроводную ячеистую сеть с некоторым количеством участников. Фигура показывает общую задачу основанной на RL маршрутизации, где текущий узел, чья очередь переадресовывать входящий пакет, помечен ссылочным знаком A. Предполагается, что узел A имеет 5 непосредственных соседей, т.е. N=5 и должен переадресовать входящий пакет в направлении заданного узла-получателя D, который в проиллюстрированном примере находится на расстоянии двух сегментов. Непосредственные линии связи проиллюстрированы жирными линиями, а опосредованные линии связи с точки зрения узла A проиллюстрированы пунктирными линиями.
После стадии обнаружения пути, когда созданы первоначальные весовые коэффициенты в направлениях узла-источника и узла получателя, с использованием алгоритма и формул, как объяснено выше, узел-источник обладает списком оценочных значений вознаграждения для всех непосредственных соседей в направлении получателя - Q(n). В заданном примере с 5 непосредственными соседями, размер списка равен 5.
Предположим, что после инициализации, список весовых коэффициентов содержит следующее, здесь представленное в формате словаря компьютерного языка Python:
Q(n) = {n1 : 50.0, n2 : 33.3, n3 : 11.1, n4 : 44.0, n5 : 51.0}
Используя упомянутое распределение Гиббса-Больцмана, вероятности выбора действия - 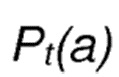 для всех действий на шаге 0 будут вычислены с параметром температуры
для всех действий на шаге 0 будут вычислены с параметром температуры 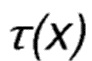 равным 10 (предполагая, что первоначальное значение PLR соответствует 0). В этом случае мы получаем следующие результаты для вероятностей выбора:
равным 10 (предполагая, что первоначальное значение PLR соответствует 0). В этом случае мы получаем следующие результаты для вероятностей выбора:
P(a) = {n1 : 0.35, n2 : 0.07, n3 : 0.01, n4 : 0.2, n5 : 0.37}
Таким образом, сосед 5 будет выбираться большую часть времени - с 37% вероятности выбора на первоначальном шаге 0.
При продолжающемся процессе выборов соседа и последующей переадресации пакета, значение 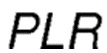 может меняться непредсказуемым образом, тем самым, оказывая влияние на надежность созданных маршрутов.
может меняться непредсказуемым образом, тем самым, оказывая влияние на надежность созданных маршрутов.
В таких сценариях, параметр температуры τ модифицируется в соответствии с формулой выше.
Например, в течение переадресации пакета, на шаге 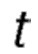 , оценочное значение изменилось с 0 до 20 процентов. Соответственно, новый параметр τ имеет новое значение в виде:
, оценочное значение изменилось с 0 до 20 процентов. Соответственно, новый параметр τ имеет новое значение в виде:
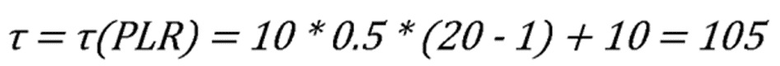
Новый список вероятностей выбора , который получается на шаге , дает:
Pt(a) = {n1 : 0.22, n2 : 0.19, n3 : 0.15, n4 : 0.21, n5 : 0.22}
Как видно, на новом шаге , вероятности выбора соседей 1 и 5 уменьшились, при том, что шансы выбора соседей 2 и 3 значительно увеличились. Эта модификация вероятностей выбора подразумевает выбор ранее менее привлекательных маршрутов, поскольку общая надежность канала снизилась кардинально (с 0 до 20%). Это показывает, что гораздо более гибкий процесс выбора маршрута получается в результате ненадежных условий связи, позволяя гарантировать то, что альтернативные маршруты исследуются более часто.
Фиг. 14 иллюстрирует зависимость между вероятностью выбора соседа и значением при ограничениях заданного примера, с первоначальными оценочными значениями вознаграждения равными 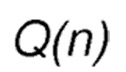 , как перечислено выше. Совершенно очевидно, сто существует значительная разница в вероятности выбора для 5 соседей, когда значение PLR находится в диапазоне от 0 до 20%.
, как перечислено выше. Совершенно очевидно, сто существует значительная разница в вероятности выбора для 5 соседей, когда значение PLR находится в диапазоне от 0 до 20%.
Для того, чтобы быстро определять изменения в маршрутах, классические протоколы маршрутизации используют так называемые служебные сообщения Ошибки Маршрута PERR, широковещательная передача которых осуществляется точно таким же образом как RREP-сообщений в случае обнаружения ошибки маршрута. Данное поведение радикально увеличивает количество служебных сообщений в сети, тем самым снижая общую эффективность сети.
В течение процесса выбора соседа и переадресации пакета, узел-отправитель ожидает входящее сообщение ACK, содержащее вычисленное значение вознаграждения для выбора этого соседа. Однако, из-за заданных условий связи в беспроводных многосегментных сетях с нестабильными линиями связи и высокими вероятностями помех, потерь сигнала, мобильности узлов и т.п., отправленные пакеты могут быть легко потеряны. Как объяснено выше, в этом случае, узел-отправитель формирует отрицательное вознаграждение для того, чтобы пометить выбранный маршрут как менее привлекательный для дальнейших передач.
В рамках заданного алгоритма основанной на RL маршрутизации предлагается экспоненциальное увеличение отрицательного значения вознаграждения. Эта экспоненциальная функция позволяет узлу-отправителю адаптироваться значительно быстрее к событиям последующих потерь пакетов, вследствие чего, увеличивая шансы быстрого нахождения альтернативного маршрута. Таким образом, значительно уменьшается Время Восстановления Маршрута, что является решающим для эффективной связи в беспроводных многосегментных сетях.
Предложенная экспоненциальная функция для формирования отрицательного вознаграждения является следующей:
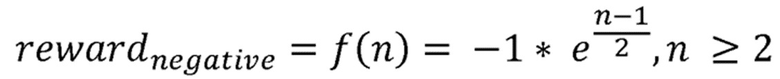 (6)
(6)
n - количество последовательных событий потери пакетов (т.е. когда был достигнут лимит времени приема на стороне отправителя).
Фиг. 15 показывает значительное преимущество в значении Коэффициента Потери Пакетов (PLR), предоставленного в процентах, в сравнении с традиционной схемой маршрутизации.
Предложенное улучшение формирования отрицательного значения вознаграждения также представлено в примере:
Узел-источник выбрал и отправил пакет данных в направлении соседа. В течение определенного лимита времени, узлу-источнику не удалось принять сообщение ACK от соседа. Таким образом, узел-источник формирует и применяет отрицательное значение вознаграждения к выбранному действию, которое на первом шаге равно -1.
На втором шаге, узел выбирает и отправляет следующий пакет тому же самому соседу и также не принимает сообщение ACK. Таким образом, он формирует новое отрицательное значение вознаграждения по формуле 6, которое тогда равно:
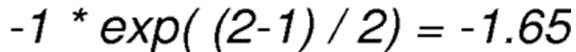 .
.
На дальнейших этапах отрицательное значение вознаграждения будет сильно увеличиваться из-за экспоненциальной функции, как проиллюстрировано на Фиг. 16. Обратите внимание на то, что отрицательные значения n не определены, даже несмотря на то, что Фиг. 16, показывает вычисленные результаты таких значений.
Следует понимать, что предложенный способ и устройство могут быть реализованы в различных формах аппаратного обеспечения, программного обеспечения, встроенного программного обеспечения, процессоров общего назначения или их сочетании. Процессоры особого назначения могут включать в себя проблемно-ориентированные интегральные микросхемы (ASIC), компьютеры с сокращенным набором команд (RISC) и/или программируемые вентильные матрицы (FPGA). Предпочтительно, предложенный способ и устройство реализуются в качестве сочетания аппаратного обеспечения и программного обеспечения. Более того, программное обеспечение предпочтительно реализуется в качестве прикладной программы, вещественным образом воплощенной на программном запоминающем устройстве. Прикладная программа может быть выгружена в, и исполнена посредством, машину, содержащую любую подходящую архитектуру. Предпочтительно, машина реализуется на компьютерной платформе с аппаратным обеспечением, таким как один или несколько центральных блоков обработки (CPU), память с произвольным доступом (RAM) и интерфейс(ы) ввода/вывода (I/O). Компьютерная платформа также включает в себя операционную систему и код микрокоманды. Различные процессы и функции, описанные в данном документе, могут либо быть частью кода микрокоманды, либо частью прикладной программы (или их сочетанием), который исполняется через операционную систему. В дополнение, различные другие периферийные устройства могут быть соединены с компьютерной платформой, такие как дополнительное устройство хранения данных и печатающее устройство.
Должно быть понятно, что элементы, показанные на фигурах, могут быть реализованы в различных формах аппаратного обеспечения, программного обеспечения или их сочетания. Предпочтительно, эти элементы реализуются в сочетании аппаратного обеспечения и программного обеспечения на одном или нескольких надлежащим образом запрограммированных устройствах общего назначения, которые могут включать в себя процессор, память и интерфейсы ввода/вывода. Здесь, фраза «связанный» определяется как означающая, непосредственное соединенный или опосредованно соединенный через один или несколько промежуточных компонентов. Такие промежуточные компоненты могут включать в себя компоненты, основанные как на аппаратном обеспечении, так и программном обеспечении.
Дополнительно следует понимать, что так как некоторые из составляющих компонентов системы и этапы способа, изображенные на сопроводительных фигурах, предпочтительно реализуются в программном обеспечении, то фактические соединения между компонентами системы (или этапами процесса) могут отличаться в зависимости от способа, которым программируется предложенный способ и устройство. Принимая во внимание приведенные в данном документе идеи, специалист в соответствующей области техники сможет рассмотреть эти и подобные реализации или конфигурации предложенного способа и устройства.
Список литературы
[1] Ahmed A., Hongchi Shi и Yi Shang «A Survey on Network Protocols for Wireless Sensor Networks», IEEE, 2003 г.
[2] David B. Johnson, David A. Maltz и Josh Broch. «DSR: The Dynamic Source Routing Protocol for Multi-Hop Wireless Ad Hoc Networks, in Ad Hoc Networking», под редакцией Charles E. Perkins, Глава 5, стр. 139-172, AddisonWesley, 2001г.
[3] C. Perkins, E. Belding-Royer и S. Das «Ad hoc On-Demand Distance Vector (AODV) Routing», IETF RFC 3561, июль 2002 г.
[4] T. Clausen и P. Jacquet «Optimized Link State Routing Protocol (OLSR)», RFC 3626 (Пробный), октябрь 2003 г.
[5] A. Neumann, C. Aichele, M. Lindner и S. Wunderlich, «Better Approach To Mobile Ad-hoc Networking (B.A.T.M.A.N.)», IETF Draft 2008 г.
[6] Perkins Charles E., Bhagwat Pravin «Highly Dynamic Destination-Sequenced Distance-Vector Routing (DSDV) for Mobile Computers», Лондон Англия UK, SIGCOMM 94-8/94.
[7] «IEEE Draft Standard for Information Technology-Telecommunications and information exchange between systems-Local and metropolitan area networks - Specific requirements - Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) specifications-Amendment 10: Mesh Networking», IEEE P802.11s/D10.0, март 2011 г., стр. 1-379, 29 2011 г.
[8] R. S. Sutton и A. G. Barto, «Reinforcement Learning: An Introduction», The MIT Press, март 1998 г.
[9] Chang, Y.-H., Ho, T., «Mobilized ad-hoc networks: A reinforcement learning approach». В: ICAC 2004 «Proceedings of the First International Conference on Autonomic Computing», стр. 240-247, IEEE Computer Society, США (2004).
[10] Landau, Lev Davidovich и Lifshitz, Evgeny Mikhailovich (1980) [1976] «Statistical Physics. Course of Theoretical Physics», (3-е издание), Oxford Pergamon Press, ISBN 0-7506-3372-7.
Изобретение относится к области беспроводной связи. Технический результат заключается в обеспечении возможности инициализации таблицы маршрутов, которая настраивается в узле для принятия решения о следующем сегменте (hop) при маршрутизации пакетов в направлении к получателю. Процедура обнаружения пути выполняется для определения пути от узла-источника к узлу-получателю, при этом в процедуре обнаружения пути выполняется процедура обучения с подкреплением, причем узлом-источником осуществляется широковещательная передача сообщения запроса маршрута, в отношении которого осуществляется повторная широковещательная передача некоторого количества сегментов одним или несколькими узлами, принимающими сообщение запроса маршрута, при этом узел-получатель в ответ на прием упомянутого сообщения запроса маршрута осуществляет широковещательную передачу сообщения ответа маршрута, в отношении которого осуществляется повторная широковещательная передача некоторого количества сегментов одним или несколькими узлами, принимающими сообщение ответа маршрута, причем узел, который принял упомянутое сообщение запроса маршрута или упомянутое сообщение ответа маршрута, обновляет таблицу маршрутов соответствующими оценочными значениями вознаграждения для соответствующего действия, для оценки упомянутого значения вознаграждения в процедуре обнаружения пути используется функция вознаграждения, которая зависит от индикатора силы принятого сигнала, измеренного во время приема упомянутого сообщения запроса маршрута или сообщения ответа маршрута, и количества сегментов, которое через сообщение запроса маршрута или сообщение ответа маршрута распространялось в сети для достижения принимающего узла. 3 н. и 11 з.п. ф-лы, 16 ил.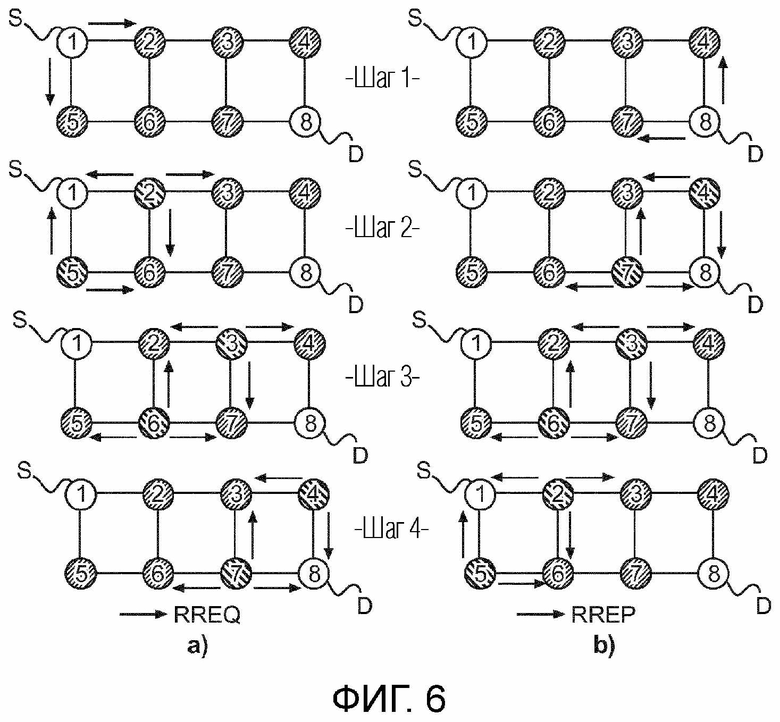
1. Способ адаптивного выбора маршрута в узле беспроводной ячеистой сети связи, причем процедура обнаружения пути выполняется для определения пути от узла-источника (S) к узлу-получателю (D), причем узлом-источником (S) осуществляется широковещательная передача сообщения запроса маршрута (RREQ), в отношении которого осуществляется повторная широковещательная передача некоторого количества сегментов одним или несколькими узлами, принимающими сообщение запроса маршрута (RREQ), при этом узел-получатель (D) в ответ на прием упомянутого сообщения запроса маршрута (RREQ) осуществляет широковещательную передачу сообщения ответа маршрута (RREP), в отношении которого осуществляется повторная широковещательная передача некоторого количества сегментов одним или несколькими узлами, принимающими сообщение ответа маршрута (RREP), причем узел, который принял упомянутое сообщение запроса маршрута (RREQ) или упомянутое сообщение ответа маршрута (RREP), обновляет таблицу маршрутов (RT) соответствующими оценочными значениями вознаграждения (Qx) для соответствующего широковещательного действия, отличающийся тем, что в процедуре обнаружения пути выполняется процедура обучения с подкреплением, и тем, что для оценки упомянутых значений вознаграждения (Qx) в процедуре обнаружения пути используется функция вознаграждения, которая зависит от индикатора силы принятого сигнала RSSI, измеренного во время приема упомянутого сообщения запроса маршрута (RREQ) или сообщения ответа маршрута (RREP), и количества сегментов, которое через сообщение запроса маршрута (RREQ) или сообщение ответа маршрута (RREP) распространялось в сети для достижения принимающего узла, при этом функция вознаграждения определяется в форме
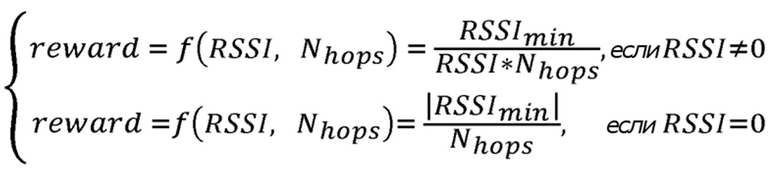 ,
,
где  является результирующим оценочным значением вознаграждения для действия по отправке сообщения следующему соседу, от которого было принято сообщение запроса маршрута (RREQ) или сообщение ответа маршрута (RREP), и
является результирующим оценочным значением вознаграждения для действия по отправке сообщения следующему соседу, от которого было принято сообщение запроса маршрута (RREQ) или сообщение ответа маршрута (RREP), и 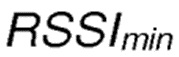 является минимальным возможным значением индикатора силы принятого сигнала RSSI, которое может быть измерено беспроводным сетевым интерфейсом (WI).
является минимальным возможным значением индикатора силы принятого сигнала RSSI, которое может быть измерено беспроводным сетевым интерфейсом (WI).
2. Способ по п.1, в котором измеряется в значениях дБм, которые меняются в диапазоне [-100,0], где ноль в данном диапазоне соответствует самому сильному принятому сигналу.
3. Способ по одному из предшествующих пунктов, в котором таблица маршрутизации (RT) также будет обновляться во время общей процедуры переадресации пакета в отсутствие процедуры обнаружения пути, при этом процедура обучения с подкреплением также используется для общей процедуры переадресации пакета, причем функция вознаграждения обратной связи используется для оценки значений вознаграждения, при этом упомянутая функция вознаграждения обратной связи определяется в форме
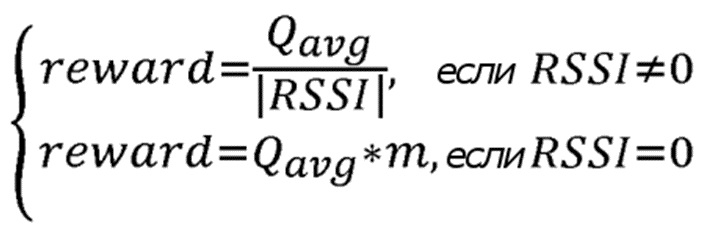 ,
,
где m является коэффициентом умножения, который увеличивает значение вознаграждения, когда индикатор силы принятого сигнала 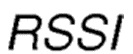 достигает максимального значения ноль, при этом коэффициент умножения находится в диапазоне: [1, 100];
достигает максимального значения ноль, при этом коэффициент умножения находится в диапазоне: [1, 100];
где 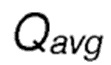 является вычисленным средним оценочным значением вознаграждения, которое принимается в отправляющем узле в сообщении обратной связи (ACK) для передачи от отправляющего узла.
является вычисленным средним оценочным значением вознаграждения, которое принимается в отправляющем узле в сообщении обратной связи (ACK) для передачи от отправляющего узла.
4. Способ по п.3, в котором вычисляется в соответствии с формулой
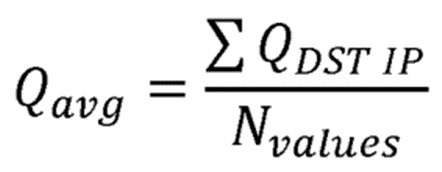 ,
,
где 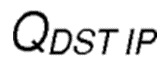 является оценочным значением вознаграждения для передачи от отправляющего узла в направлении узла-получателя (D), где
является оценочным значением вознаграждения для передачи от отправляющего узла в направлении узла-получателя (D), где 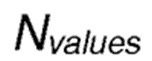 является количеством значений, по которым должно быть вычислено среднее.
является количеством значений, по которым должно быть вычислено среднее.
5. Способ по одному из предшествующих пунктов, в котором узел принимает решение о следующем сегменте на номере t шага на основе вероятностей выбора, которые вычисляются с помощью функции распределения вероятностей 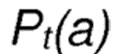 , где является вероятностью выбора действия a передачи в следующем сегменте на номере t шага.
, где является вероятностью выбора действия a передачи в следующем сегменте на номере t шага.
6. Способ по п.5, в котором функция распределения вероятностей соответствует функции распределения Гиббса-Больцмана в соответствии с формулой
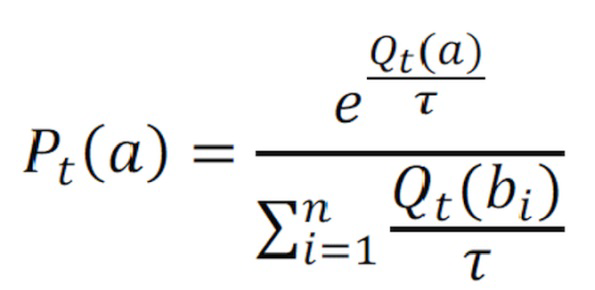
с 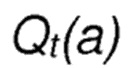 , являющимся оценочным значением вознаграждения действия a передачи в следующем сегменте на текущем шаге t,
, являющимся оценочным значением вознаграждения действия a передачи в следующем сегменте на текущем шаге t,
с 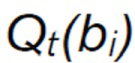 , являющимся оценочным значением вознаграждения альтернативного действия bi передачи в следующем сегменте на текущем шаге t, и
, являющимся оценочным значением вознаграждения альтернативного действия bi передачи в следующем сегменте на текущем шаге t, и
τ , являющимся положительным параметром температуры для распределения Гиббса-Больцмана, и i, являющимся значением индекса.
7. Способ по п.5 или 6, в котором параметр температуры адаптивно задается в зависимости от текущего коэффициента потери пакетов PLR.
8. Способ по п.7, в котором параметр температуры адаптивно задается в соответствии с формулой
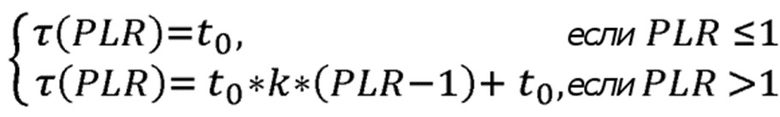 ,
,
где k является коэффициентом роста, который равен 0.5 по умолчанию и который меняется в диапазоне [0, 1]; и
t 0 является первоначальным значением параметра температуры, который взят из диапазона [0, 1000].
9. Способ по п.8, в котором текущий коэффициент потери пакетов PLR вычисляется в соответствии с формулой
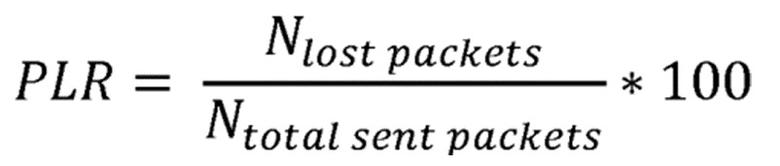 ,
,
где 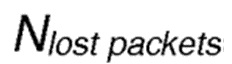 является текущим количеством потерянных пакетов, а количество всех отправленных пакетов
является текущим количеством потерянных пакетов, а количество всех отправленных пакетов  находится в диапазоне [0, 100].
находится в диапазоне [0, 100].
10. Способ по одному из предшествующих пунктов, в котором, в случае когда пакет теряется, отправляющий узел формирует отрицательное значение вознаграждения и использует его в процессе для обновления таблицы маршрутов (RT) для того, чтобы пометить выбранный маршрут как менее привлекательный для дальнейших передач.
11. Способ по п.10, в котором при вычислении отрицательного значения вознаграждения применяется экспоненциальное увеличение, когда происходят последовательные потери пакетов.
12. Способ по п.11, в котором экспоненциальное увеличение отрицательного значения вознаграждения вычисляется в соответствии с формулой
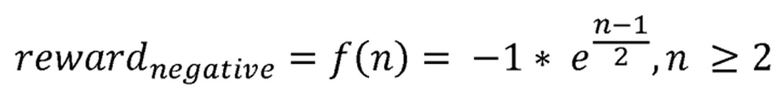 ,
,
где n соответствует количеству последовательных событий потери пакетов, при этом для n = 1 отрицательное значение вознаграждения устанавливается в -1.
13. Устройство, выполненное с возможностью осуществления этапов выбора маршрута способом по одному из предшествующих пунктов.
14. Машиночитаемый носитель информации, на котором сохранен программный код, которым при его исполнении в компьютерной системе выполняются этапы адаптивного выбора маршрута в соответствии со способом по одному из пп.1-12.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 8149715 B1, 03.04.2012 | |||
| Колосоуборка | 1923 |
|
SU2009A1 |
| СПОСОБ И УСТРОЙСТВО ПЕРЕДАЧИ ДИНАМИЧЕСКОЙ ИНФОРМАЦИИ В БЕСПРОВОДНОМ ИНФОРМАЦИОННОМ КАНАЛЕ | 2011 |
|
RU2565054C2 |

