Область техники
[0001] Настоящее описание относится к кодированию видео, и в частности к методикам разделения изображения видеоданных.
Уровень техники
[0002] Возможности цифрового видео можно применять в широком спектре устройств, включая цифровые телевизоры, ноутбуки или настольные компьютеры, планшетные компьютеры, устройства цифровой записи, цифровые медиаплееры, устройства для видеоигр, сотовые телефоны, включая так называемые смартфоны, медицинские устройства визуализации и т. п. Цифровое видео может быть закодировано в соответствии со стандартом кодирования видеосигналов. Стандарты кодирования видеосигналов могут включать в себя методики сжатия видео. Примеры стандартов кодирования видеосигналов включают в себя ISO/IEC MPEG-4 Visual и ITU-T H.264 (также известный как ISO/IEC MPEG-4 AVC), а также высокоэффективное кодирование видеоизображений (HEVC). HEVC описан в документе High Efficiency Video Coding (HEVC), Rec. ITU-T H.265, апрель 2015 г., включенном в настоящий документ путем ссылки и далее упоминаемом в настоящем документе как ITU-T H.265. В настоящее время рассматриваются расширения и усовершенствования ITU-T H.265 для разработки стандартов кодирования видеосигналов следующего поколения. Например, Экспертная группа по кодированию видеосигналов ITU-T (VCEG) и ISO/IEC (Экспертная группа по вопросам движущихся изображений (MPEG) (совместно именуемые Объединенной группой по исследованию видео (JVET)) изучают потенциальную потребность в стандартизации будущей технологии кодирования видеосигналов с возможностью сжатия, которая значительно превышает возможности сжатия нынешнего стандарта HEVC. В документе The Joint Exploration Model 6 (JEM 6), Algorithm Description of Joint Exploration Test Model 6 (JEM 6), ISO/IEC JTC1/SC29/WG11: JVET-F1001v3, April 2017, Hobart, AU, и документе Joint Exploration Model 7 (JEM 7), Algorithm Description of Joint Exploration Test Model 7 (JEM 7), ISO/ IEC JTC1/SC29/WG11: JVET-G1001, июль 2017 г., Турин, Италия, каждый из которых включен в настоящий документ путем ссылки, описаны функции кодирования, являющиеся предметом скоординированного исследования тестовой модели JVET, как способные усовершенствовать технологию кодирования видеосигналов сверх возможностей ITU-T H.265. Следует отметить, что функции кодирования JEM 6 и JEM 7 реализованы в эталонном программном обеспечении JEM. Употребляемый в настоящем документе термин JEM используется для общей ссылки на алгоритмы, включенные в JEM 6 и JEM 7, и реализации эталонного программного обеспечения JEM.
[0003] Методики сжатия видео позволяют снижать требования к данным для хранения и передачи видеоданных. Методики сжатия видео могут снижать требования к данным посредством применения присущих избыточностей в видеопоследовательности. Методики сжатия видео могут предусматривать подразделение видеопоследовательности на последовательно меньшие части (т.е. группы кадров в видеопоследовательности, кадр в группе кадров, срезы в кадре, элементы кодового дерева (например, макроблоки) в срезе, блоки кодирования в элементе кодового дерева и т. д.). Методики кодирования с внутренним (интра) прогнозированием (например, внутрикадровое (пространственное)) и методики внешнего (интер) прогнозирования (т.е. межкадровое (временное)) можно использовать для генерации значений разности между кодируемым элементом видеоданных и опорным элементом видеоданных. Значения разности могут назваться остаточными данными. Остаточные данные могут быть закодированы как квантованные коэффициенты преобразования. Элементы синтаксиса могут относиться к остаточным данным и опорному блоку кодирования (например, индексам режима внутреннего прогнозирования, векторам движения и векторам блоков). Остаточные данные и элементы синтаксиса можно подвергать энтропийному кодированию. Энтропийно закодированные остаточные данные и элементы синтаксиса могут быть включены в совместимый битовый поток.
Сущность изобретения
[0004] В целом настоящее описание представляет различные методики кодирования видеоданных. В частности, настоящее описание относится к методикам разделения изображения видеоданных. Следует отметить, что, хотя методики настоящего описания описаны применительно к ITU-T H.264, ITU-T H.265 и JEM, они в целом применимы к кодированию видеосигналов. Например, описанные в настоящем документе методики кодирования могут быть использованы в системах кодирования видеосигналов (включая системы кодирования видеосигналов на основе будущих стандартов кодирования видеосигналов), включающих в себя блочные структуры, методики внутреннего прогнозирования, методики внешнего прогнозирования, методики преобразования, методики фильтрации и/или методики энтропийного кодирования, отличные от включенных в ITU-T H.265 и JEM. Таким образом, ссылка на ITU-T H.264, ITU-T H.265 и/или JEM предназначена для описательных целей и не должна толковаться как ограничивающая объем методик, описанных в настоящем документе. Следует отметить, что включение документов посредством ссылки в настоящий документ дополнительно предназначено для описательных целей и не должно толковаться как ограничение или создание двусмысленности в отношении употребляемых в настоящем документе терминов. Например, в случае, если включенная ссылка содержит определение термина, отличное от другой включенной ссылки, и/или в контексте настоящего документа термин следует интерпретировать таким образом, что он в широком смысле включает в себя каждое соответствующее определение и/или каждое из конкретных определений в виде альтернативы.
[0005] Аспект настоящего изобретения представляет собой способ разделения видеоданных для кодирования видеосигналов, включающий: получение видеоблока, включающего в себя значения выборки для первого компонента видеоданных и второго компонента видеоданных; разделение значений выборок для первого компонента видеоданных и второго компонента видеоданных в соответствии со структурой разделения первого двоичного дерева квадродерева; и дополнительное разделение выборок в соответствии со вторым двоичным деревом квадродерева для значений выборок первого компонента видеоданных, включенных в узлы первого двоичного дерева квадродерева, связанных с внутренним типом прогнозирования.
Краткое описание чертежей
[0006] [ФИГ. 1] На ФИГ. 1 приведена концептуальная схема, иллюстрирующая пример группы изображений, кодируемых в соответствии с разделением двоичного дерева квадродерева в соответствии с одной или более методиками настоящего описания.
[ФИГ. 2] На ФИГ. 2 приведена концептуальная схема, иллюстрирующая пример двоичного дерева квадродерева в соответствии с одной или более методиками настоящего описания.
[ФИГ. 3] На ФИГ. 3 приведена концептуальная схема, иллюстрирующая разделение двоичного дерева квадродерева видеокомпонента в соответствии с одной или более методиками настоящего описания.
[ФИГ. 4] На ФИГ. 4 приведена концептуальная схема, иллюстрирующая пример формата выборки видеокомпонента в соответствии с одной или более методиками настоящего описания.
[ФИГ. 5] На ФИГ. 5 приведена концептуальная схема, иллюстрирующая возможные структуры кодирования для блока видеоданных в соответствии с одной или более методиками настоящего описания.
[ФИГ. 6A] На ФИГ. 6A приведена концептуальная схема, иллюстрирующая примеры кодирования блока видеоданных в соответствии с одной или более методиками настоящего описания.
[ФИГ. 6B] На ФИГ. 6B приведена концептуальная схема, иллюстрирующая примеры кодирования блока видеоданных в соответствии с одной или более методиками настоящего описания.
[ФИГ. 7] На ФИГ. 7 приведена блок-схема, иллюстрирующая пример системы, которая может быть выполнена с возможностью кодирования и декодирования видеоданных в соответствии с одной или более методиками настоящего описания.
[ФИГ. 8] На ФИГ. 8 приведена блок-схема, иллюстрирующая пример видеокодера, который может быть выполнен с возможностью кодирования видеоданных в соответствии с одной или более методиками настоящего описания.
[ФИГ. 9] На ФИГ. 9 приведена концептуальная схема видеокомпонента, иллюстрирующая разделение в соответствии с одной или более методиками настоящего описания.
[ФИГ. 10] На ФИГ. 10 приведена концептуальная схема видеокомпонента, иллюстрирующая разделение в соответствии с одной или более методиками настоящего описания.
[ФИГ. 11A] На ФИГ. 11A приведена концептуальная схема, иллюстрирующая разделение в соответствии с одной или более методиками настоящего описания.
[ФИГ. 11B] На ФИГ. 11B приведена концептуальная схема, иллюстрирующая разделение в соответствии с одной или более методиками настоящего описания.
[ФИГ. 12] На ФИГ. 12 приведена концептуальная схема, иллюстрирующая разделение двоичного дерева квадродерева видеокомпонента в соответствии с одной или более методиками настоящего описания.
[ФИГ. 13] На ФИГ. 13 приведена концептуальная схема, иллюстрирующая разделение видеокомпонента в соответствии с одной или более методиками настоящего описания.
[ФИГ. 14A] На ФИГ. 14A приведена концептуальная схема, иллюстрирующая разделение двоичного дерева квадродерева видеокомпонента в соответствии с одной или более методиками настоящего описания.
[ФИГ. 14B] На ФИГ. 14B приведена концептуальная схема, иллюстрирующая разделение двоичного дерева квадродерева видеокомпонента в соответствии с одной или более методиками настоящего описания.
[ФИГ. 15A] На ФИГ. 15A приведена концептуальная схема, иллюстрирующая разделение двоичного дерева квадродерева видеокомпонента в соответствии с одной или более методиками настоящего описания.
[ФИГ. 15B] На ФИГ. 15B приведена концептуальная схема, иллюстрирующая разделение двоичного дерева квадродерева видеокомпонента в соответствии с одной или более методиками настоящего описания.
[ФИГ. 16] На ФИГ. 16 приведена блок-схема, иллюстрирующая пример видеодекодера, который может быть выполнен с возможностью декодирования видеоданных в соответствии с одной или более методиками настоящего описания.
Осуществление изобретения
[0007] Видеоконтент обычно включает в себя видеопоследовательности, состоящие из ряда кадров (или изображений). Последовательность кадров может также называться группой изображений (GOP). Каждый видеокадр или изображение может включать в себя множество срезов или мозаичных фрагментов, причем срез или мозаичный фрагмент включает в себя множество видеоблоков. Используемый в настоящем описании термин «видеоблок» может по существу относиться к области изображения, или, в частности, может относиться к самому большому массиву значений выборки, которые могут быть кодированы с прогнозированием, их подразделам и/или соответствующим структурам. Термин «текущий видеоблок» может дополнительно относиться к кодируемой или декодируемой области изображения. Видеоблок может быть определен как массив значений выборки, которые могут быть кодированы с прогнозированием. Следует отметить, что в некоторых случаях значения пикселей (Pic) могут быть описаны как включающие значения выборки для соответствующих компонентов видеоданных, которые также могут упоминаться как цветовые компоненты (например, компоненты яркости (Y) и цветности (Cb и Cr) или красный, зеленый и синий компоненты). Следует отметить, что в некоторых случаях термины «значения пикселей» и «значения выборки» используют взаимозаменяемо. Видеоблоки могут быть упорядочены в изображении в соответствии с типом сканирования (например, растровое сканирование). Видеокодер может выполнять кодирование с прогнозированием для видеоблоков и их подразделов. Видеоблоки и их подразделы могут упоминаться как узлы. Кроме того, в некоторых случаях узел может относиться к концевому узлу, а в некоторых случаях и к корневому узлу.
[0008] ITU-T H.264 определяет макроблок, включающий в себя 16 × 16 выборок яркости. Таким образом, согласно ITU-T H.264 изображение сегментировано на макроблоки. ITU-T H.265 определяет аналогичную структуру элемента кодового дерева (CTU). В ITU-T H.265 изображения сегментированы на CTU. В ITU-T H.265 для изображения размер CTU может быть установлен таким образом, что он будет включать в себя 16 × 16, 32 × 32 или 64 × 64 выборок яркости. В ITU-T H.265 CTU состоит из соответствующих блоков кодового дерева (CTB) для каждого компонента видеоданных (например, яркости (Y) и цветности (Cb и Cr)). Следует отметить, что видео с одним компонентом яркости и двумя соответствующими компонентами цветности может быть описано как имеющее два канала, т.е. канал яркости и канал цветности. В ITU-T H.265 CTU может быть дополнительно разделен в соответствии со структурой разделения квадродерева (QT), что обеспечивает разделение блоков CTB элемента CTU на блоки кодирования (CB). Таким образом, в ITU-T H.265 CTU может быть разделен на концевые узлы квадродерева. В ITU-T H.265 один CB яркости вместе с двумя соответствующими CB цветности и связанными с ними элементами синтаксиса называются элементом кодирования (CU). В ITU-T H.265 посредством сигнализации может быть указан минимально допустимый размер CB. В ITU-T H.265 наименьший минимально допустимый размер CB яркости составляет 8 × 8 выборок яркости. В ITU-T H.265 решение о кодировании области изображения с использованием внутреннего или внешнего прогнозирования принимают на уровне CU.
[0009] В ITU-T H.265 CU связан со структурой элемента прогнозирования (PU) с корнем в CU. В ITU-T H.265 структуры PU позволяют разделять CB яркости и цветности с целью генерации соответствующих опорных выборок. Таким образом, согласно ITU-T H.265 CB яркости и цветности могут быть разделены на блоки прогнозирования (PB) яркости и цветности, причем PB включает в себя блок значений выборки, для которых применяют одно и то же прогнозирование. В ITU-T H.265 CB может быть разделен на 1, 2 или 4 PB. ITU-T H.265 поддерживает размеры PB от 64 × 64 до 4 × 4 выборок. В ITU-T H.265 квадратные PB поддерживаются для внутреннего прогнозирования, причем CB может формировать PB, или CB может быть разделен на четыре квадратных PB (т.е. типы PB внутреннего прогнозирования включают в себя M × M или M/2 × M/2, где M представляет собой высоту и ширину квадрата CB). Помимо квадратных PB ITU-T H.265 поддерживает прямоугольные PB для внешнего прогнозирования, причем CB может быть уменьшен вдвое по вертикали или горизонтали для формирования PB (т.е. типы PB с внешним прогнозированием включают в себя M × M, M/2 × M/2, M/2 × M или M × M/2). Следует отметить, что в ITU-T H.265 для внешнего прогнозирования дополнительно поддерживаются четыре асимметричных разделения PB, причем CB разделяют на два PB на одной четверти высоты (вверху или внизу) или ширины (слева или справа) CB (т.е. асимметричные разделения включают в себя M/4 × M слева, M/4 × M справа, M × M/4 сверху и M × M/4 снизу). Данные внутреннего прогнозирования (например, элементы синтаксиса режима внутреннего прогнозирования) или данные внешнего прогнозирования (например, элементы синтаксиса данных движения), соответствующие PB, используют для создания опорных и/или прогнозированных значений выборки для PB.
[0010] JEM определяет CTU, имеющий максимальный размер 256 × 256 выборок яркости. JEM определяет структуру блоков квадродерева и двоичного дерева (QTBT). В JEM структура QTBT позволяет осуществлять дополнительное разделение концевых узлов четверичных деревьев в соответствии со структурой двоичного дерева (BT). Таким образом, в JEM структура двоичного дерева позволяет рекурсивно разделять концевые узлы квадродерева по вертикали или горизонтали. На ФИГ. 1 приведен пример разделения CTU (например, CTU, имеющий размер 256 × 256 выборок яркости) на концевые узлы квадродерева, а концевые узлы квадродерева дополнительно разделяют в соответствии с двоичным деревом. Т.е. на ФИГ. 1 пунктирными линиями обозначены дополнительные разделения двоичного дерева в четверичном дереве. Таким образом, структура двоичного дерева в JEM допускает квадратные и прямоугольные концевые узлы, причем каждый концевой узел включает в себя CB. Как показано на ФИГ. 1, изображение, включенное в GOP, может включать в себя срезы, причем каждый срез включает в себя последовательность CTU, а каждый CTU может быть разделен в соответствии со структурой QTBT. ФИГ. 1 иллюстрирует пример разделения QTBT для одного CTU, включенного в срез. На ФИГ. 2 приведена концептуальная схема, иллюстрирующая пример QTBT, соответствующего примеру разделения QTBT, показанному на ФИГ. 1.
[0011] В JEM QTBT сигнализирован посредством сигнализации флага разделения QT и элементов синтаксиса режима разделения BT. Если флаг разделения QT имеет значение 1, указывается разделение QT. Если флаг разделения QT имеет значение 0, сигнализируется элемент синтаксиса режима BT. Если элемент синтаксиса режима разделения BT имеет значение 0 (т.е. кодовое дерево режима разделения BT=0), двоичное разделение не указывается. Если элемент синтаксиса режима разделения BT имеет значение 1 (т.е. кодовое дерево режима разделения BT=11), указывается режим разделения по вертикали. Если элемент синтаксиса режима разделения BT имеет значение 2 (т.е. кодовое дерево режима разделения BT=10), указывается режим разделения по горизонтали. Разделение BT можно дополнительно выполнять до достижения максимальной глубины BT. Таким образом, согласно JEM QTBT, проиллюстрированное на ФИГ. 2, может быть сигнализировано на основе псевдосинтаксиса, представленного в таблице 1.

[0012] В одном примере при достижении максимальной глубины QT сигнализация флага QT может быть пропущена, а его значение может быть выведено логически, например, как 0. В одном примере, если текущая глубина меньше минимальной глубины QT, сигнализация флага QT может быть пропущена, а его значение может быть выведено логически, например, как 1. В одном примере при достижении максимальной глубины для сигнализации типа разделения соответствующий элемент синтаксиса может не быть сигнализирован в битовом потоке, а его значение может быть выведено логически. В одном примере, если минимальная глубина для сигнализации типа разделения еще не достигнута, соответствующий элемент синтаксиса может не быть сигнализирован в битовом потоке, а его значение может быть выведено логически. В одном примере, если разделение QT не разрешено, а текущая глубина меньше минимальной глубины BT, сигнализация разделения BT может быть модифицирована таким образом, чтобы разделение BT не было равным 0.
[0013] Как показано на ФИГ. 2 и в таблице 1, элементы синтаксиса флага разделения QT и элементы синтаксиса режима разделения BT связаны с глубиной, причем нулевая глубина соответствует корню QTBT, а глубины с более высокими значениями соответствуют последующим глубинам за пределами корня. В JEM компоненты яркости и цветности могут дополнительно иметь отдельные разделения QTBT. Таким образом, в JEM компоненты яркости и цветности могут быть разделены независимо путем сигнализации соответствующих QTBT. На ФИГ. 3 проиллюстрирован пример разделения CTU в соответствии с QTBT для компонента яркости и отдельным QTBT для компонентов цветности. Как показано на ФИГ. 3, если для разделения CTU используют независимые QTBT, CB компонента яркости не должны совпадать и не обязательно совпадают с CB компонентов цветности. В настоящее время в JEM независимые структуры QTBT задействуют для срезов внутреннего прогнозирования.
[0014] Следует отметить, что JEM включает в себя следующие параметры для сигнализации дерева QTBT:
Размер CTU: размер корневого узла квадродерева (например, 256 × 256, 128 × 128, 64 × 64, 32 × 32, 16 × 16 выборок яркости);
MinQTSize: минимально допустимый размер концевого узла квадродерева (например, 16 × 16, 8 × 8 выборок яркости);
MaxBTSize: максимально допустимый размер корневого узла двоичного дерева, т.е. максимальный размер концевого узла квадродерева, который может быть разделен путем двоичного разделения (например, 64 × 64 выборок яркости);
MaxBTDepth: максимально допустимая глубина двоичного дерева, т.е. самый низкий уровень, на котором может происходить двоичное разделение, где концевой узел квадродерева является корнем (например, 3);
MinBTSize: минимально допустимый размер концевого узла двоичного дерева; т.е. минимальная ширина или высота двоичного концевого узла (например, 4 выборки яркости).
[0015] Следует отметить, что в некоторых примерах MinQTSize, MaxBTSize, MaxBTDepth и/или MinBTSize могут быть различными для разных компонентов видеосигнала.
[0016] В JEM CB используют для прогнозирования без дальнейшего разделения. Т.е. в JEM CB может быть блоком значений выборок, к которым применяют такое же прогнозирование. Таким образом, концевой узел JEM QTBT может быть аналогом PB в ITU-T H.265.
[0017] Формат выборки видео, который можно также называть форматом цветности, может определять количество выборок цветности, включенных в CU, по отношению к количеству выборок яркости, включенных в CU. Например, в случае формата выборки 4:2:0 частота дискретизации для компонента яркости в два раза выше, чем для компонентов цветности, как в горизонтальном, так и в вертикальном направлениях. В результате у CU, сформатированного в соответствии с форматом 4:2:0, ширина и высота массива выборок компонента яркости в два раза больше, чем для каждого массива выборок компонентов цветности. На ФИГ. 4 представлена концептуальная схема, иллюстрирующая пример элемента кодирования, сформатированного в соответствии с форматом выборки 4:2:0. На ФИГ. 4 проиллюстрировано положение выборок цветности относительно выборок яркости в CU. Как описано выше, CU обычно определяют в соответствии с количеством выборок яркости по горизонтали и вертикали. Таким образом, как показано на ФИГ. 4, CU 16 × 16, сформатированный в соответствии с форматом выборки 4:2:0, включает в себя 16 × 16 выборок компонентов яркости и 8 × 8 выборок для каждого компонента цветности. В примере, приведенном на ФИГ. 4, дополнительно проиллюстрировано положение выборок цветности относительно выборок яркости для видеоблоков, смежных с CU 16 × 16. В CU, сформатированном в соответствии с форматом 4:2:2, ширина массива выборок компонента яркости в два раза больше ширины массива выборок каждого компонента цветности, но высота массива выборок компонента яркости равна высоте массива выборок каждого компонента цветности. В CU, сформатированном в соответствии с форматом 4:4:4, массив выборок компонента яркости дополнительно имеет ту же ширину и высоту, что и массив выборок каждого компонента цветности.
[0018] Как описано выше, данные внутреннего или внешнего прогнозирования используют для получения опорных значений выборки для блока значений выборки. Разница между значениями выборки, включенными в текущий PB или структуру области изображения другого типа, и соответствующими опорными выборками (например, полученными с использованием прогнозирования) может называться остаточными данными. Остаточные данные могут включать в себя соответствующие массивы разностных значений, соответствующие каждому компоненту видеоданных. Остаточные данные могут находиться в области пикселей. Для получения коэффициентов преобразования к массиву разностных значений можно применять преобразование, такое как дискретное косинусное преобразование (DCT), дискретное синусное преобразование (DST), целочисленное преобразование, вейвлет-преобразование или концептуально подобное преобразование. Следует отметить, что в ITU-T H.265 CU связан со структурой элемента преобразования (TU), корнем которой является уровень CU. Т.е. в ITU-T H.265 массив разностных значений может быть подразделен для целей получения коэффициентов преобразования (например, четыре преобразования 8 × 8 можно применять к массиву остаточных значений 16 × 16). Для каждого компонента видеоданных такие подразделы разностных значений могут называться блоками преобразования (TB). Следует отметить, что в ITU-T H.265 TB необязательно совмещены с PB. На ФИГ. 5 проиллюстрированы примеры альтернативных комбинаций PB и TB, которые можно использовать для кодирования конкретного CB. Следует отметить, что согласно ITU-T H.265 TB могут дополнительно иметь следующие размеры: 4 × 4, 8 × 8, 16 × 16 и 32 × 32.
[0019] Следует отметить, что в JEM соответствующие CB остаточные значения используют для получения коэффициентов преобразования без дополнительного разделения. Т.е. в JEM концевой узел QTBT может быть аналогичен как PB, так и TB в ITU-T H.265. Следует отметить, что в JEM основное преобразование и последующие вторичные преобразования можно применять (в видеокодере) для получения коэффициентов преобразования. В видеодекодере используют обратный порядок преобразований. В JEM применение вторичного преобразования для получения коэффициентов преобразования может дополнительно зависеть от режима прогнозирования.
[0020] На коэффициентах преобразования можно выполнять процесс квантования. Квантование осуществляет взвешивание коэффициентов преобразования, чтобы варьировать объем данных, требуемых для представления группы коэффициентов преобразования. Квантование может включать в себя деление коэффициентов преобразования на коэффициент масштабирования квантования и соответствующие функции округления (например, округление до ближайшего целого числа). Квантованные коэффициенты преобразования могут называться значениями уровня коэффициента. Обратное квантование (или «деквантование») может включать в себя умножение значений уровня коэффициента на коэффициент масштабирования квантования. Следует отметить, что используемый в настоящем документе термин «процесс квантования» в некоторых случаях может относиться к делению на коэффициент масштабирования для получения значений уровня и умножению на коэффициент масштабирования для восстановления коэффициентов преобразования в некоторых случаях. Т.е. в некоторых случаях процесс квантования может относиться к квантованию, а в некоторых - к обратному квантованию. Следует дополнительно отметить, что, хотя в приведенных ниже примерах процессы квантования описаны с использованием арифметических операций, в которых применяется десятичная запись чисел, такие описания приведены в иллюстративных целях и не должны рассматриваться как ограничивающие. Например, описанные в настоящем документе методики могут быть реализованы в устройстве с использованием двоичных операций и т. п. Например, описанные в настоящем документе операции умножения и деления могут быть реализованы с использованием операций битового сдвига и т. п.
[0021] На ФИГ. 6A-6В приведены концептуальные схемы, иллюстрирующие примеры кодирования блока видеоданных. Как показано на ФИГ. 6A, текущий блок видеоданных (например, CB, соответствующий видеокомпоненту) кодируют посредством получения остатка путем вычитания набора значений прогнозирования из текущего блока видеоданных, преобразования остатка и квантования коэффициентов преобразования для получения значений уровня. Как показано на ФИГ. 6B, текущий блок видеоданных декодируют путем выполнения обратного квантования значений уровня, обратного преобразования и добавления набора значений прогнозирования к полученному в результате остатку. Следует отметить, что в примерах на ФИГ. 6A-6B значения выборки восстановленного блока отличаются от значений выборки текущего кодируемого видеоблока. Таким образом, можно сказать, что кодирование сопряжено с потерями. Однако разницу в значениях выборки можно считать приемлемой или незаметной для зрителя, просматривающего восстановленное видео. Как показано на ФИГ. 6A-6B, масштабирование дополнительно выполняют с использованием массива коэффициентов масштабирования.
[0022] В ITU-T H.265 массив коэффициентов масштабирования получают путем выбора матрицы масштабирования и умножения каждой записи в матрице масштабирования на коэффициент масштабирования квантования. В ITU-T H.265 матрица масштабирования выбрана на основе режима прогнозирования и компонента цвета, причем определены матрицы масштабирования следующих размеров: 4 × 4, 8 × 8, 16 × 16 и 32 × 32. Таким образом, следует отметить, что ITU-T H.265 не определяет матрицы масштабирования для размеров, отличных от 4 × 4, 8 × 8, 16 × 16 и 32 × 32. В ITU-T H.265 значение коэффициента масштабирования квантования может быть определено параметром квантования (QP). В ITU-T H.265 QP может принимать 52 значения от 0 до 51, и изменение QP на 1 обычно соответствует изменению значения коэффициента масштабирования квантования приблизительно на 12%. В ITU-T H.265 значение QP для набора коэффициентов преобразования может быть дополнительно получено с использованием прогнозируемого значения параметра квантования (которое может называться прогнозируемым значением QP) и необязательно сигнализируемого дельта-значения параметра квантования (которое может называться значением дельты QP или дельта-значением QP). В ITU-T H.265 параметр квантования может быть обновлен для каждого CU и параметр квантования может быть получен для каждого из компонентов яркости (Y) и цветности (Cb и Cr).
[0023] Как показано на ФИГ. 6A, квантованные коэффициенты преобразования кодируют в битовый поток. Квантованные коэффициенты преобразования и элементы синтаксиса (например, элементы синтаксиса, указывающие структуру кодирования для видеоблока) могут быть энтропийно кодированы согласно методике энтропийного кодирования. Примеры методик энтропийного кодирования включают в себя контентно-адаптивное кодирование с переменной длиной (CAVLC), контекстно-адаптивное двоичное арифметическое кодирование (CABAC), энтропийное кодирование с разделением по интервалам вероятностей (PIPE) и т. п. Энтропийно кодированные квантованные коэффициенты преобразования и соответствующие энтропийно кодированные элементы синтаксиса могут формировать совместимый битовый поток, который можно использовать для воспроизведения видеоданных в видеодекодере. Процесс энтропийного кодирования может включать в себя бинаризацию элементов синтаксиса. Бинаризация означает процесс преобразования значения синтаксиса в последовательность из одного или более битов. Эти биты могут называться «двоичными значениями». Бинаризация является процессом без потерь и может включать в себя одну из следующих методик кодирования или их комбинацию: кодирование с фиксированной длиной, унарное кодирование, усеченное унарное кодирование, усеченное кодирование Райса, кодирование Голомба, экспоненциальное кодирование Голомба k-го порядка и кодирование Голомба-Райса. Например, бинаризация может включать в себя представление целочисленного значения 5 для элемента синтаксиса как 00000101 с использованием методики 8-битной бинаризации с фиксированной длиной или представление целочисленного значения 5 как 11110 с использованием методики бинаризации унарного кодирования. Каждый из используемых в настоящем документе терминов «кодирование с фиксированной длиной», «унарное кодирование», «усеченное унарное кодирование», «усеченное кодирование Райса», «кодирование Голомба», «экспоненциальное кодирование Голомба k-го порядка» и «кодирование Голомба-Райса» может относиться к общим реализациям этих методик и/или более конкретным вариантам осуществления этих методик кодирования. Например, вариант реализации кодирования Голомба-Райса может быть конкретно определен в соответствии со стандартом кодирования видеосигналов, например ITU-T H.265. Процесс энтропийного кодирования дополнительно включает в себя значения двоичного кодирования с использованием алгоритмов сжатия данных без потерь. В примере CAB AC для конкретного двоичного значения контекстная модель может быть выбрана из набора доступных контекстных моделей, связанных с двоичным значением. В некоторых примерах контекстная модель может быть выбрана на основе предыдущего двоичного значения и/или значений предыдущих элементов синтаксиса. Контекстная модель может идентифицировать вероятность того, что двоичное значение представляет собой конкретное значение. Например, контекстная модель может указывать вероятность 0,7 для кодирования двоичного значения 0 и вероятность 0,3 для кодирования двоичного значения 1. Следует отметить, что в некоторых случаях вероятность кодирования двоичного значения 0 и вероятность кодирования двоичного значения 1 могут не быть равными 1. После выбора доступной контекстной модели энтропийный кодер CAB AC может арифметически кодировать двоичное значение на основе идентифицированной контекстной модели. Контекстная модель может быть обновлена на основе значения кодированного двоичного значения. Контекстная модель может быть обновлена на основе связанной переменной, сохраненной с контекстом, например размером окна адаптации, количеством двоичных значений, кодированных с использованием контекста. Следует отметить, что согласно ITU-T H.265 энтропийный кодер CABAC может быть реализован так, что некоторые элементы синтаксиса могут быть энтропийно кодированы с использованием арифметического кодирования без применения явно назначенной контекстной модели, и такое кодирование может называться обходным кодированием.
[0024] Как описано выше, значения выборки восстановленного блока могут отличаться от значений выборки текущего кодируемого видеоблока. Кроме того, следует отметить, что в некоторых случаях поблочное кодирование видеоданных может привести к появлению артефактов (например, так называемых блочных артефактов, полосчатых артефактов и т. д.). Например, возникновение блочных артефактов может привести к тому, что границы блока кодирования восстановленных видеоданных станут визуально заметными для пользователя. Таким образом, восстановленные значения выборки могут быть изменены для минимизации разницы между значениями выборки текущего кодируемого видеоблока и/или минимизации количества артефактов, вводимых процессом кодирования видеосигналов. Такие изменения в целом могут называть фильтрацией. Следует отметить, что фильтрация может происходить в рамках процесса фильтрации в цикле или процесса фильтрации после цикла. Для процесса фильтрации в цикле полученные значения выборки процесса фильтрации могут быть использованы для прогнозируемых видеоблоков (например, сохранены в буфере опорного кадра для последующего кодирования в видеокодере и последующего декодирования в видеодекодере). Для процесса фильтрации после цикла вывод полученных значений выборки процесса фильтрации происходит только в рамках процесса декодирования (например, их не используют для последующего кодирования). Например, в случае видеодекодера для процесса фильтрации в цикле значения выборки, полученные в результате фильтрации восстановленного блока, будут использованы для последующего декодирования (например, сохранены в опорном буфере) и будут выведены (например, на дисплей). Для процесса фильтрации после цикла восстановленный блок будет использован для последующего декодирования, а значения выборки, полученные в результате фильтрации восстановленного блока, будут выведены.
[0025] Деблокинг (или устранение блочности) фильтрации или применение фильтра деблокинга относится к способу сглаживания границ соседних восстановленных видеоблоков (т.е. границы делают менее заметными для зрителя). Сглаживание границ соседних восстановленных видеоблоков может включать изменение значений выборки, включенных в строки или столбцы, смежные с границей. В ITU-T H.265 предусмотрено, что фильтр деблокинга применяют в отношении восстановленных значений выборки в рамках процесса фильтрации в цикле. ITU-T H.265 включает два типа фильтров деблокинга, которые могут быть использованы для изменения выборок яркости: сильный фильтр, который изменяет значения выборки в трех смежных с границей строках или столбцах, и слабый фильтр, который изменяет значения выборки в непосредственно примыкающих к границе строке или столбце и при определенных условиях изменяет значения выборки во вторых строке или столбце относительно границы. Кроме того, ITU-T H.265 включает один тип фильтра, который может быть использован для изменения выборок цветности: нормальный фильтр.
[0026] В дополнение к применению фильтра деблокинга в рамках процесса фильтрации в цикле ITU-T H.265 предполагает применение фильтрации адаптивного смещения отсчетов (SAO) в процессе фильтрации в цикле. В ITU-T H.265 SAO представляет собой процесс, изменяющий значения деблокированной выборки в области путем добавления при определенных условиях значения смещения. ITU-T H.265 включает два типа фильтров SAO, которые могут быть применены в отношении CTB: смещение полосы или смещение края. Для каждого из смещения полосы и смещения края в битовый поток включают четыре значения смещения. Для смещения полосы применяемая величина смещения зависит от амплитуды значения выборки (например, амплитуды сопоставляют с полосами, которые сопоставляют с четырьмя смещениями сигнализации). Для смещения края применяемая величина смещения зависит от CTB, имеющего один из горизонтального, вертикального, первого диагонального или второго диагонального края (например, указанные классификации сопоставлены с четырьмя смещениями сигнализации).
[0027] Другой тип процесса фильтрации включает так называемый адаптивный фильтр контура (ALF). ALF с адаптацией на основе блока указан в JEM. В JEM ALF применяют после фильтра SAO. Следует отметить, что ALF может быть применен в отношении восстановленных выборок независимо от других методик фильтрации. Процесс применения ALF, указанного в JEM, в видеокодере может быть кратко сформулирован следующим образом: (1) каждый блок 2 × 2 компонента яркости для восстановленного изображения классифицируют в соответствии с индексом классификации; (2) составляют наборы коэффициентов фильтра для каждого индекса классификации; (3) для компонента яркости определяют решение в отношении фильтрации; (4) определяют решение в отношении фильтрации для компонентов цветности; и (5) сигнализируют параметры фильтра (например, коэффициенты и решения).
[0028] В соответствии с ALF, указанным в JEM, каждый блок 2 × 2 классифицируют в соответствии с индексом классификации C, причем C представляет собой целое число в диапазоне от 0 до 24 (включительно). C определяют на основании его направленности D и квантованного значения активности Â в соответствии со следующим уравнением:
C=5D+Â,
где D и Â, градиенты горизонтального, вертикального и двух диагональных направлений вычисляют с использованием оператора Лапласа 1-D следующим образом:
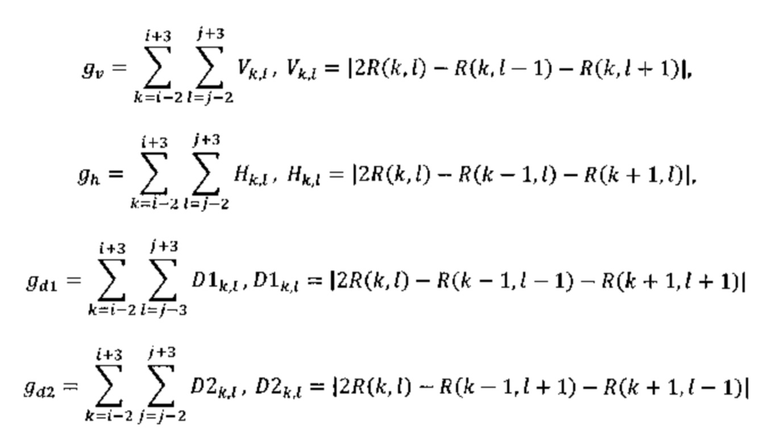 ,
,
причем индексы i и j относятся к координатам верхней левой выборки в блоке 2 × 2, а элемент R (i, j) указывает восстановленную выборку в координате (i, j).
[0029] Максимальное и минимальное значения градиентов горизонтального и вертикального направлений могут быть установлены следующим образом:
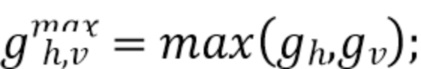
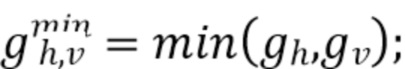
а максимальное и минимальное значения градиента для двух диагональных направлений могут быть установлены следующим образом:
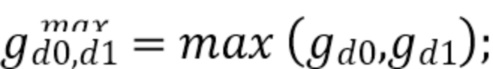
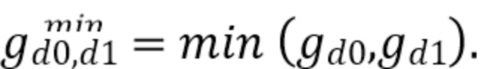
[0030] В JEM для получения значения направленности D максимальное и минимальное значения сравнивают друг с другом и с двумя пороговыми значениями времени t1 и t2:
Этап 1. Если как 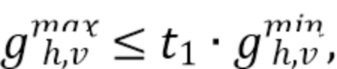 так и
так и 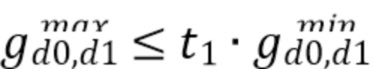 истинны, D устанавливают в 0.
истинны, D устанавливают в 0.
Этап 2. Если 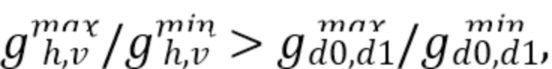 следует продолжить с этапа 3; в противном случае следует продолжить с этапа 4.
следует продолжить с этапа 3; в противном случае следует продолжить с этапа 4.
Этап 3. Если 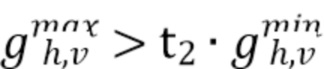 , D устанавливают в 2; в противном случае D устанавливают в 1.
, D устанавливают в 2; в противном случае D устанавливают в 1.
Этап 4. Если 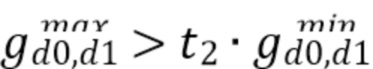 , D устанавливают в 4; в противном случае D устанавливают в 3.
, D устанавливают в 4; в противном случае D устанавливают в 3.
[0031] В JEM значение A активности вычисляют следующим образом:
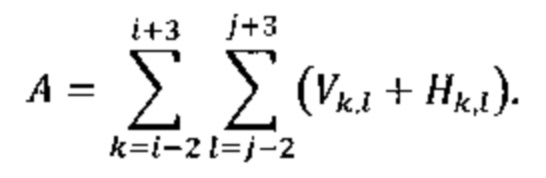
причем A дополнительно квантуют в диапазоне от 0 до 4 (включительно), а квантованное значение обозначают символом Â.
[0032] Как описано выше, применение значения ALF, указанного в JEM, в видеокодере включает получение наборов коэффициентов фильтра для каждого индекса классификации и определение решений в отношении фильтрации. Следует отметить, что получение наборов коэффициентов фильтра и определение решений в отношении фильтрации могут представлять собой итеративный процесс. Другими словами, наборы коэффициентов фильтра могут быть обновлены на основании решений в отношении фильтрации, а решения в отношении фильтрации могут обновлять на основании обновленных наборов коэффициентов фильтра, и эти действия могут повторяться множество раз. Кроме того, в видеокодере могут быть реализованы различные собственные алгоритмы для определения наборов коэффициентов фильтра и/или для определения решений в отношении фильтрации. Методики, описанные в настоящем документе, в целом применимы независимо от того, каким образом получают наборы коэффициентов фильтра для каждого индекса классификации и каким образом определяют решения в отношении фильтрации.
[0033] В соответствии с одним примером наборы коэффициентов фильтра получают путем первоначального получения набора оптимальных коэффициентов фильтра для каждого индекса классификации. Оптимальные коэффициенты фильтра получают путем сравнения требуемых значений выборки (т.е. значений выборки в исходных видеоданных) с восстановленными значениями выборки после применения фильтрации и путем минимизации суммы квадратичных погрешностей (SSE) между требуемыми значениями выборки и восстановленными значениями выборки после выполнения фильтрации. Затем, полученные оптимальные коэффициенты для каждой группы могут быть использованы для выполнения базовой фильтрации по восстановленным выборкам с целью анализа эффективности ALF. Другими словами, требуемые значения выборки, восстановленные значения выборки до применения ALF и восстановленные значения выборки после применения ALF можно сравнивать для определения эффективности применения ALF с использованием оптимальных коэффициентов.
[0034] В соответствии с указанным в JEM ALF каждую восстановленную выборку R (i, j) фильтруют путем определения полученного значения R’(i, j) выборки в соответствии с нижеследующим уравнением, где L обозначает длину фильтра, а f(k, l) обозначает коэффициенты декодированного фильтра.
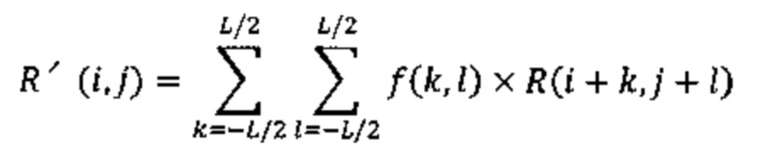
[0035] Следует отметить, что в JEM определены три конфигурации фильтра (ромб 5 × 5, ромб 7 × 7 и ромб 9 × 9). Следует отметить, что для базовой фильтрации, как правило, используют ромбовидную конфигурацию фильтра 9 × 9.
[0036] Следует отметить, что в JEM геометрические преобразования применяют в отношении коэффициентов f(k, l) фильтра в зависимости от значений градиента: gv, gh, gd1, gd2, которые указаны в таблице 2.
где отражение по диагонали, вертикали и поворот определяют следующим образом:
По диагонали: fD(k, l) = f(l, k),
Отражение по вертикали: fV(k, l) = f(k, K - l - 1),
Поворот: fR(k, l) = f(K - l - 1, k),
где K представляет собой размер фильтра, а 0≤k, 1≤K - 1 представляют собой координаты коэффициентов таким образом, что местоположение (0, 0) находится в верхнем левом углу, а местоположение (K - l, K - 1) находится в нижнем правом углу.
[0037] В соответствии с JEM могут быть сигнализированы до 25 наборов коэффициентов фильтра яркости (т.е. по одному для каждого возможного индекса классификации). Таким образом, оптимальные коэффициенты могут быть переданы для каждого индекса классификации, возникающего в соответствующей области изображения. Однако для оптимизации количества данных, требуемого для сигнализации наборов коэффициентов фильтра яркости по отношению к эффективности фильтра, могут быть выполнены оптимизации показателя «скорость-искажение» (RD). Например, в соответствии с JEM наборы коэффициентов фильтра соседних групп классификации могут быть объединены и переданы с применением массива, сопоставленного с набором коэффициентов фильтра для каждого индекса классификации. Кроме того, в соответствии с JEM для сигнализирования коэффициентов может быть использовано прогнозирование по временному коэффициенту. Другими словами, в соответствии с JEM наборы коэффициентов фильтра для текущего изображения могут быть спрогнозированы на основании наборов коэффициентов фильтра опорного изображения путем наследования набора коэффициентов фильтра, используемых для опорного изображения. Кроме того, в соответствии с JEM для изображений с внутренним прогнозированием может быть доступен набор из 16 фиксированных фильтров для прогнозирования наборов коэффициентов фильтра. Как описано выше, получение наборов коэффициентов фильтра и определение решений в отношении фильтрации могут представлять собой итеративный процесс. Другими словами, например, конфигурация ALF может быть определена на основании того, сколько наборов коэффициентов фильтра сигнализировано, и аналогичным образом то, применяют ли ALF в отношении области изображения, может быть основано на сигнализированных наборах коэффициентов фильтра и/или конфигурации фильтра.
[0038] Как описано выше, процесс применения ALF, указанного в JEM, в видеокодере включает параметры сигнализации фильтра. Другими словами, в JEM предусмотрена сигнализация, используемая видеокодером для указания параметров фильтра для видеодекодера. Затем, видеодекодер может применить ALF в отношении восстановленных значений выборки на основании указанных параметров фильтра. В соответствии с JEM для компонента яркости флаг уровня изображения может позволить выборочно применять ALF в отношении каждого CU в изображении. Кроме того, в соответствии с JEM значение индекса, переданное для уровня изображения, указывает конфигурацию фильтра, выбранную для компонента яркости (т.е. ромб 5 × 5, ромб 7 × 7 или ромб 9 × 9). Следует отметить, что конфигурации фильтра большего размера, как правило, являются более точными, но требуют определения большего количества коэффициентов фильтра. Кроме того, в соответствии с JEM для компонента яркости коэффициенты фильтра сигнализируют на уровне среза. Как описано выше, коэффициенты фильтра могут быть сигнализированы непосредственно для одной или более из 25 групп или сигнализированы с применением методик прогнозирования. Кроме того, в соответствии с JEM для компонента цветности ALF включают или отключают на уровне изображения. Следует отметить, что в JEM для компонентов цветности все изображение обрабатывают как один класс и всегда применяют ромбовидную конфигурацию фильтра 5 × 5, для каждого компонента цветности применяют один набор коэффициентов фильтра и уровень CU отсутствует. Кроме того, следует отметить, что если ALF не включен для компонента яркости, то ALF отключают для компонентов цветности.
[0039] Как описано выше, данные внутреннего прогнозирования или данные внешнего прогнозирования могут связывать область изображения (например, PB или CB) с соответствующими опорными выборками. Для кодирования с внутренним прогнозированием режим внутреннего прогнозирования может указывать местоположение опорных выборок в изображении. В ITU-T H.265 определенные возможные режимы внутреннего прогнозирования включают в себя режим планарного (т.е. подбор поверхности) прогнозирования (predMode: 0), режим прогнозирования DC (т.е. плоское полное усреднение) (predMode: 1) и 33 режима углового прогнозирования (predMode: 2-34). В JEM определенные возможные режимы внутреннего прогнозирования включают в себя режим планарного прогнозирования (predMode: 0), режим прогнозирования DC (predMode: 1) и 65 режимов углового прогнозирования (predMode: 2-66). Следует отметить, что режимы планарного прогнозирования и прогнозирования DC могут называться режимами ненаправленного прогнозирования, а режимы углового прогнозирования могут называться режимами направленного прогнозирования. Следует отметить, что методики, описанные в настоящем документе, могут быть в целом применимы, независимо от количества определенных возможных режимов прогнозирования.
[0040] В дополнение к генерации опорных выборок в соответствии с режимом прогнозирования (который может называться блоком внутреннего прогнозирования) кодирование с внутренним прогнозированием может включать изменение опорных выборок до генерации остаточных данных (например, во время кодирования) и/или изменение опорных выборок до восстановления видеоблока (например, во время декодирования). В JEM определены методики изменения опорных выборок перед генерированием остаточных данных и изменения опорных выборок перед восстановлением видеоблока. Одна из методик, указанных в JEM для изменения опорных выборок, включает генерацию прогнозируемого видеоблока с использованием взвешенной комбинации неотфильтрованных и отфильтрованных опорных выборок, т.е. так называемого внутреннего прогнозирования в зависимости от положения (PDPC).
[0041] При PDPC прогнозируемый видеоблок генерируют в соответствии с нижеследующим уравнением, причем элемент p[x, y] представляет собой новое прогнозирование. В указанном уравнении элемент r[x, y] представляет опорные выборки, сгенерированные для режима направленного прогнозирования с использованием неотфильтрованных опорных выборок, а элемент q[x, y] представляет опорные выборки, сгенерированные для режима направленного прогнозирования с использованием отфильтрованных опорных выборок.
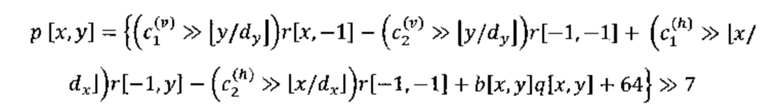 ,
,
где 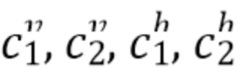 представляют собой хранимые параметры прогнозирования, dx=1 для блоков с шириной, меньшей или равной 16, а dx=2 для блоков с шириной, большей 16, dy=1 для блоков с высотой, меньшей или равной 16, а dy=2 для блоков с высотой, большей 16. b[x, y] представляет собой коэффициент нормализации, полученный следующим образом:
представляют собой хранимые параметры прогнозирования, dx=1 для блоков с шириной, меньшей или равной 16, а dx=2 для блоков с шириной, большей 16, dy=1 для блоков с высотой, меньшей или равной 16, а dy=2 для блоков с высотой, большей 16. b[x, y] представляет собой коэффициент нормализации, полученный следующим образом:
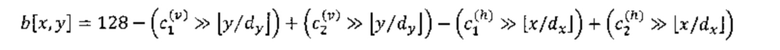 ,
,
где этап x>>y представляет собой арифметический сдвиг вправо целочисленного представления поразрядного дополнения до двух x на y двоичных разрядов; и
[x] возвращает ближайшее целое число, меньшее или равное x.
[0042] Параметры прогнозирования определяют для каждого направления прогнозирования и размера блока. В JEM один набор параметров прогнозирования определяют для каждого внутреннего прогнозирования и размера блока.
[0043] Кроме того, следует отметить, что в JEM флаг уровня CU, PDPC_idx, указывает на то, применяют ли PDPC, причем значение 0 указывает на применение существующего внутреннего прогнозирования ITU-T H.265, а значение 1 указывает на применение PDPC.
[0044] Кроме того, JEM предполагает применение механизма фильтрации опорной выборки, т.е. так называемого адаптивного сглаживания опорной выборки (ARSS). В соответствии с JEM при осуществлении ARSS для обработки опорных выборок используют два фильтра низких частот (LPF): 3-выводный LPF с коэффициентами [1, 2, 1] / 4; и 5-выводный LPF с коэффициентами [2, 3, 6, 3, 2] / 16. В соответствии с JEM при осуществлении ARSS применяют определенный набор правил для определения того, какие из следующих задействованных опорных выборок (1) не отфильтрованы; (2) опорные выборки представляют собой фильтры в соответствии с правилами ITU-T H.265 (с изменениями в некоторых случаях); (3) опорные выборки фильтруют с использованием 3-выводных LPF; или (4) опорные выборки фильтруют с использованием 5-выводных LPF. В JEM ARSS применяют только для компонента яркости в том случае, если размер CU меньше или равен 1024 выборкам яркости и больше или равен 64 выборкам яркости, по меньшей мере одна подгруппа коэффициентов в блоке кодирования яркости имеет скрытый знаковый бит, а режим внутреннего прогнозирования не является режимом DC. Кроме того, в JEM, если флаг PDPC равен 1 для CU, адаптивное сглаживание опорных выборок отключено в этом CU.
[0045] В случае кодирования с внешним прогнозированием вектор движения (MV) идентифицирует опорные выборки в изображении, отличном от изображения видеоблока, который подлежит кодированию, и, таким образом, использует временную избыточность в видео. Например, текущий видеоблок может быть спрогнозирован из опорного блока(ов), находящегося в ранее кодированном кадре(ах), и вектор движения может быть использован для указания местоположения опорного блока. Вектор движения и связанные данные могут описывать, например, горизонтальный компонент вектора движения, вертикальный компонент вектора движения, разрешение для вектора движения (например, точность в одну четверть пикселя, половину пикселя, один пиксель, два пикселя, четыре пикселя), направление прогнозирования и/или значение индекса опорного кадра. Стандарт кодирования, такой как, например, ITU-T H.265, может дополнительно поддерживать прогнозирование вектора движения. Прогнозирование вектора движения позволяет задавать вектор движения с использованием векторов движения соседних блоков. Примеры прогнозирования вектора движения включают в себя расширенное прогнозирование вектора движения (AMVP), временное прогнозирование вектора движения (TMVP), так называемый режим «слияния», а также «пропуск» и «прямое» логическое определение движения. JEM дополнительно поддерживает расширенное временное прогнозирование вектора движения (ATMVP) и пространственно-временное прогнозирование вектора движения (STMVP).
[0046] Как описано выше, остаточные данные, сгенерированные для области изображения с использованием прогнозирования и соответствующих опорных выборок, могут быть преобразованы для генерации коэффициентов преобразования. Коэффициенты преобразования могут быть сгенерированы с использованием матриц преобразования, связанных с набором для преобразования. В JEM в дополнение к использованию типов преобразования DCT-II и 4 × 4 DST-VII, используемых в ITU-T H.265, для остаточного кодирования как внутри кодируемых блоков, так и между ними используют схему адаптивного многократного преобразования (AMT). В JEM для осуществления AMT используют следующие матрицы преобразования DST-VII, DCT-VIII, DST-I и DCT-V. Каждая матрица преобразования в JEM может быть реализована с использованием горизонтального (H) и вертикального (V) преобразования. В JEM схему AMT применяют в отношении CU с шириной и высотой, меньшими или равными 64, а тем, следует ли применять AMT, управляют с помощью флага уровня CU. Если флаг уровня CU равен 0, в CU для преобразования остатка применяют DCT-II. Для блока кодирования яркости в CU с разрешенным AMT передают два дополнительных флага для идентификации горизонтального и вертикального преобразования, которое будет использоваться.
[0047] В JEM для внутреннего прогнозирования определены три заданных набора вариантов преобразования, представленные в таблице 3.
[0048] В JEM набор для преобразования выбирают на основании режима внутреннего прогнозирования, как показано в таблице 4.
[0049] Таким образом, в JEM для внутреннего прогнозирования подмножество преобразования сначала идентифицируют на основании таблицы 3 с использованием режима внутреннего прогнозирования CU с флагом AMT на уровне CU, равным 1, и для каждого из горизонтального и вертикального преобразования определяют один из двух вариантов преобразования в идентифицированном подмножестве преобразования.
[0050] Как дополнительно описано выше, в JEM применение последующего вторичного преобразования для получения коэффициентов преобразования может дополнительно зависеть от режима прогнозирования. В JEM применение последующего вторичного преобразования может включать в себя выполнение вторичного преобразования независимо для каждой подгруппы 4 × 4 коэффициента преобразования, причем независимое выполнение вторичного преобразования может упоминаться как применение зависимого от режима неразделимого вторичного преобразования (MDNSST). Следует отметить, что в JEM, если и ширина, и высота блока коэффициента преобразования больше или равны 8, то в отношении верхней левой области 8 × 8 блока коэффициентов трансформирования применяют неразделимое вторичное преобразование 8 × 8, а если или ширина, или высота блока коэффициента преобразования равна 4, применяют неразделимое вторичное преобразование 4 × 4 и неразделимое вторичное преобразование 4 × 4 выполняют в верхней левой области блока коэффициента преобразования. В JEM правило выбора преобразования применяют как в отношении компонента яркости, так и в отношении компонента цветности. В JEM для MDNSST существует 35 неразделимых матриц преобразования, в которых 11 наборов для преобразования применяют для режима направленного внутреннего прогнозирования, и каждый набор для преобразования включает 3 матрицы преобразования, а для ненаправленных режимов (например, планарного, DC и LM) применяют только один набор для преобразования, включающий 2 матрицы преобразования. В JEM каждый набор для преобразования сопоставлен с режимом прогнозирования, а 2-битовое значение индекса для уровня CU (называемое в настоящем документе «NSST_idx») включают в битовый поток для указания матрицы преобразования для набора для преобразования. Следует отметить, что в JEM NSST_idx передают один раз на один внутренний CU и включают в битовый поток после соответствующих коэффициентов преобразования. Кроме того, в JEM значение NSST_idx, равное нулю, указывает на то, что вторичное преобразование не применяют в отношении текущего CU. Следует отметить, что в JEM MDNSST разрешено только в том случае, если не применяют PDPC (т.е. задано значение PDPC_idx, равное нулю).
[0051] Как описано выше, в JEM концевой узел QTBT, который допускает произвольные прямоугольные CB, может быть аналогичен как PB, так и TB в ITU-T H.265. Таким образом, в некоторых случаях JEM может обеспечивать меньшую гибкость в отношении возможных структур PB и TB, чем это предусмотрено в ITU-T H.265. Кроме того, как описано выше, в ITU-T H.265 разрешены только квадратные TB и только PB с ограниченной конфигурацией (например, разрешены только квадратные PB для внутреннего прогнозирования). Таким образом, разделение QTBT и связанная с ним сигнализация, как определено ITU-T H.265 и JEM, могут быть далеко не идеальными. Таким образом, настоящее описание относится к методикам разделения видеоданных.
[0052] На ФИГ. 7 приведена блок-схема, иллюстрирующая пример системы, которая может быть выполнена с возможностью кодирования (т.е. кодирования и/или декодирования) видеоданных в соответствии с одной или более методиками настоящего описания. Система 100 представляет собой пример системы, которая может выполнять кодирование видеосигналов с использованием произвольных прямоугольных видеоблоков в соответствии с одной или более методиками настоящего описания. Как показано на ФИГ. 7, система 100 включает в себя устройство-источник 102, среду 110 связи и устройство 120 назначения. В проиллюстрированном на ФИГ. 7 примере устройство-источник 102 может включать в себя любое устройство, выполненное с возможностью кодирования видеоданных и передачи кодированных видеоданных в среду 110 связи. Устройство 120 назначения может включать в себя любое устройство, выполненное с возможностью приема кодированных видеоданных через среду 110 связи и декодирования кодированных видеоданных. Устройство-источник 102 и/или устройство 120 назначения могут включать в себя вычислительные устройства, оборудованные для проводной и/или беспроводной связи, и могут включать в себя телевизионные приставки, цифровые видеомагнитофоны, телевизоры, настольные компьютеры, ноутбуки или планшетные компьютеры, игровые консоли, мобильные устройства, в т. ч., например, смартфоны, сотовые телефоны, персональные игровые устройства и медицинские устройства визуализации.
[0053] Среда 110 связи может включать в себя любую комбинацию средств беспроводной и проводной связи и/или запоминающих устройств. Среда 110 связи может включать в себя коаксиальные кабели, оптоволоконные кабели, кабели витой пары, беспроводные передатчики и приемники, маршрутизаторы, коммутаторы, ретрансляторы, базовые станции или любое другое оборудование, которое может обеспечивать связь между различными устройствами и объектами. Среда 110 связи может включать в себя одну или более сетей. Например, среда 110 связи может включать в себя сеть, выполненную с возможностью обеспечения доступа к Всемирной паутине, например Интернету. Сеть может работать в соответствии с комбинацией одного или более телекоммуникационных протоколов. Телекоммуникационные протоколы могут включать в себя фирменные аспекты и/или могут включать в себя стандартизированные телекоммуникационные протоколы. Примеры стандартизированных телекоммуникационных протоколов включают в себя стандарты: цифрового видеовещания (DVB), Комитета по усовершенствованным телевизионным системам (ATSC), цифрового вещания с комплексными услугами (ISDB), спецификации интерфейса передачи данных по кабелю (DOCSIS), глобальной системы мобильной связи (GSM), множественного доступа с кодовым разделением (CDMA), партнерского проекта по системам 3-го поколения (3GPP), Европейского института телекоммуникационных стандартов (ETSI), Интернет-протокола (IP), протокола беспроводных приложений (WAP) и Института инженеров по электротехнике и электронике (IEEE).
[0054] Запоминающие устройства могут включать в себя устройства или носители любого типа, выполненные с возможностью хранения данных. Носитель данных может включать в себя материальные или энергонезависимые машиночитаемые носители. Машиночитаемый носитель может включать в себя оптические диски, флэш-память, магнитные ЗУ или любые другие подходящие цифровые носители данных. В некоторых примерах запоминающее устройство или его части могут быть описаны как энергонезависимая память, а в других примерах части запоминающих устройств могут быть описаны как энергозависимая память. Примеры энергозависимых запоминающих устройств могут включать в себя оперативные запоминающие устройства (RAM), динамические оперативные запоминающие устройства (DRAM) и статические оперативные запоминающие устройства (SRAM). Примеры энергонезависимой памяти могут включать в себя жесткие магнитные диски, оптические диски, дискеты, флэш-память или виды электрически программируемых ЗУ (EPROM) или электрически стираемых и программируемых (EEPROM) ЗУ. Запоминающее устройство(а) может включать в себя карты памяти (например, карту памяти Secure Digital (SD)), внутренние/внешние жесткие диски и/или внутренние/внешние твердотельные накопители. Данные могут храниться в запоминающем устройстве в соответствии с определенным форматом файла.
[0055] На ФИГ. 7 устройство-источник 102 включает в себя источник 104 видео, видеокодер 106 и интерфейс 108. Источник 104 видео может включать в себя любое устройство, выполненное с возможностью захвата и/или хранения видеоданных. Например, источник 104 видео может включать в себя видеокамеру и запоминающее устройство, функционально связанное с ней. Видеокодер 106 может включать в себя любое устройство, выполненное с возможностью приема видеоданных и генерирования совместимого битового потока, представляющего видеоданные. Совместимый битовый поток может относиться к битовому потоку, который видеодекодер может принимать и из которого он может воспроизводить видеоданные. Аспекты совместимого битового потока могут быть определены в соответствии со стандартом кодирования видеосигналов. При формировании совместимого битового потока видеокодер 106 может сжимать видеоданные. Сжатие может происходить с потерями (заметными или незаметными) или без потерь. Интерфейс 108 может включать в себя любое устройство, выполненное с возможностью приема совместимого битового потока видео и передачи и/или сохранения совместимого битового потока видео в среде связи. Интерфейс 108 может включать в себя карту сетевого интерфейса, такую как карта Ethernet, и может включать в себя оптический приемопередатчик, радиочастотный приемопередатчик или устройство любого другого типа, способное отправлять и/или принимать информацию. Интерфейс 108 может дополнительно включать в себя интерфейс компьютерной системы, позволяющий сохранять совместимый битовый поток в запоминающем устройстве. Например, интерфейс 108 может включать в себя набор микросхем, поддерживающий протоколы шины с взаимосвязью периферийных компонентов (PCI) и с экспресс-взаимосвязью периферийных компонентов (PCIe), проприетарные протоколы шин, протоколы универсальной последовательной шины (USB), I2C или любую другую логическую и физическую структуру, которую можно использовать для соединения одноранговых устройств.
[0056] На ФИГ. 7 устройство 120 назначения включает в себя интерфейс 122, видеодекодер 124 и дисплей 126. Интерфейс 122 может включать в себя любое устройство, выполненное с возможностью приема совместимого битового потока видео из среды связи. Интерфейс 108 может включать в себя карту сетевого интерфейса, такую как карта Ethernet, и может включать в себя оптический приемопередатчик, радиочастотный приемопередатчик или устройство любого другого типа, способное принимать и/или отправлять информацию. Интерфейс 122 может дополнительно включать в себя интерфейс компьютерной системы, позволяющий извлекать совместимый битовый поток видео из запоминающего устройства. Например, интерфейс 122 может включать в себя набор микросхем, поддерживающий протоколы шины PCI и PCIe, проприетарные протоколы шин, протоколы USB, I2C или любую другую логическую и физическую структуру, которую можно использовать для соединения одноранговых устройств. Видеодекодер 124 может включать в себя любое устройство, выполненное с возможностью приема совместимого битового потока и/или его приемлемых вариаций и воспроизведения из него видеоданных. Дисплей 126 может включать в себя любое устройство, выполненное с возможностью отображения видеоданных. Дисплей 126 может содержать одно из множества устройств отображения, таких как жидкокристаллический дисплей (ЖКД), плазменный дисплей, дисплей на органических светодиодах (OLED) или дисплей другого типа. Дисплей 126 может включать в себя дисплей высокой четкости или дисплей сверхвысокой четкости. Следует отметить, что, хотя в проиллюстрированном на ФИГ. 7 примере видеодекодер 124 описан как выводящий данные на дисплей 126, видеодекодер 124 может быть выполнен с возможностью вывода видеоданных на различные типы устройств и/или их подкомпонентов. Например, видеодекодер 124 может быть выполнен с возможностью вывода видеоданных в любую среду связи, как описано в настоящем документе.
[0057] На ФИГ. 8 приведена блок-схема, иллюстрирующая пример видеокодера 200, способного реализовывать методики кодирования видеоданных, описанные в настоящем документе. Следует отметить, что, хотя указанный в примере видеокодер 200 проиллюстрирован как имеющий различные функциональные блоки, такая иллюстрация предназначена только для описания и не ограничивает видеокодер 200 и/или его подкомпоненты конкретной архитектурой аппаратного или программного обеспечения. Функции видеокодера 200 могут быть реализованы с использованием любой комбинации аппаратных, программно-аппаратных и/или программных вариантов осуществления. В одном примере видеокодер 200 может быть выполнен с возможностью кодирования видеоданных в соответствии с описанными в настоящем документе методиками. Видеокодер 200 может выполнять кодирование с внутренним прогнозированием и кодирование с внешним прогнозированием областей изображения и в таком виде может называться гибридным видеокодером. В приведенном на ФИГ. 8 примере видеокодер 200 принимает исходные видеоблоки. В некоторых примерах исходные видеоблоки могут включать в себя области изображения, разделенные в соответствии со структурой кодирования. Например, исходные видеоданные могут включать в себя макроблоки, CTU, CB, их подразделы и/или другой эквивалентный элемент кодирования. В некоторых примерах видеокодер 200 может быть выполнен с возможностью выполнения дополнительных подразделений исходных видеоблоков. Следует отметить, что некоторые описанные в настоящем документе методики могут быть в целом применимы к кодированию видеосигналов, независимо от методов разделения исходных видеоданных до и/или во время кодирования. В приведенном на ФИГ. 8 примере видеокодер 200 включает в себя сумматор 202, генератор 204 коэффициентов преобразования, блок 206 квантования коэффициентов, блок 208 обработки обратного квантования/преобразования, сумматор 210, блок 212 обработки внутреннего прогнозирования, блок 214 обработки внешнего прогнозирования, блок 216 фильтрации и блок 218 энтропийного кодирования.
[0058] Как показано на ФИГ. 8, видеокодер 200 принимает исходные видеоблоки и выводит битовый поток. Как описано выше, JEM включает в себя следующие параметры для сигнализации дерева QTBT: размер CTU, MinQTSize, MaxBTSize, MaxBTDepth и MinBTSize. Таблица 5 иллюстрирует размеры блоков концевых узлов QT на разных глубинах QT для разных размеров CTU (в примере MinQTSize равен 8). В таблице 6 дополнительно указаны допустимые размеры блоков концевых узлов BT на различных глубинах BT для размеров корневых узлов двоичного дерева (т.е. размеров концевых узлов квадродерева).
[0059] Таким образом, согласно таблице 5 размер узла квадродерева, образующего корень двоичного дерева, может быть определен на основе размера CTU и глубины QT. Если квадродерево дополнительно разделено на двоичные деревья, размеры концевого узла двоичного дерева могут быть определены на основе размера узла QT и глубины BT, как показано в таблице 6. Каждый из MaxBTSize, MaxBTDepth и MinBTSize можно использовать для определения минимально допустимого размера концевого узла двоичного дерева. Например, если размер CTU - 128 × 128, глубина QT - 3, MaxBTSize - 16 × 16, а MaxBTDepth - 2, минимально допустимый размер концевого узла двоичного дерева включает в себя 64 выборки (т.е. 8 × 8, 16 × 4 или 4 × 16). В этом случае, если MaxBTDepth равно 1, минимально допустимый размер концевого узла двоичного дерева включает в себя 128 выборок (т.е. 16 × 8 или 8 × 16). Таблица 7 иллюстрирует размеры блоков концевых узлов BT при различных комбинациях глубин QT и глубин BT для размера CTU 128 × 128.
[0060] Как указано выше, разделение QTBT и связанная с ним сигнализация, как определено в JEM, могут быть далеко не идеальными. В некоторых примерах, в соответствии с описанными в настоящем документе методиками видеокодер 200 может быть выполнен с возможностью разделения CTU таким образом, чтобы каналы яркости и цветности имели общую структуру разделения до уровня CU, причем тип прогнозирования (например, внутренний, внешний режим или режим пропуска) связан с CU. Кроме того, в зависимости от типа прогнозирования (например, внутренний, внешний режим или режим пропуска) один или оба из каналов яркости и цветности могут быть дополнительно разделены. В одном примере каналы яркости и цветности имеют общую структуру разделения до уровня CU, и, если с CU связан внутренний тип прогнозирования, один или оба из каналов яркости и цветности могут быть дополнительно разделены. Следует отметить, что в приведенных ниже примерах уровень CU относится к концевому узлу общего QTBT, который образует корень для дополнительного разделения каналов яркости и цветности. Следует отметить, что в одном примере может быть указано явным образом, можно ли разделять каналы яркости и цветности за пределами уровня CU (например, с использованием флага на уровне CTU или флага на уровне в дереве разделения, на котором указан тип прогнозирования) или это может быть определено на основании свойств видеоданных (например, размера CTU). Следует отметить, что для среза видеоданных, относящегося к интра типу (который может упоминаться как срез, соответствующий внутреннему (интра) прогнозированию), разрешены только режимы внутреннего прогнозирования, а для среза видеоданных, относящегося к интер типу (который может упоминаться как срез внешнего (интер) прогнозирования), разрешены как режимы внутреннего прогнозирования, так и режимы внешнего прогнозирования. В одном примере для интра-срезов (внутренних срезов) и интер-срезов (внешних срезов) могут быть использованы разные схемы разделения. Например, в одном примере для внутренних срезов независимые QTBT могут быть использованы для канала яркости, канала цветности и для внешних срезов, причем канал яркости и канал цветности могут быть разделены в соответствии с методиками, описанными в настоящем документе. Кроме того, следует отметить, что в одном примере для разделения внутренних срезов и внешних срезов могут быть использованы различные другие методики (например, методики, представленные в ITU-Т H.265), причем канал яркости и канал цветности могут быть разделены в соответствии с методиками, описанными в настоящем документе.
[0061] На ФИГ. 9 и 10 приведены концептуальные схемы видеокомпонента, иллюстрирующие разделение в соответствии с одной или более методиками настоящего описания. На ФИГ. 9 представлен пример, в котором для CTU, включенного во внешний срез, каналы яркости и цветности имеют общую структуру разделения вплоть до уровня CU, а в случае, когда для CU задан внутренний тип прогнозирования, каналы яркости и цветности могут быть дополнительно разделены. На ФИГ. 10 представлен пример, в котором для CTU, включенного во внешний срез, каналы яркости и цветности имеют общую структуру разделения вплоть до уровня CU, а в случае, когда для CU задан внутренний тип прогнозирования, канал яркости может быть дополнительно разделен. Следует отметить, что на ФИГ. 9 и 10 для простоты иллюстрации только один из CU показан как относящийся к внутреннему типу прогнозирования, а другие CU относятся к внешним типам прогнозирования. Следует отметить, что любая комбинация внутреннего или внешнего типов прогнозирования может быть связана с соответствующими CU в CTU. В примерах, показанных на ФИГ. 9 и 10, каждый показанный CB может представлять собой блок значений выборки, для которых применяют одинаковое прогнозирование. Другими словами, CB, показанные на ФИГ. 9 и 10, могут быть аналогичными PB в ITU-T H.265. Однако следует отметить, что CB, показанные на ФИГ. 9 и 10, не ограничиваются конфигурациями PB, определенными в ITU-T H.265 (т.е. CB могут иметь конфигурации, получаемые при разделении QTBT).
[0062] Как показано на ФИГ. 9, для канала яркости CU, связанный с внутренним типом прогнозирования, дополнительно разделяют на четыре части, а для канала цветности CU, связанный с внутренним типом прогнозирования, дополнительно разделяют по вертикали. Таким образом, в соответствии с методиками, описанными в настоящем документе, каналы яркости и цветности могут быть независимо разделены в соответствии с QTBT, причем CU, связанный с внутренним типом прогнозирования, образует корень независимых QTBT. Как показано на ФИГ. 10, для канала яркости CU, связанный с внутренним типом прогнозирования, дополнительно разделяют в соответствии со способами разделения квадродерева, а для канала цветности соответствующий CU дополнительно не разделяют. Таким образом, в соответствии с методиками, описанными в настоящем документе, один из каналов яркости и цветности может быть независимо разделен в соответствии с QTBT, причем CU, связанный с внутренним типом прогнозирования, образует корень QTBT. Следует отметить, что в других примерах могут быть разрешены и другие типы разделения для каналов яркости и/или цветности, причем CU, связанный с внутренним типом прогнозирования, образует корень для дополнительного разделения каналов яркости и/или цветности. Например, для каждого из каналов яркости и/или цветности может быть разрешена любая из следующих комбинаций типов разделения: без дополнительного разделения, разделение QT, разделение BT и разделение QTBT.
[0063] В одном примере типы разделения, которые разрешены для каждого из каналов яркости и/или цветности, могут быть сигнализированы с использованием синтаксиса более высокого уровня. Например, каждый из типов разделения каналов яркости и/или цветности может быть сигнализирован на уровне CTU, уровне среза или на уровне набора параметров (например, набора параметров изображения (PPS) или набора параметров последовательности (SPS)). Как описано выше, элементы синтаксиса флага разделения QT и элементы синтаксиса режима разделения BT связаны с глубиной, причем нулевая глубина соответствует корню QTBT, а глубины с более высокими значениями соответствуют последующим глубинам за пределами корня. Следует отметить, что в некоторых случаях глубина может быть определена по отношению к CU, образующему корень. В одном примере, можно ли и каким образом можно дополнительно разделять каналы яркости и/или цветности за пределами CU, связанного с внутренним типом прогнозирования, может зависеть от значений максимальной глубины. Например, дополнительное разделение каналов яркости и/или цветности может быть разрешено, только если будет обеспечена глубина, которая меньше или равна максимальной глубине. В одном примере максимальные значения глубины для каждого из каналов яркости и/или цветности могут быть сигнализированы с использованием синтаксиса более высокого уровня. В одном примере максимальные значения глубины могут быть обеспечены для разделения BT и/или разделения QT. В одном примере максимальные значения глубины могут быть такими же, как и максимальные значения глубины, указанные для разделения QTBT с корнем на уровне CTU. Например, для канала яркости максимальная глубина 3 может быть указана для разделения QT, а максимальная глубина 4 может быть указана для разделения BT.
[0064] В одном примере, можно ли и каким образом можно дополнительно разделять каналы яркости и/или цветности за пределами CU, связанного с внутренним типом прогнозирования, может зависеть от полученной в результате конфигурации и/или количества выборок в CB. Например, может быть указано одно или более из минимального размера (ширина × высота), минимальной высоты и/или минимальной ширины, так что окончательный CB должен быть большим или равным указанному минимальному значению. В одном примере минимальные размеры/масштабы для каждого из каналов яркости и/или цветности могут быть сигнализированы с использованием синтаксиса более высокого уровня. В одном примере минимальные размеры/масштабы/количество выборок могут быть такими же, как и минимальные размеры/масштабы/количество выборок, указанные для разделения QTBT с корнем на уровне CTU. Кроме того, в одном примере, можно ли и каким образом можно дополнительно разделять каналы яркости и/или цветности за пределами CU, связанного с внутренним типом прогнозирования, может зависеть от конфигурации и/или количества выборок в CTU и/или CU. Например, дополнительное разделение каналов яркости и/или цветности может быть разрешено для CTU и/или CU, имеющих размер/масштаб, который больше или равен минимальным размерам/масштабам. Кроме того, в одном примере дополнительное разделение каналов яркости и/или цветности может быть разрешено для CTU и/или CU, имеющих размер/масштаб, который меньше минимального размера/масштабов. В одном примере минимальные размеры/масштабы/количество выборок могут быть такими же, как и минимальные размеры/масштабы/количество выборок, указанные для разделения QTBT с корнем на уровне CTU. В одном примере дополнительное разделение каналов яркости и/или цветности может быть разрешено для CTU и/или CU, имеющих размер/масштаб/количество выборок, которые меньше или равны максимальным размеру/масштабам/количеству выборок. Если размер блока меньше максимального, разделение (например, разделение QT) может быть определено и дополнительная сигнализация не требуется. В одном примере максимальные размеры/масштабы/количество выборок могут быть такими же, как и максимальные размеры/масштабы/количество выборок, указанные для разделения QTBT с корнем на уровне CTU. В одном примере каждое из размеров/размерностей каналов яркости и/или цветности для CTU и/или CU может быть сигнализировано с использованием синтаксиса более высокого уровня. Кроме того, в одном примере каждое из размеров/масштабов каналов яркости и/или цветности для CTU и/или CU может быть задано.
[0065] В Li, et al., "Multi-Type-Tree," 4th Meeting: Chengdu, CN, 15-21 October 2016, Doc. JVET-D0117rl (далее - «Li») описан пример, в котором помимо режимов симметричного вертикального и горизонтального разделения BT определены два дополнительных режима разделения троичного дерева (TT). Разделение троичного дерева (TT) может относиться к разделению узла на три блока вокруг некоторого направления. В Li режимы разделения TT для узла включают: (1) горизонтальное разделение ТТ на одну четверть высоты от верхнего края и нижнего края узла; и (2) вертикальное разделение ТТ на одну четверть ширины от левого края и правого края узла. На ФИГ. 11A представлены примеры вертикального разделения TT и горизонтального разделения TT. Следует отметить, что в контексте настоящего документа термин «разделение троичного дерева (TT)» может относиться к разделению узла на три блока вокруг направления для любых смещений. Другими словами, в контексте настоящего документа разделение TT не ограничивается разделением узла на смещение в одну четверть (например, другие смещения могут включать смещения на 1/3 и/или асимметричные смещения и т. д.). В одном примере типы разделения, которые могут быть разрешены для разделения каждого из каналов яркости и/или цветности за пределами CU, могут включать разделение TT. Кроме того, можно ли разделять каналы яркости и/или цветности за пределами CU в соответствии с разделением TT, может зависеть от любой из описанных выше методик (например, максимальной глубины, минимальных размеров/масштабов, количества значений выборки и т. д.).
[0066] В F. Le Léannec, et al., "Asymmetric Coding Units in QTBT," 4th Meeting: Chengdu, CN, 15-21 October 2016, Doc. JVET-D0064 (далее - «Le Léannec») описан пример, в котором в дополнение к симметричным вертикальным и горизонтальным режимам разделения BT определены четыре дополнительных асимметричных режима разделения BT. В Le Léannec четыре дополнительно определенных режима разделения BT для CU включают в себя: горизонтальное разделение на одну четверть высоты (вверху для одного режима или внизу для другого) или вертикальное разделение на одну четверть ширины (слева для одного режима или право для другого). Четыре дополнительно определенных в Le Léannec режима разделения BT показаны на ФИГ. 11B как Hor_Up, Hor_Down, Ver_Left и Ver_Right. Следует отметить, что четыре дополнительно определенных в Le Léannec режима разделения BT могут упоминаться как разделы асимметричного двоичного дерева (ABT) и они аналогичны разделам асимметричного PB, представленным в ITU-T H.265. Следует отметить, что в некоторых случаях термин «разделы ABT» может быть использован для обозначения произвольных разделов двоичного дерева.
[0067] Как описано выше, в JEM QTBT сигнализирован посредством сигнализации флага разделения QT и элементов синтаксиса режима разделения BT. На ФИГ. 12 приведена концептуальная схема, иллюстрирующая пример QTBT, соответствующего примеру разделения QTBT, показанному на ФИГ. 9. Как показано на ФИГ. 12, когда будет достигнут CU, связанный с внутренним типом прогнозирования, для каждого из компонента яркости и каналов цветности указывают QTBT. В таблице 8 представлен пример псевдосинтаксиса, который может быть использован в сигнале общего QTBT и независимых QTBT для каналов яркости и/или цветности для примера, показанного на ФИГ. 12. В отношении таблицы 8 следует отметить, что для целей иллюстрации флаг «Pred Type» лишь указывает, является ли тип прогнозирования внешним или внутренним. Как правило, во внешнем срезе флагу типа прогнозирования предшествует флаг пропуска и флаг типа прогнозирования сигнализируют лишь тогда, когда флаг пропуска=0. Методики, описанные в настоящем документе, как правило, применимы независимо от того, какой тип внутреннего прогнозирования указан в пределах внешнего среза.

[0068] Как показано в таблице 8, после достижения блока кодирования (разделение BT=0) определяют тип прогнозирования для блока кодирования. Если тип прогнозирования является внешним, сигнализацию дополнительного разделения для блока кодирования не выполняют. Если тип прогнозирования является внутренним, QTBT сигнализируют для канала яркости и QTBT сигнализируют для канала цветности. В таблице 9A представлен общий случай сигнализации, выполняемой для блока кодирования. Как описано выше, в некоторых примерах дополнительное разделение может быть запрещено для одного из канала яркости или канала цветности. В таких примерах coding_tree_unit_luma() или coding_tree_unit_chroma() в таблице 9A могут быть заменены на coding_block_luma() или coding_block_chroma().

[0069] Кроме того, как описано выше, для определения того, можно ли и каким образом можно дополнительно разделять каналы яркости и/или цветности за пределами CU, связанного с внутренним типом прогнозирования, могут быть применены различные методики. Таким образом, в таблице 9A coding_tree_unit_luma() и coding_tree_unit_chroma() могут представлять собой значения, разрешающие различные типы разделения. Например, coding_tree_unit_chroma() может включать в себя значение, связанное с применением разделения BT или TT. В одном примере каналы яркости и цветности могут быть дополнительно разделены за пределами CU, связанного с внутренним типом прогнозирования, в соответствии с отдельными деревьями разделения или общим деревом разделения. В одном примере флаг может указывать на то, разделены ли дополнительно каналы яркости и цветности в соответствии с отдельными деревьями разделения или общим деревом разделения. В таблице 9B представлен пример, в котором флаг (т.е. separate_tree_flag) указывает на то, разделены ли дополнительно каналы яркости и цветности в соответствии с отдельными деревьями разделения (т.е. coding_tree_unit_luma() и coding_tree_unit_chroma()) или общим деревом разделения (т.е. coding_tree_unit_shared()), причем coding_tree_unit_shared() представляет собой значение, разрешающее различные типы разделения.

[0070] В одном примере то, разделены ли дополнительно каналы яркости и цветности в соответствии с отдельными деревьями разделения или общим деревом разделения, может быть определено на основании свойств видеоданных и/или параметров кодирования. Например, как показано в таблице 9B, условие separate_tree_flag == TRUE может быть заменено на условие, основанное на свойствах видеоданных и/или параметров кодирования. В одном примере то, используют ли для дополнительного разделения каналов яркости и цветности отдельные деревья разделения или общее дерево разделения, может зависеть от количества выборок (например, выборок яркости или цветности), включенных в CU. В одном примере, если количество выборок, включенных в CU, меньше или равно пороговому значению (например, 64, 256 или 1024 выборок), отдельные деревья разделения могут быть использованы для дополнительного разделения каналов яркости и цветности, в противном случае используют общее дерево разделения. В одном примере, если количество выборок, включенных в CU, больше или равно пороговому значению, отдельные деревья разделения могут быть использованы для дополнительного разделения каналов яркости и цветности, в противном случае используют общее дерево разделения.
[0071] Как описано выше, для среза внутреннего прогнозирования разрешены только режимы внутреннего прогнозирования, а для среза внешнего прогнозирования разрешены как режимы внутреннего прогнозирования, так и режимы внешнего прогнозирования. Следует отметить, что срезы внешнего прогнозирования могут быть дополнительно классифицированы как срезы P-типа (или P-срезы) или срезы B-типа (B-срезы), причем для B-среза разрешено однонаправленное и двунаправленное внешнее прогнозирование, а для P-среза разрешено только однонаправленное внешнее прогнозирование. В одном примере то, используют ли для дополнительного разделения каналов яркости и цветности отдельные деревья разделения или общее дерево разделения, может зависеть от того, является ли срез внешнего прогнозирования, включающий внутренний CU, P-срезом или B-срезом. Следует отметить, что в одном примере, присутствует ли флаг и используют ли его для указания того, разделены ли дополнительно каналы яркости и цветности в соответствии с отдельными деревьями разделения или общим деревом разделения, может зависеть от типа среза. Например, в одном примере флаг separate_tree_flag из таблицы 9B может присутствовать для P-срезов и отсутствовать для B-срезов или альтернативно separate_tree_flag из таблицы 9B может присутствовать для B-срезов и отсутствовать для P-срезов. Как описано выше, внутренние CU могут быть включены во внутренние срезы и внешние срезы. В одном примере внутренние CU, включенные во внутренние срезы, могут быть дополнительно разделены, причем флаг может указывать на то, разделены ли дополнительно каналы яркости и цветности в соответствии с отдельными деревьями разделения или общим деревом разделения. Таким образом, в одном примере флаг separate_tree_flag из таблицы 9B может присутствовать для внутренних и внешних срезов. В одном примере флаг separate_tree_flag из таблицы 9B может присутствовать для любого подмножества типов срезов. В одном примере, присутствует ли флаг и используют ли его для указания того, разделены ли дополнительно каналы яркости и цветности в соответствии с отдельными деревьями разделения или общим деревом разделения, может зависеть от свойств видеоданных и/или параметров кодирования. Например, флаг separate_tree_flag из таблицы 9В может присутствовать на основании размера внутреннего CU и/или глубины, на которой возникает внутренний CU.
[0072] Следует отметить, что, хотя флаг separate_tree_flag из таблицы 9B описан как сигнализированный на уровне CU, в других примерах флаг separate_tree_flag может быть сигнализирован на уровне CTU, уровне среза, уровне фрагмента, уровне волны данных или на уровне набора параметров (например, PPS или SPS). Кроме того, в одном примере, разрешено ли дополнительное разделение каналов яркости и цветности в соответствии с отдельными деревьями разделения или общим деревом разделения (например, может ли присутствовать флаг separate_tree_flag на основании видеоданных и/или параметров кодирования), может быть определено в соответствии с флагом более высокого уровня. Например, флаг, включенный в заголовок среза, может указывать на то, может ли separate_tree_flag присутствовать на уровне CU, а фактическое присутствие флага separate_tree_flag в конкретном CU может зависеть от размера CU.
[0073] Как описано выше, можно ли и каким образом можно дополнительно разделять каналы яркости и/или цветности за пределами CU, связанного с внутренним типом прогнозирования, может зависеть от значений максимальной глубины, причем значения максимальной глубины для каждого из каналов яркости и цветности могут быть сигнализированы с использованием синтаксиса более высокого уровня. В одном примере значения максимальной глубины для каждого из каналов яркости и цветности, разделенных в соответствии с общим деревом разделения, могут быть сигнализированы независимо и в этом случае каждый канал будет разделен в соответствии с общим деревом вплоть до его максимальной глубины. В одном примере значения максимальной глубины для каждого из каналов яркости и цветности, разделенных в соответствии с отдельными деревьями разделения, могут быть сигнализированы независимо. Например, флаг, включенный в заголовок среза, может указывать на то, может ли separate_tree_flag присутствовать на уровне CU, а фактическое присутствие флага separate_tree_flag в конкретном CU может зависеть от размера CU, и заголовок среза может дополнительно указывать соответствующие максимальные значения глубины для каждого из каналов яркости и цветности.
[0074] Как описано выше, присутствие флага separate_tree_flag в таблице 9B может зависеть от глубины, на которой возникает внутренний CU. В одном примере глубина, на которой возникает внутренний CU, может быть указана относительно корня, возникающего (т.е. глубина 0) в CTU, и может упоминаться как cu_depth. Как показано в примере на ФИГ. 9 и ФИГ. 12, глубина внутреннего CU равна 2. В одном примере флаг separate_tree_flag может отсутствовать в битовом потоке для внутреннего CU в случаях, когда cu_depth больше или равно значению глубины (например, max_depth). В одном примере, если флаг separate_tree_flag отсутствует в битовом потоке, это означает, что он имеет значение 1 (или 0 в некоторых примерах), и, таким образом, для разделения каналов яркости и цветности за пределами внутреннего CU могут быть использованы отдельные деревья разделения (например, coding_tree_unit_luma() и coding_tree_unit_chroma()). В одном примере, если флаг separate_tree_flag отсутствует в битовом потоке, это означает, что он имеет значение 0 (или 1 в некоторых примерах), и, таким образом, для разделения каналов яркости и цветности за пределами внутреннего CU может быть использовано общее дерево разделения (например, coding_tree_unit_shared()).
[0075] В таблице 9C представлен пример, в котором флаг separate_tree_flag при определенных условиях присутствует в битовом потоке в зависимости от внутренних CU, для которых cu_depth больше или равно глубине, и, если флаг separate_tree_flag отсутствует в битовом потоке, для разделения каналов яркости и цветности за пределами внутреннего ТС используют отдельные деревья разделения. В таблице 9D представлен пример, в котором флаг separate_tree_flag при определенных условиях присутствует в битовом потоке в зависимости от внутренних CU, для которых cu_depth больше или равно глубине, и, если флаг separate_tree_flag отсутствует в битовом потоке, для разделения каналов яркости и цветности за пределами внутреннего CU используют общее дерево разделения. В одном примере значение max_depth в таблицах 9C и 9D может быть сигнализировано с использованием синтаксиса более высокого уровня. Например, max_depth может быть передано на уровне CTU, уровне среза или на уровне набора параметров. В одном примере значение max_depth в таблицах 9C и 9D может быть равно MaxBTDepth.


[0076] Следует отметить, что в некоторых примерах условие (cu_depth >= max_depth) в таблицах 9C-9D может быть заменено на (cu_depth == max_depth). Кроме того, в некоторых примерах условие (cu_depth >= max_depth) в таблицах 9C-9D может быть заменено на следующее условие: (cu_depth >= max_depth OR cu_width == min_width OR cu_height == min_height), где cu_width представляет собой ширину CU в некотором количестве выборок, cu_height представляет собой высоту CU в некотором количестве выборок, min_width представляет собой пороговое значение ширины в некотором количестве выборок, а min_height представляет собой пороговое значение высоты в некотором количестве выборок. Таким образом, в одном примере присутствие флага separate_tree_flag в битовом потоке также может зависеть от количества выборок (например, выборок яркости или цветности), включенных во внутренний CU. Кроме того, следует отметить, что в некоторых примерах значения max_depth, min_width и/или min_height могут быть основаны на типе среза (например, P или B) и/или значениях индекса компонента цвета. В одном примере (cu_depth >= max_depth) в каждом из примеров, показанных в таблице 9C и таблице 9D, можно поменять на условие (cu_depth <= max_depth) таким образом, что сигнализация флага separate_tree_flag будет пропущена на основании внутренних CU, имеющих cu_depth, которое меньше или равно глубине. Следует отметить, что в этом случае max_depth представляет собой значение глубины, которое отражает пороговую глубину (т.е. для внутреннего CU, имеющего глубину, меньшую или равную max_depth, в этом случае выводят значение separate_tree_flag). В одном примере (cu_depth >= max_depth) в каждом из примеров, показанных в таблице 9C и таблице 9D, можно поменять на условие (cu_height <= min_height OR cu_width <= min_width) таким образом, что сигнализация флага separate_tree_flag будет пропущена, на основании того, что внутренние CU меньше или равны размеру. Следует отметить, что в этом случае значения min_height и min_width представляют пороговые значения. В одном примере (cu_depth >= max_depth) в каждом из примеров, показанных в таблице 9C и таблице 9D, можно поменять на условие (cu_height >= min_height OR cu_width >= min_width) таким образом, что сигнализация флага separate_tree_flag будет пропущена, на основании того, что внутренний CU больше или равен минимальному размеру. Таким образом, видеодекодер может выводить значение separate_tree_flag на основании размера блока. Следует отметить, что в некоторых примерах значения max_depth, min_width и/или min_height могут зависеть от типа среза (например, среза P или B) для среза, включающего в себя CU и/или канал (например, яркости или цветности).
[0077] Как описано выше, в JEM концевой узел QTBT для компонента цвета (т.е. CB в JEM) можно рассматривать как аналогичный PB и TB в ITU-T H.265. Таким образом, в JEM после достижения концевого узла QTBT предоставляют дополнительную сигнализацию для указания прогнозирования, соответствующего концевому узлу QTBT (например, внутреннему направлению прогнозирования), и характеристики преобразования, соответствующие остатку, соответствующему концевому узлу QTBT (например, NSST_idx). Например, как показано на ФИГ. 9, для каждого из четырех CB яркости в соответствии с сигнализацией JEM соответствующие характеристики прогнозирования и преобразования, соответствующие остатку, будут включены в битовый поток. В одном примере в соответствии с методиками, описанными в настоящем документе, сигнализация характеристик прогнозирования и преобразования CB может быть основана на присутствии и/или значении флага separate_tree_flag. Например, в примере, соответствующем таблице 9C, в одном примере количество возможных значений NSST_idx, разрешенное для канала цветности, может быть основано на том, используют ли отдельные деревья разделения для разделения каналов яркости и цветности за пределами внутреннего CU. В одном примере, если отдельные деревья разделения используют для разделения каналов яркости и цветности за пределами внутреннего CU, количество возможных значений NSST_idx, разрешенное для канала цветности, может быть равно 4. В примере, соответствующем таблице 9D, в одном примере количество возможных значений NSST_idx, разрешенное для канала цветности, может быть основано на том, используют ли общие деревья разделения для разделения каналов яркости и цветности за пределами внутреннего CU. В одном примере, если общее дерево разделения используют для разделения каналов яркости и цветности за пределами внутреннего CU, количество возможных значений NSST_idx, разрешенное для канала цветности, может быть равно 3.
[0078] Как описано выше, в JEM после достижения концевого узла QTBT предоставляют дополнительную сигнализацию для указания прогнозирования, соответствующего концевому узлу QTBT, и характеристики преобразования, соответствующие остатку, соответствующему концевому узлу QTBT. Таким образом, в JEM для каждого концевого узла QTBT предоставляют соответствующую сигнализацию для указания прогнозирования, соответствующего концевому узлу QTBT, и характеристики преобразования, соответствующие остатку, соответствующему концевому узлу QTBT. В одном примере в соответствии с методиками, описанными в настоящем документе, CB за пределами внутреннего CU (например, каждый из четырех CB яркости на ФИГ. 9) могут иметь один или более общих аспектов информации прогнозирования и/или характеристик преобразования. Таким образом, в соответствии с методиками, описанными в настоящем документе, сигнализация прогнозирования и/или характеристик преобразования для соответствующих концевых узлов может быть упрощена. В одном примере в соответствии с методиками, описанными в настоящем документе, соответствующие прогнозирования и характеристики преобразования для каждого CB за пределами внутреннего CU (например, каждого из четырех CB яркости на ФИГ. 9) могут быть выведены на основании присутствия и/или значения флага separate_tree_flag. Например, как показано в примере на ФИГ. 9, в одном примере каждый из четырех CB яркости может совместно с другими CB использовать выводимую (или сигнализированную) информацию прогнозирования (например, режим направленного внутреннего прогнозирования) и/или характеристики преобразования (например, значение NSST_idx) на основании присутствия и/или значения флага separate_tree_flag.
[0079] Снова обращаясь к примерам, представленным в таблицах 9B-9D, отметим, что в примере разделение каналов яркости и цветности за пределами внутреннего CU с использованием общего дерева разделения может быть не разрешено, может быть отключено на основании сигнализации более высокого уровня (например, флага включения/выключения CTU или уровня среза), может быть отключено на основании свойств CU (например, размера и/или глубины) и/или может быть отключено на основании сигнализации более высокого уровня и/или свойств CU. В таблице 9E представлен пример, в котором разделение каналов яркости и цветности за пределами внутреннего CU с использованием общего дерева разделения не разрешено. Другими словами, в примере, представленном в таблице 9E, если каналы яркости и цветности дополнительно не разделяют в соответствии с отдельными деревьями разделения, дополнительное разделение прекращают. Другими словами, как показано в таблице 9E, синтаксис характеристики прогнозирования и преобразования сигнализируют для внутреннего CU без дополнительного разделения каналов яркости и цветности. В таблице 9F представлен пример, в котором разделение каналов яркости и цветности за пределами внутреннего CU с использованием общего дерева разделения отключено на основании сигнализации более высокого уровня и/или свойств CU. Другими словами, в таблице 9F условие (CU Condition == TRUE) может представлять собой условие, основанное на сигнализации более высокого уровня и/или свойствах CU. Следует отметить, что в некоторых примерах условие (CU Condition == TRUE) может быть основано на свойстве битового потока (т.е. определено без дополнительной сигнализации). Например, (CU Condition == TRUE) может представлять собой флаг, который присутствует на основании флага включения/выключения более высокого уровня (например, уровня CTU, уровня среза, уровня набора параметров).


[0080] В отношении примера, представленного в таблице 9E, следует отметить, что запрещение разделения каналов яркости и цветности за пределами внутреннего CU с использованием общего дерева разделения может привести к снижению сложности реализации совместимого видеокодера и совместимого видеодекодера. Однако в некоторых случаях запрещение разделения каналов яркости и цветности за пределами внутреннего CU с использованием общего дерева разделения может привести к потере эффективности кодирования.
[0081] Как описано выше, используют ли отдельные деревья разделения или общее дерево разделения для дополнительного разделения каналов яркости и цветности, причем CU, связанный с внутренним типом прогнозирования, образует корень для дополнительного разделения каналов яркости и/или цветности, может зависеть от количества выборок (например, выборок яркости или цветности), включенных в CU. В одном примере для диапазона размеров блоков может быть разрешено разделение в соответствии с общим деревом, и для диапазона размеров блоков может быть разрешено разделение в соответствии с отдельными деревьями. Таблица 9G иллюстрирует пример, в котором флаг separate_tree_flag при определенных условиях присутствует в битовом потоке на основании следующих условий: (1) является ли размер CU большим или равным верхнему пороговому значению размера (cu_width*cu_height >= Upper_TH); (2) является ли размер CU меньшим или равным нижнему пороговому значению размера (cu_width*cu_height <= lower_TH); и (3) разрешено ли дополнительное разделение (не разрешено дополнительное разделение). Следует отметить, что условие (не разрешено дополнительное разделение) в таблице 9G может быть аналогичным условию (CU Condition == TRUE), описанному выше. В одном примере значения Upper_TH и/или Lower_TH могут быть сигнализированы с использованием сигнализации высокого уровня. Например, значение Upper_TH может быть установлено равным 1024 выборкам, а Lower_TH может быть установлено равным 256 выборкам. В одном примере определение того, разрешено ли дополнительное разделение, может быть основано на приведенных выше примерах условий, например (cu_depth >= max_depth), (cu_depth >= max_depth OR cu_width == min_width OR cu_height == min_height), и т. д. В одном примере условие для определения того, разрешено ли дополнительное разделение, может быть сигнализировано с помощью сигнализации высокого уровня.

[0082] Таблица 9H иллюстрирует пример, в котором флаг separate_tree_flag при определенных условиях присутствует в битовом потоке на основании следующих условий: (1) является ли размер CU большим или равным верхнему пороговому значению размера (cu_width*cu_height >= Upper_TH); и (2) является ли размер CU меньшим или равным нижнему пороговому значению размера (cu_width*cu_height <= lower_TH).

[0083] В одном примере, используют ли отдельные деревья разделения или общее дерево разделения для дополнительного разделения каналов яркости и цветности, причем CU, связанный с внутренним типом прогнозирования, образует корень для дополнительного разделения каналов яркости и/или цветности, может зависеть от значения QP, связанного с CU. Например, в одном примере флаг separate_tree_flag может присутствовать в битовом потоке при определенных условиях, а именно на основании следующих условий: (1) является ли значение QP большим или равным верхнему пороговому значению; (2) является ли значение QP меньшим или равным нижнему пороговому значению; и/или (3) разрешено ли дополнительное разделение. Другими словами, например, условия (cu_width*cu_height >= Upper_TH) и (cu_width*cu_height <= lower_TH) в таблицах 9G и 9H могут быть соответственно заменены на условия (QP >= Upper_QP_TH) и (QP <= Lower_QP_TH), причем в одном примере Upper_QP_TH и/или Lower_QP_TH могут быть сигнализированы с использованием сигнализации высокого уровня. Например, значение Upper_QP_TH может быть установлено равным 40, а значение Lower_QP_TH может быть установлено равным 10. В одном примере минимальный допустимый размер концевого узла для каждого из значений coding_tree_unit_luma(), coding_tree_unit_chroma() и/или coding_tree_unit_shared() может быть разным. Например, значение coding_tree_unit_shared() может иметь минимально допустимый размер концевого узла 16 выборок (например, 4 × 4), а coding_tree_unit_luma() и/или coding_tree_unit_chroma() может иметь минимально допустимый размер концевого узла 256 (например, 16 × 16).
[0084] Как описано выше, срезы внешнего прогнозирования могут быть дополнительно классифицированы как срезы P-типа или срезы B-типа и то, используют ли для дополнительного разделения каналов яркости и цветности отдельные деревья разделения или общее дерево разделения, может зависеть от того, является ли срез внешнего прогнозирования, включающий внутренний CU, P-срезом или B-срезом. Кроме того, следует отметить, что в ITU-T H.265 для поддержки временной масштабируемости каждый внутренний срез может быть связан с временным идентификатором (т.е. переменной TemporalId), который указывает уровень в иерархической структуре временного прогнозирования. Например, срезы в изображениях, образующих базовый уровень 30 Гц, могут иметь TemporalId=0, а срезы в изображениях, образующих масштабируемый подуровень 60 Гц, могут иметь TemporalId=1. Следует отметить, что изображения с более низким временным идентификатором, т.е. изображения, соответствующие более низкому уровню видео, чаще используют в качестве средств прогнозирования. Например, изображения, включенные в базовый уровень 30 Гц, как правило, чаще используют в качестве средств прогнозирования, чем изображения, включенные в масштабируемый подуровень 60 Гц. Качество изображений, которые чаще используют в качестве средств прогнозирования, как правило, сильнее влияет на качество видео, чем качество изображений, которые менее часто используют в качестве средств прогнозирования. Кроме того, вследствие иерархической структуры временного прогнозирования видео с временным масштабированием, если изображения на нижних уровнях имеют низкое качество, ошибки могут распространяться на множество более высоких слоев видео (т.е. происходит распространение временных ошибок). В отличие от этого, если изображения на более высоких уровнях имеют низкое качество, распространение временных ошибок может быть ограниченным. В настоящем документе термин «глубина прогнозирования изображения» может относиться к значению, которое определяет, сколько изображений на различных иерархических уровнях применяют (непосредственно или косвенно) как изображения, применяемые в качестве средства прогнозирования. Глубину прогнозирования могут использовать для определения ожидаемого распространения временной ошибки в зависимости от качества изображения. В одном примере глубина прогнозирования может соответствовать TemporalId или может зависеть от TemporalId. В одном примере глубина прогнозирования может быть равна TemporalId плюс единица. В одном примере в соответствии с методиками, описанными в настоящем документе, используют ли отдельные деревья разделения, используют ли общее дерево разделения и/или разрешено ли дополнительное разделение внутреннего CU, включенного в срез внешнего прогнозирования, может зависеть от глубины прогнозирования среза внешнего прогнозирования. Например, в одном примере дополнительное разделение внутреннего CU, включенного в срез внешнего прогнозирования, может быть запрещено, если глубина прогнозирования является большей или равной некоторому пороговому значению.
[0085] Как описано выше, например, в отношении таблиц 9C и 9D, в одном примере флаг separate_tree_flag при определенных условиях может присутствовать в битовом потоке во внутренних CU с cu_depth, большей или равной переменной max_depth. В одном примере переменная max_depth может быть равна глубине прогнозирования или может зависеть от нее. Таким образом, с применением способа, аналогичного описанному выше, сигнализация элементов синтаксиса, используемых для дополнительного разделения внутреннего CU, включенного в срез внешнего прогнозирования, может быть пропущена на основании глубины прогнозирования и видеодекодер может быть выполнен с возможностью вывода значений элементов синтаксиса, не включенных в битовый поток. В одном примере для изображений, имеющих глубину прогнозирования, превышающую пороговое значение, дополнительное разделение каналов яркости и цветности за пределами уровня CU может быть запрещено, например может быть использовано разделение, описанное в JEM. Таким образом, более точные методики разделения могут быть разрешены для изображений, имеющих относительно высокую степень доверия к прогнозированию, по сравнению с изображениями, имеющими относительно низкую степень доверия к прогнозированию, причем в менее точных методиках разделения используют меньше битов в битовом потоке. Как описано выше, можно ли и каким образом можно дополнительно разделять каналы яркости и/или цветности за пределами CU, связанного с внутренним типом прогнозирования, может зависеть от сигнализации более высокого уровня и/или свойств видеоблоков. Например, разделение каналов яркости и цветности за пределами внутреннего CU с использованием общего дерева разделения может быть не разрешено, может быть отключено на основании сигнализации более высокого уровня (например, флага включения/выключения CTU или уровня среза), может быть отключено на основании свойств CU (например, размера и/или глубины) и/или может быть отключено на основании сигнализации более высокого уровня и/или свойств CU. Аналогичным образом, можно ли и каким образом можно дополнительно разделять каналы яркости и/или цветности за пределами CU, связанного с внутренним типом прогнозирования, может зависеть от сигнализации более высокого уровня и/или глубины прогнозирования. Например, разделение каналов яркости и цветности за пределами внутреннего CU с использованием общего дерева разделения может быть не разрешено, может быть отключено на основании сигнализации более высокого уровня (например, флага включения/выключения CTU или уровня среза), может быть отключено на основании значений глубины прогнозирования (например, размера и/или глубины) и/или может быть отключено на основании сигнализации более высокого уровня и/или глубины прогнозирования.
[0086] Как описано выше, в одном примере значение max_depth из таблиц 9C и 9D может быть сигнализировано с использованием синтаксиса более высокого уровня, например уровня CTU, уровня среза или уровня набора параметров. Аналогичным образом, если переменная max_depth равна глубине прогнозирования или зависит от нее, пороговое значение глубины прогнозирования, при котором используют отдельные деревья разделения, используют общее дерево разделения и/или то, разрешено ли дополнительное разделение для внутреннего CU, включенного в срез внешнего прогнозирования, может быть сигнализировано с использованием синтаксиса более высокого уровня. В одном примере элемент синтаксиса highest_tid_sst_plus1, основанный на следующем примере определения:
highest_tid_sst_plus1 указывает на то, что для изображения с TemporalId, превышающим highest_tid_sst_plus1, не используют общее дерево разделения. При его отсутствии предполагаемое значение highest_tid_sst_plus1 равно 7.
[0087] может быть включен в набор параметров (например, VPS, SPS или PPS) или в заголовок среза. Кроме того, в одном примере highest_tid_sst_plus1 при определенных условиях может быть сигнализирован на основании значения флага, который указывает, используют ли средство в виде общего дерева разделения для кодирования видеоданных.
[0088] В одном примере, если highest_tid_sst_plus1 имеет значение 0, может быть использована другая семантика. Другими словами, для highest_tid_sst_plusl, имеющего значение 0, могут быть определены случаи по умолчанию. В одном примере значение 0 для highest_tid_sst_plus1 может быть использовано для указания информации о связи со значением TemporalId, и используется ли общее дерево разделения, неизвестно. В одном примере значение 0 для highest_tid_sst_plus1 может указывать на то, что общее дерево разделения используют только для определенных типов изображений. В одном примере элемент синтаксиса highest_tid_sst_plus1 может быть основан на следующем примере определения:
highest_tid_sst_plus1 указывает на то, что для изображения с TemporalId, меньшим или равным значению highest_tid_sst_plus1, могут использовать или не использовать общее дерево разделения. При его отсутствии предполагаемое значение highest_tid_sst_plus1 равно 7.
[0089] Таким образом, в одном примере и согласно описанным выше примерам условие if(pred_mode_flag == MODE_INTRA) может быть заменено на if(highest_id_sst_plusl && pred_mode_flag == MODE_INTRA). В одном примере общий процесс декодирования блоков кодирования, закодированных с использованием внутреннего режима прогнозирования, может быть описан следующим образом:
Входные данные для этого процесса представляют собой:
- местоположение яркости (xCb, yCb), определяющее верхнюю левую выборку текущего блока кодирования яркости по отношению к верхней левой выборке яркости текущего изображения;
- переменную log2CbSize, задающую размер текущего блока кодирования яркости;
[0090] - TemporalId текущего изображения.
Результат этого процесса представляет собой измененное восстановленное изображение перед фильтрацией деблокинга.
[0091] Он может быть применен с учетом условий, основанных на TemporalId. Другими словами, например, следующее условие может быть включено в общий процесс декодирования для блоков кодирования, закодированных с использованием внутреннего режима прогнозирования:
Если TemporalId текущего изображения меньше или равен highest_tid_sst_plus1, выполняют вызов альтернативного процесса вычисления для внутреннего режима прогнозирования с местоположением яркости (xCb, yCb) в качестве входных данных.
[0092] Как описано выше, coding_tree_unit_shared() представляет семантику, которая обеспечивает различные типы разделения, и подобно coding_tree_unit_luma() или coding_tree_unit_chroma() может представлять семантику, обеспечивающую различные типы разделения (например, разделение BT или TT). В некоторых примерах coding_tree_unit_shared() может предполагать ограничение в отношении дополнительного разделения каналов яркости и цветности только на заданную глубину за пределами CU. В одном примере coding_tree_unit_shared() может предполагать ограничение в отношении дополнительного разделения каналов яркости и цветности только на одну глубину за пределами CU. Например, в этом случае coding_tree_unit_shared() может включать в себя один элемент синтаксиса, указывающий одно из отсутствия разделения, разделения QT, горизонтального разделения BT, вертикального разделения BT, горизонтального разделения TT и/или вертикального разделения TT. В одном примере coding_tree_unit_shared() может включать в себя один элемент синтаксиса, указывающий одно из горизонтального разделения BT, вертикального разделения BT. В одном примере, если coding_tree_unit_shared() включает в себя один элемент синтаксиса, возможные разделения могут включать любую комбинацию из: отсутствия разделения, разделения QT, горизонтального разделения BT, вертикального разделения BT, горизонтального разделения TT и/или вертикального разделения TT.
[0093] Следует отметить, что некоторые способы сигнализации конкретной структуры разделения можно рассматривать как неэффективные и/или избыточные. Например, в некоторых случаях применение разделения BT и TT может привести к появлению квадратных блоков, которые можно получить, просто используя разделение QT (например, вертикальное разделение BT и последующие горизонтальные разделения BT для каждого узла позволяют получить четыре квадрата). Видеокодер 200 изображения может быть выполнен с возможностью запрета избыточной и/или неэффективной сигнализации. Согласно JEM, если разделение BT эквивалентно разделению QT, его запрещают на видеокодере. На ФИГ. 13 представлена концептуальная схема, иллюстрирующая пример запрета разделения BT. Другими словами, как показано на ФИГ. 13, последующее горизонтальное разделение BT правого узла (узел, полученный при вертикальном разделении BT CU) приведет к созданию четырех квадратов и будет запрещено. В некоторых примерах, если разделения запрещены, для определения того, следует ли применить другие типы разделения, может быть использован логический вывод. Например, как показано на ФИГ. 13, поскольку горизонтальное разделение BT запрещено для правого узла, в отношении этого узла может быть логически выведено одно из вертикального разделения BT или отсутствие дополнительного разделения. Как описано выше в некоторых примерах, разрешено ли дополнительное разделение, может зависеть от максимальных значений глубины и т. п. Таким образом, в некоторых случаях определенные типы разделения могут быть запрещены на конкретном уровне глубины. Таким образом, разрешение разделения или отсутствия дополнительного разделения для конкретного узла может быть определено на основании глубины узла и/или того, является ли конкретное разделение неэффективным и/или избыточным.
[0094] В одном примере в соответствии с методиками, описанными в настоящем документе, при дополнительном разделении каналов яркости и/или цветности, в которых CU, связанный с внутренним типом прогнозирования, образует корневой узел, может быть применена одна или более из следующих методик для устранения неэффективной и/или избыточной сигнализации. В одном примере для канала цветности, если разделение BT эквивалентно разделению QT, это разделение может быть запрещено и сигнализация может быть изменена на основании запрета указанного разделения. Например, как показано на ФИГ. 13, для левого узла, полученного в результате вертикального разделения, могут быть разрешены следующие типы разделения: без разделения, вертикальное разделение BT и горизонтальное разделение BT. Таким образом, синтаксис позволяет сигнализировать один из трех типов разделения для узла (например, сигнализация может включать флаг разделения/отсутствия разделения и флаг выполнения вертикального/горизонтального разделения при определенных условиях). В случае правого узла, поскольку горизонтальное разделение BT запрещено, синтаксис должен разрешать сигнализацию лишь двух типов разделения BT (без разделения или вертикальное разделение BT). Таким образом, сигнализация может быть изменена таким образом, что для правого узла флаг разделения/отсутствия разделения указывает, будет ли применен вариант с отсутствием разделения или вертикальное разделение BT. Кроме того, в случаях, когда один или более вариантов разделения, отличных от BT, разрешены для правого узла (например, QT или TT), синтаксис может разрешать сигнализацию одного или более вариантов разделения, отличных от BT. Например, если флаг разделения/отсутствия разделения указывает на отсутствие разделения для правого узла, могут присутствовать дополнительные элементы синтаксиса, указывающие, следует ли применять один или более вариантов разделения, отличных от BT. Аналогичным образом, если для правого узла доступно только одно разделение, отличное от BT, и если флаг разделения/отсутствия разделения указывает на отсутствие разделения для правого узла, может быть логически выведено одно разделение, отличное от BT. Аналогичным образом в одном примере для канала яркости, если разделение BT эквивалентно разделению QT, это разделение может быть запрещено, а синтаксис может быть изменен на основании запрета указанного разделения, как описано выше. Кроме того, в одном примере может быть применено одно или более из следующих ограничений: типы разделения BT могут быть запрещены, если они ведут к разделению TT, разделение TT может быть запрещено, если оно ведет к комбинации разделения QT и разделения BT, и в целом разделение может быть запрещено, если оно ведет к комбинации из подмножества разделений. В одном примере видеокодер 200 может выбирать, следует ли отключать различные варианты разделения и осуществлять сигнализацию в отношении того, разрешены ли варианты разделения, и, таким образом, видеодекодер может определять правила логического вывода на основании того, разрешены или отключены различные разделения.
[0095] В одном примере видеокодер 200 может быть сконфигурирован таким образом, что может происходить одно или более из следующего: если для узла не разрешены дополнительные разделения, пропускают сигнализацию разделения и логически выводят отсутствие разделения; если для узла не разрешены дополнительные разделения QT, пропускают сигнализацию разделения QT и сигнализацию осуществляют только в том случае, если разрешены варианты разделения, отличные от QT/отсутствия разделения. В целом в одном примере видеокодер 200 может быть сконфигурирован таким образом, чтобы в том случае, если дополнительные разделения конкретного типа не разрешены, видеокодер 200 мог пропускать сигнализацию разделений конкретного типа и осуществлять сигнализацию только для доступных типов разделения.
[0096] Следует отметить, что если дополнительное разделение каналов яркости и/или цветности разрешено для CU, связанного с внутренним типом прогнозирования, может существовать множество QTBT, которые позволяют получить эквивалентные CB. На ФИГ. 14A-14B представлены концептуальные схемы, иллюстрирующие окончательные эквивалентные CB как для канала яркости, так и для канала цветности с использованием различных QTBT. На ФИГ. 15A-15B представлены соответствующие QTBT для CB, полученных, как показано на ФИГ. 14A-14B. Кроме того, в таблицах 10A-10B представлен соответствующий пример псевдосинтаксиса, который может быть использован для сигнализации соответствующих QTBT для CB, полученных согласно ФИГ. 14A-14B.


[0097] Как показано в таблицах 10A-10B, сигнализация, используемая в таблице 10A, может считаться менее эффективной, чем сигнализация в таблице 10B (т.е. согласно таблице 10A требуется больше битов для сигнализации эквивалентного окончательного разделения). Таким образом, в одном примере видеокодер 200 может быть сконфигурирован таким образом, чтобы сигнализация, представленная в таблице 10A, была запрещена. В одном примере видеокодер 200 может быть выполнен с возможностью осуществления итеративного процесса разделения таким образом, что видеокодер 200 оценивает, можно ли представить окончательное разделение более эффективно с помощью другого разделения. Кроме того, следует отметить, что использование сигнализации, представленной в таблице 10B, может обеспечить дополнительный прирост эффективности за счет доступности остаточных данных и метаданных в более ранних точках в последовательности битового потока.
[0098] Как описано выше, например, в отношении ФИГ. 13, в соответствии с методиками, описанными в настоящем документе, узел BT может быть дополнительно разделен в соответствии с разделением, отличным от BT (например, разделением QT или TT). Следует отметить, что в JEM узел BT не может быть дополнительно разделен в соответствии с разделением QT. Другими словами, как описано выше со ссылкой на таблицу 1, в JEM, если флаг разделения QT имеет значение 0, осуществляют сигнализацию для элемента синтаксиса режима разделения BT, указывающего одно из отсутствия двоичного разделения, режима вертикального разделения или режима горизонтального разделения.
Кроме того, как указано выше, в Le Léannec описан пример, в котором в дополнение к симметричным вертикальным и горизонтальным режимам разделения BT определены четыре дополнительных режима разделения ABT. В Le Léannec узел BT или ABT не может быть дополнительно разделен в соответствии с разделениями QT. Другими словами, в Le Léannec, если флаг разделения QT имеет значение 0, происходит сигнализация флага режима разделения BT, указывающего одно из: вертикальной ориентации разделения или горизонтальной ориентации разделения, а первый добавленный флаг сигнализирует, является ли текущий режим разделения BT асимметричным или нет.
Если режим разделения BT не асимметричен (в соответствии с первым добавленным флагом), режим разделения BT определяют как горизонтальный или вертикальный в соответствии с сигнализированной ориентацией разделения BT. Если режим разделения BT асимметричен (в соответствии с первым добавленным флагом), второй добавленный флаг указывает тип используемого асимметричного режима разделения для рассматриваемой ориентации разделения BT (т.е. вверх или вниз для горизонтальной или же влево или вправо для вертикальной). Кроме того, как указано выше, в Li описан пример, в котором помимо симметричных режимов вертикального и горизонтального разделения BT определены два дополнительных режима разделения TT. В Li узел BT или TT не может быть дополнительно разделен в соответствии с разделением QT. Другими словами, в Li, если флаг разделения QT имеет значение 0, происходит сигнализация флага разделения, указывающего одно из разделения или отсутствия разделения. Если указано разделение, осуществляют сигнализацию первого флага, указывающего горизонтальную или вертикальную ориентацию, и сигнализацию второго флага, указывающего разделение BT или разделение TT.
[0099] Как описано выше, в соответствии с методиками, описанными в настоящем документе, для каналов яркости и/или цветности могут быть разрешены различные типы разделения, причем CU, связанный с внутренним типом прогнозирования, образует корень для дополнительного разделения каналов яркости и/или цветности. В одном примере в соответствии с методиками, описанными в настоящем документе, дополнительное разделение CU, связанного с внутренним типом прогнозирования, может быть ограничено таким образом, что узел BT и/или ABT не может быть дополнительно разделен в соответствии с разделением QT. В одном примере в соответствии с методиками, описанными в настоящем документе, дополнительное разделение CU, связанного с внутренним типом прогнозирования, может разрешать дополнительное разделение узла BT и/или ABT в соответствии с разделением QT. В одном примере в соответствии с методиками, описанными в настоящем документе, дополнительное разделение CU, связанного с внутренним типом прогнозирования, может быть ограничено таким образом, что узел BT и/или TT не может быть дополнительно разделен в соответствии с разделением QT. В одном примере в соответствии с методиками, описанными в настоящем документе, дополнительное разделение CU, связанного с внутренним типом прогнозирования, может разрешать дополнительное разделение узла BT и/или TT в соответствии с вариантами разделения QT. В примерах, в которых разрешено дополнительное разделение узлов BT, ABT и TT в соответствии с разделением QT, в каждом узле BT, ABT и TT флаг разделения QT может быть сигнализирован с указанием того, применено ли разделение QT. В примерах, в которых не разрешено дополнительное разделение узлов BT, ABT и TT в соответствии с разделением QT, в каждом узле BT, ABT и TT с узлом BT, ABT или TT в качестве узла-предка не осуществляют сигнализацию флага разделения QT. В одном примере в соответствии с методиками, описанными в настоящем документе, дополнительное разделение CU, связанного с внутренним типом прогнозирования, может включать в себя комбинацию из разделений BT, ABT и TT. В таблицах 10C-10D проиллюстрированы примеры сигнализации двоичного кодирования, используемой для сигнализации разделения QT, разделения ВТ, разделения ТТ и разделения ABT в соответствии с описанными в настоящем документе методиками. Как описано выше, в примерах, в которых узлы BT, ABT и TT могут быть дополнительно разделены в соответствии с разделением QT, в каждом узле BT, ABT и TT флаг разделения QT может быть сигнализирован с указанием того, применено ли разделение QT. Как показано в таблице 10C, если QT не разрешено после BT, ABT и TT, узел Bin0 не передают для узлов, имеющих узлы BT, ABT или TT в качестве предка в дереве разделения. Что касается таблиц 10C-10D, следует отметить, что возможны случаи, когда некоторые разделения либо эквивалентны другим, либо некоторые разделения являются невозможными, и в этом случае бинаризация может быть изменена для повышения эффективности кодирования.
[0100] Как описано выше, наличие элемента синтаксиса (например, separate_tree_flag) в битовом потоке, а также возможность и способ дополнительного разделения внутреннего CU могут быть обусловлены глубиной блока в структуре разделения и размерами блоков. Следует отметить, что в одном примере глубина концевого узла ABT может соответствовать количеству выборок, включенных в концевой узел. В одном примере, если дополнительное разделение включает разделение ABT, значение separate_tree_flag может быть выведено на основании размера блока и/или глубины концевых узлов BT, TT и/или ABT.
[0101] Таким образом, видеокодер 200 представляет собой пример устройства, выполненного с возможностью получения видеоблока, включающего в себя значения выборки для первого компонента видеоданных и второго компонента видеоданных; разделения значений выборки для первого компонента видеоданных и второго компонента видеоданных в соответствии со структурой разделения первого двоичного дерева квадродерева; и дополнительного разделения выборок в соответствии со вторым двоичным деревом квадродерева для значений выборок первого компонента видеоданных, включенных в узлы первого двоичного дерева квадродерева, связанные с внутренним типом прогнозирования.
[0102] Согласно ФИГ. 8 видеокодер 200 может генерировать остаточные данные путем вычитания прогнозируемого видеоблока из исходного видеоблока. Сумматор 202 представляет компонент, выполненный с возможностью осуществления этой операции вычитания. В одном примере вычитание видеоблоков происходит в пиксельной области. Генератор 204 коэффициентов преобразования применяет преобразование, такое как дискретное косинусное преобразование (DCT), дискретное синусное преобразование (DST) или концептуально подобное преобразование, к остаточному блоку или его подразделам (например, четыре преобразования 8 × 8 можно применять к массиву остаточных значений 16 × 16) для получения набора остаточных коэффициентов преобразования. Генератор 204 коэффициентов преобразования может быть выполнен с возможностью осуществления любых и всех комбинаций преобразований, включенных в семейство дискретных тригонометрических преобразований. Как описано выше, в ITU-T H.265 TB ограничены следующими размерами: 4 × 4, 8 × 8, 16 × 16 и 32 × 32. В одном примере генератор 204 коэффициентов преобразования может быть выполнен с возможностью осуществления преобразований в соответствии с массивами, имеющими размеры 4 × 4, 8 × 8, 16 × 16 и 32 × 32. В одном примере генератор 204 коэффициентов преобразования может быть дополнительно выполнен с возможностью осуществления преобразований в соответствии с массивами других размеров. В частности, в некоторых случаях может быть полезно выполнять преобразования для прямоугольных массивов разностных значений. В одном примере генератор 204 коэффициентов преобразования может быть выполнен с возможностью осуществления преобразований в соответствии со следующими размерами массивов: 2 × 2, 2 × 4N, 4M × 2 и/или 4M × 4N. В одном примере 2-мерное (2D) обратное преобразование M × N может быть реализовано как 1-мерное (1D) обратное M-точечное преобразование с последующим 1D обратным N-точечным преобразованием. В одном примере 2D обратное преобразование может быть реализовано как 1D N-точечное вертикальное преобразование с последующим 1D N-точечным горизонтальным преобразованием. В одном примере 2D обратное преобразование может быть реализовано как 1D N-точечное горизонтальное преобразование с последующим 1D N-точечным вертикальным преобразованием. Генератор 204 коэффициентов преобразования может выводить коэффициенты преобразования в блок 206 квантования коэффициентов.
[0103] Как описано выше, в JEM для внутреннего прогнозирования основное преобразование и последующее вторичное преобразование могут быть применены к остатку, совпадающему с концевым узлом QTBT, для генерации коэффициентов преобразования на основании режима прогнозирования. Если один или оба из каналов яркости и цветности могут быть дополнительно разделены для целей прогнозирования в соответствии с методиками, описанными в настоящем документе, методики AMT и MDNSST, описанные в JEM, могут быть далеко не идеальными. В одном примере, в соответствии с методиками, описанными в настоящем документе, AMT может быть разрешен (его могут применять или не применять) или запрещен (не может быть применен) для каналов яркости и цветности в соответствии с методиками, описанными в настоящем документе. В одном примере для остатка канала яркости, соответствующего CB яркости и совпадающего с ним (причем CB яркости включен в CU внутреннего режима прогнозирования, включенного в срез внешнего прогнозирования), AMT может быть разрешено, а для остатка канала цветности, соответствующего CB цветности и совпадающего с ним, AMT может быть запрещено. Другими словами, согласно примеру, показанному на ФИГ. 9, для CU, указанного как имеющего внутренний тип прогнозирования, AMT может быть выборочно применено для остатка CB канала яркости и запрещено для остатка CB канала цветности. В одном примере AMT может быть запрещено, если ширина или высота CB превышает пороговое значение. В одном примере пороговое значение может быть равно 64. В одном примере AMT разрешено только при наличии одного CB с по меньшей мере одним или более значениями уровня коэффициента основного преобразования, не равными 0. В одном примере, может ли AMT быть разрешено или запрещено для канала CB яркости и/или канала CB цветности в CU, указанном как имеющем внутренний тип прогнозирования, включенном во внешний срез, может сигнализировано с использованием синтаксиса более высокого уровня. Следует отметить, что в некоторых примерах остатки, предоставленные в качестве входных данных для основного преобразования, могут соответствовать CU с внутренним прогнозированием и могут совпадать с ним.
[0104] Как описано выше, в JEM NSST_idx включает четыре возможных значения (т.е. вариант 0=MDNSST не применяют; а 1-3 соответствуют матрице преобразования), которые передают один раз для одного CU. В одном примере в соответствии с методиками, описанными в настоящем документе, возможные значения NSST_idx могут быть определены в соответствии с таблицей 11. В одном примере TH1 и TH2 из таблицы 11 могут быть равны 8.
[0105] Таким образом, в соответствии с методиками, описанными в настоящем документе, для коэффициентов основного преобразования канала цветности MDNSST может быть разрешено, если соответствующий CU имеет ширину и/или высоту, превышающую пороговое значение. Кроме того, в одном примере MDNSST может быть применено только в тех случаях, когда количество значений уровня коэффициента основного преобразования больше нуля превышает пороговое значение. Кроме того, в одном примере MDNSST могут не применять, если CU не включает значения уровня основного преобразования, не равные 0. В одном примере MDNSST могут применять только в тех случаях, когда не применяют обход преобразования-квантования. В одном примере NSST_idx может находиться в диапазоне от 0 до 2 для режимов DC и планарного прогнозирования. В одном примере диапазоном NSST_idx можно управлять с использованием синтаксиса более высокого уровня.
[0106] Блок 206 квантования коэффициентов может быть выполнен с возможностью квантования коэффициентов преобразования. Как описано выше, степень квантования может быть изменена путем регулировки параметра квантования. Блок 206 квантования коэффициентов может быть дополнительно выполнен с возможностью определения параметров квантования и вывода данных QP (например, данных, используемых для определения размера группы квантования и/или значений дельта QP), которые может использовать видеодекодер для восстановления параметра квантования для выполнения обратного квантования в процессе декодирования видеосигналов. Следует отметить, что в других примерах один или более дополнительных или альтернативных параметров можно использовать для определения уровня квантования (например, коэффициентов масштабирования). Описанные в настоящем документе методики могут быть в целом применимы для определения уровня квантования для коэффициентов преобразования, соответствующих компоненту видеоданных, на основании уровня квантования для коэффициентов преобразования, соответствующих другому компоненту видеоданных.
[0107] Как показано на ФИГ. 8, квантованные коэффициенты преобразования выводят в блок 208 обработки обратного квантования/преобразования. Блок 208 обработки обратного квантования/преобразования может быть выполнен с возможностью применения обратного квантования и обратного преобразования для генерации восстановленных остаточных данных. Как показано на ФИГ. 8, в сумматоре 210 восстановленные остаточные данные могут быть добавлены к прогнозируемому видеоблоку. Таким образом, кодированный видеоблок может быть восстановлен, и полученный в результате восстановленный видеоблок может быть использован для оценки качества кодирования для данного прогнозирования, преобразования и/или квантования. Видеокодер 200 может быть выполнен с возможностью осуществления множества проходов кодирования (например, выполнения кодирования с изменением одного или более из прогнозирования, параметров преобразования и квантования). Связанное со скоростью искажение битового потока или других системных параметров может быть оптимизировано на основе оценки восстановленных видеоблоков. Восстановленные видеоблоки можно дополнительно сохранять и использовать в качестве опорных для прогнозирования последующих блоков.
[0108] Как описано выше, можно кодировать видеоблок с использованием внутреннего прогнозирования. Блок 212 обработки внутреннего прогнозирования может быть выполнен с возможностью выбора режима внутреннего прогнозирования для видеоблока, подлежащего кодированию. Блок 212 обработки внутреннего прогнозирования может быть выполнен с возможностью оценки кадра и/или его области и определения режима внутреннего прогнозирования, который используют при кодировании текущего блока. Как показано на ФИГ. 8, блок 212 обработки внутреннего прогнозирования выводит данные внутреннего прогнозирования (например, элементы синтаксиса) в блок 218 энтропийного кодирования и генератор 204 коэффициентов преобразования. Как описано выше, преобразование, выполняемое для остаточных данных, может зависеть от режима. Как описано выше, возможные режимы внутреннего прогнозирования могут включать в себя режимы планарного прогнозирования, режимы прогнозирования DC и режимы углового прогнозирования. В некоторых примерах прогнозирование для компонента цветности может быть дополнительно логически выведено из внутреннего прогнозирования для режима прогнозирования яркости.
[0109] Как описано выше, в JEM определены методики изменения опорных выборок перед генерированием остаточных данных и изменения опорных выборок перед восстановлением видеоблока (например, PDPC и ARSS). Если один или оба из каналов яркости и цветности могут быть дополнительно разделены для целей прогнозирования в соответствии с методиками, описанными в настоящем документе, методики изменения опорных выборок, имеющиеся в JEM, могут быть далеко не идеальными. В одном примере, согласно методикам, описанным в настоящем документе, для CB канала яркости, включенного в CU внутреннего режима прогнозирования, включенного в срез внешнего прогнозирования, может быть разрешено PDPC, а для включенного CB канала цветности PDPC может быть запрещено. Другими словами, согласно примеру, показанному на ФИГ. 9, для каждого из четырех CB канала яркости PDPC может быть выборочно применено, а для двух CB канала цветности PDPC может быть запрещено. В одном примере, если MDNSST применяют для CU, PDPC может быть запрещено для CB, включенных в CU. В одном примере, может ли PDPC быть разрешено или запрещено для CB канала яркости и/или цветности, может быть сигнализировано с использованием синтаксиса более высокого уровня.
[0110] В одном примере, согласно методикам, описанным в настоящем документе, для CB канала яркости, включенного в CU внутреннего режима прогнозирования, включенного в срез внешнего прогнозирования, может быть разрешено ARSS, а для CB канала цветности ARSS может быть запрещено. Другими словами, согласно примеру, показанному на ФИГ. 9, для каждого из четырех CB канала яркости ARSS может быть выборочно применено, а для двух CB канала цветности ARSS может быть запрещено. В одном примере ARSS не применяют, если ширина или высота CB превышает пороговое значение. В одном примере ARSS не применяют, если режим прогнозирования CB представляет собой DC. В одном примере, может ли ARSS быть разрешено или запрещено для CB канала яркости и/или цветности в CU, может быть сигнализировано с использованием синтаксиса более высокого уровня.
[0111] Как описано выше, в JEM для MDNSST существует 35 неразделимых матриц преобразования, причем 11 наборов для преобразования применяют для режима направленного внутреннего прогнозирования и каждый набор для преобразования включает 3 матрицы преобразования, а для ненаправленных режимов (например, планарного, DC и LM) применяют только один набор для преобразования, включающий 2 матрицы преобразования. Кроме того, как описано выше, каналы цветности могут быть дополнительно разделены в соответствии с отдельными деревьями разделения. В одном примере режим LM может быть разрешен для канала цветности, если каналы цветности дополнительно разделяют в соответствии с отдельным деревом разделения для любого подмножества типов срезов (например, только типа B или внутреннего и внешнего типов срезов). Кроме того, в одном примере для каналов цветности с использованием режима DC или планарного режима прогнозирования, соответствующий набор преобразований может включать в себя 3 матрицы преобразования.
[0112] Блок 214 обработки внешнего прогнозирования может быть выполнен с возможностью кодирования с внешним прогнозированием для текущего видеоблока. Блок 214 обработки внешнего прогнозирования может быть выполнен с возможностью приема исходных видеоблоков и вычисления вектора движения для элементов PU видеоблока. Вектор движения может указывать смещение в PU (или аналогичной структуре кодирования) видеоблока внутри текущего видеокадра относительно прогнозируемого блока в опорном кадре. Кодирование с внешним прогнозированием может использовать одно или более опорных изображений. Прогнозирование движения может дополнительно быть однонаправленным (с использованием одного вектора движения) или двунаправленным (с использованием двух векторов движения). Блок 214 обработки внешнего прогнозирования может быть выполнен с возможностью выбора блока прогнозирования путем расчета разности пикселей, определенной, например, суммой абсолютной разности (SAD), суммой квадратов разности (SSD) или другими метриками разности. Как описано выше, вектор движения может быть определен и указан в соответствии с прогнозированием вектора движения. Блок 214 обработки внешнего прогнозирования может быть выполнен с возможностью прогнозирования вектора движения, как описано выше. Блок 214 обработки внешнего прогнозирования может быть выполнен с возможностью генерирования прогнозируемого блока с использованием данных прогнозирования движения. Например, блок 214 обработки внешнего прогнозирования может располагать прогнозируемый видеоблок в буфере кадров (не показан на ФИГ. 8). Следует отметить, что блок 214 обработки внешнего прогнозирования может быть дополнительно выполнен с возможностью применения одного или более интерполяционных фильтров к восстановленному остаточному блоку для вычисления значений субцелочисленных пикселей для использования при оценке движения. Блок 214 обработки внешнего прогнозирования может выводить данные прогнозирования движения для вычисленного вектора движения в блок 218 энтропийного кодирования.
[0113] Как показано на ФИГ. 8, блок 214 обработки внешнего прогнозирования может принимать восстановленный видеоблок через блок 216 фильтрации. Блок 216 фильтрации может быть выполнен с возможностью деблокинга, адаптивного смещения отсчетов (SAO) и/или фильтрации с применением ALF. Как описано выше, деблокинг относится к процессу сглаживания границ восстановленных видеоблоков (например, чтобы сделать границы менее видимыми для зрителя). Как описано выше, SAO-фильтрация представляет собой нелинейное сопоставление амплитуды, которое можно использовать для улучшения восстановления путем добавления смещения к восстановленным видеоданным. Как описано выше, в JEM определен ALF.
[0114] Как описано выше, ITU-T H.265 включает два типа фильтров деблокинга, которые могут быть использованы для изменения выборок яркости: сильный фильтр и слабый фильтр, а также один тип фильтра, который может быть использован для изменения выборок цветности: нормальный фильтр. В ITU-T H.265 меру граничной силы используют для определения того, применен ли фильтр какого-либо типа. В одном примере в соответствии с методиками, описанными в настоящем документе, блок 216 фильтрации может быть выполнен с возможностью определения граничной силы на основании того, применяют ли при кодировании видеоданных один или более из следующих способов: PDPC, ARSS, AMT и/или MDNSST.
[0115] Кроме того, как описано выше, согласно JEM для компонента яркости флаг уровня изображения может разрешать выборочное применение ALF к каждому CU в изображении, а для компонента цветности ALF на уровне изображения разрешен или запрещен. Если один или оба из каналов яркости и цветности могут быть дополнительно разделены для целей прогнозирования в соответствии с методиками, описанными в данном документе, методики в JEM, касающиеся применения ALF и сигнализации того, применяют ли ALF, могут быть далеко не идеальными. В одном примере блок 216 фильтрации может быть выполнен с возможностью применения ALF и сигнализации того, применяют ли ALF согласно методикам, описанным в настоящем документе.
[0116] В одном примере наличие флага, указывающего то, применяют ли ALF для блока (например, CU или CB), основано на глубине блока, причем глубина может быть связана с корнем CTU или корнем CU. Этот флаг может упоминаться как ВКЛ/ВЫКЛ ALF. В одном примере ВКЛ/ВЫКЛ ALF и соответствующая сигнализация ALF отсутствуют, если глубина блока превышает пороговое значение. В некоторых примерах пороговое значение может быть сигнализировано в битовых потоках. В одном примере значение ВКЛ/ВЫКЛ ALF может быть логически выведено для внутренних блоков (например, CU или CB). В одном примере значение ВКЛ/ВЫКЛ ALF для внутренних блоков может быть независимым для канала яркости и канала цветности. В одном примере сигнализация, используемая для ВКЛ/ВЫКЛ ALF, может быть передана в корне дерева внутреннего режима во внешних срезах. В одном примере сигнализация, используемая для ВКЛ/ВЫКЛ ALF, может быть передана в корне дерева внутреннего режима во внешних срезах, только если глубина корня дерева внутреннего режима меньше или равна глубине, разрешенной для сигнализации ВКЛ/ВЫКЛ ALF. В одном примере сигнализация, используемая для ВКЛ/ВЫКЛ ALF, может быть передана на глубинах дерева внутреннего режима во внешних срезах, только если глубина корня дерева внутреннего режима меньше или равна глубине, разрешенной для сигнализации ВКЛ/ВЫКЛ ALF.
В одном примере сигнализация ВКЛ/ВЫКЛ ALF для внутренних блоков может быть основана на сигнализированной глубине разделения, независимой от блоков с внешним кодированием, причем ВКЛ/ВЫКЛ ALF и соответствующая сигнализация ALF отсутствуют, если глубина блока превышает пороговое значение. В одном примере ALF может быть выборочно применен к блокам яркости и цветности с внутренним кодированием, причем указанный выбор может быть сигнализирован. В одном примере отдельные наборы коэффициентов ALF могут быть сигнализированы для блоков с внутренним кодированием независимо от блоков с внешним кодированием. В одном примере отдельные наборы коэффициентов ALF могут быть сигнализированы для каналов яркости и цветности.
[0117] В одном примере классификации выборок цветности ALF могут быть получены с использованием классификации выборок яркости для внутренних блоков во внешних срезах. В одном примере состояние ВКЛ/ВЫКЛ ALF уровня CU для цветности может быть определено с использованием состояния ВКЛ/ВЫКЛ одного или более совмещенных CB яркости для внутренних блоков во внешних срезах, например флаг уровня CU цветности включен, только если включен по меньшей мере один из совмещенных CB яркости.
[0118] Согласно ФИГ. 8 блок 218 энтропийного кодирования принимает квантованные коэффициенты преобразования и данные синтаксического прогнозирования (т.е. данные внутреннего прогнозирования, данные прогнозирования движения, данные QP и т. д.). Следует отметить, что в некоторых примерах блок 206 квантования коэффициентов может выполнять сканирование матрицы, включающей в себя квантованные коэффициенты преобразования, перед выводом коэффициентов в блок 218 энтропийного кодирования. В других примерах сканирование может выполнять блок 218 энтропийного кодирования. Блок 218 энтропийного кодирования может быть выполнен с возможностью энтропийного кодирования в соответствии с одной или более методиками, описанными в настоящем документе. Блок 218 энтропийного кодирования может быть выполнен с возможностью вывода совместимого битового потока, т.е. битового потока, который видеодекодер может принимать и из которого он может воспроизводить видеоданные.
[0119] Как описано выше, в примере CAB AC для конкретного двоичного значения контекстная модель может быть выбрана из набора доступных контекстных моделей, связанных с двоичным значением. В некоторых примерах контекстная модель может быть выбрана на основе предыдущего двоичного значения и/или значений предыдущих элементов синтаксиса. В частности, для элемента синтаксиса переменную контекста CAB AC индексируют с использованием таблицы контекста и индекса контента (ctxidx). Кроме того, как описано выше, согласно методикам, описанным в настоящем документе, для внешних срезов, если тип прогнозирования CU является внутренним, QTBT сигнализируют для канала яркости и QTBT сигнализируют для канала цветности.
[0120] В одном примере контекст информации о разделении (например, применяют ли разделение QT, BT или TT) для канала может быть определен следующим образом:
CtxtIdx устанавливают в 0;
если глубина разделения левого блока превышает текущую глубину разделения, CtxtIdx++;
если глубина разделения верхнего блока превышает текущую глубину разделения, CtxtIdx++;
CtxtIdx используют для кодирования разделения.
[0121] В одном примере выбор контекста для канала может зависеть от того, был ли закодирован смежный блок с использованием внутреннего прогнозирования. Например, контент может быть определен следующим образом:
CtxtIdx устанавливают в 0;
если глубина разделения левого блока превышает текущую глубину разделения, а режим прогнозирования не является внутренним, CtxtIdx++;
если глубина разделения верхнего блока превышает текущую глубину разделения, а режим прогнозирования не является внутренним, CtxtIdx++;
CtxtIdx используют для кодирования разделения.
[0122] В одном примере выбор контекста может зависеть от того, был ли смежный блок закодирован с использованием внутреннего прогнозирования и было ли использовано отдельное или общее дерево разделения.
[0123] В одном примере контекст информации о разделении может быть основан на глубине CU режима внутреннего прогнозирования. Следует отметить, что в одном примере значения глубины определяют отдельно для каналов яркости и цветности, если CU во внешнем срезе относится к внутреннему типу.
[0124] В одном примере контекст информации о разделении для канала может быть определен следующим образом:
CtxtIdx устанавливают в 0;
если размер левого блока меньше текущего размера, CtxtIdx++;
если размер верхнего блока меньше текущего размера, CtxtIdx++;
CtxtIdx используют для кодирования разделения.
[0125] В одном примере выбор контекста для канала может зависеть от того, был ли закодирован смежный блок с использованием внутреннего прогнозирования. Например, контент может быть определен следующим образом:
CtxtIdx устанавливают в 0;
если размер левого блока меньше текущего размера, а режим прогнозирования не является внутренним, CtxtIdx++;
если размер верхнего блока меньше текущего размера, а режим прогнозирования не является внутренним, CtxtIdx++;
CtxtIdx используют для кодирования разделения.
[0126] В одном примере контекст информации о разделении может быть основан на размере CU режима внутреннего прогнозирования. В одном примере размер может соответствовать количеству выборок в блоке.
[0127] В одном примере контекст может быть определен следующим образом:
CtxtIdx устанавливают в 0;
если глубина разделения левого блока превышает текущую глубину разделения, а режим прогнозирования не является внутренним, CtxtIdx++;
если глубина разделения верхнего блока превышает текущую глубину разделения, а режим прогнозирования не является внутренним, CtxtIdx++;
определяют максимальную глубину между смежными блоками, когда смежные блоки имеют внутреннее кодирование, а использование отдельных деревьев считают недоступным для целей определения максимальной глубины;
определяют минимальную глубину между смежными блоками, когда смежные блоки имеют внутреннее кодирование, а использование отдельных деревьев считают недоступным для целей определения максимальной глубины;
если текущая глубина, на которой сигнализирован элемент синтаксиса разделения, меньше, чем минимальная глубина для смежных блоков, CtxIdx устанавливают в 3;
если текущая глубина, на которой сигнализирован элемент синтаксиса разделения, больше или равна максимальной глубине для смежных блоков плюс 1, CtxIdx устанавливают в 4;
CtxtIdx используют для кодирования разделения.
[0128] В одном примере контекст может быть определен следующим образом:
CtxtIdx устанавливают в 0;
если глубина разделения левого блока превышает текущую глубину разделения, а режим прогнозирования не является внутренним, CtxtIdx++;
если глубина разделения верхнего блока превышает текущую глубину разделения, а режим прогнозирования не является внутренним, CtxtIdx++;
определяют максимальную глубину между смежными блоками, на которой смежные блоки доступны для целей определения максимальной глубины, только в том случае, если флаг общего/отдельного дерева для текущего и смежного блоков является одинаковым;
определяют минимальную глубину между смежными блоками, на которой смежные блоки доступны для целей определения минимальной глубины только в том случае, если флаг общего/отдельного дерева для текущего и смежного блоков является одинаковым;
если текущая глубина, на которой сигнализирован элемент синтаксиса разделения, меньше, чем минимальная глубина для смежных блоков, CtxIdx устанавливают в 3;
если текущая глубина, на которой сигнализирован элемент синтаксиса разделения, больше или равна максимальной глубине для смежных блоков плюс 1, CtxIdx устанавливают в 4;
CtxtIdx используют для кодирования разделения.
[0129] В одном примере элементы синтаксиса разделения могут сигнализировать для каждого канала, а смежные блоки могут соответствовать глубине рассматриваемого канала.
[0130] Как описано выше, в некоторых примерах флаг (например, separate_tree_flag) может указывать на то, разделены ли дополнительно каналы яркости и цветности в соответствии с отдельными деревьями разделения или общим деревом разделения. В одном примере одна переменная контекста CAB AC может быть использована для энтропийного кодирования флага, а контекст может быть обновлен на основании значений этого флага. В одном примере набор переменных контекстов CAB AC может быть доступен для энтропийного кодирования указанного флага. В одном примере переменная контекста, выбранная из набора, может быть основана на значении(ях) флага в соседних (пространственных или временных) блоках. В одном примере выбор контекста для кодирования флага может быть основан на глубине текущего блока.
[0131] В одном примере контекст для флага может быть определен следующим образом:
CtxtIdx устанавливают в 0;
если флаг левого блока имеет значение TRUE, CtxtIdx++;
если флаг верхнего блока имеет значение TRUE, CtxtIdx++;
CtxtIdx используют для кодирования флага.
Как описано выше, в одном примере дополнительное разделение может включать разделение ABT, а глубина концевого узла ABT (т.е. 1/4 концевого узла и 3/4 концевого узла) может соответствовать количеству выборок, включенных в концевой узел.
[0132] В одном примере контекст для флага, указывающего режим разделения ABT (например, второй добавленный флаг, указывающий тип используемого режима асимметричного разделения, описанного выше), может быть определен следующим образом:
CtxtIdx устанавливают в 0;
если глубина ABT левого блока превышает текущую глубину ABT, CtxtIdx++;
если глубина ABT верхнего блока превышает текущую глубину ABT, CtxtIdx++;
CtxtIdx используют для кодирования флага ABT.
[0133] В одном примере, если дополнительное разделение включает в себя разделение ABT, выбор контекста для канала может зависеть от того, был ли закодирован смежный блок с использованием внутреннего прогнозирования. Например, контекст может быть определен следующим образом:
CtxtIdx устанавливают в 0;
если глубина ABT левого блока превышает глубину текущего ABT, а режим прогнозирования не является внутренним, CtxtIdx++;
если глубина ABT верхнего блока превышает глубину текущего ABT, а режим прогнозирования не является внутренним, CtxtIdx++;
CtxtIdx используют для кодирования флага ABT.
[0134] В одном примере при кодировании информации о разделении ABT с использованием выбора контекста на основании смежного блока контекст основан на глубине, на которой был выбран внутренний режим.
[0135] Как описано выше, методики разделения, описанные в настоящем документе, могут обеспечивать получение прямоугольных блоков кодирования в отличие от методик разделения в ITU-T H.265, которые позволяют получить квадратные блоки кодирования с одинаковыми размерами по высоте и ширине, которые представляют собой степень 2. Другими словами, например, в ITU-T H.265 CU 64 × 64 может быть рекурсивно разделен на CU 32 × 32, 16 × 16 и 8 × 8. Размер квадратных блоков кодирования с одинаковыми размерами по высоте и ширине, которые представляют собой степень 2, могут быть выражены в виде 2N. Кроме того, вычисление среднего значения из значений выборки, расположенных на границе квадратного блока кодирования с одинаковыми размерами по высоте и ширине, которые представляют собой степень 2, может быть реализовано с использованием простой операции битового сдвига. Другими словами, среднее значение из значений выборки, расположенных на границе видеоблока 2N × 2N, может быть вычислено путем сдвига суммы значений выборки на N+l (т. e. SUM(значения выборки) >> (N+l)). Некоторые средства кодирования, например, включенные в ITU-T H.265, в которых используют вычисление среднего значения для выборок, расположенных на границе блока кодирования, предполагают, что блоки кодирования являются квадратными с одинаковыми размерами по высоте и ширине, которые представляют собой степень 2 и, таким образом, используют операцию битового сдвига для реализации функции усреднения. Такие вычисления среднего необходимо изменить для вычисления среднего значения для значений выборки, расположенных на границе прямоугольного блока произвольной формы (например, блока, имеющего размеры W × H), сохранив при этом возможность использования простой операции битового сдвига для реализации деления на количество значений, включенных в среднее значение. Кроме того, для средств кодирования, которые, например, описаны в H. Liu, «Local Illumination Compensation», ITU- Telecommunications Standardization Sector, Study Group 16 Question 6, Video Coding Experts Group (VCEG), 52nd Meeting, 19-26 июня 2015 г., Варшава, Польша, Document: VCEG-AZ06, Zhang и др., «Enhanced Cross-component linear model chroma intra prediction», 4th Meeting: Chengdu, CN, 15-21 October 2016, Document: JVET-D0110, требуется получение параметров линейной модели. Получение таких параметров включает в себя вычисление сумм значений и квадратов значений выборок, расположенных на границе блока кодирования, и вычисление делений на количество выборок, включенных в такие суммы. Такие деления могут быть реализованы с использованием операций битового сдвига, когда количество образцов представляет собой степень 2, что характерно для квадратных блоков, имеющих одинаковые размеры по высоте и ширине, которые представляют собой степень 2. Такие вычисления суммы необходимо изменить для вычисления сумм значений выборки и значений квадратной выборки, расположенных на границе прямоугольного блока произвольной формы, сохранив возможность использования простой операции битового сдвига для реализации деления на количество значений, включенных в сумму.
[0136] В одном примере в соответствии с методиками, описанными в настоящем документе, переменные log2NumSamplesH и log2NumSamplesV могут быть получены таким образом, что 2 в степени log2NumSamplesH меньше или равно ширине, W, текущего блока, (2log2NumSamplesH <= W), а 2 в степени log2NumSamplesV меньше или равно высоте, H, текущего блока 2log2NumSamplesV <= H). Затем переменная log2NumSamples может быть получена следующим образом:
если доступны только выборки из смежного блока по горизонтали, log2NumSamples устанавливают равной log2NumSamplesV;
если доступны только выборки из смежного блока по вертикали, log2NumSamples устанавливают равной log2NumSamplesH;
В противном случае, т.е. если доступны выборки как из смежного блока по вертикали, так и из смежного блока по горизонтали, log2NumSamples устанавливают равной минимальному значению из log2NumSamplesH и log2NumSamplesV.
[0137] После установки log2NumSamples значение numSamples может быть определено как 2 в степени log2NumSamples. Значение numSamples может быть использовано для определения количества выборок из смежного блока, используемых для вычисления среднего значения или суммы. Следует отметить, что numSamples могут быть меньше одного или обоих из W и H. Таким образом, в соответствии с методиками, описанными в настоящем документе, определение того, какие выборки numSamples из смежного блока используют при вычислении среднего значения или суммы, может быть выражено следующим образом:
При наличии выборок из смежного блока по горизонтали для вычисления среднего значения или суммы используют выборки numSamples из такого блока. Вертикальное положение i-й выборки задано выражением (i × H+H/2) >> log2NumSamples для i=0..numSamples-1. Следует отметить, что данная формула обеспечивает более или менее равномерное распределение выборок по высоте блока.
[0138] При наличии выборок из смежного блока по вертикали для вычисления среднего значения или суммы используют выборки numSamples из такого блока. Горизонтальное положение i-й выборки задано выражением (i × W+W/2) >> log2NumSamples для i=0..numSamples-1. Следует отметить, что данная формула обеспечивает более или менее равномерное распределение выборок по ширине блока.
[0139] На ФИГ. 16 приведена блок-схема, иллюстрирующая пример видеодекодера, который может быть выполнен с возможностью декодирования видеоданных в соответствии с одной или более методиками настоящего описания. В одном примере видеодекодер 300 может быть выполнен с возможностью восстановления видеоданных на основе одной или более описанных выше методик. Т.е. работа видеодекодера 300 может быть обратной по отношению к работе описанного выше видеокодера 200. Видеодекодер 300 может быть выполнен с возможностью декодирования с внутренним прогнозированием и декодирования с внешним прогнозированием и в таком случае может называться гибридным декодером. В примере, проиллюстрированном на ФИГ. 16, видеодекодер 300 включает в себя блок 302 энтропийного декодирования, блок 304 обратного квантования, блок 306 обработки обратного преобразования, блок 308 обработки внутреннего прогнозирования, блок 310 обработки внешнего прогнозирования, сумматор 312, блок 314 фильтрации и опорный буфер 316. Видеодекодер 300 может быть выполнен с возможностью декодирования видеоданных способом, соответствующим системе кодирования видеосигналов, которая может реализовывать один или более аспектов стандарта кодирования видеосигналов. Следует отметить, что, хотя указанный в примере видеодекодер 300 проиллюстрирован как имеющий различные функциональные блоки, такая иллюстрация предназначена только для описания и не ограничивает видеодекодер 300 и/или его подкомпоненты конкретной архитектурой аппаратного или программного обеспечения. Функции видеодекодера 300 могут быть реализованы с использованием любой комбинации аппаратных, программно-аппаратных и/или программных вариантов осуществления.
[0140] Как показано на ФИГ. 16, блок 302 энтропийного декодирования принимает энтропийно кодированный битовый поток. Блок 302 энтропийного декодирования может быть выполнен с возможностью декодирования квантованных элементов синтаксиса и квантованных коэффициентов из битового потока в соответствии с процессом, обратным процессу энтропийного кодирования. Блок 302 энтропийного декодирования может быть выполнен с возможностью энтропийного декодирования в соответствии с любой из описанных выше методик энтропийного кодирования. Блок 302 энтропийного декодирования может анализировать кодированный битовый поток способом, соответствующим стандарту кодирования видеосигналов. Видеодекодер 300 может быть выполнен с возможностью синтаксического анализа кодированного битового потока, причем кодированный битовый поток генерируют на основе описанных выше методик. Т.е., например, видеодекодер 300 может быть выполнен с возможностью определения структур разделения QTBT, сгенерированных и/или сигнализированных на основе одной или более описанных выше методик для восстановления видеоданных. Например, видеодекодер 300 может быть выполнен с возможностью синтаксического анализа элементов синтаксиса и/или оценки свойств видеоданных для определения QTBT.
[0141] Согласно ФИГ. 16 блок 304 обратного квантования принимает квантованные коэффициенты преобразования (т.е. значения уровня) и данные параметров квантования от блока 302 энтропийного декодирования. Данные параметров квантования могут включать в себя любую и все комбинации значений дельта QP и/или значений размера группы квантования и т. п., описанных выше. Видеодекодер 300 и/или блок 304 обратного квантования могут быть выполнены с возможностью определения значений QP, используемых для обратного квантования, на основе значений, сигнализированных видеокодером, и/или с использованием свойств видео и/или параметров кодирования. Таким образом, работа блока 304 обратного квантования может быть обратной по отношению к работе описанного выше блока 206 квантования коэффициентов. Например, блок 304 обратного квантования может быть выполнен с возможностью вывода предварительно определенных значений (например, определения суммы глубины QT и глубины BT на основе параметров кодирования), допустимых размеров групп квантования и т. п. согласно описанным выше методикам. Блок 304 обратного квантования может быть выполнен с возможностью применения обратного квантования. Блок 306 обработки обратного преобразования может быть выполнен с возможностью осуществления обратного преобразования для генерации восстановленных остаточных данных. Методики, выполняемые соответственно блоком 304 обратного квантования и блоком 306 обработки обратного преобразования, могут быть аналогичны методикам, выполняемым описанными выше блоком 208 обработки обратного квантования/преобразования. Блок 306 обработки обратного преобразования может быть выполнен с возможностью применения обратного DCT, обратного DST, обратного целочисленного преобразования, MDNSST или концептуально аналогичных процессов обратного преобразования к коэффициентам преобразования для получения остаточных блоков в пиксельной области. Как описано выше, выполняют ли конкретное преобразование (или преобразование конкретного типа), может дополнительно зависеть от режима внутреннего прогнозирования. Как показано на ФИГ. 16, сумматор 312 может быть обеспечен восстановленными остаточными данными. Сумматор 312 может добавлять восстановленные остаточные данные к прогнозируемому видеоблоку и генерировать восстановленные видеоданные. Прогнозируемый видеоблок может быть определен в соответствии с методикой прогнозирования видео (т.е. внутреннего прогнозирования и межкадрового прогнозирования). В одном примере видеодекодер 300 и блок 314 фильтрации могут быть выполнены с возможностью определения значений QP и их использования для фильтрации (например, деблокинга). В одном примере другие функциональные блоки видеодекодера 300, которые используют QP, могут определять QP на основе принятой сигнализации и использовать ее для декодирования.
[0142] Блок 308 обработки внутреннего прогнозирования может быть выполнен с возможностью приема элементов синтаксиса внутреннего прогнозирования и извлечения прогнозируемого видеоблока из опорного буфера 316. Опорный буфер 316 может включать в себя запоминающее устройство, выполненное с возможностью хранения одного или более кадров видеоданных. Элементы синтаксиса внутреннего прогнозирования могут идентифицировать режим внутреннего прогнозирования, такой как описанные выше режимы внутреннего прогнозирования. В одном примере блок 308 обработки внутреннего прогнозирования может восстанавливать видеоблок согласно одной или более методикам кодирования с внутренним прогнозированием, описанным в настоящем документе. Блок 310 обработки внешнего прогнозирования может принимать элементы синтаксиса внешнего прогнозирования и генерировать векторы движения для идентификации блока прогнозирования в одном или более опорных кадрах, хранящихся в опорном буфере 316. Блок 310 обработки внешнего прогнозирования может создавать блоки с компенсацией движения с возможным выполнением интерполяции на основе интерполяционных фильтров. Идентификаторы интерполяционных фильтров, используемых для оценки движения с точностью до субпикселя, могут быть включены в элементы синтаксиса. Блок 310 обработки внешнего прогнозирования может использовать фильтры интерполяции для расчета интерполированных значений для субцелочисленных пикселей опорного блока. Блок 314 фильтрации может быть выполнен с возможностью осуществления фильтрации восстановленных видеоданных. Например, блок 314 фильтрации может быть выполнен с возможностью деблокинга, фильтрации SAO и/или ALF, как описано выше применительно к блоку 216 фильтрации. Следует отметить, что в некоторых примерах блок 314 фильтрации может быть дополнительно выполнен с возможностью выполнения проприетарного дискреционного фильтрования (например, визуальных улучшений). Как показано на ФИГ. 16, восстановленный видеоблок может быть выведен видеодекодером 300. Таким образом, видеодекодер 300 может быть выполнен с возможностью генерации восстановленных видеоданных в соответствии с одной или более методиками, описанными в настоящем документе. Таким образом, видеодекодер 300 может быть выполнен с возможностью синтаксического анализа структуры разделения первого двоичного дерева квадродерева, применения структуры разделения первого двоичного дерева квадродерева к первому компоненту видеоданных, применения структуры разделения первого двоичного дерева квадродерева ко второму компоненту видеоданных, определения того, связан ли узел первого двоичного дерева квадродерева с внутренним типом прогнозирования, выполнения синтаксического анализа структуры разделения второго двоичного дерева квадродерева после определения того, что узел первого двоичного дерева квадродерева связан с внутренним типом прогнозирования, и применения структуры разделения второго двоичного дерева квадродерева к значениям выборок первого компонента видеоданных, включенных в узлы первого двоичного дерева квадродерева.
[0143] В одном или более примерах описанные функции могут быть реализованы в виде аппаратного обеспечения, программного обеспечения, программно-аппаратного обеспечения или любой их комбинации. При реализации в программном обеспечении функции можно хранить или передавать в виде одной или более инструкций или кода на машиночитаемом носителе и выполнять аппаратным блоком обработки. Машиночитаемые носители могут включать в себя машиночитаемые носители данных, которые соответствуют материальным носителям, таким как носители данных, или среды связи, включающие в себя любую среду, обеспечивающую передачу компьютерной программы из одного местоположения в другое, например, согласно протоколу связи. Таким образом, машиночитаемые носители обычно могут соответствовать (1) материальным машиночитаемым носителям, которые не являются энергонезависимыми, или (2) среде связи, такой как сигнал или несущая волна. Носители данных могут быть любыми доступными носителями, к которым может обращаться один или более компьютеров или один или более процессоров для извлечения команд, кода и/или структур данных для реализации методик, описанных в настоящем документе. Компьютерный программный продукт может включать в себя машиночитаемый носитель.
[0144] В качестве примера, но не для ограничения, такой машиночитаемый носитель может представлять собой RAM, ROM, EEPROM, CD-ROM или другой накопитель на оптических дисках, накопитель на магнитных дисках или другие магнитные запоминающие устройства, флэш-память, или любой другой носитель, который можно использовать для хранения требуемого программного кода в виде команд или структур данных и к которому может получать доступ компьютер. Кроме того, любое соединение, строго говоря, называется машиночитаемым носителем. Например, при передаче команд с веб-сайта, сервера или другого удаленного источника с использованием коаксиального кабеля, оптоволоконного кабеля, витой пары, цифровой абонентской линии (DSL) или беспроводных технологий, таких как инфракрасные, радио- и СВЧ-сигналы, коаксиальный кабель, оптоволоконный кабель, витая пара, DSL или беспроводные технологии, такие как инфракрасные, радио- и СВЧ-сигналы, включены в определение носителя/среды. Однако следует понимать, что машиночитаемые носители и носители данных не включают в себя соединения, несущие волны, сигналы или другие преходящие носители, а обозначают непреходящие материальные носители данных. В настоящем документе термин «диск» относится к диску, который воспроизводит данные оптическим способом с помощью лазеров, например, компакт-диск (CD), лазерный диск, оптический диск, универсальный цифровой диск (DVD) и диск Blu-ray, и к диску, который обычно воспроизводит данные магнитным способом (например, гибкий диск). Комбинации вышеперечисленного также должны быть включены в объем термина «машиночитаемый носитель».
[0145] Команды могут быть выполнены одним или более процессорами, такими как один или более цифровых сигнальных процессоров (DSP), микропроцессоров общего назначения, специализированных интегральных схем (ASIC), программируемых пользователем вентильных матриц (FPGA) или других эквивалентных интегральных или дискретных логических схем. Соответственно, употребляемый в настоящем документе термин «процессор» может относиться к любой из вышеуказанных структур или к любой другой структуре, подходящей для реализации описанных в настоящем документе методик. Кроме того, в некоторых аспектах описанные в настоящем документе функциональные возможности могут быть обеспечены в специальных аппаратных и/или программных модулях, выполненных с возможностью кодирования и декодирования или включенных в комбинированный кодек. Кроме того, методики могут быть полностью реализованы в одной или более схемах или логических элементах.
[0146] Методики настоящего описания могут быть реализованы в самых разных устройствах или аппаратах, включая беспроводную телефонную трубку, интегральную схему (IC) или набор IC (например, набор микросхем). Различные компоненты, модули или блоки описаны в настоящем документе для выделения функциональных аспектов устройств, выполненных с возможностью осуществления описанных методик, но они необязательно должны быть реализованы в виде различных аппаратных блоков. Скорее, как описано выше, различные блоки могут быть объединены в аппаратный блок кодека или представлены набором взаимодействующих аппаратных блоков, включая один или более процессоров, как описано выше, в сочетании с подходящим программным обеспечением и/или программно-аппаратным обеспечением.
[0147] Более того, каждый функциональный блок или различные элементы устройства базовой станции и терминального устройства, используемые в каждом из вышеупомянутых вариантов осуществления, могут быть реализованы или исполнены схемой, которая обычно представляет собой интегральную схему или множество интегральных схем. Схема, выполненная с возможностью исполнения функций, описанных в настоящей спецификации, может содержать процессор общего назначения, цифровой сигнальный процессор (DSP), заказную или специализированную интегральную схему (ASIC), программируемую пользователем вентильную матрицу (FPGA) или другие программируемые логические устройства, схемы на дискретных компонентах или транзисторные логические схемы, дискретный аппаратный компонент или их комбинацию. Процессор общего назначения может представлять собой микропроцессор или в альтернативном варианте осуществления процессор может представлять собой стандартный процессор, контроллер, микроконтроллер или машину состояний. Процессор общего назначения или каждая схема, описанная выше, могут быть выполнены в виде цифровой схемы или могут быть выполнены в виде аналоговой схемы. Дополнительно при появлении в области полупроводников технологии, воплощающейся в интегральной схеме, вытесняющей существующие интегральные схемы, также можно использовать интегральную схему по данной технологии.
[0148] Описаны различные примеры. Эти и другие примеры включены в объем следующей формулы изобретения.
[0149] <общее описание>
В одном примере способ разделения видеоданных для кодирования видеосигналов включает прием видеоблока, включающего в себя значения выборки для первого компонента видеоданных и второго компонента видеоданных; разделение значений выборки для первого компонента видеоданных и второго компонента видеоданных в соответствии со структурой разделения первого двоичного дерева квадродерева; и дополнительное разделение выборок в соответствии со вторым двоичным деревом квадродерева для значений выборок первого компонента видеоданных, включенных в узлы первого двоичного дерева квадродерева, связанных с внутренним типом прогнозирования.
[0150] В одном примере устройство для разделения видеоданных для кодирования видеосигналов содержит один или более процессоров, выполненных с возможностью приема видеоблока, включающего в себя значения выборки для первого компонента видеоданных и второго компонента видеоданных; разделения значений выборки для первого компонента видеоданных и второго компонента видеоданных в соответствии со структурой разделения первого двоичного дерева квадродерева; и дополнительного разделения выборок в соответствии со вторым двоичным деревом квадродерева для значений выборок первого компонента видеоданных, включенных в узлы первого двоичного дерева квадродерева, связанных с внутренним типом прогнозирования.
[0151] В одном примере энергонезависимый машиночитаемый носитель данных содержит хранящиеся на нем команды, в результате исполнения которых один или более процессоров устройства принимает видеоблок, включающий в себя значения выборки для первого компонента видеоданных и второго компонента видеоданных; разделяет значения выборки для первого компонента видеоданных и второго компонента видеоданных в соответствии со структурой разделения первого двоичного дерева квадродерева; и дополнительно разделяет выборки в соответствии со вторым двоичным деревом квадродерева для значений выборок первого компонента видеоданных, включенных в узлы первого двоичного дерева квадродерева, связанных с внутренним типом прогнозирования.
[0152] В одном примере устройство содержит средство для приема видеоблока, включающего в себя значения выборки для первого компонента видеоданных и второго компонента видеоданных, средство для разделения значений выборки для первого компонента видеоданных и второго компонента видеоданных в соответствии со структурой разделения первого двоичного дерева квадродерева и средство для дополнительного разделения выборок в соответствии со вторым двоичным деревом квадродерева для значений выборок первого компонента видеоданных, включенных в узлы первого двоичного дерева квадродерева, связанные с внутренним типом прогнозирования.
[0153] В одном примере способ определения разделения видеоданных включает синтаксический анализ структуры разделения первого двоичного дерева квадродерева, применение структуры разделения первого двоичного дерева квадродерева к первому компоненту видеоданных, применение структуры разделения первого двоичного дерева квадродерева ко второму компоненту видеоданных, определение того, связан ли узел первого двоичного дерева квадродерева с внутренним типом прогнозирования, синтаксический анализ структуры разделения второго двоичного дерева квадродерева после определения того, что узел первого двоичного дерева квадродерева связан с внутренним типом прогнозирования, и применение структуры разделения второго двоичного дерева квадродерева к значениям выборок первого компонента видеоданных, включенных в узлы первого двоичного дерева квадродерева.
[0154] В одном примере устройство для определения разделения видеоданных содержит один или более процессоров, выполненных с возможностью осуществления синтаксического анализа структуры разделения первого двоичного дерева квадродерева, применения структуры разделения первого двоичного дерева квадродерева к первому компоненту видеоданных, применения структуры разделения первого двоичного дерева квадродерева ко второму компоненту видеоданных, определения того, связан ли узел первого двоичного дерева квадродерева с внутренним типом прогнозирования, выполнения синтаксического анализа структуры разделения второго двоичного дерева квадродерева после определения того, что узел первого двоичного дерева квадродерева связан с внутренним типом прогнозирования, и применения структуры разделения второго двоичного дерева квадродерева к значениям выборок первого компонента видеоданных, включенных в узлы первого двоичного дерева квадродерева.
[0155] В одном примере энергонезависимый машиночитаемый носитель данных содержит хранящиеся на нем команды, в результате исполнения которых один или более процессоров устройства осуществляет синтаксический анализ структуры разделения первого двоичного дерева квадродерева, применяет структуру разделения первого двоичного дерева квадродерева к первому компоненту видеоданных, применяет структуру разделения первого двоичного дерева квадродерева ко второму компоненту видеоданных, определяет, связан ли узел первого двоичного дерева квадродерева с внутренним типом прогнозирования, осуществляет синтаксический анализ структуры разделения второго двоичного дерева квадродерева после определения того, что узел первого двоичного дерева квадродерева связан с внутренним типом прогнозирования, и применяет структуру разделения второго двоичного дерева квадродерева к значениям выборок первого компонента видеоданных, включенных в узлы первого двоичного дерева квадродерева.
[0156] В одном примере устройство содержит средство для синтаксического анализа структуры разделения первого двоичного дерева квадродерева, средство для применения структуры разделения первого двоичного дерева квадродерева к первому компоненту видеоданных, средство для применения структуры разделения первого двоичного дерева квадродерева ко второму компоненту видеоданных, средство для определения того, связан ли узел первого двоичного дерева квадродерева с внутренним типом прогнозирования, средство для синтаксического анализа структуры разделения второго двоичного дерева квадродерева после определения того, что узел первого двоичного дерева квадродерева связан с внутренним типом прогнозирования, и средство для применения структуры разделения второго двоичного дерева квадродерева к значениям выборок первого компонента видеоданных, включенных в узлы первого двоичного дерева квадродерева.
[0157] Подробности одного или более примеров изложены в приведенном ниже описании и на сопроводительных чертежах. Прочие признаки, объекты и преимущества будут понятны из описания, и чертежей, и формулы изобретения.
[0158] <Перекрестная ссылка>
Настоящая обычная заявка испрашивает приоритет согласно 35 USC § 119 по предварительной заявке № 62/541,032 от 3 августа 2017 года, предварительной заявке № 62/542,268 от 7 августа 2017 года, предварительной заявке № 62/553,020 от 31 августа 2017 года, предварительной заявке № 62/564,020 от 27 сентября 2017 года, предварительной заявке № 62/598,956 от 14 декабря 2017 года и предварительной заявке № 62/636,667 от 28 февраля 2018 года, полное содержание которых включено в настоящий документ путем ссылки.
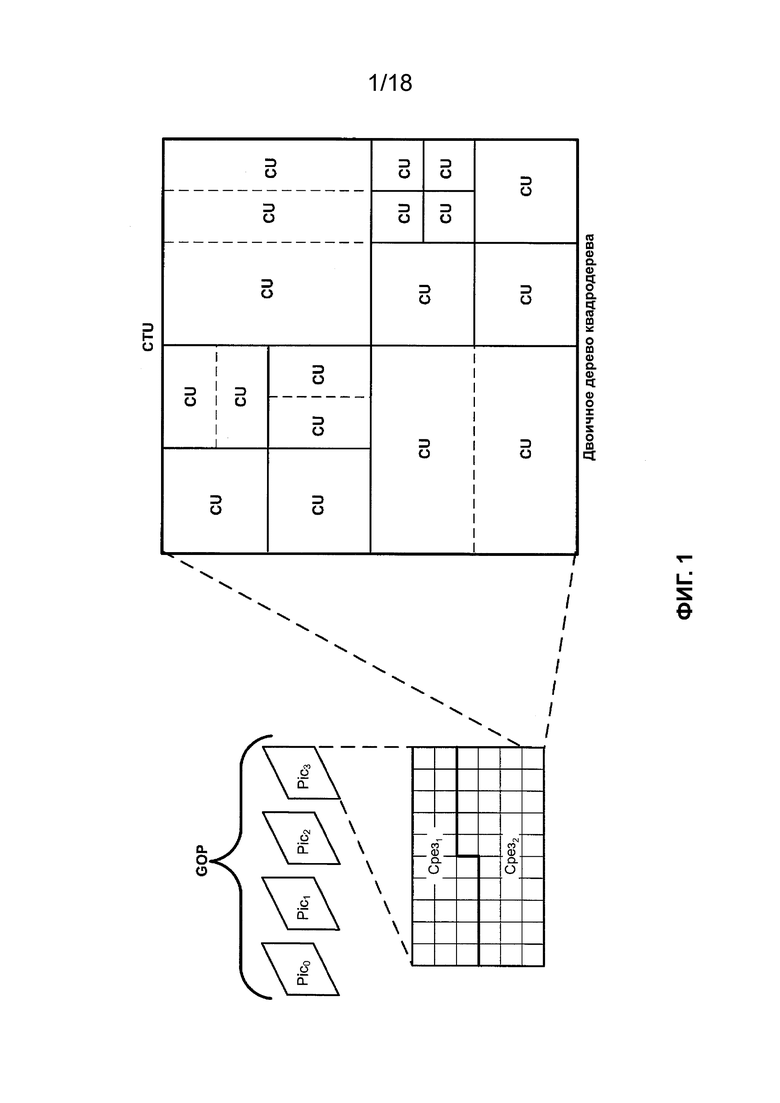
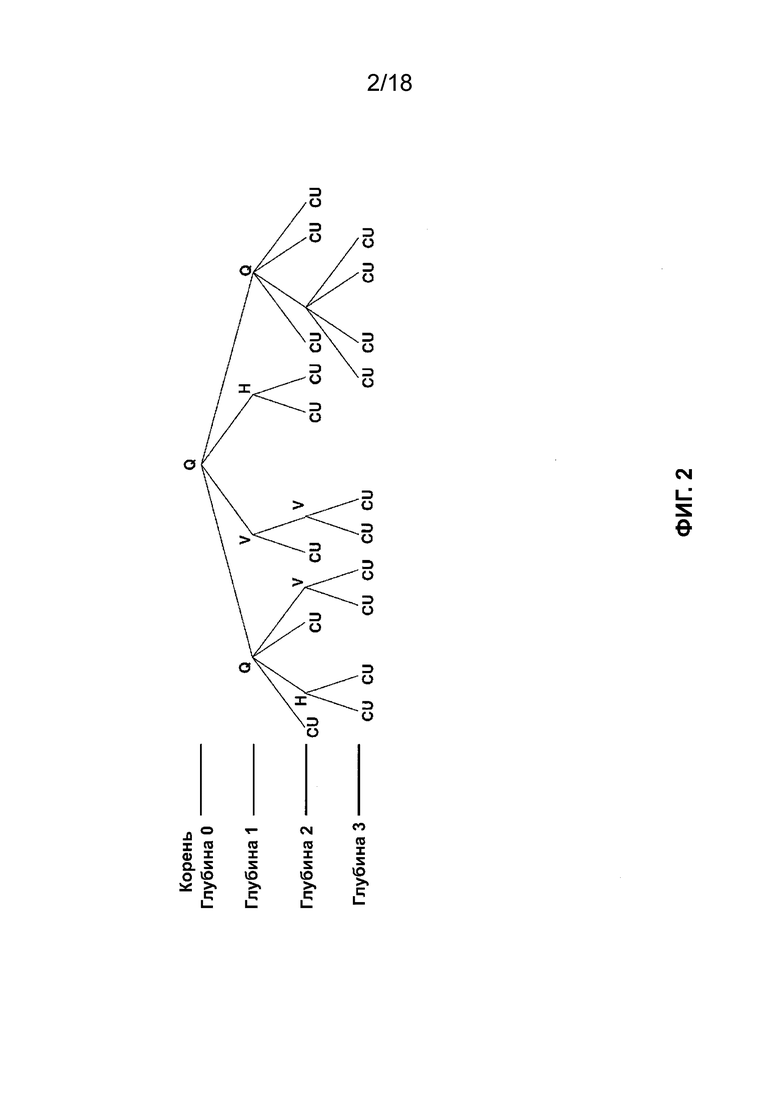
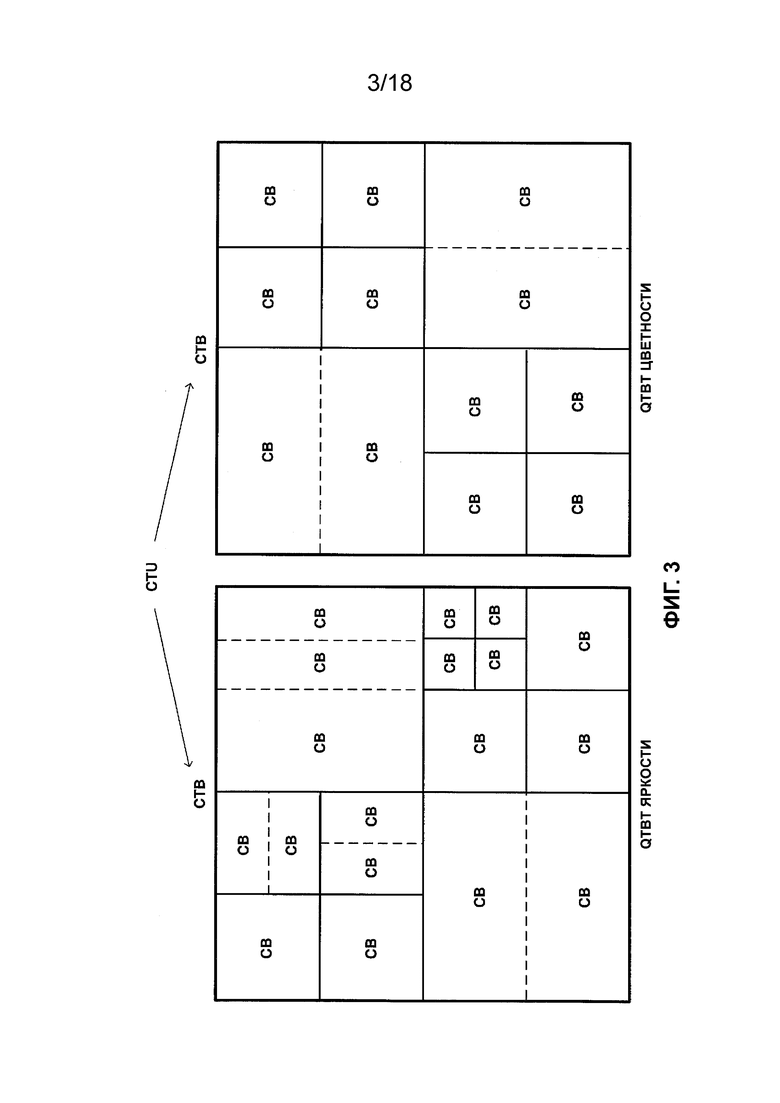
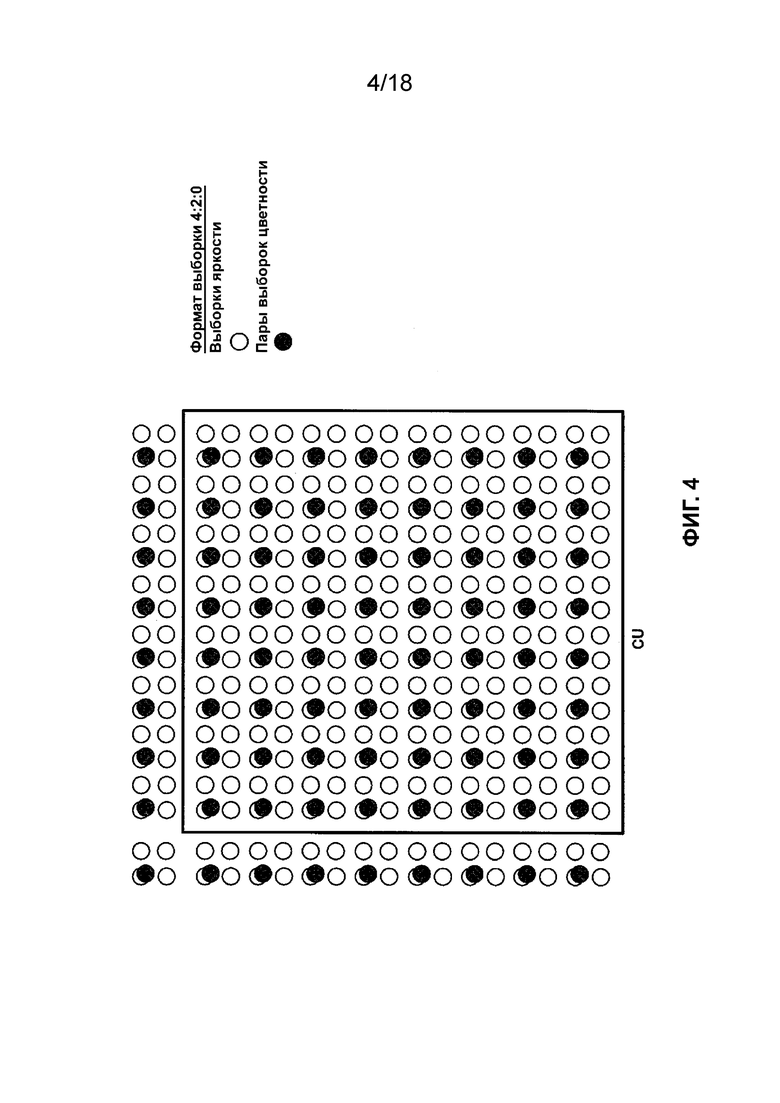
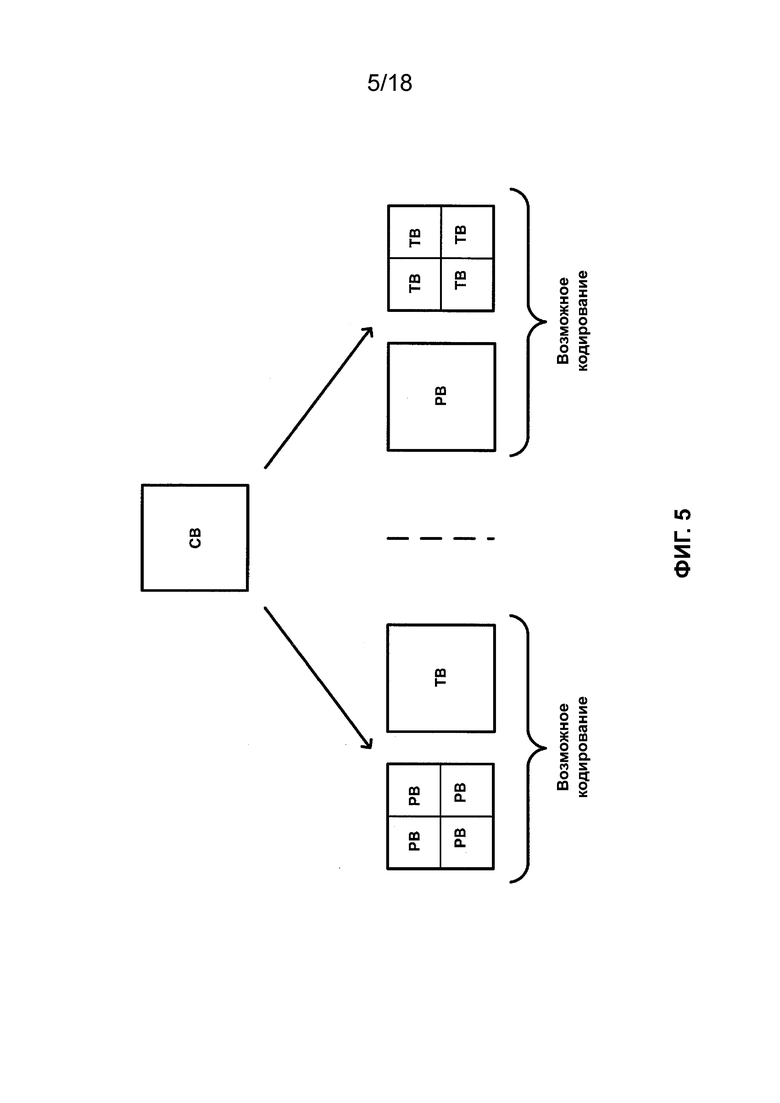
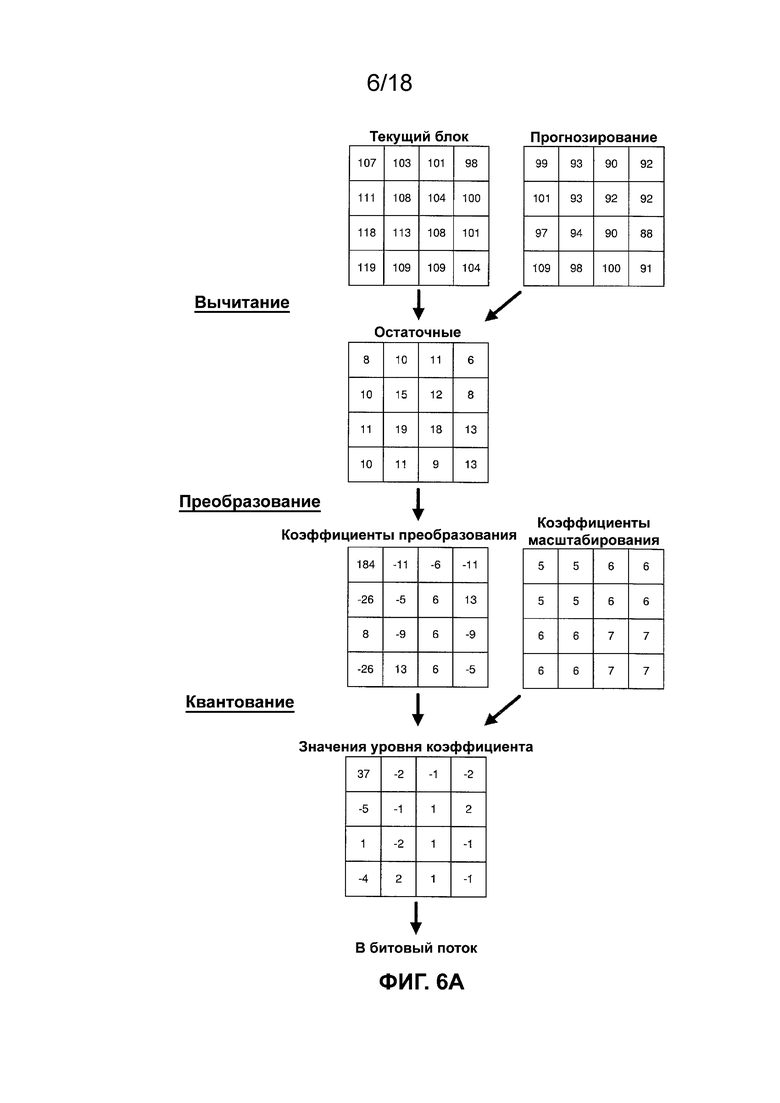
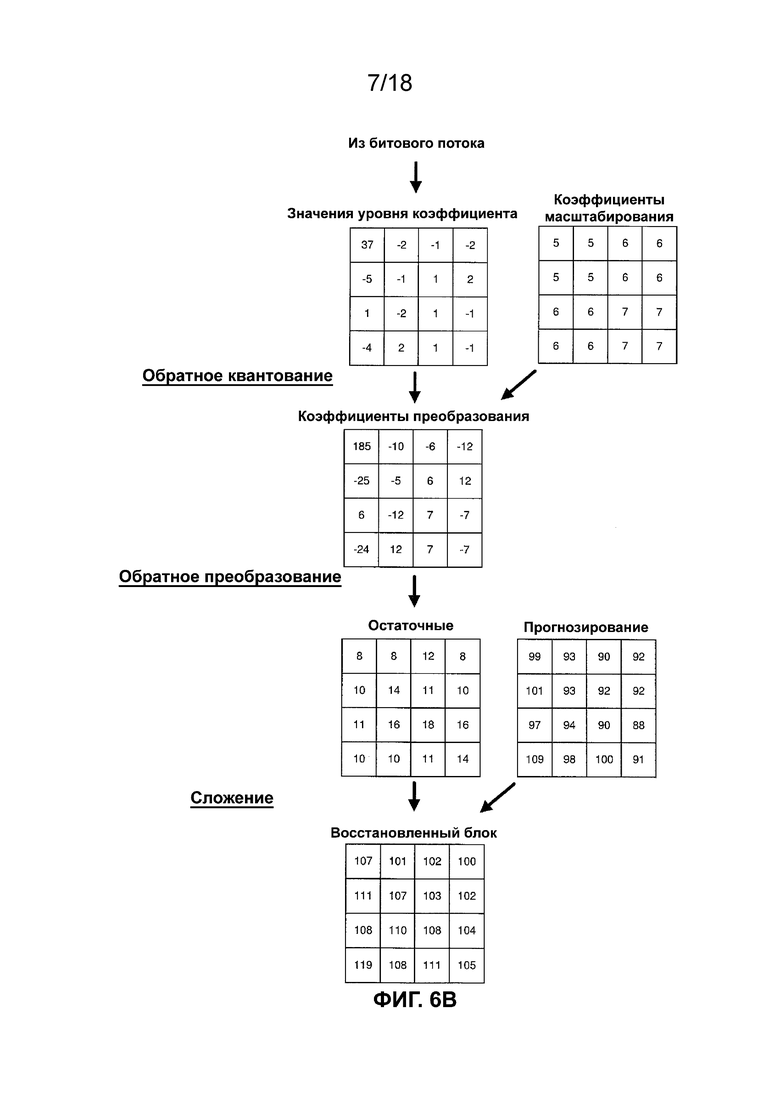
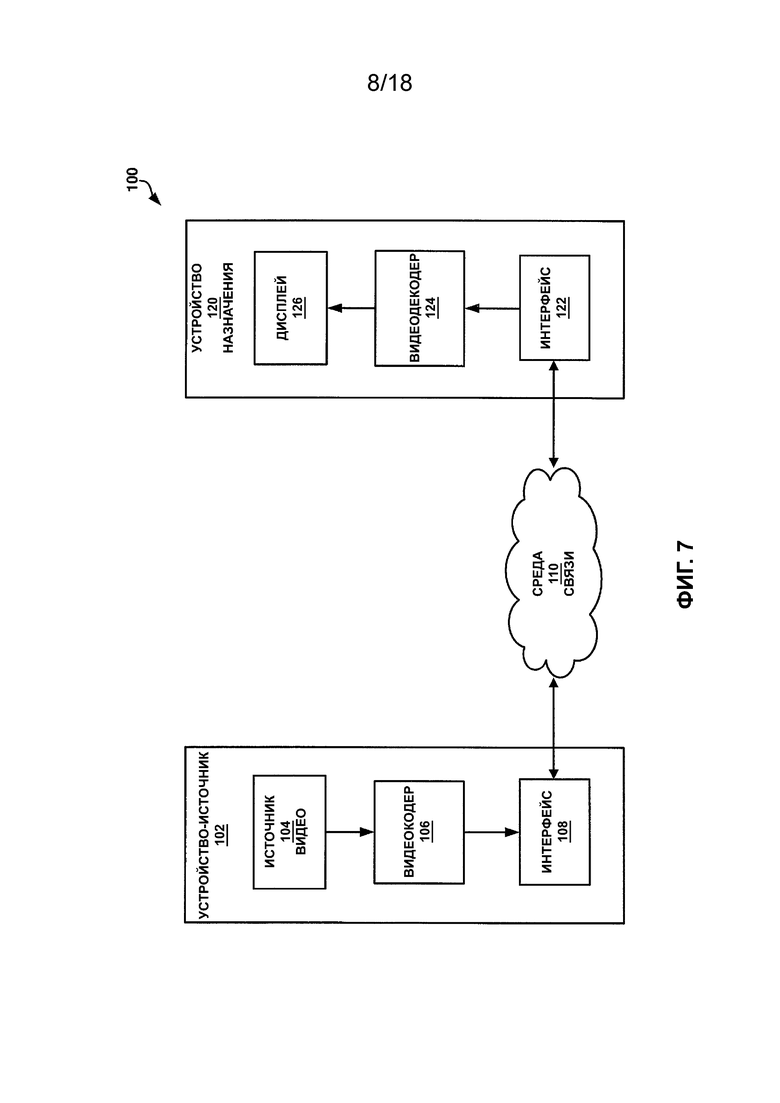
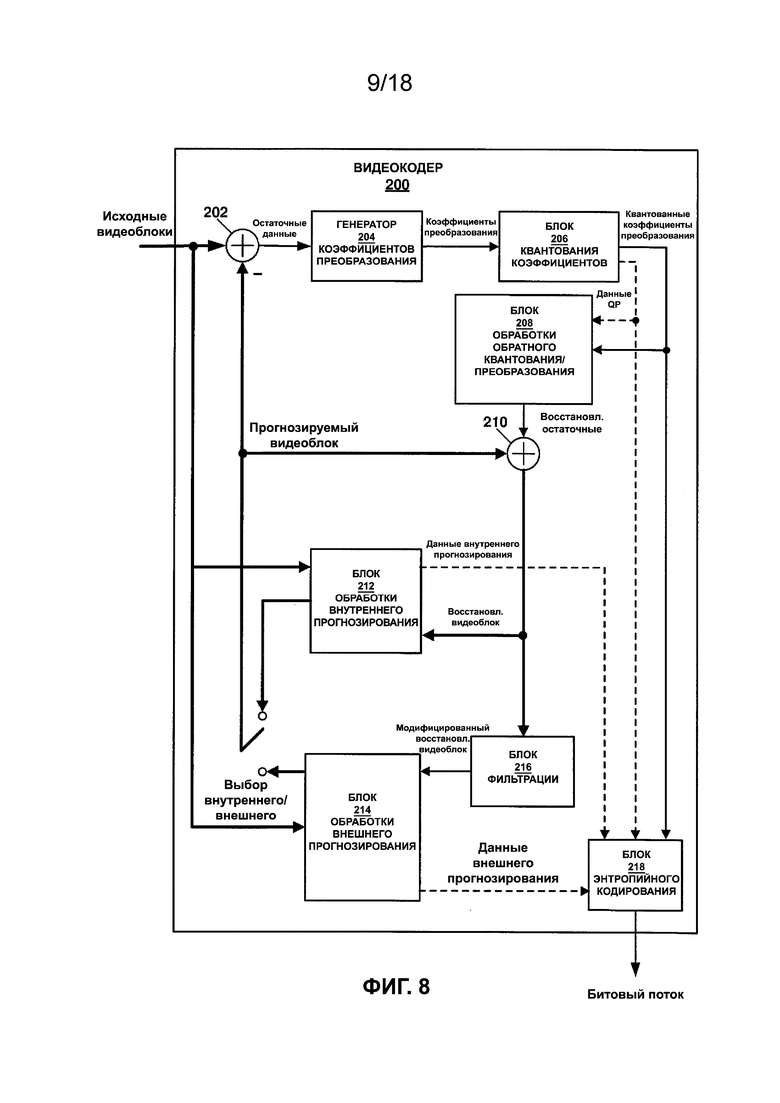
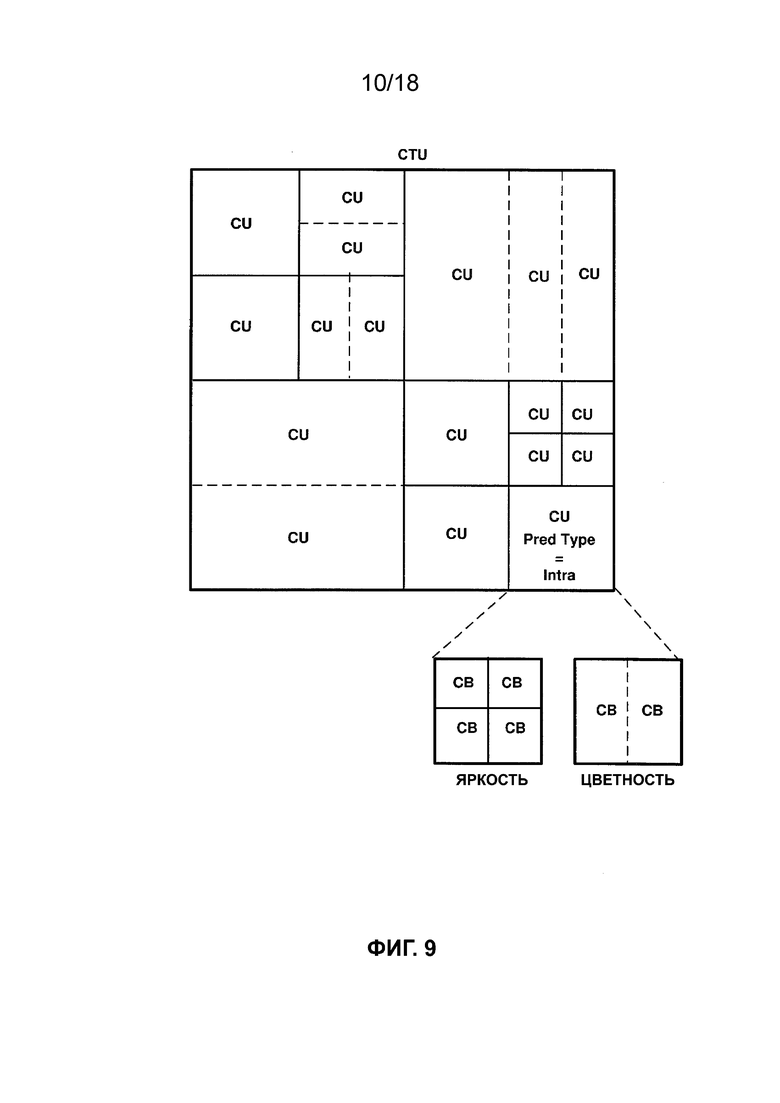
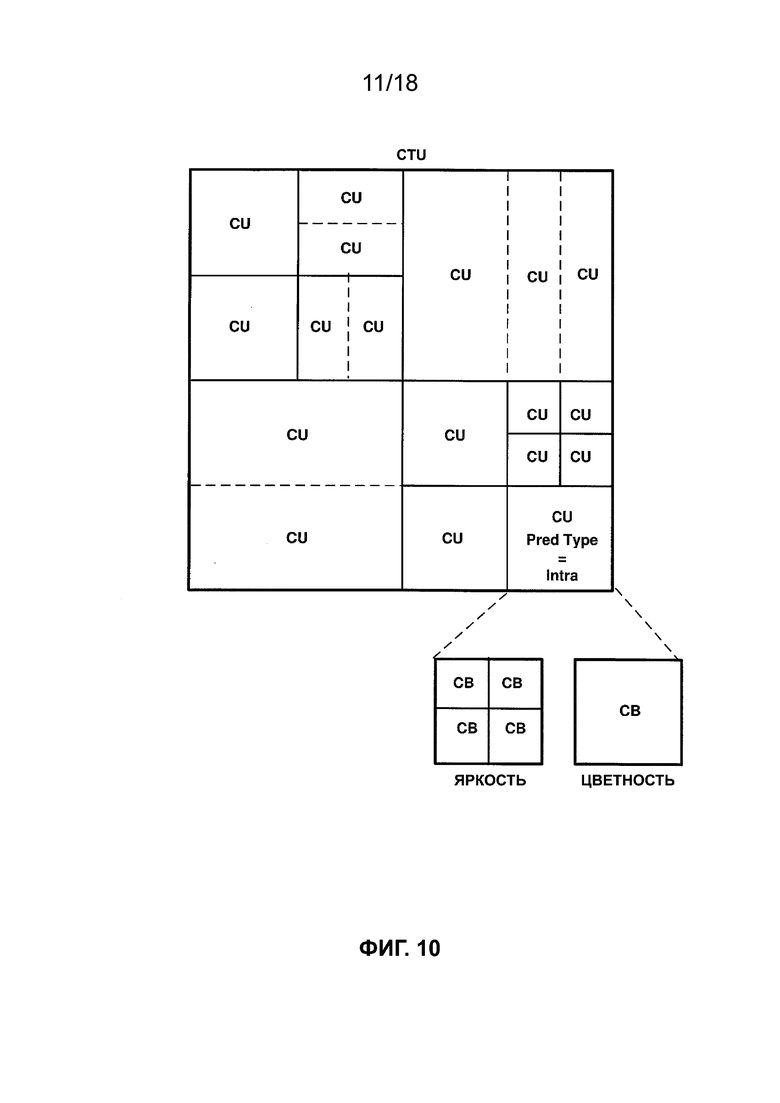
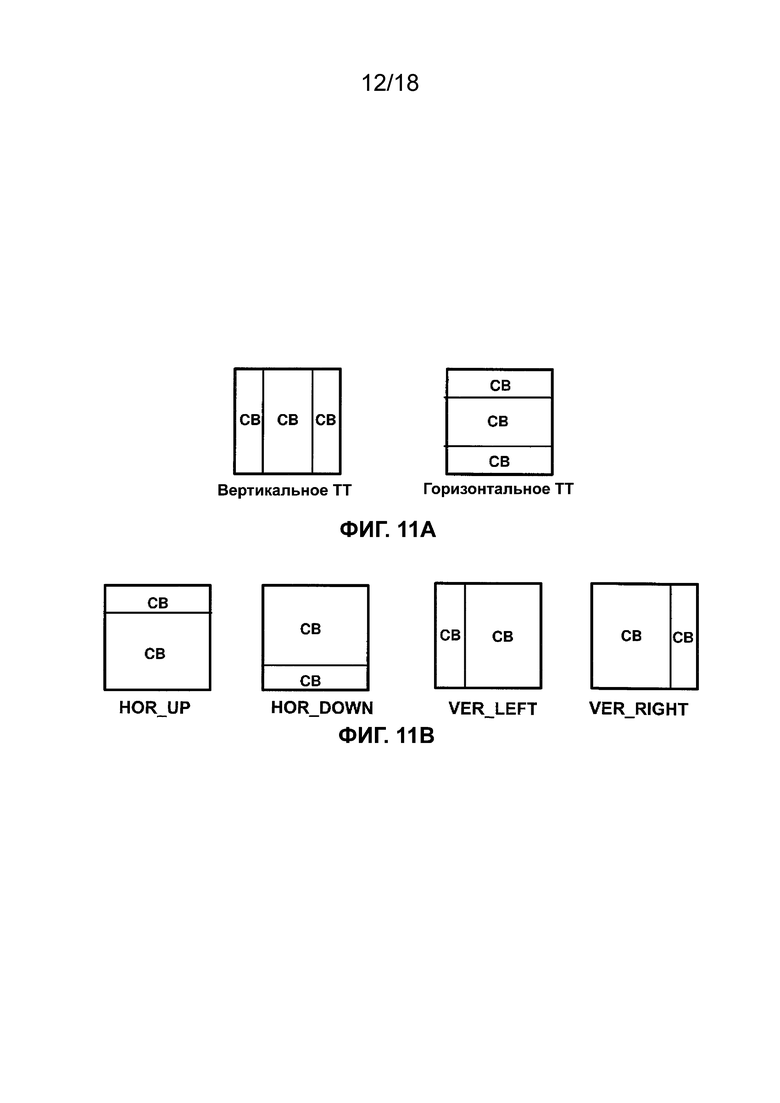
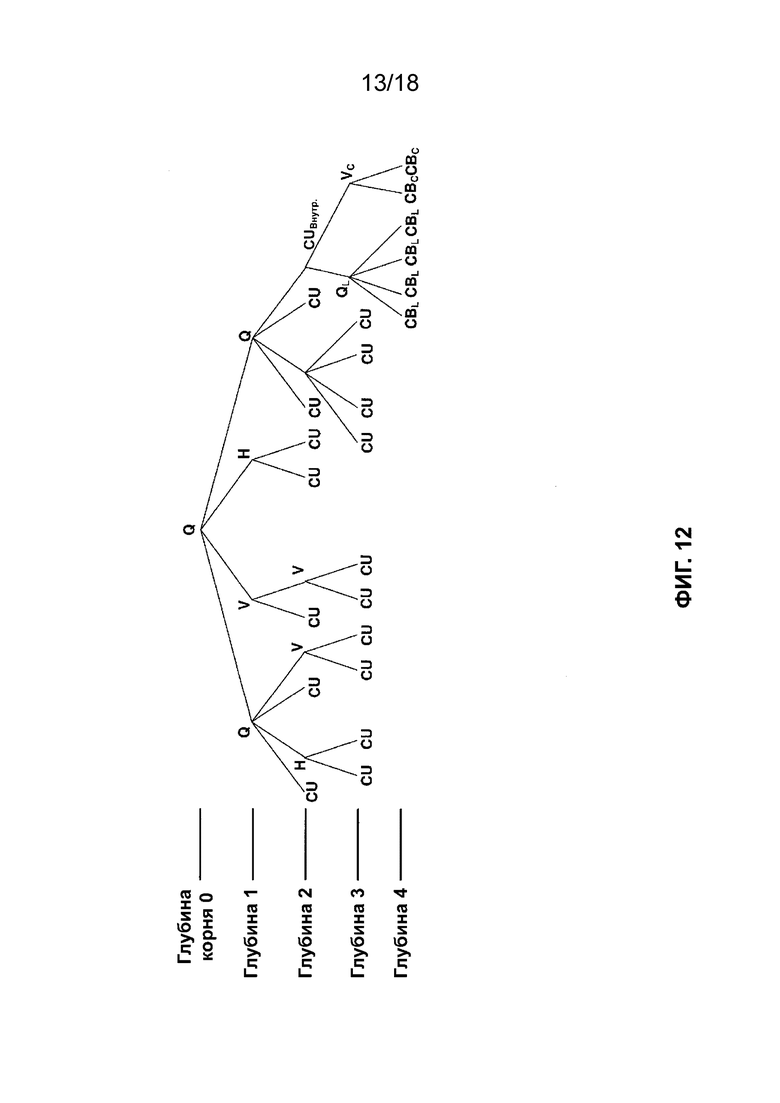
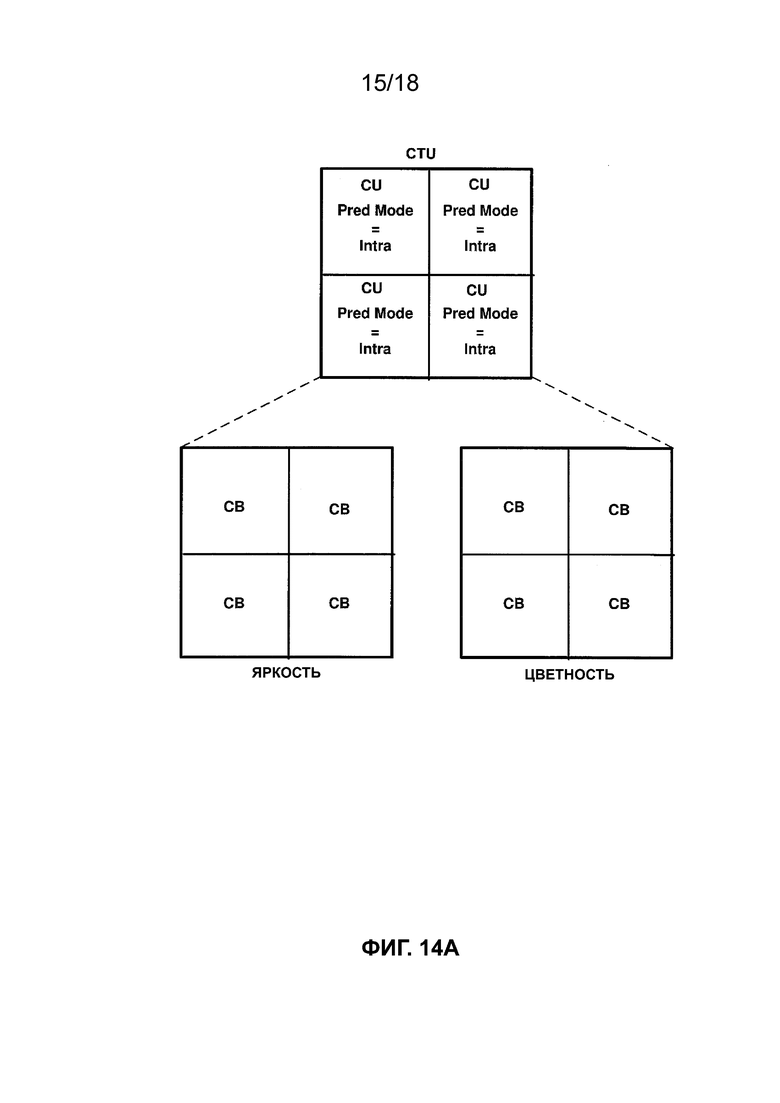
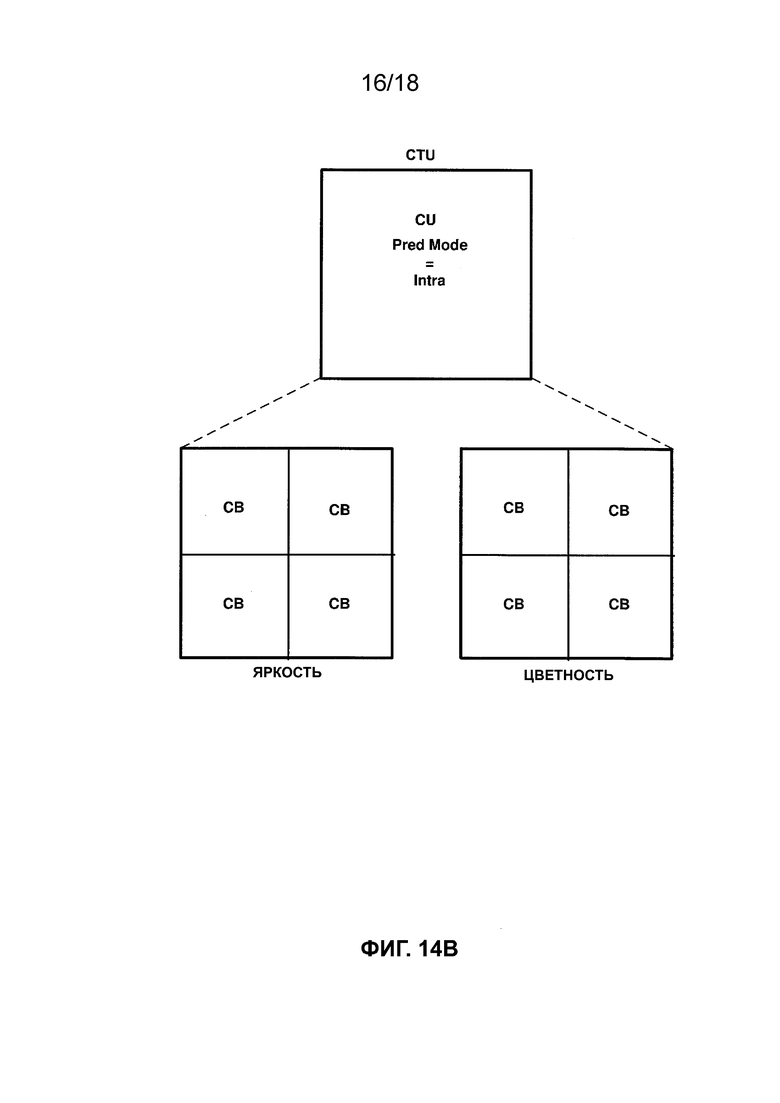
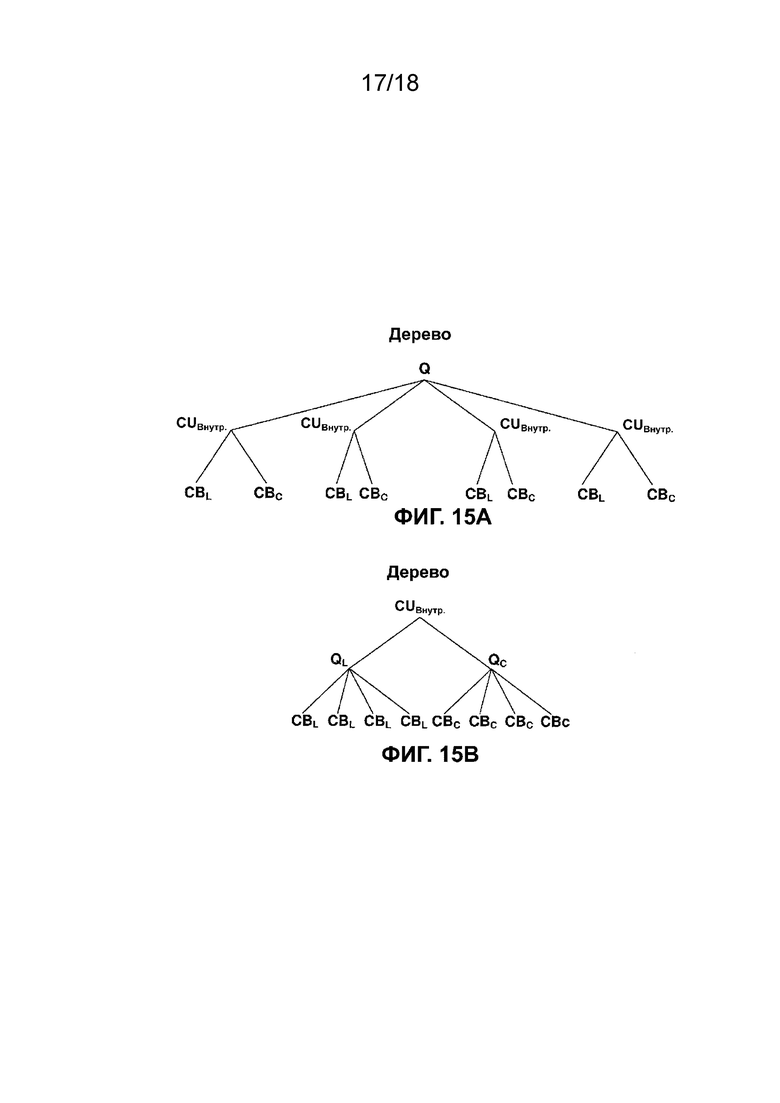
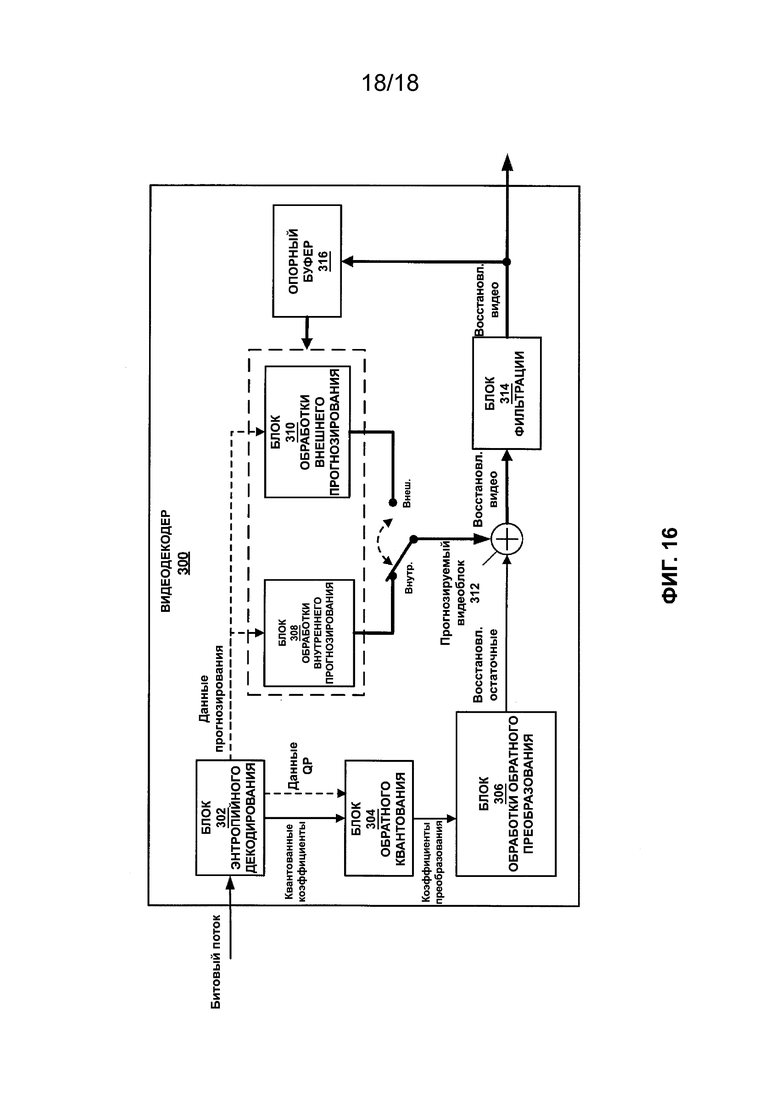
Изобретение относится к области кодирования видео, в частности к способам разделения изображения видеоданных. Технический результат заключается в обеспечении эффективного способа разделения видеоданных для кодирования видеосигналов. Предложенное устройство для кодирования видеосигналов может быть выполнено с возможностью осуществления кодирования видеосигналов, включающего: прием видеоблока, включающего в себя значения выборок первого компонента видеоданных и второго компонента видеоданных; разделение значений выборки для первого компонента видеоданных и второго компонента видеоданных в соответствии со структурой разделения первого двоичного дерева квадродерева (QTBT); и дополнительное разделение выборок в соответствии со вторым двоичным деревом квадродерева для значений выборок первого компонента видеоданных, включенных в узлы первого двоичного дерева квадродерева, связанных с внутренним типом прогнозирования. 3 н. и 9 з.п. ф-лы, 20 ил., 21 табл.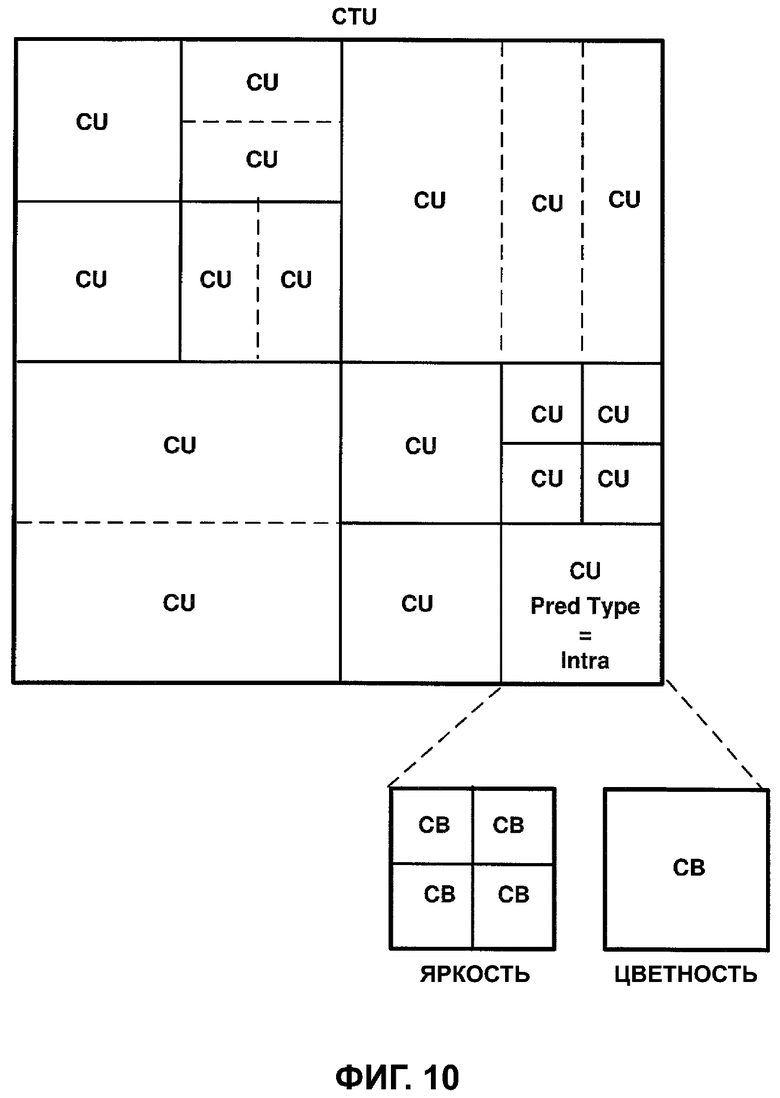
1. Способ разделения видеоданных для кодирования видео, содержащий этапы, на которых:
определяют тип двоичного дерева квадродерева для блока кодового дерева;
разделяют блок кодового дерева на один или более первых блоков кодирования на основе типа двоичного дерева квадродерева, в случае когда тип двоичного дерева квадродерева является общей структурой разделения в канале яркости и канале цветности;
определяют, является ли тип предсказания для одного из упомянутых одного или более первых блоков кодирования типом интра-предсказания, когда блок кодового дерева включен в срез интер-предсказания; и
разделяют канал яркости для этого одного из одного или более первых блоков кодирования, относящихся к режиму интра-предсказания, на вторые блоки кодирования, в случае когда типом предсказания является тип интра-предсказания.
2. Способ по п.1, в котором срез интер-предсказания является одним из P-среза и B-среза.
3. Способ по п.1, в котором тип предсказания задается посредством использования размера блока кодирования, представляемого умножением ширины блока кодирования на высоту блока кодирования.
4. Способ по п.1, в котором тип предсказания задается посредством использования флага отдельного дерева, задающего, используется ли тип интра-предсказания.
5. Способ по п.1, в котором тип предсказания задается посредством использования режима разбиения, указывающего один из режима вертикального разбиения, режима горизонтального разбиения, режима вертикального разбиения троичного дерева и режима горизонтального разбиения троичного дерева.
6. Способ по п.1, дополнительно содержащий этапы, на которых:
принимают флаг режима предсказания, указывающий тип предсказания для упомянутого одного из одного или более первых блоков кодирования, и определяют, основываясь на флаге режима предсказания, разделен ли канал яркости для этого одного из одного или более первых блоков кодирования дополнительно на вторые блоки кодирования, когда блок кодового дерева включен в срез интер-предсказания;
определяют, без синтаксического анализа флага режима предсказания, разделен ли канал яркости для упомянутого одного из одного или более первых блоков кодирования дополнительно на вторые блоки кодирования, когда блок кодового дерева включен в срез интра-предсказания.
7. Способ по п.1, дополнительно содержащий этап, на котором определяют, является ли типом предсказания тип интра-предсказания, для определения того, разделен ли канал яркости для упомянутого одного из одного или более первых блоков кодирования на вторые блоки кодирования, когда блок кодового дерева включен в срез интер-предсказания.
8. Способ по п.1, дополнительно содержащий этап, на котором разделяют канал яркости для упомянутого одного из одного или более первых блоков кодирования, относящихся к режиму интра-предсказания, на один или более третьих блоков кодирования, в случае когда типом предсказания является тип интра-предсказания.
9. Способ по п.8, в котором вторые блоки кодирования формируются посредством первой структуры разделения, а упомянутые один или более третьих блоков кодирования формируются посредством второй структуры разделения.
10. Способ по п.1, дополнительно содержащий этапы, на которых:
разделяют упомянутый один из одного или более первых блоков кодирования на основе двух разных структур разделения на вторые блоки кодирования в канале яркости и один или более третьих блоков кодирования в канале цветности, когда блок кодового дерева включен в срез интра-предсказания или типом предсказания для этого одного из одного или более первых блоков кодирования, включенных в срез интер-предсказания, является тип интра-предсказания; и
разделяют упомянутый один из одного или более первых блоков кодирования на основе совместно используемой структуры разделения на один или более четвертых блоков кодирования в канале яркости и канале цветности, когда типом предсказания для этого одного из одного или более первых блоков кодирования, включенных в срез интер-предсказания, является тип интер-предсказания.
11. Устройство для кодирования видеоданных, содержащее один или более процессоров, выполненных с возможностью осуществления способа по п.1.
12. Устройство для декодирования видеоданных, содержащее один или более процессоров, выполненных с возможностью осуществления способа по п.1.
| WO 2016091161 A1 - 2016-06-16 | |||
| WO 2017088810 A1 - 2017-06-01 | |||
| JIANLE CHEN ET AL, Algorithm Description of Joint Exploration Test Model 7 (JEM 7), JOINT VIDEO EXPLORATION TEAM (JVET) OF ITU-T SG 16 WP 3 AND ISO/IEC JTC 1/SC 29/WG 11, no.G1001-v1, 2017-07-21 | |||
| РАСШИРЕННАЯ СИГНАЛИЗАЦИЯ РЕЖИМА ВНУТРЕННЕГО ПРЕДСКАЗАНИЯ ДЛЯ КОДИРОВАНИЯ ВИДЕО, ИСПОЛЬЗУЮЩЕГО РЕЖИМ СОСЕДСТВА | 2012 |
|
RU2601843C2 |
| WO 2016090568 A1 - 2016-06-16 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ ВИДЕОИНФОРМАЦИИ ПОСРЕДСТВОМ ПРЕДСКАЗАНИЯ ДВИЖЕНИЯ С ИСПОЛЬЗОВАНИЕМ ПРОИЗВОЛЬНОЙ ОБЛАСТИ, А ТАКЖЕ УСТРОЙСТВО И СПОСОБ ДЕКОДИРОВАНИЯ ВИДЕОИНФОРМАЦИИ ПОСРЕДСТВОМ ПРЕДСКАЗАНИЯ ДВИЖЕНИЯ С ИСПОЛЬЗОВАНИЕМ ПРОИЗВОЛЬНОЙ ОБЛАСТИ | 2013 |
|
RU2517253C1 |
| LE | |||

