Область техники, к которой относится изобретение
Данный патентный документ относится к технологиям, устройствам и системам кодирования и декодирования видео.
Уровень техники
Несмотря на достижения в области сжатия видео, цифровое видео по-прежнему занимает самую большую полосу пропускания в Интернете и других сетях цифровой связи. По мере увеличения количества подключенных пользовательских устройств, способных принимать и отображать видео, ожидается, что потребность в полосе пропускания для использования цифрового видео будет продолжать расти.
Раскрытие сущности изобретения
В данном документе раскрыты способы, системы и устройства для кодирования и декодирования цифрового видео с использованием списка слияния векторов движения.
В одном примерном аспекте предусмотрен способ декодирования видео, включающий в себя ведение набора таблиц, причем каждая таблица включает в себя кандидаты движения, и каждый кандидат движения ассоциируется с соответствующей информацией о движении; обновление списка кандидатов на основе кандидатов движения в одной или более таблицах с использованием операции сокращения кандидатов движения; и выполнение преобразования между первым видеоблоком и представлением битового потока видео, включающего в себя первый видеоблок, с использованием созданного списка кандидатов.
В другом примерном аспекте предусмотрен способ декодирования видео, содержащий прием представления битового потока видео, включающего в себя первый видеоблок; применение операции сокращения к кандидатам движения в одной или более таблицах для обновления списка кандидатов, причем каждая таблица включает в себя кандидаты движения, и каждый кандидат движения ассоциируется с соответствующей информацией о движении; и выполнение преобразования между представлением битового потока и первым видеоблоком с использованием созданного списка кандидатов.
В еще одном характерном аспекте различные технологии, описанные в данном документе, могут быть воплощены в виде компьютерного программного продукта, хранящегося на энергонезависимом машиночитаемом носителе информации. Компьютерный программный продукт включает в себя программный код для выполнения способов, описанных в данном документе.
В еще одном характерном аспекте устройство декодирования или декодирования видео может реализовывать способ, который описан в данном документе.
Подробности одной или более реализаций изложены в сопроводительных приложениях, чертежах и описании, которые представлены ниже. Другие признаки будут очевидны из описания и чертежей, а также из формулы изобретения.
Краткое описание чертежей
Фиг.1 – блок-схема, показывающая пример реализации видеокодера.
Фиг.2 иллюстрирует разбиение макроблоков в стандарте кодирования видео H.264.
Фиг.3 – пример разделения блоков кодирования (CB) на единицы прогнозирования (PU).
Фиг.4 – примерная реализация для подразбиения CTB на CB и блок преобразования (TB). Сплошными линиями указаны границы CB, и пунктирными линиями указаны границы TB, включая пример CTB с его разбиением и соответствующее квадродерево.
Фиг.5 – пример структуры двоичного дерева квадродерева (QTBT) для разбиения видеоданных.
Фиг.6 – пример разбиения видеоблока.
Фиг.7 – пример разбиения квадродерева.
Фиг.8 – пример сигнализации древовидного типа.
Фиг.9 – пример процесса получения для создания списка кандидатов слияния.
Фиг.10 – примерные позиции пространственных кандидатов слияния.
Фиг.11 – примеры пар кандидатов, рассматриваемых для проверки на избыточность пространственных кандидатов слияния.
Фиг.12 – примеры позиций для второй PU разбиений Nx2N и 2NxN.
Фиг.13 иллюстрирует масштабирование вектора движения для временных кандидатов слияния.
Фиг.14 – позиции кандидатов для временных кандидатов слияния и их совмещенное изображение.
Фиг.15 – пример объединенного кандидата слияния с бипрогнозированием.
Фиг.16 – пример процесса получения кандидатов прогнозирования вектора движения.
Фиг.17 – пример масштабирования вектора движения для пространственных кандидатов вектора движения.
Фиг.18 – пример альтернативного прогнозирования временного вектора движения (ATMVP) для прогнозирования движения CU.
Фиг.19 графически изображает пример идентификации исходного блока и исходного изображения.
Фиг.20 – пример одной CU с четырьмя подблоками и соседними блоками.
Фиг.21 – пример двустороннего согласования.
Фиг.22 – пример согласования с шаблоном.
Фиг.23 – пример односторонней оценки движения (ME) при преобразовании с повышением частоты кадров (FRUC).
Фиг.24 – пример DMVR на основе двустороннего согласования с шаблоном.
Фиг.25 – пример пространственно разнесенных соседних блоков, используемых для получения пространственных кандидатов на слияние
Фиг.26 – пример того, как обновляется выбор репрезентативной позиции для таблицы поиска.
Фиг.27A и 27B – примеры обновления таблицы поиска новым набором информации о движении.
Фиг.28 – блок-схема примера аппаратной платформы для реализации технологии кодирования визуального мультимедиа или декодирования визуального мультимедиа, описанной в данном документе.
Фиг.29 – блок-схема последовательности операций примерного способа видеообработки.
Фиг.30 – пример блок-схемы последовательности операций другого примерного способа видеообработки.
Фиг.31 –пример блок-схемы декодирования с использованием предложенного способа HMVP.
Фиг.32 – примеры обновления таблиц с использованием предложенного способа HMVP.
Фиг.33A и 33B – примеры способа обновления LUT, основанного на уменьшении избыточности (с удалением многочисленных избыточных кандидатов движения).
Фиг.34A и 34B – примеры способа обновления LUT основанного на уменьшении избыточности (с удалением нескольких кандидатов движения избыточности).
Осуществление изобретения
Чтобы улучшить степень сжатия видео, исследователи постоянно ищут новые способы кодирования видео.
1. Введение
Данный документ относится к технологиям кодирования видео. В частности, он относится к кодированию информации о движении (например, в режиме слияния и в режиме AMVP) при кодировании видео. Его можно применить к существующему стандарту кодирования видео, например, HEVC, или к стандарту (универсальное кодирование видео), который будет доработан. Его можно также применить к будущим стандартам кодирования видео или видеокодекам.
Краткое изложение
Стандарты кодирования видео развивались в основном благодаря развитию хорошо известных стандартов ITU-T и ISO/IEC. ITU-T выпустил H.261 и H.263, ISO/IEC выпустил MPEG-1 и MPEG-4 Visual, и две организации совместно выпустили стандарты H.262/MPEG-2 Video, H.264/MPEG-4 Advanced, усовершенствованное кодирование видео (AVC) и H.265/HEVC. Начиная с H.262, стандарты кодирования видео основаны на структуре гибридного кодирования видео, в которой используются временное прогнозирование плюс кодирование с преобразованием. Пример типичной структуры кодера HEVC показан на фиг.1.
2.1 Структура разбиения
2.1.1 Древовидная структура разбиения в H.264/AVC
Основой уровня кодирования в предыдущих стандартах был макроблок, содержащий блок 16×16 отсчетов яркости и в обычном случае дискретизации цвета 4:2:0 два соответствующих блока 8×8 отсчетов цветности.
Интракодированный блок использует пространственное прогнозирование, чтобы использовать пространственную корреляцию между пикселями. Определены два разбиения: 16x16 и 4×4.
Интеркодированный блок использует временное прогнозирование вместо пространственного прогнозирования посредством оценки движения среди изображений. Движение можно оценить независимым образом либо для макроблока 16x16, либо для любого из его разбиений на подмакроблоки: 16x8, 8x16, 8x8, 8x4, 4x8, 4×4 (смотри фиг.2). Допускается только один вектор движения (MV) на одно разбиение подмакроблока.
2.1.2 Древовидная структура разбиения в HEVC
В HEVC CTU разделяется на CU с использованием структуры квадродерева, обозначенной как дерево кодирования, для адаптации к различным локальным характеристикам. Решение о том, кодировать ли область изображения с использованием межкадрового (временного) или внутрикадрового (пространственного) прогнозирования, принимается на уровне CU. Каждая CU может быть дополнительно разделена на один, два или четыре PU в соответствии с типом разделения PU. Внутри одного PU применяется один и тот же процесс прогнозирования, и соответствующая информация передается в декодер на основе PU. После получения остаточного блока путем применения процесса прогнозирования на основе типа разделения PU, CU может быть разбита на единицы преобразования (TU) в соответствии с другой структурой квадродерева, аналогичной дереву кодирования для CU. Одной из ключевых особенностей структуры HEVC является то, что она имеет концепции нескольких разбиения, включая CU, PU и TU.
Далее, различные функции, задействованные в гибридном кодировании видео с использованием HEVC, выделены следующим образом.
1) Единицы дерева кодирования и структура блока дерева кодирования (CTB): аналогичная структура в HEVC представляет собой единицу дерева кодирования (CTU), которая имеет размер, выбранный кодером, и может быть больше, чем у традиционного макроблока. CTU состоит из CTB яркости и соответствующих CTB цветности и элементов синтаксиса. Размер L×L яркости CTB может быть выбран как L=16, 32 или 64 отсчета, причем большие размеры обычно обеспечивают лучшее сжатие. Затем HEVC поддерживает разбиение CTB на меньшие блоки с использованием структуры дерева и сигнализации, подобной квадродереву.
2) Единицы кодирования (CU) и блоки кодирования (CB): синтаксис квадродерева CTU определяет размер и позиции их CB яркости и цветности. Корень квадродерева ассоциируется с CTU. Следовательно, размер CTB яркости является наибольшим поддерживаемым размером CB яркости. Разделение CTU на CB яркости и разделение CTU на CB цветности сигнализируются совместно. Один CB яркости и обычно два CB цветности вместе с ассоциированным синтаксисом образуют единицу кодирования (CU). CTB может содержать только одну CU или может быть разделен для формирования нескольких CU, и каждая CU имеет ассоциированное разбиение на единицы прогнозирования (PU) и дерево единиц преобразования (TU).
3) Единицы прогнозирования и блоки прогнозирования (PB): решение о том, кодировать ли область изображения с использованием прогнозирования с интеризображением или интраизображением, принимается на уровне CU. Структура разбиения PU имеет свой корень на уровне CU. Затем, в зависимости от основного решения о типе прогнозирования, CB яркости и цветности могут быть дополнительно разделены по размеру и спрогнозированы исходя из блоков прогнозирования яркости и цветности (PB). HEVC поддерживает переменные размеры PB от 64×64 до 4×4 отсчетов. На фиг.3 показаны примеры разрешенных PB для CU M×M.
4) TU и блоки преобразования: Остаток прогнозирования кодируется с использованием преобразований блоков. Древовидная структура TU имеет корень на уровне CU. Остаток CB яркости может быть идентичен блоку преобразования яркости (TB) или может быть дополнительно разделен на меньшие TB яркости. То же самое относится к TB цветности. Целочисленные базисные функции, аналогичные функциям дискретного косинусного преобразования (DCT), определены для квадратных TB размером 4×4, 8×8, 16×16 и 32×32. В качестве альтернативы, для преобразования 4×4 остатков прогнозирования интраизображений яркости указывается целочисленное преобразование, полученное из формы дискретного синусоидального преобразования (DST).
На фиг.4 показан пример подразделения CTB на CB (и блоки преобразования (TB)). Сплошными линиями указаны границы CB, и пунктирными линиями указаны границы TB, при этом (a) представляет собой CTB с его разбиением, и (b) – соответствующее квадродерево.
2.1.2.1 Древовидное разбиение на блоки и единицы преобразования
Для остаточного кодирования CB может быть рекурсивно разбит на блоки преобразования (TB). Разбиение сигнализируется с помощью остаточного квадродерева. Указывается только разбиение на квадратные CB и TB, где блок может быть рекурсивно разделен на квадранты, как показано на фиг.4. Для данной яркости CB размером M×M флаг сигнализирует то, разделен ли он на четыре блока размером M/2×M/2. Если дальнейшее разделение возможно, о чем свидетельствует максимальная глубина остаточного квадродерева, указанная в SPS, каждому квадранту назначается флаг, который указывает то, разделен ли он на четыре квадранта. Блоки листовых узлов, полученные из остаточного квадродерева, являются блоками преобразования, которые дополнительно обрабатываются путем кодирования преобразования. Кодер указывает максимальный и минимальный размеры TB яркости, которые он будет использовать. Разделение подразумевается тогда, когда размер CB больше максимального размера TB. Отсутствие разделения подразумевается тогда, когда разделение может привести к тому, что размер TB яркости меньше указанного минимума. Размер TB цветности составляет половину размера TB яркости в каждом измерении, за исключением случая, когда размер TB яркости составляет 4×4, и в этом случае один TB цветности 4×4 используется для области, охваченной четырьмя TB яркости 4×4. В случае CU с интрапрогнозированием изображений декодированные отсчеты ближайших соседних блоков TB (внутри или вне CB) используются в качестве контрольных данных для интрапрогнозирования изображений.
В отличие от предыдущих стандартов, конструкция HEVC позволяет TB охватывать многочисленные PB для CU с интерпрогнозированием изображений, чтобы максимизировать потенциальные преимущества эффективности кодирования разбиения TB со структурой квадродерева.
2.1.2.2 Родительские и дочерние узлы
CTB разделяется в соответствии со структурой квадродерева, узлы которого являются единицами кодирования. Множество узлов в структуре квадродерева включает в себя листовые узлы и нелистовые узлы. Листовые узлы не имеют дочерних узлов в древовидной структуре (то есть листовые узлы не разделяются далее). Нелистовые узлы включают в себя корневой узел древовидной структуры. Корневой узел соответствует начальному видеоблоку видеоданных (например, CTB). Для каждого соответствующего некорневого узла из множества узлов соответствующий некорневой узел соответствует видеоблоку, который является подблоком видеоблока, соответствующего родительскому узлу в древовидной структуре соответствующего некорневого узла. Каждый соответствующий нелистовой узел из множества нелистовых узлов имеет один или несколько дочерних узлов в древовидной структуре.
2.1.3 Структура "квадрадерево плюс блок двоичного дерева с большими CTU" в JEM
В 2015 году была основана совместно с VCEG и MPEG объединенная группа по исследованию видео (JVET) для исследования будущих технологий кодирования видео за рамками HEVC. С тех пор JVET были одобрены многие новые способы и добавлены в справочное программное обеспечение под названием "модель совместного исследования (JEM)".
2.1.3.1 Структура разбиения блоков QTBT
В отличие от HEVC структура QTBT исключает концепции множественных типов разбиения, то есть устраняет разделение концепций CU, PU и TU и поддерживает большую гибкость для форм разбиения CU. В структуре блока QTBT CU может иметь квадратную или прямоугольную форму. Как показано на фиг.5, единица дерева кодирования (CTU) сначала разбивается на структуру квадродерева. Листовые узлы квадродерева дополнительно разбиваются на структуру двоичного дерева. При разделении двоичного дерева используются два типа разделения: симметричное горизонтальное разделение и симметричное вертикальное разделение. Листовые узлы двоичного дерева называются единицами кодирования (CU), и эта сегментация используется для прогнозирования и обработки преобразования без какого-либо дальнейшего разбиения. Это означает, что CU, PU и TU имеют одинаковый размер блоков в структуре блока кодирования QTBT. В JEM CU иногда состоит из блоков кодирования (CB) разных цветовых компонентов, например, одна CU содержит один CB яркости и два CB цветности в случае слайсов P и B формата цветности 4:2:0, и иногда состоит из CB одного компонента, например, одна CU содержит только один CB яркости или только два CB цветности в случае слайсов I.
Для схемы разбиения QTBT определены следующие параметры.
- Размер CTU: размер корневого узла квадродерева, та же самая концепция, что и в HEVC
- MinQTSize: минимально допустимый размер листового узла квадродерева
- MaxBTSize: максимально допустимый размер корневого узла двоичного дерева
- MaxBTDepth: максимально допустимая глубина двоичного дерева
- MinBTSize: минимально допустимый размер узла листа двоичного дерева
В одном примере структуры разбиения QTBT размер CTU установлен как 128×128 отсчетов яркости с двумя соответствующими блоками 64×64 отсчетов цветности, MinQTSize установлен как 16×16, MaxBTSize установлен как 64×64, MinBTSize (как для ширины, так и для высоты) установлен как 4×4, и MaxBTDepth установлен как 4. Разбиение квадродерева сначала применяется к CTU для выработки листовых узлов квадродерева. Листовые узлы квадродерева могут иметь размер от 16×16 (то есть MinQTSize) до 128×128 (то есть размер CTU). Если листовой узел квадродерева имеет размер 128×128, он не будет далее разделяться двоичным деревом, так как размер превышает MaxBTSize (то есть 64×64). В противном случае листовой узел квадродерева может быть дополнительно разбит двоичным деревом. Таким образом, листовой узел квадродерева также является корневым узлом для двоичного дерева, и его глубина двоичного дерева равна 0. Когда глубина двоичного дерева достигает MaxBTDepth (то есть 4), дальнейшее разделение не рассматривается. Когда узел двоичного дерева имеет ширину, равную MinBTSize (то есть 4), дальнейшее горизонтальное разделение не рассматривается. Аналогичным образом, когда узел двоичного дерева имеет высоту, равную MinBTSize, дальнейшее вертикальное разделение не рассматривается. Листовые узлы двоичного дерева дополнительно обрабатываются с помощью процессов прогнозирования и преобразования без какого-либо дальнейшего разбиения. В JEM максимальный размер CTU составляет 256×256 отсчетов яркости.
На фиг.5 (слевa) показан пример разбиения блоков с использованием QTBT, и на фиг.5 (справa) показано соответствующее представление древа. Сплошными линиями указано разделение квадродерева, и пунктирными линиями указано разделение двоичного дерева. При каждом разделении (то есть нелистового) узла двоичного дерева один флаг сигнализируется для указания того, какой используется тип разделения (то есть горизонтальный или вертикальный), где 0 указывает горизонтальное разделение, и 1 указывает вертикальное разделение. Для разделения квадродерева нет необходимости указывать тип разделения, так как разделение квадродерева всегда разделяет блок как по горизонтали, так и по вертикали, чтобы получить 4 подблока одинакового размера.
Кроме того, схема QTBT поддерживает возможность иметь отдельную структуру QTBT для яркости и цветности. В настоящее время для слайсов P и B CTB яркости и цветности в одной CTU совместно используют одну и ту же структуру QTBT. Однако для слайсов I CTB яркости разбивается на CU со структурой QTBT, и CTB цветности разбиваются на CU цветности с другой структурой QTBT. Это означает, что CU в слайсе I состоит из блока кодирования компонента яркости или блоков кодирования двух компонентов цветности, и CU в слайсе P или B состоит из блоков кодирования всех трех цветовых компонентов.
В HEVC интерпрогнозирование для маленьких блоков ограничено с тем, чтобы уменьшить доступ к памяти для компенсации движения, так что бипрогнозирование не поддерживается для блоков 4×8 и 8×4, и интерпрогнозирование не поддерживается для блоков 4×4. В QTBT JEM эти ограничения сняты.
2.1.4 Тернарное дерево для VVC
В некоторых вариантах осуществления поддерживаются типы дерева, отличные от квадродерева и двоичного дерева. В реализации вводятся еще два разбиения троичного дерева (TT), то есть горизонтальное и вертикальное разбиения троичного дерева по центру, как показано на фиг.6, части (d) и (e).
На фиг.6 показано: (a) разбиение квадродерева; (b) вертикальное разбиение двоичного дерева; (c) горизонтальное разбиение двоичного дерева; (d) вертикальное разбиение троичного дерева по центру; и (e) горизонтальное разбиение троичного дерева по центру.
В некоторых реализациях существует два уровня деревьев: дерево областей (квадродерево) и дерево прогнозирования (двоичное дерево или троичное дерево). CTU сначала разбивается деревом областей (RT). Лист RT может быть дополнительно разделен деревом прогнозирования (PT). Лист PT также может быть дополнительно разделен с помощью PT, пока не будет достигнута максимальная глубина PT. Лист PT является основной единицей кодирования. Для удобства она по-прежнему называется CU. В дальнейшем CU не может быть разделена. Как прогнозирование, так и преобразование применимы к CU так же, как и к JEM. В целом структура разбиения называется "деревом множественных типов".
2.1.5 Структура разбиения [8]
Структура типа дерева, используемая в этом ответе, называемая типом множественного дерева (MTT), представляет собой обобщение QTBT. При QTBT, как показано на фиг.5, единица дерева кодирования (CTU) сначала разбивается в соответствии со структурой квадродерева. Листовые узлы квадродерева дополнительно разбиваются в соответствии со структурой двоичного дерева.
Фундаментальная структура MTT состоит из узлов дерева двух типов: дерева областей (RT) и дерева прогнозирования (PT), поддерживающих девять типов разбиения, как показано на фиг.7.
На фиг.7 показано: (a) разбиение квадродерева; (b) вертикальное разбиение двоичного дерева; (c) горизонтальное разбиение двоичного дерева; (d) вертикальное разбиение троичного дерева; (e) горизонтальное разбиение троичного дерева; (f) асимметричное разбиение двоичного дерева по горизонтали вверх; (g) асимметричное разбиение двоичного дерева по горизонтали вниз; (h) асимметричное разбиение двоичного дерева по вертикали влево; и (1) асимметричное разбиение двоичного дерева по вертикали вправо.
Дерево области может рекурсивно разделить CTU на квадратные блоки вплоть до листового узла дерева области размером 4×4. В каждом узле в дереве областей дерево прогнозирования может быть сформировано из одного из трех типов дерева: двоичного дерева (BT), троичного дерева (TT) и асимметричного двоичного дерева (ABT). При разделении PT запрещено иметь разбиение квадродерева в ветвях дерева прогнозирования. Как и в JEM, дерево яркости и дерево цветности разбиты на I слайсов. Способы передачи сигналов для RT и PT показаны на фиг.8.
2.2 Интерпрогнозирование в HEVC/H.265
Каждая PU с интерпрогнозированием имеет параметры движения для одного или двух списков опорных изображений. Параметры движения включают в себя вектор движения и индекс опорного изображения. Использование одного из двух списков опорных изображений также может сигнализироваться с помощью inter_pred_idc. Векторы движения могут быть закодированы явным образом как дельты относительно предикторов, и такой режим кодирования называется режимом AMVP.
Когда CU кодируются с режимом пропуска, одна PU ассоциируется с ТС, и отсутствуют существенные остаточные коэффициенты, дельта некодированных векторов движения или индекс опорного изображения. Указан режим слияния, при котором параметры движения для текущей PU получаются из соседних PU, включая пространственные и временные кандидаты. Режим слияния может применяться к любой интерпрогнозированной PU, а не только к режиму пропуска. Альтернативой режиму слияния является явная передача параметров движения, где вектор движения, соответствующий индексу опорного изображения для каждого списка опорных изображений, и использование списка опорных изображений сигнализируются явным образом в расчета на каждую PU.
Когда сигнализация указывает, что должен использоваться один из двух списков опорных изображений, PU создается из одного блока отсчетов. Это называется "универсальным прогнозированием". Универсальное прогнозирование доступно как для P-слайсов, так и для B-слайсов.
Когда сигнализация указывает, что должны использоваться оба списка опорных изображений, PU создается из двух блоков отсчетов. Это называется "бипрогнозированием". Бипрогнозирование доступно только для B-слайсов.
Следующий текст предоставляет подробные сведения о режимах интерпрогнозирования, определенных в HEVC. Описание начинается с режима слияния.
2.2.1 Режим слияния
2.2.1.1 Получение кандидатов для режима слияния
Когда PU прогнозируется с использованием режима слияния, индекс, указывающий на запись в списке кандидатов слияния, синтаксически анализируется из битового потока и используется для извлечения информации о движении. Создание этого списка определено в стандарте HEVC и может быть кратко изложено в соответствии со следующей последовательностью этапов:
• Этап 1: Определение исходных кандидатов
○ Этап 1.1: Получение пространственных кандидатов
○ Этап 1.2: Проверка на избыточность для пространственных кандидатов
○ Этап 1.3: Получение временных кандидатов
• Этап 2. Добавление дополнительных кандидатов
○ Этап 2.1: Выработка кандидатов с бипрогнозированием
○ Этап 2.2: Вставка кандидатов с нулевым движением
Эти этапы также схематично показаны на фиг.9. Для получения пространственных кандидатов слияния выбирается максимум четыре кандидата слияния из кандидатов, которые расположены в пяти разных позициях. Для получения временного кандидата слияния из двух кандидатов выбирается максимум один кандидат слияния. Так как в декодере предполагается постоянное количество кандидатов для каждой PU, дополнительные кандидаты вырабатываются тогда, когда количество кандидатов не достигает максимального количества кандидатов слияния (MaxNumMergeCand), о чем сигнализируется в заголовке слайса. Так как количество кандидатов является постоянным, индекс лучшего кандидата слияния кодируется с использованием усеченной унарной бинаризации (TU). Если размер CU равен 8, все PU текущей CU совместно используют один список кандидатов слияния, который идентичен списку кандидатов слияния единицы прогнозирования 2N×2N.
Далее подробно описаны операции, ассоциированные с вышеупомянутыми этапами.
2.2.1.2 Получение пространственного кандидата
При получении пространственных кандидатов слияния максимум четыре кандидата слияния выбираются среди кандидатов, расположенных в позициях, изображенных на фиг.10. Очередность получения представляет собой A1, B1, B0, A0 и B2. Позиция B2 рассматривается только тогда, когда любая PU позиции A1, B1, B0, A0 недоступна (например, в связи с тем, что она принадлежит другому слайсу или тайлу) или интракодирована. После добавления кандидата в позиции A1 добавление оставшихся кандидатов подлежит проверке на избыточность, которая гарантирует, что кандидаты с одинаковой информацией о движении исключены из списка, поэтому эффективность кодирования повышается. Чтобы уменьшить вычислительную сложность, в упомянутой проверке на избыточность рассматриваются не все возможные пары кандидатов. Вместо этого рассматриваются только пары, обозначенные стрелкой на фиг.11, и кандидат добавляется в список только в том случае, если соответствующий кандидат, используемый для проверки на избыточность, не имеет такой же информации о движении. Другим источником дублированной информации о движении является "вторая PU", ассоциированная с разбиениями, отличными от 2Nx2N. В качестве примера на фиг.12 показана вторая PU для случая N×2N и 2N×N, соответственно. Когда текущая PU разбита как N×2N, кандидат в позиции A1 не рассматривается для создания списка. Фактически, добавление этого кандидата приведет к двум единицам прогнозирования, имеющим одинаковую информацию о движении, которая избыточна, чтобы иметь только одну PU в единице кодирования. Аналогичным образом позиция B1 не рассматривается в том случае, когда текущая PU разбита как 2N×N.
2.2.1.3 Получение временных кандидатов
На этом этапе в список добавляется только один кандидат. В частности, при получении этого временного кандидата слияния масштабированный вектор движения получается на основе совмещенной PU, принадлежащей изображению, которое имеет наименьшую разницу POC с текущим изображением в данном списке опорных изображений. Список опорных изображений, который должен использоваться для получения совмещенной PU, указывается явным образом в заголовке слайса. Для временного кандидата слияния получается масштабированный вектор движения, показанный пунктирной линией на фиг.13, который масштабируется исходя из вектора движения совмещенной PU с использованием расстояний POC, tb и td, где tb определяется как разность POC между опорным изображением текущего изображения и текущим изображением, и td определяется как разница POC между опорным изображением совмещенного изображения и совмещенным изображением. Индекс опорного изображения временного кандидата объединения устанавливается равным нулю. Практическая реализация процесса масштабирования описана в спецификации HEVC. Для B-слайса два вектора движения, один для списка 0 опорных изображений, и другой – для списка 1 опорных изображений, получаются и объединяются для создания кандидата слияния с бипрогнозированием. Ниже приведена иллюстрация масштабирования вектора движения для временного кандидата слияния.
В совмещенной PU (Y), принадлежащей к системе отсчета, позиция для временного кандидата выбирается между кандидатами C0 и C1, как показано на фиг.14. Если PU в позиции C0 является недоступной, интракодированной или находится за пределами текущей CTU, используется позиция C1. В противном случае позиция C0 используется при получении временного кандидата слияния.
2.2.1.4 Вставка дополнительных кандидатов
Помимо пространственно-временных кандидатов слияния, существует два дополнительных типа кандидатов слияния: объединенный кандидат слияния с бипрогнозированием и нулевой кандидат слияния. Объединенные кандидаты слияния с бипрогнозированием вырабатываются с использованием пространственно-временных кандидатов слияния. Объединенный кандидат слияния с двунаправленным прогнозированием используется только для B-слайса. Объединенные кандидаты с бипрогнозированием вырабатываются путем объединения параметров движения первого списка опорных изображений одного исходного кандидата с параметрами движения второго списка опорных изображений другого исходного кандидата. Если эти два кортежа предоставляют разные гипотезы движения, они будут формировать нового кандидата с бипрогнозированием. В качестве примера на фиг.15 показан случай, когда два кандидата в исходном списке (слевa), которые имеют mvL0 и refIdxL0 или mvL1 и refIdxL1, используются для создания объединенного кандидата слияния с бипрогнозированием, добавленного в окончательный список (справa). Существует множество правил относительно комбинаций, которые рассматриваются для выработки этих дополнительных кандидатов слияния, определенных в данном документе.
Нулевые кандидаты движения вставляются для заполнения оставшихся записей в списке кандидатов слияния и, следовательно, достигают максимального числа кандидатов на слияние MaxNumMergeCand. Эти кандидаты имеют нулевое пространственное смещение и индекс опорного изображения, который начинается от нуля и увеличивается каждый раз, когда новый кандидат нулевого движения добавляется в список. Количество опорных изображений, используемых этими кандидатами, равно единице и двум для однонаправленного и двунаправленного прогнозирования, соответственно. Наконец, для этих кандидатов не выполняется проверка на избыточность.
2.2.1.5 Области оценки движения для параллельной обработки
Чтобы ускорить процесс кодирования, оценка движения может выполняться параллельно, в результате чего векторы движения для всех единиц прогнозирования внутри данной области получаются одновременно. Получение кандидатов слияния из пространственного соседства может мешать параллельной обработке, так как одна единица прогнозирования не может получать параметры движения из соседней PU до тех пор, пока не будет завершена ассоциированная с ней оценка движения. Чтобы смягчить компромисс между эффективностью кодирования и задержкой обработки, HEVC определяет область оценки движения (MER), размер которой указывается в наборе параметров изображения с использованием элемента синтаксиса "log2_parallel_merge_level_minus2". Когда MER определен, кандидаты слияния, попадающие в ту же область, помечаются как недоступные и, следовательно, не учитываются при создании списка.
7.3.2.3 Синтаксис RBSP набора параметров изображения
7.3.2.3.1 Синтаксис RBSP набора общих параметров изображения
log2_parallel_merge_level_minus2 plus 2 указывает значение переменной Log2ParMrgLevel, которая используется в процессе получения векторов движения яркости для режима слияния, как указано в пункте 8.5.3.2.2, и в процессе получения кандидатов для пространственного объединения, как указано в пункте 8.5.3.2.3. Значение log2_parallel_merge_level_minus2 должно находиться в диапазоне от 0 до CtbLog2SizeY-2 включительно.
Переменная Log2ParMrgLevel получается следующим образом:
Log2ParMrgLevel = log2_parallel_merge_level_minus2 + 2 (7-37)
Примечание 3. Значение Log2ParM rgLevel указывает на встроенную возможность параллельного получения списков кандидатов слияния. Например, когда Log2ParMrgLevel равно 6, списки кандидатов слияния для всех единиц прогнозирования (PU) и единиц кодирования (CU), содержащихся в блоке 64×64, могут быть получены параллельно.
2.2.2 Прогнозирование вектора движения в режиме AMVP
При прогнозировании вектора движения используется пространственно-временная корреляция вектора движения с соседними PU, которая используется для явной передачи параметров движения. Она позволяет создать список кандидатов вектора движения, во-первых, путем проверки доступности левых, расположенных выше, временно соседних позиций PU, удаления избыточных кандидатов и добавления нулевого вектора для создания списка кандидатов постоянной длины. Во-вторых, кодер может выбрать лучший предиктор из списка кандидатов и передать соответствующий индекс, указывающий выбранного кандидата. Аналогично сигнализации индекса слияния, индекс лучшего кандидата вектора движения кодируется с использованием усеченной унарной бинаризации. Максимальное значение, которое должно быть закодировано в этом случае, равно 2 (например, фиг.2-8). В следующих разделах представлены подробности процесса получения кандидата прогнозирования вектора движения.
2.2.2.1 Получение кандидатов прогнозирования вектора движения
На фиг.16 показан обобщенный процесс получения кандидата прогнозирования вектора движения.
При прогнозировании вектора движения рассматриваются два типа кандидатов вектора движения: кандидат пространственного вектора движения и кандидат временного вектора движения. Для получения кандидатов пространственных векторов движения в конечном итоге получаются два кандидата векторов движения на основе векторов движения каждой PU, расположенной в пяти разных позициях, как показано на фиг.11.
Для получения кандидата временного вектора движения один кандидат вектора движения выбирается из двух кандидатов, которые получаются на основе двух разных совмещенных позиций. После создания первого списка пространственно-временных кандидатов дублированные кандидаты вектора движения в списке удаляются. Если количество потенциальных кандидатов больше двух, из списка удаляются кандидаты векторов движения, чей индекс опорного изображения в ассоциированном списке опорного изображения больше 1. Если количество кандидатов пространственно-временного вектора движения меньше двух, в список добавляются дополнительные кандидаты нулевых векторов движения.
2.2.2.2 Пространственные кандидаты вектора движения
При получении кандидатов векторов пространственного движения максимум два кандидата рассматриваются среди пяти потенциальных кандидатов, которые получены из PU, расположенных в позициях, показанных на фиг.11, при этом позиции являются одинаковыми, как и позиции слияния векторов движения. Очередность получения для левой части текущей PU определяется в виде A0, A1, масштабированный A0, масштабированный A1. Очередность получения для указанной выше стороны текущей PU определяется в виде B0, B1, B2, масштабированный B0, масштабированный B1, масштабированный B2. Таким образом, для каждой стороны существует четыре случая, которые можно использовать в качестве кандидата вектора движения: два случая, которые не требуют использования пространственного масштабирования, и два случая, когда используется пространственное масштабирование. Четыре различных случая кратко изложены следующим образом.
• Отсутствует пространственное масштабирование:
- (1) Один и тот же список опорных изображений и один и тот же индекс опорных изображений (один и тот же POC)
- (2) Разный список опорных изображений, но одно и то же опорное изображение (один и тот же POC)
• Пространственное масштабирование
- (3) Один и тот же список опорных изображений, но другое опорное изображение (разный POC)
- (4) Разный список опорных изображений и разное опорное изображение (разный POC)
Сначала проверяются случаи отсутствия пространственного масштабирования, и затем пространственное масштабирование. Пространственное масштабирование рассматривается в том случае, когда POC отличается между опорным изображением соседней PU и текущей PU независимо от списка опорных изображений. Если все PU левых кандидатов являются недоступными или интракодированными, разрешается масштабирование для вышеупомянутого вектора движения, чтобы помочь параллельному получению левых и расположенных выше кандидатов MV. В противном случае пространственное масштабирование для вышеуказанного вектора движения не разрешено.
В процессе пространственного масштабирования вектор движения соседней PU масштабируется таким же образом, как и для временного масштабирования, как показано на фиг.17. Основное отличие состоит в том, что список опорных изображений и индекс текущей PU задаются в виде входных данных, при этом фактический процесс масштабирования является таким же, как и при временном масштабировании.
2.2.2.3 Временные кандидаты вектора движения
Помимо получения индекса опорного изображения, все процессы получения временных кандидатов слияния являются такими же, как и при получении пространственных кандидатов векторов движения (смотри, например, фиг.6). Индекс опорного изображения сигнализируется в декодер.
2.2.2.4 Передача информации AMVP
Для режима AMVP в битовом потоке могут быть просигнализированы четыре части, то есть направление прогнозирования, опорный индекс, MVD и индекс кандидата предиктора mv.
Синтаксические таблицы:
7.3.8.9 Синтаксис разности векторов движения
2.3 Новые методы межкадрового прогнозирования в модели совместного исследования (JEM)
2.3.1 Прогнозирование вектора движения на основе под-CU
В JEM с QTBT каждая CU может иметь не более одного набора параметров движения для каждого направления прогнозирования. В кодере рассматриваются два способа прогнозирования вектора движения на уровне под-CU путем разделения большой CU на под-CU и получения информации о движении для всех под-CU большой CU. Способ альтернативного прогнозирования временного вектора движения (ATMVP) позволяет каждой CU извлекать многочисленные наборы информации о движении из нескольких блоков с размером, меньшим чем текущая CU в совмещенном опорном изображении. В способе пространственно-прогнозирования временного вектора движения (STMVP) векторы движения под-CU получаются рекурсивно с использованием предиктора временного вектора движения и соседнего вектора движения.
Чтобы сохранить более точное поле движения для прогнозирования движения под-CU, в данный момент сжатие движения для опорных изображений отключается.
2.3.1.1 Альтернативное прогнозирование временного вектора движения
В способе альтернативного прогнозирования временного вектора движения (ATMVP) прогнозирование временного вектора движения (TMVP) для векторов движения модифицируется путем выборки многочисленных наборов информации о движении (включая векторы движения и опорные индексы) из блоков, меньших, чем текущая CU. Как показано на фиг.18, под-CU представляют собой квадратные блоки размером N×N (по умолчанию N установлено равным 4).
ATMVP прогнозирует векторы движения под-CU в CU в два этапа. Первый этап состоит в идентификации соответствующего блока в опорном изображении с так называемым временным вектором. Опорное изображение называется изображением источника движения. Второй этап представляет собой разделение текущей CU на под-CU и получение векторов движения, а также опорных индексов каждой под-CU из блока, соответствующего каждому под-CU, как показано на фиг.18.
На первом этапе опорное изображение и соответствующий блок определяются с помощью информации о движении пространственных соседних блоков текущей CU. Чтобы избежать процесса повторного сканирования соседних блоков, используется первый кандидат слияния в списке кандидатов слияния текущей CU. Первый доступный вектор движения, а также ассоциированный с ним опорный индекс устанавливаются как временной вектор и индекс для изображения источника движения. Таким образом, в ATMVP соответствующий блок может быть более точно идентифицирован по сравнению с TMVP, где соответствующий блок (иногда называемый совмещенным блоком) всегда находится в нижней правой или центральной позиции относительно текущей CU. В одном примере, если первый кандидат слияния отличается от левого соседнего блока (то есть A1 на фиг.19), ассоциированный MV и опорное изображение используются для идентификации блока источника и изображения источника.
На фиг.19 показан пример идентификации исходного блока и исходного изображения.
На втором этапе соответствующий блок под-CU идентифицируется временным вектором в изображении источника движения путем добавления к координате текущей CU временного вектора. Для каждой под-CU информация о движении соответствующего ему блока (наименьшая сетка движения, охватывающая центральный отсчет) используется для получения информации о движении для под-CU. После того, как информация о движении соответствующего блока N×N идентифицирована, она преобразуется в векторы движения и опорные индексы текущей под-CU таким же образом, как TMVP в HEVC, при этом применяется масштабирование движения и другие процедуры. Например, декодер проверяет, выполняется ли условие низкой задержки (то есть POC всех опорных изображений текущего изображения меньше, чем РОС текущего изображения), и, возможно, использует вектор движения MVx (вектор движения, соответствующий списку X опорных изображений) для прогнозирования вектора MVy движения (при этом X равно 0 или 1, и Y равен 1-X) для каждой под-CU.
2.3.1.2 Прогнозирование пространственно-временного вектора движения
В этом способе векторы движения под-CU получаются рекурсивно, следуя порядку сканирования растра. На фиг.20 показана эта концепция. Рассмотрим CU 8×8, которая содержит четыре под-CU A, B, C и D размером 4×4. Соседние блоки 4×4 в текущем кадре помечены как a, b, c и d.
Получение движения для под-CU A начинается с идентификации двух ее пространственных соседей. Первый сосед представляет собой блок размером N×N выше под-CU A (блока c). Если этот блок c недоступен или интразакодирован, проверяются другие блоки N×N выше под-CU A (слева направо, начиная с блока c). Второй сосед представляет собой блок слева от под-CU A (блок b). Если блок b недоступен или интразакодирован, проверяются другие блоки слева от под-CU A (сверху вниз, начиная с блока b). Информация о движении, полученная из соседних блоков для каждого списка, масштабируется в соответствии с первым опорным кадром для данного списка. Затем получается временный предиктор вектора движения (TMVP) подблока A, следуя той же самой процедуре получения TMVP, которая указана в HEVC. Информация о движении совмещенного блока в местоположении D выбирается и масштабируется, соответственно. Наконец, после извлечения и масштабирования информации о движении все имеющиеся векторы движения (до 3) усредняются по отдельности для каждого опорного списка. Усредненный вектор движения назначается как вектор движения текущей под-CU.
На фиг.20 показан пример одной CU с четырьмя подблоками (AD) и его соседними блоками (a-d).
2.3.1.3 Сигнализация режима прогнозирования движения под-CU
Режимы под-CU поддерживаются как дополнительные кандидаты слияния, и отсутствует дополнительный элемент синтаксиса, необходимый для сигнализации режимов. Два дополнительных кандидата слияния добавляются в список кандидатов слияния каждой CU, чтобы представить режим ATMVP и режим STMVP. Вплоть до семи кандидатов слияния используются в том случае, если набор параметров последовательности указывает, что поддерживаются ATMVP и STMVP. Логика кодирования дополнительных кандидатов слияния является такой же, как и для кандидатов слияния в HM, что означает, что для каждой CU в слайсе P или B требуются еще две проверки RD для двух дополнительных кандидатов слияния.
В JEM все бины индекса слияния контекстно кодируются CABAC. В HEVC только первый бин кодируется контекстно, а остальные бины кодируются в обход контекста.
2.3.2 Адаптивное разрешение разности векторов движения
В HEVC разности векторов движения (MVD) (между вектором движения и прогнозируемым вектором движения PU) передаются в единицах четвертей отсчетов яркости, когда в заголовке слайса параметр use_integer_mv_flag равен 0. В JEM вводится локально адаптивное разрешение вектора движения (LAMVR). В JEM MVD может быть закодирована в единицах четвертей отсчетов яркости, целочисленных отсчетов яркости или четырех отсчетов яркости. Управление разрешением MVD осуществляется на уровне единицы кодирования (CU), и флаги разрешения MVD условно сигнализируются для каждой CU, которая имеет по меньшей мере один ненулевой компонент MVD.
Для CU, которая имеет по меньшей мере один ненулевой компонент MVD, первый флаг сигнализируется для того, чтобы указать, используется ли точность MV с одной четвертой отсчета яркости в CU. Когда первый флаг (равный 1) указывает, что точность MV с одной четвертой отсчета яркости не используется, сигнализируется другой флаг для того, чтобы указать, используется ли точность MV с целочисленным отсчетом яркости или точность MV с четырьмя отсчетами яркости.
Когда первый флаг разрешения MVD CU равен нулю или не закодирован для CU (что означает, что все MVD в CU равны нулю), для CU используется разрешение MV с одной четвертой отсчета яркости. Когда CU использует точность MV с целочисленным отсчетом яркости или точность MV с четырьмя отсчетами яркости, MVP в списке кандидатов AMVP для CU округляются до соответствующей точности.
В кодере проверки RD на уровне CU используются для определения того, какое разрешение MVD должно использоваться для CU. То есть проверка RD на уровне CU выполняется три раза для каждого разрешения MVD. Для увеличения скорости кодера в JEM применяются следующие схемы кодирования.
Во время проверки RD CU с нормальным разрешением MVD с одной четвертой отсчета яркости сохраняется информация о движении текущей CU (точность целочисленных отсчетов яркости). Сохраненная информация о движении (после округления) используется в качестве отправной точки для дальнейшего уточнения вектора движения в небольшом диапазоне во время проверки RD для одной и той же CU с целочисленным отсчетом яркости и разрешением MVD с 4 отсчетами яркости, поэтому трудоемкий процесс оценки движения не дублируется трижды.
Проверка RD CU с разрешением MVD 4 образца яркости вызывается условно. Для CU, когда разрешение MVD с целочисленным отсчетом яркости для RD намного больше, чем разрешение MVD с одной четвертой отсчета яркости, проверка RD разрешения MVD с 4-мя отсчетами яркости для CU пропускается.
2.3.3 Получение вектора движения с согласованным шаблоном
Режим получения вектора движения при согласовании с шаблоном (PMMVD) представляет собой специальный режим слияния, основанный на технологиях преобразования с повышением частоты кадров (FRUC). В этом режиме информация о движении блока не передается, а получается на стороне декодера.
Флаг FRUC сигнализируется для CU в том случае, когда его флаг слияния имеет значение "истина". Когда флаг FRUC имеет значение "ложь", сигнализируется индекс слияния, и используется обычный режим слияния. Когда флаг FRUC имеет значение "истина", сигнализируется дополнительный флаг режима FRUC для того, чтобы указать, какой способ (двустороннее согласование или согласование с шаблоном) должен использоваться для получения информации о движении для блока.
На стороне кодера решение относительно того, использовать ли режим слияния FRUC для CU, основано на выборе стоимости RD, так как это делается для обычного кандидата слияния. То есть два режима согласования (двустороннее согласование и согласование с шаблоном) проверяются для CU с помощью выбора стоимости RD. Тот режим, который ведет к минимальной стоимости, дополнительно сравнивается с другими режимами CU. Если режим согласования FRUC является наиболее эффективным, флаг FRUC устанавливается в значение "истина" для CU, и используется соответствующий режим согласования.
Процесс получения движения в режиме слияния FRUC состоит из двух этапов. Сначала выполняется поиск движения на уровне CU, затем следует уточнение движения на уровне под-CU. На уровне CU исходный вектор движения получается для всей CU на основе двустороннего согласования или согласования с шаблоном. Сначала создается список кандидатов MV, и кандидат, который приводит к минимальной стоимости согласования, выбирается в качестве отправной точки для дальнейшего уточнения на уровне CU. Затем выполняется локальный поиск, основанный на двустороннем согласовании или согласовании с шаблоном вокруг начальной точки, и результат MV при минимальной стоимости согласования принимается в качестве MV для всей CU. В дальнейшем информация о движении дополнительно уточняется на уровне под-CU с полученными векторами движения CU в качестве начальных точек.
Например, следующий процесс получения выполняется для получения информации о движении CU. На первом этапе получается MV для всей CU. На втором этапе CU разделяется на под-CU размером 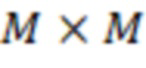 . Значение
. Значение 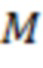 рассчитывается, как в (16),
рассчитывается, как в (16), 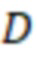 представляет собой предварительно заданную глубину разделения, которая в JEM по умолчанию установлена на 3. Затем получается MV для каждой под-CU.
представляет собой предварительно заданную глубину разделения, которая в JEM по умолчанию установлена на 3. Затем получается MV для каждой под-CU.
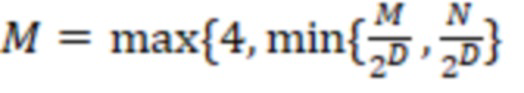 (1)
(1)
Как показано на фиг.21, двустороннее согласование используется для получения информации о движении текущей CU путем нахождения наиболее близкого совпадения между двумя блоками вдоль траектории движения текущей CU в двух разных опорных изображениях. Предполагая, что траектория движения является непрерывной, векторы MV0 и MV1 движения, указывающие на два опорных блока, должны быть пропорциональны временным расстояниям, то есть TD0 и TD1, между текущим изображением и двумя опорными изображениями. В качестве особого случая, когда текущее изображение находится во времени между двумя опорными изображениями, и временное расстояние от текущего изображения до двух опорных изображений является одинаковым, двустороннее совпадение становится зеркальным на основе двунаправленного MV.
Как показано на фиг.22 согласование с шаблоном используется для получения информации о движении текущей CU путем нахождения наиболее близкого совпадения между шаблоном (верхние и/или левые соседние блоки текущей CU) в текущем изображении и блоком (такого же размера, как у шаблонa) в опорном изображении. За исключением вышеупомянутого режима слияния FRUC, согласование с шаблоном также применяется к режиму AMVP. В JEM, как и в HEVC, у AMVP есть два кандидата. Используя способ согласования с шаблоном, получается новый кандидат. Если вновь полученный кандидат после согласования с шаблоном отличается от первого существующего кандидата AMVP, он вставляется в самое начало списка кандидатов AMVP, и затем размер списка устанавливается равным двум (что означает удаление второго существующего кандидата AMVP). Если это применяется к режиму AMVP, то применяется только поиск на уровне CU.
2.3.3.1 Набор кандидатов MV на уровне CU
Набор кандидатов MV на уровне CU состоит из:
(1) первоначальных кандидатов AMVP, если текущая CU находится в режиме AMVP
(2) всех кандидатов слияния,
(3) нескольких MV в интерполированном поле MV.
(4) верхнего и левого соседних векторов движения
При использовании двустороннего согласования каждый действительный MV кандидата слияния используется в качестве входных данных для выработки пары MV с предположением двустороннего согласования, например, один действительный MV кандидата слияния (MVa, refa) в опорном списке А. Затем находится опорное изображение refb его парного двустороннего MV в другом опорном списке B, поэтому refa и refb временно находятся на разных сторонах текущего изображения. Если такой refb отсутствует в списке B ссылок, refb определяется как ссылка, которая отличается от refa, и ее временное расстояние до текущего изображения является минимальным в списке B. После того, как refb определен, MVb получается путем масштабирования MVa| на основе временного расстояния между текущим изображением и refa, refb.
Четыре MV из интерполированного поля MV также добавляются в список кандидатов на уровне CU. Более конкретно, добавляются интерполированные MV в позиции (0, 0), (W/2, 0), (0, H/2) и (W/2, H/2) текущей CU.
Когда FRUC применяется в режиме AMVP, исходные кандидаты AMVP также добавляются в набор кандидатов MV на уровне CU.
На уровне CU в список кандидатов добавляется до 15 MV для AMVP CU и до 13 MV для CU слияния.
2.3.3.2 Набор кандидатов MV на уровне под-CU
Набор кандидатов MV на уровне под-CU состоит из:
(1) MV, определенного в результате поиска на уровне CU,
(2) соседних MV сверху, слева сверху и справа сверху,
(3) масштабированных версий совмещенных MV из опорных изображений,
(4) до 4 кандидатов ATMVP,
(5) до 4 кандидатов STMVP
Масштабированные MV из опорных изображений получаются следующим образом. Все опорные изображения в обоих списках пересекаются. MV в совмещенной позиции под-CU в опорном изображении масштабируется до опорного изображения исходного MV на уровне CU.
[00159] Кандидаты ATMVP и STMVP ограничены четырьмя первыми кандидатами.
На уровне под-CU в список кандидатов добавляется до 17 MV.
2.3.3.3 Выработка интерполированного поля MV
Перед кодированием кадра вырабатывается интерполированное поле движения для всего изображения на основе одностороннего ME. Затем поле движения может использоваться в дальнейшем как кандидаты MV уровня CU или уровня под-CU.
Во-первых, поле движения каждого из опорных изображений в обоих опорных списках пересекается на уровне блоков 4×4. Для каждого блока 4×4, если движение, ассоциированное с блоком, проходящим через блок 4×4 в текущем изображении (как показано на фиг.23) и блок, не было назначено каким-либо интерполированным движением, движение опорного блока масштабируется до текущего изображения в соответствии с временным расстоянием TD0 и TD1 (таким же, как при масштабировании MV TMVP в HEVC), и масштабированное движение назначается блоку в текущем кадре. Если масштабированный MV не назначен блоку 4×4, движение блока помечается как недоступное в интерполированном поле движения.
2.3.3.4 Стоимость интерполяции и согласования
Когда вектор движения указывает на позицию с дробным отсчетом, требуется интерполяция с компенсацией движения. Чтобы уменьшить сложность, как для двустороннего согласования, так и для согласования с шаблоном используется билинейная интерполяция вместо обычной 8-ступенчатой интерполяции HEVC.
Расчет стоимости согласования немного отличается на разных этапах. При выборе кандидата из набора кандидатов на уровне CU стоимость согласования представляет собой сумму абсолютных разностей (SAD) двустороннего согласования или согласования с шаблоном. После определения начального MV стоимость согласования двустороннего согласования при поиске на уровне под-CU рассчитывается следующим образом:
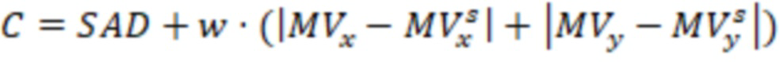 (2)
(2)
где 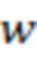 – весовой коэффициент, который эмпирически установлен на 4 и указывает текущий MV и начальный MV, соответственно. SAD по-прежнему используется как стоимость согласования с шаблоном при поиске на уровне под-CU.
– весовой коэффициент, который эмпирически установлен на 4 и указывает текущий MV и начальный MV, соответственно. SAD по-прежнему используется как стоимость согласования с шаблоном при поиске на уровне под-CU.
В режиме FRUC MV получается только с использованием образцов яркости. Полученное движение будет использоваться как для яркости, так и для цветности для интерпрогнозирования MC. После определения MV выполняется окончательный MC с использованием 8-отводного интерполяционного фильтра для яркости и 4-отводного интерполяционного фильтра для цветности.
2.3.3.5 Уточнение MV
Уточнение MV представляет собой поиск MV на основе шаблона с критерием стоимости двустороннего согласования или стоимости согласования с шаблоном. В JEM поддерживаются два шаблона поиска: неограниченный ромбовидный поиск со смещением относительно центра (UCBDS) и адаптивный перекрестный поиск для уточнения MV на уровне CU и под-CU, соответственно. Для уточнения MV как на уровне CU, так и на уровне под-CU, MV отыскивается напрямую с точностью MV одной четвертой отсчета яркости, после чего выполняется уточнение MV с одной восьмой отсчета яркости. Диапазон поиска уточнения MV для этапа CU и под-CU устанавливается равным 8 отсчетам яркости.
2.3.3.6 Выбор направления прогнозирования в режиме слияния FRUC с согласованием шаблонов
В режиме слияния с двусторонним согласованием всегда применяется бипрогнозирование, так как информация о движении CU получается на основе наиболее близкого согласования между двумя блоками вдоль траектории движения текущей CU в двух разных опорных изображениях. Для режима слияния при согласовании с шаблоном такого ограничения нет. В режиме слияния при согласовании с шаблоном кодер может выбирать между унипрогнозированием из списка 0, унипрогнозированием из списка 1 или бипрогнозированием для CU. Выбор основан на следующей стоимости согласования шаблона:
Если costBi <= множитель*min (cost0, cost1)
используется бипрогнозирование;
В противном случае, если cost0 <= cost1
используется унипрогнозирование из списка 0;
В противном случае,
используется унипрогнозирование из списка 1;
где cost0 представляет собой SAD согласования с шаблоном list0, cost1 – SAD согласования с шаблоном list1, и costBi – SAD согласования с шаблоном с бипрогнозированием. Значение множителя равно 1,25, что означает, что процесс выбора смещен в сторону бипрогнозирования.
Выбор направления интерпрогнозирования применяется только к процессу согласования с шаблоном на уровне CU.
2.3.4 Уточнение вектора движения на стороне декодера
В операции бипрогнозирования для прогнозирования одной области блока два блока прогнозирования, сформированные с использованием вектора движения (MV) списка 0 и MV списка 1, соответственно, объединяются для формирования единого сигнала прогнозирования. В способе уточнения вектора движения на стороне декодера (DMVR) два вектора движения бипрогнозирования дополнительно уточняются посредством процесса двустороннего согласования с шаблоном. Двустороннее согласование с шаблоном применяется в декодере для выполнения поиска на основе искажения между двусторонним шаблоном и отсчетами восстановления в опорных изображениях для того, чтобы получить уточненный MV без передачи дополнительной информации о движении.
В DMVR двусторонний шаблон вырабатывается в виде взвешенной комбинации (то есть среднего значения) двух блоков прогнозирования из начального MV0 списка 0 и MV1 списка 1, соответственно, как показано на фиг.23. Операция согласования шаблона состоит из расчета мер стоимости между выработанным шаблоном и областью отсчетов (вокруг блока начального прогнозирования) в опорном изображении. Для каждого из двух опорных изображений MV, который дает минимальную стоимость шаблона, считается обновленным MV этого списка для замены исходного. В JEM для каждого списка отыскивается девять кандидатов MV. Девять кандидатов MV включают в себя исходный MV и 8 окружающих MV с одним смещением отсчета яркости относительно исходного MV либо в горизонтальном, либо в вертикальном направлении, либо в обоих направлениях. Наконец, два новых MV, то есть MV0' и MV1', как показано на фиг.24, используются для выработки окончательных результатов бипрогнозирования. Сумма абсолютных разностей (SAD) используется в качестве меры стоимости.
DMVR применяется для режима слияния бипрогнозирования с одним MV из опорного изображения в прошлом и другим MV из опорного изображения в будущем без передачи дополнительных элементов синтаксиса. В JEM, когда для CU разрешены LIC, аффинное движение, FRUC или кандидат слияния под-CU, DMVR не применяется.
2.3.5 Режим слияния/пропуска с уточнением двустороннего согласования
Список кандидатов слияния сначала создается путем вставки векторов движения и опорных индексов пространственно-соседних и временных соседних блоков в список кандидатов с проверкой на избыточность до тех пор, пока количество имеющихся кандидатов не достигнет максимального размера кандидата, равного 19. Список кандидатов слияния для режима слияния/пропуска создается путем вставки пространственных кандидатов (фиг.11), временных кандидатов, аффинных кандидатов, кандидата с расширенным временным MVP (ATMVP), кандидата с пространственно-временным MVP (STMVP) и дополнительных кандидатов, используемых в HEVC (объединенных кандидатов и нулевых кандидатов) в соответствии с заранее определенным порядком вставки:
- Пространственные кандидаты для блоков 1-4.
- Экстраполированные аффинные кандидаты для блоков 1-4.
- ATMVP.
- STMVP.
- Виртуальный аффинный кандидат.
- Пространственный кандидат (блок 5) (используется только тогда, когда количество имеющихся кандидатов меньше 6).
- Экстраполированный аффинный кандидат (блок 5).
- Временный кандидат (полученный как в HEVC).
- Несмежные пространственные кандидаты, за которыми следует экстраполированный аффинный кандидат (блоки 6-49, показанные на фиг.25).
- Объединенные кандидаты.
- Нулевые кандидаты
Следует отметить, что флаги IC также наследуются от кандидатов слияния, за исключением STMVP и афинного флага. Более того, для первых четырех пространственных кандидатов кандидаты с двойным прогнозированием вставляются перед кандидатами с унипрогнозированием.
В [8] доступ может быть осуществлен к блокам, которые не связаны с текущим блоком. Если несмежный блок кодируется с помощью не-интрарежима, ассоциированная информация о движении может быть добавлена в качестве дополнительного кандидата слияния.
3. Примеры проблем, решаемых с помощью раскрытых в данном документе вариантов осуществления
Текущая конструкция HEVC может учитывать корреляцию текущего блока с его соседними блоками (рядом с текущим блоком), чтобы лучше кодировать информацию о движении. Однако возможно, что соседние блоки соответствуют разным объектам с разными траекториями движения. В этом случае прогнозирование из своих соседних блоков неэффективно.
Прогнозирование на основе информации о движении несмежных блоков может принести дополнительную выгоду от кодирования за счет затрат на хранение всей информации о движении (обычно на уровне 4x4) в кэш-памяти, что значительно увеличивает сложность аппаратной реализации.
4. Некоторые примеры технических решений
Варианты осуществления раскрытой в данном документе технологии устраняют недостатки существующих реализаций, тем самым обеспечивая кодирование видео с более высокой эффективностью кодирования. В описании, представленном в данном документе, LUT может быть таблицей, списком, массивом или другим размещением индексированных записей.
Чтобы устранить недостатки существующих реализаций, технологии прогнозирования вектора движения на основе LUT, использующие одну или несколько таблиц (например, таблиц поискa) по меньшей мере с одним кандидатом движения, сохраненным для прогнозирования информации о движении блока, могут быть реализованы в различных вариантах осуществления для обеспечения кодирования видео с более высокой эффективностью кодирования. Таблица поиска является примером таблицы, которая может использоваться для включения кандидатов движения для прогнозирования информации о движении блока, и возможны также другие реализации. Каждая LUT может включать в себя один или более кандидатов движения, каждый из которых ассоциируется с соответствующей информацией о движении. Информация о движении кандидата движения может включать в себя, частично или полностью, направление прогнозирования, опорные индексы/изображения, векторы движения, флаги LIC, аффинные флаги, значения точности получения вектора движения (MVD) и/или значения MVD. Информация о движении может дополнительно включать в себя информацию о позиции блока для указания того, откуда поступает информация о движении.
Прогнозирование вектора движения на основе LUT на основе раскрытой технологии, которая позволяет улучшить как существующие, так и будущие стандарты кодирования видео, поясняется в следующих примерах, описанных для различных реализаций. Так как LUT позволяют выполнять процесс кодирования/декодирования на основе исторических данных (например, блоков, которые были обработаны), прогнозирование вектора движения на основе LUT также может называться способом прогнозирования вектора движения на основе истории (HMVP). В способе прогнозирования вектора движения на основе LUT одна или несколько таблиц с информацией о движении из ранее кодированных блоков поддерживаются во время процесса кодирования/декодирования. Эти кандидаты движения, хранящиеся в LUT, называются кандидатами HMVP. Во время кодирования/декодирования одного блока ассоциированная информация о движении в LUT может быть добавлена в списки кандидатов движения (например, списки кандидатов слияния/AMVP), и LUT могут быть обновлены после кодирования/декодирования одного блока. Затем обновленные LUT используются для кодирования последующих блоков. Таким образом, обновление кандидатов движения в LUT основывается на последовательности кодирования/декодирования блоков.
Приведенные ниже примеры следует рассматривать как примеры, объясняющие общие концепции. Эти примеры не следует истолковывать в узком смысле. Кроме того, эти примеры можно комбинировать любым способом.
В некоторых вариантах осуществления могут использоваться одна или несколько таблиц поиска с сохраненным по меньшей мере одним кандидатом движения для прогнозирования информации о движении блока. Варианты осуществления могут использовать кандидата движения для указания набора информации о движении, хранящейся в таблице поиска. Для традиционных режимов AMVP или слияния в вариантах осуществления могут использоваться AMVP или кандидаты слияния для сохранения информации о движении.
Приведенные ниже примеры объясняют общие концепции.
Примеры таблиц поиска
Каждая таблица поиска может содержать один или несколько кандидатов движения, при этом каждый кандидат ассоциируется с его информацией о движении.
Выбор LUT
Для кодирования блока часть или все кандидаты движения из одной таблицы поиска могут проверяться по порядку. Когда один кандидат движения проверяется во время кодирования блока, он может быть добавлен в список кандидатов движения (например, AMVP, списки кандидатов слияния).
Использование таблиц поиска
Общее количество кандидатов движения в таблице поиска, подлежащей проверке, может быть определено заранее.
а) Оно может дополнительно зависеть от кодированной информации, размера блока, формы блока и т.п. Например, для режима AMVP, только m кандидатов движения могут проверяться, в то время как в режиме объединения могут проверяться n кандидатов движения (например m=2, n=44).
b) В одном примере, общее число кандидатов движения подлежащих проверке может быть передано посредством сигнала Установки параметра видео (VPS), Установки параметра последовательности (SPS), Установки параметра картинки (PPS), заголовке слайса, заголовке тайла, Единице кодового дерева (CTU), Блоке кодового дерева (CTB), Единице кодирования (CU), Единице прогнозирования (PU), области покрытия множества CTU/CTB/CU/PUs.
Пример C1: Один или более кандидатов движения, включенных в таблицу поиска, могут быть непосредственно унаследованы блоком.
a) Они могут использоваться для кодирования в режиме слияния, то есть кандидаты движения могут быть проверены в процессе создания списка кандидатов слияния.
b) Их можно использовать для кодирования в режиме аффинного слияния.
1) Кандидат движения в таблицу поиска может быть добавлен в качестве кандидата аффинного слияния, если его аффинный флаг равен единице.
c) Проверка кандидатов движения в таблицах поиска может быть разрешена в случае, когда:
1) список кандидатов слияния не заполнен после вставки кандидата TMVP;
2) список кандидатов слияния не является полным после проверки определенного пространственного соседнего блока для получения пространственных кандидатов слияния;
3) список кандидатов слияния не является полным после всех пространственных кандидатов слияния;
4) список кандидатов слияния не является полным после объединенных кандидатов слияния с двойным прогнозированием;
5) когда количество пространственных или временных (например, включая смежные пространственные и несмежные пространственные, TMVP, STMVP, ATMVP и т.д.) кандидатов слияния, которые были занесены в список кандидатов слияния из других способов кодирования (например, процесс получения слияния конструкции HEVC или конструкции JEM) меньше максимально разрешенных кандидатов слияния минус заданное пороговое значение.
1. В одном примере пороговое значение установлено на 1 или 0.
2. В качестве альтернативы, порог может быть сигнализирован или заранее определен в SPS/PPS/последовательности, изображении, заголовке/тайле слайса.
3. В качестве альтернативы, пороговое значение может адаптивно изменяться от блока к блоку. Например, это может зависеть от информации о кодированном блоке, такой как размер блока/форма блока/тип слайса, и/или зависеть от количества имеющихся пространственных или временных кандидатов слияния.
4. В другом примере, когда количество определенных типов кандидатов слияния по сравнению с количеством типов кандидатов слияния, помещенных в список кандидатов слияния, меньше количества максимально разрешенных кандидатов слияния минус заданное пороговое значение. "Определенные типы кандидатов слияния" могут быть пространственными кандидатами, как в HEVC, или несмежными кандидатами слияния.
6) Перед добавлением кандидата движения в список кандидатов слияния может применяться операция сокращения. В различных реализациях этого примера и других примеров, раскрытых в данном патентном документе, сокращение может включать в себя a) сравнение информации о движении с существующими записями на предмет уникальности, или б) если она является уникальной, то добавление информации о движении в список, или в) если она не является уникальной, то либо c1) не добавляется, либо c2) добавляется информация о движении и удаляется существующая запись, которая совпадает с ней. В некоторых реализациях операция сокращения не выполняется при добавлении кандидата движения из таблицы в список кандидатов.
1. В одном примере кандидат движения может быть сокращен до всех или частично имеющихся пространственных или временных (например, включая соседние пространственные и несмежные пространственные, TMVP, STMVP, ATMVP и т.д.) кандидатов слияния из других способов кодирования в списке кандидатов слияния.
2. Кандидат движения НЕ может быть сокращен до кандидатов движения на основе подблока, например, ATMVP, STMVP.
3. В одном примере текущий кандидат движения может быть сокращен до всех или части имеющихся кандидатов движения (вставленных перед текущим кандидатом движения) в списке кандидатов слияния.
4. Количество операций сокращения, связанных с кандидатами движения (например, сколько раз необходимо сравнить кандидаты движения с другими кандидатами в списке слияния), может зависеть от количества имеющихся пространственных или временных кандидатов слияния. Например, при проверке нового кандидата движения, если в списке слияния имеется M кандидатов, новый кандидат движения может сравниваться только с первыми K (K <= M) кандидатами. Если результатом функции сокращения является "ложь" (например, отсутствует идентичность с каким-либо из первых K кандидатов), новый кандидат движения считается отличным от всех M кандидатов, и его можно добавить в список кандидатов слияния. В одном примере K устанавливается равным min(K, 2).
5. В одном примере вновь добавленный кандидат движения сравнивается только с первыми N кандидатами в списке кандидатов слияния. Например, N=3, 4 или 5. N может быть передан из кодера в декодер.
6. В одном примере проверяемый новый кандидат движения сравнивается только с последними N кандидатами в списке кандидатов слияния. Например, N=3, 4 или 5. N может быть передан из кодера в декодер.
7. В одном примере, как выбрать кандидаты, ранее добавленные в список, для сравнения с новым кандидатом движения из таблицы, может зависеть от того, откуда были получены ранее добавленные кандидаты.
a) В одном примере кандидат движения в таблице поиска может сравниваться с кандидатами, полученными из заданного временного и/или пространственного соседнего блока.
b) В одном примере разные записи кандидатов движения в таблице поиска могут сравниваться с разными ранее добавленными кандидатами (то есть полученными из разных мест).
Пример C2: Кандидат(ы) движения, включенный(е) в таблицу поиска, может/могут использоваться в качестве предиктора для кодирования информации о движении блока.
a) Они могут использоваться для кодирования в режиме AMVP, то есть кандидаты движения могут проверяться в процессе получения списка кандидатов AMVP.
b) Проверка кандидатов движения в таблицах поиска может быть включена тогда, когда:
1) список кандидатов AMVP не заполнен после проверки или вставки кандидата TMVP;
2) список кандидатов AMVP не заполнен после выбора из пространственных соседей и сокращения непосредственно перед вставкой кандидата TMVP;
3) когда отсутствует кандидат AMVP из вышеуказанных соседних блоков без масштабирования, и/или когда отсутствует кандидат AMVP из левых соседних блоков без масштабирования;
4) Сокращение может применяться перед добавлением кандидата движения в список кандидатов AMVP.
c) Проверяются кандидаты движения с идентичным опорным изображением для текущего опорного изображения.
1) В качестве альтернативы, кроме того, проверяются также (с масштабированными MV) кандидаты движения с различными опорными изображениями из текущего опорного изображения.
2) Кроме того, проверяются все кандидаты движения с идентичным опорным изображением текущего опорного изображения сначала, и затем проверяются кандидаты движения с различными опорными изображениями из текущего опорного изображения.
3) В качестве альтернативы кандидаты движения проверяются таким же образом, как и при слиянии.
Пример C3: Кандидаты движения из таблицы поиска в ранее кодированных кадрах/слайсах/тайлах могут использоваться для прогнозирования информации о движении блока в другом кадре/слайсе/тайле.
Обновление таблиц поиска
Пример D1: После кодирования блока с помощью информации о движении (то есть в режиме IntraBC или в режиме интеркодирования) могут быть обновлены одна или несколько таблиц поиска.
Пример D2: Если один блок расположен на границе изображения/слайса/тайла, обновление таблиц поиска всегда будет запрещено.
Пример D3: Информация о движении для вышеперечисленных строк LCU может быть отключена для кодирования текущей строки LCU.
Пример D4: В начале кодирования слайса/тайла с новым индексом временного слоя количество доступных кандидатов движения в LUT может быть сброшено в 0.
Пример D5: Таблица поиска может непрерывно обновляться с помощью одного слайса/тайла/строки/слайса LCU с одним и тем же индексом временного слоя.
Пример D6: Процесс обновления таблицы поиска может быть вызван в рамках различных процедур.
Дополнительные примерные варианты осуществления
Предложен способ MVP на основе истории (HMVP), в котором кандидат HMVP определяется как информация о движении ранее кодированного блока. Таблица с несколькими кандидатами HMVP поддерживается в процессе кодирования/декодирования. Таблица очищается при обнаружении нового слайса. Всякий раз, когда имеется блок с интеркодированием, ассоциированная информация о движении добавляется к последней записи таблицы в качестве нового кандидата HMVP. Общий поток кодирования показан на фиг.31.
В одном примере размер таблицы установлен равным L (например, L=16, или 6 или 44), что указывает на то, что в таблицу могут быть добавлены до L кандидатов HMVP.
В одном варианте осуществления (соответствующем примеру 11.g)1), если имеется более L кандидатов HMVP из ранее кодированных блоков, применяется правило "первым пришел - первым вышел" (FIFO), поэтому таблица всегда содержит L последних ранее кодированных кандидатов движения. На фиг.32 показан пример, в котором правило FIFO применяется для удаления кандидата HMVP и добавления нового кандидата HMVP в таблицу, используемую в предложенном способе.
В другом варианте осуществления (соответствующем изобретению 11.g)3) всякий раз, когда добавляется новый кандидат движения (например, текущий блок является межкодированным и находится в неаффинном режиме), сначала применяется процесс проверки на избыточность, чтобы определить, имеются ли в LUT идентичные или аналогичные кандидаты движения.
Некоторые примеры проиллюстрированы следующим образом:
На фиг.33A показан пример, когда LUT заполнена перед добавлением нового кандидата движения.
На фиг.33B показан пример, когда LUT не заполнена перед добавлением нового кандидата движения.
На фиг.33A и 33B совместно показан пример способа обновления LUT, основанного на уменьшении избыточности (с удалением одного кандидата движения избыточности).
На фиг.34A и 34B показаны примерные реализации для двух случаев способа обновления LUT на основе уменьшение избыточности (с удалением нескольких кандидатов движения избыточности, на фигурах показано 2 кандидатa).
На фиг.34A показан примерный случай, когда LUT заполнена перед добавлением нового кандидата движения.
На фиг.34B показан примерный случай, когда LUT не заполнена перед добавлением нового кандидата движения.
Кандидаты HMVP могут использоваться в процессе создания списка кандидатов слияния. Все кандидаты HMVP от последней записи до первой (или последний K0 HMVP, например, K0, равный 16 или 6) в таблице вставляются после кандидата TMVP. К кандидатам HMVP применяется операция сокращения. Когда общее количество имеющихся кандидатов слияния достигает просигнализированных максимально разрешенных кандидатов слияния, процесс создания списка кандидатов слияния завершается. В качестве альтернативы, когда общее количество добавленных кандидатов движения достигает заданного значения, прекращается вызов кандидатов движения из LUT.
Аналогичным образом, в процессе создания списка кандидатов AMVP могут также использоваться кандидаты HMVP. Векторы движения последних кандидатов K1 HMVP в таблице вставляются после кандидата TMVP. Только кандидаты HMVP с одним и тем же опорным изображением в качестве целевого опорного изображения AMVP используется для создания списка кандидатов AMVP. К кандидатам HMVP применяется операция сокращения. В одном примере K1 установлен на 4.
На фиг.28 показана блок-схема устройства 2800 обработки видео. Устройство 2800 может использоваться для реализации одного или более способов, описанных в данном документе. Устройство 2800 может быть воплощено в смартфоне, планшете, компьютере, приемнике Интернета вещей (IoT) и т.д. Устройство 2800 может включать в себя один или несколько процессоров 2802, одно или несколько устройств 2804 памяти и аппаратные средства 2806 обработки видео. Процессор(ы) 2802 может/могут быть выполнен(ы) с возможностью реализации одного или более способов, описанных в данном документе. Устройство(a) 2804 памяти может/могут использоваться для хранения данных и кода, используемых для реализации способов и технологий, описанных в данном документе. Аппаратные средства 2806 обработки видео могут использоваться для реализации в аппаратных схемах некоторых способов, описанных в данном документе.
На фиг. 29 показана блок-схема последовательности операций примерного способа 2900 обработки видео. Способ 2900 включает в себя на этапе 2902 ведение набора таблиц, причем каждая таблица включает в себя кандидаты движения, и каждый кандидат движения ассоциируется с соответствующей информацией о движении. Способ 2900 дополнительно включает в себя на этапе 2904 обновление списка кандидатов движения на основе кандидатов движения в одной или более таблицах с использованием операции сокращения для кандидатов движения. Способ 2900 дополнительно включает в себя на этапе 2906 выполнение преобразования между первым видеоблоком и представлением битового потока видео, включающего в себя первый видеоблок, с использованием созданного списка кандидатов движения.
На фиг. 30 показана блок-схема последовательности операций примерного способа 3000 обработки видео. Способ 3000 включает в себя на этапе 3002 прием представления битового потока видео, включающего в себя первый видеоблок. Способ 3000 дополнительно включает в себя на этапе 3004 применение операции сокращения к кандидатам движения в одной или более таблицах для обновления списка кандидатов, причем каждая таблица включает в себя кандидаты движения, и каждый кандидат движения ассоциируется с соответствующей информацией о движении. Способ 3000 дополнительно включает в себя на этапе 3006 выполнение преобразования между представлением битового потока и первым видеоблоком с использованием созданного списка кандидатов.
Дополнительные признаки и варианты осуществления вышеописанных способов/технологий представлены ниже с использованием формата описания на основе пунктов.
1. Способ обработки видео, содержащий: ведение набора таблиц, причем каждая таблица включает в себя кандидаты движения, и каждый кандидат движения ассоциируется с соответствующей информацией о движении; обновление списка кандидатов на основе кандидатов движения в одной или более таблицах с использованием операции сокращения кандидатов движения; и выполнение преобразования между первым видеоблоком и представлением битового потока видео, включающего в себя первый видеоблок, с использованием созданного списка кандидатов.
2. Способ обработки видео, содержащий: прием представления битового потока видео, включающего в себя первый видеоблок; и применение операции сокращения к кандидатам движения в одной или более таблицах для создания списка кандидатов, причем каждая таблица включает в себя кандидаты движения, и каждый кандидат движения ассоциируется с соответствующей информацией о движении; и выполнение преобразования между представлением битового потока и первым видеоблоком с использованием созданного списка кандидатов.
3. Способ по 1 или 2, в котором по меньшей мере одна из таблиц включает в себя кандидаты движения, полученные из ранее декодированных видеоблоков, которые декодируются перед первым видеоблоком.
4. Способ по 1 или 2, в котором операция сокращения выполняется перед добавлением кандидата движения из таблицы в список кандидатов.
5. Способ по 3, в котором список кандидатов соответствует списку кандидатов слияния.
6. Способ по 1 или 2, в котором операция сокращения включает в себя сравнение кандидата движения из таблицы по меньшей мере с частью доступных пространственных или временных кандидатов слияния.
7. Способ по 1 или 2, в котором операция сокращения включает в себя сравнение кандидата движения из таблицы со всеми доступными кандидатами пространственного слияния.
8. Способ по 1, 2 или 4, в котором операция сокращения выполняется без изменения кандидата движения из таблицы применительно к кандидату движения на основе подблока.
9. Способ по 1 или 2, в котором операция сокращения включает в себя сравнение кандидата движения из таблицы по меньшей мере с частью доступных кандидатов движения в списке кандидатов слияния перед добавлением кандидата движения.
10. Способ по 1 или 2, в котором операция сокращения включает в себя ряд операций, количество которых является функцией количества пространственных или временных кандидатов слияния.
11. Способ по 9, в котором количество операций является таким, что в случае, если M кандидатов доступны в списке кандидатов слияния, то сокращение применяется только к K кандидатов слияния, где K <= M и где K и M – целые числа.
12. Способ по 10, в котором K устанавливается равным min(K, 2).
13. Способ по 1, в котором операция сокращения включает в себя сравнение кандидата движения из таблицы с первыми N кандидатами в списке кандидатов перед добавлением кандидата движения в список кандидатов, где N – целое число.
14. Способ по 1 или 2, в котором операция сокращения включает в себя сравнение кандидата движения из таблицы, подлежащей проверке, с последними N кандидатами в списке кандидатов перед добавлением кандидата движения в список кандидатов, где N – целое число.
15. Способ по 12 или 13, дополнительно содержащий сигнализацию значения N.
16. Способ по 1, в котором операция сокращения включает в себя сравнение кандидата движения из таблицы с определенным кандидатом в списке кандидатов на основе того, как был получен кандидат.
17. Способ по 15, в котором операция сокращения включает в себя сравнение кандидата движения из таблицы с кандидатами, полученными из заданного временного или пространственного соседнего блока.
18. Способ по 15, в котором разные записи кандидатов движения в таблице сравниваются с разными ранее добавленными кандидатами, которые были получены из разных местоположений.
19. Способ по 1, дополнительно содержащий этап, в котором операция сокращения не запускается при добавлении кандидата движения из таблицы в список кандидатов.
20. Способ по любому из 1-19, в котором выполнение преобразования включает в себя выработку представления битового потока из видеоблока.
21. Способ по любому из 1-19, в котором выполнение преобразования включает в себя выработку видеоблока из представления битового потока.
22. Способ по любому из 1-21, в котором кандидат движения ассоциируется с информацией о движении, включающей в себя по меньшей мере одно из: направления прогнозирования, индекса опорного изображения, вектора движения, значения флага компенсации интенсивности, аффинного флага, точности разности векторов движения или значения разности векторов движения.
23. Способ по любому из 1-22, в котором кандидаты движения соответствуют кандидатам движения для режимов интрапредсказания для кодирования в интрарежиме.
24. Способ по любому из 1-22, в котором кандидаты движения соответствуют кандидатам движения, которые включают в себя параметры компенсации освещения для кодирования параметров IC.
25. Способ по любому из 1-22, дополнительно содержащий обновление, на основе преобразования, одной или более таблиц.
26. Способ по 25, в котором обновление одной или более таблиц включает в себя обновление одной или более таблиц на основе информации о движении первого видеоблока после выполнения преобразования.
27. Способ по 26, дополнительно содержащий: выполнение преобразования между последующим видеоблоком видео и представлением битового потока видео на основе обновленных таблиц.
28. Устройство, содержащее процессор и энергонезависимую память с инструкциями, хранящимися в ней, причем инструкции при их исполнении процессором предписывают процессору реализовать способ, изложенный в одном или более из 1-27.
29. Компьютерный программный продукт, хранящийся на энергонезависимом машиночитаемом носителе, причем компьютерный программный продукт включает в себя программный код для выполнения способа, изложенного в одном или более из пп.1-27.
Из вышеизложенного следует понимать, что конкретные варианты осуществления раскрытой в настоящее время технологии были описаны в данном документе в целях иллюстрации, но что различные модификации могут быть выполнены без отклонения от объема изобретения. Соответственно, раскрытая в настоящее время технология не является ограниченной, за исключением прилагаемой формулы изобретения.
Раскрытые и другие варианты осуществления, модули и функциональные операции, описанные в данном документе, могут быть реализованы в цифровых электронных схемах или в компьютерном программном обеспечении, встроенном программном обеспечении или аппаратных средствах, включая структуры, раскрытые в данном документе и их структурных эквивалентах, либо в комбинации одного или более из них. Раскрытые и другие варианты осуществления могут быть реализованы в виде одного или более компьютерных программных продуктов, то есть в виде одного или более модулей компьютерных программных инструкций, закодированных на машиночитаемом носителе информации, для выполнения или для управления работой устройства обработки данных. Машиночитаемый носитель информации может быть машиночитаемым запоминающим устройством, машиночитаемым запоминающим носителем информации, запоминающим устройством, смесью веществ, воздействующей на машиночитаемый распространяемый сигнал, или комбинацией одного или более из них. Термин "устройство обработки данных" охватывает все аппаратные устройства, устройства и машины для обработки данных, включая, например, программируемый процессор, компьютер или несколько процессоров или компьютеров. Устройство может включать в себя, помимо аппаратного обеспечения, код, который создает среду выполнения для рассматриваемой компьютерной программы, например, код, который составляет микропрограммное обеспечение процессора, стек протоколов, систему управления базой данных, операционную систему или комбинацию одного или большего количества из них. Распространяемый сигнал представляет собой искусственно выработанный сигнал, например, выработанный с помощью машины, электрический, оптический или электромагнитный сигнал, который вырабатывается для кодирования информации для передачи в подходящее приемное устройство.
Компьютерная программа (также известная как программа, программное обеспечение, программное приложение, программный модуль, сценарий или код) может быть написана на языке программирования любого вида, включая компилированные или интерпретируемые языки, и может быть развернута в любом виде, в том числе как автономная программа или как модуль, компонент, подпрограмма или другая единица, подходящая для использования в вычислительной среде. Компьютерная программа не обязательно соответствует файлу в файловой системе. Программа может храниться в части файла, который содержит другие программы или данные (например, один или несколько сценариев, хранящихся в документе на языке разметки), в одном файле, выделенном для рассматриваемой программы, или в нескольких скоординированных файлах (например, файлах, в которых хранятся один или несколько модулей, подпрограмм или частей кодa). Компьютерная программа может быть развернута для исполнения на одном компьютере или на нескольких компьютерах, которые расположены на одном сайте или распределены по нескольким сайтам и связаны между собой сетью связи.
Процессы и логические потоки, описанные в данном документе, могут выполняться одним или несколькими программируемыми процессорами, исполняющими одну или более компьютерных программ для выполнения функций, оперируя входными данными и вырабатывая выходные данные. Процессы и логические потоки также могут выполняться с помощью, и устройство может быть реализовано также в виде логической схемы специального назначения, например, программируемой пользователем вентильной матрицы (FPGA) или специализированной интегральной схемы (ASIC).
Процессоры, подходящие для выполнения компьютерной программы, включают в себя, например, микропроцессоры как общего, так и специального назначения, а также любой один или более процессоров любого типа цифрового компьютера. В общем, процессор будет принимать инструкции и данные из постоянного запоминающего устройства, оперативного запоминающего устройства или того и другого. Существенными элементами компьютера являются процессор, предназначенный для выполнения инструкций, и одно или более запоминающих устройств для хранения инструкций и данных. Как правило, компьютер также будет включать в себя или будет функционально подключенным для приема данных из или передачи данных в, или и того и другого, одно или более устройств массовой памяти для хранения данных, например, магнитные диски, магнитооптические диски или оптические диски. Однако компьютер необязательно должен иметь такие устройства. Машиночитаемые носители информации, подходящие для хранения инструкций компьютерных программ и данных, включают в себя все виды энергонезависимой памяти, носителей информации и запоминающих устройств, в том числе, например, полупроводниковые запоминающие устройства, например, EPROM, EEPROM и устройства флэш-памяти; магнитные диски, например, внутренние жесткие диски или съемные диски; магнитооптические диски; и диски CD-ROM и DVD-ROM. Процессор и память могут быть дополнены специальной логической схемой или включены в нее.
Хотя данный патентный документ содержит много конкретных деталей, таковые не должны толковаться в качестве ограничений на объем какого бы то ни было изобретения или на объем того, что может быть заявлено в формуле изобретения, но скорее в качестве описаний признаков, которые могут быть характерны для конкретных реализаций конкретных изобретений. Некоторые признаки, которые описаны в данном патентном документе в контексте отдельных вариантов осуществления, могут быть также реализованы в комбинации в одном варианте осуществления. И наоборот, различные признаки, которые описаны в контексте одного варианта осуществления, могут быть также реализованы в многочисленных вариантах осуществления по отдельности или в любой подходящей подкомбинации. Более того, хотя признаки могут быть описаны выше как действующие в определенных комбинациях и даже первоначально заявленные как таковые, один или несколько признаков заявленной комбинации в некоторых случаях могут быть исключены из комбинации, и заявленная комбинация может быть направлена на подкомбинацию или вариацию подкомбинации.
Аналогичным образом, хотя операции изображены на чертежах в определенном порядке, это не следует понимать как требование, чтобы такие операции выполнялись в конкретном показанном порядке или в последовательном порядке, или чтобы все проиллюстрированные операции выполнялись для достижения желаемых результатов. Более того, разбиение различных компонентов системы в вариантах осуществления, описанных в данном патентном документе, не следует понимать как требующее такого разбиения во всех вариантах осуществления.
Выше было описано только несколько реализаций и примеров, и другие реализации, улучшения и изменения могут быть сделаны на основе того, что описано и проиллюстрировано в данном патентном документе.
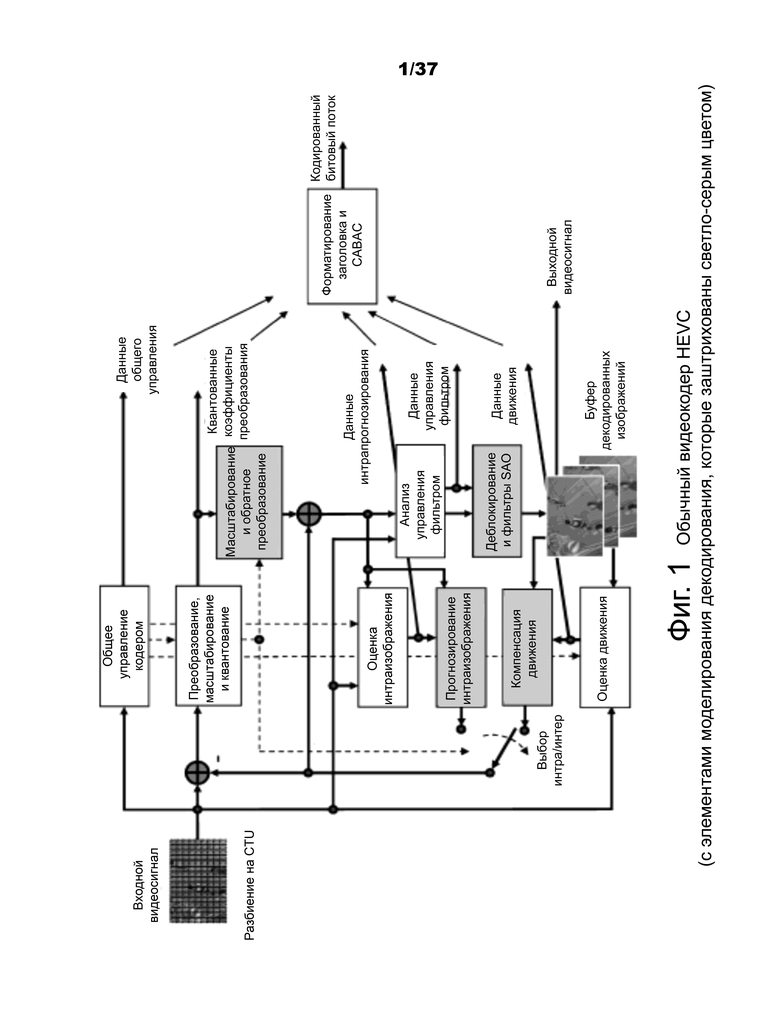
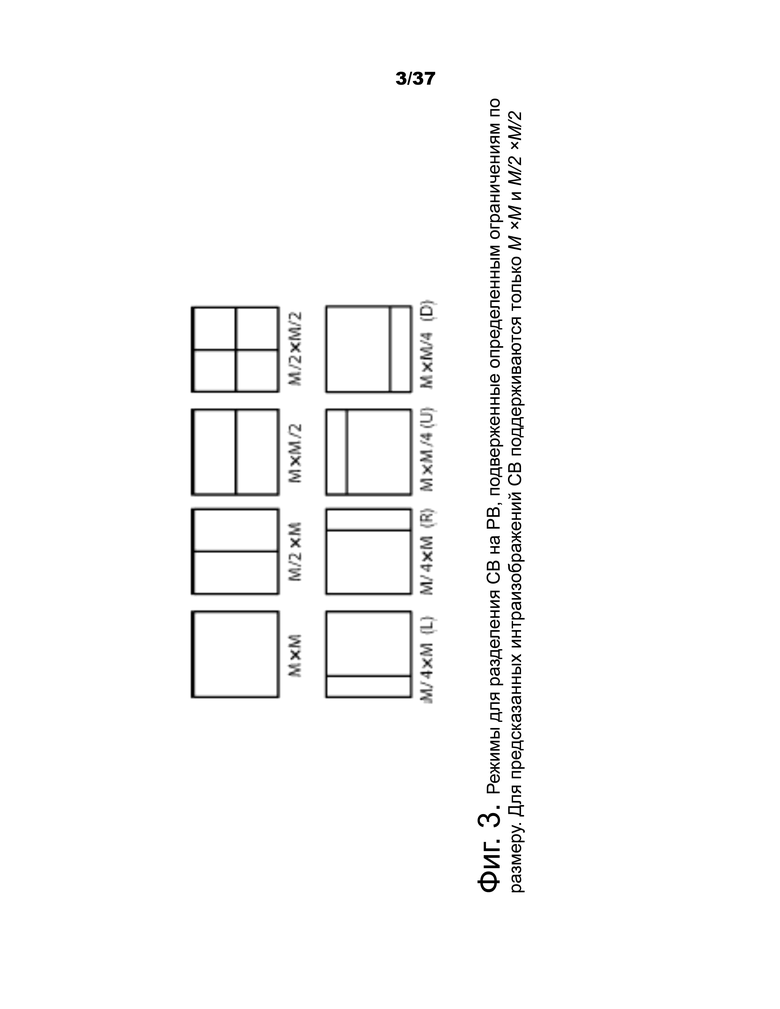
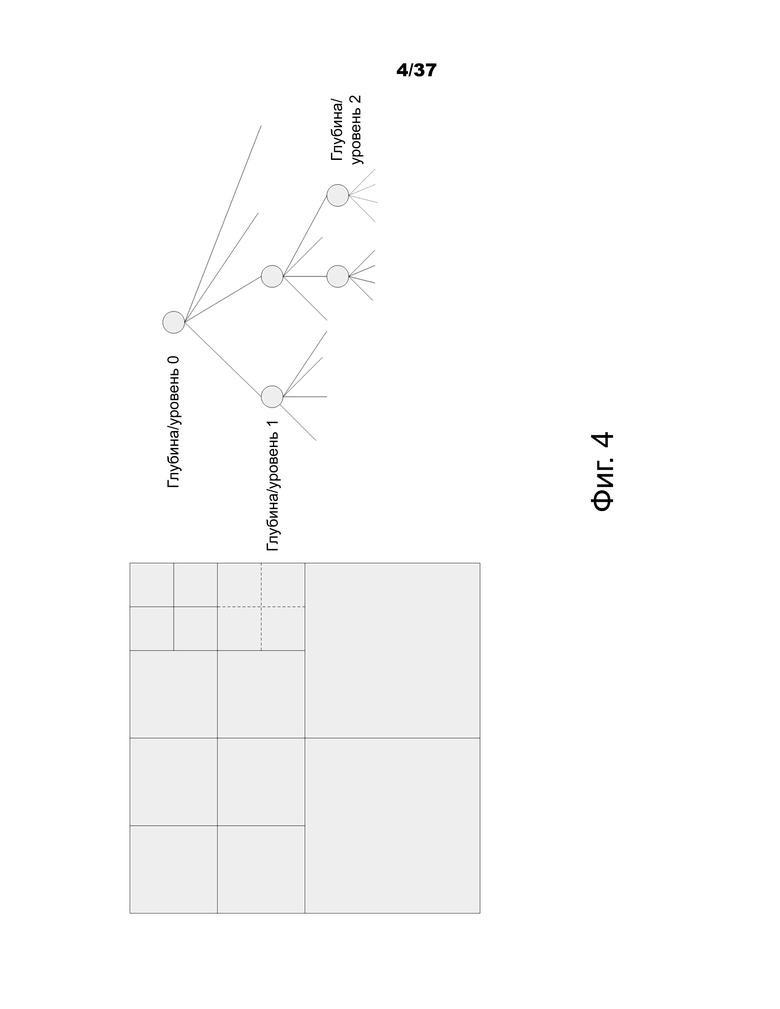
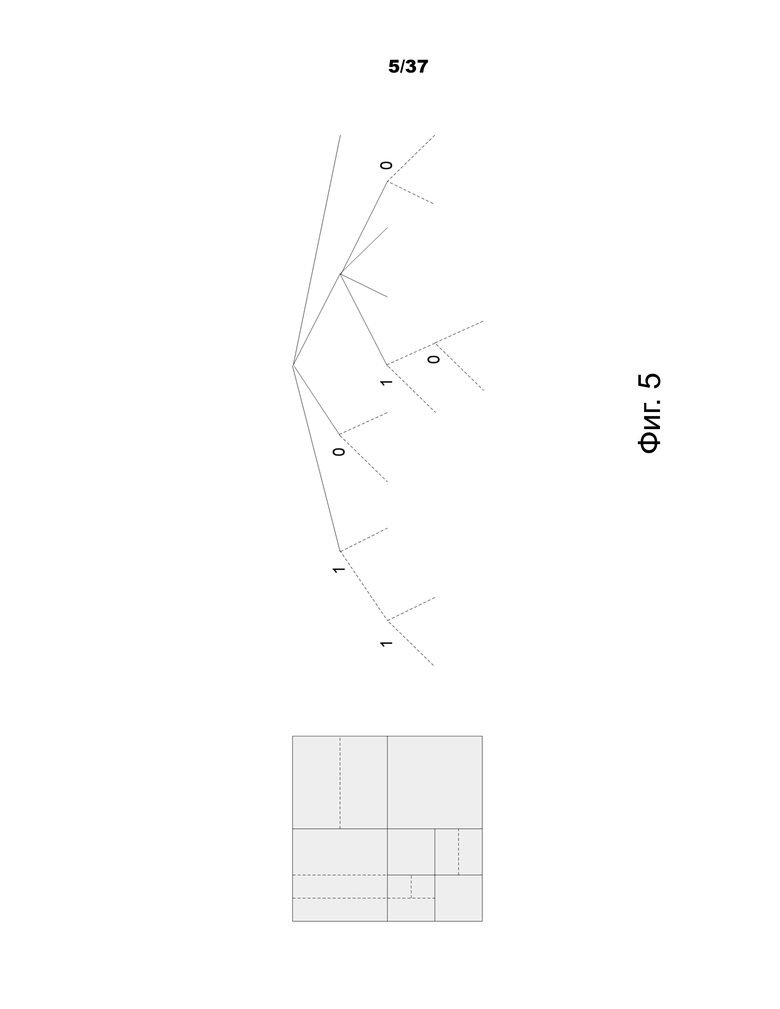
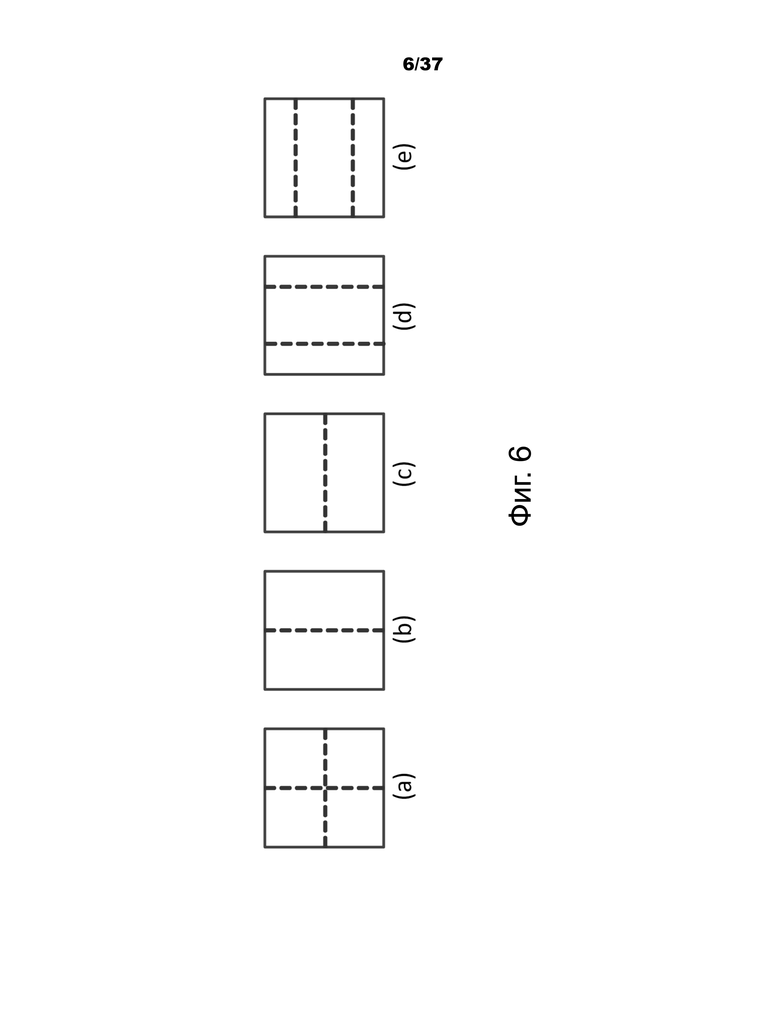
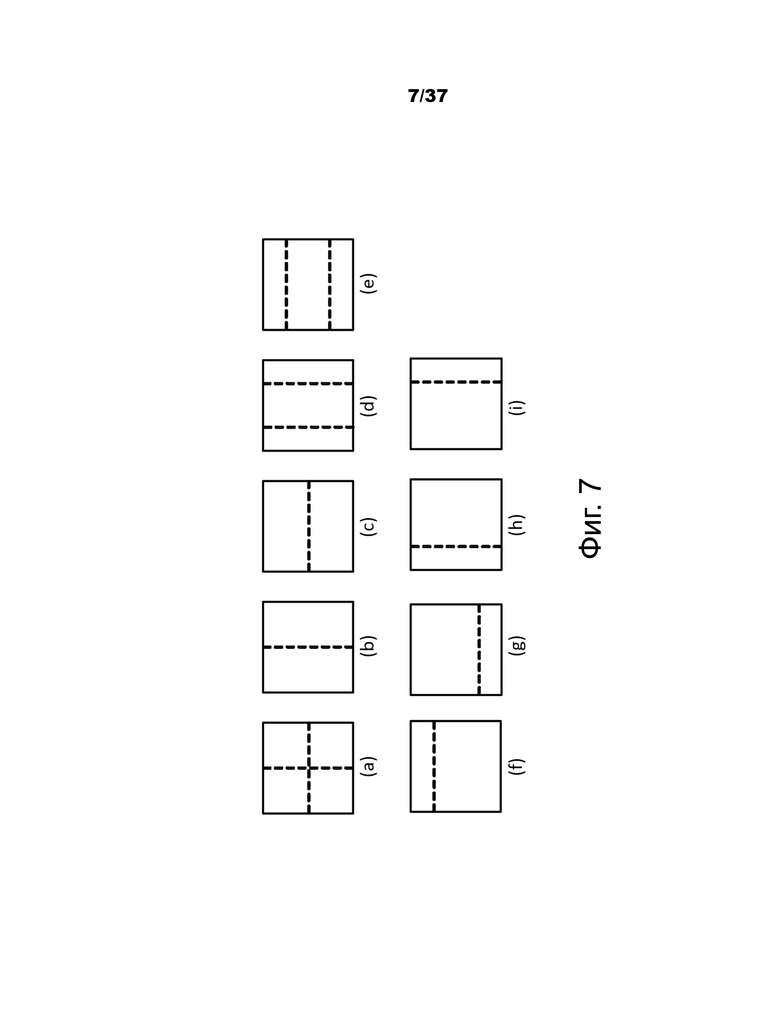
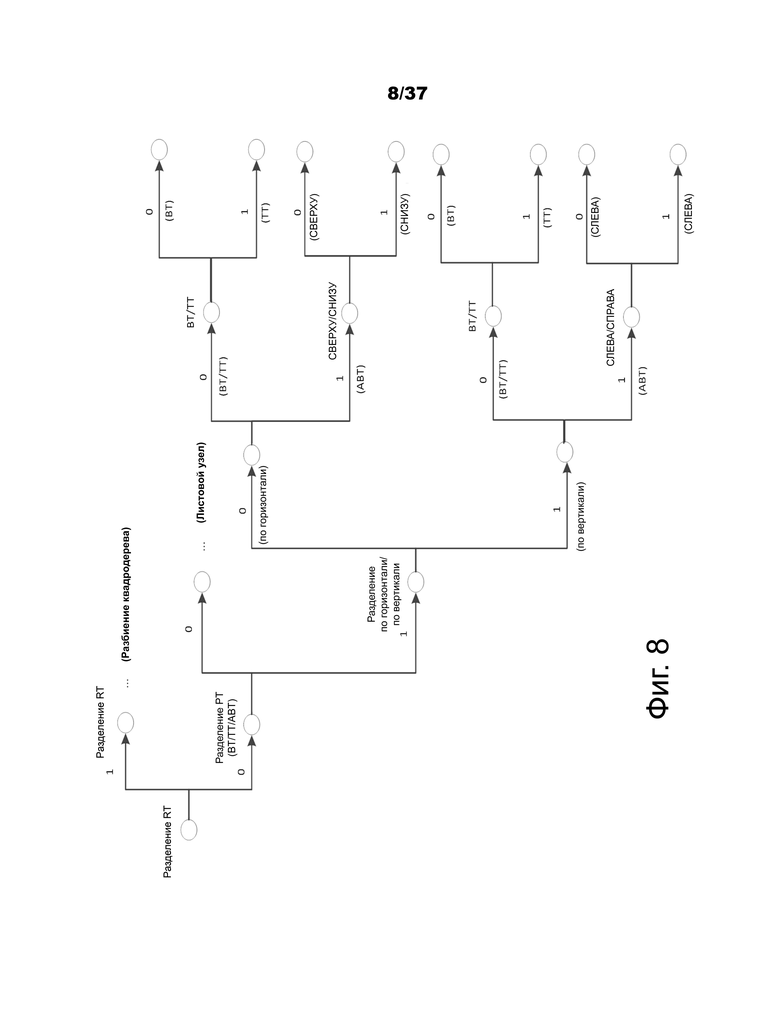
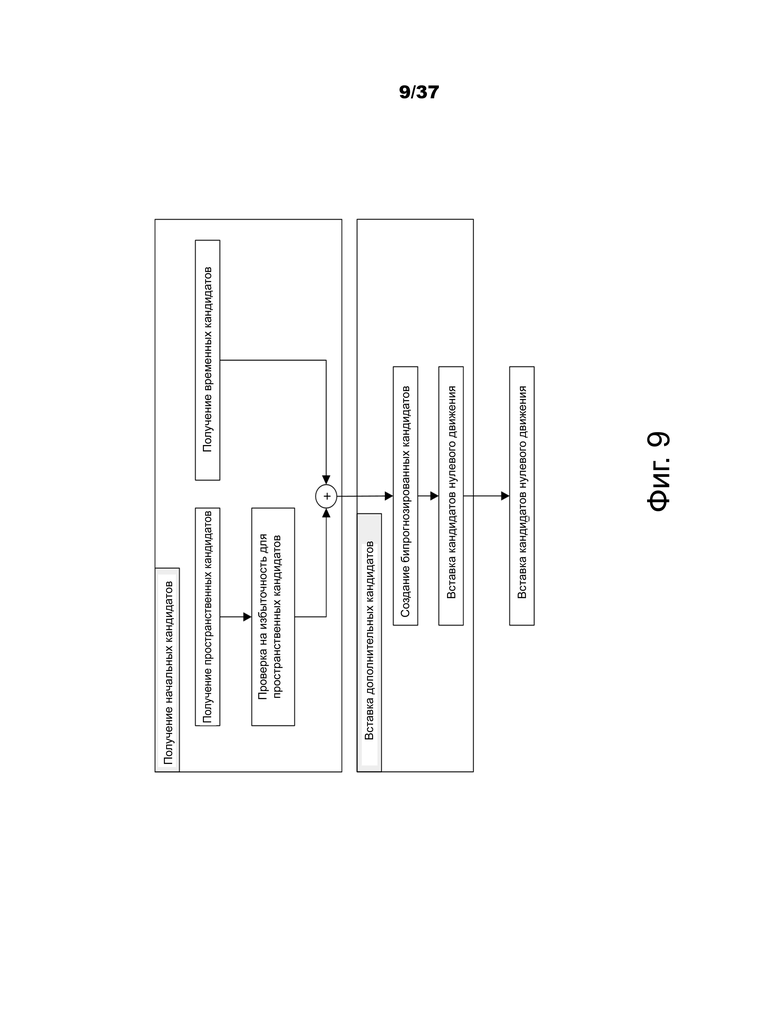
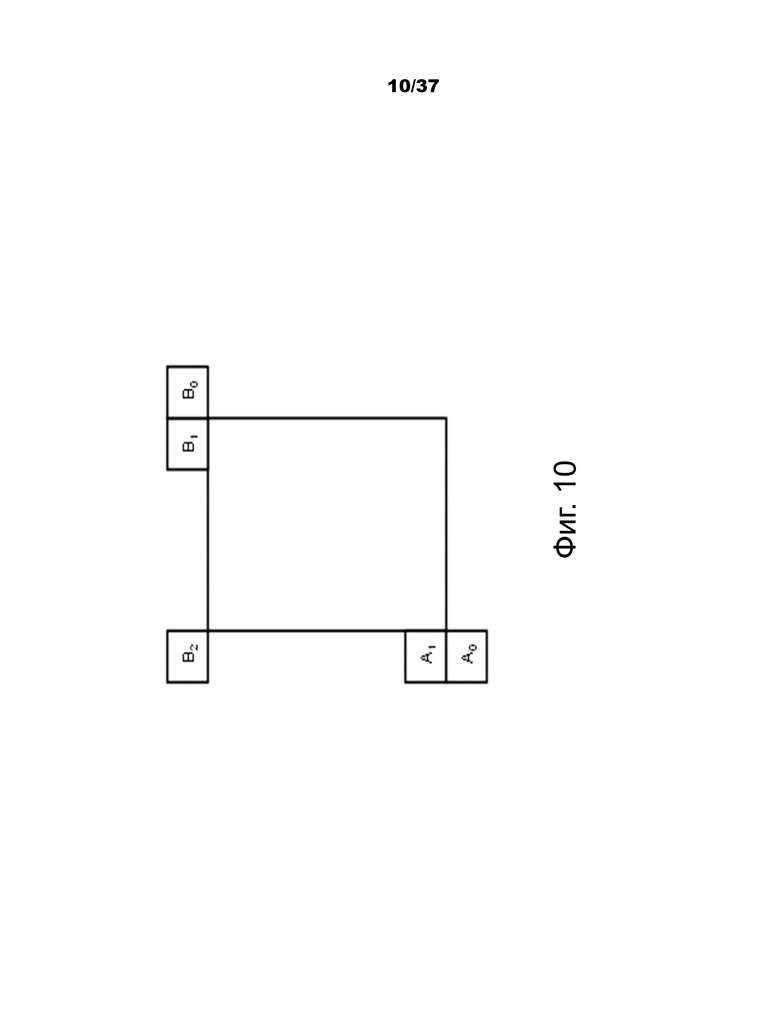
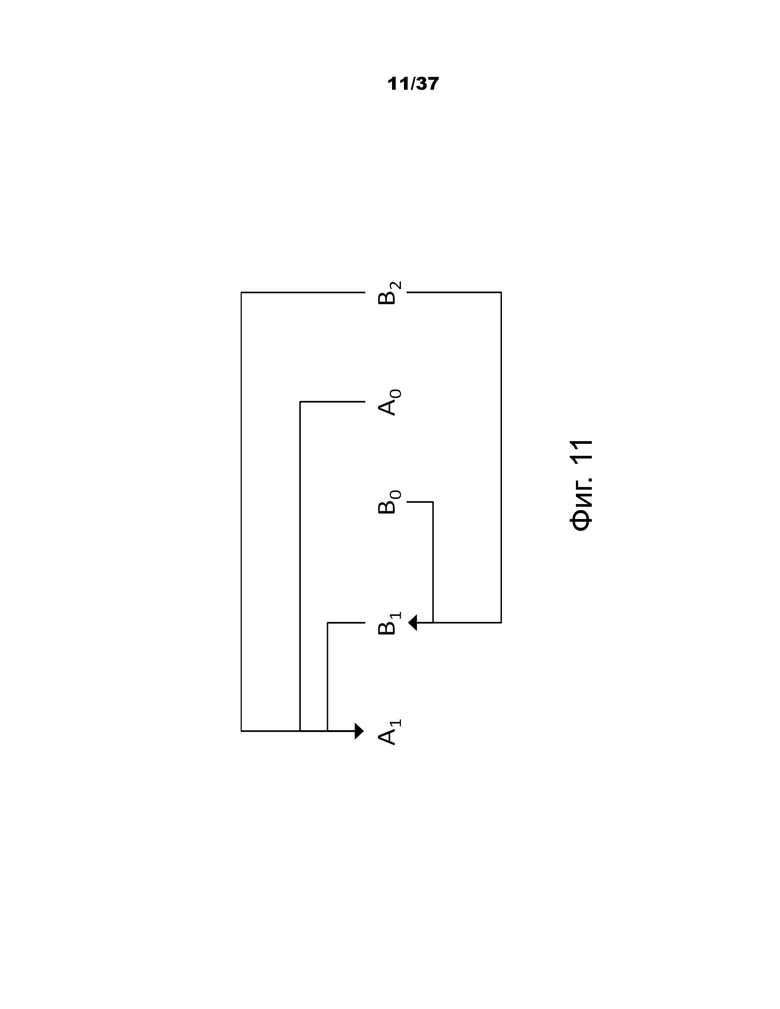
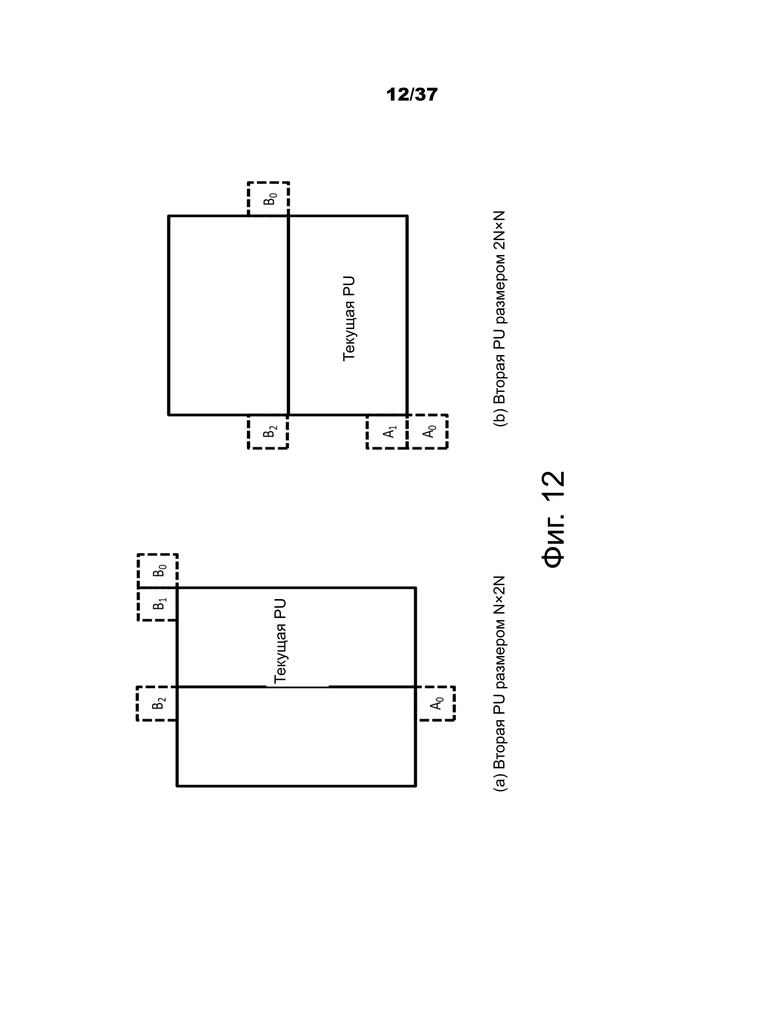
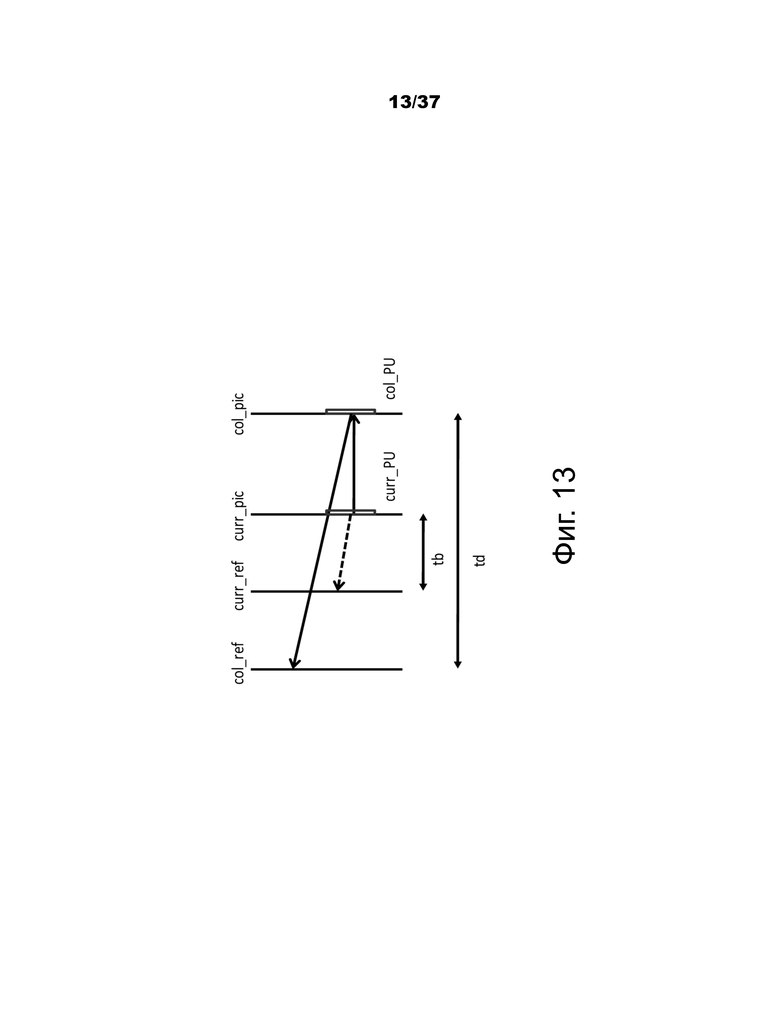
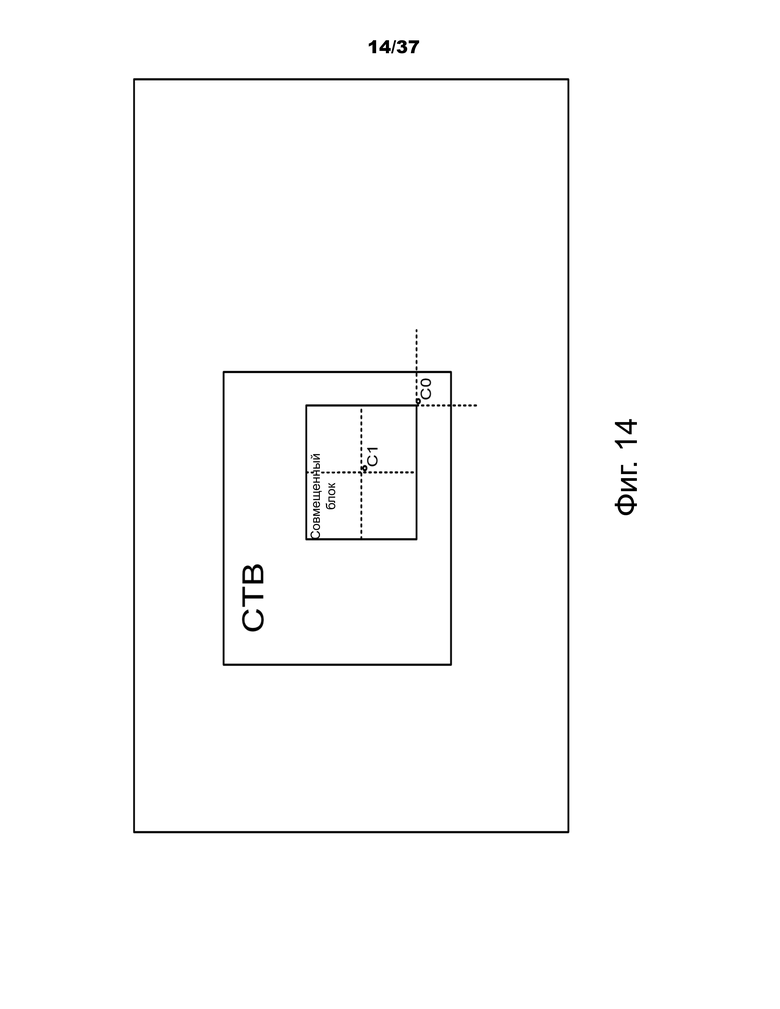
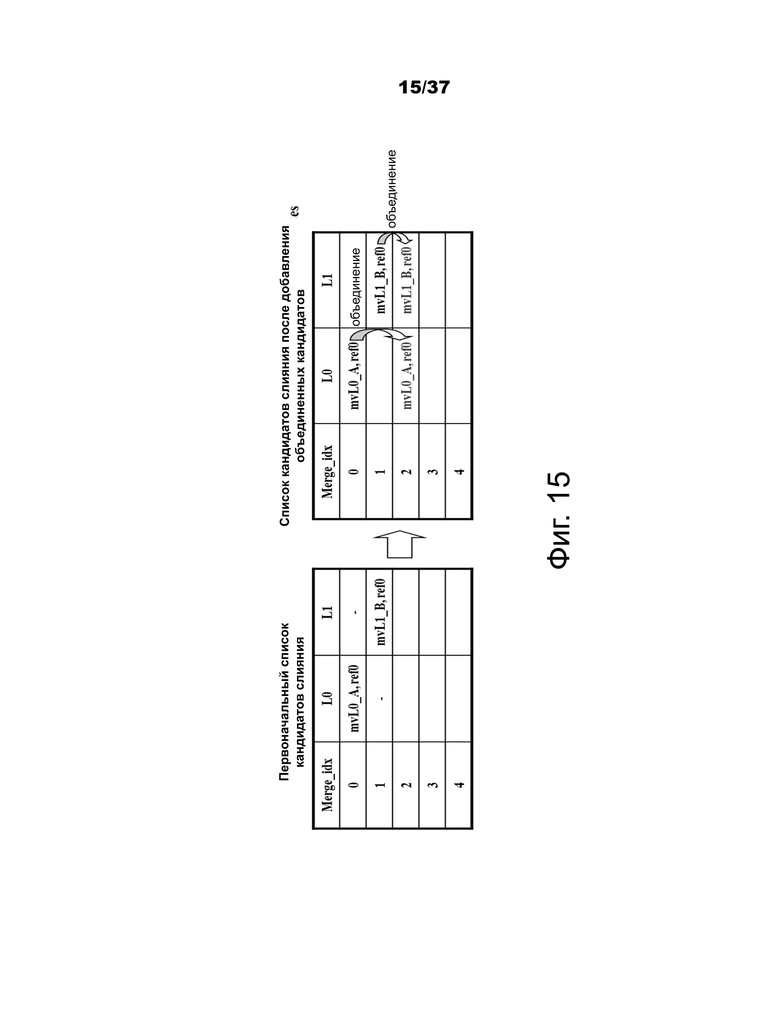
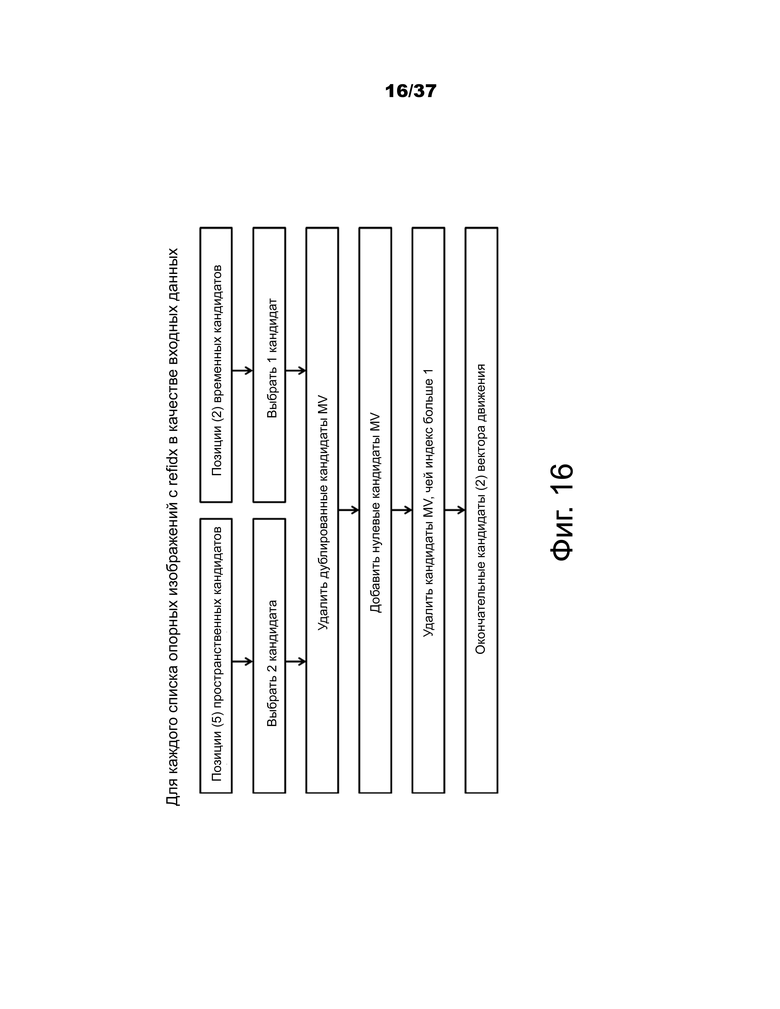
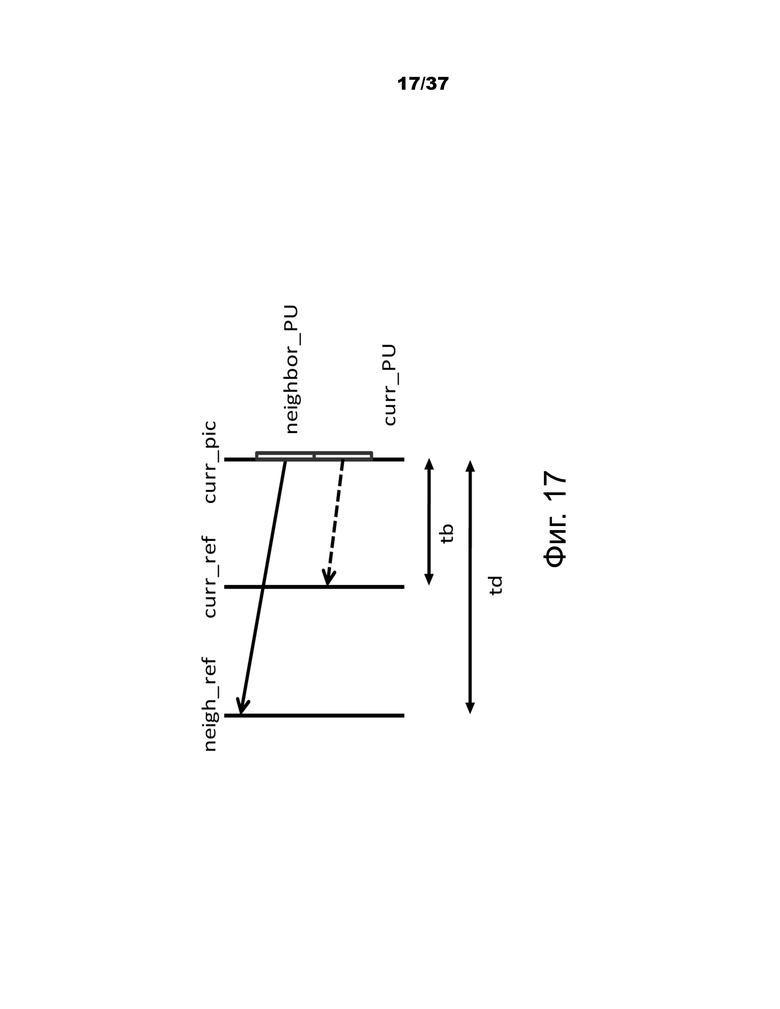
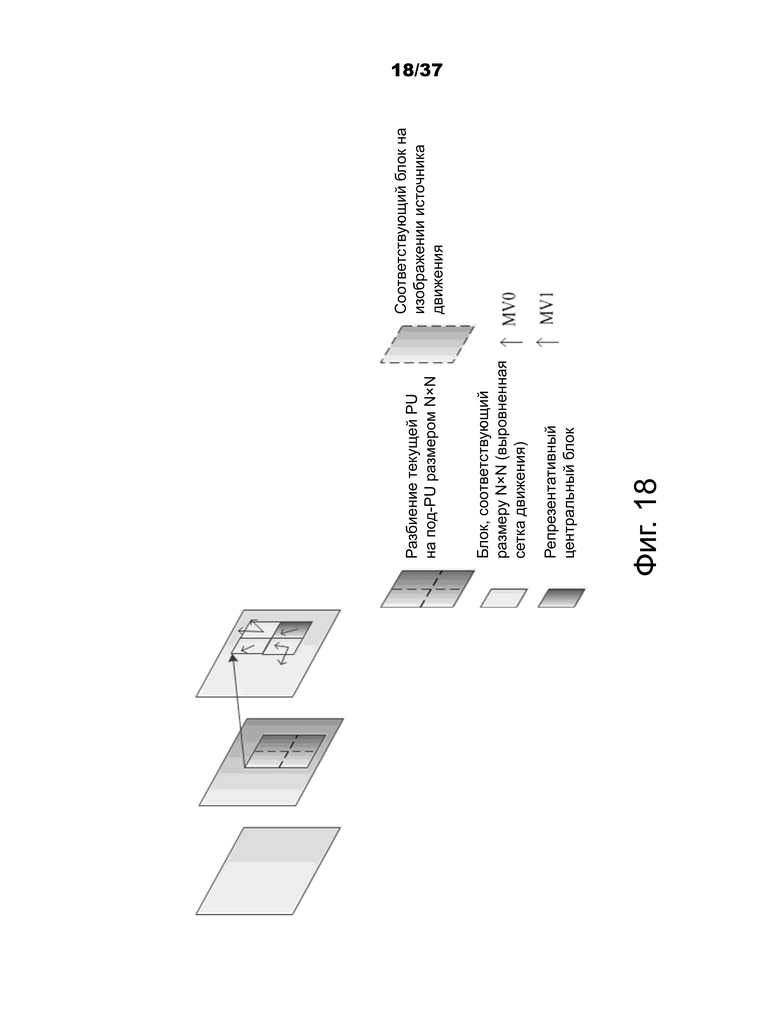
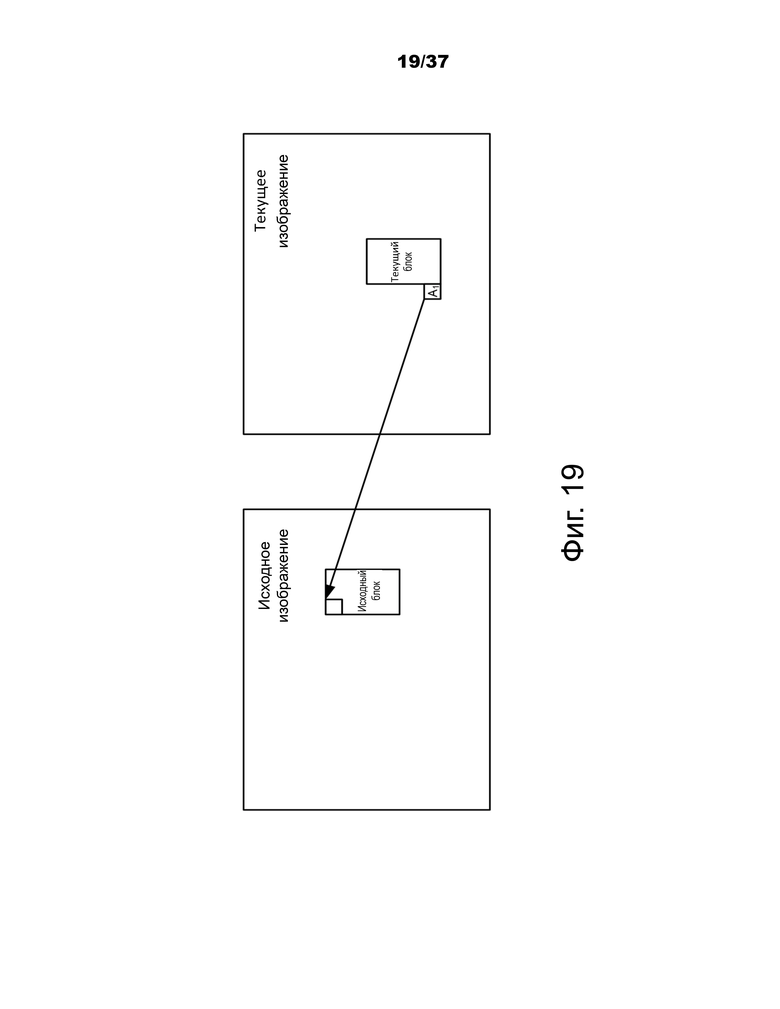
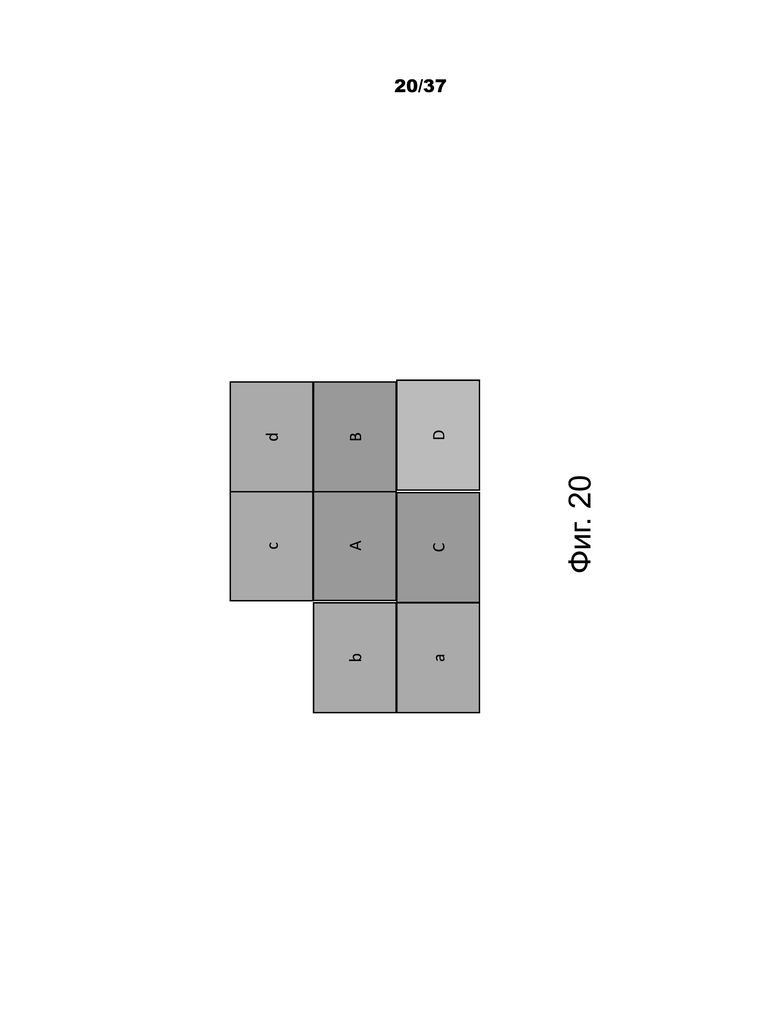
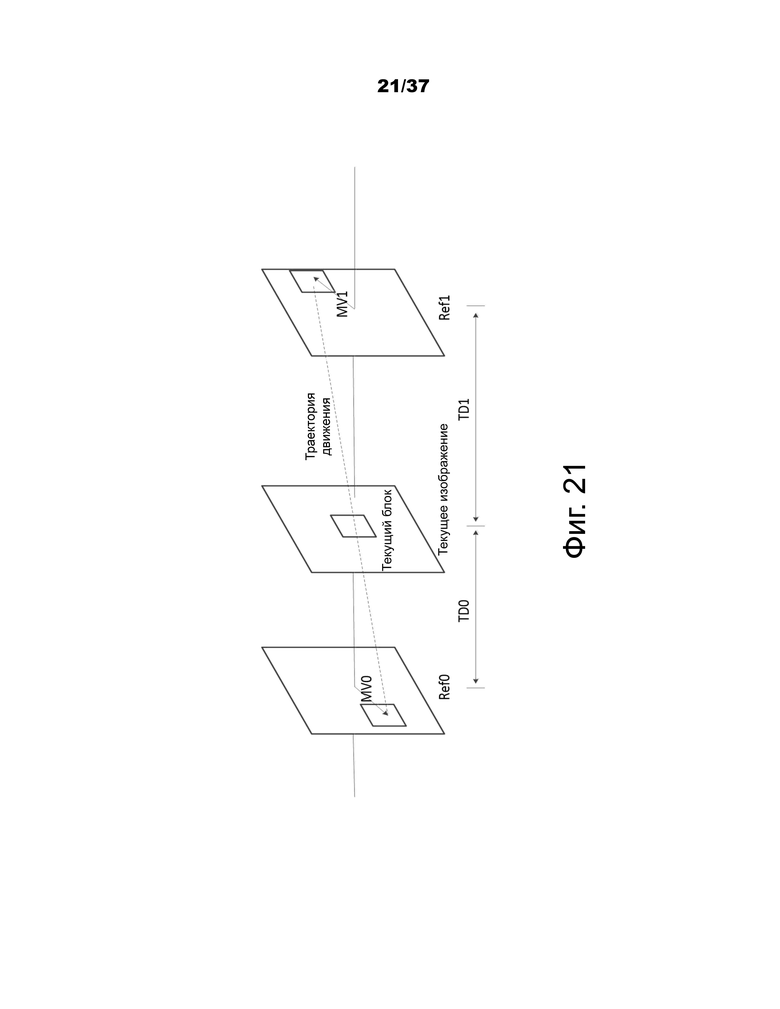
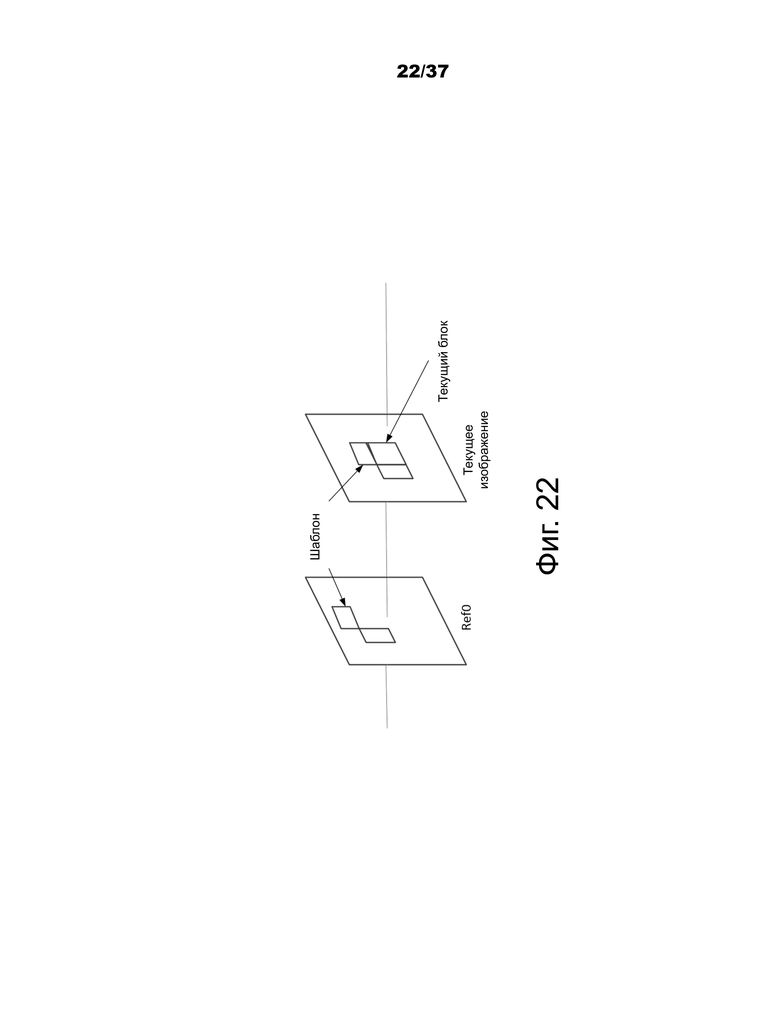
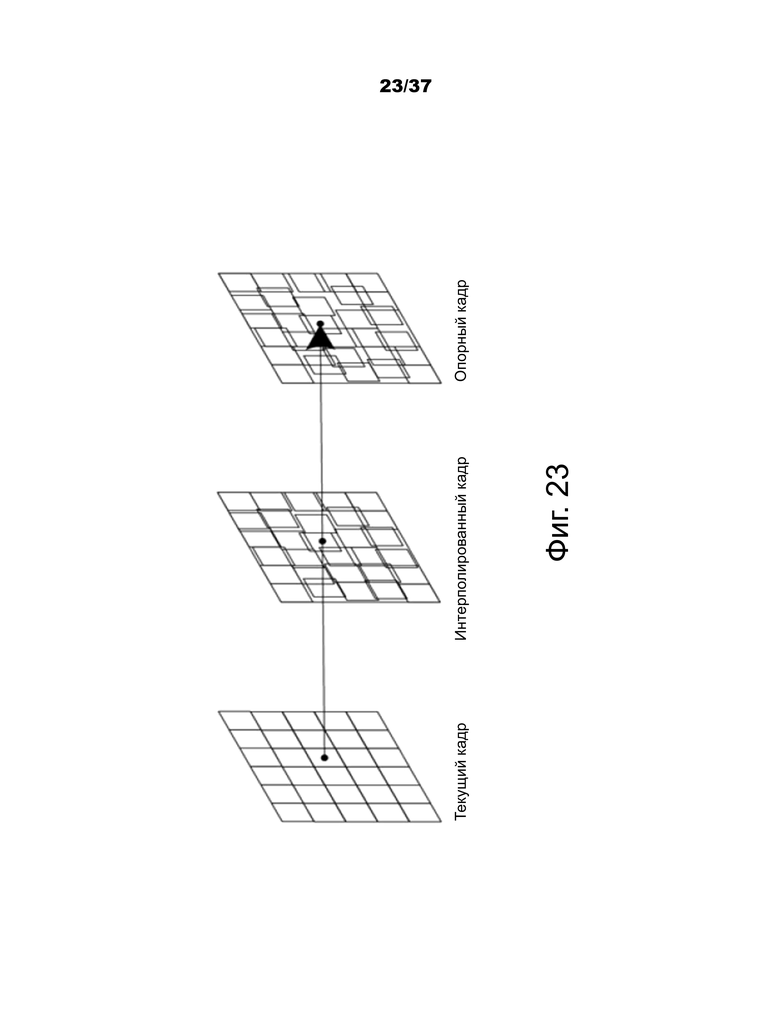
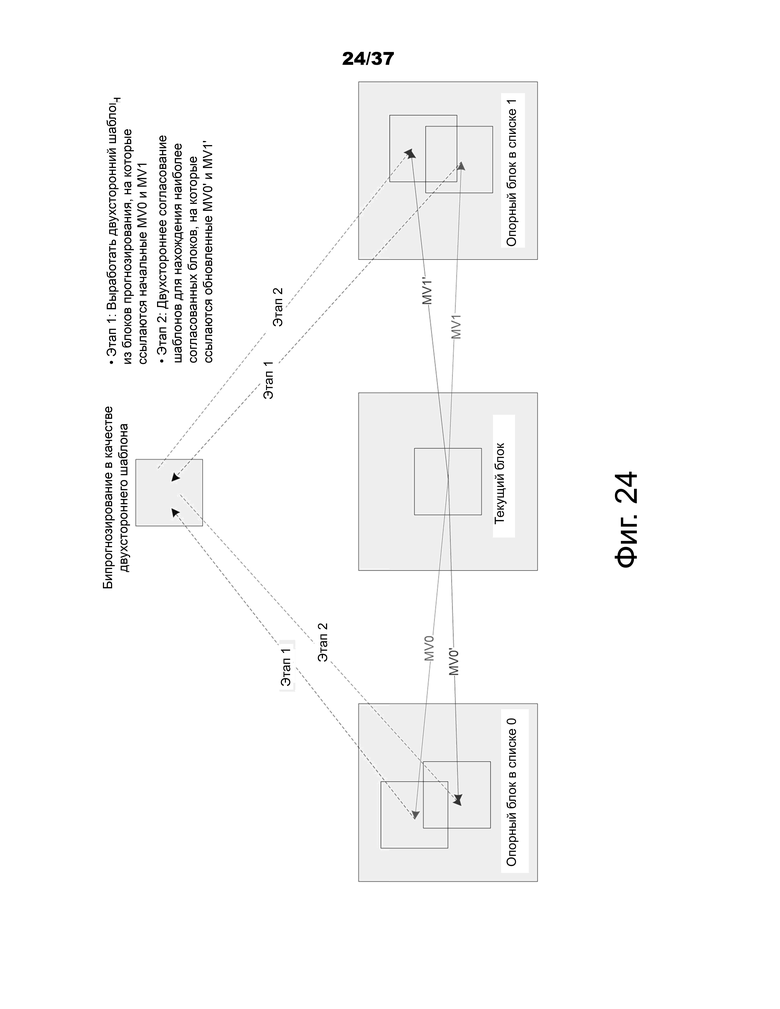
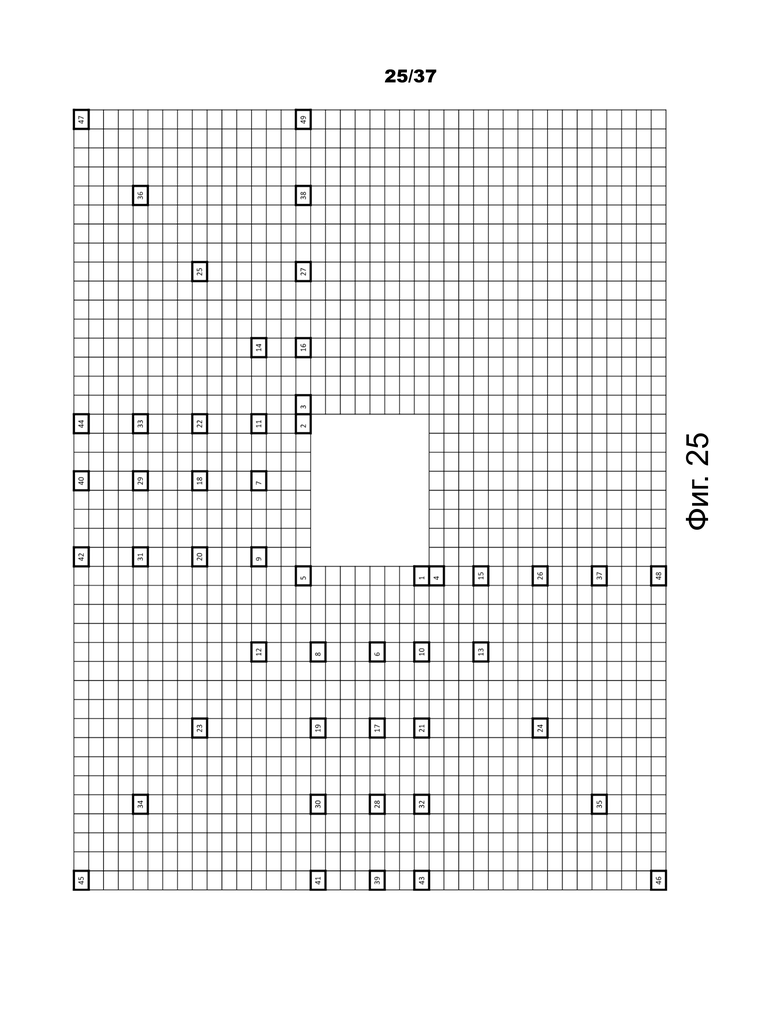
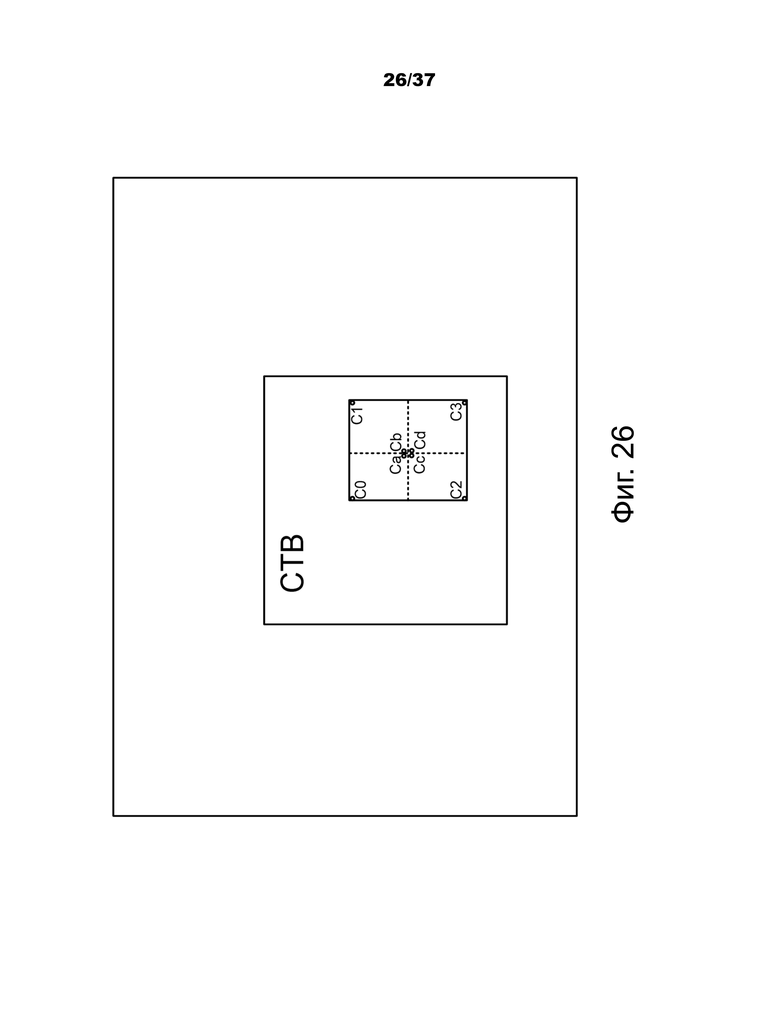
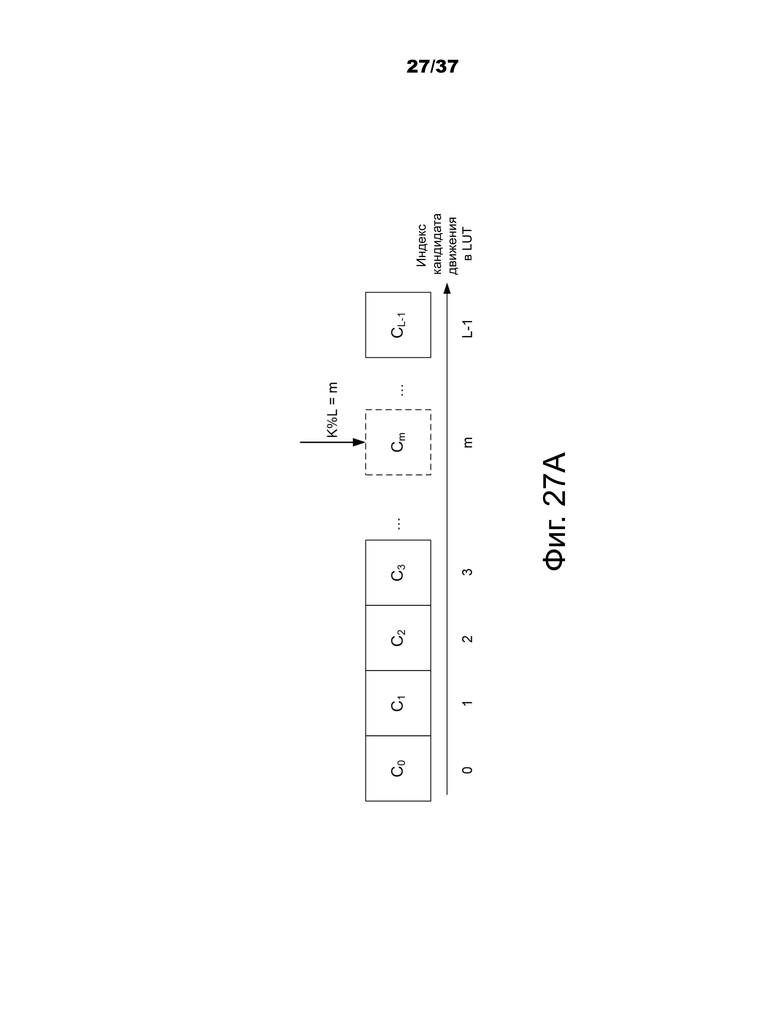
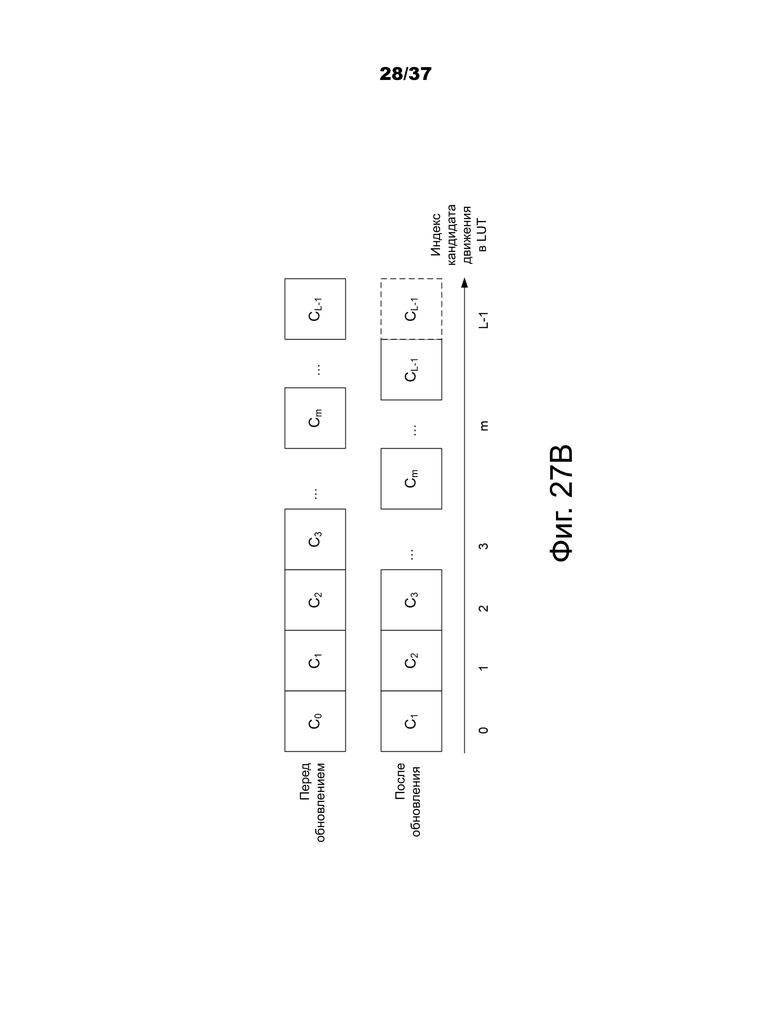
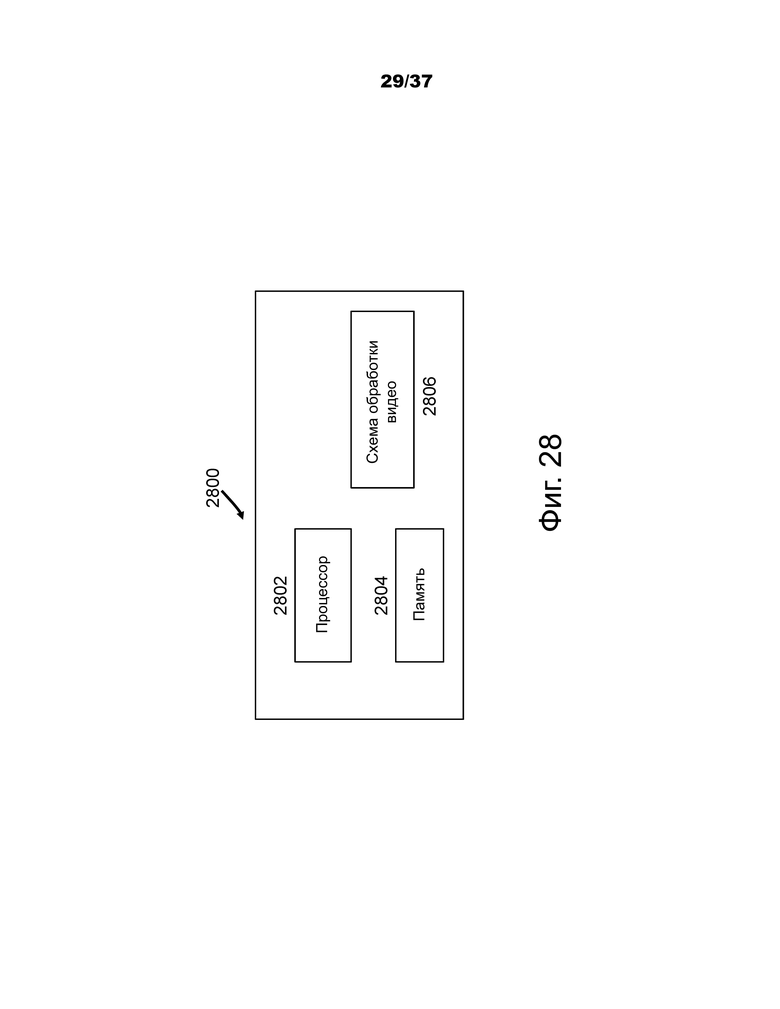
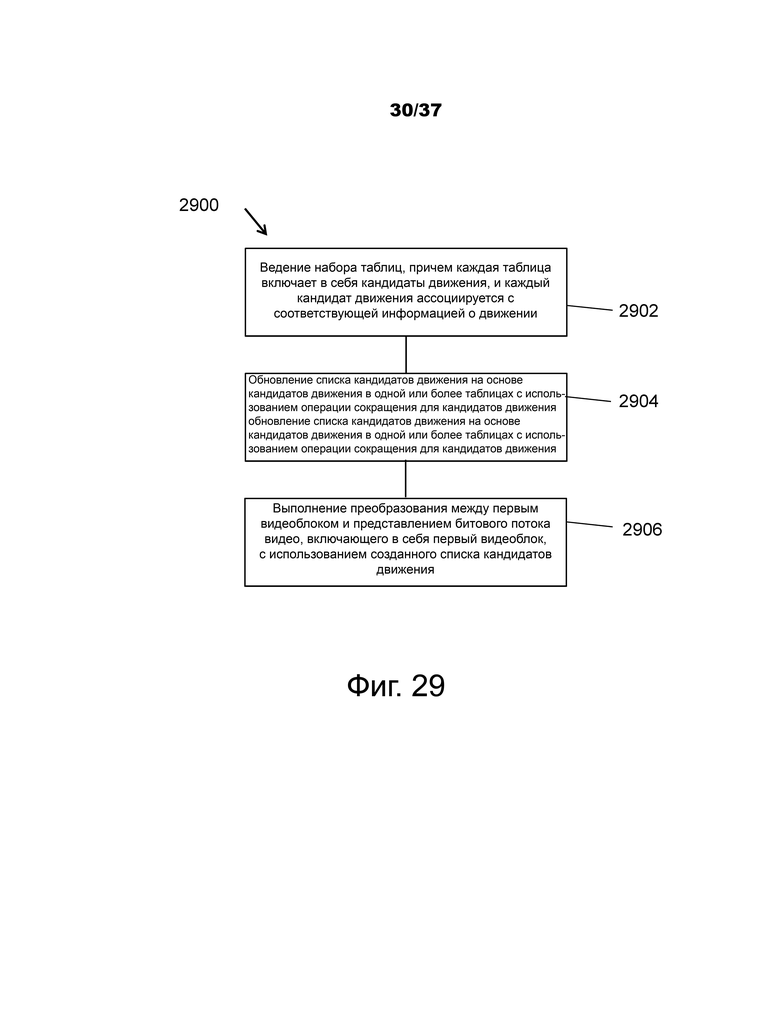
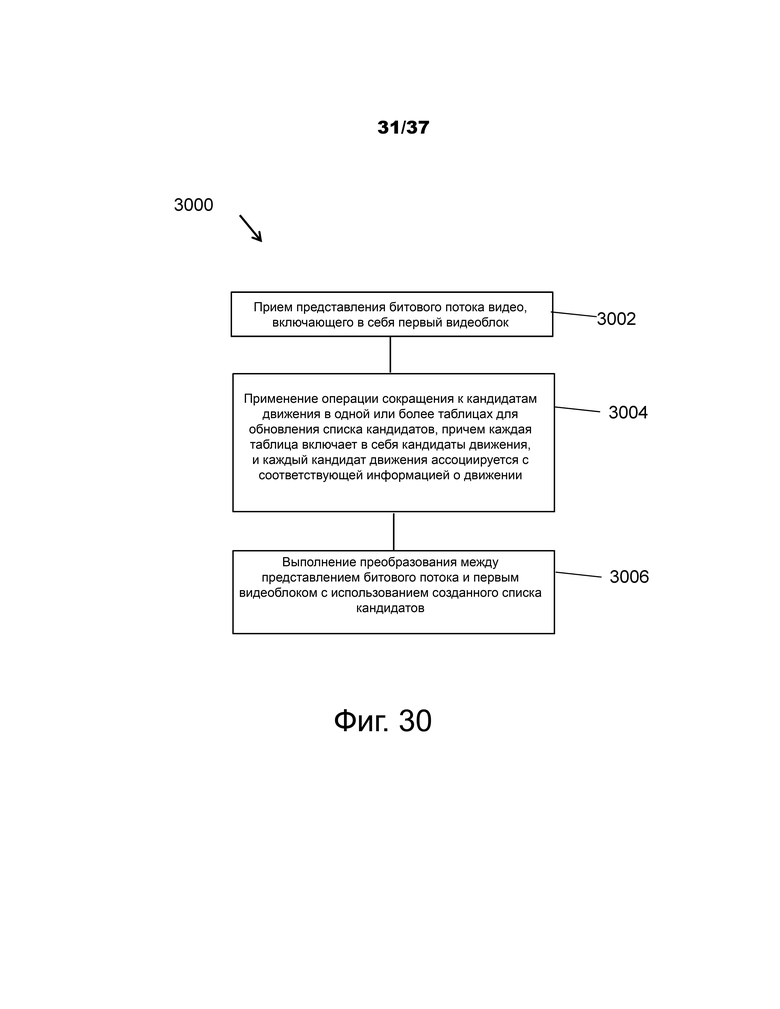
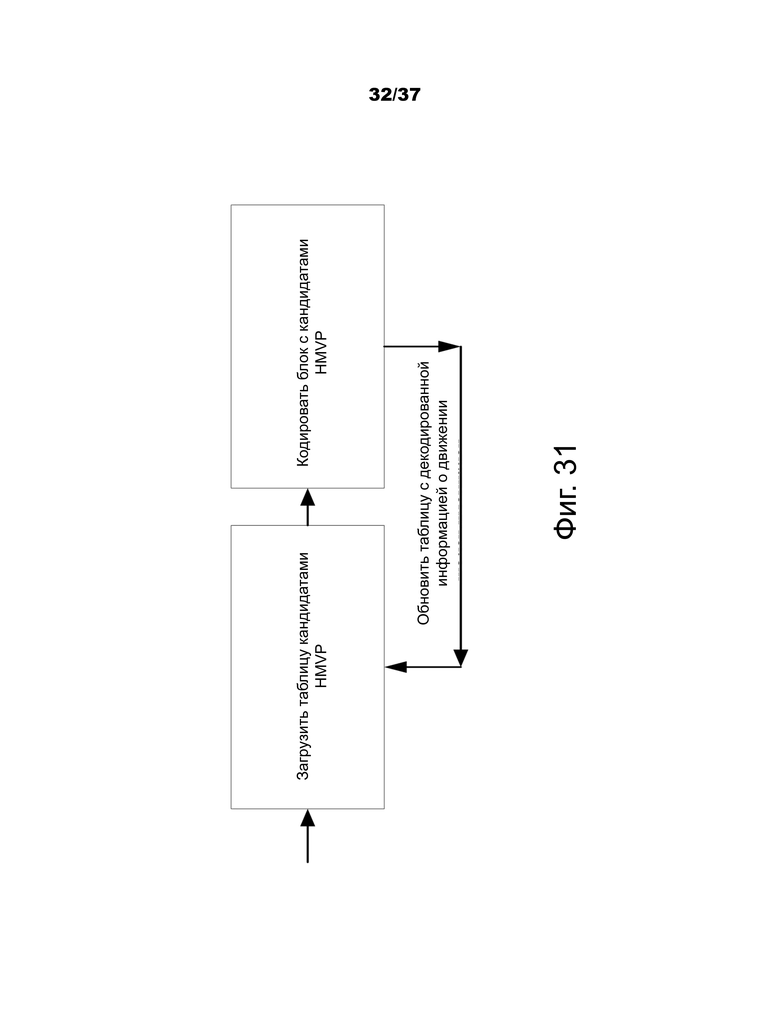
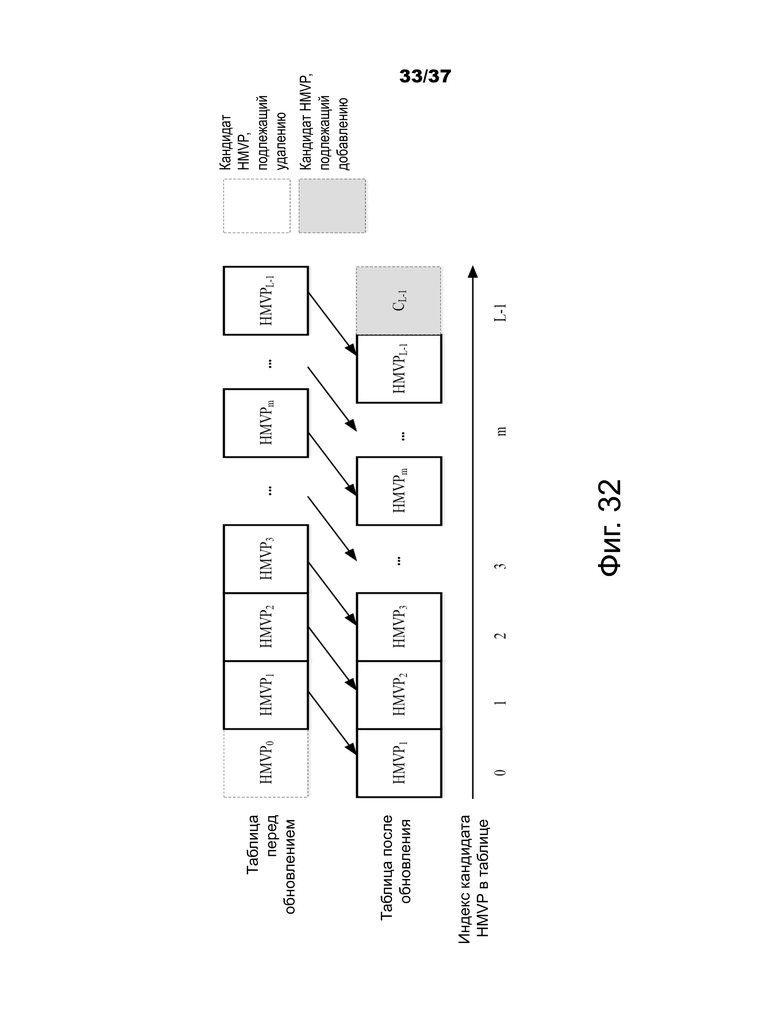
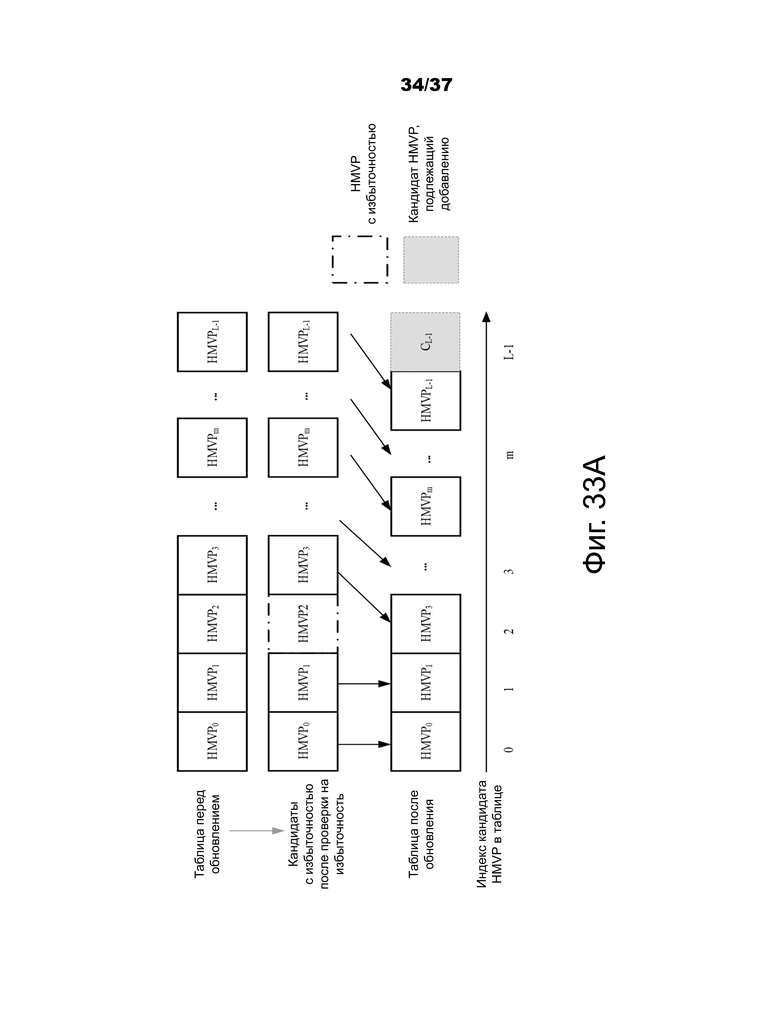
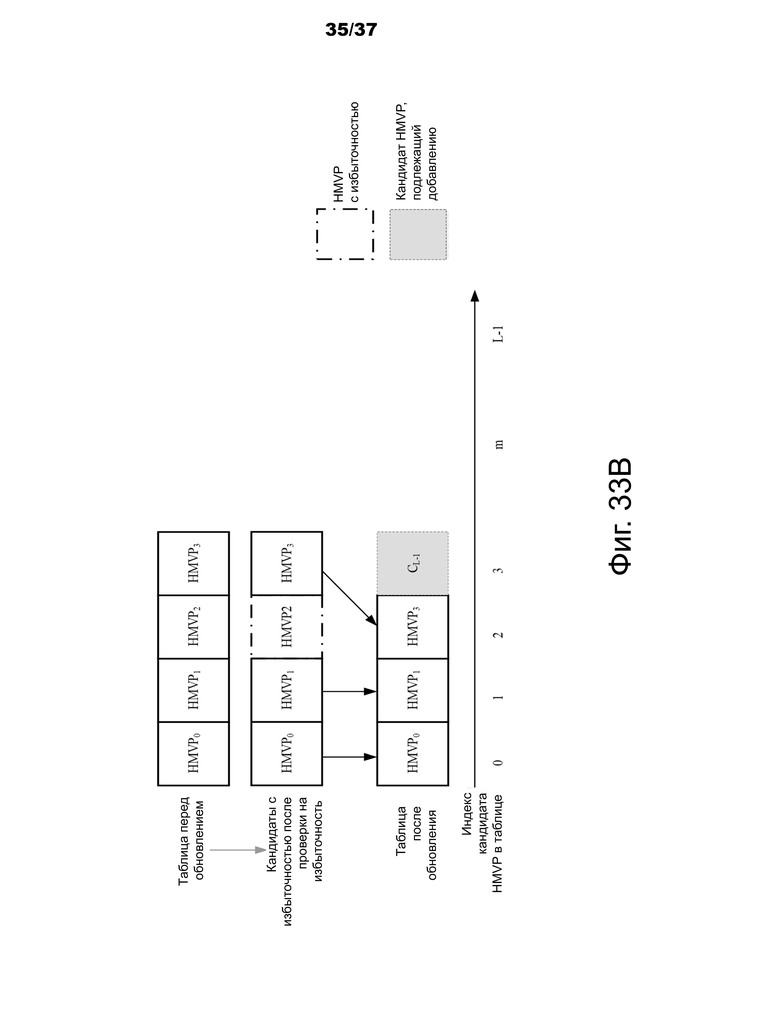
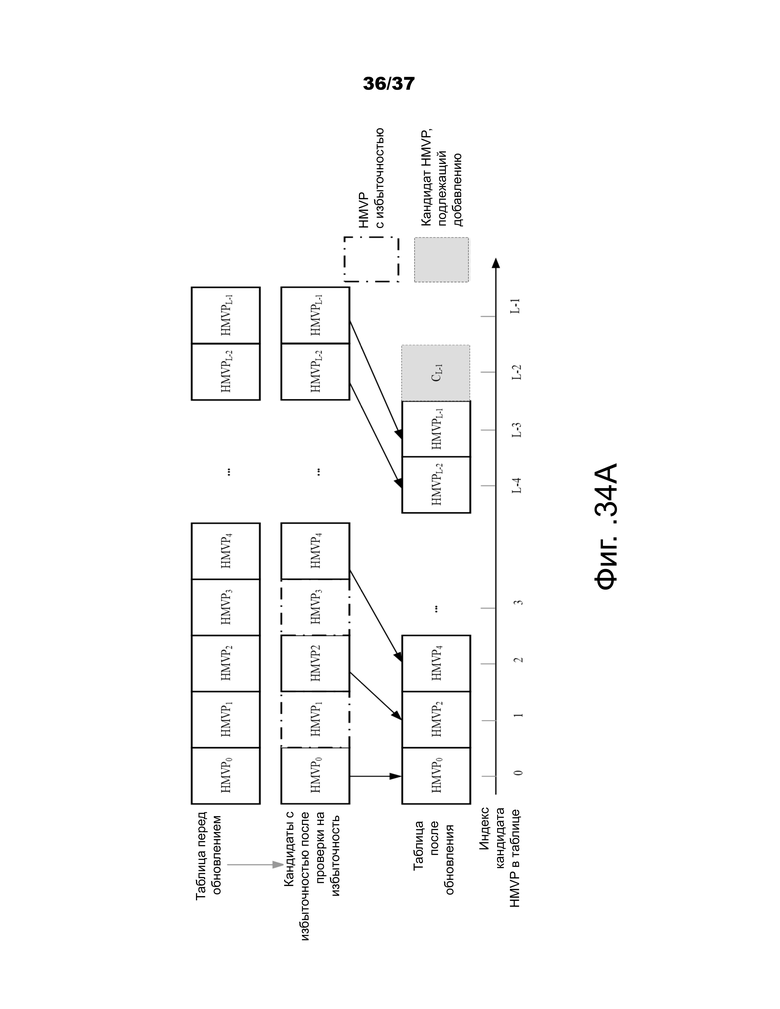
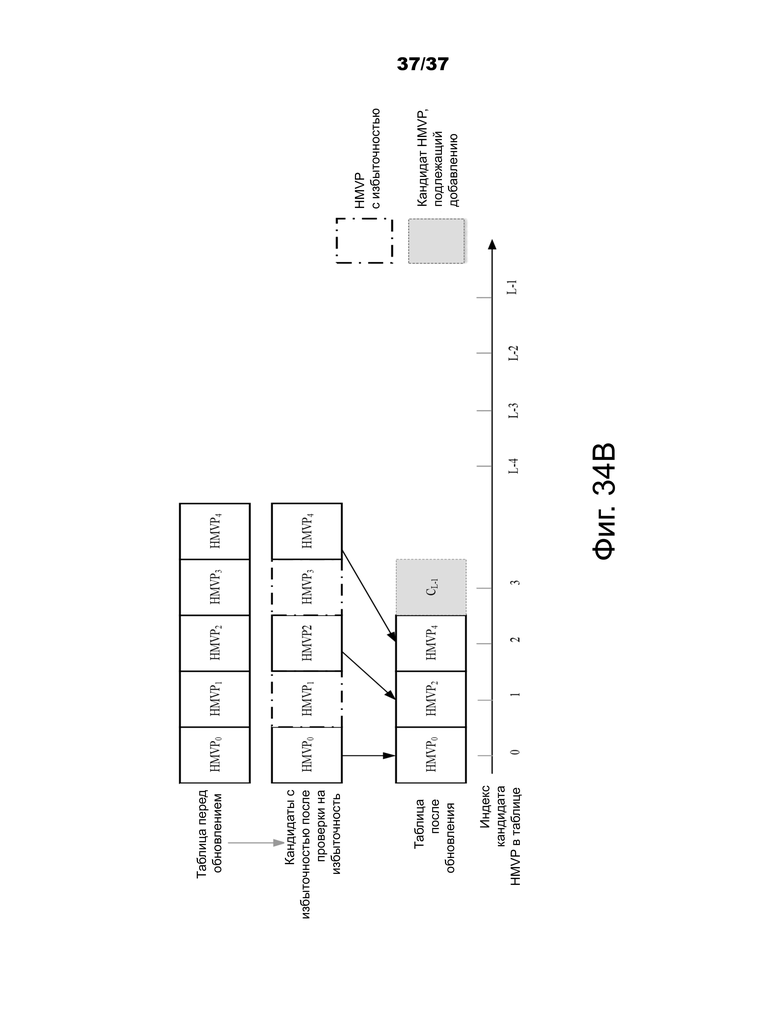
Изобретение относится к технологиям, устройствам и системам кодирования и декодирования видео. Техническим результатом является повышение степени сжатия видео. Результат достигается тем, что способ обработки видео включает в себя: введение набора таблиц, причем каждая таблица включает в себя кандидаты движения, и каждый кандидат движения ассоциируется с соответствующей информацией о движении; обновление списка кандидатов движения на основе кандидатов движения в одной или более таблицах с использованием операции сокращения кандидатов движения; и выполнение преобразования между первым видеоблоком и представлением битового потока видео, включающего в себя первый видеоблок, с использованием созданного списка кандидатов движения. 4 н. и 14 з.п. ф-лы, 37 ил., 3 табл.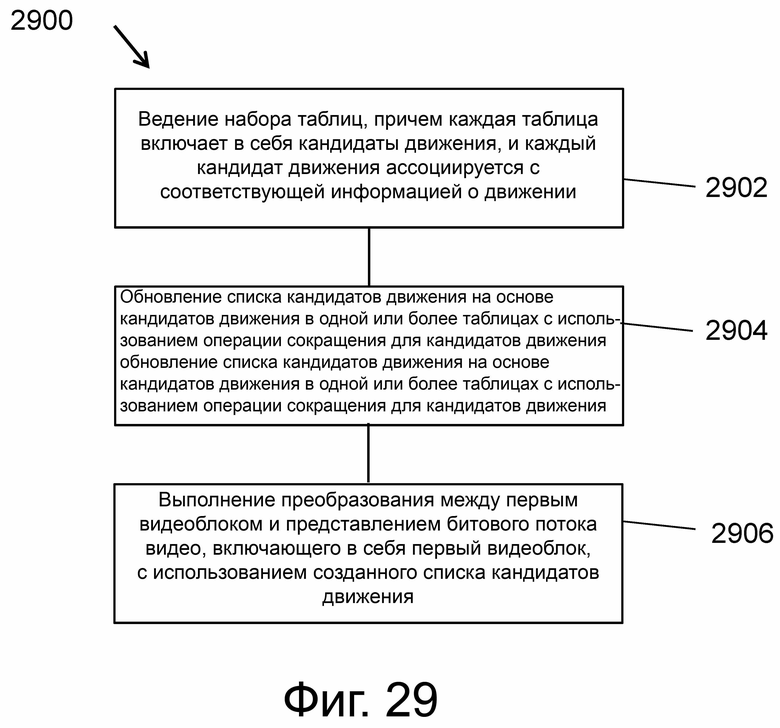
1. Способ обработки видео, содержащий этапы, на которых:
вводят таблицу, причем таблица включает в себя одного или более кандидатов, полученных из одного или более видеоблоков, подлежащих кодированию, и размещают кандидатов в таблицу на основе последовательности добавления кандидатов в таблицу;
создают список кандидатов, причем по меньшей мере один первый кандидат в таблице является проверенным во время создания, при этом для указанного по меньшей мере одного первого кандидата используется операция сокращения для определения, добавлен ли первый кандидат в список кандидатов;
получают информацию движения с использованием списка кандидатов;
кодируют текущий видеоблок на основе информации движения, причем
указанный по меньшей мере один первый кандидат является сокращенным по меньшей мере одним вторым кандидатом, включенным в список кандидатов, каждый из по меньшей мере одного второго кандидата выбран из списка кандидатов на основе того, откуда получен каждый из них, причем второй кандидат является пространственным кандидатом, полученным из заданного пространственного соседнего блока для текущего видеоблока; и
общее количество по меньшей мере одного второго кандидата равно К, где К равно или менее 2.
2. Способ по п. 1, в котором по меньшей мере один второй кандидат содержит одного первого кандидата или N кандидатов в списке кандидатов, где N целое число, большее 1.
3. Способ по п. 1, в котором по меньшей мере один второй кандидат содержит по меньшей мере одного пространственного кандидата, полученного из блока А1, или пространственного кандидата, полученного из блока В1; причем блок А1 является левым соседним блоком относительно текущего видеоблока, а блок В1 является соседним сверху блоком относительно текущего видеоблока.
4. Способ по п. 1, в котором по меньшей мере один второй кандидат является частью кандидатов из списка кандидатов.
5. Способ по п. 4, в котором указанная часть кандидатов из списка кандидатов являются пространственными кандидатами.
6. Способ по п. 1, в котором когда по меньшей мере один первый кандидат отличается от по меньшей мере одного второго кандидата, указанный кандидат добавляется в список кандидатов.
7. Способ по п. 1, в котором по меньшей мере один второй кандидат не содержит кандидатов на основе подблоков.
8. Способ по п. 1, в котором операция сокращения не вызывается при добавлении кандидата из таблицы в список кандидатов.
9. Способ по п. 1, в котором кандидаты в таблице ассоциированы с информацией движения, включающей в себя по меньшей мере одно из: направления предсказания, индекса опорного кадра, значения вектора движения, флага компенсации интенсивности, аффинного флага, точности разности вектора движения и значения разности вектора движения.
10. Способ по п. 1, дополнительно содержащий этап, на котором обновляют таблицу с использованием информации движения, добавленной в список.
11. Способ по п. 10, в котором удаляют кандидата из таблицы, когда таблица полностью заполняется до добавления кандидата, соответствующего информации движения, в список.
12. Способ по п. 1, в котором список кандидатов является объединенным списком кандидатов.
13. Способ по п. 1, в котором этап кодирования содержит кодирование текущего видеоблока в поток битов.
14. Способ по п. 1, в котором этап кодирования содержит декодирование текущего видеоблока из потока битов.
15. Способ по п. 1, в котором проверка является завершенной, когда количество кандидатов, в списке кандидатов, достигает максимально допустимого количества кандидатов в списке кандидатов минус пороговое значение, причем пороговое значение является положительным целым числом.
16. Устройство кодирования видеоданных, содержащее процессор и энергонезависимую память, хранящую инструкции, вызывающие, при их исполнении процессором, выполнение процессором:
вводят таблицу, причем таблица включает в себя одного или более кандидатов, полученных из ранее кодированных видеоблоков, кодированных до текущего видеоблока, и размещают кандидатов в таблицу на основе последовательности добавления кандидатов в таблицу;
создают список кандидатов, причем во время создания используют таблицу, при этом для по меньшей мере одного первого кандидата в таблице используется операция сокращения для определения, добавлен ли первый кандидат в список кандидатов;
получают информацию движения с использованием списка кандидатов;
кодируют текущий видеоблок на основе информации движения, причем
указанный по меньшей мере один первый кандидат является сокращенным по меньшей мере одним вторым кандидатом, включенным в список кандидатов, каждый из по меньшей мере одного второго кандидата выбран из списка кандидатов на основе того, откуда получен каждый из них, причем второй кандидат является пространственным кандидатом, полученным из заданного пространственного соседнего блока для текущего видеоблока; и
общее количество по меньшей мере одного второго кандидата равно К, где К равно или менее 2.
17. Энергонезависимый машиночитаемый носитель информации, хранящий инструкции, вызывающие выполнение процессором:
вводят таблицу, причем таблица включает в себя одного или более кандидатов, полученных из ранее кодированных видеоблоков, кодированных до текущего видеоблока, и размещают кандидатов в таблицу на основе последовательности добавления кандидатов в таблицу;
создают список кандидатов, причем во время создания используют таблицу, при этом для по меньшей мере одного первого кандидата в таблице используется операция сокращения для определения, добавлен ли первый кандидат в список кандидатов;
получают информацию движения с использованием списка кандидатов;
кодируют текущий видеоблок на основе информации движения, причем
указанный по меньшей мере один первый кандидат является сокращенным по меньшей мере одним вторым кандидатом, включенным в список кандидатов, каждый из по меньшей мере одного второго кандидата выбран из списка кандидатов на основе того, откуда получен каждый из них, причем второй кандидат является пространственным кандидатом, полученным из заданного пространственного соседнего блока для текущего видеоблока; и
общее количество по меньшей мере одного второго кандидата равно К, где К равно или менее 2.
18. Энергонезависимый машиночитаемый носитель информации, хранящий представление потока битов, сгенерированного посредством способа, реализуемого устройством обработки видео, содержащего этапы, на которых:
вводят таблицу, причем таблица включает в себя одного или более кандидатов, полученных из одного или более видеоблоков, подлежащих кодированию, и размещают кандидатов в таблицу на основе последовательности добавления кандидатов в таблицу;
создают список кандидатов, причем по меньшей мере один первый кандидат в таблице является проверенным во время создания, при этом для указанного по меньшей мере одного первого кандидата используется операция сокращения для определения, добавлен ли первый кандидат в список кандидатов;
получают информацию движения с использованием списка кандидатов;
кодируют текущий видеоблок на основе информации движения, причем
указанный по меньшей мере один первый кандидат является сокращенным по меньшей мере одним вторым кандидатом, включенным в список кандидатов, каждый из по меньшей мере одного второго кандидата выбран из списка кандидатов на основе того, откуда получен каждый из них, причем второй кандидат является пространственным кандидатом, полученным из заданного пространственного соседнего блока для текущего видеоблока; и
общее количество по меньшей мере одного второго кандидата равно К, где К равно или менее 2.
| US 20110194609 A1, 2011.08.11 | |||
| US 20140161186 A1, 2014.06.12 | |||
| US 20170332099 A1, 2017.11.16 | |||
| US 20130128982 A1, 2013.05.23 | |||
| WO 2015180014 A1, 2015.12.03 | |||
| US 20170006302 A1, 2017.01.05 | |||
| WO 2017058633 A1, 2017.04.06 | |||
| ВЫПОЛНЕНИЕ ПРЕДСКАЗАНИЯ ВЕКТОРА ДВИЖЕНИЯ ДЛЯ ВИДЕОКОДИРОВАНИЯ | 2012 |
|
RU2550554C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ СОВМЕСТНОГО ИСПОЛЬЗОВАНИЯ СПИСКА КАНДИДАТОВ | 2016 |
|
RU2632158C2 |

