ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к области голосовых взаимодействий и, в частности, сохраняет конфиденциальность пользователей в многопользовательской среде помощников по дому.
УРОВЕНЬ ТЕХНИКИ
Настоящий раздел предназначен для ознакомления читателя с различными аспектами данной области техники, которые могут быть связаны с различными аспектами настоящего изобретения, описываемыми и/или заявляемыми ниже. Предполагается, что обсуждаемая тема поможет представить вниманию читателя дополнительную информацию для улучшения понимания различных аспектов настоящего изобретения. В этой связи следует понимать, что приведенные выше высказывания следует воспринимать в свете этого, а не как признания уровня техники.
Использование в жилой среде голосового управления с помощью устройств виртуального помощника по дому, таких как Amazon Echo или Google Home, а также служб виртуального помощника по дому, таких как Microsoft Cortana или Apple Siri, стало реальностью массового рынка; такие устройства или службы используются в миллионах домов. Устройство виртуального помощника по дому захватывает естественную речь пользователей жилого дома с помощью микрофонов, анализирует пользовательский запрос и обеспечивает соответствующий отклик или службу. В выполняемых запросах могут применяться домашние устройства (например: выключение звука телевизора, закрывание жалюзи и т.д.), но также и внешние службы (например: поиск прогноза погоды или стоимости акций, получение справки о неисправности устройства и т.д.). Кроме того, последнее поколение устройства виртуального помощника по дому осуществляет также распознавание говорящего. Такое распознавание обеспечивает множество функций, таких как контроль доступа (например: ребенок не может настраивать домашнюю сеть, не может осуществлять доступ к фильмам для взрослых и т.д.), персонализация взаимодействий (например: словарь взаимодействия может адаптироваться к категории говорящего, выбираемой из младших детей, подростков, взрослых или пожилых). Однако это достигается ценой пониженной конфиденциальности пользователя. Действительно, анализ речи и логика разговора, которые используются в таких экосистемах голосового взаимодействия, традиционно осуществляются вне домашней среды, как правило, в облаке.
Поэтому можно понять, что имеется необходимость в решении для распознавания говорящего в жилой среде, в котором решаются, по меньшей мере, некоторые из проблем уровня техники. Такое решение предлагается в настоящем изобретении.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В настоящем изобретении описываются устройство и способ виртуального помощника по дому для голосовых взаимодействий с сохранением конфиденциальности. Микрофон захватывает звуковой сигнал, соответствующий голосовому пользовательскому запросу. Определяются идентификационные данные говорящего, и генерируется замаскированное имя, соответствующее идентифицированному говорящему. Анализируется звуковой сигнал для определения намерения пользователя, и генерируется персонализированный ответ в совокупности с замаскированным именем. Этот ответ затем демаскируется путем повторного представления имени говорящего. Такой демаскированный ответ затем передается говорящему.
В первом аспекте данное изобретение относится к устройству для выполнения голосовых взаимодействий с сохранением конфиденциальности, содержащему: микрофон, выполненный с возможностью захвата звукового сигнала, характеризующего голосовое произнесение, связанное с запросом от говорящего; идентификатор говорящего, выполненный с возможностью определения идентификационных данных говорящего по захватываемому звуковому сигналу; контроллер конфиденциальности, выполненный с возможностью генерирования замаскированного имени говорящего, соответствующего идентифицированному говорящему, и хранения списка соответствий между именами говорящих и замаскированными именами говорящих; интерфейс передачи данных, выполненный с возможностью выдачи во внешнее устройство захватываемого звукового сигнала и замаскированного имени говорящего; приема от внешнего устройства ответа на запрос говорящего; причем контроллер конфиденциальности дополнительно выполнен с возможностью определения того, содержит ли принятый ответ замаскированное имя говорящего из списка, и в этом случае замены в принятом ответе замаскированного имени говорящего соответствующим именем, благодаря чему генерируется демаскированный ответ.
В первом варианте первого аспекта принимаемый ответ находится в текстовой форме, а устройство дополнительно содержит преобразователь текста в речь, выполненный с возможностью преобразования демаскированного ответа из текстовой формы в звуковой сигнал.
Во втором варианте первого аспекта принимаемый ответ находится в звуковом формате, а контроллер конфиденциальности дополнительно выполнен с возможностью маскирования захватываемого звукового сигнала путем обнаружения имени говорящего из списка и замены его звуковым сигналом, характеризующим соответствующее замаскированное имя говорящего.
В третьем варианте первого аспекта контроллер конфиденциальности дополнительно содержит настройку для включения или выключения режима инкогнито, причем в первом случае контроллер конфиденциальности маскирует имя говорящего перед его выдачей и демаскирует принимаемый ответ, когда он содержит замаскированное имя говорящего, а во втором случае контроллер конфиденциальности более не маскирует имя говорящего и более не определяет, содержит ли принимаемый ответ замаскированное имя говорящего.
Во втором аспекте данное изобретение относится к способу выполнения голосовых взаимодействий с сохранением конфиденциальности, включающему в себя: захват звукового сигнала, характеризующего голосовое произнесение, связанное с запросом от говорящего; идентификацию говорящего по захватываемому звуковому сигналу; генерирование замаскированного имени говорящего, соответствующего идентифицированному говорящему, и сохранение списка соответствий между именами говорящих и замаскированными именами говорящих; выдачу во внешнее устройство захватываемого звукового сигнала и замаскированного имени говорящего; получение от внешнего устройства ответа на запрос говорящего; определение того, содержит ли принятый ответ замаскированное имя говорящего из списка, и в этом случае замену в принятом ответе замаскированного имени говорящего соответствующим именем, благодаря чему генерируется демаскированный ответ; и выдачу ответа говорящему.
В первом варианте второго аспекта принимаемый ответ находится в текстовой форме, а способ дополнительно включает в себя обнаружение имени говорящего из списка и замену его звуковым сигналом, характеризующим соответствующее замаскированное имя говорящего.
Второй вариант второго аспекта дополнительно включает в себя настройку для включения или выключения режима инкогнито, причем, в первом случае маскируют имя говорящего перед его выдачей и демаскируют принимаемый ответ, когда он содержит замаскированное имя говорящего, а во втором случае более не маскируют имя говорящего и более не определяют, содержит ли принимаемый ответ замаскированное имя говорящего.
Третий вариант второго аспекта включает в себя обновление замаскированных имен говорящих.
В третьем аспекте данное изобретение относится к компьютерной программе, содержащей команды программного кода, исполнимые процессором, для реализации любого варианта осуществления способа второго аспекта.
В четвертом аспекте данное изобретение относится к компьютерному программному продукту, который хранится на энергонезависимом машиночитаемом носителе и содержит команды программного кода, исполнимые процессором, для реализации любого варианта осуществления способа второго аспекта.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Предпочтительные признаки настоящего изобретения описываются далее в качестве неограничительного примера со ссылкой на прилагаемые чертежи, на которых:
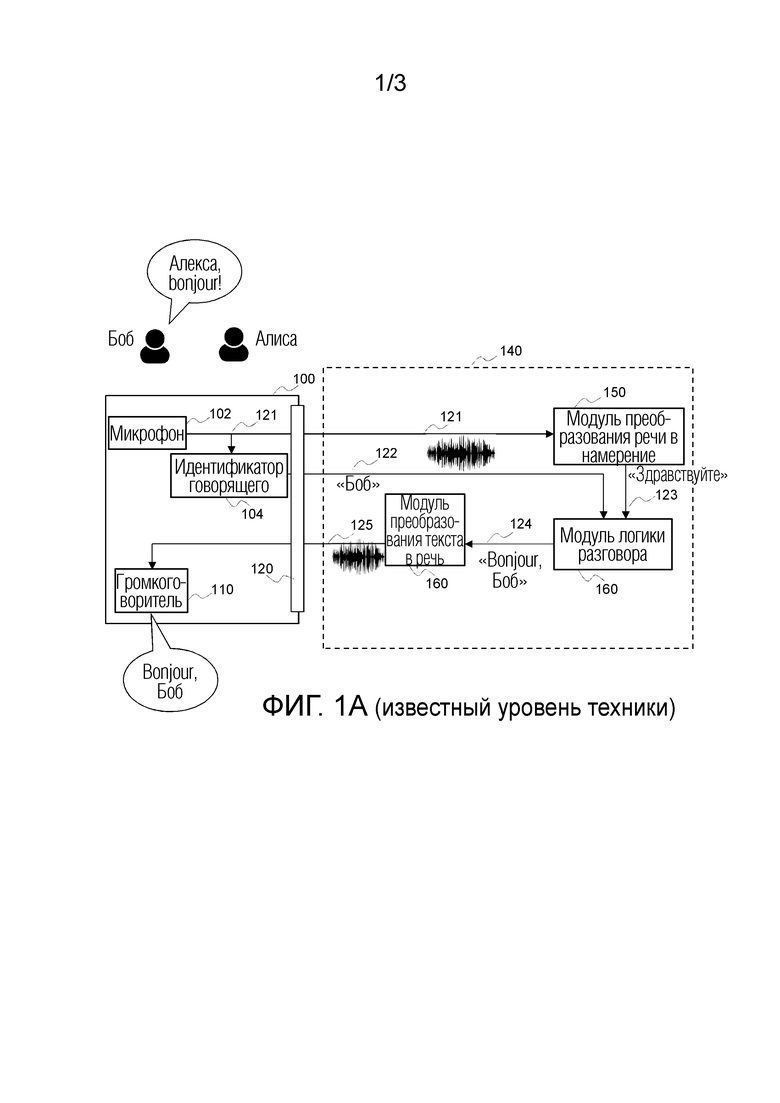
фиг. 1А иллюстрирует пример экосистемы виртуального помощника по дому в соответствии с уровнем техники,
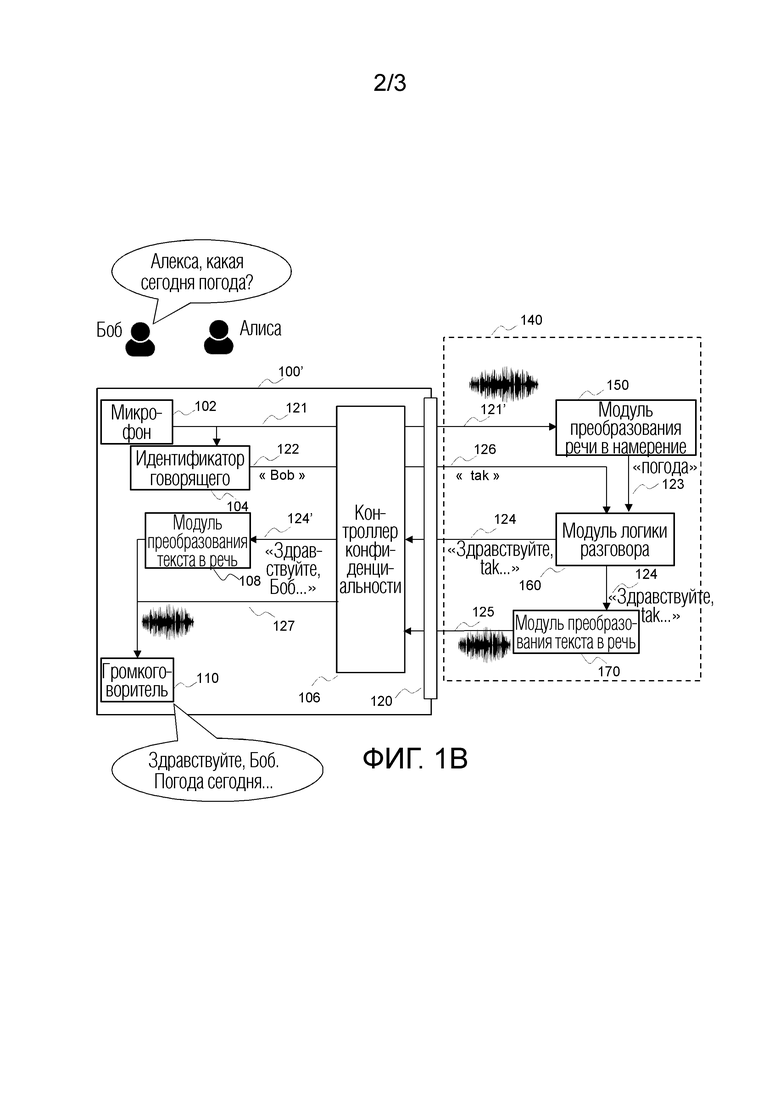
фиг. 1В иллюстрирует пример экосистемы виртуального помощника по дому, в которой может быть реализована, по меньшей мере, часть данного изобретения,
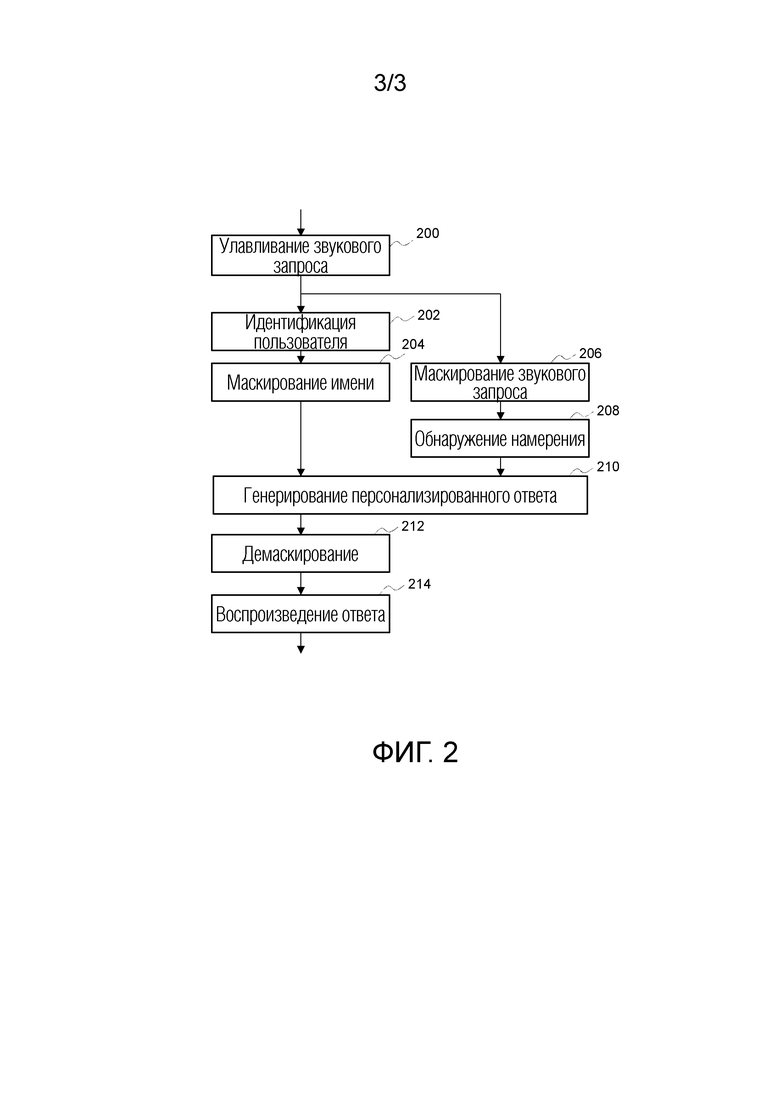
фиг. 2 иллюстрирует пример структурной схемы способа голосового взаимодействия с сохранением конфиденциальности в соответствии с одним из вариантов осуществления изобретения.
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Фиг. 1А иллюстрирует пример экосистемы виртуального помощника по дому в соответствии с уровнем техники. Специалисту в данной области техники будет понятно, что для наглядности изображенное устройство упрощено. Экосистема виртуального помощника по дому содержит, по меньшей мере, устройство 100 виртуального помощника по дому, которое взаимодействует с поставщиками услуг посредством интерфейса 120 передачи данных. Поставщики услуг предлагают пользователю множество услуг с той особенностью, что эти услуги основаны на голосовых взаимодействиях и персонализированы для отдельных пользователей. Услуги предоставляются специализированными программными приложениями, которые взаимодействуют для ответа на запрос говорящего. Эти программные приложения традиционно исполняются на внешних устройствах, как правило, в облаке и могут осуществляться единым оператором 140 услуг, как показано на фиг. 1А, или могут быть разделены между множеством взаимодействующих поставщиков услуг.
Устройство виртуального помощника по дому содержит микрофон 102 для захвата генерируемых пользователем голосовых произнесений, создающих голосовой запрос, и генерирования соответствующего звукового сигнала 121. Модуль 104 идентификатора говорящего анализирует звуковой сигнал 121 для идентификации говорящего из группы пользователей жилого дома и выдает идентификационные данные 122 говорящего поставщику 140 услуг. Модуль 150 преобразования речи в намерение принимает звуковой сигнал 121, анализирует его, преобразует его в текст и генерирует намерение. Функция преобразования речи в намерение отличается от функции преобразования речи в текст. Действительно, намерение соответствует концепции и является более общим, чем простое распознанное слово. Например, намерение может представлять собой «здравствуйте», когда говорящие произносят «гутен таг» («guten Tag»), «бонжур» («bonjour»), «хай» («hi») и т.д. Модуль 160 логики разговора принимает намерение 123 и идентификационные данные 122 говорящего. Зная о предыдущих взаимодействиях с говорящим, модуль 160 логики разговора генерирует надлежащий ответ 124 в качестве отклика на последнее намерение. Поскольку модуль логики разговора знает идентификационные данные говорящего, он персонализирует ответ, например, вставляя в отклик имя говорящего. Ответ 124 представляет собой текстовую строку и выдается в модуль 160 преобразования текста в речь, который преобразует его в звуковой сигнал 125, передаваемый в устройство виртуального помощника по дому и воспроизводимый в громкоговорителе 110.
Например, как показано на фиг. 1A, когда пользователь Боб желает взаимодействовать с экосистемой, он начинает с простого запроса: «Алекса, бонжур!» в случае экосистемы Amazon. Экосистема ответит, сказав: «Бонжур, Боб», тем самым персонализируя отклик путем вставления имени распознанного говорящего.
При использовании такой настройки устройство 100 виртуального помощника по дому выдает поставщикам услуг идентификационные данные говорящего. Однако пользователи не всегда хотят, чтобы их идентификационные данные раскрывались, и ожидают улучшений в отношении их конфиденциальности.
Фиг. 1В иллюстрирует пример экосистемы виртуального помощника по дому, в которой может быть реализована, по меньшей мере, часть данного изобретения. Экосистема виртуального помощника по дому содержит ориентированное на конфиденциальность устройство 100' виртуального помощника по дому и может использоваться с точно такой же средой 140 оператора услуг, как и в системе уровня техники, описанной на фиг. 1А, при этом улучшая конфиденциальность говорящего.
Устройство 100' виртуального помощника по дому содержит микрофон 102, выполненный с возможностью захвата звука от пользователей, идентификатор 104 говорящего, выполненный с возможностью обнаружения идентификационных данных говорящего среди пользователей жилого дома, контроллер 106 конфиденциальности, выполненный с возможностью маскирования идентификационных данных говорящего в исходящих данных путем замены имени говорящего временным именем и вставки его назад во входящие данные, опциональный преобразователь 108 текста в речь, выполненный с возможностью преобразования текстовых ответов в голосовой сигнал, громкоговоритель 110, выполненный с возможностью выдачи звукового сигнала, и интерфейс 120 передачи данных. Устройство 100' виртуального помощника по дому также содержит прочие элементы, которые не показаны, поскольку они не имеют отношения к данному изобретению (такие как кнопки для конфигурирования системы, источник питания для приведения в действие электронных компонентов, звуковой усилитель для возбуждения громкоговорителя и т.д.), но важны для работы устройства. Устройство 100' виртуального помощника по дому может быть реализовано в виде автономного устройства или может быть встроено в традиционное бытовое устройство, такое как телевизионная приставка, межсетевой шлюз, телевизор, компьютер, смартфон, планшет и т.д.
Интерфейс 120 передачи данных выполнен с возможностью взаимодействия с внешними устройствами, такими как серверы данных и процессоры в облаке, выполняющими, по меньшей мере, функции преобразования речи в намерение и разговорной логики. Асимметричная цифровая абонентская линия (ADSL), кабельный модем, 3G или 4G являются примерами интерфейсов передачи данных, которые могут использоваться для этой цели. Могут использоваться и другие интерфейсы передачи данных.
Устройство 100' виртуального помощника по дому работает в одном из двух режимов в зависимости от типа ответа, выдаваемого модулем логики разговора в устройство 100' виртуального помощника по дому. Первый режим используется, когда модуль 160 логики разговора передает ответ в текстовом формате. В этом случае преобразователь 170 текста в речь поставщика 140 услуг не используется, а преобразование звука осуществляется в устройстве 100' виртуального помощника по дому преобразователем 108 текста в речь. Второй режим используется с существующими поставщиками услуг, когда ответ передается в виде звукового сигнала, тем самым используется преобразователь 170 текста в речь поставщика 140 услуг.
В соответствии с предпочтительным вариантом осуществления экосистема виртуального помощника по дому работает в первом режиме. Говорящий генерирует голосовое произнесение, чтобы выполнить голосовой запрос, например: «Алекса, какая сегодня погода?». Микрофон 102 захватывает это голосовое произнесение и генерирует соответствующий звуковой сигнал 121. Модуль 104 идентификатора говорящего анализирует звуковой сигнал 121 и идентифицирует говорящего как являющегося говорящим, который имеет идентификатор XYZ-002 и имя Боб. Такая идентификация, например, осуществляется с использованием традиционных технологий распознавания говорящего, таких как классификация с использованием моделей GMM-UBM (модели смеси Гауссовых распределений - универсальной фоновой модели). Как только говорящий идентифицирован, имя 122 говорящего выдается в контроллер 106 конфиденциальности, который генерирует временное имя 126 (в примере на фиг. 1B: «tak») и выдает его поставщику 140 услуг, тем самым маскируя реальное имя и идентификационные данные говорящего. Контроллер 106 конфиденциальности сохраняет отношение между идентификатором говорящего и замаскированным именем 126. Это осуществляется, например, путем сохранения ассоциации между именем идентифицированного говорящего (или его локальным идентификатором/профилем) и замаскированным именем в таблице соответствий. В таблице 1 приведен пример такой таблицы соответствий.
Таблица 1. Таблица соответствий
Для генерирования замаскированного имени могут использоваться различные методы, такие как генерирование случайной текстовой строки или случайный выбор в списке случайных текстов одного элемента, отличного от имен домочадцев. Замаскированное имя предпочтительно не соответствует распространенному имени или общеупотребительному слову. С этой целью генерированный случайный текст может использоваться только в том случае, если он не входит в состав словаря имен и словаря общего словоупотребления. В тех случаях, когда это не так, должно осуществляться новое генерирование.
Контроллер 106 конфиденциальности после этого выдает звуковой сигнал 121' и замаскированное имя 126 оператору 140 услуг. Модуль 150 преобразования речи в намерение анализирует принятый звуковой сигнал 121' и генерирует соответствующее намерение 123. Модуль 160 логики разговора после этого анализирует намерение 123 и генерирует персонализированный ответ 124, например, содержащий замаскированное имя. Данный ответ после этого непосредственно отправляется назад в устройство 100' виртуального помощника по дому в текстовой форме. Контроллер 106 конфиденциальности анализирует принятый ответ 124 и проверяет, содержит ли он замаскированное имя из списка замаскированных имен таблицы соответствия. В тех случаях, когда это так, обнаруженное замаскированное имя заменяется соответствующим именем говорящего, тем самым генерируется демаскированный ответ 124', который преобразуется преобразователем 108 текста в речь в звуковой сигнал 127, воспроизводимый громкоговорителем 110.
В примере, приведенном на фиг. 1В, Боб говорит: «Алекса, какая сегодня погода?». Говорящий идентифицируется как «Боб», и, следовательно, соответствующее замаскированное имя представляет собой «tak». Анализ звуков показывает, что намерением являлась «погода на сегодня». После этого вызывается сводка погоды на сегодня, и ответ персонализируется путем добавления имени говорящего: «Здравствуйте, tak. Погода на сегодня -...», тем не менее, включая в себя замаскированное имя говорящего. Когда анализируется ответ, обнаруживается одно из замаскированных имен говорящих из списка («tak»). Оно заменяется соответствующим реальным именем говорящего «Боб», вследствие чего генерируется окончательный отклик «Здравствуйте, Боб. Погода на сегодня -...». Результат состоит в том, что имя говорящего не было раскрыто за пределами устройства 100' виртуального помощника по дому, вследствие чего сохраняется конфиденциальность множества пользователей устройства виртуального помощника по дому.
В соответствии с альтернативным вариантом осуществления, экосистема виртуального помощника по дому работает во втором режиме. Отличие от первого режима состоит в том, что когда модуль логики разговора генерирует ответ 124, этот ответ выдается в устройство 100' виртуального помощника по дому непосредственно не в текстовой форме, а в форме звука, поскольку звуковой сигнал 125 генерируется преобразователем 170 текста в речь поставщика 140 услуг. Следовательно, когда устройство 100' виртуального помощника по дому принимает ответ 125, контроллер 106 конфиденциальности анализирует звуковой сигнал 125 для обнаружения замаскированного имени. С этой целью контроллер конфиденциальности получает представления звуков замаскированных имен и ищет эти представления в звуковом сигнале 125 в звуковой области, например, используя взаимную корреляцию двух звуковых сигналов. Когда замаскированное имя найдено, оно заменяется соответствующим именем говорящего, тем самым генерируется демаскированный ответ 127, который воспроизводится громкоговорителем 110.
В этом втором режиме выбранное замаскированное имя может иметь такую же длину, как и имя говорящего, как показано в таблице 1. В альтернативном варианте оно может иметь фиксированную длину во избежание выдачи информации, которая может использоваться для определения количества людей в жилом доме. Одним примером методов генерирования такого замаскированного имени является чередование случайного согласного звука и случайного гласного звука при фиксированном числе букв. В таком случае примерами замаскированных имен для таблицы 1 могут являться «kadopabo», «jilybelo», «gatekomu» и «dagopasa».
В альтернативном варианте осуществления для улучшения конфиденциальности записанный звуковой сигнал 121 модифицируется контроллером конфиденциальности в другой звуковой сигнал 121' таким образом, что голосовые характеристики записанного голоса не могут быть распознаны. Это осуществляется с помощью любого алгоритма преобразования голоса (голосового морфинга, просодических модификаций или даже применения преобразования речи в текст с последующим преобразованием текста в речь и т.д.), благодаря чему характеристики преобразуются без изменения произносимого текста. Результат такого преобразования состоит в том, что все голоса, покидающие домашнюю сеть, являются одинаковыми и тем самым становятся неразличимыми. Такая дополнительная меры безопасности применяется к обоим режимам.
В альтернативном варианте осуществления контроллер конфиденциальности также маскирует текст исходящего звукового сигнала 121' из устройства записи звукового сигнала 121. Это осуществляется путем обнаружения в звуковом сигнале одного из имен говорящих жилого дома, перечисленных, например, в таблице соответствия, приведенной в виде таблицы 1. Когда найдено имя говорящего, оно заменяется соответствующим замаскированным именем. Данный вариант осуществления является опциональным, поскольку в некоторых ситуациях он может приводить к безуспешным запросам. Например, если данный признак активирован, при использовании таблицы 1 станет невозможным смотреть фильм «Алиса в стране чудес», поскольку запрос преобразуется в «okul в стране чудес».
В альтернативном варианте осуществления маскирование периодически обновляется под контролем настройки по умолчанию, выбора пользователя или настройки в предпочтениях пользователя, например, при каждом запуске устройства, каждый день, каждые 15 минут, для каждого запроса и т.д. Случай, в котором маскирование обновляется для каждого запроса, улучшает несвязность между двумя последовательными запросами. Однако это сопровождается недостатком, состоящим в пониженной контекстуализации запроса, поскольку после обновления логика разговора всегда начинается с пустого контекста, так как он осуществляется предположительно новым говорящим.
В соответствии с одним из вариантов осуществления, контроллер 106 конфиденциальности может включаться или выключаться, например, под контролем выбора пользователя или настройки в предпочтениях пользователя. Это контролирует уровень конфиденциальности, обеспечиваемый контроллером конфиденциальности, и вследствие этого называется настройкой уровня конфиденциальности. Когда настройка уровня конфиденциальности представляет собой «NO_CONFIDENTIALITY», контроллер 106 конфиденциальности полностью прозрачен: он не оказывает влияния на исходящие запросы устройства 100' виртуального помощника по дому и не изменяет входящие результаты. Когда настройка уровня конфиденциальности представляет собой «INCOGNITO», контроллер 106 конфиденциальности полностью активен: он анализирует исходящие запросы для маскирования имени говорящего в запросе, исключает любое имя говорящего из звука, преобразует исходящий голосовой запрос и восстанавливает имя говорящего во входящих результатах. Возможны и другие промежуточные настройки уровня конфиденциальности, например, без выполнения преобразования голоса.
В соответствии с одним из вариантов осуществления, настройка уровня конфиденциальности может корректироваться с помощью самого голосового запроса, например, «запустить конфиденциальный режим», «запустить режим инкогнито», «спрятать мои идентификационные данные» и т.д. для активации контроллера конфиденциальности и «остановить конфиденциальный режим», «остановить режим инкогнито» и т.д. для обхода контроллера конфиденциальности. Такой запрос обнаруживается контроллером конфиденциальности, который соответствующим образом корректирует свое поведение.
Фиг. 2 иллюстрирует пример структурной схемы способа голосового взаимодействия с сохранением конфиденциальности в соответствии с одним из вариантов осуществления изобретения. На этапе 200 микрофон захватывает голосовые произнесения, которые выполняются пользователем, формирующим голосовой запрос, и генерирует соответствующий звуковой сигнал. На этапе 202 идентификатор говорящего идентифицирует идентификационные данные говорящего захватываемый звуковой сигнал, а на этапе 204 контроллер конфиденциальности генерирует замаскированное имя говорящего. При необходимости на параллельном этапе 206 контроллер конфиденциальности маскирует звуковой сигнал. На этапе 208 звуковой сигнал поступает, анализируется, и генерируется соответствующее намерение. На этапе 210 персонализированный отклик генерируется после получения замаскированного имени говорящего. На этапе 212 отклик анализируется контроллером конфиденциальности, который заменяет замаскированные имена отклика соответствующими именами говорящих. На этапе 214 громкоговорители воспроизводят демаскированный отклик. Этапы 204 и 206 маскирования и этап 212 демаскирования выполняются под контролем настроек уровня конфиденциальности и обходятся, когда настройки представляют собой «NO_CONFIDENTIALITY».
Специалистам в данной области техники очевидно, что аспекты настоящих принципов и признаков, описанных выше, могут принимать форму полностью аппаратного варианта осуществления, полностью программного варианта осуществления (включая микропрограммные средства, резидентные программные средства, микрокод и так далее) или варианта осуществления, комбинирующего аппаратные и программные аспекты. Например, несмотря на то, что описание выполнено с использованием аппаратных компонентов идентификатора 104 говорящего, контроллера 106 конфиденциальности и преобразователя 108 текста в речь, эти элементы могут быть реализованы в виде программных компонентов с использованием, по меньшей мере, одного аппаратного процессора, выполненного с возможностью осуществления способа, по меньшей мере, одного варианта осуществления настоящего изобретения, памяти, выполненной с возможностью хранения данных, необходимых для осуществления способа, по меньшей мере, одного варианта осуществления настоящего изобретения, и машиночитаемого программного кода, исполнимого процессором, для осуществления, по меньшей мере, одного варианта осуществления настоящего изобретения. Таким образом, в такой реализации аппаратный процессор выполнен с возможностью реализации, по меньшей мере, функций идентификатора 104 говорящего, контроллера 106 конфиденциальности и преобразователя 108 текста в речь и взаимодействия с поставщиком услуг посредством интерфейса 120 передачи данных. С этой целью аппаратный процессор выполнен с возможностью реализации, по меньшей мере, приведенных на фиг. 2 этапов, включающих в себя этап 202 идентификации пользователя, этап 204 маскирования имени, этап 206 маскирования звукового запроса, этап 212 демаскирования и этап 214 воспроизведения ответа.
Кроме того, несмотря на то, что различные альтернативные варианты осуществления описаны по отдельности, они могут быть объединены друг с другом в любой форме.
| название | год | авторы | номер документа |
|---|---|---|---|
| ИСПОЛЬЗОВАНИЕ КОНТЕКСТНОЙ ИНФОРМАЦИИ ДЛЯ ОБЛЕГЧЕНИЯ ОБРАБОТКИ КОМАНД В ВИРТУАЛЬНОМ ПОМОЩНИКЕ | 2012 |
|
RU2542937C2 |
| СОВЕРШЕНИЕ ЗАДАЧИ БЕЗ МОНИТОРА В ЦИФРОВОМ ПЕРСОНАЛЬНОМ ПОМОЩНИКЕ | 2015 |
|
RU2710984C2 |
| ОБЕСПЕЧЕНИЕ АВТОНОМНОЙ СЕМАНТИЧЕСКОЙ ОБРАБОТКИ В УСТРОЙСТВЕ С ОГРАНИЧЕННЫМИ РЕСУРСАМИ | 2016 |
|
RU2685392C1 |
| КОНТРОЛЛЕР КОММУТАЦИИ ДЛЯ РАСПРЕДЕЛЕНИЯ ГОЛОСОВЫХ ПАКЕТОВ | 2016 |
|
RU2700272C2 |
| СИСТЕМА И СПОСОБ, ПРЕДНАЗНАЧЕННЫЕ ДЛЯ ПРЕДОСТАВЛЕНИЯ УСЛУГ, СООТВЕТСТВУЮЩИХ МЕСТОПОЛОЖЕНИЮ, С ИСПОЛЬЗОВАНИЕМ СОХРАНЕННОЙ ИНФОРМАЦИИ О МЕСТОПОЛОЖЕНИИ | 2002 |
|
RU2292089C2 |
| ОСНОВАННАЯ НА КОНФИДЕНЦИАЛЬНОСТИ ДЕГРАДАЦИЯ СИГНАЛОВ АКТИВНОСТИ И АВТОМАТИЧЕСКАЯ АКТИВАЦИЯ РЕЖИМОВ КОНФИДЕНЦИАЛЬНОСТИ | 2015 |
|
RU2678154C1 |
| СПОСОБ И СИСТЕМА УПРАВЛЕНИЯ ДИАЛОГОВЫМ АГЕНТОМ В КАНАЛЕ ВЗАИМОДЕЙСТВИЯ С ПОЛЬЗОВАТЕЛЕМ | 2019 |
|
RU2818036C1 |
| КЛАССИФИКАЦИЯ ТИПА ЭМОЦИИ ДЛЯ ИНТЕРАКТИВНОЙ ДИАЛОГОВОЙ СИСТЕМЫ | 2015 |
|
RU2705465C2 |
| СПОСОБ И СИСТЕМА ОПРЕДЕЛЕНИЯ ГОВОРЯЩЕГО ПОЛЬЗОВАТЕЛЯ УПРАВЛЯЕМОГО ГОЛОСОМ УСТРОЙСТВА | 2018 |
|
RU2744063C1 |
| СОХРАНЯЮЩАЯ КОНФИДЕНЦИАЛЬНОСТЬ СЛУЖБА ДОМЕННЫХ ИМЕН (DNS) | 2021 |
|
RU2837326C2 |
Настоящее техническое решение относится к области вычислительной техники. Технический результат заключается в сохранении конфиденциальности пользователя в многопользовательской среде при голосовом взаимодействии с устройством виртуального помощника по дому. Технический результат достигается за счёт устройства и способа для голосовых взаимодействий, где микрофон захватывает звуковой сигнал, соответствующий голосовому запросу пользователя; определяются идентификационные данные говорящего, и генерируется замаскированное имя, соответствующее идентифицированному говорящему; звуковой сигнал анализируется для определения намерения пользователя, и генерируется персонализированный ответ в совокупности с замаскированным именем; ответ затем демаскируется путем повторного представления имени говорящего; демаскированный ответ воспроизводится говорящему. 3 н. и 11 з.п. ф-лы, 1 табл., 2 ил.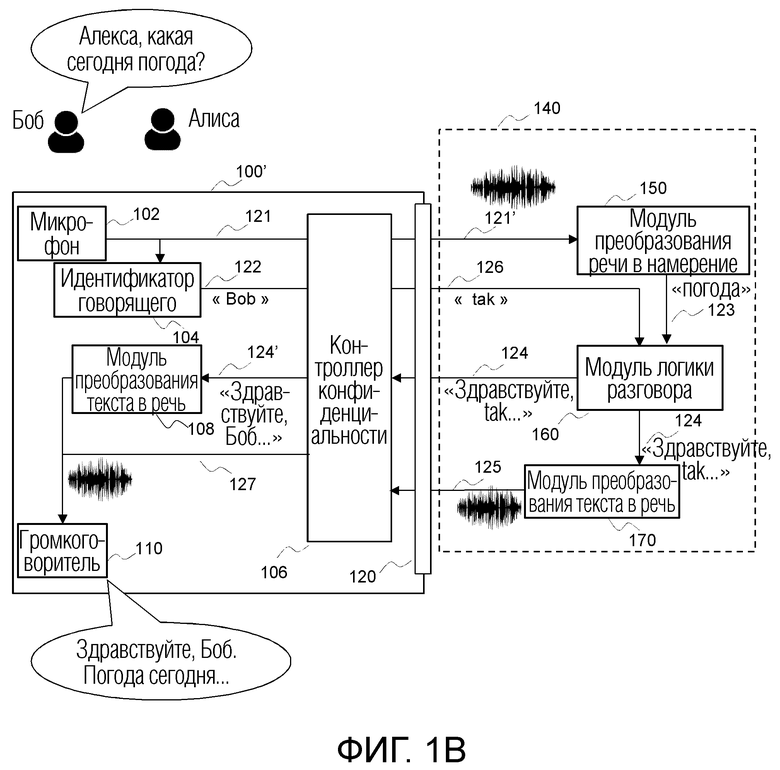
1. Устройство (100') для выполнения голосовых взаимодействий с сохранением конфиденциальности, содержащее:
- микрофон (102), выполненный с возможностью захвата звукового сигнала (121), характеризующего голосовое произнесение, связанное с запросом от говорящего;
- идентификатор (104) говорящего, выполненный с возможностью определения идентификационных данных говорящего по захватываемому звуковому сигналу (121);
- контроллер (106) конфиденциальности, выполненный с возможностью выдачи замаскированного имени (122) говорящего, соответствующего идентифицированному говорящему, и хранения списка соответствий между именами говорящих и замаскированными именами говорящих;
- интерфейс (120) передачи данных, выполненный с возможностью:
- выдачи во внешнее устройство захватываемого звукового сигнала (121) и замаскированного имени (122) говорящего;
- приема от внешнего устройства ответа (124, 125) на запрос говорящего;
причем контроллер конфиденциальности дополнительно выполнен с возможностью определения того, содержит ли принятый ответ замаскированное имя говорящего из списка, и в этом случае замены в принятом ответе замаскированного имени говорящего соответствующим именем.
2. Устройство по п. 1, дополнительно содержащее выдачу ответа говорящему.
3. Устройство по п. 1, причем принимаемый ответ (124) находится в текстовой форме.
4. Устройство по п. 3, дополнительно содержащее преобразователь (108) текста в речь, выполненный с возможностью преобразования демаскированного ответа (124') из текстовой формы в звуковой сигнал (127).
5. Устройство по п. 1, причем принимаемый ответ (124) находится в звуковом формате.
6. Устройство по п. 1, причем контроллер конфиденциальности дополнительно выполнен с возможностью маскирования захватываемого звукового сигнала (121) путем обнаружения имени говорящего из списка и замены его звуковым сигналом, характеризующим соответствующее замаскированное имя говорящего.
7. Устройство по п. 1, причем контроллер конфиденциальности дополнительно содержит настройку для включения или выключения режима инкогнито, причем в первом случае контроллер конфиденциальности маскирует имя говорящего перед его выдачей и демаскирует принимаемый ответ, когда он содержит замаскированное имя говорящего, а во втором случае контроллер конфиденциальности не маскирует имя говорящего и не определяет, содержит ли принимаемый ответ замаскированное имя говорящего.
8. Способ выполнения голосовых взаимодействий с сохранением конфиденциальности, содержащий этапы, на которых:
- захватывают (200) звуковой сигнал, характеризующий голосовое произнесение, связанное с запросом от говорящего;
- идентифицируют (202) говорящего по захватываемому звуковому сигналу;
- генерируют (204) замаскированное имя говорящего, соответствующее идентифицированному говорящему, и сохраняют список соответствий между именами говорящих и замаскированными именами говорящих;
- выдают во внешнее устройство захватываемый звуковой сигнал и замаскированное имя говорящего;
- получают от внешнего устройства ответ на запрос; и
- определяют (212) то, содержит ли принятый ответ замаскированное имя говорящего из списка, и в этом случае заменяют в принятом ответе замаскированное имя говорящего соответствующим именем.
9. Способ по п. 8, дополнительно содержащий выдачу ответа говорящему.
10. Способ по п. 8, в котором принимаемый ответ (124) находится в текстовой форме или звуковой форме
11. Способ по п. 8, дополнительно содержащий маскирование захватываемого звукового сигнала (121) путем обнаружения имени говорящего из списка и замены его звуковым сигналом, характеризующим соответствующее замаскированное имя говорящего.
12. Способ по п. 8, дополнительно содержащий настройку для включения или выключения режима инкогнито, причем, в первом случае маскируют имя говорящего перед его выдачей и демаскируют принимаемый ответ, когда он содержит замаскированное имя говорящего, а во втором случае более не маскируют имя говорящего и более не определяют, содержит ли принимаемый ответ замаскированное имя говорящего.
13. Способ по п. 8, дополнительно содержащий обновление замаскированных имен говорящих из списка.
14. Энергонезависимый машиночитаемый носитель, содержащий команды программного кода, исполнимые процессором, для реализации этапов способа, по меньшей мере, по одному из пп. 8-13.
| US 8682676 B2, 25.03.2014 | |||
| US 9542956 B1, 10.01.2017 | |||
| US 9330668 B2, 03.05.2016 | |||
| US 7698131 B2, 13.04.2010 | |||
| US 7920682 B2, 05.04.2011 | |||
| СИСТЕМА ГОЛОСОВОГО РАСПОЗНАВАНИЯ ПОЛЬЗОВАТЕЛЯ ТРАНСПОРТНОГО СРЕДСТВА | 2007 |
|
RU2337020C1 |

