Область техники
Варианты осуществления в соответствии с изобретением относятся к процессору сигналов для обеспечения обработанного аудиосигнала.
Дополнительные варианты осуществления в соответствии с изобретением относятся к способу обеспечения обработанного аудиосигнала.
Дополнительные варианты осуществления в соответствии с изобретением относятся к компьютерной программе для выполнения упомянутых способов.
Варианты осуществления в соответствии с изобретением относятся к способу и устройству для онлайнового подавления реверберации и шума (например, с использованием параллельной структуры) с управлением подавлением.
Дополнительные варианты осуществления в соответствии с изобретением относятся к онлайновому подавлению реверберации и шума на основе линейного предсказания с использованием чередующихся фильтров Калмана.
Варианты осуществления в соответствии с изобретением относятся к процессору сигналов, способу и компьютерной программе для подавления шума и реверберации.
Уровень техники
Обработка аудиосигналов, речевая связь и передача аудиоинформации являются непрерывно развивающимися областями техники. Однако при обработке аудиосигналов шум и реверберация часто ухудшают качество звука.
Например, в сценариях речевой связи на большом расстоянии, когда требуемый источник речи находится далеко от устройства захвата, качество и разборчивость речи обычно ухудшаются вследствие высокого уровня реверберации и шума по сравнению с требуемым уровнем речевого сигнала.
Также рабочие характеристики устройств распознавания речи резко ухудшаются в сценариях разговора на большом расстоянии [15], [34].
Таким образом, подавление реверберации в шумных средах для покадровой обработки в реальном времени с высоким качеством восприятия остается сложной и частично нерешенной задачей.
Многоканальные алгоритмы подавления реверберации существующего уровня техники основаны на пространственно-спектральной фильтрации [2], [27], системной идентификации [25], [26], акустической инверсии канала [20], [22] или линейном предсказании с использованием авторегрессивной (AR) модели реверберации [21], [29], [32]. Успешное применение подходов на основе линейного предсказания было достигнуто посредством использования многоканальной авторегрессивной модели (MAR) для каждой частотной полосы в области оконного преобразования Фурье (STFT). Преимущества способов на основе модели MAR состоят в том, что они пригодны для нескольких источников, они непосредственно оценивают фильтр подавления реверберации конечной длины, требуемые фильтры являются относительно короткими, и они подходят в качестве методик предварительной обработки для алгоритмов формирования диаграммы направленности. Большой проблемой модели сигнала MAR является интеграция аддитивного шума, который должен быть удален заранее [30], [32], без разрушения отношений между соседними периодами времени реверберирующего сигнала. В [33] была представлена обобщенная структура для способов многоканального линейного предсказания, названная слепым сокращением импульсной характеристики, которая стремится сократить реверберирующий хвост в каждом микрофоне и приводит к такому же количеству выходных каналов, как и входных каналов, обеспечивая сохранность корреляции между микрофонами требуемого сигнала.
Поскольку первыми решениями на основе структуры многоканального линейного предсказания были пакетные алгоритмы, дополнительные усилия были приложены, чтобы разработать онлайновые алгоритмы, которые подходят для обработки в режиме реального времени [4, 12, 13, 31, 35]. Однако, насколько нам известно, подавление аддитивного шума в онлайновом решении было рассмотрено только в [31].
Принимая во внимание традиционные решения, существует потребность в концепции, которая обеспечивает улучшенный компромисс между сложностью, стабильностью и качеством сигнала, сокращая и шум, и реверберацию аудиосигнала.
Сущность изобретения
Вариант осуществления в соответствии с изобретением создает процессор сигналов для обеспечения обработанного аудиосигнала (например, аудиосигнала с подавленным шумом и с подавленной реверберацией, который может быть одноканальным или многоканальным аудиосигналом) (или, вообще говоря, одного или более обработанных аудиосигналов) на основе входного аудиосигнала (например, одноканального или многоканального входного аудиосигнала) (или, вообще говоря, на основе одного или более выходных аудиосигналов). Процессор сигналов выполнен с возможностью оценивать коэффициенты (например, многоканальной) авторегрессивной модели реверберации (например, коэффициенты AR или коэффициенты MAR) с использованием входного аудиосигнала (например, шумного и реверберирующего входного аудиосигнала или нескольких шумных и реверберирующих входных аудиосигналов, или непосредственно наблюдаемого сигнала y(n), который может происходить, например, от одного или более микрофонов) (или, вообще говоря, с использованием одного или более входных аудиосигналов) и (одного или более) задержанных реверберирующих сигналов с подавленным шумом, полученных с использованием шумоподавления (или стадии шумоподавления). Например, задержанный реверберирующий сигнал с подавленным шумом может содержать (один или более) прошлые реверберирующие сигналы с подавленным шумом, которые могут быть представлены как  . Например, оценка коэффициентов может быть выполнена посредством стадии оценки коэффициентов AR или стадии оценки коэффициентов MAR процессора сигналов.
. Например, оценка коэффициентов может быть выполнена посредством стадии оценки коэффициентов AR или стадии оценки коэффициентов MAR процессора сигналов.
Кроме того, процессор сигналов выполнен с возможностью обеспечивать реверберирующий сигнал с подавленным шумом (например, текущего кадра) (или, вообще говоря, один или более реверберирующих сигналов с подавленным шумом) с использованием входного аудиосигнала (который может являться шумным и реверберирующим входным аудиосигналом, или который может являться шумным наблюдаемым сигналом y(n) который может происходить от одного или более микрофонов) и оценочных коэффициентов авторегрессивной модели реверберации (которая может представлять собой многоканальную авторегрессивную модель реверберации) (и причем оценочные коэффициенты могут быть ассоциированы с текущим кадром и могут называться «коэффициентами MAR»). Кроме того, часть процессора сигналов, выполненную с возможностью обеспечивать реверберирующий сигнал с подавленным шумом, можно рассматривать как «стадию (или каскад) шумоподавления».
Кроме того, процессор аудиосигналов выполнен с возможностью обеспечивать выходной сигнал с подавленным шумом и с подавленной реверберацией (или, вообще говоря, один или несколько выходных сигналов с подавленным шумом и с подавленной реверберацией) с использованием (реверберирующего) сигнала с подавленным шумом (или, вообще говоря, одного или более реверберирующих сигналов с подавленным шумом) и оценочных коэффициентов авторегрессивной модели реверберации (или многоканальной авторегрессивной модели реверберации). Это может быть выполнено с использованием оценки реверберации и вычитания сигнала.
Этот вариант осуществления в соответствии с изобретением основан на том, что возможно преодолеть проблему причинной связи, которая обнаружена в некоторых традиционных решениях, посредством оценки коэффициентов авторегрессивной модели реверберации, ассоциированных с некоторым кадром, на основе задержанного реверберирующего сигнала с подавленным шумом, который может быть ассоциирован с одним или более предыдущими кадрами, и что возможно обеспечить реверберирующий сигнал с подавленным шумом текущего кадра с использованием входного аудиосигнала и оценочных коэффициенты авторегрессивной модели реверберации, ассоциированных с текущим кадром, и полученных на основе сигналов с подавленным шумом (и обычно реверберирующих) (например, обеспеченных посредством стадии шумоподавления), ассоциированных с одним или более предыдущими кадрами. В соответствии с этим вычислительная сложность может быть сохранена довольно малой, поскольку оценка коэффициентов авторегрессивной модели реверберации и оценка реверберирующего сигнала с подавленным шумом могут быть выполнены отдельно и с чередованием. Другими словами, раздельная оценка коэффициентов авторегрессивной модели реверберации и реверберирующего сигнала с подавленным шумом может быть выполнена более эффективно, чем совместная оценка коэффициентов авторегрессивной модели реверберации и реверберирующего сигнала с подавленным шумом, а также более эффективно, чем совместная оценка (с одним этапом) аудиосигнала с подавленным шумом и с подавленной реверберацией. Тем не менее, было обнаружено, что рассмотрение задержанных (или, эквивалентно, прошедших) реверберирующих сигналов с подавленным шумом, полученных с использованием шумоподавления при оценке коэффициентов авторегрессивной модели реверберации, приводит к довольно хорошей оценке коэффициентов авторегрессивной модели реверберации, в результате чего нет какого-либо серьезного ухудшения качества звука обработанного сигнала (выходного сигнала). В соответствии с этим возможно попеременно оценивать коэффициенты авторегрессивной модели реверберации и кадры реверберирующего сигнала с подавленным шумом, по-прежнему получая высокое качество звука.
Следовательно, компромисс между сложностью, стабильностью и качеством сигнала можно считать хорошим.
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью оценивать коэффициенты многоканальной авторегрессивной модели реверберации. Было обнаружено, что концепция, описанная в настоящем документе, хорошо подходит для обработки многоканальных сигналов и способствует конкретным улучшениям в сложности для таких многоканальных сигналов.
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью использовать оценочные коэффициенты авторегрессивной модели реверберации, ассоциированные с текущим обрабатываемым участком (например, с временным кадром, имеющим индекс кадра n) входного аудиосигнала, чтобы произвести реверберирующий сигнал с подавленным шумом, ассоциированный с текущим обрабатываемым участком (например, с периодом времени, имеющим индекс кадра n) входного аудиосигнала. В соответствии с этим обеспечение реверберирующего сигнала с подавленным шумом, ассоциированного с текущим обрабатываемым участком, может полагаться на предыдущую оценку коэффициентов авторегрессивной модели реверберации, ассоциированных с текущим обрабатываемым участком входного аудиосигнала, или оценка коэффициентов авторегрессивной модели реверберации, ассоциированных с текущим обрабатываемым участком (или кадром), может предшествовать обеспечению реверберирующего сигнала с подавленным шумом, ассоциированного с текущим обрабатываемым участком (или кадром). В соответствии с этим при обработке аудиокадра с индексом кадра n оценка коэффициентов авторегрессивной модели реверберации может быть выполнена сначала (например, с использованием прошлого сигнала с подавленным шумом, но реверберирующего), и затем может быть выполнено обеспечение реверберирующего сигнала с подавленным шумом, ассоциированного с текущим обрабатываемым кадром. Было обнаружено, что такой порядок обработки приводит к особенно хорошим результатам, в то время как обратный порядок обычно не будет выполняться достаточно хорошо.
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью использовать один или более задержанных реверберирующих сигналов с подавленным шумом (или в качестве альтернативы реверберирующего сигнала с подавленным шумом), ассоциированных (или основанных) с ранее обработанным участком (например, с кадром, имеющим индекс кадра n-1) входного аудиосигнала (например, входного сигнала y(n)) для оценки коэффициентов авторегрессивной модели реверберации, ассоциированных с текущим обрабатываемым участком (например, имеющим индекс кадра n) входного аудиосигнала. Посредством использования реверберирующего сигнала с подавленным шумом, ассоциированного с ранее обработанным участком (или кадром) входного аудиосигнала, для оценки коэффициента авторегрессивной модели реверберации, ассоциированного с текущим обрабатываемым участком (или кадром) входного аудиосигнала, возможно избежать проблемы причинной связи, поскольку обеспечение реверберирующего сигнала с подавленным шумом, ассоциированного с ранее обработанным кадром, обычно может выполняться перед оценкой коэффициентов авторегрессивной модели реверберации, ассоциированных с текущим обрабатываемым участком (или кадром) входного аудиосигнала. Кроме того, было обнаружено, что использование реверберирующего сигнала с подавленным шумом, ассоциированного с ранее обработанным участком входного аудиосигнала, приводит к достаточно хорошей оценке коэффициентов авторегрессивной модели реверберации.
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью попеременно обеспечивать оценочные коэффициенты авторегрессивной модели реверберации (или многоканальной авторегрессивной модели реверберации) и участки реверберирующего сигнала с подавленным шумом. Кроме того, процессор сигналов выполнен с возможностью использовать оценочные коэффициенты (или в качестве альтернативы ранее оцененные коэффициенты) (предпочтительно многоканальной) авторегрессивной модели реверберации для обеспечения участков реверберирующего сигнала с подавленным шумом. Кроме того, процессор сигналов выполнен с возможностью использовать один или более задержанных реверберирующих сигналов с подавленным шумом (или в качестве альтернативы ранее обеспеченных участков реверберирующего сигнала с подавленным шумом) для оценки коэффициентов многоканальной авторегрессивной модели реверберации. Посредством выполнения такого попеременного обеспечения оценочных коэффициентов авторегрессивной модели реверберации и участков реверберирующего сигнала с подавленным шумом вычислительная сложность может быть поддержана на низком уровне, и результаты могут быть получены с небольшой задержкой. Кроме того, можно избежать вычислительной нестабильности, которая могла быть вызвана совместной оценкой коэффициентов многоканальной авторегрессивной модели реверберации и участков реверберирующего сигнала с подавленным шумом.
В предпочтительном варианте осуществления процессор сигналов может быть выполнен с возможностью применять алгоритм, минимизирующий функцию стоимости (например, фильтр Калмана, рекурсивный фильтр наименьших квадратов или фильтр нормализованных наименьших средних квадратов (NLMS)), чтобы оценить коэффициенты (предпочтительно многоканальной) авторегрессивной модели реверберации. Было обнаружено, что использование таких алгоритмов хорошо подходит для оценки коэффициентов авторегрессивной модели реверберации. Функция стоимости может быть определенна, например, как показано в уравнении (15), и минимизация может выполнять функциональность, показанную в уравнении, (17) или минимизировать след матрицы ошибки, как показано в уравнении (19). Минимизация функции стоимости может следовать уравнениям (20)-(25). Минимизация функции стоимости также может использовать этапы 4-6 Алгоритма 1.
В предпочтительном варианте осуществления функцией стоимости, используемой для оценки коэффициентов авторегрессивной модели реверберации (например, в алгоритме, который минимизирует функцию стоимости), является значение ожидания для среднеквадратической ошибки коэффициентов авторегрессивной модели реверберации, например, как показано в уравнении (19). В соответствии с этим могут быть достигнуты коэффициенты авторегрессивной модели реверберации, которые, как ожидается, будут хорошо соответствовать акустической среде, вызывающей реверберацию. Следует отметить, что ожидаемые статистические свойства шума коэффициента MAR и шумных сигналов с подавленной реверберацией (шумы состояния и наблюдения), например, могут быть оценены в отдельном, предварительном этапе (например, с использованием одного или более уравнений (26)-(29).
В предпочтительном варианте осуществления процессор сигналов может быть выполнен с возможностью применять алгоритм для минимизации функции стоимости, чтобы оценить коэффициенты (предпочтительно многоканальной) авторегрессивной модели реверберации при допущении, что реверберирующий сигнал с подавленным шумом является фиксированным (например, не затрагиваемым коэффициентами авторегрессивной модели реверберации, ассоциированными с текущим обрабатываемым участком входного аудиосигнала). Посредством такого предположения вычислительная сложность может быть значительно сокращена, а также можно избежать нестабильности вычисления. Например, алгоритм уравнений (20)-(25) делает такое предположение.
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью применять алгоритм для минимизации функции стоимости (например, фильтр Калмана, или рекурсивный фильтр наименьших квадратов, или фильтр NLMS), чтобы оценить реверберирующий сигнал с подавленным шумом. Функция стоимости может быть определенна, например, как показано в уравнении (16), и минимизация может выполнять функциональность, показанную в уравнении, (18) или минимизировать след матрицы ошибки, как показано в уравнении (30). Минимизация функции стоимости может следовать уравнениям (31) к (36).
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью применять алгоритм для минимизации функции стоимости (например, фильтр Калмана, рекурсивный фильтр наименьших квадратов или фильтр NLMS), чтобы оценить реверберирующий сигнал с подавленным шумом. Было обнаружено, что использование такого алгоритма для минимизации функции стоимости является также очень эффективном для определения реверберирующего сигнала с подавленным шумом, например, если статистические свойства шума известны или оценены. Кроме того, вычислительная сложность может быть в значительной степени улучшена, если сходные алгоритмы (например, алгоритмы, минимизирующие функцию стоимости) используются и для оценки коэффициентов авторегрессивной модели реверберации, и для оценки реверберирующего сигнала с подавленным шумом. Например, может использоваться алгоритм в соответствии с уравнениями (31)-(36), причем параметры, которые будут использоваться в упомянутом алгоритме, могут быть определены в соответствии с одним или более уравнениями (37)-(42). Кроме того, функциональность может быть выполнена с использованием этапов 7-9 Алгоритма 1.
В предпочтительном варианте осуществления функцией стоимости, используемой для оценки реверберирующего сигнала (в некоторых случаях с подавленным шумом), является значение ожидания для среднеквадратической ошибки реверберирующего сигнала (в некоторых случаях с подавленным шумом). Было обнаружено, что такая функция стоимости (например, в соответствии с уравнением (16) или в соответствии с уравнением (30)) обеспечивает хорошие результаты и может быть оценена с использованием разумных вычислительных затрат. Кроме того, следует отметить, что оценка среднеквадратической ошибки реверберирующего сигнала с подавленным шумом возможна, например, если доступна информация (или предположение) относительно статистических характеристик шума (например, ковариационная матрица шума), и также, возможно, относительно требуемого сигнала (например, требуемой ковариационной матрицы речи).
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью применять алгоритм для минимизации функции стоимости, чтобы оценить реверберирующий сигнал (в некоторых случаях с подавленным шумом) при допущении, что коэффициенты авторегрессивной модели реверберации фиксированы (например, не затрагиваются реверберирующим сигналом с подавленным шумом, ассоциированным с текущим обрабатываемым участком входного аудиосигнала). Было обнаружено, что такое «идеальное» предположение (которое делается, например, при вычислении в соответствии с уравнениями (31)-(36)) значительно не ухудшает результаты оценки реверберирующего сигнала с подавленным шумом, но значительно сокращает вычислительные затраты (например, по сравнению с совместной оценкой реверберирующего сигнала с подавленным шумом и коэффициентов авторегрессивной модели реверберации, или по сравнению с прямой оценкой выходного сигнала с подавленным шумом и с подавленной реверберацией (в процедуре с одним этапом)).
Кроме того, предположение допускает чередующуюся процедуру, в которой реверберирующий сигнал с подавленным шумом и коэффициенты авторегрессивной модели реверберации оцениваются раздельно (например, переменное выполнение этапов 4-6 и этапов 7-9 Алгоритма 1).
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью определять компонент реверберации на основе оценочных коэффициентов (предпочтительно многоканальной) авторегрессивной модели реверберации и на основе одного или более задержанных реверберирующих сигналов с подавленным шумом (или в качестве альтернативы на основе реверберирующего сигнала с подавленным шумом), ассоциированных с ранее обработанным участком (например, кадром) входного аудиосигнала (например, посредством фильтрации реверберирующего сигнала с подавленным шумом с использованием оценочных коэффициентов авторегрессивной модели реверберации). Кроме того, процессор сигналов предпочтительно выполнен с возможностью (по меньшей мере частично) подавлять (например, вычитать) компонент реверберации из реверберирующего сигнала с подавленным шумом, ассоциированного с текущим обрабатываемым участком (например, кадром) входного аудиосигнала, чтобы получить выходной сигнал с подавленным шумом и с подавленной реверберацией (например, требуемый речевой сигнал). Это может быть выполнено, например, с использованием уравнения (44).
Было обнаружено, что определение компонента реверберации на основе реверберирующего сигнала с подавленным шумом приносит хороший результат. Например, имеется преимущество в оценке фильтра реверберации (коэффициентов MAR) на основе наблюдения с шумом y(n) и прошлых бесшумных сигналов X(n-D). Кроме того, предпочтительно предполагается, что шум не имеет каких-либо реверберирующих характеристик. Поскольку только прошлые бесшумные сигналы X(n-D) требуются для оценки коэффициентов MAR, используемая концепция может работать обусловленным образом и сохранять вычислительные затраты довольно медленными, по-прежнему достигая хороших результатов.
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью выполнять взвешенную комбинацию входного аудиосигнала и реверберирующего сигнала с подавленным шумом (например, в соответствии с уравнением 44), а также включать компонент реверберации во взвешенную комбинацию (например, таким образом, что выполняется взвешенная комбинация входного аудиосигнала, реверберирующего сигнала с подавленным шумом и компонента реверберации). Другими словами, сигнал с подавленным шумом и с подавленной реверберацией получается посредством взвешенной комбинации входного сигнала, сигнала с подавленным шумом и компонента реверберации. В соответствии с этим возможно точно настроить характеристики сигнала, такие как величина подавления реверберации и шума. Следовательно, характеристики сигнала обработанного аудиосигнала (например, аудиосигнала с подавленным шумом и с подавленной реверберацией) могут регулироваться в соответствии с требованиями в текущей ситуации.
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью также включать в себя оформленную версию компонента реверберации во взвешенной комбинации (например, таким образом, что выполняется взвешенная комбинация входного аудиосигнала, реверберирующего сигнала с подавленным шумом, оформленной версии компонента реверберации, а также самого компонента реверберации). Например, это может быть сделано, как показано в последнем уравнении секции, описывающей «Способ и устройство для онлайнового подавления реверберации и шума (с использованием параллельной структуры) с управлением подавлением». В соответствии с этим возможно выполнить дополнительное спектральное и динамическое оформление разностной реверберации. В соответствии с этим существует еще большая степень гибкости относительно результата, который будет достигнут.
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью оценивать статистическую величину (например, ковариацию) (или статистическое свойство) шумового компонента входного аудиосигнала. Такая статистическая величина шумового компонента входного аудиосигнала, например, может быть полезной при оценке (или обеспечении) реверберирующего сигнала с подавленным шумом. Кроме того, оценка (или определение) статистической величины шумового компонента входного аудиосигнала может обеспечить возможность формулировки функции стоимости, поскольку статистическая величина шумового компонента входного аудиосигнала может использоваться в качестве части упомянутой функции стоимости.
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью оценивать статистическую величину (например, ковариацию) (или статистическое свойство) шумового компонента входного аудиосигнала в период отсутствия речи (причем, например, период отсутствия речи обнаруживается с использованием детектора речи). Было обнаружено, что обнаружение периодов отсутствия речи возможно с разумным усилием, и также было обнаружено, что шум, который присутствует в периоды отсутствия речи, обычно также присутствует в периоды наличия речи без слишком многих изменений. В соответствии с этим возможно эффективно получить статистические данные шумового компонента, которые применимы для обеспечения реверберирующего сигнала с подавленным шумом.
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью оценивать коэффициенты (предпочтительно многоканальной) авторегрессивной модели реверберации с использованием фильтра Калмана. Было обнаружено, что такой фильтр Калмана допускает эффективное вычисление и хорошо адаптирован к требованиям задачи обработки сигналов. Например, может использоваться реализация в соответствии с уравнениями (20)-(25).
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью оценивать коэффициенты (предпочтительно многоканальной) авторегрессивной модели реверберации на основе оценочной матрицы ошибки вектора коэффициентов (предпочтительно многоканальной) авторегрессивной модели реверберации (например, ассоциированного с ранее обработанным участком аудиосигнала) на основе оценочной ковариации шума погрешности вектора коэффициента (предпочтительно многоканальной) авторегрессивной модели реверберации (например, как задано в уравнении (26)), на основе предыдущего вектора (оценочных) коэффициентов (предпочтительно многоканальной) авторегрессивной модели реверберации (например, ассоциированных с ранее обработанным участком или версией входного аудиосигнала), на основе одного или более задержанных реверберирующих сигналов с подавленным шумом (например, (прошлых) реверберирующих сигналов с подавленным шумом, представленных как , например, ассоциированных с предыдущими участками или кадрами входного аудиосигнала), (в некоторых случаях) на основе оценочной ковариации, ассоциированной с шумными (например, с не подавленным шумом), но с подавленной реверберацией (или без реверберации) компонентами сигнала входного аудиосигнала, и на основе входного аудиосигнала. Было обнаружено, что оценка коэффициентов авторегрессивной модели реверберации на основе этих входных переменных является эффективной в вычислительном отношении и способствует получению точных оценок коэффициентов авторегрессивной модели реверберации.
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью оценивать реверберирующий сигнал с подавленным шумом с использованием фильтра Калмана. Было обнаружено, что использование такого фильтра Калмана (который может реализовать функциональность, заданную в уравнениях 31-36) также имеет преимущество для оценки реверберирующего сигнала с подавленным шумом. Кроме того, использование фильтра Калмана и для оценки коэффициента авторегрессивной модели реверберации, и для оценки реверберирующего сигнала с подавленным шумом может обеспечить хорошие результаты.
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью оценивать реверберирующий сигнал с подавленным шумом на основе оценочной матрицы ошибки реверберирующего сигнала с подавленным шумом (например, ассоциированного с ранее обработанным участком или кадром входного аудиосигнала), на основе оценочной ковариации требуемого речевого сигнала (например, ассоциированного с текущим обрабатываемым участком или кадром входного аудиосигнала, например, как задано в уравнениях 37-42), на основе одной или более предыдущих оценок реверберирующего сигнала с подавленным шумом (например, ассоциированного с одним или более ранее обработанными участками или кадрами входного аудиосигнала), на основе множества коэффициентов (предпочтительно многоканальной) авторегрессивной модели реверберации (например, ассоциированной с текущим обрабатываемым участком или кадром входного аудиосигнала, например, определяя матрицу F(n)), на основе оценочной ковариации шума, ассоциированной с входным аудиосигналом, и на основе входного аудиосигнала. Было обнаружено, что оценка реверберирующего сигнала с подавленным шумом на основе этих величин является эффективной в вычислительном отношении и способствует хорошему качеству аудиосигнала.
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью получать оценочную ковариацию, ассоциированную с шумными, но с подавленной реверберацией (или без реверберации) компонентами сигнала входного аудиосигнала на основе взвешенной комбинации (например, в соответствии с уравнением 28) рекурсивной оценки ковариации, определенной рекурсивно с использованием предыдущих оценок шумных, но с подавленной реверберацией (или без реверберации) компонентов сигнала входного аудиосигнала (например, ассоциированных с ранее обработанными участками или кадрами входного аудиосигнала, например, в соответствии с уравнением 29) и внешнего произведения (например, промежуточного) оценки шумных, но с подавленной реверберацией (или без реверберации) компонентов сигнала входного аудиосигнала (например, ассоциированных с текущим обрабатываемым участком входного аудиосигнала). Например, промежуточная оценка шумных, но с подавленной реверберацией компонентов сигнала может быть получена как новшество в процессе фильтрации Калмана (например, в соответствии с уравнением (22)). Например, промежуточная оценка может являться предсказанием с использованием предсказанных коэффициентов (например, как определено уравнением (21)).
Было обнаружено, что такая концепция обеспечивает хорошую оценку ковариации, ассоциированной с шумными, но с подавленной реверберацией (или без реверберации) компонентами сигнала с разумной вычислительной сложностью.
В предпочтительном варианте осуществления рекурсивная оценка ковариации требуемого сигнала плюс шум основана на оценке шумных, но с подавленной реверберацией (или без реверберации) компонентов сигнала входного аудиосигнала, вычисленных с использованием окончательных коэффициентов оценки (предпочтительно многоканальной) авторегрессивной модели реверберации и с использованием окончательной оценки реверберирующего сигнала с подавленным шумом (например, в соответствии с уравнением (29) в сочетании с определением û(n)). В качестве альтернативы или в дополнение процессор сигналов выполнен с возможностью получать внешнее произведение шумных, но с подавленной реверберацией компонентов сигнала входного аудиосигнала на основе промежуточной оценки (например, предсказания) коэффициентов (предпочтительно многоканальной) авторегрессивной модели реверберации (например, в процессе фильтрации Калмана) (например, чтобы получить оценку ковариации) (например, полученной в соответствии с уравнением (21)). Посредством использования такой концепции (например, в соответствии с описанными ниже уравнениями (28) и (29), взятыми в сочетании с определениями e(n) и û(n)) оценочная ковариация может быть получена эффективным образом.
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью получать оценочную ковариацию, ассоциированную с компонентами сигнала с подавленным шумом и с подавленной реверберацией (или без реверберации) входного аудиосигнала на основе взвешенной комбинации (например, в соответствии с уравнением (37)) рекурсивной оценки ковариации, определенной рекурсивно с использованием предыдущих оценок компонентов сигнала с подавленным шумом и с подавленной реверберацией входного аудиосигнала (например, ассоциированных с ранее обработанными участками или кадрами входного аудиосигнала) (которые можно рассмотреть, например, как рекурсивную апостериорную оценка максимального правдоподобия), и априорной оценки ковариации, которая основана на текущем обрабатываемом участке входного аудиосигнала (и полученной, например, в соответствии с уравнением (41)). Таким образом, значащая оценка ковариации, ассоциированной с компонентом сигнала с подавленным шумом и с подавленной реверберацией входного аудиосигнала, может быть получена с умеренной вычислительной сложностью. Например, использование подхода, описанного в уравнении (37), допускает использование фильтра Калмана для шумоподавления с хорошими результатами.
В предпочтительном варианте осуществления процессор сигналов выполнен с возможностью получать рекурсивную оценку ковариации на основе оценки компонентов сигнала с подавленным шумом и с подавленной реверберацией (или без реверберации) входного аудиосигнала, вычисленных с использованием окончательных оценочных коэффициентов (предпочтительно многоканальной) авторегрессивной модели реверберации и с использованием окончательной оценки реверберирующего (выходного) сигнала с подавленным шумом (например, с использованием уравнения (38)). В качестве альтернативы или в дополнение процессор сигналов выполнен с возможностью получать априорную оценку ковариации с использованием фильтрации Винера входного сигнала (как показано, например, в уравнении (41)), причем операция фильтрации Винера определена в зависимости от информации ковариации относительно входного аудиосигнала, в зависимости от информации ковариации относительно компонента реверберации входного аудиосигнала и в зависимости от информации ковариации относительно шумового компонента входного аудиосигнала (как показано, например, в уравнении (42)). Было обнаружено, что эти концепции являются полезными при эффективном вычислении оценочной ковариации, ассоциированной с компонентом сигнала с подавленным шумом и с подавленной реверберацией.
Процессоры сигналов, описанные здесь, и процессоры сигналов, определенные в формуле изобретения, могут быть дополнены любыми из признаков, функций и элементов, описанных в настоящем документе, как отдельно, таки и в комбинации. Подробные сведения относительно вычисления различных параметров могут использоваться независимо. Также подробные сведения относительно этапов индивидуальной обработки могут использоваться независимо.
Другой вариант осуществления в соответствии с изобретением создает способ обеспечения обработанного аудиосигнала (например, аудиосигнала с подавленным шумом и с подавленной реверберацией, который может представлять собой одноканальный аудиосигнал или многоканальный аудиосигнал) на основе входного аудиосигнала (например, одноканального или многоканального входного аудиосигнала). Способ содержит оценку коэффициентов (предпочтительно, но не обязательно многоканальной) авторегрессивной модели реверберации (например, коэффициентов AR или коэффициентов MAR) с использованием (обычно шумного и реверберирующего) входного аудиосигнала (или входных аудиосигналов) (например, непосредственно из наблюдаемого сигнала y(n) и задержанных (или прошлых) реверберирующих сигналов с подавленным шумом, полученных с использованием шумоподавления (стадии шумоподавления) (например, прошлые реверберирующие сигналы с подавленным шумом ). Эта функциональность может быть выполнена, например, посредством стадии оценки коэффициентов AR.
Кроме того, способ содержит обеспечение реверберирующего сигнала с подавленным шумом (например, текущего кадра) с использованием (обычно шумного и реверберирующего) входного аудиосигнала (например, шумного наблюдаемого сигнала y(n) и оценочных коэффициентов (предпочтительно многоканальной) авторегрессивной модели реверберации (например, ассоциированных с текущим кадром). Оценочные коэффициенты авторегрессивной модели реверберации, например, могут являться "коэффициентами MAR". Кроме того, функциональность обеспечения реверберирующего сигнала с подавленным шумом может быть выполнена, например, посредством стадии шумоподавления.
Способ дополнительно содержит производство выходного сигнала с подавленным шумом и с подавленной реверберацией с использованием реверберирующего сигнала с подавленным шумом и оценочных коэффициентов (предпочтительно многоканальной) авторегрессивной модели реверберации.
Этот способ основан на тех же самых соображениях, как и упомянутый выше процессор сигналов, в результате чего упомянутые выше разъяснения также являются применимыми.
Кроме того, способ может быть дополнен любыми признаками, функциями и элементами, описанными в настоящем документе относительно процессора сигналов, как отдельно, так и в комбинации.
Другой вариант осуществления в соответствии с изобретением создает компьютерную программу для выполнения способа согласно настоящему описанию, когда компьютерная программа выполняется на компьютере.
Краткое описание чертежей
Далее будут описаны варианты осуществления в соответствии с настоящим изобретением со ссылкой на приложенные чертежи.
Фиг. 1 показывает блок-схему процессора сигналов в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 2 показывает традиционную структуру для оценки коэффициентов MAR (многоканальных авторегрессивных) в шумной среде;
Фиг. 3 показывает блок-схему устройства (или процессора сигналов) в соответствии с настоящим изобретением (вариант осуществления 2);
Фиг. 4 показывает блок-схему устройства (или процессора сигналов) в соответствии с настоящим изобретением (вариант осуществления 3);
Фиг. 5 показывает блок-схему устройства (или процессора сигналов) в соответствии с настоящим изобретением (вариант осуществления 4);
Фиг. 6 показывает схематическое представление генеративной модели реверберирующего сигнала, многоканальных авторегрессивных коэффициентов и шумного наблюдаемого сигнала;
Фиг. 7 показывает блок-схему устройства (или процессора сигналов), содержащего предложенную структуру параллельного двойного фильтра Калмана в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 8 показывает блок-схему традиционного последовательного шумоподавления и структуру подавления реверберации в соответствии со ссылкой [31];
Фиг. 9 показывает блок-схему предложенной структуры для управления величиной шумоподавления βv и подавления реверберации βr;
Таблица 1 показывает табличное представление целевых показателей для изменения iSNR (стационарный шум) с использованием измеренных характеристик RIR, M=2, L=12, βv =-10 дБ, βr, min=-15 дБ;
Фиг. 10 показывает схематическое представление целевых показателей для переменного количества микрофонов с использованием измеренных характеристик RIR, iSNR=10 дБ, L=15, без управления подавлением (βv=βr=0);
Фиг. 11 показывает графическое представление целевых показателей для переменной длины фильтра L, параметров iSNR=15 дБ, M=2, без управления подавлением (βv=βr=0),
Фиг. 12 показывает графическое представление краткосрочных показателей для движущегося источника между 8-13 с в моделируемом маленьком помещении обувной коробки с T60=500 мс, iSNR=15 дБ, M=2, L=15, βv=-15 дБ, βr, min=-15 дБ;
Фиг. 13 показывает графическое представление шумоподавления и подавления реверберации для переменных управляющих параметров βv и βr, MIN, iSNR=15 дБ, M=2, L=12;
Таблица 2 показывает табличное представление таблицы целевых показателей для изменения iSNR (невнятный шум) с использованием измеренных характеристик RIR, M=2, L=12, βv=-10 дБ, βr, min=-15 дБ; и
Фиг. 14 показывает блок-схему последовательности этапов способа обеспечения обработанного аудиосигнала на основе входного аудиосигнала в соответствии с вариантом осуществления настоящего изобретения.
Подробное описание вариантов осуществления
1. Вариант осуществления в соответствии с фиг. 1
Фиг. 1 показывает блок-схему процессора 100 сигналов в соответствии с вариантом осуществления настоящего изобретения. Процессор 100 сигналов выполнен с возможностью принимать входной аудиосигнал 110 и выполнен с возможностью обеспечивать на его основе обработанный аудиосигнал 112, который, например, может представлять собой аудиосигнал с подавленным шумом и с подавленной реверберацией. Следует отметить, что входной аудиосигнал 110 может представлять собой одноканальный аудиосигнал, но предпочтительно представляет собой многоканальный аудиосигнал. Аналогичным образом, обработанный аудиосигнал 112 может представлять собой одноканальный аудиосигнал, но предпочтительно представляет собой многоканальный аудиосигнал. Процессор 100 сигналов, например, может содержать блок 120 оценки коэффициентов, который выполнен с возможностью оценивать коэффициенты 124 авторегрессивной модели реверберации (например, коэффициенты AR или коэффициенты MAR многоканальной авторегрессивной модели реверберации) с использованием одноканального или многоканального входного аудиосигнала 110 и задержанного реверберирующего сигнала 122 с подавленным шумом.
Например, блок 120 оценки коэффициентов авторегрессивной модели реверберации может принять входной аудиосигнал 110 и задержанный реверберирующий сигнал 122 с подавленным шумом.
Процессор 100 сигналов также содержит блок 130 шумоподавления, который принимает входной аудиосигнал 110, и который обеспечивает сигнал 132 с подавленным шумом (но обычно реверберирующий, или без подавленной реверберации). Блок 130 шумоподавления выполнен с возможностью обеспечивать сигнал с подавленным шумом (но обычно реверберирующий) с использованием входного аудиосигнала 110 (обычно шумного и реверберирующего) и оценочные коэффициенты 124 авторегрессивной модели реверберации, которые обеспечены блоком 120 оценки.
Здесь следует отметить, что шумоподавление 130, например, может использовать коэффициенты 124 авторегрессивной модели реверберации, которые были получены на основе ранее определенного реверберирующего сигнала 132 с подавленным шумом (возможно, в сочетании со входным аудиосигналом 110).
Устройство 100 в некоторых случаях содержит блок 140 задержки, который может быть выполнен с возможностью получать реверберирующий сигнал 132 с подавленным шумом, обеспеченный блоком 130 шумоподавления, чтобы обеспечить на выходе его задержанную версию 122. В соответствии с этим оценка 120 коэффициентов авторегрессивной модели реверберации может работать с ранее полученным (произведенным) реверберирующим сигналом с подавленным шумом (который обеспечен или произведен блоком 130 шумоподавления) и входным аудиосигналом 110.
Устройство 100 также содержит блок 150 для производства выходного сигнала с подавленным шумом и с подавленной реверберацией, который может служить в качестве обработанного аудиосигнала 112. Блок 150 предпочтительно принимает реверберирующий сигнал 132 с подавленным шумом от блока 130 шумоподавления и коэффициенты 124 авторегрессивной модели реверберации, обеспеченные блоком 120 оценки. Таким образом, блок 150, например, может удалять или подавлять реверберацию реверберирующего сигнала 132 с подавленным шумом. Например, с этой целью может использоваться подходящая фильтрация в сочетании с операцией подавления (например, в спектральной области), причем коэффициенты 124 авторегрессивной модели реверберации могут определить фильтрацию (который используется для оценки реверберации).
Относительно устройства 100 следует отметить, что разделение функций на блоки можно рассматривать как эффективный, но произвольный выбор. Функциональности, описанные в настоящем документе, также могут быть по-другому распределены по аппаратным устройствам при условии, что сохраняется базовая функциональность. Кроме того, следует отметить, что блоки могут представлять собой программные блоки, которые одни и те же аппаратные средства (как, например, микропроцессор).
Относительно функциональности устройства 100 можно сказать, что разделение между функциональностью шумоподавления (блок 130 шумоподавления) и оценкой коэффициентов авторегрессивной модели реверберации (блок 120 оценки) обеспечивает довольно малую вычислительную сложность и по-прежнему позволяет получить достаточно высокое качество звука. Даже при том, что теоретически было бы лучше оценивать выходной сигнал с подавленным шумом и с подавленной реверберацией с использованием совместной функции стоимости, было обнаружено, что отдельное выполнение шумоподавления и оценки коэффициентов авторегрессивной модели реверберации с использованием раздельных функций стоимости по-прежнему может обеспечить довольно хорошие результаты, в то время как сложность может быть сокращена, и можно избежать проблем стабильности. Кроме того, было обнаружено, что реверберирующий сигнал 132 с подавленным шумом служит в качестве очень хорошего промежуточного качества, поскольку выходной сигнал с подавленным шумом и с подавленной реверберацией (т.е., обработанный аудиосигнал 112) может быть произведен из сигнала 132 с подавленным шумом (но реверберирующего, или без подавленной реверберации) с небольшими усилиями при условии, что известны коэффициенты 124 авторегрессивной модели реверберации.
Однако следует отметить, устройство 100, описанное на фиг. 1, может быть дополнено любыми из описанных далее признаков, функций и элементов, как отдельно, так и в комбинации.
2. Варианты осуществления в соответствии с фиг. 3, 4 и 5
Далее будут описаны некоторые дополнительные варианты осуществления со ссылкой на фиг. 3, 4 и 5. Однако, прежде чем будут описаны подробности вариантов осуществления, будет описана некоторая информация относительно традиционных решений, и будет определена модель сигнала.
Вообще говоря, будут описаны способы и устройства для онлайнового подавления реверберации и шума (с использованием параллельной структуры), в некоторых случаях с управлением подавлением.
2.1 Введение
Следующие варианты осуществления изобретения находятся в области обработки акустических полей, например, чтобы удалить шум и реверберацию от одного или нескольких микрофонов.
В сценариях речевой связи на большом расстоянии, когда требуемый источник речи находится далеко от устройства захвата, качество и разборчивость речи, а также рабочие характеристики устройств распознавания речи обычно ухудшаются вследствие высокого уровня реверберации и шума по сравнению с требуемым уровнем речевого сигнала.
Способы подавления реверберации на основе авторегрессивной модели (AR) на каждую частотную полосу в области оконного преобразования Фурье (STFT) оказались лучше других моделей реверберации. Способы подавления реверберации на основе этой модели обычно решают проблему с использованием подходов, относящихся к линейному предсказанию. Кроме того, общая многоканальная авторегрессивная модель (MAR) пригодна для нескольких источников и может быть сформулирована таким образом, что она обеспечивает такое же количество каналов на выходе, как на входе. Поскольку полученный в результате процесс улучшения, который является линейным фильтром на каждую частотную полосу в пределах нескольких кадров преобразования STFT, не изменяет пространственную корреляцию требуемого сигнала, улучшение является подходящим в качестве предварительной обработки для дальнейших методик обработки массивов.
В то время как большинство существующих методик на основе модели MAR являются пакетными алгоритмами [Nakatani 2010, Yoshioka 2009, Yoshioka 2012], некоторые онлайновые алгоритмы были предложены в [Yoshioka 2013, Togami 2019, Jukic 2016]. Однако сложная проблема в шумных средах c использованием онлайнового алгоритма была решена только в [Togami 2015].
Было обнаружено, что в шумных средах проблема обычно может быть решена посредством выполнения этапа шумоподавления, после которого выполняются способы на основе линейного предсказания для оценки коэффициентов MAR (также известных как коэффициенты регрессии помещения), а затем фильтрации сигнала.
В вариантах осуществления изобретения предложена новая параллельная структура для оценки коэффициентов MAR и сигнала с подавленным шумом непосредственно из наблюдаемых сигналов микрофона вместо последовательной структуры. Параллельная структура позволяет полностью причинную оценку потенциально изменяющихся во времени коэффициентов MAR и решает проблему неоднозначности, какая из зависимых стадий должна быть сначала исполнена - стадия оценки коэффициентов MAR или стадия шумоподавления. Кроме того, параллельная структура дает возможность создать выходной сигнал, когда можно эффективно управлять величиной разностной реверберации и шума.
2.2 Определения и традиционные решения
2.2.1 Модель сигнала
Следующие подразделы обобщенно представляют традиционные подходы для подавления реверберации в шумных средах на основе многоканальной авторегрессивной модели.
С использованием модели мы предполагаем, что сигналы микрофона в частотно-временной области 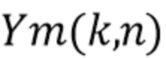 , где
, где 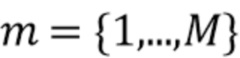 , с частотным и временным индексами k и n, записанные в векторе
, с частотным и временным индексами k и n, записанные в векторе  , могут быть описаны как
, могут быть описаны как
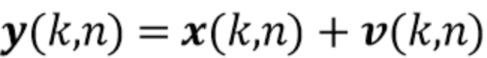
где вектор 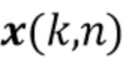 обозначает реверберирующий речевой сигнал в микрофонах, и вектор
обозначает реверберирующий речевой сигнал в микрофонах, и вектор  обозначает аддитивный шум. Вектор реверберирующего речевого сигнала смоделирован как многоканальный авторегрессивный процесс
обозначает аддитивный шум. Вектор реверберирующего речевого сигнала смоделирован как многоканальный авторегрессивный процесс

где вектор 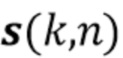 обозначает ранние речевые сигналы в микрофонах, и матрицы
обозначает ранние речевые сигналы в микрофонах, и матрицы 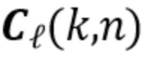 , где
, где  , содержат коэффициенты MAR. Количество кадров L описывает длину, необходимую, чтобы смоделировать реверберацию, в то время как задержка
, содержат коэффициенты MAR. Количество кадров L описывает длину, необходимую, чтобы смоделировать реверберацию, в то время как задержка 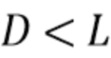 управляет начальным временем поздней реверберации и в соответствии с аспектом изобретения должна быть выбрана таким образом, что между прямым звуком, содержащемся в , и поздней реверберацией нет корреляции.
управляет начальным временем поздней реверберации и в соответствии с аспектом изобретения должна быть выбрана таким образом, что между прямым звуком, содержащемся в , и поздней реверберацией нет корреляции.
Цель (и концепция) этого изобретения (или его вариантов осуществления) состоит в том, чтобы получить ранние речевые сигналы посредством оценки реверберирующих бесшумных речевых сигналов и коэффициентов MAR, обозначенных  и
и 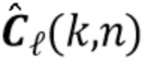 , соответственно. В соответствии с аспектом изобретения с использованием этих оценок вектор требуемых сигналов оценивается посредством процесса линейной фильтрации
, соответственно. В соответствии с аспектом изобретения с использованием этих оценок вектор требуемых сигналов оценивается посредством процесса линейной фильтрации

Для простоты записи в следующих уравнениях частотный индекс k опущен, и мы переформулируем наблюдаемый сигнал микрофона с использованием матричной нотации
 ,
,
где
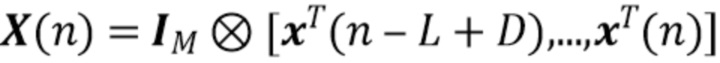
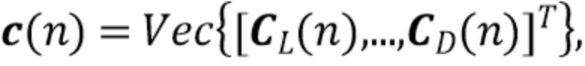
 - единичная матрица размером
- единичная матрица размером  ,
,  обозначает произведение Кронекера,
обозначает произведение Кронекера, 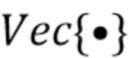 обозначает оператор преобразования столбца матрицы в вектор, и вектор
обозначает оператор преобразования столбца матрицы в вектор, и вектор 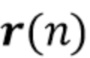 обозначает позднюю реверберацию в каждом микрофоне.
обозначает позднюю реверберацию в каждом микрофоне.
В традиционных решениях коэффициенты MAR смоделированы как детерминированная переменная, которая подразумевает стационарность  . В [Braun2016] была введена стохастическая модель для потенциально изменяющихся во времени коэффициентов MAR, более конкретно, модель Маркова первого порядка
. В [Braun2016] была введена стохастическая модель для потенциально изменяющихся во времени коэффициентов MAR, более конкретно, модель Маркова первого порядка
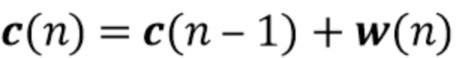 ,
,
где 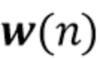 - случайный шум, моделирующий неопределенность распространения коэффициентов. Однако в [Braun2016] решение дано только при условии отсутствия аддитивного шума.
- случайный шум, моделирующий неопределенность распространения коэффициентов. Однако в [Braun2016] решение дано только при условии отсутствия аддитивного шума.
2.2.2 Последовательное онлайновое решение
Способы оценки переменных и в пакетном алгоритме, в котором коэффициенты предполагаются стационарными, предложены в [Yoshioka2009, Togami2013]. Однако было обнаружено, что в общих реалистических приложениях акустическая сцена, т.е. коэффициенты MAR , может изменяться во времени. Только онлайновое решение проблемы оценки коэффициентов MAR в шумных средах предложено в [Togami2015], хотя при допущении, что коэффициенты MAR являются стационарными.
Традиционные подходы для таких сходных проблем оценки сигнала AR и параметров AR используют последовательную структуру, как показано на фиг. 2, такую как традиционный онлайновый подход [Togami2015]. Сначала стадия 202 шумоподавления пытается удалить шум из наблюдаемых сигналов 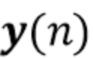 , и на втором этапе 203 коэффициенты AR оцениваются на основе выходных сигналов первой стадии. Было обнаружено, что эта структура является недостаточно оптимальной по двум причинам: 1) стадия 203 оценки параметров MAR предполагает, что оценочный сигнал является бесшумным, что часто невозможно на практике; 2) чтобы использовать информацию коэффициентов MAR на стадии 202 шумоподавления, следует предполагать, что коэффициенты являются стационарными, поскольку требуется, чтобы предположение
, и на втором этапе 203 коэффициенты AR оцениваются на основе выходных сигналов первой стадии. Было обнаружено, что эта структура является недостаточно оптимальной по двум причинам: 1) стадия 203 оценки параметров MAR предполагает, что оценочный сигнал является бесшумным, что часто невозможно на практике; 2) чтобы использовать информацию коэффициентов MAR на стадии 202 шумоподавления, следует предполагать, что коэффициенты являются стационарными, поскольку требуется, чтобы предположение 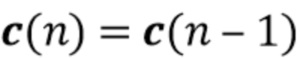 передавало оценочные коэффициенты MAR от стадии оценки коэффициентов MAR обратно к стадии шумоподавления.
передавало оценочные коэффициенты MAR от стадии оценки коэффициентов MAR обратно к стадии шумоподавления.
Итак, фиг. 2 показывает блок-схему традиционной структуры для оценки коэффициентов MAR в шумной среде. Устройство 200 содержит оценку 201 статистики шума, шумоподавление 202, оценку 203 коэффициентов AR и оценку 204 реверберации.
Другими словами, блоки 201-204 являются блоками традиционной системы последовательного подавления шума и реверберации.
2.3 Варианты осуществления в соответствии с настоящим изобретением
Далее будут описаны три варианта осуществления в соответствии с настоящим изобретением. Фиг. 3 показывает блок-схему варианта осуществления 2 в соответствии с настоящим изобретением. Фиг. 4 показывает блок-схему варианта осуществления 3 в соответствии с настоящим изобретением. Фиг. 5 показывает блок-схему варианта осуществления 4 в соответствии с настоящим изобретением.
В следующем будет представлено краткое описание фигур и номеров блоков.
Следует отметить, что блоки 301-305 представляют собой блоки предложенной системы подавления шума и реверберации. Также следует отметить, что идентичные номера для ссылок используются для идентичных блоков (или для блоков, имеющих идентичные функциональности) в вариантах осуществления в соответствии с фиг. 3, 4 и 5.
Далее в качестве вариантов осуществления изобретения предложены решения проблемы подавления реверберации посредством оценки коэффициентов MAR и реверберирующего сигнала обусловленным онлайновым методом при наличии аддитивного шума. Статистика пространственного шума может быть оценена заранее блоком 301 вычисления, например, как предложено в [Gerkmann 2012].
2.3.1 Вариант осуществления 2: параллельная структура для оценки коэффициентов AR и требуемого сигнала
Фиг. 3 показывает блок-схему устройства (или процессора сигналов) в соответствии с вариантом осуществления настоящего изобретения (или, в целом, блок-схему варианта осуществления предложенного изобретения).
Устройство 300 в соответствии с фиг. 3 выполнено с возможностью принимать входной сигнал 310, который может представлять собой одноканальный аудиосигнал или многоканальный аудиосигнал. Устройство 300 также выполнено с возможностью обеспечивать обработанный аудиосигнал 312, который может представлять собой сигнал с подавленным шумом и с подавленной реверберацией. Устройство 300 опционально может содержать блок 301 оценки статистики шума, который может быть выполнен с возможностью производить информацию о статистике шума на основе входного аудиосигнала 310. Например, блок 301 оценки статистики шума может оценить статистику шума в отсутствие речевого сигнала (например, во время пауз речи).
Устройство 300 также содержит блок 303 шумоподавления, который принимает входной аудиосигнал 310, информацию 301a о статистике шума и коэффициенты 302a авторегрессивной модели реверберации (которые обеспечены блоком 302 оценки авторегрессивных коэффициентов). Блок 303 шумоподавления обеспечивает сигнал 303a с подавленным шумом (но обычно реверберирующий).
Устройство 300 также содержит блок 302 оценки авторегрессивных коэффициентов (оценки коэффициентов AR), который выполнен с возможностью принимать входной аудиосигнал 301 и задержанную версию (или прошлую версию) сигнала 303a с подавленным шумом (но обычно реверберирующего), обеспеченную блоком 303 шумоподавления. Кроме того, блок 302 оценки авторегрессивных коэффициентов выполнен с возможностью обеспечивать коэффициенты 302a авторегрессивной модели реверберации.
Устройство 300 в некоторых случаях содержит блок 320 задержки, который выполнен с возможностью производить задержанную версию 320a на основе сигнала 303a с подавленным шумом (но обычно реверберирующего), обеспеченного блоком 303 шумоподавления.
Устройство 300 также содержит блок 304 оценки реверберации, который выполнен с возможностью принимать задержанную версию 320a сигнала 303a с подавленным шумом (но обычно реверберирующего), обеспеченного блоком 303 шумоподавления. Кроме того, блок 304 оценки реверберации также принимает коэффициенты 302a авторегрессивной модели реверберации от блока 302 оценки авторегрессивных коэффициентов. Блок 304 оценки реверберации обеспечивает оценочный сигнал 304a реверберации.
Устройство 300 также содержит блок 330 вычитания сигнала, который выполнен с возможностью удалять (или вычитать) оценочный сигнал 304a реверберации из сигнала 303a с подавленным шумом (но обычно реверберирующего), обеспеченного блоком 303 шумоподавления, чтобы тем самым получить обработанный аудиосигнал 312, который обычно является сигналом с подавленным шумом и с подавленной реверберацией.
Далее будет более подробно описана функциональность устройства 300 в соответствии с фиг. 3. В частности, следует отметить, что блок 302 оценки авторегрессивных коэффициентов использует и входной сигнал 310, и выходной сигнал 303a с подавленным шумом (но обычно реверберирующий) блока 303 шумоподавления (или, более точно, его задержанную версию 320a). В соответствии с этим оценка 302 авторегрессивных коэффициентов может быть выполнена отдельно от шумоподавления 303, причем шумоподавление 303 тем не менее может извлечь выгоду из коэффициентов 302a авторегрессивной модели реверберации, и причем оценка 302 авторегрессивных коэффициентов тем не менее может извлечь выгоду из сигнала 303a с подавленным шумом, обеспеченного блоком 303 шумоподавления. Наконец, реверберация может быть удалена из сигнала 303a с подавленным шумом (но обычно реверберирующего), обеспеченного блоком 303 шумоподавления.
Далее будет снова, другими словами описана функциональность устройства 300.
Посредством использования процедуры чередующейся минимизации для оценки коэффициентов MAR и реверберирующих сигналов  (оценки обозначены как
(оценки обозначены как  и
и  (n)) мы получаем процедуру с тремя этапами, в которой на первом этапе (блок 302) коэффициенты MAR оцениваются непосредственно на основе наблюдаемых сигналов , и требуется только информация о прошлых реверберирующих сигналах, содержащихся в матрице
(n)) мы получаем процедуру с тремя этапами, в которой на первом этапе (блок 302) коэффициенты MAR оцениваются непосредственно на основе наблюдаемых сигналов , и требуется только информация о прошлых реверберирующих сигналах, содержащихся в матрице  . На втором этапе (блок 303) выполняется шумоподавление, чтобы оценить реверберирующие сигналы на основе наблюдений шума . Этап шумоподавления требует знания коэффициентов MAR , которые доступны как текущая оценка вследствие параллельной структуры от блока 302, и статистики шума от блока 301.
. На втором этапе (блок 303) выполняется шумоподавление, чтобы оценить реверберирующие сигналы на основе наблюдений шума . Этап шумоподавления требует знания коэффициентов MAR , которые доступны как текущая оценка вследствие параллельной структуры от блока 302, и статистики шума от блока 301.
На третьем этапе (блок 304) поздняя реверберация вычисляется как 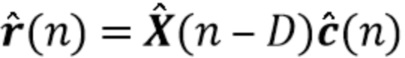 и вычитается из реверберирующих сигналов , чтобы получить оценочные требуемые речевые сигналы
и вычитается из реверберирующих сигналов , чтобы получить оценочные требуемые речевые сигналы  (например, блок 330). Процедура проиллюстрирована на фиг. 3.
(например, блок 330). Процедура проиллюстрирована на фиг. 3.
Онлайновая оценка и может быть выполнена рекурсивными блоками оценки, такими как фильтры Калмана, в то время как требуемые ковариации могут быть оценены в смысле максимального правдоподобия. Конкретный пример того, как вычислить и , описан в разделе 3, разъясняющим “Онлайновое подавление реверберации и шума на основе линейного предсказания с использованием чередующихся фильтров Калмана”.
Однако вместо этого в блоках 302 и 303 также могут использоваться другие способы оценки, такие как рекурсивный метод наименьших квадратов, NLMS и т.д. ковариационная матрица шума 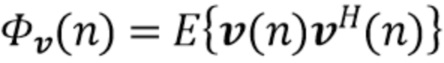 (который может потребоваться для информации 301a) предпочтительно должна быть известна заранее и, например, может быть оценена в периоды отсутствия речи. Подходящие способы для оценки статистики шума в блоке 301 с использованием вероятности присутствия речи описаны в [Gerkmann2012, Taseska2012].
(который может потребоваться для информации 301a) предпочтительно должна быть известна заранее и, например, может быть оценена в периоды отсутствия речи. Подходящие способы для оценки статистики шума в блоке 301 с использованием вероятности присутствия речи описаны в [Gerkmann2012, Taseska2012].
2.3.2 Варианты осуществления 3 и 4: управление подавлением
Далее будут описаны варианты осуществления в соответствии с фиг. 4 и 5.
Фиг. 4 показывает блок-схему устройства или процессора 400 сигналов в соответствии с вариантом осуществления настоящего изобретения. Процессор 400 сигналов содержит блок 303 шумоподавления и блок 304 оценки реверберации. Блок 303 шумоподавления обеспечивает сигнал 303a с подавленным шумом (но обычно реверберирующий). Блок 304 оценки реверберации обеспечивает сигнал 304a реверберации. Например, блок 303 шумоподавления устройства 400 может содержать такую же функциональность, как блок 303 шумоподавления устройства 300 (возможно в сочетании с блоком 301).
Кроме того, блок 304 оценки реверберации устройства 400, например, может выполнять функциональность блока 304 оценки реверберации устройства 300, возможно в сочетании с функциональностью блоков 302 и 320.
Кроме того, устройство 400 выполнено с возможностью комбинировать масштабированную версию входного сигнала 410 (который может соответствовать входному сигналу 310) с масштабированной версией сигнала 303a с подавленным шумом (но обычно реверберирующего), и также с масштабированной версией сигнала 304a реверберации, обеспеченного блоком 304 оценки реверберации. Например, входной сигнал 410 может быть масштабирован с помощью масштабного коэффициента βv. Кроме того, сигнал 303a с подавленным шумом, обеспеченный блоком 303 шумоподавления, может быть масштабирован с помощью коэффициента (1-βv). Кроме того, сигнал 304a реверберации может быть масштабирован с помощью коэффициента (1-βr). Например, масштабированная версия 410a входного сигнала 410 и масштабированная версия 303b сигнала 303a с подавленным шумом могут быть объединены с одинаковыми знаками. Напротив, масштабированная версия 304b сигнала 304a реверберации может быть вычтена из суммы сигналов 410a, 303b, чтобы тем самым получить выходной сигнал 412. Итак, масштабированная версия 410a входного сигнала может быть объединена с масштабированной версией 303b сигнала 303a с подавленным шумом, и по меньшей мере часть реверберации может быть удалена посредством вычитания масштабированной версии 304b сигнала 304a реверберации, полученного блоком 304 оценки реверберации.
В соответствии с этим характеристики выходного сигнала 412 могут регулироваться желаемым образом. Степень шумоподавления и степень подавления реверберации могут регулироваться посредством соответствующего выбора масштабных коэффициентов, например, βv и βr.
Фиг. 5 показывает блок-схему другого устройства или процессора сигналов в соответствии с вариантом осуществления изобретения.
Устройство или процессор 500 сигналов в соответствии с фиг. 5 является сходным с устройством или процессором 400 сигналов в соответствии с фиг. 4, поэтому делается отсылка на приведенные выше разъяснения и одинаковые компоненты не будут описываться снова.
Однако устройство 500 также содержит блок 305 оформления реверберации, который принимает сигнал 304a реверберации, обеспеченный блоком оценки реверберации. Блок 305 оформления реверберации обеспечивает оформленный сигнал 305a реверберации.
В соответствии с концепцией, показанной на фиг. 5, сигнал 304a реверберации вычитается из суммы масштабированного сигнала 303b с подавленным шумом и масштабированного входного сигнала 410a, соответственно, получается промежуточный сигнал 520. Кроме того, масштабированная версия 305b оформленного сигнала 305a реверберации добавляется к промежуточному сигналу 520, чтобы получить выходной сигнал 512.
Однако также была бы возможна прямая комбинация сигналов 410a, 303b, 304a и 305b (без использования промежуточного сигнала).
В соответствии с этим устройство 500 позволяет регулировать характеристики выходного сигнала 512. Первоначальная реверберация может быть удалена (по меньшей мере в значительной степени), например, посредством вычитания (оценочного) сигнала 304a реверберации из суммы сигналов 303b, 410a. В соответствии с этим модифицированный (оформленный) сигнал 305b реверберации может быть добавлен (например, после опционального масштабирования), чтобы тем самым получить выходной сигнал 512. В соответствии с этим выходной сигнал может быть получен с помощью оформленной реверберации и с помощью регулируемой степени шумоподавления.
Далее вариант осуществления в соответствии с фиг. 4 и 5, фиг. 5 будет обобщенно представлен другими словами.
Параллельная структура, показанная на фиг. 3 (с некоторыми расширениями и поправками) допускает простой и эффективный способ управления величиной подавления реверберации и шума. Такое управление может потребоваться в сценариях речевой связи, например, чтобы поддерживать некоторый разностный шум и реверберацию, учитывая восприятие, или для маскировки артефактов, произведенных алгоритмом подавления.
Мы определяем (требуемый) новый выходной сигнал

где  и
и 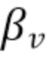 - управляющие параметры для разностной реверберации и шума. Перестраивая уравнение и заменяя неизвестные переменные доступными оценками, мы можем вычислить управляемые выходные сигналы (например, выходной сигнал (412)
- управляющие параметры для разностной реверберации и шума. Перестраивая уравнение и заменяя неизвестные переменные доступными оценками, мы можем вычислить управляемые выходные сигналы (например, выходной сигнал (412)
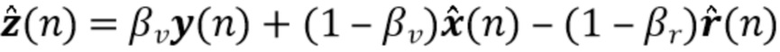 ,
,
как показано на фиг. 4. Этапы 301 и 302 опущены на этой фиг. 4 (но в некоторых случаях могут быть добавлены).
Для дополнительного спектрального и динамического оформления разностной реверберации опциональная обработка сигнала реверберации 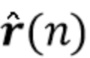 может быть вставлена, как показано на фиг. 4 в блоке 305 (например, как показано на фиг. 5). Выходной сигнал с оформлением реверберации тогда вычисляется как
может быть вставлена, как показано на фиг. 4 в блоке 305 (например, как показано на фиг. 5). Выходной сигнал с оформлением реверберации тогда вычисляется как

где 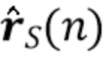 - оформленный сигнал реверберации блока 305. Оформление реверберации может быть выполнено, например, посредством эквалайзера или компрессора/декомпрессора, традиционно используемых в производстве музыкальной и аудиопродукции.
- оформленный сигнал реверберации блока 305. Оформление реверберации может быть выполнено, например, посредством эквалайзера или компрессора/декомпрессора, традиционно используемых в производстве музыкальной и аудиопродукции.
3. Варианты осуществления в соответствии с фиг. 7 и 9
Далее будут описаны дополнительные варианты осуществления для онлайнового подавления реверберации и шума на основе линейного предсказания с использованием чередующихся фильтров Калмана.
Например, будет описано онлайновое подавление реверберации и шума на основе линейного предсказания с использованием чередующихся фильтров Калмана.
3.1 Введение и обзор
Далее будут описан обзор вариантов осуществления, лежащих в основе концепции в соответствии настоящим изобретением.
Подавление реверберации на основе многоканального линейного предсказания в области оконного преобразования Фурье (STFT), как было показано, является очень эффективным. Однако было обнаружено, что использование таких способов при наличии шума, особенно в случае онлайновой обработки, остается сложной проблемой. Чтобы решить эту проблему, был предложен алгоритм чередующейся минимизации, который состоит из двух интерактивных фильтров Калмана, для оценки бесшумного реверберирующего сигнала, и многоканальные авторегрессивные (MAR) коэффициенты. Тогда требуемые сигналы с подавленной реверберацией получаются посредством фильтрации бесшумных сигналов (или сигналов с подавленным шумом) с использованием оценочных коэффициентов MAR.
Было обнаружено, что существующие последовательные структуры улучшения, используемые для сходных задач, имеют проблему причинной связи, состоящую в том, что и стадия оптимального шумоподавления, и стадия реверберации зависят от текущего выхода друг друга. Чтобы преодолеть эту проблему причинной связи, разработана новая параллельная двойная структура Калмана, которая решает проблемы с использованием чередующихся фильтров Калмана. Было обнаружено, что эта причинная связь является важной в переменных во времени акустических сценариях, в которых коэффициенты MAR не стационарны.
Предложенный способ оценивается с использованием смоделированных и измеренных акустических импульсных характеристик и сравнивается со способом на основе такой же модели сигнала. Кроме того, независимо описан способ (и концепция) для управления величиной подавления реверберации и шума.
Итак, варианты осуществления в соответствии с изобретением могут использоваться для подавления реверберации. Варианты осуществления в соответствии с изобретением используют многоканальное линейное предсказание и авторегрессивную модель. Варианты осуществления в соответствии с изобретением используют фильтр Калмана, предпочтительно в сочетании с чередующейся минимизацией.
В настоящей заявке (и, в частности, в этом разделе) предложен способ (и концепция) на основе модели реверберации MAR для подавления реверберации и шума с использованием онлайнового алгоритма. Предлагаемое решение имеет преимущества перед бесшумным решением, представленным в [3], где коэффициенты MAR смоделированы изменяющейся во времени моделью Маркова первого порядка. Чтобы получить требуемые речевые сигналы с подавленной реверберацией, возможно оценить коэффициенты MAR и бесшумный реверберирующий речевой сигнал.
Предлагаемое решение имеет несколько преимуществ над традиционными решениями: Во-первых, в отличие от последовательного сигнала и способов оценки авторегрессивных (AR) параметров, используемых для шумоподавления, представленного в [8] и [17], предложена параллельная структура оценки в качестве алгоритма чередующейся минимизации, например, два интерактивных фильтра Калмана для оценки коэффициентов MAR и бесшумных реверберирующих сигналов. Эта параллельная структура обеспечивает возможность полностью обусловленной цепи оценки в противоположность последовательной структуре, где стадия шумоподавления использовала бы устаревшие коэффициенты MAR.
Во-вторых, в предложенном способе мы (опционально) предполагаем случайно изменяющийся во времени процесс MAR вместо того, чтобы вычислять независимый от времени линейный фильтр и изменяющийся во времени нелинейный фильтр, как в алгоритме максимизации ожидания (EM), предложенном в [31]. В-третьих, предложенный алгоритм и концепция не требуют многократных итераций на каждый временной кадр, а могут представлять собой адаптивный алгоритм, который сходится со временем. Наконец, в качестве опционального расширения, также независимо предложен способ управления величиной подавления реверберации и шума.
Оставшаяся часть этого раздела организована следующим образом.
В подразделе 2 представлены модели сигнала для реверберирующего сигнала, наблюдаемого шума и коэффициентов MAR и изложена проблема. В подразделе 3 два чередующихся фильтра Калмана производятся как часть задачи чередующейся минимизации для оценки коэффициентов MAR и бесшумных сигналов. Опциональная методика управления подавлением реверберации и шума представлена в подразделе 4. В подразделе 5 предложенный способ и концепция оцениваются и сравниваются со способами существующего уровня техники. Некоторые заключения представлены в подразделе 6.
Относительно обозначений следует отметить, что коэффициенты обозначены как полужирные строчные символы, например, a. Матрицы обозначены как полужирные прописные символы, например, A, а скаляры в нормальные прописные символы (например, A). Оценочные количества обозначены как  , например,
, например, 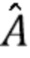 .
.
В вариантах осуществления оценочные количества в некоторых случаях могут занимать место идеальных количеств.
3.2 Модель сигнала и формулировка проблемы
Предположим, например, имеется массив из  микрофонов с произвольной направленностью и произвольной геометрией. Сигналы микрофона заданы в области преобразования STFT как
микрофонов с произвольной направленностью и произвольной геометрией. Сигналы микрофона заданы в области преобразования STFT как 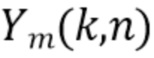 для
для  , где
, где 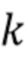 и
и  обозначают соответственно частотные и временные индексы. В векторном обозначении сигналы микрофонов могут быть записаны как
обозначают соответственно частотные и временные индексы. В векторном обозначении сигналы микрофонов могут быть записаны как 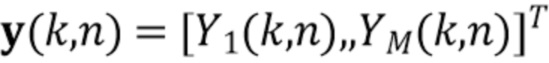 . Предположим, что сигнальный вектор микрофона составлен как
. Предположим, что сигнальный вектор микрофона составлен как
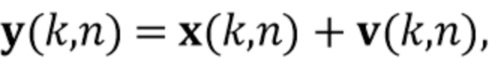 (1)
(1)
где векторы 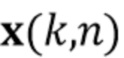 и
и  содержат соответственно реверберирующую речь в каждом микрофоне и аддитивный шум.
содержат соответственно реверберирующую речь в каждом микрофоне и аддитивный шум.
A. Многоканальная авторегрессивная модель реверберации
Как предложено в [21, 32, 33], мы моделируем реверберирующий речевой сигнальный вектор как процесс MAR
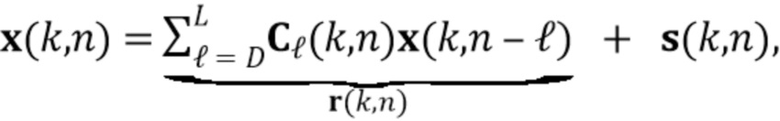 (2)
(2)
где вектор 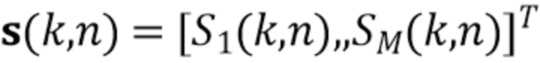 содержит требуемую раннюю речь в каждом микрофоне
содержит требуемую раннюю речь в каждом микрофоне 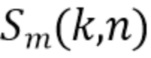 , и матрицы
, и матрицы 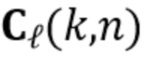 ,
,  размером содержат коэффициенты MAR, предсказывающие компонент
размером содержат коэффициенты MAR, предсказывающие компонент 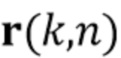 поздней реверберации на основе прошлых кадров . Требуемый ранний речевой сигнал
поздней реверберации на основе прошлых кадров . Требуемый ранний речевой сигнал  является новшеством в этом авторегрессивном процессе (также известен как ошибка предсказания в терминологии линейного предсказания). Выбор задержки
является новшеством в этом авторегрессивном процессе (также известен как ошибка предсказания в терминологии линейного предсказания). Выбор задержки  определяет, сколько ранних отражений мы хотим поддержать в требуемом сигнале, и они должны быть выбраны в зависимости от величины наложения между кадрами преобразования STFT, чтобы было мало или не было никакой корреляции между прямым звуком, содержащимся в , и поздней реверберацией . Длина
определяет, сколько ранних отражений мы хотим поддержать в требуемом сигнале, и они должны быть выбраны в зависимости от величины наложения между кадрами преобразования STFT, чтобы было мало или не было никакой корреляции между прямым звуком, содержащимся в , и поздней реверберацией . Длина  определяет количество прошлых кадров, которые используются для предсказания реверберирующего сигнала.
определяет количество прошлых кадров, которые используются для предсказания реверберирующего сигнала.
Предположим, что требуемый ранний речевой векторный сигнал 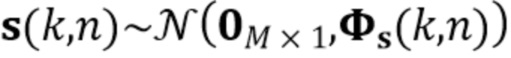 и вектор шума
и вектор шума 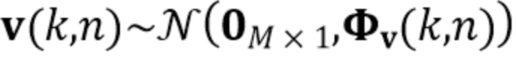 являются циркулярно комплексными Гауссовыми случайными переменным с нулевым средним значением с соответствующим ковариационными матрицами
являются циркулярно комплексными Гауссовыми случайными переменным с нулевым средним значением с соответствующим ковариационными матрицами  и
и  . Кроме того, предположим, что и не коррелированы по времени, и обе переменные взаимно не коррелированы.
. Кроме того, предположим, что и не коррелированы по времени, и обе переменные взаимно не коррелированы.
B. Модель сигнала, сформулированная в двух компактных записях
Чтобы сформулировать функцию стоимости, которая раскладывается на две подфункции стоимости в подразделе 3 в соответствии с концепцией настоящего изобретения, сначала введем две эквивалентно применимых матричных записи, чтобы описать наблюдаемый сигнальный вектор (1). Для более компактной записи в оставшемся описании частотные индексы опущены. Сначала определим значения
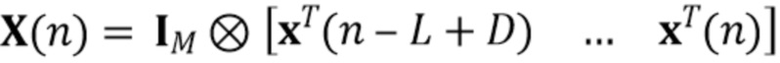 (3)
(3)
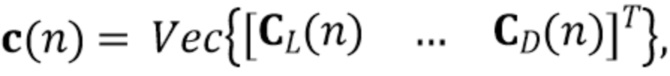 (4)
(4)
где 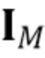 - единичная матрица размера , обозначает произведение Кронекера, и оператор
- единичная матрица размера , обозначает произведение Кронекера, и оператор  последовательно преобразует столбцы матрицы в вектор. Следовательно,
последовательно преобразует столбцы матрицы в вектор. Следовательно, 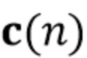 представляет собой вектор-столбец длины
представляет собой вектор-столбец длины 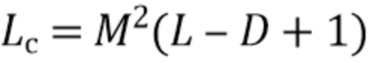 , и
, и  является разреженной матрицей размера
является разреженной матрицей размера  . Используя определения (3) и (4) с моделью сигнала (1) и (2), наблюдаемый сигнальный вектор задается как
. Используя определения (3) и (4) с моделью сигнала (1) и (2), наблюдаемый сигнальный вектор задается как
 (5)
(5)
где вектор 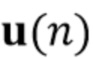 содержит сигналы ранней речи плюс шума, которые, таким образом, имеют ковариационную матрицу
содержит сигналы ранней речи плюс шума, которые, таким образом, имеют ковариационную матрицу  .
.
Вторая компактная запись использует векторы, полученные из столбцов матрицы
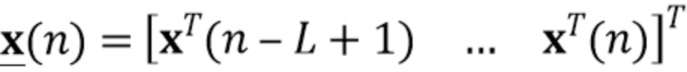 (6)
(6)
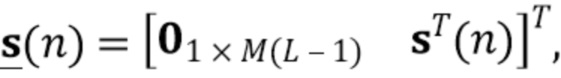 (7)
(7)
обозначенные как подчеркнутые переменные, которые являются вектор-столбцами длины 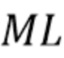 , и матрицами распространения и наблюдения
, и матрицами распространения и наблюдения
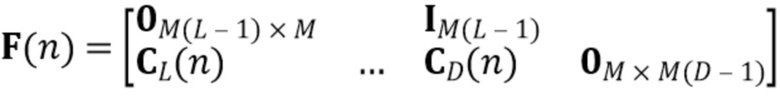 (8)
(8)
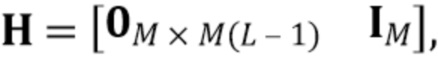 (9)
(9)
соответственно, где матрица 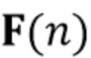 распространения размера
распространения размера  содержит коэффициенты MAR
содержит коэффициенты MAR 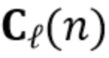 в нижних рядах,
в нижних рядах, 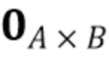 обозначает нулевую матрицу размера
обозначает нулевую матрицу размера 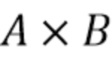 , и
, и 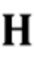 представляет собой матрицу выбора размера
представляет собой матрицу выбора размера  . Используя (8) и (9), мы можем в качестве альтернативы переписать (2) и (1) как
. Используя (8) и (9), мы можем в качестве альтернативы переписать (2) и (1) как
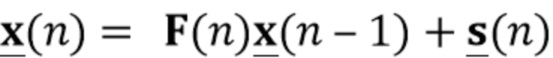 (10)
(10)
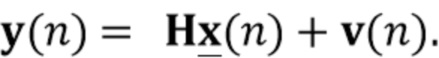 (11)
(11)
Следует отметить, что уравнения (5) и (11) являются эквивалентами, использующими разные обозначения.
C. Стохастическое моделирование пространства состояний коэффициентов MAR
Чтобы смоделировать возможно изменяющиеся во времени акустические среды и нестационарные коэффициенты MAR, из-за ошибок модели области преобразования STFT [3] мы используем модель Маркова первого порядка для описания вектора коэффициентов MAR [6]
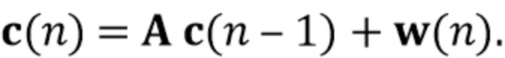 (12)
(12)
Предположим, что матрица перехода  является единичной матрицей, в то время как шум процесса
является единичной матрицей, в то время как шум процесса  моделирует погрешность во времени. Предположим, что
моделирует погрешность во времени. Предположим, что 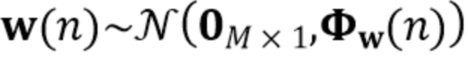 представляет собой циркулярно комплексную Гауссову случайную переменную с нулевым средним значением с ковариацией
представляет собой циркулярно комплексную Гауссову случайную переменную с нулевым средним значением с ковариацией  , и что не зависит от времени и не коррелировано с .
, и что не зависит от времени и не коррелировано с .
Фиг. 6 показывает процесс формирования наблюдаемых сигналов и низлежащие (скрытые) процессы реверберирующих сигналов и коэффициентов MAR.
Со ссылкой на фиг. 6 можно заметить, что входной сигнал s(n) накладывается на выходной сигнал фильтра, определенного коэффициентами c(n). В соответствии с этим получается сигнал x(n). Фильтр, имеющий коэффициенты c(n), принимает в качестве входного сигнала сумму задержанной версии сигнала x(n) и требуемого раннего речевого сигнала s(n). Коэффициенты c(n) фильтра могут изменяться во времени, причем предполагается, что предыдущее множество коэффициентов фильтра масштабируется матрицей A и затрагивается “шумом процесса” w(n).
Кроме того, в модели сигнала y(n) предполагается, что сигнал v(n) фонового шума добавляется к реверберирующему сигналу x(n).
Однако следует отметить, что генеративную модель реверберирующего сигнала, многоканальных авторегрессивных коэффициентов и наблюдаемого шума, проиллюстрированную на фиг. 6, следует рассматривать только в качестве примера.
D. Формулировка проблемы
Наша цель состоит в том, чтобы получить оценку ранних речевых сигналов  . Вместо того, чтобы непосредственно оценивать , мы предлагаем сначала оценить бесшумные реверберирующие сигналы
. Вместо того, чтобы непосредственно оценивать , мы предлагаем сначала оценить бесшумные реверберирующие сигналы  и коэффициенты MAR , обозначенные как
и коэффициенты MAR , обозначенные как  и
и 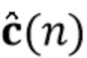 . Тогда мы сможем получить оценку требуемых сигналов, применяя коэффициенты MAR методом конечного фильтра MIMO к реверберирующим сигналам, т.е.
. Тогда мы сможем получить оценку требуемых сигналов, применяя коэффициенты MAR методом конечного фильтра MIMO к реверберирующим сигналам, т.е.
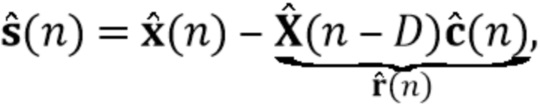 (13)
(13)
где  строится с использованием (3) с , и
строится с использованием (3) с , и  рассматривается как оценочная поздняя реверберация. В следующем подразделе мы показываем, как можно совместно оценить и .
рассматривается как оценочная поздняя реверберация. В следующем подразделе мы показываем, как можно совместно оценить и .
3.3 Оценка MMSE, посредством чередующейся минимизации
Далее будет описана концепция в соответствии с вариантом осуществления настоящего изобретения.
Полученный из столбца матрицы вектор  реверберирующий речевого сигнала и вектор коэффициентов MAR (который инкапсулирован в ) могут быть оценены в смысле MMSE посредством минимизации функции стоимости
реверберирующий речевого сигнала и вектор коэффициентов MAR (который инкапсулирован в ) могут быть оценены в смысле MMSE посредством минимизации функции стоимости
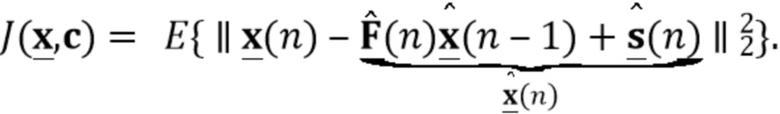 (14)
(14)
Для упрощения в соответствии с аспектом изобретения проблема оценки (14) для получения аналитического решения обратимся к методике чередующейся минимизации [23], которая минимизирует функцию стоимости для каждой переменной отдельно, сохраняя другую переменную зафиксированной и используя доступное оценочное значение. Эти две подфункциями стоимости, в которых соответствующая другая переменная предполагается зафиксированной, заданы как
 (15)
(15)
 (16)
(16)
Следует отметить, что для решения уравнения (15) в кадре достаточно знать задержанный полученный из столбца матрицы вектор  , чтобы построить
, чтобы построить 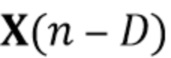 , поскольку модель сигнала (5) во временном кадре зависит только от прошлых значений с . Таким образом, мы можем заявить для заданной модели
, поскольку модель сигнала (5) во временном кадре зависит только от прошлых значений с . Таким образом, мы можем заявить для заданной модели  .
.
Посредством замены детерминированных зависимостей функций стоимости (15) и (16) в и доступными оценками мы естественным образом приходим к процедуре чередующейся минимизации для каждого временного шага :
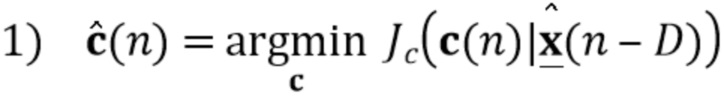 (17)
(17)
 (18)
(18)
Порядок следования решения (17) перед (18) в некоторых вариантах осуществления особенно важен, если коэффициенты изменяются во времени. Хотя схождение глобальной функции стоимости (14) к глобальному минимуму не гарантируется, она сходится к локальным минимумам, если (15) и (16) уменьшаются по-отдельности. Для данной модели сигнала уравнения (15) и (16) могут быть решены с использованием фильтра Калмана [14].
Полученная в результате процедура (или концепция) оценки требуемого сигнального вектора посредством (13) приводит к следующим трем шагам, которые также изложены на фиг. 7.
1. Оценить коэффициенты MAR на основе наблюдаемых шумных сигналов (например, y(n), и задержанных бесшумных сигналов 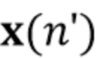 для
для  , которые, как предполагается, детерминированы и известны. На практике эти сигналы заменяются на оценки
, которые, как предполагается, детерминированы и известны. На практике эти сигналы заменяются на оценки 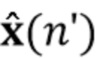 , полученные из второго фильтра Калмана на этапе 2.
, полученные из второго фильтра Калмана на этапе 2.
2. Оценить реверберирующие сигналы микрофонов посредством использования авторегрессивной модели. Этот этап рассматривается как стадия шумоподавления. Здесь предполагается, что коэффициенты MAR детерминированы и известны. На практике коэффициенты MAR получаются как оценки из этапа 1. Полученный фильтр Калмана сходен более мягкому Калману, используемому в [30].
3. На основе оценочных коэффициентов MAR и задержанных версий бесшумных сигналов может быть получена оценка  (n) поздней реверберации
(n) поздней реверберации  . Тогда требуемый сигнал
. Тогда требуемый сигнал  (n) получается посредством вычитания оценочной реверберации из бесшумного сигнала с использованием (13) (опционально).
(n) получается посредством вычитания оценочной реверберации из бесшумного сигнала с использованием (13) (опционально).
Стадия шумоподавления в некоторых случаях требует статистики шума второго порядка, как обозначено серым блоком оценки на фиг. 7. Существуют сложные способы оценки статистики шума второго порядка, например, [9, 19, 28]. Далее мы предполагаем, что статистика шума известна.
Далее будут описан возможный простой вариант осуществления и некоторые опциональные подробности со ссылкой на фиг. 7, которая показывает блок-схему предложенной параллельной двойной структуры фильтров Калмана (в соответствии с вариантом осуществления изобретения). Здесь следует отметить, что процедура с тремя этапами, показанная на фиг. 7, гарантирует, что все блоки принимают текущие оценки параметров без задержки на каждом временном шаге n. Для серого блока оценки шума (например, для оценки статистики шума) существуют несколько подходящих решений, которые выходят за рамки настоящей заявки.
Как можно видеть, процессор сигналов или устройство 700 в соответствии с фиг. 7 содержит блок 701 оценки статистики шума, блок 702 оценки коэффициентов AR (который может, например, содержать или использовать фильтр Калмана) и блок 703 шумоподавления, который может, например, содержать или использовать фильтр Калмана, использующий модель реверберирующего сигнала AR. Кроме того, устройство 700 содержит блок 704 оценки реверберации. Устройство 700 выполнено с возможностью принимать входной сигнал 710 и обеспечивать выходной сигнал 712.
Например, блок 701 оценки статистики шума может принимать входной сигнал 710 и обеспечивать на его основе информацию 701a о статистике шума, которая также может быть назначена как фv(n) (например, в соответствии с этапом 3 «Алгоритма 1»).
Блок 702 оценки коэффициентов AR может, например, принимать входной сигнал 710, а также задержанную версию сигнала 720a с подавленным шумом (и обычно реверберирующего), который может быть обозначен как  (n-D) (или который может быть представлен как
(n-D) (или который может быть представлен как  ). Например, блок 702 оценки коэффициентов AR будет выполнять оценку коэффициентов MAR c(n) на основе наблюдаемых сигналов шума (например, y(n)) и задержанных сигналов с подавленным шумом (или бесшумных) (n-D)). Например, блок 702 оценки коэффициента AR может быть выполнен с возможностью выполнять функциональность, определенную уравнениями (20)-(25) и/или в соответствии с этапами 4-6 “Алгоритма 1”, причем фильтр 702 оценки коэффициентов AR также может получать оценку ковариации погрешности фw(n) и ковариацию фu(n).
). Например, блок 702 оценки коэффициентов AR будет выполнять оценку коэффициентов MAR c(n) на основе наблюдаемых сигналов шума (например, y(n)) и задержанных сигналов с подавленным шумом (или бесшумных) (n-D)). Например, блок 702 оценки коэффициента AR может быть выполнен с возможностью выполнять функциональность, определенную уравнениями (20)-(25) и/или в соответствии с этапами 4-6 “Алгоритма 1”, причем фильтр 702 оценки коэффициентов AR также может получать оценку ковариации погрешности фw(n) и ковариацию фu(n).
Блок 703 шумоподавления принимает входной сигнал 710, информацию 701a о статистике шума и информацию 702a об оценочных коэффициентах MAR (также обозначаемую как 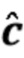 (n)). Кроме того, блок 703 шумоподавление может, например, обеспечить оценку сигнала 703a подавленного шума (но обычно реверберирующего), который также обозначается как (n). Например, блок 703 шумоподавления может выполнять функциональность, определенную уравнениями (31)-(36), и/или в соответствии с этапами 7-9 “алгоритма 1”. Кроме того, следует отметить, что этапы 4-6 “алгоритма 1” могут быть выполнены блоком 702 оценки коэффициентов AR.
(n)). Кроме того, блок 703 шумоподавление может, например, обеспечить оценку сигнала 703a подавленного шума (но обычно реверберирующего), который также обозначается как (n). Например, блок 703 шумоподавления может выполнять функциональность, определенную уравнениями (31)-(36), и/или в соответствии с этапами 7-9 “алгоритма 1”. Кроме того, следует отметить, что этапы 4-6 “алгоритма 1” могут быть выполнены блоком 702 оценки коэффициентов AR.
Кроме того, следует отметить, что блок 720 задержки может производить задержанную версию 720a из сигнала 703a с подавленным шумом.
Блок 704 оценки реверберации может производить сигнал 704a реверберации (который также обозначается как 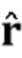 (n)) из задержанной версии сокращенного сигнала 720a шума, учитывая коэффициенты 702a MAR. Например, блок 704 оценки реверберации может оценить сигнал 704a реверберации, как показано в уравнении (13).
(n)) из задержанной версии сокращенного сигнала 720a шума, учитывая коэффициенты 702a MAR. Например, блок 704 оценки реверберации может оценить сигнал 704a реверберации, как показано в уравнении (13).
Блок 730 вычитания может вычитать оценочный сигнал 704a реверберации из сигнала 703a с подавленным шумом, например, как показано в уравнении (13). В соответствии с этим получается выходной сигнал 712 (также обозначаемый как 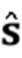 (n)).
(n)).
Таким образом, модуль оценки реверберации и модуль вычитания могут выполнить этап 10 «Алгоритма 1».
Относительно функциональности устройства 700 следует отметить, что устройство 700 в качестве альтернативы может, использовать разные концепции для оценки сигнала 703 с подавленным шумом и для оценки коэффициентов 702 MAR.
С другой стороны, устройство 700 может быть дополнено любыми из признаков, функций и элементов, описанных в настоящем документе, например, относительно фильтрации Калмана и/или относительно оценки статистических параметров, таких как фu(n), фw(n), фs(n), фv(n).
Однако следует отметить, что любые из подробностей, описанных со ссылкой на фиг. 7, должны рассматриваться опциональные.
Предложенная структура преодолевает проблему причинной связи обычно используемых последовательных структур для сигнала AR и оценки параметра [8], [31], причем каждый этап оценки требует текущей оценки друг от друга. Такие традиционные последовательные структуры проиллюстрированы на фиг. 8 для заданной модели сигнала, причем в этом случае стадия шумоподавления принимает задержанные коэффициенты MAR. Это было бы недостаточно оптимально в случае изменяющихся во времени коэффициентов .
В отличие от соответствующих способов оценки параметра состояния [8], [17] наш требуемый сигнал не является переменной состояния, а представляет собой сигнал, полученный на основе обеих оценок состояния (13).
Далее будут описаны дополнительные (опциональные) подробности относительно оценки коэффициентов MAR и относительно шумоподавления. Кроме того, будут описаны некоторые подробности относительно оценки параметров. Однако следует отметить, что все эти подробности рассматриваются как опциональные. В некоторых случаях эти подробности могут быть добавлены к вариантам осуществления, описанным в настоящем документе и определенным в формуле изобретения, как индивидуально, так и в комбинации.
A. Оптимальная последовательная оценка коэффициентов MAR
В этом подразделе с учетом знания о задержанных реверберирующих сигналах , которые оцениваются, как показано на фиг. 7, мы производим фильтр Калмана для оценки коэффициентов MAR.
1) Фильтр Калмана для оценки коэффициентов MAR
Предположим, что мы знаем прошлые реверберирующие сигналы, содержавшиеся в матрице . Далее рассмотрим (12) и (5) как уравнения состояния и наблюдения, соответственно. Учитывая, что и представляют собой процессы Гауссова шума с нулевыми средними значениями, которые взаимно не коррелированы, мы можем получить оптимальную последовательную оценку вектора коэффициентов MAR, минимизируя след матрицы ошибки
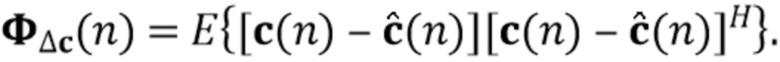 (19)
(19)
Решение получается, например, с использованием уравнений известных фильтров Калмана [3, 14]
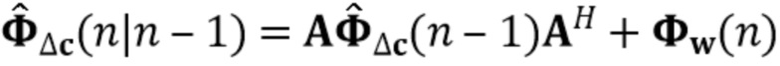 (20)
(20)
 (21)
(21)
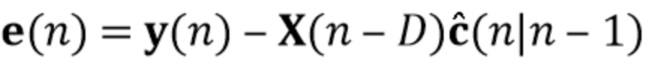 (22)
(22)
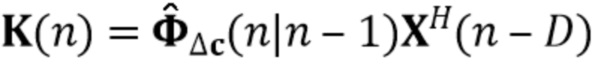 (23)
(23)

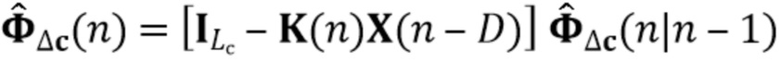 (24)
(24)
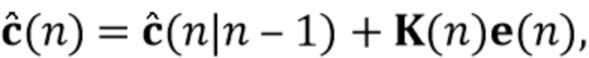 (25)
(25)
где  называется коэффициентом усиления Калмана, и
называется коэффициентом усиления Калмана, и  представляет собой ошибку предсказания. Следует отметить, что ошибка предсказания является оценкой вектора ранней речи плюс шума, используя предсказанные коэффициенты MAR, т.е.
представляет собой ошибку предсказания. Следует отметить, что ошибка предсказания является оценкой вектора ранней речи плюс шума, используя предсказанные коэффициенты MAR, т.е.  .
.
2) Оценка параметров
Матрица , содержащая только задержанные кадры реверберирующих сигналов , оценивается с использованием второго фильтра Калмана, описанного в подразделе 3. B.
Предположим и ковариация шума погрешности  , причем предлагаем оценить скалярную дисперсию
, причем предлагаем оценить скалярную дисперсию  посредством [6]
посредством [6]
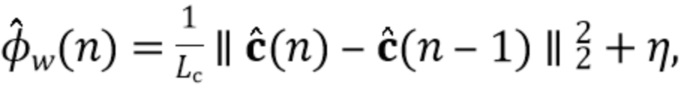 (26)
(26)
и  - малое положительное число для моделирования непрерывной изменчивости коэффициентов MAR, если разность между последующими оценочными коэффициентами равна нулю.
- малое положительное число для моделирования непрерывной изменчивости коэффициентов MAR, если разность между последующими оценочными коэффициентами равна нулю.
Ковариация  может быть оценена в смысле ML, как предложено в [3], при условии, что функция плотности распределения вероятности
может быть оценена в смысле ML, как предложено в [3], при условии, что функция плотности распределения вероятности 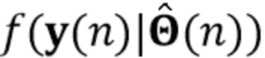 , где
, где 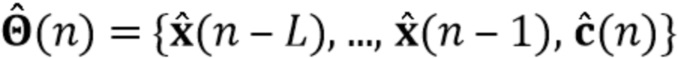 - текущие доступные оценки параметра в кадре . Предполагая стационарность в пределах
- текущие доступные оценки параметра в кадре . Предполагая стационарность в пределах  кадров, оценка ML, при условии, что текущая доступная информация получена как
кадров, оценка ML, при условии, что текущая доступная информация получена как
 (27)
(27)
где 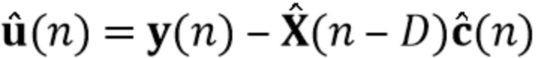 и - предсказанный сигнал речи плюс шума, поскольку еще не доступно.
и - предсказанный сигнал речи плюс шума, поскольку еще не доступно.
На практике среднее арифметическое в (27) может быть заменено рекурсивным средним значением, приводящим к рекурсивной оценке
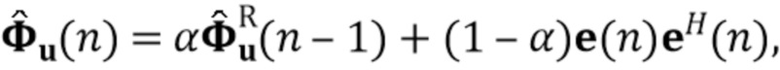 (28)
(28)
где рекурсивная оценка ковариации, которая может быть вычислена только для предыдущего кадра, получена как
 (29)
(29)
и 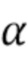 - коэффициент рекурсивного усреднения.
- коэффициент рекурсивного усреднения.
B. Оптимальное последовательное шумоподавление
В этом подразделе с учетом знания о текущих коэффициентах MAR , которые оценены, как показано на фиг. 7, мы производим второй фильтр Калмана для оценки вектора бесшумных реверберирующих сигналов.
1) Фильтр Калмана для шумоподавления
Предполагая коэффициенты MAR , соответственно матрицу , как заданные, и рассматривая полученный из столбца матрицы вектор реверберирующих сигналов, содержащий самые последние 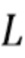 кадров как переменную состояния, мы рассматриваем (10) и (11) как уравнения наблюдения и состояния. Вследствие предположений на и (7),
кадров как переменную состояния, мы рассматриваем (10) и (11) как уравнения наблюдения и состояния. Вследствие предположений на и (7), 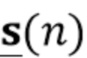 также является Гауссовской случайной переменной с нулевым средним значением, и ее ковариационная матрица
также является Гауссовской случайной переменной с нулевым средним значением, и ее ковариационная матрица  содержит
содержит 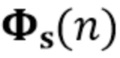 в правом нижнем углу и нули во всех других местах.
в правом нижнем углу и нули во всех других местах.
При условии, что и 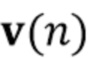 являются процессами Гауссова шума с нулевыми средними значениями, которые взаимно не коррелированы, мы можем получить оптимальную последовательную оценку , минимизируя след матрицы ошибки
являются процессами Гауссова шума с нулевыми средними значениями, которые взаимно не коррелированы, мы можем получить оптимальную последовательную оценку , минимизируя след матрицы ошибки
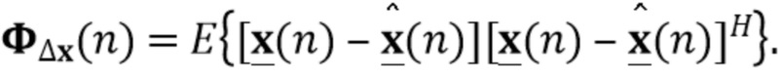 (30)
(30)
Стандартные уравнения фильтрации Калмана для оценки вектора состояния заданы предсказаниями
 (31)
(31)
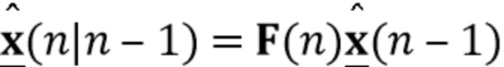 (32)
(32)
и обновлениями
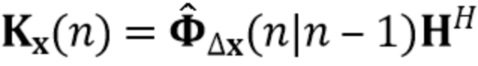
 (33)
(33)
 (34)
(34)
 (35)
(35)
 (36)
(36)
где  и
и  - коэффициент усиления Калмана и ошибка предсказания фильтра Калмана с шумоподавлением.
- коэффициент усиления Калмана и ошибка предсказания фильтра Калмана с шумоподавлением.
Вектор оценочных бесшумных реверберирующих сигналов в кадре содержится в векторе состояния и задан как  .
.
2) Оценка параметров
Предполагается, что ковариационная матрица шума 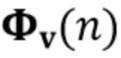 известна. Для стационарного шума она может быть оценена на основе сигналов микрофонов в отсутствие речи, например, с использованием способов, предложенных в [9, 19, 28].
известна. Для стационарного шума она может быть оценена на основе сигналов микрофонов в отсутствие речи, например, с использованием способов, предложенных в [9, 19, 28].
Кроме того, мы должны оценить  , т.е., требуемую ковариационную матрицу речи . Чтобы сократить музыкальные тона, являющиеся результатом процедуры шумоподавления, выполненной фильтром Калмана, используем направленный на решение подход [7] для оценки текущий ковариационной матрицы речи , которая представляет собой в этом случае взвешивание между апостериорной оценкой
, т.е., требуемую ковариационную матрицу речи . Чтобы сократить музыкальные тона, являющиеся результатом процедуры шумоподавления, выполненной фильтром Калмана, используем направленный на решение подход [7] для оценки текущий ковариационной матрицы речи , которая представляет собой в этом случае взвешивание между апостериорной оценкой 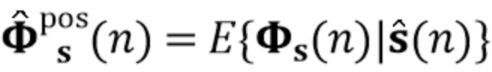 в предыдущем кадре и априорной оценкой
в предыдущем кадре и априорной оценкой 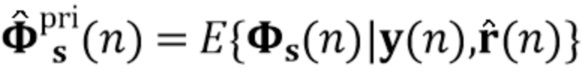 в текущем кадре. Направленная на решение оценка задана как
в текущем кадре. Направленная на решение оценка задана как
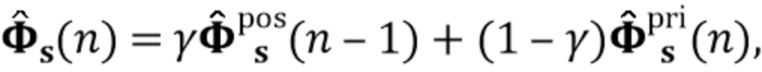 (37)
(37)
где 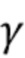 - направленный на решение весовой параметр. Для сокращения музыкальных тонов параметр обычно выбирается таким, чтобы поместить больший вес на предыдущую апостериорную оценку.
- направленный на решение весовой параметр. Для сокращения музыкальных тонов параметр обычно выбирается таким, чтобы поместить больший вес на предыдущую апостериорную оценку.
Рекурсивная апостериорная оценка ML получается как
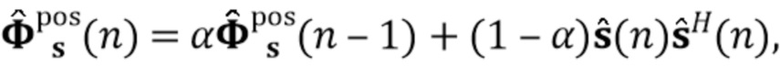 (38)
(38)
где - коэффициент рекурсивного усреднения.
Чтобы получить априорную оценку  , производим MWF, т.е.
, производим MWF, т.е.
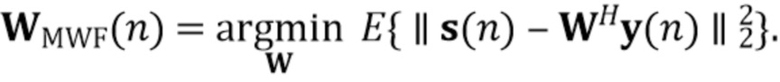 (39)
(39)
Вставляя (10) в (11), можем переписать вектор наблюдаемого сигнала как
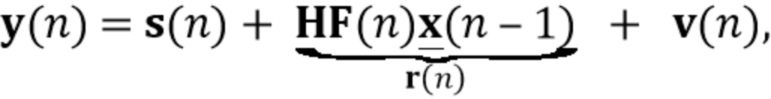 (40)
(40)
где все три компонента взаимно не коррелированы. Следует отметить, что оценки всех компонентов поздней реверберации в этот момент уже доступны. Мгновенная оценка с использованием блока оценки MMSE при условии текущей доступной информации тогда получается как
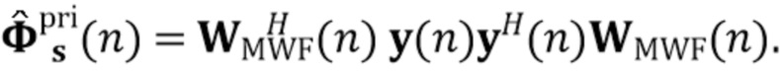 (41)
(41)
Матрица фильтра MWF задана как
 (42)
(42)
где  и
и 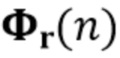 оценены с использованием рекурсивного усреднения из сигналов
оценены с использованием рекурсивного усреднения из сигналов 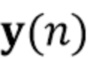 и , аналогично (38).
и , аналогично (38).
C. Обзор алгоритма
Пример полного алгоритма изложен в следующем «Алгоритме 1».
___________________________________________________________
Алгоритм 1: Предложенный алгоритм на каждую частотную полосу
1. Инициализировать:  ,
,  ,
, 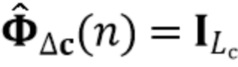 ,
, 
2. для каждого 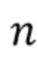 выполнить
выполнить
3. Оценить ковариацию шума , например, с использованием [9]
4. 
5. Вычислить  с использованием (26)
с использованием (26)
6. Получить с использованием (37) посредством вычисления (20)-(22), (27), (23)-(25)
7. 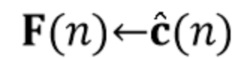
8. 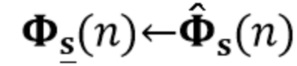 с использованием (37)
с использованием (37)
9. Получить 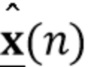 посредством вычисления (32)-(35)
посредством вычисления (32)-(35)
10. Оценить требуемый сигнал посредством (13)
11. конец для каждого
___________________________________________________________
Инициализация фильтров Калмана не является критичной. Начальная фаза схождения может быть улучшена, если доступны хорошие первоначальные оценки переменных состояния, но на практике алгоритм всегда сходится и остается стабильным.
Хотя предложенный алгоритм отлично подходит для приложений обработки в реальном времени, его вычислительная сложность довольно высока. Сложность зависит от количества микрофонов и длины фильтра на каждую частоту и количества частотных полос.
3.4. Управление подавлением
В некоторых приложениях полезно иметь независимый контроль над подавлением нежелательных звуковых компонентов, таких как реверберация и шум. Таким образом, мы показываем, каким образом (в некоторых случаях) вычислить альтернативный выходной сигнал 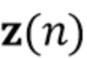 , когда мы управляем подавлением реверберации и шума. Другими словами, функциональность, описанная в этом подразделе, можно рассмотреть как опциональную.
, когда мы управляем подавлением реверберации и шума. Другими словами, функциональность, описанная в этом подразделе, можно рассмотреть как опциональную.
Требуемый управляемый выходной сигналом задан как
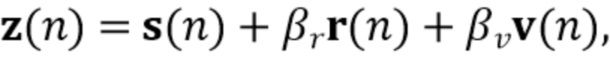 (43)
(43)
где и - коэффициенты ослабления реверберации и шума. Перестраивая уравнение (43) с использованием (5) и заменяя неизвестные переменные доступными оценками, можем вычислить требуемые управляемые выходные сигналы как
 (44)
(44)
Следует отметить, что для 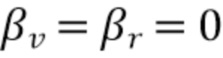 вывод
вывод 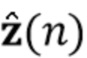 идентичен ранней речевой оценке
идентичен ранней речевой оценке  , и для
, и для 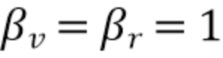 , вывод равен .
, вывод равен .
Обычно алгоритмы улучшения речи имеют компромисс между величиной подавления взаимных помех и артефактами, такими как искажение речи или музыкальные тона. Чтобы сократить слышимые артефакты в периоды, когда фильтр Калмана оценки коэффициентов MAR быстро адаптируется и проявляет большую ошибку предсказания, мы в некоторых случаях используем ковариационную матрицу оценочной ошибки 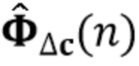 , заданную посредством (24), чтобы адаптивно управлять коэффициентом ослабления реверберации . Если ошибка фильтра Калмана высока, нам хотелось бы, чтобы коэффициент ослабления был близок к единице. Например, мы предлагаем вычислить коэффициент ослабления реверберации во временном кадре посредством эвристически выбранной функции преобразования
, заданную посредством (24), чтобы адаптивно управлять коэффициентом ослабления реверберации . Если ошибка фильтра Калмана высока, нам хотелось бы, чтобы коэффициент ослабления был близок к единице. Например, мы предлагаем вычислить коэффициент ослабления реверберации во временном кадре посредством эвристически выбранной функции преобразования
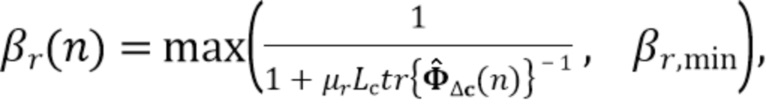 (45)
(45)
где фиксированная нижняя граница 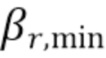 ограничивает разрешенное ослабление реверберации, и коэффициент
ограничивает разрешенное ослабление реверберации, и коэффициент 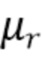 управляет ослаблением в зависимости от ошибки Калмана.
управляет ослаблением в зависимости от ошибки Калмана.
Структура предложенной системы с управлением подавлением проиллюстрирована на фиг. 9. Блок оценки шума здесь опущен, поскольку он также может быть интегрирован в блок шумоподавления.
Другими словами, фиг. 9 показывает устройство или процессор 900 сигналов в соответствии с вариантом осуществления изобретения. Устройство 900 выполнено с возможностью принимать входной сигнал 910 и обеспечивать на его основе обработанный сигнал или выходной сигнал 912. Устройство содержит блок 903 шумоподавления и блок 904 оценки реверберации. Кроме того, следует отметить, что блок 903 шумоподавления может обеспечить сигнал 903a с подавленным шумом, который может быть масштабирован с помощью масштабного коэффициента (1-βv), чтобы получить масштабированную версию 903b сигнала 903a с подавленным шумом. Аналогичным образом, блок 904 оценки реверберации может быть выполнен с возможностью обеспечивать (оценочный) сигнал 904a реверберации, который может быть масштабирован, например, с помощью масштабного коэффициента (1-βr), чтобы получить масштабированный сигнал 904b реверберации. Кроме того, входной сигнал 910 масштабируется, например, с помощью масштабного коэффициента βv, чтобы получить масштабированный входной сигнал. Кроме того, масштабированный входной сигнал, масштабированный сигнал 903b с подавленным шумом и масштабированный сигнал 904b реверберации объединяются, чтобы тем самым получить выходной сигнал 912, причем масштабированный сигнал 904 реверберации может быть вычтен из суммы масштабированного входного сигнала 910a и масштабированного сигнала 903b с подавленным шумом.
Следует отметить, что функциональность устройства 900 может быть сходна с функциональностью описанного выше устройства 400. В соответствии с этим входной сигнал 910 может соответствовать входному сигналу 410, выходной сигнал 912 может соответствовать выходному сигналу 412, блок 903 шумоподавления может соответствовать блоку 303 шумоподавления, блок 904 оценки реверберации может соответствовать блоку 304 оценки реверберации, масштабированный входной сигнал 910a может соответствовать масштабированному входному сигналу 410a, сигнал 903a с подавленным шумом может соответствовать сигналу 303a с подавленным шумом, масштабированный сигнал 903b с подавленным шумом может соответствовать масштабированному сигналу 303b с подавленным шумом, сигнал 904a реверберации может соответствовать сигналу 304a реверберации, и масштабированный сигнал 904b реверберации может соответствовать масштабированному сигналу 304b реверберации.
Кроме того, полная функциональность устройства 900 может быть сходна с полной функциональностью устройства 400, если здесь не будут упомянуты различия.
Блок 903 шумоподавление может содержать функциональность блока 703 шумоподавления. Блок оценки реверберации может содержать функциональность блока 703 оценки реверберации, например, когда он берется в сочетании с блоком 702 оценки коэффициента AR и блоком 720 задержки. Кроме того, блок 903 шумоподавления может принимать информацию о статистике шума, как блок 701 информации о статистике шума, и также может принимать оценочные коэффициенты AR или коэффициенты MAR, как коэффициенты 702a.
В соответствии с этим возможно регулировать характеристики выходного сигнала 912, например, устанавливая параметры βv и βr.
Опционально параметр βr может изменяться во времени и может вычисляться, например, в соответствии с уравнением (45).
3.5 Оценка
В этом подразделе мы оцениваем предложенную систему с использованием экспериментальной установки, описанной в подразделе 3.5-A, проводя сопоставление с двумя сравнительными способами, рассмотренными в подразделе 3.5-B. Результаты показаны в подразделе 3.5-C.
A. Экспериментальная установка (опциональная)
Реверберирующие сигналы были формированы посредством свертки импульсных характеристик помещения (RIR) с безэховыми речевыми сигналами из [5]. Мы использовали характеристики RIR двух разных видов: измеренные характеристики RIR в акустической лаборатории с переменной акустикой в Университете имени Бар-Илана, Израиль и смоделированные характеристики RIR с использованием зеркального способа [1] для движущихся источников. В случае движущихся источников смоделированные характеристики RIR обеспечивают возможность оценки, поскольку в этом случае возможно дополнительно формировать характеристики RIR, содержащие только прямой звук и ранние отражения, чтобы получить целевой сигнал для оценки.
В смоделированном и измеренном случаях мы использовали линейный массив микрофонов, содержащий до  всенаправленных микрофонов с интервалом между микрофонами
всенаправленных микрофонов с интервалом между микрофонами  см. Следует отметить, что во всех экспериментах, кроме эксперимента в подразделе 3.5-C1, используются только 2 микрофона с интервалом 11 см. Либо стационарный розовый шум, либо записанный невнятный шум добавлялся к реверберирующим сигналам с некоторым входным отношением сигнал-шум (iSNR). Мы использовали частоту дискретизации 16 кГц, и следующие параметры преобразования STFT: окно Ханна с квадратным корнем длиной 32 мс, 50%-е наложение и длина FFT 1024 отсчетов. Задержка в зависимости от наложения была установлена равной
см. Следует отметить, что во всех экспериментах, кроме эксперимента в подразделе 3.5-C1, используются только 2 микрофона с интервалом 11 см. Либо стационарный розовый шум, либо записанный невнятный шум добавлялся к реверберирующим сигналам с некоторым входным отношением сигнал-шум (iSNR). Мы использовали частоту дискретизации 16 кГц, и следующие параметры преобразования STFT: окно Ханна с квадратным корнем длиной 32 мс, 50%-е наложение и длина FFT 1024 отсчетов. Задержка в зависимости от наложения была установлена равной 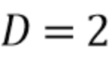 . Коэффициент рекурсивного усреднения составлял
. Коэффициент рекурсивного усреднения составлял 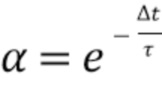 с
с 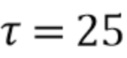 мс, где
мс, где 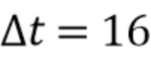 мс - сдвиг кадра, направленный на решение весовой коэффициент составлял γ=0,98, и мы выбрали
мс - сдвиг кадра, направленный на решение весовой коэффициент составлял γ=0,98, и мы выбрали 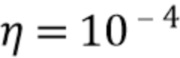 . Представляем результаты без RC, т.е. , и с RC с использованием разных настроек для и , причем мы выбрали
. Представляем результаты без RC, т.е. , и с RC с использованием разных настроек для и , причем мы выбрали  дБ в уравнении (45).
дБ в уравнении (45).
Для оценки целевые сигналы были формированы как прямой речевой сигнал с ранними отражениями до 32 мс после прямого звукового пика (соответствует задержке кадров). Обработанные сигналы оцениваются с точки зрения кепстрального расстояния (CD) [16], перцептивной оценки качества речи (PESQ) [11], частотно-взвешенного сегментального отношения сигнала к взаимным помехам (fwSSIR) [18], причем реверберация и шум рассматриваются как взаимные помехи, и нормализованного отношения модуляции речи к реверберации (SRMR) [24]. Было продемонстрировано, что эти показатели приводят к разумной корреляции с воспринятой величиной реверберации и общего качества в контексте подавления реверберации [10, 15]. Показатель CD отражает более общее качество и чувствителен к искажению речи, в то время как PESQ, SIR и SRMR более чувствительны к подавлению реверберации/взаимных помех. Мы представляем результаты только для первого микрофона, поскольку все другие микрофоны проявляют такое же поведение.
В. Сравнительные способы (опциональные)
Чтобы показать эффективность и производительность предложенного способа (двойной фильтр Калмана), мы сравниваем его со следующими двумя способами:
одиночный фильтр Калмана: один фильтр Калмана для оценки коэффициентов MAR без шумоподавления, как предложено в [3]. Первоначальный алгоритм не воспринимает аддитивный шум. Однако он все же может использоваться для оценки коэффициентов MAR из сигнала шума и затем получения в качестве вывода отфильтрованного сигнала с подавленной реверберацией, но все еще с шумом.
MAP-EM: В способе, предложенном в [31], коэффициенты MAR оцениваются с использованием Байесовского подхода на основе оценки MAP, и затем оценивается бесшумный требуемый сигнал с использованием алгоритма EM. Алгоритм онлайновый, но процедура EM требует приблизительно 20 итераций на кадр для сходимости.
C. Результаты
1) Зависимость от количества микрофонов. Мы исследовали рабочие характеристики предложенного алгоритма в зависимости от количества микрофонов . Требуемый сигнал с полной продолжительностью 34 с состоял из двух последовательных динамиков в разных позициях: в течение первых 15 с был активным первый динамик, в то время как после 15 с был активным второй динамик. Каждый сигнал динамика был подвергнут свертке с измеренными характеристиками RIR в разных позициях с 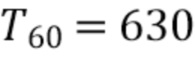 мс. Стационарный розовый шум был добавлен к реверберирующим сигналам с
мс. Стационарный розовый шум был добавлен к реверберирующим сигналам с 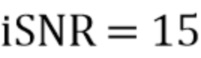 дБ. Фиг. 10 показывает показатели CD, PESQ, SIR и SRMR для переменного количества микрофонов . Показатели для шумного реверберирующего входного сигнала обозначены светло-серой штриховой линией, и показатель SRMR целевого сигнала, т.е. ранняя речь, обозначен темно-серой штрихпунктирной линией. Для
дБ. Фиг. 10 показывает показатели CD, PESQ, SIR и SRMR для переменного количества микрофонов . Показатели для шумного реверберирующего входного сигнала обозначены светло-серой штриховой линией, и показатель SRMR целевого сигнала, т.е. ранняя речь, обозначен темно-серой штрихпунктирной линией. Для  показатель CD больше, чем для входного сигнала, это указывает на ухудшение общего качества, тогда как показатели PESQ, SIR и SRMR пока улучшаются относительно входа, т.е. реверберация и шум подавляются. Рабочие характеристики с точки зрения всех показателей улучшаются с увеличением количества микрофонов.
показатель CD больше, чем для входного сигнала, это указывает на ухудшение общего качества, тогда как показатели PESQ, SIR и SRMR пока улучшаются относительно входа, т.е. реверберация и шум подавляются. Рабочие характеристики с точки зрения всех показателей улучшаются с увеличением количества микрофонов.
2) Зависимость от длины фильтра
Эффект длины фильтра был исследован с использованием измеренной характеристики RIR с разными временами реверберации. Как и в первом эксперименте, два не параллельных динамика были активными в разных позициях, и был добавлен стационарный розовый шум с дБ. Фиг. 11 показывает улучшение целевых показателей по сравнению с необработанным сигналом микрофона. Положительные значения указывают улучшение для всех относительных показателей, где  обозначает улучшение. Рассматривая данные параметры преобразования STFT, времена реверберации
обозначает улучшение. Рассматривая данные параметры преобразования STFT, времена реверберации  с соответствуют длинам фильтра
с соответствуют длинам фильтра  кадров. Можно заметить, что наилучшие значения показателей CD, PESQ и SIR зависят от времени реверберации, но оптимальные значения получены около 25% от соответствующей продолжительности времени реверберации. Напротив, показатель SRMR монотонно возрастает с увеличением . Следует отметить, что подавление реверберации становится более агрессивным с увеличением . Если подавление слишком агрессивное посредством выбора слишком большого значения , требуемая речь искажается, как CD указывает отрицательными значениями.
кадров. Можно заметить, что наилучшие значения показателей CD, PESQ и SIR зависят от времени реверберации, но оптимальные значения получены около 25% от соответствующей продолжительности времени реверберации. Напротив, показатель SRMR монотонно возрастает с увеличением . Следует отметить, что подавление реверберации становится более агрессивным с увеличением . Если подавление слишком агрессивное посредством выбора слишком большого значения , требуемая речь искажается, как CD указывает отрицательными значениями.
3) Сравнение с традиционными способами
Предложенный алгоритм и два сравнительных алгоритма были оценены для двух типов шума при изменении показателей iSNR. Как и в первых экспериментах, требуемый сигнал состоял из двух параллельных динамиков в разных позициях с полной продолжительностью 34 с с использованием измеренных характеристик RIR с мс. Либо стационарный розовый шум, либо записанный невнятный шум был добавлен с изменением iSNR. Таблицы 1 и 2 показывают улучшение целевых показателей по сравнению с необработанным сигналом микрофона при стационарном розовом шуме и при невнятном шуме, соответственно. Следует отметить, что хотя невнятный шум не является краткосрочно стационарным, мы использовали стационарную долгосрочную оценку ковариационной матрицы шума, что является реалистичным для получения оценки на практике.
Можно заметить, что предложенный алгоритм либо без RC, либо с RC превосходит оба конкурирующих алгоритма при всех условиях. RC обеспечивает компромисс между подавлением взаимных помех и желаемым искажением сигнала. CD как индикатор для искажения речи всякий раз лучше с RC, тогда как другие показатели, которые значительно отражают величину подавления взаимных помех, всякий раз достигают немного более высоких результатов без RC при стационарном шуме. Пи невнятном шуме двойной фильтр Калмана с RC приводит к более высокому показателю PESQ при низком iSNR, чем без RC. Это указывает, что RC может помочь улучшить качество, маскируя артефакты при сложных условиях iSNR и при наличии ошибок оценки ковариации шума. Как и ожидалось, в условиях высокого iSNR рабочие характеристики двойного фильтра Калмана становятся сходными с рабочим характеристикам одиночного фильтра Калмана.
4) Отслеживание движущихся динамиков
Движущийся источник моделировался с использованием смоделированных характеристик RIR в маленьком помещении с 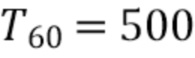 мс на основе зеркального способа [1, 36]: требуемый источник сначала находился в позиции A, и в течение временного интервала [8, 13] с он непрерывно перемещался из позиции A в позицию B, где он затем оставался в течение оставшегося времени. Позиции A и B находились на расстоянии 2 м.
мс на основе зеркального способа [1, 36]: требуемый источник сначала находился в позиции A, и в течение временного интервала [8, 13] с он непрерывно перемещался из позиции A в позицию B, где он затем оставался в течение оставшегося времени. Позиции A и B находились на расстоянии 2 м.
Фиг. 12 показывает сегментальное улучшение показателей CD, PESQ, SIR и SRMR для этого динамического сценария. В этом эксперименте целевой сигнал для оценки формировался посредством моделирования отражений от стен только до второго порядка.
Мы замечаем, что все показатели уменьшаются во время движения, в то время как после достижения динамиком позиции B показатели снова значительно улучшаются. Сходимость всех способов ведет себя похожим образом, в то время как двойной фильтр Калмана без RC и с RC выполняется лучше всех. Во время движения MAP-EM иногда приводит к более высоким показателям fwSSIR и SRMR, но за счет намного худших показателей CD и PESQ. Управление подавлением улучшает показатель CD, в результате чего улучшение CD всегда остается положительным, и это указывает на то, что показатель RC может сократить искажение речи и артефакты. Следует отметить, что даже если подавление реверберации может стать менее эффективным во время движения источника речи, алгоритм двойного фильтра Калмана не становится нестабильным, и улучшения показателей PESQ, SIR и SRMR всегда были положительными, и CD всегда был положительным посредством использования RC. Это также было подтверждено с использованием реальных записей с движущимися динамиками.
5) Оценка управления подавлением
В этом подразделе мы оцениваем рабочие характеристики RC с точки зрения подавления шума и реверберации посредством предложенной системы. В приложении показано, как могут быть вычислены сигналы разностного шума и реверберации после обработки с помощью RC  и
и 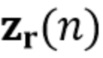 для предложенной системы двойного фильтра Калмана. Показатели шумоподавления и подавления реверберации тогда вычисляются как
для предложенной системы двойного фильтра Калмана. Показатели шумоподавления и подавления реверберации тогда вычисляются как
 (46)
(46)
 (47)
(47)
В этом эксперименте мы смоделировали сценарий с одним динамиком в стационарной позиции с использованием измеренных характеристик RIR в акустической лаборатории с мс. На фиг. 13 показаны пять разных настроек для коэффициентов ослабления: без управления подавлением (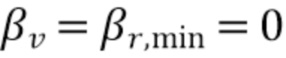 ), умеренная настройка с
), умеренная настройка с 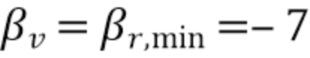 дБ, подавление либо только реверберации, либо только шума и настройка с более сильным ослаблением с
дБ, подавление либо только реверберации, либо только шума и настройка с более сильным ослаблением с 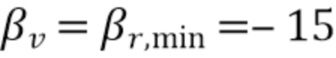 дБ. Можно заметить, что показатель шумоподавления приводит к требуемым уровням подавления только во время речевых пауз. Показатель подавления реверберации неожиданно показывает, что высокое подавление достигается только во время отсутствия речи. Это не означает, что разностная реверберация слышится больше во время наличия речи, поскольку прямой звук речи при восприятии маскирует разностную реверберацию. В течение первых 5 секунд мы можем наблюдать пониженное подавление реверберации, вызванное адаптивным коэффициентом ослабления реверберации (45), поскольку ошибка фильтра Калмана является высокой во время начальной сходимости.
дБ. Можно заметить, что показатель шумоподавления приводит к требуемым уровням подавления только во время речевых пауз. Показатель подавления реверберации неожиданно показывает, что высокое подавление достигается только во время отсутствия речи. Это не означает, что разностная реверберация слышится больше во время наличия речи, поскольку прямой звук речи при восприятии маскирует разностную реверберацию. В течение первых 5 секунд мы можем наблюдать пониженное подавление реверберации, вызванное адаптивным коэффициентом ослабления реверберации (45), поскольку ошибка фильтра Калмана является высокой во время начальной сходимости.
3.6 Заключение
Далее будут представлены некоторые выводы относительно вариантов осуществления, описанных в этом подразделе.
В соответствии с концепцией настоящего изобретения в качестве варианта осуществления был описан алгоритм чередующейся минимизации на основе двух взаимодействующих фильтров Калмана для оценки многоканальных авторегрессивных параметров и реверберирующего сигнала для подавления шума и реверберации в каждом сигнале микрофона (например, многоканальном сигнале микрофона, который служит в качестве входного сигнала). Предлагаемое решение, использующее рекурсивные фильтры Калмана, подходит для приложений онлайновой обработки.
Эффективность и преимущества рабочих характеристик по сравнению со сходными онлайновыми способами были показаны в разных экспериментах.
Кроме того, были описаны способ и концепция независимого управления подавлением шума и реверберации для маскировки возможных артефактов и подстройки выходного сигнала к перцептивным требованиям. Способ и концепция управления подавлением шума и реверберации могут использоваться в сочетании с концепцией оценки многоканальных авторегрессивных параметров и реверберирующего сигнала (например, как опциональное расширение).
3.7. Приложение: вычисление разностного шума и реверберации
Далее будут описаны некоторые концепции вычисления разностного шума и реверберации, который может использоваться при оценке концепции в соответствии с настоящим изобретением. Однако опционально описанные здесь концепции также могут использоваться в вариантах осуществления в соответствии с изобретением, в которых требуется дополнительная информация относительно обработанных сигналов.
Вычисление разностного шума и реверберации
Чтобы вычислить разностную мощность шума и реверберации на выходе предложенной системы, возможно пропустить эти сигналы через систему.
Пропуская только шум на входе через систему двойного фильтра Калмана вместо , как на фиг. 7, мы получаем на выходе 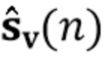 , который представляет собой разностный шум, содержащийся в . Также, принимая во внимание RC, разностный вклад шума
, который представляет собой разностный шум, содержащийся в . Также, принимая во внимание RC, разностный вклад шума 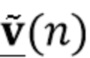 в выходном сигнале представляет собой . Обследуя (32), (34) и (36), шум питается через шумоподавление фильтр Калмана уравнением
в выходном сигнале представляет собой . Обследуя (32), (34) и (36), шум питается через шумоподавление фильтр Калмана уравнением
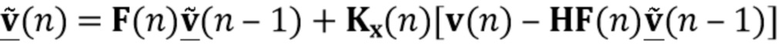
 (48)
(48)
где - вектор разностного шума длины , определенный аналогично уравнению (6), после шумоподавления. Вывод после этапа подавления реверберации получается как
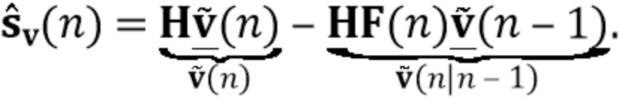 (49)
(49)
С RC разностный шум задается по аналогии с (44)
 (50)
(50)
Вычисление разностной реверберации является более сложным. Чтобы исключить шум из этого вычисления, сначала подается вектор предсказанных реверберирующих бесшумных сигналов через стадию шумоподавления:
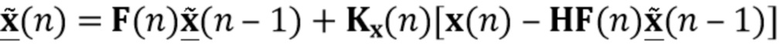
 (51)
(51)
где 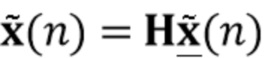 - вывод вектора бесшумного сигнала после стадии шумоподавления. В соответствии с (44) вывод вектора бесшумного сигнала после подавления реверберации и RC получается посредством
- вывод вектора бесшумного сигнала после стадии шумоподавления. В соответствии с (44) вывод вектора бесшумного сигнала после подавления реверберации и RC получается посредством
 (52)
(52)
где  и матрица
и матрица 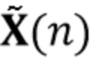 получены с использованием
получены с использованием  по аналогии с (3).
по аналогии с (3).
Теперь предположим, что вектор бесшумных сигналов после шумоподавления и вектор бесшумных выходных сигналов после подавления реверберации и RC 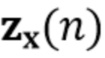 будут составлены как
будут составлены как
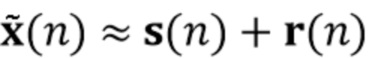 (53)
(53)
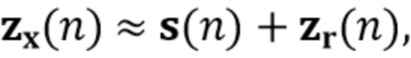 (54)
(54)
где обозначает разностную реверберацию на выходе RC . Посредством использования (53) и информации о векторе предсказанного требуемого сигнала можно вычислить сигнал реверберации
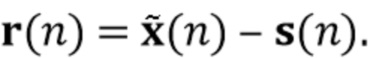 (55)
(55)
Из разности (53) и (54) и с использованием (55) возможно получить разностные сигналы реверберации как
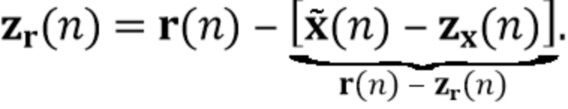 (56)
(56)
Теперь мы можем проанализировать мощность разностного шума и/или реверберации на выходе и сравнить его с их соответствующей мощностью на входе.
4. Выводы
Далее будут сделаны некоторые выводы.
Варианты осуществления в соответствии с изобретением опционально могут содержать один или более из следующих признаков.
- Прием по меньшей мере одного сигнала микрофона или, в качестве альтернативы, прием по меньшей мере двух сигналов микрофона (опционально).
- Преобразование сигнала микрофона или сигналов микрофонов в частотно-временную область или другую подходящую область (опционально).
- Оценка ковариационной матрицы шума (опционально).
- Использование параллельной структуры оценки для совместной оценки коэффициентов MAR и бесшумного реверберирующего сигнала.
- Коэффициенты MAR оцепеневаются с использованием реверберирующих входных сигналов с шумом и задержанных оценочных реверберирующих выходных сигналов со стадии шумоподавления.
- Стадия шумоподавления принимает текущие оценки коэффициента MAR в каждом кадре (опционально).
- Вычисление выходного сигнала (или в качестве альтернативы выходных сигналов) посредством фильтрации бесшумного реверберирующего сигнала (или в качестве альтернативы бесшумных реверберирующих сигналов) (опционально).
- Вычисление управляемого выходного сигнала (или в качестве альтернативы выходных сигналов) на основе оценочных компонентов сигнала, чтобы установить величину разностного шума и реверберации (опционально).
- Опциональное вычисление модифицированного выходного сигнала (или в качестве альтернативы выходных сигналов) посредством сложения одного или более обработанных/оформленных сигналов реверберации с сигналом с подавленной до определенного уровня реверберацией (или, в качестве альтернативы, с оценочными сигналами с подавленной реверберацией), чтобы достигнуть другой характеристики реверберации в выходном сигнале.
В заключение в настоящем описании разные варианты осуществления изобретения и аспекты были описаны в главе «Способ и устройство для подавления реверберации и шума (с использованием параллельной структуры) с управлением подавлением» (раздел 2) и в главе “Линейное предсказание на основе онлайнового подавления реверберации и шума с использованием чередующегося фильтра Калмана (Раздел 3).
Кроме того, дополнительные варианты осуществления определены приложенной формулой изобретения и в других разделах (например, в разделе «Сущность изобретения» и в разделе 1).
Следует отметить, что любой вариант осуществления, определенный формулой изобретения, может быть дополнен любыми из элементов (например, признаками и функциональностью), описанными в настоящем документе. Кроме того, описанные выше варианты осуществления могут использоваться отдельно, и они могут быть дополнены любыми признаками в другом разделе или любыми признаками, включенными в формулу изобретения.
Кроме того, следует отметить, что индивидуальные аспекты, описанные в настоящем документе, могут использоваться индивидуально или в комбинации. Таким образом, подробности могут быть добавлены к каждому из упомянутых индивидуальных аспектов без добавления подробностей к другим аспектам
Также следует отметить, что настоящее раскрытие описывает явно или неявно признаки, применимые в аудиокодере (устройство для обеспечения закодированного представления входного аудиосигнала) и в аудиодекодере (устройство для обеспечения декодированного представления аудиосигнала на основе закодированного представления). Таким образом, любая из функций, описанных в настоящем документе, может быть использована в контексте аудиокодера и в контексте аудиодекодера.
Кроме того, раскрытые в настоящем документе признаки и функциональность, относящиеся к способу, также могут быть использованы в устройстве (выполненном с возможностью выполнять такой способ или функциональность). Кроме того, любые из признаков и функций, раскрытых в настоящем документе относительно устройства, также может использоваться соответствующим образом. Иными словами, способы, раскрытые в настоящем документе, могут быть дополнены любыми из признаков и функциональности, описанных относительно устройства, и наоборот. Кроме того, любые из вариантов и функций, описанных в настоящем документе, могут быть реализованы в аппаратном и программном обеспечении (или с использованием аппаратного и/или программного обеспечения), или даже в комбинации аппаратного и программного обеспечения, как будет описано в разделе «Альтернативы реализации».
Кроме того, следует отметить, что обработка, описанная в настоящем документе, может быть выполнена (но не обязательно) на каждую частотную полосу или на каждый элемент разрешения по частоте, или для разных областей частот.
Следует отметить, что аспекты изобретения относятся к способу и устройству для онлайнового подавления реверберации и подавления шума с управлением.
Варианты осуществления в соответствии с изобретением создают новую параллельную структуру для совместного подавления реверберации и шума. Реверберирующий сигнал моделируется с использованием узкополосной многоканальной авторегрессивной модели реверберации с изменяющимися во времени коэффициентами, которые представляют нестационарные акустические окружающие среды. В отличие от существующих структур последовательной оценки, варианты осуществления в соответствии с изобретением оценивают бесшумный реверберирующий сигнал и авторегрессивные коэффициенты помещения параллельно, в результате чего предположения на требуются стационарные коэффициенты помещения. Кроме того, предложен способ независимого управления уровнем подавления шума и реверберации.
5. Способ в соответствии с фиг. 14
Фиг. 14 показывает блок-схему последовательности этапов способа 1400 в соответствии с вариантом осуществления настоящего изобретения.
Способ 1400 для обеспечения обработанного аудиосигнала на основе входного аудиосигнала содержит оценку 1410 коэффициентов авторегрессивной модели реверберации с использованием входного аудиосигнала и задержанного реверберирующего сигнала с подавленным шумом, полученного с использованием шумоподавления.
Способ также содержит обеспечение 1420 реверберирующего сигнала с подавленным шумом с использованием входного аудиосигнала и оценочных коэффициентов авторегрессивной модели реверберации.
Способ также содержит производство 1430 выходного сигнала с подавленным шумом и подавленной реверберацией с использованием реверберирующего сигнала с подавленным шумом и оценочных коэффициентов авторегрессивной модели реверберации.
Способ 1400 опционально может быть дополнен любыми из признаков, функций и элементов, описанных в настоящем документе, как отдельно, так и в комбинации.
6. Альтернативы реализации
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где модуль или устройство соответствуют этапу способа или признаку этапа способа. Аналогичным образом аспекты, описанные в контексте этапа способа также представляют описание соответствующего модуля, или элемента, или признака соответствующего устройства. Некоторые или все этапы способа могут быть исполнены посредством (или с использованием) аппаратного устройства, такого как, например, микропроцессора, программируемого компьютера или электронной схемы. В некоторых вариантах осуществления один или более из самых важных этапов способа могут быть исполнены таким устройством.
В зависимости от некоторых требований реализации варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может быть выполнена с использованием цифрового запоминающего носителя, например гибкого диска, DVD, Blu-ray, CD, ПЗУ (ROM), ППЗУ (PROM), СППЗУ (EPROM), ЭСППЗУ (EEPROM) или флэш-памяти, имеющих сохраненные на них читаемые в электронном виде управляющие сигналы, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой, в результате чего выполняется соответствующий способ. Таким образом, цифровой запоминающий носитель может являться машиночитаемым.
Некоторые варианты осуществления в соответствии с изобретением содержат носитель данных, имеющий читаемые в электронном виде управляющие сигналы, которые способны взаимодействовать с программируемой компьютерной системой, в результате чего выполняется один из способов, описанных в настоящем документе.
Обычно варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, программный код выполнен с возможностью выполнения одного из способов, когда компьютерный программный продукт исполняется на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных в настоящем документе, сохраненных на машиночитаемом носителе.
Другими словами, вариант осуществления способа изобретения, таким образом, представляет собой компьютерную программу, имеющую программный код для выполнения одного из способов, описанных в настоящем документе, когда компьютерная программа исполняется на компьютере.
Дополнительный вариант осуществления способов изобретения, таким образом, представляет собой носитель данных (или цифровой запоминающий носитель, или машиночитаемый носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Носитель данных, цифровой запоминающий носитель или носитель с записанными данными обычно является материальными и/или долгого хранения.
Дополнительный вариант осуществления способа изобретения, таким образом, поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Поток данных или последовательность сигналов могут, например, быть выполнен с возможностью быть перенесенными сквозное отверстие соединение обмена данными, например, сквозное отверстие Интернет.
Дополнительный вариант осуществления содержит средство обработки, например компьютер или программируемое логическое устройство, выполненное с возможностью или адаптированное для выполнения одного из способов, описанных в настоящем документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
Дополнительный вариант осуществления в соответствии с изобретением содержит устройство или систему, выполненную с возможностью переносить (например, в электронном или оптическом виде) компьютерную программу для выполнения одного из способов, описанных в настоящем документе, к приемнику. Приемник, например, может являться компьютером, мобильным устройством, запоминающим устройством и т.п. Устройство или система, например, могут содержать файловый сервер для переноса компьютерной программы к приемнику.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторой или всей функциональности способов, описанных в настоящем документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из способов, описанных в настоящем документе. Обычно способы предпочтительно выполняются любым аппаратным устройством.
Устройство, описанное в настоящем документе, может быть реализовано с использованием аппаратного устройства, или с использованием компьютера, или с использованием комбинации аппаратного устройства и компьютера.
Устройство, описанное в настоящем документе, или любые компоненты устройства, описанного в настоящем документе, могут быть реализованы по меньшей мере частично в аппаратных средствах и/или в программном обеспечении.
Способы, описанные в настоящем документе, могут быть выполнены с использованием аппаратного устройства, или с использованием компьютера, или с использованием комбинации аппаратного устройства и компьютера.
Способы, описанные в настоящем документе, или любые компоненты устройства, описанного в настоящем документе, могут быть выполнены по меньшей мере частично аппаратными средствами и/или программным обеспечением.
Описанные выше варианты осуществления являются лишь иллюстрацией принципов настоящего изобретения. Подразумевается, что модификации и вариации размещений и подробностей, описанных в настоящем документе, будут очевидны для других специалистов в области техники. Таким образом, подразумевается, что изобретение ограничено только объемом последующей формулы изобретения по патенту, а не конкретными подробностями, представленными посредством описания и разъяснения представленных в настоящем документе вариантов осуществления.
Источники информации
[Yoshioka2009] T. Yoshioka, T. Nakatani, and M. Miyoshi, "Integrated speech enhancement method using noise suppression and dereverberation," IEEE Trans. Audio, Speech, Lang. Process., vol. 17, no. 2, pp. 231-246, Feb 2009.
[Togami2013] M. Togami and Y. Kawaguchi, "Noise robust speech dereverberation with Kalman smoother," in Proc. IEEE Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP), May 2013, pp. 7447-7451.
[Yoshioka2013] T. Yoshioka and T. Nakatani, "Dereverberation for reverberation-robust microphone arrays," in Proc. European Signal Processing Conf. (EUSIPCO), Sept 2013, pp. 1-5.
[Togami2015] M. Togami, "Multichannel online speech dereverberation under noisy environments," in Proc. European Signal Processing Conf. (EUSIPCO), Nice, France, Sep. 2015, pp. 1078-1082.
[Yoshioka2012] T. Yoshioka and T. Nakatani, "Generalization of multi-channel linear prediction methods for blind MIMO impulse response shortening," IEEE Trans. Audio, Speech, Lang. Process., vol. 20, no. 10, pp. 2707-2720, Dec. 2012.
[Nakatani2010] T. Nakatani, T. Yoshioka, K. Kinoshita, M. Miyoshi, and J. Biing- Hwang, "Speech dereverberation based on variance-normalized delayed linear prediction," IEEE Trans. Audio, Speech, Lang. Process., vol. 18, no. 7, pp. 1717-1731, 2010.
[Jukic2016] A. Jukic, Z. Wang, T. van Waterschoot, T. Gerkmann, and S. Doclo, "Constrained multi-channel linear prediction for adaptive speech dereverberation," in Proc. Intl. Workshop Acoust. Signal Enhancement (IWAENC), Xi’an, China, Sep. 2016.
[Braun2016] S. Braun and E. A. P. Habets, "Online dereverberation for dynamic scenarios using a Kalman filter with an autoregressive models, " IEEE Signal Process. Lett., vol. 23, no. 12, pp. 1741-1745, Dec. 2016.
[Gerkmann2012] T. Gerkmann and R. C. Hendriks, "Unbiased MMSE-based noise power estimation with low complexity and low tracking delay," IEEE Trans. Audio, Speech, Lang. Process., vol. 20, no. 4, pp. 1383 -1393, May 2012.
[Taseska2012] M. Taseska and E. A. P. Habets, "MMSE-based blind source extraction in diffuse noise fields using a complex coherence-based SAP estimator," in Proc. Intl. Workshop Acoust. Signal Enhancement (IWAENC), Aachen, Germany, Sep. 2012.
[1] J.B. Allen and D.A. Berkley, "Image method for efficiently simulating small-room acoustics," J. Acoust. Soc. Am., vol. 65, no. 4, pp. 943-950, Apr. 1979.
[2] S. Braun and E.A.P. Habets, "A multichannel diffuse power estimator for dereverberation in the presence of multiple sources," EURASIP Journal on Audio, Speech, and Music Processing, vol. 2015, no. 1, pp. 1-14, 2015.
[3] S. Braun and E.A.P. Habets, "Online dereverberation for dynamic scenarios using a Kalman filter with an autoregressive models," IEEE Signal Process. Lett., vol. 23, no. 12, pp. 1741-1745, Dec. 2016.
[4] T. Dietzen, A. Spriet, W. Tirry, S. Doclo, M. Moonen, and T. van Waterschoot, "Partitioned block frequency domain Kalman filter for multi-channel linear prediction based blind speech dereverberation," in Proc. Intl. Workshop Acoust. Signal Enhancement (IWAENC), Xi’an, China, Sep. 2016.
[5] E.B. Union. (1988) Sound quality assessment material recordings for subjective tests. [Онлайн]. Доступен по адресу: http://tech.ebu.ch/publications/sqamcd
[6] G. Enzner and P. Vary, "Frequency-domain adaptive Kalman filter for acoustic echo control in hands-free telephones," Signal Processing, vol. 86, no. 6, pp. 1140-1156, 2006.
[7] Y. Ephraim and D. Malah, "Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator," IEEE Trans. Acoust., Speech, Signal Process., vol. 32, no. 6, pp. 1109-1121, Dec. 1984.
[8] S. Gannot, D. Burshtein, and E. Weinstein, "Iterative and sequential Kalman filter-based speech enhancement algorithms," IEEE Trans. Speech Audio Process., vol. 6, no. 4, pp. 373-385, Jul. 1998.
[9] T. Gerkmann and R.C. Hendriks, "Unbiased MMSE-based noise power estimation with low complexity and low tracking delay," IEEE Trans. Audio, Speech, Lang. Process., vol. 20, no. 4, pp. 1383 -1393, May 2012.
[10] S. Goetze, A. Warzybok, I. Kodrasi, J.O. Jungmann, B. Cauchi, J. Rennies, E.A.P. Habets, A. Mertins, T. Gerkmann, S. Doclo, and B. Kollmeier, "A study on speech quality and speech intelligibility measures for quality assessment of single-channel dereverberation algorithms, " in Proc. Intl. Workshop Acoust. Signal Enhancement (IWAENC), Sep. 2014, pp. 233-237.
[11] ITU-T, Perceptual evaluation of speech quality (PESQ), an objective method for end-to-end speech quality assessment of narrowband telephone networks and speech codecs, International Telecommunications Union (ITU-T) Recommendation P.862, Feb. 2001.
[12] A. Jukic, Z. Wang, T. van Waterschoot, T. Gerkmann, and S. Doclo, "Constrained multi-channel linear prediction for adaptive speech dereverberation," in Proc. Intl. Workshop Acoust. Signal Enhancement (IWAENC), Xi’an, China, Sep. 2016.
[13] A. Jukic, T. van Waterschoot, and S. Doclo, "Adaptive speech dereverberation using constrained sparse multichannel linear prediction," IEEE Signal Process. Lett., vol. 24, no. 1, pp. 101-105, Jan 2017.
[14] R.E. Kalman, "A new approach to linear filtering and prediction problems," Trans. of the ASME Journal of Basic Engineering, vol. 82, no. Series D, pp. 35-45, 1960.
[15] K. Kinoshita, M. Delcroix, S. Gannot, E.A.P. Habets, R. Haeb-Umbach, W. Kellermann, V. Leutnant, R. Maas, T. Nakatani, B. Raj, A. Sehr, and T. Yoshioka, "A summary of the REVERB challenge: state-of-the-art and remaining challenges in reverberant speech processing research, " EURASIP Journal on Advances in Signal Processing, vol. 2016, no. 1, p. 7, Jan 2016.
[16] N. Kitawaki, H. Nagabuchi, and K. Itoh, "Objective quality evaluation for low bit-rate speech coding systems," IEEE J. Sel. Areas Commun., vol. 6, no. 2, pp. 262-273, 1988.
[17] D. Labarre, E. Grivel, Y. Berthoumieu, E. Todini, and M. Najim, "Consistent estimation of autoregressive parameters from noisy observations based on two interacting Kalman filters," Signal Processing, vol. 86, no. 10, pp. 2863-2876, 2006, special Section: Fractional Calculus Applications in Signals and Systems.
[18] P.C. Loizou, Speech Enhancement Theory and Practice. 1em plus 0.5em minus 0.4em Taylor & Francis, 2007.
[19] R. Martin, "Noise power spectral density estimation based on optimal smoothing and minimum statistics," IEEE Trans. Speech Audio Process., vol. 9, pp. 504-512, Jul. 2001.
[20] M. Miyoshi and Y. Kaneda, "Inverse filtering of room acoustics," IEEE Trans. Acoust., Speech, Signal Process., vol. 36, no. 2, pp. 145-152, Feb. 1988.
[21] T. Nakatani, T. Yoshioka, K. Kinoshita, M. Miyoshi, and J. Biing-Hwang, "Speech dereverberation based on variance-normalized delayed linear prediction," IEEE Trans. Audio, Speech, Lang. Process., vol. 18, no. 7, pp. 1717-1731, 2010.
[22] P.A. Naylor and N.D. Gaubitch, Eds., Speech Dereverberation. 1em plus 0.5em minus 0.4em London, UK: Springer, 2010.
[23] U. Niesen, D. Shah, and G.W. Wornell, "Adaptive alternating minimization algorithms," IEEE Transactions on Information Theory, vol. 55, no. 3, pp. 1423-1429, March 2009.
[24] J.F. Santos, M. Senoussaoui, and T.H. Falk, "An updated objective intelligibility estimation metric for normal hearing listeners under noise and reverberation," in Proc. Intl. Workshop Acoust. Signal Enhancement (IWAENC), Antibes, France, Sep. 2014.
[25] D. Schmid, G. Enzner, S. Malik, D. Kolossa, and R. Martin, "Variational Bayesian inference for multichannel dereverberation and noise reduction," IEEE Trans. Audio, Speech, Lang. Process., vol. 22, no. 8, pp. 1320-1335, Aug 2014.
[26] B. Schwartz, S. Gannot, and E. Habets, "Online speech dereverberation using Kalman filter and EM algorithm," IEEE Trans. Audio, Speech, Lang. Process., vol. 23, no. 2, pp. 394-406, 2015.
[27] O. Schwartz, S. Gannot, and E. Habets, "Multi-microphone speech dereverberation and noise reduction using relative early transfer functions," IEEE Trans. Audio, Speech, Lang. Process., vol. 23, no. 2, pp. 240-251, Jan. 2015.
[28] M. Taseska and E.A.P. Habets, "MMSE-based blind source extraction in diffuse noise fields using a complex coherence-based a priori SAP estimator," in Proc. Intl. Workshop Acoust. Signal Enhancement (IWAENC), Sep. 2012.
[29] M. Togami, Y. Kawaguchi, R. Takeda, Y. Obuchi, and N. Nukaga, "Optimized speech dereverberation from probabilistic perspective for time varying acoustic transfer function," IEEE Trans. Audio, Speech, Lang. Process., vol. 21, no. 7, pp. 1369-1380, Jul. 2013.
[30] M. Togami and Y. Kawaguchi, "Noise robust speech dereverberation with Kalman smoother," in Proc. IEEE Intl. Conf. on Acoustics, Speech and Signal Processing (ICASSP), May 2013, pp. 7447-7451.
[31] M. Togami, "Multichannel online speech dereverberation under noisy environments," in Proc. European Signal Processing Conf. (EUSIPCO), Nice, France, Sep. 2015, pp. 1078-1082.
[32] T. Yoshioka, T. Nakatani, and M. Miyoshi, "Integrated speech enhancement method using noise suppression and dereverberation," IEEE Trans. Audio, Speech, Lang. Process., vol. 17, no. 2, pp. 231-246, Feb 2009.
[33] T. Yoshioka and T. Nakatani, "Generalization of multi-channel linear prediction methods for blind MIMO impulse response shortening," IEEE Trans. Audio, Speech, Lang. Process., vol. 20, no. 10, pp. 2707-2720, Dec. 2012.
[34] T. Yoshioka, A. Sehr, M. Delcroix, K. Kinoshita, R. Maas, T. Nakatani, and W. Kellermann, "Making machines understand us in reverberant rooms: Robustness against reverberation for automatic speech recognition," IEEE Signal Processing Magazine, vol. 29, no. 6, pp. 114-126, Nov 2012.
[35] T. Yoshioka and T. Nakatani, "Dereverberation for reverberation-robust microphone arrays," in Proc. European Signal Processing Conf. (EUSIPCO), Sept 2013, pp. 1-5.
[36] [Онлайн]. Доступен по адресу: http://www.audiolabs-erlangen.de/fau/professor/habets/software/signal-generator
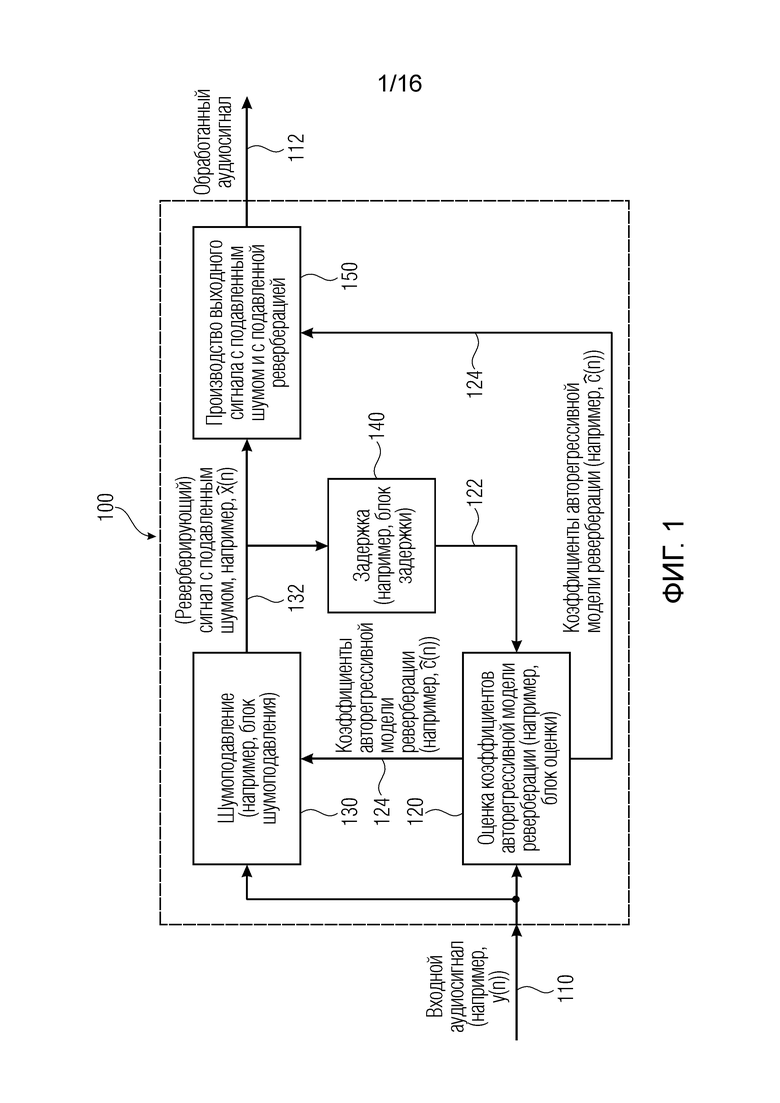


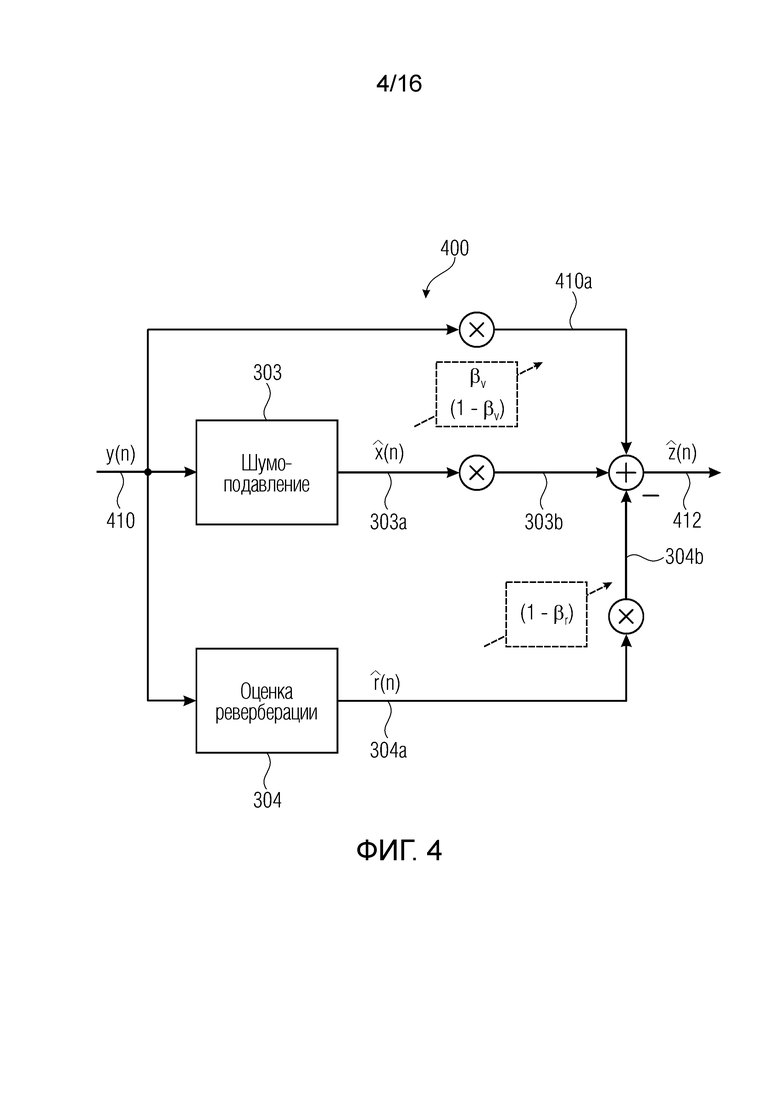
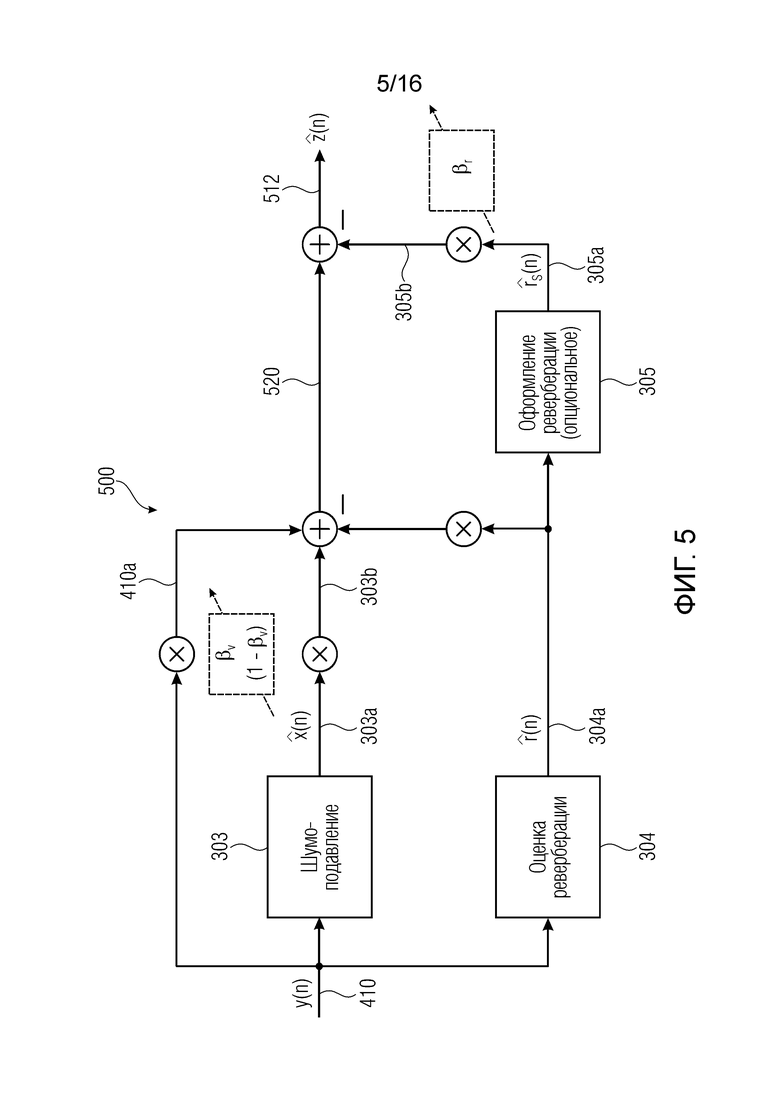

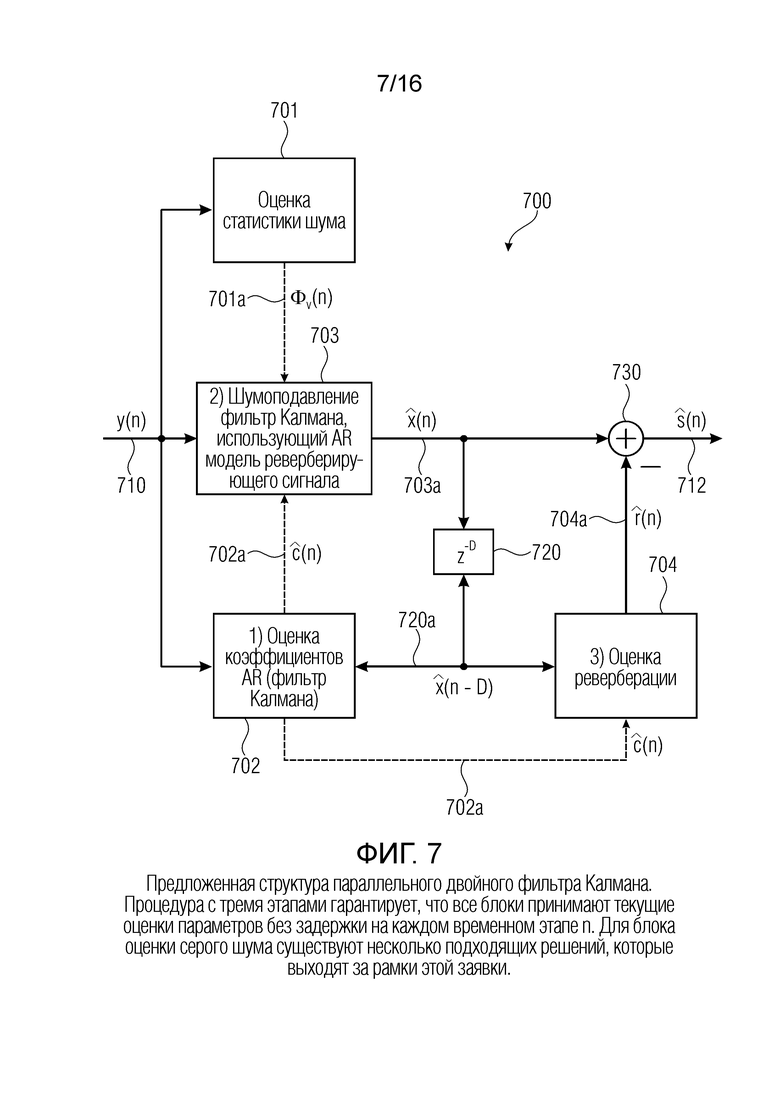

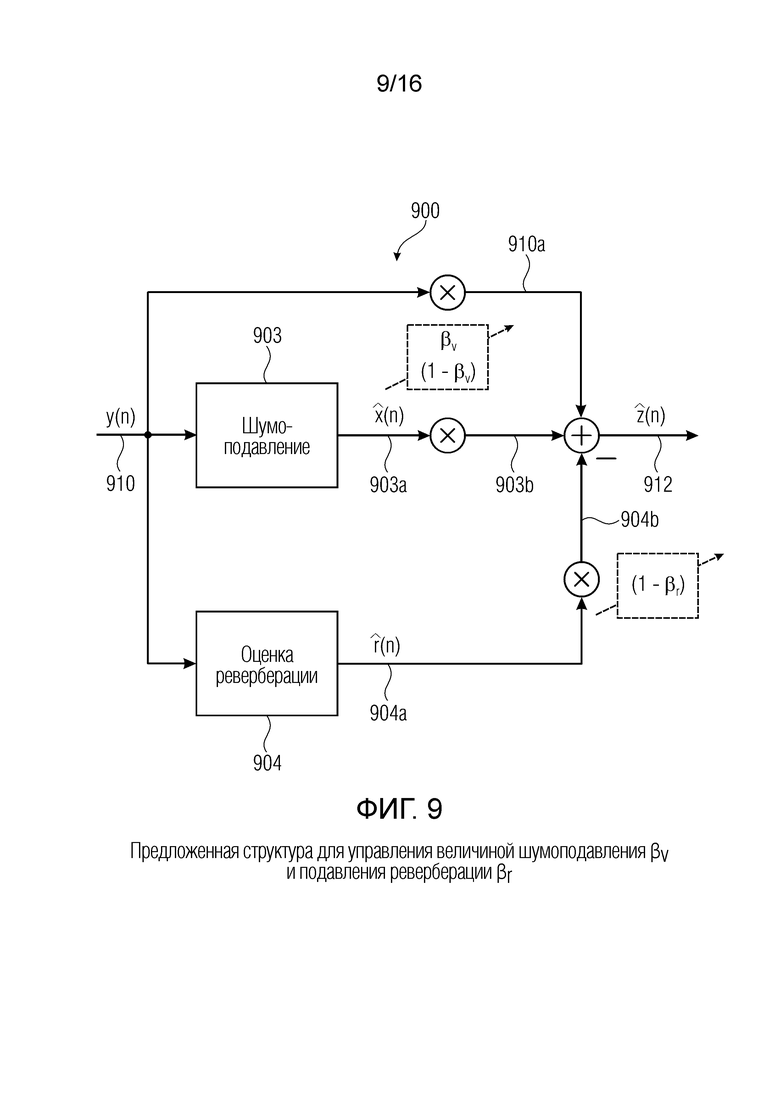
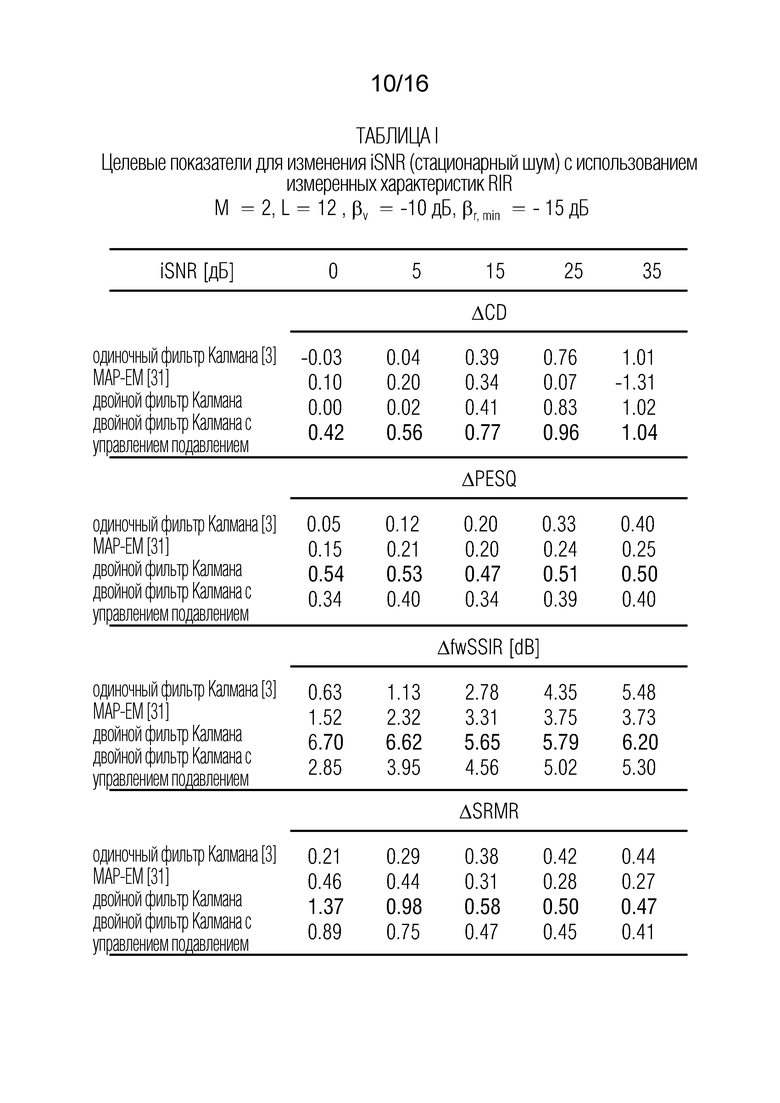
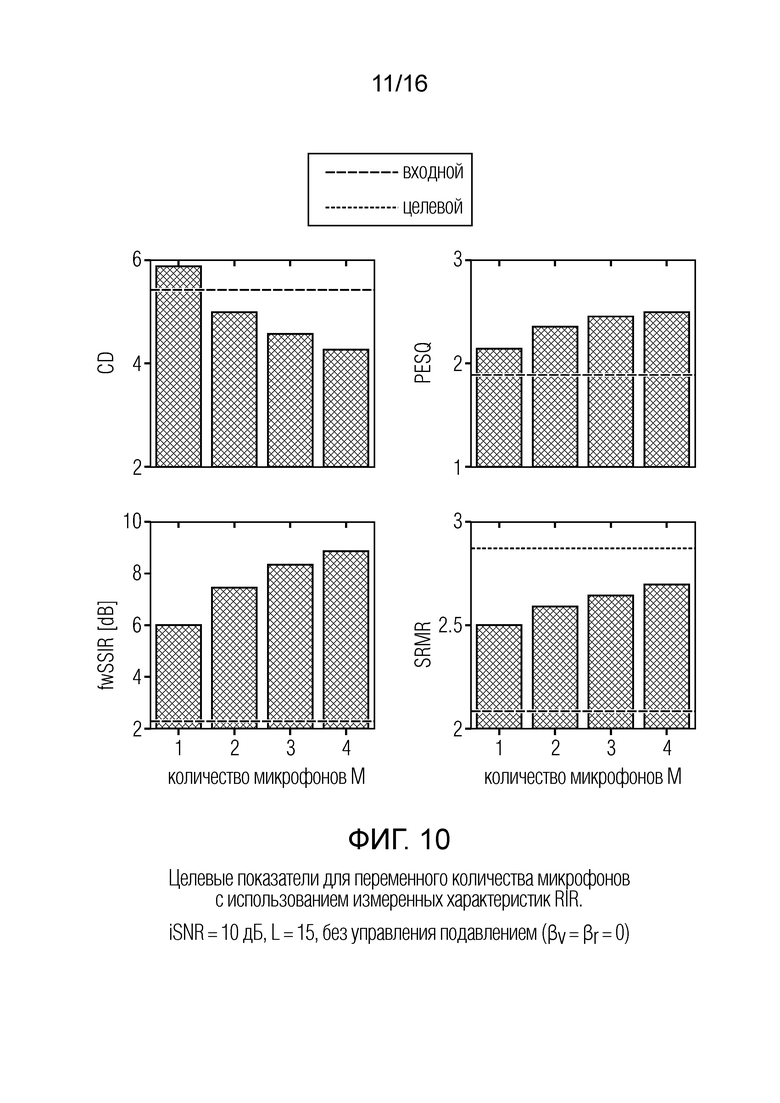

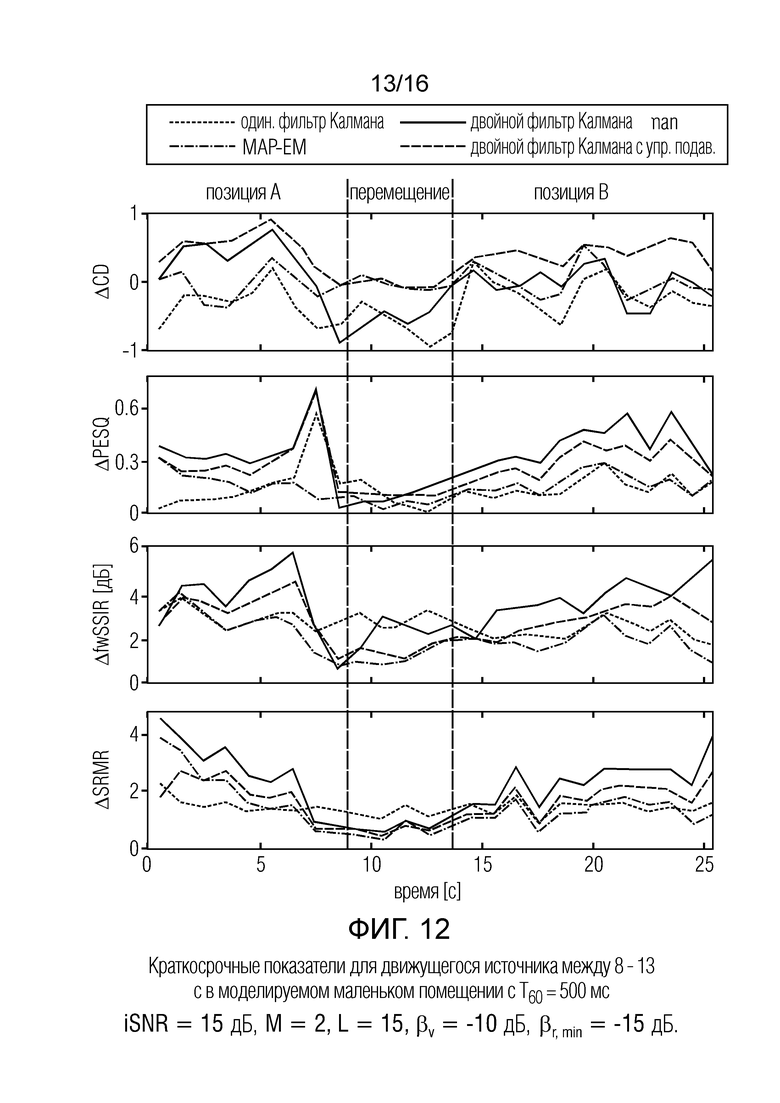
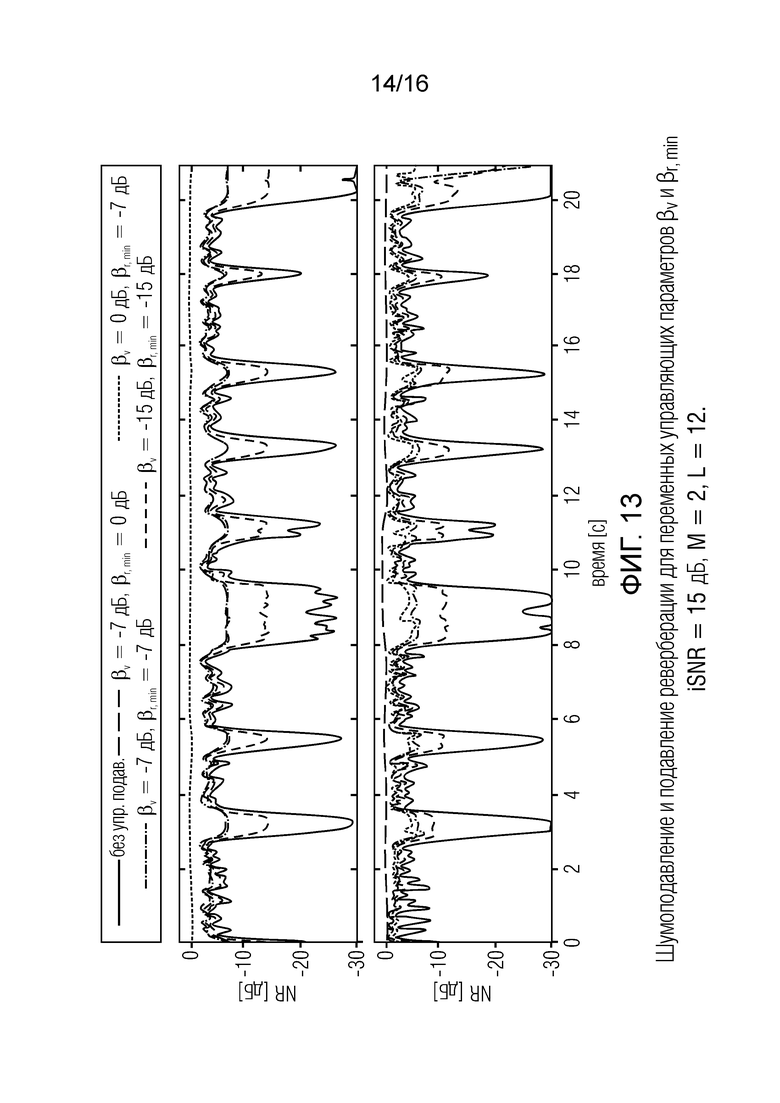


Изобретение относится к области обработки аудиосигналов. Техническим результатом является обеспечение подавления шума и подавления реверберации для аудиосигналов. Раскрыт процессор сигналов для обеспечения одного или более обработанных аудиосигналов ( (n);
(n);  (n)) на основе одного или более входных аудиосигналов (y(n)), причем процессор сигналов выполнен с возможностью оценивать коэффициенты (
(n)) на основе одного или более входных аудиосигналов (y(n)), причем процессор сигналов выполнен с возможностью оценивать коэффициенты (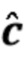 (n)) авторегрессивной модели реверберации с использованием одного или более входных аудиосигналов и одного или более задержанных реверберирующих сигналов с подавленным шумом (
(n)) авторегрессивной модели реверберации с использованием одного или более входных аудиосигналов и одного или более задержанных реверберирующих сигналов с подавленным шумом ( (n)), полученных с использованием шумоподавления; и причем процессор сигналов выполнен с возможностью обеспечивать один или более реверберирующих сигналов с подавленным шумом ((n)) с использованием входного аудиосигнала и оценочных коэффициентов ((n)) авторегрессивной модели реверберации; и причем процессор сигналов выполнен с возможностью производить один или более выходных сигналов с подавленным шумом и с подавленной реверберацией ((n); (n)) с использованием одного или более реверберирующих сигналов с подавленным шумом ((n)) и оценочных коэффициентов ((n)) авторегрессивной модели реверберации. 3 н. и 23 з.п. ф-лы, 16 ил.
(n)), полученных с использованием шумоподавления; и причем процессор сигналов выполнен с возможностью обеспечивать один или более реверберирующих сигналов с подавленным шумом ((n)) с использованием входного аудиосигнала и оценочных коэффициентов ((n)) авторегрессивной модели реверберации; и причем процессор сигналов выполнен с возможностью производить один или более выходных сигналов с подавленным шумом и с подавленной реверберацией ((n); (n)) с использованием одного или более реверберирующих сигналов с подавленным шумом ((n)) и оценочных коэффициентов ((n)) авторегрессивной модели реверберации. 3 н. и 23 з.п. ф-лы, 16 ил.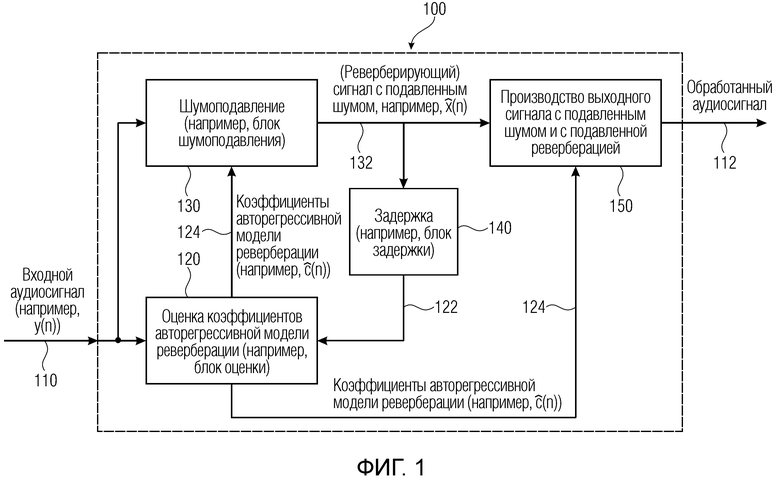
1. Процессор (100; 300; 400; 500; 700; 900) сигналов для обеспечения одного или более обработанных аудиосигналов (112; 312; 412; 512; 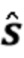 (n);
(n);  (n)) на основе одного или более входных аудиосигналов (110; 310; 410; 710; 910; y(n)),
(n)) на основе одного или более входных аудиосигналов (110; 310; 410; 710; 910; y(n)),
причем процессор сигналов выполнен с возможностью оценивать коэффициенты (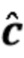 (n)) авторегрессивной модели реверберации с использованием одного или более входных аудиосигналов и одного или более задержанных реверберирующих сигналов с подавленным шумом (
(n)) авторегрессивной модели реверберации с использованием одного или более входных аудиосигналов и одного или более задержанных реверберирующих сигналов с подавленным шумом (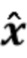 (n)), полученных с использованием шумоподавления (130; 303; 703; 903); и
(n)), полученных с использованием шумоподавления (130; 303; 703; 903); и
причем процессор сигналов выполнен с возможностью обеспечивать один или более реверберирующих сигналов с подавленным шумом ((n)) с использованием входного аудиосигнала и оценочных коэффициентов (124; 302a; 702a; (n)) авторегрессивной модели реверберации; и
причем процессор сигналов выполнен с возможностью производить один или более выходных сигналов с подавленным шумом и с подавленной реверберацией (112; 312; 412; 512; (n); (n)) с использованием одного или более реверберирующих сигналов с подавленным шумом ((n)) и оценочных коэффициентов ((n)) авторегрессивной модели реверберации.
2. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью оценивать коэффициенты ((n)) многоканальной авторегрессивной модели реверберации.
3. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью использовать оценочные коэффициенты ((n)) авторегрессивной модели реверберации, ассоциированные с текущим обрабатываемым участком входного аудиосигнала, чтобы обеспечить реверберирующий сигнал с подавленным шумом ((n)), ассоциированный с текущим обрабатываемым участком входного аудиосигнала (110; 310; 410; 710; 910; y(n)).
4. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью использовать один или более задержанных реверберирующих сигналов с подавленным шумом (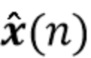 ), ассоциированных с ранее обработанной частью входного аудиосигнала (110; 310; 410; 710; 910; y(n)) для оценки коэффициентов ((n)) авторегрессивной модели реверберации, ассоциированной с текущей обрабатываемой частью входного аудиосигнала.
), ассоциированных с ранее обработанной частью входного аудиосигнала (110; 310; 410; 710; 910; y(n)) для оценки коэффициентов ((n)) авторегрессивной модели реверберации, ассоциированной с текущей обрабатываемой частью входного аудиосигнала.
5. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью поочередно обеспечивать оценочные коэффициенты ((n)) авторегрессивной модели реверберации и части реверберирующих сигналов с подавленным шумом (), и
причем процессор сигналов выполнен с возможностью использовать оценочные коэффициенты ((n)) авторегрессивной модели реверберации для предоставления частей реверберирующего сигнала с подавленным шумом (), и
причем процессор сигналов выполнен с возможностью использовать один или более задержанных реверберирующих сигналов с подавленным шумом () для оценки коэффициентов ((n)) многоканальной авторегрессивной модели реверберации.
6. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью применять алгоритм, который минимизирует функцию стоимости для оценки коэффициентов ((n)) авторегрессивной модели реверберации.
7. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 6, в котором функция стоимости, используемая для оценки коэффициентов ((n)) авторегрессивной модели реверберации, является значением ожидания для среднеквадратической ошибки коэффициентов ((n)) авторегрессивной модели реверберации.
8. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 6, причем процессор сигналов выполнен с возможностью применять алгоритм для минимизации функции стоимости для оценки коэффициентов ((n)) авторегрессивной модели реверберации при допущении, что реверберирующий сигнал с подавленным шумом ((n)) является фиксированным.
9. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью применять алгоритм для минимизации функции стоимости для оценки реверберирующего сигнала с подавленным шумом ().
10. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 9, в котором функция стоимости, используемая для оценки реверберирующего сигнала ( ), представляет собой значение ожидания для среднеквадратической ошибки реверберирующего сигнала ().
), представляет собой значение ожидания для среднеквадратической ошибки реверберирующего сигнала ().
11. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 9, причем процессор сигналов выполнен с возможностью применять алгоритм для минимизации функции стоимости для оценки реверберирующего сигнала ( ) при допущении, что коэффициенты ((n)) авторегрессивной модели реверберации являются фиксированными.
) при допущении, что коэффициенты ((n)) авторегрессивной модели реверберации являются фиксированными.
12. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью определять компонент реверберации (124; 304a; 704a; 904a; 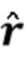 (n)) на основе оценочных коэффициентов ((n)) авторегрессивной модели реверберации и на основе одного или более задержанных реверберирующих сигналов с подавленным шумом (), ассоциированных с ранее обработанной частью входного аудиосигнала (110; 310; 410; 710; 910; y(n)), и
(n)) на основе оценочных коэффициентов ((n)) авторегрессивной модели реверберации и на основе одного или более задержанных реверберирующих сигналов с подавленным шумом (), ассоциированных с ранее обработанной частью входного аудиосигнала (110; 310; 410; 710; 910; y(n)), и
причем процессор сигналов выполнен с возможностью подавлять компонент реверберации ((n)) реверберирующего сигнала с подавленным шумом (), ассоциированного с текущим обрабатываемым участком входного аудиосигнала (110; 310; 410; 710; 910; y(n)), для получения выходного сигнала с подавленным шумом и с подавленной реверберацией (112; 312; 412; 512; (n); (n)).
13. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью выполнять взвешенную комбинацию входного аудиосигнала (110; 310; 410; 710; 910; y(n)) и реверберирующего сигнала с подавленным шумом ((n)) и компонента реверберации для получения выходного сигнала с подавленным шумом и с подавленной реверберацией (112; 312; 412; 512; (n); (n)).
14. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 13, причем процессор сигналов выполнен с возможностью также включать в себя сформированную версию (305a, 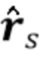 (n)) компонента реверберации (304a, (n)) во взвешенной комбинации.
(n)) компонента реверберации (304a, (n)) во взвешенной комбинации.
15. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью оценивать статистическую величину ( ) компонента шума входного аудиосигнала.
) компонента шума входного аудиосигнала.
16. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью оценивать статистическую величину (301a, 701a, 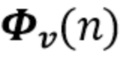 ) компонента шума входного аудиосигнала в период отсутствия речи.
) компонента шума входного аудиосигнала в период отсутствия речи.
17. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью оценивать коэффициенты ((n)) авторегрессивной модели реверберации с использованием фильтров Калмана.
18. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью оценивать коэффициенты ((n)) авторегрессивной модели реверберации на основе
- оценочной матрицы ошибок 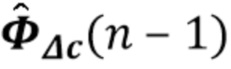 вектора коэффициентов (
вектора коэффициентов (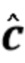 (n-1)) авторегрессивной модели реверберации;
(n-1)) авторегрессивной модели реверберации;
- оценочной ковариации 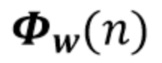 шума погрешности вектора коэффициентов ((n)) авторегрессивной модели реверберации;
шума погрешности вектора коэффициентов ((n)) авторегрессивной модели реверберации;
- предыдущего вектора коэффициентов ((n-1)) авторегрессивной модели реверберации;
- одного или более задержанных реверберирующих сигналов с подавленным шумом ( );
);
- оценочной ковариации 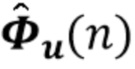 , ассоциированной с шумными, но с подавленной реверберацией компонентами сигнала входного аудиосигнала;
, ассоциированной с шумными, но с подавленной реверберацией компонентами сигнала входного аудиосигнала;
- входного аудиосигнала (y(n)).
19. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью оценивать реверберирующий сигнал с подавленным шумом ((n)) с использованием фильтра Калмана.
20. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью оценивать реверберирующий сигнал с подавленным шумом ((n)) на основе
- оценочной матрицы ошибок 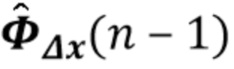 реверберирующего сигнала с подавленным шумом (
реверберирующего сигнала с подавленным шумом ( (n-1));
(n-1));
- оценочной ковариации 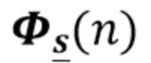 требуемого речевого сигнала;
требуемого речевого сигнала;
- одной или более предыдущих оценок реверберирующего сигнала с подавленным шумом ((n-1));
- множества коэффициентов ((n)) авторегрессивной модели реверберации;
- оценочной ковариации шума 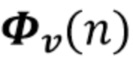 , ассоциированной с входным аудиосигналом; и
, ассоциированной с входным аудиосигналом; и
- входного аудиосигнала y(n).
21. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью получать оценочную ковариацию ( ), ассоциированную с шумными, но с подавленной реверберацией компонентами сигнала входного аудиосигнала на основе взвешенной комбинации
), ассоциированную с шумными, но с подавленной реверберацией компонентами сигнала входного аудиосигнала на основе взвешенной комбинации
- рекурсивной оценки ( ) ковариации, определенной рекурсивно с использованием предыдущих оценок (
) ковариации, определенной рекурсивно с использованием предыдущих оценок ( (n)) шумных, но с подавленной реверберацией компонентов сигнала входного аудиосигнала; и
(n)) шумных, но с подавленной реверберацией компонентов сигнала входного аудиосигнала; и
- внешнего произведения оценки шумных, но с подавленной реверберацией компонентов сигнала (e(n)) входного аудиосигнала.
22. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 21, в котором рекурсивная оценка () ковариации основана на оценке шумных, но с подавленной реверберацией компонентов сигнала ((n-1)) входного аудиосигнала, вычисленных с использованием окончательных коэффициентов оценки ((n-1)) авторегрессивной модели реверберации и с использованием окончательной оценки реверберирующего сигнала с подавленным шумом ((n-1)); и/или
причем процессор сигналов выполнен с возможностью получать внешнее произведение шумных, но с подавленной реверберацией компонентов сигнала входного аудиосигнала (e(n)eH(n)) на основе промежуточной оценки ((n|n-1) коэффициентов ((n)) авторегрессивной модели реверберации.
23. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 1, причем процессор сигналов выполнен с возможностью получать оценочную ковариацию (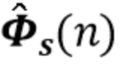 ), ассоциированную с компонентом сигнала с подавленным шумом и с подавленной реверберацией (
), ассоциированную с компонентом сигнала с подавленным шумом и с подавленной реверберацией ( ) входного аудиосигнала на основе взвешенной комбинации
) входного аудиосигнала на основе взвешенной комбинации
- рекурсивной оценки ( ) ковариации, определенной рекурсивно с использованием предыдущих оценок ((n-1)) компонентов сигнала с подавленным шумом и с подавленной реверберацией ((n-1)) входного аудиосигнала; и
) ковариации, определенной рекурсивно с использованием предыдущих оценок ((n-1)) компонентов сигнала с подавленным шумом и с подавленной реверберацией ((n-1)) входного аудиосигнала; и
- априорной оценки (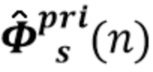 ) ковариации, которая основана на текущей обрабатываемой части входного аудиосигнала (y(n)).
) ковариации, которая основана на текущей обрабатываемой части входного аудиосигнала (y(n)).
24. Процессор (100; 300; 400; 500; 700; 900) сигналов по п. 23,
причем процессор сигналов выполнен с возможностью получать рекурсивную оценку () ковариации на основе оценки компонентов сигнала с подавленным шумом и с подавленной реверберацией ((n-1)) входного аудиосигнала, вычисленных с использованием окончательных оценочных коэффициентов ((n)) авторегрессивной модели реверберации и с использованием окончательной оценки реверберирующего выходного сигнала с подавленным шумом ((n)); и/или
причем процессор сигналов выполнен с возможностью получать априорную оценку () ковариации с использованием фильтрации Винера входного аудиосигнала,
причем операция фильтрации Винера определена в зависимости от информации ковариации (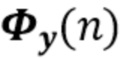 ) относительно входного аудиосигнала в зависимости от информации ковариации (
) относительно входного аудиосигнала в зависимости от информации ковариации ( ) относительно компонента реверберации входного аудиосигнала и в зависимости от информации ковариации () относительно шумового компонента входного аудиосигнала.
) относительно компонента реверберации входного аудиосигнала и в зависимости от информации ковариации () относительно шумового компонента входного аудиосигнала.
25. Способ (1400) обеспечения одного или более обработанных аудиосигналов на основе одного или более входных аудиосигналов,
причем способ содержит оценку (1410) коэффициентов ((n)) авторегрессивной модели реверберации с использованием одного или более входных аудиосигналов и одного или более задержанных реверберирующих сигналов с подавленным шумом, полученных с использованием шумоподавления; и
причем способ содержит обеспечение (1420) одного или более реверберирующих сигналов с подавленным шумом ((n)) с использованием одного или более входных аудиосигналов и оценочных коэффициентов ((n)) авторегрессивной модели реверберации; и
причем способ содержит получение (1430) одного или более выходных сигналов с подавленным шумом и с подавленной реверберацией ((n)) с использованием одного или более реверберирующих сигналов с подавленным шумом ((n)) и оценочных коэффициентов ((n)) авторегрессивной модели реверберации.
26. Носитель данных, содержащий записанную на нем компьютерную программу для выполнения способа по п. 25, когда компьютерная программа выполняется на компьютере.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| US 6324502 B1, 27.11.2001 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| АКТИВНОЕ ПОДАВЛЕНИЕ АУДИОШУМОВ | 2009 |
|
RU2545384C2 |

