ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0001] Настоящее изобретение относится к обработке аудиосигнала и, в частности, к улучшению речевого сигнала с низкой задержкой, реализуемому с использованием нейронной генеративной модели, обучаемой в режиме форсирования учителем (TFM) совместно с итерационным авторегрессивным обусловливанием (IAC).
УРОВЕНЬ ТЕХНИКИ
[0002] Задача обработки потокового ("живого") речевого сигнала в реальном времени имеет большое практическое значение в таких областях применения, как мобильная телефония, интернет-телефония (Voice over Internet Protocol, VoIP), телеконференцсвязь, распознавание речи и слуховые аппараты. Пределы необнаружимого человеком отставания для живой, в реальном времени обработки речевого сигнала являются предметом исследования и обсуждения, но оцениваются около 5-30 миллисекунд в зависимости от области применения. С учетом того, что инструменты улучшения речевого сигнала обычно применяются в объединенных конвейерах с другими инструментами обработки речевого сигнала (например, эхоподавления) и в каналах передачи сигнала, требования к полной задержке очень строги и, для многих вариантов применения, вряд ли удовлетворяются традиционными решениями улучшения речевого сигнала, которые обычно опираются на алгоритмическую (согласно архитектуре модели) задержку более 30-60 мс. Поэтому в уровне техники имеется необходимость в улучшении речевого сигнала с низкой задержкой (т.е. с задержкой менее 10 мс), которое можно осуществлять в применениях реального времени.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0003] В нижеследующем описании раскрыт способ улучшения речевого сигнала с низкой задержкой, а также вычислительное устройство и считываемый компьютером носитель, реализующий способ. Кроме того, в нижеследующем описании детализирован способ обучения, позволяющий эффективно обучать авторегрессивные модели улучшения речевого сигнала для приложений с низкой задержкой, например, упомянутого способа улучшения речевого сигнала с низкой задержкой.
[0004] Согласно первому аспекту настоящего изобретения предложен способ улучшения речевого сигнала, причем способ включает в себя: получение зашумленной формы волны; и последовательную обработку блоков выборок зашумленной формы волны с помощью модели улучшения речевого сигнала для предсказания соответствующих блоков выборок обесшумленной формы волны, причем в ходе упомянутой последовательной обработки каждого блока выборок зашумленной формы волны модель улучшения речевого сигнала авторегрессивно обусловливается дополнительными входными признаками одного или более предыдущих блоков выборок обесшумленной (чистой) формы волны, причем упомянутые один или более предыдущих блоков выборок обесшумленной формы волны предсказываются моделью улучшения речевого сигнала ранее посредством упомянутой последовательной обработки соответствующего одного или более предыдущих блоков выборок зашумленной формы волны, причем модель улучшения речевого сигнала обучается в режиме форсирования учителем (TFM) совместно с итерационным авторегрессивным обусловливанием (IAC).
[0005] Согласно второму аспекту настоящего изобретения предложено вычислительное устройство, включающее в себя процессор и память, хранящую исполняемые процессором инструкции, и весовые коэффициенты и смещения обученной модели улучшения речевого сигнала, причем при исполнении исполняемых процессором инструкций процессором процессор побуждает вычислительное устройство к осуществлению способа улучшения речевого сигнала согласно первому аспекту настоящего изобретения или любому развитию упомянутого первого аспекта.
[0006] Согласно третьему аспекту настоящего изобретения предложен нетранзиторный считываемый компьютером носитель, хранящий исполняемые компьютером инструкции, и весовые коэффициенты и смещения обученной модели улучшения речевого сигнала, причем при исполнении исполняемых компьютером инструкций вычислительным устройством вычислительное устройство побуждается к осуществлению способа улучшения речевого сигнала согласно первому аспекту настоящего изобретения или любому развитию упомянутого первого аспекта.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0007] Далее настоящее изобретение будет описано более подробно со ссылкой на прилагаемые чертежи, на которых:
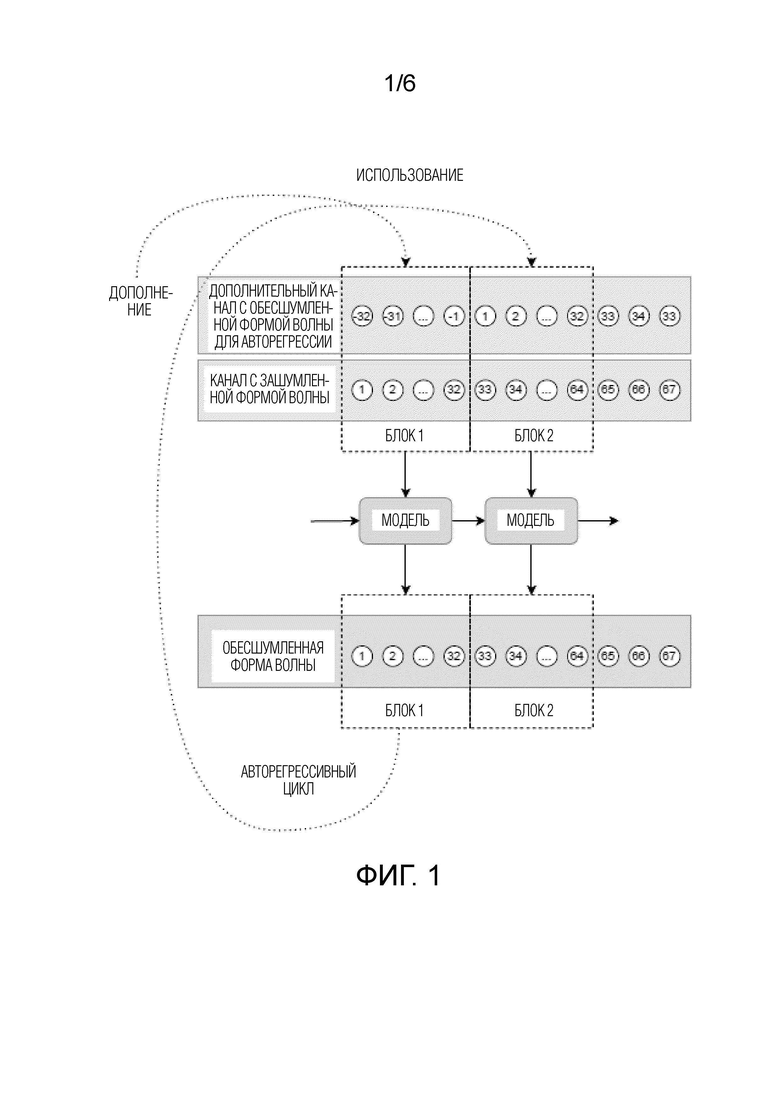
[ФИГ. 1] Фиг. 1 схематически иллюстрирует стадию использования модели улучшения речевого сигнала, используемой в способе улучшения речевого сигнала согласно первому аспекту настоящего изобретения.
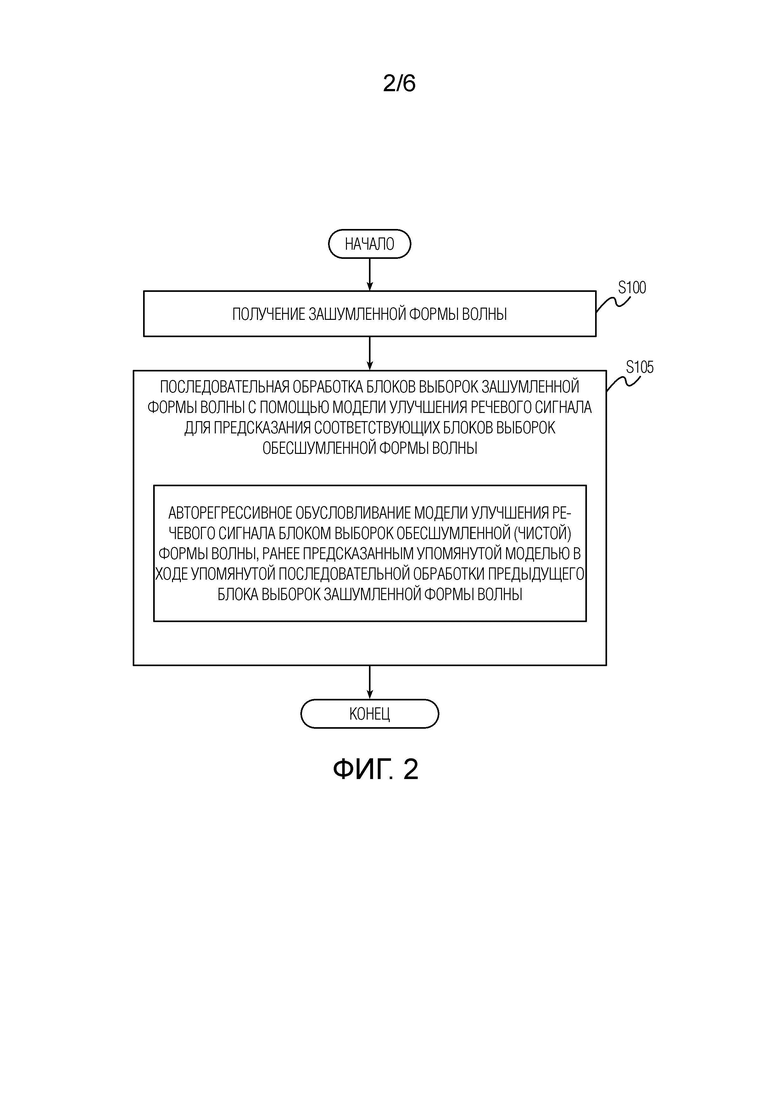
[ФИГ. 2] Фиг. 2 иллюстрирует блок-схему операций способа улучшения речевого сигнала согласно первому аспекту настоящего изобретения.
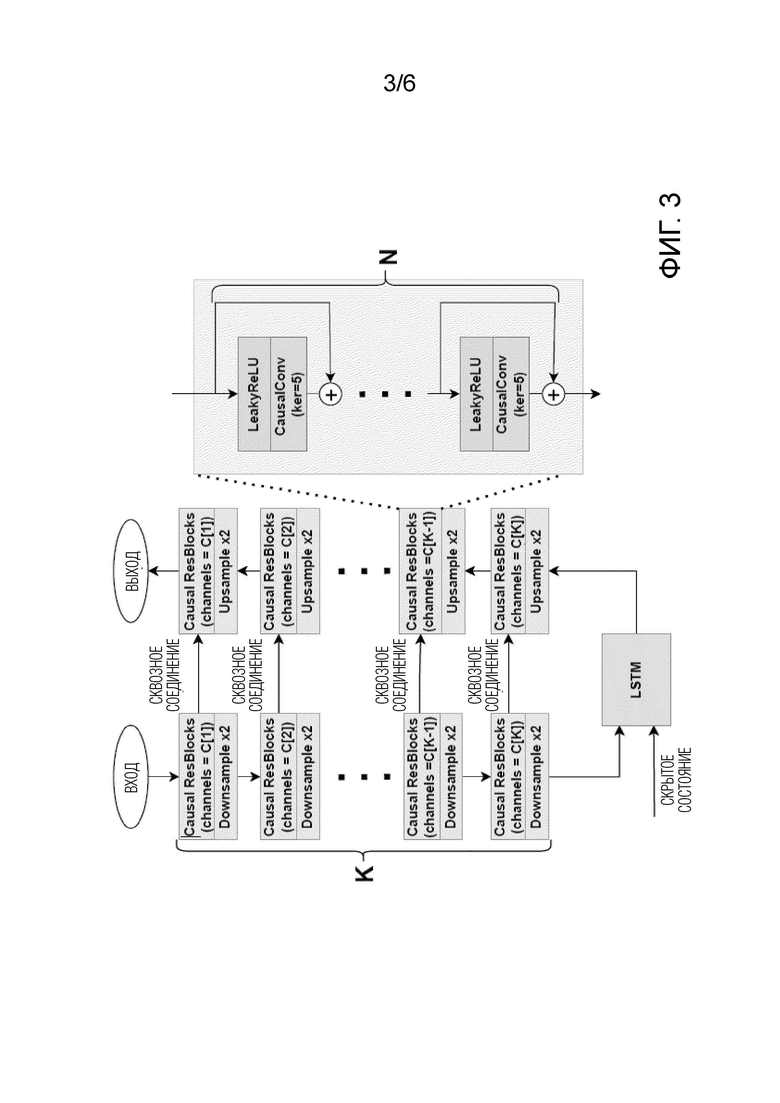
[ФИГ. 3] Фиг. 3 иллюстрирует возможную архитектуру модели улучшения речевого сигнала, используемой в способе улучшения речевого сигнала согласно первому аспекту настоящего изобретения.
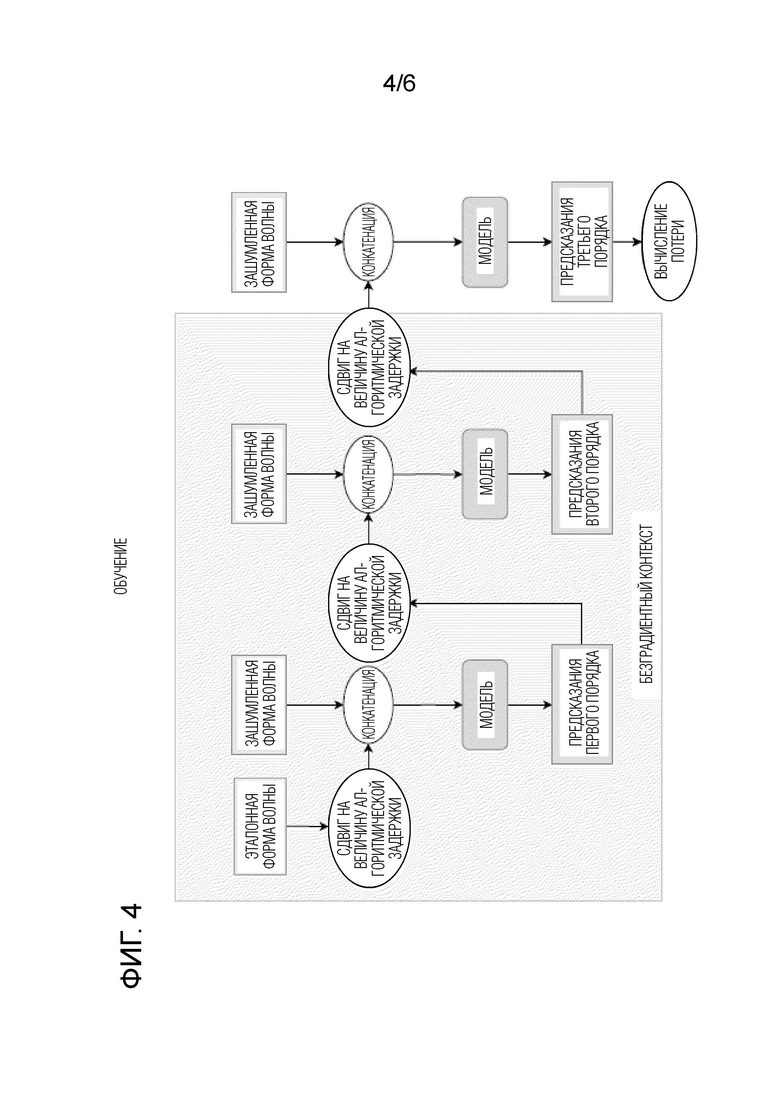
[ФИГ. 4] Фиг. 4 схематически иллюстрирует стадию обучения модели улучшения речевого сигнала, используемой в способе улучшения речевого сигнала согласно первому аспекту настоящего изобретения.
[ФИГ. 5] Фиг. 5 - график, демонстрирующий характеристики итерационного обучения (с итерационной авторегрессией (IA) и без нее) модели улучшения речевого сигнала в отношении средней абсолютной ошибки (МАЕ) между формами волны, предсказанными моделью, и соответствующими эталонными формами волны в зависимости от количества завершенных эпох обучения.
[ФИГ. 6] Фиг. 6 схематически иллюстрирует вычислительное устройство согласно второму аспекту настоящего изобретения, которое выполнено с возможностью осуществления способа улучшения речевого сигнала согласно первому аспекту настоящего изобретения.
[0008] Следует понимать, что фигуры могут быть представлены схематически и предназначены главным образом для улучшения понимания настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0009] Способ улучшения речевого сигнала согласно первому аспекту настоящего изобретения и стадия использования модели улучшения речевого сигнала, используемой в упомянутом способе, будут описаны ниже со ссылкой на фиг. 1 и 2. Здесь следует обратить внимание на то, что термин 'улучшение речевого сигнала' следует интерпретировать в широком смысле для включения общего улучшения качества речевого сигнала. В конце настоящего описания изобретения приведены экспериментальные данные, подтверждающие на основании определенных метрик объективного качества речевого сигнала, что настоящее изобретение достигает такого улучшения по сравнению с базовыми решениями уровня техники. Термин 'модель улучшения речевого сигнала' используется здесь в смысле модели нейронной сети, обученной осуществлять улучшение речевого сигнала.
[0010] Как показано на фиг. 2, предложенный способ улучшения речевого сигнала начинается с этапа S100 получения зашумленной формы волны. Зашумленную форму волны можно получать любым известным в технике способом. В порядке неограничительного примера один или более микрофонов (например, микрофон 50.2, проиллюстрированный на фиг. 6) может быть выполнен с возможностью преобразования воспринимаемого звука в электрический сигнал, который затем обрабатывается аналого-цифровым преобразователем (не показан) и затем одним или более цифровыми сигнальными процессорами (например, процессором 50.1, также проиллюстрированным на фиг. 6) в цифровой аудиосигнал, именуемый далее формой волны. Один или более процессоров могут осуществлять разнообразную предобработку обрабатываемого сигнала (например, эхоподавление и т.д.).
[0011] Следует понимать, что зашумленная форма волны может представлять полный аудиосигнал или быть по меньшей мере его частью. В последнем случае, полный аудиосигнал представлен двумя или более последовательными формами волны. Предполагается, что термины "зашумленная форма волны" и соответствующий ему "обесшумленная форма волны", используемые на всем протяжении настоящего описания, означают, что последний объективно лучше по качеству, чем первый. Согласно другому неограничительному примеру зашумленная форма волны может приниматься на устройстве (например, вычислительном устройстве 50, проиллюстрированном на фиг. 6) от любого другого устройства в процессе, например, телеконференцсвязи. В другом неограничительном примере, зашумленную форму волны можно получать от ранее записанного звука для осуществления улучшения речевого сигнала, например, для последующего распознавания речи.
[0012] После получения зашумленной формы волны способ переходит к этапу S105 последовательной обработки блоков выборок упомянутой зашумленной формы волны с помощью модели улучшения речевого сигнала, предсказывающей блоки выборок соответствующей обесшумленной формы волны. Потоковая (в реальном времени) обработка речевого сигнала (наподобие осуществляемой на этапе S105) осуществляется посредством последовательной обработки дискретных блоков выборок формы волны. Размер блока и полный будущий контекст, используемый для его обработки, определяют алгоритмическую задержку, т.е. полную задержку, возникающую по алгоритмическим причинам. Алгоритмическая задержка также может рассматриваться как максимальная длительность будущего контекста, необходимого для создания каждой выборки (также именуемой временным шагом) обрабатываемой формы волны.
[0013] Согласно неограничительному примеру, представленному на фиг. 1, зашумленная форма волны дискретизируется с частотой дискретизации 16 кГц и обрабатывается блоками по 2 мс. Таким образом, алгоритмическая задержка модели улучшения речевого сигнала в примере равна 32 выборки = размер блока (2 мс) * частота дискретизации (16 кГц). Конкретные значения, указанные ранее, не следует рассматривать как ограничения, поскольку согласно настоящему изобретению, размер блока может принимать значения в диапазоне от менее 1 мс до 10 мс для улучшения речевого сигнала для достижения низкой задержки. Соответственно, алгоритмическая задержка в выборках может быть больше или меньше 32, и частота дискретизации может быть более 16 кГц, например, она может принимать значения в диапазоне от 16 кГц до 96 кГц.
[0014] Как показано в неограничительном примере на фиг. 1, выборки, предсказанные моделью улучшения речевого сигнала для блока л затем повторно используются при создании предсказаний моделью улучшения речевого сигнала для блока n+1, выборки, предсказанные моделью улучшения речевого сигнала (авторегрессивно обусловленные предыдущими выборками обесшумленной (чистой) формы волны, предсказанной для блока n) для блока n+1 затем повторно используются при создании предсказаний для блока n+2, и т.д. Для авторегрессивного обусловливания модели улучшения речевого сигнала, предсказанные выборки могут конкатенироваться как дополнительные входные признаки к входным признакам следующего обрабатываемого блока выборок зашумленной формы волны. Поскольку первый блок зашумленной формы волны обычно не имеет никаких предыдущих выборок (ввиду отсутствия предыдущих блоков), дополнение может использоваться для первого блока вместо авторегрессивного обусловливания. В неограничительном примере, дополнение может быть реализовано с использованием блока, состоящего из некоторых значений, принятых по умолчанию, например 0, вместо авторегрессивного обусловливания, для первого блока зашумленной формы волны.
[0015] Фиг. 3 иллюстрирует возможную неограничительную архитектуру модели улучшения речевого сигнала, используемой в способе улучшения речевого сигнала согласно первому аспекту настоящего изобретения. Как показано модель улучшения речевого сигнала базируется на архитектуре UNet сверточного кодера-декодера (например WaveUNet), в bottleneck-части которой используется слой однонаправленной долгой краткосрочной памяти (LSTM). Параметр К регулирует общую глубину архитектуры UNet, параметр N определяет количество остаточных блоков в каждом слое, массив С определяет количество каналов в каждом слое архитектуры UNet. В неограничительных примерах параметры N, K, С архитектуры могут устанавливаться равными 4, 7 и [16, 24, 32, 48, 64, 96, 128], соответственно.
[0016] Как показано на фиг. 3, кодирующая часть (левая ветвь на фигуре) архитектуры UNet содержит кодирующую последовательность блоков обработки, где каждый блок обработки располагается в соответствующем K-ом слое архитектуры UNet. Каждый из блоков обработки состоит из последовательности из N остаточных блоков, за которой следует понижающая дискретизация х2. Каждый из N остаточных блоков состоит из функции активации, за которой следует каузальная свертка с предопределенными размером ядра и шагом. В неограничительном примере, и размер ядра, и шаг могут устанавливаться как целое число в диапазоне от 2 до 10.
[0017] Декодирующая часть (правая ветвь на фигуре) архитектуры UNet содержит декодирующую последовательность блоков обработки, где каждый блок обработки располагается в соответствующем K-ом слое архитектуры UNet. Каждый из блоков обработки состоит из последовательности из N остаточных блоков, за которой следует повышающая дискретизация х2. В неограничительном примере, повышающая дискретизация может осуществляться согласно алгоритму ближайших соседей. Каждый из N остаточных блоков состоит из функции активации, за которой следует каузальная свертка с предопределенными размером ядра и шагом. В неограничительном примере, и размер ядра, и шаг могут устанавливаться как целое число в диапазоне от 2 до 10.
[0018] N остаточных блоков уложены в стопку в каждом из блоков обработки благодаря чему вход (либо из предыдущего остаточного блока в том же слое архитектуры Unet, либо из предыдущего слоя архитектуры UNet) в остаточный блок из N остаточных блоков дополнительно конкатенируется как есть (минуя остаточный блок) к выходу упомянутого остаточного блока. Дополнительно, как показано на фиг. 3, между соответствующими слоями архитектуры UNet предусмотрены сквозные (skip-) соединения. Как хорошо известно в технике, такие сквозные соединения позволяют решать проблему исчезающих и взрывающихся градиентов за счет обеспечения непрерывного градиентного потока от первого до последнего слоя архитектуры UNet. Блок линейной ректификации (ReLU) или его версия с "утечкой" (LeakyReLU), но без ограничения, можно использовать в качестве функции активации в каждом из N остаточных блоков. Каузальные свертки, используемые в N остаточных блоков, являются разновидностью свертки, используемой для временных данных (например, блоков форм волны), которая гарантирует, что упорядочение данных моделью не нарушается.
[0019] Кодирующая часть и декодирующая часть архитектуры UNet соединяются в bottleneck-части ("бутылочном горлышке") со слоем однонаправленной LSTM, обеспечивающим большое поле восприятия для прошлых временных шагов. Другими словами, использование слоя LSTM позволяет выучивать долговременные зависимости между временными шагами во временных рядах и данными последовательности, например, зашумленными формами волны, подлежащими обработке моделью улучшения речевого сигнала. Архитектура Unet, показанная на фиг. 3, может быть реализована с использованием библиотек машинного обучения с открытым исходным кодом, например, Keras, PyTorch. Алгоритмическая задержка проиллюстрированной архитектуры UNet может регулироваться количеством K слоев понижающей дискретизации/повышающей дискретизации и равняется 2K временных шагов.
[0020] Далее со ссылкой на фиг. 4-5 будет описано обучение модели улучшения речевого сигнала. В общем случае, обучение модели улучшения речевого сигнала осуществляется в режиме форсирования учителем (Teacher Forcing Mode, TFM) совместно с итерационным авторегрессивным обусловливанием (IAC), как будет подробно описано ниже. TFM является очень популярным способом обучения авторегрессивных моделей. Идея состоит в передаче модели предыдущих эталонных выборок в ходе обучения с последующим выучиванием предсказания следующей выборки. На стадии использования, модель использует свои собственные (предсказанные) выборки для авторегрессивного обусловливания (режим свободного прогона), поскольку эталонные выборки недоступны. Авторы настоящего изобретения установили, что использование эталонных выборок (согласно TFM) значительно улучшает качество улучшения речевого сигнала в режиме обучения. Однако, модели, обученные только в TFM, демонстрируют неудовлетворительные результаты на стадии использования вследствие рассогласования обучения-использования (см. Таблицу 1 ниже).
[0021] Для устранения этого рассогласования и решения других имеющихся в уровне техники технических проблем в настоящей заявке предлагается объединять обучение модели улучшения речевого сигнала согласно TFM с IAC. TFM является удобным способом обучения авторегрессивных моделей исходя из скорости обучения. При обучении в TFM нет необходимости во времязатратной нераспараллеливаемой обработке (режиме свободного прогона). Это особенно важно для сверточных авторегрессивных моделей, которые можно эффективно распараллеливать на стадии обучения. Без такого распараллеливания, трудно обучать такие модели за разумное время. Например, авторегрессивное выведение в режиме свободного прогона 2-секундного аудио-фрагмента моделью WaveNet в 1000 раз длительнее, чем выведение в режиме форсирования учителем (прямой проход на стадии обучения), даже в случае использования эффективной реализации с кэшированием активации.
[0022] Общая схема одной стадии обучения модели улучшения речевого сигнала, используемой в способе улучшения речевого сигнала согласно первому аспекту настоящего изобретения, представлена на фиг. 4. Как показано на фиг. 4, для обучения модели улучшения речевого сигнала здесь предлагается итерационно заменять авторегрессивное обусловливание предсказаниями модели в режиме форсирования учителем. В частности, на начальной стадии обучения, модель обучается в традиционном TFM, т.е. авторегрессивный канал содержит эталонную форму волны (сдвинутую, как показано на фиг. 1). На одной или более следующих стадиях, эталонная форма волны в авторегрессивном канале заменяется предсказаниями модели, полученными в TFM (с эталоном в качестве авторегрессивного обусловливания). На каждой последующей стадии обучения, авторегрессивный входной канал содержит предсказания модели, как если бы они были получены на предыдущей стадии.
[0023] В целом, в этой процедуре обучения, модель обусловливается на своих собственных предсказаниях. По ходу обучения, порядок предсказаний для обусловливаемой модели постепенно увеличивается, т.е. количество прямых проходов до вычисления функции потери и осуществления обратных проходов увеличивается. Заметим, что здесь предлагается распространять градиент только через последний прямой проход. С учетом стандартного конвейера обучения, который включает в себя прямой проход, вычисление функции потери, обратное распространение ошибки и оптимизацию весовых коэффициентов, предложенный способ влияет на только прямой проход, точнее говоря прямую функцию модели. Модифицированная итерационная прямая функция обобщена в алгоритме.
[0024] Алгоритм (псевдокод) предложенной прямой функции обучения:
требуется:
1. Модель f (x, ус), которая берет тензор с двумя каналами, содержащими зашумленный аудиосигнал x и авторегрессивное обусловливание ус (в случае базового TFM это чистый аудиосигнал Yclean);
2. Целые числа estart, estep, ecurrent (начиная с эпохи estart, увеличивать количество итераций на 1 каждые estep эпох, ecurrent - номер текущей эпохи);
3. Целое число 1, обозначающее алгоритмическую задержку модели во временных шагах, функция shift (x, n), которая удаляет последние n элементов из последнего измерения тензора x и дополняет n нулями начало х.


[0025] Было экспериментально подтверждено, что эта итерационная процедура, в которой TFM объединен с IAC, значительно уменьшает рассогласование между режимами обучения и свободного прогона (использования) (см. Таблицу 1 и фиг. 5).
[0026]
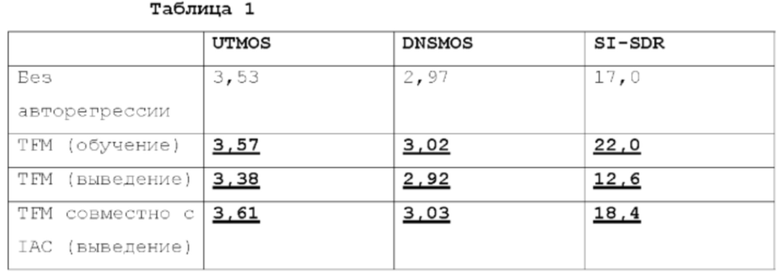
[0027] Как явствует из таблицы 1, обучение только в TFM приводит к значительному улучшению качества в режиме обучения, одновременно с этим обеспечивая низкое качество в ходе использования. Предложенный совмещение TFM с IAC уменьшает рассогласование обучения-использования и позволяет превзойти неавторегрессивное базовое решение (см. Таблицу 2 ниже) в ходе использования. В частности, чтобы увидеть улучшение, посмотрите на абсолютную разность между TFM (обучение) и TFM (использование), которая больше абсолютной разности между TFM (обучение) и TFM совместно с IAC (использование).
[0028] На фиг. 5 показан график, демонстрирующий среднюю абсолютную ошибку между выходными данными модели в режимах использования (свободный прогон) и обучения (с или без IAC), в зависимости от эпохи обучения. При обучении с IAC, выходные данные режима обучения становятся ближе к выходным данным режима использования по мере продвижения обучения. Таким образом, обучение в TFM совместно с IAC позволяет уменьшать рассогласование обучения-использования и улучшает качество.
[0029] Теперь опишем одну конкретную неограничительную реализацию обучения модели улучшения речевого сигнала. Модель улучшения речевого сигнала может обучаться на нескольких стадиях обучения на основании обучающего массива данных размером 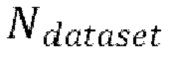 пар, причем каждая пара содержит зашумленную форму волны x и соответствующую эталонную чистую форму волны
пар, причем каждая пара содержит зашумленную форму волны x и соответствующую эталонную чистую форму волны 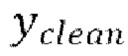 , так что
, так что 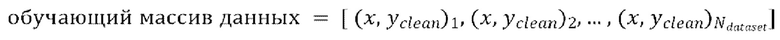 .
.
[0030] Начальная стадия обучения, осуществляемая в TFM, может содержать проведение множества начальных эпох обучения, причем каждая эпоха содержит 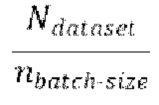 пакетных (batch) итераций.
пакетных (batch) итераций.
Каждая пакетная итерация содержит: (а) выбор 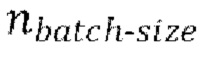 разных пар из массива данных произвольным образом, причем эти
разных пар из массива данных произвольным образом, причем эти 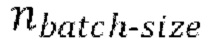 пар образуют
пар образуют 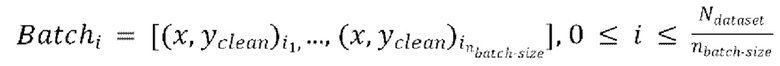 , при этом эталонная чистая форма волны
, при этом эталонная чистая форма волны 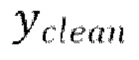 сдвинута относительно зашумленной формы волны x на заранее определенную величину алгоритмической задержки
сдвинута относительно зашумленной формы волны x на заранее определенную величину алгоритмической задержки 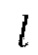 , (b) обеспечение прямого прохода (пропускание)
, (b) обеспечение прямого прохода (пропускание) 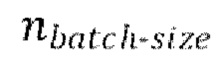 пар
пар 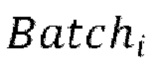 через модель улучшения речевого сигнала для получения
через модель улучшения речевого сигнала для получения 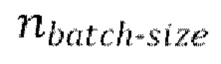 предсказанных форм волны
предсказанных форм волны 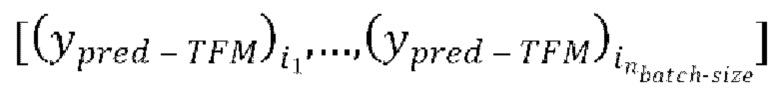 , (с) вычисление потери между предсказанными формами волны
, (с) вычисление потери между предсказанными формами волны 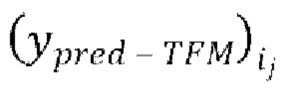 и соответствующими эталонными чистыми формами волны
и соответствующими эталонными чистыми формами волны 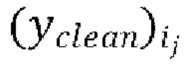 , и (d) обратное распространение градиентов, вычисляемых на основании потери, через обучающуюся модель улучшения речевого сигнала.
, и (d) обратное распространение градиентов, вычисляемых на основании потери, через обучающуюся модель улучшения речевого сигнала.
[0031] Одна или более последующих стадий обучения может содержать проведение множества эпох обучения, причем каждая эпоха содержит 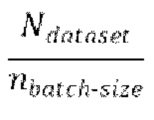 пакетных итераций. Каждая пакетная итерация содержит: (е) выбор
пакетных итераций. Каждая пакетная итерация содержит: (е) выбор 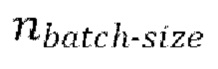 разных пар из массива данных произвольным образом, причем эти
разных пар из массива данных произвольным образом, причем эти 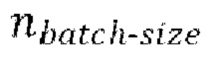 пар образуют
пар образуют 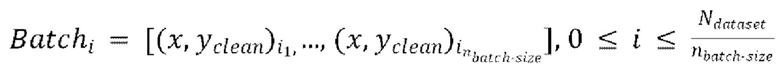 , при этом эталонная чистая форма волны
, при этом эталонная чистая форма волны 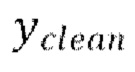 сдвинута относительно зашумленной формы волны x на упомянутую заранее определенную величину алгоритмической задержки
сдвинута относительно зашумленной формы волны x на упомянутую заранее определенную величину алгоритмической задержки 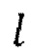 , (f) обеспечение прямого прохода
, (f) обеспечение прямого прохода 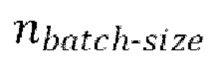 пар
пар 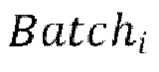 через модель улучшения речевого сигнала для получения
через модель улучшения речевого сигнала для получения 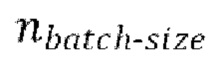 предсказанных форм волны
предсказанных форм волны 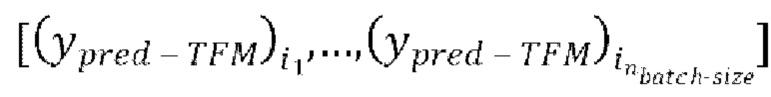 , (g) осуществление IAC, которое включает в себя
, (g) осуществление IAC, которое включает в себя 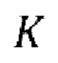 авторегрессивных итераций, где
авторегрессивных итераций, где 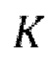 - порядок IAC,
- порядок IAC, 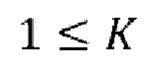 .
.
[0032] в ходе 1-ой авторегрессивной итерации, имеющей 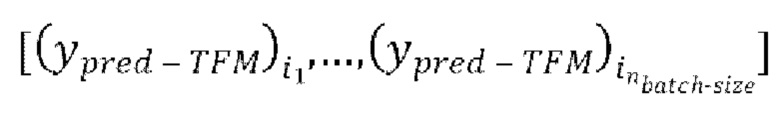 , (g1) обеспечение прямого прохода
, (g1) обеспечение прямого прохода 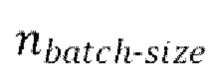 пар из
пар из 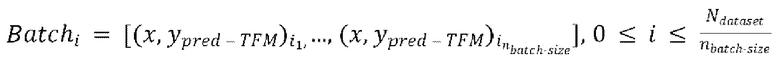 через модель улучшения речевого сигнала для получения
через модель улучшения речевого сигнала для получения 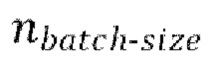 предсказанных форм волны
предсказанных форм волны 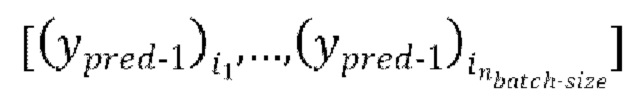 , при этом предсказанная форма волны
, при этом предсказанная форма волны 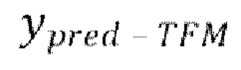 сдвинута относительно зашумленной формы волны x на упомянутую заранее определенную величину алгоритмической задержки
сдвинута относительно зашумленной формы волны x на упомянутую заранее определенную величину алгоритмической задержки 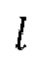 . В ходе каждой следующей k-ой,
. В ходе каждой следующей k-ой, 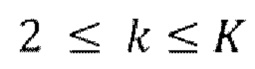 , авторегрессивной итерации, имеющей
, авторегрессивной итерации, имеющей 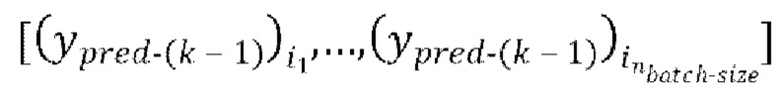 , где
, где 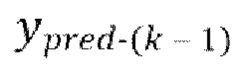 - предсказание, полученное на предыдущей авторегрессивной итерации, (gnext) обеспечение прямого прохода
- предсказание, полученное на предыдущей авторегрессивной итерации, (gnext) обеспечение прямого прохода 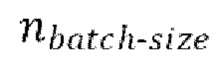 пар из
пар из 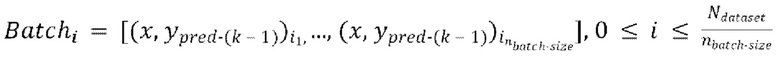 через модель улучшения речевого сигнала для получения
через модель улучшения речевого сигнала для получения 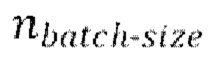 предсказанных форм волны
предсказанных форм волны 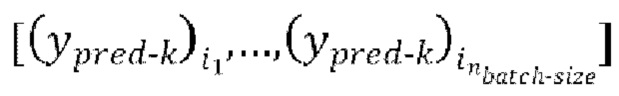 , при этом предсказанная форма волны
, при этом предсказанная форма волны 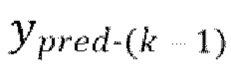 сдвинута относителвно зашумленной формы волны x на упомянутую заранее определенную величину алгоритмической задержки
сдвинута относителвно зашумленной формы волны x на упомянутую заранее определенную величину алгоритмической задержки 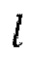 .
.
[0033] Последняя авторегрессивная итерация (glast) IAC на каждой пакетной итерации множества эпох обучения, проводимых на каждой из одной или более последующих стадий обучения, содержит этапы: (glast_1) вычисление функции потери между формами волны 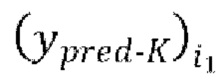 , предсказанными в ходе последней авторегрессивной итерации текущей пакетной итерации, и соответствующими эталонными чистыми формами волны
, предсказанными в ходе последней авторегрессивной итерации текущей пакетной итерации, и соответствующими эталонными чистыми формами волны 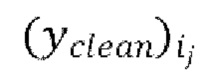 , и (glast_2) обратное распространение градиентов, вычисляемых на основании потери, через обучающуюся модель улучшения речевого сигнала.
, и (glast_2) обратное распространение градиентов, вычисляемых на основании потери, через обучающуюся модель улучшения речевого сигнала.
[0034] Одна или более промежуточных авторегрессивных итераций (ginterm) IAC на каждой пакетной итерации из множества эпох обучения, проводимых на каждой из одной или более последующих стадий обучения может дополнительно содержать этапы: (ginterm_1) вычисление функции потери между формами волны 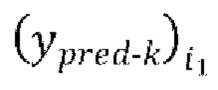 предсказанными в ходе промежуточной авторегрессивной итерации текущей пакетной итерации, и соответствующими эталонными чистыми формами волны
предсказанными в ходе промежуточной авторегрессивной итерации текущей пакетной итерации, и соответствующими эталонными чистыми формами волны 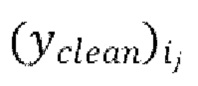 , и (ginterm_2) обратное распространение градиентов, вычисляемых на основании потери, через обучающуюся модель улучшения речевого сигнала.
, и (ginterm_2) обратное распространение градиентов, вычисляемых на основании потери, через обучающуюся модель улучшения речевого сигнала.
[0035] Обучение может дополнительно содержать, для множества эпох обучения на одной или более последующих стадий обучения: установление порядка 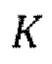 IAC одинаковым для всех эпох обучения; или установление порядка
IAC одинаковым для всех эпох обучения; или установление порядка 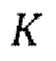 IAC по-разному так, чтобы порядок изменялся постепенно от одной эпохи обучения к другой эпохи обучения.
IAC по-разному так, чтобы порядок изменялся постепенно от одной эпохи обучения к другой эпохи обучения.
[0036] При обучении можно использовать любой тип функции потерь. Однако, предпочтительно использовать одну или более из следующих функций потерь: функция потери L1, функция потери в генеративной состязательной сети (LS-GAN) на основе метода наименьших квадратов, функция потери на сопоставлении признаков и масштабно-инвариантное отношение сигнал-шум (SI-SNR).
[0037] Функция потери L1 представляет абсолютную разность между предсказанными формами волны 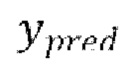 и эталонными чистыми формами волны
и эталонными чистыми формами волны 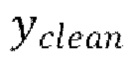 . Функция потери L1 вычисляется следующим образом:
. Функция потери L1 вычисляется следующим образом:
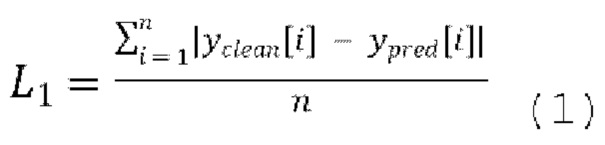
[0038] Функция потери LS-GAN может использоваться для состязательного обучения. Функция потери LS-GAN вычисляется следующим образом:
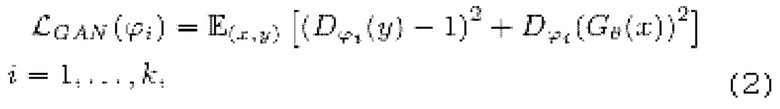
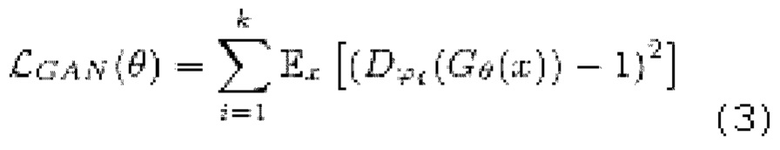
где
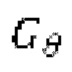 обозначает генератор с набором параметров θ, при состязательном обучении обучающаяся модель улучшения речевого сигнала выступает в роли генератора
обозначает генератор с набором параметров θ, при состязательном обучении обучающаяся модель улучшения речевого сигнала выступает в роли генератора 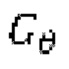 ,
,
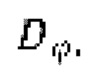 обозначает соответствующий дискриминатор с набором параметров {ϕi} с i=от 1 до k, где k - заранее определенное количество дискриминаторов,
обозначает соответствующий дискриминатор с набором параметров {ϕi} с i=от 1 до k, где k - заранее определенное количество дискриминаторов,
x обозначает зашумленную форму волны,
y обозначает эталонную чистую форму волны,
(x, y) обозначает математическое ожидание, определяемое по пространству как зашумленных, так и эталонных чистых форм волны для обучения дискриминатора 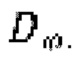 ,
,
(x) обозначает математическое ожидание, определяемое по пространству зашумленных форм волны для обучения генератора 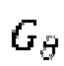 , и
, и
Σ обозначает сумму по всем дискриминаторам,
при состязательном обучении генератор 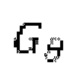 (т.е. модель улучшения речевого сигнала) оперирует на зашумленных формах волны
(т.е. модель улучшения речевого сигнала) оперирует на зашумленных формах волны 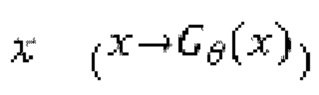 , пытаясь сделать звук зашумленной формы волны чистым, когда дискриминатор оперирует на эталонных чистых формах волны
, пытаясь сделать звук зашумленной формы волны чистым, когда дискриминатор оперирует на эталонных чистых формах волны 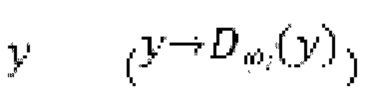 и на выходных данных генератора
и на выходных данных генератора 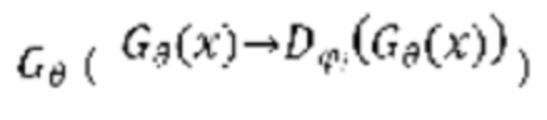 в попытке различения чистых форм волны и форм волны, сгенерированных
в попытке различения чистых форм волны и форм волны, сгенерированных 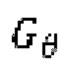 . Это состязание приводит к улучшению субъективного качества
. Это состязание приводит к улучшению субъективного качества 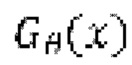 .
.
[0039] Функция потери на сопоставлении признаков вычисляется как расстояние L1 между картами признаков дискриминаторов, вычисляемыми для эталонной чистой формы волны y, и картами признаков дискриминаторов, генерируемыми с обусловливанием на зашумленных формах волны x:
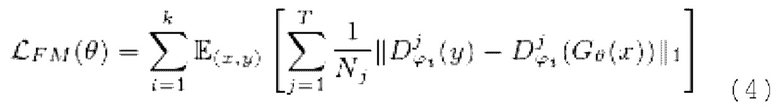
где
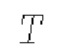 обозначает заранее определенное количество слоев в дискриминаторе
обозначает заранее определенное количество слоев в дискриминаторе 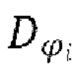 ,
,
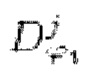 и
и 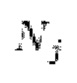 соответственно обозначают активации и размер активаций в j-ом слое i-ого дискриминатора, и
соответственно обозначают активации и размер активаций в j-ом слое i-ого дискриминатора, и
 обозначает вычисление функции потери L1.
обозначает вычисление функции потери L1.
[0040] Функция потери SI-SNR может вычисляться следующим образом:
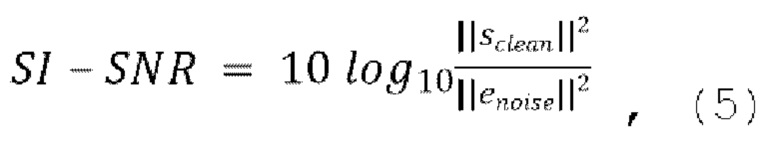
где
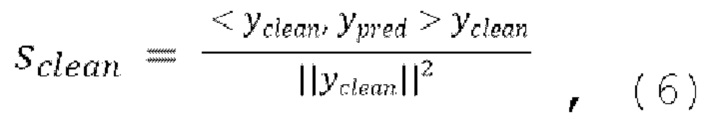
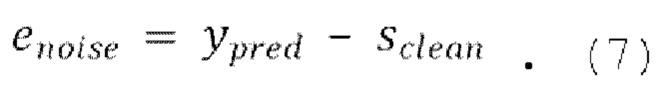
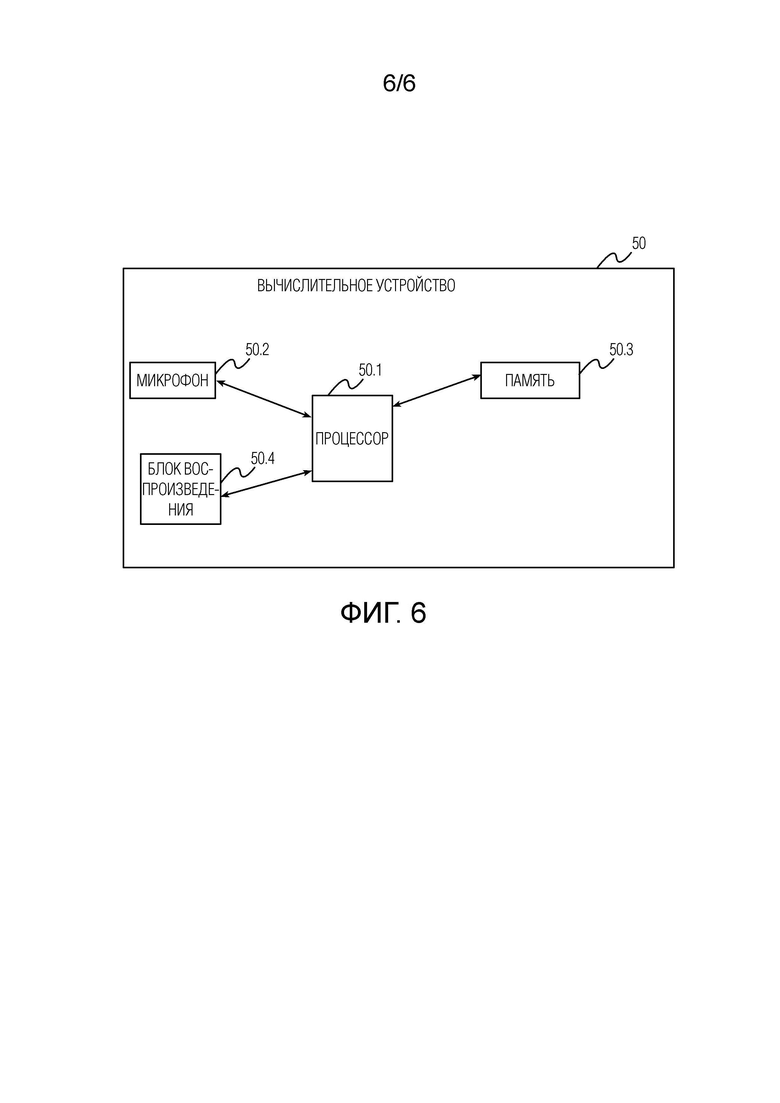
[0041] Фиг. 6 схематически иллюстрирует вычислительное устройство 50 согласно второму аспекту настоящего изобретения, которое выполнено с возможностью осуществления способа улучшения речевого сигнала согласно первому аспекту настоящего изобретения или любому развитию упомянутого первого аспекта. Вычислительное устройство 50 содержит процессор 50.1, микрофон 50.2, память 50.3 и блок 50.4 воспроизведения. Память 50.3 может включать в себя постоянную память (ROM) и оперативную память (RAM). Можно использовать любые типы RAM и ROM. В памяти 50.3 хранятся исполняемые процессором инструкции, и весовые коэффициенты и смещения обученной модели улучшения речевого сигнала.
[0042] При исполнении исполняемых процессором инструкций процессором 50.1, процессор 50.1 побуждает вычислительное устройство 50 к осуществлению способа улучшения речевого сигнала согласно первому аспекту настоящего изобретения или любому развитию упомянутого первого аспекта. Процессор 50.1 может быть любого типа. Процессор 50.1 может включать в себя один или более из следующих процессоров: процессора общего назначения (например CPU), цифрового сигнального процессора (DSP), процессора приложений (АР), графического процессора (GPU), процессора машинного зрения (VPU), выделенного под AI процессора (например NPU). Процессор может быть реализован как однокристальная система (SOC), специализированная интегральная схема (ASIC), вентильная матрица, программируемая пользователем (FPGA) или другое программируемое логическое устройство (PLD), дискретный логический элемент, транзисторная логика, дискретные аппаратные компоненты или любая их комбинация.
[0043] Микрофон 50.2 выполнен с возможностью преобразования звука в электрический сигнал, перерабатываемый аналого-цифровым преобразователем (не показан) в цифровой сигнал, из которого зашумленную форму волны можно получать для улучшения речевого сигнала. Блок 50.4 воспроизведения выполнен с возможностью воспроизведения обесшумленной формы волны, полученной в результате улучшения речевого сигнала.
[0044] Вычислительное устройство 50 может работать на любой операционной системе и может включать в себя любое другое необходимое программное обеспечение, программно-аппаратное обеспечение и оборудование (например, блок связи, интерфейс I/O, камеру, источник питания и т.д.). Неограничительные примеры вычислительного устройства 50 включают в себя смартфон, умные часы, планшет, слуховой аппарат, компьютер, ноутбук, головную гарнитуру AR/VR и т.д.
[0045] Раскрытое изобретение также может быть реализовано как нетранзиторный считываемый компьютером носитель, хранящий исполняемые компьютером инструкции, и весовые коэффициенты и смещения обученной модели улучшения речевого сигнала. При исполнения исполняемых компьютером инструкций вычислительным устройством (например, вычислительным устройством 50) вычислительное устройство побуждается к осуществлению способа улучшения речевого сигнала согласно первому аспекту настоящего изобретения или любому развитию упомянутого первого аспекта.
[0046] Экспериментальные данные и определенные детали реализации. Во всех проводимых экспериментах, аддитивный шум рассматривался как искажение, подлежащее удалению из речевых записей. Авторы настоящего изобретения провели ряд экспериментов для проверки эффективности вышеописанного способа и предложенной процедуры обучения (с совмещением TFM с IAC) в разных сценариях обучения. Для каждой группы эксперимента были подготовлены и обучены базовая модель и модель, основанная на вышеописанной процедуре обучения. Условия обучения были одинаковыми для базовой модели и предложенной в данной заявке модели (с совмещением TFM с IAC).
[0047] Эксперименты были разделены на 5 групп, в зависимости от применяемого сценария обучения. В каждом сценарии обучения одно условие обучения (массив данных/модель/архитектура/потеря/задержка) изменялось, тогда как другие параметры оставались такими же как в описанной ниже базовой конфигурации.
[0048] Гиперпараметры обучения. Указанные ниже параметры обучения не следует интерпретировать для ограничения раскрытого изобретения ни в каком смысле. Все основанные на совмещении TFM с IAC модели (согласно настоящей заявке) обучались в течение 1000 эпох, а все соответствующие базовые модели обучались в течение 2000 эпох (поэтому время обучения одинаково для соответствующих прогонов), причем каждая эпоха включала в себя 1000 пакетных итераций. Наилучшую эпоху выбирали путем максимизации метрики UTMOS на контрольных данных. Во всех экспериментах размер пакета (batch) был задан равным 16, размер сегмента был задан равным 2 с, алгоритм оптимизации "Адам" использовалось при скорости обучения 0,0002 и значениях бета 0,8 и 0,9. estart и estep были заданы равными 300 и 100, соответственно, для всех авторегрессивных прогонов.
[0049] Метрики. Использовалась метрика объективного качества речевого сигнала UTMOS, соответствующая уровню техники [Takaaki Saeki, Detai Xinr Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hiroshi Saruwatari, "Utmos: Utokyo-sarulab system for voicemos challenge 2022", arXiv preprint arXiv:2204. 02152, 2022]. Проведенные авторами эксперименты позволили установить, что метрика UTMOS имеет наилучшую корреляцию среди общеизвестных объективных метрик (например, STOI, SI-SDR, DNSMOS, PESQ) с назначаемой людьми средними экспертными оценками (MOS) для задачи улучшения речевого сигнала. Дополнительно приведены сведения о традиционных метриках DNSMOS [Chandan KA Reddy, Vishak Gopal, and Ross Cutler, "Dnsmos p. 835: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors", in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 886-890] и SI-SDR [Jonathan Le Roux, Scott Wisdom, Hakan Erdogan, and John R Hershey, "Sdr-half-baked or well done?", in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 626-630]. Для подтверждения улучшения за счет IAC, проводили субъективные тесты рейтинга сравнительных категорий (CCR) [Ross Cutler Babak Naderi, Sebastian Moller, "Speech quality assessment in crowdsourcing: Comparison category rating method", 2021], и сравнительные средние экспертные оценки (CMOS) также приведены в нижеследующей таблице 2.
[0050] Базовая конфигурация. Для основной конфигурации, параметры N, K, C архитектуры модели были установлены равными 4, 7, и [16, 24, 32, 48, 64, 96, 128], соответственно. Ширина LSTM равна 512. Эта конфигурация соответствует алгоритмической задержке 8 мс. Для обучения модели использовалась функция потерь L1 во временной области. Использовался массив данных VoiceBank-DEMAND [Cassia Valentini-Botinhao et al., "Noisy speech database for training speech enhancement algorithms and tts models", 2017], который представляет собой стандартные исходные данные для систем улучшения речи. Этот обучающий набор состоит из 28 говорящих с 4 отношениями сигнал-шум (SNR) (15, 10, 5 и 0 дБ) и содержит 11572 высказываний. Испытательный набор (824 высказывания) состоит из 2 говорящих, которые модель в ходе обучения с 4 SNR (17,5, 12,5, 7,5 и 2,5 дБ) не видит.
[0051] Разные функции потерь. В ряде экспериментов была проверена эффективность моделей с совмещением TFM с IAC при обучении с разными функциями потерь. В частности, функция потерь L1 была заменена потерями состязательного обучения [Ivan Shchekotov, Pavel Andreev, Oleg Ivanov, Aibek Alanov, and Dmitry Vetrov, "Ffc-se: Fast Fourier convolution for speech enhancement", arXiv preprint arXiv:2204.03042, 2022] and SI-SNR loss [Yi Luo and Nima Mesgarani, "Conv-tasnet: Surpassing ideal time-frequency magnitude masking for speech separation", IEEE/ACM transactions on audio, speech, and language processing, vol. 27, no. 8, pp. 1256-1266, 2019].
[0052] Массив данных DNS. В этом эксперименте, вместо массива данных VoiceBank-DEMAND использовался массив данных для задачи глубокого шумоподавления (DNS) [Harishchandra Dubey, Vishak Gopal, Ross Cutler, Ashkan Aazami, Sergiy Matusevych, Sebastian Rraun, Sefik Emre Eskimez, Manthan Thakker, Takuya Yoshioka, Hannes Gamper, et al., "Icassp 2022 deep noise suppression challenge", in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 9271-9275]. 100 часов обучающих данных синтезировались с использованием обеспеченных кодов и принятой по умолчанию конфигурации из официального хранилища для задачи глубокого шумоподавления. Единственной модификацией, которая не использовалась в ходе синтеза, была искусственная реверберация. Модели испытывались на контрольных данных, произвольно выбранных и исключенных из синтезированных 100 часов обучающих данных.
[0053] ConvTasNet. В качестве альтернативной архитектуры, применялась концепция ConvTasNet [Yi Luo and Nima Mesgarani, "Conv-tasnet: Surpassing ideal time-frequency magnitude masking for speech separation", IEEE/ACM transactions on audio, speech, and language processing, vol. 27, no. 8, pp. 1256-1266, 2019] глубокого обучения для сквозного выделения речи во временной области, которая также может использоваться в качестве модели улучшения речи. ConvTasNet состоит из линейного кодера, декодера и временной сверточной сети (TCN), состоящей из уложенных в стопку 1-D расширенных сверточных блоков. Для экспериментов, первоначальная реализация архитектуры использовалась с параметрами, отрегулированными для соответствия алгоритмической задержке равной 8 мс и количеству операций умножения с накоплением в секунду равному 2 миллиардам (2 GMAC, такому же, как и в базовой конфигурации).
[0054] Разные задержки. Для исследования влияния алгоритмической задержки на улучшение, достигаемое обучением TFM совместно с IAC, дополнительно были испытаны 3 модели с задержками 2 мс, 4 мс и 16 мс. Параметры архитектуры WaveUNet + LSTM были тонко настроены для регулировки алгоритмической задержки при поддержании количества операций умножения с накоплением таким же, как и в базовых конфигурациях (2 GMAC).
[0055]

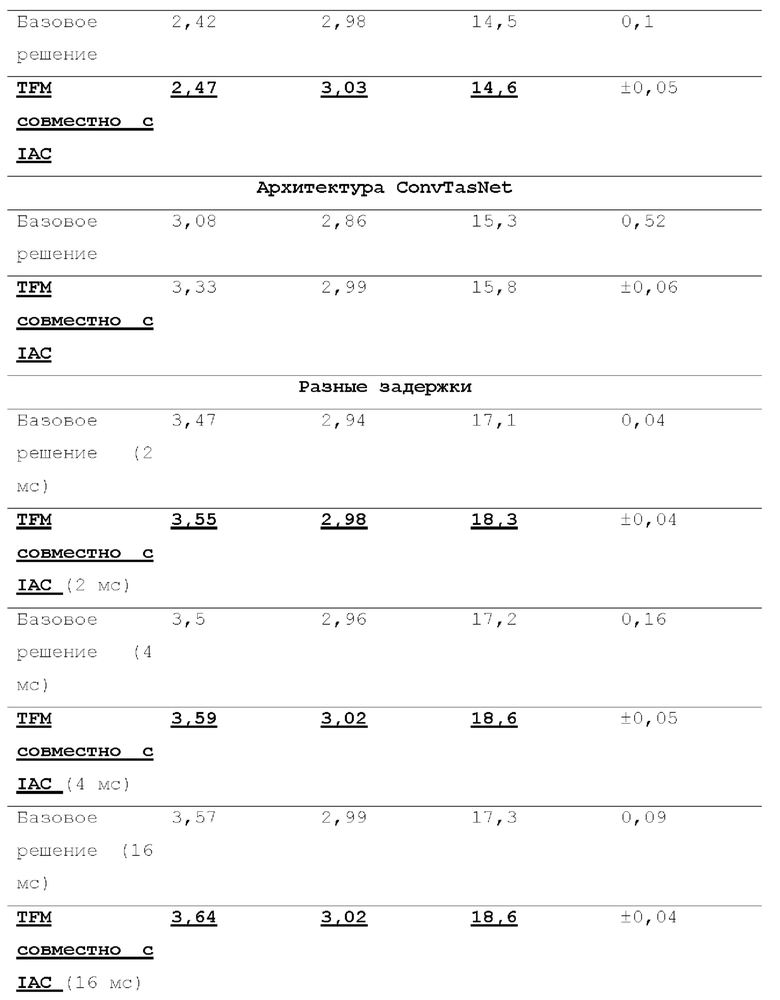
[0056] Во всей последовательности проводимых экспериментов предложенный способ продемонстрировал значительные преимущества над соответствующими базовыми решениями, таким образом демонстрируя высокую практическую ценность и универсальность.
[0057] Следует отчетливо понимать, что не все упомянутые здесь технические результаты должны реализовываться в каждом варианте осуществления настоящего изобретения. Например, могут реализовываться варианты осуществления настоящего изобретения, в которых пользователь не получает пользу от некоторых из упомянутых технических результатов, кроме того, могут реализовываться другие варианты осуществления, в которых пользователь получает пользу от других технических результатов.
[0058] Специалистам в данной области техники будут понятны модификации и улучшения вышеописанных вариантов осуществления настоящего изобретения. Например, конкретные значения параметров, указанные в вышеприведенном описании изобретения, не следует рассматривать как ограничение, поскольку эти значения параметров можно выбирать экспериментально из подходящих диапазонов, например, +/-10-50% от указанных конкретных значений. Вышеприведенное описание призвано быть иллюстративным, а не ограничительным. Поэтому объем настоящего изобретения подлежит ограничению только объемом нижеследующей формулы изобретения.
[0059] Хотя вышеописанные реализации были описаны и показаны со ссылкой на конкретные этапы, осуществляемые в конкретном порядке, следует понимать, что эти этапы можно объединять, делить на подэтапы или переупорядочивать, не выходя за рамки принципов настоящего изобретения. Соответственно, порядок и группировка этапов не являются ограничением настоящего изобретения. Использование формы единственного числа в отношении любого элемента, раскрытого в этой заявке, не означает, что в фактической реализации не может существовать два или более таких элементов. Используемый здесь термин "множество" следует интерпретировать как два или более. Термины "содержать", "включать в себя" следует интерпретировать как представление открытых списков элементов, при том, что другие явно не ука5занные элементы могут существовать. Напротив, термин "состоит из" следует интерпретировать как представление закрытых списков элементов.
| название | год | авторы | номер документа |
|---|---|---|---|
| Неконтролируемое восстановление голоса с использованием модели безусловной диффузии без учителя | 2023 |
|
RU2823017C1 |
| СПОСОБ И УСТРОЙСТВО УЛУЧШЕНИЯ РЕЧЕВОГО СИГНАЛА С ИСПОЛЬЗОВАНИЕМ БЫСТРОЙ СВЕРТКИ ФУРЬЕ | 2022 |
|
RU2795573C1 |
| СПОСОБ СИНТЕЗА ВИДЕО ИЗ ВХОДНОГО КАДРА АВТОРЕГРЕССИОННЫМ МЕТОДОМ, ПОЛЬЗОВАТЕЛЬСКОЕ ЭЛЕКТРОННОЕ УСТРОЙСТВО И СЧИТЫВАЕМЫЙ КОМПЬЮТЕРОМ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2829010C1 |
| АДАПТИВНОЕ УЛУЧШЕНИЕ АУДИО ДЛЯ РАСПОЗНАВАНИЯ МНОГОКАНАЛЬНОЙ РЕЧИ | 2016 |
|
RU2698153C1 |
| СПОСОБ ОБУЧЕНИЯ СВЕРТОЧНОЙ НЕЙРОННОЙ СЕТИ ОСУЩЕСТВЛЯТЬ РАЗМЕТКИ ТЕЛЕРЕНТГЕНОГРАММ В ПРЯМОЙ И БОКОВОЙ ПРОЕКЦИЯХ | 2019 |
|
RU2717911C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ УЛУЧШЕНИЯ РЕЧИ С ПОМОЩЬЮ НЕСКОЛЬКИХ ДАТЧИКОВ | 2005 |
|
RU2389086C2 |
| СИСТЕМА И СПОСОБ АВТОМАТИЧЕСКОГО МАШИННОГО ОБУЧЕНИЯ (AutoML) МОДЕЛЕЙ КОМПЬЮТЕРНОГО ЗРЕНИЯ ДЛЯ АНАЛИЗА БИОМЕДИЦИНСКИХ ИЗОБРАЖЕНИЙ | 2021 |
|
RU2787558C1 |
| ГЕНЕРАТОР АУДИОДАННЫХ И СПОСОБЫ ФОРМИРОВАНИЯ АУДИОСИГНАЛА И ОБУЧЕНИЯ ГЕНЕРАТОРА АУДИОДАННЫХ | 2021 |
|
RU2823016C1 |
| ГЕНЕРАТОР АУДИОДАННЫХ И СПОСОБЫ ФОРМИРОВАНИЯ АУДИОСИГНАЛА И ОБУЧЕНИЯ ГЕНЕРАТОРА АУДИОДАННЫХ | 2021 |
|
RU2823015C1 |
| СПОСОБ И УСТРОЙСТВО ГЕНЕРИРОВАНИЯ ВИДЕОКЛИПА ПО ТЕКСТОВОМУ ОПИСАНИЮ И ПОСЛЕДОВАТЕЛЬНОСТИ КЛЮЧЕВЫХ ТОЧЕК, СИНТЕЗИРУЕМОЙ ДИФФУЗИОННОЙ МОДЕЛЬЮ | 2024 |
|
RU2823216C1 |

Изобретение относится к области вычислительной техники для обработки речевого сигнала с низкой задержкой. Технический результат заключается в повышении точности обработки речевого сигала с низкой задержкой. Технический результат достигается за счет способа улучшения речевого сигнала, причем способ содержит получение зашумленной формы волны и последовательную обработку блоков выборок зашумленной формы волны с помощью модели улучшения речевого сигнала для предсказания соответствующих блоков выборок обесшумленной формы волны. В ходе упомянутой последовательной обработки каждого блока выборок зашумленной формы волны модель улучшения речевого сигнала авторегрессивно обусловливается блоком предыдущих выборок обесшумленной формы волны, причем упомянутый блок предыдущих выборок обесшумленной формы волны предсказывается моделью улучшения речевого сигнала ранее в ходе упомянутой последовательной обработки блока предыдущих выборок зашумленной формы волны. Модель улучшения речевого сигнала обучается в TFM совместно с IAC. 3 н. и 10 з.п. ф-лы, 6 ил.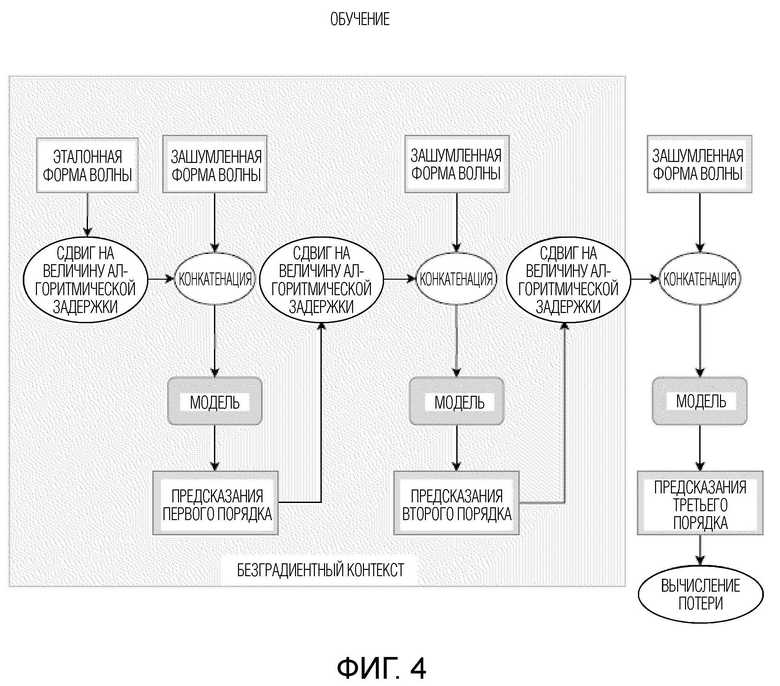
1. Способ улучшения речевого сигнала, причем способ содержит этапы, на которых:
получают (S100) зашумленную форму волны; и
последовательно (S105) обрабатывают блоки выборок зашумленной формы волны с помощью модели улучшения речевого сигнала для предсказания соответствующих блоков выборок обесшумленной формы волны;
причем в ходе упомянутой последовательной обработки каждого блока выборок зашумленной формы волны модель улучшения речевого сигнала авторегрессивно обусловливается предыдущим блоком выборок обесшумленной формы волны, причем упомянутый предыдущий блок выборок обесшумленной формы волны предсказывается моделью улучшения речевого сигнала ранее в ходе упомянутой последовательной обработки соответствующего предыдущего блока выборок зашумленной формы волны,
причем модель улучшения речевого сигнала обучается в режиме форсирования учителем (TFM) совместно с итерационным авторегрессивным обусловливанием (IAC).
2. Способ по п. 1, в котором модель улучшения речевого сигнала базируется на архитектуре UNet сверточного кодера-декодера, в bottleneck-части которой используется слой однонаправленной долгой краткосрочной памяти (LSTM).
3. Способ по п. 1, причем модель улучшения речевого сигнала обучается на нескольких стадиях обучения на основании обучающего массива данных размером 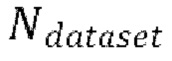 пар, причем каждая пара содержит зашумленную форму волны x и соответствующую эталонную чистую форму волны
пар, причем каждая пара содержит зашумленную форму волны x и соответствующую эталонную чистую форму волны 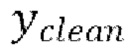 , так что
, так что
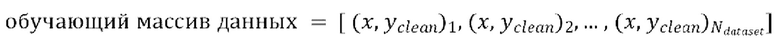
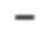 на начальной стадии обучения, осуществляемой в TFM:
на начальной стадии обучения, осуществляемой в TFM:
 проводят множество начальных эпох обучения, причем каждая эпоха содержит
проводят множество начальных эпох обучения, причем каждая эпоха содержит 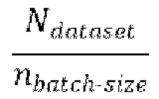 пакетных итераций, причем каждая пакетная итерация содержит:
пакетных итераций, причем каждая пакетная итерация содержит:
 выбор
выбор  разных пар из массива данных произвольным образом, причем эти
разных пар из массива данных произвольным образом, причем эти 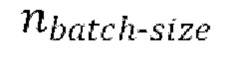 пар образуют
пар образуют 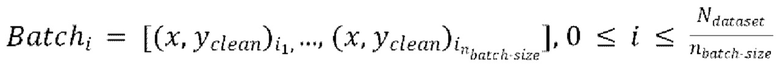 , при этом эталонная чистая форма волны
, при этом эталонная чистая форма волны 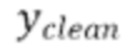 сдвинута относительно зашумленной формы волны x на заранее определенную величину алгоритмической задержки
сдвинута относительно зашумленной формы волны x на заранее определенную величину алгоритмической задержки 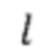 ,
,
 обеспечение прямого прохода
обеспечение прямого прохода 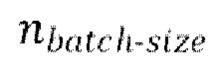 пар
пар 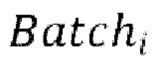 через модель улучшения речевого сигнала для получения
через модель улучшения речевого сигнала для получения 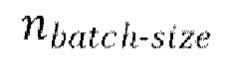 предсказанных форм волны
предсказанных форм волны 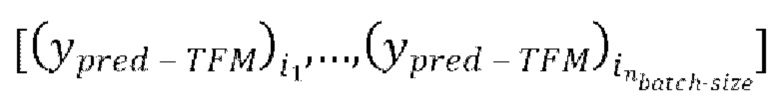 ,
,
 вычисление потери между предсказанными формами волны
вычисление потери между предсказанными формами волны 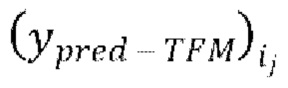 и соответствующими эталонными чистыми формами волны
и соответствующими эталонными чистыми формами волны 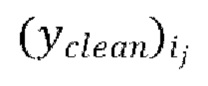 , и
, и
 обратное распространение градиентов, вычисляемых на основании потери, через обучающуюся модель улучшения речевого сигнала;
обратное распространение градиентов, вычисляемых на основании потери, через обучающуюся модель улучшения речевого сигнала;
 на одной или более последующих стадий обучения:
на одной или более последующих стадий обучения:
 проводят множество эпох обучения, причем каждая эпоха содержит
проводят множество эпох обучения, причем каждая эпоха содержит 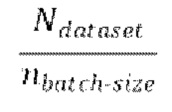 пакетных итераций, причем каждая пакетная итерация содержит:
пакетных итераций, причем каждая пакетная итерация содержит:
 выбор
выбор 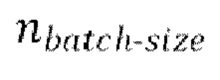 разных пар из массива данных произвольным образом, причем эти
разных пар из массива данных произвольным образом, причем эти 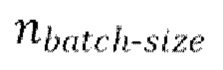 пар образуют
пар образуют 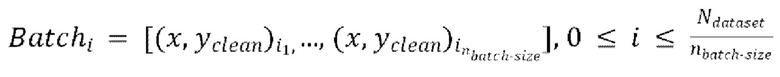 , при этом эталонная чистая форма волны
, при этом эталонная чистая форма волны 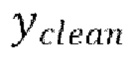 сдвинута относительно зашумленной формы волны x на упомянутую заранее определенную величину алгоритмической задержки
сдвинута относительно зашумленной формы волны x на упомянутую заранее определенную величину алгоритмической задержки 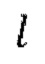 ,
,
обеспечение прямого прохода 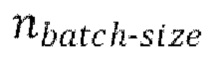 пар
пар 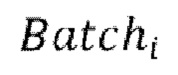 через модель улучшения речевого сигнала для получения
через модель улучшения речевого сигнала для получения 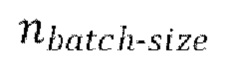 предсказанных форм волны
предсказанных форм волны 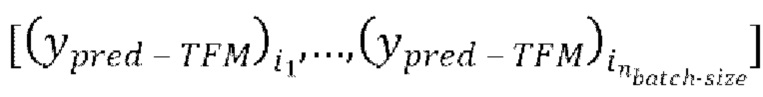 ,
,
осуществление IAC, которое включает в себя 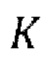 авторегрессивных итераций, где
авторегрессивных итераций, где 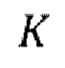 - порядок IAC,
- порядок IAC, 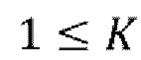 :
:
 в ходе 1-ой авторегрессивной итерации, имеющей
в ходе 1-ой авторегрессивной итерации, имеющей 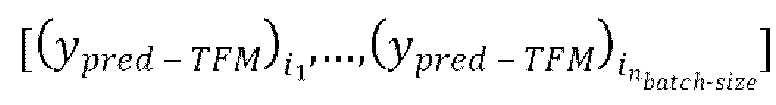 , обеспечение прямого прохода
, обеспечение прямого прохода 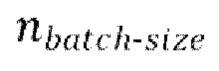 пар из
пар из 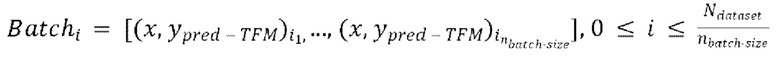 через модель улучшения речевого сигнала для получения
через модель улучшения речевого сигнала для получения 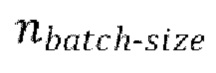 предсказанных форм волны
предсказанных форм волны 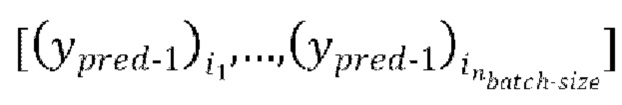 , при этом предсказанная форма волны
, при этом предсказанная форма волны 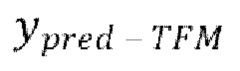 сдвинута относительно зашумленной формы волны x на упомянутую заранее определенную величину алгоритмической задержки
сдвинута относительно зашумленной формы волны x на упомянутую заранее определенную величину алгоритмической задержки 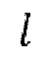 ,
,
в ходе каждой следующей k-ой, 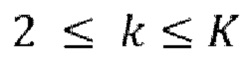 , авторегрессивной итерации, имеющей
, авторегрессивной итерации, имеющей 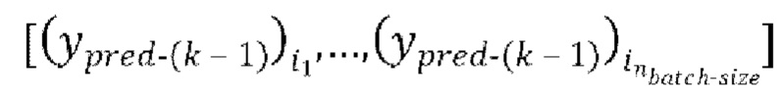 , где
, где 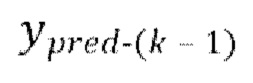 предсказание, полученное на предыдущей авторегрессивной итерации, обеспечение прямого прохода
предсказание, полученное на предыдущей авторегрессивной итерации, обеспечение прямого прохода 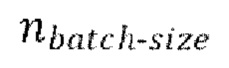 пар из
пар из 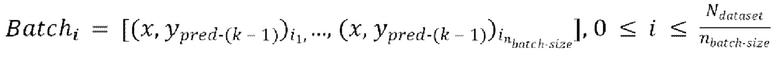 через модель улучшения речевого сигнала для получения
через модель улучшения речевого сигнала для получения 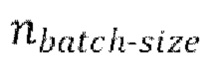 предсказанных форм волны
предсказанных форм волны 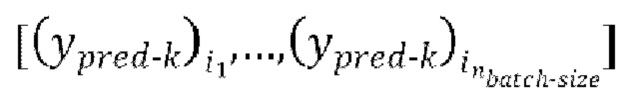 , при этом предсказанная форма волны
, при этом предсказанная форма волны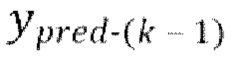 сдвинута относительно зашумленной формы волны x на упомянутую заранее определенную величину алгоритмической задержки
сдвинута относительно зашумленной формы волны x на упомянутую заранее определенную величину алгоритмической задержки 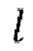 .
.
4. Способ по п. 3, в котором последняя авторегрессивная итерация IAC на каждой пакетной итерации из множества эпох обучения, проводимых на каждой из одной или более последующих стадий обучения, содержит этапы, на которых:
вычисляют потери между формами волны 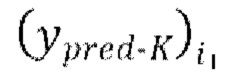 , предсказанными в ходе последней авторегрессивной итерации текущей пакетной итерации, и соответствующими эталонными чистыми формами волны
, предсказанными в ходе последней авторегрессивной итерации текущей пакетной итерации, и соответствующими эталонными чистыми формами волны 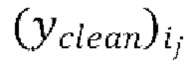 , и
, и
обратно распространяют градиенты, вычисляемые на основании потерь, через обучающуюся модель улучшения речевого сигнала.
5. Способ по п. 3, в котором одна или более промежуточных авторегрессивных итераций IAC на каждой пакетной итерации из множества эпох обучения, проводимых на каждой из одной или более последующих стадий обучения, дополнительно содержит этапы, на которых:
вычисляют потери между формами волны 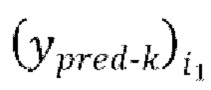 , предсказанными в ходе промежуточной авторегрессивной итерации текущей пакетной итерации, и соответствующими эталонными чистыми формами волны
, предсказанными в ходе промежуточной авторегрессивной итерации текущей пакетной итерации, и соответствующими эталонными чистыми формами волны 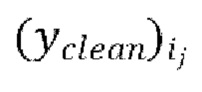 , и
, и
обратно распространяют градиенты, вычисляемые на основании потерь, через обучающуюся модель улучшения речевого сигнала.
6. Способ по п. 3, дополнительно содержащий, для множества эпох обучения на одной или более последующих стадий обучения, этапы, на которых:
устанавливают порядок 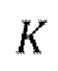 IAC одинаковым для всех эпох обучения; или
IAC одинаковым для всех эпох обучения; или
устанавливают порядок 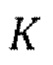 IAC по-разному так, чтобы порядок изменялся постепенно от одной эпохи обучения к другой эпохе обучения.
IAC по-разному так, чтобы порядок изменялся постепенно от одной эпохи обучения к другой эпохе обучения.
7. Способ по любому из пп. 3-6, в котором потеря является потерей L1, представляющей абсолютную разность между предсказанными формами волны 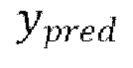 и эталонными чистыми формами волны
и эталонными чистыми формами волны 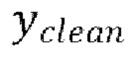 :
:
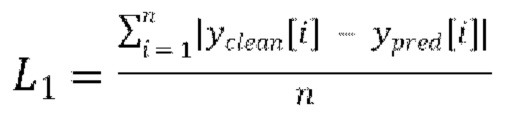 .
.
8. Способ по любому из пп. 3-6, в котором потеря является потерей в генеративной состязательной сети (LS-GAN) на основе метода наименьших квадратов, используемой для состязательного обучения:
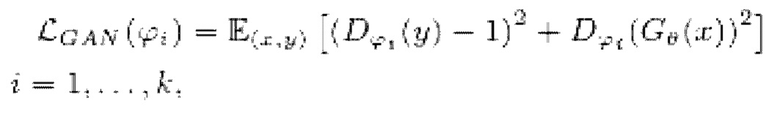
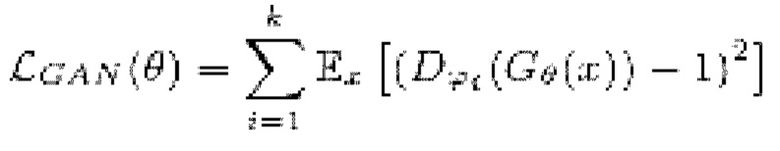
где
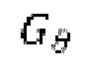 обозначает генератор с набором параметров θ, при состязательном обучении обучающаяся модель улучшения речевого сигнала выступает в роли генератора
обозначает генератор с набором параметров θ, при состязательном обучении обучающаяся модель улучшения речевого сигнала выступает в роли генератора 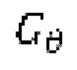 ,
,
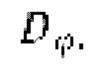 обозначает соответствующий дискриминатор с набором параметров {ϕi} с i = от 1 до k, где k - заранее определенное количество дискриминаторов,
обозначает соответствующий дискриминатор с набором параметров {ϕi} с i = от 1 до k, где k - заранее определенное количество дискриминаторов,
x обозначает зашумленную форму волны,
y обозначает эталонную чистую форму волны,
(x, y) обозначает математическое ожидание, определяемое по пространству как зашумленных, так и эталонных чистых форм волны для обучения дискриминатора 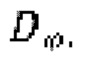 ,
,
(x) обозначает математическое ожидание, определяемое по пространству зашумленных форм волны для обучения генератора 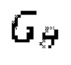 , и
, и
Σ обозначает сумму по всем дискриминаторам,
при состязательном обучении генератор 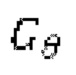 оперирует на зашумленных формах волны
оперирует на зашумленных формах волны 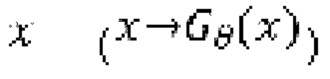 , тогда как дискриминатор оперирует на эталонных чистых формах волны
, тогда как дискриминатор оперирует на эталонных чистых формах волны 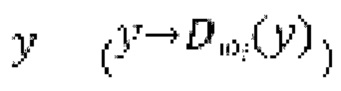 , а также на выходных данных генератора
, а также на выходных данных генератора 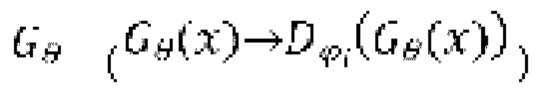 .
.
9. Способ по п. 8, в котором потеря является потерей на сопоставлении признаков, вычисляемой как расстояние L1 между картами признаков дискриминаторов, вычисляемыми для эталонной чистой формы волны y, и картами признаков дискриминаторов, генерируемыми с обусловливанием на зашумленных формах волны x:
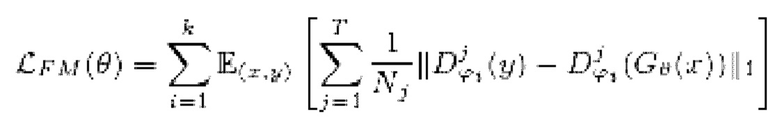
где
 обозначает заранее определенное количество слоев в дискриминаторе
обозначает заранее определенное количество слоев в дискриминаторе 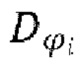 ,
,
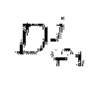 и
и 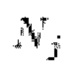 соответственно обозначают активации и размер активаций в j-м слое i-го дискриминатора, и
соответственно обозначают активации и размер активаций в j-м слое i-го дискриминатора, и
 обозначает вычисление потери L1.
обозначает вычисление потери L1.
10. Способ по любому из пп. 3-6, в котором потеря является масштабно-инвариантным отношением сигнал-шум (SI-SNR), вычисляемым следующим образом:
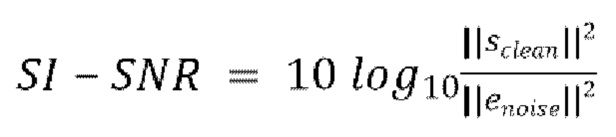 ,
,
где 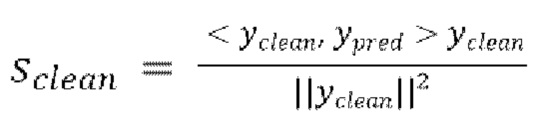 , и
, и 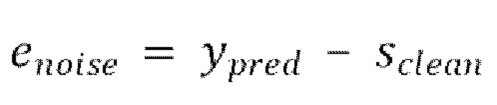 .
.
11. Вычислительное устройство (50), содержащее процессор (50.1) и память (50.3), хранящую исполняемые процессором инструкции, и весовые коэффициенты и смещения обученной модели улучшения речевого сигнала, причем при исполнении исполняемых процессором инструкций процессором (50.1) процессор (50.1) побуждает вычислительное устройство (50) к осуществлению способа улучшения речевого сигнала по любому из пп. 1-10.
12. Вычислительное устройство (50) по п. 11, дополнительно содержащее по меньшей мере один микрофон (50.2), выполненный с возможностью преобразования звука в электрический сигнал, перерабатываемый в форму волны, подвергаемую улучшению речевого сигнала, и по меньшей мере один блок (50.4) воспроизведения, выполненный с возможностью воспроизведения обесшумленной формы волны, полученной в результате улучшения речевого сигнала.
13. Считываемый компьютером носитель, хранящий исполняемые компьютером инструкции, и весовые коэффициенты и смещения обученной модели улучшения речевого сигнала, причем при исполнении исполняемых компьютером инструкций вычислительным устройством вычислительное устройство побуждается к осуществлению способа улучшения речевого сигнала по любому из пп. 1-10.
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ЗВУКОВОГО СИГНАЛА | 2010 |
|
RU2517315C2 |
