Область техники, к которой относится изобретение
Варианты осуществления в соответствии с настоящим изобретением относятся к процессору аудиосигнала для обеспечения каналов окружающего сигнала на основе входного аудиосигнала.
Варианты осуществления в соответствии с изобретением относятся к системе для рендеринга аудиоконтента, представленного многоканальным входным аудиосигналом.
Варианты осуществления в соответствии с изобретением относятся к способу обеспечения каналов окружающего сигнала на основе входного аудиосигнала.
Варианты осуществления в соответствии с изобретением относятся к способу рендеринга аудиоконтента, представленного многоканальным входным аудиосигналом.
Варианты осуществления в соответствии с изобретением относятся к компьютерной программе.
Варианты осуществления в соответствии с изобретением в целом относятся к выделению окружающего сигнала с множеством выходных каналов.
Уровень техники
Обработка и рендеринг аудиосигналов является развивающейся областью техники. В частности, правильный рендеринг многоканальных сигналов, содержащих как прямые звуки, так и окружающие звуки, представляет собой проблему.
Аудиосигналы могут быть смесью множества прямых звуков и окружающих (или рассеянных) звуков. Сигналы прямого звука испускаются источниками звука, например, музыкальными инструментами, и достигают уха слушателя по прямому (кратчайшему) пути между источником и слушателем. Слушатель может локализовать их положение в пространственном звуковом образе и указать направление, в котором располагается источник звука. Соответствующими слуховыми подсказками для локализации являются интерауральная разность интенсивностей, интерауральная временная разность и интерауральная когерентность. Волны прямого звука, вызывающие одинаковую интерауральную разность интенсивностей и интерауральную временную разность, воспринимаются как исходящие из одного и того же направления. При отсутствии рассеянного звука сигналы, достигающие левого и правого уха или любого другого множества датчиков, являются когерентными [1].
Напротив, окружающие звуки воспринимаются как рассеянные, не локализуемые и вызывают у слушателя восприятие обволакивания («погружения в звук»). При захвате окружающего звукового поля с использованием множества находящихся на расстоянии друг от друга датчиков, записанные сигналы являются по меньшей мере частично некогерентными. Окружающие звуки состоят из множества находящихся на расстоянии друг от друга источников звука. Примером являются аплодисменты, т.е. наложение множества хлопков в ладоши во множестве положений. Другим примером является реверберация, т.е. наложение звуков, отраженных от границ или стен. Когда звуковая волна достигает стены в помещении, часть ее отражается, и наложение всех отражений в помещении, реверберация, является наиболее известным окружающим звуком. Все отраженные звуки происходят из сигнала возбуждения, сформированного источником прямого звука, например, реверберирующая речь создается говорящим в помещении в локализуемом положении.
Различные применения постобработки и воспроизведения звука применяют разложение аудиосигналов на компоненты прямого сигнала и компоненты окружающего сигнала, т.е. разложение (DAD) на прямой и окружающий сигналы, или выделение окружающего (рассеянного) сигнала, т.е. выделение окружающего сигнала (ASE). Цель выделения окружающего сигнала состоит в вычислении окружающего сигнала, где все компоненты прямого сигнала ослаблены и слышны только компоненты рассеянного сигнала.
До сих пор выделение окружающего сигнала ограничивалось выходными сигналами с тем же самым количеством каналов, что и у входного сигнала (см., например, библиографический список [2], [3], [4], [5], [6], [7], [8]) или даже меньше. При обработке двухканального стереосигнала создается окружающий сигнал с одним или двумя каналами.
В [9] был предложен способ выделения окружающего сигнала из сигналов объемного звука, в котором обрабатываются входные сигналы с N каналами, где N > 2. В способе вычисляются спектральные весовые коэффициенты, которые применяются к каждому входному каналу из понижающего микширования многоканального входного сигнала и тем самым создает выходной сигнал с N сигналами.
Кроме того, были предложены различные способы отделения компонентов слухового сигнала и компонентов прямого сигнала только в соответствии с их местоположением в стерео образе, например [2], [10], [11], [12].
С учётом традиционных решений существует потребность в создании концепции для получения окружающих сигналов, которая позволяет получить улучшенное слуховое восприятие.
Раскрытие изобретения
Вариант осуществления в соответствии с изобретением создает процессор аудиосигнала для обеспечения каналов окружающего сигнала на основе входного аудиосигнала. Процессор аудиосигнала выполнен с возможностью получения каналов окружающего сигнала, при этом количество полученных каналов окружающего сигнала, содержащих разный аудиоконтент, больше, чем количество каналов входного аудиосигнала. Процессор аудиосигнала выполнен с возможностью получения каналов окружающего сигнала таким образом, что компоненты окружающего сигнала распределяются по каналам окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале.
Данный вариант осуществления в соответствии с изобретением основан на обнаружении того, что желательно иметь количество каналов окружающего сигнала, которое больше, чем количество каналов входного аудиосигнала, и что в таком случае предпочтительным является учитывать положения или направления источников звука при обеспечении каналов окружающего сигнала. Соответственно, содержимое окружающих сигналов может быть адаптировано к аудиоконтентам, представленным входным аудиосигналом. Например, окружающие аудиоконтенты могут быть включены в разные каналы окружающего сигнала, при этом окружающие аудиоконтенты, включенные в разные каналы окружающего сигнала, могут быть определены на основе анализа входного аудиосигнала. Соответственно, решение о том, в какой из каналов окружающего сигнала включать какой окружающий аудиоконтент, может быть принято в зависимости от положений или направлений источников звука (например, источников прямого звука), возбуждающих разный окружающий аудиоконтент.
Соответственно, могут быть варианты осуществления, в которых сначала присутствует основанное на направлении разложение (или повышающее микширование) входных аудиосигналов, и затем разложение на прямой и окружающий сигналы. Однако, также присутствуют варианты осуществления, в которых сначала присутствует разложение на прямой и окружающий сигналы, за которым следует повышающее микширование выделенных компонентов окружающего сигнала (например, на сигналы окружающего канала). Также присутствуют варианты осуществления, в которых может быть объединенное повышающее микширование и выделение окружающего сигнала (или разложение на прямой и окружающий сигналы).
В предпочтительном варианте осуществления процессор аудиосигнала выполнен с возможностью получения каналов окружающего сигнала таким образом, что компоненты окружающего сигнала распределяются по каналам окружающего сигнала в соответствии с положениями или направлениями источников прямого звука, возбуждающих соответствующие компоненты окружающего сигнала. Соответственно, может быть достигнуто хорошее слуховое восприятие и можно избежать того, что каналы окружающего сигнала содержат окружающие аудиоконтенты, которые не подходят для аудиоконтентов источников прямого звука в определённом положении или в определённом направлении. Другими словами, можно избежать того, что рендеринг окружающего звука осуществляется в аудиоканале, который ассоциирован с положением или направлением из которого не поступает прямой звук, возбуждающий окружающий звук. Было обнаружено, что однородное распределение окружающего звука может иногда приводить к неудовлетворительному слуховому восприятию, и что можно избежать такого неудовлетворительного слухового восприятия путем использования концепции для распределения компонентов окружающего сигнала в соответствии с положениями или направлениями источников прямого звука, возбуждающих соответствующие компоненты окружающего сигнала.
В предпочтительном варианте осуществления процессор аудиосигнала выполнен с возможностью распределения одного или более каналов входного аудиосигнала по множеству каналов с повышающим микшированием, при этом количество каналов с повышающим микшированием больше, чем количество каналов входного аудиосигнала. Также процессор аудиосигнала выполнен с возможностью выделения каналов окружающего сигнала из каналов с повышающим микшированием. Соответственно, может быть получена эффективная обработка, поскольку выполняется простое совместное повышающее микширование для компонентов прямого сигнала и компонентов окружающего сигнала. Отделение компонентов окружающего сигнала и компонентов прямого сигнала выполняется после повышающего микширования (распределения одного или более каналов входного аудиосигнала по множеству каналов с повышающим микшированием). Следовательно, путём умеренных усилий может быть достигнуто то, что окружающие сигналы исходят с направлений, аналогичных тем, что и прямые сигналы, возбуждающие окружающие сигналы.
В предпочтительном варианте осуществления процессор аудиосигнала выполнен с возможностью выделения каналов окружающего сигнала из каналов с повышающим микшированием с использованием многоканального выделения окружающего сигнала или с использованием многоканального разделения прямого сигнала/окружающего сигнала. Соответственно, наличие множества каналов может быть использовано в выделении окружающего сигнала или разделении прямого сигнала/окружающего сигнала. Другими словами, можно использовать сходства и/или различия между каналами с повышающим микшированием для выделения каналов окружающего сигнала, что способствует выделению каналов окружающего сигнала и влечет за собой хорошие результаты (например, при сравнении с отдельным выделением окружающего сигнала на основе отдельных каналов).
В предпочтительном варианте осуществления процессор аудиосигнала выполнен с возможностью определения коэффициентов повышающего микширования и определения коэффициентов выделения окружающего сигнала. Также процессор аудиосигнала выполнен с возможностью получения каналов окружающего сигнала с использованием коэффициентов повышающего микширования и коэффициентов выделения окружающего сигнала. Соответственно, можно извлекать каналы окружающего сигнала на одном этапе обработки (например, путем извлечения матрицы обработки сигнала на основе коэффициентов повышающего микширования и коэффициентов выделения окружающего сигнала).
Вариант осуществления в соответствии с изобретением (который при необходимости может содержать один или более из описанных выше признаков) создает процессор аудиосигнала для обеспечения каналов окружающего сигнала на основе входного аудиосигнала (который может, например, быть многоканальным входным аудиосигналом). Процессор аудиосигнала выполнен с возможностью выделения окружающего сигнала на основе входного аудиосигнала.
Например, процессор аудиосигнала может быть выполнен с возможностью выполнения разделения прямого и окружающего сигналов или разложения на прямой и окружающий сигналы на основе входного аудиосигнала для извлечения («выделения») (промежуточного) окружающего сигнала, или процессор аудиосигнала может быть выполнен с возможностью выполнения выделения окружающего сигнала для извлечения окружающего сигнала. Например, в качестве альтернативы могут быть выполнены разделение прямого и окружающего сигналов или разложение на прямой и окружающий сигналы, или выделение окружающего сигнала. Например, окружающий сигнал может быть многоканальным сигналом, при этом количество каналов окружающего сигнала может, например, быть идентично количеству каналов входного аудиосигнала.
Более того, процессор сигнала выполнен с возможностью распределения (или «повышающего микширования) (выделенного) окружающего сигнала по множеству каналов окружающего сигнала, при этом количество каналов окружающего сигнала (например, каналов окружающего сигнала с разным содержимым сигнала) больше, чем количество каналов входного аудиосигнала (и/или, например, больше, чем количество каналов выделенного окружающего сигнала), в зависимости от положений или направлений источников звука (например, источников прямого звука) во входном аудиосигнале.
Другими словами, процессор аудиосигнала может быть выполнен с возможностью учета направлений или положений источников звука (например, источников прямого звука) во входном аудиосигнале при повышающем микшировании выделенного окружающего сигнала на большее число каналов.
Соответственно, окружающий сигнал не распределяется «однородно» по каналам окружающего сигнала, а учитываются положения или направления источников звука, которые могут лежать в основе (или формировать, или возбуждать) окружающего сигнала(ов).
Было обнаружено, что такая концепция, при которой окружающие сигналы не распределяются произвольно по каналам окружающего сигнала (при этом количество каналов окружающего сигнала больше, чем количество каналов входного аудиосигнала), а распределяются в зависимости от положений или направлений источников звука во входном аудиосигнале, обеспечивает более благоприятное слуховое восприятие во многих ситуациях. Например, распределение окружающих сигналов однородно по всем каналам окружающего сигнала может привести к очень неестественному или сбивающему с толку слуховому восприятию. Например, было обнаружено, что это тот случай, когда источник прямого звука может быть четко локализован по определенному направлению поступления, при том, что эхо упомянутого источника звука (которое является окружающим сигналом) распределяется по всем каналам окружающего сигнала.
В заключение, было обнаружено, что слуховое восприятие, которое вызывается окружающим сигналом, содержащим множество каналов окружающего сигнала, часто улучшено, если положение или направление источника звука, или источников звука, во входном аудиосигнале, из которого извлекаются каналы окружающего сигнала, учитываются при распределении выделенного окружающего сигнала по каналам окружающего сигнала, потому что неоднородное распределение содержимого окружающего сигнала во входном аудиосигнале (в зависимости от положений или направлений источников звука во входном аудиосигнале) лучше отражает действительность (например, в сравнении с однородным или произвольным распределением окружающих сигналов без учета положений или направлений источников звука во входном аудиосигнале).
В предпочтительном варианте осуществления процессор аудиосигнала выполнен с возможностью выполнения разделения прямого и окружающего сигналов (например, разложения аудиосигнала на компоненты прямого звука и компоненты окружающего звука, которое также может называться разложением на прямой и окружающий сигналы) на основе входного аудиосигнала для извлечения (промежуточного) окружающего сигнала. При использовании такой методики, как окружающий сигнал, так и прямой сигнал могут быть получены на основе входного аудиосигнала, что повышает эффективность обработки, поскольку, как правило, как прямой сигнал, так и окружающий сигнал, требуются для дальнейшей обработки.
В предпочтительном варианте осуществления процессор аудиосигнала выполнен с возможностью распределения компонентов окружающего сигнала (например, выделенного окружающего сигнала, который может быть многоканальным окружающим сигналом) по каналам окружающего сигнала в соответствии с положениями или направлениями источников прямого звука, возбуждающих соответствующие компоненты окружающего сигнала (где количество каналов окружающего сигнала может, например, быть больше, чем количество каналов входного аудиосигнала и/или больше, чем количество каналов выделенного окружающего сигнала). Соответственно, может быть учтено положение или направление источников прямого звука, возбуждающих компоненты окружающего сигнала, тем самым, например, разные компоненты окружающего сигнала, возбужденные разными источниками прямого звука, расположенными в разных положениях, могут быть распределены по-разному по каналам окружающего сигнала. Например, компоненты окружающего сигнала, возбужденные определённым источником прямого звука, могут быть в первую очередь распределены по одному или более каналам окружающего сигнала, которые ассоциированы с одним или более каналами прямого сигнала, по которым компоненты прямого сигнала соответствующего источника прямого звука распределяются в первую очередь. Таким образом, распределение компонентов окружающего сигнала по разным каналам окружающего сигнала может соответствовать распределению компонентов прямого сигнала, возбуждающих соответствующие компоненты окружающего сигнала по разным каналам прямого сигнала. Следовательно, в среде рендеринга, компоненты окружающего сигнала могут восприниматься как исходящие с тех же самых или аналогичных направлений, что и источники прямого звука, возбуждающие соответствующие компоненты окружающего сигнала. Таким образом, можно избежать неестественного слухового восприятия в некоторых случаях. Например, можно избежать того, что сигнал эха поступает из совершенно другого направления, в сравнении с источником прямого звука, возбуждающего эхо, что не подходит для некоторых желаемых синхронизированных слуховых сред.
В предпочтительном варианте осуществления каналы окружающего сигнала ассоциированы с разными направлениями. Например, каналы окружающего сигнала могут быть ассоциированы с теми же самыми направлениями, что и у соответствующих каналов прямого сигнала, или могут быть ассоциированы с аналогичными направлениями, что и у соответствующих каналов прямого сигнала. Таким образом, компоненты окружающего сигнала могут быть распределены по каналам окружающего сигнала таким образом, что может быть достигнуто то, что компоненты окружающего сигнала воспринимаются как исходящие с определенного направления, которое соотносится с направлением источника прямого звука, возбуждающего соответствующие компоненты окружающего сигнала.
В предпочтительном варианте осуществления каналы прямого сигнала ассоциированы с разными направлениями, и каналы окружающего сигнала и каналы прямого сигнала ассоциированы с одним и тем же набором направлений (например, по меньшей мере относительно азимутального направления, и по меньшей мере в рамках приемлемого допуска в, например, +/-20° или +/-10°). Более того, процессор аудиосигнала выполнен с возможностью распределения компонентов прямого сигнала по каналам прямого сигнала (или, эквивалентно, панорамирования компонентов прямого сигнала по каналам прямого сигнала) в соответствии с положениями или направлениями соответствующих компонентов прямого звука. Более того, процессор аудиосигнала выполнен с возможностью распределения компонентов окружающего сигнала (например, выделенного окружающего сигнала) по каналам окружающего сигнала в соответствии с положениями или направлениями источников прямого звука, возбуждающих соответствующие компоненты окружающего сигнала таким же образом (например, с использованием тех же самых коэффициентов панорамирования или спектральных весовых коэффициентов), как распределяются компоненты прямого сигнала (при этом каналы окружающего сигнала предпочтительно отличаются от каналов прямого сигнала, т.е. независимые каналы). Соответственно, хорошее слуховое восприятие может быть получено в некоторых ситуациях, в которых произвольное распределение окружающих сигналов будет звучать неестественно без учета (пространственного) распределения компонентов прямого звука.
В предпочтительном варианте осуществления процессор аудиосигнала выполнен с возможностью обеспечения каналов окружающего сигнала таким образом, что окружающий сигнал разделяется на компоненты окружающего сигнала в соответствии с положениями сигналов источника, лежащих в основе компонентов окружающего сигнала (например, сигналов прямого источника, которые создают соответствующие компоненты окружающего сигнала). Соответственно, можно отделить разные компоненты окружающего сигнала, которые, как ожидается, исходят от разных прямых источников. Это обеспечивает отдельную обработку (например, манипулирование, масштабирование, задержку или фильтрацию) сигналов прямого звука и окружающих сигналов, возбужденных разными источниками.
В предпочтительном варианте осуществления процессор аудиосигнала выполнен с возможностью применения спектральных весовых коэффициентов (например, зависимых от времени или зависимых от частоты спектральных весовых коэффициентов) для распределения (или повышающего микширования, или панорамирования) окружающего сигнала по каналам окружающего сигнала (таким образом, что обработка осуществляется в частотно-временной области). Было обнаружено, что такая обработка в частотно-временной области, которая использует спектральные весовые коэффициенты, хорошо подходит для обработки случаев, когда присутствует множество источников звука. При использовании данной концепции, положение или направление прибытия могут быть ассоциированы с каждым спектральным бином, и распределение окружающего сигнала по множеству каналов окружающего сигнала также может быть выполнено в очередности спектральный бин за спектральным бином. Другими словами, для каждого спектрального бина, может быть определено, каким образом окружающий сигнал должен быть распределен по каналам окружающего сигнала. Также определения зависимых от времени или зависимых от частоты спектральных весовых коэффициентов может соответствовать определению положений или направлений источников звука во входном сигнале. Соответственно, может быть легко достигнуто то, что окружающий сигнал распределяется по множеству каналов окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале.
В предпочтительном варианте осуществления процессор аудиосигнала выполнен с возможностью применения спектральных весовых коэффициентов, которые вычисляются для отдельных прямых аудиоисточников в соответствии с их положениями или направлениями, для осуществления повышающего микширования (или панорамирования) окружающего сигнала по множеству каналов окружающего сигнала. В качестве альтернативы, процессор аудиосигнала выполнен с возможностью применения версии спектральных весовых коэффициентов с задержкой, которые вычисляются для отдельных прямых аудиоисточников в соответствии с их положениями или направлениями, для осуществления повышающего микширования окружающего сигнала на множество каналов окружающего сигнала. Было обнаружено, что хорошее слуховое восприятие может быть достигнуто при низкой сложности вычислений путем применения этих спектральных весовых коэффициентов, которые вычисляются для отдельных прямых аудиоисточников в соответствии с их положениями или направлениями, или их версий с задержкой, для распределения (или повышающего микширования или панорамирования) окружающего сигнала по множеству каналов окружающего сигнала. Использование версии с задержкой для спектральных весовых коэффициентов может, например, быть целесообразно для учета временного сдвига между прямым сигналом и эхом.
В предпочтительном варианте осуществления процессор аудиосигнала выполнен с возможностью извлечения спектральных весовых коэффициентов таким образом, что спектральные весовые коэффициенты являются зависимыми от времени и зависимыми от частоты. Соответственно, могут быть учтены меняющиеся во времени сигналы источников прямого звука и возможное движение источников прямого звука. Также, могут быть учтены меняющиеся интенсивности источников прямого звука. Таким образом, распределение окружающего сигнала по каналам окружающего сигнала не является статичным, а относительное присвоение весовых коэффициентов окружающего сигнала множеству каналов окружающего сигнала (с повышающим микшированием) меняется динамически.
В предпочтительном варианте осуществления процессор аудиосигнала выполнен с возможностью извлечения спектральных весовых коэффициентов в зависимости от положений источников звука в пространственном звуковом образе входного аудиосигнала. Таким образом, спектральный весовой коэффициент хорошо отражает положения источников прямого звука, возбуждающих окружающий сигнал, и, вследствие этого, легко возможно, чтобы компоненты окружающего сигнала, возбужденные конкретным источником звука, могли быть ассоциированы с подходящими каналами окружающего сигнала, которые соответствуют направлению источника прямого звука (в пространственном звуковом образе входного аудиосигнала).
В предпочтительном варианте осуществления, входной аудиосигнал содержит по меньшей мере два сигнала входного канала, и процессор аудиосигнала выполнен с возможностью извлечения спектральных весовых коэффициентов в зависимости от различий между по меньшей мере двумя сигналами входного канала. Было обнаружено, что различия между сигналами входного канала (например, разности фаз и/или разности амплитуд) могут быть хорошо оценены для получения информации о направлении источника прямого звука, при этом предпочтительным является то, что спектральные весовые коэффициенты соответствуют по меньшей мере в некоторой степени направлениям источников прямого звука.
В предпочтительном варианте осуществления процессор аудиосигнала выполнен с возможностью определения спектральных весовых коэффициентов в зависимости от положений или направлений, из которых исходят спектральные компоненты (например, компоненты прямого звука во входном сигнале или в прямом сигнале) таким образом, что спектральным компонентам, исходящим из определённого положения или направления (например, из положения p), присваивается более сильный весовой коэффициент в канале (например, из каналов окружающего сигнала), ассоциированном с соответствующим положением или направлением, в сравнении с другими каналами (например, из каналов окружающего сигнала). Другими словами, спектральные весовые коэффициенты определяются, чтобы различать (или отделять) компоненты окружающего сигнала в зависимости от направления, с которого исходят компоненты прямого сигнала, возбуждающие компоненты окружающего сигнала. Таким образом, например, может быть достигнуто то, что окружающие сигналы, исходящие от разных источников звука, распределяются по разным каналам окружающего сигнала таким образом, что разные каналы окружающего сигнала как правило имеют разное присвоение весовых коэффициентов для разных компонентов окружающего сигнала (например, разных спектральных бинов).
В предпочтительном варианте осуществления процессор аудиосигнала выполнен с возможностью определения спектральных весовых коэффициентов таким образом, что спектральные весовые коэффициенты описывают присвоение весовых коэффициентов спектральным компонентам сигналов входного канала (например, входного сигнала) во множестве сигналов выходного канала. Например, спектральные весовые коэффициенты могут описывать, что определённый сигнал входного канала включается в первый сигнал выходного канала с присвоением сильного весового коэффициента и, что тот же самый сигнал входного канала включается во второй сигнал выходного канала с присвоением меньшего весового коэффициента. Весовой коэффициент может быть определен отдельно для разных спектральных компонентов. Поскольку входной сигнал может, например, быть многоканальным сигналом, то спектральные весовые коэффициенты могут описывать присвоение весовых коэффициентов для множества сигналов входного канала во множестве сигналов выходного канала, при этом, как правило, присутствует больше сигналов выходного канала, чем сигналов входного канала (повышающее микширование). Также возможно, что сигналы от конкретного сигнала входного канала никогда не будут приняты в конкретном сигнале выходного канала. Например, может отсутствовать включение любых сигналов входного канала, которые ассоциированы с левой стороной среды рендеринга в сигналы выходного канала, ассоциированные с правой стороной среды рендеринга, и наоборот.
В предпочтительном варианте осуществления процессор аудиосигнала выполнен с возможностью применения одного и того же набора спектральных весовых коэффициентов для распределения компонентов прямого сигнала по каналам прямого сигнала и для распределения компонентов окружающего сигнала у окружающего сигнала по каналам окружающего сигнала (при этом задержка времени может учитываться при распределении компонентов окружающего сигнала). Соответственно, компоненты окружающего сигнала могут быть распределены по каналам окружающего сигнала точно таким же образом, как компоненты прямого сигнала распределяются по каналам прямого сигнала. Следовательно, в некоторых случаях, все компоненты окружающего сигнала подходят к компонентам прямого сигнала и в частности достигается хорошее слуховое восприятие.
В предпочтительном варианте осуществления входной аудиосигнал содержит по меньшей мере два канала и/или окружающий сигнал содержит по меньшей мере два канала. Следует отметить, что концепция, которая обсуждается в данном документе, в частности, хорошо подходит для входных аудиосигналов с двумя или более каналами, так как такие входные аудиосигналы могут представлять местоположение (или направление) компонентов сигнала.
Вариант осуществления в соответствии с изобретением создает систему для рендеринга аудиоконтента, представленного многоканальным входным аудиосигналом. Система содержит процессор аудиосигнала, описанный выше, при этом процессор аудиосигнала выполнен с возможностью обеспечения более двух каналов прямого сигнала и более двух каналов окружающего сигнала. Более того, система содержит систему громкоговорителей, содержащую набор громкоговорителей прямого сигнала и набор громкоговорителей окружающего сигнала. Каждый из каналов прямого сигнала ассоциирован по меньшей мере с одним из громкоговорителей прямого сигнала, и каждый из каналов окружающего сигнала ассоциирован по меньшей мере с одним из громкоговорителей окружающего сигнала. Соответственно, рендеринг прямых сигналов и окружающих сигналов может, например, осуществляться с использованием разных громкоговорителей, при этом может, например, присутствовать пространственная корреляция между громкоговорителями прямого сигнала и соответствующими громкоговорителями окружающего сигнала. Соответственно, в отношении как прямых сигналов (или компонентов прямого сигнала), так и окружающих сигналов (или компонентов окружающего сигнала) может быть осуществлено повышающее микширование на количество громкоговорителей, которое больше, чем количество каналов входного аудиосигнала. Рендеринг окружающих сигналов или компонентов окружающего сигнала также осуществляется посредством множества громкоговорителей неоднородным образом, распределенным по разным громкоговорителям окружающего сигнала в соответствии с направлениями, в которых размещаются источники звука. Следовательно, может быть достигнутого хорошее слуховое восприятие.
В предпочтительном варианте осуществления каждый из громкоговорителей окружающего сигнала ассоциирован с одним из громкоговорителей прямого сигнала. Соответственно, хорошее слуховое восприятие может быть достигнуто путем распределения компонентов окружающего сигнала по громкоговорителям окружающего сигнала таким же образом, как компоненты прямого сигнала распределяются по громкоговорителям прямого сигнала.
В предпочтительном варианте осуществления положения громкоговорителей окружающего сигнала приподняты по отношению к положениям громкоговорителей прямого сигнала. Было обнаружено, что хорошее слуховое восприятие может быть достигнуто посредством такой конфигурации. Также конфигурация может быть использована, например, в транспортном средстве и обеспечивать хорошее слуховое восприятие в таком транспортном средстве.
Вариант осуществления в соответствии с изобретением создает способ обеспечения каналов окружающего сигнала на основе входного аудиосигнала (который может, предпочтительно, быть многоканальным аудиосигналом). Способ содержит этап, на котором выделают окружающий сигнал на основе входного аудиосигнала (что может, например, содержать выполнение разделения прямого и окружающего сигналов или разложения на прямой и окружающий сигналы на основе входного аудиосигнала для извлечения окружающего сигнала или так называемого «выделения окружающего сигнала»).
Более того, способ содержит этап, на котором распределяют (например, осуществляют повышающее микширование) окружающий сигнал по множеству каналов окружающего сигнала, при этом количество каналов окружающего сигнала (которые могут, например, иметь ассоциированное разное содержимое сигнала) больше, чем количество каналов входного аудиосигнала (например, больше, чем количество каналов выделенного окружающего сигнала), в зависимости от положений или направлений источников звука во входном аудиосигнале. Данный способ основан на тех же соображениях, что и описанное выше устройство. Также следует отметить, что способ может быть дополнен любым из признаков, функциональных возможностей и подробностей, описанных в данном документе в отношении соответствующего устройства.
Другой вариант осуществления содержит способ рендеринга аудиоконтента, представленного многоканальным входным аудиосигналом. Способ содержит этап, на котором обеспечивают каналы окружающего сигнала на основе входного аудиосигнала, как описано выше. В данном случае обеспечивается более двух каналов окружающего сигнала. Более того, способ также содержит этап, на котором обеспечивают более двух каналов прямого сигнала. Способ также содержит этап, на котором подают каналы окружающего сигнала и каналы прямого сигнала на систему громкоговорителей, содержащую набор громкоговорителей прямого сигнала и набор громкоговорителей окружающего сигнала, при этом каждый из каналов прямого сигнала подается по меньшей мере на один из громкоговорителей прямого сигнала, и при этом каждый из каналов окружающего сигнала подается по меньшей мере на один из громкоговорителей окружающего сигнала. Данный способ основан на тех же самых соображениях, как и описанная выше система. Также следует отметить, что способ может быть дополнен любыми признаками, функциональными возможностями и подробностями, описанными в данном документе в отношении упомянутой выше системы.
Другой вариант осуществления в соответствии с изобретением создает компьютерную программу для выполнения одного из способов, упомянутых ранее, когда компьютерная программа выполняется на компьютере.
Краткое описание фигур
Фиг. 1a показывает принципиальную структурную схему процессора аудиосигнала, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 1b показывает принципиальную структурную схему процессора аудиосигнала, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 2 показывает принципиальную структурную схему системы, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 3 показывает схематическое представление потока сигналов в процессоре аудиосигнала, в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 4 показывает схематическое представление извлечения спектральных весовых коэффициентов, в соответствии с вариантом осуществления изобретения;
Фиг. 5 показывает блок-схему способа обеспечения каналов окружающего сигнала в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 6 показывает блок-схему способа рендеринга аудиоконтента в соответствии с вариантом осуществления настоящего изобретения;
Фиг. 7 показывает схематическое представление стандартной установки громкоговорителей с двумя громкоговорителями (с левой и правой стороны, «L», «R», соответственно) для двухканальной стереофонии;
Фиг. 8 показывает схематическое представление квадрафонической установки громкоговорителей с четырьмя громкоговорителями (передний левый «fL», передний правый «fR», задний левый «rL», задний правый «rR»); и
Фиг. 9 показывает схематическое представление квадрафонической установки громкоговорителей с дополнительными громкоговорителями возвышения, помеченными «h».
Осуществление изобретения
1. Процессор аудиосигнала в соответствии с Фиг. 1a и Фиг. 1b
1a) Процессор аудиосигнала в соответствии с Фиг. 1a.
Фиг. 1a показывает принципиальную структурную схему процессора аудиосигнала в соответствии с вариантом осуществления настоящего изобретения. Процессор аудиосигнала в соответствии с Фиг. 1a обозначен полностью как 100.
Процессор 100 аудиосигнала принимает входной аудиосигнал 110, который может, например, быть многоканальным входным аудиосигналом. Входной аудиосигнал 110 может, например, содержать N каналов. Более того, процессор 100 аудиосигнала обеспечивает каналы 112a, 112b, 112c окружающего сигнала на основе входного аудиосигнала 110.
Процессор 100 аудиосигнала выполнен с возможностью выделения окружающего сигнала 130 (который также может быть рассмотрен в качестве промежуточного окружающего сигнала) на основе входного аудиосигнала 110. С этой целью процессор аудиосигнала может, например, содержать выделение 120 окружающего сигнала. Например, выделения 120 окружающего сигнала может выполнять разделение прямого и окружающего сигналов или разложение на прямой и окружающий сигналы на основе входного аудиосигнала 110 для извлечения окружающего сигнала 130. Например, выделение 120 окружающего сигнала также обеспечивает прямой сигнал (например, оценочный или выделенный прямой сигнал), который может быть обозначен с помощью 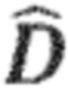 , и который не показан на Фиг. 1a. В качестве альтернативы, выделение окружающего сигнала может выделять только окружающий сигнал 130 из входного сигнала 110 без обеспечения прямого сигнала. Например, выделение 120 окружающего сигнала может выполнять «слепое» разделение прямого и окружающего сигналов или разложение на прямой и окружающий сигналы, или выделение окружающего сигнала. Однако, в качестве альтернативы, выделение 120 окружающего сигнала может принимать параметры, которые поддерживают разделение прямого и окружающего сигналов или разложение на прямой и окружающий сигналы, или выделение окружающего сигнала.
, и который не показан на Фиг. 1a. В качестве альтернативы, выделение окружающего сигнала может выделять только окружающий сигнал 130 из входного сигнала 110 без обеспечения прямого сигнала. Например, выделение 120 окружающего сигнала может выполнять «слепое» разделение прямого и окружающего сигналов или разложение на прямой и окружающий сигналы, или выделение окружающего сигнала. Однако, в качестве альтернативы, выделение 120 окружающего сигнала может принимать параметры, которые поддерживают разделение прямого и окружающего сигналов или разложение на прямой и окружающий сигналы, или выделение окружающего сигнала.
Более того, процессор 100 аудиосигнала выполнен с возможностью распределения (например, повышающего микширования) окружающего сигнала 130 (который может рассматриваться в качестве промежуточного окружающего сигнала) по множеству каналов 112a, 112b, 112c окружающего сигнала, при этом количество каналов 112a, 112b, 112c окружающего сигнала больше, чем количество каналов входного аудиосигнала 110 (и, как правило, также больше, чем количество каналов промежуточного окружающего сигнала 130). Следует отметить, что функциональная возможность для распределения окружающего сигнала 130 по множеству каналов 112a, 112b, 112c окружающего сигнала может, например, быть обеспечена распределением 140 окружающего сигнала, которое может принимать (промежуточный) окружающий сигнал 130 и которое также может принимать входной аудиосигнал 110, или информацию, например, в отношении положений или направлений источников звука во входном аудиосигнале. Также следует отметить, что процессор аудиосигнала выполнен с возможностью распределения окружающего сигнала 130 по множеству каналов окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале 110. Соответственно, каналы 112a, 112b, 112c окружающего сигнала могут, например, содержать разное содержимое сигнала, при этом распределение (промежуточного) окружающего сигнала 130 по множеству каналов 112a, 112b, 112c окружающего сигнала также может быть зависимым от времени и/или зависимым от частоты и отражать меняющиеся положения и/или меняющееся содержимое источников звука, лежащих в основе входного аудиосигнала.
В заключение, процессор 110 аудиосигнала может выделять (промежуточный) окружающий сигнал 130 с использованием выделения окружающего сигнала, и затем может распределять (промежуточный) окружающий сигнал 130 по каналам 112a, 112b, 112c окружающего сигнала, при этом количество каналов окружающего сигнала больше, чем количество каналов входного аудиосигнала. Распределение (промежуточного) окружающего сигнала 130 по каналам 112a, 112b, 112c окружающего сигнала может быть определено не статически, а может использовать переменные по времени положения или направления источников звука во входном аудиосигнале. Также, компоненты сигнала у окружающего сигнала 130 могут быть распределены по каналам 112a, 112b, 112c окружающего сигнала таким образом, что распределение соответствует положениям или направлениям источников прямого звука, возбуждающих окружающие сигналы.
Соответственно, разные каналы 112a, 112b, 112c окружающего сигнала могут, например, содержать разные компоненты окружающего сигнала, при этом один из каналов окружающего сигнала может, преимущественно, содержать компоненты окружающего сигнала, исходящие из (или возбуждаемые посредством) первого источника прямого звука, и при этом другой из каналов окружающего сигнала может, преимущественно, содержать компоненты окружающего сигнала, писходящие из (или возбуждаемые посредством) другого источника прямого сигнала.
В заключение, процессор 100 аудиосигнала в соответствии с Фиг. 1a может распределять компоненты окружающего сигнала, исходящие из разных источников прямого звука, по разным каналам окружающего сигнала таким образом, что, например, компоненты окружающего сигнала могут быть пространственно распределенными.
Это может привести к улучшенному слуховому восприятию в некоторых ситуациях. Можно избежать того, что рендеринг компонентов окружающего сигнала осуществляется через каналы окружающего сигнала, которые ассоциированы с направлениями, которые «абсолютно не подходят» для направления, с которого исходит прямой звук.
Более того, следует отметить, что процессор аудиосигнала в соответствии с Фиг. 1a может быть дополнен любыми признаками, функциональными возможностями и подробностями, описанными в данном документе, как по отдельности, так и взятых в сочетании.
1b) Процессор аудиосигнала в соответствии с Фиг. 1b
Фиг. 1b показывает принципиальную структурную схему процессора аудиосигнала, в соответствии с вариантом осуществления настоящего изобретения. Процессор аудиосигнала в соответствии с Фиг. 1b обозначен полностью как 150.
Процессор 150 аудиосигнала принимает входной аудиосигнал 160, который может, например, быть многоканальным входным аудиосигналом. Входной аудиосигнал 160 может, например, содержать N каналов. Более того, процессор 150 аудиосигнала обеспечивает каналы 162a, 162b, 162c окружающего сигнала на основе входного аудиосигнала 160.
Процессор 150 аудиосигнала выполнен с возможностью обеспечения каналов окружающего сигнала таким образом, что компоненты окружающего сигнала распределяются по каналам окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале.
Данный процессор аудиосигнала имеет преимущество в том, что каналы окружающего сигнала хорошо адаптированы к содержимому прямого сигнала, которое может быть включено в каналы прямого сигнала. В отношении дополнительных подробностей обратитесь к вышеприведенным объяснениям в разделе «раскрытие изобретения», а также к объяснениям в отношении других вариантов осуществления.
Более того, следует отметить, что процессор 150 сигнала может при необходимости быть дополнен любыми признаками, функциональными возможностями и подробностями, описанными в данном документе.
2) Система в соответствии с Фиг. 2
Фиг. 2 показывает принципиальную структурную схему системы, в соответствии с вариантом осуществления настоящего изобретения. Система обозначена полностью как 200. Система 200 выполнена с возможностью приема многоканального входного аудиосигнала 210, который может соответствовать входному аудиосигналу 110. Более того, система 200 содержит процессор 250 аудиосигнала, который может, например, содержать функциональные возможности процессора 100 аудиосигнала, как описано при обращении к Фиг. 1a или Фиг. 1b. Однако, следует отметить, что процессор 250 аудиосигнала может обладать расширенными функциональными возможностями в некоторых вариантах осуществления.
Более того, система также содержит систему 260 громкоговорителей, которая может, например, содержать набор громкоговорителей 262a, 262b, 262c прямого сигнала и набор громкоговорителей 264a, 264b, 264c окружающего сигнала. Например, процессор аудиосигнала может обеспечивать множество каналов 252a, 252b, 252c прямого сигнала громкоговорителям 262a, 262b, 262c прямого сигнала, и процессор 250 аудиосигнала может обеспечивать каналы 254a, 254b, 254c окружающего сигнала громкоговорителям 264a, 264b, 264c окружающего сигнала. Например, каналы 254a, 254b, 254c окружающего сигнала могут соответствовать каналам 112a, 112b, 112c окружающего сигнала.
Таким образом, вообще говоря, можно сказать, что процессор 250 аудиосигнала обеспечивает более двух каналов 252a, 252b, 252c прямого сигнала и более двух каналов 254a, 254b, 254c окружающего сигнала. Каждый из каналов 252a, 252b, 252c прямого сигнала ассоциирован по меньшей мере с одним из громкоговорителей 262a, 262b, 262c прямого сигнала. Также каждый из каналов 254a, 254b, 254c окружающего сигнала ассоциирован по меньшей мере с одним из громкоговорителей 264a, 264b, 264c окружающего сигнала.
В дополнение, может присутствовать, например, ассоциация (например, парная ассоциация) между громкоговорителями прямого сигнала и громкоговорителями окружающего сигнала. Однако, в качестве альтернативы, может иметь место ассоциация между поднабором громкоговорителей прямого сигнала и громкоговорителями окружающего сигнала. Например, может присутствовать больше громкоговорителей прямого сигнала, чем громкоговорителей окружающего сигала (например, 6 громкоговорителей прямого сигнала и 4 громкоговорителя окружающего сигнала). Таким образом, только некоторые из громкоговорителей прямого сигнала могут иметь ассоциированные громкоговорители окружающего сигнала, при том, что некоторые другие громкоговорители прямого сигнала не имеют ассоциированные громкоговорители окружающего сигнала. Например, громкоговоритель 264a окружающего сигнала может быть ассоциирован с громкоговорителем 262a окружающего сигнала, громкоговоритель 264b окружающего сигнала может быть ассоциирован с громкоговорителем 262b окружающего сигнала, и громкоговоритель 264с окружающего сигнала может быть ассоциирован с громкоговорителем 262с окружающего сигнала. Например, ассоциированные громкоговорители могут быть расставлены в равных или аналогичных азимутальных положениях (которые могут, например, отличаться на не более чем 20° или на не более чем 10°, при просмотре с положения слушателя). Однако, ассоциированные громкоговорители (например, громкоговоритель прямого сигнала и его ассоциированный громкоговоритель окружающего сигнала) могут содержать разные возвышения.
Ниже будут пояснены некоторые подробности в отношении процессора 250 аудиосигнала. Процессор 250 аудиосигнала содержит разложение 220 на прямой и окружающий сигналы, которое может, например, соответствовать выделению 120 окружающего сигнала. Разложение 220 на прямой и окружающий сигналы может, например, принимать входной аудиосигнал 210 и выполнять слепое (или, в качестве альтернативы, управляемое) разложение на прямой и окружающий сигналы (при этом управляемое разложение на прямой и окружающий сигналы принимает и использует параметры от аудиокодера, описывающие, например, энергии, соответствующие прямым компонентам и окружающим компонентам в разных полосах или субполосах частот), чтобы тем самым обеспечивать (промежуточный) прямой сигнал (который также может быть обозначен как 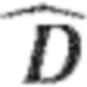 ), и (промежуточный) окружающий сигнал 230, который может, например, соответствовать (промежуточному) окружающему сигналу 130, и который может, например, быть обозначен как
), и (промежуточный) окружающий сигнал 230, который может, например, соответствовать (промежуточному) окружающему сигналу 130, и который может, например, быть обозначен как 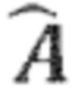 . Прямой сигнал 226 может, например, быть введен в распределение 246 прямого сигнала, которое распределяет (промежуточный) прямой сигнал 226 (который может, например, содержать два канала) по каналам 252a, 252b, 252c прямого сигнала. Например, распределение 246 прямого сигнала может выполнять повышающее микширование. Также, распределение 246 прямого сигнала может, например, учитывать положения (или направления) источников прямого сигнала при повышающем микшировании (промежуточного) прямого сигнала 226 от разложения 226 на прямой и окружающий сигналы для получения каналов 252a, 252b, 252c прямого сигнала. Распределение 246 прямого сигнала может, например, извлекать информацию о положениях или направлениях источников звука из входного аудиосигнала 210, например, из различий между разными каналами многоканального входного аудиосигнала 210.
. Прямой сигнал 226 может, например, быть введен в распределение 246 прямого сигнала, которое распределяет (промежуточный) прямой сигнал 226 (который может, например, содержать два канала) по каналам 252a, 252b, 252c прямого сигнала. Например, распределение 246 прямого сигнала может выполнять повышающее микширование. Также, распределение 246 прямого сигнала может, например, учитывать положения (или направления) источников прямого сигнала при повышающем микшировании (промежуточного) прямого сигнала 226 от разложения 226 на прямой и окружающий сигналы для получения каналов 252a, 252b, 252c прямого сигнала. Распределение 246 прямого сигнала может, например, извлекать информацию о положениях или направлениях источников звука из входного аудиосигнала 210, например, из различий между разными каналами многоканального входного аудиосигнала 210.
Распределение 240 окружающего сигнала, которое может, например, соответствовать распределению 140 окружающего сигнала, будет распределять (промежуточный) окружающий сигнал 230 по каналам 254a, 254b и 254c окружающего сигнала. Распределение 240 окружающего сигнала также может выполнять повышающее микшированием, поскольку количество каналов (промежуточного) окружающего сигнала 230, как правило, меньше, чем количество каналов 254a, 254b, 254c окружающего сигнала.
Распределение 240 окружающего сигнала также может учитывать положения и направления источников звука во входном аудиосигнале 210, при выполнении функциональной возможности повышающего микширования, таким образом, что компоненты окружающего сигнала также распределяются пространственным образом (поскольку каналы 254a, 254b, 254c окружающего сигнала, как правило, ассоциированы с разными положениями рендеринга).
Более того, следует отметить, что распределение 246 прямого сигнала и распределение 240 окружающего сигнала могут, например, работать координированным образом. Распределение компонентов сигнала (например, частотно-временных бинов или блоков представления в частотно-временной области прямого сигнала и окружающего сигнала) может быть распределено одним и тем же образом распределением 246 прямого сигнала и распределением 240 окружающего сигнала (при этом может присутствовать временной сдвиг в операции распределения окружающего сигнала для того, чтобы правильно учитывать задержку компонентов окружающего сигнала по отношению к компонентам прямого сигнала). Другими словами, масштабирование частотно-временных бинов или блоков распределением 246 прямого сигнала (которое может быть выполнено, если распределение 246 прямого сигнала работает в представлении частотно-временной области прямого сигнала) может быть идентичным масштабированию соответствующих частотно-временных бинов или блоков, которое применяется распределением 240 окружающего сигнала для извлечения каналов 254a, 254b, 254c окружающего сигнала из окружающего сигнала 230. Подробности в отношении данной факультативной функциональной возможности будут описан ниже.
В заключение, в системе 200 в соответствии с Фиг. 2, присутствует отделение между (промежуточным) прямым сигналом и (промежуточным) окружающим сигналом (оба из которых могут быть многоканальными промежуточными сигналами). Следовательно, (промежуточный) прямой сигнал и (промежуточный) окружающий сигнал распределяются (в отношении них осуществляется повышающее микширование) для получения соответствующих каналов прямого сигнала и каналов окружающего сигнала. Повышающее микширование может соответствовать пространственному распределению компонентов прямого сигнала и компонентов окружающего сигнала, поскольку каналы прямого сигнала и каналы окружающего сигнала могут быть ассоциированы с пространственными позициями. Также повышающее микширование (промежуточного) прямого сигнала и (промежуточного) окружающего сигнала может быть скоординированным, таким образом, что соответствующие компоненты сигнала (например, соответствующие в отношении их частоты, и соответствующие в отношении их времени, возможно с учетом временного сдвига между компонентами окружающего сигнала и компонентами прямого сигнала) могут быть распределены одним и тем же образом (например, с тем же самым масштабированием повышающего микширования). Соответственно, может быть достигнуто хорошее слуховое восприятие и можно избежать того, что окружающие сигналы воспринимаются как исходящие с неподходящего положения.
Более того, следует отметить, что система 200 или ее процессор 250 аудиосигнала могут быть дополнены любыми из признаков и функциональных возможностей и подробностей, описанных в данном документе, либо по отдельности, либо в сочетании. Более того, следует отметить, что функциональные возможности, описанные в отношении процессора 250 аудиосигнала, также могут быть включены в процессор 100 аудиосигнала в качестве факультативных расширений.
3) Обработка сигнала в соответствии с Фиг. 3 и 4
Ниже обработка сигнала будет описана при обращении к Фиг. 3 и 4, которые могут, например, быть реализованы в процессоре 100 аудиосигнала на Фиг. 1 или в процессоре аудиосигнала в соответствии с Фиг. 1b, или в процессоре 250 аудиосигнала в соответствии с Фиг. 2.
Однако, следует отметить, что признаки, функциональные возможности и подробности, описанные ниже, следует рассматривать как факультативные. Более того, следует отметить, что признаки, функциональные возможности и подробности, описанные ниже, могут быть введены по отдельности или в сочетании в процессоры 100, 250 аудиосигнала.
Ниже сначала будет описан общий поток сигналов при обращении к Фиг. 3. Впоследствии, подробности в отношении вычисления спектральных весовых коэффициентов будут описаны при обращении к примеру, показанному на Фиг. 4.
Теперь обращаясь к потоку сигналов на Фиг. 3, следует отметить, что предполагается, что присутствует входной аудиосигнал 310 с N каналами, при этом N как правило больше или равно 2. Выходной аудиосигнал также может быть представлен как x(t), что обозначает представление во временной области входного аудиосигнала, или как X(m, k), что обозначает представление в частотной области или представление в спектральной области или представление в частотно-временной области входного аудиосигнала. Например, m является индексом времени, а k является индексом частотного бина (или субполосы).
Более того, следует отметить, что в случае, когда входной аудиосигнал находится в представлении во временной области, при необходимости может присутствовать преобразование из временной области в частотную область. Также следует отметить, что обработка предпочтительно выполняется в спектральной области (т.е. на основе сигнала X(m, k)).
Также следует отметить, что входной аудиосигнал 310 может соответствовать входному аудиосигналу 110 и входному аудиосигналу 210.
Более того, присутствует разложение 320 на прямой и окружающий сигналы, которое выполняется на основе входного аудиосигнала 310. Предпочтительно, но не обязательно, разложение 320 на прямой и окружающий сигналы выполняется на основе представления X(m, k) в спектральной области входного аудиосигнала. Также разложение на прямой и окружающий сигналы может, например, соответствовать выделению 120 окружающего сигнала и разложению 220 на прямой и окружающий сигналы.
Дополнительно следует отметить, что специалисту в соответствующей области техники известны разные реализации разложения 220 на прямой и окружающий сигналы. Можно обратиться, например, к отделению окружающего сигнала, описанному в документе PCT/EP2013/072170. Однако, следует отметить, что здесь могут быть использованы любые из концепций разложения на прямой и окружающий сигналы, известные специалисту в соответствующей области техники.
Соответственно, разложение на прямой и окружающий сигналы обеспечивает (промежуточный) прямой сигнал, который, как правило, содержит N каналов (также, как входной аудиосигнал 310). (Промежуточный) прямой сигнал обозначен как 322, и также может быть обозначен как . (Промежуточный) прямой сигнал может, например, соответствовать (промежуточному) прямому сигналу 226.
Более того, разложение 320 на прямой и окружающий сигналы также обеспечивает (промежуточный) окружающий сигнал 324, который может, например, также содержать N каналов (также, как входной аудиосигнал 310). (Промежуточный) окружающий сигнал также может быть обозначен как .
Следует отметить, что разложение 320 на прямой и окружающий сигналы не обязательно обеспечивает безупречное разложение на прямой и окружающий сигналы или разделение прямого и окружающего сигналов. Другими словами, не требуется, чтобы (промежуточный) прямой сигнал 320 безупречно представлял исходный прямой сигнал, и не требуется, чтобы (промежуточный) окружающий сигнал безупречно представлял исходный окружающий сигнал. Однако, (промежуточный) прямой сигнал и (промежуточный) окружающий сигнал должны рассматриваться в качестве оценок исходного прямого сигнала и исходного окружающего сигнала, при этом качество оценки зависит от количества (и/или сложности) алгоритма, который используется для разложения 320 на прямой и окружающий сигналы. Однако, как известно специалисту в соответствующей области техники, приемлемое отделение компонентов прямого сигнала и компонентов окружающего сигнала может быть достигнуто алгоритмами, известными из литературы.
Обработка 300 сигнала, как показано на Фиг. 3, также содержит вычисление 330 спектральных весовых коэффициентов. Вычисление 330 спектральных весовых коэффициентов может, например, принимать входной аудиосигнал 310 и/или (промежуточный) прямой сигнал 322. Цель вычисления 330 спектральных весовых коэффициентов состоит в обеспечении спектральных весовых коэффициентов 332 для повышающего микширования прямого сигнала и для повышающего микширования окружающего сигнала в зависимости от (оценочных) положений или направлений источников сигнала в слуховой сцене. Вычисление спектральных весовых коэффициентов может, например, определять эти спектральные весовые коэффициенты на основе анализа входного аудиосигнала 310. Вообще говоря, анализ входного аудиосигнала 310 позволяет вычислению 330 спектральных весовых коэффициентом оценивать положение или направление, из которого исходит звук конкретного спектрального бина (или прямое извлечение спектральных весовых коэффициентов). Например, вычисление 330 спектральных весовых коэффициентов может сравнивать (или, говоря в общем, оценивать) амплитуды и/или фазы спектрального бина (или множества спектральных бинов) каналов входного аудиосигнала (например, левого канала и правого канала). На основании такого сравнения (или оценки), может быть извлечена (явная или неявная) информация о том, из какого положения или направления исходит спектральный компонент в рассматриваемом спектральном бине. Соответственно, на основании оценки того, из какого положения или направления исходит звук определённого спектрального бина, можно сделать вывод о том, в какой канал или каналы сигнала аудиоканала (с повышающим микшированием) должно быть осуществлено повышающее микширование спектрального компонента (и с использованием какой интенсивности и масштабирования). Другими словами, спектральные весовые коэффициенты 332, полученные вычислением 330 спектральных весовых коэффициентов, могут, например, определять, для каждого канала (промежуточного) прямого сигнала 322, присвоение весовых коэффициентов, которое должно быть использовано при повышающим микшировании 340 прямого сигнала.
Другими словами, повышающее микширование 340 прямого сигнала может принимать (промежуточный) прямой сигнал 322 и спектральные весовые коэффициенты 332 и, следовательно, извлекать прямой аудиосигнал 342, который может содержать Q каналов, при Q > N. Более того, каналы прямых аудиосигналов 342 с повышающим микшированием могут, например, соответствовать каналам 252a, 252b, 252c прямого сигнала. Например, спектральные весовые коэффициента 332, полученные вычислением 330 спектральных весовых коэффициентов, могут определять матрицу Gp повышающего микширования, которая определяет весовые коэффициенты, ассоциированные с N каналами (промежуточного) прямого сигнала 322 при вычислении Q каналов прямого аудиосигнала 342 с повышающим микшированием. Спектральные весовые коэффициента и, следовательно, матрица Gp повышающего микширования, используемая повышающим микшированием 340, могут, например, отличаться от спектрального бина к спектральному бину (или между разными блоками спектральных бинов).
Аналогичным образом, спектральные весовые коэффициенты 332, полученные вычислением 330 спектральных весовых коэффициентов, могут также быть использованы при повышающем микшировании 350 (промежуточного) окружающего сигнала 324. Повышающее микширование 350 может принимать спектральные весовые коэффициенты 332 и (промежуточный) окружающий сигнал, который может содержать N каналов 324, и обеспечивать на их основе окружающий сигнал 352 с повышающим микшированием, который может содержать Q каналов, при Q > N. Например, Q каналов окружающего аудиосигнала 352 с повышающим микшированием могут, например, соответствовать каналам 254a, 254b, 254c окружающего сигнала. Также повышающее микширование 350 может, например, соответствовать распределению 240 окружающего сигнала, показанному на Фиг. 2 и распределению 140 окружающего сигнала, показанному на Фиг. 1a или Фиг. 1b.
Вновь спектральные весовые коэффициенты 332 могут определять матрицу повышающего микширования, которая описывает вклады (весовые коэффициенты) N каналов (промежуточного) окружающего сигнала 324, полученного разложением 320 на прямой и окружающий сигналы, в обеспечение Q каналов окружающего аудиосигнала 352 с повышающим микшированием.
Например, повышающее микширование 340 и повышающее микширование 350 могут использовать одну и ту же матрицу Gp повышающего микширования. Однако, также возможно использование разных матриц повышающего микширования.
Вновь, повышающее микширование окружающего сигнала является зависимым от частоты и может быть выполнено отдельно (с использованием разных матриц Gp для разных спектральных бинов или для разных групп спектральных бинов).
Факультативные подробности в отношении возможного вычисления спектральных весовых коэффициентов, которое выполняется вычислением 330 спектральных весовых коэффициентов, будут описаны ниже.
Более того, следует отметить, что функциональные возможности, описанные в данном документе, например, в отношении вычисления 330 спектральных весовых коэффициентов, в отношении повышающего микширования 340 прямого сигнала и в отношении повышающего микширования 350 окружающего сигнала могут не обязательно быть включены в варианты осуществления в соответствии с Фиг. 1 и 2, либо по отдельности, либо взятые в сочетании.
Ниже упрощенный пример вычисления спектральных весовых коэффициентов будет описан при обращении к Фиг. 4. Однако следует отметить, что вычисление спектральных весовых коэффициентов может, например, быть выполнено, как описано в документе WO 2013004698 A1.
Однако, следует отметить, что также могут быть использованы разные концепции для вычисления спектральных весовых коэффициентов, которые предназначены для повышающего микширования N-канального сигнала в Q-канальный сигнал. Однако, следует отметить, что спектральные весовые коэффициенты, которые традиционно применяются в повышающем микшировании на основе входного аудиосигнала, теперь применяются в повышающем микшировании окружающего сигнала 324, полученного разложением 320 на прямой и окружающий сигналы (на основе входного аудиосигнала). Однако, определение спектральных весовых коэффициентов может по-прежнему быть выполнено на основе входного аудиосигнала (перед разложением на прямой и окружающий сигналы) или на основе (промежуточного) прямого сигнала. Другими словами, определение спектральных весовых коэффициентов может быть аналогичным или идентичным традиционному определению спектральных весовых коэффициентом, но, в вариантах осуществления в соответствии с настоящим изобретением, спектральные весовые коэффициенты применяются к разным типам сигналов, а именно выделенному окружающему сигналу, чтобы тем самым улучшить слуховое восприятие.
Ниже упрощенный пример для определения спектральных весовых коэффициентов будет описан при обращении к Фиг. 4. Представление в частотной области двухканального входного аудиосигнала (например, сигнала 310) показано под номером 410 позиции. Левый столбец 410a представляет собой спектральные бины первого канала входного аудиосигнала (например, левый канал), а правый столбец 418b представляет собой спектральные бины второго канала (например, правого канала) входного аудиосигнала (например, входного аудиосигнала 310). Разные строки 419a-419d ассоциированы с разными спектральными бинами.
Более того, разные интенсивности сигнала указываются разным заполнением соответствующих полей в представлении 410, как показано условными обозначениями 420.
Другими словами, представление сигнала под номером 410 позиции может представлять собой представление в частотной области входного аудиосигнала X в определённое время (например, для определённого кадра) и по множеству частотных бинов (с индексом k). Например, в первом спектральном бине, показанном в строке 419a, сигналы первого канала и второго канала могут иметь приблизительно идентичные интенсивности (например, средняя сила сигнала). Это может, например, указывать на то (или предполагать), что источник звука находится приблизительно перед слушателем, т.е. в центральной области. Однако, при рассмотрении второго спектрального бина, который представлен в строке 419b, может быть видно, что сигнал в первом канале значительно сильнее, чем сигнал во втором канале, что может указывать на то, например, что источник звука находится на конкретной стороне (например, на левой стороне) слушателя. В третьем спектральном бине, который представлен в строке 419c, сигнал сильнее в первом канале при сравнении со вторым каналом, при этом разность (относительная разность) может быть меньше, чем во втором спектральном бине (показанном в строке 419b). Это может указывать на то, что источник звука несколько смещен от центра, например, несколько смещен в левую сторону, если смотреть с точки зрения слушателя.
Ниже будут описаны спектральные весовые коэффициенты. Представление спектральных весовых коэффициентов показано под номером 440 позиции. Четыре столбца с 448a по 448d ассоциированы с разными каналами сигнала с повышающим микшированием (т.е. прямого аудиосигнала 342 с повышающим микшированием и/или окружающего аудиосигнала 352 с повышающим микшированием). Другими словами, предполагается, что Q=4 в примере, показанном под номером 440 позиции. Строки с 449a по 449e ассоциированы с разными спектральными бинами. Однако, следует отметить, что каждая из строк с 449a по 449e содержит две строки чисел (спектральных весовых коэффициентов). Первая, верхняя строка чисел в каждой из строк 449a-449e представляет собой вклад первого канала (промежуточного прямого сигнала и/или промежуточного окружающего сигнала) в каналы соответствующего сигнала с повышающим микшированием (например, прямого аудиосигнала с повышающим микшированием или окружающего аудиосигнала с повышающим микшированием) для соответствующего спектрального бина. Аналогичным образом, вторая строка чисел (спектральные весовые коэффициенты) описывает вклад второго канала промежуточного прямого сигнала или промежуточного окружающего сигнала в разные каналы соответствующего сигнала с повышающим микшированием (прямого аудиосигнала с повышающим микшированием и/или окружающего аудиосигнала с повышающим микшированием) для соответствующего спектрального бина.
Следует отметить, что каждая строка 449a 449b, 449c, 449d, 449e может соответствовать транспонированной версии матрицы Gp повышающего микширования.
Ниже будет описана некоторая логика в отношении того, каким образом коэффициенты повышающего микширования могут быть извлечены из входного аудиосигнала. Однако, нижеследующее объяснение должно считаться только упрощенными примерами для облегчения фундаментального понимания настоящего изобретения. Однако, следует отметить, что нижеследующие примеры сосредоточены только на амплитудах и с оставленными неучтенными фазами, при том, что фактические реализации также могут учитывать фазы. Кроме того, следует отметить, что использованные алгоритмы могут быть более сложными, например, как описано в ссылочных документах.
Обращаясь теперь к первому спектральному бину, можно обнаружить (например, путем вычисления спектральных весовых коэффициентов), что амплитуды первого канала и второго канала входного аудиосигнала похожи, как показано в строке 419a. Соответственно, можно сделать вывод, путем вычисления 230 спектральных весовых коэффициентов, о том, что для первого спектрального бина, первый канал (промежуточного) прямого сигнала и/или (промежуточного) окружающего сигнала должен вносить свой вклад во второй канал (канала 2’) прямого аудиосигнала с повышающим микшированием или окружающего аудиосигнала с повышающим микшированием (только). Соответственно, подходящий спектральный весовой коэффициент в 0.5 можно видеть в верхней строчке строки 449a. Аналогичным образом, можно сделать вывод, путем вычисления спектрального весового коэффициента, о том, что второй канал (промежуточного) прямого сигнала и/или промежуточного окружающего сигнала должен вносить свой вклад в третий канал (канал 3’) прямого аудиосигнала с повышающим микшированием и/или окружающего аудиосигнала с повышающим микшированием, как может быть видно из соответствующего значения 0.5 во второй строчке первой строки 449a. Например, можно предположить, что второй канал (канал 2’) и третий канал (канал 3’) прямого аудиосигнала с повышающим микшированием и окружающего аудиосигнала с повышающим микшированием сравнительно близки к центру слуховой сцены, при том, что, например, первый канал (канал 1’) и четвертый канала (канал 4’) отдалены от центра слуховой сцены. Таким образом, если путем вычисления 330 спектральных весовых коэффициентов обнаруживается, что аудиоисточник находится приблизительно перед слушателем, то спектральные весовые коэффициенты могут быть выбраны таким образом, что рендеринг компонентов окружающего сигнала, возбуждаемых данным аудиоисточником, будет осуществляться (или главным образом осуществляется) в одном или более каналах, близких к центру аудиосцены.
Обращаясь теперь к второму спектральному бину может быть видно в строке 419b, что источник звука вероятно находится с левой стороны слушателя. Следовательно, вычисление 330 спектральных весовых коэффициентов может выбирать спектральные весовые коэффициенты таким образом, что окружающий сигнал данного спектрального бина будет включен в канал окружающего аудиосигнала с повышающим микшированием, который предназначен для громкоговорителя далеко на левой стороне слушателя. Соответственно, для данного второго частотного бина может быть принято решение, путем вычисления 330 спектральных весовых коэффициентов, о том, что окружающие сигналы для данного спектрального бина должны быть включены только в первый канал (канал 1’) окружающего аудиосигнала с повышающим микшированием. Это может быть осуществлено, например, путем выбора спектрального весового коэффициента, ассоциированного с первым каналом с повышающим микшированием (каналом 1’), отличным от 0 (например, 1) и путем выбора других спектральных весовых коэффициентов (ассоциированных с другими каналами 2’, 3’, 4’ повышающего микширования) как равных 0. Таким образом, если обнаруживается, путем вычисления 330 спектральных весовых коэффициентов, что аудиоисточник находится сильно слева аудиосцены, то вычисление спектральных весовых коэффициентов выбирает спектральные весовые коэффициенты таким образом, что компоненты окружающего сигнала в соответствующем спектральном бине распределяются (в отношении них осуществляется повышающее микширование) по (одному или более) каналам окружающего аудиосигнала с повышающим микшированием, которые ассоциированы с громкоговорителями с левой стороны аудиосцены. Конечно, если обнаруживается, путем вычислений 330 спектральных весовых коэффициентом, что аудиоисточник находится с правой стороны аудиосцены (при рассмотрении входного аудиосигнала или прямого сигнала, то вычисление 330 спектральных весовых коэффициентов выбирает спектральные весовые коэффициенты таким образом, что соответствующие спектральные компоненты выделенного окружающего сигнала будут распределены (в отношении них будет осуществлено повышающее микширование) по (одному или более) каналам окружающего аудиосигнала с повышающим микшированием, которые ассоциированы с положениями громкоговорителя с правой стороны аудиосцены.
В качестве третьего примера, рассматривается третий спектральный бин. В третьем спектральном бине, вычисление 330 спектральных весовых коэффициентов может обнаруживать, что аудиоисточник находится «несколько» с левой стороны аудиосцены (но не очень далеко с левой стороны аудиосцены). Например, это может быть видно из того факта, что присутствует сильный сигнал в первом канале и средний сигнал во втором канале (см. строку 419c).
В данном случае вычисление 330 спектральных весовых коэффициентов может устанавливать спектральные весовые коэффициенты таким образом, что компонент окружающего сигнала в третьем спектральном бине распределяется по каналам 1’ и 2’ окружающего аудиосигнала с повышающим микшированием, что соответствует расположению окружающего сигнала несколько с левой стороны слуховой сцены (но не очень далеко с левой стороны аудиосцены).
В заключение, путем подходящего выбора спектральных весовых коэффициентов, вычисление 330 спектральных весовых коэффициентов может определять, где располагаются (или как панорамируются) выделенные компоненты окружающего сигнала в сцене аудиосигнала. Расположение компонентов окружающего сигнала выполняется, например, на основе спектральный бин за спектральным бином. Решение о том, где в спектральной сцене должен быть расположен конкретный частотный бин выделенного окружающего сигнала, может быть принято на основе анализа входного аудиосигнала или на основе анализа выделенного прямого сигнала. Также может быть учтена временная задержка между прямым сигналом и окружающим сигналом таким образом, что спектральные весовые коэффициенты, используемые при повышающем микшировании 350 окружающего сигнала, могут быть задержаны по времени (например, на один или более кадров) в сравнении со спектральными весовыми коэффициентами, использованными при повышающем микшировании 340 прямого сигнала.
Однако, фазы и разности фаз входных аудиосигналов или выделенных прямых сигналов также могут быть учтены вычислением спектральных весовых коэффициентов. Также, спектральные весовые коэффициенты могут, конечно, быть определены образом с точной регулировкой. Например, не требуется, чтобы спектральные весовые коэффициенты представляли собой распределение канала (промежуточного) окружающего сигнала в точно одном канале окружающего аудиосигнала с повышающим микшированием. Наоборот, ровное распределение по множеству каналов или даже по всем каналам может быть указано посредством спектральных весовых коэффициентов.
Следует отметить, что функциональные возможности, описанные при обращении к Фиг. 3 и 4 могут при необходимости быть использованы в любом из вариантов осуществления в соответствии с настоящим изобретением. Однако, также могут быть использованы другие концепции для выделения окружающего сигнала и распределения окружающего сигнала.
Также следует отметить, что признаки, функциональные возможности и подробности, описанные в отношении Фиг. 3 и 4 могут быть введены в другие варианты осуществления по отдельности или в сочетании.
4) Способ в соответствии с Фиг. 5
Фиг. 5 показывает блок-схему способа 500 обеспечения каналов окружающего сигнала на основе входного аудиосигнала.
Способ содержит, на этапе 510, выделение (промежуточного) окружающего сигнала на основе входного аудиосигнала. Способ 500 дополнительно содержит, на этапе 520, распределение (выделенного промежуточного) окружающего сигнала по множеству каналов окружающего сигнала (с повышающим микшированием), при этом количество каналов окружающего сигнала больше, чем количество каналов входного аудиосигнала, в зависимости от положений или направлений источников звука во входном аудиосигнале.
Способ 500 в соответствии с Фиг. 5 может быть дополнен любым из признаков и функциональных возможностей, описанных в данном документе, либо по отдельности, либо в сочетании. В частности, следует отметить, что способ 500 в соответствии с Фиг. 5 может быть дополнен любым из признаков и функциональных возможностей и подробностей, описанных в отношении процессора аудиосигнала и/или в отношении системы.
5) Способ в соответствии с Фиг. 6
Фиг. 6 показывает блок-схему способа 600 рендеринга аудиоконтента, представленного многоканальным входным аудиосигналом.
Способ содержит обеспечение 610 каналов окружающего сигнала на основе входного аудиосигнала, при этом обеспечивается более двух каналов окружающего сигнала. Обеспечение каналов окружающего сигнала может, например, быть выполнено в соответствии со способом 500, описанным в отношении Фиг. 5.
Способ 600 также содержит обеспечение 620 более двух каналов прямого сигнала.
Способ 600 также содержит подачу 630 каналов окружающего сигнала и каналов прямого сигнала на систему громкоговорителей, содержащую набор громкоговорителей прямого сигнала и набор громкоговорителей окружающего сигнала, при этом каждый из каналов прямого сигнала подается по меньшей мере на один из громкоговорителей прямого сигнала, и при этом каждый из каналов окружающего сигнала подается по меньшей мере на один из громкоговорителей окружающего сигнала.
Способ 600 может быть при необходимости дополнен любым из признаков и функциональных возможностей и подробностей, описанных в данном документе, либо по отдельности, либо в сочетании. Например, способ 600 также может быть дополнен признаками, функциональными возможностями и подробностями, описанными в отношении процессора аудиосигнала или в отношении системы.
6) Дополнительные аспекты и варианты осуществления
Ниже будет представлен вариант осуществления в соответствии с настоящим изобретением. В частности, будут представлены подробности, которые могут быть перенесены в любой из других вариантов осуществления, либо по отдельности, либо взятые в сочетании. Следует отметить, что будет описан способ, который, однако, может быть выполнен устройствами и системой, упомянутыми в данном документе.
6.1 Обзор
Ниже будет представлен обзор. Признаки, описанные в обзоре, могут формировать вариант осуществления, или могут быть введены в другие варианты осуществления, описанные в данном документе.
Варианты осуществления в соответствии с настоящим изобретением вводят отделение окружающего сигнала, где окружающий сигнал сам разделяется на компоненты сигнала в соответствии с положением их исходного сигнала (например, в соответствии с положением аудиоисточников, возбуждающих окружающий сигнал). Несмотря на то, что все окружающие сигналы являются рассеянными и, вследствие этого, не обладают локализуемым положением, многие окружающие сигналы, например, реверберация, формируются из (прямого) сигнал возбуждения с локализуемым положением. Полученный окружающий выходной сигнал (например, каналы с 112a по 112c окружающего сигнала или каналы с 254a по 254c окружающего сигнала или окружающий аудиосигнал 352 с повышающим микшированием) имеет больше каналов (например, Q каналов), чем входной сигнал (например, N каналов), где выходные каналы (например, каналы окружающего сигнала) соответствуют положениям сигнала прямого источника, который создает компонент окружающего сигнала.
Полученный многоканальный окружающий сигнал (например, представленный каналами с 112a по 112c окружающего сигнала или каналами с 254a по 254c окружающего сигнала или окружающим аудиосигналом 352 с повышающим микшированием) необходим для повышающего микширования аудиосигналов, т.е. для создания сигнала с Q каналами при определённом входном сигнале с N каналами, где Q > N. Рендеринг выходных сигналов в системе воспроизведения многоканального звука описан ниже (и также в некоторой степени в вышеприведённом описании).
6.2 Предложенный рендеринг выделенного сигнала
Важный аспект представленного способа (и концепции) состоит в том, что выделенные компоненты окружающего сигнала (например, выделенный окружающий сигнал 130 или выделенный окружающий сигнал 230 или выделенный окружающий сигнал 324) распределяются по сигналам окружающего канала (например, по сигналам с 112a по 112c или по сигналам с 254a по 254c, или по каналам окружающего аудиосигнала 352 с повышающим микшированием) в соответствии с положением их сигнала возбуждения (например, источника прямого звука, возбуждающего соответствующие окружающие сигналы или компоненты окружающего сигнала). В целом, все каналы (громкоговорители) могут быть использованы для воспроизведения прямых сигналов или окружающих сигналов, или как тех, так и других.
Фиг. 7 показывает общую установку громкоговорителей с двумя громкоговорителями, которая является подходящей для воспроизведения стереофонических аудиосигналов с двумя каналами. Другими словами, Фиг. 7 показывает стандартную установку громкоговорителей с двумя громкоговорителями (с левой и правой стороны, «L», «R», соответственно) для двухканальной стереофонии.
Когда доступна установка громкоговорителей с большим числом каналов, двухканальный входной сигнал (например, входной аудиосигнал 110 или входной аудиосигнал 210, или входной аудиосигнал 310) может быть разделен на множество канальных сигналов, и дополнительные выходные сигналы подаются на дополнительные громкоговорители. Данный процесс формирования и вывода сигнала с большим количеством каналов, чем доступные входные каналы, обычно упоминается как повышающее микширование.
Фиг. 8 иллюстрирует установку громкоговорителей с четырьмя громкоговорителями. Фиг. 8 показывает квадрафоническую установку громкоговорителей с четырьмя громкоговорителями (передний левый «fL», передний правый «fR», задний левый «rL», задний правый «rR»). Сформулировав иначе, Фиг. 8 иллюстрирует установку громкоговорителей с четырьмя громкоговорителями. Чтобы воспользоваться преимуществом всех четырех громкоговорителей при воспроизведении сигнала с двумя каналами, например, входной сигнал (например, входной аудиосигнал 110 или входной аудиосигнал 210, или входной аудиосигнал 310) может быть разбит на сигнал с четырьмя каналами.
Другая установка громкоговорителей показана на Фиг. 9 с восемью громкоговорителями, где четыре громкоговорителя (громкоговорители «возвышения») приподняты, например, смонтированы ниже потолка помещения для прослушивания. Другими словами, Фиг. 9 показывает квадрафоническую установку громкоговорителей с дополнительными громкоговорителями возвышения, помеченными «h».
При воспроизведении аудиосигналов с использованием установок громкоговорителей с большим количеством каналов, чем входной сигнал, обычной практикой является разложение входного сигнала на существенные компоненты сигнала. Для приведенного примера, все прямые звуки подаются на один из четырех нижних громкоговорителей таким образом, что источники звука, в отношении которых осуществляется панорамирование по сторонам входного сигнала воспроизводятся задними громкоговорителями «rL» и «rR». Для источников звука, в отношении которых осуществляется панорамирование в центр или немного от центра, панорамирование осуществляется по передним громкоговорителям «fL» и «fR». Таким образом, источники прямого звука могут быть распределены по громкоговорителям в соответствии с их воспринимаемым положением в стерео-панораме. Традиционные способы вычисляют окружающие сигналы с тем же самым количеством каналов, как то, которое имеют входные сигналы. При повышающем микшировании двухканального стерео входного сигнала, двухканальный окружающий сигнал либо подается на поднабор доступных громкоговорителей, либо распределяется по всем четырем громкоговорителям путем подачи одного сигнала окружающего канала на множество громкоговорителей.
Важным аспектом представленного способа является отделение окружающего сигнала с Q каналами из входных сигналов с N каналами при Q > N. Для приведенного примера, окружающий сигнал с четырьмя каналами вычисляется таким образом, что в отношении окружающих сигналов, которые возбуждаются от источников прямого звука, панорамирование осуществляется в направлении этих сигналов.
В данном аспекте следует отметить, что, например, вышеупомянутое распределение источников прямого звука по громкоговорителям может быть выполнено путем взаимодействия разложения 220 на прямой и окружающий сигналы и распределения 240 окружающего сигнала. Например, вычисление 330 спектральных весовых коэффициентов может определять спектральные весовые коэффициенты таким образом, что повышающее микширование прямого сигнала выполняет распределение источников прямого сигнала как описано здесь (например, таким образом, что источники звука, панорамирование которых осуществляется по сторонам входного сигнала, воспроизводятся задними громкоговорителями, и таким образом, что для источников звука, панорамирование которых осуществляется в центр или немного от центра, панорамирование осуществляется в передние громкоговорители).
Более того, следует отметить, что четыре нижних громкоговорителя, упомянутых выше (fL, fR, rL, rR), могут соответствовать громкоговорителям с 262a по 262c. Более того, громкоговорители h возвышения могут соответствовать громкоговорителям c 264a по 264c.
Другими словами, вышеупомянутая концепция для распределения прямых звуков также может реализована в системе 200 в соответствии с Фиг. 2, и может быть достигнута путем обработки, объясненной в отношении Фиг. 3 и 4.
6.3. Способ отделения сигнала
Ниже будет описан способ отделения сигнала, который может быть использован в вариантах осуществления в соответствии с изобретением.
В реверберирующей среде (звукозаписывающая студия или концертный зал) источники звука формируют реверберацию и тем самым вносят свой вклад в окружение, вместе с другими рассеянными звуками, аналогичными звукам аплодисментов и рассеянному шуму окружающей среды (например, шум ветра или дождя). Для большинства музыкальных записей реверберация является наиболее заметным окружающим сигналом. Она может быть сформирована акустическим образом путем записи источников звука в помещении или путем подачи сигнала громкоговорителя в помещении и записи сигнала реверберации с помощью микрофона. Реверберация также может быть искусственно сформирована посредством обработки сигнала.
Реверберация создается источниками звука, которые отражаются на границах (стена, пол, потолок). Более ранние отражения обладают, как правило, наибольшей величиной и достигают микрофона первыми. Отражения в дальнейшем отражаются с затухающими величинами и вносят свой вклад в реверберацию с задержкой. Данный процесс может быть смоделирован в качестве аддитивной смеси множества отмасштабированных и с задержкой копий сигнала источника. Вследствие этого он часто реализуется посредством свертывания.
Повышающее микширование может быть выполнено либо с управлением путем использования дополнительной информации, либо без управления путем использования исключительно входного аудиосигнала без какой-либо дополнительной информации. В данном документе мы сосредоточим своё внимание на более сложной процедуре слепого повышающего микширования. Аналогичные концепции могут быть применены при использовании подхода с управлением посредством подходящих метаданных.
Предполагается, что входной сигнал x(t) является аддитивной смесью прямого сигнала d(t) и окружающего сигнала a(t).
x(t) = d(t) + a(t). (1)
Все сигналы имеют множество канальных сигналов. i-ый канальный сигнал входного, прямого или окружающего сигнала обозначается как xi(t), di(t) и ai(t), соответственно. Тогда многоканальные сигналы могут быть записаны как x(t) = [x1(t) … xN(t)]T , d(t) = [d1(t) … dN(t)]T и a(t) = [a1(t) … aN(t)]T, где N является количеством каналов.
Обработка (например, обработка, которая выполняется устройствами и способами в соответствии с настоящим изобретением; например, обработка, которая выполняется устройством 100 или системой 200, или обработка, как показано на Фиг. 3 и 4) осуществляется в частотно-временной области путем использования кратковременного преобразования Фурье или другой гребенки фильтров восстановления. В частотно-временной области модель сигнала записывается как
X(m, k) = D(m, k) + A(m, k), (2)
где X(m, k), D(m, k) и A(m, k) являются спектральными коэффициентами x(t), d(t) и a(t), соответственно, m обозначает индекс времени, а k обозначает индекс частотного бина (или субполосы). Ниже индексы времени и субполосы при возможности не рассматриваются.
Сам прямой сигнал может состоять из множества компонентов  сигнала, которые формируются множеством источников звука, который записывается в записи в частотной области как
сигнала, которые формируются множеством источников звука, который записывается в записи в частотной области как
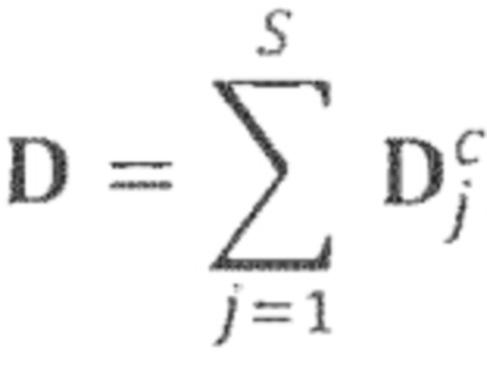 , (3)
, (3)
и в записи во временной области как
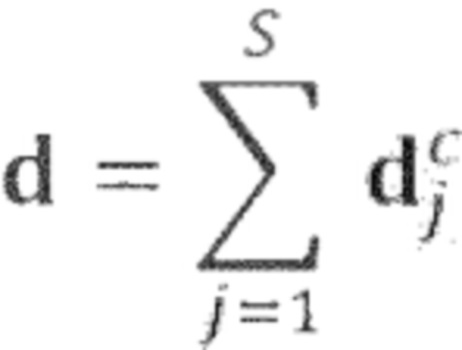 , (4)
, (4)
где S является количеством источников звука. В отношении компонентов сигнала осуществляется панорамирование по разным положениям.
Формирование компонента rc сигнала реверберации посредством компонента dc прямого сигнала моделируется как линейный инвариантный во времени (LTI) процесс и может во временной области быть синтезирован посредством свертывания прямого сигнала с импульсной характеристикой, отличающей процесс реверберации.
rc=hc * dc, (5)
Импульсные характеристики процессов реверберации, которые используются для производства музыки, являются затухающими, часто экспоненциально затухающими. Затухание может быть указано посредством времени реверберации. Время реверберации является времени, после которого уровень сигнал реверберации затухает до доли первоначального звука после того, как первоначальный звук затих. Время реверберации может, например, быть указано как «RT60», т.е. время, которое требуется для того, чтобы сигнал реверберации уменьшился до 60дБ. Время RT60 реверберации обычных помещений, залов и других процессов реверберации находится в диапазоне от 100мс до 6с.
Следует отметить, что вышеупомянутые модели сигналов x(t), x(t), X(m, k) и rc, описанные выше, могут представлять характеристики входного аудиосигнала 110, входного аудиосигнала 210 и/или входного аудиосигнала 310, и могут быть использованы при выполнении выделения 120 окружающего сигнала или при выполнении разложения 220 на прямой и окружающий сигналы или разложения 320 на прямой и окружающий сигналы.
Ниже будет описана ключевая концепция, лежащая в основе настоящего изобретения, которая может быть применена в устройстве 100, в системе 200 и реализована функциональными возможностями, описанными в отношении Фиг. 3 и 4.
В соответствии с аспектом настоящего изобретения предлагается отделить (или обеспечить) окружающий сигнал 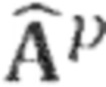 с Q каналами. Например, способ содержит следующее:
с Q каналами. Например, способ содержит следующее:
1. отделяют окружающий сигнал 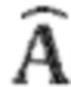 с N каналами,
с N каналами,
2. вычисляют спектральные весовые коэффициенты (7) для отделения источников звука в соответствии с их положением в пространственном образе из входного сигнала, для всех положений p=1…P,
3. осуществляют повышающее микширование полученного окружающего сигнала на Q каналов посредством присвоения спектральных весовых коэффициентов (6).
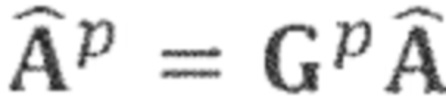 (6)
(6)
Например, отделение окружающего сигнала 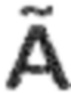 с N каналами может быть выполнено путем выделения 120 окружающего сигнала или путем разложения 220 на прямой и окружающий сигналы или путем разложения 320 на прямой и окружающий сигналы.
с N каналами может быть выполнено путем выделения 120 окружающего сигнала или путем разложения 220 на прямой и окружающий сигналы или путем разложения 320 на прямой и окружающий сигналы.
Более того, вычисление спектральных весовых коэффициентов может быть выполнено процессором 100 аудиосигнала или процессором 250 аудиосигнала или вычислением 330 спектральных весовых коэффициентов. Кроме того, повышающее микширование полученного окружающего сигнала на Q каналов может, например, быть выполнено распределением 140 окружающего сигнала или распределением 240 окружающего сигнала или повышающим микшированием 350. Спектральные весовые коэффициенты (например, спектральные весовые коэффициенты 332, которые могут быть представлены строками с 449a по 449e на Фиг. 4) могут, например, быть извлечены из анализа входного сигнала X (например, входного аудиосигнала 110 или входного аудиосигнала 210 или входного аудиосигнала 310).
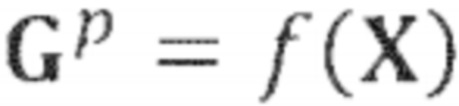 , (7)
, (7)
Спектральные весовые коэффициенты 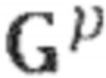 вычисляются таким образом, что они могут отделять источники звука, панорамирование которых осуществляется в позиции
вычисляются таким образом, что они могут отделять источники звука, панорамирование которых осуществляется в позиции 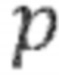 из входного сигнала. К спектральным весовым коэффициентам при необходимости применяется задержка (осуществляется временной сдвиг) перед применением к оценочному окружающему сигналу
из входного сигнала. К спектральным весовым коэффициентам при необходимости применяется задержка (осуществляется временной сдвиг) перед применением к оценочному окружающему сигналу  , чтобы учесть задержку времени в импульсной характеристике реверберации (предварительная задержка).
, чтобы учесть задержку времени в импульсной характеристике реверберации (предварительная задержка).
Для обоих этапов обработки по отделению сигнала могут быть реализованы различные способы. Ниже описаны два подходящих способа.
Однако следует отметить, что способы, описанные ниже, должны рассматриваться лишь в качестве примеров, и что способы должны быть адаптированы к конкретному применению в соответствии с изобретением. Следует отметить, что в отношении способа отделения окружающего сигнала не требуются никакие или требуются лишь незначительные изменения.
Более того, следует отметить, что вычисление весовых коэффициентов также не нуждается в сильной адаптации. Наоборот, вычисление спектральных весовых коэффициентов, упомянутое ниже, может, например, быть выполнено на основе входного аудиосигнала 110, 210, 310. Однако, спектральные весовые коэффициентов, полученные посредством способа (для вычисления спектральных весовых коэффициентов), описанного ниже, будут применены для повышающего микширования выделенного окружающего сигнала вместо повышающего микширования входного сигнала или повышающего микширования прямого сигнала.
6.4 Способ отделения окружающего сигнала
Возможный способ отделения окружающего сигнала описан в международной заявке PCT/EP2013/072170 “Apparatus and method for multi-channel direct-ambient decomposition for audio signal processing”.
Однако для отделения окружающего сигнала могут быть использованы разные способы, а также возможны модификации упомянутого способа при условии, что имеет место выделение окружающего сигнала или разложение входного сигнала на прямой сигнал и окружающий сигнал.
6.4 Способ вычисления спектральных весовых коэффициентов для пространственных положений
Возможный способ вычисления спектральных весовых коэффициентов для пространственных положений описан в международной заявке WO 2013004698 A1 “Method and apparatus for decomposing a stereo recording using frequency-domain processing employing a spectral weights generator”.
Однако следует отметить, что для получения спектральных весовых коэффициентов могут быть использованы другие способы (которые могут, например, определять матрицу Gp). Также способ в соответствии с документом WO 2013004698 A1 также может быть модифицирован при условии, что гарантируется то, что спектральные весовые коэффициенты для отделения источников звука в соответствии с их положениями в пространственном образе извлекаются для некоторого количества каналов, которое соответствует требуемому количеству выходных каналов.
7. Выводы
Ниже будут приведены некоторые выводы. Однако следует отметить, что идеи, описанные в выводах, также могут быть включены в любой из вариантов осуществления, раскрытых в данном документе.
Следует отметить, что описан способ разложения входного аудиосигнала на компоненты прямого сигнала и компоненты окружающего сигнала. Способ может быть применен к постобработке и воспроизведению звука. Цель состоит в вычислении окружающего сигнала, в котором все компоненты прямого сигнала ослаблены и слышны только компоненты рассеянного сигнала.
Важным аспектом представленного способа является то, что такие компоненты окружающего сигнала отделяются в соответствии с положением их сигнала источника. Несмотря на то, что все окружающие сигналы являются рассеянными и, вследствие этого, не обладают положением, многие окружающие сигналы, например, реверберация, формируются из прямого сигнала возбуждения с определенным положением. Полученный окружающий выходной сигнал, который может, например, быть представлен каналами с 112a по 112c окружающего сигнала или каналами с 254a по 254c окружающего сигнала или посредством окружающего аудиосигнала 352 с повышающим микшированием, имеет больше каналов (например, Q каналов), чем входной сигнал (например, N каналов), при этом выходные каналы (например, каналы с 112a по 112c окружающего сигнала или каналы с 254a по 254c) соответствуют положениям прямого сигнала возбуждения (которые могут, например, быть включены во входной аудиосигнал 110 или во входной аудиосигнал 210 или во входной аудиосигнал 310).
В качестве дополнительного вывода, различные способы были предложены для отделения компонентов сигнала (или всех компонентов сигнала) или компонентов прямого сигнала только в соответствии с их местоположениями в стерео-образе (см, например, библиографический список [2], [10], [11] и [12]). Варианты осуществления в соответствии с изобретением расширяют эту (традиционную) концепцию на компоненты окружающего сигнала.
В качестве дополнительного вывода, варианты осуществления в соответствии с изобретением относятся к выделению и повышающему микшированию окружающего сигнала. Варианты осуществления в соответствии с изобретением могут быть применены, например, в автомобильных применениях.
Варианты осуществления в соответствии с изобретением могут, например, быть применены в контексте концепции “symphoria”.
Варианты осуществления в соответствии с изобретением также могут быть применены для создания 3D-панорамы.
8. Альтернативные варианты реализации
При том, что некоторые аспекты были описаны в контексте устройства, очевидно, что эти аспекты также представляют собой описание соответствующего способа, в котором блок или устройство соответствуют этапу способа или признаку этапа способа. Аналогичным образом, аспекты, описанные в контексте этапов способа, также представляют собой описание соответствующих блоков или элементов или признаков соответствующего устройства. Некоторые или все из этапов способа могут быть осуществлены посредством (или с использованием) устройства аппаратного обеспечения, аналогичного, например, микропроцессору, программируемому компьютеру или электронной схеме. В некоторых вариантах осуществления один или более из наиболее важных этапов способа могут быть осуществлены таким устройством.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратном обеспечении или в программном обеспечении. Реализация может быть выполнена с использованием цифрового запоминающего носителя информации, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или Флэш-памяти, с хранящимися на нем электронно-читаемыми сигналами управления, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой, так что выполняется соответствующий способ. Вследствие этого, цифровой запоминающий носитель информации может быть машиночитаемым.
Некоторые варианты осуществления в соответствии с изобретением содержат носитель данных с электронно-читаемыми сигналами управления, которые способны взаимодействовать с программируемой компьютерной системой, так, что выполняется один из описанных в данном документе способов.
В целом, варианты осуществления настоящего изобретения могут быть реализованы в качестве компьютерного программного продукта с программным кодом, причем программный код работает для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может, например, быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных в данном документе, которая хранится на машиночитаемом носителе.
Другими словами, вариант осуществления способа изобретения является, вследствие этого, компьютерной программой с программным кодом для выполнения одного из способов, описанных в этом документе, при этом компьютерная программа выполняется на компьютере.
Дополнительный вариант осуществления способа изобретения является, вследствие этого, носителем данных (или цифровым запоминающим носителем информации или машиночитаемым носителем информации), содержащим, записанную на нем, компьютерную программу для выполнения одного из способов, описанных в данном документе. Носитель данных, цифровой запоминающий носитель информации или записанный носитель информации как правило являются вещественными и/или не временными.
Дополнительный вариант осуществления способа изобретения является, вследствие этого, потоком данных или последовательностью сигналов, представляющими собой компьютерную программу для выполнения одного из способов, описанных в данном документе. Поток данных или последовательность сигналов могут, например, быть выполнены с возможностью переноса через соединение связи для передачи данных, например, через Интернет.
Дополнительный варианты осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью или адаптированное для выполнения одного из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер с инсталлированной на нем компьютерной программой для выполнения одного из способов, описанных в данном документе.
Дополнительный вариант осуществления в соответствии с изобретением содержит устройство или систему, выполненные с возможностью переноса (например, электронным или оптическим образом) компьютерной программы для выполнения одного из способов, описанных в данном документе для приемника. Приемник может, например, быть компьютером, мобильным устройством, устройством памяти или аналогичным. Устройство или система могут, например, быть выполнены в виде файлового сервера для переноса компьютерной программы к приемнику.
В некоторых вариантах осуществлений программируемое логическое устройство (например, программируемая вентильная матрица) может быть использовано для выполнения некоторых или всех из функциональных возможностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая вентильная матрица может взаимодействовать с микропроцессором для того, чтобы выполнять один из способов, описанных в данном документе. В целом, способы предпочтительно выполняются любым устройством аппаратного обеспечения.
Устройство, описанное в данном документе, может быть реализовано с использованием устройства аппаратного обеспечения или с использованием компьютера, или с использованием сочетания устройства аппаратного обеспечения и компьютера.
Устройство, описанное в данном документе, или любые компоненты устройства, описанного в данном документе, могут быть реализованы по меньшей мере частично в аппаратном обеспечении и/или в программном обеспечении.
Способы, описанные в данном документе, могут быть выполнены с использованием устройства аппаратного обеспечения или с использованием компьютера, или с использованием сочетания устройства аппаратного обеспечения и компьютера.
Способы, описанные в данном документе, или любые компоненты устройства, описанного в данном документе, могут быть выполнены по меньшей мере частично посредством аппаратного обеспечения и/или программного обеспечения.
Описанные выше варианты осуществления являются лишь иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения конфигурации и подробностей, описанных в данном документе, будут очевидны специалистам в соответствующей области техники. Вследствие этого, подразумевается, что изобретение ограничено лишь объемом нижеприведённой формулы изобретения, а не конкретными подробностями, представленными в данном документе в качестве описания и пояснения вариантов осуществления.
библиографический список
[1] J.B. Allen, D.A, Berkeley и J. Blauert, “Multi- microphone signal-processing technique to remove room reverberation from speech signals”, J. Acoust. Soc. Am., том 62, 1977 г.
[2] C. Avendano и J.-M. Jot, “A frequency-domain approach to multi-channel upmix”, J. Audio Eng. Soc., том 52, 2004 г.
[3] C. Faller, “Multiple-loudspeaker playback of stereo signals”, J. Audio Eng. Soc., том 54, 2006 г.
[4] J. Merimaa, M. Goodwin и J.-M. Jot, “Correlation-based ambience extraction from stereo recordings”, в Proc. Audio Eng. Soc. /23rd Conv., 2007 г.
[5] J. Usher и J. Benesty, “Enhancement of spatial sound quality: A new reverberation extraction audio upmixer”, IEEE Trans. Audio, Speech, and Language Process., том 15, стр. 2141-2150, 2007 г.
[6] G. Soulodre, “System for extracting and changing the reverberant content of an audio input signal”, патент US 8,036,767, октябрь 2011 г.
[7] J. He, E.-L. Tan и W.-S. Gan, “Linear estimation based primary-ambient extraction for stereo audio signals”, IEEE/ACM Trans. Audio, Speech, and Language Process., том 22, № 2, 2014 г.
[8] C. Uhle и E. Habets, “Direct-ambient decomposition using parametric Wiener filtering wih spatial cue control” в Proc.Int. Conf on Acoust., Speech and Sig. Process., ICASSP, 2015 г.
[9] A. Walther и C. Faller, “Direct-ambient decomposition and upmix of surround sound signals” в Proc.IEEE WASPAA, 2011 г.
[10] D. Barry, B. Lawlor и E. Coyle, “Sound source separation: Azimuth discrimination and resynthesis” в Proc. Int. Conf Digital Audio Effects (DAFx), 2004 г.
[11] C. Uhle, “Center signal scaling using signal-to- downmix ratios” в Proc. Int. Conf. Digital Audio Effects, DAFx, 2013 г.
[12) C. Uhle и E. Habets, “Subband center signal scaling using power ratios”, в Proc. AES 53rd Conf Semantic Audio, 2014 г.
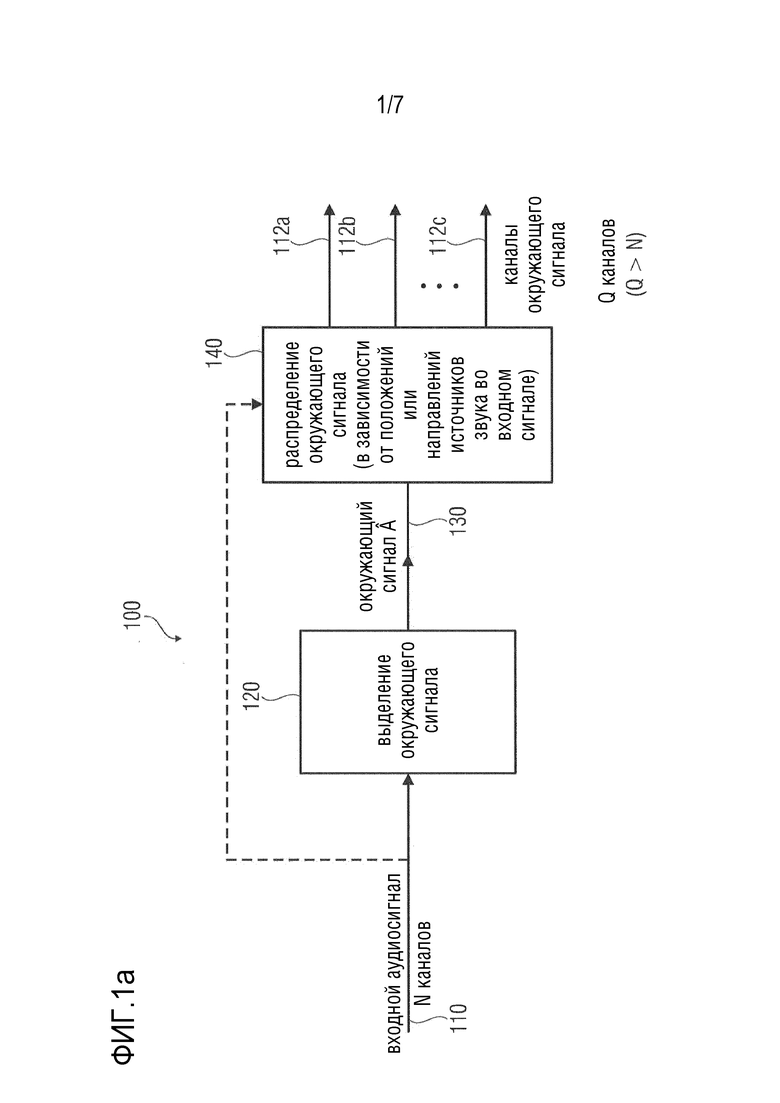
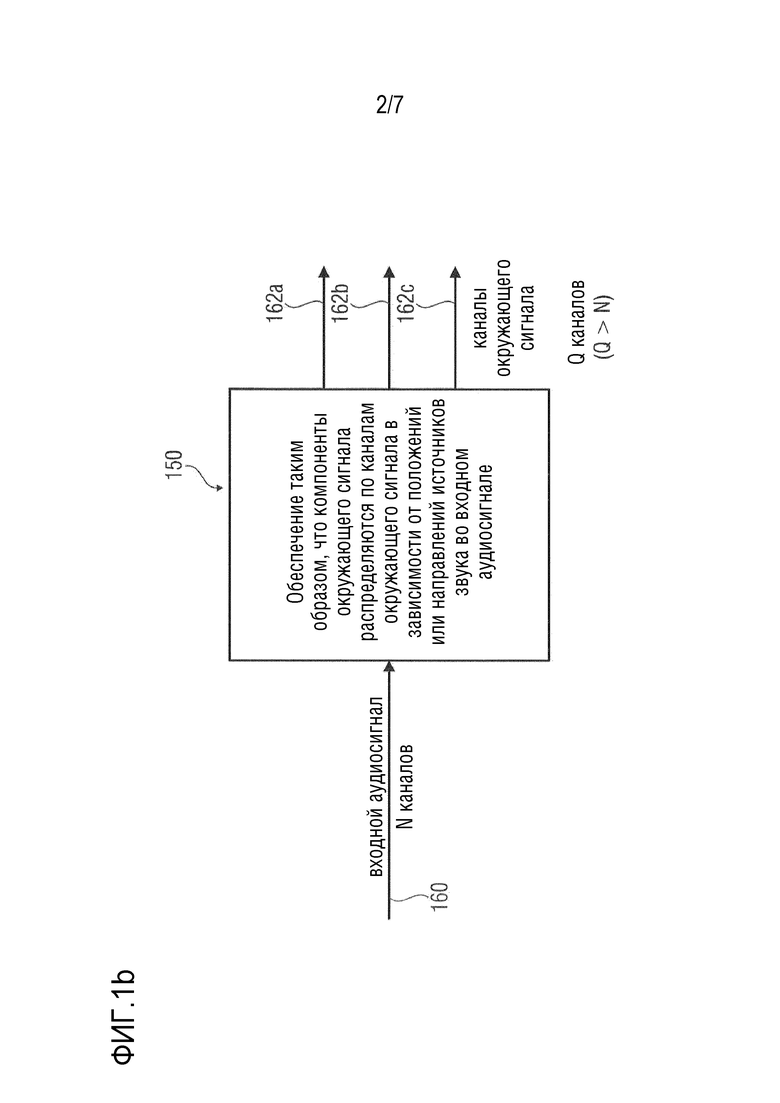
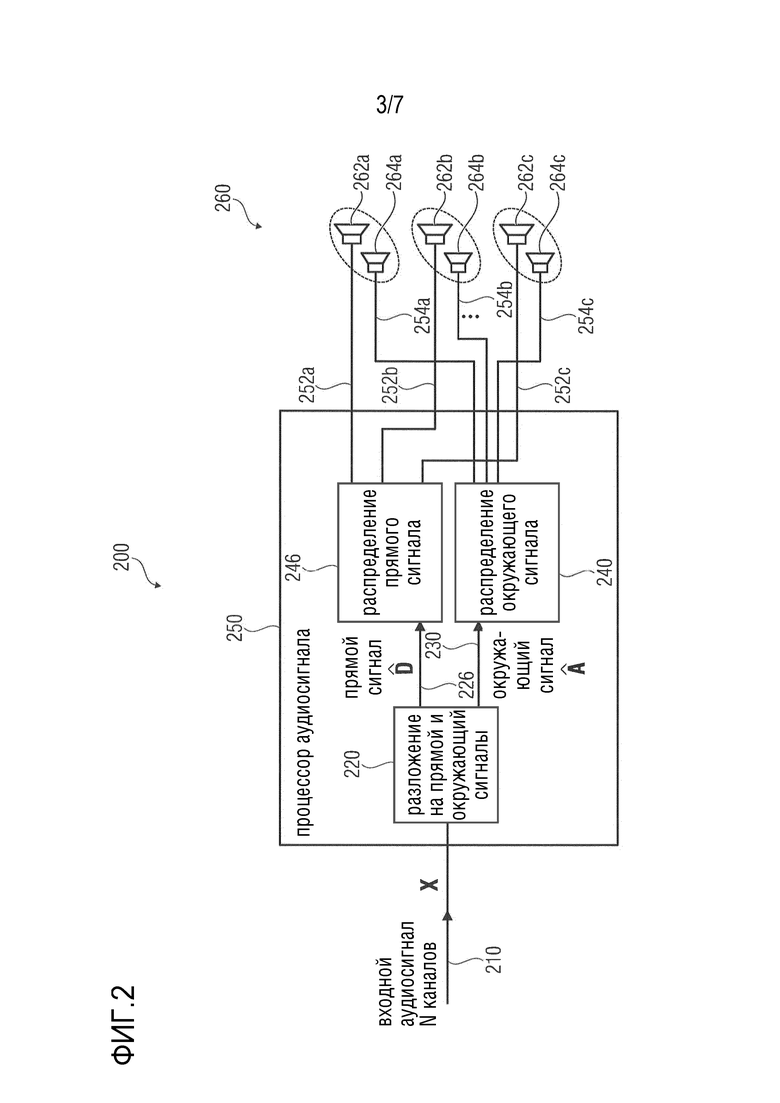
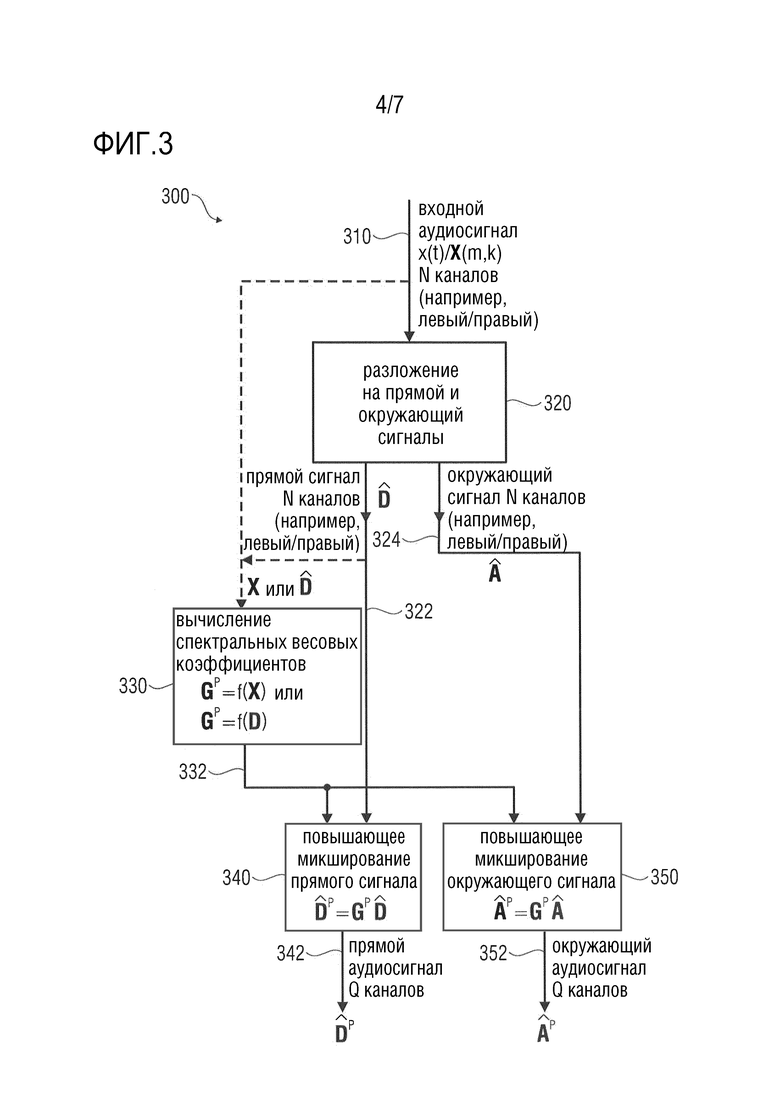
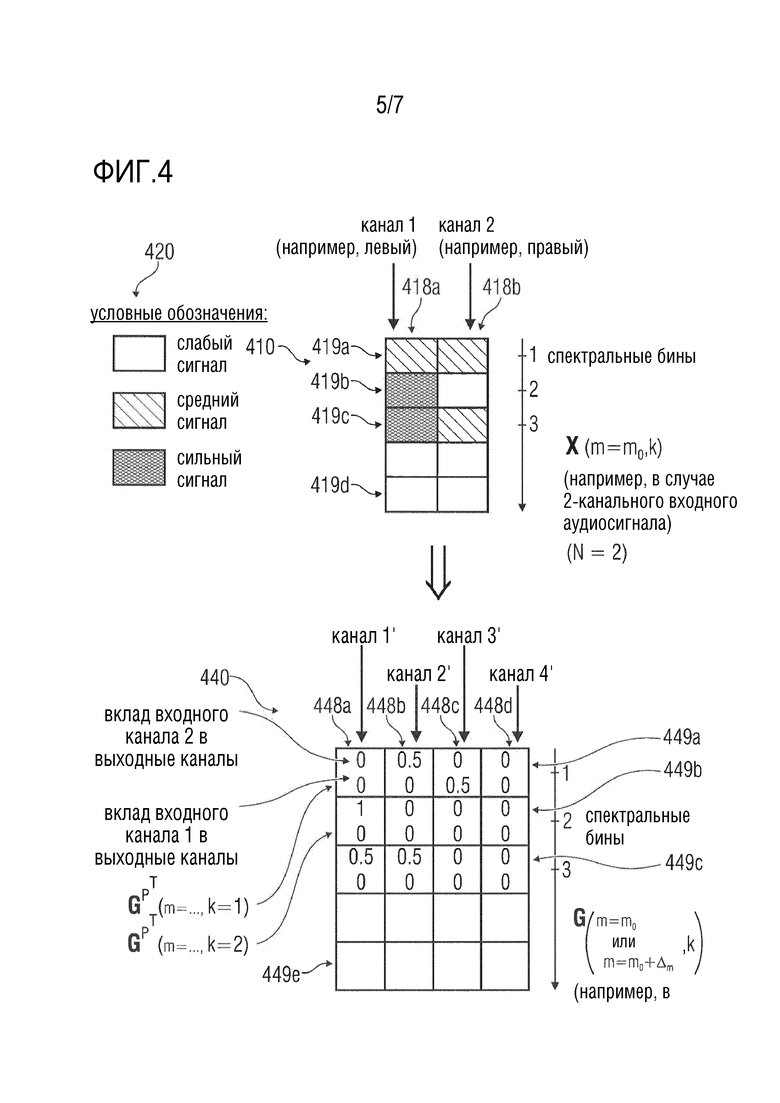
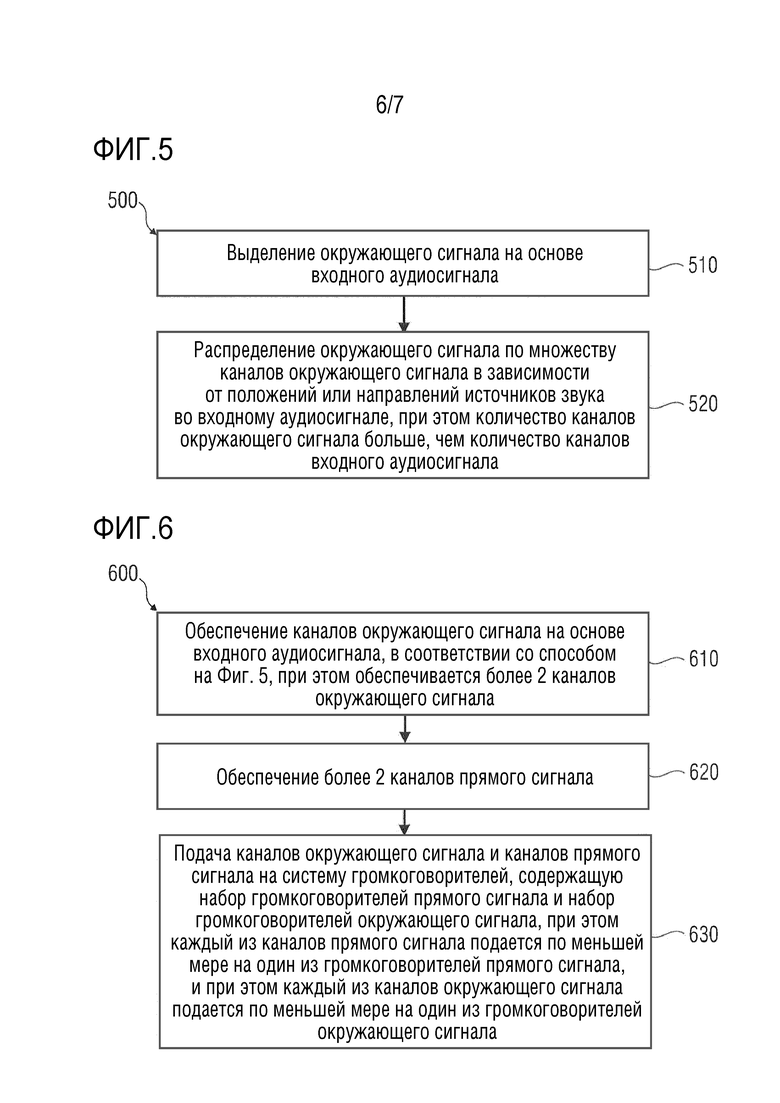
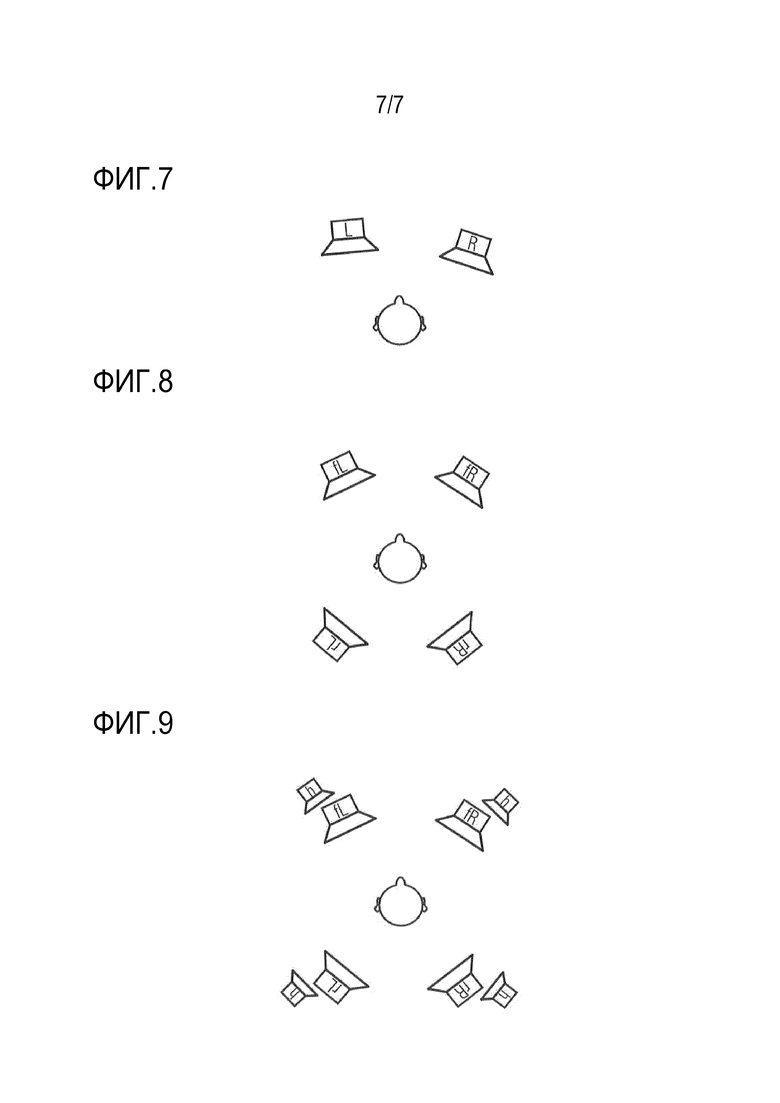
Изобретение относится к средствам для распределения сигнала по множеству каналов. Технический результат заключается в повышении эффективности получения окружающих сигналов. Получают каналы окружающего сигнала таким образом, что компоненты окружающего сигнала распределяются по каналам окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале. Количество полученных каналов окружающего сигнала, содержащих разный аудиоконтент, больше, чем количество каналов входного аудиосигнала. Получают прямой сигнал, который содержит компоненты прямого звука, на основе входного аудиосигнала. Выделяют окружающий сигнал на основе входного аудиосигнала. Распределяют окружающий сигнал по множеству каналов окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале, при этом количество каналов окружающего сигнала больше, чем количество каналов входного аудиосигнала. Каналы окружающего сигнала и каналы прямого сигнала ассоциированы с одним и тем же набором направлений, или при этом каналы окружающего сигнала ассоциированы с поднабором из набора направлений, ассоциированных с каналами прямого сигнала. 10 н. и 23 з.п. ф-лы, 10 ил.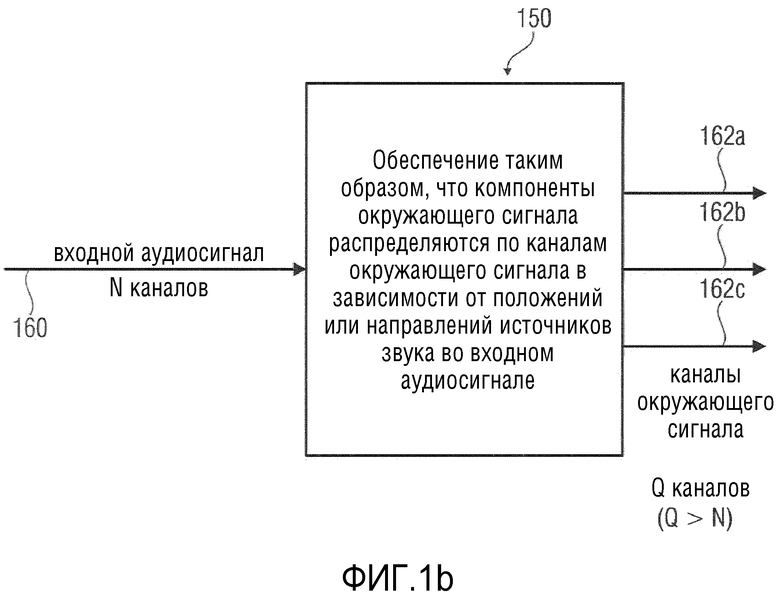
1. Процессор (100; 150; 250) аудиосигнала для обеспечения каналов (112a-112c; 162a-162c; 254a-254c; 352; 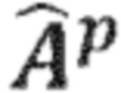 ) окружающего сигнала на основе входного аудиосигнала (110; 160; 210; 310, x(t), x(t), X(m, k)),
) окружающего сигнала на основе входного аудиосигнала (110; 160; 210; 310, x(t), x(t), X(m, k)),
при этом процессор аудиосигнала выполнен с возможностью получения каналов окружающего сигнала,
при этом количество (Q) полученных каналов окружающего сигнала, содержащих разный аудиоконтент, больше, чем количество (N) каналов входного аудиосигнала;
при этом процессор аудиосигнала выполнен с возможностью получения каналов окружающего сигнала таким образом, что компоненты окружающего сигнала распределяются по каналам окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале;
при этом процессор аудиосигнала выполнен с возможностью выделения окружающего сигнала (130; 230; 324; 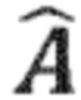 ) на основе входного аудиосигнала;
) на основе входного аудиосигнала;
при этом процессор аудиосигнала выполнен с возможностью распределения компонентов окружающего сигнала по каналам окружающего сигнала в соответствии с положениями или направлениями источников прямого звука, возбуждающих соответствующие компоненты окружающего сигнала,
таким образом, что разные компоненты окружающего сигнала, которые возбуждаются разными источниками, расположенными в разных положениях, по-разному распределяются по каналам окружающего сигнала, и
таким образом, что распределение компонентов окружающего сигнала по разным каналам окружающего сигнала соответствует распределению компонентов прямого сигнала, возбуждающих соответствующие компоненты окружающего сигнала, по разным каналам прямого сигнала.
2. Процессор (100; 150; 250) аудиосигнала для обеспечения каналов (112a-112c; 162a-162c; 254a-254c; 352; ) окружающего сигнала на основе входного аудиосигнала (110; 160; 210; 310, x(t), x(t), X(m, k)),
при этом процессор аудиосигнала выполнен с возможностью получения каналов окружающего сигнала,
при этом количество (Q) полученных каналов окружающего сигнала, содержащих разный аудиоконтент, больше, чем количество (N) каналов входного аудиосигнала;
при этом процессор аудиосигнала выполнен с возможностью получения каналов окружающего сигнала таким образом, что компоненты окружающего сигнала распределяются по каналам окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале;
при этом процессор аудиосигнала выполнен с возможностью получения прямого сигнала, который содержит компоненты прямого звука, на основе входного аудиосигнала;
при этом процессор аудиосигнала выполнен с возможностью выделения окружающего сигнала (130; 230; 324; ) на основе входного аудиосигнала; и
при этом процессор сигнала выполнен с возможностью распределения окружающего сигнала по множеству каналов окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале, при этом количество (Q) каналов окружающего сигнала больше, чем количество (N) каналов входного аудиосигнала;
при этом каналы (112a-112c; 254a-254c; 352; ) окружающего сигнала ассоциированы с разными направлениями;
при этом каналы (252a-252c; 324; 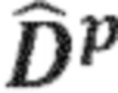 ) прямого сигнала ассоциированы с разными направлениями,
) прямого сигнала ассоциированы с разными направлениями,
при этом каналы (254a-254c; 352; ) окружающего сигнала и каналы (252a-252c; 324; ) прямого сигнала ассоциированы с одним и тем же набором направлений, или при этом каналы окружающего сигнала ассоциированы с поднабором из набора направлений, ассоциированных с каналами прямого сигнала; и
при этом процессор аудиосигнала выполнен с возможностью распределения компонентов прямого сигнала по каналам прямого сигнала в соответствии с положениями или направлениями соответствующих компонентов прямого звука, и
при этом процессор аудиосигнала выполнен с возможностью распределения компонентов окружающего сигнала по каналам окружающего сигнала в соответствии с положениями или направлениями источников прямого звука, возбуждающих соответствующие компоненты окружающего сигнала, с использованием тех же самых коэффициентов панорамирования или спектральных весовых коэффициентов, с использованием которых распределяются компоненты прямого сигнала.
3. Процессор (100; 150; 250) аудиосигнала для обеспечения каналов (112a-112c; 162a-162c; 254a-254c; 352; ) окружающего сигнала на основе входного аудиосигнала (110; 160; 210; 310, x(t), x(t), X(m, k)),
при этом процессор аудиосигнала выполнен с возможностью получения каналов окружающего сигнала,
при этом количество (Q) полученных каналов окружающего сигнала, содержащих разный аудиоконтент, больше, чем количество (N) каналов входного аудиосигнала;
при этом процессор аудиосигнала выполнен с возможностью получения каналов окружающего сигнала таким образом, что компоненты окружающего сигнала распределяются по каналам окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале;
при этом процессор аудиосигнала выполнен с возможностью получения прямого сигнала, который содержит компоненты прямого звука, на основе входного аудиосигнала;
при этом процессор аудиосигнала выполнен с возможностью выделения окружающего сигнала (130; 230; 324; ) на основе входного аудиосигнала; и
при этом процессор сигнала выполнен с возможностью распределения окружающего сигнала по множеству каналов окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале, при этом количество (Q) каналов окружающего сигнала больше, чем количество (N) каналов входного аудиосигнала;
при этом процессор аудиосигнала выполнен с возможностью получения прямого сигнала на основе входного аудиосигнала;
при этом процессор аудиосигнала выполнен с возможностью применения спектральных весовых коэффициентов (332; 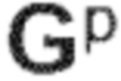 ) для того, чтобы распределять окружающий сигнал (130; 230; 324; ) по каналам (112a-112c; 254a-254c; 352; ) окружающего сигнала;
) для того, чтобы распределять окружающий сигнал (130; 230; 324; ) по каналам (112a-112c; 254a-254c; 352; ) окружающего сигнала;
при этом процессор аудиосигнала выполнен с возможностью применения одного и того же набора спектральных весовых коэффициентов (332; ) для распределения компонентов (226; 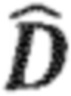 ; 322) прямого сигнала по каналам (252a-252c; 324; ) прямого сигнала и для распределения компонентов (230; ; 324) окружающего сигнала у окружающего сигнала по каналам (112a-112c; 254a-254c; 352; ) окружающего сигнала.
; 322) прямого сигнала по каналам (252a-252c; 324; ) прямого сигнала и для распределения компонентов (230; ; 324) окружающего сигнала у окружающего сигнала по каналам (112a-112c; 254a-254c; 352; ) окружающего сигнала.
4. Процессор (100; 150; 250) по п. 1, при этом процессор аудиосигнала выполнен с возможностью получения каналов (112a-112c; 162a-162c; 254a-254c; 352; ) окружающего сигнала таким образом, что компоненты окружающего сигнала распределяются по каналам окружающего сигнала в соответствии с положениями или направлениями источников прямого звука, возбуждающих соответствующие компоненты окружающего сигнала.
5. Процессор (150; 250) аудиосигнала по п. 1,
при этом процессор аудиосигнала выполнен с возможностью распределения одного или более каналов входного аудиосигнала по множеству каналов с повышающим микшированием, при этом количество каналов с повышающим микшированием больше, чем количество каналов входного аудиосигнала, и
при этом процессор аудиосигнала выполнен с возможностью выделения каналов окружающего сигнала из каналов с повышающим микшированием.
6. Процессор (150; 250) аудиосигнала по п. 5, при этом процессор аудиосигнала выполнен с возможностью выделения каналов окружающего сигнала из каналов с повышающим микшированием с использованием многоканального выделения окружающего сигнала или с использованием многоканального разделения прямого сигнала/окружающего сигнала.
7. Процессор (150; 250) аудиосигнала по п. 1, при этом процессор аудиосигнала выполнен с возможностью определения коэффициентов повышающего микширования и определения коэффициентов выделения окружающего сигнала, и при этом процессор аудиосигнала выполнен с возможностью получения каналов окружающего сигнала с использованием коэффициентов повышающего микширования и коэффициентов выделения окружающего сигнала.
8. Процессор (100; 250) аудиосигнала для обеспечения каналов (112a-112c; 254a-254c; 352; ) окружающего сигнала на основе входного аудиосигнала (110; 210; 310, x(t), x(t), X(m, k)) по п. 1,
при этом процессор аудиосигнала выполнен с возможностью выделения окружающего сигнала (130; 230; 324; ) на основе входного аудиосигнала; и
при этом процессор сигнала выполнен с возможностью распределения окружающего сигнала по множеству каналов окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале, при этом количество (Q) каналов окружающего сигнала больше, чем количество (N) каналов входного аудиосигнала.
9. Процессор аудиосигнала по п. 1, при этом процессор аудиосигнала выполнен с возможностью выполнения разделения (120; 220; 230) прямого и окружающего сигналов на основе входного аудиосигнала (110; 210; 310, x(t), x(t), X(m, k)) для извлечения окружающего сигнала.
10. Процессор аудиосигнала по п. 1, при этом процессор аудиосигнала выполнен с возможностью распределения компонентов окружающего сигнала по каналам окружающего сигнала в соответствии с положениями или направлениями источников прямого звука, возбуждающих соответствующие компоненты окружающего сигнала.
11. Процессор аудиосигнала по п. 10, в котором каналы (112a-112c; 254a-254c; 352; ) окружающего сигнала ассоциированы с разными направлениями.
12. Процессор аудиосигнала по п. 11, в котором каналы (252a-252c; 324; ) прямого сигнала ассоциированы с разными направлениями,
при этом каналы (254a-254c; 352; ) окружающего сигнала и каналы (252a-252c; 324; ) прямого сигнала ассоциированы с одним и тем же набором направлений, или при этом каналы окружающего сигнала ассоциированы с поднабором из набора направлений, ассоциированных с каналами прямого сигнала; и
при этом процессор аудиосигнала выполнен с возможностью распределения компонентов прямого сигнала по каналам прямого сигнала в соответствии с положениями или направлениями соответствующих компонентов прямого звука, и
при этом процессор аудиосигнала выполнен с возможностью распределения компонентов окружающего сигнала по каналам окружающего сигнала в соответствии с положениями или направлениями источников прямого звука, возбуждающих соответствующие компоненты окружающего сигнала таким же образом, как распределяются компоненты прямого сигнала.
13. Процессор аудиосигнала по п. 1, при этом процессор аудиосигнала выполнен с возможностью обеспечения каналов (112a-112c; 254a-254c; 352; ) окружающего сигнала таким образом, что окружающий сигнал разделяется на компоненты окружающего сигнала в соответствии с положениями сигналов источника, лежащих в основе компонентов окружающего сигнала.
14. Процессор аудиосигнала по п. 1, при этом процессор аудиосигнала выполнен с возможностью применения спектральных весовых коэффициентов (332; ) для распределения окружающего сигнала (130; 230; 324; ) по каналам (112a-112c; 254a-254c; 352; ) окружающего сигнала.
15. Процессор аудиосигнала по п. 14, при этом процессор аудиосигнала выполнен с возможностью применения спектральных весовых коэффициентов (332; ), которые вычисляются для отдельных направленных аудиоисточников в соответствии с их положениями или направлениями, для осуществления повышающего микширования окружающего сигнала (130; 230; 324; ) по множеству каналов (112a-112c; 254a-254c; 352; ) окружающего сигнала, или
при этом процессор аудиосигнала выполнен с возможностью применения версии спектральных весовых коэффициентов с задержкой, которые вычисляются для отдельных направленных аудиоисточников в соответствии с их положениями или направлениями, для того, чтобы осуществлять повышающее микширование окружающего сигнала на множество каналов окружающего сигнала.
16. Процессор аудиосигнала по п. 14, при этом процессор аудиосигнала выполнен с возможностью извлечения спектральных весовых коэффициентов (332; ) таким образом, что спектральные весовые коэффициенты являются зависимыми от времени и зависимыми от частоты.
17. Процессор аудиосигнала по п. 14, при этом процессор аудиосигнала выполнен с возможностью извлечения спектральных весовых коэффициентов (332; ) в зависимости от положений источников звука в пространственном звуковом образе входного аудиосигнала (110; 210; 310, x(t), x(t), X(m, k)).
18. Процессор аудиосигнала по п. 14, в котором входной аудиосигнал (110; 210; 310, x(t), x(t), X(m, k)) содержит по меньшей мере два сигнала входного канала, и процессор аудиосигнала выполнен с возможностью извлечения спектральных весовых коэффициентов (332; ) в зависимости от различий между по меньшей мере двумя сигналами входного канала.
19. Процессор аудиосигнала по п. 14, при этом процессор аудиосигнала выполнен с возможностью определения спектральных весовых коэффициентов (332; ) в зависимости от положений или направлений, из которых исходят спектральные компоненты таким образом, что спектральным компонентам, исходящим из определённого положения или направления, присваивается более сильный весовой коэффициент в канале, ассоциированном с соответствующим положением или направлением, в сравнении с другими каналами.
20. Процессор аудиосигнала по п. 14, при этом процессор аудиосигнала выполнен с возможностью определения спектральных весовых коэффициентов (332; ) таким образом, что спектральные весовые коэффициенты описывают присвоение весовых коэффициентов спектральным компонентам сигналов (322, 324) входного канала во множестве сигналов (342, 352) выходного канала.
21. Процессор аудиосигнала по п. 14, при этом процессор аудиосигнала выполнен с возможностью применения одного и того же набора спектральных весовых коэффициентов (332; ) для распределения компонентов (226; ; 322) прямого сигнала по каналам (252a-252c; 324; ) прямого сигнала и для распределения компонентов (230; ; 324) окружающего сигнала у окружающего сигнала по каналам (112a-112c; 254a-254c; 352; ) окружающего сигнала.
22. Процессор аудиосигнала по п. 1, в котором входной аудиосигнал (110; 210; 310, x(t), x(t), X(m, k)) содержит по меньшей мере 2 канала и/или в котором окружающий сигнал (130; 230; 324; ) содержит по меньшей мере 2 канала.
23. Система (200) для рендеринга аудиоконтента, представленного многоканальным входным аудиосигналом (210, X), содержащая:
процессор (100; 250) аудиосигнала по п. 1, при этом процессор аудиосигнала выполнен с возможностью обеспечения более 2 каналов (252a-252c) прямого сигнала и более 2 каналов (254a-254c) окружающего сигнала; и
систему (260) громкоговорителей, содержащую набор громкоговорителей (262a-262c) прямого сигнала и набор громкоговорителей (264a-264c) окружающего сигнала,
при этом каждый из каналов прямого сигнала ассоциирован по меньшей мере с одним из громкоговорителей прямого сигнала, и
при этом каждый из каналов окружающего сигнала ассоциирован по меньшей мере с одним из громкоговорителей окружающего сигнала.
24. Система по п. 23, в которой каждый из громкоговорителей (264a-264c) окружающего сигнала ассоциирован с одним из громкоговорителей (262a-262c) прямого сигнала.
25. Система по п. 23, в которой положения громкоговорителей (264a-264c; h) окружающего сигнала приподняты по отношению к положениям громкоговорителей (262a-262c; fL, fR, rL, rR) прямого сигнала.
26. Способ обеспечения каналов окружающего сигнала на основе входного аудиосигнала,
при этом способ содержит этап, на котором получают каналы окружающего сигнала таким образом, что компоненты окружающего сигнала распределяются по каналам окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале,
при этом количество полученных каналов окружающего сигнала, содержащих разный аудиоконтент, больше, чем количество каналов входного аудиосигнала;
при этом компоненты окружающего сигнала распределяются по каналам окружающего сигнала в соответствии с положениями или направлениями источников прямого звука, возбуждающих соответствующие компоненты окружающего сигнала,
таким образом, что разные компоненты окружающего сигнала, которые возбуждаются разными источниками, расположенными в разных положениях, распределяются по-разному по каналам окружающего сигнала, и
таким образом, что распределение компонентов окружающего сигнала по разным каналам окружающего сигнала соответствует распределению компонентов прямого сигнала, возбуждающих соответствующие компоненты окружающего сигнала, по разным каналам прямого сигнала.
27. Способ обеспечения каналов окружающего сигнала на основе входного аудиосигнала,
при этом способ содержит этап, на котором получают каналы окружающего сигнала таким образом, что компоненты окружающего сигнала распределяются по каналам окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале,
при этом количество полученных каналов окружающего сигнала, содержащих разный аудиоконтент, больше, чем количество каналов входного аудиосигнала;
при этом способ содержит этап, на котором получают прямой сигнал, который содержит компоненты прямого звука, на основе входного аудиосигнала;
при этом способ содержит этап, на котором выделяют окружающий сигнал (130; 230; 324; ) на основе входного аудиосигнала; и
при этом способ содержит этап, на котором распределяют окружающий сигнал по множеству каналов окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале, при этом количество (Q) каналов окружающего сигнала больше, чем количество (N) каналов входного аудиосигнала;
при этом каналы (112a-112c; 254a-254c; 352; ) окружающего сигнала ассоциированы с разными направлениями;
при этом каналы (252a-252c; 324; ) прямого сигнала ассоциированы с разными направлениями,
при этом каналы (254a-254c; 352; ) окружающего сигнала и каналы (252a-252c; 324; ) прямого сигнала ассоциированы с одним и тем же набором направлений, или при этом каналы окружающего сигнала ассоциированы с поднабором из набора направлений, ассоциированных с каналами прямого сигнала; и
при этом компоненты прямого сигнала распределяются по каналам прямого сигнала в соответствии с положениями или направлениями соответствующих компонентов прямого звука, и
при этом компоненты окружающего сигнала распределяются по каналам окружающего сигнала в соответствии с положениями или направлениями источников прямого звука, возбуждающих соответствующие компоненты окружающего сигнала, с использованием тех же самых коэффициентов панорамирования или спектральных весовых коэффициентов, с использованием которых распределяются компоненты прямого сигнала.
28. Способ обеспечения каналов окружающего сигнала на основе входного аудиосигнала,
при этом способ содержит этап, на котором получают каналы окружающего сигнала таким образом, что компоненты окружающего сигнала распределяются по каналам окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале,
при этом количество полученных каналов окружающего сигнала, содержащих разный аудиоконтент, больше, чем количество каналов входного аудиосигнала;
при этом способ содержит этап, на котором получают прямой сигнал, который содержит компоненты прямого звука, на основе входного аудиосигнала;
при этом способ содержит этап, на котором выделяют окружающий сигнал (130; 230; 324; ) на основе входного аудиосигнала; и
при этом окружающий сигнал распределяется по множеству каналов окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале, при этом количество (Q) каналов окружающего сигнала больше, чем количество (N) каналов входного аудиосигнала;
при этом прямой сигнал получается на основе входного аудиосигнала;
при этом спектральные весовые коэффициенты (332; ) применяются для распределения окружающего сигнала (130; 230; 324; ) по каналам (112a-112c; 254a-254c; 352; ) окружающего сигнала;
при этом один и тот же набор спектральных весовых коэффициентов (332; ) применяется для распределения компонентов (226; ; 322) прямого сигнала по каналам (252a-252c; 324; ) прямого сигнала и для распределения компонентов (230; ; 324) окружающего сигнала у окружающего сигнала по каналам (112a-112c; 254a-254c; 352; ) окружающего сигнала.
29. Способ (500) обеспечения каналов окружающего сигнала на основе входного аудиосигнала по одному из пп. 26 - 28,
при этом способ содержит этап, на котором выделают (510) окружающий сигнал на основе входного аудиосигнала; и
при этом способ содержит этап, на котором распределяют (520) окружающий сигнал по множеству каналов окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале,
при этом количество каналов окружающего сигнала больше, чем количество каналов входного аудиосигнала.
30. Способ (600) рендеринга аудиоконтента, представленного многоканальным входным аудиосигналом, содержащий, этапы, на которых:
обеспечивают (610) каналы окружающего сигнала на основе входного аудиосигнала по одному из пп. 26 - 28, при этом обеспечиваются более 2 каналов окружающего сигнала;
обеспечивают (620) более 2 каналов прямого сигнала;
подают (630) каналы окружающего сигнала и каналы прямого сигнала на систему громкоговорителей, содержащую набор громкоговорителей прямого сигнала и набор громкоговорителей окружающего сигнала,
при этом каждый из каналов прямого сигнала подается по меньшей мере на один из громкоговорителей прямого сигнала, и
при этом каждый из каналов окружающего сигнала подается по меньшей мере на один из громкоговорителей окружающего сигнала.
31. Машиночитаемый носитель, на котором сохранена компьютерная программа для выполнения способа по одному из пп. 26 или 27 или 28 или 30, когда компьютерная программа выполняется на компьютере.
32. Система (200) для рендеринга аудиоконтента, представленного многоканальным входным аудиосигналом (210, X), содержащая:
процессор (100; 150; 250) аудиосигнала для обеспечения каналов (112a-112c; 162a-162c; 254a-254c; 352; ) окружающего сигнала на основе входного аудиосигнала (110; 160; 210; 310, x(t), x(t), X(m, k)),
при этом процессор аудиосигнала выполнен с возможностью получения каналов окружающего сигнала,
при этом количество (Q) полученных каналов окружающего сигнала, содержащих разный аудиоконтент, больше, чем количество (N) каналов входного аудиосигнала;
при этом процессор аудиосигнала выполнен с возможностью получения каналов окружающего сигнала таким образом, что компоненты окружающего сигнала распределяются по каналам окружающего сигнала в зависимости от положений или направлений источников звука во входном аудиосигнале;
при этом процессор аудиосигнала выполнен с возможностью обеспечения более 2 каналов (252a-252c) прямого сигнала и более 2 каналов (254a-254c) окружающего сигнала; и
систему (260) громкоговорителей, содержащую набор громкоговорителей (262a-262c) прямого сигнала и набор громкоговорителей (264a-264c) окружающего сигнала,
при этом каждый из каналов прямого сигнала ассоциирован по меньшей мере с одним из громкоговорителей прямого сигнала, и
при этом каждый из каналов окружающего сигнала ассоциирован по меньшей мере с одним из громкоговорителей окружающего сигнала,
таким образом, что рендеринг прямых сигналов и окружающих сигналов осуществляется с использованием разных громкоговорителей.
33. Система по п. 32,
в которой имеет место ассоциация между громкоговорителями прямого сигнала и громкоговорителями окружающего сигнала, или
в которой имеет место ассоциация между поднабором громкоговорителей прямого сигнала и громкоговорителями окружающего сигнала.
| Токарный резец | 1924 |
|
SU2016A1 |
| US 6658117 B2, 02.12.2003 | |||
| Способ электронно-лучевой сварки закрытых сферических и цилиндрических сосудов и защитное приспособление для его реализации | 2020 |
|
RU2733964C1 |
| US 8932134 B2, 13.01.2015 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ЗВУКОВОГО СИГНАЛА | 2008 |
|
RU2437247C1 |

