ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
[0001] Настоящая заявка испрашивает приоритет в соответствии с предварительной заявкой на патент США № 62/631710, поданной 17 февраля 2018 года и включенной таким образом в данный документ посредством ссылки во всей своей полноте.
УРОВЕНЬ ТЕХНИКИ
[0002] Одна из самых больших проблем, с которыми сталкивается машинное обучение, представляет собой отсутствие больших аннотированных наборов данных. Аннотации данных не только являются дорогостоящими и затратными по времени, но и сильно зависят от наличия экспертов-наблюдателей. Ограниченный объем данных для обучения может снизить эффективность алгоритмов машинного обучения с учителем, которым часто требуются очень большие объемы данных для обучения, чтобы избежать переобучения. До недавнего времени было направлено множество усилий на извлечение как можно большего количества информации из имеющихся данных. Одной из областей, в которой в частности не хватает больших аннотированных наборов данных, является анализ биологических данных, таких как данные взаимодействия белков. Способность прогнозировать, как белки могут взаимодействовать, неоценима для определения новых терапевтических средств.
[0003] Достижения в области иммунотерапии быстро развиваются и обеспечивают получение новых лекарственных препаратов, которые модулируют иммунную систему пациента, помогая бороться с заболеваниями, в том числе с раком, аутоиммунными нарушениями и инфекциями. Например, были идентифицированы молекулы ингибиторов иммунных контрольных точек, например, PD-1 и лиганды PD-1, которые используются для разработки лекарственных средств, которые ингибируют или стимулируют передачу сигнала через PD-1 и тем самым модулируют иммунную систему пациента. Эти новые лекарственные средства оказались очень эффективными в некоторых случаях, но не во всех. Одна из причин заключается в том, что в опухолях у около 80 процентов пациентов с раком недостаточно раковых антигенов для привлечения Т-клеток.
[0004] Нацеливание на опухолеспецифические мутации индивидуума является перспективным, поскольку такие специфические мутации продуцируют опухолеспецифические пептиды, называемые неоантигенами, которые являются новыми для иммунной системы и не обнаруживаются в нормальных тканях. По сравнению с ассоциированными с опухолью аутоантигенами неоантигены вызывают Т-клеточные ответы, не зависящие от центральной толерантности организма-хозяина, обусловленной тимусом, а также вызывают меньшую токсичность, обусловленную аутоиммунными реакциями на доброкачественные клетки (Nature Biotechnology 35, 97 (2017).
[0005] Ключевой вопрос для открытия неоэпитопа заключается в том, какие мутированные белки процессируются протеасомой в пептиды с 8-11 остатками, перемещаются в эндоплазматический ретикулум с помощью транспортера, связанного с процессингом антигена (TAP), и загружаются на вновь синтезированный главный комплекс гистосовместимости класса I (MHC-I) для распознавания CD8+ Т-клетками (Nature Biotechnology 35, 97 (2017)).
[0006] Вычислительные способы прогнозирования взаимодействия пептида с MHC-I известны в данной области. Хотя некоторые вычислительные способы сосредоточены на прогнозировании того, что происходит во время процессинга антигена (например, NetChop) и транспорта пептидов (например, NetCTL), большинство усилий сосредоточено на моделировании того, какие пептиды связываются с молекулой MHC-I. Способы на основе нейронных сетей, такие как NetMHC, используются для прогнозирования последовательностей антигенов, которые образуют эпитопы, соответствующие полости молекул MHC-I пациента. Другие фильтры могут применяться для деприоритизации гипотетических белков и определения того, ориентирована ли мутированная аминокислота так, что она, вероятно, обращена наружу от MHC (в сторону Т-клеточного рецептора), или снижает аффинность эпитопа к самой молекуле MHC-I (Nature Biotechnology 35, 97 (2017).
[0007] Эти прогнозы могут быть неверными по многим причинам. Секвенирование уже вносит ошибки амплификации и технические ошибки в риды, используемые в качестве исходного материала для пептидов. При моделировании процессинга и представления эпитопа также необходимо учитывать тот факт, что люди имеют ∼ 5000 аллелей, кодирующих молекулы MHC-I, при этом у отдельного пациента экспрессируется до шести из них, причем все с разной эпитопной аффинностью. Такие способы, как NetMHC, как правило, требуют 50-100 экспериментально определенных измерений связывания пептидов для конкретного аллеля для построения модели с достаточной точностью. Но поскольку многие аллели MHC не имеют таких данных, «панспецифические» способы - способные прогнозировать связывание на основе того, имеют ли аллели MHC с подобными контактными средами сходные специфичности связывания - все чаще выходят на первый план.
[0008] Таким образом, существует потребность в улучшенных системах и способах для генерирования наборов данных для применения в приложениях машинного обучения, в частности, наборов биологических данных. Методы прогнозирования связывания пептидов могут выиграть от таких улучшенных систем и способов. Таким образом, целью настоящего изобретения является обеспечение реализуемых на компьютере систем и способов, которые характеризуются улучшенными возможностями генерирования наборов данных для обучения приложений машинного обучения делать прогнозы, в том числе прогнозирование связывания пептида с MHC-I.
КРАТКОЕ ОПИСАНИЕ
[0009] Следует понимать, что и нижеследующее общее описание, и нижеследующее подробное описание являются лишь иллюстративными и поясняющими, но не являются ограничивающими.
[0010] Представлены способы и системы для обучения генеративно-состязательной сети (GAN), предусматривающие генерирование посредством генератора GAN все более точных положительных смоделированных данных до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные как положительные, представление положительных смоделированных данных, положительных реальных данных и отрицательных реальных данных в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует каждый тип данных как положительный или отрицательный, представление положительных реальных данных и отрицательных реальных данных в CNN для генерирования оценок прогноза, определение на основании оценок прогноза того, обучена ли GAN или нет, и выведение GAN и CNN. Этот способ можно повторять до тех пор, пока GAN не будет обучена должным образом. Положительные смоделированные данные, положительные реальные данные и отрицательные реальные данные включают биологические данные. Биологические данные могут включать данные взаимодействия белок-белок. Биологические данные могут включать данные взаимодействия полипептид-MHC-I. Положительные смоделированные данные могут включать положительные смоделированные данные взаимодействия полипептид-MHC-I, положительные реальные данные включают положительные реальные данные взаимодействия полипептид-MHC-I, и отрицательные реальные данные включают отрицательные реальные данные взаимодействия полипептид-MHC-I.
[0011] Дополнительные преимущества будут частично изложены в нижеследующем описании или могут быть получены в ходе практического осуществления. Преимущества будут реализованы и достигнуты с помощью признаков и комбинаций, конкретно указанных в прилагаемой формуле изобретения.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
[0012] Прилагаемые графические материалы, которые включены в настоящее описание и составляют его часть, иллюстрируют варианты осуществления и вместе с описанием служат для пояснения принципов способов и систем.
На фигуре 1 представлена блок-схема, иллюстрирующая пример способа.
На фигуре 2 представлена примерная схема, отображающая часть процесса прогнозирования связывания пептида, в том числе генерирование и обучение моделей GAN.
На фигуре 3 представлена примерная схема, отображающая часть процесса прогнозирования связывания пептида, в том числе генерирование данных с применением обученных моделей GAN и обучение моделей CNN.
На фигуре 4 представлена примерная схема, отображающая часть процесса прогнозирования связывания пептида, в том числе завершение обучения моделей CNN и генерирование прогнозов связывания пептидов с применением обученных моделей CNN.
На фигуре 5А представлена примерная схема потока данных типичной GAN.
На фигуре 5В представлена примерная схема потока данных генератора GAN.
На фигуре 6 представлена примерная блок-диаграмма части стадий обработки, предусматриваемых генератором, используемым в GAN.
На фигуре 7 представлена примерная блок-диаграмма части стадий обработки, предусматриваемых генератором, используемым в GAN.
На фигуре 8 представлена примерная блок-диаграмма части стадий обработки, предусматриваемых дискриминатором, используемым в GAN.
На фигуре 9 представлена примерная блок-диаграмма части стадий обработки, предусматриваемых дискриминатором, используемым в GAN.
На фигуре 10 представлена блок-схема, иллюстрирующая пример способа.
На фигуре 11 представлена примерная блок-схема компьютерной системы, в которой могут быть реализованы процессы и структуры, участвующие в прогнозировании связывания пептида.
На фигуре 12 представлена таблица, показывающая результаты указанных моделей прогнозирования для прогнозирования связывания белка с белковым комплексом MHC-I для указанных аллелей HLA.
На фигуре 13A представлена таблица, в которой показаны данные, используемые для сравнения моделей прогнозирования.
На фигуре 13B представлена гистограмма сравнения AUC настоящей реализации архитектуры CNN и такой же из статьи Ванга.
На фигуре 13C представлена гистограмма сравнения настоящей реализации с существующими системами.
На фигуре 14 представлена таблица, показывающая смещение, полученное при выборе смещенного тестового набора.
На фигуре 15 представлен линейный график зависимости SRCC от размера теста, показывающий, что чем меньше размер теста, тем лучше SRRC.
На фигуре 16A представлена таблица, в которой показаны данные, используемые для сравнения нейронных сетей Adam и RMSprop.
На фигуре 16B представлена гистограмма сравнения AUC нейронных сетей, обученных оптимизатором Adam и RMSprop.
На фигуре 16С представлена гистограмма сравнения SRCC нейронных сетей, обученных оптимизатором Adam и RMSprop.
На фигуре 17 представлена таблица, показывающая, что сочетание поддельных и реальных данных обеспечивает лучшее прогнозирование, чем одни только поддельные данные.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0013] Прежде чем настоящие способы и системы будут раскрыты и описаны, следует понять, что способы и системы не ограничиваются конкретными способами, конкретными компонентами или конкретными вариантами реализации. Также следует понимать, что терминология, используемая в данном документе, представлена только с целью описания определенных вариантов осуществления и не подразумевается как ограничивающая.
[0014] Используемая в описании и прилагаемой формуле изобретения форма единственного числа включает ссылки на множественное число, если контекст явно не предусматривает иное. Диапазоны могут быть выражены в данном документе как от «приблизительно» одного определенного значения и/или до «приблизительно» другого определенного значения. В тех случаях, когда такой диапазон выражен, тогда другой вариант осуществления включает от одного определенного значения и/или до другого определенного значения. Подобным образом, когда значения выражены в виде приближений с использованием предшествующего «приблизительно», тогда будет понятно, что определенное значение образует другой вариант осуществления. Также будет понятно, что конечные точки каждого из диапазонов являются значимыми как в отношении другой конечной точки, так и независимо от другой конечной точки.
[0015] «Необязательный» или «необязательно» означает, что далее описанное событие или обстоятельство может или не может происходить, и что описание включает случаи, при которых указанное событие или обстоятельство имеет место, и случаи, при которых оно не происходит.
[0016] Во всем описании и формуле данного документа слово «содержать» и варианты этого слова, такие как «содержащий» и «содержит», означает «в том числе без ограничения», и не предназначено для исключения, например, других компонентов, целых чисел или стадий. Выражение «примерный» означает «пример» и не предназначено для указания предпочтительного или идеального варианта осуществления. Выражение «такой как» используется не в ограничительном смысле, а в пояснительных целях.
[0017] Понятно, что способы и системы не ограничиваются конкретными описанными методологией, протоколами и реагентами, поскольку они могут варьировать. Также следует понимать, что используемая в данном документе терминология предназначена только для описания конкретных вариантов осуществления и не предназначена для ограничения объема настоящих способов и системы, которые будут ограничены только прилагаемой формулой изобретения.
[0018] Если в данном документе не определено иное, все технические и научные термины, используемые в данном документе, имеют те же значения, которые обычно понимаются специалистом в области техники, к которой принадлежат способы и системы. Хотя при практическом осуществлении или тестировании настоящего способа или композиций можно применять любые способы и материалы, сходные с описанными в данном документе или эквивалентные им, в данном документе описаны только самые предпочтительные способы, устройства и материалы. Публикации, цитируемые в данном документе, и материалы, в отношении которых они цитируются, тем самым специально включены посредством ссылки. Ничто в данном документе не должно толковаться как признание того, что настоящие способы и системы не имеют права предшествовать такому раскрытию на основании предшествующего изобретения. Не делается допущения, что какие-либо ссылки составляют предшествующий уровень техники. Обсуждение ссылок указывает на то, что утверждают их авторы, и заявители оставляют за собой право оспорить точность и актуальность цитируемых документов. Будет четко понятно, что, хотя в данном документе упоминается ряд публикаций, такая ссылка не является признанием того, что какой-либо из этих документов составляет часть общих знаний в данной области.
[0019] В данном документе раскрыты компоненты, которые можно применять для выполнения указанных способов и систем. В данном документе раскрыты эти и другие компоненты, и известно, что при раскрытии комбинаций, подмножеств, взаимодействий, групп и т. д. таких компонентов, хотя конкретная ссылка на каждую из различных отдельных и совокупных комбинаций и перестановки таких компонентов может не быть четко описана в данном документе, каждое из этого конкретно предположено и описано в данном документе, в отношении всех способов и систем. Это применимо ко всем вариантам осуществления данной заявки, в том числе стадиям в указанных способах. Таким образом, если существует ряд дополнительных стадий, которые можно выполнить, следует понимать, что каждая из этих дополнительных стадий может быть выполнена с любым конкретным вариантом осуществления или комбинацией вариантов осуществления раскрытых способов.
[0020] Настоящие способы и системы можно легче понять, обратившись к нижеследующему подробному описанию предпочтительных вариантов осуществления и примерам, включенным в них, а также к фигурам и их предыдущему и последующему описанию.
[0021] Способы и системы могут принимать форму полностью аппаратного варианта осуществления, полностью программного варианта осуществления или варианта осуществления, сочетающего программные и аппаратные варианты осуществления. Кроме того, способы и системы могут принимать форму компьютерного программного продукта на машиночитаемом носителе данных, имеющем машиночитаемые программные инструкции (например, компьютерное программное обеспечение), воплощенные на носителе данных. Более конкретно, настоящие способы и системы могут принимать форму компьютерного программного обеспечения, реализуемого через Интернет. Может использоваться любой подходящий машиночитаемый носитель данных, в том числе жесткие диски, CD-ROM, оптические запоминающие устройства или магнитные запоминающие устройства.
[0022] Варианты осуществления способов и систем описаны ниже со ссылкой на блок-диаграммы и блок-схемы, иллюстрирующие способы, системы, устройства и компьютерные программные продукты. Будет понятно, что каждый блок иллюстраций в виде блок-диаграмм и блок-схем и комбинации блоков на иллюстрациях в виде блок-диаграмм и блок-схем соответственно могут быть реализованы посредством команд компьютерных программ. Данные команды компьютерных программ могут быть загружены на компьютер общего назначения, компьютер специализированного назначения или другое программируемое устройство обработки данных, представляющее собой машину, за счет которых команды, выполняемые компьютером или другим программируемым устройством обработки данных, обеспечивают реализацию функций, указанных в блоке или блоках блок-схемы.
[0023] Такие команды компьютерных программ также могут храниться в машиночитаемом запоминающем устройстве, которое может управлять компьютером или другим программируемым устройством обработки данных для выполнения их функций надлежащим образом, за счет чего команды, хранящиеся в машиночитаемом запоминающем устройстве, обеспечивают получение готового изделия, включая машиночитаемые команды, предназначенные для реализации функции, указанной в блоке или блоках блок-схемы. Команды компьютерных программ также могут быть загружены на компьютер или другое программируемое устройство обработки данных для обеспечения выполнения ряда технологических стадий на компьютере или другом программируемом устройстве с получением реализуемого на компьютере процесса, за счет чего команды, выполняемые на компьютере или другом программируемом устройстве, обеспечивают стадии для реализации функций, указанных в блоке или блоках блок-схемы.
[0024] Соответственно, блоки иллюстраций в виде блок-диаграмм и блок-схем обеспечивают комбинации средств, предназначенных для выполнения указанных функций, комбинации стадий, предназначенных для выполнения указанных функций, и средства, представленные командами программ, предназначенные для выполнения указанных функций. Также следует понимать, что каждый блок иллюстраций в виде блок-диаграмм и блок-схем и комбинации блоков иллюстраций в виде блок-диаграмм и блок-схем могут быть реализованы с помощью аппаратных компьютерных систем специализированного назначения, которые выполняют указанные функции или стадии, или комбинаций аппаратных средств специализированного назначения и компьютерных программ.
I. Определения
[0025] Аббревиатура «SRCC» относится к расчетам коэффициента ранговой корреляции Спирмена (SRCC).
[0026] Термин «кривая ROC» относится к кривой рабочих характеристик приемника.
[0027] Аббревиатура «CNN» относится к сверточной нейронной сети.
[0028] Аббревиатура «GAN» относится к генеративно-состязательной сети.
[0029] Термин «HLA» относится к лейкоцитарному антигену человека. Система или комплекс HLA представляет собой генный комплекс, кодирующий белки главного комплекса гистосовместимости (MHC) у человека. Основными генами HLA класса I являются HLA-A, HLA-B и HLA-C, тогда как HLA-E, HLA-F и HLA-G - минорные гены.
[0030] Термин «MHC I» или «главный комплекс гистосовместимости I» относится к набору белков клеточной поверхности, состоящим из α-цепи, имеющей три домена - α1, α2 и α3. Домен α3 является трансмембранным доменом, в то время как домены α1 и α2 отвечают за образование пептид-связывающей полости.
[0031] «Взаимодействие полипептид-MHC I» относится к связыванию полипептида в пептид-связывающей полости MHC I.
[0032] Используемый в данном документе термин «биологические данные» означает любые данные, полученные в результате измерения биологических состояний человека, животных или других биологических организмов, включая микроорганизмы, вирусы, растения и другие живые организмы. Измерения могут быть выполнены с помощью любых тестов, анализов или наблюдений, которые известны врачам, ученым, диагностам и т. п. Биологические данные могут включать без ограничения последовательности ДНК, последовательности РНК, последовательности белков, взаимодействия белков, клинические тесты и наблюдения, физические и химические измерения, геномные определения, протеомные определения, уровни лекарственных средств, гормональные и иммунологические тесты, нейрохимические или нейрофизические измерения, определения уровня минералов и витаминов, генетический и семейный анамнез и другие определения, которые могут дать представление о состоянии человека или лиц, проходящих тестирование. В данном документе термин «данные» используется взаимозаменяемо с термином «биологические данные».
II. Системы прогнозирования связывания пептидов
[0033] В одном варианте осуществления настоящего изобретения представлена система прогнозирования связывания пептида с MHC-I, которая имеет структуру генеративно-состязательная сеть (GAN) - сверточная нейронная сеть (CNN), также называемая глубокой сверточной генеративно- состязательной сетью. GAN содержит дискриминатор CNN и генератор CNN и может быть обучена посредством существующих данных связывания пептид-MHC-I. Раскрытые системы GAN-CNN имеют несколько преимуществ по сравнению с существующими системами для прогнозирования связывания пептид-MHC-I, в том числе без ограничения возможность обучения посредством неограниченного количества аллелей и лучшая эффективность прогнозирования. Настоящие способы и системы, хотя и описаны в данном документе в отношении прогнозирования связывания пептида с MHC-I, пути применения указанных способов и систем этим не ограничиваются. Прогнозирование связывания пептида с MHC-I представлено как пример применения улучшенной системы GAN-CNN, описанной в данном документе. Улучшенная система GAN-CNN применима к широкому спектру биологических данных для получения различных прогнозов.
A. Примерные системы нейронной сети и способы
[0034] На фигуре 1 представлена блок-схема 100, иллюстрирующая пример способа. Начиная со стадии 110, генератор GAN (см. 504 на фиг. 5A) может генерировать все более точные положительные смоделированные данные. Положительные смоделированные данные могут включать биологические данные, такие как данные взаимодействия белков (например, аффинность связывания). Аффинность связывания является одним из примеров измерения силы связывающего взаимодействия между биомолекулой (например, белком, ДНК, лекарственным средством и т. д.) и биомолекулой (например, белком, ДНК, лекарственным средством и т. д.). Аффинность связывания может быть выражена численно как значение полумаксимальной ингибирующей концентрации (IC50). Меньшее число указывает на более высокую аффинность. Пептиды со значениями IC50 <50 нМ считаются высокоаффинными, с <500 нМ - с промежуточной аффинностью, а с <5000 нМ - низкой аффинностью. IC50 может быть преобразована в категорию связывания как связывание (1) или отсутствие связывания (-1).
[0035] Положительные смоделированные данные могут включать положительные смоделированные данные взаимодействия полипептид-MHC-I. Создание положительных смоделированных данных взаимодействия полипептид-MHC-I может быть основано, по меньшей мере частично, на реальных данных взаимодействия полипептид-MHC-I. Данные взаимодействия белков могут включать показатель аффинности связывания (например, IC50, категория связывания), представляющий вероятность связывания двух белков. Данные взаимодействия белков, например, данные взаимодействия полипептид-MHC-I, могут быть получены, например, из любого количества баз данных, таких как PepBDB, PepBind, Банк данных белков, База данных сети биомолекулярного взаимодействия (BIND), Cellzome (Heidelberg, Германия), База данных взаимодействующих белков (DIP), Онкологический институт Даны Фарбер (Бостон, Массачусетс, США), Справочная база данных белков человека (HPRD), Hybrigenics (Париж, Франция), Европейский институт биоинформатики (EMBL-EBI, Hinxton, Великобритания) IntAct, база данных по молекулярным взаимодействиям (MINT, Рим, Италия), база данных по взаимодействию белок-белок (PPID, Эдинбург, Великобритания) и инструмент поиска по восстановлению взаимодействия гены/белки (STRING, EMBL, Гейдельберг, Германия) и тому подобное. Данные взаимодействия белков могут храниться в структуре данных, содержащей одно или более из конкретной полипептидной последовательности, а также указания, касающегося взаимодействия полипептидов (например, взаимодействия между полипептидной последовательностью и MHC-I). В одном из вариантов осуществления структура данных может соответствовать формату HUPO PSI Molecular Interaction (PSI MI), который может содержать одну или более записей, где запись описывает одно или более взаимодействий белков. Структура данных может указывать на источник записи, например, поставщика данных. Могут быть указаны номер выпуска и дата выпуска, назначенные поставщиком данных. Перечень доступности может содержать заявления о доступности данных. В перечне экспериментов могут быть указаны описания экспериментов, в том числе по меньшей мере один набор экспериментальных параметров, обычно связанных с отдельной публикацией. В крупномасштабных экспериментах как правило в серии экспериментов варьируется только один параметр, часто затравка (интересующий белок). Формат PSI MI может указывать как постоянные параметры (например, методику эксперимента), так и переменные параметры (например, затравку). Перечень партнеров может указывать на набор партнеров (например, белки, малые молекулы и т. д.), участвующих во взаимодействии. Элемент белкового партнера может указывать на «нормальную» форму белка, обычно обнаруживаемую в базах данных, например, Swiss-Prot и TrEMBL, которые могут включать такие данные, как название, перекрестные ссылки, организм и аминокислотная последовательность. Перечень партнеров может указывать один или более элементов взаимодействия. Каждое взаимодействие может указывать на описание доступности (описание доступности данных) и описание экспериментальных условий, при которых оно было определено. Взаимодействие также может указывать на атрибут достоверности. Разработаны различные меры достоверности во взаимодействии, например, способ верификации паралогов и биологическая оценка карты взаимодействия белков (PIM). Каждое взаимодействие может указывать перечень участников, содержащий два или более белковых элементов-участников (то есть белки, участвующие во взаимодействии). Каждый белковый элемент-участник может включать описание молекулы в ее нативной форме и/или конкретной форме молекулы, в которой он участвовал во взаимодействии. Список характеристик может указывать на особенности последовательности белка, например связывающие домены или посттрансляционные модификации, относящиеся к взаимодействию. Может быть указана роль, которая описывает особую роль белка в эксперименте, например, был ли белок затравкой или добычей. Некоторые или все предыдущие элементы могут храниться в структуре данных. Примером структуры данных может быть файл XML, например:
<entry>
<interactorList>
<Interactor id="Succinate>
<names>
<shortLabel>Succinate</shortLabel>
<fullName>Succinate</fullName>
</names>
</Interactor>
</interactorList>
<interactionList>
<interaction>
<names>
<shortLabel> Succinate dehydrogenas catalysis </shortLabel> <fullName>Interaction between </fullName>
</names>
<participantList> <Participant>
<proteinInteractorRef ref="Succinate"/› <biologicalrole>neutral</role> </proteinParticipant> <proteinParticipant> <proteinInteractorRef ref="Fumarate"/> <role>neutral</role> </proteinParticipant> <proteinParticipant> <proteinInteractorRef ref="Succdeh"/> <role>neutral</role> </proteinParticipant> </participantList> </interaction>
</interactionList>
[0036] GAN может включать, например, глубокую сверточную GAN (DCGAN). На фиг. 5A показан пример базовой структуры GAN. GAN представляет собой, по сути, способ обучения нейронной сети. Сети GAN обычно содержат две независимые нейронные сети, дискриминатор 502 и генератор 504, которые работают независимо и могут действовать как противодействующие стороны. Дискриминатор502 может представлять собой нейронную сеть, которую нужно обучить с использованием данных для обучения, сгенерированных посредством генератора 504. Дискриминатор 502 может содержать классификатор506, который может быть обучен выполнять задачу различения экземпляров данных. Генератор 504 может генерировать случайные экземпляры данных, подобные реальным экземплярам, но которые могут быть сгенерированы, включая характеристики, или могут быть модифицированы для включения в них характеристик, которые делают их поддельными или фальшивыми экземплярами. Нейронные сети, содержащие дискриминатор 502 и генератор 504, как правило, могут быть реализованы в виде многослойных сетей, состоящих из множества слоев обработки, таких как обработка плотности, обработка с пакетной нормализацией, обработка активации, обработка с изменением формы ввода, обработка с гауссовским исключением, обработка гауссовского шума, двумерная свертка и двумерная повышающая дискретизация. Более подробно это показано на фиг. 6 - фиг. 9 ниже.
[0037] Например, классификатор 506 может быть разработан для идентификации экземпляров данных, указывающих различные характеристики. Генератор 504 может содержать состязательную функцию508, которая может генерировать данные, предназначенные для введения в заблуждение дискриминатора 502, с применением экземпляров данных, которые являются почти корректными, но не совсем. Например, это может быть выполнено путем случайного выбора допустимого экземпляра из набора 510 для обучения (скрытое пространство) и синтеза экземпляра данных (пространства данных) путем случайного изменения его характеристик, например, путем добавления случайного шума 512. Генеративную сеть G можно рассматривать как перенос некоторого скрытого пространства в пространство данных. Формально это можно выразить как G: G (z) → R|x|, где z ∈ R|x| - экземпляр из скрытого пространства, x ∈ R|x| - экземпляр из пространства данных, а | | обозначает количество измерений.
[0038] Дискриминаторную сеть, D, можно рассматривать как перенос из пространства данных в вероятность того, что данные (например, пептид) взяты из реального набора данных, а не из сгенерированного (поддельного или фальшивого) набора данных. Формально это можно выразить как: D : D(x) → (0; 1). Во время обучения в дискриминатор 502 может быть представлено посредством рандомизатора 514 случайное сочетание экземпляров 516 допустимых данных из реальных данных для обучения вместе с поддельными или фальшивыми (например, смоделированными) экземплярами данных, сгенерированными при помощи генератора 504. Для каждого экземпляра данных дискриминатор 502 может пытаться идентифицировать допустимые и поддельные или фальшивые входные данные, выдавая результат 518. Например, для фиксированного генератора G дискриминатор D может быть обучен классифицировать данные (например, пептиды) как полученные из данных для обучения (реальные, близкие к 1) или из фиксированного генератора (смоделированные, близкие к 0). Для каждого экземпляра данных дискриминатор 502 может дополнительно пытаться идентифицировать положительные или отрицательные входные данные (независимо от того, являются ли входные данные смоделированными или реальными), выдавая результат 518.
[0039] На основании серии результатов 518 и дискриминатор 502, и генератор 504 могут попытаться точно настроить свои параметры для улучшения своей работы. Например, если дискриминатор 502 делает правильный прогноз, генератор 504 может обновлять свои параметры для получения лучше смоделированных экземпляров, чтобы ввести в заблуждение дискриминатор 502. Если дискриминатор 502 делает неверный прогноз, дискриминатор 502 может учиться на своей ошибке, с целью избежания подобных ошибок. Таким образом, обновление дискриминатора 502 и генератора 504 может включать в себя процесс обратной связи. Этот процесс обратной связи может быть непрерывным или инкрементным. Генератор 504 и дискриминатор 502 могут работать итеративно для оптимизации генерирования данных и классификации данных. В процессе инкрементной обратной связи состояние генератора 504 фиксируется, и дискриминатор 502 подвергается обучению до тех пор, пока не установится равновесие и не оптимизируется обучение дискриминатора 502. Например, для заданного фиксированного состояния генератора 504 дискриминатор 502 может быть обучен таким образом, чтобы быть оптимизированным относительно состояния генератора 504. Затем это оптимизированное состояние дискриминатора 502 может быть зафиксировано, и генератор 504 может подвергаться обучению для снижения точности дискриминатора до некоторого заранее определенного порогового значения. Затем состояние генератора 504 может быть зафиксировано, и дискриминатор 502 может быть обучен, и так далее.
[0040] В процессе непрерывной обратной связи дискриминатор не может подвергаться обучению до тех пор, пока его состояние не будет оптимизировано, а может быть обучен только для одной или небольшого количества итераций, и генератор может обновляться одновременно с дискриминатором.
[0041] Если распределение сгенерированного смоделированного набора данных может идеально соответствовать распределению реального набора данных, то дискриминатор будет максимально запутан и не сможет отличить реальные экземпляры от поддельных (прогноз 0,5 для всех входных данных).
[0042] Вернемся к фиг. 1 к стадии 110; генерирование все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I может выполняться (например, посредством генератора504) до тех пор, пока дискриминатор 502 GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные. В другом аспекте генерирование все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I может выполняться (например, посредством генератора504) до тех пор, пока дискриминатор 502 GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные. Например, генератор 504 может генерировать все более точные положительные смоделированные данные взаимодействия полипептид-MHC-I, генерируя первый смоделированный набор данных, содержащий положительные смоделированные взаимодействия полипептид-MHC-I для аллеля MHC. Первый смоделированный набор данных может быть сгенерирован согласно одному или более параметрам GAN. Параметры GAN могут включать, например, одно или более из типа аллеля (например, HLA-A, HLA-B, HLA-C или их подтипы), длины аллеля (например, приблизительно от 8 до 12 аминокислот, приблизительно от 9 до 11 аминокислот), категории генерирования, сложности модели, скорости обучения, размера пакета или другого параметра.
[0043] На фиг. 5B представлена иллюстративная схема потока данных генератора GAN, выполненного с возможностью генерирования положительных смоделированных данных взаимодействия полипептид-MHC-I для аллеля MHC. Как показано на фиг. 5B, вектор гауссовского шума может быть введен в генератор, который выводит матрицу распределения. Входные шумы, отобранные по Гауссу, обеспечивают изменчивость, имитирующую различные паттерны связывания. Выходная матрица распределения представляет собой распределение вероятностей выбора каждой аминокислоты для каждого положения в пептидной последовательности. Матрица распределения может быть нормализована, чтобы избавиться от вариантов, которые с меньшей вероятностью обеспечивают сигналы связывания, и конкретная пептидная последовательность может быть взята из нормализованной матрицы распределения.
[0044] Затем первый смоделированный набор данных можно объединить с положительными реальными данными взаимодействия полипептида и/или отрицательными реальными данными взаимодействия полипептида (или их комбинацией) для аллеля MHC для создания набора для обучения GAN. Дискриминатор 502 затем может определить (например, в соответствии с решающей границей), является ли взаимодействие полипептид-MHC-I для аллеля MHC в наборе данных для обучения GAN положительным или отрицательным и/или смоделированным или реальным. На основании точности определения, выполненного дискриминатором 502 (например, правильно ли дискриминатор 502 идентифицировал взаимодействие полипептид-MHC-I как положительное или отрицательное и/или смоделированное или реальное), один или более параметров GAN или решающую границу можно скорректировать. Например, один или более параметров GAN решающей границы могут быть скорректированы для оптимизации дискриминатора 502, чтобы увеличить возможность присвоения высокой вероятности положительным реальным данным взаимодействия полипептид-MHC-I, низкой вероятности положительным смоделированным данным взаимодействия полипептид-MHC-I и/или низкой вероятности отрицательным реальным данным взаимодействия полипептид-MHC-I. Один или более параметров GAN решающей границы могут быть скорректированы для оптимизации генератора 504, чтобы увеличить вероятность того, что положительные смоделированные данные взаимодействия полипептид-MHC-I будут иметь высокую оценку.
[0045] Процесс генерирования первого смоделированного набора данных, объединения первого набора данных с положительными реальными данными полипептидного взаимодействия и/или отрицательными реальными данными полипептидного взаимодействия для генерирования набора данных для обучения GAN, определения с помощью дискриминатора и корректировки параметров GAN и/или решающей границы можно повторять до тех пор, пока не будет соблюден первый критерий останова. Например, можно определить, соблюдается ли первый критерий останова, путем оценки выражения градиентного спуска для генератора 504. В качестве другого примера, можно определить, соблюдается ли первый критерий останова, путем оценки функции среднеквадратичной ошибки (MSE):
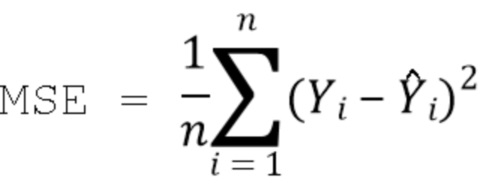
[0046] В качестве другого примера, можно определить, соблюдается ли первый критерий останова, путем оценки того, достаточно ли велик градиент для продолжения осмысленного обучения. Поскольку генератор504 обновляется с помощью алгоритма обратного распространения, каждый слой генератора будет иметь один или более градиентов, например, с учетом того, что график имеет 2 слоя и каждый слой имеет 3 узла, выведение графика 1 является 1-мерным (скаляр) и данные являются 2-мерными. На этом графике 1-й слой имеет 2*3 =6 ребер (w111, w112, w121, w122, w131, w132), подключенных к данным, и w111*data1+w112*data2=net11, и может использоваться функция активации сигмоида для выведения o11=sigmoid(net11), аналогично можно получить o12, o13, которые формируют выходные данные 1-го слоя; 2-й слой имеет 3*3=9 ребер (w211, w212, w213, w221, w222, w223, w231, w232, w233), соединяющихся с выходными данными 1-го слоя, и выходные данные 2-го слоя представляют собой o21, o22, o23, и соединяет окончательные выходные данные с 3 ребрами, которые представляют собой w311, w312, w313.
[0047] У каждого w на этом графике есть градиент (команда о том, как обновить w, по сути, число, которое нужно добавить), число может быть вычислено с помощью алгоритма, называемого обратным распространением, следуя идее изменения параметра в направлении, где потеря (MSE) уменьшается, что составляет:
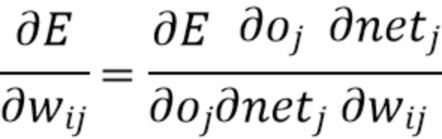
Где E представляет собой ошибку MSE, wij представляет собой i-тый параметр на j-том слое. Oj представляет собой выходные данные на j-том слое, netj - до активации, результат умножения на j-том слое. И если значение de/dwij (градиент) для wij недостаточно велико, в результате обучение не вносит изменений для wij генератора 504, и обучение следует прекратить.
[0048] Затем, после того как дискриминатор 502 GAN классифицирует положительные смоделированные данные (например, положительные смоделированные данные взаимодействия полипептид-MHC-I) как положительные и/или реальные, на стадии 120 положительные смоделированные данные, положительные реальные данные и/или отрицательные реальные данные (или их комбинация) могут представляться в CNN до тех пор, пока CNN не классифицирует каждый тип данных как положительный или отрицательный. Положительные смоделированные данные, положительные реальные данные и/или отрицательные реальные данные могут составлять биологические данные. Положительные смоделированные данные могут включать положительные смоделированные данные взаимодействия полипептид-MHC-I. Положительные реальные данные могут включать положительные реальные данные взаимодействия полипептид-MHC-I. Отрицательные реальные данные могут включать отрицательные реальные данные взаимодействия полипептид-MHC-I. Классифицированные данные могут включать данные в отношении взаимодействия полипептид-MHC-I. Каждое из положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I может быть связано с выбранным аллелем. Например, выбранный аллель может быть выбран из группы, состоящей из A0201, A202, A203, B2703, B2705 и их комбинаций.
[0049] Представление положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в CNN может включать генерирование, например, с помощью генератора 504 в соответствии с набором параметров GAN, второго набора смоделированных данных, содержащего положительные смоделированные взаимодействия полипептид-MHC-I для аллеля MHC. Затем второй смоделированный набор данных можно объединить с положительными реальными данными взаимодействия полипептида и/или отрицательными реальными данными взаимодействия полипептида (или их комбинацией) для аллеля MHC для создания набора данных для обучения CNN.
[0050] Затем набор данных для обучения CNN может быть представлен в CNN для обучения CNN. Затем CNN может классифицировать в соответствии с одним или более параметрами CNN взаимодействие полипептид-MHC-I как положительное или отрицательное. Это может включать выполнение посредством CNN процедуры свертки, выполнение процедуры нелинейности (например, ReLu), выполнение процедуры объединения или субдискретизации и/или выполнение процедуры классификации (например, полносвязный слой).
[0051] На основании точности классификации CNN можно скорректировать один или более параметров CNN. Процесс генерирования второго смоделированного набора данных, генерирования набора данных для обучения CNN, классификации взаимодействия полипептид-MHC-I и корректировки одного или более параметров CNN может повторяться до тех пор, пока не будет соблюден второй критерий останова. Например, можно определить, соблюдается ли второй критерий останова, путем оценки функции среднеквадратичной ошибки (MSE):
[0052] Затем, на стадии 130, положительные реальные данные и/или отрицательные реальные данные могут быть представлены в CNN для генерирования оценок прогноза. Положительные реальные данные и/или отрицательные реальные данные могут содержать биологические данные, такие как данные взаимодействия белков, включая, например, данные об аффинности связывания. Положительные реальные данные могут включать положительные реальные данные взаимодействия полипептид-MHC-I. Отрицательные реальные данные могут включать отрицательные реальные данные взаимодействия полипептид-MHC-I. Оценки прогноза могут представлять собой оценки аффинности связывания. Оценки прогноза могут включать вероятность того, что положительные реальные данные взаимодействия полипептид-MHC-I классифицированы как положительные данные взаимодействия полипептид-MHC-I. Это может включать представление в CNN реального набора данных и классификацию посредством CNN в соответствии с параметрами CNN взаимодействия полипептид-MHC-I для аллеля MHC как положительного или отрицательного.
[0053] На стадии 140 можно определить, обучена ли GAN, на основании оценок прогноза. Это может включать определение того, обучена ли GAN, путем определения точности CNN на основе оценок прогноза. Например, сеть GAN может быть определена как обученная, если соблюден третий критерий останова. Определение того, соблюден ли третий критерий останова, может включать определение того, соблюдена ли функция площади под кривой (AUC). Определение того, обучена ли GAN, может включать сравнение одной или более оценок прогноза с пороговым значением. Если GAN обучена, как определено на стадии 140, то GAN может дополнительно выводиться на стадии 150. Если GAN не определена как обученная, GAN можно вернуть к стадии 110.
[0054] После обучения CNN и GAN набор данных (например, неклассифицированный набор данных) может быть представлен в CNN. Набор данных может содержать неклассифицированные биологические данные, такие как неклассифицированные данные взаимодействия белков. Биологические данные могут включать множество кандидатных взаимодействий полипептид-MHC-I. CNN может генерировать прогнозируемую аффинность связывания и/или классифицировать каждое из кандидатных взаимодействий полипептид-MHC-I как положительное или отрицательное. Затем можно синтезировать полипептид с применением кандидатных взаимодействий полипептид-MHC-I, классифицированных как положительные. Например, полипептид может содержать опухолеспецифический антиген. В качестве другого примера полипептид может содержать аминокислотную последовательность, которая специфически связывается с белком MHC-I, кодируемым выбранным аллелем MHC.
[0055] Более подробная примерная блок-схема процесса 200 прогнозирования с применением генеративно-состязательной сети (GAN) показана на фиг. 2 - фиг. 4. Стадии 202-214 в целом соответствуют стадии 110, показанной на фиг. 1. Процесс 200 может начинаться с 202, в котором осуществляется настройка обучения GAN, например, путем установки ряда параметров 204-214 для управления обучением 216 GAN. Примеры параметров, которые могут быть установлены, могут включать тип 204 аллеля, длину 206 аллеля, категорию 208 генерирования, сложность 210 модели, скорость 212 обучения и размер 214 пакета. Параметры 204 типа аллеля могут предоставлять возможность указывать один или более типов аллелей, которые должны быть включены в обработку GAN. Примеры таких типов аллелей представлены на фиг. 12. Например, указанные аллели могут включать A0201, A0202, A0203, B2703, B2705 и т. д., показанные на фиг. 12. Параметры 206 длины аллеля могут предоставлять возможность указывать длины пептидов, которые могут связываться с каждым указанным типом 204 аллеля. Примеры таких длин аллелей показаны на фиг. 13. Например, для A0201 указанная длина отображается как 9 или 10, для A0202 указанная длина отображается как 9, для A0203 указанная длина отображается как 9 или 10, для B2705 указанная длина отображается как 9 и т. д. Параметры 208 категории генерирования может предоставить возможность определять категории данных, которые должны быть сгенерированы во время обучения GAN 216. Например, могут быть указаны категории связывание/отсутствие связывания. Набор параметров, соответствующих сложности 210 модели, может предоставить возможность определять аспекты сложности моделей, которые будут использоваться во время обучения 216 GAN. Примеры таких аспектов могут включать количество слоев, количество узлов на слой, размер окна для каждого сверточного слоя и т. д. Параметры скорости 212 обучения могут предоставлять возможность указывать одну или более скоростей, с которыми обработка обучения, выполняемая при обучении 216 GAN, должна сходиться. Примеры таких параметров скорости обучения могут включать 0,0015, 0,015, 0,01, которые представляют собой безразмерные значения, определяющие относительные скорости обучения. Параметры 214 размера пакета могут предоставлять возможность указывать размеры пакетов данных 218 для обучения, которые должны быть обработаны во время обучения 216 GAN. Примеры таких размеров пакетов могут включать в себя пакеты, содержащие 64 или 128 экземпляров данных. Обработка 202 настройки обучения GAN может собирать параметры 204-214 обучения, обрабатывать их так, чтобы они были совместимы с обучением 216 GAN, и вводить обработанные параметры в обучение 216 GAN или сохранять обработанные параметры в соответствующих файлах или местах для использования в обучении 216 GAN.
[0056] На стадии 216 может быть начато обучение GAN. Стадии 216-228 также в целом соответствуют стадии 110, показанной на фиг. 1. Обучение 216 GAN может принимать данные 218 для обучения, например, пакетами, как указано посредством параметров 214 размера пакета. Данные 218 для обучения могут включать данные, представляющие пептиды с разными обозначениями аффинности связывания (связываются или нет) для белковых комплексов MHC-I, кодируемых разными типами аллелей, такими как типы аллелей HLA и т. д. Например, такие данные для обучения могут включать информацию, относящуюся к биннингу и отбору положительного/отрицательного взаимодействия MHC-пептид. Данные для обучения могут включать одно или более из положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I.
[0057] На стадии 220 процесс градиентного спуска может быть применен к принятым данным 218 для обучения. Градиентный спуск представляет собой итеративный процесс для выполнения машинного обучения, например нахождения минимума или локального минимума функции. Например, чтобы найти минимум или локальный минимум функции с использованием градиентного спуска, значения переменных обновляются с шагом, пропорциональным отрицательному значению градиента (или приблизительного градиента) функции в текущей точке. Для машинного обучения пространство параметров можно искать с помощью градиентного спуска. Различные стратегии градиентного спуска могут находить разные «места назначения» в пространстве параметров, ограничивая тем самым прогнозируемые ошибки до приемлемой степени. В вариантах осуществления процесс градиентного спуска может адаптировать скорость обучения к входным параметрам, например, выполняя большие обновления для редко повторяющихся параметров и меньшие обновления для часто повторяющихся параметров. Такие варианты осуществления могут подходить для работы с разреженными данными. Например, стратегия градиентного спуска, известная как RMSprop, может обеспечить улучшенную эффективность с наборами данных о связывании пептидов.
[0058] На стадии 221 может применяться измерение потерь для измерения потерь или «расходов» на обработку. Примеры таких измерений потерь могут включать среднеквадратичную ошибку или перекрестную энтропию.
[0059] На стадии 222 может быть определено, были ли соблюдены критерии выхода для градиентного спуска. Поскольку градиентный спуск является итеративным процессом, могут быть указаны критерии для определения момента, когда итерационный процесс должен остановиться, указывая, что генератор 228 способен генерировать положительные смоделированные данные взаимодействия полипептид-MHC-I, которые классифицируются дискриминатором 226 как положительные и/или реальные. На стадии 222, если определено, что критерии выхода для градиентного спуска не были соблюдены, то процесс может возвращаться к 220, и процесс градиентного спуска продолжается. На стадии 222, если определено, что были соблюдены критерии выхода для градиентного спуска, процесс может продолжаться со стадии 224, на которой дискриминатор 226 и генератор 228 могут быть обучены, например, как описано со ссылкой на фиг. 5A. На стадии 224 могут быть сохранены обученные модели для дискриминатора 226 и генератора 228. Эти сохраненные модели могут включать в себя данные, определяющие структуру и коэффициенты, составляющие модели для дискриминатора 226 и генератора 228. Сохраненные модели предоставляют возможность использовать генератор 228 для генерирования фальшивых данных и дискриминатор 226 для идентификации данных, и при надлежащем обучении предоставлять точные и применимые результаты от дискриминатора 226 и генератора 228.
[0060] Затем процесс может продолжаться со стадий 230-238, которые в целом соответствуют стадии 120 на фиг. 1. На стадиях 230-238 сгенерированные экземпляры данных (например, положительные смоделированные данные взаимодействия полипептид-MHC-I) могут быть получены с использованием обученного генератора 228. Например, на стадии 230 процесс генерирования GAN может быть настроен, например, путем установки ряда параметров 232, 234 для управления генерированием 236 GAN. Примеры параметров, которые могут быть установлены, могут включать размер 232 генерирования и размер 234 дискретизации. Параметры 232 размера генерирования могут обеспечивать возможность указания размера генерируемого набора данных. Например, размер генерируемого набора данных (положительные смоделированные данные взаимодействия полипептид-MHC-I) может быть установлен как в 2,5 раза больший размера реальных данных (положительные реальные данные взаимодействия полипептид-MHC-I и/или отрицательные реальные данные взаимодействия полипептид-MHC-I). В этом примере, если исходные реальные данные в пакете равны 64, то соответствующие генерируемые смоделированные данные в пакете равны 160. Параметры 234 размера дискретизации могут предоставлять возможность указывать размер дискретизации, которая будет использоваться для генерирования набора данных. Например, этот параметр может быть задан как процентиль отсечения для выбора 20 аминокислот в последнем слое генератора. Например, указание 90-го процентиля означает, что все точки ниже 90-го процентиля будут установлены на 0, а остальные могут быть нормализованы с помощью функции нормализации, такой как нормализованная экспоненциальная функция (softmax). На стадии 236 обученный генератор 228 может использоваться для генерирования набора 236 данных, который может использоваться для обучения модели CNN.
[0061] На стадии 240 экземпляры 238 смоделированных данных, созданные обученным генератором 228, и экземпляры реальных данных из исходного набора данных могут быть смешаны для формирования нового набора данных 240 для обучения, что в целом соответствует стадии 120 на фиг. 1. Данные 240 для обучения могут включать одно или более из положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I. На стадиях 242-262 модель 262 классификатора сверточной нейронной сети (CNN) может быть обучена с использованием смешанных данных 240 для обучения. На стадии 242 обучение CNN может быть настроено, например, путем установки ряда параметров 244-252 для управления обучением CNN 254. Примеры параметров, которые могут быть установлены, могут включать тип 244 аллеля, длину 246 аллеля, сложность 248 модели, скорость 250 обучения и размер 252 пакета. Параметры 244 типа аллеля могут предоставлять возможность указывать один или более типов аллелей, которые должны быть включены в обработку CNN. Примеры таких типов аллелей представлены на фиг. 12. Например, указанные аллели могут включать A0201, A0202, B2703, B2705 и т. д., показанные на фиг. 12. Параметры 246 длины аллеля могут предоставлять возможность указывать длины пептидов, которые могут связываться с каждым указанным типом 244 аллеля. Примеры таких длин аллелей показаны на фиг. 13А. Например, для A0201 указанная длина отображается как 9 или 10, для A0202 указанная длина отображается как 9, для B2705 указанная длина отображается как 9 и т. д. Набор параметров, соответствующих сложности 248 модели, может предоставить возможность определять аспекты сложности моделей, которые будут использоваться во время обучения 254 CNN. Примеры таких аспектов могут включать количество слоев, количество узлов на слой, размер окна для каждого сверточного слоя и т. д. Параметры 250 скорости обучения могут предоставлять возможность указывать одну или более скоростей, с которыми обработка обучения, выполняемая при обучении CNN 254, должна сходиться. Примеры таких параметров скорости обучения могут включать 0,001, который является безразмерным параметром, определяющим относительную скорость обучения. Параметры 252 размера пакета могут предоставлять возможность указывать размеры пакетов данных 240 для обучения, которые должны быть обработаны во время обучения 254 CNN. Например, если набор данных для обучения разделен на 100 равных частей, размер пакета может быть целым числом от размера обучающих данных (train_data_size)/100. Обработка 242 настройки обучения CNN может собирать параметры 244-252 обучения, обрабатывать их так, чтобы они были совместимы с обучением 254 CNN, и вводить обработанные параметры в обучение 254 CNN или сохранять обработанные параметры в соответствующих файлах или местах для использования в обучении 254 CNN.
[0062] На стадии 254 может быть начато обучение CNN. Обучение 254 CNN может принимать данные 240 для обучения, например, пакетами, как указано посредством параметров 252 размера пакета. На стадии 256процесс градиентного спуска может быть применен к принятым данным 240 для обучения. Как описано выше, градиентный спуск представляет собой итеративный процесс для выполнения машинного обучения, например нахождения минимума или локального минимума функции. Например, стратегия градиентного спуска, известная как RMSprop, может обеспечить улучшенную эффективность с наборами данных о связывании пептидов.
[0063] На стадии 257 может применяться измерение потерь для измерения потерь или «расходов» на обработку. Примеры таких измерений потерь могут включать среднеквадратичную ошибку или перекрестную энтропию.
[0064] На стадии 258 может быть определено, были ли соблюдены критерии выхода для градиентного спуска. Поскольку градиентный спуск является итеративным процессом, могут быть указаны критерии для определения момента, когда итерационный процесс должен остановиться. На стадии 258, если определено, что критерии выхода для градиентного спуска не были соблюдены, то процесс может возвращаться к 256, и процесс градиентного спуска продолжается. На стадии 258, если определено, что критерии выхода для градиентного спуска соблюдены (что указывает на то, что gCNN способна классифицировать положительные (реальные или смоделированные) данные взаимодействия полипептид-MHC-I как положительные и/или отрицательные реальные данные взаимодействия полипептид-MHC-I как отрицательные), затем процесс может продолжиться с 260, где модель 262 классификатора CNN может быть сохранена как модель 262 классификатора CNN. Эти сохраненные модели могут включать в себя данные, определяющие структуру и коэффициенты, которые составляют модель 262 классификатора CNN. Сохраненные модели предоставляют возможность использовать модель 262 классификатора CNN для классификации пептидных связываний экземпляров входных данных и, при правильном обучении, предоставлять точные и применимые результаты из модели 262 классификатора CNN. На стадии 264 обучение CNN завершается.
[0065] На стадиях 266-280 модель 262 классификатора обученной сверточной нейронной сети (CNN) может использоваться для предоставления и оценки прогнозов на основе тестовых данных (тестовые данные могут содержать одно или более из положительных реальных данных взаимодействия полипептид-MHC-I и/или отрицательных реальных данных взаимодействия полипептид-MHC-I) для измерения эффективности всей модели GAN, что в целом соответствует стадии 130 на фиг. 1. На стадии 270 критерии выхода GAN могут быть установлены, например, путем установки ряда параметров 272-276 для управления процессом 266 оценки. Примеры параметров, которые могут быть установлены, могут включать параметры 272 точности прогнозирования, параметры 274 достоверности прогнозирования и параметры 276 потерь. Параметры 272 точности прогнозирования могут обеспечивать возможность определять точность прогнозов, которые должны быть предоставлены посредством оценки 266. Например, пороговое значение точности для прогнозирования реальной положительной категории может быть больше или равно 0,9. Параметры 274 достоверности прогнозирования могут обеспечивать возможность указывать уровни достоверности (например, нормализация softmax) для прогнозов, которые должны быть предоставлены посредством оценки 266. Например, пороговое значение достоверности прогнозирования поддельной или фальшивой категории может быть установлено на значение большее или равное 0,4 и большее или равное 0,6 для реальной отрицательной категории. Обработка 270 настройки критериев выхода GAN может собирать параметры 272-276 обучения, обрабатывать их так, чтобы они были совместимы с прогнозной оценкой 266 GAN, и вводить обработанные параметры в прогнозную оценку 266 GAN или сохранять обработанные параметры в соответствующих файлах или местах для использования в прогнозной оценке 266 GAN. На стадии 266 может быть начата прогнозная оценка GAN. Прогнозная оценка 266 GAN может принимать тестовые данные 268.
[0066] На стадии 267 может быть выполнено измерение площади под кривой рабочих характеристик приемника (ROC) (AUC). AUC представляет собой нормализованную меру эффективности классификации. Посредством AUC измеряют вероятность того, что с учетом двух случайных точек - одной из положительного и одной из отрицательного класса - классификатор оценит точку из положительного класса выше, чем точку из отрицательного. На самом деле таким образом измеряется эффективность ранжирования. AUC основывается на идее того, что, чем больше классов прогнозирования, которые смешаны между собой (в выходном пространстве классификатора), тем хуже работает классификатор. ROC сканирует выходное пространство классификатора с движущейся границей. В каждой точке сканирования записываются ложноположительные результаты (FPR) и истинноположительные результаты (TPR) (как нормализованная мера). Чем больше разница между двумя значениями, тем меньше смешиваются точки и тем лучше они классифицируются. После получения всех пар FPR и TPR их можно отсортировать и построить кривую ROC. AUC - это площадь под этой кривой.
[0067] На стадии 278 может быть определено, были ли соблюдены критерии выхода для градиентного спуска, или нет, что в целом соответствует стадии 140 на фиг. 1 Поскольку градиентный спуск является итеративным процессом, могут быть указаны критерии для определения момента, когда итерационный процесс должен остановиться. На стадии 278, если определено, что критерии выхода для процесса 266 оценки не были соблюдены, тогда процесс может вернуться к 220, и процесс 220-264 обучения GAN и процесс 266 оценки продолжаются. Таким образом, когда критерий выхода не соблюдается, процесс будет возвращен к обучению GAN (в целом соответствующему возвращению к стадии 110 на фиг. 1) для создания генератора с лучшими результатами. На стадии 278, если определено, что соблюдены критерии выхода из процесса 266 оценки (что указывает на то, что CNN классифицировала положительные реальные данные взаимодействия полипептид-MHC-I как положительные и/или отрицательные реальные данные взаимодействия полипептид-MHC-I как отрицательные), затем процесс может продолжаться на 280, где обработка с прогнозной оценкой и процесс 200 завершаются, что в целом соответствует стадии 150 на фиг. 1.
[0068] Пример варианта осуществления внутренней структуры обработки генератора 228 показан на фиг. 6 - фиг. 7. В этом примере каждый блок обработки может выполнять указанный тип обработки и может выполняться в показанном порядке. Следует отметить, что это всего лишь пример. В вариантах осуществления типы выполняемой обработки, а также порядок, в котором выполняется обработка, могут быть изменены.
[0069] На фиг. 6 - фиг. 7описывается примерный поток обработки для генератора 228. Поток обработки является только примером и не предназначен для ограничения. Обработка, включенная в генератор 228, может начинаться с обработки 602 плотности, при которой входные данные вводятся в нейронный слой с прямой связью для оценки пространственного изменения плотности входных данных. На 604 может выполняться обработка с пакетной нормализацией. Например, обработка с нормализацией может включать корректировку значений, измеренных в разных масштабах, с приведением к общему масштабу, для корректировки всех распределений вероятностей значений данных для согласования. Такая нормализация может обеспечить повышенную скорость сходимости, поскольку исходные (глубокие) нейронные сети чувствительны к изменениям на слоях в начале, а параметр направления оптимизируется, чтобы можно было отвлечься попыткой снизить ошибки для выбросов в данных в начале. Пакетная нормализация упорядочивает градиенты от этих отвлекающих факторов и, следовательно, выполняется быстрее. На 606 может выполняться обработка активации. Например, обработка активации может включать в себя tanh, сигмоидную функцию, ReLU (выпрямленные линейные блоки) или ступенчатую функцию и т. д. Например, ReLU имеет выход 0, если вход меньше 0, и необработанный вход в противном случае. Он проще (требует меньше вычислений) по сравнению с другими функциями активации и, следовательно, может обеспечить ускоренное обучение. На стадии 608 может выполняться обработка с изменением формы ввода. Например, такая обработка может помочь преобразовать форму (размеры) ввода в целевую форму, которая может быть принята в качестве допустимого ввода на следующей стадии. На стадии 610 может выполняться обработка с гауссовским исключением. Исключение представляет собой методику регуляризации для уменьшения переобучения в нейронных сетях на основе определенных данных обучения. Исключение может быть выполнено путем удаления узлов нейронной сети, которые могут вызывать или усугублять переобучение. Обработка с гауссовским исключением может использовать гауссовское распределение для определения узлов, которые необходимо удалить. Такая обработка может создавать шум в виде исключения, но может сохранять среднее и дисперсию входных данных относительно их исходных значений на основе гауссовского распределения, чтобы гарантировать свойство самонормализации даже после исключения.
[0070] На стадии 612 может выполняться обработка гауссовского шума. Гауссовский шум представляет собой статистический шум, имеющий функцию плотности вероятности (PDF), равную функции нормального, или гауссовского, распределения. Обработка гауссовского шума может включать добавление шума к данным для предотвращения обучения модели небольшим (часто тривиальным) изменениям в данных, тем самым добавляя устойчивость к переобучению модели. Этот процесс может повысить точность прогнозов. На стадии 614 может выполняться двумерная (2D) сверточная обработка. 2D свертка является расширением 1D свертки за счет свертки как горизонтального, так и вертикального направлений в двумерной пространственной области и может обеспечивать сглаживание данных. Такая обработка может сканировать все частичные входные данные с помощью нескольких движущихся фильтров. Каждый фильтр можно рассматривать как нейронный слой с совместно используемыми параметрами, который подсчитывает появление определенной характеристики (совпадающей со значениями параметров фильтра) во всех местах на карте характеристик. На стадии 616 может выполняться вторая обработка с пакетной нормализацией. На стадии 618 может выполняться вторая обработка активации, на стадии 620 может выполняться вторая обработка с гауссовским исключением, а на стадии 622может выполняться 2D обработка с повышающей дискретизацией. Обработка с повышающей дискретизацией может преобразовать входные данные из исходной формы в желаемую (в основном более крупную) форму. Например, для этого может использоваться передискретизация или интерполяция. Например, входные данные можно повторно масштабировать до желаемого размера, и значение в каждой точке может быть вычислено с использованием интерполяции, такой как билинейная интерполяция. На стадии 624 может выполняться вторая обработка гауссовского шума, а на стадии 626 может выполняться двумерная (2D) сверточная обработка.
[0071] На фиг. 7, на стадии 628 может выполняться третья обработка с пакетной нормализацией, на стадии 630 может выполняться третья обработка активации, на стадии 632 может выполняться третья обработка с гауссовским исключением, и на стадии 634 может выполняться третья обработка гауссовского шума. На стадии 636 может выполняться вторая двумерная (2D) сверточная обработка, а на стадии 638 может выполняться четвертая обработка с пакетной нормализацией. Обработка активации может выполняться после стадии 638 и до стадии 640. На стадии 640 может выполняться четвертая обработка с гауссовским исключением.
[0072] На стадии 642 может выполняться четвертая обработка гауссовского шума, на стадии 644 - третья двумерная (2D) сверточная обработка, а на стадии 646 может выполняться пятая обработка с пакетной нормализацией. На стадии 648 может выполняться пятая обработка с гауссовским исключением, на стадии 650 может выполняться пятая обработка гауссовского шума, а на стадии 652 может выполняться четвертая обработка активации. Такая обработка активации может использовать сигмоидную функцию активации, которая преобразует входные данные из [- бесконечность, бесконечность] в выходные данные [0,1]. Типичные системы распознавания данных могут использовать функцию активации на последнем слое. Однако из-за категориального характера настоящих методик сигмоидная функция может обеспечивать улучшенное прогнозирование связывания MHC. Сигмоидная функция более мощная, чем ReLU, и может обеспечить подходящий вывод вероятности. Например, в настоящей задаче классификации может быть желательным выведение как вероятность. Однако, поскольку сигмоидная функция может быть намного медленнее, чем ReLU или tanh, по соображениям эффективности может быть нежелательно использовать сигмоидную функцию для предыдущих слоев активации. Однако, поскольку последние плотные слои более непосредственно связаны с окончательным выведением, применение сигмоидной функции на этом слое активации может значительно улучшить сходимость по сравнению с ReLU.
[0073] На стадии 654 может выполняться вторая обработка с изменением формы ввода для изменения выходных данных относительно размерности данных (которые могут быть поданы на дискриминатор позже).
[0074] Пример варианта осуществления потока обработки дискриминатора 226 показан на фиг. 8 - фиг. 9. Поток обработки является только примером и не предназначен для ограничения. В этом примере каждый блок обработки может выполнять указанный тип обработки и может выполняться в показанном порядке. Следует отметить, что это всего лишь пример. В вариантах осуществления типы выполняемой обработки, а также порядок, в котором выполняется обработка, могут быть изменены.
[0075] Вернемся к фиг. 8, обработка, включенная в дискриминатор 226, может начинаться с одномерной (1D) сверточной обработки 802, которая может принимать входной сигнал, применять 1D сверточный фильтр к входным данным и создавать выходные данные. На стадии 804 может выполняться обработка с пакетной нормализацией, а на стадии 806 может выполняться обработка активации. Например, для выполнения обработки активации может использоваться обработка посредством выпрямленных линейных блоков (RELU) с утечкой. RELU представляет собой один из типов функции активации для узла или нейрона в нейронной сети. RELU с утечкой может допускать небольшой ненулевой градиент, когда узел не активен (вход меньше 0). У ReLU есть проблема под названием «умирание», при которой он продолжает выводить 0, когда вход функции активации имеет большое отрицательное смещение. Когда это происходит, модель прекращает обучение. ReLU с утечкой решает эту проблему, предоставляя ненулевой градиент, даже когда он неактивен. Например, f (x) = alpha * x для x <0, f (x) = x для x> = 0. На стадии 808 может выполняться обработка с изменением формы ввода, а на стадии 810 может выполняться 2D обработка с повышающей дискретизацией.
[0076] Необязательно на стадии 812 может выполняться обработка гауссовского шума, на стадии 814 может выполняться двумерная (2D) сверточная обработка, на стадии 816 может выполняться вторая обработка с пакетной нормализацией, на стадии 818 может выполняться вторая обработка активации, на стадии 820может выполняться вторая 2D обработка с повышающей дискретизацией, на стадии 822 может выполняться вторая 2D сверточная обработка, на стадии 824 может выполняться третья обработка с пакетной нормализацией и на стадии 826 может выполняться третья обработка активации.
[0077] Продолжим рассматривать фиг. 9; на стадии 828 может выполняться третья 2D сверточная обработка, на стадии 830 может выполняться четвертая обработка с пакетной нормализацией, на стадии 832 может выполняться четвертая обработка активации, на стадии 834 может выполняться четвертая 2D сверточная обработка, на стадии 836 может выполняться пятая обработка с пакетной нормализацией, на стадии 838 может выполняться пятая обработка активации и на стадии 840 может выполняться обработка с выравниванием данных. Например, обработка с выравниванием данных может включать объединение данных из разных таблиц или наборов данных для формирования единой таблицы или набора данных или их уменьшенного количества. На 842 может выполняться обработка плотности. На стадии 844 может выполняться шестая обработка активации, на стадии 846 может выполняться вторая обработка плотности, на стадии 848 может выполняться шестая обработка с пакетной нормализацией, и на стадии 850 может выполняться седьмая обработка активации.
[0078] Сигмоидная функция может использоваться вместо ReLU с утечкой в качестве функций активации для последних 2 плотных слоев. Сигмоид более мощный, чем ReLU с утечкой, и может обеспечивать выход с разумной вероятностью (например, в задаче классификации желателен выход как вероятность). Однако сигмоидная функция медленнее, чем ReLU с утечкой, использование сигмоида может быть нежелательным для всех слоев. Однако, поскольку последние два плотных слоя более непосредственно связаны с конечным выходом, сигмоид значительно улучшает сходимость по сравнению с ReLU с утечкой. В вариантах осуществления два плотных слоя (или полносвязные слои нейронной сети) 842 и 846 могут использоваться для получения достаточной сложности для преобразования их входных данных. В частности, один плотный слой может быть недостаточно сложным для преобразования результатов свертки в выходное пространство дискриминатора, хотя этого может быть достаточно для использования в генераторе 228.
[0079] В варианте осуществления раскрыты способы использования нейронной сети (например, CNN) для классификации входных данных на основе предыдущего процесса обучения. Нейронная сеть может генерировать оценку прогноза и, таким образом, может классифицировать входные биологические данные как успешные или неуспешные на основе нейронной сети, предварительно обученной на наборе успешных и неуспешных биологических данных, включая оценки прогноза. Оценки прогноза могут представлять собой оценки аффинности связывания. Нейронная сеть может использоваться для генерирования прогнозируемого показателя аффинности связывания. Показатель аффинности связывания может численно представлять вероятность того, что одна биомолекула (например, белок, ДНК, лекарственное средство и т. д.) свяжется с другой биомолекулой (например, с белком, ДНК, лекарственным средством и т. д.). Прогнозируемая оценка аффинности связывания может численно представлять вероятность того, что пептид (например, MHC) будет связываться с другим пептидом. Однако до сих пор методики машинного обучения не могли применяться ввиду, по меньшей мере, неспособности производить надежные прогнозы, когда нейронная сеть обучается на небольших объемах данных.
[0080] Описанные способы и системы решают эту проблему за счет применения комбинации признаков для более надежного прогнозирования. Первый признак - это применение расширенного набора биологических данных для обучения в целях обучения нейронной сети. Этот расширенный набор для обучения разработан путем обучения GAN созданию смоделированных биологических данных. Затем нейронные сети подвергают обучению с помощью этого расширенного набора для обучения (например, с применением стохастического обучения с обратным распространением, которое представляет собой тип алгоритма машинного обучения, который использует градиент математической функции потерь для корректировки весов сети). К сожалению, введение расширенного набора для обучения может увеличить количество ложноположительных результатов при классификации биологических данных. Соответственно, вторым признаком описанных способов и систем является минимизация этих ложноположительных результатов путем выполнения итеративного алгоритма обучения по мере необходимости, в котором GAN дополнительно задействуется для генерирования обновленного смоделированного набора для обучения, содержащего смоделированные данные более высокого качества, и нейронная сеть проходит переобучение посредством обновленного набора для обучения. Эта комбинация функций обеспечивает надежную модель прогнозирования, которая может спрогнозировать успех (например, оценки аффиности связывания) определенных биологических данных, ограничивая количество ложноположительных результатов.
[0081] Набор данных может содержать неклассифицированные биологические данные, такие как неклассифицированные данные взаимодействия белков. Неклассифицированные биологические данные могут включать данные, касающиеся белка, для которого не доступна оценка аффинности связывания в отношении другого белка. Биологические данные могут включать множество кандидатных взаимодействий белок-белок, например кандидатные данные взаимодействия белок-MHC-I. CNN может генерировать оценку прогноза, указывающую аффинность связывания и/или классифицировать каждое из кандидатных взаимодействий полипептид-MHC-I как положительное или отрицательное.
[0082] В варианте осуществления, показанном на фиг. 10, реализуемый на компьютере способ 1000 обучения нейронной сети для прогнозирования аффинности связывания может включать сбор набора положительных биологических данных и отрицательных биологических данных из базы данных на стадии 1010. Биологические данные могут включать данные взаимодействия белок-белок. Данные взаимодействия белок-белок могут включать одно или более из следующего: последовательность первого белка, последовательность второго белка, идентификатор первого белка, идентификатор второго белка и/или оценку аффинности связывания, и т. п. В одном варианте осуществления оценка аффинности связывания может быть равна 1, указывая на успешное связывание (например, положительные биологические данные), или -1, указывая на неуспешное связывание (например, отрицательные биологические данные).
[0083] Реализуемый на компьютере способ 1000 может предусматривать применение генеративно-состязательной сети (GAN) к набору положительных биологических данных для создания набора смоделированных положительных биологических данных на стадии 1020. Применение GAN к набору положительных биологических данных для создания набора смоделированных положительных биологических данных может включать генерирование посредством генератора GAN все более точных положительных смоделированных биологических данных до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные биологические данные как положительные.
[0084] Реализуемый на компьютере способ 1000 может предусматривать создание первого набора для обучения, содержащего собранный набор положительных биологических данных, смоделированный набор положительных биологических данных и набор отрицательных биологических данных, на стадии 1030.
[0085] Реализуемый на компьютере способ 1000 может предусматривать обучение нейронной сети на первой стадии с применением первого набора для обучения на стадии 1040. Обучение нейронной сети на первой стадии с применением первого набора для обучения может включать представление положительных смоделированных биологических данных, положительных биологических данных и отрицательных биологических данных в сверточную нейронную сеть (CNN) до тех пор, пока CNN не будет способна классифицировать биологические данные как положительные или отрицательные.
[0086] Реализуемый на компьютере способ 1000 может предусматривать создание второго набора для обучения для второй стадии обучения путем повторного применения GAN для создания дополнительных смоделированных положительных биологических данных на стадии 1050. Создание второго набора для обучения может быть основано на представлении положительных биологических данных и отрицательных биологических данных в CNN для генерирования оценок прогноза и определения того, что оценки прогноза неточны. Оценки прогноза могут представлять собой оценки аффинности связывания. Неточные оценки прогноза указывают на то, что CNN не полностью обучена, что может быть прослежено до обнаружения того, что GAN не полностью обучена. Соответственно, может выполняться одна или более итераций генератора GAN, генерирующего все более точные положительные смоделированные биологические данные до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные биологические данные как положительные, для генерирования дополнительных смоделированных положительных биологических данных. Второй набор для обучения может содержать положительные биологические данные, смоделированные положительные биологические данные и отрицательные биологические данные.
[0087] Реализуемый на компьютере способ 1000 может предусматривать обучение нейронной сети на второй стадии с применением второго набора для обучения на стадии 1060. Обучение нейронной сети на второй стадии с применением второго набора для обучения может предусматривать представление положительных биологических данных, смоделированных положительных биологических данных и отрицательных биологических данных в CNN до тех пор, пока CNN не будет способна классифицировать биологические данные как положительные или отрицательные.
[0088] После того, как CNN будет полностью обучена, в CNN могут быть представлены новые биологические данные. Новые биологические данные могут включать данные в отношении взаимодействия белок-белок. Данные взаимодействия белок-белок могут включать одно или более из последовательности первого белка, последовательности второго белка, идентификатора первого белка и/или идентификатора второго белка и т. п. CNN может анализировать новые биологические данные и генерировать оценку прогноза (например, прогнозируемую аффинность связывания), указывающую на прогнозируемое успешное или неуспешное связывание.
[0089] В иллюстративном аспекте способы и системы могут быть реализованы на компьютере 1101, как проиллюстрировано на фиг. 11 и описано ниже. Сходным образом, в раскрытых способах и системах может использоваться один или более компьютеров для выполнения одной или более функций в одном или более местоположениях. На фиг. 11 показана блок-диаграмма, демонстрирующая иллюстративную операционную среду, предназначенную для выполнения раскрытых способов. Данная иллюстративная операционная среда является лишь примером операционной среды и не предполагает каких-либо ограничений в отношении объема применения или функциональности архитектуры операционной среды. Также не следует истолковывать операционную среду как каким-либо образом зависящую от или требующую наличия любого из компонентов или их комбинации, показанных в иллюстративной операционной среде.
[0090] Способы и системы по настоящему изобретению могут функционировать с многочисленными другими средами или конфигурациями вычислительных систем общего назначения или специализированного назначения. Примеры хорошо известных вычислительных систем, сред и/или конфигураций, которые могут быть подходящими для использования с системами и способами, включают без ограничения персональные компьютеры, серверные компьютеры, портативные компьютеры и многопроцессорные системы. Дополнительные примеры включают компьютерные приставки, программируемую бытовую электронную технику, сетевые компьютеры, миникомпьютеры, суперкомпьютеры, распределенные вычислительные среды, которые содержат любые из вышеперечисленных систем или устройств и т. п.
[0091] Вычисление, предусматриваемое раскрытыми способами и системами, можно выполнять с помощью компонентов программного обеспечения. Раскрытые системы и способы могут быть описаны в общем контексте выполняемых компьютером команд, как, например, блоки программ, выполняемые одним или более компьютерами или другими устройствами. Как правило, блоки программ включают программный код, алгоритмы, программы, объекты, компоненты, структуры данных и т. д., которые выполняют конкретные задачи или обеспечивают реализацию конкретных типов абстрактных данных. Раскрытые способы также можно осуществлять на практике с помощью сетевых и распределенных вычислительных сред, в которых задачи выполняются устройствами дистанционной обработки данных, которые связаны посредством коммуникационной сети. В распределенной вычислительной среде блоки программ могут быть расположены как в локальных, так и в удаленных компьютерных носителях информации, в том числе в запоминающих устройствах.
[0092] Кроме того, специалисту в данной области техники будет понятно, что системы и способы, раскрытые в данном документе, могут быть реализованы посредством вычислительного устройства общего назначения в виде компьютера 1101. Компоненты компьютера 1101 могут предусматривать без ограничения один или более процессоров 1103, системное запоминающее устройство 1112 и системную шину 1113, которая соединяет разные компоненты системы, в том числе один или более процессоров 1103 с системным запоминающим устройством 1112. Система может использовать параллельную вычислительную обработку.
[0093] Системная шина 1113 представляет собой один или более из нескольких возможных типов шинных структур, в том числе шину запоминающего устройство или контроллер запоминающего устройства, периферийную шину, ускоренный графический порт или локальную шину с использованием любой из множества шинных архитектур. В качестве примера такие архитектуры могут включать в себя шину со стандартной промышленной архитектурой (ISA), шину с микроканальной архитектурой (MCA), шину с улучшенной стандартной промышленной архитектурой (EISA), локальную шину ассоциации стандартов видеоэлектроники (VESA), шину расширения стандарта AGP для подключения видеоадаптеров (AGP) и локальную шину соединения периферийных устройств (PCI), последовательную шину/последовательный интерфейс PCI Express, карту памяти персонального компьютера международной ассоциации (PCMCIA), универсальную последовательную шину (USB) и т. п. Шина 1113 и все шины, указанные в данном описании, могут быть также реализованы посредством проводного или беспроводного сетевого соединения, при этом каждая из подсистем, в том числе один или более процессоров 1103, запоминающее устройство 1104 большой емкости, операционная система 1105, программное обеспечение 1106 для классификации (например, GAN, CNN), классификационные данные 1107 (например, «реальные» или «смоделированные» данные, в том числе положительные смоделированные данные взаимодействия полипептид-MHC-I, положительные реальные данные взаимодействия полипептид-MHC-I и/или отрицательные реальные данные взаимодействия полипептида и MHC-I), сетевой адаптер 1108, системное запоминающее устройство 1112, интерфейс 1110 ввода/вывода, графический адаптер 1109, устройство 1111 отображения и интерфейс 1102 «пользователь-машина», может находиться в пределах одного или более удаленных вычислительных устройств 1114a, b,c, находящихся в физически отделенных местоположениях, соединенных посредством шин данного типа, в результате чего реализуется полностью распределенная система.
[0094] Компьютер 1101, как правило, содержит ряд различных машиночитаемых носителей. Иллюстративные носители данных могут представлять собой любые доступные носители, доступ к которым осуществляется с помощью компьютера 1101, и они предусматривают, например, без ограничения как энергозависимые, так и энергонезависимые носители, съемные и несъемные носители. Системное запоминающее устройство 1112 содержит машиночитаемые носители в виде энергозависимого запоминающего устройства, такого как запоминающее устройство с произвольным доступом (RAM), и/или энергонезависимого запоминающего устройства, такого как запоминающее устройство с постоянным доступом (ROM). Системная память 1112, как правило, содержит данные, как, например, классификационные данные 1107, и/или блоки программ, как, например, операционная система 1105 и программное обеспечение для классификации 1106, которые непосредственно доступны для одного или более процессоров 1103 и/или в данный момент подвергаются обработке с их помощью.
[0095] В другом аспекте компьютер 1101 также может содержать другие съемные/несъемные энергозависимые/энергонезависимые компьютерные носители информации. В качестве примера на фиг. 11 показано запоминающее устройство 1104 большой емкости, которое может обеспечивать энергонезависимое хранение программного кода, машиночитаемых команд, структур данных, блоков программ и других данных для компьютера 1101. Например, без ограничения запоминающее устройство 1104 большой емкости может представлять собой жесткий диск, съемный магнитный диск, съемный оптический диск, магнитные кассеты или другие магнитные запоминающие устройства, карты флеш-памяти, CD-ROM, универсальные цифровые диски (DVD) или другое оптическое запоминающее устройство, запоминающие устройства с произвольным доступом (RAM), запоминающие устройства с постоянным доступом (ROM), электрически стираемое программируемое постоянное запоминающее устройство (EEPROM) и т. п.
[0096] Необязательно любое число программных модулей может храниться на запоминающем устройстве 1104 большой емкости, в том числе в качестве примера операционная система 1105 и программное обеспечение 1106 для классификации. Как операционная система 1105, так и программное обеспечение 1106 для классификации (или какая-либо их комбинация) могут содержать элементы программ и программное обеспечение 1106 для классификации. Классификационные данные 1107 также могут храниться на запоминающем устройстве 1104 большой емкости. Классификационные данные 1107 могут храниться в любой одной или более баз данных, известных в данной области техники. Примеры таких баз данных включают DB2®, Microsoft® Access, Microsoft® SQL Server, Oracle®, mySQL, PostgreSQL и т. п. Базы данных могут быть централизованными или распределенными между несколькими системами.
[0097] В другом аспекте пользователь может вводить команды и информацию в компьютер 1101 с помощью устройства ввода данных (не показано). Примеры таких устройств ввода данных включают без ограничения клавиатуру, указательное устройство (например, «мышь»), микрофон, джойстик, сканер, устройства тактильного ввода, как, например, перчатки и другие покрывающие тело предметы и т. п. Эти и другие устройства ввода данных могут быть соединены с одним или более процессорами 1103 посредством интерфейса 1102 «пользователь-машина», который соединен с системной шиной 1113, но могут быть соединены посредством другого интерфейса и шинных структур, таких как параллельный порт, игровой порт, порт IEEE 1394 (также известный как порт Firewire), последовательный порт или универсальная последовательная шина (USB).
[0098] В еще одном аспекте устройство 1111 отображения также может быть соединено с системной шиной 1113 посредством интерфейса, такого как графический адаптер 1109. Предполагается, что компьютер 1101 может иметь более одного графического адаптера 1109, и компьютер 1101 может иметь более одного устройства 1111 отображения. Например, устройство отображения 1111 может представлять собой монитор, LCD (жидкокристаллический дисплей) или проектор. В дополнение к устройству 1111 отображения другие периферийные устройства вывода могут предусматривать такие компоненты, как громкоговорители (не показаны) и принтер (не показан), которые могут быть соединены с компьютером 1101 посредством интерфейса 1110 ввода/вывода. Любая стадия и/или результат способов могут быть выведены в любой форме на устройство вывода. Такой выводимый результат может быть представлен в любой форме визуального представления, в том числе без ограничения в текстовой, графической, анимационной, звуковой, тактильной формах и т. п. Устройство 1111 отображения и компьютер 1101 могут быть частью одного устройства или отдельными устройствами.
[0099] Компьютер 1101 может функционировать в сетевой среде с использованием логических соединений с одним или более удаленными вычислительными устройствами 1114a, b,c. В качестве примера удаленное вычислительное устройство может представлять собой персональный компьютер, портативный компьютер, смартфон, сервер, маршрутизатор, сетевой компьютер, одноранговое устройство или другой общий узел сети и т. д. Логические соединения между компьютером 1101 и удаленным вычислительным устройством 1114a, b,c могут быть установлены посредством сети 1115, такой как локальная вычислительная сеть (LAN) и/или общая глобальная вычислительная сеть (WAN). Такие сетевые соединения могут быть осуществлены посредством сетевого адаптера 1108. Сетевой адаптер 1108 может быть реализован как в проводной, так и беспроводной средах. Такие сетевые среды являются традиционными и общеупотребительными для жилых помещений, офисов, компьютерных сетей масштаба предприятия, внутренних сетей и сети Интернет.
[00100] В целях иллюстрации прикладные программы и другие выполняемые компоненты программ, как, например, операционная система 1105, проиллюстрированы в данном документе в виде дискретных блоков, хотя понятно, что такие программы и компоненты находятся в различные моменты времени в разных компонентах памяти вычислительного устройства 1101 и их выполнение реализуется одним или более процессорами 1103 компьютера. Вариант реализации программного обеспечения 1106 для классификации может храниться на машиночитаемых носителях или передаваться посредством какого-либо типа машиночитаемых носителей. Любой из раскрытых способов можно осуществлять посредством машиночитаемых команд, реализованных на машиночитаемых носителях. Машиночитаемые носители могут представлять собой любые доступные носители, доступ к которым может быть получен с помощью компьютера. В качестве примера и без ограничения машиночитаемые носители могут предусматривать «компьютерные носители информации» и «средства связи». «Компьютерные носители информации» включают энергозависимые и энергонезависимые съемные и несъемные носители, реализованные посредством любых способов или технологии хранения информации, такой как машиночитаемые команды, структуры данных, программные модули или другие данные. Иллюстративные компьютерные носители информации включают без ограничения RAM, ROM, EEPROM, флеш-память или другую технологию хранения информации, CD-ROM, универсальные цифровые диски (DVD) или другое оптическое запоминающее устройство, магнитные кассеты, магнитную ленту, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства или любой другой носитель, который можно использовать для хранения требуемой информации и доступ к которому может быть получен с помощью компьютера.
[00101] В способах и системах могут использоваться методики искусственного интеллекта, такие как машинное обучение и итеративное обучение. Примеры таких методик включают без ограничения экспертные системы, рассуждение на основе аналогичных случаев, Байесовские сети, поведенческий искусственный интеллект, нейронные сети, системы на основе нечеткой логики, эволюционное моделирование (например генетические алгоритмы), роевый интеллект (например, алгоритмы муравьиной колонии) и гибридные интеллектуальные системы (например экспертные правила вывода, полученные посредством нейронной сети, или продукционные правила, полученные в результате статистического обучения).
[00102] Следующие примеры изложены с тем, чтобы обеспечить специалистов в данной области полным раскрытием и описанием того, как получают и оценивают соединения, композиции, изделия, устройства и/или способы, заявленные в данном документе, и они предназначены для того, чтобы быть лишь иллюстративными и не предназначены для ограничения объема способов и систем. Были приложены усилия для обеспечения точности в отношении чисел (например, количеств, температуры и т. п.), однако необходимо учитывать некоторые ошибки и отклонения. Если не указано иное, то части являются частями по массе, температура представлена в°C или предусмотрена на уровне температуры окружающей среды, и давление равно атмосферному или близко к нему.
B. Аллели HLA
[00103] Раскрытые системы могут быть обучены на неограниченном количестве аллелей HLA. Данные о связывании пептида с белковыми комплексами MHC-I, кодируемыми аллелями HLA, известны в данной области и доступны из баз данных, в том числе без ограничения, IEDB, AntiJen, MHCBN, SYFPEITHI и т. п.
[00104] В одном варианте осуществления раскрытые системы и способы улучшают прогностичность связывания пептида с белковыми комплексами MHC-I, кодируемыми аллелями HLA: A0201, A0202, B0702, B2703, B2705, B5701, A0203, A0206, A6802 и их комбинациями. Например, 1028790 представляет собой тестовый набор для A0201, A0202, A0203, A0206, A6802.
[00105] Прогностичность может быть улучшена по сравнению с существующими нейронными системами, в том числе без исключения NetMHCpan, MHCflurry, sNeubula и PSSM.
III. Терапевтические средства
[00106] Раскрытые системы и способы применимы для идентификации пептидов, которые связываются с MHC-I Т-клеток и целевых клеток. В одном варианте осуществления пептиды представляют собой опухолеспецифические пептиды, вирусные пептиды или пептид, который демонстрируется на MHC-I целевой клетки. Целевая клетка может представлять собой опухолевую клетку, раковую клетку или клетку, инфицированную вирусом. Пептиды как правило демонстрируются на антигенпрезентирующих клетках, которые затем представляют пептидный антиген CD8+ клеткам, например цитотоксическим Т-клеткам. Связывание пептидного антигена с Т-клеткой активирует или стимулирует Т-клетку. Таким образом, в одном варианте осуществления представлена вакцина, например противораковая вакцина, содержащая один или более пептидов, идентифицированных с помощью раскрытых систем и способов.
[00107] Другой вариант осуществления относится к антителу или его антигенсвязывающему фрагменту, который связывается с пептидом, комплексом пептидный антиген-MHC-I или и тем, и другим.
[00108] Хотя были описаны конкретные варианты осуществления настоящего изобретения, специалистам в данной области техники будет понятно, что существуют другие варианты осуществления, которые эквивалентны описанным вариантам осуществления. Соответственно, следует понимать, что настоящее изобретение не ограничивается конкретными проиллюстрированными вариантами осуществления, а только объемом прилагаемой формулы изобретения.
ПРИМЕРЫ
Пример 1: Оценка существующих моделей прогнозирования
[00109] Оценивали модели прогнозирования NetMHCpan, sNebula, MHCflurry, CNN, PSSM. Площадь под кривой ROC использовали в качестве измерения эффективности. Значение 1 - хорошая эффективность, 0 - плохая эффективность, и 0,5 - случайное предположение. В таблице 1 показаны модели и используемые данные.
Таблица 1: различные модели для прогнозирования связывания пептида с белковыми комплексами MHC-I, кодируемыми указанными аллелями
[00110] На фиг. 12 показаны данные оценки, показывающие, что CNN, обученная, как описано в данном документе, превосходит другие модели в большинстве тестовых случаев, включая текущий аналог, NetMHCpan. На фиг. 12 показана тепловая карта AUC, демонстрирующая результаты применения современных моделей и описанных в настоящее время способов («CNN_ours») к тем же 15 наборам тестовых данных. На фиг. 12 диагональные линии от нижнего левого угла к верхнему правому обычно указывают на более высокое значение, чем тоньше линии, тем выше значение, а чем толще линии, тем ниже значение. Диагональные линии снизу справа к верху слева указывают на более низкое значение, чем тоньше линии, тем ниже значение и чем толще линии, тем выше значение.
Пример 2: Проблемы модели CNN
[00111] Обучение CNN предусматривает множество случайных процессов (например, подача данных в мини-пакетах, стохастический элемент, входящий в градиент по исключению, шумы и т. д.), поэтому воспроизводимость процесса обучения может быть проблематичной. Например, на фиг. 12 показано, что AUC Vang(«Yeeling») не может быть воспроизведена идеально при реализации одного и того же алгоритма на одних и тех же данных. Vang, et al., HLA class I binding prediction via convolutional neural networks, Bioinformatics, Sep 1;33(17):2658-2665 (2017).
[00112] В целом, CNN менее сложна, чем другие фреймворки глубокого обучения, такие как Deep Neural Network, ввиду характера совместного использования параметров, однако это она по-прежнему представляет собой сложный алгоритм.
[00113] Стандартная CNN обеспечивает извлечение признаков из данных с помощью окна фиксированного размера, но информация о связывании пептида может не кодироваться с одинаковой длиной. В настоящем раскрытии, поскольку исследования в области биологии показали, что один тип механизма связывания происходит в масштабе с 7 аминокислотами в пептидной цепи, можно использовать размер окна 7, и хотя данный размер окна обеспечивает хорошее выполнение, он может быть не достаточным для объяснения других типов факторов связывания во всех проблемах связывания HLA.
[00114] На фиг. 13A - фиг. 13C показано расхождение между различными моделями. На фиг. 13A показано 15 наборов тестовых данных из данных связывания HLA, еженедельно публикуемых IEDB. Test_id помечен авторами данного раскрытия как уникальный идентификатор для всех 15 наборов тестовых данных. IEDB - это идентификатор выпуска данных IEDB, в одном выпуске IEDB может быть несколько различных поднаборов данных, относящихся к разным категориям HLA. HLA представляет собой тип HLA, который связывается с пептидами. Длина представляет собой длину связывания пептидов с HLA. Тестовый размер - это количество записей, которые есть в этом наборе тестирования. Обучающий размер - это количество записей, имеющихся в этом наборе для обучения. Доля связываний - это отношение связываний к сумме связываний и отсутствие связываний в наборе данных для обучения, авторы перечисляют его в данном документе для измерения асимметрии данных для обучения. Размер связываний - это количество связываний в наборе данных для обучения, авторы используют его для вычисления доли связываний.
[00115] На фиг. 13B - фиг. 13C продемонстрированы трудности с воспроизведением реализации CNN. Что касается различий между моделями, на фиг. 13B - фиг. 13C представлены 0 различий между моделями. На фиг. 13B - фиг. 13C показано, что реализация Adam не соответствует опубликованным результатам.
Пример 3: Смещение в наборах данных
[00116] Было выполнено разделение обучающего/тестового набора. Разделение обучающего/тестового набора - это измерение, предназначенное для предотвращения переобучения, однако эффективность измерения может зависеть от выбранных данных. Эффективность между моделями значительно различается независимо от того, как они тестируются на одном и том же аллеле гена MHC (A*02:01). Это показывает смещение AUC, полученное при выборе смещенного тестового набора, фиг. 14. Результаты с применением описанных способов на обучающем/тестовом наборе со смещением указаны в столбце «CNN*1», где показана более низкая эффективность, чем представленная на фиг. 12. На фиг. 14 диагональные линии от нижнего левого угла к верхнему правому обычно указывают на более высокое значение, чем тоньше линии, тем выше значение, а чем толще линии, тем ниже значение. Диагональные линии снизу справа к верху слева указывают на более низкое значение, чем тоньше линии, тем ниже значение и чем толще линии, тем выше значение.
Пример 4: Смещение SRCC
[00117] Выбирали лучший коэффициент ранговой корреляции Спирмена (SRCC) из 5 протестированных моделей и сравнивали с размером нормализованных данных. На фиг. 15 показано, что, чем меньше размер теста, тем лучше SRRC. SRCC измеряет несоответствие между рангом прогнозирования и рангом метки. Чем больше размер теста, тем больше вероятность нарушения порядка ранжирования.
Пример 5: Сравнение градиентного спуска
[00118] Проводили сравнение между Adam и RMSprop. Adam представляет собой алгоритм для градиентной оптимизации первого порядка стохастических целевых функций, основанный на адаптивных оценках моментов более низкого порядка. RMSprop (для среднеквадратичного распространения) также является способом, в котором скорость обучения адаптируется для каждого из параметров.
[00119] На фиг. 16A - фиг. 16C показано, что RMSprop имеет улучшение по большей части набора данных по сравнению с Adam. Adam представляет собой оптимизатор на основе импульса, который вначале существенно изменяет параметры по сравнению с RMSprop. Улучшение может относиться к следующему: 1) поскольку дискриминатор руководит всем процессом обучения GAN, если он следует импульсу и существенно обновляет свои параметры, то генератор завершает работу в неоптимальном состоянии; 2) пептидные данные отличаются от изображений, которые допускают меньше ошибок при генерировании. Небольшая разница в 9~30 положениях может значительно изменить результаты связывания, тогда как целые пиксели изображения могут быть изменены, но останутся в той же категории изображения. Adam стремится к дальнейшему исследованию в зоне параметров, но это означает, что для каждой позиции в зоне легче; в то время как RMSprop останавливается дольше в каждой точке и может обнаруживать незначительные изменения параметра, указывающие на значительное улучшение конечного результата дискриминатора, и передавать эти знания генератору для создания лучше смоделированных пептидов.
Пример 5: Формат пептидного обучения
[00120] В таблице 2 показан пример данных взаимодействия MHC-I. Показаны пептиды с разной аффинностью связывания для указанного аллеля HLA. Пептиды были обозначены как связывающие (1) или несвязывающие (-1). Категория связывания была преобразована из полумаксимальной ингибирующей концентрации (IC50). Прогнозируемый выход указан в единицах IC50 нМ. Меньшее число указывает на более высокую аффинность. Пептиды со значениями IC50 <50 нМ считаются высокоаффинными, с <500 нМ - с промежуточной аффинностью, а с <5000 нМ - низкой аффинностью. Большинство известных эпитопов характеризуются высокой или промежуточной аффинностью. Некоторые характеризуются низкой активностью. Ни один из известных Т-клеточных эпитопов не имеет значения IC50 более 5000 нМ.
Таблица 2. Пептиды для идентифицированного аллеля HLA, демонстрирующие связывание или отсутствие связывания пептида с белковым комплексом MHC-I, кодируемым аллелем HLA.
Пример 6: Сравнение GAN
[00121] На фиг. 17 показано, что сочетание смоделированных (например, фальшивых, поддельных) положительных данных, реальных положительных данных и реальных отрицательных данных приводит к лучшему прогнозированию, чем одни только реальные положительные и реальные отрицательные данные или смоделированные положительные данные и реальные отрицательные данные. Результаты описанных способов показаны в столбце «CNN» и двух столбцах «GAN-CNN». На фиг. 17 диагональные линии от нижнего левого угла к верхнему правому обычно указывают на более высокое значение, чем тоньше линии, тем выше значение, а чем толще линии, тем ниже значение. Диагональные линии снизу справа к верху слева указывают на более низкое значение, чем тоньше линии, тем ниже значение и чем толще линии, тем выше значение. GAN улучшает эффективность A0201 на всех тестовых наборах. Применение экстрактора информации (например, встраивание CNN+skip-gram) хорошо работает для пептидных данных, поскольку информация о связывании пространственно закодирована. Данные, полученные из раскрытой GAN, можно рассматривать как способ «условного исчисления», который помогает сделать распределение данных более плавным, что упрощает обучение модели. Кроме того, функция потерь GAN заставляет GAN создавать четкие экземпляры, а не среднее значение blue, что отличается от классических способов, таких как вариационные автокодировщики. Поскольку потенциальных схем химического связывания много, усреднение различных паттернов к средней точке было бы оптимальным, следовательно, даже если GAN может переобучиться и столкнуться с проблемой коллапса режима, она будет лучше моделировать паттерны.
[00122] Раскрытые способы превосходят современные системы отчасти ввиду применения различных данных для обучения. Раскрытые способы превосходят применение только реальных положительных и реальных отрицательных данных, поскольку генератор может увеличивать частоту некоторых слабых сигналов связывания, что увеличивает частоту некоторых паттернов связывания и уравновешивает веса различных паттернов связывания в наборе данных для обучения, что делает обучение модели более легким.
[00123] Раскрытые способы превосходят применение только поддельных положительных и реальных отрицательных данных, поскольку класс поддельных положительных данных имеет проблему коллапса режима, что означает, что он не может представлять паттерны связывания для всей популяции; аналогично вводу реальных положительных и реальных отрицательных данных в модель в качестве данных для обучения, но при этом сокращается количество обучающих экземпляров, в результате чего модель имеет меньше данных для применения в обучении.
[00124] На фиг. 17 используются следующие столбцы: тестовый идентификатор: уникальный для одного тестового набора, используется для различения тестовых наборов; IEDB: идентификатор набора данных в базе данных IEDB; HLA: тип аллеля комплекса, связывающегося с пептидами; длина: количество аминокислот в пептидах; тестовый размер: количество найденных наблюдений в этом наборе данных тестирования; обучающий размер: количество наблюдений в этом наборе данных для обучения; доля связываний: доля связываний в наборе данных для обучения; размер связываний: количество связываний в наборе данных для обучения.
[00125] Если четко не указано иное, ни в коем случае не предполагается, что любой способ, изложенный в данном документе, должен истолковываться как требующий выполнения его стадий в определенном порядке. Соответственно, если в формуле изобретения в действительности не указан порядок стадий или в формуле изобретения или в описании конкретно не указано, что стадии должны ограничиваться конкретным порядком, то никоим образом не предполагается, что порядок таким образом выводится из контекста. Это справедливо для любого возможного неявного основания для интерпретации, в том числе логики порядка стадий или последовательности выполнения технологических операций; общеупотребительного значения, полученного на основе грамматической конструкции или пунктуации; числа или типа вариантов осуществления, описанных в описании.
[00126] Хотя в вышеприведенном описании настоящее изобретение было описано применительно к некоторым вариантам его осуществления и было приведено много подробностей с целью иллюстрации, специалистам в данной области будет очевидно, что настоящее изобретение допускает дополнительные варианты осуществления, и что некоторые из подробностей, описанных в данном документе, могут значительно варьироваться без отклонения от основных принципов настоящего изобретения.
[00127] Все ссылки, цитируемые в данном документе, полностью включены посредством ссылки. Настоящее изобретение может быть осуществлено в других конкретных формах без отклонения от его сущности или основных атрибутов, и соответственно следует сделать ссылку на прилагаемую формулу изобретения, а не на предшествующее описание, которое указывает на объем настоящего изобретения.
Иллюстративные варианты осуществления
Вариант осуществления 1. Способ обучения генеративно-состязательной сети (GAN), предусматривающий: генерирование посредством генератора GAN все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные; представление положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные; представление положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействии полипептид-MHC-I в CNN для генерирования оценок прогноза; определение на основании оценок прогноза того, что GAN обучена; и выведение GAN и CNN.
Вариант осуществления 2. Способ по варианту осуществления 1, где генерирование все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как реальные, предусматривает: генерирование посредством генератора GAN в соответствии с набором параметров GAN первого смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC; объединение первого смоделированного набора данных с положительными реальными взаимодействиями полипептид-MHC-I для аллеля MHC и отрицательными реальными взаимодействиями полипептид-MHC-I для аллеля MHC для создания набора данных для обучения GAN; определение с помощью дискриминатора в соответствии с решающей границей, является ли взаимодействие полипептид-MHC-I для аллеля MHC в наборе данных для обучения GAN смоделированным положительным, реальным положительным или реальным отрицательным; корректировку, основанную на точности определения дискриминатором, одного или более из набора параметров GAN или решающей границы; и повторение стадий a-d до тех пор, пока не будет соблюден первый критерий останова.
Вариант осуществления 3. Способ по варианту осуществления 2, где представление положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные, предусматривает: генерирование посредством генератора GAN в соответствии с набором параметров GAN второго смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля HLA; объединение второго смоделированного набора данных, положительных реальных взаимодействий полипептид-MHC-I для аллеля MHC и отрицательных реальных взаимодействий полипептид-MHC-I для аллеля MHC для создания набора данных для обучения CNN; представление набора данных для обучения CNN в сверточную нейронную сеть (CNN); классификацию посредством CNN в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC в наборе данных для обучения CNN как положительного или отрицательного; корректировку, основанную на точности классификации посредством CNN, одного или более из набора параметров CNN; и повторение стадий h-j до тех пор, пока не будет соблюден второй критерий останова.
Вариант осуществления 4. Способ по варианту осуществления 3, где представление положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в CNN для генерирования оценок прогноза предусматривает: классификацию посредством CNN в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC как положительного или отрицательного.
Вариант осуществления 5. Способ по варианту осуществления 4, где определение на основании оценок прогноза того, что GAN обучена, предусматривает определение точности классификации посредством CNN, при этом, когда (если) точность классификации удовлетворяет третьему критерию останова, выведение GAN и CNN.
Вариант осуществления 6. Способ по варианту осуществления 4, где определение на основании оценок прогноза того, что GAN обучена, предусматривает определение точности классификации посредством CNN, при этом, когда (если) точность классификации не удовлетворяет третьему критерию останова, возвращение к стадии а.
Вариант осуществления 7. Способ по варианту осуществления 2, где параметры GAN включают одно или более из типа аллеля, длины аллеля, категории генерирования, сложности модели, скорости обучения или размера пакета.
Вариант осуществления 8. Способ по варианту осуществления 2, где аллель MHC представляет собой аллель HLA.
Вариант осуществления 9. Способ по варианту осуществления 8, где тип аллеля HLA включает один или более из HLA-A, HLA-B, HLA-C или их подтип.
Вариант осуществления 10. Способ по варианту осуществления 8, где длина аллеля HLA составляет от приблизительно 8 до приблизительно 12 аминокислот.
Вариант осуществления 11. Способ по варианту осуществления 8, где длина аллеля HLA составляет от приблизительно 9 до приблизительно 11 аминокислот.
Вариант осуществления 12. Способ по варианту осуществления 1, дополнительно предусматривающий: представление набора данных в CNN, где набор данных содержит множество кандидатных взаимодействий полипептид-MHC-I; классификацию посредством CNN каждого из множества кандидатных взаимодействий полипептид-MHC-I как положительного или отрицательного взаимодействия полипептид-MHC-I; и синтез полипептида из кандидатного взаимодействия полипептид-MHC-I, классифицируемого как положительное взаимодействие полипептид-MHC-I.
Вариант осуществления 13. Полипептид, полученный посредством способа по варианту осуществления 12.
Вариант осуществления 14. Способ по варианту осуществления 12, где полипептид представляет собой опухолеспецифический антиген.
Вариант осуществления 15. Способ по варианту осуществления 12, где полипептид содержит аминокислотную последовательность, которая специфически связывается с белком MHC-I, кодируемым выбранным аллелем MHC.
Вариант осуществления 16. Способ по варианту осуществления 1, где положительные смоделированные данные взаимодействия полипептид-MHC-I, положительные реальные данные взаимодействия полипептид-MHC-I и отрицательные реальные данные взаимодействия полипептид-MHC-I связаны с выбранным аллелем.
Вариант осуществления 17. Способ по варианту осуществления 16, где выбранный аллель выбран из группы, состоящей из A0201, A0202, A0203, B2703, B2705 и их комбинаций.
Вариант осуществления 18. Способ по варианту осуществления 1, где генерирование все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, предусматривает оценку выражения градиентного спуска для генератора GAN.
Вариант осуществления 19. Способ по варианту осуществления 1, где генерирование все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, предусматривает: итеративное выполнение (например, оптимизацию) дискриминатора GAN для увеличения возможности присвоения высокой вероятности положительным реальным данным взаимодействия полипептид-MHC-I, низкой вероятности положительным смоделированным данным взаимодействия полипептид-MHC-I и низкой вероятности отрицательным реальным данным взаимодействия полипептид-MHC-I; и итеративное выполнение (например, оптимизацию) генератора GAN для увеличения вероятности того, что положительные смоделированные данные взаимодействия полипептид-MHC-I будут иметь высокую оценку.
Вариант осуществления 20. Способ по варианту осуществления 1, где представление положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные, предусматривает: выполнение процедуры свертки; выполнение процедуры нелинейности (например, ReLu), выполнение процедуры объединения или субдискретизации; и выполнение процедуры классификации (полносвязный слой).
Вариант осуществления 21. Способ по варианту осуществления 1, где GAN включает глубокую сверточную GAN (DCGAN).
Вариант осуществления 22. Способ по варианту осуществления 2, где первый критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 23. Способ по варианту осуществления 3, где второй критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 24. Способ по варианту осуществления 5 или 6, где третий критерий останова включает оценку функции площади под кривой (AUC).
Вариант осуществления 25. Способ по варианту осуществления 1, где оценка прогноза представляет собой вероятность того, что положительные реальные данные взаимодействия полипептид-MHC-I классифицированы как положительные данные взаимодействия полипептид-MHC-I.
Вариант осуществления 26. Способ по варианту осуществления 1, где определение на основании оценок прогноза того, обучена ли GAN, предусматривает сравнение одной или более оценок прогноза с пороговым значением.
Вариант осуществления 27. Способ обучения генеративно-состязательной сети (GAN), предусматривающий: генерирование посредством генератора GAN все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные; представление положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные; представление положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействии полипептид-MHC-I в CNN для генерирования оценок прогноза; определение на основании оценок прогноза того, что GAN не обучена; повторение стадий а-с до тех пор, пока не будет выполнено определение на основании оценок прогноза того, что GAN обучена; и выведение GAN и CNN.
Вариант осуществления 28. Способ по варианту осуществления 27, где генерирование посредством генератора GAN все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, предусматривает: генерирование посредством генератора GAN в соответствии с набором параметров GAN первого смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC; объединение первого смоделированного набора данных с положительными реальными взаимодействиями полипептид-MHC-I для аллеля MHC и отрицательными реальными взаимодействиями полипептид-MHC-I для аллеля MHC для создания набора данных для обучения GAN; определение с помощью дискриминатора в соответствии с решающей границей, является ли положительное взаимодействие полипептид-MHC-I для аллеля MHC в наборе данных для обучения GAN смоделированным положительным, реальным положительным или реальным отрицательным; корректировку, основанную на точности определения дискриминатором, одного или более из набора параметров GAN или решающей границы; и повторение стадий g-j до тех пор, пока не будет соблюден первый критерий останова.
Вариант осуществления 29. Способ по варианту осуществления 28, где представление положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные, предусматривает: генерирование посредством генератора GAN в соответствии с набором параметров GAN второго смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC; объединение второго смоделированного набора данных, известных положительных взаимодействий полипептид-MHC-I для аллеля MHC и известных отрицательных взаимодействий полипептид-MHC-I для аллеля MHC для создания набора данных для обучения CNN; представление набора данных для обучения CNN в сверточную нейронную сеть (CNN); классификацию посредством CNN в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC в наборе данных для обучения CNN как положительного или отрицательного; корректировку, основанную на точности классификации посредством CNN, одного или более из набора параметров CNN; и повторение стадий n-p до тех пор, пока не будет соблюден второй критерий останова.
Вариант осуществления 30. Способ по варианту осуществления 29, где представление положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в CNN для генерирования оценок прогноза предусматривает: классификацию посредством CNN в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC как положительного или отрицательного.
Вариант осуществления 31. Способ по варианту осуществления 30, где определение на основании оценок прогноза того, что GAN обучена, предусматривает определение точности классификации посредством CNN, при этом, когда (если) точность классификации удовлетворяет третьему критерию останова, выведение GAN и CNN.
Вариант осуществления 32. Способ по варианту осуществления 31, где определение на основании оценок прогноза того, что GAN обучена, предусматривает определение точности классификации посредством CNN, при этом, когда (если) точность классификации не удовлетворяет третьему критерию останова, возвращение к стадии а.
Вариант осуществления 33. Способ по варианту осуществления 28, где параметры GAN включают одно или более из типа аллеля, длины аллеля, категории генерирования, сложности модели, скорости обучения или размера пакета.
Вариант осуществления 34. Способ по варианту осуществления 33, где тип аллеля HLA включает один или более из HLA-A, HLA-B, HLA-C или их подтип.
Вариант осуществления 35. Способ по варианту осуществления 33, где длина аллеля HLA составляет от приблизительно 8 до приблизительно 12 аминокислот.
Вариант осуществления 36. Способ по варианту осуществления 35, где длина аллеля HLA составляет от приблизительно 9 до приблизительно 11 аминокислот.
Вариант осуществления 37. Способ по варианту осуществления 27, дополнительно предусматривающий: представление набора данных в CNN, где набор данных содержит множество кандидатных взаимодействий полипептид-MHC-I; классификацию посредством CNN каждого из множества кандидатных взаимодействий полипептид-MHC-I как положительного или отрицательного взаимодействия полипептид-MHC-I; и синтез полипептида из кандидатного взаимодействия полипептид-MHC-I, классифицируемого как положительное взаимодействие полипептид-MHC-I.
Вариант осуществления 38. Полипептид, полученный посредством способа по варианту осуществления 37.
Вариант осуществления 39. Способ по варианту осуществления 37, где полипептид представляет собой опухолеспецифический антиген.
Вариант осуществления 40. Способ по варианту осуществления 37, где полипептид содержит аминокислотную последовательность, которая специфически связывается с белком MHC-I, кодируемым выбранным аллелем MHC.
Вариант осуществления 41. Способ по варианту осуществления 27, где положительные смоделированные данные взаимодействия полипептид-MHC-I, положительные реальные данные взаимодействия полипептид-MHC-I и отрицательные реальные данные взаимодействия полипептид-MHC-I связаны с выбранным аллелем.
Вариант осуществления 42. Способ по варианту осуществления 41, где выбранный аллель выбран из группы, состоящей из A0201, A0202, A0203, B2703, B2705 и их комбинаций.
Вариант осуществления 43. Способ по варианту осуществления 27, где генерирование посредством генератора GAN все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, предусматривает оценку выражения градиентного спуска для генератора GAN.
Вариант осуществления 44. Способ по варианту осуществления 27, где генерирование посредством генератора GAN все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, предусматривает: итеративное выполнение (например, оптимизацию) дискриминатора GAN для увеличения возможности присвоения высокой вероятности положительным реальным данным взаимодействия полипептид-MHC-I, низкой вероятности положительного смоделированного взаимодействия полипептид-MHC-I и низкой вероятности отрицательным реальным данным взаимодействия полипептид-MHC-I; и итеративное выполнение (например, оптимизацию) генератора GAN для увеличения вероятности того, что положительные смоделированные данные взаимодействия полипептид-MHC-I будут иметь высокую оценку.
Вариант осуществления 45. Способ по варианту осуществления 27, где представление положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные, предусматривает: выполнение процедуры свертки; выполнение процедуры нелинейности (например, ReLu), выполнение процедуры объединения или субдискретизации; и выполнение процедуры классификации (полносвязный слой).
Вариант осуществления 46. Способ по варианту осуществления 27, где GAN включает глубокую сверточную GAN (DCGAN).
Вариант осуществления 47. Способ по варианту осуществления 28, где первый критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 48. Способ по варианту осуществления 27, где второй критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 49. Способ по варианту осуществления 31 или 32, где третий критерий останова включает оценку функции площади под кривой (AUC).
Вариант осуществления 50. Способ по варианту осуществления 27, где оценка прогноза представляет собой вероятность того, что положительные реальные данные взаимодействия полипептид-MHC-I классифицированы как положительные данные взаимодействия полипептид-MHC-I.
Вариант осуществления 51. Способ по варианту осуществления 27, где определение на основании оценок прогноза того, обучена ли GAN, предусматривает сравнение одной или более оценок прогноза с пороговым значением.
Вариант осуществления 52. Способ обучения генеративно-состязательной сети (GAN), предусматривающий: генерирование посредством генератора GAN в соответствии с набором параметров GAN первого смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC; объединение первого смоделированного набора данных с положительными реальными взаимодействиями полипептид-MHC-I и отрицательными реальными взаимодействиями полипептид-MHC-I для аллеля MHC; определение с помощью дискриминатора в соответствии с решающей границей, является ли положительное взаимодействие полипептид-MHC-I для аллеля MHC в наборе данных для обучения GAN положительным или отрицательным; корректировку, основанную на точности определения дискриминатором, одного или более из набора параметров GAN или решающей границы; повторение стадий a-d до тех пор, пока не будет соблюден первый критерий останова; генерирование посредством генератора GAN в соответствии с набором параметров GAN второго смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC; объединение второго смоделированного набора данных, положительных реальных взаимодействий полипептид-MHC-I и отрицательных реальных взаимодействий полипептид-MHC-I для создания набора данных для обучения CNN; представление набора данных для обучения CNN в сверточную нейронную сеть (CNN); классификацию посредством CNN в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC в наборе данных для обучения CNN как положительного или отрицательного; корректировку, основанную на точности классификации посредством CNN взаимодействия полипептид-MHC-I для аллеля MHC в наборе данных для обучения CNN, одного или более из набора параметров CNN; повторение стадий h-j до тех пор, пока не будет соблюден второй критерий останова; представление в CNN положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I; классификацию CNN в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC как положительного или отрицательного; и определение точности классификации посредством CNN взаимодействия полипептид-MHC-I для аллеля MHC, при этом, когда (если) точность классификации удовлетворяет третьему критерию останова, вывод GAN и CNN, при этом, когда (если) точность классификации не удовлетворяет третьему критерию останова, возвращение к стадии а.
Вариант осуществления 53. Способ по варианту осуществления 52, где параметры GAN включают одно или более из типа аллеля, длины аллеля, категории генерирования, сложности модели, скорости обучения или размера пакета.
Вариант осуществления 54. Способ по варианту осуществления 52, где аллель MHC представляет собой аллель HLA.
Вариант осуществления 55. Способ по варианту осуществления 54, где тип аллеля HLA включает один или более из HLA-A, HLA-B, HLA-C или их подтип.
Вариант осуществления 56. Способ по варианту осуществления 54, где длина аллеля HLA составляет от приблизительно 8 до приблизительно 12 аминокислот.
Вариант осуществления 57. Способ по варианту осуществления 54, где длина аллеля HLA составляет от приблизительно 9 до приблизительно 11 аминокислот.
Вариант осуществления 58. Способ по варианту осуществления 52, дополнительно предусматривающий: представление набора данных в CNN, где набор данных содержит множество кандидатных взаимодействий полипептид-MHC-I; классификацию посредством CNN каждого из множества кандидатных взаимодействий полипептид-MHC-I как положительного или отрицательного взаимодействия полипептид-MHC-I; и синтез полипептида из кандидатного взаимодействия полипептид-MHC-I, классифицируемого как положительное взаимодействие полипептид-MHC-I.
Вариант осуществления 59. Полипептид, полученный посредством способа по варианту осуществления 58.
Вариант осуществления 60. Способ по варианту осуществления 58, где полипептид представляет собой опухолеспецифический антиген.
Вариант осуществления 61. Способ по варианту осуществления 58, где полипептид содержит аминокислотную последовательность, которая специфически связывается с белком MHC-I, кодируемым выбранным аллелем лейкоцитарного антигена человека (HLA).
Вариант осуществления 62. Способ по варианту осуществления 52, где положительные смоделированные данные взаимодействия полипептид-MHC-I, положительные реальные данные взаимодействия полипептид-MHC-I и отрицательные реальные данные взаимодействия полипептид-MHC-I связаны с выбранным аллелем.
Вариант осуществления 63. Способ по варианту осуществления 62, где выбранный аллель выбран из группы, состоящей из A0201, A0202, A0203, B2703, B2705 и их комбинаций.
Вариант осуществления 64. Способ по варианту осуществления 52, где повторение стадий a-d до тех пор, пока не будет соблюден первый критерий останова, предусматривает оценку выражения градиентного спуска для генератора GAN.
Вариант осуществления 65. Способ по варианту осуществления 52, где повторение стадий a-d до тех пор, пока не будет соблюден первый критерий останова, предусматривает: итеративное выполнение (например, оптимизацию) дискриминатора GAN для увеличения возможности присвоения высокой вероятности положительным реальным данным взаимодействия полипептид-MHC-I, низкой вероятности положительным смоделированным данным взаимодействия полипептид-MHC-I и низкой вероятности отрицательным реальным данным взаимодействия полипептид-MHC-I; и итеративное выполнение (например, оптимизацию) генератора GAN для увеличения вероятности того, что положительные смоделированные данные взаимодействия полипептид-MHC-I будут иметь высокую оценку.
Вариант осуществления 66. Способ по варианту осуществления 52, где представление в CNN данных для обучения в CNN предусматривает: выполнение процедуры свертки, выполнение процедуры нелинейности (например, ReLu), выполнение процедуры объединения или субдискретизации и выполнение процедуры классификации (например, полносвязный слой).
Вариант осуществления 67. Способ по варианту осуществления 52, где GAN включает глубокую сверточную GAN (DCGAN).
Вариант осуществления 68. Способ по варианту осуществления 52, где первый критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 69. Способ по варианту осуществления 52, где второй критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 70. Способ по варианту осуществления 52, где третий критерий останова включает оценку функции площади под кривой (AUC).
Вариант осуществления 71. Способ, предусматривающий: обучение сверточной нейронной сети (CNN) в соответствии со способом по варианту осуществления 1; представление набора данных в CNN, где набор данных содержит множество кандидатных взаимодействий полипептид-MHC-I; классификацию посредством CNN каждого из множества кандидатных взаимодействий полипептид-MHC-I как положительного или отрицательного взаимодействия полипептид-MHC-I; и синтез полипептида, связанного с кандидатным взаимодействием полипептид-MHC-I, классифицируемым как положительное взаимодействие полипептид-MHC-I.
Вариант осуществления 72. Способ по варианту осуществления 71, где CNN подвергают обучению на основании одного или более параметров GAN, включающих одно или более из типа аллеля, длины аллеля, категории генерирования, сложности модели, скорости обучения или размера пакета.
Вариант осуществления 73. Способ по варианту осуществления 72, где тип аллеля представляет собой тип аллеля HLA.
Вариант осуществления 74. Способ по варианту осуществления 73, где тип аллеля HLA включает один или более из HLA-A, HLA-B, HLA-C или их подтип.
Вариант осуществления 75. Способ по варианту осуществления 73, где длина аллеля HLA составляет от приблизительно 8 до приблизительно 12 аминокислот.
Вариант осуществления 76. Способ по варианту осуществления 73, где длина аллеля HLA составляет от приблизительно 9 до приблизительно 11 аминокислот.
Вариант осуществления 77. Полипептид, полученный посредством способа по варианту осуществления 71.
Вариант осуществления 78. Способ по варианту осуществления 71, где полипептид представляет собой опухолеспецифический антиген.
Вариант осуществления 79. Способ по варианту осуществления 71, где полипептид содержит аминокислотную последовательность, которая специфически связывается с белком MHC-I, кодируемым выбранным аллелем лейкоцитарного антигена человека (HLA).
Вариант осуществления 80. Способ по варианту осуществления 71, где положительные смоделированные данные взаимодействия полипептид-MHC-I, положительные реальные данные взаимодействия полипептид-MHC-I и отрицательные реальные данные взаимодействия полипептид-MHC-I связаны с выбранным аллелем.
Вариант осуществления 81. Способ по варианту осуществления 80, где выбранный аллель выбран из группы, состоящей из A0201, A0202, A0203, B2703, B2705 и их комбинаций.
Вариант осуществления 82. Способ по варианту осуществления 71, где GAN включает глубокую сверточную GAN (DCGAN).
Вариант осуществления 83. Устройство для обучения генеративно-состязательной сети (GAN), содержащее: один или более процессоров; и запоминающее устройство, в котором хранятся исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: генерирования все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные; представления положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные; представления положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействии полипептид-MHC-I в CNN для генерирования оценок прогноза; определения на основании оценок прогноза того, что GAN обучена; и выведения GAN и CNN.
Вариант осуществления 84. Устройство по варианту осуществления 83, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают генерирование устройством все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: генерирования в соответствии с набором параметров GAN первого смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC; объединения первого смоделированного набора данных положительных реальных взаимодействий полипептид-MHC-I для аллеля MHC и отрицательных реальных взаимодействия полипептид-MHC-I для аллеля MHC для создания набора данных для обучения GAN; получения информации от дискриминатора, при этом дискриминатор выполнен с возможностью определения, в соответствии с решающей границей, является ли положительное взаимодействие полипептид-MHC-I для аллеля MHC в наборе данных для обучения GAN положительным или отрицательным; корректировки, основанной на точности информации от дискриминатора, одного или более из набора параметров GAN или решающей границы; и повторения стадий a-d до тех пор, пока не будет соблюден первый критерий останова.
Вариант осуществления 85. Устройство по варианту осуществления 84, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление устройством положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: генерирования в соответствии с набором параметров GAN второго смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC; объединения второго смоделированного набора данных, положительных реальных взаимодействий полипептид-MHC-I для аллеля MHC и отрицательных реальных данных взаимодействия полипептид-MHC-I для аллеля MHC для создания набора данных для обучения CNN; представление набора данных для обучения CNN в сверточную нейронную сеть (CNN); получения информации для обучения от CNN, при этом CNN выполнена с возможностью определения информации для обучения путем классификации в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC в наборе данных для обучения CNN как положительного или отрицательного; корректировки, основанной на точности информации для обучения, одного или более из набора параметров CNN; и повторения стадий h-j до тех пор, пока не будет соблюден второй критерий останова.
Вариант осуществления 86. Устройство по варианту осуществления 85, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление устройством положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в CNN для генерирования оценок прогноза, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают классификацию устройством в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC как положительного или отрицательного.
Вариант осуществления 87. Устройство по варианту осуществления 86, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают определение устройством на основании оценок прогноза того, обучена ли GAN, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают определение устройством точности классификации взаимодействия полипептид-MHC-I для аллеля MHC как положительного или отрицательного и, когда (если) точность классификации удовлетворяет третьему критерию останова, выведение GAN и CNN.
Вариант осуществления 88. Устройство по варианту осуществления 86, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают определение устройством на основании оценок прогноза того, обучена ли GAN, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают определение устройством точности классификации взаимодействия полипептид-MHC-I для аллеля MHC как положительного или отрицательного и, когда (если) точность классификации не удовлетворяет третьему критерию останова, возвращение к стадии а.
Вариант осуществления 89. Устройство по варианту осуществления 84, где параметры GAN включают одно или более из типа аллеля, длины аллеля, категории генерирования, сложности модели, скорости обучения или размера пакета.
Вариант осуществления 90. Устройство по варианту осуществления 89, где тип аллеля HLA включает один или более из HLA-A, HLA-B, HLA-C или их подтип.
Вариант осуществления 91. Устройство по варианту осуществления 89, где длина аллеля HLA составляет от приблизительно 8 до приблизительно 12 аминокислот.
Вариант осуществления 92. Устройство по варианту осуществления 89, где длина аллеля HLA составляет от приблизительно 9 до приблизительно 11 аминокислот.
Вариант осуществления 93. Устройство по варианту осуществления 83, где исполняемые процессором команды при исполнении одним или более процессорами дополнительно обеспечивают выполнение устройством следующего: представление набора данных в CNN, при этом набор данных содержит множество кандидатных взаимодействий полипептид-MHC-I, при этом CNN дополнительно выполнена с возможностью классификации каждого из множества кандидатных взаимодействий полипептид-MHC-I как положительного или отрицательного взаимодействия полипептид-MHC-I; и синтез полипептида из кандидатного взаимодействия полипептид-MHC-I, которое CNN классифицирует как положительное взаимодействие полипептид-MHC-I.
Вариант осуществления 94. Полипептид, полученный при помощи устройства по варианту осуществления 93.
Вариант осуществления 95. Устройство по варианту осуществления 93, где полипептид представляет собой опухолеспецифический антиген.
Вариант осуществления 96. Устройство по варианту осуществления 93, где полипептид содержит аминокислотную последовательность, которая специфически связывается с белком MHC-I, кодируемым выбранным аллелем лейкоцитарного антигена человека (HLA).
Вариант осуществления 97. Устройство по варианту осуществления 83, где положительные смоделированные данные взаимодействия полипептид-MHC-I, положительные реальные данные взаимодействия полипептид-MHC-I и отрицательные реальные данные взаимодействия полипептид-MHC-I связаны с выбранным аллелем.
Вариант осуществления 98. Устройство по варианту осуществления 97, где выбранный аллель выбран из группы, состоящей из A0201, A0202, A0203, B2703, B2705 и их комбинаций.
Вариант осуществления 99. Устройство по варианту осуществления 83, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают генерирование устройством все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают оценивание устройством выражения градиентного спуска для генератора GAN.
Вариант осуществления 100. Устройство по варианту осуществления 83, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают генерирование устройством все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: итеративное выполнение (например, оптимизацию) дискриминатора GAN для увеличения возможности присвоения высокой вероятности положительным реальным данным взаимодействия полипептид-MHC-I, низкой вероятности положительным смоделированным данным взаимодействия полипептид-MHC-I и низкой вероятности отрицательных смоделированных данных взаимодействия полипептид-MHC-I; и итеративное выполнение (например, оптимизацию) генератора GAN для увеличения возможности того, что положительные смоделированные данные взаимодействия полипептид-MHC-I будут иметь высокую оценку.
Вариант осуществления 101. Устройство по варианту осуществления 83, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление устройством положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: выполнения процедуры свертки;
выполнения процедуры нелинейности (например, ReLu), выполнения процедуры объединения или субдискретизации и выполнения процедуры классификации (полносвязный слой).
Вариант осуществления 102. Устройство по варианту осуществления 83, где GAN включает глубокую сверточную GAN (DCGAN).
Вариант осуществления 103. Устройство по варианту осуществления 84, где первый критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 104. Устройство по варианту осуществления 85, где второй критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 105. Устройство по варианту осуществления 87 или 88, где третий критерий останова включает оценку функции площади под кривой (AUC).
Вариант осуществления 106. Устройство по варианту осуществления 83, где оценка прогноза представляет собой вероятность того, что положительные реальные данные взаимодействия полипептид-MHC-I классифицированы как положительные данные взаимодействия полипептид-MHC-I.
Вариант осуществления 107. Устройство по варианту осуществления 83, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают определение устройством на основании оценок прогноза того, обучена ли GAN, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают сравнение устройством одной или более оценок прогноза с пороговым значением.
Вариант осуществления 108. Устройство для обучения генеративно-состязательной сети (GAN), содержащее:
один или более процессоров и
запоминающее устройство, в котором хранятся исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: генерирования все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные; представления положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные; представления положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействии полипептид-MHC-I в CNN для генерирования оценок прогноза; определения на основании оценок прогноза того, что GAN не обучена; повторения стадий а-с до тех пор, пока не будет выполнено определение на основании оценок прогноза того, что GAN обучена; и выведения GAN и CNN.
Вариант осуществления 109. Устройство по варианту осуществления 108, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают генерирование устройством все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: генерирования в соответствии с набором параметров GAN первого смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC; объединения первого смоделированного набора данных с положительными реальными взаимодействиями полипептид-MHC-I для аллеля MHC и положительными реальными взаимодействиями полипептид-MHC-I для аллеля MHC для создания набора данных для обучения GAN; получения информации от дискриминатора, при этом дискриминатор выполнен с возможностью определения того, является ли положительное взаимодействие полипептид-MHC-I для аллеля MHC в наборе данных для обучения GAN положительным или отрицательным; корректировки, основанной на точности информации от дискриминатора, одного или более из набора параметров GAN или решающей границы; и повторения стадий i-j до тех пор, пока не будет соблюден первый критерий останова.
Вариант осуществления 110. Устройство по варианту осуществления 109, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление устройством положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: генерирования в соответствии с набором параметров GAN второго смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC; объединения второго смоделированного набора данных, положительных реальных взаимодействий полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I для создания набора данных для обучения CNN; представления набора данных для обучения CNN в сверточную нейронную сеть (CNN); получения информации от CNN, при этом CNN выполнена с возможностью определения информации путем классификации в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC в наборе данных для обучения CNN как положительного или отрицательного; корректировки, основанной на точности информации для обучения от CNN, одного или более из набора параметров CNN; и повторения стадий n-p до тех пор, пока не будет соблюден второй критерий останова.
Вариант осуществления 111. Устройство по варианту осуществления 110, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление устройством положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в CNN для генерирования оценок прогноза, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление устройством в CNN положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I, где CNN дополнительно выполнена с возможностью классификации в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC как положительного или отрицательного.
Вариант осуществления 112. Устройство по варианту осуществления 111, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают определение устройством на основании оценок прогноза того, обучена ли GAN, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: определения точности классификации посредством CNN; определения того, что точность классификации удовлетворяет третьему критерию останова; и в ответ на определение того, что точность классификации удовлетворяет третьему критерию останова, выведения GAN и CNN.
Вариант осуществления 113. Устройство по варианту осуществления 112, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают определение устройством на основании оценок прогноза того, обучена ли GAN, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: определения точности классификации посредством CNN; определения того, что точность классификации не удовлетворяет третьему критерию останова; и в ответ на определение того, что точность классификации не удовлетворяет третьему критерию останова, возвращения к стадии а.
Вариант осуществления 114. Устройство по варианту осуществления 109, где параметры GAN включают одно или более из типа аллеля, длины аллеля, категории генерирования, сложности модели, скорости обучения или размера пакета.
Вариант осуществления 115. Устройство по варианту осуществления 109, где аллель MHC представляет собой аллель HLA.
Вариант осуществления 116. Устройство по варианту осуществления 115, где тип аллеля HLA включает один или более из HLA-A, HLA-B, HLA-C или их подтип.
Вариант осуществления 117. Устройство по варианту осуществления 115, где длина аллеля HLA составляет от приблизительно 8 до приблизительно 12 аминокислот.
Вариант осуществления 118. Устройство по варианту осуществления 115, где длина аллеля HLA составляет от приблизительно 9 до приблизительно 11 аминокислот.
Вариант осуществления 119. Устройство по варианту осуществления 108, где исполняемые процессором команды при исполнении одним или более процессорами дополнительно обеспечивают выполнение устройством следующего: представления набора данных в CNN, при этом набор данных содержит множество кандидатных взаимодействий полипептид-MHC-I, при этом CNN дополнительно выполнена с возможностью классификации каждого из множества кандидатных взаимодействий полипептид-MHC-I как положительного или отрицательного взаимодействия полипептид-MHC-I; и синтеза полипептида из кандидатного взаимодействия полипептид-MHC-I, классифицируемого посредством CNN как положительное взаимодействие полипептид-MHC-I.
Вариант осуществления 120. Полипептид, полученный при помощи устройства по варианту осуществления 119.
Вариант осуществления 121. Устройство по варианту осуществления 119, где полипептид представляет собой опухолеспецифический антиген.
Вариант осуществления 122. Устройство по варианту осуществления 119, где полипептид содержит аминокислотную последовательность, которая специфически связывается с белком MHC-I, кодируемым выбранным аллелем лейкоцитарного антигена человека (HLA).
Вариант осуществления 123. Устройство по варианту осуществления 108, где положительные смоделированные данные взаимодействия полипептид-MHC-I, положительные реальные данные взаимодействия полипептид-MHC-I и отрицательные реальные данные взаимодействия полипептид-MHC-I связаны с выбранным аллелем.
Вариант осуществления 124. Устройство по варианту осуществления 123, где выбранный аллель выбран из группы, состоящей из A0201, A0202, A0203, B2703, B2705 и их комбинаций.
Вариант осуществления 125. Устройство по варианту осуществления 108, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают генерирование устройством все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают оценивание устройством выражения градиентного спуска для генератора GAN.
Вариант осуществления 126. Устройство по варианту осуществления 108, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают генерирование устройством все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: итеративного выполнения (например, оптимизации) дискриминатора GAN для увеличения возможности присвоения высокой вероятности положительным реальным данным взаимодействия полипептид-MHC-I, низкой вероятности положительным смоделированным данным взаимодействия полипептид-MHC-I и низкой вероятности отрицательных смоделированных данных взаимодействия полипептид-MHC-I; и итеративного выполнения (например, оптимизации) генератора GAN для увеличения возможности того, что положительные смоделированные данные взаимодействия полипептид-MHC-I будут иметь высокую оценку.
Вариант осуществления 127. Устройство по варианту осуществления 108, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление устройством положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: выполнения процедуры свертки; выполнения процедуры нелинейности (например, ReLu), выполнения процедуры объединения или субдискретизации; и выполнения процедуры классификации (полносвязный слой).
Вариант осуществления 128. Устройство по варианту осуществления 108, где GAN включает глубокую сверточную GAN (DCGAN).
Вариант осуществления 129. Устройство по варианту осуществления 109, где первый критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 130. Устройство по варианту осуществления 108, где второй критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 131. Устройство по варианту осуществления 112 или 113, где третий критерий останова включает оценку функции площади под кривой (AUC).
Вариант осуществления 132. Устройство по варианту осуществления 108, где оценка прогноза представляет собой вероятность того, что положительные реальные данные взаимодействия полипептид-MHC-I классифицированы как положительные данные взаимодействия полипептид-MHC-I.
Вариант осуществления 133. Устройство по варианту осуществления 108, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают определение устройством на основании оценок прогноза того, обучена ли GAN, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают сравнение устройством одной или более оценок прогноза с пороговым значением.
Вариант осуществления 134. Устройство для обучения генеративно-состязательной сети (GAN), содержащее: один или более процессоров; и запоминающее устройство, в котором хранятся исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: генерирования в соответствии с набором параметров GAN первого смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC; объединения первого смоделированного набора данных с положительными реальными взаимодействиями полипептид-MHC-I для аллеля MHC и отрицательными реальными взаимодействиями полипептид-MHC-I для аллеля MHC для создания набора данных для обучения GAN; получения информации от дискриминатора, при этом дискриминатор выполнен с возможностью определения, в соответствии с решающей границей, является ли положительное взаимодействие полипептид-MHC-I для аллеля MHC в наборе данных для обучения GAN положительным или отрицательным; корректировки, основанной на точности информации от дискриминатора, одного или более из набора параметров GAN или решающей границы;
повторения стадий a-d до тех пор, пока не будет соблюден первый критерий останова; генерирования с помощью генератора GAN в соответствии с набором параметров GAN второго смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC; объединения второго смоделированного набора данных, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I для аллеля MHC для создания набора данных для обучения CNN; представления набора данных для обучения CNN в сверточную нейронную сеть (CNN); получения информации для обучения от CNN, где CNN выполнена с возможностью определения информации для обучения путем классификации в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC в наборе данных для обучения CNN как положительного или отрицательного; корректировки, основанной на точности информации для обучения, одного или более из набора параметров CNN; повторения стадий h-j до тех пор, пока не будет соблюден второй критерий останова; представления в CNN положительных реальных взаимодействий полипептид-MHC-I для аллеля MHC и отрицательных реальных взаимодействий полипептид-MHC-I для аллеля MHC; получения информации для обучения от CNN, где CNN выполнена с возможностью определения обучающей информации путем классификации в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC как положительного или отрицательного; и определения точности информации для обучения, при этом, когда (если) точность информации для обучения удовлетворяет третьему критерию останова, выведения GAN и CNN, при этом, когда (если) точность информации для обучения не удовлетворяет третьему критерию останова, возвращения к стадии а.
Вариант осуществления 135. Устройство по варианту осуществления 134, где параметры GAN включают одно или более из типа аллеля, длины аллеля, категории генерирования, сложности модели, скорости обучения или размера пакета.
Вариант осуществления 136. Устройство по варианту осуществления 134, где аллель MHC представляет собой аллель HLA.
Вариант осуществления 137. Устройство по варианту осуществления 136, где тип аллеля HLA включает один или более из HLA-A, HLA-B, HLA-C или их подтип.
Вариант осуществления 138. Устройство по варианту осуществления 136, где длина аллеля HLA составляет от приблизительно 8 до приблизительно 12 аминокислот.
Вариант осуществления 139. Устройство по варианту осуществления 136, где длина аллеля HLA составляет от приблизительно 9 до приблизительно 11 аминокислот.
Вариант осуществления 140. Устройство по варианту осуществления 134, где исполняемые процессором команды при исполнении одним или более процессорами дополнительно обеспечивают выполнение устройством следующего: представления набора данных в CNN, при этом набор данных содержит множество кандидатных взаимодействий полипептид-MHC-I, при этом CNN дополнительно выполнена с возможностью классификации каждого из множества кандидатных взаимодействий полипептид-MHC-I как положительного или отрицательного взаимодействия полипептид-MHC-I; и синтеза полипептида из кандидатного взаимодействия полипептид-MHC-I, классифицируемого посредством CNN как положительное взаимодействие полипептид-MHC-I.
Вариант осуществления 141. Полипептид, полученный при помощи устройства по варианту осуществления 140.
Вариант осуществления 142. Устройство по варианту осуществления 140, где полипептид представляет собой опухолеспецифический антиген.
Вариант осуществления 143. Устройство по варианту осуществления 140, где полипептид содержит аминокислотную последовательность, которая специфически связывается с белком MHC-I, кодируемым аллелем MHC.
Вариант осуществления 144. Устройство по варианту осуществления 134, где положительные смоделированные данные взаимодействия полипептид-MHC-I, положительные реальные данные взаимодействия полипептид-MHC-I и отрицательные реальные данные взаимодействия полипептид-MHC-I связаны с выбранным аллелем.
Вариант осуществления 145. Устройство по варианту осуществления 144, где выбранный аллель выбран из группы, состоящей из A0201, A0202, A0203, B2703, B2705 и их комбинаций.
Вариант осуществления 146. Устройство по варианту осуществления 134, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают повторение устройством стадий a-d до тех пор, пока первый критерий останова не будет соблюден, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают оценивание устройством выражения градиентного спуска для генератора GAN.
Вариант осуществления 147. Устройство по варианту осуществления 134, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают повторение устройством стадий a-d до тех пор, пока первый критерий останова не будет соблюден, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: итеративного выполнения (например, оптимизации) дискриминатора GAN для увеличения возможности присвоения высокой вероятности положительным реальным данным взаимодействия полипептид-MHC-I, низкой вероятности положительным смоделированным данным взаимодействия полипептид-MHC-I и низкой вероятности отрицательных смоделированных данных взаимодействия полипептид-MHC-I; и итеративного выполнения (например, оптимизации) генератора GAN для увеличения возможности того, что положительные смоделированные данные взаимодействия полипептид-MHC-I будут иметь высокую оценку.
Вариант осуществления 148. Устройство по варианту осуществления 134, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление устройством в CNN данных для обучения CNN, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: выполнения процедуры свертки; выполнения процедуры нелинейности (например, ReLu), выполнения процедуры объединения или субдискретизации; и выполнения процедуры классификации (полносвязный слой).
Вариант осуществления 149. Устройство по варианту осуществления 134, где GAN включает глубокую сверточную GAN (DCGAN).
Вариант осуществления 150. Устройство по варианту осуществления 134, где первый критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 151. Устройство по варианту осуществления 134, где второй критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 152. Устройство по варианту осуществления 134, где третий критерий останова включает оценку функции площади под кривой (AUC).
Вариант осуществления 153. Устройство, содержащее: один или более процессоров; и запоминающее устройство, в котором хранятся исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: обучения сверточной нейронной сети (CNN) теми же средствами, что и устройство по варианту 83 осуществления; представления набора данных в CNN, где набор данных содержит множество кандидатных взаимодействий полипептид-MHC-I, где CNN выполнена с возможностью классификации каждого из множества кандидатных взаимодействий полипептид-MHC-I как положительного или отрицательного взаимодействия полипептид-MHC-I; и синтеза полипептида, связанного с кандидатным взаимодействием полипептид-MHC-I, классифицируемого посредством CNN как положительное взаимодействие полипептид-MHC-I.
Вариант осуществления 154. Устройство по варианту осуществления 153, где CNN подвергается обучению на основании одного или более параметров GAN, включающих одно или более из типа аллеля, длины аллеля, категории генерирования, сложности модели, скорости обучения или размера пакета.
Вариант осуществления 155. Устройство по варианту осуществления 154, где тип аллеля HLA включает один или более из HLA-A, HLA-B, HLA-C или их подтип.
Вариант осуществления 156. Устройство по варианту осуществления 154, где длина аллеля HLA составляет от приблизительно 8 до приблизительно 12 аминокислот.
Вариант осуществления 157. Устройство по варианту осуществления 155, где длина аллеля HLA составляет от приблизительно 9 до приблизительно 11 аминокислот.
Вариант осуществления 158. Полипептид, полученный при помощи устройства по варианту осуществления 153.
Вариант осуществления 159. Устройство по варианту осуществления 153, где полипептид представляет собой опухолеспецифический антиген.
Вариант осуществления 160. Устройство по варианту осуществления 153, где полипептид содержит аминокислотную последовательность, которая специфически связывается с белком MHC-I, кодируемым выбранным аллелем MHC.
Вариант осуществления 161. Устройство по варианту осуществления 153, где положительные смоделированные данные взаимодействия полипептид-MHC-I, положительные реальные данные взаимодействия полипептид-MHC-I и отрицательные реальные данные взаимодействия полипептид-MHC-I связаны с выбранным аллелем.
Вариант осуществления 162. Устройство по варианту осуществления 161, где выбранный аллель выбран из группы, состоящей из A0201, A0202, A0203, B2703, B2705 и их комбинаций.
Вариант осуществления 163. Устройство по варианту осуществления 153, где GAN включает глубокую сверточную GAN (DCGAN).
Вариант осуществления 164. Энергонезависимый машиночитаемый носитель для обучения генеративно-состязательной сети (GAN), причем энергонезависимый машиночитаемый носитель хранит исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами следующего: генерирования все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные; представления положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные; представления положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в CNN для генерирования оценок прогноза; определения на основании оценок прогноза того, что GAN обучена; и выведения GAN и CNN.
Вариант осуществления 165. Энергонезависимый машиночитаемый носитель по варианту осуществления 164, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают генерирование одним или более процессорами все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, дополнительно обеспечивают выполнение одним или более процессорами следующего: генерирования в соответствии с набором параметров GAN первого смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC; объединения первого смоделированного набора данных с положительными реальными взаимодействиями полипептид-MHC-I для аллеля MHC и отрицательными реальными взаимодействиями полипептид-MHC-I для аллеля MHC для создания набора данных для обучения GAN; получения информации от дискриминатора, при этом дискриминатор выполнен с возможностью определения, в соответствии с решающей границей, является ли положительное взаимодействие полипептид-MHC-I для аллеля MHC в наборе данных для обучения GAN положительным или отрицательным; корректировки, основанной на точности информации от дискриминатора, одного или более из набора параметров GAN или решающей границы; и повторения стадий a-d до тех пор, пока не будет соблюден первый критерий останова.
Вариант осуществления 166. Энергонезависимый машиночитаемый носитель по варианту осуществления 165, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление одним или более процессорами положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами следующего: генерирования в соответствии с набором параметров GAN второго смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I; объединения второго смоделированного набора данных, положительных реальных взаимодействий полипептид-MHC-I для аллеля MHC и отрицательных реальных данных взаимодействия полипептид-MHC-I для аллеля MHC для создания набора данных для обучения CNN; представления набора данных для обучения CNN в сверточную нейронную сеть (CNN); получения информации для обучения от CNN, при этом CNN выполнена с возможностью определения информации для обучения путем классификации в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC в наборе данных для обучения CNN как положительного или отрицательного; корректировки, основанной на точности информации для обучения, одного или более из набора параметров CNN; и повторения стадий h-j до тех пор, пока не будет соблюден второй критерий останова.
Вариант осуществления 167. Энергонезависимый машиночитаемый носитель по варианту осуществления 166, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление одним или более процессорами положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в CNN для генерирования оценок прогноза, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление одним или более процессорами в CNN положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I, где CNN дополнительно выполнена с возможностью классификации в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC как положительного или отрицательного.
Вариант осуществления 168. Энергонезависимый машиночитаемый носитель по варианту осуществления 167, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают определение одним или более процессорами на основании оценок прогноза того, обучена ли GAN, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами определения точности классификации взаимодействия полипептид-MHC-I для аллеля MHC как положительного или отрицательного и, когда (если) точность классификации удовлетворяет третьему критерию останова, выведения GAN и CNN.
Вариант осуществления 169. Энергонезависимый машиночитаемый носитель по варианту осуществления 167, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают определение одним или более процессорами на основании оценок прогноза того, обучена ли GAN, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами определения точности классификации взаимодействия полипептид-MHC-I для аллеля MHC как положительного или отрицательного и, когда (если) точность классификации не удовлетворяет третьему критерию останова, возвращения к стадии а.
Вариант осуществления 170. Энергонезависимый машиночитаемый носитель по варианту осуществления 165, где параметры GAN включают одно или более из типа аллеля, длины аллеля, категории генерирования, сложности модели, скорости обучения или размера пакета.
Вариант осуществления 171. Энергонезависимый машиночитаемый носитель по варианту осуществления 165, где аллель MHC представляет собой аллель HLA.
Вариант осуществления 172. Энергонезависимый машиночитаемый носитель по варианту осуществления 171, где тип аллеля HLA включает один или более из HLA-A, HLA-B, HLA-C или их подтип.
Вариант осуществления 173. Энергонезависимый машиночитаемый носитель по варианту осуществления 171, где длина аллеля HLA составляет от приблизительно 8 до приблизительно 12 аминокислот.
Вариант осуществления 174. Энергонезависимый машиночитаемый носитель по варианту осуществления 171, где длина аллеля HLA составляет от приблизительно 9 до приблизительно 11 аминокислот.
Вариант осуществления 175. Энергонезависимый машиночитаемый носитель по варианту осуществления 164, где исполняемые процессором команды при исполнении одним или более процессорами дополнительно обеспечивают выполнение одним или более процессорами следующего: представления набора данных в CNN, при этом набор данных содержит множество кандидатных взаимодействий полипептид-MHC-I, при этом CNN дополнительно выполнена с возможностью классификации каждого из множества кандидатных взаимодействий полипептид-MHC-I как положительного или отрицательного взаимодействия полипептид-MHC-I; и синтеза полипептида из кандидатного взаимодействия полипептид-MHC-I, которое CNN классифицирует как положительное взаимодействие полипептид-MHC-I.
Вариант осуществления 176. Полипептид, полученный при помощи энергонезависимого машиночитаемого носителя по варианту осуществления 175.
Вариант осуществления 177. Энергонезависимый машиночитаемый носитель по варианту осуществления 175, где полипептид представляет собой опухолеспецифический антиген.
Вариант осуществления 178. Энергонезависимый машиночитаемый носитель по варианту осуществления 175, где полипептид содержит аминокислотную последовательность, которая специфически связывается с белком MHC-I, кодируемым выбранным аллелем MHC.
Вариант осуществления 179. Энергонезависимый машиночитаемый носитель по варианту осуществления 164, где положительные смоделированные данные взаимодействия полипептид-MHC-I, положительные реальные данные взаимодействия полипептид-MHC-I и отрицательные реальные данные взаимодействия полипептид-MHC-I связаны с выбранным аллелем.
Вариант осуществления 180. Энергонезависимый машиночитаемый носитель по варианту осуществления 179, где выбранный аллель выбран из группы, состоящей из A0201, A0202, A0203, B2703, B2705 и их комбинаций.
Вариант осуществления 181. Энергонезависимый машиночитаемый носитель по варианту осуществления 164, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают генерирование одним или более процессорами все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают оценивание одним или более процессорами выражения градиентного спуска для генератора GAN.
Вариант осуществления 182. Энергонезависимый машиночитаемый носитель по варианту осуществления 164, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают генерирование одним или более процессорами все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами следующего: итеративного выполнения (например, оптимизации) дискриминатора GAN для увеличения возможности присвоения высокой вероятности положительным реальным данным взаимодействия полипептид-MHC-I и низкой вероятности положительным смоделированным данным взаимодействия полипептид-MHC-I; и итеративного выполнения (например, оптимизации) генератора GAN для увеличения возможности того, что положительные смоделированные данные взаимодействия полипептид-MHC-I будут иметь высокую оценку.
Вариант осуществления 183. Энергонезависимый машиночитаемый носитель по варианту осуществления 164, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление одним или более процессорами положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как реальные положительные или отрицательные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами следующего: выполнения процедуры свертки; выполнения процедуры нелинейности (например, ReLu), выполнения процедуры объединения или субдискретизации; и выполнения процедуры классификации (полносвязный слой).
Вариант осуществления 184. Энергонезависимый машиночитаемый носитель по варианту осуществления 164, где GAN включает глубокую сверточную GAN (DCGAN).
Вариант осуществления 185. Энергонезависимый машиночитаемый носитель по варианту осуществления 165, где первый критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 186. Энергонезависимый машиночитаемый носитель по варианту осуществления 166, где второй критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 187. Энергонезависимый машиночитаемый носитель по варианту осуществления 168 или 169, где третий критерий останова включает оценку функции площади под кривой (AUC).
Вариант осуществления 188. Энергонезависимый машиночитаемый носитель по варианту осуществления 164, где оценка прогноза представляет собой вероятность того, что положительные реальные данные взаимодействия полипептид-MHC-I классифицированы как положительные данные взаимодействия полипептид-MHC-I.
Вариант осуществления 189. Энергонезависимый машиночитаемый носитель по варианту осуществления 164, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают определение одним или более процессорами на основании оценок прогноза того, обучена ли GAN, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают сравнение одним или более процессорами одной или более оценок прогноза с пороговым значением.
Вариант осуществления 190. Энергонезависимый машиночитаемый носитель для обучения генеративно-состязательной сети (GAN), причем энергонезависимый машиночитаемый носитель хранит исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами следующего: генерирования все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные; представления положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные; представления положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в CNN для генерирования оценок прогноза; определения на основании оценок прогноза того, что GAN не обучена; повторения стадий а-с до тех пор, пока не будет выполнено определение на основании оценок прогноза того, что GAN обучена; и выведения GAN и CNN.
Вариант осуществления 191. Энергонезависимый машиночитаемый носитель по варианту осуществления 190, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают генерирование одним или более процессорами все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами следующего: генерирования в соответствии с набором параметров GAN первого смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC; объединения первого смоделированного набора данных с положительными реальными взаимодействиями полипептид-MHC-I для аллеля MHC и положительными реальными взаимодействиями полипептид-MHC-I для аллеля MHC для создания набора данных для обучения GAN; получения информации от дискриминатора, при этом дискриминатор выполнен с возможностью определения того, является ли положительное взаимодействие полипептид-MHC-I для аллеля MHC в наборе данных для обучения GAN положительным или отрицательным; корректировки, основанной на точности информации от дискриминатора, одного или более из набора параметров GAN или решающей границы; и повторения стадий g-j до тех пор, пока не будет соблюден первый критерий останова.
Вариант осуществления 192. Энергонезависимый машиночитаемый носитель по варианту осуществления 191, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление устройством положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами следующего: генерирования в соответствии с набором параметров GAN второго смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I; объединения второго смоделированного набора данных, положительных реальных взаимодействий полипептид-MHC-I для аллеля MHC и отрицательных реальных данных взаимодействия полипептид-MHC-I для аллеля MHC для создания набора данных для обучения CNN; представления набора данных для обучения CNN в сверточную нейронную сеть (CNN); получения информации от CNN, при этом CNN выполнена с возможностью определения информации путем классификации в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC в наборе данных для обучения CNN как положительного или отрицательного; корректировки, основанной на точности информации для обучения от CNN, одного или более из набора параметров CNN; и повторения стадий l-p до тех пор, пока не будет соблюден второй критерий останова.
Вариант осуществления 193. Энергонезависимый машиночитаемый носитель по варианту осуществления 192, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление одним или более процессорами положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в CNN для генерирования оценок прогноза, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление одним или более процессорами в CNN положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I, где CNN дополнительно выполнена с возможностью классификации в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC как положительного или отрицательного.
Вариант осуществления 194. Энергонезависимый машиночитаемый носитель по варианту осуществления 193, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают определение одним или более процессорами на основании оценок прогноза того, обучена ли GAN, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами следующего: определения точности классификации посредством CNN; определения того, что точность классификации удовлетворяет третьему критерию останова; и в ответ на определение того, что точность классификации удовлетворяет третьему критерию останова, выведения GAN и CNN.
Вариант осуществления 195. Энергонезависимый машиночитаемый носитель по варианту осуществления 194, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают определение одним или более процессорами на основании оценок прогноза того, обучена ли GAN, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами следующего: определения точности классификации посредством CNN; определения того, что точность классификации не удовлетворяет третьему критерию останова; и в ответ на определение того, что точность классификации не удовлетворяет третьему критерию останова, возвращения к стадии а.
Вариант осуществления 196. Энергонезависимый машиночитаемый носитель по варианту осуществления 191, где параметры GAN включают одно или более из типа аллеля, длины аллеля, категории генерирования, сложности модели, скорости обучения или размера пакета.
Вариант осуществления 197. Энергонезависимый машиночитаемый носитель по варианту осуществления 191, где аллель MHC представляет собой аллель HLA.
Вариант осуществления 198. Энергонезависимый машиночитаемый носитель по варианту осуществления 197, где тип аллеля HLA включает один или более из HLA-A, HLA-B, HLA-C или их подтип.
Вариант осуществления 199. Энергонезависимый машиночитаемый носитель по варианту осуществления 197, где длина аллеля HLA составляет от приблизительно 8 до приблизительно 12 аминокислот.
Вариант осуществления 200. Энергонезависимый машиночитаемый носитель по варианту осуществления 197, где длина аллеля HLA составляет от приблизительно 9 до приблизительно 11 аминокислот.
Вариант осуществления 201. Энергонезависимый машиночитаемый носитель по варианту осуществления 190, где исполняемые процессором команды при исполнении одним или более процессорами дополнительно обеспечивают выполнение одним или более процессорами следующего: представления набора данных в CNN, при этом набор данных содержит множество кандидатных взаимодействий полипептид-MHC-I, при этом CNN дополнительно выполнена с возможностью классификации каждого из множества кандидатных взаимодействий полипептид-MHC-I как положительного или отрицательного взаимодействия полипептид-MHC-I; и синтеза полипептида из кандидатного взаимодействия полипептид-MHC-I, классифицируемого посредством CNN как положительное взаимодействие полипептид-MHC-I.
Вариант осуществления 202. Полипептид, полученный при помощи энергонезависимого машиночитаемого носителя по варианту осуществления 201.
Вариант осуществления 203. Энергонезависимый машиночитаемый носитель по варианту осуществления 201, где полипептид представляет собой опухолеспецифический антиген.
Вариант осуществления 204. Энергонезависимый машиночитаемый носитель по варианту осуществления 201, где полипептид содержит аминокислотную последовательность, которая специфически связывается с белком MHC-I, кодируемым выбранным аллелем MHC.
Вариант осуществления 205. Энергонезависимый машиночитаемый носитель по варианту осуществления 190, где положительные смоделированные данные взаимодействия полипептид-MHC-I, положительные реальные данные взаимодействия полипептид-MHC-I и отрицательные реальные данные взаимодействия полипептид-MHC-I связаны с выбранным аллелем.
Вариант осуществления 206. Энергонезависимый машиночитаемый носитель по варианту осуществления 205, где выбранный аллель выбран из группы, состоящей из A0201, A0202, A0203, B2703, B2705 и их комбинаций.
Вариант осуществления 207. Энергонезависимый машиночитаемый носитель по варианту осуществления 190, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают генерирование одним или более процессорами все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают оценивание одним или более процессорами выражения градиентного спуска для генератора GAN.
Вариант осуществления 208. Энергонезависимый машиночитаемый носитель по варианту осуществления 190, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают генерирование одним или более процессорами все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами следующего: итеративного выполнения (например, оптимизации) дискриминатора GAN для увеличения возможности присвоения высокой вероятности положительным реальным данным взаимодействия полипептид-MHC-I, низкой вероятности положительным смоделированным данным взаимодействия полипептид-MHC-I и низкой вероятности отрицательных смоделированных данных взаимодействия полипептид-MHC-I; а также итеративного выполнения (например, оптимизации) генератора GAN для увеличения возможности того, что положительные смоделированные данные взаимодействия полипептид-MHC-I будут иметь высокую оценку.
Вариант осуществления 209. Энергонезависимый машиночитаемый носитель по варианту осуществления 190, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление одним или более процессорами положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует данные взаимодействия полипептид-MHC-I как положительные или отрицательные, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами следующего: выполнения процедуры свертки; выполнения процедуры нелинейности (например, ReLu), выполнения процедуры объединения или субдискретизации; и выполнения процедуры классификации (полносвязный слой).
Вариант осуществления 210. Энергонезависимый машиночитаемый носитель по варианту осуществления 190, где GAN включает глубокую сверточную GAN (DCGAN).
Вариант осуществления 211. Энергонезависимый машиночитаемый носитель по варианту осуществления 191, где первый критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 212. Энергонезависимый машиночитаемый носитель по варианту осуществления 190, где второй критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 213. Энергонезависимый машиночитаемый носитель по варианту осуществления 194 или 195, где третий критерий останова включает оценку функции площади под кривой (AUC).
Вариант осуществления 214. Энергонезависимый машиночитаемый носитель по варианту осуществления 190, где оценка прогноза представляет собой вероятность того, что положительные реальные данные взаимодействия полипептид-MHC-I классифицированы как положительные данные взаимодействия полипептид-MHC-I.
Вариант осуществления 215. Энергонезависимый машиночитаемый носитель по варианту осуществления 190, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают определение одним или более процессорами на основании оценок прогноза того, обучена ли GAN, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают сравнение одним или более процессорами одной или более оценок прогноза с пороговым значением.
Вариант осуществления 216. Энергонезависимый машиночитаемый носитель для обучения генеративно-состязательной сети (GAN), причем энергонезависимый машиночитаемый носитель хранит исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение устройством следующего: генерирования в соответствии с набором параметров GAN первого смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC; объединение первого смоделированного набора данных с положительными реальными взаимодействиями полипептид-MHC-I для аллеля MHC и отрицательными реальными взаимодействиями полипептид-MHC-I для аллеля MHC для создания набора данных для обучения GAN; получения информации от дискриминатора, при этом дискриминатор выполнен с возможностью определения, в соответствии с решающей границей, является ли положительное взаимодействие полипептид-MHC-I для аллеля MHC в наборе данных для обучения GAN положительным или отрицательным; корректировки, основанной на точности информации от дискриминатора, одного или более из набора параметров GAN или решающей границы; повторения стадий a-d до тех пор, пока не будет соблюден первый критерий останова; генерирования с помощью генератора GAN в соответствии с набором параметров GAN второго смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC; объединения второго смоделированного набора данных, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I для аллеля MHC для создания набора данных для обучения CNN; представление набора данных для обучения CNN в сверточную нейронную сеть (CNN); получения информации для обучения от CNN, где CNN выполнена с возможностью определения информации для обучения путем классификации в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC в наборе данных для обучения CNN как положительного или отрицательного; корректировки, основанной на точности информации для обучения, одного или более из набора параметров CNN; повторения стадий h-j до тех пор, пока не будет соблюден второй критерий останова; представления в CNN положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I; получения информации для обучения от CNN, где CNN выполнена с возможностью определения обучающей информации путем классификации в соответствии с набором параметров CNN взаимодействия полипептид-MHC-I для аллеля MHC как положительного или отрицательного; и определения точности информации для обучения, при этом, когда (если) точность информации для обучения удовлетворяет третьему критерию останова, выведения GAN и CNN,
при этом, когда (если) точность информации для обучения не удовлетворяет третьему критерию останова, возвращения к стадии а.
Вариант осуществления 217. Энергонезависимый машиночитаемый носитель по варианту осуществления 216, где параметры GAN включают одно или более из типа аллеля, длины аллеля, категории генерирования, сложности модели, скорости обучения или размера пакета.
Вариант осуществления 218. Энергонезависимый машиночитаемый носитель по варианту осуществления 216, где аллель MHC представляет собой аллель HLA.
Вариант осуществления 219. Энергонезависимый машиночитаемый носитель по варианту осуществления 218, где тип аллеля HLA включает один или более из HLA-A, HLA-B, HLA-C или их подтип.
Вариант осуществления 220. Энергонезависимый машиночитаемый носитель по варианту осуществления 218, где длина аллеля HLA составляет от приблизительно 8 до приблизительно 12 аминокислот.
Вариант осуществления 221. Энергонезависимый машиночитаемый носитель по варианту осуществления 218, где длина аллеля HLA составляет от приблизительно 9 до приблизительно 11 аминокислот.
Вариант осуществления 222. Энергонезависимый машиночитаемый носитель по варианту осуществления 216, где исполняемые процессором команды при исполнении одним или более процессорами дополнительно обеспечивают выполнение одним или более процессорами следующего: представления набора данных в CNN, при этом набор данных содержит множество кандидатных взаимодействий полипептид-MHC-I, при этом CNN дополнительно выполнена с возможностью классификации каждого из множества кандидатных взаимодействий полипептид-MHC-I как положительного или отрицательного взаимодействия полипептид-MHC-I; и синтеза полипептида из кандидатного взаимодействия полипептид-MHC-I, классифицируемого посредством CNN как положительное взаимодействие полипептид-MHC-I.
Вариант осуществления 223. Полипептид, полученный при помощи энергонезависимого машиночитаемого носителя по варианту осуществления 222.
Вариант осуществления 224. Энергонезависимый машиночитаемый носитель по варианту осуществления 222, где полипептид представляет собой опухолеспецифический антиген.
Вариант осуществления 225. Энергонезависимый машиночитаемый носитель по варианту осуществления 222, где полипептид содержит аминокислотную последовательность, которая специфически связывается с белком MHC-I, кодируемым выбранным аллелем MHC.
Вариант осуществления 226. Энергонезависимый машиночитаемый носитель по варианту осуществления 216, где положительные смоделированные данные взаимодействия полипептид-MHC-I, положительные реальные данные взаимодействия полипептид-MHC-I и отрицательные реальные данные взаимодействия полипептид-MHC-I связаны с выбранным аллелем.
Вариант осуществления 227. Энергонезависимый машиночитаемый носитель по варианту осуществления 226, где выбранный аллель выбран из группы, состоящей из A0201, A0202, A0203, B2703, B2705 и их комбинаций.
Вариант осуществления 228. Энергонезависимый машиночитаемый носитель по варианту осуществления 216, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают повторение одним или более процессорами стадий a-d до тех пор, пока первый критерий останова не будет соблюден, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают оценивание одним или более процессорами выражения градиентного спуска для генератора GAN.
Вариант осуществления 229. Энергонезависимый машиночитаемый носитель по варианту осуществления 216, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают повторение одним или более процессорами стадий a-d до тех пор, пока первый критерий останова не будет соблюден, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами следующего: итеративного выполнения (например, оптимизации) дискриминатора GAN для увеличения возможности присвоения высокой вероятности положительным реальным данным взаимодействия полипептид-MHC-I, низкой вероятности положительным смоделированным данным взаимодействия полипептид-MHC-I и низкой вероятности отрицательных смоделированных данных взаимодействия полипептид-MHC-I; и итеративного выполнения (например, оптимизации) генератора GAN для увеличения возможности того, что положительные смоделированные данные взаимодействия полипептид-MHC-I будут иметь высокую оценку.
Вариант осуществления 230. Энергонезависимый машиночитаемый носитель по варианту осуществления 216, где исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают представление одним или более процессорами в CNN данных для обучения CNN, дополнительно предусматривают исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами следующего: выполнения процедуры свертки; выполнения процедуры нелинейности (например, ReLu), выполнения процедуры объединения или субдискретизации; и выполнения процедуры классификации (полносвязный слой).
Вариант осуществления 231. Энергонезависимый машиночитаемый носитель по варианту осуществления 216, где GAN включает глубокую сверточную GAN (DCGAN).
Вариант осуществления 232. Энергонезависимый машиночитаемый носитель по варианту осуществления 216, где первый критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 233. Энергонезависимый машиночитаемый носитель по варианту осуществления 216, где второй критерий останова включает оценку функции среднеквадратичной ошибки (MSE).
Вариант осуществления 234. Энергонезависимый машиночитаемый носитель по варианту осуществления 216, где третий критерий останова включает оценку функции площади под кривой (AUC).
Вариант осуществления 235. Энергонезависимый машиночитаемый носитель для обучения генеративно-состязательной сети (GAN), причем энергонезависимый машиночитаемый носитель хранит исполняемые процессором команды, которые при исполнении одним или более процессорами обеспечивают выполнение одним или более процессорами следующего: обучения сверточной нейронной сети (CNN) теми же средствами, что и устройство по варианту 83 осуществления; представления набора данных в CNN, где набор данных содержит множество кандидатных взаимодействий полипептид-MHC-I, где CNN выполнена с возможностью классификации каждого из множества кандидатных взаимодействий полипептид-MHC-I как положительного или отрицательного взаимодействия полипептид-MHC-I; и синтеза полипептида, связанного с кандидатным взаимодействием полипептид-MHC-I, классифицируемого посредством CNN как положительное взаимодействие полипептид-MHC-I.
Вариант осуществления 236. Энергонезависимый машиночитаемый носитель по варианту осуществления 235, где CNN подвергается обучению на основании одного или более параметров GAN, включающих одно или более из типа аллеля, длины аллеля, категории генерирования, сложности модели, скорости обучения или размера пакета.
Вариант осуществления 237. Энергонезависимый машиночитаемый носитель по варианту осуществления 236, где тип аллеля HLA включает один или более из HLA-A, HLA-B, HLA-C или их подтип.
Вариант осуществления 238. Энергонезависимый машиночитаемый носитель по варианту осуществления 236, где длина аллеля HLA составляет от приблизительно 8 до приблизительно 12 аминокислот.
Вариант осуществления 239. Энергонезависимый машиночитаемый носитель по варианту осуществления 236, где длина аллеля HLA составляет от приблизительно 9 до приблизительно 11 аминокислот.
Вариант осуществления 240. Полипептид, полученный при помощи энергонезависимого машиночитаемого носителя по варианту осуществления 235.
Вариант осуществления 241. Энергонезависимый машиночитаемый носитель по варианту осуществления 235, где полипептид представляет собой опухолеспецифический антиген.
Вариант осуществления 242. Энергонезависимый машиночитаемый носитель по варианту осуществления 235, где полипептид содержит аминокислотную последовательность, которая специфически связывается с белком MHC-I, кодируемым выбранным аллелем лейкоцитарного антигена человека (HLA).
Вариант осуществления 243. Энергонезависимый машиночитаемый носитель по варианту осуществления 235, где положительные смоделированные данные взаимодействия полипептид-MHC-I, положительные реальные данные взаимодействия полипептид-MHC-I и отрицательные реальные данные взаимодействия полипептид-MHC-I связаны с выбранным аллелем.
Вариант осуществления 244. Энергонезависимый машиночитаемый носитель по варианту осуществления 243, где выбранный аллель выбран из группы, состоящей из A0201, A0202, A0203, B2703, B2705 и их комбинаций.
Вариант осуществления 245. Энергонезависимый машиночитаемый носитель по варианту осуществления 235, где GAN включает глубокую сверточную GAN (DCGAN).
| название | год | авторы | номер документа |
|---|---|---|---|
| GAN-CNN ДЛЯ ПРОГНОЗИРОВАНИЯ СВЯЗЫВАНИЯ MHC-ПЕПТИД | 2019 |
|
RU2836823C2 |
| СПОСОБ И СИСТЕМЫ ДЛЯ ПРОГНОЗИРОВАНИЯ СПЕЦИФИЧЕСКИХ ДЛЯ HLA КЛАССА II ЭПИТОПОВ И ОХАРАКТЕРИЗАЦИИ CD4+ T-КЛЕТОК | 2019 |
|
RU2826261C2 |
| СПОСОБ ПЕРЕДАЧИ ДВИЖЕНИЯ СУБЪЕКТА ИЗ ВИДЕО НА АНИМИРОВАННОГО ПЕРСОНАЖА | 2019 |
|
RU2708027C1 |
| БЫСТРОЕ ВЫЧИСЛЕНИЕ СВЕРТОЧНОЙ НЕЙРОННОЙ СЕТИ | 2018 |
|
RU2722473C1 |
| Способ локального генерирования и представления потока обоев и вычислительное устройство, реализующее его | 2020 |
|
RU2768551C1 |
| Обучение по нескольким кадрам реалистичных нейронных моделей голов говорящих персон | 2019 |
|
RU2720361C1 |
| СВЕРТОЧНАЯ НЕЙРОННАЯ СЕТЬ НА ОСНОВЕ ОКТОДЕРЕВА | 2018 |
|
RU2767162C2 |
| Повторный синтез изображения, использующий прямое деформирование изображения, дискриминаторы пропусков и основанное на координатах реконструирование | 2019 |
|
RU2726160C1 |
| УСТРОЙСТВО ОБРАБОТКИ ДАННЫХ, СПОСОБ ОБРАБОТКИ ДАННЫХ И НОСИТЕЛЬ ДАННЫХ | 2017 |
|
RU2747445C1 |
| СИСТЕМА И СПОСОБ ПОДДЕРЖКИ ВЫЯВЛЕНИЯ БОЛЕЗНЕЙ РАСТЕНИЙ | 2020 |
|
RU2815542C2 |
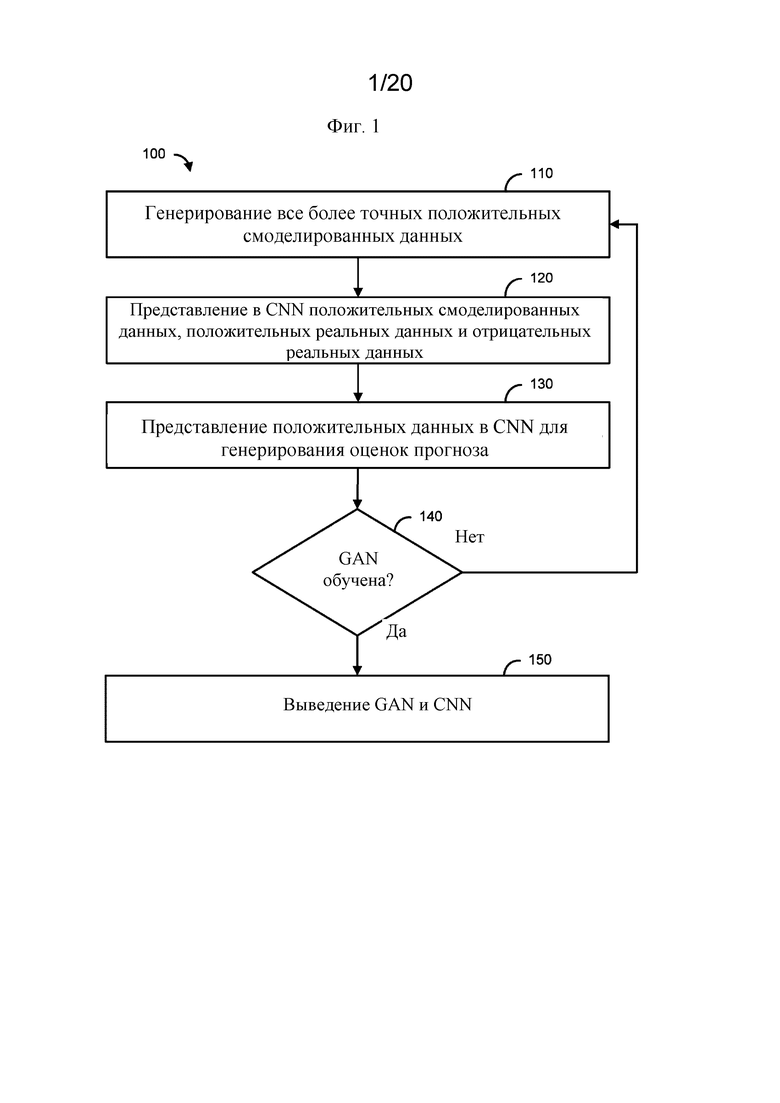
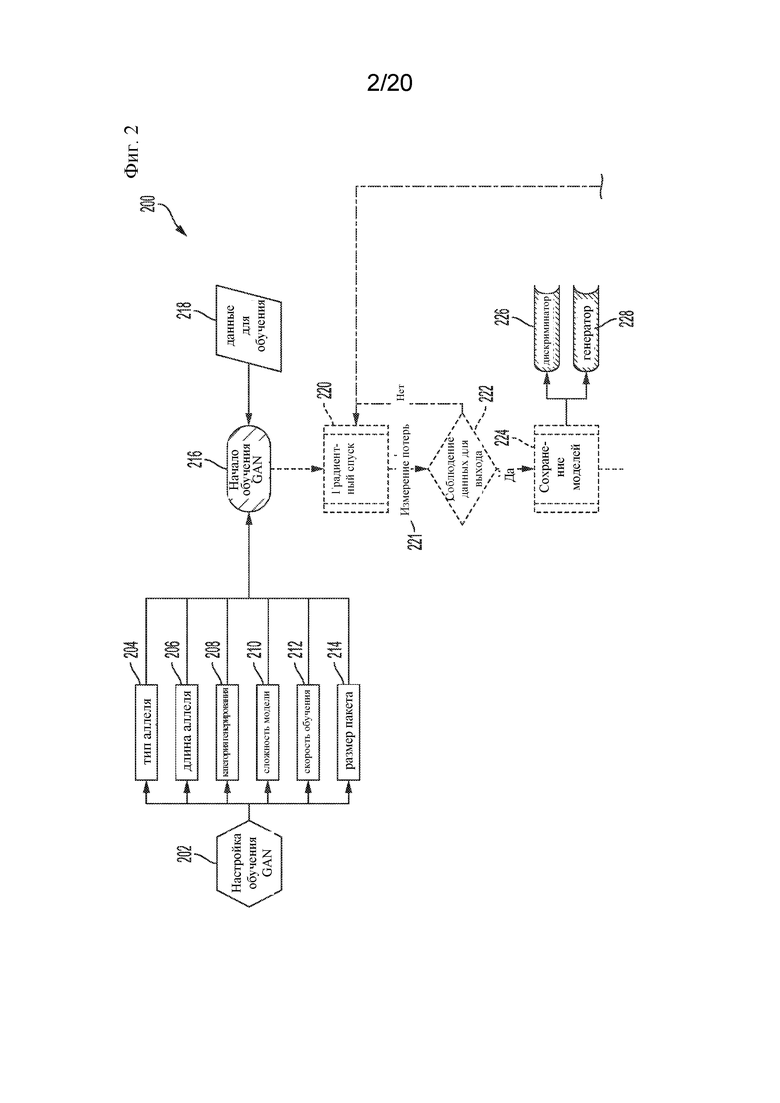
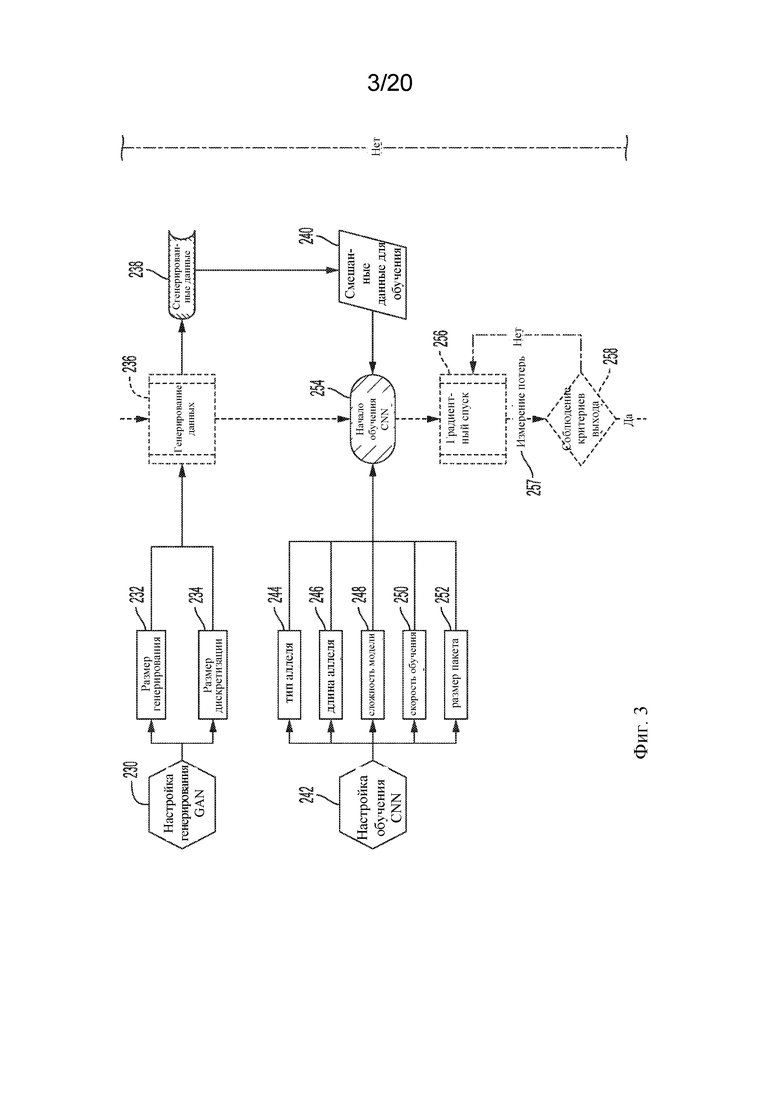
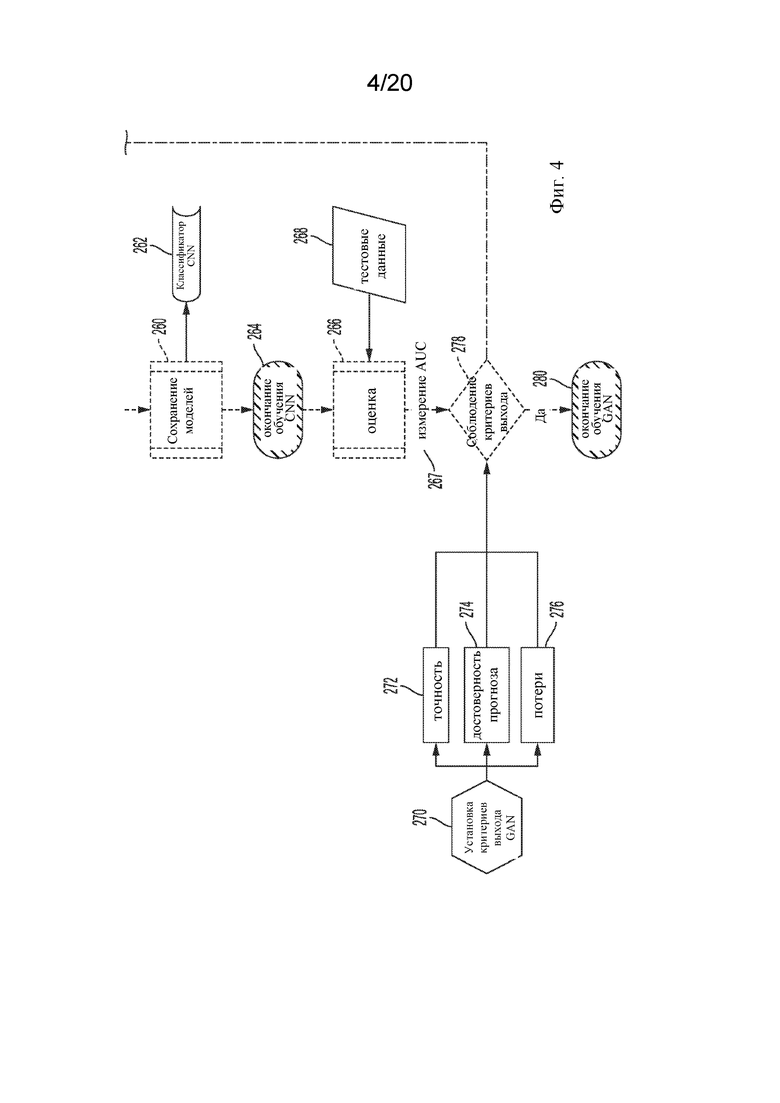
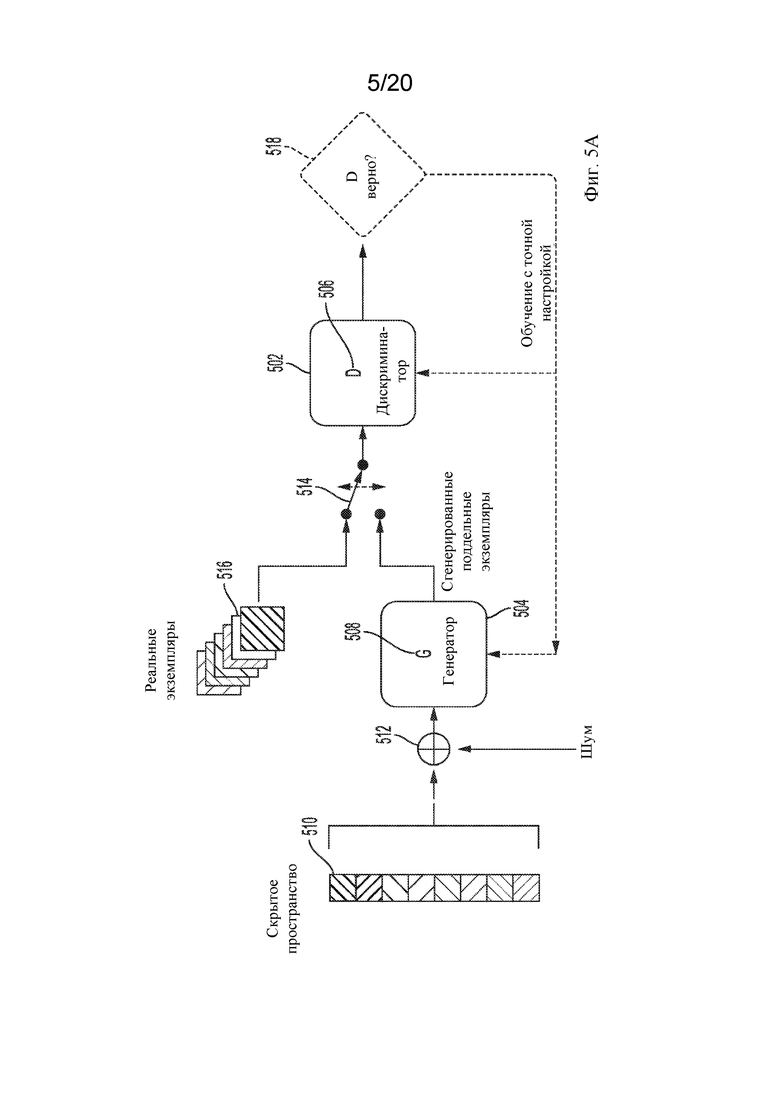
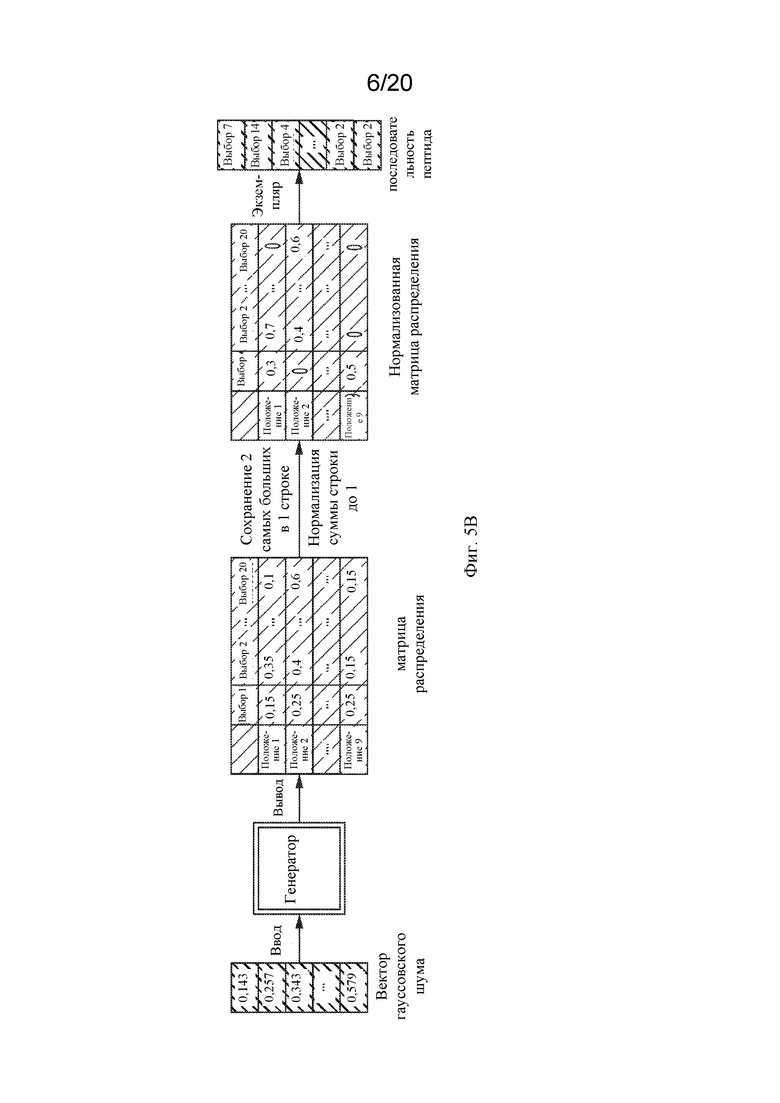
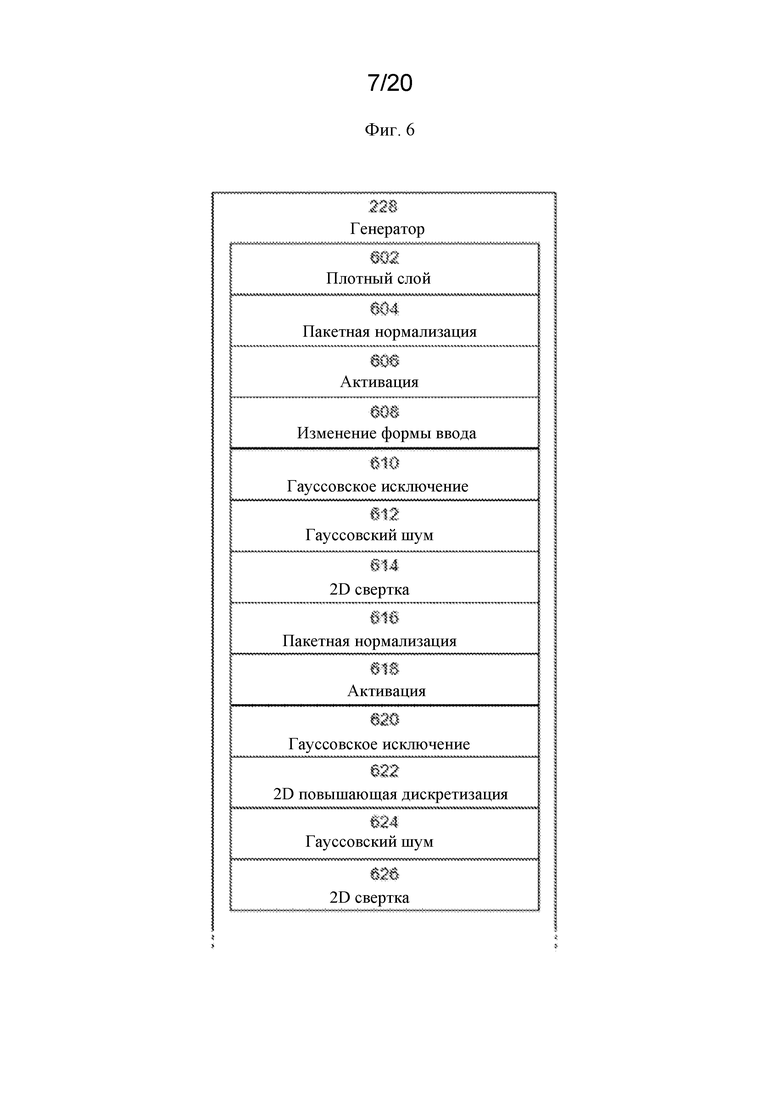


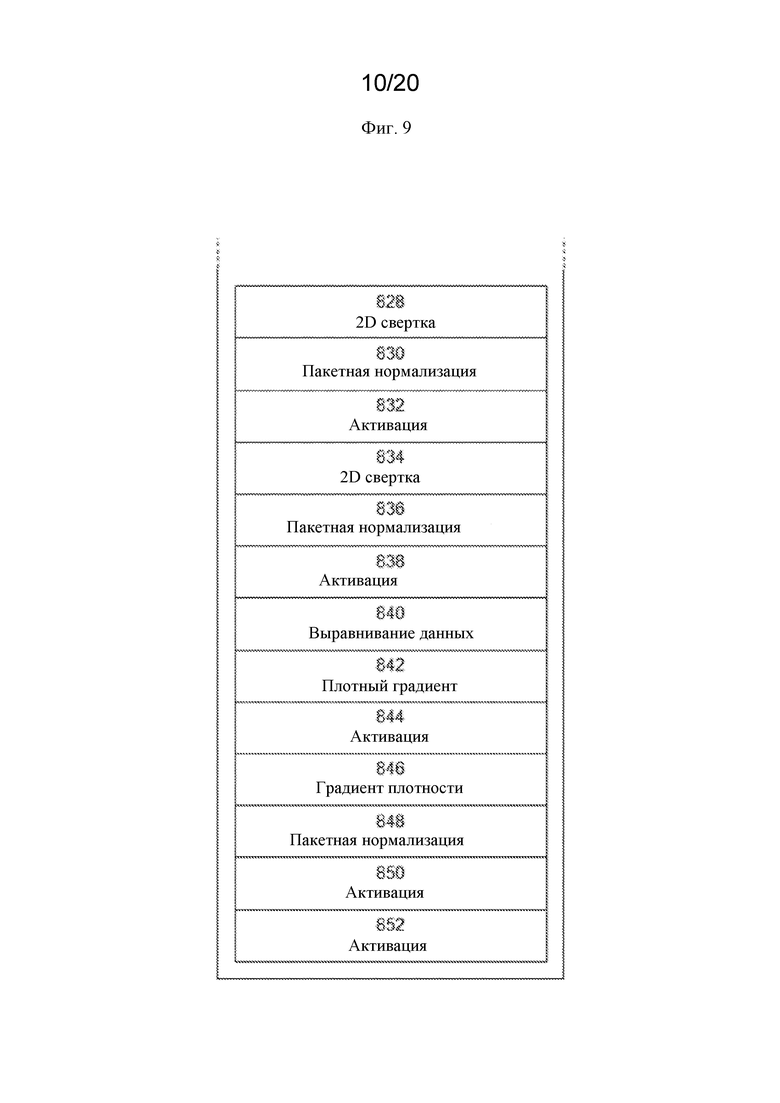
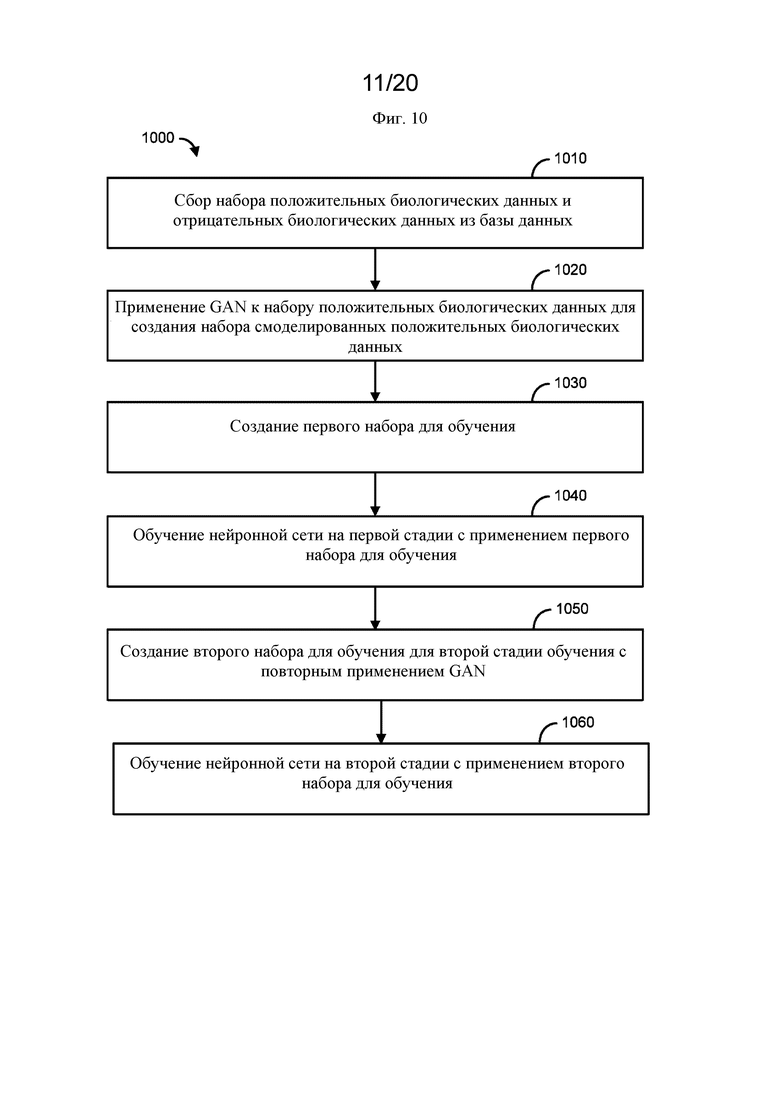

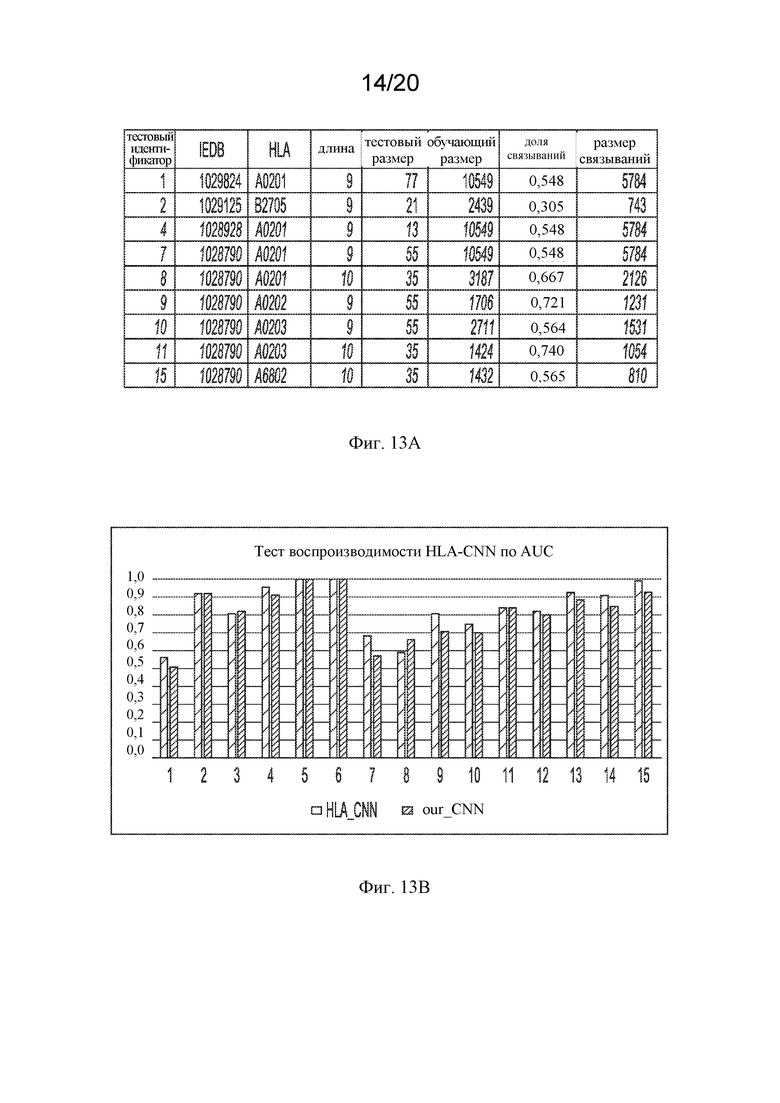

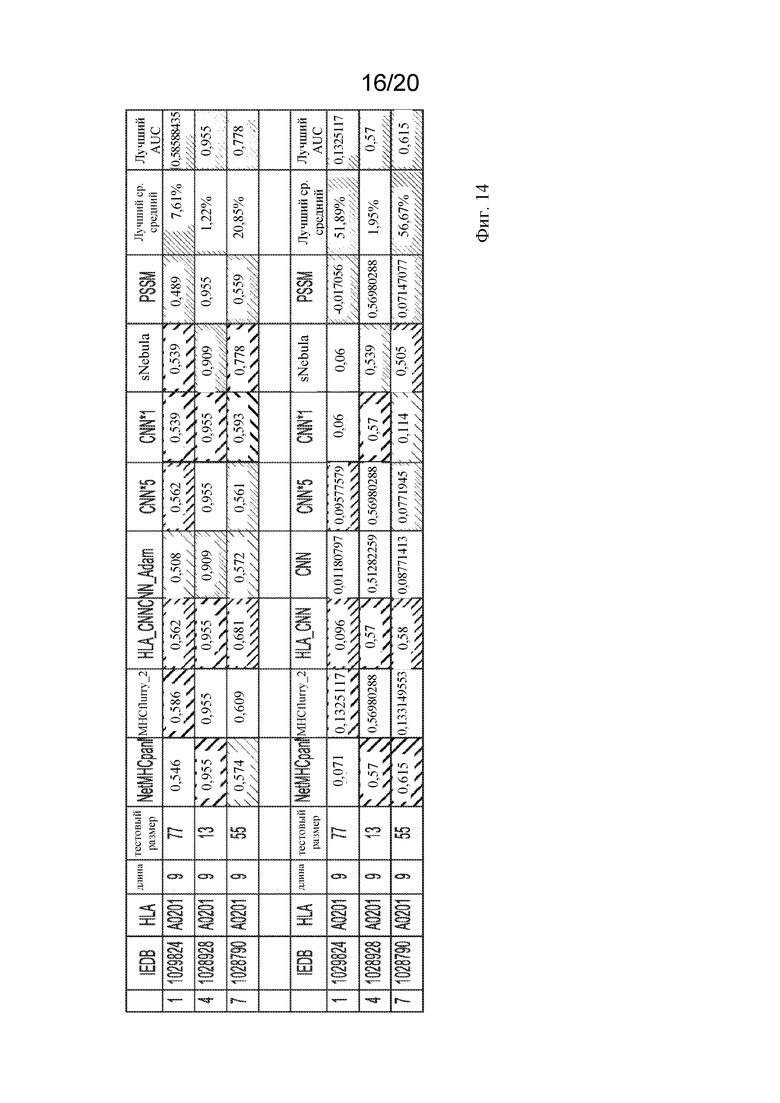
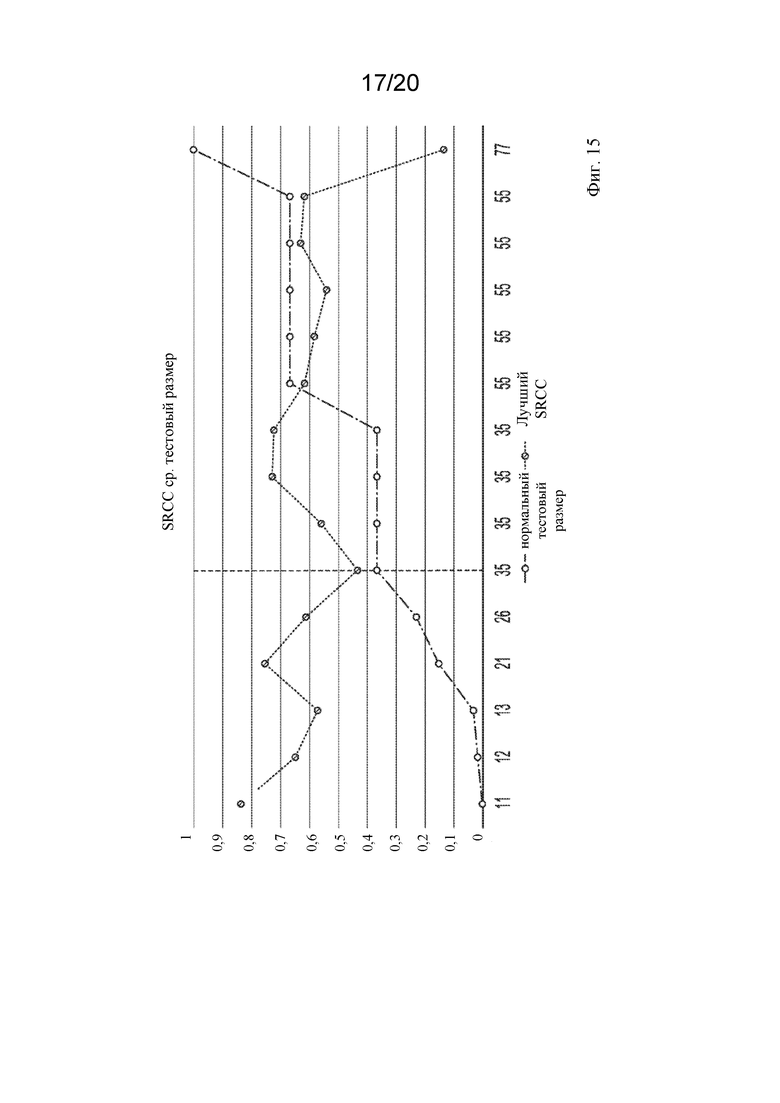
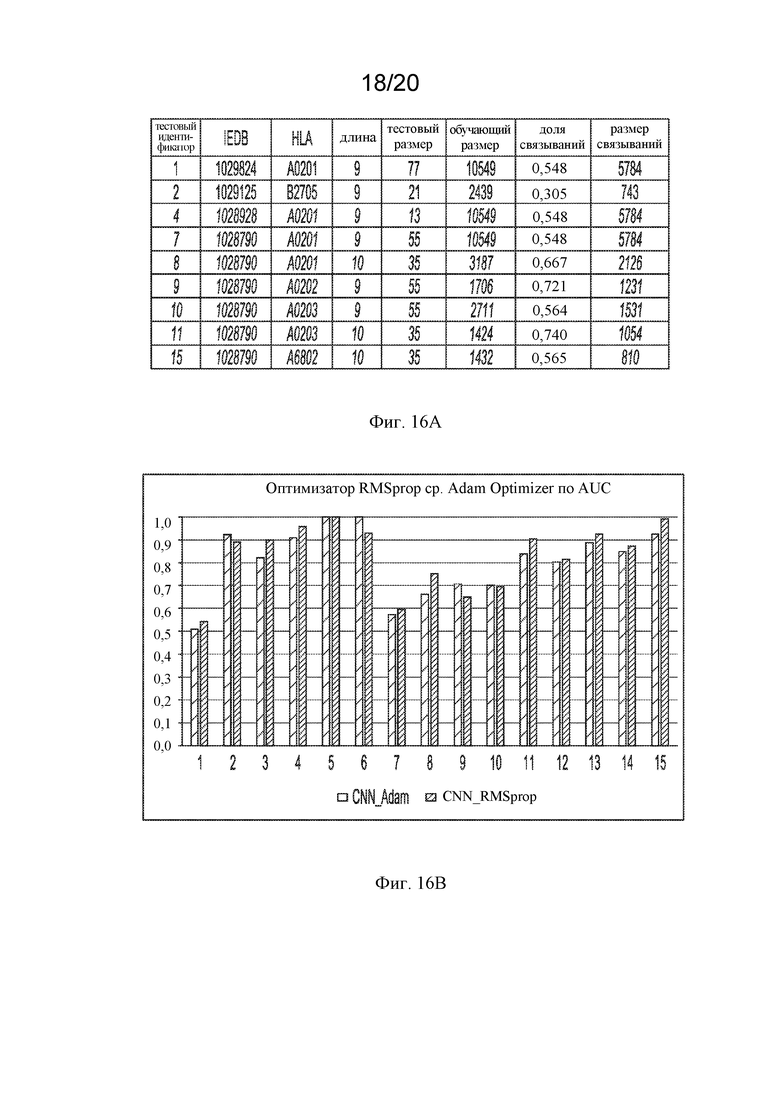
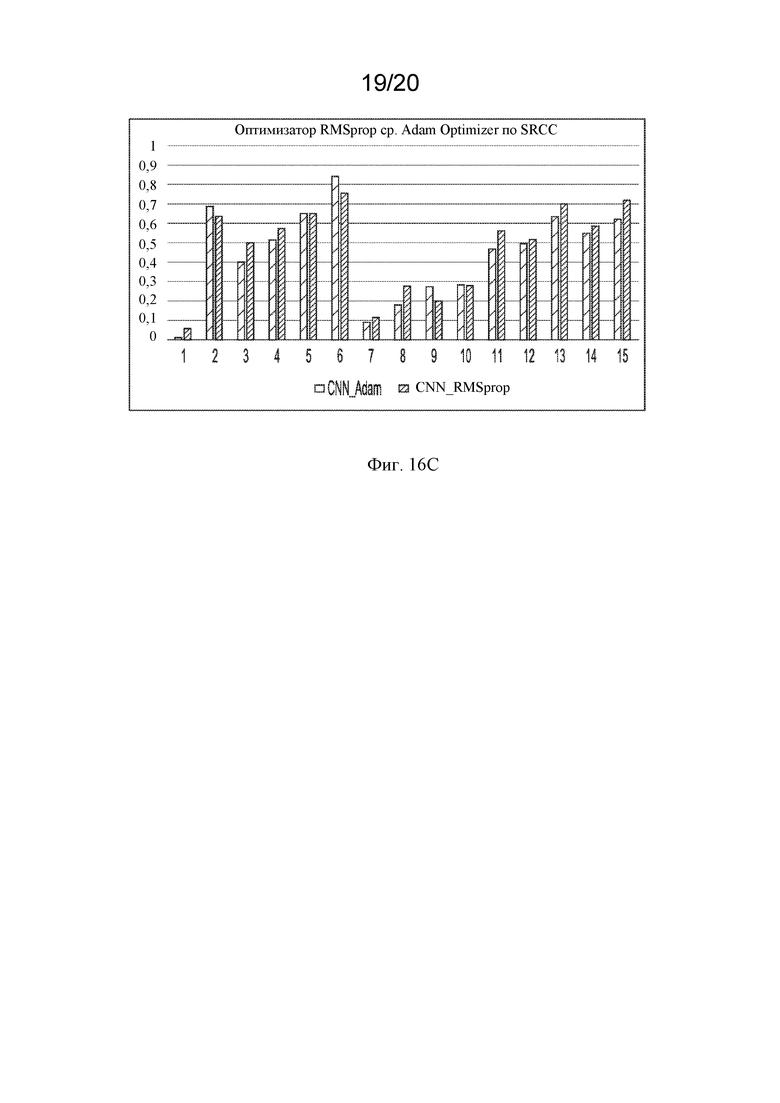
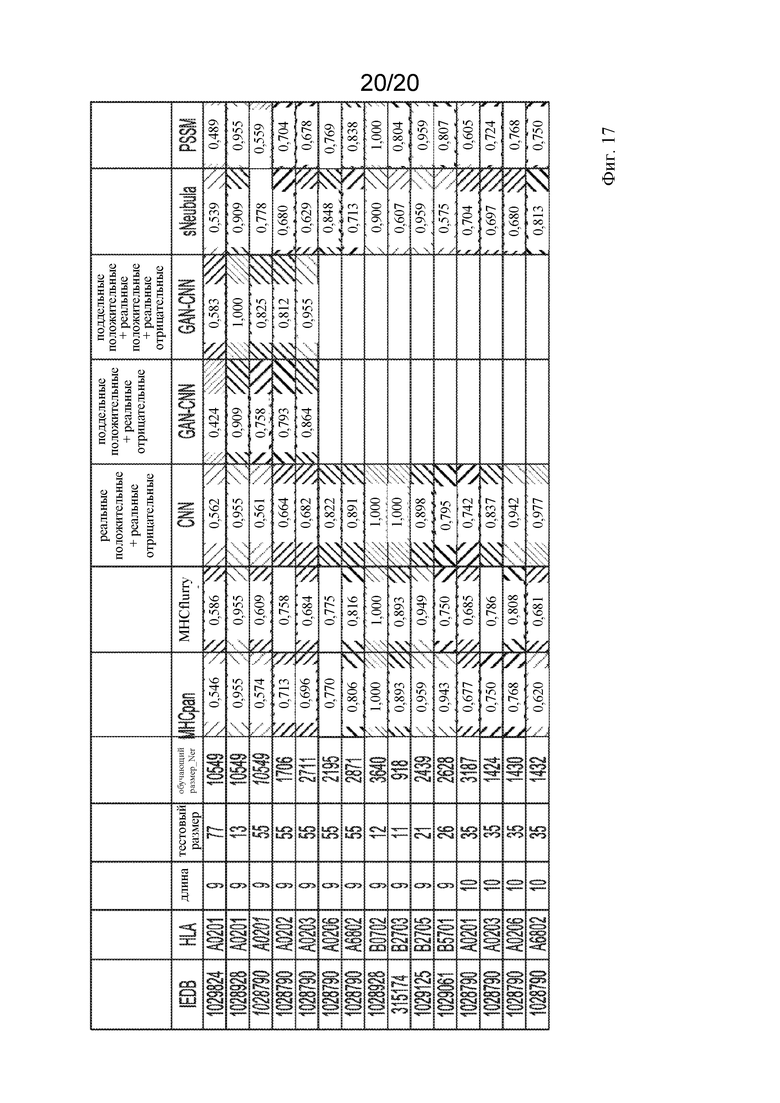
Раскрыты способы обучения генеративно-состязательной сети (GAN) в сочетании со сверточной нейронной сетью (CNN). GAN и CNN могут быть обучены с применением биологических данных, таких как данные взаимодействия белков. CNN можно применять для идентификации новых данных как положительных или отрицательных. Раскрыты способы синтеза полипептида, связанного с новыми данными взаимодействия белков, идентифицированными как положительные. 24 з.п. ф-лы, 17 ил., 2 табл., 6 пр.
1. Способ обучения генеративно-состязательной сети (GAN), предусматривающий:
a. получение положительных и отрицательных реальных данных в результате измерения биологических состояний человека, животных, микроорганизмов, вирусов или растений;
b. генерирование посредством вычислительного устройства с генератором GAN все более точных положительных смоделированных данных до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные как положительные;
c. представление посредством вычислительного устройства положительных смоделированных данных, положительных реальных данных и отрицательных реальных данных в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует каждый тип данных как положительный или отрицательный;
d. представление посредством вычислительного устройства положительных реальных данных и отрицательных реальных данных CNN для генерирования оценок прогноза и
e. определение посредством вычислительного устройства на основании оценок прогноза того, обучена или не обучена GAN, и, когда GAN не обучена, повторение стадий b—d до тех пор, пока не будет выполнено определение на основании оценок прогноза того, что GAN обучена.
2. Способ по п. 1, где положительные смоделированные данные, положительные реальные данные и отрицательные реальные данные включают биологические данные.
3. Способ по п. 1, где положительные смоделированные данные включают положительные смоделированные данные взаимодействия полипептид-главный комплекс гистосовместимости класса I (MHC-I), положительные реальные данные включают положительные реальные данные взаимодействия полипептид-MHC-I, и отрицательные реальные данные включают отрицательные реальные данные взаимодействия полипептид-MHC-I.
4. Способ по п. 3, где генерирование все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как реальные, предусматривает:
e. генерирование посредством генератора GAN в соответствии с набором параметров GAN первого смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC;
f. объединение первого смоделированного набора данных с положительными реальными взаимодействиями полипептид-MHC-I для аллеля MHC и отрицательными реальными взаимодействиями полипептид-MHC-I для аллеля MHC для создания набора данных для обучения GAN;
g. определение с помощью дискриминатора в соответствии с решающей границей, является ли соответствующее взаимодействие полипептид-MHC-I для аллеля MHC в наборе данных для обучения GAN смоделированным положительным, реальным положительным или реальным отрицательным;
h. корректировку, основанную на точности определения при помощи дискриминатора, одного или более из набора параметров GAN или решающей границы и
i. повторение стадий e—h до тех пор, пока не будет соблюден первый критерий останова.
5. Способ по п. 4, где представление положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует соответствующие данные взаимодействия полипептид-MHC-I как положительные или отрицательные, предусматривает:
j. генерирование посредством генератора GAN в соответствии с набором параметров GAN второго смоделированного набора данных, содержащего смоделированные положительные взаимодействия полипептид-MHC-I для аллеля MHC;
k. объединение второго смоделированного набора данных, положительных реальных взаимодействий полипептид-MHC-I для аллеля MHC и отрицательных реальных взаимодействий полипептид-MHC-I для аллеля MHC для создания набора данных для обучения CNN;
l. представление набора данных для обучения CNN в сверточную нейронную сеть (CNN);
m. классификацию посредством CNN в соответствии с набором параметров CNN соответствующего взаимодействия полипептид-MHC-I для аллеля MHC в наборе данных для обучения CNN как положительного или отрицательного;
n. корректировку, основанную на точности классификации посредством CNN, одного или более из набора параметров CNN и
o. повторение стадий l—n до тех пор, пока не будет соблюден второй критерий останова.
6. Способ по п. 5, где представление положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в CNN для генерирования оценок прогноза предусматривает:
классификацию посредством CNN в соответствии с набором параметров CNN соответствующего взаимодействия полипептид-MHC-I для аллеля MHC как положительного или отрицательного.
7. Способ по п. 6, где определение на основании оценок прогноза того, обучена ли GAN, предусматривает определение точности классификации посредством CNN, при этом, когда точность классификации удовлетворяет третьему критерию останова, выведение GAN и CNN.
8. Способ по п. 6, где определение на основании оценок прогноза того, обучена ли GAN, предусматривает определение точности классификации посредством CNN, при этом, когда точность классификации не удовлетворяет третьему критерию останова, возвращение к стадии b.
9. Способ по п. 4, где параметры GAN включают одно или более из типа аллеля, длины аллеля, категории генерирования, сложности модели, скорости обучения или размера пакета.
10. Способ по п. 9, где тип аллеля включает один или более из HLA-A, HLA-B, HLA-C или их подтип.
11. способ по п. 9, где длина аллеля составляет от приблизительно 8 до приблизительно 12 аминокислот.
12. Способ по п. 11, где длина аллеля составляет от приблизительно 9 до приблизительно 11 аминокислот.
13. Способ по п. 3, дополнительно предусматривающий:
представление набора данных в CNN, где набор данных содержит множество кандидатных взаимодействий полипептид-MHC-I;
классификацию посредством CNN каждого из множества кандидатных взаимодействий полипептид-MHC-I как положительного или отрицательного взаимодействия полипептид-MHC-I; и
синтез полипептида из кандидатного взаимодействия полипептид-MHC-I, классифицируемого как положительное взаимодействие полипептид-MHC-I.
14. Способ по п. 13, где полипептид представляет собой опухолеспецифический антиген.
15. Способ по п. 13, где полипептид содержит аминокислотную последовательность, которая специфически связывается с белком MHC-I, кодируемым выбранным аллелем MHC.
16. Способ по п. 3, где положительные смоделированные данные взаимодействия полипептид-MHC-I, положительные реальные данные взаимодействия полипептид-MHC-I и отрицательные реальные данные взаимодействия полипептид-MHC-I связаны с выбранным аллелем.
17. Способ по п. 16, где выбранный аллель выбран из группы, состоящей из A0201, A0202, A0203, B2703, B2705 и их комбинаций.
18. Способ по п. 3, где генерирование все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, предусматривает оценку выражения градиентного спуска для генератора GAN.
19. Способ по п. 3, где генерирование все более точных положительных смоделированных данных взаимодействия полипептид-MHC-I до тех пор, пока дискриминатор GAN не классифицирует положительные смоделированные данные взаимодействия полипептид-MHC-I как положительные, предусматривает:
итеративное выполнение дискриминатора GAN для увеличения возможности присвоения высокой вероятности положительным реальным данным взаимодействия полипептид-MHC-I, низкой вероятности положительным смоделированным данным взаимодействия полипептид-MHC-I и низкой вероятности отрицательным реальным данным взаимодействия полипептид-MHC-I и
итеративное выполнение генератора GAN для увеличения вероятности того, что положительные смоделированные данные взаимодействия полипептид-MHC-I будут иметь высокую оценку.
20. Способ по п. 3, где представление положительных смоделированных данных взаимодействия полипептид-MHC-I, положительных реальных данных взаимодействия полипептид-MHC-I и отрицательных реальных данных взаимодействия полипептид-MHC-I в сверточную нейронную сеть (CNN) до тех пор, пока CNN не классифицирует соответствующие данные взаимодействия полипептид-MHC-I как положительные или отрицательные, предусматривает:
выполнение процедуры свертки;
выполнение процедуры нелинейности (ReLU);
выполнение процедуры объединения или субдискретизации и
выполнение процедуры классификации (полносвязный слой).
21. Способ по п. 1, где GAN включает глубокую сверточную GAN (DCGAN).
22. Способ по п. 8, где первый критерий останова включает оценку функции среднеквадратичной ошибки (MSE), второй критерий останова включает оценку функции среднеквадратичной ошибки (MSE) и третий критерий останова включает оценку функции области под кривой (AUC).
23. Способ по п. 3, где оценка прогноза представляет собой вероятность того, что положительные реальные данные взаимодействия полипептид-MHC-I классифицированы как положительные данные взаимодействия полипептид-MHC-I.
24. Способ по п. 1, где определение на основании оценок прогноза того, обучена ли GAN, предусматривает сравнение одной или более оценок прогноза с пороговым значением.
25. Способ по п. 1, дополнительно предусматривающий выведение GAN и CNN.
| RU 2016106004 A, 08.12.2017 | |||
| РЕАЛИЗУЕМЫЙ КОМПЬЮТЕРОМ СПОСОБ ОБЕСПЕЧЕНИЯ ГРАФИЧЕСКОГО ПОЛЬЗОВАТЕЛЬСКОГО ИНТЕРФЕЙСА НА ЭКРАНЕ ДИСПЛЕЯ ЭЛЕКТРОННОГО УСТРОЙСТВА БРАУЗЕРНЫМ КОНТЕКСТНЫМ ПОМОЩНИКОМ (ВАРИАНТЫ), СЕРВЕР И ЭЛЕКТРОННОЕ УСТРОЙСТВО, ИСПОЛЬЗУЕМЫЕ В НЕМ | 2014 |
|
RU2608884C2 |
| WO 2014082179 A1, 05.06.2014. | |||

