Область техники
[0001] Настоящая заявка относится к способу и устройствам для обучения по нескольким кадрам (few–shot learning) (фотоснимкам) реалистичных нейронных моделей голов говорящих персон, а также к способу и устройствам для создания персонализированных фотореалистичных последовательностей изображений головы говорящей персоны, т.е. модулям программного обеспечения и/или аппаратных средств, которые могут синтезировать последовательности правдоподобных видео головы конкретного индивидуума в процессе эмоционального разговора и мимики. Также раскрыты считываемые компьютером носители, хранящие исполняемые компьютером инструкции, которые, при исполнении процессором устройства, побуждают процессор выполнять любой один из раскрытых способов.
Предшествующий уровень техники
[0002] В настоящей заявке рассматривается задача создания персонализированных фотореалистичных моделей головы говорящей персоны, т.е. систем, которые могут синтезировать последовательности правдоподобных видео эмоций и мимики при разговоре конкретного индивидуума. Более конкретно, рассматривается проблема синтезирования фотореалистичных персонализированных изображений головы, при заданном наборе распознаваемых элементов (ориентиров) лица, которые стимулируют анимацию модели. Такая способность имеет практические применения для дистанционного присутствия (телеприсутствия), включая режим видеоконференции и многопользовательские игры, а также индустрию спецэффектов. Известно, что синтезирование последовательностей реалистичных изображений головы говорящей персоны является затруднительным по двум причинам. Во–первых, человеческие головы характеризуются высокой фотометрической, геометрической и кинематической сложностью. Эта сложность обусловлена не только моделированием лиц (для чего существует большое количество методов моделирования), но и моделированием полости рта, волос и одежды. Вторым фактором сложности является острота зрительной системы человека даже к малейшим погрешностям в моделировании внешнего вида голов людей (так называемый “эффект зловещей долины” [24]). Такой малый допуск для погрешностей моделирования объясняет то, что в настоящее время преобладают не–фотореалистичные карикатурно–подобные аватары во многих практически развертываемых системах телеконференции.
Связанные работы
[0003] Для преодоления упомянутых проблем, был представлен ряд работ по синтезированию связанных последовательностей изображений головы путем деформирования одиночного или нескольких статических кадров. Как классические алгоритмы деформации [5, 28], так и поля деформации, синтезированные с использованием машинного обучения (включая глубокое обучение) [11, 29, 40], могут быть использованы для такой цели. Хотя основанные на деформации системы могут создавать последовательности изображений головы говорящей персоны даже из одиночного изображения, однако величина движения, поворота головы и устранения перекрытия (дезокклюзии), которую они могут обрабатывать без заметных артефактов, является ограниченной.
[0004] Прямой (без деформации) синтез кадров видео с использованием состязательно–обучаемых глубоких сверточных сетей (ConvNets) представляет новое решение, с которым связаны надежды на создание фотореалистичных изображений головы говорящей персоны. В последнее время, некоторые весьма реалистичные результаты были продемонстрированы такими системами [16, 20, 37]. Однако, чтобы добиться успеха, такие способы должны обучать большие сети, где как генератор, так и дискриминатор имеют десятки миллионов параметров для каждой головы говорящей персоны. Поэтому таким системам требуются видео длительностью несколько минут [20, 37] или большие наборы данных фотоснимков [16], а также часы обучения GPU, чтобы создать новую персонализированную модель головы говорящей персоны. Хотя такие усилия меньше, чем те, которые требуются системам, которые конструируют фотореалистичные модели головы говорящей персоны с использованием сложного физического и оптического моделирования [1], они все еще является непомерными для большинства практических сценариев телеприсутствия, где желательно обеспечить возможность пользователям создавать их персонализированные модели головы говорящей персоны с наименьшими возможными усилиями.
[0005] Огромное количество работ посвящено статистическому моделированию внешнего вида человеческих лиц [6], причем весьма хорошие результаты получены как классическими методами [35], так и, в последнее время, с помощью глубокого обучения [22, 25] (только в качестве нескольких примеров). Хотя моделирование лица является задачей, довольно тесно связанной с моделированием головы говорящей персоны, обе эти задачи не являются идентичными, так как последняя также предполагает моделирование не относящихся к лицу частей, таких как волосы, шея, полость рта и часто плечи/верхняя одежда. Эти не относящиеся к лицу части не могут быть обработаны некоторым тривиальным расширением способов моделирования лица, поскольку они намного меньше поддаются точному совмещению и часто имеют более высокую вариабельность и более высокую сложность, чем части лица. В принципе, результаты моделирования лица [35] или моделирования губ [31] могут быть “вшиты” в существующее видео головы. Однако такое проектирование не позволяет осуществить полное управление по повороту головы в результирующем видео и поэтому не приводит в результате к полностью отработанной системе моделирования головы говорящей персоны.
[0006] Безразличный к модели модуль обучения (MAML) [10] использует мета–обучение, чтобы получать начальное состояние классификатора изображения, из которого он может быстро конвергировать к классификатору изображения классов без подготовки, если задано несколько обучающих выборок. Эта идея высокого уровня используется способом, предложенным в настоящем документе, хотя ее реализация является довольно затруднительной. Было представлено несколько работ, которые объединяют состязательное обучение с мета–обучением. Так, GAN с увеличением данных [3], мета–GAN [43], состязательное мета–обучение [41] используют состязательно обучаемые сети, чтобы генерировать дополнительные примеры для классов, не наблюдаемых на стадии мета–обучения. В то время как эти способы сфокусированы на повышении эффективности классификации по нескольким кадрам, способ, раскрытый в настоящем документе, направлен на обучение моделей генерации изображения с использованием состязательных целей. В итоге, в настоящем изобретении, состязательная тонкая настройка вносится в инфраструктуру мета–обучения. Первая применяется после того, как начальное состояние сетей генератора и дискриминатора получено посредством стадии мета–обучения.
[0007] Наконец, две последние работы относятся к генерации из текста в речь [4, 18]. Их назначение (обучение по нескольким кадрам генеративных моделей) и некоторые из компонентов (автономная сеть встраивания, тонкая настройка генератора) также используются в настоящем изобретении. Тем не менее, отличия настоящего изобретения заключаются по меньшей мере в области применения, использовании состязательного обучения, его специфической адаптации к процессу мета–обучения и многочисленных деталях реализации. Упомянутые отличия детально описаны ниже в разделе “Подробное описание изобретения”.
Краткое описание сущности изобретения
[0008] В настоящей заявке раскрыты способ, устройства и системы для создания моделей головы говорящей персоны из небольшого количества (“горстки”) фотоснимков (так называемое обучение по нескольким кадрам). Фактически, предложенная система может генерировать приемлемый результат на основе одного фотоснимка (обучение на одном кадре), хотя добавление несколько большего количества фотоснимков повышает точность персонализации. Подобно [16, 20, 37], “говорящие головы”, созданные моделью, раскрытой здесь, соответствуют глубоким ConvNets, которые синтезируют кадры видео прямым способом посредством последовательности операций свертки, а не посредством деформации. “Говорящие головы”, созданные системой, раскрытой в настоящем документе, могут, поэтому, обрабатывать большое разнообразие поз, что выходит за пределы возможностей систем, основанных на деформации.
[0009] Способность обучения по нескольким кадрам получена посредством экстенсивного предварительного обучения (мета–обучения, meta-learning) на большом корпусе (совокупности) видео голов говорящих персон, соответствующих разным говорящим с различным внешнем видом. В ходе мета–обучения, предложенная система моделирует задачи обучения по нескольким кадрам и обучается трансформировать положения ориентиров в реалистично выглядящие персонализированные фотоснимки, при заданном небольшом обучающем наборе изображений данного человека. После этого небольшой набор фотоснимков нового человека ставит новую проблему состязательного обучения с высокопроизводительным генератором и дискриминатором, предварительно обученным посредством мета–обучения. Новая состязательная проблема конвергирует в состояние, которое генерирует реалистичные и персонализированные изображения после нескольких этапов обучения.
[0010] Архитектура предложенной системы заимствует многое из последних достижений в генеративном моделировании изображений. Так, архитектура, предложенная в настоящем документе, использует состязательное обучение и, более конкретно, идеи, лежащие в основе условных дискриминаторов, включая дискриминаторы проекции. Стадия мета–обучения использует адаптивный механизм нормализации экземпляра (образца), который проявил себя полезным в задачах крупномасштабной условной генерации. Таким образом, настоящее изобретение обеспечивает улучшенное качество синтезированных изображений и исключение эффекта зловещей долины из таких изображений.
Краткое описание чертежей
[Фиг. 1] Фиг. 1 иллюстрирует предложенную архитектуру мета–обучения в соответствии с вариантом осуществления настоящего изобретения.
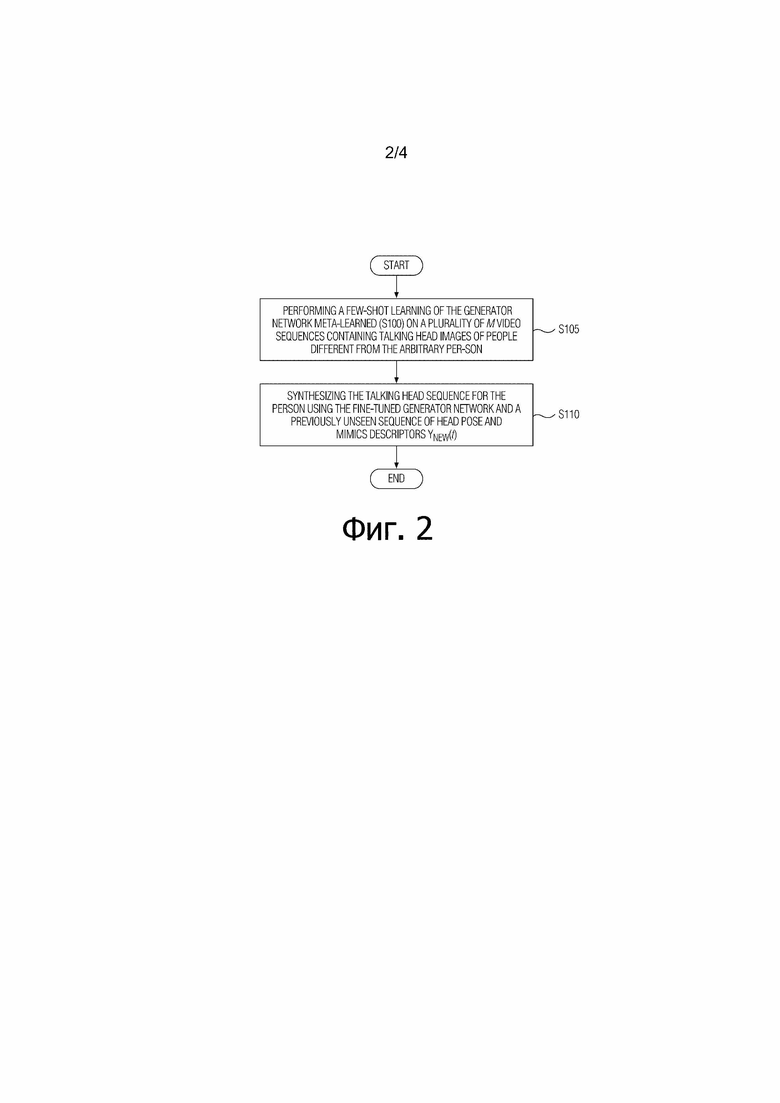
[Фиг. 2] Фиг. 2 иллюстрирует вариант осуществления способа синтезирования последовательности изображений головы говорящей персоны для произвольной персоны в соответствии с настоящим изобретением.
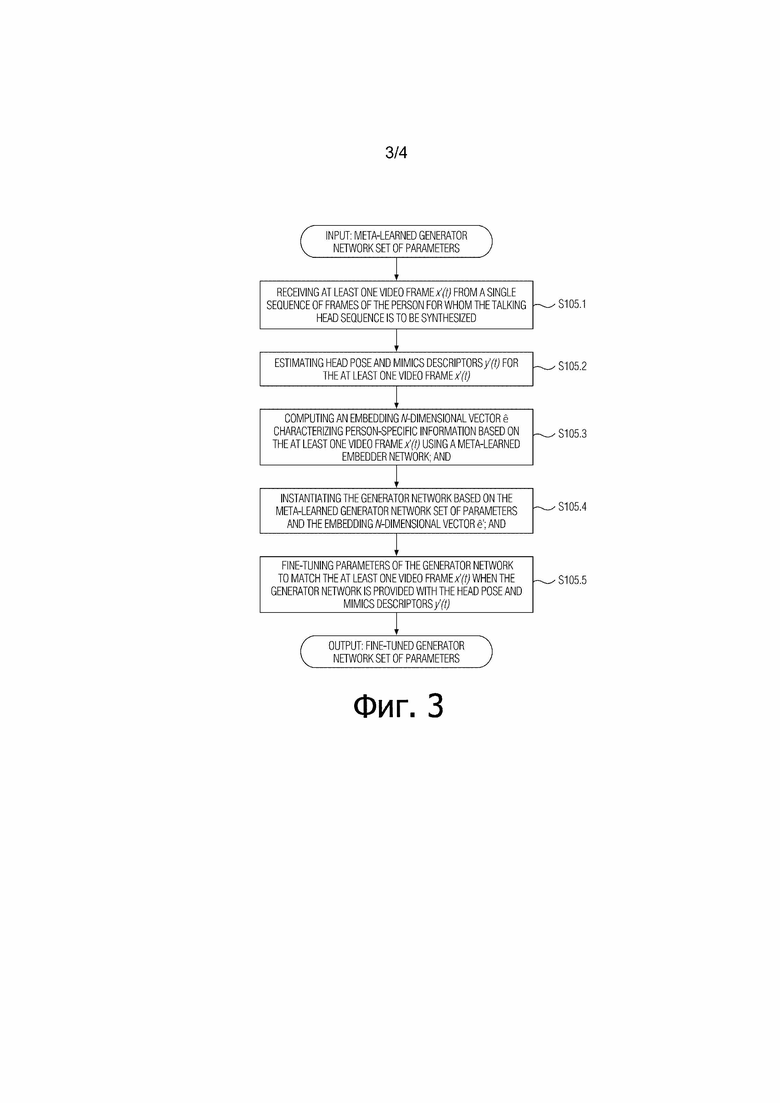
[Фиг. 3] Фиг. 3 иллюстрирует вариант осуществления обучения по нескольким кадрам сети генератора в соответствии с настоящим изобретением.
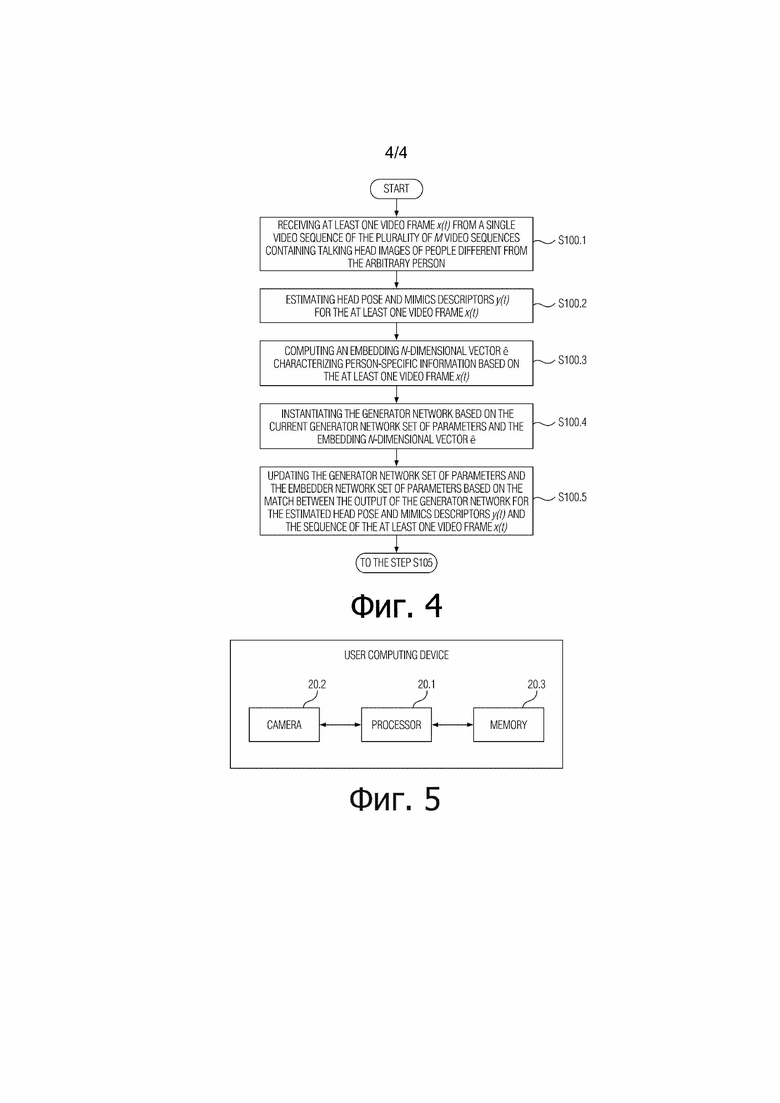
[Фиг. 4] Фиг. 4 иллюстрирует вариант осуществления мета–обучения сети генератора в соответствии с настоящим изобретением.
[Фиг. 5] Фиг. 5 иллюстрирует упрощенную структурную схему вычислительного устройства, которое способно выполнять способ синтезирования модели головы говорящей персоны для произвольной персоны в соответствии с вариантом осуществления настоящего изобретения.
Детальное описание изобретения
[0011] Архитектура и обозначение. Стадия мета–обучения предложенного способа предполагает доступность M последовательностей видео, содержащих изображения голов различных говорящих персон. 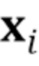 обозначает
обозначает 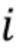 –ую последовательность видео и
–ую последовательность видео и 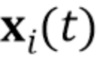 обозначает
обозначает 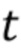 –ый кадр видео упомянутой последовательности видео. Во время мета–обучения, а также во время тестирования, местоположения ориентиров лица предполагаются доступными для всех кадров (стандартный код совмещения лиц [7] может быть использован для получения местоположений ориентиров лица). Ориентиры растризованы (преобразованы в растровый формат) в трехканальные изображения (т.е. изображения ориентиров лица) с использованием предопределенного набора цветов, чтобы связывать определенные ориентиры с линейными сегментами.
–ый кадр видео упомянутой последовательности видео. Во время мета–обучения, а также во время тестирования, местоположения ориентиров лица предполагаются доступными для всех кадров (стандартный код совмещения лиц [7] может быть использован для получения местоположений ориентиров лица). Ориентиры растризованы (преобразованы в растровый формат) в трехканальные изображения (т.е. изображения ориентиров лица) с использованием предопределенного набора цветов, чтобы связывать определенные ориентиры с линейными сегментами. 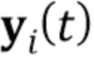 обозначает полученное в результате изображение ориентиров лица, вычисленное для .
обозначает полученное в результате изображение ориентиров лица, вычисленное для .
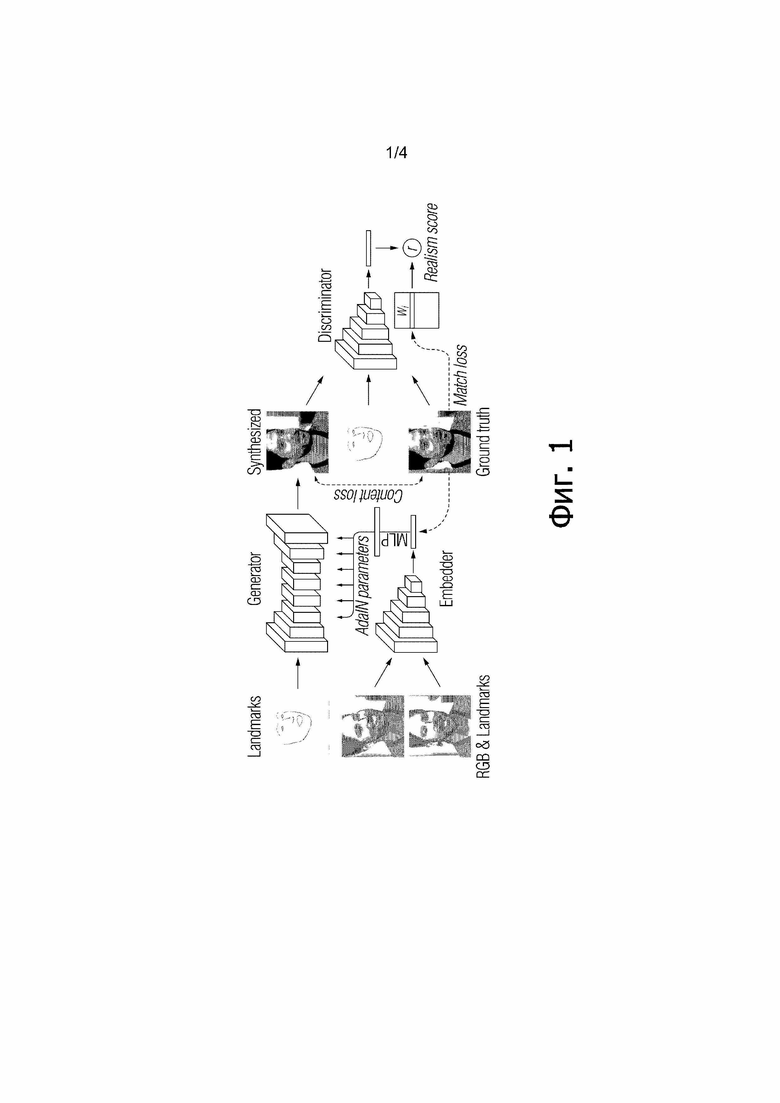
[0012] Как показано на Фиг. 1, предложенная архитектура мета–обучения использует сеть встраивания (встраивателя, embedder) которая отображает изображения головы (с оцененными ориентирами лица) на векторы встраивания (эмбеддинга), которые содержат зависимую от позы информацию, сеть генератора, которая отображает входные ориентиры лица на выходные кадры через набор сверточных уровней, которые модулированы векторами встраивания через адаптивную нормализацию образца (AdaIN). Обычно, во время стадии мета–обучения, наборы кадров из того же самого видео пропускаются через сеть встраивателя, результирующие встраивания усредняются и используются, чтобы предсказывать адаптивные параметры сети генератора. Затем, ориентиры другого кадра пропускаются через сеть генератора, и сгенерированное изображение сравнивается контрольными (истинно верными) данными. Целевая функция включает в себя потери из–за восприятия (перцепционные) и состязательности, причем последнее реализуется через сеть дискриминатора условной проекции. Архитектура мета–обучения и соответствующие операции описаны ниже более детально.
[0013] Таким образом, на стадии мета–обучения предложенного способа, обучаются следующие три сети (совместно упоминаемые как состязательная сеть или генеративная состязательная сеть (GAN)) (см. Фиг. 1):
1. Встраиватель E(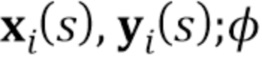 ). Встраиватель сконфигурирован, чтобы брать кадр видео
). Встраиватель сконфигурирован, чтобы брать кадр видео  , ассоциированное изображение ориентиров лица
, ассоциированное изображение ориентиров лица 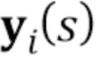 и отображать эти входы на N–мерный вектор встраивания
и отображать эти входы на N–мерный вектор встраивания 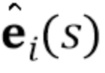 . Кадр видео берется из обучающей последовательности, т.е. из множества M последовательностей видео, содержащих изображения голов говорящих персон, отличающихся от произвольной персоны, для которой позже должна быть синтезирована модель головы говорящей персоны. Здесь,
. Кадр видео берется из обучающей последовательности, т.е. из множества M последовательностей видео, содержащих изображения голов говорящих персон, отличающихся от произвольной персоны, для которой позже должна быть синтезирована модель головы говорящей персоны. Здесь, 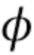 обозначает параметры встраивателя, которые обучаются во время стадии мета–обучения. В принципе, целью стадии мета–обучения для встраивателя E является обучение
обозначает параметры встраивателя, которые обучаются во время стадии мета–обучения. В принципе, целью стадии мета–обучения для встраивателя E является обучение 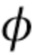 таким образом, что N–мерный вектор встраивания
таким образом, что N–мерный вектор встраивания 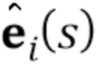 содержит специфическую для видео информацию (такую как идентичность человека), которая инвариантна к позе и мимике в конкретном кадре s. N–мерные вектора встраивания s, вычисленные встраивателем, обозначаются как
содержит специфическую для видео информацию (такую как идентичность человека), которая инвариантна к позе и мимике в конкретном кадре s. N–мерные вектора встраивания s, вычисленные встраивателем, обозначаются как  .
.
2. Генератор G(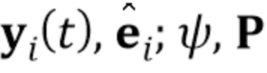 ). Генератор сконфигурирован, чтобы брать изображение ориентиров лица для кадра видео
). Генератор сконфигурирован, чтобы брать изображение ориентиров лица для кадра видео 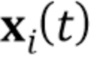 , не наблюдавшегося встраивателем E, и соответственно вычисленный N–мерный вектор встраивания
, не наблюдавшегося встраивателем E, и соответственно вычисленный N–мерный вектор встраивания 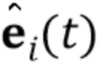 и генерировать синтезированный кадр видео
и генерировать синтезированный кадр видео 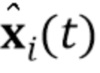 . Генератор G обучается максимизировать подобие между его выходами (т.е. синтезированными кадрами видео
. Генератор G обучается максимизировать подобие между его выходами (т.е. синтезированными кадрами видео 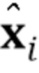 ) и соответствующими истинно верными кадрами. Все параметры генератора G разбиты на два набора: общие для человека параметры
) и соответствующими истинно верными кадрами. Все параметры генератора G разбиты на два набора: общие для человека параметры 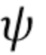 и специфические для человека параметры
и специфические для человека параметры 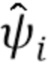 . Во время стадии мета–обучения, только общие для человека параметры
. Во время стадии мета–обучения, только общие для человека параметры  обучаются напрямую, в то время как специфические для человека параметры предсказываются из N–мерного вектора встраивания
обучаются напрямую, в то время как специфические для человека параметры предсказываются из N–мерного вектора встраивания 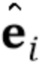 во время стадии тонкой настройки (которая подробно описана ниже) мета–обучения с использованием обучаемой матрицы проекции
во время стадии тонкой настройки (которая подробно описана ниже) мета–обучения с использованием обучаемой матрицы проекции 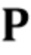 :
: 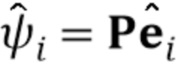 .
.
3. Дискриминатор D( ). Дискриминатор сконфигурирован, чтобы брать входной кадр видео
). Дискриминатор сконфигурирован, чтобы брать входной кадр видео  , ассоциированное изображение ориентиров лица и индекс обучающей последовательности и вычислять оценку реалистичности r (одиночный скаляр). Здесь,
, ассоциированное изображение ориентиров лица и индекс обучающей последовательности и вычислять оценку реалистичности r (одиночный скаляр). Здесь,  обозначают параметры дискриминатора, которые обучаются во время стадии мета–обучения. Дискриминатор содержит часть V(
обозначают параметры дискриминатора, которые обучаются во время стадии мета–обучения. Дискриминатор содержит часть V(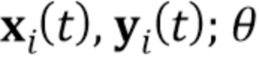 ) сверточной сети (ConvNet), которая сконфигурирована, чтобы отображать входной кадр видео и ассоциированное изображение ориентиров лица на N–мерный вектор. Оценка реалистичности r затем вычисляется дискриминатором на основе упомянутого N–мерного вектора и параметров дискриминатора
) сверточной сети (ConvNet), которая сконфигурирована, чтобы отображать входной кадр видео и ассоциированное изображение ориентиров лица на N–мерный вектор. Оценка реалистичности r затем вычисляется дискриминатором на основе упомянутого N–мерного вектора и параметров дискриминатора  . Оценка реалистичности r указывает, является ли входной кадр видео реальным (т.е. не синтезированным) кадром видео –ой последовательности видео, и соответствует ли входной кадр видео ассоциированному изображению ориентиров лица . Кадр видео , который вводится в дискриминатор, может быть синтезированным кадром видео ; однако, тот факт, что входной кадр видео является синтезированным, не известен дискриминатору.
. Оценка реалистичности r указывает, является ли входной кадр видео реальным (т.е. не синтезированным) кадром видео –ой последовательности видео, и соответствует ли входной кадр видео ассоциированному изображению ориентиров лица . Кадр видео , который вводится в дискриминатор, может быть синтезированным кадром видео ; однако, тот факт, что входной кадр видео является синтезированным, не известен дискриминатору.
[0014] Стадия мета–обучения. Во время стадии мета–обучения предложенного способа, параметры всех трех сетей обучаются состязательным способом. Это может осуществляться путем моделирования эпизодов K–кадрового обучения. K было равно 8 в экспериментах, выполненных авторами настоящего изобретения. Однако настоящее изобретение не должно быть ограничено вариантом осуществления, в котором K=8, поскольку K может выбираться специалистом в данной области техники, чтобы быть больше или меньше, чем 8, в зависимости от производительности аппаратных средств, используемых для стадии мета–обучения, или в зависимости от точности изображений, генерируемых мета–обучаемой GAN, и целей, для которых осуществляется мета–обучение такой GAN. В каждом эпизоде, обучающая последовательность видео и одиночный истинно верный кадр видео из этой последовательности выбираются случайным образом. В дополнение к , дополнительные K кадров видео  выбираются из той же самой обучающей последовательности видео . Затем, во встраивателе E, N–мерный вектор встраивания вычисляется для обучающей последовательности видео путем усреднения N–мерных векторов встраивания
выбираются из той же самой обучающей последовательности видео . Затем, во встраивателе E, N–мерный вектор встраивания вычисляется для обучающей последовательности видео путем усреднения N–мерных векторов встраивания 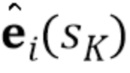 , вычисленных для дополнительных K кадров видео следующим образом:
, вычисленных для дополнительных K кадров видео следующим образом:
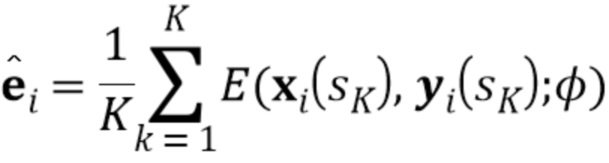 (1)
(1)
[0015] Затем, в генераторе G, синтезированный кадр видео (т.е. реконструкция –го кадра) вычисляется на основе вычисленного N–мерного вектора встраивания , т.е.:
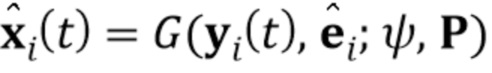 (2)
(2)
Параметры модуля встраивания E и генератора G затем оптимизируются, чтобы минимизировать следующую целевую функцию, которая содержит член потерь содержимого 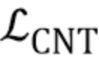 , состязательный член
, состязательный член 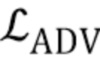 и член соответствия встраивания
и член соответствия встраивания 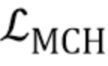 :
:
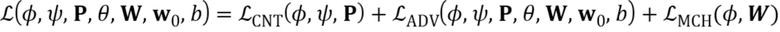 (3)
(3)
В целевой функции (3), член потерь содержимого измеряет различие между истинно верным кадром видео и синтезированным кадром видео  с использованием меры перцепционного подобия. В качестве примера, может использоваться мера перцепционного сходства, которая соответствует сети VGG19, обучаемой для классификации ILSVRC, и сети VGGFace, обучаемой для верификации лица. Однако настоящее изобретение не должно быть ограничено таким примером меры перцепционного сходства, поскольку в нем могут быть использованы любые меры перцепционного сходства, известные из предшествующего уровня техники. Если сети VGG19 и VGGFace используются для получения меры перцепционного сходства, член потерь содержимого может быть вычислен как взвешенная сумма потерь L1 между признаками упомянутых сетей.
с использованием меры перцепционного подобия. В качестве примера, может использоваться мера перцепционного сходства, которая соответствует сети VGG19, обучаемой для классификации ILSVRC, и сети VGGFace, обучаемой для верификации лица. Однако настоящее изобретение не должно быть ограничено таким примером меры перцепционного сходства, поскольку в нем могут быть использованы любые меры перцепционного сходства, известные из предшествующего уровня техники. Если сети VGG19 и VGGFace используются для получения меры перцепционного сходства, член потерь содержимого может быть вычислен как взвешенная сумма потерь L1 между признаками упомянутых сетей.
[0016] Состязательный член в целевой функции (3) соответствует оценке реалистичности r, вычисленной дискриминатором D, которая должна быть максимизирована, и члену соответствия признаков 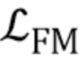 , который по существу является мерой перцепционного подобия, вычисленному с использованием дискриминатора (это улучшает стабильность мета–обучения):
, который по существу является мерой перцепционного подобия, вычисленному с использованием дискриминатора (это улучшает стабильность мета–обучения):
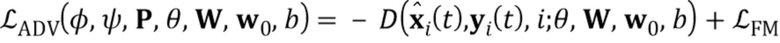 (4)
(4)
Следуя подходу дискриминатора проекции, столбцы матрицы 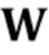 содержат N–мерные векторы встраивания, которые соответствуют индивидуальным видео. Дискриминатор D сначала отображает свои входы (т.е. входной кадр видео , ассоциированное изображение ориентиров лица и индекс обучающей последовательности ) на N–мерный вектор V() и затем вычисляет оценку реалистичности r следующим образом:
содержат N–мерные векторы встраивания, которые соответствуют индивидуальным видео. Дискриминатор D сначала отображает свои входы (т.е. входной кадр видео , ассоциированное изображение ориентиров лица и индекс обучающей последовательности ) на N–мерный вектор V() и затем вычисляет оценку реалистичности r следующим образом:
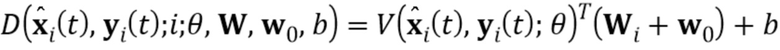 (5)
(5)
где 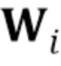 обозначает –ый столбец матрицы . В то же время,
обозначает –ый столбец матрицы . В то же время, 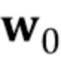 и
и 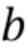 не зависят от индекса видео, так что эти члены соответствуют обобщенной реалистичности
не зависят от индекса видео, так что эти члены соответствуют обобщенной реалистичности 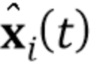 и ее совместимости с изображением ориентиров лица .
и ее совместимости с изображением ориентиров лица .
[0017] Таким образом, имеется два типа N–мерных векторов встраивания в предложенной системе: одни, вычисленные встраивателем E, и другие, которые соответствуют столбцам матрицы в дискриминаторе D. Член соответствия 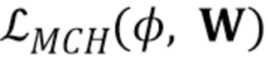 в вышеуказанной целевой функции (3) стимулирует подобие двух типов N–мерных векторов встраивания путем штрафования L1–разности между
в вышеуказанной целевой функции (3) стимулирует подобие двух типов N–мерных векторов встраивания путем штрафования L1–разности между 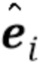 и Wi.
и Wi.
[0018] Когда параметры встраивателя E и параметры генератора G обновляются, параметры  дискриминатора D также обновляются. Обновление приводится в действие минимизацией следующей целевой функции “потери шарнира” (hinge–loss) (6), что стимулирует увеличение оценки реалистичности r по реальным (т.е. нефальсифицированным) кадрам видео и ее снижение по синтезированным (т.е. фальсифицированным) кадрам видео :
дискриминатора D также обновляются. Обновление приводится в действие минимизацией следующей целевой функции “потери шарнира” (hinge–loss) (6), что стимулирует увеличение оценки реалистичности r по реальным (т.е. нефальсифицированным) кадрам видео и ее снижение по синтезированным (т.е. фальсифицированным) кадрам видео :
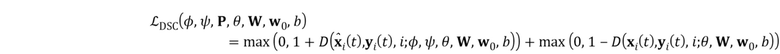 (6)
(6)
Целевая функция (6), таким образом, сравнивает реалистичность фальсифицированного образца и реального образца и затем обновляет параметры дискриминатора, чтобы сдвигать эти оценки ниже –1 и выше +1 соответственно. Мета–обучение продолжается попеременными обновлениями параметров встраивателя E и генератора G, которые минимизируют потери , и , с обновлениями дискриминатора D, которые минимизируют потери 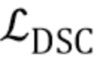 .
.
[0019] Обучение по нескольким кадрам посредством тонкой настройки. После достижения конвергенции мета–обучения, предложенная система может дополнительно обучаться, чтобы синтезировать модели головы говорящей персоны для нового человека, не наблюдавшегося во время стадии мета–обучения. Как ранее, синтез кондиционируется на изображениях ориентиров лиц. Система обучается способом обучения по нескольким кадрам, в предположении, что задано T обучающих изображений x(1), x(2),…, x(T) (т.е. T кадров того же самого видео), и что y(1), y(2),…, y(T) являются соответствующими изображениями ориентиров лица. Отметим, что число T кадров не обязательно должно быть равно K, используемым на стадии мета–обучения. Предложенная система может генерировать приемлемый результат на основе одного фотоснимка (обучение на одном кадре, T=1), в то время как добавление еще нескольких фотоснимков (обучение по нескольким кадрам, T>1) увеличивает точность персонализации. Эксперименты, выполненные авторами настоящего изобретения, охватывают диапазон [1, 33] для T. Однако настоящее изобретение не должно быть ограничено вариантом осуществления, в котором T лежит в пределах диапазона [1, 33], поскольку T может выбираться специалистом в данной области техники, чтобы превышать этот диапазон, в зависимости от производительности аппаратных средств, используемых для обучения по нескольким кадрам, или в зависимости от точности изображений, генерируемых обучаемой по нескольким кадрам GAN (которая была предварительно мета–обучена, как описано выше), и целей, для достижения которых мета–обученная GAN обучается по нескольким кадрам (т.е. подвергается тонкой настройке).
[0020] Предпочтительно, мета–обученный встраиватель E используется в текущей стадии обучения по нескольким кадрам, чтобы вычислить N–мерные векторы встраивания  для нового человека, для которого должна быть синтезирована модель головы говорящей персоны. Иными словами, вычисление может выполняться в соответствии со следующим:
для нового человека, для которого должна быть синтезирована модель головы говорящей персоны. Иными словами, вычисление может выполняться в соответствии со следующим:
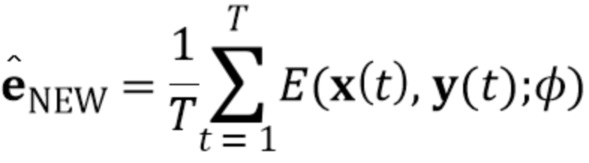 (7)
(7)
повторно используя параметры встраивателя E, ранее полученные на стадии мета–обучения. Простым способом генерировать новые синтезированные кадры, соответствующие новым изображениям ориентиров, является тогда применение генератора G, использующего вычисленный N–мерный вектор встраивания и полученные мета–обучением параметры генератора G, а также матрицы проекции P. Авторами настоящего изобретения установлено, что при таком выполнении синтезированные изображения головы говорящей персоны являются верными и реалистичными, однако часто имеется значительный пробел в идентичности, который является неприемлемым для большинства приложений, нацеленных на высокую степень персонализации.
[0021] Этот пробел в идентичности часто может быть перекрыт посредством стадии тонкой настройки, предложенной в настоящем документе. Процесс тонкой настройки может рассматриваться как упрощенная версия мета–обучения с единственной последовательностью видео и малым числом кадров. Процесс тонкой настройки включает в себя следующие компоненты:
1. Генератор G(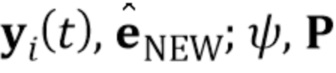 ) теперь заменяется генератором G’(y
) теперь заменяется генератором G’(y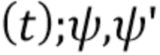 ). Как ранее, генератор G’ сконфигурирован, чтобы получать изображение ориентиров лица y
). Как ранее, генератор G’ сконфигурирован, чтобы получать изображение ориентиров лица y и генерировать синтезированный кадр видео
и генерировать синтезированный кадр видео 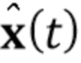 . Важно, что специфические для человека параметры генератора, которые теперь обозначены как
. Важно, что специфические для человека параметры генератора, которые теперь обозначены как 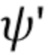 , напрямую оптимизируются на стадии обучения по нескольким кадрам, вместе с общими для человека параметрами . Вычисленные N–мерные векторы встраивания и матрица проекции P, полученная на стадии мета–обучения, могут по–прежнему использоваться, чтобы инициализировать специфические для человека параметры генератора , т.е.
, напрямую оптимизируются на стадии обучения по нескольким кадрам, вместе с общими для человека параметрами . Вычисленные N–мерные векторы встраивания и матрица проекции P, полученная на стадии мета–обучения, могут по–прежнему использоваться, чтобы инициализировать специфические для человека параметры генератора , т.е. 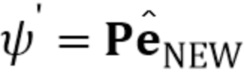 .
.
2. Дискриминатор D’(  ), как ранее на стадии мета–обучения, сконфигурирован, чтобы вычислять оценку реалистичности r. Параметры
), как ранее на стадии мета–обучения, сконфигурирован, чтобы вычислять оценку реалистичности r. Параметры 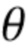 части V(
части V(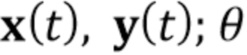 ) ConvNet дискриминатора D’ и смещение b инициализируются в те же самые параметры , b, полученные на стадии мета–обучения. Инициализация
) ConvNet дискриминатора D’ и смещение b инициализируются в те же самые параметры , b, полученные на стадии мета–обучения. Инициализация 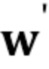 описана ниже.
описана ниже.
[0022] Во время стадии тонкой настройки, оценку реалистичности r дискриминатора D’ получают аналогичным путем, как на стадии мета–обучения:
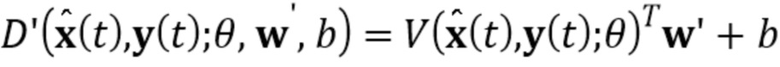 (8)
(8)
Как можно видеть из сравнения выражений (5) и (8), роль вектора 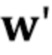 на стадии тонкой настройки является той же самой, что и роль вектора
на стадии тонкой настройки является той же самой, что и роль вектора 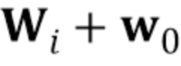 на стадии мета–обучения. Для инициализации на стадии обучения по нескольким кадрам, аналог не доступен для нового человека (поскольку кадры видео этого человека не использовались в обучающем наборе данных мета–обучения). Однако член соответствия
на стадии мета–обучения. Для инициализации на стадии обучения по нескольким кадрам, аналог не доступен для нового человека (поскольку кадры видео этого человека не использовались в обучающем наборе данных мета–обучения). Однако член соответствия 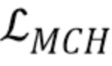 в процессе мета–обучения гарантирует подобие между N–мерными векторами встраивания дискриминатора и N–мерными векторами встраивания, вычисленными встраивателем. Поэтому, инициализируется на стадии обучения по нескольким кадрам в сумму w0 и .
в процессе мета–обучения гарантирует подобие между N–мерными векторами встраивания дискриминатора и N–мерными векторами встраивания, вычисленными встраивателем. Поэтому, инициализируется на стадии обучения по нескольким кадрам в сумму w0 и .
[0023] После того как новая проблема обучения установлена, функции потерь стадии тонкой настройки непосредственно следуют из вариантов мета–обучения. Таким образом, специфические для человека параметры и общие для человека параметры генератора G’ оптимизируются, чтобы минимизировать упрощенную целевую функцию:
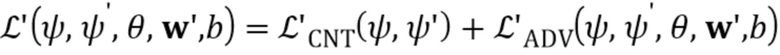 (9)
(9)
где t ∈ {1…T} является номером примера обучения.
[0024] Параметры дискриминатора , wnew, b оптимизируются путем минимизации той же самой функции hinge loss, что и в (6):
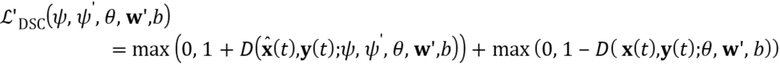 (10)
(10)
[0025] В большинстве ситуаций, генератор тонкой настройки обеспечивает намного лучшее соответствие обучающей последовательности. Инициализация всех параметров через стадию мета–обучения является, таким образом, критической. Как выявлено в экспериментах, такая инициализация предварительно вводит высоко реалистичное изображение головы говорящей персоны, что позволяет раскрытой модели экстраполировать и предсказывать реалистичные изображения для поз (ориентаций) с изменяющимися ориентациями головы и выражениями лиц.
[0026] Детали реализации и конкретные варианты осуществления. Сеть генератора G() может быть основана на архитектуре переноса изображения к изображению, предложенной Johnson et. al. [19], но слои понижающей дискретизации и повышающей дискретизации должны быть заменены остаточными блоками с нормализацией образца. Специфические для человека параметры служат в качестве аффинных коэффициентов слоев нормализации образца, следуя методу адаптивной нормализации образца, известному в технике, хотя слои регулярной (неадаптивной) нормализации образца в блоках понижающей дискретизации, которые кодируют изображения ориентиров лица , все еще используются.
[0027] Для модуля встраивания E() и части V() ConvNet дискриминатора, могут использоваться подобные сети, которые состоят из остаточных блоков понижающей дискретизации (тех же, что и те, которые используются в генераторе, но без слоев нормализации). Сеть дискриминатора, по сравнению со встраивателем, имеет дополнительный остаточный блок на конце, который работает при пространственном разрешении 4×4. Чтобы получить векторизованные выходы в обеих сетях, может выполняться глобально суммарный опрос по пространственным размерностям с последующим выпрямленным линейным блоком (ReLU).
[0028] Спектральная нормализация может быть использована для всех сверточных и полностью связанных слоев во всех сетях. Блоки самообслуживания также используются. Они вставляются с пространственным разрешением 32×32 во всех частях понижающей дискретизации сетей и с разрешением 64×64 в части повышающей дискретизации генератора.
[0029] Для вычисления , потеря L1 может оцениваться между активациями слоев Conv1,6,11,20,29 VGG19 и слоев Conv1,6,11,18,25 VGGFace для реалистичных и фальсифицированных изображений. Эти потери с весами равными 1⋅10–2 для VGG19 и 2⋅10–3 для членов VGGFace могут суммироваться. Могут использоваться Caffe–обученные версии для обеих из этих сетей. Для , могут использоваться активации после каждого остаточного блока сети дискриминатора и веса равные 1⋅101. Наконец, для вес устанавливается на 8⋅101.
[0030] Минимальное число каналов в сверточных слоях может быть установлено на 64, и максимальное число каналов, а также размер N векторов встраивания могут быть установлены на 512. В итоге, встраиватель имеет 15 миллионов параметров, генератор имеет 38 миллионов параметров. Часть ConvNet дискриминатора имеет 20 миллионов параметров. Сети могут быть оптимизированы с использованием метода Adam. Скорость обучения сетей встраивателя и генератора могут быть установлены на 5×10–5 и на 2×10–4 для дискриминатора, таким образом, выполняя два шага обновления для последнего на один для первого. Настоящее изобретение не должно ограничиваться вышеописанными конкретными подходами, значениями и деталями, поскольку некоторые изменения и модификации в вышеописанных подходах, значениях и деталях будут очевидны для специалиста в данной области техники без приложения каких–либо творческих усилий. Таким образом, такие изменения и модификации считаются входящими в объем формулы изобретения.
Наилучший вариант осуществления вышеописанного способа
[0031] Способ синтезирования последовательности изображений головы говорящей персоны для произвольной персоны с использованием сети генератора, сконфигурированной, чтобы отображать дескрипторы ориентации головы и мимики на одно или несколько изображений последовательности изображений головы говорящей персоны на вычислительном устройстве (20), обеспечен в соответствии с первым аспектом настоящего раскрытия. Способ содержит этапы выполнения (S105) обучения по нескольким кадрам сети генератора, мета–обученной (S100) на множестве M последовательностей видео, содержащих изображения головы говорящих персон, отличающихся от произвольной персоны, и синтезирования (S110) последовательности изображений головы говорящей персоны для упомянутой персоны с использованием тонко настроенной сети генератора и ранее не наблюдавшейся последовательности дескрипторов ориентации головы и мимики,  . См. Фиг. 2.
. См. Фиг. 2.
[0032] Этап выполнения (S105) обучения по нескольким кадрам сети генератора, мета–обученной (S100) на множестве M последовательностей видео, содержащих изображения головы говорящих персон, отличающихся от произвольной персоны, содержит подэтапы: приема (S105.1) по меньшей мере одного кадра видео 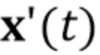 из единственной последовательности кадров упомянутой персоны, для которой должна быть синтезирована последовательность изображений головы говорящей персоны; оценивания (S105.2) дескрипторов ориентации головы и мимики
из единственной последовательности кадров упомянутой персоны, для которой должна быть синтезирована последовательность изображений головы говорящей персоны; оценивания (S105.2) дескрипторов ориентации головы и мимики 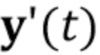 для по меньшей мере одного кадра видео ; вычисления (S105.3) N–мерного вектора встраивания
для по меньшей мере одного кадра видео ; вычисления (S105.3) N–мерного вектора встраивания 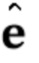 , характеризующего специфическую для персоны информацию, на основе по меньшей мере одного кадра видео с использованием мета–обученной сети встраивателя; реализации (создания экземпляра) (S105.4) сети генератора на основе набора параметров мета–обученной сети генератора и N–мерного вектора встраивания
, характеризующего специфическую для персоны информацию, на основе по меньшей мере одного кадра видео с использованием мета–обученной сети встраивателя; реализации (создания экземпляра) (S105.4) сети генератора на основе набора параметров мета–обученной сети генератора и N–мерного вектора встраивания 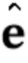 ’; и тонкой настройки (S105.5) параметров сети генератора, чтобы соответствовать по меньшей мере одному кадру видео , когда сеть генератора обеспечивается дескрипторами ориентации головы и мимики . Набор параметров мета–обученной сети генератора является входом на этап (S105), а набор параметров тонко настроенной сети генератора является выходом этапа (S105). См. Фиг. 3.
’; и тонкой настройки (S105.5) параметров сети генератора, чтобы соответствовать по меньшей мере одному кадру видео , когда сеть генератора обеспечивается дескрипторами ориентации головы и мимики . Набор параметров мета–обученной сети генератора является входом на этап (S105), а набор параметров тонко настроенной сети генератора является выходом этапа (S105). См. Фиг. 3.
[0033] Дескрипторы ориентации головы и мимики и могут содержать, но без ограничения, ориентиры лица. Дескрипторы ориентации головы и мимики 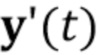 используются вместе с по меньшей мере одним кадром видео , чтобы вычислять N–мерный вектор встраивания
используются вместе с по меньшей мере одним кадром видео , чтобы вычислять N–мерный вектор встраивания 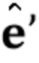 .
.
[0034] Мета–обучение сети генератора и сети встраивателя выполняется в эпизодах K–кадрового обучения, где K является предопределенным целым числом, и каждый из эпизодов содержит этапы: приема (S100.1) по меньшей мере одного кадра видео 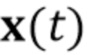 из одной последовательности видео из множества M последовательностей видео, содержащих изображения головы говорящих персон, отличающихся от произвольной персоны; оценивания (S100.2) дескрипторов ориентации головы и мимики
из одной последовательности видео из множества M последовательностей видео, содержащих изображения головы говорящих персон, отличающихся от произвольной персоны; оценивания (S100.2) дескрипторов ориентации головы и мимики 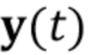 для по меньшей мере одного кадра видео ; вычисления (S100.3) N–мерного вектора встраивания , характеризующего специфическую для персоны информацию, на основе по меньшей мере одного кадра видео ; реализации (S100.4) сети генератора на основе текущего набора параметров сети генератора и N–мерного вектора встраивания ; и обновления (S100.5) набора параметров сети генератора и набора параметров сети встраивателя на основе соответствия между выходом сети генератора для оцененных дескрипторов ориентации головы и мимики и последовательности из по меньшей мере одного кадра видео . См. Фиг. 4.
для по меньшей мере одного кадра видео ; вычисления (S100.3) N–мерного вектора встраивания , характеризующего специфическую для персоны информацию, на основе по меньшей мере одного кадра видео ; реализации (S100.4) сети генератора на основе текущего набора параметров сети генератора и N–мерного вектора встраивания ; и обновления (S100.5) набора параметров сети генератора и набора параметров сети встраивателя на основе соответствия между выходом сети генератора для оцененных дескрипторов ориентации головы и мимики и последовательности из по меньшей мере одного кадра видео . См. Фиг. 4.
[0035] Сеть генератора и сеть встраивателя могут представлять собой традиционные сверточные сети. Во время этапов реализации (S105.4, S100.4), коэффициенты нормализации в реализованной сети генератора вычисляются на основе N–мерных векторов встраивания, вычисленных сетью встраивателя. Сеть дискриминатора мета–обучается вместе с сетью генератора и сетью встраивателя, причем способ дополнительно содержит этап: вычисления с использованием сети дискриминатора оценки реалистичности r выхода сети генератора, и обновления параметров сети генератора и сети встраивателя на основе оценки реалистичности r; обновления параметров сети дискриминатора, чтобы увеличить оценку реалистичности r по кадрам видео из множества M последовательностей видео и уменьшить оценку реалистичности r по выходу (т.е. синтезированному изображению) сети генератора.
[0036] Сеть дискриминатора представляет собой сеть дискриминатора проекции, которая сконфигурирована, чтобы вычислять оценку реалистичности r выхода сети генератора с использованием N–мерного вектора встраивания w, отличающегося от N–мерного вектора встраивания , который обучается для каждой из последовательностей видео во множестве M последовательностей видео. Различия между N–мерным вектором встраивания и N–мерным вектором встраивания w штрафуются во время мета–обучения (S100), дискриминатор проекции используется во время стадии тонкой настройки (S105), и N–мерный вектор встраивания w дискриминатора проекции инициализируется в N–мерный вектор встраивания ’ в начале тонкой настройки.
[0037] Вычислительное устройства (20) обеспечено в соответствии с вторым аспектом настоящего раскрытия. Все этапы вышеописанного способа могут выполняться вычислительным устройством (20), проиллюстрированным на Фиг. 5. Вычислительное устройство (20) содержит процессор (20.1) и память (20.3). Память (20.3) сконфигурирована, чтобы хранить исполняемые компьютером инструкции, которые, при исполнении процессором (20.1) вычислительного устройства, побуждают процессор выполнять раскрытый способ синтезирования модели головы говорящей персоны для произвольной персоны с использованием сети генератора. Опционально, вычислительное устройство (20) может содержать камеру (20.2), сконфигурированную, чтобы захватывать видео или одиночный кадр человека, для которого должна быть синтезирована модель головы говорящей персоны. Вычислительное устройство (20) может представлять собой смартфон, планшет, PC, ноутбук или любое другое пользовательское вычислительное устройство такое как, например, AR–очки, VR–очки, смарт–часы и т.п. Процессор (20.1) вычислительного устройства (20) может представлять собой любое вычислительное средство, включая, но без ограничения, специализированную интегральную схему (ASIC), программируемую пользователем вентильную матрицу (FPGA) или систему на кристалле (SoC). Любые типы данных могут обрабатываться предложенными способами, устройствами и системами.
[0038] Различные способы, устройства и системы, обеспечивающие фотореалистичные аватары, могут быть практически осуществлены на основе вышеизложенного раскрытия. Дополнительно, различные способы, устройства и системы для обучения по нескольким кадрам реалистичных нейронных моделей голов говорящей персоны и/или использования обученных таким образом моделей/сетей для обеспечения фотореалистичных аватаров могут быть созданы на основе вышеизложенного раскрытия. Варианты осуществления раскрытия также могут быть реализованы как не–переходный (не–временный) машиночитаемый носитель, переносящий исполняемые компьютером инструкции, которые, при исполнении блоком обработки устройства, побуждают блок обработки выполнять раскрытый способ синтезирования модели головы говорящей персоны для произвольной персоны с использованием состязательной сети.
[0039] Предложенный способ также может быть реализован как система для синтезирования модели головы говорящей персоны для произвольной персоны с использованием состязательной сети. В такой системе, конкретные этапы способа могут быть реализованы как различные функциональные блоки, схемы и/или процессоры. Однако должно быть очевидно, что любое подходящее распределение функциональности между различными функциональными блоками, схемами и/или процессорами может быть использовано без отклонения от описанных вариантов осуществления.
[0040] Варианты осуществления могут быть реализованы в любой подходящей форме, включая аппаратные средства, программное обеспечение, встроенное программное обеспечение или любую их комбинацию. Варианты осуществления опционально могут быть реализованы, по меньшей мере частично, как компьютерное программное обеспечение, исполняющееся на одном или нескольких процессорах данных и/или процессорах цифровых сигналов. Элементы и компоненты любого варианта осуществления могут быть физически, функционально или логически реализованы любым подходящим способом. Фактически, функциональность может быть реализована в одном блоке, во множестве блоков или как часть других блоков общего назначения.
[0041] Предшествующие описания вариантов осуществления изобретения являются иллюстративными, и предполагается, что модификации в конфигурации и реализации будут входить в объем формулы изобретения. Например, в то время как варианты осуществления изобретения в основном описаны по отношению к этапам способа, эти описания являются иллюстративными. Хотя заявленный предмет описан в терминах, специфических для структурных признаков и методологических действий, должно быть понятно, что заявленный предмет, определенный в приложенной формуле изобретения, не обязательно ограничен конкретными признаками или действиями, описанными выше. Скорее, конкретные признаки и действия, описанные выше, раскрыты как примерные формы реализации пунктов формулы изобретения. Более того, изобретение не ограничено иллюстрируемым порядком этапов способа, порядок может быть модифицирован специалистом в данной области техники без приложения творческих усилий. Некоторые или все из этапов способа могут выполняться последовательно или одновременно. Соответственно, подразумевается, что объем варианта осуществления изобретения должен быть ограничен только следующей формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| НЕЙРОСЕТЕВОЙ ПЕРЕНОС ВЫРАЖЕНИЯ ЛИЦА И ПОЗЫ ГОЛОВЫ С ИСПОЛЬЗОВАНИЕМ СКРЫТЫХ ДЕСКРИПТОРОВ ПОЗЫ | 2020 |
|
RU2755396C1 |
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
| Способ локального генерирования и представления потока обоев и вычислительное устройство, реализующее его | 2020 |
|
RU2768551C1 |
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |
| ТЕКСТУРИРОВАННЫЕ НЕЙРОННЫЕ АВАТАРЫ | 2019 |
|
RU2713695C1 |
| Способ 3D-реконструкции человеческой головы для получения рендера изображения человека | 2022 |
|
RU2786362C1 |
| НЕЙРОСЕТЕВОЙ РЕНДЕРИНГ ТРЕХМЕРНЫХ ЧЕЛОВЕЧЕСКИХ АВАТАРОВ | 2021 |
|
RU2775825C1 |
| НЕЙРОННАЯ ТОЧЕЧНАЯ ГРАФИКА | 2019 |
|
RU2729166C1 |
| СПОСОБ ВИЗУАЛИЗАЦИИ 3D ПОРТРЕТА ЧЕЛОВЕКА С ИЗМЕНЕННЫМ ОСВЕЩЕНИЕМ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ НЕГО | 2021 |
|
RU2757563C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЗИРОВАННОГО ГЕНЕРИРОВАНИЯ ВИДЕОПОТОКА С ЦИФРОВЫМ АВАТАРОМ НА ОСНОВЕ ТЕКСТА | 2020 |
|
RU2748779C1 |
Настоящее изобретение относится к области вычислительной техники. Технический результат состоит в улучшении качества синтезированных изображений. Способ содержит этапы: приема по меньшей мере одного кадра видео из единственной последовательности кадров упомянутой персоны; оценивания дескрипторов ориентации головы и мимики для по меньшей мере одного кадра видео; вычисления N–мерного вектора встраивания, характеризующего специфическую для персоны информацию, на основе по меньшей мере одного кадра видео с использованием мета–обученной сети встраивателя; реализации сети генератора на основе набора параметров мета–обученной сети генератора и N–мерного вектора встраивания; и тонкой настройки параметров сети генератора, чтобы соответствовать по меньшей мере одному кадру видео, когда сеть генератора обеспечивается дескрипторами ориентации головы и мимики, синтезирования последовательности изображений головы говорящей персоны для упомянутой персоны с использованием тонко настроенной сети генератора и ранее не наблюдавшейся последовательности дескрипторов ориентации головы и мимики. 2 н. и 7 з.п. ф-лы, 5 ил.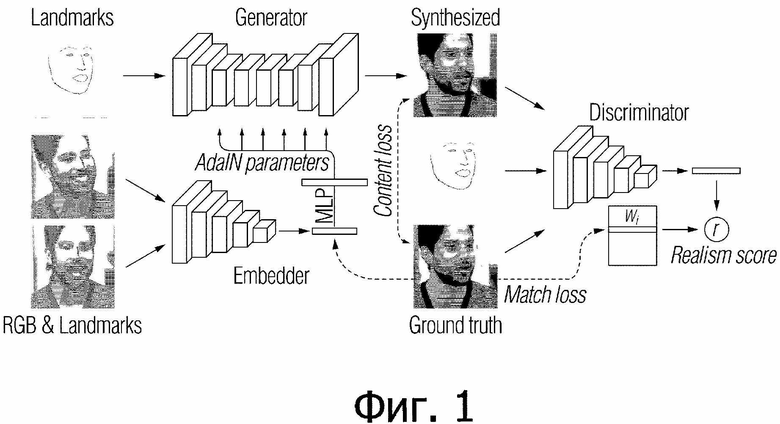
1. Способ синтезирования последовательности изображений головы говорящей персоны для произвольной персоны с использованием сети генератора, сконфигурированной, чтобы отображать дескрипторы ориентации головы и мимики на одно или несколько изображений последовательности изображений головы говорящей персоны на вычислительном устройстве (20), причем способ содержит этапы:
выполнения обучения по нескольким кадрам (S105) сети генератора, мета–обученной (S100) на множестве M последовательностей видео, содержащих изображения голов говорящих персон, отличающихся от упомянутой произвольной персоны, посредством:
приема (S105.1) по меньшей мере одного кадра  видео из единственной последовательности кадров упомянутой персоны, для которой должна быть синтезирована последовательность изображений головы говорящей персоны;
видео из единственной последовательности кадров упомянутой персоны, для которой должна быть синтезирована последовательность изображений головы говорящей персоны;
оценивания (S105.2) дескрипторов 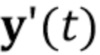 ориентации головы и мимики для по меньшей мере одного кадра видео;
ориентации головы и мимики для по меньшей мере одного кадра видео;
вычисления (S105.3) N–мерного вектора 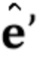 встраивания, характеризующего специфическую для персоны информацию, на основе по меньшей мере одного кадра видео с использованием мета–обученной сети встраивателя; и
встраивания, характеризующего специфическую для персоны информацию, на основе по меньшей мере одного кадра видео с использованием мета–обученной сети встраивателя; и
реализации (S105.4) сети генератора на основе набора параметров мета–обученной сети генератора и N–мерного вектора 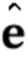 встраивания; и
встраивания; и
тонкой настройки (S105.5) параметров сети генератора, чтобы соответствовать по меньшей мере одному кадру видео, когда сеть генератора обеспечивается дескрипторами ориентации головы и мимики;
синтезирования (S110) последовательности изображений головы говорящей персоны для упомянутой персоны с использованием тонко настроенной сети генератора и ранее не наблюдавшейся последовательности дескрипторов 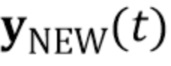 ориентации головы и мимики.
ориентации головы и мимики.
2. Способ по п. 1, причем дескрипторы и ориентации головы и мимики содержат изображения ориентиров лица.
3. Способ по п. 1, причем дескрипторы 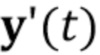 ориентации головы и мимики используются вместе с по меньшей мере одним кадром видео, чтобы вычислять N–мерный вектор
ориентации головы и мимики используются вместе с по меньшей мере одним кадром видео, чтобы вычислять N–мерный вектор 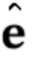 встраивания.
встраивания.
4. Способ по п. 1, причем мета–обучение сети генератора и сети встраивателя выполняется в эпизодах K–кадрового обучения, причем K является предопределенным целым числом, и каждый из эпизодов содержит этапы:
приема (S100.1) по меньшей мере одного кадра 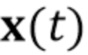 видео из одной последовательности видео из множества M последовательностей видео, содержащих изображения голов говорящих персон, отличающихся от упомянутой произвольной персоны;
видео из одной последовательности видео из множества M последовательностей видео, содержащих изображения голов говорящих персон, отличающихся от упомянутой произвольной персоны;
оценивания (S100.2) дескрипторов  ориентации головы и мимики для по меньшей мере одного кадра видео;
ориентации головы и мимики для по меньшей мере одного кадра видео;
вычисления (S100.3) N–мерного вектора встраивания, характеризующего специфическую для персоны информацию, на основе по меньшей мере одного кадра видео;
реализации (S100.4) сети генератора на основе текущего набора параметров сети генератора и N–мерного вектора встраивания; и
обновления (S100.5) набора параметров сети генератора и набора параметров сети встраивателя на основе соответствия между выходом сети генератора для оцененных дескрипторов ориентации головы и мимики и последовательности из по меньшей мере одного кадра видео.
5. Способ по любому из пп. 1–4, причем сеть генератора и сеть встраивателя представляют собой сверточные сети, причем во время этапов реализации (S105.4, S100.4) коэффициенты нормализации в пределах реализованной сети генератора вычисляются на основе N–мерных векторов встраивания, вычисленных сетью встраивания.
6. Способ по п. 4, причем сеть дискриминатора мета–обучается вместе с сетью генератора и сетью встраивания, причем способ дополнительно содержит этапы:
вычисления с использованием сети дискриминатора оценки r реалистичности выхода сети генератора; и
обновления параметров сети генератора и сети встраивателя на основе оценки r реалистичности;
обновления параметров сети дискриминатора, чтобы увеличить оценку r реалистичности по кадрам видео из множества M последовательностей видео и уменьшить оценку r реалистичности по выходу сети генератора.
7. Способ по п. 6, причем сеть дискриминатора представляет собой сеть дискриминатора проекции, сконфигурированную, чтобы оценивать оценку r реалистичности выхода сети генератора с использованием N–мерного вектора w встраивания, отличающегося от N–мерного вектора встраивания, которым выполнено обучение для каждой из последовательностей видео во множестве M последовательностей видео.
8. Способ по п. 7, причем различия между N–мерным вектором встраивания и N–мерным вектором w встраивания штрафуются во время мета–обучения (S100), дискриминатор проекции используется во время стадии точной настройки (S105), и N–мерный вектор w встраивания дискриминатора проекции инициализируется в N–мерный вектор встраивания в начале тонкой настройки.
9. Вычислительное устройство (20), содержащее память (20.3), хранящую исполняемые компьютером инструкции, которые, при исполнении процессором (20.1) вычислительного устройства, побуждают процессор выполнять способ синтезирования последовательности изображений головы говорящей персоны для произвольной персоны с использованием сети генератора в соответствии с любым одним из пп. 1–8.
| US 2006192785 A1, 31.08.2006 | |||
| US 2018174348 A1, 21.06.2018 | |||
| JP 2000123192 A, 28.04.2000 | |||
| CN 102568023 A, 11.07.2012 | |||
| RU 2004126185 A, 10.02.2006. |

