Ссылка на родственные заявки
[0001] Согласно настоящей заявке испрашивается преимущество в соответствии с предварительной заявкой на выдачу патента США № 62/542865, поданной 9 августа 2017 года, которая во всей своей полноте включена в настоящий документ посредством ссылки.
[0002] В родственной патентной заявке, международной заявке № PCT/US2014/000041, поданной 13 марта 2014 года (включенной в настоящий документ посредством ссылки во всей своей полноте), описаны способы улучшения прогнозирования заболевания с применением независимой переменной для корреляционного анализа, которая не является непосредственно концентрацией измеряемых аналитов, а является рассчитанным значением, называемым «показателем близости», который вычисляют из концентрации, но также нормализуют по определенному возрасту (или другим физиологическим параметрам) для устранения смещения по возрасту и нелинейности того, как значения концентрации смещаются или сдвигаются с физиологическим параметром (например, возрастом, менопаузальным статусом и т. д.) при сдвиге статуса заболевания от отсутствия заболевания к наличию заболевания.
Область техники, к которой относится настоящее изобретение
[0003] Настоящее изобретение относится к способам повышения точности диагностики заболеваний и к связанным диагностическим тестам, которые предусматривают использование корреляции измеряемых аналитов с двоичными выходными результатами (например, отсутствием заболевания или наличием заболевания), а также с результатами более высокого порядка (например, одной из нескольких фаз заболевания).
Уровень техники настоящего изобретения
[0004] Способы определения корреляций, где используют три или более независимых переменных для установления корреляции двоичных выходных результатов (таких как наличие или отсутствие данного заболевания), обычно предусматривают применение способа определения корреляции по пространственной близости (также называемого способом поиска кластера или окрестности), регрессионного способа и вейвлет-способов. В случае прогнозирования заболевания измеряют общий состав крови или сыворотки и пробуют установить корреляцию с применением этих значений концентрации в качестве независимых переменных для прогнозирования статусов различных заболеваний. В случае статуса заданного заболевания, где результатом является либо «наличие заболевания», либо «отсутствие заболевания», обычно применяют способ логистической регрессии. Другие методики предусматривают использование, например, генетических алгоритмов. Прогностическая сила этих способов сильно зависит от составляющих аналитов, выбранных для данного способа. Специалисты в настоящей области техники признают, что многие аналиты и параметры, которые, судя по всему, будут обладать прогностической силой, не улучшают диагностическую и аналитическую силу на практике.
[0005] Регрессионные способы предусматривают использование тенденций в независимых переменных для обнаружения корреляции с выходными результатами. Линейный способ основан на линейных тенденциях, в то время как логистическая регрессия основана на логарифмических тенденциях. При прогнозировании биологических заболеваний чаще всего для определения выходных результатов используют логистическую регрессию.
[0006] Групповой способ пространственной близости позволяет исследовать переменную топологию корреляции для группы схожих результатов. Способ пространственной близости обладает преимуществом, которое заключается в том, что с его помощью можно находить корреляции, где тенденции не являются родственными, но имеют локальные обратные изменения топологий в тенденциях. Тем не менее, данный способ является в высокой степени нелинейным и чувствительным к очень локально вариабельным результатам с небольшими ошибками измерения, что может давать более точный прогноз при биологическом применении. Кроме того, оба рассматриваемых здесь способа можно объединить со способом пространственной близости, применяемым в небольшом масштабе, для создания консолидированного общего регрессионного способа.
[0007] Тем не менее, у некоторых независимых переменных, которые, с точки зрения логики, должны иметь корреляцию, на практике не наблюдается прогностическая тенденция. Поэтому необходима разработка подхода, который повышает диагностическую точность за счет использования специфичных для пациента и специфичных для совокупности переменных, для которых до настоящего момента не было обнаружено, что они несут полезную информацию для диагностики статусов различных заболеваний.
[0008] Было проведено множество исследований с целью поиска биомаркеров, которые по отдельности или в комбинации могут позволить прогнозировать статусы различных заболеваний с достаточной воспроизводимостью и прогностической силой для использования в клинических условиях. Данное исследование имело ограниченный успех или вовсе не имело успеха. Были тщательно исследованы белки с высокой частотой встречаемости (HAP) в поиске одного белка, который может позволить делать такой прогноз. Было найдено множество примеров, но ни один из них не имеет достаточно низких уровней ложноотрицательных результатов, чтобы сделать возможным скрининг пациентов на наличие заболевания с помощью такого маркера.
[0009] Как результат, такие отдельные биомаркеры применяют лишь для терапевтического отслеживания, за исключением PSA в случае рака предстательной железы. Для этого теста необходимо, чтобы концентрация, которая свидетельствует, что была бы уместна биопсия, имела высокое значение отклонения от нормы для снижения количества ложноотрицательных результатов, что приводит к появлению очень высоких уровней ложноположительных результатов. До 80% мужчин, которым показана необходимость биопсии, на самом деле имеют отрицательный результат по раку предстательной железы. Также было обнаружено, что в некоторых случаях ДНК-маркеры очень хороши для выявления подтипа рака, но, опять же, не подходят для скрининга по тем же причинам, что и HAP, как отмечалось выше.
[0010] Также были исследованы протеомные подходы с использованием множества белков. Эта работа снова была сосредоточена на HAP или эффекторных белках с высоким уровнем содержания. В этой работе преобладали мультиплексные способы измерения белка, такие как иммуноанализы, чипы и масс-спектрофотометрия. В очень ранней работе был достигнут некоторый успех в случае с раком яичников. Однако проблема всех этих способов заключается в том, что многие из выбранных белков не имеют сильной корреляции с прогрессированием от здорового статуса к статусу наличия заболевания (и многие не имеют известной биологической связи со статусом заболевания, например, как это обычно бывает в случае с масс-спектрометрией). Более того, для масс-спектрометрии характерен серьезный недостаток, который заключается в том, что спектрофотометром на предмет уровней белка исследуется образец цельной сыворотки, и поэтому обучение алгоритма поиска корреляции является затруднительным. В случае масс-спектрометрии образец цельной сыворотки может содержать более 200 разновидностей белков и иметь 10000 масс-спектрометрических пиков.
[0011] В области диагностики также необходимы методики, которые предусматривают использование белков с более низкой частотой встречаемости, которые более пригодны для диагностических целей, чем HAPS, а также аналитические методики, которые предусматривают анализ биомаркеров с низкой частотой встречаемости.
[0012] В области диагностической медицины уже долго ищут простой и точный сывороточный анализ крови для обнаружения рака и для обнаружения, имеет ли рак тяжелую форму или же является латентным. Например, текущий тест на простатоспецифический антиген (PSA) для выявления рака предстательной железы страдает от очень высокого уровня ложноположительных результатов с истинным показателем ложноотрицательных результатов, достигающим 1 из десяти мужчин. Этот тест имеет прогностическую силу приблизительно 57%. Более того, мужчинам, у которых диагностирован рак предстательной железы низкой степени тяжести, может не требоваться лечение в течение многих лет или до конца жизни. Сегодня этот диагноз можно точно получить только с помощью биопсии на PCa. Текущий тест на PSA отправляет всех без исключения (90%, пропускается каждый десятый) с уровнем PSA выше 4,0 нг/мл на биопсию, и лишь приблизительно 20% из них имеют какую-либо форму PCa, независимо от оценки по шкале Глисона. Кроме того, мужчины с PCa с низкой степенью тяжести находятся в группе риска перехода в более высокую степень тяжести в более поздние годы жизни, и единственный надежный способ точной диагностики этого заключается в большем количестве биопсий. Дополнительные биопсии для отслеживания не приемлемы для медицинского сообщества из-за стоимости и неприемлемы для пациента из-за боли и побочных эффектов. Таким образом, постоянное отслеживание мужчин с PCa с низкой степенью тяжести проводят с помощью периодического теста PSA, сопровождаемого цифровыми исследованиями прямой кишки (DRE) и иногда КТ-исследованиями. Во многих случаях проводят профилактическое лечение, удаление предстательной железы, даже когда в этом нет необходимости с медицинской точки зрения. В этом патенте раскрыт новый сывороточный тест, который позволяет отличить мужчин без PCa от мужчин с PCa с высокой степенью тяжести и позволяет обнаружить мужчин с PCa с низкой степенью тяжести, у которых позднее может иметь место ухудшение. Кроме того, в нем раскрыт анализ крови, который позволяет распознать раковые заболевания с солидной опухолью на ранней стадии, такие как рак легких или рак молочной железы, или стадию рака.
[0013] Текущий скрининговый тест на PSA был утвержден в середине 1980-х годов и в настоящее не защищен патентом. Новый, так называемый тест в 4K оценке, предлагаемый OPKO под названием «Lab developed Test», не имеет одобрения регуляторным органом. Он предназначен для обнаружения мужчин с PCa с высокой степенью тяжести, при этом отделяя данное патологическое состояние от PCa с низкой степенью тяжести. Обычно PCa с высокой степенью тяжести считают соответствующим оценке по шкале Глисона (полученной при биопсии), равной 7(4+3) или выше (8, 9 или 10), в то время как оценку для низкой степени тяжести считают равной 7(3+4) или ниже. Тест на PSA для обнаружения мужчин с PCa любой степени тяжести имеет приблизительно 57% прогностическую силу, или для чувствительности в 90% уровень ложноположительных результатов составляет приблизительно 80% (1 из 4 положительных результатов фактически является отрицательным). Данный тест 4K оценки имеет прогностическую силу приблизительно 64%. Таким образом, на 1 из 10 ложноотрицательных результатов ложноположительных результатов приходится приблизительно 50%, или приблизительно 5 из 10 являются фактически отрицательными. Это текущее состояние тестирования с целью диагностики PCa в медицине на сегодня.
[0014] В настоящее время не существует утвержденных регуляторными органами способов обнаружения заболеваний, таких как рак легких и рак молочной железы, с помощью простого теста крови. Более того, эти заболевания можно оценить по степени тяжести только с помощью биопсии. Авторами настоящего изобретения также предложены дополнительные тесты для оценки стадии развития опухоли с применением, опять же, активных цитокинов в микроокружении опухоли с использованием сыворотки крови в качестве заместителя для этих белков.
[0015] Для уменьшения этих и других недостатков уровня техники в настоящем документе иллюстративно описан новый тест с применением активных цитокинов в микроокружении опухоли, причем сыворотка крови играет роль заместителя для этих белков.
Краткое описание чертежей
[0016] В более полной мере настоящее изобретение и многие сопутствующие его преимущества можно будет легко уяснить по мере его более полного понимания с привязкой к последующему подробному описанию при рассмотрении в связи с сопровождающими фигурами, где
[0017] на фиг. 1 представлена диаграмма, на которой отображены колебания концентраций биомаркеров согласно оценке по шкале Глисона для рака предстательной железы;
[0018] на фиг. 2 представлена диаграмма, на которой отображены колебания концентраций биомаркеров согласно оценке по шкале Глисона для рака легкого;
[0019] на фиг. 3 представлена диаграмма, на которой отображено среднее повышение концентраций биомаркеров, соответствующих стадиям развития рака молочной железы;
[0020] на фиг. 4 представлена диаграмма, на которой отображена кривая зависимости чувствительности от частоты ложноположительных заключений («ROC») VEGF для агрессивного рака предстательной железы по сравнению с отсутствием рака;
[0021] на фиг. 5 представлена диаграмма, на которой отображена кривая ROC TNFα для агрессивного рака предстательной железы по сравнению с отсутствием рака;
[0022] на фиг. 6 представлена диаграмма, на которой отображена кривая ROC PSA для агрессивного рака предстательной железы по сравнению с отсутствием рака;
[0023] на фиг. 7 представлена диаграмма, на которой отображена кривая ROC IL 6 для агрессивного рака предстательной железы по сравнению с отсутствием рака;
[0024] на фиг. 8 представлена диаграмма, на которой отображена кривая ROC IL 10 для рака легких на поздних стадиях по сравнению с раком легких на ранних стадиях;
[0025] на фиг. 9 представлена диаграмма, на которой отображена кривая ROC IL 6 для рака легких на поздних стадиях по сравнению с раком легких на ранних стадиях;
[0026] на фиг. 10 представлена диаграмма, на которой отображена кривая ROC VEGF для рака легких на поздних стадиях по сравнению с раком легких на ранних стадиях;
[0027] на фиг. 11 представлена диаграмма, на которой показаны результаты слепых тестов с двумя образцами, которые не прошли тест на нестабильность топологии и были скорректированы с помощью неконгруэнтного алгоритма в соответствии с вариантом осуществления раскрываемого способа диагностики;
[0028] на фиг. 12 представлена диаграмма, на которой показаны результаты клинического исследования рака молочной железы, в данном случае значения оценки рака обучающей выборки показаны для модели I обучающей группы с использованием 10 двухмаркерных плоскостей в соответствии с вариантом осуществления раскрываемого способа диагностики;
[0029] на фиг. 13 представлена диаграмма, на которой показаны результаты клинического исследования рака молочной железы, в данном случае значения оценки рака обучающей выборки показаны для модели II обучающей группы с использованием 105 двухмаркерных плоскостей в соответствии с вариантом осуществления раскрываемого способа диагностики;
[0030] на фиг. 14 представлена диаграмма, на которой показаны результаты с фактическим диагнозом для слепых образцов, задействованных в клиническом исследовании в соответствии с вариантом осуществления раскрываемого способа диагностики;
[0031] на фиг. 15 представлена диаграмма, на которой показана двухмаркерная плоскость для одной из десяти таких плоскостей, на которой видны значения показателя близости двух биомаркеров, используемых в соответствии с вариантом осуществления раскрываемого способа диагностики;
[0032] на фиг. 16 представлена диаграмма, на которой показана двухмаркерная плоскость с точками данных обучающей выборки в соответствии с вариантом осуществления раскрываемого способа диагностики;
[0033] на фиг. 17 представлена диаграмма, на которой показана двухмаркерная плоскость без точек данных обучающей выборки в соответствии с вариантом осуществления раскрываемого способа диагностики;
[0034] на фиг. 18 представлена диаграмма, на которой показана двухмаркерная плоскость с заштрихованной областью, где снижено влияние ответа иммунной системы в соответствии с вариантом осуществления раскрываемого способа диагностики;
[0035] на фиг. 19 представлена диаграмма, на которой показана двухмаркерная плоскость с заштрихованной областью, где снижено влияние проблем стабильности топологии в соответствии с вариантом осуществления раскрываемого способа диагностики;
[0036] на фиг. 20 представлена диаграмма, на которой показана двухмаркерная плоскость с заштрихованной областью, где снижено влияние недостоверности результатов измерения с помощью известного анализа в соответствии с вариантом осуществления раскрываемого способа диагностики;
[0037] на фиг. 21 представлена диаграмма, на которой показаны результаты слепых тестов с двумя образцами, которые не прошли тест на нестабильность топологии и были скорректированы с помощью неконгруэнтного алгоритма в соответствии с вариантом осуществления раскрываемого способа диагностики;
[0038] на фиг. 22 представлена блок-схема, с помощью которой показан общий логический путь, по которому следует программное обеспечение по настоящему изобретению, в соответствии с иллюстративным вариантом осуществления;
[0039] на фиг. 23 представлена блок-схема, с помощью которой показан процесс построения модели обучающей выборки (или диагностической модели), а затем обработки значений диагностической оценки для слепых образцов, в результате которой оценивают риск наличия заболевания или статус отсутствия заболевания;
[0040] на фиг. 24 показано типичное распределение генеральной совокупности, в данном случае для цитокина, интерлейкина 6 (IL 6);
[0041] на фиг. 25 представлена диаграмма, на которой показано преобразование концентрации биомаркера в показатель близости (один тип псевдоконцентрации); и
[0042] на фиг. 26 показана типичная схема аппаратного обеспечения, используемого при реализации программного обеспечения по настоящему изобретению, в соответствии с иллюстративным вариантом осуществления.
Краткое раскрытие настоящего изобретения
[0043] Не ограничивая вышесказанное, в соответствии с предпочтительным вариантом осуществления, настоящее изобретение относится к повышению прогностической силы и диагностической точности способов прогнозирования статусов заболевания с помощью многопараметрических (многовариантных) способов определения корреляции. К таким способам относятся протеомные, метаболические и другие методики, которые предусматривают определение уровней различных биомаркеров, встречающихся в жидкостях организма и образцах тканей.
[0044] Различные варианты осуществления, предусмотренные авторами изобретения и рассматриваемые в настоящей заявке, включают применение метапеременных, в частности с помощью способов, которые корректируют влияние аналитов измеряемых биомаркеров на показатель корреляции. Такие метапеременные можно определить, исходя из специальных знаний об ответе иммунной системы и знаний о возможных ошибках измерения. Такие способы можно применять либо к конструкции модели обучающей выборки, либо к подвергаемым диагностике слепым образцам.
[0045] Согласно одному аспекту, настоящее изобретение относится к способу диагностики заболевания, предусматривающему стадии a) определения концентраций по меньшей мере трех предварительно определенных аналитов в слепом образце от субъекта; b) выбор одной или нескольких метапеременных, связанных с субъектом, которые варьируют в связанной с субъектом совокупности у представителей такой совокупности, для которых известно, что у них либо есть заболевание, либо его нет; c) преобразование концентраций аналитов в виде функции одной или нескольких характеристик распределения генеральной совокупности и одной или нескольких метапеременных для расчета показателя близости, которым представляют каждый аналит; d) сравнение показателей близости с моделью обучающей выборки для показателей близости, определенных у представителей совокупности, для которых известно, что у них либо есть заболевание, либо его нет; и e) определение, указывают ли результаты сравнения, что у субъекта есть заболевание. Предусмотрено, что стадия (а) определения концентраций (или уровней) предварительно определенных аналитов может быть реализована в другой момент времени и в другом месте от остальных стадий способа. Аналогично, одну или несколько других стадий способа можно полностью или частично реализовать на практике в другие моменты времени и в других местах. Следовательно, авторы настоящего изобретения рассматривают в качестве своего изобретения способ, который предусматривает только стадии (b) - (f).
Подробное раскрытие настоящего изобретения
[0046] При описании предпочтительных вариантов осуществления настоящего изобретения, проиллюстрированных на чертежах, для ясности будет использована конкретная терминология. Тем не менее, не подразумевается, что настоящее изобретение ограничено конкретными выбранными терминами, и следует понимать, что каждый конкретный термин включает все технические эквиваленты, которые функционируют аналогичным образом при реализации аналогичного назначения. С целью иллюстрации описано несколько предпочтительных вариантов осуществления настоящего изобретения, при этом следует понимать, что настоящее изобретение можно осуществить в других формах, которые конкретно не показаны на чертежах.
[0047] В контексте настоящей заявки для лучшего описания предпочтительных вариантов осуществления настоящего изобретения применяют конкретную терминологию, определение которой дано ниже.
[0048] Термин «аналитическая чувствительность» определяют как три стандартных отклонения выше нулевого калибровочного стандарта. Диагностические представления не считают точными для концентраций, которые ниже этого уровня. Следовательно, релевантные с клинической точки зрения концентрации, которые ниже этого уровня, не считают точными и не применяют для диагностических целей в клинической лаборатории.
[0049] «Измерение аналита на исходном уровне у индивидуума» означает измерение набора представляющих интерес биомаркеров для перевода индивидуального пациента из статуса отсутствия заболевания в статус наличия заболевания, который измеряют у одного индивидуума несколько раз в течение определенного периода времени. Результат измерения аналита на исходном уровне по статусу отсутствия заболевания получают, если у индивидуального пациента отсутствует заболевание, и, альтернативно, результат измерения аналита на исходном уровне по статусу наличия заболевания получают, если у индивидуального пациента присутствует заболевание. Такие результаты измерения на исходном уровне считают характерными для индивидуального пациента, и они могут быть полезны для диагностики перехода из статуса отсутствия заболевания в статус наличия заболевания такого индивидуального пациента. Измерение аналита на исходном уровне в случае статуса наличия заболевания может быть полезным для диагностики заболевания при втором или более возникновении заболевания у такого индивидуума.
[0050] «Биологический образец» означает ткань или биологическую жидкость, такую как кровь или плазма, которые взяты у субъекта и в которых можно определить концентрации или уровни диагностически информативных аналитов (также называемых маркерами или биомаркерами).
[0051] «Биомаркер» или «маркер» означает биологический компонент биологического образца субъекта, который обычно представляет собой белок или метаболический аналит, измеряемый в жидкости организма, такой как белок сыворотки крови. Примеры включают цитокины, опухолевые маркеры и тому подобное. Настоящее изобретение также предусматривает другие признаки в качестве «биомаркеров» и «маркеров», включая без ограничения рост, цвет глаз, географический фактор, факторы окружающей среды и т. д. В целом, такие признаки будут включать любые результаты измерений или атрибуты, которые варьируют в совокупности и остаются измеряемыми, определяемыми или наблюдаемыми.
[0052] «Слепой образец» представляет собой биологический образец, взятый у субъекта без известного диагноза данного заболевания, и для которого необходим прогноз о наличии или отсутствии такого заболевания.
[0053] «Связанная с заболеванием функциональность» является характеристикой биомаркера, которая либо оказывает действие, продолжая или ухудшая заболевание, или оказывает действие на организм, останавливая прогрессирование заболевания. В случае рака опухоль будет действовать на организм, вынуждая, чтобы продолжался и увеличивался рост кровеносных сосудов, а иммунная система будет усиливать провоспалительные действия для уничтожения опухоли. Эти биомаркеры отличаются от опухолевых маркеров, которые не имеют связанной с заболеванием функциональности, но попадают в систему кровообращения, и поэтому их можно измерить. В качестве примера функциональных биомаркеров можно привести интерлейкин 6, который усиливает действие иммунной системы, или VEGF, который секретируется опухолью, вызывая локальный рост кровеносных сосудов. Тогда как в качестве нефункционального примера можно привести CA 125. Это структурный белок, расположенный в глазу и женском репродуктивном тракте, который не задействуется организмом для уничтожения опухоли или задействуется опухолью, чтобы помочь росту опухоли.
[0054] «Предел обнаружения» (LOD) определяют как 2 стандартных отклонения от значения концентрации, превышающего значение концентрации у «нулевого» калибровочного стандарта. Обычно нулевой калибровочный стандарт прогоняют в 20 или более повторностях для получения точного представления о стандартном отклонении результатов измерения. Результаты определения концентрации ниже данного уровня рассматривают как нулевые или отсутствующие, например, при обнаружении вирусов или бактерий. В контексте настоящего изобретения можно использовать 1,5 стандартного отклонения, если образцы прогоняют в двух повторностях, хотя предпочтительно использовать 20 повторностей. Диагностические представления, требующие единственное число концентрации, как правило, не отображаются ниже этого уровня. Результаты измерений на уровне предела обнаружения статистически находятся на уровне достоверности 95%. Прогнозирование статуса заболевания с помощью рассматриваемых в настоящем документе способов не основано на одной концентрации, и было показано, что прогнозирование возможно на уровнях измерения, которые ниже концентрационного LOD.
[0055] «Белки с низкой частотой встречаемости» представляют собой белки в сыворотке, которые представлена на очень низких уровнях. Определение этого уровня в литературе четко не дано, но при использовании в данном описании уровень будет ниже приблизительно 1 пикограмма/миллилитр в сыворотке крови или плазме и других жидкостях организма, из которых забирают образцы.
[0056] «Метапеременная» означает информацию, которая характерна для данного субъекта, за исключением концентраций или уровней аналитов и биомаркеров, но которая не обязательно индивидуализирована или уникальна для такого субъекта. Примеры таких метапеременных включают без ограничения возраст субъекта, менопаузальный статус (пре-, пери- и пост-) и другие условия и характеристики, такие как половое созревание, масса тела, географическое местоположение или регион проживания пациента, географический источник биологического образца, процентное содержание телесного жира, возраст, раса или расовая принадлежность или эпоха времени.
[0057] «Распределение генеральной совокупности» означает диапазон концентраций конкретного аналита в биологических образцах данной совокупности субъектов. Конкретная «совокупность» означает без ограничения индивидуумов, выбранных из географического региона, конкретной расы или конкретного пола. И выбранная для использования характеристика распределения генеральной совокупности, как описано в настоящей заявке, дополнительно предусматривает использование двух отдельных подсовокупностей в пределах этой более крупной определенной совокупности, которые являются членами совокупности и для которых было диагностировано наличие указанного заболевания (подсовокупность наличия заболевания) и отсутствие заболевания (подсовокупность отсутствия заболевания). Совокупность может быть любой группой, для которой необходимо прогнозирование статуса заболевания. Более того, предусмотрено, что соответствующие совокупности включают тех субъектов, у которых присутствует заболевание, развившееся до определенной клинической стадии по сравнению с другими стадиями прогрессирования заболевания.
[0058] «Характеристики распределения генеральной совокупности» можно определить в пределах распределения генеральной совокупности биомаркера, такого как среднее значение концентрации конкретного аналита, или его медианное значение концентрации, или динамический диапазон концентрации, или как распределение генеральной совокупности подпадает в группы, которые можно распознать в виде отдельных пиков, поскольку степень положительной или отрицательной регуляции различных представляющих интерес биомаркеров и метапеременных зависит от начала и прогрессирования заболевания по мере того, как пациент испытывает биологический переход или прогрессирование из статуса отсутствия заболевания к статусу наличия заболевания.
[0059] «Прогностическая сила» означает среднее значение чувствительности и специфичности для диагностического анализа или теста или один минус общее количество ошибочных прогнозов (как ложноотрицательных, так и ложноположительных), деленное на общее количество образцов.
[0060] «Показатель близости» означает замещающее или заменяющее значение для концентрации измеряемого биомаркера и, по сути, является новой независимой переменной, которую можно использовать в диагностическом корреляционном анализе. Показатель близости связан с концентрацией измеряемых аналитов биомаркеров и рассчитывается из них, при этом такие аналиты имеют прогностическую силу для статуса заданного заболевания. Показатель близости рассчитывают с помощью скорректированной по метапеременной представляющей интерес характеристики распределения генеральной совокупности для преобразования фактической измеренной концентрации прогностического биомаркера у заданного пациента, для которого необходимо поставить диагноз, как раскрыто в международной публикации № WO 2017/127822 и международной публикации № WO 2014/158287. «Показатель близости» и «псевдоконцентрация» имеют одно и то же определение, и их можно использовать взаимозаменяемо.
[0061] «Специфичность» представляет собой истинно/ложноположительный результат теста. Математически это один минус количество ложноположительных результатов измерений с помощью теста, деленное на общее количество измеренных истинноотрицательных образцов.
[0062] «Неконгруэнтная модель обучающей выборки» (или «вторичный алгоритм») представляет собой вторичную модель обучающей выборки, в которой используют другой феноменологический способ сокращения данных с тем, чтобы отдельные точки на сетках двухмаркерных плоскостей имели малую вероятность нестабильного состояния в первичной корреляционной модели обучающей выборки и данном вторичном алгоритме.
[0063] «Способ определения корреляции по пространственной близости» (или поиск кластера или кластерный анализ) является способом определения корреляционной связи между независимыми переменными и двоичным выходным результатом, при этом независимые переменные отложены по ортогональным осям. Прогнозирование для слепых образцов основано на близости к числу (3, 4, 5 или более) точек данных так называемой «обучающей выборки», у которой известен выходной результат. Оценка двоичного выходного результата основана на общем расстоянии, рассчитанном от слепой точки на многомерном пространстве до точек противоположного выходного результата обучающей выборки. Оценку индивидуальной слепой точки данных определяет наименьшее расстояние. Этот же анализ можно провести на двухмаркерных плоскостях, размеченных многомерной сеткой, при этом индивидуальную оценку двухмаркерной плоскости объединяют с оценкой других плоскостей с получением общей оценки. Такое использование срезов или двумерных ортогональных проекций в пространстве может сократить время вычислений.
[0064] «Обучающая выборка» обозначает группу пациентов (обычно 200 или более для достижения статистической значимости) с известными концентрациями биомаркеров, известными значениями метапеременных и известным диагнозом. Обучающую выборку используют для определения значений осей «показатели близости» «двухмаркерных» плоскостей, а также точек сетки оценки, полученных по результатам анализа пространственной близости, которые будут использованы для оценки индивидуальных слепых образцов.
[0065] «Модель обучающей выборки» представляет собой алгоритм или группу алгоритмов, созданных из обучающей выборки, которые делают возможной оценку слепых образцов в отношении прогностического выходного результата касательно вероятности того, что у субъекта (или пациента) присутствует заболевание или не присутствует заболевание. Затем «модель обучающей выборки» используют для расчета оценок для слепых образцов в клинических и диагностических целях. Для этой цели получают оценку в произвольном диапазоне, которая указывает процент вероятности наличия заболевания или отсутствия заболевания или какого-либо другого заранее определенного указателя, который предпочитает использовать медицинский работник, который проводит диагностику пациента.
[0066] «Кривая зависимости чувствительности от частоты ложноположительных заключений (ROC)» представляет собой графический способ представления эффективности способа передачи сигнала, используемого для принятия решения, есть ли компромисс между ложноположительными, ложноотрицательными результатами и интенсивностью детектирующего сигнала. В данном графическом представлении по ординате графика представлена чувствительность способа тестирования, а по абсциссе представлен уровень ложноположительных результатов. Для биомаркеров (или сигналов) с восходящим действием к точке возникновения заболевания кривая будет находиться выше 45° нулевой линии, начинающейся в точке начале координат (0,0) графика и идущей в правый верхний угол графика (1.0,1.0). По площади под кривой видно, насколько хорошо биомаркер позволяет делать прогноз.
[0067] «'Площадь под кривой' (AUC) для кривой ROC» является площадью между характеристической кривой биомаркера и абсциссой. Для совершенно бесполезного биомаркера AUC будет составлять 0,5, а его площадь под 45° нулевой линией будет такой, как указано выше. Идеальный тест имеет AUC, равную 1,0, и кривая проходит от точки начала координат по ординате до точки 100% чувствительности, а затем по кривой ROC до точки 1.0,1.0 в правом верхнем углу.
[0068] «Микроокружение опухоли» омывается интерстициальной жидкостью опухоли (TIF) и является клеточной средой, в которой существует опухоль, включая окружающие кровеносные сосуды, иммуноциты, фибробласты, воспалительные клетки из костного мозга, лимфоциты, сигнальные молекулы и внеклеточный матрикс.
[0069] «Опухолевый маркер» представляет собой белковый маркер, который попадает в TME или в кровоснабжение, который не имеет видимой функции, является маркером либо роста опухоли за счет секретов опухоли, либо маркером подавления опухоли иммунной системой.
[0070] В последние годы в исследовании противораковой иммунотерапии все больший интерес уделяют микроокружению опухоли (TME), которое обеспечивает идеальную научно-исследовательскую платформу для разработки и усовершенствования новых средств терапии и представляет собой потенциально огромный кладезь диагностического содержимого. TME, которое омывается интерстициальной жидкостью опухоли (TIF), является клеточной средой, в которой существует опухоль, включая окружающие кровеносные сосуды, иммуноциты, фибробласты, воспалительные клетки из костного мозга, лимфоциты, сигнальные молекулы и внеклеточный матрикс.
[0071] TIF также является транспортной жидкостью, связывающей опухоль (и TME) с кровоснабжением, и является важной, поскольку она является «посредником на поле боя» для активных белков, которые иммунная система использует в попытке подавить опухоль, или которые опухоль экспрессирует, чтобы помочь своему росту. Эти конкурирующие белки или цитокины, которые постоянно находятся в состоянии войны друг с другом, подразделяются на несколько функциональных категорий низкоуровневых сигнальных белков: про- и противовоспалительные, противоопухолевого происхождения (или вызывающие апоптоз клеток), вызывающие ангиогенез и васкуляризацию.
[0072] Несмотря на признание в качестве потенциального источника богатой диагностической информации, разработка анализа с помощью TIF в качестве метода скрининга рака не продвигается, поскольку взятие проб этой жидкости является очень затруднительным, а для того, чтобы сделать это, означает, что должно быть известно расположение опухоли, а, значит, существует ли сама опухоль. Обнаружение наличия TME/TIF, а значит и злокачественной опухоли, является достаточно сложным без этих сведений. Для этого необходима более доступная жидкость для клинической диагностики, такая как сыворотка крови, в сочетании с анализом множества белков, известного как протеомика, которые предположительно могут коррелировать с наличием или отсутствием заболевания. В этом отношении с сывороткой возникают некоторые трудности, так как она является скорее отражением сочетания состояний организма пациента, чем прямым способом обнаружения наличия активного ТМЕ (и, следовательно, опухоли).
[0073] В настоящем раскрытии рассмотрен способ анализа специфических цитокинов, присутствующих в сыворотке крови, в качестве точного заместителя белков, активных в ТМЕ и TIF. Способ предусматривает несколько стадий, включая два запатентованных способа, называемых подавлением протеомного шума и многомерной (или пространственной) корреляцией. С помощью описываемого способа можно получить точного заместителя в отношении действий белков, встречающихся в TIF, и, таким образом, данный способ полезен для обнаружения присутствия активного ТМЕ в организме и, следовательно, опухоли. По сути, с помощью данного способа выделяют сигнатуру ТМЕ в сыворотке и получают указание на присутствие (или отсутствие) активного ТМЕ, что свидетельствует о присутствии активной опухоли. Помимо этого, данный способ позволяет измерять модуляцию этих белков, что дает ценную информацию о статусе опухоли, степени агрессивного действия и стадии, а также информацию о прогрессе иммунной системы в подавлении опухоли.
[0074] Представляющие интерес биомаркеры
[0075] Представляющими интерес биомаркерами в настоящем раскрытии являются провоспалительные (интерлейкин 6, IL 6, или другие); противовоспалительные (интерлейкин 10, IL 10, или другие.) противоопухолевые или лизирующие опухоль цитокины (фактор некроза опухолей альфа, TNFα, или другие) и циркулирующие факторы роста, такие как стимулирующие ангиогенез (интерлейкин 8, IL 8, или другие) и стимулирующие васкуляризацию цитокины (фактор роста эндотелия сосудов, VEGF, или другие). Это цитокины с имеющей непосредственное отношение функциональностью ответа иммунной системы на опухоль или действие опухоли на организм. Стимулирующие васкуляризацию факторы, VEGF, являются действием опухоли, стимулирующим рост кровеносной системы в массу растущей опухоли. Подавляющие развитие опухоли факторы, TNFα, являются действием иммунной системы, направленным на цитолиз опухоли (апоптоз), а провоспалительный фактор IL 6 является медиатором действия всей иммунной системы. Противовоспалительный IL 10 секретируется опухолью в интерстициальную жидкость опухоли для подавления иммунной системы. И наконец, стимулирующие ангиогенез факторы, такие как IL 8, секретируются опухолью для увеличения васкуляризации в окружающей ткани.
[0076] В целом, рак является провоспалительным заболеванием, при котором такие факторы, как IL-6, подвергаются положительной регуляции. Тем не менее, в трех описанных в настоящем документе случаях опухоль на более поздней стадии секретирует противовоспалительный цитокин в интерстициальную жидкость опухоли (и, следовательно, в кровь). Было показано, что такое действие имеет место на поздних стадиях рака, на 3-й или 4-й стадии, в легких и молочной железе, и при более высокой оценке по шкале Глисона (8, 9 или 10 по шкале Глисона). В этот момент противовоспалительное действие имеет тенденцию подавлять провоспалительный ответ иммунной системы организма. В некоторых случаях, при раке молочной железы, на более поздних стадиях также подавляется ответ в форме ангиогенеза. Наконец, стимулирующее васкуляризацию действие опухоли возрастает, как и следовало ожидать, по мере увеличения опухоли в размерах на 3-й или 4-й стадиях рака молочной железы или легкого и при раке предстательной железы при оценке 8, 9 и 10 по шкале Глисона. Все эти действия, происходящие в микроокружении опухоли, можно установить путем забора образцов сыворотки из организма и применения способов, описанных в международных публикациях № WO 2017/127822 и № WO 2014/158287.
[0077] В частном случае рака высокая степень интереса в последних терапевтических исследованиях была сосредоточена на так называемом «микроокружении опухоли» (ТМЕ) для разработки методов лечения. Считается, что плодотворным путем разработки этих средств лечения является подавление или усиление регуляции белков, активных в интерстициальной жидкости опухоли (TIF) и встречающихся в TME. Белки в TIF, для которых было установлено, что они являются хорошими индикаторами, как правило, относятся к пяти функциональным группам цитокинов: провоспалительного или противовоспалительного, противоопухолевого генеза (или вызывающие клеточный апоптоз), воздействующие на ангиогенез и васкуляризацию.
[0078] Измерение активности этих белков может дать лучшее представление об опухолевой активности и терапевтическом действии. Например, методы лечения, с помощью которых стимулируют или подавляют активность белков, для определения эффективности можно отслеживать в TIF. Если уместно в терапевтических целях, и когда известно, что рак существует, не проводят забор образцов TIF для диагностики. Поскольку наличие TIF (и наличие TME) по определению означает, что у пациента присутствует активная опухоль с известным местоположением, ее применение в качестве диагностического инструмента становится неактуальным. Кроме того, не было рассмотрено использование этих белков для диагностики при их присутствии в других жидкостях организма, таких как сыворотка или моча, поскольку до сих пор проблема протеомного шума делала их непригодными для использования.
[0079] В настоящем документе описаны системы и способы получения точного заместителя в отношении активности TME, которую используют активные белки в TIF, с помощью легко доступной замещающей жидкости, в данном случае сыворотки (но возможны и другие жидкости, такие как моча). Следует отметить, что сыворотка является сочетанием состояний всего организма (называемым «протеомным шумом») и не специфична для опухоли. Методология, которую мы предлагаем, также позволяет устранить протеомный шум, делая возможной точную оценку состояния пациента.
[0080] В целом, раскрываемые в настоящем документе системы и способы предусматривают: 1) отбор активных белков TIF, которые свидетельствуют о состояниях в TME, 2) измерение этих белков в сывороточном заместителе, 3) подавление протеомного шума для точной идентификации связанной с раком активности белков, 4) затем осуществление способа определения корреляции, который усиливает действия этих белков в многомерной матрице, и 5) оценку активности белка, указывающей на наличие или отсутствие рака и, если он есть, стадию его развития. Это делают в первую очередь для создания обучающей выборки, представляющей совокупность в целом, которая служит эталоном, с которым затем сравнивают индивидуальные образцы для определения их статуса: либо пораженные заболеванием, либо не имеющие заболевания.
[0081] Комбинированные действия биомаркеров
[0082] Эти цитокиновые биомаркеры очень активны при раке предстательной железы с высокой степенью тяжести, и, по сравнению с уровнем у «здоровых» мужчин, подвергаются очень сильной положительной или отрицательной регуляции, и поэтому являются очень хорошими индикаторами статуса заболевания. Также следует отметить, что они активны при раке легкого и молочной железы. На фиг. 1, 2 и 3 видно такое действие по мере прогрессирования опухоли. Следует отметить, что при немелкоклеточном раке легкого и предстательной железы, как видно на фиг. 1 и 2, IL 6 оказывает отрицательную регуляцию на поздней стадии рака или при высокой оценке, равной 8, 9 или 10, по шкале Глисона. Также следует отметить, что в обоих случаях при переходе с низкой степени тяжести рака легкого или низкой оценки по шкале Глисона рака предстательной железы повышенные количества интерлейкина 10, секретируемые опухолью, приводят к отрицательной регуляции уровня IL 6. Также следует отметить, что секреция IL 10 в интерстициальную жидкость опухоли и, следовательно, в кровь связана с плохим прогнозом для пациентки. Это обычно означает, что имеет место поздняя стадия рака молочной железы. Таким образом, сочетание IL 6 и IL 10 в корреляционном анализе статуса наличия заболевания улучшается с помощью сочетания провоспалительных и противовоспалительных цитокинов. Более того, следует отметить, что влияющие на васкуляризацию цитокины продолжают оказывать в целом положительную регуляцию по мере того, как опухоль прогрессирует до более поздней стадии или становится более агрессивной.
[0083] Трое из этих биомаркеров имеют уникальные характеристики кривой ROC, которые не являются общими для опухолевых биомаркеров. Они имеют плоскую часть со 100% чувствительностью для определенных более низких уровней концентраций биомаркера. Они также характеризуются довольно большими площадями под кривой (AUC), что указывает на то, что они являются очень хорошими биомаркерами для данного заболевания, т.е. рака предстательной железы с высокой степенью тяжести (PCa) по сравнению с отличным от PCa заболеванием. Один из них имеет прямой вертикальный участок, идущий вверх по ординате от [0,0], что указывает на то, что образцы в этом диапазоне сигналов должны иметь PCa с нулевым уровнем ложноположительных результатов.
[0084] В научной литературе есть ограниченное число публикаций по нескольким выбранным биомаркерам, упомянутым в этом описании. И нет ничего, связанного с выявлением PCa с высокой степенью тяжести в сравнении с генеральной совокупностью, то есть пациентами без PCa. В случае VEGF в литературе действительно упоминается положительная регуляция биомаркеров, но ничего не указано в отношении стадии рака или, в частности, оценки по шкале Глисона. Большая часть литературы ограничивается применением VEGF в качестве прогностического средства для лечения мужчин с уже диагностированным PCa. TNFα также не имеет никакого отношения к установлению различия действий биомаркеров, связанных со стадией опухоли или, в частности, оценкой опухоли по шкале Глисона. Результаты научных исследований интерлейкина 6 дают аналогичную информацию. Известно, что для PCa с низкой степенью тяжести в некоторых литературных источниках упоминается небольшая положительная регуляция уровня биомаркера. Результаты наших измерений не подтверждают этого, поскольку небольшую отрицательную регуляцию наблюдают при PCa с низкой степенью тяжести, но очень сильную отрицательную регуляцию наблюдают при PCa с высокой оценкой по шкале Глисона, что делает этот цитокин, наряду с другими, сильным индикатором наличия PCa с высокой степенью тяжести. Большая часть литературы посвящена применению этих биомаркеров в качестве прогностических факторов у мужчин с PCa и in vitro экспрессии белка из линий клеток PCa, а также изучению способов подавления экспрессии (особенно VEGF) для лечебных целей.
[0085] Кривые ROC в случае рака предстательной железы
[0086] VEGF
[0087] На фиг. 4 показана кривая ROC для VEGF при агрессивной форме (оценка по шкале Глисона 7 (4+3), 8, 9 и 10). Следует отметить, что большая плоская часть ROC проходит через верхнюю границу, где чувствительность составляет 100%. При уровнях концентрации VEGF на этом уровне чувствительности или ниже приблизительно 50 пг/мл PCa с высокой степенью тяжести отсутствует, и не было выявлено ни единого такого случая. AUC для данного биомаркера при сравнении статуса наличия данного заболевания / отсутствия данного заболевания составляет 0,87. Кроме того, уникальная форма без ложноположительных результатов ниже уровня 50 пг/мл делает его очень хорошим кандидатом в качестве биомаркера для определения «PCa» с высокой степенью тяжести в сравнении «отличным от PCa» заболеванием, поскольку уровни концентрации ниже приблизительно 50 пг/мл вовсе не указывают на PCa.
[0088] TNFα
[0089] Комментарии к TNFα аналогичны тем, которые были описаны в отношении характера кривой ROC для агрессивной формы (оценка по шкале Глисона 7 (4+3), 8, 9 и 10), как видно на фиг. 5. В этом случае AUC составляет 0,85, и снова, высокая и такая же граничная точка не дает ложноотрицательных результатов ниже приблизительно 6,5 пг/мл. Для TNFα также видна часть кривой, которая имеет нулевой уровень ложноположительных результатов (абсцисса) для образцов с концентрацией более приблизительно 9,85 пг/мл. В этом участке нет ложноположительных результатов.
[0090] PSA
[0091] Комментарии к PSA аналогичны тем, которые были описаны в отношении характера кривой ROC для агрессивной формы (оценка по шкале Глисона 7 (4+3), 8, 9 и 10), как видно на фиг. 6. В этом случае AUC составляет 0,85, и снова, высокая и такая же граничная точка не дает ложноотрицательных результатов ниже приблизительно 2 нг/мл. Кривая ROC для общего анализа на PSA для PCa с любой оценкой по шкале Глисона показана для справки зеленым цветом (показана под названием «Все PCa»).
[0092] IL6
[0093] В отличие от этого, для IL 6 наблюдают сильную отрицательную регуляцию при агрессивной форме (оценка по шкале Глисона 7 (4+3), 8, 9 и 10), с AUC приблизительно в два раза превышающей для текущего PSA, необходимого для обнаружения PCa, как видно на фиг. 7, в генеральной совокупности (кривая должна быть перевернута для учета такой отрицательной регуляции). Можно предположить, что, возможно, PCa с высокой степенью тяжести эффективен в подавлении иммунной системы, но это не является предметом настоящего рассмотрения. Дело в том, что для этого биомаркера наблюдают сильную отрицательную регуляцию. В ограниченном числе литературных источников указана небольшая положительная регуляция при общем PCa. По результатам наших измерений для PCa с любой оценкой по шкале Глисона видна небольшая отрицательная регуляция. Тем не менее, при высокой оценке по шкале Глисона у данного цитокина наблюдают сильную отрицательную регуляцию. Общая совокупность PCa имеет приблизительно 80% случаев низкой степени тяжести, поэтому при заборе образцов на PCa в характеристиках группы будет преобладать низкая степень тяжести. Такая отрицательная регуляция, вероятно, вызвана секрецией противовоспалительного цитокина (IL 10) при прогрессировании опухоли до агрессивной формы с оценкой по шкале Глисона 7 (4+3) и выше.
[0094] Кривые ROC в случае рака легкого
[0095] IL 10
[0096] На фиг. 8 показана кривая ROC для интерлейкина 10 в случае отделения низкой степени тяжести (1-й и 2-й стадии от более поздней 3-й и 4-й стадии немелкоклеточного рака легкого). Следует отметить, что имеет место положительная регуляция при переходе от ранней стадии (1-й и 2-й) к более поздним стадиям (3-й и 4-й). Это соответствует отрицательной регуляции интерлейкина 6 и вызвано противовоспалительным действием опухоли, секретирующей IL 10 в микроокружение опухоли, а затем в кровоток.
[0097] IL6
[0098] Кривая ROC для IL 6 показана на фиг. 9 и снова для случая немелкоклеточного рака легкого на ранних стадиях (1-й и 2-й) в сравнении с поздними стадиями (3-й и 4-й). Как показано на фиг. 9, данное действие IL 6 подавляется противовоспалительным действием опухоли.
[0099] VEGF
[0100] Кривая ROC для VEGF показана на фиг. 10, на которой видна положительная регуляция стимулирующего васкуляризацию фактора, который встречается при других формах рака по мере роста и прогрессирования опухоли до более поздних стадий.
[0101] Тест на агрессивную форму или позднюю стадию рака в сравнении с неагрессивной формой или ранней стадией рака
[0102] Данные биомаркеры можно взять совместно для разработки очень простого протеомного алгоритма для отслеживания мужчин с низкой степенью тяжести рака предстательной железы с оценкой по шкале Глисона 5, 6 или 7(3+4) в отношении перехода к высокой степени тяжести PCa с оценкой по шкале Глисона 7 (4+3), 8, 9 или 10. Кроме того, эти биомаркеры позволяют отличать раннюю стадию рака, 1-ю или 2-ю стадию от 3-й или 4-й стадии. Сочетание IL 6 и IL 10 с противоположными действиями может дать (с простым способом определения корреляции, таким как логистическая регрессия) 80% прогностическую силу. Добавление подавления протеомного шума и способа определения корреляции по пространственной близости будет давать значения прогностической силы, равные 90%. Добавление действия VEGF к панели биомаркеров улучшит прогностическую силу до 95% и более.
[0103] Тест на агрессивную форму рака предстательной железы в сравнении с мужчинами без рака
[0104] На самом деле, VEGF и сам по себе будет давать тест с 76% прогностической силой, 100% чувствительностью и 76% специфичностью (24% ложноположительных результатов). Эта простая модель будет просто исключать образцы с диагнозом отсутствия PCa в тех диапазонах концентраций, где кривая ROC их исключает, и будет снова включать образцы с PCa в тех зонах, где его включает кривая ROC. Затем она будет использовать простой подсчет граничных точек и количество положительных и отрицательных оценок каждого биомаркера, не входящих в критерий исключения или включения. Количество должно превышать 3 из 4 для тех случаев, которые не были предварительно исключены или включены. Эта простая модель позволяет получить 100% репрезентативный набор образцов из 100 образцов с диагнозом наличия PCa с высокой оценкой по шкале Глисона (определяемой как 7 (4+3) и выше) и 100 образцов с диагнозом отсутствия PCa. Сочетание VEGF, IL 6, TNFα и PSA будет давать прогностическую силу, равную 90%. Кроме того, этот тест будет позволять прогнозировать «отсутствие рака» для мужчин с повышенным уровнем PSA, но не цитокинов. У этих мужчин присутствует доброкачественная гиперплазия предстательной железы или другое незлокачественное состояние предстательной железы, и они составляют основную массу многочисленных ложноположительных результатов текущего скринингового теста с помощью PSA на рак предстательной железы. Тест, включающий такие цитокины, позволяет решить эту проблему ложноположительных результатов.
[0105] Прогнозирование стадии рака
[0106] Данные, полученные в ходе исследования рака молочной железы под наблюдением института Герцена в Москве, позволяли спрогнозировать с высокой точностью стадии рака молочной железы с использованием описанных ниже оборудования и реагентов. Было получено 189 образцов ткани молочной железы с информацией о стадии (от 0 до 4). Измерения проводили для опухолевого маркера PSA и четырех упомянутых цитокинов провоспалительного (IL 6), противоопухолевого генеза (TNFα), воздействующих на ангиогенез (IL 8) и васкуляризацию (VEGF). В этом случае целью было оценить каждый образец в отношении полученной по результатам биопсии информации о возможной стадии. Все способы определения корреляции являются двоичными по природе и не могут быть реализованы без некоторой манипуляционной оценки четырех различных выходных результатов. Поэтому группы стадий объединяли в бинарные группы, представляющие все группы стадий; 1 плюс 2, 3, 4; 2 плюс 1, 3, 4; 3 плюс 1, 2, 4 и 4 плюс 1, 2, 3. Все четыре группы были смоделированы и оценены с помощью способов нормализации по возрасту, подавления шума и определения корреляции по пространственной близости, описанных в международной публикации № WO 2017/127822 и международной публикации № WO 2014/158287. Оценку для каждого отдельного образца затем рассчитывали с помощью каждой индивидуальной групповой оценки каждого образца совместно со взвешиванием по вкладу каждого в эту группу (1 или 1/3). Данная модель давала 99% точность.
[0107] В настоящем описании было описано несколько способов улучшения прогностической силы традиционных способов определения корреляции в протеомике для диагностики заболевания. Они предусматривают: 1) использование метапеременной и значений оценки близости для установления корреляции, и 2) использование специальных сведений о стабильности топологии и характеристик измерения в ходе анализа для корректировки влияния двухмаркерной плоскости в модели обучающей выборки. Кроме того, описаны способы обнаружения и коррекции проблем со стабильностью для слепых образцов, уникальных для конкретной модели обучающей выборки, с использованием неконгруэнтной модели обучающей выборки. Кроме того, описаны способы поиска и коррекции не связанных с заболеванием состояний, которые частично имитируют модель обучающей выборки набора для статуса данного заболевания. Все эти способы являются взаимодополняющими и могут быть использованы совместно. Например, корректировка модели обучающей выборки для областей с высокой вероятностью нестабильности не может полностью устранить данную проблему из прогностических расчетов для слепого образца, и поэтому можно использовать оба способа для улучшения прогностической силы. Авторами настоящего изобретения было обнаружено, что сочетание этих способов может давать прогностическую силу выше 95%, а исследование рака молочной железы, рассмотренное в Примере 1 ниже, дает прогностическую силу более 98% (100% чувствительность, 97,5% специфичность).
[0108] ПРИМЕР 1: клиническое исследование по оценке теста крови на рак молочной железы
[0109] Характеристики набора для проведения теста OTraces BC Sera Dx и системы OTraces CDx Immunochemistry Instrument (www.otraces.com) оценивали в эксперименте по оценке риска наличия рака молочной железы. С помощью набора для проведения теста измеряли концентрации пяти очень низкоуровневых цитокинов и маркеров ткани, и данный набор предусматривал использование модели обучающей выборки, которая была разработана, как описано выше, для расчета оценок CS1 и CSq для оценки риска наличия рака молочной железы. Измеряемыми белками были IL-6, IL-8, VEGF, TNFα и PSA. Эксперимент заключался в измерении приблизительно 300 образцов пациентов, разделенных примерно по 50% между случаями рака молочной железы, диагностированными с помощью биопсии, и 50% от пациентов, которых предположительно считали со статусом отсутствия заболевания (или в этом случае не имеющих рак молочной железы). Из этой группы результаты биопсии для 200 образцов разделяли точно на 50% случаев со статусом отсутствия заболевания и 50% случаев с наличием рака молочной железы и каждую группу дополнительно разделяли на определенные возрастные группы.
[0110] Результаты анализа образцов применяли для разработки модели обучающей выборки, которая позволяла прогнозировать статус наличия заболевания. Оставшиеся образцы (приблизительно 110) затем обрабатывали как слепые образцы с помощью модели обучающей выборки для получения конечных цифровых оценок риска наличия рака и такие оценки передавали в основной клинический центр. Такие оценки слепых образцов затем анализировали в клиническом центре для оценки клинической точности результатов.
[0111] Для этого эксперимента были разработаны две диагностические модели и названы в настоящем описании алгоритмом I и алгоритмом II. Для обоих алгоритмов использовали способ анализа пространственной близости. Возраст участников использовали не как независимую переменную, а как метапеременную для преобразования измеренных концентраций в новые независимые переменные, называемые в настоящем описании показателями близости, которые непосредственно применяли в корреляционном анализе. Разница между алгоритмом I и алгоритмом II заключалась в количестве новых независимых переменных, используемых при определении корреляции. В алгоритме I использовали пять переменных показателей близости в десятимерном кластерном пространстве. Нижний предел алгоритма I имел два измерения, и он был основан не на конкретном способе, а на том факте, что вообще определяют корреляцию. При корреляции, по сути, было задействовано более одного измерения. Верхний предел алгоритма I теоретически представлял собой бесконечность, но практически был ограничен временем расчета и статистической мощностью исследования. Кластерное пространство можно было увидеть невооруженным взглядом с помощью проекции или срезов такого многомерного пространства, позволяющих видеть его в двухмерной двухмаркерной плоскости. В соответствии с этим иллюстративным вариантом осуществления алгоритма I, есть десять таких плоскостей.
[0112] В алгоритме II предусмотрено использование в десять раз большего количества созданных независимых переменных, так чтобы было приблизительно 100 двухмаркерных плоскостей. Ожидали, что 200 образцов будет достаточно для модели обучающей выборки с тем, чтобы она достаточно близко моделировала генеральную совокупность. Вторичную или неконгруэнтную модель обучающей выборки разрабатывали на основе того же набора обучающих данных из 200 образцов. Модель обучающей выборки является основным способом оценки, применяемым для описания результатов в настоящем описании. Неконгруэнтную модель обучающей выборки применяли для вынесения арбитражного решения для оценок статуса рака, рассчитанных с помощью первичной модели обучающей выборки, которые считались нестабильными, т.е. оценок, которые оставались на области топологической нестабильности. Хотя неконгруэнтная модель обучающей выборки была несколько менее точной на слепых образцах, она все же могла выносить арбитражное решение для основной модели обучающей выборки и, таким образом, улучшать прогностическую силу.
[0113] Вышеупомянутый способ анализа пространственной близости обладает существенными преимуществами по сравнению с логистической регрессией в том, что его можно приспособить к сильно нелинейным тенденциям в независимых переменных, используемых для получения рассчитываемого выходного результата. Выходным результатом является либо статус наличия заболевание, либо статус отсутствия заболевания (в данном случае наличия рака или отсутствия рака), и он основан на показателях близости результатов расчета с помощью модели обучающей выборки. Недостатком этого способа является то, что сильно нелинейные области могут быть связаны с очень большими значениями крутизны топологии. Таким образом, неизвестный (или слепой) образец может находиться на резком пике или в глубокой крутой впадине, что приводит к усилению небольших ошибок в рассчитанных показателях близости. Авторами настоящего изобретения была оценена стабильность рассчитанных оценок с помощью собственного запатентованного теста на стабильность, а затем был использован алгоритм II для вынесения арбитражного решения по результатам, полученным с помощью алгоритма I, для образцов, у которых наблюдали стабильность.
[0114] На фиг. 11, 12 и 13 показаны результаты, полученные с помощью алгоритма I для обучающей выборки. Сама модель состояла из 10 двухмаркерных плоскостей с 40000 точек топологии, каждую из которых оценивали на статус отсутствия заболевания и статус наличия заболевания (в данном случае рака молочной железы) с помощью способа пространственной близости. На данных фигурах показана способность модели разделять на две выборки: отсутствие рака и наличия рака. Модель должна была быть построена из очень приближенных к или предпочтительно точно 50% на 50% или очень приближенных к одному из двух статусов выходных результатов. Кроме того, способ предусматривал использование возраста в качестве преобразующей метапеременной. Образцы обучающей выборки включали образцы, распределенные по всем представляющим интерес возрастным группам. Модель (фиг. 12) для алгоритма I строили из данных, полученных от 100 здоровых женщин и 98 женщин с раком молочной железы. В сводной таблице на фиг. 12 показаны числовые результаты, где N=198 является количеством образцов. CI обозначает дающие правильные результаты образцы, а FI обозначает дающие ложные результаты образцы, и 4 образца посчитали неопределенными. Вторичную модель обучающей выборки разрабатывали для распознания четырех неопределенных образцов, которые возникли в результате применения основной модели обучающей выборки. Эта модель является неконгруэнтной моделью обучающей выборки. Данная вторичная модель использовала те же данные обучающей выборки, что и основная модель. На фиг. 13 показаны результаты расчетов неконгруэнтной моделью обучающей выборки. Алгоритм II давал 100% разделение с более 60 точками разделения.
[0115] Результаты тестирования слепых образцов в исследовании рака молочной железы
[0116] На фиг. 14 показаны результаты для слепых образцов, оцениваемых в клиническом исследовании. Из результатов видна 100% чувствительность и 97,5% специфичность. Онкологами в центре клинических исследований было установлено такое значение диагностического перехода, чтобы были правильно идентифицированы все положительные по раку молочной железы образцы. Так, два образца со статусом отсутствия заболевания были обозначены положительными на рак. С точки зрения медицины это обосновывали тем, что все образцы, оцененные как положительные, будут направлены на следующую стадию диагностики - маммографию. Многих женщин не направляли на маммографию, поскольку они жили достаточно далеко от учреждений с медицинским оборудованием. Тем не менее, их кровь можно было взять удаленно в клинической лаборатории и отправить на льду в лабораторию в крупном городе.
[0117] ПРИМЕР 2: применение метапеременной «возраст» для повышения точности диагностики
[0118] В таблице 1 (приведенной ниже) показаны сведенные в таблицу результаты исследования образцов от 868 субъектов на предмет рака молочной железы.
Таблица 1. Сводные данные по диагностической точности при раке молочной железы
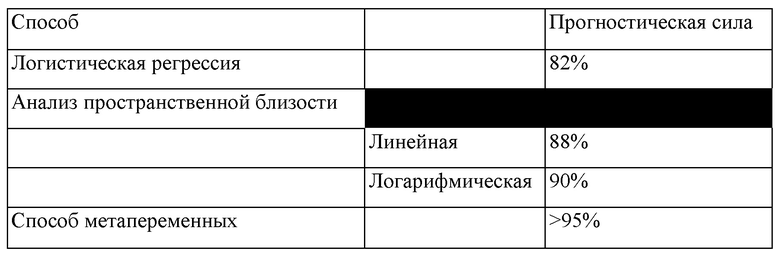
[0119] В таблице 2 (приведенной ниже) показаны результаты сравнения различных способов расчета корреляции. Стандартный способ, логистической регрессии, давал лишь 82% прогностическую силу. При этом улучшался стандартный анализ пространственной близости, дававший приблизительно 88% прогностическую силу в линейной форме и 90% прогностическую силу в логарифмической форме. Описанные в настоящем описании способы с применением подходов с метапеременными и взвешиванием, нормализации стабильности топологии, группировки ответов иммунной системы и нормализации весовых коэффициентов для выполнения анализа, в сочетании с тестированием на нестабильность слепых образцов и коррекцией с помощью неконгруэнтного алгоритма, давали прогностическую силу более 97%.
Таблица 2. Сравнительная прогностическая сила результатов расчетов корреляции заболеваний
[0120] ПРИМЕР 3: применение метапеременной «возраст» для повышения точности диагностики в исследовании рака яичников
[0121] В таблице 3 (ниже) показаны результаты исследования 107 женщин с раком яичников или без рака яичников с помощью способа метапеременных, описанного в вариантах осуществления настоящего изобретения. В этом исследовании не использовали все улучшения прогностической силы, описанные в настоящем описании, но при этом все же достигали относительно превосходящей прогностической силы, составлявшей приблизительно 95%.
Таблица 3. Сводные данные по диагностической точности при раке яичников
[0122] ПРИМЕР 4: применение метапеременной «возраст» для повышения точности диагностики при раке предстательной железы
[0123] В таблице 4 (ниже) показаны результаты исследования 259 мужчин, страдающих раком предстательной железы или доброкачественной гиперплазией предстательной железы (BPH), с помощью способа метапеременных, описанного в настоящем описании. В этом исследовании также не использовали все улучшения прогностической силы, описанные в настоящем документе, но при этом все же достигали относительно превосходящей прогностической силы, составлявшей приблизительно 94%. Следует отметить, что BPH является наиболее распространенным патологическим состоянием, которое дает ложноположительные результаты в текущем тесте на PSA при определении рака предстательной железы. Мужчины с BPH имеют приблизительно 4 из пяти положительных результатов при традиционной диагностике рака предстательной железы, в результате чего большинство биопсий рака предстательной железы являются отрицательными. Способ метапеременных позволяет исправить эти ошибочные диагнозы, как рассмотрено выше.
Таблица 4. Сводные данные по диагностической точности при раке предстательной железы
[0124] Для вышеуказанных результатов, указанных в примерах 3 и 4 (для рака яичника и рака предстательной железы соответственно), не использовали способы метапеременных или корректировки влияния (LOD, подсовокупности, группы и нестабильность), а также способ определения стабильности у слепого образца.
[0125] Для дополнительного улучшения прогностической силы эти концентрации, скорректированные по возрасту или группе, ограничивали условием для их нормализации и уменьшения или устранения смещения в пространстве (также известного как пространственное смещение) при кластеризации многомерных графиков сгруппированных маркеров для анализа пространственной близости. См., например, фиг. 15, на которой представлена двухмаркерная плоскость для IL-6 и VEGF. Для диагностической панели тестов на рак молочной железы по пяти биомаркерам было десять таких плоскостей. В этом случае рассчитанные значения показателя близости нормализовали и смещали для получения произвольных значений от нуля до двадцати, при этом вылетающие значения очень повышенных концентраций подвергали высокой степени сжатия.
[0126] Каждую из двухмаркерных проекций многомерных маркерных плоскостей на одном и том же нормализованном расстоянии относительно концентраций, полученных в результате анализа с использованием возраста/группы, сжимали и нормализовали относительно скорректированных по возрасту средних, а также скорректированных по возрасту (или всей совокупности) подгрупп.
[0127] Улучшения прогностической силы модели обучающей выборки с помощью корректируемых уровней влияния на двухмаркерной плоскости
[0128] Как правило, двухмаркерную плоскость оценивали двоичными числами для статуса отсутствия заболевания и статуса наличия заболевания (например, +1 и -1). Описанный в настоящем документе способ с использованием показателей близости можно изменить, дополнительно улучшив прогностическую силу, путем выборочной корректировки уровней влияния у этих двух двоичных чисел. Приведенные ниже способы были реализованы в модели обучающей выборки и после их создания зафиксированы в данной модели.
[0129] На фиг. 16 и 17 показаны проекции одной двухмаркерной плоскости для случая пяти биомаркеров, применяемых для прогнозирования наличия заболевания, в данном случае рака молочной железы, с помощью пяти маркеров: IL-6, IL-8, TNFα, VEGF и PSA. На фиг. 16 показана модель обучающей выборки с данными, применяемыми для оценки точек сетки на графике с помощью способа анализа пространственной близости. На фиг. 17 показана модель обучающей выборки без данных. Она является моделью обучающей выборки. Данные обучающей выборки, использованные для создания модели, не были нужны, поскольку оценивали каждую из 40000 точек сетки, а слепой образец оценивали путем его размещения на сетке. На топологии можно было видеть красный положительный сигнал в случае наличия рака, а синий сигнал означал отрицательный по наличию рака статус. При расчете общей оценки в этом случае точки на сетке со статусом отсутствия заболевания задавали равными +1, а точки на сетки со статусом наличия заболевания (рака) задавали равными -1. Каждый двойной маркер в этом примере с пятью биомаркерами анализировали в пятиортогональном пространстве, для которого на фиг. 16 представлена одна проекция в двух измерениях. На этом графике показана топология различных подгрупп ответа иммунной системы. В этом случае все точки сетки (2000×2000 или 40000 в данном случае) оценивали обычным способом, и назначенное значение равно -1 для положительного статуса наличия заболевания (рака молочной железы), а для статуса отсутствия заболевания равно +1. Эту двухмаркерную плоскость нормализовали с помощью расстояния к показателю близости и метапеременной возраста, как отмечено выше.
[0130] На фиг. 18 показана та же двухмаркерная модель и, кроме того, группы иммунного ответа (см. фиг. 24) внутри серых областей. Влияние серых областей корректировали с учетом того факта, что каждая серая занятая область оказывала несколько иное влияние на вероятность того, что пациент имеет статус отсутствия заболевания или статус наличия заболевания. Эту корректировку можно было производить либо путем оценки человека с проверкой обучающей выборкой, либо путем строгого компьютерного многопараметрического инкрементального анализа. Эти корректировки улучшали модель обучающей выборки. Для двух выходных результатов, которые представляли собой статус наличия заболевания или статус отсутствия заболевания, создавали две отдельные двухмаркерные плоскости. В этом случае слепые точки данных в IV группе иммунного ответа с большей вероятностью указывали на статус наличия заболевания, а влияние незначительно увеличивалось (абсолютное значение) (например, при изменении оценки с -1 на -1,1). Фактическую величину этого прироста предпочтительно определяли с помощью компьютерного анализа или, возможно, с помощью строгих ручных способов. Этот способ пригоден для способа пространственной близости (также известного как псевдоконцентрации) корреляционного анализа, но для получения аналогичного результата можно использовать и другие средства. Такие способы взвешивания влияния в связи с заболеванием могут давать улучшение прогностической силы приблизительно на 1%. Это очень важно при значениях прогностической силы, превышающих 95%.
[0131] На фиг. 19 снова показана та же самая двухмаркерная плоскость с серой областью, обведенной кружком в комплексной области нелинейной, быстро изменяющейся топологии статуса наличия заболевания относительно статуса отсутствия заболевания. Такие области можно было выявить путем подстановки значений тестового слепого образца с включенным шумом (скажем, +/- 10%) в модель, а затем включения измеренной величины шума. Большинство из этих слепых точек практически не изменяли оценку статуса заболевания (в данном случае - рака). Тем не менее, можно было найти некоторые точки сетки, которые после такого рода корректировки шума резко переходили из оценки отсутствия заболевания в наличие заболевания. Это были области, где большинство или все двухмаркерные плоскости имели быстро меняющуюся топологию, которая перекрывала многомерные общие двухмаркерные плоскости. Путем осторожного уменьшения влияния в этих областях можно увеличить вес в нескольких релевантных двухмаркерных плоскостях, у которых зашумленные данные расположены на широкой плоскости, при этом не приближаясь к изменению границ выходных результатов. Было показано, что с помощью данного способа можно исправлять ошибочные прогнозы. В приведенном выше случае влияние красных областей, относящихся к статусу наличия рака, смещалось вниз (в абсолютном значении), например, с -1,0 до -0,9. Или же синие области, относящиеся к статусу отсутствия заболевания, смещались с +1,0 до -0,9. Уровень оптимального смещения можно было определить с помощью строгого компьютерного анализа.
[0132] Шум анализа может оказывать влияние на точность корреляционного анализа. Этот шум может быть особенно проблематичным на уровнях в пределах или ниже предела обнаружения с помощью такого анализа. Этот шум также можно смягчить путем уменьшения влияния измеренных точек для отдельных биомаркеров, которые находятся в этих нестабильных зонах. На фиг. 20 снова показана двухмаркерная плоскость для PSA и IL-6 для диагностической панели определения рака молочной железы. Области внутри серой прямоугольной области в левом нижнем углу фигуры находятся ниже общепринятого предела обнаружения (LOD) анализа. Общепринятый LOD определяют как два стандартных отклонения 20 нулевых калибровочных стандартов плюс среднее значение двадцати нулевых калибровочных стандартов. Статистическая достоверность для таких значений на этом уровне составляет 95% в пределах двух стандартных отклонений, и, конечно, достоверность измерений снижается по мере того, как измеряемый образец становится ниже LOD. Эти данные все еще могут давать полезную информацию, но к анализу их следует применять с меньшим влиянием. В этом случае влияние на базовые точки слепого образца в серой области уменьшалось, например, с +1,0 до -0,9, для точек сетки модели обучающей выборки в пределах серой области. Это увеличивало влияние базовых точек для этого тестового образца, которые превышали предел обнаружения на своих двухмаркерных плоскостях. Вышеуказанные способы являются взаимодополняющими и могут быть использованы совместно.
[0133] Способы повышения прогностической силы путем тестирования слепых образцов на нестабильность
[0134] После завершения формирования и фиксации модели обучающей выборки ее применяли для расчета оценок статуса рака для слепых образцов от пациентов. Авторами настоящего изобретения было использовано два предпочтительных способа получения оценок статуса рака. В первом, называемым линейным способом (CS1), брали оценку местоположения топологии (+1 или -1), умноженную на прогностическую силу для этой двухмаркерной плоскости. Затем их складывали, масштабировали и смещали с получением оценки от 0 до 200. Вторую оценку, называемую оценкой q (CSq), рассчитывали с помощью квадратного корня из суммы квадратов для этих же значений. Согласно этому второму способу, внимание акцентировали на различиях в индивидуальных двухмаркерных оценках, и он полезен в постановке окончательного диагноза врачом.
[0135] Нестабильность топологии все еще сохранялась в двухмаркерных плоскостях из-за крайне нелинейной природы способа установления корреляции с помощью пространственной близости, и ее нельзя было полностью устранить. Согласно другим аспектам настоящего изобретения, к слепому набору данных можно применять тест стабильности и методики, учитывающие включенный шум. А неконгруэнтную модель обучающей выборки можно использовать для вынесения арбитражного решения или коррекции оценок статуса рака. В случае данного аспекта настоящего изобретения для каждого набора слепых данных от пациента включали фиксированный уровень шума (например, плюс или минус 10%). Если набор слепых образцов брали от приблизительно 100 пациентов, то фактический цикл работы компьютера для создания модели обучающей выборки проводили для набора из 300 образцов, при этом каждый проводили в трех повторностях (необработанные данные плюс шум и минус шум). Полученный набор трехкратных данных затем тестировали на стабильность (a составляет -10%, b составляет +10%, а точка c является необработанными данными). В таблице 5 (ниже) показан результат теста на стабильность для данных, полученных в ходе клинического исследования. Следует отметить, что у трех образцов наблюдали очень высокую нестабильность оценок статуса рака. У всех образцов 138, 207, 34 и 29 наблюдали очень высокий показатель. Данный показатель (чем ниже, тем лучше) должен охватывать как степень сдвига оценки, так и особенно то, сдвигается ли или нет в ходе прогнозирования оценка из статуса здорового состояния в статус наличия рака или наоборот. Эти наборы данных, полученные от слепых образцов, имеют высокую степень риска быть ошибочными при постановке прогнозируемого диагноза.
Таблица. Результаты теста нестабильности топологии
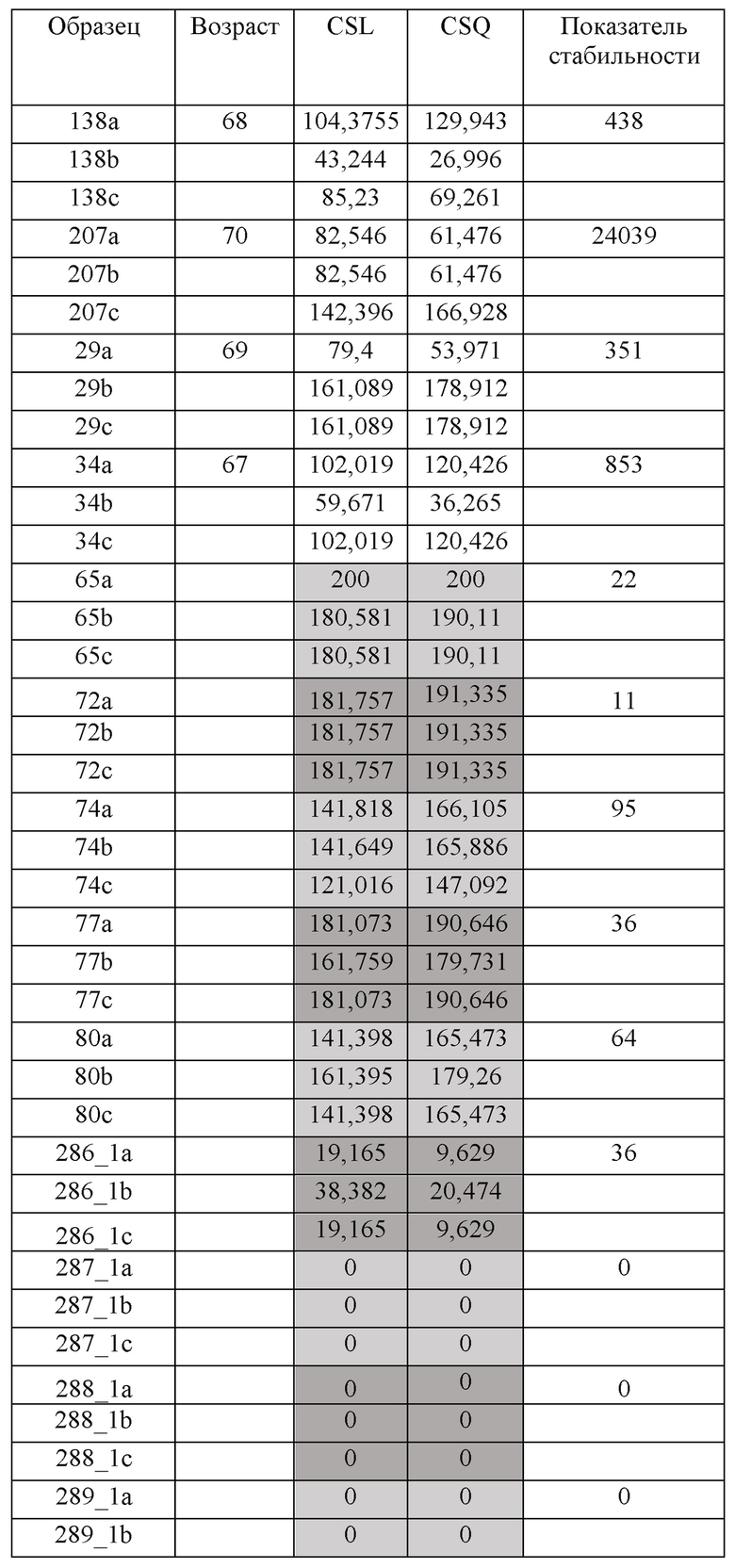
[0136] Неконгруэнтную модель обучающей выборки можно использовать для вынесения арбитражного решения по наборам данных от образцов пациентов «в группе риска», которые не прошли тест на уровень шума. Эти точки попадают в группу риска из-за неминуемого шума при измерениях, либо случайно, либо систематически связанного с чрезвычайной нестабильностью топологии, обусловленной тем фактом, что точка данных слепого образца лежит на очень крутом склоне почти на всех, если не на всех, двухмаркерных плоскостях, поэтому небольшие возмущения дают большие отклонения по результату оценки. В таблице 5 приведены образцы с включенным шумом. Каждый образец имеет три значения: 1) плюс шум, 2) минус шум и 3) необработанные данные без шума. Для этих образцов показаны оценки статуса рака, которые переходят из статуса наличия заболевания в статус отсутствия заболевания и обратно с включением +-10% шума. Данные по этим образцам в этом случае оценивали как нестабильные. Уровень нестабильности не был точно определен, и можно было вносить корректировки для различных уровней включения шума. В этом случае их корректировали на +- 10% шума и оценки стабильности, превышающей 200 (следует отметить, что оценка стабильности и оценка статуса рака представляют собой два совершенно разных числа с разными значениями).
[0137] С помощью такого неконгруэнтного второго алгоритма (алгоритм II) можно было вынести арбитражное решение по шуму результатов измерений. Используемый для определения неконгруэнтный алгоритм можно было использовать для коррекции этих наборов образцов пациентов «в группе риска», даже если он имел немного меньшую прогностическую силу, чем основной алгоритм, так как это повышало вероятность того, что точка верна. В этом случае корректировали два из них (см. фиг. 21); образец 138 имел оценку 85 статуса отсутствия и был скорректирован до 195 с помощью неконгруэнтного алгоритма (эта точка была стабильной при использовании алгоритма I), образец 34 имел оценку 102 (линейный способ) и был снова скорректирован до 198 с помощью алгоритма II. Образцы 29 и 207 не претерпевали изменений при использовании неконгруэнтного алгоритма.
[0138] В неконгруэнтной модели обучающей выборки (алгоритме II) были использованы 105 двухмаркерных плоскостей, и она была неконгруэнтной в отношении основной модели обучающей выборки (алгоритма I) в том, что те же самые образцы выглядели стабильными в тесте стабильности с помощью алгоритма II. Тестирование неконгруэнтной модели обучающей выборки выполняли точно так же, как и в случае основной модели обучающей выборки. Следует отметить, что для расчета этих оценок образцов также можно было использовать способ логистической регрессии. Алгоритм II обладает высокой прогностической силой, поэтому его и использовали. Арбитражную модель обучающей выборки можно использовать, если ее прогностическая сила меньше (но предпочтительно не меньше 50% прогностической силы), чем у основного алгоритма, при условии, что она дает относительно правильный результат без нестабильности. Следует отметить, что коррекция является важной для слепых образцов, которые не прошли тест на шум. Все эти образцы действительно имели статус наличия рака с высокими оценками. Восемь из десяти двухмаркерных плоскостей для этих образцов лежали на топологии с очень высоконестабильными точками сетки. Таким образом, оценки попадали в группу риска и действительно были неверными (одна была неверной, а другая была неопределенной и имели оценки 100/120). В этом случае был скорректирован один образец с улучшением прогностической силы с 97% до 98%, что было очень значительным снижением погрешности (на 50%). Один образец, хотя имел неопределенный статус, был изменен на статус наличия рака и также был скорректирован.
[0139] Способ улучшения прогностической силы двоичного выходного результата с коррекцией по статусу заболевания путем исключения независимого статуса, который частично имитирует один из статусов выходного результата, полученного в основном анализе статуса заболевания
[0140] Анализ пространственной близости обычно предусматривает использование трех или большего числа независимых переменных, зачастую концентрации белков в сыворотке крови пациента. Алгоритм расчета корреляции может оказывать влияние только на двоичный выходной результат, т. е. статус отсутствия заболевания или статус наличия заболевания, но он производит непрерывную оценку, что более тесно связано с вероятностью, что фактический выходной результат является двумя бинарными состояниями. В некоторых случаях существуют другие состояния, которые номинально классифицируют как статус отсутствия заболевания, которые частично имитируют статус наличия заболевания в распределениях генеральной совокупности используемых биомаркеров. В некоторых из этих случаев данный статус «MIMIC (имитирования)» отсутствия заболевания может привести к ложноположительному выходному результату корреляционного анализа. Решением для устранения такого ложноположительного результата является создание дополнительного нового корреляционного анализа, полностью отделенного от анализа статуса наличия или отсутствия заболевания. Этот новый корреляционный анализ предпочтительно предусматривает использование тех же самых измеренных данных по биомаркерам, что и в случае корреляции для статусов отсутствия или наличия заболевания, или же он может предусматривать использование некоторых или полностью иных биомаркеров. Такой новый корреляционный анализ дает в результате статус «MIMIC отсутствия заболевания» или «наличия заболевания» или, по меньшей мере, дает оценку, позволяющую сделать заключение о реальном состоянии пациента. Неопределенная или почти переходная оценка в случае анализа статуса отсутствия заболевания или наличия заболевания в сочетании с очень низкой или высокой оценкой по корреляции MIMIC отсутствия заболевания или наличия заболевания может помочь практикующему врачу улучшить заключение по статусу наличия заболевания и уменьшить количество ложноположительных оценок.
[0141] Примером такой ситуации, когда состояние отсутствия заболевания имитирует состояние наличия заболевания, является такое незлокачественное состояние, как доброкачественная гипертрофия предстательной железы (BPH). При таком состоянии обычно будут наблюдаться высокие уровни по меньшей мере одного биомаркера, используемого для диагностики рака предстательной железы. Например, такой биомаркер, как простатоспецифический антиген (PSA), будет повышен у мужчин с ВНР, а также с раком предстательной железы. В таблице 4 показано, что дополнительный способ корреляционного анализа может помочь распознать мужчин с ВНР и мужчин с раком предстательной железы, и, аналогично, с использованием тех же биомаркеров, но иной модели обучающей выборки, можно распознать мужчин, которые предположительно находятся в статусе отсутствия заболевания, и мужчин с подтвержденным раком предстательной железы в статусе наличия заболевания. У небольшой части мужчин ложноположительный результат будет получаться в случае использования модели обучающей выборки статуса отсутствия заболевания в сравнении со статусом наличия рака, но его можно будет распознать с помощью модели обучающей выборки статуса наличия BHP в сравнении со статусом наличия рака. В этих случаях две оценки, одна - для статуса предположительно отсутствия заболевания в сравнении со статусом наличия рака, а другая - для статуса наличия BHP в сравнении со статусом наличия рака, помогут врачу или другому специалисту в области медицины решить, какую выбрать следующую стадию диагностики. Например, в случае общей оценки (в случае либо CS1, либо CSq) от 0 до 200 для обеих моделей оценка, равная 110, для «СТАТУСА ОТСУТСТВИЯ РАКА ПРЕДСТАТЕЛЬНОЙ ЖЕЛЕЗЫ ИЛИ СТАТУСА НАЛИЧИЯ РАКА ПРЕДСТАТЕЛЬНОЙ ЖЕЛЕЗЫ» означает слабую оценку для положительного статуса по раку, но в случае второй оценки, равной 30, для статуса наличия BPH или рака, она также будет указывать практикующему врачу о высокой вероятности наличия BPH, но не рака. Практикующий врач будет использовать эту дополнительную информацию вместе с другой медицинской информацией и историей болезни пациента для принятия решения о следующих стадиях в диагностике.
[0142] Подробное рассмотрение способов
[0143] Стадии анализа / алгоритм
[0144] Процесс разработки аналитической модели в соответствии с настоящим изобретением обычно следует описанному ниже логическому пути, который проиллюстрирован на фиг. 22.
[0145] На стадии 2200 «Забор образцов у пациентов» программное обеспечение собирало большую группу образцов от пациентов с известным статусом отсутствия и наличия заболевания. Образцы, как правило, не подвергали скринингу на наличие каких-либо других не связанных патологических состояний (незлокачественных в случае новообразований), но собирали таким образом, чтобы наборы образцов выглядели статистически как генеральная совокупность.
[0146] На стадии 2202 «Измерение концентраций биомаркеров» программное обеспечение измеряло такие параметры, как концентрации биомаркеров, с использованием способов и устройств, известных в настоящей области техники.
[0147] На стадии 2204 «Расчет показателя близости для каждого биомаркера» программное обеспечение рассчитывало кривые показателей близости для каждого биомаркера и устанавливало зоны для каждого из них, как показано на фиг. 25.
[0148] На стадии 2206, «Оценка образцов по статусу наличия или отсутствия рака» программное обеспечение запускало программу модели для оценки образцов с помощью способа определения корреляции по пространственной близости. В модели использовали уравнения сжатия или ренормализации, уникальные для каждой из 4 зон (см. Уравнение 1 ниже).
[0149] На стадии 2208 «Тестирование и коррекция оценки» программное обеспечение тестировало индивидуальные образцы в отношении стабильности топологии и корректировало те, которые получалось правильно рассчитать с помощью неконгруэнтного алгоритма. Сначала все раковые оценки тестировали в отношении стабильности топологии обычным способом, включая плюс-минус шум на измеряемом уровне концентрации, рассчитывая оценки близости с внесенными искажениями и применяя их к основной модели пространственной близости. Если эти оценки статуса рака с внесенными искажениями смещались за заранее определенный предел, оценку статуса рака, рассчитанную с помощью первичной модели, отклоняли. Первоначальные уровни концентраций у неудачных тестов затем переводили в новые показатели близости, используя вторичную или неконгруэнтную модель. Эти новые показатели близости для этих неудачных образцов затем применяли к модели анализа корреляции по пространственной близости. Эти новые оценки статуса рака затем таким же образом тестировали с помощью вторичной модели на стабильность. Если эти образцы проходили тест на стабильность, то регистрировали, что они были проанализированы неконгруэнтной моделью. Если как первичная, так и вторичная модель были нестабильны, образец регистрировали как неопределенный.
[0150] Наконец, на стадии 2210 программное обеспечение выдавало рассмотренный выше результат в модели обучающей выборки, относя к категории статус наличия заболевания или статус отсутствия заболевания.
[0151] Устройства и реагенты, применяемые для валидационного исследования рака молочной железы: описание тестовой платформы
[0152] Система OTraces CDx Instrument
[0153] Данные теста, включенные для приведенной ниже части и для большей части работы, рассмотренной выше, измеряли на устройствах и с реагентами, которые указаны ниже. Данные обрабатывали в системе OTraces LEVIS или, в некоторых случаях, расчеты проводили с помощью программного обеспечения для ПК. Все вычислительное программное обеспечение было написано и валидировано компанией OTraces Inc. Специалист в настоящей области техники без труда поймет, что для получения аналогичных результатов можно применять другие эквивалентные аппаратные средства, устройства и реагенты.
[0154] Система CDx Instrument основана на системе MicroLab Starlet от компании Hamilton. Она индивидуализирована посредством программы для передачи способов иммуноанализа OTraces высокоскоростному роботу для проведения ИФА от компании Hamilton. Компания Hamilton является уважаемой компанией, которая по всему миру продает автоматизированные системы работы с жидкостями, в том числе систему MicroLab Starlet. Устройство индивидуализировано компанией Hamilton для OTraces с целью обеспечения полной автоматизации. Система OTraces CDx включает встроенную систему промывки микропланшетов и планшет-ридер. Эти два дополнительных устройства позволяют системе выполнять один полный цикл из суммарно пяти иммуноанализов на тестовой панели за одну смену без вмешательства оператора после первоначальной настройки. Настроенная система выполняла 40 оценок статуса рака в день. Усовершенствования включают программное обеспечение для проведения анализа одного целевого аналита за раз. Это необходимо для возможности повторного проведения определенного теста при возникновении ошибки в ходе полного прохождения теста.
[0155] Тестовый набор BC Sera DX
[0156] Данный тестовый набор включает в себя все реагенты и одноразовые устройства для проведения 120 тестовых оценок статуса рака, в том числе все буферы, блокирующие растворы, промывочный раствор, антитела и калибраторы. Усовершенствования, необходимые для полной коммерциализации этого набора, включают добавление двух контрольных образцов. Эти контроли обеспечивают независимую проверку того, что «слепой» тестовый образец дает правильную оценку статуса рака. Два контроля предназначены для получения показателя близости 50 и 150 соответственно. Программа контроля качества системы LIMS (см. ниже) проверяла правильность этих контролей, тем самым проверяя проведение отдельных тестов в эксплуатационных условиях. Тестовые наборы были собраны на заводе стандарта GMP и получили знак CE. Микротитрационный планшет предварительно был покрыты на заводе растворами антител для захвата и белка для блокировки.
[0157] Система организации лабораторной информации (LIMS)
[0158] Все системы клинической химии, представленные на рынке на сегодняшний день, например, Roche и Abbott, включают графический интерфейс с программным обеспечением, достаточным для управления данными пациента, обеспечения контроля качества прибора и химическими операциями и облегчения идентификации тестового образца и введения его в систему для проведения теста. Эти меню интегрированы в поставляемую химическую систему. Бизнес-модель OTraces заключается в том, чтобы включить эти функции на компьютерные серверы OTraces, расположенные на предприятиях OTraces в США, и подключить прибор CDx к этим серверам через Интернет с помощью облачных технологий. Это дает несколько существенных преимуществ. 1) Программное обеспечение LIMS включает в себя FDA-совместимое архивирующее программное обеспечение, так что с данными всех циклов тестирования с каждой системы CDx, развернутой в эксплуатационных условиях, работают на серверах OTraces. С помощью обратной связи от установленной базы вводные данные от ключевых учреждений о результатах лечения пациентов позволяют OTraces собирать соответствующие требованиям FDA данные для установления рыночного равновесия FDA в США. 2) Предпочтительно, упаковка реагентов со штрих-кодом позволяет прибору и LEVIS соединять все результаты QC-тестов из заводских QC-тестов. Эти данные доступны в режиме реального времени по мере проведения тестов в эксплуатационных условиях для дальнейшей проверки результатов тестов, проведенных в эксплуатационных условиях. 3) Система CDx работает только на валидированных реагентах OTraces и, следовательно, тестовые циклы с использованием реагентов, отличных от OTraces, невозможны. Данная система представляет собой типичный пользовательский интерфейс для оператора со всеми функциями, работающими в режиме реального времени, и отчеты о пациентах становятся доступны сразу после завершения теста.
[0159] Поэтапный способ разработки модели обучающей выборки и расчета оценки риска показан на блок-схеме на фиг. 23. Данный способ можно реализовать в программном обеспечении в определенных вариантах осуществления настоящего изобретения. Сначала производят построение модели обучающей выборки, и ее конечный продукт позволяет получать результаты диагностики для неизвестных образцов пациентов, называемых слепыми образцами, поскольку правильный диагноз на момент анализа этих слепых образцов неизвестен. В целом, настоящее изобретение позволяет медицинскому работнику определить оценку риска, при этом работник затем рассматривает эту оценку вместе с другими факторами пациента, чтобы вынести медицинское заключение о наличии или отсутствии данного заболевания.
[0160] Стадии 2302-2318 представляют собой описание способа, с помощью которого создают модель обучающей выборки. На стадии 2302 программное обеспечение определяло требования к образцам обучающей выборки, исходя из диагностических потребностей, которые являются заранее определенными критериями, которые могут быть заданы специалистом в настоящей области техники. Например, эти критерии могут представлять собой статус наличия заболевания в сравнении со статусом отсутствия заболевания, более конкретно, например, рака молочной железы, сравнивая положительные по раку молочной железы образцы с образцами, для которых известно, что у них отсутствует рак молочной железы.
[0161] На стадии 2304 программа определяла подлежащие расчету метапеременные, а также подлежащие измерению независимые переменные (т.е. биомаркеры).
[0162] На стадии 2306 программное обеспечение собирало образцы обучающей выборки в соответствии с параметрами, установленными на стадиях 2302-2304. На стадии 2308 программное обеспечение определяло измеренные независимые переменные и метапеременные, а также правильный диагноз заболевания, связанный с этими результатами, используя подходящее медицинское оборудование для каждого образца обучающей выборки. На стадии 2310 программное обеспечение рассчитывало двухмаркерную топологию для каждого образца и обучающей выборки. На стадии 2312 программное обеспечение рассчитывало оптимальные весовые корректировки или корректировки влияния двухмаркерной топологии для следующего: (1) неопределенностей предела обнаружения, например, образцов для которых было определено, что они ниже классического предела обнаружения; (2) нестабильностей экстремальной топологии, например, определенных с помощью способов, описанных в абзаце [0111] и в отношении рассмотренной выше стабильности топологии. На стадии 2314 расчеты считали завершенными и основную обучающую модель фиксировали для диагностики заболевания (например, рака). На стадии 2316 программное обеспечение разрабатывало вторичную обучающую модель с использованием фундаментально неконгруэнтного моделирования корреляции (см., например, фиг. 10). На стадии 2318 расчеты считали завершенными и зафиксированными, поскольку создавали вторичную обучающую модель для диагностики статуса наличия заболевания. Таким образом был создан набор обучающих моделей для диагностики заболевания.
[0163] Стадии 2320-2338 представляют собой описание, как программное обеспечение по настоящему изобретению использовало разработанную обучающую модель для диагностики заболеваний, таких как рак. На стадии 2320 программное обеспечение измеряло независимые переменные слепого образца, такие как биомаркеры, с использованием медицинского оборудования, аналогичного тому, которое было использовано при разработке модели обучающей выборки. На стадии 2322 программное обеспечение получало или измеряло и рассчитывало метапеременные данные для каждого слепого образца. На стадии 2324 программное обеспечение использовало эти данные для вычисления начальной оценки риска наличия заболевания для слепого образца с помощью первичной модели обучающей выборки. На стадии 2326 программное обеспечение определяло стабильность топологии оценки слепого образца от пациента. На стадии 2328 программное обеспечение проверяло, прошла ли оценка тест по стабильности топологии. Критерии для пройдено/не пройдено подразумевали определение того, насколько велика ошибка, вызванная нестабильностью, и, что наиболее важно, меняется ли оценка от положительного к отрицательному статусу наличия заболевания или наоборот. На стадии 2330, если было обнаружено, что оценкой был пройден тест на стабильность, выводился и/или публиковался отчет о диагностике и оценка риска. Если оценкой не был пройден тест, то на стадии 2332 программное обеспечение дополнительно рассчитывало вторичную оценку риска наличия заболевания с помощью неконгруэнтного алгоритма способа (алгоритма II), который описан выше. На стадии 2334 программное обеспечение снова проверяло, прошла ли оценка тест по стабильности топологии. На стадии 2336, если было обнаружено, что оценкой был пройден тест на стабильность, выводился и/или публиковался отчет о диагностике и оценка риска. Если оценкой все еще не был пройден тест, на стадии 2338 программное обеспечение готовило отчет о диагностике и выводило и/или публиковало результаты как неопределенные относительно того, имеет ли место заболевание.
[0164] Показатели близости, рассчитанные согласно настоящему изобретению, имеют несколько уникальных свойств. В соответствии с определенными вариантами осуществления, средние значения белков включены в логарифмическое сжатие в виде соотношения к фактической измеренной концентрации для пациента с данным возрастом. По сути, с помощью данного способа создавали веер схожих уравнений, каждое из которых уникально, например, по возрасту в годах для совокупности пациентов. Каждый неизвестный образец получал уникальное уравнение для возраста образца.
[0165] Можно было использовать соотношение, которое включало в себя скорректированное по возрасту среднее значение для статуса отсутствия заболевания и статуса наличия заболевания и фактическую концентрацию в образце пациента, в приведенной далее форме.
[0166] УРАВНЕНИЕ 1
[0167] Показатель близости = (K) * ln ((Ci/C(c или h))-(Ch/Cc))2, где:
[0168] K = пропорциональная константа;
[0169] Ci = измеренная концентрация фактического аналита пациента;
[0170] C(C или h) = скорректированная по возрасту пациента концентрация аналита этого пациента; значение корректируют в зависимости от того, имеет ли пациент статус отсутствия заболевания или наличия заболевания;
[0171] Ch = скорректированная по возрасту пациента средняя концентрация аналита пациента со статусом отсутствия заболевания; и
[0172] Cc = скорректированная по возрасту пациента средняя концентрация аналита пациента со статусом наличия заболевания.
[0173] Данное Уравнение 1 предназначено для корректировки сжатия и расширения в зависимости от зоны группы с положительной регуляцией, как показано на фиг. 25. Приведенная выше формула для показателя близости выполняет это требование; однако можно реализовать и многие другие формы данного уравнения, что будет очевидно специалистам в настоящей области техники. Например, Ci, Ch и Cc могут быть фактическими концентрациями или концентрационными расстояниями от среднего значения, медианного значения или расстоянием от медиан подгруппы или краев динамического диапазона, как рассмотрено выше. Другие варианты этого расчета приведены ниже в виде Уравнений 2 и 3.
[0174] УРАВНЕНИЕ 2
[0175] Показатель близости = K * ln (((концентрация у неизвестного образца) / (концентрация со средним значением для статуса наличия рака при возрасте пациента, у которого взят неизвестный образец)) - ((концентрация со средним значением статуса отсутствия рака при возрасте пациента, у которого взят неизвестный образец) / (концентрация со средним значением для статуса наличия рака при возрасте пациента, у которого взят неизвестный образец)))2.
[0176] Данное уравнение дает отрицательную бесконечность (натуральный логарифм нуля), если значение неизвестного образца равно среднему значению статуса отсутствия рака со значением возраста пациентов, у которых взяты неизвестные образцы. Ее заменяют в фактическом уравнении на заданное значение, например 2, как показано на фиг. 25. Другими словами, программным обеспечением тестировались значения вне предустановленного диапазона и сбрасывались до значения на пределе предустановленного диапазона.
[0177] УРАВНЕНИЕ 3
[0178] Показатель близости = K * ln (((концентрация у неизвестного образца) / (концентрация со средним значением для статуса отсутствия рака при возрасте пациента, у которого взят неизвестный образец)) - ((концентрация со средним значением статуса наличия рака при возрасте пациента, у которого взят неизвестный образец) / (концентрация со средним значением для статуса отсутствия рака при возрасте пациента, у которого взят неизвестный образец)))2.
[0179] Уравнение 3 дает натуральный логарифм нуля, т.е. отрицательную бесконечность, если значение неизвестного образца равно среднему значению статуса наличия рака для такого значения возраста пациента, у которого взят неизвестный образец. Данный вариант осуществления уравнения используют, если неизвестный образец имеет значение, превышающее среднюю концентрацию между средними значениями статусов наличия или отсутствия рака, при возрасте пациента, у которого взят неизвестный образец (предположительное наличие рака). В этой ситуации все уравнение обращается, таким образом, в положительную бесконечность, если неизвестный образец имеет среднее значение статуса наличия рака для значения его возраста. Данную бесконечность заменяют в фактическом уравнении на заданное значение, например, 18. На графике на фиг. 25 показано семейство уравнений, которые приводят к представляющему интерес возрастному диапазону. Уравнения независимо работают на каждой из четырех зон, показанных на фиг. 25. Этими зонами являются: 1) ниже среднего значения для совокупности со статусом отсутствия заболевания; (2) выше среднего значения статуса отсутствия заболевания и ниже производной средней точки между средним значением статуса отсутствия заболевания и статуса наличия заболевания (переход из статуса отсутствия заболевания/в статус наличия заболевания); (3) между производной средней точкой между средним значением статуса отсутствия заболевания / статуса наличия заболевания и средним значением статуса наличия заболевания у совокупности; и (4) выше среднего значения для статуса наличия заболевания. Следует отметить, что эти зоны не указывают, что образцы, расположенные внутри зоны, имеют статус наличия заболевания или статус отсутствия заболевания. Истинный диагноз индивидуального образца может быть любым, и его положение, если он «неправильный», может быть обусловлено другим состоянием, которое влияет на данный биомаркер. Мы называем это протеомным шумом. Зоны лишь обозначают, как индивидуальные образцы относятся к средним значениям, и являются каркасом для сжатия или ренормализации, проводимыми, например, по Уравнению 1. Следует отметить, что каждое уравнение представляет лишь одно значение возраста, и что общий набор представляет собой множество уравнений, каждое из которых представляет одно значение возраста. Общий набор уравнений предназначен для установки значений показателя близости на одно и то же заранее определенное значение для всех возрастов, когда фактическая концентрация точно равна средним значениям. Показанные возрасты составляют 35, 50 и 65. Полный набор выглядит как веер, с одним уравнением для каждого значения возраста пациента, у которого взят неизвестный образец.
[0180] Показатели близости (без единиц измерения и, следовательно, не являющиеся концентрациями или уровнями), например, иллюстративно рассчитывают так, как описано выше, а затем используют на многомерном графике корреляции по пространственной близости для анализа. Кроме того, все графики нормированы к общим характеристикам распределения генеральной совокупности; средним значениям возраста у статуса отсутствия заболевания и статуса наличия заболевания (с коррекцией на возраст или без нее), медианному значению или динамическому диапазону подгрупп. Эти способы могут улучшить прогностическую силу на 5 и более процентных пунктов.
[0181] Вышеупомянутые иллюстративные варианты осуществления систем и способов по настоящему изобретению можно реализовать в программном обеспечении, работающем как на подключенном к сети, так и на не подключенном к сети аппаратном обеспечении. Иллюстративный вариант осуществления аппаратного обеспечения, используемого для реализации настоящего изобретения, описан в связи с фиг. 26. В иллюстративной системе 2600 одно или несколько периферийных устройств 2610 подключены к одному или нескольким компьютерам 2620 через сеть 2630. Примеры периферийных устройств 2610 включают смартфоны, умные часы, планшеты, носимые электронные устройства, медицинские устройства, такие как ЭКГ и мониторы кровяного давления, и любые другие устройства, собирающие данные о биомаркерах, которые известны в настоящей области техники. Сеть 2630 может быть глобальной сетью, такой как Интернет, или локальной сетью, такой как интрасеть. Из-за сети 2630 физическое местоположение периферийных устройств 2610 и компьютеров 2620 не влияет на функциональные возможности настоящего изобретения. Обе реализации описаны в настоящем документе, и, если не указано иное, предполагают, что периферийные устройства 2610 и компьютеры 2620 могут находиться в одном и том же или в разных физических местоположениях. Связь между аппаратными компонентами системы может осуществляться множеством известных способов, например, с помощью компонентов сетевого подключения, таких как модем или Ethernet-адаптер. Как периферийные устройства 2610, так и компьютеры 2620 будут включать или будут подключены к оборудованию связи. Предполагают, что связь происходит через стандартизованные протоколы производственной сети, такие как HTTP.
[0182] Каждый компьютер 2620 состоит из центрального процессора 2622, носителя 2624 данных, пользовательского устройства 2626 ввода и дисплея 2628. Примерами компьютеров, которые можно использовать, являются коммерчески доступные персональные компьютеры, вычислительные устройства с открытым исходным кодом (например, Raspberry Pi), коммерчески доступные серверы и коммерчески доступные портативные устройства (например, смартфоны, умные часы, планшеты). В соответствии с одним вариантом осуществления, каждое из периферийных устройств 2610 и каждый из компьютеров 2620 системы могут иметь программное обеспечение, связанное с установленной на нем системой. В соответствии с таким вариантом осуществления, данные по биомаркеру могут храниться локально на подключенных к сети компьютерах 2620 или, альтернативно, на одном или нескольких удаленных серверах 2640, которые доступны любому из подключенных к сети компьютеров 2620 через сеть 2630. В соответствии с альтернативными вариантами осуществления, программное обеспечение работает в виде приложения на периферийных устройствах 2610.
[0183] Несмотря на что были проиллюстрированы определенные признаки описанных вариантов осуществления, специалистам в настоящей области техники теперь будут очевидны многие модификации, замены, изменения и эквиваленты. Поэтому понятно, что настоящее изобретение не ограничено конкретными раскрытыми вариантами осуществления или схемами, а скорее подразумевается как охватывающее любые изменения, адаптации или модификации, которые находятся в пределах объема и сущности настоящего изобретения, которые определены в прилагаемой формуле изобретения. Все упоминаемые в настоящем документе источники, в том числе патенты и заявки, в прямой форме включены во всей своей полноте.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ВЫЯВЛЕНИЯ ПРИСУТСТВИЯ ИЛИ ОТСУТСТВИЯ АГРЕССИВНОГО РАКА ПРЕДСТАТЕЛЬНОЙ ЖЕЛЕЗЫ | 2013 |
|
RU2675370C2 |
| СПОСОБ ПРОГНОЗА ДЛЯ ИНДИВИДУУМОВ С РАКОМ ПРЕДСТАТЕЛЬНОЙ ЖЕЛЕЗЫ | 2013 |
|
RU2669809C2 |
| СПОСОБЫ ПРОГНОЗИРОВАНИЯ РАКА ПРЕДСТАТЕЛЬНОЙ ЖЕЛЕЗЫ | 2016 |
|
RU2760577C2 |
| СПОСОБ ОБНАРУЖЕНИЯ СОЛИДНОЙ ЗЛОКАЧЕСТВЕННОЙ ОПУХОЛИ | 2015 |
|
RU2720148C2 |
| АУТОИММУННАЯ РЕГУЛЯЦИЯ РАКА ПРЕДСТАТЕЛЬНОЙ ЖЕЛЕЗЫ АННЕКСИНОМ А3 | 2008 |
|
RU2484482C2 |
| СПОСОБ СКРИНИНГОВОГО ОПРЕДЕЛЕНИЯ ВЕРОЯТНОСТИ НАЛИЧИЯ РАКА МОЧЕВОГО ПУЗЫРЯ | 2019 |
|
RU2718284C1 |
| КОГОРТЫ БИОМАРКЕРОВ МОЧИ, ПРОФИЛЬ ЭКСПРЕССИИ ГЕНОВ И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2014 |
|
RU2668164C2 |
| Способ определения риска рецидива локализованного рака предстательной железы после выполнения высокоинтенсивной фокусированной ультразвуковой абляции | 2018 |
|
RU2692681C1 |
| Способ прогнозирования вероятности степени злокачественности ацинарной аденокарциномы предстательной железы у мужчин по шкале Глисона 7=3+4 и 7=4+3 на основе бпМРТ-радиомики | 2023 |
|
RU2825524C1 |
| Способ прогнозирования вероятности выявления рака предстательной железы у мужчин на основе МРТ-радиомики | 2024 |
|
RU2839227C1 |
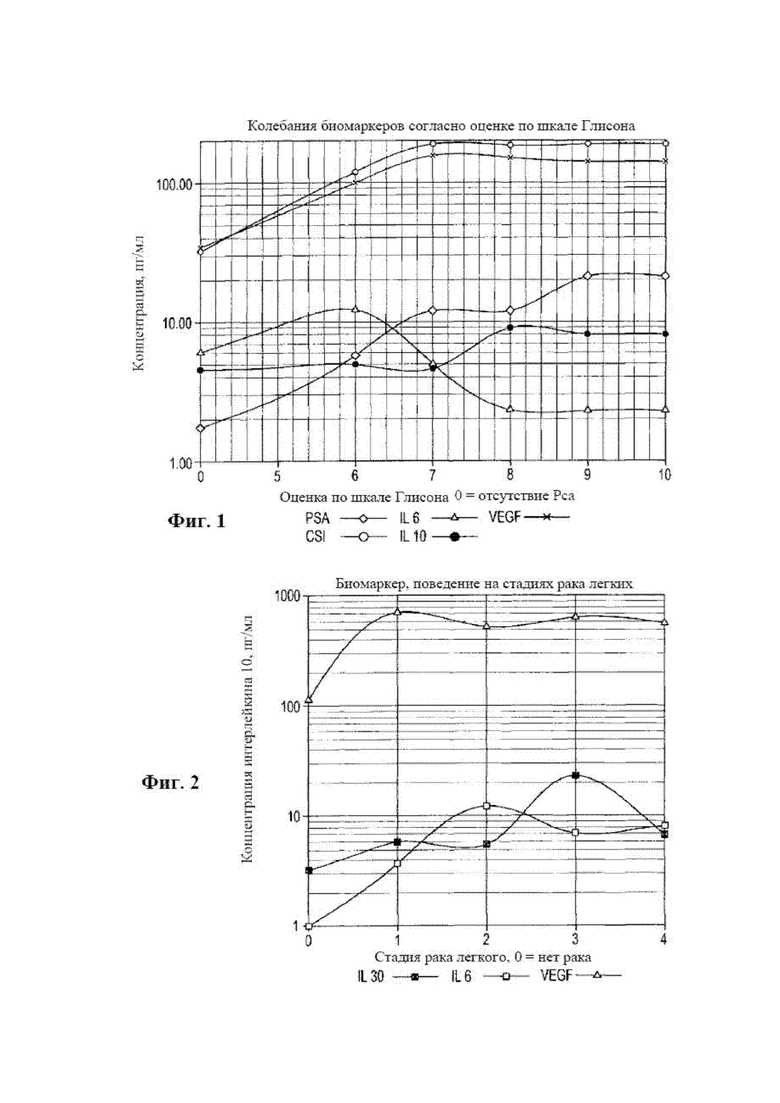
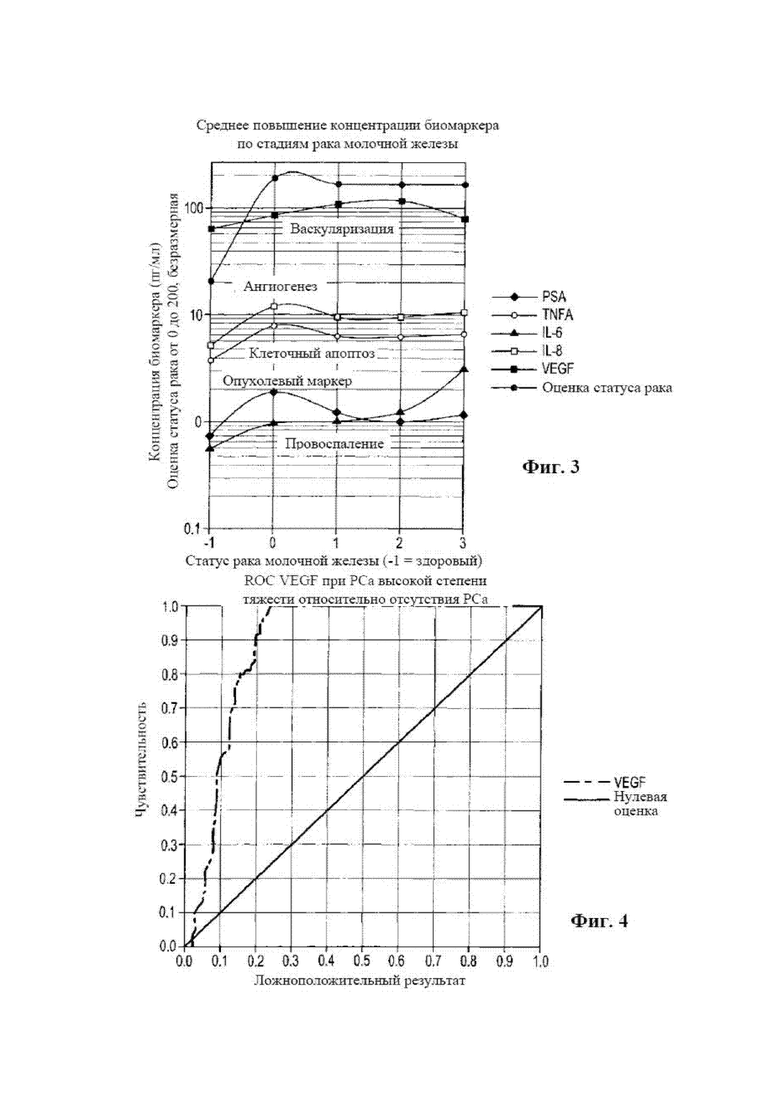
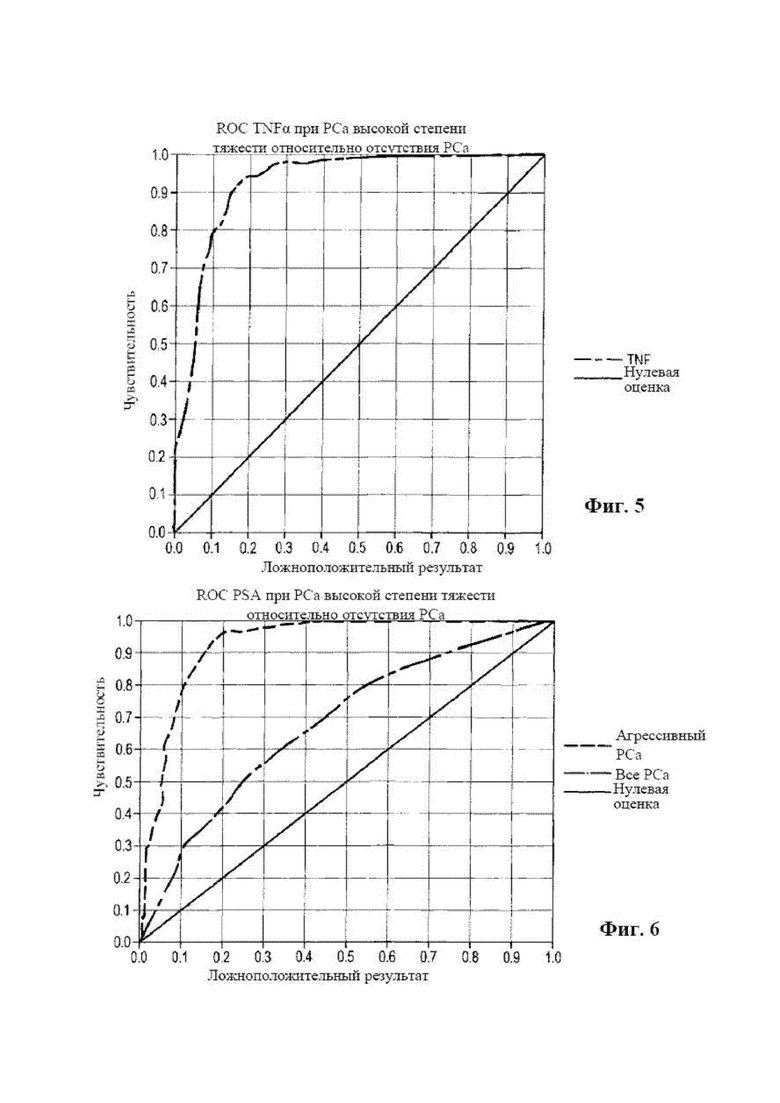
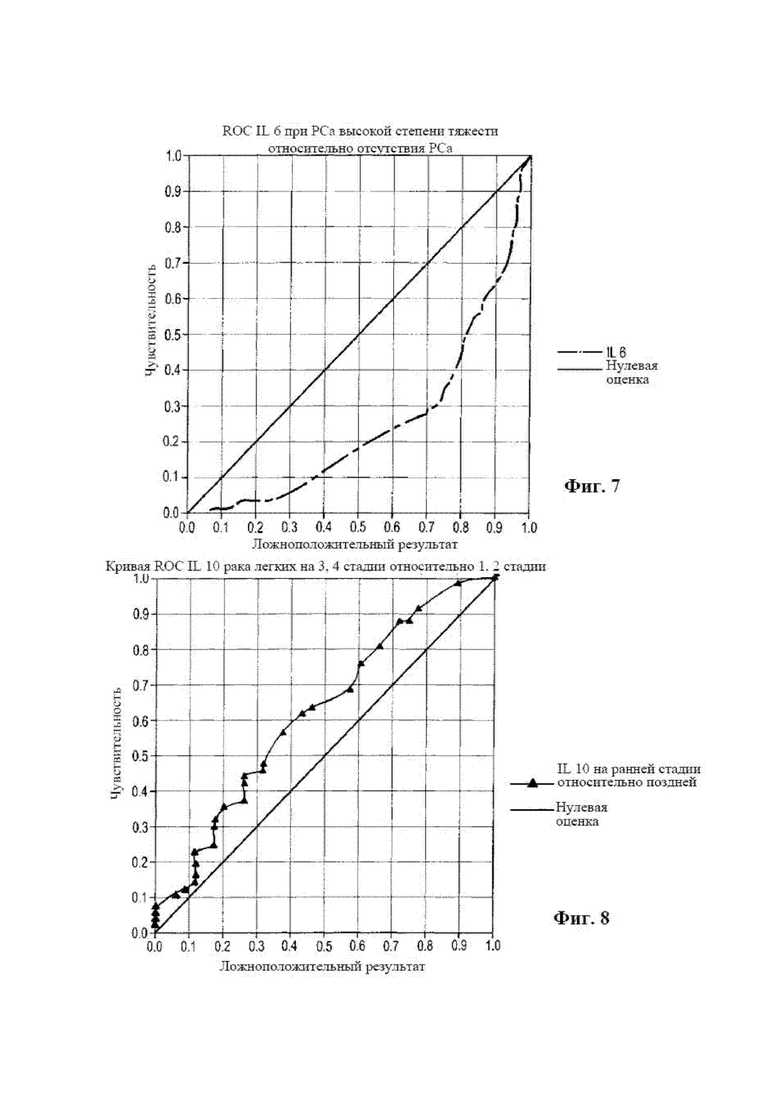
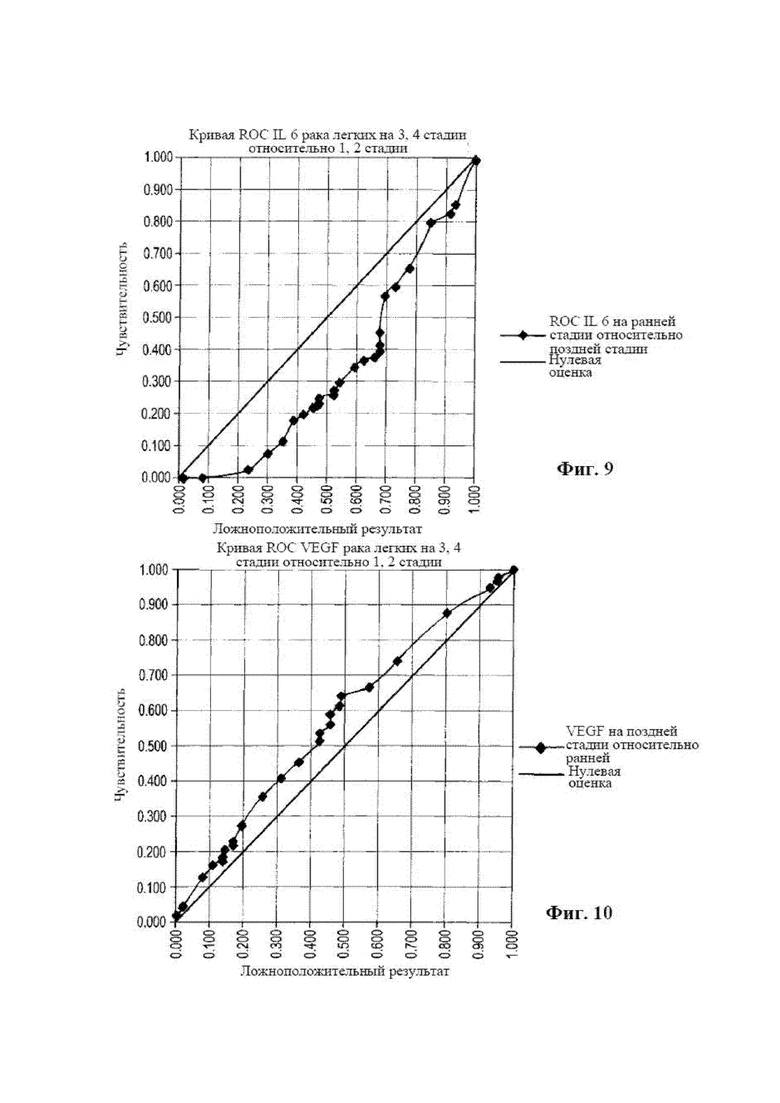
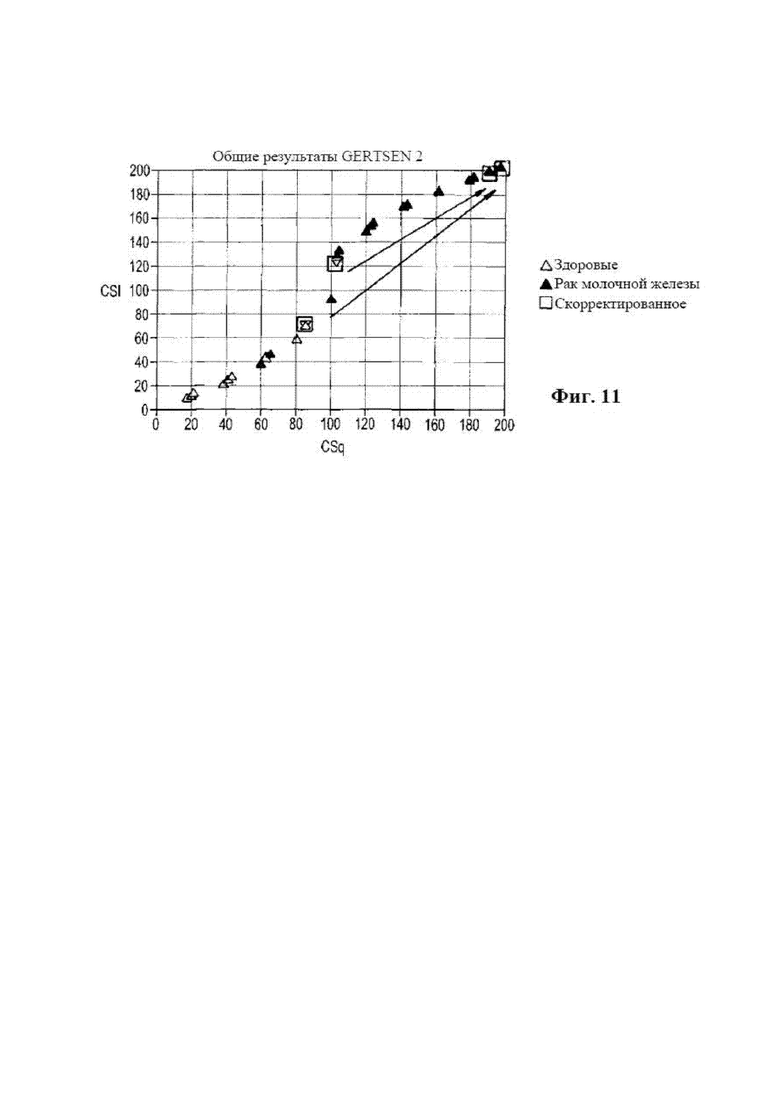
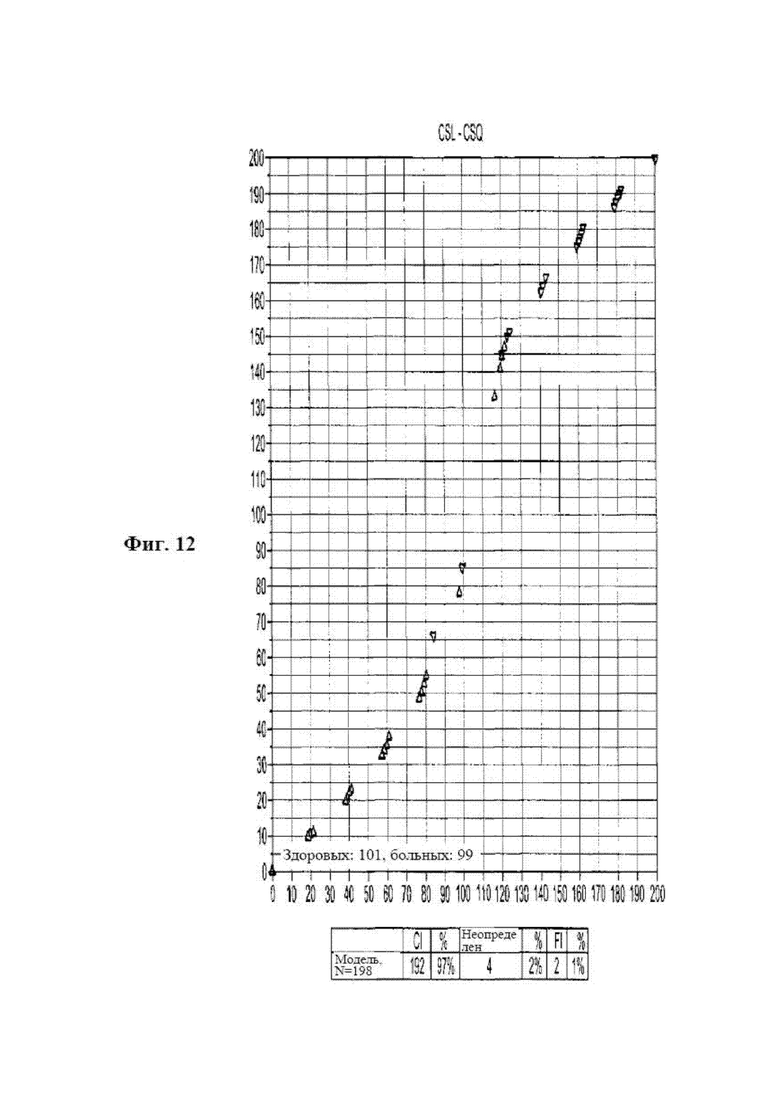
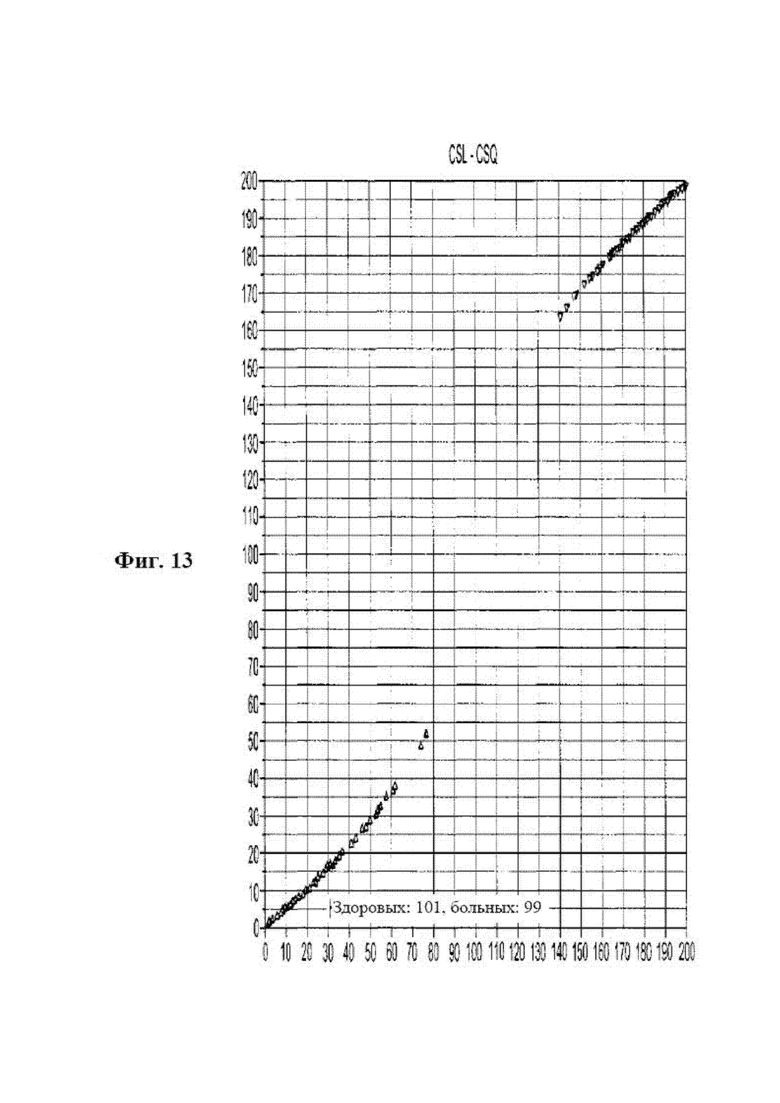
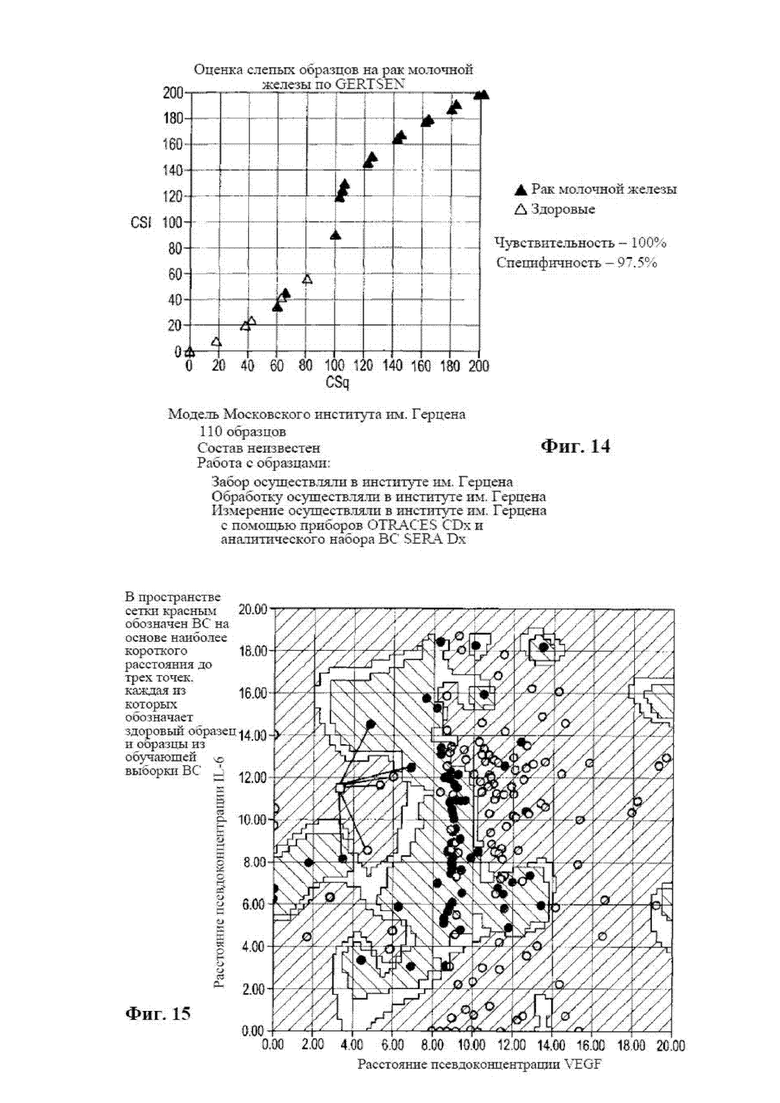
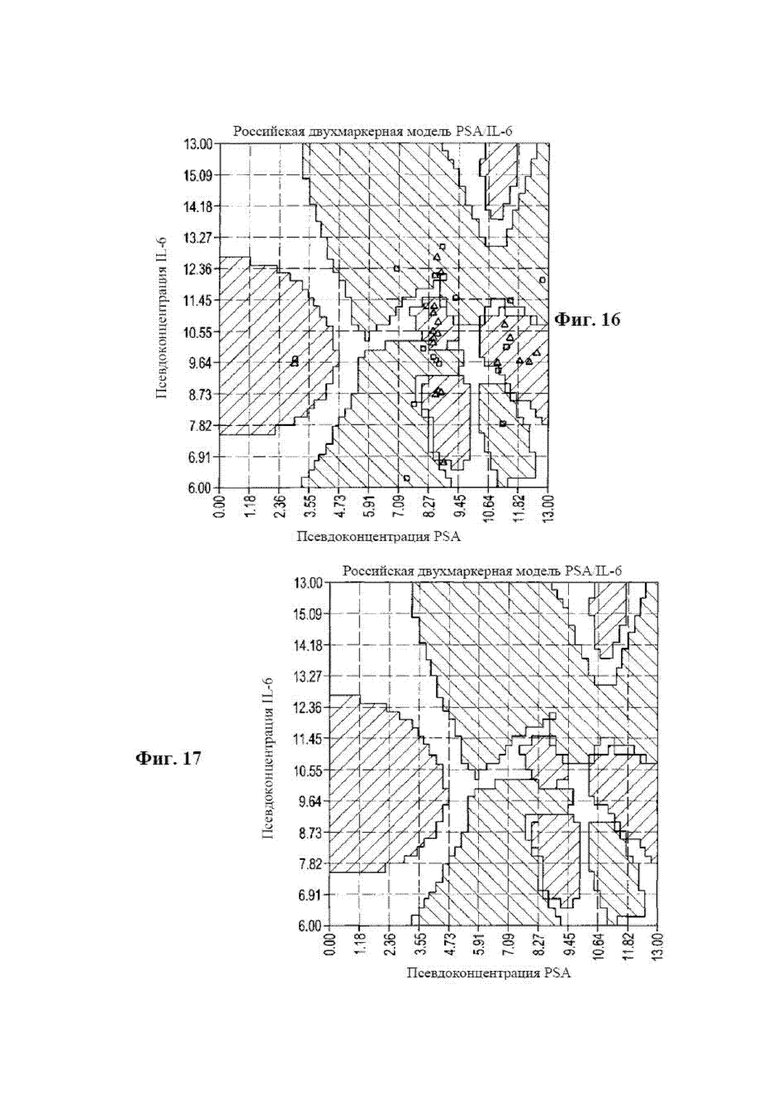
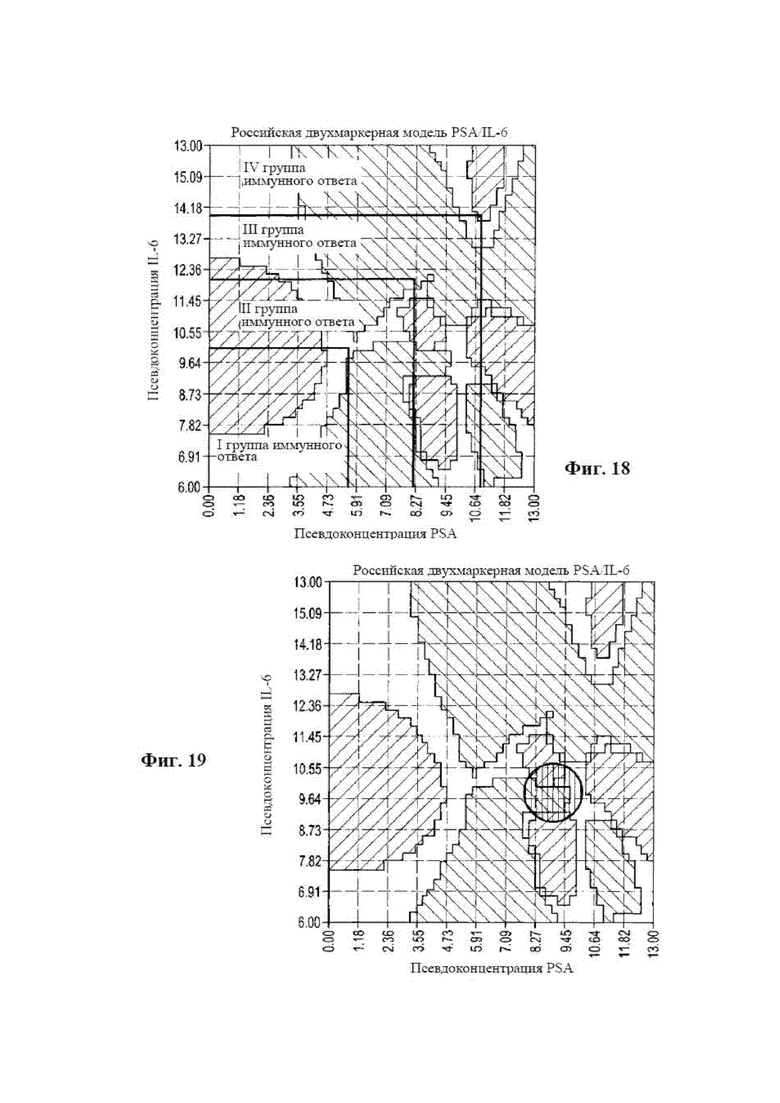
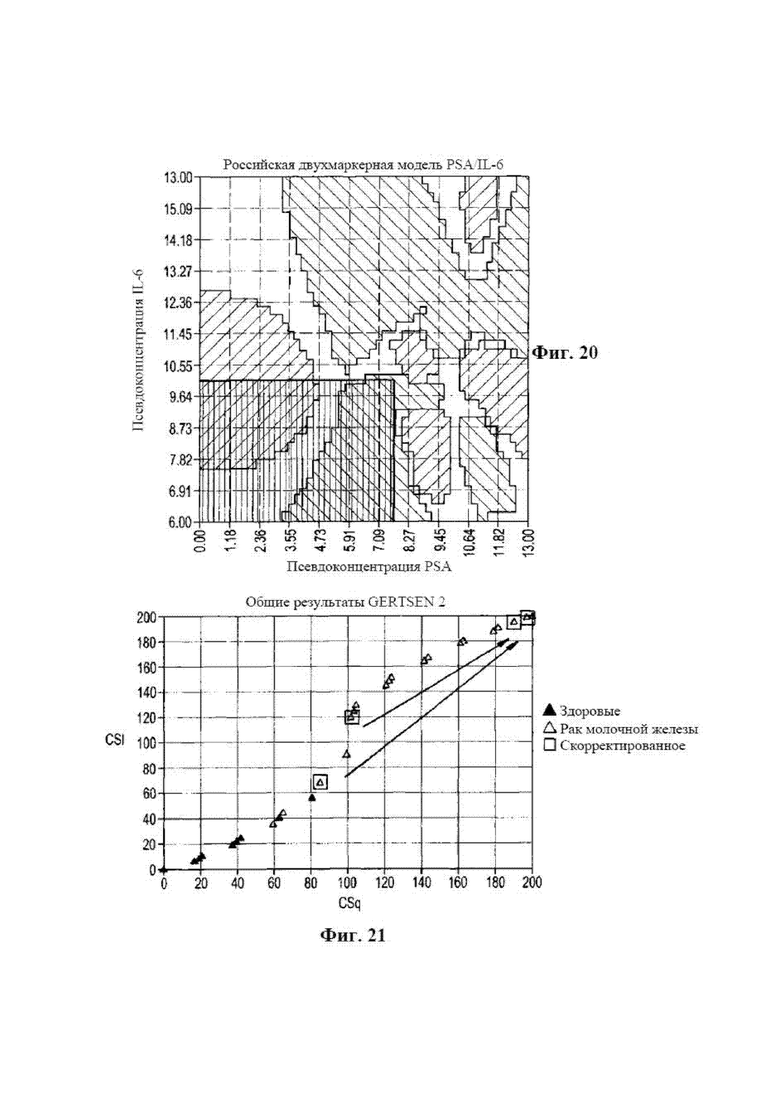
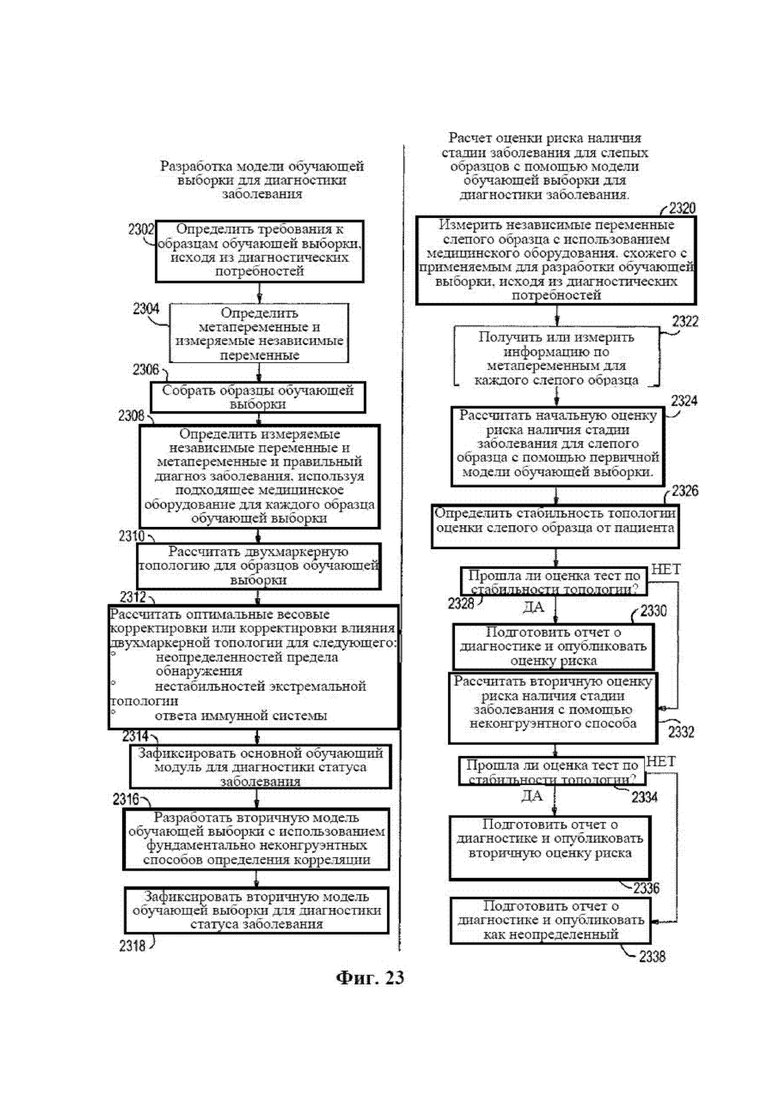
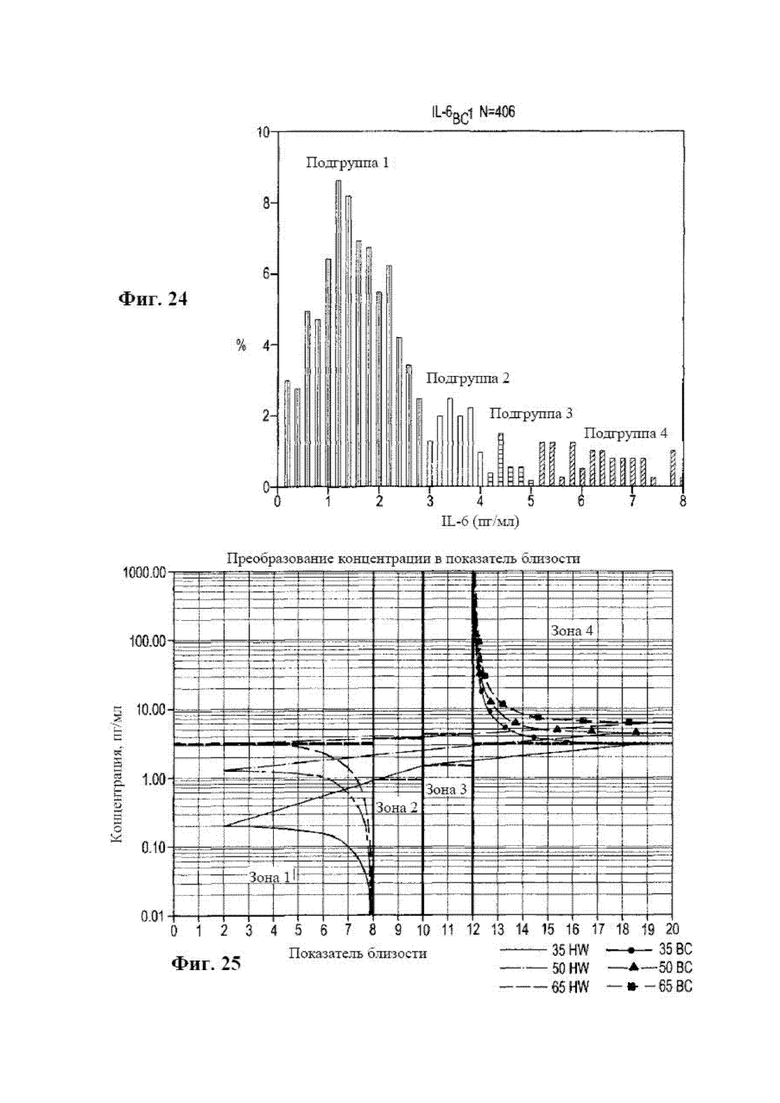
Изобретение относится к биотехнологии, в частности, раскрыты системы и способы диагностики заболеваний, таких как рак предстательной железы, рак молочной железы, рак легкого, рак яичника и их стадии. В соответствии с определенными вариантами осуществления раскрываемые системы и способы предусматривают сбор образцов пациента, расчет концентраций и показателей близости биомаркеров и применение результатов таких расчетов для создания модели обучающей выборки, которую применяют для установления корреляции концентраций биомаркеров и показателей близости с диагнозами заболеваний и статусами заболеваний (например, стадиями рака). В соответствии с определенными вариантами осуществления к используемым корреляционным методикам относятся простая регрессия, максимизация площади под кривой ROC, стабилизация топологии или анализ корреляции по пространственной близости. 2 н. и 18 з.п. ф-лы, 26 ил., 5 табл., 4 пр.
1. Компьютеризованный способ диагностики заболевания, согласно которому компьютер, на котором реализуется способ, содержит один или более процессоров, содержащих память, функционально связанную с указанными одним или более процессорами, причем способ предусматривает следующие стадии:
(a) получение первого набора одного или нескольких значений концентрации первого биомаркера из первого образца пациента, причем первый образец пациента диагностирован со статусом отсутствия заболевания, причем первый биомаркер представляет собой белок интерстициальной жидкости активной опухоли, который отобран в сыворотку в качестве заместителя активности в микроокружении опухоли;
(b) получение второго набора одного или нескольких значений концентрации первого биомаркера из второго образца пациента, причем второй образец пациента диагностирован со статусом наличия заболевания, причем первый биомаркер представляет собой белок интерстициальной жидкости активной опухоли, который отобран в сыворотку в качестве заместителя активности в микроокружении опухоли;
(c) расчет первого набора показателей близости из первого набора значений концентрации и второго набора показателей близости из второго набора значений концентрации; и
(d) расчет корреляции для первого биомаркера с диагнозом наличия заболевания из первого и второго набора значений концентрации и первого и второго набора значений показателя близости, причем корреляция представляет собой одно из простой регрессии, максимизации площади под кривой ROC, стабилизации топологии или анализа пространственной близости; и
(e) диагностику заболевания пациента с помощью рассчитанной корреляции для первого биомаркера.
2. Компьютеризованный способ по п. 1, причем стадии (a) - (d) повторяют для максимум пяти биомаркеров.
3. Компьютеризованный способ по п. 1, причем корреляция сочетает два или более из простой регрессии, максимизации площади под кривой ROC, стабилизации топологии и анализа пространственной близости.
4. Компьютеризованный способ по п. 1, причем первый и второй образцы пациента включают по меньшей мере одно из образцов крови, образцов мочи или образцов ткани.
5. Компьютеризованный способ по п. 1, причем диагностируемое заболевание представляет собой одно из рака предстательной железы, рака молочной железы, рака легкого или рака яичника.
6. Компьютеризованный способ по п. 5, причем диагностируемое заболевание представляет собой стадию рака предстательной железы, рака молочной железы, рака легкого или рака яичника на основании оценки по шкале Глисона.
7. Компьютеризованный способ по п. 6, причем первый и второй образцы пациента содержат данные о стадии рака, и причем данные о стадии рака категоризируют на множество двоичных групп.
8. Компьютеризованный способ по п. 7, в котором оценивают каждую двоичную группу.
9. Компьютеризованный способ по п. 1, причем биомаркеры выбраны из функциональной группы цитокинов, и причем функциями цитокинов являются по меньшей мере три из провоспалительного, противовоспалительного, противоопухолевого генеза, клеточного апоптоза и васкуляризации.
10. Компьютеризованный способ по п. 1, причем первый биомаркер представляет собой VEGF.
11. Сервер для диагностики заболевания, содержащий:
центральный процессор и носитель данных, содержащий хранящиеся на нем инструкции, которые при их исполнении процессором побуждает сервер:
(a) получать первый набор одного или нескольких значений концентрации первого биомаркера из первого образца пациента, причем первый образец пациента диагностирован со статусом отсутствия заболевания, причем первый биомаркер представляет собой белок интерстициальной жидкости активной опухоли, который отобран в сыворотку в качестве заместителя активности в микроокружении опухоли;
(b) получать второй набор одного или нескольких значений концентрации первого биомаркера из второго образца пациента, причем второй образец пациента диагностирован со статусом наличия заболевания, причем первый биомаркер представляет собой белок интерстициальной жидкости активной опухоли, который отобран в сыворотку в качестве заместителя активности в микроокружении опухоли;
(c) рассчитывать первый набор показателей близости из первого набора значений концентрации и второй набор показателей близости из второго набора значений концентрации;
(d) рассчитывать корреляции для первого биомаркера с диагнозом наличия заболевания из первого и второго набора значений концентрации и первого и второго набора значений показателя близости, причем корреляция представляет собой одно из простой регрессии, максимизации площади под кривой ROC, стабилизации топологии или анализа пространственной близости; и
(e) диагностировать заболевание пациента с помощью рассчитанной корреляции для первого биомаркера.
12. Сервер по п. 11, причем стадии (a) - (d) повторяют для максимум пяти биомаркеров.
13. Сервер по п. 11, причем корреляция сочетает два или более из простой регрессии, максимизации площади под кривой ROC, стабилизации топологии и анализа пространственной близости.
14. Сервер по п. 11, причем первый и второй образцы пациента включают по меньшей мере одно из образцов крови, образцов мочи или образцов ткани.
15. Сервер по п. 11, причем диагностируемое заболевание представляет собой одно из рака предстательной железы, рака молочной железы, рака легкого или рака яичника.
16. Сервер по п. 15, причем диагностируемое заболевание представляет собой стадию рака предстательной железы, рака молочной железы, рака легкого или рака яичника на основании оценки по шкале Глисона.
17. Сервер по п. 16, причем первый и второй образцы пациента содержат данные о стадии рака, и причем данные о стадии рака категоризируют на множество двоичных групп.
18. Сервер по п. 17, причем оценивают каждую двоичную группу.
19. Сервер по п. 11, причем биомаркеры выбраны из функциональной группы цитокинов, и причем функциями цитокинов являются по меньшей мере три из провоспалительного, противовоспалительного, противоопухолевого генеза, клеточного апоптоза и васкуляризации.
20. Сервер по п. 11, причем первый биомаркер представляет собой VEGF.
| СПОСОБ, КОМПЬЮТЕРНЫЙ ПРОГРАММНЫЙ ПРОДУКТ И СИСТЕМА ОБЕСПЕЧЕНИЯ ПОДДЕРЖКИ ПРИНЯТИЯ КЛИНИЧЕСКОГО РЕШЕНИЯ | 2009 |
|
RU2560423C2 |
| WO 2017127822 A1, 27.07.2017 | |||
| US 20160034651 A1, 04.02.2016. | |||

