Изобретение относится к области автоматизированного анализа и обработки скважинных данных, получаемых в процессе и после бурения с целью поддержки принятия решений, управления рисками и эффективной оценки скважинной информации с применением современных компьютерных технологий, в частности, методов машинного обучения.
Строительство скважин – первый и наиболее затратный этап разработки нефтегазовых месторождений. Бурение скважин обеспечивает доступ к нефтеносным пластам, от качества бурения и корректной интерпретации геологических данных будет зависеть уровень добычи углеводородов. В настоящий момент контроль за скважинной информацией осуществляется специалистами непосредственно на буровой или в удаленных офисах. Специалисты визуально отслеживают изменение основных параметров, характеризующих процесс бурения и свойства пластовых систем.
Для контроля процесса бурения используют датчики, находящиеся на буровой и передающие данные на станции геолого-технических исследований (ГТИ). Данные включают в себя положение долота, положение талевого блока, параметры вращения, гидравлические характеристики и др.
Для контроля траектории скважины, оценки ее потенциала добычи и выбора наиболее эффективных методов воздействия на пласт используют геофизические методы исследования скважин (ГИС) - методы прямого измерения физических свойств залежей в скважинах во время бурения или после. Для этого используют комплекс методов разведочной геофизики, включающий электрические, радиометрические, сейсмоакустические, тепловые методы и др.
Специалисты вручную анализируют поступающие данные, составляют суточные сводки проведенных работ, оценивают текущую ситуацию и принимают решения о необходимости изменения процесса бурения, вносят корректировки в планы по разработке месторождения.
Примером традиционного подхода, при котором специалисты наблюдают за показаниями приборов, работой оборудования, состоянием промывочной жидкости и пр. являются программные продукты ООО «Петровайзер» - информационная система «Мониторинг удаленных объектов WellOnline» (Нестерова Т.Н. Макаров А.А., «Мониторинг? Мониторинг... Мониторинг!!!», № 5, 2015, стр. 62-64; http://www.petroviser.ru/services/it/wellonline/). Информационная система «Мониторинг удаленных объектов – WellOnline» предназначена для контроля удаленных объектов бурения путем передачи по каналам связи информации с буровой площадки на уровни управления Заказчика. Аналогичное решение «GTI-online» предлагается компанией ООО «ТетраСофт-Сервис» https://www.tetraservice.ru/uslugi/umb.html. Данная технология представляет собой совокупность технических средств, программно-информационных комплексов, а также нормативных и регламентирующих документов, обеспечивающих получение, доставку, обработку, анализ и хранение исходной и обработанной информации по строительству скважин. Программный комплекс «Формирование производственной отчетности по строительству скважин – WellReport» обеспечивает документирование всех работ и операций, проводимых на буровой в процессе строительства скважин. http://www.petroviser.ru/services/it/wellreport/. Программный комплекс «Визуализация и печать данных ГИС/ГТИ – Ultimate Logs» предназначен для просмотра, редактирования и печати геологической, геохимической, геофизической и технологической информации. http://www.petroviser.ru/services/it/ultimate_logs/.
Традиционный подход наблюдения за скважинными данными имеет следующие недостатки:
• внештатные ситуации, возникающие в процессе бурения связаны с недостаточным контролем со стороны специалистов, сопровождающих строительство скважины или с невозможностью выявить видимые признаки приближающегося негативного события;
• контроль бурения, производимый человеком, обуславливает формирование отчетных документов вручную, что требует существенных трудозатрат, приводит к неточностям и возможности фальсификации данных, затрудняет их дальнейшую обработку;
• попытки вручную оптимизировать процесс бурения приводят к тому, что часть критических факторов, влияющих на достижение целей бурения, может быть не учтена, что приводит к снижению эффективности бурения;
• обработка геологических данных в ручном режиме требует значительных временных затрат, что не позволяет принимать оперативные решения;
• обработка геологических данных в ручном режиме приводит к субъективизму в интерпретации литологического разреза и выбору неоптимальной траектории скважины и неоптимальных подходов к разработке месторождений.
Технический результат, достигаемый при реализации изобретения, заключается в обеспечении возможности определения в автоматическом режиме типа породы и характера ее насыщения (нефть, газ, вода), а также типа выполняемых операций и вероятности наступления и/или развития событий при бурении путем интерпретации и контроля геологической и технологической скважинной информации, получаемой как непосредственно в процессе бурения в реальном времени, так и используя исторические данные с ранее пробуренных скважин.
На основании полученной информации могут вычисляться различные агрегированные статистики, позволяющие оценить вероятность наступления различных событий, например, геологических осложнений или аварийных ситуаций. Это позволяет обоснованно принимать оперативные решения для снижения непроизводительного времени, при необходимости, оперативно изменить траекторию скважины или способ заканчивания для получения максимальной добычи, сократить трудозатраты и время на интерпретацию данных, получить объективную оценку потенциала залежи.
Указанный технический результат достигается тем, что в соответствии с предлагаемым способом обработки скважинных данных собирают исходные скважинные данные, содержащие по меньшей мере один тип данных, выбранных из группы, содержащей данные, характеризующие процесс бурения и представляющие собой результаты измерений с датчиков, расположенных на поверхности, и данные каротажа в каждый момент времени. Осуществляют компьютерную обработку всех собранных исходных скважинных данных, в соответствии с которой из собранных данных формируют структурированные массивы данных каждого типа. При этом структурированные массивы данных, сформированные в результате обработки данных, характеризующих процесс бурения, содержат полную технологическую характеристику процесса бурения в каждый момент времени, а структурированные массивы данных, сформированные в результате обработки данных каротажа, содержат геофизическую характеристику прискважинной зоны. Используя в качестве входных данных сформированные структурированные массивы данных каждого типа, посредством предварительно обученного алгоритма искусственного интеллекта осуществляют автоматическую разметку собранных исходных скважинных данных каждого типа, и, используя в качестве входных данных размеченные данные каждого типа, формируют результат для выдачи пользователю в виде интересующего фрагмента размеченных данных по времени и/или глубине.
Автоматическая разметка исходных данных, характеризующих процесс бурения, представляет собой дополнение исходных данных информацией о типах выполняемых операций и событий в каждый момент времени, а также информацией о вероятности наступления или развития событий.
Автоматическая разметка исходных данных каротажа представляет собой дополнение исходных данных информацией о типах и насыщении породы в каждой точке вдоль скважины.
Для осуществления автоматической разметки исходных данных, характеризующих процесс бурения, в начале производится обучение алгоритма искусственного интеллекта. Для этого формируют обучающий набор данных, содержащий исходные данные о бурении в каждый момент времени с соответствующими им типами выполняемых операций и событиями и выбирают по меньшей мере один алгоритм искусственного интеллекта. По меньшей мере один раз на основе сформированного обучающего набора данных отбирают признаки для выбранного алгоритма искусственного интеллекта, содержащие данные о бурении в каждый момент времени, и формируют ответы, содержащие соответственно информацию о типах выполняемых операций и событий. По меньшей мере один раз обучают выбранный алгоритм искусственного интеллекта на основе сформированного обучающего набора данных, отобранных признаков и ответов.
Для осуществления автоматической разметки исходных данных каротажа в начале производится обучение алгоритма искусственного интеллекта. Для этого формируют обучающий набор данных, содержащий исходные данные каротажа с соответствующими им типами породы и характером ее насыщения, выбирают по меньшей мере один алгоритм искусственного интеллекта. По меньшей мере один раз на основе сформированного обучающего набора данных отбирают признаки для выбранного алгоритма искусственного интеллекта, содержащие данные каротажа, и формируют ответы, содержащие соответственно информацию о типах и насыщении породы. По меньшей мере один раз обучают выбранный алгоритм искусственного интеллекта на основе сформированного обучающего набора данных, отобранных признаков и ответов.
Результаты измерений с датчиков, расположенных на поверхности, выбирают из группы, содержащей вес бурильной колонны или инструмента, глубину забоя, давление на входе, нагрузку на долото, частоту ходов насосов, скорость инструмента, температуру, концентрацию углеводородных компонентов и др.
Типы выполняемых операций представляют собой бурение, спуск бурильной или обсадной колонны, подъем бурильной или обсадной колонны, проработку ствола скважины, обратную проработку ствола скважины, промывку ствола скважины, простой и др.
События, информация о которых дополняет исходные данные о бурении, представляют собой геологические осложнения.
События, информация о которых дополняет исходные данные о бурении, представляют собой аварийные ситуации.
События, информация о которых дополняет исходные данные о бурении, представляют собой предвестники аварийных ситуаций.
События, информация о которых дополняет исходные данные о бурении, представляют собой события, выбранные пользователем и имеющие характерные признаки в записях режимных параметров бурения.
В качестве исходных данных каротажа используют результаты прямых измерений физических свойств пород в скважинах.
Компьютерная система обработки скважинных данных для осуществления способа содержит блок сбора данных, предназначенный для сбора по меньшей мере одного типа данных, выбранных из группы, содержащей данные, характеризующие процесс бурения и представляющие собой результаты измерений с датчиков, расположенных на поверхности, и данные каротажа в каждый момент времени; блок обработки и подготовки собранных исходных данных, предназначенный для формирования структурированных массивов данных, при этом структурированные массивы данных, сформированные в результате обработки данных, характеризующих процесс бурения, содержат полную технологическую характеристику процесса бурения в каждый момент времени, а структурированные массивы данных, сформированные в результате обработки данных каротажа, содержат геофизическую характеристику прискважинной зоны, блок автоинтерпретации, осуществляющий автоматическую разметку собранных исходных данных, и блок выдачи результата, предоставляющий информацию пользователю.
Дополнительно компьютерная система обработки скважинных данных содержит блок автоматического машинного обучения, предназначенный для обучения и выбора оптимального алгоритма обработки данных.
Изобретение поясняется чертежами, на которых на фиг. 1 представлена общая схема компьютерной системы обработки скважинных данных, на фиг. 2 представлена схема обработки собранных исходных данных посредством препроцессора, на фиг.3 представлена схема автоматического выбора алгоритмов разметки скважинных данных и их обучения, на фиг.4 представлена схема работы блока автоматического машинного обучения.
Предлагаемые способ и система обработки скважинных данных представляют собой сочетание блоков программных средств и операций, обеспечивающих контроль за процессом бурения, автоматическую интерпретацию каротажа и автоматическое формирование отчетных документов.
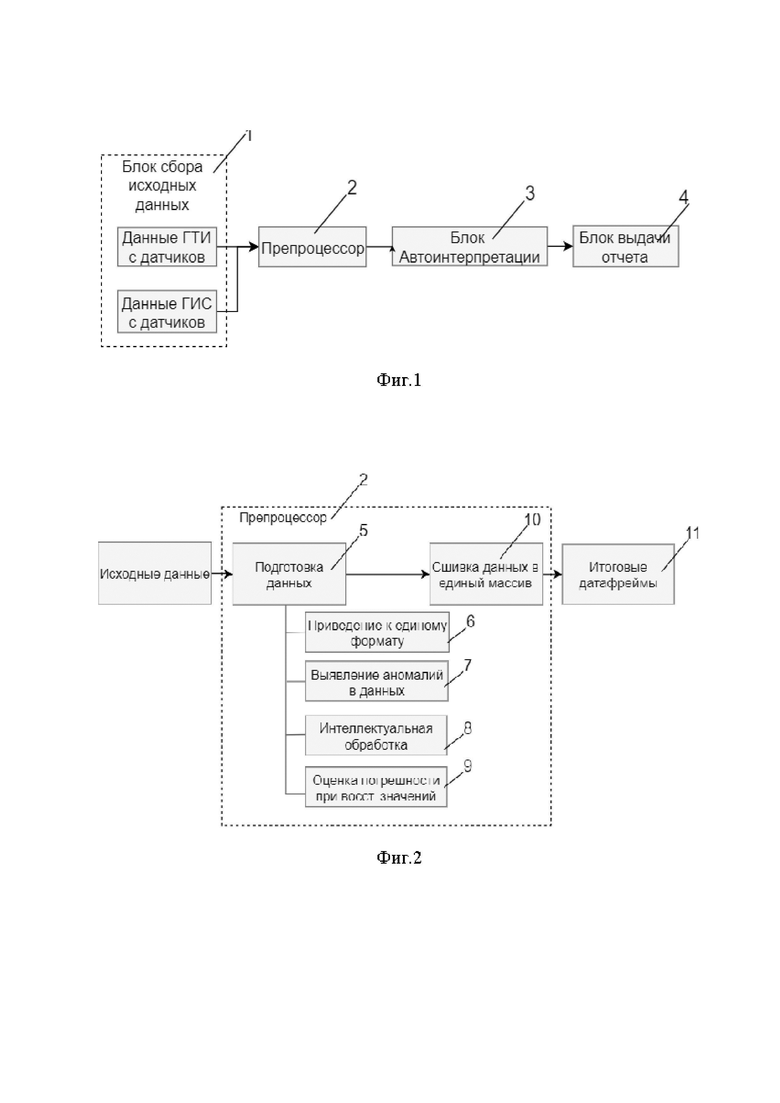
На фиг.1 представлена общая схема системы автоматической разметки скважинных данных, содержащая блок 1 сбора исходных данных, препроцессор 2 - блок компьютерной обработки и подготовки собранных данных, блок 3 автоинтерпретации, блок 4 выдачи отчета.
Как показано на фиг.1, посредством блока 1 сбора исходных данных собирают исходные технологические данные о бурении, в качестве которых используют результаты измерений с датчиков, расположенных на поверхности (датчики буровой или станции геолого-технических исследований - ГТИ), и/или данные каротажа – геофизических исследований скважины (ГИС). В процессе бурения с датчиков на поверхности получают сырые технологические данные, характеризующие механику бурения и выбираемые из группы, содержащей вес бурильной колонны, вес инструмента, глубину забоя, давление на входе, нагрузку на долото, частоту ходов насосов, скорость инструмента, температуру, концентрацию углеводородных компонентов (метан, этан, пропан и др.), и др.
К результатам каротажа при бурении и после бурения (ГИС) относятся данные, полученные методами прямого измерения физических свойств залежей в скважинах, таких как электрические, радиометрические, сейсмоакустические, тепловые методы и др. И данные ГТИ, измеряемые на поверхности, и данные ГИС, измеряемые в скважине, представляют собой последовательные измерения с различных приборов, а значит, могут быть обработаны с применением методов искусственного интеллекта.
Собранные в блоке 1 исходные данные поступают в блок обработки и подготовки данных - препроцессор 2, который осуществляет компьютерную обработку и подготовку собранных данных.
Затем обработанные и подготовленные препроцессором 2 данные поступают в блок 3 автоинтерпретации, который анализирует обработанные данные и с помощью предварительно обученных алгоритмов искусственного интеллекта, осуществляет автоматическую разметку данных, то есть дополняет исходные данные, характеризующие процесс бурения, информацией о типах выполняемых операций и событий в каждый момент времени, а также вероятностью наступления или развития событий; исходные данные каротажа дополняются информацией о типах и насыщении породы в каждой точке вдоль скважины,
Блок 4 выдачи отчетов использует автоматическую разметку, осуществленную блоком 3 автоинтерпретации, для выдачи предупреждений или формирования отчетного документа исходя из заданных пользователем настроек - выдачи по времени или по глубине.
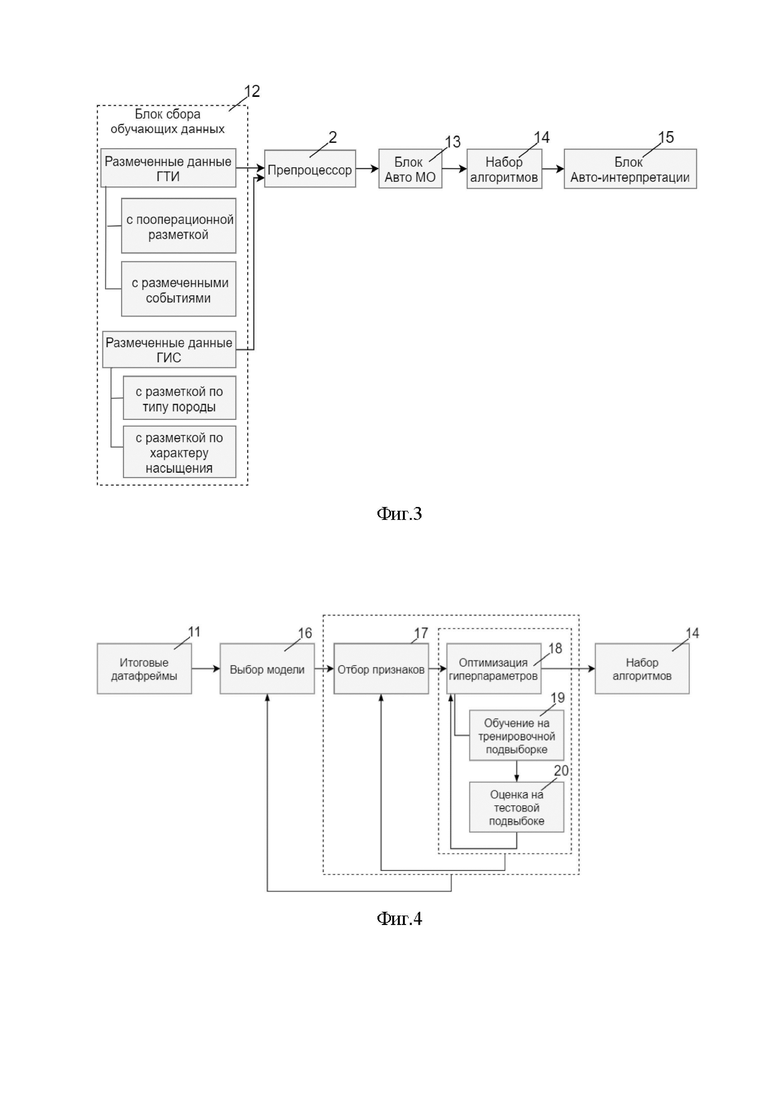
На фиг.2 представлена схема работы блока обработки и подготовки данных – препроцессора 2.
Препроцессор 2 осуществляет компьютерную обработку и подготовку собранных исходных данных, а именно производит агрегирование данных по измерениям различного формата в единую базу данных с применением интеллектуальных алгоритмов приближенного поиска соответствий и исправления ошибок. Препроцессор 2 использует методы искусственного интеллекта для подготовки 5 собранных исходных данных, включающей выполнение одного или нескольких действий, выбранных из группы:
- действие 6 - приведение данных к единому формату, включающее выравнивание размерностей и единиц измерения;
- действие 7 - выявление аномалий в собранных данных: пропусков, выбросов, некорректных значений, фактов калибровки датчиков в процессе бурения с помощью методов искусственного интеллекта;
- действие 8 - интеллектуальная обработка собранных данных: заполнение пропусков в показаниях датчиков, устранение части данных, содержащие калибровки датчиков и восстановление пропущенных значений с помощью методов искусственного интеллекта;
- действие 9 - оценка погрешности при восстановлении пропущенных значений в показаниях датчиков методами искусственного интеллекта.
Затем осуществляют действие 10 - сшивку подготовленных данных в единый массив, т.е. приведение в соответствие данных, записывающихся на поверхности по времени, и данных в скважине, записывающихся по глубине.
Функция 5 подготовки данных препроцессора 2 включает в себя следующие действия:
Действие 6 препроцессора 2 – «приведение собранных данных к единому формату» – осуществляет такие операции, как агрегация временных рядов для разделения стволов многоствольных скважин, перевод файлов .las в формат .csv, определение единиц измерения (на основе статистических тестов соответствия распределений значений эталонным выборкам с известными единицами), выравнивание размерностей и единиц измерения (с помощью таблиц перевода известных размерностей и правил на основе обученных решающих деревьев в общем случае), разделение временных рядов по секциям (направление, кондуктор, эксплуатационная колонна и пр.), разделение операций на фазы (бурение, спуск, подъем, проработка, обратная проработка, промывка, простой), агрегация временных рядов по глубине, выделение из проектных данных информации о составе КНБК, бурильной колонны, свойствах промывочных жидкостей и пр.
Действие 7 препроцессора 2 - «выявление аномалий в собранных данных» - использует обученные алгоритмы для определения наличия в показаниях датчиков аномалий, соответствующим пропускам, выбросам, некорректным значениям (например, значения, во много десятков раз превышающие физически обоснованные значения), калибровкам приборов и маркирует их в соответствии с выявленной аномалией.
Действие 8 препроцессора 2 - «интеллектуальная обработка» - использует алгоритмы искусственного интеллекта для восстановления пропущенных значений, обучившись на интервалах с полным комплексом измерений, корректирует выбросы, устраняет часть данных, содержащих паразитную информацию от процесса калибровки датчиков. В качестве таких алгоритмов используются рекуррентные нейронные сети для многомерных временных рядов (см., например, Graves, Alex. «Generating sequences with recurrent neural networks». arXiv preprint arXiv:1308.0850 (2013)), а также генеративные автоэнкодеры (см., например, Makhzani, A., Shlens, J., Jaitly, N., Goodfellow, I., & Frey, B. (2015). Adversarial autoencoders. arXiv preprint arXiv:1511.05644). Таким образом препроцессор 2 восстанавливает пропущенные значения, не удаляет, а корректирует аномальные значения.
Действие 9 препроцессора 2 - «оценка погрешности при восстановлении пропущенных значений в показаниях датчиков» - использует информацию о доле пропущенных значений и размере обучающей выборки для расчета вероятности корректного восстановления пропущенных значений. Модель оценки вероятности корректного восстановления предварительно обучается на основе искусственно создаваемых пропусков различного характера на полных данных.
Действие 10 препроцессора 2 – «сшивка данных в единый массив» -объединяет таблицы, содержащие информацию о бурении с датчиков на поверхности и геологическую информацию из скважины в единую таблицу таким образом, что участки данных, на которых происходило углубление скважины, содержат также информацию о свойствах разбуриваемой породы. Действие 10 обеспечивает сопоставление данных, замеряемых по времени с данными, замеряемыми по глубине.
Как показано на Фиг.2, результатом работы препроцессора 2 являются структурированные массивы данных, содержащие полную характеристику процесса бурения в каждый момент времени – датафреймы 11, представляющие собой таблицы в формате .csv, содержащие в структурированном виде полную характеристику процесса бурения в каждый момент времени на протяжении всего цикла строительства скважины.
Таким образом, препроцессор 2 - блок компьютерной обработки собранных данных - обеспечивает формирование структурированных массивов данных, содержащих полную характеристику процесса бурения в каждый момент времени – датафреймов 11. В качестве исходных данных могут быть использованы данные ГТИ различных подрядчиков и полученные с различных датчиков, а также данные каротажа, полученные с различных датчиков, включая каротаж в процессе бурения и каротаж после бурения на кабеле. При этом не требуется ручного ввода дополнительных параметров. На датафреймах проводят обучение прогнозных и оптимизационных алгоритмов, построенных на методах искусственного интеллекта, и используют обученные модели для работы с новыми входными данными и генерации прогнозов.
Блок 3 автоинтерпретации использует в качестве входных данных сформированные структурированные массивы данных, содержащие информацию с датчиков каротажа и/или технологические параметры бурения скважины в данном разрезе в каждый момент времени. Блок 3 использует технологии искусственного интеллекта для автоматической разметки исходных данных, то есть для дополнения данных, характеризующих процесс бурения, информацией о типах выполняемых операций и событий в каждый момент времени, а также о вероятности наступления или развития событий; данные каротажа дополняют информацией о типах (например, песчаник, доломит, аргиллит, глина и др.) и насыщении породы (нефть, газ, вода) в каждой точке вдоль скважины.
К типам выполняемых операций относятся такие категории, как бурение, спуск, подъем, проработка, обратная проработка, наращивания, промывка, простой и др. К событиям относятся такие, как геологические осложнения, аварийные ситуации, калибровки приборов и любые другие события, размеченные пользователем.
В случае перехода на новый объект разработки, вводе дополнительных событий для разметки или при появлении новых математических алгоритмов необходимо проведение обучения.
На фиг.3 представлена общая схема автоматического выбора наилучших алгоритмов системы автоматической разметки скважинных данных, и их обучения, содержащая блок 12 сбора обучающих данных, препроцессор 2 - блок обработки и подготовки собранных данных, блок 13- Авто-МО (автоматического машинного обучения)- блок определения наилучших алгоритмов машинного обучения, набора признаков и гиперпараметров.
Как показано на фиг.3, посредством блока 12 сбора обучающих данных собирают исходные данные о бурении (ГТИ) с соответствующей разметкой по типам выполняемых операций, отрезки данных с размеченными событиями, и/или данные каротажа (ГИС) с соответствующей разметкой по типам породы и характеру насыщения.
В качестве исходных данных используют результаты измерений с датчиков, расположенных на поверхности (датчики буровой или станции геолого-технических исследований - ГТИ) с соответствующей разметкой и результаты каротажа при бурении (ГИС) с соответствующей разметкой.
К результатам измерений с датчиков, расположенных на поверхности, относятся такие, как вес бурильной колонны или инструмента, глубина забоя, давление на входе, нагрузка на долото, частота ходов насосов, скорость инструмента, температура, концентрации углеводородных компонентов (метан, этан, пропан и др.), и др., к данным разметки по типам выполняемой операции относятся такие категории, как бурение, спуск, подъем, проработка, обратная проработка, промывка, простой. К данным ГТИ с размеченными событиями относятся такие, как геологические осложнения, аварийные ситуации, калибровки приборов и любые другие события, размеченные пользователем.
К размеченным данным каротажа относятся прямые измерения физических свойств пород в скважинах такие, как электрические, радиометрические, сейсмоакустические, тепловые методы и др. с отметками о типах пород (например, песчаник, доломит, аргиллит, глина и др.), а также с отметками по характеру насыщения (нефть, газ, вода).
Обучающие данные 12 поступают в препроцессор 2 (см. фиг. 2) – блок компьютерной обработки собранных данных, который осуществляет компьютерную обработку собранных данных. При подготовке обучающих данных в функционал препроцессора входит также объединение разметки с данными ГТИ и ГИС в блоке 10 на фиг. 2. В режиме обучения, обработанные препроцессором 2 данные, поступают в блок 13 Авто-МО, который анализирует поступившие обучающие данные, выбирает оптимальный для решения задач разметки алгоритм и производит настройку параметров.
На фиг. 4 представлен принцип работы показанного блока 13 Авто-МО. Блок 13 Авто-МО, который с применением методов машинного обучения производит подготовку обучающей выборки, выбирает наиболее репрезентативную выборку из объема загруженной, производит конструирование и выявление значимости входных признаков для различных задач разметки событий и интерпретации скважинных данных, осуществляет автоматическую настройку алгоритмов машинного обучения для выбора наиболее перспективного набора алгоритмов (фиг. 3, модуль 14) по результатам оценки алгоритмов машинного обучения на контрольной выборке данных, соответствующей наибольшему разнообразию возможных исходов для выбранного события.
Подготовленные препроцессором 2 датафреймы поступают в модуль 16 на фиг. 4 выбора модели. Модуль 16 включает в себя большое разнообразие алгоритмов машинного обучения от простых линейных моделей до более продвинутых, в основе которых лежат ансамбли решающих деревьев, рекуррентные нейронные сети и др. Модуль 16 может постоянно пополняться новыми алгоритмами с целью повышения качества автоматический системы. Модуль 16 по очереди проверяет все загруженные в него модели машинного обучения. Далее для выбранной модулем 16 модели, блоком 17 производится отбор наиболее значимых признаков, определяется коэффициенты их значимости, которые вместе с выбранной моделью и датафреймами поступают в модуль 18 оптимизации гиперпараметров. В модуле 18 производится условное деление обучающего дата-сета на обучающую (19) и тестовую (20) подвыборки в таком соотношении, чтобы обучающая была значительно больше тестовой. В качестве тестовой выборки могут быть выбраны скважинные данные с некоторых интервалов скважины или соседние скважины целиком в рамках выбранного объекта.
Затем производится подбор гиперпараметров модели таким образом, чтобы получить максимальный результат на тестовой подвыборке. В результате работы модуля 18 получают оптимально настроенные гиперпараметры для данного набора признаков выбранной модели. Аналогичным образом осуществляется проверка всех моделей машинного обучения блока 16 при различных наборах признаков в модуле 17 и различных гиперпараметрах модуля 18.
Сравнивая значения, полученные при тестировании различных алгоритмов, блок выбора модели 16 определяет набор алгоритмов 14, показавших наилучший результат с настройками значимости признаков и выбранными гиперпараметрами. Набор алгоритмов 14, который передается на вход блоку 3 автоинтерпретации для формирования автоматической разметки по типу выполняемой операции, детекции/ предсказания событий или интерпретации данных по объекту разработки с целью выявления геологических особенностей объекта и характера насыщения залежей углеводородами.
Все алгоритмы, применяемые в системе и способе обработки скважинных данных, обучены на наборе исторических данных с ранее пробуренных скважин. При этом работа настроенных алгоритмов может осуществляться даже при поступлении неполного комплекса данных, а выдаваемый результат содержит информацию о точности разметки. Кроме того, данные ГТИ и ГИС могут размечаться как совместно, так и автономно.
Таким образом, предлагаемые способ и система автоматической разметки скважинных данных позволяют:
• автоматически определить тип породы по данным каротажа на кабеле;
• автоматически определить тип породы по данным каротажа в процессе бурения;
• автоматически определить характер насыщения по данным каротажа на кабеле;
• автоматически определить характер насыщения по данным каротажа в процессе бурения;
• автоматически разделить исторические данные ГТИ по типу выполняемой операции;
• автоматически разделить данные ГТИ по типу выполняемой операции в реальном времени;
• автоматически выделять в исторических данных ГТИ заданные пользователем события, например, геологические осложнения, аварийные ситуации;
• автоматически выделять в реальновременных данных ГТИ заданные пользователем события, например, геологические осложнения, аварийные ситуации;
• автоматически определить вероятность возникновения заданных событий;
• автоматически формировать для пользователя сводку или отчет по заданным данным.
Далее приведен пример работы способа и компьютерной системы обработки скважинных данных.
Данные ГТИ и/или данные ГИС, представляющие собой последовательные измерения с датчиков, находящихся на буровой или в скважине, либо выгружают из базы данных, либо поступают в реальном времени. Данные сохраняют в специальном локальном хранилище блока сбора исходных данных пользователя в las, csv, xls, xlsx или другом табличном формате.
Препроцессор 2 обрабатывает либо все загруженные со скважины исторические данные, либо по определенному расписанию, заданному пользователем, загружает новую базу исходных реальновременных данных ГТИ и /или ГИС.
При поступлении каждой новой порции базы данных, препроцессор 2, приводит их к единому формату – осуществляет такие операции, как агрегация временных рядов, перевод в формат .csv или .xlsx, определение и выравнивание единиц измерения.
Затем выявляют аномалии данных, соответствующие пропускам, выбросам, некорректным значениям, калибровкам приборов. С помощью алгоритмов искусственного интеллекта прогнозируют ожидаемые значения, затем они сравниваются с фактическими, и, при наличии сильного несоответствия, помечаются как аномальные. В результате выполнения данной функции в массивах данных появляется дополнительный служебный файл с указанием наличия аномалий и их типов для каждого ствола.
После этого осуществляют интеллектуальную обработку аномалий. Алгоритмы препроцессора восстанавливают пропущенные значения, корректируют выбросы, устраняют часть данных, содержащих калибровки датчиков. В результате мы получаем аналогичные исходным массивы данных, но с исправленными значениями.
При этом производится оценка погрешности при восстановлении пропущенных значений в показаниях датчиков. Алгоритмы используют информацию о доле пропущенных значений и размере выборки для расчета вероятности корректного восстановления пропущенных значений. В результате выполнения данной функции в массивах данных для каждого ствола появляется дополнительный столбец с указанием достоверности в восстановлении пропущенных значений.
Результат работы препроцессора записывается в терминальную таблицу в виде датафреймов, представляющих собой csv-файлы. Обработанные датафреймы поступают в блок 3 автоинтерпретации.
Получая на вход датафреймы предобработанных данных, блок 3 автоинтерпретации выполняет автоматическую разметку данных ГТИ и/или автоматическое распознавание/прогноз событий по ГТИ, и/или автоматическое определение литотипа и/или автоматическое определение характера насыщения.
Результат работы алгоритмов записывается в терминальную таблицу базы данных и отображаются пользователям с помощью графического интерфейса либо по всей скважине, либо по выбранному пользователем временному промежутку.
При переходе на новый объект разработки, вводе дополнительных событий для разметки или при появлении новых математических алгоритмов, пользователь запускает процедуру обучения.
Данные ГТИ и/или данные ГИС, представляющие собой последовательные измерения с датчиков, и содержащие соответствующую разметку загружаются в блок сбора обучающих данных 12. Обучающие данные проходят процедуру препроцессинга и попадают в блок Авто-МО, где производится подготовка обучающей выборки, выбор наилучших алгоритмов и их обучение.
Модуль 15 блока Авто-МО выбирает наиболее репрезентативную выборку для обучения. Эффективный выбор достигается комбинацией методов машинного обучения и классическими статистическими подходами. Данная комбинация в автоматическом режиме производит анализ доступных входных параметров с последующим определением степени информативности. Полученная информация используется алгоритмами для дальнейшего конструирования входных параметров. Процесс конструирования включает ряд математических методов, например, логарифмические преобразования, масштабирование, разделение признаков, бинаризация и др., способных положительно влиять на информативность входной информации ГТИ и/или ГИС. В результате формируется обучающий датасет, который в свою очередь условно делится на обучающую и тестовую подвыборку, произвольно или последовательно в соответствии с временной шкалой или глубиной.
Далее выполняется обучение алгоритмов (линейные, нейронные сети, решающие деревья, гауссовские процессы, метод опорных векторов и др.) над соответствующими гиперпараметрами, используя алгоритм кросс-валидации. Обучение алгоритмов осуществляется на обучающей выборке с последующей оценкой качества на контрольной выборке и выбором оптимального алгоритма по результатам сравнения качества на метриках для задач классификации объектов (событий) или регрессионного анализа.
Результат работы блока 13 Авто-МО сохраняется в виде набора обученных моделей в отдельный файл 14 и в дальнейшем используются блоком 3 для автоинтерпретации для автоматической разметки новых данных ГТИ и/или ГИС.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И КОМПЬЮТЕРНАЯ СИСТЕМА УПРАВЛЕНИЯ БУРЕНИЕМ СКВАЖИН | 2019 |
|
RU2723805C1 |
| СПОСОБ АВТОМАТИЗИРОВАННОГО ПОСТРОЕНИЯ ГЕОЛОГИЧЕСКОЙ МОДЕЛИ ЗАЛЕЖИ | 2020 |
|
RU2799775C2 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА ВЫЯВЛЕНИЯ И ПРОГНОЗИРОВАНИЯ ОСЛОЖНЕНИЙ В ПРОЦЕССЕ СТРОИТЕЛЬСТВА НЕФТЯНЫХ И ГАЗОВЫХ СКВАЖИН | 2020 |
|
RU2745136C1 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА ВЫЯВЛЕНИЯ И ПРОГНОЗИРОВАНИЯ ОСЛОЖНЕНИЙ В ПРОЦЕССЕ СТРОИТЕЛЬСТВА НЕФТЯНЫХ И ГАЗОВЫХ СКВАЖИН | 2020 |
|
RU2745137C1 |
| Способ и система для предупреждения о предстоящих аномалиях в процессе бурения | 2021 |
|
RU2772851C1 |
| ПРОГНОЗИРОВАНИЕ СВОЙСТВ ПОДЗЕМНОЙ ФОРМАЦИИ | 2008 |
|
RU2462755C2 |
| Способ прогнозирования прихватов бурильных труб в процессе бурения скважины в режиме реального времени | 2020 |
|
RU2753289C1 |
| ОЦЕНКА ПАРАМЕТРОВ НАКЛОННО-НАПРАВЛЕННОГО БУРЕНИЯ НА ОСНОВЕ МОДЕЛИ ПРИ ПРОВЕДЕНИИ СКВАЖИННЫХ ОПЕРАЦИЙ | 2019 |
|
RU2754892C1 |
| СПОСОБ ПОИСКА, РАЗВЕДКИ, ИССЛЕДОВАНИЯ И СОЗДАНИЯ МОДЕЛИ МЕСТОРОЖДЕНИЯ ПОЛЕЗНЫХ ИСКОПАЕМЫХ | 2001 |
|
RU2206911C2 |
| СПОСОБ И СИСТЕМА ОПТИМИЗАЦИИ ЛАБОРАТОРНЫХ ИССЛЕДОВАНИЙ ОБРАЗЦОВ ГОРНЫХ ПОРОД | 2019 |
|
RU2725506C1 |
Изобретение относится к области автоматизированного анализа и обработки скважинных данных, получаемых в процессе и после бурения. В соответствии с предлагаемым способом собирают исходные скважинные данные, содержащие по меньшей мере один тип данных, выбранных из группы, содержащей данные, характеризующие процесс бурения и представляющие собой результаты измерений с датчиков, расположенных на поверхности, и данные каротажа в каждый момент времени. Осуществляют компьютерную обработку всех собранных исходных скважинных данных, в соответствии с которой из собранных данных формируют структурированные массивы данных каждого типа. При этом структурированные массивы данных, сформированные в результате обработки данных, характеризующих процесс бурения, содержат полную технологическую характеристику процесса бурения в каждый момент времени, а структурированные массивы данных, сформированные в результате обработки данных каротажа, содержат геофизическую характеристику прискважинной зоны. Используя в качестве входных данных сформированные структурированные массивы данных каждого типа посредством предварительно обученного алгоритма искусственного интеллекта, осуществляют автоматическую разметку собранных исходных скважинных данных каждого типа, и, используя в качестве входных данных размеченные данные каждого типа, формируют результат для выдачи пользователю в виде интересующего фрагмента размеченных данных по времени и/или глубине. Технический результат, достигаемый при реализации изобретения, заключается в обеспечении возможности определения в автоматическом режиме типа породы и характера ее насыщения (нефть, газ, вода), а также типа выполняемых операций и вероятности наступления и/или развития событий при бурении (например, осложнения или аварии) путем интерпретации и контроля геологической и технологической скважинной информации, получаемой как непосредственно в процессе бурения в реальном времени, так и используя исторические данные с ранее пробуренных скважин. 9 з.п. ф-лы, 4 ил.
1. Способ обработки скважинных данных, в соответствии с которым:
- собирают исходные скважинные данные, содержащие по меньшей мере один тип данных, выбранных из группы, содержащей данные геолого-технических исследований, характеризующие процесс бурения и представляющие собой результаты измерений с датчиков, расположенных на поверхности, и данные геофизических исследований скважины в каждый момент времени;
- осуществляют компьютерную обработку всех собранных исходных скважинных данных, предусматривающую приведение данных к единому формату, выявление аномалий в собранных данных, восстановление пропущенных значений в собранных данных посредством использования алгоритмов искусственного интеллекта, оценку погрешности при восстановлении пропущенных значений и последующую сшивку данных в единый массив, в результате которой получают структурированные массивы данных в виде таблиц, содержащих полную технологическую характеристику процесса бурения в каждый момент времени,
- используя в качестве входных данных сформированные структурированные массивы данных каждого типа посредством предварительно обученного алгоритма машинного обучения, дополняют исходные данные геолого-технических исследований, характеризующих процесс бурения, информацией о типах выполняемых операций и событий в каждый момент времени, а также информацией о вероятности наступления или развития событий, а исходные данные геофизических исследований скважины дополняют информацией о типах и насыщении породы в каждой точке вдоль скважины,
- используя в качестве входных данных дополненные данные каждого типа, формируют результат для выдачи пользователю в виде интересующего фрагмента дополненных данных по времени и/или глубине, на основе которых принимаются оперативные решения по изменению траектории скважины или способу заканчивания для получения максимальной добычи.
2. Способ обработки скважинных данных по п. 1, в соответствии с которым для обучения алгоритма машинного обучения:
- формируют обучающий набор данных для алгоритма, содержащий исходные данные о бурении в каждый момент времени с соответствующими им типами выполняемых операций и событиями,
- выбирают по меньшей мере один алгоритм машинного обучения,
- по меньшей мере один раз на основе сформированного обучающего набора данных отбирают признаки для выбранного алгоритма машинного обучения, содержащие данные о бурении в каждый момент времени, и формируют ответы, содержащие соответственно информацию о типах выполняемых операций и событий,
- по меньшей мере один раз обучают выбранный алгоритм машинного обучения на основе сформированного обучающего набора данных, отобранных признаков и ответов.
3. Способ обработки скважинных данных по п. 1, в соответствии с которым для обучения алгоритма машинного обучения:
- формируют обучающий набор данных для алгоритма, содержащий исходные данные каротажа с соответствующими им типами породы и характером ее насыщения,
- выбирают по меньшей мере один алгоритм машинного обучения,
- по меньшей мере один раз на основе сформированного обучающего набора данных отбирают признаки для выбранного алгоритма машинного обучения, содержащие данные каротажа, и формируют ответы, содержащие соответственно информацию о типах и насыщении породы, и
- по меньшей мере один раз обучают выбранный алгоритм машинного обучения на основе сформированного обучающего набора данных, отобранных признаков и ответов.
4. Способ обработки скважинных данных по п. 1, в соответствии с которым данные геолого-технических исследований, характеризующие процесс бурения и представляющие собой результаты измерений с датчиков, расположенных на поверхности, выбирают из группы, содержащей вес бурильной колонны или инструмента, глубину забоя, давление на входе, нагрузку на долото, частоту ходов насосов, скорость инструмента, температуру, концентрацию углеводородных компонентов.
5. Способ обработки скважинных данных по п. 1, в соответствии с которым типы выполняемых операций представляют собой бурение, спуск бурильной или обсадной колонны, подъем бурильной или обсадной колонны, проработку ствола скважины, обратную проработку ствола скважины, промывку ствола скважины, простой.
6. Способ обработки скважинных данных по п. 1, в соответствии с которым события, информация о которых дополняет исходные данные о бурении, представляют собой геологические осложнения.
7. Способ обработки скважинных данных по п. 1, в соответствии с которым события, информация о которых дополняет исходные данные о бурении, представляют собой аварийные ситуации.
8. Способ обработки скважинных данных по п. 1, в соответствии с которым события, информация о которых дополняет исходные данные о бурении, представляют собой предвестники аварийных ситуаций.
9. Способ обработки скважинных данных по п. 1, в соответствии с которым события, информация о которых дополняет исходные данные о бурении, представляют собой события, выбранные пользователем и имеющие характерные признаки в записях режимных параметров бурения.
10. Способ обработки скважинных данных по п. 1, в соответствии с которым в качестве исходных данных геофизических исследований скважины используют результаты прямых измерений физических свойств пород в скважинах.
| АНТИПОВА К.А., ГУРИНА Е.В., КЛЮЧНИКОВ Н.А | |||
| и др | |||
| " ИНФОРМАЦИОННАЯ СИСТЕМА ДЕТЕКТИРОВАНИЯ ПРЕДВЕСТНИКОВ АВАРИЙНЫХ СИТУАЦИЙ", ж-л "НЕФТЬ.ГАЗ.НОВАЦИИ", номер 6, 2020, с | |||
| Прибор с двумя призмами | 1917 |
|
SU27A1 |
| ЧЕРНИКОВ А.Д., ЕРЕМИН Н.А., СТОЛЯРОВ В.Е | |||
| и др | |||
| "ПРИМЕНЕНИЕ МЕТОДОВ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ДЛЯ ВЫЯВЛЕНИЯ И ПРОГНОЗИРОВАНИЯ ОСЛОЖНЕНИЙ ПРИ СТРОИТЕЛЬСТВЕ НЕФТЯНЫХ И ГАЗОВЫХ | |||

